Dieser Inhalt ist in der von Ihnen ausgewählten Sprache nicht verfügbar.
Chapter 10. Scalability and performance optimization
10.1. Optimizing storage
Optimizing storage helps to minimize storage use across all resources. By optimizing storage, administrators help ensure that existing storage resources are working in an efficient manner.
10.1.1. Available persistent storage options
To optimize your OpenShift Container Platform environment, review the available persistent storage options. By understanding these choices, you can select the appropriate storage configuration to meet your specific workload requirements.
| Storage type | Description | Examples |
|---|---|---|
| Block |
| AWS EBS and VMware vSphere support dynamic persistent volume (PV) provisioning natively in OpenShift Container Platform. |
| File |
| RHEL NFS, NetApp NFS, and Vendor NFS. |
| Object |
| AWS S3. |
-
File: NetApp NFS supports dynamic PV provisioning when using the Trident plugin.
10.1.2. Recommended configurable storage technology
To select the optimal storage solution for your OpenShift Container Platform cluster application, review the recommended and configurable storage technologies. By reviewing this summary, you can identify the supported options that best meet your specific workload requirements.
| Storage type | Block | File | Object |
|---|---|---|---|
| ROX | Yes | Yes | Yes |
| RWX | No | Yes | Yes |
| Registry | Configurable | Configurable | Recommended |
| Scaled registry | Not configurable | Configurable | Recommended |
| Metrics | Recommended | Configurable | Not configurable |
| Elasticsearch Logging | Recommended | Configurable | Not supported |
| Loki Logging | Not configurable | Not configurable | Recommended |
| Apps | Recommended | Recommended | Not configurable |
where:
ROX-
Specifies
ReadOnlyManyaccess mode. ROX.Yes- Specifies that this access mode
RWX-
Specifies
ReadWriteManyaccess mode. Metrics- Specifies Prometheus as the underlying technology used for metrics.
Metrics.Configurable-
For metrics, using file storage with the
ReadWriteMany(RWX) access mode is unreliable. If you use file storage, do not configure the RWX access mode on any persistent volume claims (PVCs) that are configured for use with metrics. Elasticsearch Logging.Configurable- For logging, review the recommended storage solution in Configuring persistent storage for the log store section. Using NFS storage as a persistent volume or through NAS, such as Gluster, can corrupt the data. Therefore, NFS is not supported for Elasticsearch storage and LokiStack log store in OpenShift Container Platform Logging. You must use one persistent volume type per log store.
Apps.Not configurable- Specifies that object storage is not consumed through PVs or PVCs of OpenShift Container Platform. Apps must integrate with the object storage REST API.
A scaled registry is an OpenShift image registry where two or more pod replicas are running.
10.1.2.1. Specific application storage recommendations
To select the optimal storage solution for your OpenShift Container Platform cluster application, review the recommended and configurable storage technologies. By understanding these recommendations, you can identify the supported options that best meet your specific workload requirements.
Testing shows issues with using the NFS server on Red Hat Enterprise Linux (RHEL) as a storage backend for core services. This includes the OpenShift Container Registry and Quay, Prometheus for monitoring storage, and Elasticsearch for logging storage. Therefore, using RHEL NFS to back PVs used by core services is not recommended.
Other NFS implementations in the marketplace might not have these issues. Contact the individual NFS implementation vendor for more information on any testing that was possibly completed against these OpenShift Container Platform core components.
- Registry
In a non-scaled/high-availability (HA) OpenShift image registry cluster deployment:
- The storage technology does not have to support RWX access mode.
- The storage technology must ensure read-after-write consistency.
- The preferred storage technology is object storage followed by block storage.
- File storage is not recommended for OpenShift image registry cluster deployment with production workloads.
- Scaled registry
In a scaled/HA OpenShift image registry cluster deployment:
- The storage technology must support RWX access mode.
- The storage technology must ensure read-after-write consistency.
- The preferred storage technology is object storage.
- Red Hat OpenShift Data Foundation, Amazon Simple Storage Service (Amazon S3), Google Cloud Storage (GCS), Microsoft Azure Blob Storage, and OpenStack Swift are supported.
- Object storage should be S3 or Swift compliant.
- For non-cloud platforms, such as vSphere and bare-metal installations, the only configurable technology is file storage.
- Block storage is not configurable.
