8.5. 聚合器
概述
图 8.5 “聚合器模式” 中显示的 聚合器 模式允许您将相关消息批量组合成单个消息。
图 8.5. 聚合器模式
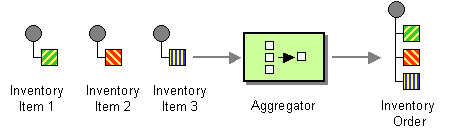
为了控制聚合器的行为,Apache Camel 允许您指定 企业集成模式 中描述的属性,如下所示:
- 关联表达式 HEKETI-是确定应将哪些消息聚合在一起。关联表达式在每个传入消息上评估,以生成 关联键。具有相同关联键的传入消息会分组到同一个批处理中。例如,如果要将 所有传入 的信息聚合到一个消息中,您可以使用恒定表达式。
- 完成一批消息时,完整性条件.您可以将它指定为简单大小限制,或者更频繁地指定在批处理完成后标记的 predicate 条件。
- 将单个关联密钥的消息交换 聚合 聚合到一个消息交换中。
例如,假设一个股票市场数据系统每秒接收 30,000 个消息。如果您的 GUI 工具无法应对这样的大规模更新率,您可能希望减慢消息流。传入的股票引号可以通过选择最新的引号并丢弃旧的价格来聚合。(如果您想捕获某些历史记录,您可以应用 delta 处理算法。)
现在,聚合器使用包括更多信息的 ManagedAggregateProcessorMBean 的 JMX 中的 enlists。它允许您使用聚合控制器来控制它。
聚合器如何工作
图 8.6 “聚合器实施” 显示聚合器的工作方式概述,假设它是与具有关联键(如 A、B、C 或 D)的交换流。
图 8.6. 聚合器实施
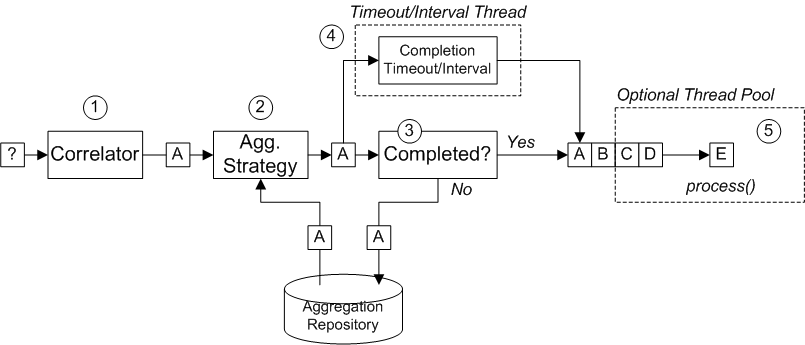
图 8.6 “聚合器实施” 中显示的交换的传入流处理如下:
- correlator 负责根据关联密钥排序交换。对于每个传入的交换,将评估关联表达式,生成关联密钥。例如,对于 图 8.6 “聚合器实施” 中显示的交换,关联密钥评估为 A。
聚合策略 负责将交换与相同的关联键合并。当一个新交换时,A 会被放入,聚合器会在聚合存储库中查找对应的 聚合交换、A',并将它与新的交换合并。
在完成了特定的聚合周期前,传入的交换会与相应的聚合交换不断聚合。聚合周期会持续到由其中一个完成机制终止为止。
注意从 Camel 2.16,新的 XSLT 聚合策略允许您将两个消息与 XSLT 文件合并。您可以从 toolbox 访问
AggregationStrategies.xslt ()文件。如果在聚合器上指定了 completion predicate,则会测试聚合交换,以确定它是否已准备好发送到路由中的下一个处理器。处理会继续,如下所示:
- 如果完成,聚合交换由路由的后方部分处理。这有两种替代模型: 同步 (默认),这会导致调用线程阻止或 异步 (如果启用了并行处理),其中聚合交换将提交到 executor 线程池(如 图 8.6 “聚合器实施”所示)。
- 如果没有完成,聚合交换会保存回聚合存储库。
-
与同步的完成测试并行,可以通过启用
completionTimeout选项或completionInterval选项来启用异步完成测试。这些完成测试在单独的线程中运行,每当完成测试满足时,对应的交换都会标记为完成并开始由路由的后部分处理(同步或异步处理,具体取决于是否启用并行处理)。 - 如果启用了并行处理,线程池负责处理路由后部分的交换。默认情况下,这个线程池包含十个线程,但您可以选择自定义池(“线程选项”一节)。
Java DSL 示例
以下示例使用 UseLatestAggregationStrategy 聚合策略,聚合具有相同 StockSymbol 标头值的交换。对于给定的 StockSymbol 值,自上次收到关联密钥后的三秒以上,则聚合交换被视为已完成,并发送到 模拟 端点。
from("direct:start")
.aggregate(header("id"), new UseLatestAggregationStrategy())
.completionTimeout(3000)
.to("mock:aggregated");XML DSL 示例
以下示例演示了如何在 XML 中配置相同的路由:
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<aggregate strategyRef="aggregatorStrategy"
completionTimeout="3000">
<correlationExpression>
<simple>header.StockSymbol</simple>
</correlationExpression>
<to uri="mock:aggregated"/>
</aggregate>
</route>
</camelContext>
<bean id="aggregatorStrategy"
class="org.apache.camel.processor.aggregate.UseLatestAggregationStrategy"/>指定关联表达式
在 Java DSL 中,关联表达式始终作为第一个参数传递给 aggregate () DSL 命令。您不限于此处使用简单表达式语言。您可以使用任何表达式语言或脚本语言(如 XPath、XQuery、SQL 等)指定关联表达式。
对于考试,要使用 XPath 表达式来关联交换,您可以使用以下 Java DSL 路由:
from("direct:start")
.aggregate(xpath("/stockQuote/@symbol"), new UseLatestAggregationStrategy())
.completionTimeout(3000)
.to("mock:aggregated");
如果无法在特定的传入交换上评估关联表达式,则聚合器默认抛出 CamelExchangeException。您可以通过设置 ignoreInvalidCorrelationKeys 选项来限制这个异常。例如,在 Java DSL 中:
