第 23 章 如何计算内核小时使用数据?
2021 年引入了新的 pay-as-you-go On-Demand 订阅类型,除了套接字或内核测量单位外,还会导致订阅服务中的新类型的测量单位。这些新测量单位是作为派生单元的复合单元,其中测量单位从其他基本单元计算。
目前,订阅服务更新的派生单元会添加基本时间单位,因此这些新单元会测量一段时间内的消耗。时间基础单元可以和适合特定产品的基本单元相结合,从而根据它消耗的资源类型对产品进行计量。
另外,对于那些基于时间的单元的子集,使用数据从频繁、基于时间的数据抽样衍生而获得,而不是直接计数。部分,抽样方法可能用于特定的产品或服务,因为所需的测量单元和 Red Hat OpenShift 监控堆栈工具的功能可能会用于特定的产品或服务。
当订阅服务跟踪带有使用抽样的时间指标的订阅使用量时,应用于这些指标的指标以及应用于这些指标的测量单位取决于这些产品的订阅条款。下表显示了基于时间的指标示例,它们也使用抽样来收集使用数据:
- Red Hat OpenShift Container Platform On-Demand 使用单一派生的测量单位是内核小时的。core 小时 是在一个内核(由订阅术语定义)上计算活动的单位,单位为 1 小时,测量使用的量表的粒度。
- Red Hat OpenShift Dedicated On-Demand 通过两个派生的测量单位来衡量。以核心小时计算,以跟踪计算机器的工作负载使用量,并在实例小时中跟踪 control plane 机器上的实例可用性(以前称为旧版本的 Red Hat OpenShift 中的 master 机器)。实例小时 是红帽服务实例的可用性,其中可以接受和执行客户工作负载。对于 Red Hat OpenShift Dedicated On-Demand,实例小时数通过汇总所有活跃集群(以小时为单位)来测量。
- Red Hat OpenShift AI (RHOAI) On-Demand 使用和 Red Hat Advanced Cluster Security for Kubernetes (RHACS) On-Demand 使用单一派生单位来测量 vCPU 小时。vCPU 小时 是在一个虚拟内核(由订阅术语定义)上集群大小的测量单位,单位为一小时,测量使用的量表的粒度。
23.1. Red Hat OpenShift On-Demand 订阅示例
以下有关 Red Hat OpenShift On-Demand 订阅的信息包括适用测量单元的说明,一个详细的场景,显示订阅服务和其他混合云控制台和监控堆栈工具的步骤,用于计算核心小时使用情况,以及可帮助您了解在订阅服务中报告核心小时使用情况的额外信息。您可以使用此信息帮助您了解订阅服务如何计算使用抽样基于时间测量单位的基本原则。
23.1.1. Red Hat OpenShift On-Demand 订阅的测量单位
下表提供了有关用于 Red Hat OpenShift On-Demand 产品的派生测量单元的更多详情。这些详细信息包括测量单位的名称和定义,以及等于该单位的使用量示例。另外,为每个单元提供了一个 Prometheus 查询语言(PromQL)查询示例。这个示例查询不是订阅服务计算使用情况的完整进程集合,但它是一个可以在集群本地运行的查询,以帮助您了解其中的一些进程。
| 测量单位 | 定义 | 例子 |
|---|---|---|
| core 小时 | 在一个核心上计算活动(根据订阅条款定义)的总小时,测量使用的量表的粒度。 | 对于 Red Hat OpenShift Container Platform On-Demand 和 Red Hat OpenShift Dedicated On-Demand 工作负载使用:
|
|
Core hour 基本 PromQL 查询,您可以在集群本地运行: sum_over_time((max by (_id) (cluster:usage:workload:capacity_physical_cpu_cores:min:5m))[1h:1s]) | ||
| 实例小时,在集群小时内 | 红帽服务实例的可用性,可在其中接受和执行客户工作负载。 | 在集群一小时内,用于 Red Hat OpenShift Dedicated On-Demand control plane 使用:
|
|
实例小时基本 PromQL 查询,您可以在集群本地运行: group(cluster:usage:workload:capacity_physical_cpu_cores:max:5m[1h:5m]) by (_id) | ||
