3.2. Ceph 存储集群的低级别监控
作为存储管理员,您可以从低级角度监控 Red Hat Ceph Storage 集群的健康状态。低级监控通常涉及确保 Ceph OSD 正确对等。当发生对等错误时,放置组将处于降级状态。这种降级状态可能是许多不同的事情,如硬件故障、挂起或崩溃的 Ceph 守护进程、网络延迟或完整的站点中断。
3.2.1. 监控放置组设置
当 CRUSH 将 PG 分配给 Ceph OSD 时,它会查看池的副本数量,并将 PG 分配到 Ceph OSD,使得 PG 的每个副本分配到不同的 Ceph OSD。例如,如果池需要三个放置组副本,则 CRUSH 可以分别分配给 osd.1、 osd.2 和 osd.3。CRUSH 实际上寻求伪随机放置,这会考虑您在 CRUSH 映射中设置的故障域,因此您很少会在大型集群中看到放置组被分配给最接近的邻居 Ceph OSD。对于包含特定放置组的 Ceph OSD 集合被称为活跃集(Acting Set)。在某些情况下,Acting Set 中的 OSD 为 down,否则无法在放置组中对对象进行服务请求。当出现这些情况时,不需要紧张。常见示例包括:
- 添加或删除 OSD。然后,CRUSH 将放置组重新分配到其他 Ceph OSD,从而改变了活跃集的组成,并使用 "backfill" 进程生成数据的迁移。
-
Ceph OSD 过去为
down并被重启,现在正在恢复。 -
在活跃集合中的一个 Ceph OSD 为
down,或无法服务请求时,另一个 Ceph OSD 会暂时担负其职责。
Ceph 使用 Up Set 处理客户端请求,这是实际处理请求的 Ceph OSD 集合。在大多数情况下,在线集和活跃集是相同的。如果它们不同,则表明 Ceph 正在迁移数据、Ceph OSD 正在恢复,或出现了问题,Ceph 通常会在此类情形中出现带有 "stuck stale" 消息的 HEALTH WARN 状态。
先决条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 节点的根级别访问权限。
流程
登录到 Cephadm shell:
示例
[root@host01 ~]# cephadm shell
检索放置组列表:
示例
[ceph: root@host01 /]# ceph pg dump
查看对于一个给定的放置组,哪些 Ceph OSD 在 Acting Set 中或在 Up Set 中:
语法
ceph pg map PG_NUM示例
[ceph: root@host01 /]# ceph pg map 128
注意如果设置与 Up Set 和 Acting 设置不匹配,这可能表明存储集群对自身或存储集群潜在的问题进行负载平衡。
3.2.2. Ceph OSD 对等
在将数据写入放置组之前,它必须处于 active 状态,且应该处于 clean 状态。若要让 Ceph 确定放置组的当前状态,PG 的 Primary OSD(活跃集中的第一个 OSD)与二级和三级 OSD 为对等,以变为放置组的当前状态建立协议。假设有三个 PG 副本的池。
图 3.1. 对等(peering)
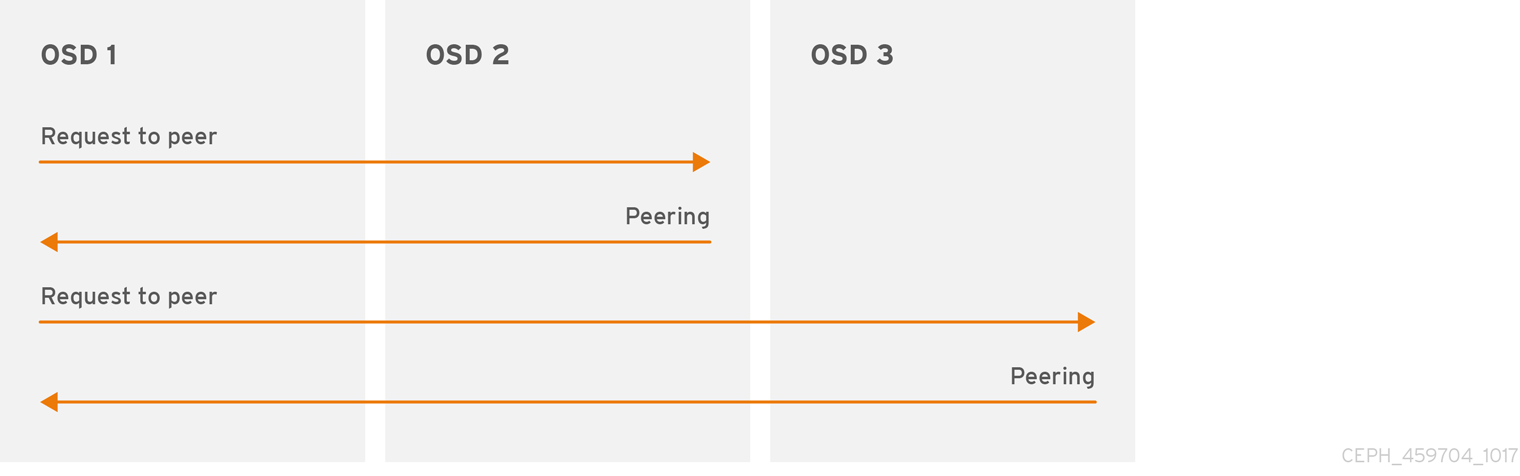
3.2.3. 放置组状态
如果执行诸如 ceph health, ceph -s 或 ceph -w 等命令,您可能会注意到集群并不总是回显 HEALTH OK。检查 OSD 是否在运行后,您也应检查放置组状态。您应该可以预计,在与放置组对等相关的一些情况下,集群不会反映 HEALTH OK :
- 您刚刚创建了一个池,放置组还没有对等。
- 放置组正在恢复。
- 您刚刚向集群添加一个 OSD 或从集群中移除一个 OSD。
- 您刚修改了 CRUSH map,并且已迁移了放置组。
- 在放置组的不同副本中,数据不一致。
- Ceph 清理放置组的副本。
- Ceph 没有足够存储容量来完成回填操作。
如果一个预期的情况导致 Ceph 反映了 HEALTH WARN,请不要紧张。在很多情况下,集群将自行恢复。在某些情况下,您可能需要采取措施。监控放置组的一个重要方面是确保在集群启动并运行所有放置组处于 active 状态,并且最好处于 clean 状态。
