Serverless アプリケーション
OpenShift Serverless のインストール、使用法、およびリリースノート
概要
第1章 OpenShift Serverless リリースノート
OpenShift Serverless 機能の概要については、OpenShift Serverless の使用開始 を参照してください。
Knative Eventing はテクノロジープレビュー機能としてのみご利用いただけます。テクノロジープレビュー機能は Red Hat の実稼働環境でのサービスレベルアグリーメント (SLA) ではサポートされていないため、Red Hat では実稼働環境での使用を推奨していません。Red Hat は実稼働環境でこれらを使用することを推奨していません。テクノロジープレビューの機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストを行いフィードバックを提供していただくことを目的としています。
Red Hat のテクノロジープレビュー機能のサポート範囲についての詳細は、https://access.redhat.com/ja/support/offerings/techpreview/ を参照してください。
1.1. Red Hat OpenShift Serverless 1.7.2 のリリースノート
OpenShift Serverless の本リリースでは、CVE (Common Vulnerabilities and Exposures) およびバグ修正に対応しています。
1.1.1. 修正された問題
-
以前のバージョンの OpenShift Serverless では、
KnativeServingカスタムリソースは、Kourier がデプロイしない場合でもReadyのステータスを表示します。この問題は OpenShift Serverless 1.7.2 で修正されました。
1.2. Red Hat OpenShift Serverless 1.7.1 のリリースノート
1.2.1. 新機能
- OpenShift Serverless は Knative Serving 0.13.3 を使用するようになりました。
- OpenShift Serverless は Knative Serving Operator 0.13.3 を使用するようになりました。
-
OpenShift Serverless は Knative
knCLI 0.13.2 を使用するようになりました。 - OpenShift Serverless は Knative Eventing 0.13.0 を使用するようになりました。
- OpenShift Serverless は Knative Eventing Operator 0.13.3 を使用するようになりました。
1.2.2. 修正された問題
- OpenShift Serverless 1.7.0 では、ルートは不要になった場合に継続的に調整されました。この問題は OpenShift Serverless 1.7.1 で修正されました。
1.3. Red Hat OpenShift Serverless 1.7.0 のリリースノート
1.3.1. 新機能
- OpenShift Serverless 1.7.0 は、OpenShift Container Platform 4.3 以降のバージョンで一般に利用可能 (GA) になりました。以前のバージョンでは、OpenShift Serverless はテクノロジープレビューでした。
- OpenShift Serverless は Knative Serving 0.13.2 を使用するようになりました。
- OpenShift Serverless は Knative Serving Operator 0.13.2 を使用するようになりました。
-
OpenShift Serverless は Knative
knCLI 0.13.2 を使用するようになりました。 -
Knative
knCLI ダウンロードが、非接続またはネットワークが制限されたインストールをサポートするようになりました。 -
Knative
knCLI ライブラリーが Red Hat によって署名されるようになりました。 - Knative Eventing が OpenShift Serverless でテクノロジープレビューとして利用可能になりました。OpenShift Serverless は Knative Eventing 0.13.2 を使用するようになりました。
最新の Serverless リリースにアップグレードする前に、事前にインストールしている場合には、コミュニティー Knative Eventing Operator を削除する必要があります。Knative Eventing Operator をインストールすると、OpenShift Serverless 1.7.0 に含まれる Knative Eventing の最新のテクノロジープレビューバージョンをインストールできなくなります。
高可用性 (HA) は、
autoscaler-hpa、controller、activator、kourier-control、およびkourier-gatewayコントローラーに対してデフォルトで有効にされます。以前のバージョンの OpenShift Serverless をインストールしている場合、
KnativeServingカスタムリソース (CR) が更新されると、デプロイメントはデフォルトでKnativeServing.spec.high-availability.replicas = 2の仕様が指定される HA 設定になります。高可用性コンポーネントの設定の手順を実行して、これらのコンポーネントの HA を無効にすることができます。
-
OpenShift Serverless は、OpenShift Container Platform のクラスター全体のプロキシーで
trustedCA設定をサポートし、OpenShift Container Platform のプロキシー設定と完全に互換性があります。 - OpenShift Serverless は、OpenShift Container Platform ルートに登録されているワイルドカード証明書を使用して HTTPS をサポートするようになりました。Knative Serving の http および https の詳細は、サーバーレスアプリケーションのデプロイメントの確認を参照してください。
1.3.2. 修正された問題
-
以前のバージョンでは、API グループを指定せずに
KnativeServingCR を要求すると (コマンドoc get knativeserving -n knative-servingを使用するなど)、エラーが発生することがありました。この問題は OpenShift Serverless 1.7.0 で修正されました。 以前のバージョンでは、Knative Serving コントローラーは、サービス CA 証明書のローテーションにより新規サービス CA 証明書が生成されても通知されませんでした。サービス CA 証明書のローテーション後に作成された新規リビジョンはエラーを出して失敗しました。
Revision "foo-1" failed with message: Unable to fetch image "image-registry.openshift-image-registry.svc:5000/eap/eap-app": failed to resolve image to digest: failed to fetch image information: Get https://image-registry.openshift-image-registry.svc:5000/v2/: x509: certificate signed by unknown authority.OpenShift Serverless Operator は、新規サービス CA 証明書が生成されるたびに Knative Serving コントローラーを再起動するようになりました。これにより、コントローラーは常に現在のサービス CA 証明書を使用するように設定されます。詳細は、OpenShift Container Platform ドキュメントの 認証のサービス提供証明書のシークレットによるサービストラフィックのセキュリティー保護を参照してください。
1.3.3. 既知の問題
- OpenShift Serverless 1.6.0 から 1.7.0 にアップグレードする場合、HTTPS のサポートではルートの形式を変更する必要があります。OpenShift Serverless 1.6.0 で作成された Knative サービスは、古い形式の URL で到達できなくなりました。OpenShift Serverless のアップグレード後に、各サービスの新規 URL を取得する必要があります。詳細は、OpenShift Serverless のアップグレードについてのドキュメントを参照してください。
-
Azure クラスターで Knative Eventing を使用している場合、
imc-dispatcherPod が起動しない可能性があります。これは、Pod のデフォルトresources設定によって生じます。回避策として、resources設定を削除できます。 クラスターに 1000 の Knative サービスがあり、Knative Serving の再インストールまたはアップグレードを実行する場合、
KnativeServingCR の状態が Ready になった後に最初の新規サービスを作成すると遅延が生じます。3scale-kourier-controlコントローラーは、新規サービスの作成を処理する前に以前の Knative サービスをすべて調整します。これにより、新規サービスは状態がReadyに更新されるまでIngressNotConfiguredまたはUnknownの状態になり、約 800 秒の時間がかかります。
1.4. Red Hat OpenShift Serverless テクノロジープレビューリリースノート (1.6.0)
1.4.1. 新機能
- OpenShift Serverless 1.6.0 は OpenShift Container Platform 4.3 以降のバージョンで利用できます。
- OpenShift Serverless は Knative Serving 0.13.1 を使用するようになりました。
-
OpenShift Serverless は Knative
knCLI 0.13.1 を使用するようになりました。 - OpenShift Serverless は Knative Serving Operator 0.13.1 を使用するようになりました。
serving.knative.devAPI グループは完全に非推奨となり、operator.knative.devAPI グループによって置き換えられました。OpenShift Serverless 1.4.0 リリースノートで説明されている手順を完了して、
serving.knative.devAPI グループをoperator.knative.devAPI グループに置き換えてから、OpenShift Serverless の最新バージョンにアップグレードできるようにする必要があります。重要この変更により、
oc get knativeservingなどの完全修飾 API グループおよび kind がないコマンドの信頼性は低くなり、常に正常に機能する状態を保てなくなります。OpenShift Serverless 1.6.0 へのアップグレード後に、古いカスタムリソース定義 (CRD) を削除してこの問題を修正する必要があります。以下のコマンドを実行して古い CRD を削除できます。
$ oc delete crd knativeservings.serving.knative.devWeb コンソールの新規 OpenShift Serverless リリースの Subscription Update Channel は、
