This documentation is for a release that is no longer maintained
See documentation for the latest supported version 3 or the latest supported version 4.8.2. 开发人员指标
8.2.1. Serverless 开发人员指标概述
指标 (metrics) 使开发人员能够监控 Knative 服务的运行情况。您可以使用 OpenShift Container Platform 监控堆栈记录并查看 Knative 服务的健康检查和指标。
您可以通过在 OpenShift Container Platform Web 控制台 Developer 视角中导航到 Dashboards 来查看 OpenShift Serverless 的不同指标。
如果使用 mTLS 启用 Service Mesh,则 Knative Serving 的指标会被默认禁用,因为 Service Mesh 会防止 Prometheus 提取指标。
有关解决这个问题的详情,请参阅在使用带有 mTLS 的 Service Mesh 时启用 Knative Serving 指标。
提取指标不会影响 Knative 服务的自动扩展,因为提取请求不会通过激活器。因此,如果没有 pod 正在运行,则不会进行提取。
8.2.2. Knative 服务指标默认公开
| 指标名称、单元和类型 | 描述 | 指标标签 |
|---|---|---|
|
指标单元:无维度 指标类型:量表 | 每秒到达队列代理的请求数。
公式:
| destination_configuration="event-display", destination_namespace="pingsource1", destination_pod="event-display-00001-deployment-6b455479cb-75p6w", destination_revision="event-display-00001" |
|
指标单元:无维度 指标类型:量表 | 每秒代理请求数.
公式:
| |
|
指标单元:无维度 指标类型:量表 | 此 pod 当前处理的请求数。
在网络
| destination_configuration="event-display", destination_namespace="pingsource1", destination_pod="event-display-00001-deployment-6b455479cb-75p6w", destination_revision="event-display-00001" |
|
指标单元:无维度 指标类型:量表 | 当前由此 pod 处理的代理请求数:
| destination_configuration="event-display", destination_namespace="pingsource1", destination_pod="event-display-00001-deployment-6b455479cb-75p6w", destination_revision="event-display-00001" |
|
指标单元: 秒 指标类型:量表 | 进程启动的秒数。 | destination_configuration="event-display", destination_namespace="pingsource1", destination_pod="event-display-00001-deployment-6b455479cb-75p6w", destination_revision="event-display-00001" |
| 指标名称、单元和类型 | 描述 | 指标标签 |
|---|---|---|
|
指标单元:无维度 指标类型:计数器 |
路由到 | configuration_name="event-display", container_name="queue-proxy", namespace_name="apiserversource1", pod_name="event-display-00001-deployment-658fd4f9cf-qcnr5", response_code="200", response_code_class="2xx", revision_name="event-display-00001", service_name="event-display" |
|
指标单元:毫秒 指标类型:togram | 以毫秒为单位的响应时间。 | configuration_name="event-display", container_name="queue-proxy", namespace_name="apiserversource1", pod_name="event-display-00001-deployment-658fd4f9cf-qcnr5", response_code="200", response_code_class="2xx", revision_name="event-display-00001", service_name="event-display" |
|
指标单元:无维度 指标类型:计数器 |
路由到 | configuration_name="event-display", container_name="queue-proxy", namespace_name="apiserversource1", pod_name="event-display-00001-deployment-658fd4f9cf-qcnr5", response_code="200", response_code_class="2xx", revision_name="event-display-00001", service_name="event-display" |
|
指标单元:毫秒 指标类型:togram | 以毫秒为单位的响应时间。 | configuration_name="event-display", container_name="queue-proxy", namespace_name="apiserversource1", pod_name="event-display-00001-deployment-658fd4f9cf-qcnr5", response_code="200", response_code_class="2xx", revision_name="event-display-00001", service_name="event-display" |
|
指标单元:无维度 指标类型:量表 |
服务和等待队列中的当前项目数,或者如果无限并发,则不报告。使用 | configuration_name="event-display", container_name="queue-proxy", namespace_name="apiserversource1", pod_name="event-display-00001-deployment-658fd4f9cf-qcnr5", response_code="200", response_code_class="2xx", revision_name="event-display-00001", service_name="event-display" |
8.2.3. 带有自定义应用程序指标的 Knative 服务
您可以扩展 Knative 服务导出的指标集合。具体的实施取决于您的应用和使用的语言。
以下列表实施了一个 Go 应用示例,它导出处理的事件计数自定义指标。
8.2.4. 配置提取自定义指标
自定义指标提取由专门用于用户工作负载监控的 Prometheus 实例执行。启用用户工作负载监控并创建应用程序后,您需要一个配置来定义监控堆栈提取指标的方式。
以下示例配置为您的应用程序定义了 ksvc 并配置服务监控器。确切的配置取决于您的应用程序以及它如何导出指标。
8.2.5. 检查服务的指标
在将应用配置为导出指标和监控堆栈以提取它们后,您可以在 web 控制台中查看指标数据。
先决条件
- 已登陆到 OpenShift Container Platform Web 控制台。
- 安装了 OpenShift Serverless Operator 和 Knative Serving。
流程
可选:针对应用程序运行请求,您可以在指标中看到:
hello_route=$(oc get ksvc helloworld-go -n ns1 -o jsonpath='{.status.url}') && \ curl $hello_route$ hello_route=$(oc get ksvc helloworld-go -n ns1 -o jsonpath='{.status.url}') && \ curl $hello_routeCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输出示例
Hello Go Sample v1!
