此内容没有您所选择的语言版本。
3.2. Shared JDBC Master/Slave
Overview
A shared JDBC master/slave group works by sharing a common database using the JDBC persistence adapter. Brokers automatically configure themselves to operate in master mode or slave mode, depending on whether or not they manage to grab a mutex lock on the underlying database table.
The disadvantages of this configuration are:
- The shared database is a single point of failure. This disadvantage can be mitigated by using a database with built in high availability(HA) functionality. The database will handle replication and fail over of the data store.
- You cannot enable high speed journaling. This has a significant impact on performance.
Initial state
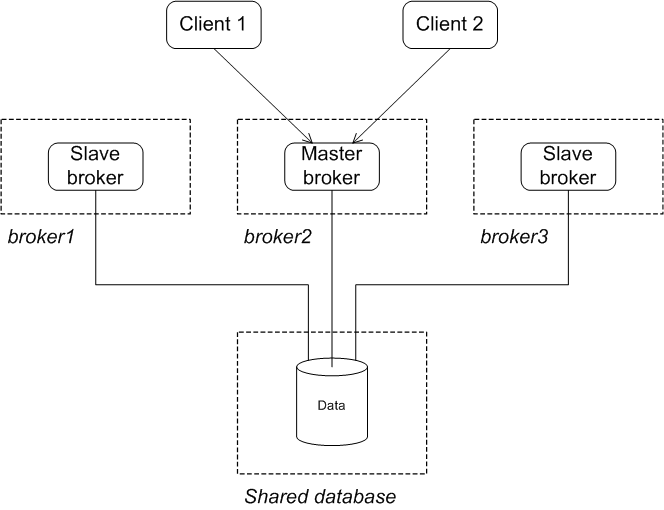
Figure 3.4, “JDBC Master/Slave Initial State” shows the initial state of a JDBC master/slave group. When all of the brokers are started, one of them grabs the mutex lock on the database table and becomes the master. All of the other brokers become slaves and pause while waiting for the lock to be freed up. Only the master starts its transport connectors, so all of the clients connect to it.
Figure 3.4. JDBC Master/Slave Initial State
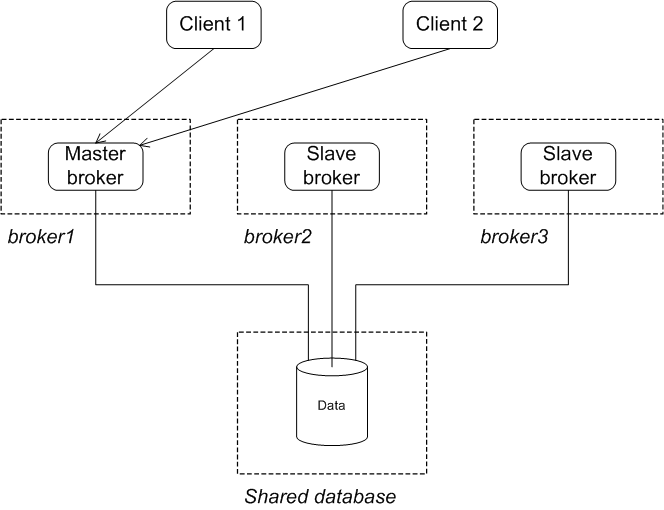
After failure of the master
Figure 3.5, “JDBC Master/Slave after Master Failure” shows the state of the group after the original master has shut down or failed. As soon as the master gives up the lock (or after a suitable timeout, if the master crashes), the lock on the database table frees up and another broker grabs the lock and gets promoted to master.
Figure 3.5. JDBC Master/Slave after Master Failure
After the clients lose their connection to the original master, they automatically try all of the other brokers listed in the failover URL. This enables them to find and connect to the new master.
Configuring the brokers
In a JDBC master/slave configuration, there is nothing special to distinguish a master broker from the slave brokers. The membership of a particular master/slave group is defined by the fact that all of the brokers in the cluster use the same JDBC persistence layer and store their data in the same database tables.
There is one important requirement when configuring the JDBC persistence adapter for use in a shared database master/slave cluster. You must use the direct JDBC persistence adapter. This is because the journal used by the journaled JDBC persistence adapter is not replicated and batch updates are used to sync with the JDBC store. Therefore it is not possible to guarantee that the latest updates are on the shared JDBC store.
Example 3.3, “JDBC Master/Slave Broker Configuration” shows the configuration used be a master/slave group that stores the shared broker data in an Oracle database.
Example 3.3. JDBC Master/Slave Broker Configuration
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:amq="http://activemq.apache.org/schema/core"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-2.0.xsd
http://activemq.apache.org/schema/core
http://activemq.apache.org/schema/core/activemq-core.xsd">
<broker xmlns="http://activemq.apache.org/schema/core"
brokerName="brokerA">
...
<persistenceAdapter>
<jdbcPersistenceAdapter dataSource="#oracle-ds"/>
</persistenceAdapter>
...
</broker>
<bean id="oracle-ds"
class="org.apache.commons.dbcp.BasicDataSource"
destroy-method="close">
<property name="driverClassName" value="oracle.jdbc.driver.OracleDriver"/>
<property name="url" value="jdbc:oracle:thin:@localhost:1521:AMQDB"/>
<property name="username" value="scott"/>
<property name="password" value="tiger"/>
<property name="poolPreparedStatements" value="true"/>
</bean>
</beans>Note
Share the scheduled messages between the brokers and adjust the schedule store directory along with the
schedulerDirectory as shown below:
<broker xmlns="http://activemq.apache.org/schema/core” schedulerSupport="true" schedulerDirectory="{activemq.data}/broker/scheduler”/>
Configuring the clients
Clients of shared JDBC master/slave group must be configured with a failover URL that lists the URLs for all of the brokers in the group. Example 3.4, “Client URL for a Shared JDBC Master/Slave Group” shows the client failover URL for a group that consists of three brokers:
broker1, broker2, and broker3.
Example 3.4. Client URL for a Shared JDBC Master/Slave Group
failover:(tcp://broker1:61616,tcp://broker2:61616,tcp://broker3:61616)
For more information about using the failover protocol see Section 2.1.1, “Static Failover”.
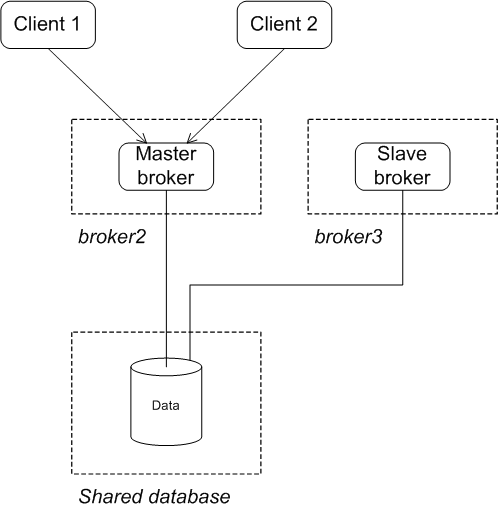
Reintroducing a failed node
You can restart the failed node at any time and it will rejoin the group. It will rejoin the group as a slave because one of the other brokers already owns the mutex lock on the database table, as shown in Figure 3.6, “JDBC Master/Slave after Master Restart”.
Figure 3.6. JDBC Master/Slave after Master Restart