techpreviewからpreview-4.3に更新されました。重要アップグレードについてのドキュメントに従ってチャネルを更新し、最新の OpenShift Serverless バージョンを使用できるようにする必要があります。
-
OpenShift Serverless が
HTTP_PROXYの使用をサポートするようになりました。 OpenShift Serverless は
HTTPS_PROXYクラスタープロキシー設定をサポートするようになりました。注記この
HTTP_PROXYサポートにはカスタム証明書の使用は含まれません。-
KnativeServingCRD はデフォルトで Developer Catalog から非表示になり、クラスター管理者のパーミッションを持つユーザーのみがこれを表示できるようになりました。 -
KnativeServingコントロールプレーンおよびデータプレーンの一部は、デフォルトで可用性が高い (HA) ものとしてデプロイされるようになりました。 - Kourier はアクティブに監視され、変更を自動的に調整するようになりました。
- OpenShift Serverless は OpenShift Container Platform の夜間ビルドでの使用をサポートするようになりました。
1.4.2. 修正された問題
-
以前のバージョンでは、
oc explainコマンドが適切に動作しませんでした。KnativeServingCRD の構造スキーマが OpenShift Serverless 1.6.0 で更新され、oc explainコマンドが正常に機能するようになりました。 -
以前のバージョンでは、複数の
KnativeServingカスタムリソース (CR) を作成できました。OpenShift Serverless 1.6.0 では、複数のKnativeServingCR が同期的に回避されるようになりました。複数のKnativeServingCR を作成しようとすると、エラーが発生します。 - 以前のバージョンでは、OpenShift Serverless には GCP での OpenShift Container Platform デプロイメントとの互換性がありませんでした。この問題は OpenShift Serverless 1.6.0 で修正されました。
- 以前のリリースでは、Knative Serving Webhook は、クラスターに 170 を超える namespace がある場合にメモリー不足のエラーでクラッシュしていました。この問題は OpenShift Serverless 1.6.0 で修正されました。
- 以前のリリースでは、OpenShift Serverless は、ルートが別のコンポーネントによって変更された場合に作成された OpenShift Container Platform ルートを自動的に修正しませんでした。この問題は OpenShift Serverless 1.6.0 で修正されました。
-
以前のバージョンでは、
KnativeServingCR を削除すると、システムがハングすることがありました。この問題は OpenShift Serverless 1.6.0 で修正されました。 - OpenShift Serverless 1.5.0 で発生したサービスメッシュから Kourier への ingress の移行により、孤立した VirtualServices がシステムに残ることがありました。OpenShift Serverless 1.6.0 では、孤立した VirtualServices が自動的に削除されます。
1.4.3. 既知の問題
OpenShift Serverless 1.6.0 では、クラスター管理者がドキュメントで説明されているアンインストール手順に従って OpenShift Serverless をアンインストールしても、Serverless のドロップダウンは OpenShift Container Platform Web コンソールの Administrator パースペクティブに依然として表示され、Knative Service リソースは OpenShift Container Platform Web コンソールの Developer パースペクティブに依然として表示されます。このオプションを使用して Knative サービスを作成することはできますが、これらの Knative サービスは動作しません。
OpenShift Serverless が OpenShift Container Platform Web コンソールに表示されないようにするには、クラスター管理者は Knative Serving CR を削除した後にデプロイメントから追加の CRD を削除する必要があります。
クラスター管理者は、以下のコマンドを実行してこれらのロールを削除できます。
$ oc get crd -oname | grep -E '(serving|internal).knative.dev' | xargs oc delete
1.5. Red Hat OpenShift Serverless テクノロジープレビューリリースノート (1.5.0)
1.5.1. 新機能
- OpenShift Serverless 1.5.0 は OpenShift Container Platform 4.3 以降のバージョンで利用できます。
- OpenShift Serverless が Knative Serving 0.12.1 を使用するように更新されました。
-
OpenShift Serverless が Knative
knCLI 0.12.0 を使用するように更新されました。 - OpenShift Serverless が Knative Serving Operator 0.12.1 を使用するように更新されました。
- OpenShift Serverless Ingress 実装は、サービスメッシュの代わりに Kourier を使用するように更新されました。OpenShift Serverless Operator が 1.5.0 にアップグレードされる際にとこの変更は自動的に実行されるため、ユーザーの介入は必要ありません。
1.5.2. 修正された問題
- 以前のリリースでは、OpenShift Container Platform がゼロレイテンシーからスケーリングすると、Pod の作成時に約 10 秒の遅延が発生しました。この問題は OpenShift Container Platform 4.3.5 バグ修正の更新で修正されています。
1.5.3. 既知の問題
-
KnativeServing.operator.knative.devカスタムリソース定義 (CRD) をknative-servingnamespace から削除すると、削除プロセスがハングする可能性があります。これは、CRD の削除とknative-openshift-ingressingress がファイナライザーを削除する間に競合状態が生じるためです。
1.6. 追加リソース
OpenShift Serverless はオープンソースの Knative プロジェクトに基づいています。
- 最新の Knative Serving リリースについての詳細は、Knative Serving リリースページ を参照してください。
- 最新の Knative Serving Operator のリリースについての詳細は、Knative Serving Operator リリースページ を参照してください。
- 最新の Knative CLI リリースの詳細は、Knative client リリースページ を参照してください。
- 最新の Knative Eventing リリースの詳細は、Knative Eventing リリースページ を参照してください。
第2章 OpenShift Serverless のサポート
2.1. サポート
本書で説明されている手順で問題が発生した場合は、Red Hat カスタマーポータル (http://access.redhat.com) にアクセスしてください。カスタマーポータルでは、次のことができます。
- Red Hat 製品に関する技術サポート記事の Red Hat ナレッジベースの検索またはブラウズ。
- Red Hat グローバルサポートサービス (GSS) へのサポートケースの送信
- その他の製品ドキュメントへのアクセス
本書の改善が提案されている場合やエラーが見つかった場合は、Documentation コンポーネントの Product に対して、http://bugzilla.redhat.com から Bugzilla レポートを送信してください。コンテンツを簡単に見つけられるよう、セクション番号、ガイド名、OpenShift Serverless のバージョンなどの詳細情報を記載してください。
2.2. サポート用の診断情報の収集
サポートケースを作成する際、ご使用のクラスターについてのデバッグ情報を Red Hat サポートに提供していただくと Red Hat のサポートに役立ちます。
must-gather ツールを使用すると、OpenShift Serverless に関連するデータを含む、 OpenShift Container Platform クラスターについての診断情報を収集できます。
迅速なサポートを得るには、OpenShift Container Platform と OpenShift Serverless の両方の診断情報を提供してください。
2.2.1. must-gather ツールについて
oc adm must-gather CLI コマンドは、以下のような問題のデバッグに必要となる可能性のあるクラスターからの情報を収集します。
- リソース定義
- 監査ログ
- サービスログ
--image 引数を指定してコマンドを実行する際にイメージを指定できます。イメージを指定する際、ツールはその機能または製品に関連するデータを収集します。
oc adm must-gather を実行すると、新しい Pod がクラスターに作成されます。データは Pod で収集され、must-gather.local で始まる新規ディレクトリーに保存されます。このディレクトリーは、現行の作業ディレクトリーに作成されます。
2.2.2. OpenShift Serverless データの収集について
oc adm must-gather CLI コマンドを使用してクラスターについての情報を収集できます。これには、OpenShift Serverless に関連する機能およびオブジェクトが含まれます。
must-gather ツールを使用して OpenShift Serverless データを収集するには、OpenShift Serverless イメージを指定する必要があります。
$ oc adm must-gather --image=registry.redhat.io/openshift-serverless-1/svls-must-gather-rhel8第3章 アーキテクチャー
3.1. Knative Serving アーキテクチャー
OpenShift Container Platform 上の Knative Serving により、開発者は サーバーレスアーキテクチャー を使用して、クラウドネイティブアプリケーション を作成できます。Serverless は、アプリケーション開発者がサーバーのプロビジョニングやアプリケーションのスケーリングを管理する必要がないクラウドコンピューティングのモデルです。これらのルーチンタスクはプラットフォームによって抽象化されるため、開発者は従来のモデルの場合よりも速くコードを実稼働にプッシュできます。
Knative Serving は、OpenShift Container Platform クラスター上のサーバーレスワークロードの動作を定義し、制御する Kubernetes カスタムリソース定義 (CRD) としてオブジェクトのセットを提供し、クラウドネイティブアプリケーションのデプロイおよび管理をサポートします。CRD についての詳細は、カスタムリソース定義による Kubernetes API の拡張 を参照してください。
