アーキテクチャー
OpenShift Container Platform 4.2 のアーキテクチャーの概要
概要
第1章 OpenShift Container Platform アーキテクチャー
1.1. OpenShift Container Platform の紹介
OpenShift Container Platform は、コンテナー化されたアプリケーションを開発し、実行するためのプラットフォームです。アプリケーションおよびアプリケーションをサポートするデータセンターで、わずか数台のマシンとアプリケーションから、何百万ものクライアントに対応する何千ものマシンに拡張できるように設計されています。
Kubernetes をその基盤とする OpenShift Container Platform には、大規模な通信、ビデオストリーミング、ゲーミング、バンキングその他のアプリケーションのエンジンと同様に機能する技術が組み込まれています。Red Hat のオープンテクノロジーに実装することで、コンテナー化されたアプリケーションを、単一クラウドを超えてオンプレミスおよびマルチクラウド環境へと拡張することが可能です。
1.1.1. Kubernetes について
コンテナーイメージとそれらのイメージから実行されるコンテナーは、最先端のアプリケーション開発における主要な構成要素ですが、それらを大規模に実行するには、信頼性と柔軟性に優れた分配システムが必要となります。Kubernetes は、コンテナーをオーケストレーションするための事実上の業界標準です。
Kubernetes は、コンテナー化されたアプリケーションのデプロイ、スケーリング、管理を自動化するための、オープンソースのコンテナーオーケストレーションエンジンです。Kubernetes の一般的概念は非常にシンプルです。
- 1 つまたは複数のワーカーノードを使用することからスタートし、コンテナーのワークロードを実行します。
- 1 つまたは複数のマスターノードからワークロードのデプロイを管理します。
- Pod と呼ばれるデプロイメント単位にコンテナーをラップします。Pod を使うことでコンテナーに追加のメタデータが付与され、複数のコンテナーを単一のデプロイメントエンティティーにグループ化する機能が提供されます。
- 特殊な種類のアセットを作成します。たとえば、サービスは一連の Pod とそのアクセス方法を定義するポリシーによって表されます。このポリシーにより、コンテナーはサービス用の特定の IP アドレスを持っていない場合でも、必要とするサービスに接続することができます。レプリケーションコントローラーは、一度に実行するのに必要な Pod レプリカ数を示すもう一つの特殊なアセットです。この機能を使うと、現在の需要に対応できるようにアプリケーションを自動的にスケーリングすることができます。
Kubernetesは、わずか数年でクラウドとオンプレミスに非常に幅広く採用されるようになりました。このオープンソースの開発モデルにより、多くの人々がネットワーク、ストレージ、認証といったコンポーネント向けの各種の技術を実装し、Kubernetes を拡張することができます。
1.1.2. コンテナー化されたアプリケーションの利点
コンテナー化されたアプリケーションには、従来のデプロイメント方法を使用する場合と比べて多くの利点があります。アプリケーションはこれまで、すべての依存関係を含むオペレーティングシステムにインストールすることが必要でしたが、コンテナーの場合はアプリケーションがそれぞれの依存関係を持ち込むことができます。コンテナー化されたアプリケーションを作成すると多くの利点が得られます。
1.1.2.1. オペレーティングシステムの利点
コンテナーは、小型の、専用の Linux オペレーティングシステムをカーネルなしで使用します。ファイルシステム、ネットワーク、cgroups、プロセステーブル、namespace は、ホストの Linux システムから分離されていますが、コンテナーは、必要に応じてホストとシームレスに統合できます。Linux を基盤とすることで、コンテナーでは、迅速なイノベーションを可能にするオープンソース開発モデルに備わっているあらゆる利点を活用することができます。
各コンテナーは専用のオペレーティングシステムを使用するため、競合するソフトウェアの依存関係を必要とする複数のアプリケーションを、同じホストにデプロイできます。各コンテナーは、それぞれの依存するソフトウェアを持ち運び、ネットワークやファイルシステムなどの独自のインターフェイスを管理します。 したがってアプリケーションはそれらのアセットについて競い合う必要はありません。
1.1.2.2. デプロイメントとスケーリングの利点
アプリケーションのメジャーリリース間でローリングアップグレードを行うと、ダウンタイムなしにアプリケーションを継続的に改善し、かつ現行リリースとの互換性を維持することができます。
さらに、アプリケーションの新バージョンを、旧バージョンと並行してデプロイおよびテストすることもできます。アプリケーションの旧バージョンに加えて、新バージョンをデプロイできます。コンテナーがテストにパスしたら、新規コンテナーを追加でデプロイし、古いコンテナーを削除できます。
アプリケーションのソフトウェアの依存関係すべてはコンテナー内で解決されるので、データセンターの各ホストには汎用のオペレーティングシステムを使用できます。各アプリケーションホスト向けに特定のオペレーティングシステムを設定する必要はありません。データセンターでさらに多くの容量が必要な場合は、別の汎用ホストシステムをデプロイできます。
同様に、コンテナー化されたアプリケーションのスケーリングも簡単です。OpenShift Container Platform には、どのようなコンテナー化したサービスでもスケーリングできる、シンプルで標準的な方法が用意されています。アプリケーションを大きなモノリシックな (一枚岩的な) サービスではなく、マイクロサービスのセットとしてビルドする場合、個々のマイクロサービスを、需要に合わせて個別にスケーリングできます。この機能により、アプリケーション全体ではなく必要なサービスのみをスケーリングすることができ、使用するリソースを最小限に抑えつつ、アプリケーションの需要を満たすことができます。
1.1.3. OpenShift Container Platform の概要
OpenShift Container Platform は、以下を含むエンタープライズ対応の拡張機能を Kubernetes に提供します。
- ハイブリッドクラウドのデプロイメント。OpenShift Container Platform クラスターをさまざまなパブリッククラウドのプラットフォームまたはお使いのデータセンターにデプロイできます。
- Red Hat の統合されたテクノロジー。OpenShift Container Platform の主なコンポーネントは、Red Hat Enterprise Linux と関連する Red Hat の技術に由来します。OpenShift Container Platform は、Red Hat の高品質エンタープライズソフトウェアの集中的なテストや認定の取り組みによる数多くの利点を活用しています。
- オープンソースの開発モデル。開発はオープンソースで行われ、ソースコードはソフトウェアのパブリックリポジトリーから入手可能です。このオープンな共同作業が迅速な技術と開発を促進します。
Kubernetes はアプリケーションの管理で威力を発揮しますが、プラットフォームレベルの各種要件やデプロイメントプロセスを指定したり、管理したりすることはありません。そのため、OpenShift Container Platform 4.2 が提供する強力かつ柔軟なプラットフォーム管理ツールとプロセスは重要な利点の1つとなります。以下のセクションでは、OpenShift Container Platform のいくつかのユニークな機能と利点について説明します。
1.1.3.1. カスタムオペレーティングシステム
OpenShift Container Platform はコンテナー指向のオペレーティングシステムであり、CoreOS と Red Hat Atomic Host オペレーティングシステムの最良の機能の一部を組み合わせた Red Hat Enterprise Linux CoreOS (RHCOS) を採用しています。RHCOS は、OpenShift Container Platform のコンテナー化されたアプリケーションを実行する目的で設計されており、新規ツールと連携して迅速なインストール、Operator ベースの管理、および単純化されたアップグレードを実現します。
RHCOS には以下が含まれます。
- Ignition。OpenShift Container Platform が使用するマシンを最初に起動し、設定するための初回起動時のシステム設定です。
- CRI-O、Kubernetes ネイティブコンテナーランタイム実装。これはオペレーティングシステムに密接に統合し、Kubernetes の効率的で最適化されたエクスペリエンスを提供します。CRI-O は、コンテナーを実行、停止および再起動を実行するための機能を提供します。これは、OpenShift Container Platform 3 で使用されていた Docker Container Engine を完全に置き換えます。
- Kubelet、Kubernetes のプライマリーノードエージェント。 これは、コンテナーを起動し、これを監視します。
OpenShift Container Platform 4.2 ではすべてのコントロールプレーンマシンで RHCOS を使用する必要がありますが、Red Hat Enterprise Linux (RHEL) をコンピュートまたはワーカーマシンのオペレーティングシステムとして使用することができます。RHEL のワーカーを使用する選択をする場合、すべてのクラスターマシンに 対してRHCOS を使用する場合よりも多くのシステムメンテナンスを実行する必要があります。
1.1.3.2. 単純化されたインストールおよび更新プロセス
OpenShift Container Platform 4.2 では、適切なパーミッションを持つアカウントを使用している場合、単一のコマンドを実行し、いくつかの値を指定することで、サポートされているクラウドに実稼働用のクラスターをデプロイすることができます。また、サポートされているプラットフォームを使用している場合、クラウドのインストールをカスタマイズしたり、クラスターをお使いのデータセンターにインストールすることも可能です。
クラスターのすべてのマシンが RHCOS を使用している場合、OpenShift Container Platform の更新またはアップグレードは、高度に自動化された単純なプロセスで実行できます。OpenShift Container Platform は、各マシンで実行される、オペレーティングシステム自体を含むシステムとサービスを中央のコントロールプレーンから完全に制御するので、アップグレードは自動イベントになるように設計されています。クラスターに RHEL のワーカーマシンが含まれる場合、コントロールプレーンの使用には単純化された更新プロセスの利点があるものの、RHEL マシンのアップグレードには、より多くのタスクの実行が必要になります。
1.1.3.3. その他の主な機能
Operator は、OpenShift Container Platform 4.2 コードベースの基本単位であるだけでなく、アプリケーションとアプリケーションで使用されるソフトウェアコンポーネントをデプロイするための便利な手段です。Operator をプラットフォームの基盤として使用することで、OpenShift Container Platform ではオペレーティングシステムおよびコントロールプレーンアプリケーションの手動によるアップグレードが不要になります。Cluster Version Operator や Machine Config Operator などの OpenShift Container Platform の Operator が、それらの重要なコンポーネントのクラスター全体での管理を単純化します。
Operator Lifecycle Manager (OLM) および OperatorHub は、Operator を保管し、アプリケーションの開発やデプロイを行う人々に Operator を提供する機能を提供します。
Red Hat Quay Container Registry は、ほとんどのコンテナーイメージと Operator を OpenShift Container Platform クラスターに提供する Quay.io コンテナーレジストリーです。Quay.io は、何百万ものイメージやタグを保存する Red Hat Quay の公開レジストリー版です。
OpenShift Container Platform での Kubernetes のその他の拡張には、SDN (Software Defined Networking)、認証、ログ集計、監視、およびルーティングの強化された機能が含まれます。OpenShift Container Platform は、包括的な Web コンソールとカスタム OpenShift CLI (oc) インタフェースも提供します。
1.1.3.4. OpenShift Container Platform のライフサイクル
以下の図は、OpenShift Container Platform の基本的なライフサイクルを示しています。
- OpenShift Container Platform クラスターの作成
- クラスターの管理
- アプリケーションの開発とデプロイ
- アプリケーションのスケールアップ
図1.1 OpenShift Container Platform の概要