- The use of Network File System (NFS) storage with OpenShift Container Platform is supported. However, the use of NFS storage with a scaled registry can cause known issues. For more information, see the "Is NFS supported for OpenShift cluster internal components in Production?" Red Hat Knowledgebase solution.
- Metrics
In an OpenShift Container Platform hosted metrics cluster deployment:
- The preferred storage technology is block storage.
- Object storage is not configurable.
It is not recommended to use file storage for a hosted metrics cluster deployment with production workloads.
- Logging
In an OpenShift Container Platform hosted logging cluster deployment:
Loki Operator:
- The preferred storage technology is S3 compatible Object storage.
- Block storage is not configurable.
OpenShift Elasticsearch Operator:
- The preferred storage technology is block storage.
- Object storage is not supported.
As of logging version 5.4.3 the OpenShift Elasticsearch Operator is deprecated and is planned to be removed in a future release. Red Hat will provide bug fixes and support for this feature during the current release lifecycle, but this feature will no longer receive enhancements and will be removed. As an alternative to using the OpenShift Elasticsearch Operator to manage the default log storage, you can use the Loki Operator.
- Applications
Application use cases vary from application to application, as described in the following examples:
- Storage technologies that support dynamic PV provisioning have low mount time latencies, and are not tied to nodes to support a healthy cluster.
- Application developers are responsible for knowing and understanding the storage requirements for their application, and how it works with the provided storage to ensure that issues do not occur when an application scales or interacts with the storage layer.
- Other specific application storage recommendations
Red Hat does not recommend using RAID configurations on Write intensive workloads, such as etcd. If you are running etcd with a RAID configuration, you might be at risk of encountering performance issues with your workloads.
- Red Hat OpenStack Platform (RHOSP) Cinder: RHOSP Cinder tends to be adept at ROX access mode use cases.
- Databases: Databases (RDBMSs, NoSQL DBs, etc.) tend to perform best with dedicated block storage.
- The etcd database must have enough storage and adequate performance capacity to enable a large cluster. Information about monitoring and benchmarking tools to establish ample storage and a high-performance environment is described in Recommended etcd practices.
10.1.4. Data storage management
To effectively manage data storage in OpenShift Container Platform, review the main directories where components write data. By viewing this reference, you can identify the specific paths used by system components, so that you can plan for capacity requirements and perform necessary maintenance.
The following table summarizes the main directories that OpenShift Container Platform components write data to.
| Directory | Notes | Sizing | Expected growth |
|---|---|---|---|
| /var/lib/etcd | Used for etcd storage when storing the database. | Less than 20 GB. Database can grow up to 8 GB. | Will grow slowly with the environment. Only storing metadata. Additional 20-25 GB for every additional 8 GB of memory. |
| /var/lib/containers | This is the mount point for the CRI-O runtime. Storage used for active container runtimes, including pods, and storage of local images. Not used for registry storage. | 50 GB for a node with 16 GB memory. Note that this sizing should not be used to determine minimum cluster requirements. Additional 20-25 GB for every additional 8 GB of memory. | Growth is limited by capacity for running containers. |
| /var/lib/kubelet | Ephemeral volume storage for pods. This includes anything external that is mounted into a container at runtime. Includes environment variables, kube secrets, and data volumes not backed by persistent volumes. | Varies | Minimal if pods requiring storage are using persistent volumes. If using ephemeral storage, this can grow quickly. |
| /var/log | Log files for all components. | 10 to 30 GB. | Log files can grow quickly; size can be managed by growing disks or by using log rotate. |
10.1.5. Optimizing storage performance for Microsoft Azure
To ensure optimal cluster performance on Microsoft Azure, configure faster storage for OpenShift Container Platform and Kubernetes. Prioritize high-performance disks for etcd on the control plane nodes, as these components are sensitive to disk latency.
For production Azure clusters and clusters with intensive workloads, the virtual machine operating system disk for control plane machines should be able to sustain a tested and recommended minimum throughput of 5000 IOPS / 200 MBps. This throughput can be provided by having a minimum of 1 TiB Premium SSD (P30). In Azure and Azure Stack Hub, disk performance is directly dependent on SSD disk sizes. To achieve the throughput supported by a Standard_D8s_v3 virtual machine, or other similar machine types, and the target of 5000 IOPS, at least a P30 disk is required.