開発者はこれらの CRD を使用して、複雑なユースケースに対応するためにビルディングブロックとして使用できるカスタムリソース (CR) インスタンスを作成します。以下に例を示します。
- サーバーレスコンテナーの迅速なデプロイ
- Pod の自動スケーリング
CR についての詳細は、カスタムリソース定義からのリソースの管理 を参照してください。
3.1.1. Knative Serving CRD
- Service
-
service.serving.knative.devCRD はワークロードのライフサイクルを自動的に管理し、アプリケーションがネットワーク経由でデプロイされ、到達可能であることを確認します。これは、ユーザーが作成したサービスまたは CR に対して加えられるそれぞれの変更についての ルート、設定、および新規リビジョンを作成します。Knative での開発者の対話のほとんどは、サービスを変更して実行されます。 - Revision
-
revision.serving.knative.devCRD は、ワークロードに対して加えられるそれぞれの変更についてのコードおよび設定の特定の時点におけるスナップショットです。Revision (リビジョン) はイミュータブル (変更不可) オブジェクトであり、必要な期間保持することができます。 - Route
-
route.serving.knative.devCRD は、ネットワークのエンドポイントを、1 つ以上のリビジョンにマップします。部分的なトラフィックや名前付きルートなどのトラフィックを複数の方法で管理することができます。 - Configuration
-
configuration.serving.knative.devCRD は、デプロイメントの必要な状態を維持します。これにより、コードと設定を明確に分離できます。設定を変更すると、新規リビジョンが作成されます。
3.2. Knative Eventing アーキテクチャー
OpenShift Container Platform 上の Knative Eventing を使用すると、開発者はサーバーレスアプリケーションと共に イベント駆動型のアーキテクチャー を使用できます。イベント駆動型のアーキテクチャーは、イベントを作成するイベントプロデューサーと、イベントを受信するイベント シンク またはコンシューマーとの間の切り離された関係の概念に基づいています。
Knative Eventing は、標準の HTTP POST リクエストを使用してイベントプロデューサーとコンシューマー間でイベントを送受信します。これらのイベントは CloudEvents 仕様 に準拠しており、すべてのプログラミング言語でのイベントの作成、解析、および送受信を可能にします。
以下を使用して、イベントを イベントソース から複数のイベントシンクに伝播できます。
チャネルおよびブローカーの実装は、サブスクリプションおよびトリガーを使用してイベントのイベントシンクへの配信を管理します。イベントは、宛先のシンクが利用できない場合にバッファーされます。
Knative Eventing は以下のシナリオをサポートします。
- コンシューマーを作成せずにイベントを公開する
- イベントを HTTP POST としてブローカーに送信し、SinkBinding を使用してイベントを生成するアプリケーションから宛先設定を分離できます。
- パブリッシャーを作成せずにイベントを消費
- Trigger を使用して、イベント属性に基づいて Broker からイベントを消費できます。アプリケーションはイベントを HTTP POST として受信します。
3.2.1. イベントシンク
複数のタイプのシンクへの配信を有効にするために、Knative Eventing は複数の Kubernetes リソースで実装できる以下の汎用インターフェイスを定義します。
- アドレス指定可能なオブジェクト
-
HTTP 経由で
status.address.urlフィールドに定義されるアドレスに配信されるイベントを受信し、確認することができます。Kubernetes Service オブジェクトはアドレス指定可能なインターフェイスにも対応します。 - 呼び出し可能なオブジェクト
- HTTP 経由で配信されるイベントを受信し、これを変換できます。HTTP 応答ペイロードで 0 または 1 の新規イベントを返します。返されるイベントは、外部イベントソースからのイベントが処理されるのと同じ方法で処理できます。
第4章 OpenShift Serverless の使用開始
OpenShift Serverless は、開発者のインフラストラクチャーのセットアップまたはバックエンド開発に対する要件を軽減することにより、開発から実稼働までのコードの提供プロセスを単純化します。
4.1. OpenShift Serverless の仕組み
OpenShift Serverless 上の開発者は、使い慣れた言語およびフレームワークと共に、提供される Kubernetes ネイティブの API を使用してアプリケーションおよびコンテナーのワークロードをデプロイできます。
OpenShift Container Platform 上の OpenShift Serverless を使用することにより、ステートレスのサーバーレスワークロードのすべてを、自動化された操作によって単一のマルチクラウドコンテナープラットフォームで実行することができます。開発者は、それぞれのマイクロサービス、レガシーおよびサーバーレスアプリケーションをホストするために単一プラットフォームを使用することができます。
OpenShift Serverless はオープンソースの Knative プロジェクトをベースとし、エンタープライズレベルのサーバーレスプラットフォームを有効にすることで、ハイブリッドおよびマルチクラウド環境における移植性と一貫性をもたらします。
4.2. サポートされる設定
OpenShift Serverless(最新バージョンおよび以前のバージョン) のサポートされる機能、設定、および統合のセットは、 サポートされる設定ページ で確認できます。
Knative Eventing はテクノロジープレビュー機能としてのみご利用いただけます。テクノロジープレビュー機能は Red Hat の実稼働環境でのサービスレベルアグリーメント (SLA) ではサポートされていないため、Red Hat では実稼働環境での使用を推奨していません。Red Hat は実稼働環境でこれらを使用することを推奨していません。テクノロジープレビューの機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストを行いフィードバックを提供していただくことを目的としています。
Red Hat のテクノロジープレビュー機能のサポート範囲についての詳細は、https://access.redhat.com/ja/support/offerings/techpreview/ を参照してください。
4.3. 次のステップ
- OpenShift Serverless Operator を OpenShift Container Platform クラスターにインストールして開始します。
- OpenShift Serverless リリースノート を確認します。
- サーバーレスアプリケーションの作成および管理 についての文書に従ってアプリケーションを作成します。
第5章 OpenShift Serverless のインストール
5.1. OpenShift Serverless のインストール
以下では、クラスター管理者を対象に、OpenShift Serverless Operator の OpenShift Container Platform クラスターへのインストールについて説明します。
OpenShift Serverless は、ネットワークが制限された環境でのインストールに対してサポートされません。詳細は、ネットワークが制限された環境での Operator Lifecycle Manager の使用 を参照してください。
最新の Serverless リリースにアップグレードする前に、事前にインストールしている場合には、コミュニティー Knative Eventing Operator を削除する必要があります。Knative Eventing Operator をインストールすると、OpenShift Serverless Operator を使用して Knative Eventing の最新のバージョンをインストールできなくなります。
5.1.1. OpenShift Serverless インストールのクラスターサイズ要件の定義
OpenShift Serverless をインストールし、使用するには、OpenShift Container Platform クラスターのサイズを適切に設定する必要があります。OpenShift Serverless の最小要件は、10 CPU および 40GB メモリーを持つクラスターです。OpenShift Serverless を実行するための合計サイズ要件は、デプロイされたアプリケーションによって異なります。デフォルトで、各 Pod は約 400m の CPU を要求し、推奨値のベースはこの値になります。指定されるサイズ要件において、アプリケーションはレプリカを最大 10 つにスケールアップできます。アプリケーションの実際の CPU 要求を減らすと、レプリカ数が増える可能性があります。
指定される要件は、OpenShift Container Platform クラスターのワーカーマシンのプールにのみ関連します。マスターノードは一般的なスケジューリングには使用されず、要件から省略されます。
以下の制限は、すべての OpenShift Serverless デプロイメントに適用されます。
- Knative サービスの最大数: 1000
- Knative リビジョンの最大数: 1000
5.1.2. 高度なユースケースの追加要件
OpenShift Container Platform でのロギングまたはメータリングなどの高度なユースケースの場合は、追加のリソースをデプロイする必要があります。このようなユースケースで推奨される要件は 24 vCPU および 96GB メモリーです。
クラスターで高可用性 (HA) を有効にしている場合、これには Knative Serving コントロールプレーンの各レプリカについて 0.5 - 1.5 コアおよび 200MB - 2GB のメモリーが必要です。HA は、デフォルトで一部の Knative Serving コンポーネントについて有効にされます。OpenShift Serverless での高可用性レプリカの設定 についてのドキュメントに従って HA を無効にできます。
5.1.3. マシンセットを使用したクラスターのスケーリング
OpenShift Container Platform MachineSet API を使用して、クラスターを必要なサイズに手動でスケールアップすることができます。最小要件は、通常 2 つのマシンを追加することによってデフォルトのマシンセットのいずれかをスケールアップする必要があることを意味します。マシンセットの手動によるスケーリング を参照してください。
5.1.4. OpenShift Serverless Operator のインストール
この手順では、OpenShift Container Platform Web コンソールを使用して、OperatorHub から OpenShift Serverless Operator をインストールし、これにサブスクライブする方法を説明します。
手順
- OpenShift Container Platform Web コンソールで、Operators → OperatorHub ページに移動します。
スクロールするか、またはこれらのキーワード Serverless を Filter by keyword ボックス に入力して OpenShift Serverless Operator を検索します。
Operator についての情報を確認してから、Install をクリックします。
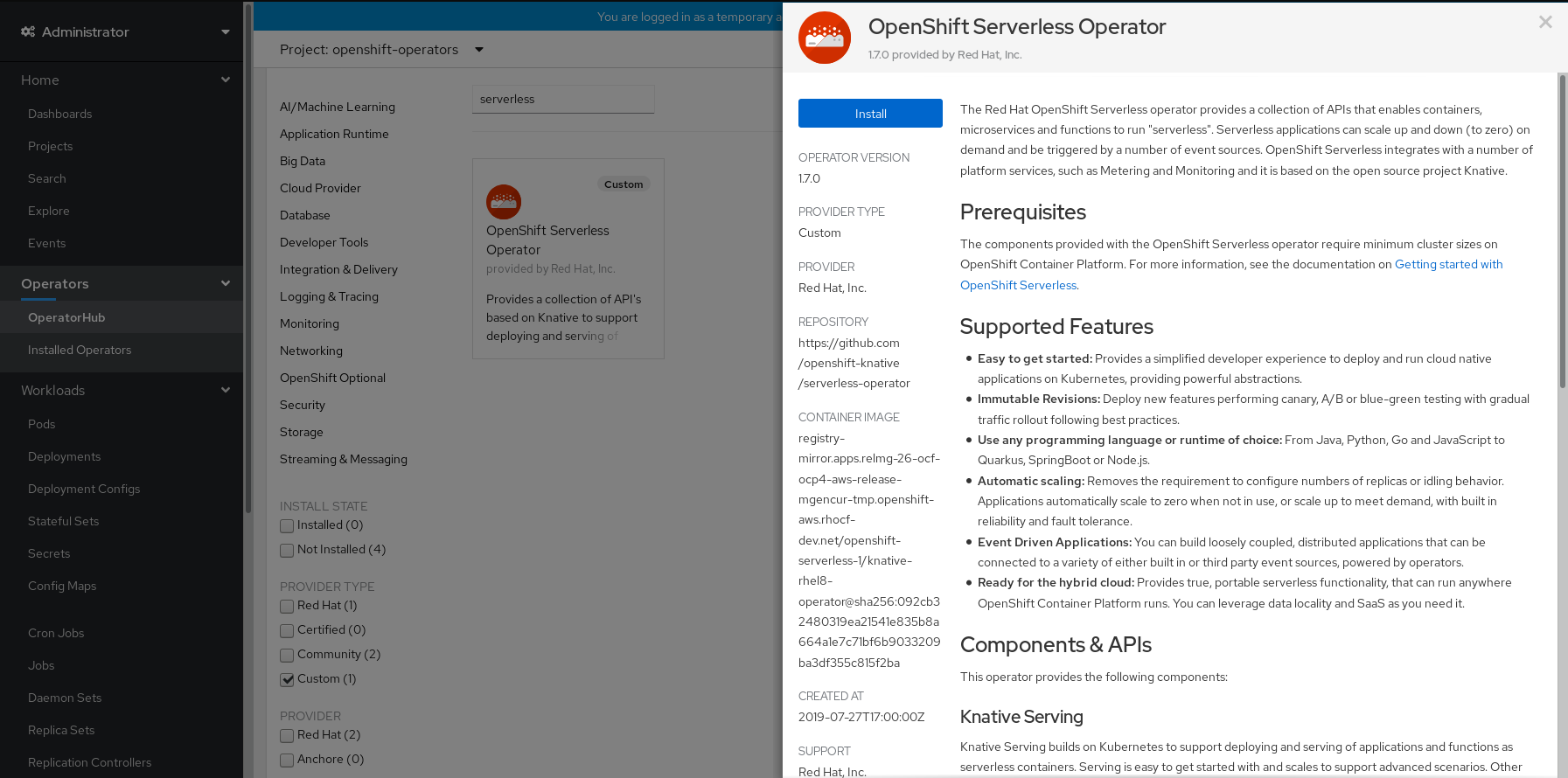