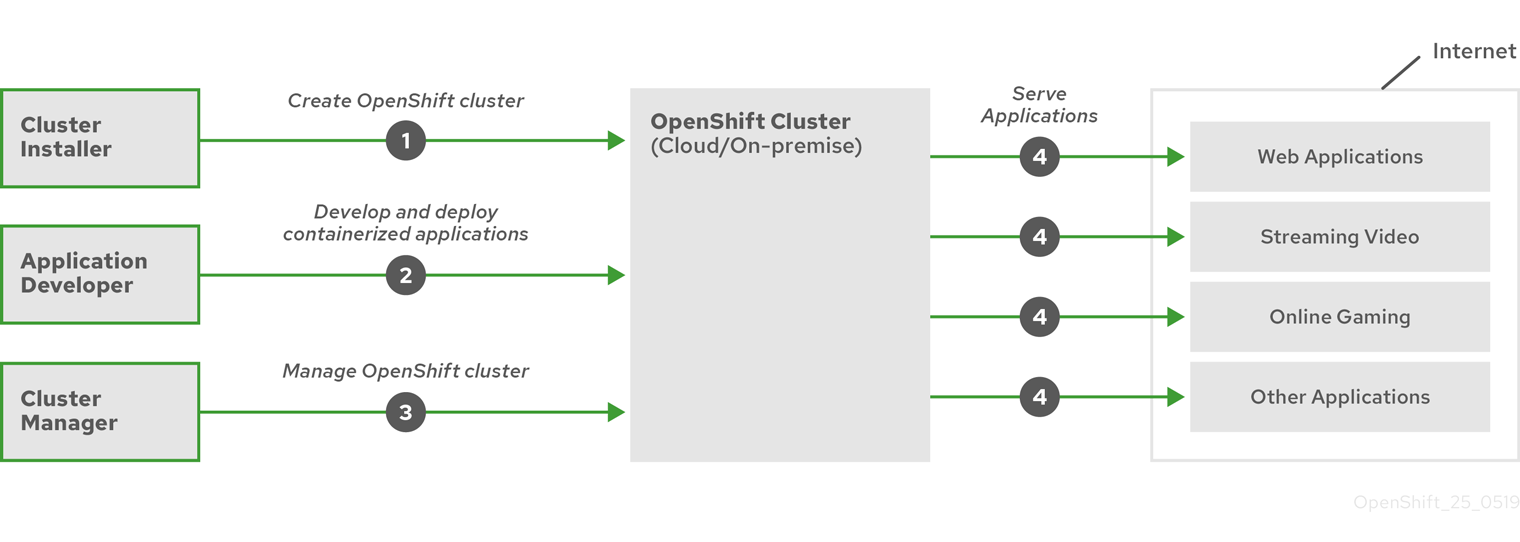
1.1.4. OpenShift Container Platform のインターネットアクセスおよび Telemetry アクセス
OpenShift Container Platform 4.2 では、クラスターをインストールするためにインターネットアクセスが必要になります。クラスターの健全性および正常に実行された更新についてのメトリクスを提供するためにデフォルトで実行される Telemetry サービスにもインターネットアクセスが必要です。クラスターがインターネットに接続されている場合、Telemetry は自動的に実行され、クラスターは Red Hat OpenShift Cluster Manager (OCM) に登録されます。
Red Hat OpenShift Cluster Manager インベントリーが Telemetry によって自動的に維持されるか、または OCM を手動で使用しているかのいずれによって正常であることを確認した後に、subscription watch を使用して、アカウントまたはマルチクラスターレベルで OpenShift Container Platform サブスクリプションを追跡します。
インターネットへのアクセスは以下を実行するために必要です。
- Red Hat OpenShift Cluster Manager ページにアクセスし、インストールプログラムをダウンロードし、サブスクリプション管理を実行します。クラスターにインターネットアクセスがあり、Telemetry を無効にしない場合、そのサービスは有効なサブスクリプションでクラスターを自動的に使用します。
- クラスターのインストールに必要なパッケージを取得するために Quay.io にアクセスします。
- クラスターの更新を実行するために必要なパッケージを取得します。
クラスターでインターネットに直接アクセスできない場合、プロビジョニングする一部のタイプのインフラストラクチャーでネットワークが制限されたインストールを実行できます。このプロセスで、必要なコンテンツをダウンロードし、これを使用してミラーレジストリーにクラスターのインストールおよびインストールプログラムの生成に必要なパッケージを設定します。 インストールタイプによっては、クラスターのインストール環境でインターネットアクセスが不要となる場合があります。クラスターを更新する前に、ミラーレジストリーのコンテンツを更新します。
第2章 インストールおよび更新
2.1. OpenShift Container Platform インストールの概要
OpenShift Container Platform インストールプログラムは柔軟性を提供します。インストールプログラムを使用して、インストールプログラムがプロビジョニングし、クラスターで維持するインフラストラクチャーでクラスターをデプロイしたり、ユーザーが独自に準備し、維持するインフラストラクチャーでクラスターをデプロイしたりすることができます。
OpenShift Container Platform クラスターの基本的な 2 つのタイプとして、インストーラーでプロビジョニングされるインフラストラクチャークラスターとユーザーによってプロビジョニングされるインフラストラクチャークラスターがあります。
これらのクラスターのタイプにはどちらにも以下の特徴があります。
- 単一障害点のない可用性の高いインフラストラクチャーがデフォルトで利用可能である。
- 管理者は適用される更新内容および更新タイミングを制御できる。
同一のインストールプログラムを使用してこれらクラスターの両方のタイプをデプロイできます。インストールプログラムで生成される主なアセットは ブートストラップ、マスターおよびワーカーマシンの Ignition 設定です。これらの 3 つの設定および適切に設定されたインフラストラクチャーを使用して、OpenShift Container Platform クラスターを起動することができます。
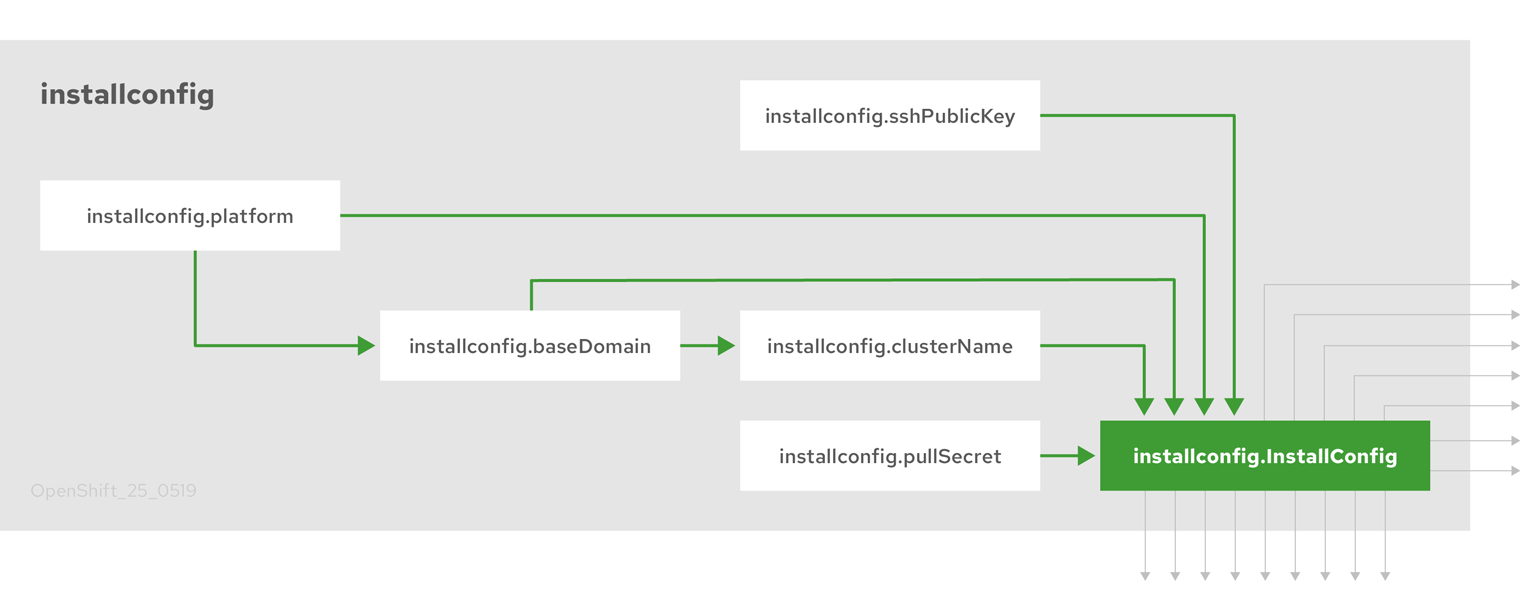
OpenShift Container Platform インストールプログラムは、クラスターのインストールを管理するために一連のターゲットおよび依存関係を使用します。インストールプログラムには、達成する必要のある一連のターゲットが設定され、それぞれのターゲットには一連の依存関係が含まれます。各ターゲットはそれぞれの依存関係の条件が満たされ次第、別個に解決されるため、インストールプログラムは複数のターゲットを並行して達成できるように動作します。最終的なターゲットはクラスターを実行することです。コマンドを実行するのではなく依存関係の条件を満たすことにより、インストールプログラムは、コマンドを実行してコンポーネントを再度作成する代わりに、既存のコンポーネントを認識し、それらを使用することができます。
以下の図は、インストールのターゲットと依存関係のサブセットを示しています。
図2.1 OpenShift Container Platform インストールのターゲットおよび依存関係
インストール後に、各クラスターマシンは Red Hat Enterprise Linux CoreOS (RHCOS) をオペレーティングマシンとして使用します。RHCOS は Red Hat Enterprise Linux (RHEL) の不変のコンテナーホストのバージョンであり、デフォルトで SELinux が有効にされた RHEL カーネルを特長としています。これには、Kubernetes ノードエージェントである kubelet や、Kubernetes に対して最適化される CRI-O コンテナーランタイムが含まれます。
OpenShift Container Platform 4.2 クラスターのすべてのコントールプレーンは、Ignition と呼ばれる最初の起動時に使用される重要なプロビジョニングツールが含まれる RHCOS を使用する必要があります。このツールは、クラスターのマシンの設定を可能にします。オペレーティングシステムの更新は、Operator によってクラスター全体に展開されるコンテナーイメージに組み込まれる Atomic OSTree リポジトリーとして提供されます。実際のオペレーティングシステムの変更については、rpm-ostree を使用する atomic 操作として各マシンでインプレースで実行されます。これらのテクノロジーを組み合わせて使用することにより、OpenShift Container Platform では、プラットフォーム全体を最新の状態に保つインプレースアップグレードで、その他のアプリケーションをクラスターで管理するかのようにオペレーティングシステムを管理することができます。これらのインプレースアップグレードにより、オペレーションチームの負担を軽減することができます。
RHCOS をすべてのクラスターマシンのオペレーティングシステムとして使用する場合、クラスターはオペレーティングシステムを含む、そのコンポーネントとマシンのすべての側面を管理します。このため、インストールプログラムと Machine Config Operator のみがマシンを変更することができます。インストールプログラムは Ignition 設定ファイルを使用して各マシンの状態を設定し、Machine Config Operator はインストール後に、新規証明書またはキーの適用などのマシンへの変更を実行します。
2.1.1. 利用可能なプラットフォーム
OpenShift Container Platform バージョン 4.2 では、インストーラーでプロビジョニングされるインフラストラクチャーを使用するクラスターの場合、以下のプラットフォームにインストールできます。
- Amazon Web Services (AWS)
- Google Cloud Platform (GCP)
- Microsoft Azure
Red Hat OpenStack Platform (RHOSP) バージョン 13 および 15
- OpenShift Container Platform の最新リリースは、最新の RHOSP のロングライフリリースおよび中間リリースの両方をサポートします。RHOSP リリースの互換性についての詳細は、「OpenShift Container Platform on RHOSP support matrix」を参照してください。
- Red Hat Virtualization (RHV)
これらのクラスターの場合、インストールプロセスを実行するコンピューターを含むすべてのマシンが、プラットフォームコンテナーのイメージをプルし、Telemetry データを Red Hat に提供できるようインターネットに直接アクセスできる必要があります。
OpenShift Container Platform バージョン 4.2 では、ユーザーによってプロビジョニングされるインフラストラクチャーを使用するクラスターの場合、以下のプラットフォームにインストールできます。
- AWS
- GCP
- VMware vSphere
- ベアメタル
ユーザーによってプロビジョニングされるインフラストラクチャーでのインストールでは、各マシンにインターネットのフルアクセスを持たせることができ、クラスターをプロキシーの背後に配置するか、または ネットワークの制限されたインストール を実行できます。ネットワークが制限された環境でのインストールでは、クラスターのインストールに必要なイメージをダウンロードして、ミラーレジストリーに配置し、そのデータを使用してクラスターをインストールできます。vSphere またはベアメタルインフラストラクチャーのネットワークが制限されたインストールでは、プラットフォームコンテナーのイメージをプルするためにインターネットにアクセスする必要がありますが、クラスターマシンはインターネットへの直接のアクセスを必要としません。
「OpenShift Container Platform 4.x Tested Integrations」のページには、各種プラットフォームの統合テストについての詳細が記載されています。
2.1.2. インストールプロセス
OpenShift Container Platform クラスターをインストールする場合は、Red Hat OpenShift Cluster Manager サイトの該当するインフラストラクチャープロバイダーページからインストールプログラムをダウンロードします。このサイトでは以下を管理しています。
- アカウントの REST API
- 必要なコンポーネントを取得するために使用するプルシークレットであるレジストリートークン
- クラスターのアイデンティティーを Red Hat アカウントに関連付けて使用状況のメトリクスの収集を容易にするクラスター登録
OpenShift Container Platform 4.2 では、インストールプログラムは、一連のアセットに対して一連のファイル変換を実行する Go バイナリーファイルです。インストールプログラムと対話する方法は、インストールタイプによって異なります。
- インストーラーでプロビジョニングされるインフラストラクチャーのクラスターの場合、インフラストラクチャーのブートストラップおよびプロビジョニングは、ユーザーが独自に行うのではなくインストールプログラムが代行します。インストールプログラムは、クラスターをサポートするために必要なネットワーク、マシン、およびオペレーティングシステムのすべてを作成します。
- クラスターのインフラストラクチャーを独自にプロビジョニングし、管理する場合には、ブートストラップマシン、ネットワーク、負荷分散、ストレージ、および個々のクラスターマシンを含む、すべてのクラスターインフラストラクチャーおよびリソースを指定する必要があります。インストーラーでプロビジョニングされるインフラストラクチャークラスターが提供する高度なマシン管理およびスケーリング機能を使用することはできません。
インストール時には、お使いのマシンタイプ用の install-config.yaml という名前のインストール設定ファイル、Kubernetes マニフェスト、および Ingition 設定ファイルの 3 つのファイルセットを使用します。
インストール時に、Kubernetes および基礎となる RHCOS オペレーティングシステムを制御する Ignition 設定ファイルを変更することができます。ただし、これらのオブジェクトに対して加える変更の適合性を確認するための検証の方法はなく、これらのオブジェクトを変更するとクラスターが機能しなくなる可能性があります。これらのオブジェクトを変更する場合、クラスターが機能しなくなる可能性があります。このリスクがあるために、変更方法についての文書化された手順に従っているか、または Red Hat サポートが変更することを指示した場合を除き、Kubernetes および Ignition 設定ファイルの変更はサポートされていません。
インストール設定ファイルは Kubernetes マニフェストに変換され、その後マニフェストは Ignition 設定にラップされます。インストールプログラムはこれらの Ignition 設定ファイルを使用してクラスターを作成します。
インストール設定ファイルはインストールプログラムの実行時にすべてプルーニングされるため、再び使用する必要のあるすべての設定ファイルをバックアップしてください。
インストール時に設定したパラメーターを変更することはできませんが、インストール後に数多くのクラスター属性を変更することができます。
インストーラーでプロビジョニングされるインフラストラクチャーでのインストールプロセス