Host caching must be set to ReadOnly for low latency and high IOPS and throughput when reading data. Reading data from the cache, which is present either in the VM memory or in the local SSD disk, is much faster than reading from the disk, which is in the blob storage.
10.2. Optimizing routing
To optimize performance, scale or configure the OpenShift Container Platform HAProxy router. By doing this task, you can ensure efficient traffic management and accommodate specific workload requirements.
10.2.1. Baseline Ingress Controller (router) performance
To establish a performance baseline, review the role of the OpenShift Container Platform Ingress Controller. As the router for your cluster, this component serves as the entry point for ingress traffic, directing requests to applications and services configured by using routes and ingresses.
When evaluating a single HAProxy router performance in terms of HTTP requests handled per second, the performance varies depending on many factors. In particular:
- HTTP keep-alive/close mode
- Route type
- TLS session resumption client support
- Number of concurrent connections per target route
- Number of target routes
- Back end server page size
- Underlying infrastructure (network, CPU, and so on)
While performance in your specific environment will vary, Red Hat lab tests on a public cloud instance of size 4 vCPU/16GB RAM. A single HAProxy router handling 100 routes terminated by backends serving 1kB static pages is able to handle the following number of transactions per second.
In HTTP keep-alive mode scenarios:
| Encryption | LoadBalancerService | HostNetwork |
|---|---|---|
| none | 21515 | 29622 |
| edge | 16743 | 22913 |
| passthrough | 36786 | 53295 |
| re-encrypt | 21583 | 25198 |
In HTTP close (no keep-alive) scenarios:
| Encryption | LoadBalancerService | HostNetwork |
|---|---|---|
| none | 5719 | 8273 |
| edge | 2729 | 4069 |
| passthrough | 4121 | 5344 |
| re-encrypt | 2320 | 2941 |
The default Ingress Controller configuration was used with the spec.tuningOptions.threadCount field set to 4. Two different endpoint publishing strategies were tested: Load Balancer Service and Host Network. TLS session resumption was used for encrypted routes. With HTTP keep-alive, a single HAProxy router is capable of saturating a 1 Gbit NIC at page sizes as small as 8 kB.
When running on bare metal with modern processors, you can expect roughly twice the performance of the public cloud instance above. This overhead is introduced by the virtualization layer in place on public clouds and holds mostly true for private cloud-based virtualization as well. The following table is a guide to how many applications to use behind the router:
| Number of applications | Application type |
|---|---|
| 5-10 | static file/web server or caching proxy |
| 100-1000 | applications generating dynamic content |
In general, HAProxy can support routes for up to 1000 applications, depending on the technology in use. Ingress Controller performance might be limited by the capabilities and performance of the applications behind it, such as language or static versus dynamic content.
Ingress, or router, sharding should be used to serve more routes towards applications and help horizontally scale the routing tier.
10.2.3. Configuring Ingress Controller liveness, readiness, and startup probes
To ensure accurate health monitoring for your router deployments, configure the timeout values for liveness, readiness, and startup probes. By doing this task, you can adjust the default settings used by the OpenShift Container Platform Ingress Controller to better suit your environment.
The liveness and readiness probes of the router use the default timeout value of 1 second, which is too brief when networking or runtime performance is severely degraded. Probe timeouts can cause unwanted router restarts that interrupt application connections. The ability to set larger timeout values can reduce the risk of unnecessary and unwanted restarts.
You can update the timeoutSeconds value on the livenessProbe, readinessProbe, and startupProbe parameters of the router container.
| Parameter | Description |
|---|---|
|
|
The |
|
|
The |
|
|
The |
The timeout configuration option is an advanced tuning technique that can be used to work around issues. However, these issues should eventually be diagnosed and possibly a support case or Jira issue opened for any issues that cause probes to time out.
The following example demonstrates how you can directly patch the default router deployment to set a 5-second timeout for the liveness and readiness probes:
$ oc -n openshift-ingress patch deploy/router-default --type=strategic --patch='{"spec":{"template":{"spec":{"containers":[{"name":"router","livenessProbe":{"timeoutSeconds":5},"readinessProbe":{"timeoutSeconds":5}}]}}}}'Verification
$ oc -n openshift-ingress describe deploy/router-default | grep -e Liveness: -e Readiness:
Liveness: http-get http://:1936/healthz delay=0s timeout=5s period=10s #success=1 #failure=3
Readiness: http-get http://:1936/healthz/ready delay=0s timeout=5s period=10s #success=1 #failure=310.2.4. Configuring HAProxy reload interval
To optimize router performance, configure the HAProxy reload interval. The OpenShift Container Platform router reloads HAProxy to apply changes to routes or endpoints, generating a new process to handle connections for each update.