Create Operator Subscription ページで以下を実行します。
-
Installation Mode は All namespaces on the cluster (default) になります。このモードは、デフォルトの
openshift-operatorsnamespace で Operator をインストールし、クラスターのすべての namespace を監視し、Operator をこれらの namespace に対して利用可能にします。 -
Installed Namespace は
openshift-operatorsになります。 - Update Channel として 4.4 チャネルを選択します。4.4 チャネルは、OpenShift Serverless Operator の最新の安定したリリースのインストールを可能にします。
- Automatic または Manual 承認ストラテジーを選択します。
-
Installation Mode は All namespaces on the cluster (default) になります。このモードは、デフォルトの
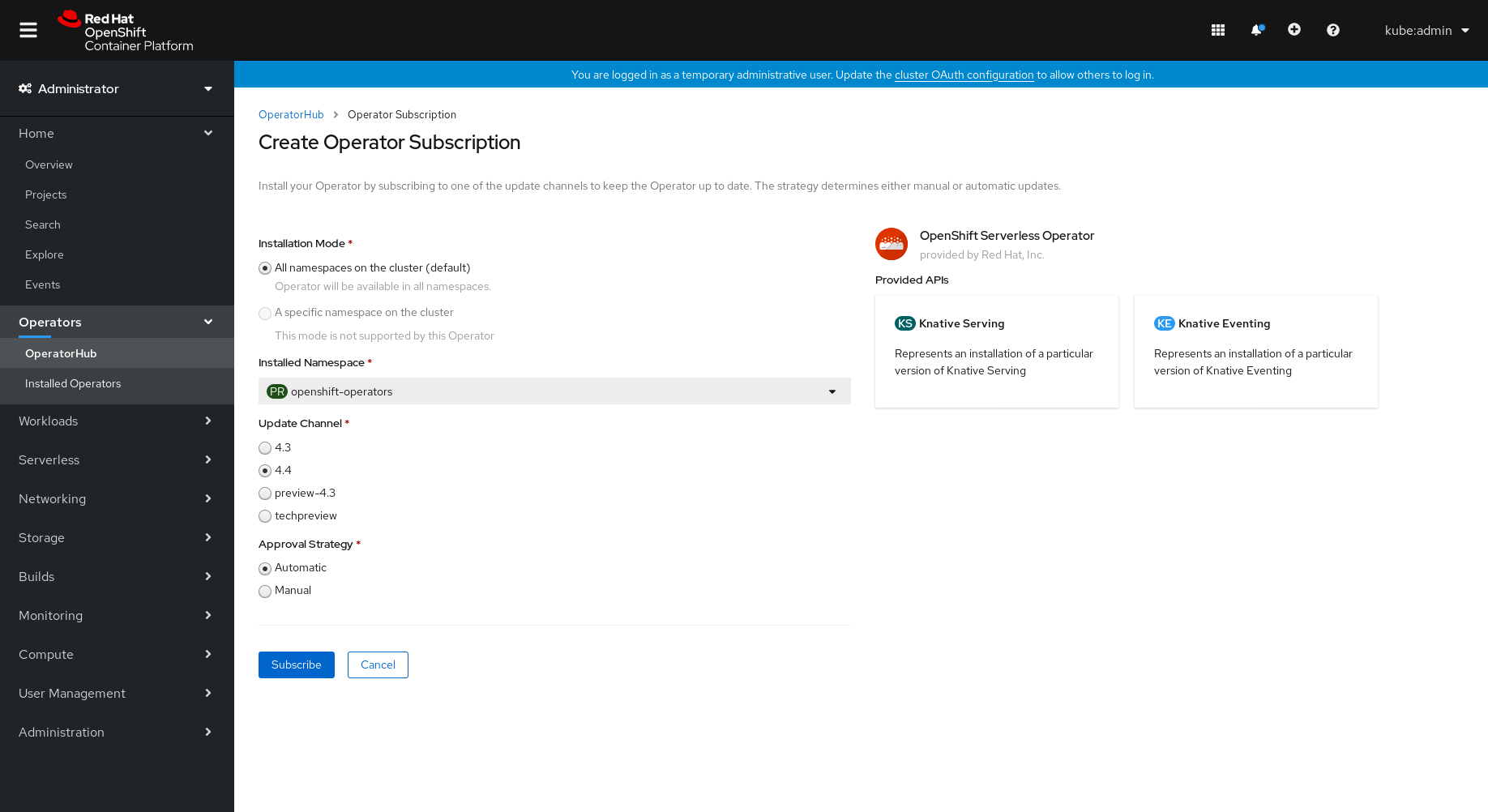
- Subscribe をクリックし、Operator をこの OpenShift Container Platform クラスターの選択した namespace で利用可能にします。
Catalog → Operator Management ページから、OpenShift Serverless Operator サブスクリプションのインストールおよびアップグレードの進捗をモニターできます。
- 手動 の承認ストラテジーを選択している場合、サブスクリプションのアップグレードステータスは、その Install Plan を確認し、承認するまで Upgrading のままになります。Install Plan ページでの承認後に、サブスクリプションのアップグレードステータスは Up to date に移行します。
- 自動 の承認ストラテジーを選択している場合、アップグレードステータスは、介入なしに Up to date に解決するはずです。
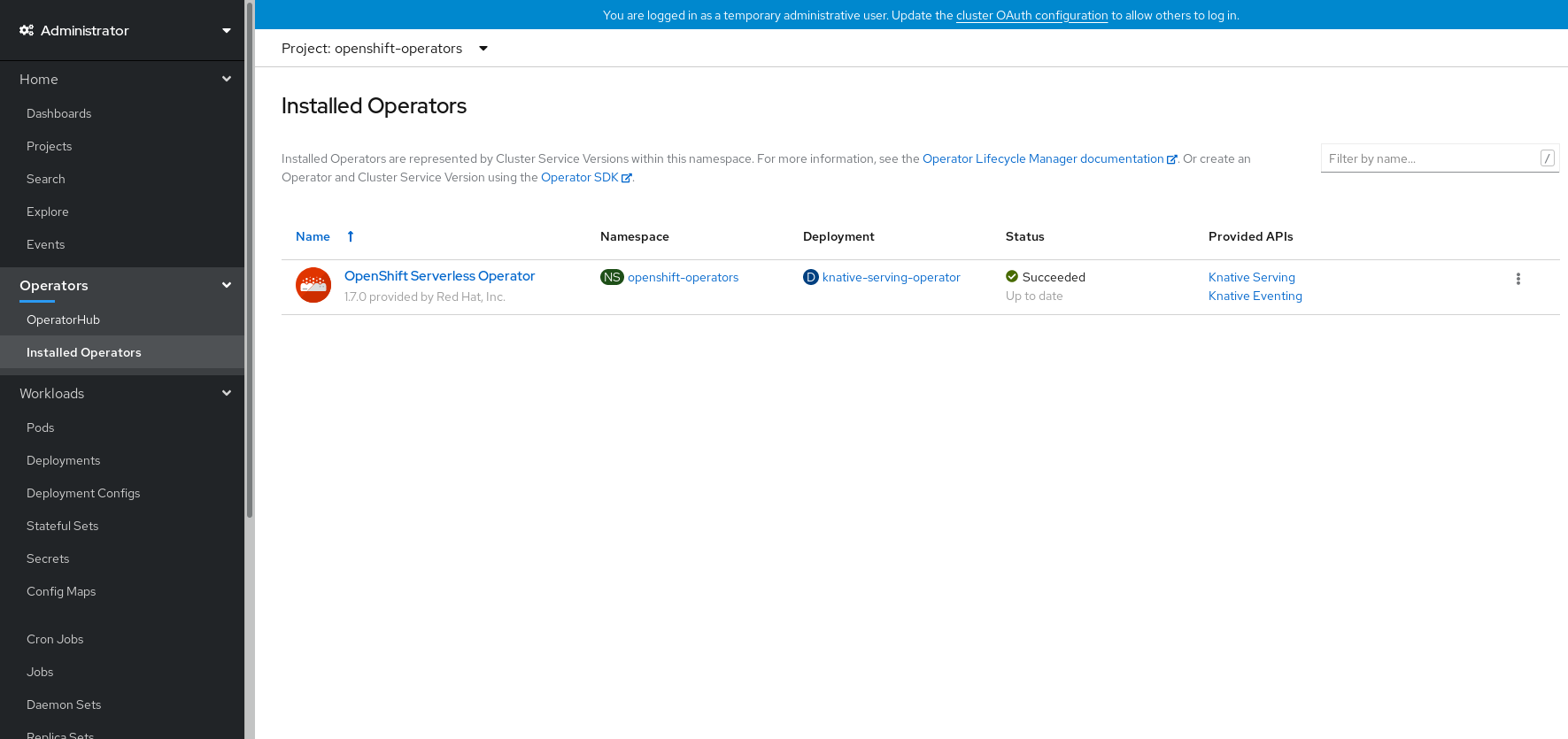
検証手順
サブスクリプションのアップグレードステータスが Up to date に移行したら、Catalog → Installed Operators を選択して OpenShift Serverless Operator が表示され、その Status が最終的に関連する namespace で InstallSucceeded に解決することを確認します。
上記通りにならない場合:
- Catalog → Operator Management ページに切り替え、Operator Subscriptions および Install Plans タブで Status の下の失敗またはエラーの有無を確認します。
-
さらにトラブルシューティングの必要な問題を報告している Pod のログについては、Workloads → Pods ページの
openshift-operatorsプロジェクトの Pod のログで確認できます。
追加リソース
- 詳細は、OpenShift Container Platform ドキュメントの Operator のクラスターへの追加 について参照してください。
5.1.5. 次のステップ
- OpenShift Serverless Operator がインストールされた後に、Knative Serving コンポーネントをインストールできます。Knative Serving のインストール についてのドキュメントを参照してください。
- OpenShift Serverless Operator がインストールされた後に、Knative Eventing コンポーネントをインストールできます。Knative Eventing のインストール についてのドキュメントを参照してください。
5.2. Knative Serving のインストール
OpenShift Serverless Operator のインストール後に、本書で説明されている手順に従って Knative Serving をインストールできます。
本書では、デフォルト設定を使用した Knative Serving のインストールについて説明します。ただし、KnativeServing カスタムリソース定義でより高度な設定を行うことができます。
KnativeServing カスタムリソース定義の設定オプションについての詳細は、高度なインストール設定オプション を参照してください。
5.2.1. knative-serving namespace の作成
knative-serving namespace を作成する際に、knative-serving プロジェクトも作成されます。
Knative Serving をインストールする前に、この手順を完了する必要があります。
Knative Serving のインストール時に作成された KnativeServing オブジェクトが knative-serving namespace で作成されていない場合、これは無視されます。
前提条件
- クラスター管理者のアクセスを持つ OpenShift Container Platform アカウント。
- OpenShift Serverless Operator がインストールされていること。
5.2.1.1. Web コンソールを使用した knative-serving namespace の作成
手順
OpenShift Container Platform Web コンソールで、Administration → Namespaces に移動します。
プロジェクトの Name として
knative-servingを入力します。他のフィールドはオプションです。
- Create をクリックします。
5.2.1.2. CLI を使用した knative-serving namespace の作成
手順
以下を入力して
knative-servingnamespace を作成します。$ oc create namespace knative-serving
5.2.2. 前提条件
- クラスター管理者のアクセスを持つ OpenShift Container Platform アカウント。
- OpenShift Serverless Operator がインストールされていること。
-
knative-servingnamespace が作成されていること。
5.2.3. Web コンソールを使用した Knative Serving のインストール
手順
- OpenShift Container Platform Web コンソールの Administrator パースペクティブで、Operators → Installed Operators に移動します。
- ページ上部の Project ドロップダウンメニューが Project: knative-serving に設定されていることを確認します。
OpenShift Serverless Operator の Provided API 一覧で Knative Serving をクリックし、Knative Serving タブに移動します。
Create Knative Serving ボタンをクリックします。
Create Knative Serving ページで、Create をクリックしてデフォルト設定を使用し、Knative Serving をインストールできます。
また、Knative Serving インストールの設定を変更するには、提供されるフォームを使用するか、または YAML を編集して
KnativeServingオブジェクトを編集します。-
KnativeServingオブジェクト作成を完全に制御する必要がない単純な設定には、このフォームの使用が推奨されます。 KnativeServingオブジェクトの作成を完全に制御する必要のあるより複雑な設定には、YAML の編集が推奨されます。YAML にアクセスするには、Create Knative Serving ページの右上にある edit YAML リンクをクリックします。フォームを完了するか、または YAML の変更が完了したら、Create をクリックします。
注記KnativeServing カスタムリソース定義の設定オプションについての詳細は、高度なインストール設定オプション についてのドキュメントを参照してください。
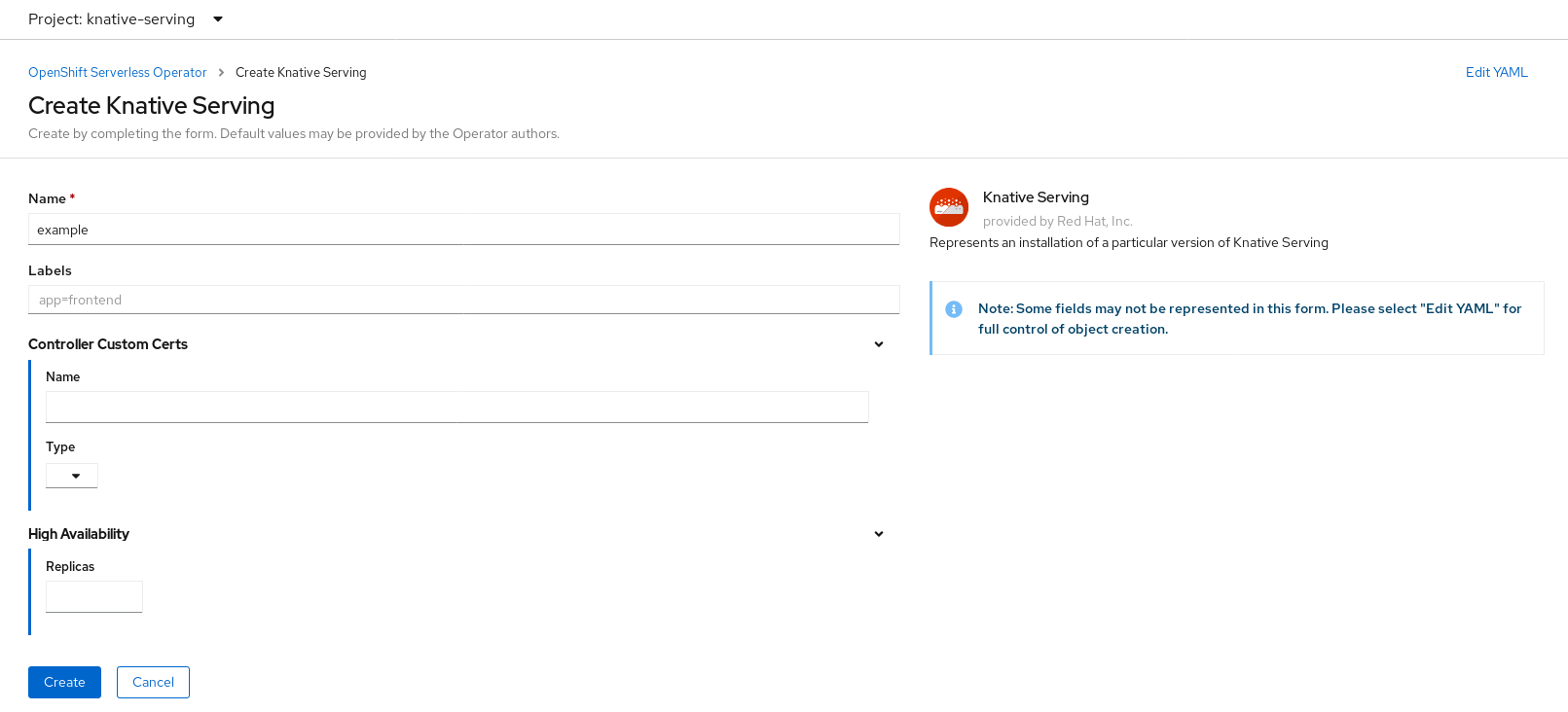
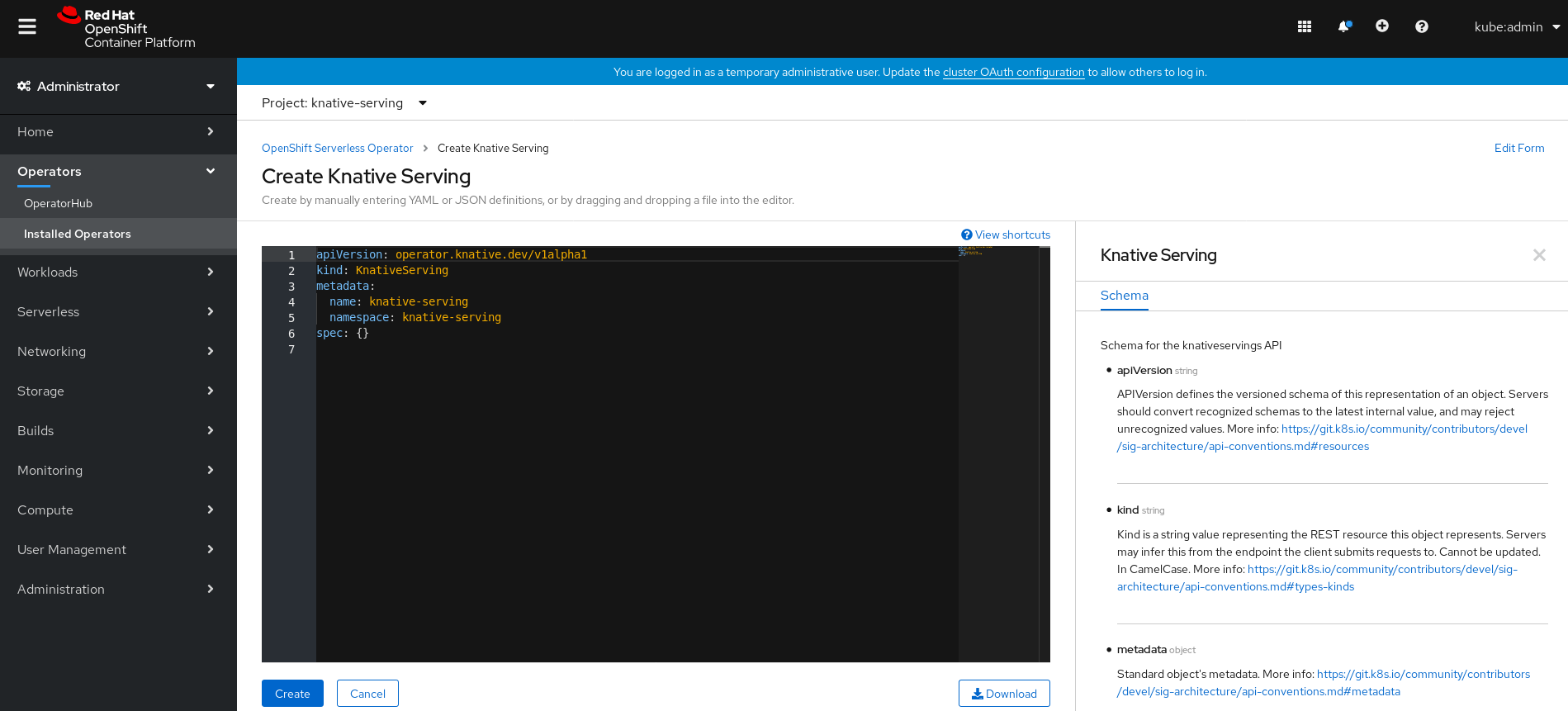
-
Knative Serving のインストール後に、
KnativeServingオブジェクトが作成され、Knative Serving タブに自動的にダイレクトされます。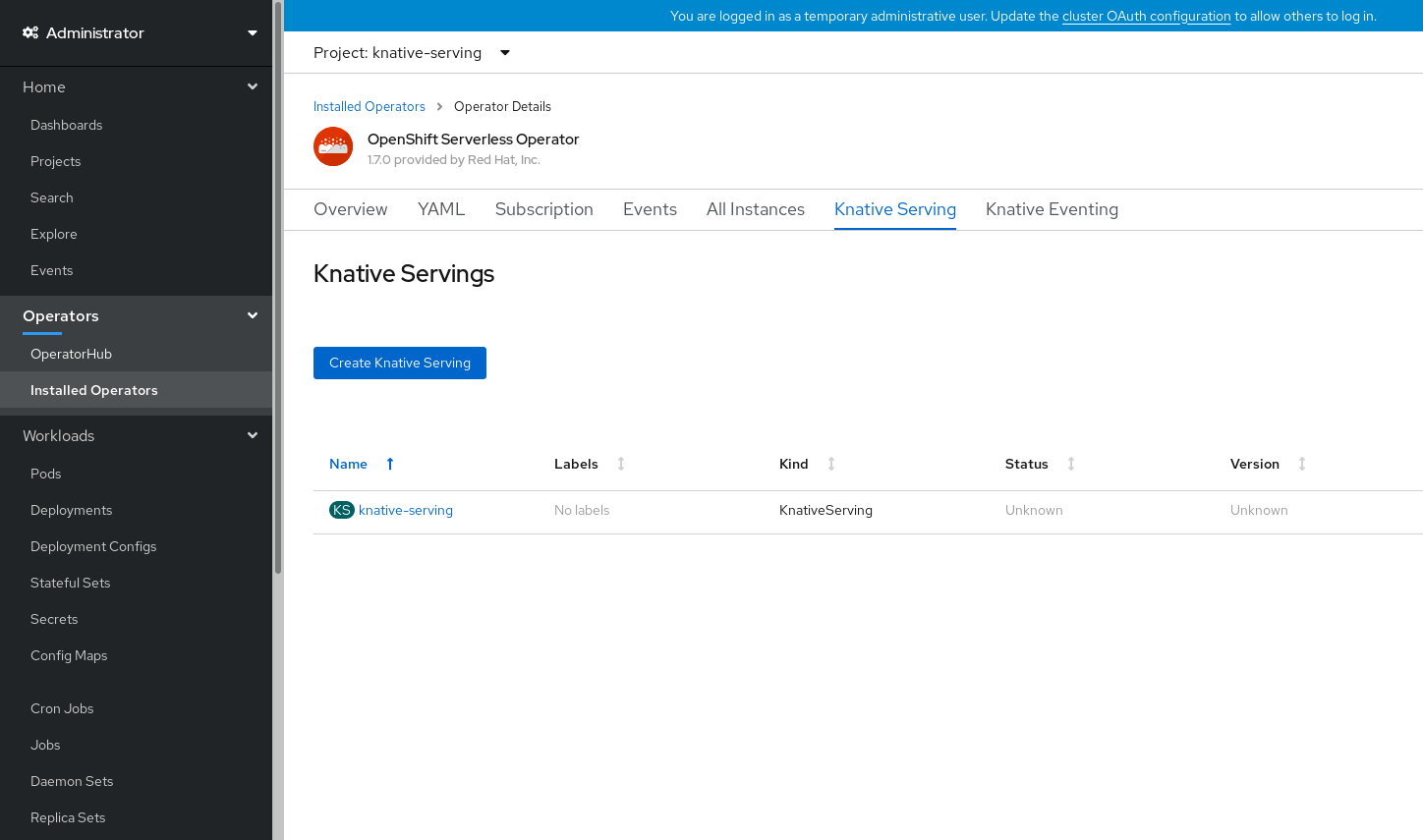
リソースの一覧に
knative-servingが表示されます。
検証手順
-
Knative Serving タブの
knative-servingをクリックします。 Knative Serving Overview ページに自動的にダイレクトされます。
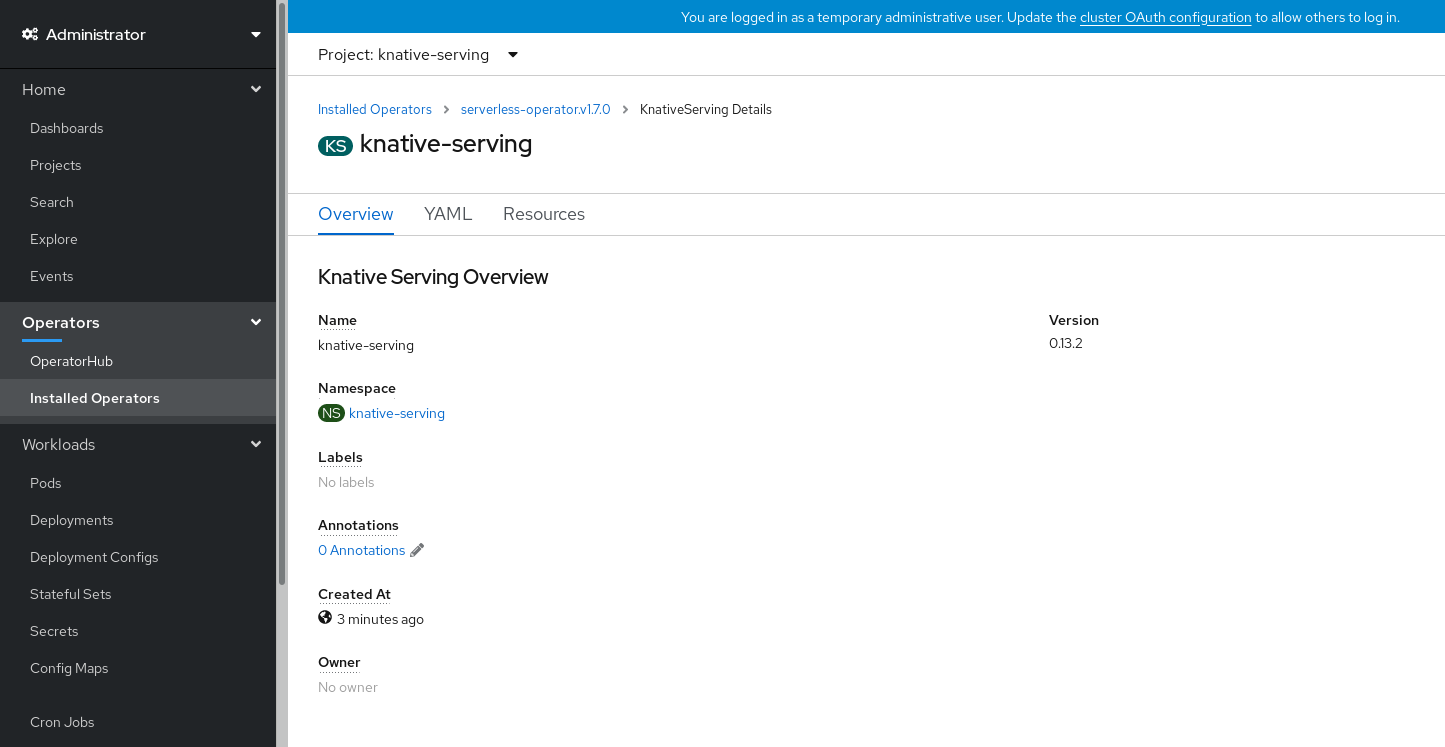
- スクロールダウンして、Conditions の一覧を確認します。
ステータスが True の条件の一覧が表示されます (例のイメージを参照)。
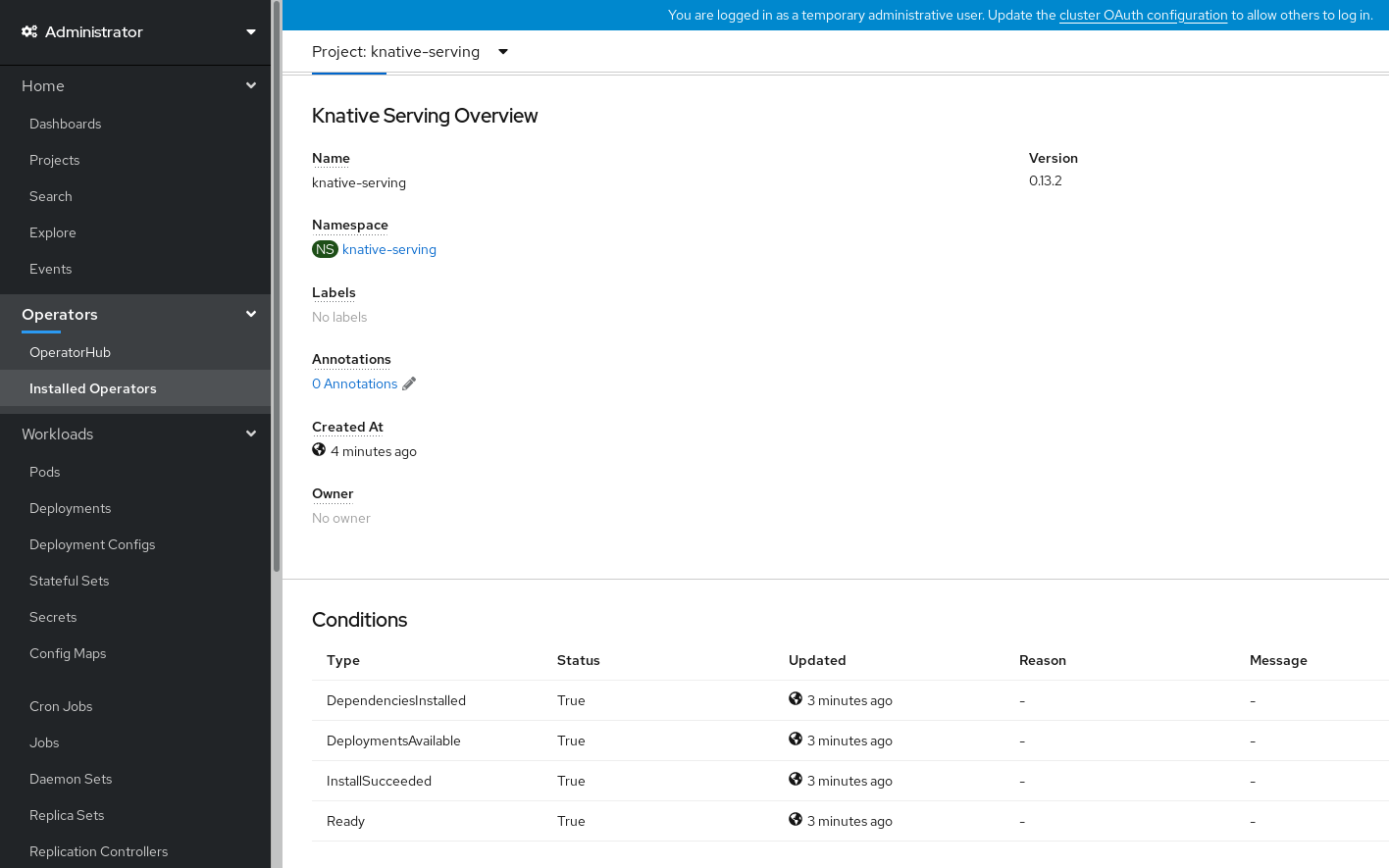 注記
注記Knative Serving リソースが作成されるまでに数分の時間がかかる場合があります。Resources タブでステータスを確認できます。
- 条件のステータスが Unknown または False である場合は、しばらく待ってから、リソースが作成されたことを再度確認します。
5.2.4. YAML を使用した Knative Serving のインストール
手順
-
serving.yamlという名前のファイルを作成します。 以下のサンプル YAML を
serving.yamlにコピーします。apiVersion: operator.knative.dev/v1alpha1 kind: KnativeServing metadata: name: knative-serving namespace: knative-servingserving.yamlファイルを適用します。$ oc apply -f serving.yaml
検証手順
インストールが完了したことを確認するには、以下のコマンドを実行します。
$ oc get knativeserving.operator.knative.dev/knative-serving -n knative-serving --template='{{range .status.conditions}}{{printf "%s=%s\n" .type .status}}{{end}}'出力は以下のようになります。
DependenciesInstalled=True DeploymentsAvailable=True InstallSucceeded=True Ready=True注記Knative Serving リソースが作成されるまでに数分の時間がかかる場合があります。
-
条件のステータスが
UnknownまたはFalseである場合は、しばらく待ってから、リソースが作成されたことを再度確認します。 以下を入力して Knative Serving リソースが作成されていることを確認します。
$ oc get pods -n knative-serving出力は以下のようになります。