デフォルトのインストールタイプは、インストーラーでプロビジョニングされるインフラストラクチャーです。デフォルトで、インストールプログラムはインストールウィザードとして機能し、独自に判別できない値の入力を求めるプロンプトを出し、残りのパラメーターに妥当なデフォルト値を提供します。インストールプロセスは、高度なインフラストラクチャーシナリオに対応するようカスタマイズすることもできます。インストールプログラムは、クラスターの基盤となるインフラストラクチャーをプロビジョニングします。
標準クラスターまたはカスタマイズされたクラスターのいずれかをインストールすることができます。標準クラスターの場合、クラスターをインストールするために必要な最小限の詳細情報を指定します。カスタマイズされたクラスターの場合、コントロールプレーンが使用するマシン数、クラスターがデプロイする仮想マシンのタイプ、または Kubernetes サービスネットワークの CIDR 範囲などのプラットフォームについての詳細を指定することができます。
可能な場合は、この機能を使用してクラスターインフラストラクチャーのプロビジョニングと保守の手間を省くようにしてください。他のすべての環境の場合には、インストールプログラムを使用してクラスターインフラストラクチャーをプロビジョニングするために必要なアセットを生成できます。
インストーラーでプロビジョニングされるインフラストラクチャークラスターの場合、OpenShift Container Platform は、オペレーティングシステム自体を含むクラスターのすべての側面を管理します。各マシンは、それが参加するクラスターでホストされるリソースを参照する設定に基づいて起動します。この設定により、クラスターは更新の適用時に自己管理できます。
ユーザーによってプロビジョニングされるインフラストラクチャーでのインストールプロセス
OpenShift Container Platform はユーザーが独自にプロビジョニングするインフラストラクチャーにインストールすることもできます。インストールプログラムを使用してクラスターインフラストラクチャーのプロビジョニングに必要なアセットを生成し、クラスターインフラストラクチャーを作成し、その後にクラスターをプロビジョニングしたインフラストラクチャーにデプロイします。
インストールプログラムがプロビジョニングするインフラストラクチャーを使用しない場合、以下を含むクラスターリソースを管理し、維持する必要があります。
- クラスターを構成するコントロールプレーンおよびコンピュートマシン
- ロードバランサー
- DNS レコードおよび必要なサブネットを含むクラスターネットワーク
- クラスターインフラストラクチャーおよびアプリケーションのストレージ
クラスターでユーザーによってプロビジョニングされるインフラストラクチャーを使用する場合には、RHEL ワーカーマシンをクラスターに追加するオプションを使用できます。
インストールプロセスの詳細
クラスターの各マシンにはプロビジョニング時にクラスターについての情報が必要になるため、OpenShift Container Platform は初期設定時に一時的な bootstrap マシンを使用し、必要な情報を永続的なコントロールマシンに提供します。これは、クラスターの作成方法を記述する Ignition 設定ファイルを使用して起動されます。ブートストラップマシンは、コントロールプレーンを構成するマスターマシンを作成します。その後、コントロールプレーンマシンはコンピュートマシン (ワーカーマシンとしても知られる) を作成します。以下の図はこのプロセスを示しています。
図2.2 ブートストラップ、マスター、およびワーカーマシンの作成
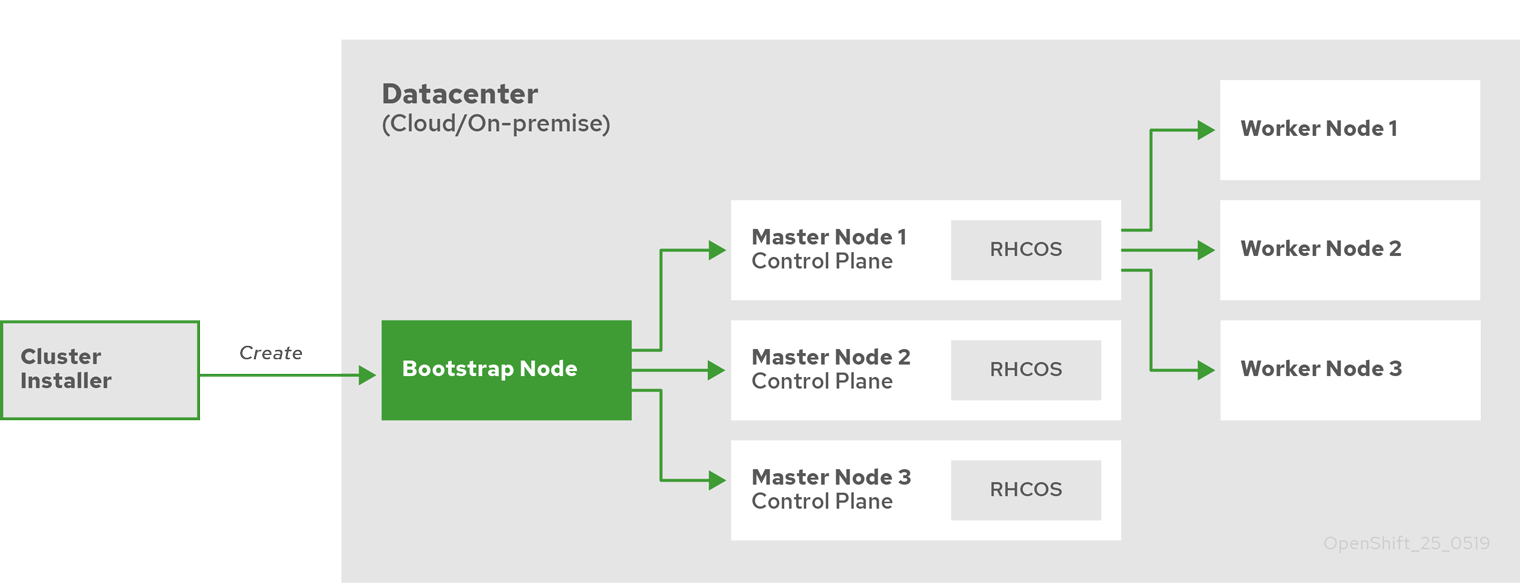
クラスターマシンを初期化した後、ブートストラップマシンは破棄されます。すべてのクラスターがこのブートストラッププロセスを使用してクラスターを初期化しますが、ユーザーがクラスターのインフラストラクチャーをプロビジョニングする場合には、多くの手順を手動で実行する必要があります。
インストールプログラムが生成する Ignition 設定ファイルには、24 時間が経過すると期限切れになる証明書が含まれます。最初の証明書のローテーションが正常に実行されるようにするには、クラスターのインストールを完了し、クラスターを動作が低下していない状態で 24 時間実行し続ける必要があります。
クラスターのブートストラップには、以下のステップが関係します。
- ブートストラップマシンが起動し、マスターマシンの起動に必要なリモートリソースのホスティングを開始します。(ユーザーがインフラストラクチャーをプロビジョニングする場合には手動の介入が必要になります)。
- マスターマシンは、ブートストラップマシンからリモートリソースをフェッチし、起動を終了します。(ユーザーがインフラストラクチャーをプロビジョニングする場合には手動の介入が必要になります)。
- マスターマシンはブートストラップマシンを使用して、etcd クラスターを作成します。
- ブートストラップマシンは、新規 etcd クラスターを使用して一時的な Kubernetes コントロールプレーンを起動します。
- 一時的なコントロールプレーンは、マスターマシンに対して実稼働コントロールプレーンをスケジュールします。
- 一時的なコントロールプレーンはシャットダウンし、コントロールを実稼働コントロールプレーンに渡します。
- ブートストラップマシンは OpenShift Container Platform コンポーネントを実稼働コントロールプレーンに挿入します。
- インストールプログラムはブートストラップマシンをシャットダウンします。(ユーザーがインフラストラクチャーをプロビジョニングする場合には手動の介入が必要になります)。
- コントロールプレーンはワーカーノードをセットアップします。
- コントロールプレーンは一連の Operator の形式で追加のサービスをインストールします。
このブートストラッププロセスの結果として、OpenShift Container Platform クラスターが完全に実行されます。次に、クラスターはサポートされる環境でのワーカーマシンの作成など、日常の操作に必要な残りのコンポーネントをダウンロードし、設定します。
インストールプロセスの詳細
インストールのスコープ
OpenShift Container Platform インストールプログラムのスコープは意図的に狭められています。単純さを確保し、確実にインストールを実行できるように設計されているためです。インストールが完了した後に数多くの設定タスクを実行することができます。
2.2. OpenShift Container Platform の更新サービスについて
OpenShift Container Platform の更新サービスとは、OpenShift Container Platform と Red Hat Enterprise Linux CoreOS (RHCOS) の両方に OTA(over-the-air) 更新を提供するホスト型サービスです。コンポーネント Operator のグラフ、または頂点とそれらを結ぶ辺を含む図表が提示されます。グラフの辺は、どのバージョンであれば安全に更新できるかを示します。 頂点は、管理されたクラスターコンポーネントの想定された状態を特定する更新のペイロードです。
クラスター内の Cluster Version Operator (CVO) は、OpenShift Container Platform の更新サービスをチェックして、グラフの現在のコンポーネントバージョンとグラフの情報に基づき、有効な更新および更新パスを確認します。ユーザーが更新をリクエストすると、OpenShift Container Platform CVO はその更新のリリースイメージを使ってクラスターをアップグレードします。リリースアーティファクトは、コンテナーイメージとして Quay でホストされます。
OpenShift Container Platform 更新サービスが互換性のある更新のみを提供できるようにするために、自動化を支援するリリース検証 Pipeline が使用されます。それぞれのリリースアーティファクトについて、他のコンポーネントパッケージだけでなくサポートされているクラウドプラットフォームおよびシステムアーキテクチャーとの互換性の有無が検証されます。Pipeline がリリースの適合性を確認した後に、OpenShift Container Platform 更新サービスは更新が利用可能であることを通知します。
更新サービスが有効な更新をすべて表示するために、更新サービスが表示しないバージョンへの更新を強制することはできません。
連続更新モードでは、2 つのコントローラーが実行されます。1 つのコントローラーはペイロードマニフェストを絶えず更新し、それらをクラスターに適用し、Operator が利用可能か、アップグレード中か、または失敗しているかに応じて Operator の制御されたロールアウトのステータスを出力します。2 つ目のコントローラーは OpenShift Container Platform 更新サービスをポーリングして、更新が利用可能かどうかを判別します。
クラスターを以前のバージョンに戻すこと、つまりロールバックはサポートされていません。サポートされているのは、新規バージョンへのアップグレードのみです。
2.3. 管理外の Operator のサポートポリシー
Operator の 管理状態 は、Operator が設計通りにクラスター内の関連するコンポーネントのリソースをアクティブに管理しているかどうかを定めます。Operator が unmanaged 状態に設定されている場合、これは設定の変更に応答せず、更新を受信しません。
これは非実稼働クラスターやデバッグ時に便利ですが、管理外の状態の Operator はサポートされず、クラスター管理者は個々のコンポーネント設定およびアップグレードを完全に制御していることを前提としています。
Operator は以下の方法を使用して管理外の状態に設定できます。
個別の Operator 設定
個別の Operator には、それらの設定に
managementStateパラメーターがあります。これは Operator に応じてさまざまな方法でアクセスできます。たとえば、Cluster Logging Operator は管理するカスタムリソース (CR) を変更することによってこれを実行しますが、Samples Operator はクラスター全体の設定リソースを使用します。managementStateパラメーターをUnmanagedに変更する場合、Operator はそのリソースをアクティブに管理しておらず、コンポーネントに関連するアクションを取らないことを意味します。Operator によっては、クラスターが破損し、手動リカバリーが必要になる可能性があるため、この管理状態に対応しない可能性があります。警告個別の Operator を
Unmanaged状態に変更すると、特定のコンポーネントおよび機能がサポート対象外になります。サポートを継続するには、報告された問題をManaged状態で再現する必要があります。Cluster Version Operator (CVO) のオーバーライド
spec.overridesパラメーターを CVO の設定に追加すると、管理者はコンポーネントについての CVO の動作に対してオーバーライドの一覧を追加できます。コンポーネントについてspec.overrides[].unmanagedパラメーターをtrueに設定すると、クラスターのアップグレードがブロックされ、CVO のオーバーライドが設定された後に管理者にアラートが送信されます。Disabling ownership via cluster version overrides prevents upgrades. Please remove overrides before continuing.警告CVO のオーバーライドを設定すると、クラスター全体がサポートされない状態になります。サポートを継続するには、オーバーライドを削除した後に、報告された問題を再現する必要があります。
第3章 OpenShift Container Platform コントロールプレーン
3.1. OpenShift Container Platform コントロールプレーンについて
コンテナープレーンはマスターマシンから構成されており、OpenShift Container Platform クラスターを管理します。コントロールプレーンマシンは、コンピュートマシン (ワーカーマシンとしても知られる) のワークロードを管理します。クラスター自体は、Cluster Version Operator、Machine Config Operator、および個々の Operator のアクションによって、マシンへのすべてのアップグレードを管理します。
3.1.1. OpenShift Container Platform のマシンのロール
OpenShift Container Platform はホストに複数の異なるロールを割り当てます。これらのロールは、クラスター内のマシンの機能を定義します。クラスターには、標準のマスターおよびワーカーのロールタイプの定義が含まれます。
また、クラスターにはブートストラップロールの定義も含まれます。ブートストラップマシンが使用されるのはクラスターのインストール時のみであり、この機能については、クラスターインストールのドキュメントで説明されています。
3.1.1.1. クラスターのワーカー
Kubernetes のクラスターでは、Kubernetes のユーザーがリクエストした実際のワークロードは、ワーカーノードで実行され、管理されます。ワーカーノードは、独自の容量と (マスターサービスの一部である) スケジューラを公開し、どのノードでコンテナーと Pod を起動するかを決定します。重要なサービスは各ワーカーノードで実行されますが、これには、コンテナーエンジンである CRI-O、コンテナーのワークロードの実行と停止の要求を受け入れ、実行するサービスである Kubelet、ワーカー間での Pod の通信を管理するサービスプロキシーが含まれます。