要查看所有放置组的状态,请执行:
示例
[ceph: root@host01 /]# ceph pg stat
结果显示放置组映射版本 vNNNNNN、放置组总数 x 以及放置组数量 y 都处于特定的状态,如 active+clean :
vNNNNNN: x pgs: y active+clean; z bytes data, aa MB used, bb GB / cc GB avail
Ceph 通常会报告放置组的多个状态。
Snapshot Trimming PG States
当快照存在时,将报告两个额外的 PG 状态。
-
snaptrim:PG 目前被修剪 -
snaptrim_wait:PG 等待被修剪
输出示例:
244 active+clean+snaptrim_wait 32 active+clean+snaptrim
除了放置组状态外,Ceph 还会回显所使用的数据量,aa(剩余存储容量),bb(放置组的总存储容量)。在一些情况下,这些数字非常重要:
-
您达到了
几乎全满比率或全满比率。 - 由于 CRUSH 配置中的一个错误,您的数据不会分散到集群中。
放置组 ID
放置组 ID 由池的号而不是名称组成,后跟一个句点 (.) 和放置组 ID(一个十六进制数字)。您可以从 ceph osd lspools 的输出中查看池编号及其名称。默认池名称为 data, metadata 和 rbd,分别与池号 0, 1 和 2 对应。完全限定的放置组 ID 的格式如下:
语法
POOL_NUM.PG_ID
输出示例:
0.1f
检索放置组列表:
示例
[ceph: root@host01 /]# ceph pg dump
以 JSON 格式格式化输出并将其保存到文件中:
语法
ceph pg dump -o FILE_NAME --format=json示例
[ceph: root@host01 /]# ceph pg dump -o test --format=json
查询特定放置组:
语法
ceph pg POOL_NUM.PG_ID query
示例
[ceph: root@host01 /]# ceph pg 5.fe query { "snap_trimq": "[]", "snap_trimq_len": 0, "state": "active+clean", "epoch": 2449, "up": [ 3, 8, 10 ], "acting": [ 3, 8, 10 ], "acting_recovery_backfill": [ "3", "8", "10" ], "info": { "pgid": "5.ff", "last_update": "0'0", "last_complete": "0'0", "log_tail": "0'0", "last_user_version": 0, "last_backfill": "MAX", "purged_snaps": [], "history": { "epoch_created": 114, "epoch_pool_created": 82, "last_epoch_started": 2402, "last_interval_started": 2401, "last_epoch_clean": 2402, "last_interval_clean": 2401, "last_epoch_split": 114, "last_epoch_marked_full": 0, "same_up_since": 2401, "same_interval_since": 2401, "same_primary_since": 2086, "last_scrub": "0'0", "last_scrub_stamp": "2021-06-17T01:32:03.763988+0000", "last_deep_scrub": "0'0", "last_deep_scrub_stamp": "2021-06-17T01:32:03.763988+0000", "last_clean_scrub_stamp": "2021-06-17T01:32:03.763988+0000", "prior_readable_until_ub": 