NAME READY STATUS RESTARTS AGE activator-5c596cf8d6-5l86c 1/1 Running 0 9m37s activator-5c596cf8d6-gkn5k 1/1 Running 0 9m22s autoscaler-5854f586f6-gj597 1/1 Running 0 9m36s autoscaler-hpa-78665569b8-qmlmn 1/1 Running 0 9m26s autoscaler-hpa-78665569b8-tqwvw 1/1 Running 0 9m26s controller-7fd5655f49-9gxz5 1/1 Running 0 9m32s controller-7fd5655f49-pncv5 1/1 Running 0 9m14s kn-cli-downloads-8c65d4cbf-mt4t7 1/1 Running 0 9m42s webhook-5c7d878c7c-n267j 1/1 Running 0 9m35s
5.2.5. 次のステップ
- OpenShift Serverless のクラウドイベント機能については、Knative Eventing コンポーネントをインストールできます。Knative Eventing のインストール についてのドキュメントを参照してください。
-
Knative CLI をインストールして、Knative Serving で
knコマンドを使用します。例:kn serviceコマンドKnative CLI (kn)のインストール についてのドキュメントを参照してください。
5.3. Knative Eventing のインストール
OpenShift Serverless Operator のインストール後に、本書で説明されている手順に従って Knative Eventing をインストールできます。
Knative Eventing はテクノロジープレビュー機能としてのみご利用いただけます。テクノロジープレビュー機能は Red Hat の実稼働環境でのサービスレベルアグリーメント (SLA) ではサポートされていないため、Red Hat では実稼働環境での使用を推奨していません。Red Hat は実稼働環境でこれらを使用することを推奨していません。テクノロジープレビューの機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストを行いフィードバックを提供していただくことを目的としています。
Red Hat のテクノロジープレビュー機能のサポート範囲についての詳細は、https://access.redhat.com/ja/support/offerings/techpreview/ を参照してください。
本書では、デフォルト設定を使用した Knative Eventing のインストールについて説明します。
5.3.1. knative-eventing namespace の作成
knative-eventing namespace の作成時に、 knative-eventing プロジェクトも作成されます。
Knative Serving をインストールする前に、この手順を実行する必要があります。
Knative Eventing のインストール時に作成された KnativeEventing オブジェクトが knative-eventing namespace で作成されていない場合、これは無視されます。
前提条件
- クラスター管理者のアクセスを持つ OpenShift Container Platform アカウント。
- OpenShift Serverless Operator がインストールされていること。
5.3.1.1. Web コンソールを使用した knative-eventing namespace の作成
手順
- OpenShift Container Platform Web コンソールで、Administration → Namespaces に移動します。
Create Namespace をクリックします。
プロジェクトの Name として
knative-eventingを入力します。その他のフィールドは任意です。
- Create をクリックします。
5.3.1.2. CLI を使用した knative-eventing namespace の作成
手順
以下を入力して
knative-eventingnamespace を作成します。$ oc create namespace knative-eventing
5.3.2. 前提条件
- クラスター管理者のアクセスを持つ OpenShift Container Platform アカウント。
- OpenShift Serverless Operator がインストールされていること。
-
knative-eventingnamespace が作成されていること。
5.3.3. Web コンソールを使用した Knative Eventing のインストール
手順
- OpenShift Container Platform Web コンソールの Administrator パースペクティブで、Operators → Installed Operators に移動します。
- ページ上部の Project ドロップダウンメニューが Project: knative-eventing に設定されていることを確認します。
OpenShift Serverless Operator の Provided API 一覧で Knative Eventing をクリックし、Knative Eventing タブに移動します。
Create Knative Eventing ボタンをクリックします。
Create Knative Eventing ページでは、提供されるデフォルトのフォームを使用するか、または YAML を編集して
KnativeEventingオブジェクトを設定できます。KnativeEventingオブジェクト作成を完全に制御する必要がない単純な設定には、このフォームの使用が推奨されます。オプション。フォームを使用して
KnativeEventingオブジェクトを設定する場合は、Knative Eventing デプロイメントに対して実装する必要のある変更を加えます。
Create をクリックします。
KnativeEventingオブジェクトの作成を完全に制御する必要のあるより複雑な設定には、YAML の編集が推奨されます。YAML にアクセスするには、Create Knative Eventing ページの右上にある edit YAML リンクをクリックします。オプション。YAML を編集して
KnativeEventingオブジェクトを設定する場合は、Knative Eventing デプロイメントについて実装する必要のある変更を YAML に加えます。
Create をクリックします。
Knative Eventing のインストール後に、
KnativeEventingオブジェクトが作成され、Knative Eventing タブに自動的にダイレクトされます。
リソースの一覧に
knative-eventingが表示されます。
検証手順
-
Knative Eventing タブの
knative-eventingをクリックします。 Knative Eventing Overview ページに自動的にダイレクトされます。
- スクロールダウンして、Conditions の一覧を確認します。
ステータスが True の条件の一覧が表示されます (例のイメージを参照)。
 注記
注記Knative Eventing リソースが作成されるまでに数秒の時間がかかる場合があります。Resources タブでステータスを確認できます。
- 条件のステータスが Unknown または False である場合は、しばらく待ってから、リソースが作成されたことを再度確認します。
5.3.4. YAML を使用した Knative Eventing のインストール
手順
-
eventing.yamlという名前のファイルを作成します。 以下のサンプル YAML を
eventing.yamlにコピーします。apiVersion: operator.knative.dev/v1alpha1 kind: KnativeEventing metadata: name: knative-eventing namespace: knative-eventing- オプション。Knative Eventing デプロイメントについて実装する必要のある変更を YAML に加えます。
以下を入力して
eventing.yamlファイルを適用します。$ oc apply -f eventing.yaml
検証手順
インストールが完了したことを確認するには、以下を入力します。
$ oc get knativeeventing.operator.knative.dev/knative-eventing \ -n knative-eventing \ --template='{{range .status.conditions}}{{printf "%s=%s\n" .type .status}}{{end}}'出力は以下のようになります。
InstallSucceeded=True Ready=True注記Knative Eventing リソースが作成されるまでに数秒の時間がかかる場合があります。
-
条件のステータスが
UnknownまたはFalseである場合は、しばらく待ってから、リソースが作成されたことを再度確認します。 以下のコマンドを実行して Knative Eventing リソースが作成されていることを確認します。
$ oc get pods -n knative-eventing出力は以下のようになります。
NAME READY STATUS RESTARTS AGE broker-controller-58765d9d49-g9zp6 1/1 Running 0 7m21s eventing-controller-65fdd66b54-jw7bh 1/1 Running 0 7m31s eventing-webhook-57fd74b5bd-kvhlz 1/1 Running 0 7m31s imc-controller-5b75d458fc-ptvm2 1/1 Running 0 7m19s imc-dispatcher-64f6d5fccb-kkc4c 1/1 Running 0 7m18s
5.3.5. 次のステップ
- OpenShift Serverless のサービスおよび提供側の機能については、Knative Serving コンポーネントをインストールできます。Knative Serving のインストール についてのドキュメントを参照してください。
-
Knative CLI をインストールして、Knative Eventing で
knコマンドを使用します。例:kn sourceコマンドKnative CLI (kn)のインストール についてのドキュメントを参照してください。
5.4. 高度なインストール設定オプション
以下では、OpenShift Serverless コンポーネントの高度なインストール設定オプションについてのクラスター管理者向けの情報を提供します。
5.4.1. Knative Serving でサポートされるインストール設定オプション
以下では、Knative Serving の高度なインストール設定オプションについてのクラスター管理者向けの情報を提供します。
config フィールドに含まれる YAML は変更しないでください。このフィールドの設定値の一部は OpenShift Serverless Operator によって挿入され、これらを変更すると、デプロイメントはサポートされなくなります。
5.4.1.1. コントローラーのカスタム証明書
レジストリーが自己署名証明書を使用する場合、ConfigMap またはシークレットを作成して、 tag-to-digest の解決策を有効にする必要があります。次に、OpenShift Serverless Operator は Knative Serving コントローラーをレジストリーにアクセスできるように自動的に設定します。
tag-to-digest の解決策を有効にするには、Knative Serving コントローラーがコンテナーレジストリーにアクセスする必要があります。