from(...).aggregate(...).ignoreInvalidCorrelationKeys()
在 XML DSL 中,您可以将 ignoreInvalidCorrelationKeys 选项设置为属性,如下所示:
<aggregate strategyRef="aggregatorStrategy"
ignoreInvalidCorrelationKeys="true"
...>
...
</aggregate>指定聚合策略
在 Java DSL 中,您可以将聚合策略作为第二个参数传递给 aggregate () DSL 命令,或使用 aggregationStrategy () 子句指定它。例如,您可以使用 aggregationStrategy () 子句,如下所示:
from("direct:start")
.aggregate(header("id"))
.aggregationStrategy(new UseLatestAggregationStrategy())
.completionTimeout(3000)
.to("mock:aggregated");
Apache Camel 提供以下基本聚合策略(类属于 org.apache.camel.processor.aggregate Java 软件包):
UseLatestAggregationStrategy- 返回给定关联密钥的最后交换,丢弃所有之前使用此密钥的交换。例如,此策略对于从库存交易中节流源非常有用,您只想了解特定股票符号的最新价格。
UseOriginalAggregationStrategy-
返回给定关联密钥的第一个交换,并丢弃此密钥的所有后期交换。您必须先调用
UseOriginalAggregationStrategy.setOriginal ()来设置第一个交换,然后才能使用此策略。 GroupedExchangeAggregationStrategy-
将给定关联密钥 的所有 交换连接到列表,该列表存储在
Exchange.GROUPED_EXCHANGE交换属性中。请参阅 “分组的交换”一节。
实施自定义聚合策略
如果要应用不同的聚合策略,可以实施以下聚合策略基本接口之一:
org.apache.camel.processor.aggregate.AggregationStrategy- 基本聚合策略接口。
org.apache.camel.processor.aggregate.TimeoutAwareAggregationStrategy实现此接口,如果您希望实施在聚合周期超时时收到通知。
超时通知方法有以下签名:void timeout(Exchange oldExchange, int index, int total, long timeout)
org.apache.camel.processor.aggregate.CompletionAwareAggregationStrategy如果一个聚合周期可以正常完成时,实施此接口,以接收通知。通知方法有以下签名:
void onCompletion(Exchange exchange)
例如,以下代码显示了两种不同的自定义聚合策略,即 StringAggregationStrategy 和 ArrayListAggregationStrategy::
//simply combines Exchange String body values using '' as a delimiter class StringAggregationStrategy implements AggregationStrategy { public Exchange aggregate(Exchange oldExchange, Exchange newExchange) { if (oldExchange == null) { return newExchange; } String oldBody = oldExchange.getIn().getBody(String.class); String newBody = newExchange.getIn().getBody(String.class); oldExchange.getIn().setBody(oldBody + "" + newBody); return oldExchange; } } //simply combines Exchange body values into an ArrayList<Object> class ArrayListAggregationStrategy implements AggregationStrategy { public Exchange aggregate(Exchange oldExchange, Exchange newExchange) { Object newBody = newExchange.getIn().getBody(); ArrayList<Object> list = null; if (oldExchange == null) { list = new ArrayList<Object>(); list.add(newBody); newExchange.getIn().setBody(list); return newExchange; } else { list = oldExchange.getIn().getBody(ArrayList.class); list.add(newBody); return oldExchange; } } }
自 Apache Camel 2.0 起,还会为非常第一个交换调用 AggregationStrategy.aggregate () 回调方法。在聚合方法的第一次 调用时,oldExchange 参数为 null,newExchange 参数包含第一个传入的交换。