0 }, "stats": { "version": "0'0", "reported_seq": "2989", "reported_epoch": "2449", "state": "active+clean", "last_fresh": "2021-06-18T05:16:59.401080+0000", "last_change": "2021-06-17T01:32:03.764162+0000", "last_active": "2021-06-18T05:16:59.401080+0000", ....
其它资源
- 有关快照修剪设置的更多详情,请参阅 Red Hat Ceph Storage Configuration Guide 中的 OSD Object storage daemon configuratopn options 部分的章节 Object Storage Daemon (OSD) configuration options。
3.2.4. 放置组创建状态
在创建池时,将创建您指定的 PG 数量。Ceph 将在创建一个或多个放置组时回显 creating。创建之后,作为 PG Acting 设置一部分的 OSD 将会被对等点。对等点完成后,PG 状态应当为 active+clean,即 Ceph 客户端可以开始写入到 PG。

3.2.5. 放置组对等状态
当 Ceph 对等一个放置组时,Ceph 会将存储放置组副本的 OSD 变为与放置组中的对象和元数据的同意状态。当 Ceph 完成对等时,这意味着存储放置组的 OSD 同意该放置组的当前状态。但是,完成 peering 的进程并不表示每个副本都有最新的内容。
权威历史
Ceph 将不会确认对客户端的写操作,直到该工作集合的所有 OSD 都会保留这个写入操作。这种做法可确保,自上一次成功的对等操作,至少有一个成员具有每个确认的写操作的记录。
通过使用对每个已确认的写入操作的准确记录,Ceph 可以构建并分离 PG 的新权威历史记录。执行后,一组完全排序的操作(如果执行)会将使 OSD 的副本保持最新状态。
3.2.6. 放置组激活状态
Ceph 完成对等进程后,PG 可能会变为 active 状态。Active 状态表示放置组中的数据通常在主放置组中可用,而副本用于读取和写入操作。
3.2.7. 放置组清理状态
当放置组处于 clean 状态时,主 OSD 和副本 OSD 已成功对等,并且放置组没有预先复制。Ceph 复制 PG 中正确次数的所有对象。
3.2.8. 放置组降级状态
当客户端将对象写入 Primary OSD 时,OSD 负责将副本写入副本 OSD。在主 OSD 将对象写入存储后,PG 将会维持为 degraded 状态,直到主 OSD 收到来自副本 OSD 的 Ceph 已成功创建副本对象的确认。
PG 可以是 active+degraded 的原因是,OSD 可以处于 active 状态,尽管它还没有保存所有对象。如果 OSD 停机,Ceph 会将分配到 OSD 的每个 PG 标记为 degraded。当 Ceph OSD 重新上线时,Ceph OSD 必须再次进行对等。但是,如果客户端处于 active 状态,客户端仍然可以将新对象写入到一个降级的(degraded) PG。
如果 OSD 为 down 并且一直处于 degraded 状况,Ceph 可能会将 down OSD 标记为集群 out,并将 down OSD 的数据重新映射到另一个 OSD。在标记为 down 和标记为 out 之间的时间由 mon_osd_down_out_interval 控制。它被默认设置为 600 秒。
放置组也可以为 degraded,因为 Ceph 找不到一个或多个 Ceph 认为应该在放置组里的对象。虽然您无法读取或写入到未找到的对象,但您仍可以访问 degraded PG 中所有其他对象。
例如,如果在三方副本池中有九个 OSD:如果 OSD 数量 9 停机,分配给 OSD 9 的 PG 会进入降级状态。如果 OSD 9 没有恢复,则会退出存储集群和存储集群会重新平衡。在这种情况下,PG 被降级,然后恢复到 active 状态。