ConfigMap または Secret は Knative Serving CustomResourceDefinition (CRD) と同じ namespace になければなりません。
次の例では、以下を実行するために OpenShift Serverless Operator をトリガーします。
- コントローラーに証明書を含むボリュームを作成してマウントします。
- 必要な環境変数を適切に設定します。
サンプル YAML
apiVersion: operator.knative.dev/v1alpha1
kind: KnativeServing
metadata:
name: knative-serving
namespace: knative-serving
spec:
controller-custom-certs:
name: certs
type: ConfigMap
以下の例では、knative-serving namespace の certs という名前の ConfigMap の証明書を使用します。
サポートされるタイプは ConfigMap および Secret です。
コントローラーカスタム証明書が指定されていない場合、デフォルトは config-service-ca ConfigMap に設定されます。
デフォルト YAML の例
spec:
controller-custom-certs:
name: config-service-ca
type: ConfigMap5.4.1.2. 高可用性
レプリカの数が指定されていない場合、高可用性 (HA) はデフォルトでコントローラーあたり 2 つのレプリカに設定されます。
これを 1 に設定すると HA を無効にするか、またはより高い整数を設定してレプリカを追加できます。
サンプル YAML
spec:
high-availability:
replicas: 25.4.2. 追加リソース
- 高可用性の設定に関する詳細は、OpenShift Serverless での高可用性 を参照してください。
5.5. OpenShift Serverless のアップグレード
以前のバージョンの OpenShift Serverless をインストールしている場合には、本ガイドの手順に従って最新バージョンにアップグレードしてください。
最新の Serverless リリースにアップグレードする前に、事前にインストールしている場合はコミュニティー Knative Eventing Operator を削除する必要があります。Knative Eventing Operator をインストールすると、Knative Eventing の最新のテクノロジープレビューバージョンをインストールできなくなります。
5.5.1. Knative サービス URL 形式の更新
以前のバージョンの OpenShift Serverless から 1.7.0 にアップグレードする場合、HTTPS のサポートではルートの形式への変更が必要です。OpenShift Serverless 1.6.0 以前のバージョンで作成された Knative サービスには、以前の形式の URL で到達できなくなりました。OpenShift Serverless のアップグレード後に、各サービスの新規 URL を取得する必要があります。
Knative サービス URL の取得に関する詳細は、 サーバーレスアプリケーションのデプロイメントの検証 について参照してください。
5.5.2. サブスクリプションチャネルのアップグレード
OpenShift Container Platform 4.4 で最新バージョンの OpenShift Serverless にアップグレードするには、チャネルを 4.4 に更新する必要があります。
OpenShift Serverless バージョン 1.5.0 以前からバージョン 1.7.0 にアップグレードする場合は、以下の手順を実行する必要があります。
-
techpreviewチャネルを選択して、OpenShift Serverless バージョン 1.5.0 にアップグレードします。 -
1.5.0 にアップグレードしたら、
preview-4.3チャネルを選択して 1.6.0 にアップグレードします。 -
最後に、1.6.0 にアップグレードしたら、
4.4チャネルを選択して最新バージョンにアップグレードします。
各チャネルの変更後に、knative-serving namespace の Pod がアップグレードされるのを待機してから、チャネルを再度変更します。
前提条件
以前のバージョンの OpenShift Serverless Operator をインストールし、インストールプロセス時に自動更新を選択している。
注記手動更新を選択した場合は、本書で説明するようにチャネルの更新後に追加の手順を実行する必要があります。Subscription のアップグレードステータスは、その Install Plan を確認し、承認するまで Upgrading のままになります。Install Plan についての詳細は、OpenShift Container Platform Operator のドキュメントを参照してください。
- OpenShift Container Platform Web コンソールにログインしている。
手順
-
OpenShift Container Platform Web コンソールで
openshift-operatorsnamespace を選択します。 - Operators → Installed Operators ページに移動します。
- OpenShift Serverless Operator を選択します。
- Subscription → Channel をクリックします。
-
Change Subscription Update Channel ウィンドウで
4.4を選択し、Save をクリックします。 -
すべての Pod が
knative-servingnamespace でアップグレードされ、KnativeServing カスタムリソースが最新の Knative Serving バージョンを報告するまで待機します。
検証手順
アップグレードが成功したことを確認するには、knative-serving namespace の Pod のステータスと KnativeServing CR のバージョンを確認します。
以下のコマンドを実行して Pod のステータスを確認します。
$ oc get knativeserving.operator.knative.dev knative-serving -n knative-serving -o=jsonpath='{.status.conditions[?(@.type=="Ready")].status}'上記のコマンドは
Trueのステータスを返すはずです。以下のコマンドを実行して、KnativeServing CR のバージョンを確認します。
$ oc get knativeserving.operator.knative.dev knative-serving -n knative-serving -o=jsonpath='{.status.version}'直前のコマンドは、Knative Serving の最新バージョンを返すはずです。OpenShift Serverless Operator リリースノートで最新バージョンを確認できます。
5.6. OpenShift Serverless の削除
本書では、OpenShift Serverless Operator および他の OpenShift Serverless コンポーネントを削除する方法を説明します。
OpenShift Serverless Operator を削除する前に、Knative Serving および Knative Eventing を削除する必要があります。
5.6.1. Knative Serving のアンインストール
Knative Serving をアンインストールするには、そのカスタムリソースを削除してから knative-serving namespace を削除する必要があります。
手順
Knative Serving を削除するには、以下のコマンドを実行します。
$ oc delete knativeservings.operator.knative.dev knative-serving -n knative-servingコマンドが実行され、すべての Pod が
knative-servingnamespace から削除された後に、以下のコマンドを使用して namespace を削除します。$ oc delete namespace knative-serving
5.6.2. Knative Eventing のアンインストール
Knative Eventing をアンインストールするには、そのカスタムリソースを削除してから knative-eventing namespace を削除する必要があります。
手順
Knative Eventing を削除するには、以下のコマンドを実行します。
$ oc delete knativeeventings.operator.knative.dev knative-eventing -n knative-eventingコマンドが実行され、すべての Pod が
knative-eventingnamespace から削除された後に、以下のコマンドを入力して namespace を削除します。$ oc delete namespace knative-eventing
5.6.3. OpenShift Serverless Operator の削除
Operator のクラスターからの削除方法 についての OpenShift Container Platform の説明に従って、OpenShift Serverless Operator をホストクラスターから削除できます。
5.6.4. OpenShift Serverless CRD の削除
OpenShift Serverless のアンインストール後に、Operator および API CRD はクラスター上に残ります。以下の手順を使用して、残りの CRD を削除できます。
Operator および API CRD を削除すると、Knative サービスを含む、それらを使用して定義されたすべてのリソースも削除されます。
5.6.5. 前提条件
- Knative Serving をアンインストールし、OpenShift Serverless Operator を削除していること。
手順
残りの OpenShift Serverless CRD を削除するには、以下のコマンドを実行します。
$ oc get crd -oname | grep 'knative.dev' | xargs oc delete
5.7. Knative CLI (kn) のインストール
kn には、独自のログインメカニズムは含まれません。クラスターにログインするには、oc CLI をインストールし、oc ログインを使用する必要があります。
oc CLI のインストールオプションは、お使いのオペレーティングシステムによって異なります。
ご使用のオペレーティングシステム用に oc CLI をインストールする方法および oc でのログイン方法についての詳細は、CLI の使用開始 についてのドキュメントを参照してください。
5.7.1. OpenShift Container Platform Web コンソールを使用した kn CLI のインストール
OpenShift Serverless Operator がインストールされると、OpenShift Container Platform Web コンソールの Command Line Tools ページから Linux、macOS および Windows の kn CLI をダウンロードするためのリンクが表示されます。
Command Line Tools ページには、Web コンソールの右上の
 アイコンをクリックして、ドロップダウンメニューの Command Line Tools を選択します。
アイコンをクリックして、ドロップダウンメニューの Command Line Tools を選択します。
手順
-