HAProxy keeps the old process running to handle existing connections until those connections are all closed. When old processes have long-lived connections, these processes can accumulate and consume resources.
The default minimum HAProxy reload interval is 5 seconds. You can configure an Ingress Controller using its spec.tuningOptions.reloadInterval field to set a longer minimum reload interval.
Setting a large value for the minimum HAProxy reload interval can cause latency in observing updates to routes and their endpoints. To lessen the risk, avoid setting a value larger than the tolerable latency for updates.
Procedure
Change the minimum HAProxy reload interval of the default Ingress Controller to 15 seconds by running the following command:
$ oc -n openshift-ingress-operator patch ingresscontrollers/default --type=merge --patch='{"spec":{"tuningOptions":{"reloadInterval":"15s"}}}'
10.3. Optimizing networking
To tunnel traffic between nodes, use Generic Network Virtualization Encapsulation (Geneve). You can tune the performance of this network by using network interface controller (NIC) offloads.
Geneve provides benefits over VLANs, such as an increase in networks from 4096 to over 16 million, and layer 2 connectivity across physical networks. This allows for all pods behind a service to communicate with each other, even if they are running on different systems.
Cloud, virtual, and bare-metal environments running OpenShift Container Platform can use a high percentage of the capabilities of a network interface card (NIC) with minimal tuning. Production clusters using OVN-Kubernetes with Geneve tunneling can handle high-throughput traffic effectively and scale up (for example, utilizing 100 Gbps NICs) and scale out (for example, adding more NICs) without requiring special configuration.
In some high-performance scenarios where maximum efficiency is critical, targeted performance tuning can help optimize CPU usage, reduce overhead, and ensure that you are making full use of the NIC’s capabilities.
For environments where maximum throughput and CPU efficiency are critical, you can further optimize performance with the following strategies:
-
Validate network performance by using tools such as
iPerf3andk8s-netperf. By using these tools, you can benchmark throughput, latency, and packets-per-second (PPS) across pod and node interfaces. - Evaluate OVN-Kubernetes User Defined Networking (UDN) routing techniques, such as border gateway protocol (BGP).
- Use Geneve-offload capable network adapters. Geneve-offload moves the packet checksum calculation and associated CPU overhead off of the system CPU and onto dedicated hardware on the network adapter. This frees up CPU cycles for use by pods and applications, so that users can use the full bandwidth of their network infrastructure.
10.3.2. Optimizing the MTU for your network
To optimize network performance, configure the Maximum Transmission Unit (MTU) settings. By understanding the relationship between the network interface controller (NIC) MTU and the cluster network MTU, you can ensure efficient data transmission and prevent packet fragmentation.
The NIC MTU is configured at the time of OpenShift Container Platform installation, and you can also change the MTU of a cluster as a postinstallation task. For more information, see "Changing cluster network MTU".
For a cluster that uses the OVN-Kubernetes plugin, the MTU must be at least 100 bytes less than the maximum supported value of the NIC of your network. If you are optimizing for throughput, choose the largest possible value, such as 8900. If you are optimizing for lowest latency, choose a lower value.
If your cluster uses the OVN-Kubernetes plugin and the network uses a NIC to send and receive unfragmented jumbo frame packets over the network, you must specify 9000 bytes as the MTU value for the NIC so that pods do not fail.
10.3.3. Recommended practices for installing large-scale clusters
To support large clusters or scale to higher node counts, configure the cluster network cidr in your install-config.yaml file before installation. Setting this address range correctly ensures your cluster has sufficient capacity for the required number of nodes.
Example install-config.yaml file with a network configuration for a cluster with a large node count
apiVersion: v1
metadata:
name: cluster-name
# ...
networking:
clusterNetwork:
- cidr: 10.128.0.0/14
hostPrefix: 23
machineNetwork:
- cidr: 10.0.0.0/16
networkType: OVNKubernetes
serviceNetwork:
- 172.30.0.0/16
# ...-
The default cluster network
cidr10.128.0.0/14cannot be used if the cluster size is more than 500 nodes. Thecidrmust be set to10.128.0.0/12or10.128.0.0/10to support larger node counts beyond 500 nodes.