OpenShift Container Platform では、MachineSet がワーカーマシンを制御します。ワーカーのロールを持つマシンは、自動スケーリングを行う特定のマシンプールによって制御されるコンピュートワークロードを実行します。OpenShift Container Platform は複数のマシンタイプをサポートすることができ、ワーカーマシンは コンピュートマシンとして分類されています。コンピュートマシンの唯一のデフォルトタイプはワーカーマシンであるため、本リリースでは「ワーカーマシン」と「コンピュートマシン」は相互に置き換え可能な用語として使用されています。OpenShift Container Platform の今後のバージョンでは、インフラストラクチャーマシンなどの異なる種類のコンピュートマシンがデフォルトで使用される可能性があります。
3.1.1.2. クラスターのマスター
Kubernetes のクラスターでは、マスターノードは Kubernetes クラスターの制御に必要なサービスを実行します。OpenShift Container Platform では、マスターマシンはコントロールプレーンになります。これには、OpenShift Container Platform のクラスターを管理する Kubernetes サービス以外も含まれます。コントロールプレーンのロールを持つすべてのマシンがマスターマシンであるため、 マスター と コントロールプレーン はこれらを説明する際の相互に置き換え可能な用語として使用されています。マスターマシンは、MachineSet にグループ化されるのではなく、一連のスタンドアロンマシン API リソースによって定義されます。 すべてのマスターマシンが削除されてクラスターが切断されないようにするために、追加の制御がマスターマシンに適用されます。
3 つのマスターノードを使用します。理論的には任意の数のマスターノードを使用できますが、マスターの静的 Pod および etcd の静的 Pod が同じホストで動作するため、この数は etcd クォーラム (定足数) で制限されます。
マスター上の Kubernetes カテゴリーに分類されるサービスには、API サーバー、etcd、コントローラーマネージャーサーバー、HAProxy サービスがあります。
| Component | 説明 |
|---|---|
| API サーバー | Kubernetes の API サーバーは、Pod、サービス、レプリケーションコントローラーのデータを検証し、設定します。また、クラスターの共有される状態を確認できる中心的な部分として機能します。 |
| etcd | etcd はマスターの永続的な状態を保存し、他のコンポーネントは etcd で変更の有無を監視して、それぞれを指定された状態に切り替えます。 |
| コントローラーマネージャーサーバー | コントローラーマネージャーサーバーは etcd でレプリケーション、namespace、サービスアカウントコントローラーのオブジェクトへの変更の有無を監視し、API を使用して指定された状態を実行します。このような複数のプロセスは、一度に 1 つのアクティブなリーダーを設定してクラスターを作成します。 |
マスターマシン上のこれらサービスの一部は systemd サービスとして実行し、それ以外は 静的な Pod として実行されます。
systemd サービスは、起動直後の特定のシステムで常に起動している必要のあるサービスに適しています。マスターマシンの場合は、リモートログインを可能にする sshd も含まれます。また、以下のようなサービスも含まれます。
- CRI-O コンテナーエンジン (crio): コンテナーを実行し、管理します。OpenShift Container Platform 4.2 は、Docker Container Engine ではなく CRI-O を使用します。
- Kubelet (kubelet): マシン上で、マスターサービスからのコンテナー管理要求を受け入れます。
CRI-O および Kubelet は、他のコンテナーを実行する前に実行されている必要があるため、systemd サービスとしてホスト上で直接実行される必要があります。
3.1.2. OpenShift Container Platform の Operator
OpenShift Container Platform では、Operator はコントロールプレーンでサービスをパッケージ化し、デプロイし、管理するための推奨される方法です。Operator の使用は、ユーザーが実行するアプリケーションにも各種の利点があります。Operator は kubectl や oc コマンドなどの Kubernetes API および CLI ツールと統合します。Operator はアプリケーションの監視、ヘルスチェックの実行、OTA (over-the-air) 更新の管理を実行し、アプリケーションが指定した状態にあることを確認するための手段となります。
CRI-O と Kubelet はすべてのノード上で実行されるため、Operator を使用することにより、ほぼすべての他のクラスター機能をコントロールプレーンで管理できます。Operator は OpenShift Container Platform 4.2 の最も重要なコンポーネントです。Operator を使用してコントロールプレーンに追加されるコンポーネントには、重要なネットワークおよび認証情報サービスが含まれます。
OpenShift Container Platform クラスターの他の Operator を管理する Operator は Cluster Version Operator です。
OpenShift Container Platform 4.2 は複数の異なるクラスの Operator を使用してクラスター操作を実行し、アプリケーションが使用するクラスターでサービスを実行します。
3.1.2.1. OpenShift Container Platform の Platform Operator
OpenShift Container Platform 4.2 では、すべてのクラスター機能は一連の Platform Operator に分類されます。Platform Operator は、クラスター全体でのアプリケーションロギング、Kubernetes コントロールプレーンの管理、またはマシンプロビジョニングシステムなどの、クラスター機能の特定の分野を管理します。
各 Operator は、クラスター機能を判別するための単純な API を提供します。Operator は、コンポーネントのライフサイクルの管理についての詳細を非表示にします。Operator は単一コンポーネントも、数十のコンポーネントも管理できますが、最終目標は常に、共通アクションの自動化によって操作上の負担の軽減することにあります。また、Operator はより粒度の高いエクスペリエンスも提供します。各コンポーネントは、グローバル設定ファイルではなく、Operator が公開する API を変更して設定できます。
3.1.2.2. OLM によって管理される Operator
クラスターの Operator Lifecycle Management (OLM) コンポーネントはアプリケーションで使用できる Operator を管理します。これは OpenShift Container Platform を構成する Operator を管理しません。OLM は、Kubernetes ネイティブアプリケーションを Operator として管理するフレームワークです。これは、Kubernetes マニフェストを管理する代わりに、Kubernetes Operator を管理します。OLM は Red Hat Operator と認定 Operator の 2 つのクラスの Operator を管理します。
一部の Red Hat Operator は、スケジューラーおよび問題検出機能などのクラスター機能を実行します。他の Operator は etcd などのように各自で管理し、アプリケーションで使用できるように提供されます。また OpenShift Container Platform は、コミュニティーが構築し、保守する認定 Operator を提供します。これらの認定 Operator は API 層を従来のアプリケーションに提供し、アプリケーションを Kubernetes コンストラクトで管理できるようにします。
3.1.2.3. OpenShift Container Platform の更新サービスについて
OpenShift Container Platform の更新サービスとは、OpenShift Container Platform と Red Hat Enterprise Linux CoreOS (RHCOS) の両方に OTA(over-the-air) 更新を提供するホスト型サービスです。コンポーネント Operator のグラフ、または頂点とそれらを結ぶ辺を含む図表が提示されます。グラフの辺は、どのバージョンであれば安全に更新できるかを示します。 頂点は、管理されたクラスターコンポーネントの想定された状態を特定する更新のペイロードです。
クラスター内の Cluster Version Operator (CVO) は、OpenShift Container Platform の更新サービスをチェックして、グラフの現在のコンポーネントバージョンとグラフの情報に基づき、有効な更新および更新パスを確認します。ユーザーが更新をリクエストすると、OpenShift Container Platform CVO はその更新のリリースイメージを使ってクラスターをアップグレードします。リリースアーティファクトは、コンテナーイメージとして Quay でホストされます。
OpenShift Container Platform 更新サービスが互換性のある更新のみを提供できるようにするために、自動化を支援するリリース検証 Pipeline が使用されます。それぞれのリリースアーティファクトについて、他のコンポーネントパッケージだけでなくサポートされているクラウドプラットフォームおよびシステムアーキテクチャーとの互換性の有無が検証されます。Pipeline がリリースの適合性を確認した後に、OpenShift Container Platform 更新サービスは更新が利用可能であることを通知します。
更新サービスが有効な更新をすべて表示するために、更新サービスが表示しないバージョンへの更新を強制することはできません。
連続更新モードでは、2 つのコントローラーが実行されます。1 つのコントローラーはペイロードマニフェストを絶えず更新し、それらをクラスターに適用し、Operator が利用可能か、アップグレード中か、または失敗しているかに応じて Operator の制御されたロールアウトのステータスを出力します。2 つ目のコントローラーは OpenShift Container Platform 更新サービスをポーリングして、更新が利用可能かどうかを判別します。
クラスターを以前のバージョンに戻すこと、つまりロールバックはサポートされていません。サポートされているのは、新規バージョンへのアップグレードのみです。
3.1.2.4. Machine Config Operator について
OpenShift Container Platform 4.2 は、オペレーティングシステムとクラスター管理を統合します。クラスターは、クラスターノードでの Red Hat Enterprise Linux CoreOS (RHCOS) への更新を含め、独自の更新を管理するので、OpenShift Container Platform では事前に設定されたライフサイクル管理が実行され、ノードのアップグレードのオーケストレーションが単純化されます。
OpenShift Container Platform は、ノードの管理を単純化するために 3 つの DaemonSet とコントローラーを採用しています。これらの DaemonSet は、Kubernetes 形式のコンストラクトを使用してオペレーティングシステムの更新とホストの設定変更をオーケストレーションします。これには、以下が含まれます。
-
machine-config-controller: コントロールプレーンからマシンのアップグレードを調整します。すべてのクラスターノードを監視し、その設定の更新をオーケストレーションします。 -
machine-config-daemonDaemonSet: クラスターの各ノードで実行され、MachineConfigController の指示通りに MachineConfig が定義した設定でマシンを更新します。 ノードは、変更を確認すると Pod からドレイン (解放) され、更新を適用して再起動します。これらの変更は、指定されたマシン設定を適用し、 kubelet 設定を制御する Ignition 設定ファイルの形式で実行されます。更新自体はコンテナーで行われます。このプロセスは、OpenShift Container Platform と RHCOS の更新を同時に管理する際に不可欠です。 -
machine-config-serverDaemonSet: マスターノードがクラスターに参加する際に Ignition 設定ファイルをマスターノードに提供します。
このマシン設定は Ignition 設定のサブセットです。machine-config-daemon はマシン設定を読み取えり、OSTree の更新を行う必要があるか、または一連の systemd kubelet ファイルの変更、設定の変更、オペレーティングシステムまたは OpenShift Container Platform 設定などへのその他の変更を適用する必要があるかを確認します。