Command Line Tools ページから
knCLI をダウンロードします。 アーカイブを展開します。
$ tar -xf <file>-
knバイナリーをパスにあるディレクトリーに移動します。 PATH を確認するには、以下を実行します。
$ echo $PATH注記RHEL または Fedora を使用しない場合は、libc がライブラリーパスのディレクトリーにインストールされていることを確認してください。libc が利用できない場合は、CLI コマンドの実行時に以下のエラーが表示される場合があります。
$ kn: No such file or directory
5.7.2. RPM を使用した Linux 用の kn CLI のインストール
Red Hat Enterprise Linux (RHEL) の場合、Red Hat アカウントに有効な OpenShift Container Platform サブスクリプションがある場合は、kn を RPM としてインストールできます。
手順
-
以下のコマンドを使用して、
knをインストールします。
# subscription-manager register
# subscription-manager refresh
# subscription-manager attach --pool=<pool_id>
# subscription-manager repos --enable="openshift-serverless-1-for-rhel-8-x86_64-rpms"
# yum install openshift-serverless-clients- 1
- 有効な OpenShift Container Platform サブスクリプションのプール ID
5.7.3. Linux の kn CLI のインストール
Linux ディストリビューションの場合、CLI を tar.gz アーカイブとして直接ダウンロードできます。
手順
- CLI をダウンロードします。
アーカイブを展開します。
$ tar -xf <file>-
knバイナリーをパスにあるディレクトリーに移動します。 PATH を確認するには、以下を実行します。
$ echo $PATH注記RHEL または Fedora を使用しない場合は、libc がライブラリーパスのディレクトリーにインストールされていることを確認してください。libc が利用できない場合は、CLI コマンドの実行時に以下のエラーが表示される場合があります。
$ kn: No such file or directory
5.7.4. macOS の kn CLI のインストール
macOS の kn は、tar.gz アーカイブとして提供されます。
手順
- CLI をダウンロードします。
- アーカイブを展開および解凍します。
-
knバイナリーをパスにあるディレクトリーに移動します。 パスを確認するには、ターミナルウィンドウを開き、以下を実行します。
$ echo $PATH
5.7.5. Windows の kn CLI のインストール
Windows の CLI は zip アーカイブとして提供されます。
手順
- CLI をダウンロードします。
- ZIP プログラムでアーカイブを解凍します。
-
knバイナリーをパスにあるディレクトリーに移動します。 パスを確認するには、コマンドプロンプトを開いて以下のコマンドを実行します。
C:\> path
第6章 サーバーレスアプリケーションの作成および管理
6.1. Knative サービスを使用した Serverless アプリケーション
OpenShift Serverless でサーバーレスアプリケーションをデプロイするには、Knative サービス を作成する必要があります。Knative サービスは、ルートおよび YAML ファイルに含まれる設定によって定義される Kubernetes サービスです。
Knative サービス YAML の例
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: hello
namespace: default
spec:
template:
spec:
containers:
- image: docker.io/openshift/hello-openshift
env:
- name: RESPONSE
value: "Hello Serverless!"以下の方法のいずれかを使用してサーバーレスアプリケーションを作成できます。
- OpenShift Container Platform Web コンソールからの Knative サービスの作成
-
knCLI を使用して Knative サービスを作成します。 - YAML ファイルを作成し、これを適用します。
6.2. OpenShift Container Platform Web コンソールでのサーバーレスアプリケーションの作成
OpenShift Container Platform Web コンソールの Developer または Administrator パースペクティブのいずれかを使用してサーバーレスアプリケーションを作成できます。
6.2.1. Administrator パースペクティブを使用したサーバーレスアプリケーションの作成
前提条件
Administrator パースペクティブを使用してサーバーレスアプリケーションを作成するには、以下の手順を完了していることを確認してください。
- OpenShift Serverless Operator および Knative Serving がインストールされていること。
- Web コンソールにログインしており、Administrator パースペクティブを使用している。
手順
Serverless → Services ページに移動します。
- Create Service をクリックします。
YAML または JSON 定義を手動で入力するか、またはファイルをエディターにドラッグし、ドロップします。
- Create をクリックします。
6.2.2. Developer パースペクティブを使用したサーバーレスアプリケーションの作成
OpenShift Container Platform で Developer パースペクティブを使用してアプリケーションを作成する方法についての詳細は、Developer パースペクティブを使用したアプリケーションの作成 ドキュメントを参照してください。
6.3. kn CLI を使用したサーバーレスアプリケーションの作成
以下の手順では、kn CLI を使用して基本的なサーバーレスアプリケーションを作成する方法を説明します。
前提条件
- OpenShift Serverless Operator および Knative Serving がクラスターにインストールされていること。
-
knCLI がインストールされていること。
手順
Knative サービスを作成します。
$ kn service create <service_name> --image <image> --env <key=value>コマンドの例
$ kn service create hello --image docker.io/openshift/hello-openshift --env RESPONSE="Hello Serverless!"出力例
Creating service 'hello' in namespace 'default': 0.271s The Route is still working to reflect the latest desired specification. 0.580s Configuration "hello" is waiting for a Revision to become ready. 3.857s ... 3.861s Ingress has not yet been reconciled. 4.270s Ready to serve. Service 'hello' created with latest revision 'hello-bxshg-1' and URL: http://hello-default.apps-crc.testing
6.4. YAML を使用したサーバーレスアプリケーションの作成
サーバーレスアプリケーションを作成するには、YAML ファイルを作成し、oc apply を使用してこれを適用します。
手順
以下のサンプルをコピーして YAML ファイルを作成します。
Knative サービス YAML の例
apiVersion: serving.knative.dev/v1 kind: Service metadata: name: hello namespace: default spec: template: spec: containers: - image: docker.io/openshift/hello-openshift env: - name: RESPONSE value: "Hello Serverless!"この例では、YAML ファイルの名前は
hello-service.yamlです。hello-service.yamlファイルが含まれるディレクトリーに移動し、YAML ファイルを適用してアプリケーションをデプロイします。$ oc apply -f hello-service.yaml
サービスが作成され、アプリケーションがデプロイされた後に、Knative はこのバージョンのアプリケーションのイミュータブルなリビジョンを新規に作成します。
また、Knative はネットワークプログラミングを実行し、アプリケーションのルート、ingress、サービスおよびロードバランサーを作成し、アクティブでない Pod を含む Pod をトラフィックに基づいて自動的にスケールアップ/ダウンします。
6.5. サーバーレスアプリケーションのデプロイメントの確認
サーバーレスアプリケーションが正常にデプロイされたことを確認するには、Knative によって作成されたアプリケーション URL を取得してから、その URL に要求を送信し、出力を確認する必要があります。
OpenShift Serverless は HTTP および HTTPS URL の両方の使用をサポートしますが、 oc get ksvc <service_name> からの出力は常に http:// 形式を使用して URL を出力します。
手順
アプリケーション URL を検索します。
$ oc get ksvc <service_name>出力例
NAME URL LATESTCREATED LATESTREADY READY REASON hello http://hello-default.example.com hello-4wsd2 hello-4wsd2 Trueクラスターに対して要求を実行し、出力を確認します。
HTTP 要求の例
$ curl http://hello-default.example.comHTTPS 要求の例
$ curl https://hello-default.example.com出力例
Hello Serverless!オプション。証明書チェーンで自己署名証明書に関連するエラーが発生した場合は、curl コマンドに
--insecureフラグを追加して、エラーを無視できます。重要自己署名証明書は、実稼働デプロイメントでは使用しないでください。この方法は、テスト目的にのみ使用されます。
コマンドの例
$ curl https://hello-default.example.com --insecure出力例
Hello Serverless!オプション。OpenShift Container Platform クラスターが認証局 (CA) で署名されているが、システムにグローバルに設定されていない証明書で設定されている場合、curl コマンドでこれを指定できます。証明書へのパスは、
--cacertフラグを使用して curl コマンドに渡すことができます。コマンドの例
$ curl https://hello-default.example.com --cacert <file>出力例
Hello Serverless!