要使用自定义策略类( ArrayListAggregationStrategy )来聚合消息,请定义类似如下的路由:
from("direct:start")
.aggregate(header("StockSymbol"), new ArrayListAggregationStrategy())
.completionTimeout(3000)
.to("mock:result");您还可以在 XML 中使用自定义聚合策略配置路由,如下所示:
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<aggregate strategyRef="aggregatorStrategy"
completionTimeout="3000">
<correlationExpression>
<simple>header.StockSymbol</simple>
</correlationExpression>
<to uri="mock:aggregated"/>
</aggregate>
</route>
</camelContext>
<bean id="aggregatorStrategy" class="com.my_package_name.ArrayListAggregationStrategy"/>控制自定义聚合策略的生命周期
您可以实施自定义聚合策略,以便其生命周期与控制它的企业集成模式的生命周期一致。这对于确保聚合策略可以安全关闭非常有用。
要实施具有生命周期支持的聚合策略,您必须实施 org.apache.camel.Service 接口(除了 AggregationStrategy 接口),并提供 start () 和 stop () 生命周期方法的实现。例如,以下代码示例显示了带有生命周期支持的聚合策略概述:
// Java
import org.apache.camel.processor.aggregate.AggregationStrategy;
import org.apache.camel.Service;
import java.lang.Exception;
...
class MyAggStrategyWithLifecycleControl
implements AggregationStrategy, Service {
public Exchange aggregate(Exchange oldExchange, Exchange newExchange) {
// Implementation not shown...
...
}
public void start() throws Exception {
// Actions to perform when the enclosing EIP starts up
...
}
public void stop() throws Exception {
// Actions to perform when the enclosing EIP is stopping
...
}
}Exchange 属性
在每个聚合交换上设置以下属性:
| 标头 | 类型 | 描述 Aggregated Exchange Properties |
|---|---|---|
|
|
| 聚合至此交换的交换总数。 |
|
|
|
指明负责完成聚合交换的机制。可能的值有: |
SQL 组件聚合存储库在交换上设置以下属性(请参阅 “持久性聚合存储库”一节):
| 标头 | 类型 | 描述 Redelivered Exchange Properties |
|---|---|---|
|
|
|
当前重新传送尝试的序列号(从 |
指定完成条件
必须至少 指定一个完成条件,这决定了聚合交换何时保留聚合器并继续路由上的下一个节点。可以指定以下完成条件:
completionPredicate-
在聚合每个交换后评估 predicate,以确定完整性。值为
true表示聚合交换已完成。另外,您还可以定义实现Predicate接口的自定义AggregationStrategy,在这种情况下,AggregationStrategy将用作 completion predicate。 completionSize- 在聚合指定数量的传入交换后完成聚合交换。
completionTimeout(与
completionInterval兼容) 在指定的超时时间内没有聚合,则完成聚合交换。换句话说,超时机制会跟踪 每个 关联键值的超时。在收到带有特定键值的最新交换后,时钟开始勾选。如果在指定超时中 没有收到 具有相同 key 值的另一个交换,则对应的聚合交换会被标记为完成并发送到路由上的下一个节点。
completionInterval(与
completionTimeout不兼容) 可在每个时间间隔(指定长度)过后 完成所有 未完成的聚合交换。间隔 不是 为每个聚合交换量身定制的。这种机制会强制完成所有未完成的聚合交换。因此,在某些情况下,此机制可以在启动聚合后立即完成聚合交换。
completionFromBatchConsumer- 当与支持 批处理消费者 机制的消费者端点结合使用时,此完成选项会在当前批处理完成后自动找出它从消费者端点接收的信息。请参阅 “批处理消费者”一节。
forceCompletionOnStop- 启用此选项后,它会在当前路由上下文停止时强制完成所有未完成的聚合交换。
前面的完成条件可以任意组合,但 completionTimeout 和 completionInterval 条件除外,这些条件不能同时启用。当条件组合使用时,常规规则是触发的第一个完成条件是有效的完成条件。
指定完成 predicate
您可以指定一个任意 predicate 表达式,用于决定聚合交换何时完成。评估 predicate 表达式的方法有两种:
- 在最新的聚合交换 swig-wagon 中,这是默认行为。
-
在最新的传入的交换 5-4-wagon 中,当您启用
eagerCheckCompletion选项时,会选择此行为。
例如,如果您要在每次收到 ALERT 消息时终止库存引号流(如最新传入交换中的 MsgType 标头值所示),您可以定义一个类似于以下内容的路由:
from("direct:start")
.aggregate(
header("id"),
new UseLatestAggregationStrategy()
)
.completionPredicate(
header("MsgType").isEqualTo("ALERT")
)
.eagerCheckCompletion()
.to("mock:result");以下示例演示了如何使用 XML 配置相同的路由:
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<aggregate strategyRef="aggregatorStrategy"
eagerCheckCompletion="true">
<correlationExpression>
<simple>header.StockSymbol</simple>
</correlationExpression>
<completionPredicate>
<simple>$MsgType = 'ALERT'</simple>
</completionPredicate>
<to uri="mock:result"/>
</aggregate>
</route>
</camelContext>
<bean id="aggregatorStrategy"
class="org.apache.camel.processor.aggregate.UseLatestAggregationStrategy"/>指定动态完成超时
可以指定 动态完成超时,其中为每个传入的交换重新计算超时值。例如,要为每个传入交换中的 timeout 标头设置超时值,您可以按照以下方式定义路由:
from("direct:start")
.aggregate(header("StockSymbol"), new UseLatestAggregationStrategy())
.completionTimeout(header("timeout"))
.to("mock:aggregated");您可以在 XML DSL 中配置相同的路由,如下所示:
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<aggregate strategyRef="aggregatorStrategy">
<correlationExpression>
<simple>header.StockSymbol</simple>
</correlationExpression>
<completionTimeout>
<header>timeout</header>
</completionTimeout>
<to uri="mock:aggregated"/>
</aggregate>
</route>
</camelContext>
<bean id="aggregatorStrategy"
class="org.apache.camel.processor.UseLatestAggregationStrategy"/>
您还可以添加固定的超时值,如果动态值为 null 或 0, 则 Apache Camel 将回退到使用这个值。
指定动态完成大小
可以指定 动态完成大小,其中为每个传入的交换重新计算完成大小。例如,要在每个传入的交换中设置 mySize 标头的完成大小,您可以定义一个路由,如下所示:
from("direct:start")
.aggregate(header("StockSymbol"), new UseLatestAggregationStrategy())
.completionSize(header("mySize"))
.to("mock:aggregated");和使用 Spring XML 的同一示例:
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<aggregate strategyRef="aggregatorStrategy">
<correlationExpression>
<simple>header.StockSymbol</simple>
</correlationExpression>
<completionSize>
<header>mySize</header>
</completionSize>
<to uri="mock:aggregated"/>
</aggregate>
</route>
</camelContext>
<bean id="aggregatorStrategy"
class="org.apache.camel.processor.UseLatestAggregationStrategy"/>
您还可以添加固定大小值,如果动态值为 null 或 0, 则 Apache Camel 将回退到使用这个值。
在 AggregationStrategy 中强制完成单个组
如果您实施自定义 AggregationStrategy 类,则有一个机制来强制完成当前消息组,方法是在 AggregationStrategy 交换属性设置为 .aggregate () 方法返回的交换属性上将 Exchange.AGGREGATION_COMPLETE_CURRENTtrue。此机制 仅影响 当前组:其他消息组(具有不同关联 ID) 不会被 强制完成。此机制会覆盖任何其他完成机制,如 predicate、size、timeout 等。