10.3.4. Impact of IPsec
To account for performance overhead, review the impact of enabling IPsec. Encrypting and decrypting traffic on node hosts consumes CPU power, which affects both throughput and CPU usage regardless of the specific IP security system.
IPSec encrypts traffic at the IP payload level, before it hits the NIC, protecting fields that would otherwise be used for NIC offloading. This means that some NIC acceleration features might not be usable when IPSec is enabled. This situation leads to decreased throughput and increased CPU usage.
10.4. Optimizing CPU usage with mount namespace encapsulation
You can optimize CPU usage in OpenShift Container Platform clusters by using mount namespace encapsulation to provide a private namespace for kubelet and CRI-O processes. This reduces the cluster CPU resources used by systemd with no difference in functionality.
Mount namespace encapsulation is a Technology Preview feature only. Technology Preview features are not supported with Red Hat production service level agreements (SLAs) and might not be functionally complete. Red Hat does not recommend using them in production. These features provide early access to upcoming product features, enabling customers to test functionality and provide feedback during the development process.
For more information about the support scope of Red Hat Technology Preview features, see Technology Preview Features Support Scope.
10.4.1. Encapsulating mount namespaces
To prevent the host operating system from constantly scanning mount points, review the process of encapsulation. This mechanism moves Kubernetes mount namespaces to an alternative location, ensuring that processes in different namespaces remain isolated and cannot view each other’s files.