3.2.9. 放置组恢复状态
Ceph 设计为容错性,可以大规模地出现硬件和软件问题持续发展的问题。当 OSD 为 down 时,其内容可能落后于 PG 中其他副本的当前状态。当 OSD 变为 up,必须更新放置组的内容,以反映当前状态。在该时间段内,OSD 可能会处于 recovering 状态。
恢复并不总是不重要,因为硬件故障可能会导致多个 Ceph OSD 的级联故障。例如,一个机箱中的网络交换机可能会失败,这可能会导致多个主机机器的 OSD 落后于存储集群的当前状态。在错误解决后,每个 OSD 必须恢复。
Ceph 提供了多个设置,用于在新服务请求和恢复数据对象之间平衡资源争用,并将放置组恢复到当前状态。osd recovery delay start 设置允许 OSD 重新启动、重复操作,甚至在开始恢复过程前处理一些重播请求。osd recovery threads 设置限制恢复过程的线程数量,默认为一个线程。osd recovery thread timeout 设置一个线程超时,因为多个 Ceph OSD 失败,会以不同的频率重启和重新对等。osd recovery max active 设置限制了 Ceph OSD 可以同时处理的恢复请求数量,以防止 Ceph OSD 无法提供。osd recovery max chunk 设置限制了恢复的数据块的大小,以防止网络拥塞。
3.2.10. Back fill 状态
当新的 Ceph OSD 加入存储集群时,libvirt 会将放置组从集群中的 OSD 重新分配到新添加的 Ceph OSD。强制新 OSD 接受重新分配的 PG,可立即对新的 Ceph OSD 产生过量负载。使用放置组回填 OSD 使此过程在后台开始。回填完成后,新 OSD 会在请求就绪时开始提供请求。
在回填操作中,您可能会看到以下几个状态之一:
-
backfill_wait表示回填操作是待处理,但还没有进行。 -
backfill表示回填操作正在进行 -
back_too_full表示请求回填操作,但可能会因为存储容量不足而无法完成。
当无法回填放置组时,它被视为不完整。
Ceph 提供了多个设置,以管理与将放置组重新分配给 Ceph OSD(特别是新的 Ceph OSD)关联的负载激增。默认情况下,osd_max_backfills 将最大并发回填数量(来自或到一个 Ceph OSD)设置为 10。osd backfill full ratio 可让 Ceph OSD 在 OSD 接近其完整比率时拒绝回填请求,默认为 85%。如果 OSD 拒绝回填请求,osd backfill retry interval 可让 OSD 在 10 秒后重试请求。OSD 也可以设置 osd backfill scan min 和 osd backfill scan max,以管理扫描间隔(默认为 64 和 512)。
对于某些工作负载,完全避免常规恢复并使用回填会很有帮助。由于回填在后台发生,因此这允许 I/O 继续进行 OSD 中的对象。您可以通过将 osd_min_pg_log_entries 选项设置为 1,并将 osd_max_pg_log_entries 选项设置为 2 来强制进行回填,而不是恢复。当这个情况与您的工作负载相符,请联系您的红帽支持团队。
3.2.11. PG 重新映射状态
当决定服务设置放置组更改时,数据会从旧操作集迁移到新行为集。这可能需要经过一定时间后,新的 Primary OSD 才会处理服务请求。因此,可能需要旧的主系统继续服务请求,直到放置组迁移完成为止。数据迁移完成后,映射将使用新操作集合的 Primary OSD。
3.2.12. 放置组已过时状态
虽然 Ceph 使用心跳来确保主机和守护进程正在运行,ceph-osd 守护进程也会在没有及时报告统计数据的情况下变为 stuck 状态。例如,临时网络故障。默认情况下,OSD 守护进程每半秒钟报告其放置组、启动和失败统计,即 0.5,它比心跳阈值更频繁。如果放置组所采取集合的 Primary OSD 报告监控器失败,或者其他 OSD 报告了 Primary OSD down,则监视器会将 PG 标记为 stale。