ノード管理操作の実行時に、KubeletConfig カスタムリソース (CR、Custom Resource) を作成または変更します。
第4章 OpenShift Container Platform の開発について
高品質のエンタープライズアプリケーションの開発および実行時にコンテナーの各種機能をフルに活用できるようにするには、使用する環境が、コンテナーの以下の機能を可能にするツールでサポートされている必要があります。
- 他のコンテナー化された/されていないサービスに接続できる分離したマイクロサービスとして作成される。たとえば、アプリケーションをデータベースに結合するが、またはアプリケーションに監視アプリケーションを割り当てることが必要になることがあります。
- 回復性がある。 サーバーがクラッシュしたときやメンテナンスのために停止する必要があるとき、またはまもなく使用停止になる場合などに、コンテナーを別のマシンで起動することができます。
- 自動化されている。コードの変更を自動的に選択し、新規バージョンの起動およびデプロイを自動化します。
- スケールアップまたは複製が可能である。 需要の上下に合わせてクライアントに対応するインスタンスの数を増やしたり、インスタンスの数を減らしたりできます。
- アプリケーションの種類に応じて複数の異なる方法で実行できる。たとえば、あるアプリケーションは月一回実行してレポートを作成した後に終了させる場合があります。別のアプリケーションは継続的に実行して、クライアントに対する高可用性が必要になる場合があります。
- 管理された状態を保つ。 アプリケーションの状態を監視し、異常が発生したら対応できるようにします。
コンテナーが広く浸透し、エンタープライズレベルでの対応を可能にするためのツールや方法への要求が高まっていることにより、多くのオプションがコンテナーで利用できるようになりました。
このセクションの残りの部分では、 OpenShift Container Platform で Kubernetes のコンテナー化されたアプリケーションをビルドし、デプロイする際に作成できるアセットの各種のオプションについて説明します。また、各種の異なるアプリケーションや開発要件に適した方法についても説明します。
4.1. コンテナー化されたアプリケーションの開発について
コンテナーを使用したアプリケーションの開発にはさまざまな方法を状況に合わせて使用できます。単一コンテナーの開発から、最終的にそのコンテナーの大企業のミッションクリティカルなアプリケーションとしてのデプロイに対応する一連の方法の概要を示します。それぞれのアプローチと共に、コンテナー化されたアプリケーションの開発に使用できる各種のツール、フォーマットおよび方法を説明します。扱う内容は以下の通りです。
- 単純なコンテナーをビルドし、レジストリーに格納する
- Kubernetes マニフェストを作成し、それを Git リポジトリーに保存する
- Operator を作成し、アプリケーションを他のユーザーと共有する
4.2. 単純なコンテナーのビルド
たとえば、アプリケーションをコンテナー化しようと考えているとします。
その場合、まず必要になるのは buildah や docker などのコンテナーをビルドするためのツール、およびコンテナーの内部で実行されることを記述したファイルです。 これは通常、Dockerfile になります。
次に、作成したコンテナーイメージをプッシュする場所が必要になります。ここからコンテナーイメージをプルすると、任意の場所で実行することができます。 この場所はコンテナーレジストリーになります。
各コンポーネントのサンプルは、ほとんどの Linux オペレーティングシステムにデフォルトでインストールされています。 ただし Dockerfile はユーザーが各自で用意する必要があります。
以下の図は、イメージをビルドし、プッシュするプロセスを示しています。
図4.1 単純なコンテナー化アプリケーションを作成し、レジストリーにプッシュする
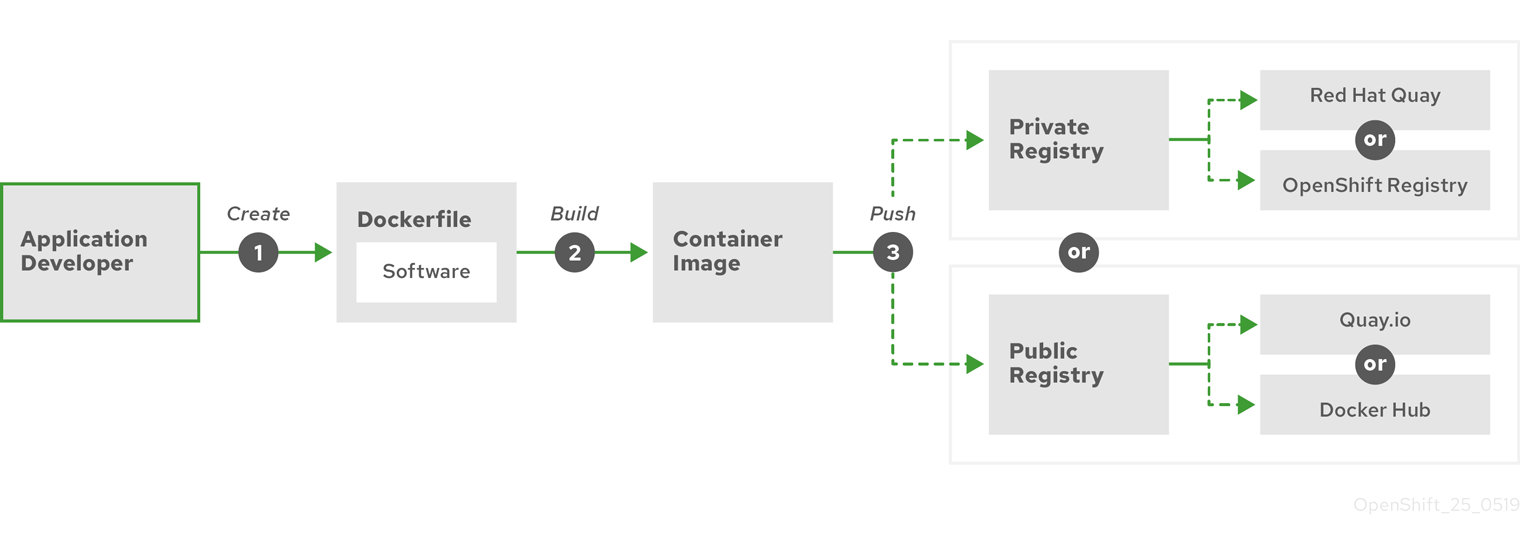
Red Hat Enterprise Linux (RHEL) をオペレーティングシステムとして実行しているコンピューターを使用している場合、コンテナー化されているアプリケーションを作成するプロセスには以下の手順が必要になります。
- コンテナービルドツールのインストール。 RHEL には、コンテナーのビルドと管理に使用される podman、buildah、skopeo など一連のツールが含まれています。
-
Dockerfile を作成してベースイメージとソフトウェアを組み合わせる。コンテナーのビルドに関する情報は、
Dockerfileというファイルに保管されます。このファイルでビルドの起点となるベースイメージ、インストールするソフトウェアパッケージ、コンテナーにコピーするソフトウェアを指定します。さらに、コンテナーの外部に公開するネットワークポートやコンテナーの内部にマウントするボリュームのなどのパラメーター値も指定します。Dockerfile とコンテナー化するソフトウェアは、 RHEL システムのディレクトリーに配置します。 -
buildah または docker build を実行する。
buildah build-using-dockerfileまたはdocker buildコマンドを実行し、選択したベースイメージをローカルシステムにプルして、ローカルに保存されるコンテナーイメージを作成します。 buildah を使用して、Dockerfile なしにコンテナーをビルドすることもできます。 -
タグ付けおよびレジストリーへのプッシュを実行します。コンテナーの格納および共有に使用するレジストリーの場所を特定する新しいコンテナーイメージにタグを追加します。次に、
podman pushまたはdocker pushコマンドを実行してそのイメージをレジストリーにプッシュします。 -
イメージのプルと実行 Podman や Docker などのコンテナークライアントツールがある任意のシステムから、新しいイメージを特定するコマンドを実行します。たとえば、
podman run <image_name>やdocker run <image_name>のコマンドを実行します。ここで、<image_name>は新しいイメージの名前であり、quay.io/myrepo/myapp:latestのようになります。レジストリーでは、イメージをプッシュおよびプルするために認証情報が必要になる場合があります。
コンテナーイメージをビルドし、レジストリーにプッシュし、それらを実行するプロセスについての詳細は、「Custom image builds with Buildah」を参照してください。
4.2.1. コンテナービルドツールのオプション
Docker Container Engine と docker コマンドは、 RHEL や他の多くの Linux システムでコンテナーを使用する際に使う一般的なツールですが、代わりに、Podman、Skopeo、Buildah を含む、異なるコンテナーツールのセットを選択することもできます。さらに、Docker Container Engine ツールを使用して、OpenShift Container Platform やその他のコンテナープラットフォームで動作するコンテナーを作成することもできます。
Buildah、Podman、Skopeo を使用してコンテナービルドし、管理すると、それらのコンテナーを最終的に OpenShift Container Platform またはその他の Kubernetes 環境にデプロイする目的で調整された各種機能が含まれる業界標準のコンテナーイメージが生成されます。これらのツールにはデーモンが不要であり、root権限なしで実行できるので、これらのツールを実行するときはオーバーヘッドが少なくてすみます。
コンテナーを最終的に OpenShift Container Platform で実行するときは、CRI-O コンテナーエンジンを使用します。CRI-O は、OpenShift Container Platform クラスターのすべてのワーカーマシンおよびマスターマシン上で実行されますが、CRI-Oは、OpenShift Container Platform の外部のスタンドアロンランタイムとしてはまだサポートされていません。
4.2.2. ベースイメージのオプション
アプリケーションをビルドするために選択するベースイメージには、Linux システムがアプリケーションのように表示されるソフトウェアのセットが含まれます。ユーザーが独自のイメージをビルドする場合、ソフトウェアはそのファイルシステム内に配置され、ファイルシステムはオペレーティングシステムのように表示されます。このベースイメージの選択により、コンテナーの将来の安全性、効率性およびアップグレードの可能性に大きな影響を与えます。
Red Hat は、Red Hat Universal Base Images (UBI) と呼ばれるベースイメージの新たなセットを提供します。これらのベースイメージは、Red Hat Enterprise Linux をベースとし、Red Hat が過去に提供してきたベースイメージに類似したものですが、次の大きな違いがあります。UBI は、Red Hat のサブスクリプションなしの再ディストリビューションが可能です。 そのため、UBI イメージの共有方法を検討したり、環境ごとに異なるイメージを作成する必要なしに、UBI イメージでアプリケーションをビルドすることができます。
これらの UBI イメージは、標準で最小限の init バージョンです。また、Red Hat Software Collections イメージを、Node.js、Perl、Python などの特定のランタイム環境に依存するアプリケーションの基盤として使用することができます。これらのランタイムベースイメージの特殊なバージョンは Source-to-image (S2I) イメージと呼ばれています。S2I イメージを使用して、コードを、そのコードを実行できるベースイメージ環境に挿入することができます。
S2I イメージは、以下の図に示すように、OpenShift Container Platform Web UI のCatalog → Developer Catalog を選択することにより直接使用することができます。
図4.2 特定のランタイムを必要とするアプリケーションの S2I ベースイメージを選択する

4.2.3. レジストリーオプション
コンテナーレジストリーはコンテナーイメージを保管する場所です。ここから、コンテナーイメージを他の人と共有したり、最終的に実行するプラットフォームで使用できるようにしたりできます。無料アカウントを提供する大規模なパブリックコンテナーレジストリーや、容量の大きいストレージや特殊な機能を備えたプレミアムバージョンを選択することができます。 また、ご自身の組織にのみ限定される独自のレジストリーをインストールしたり、共有する相手を選択して独自のレジストリーをインストールすることもできます。
Red Hat のイメージおよび認定パートナーのイメージを取得するには、Red Hat レジストリーから取り出すことができます。Red Hat レジストリーは、認証されていない非推奨の registry.access.redhat.com、および認証が必要な registry.redhat.io の2つの場所によって表わされます。Red Hat Container Catalog で、Red Hat レジストリーの Red Hat イメージおよびパートナーのイメージを確認することができます。これは、Red Hat コンテナーイメージのを一覧表示するだけでなく、適用されたセキュリティーアップデートに基づくヘルススコアなどの、これらのイメージのコンテンツと品質に関する広範な情報も表示します。
大規模なパブリックレジストリーには、Docker Hub および Quay.io が含まれます。Quay.io レジストリーは Red Hat が所有し、管理しています。OpenShift Container Platform で使用されるコンポーネントの多くは Quay.io に保管されます。これには OpenShift Container Platform 自体をデプロイするために使用されるコンテナーイメージおよび Operator が含まれます。 Quay.io は、Helm チャートなどの他のタイプのコンテンツを保管する手段ともなります。
専用のプライベートコンテナーレジストリーが必要な場合、OpenShift Container Platform 自体にプライベートコンテナーレジストリーが含まれています。これは、OpenShift Container Platform と共にインストールされ、そのクラスター上で実行されます。また、Red Hat は Red Hat Quay と呼ばれるプライベートバージョンの Quay.io レジストリーも提供しています。 Red Hat Quay には、geo レプリケーション、Git ビルドトリガー、Clair イメージスキャンなどの機能が含まれています。
ここで言及したすべてのレジストリーでは、これらのレジストリーからイメージをダウンロードする際に認証情報が必要です。これらの認証情報の一部は OpenShift Container Platform のクラスター全体に提供されますが、他の認証情報は個別に割り当てられます。
4.3. OpenShift Container Platform 用の Kubernetes マニフェストの作成
コンテナーイメージは、コンテナー化されたアプリケーション用の基本的なビルディングブロックですが、OpenShift Container Platform などの Kubernetes 環境でそのアプリケーションを管理し、デプロイするには、より多くの情報が必要になります。イメージ作成後に実行される通常の手順は以下のとおりです。