The host operating system uses systemd to constantly scan all mount namespaces: both the standard Linux mounts and the numerous mounts that Kubernetes uses to operate. The current implementation of kubelet and CRI-O both use the top-level namespace for all container runtime and kubelet mount points. However, encapsulating these container-specific mount points in a private namespace reduces systemd overhead with no difference in functionality. Using a separate mount namespace for both CRI-O and kubelet can encapsulate container-specific mounts from any systemd or other host operating system interaction.
This ability to potentially achieve major CPU optimization is now available to all OpenShift Container Platform administrators. Encapsulation can also improve security by storing Kubernetes-specific mount points in a location safe from inspection by unprivileged users.
The following diagrams illustrate a Kubernetes installation before and after encapsulation. Both scenarios show example containers which have mount propagation settings of bidirectional, host-to-container, and none.
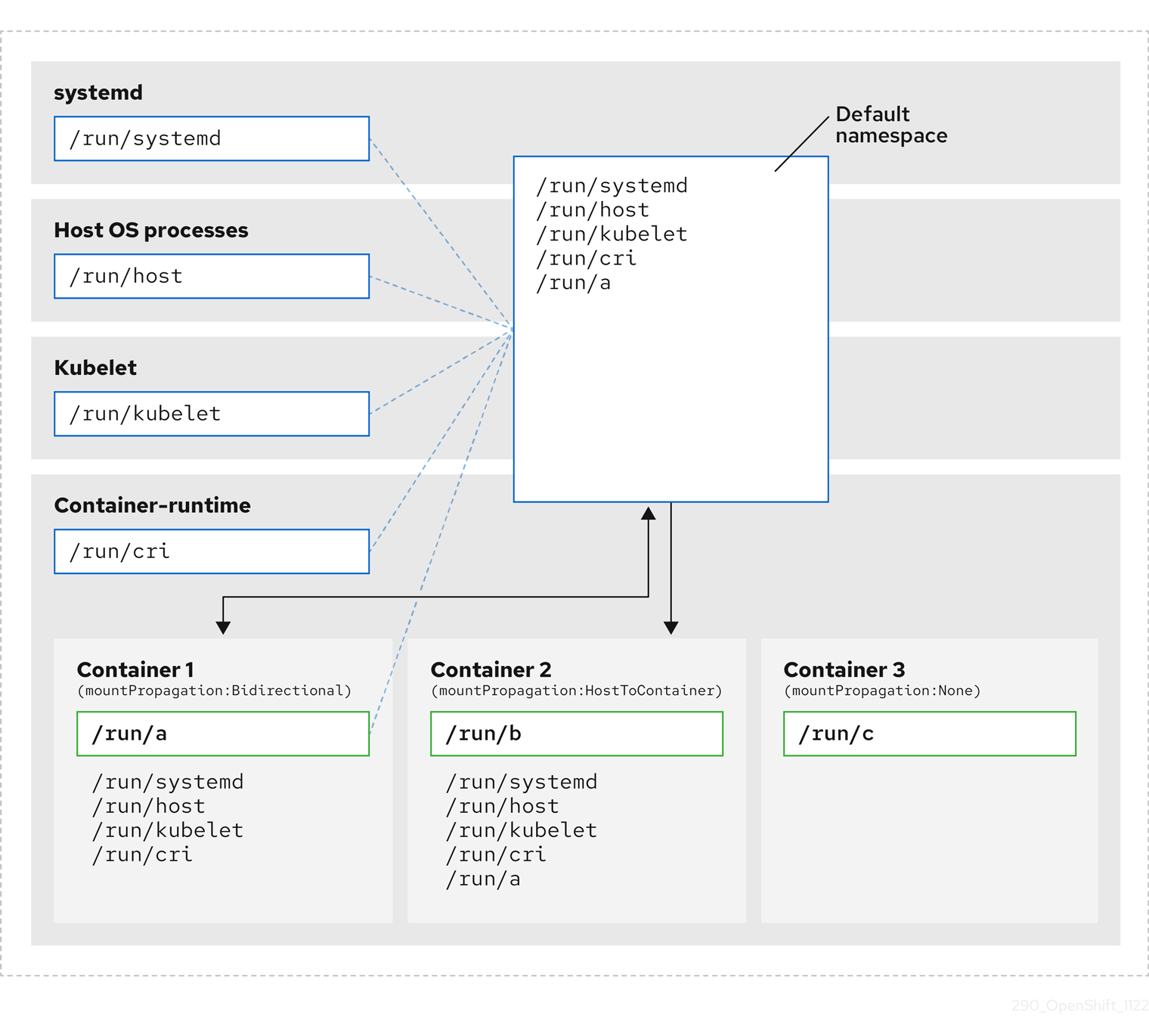
The diagram shows systemd, host operating system processes, kubelet, and the container runtime sharing a single mount namespace.
- systemd, host operating system processes, kubelet, and the container runtime each have access to and visibility of all mount points.
-
Container 1, configured with bidirectional mount propagation, can access systemd and host mounts, kubelet and CRI-O mounts. A mount originating in Container 1, such as
/run/ais visible to systemd, host operating system processes, kubelet, container runtime, and other containers with host-to-container or bidirectional mount propagation configured (as in Container 2). -
Container 2, configured with host-to-container mount propagation, can access systemd and host mounts, kubelet and CRI-O mounts. A mount originating in Container 2, such as
/run/b, is not visible to any other context. -
Container 3, configured with no mount propagation, has no visibility of external mount points. A mount originating in Container 3, such as
/run/c, is not visible to any other context.
The following diagram illustrates the system state after encapsulation.
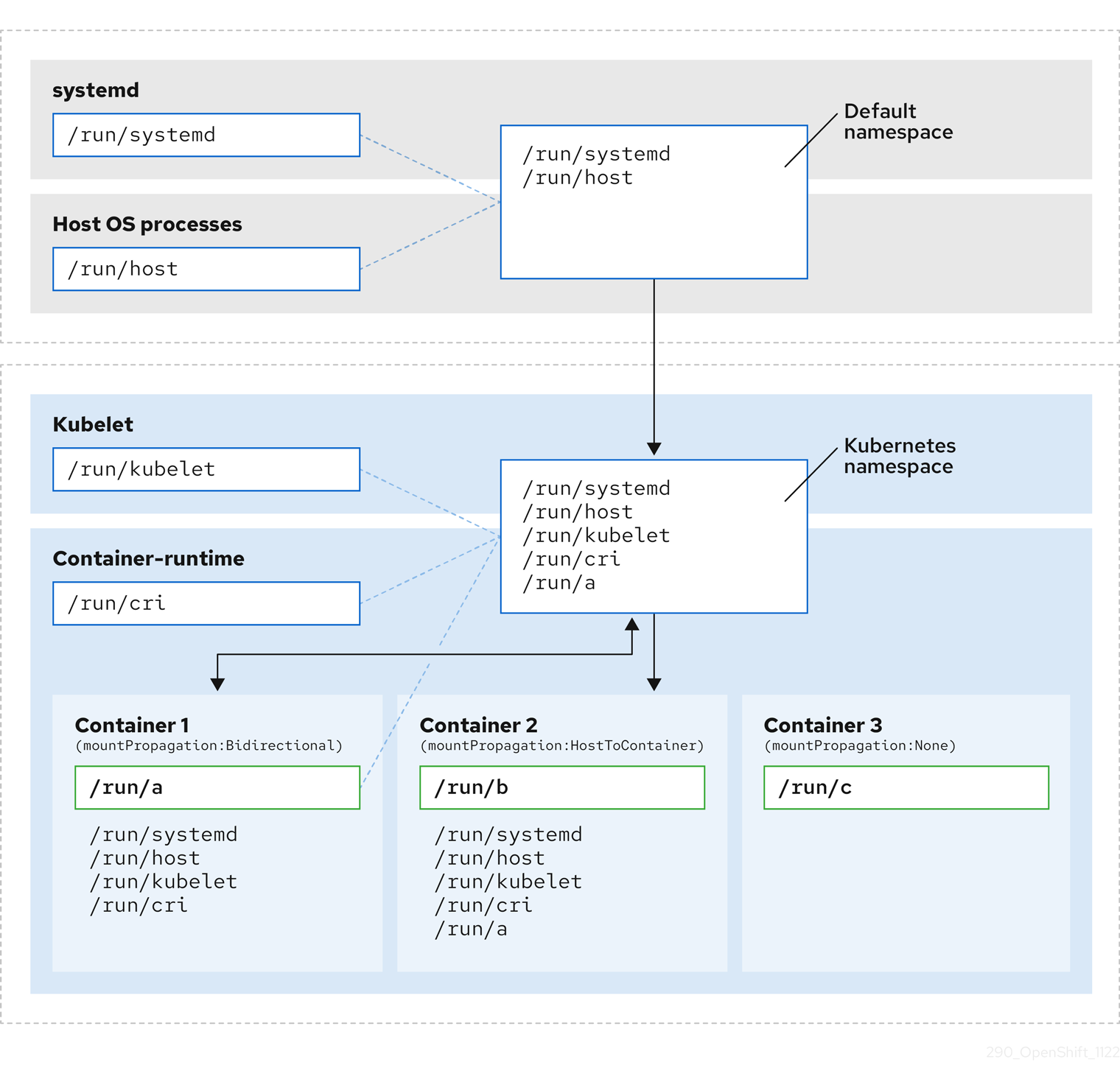
- The main systemd process is no longer devoted to unnecessary scanning of Kubernetes-specific mount points. It only monitors systemd-specific and host mount points.
- The host operating system processes can access only the systemd and host mount points.
- Using a separate mount namespace for both CRI-O and kubelet completely separates all container-specific mounts away from any systemd or other host operating system interaction whatsoever.
-
The behavior of Container 1 is unchanged, except a mount it creates such as
/run/ais no longer visible to systemd or host operating system processes. It is still visible to kubelet, CRI-O, and other containers with host-to-container or bidirectional mount propagation configured (like Container 2). - The behavior of Container 2 and Container 3 is unchanged.
10.4.2. Configuring mount namespace encapsulation
To run your cluster with less resource overhead, configure mount namespace encapsulation. This setting optimizes performance by moving mount namespaces to an alternative location, preventing the host operating system from constantly scanning them.
Mount namespace encapsulation is a Technology Preview feature and the feature is disabled by default. To use the feature, you must enable the feature manually.
Prerequisites
-
You have installed the OpenShift CLI (
oc). -
You have logged in as a user with
cluster-adminprivileges.
Procedure
Create a file called
mount_namespace_config.yamlwith the following YAML:apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: master name: 99-kubens-master spec: config: ignition: version: 3.2.0 systemd: units: - enabled: true name: kubens.service --- apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: worker name: 99-kubens-worker spec: config: ignition: version: 3.2.0 systemd: units: - enabled: true name: kubens.serviceApply the mount namespace
MachineConfigCR by running the following command:$ oc apply -f mount_namespace_config.yamlExample output
machineconfig.machineconfiguration.openshift.io/99-kubens-master created machineconfig.machineconfiguration.openshift.io/99-kubens-worker createdThe
MachineConfigCR can take up to thirty minutes to finish being applied in the cluster. You can check the status of theMachineConfigCR by running the following command:$ oc get mcpExample output
NAME CONFIG UPDATED UPDATING DEGRADED MACHINECOUNT READYMACHINECOUNT UPDATEDMACHINECOUNT DEGRADEDMACHINECOUNT AGE master rendered-master-03d4bc4befb0f4ed3566a2c8f7636751 False True False 3 0 0 0 45m worker rendered-worker-10577f6ab0117ed1825f8af2ac687ddf False True False 3 1 1Wait for the
MachineConfigCR to be applied successfully across all control plane and worker nodes after running the following command:$ oc wait --for=condition=Updated mcp --all --timeout=30mExample output
machineconfigpool.machineconfiguration.openshift.io/master condition met machineconfigpool.machineconfiguration.openshift.io/worker condition met
Verification
Open a debug shell to the cluster host:
$ oc debug node/<node_name>Open a
chrootsession:sh-4.4# chroot /hostCheck the systemd mount namespace:
sh-4.4# readlink /proc/1/ns/mntExample output
mnt:[4026531953]Check kubelet mount namespace:
sh-4.4# readlink /proc/$(pgrep kubelet)/ns/mntExample output
mnt:[4026531840]Check the CRI-O mount namespace:
sh-4.4# readlink /proc/$(pgrep crio)/ns/mntExample output
mnt:[4026531840]These commands return the mount namespaces associated with systemd, kubelet, and the container runtime. In OpenShift Container Platform, the container runtime is CRI-O.
Encapsulation is in effect if systemd is in a different mount namespace from kubelet and CRI-O as in the previous output example. Encapsulation is not in effect if all three processes are in the same mount namespace.
10.4.3. Inspecting encapsulated namespaces
You can inspect Kubernetes-specific mount points in the cluster host operating system for debugging or auditing purposes by using the kubensenter script that is available in Red Hat Enterprise Linux CoreOS (RHCOS).
SSH shell sessions to the cluster host are in the default namespace. To inspect Kubernetes-specific mount points in an SSH shell prompt, you need to run the kubensenter script as root. The kubensenter script is aware of the state of the mount encapsulation, and the script is safe to run even if encapsulation is not enabled.
oc debug remote shell sessions start inside the Kubernetes namespace by default. You do not need to run kubensenter to inspect mount points when you use oc debug.
If the encapsulation feature is not enabled, the kubensenter findmnt and findmnt commands return the same output, regardless of whether they are run in an oc debug session or in an SSH shell prompt.
Prerequisites
-
You have installed the OpenShift CLI (
oc). -
You have logged in as a user with
cluster-adminprivileges. - You have configured SSH access to the cluster host.
Procedure
Open a remote SSH shell to the cluster host. For example:
$ ssh core@<node_name>Run commands using the provided
kubensenterscript as the root user. To run a single command inside the Kubernetes namespace, provide the command and any arguments to thekubensenterscript. For example, to run thefindmntcommand inside the Kubernetes namespace, run the following command:[core@control-plane-1 ~]$ sudo kubensenter findmntExample output
kubensenter: Autodetect: kubens.service namespace found at /run/kubens/mnt TARGET SOURCE FSTYPE OPTIONS / /dev/sda4[/ostree/deploy/rhcos/deploy/32074f0e8e5ec453e56f5a8a7bc9347eaa4172349ceab9c22b709d9d71a3f4b0.0] | xfs rw,relatime,seclabel,attr2,inode64,logbufs=8,logbsize=32k,prjquota shm tmpfs ...To start a new interactive shell inside the Kubernetes namespace, run the
kubensenterscript without any arguments:[core@control-plane-1 ~]$ sudo kubensenterExample output
kubensenter: Autodetect: kubens.service namespace found at /run/kubens/mnt
10.4.4. Running additional services in the encapsulated namespace
To enable monitoring tools to view mount points created by kubelet, CRI-O, or containers, use the kubensenter script provided with OpenShift Container Platform. By using this tool, you can execute commands inside the Kubernetes mount point, ensuring existing tools can run within the encapsulated namespace.
The kubensenter script is aware of the state of the mount encapsulation feature status, and is safe to run even if encapsulation is not enabled. In that case the script executes the provided command in the default mount namespace.
For example, if a systemd service needs to run inside the new Kubernetes mount namespace, edit the service file and use the ExecStart= command line with kubensenter.
[Unit]
Description=Example service
[Service]
ExecStart=/usr/bin/kubensenter /path/to/original/command arg1 arg2