当您启动存储集群时,通常会看到 stale 状态,直到对等进程完成为止。在存储集群运行一段时间后,如果放置组处于 stale 状态则代表这些放置组的主 OSD 的状态为 down 或者没有向监控器报告放置组统计信息。
3.2.13. 放置组错误替换状态
当 PG 临时映射到一个 OSD 时会有一些临时回填情况。当这个临时状态已不存在时,PG 可能仍然位于临时位置,而没有位于正确的位置。在这种情况下,它们被认为是 misplaced。这是因为实际上存在正确的额外副本数量,但一个或多个副本位于错误的地方。
例如,有 3 个 OSD:0、1,2 和所有 PG 映射到这三个。如果您添加了另一个 OSD(OSD 3),一些 PG 现在将映射到 OSD 3,而不是另一个 OSD 3。但是,在 OSD 3 回填之前,PG 有一个临时映射,允许它继续从旧映射提供 I/O。在此期间,PG 为 misplaced,因为它有一个临时映射,但不是 degraded,因为存在 3 个副本。
示例
pg 1.5: up=acting: [0,1,2]
ADD_OSD_3
pg 1.5: up: [0,3,1] acting: [0,1,2]
[0,1,2] 是一个临时映射,因此 up 与 acting 并不完全相同。PG 为 misplaced 而不是 degraded,因为 [0,1,2] 仍然是三个副本。
示例
pg 1.5: up=acting: [0,3,1]
OSD 3 现在被回填,临时映射已被删除,而不是降级。
3.2.14. 放置组不完整状态
当内容不完整且对等失败(没有足够完整的 OSD 来执行恢复),PG 就会变为 incomplete 状态。
假设 OSD 1、2 和 3 是活跃的 OSD 集,它切换到 OSD 1、4 和 3,然后 osd.1 将请求一个临时活跃集包括 OSD 1、2 和 3,同时对 OSD 4 进行回填。在此期间,如果 OSD 1、2 和 3 都停机,则 osd.4 将是唯一没有完全回填所有数据的 OSD。此时,PG 会变为 incomplete,表明没有足够完整的 OSD 来执行恢复。
另外,如果没有涉及 osd.4,并且在 OSD 1、2 和 3 停机时,如果 osd.4 没有被涉及到,并且当 OSD 1、2 和 3 停机时,PG 就有可能变为 stale,这代表 mons 没有在这个 PG 上听到任何信息,因为执行集发生了变化。没有 OSD 以通知新的 OSD 的原因。
3.2.15. 找出卡住的 PG
仅仅因为放置组没有处于 active+clean 状态,并不一定代表它存在问题。通常,当 PG 卡住时,Ceph 无法进行自我修复。卡住状态包括:
- Unclean: 放置组包含不会复制所需次数的对象。它们应该正在进行恢复。
-
Inactive :放置组无法处理读取或写入,因为它们正在等待具有最新数据的 OSD 返回到
up状态。 -
Stale:放置组处于未知状态,因为托管它们的 OSD 在一段时间内未报告到监控集群,并可使用
mon osd report timeout配置。
先决条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 节点的根级别访问权限。
流程
要识别卡的放置组,请执行以下操作:
语法
ceph pg dump_stuck {inactive|unclean|stale|undersized|degraded [inactive|unclean|stale|undersized|degraded...]} {<int>}示例
[ceph: root@host01 /]# ceph pg dump_stuck stale OK
3.2.16. 查找对象的位置
Ceph 客户端检索最新的集群映射,并且 CRUSH 算法计算如何将对象映射到放置组,然后计算如何动态将 PG 分配给 OSD。
先决条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 节点的根级别访问权限。
流程
要查找对象位置,您需要对象名称和池名称:
语法
ceph osd map POOL_NAME OBJECT_NAME
示例
[ceph: root@host01 /]# ceph osd map mypool myobject