Dieser Inhalt ist in der von Ihnen ausgewählten Sprache nicht verfügbar.
Chapter 314. Apache Spark Component
Available as of Camel version 2.17
This documentation page covers the Apache Spark component for the Apache Camel. The main purpose of the Spark integration with Camel is to provide a bridge between Camel connectors and Spark tasks. In particular Camel connector provides a way to route message from various transports, dynamically choose a task to execute, use incoming message as input data for that task and finally deliver the results of the execution back to the Camel pipeline.
314.1. Supported architectural styles
Spark component can be used as a driver application deployed into an application server (or executed as a fat jar).
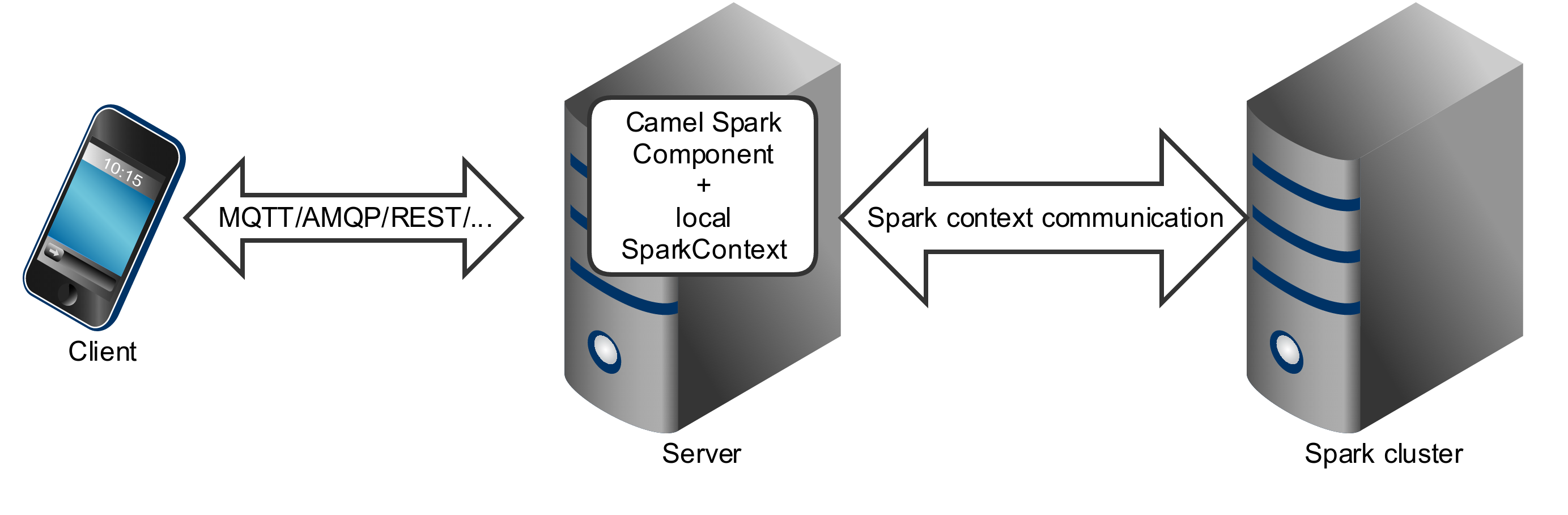
Spark component can also be submitted as a job directly into the Spark cluster.
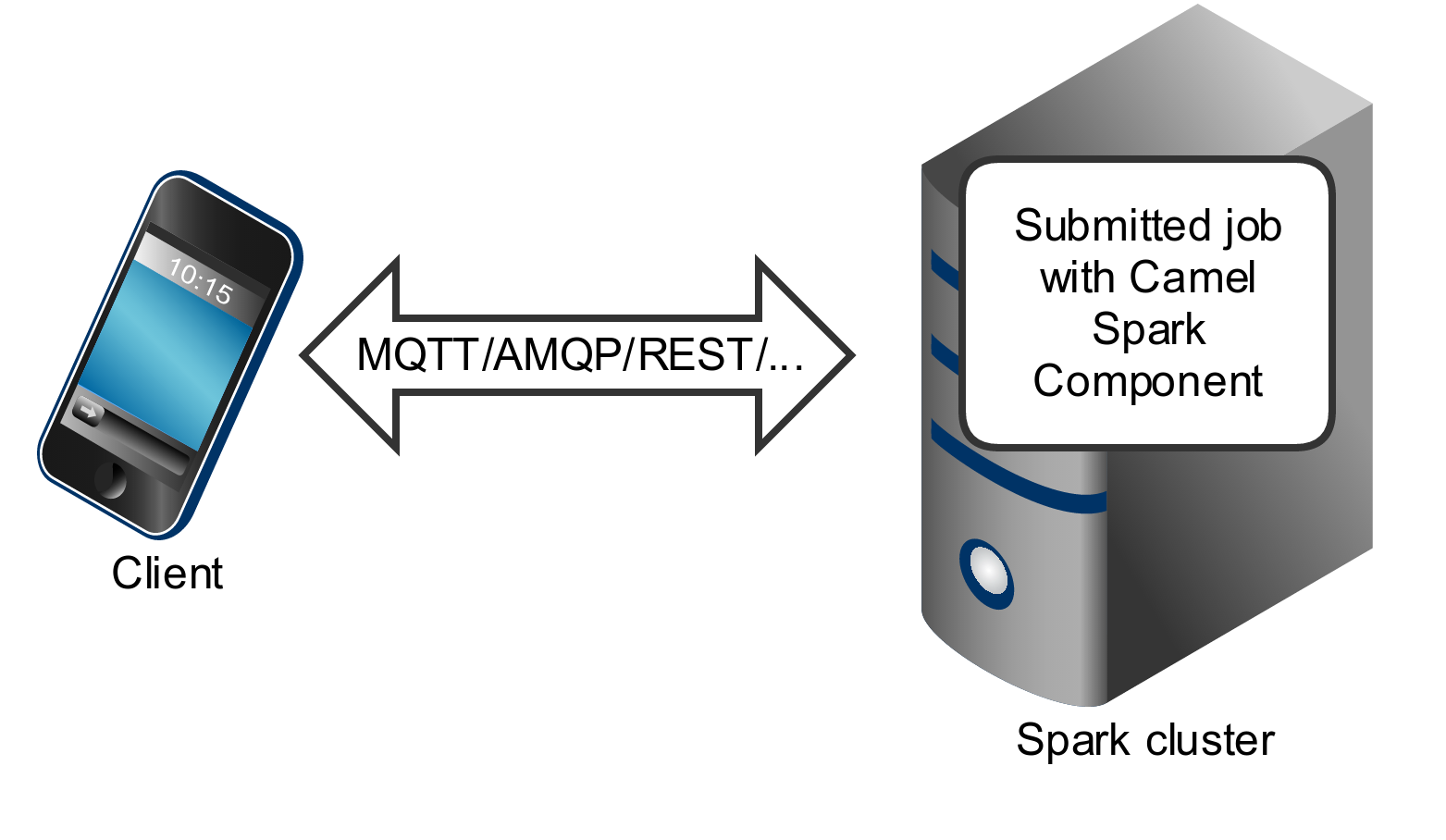
While Spark component is primary designed to work as a long running job serving as an bridge between Spark cluster and the other endpoints, you can also use it as a fire-once short job.
314.2. Running Spark in OSGi servers
Currently the Spark component doesn’t support execution in the OSGi container. Spark has been designed to be executed as a fat jar, usually submitted as a job to a cluster. For those reasons running Spark in an OSGi server is at least challenging and is not support by Camel as well.
314.3. URI format
Currently the Spark component supports only producers - it it intended to invoke a Spark job and return results. You can call RDD, data frame or Hive SQL job.
Spark URI format
spark:{rdd|dataframe|hive}