例如,如果消息正文大小大于 5,则以下示例 AggregationStrategy 类完成当前的组:
// Java
public final class MyCompletionStrategy implements AggregationStrategy {
@Override
public Exchange aggregate(Exchange oldExchange, Exchange newExchange) {
if (oldExchange == null) {
return newExchange;
}
String body = oldExchange.getIn().getBody(String.class) + "+"
+ newExchange.getIn().getBody(String.class);
oldExchange.getIn().setBody(body);
if (body.length() >= 5) {
oldExchange.setProperty(Exchange.AGGREGATION_COMPLETE_CURRENT_GROUP, true);
}
return oldExchange;
}
}使用特殊消息强制完成所有组
通过向路由发送带有特殊标头的消息,可以强制完成所有未完成的聚合消息。您可以使用两种替代标头设置来强制完成:
Exchange.AGGREGATION_COMPLETE_ALL_GROUPS-
设置为
true,以强制完成当前聚合周期。此消息单纯充当信号,不包含在 任何聚合周期中。处理此信号消息后,消息的内容将被丢弃。 Exchange.AGGREGATION_COMPLETE_ALL_GROUPS_INCLUSIVE-
设置为
true,以强制完成当前聚合周期。此消息 包含在 当前的聚合周期中。
使用 AggregateController
org.apache.camel.processor.aggregate.AggregateController 可让您使用 Java 或 JMX API 在运行时控制聚合。这可用于强制完成一组交换,或查询当前的运行时统计信息。
如果没有配置自定义,聚合器会提供默认的实现,您可以使用 getAggregateController () 方法进行访问。但是,使用 aggregateController 在路由中轻松配置控制器。
private AggregateController controller = new DefaultAggregateController();
from("direct:start")
.aggregate(header("id"), new MyAggregationStrategy()).completionSize(10).id("myAggregator")
.aggregateController(controller)
.to("mock:aggregated");
另外,您可以使用 AggregateController上的 API 来强制完成。例如,使用键 foo 完成组
int groups = controller.forceCompletionOfGroup("foo");返回的数字将是已完成的组数。以下是完成所有组的 API:
int groups = controller.forceCompletionOfAllGroups();
强制唯一关联键
在一些聚合场景中,您可能希望强制条件,使关联键对于每个批处理交换是唯一的。换句话说,当特定关联密钥的聚合交换完成时,您希望确保不允许与该关联键进行进一步聚合的交换。例如,如果路由的后者部分需要处理具有唯一关联键值的交换,您可能希望强制实施此条件。
根据完成条件的配置方式,使用特定的关联键可能会存在多个聚合交换的风险。例如,虽然您可以定义一个完成 predicate,它旨在等待收到带有特定关联键 的所有 交换,但您可能也定义完成超时,这可以在使用该键到达的所有交换前触发。在这种情况下,late-arriving 交换可能会以相同的关联键值增加到 第二个 聚合交换。
在这种情况下,您可以通过设置 closeCorrelationKeyOnCompletion 选项,将聚合器配置为阻止重复关联密钥值的聚合交换。为了抑制重复关联键值,需要聚合器在缓存中记录以前的关联密钥值。此缓存的大小(缓存的关联密钥数量)指定为 closeCorrelationKeyOnCompletion () DSL 命令的参数。要指定无限大小的缓存,您可以传递值为零或负整数。例如,指定 10000 键值的缓存大小:
from("direct:start")
.aggregate(header("UniqueBatchID"), new MyConcatenateStrategy())
.completionSize(header("mySize"))
.closeCorrelationKeyOnCompletion(10000)
.to("mock:aggregated");
如果聚合交换以重复的关联键值完成,聚合器会抛出 ClosedCorrelationKeyException 异常。
使用简单表达式的基于流的处理
您可以使用 Simple 语言表达式作为令牌,并在流模式下通过 tokenizeXML 子命令使用。使用简单语言表达式将启用对动态令牌的支持。
例如,若要使用 Java 将一系列名称分割为标签 人员,您可以使用令牌化 XML Bean 和简单语言令牌将文件分成 name 元素。
public void testTokenizeXMLPairSimple() throws Exception {
Expression exp = TokenizeLanguage.tokenizeXML("${header.foo}", null);
