第 1 章 Data Grid 部署模型和使用案例
数据网格提供灵活的部署模型,支持多种用例。
- 显著提高红帽 Build of Quarkus、Red Hat JBoss EAP 和 Spring 应用程序的性能。
- 确保服务可用性和连续性。
- 降低运营成本。
1.1. 数据网格部署模型
数据网格有两个用于缓存、远程和嵌入的部署模型。与传统数据库系统相比,两种部署模型都允许应用程序在读取操作和更高吞吐量的情况下访问数据,同时提高写操作的速度。
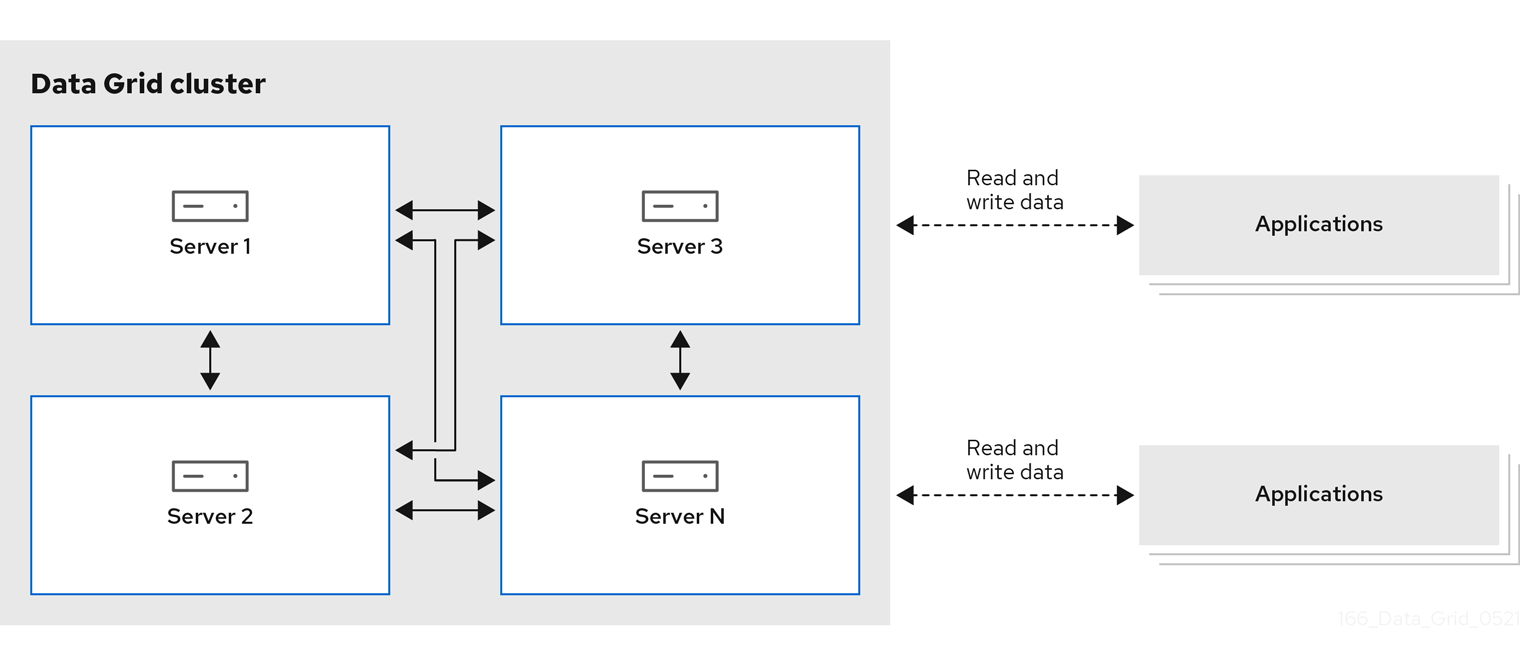
- 远程缓存
- 数据网格服务器节点在专用的 Java 虚拟机(JVM)中运行。客户端使用 Hot Rod、二进制 TCP 协议或 REST 通过 HTTP 访问远程缓存。
- 嵌入缓存
- 数据网格与 Java 应用程序在同一个 JVM 中运行,这意味着数据存储在执行代码的内存空间中。
红帽建议在大多数部署中使用服务器/客户端架构。使用远程缓存部署速度要快得多,因为数据层与业务逻辑分离。Data Grid Server 还提供监控和可观察性功能,以及其它内置功能以帮助您降低开发成本。
近乎缓存
近乎缓存功能允许远程客户端在本地存储数据,这意味着读取密集型应用程序不需要在每次调用时遍历网络。近乎缓存可显著增加读取操作速度,并获得与嵌入式缓存相同的性能。
图 1.1. 远程缓存部署模型
1.1.1. 平台和自动化工具
实现所需的服务质量意味着提供数据网格最优的 CPU 和 RAM 资源。太多资源降级了数据网格性能,同时使用过多的主机资源可以快速增加成本。
在对数据网格集群进行基准测试和调优以找到正确的 CPU 或 RAM 分配时,您应考虑哪个主机平台提供正确的自动化工具,以有效地扩展和管理资源。
裸机或虚拟机
结合 RHEL 或 Microsoft Windows,红帽 Ansible 用于管理数据网格配置并轮询服务,以确保可用性达到最佳资源使用。
Data Grid 的 Ansible 集合,可通过 Automation Hub 自动执行集群安装,并包括 Keycloak 集成和跨站点复制选项。
OpenShift
利用 Kubernetes 编排来自动置备 pod,对资源施加限制,并自动扩展数据网格集群来满足工作负载需求。