- Kubernetes Manifest マニフェストで使用する各種リソースを理解する
- 実行するアプリケーションの種類についての決定
- サポートコンポーネントの収集
- マニフェストの作成、およびそのマニフェストの Git リボジトリーへの保管。これにより、マニフェストをソースバージョン管理システムに保管し、監査と追跡、次の環境へのプロモートとデプロイ、必要な場合は以前のバージョンへのロールバックなどを実行でき、これを他者と共有することができます。
4.3.1. Kubernetes Pod およびサービスについて
コンテナーイメージは Docker を使用する基本単位であり、Kubernetes が使用する基本単位は Pod と呼ばれます。Pod はアプリケーションのビルドの次の手順で使用されます。Pod には、1 つ以上のコンテナーを含めることができます。Pod はデプロイやスケーリングおよび管理を実行する単一の単位であることに留意してください。
Pod での実行内容を決定する際に考慮する必要のある主要な点として、スケーラビリティーと namespace を考慮することができます。デプロイメントを容易にするには、コンテナーを Pod にデプロイして、Pod 内に独自のロギングとモニタリングコンテナーを含めることができるかもしれません。後に、Pod を実行し、追加のインスタンスをスケールアップすることが必要になると、それらの他のコンテナーもスケールアップできます。namespace の場合、Pod 内のコンテナーは同じネットワークインターフェース、共有ストレージボリューム、メモリーや CPU などのリソース制限を共有します。これにより、Pod のコンテンツを単一の単位として管理することが容易になります。また Pod 内のコンテナーは、System V セマフォや POSIX 共有メモリーなどの標準的なプロセス間通信を使用することにより、相互に通信することができます。
個々の Pod が Kubernetes 内のスケーラブルな単位を表すのに対し、サービス は、負荷分散などの完全なタスクを実行する完全で安定したアプリケーションを作成するために複数の Pod をグループ化する手段を提供します。 また、サービスは削除されるまで同じIP アドレスで利用可能な状態になるため、Pod より永続性があります。サービスが使用できる状態の場合、サービスは名前で要求され、OpenShift Container Platform クラスターはその名前を IP アドレスとポートに解決し、そこからサービスを構成する Pod に到達することができます。
性質上、コンテナー化されたアプリケーションは、それらが実行されるオペレーティングシステムから分離され、したがってユーザーからも分離されます。Kubernetes マニフェストの一部には、コンテナー化されたアプリケーションとの通信の詳細な制御を可能にするネットワークポリシー を定義して、アプリケーションを内外のネットワークに公開する方法が記述されています。HTTP、HTTPS の受信要求やクラスター外からの他のサービスをクラスター内のサービスに接続するには、Ingress リソースを使用することができます。
コンテナーが、サービスを通じて提供されるデータベースストレージではなくディスク上のストレージを必要とする場合、ボリュームをマニフェストに追加して、そのディスクを Pod で使用可能にすることができます。永続ボリューム(PV)を作成するか、Pod 定義に追加されるボリュームを動的に作成するようにマニフェストを設定することができます。
アプリケーションを構成する Pod のグループを定義した後、それらの Pod を deployments と deploymentconfig で定義することができます。
4.3.2. アプリケーションのタイプ
次に、アプリケーションのタイプが、その実行方法にどのように影響するかを検討します。
Kubernetes は、各種のアプリケーションに適した異なるタイプのワークロードのタイプを定義します。アプリケーションに適したワークロードを決定するために、アプリケーションが以下のどのタイプに該当するかを確認してください。
- 完了まで実行されることが意図されている。 例として、アプリケーションはレポートを作成するために起動される場合、レポートの完了時に終了することが想定されます。このアプリケーションはその後一ヵ月間再度実行されない場合もあります。これらのタイプのアプリケーションに適した OpenShift Container Platform オブジェクトには、Jobs および CronJob オブジェクトがあります。
- 継続的に実行することが予想されている。 長時間実行されるアプリケーションの場合、Deployment または DeploymentConfig を作成することができます。
- 高い可用性が必要。 使用しているアプリケーションに高可用性が必要な場合は、2 つ以上のインスタンスを持てるようにデプロイメントのサイズを設定する必要があります。Deployment または DeploymentConfig の場合、このタイプのアプリケーション用に ReplicaSet を組み込むことができます。ReplicaSet を使用すると、Pod は複数のノード間で実行され、ワーカーが停止してもアプリケーションを常に利用可能な状態にすることができます。
- すべてのノード上で実行される必要がある。 Kubernetes アプリケーションのタイプによっては、すべてのマスターまたはワーカーノード上のクラスターで実行することが意図されています。DNS およびモニタリングアプリケーションは、すべてのノード上で継続的に実行する必要があるアプリケーションの例です。このタイプのアプリケーションは、 DaemonSet として実行することができます。また、DaemonSet はノードラベルに基づいて、ノードのサブセット上でも実行できます。
- ライフサイクル管理を必要とする。 アプリケーションが他者も使用できるようにする場合には、Operator を作成することを検討してください。Operator を使用すると、インテリジェンスを組み込むことが可能となり、自動的なバックアップやアップグレードなどを自動かできます。Operator Lifecycle Manager (OLM) と組み合わせることで、クラスターマネージャーは、Operator を選択された namespace に公開し、クラスター内のユーザーが Operator を実行できるようになります。
-
アイデンティティーまたは番号付けの要件がある。アプリケーションには、アイデンティティーや番号付けの要件がある場合があります。 たとえば、アプリケーションの 3 つのインスタンスのみを実行し、インスタンスに
0、1、2という名前を付けることが求められる場合があります。このタイプのアプリケーションには StatefulSet が適しています。 StatefulSet は、データベースや zookeeper クラスターなどの独立したストレージが必要なアプリケーションに最も適しています。
4.3.3. 利用可能なサポートコンポーネント
作成するアプリケーションには、データベースやロギングコンポーネントなどのサポートコンポーネントが必要な場合があります。このニーズに対応するために、OpenShift Container Platform の Web コンソールで利用可能な以下のカタログから必要なコンポーネントを取得できる場合があります。
- OperatorHub: 各 OpenShift Container Platform 4.2 クラスターで利用できます。OperatorHub により、Red Hat、認定 Red Hat パートナー、コミュニティーメンバーおよびクラスターのオペレーターなどから Operator が利用可能になります。クラスター Operator は、それらの Operator をクラスター内のすべての場所が、または選択された namespace で利用可能にします。 そのため、開発者は Operator を起動し、それらをアプリケーションと共に設定することができます。
- サービスカタログ: Operator の代替機能を提供します。OpenShift Container Platform でパッケージ化されたアプリケーションを取得する方法として、Operator のデプロイが優先されますが、独自のアプリケーションのサポートアプリケーションを取得するためにサービスカタログを使用することが望ましい場合があります。たとえば、既存の OpenShift Container Platform 3 のユーザーで、サービスカタログアプリケーションに投資をしている場合や、Cloud Foundry 環境がすでにあり、その環境で他のエコシステムからブローカーを利用することを検討している場合などがこれに含まれます。
- テンプレート: ワンオフタイプのアプリケーションの場合に役立ちます。この場合、インストール後のコンポーネントのライフサイクルは重要ではありません。テンプレートは、最小限のオーバーヘッドで Kubernetes アプリケーションの開発を始める簡単な方法を提供します。テンプレートは、デプロイメント、サービス、ルートまたはその他のオブジェクトなどのリソース定義の一覧である場合があります。名前またはリソースを変更する必要がある場合に、それらの値をパラメーターとしてテンプレートに設定できます。テンプレートサービスブローカー Operator は、独自のテンプレートをインスタンス化するために使用できるサービスブローカーです。 テンプレートはコマンドラインから直接インストールすることもできます。
サポートする Operator、サービスカタログアプリケーションおよびテンプレートは、開発チームの特定のニーズに合わせて設定し、開発者が作業に使用する namespace で利用可能にすることができます。 多くの場合、共有テンプレートは他のすべての namespace からアクセス可能になるために openshift namespace に追加されます。
4.3.4. マニフェストの適用
Kubernetes マニフェストを使用して、Kubernetes アプリケーションを構成するコンポーネントのより詳細な情報を得ることができます。これらのマニフェストは YAML ファイルとして作成し、oc apply などのコマンドを実行して、それらをクラスターに適用してデプロイできます。
4.3.5. 次のステップ
この時点で、コンテナー開発のプロセスを自動化する方法を検討します。この際、イメージをビルドしてレジストリーにプッシュするいくつかの CI パイプラインがあることが望ましいと言えます。とくに GitOps パイプラインは、アプリケーションのビルドに必要なソフトウェアを保管する Git リボジトリーにコンテナー開発を統合します。
ここまでのワークフローは以下のようになります。
-
Day 1: YAML を作成します。次に
oc applyコマンドを実行して、YAML をクラスターに適用し、機能することを確かめます。 - Day 2: YAML コンテナー設定ファイルを独自の Git リポジトリーに配置します。ここから、アプリのインストールやその改善の支援に携わるメンバーが YAML をプルダウンし、アプリを実行するクラスターにこれを適用できます。
- Day 3: アプリケーション用の Operator の作成を検討します。
4.4. Operator 向けの開発
アプリケーションを他者が実行できるようにする場合、アプリケーションを Operator としてパッケージ化し、デプロイすることが適切である場合があります。前述のように、Operator は、ライフサイクルコンポーネントをアプリケーションに追加し、インストール後すぐにアプリケーションを実行するジョブが完了していないことを認識します。
アプリケーションを Operator として作成する場合、アプリケーションを実行し、維持する方法についての独自のノウハウを盛り込むことができます。アプリケーションのアップグレード、バックアップ、スケーリング、状態のトラッキングなどを行う機能を組み込むことができます。アプリケーションを正しく設定すれば、Operator の更新などのメンテナンスタスクは、Operator のユーザーに非表示の状態で自動的に実行されます。
役に立つ Operator の一例として、データを特定のタイミングで自動的にバックアップするように設定された Operator を挙げることができます。Operator は設定されたタイミングでのアプリケーションのバックアップを管理するため、システム管理者はバックアップのタイミングを覚えておく必要がありません。
データのバックアップや証明書のローテーションなど、これまで手作業で行われていたアプリケーションのメンテナンスは、Operator によって自動化されます。
第5章 Red Hat Enterprise Linux CoreOS (RHCOS)
5.1. RHCOS について
Red Hat Enterprise LinuxにCoreOS (RHCOS) は、次世代の専用コンテナーオペレーティングシステムテクノロジーの代表格です。Red Hat Enterprise Linux Atomic Host と CoreOS Container Linux を開発した同じチームによって開発された RHCOS は、Red Hat Enterprise Linux (RHEL) の品質基準と Container Linux の自動化されたリモートアップグレード機能を兼ね備えています。
RHCOS は、すべての OpenShift Container Platform マシンの1つの OpenShift Container Platform 4.2 コンポーネントとしてのみサポートされます。RHCOS は、OpenShift Container Platform のコントロールプレーンまたはマスターマシン向けに唯一サポートされるオペレーティングシステムです。RHCOS はすべてのクラスターマシンのデフォルトオペレーティングシステムですが、 RHEL をオペレーティングシステムとして使用するコンピュートマシン (ワーカーマシンとしても知られる) を作成することもできます。