23.1.2. 内核小时使用量计算示例
以下示例描述了计算 Red Hat OpenShift On-Demand 订阅的核心小时使用情况的流程。您可以使用此示例帮助您了解其他派生的测量单位,其中 time 是使用计算和抽样的基本单元之一。例如,Red Hat OpenShift AI On-Demand 的 vCPU 小时计算方式相同,除了测量用于虚拟内核外。
为了在核心小时内获得使用情况,订阅服务将使用数字集成。数字集成通常也称为"曲线"计算,其中复杂形形的区域通过使用一系列恢复栏的区域来计算。
Red Hat OpenShift 监控堆栈中的工具包含 Prometheus 查询语言(PromQL)功能 sum_over_time,它是一个聚合了时间间隔数据的功能。此功能是订阅服务中核心小时计算的基础。
sum_over_time((max by (_id) (cluster:usage:workload:capacity_physical_cpu_cores:min:5m))[1h:1s])
您可以在集群中本地运行此 PromQL 查询,以显示包括集群大小和使用快照的结果。
每 2 分钟,集群将内核大小报告为监控堆栈工具,包括 Telemetry。混合云控制台工具之一(Tally 引擎)会在 5 分钟间隔内每小时检查此信息。由于集群每 2 分钟报告监控堆栈工具,因此每个 5 分钟间隔最多可包含集群大小的三个值。Tally 引擎选择最小集群大小值,以代表完整 5 分钟间隔。
以下示例演示了如何每 2 分钟收集一次集群大小,以及如何为 5 分钟间隔选择最小大小。
图 23.1. 计算集群大小

然后,对于每个集群,Tally 引擎使用所选值,并为每个 5 分钟间隔创建一个用量框。5 分钟框的区域是内核高度达到 300 秒的时间。每 5 分钟框中,存储了这个核心秒值,最终用于计算日常、集群范围的内核小时使用聚合。
以下示例显示了如何计算 curve 下的区域的图形表示,集群大小和时间用于创建使用框,以及用作构建块的各框区域,以创建每日核心小时使用量。
图 23.2. 计算内核小时
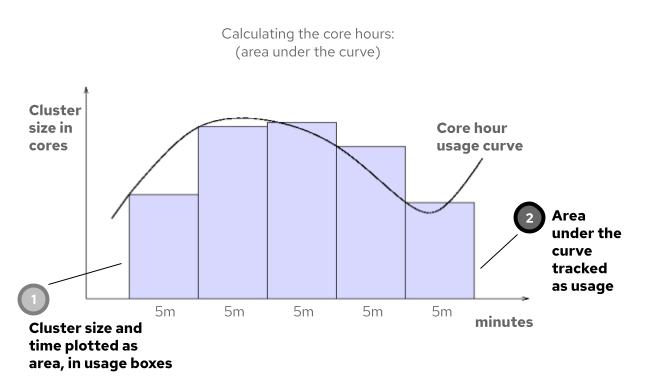
每天都添加 5 分钟用量值,以便在该天创建集群的总使用量。然后,会合并每个集群的总信息,以便为帐户中的所有集群创建每日使用信息。另外,内核秒数将转换为内核小时。
在使用前几天的数据定期 24 小时更新订阅服务期间,会更新用于付费订阅的核心小时使用量信息。在订阅服务中,该帐户的每日内核小时使用量会在使用和使用图表中绘制,而额外的 内核小时 信息则显示帐户的总累计。当前实例表还列出帐户中的每个集群,并显示该集群中使用的核心小时数。
订阅服务界面中显示的帐户和单个集群的核心小时使用数据被舍入为两个十进制位置,用于显示目的。但是,用于订阅服务计算的数据以及提供给 Red Hat Marketplace 账单服务的数据处于 millicore 级别,舍入到 6 个十进制位置。
每个月,您的帐户的每月内核小时用量总数提供给 Red Hat Marketplace,以进行发票准备和计费。对于提供四对核心小时关系到 vCPU 小时的订阅类型,订阅服务的核心小时总数被分为 4 个用于 Red Hat Marketplace 计费活动。对于提供一对一核心小时关系到 vCPU 小时的订阅类型,不会进行总的转换。
每月发送到 Red Hat Marketplace 并且新月开始后,订阅服务的使用值会显示为新的当前月份重置为 0。您可以使用过滤查看前几个月的使用量数据。
23.1.3. 解决有关内核小时使用的问题
如果您对核心小时使用有疑问,首先使用以下步骤作为诊断工具:
在订阅服务中,查看当前实例表中每个集群的月份总数。根据您了解如何配置和部署集群,查找显示异常使用情况的集群。
注意当前实例表显示每个集群最近每月累计总数的快照。目前,此信息每天更新几次。这个值会在每个月开始时重置为 0。
- 然后,查看用量和利用率图中的每日内核小时总数和趋势。查找显示异常使用的任何日期。您上一步中找到的集群上可能会意外使用这个日期。
在这些初始故障排除步骤中,您可能会发现集群所有者,并讨论异常使用情况是因为负载非常高、集群配置问题或其他问题。
如果在使用这些步骤后继续有疑问,您可以联系红帽帐户团队,以帮助您了解您的核心小时使用情况。有关计费的问题,请使用 Red Hat Marketplace 支持说明。