获取由 < person > 划分的名称的输入字符串,并将 < ;person& gt; 设置为令牌。
exchange.getIn().setHeader("foo", "<person>");
exchange.getIn().setBody("<persons><person>James</person><person>Claus</person><person>Jonathan</person><person>Hadrian</person></persons>");列出从输入中分割的名称。
List<?> names = exp.evaluate(exchange, List.class);
assertEquals(4, names.size());
assertEquals("<person>James</person>", names.get(0));
assertEquals("<person>Claus</person>", names.get(1));
assertEquals("<person>Jonathan</person>", names.get(2));
assertEquals("<person>Hadrian</person>", names.get(3));
}分组的交换
您可以将传出批处理中的所有聚合交换合并到一个 org.apache.camel.impl.GroupedExchange holder 类中。要启用分组的交换,请指定 groupExchanges () 选项,如以下 Java DSL 路由中所示:
from("direct:start")
.aggregate(header("StockSymbol"))
.completionTimeout(3000)
.groupExchanges()
.to("mock:result");
发送到 mock:result 的分组交换包含消息正文中的聚合交换列表。以下行的代码显示了后续处理器如何以列表的形式访问分组交换的内容:
// Java List<Exchange> grouped = ex.getIn().getBody(List.class);
启用分组的交换功能时,不得 配置聚合策略(分组的交换功能本身就是聚合策略)。
从传出交换上的属性访问分组交换的旧方法现已弃用,并将在以后的发行版本中删除。
批处理消费者
聚合器可与 批处理消费者 模式协同工作,以聚合批处理消费者报告的消息总数(批处理消费者端点设置 CamelBatchSize、CamelBatchIndex、CamelBatchIndex 和 CamelBatchComplete 属性)。例如,要聚合 File consumer 端点找到的所有文件,您可以使用类似如下的路由:
from("file://inbox")
.aggregate(xpath("//order/@customerId"), new AggregateCustomerOrderStrategy())
.completionFromBatchConsumer()
.to("bean:processOrder");目前,以下端点支持批处理消费者机制:file、FTP、Mail、iBatis 和 JPA。
持久性聚合存储库
默认聚合器仅使用内存的 AggregationRepository。如果要持久存储待处理的聚合交换,您可以使用 SQL 组件作为 持久聚合存储库。SQL 组件包含一个 JdbcAggregationRepository,可持续保留聚合消息,并确保您不会丢失任何消息。
成功处理交换后,当存储库上调用 confirm 方法时,它将标记为 complete。这意味着,如果同一交换再次失败,它将重试,直到成功为止。
添加对 camel-sql 的依赖关系
要使用 SQL 组件,您必须在项目中包含对 camel-sql 的依赖项。例如,如果您使用 Maven pom.xml 文件:
<dependency>
<groupId>org.apache.camel</groupId>
<artifactId>camel-sql</artifactId>
<version>x.x.x</version>
<!-- use the same version as your Camel core version -->
</dependency>创建聚合数据库表
您必须创建单独的聚合和已完成的数据库表以实现持久性。例如,以下查询会为名为 my_aggregation_repo 的数据库创建表:
CREATE TABLE my_aggregation_repo ( id varchar(255) NOT NULL, exchange blob NOT NULL, constraint aggregation_pk PRIMARY KEY (id) ); CREATE TABLE my_aggregation_repo_completed ( id varchar(255) NOT NULL, exchange blob NOT NULL, constraint aggregation_completed_pk PRIMARY KEY (id) ); }
配置聚合存储库
您还必须在框架 XML 文件中配置聚合存储库(如 Spring 或 Blueprint):
<bean id="my_repo"
class="org.apache.camel.processor.aggregate.jdbc.JdbcAggregationRepository">
<property name="repositoryName" value="my_aggregation_repo"/>
<property name="transactionManager" ref="my_tx_manager"/>
<property name="dataSource" ref="my_data_source"/>
...
</bean>
repositoryName、transactionManager 和 dataSource 属性是必需的。有关持久聚合存储库的更多配置选项的详情,请参阅 Apache Camel 组件参考指南 中的 SQL 组件。
线程选项
如 图 8.6 “聚合器实施” 所示,聚合器与路由的后方部分分离,其中发送到路由的后一种交换由专用线程池处理。默认情况下,这个池仅包含一个线程。如果要指定具有多个线程的池,请启用 parallelProcessing 选项,如下所示:
from("direct:start")
.aggregate(header("id"), new UseLatestAggregationStrategy())
.completionTimeout(3000)
.parallelProcessing()
.to("mock:aggregated");默认情况下,这会创建一个有 10 个 worker 线程的池。
如果要对创建的线程池进行更多控制,请使用 executorService 选项指定自定义 java.util.concurrent.ExecutorService 实例(在这种情况下,不需要启用 parallelProcess 选项)。
聚合到一个列表
常见的聚合方案涉及将一系列传入消息聚合到一个 List 对象中。为了促进这种情况,Apache Camel 提供了 AbstractListAggregationStrategy 抽象类,您可以快速扩展该类来为这种情况创建聚合策略。传入的消息正文类型 T 会被聚合到一个已完成的交换中,消息正文类型为 List<T>。
例如,要将一系列 Integer 消息正文聚合到一个 List<Integer& gt; 对象中,您可以使用定义的聚合策略:
import org.apache.camel.processor.aggregate.AbstractListAggregationStrategy;
...
/**
* Strategy to aggregate integers into a List<Integer>.
*/
public final class MyListOfNumbersStrategy extends AbstractListAggregationStrategy<Integer> {
@Override
public Integer getValue(Exchange exchange) {
// the message body contains a number, so just return that as-is
return exchange.getIn().getBody(Integer.class);
}
}聚合器选项
聚合器支持以下选项:
| 选项 | 默认 | 描述 |
|---|---|---|
|
|
强制 Expression,用于评估用于聚合的关联键。具有相同关联密钥的 Exchange 聚合在一起。如果无法评估 correlation 键,则抛出一个 Exception。您可以使用 | |
|
|
强制 | |
|
|
在 Registry 中查找 | |
|
|
聚合完成前聚合的消息数。这个选项可以被设置为一个固定值,也可以使用表达式来动态评估大小 - 因此将使用 | |
|
|
聚合交换在完成前应处于非活动状态的时间。这个选项可以被设置为一个固定值,也可以使用表达式来动态评估超时 - 因此将使用 | |
|
| millis 中重复的周期,聚合器将完成所有当前的聚合交换。Camel 有一个后台任务,它触发每个周期。您不能将此选项与 completionTimeout 一起使用,只有其中一个选项可以被使用。 | |
|
|
指定 predicate ( | |
|
|
|
如果交换来自 Batch Consumer,则此选项是。当启用 第 8.5 节 “聚合器” 时,将使用消息标头 |
|
|
|
收到新传入的交换时,是否强制检查是否完成。这个选项会影响 |
|
|
|
如果为 |
|
|
|
如果启用,Camel 会将所有聚合的 Exchange 分组到一个组合的 |
|
|
| 是否忽略无法评估为值的关联键。默认情况下,Camel 将抛出一个例外,但您可以启用这个选项并忽略这种情况。 |
|
|
是否应接受 late Exchange。您可以启用此选项,以指示 correlation 键是否已完成,然后任何具有相同关联键的新交换都会被拒绝。然后,Camel 会抛出一个 | |
|
|
| Camel 2.5: 是否应丢弃因为超时而完成的交换。如果启用,则当超时发生超时时,不会发送聚合消息,而是丢弃(丢弃)。 |
|
|
允许您自行插入 | |
|
|
引用在 Registry | |
|
|
| 当聚合完成后,它们会从聚合器中发送。这个选项表示 Camel 是否应该使用带有多个线程的线程池进行并发。如果没有指定自定义线程池,则 Camel 会创建一个具有 10 个并发线程的默认池。 |
|
|
如果使用 | |
|
|
引用在 Registry 中查找 | |
|
|
如果使用 | |
|
|
引用在 registry 中查找 | |
|
| 当您停止聚合器时,此选项允许它从聚合存储库完成所有待处理的交换。 | |
|
|
| 打开最佳锁定,可与聚合存储库结合使用。 |
|
| 为 optimistic locking 配置重试策略。 |