クラスターがプロビジョニングするインフラストラクチャーにクラスターをインストールする場合は、インストール時に RHCOS イメージがターゲットのプラットフォームにダウンロードされ、RHCOS 設定を制御する適切な Ignition 設定ファイルがマシンをデプロイするために使用されます。クラスターを独自に管理するインフラストラクチャーにインストールする場合、インストールについてのドキュメントを参照して RHCOS イメージの取得や、Ignition 設定ファイルの生成、および設定ファイルの使用によるマシンのプロビジョニングを行ってください。
5.1.1. RHCOS の主な機能
以下は、RHCOS オペレーティングシステムの主要な機能について説明しています。
基礎となるオペレーティングシステムは、主に RHEL のコンポーネントで構成されます。RHEL をサポートする品質、セキュリティーおよび管理基準が RHCOS にも同様に適用されます。たとえば、RHCOS ソフトウェアは RPM パッケージにあり、各 RHCOS システムは、RHEL カーネル、および systemd init システムで管理される一連のサービスと共に起動します。
RHCOS には、RHEL コンポーネントが含まれているものの、RHCOS はデフォルトの RHEL インストールの場合よりも厳密に管理されるように設計されています。これは OpenShift Container Platform クラスターからリモートで管理されます。RHCOS マシンをセットアップする際には、いくつかのシステム設定のみを変更するだけで対応することが可能です。RHCOS のこの管理機能および不変性により、OpenShift Container Platform では RHCOS システムの最新の状態をクラスターに保存し、最新の RHCOS 設定に基づいて追加のマシンの作成や更新を実行することができます。
RHCOS には Docker で必要な OCI および libcontainer 形式のコンテナーを実行する機能が含まれていますが、Docker コンテナーエンジンではなく CRI-O コンテナーエンジンが組み込まれています。OpenShift Container Platform などの、Kubernetes プラットフォームが必要とする機能に重点が置かれている CRI-O では、複数の異なる Kubernetes バージョンとの特定の互換性が提供されます。また、CRI-O は、大規模な機能セットを提供するコンテナーエンジンの場合よりもフットプリントや攻撃領域を縮小できます。現時点で、 CRI-O は OpenShift Container Platform クラスター内で利用可能な唯一のコンテナーエンジンです。
ビルド、コピーまたはコンテナーの管理などのタスクに備え、RHCOS では Docker CLI ツールが互換性のあるコンテナーツールセットに置き換えられます。Podman CLI ツールは、コンテナーおよびコンテナーイメージの実行、起動、停止、一覧表示および削除などの数多くのコンテナーランタイム機能をサポートします。skopeo CLI ツールは、イメージのコピー、認証およびイメージへの署名を実行できます。crictl CLI ツールを使用すると、CRI-O コンテナーエンジンからコンテナーおよび Pod を使用できます。これらのツールを RHCOS 内で直接使用することは推奨されていませんが、デバッグの目的で使用することは可能です。
RHCOS は、rpm-ostree システムを使用したトランザクション型のアップグレードを特長としています。更新はコンテナーイメージ経由で提供され、OpenShift 更新プロセスの一部となっています。コンテナーイメージはデプロイされると、プルされ、展開されてディスクに書き込まれます。その後にブートローダーが新規バージョンで起動するように変更されます。 マシンはローリング方式で更新に対して再起動し、クラスターの容量への影響が最小限に抑えられます。
RHCOS システムの場合、rpm-ostree ファイルシステムのレイアウトには、以下の特徴があります。
-
/usr: オペレーティングシステムのバイナリーとライブラリーが保管される場所で、読み取り専用です。これを変更することはサポートされていません。 -
/etc、/boot、/var: システム上で書き込み可能ですが、Machine Config Operator によってのみ変更されることが意図されています。 -
/var/lib/containers: コンテナーイメージを保管するためのグラフストレージの場所です。
OpenShift Container Platform では、Machine Config Operator がオペレーティングシステムのアップグレードを処理します。yum で実行される場合のように個々のパッケージをアップグレードする代わりに、rpm-ostree は OS のアップグレードを atomic 単位として提供します。新規の OS デプロイメントはアップグレード時に段階が設定され、次回の再起動時に実行されます。アップグレードに不具合が生じた場合は、単一ロールバックおよび再起動によってシステムが以前の状態に戻ります。OpenShift Container Platform での RHCOS アップグレードは、クラスターの更新時に実行されます。
5.1.2. OpenShift Container Platform での RHCOS の設定
OpenShift Container Platform では、RHCOS イメージは最初に Ignition と呼ばれる機能でセットアップされます。これは、システムの初回起動時にのみ実行されます。初回の起動後に、RHCOS システムは、OpenShift Container Platform クラスターで実行される Machine Config Operator (MCO) によって管理されます。
OpenShift Container Platform の RHCOS システム は OpenShift Container Platform クラスターから完全に管理されるように設計されているため、RHCOS マシンに直接ログインすることは推奨されていません。OpenShift Container Platform クラスターでの RHCOS マシンへの限定的な直接アクセスは、デバッグの目的で実行できます。
5.1.3. Ignition について
Ignition は、初回設定時にディスクを操作するために RHCOS によって使用されるユーティリティーです。これにより、ディスクのパーティション設定やパーティションのフォーマット、ファイル作成、ユーザー設定などの一般的なディスク関連のタスクが実行されます。初回起動時に、Ignition はインストールメディアや指定した場所からその設定を読み込み、その設定をマシンに適用します。
クラスターをインストールする場合かマシンをクラスターに追加する場合かを問わず、Ignition は常に OpenShift Container Platform クラスターマシンの初期設定を実行します。実際のシステム設定のほとんどは、各マシン自体で行われます。各マシンで、Ignition は、RHCOS イメージを取得し、RHCOS カーネルを起動します。カーネルコマンドラインのオプションで、デプロイメントのタイプや Ignition で有効にされた初期 RAM ディスク (initramfs) の場所を特定します。
OpenShift Container Platform は、Ignition のバージョン 2 および Ignition 設定バージョン 2.3 を使用します。
5.1.3.1. Ignition の仕組み
Ignition を使用してマシンを作成するには、Ignition 設定ファイルが必要です。OpenShift Container Platform のインストレーションプログラムは、クラスターを作成するのに必要な Ignition 設定ファイルを作成します。これらのファイルは、インストレーションプログラムに直接指定するか、または install-config.yaml ファイルを通じて提供される情報に基づくものです。
Ignition がマシンを設定する方法は、cloud-init や Linux Anacondakickstart などのツールがシステムを設定する方法に似ていますが、以下のような重要な違いがあります。
- Ignition はインストール先のシステムから分離され初期 RAM ディスクから実行されます。そのため、Ignition はディスクのパーティション設定を再度実行し、ファイルシステムをセットアップし、さらにマシンの永続ファイルシステムに他の変更を加える可能性があります。これとは対照的に、cloud-init はシステムの起動時にマシンの init システムの一部として実行されるため、ディスクパーティションなどへの基礎的な変更を簡単に行うことはできません。cloud-ini では、ノードの起動プロセスの実行中の起動プロセスの再設定は簡単に実行できません。
- Ignition は既存システムを変更することなく、システムを初期化することが意図されています。マシンが初期化され、インストールされたシステムからカーネルが実行された後に、OpenShift Container Platform クラスターの Machine Config Operator がその後のすべてのマシン設定を行います。
- 定義されたアクションセットを実行する代わりに、Ignition は宣言型の設定を実装します。これは新規マシンの起動前にすべてのパーティション、ファイル、サービスその他のアイテムがあることを検査します。また、新規マシンを指定された設定に一致させるために必要なファイルのディスクへのコピーなどの変更を行います。
- Ignition がマシンの設定を終了した後もカーネルは実行し続けますが、初期 RAM ディスクを破棄し、ディスクにインストールされたシステムにピボットします。システムを再起動しなくても、すべての新しいシステムサービスとその他の機能は起動します。
- Ignition は新しいマシンすべてが宣言型の設定に一致することを確認するため、部分的に設定されたマシンを含めることはできません。マシンのセットアップが失敗し、初期化プロセスが終了しない場合、Ignition は新しいマシンを起動しません。クラスターには部分的に設定されたマシンが含まれることはありません。Ignition が完了しない場合、マシンがクラスターに追加されることはありません。その場合、新しいマシンを各自で追加する必要があります。この動作は、失敗した設定タスクに依存するタスクが後で失敗するまで設定タスクに問題があることが認識されない場合などの、マシンのデバックが困難になる状況を防ぐことができます。
- マシンのセットアップの失敗を引き起こす問題が Ignition 設定にある場合、Ignition は他のマシンの設定に同じ設定を使用することを避けようとします。たとえば、失敗の原因は、同じファイルを作成しようとする親と子で構成される Ignition 設定にある場合があります。この場合、問題が解決されない限り、その Ignition 設定を使用して他のマシンをセットアップすることはできません。
- 複数の Ignition 設定ファイルがある場合、それらの設定の集合体を取得します。Ignition は宣言型であるため、これらの設定間で競合が生じると、Ignition はマシンのセットアップに失敗します。ここで、それらのファイルの情報の順序は問題にはなりません。Ignition はそれぞれの設定を最も妥当な仕方で並べ替え、実行します。たとえば、あるファイルが数レベル分深いレベルのディレクトリーを必要としており、他のファイルがそのパスにあるディレクトリーを必要とする場合、後者のファイルが先に作成されます。Ignition はすべてのファイル、ディレクトリーおよびリンクを深さに応じて作成します。
- Ignition は完全に空のハードディスクで起動できるので、cloud-init では実行できないことを行うことができます。これには、 (PXE ブートなどの機能を使用して)、システムをベアメタルでゼロからセットアップすることが含まれます。ベアメタルの場合、Ignition 設定は起動パーティションに挿入されるので、 Ignition はこれを見つけ、システムを正しく設定することができます。
5.1.3.2. Ignition の順序
OpenShift Container Platform クラスター内の RHCOS マシンの Ignition プロセスには、以下の手順が含まれます。
- マシンがその Ignition 設定ファイルを取得します。マスターマシンは Ignition 設定ファイルをブートストラップマシンから取得し、ワーカーマシンは Ignition 設定ファイルをマスターから取得します。
- Ignition はマシン上でディスクパーティション、ファイルシステム、ディレクトリーおよびリンクを作成します。Ignition は RAID アレイをサポートしますが、LVM ボリュームはサポートしません。
-
Ignition は永続ファイルシステムのルートを initramfs 内の
/sysrootディレクトリーにマウントし、その/sysrootディレクトリーで機能し始めます。 - Ignition はすべての定義されたファイルシステムを設定し、それらをランタイム時に適切にマウントされるようセットアップします。
-
Ignition は
systemd一時ファイルを実行して、必要なファイルを/varディレクトリーに設定します。 - Ignition は Ignition 設定ファイルを実行し、ユーザー、systemd ユニットファイルその他の設定ファイルをセットアップします。