spark:{rdd|dataframe|hive}314.3.1. Spark options
The Apache Spark component supports 3 options, which are listed below.
| Name | Description | Default | Type |
|---|---|---|---|
| rdd (producer) | RDD to compute against. | JavaRDDLike | |
| rddCallback (producer) | Function performing action against an RDD. | RddCallback | |
| resolveProperty Placeholders (advanced) | Whether the component should resolve property placeholders on itself when starting. Only properties which are of String type can use property placeholders. | true | boolean |
The Apache Spark endpoint is configured using URI syntax:
spark:endpointType
spark:endpointTypewith the following path and query parameters:
314.3.2. Path Parameters (1 parameters):
| Name | Description | Default | Type |
|---|---|---|---|
| endpointType | Required Type of the endpoint (rdd, dataframe, hive). | EndpointType |
314.3.3. Query Parameters (6 parameters):
| Name | Description | Default | Type |
|---|---|---|---|
| collect (producer) | Indicates if results should be collected or counted. | true | boolean |
| dataFrame (producer) | DataFrame to compute against. | Dataset | |
| dataFrameCallback (producer) | Function performing action against an DataFrame. | DataFrameCallback | |
| rdd (producer) | RDD to compute against. | JavaRDDLike | |
| rddCallback (producer) | Function performing action against an RDD. | RddCallback | |
| synchronous (advanced) | Sets whether synchronous processing should be strictly used, or Camel is allowed to use asynchronous processing (if supported). | false | boolean |
314.4. Spring Boot Auto-Configuration
The component supports 4 options, which are listed below.