Hello Go Sample v1!Copy to Clipboard Copied! Toggle word wrap Toggle overflow -
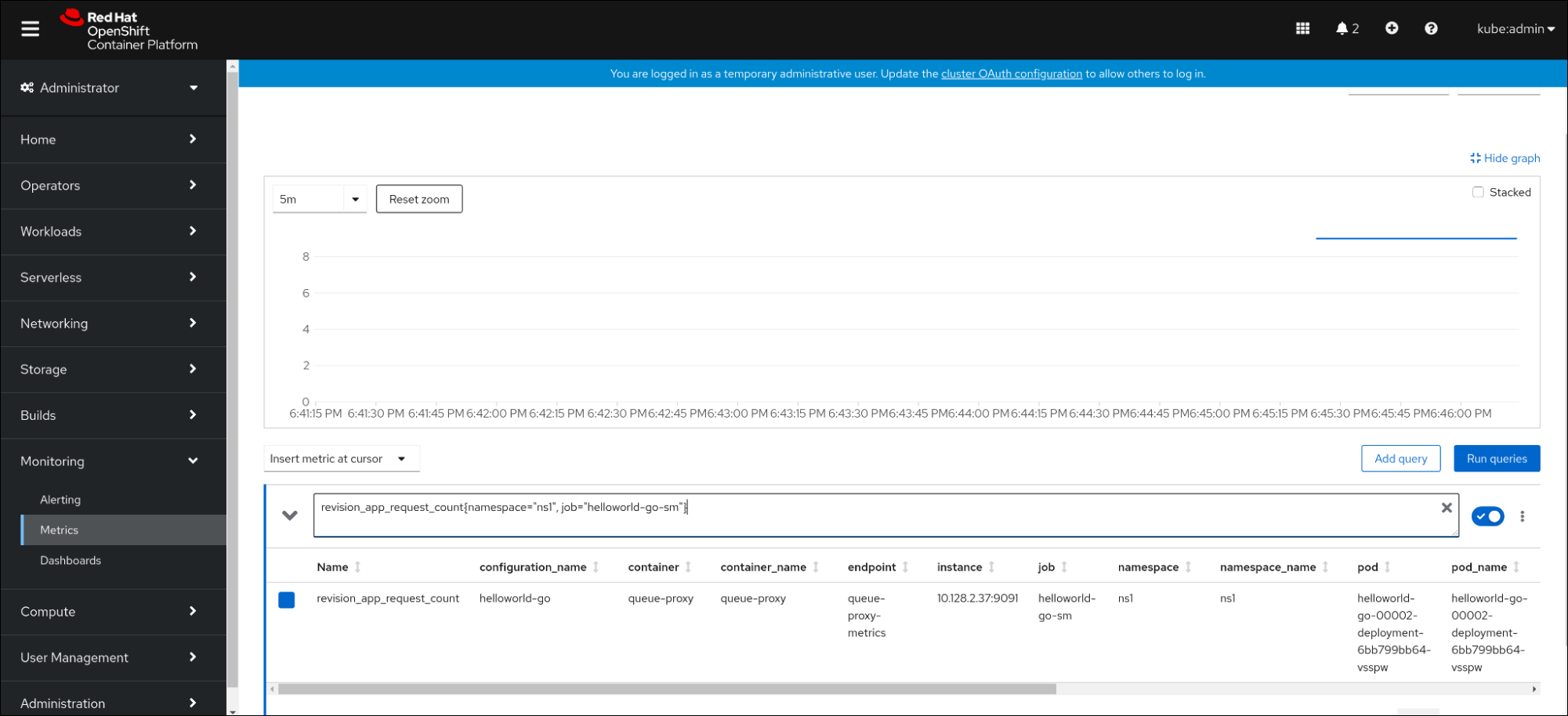
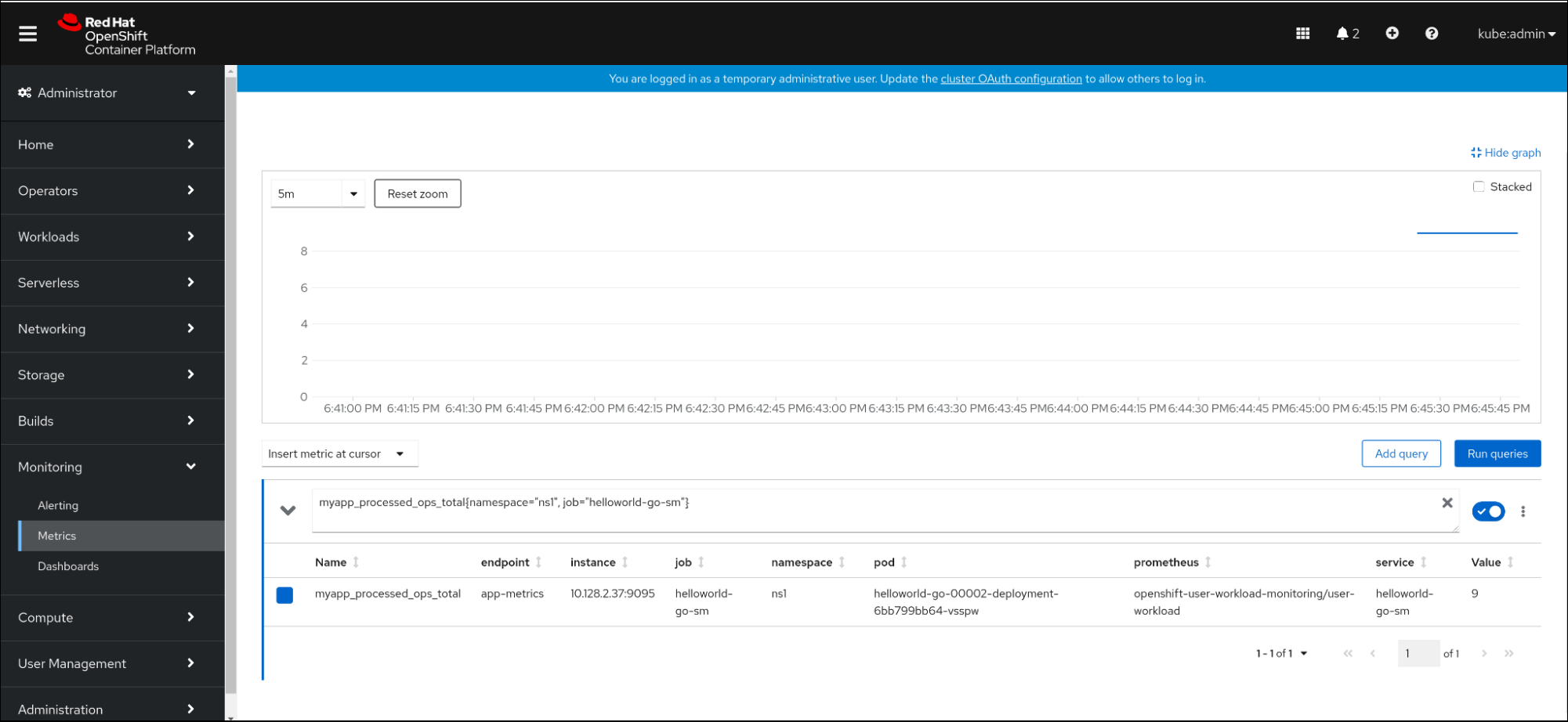
在 Web 控制台中,进入 Observe
Metrics 界面。 在输入字段中,输入您要观察到的指标的查询,例如:
revision_app_request_count{namespace="ns1", job="helloworld-go-sm"}revision_app_request_count{namespace="ns1", job="helloworld-go-sm"}Copy to Clipboard Copied! Toggle word wrap Toggle overflow 另一个示例:
myapp_processed_ops_total{namespace="ns1", job="helloworld-go-sm"}myapp_processed_ops_total{namespace="ns1", job="helloworld-go-sm"}Copy to Clipboard Copied! Toggle word wrap Toggle overflow 观察视觉化的指标:
8.2.5.1. 队列代理指标
每个 Knative 服务都有一个代理容器,用于代理到应用程序容器的连接。报告多个用于队列代理性能的指标。
您可以使用以下指标来测量请求是否排入代理端,并在应用一侧服务请求的实际延迟。
| 指标名称 | 描述 | 类型 | Tags | 单位 |
|---|---|---|---|---|
|
|
路由到 | 计数 |
| 整数(无单位) |
|
| 修订请求的响应时间。 | Histogram |
| Milliseconds |
|
|
路由到 | 计数 |
| 整数(无单位) |
|
| 修订应用程序请求的响应时间。 | Histogram |
| Milliseconds |
|
|
当前在 | 量表 |
| 整数(无单位) |
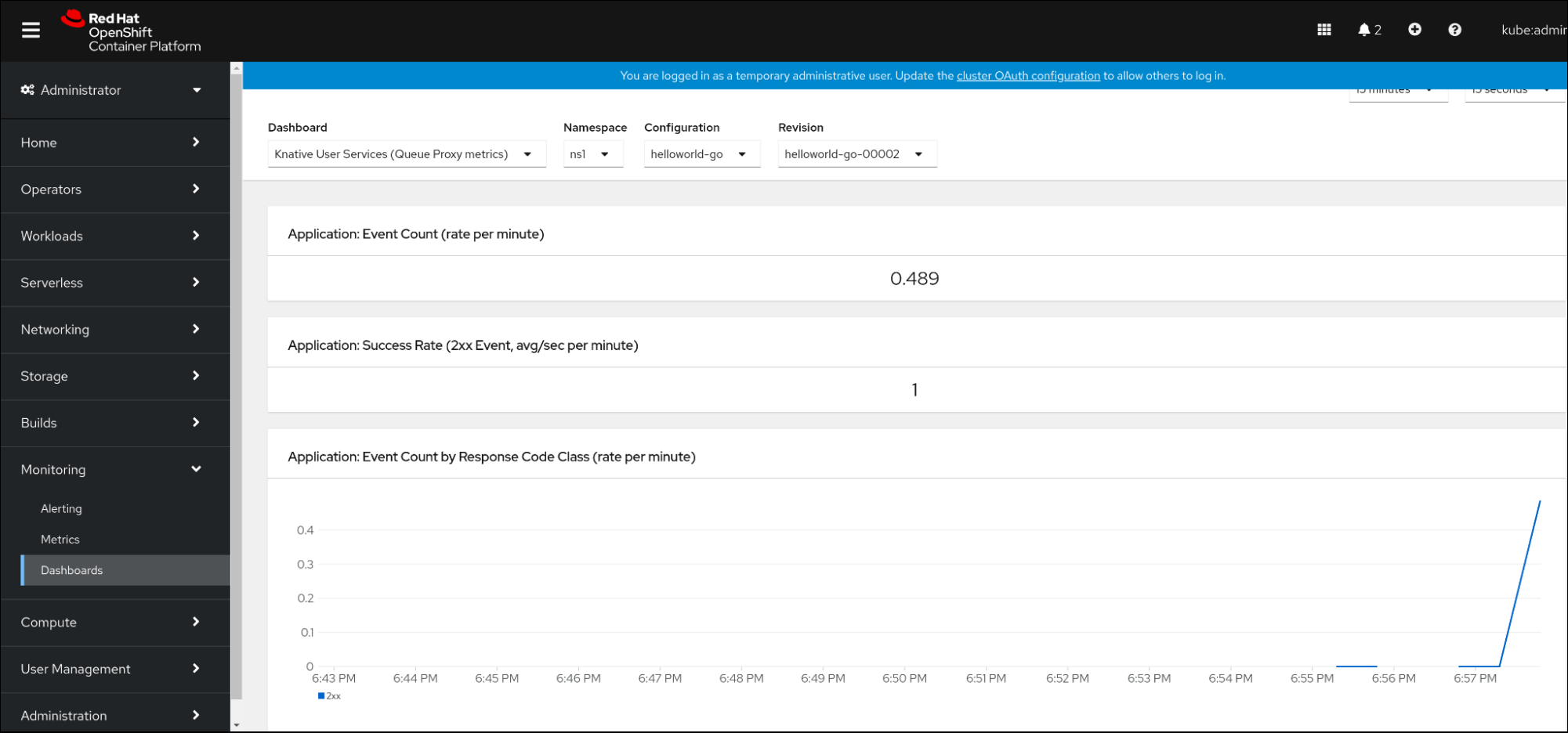
8.2.6. 服务指标的仪表板
您可以使用专用的仪表板来按命名空间聚合队列代理指标,以检查指标。
8.2.6.1. 在仪表板中检查服务的指标
先决条件
- 已登陆到 OpenShift Container Platform Web 控制台。
- 安装了 OpenShift Serverless Operator 和 Knative Serving。
流程
-
在 Web 控制台中,进入 Observe
Metrics 界面。 -
选择
Knative User Services (Queue Proxy metrics)仪表板。 - 选择与应用程序对应的 Namespace 、Configuration 和 Revision。
观察视觉化的指标: