第 2 章 Kafka 的 Apache Kafka 部署流
Apache Kafka 的流允许将 Apache Kafka 组件部署到 OpenShift 集群,通常作为集群运行以实现高可用性。
使用 Streams for Apache Kafka 的标准 Kafka 部署可能包括以下组件:
- 代理节点的 Kafka 集群作为核心组件
- 用于外部数据连接的 Kafka 连接 集群
- Kafka MirrorMaker 集群将数据镜像到另一个 Kafka 集群
- Kafka Exporter 来提取额外的 Kafka 指标数据以进行监控。
- Kafka Bridge 以启用与 Kafka 的基于 HTTP 的通信
- Cruise Control 在代理间重新平衡主题分区
并非所有组件都是必需的,但您需要 Kafka 作为 Apache Kafka 管理的 Kafka 集群的流最小值。根据您的用例,您可以根据需要部署其他组件。这些组件也可以与不是由 Apache Kafka 的 Streams 管理的 Kafka 集群一起使用。
2.1. Kafka 组件架构
复制链接链接已复制到粘贴板!
基于 KRaft 的 Kafka 集群由代理节点组成,负责管理集群元数据和协调集群的消息交付和控制器节点。这些角色可以使用 Apache Kafka 的 Streams 中的节点池进行配置。
其他 Kafka 组件与特定任务与 Kafka 集群交互。
Kafka 组件交互
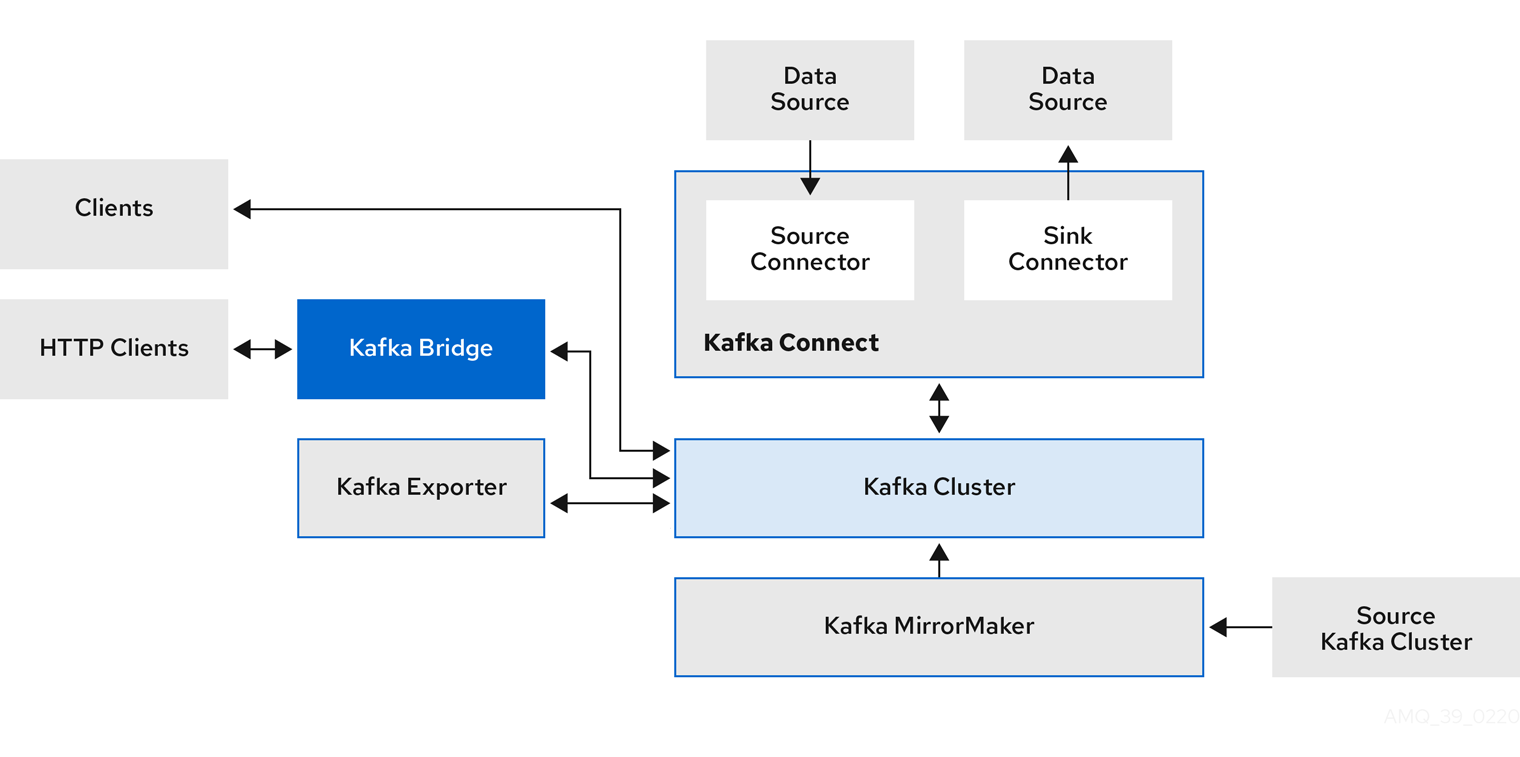
- Kafka Connect
Kafka Connect 是一个集成工具包,用于使用连接器插件在 Kafka 代理和其他系统间流传输数据。Kafka Connect 提供了一个框架,用于将 Kafka 与外部数据源或目标(如数据库)集成,如数据库,用于使用连接器导入或导出数据。连接器提供所需的连接配置。
- source(源)连接器将外部数据推送到 Kafka 中。
- sink(接收器)连接器从 Kafka 中提取数据
外部数据会被转换并转换为适当的格式。
Kafka Connect 可以配置为构建带有所需连接器的自定义容器镜像。
- Kafka MirrorMaker
- Kafka MirrorMaker 在两个 Kafka 集群之间复制数据,无论是在同一数据中心或不同位置。
- Kafka Bridge
- Kafka Bridge 提供了一个 API,用于将基于 HTTP 的客户端与 Kafka 集群集成。
- Kafka Exporter
- Kafka Exporter 提取数据以 Prometheus 指标的形式提取,主要与偏移、消费者组、消费者和主题有关的数据。consumer lag 是写入分区的最后一条消息之间的延迟,以及当前由消费者从那个分区获取的消息之间的延迟
- Apache ZooKeeper (可选)
- Apache ZooKeeper 提供了一个集群协调服务,用于存储和跟踪代理和消费者的状态。Zookeeper 也用于控制器选举。如果使用 ZooKeeper,则 ZooKeeper 集群必须在运行 Kafka 前就绪。但是,由于引入 KRaft,因此不再需要 ZooKeeper,因为 Kafka 节点可以原生处理集群协调和控制。