| Name | Description | Default | Type |
|---|---|---|---|
| camel.component.spark.enabled | Enable spark component | true | Boolean |
| camel.component.spark.rdd | RDD to compute against. The option is a org.apache.spark.api.java.JavaRDDLike type. | String | |
| camel.component.spark.rdd-callback | Function performing action against an RDD. The option is a org.apache.camel.component.spark.RddCallback type. | String | |
| camel.component.spark.resolve-property-placeholders | Whether the component should resolve property placeholders on itself when starting. Only properties which are of String type can use property placeholders. | true | Boolean |
314.5. RDD jobs
To invoke an RDD job, use the following URI:
Spark RDD producer
spark:rdd?rdd=#testFileRdd&rddCallback=#transformation
spark:rdd?rdd=#testFileRdd&rddCallback=#transformationSpark RDD callback
public interface RddCallback<T> {
T onRdd(JavaRDDLike rdd, Object... payloads);
}
public interface RddCallback<T> {
T onRdd(JavaRDDLike rdd, Object... payloads);
}The following snippet demonstrates how to send message as an input to the job and return results:
Calling spark job
String pattern = "job input";
long linesCount = producerTemplate.requestBody("spark:rdd?rdd=#myRdd&rddCallback=#countLinesContaining", pattern, long.class);
String pattern = "job input";
long linesCount = producerTemplate.requestBody("spark:rdd?rdd=#myRdd&rddCallback=#countLinesContaining", pattern, long.class);The RDD callback for the snippet above registered as Spring bean could look as follows:
Spark RDD callback
The RDD definition in Spring could looks as follows:
Spark RDD definition
@Bean
JavaRDDLike myRdd(JavaSparkContext sparkContext) {
return sparkContext.textFile("testrdd.txt");
}
@Bean
JavaRDDLike myRdd(JavaSparkContext sparkContext) {
return sparkContext.textFile("testrdd.txt");
}314.5.1. Void RDD callbacks
If your RDD callback doesn’t return any value back to a Camel pipeline, you can either return null value or use VoidRddCallback base class:
Spark RDD definition
314.5.2. Converting RDD callbacks
If you know what type of the input data will be sent to the RDD callback, you can use ConvertingRddCallback and let Camel to automatically convert incoming messages before inserting those into the callback:
Spark RDD definition
314.5.3. Annotated RDD callbacks
Probably the easiest way to work with the RDD callbacks is to provide class with method marked with @RddCallback annotation:
Annotated RDD callback definition
If you will pass CamelContext to the annotated RDD callback factory method, the created callback will be able to convert incoming payloads to match the parameters of the annotated method:
Body conversions for annotated RDD callbacks
314.6. DataFrame jobs
Instead of working with RDDs Spark component can work with DataFrames as well.
To invoke an DataFrame job, use the following URI:
Spark RDD producer
spark:dataframe?dataFrame=#testDataFrame&dataFrameCallback=#transformation
spark:dataframe?dataFrame=#testDataFrame&dataFrameCallback=#transformationSpark RDD callback
public interface DataFrameCallback<T> {
T onDataFrame(Dataset<Row> dataFrame, Object... payloads);
}
public interface DataFrameCallback<T> {
T onDataFrame(Dataset<Row> dataFrame, Object... payloads);
}The following snippet demonstrates how to send message as an input to a job and return results:
Calling spark job
String model = "Micra";
long linesCount = producerTemplate.requestBody("spark:dataFrame?dataFrame=#cars&dataFrameCallback=#findCarWithModel", model, long.class);
String model = "Micra";
long linesCount = producerTemplate.requestBody("spark:dataFrame?dataFrame=#cars&dataFrameCallback=#findCarWithModel", model, long.class);The DataFrame callback for the snippet above registered as Spring bean could look as follows:
Spark RDD callback
The DataFrame definition in Spring could looks as follows:
Spark RDD definition
314.7. Hive jobs
Instead of working with RDDs or DataFrame Spark component can also receive Hive SQL queries as payloads. To send Hive query to Spark component, use the following URI:
Instead of working with RDDs or DataFrame Spark component can also
receive Hive SQL queries as payloads. To send Hive query to Spark
component, use the following URI:Spark RDD producer
spark:hive
spark:hiveThe following snippet demonstrates how to send message as an input to a job and return results:
Calling spark job
long carsCount = template.requestBody("spark:hive?collect=false", "SELECT * FROM cars", Long.class);
List<Row> cars = template.requestBody("spark:hive", "SELECT * FROM cars", List.class);
long carsCount = template.requestBody("spark:hive?collect=false", "SELECT * FROM cars", Long.class);
List<Row> cars = template.requestBody("spark:hive", "SELECT * FROM cars", List.class);The table we want to execute query against should be registered in a HiveContext before we query it. For example in Spring such registration could look as follows:
Spark RDD definition
314.8. See Also
- Configuring Camel
- Component
- Endpoint
- Getting Started