- Ignition は initramfs にマウントされた永続システムのコンポーネントをすべてアンマウントします。
- Ignition は新しいマシンの init プロセスを開始し、システムの起動時に実行されるマシン上の他のすべてのサービスを開始します。
マシンはクラスターに参加できる状態になります。再起動は不要です。
5.2. Ignition 設定ファイルの表示
ブートストラップマシンをデプロイするのに使用される Ignition 設定ファイルを表示するには、以下のコマンドを実行します。
$ openshift-install create ignition-configs --dir $HOME/testconfig
いくつかの質問に回答すると、bootstrap.ign、master.ign、worker.ign ファイルが入力したディレクトリーに表示されます。
bootstrap.ign ファイルの内容を確認するには、そのファイルを jq フィルターでそのファイルをパイプします。以下は、そのファイルの抜粋です。
$ cat $HOME/testconfig/bootstrap.ign | jq
\\{
"ignition": \\{
"config": \\{},
…
"storage": \\{
"files": [
\\{
"filesystem": "root",
"path": "/etc/motd",
"user": \\{
"name": "root"
},
"append": true,
"contents": \\{
"source": "data:text/plain;charset=utf-8;base64,VGhpcyBpcyB0aGUgYm9vdHN0cmFwIG5vZGU7IGl0IHdpbGwgYmUgZGVzdHJveWVkIHdoZW4gdGhlIG1hc3RlciBpcyBmdWxseSB1cC4KClRoZSBwcmltYXJ5IHNlcnZpY2UgaXMgImJvb3RrdWJlLnNlcnZpY2UiLiBUbyB3YXRjaCBpdHMgc3RhdHVzLCBydW4gZS5nLgoKICBqb3VybmFsY3RsIC1iIC1mIC11IGJvb3RrdWJlLnNlcnZpY2UK",
bootstrap.ign ファイルに一覧表示されたファイルの内容をデコードするには、そのファイルの内容を表す base64 でエンコードされたデータ文字列を base64 -d コマンドに渡します。以下に示すのは、上記の出力からブートストラップマシンに追加された /etc/motd ファイルの内容の使用例です。
$ echo VGhpcyBpcyB0aGUgYm9vdHN0cmFwIG5vZGU7IGl0IHdpbGwgYmUgZGVzdHJveWVkIHdoZW4gdGhlIG1hc3RlciBpcyBmdWxseSB1cC4KClRoZSBwcmltYXJ5IHNlcnZpY2UgaXMgImJvb3RrdWJlLnNlcnZpY2UiLiBUbyB3YXRjaCBpdHMgc3RhdHVzLCBydW4gZS5nLgoKICBqb3VybmFsY3RsIC1iIC1mIC11IGJvb3RrdWJlLnNlcnZpY2UK | base64 -dこれはブートストラップマシンです。マスターが完全に起動すると破棄されます。
プライマリーサービスは「bootkube.service」です。ステータスを確認するには、以下を実行します。
journalctl -b -f -u bootkube.service
これらのコマンドを master.ign と worker.ign ファイル上で繰り返し実行し、マシンタイプごとの Ignition 設定ファイルのソースを参照します。 ブートストラップマシンから Ignition 設定を取得する方法を特定する、worker.ign についての以下のような行が表示されるはずです。
"source": "https://api.myign.develcluster.example.com:22623/config/worker",
bootstrap.ign ファイルについて、以下のいくつかの点に留意してください
- フォーマット: ファイルのフォーマットは Ignition config spec に定義されています。同じフォーマットのファイルが後に MCO によって使用され、マシンの設定に変更がマージされます。
-
コンテンツ: ブートストラップマシンは他のマシンの Ignition 設定を提供するため、マスターマシンとワーカーマシンの両方の Ignition 設定情報は、ブートストラップの設定情報と共に
bootstrap.ignに保管されます。 - サイズ: 各種タイプのリソースへのパスを含むファイルのサイズは、1,300 行を超える長さです。
- マシンにコピーされる各ファイルの内容は実際にデータ URL にエンコードされます。この場合、内容は少し読み取りにくくなる傾向があります (前述の jq や base64 コマンドを使用すると内容がより読みやすくなります)。
- 設定: Ignition 設定ファイルのそれぞれのセクションは、一般的には既存ファイルを修正するコマンドではなく、マシンのファイルシステムに単にドロップされるファイルを含むことが想定されています。たとえば、そのサービスを設定する NFS 上のセクションを設定するのではなく、単に NFS 設定ファイルを追加します。 これはその後のシステムの起動時に init プロセスによって開始されます。
- ユーザー: core という名前のユーザーが作成され、SSH キーがそのユーザーに割り当てられます。これにより、そのユーザー名と認証情報を使用してクラスターにログインすることができます。
-
ストレージ: ストレージセクションは、各マシンに追加されるファイルを特定します。これらのファイルには、(実際のクラスターがコンテナイメージレジストリーからプルする必要のある認証情報を提供する)
/root/.docker/config.jsonと、クラスターを設定するのに使用される/opt/openshift/manifests内のマニフェストファイルのセットがあります。 - systemd: systemd セクションは、systemd ユニットファイルを作成するコンテンツを保持します。これらのファイルは、起動時にサービスを開始するために、また実行システムでサービスを管理するために使用されます。
- プリミティブ: Ignition は他のツールがビルドに使用できる低レベルのプリミティブも公開します。
5.3. インストール後の Ignition 設定の変更
Machine Config Pool はノードのクラスターおよびそれらの対応する Machine Config を管理します。Machine Config にはクラスターの設定情報が含まれます。既知のすべての Machine Config Pool を一覧表示するには、以下を実行します。
$ oc get machineconfigpools
NAME CONFIG UPDATED UPDATING DEGRADED
master master-1638c1aea398413bb918e76632f20799 False False False
worker worker-2feef4f8288936489a5a832ca8efe953 False False Falseすべての Machine Config を一覧表示するには、以下を実行します。
$ oc get machineconfig
NAME GENERATEDBYCONTROLLER IGNITIONVERSION CREATED OSIMAGEURL
00-master 4.0.0-0.150.0.0-dirty 2.2.0 16m
00-master-ssh 4.0.0-0.150.0.0-dirty 16m
00-worker 4.0.0-0.150.0.0-dirty 2.2.0 16m
00-worker-ssh 4.0.0-0.150.0.0-dirty 16m
01-master-kubelet 4.0.0-0.150.0.0-dirty 2.2.0 16m
01-worker-kubelet 4.0.0-0.150.0.0-dirty 2.2.0 16m
master-1638c1aea398413bb918e76632f20799 4.0.0-0.150.0.0-dirty 2.2.0 16m
worker-2feef4f8288936489a5a832ca8efe953 4.0.0-0.150.0.0-dirty 2.2.0 16mMachine Config Operator が Machineconfig を適用するときの動作は Ignition とは若干異なります。Machineconfig は (00* から 99* までの) 順序で読み取られます。Machineconfig 内のラベルは、それぞれのノードのタイプ (マスターまたはワーカー) を特定します。同じファイルが複数の Machineconfig ファイルに表示される場合、最後のファイルが有効になります。たとえば、99* ファイルに出現するファイルは、00* ファイルに出現する同一のファイルを置き換えます。入力された Machineconfig オブジェクトは「レンダリングされた」Machineconfig オブジェクトに結合されます。 これは Operator のターゲットとして使用、Machine Config Poolで確認できる値です。
Machineconfig から管理されているファイルを表示するには、特定の Machineconfig 内で “Path:” を検索します。以下は例になります。
$ oc describe machineconfigs 01-worker-container-runtime | grep Path:
Path: /etc/containers/registries.conf
Path: /etc/containers/storage.conf
Path: /etc/crio/crio.conf
これらのいずれかのファイルの設定を変更する場合、たとえば、crio.conf ファイル内の pids_limit を1500 ((pids_limit = 1500) に変更するには、変更する必要のあるファイルのみが含まれる新規の Machineconfig を作成することができます。
Machineconfig には (10-worker-container-runtime などの) より新しい名前を付けてください。各ファイルの内容については、URL 形式のデータであることに留意してください。次に、新規 Machineconfig をクラスターに適用します。
Legal Notice
Copyright © Red Hat
OpenShift documentation is licensed under the Apache License 2.0 (https://www.apache.org/licenses/LICENSE-2.0).
Modified versions must remove all Red Hat trademarks.
Portions adapted from https://github.com/kubernetes-incubator/service-catalog/ with modifications by Red Hat.
Red Hat, Red Hat Enterprise Linux, the Red Hat logo, the Shadowman logo, JBoss, OpenShift, Fedora, the Infinity logo, and RHCE are trademarks of Red Hat, Inc., registered in the United States and other countries.
Linux® is the registered trademark of Linus Torvalds in the United States and other countries.
Java® is a registered trademark of Oracle and/or its affiliates.
XFS® is a trademark of Silicon Graphics International Corp. or its subsidiaries in the United States and/or other countries.
MySQL® is a registered trademark of MySQL AB in the United States, the European Union and other countries.
Node.js® is an official trademark of the OpenJS Foundation.
The OpenStack® Word Mark and OpenStack logo are either registered trademarks/service marks or trademarks/service marks of the OpenStack Foundation, in the United States and other countries and are used with the OpenStack Foundation’s permission. We are not affiliated with, endorsed or sponsored by the OpenStack Foundation, or the OpenStack community.
All other trademarks are the property of their respective owners.