6.6. HTTP2 / gRPC を使用したサーバーレスアプリケーションとの対話
OpenShift Container Platform ルートは HTTP2 をサポートしません。gRPC も HTTP2 によるトランスポートが使用されるため、サポートされません。アプリケーションでこれらのプロトコルを使用する場合は、Ingress ゲートウェイを使用してアプリケーションを直接呼び出す必要があります。これを実行するには、Ingress ゲートウェイのパブリックアドレスとアプリケーションの特定のホストを見つける必要があります。
手順
- アプリケーションホストを検索します。サーバーレスアプリケーションのデプロイメントの確認の説明を参照してください。
ingress ゲートウェイのパブリックアドレスを取得します。
$ oc -n knative-serving-ingress get svc kourier出力例
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kourier LoadBalancer 172.30.51.103 a83e86291bcdd11e993af02b7a65e514-33544245.us-east-1.elb.amazonaws.com 80:31380/TCP,443:31390/TCP 67mパブリックアドレスは
EXTERNAL-IPフィールドで表示され、この場合は以下のようになります。a83e86291bcdd11e993af02b7a65e514-33544245.us-east-1.elb.amazonaws.comHTTP 要求のホストヘッダーを手動でアプリケーションのホストに手動で設定しますが、Ingress ゲートウェイのパブリックアドレスに対して要求自体をダイレクトします。
以下は、サーバーレスアプリケーションのデプロイメントの確認の手順で記載された情報を使用した例です。
$ curl -H "Host: hello-default.example.com" a83e86291bcdd11e993af02b7a65e514-33544245.us-east-1.elb.amazonaws.com Hello Serverless!Ingress ゲートウェイに対して要求を直接ダイレクトする間に、権限をアプリケーションのホストに設定して gRPC 要求を行うこともできます。
以下は、Golang gRPC クライアントの内容の例です。
注記以下の例のように、それぞれのポート (デフォルトでは 80) を両方のホストに追加します。
grpc.Dial( "a83e86291bcdd11e993af02b7a65e514-33544245.us-east-1.elb.amazonaws.com:80", grpc.WithAuthority("hello-default.example.com:80"), grpc.WithInsecure(), )
第7章 OpenShift Serverless での高可用性
高可用性 (HA) は Kubernetes API の標準的な機能で、中断が生じる場合に API が稼働を継続するのに役立ちます。HA デプロイメントでは、アクティブなコントローラーがクラッシュするか、または削除されると、現在利用できないコントローラーが提供されている API の処理を引き継ぐために別のコントローラーが利用可能になります。
OpenShift Serverless の HA は、リーダーの選択によって利用できます。これは、Knative Serving コントロールプレーンのインストール後にデフォルトで有効になります。
リーダー選択の HA パターンを使用する場合、必要時に備えてコントローラーのインスタンスはスケジュールされ、クラスター内で実行されます。これらのコントローラーインスタンスは、共有リソースの使用に向けて競います。これは、リーダー選択ロックとして知られています。リーダー選択ロックのリソースにアクセスできるコントローラーのインスタンスはリーダーと呼ばれます。
7.1. OpenShift Serverless での高可用性レプリカの設定
高可用性 (HA) 機能は、autoscaler-hpa、controller、activator、kourier-control、および kourier-gateway コントローラーについてデフォルトで OpenShift Serverless で利用できます。これらのコントローラーは、デフォルトで 2 つのレプリカで設定されます。
KnativeServing カスタムリソース定義 (CRD) の KnativeServing.spec.highAvailability 仕様の設定を変更して、コントローラーごとに作成されるレプリカの数を変更できます。
前提条件
- クラスター管理者のアクセスを持つ OpenShift Container Platform アカウントを使用できる。
- OpenShift Serverless Operator および Knative Serving がインストールされていること。
- OpenShift Container Platform Web コンソールへのアクセスがあり、ログインしている必要があります。
手順
Web コンソールの Administrator パースペクティブで、OperatorHub → Installed Operators に移動します。
-
knative-servingnamespace を選択します。 OpenShift Serverless Operator の Provided API 一覧で Knative Serving をクリックし、Knative Serving タブに移動します。
knative-serving をクリックしてから、knative-serving ページの YAML タブに移動します。
CRD YAML を編集します。
サンプル YAML
apiVersion: operator.knative.dev/v1alpha1 kind: KnativeServing metadata: name: knative-serving namespace: knative-serving spec: high-availability: replicas: 3重要configフィールドに含まれる YAML は変更しないでください。このフィールドの設定値の一部は OpenShift Serverless Operator によって挿入され、これらを変更すると、デプロイメントはサポートされなくなります。-
デフォルトの
replicas値は2です。 -
値を
1に設定すると HA が無効になります。または、必要に応じてレプリカの数を増やすことができます。上記の設定例は、すべての HA コントローラーのレプリカ数3を指定します。
-
デフォルトの
第8章 Jaeger を使用した要求のトレース
Jaeger を OpenShift Serverless で使用すると、OpenShift Container Platform でのサーバーレスアプリケーションの 分散トレース を有効にできます。
分散トレースは、アプリケーションを設定する各種のサービスを使用した要求のパスを記録します。これは、各種の異なる作業単位についての情報を連携させ、分散トランザクションでのイベントチェーン全体を把握できるようにするために使用されます。作業単位は、異なるプロセスまたはホストで実行される場合があります。
開発者は分散トレースを使用し、大規模なアーキテクチャーで呼び出しフローを可視化できます。これは、シリアル化、並行処理、およびレイテンシーのソースについての理解に役立ちます。
Jaeger についての詳細は、Jaeger アーキテクチャー および Jaeger のインストール を参照してください。
8.1. OpenShift Serverless で使用する Jaeger の設定
前提条件
- OpenShift Container Platform クラスターでのクラスター管理者パーミッション。
- OpenShift Serverless Operator および Knative Serving がインストールされていること。
- Jaeger Operator をインストールしていること。
手順
以下のサンプル YAML を含む Jaeger カスタムリソース YAML ファイルを作成し、これを適用します。
apiVersion: jaegertracing.io/v1 kind: Jaeger metadata: name: jaeger namespace: defaultKnativeServingカスタムリソースを編集し、トレース用に YAML 設定を追加して、Knative Serving のトレースを有効にします。apiVersion: operator.knative.dev/v1alpha1 kind: KnativeServing metadata: name: knative-serving namespace: knative-serving spec: config: tracing: sample-rate: "0.1"1 backend: zipkin2 zipkin-endpoint: http://jaeger-collector.default.svc.cluster.local:9411/api/v2/spans3 debug: "false"4 - 1
sample-rateはサンプリングの可能性を定義します。sample-rate: "0.1"を使用すると、10 トレースの内の 1 つがサンプリングされます。- 2
backendはzipkinに設定される必要があります。- 3
zipkin-endpointはjaeger-collectorサービスエンドポイントを参照する必要があります。このエンドポイントを取得するには、Jaeger カスタムリソースが適用される namespace を置き換えます。- 4
- デバッグは
falseに設定する必要があります。debug: "true"を設定してデバッグモードを有効にすることで、サンプリングをバイパスしてすべてのスパンがサーバーに送信されるようにします。
検証手順
jaeger ルートを使用して Jaeger Web コンソールにアクセスし、追跡データを表示できます。
jaegerルートのホスト名を取得します。$ oc get route jaeger出力例
NAME HOST/PORT PATH SERVICES PORT TERMINATION WILDCARD jaeger jaeger-default.apps.example.com jaeger-query <all> reencrypt None- ブラウザーでエンドポイントアドレスを開き、コンソールを表示します。
第9章 Knative Serving
9.1. kn の使用による Knative Serving タスクの実行
Knative kn CLI は oc または kubectl CLI ツールの機能を拡張し、OpenShift Container Platform の Knative コンポーネントとの対話を統合します。kn を使用すると、開発者は YAML ファイルを直接編集せずにアプリケーションをデプロイし、管理できます。
9.1.1. kn を使用した基本ワークフロー
以下の基本的なワークフローでは、環境変数 RESPONSE を読み取る単純な hello サービスをデプロイし、その出力を印刷します。
本書は、サービスでの作成、読み取り、更新、削除 (CRUD) 操作を実行する際の参照情報として使用できます。
手順
イメージからサービスを
デフォルトnamespace に作成します。$ kn service create hello --image docker.io/openshift/hello-openshift --env RESPONSE="Hello Serverless!"出力例
Creating service 'hello' in namespace 'default': 0.085s The Route is still working to reflect the latest desired specification. 0.101s Configuration "hello" is waiting for a Revision to become ready. 11.590s ... 11.650s Ingress has not yet been reconciled. 11.726s Ready to serve. Service 'hello' created with latest revision 'hello-gsdks-1' and URL: http://hello-default.apps-crc.testingサービスを一覧表示します。
$ kn service list出力例
NAME URL LATEST AGE CONDITIONS READY REASON hello http://hello-default.apps-crc.testing hello-gsdks-1 8m35s 3 OK / 3 Truecurlサービスエンドポイントコマンドを使用して、サービスが機能しているかどうかを確認します。$ curl http://hello-default.apps-crc.testing出力例
Hello Serverless!サービスを更新します。
$ kn service update hello --env RESPONSE="Hello OpenShift!"出力例
Updating Service 'hello' in namespace 'default': 10.136s Traffic is not yet migrated to the latest revision. 10.175s Ingress has not yet been reconciled. 10.348s Ready to serve. Service 'hello' updated with latest revision 'hello-dghll-2' and URL: http://hello-default.apps-crc.testingサービスの環境変数
RESPONSEは Hello OpenShift! に設定されるようになりました。サービスを記述します。
$ kn service describe hello出力例
Name: hello Namespace: default Age: 13m URL: http://hello-default.apps-crc.testing Revisions: 100% @latest (hello-dghll-2) [2] (1m) Image: docker.io/openshift/hello-openshift (pinned to 5ea96b) Conditions: OK TYPE AGE REASON ++ Ready 1m ++ ConfigurationsReady 1m ++ RoutesReady 1mサービスを削除します。
$ kn service delete hello出力例
Service 'hello' successfully deleted in namespace 'default'.この一覧表示を試行して、
helloサービスが削除されていることを確認します。$ kn service list hello出力例
No services found.
9.1.2. kn を使用した自動スケーリングのワークフロー
YAML ファイルを直接編集せずに kn を使用して Knative サービスを変更することで、自動スケーリング機能にアクセスできます。
適切なフラグと共に service create および service update コマンドを使用して、自動スケーリング動作を設定します。
| フラグ | 詳細 |
|---|---|
|
| 単一レプリカによって処理される同時要求のハード制限。 |
|
|
受信する同時要求の数に基づくスケールアップのタイミングの推奨。デフォルトは |
|
| レプリカの最大数。 |
|
| レプリカの最小数。 |
9.1.3. kn を使用したトラフィック分割
kn を使用して、Knative サービス上でルート指定されたトラフィックを取得するリビジョンを制御できます。
Knative サービスは、トラフィックのマッピングをサポートします。これは、サービスのリビジョンのトラフィックの割り当てられた部分へのマッピングです。これは特定のリビジョンに固有の URL を作成するオプションを提供し、トラフィックを最新リビジョンに割り当てる機能を持ちます。
サービスの設定が更新されるたびに、サービスルートがすべてのトラフィックを準備状態にある最新リビジョンにポイントする状態で、新規リビジョンが作成されます。この動作は、トラフィックの一部を取得するリビジョンを定義して変更することができます。
手順
kn service updateコマンドを--trafficフラグと共に使用して、トラフィックを更新します。たとえば、すべてのトラフィックを配置する前に 10% のトラフィックを新規リビジョンにルート指定するには、以下を実行します。
$ kn service update svc --traffic @latest=10 --traffic svc-vwxyz=90--traffic RevisionName=Percentは以下の構文を使用します。-
--trafficフラグには、等号 (=) で区切られた 2 つの値が必要です。 -
RevisionName文字列はリビジョンの名前を参照します。 -
Percent整数はトラフィックのリビジョンに割り当てられた部分を示します。 -
RevisionName の識別子
@latestを使用して、サービスの準備状態にある最新のリビジョンを参照します。この識別子は--trafficフラグと共に 1 回のみ使用できます。 -
service updateコマンドがトラフィックフラグと共にサービスの設定値を更新する場合、@latest参照は更新が適用される作成済みリビジョンをポイントします。 -
--trafficフラグは複数回指定でき、すべてのフラグのPercent値の合計が 100 になる場合にのみ有効です。
-
9.1.3.1. タグリビジョンの割り当て
サービスのトラフィックブロック内のタグは、参照されるリビジョンをポイントするカスタム URL を作成します。ユーザーは、http(s)://TAG-SERVICE.DOMAIN 形式を使用して、カスタム URL を作成するサービスの利用可能なリビジョンの固有タグを定義できます。
指定のタグは、サービスのトラフィックブロックに固有のものである必要があります。kn は、kn service update コマンドの一環として、サービスのリビジョンのカスタムタグの割り当ておよび割り当て解除に対応します。
タグを特定のリビジョンに割り当てた場合、ユーザーは、--traffic フラグ内で --traffic Tag=Percent として示されるタグでこのリビジョンを参照できます。
手順
サービスを更新してタグリビジョンを割り当てます。
$ kn service update svc --tag @latest=candidate --tag svc-vwxyz=current--tag RevisionName=Tagは以下の構文を使用します。-
--tagフラグには、=で区切られる 2 つの値が必要です。 -
RevisionName文字列はRevisionの名前を参照します。 -
Tag文字列は、このリビジョンに指定されるカスタムタグを示します。 -
RevisionNameの識別子@latestを使用して、サービスの準備状態にある最新のリビジョンを参照します。この識別子は--tagフラグで 1 回のみ使用できます。 -
service updateコマンドがサービスの設定値を (タグフラグと共に) 更新している場合、@latest参照は更新の適用後に作成されるリビジョンをポイントします。 -
--tagフラグは複数回指定できます。 -
--tagフラグは、同じリビジョンに複数の異なるタグを割り当てる場合があります。
-
9.1.3.2. タグリビジョンの割り当て解除
トラフィックブロックのリビジョンに割り当てられたタグは、割り当て解除できます。タグの割り当てを解除すると、カスタム URL が削除されます。
リビジョンのタグが解除され、0% のトラフィックが割り当てられる場合、このリビジョンはトラフィックブロックから完全に削除されます。
手順
kn service updateコマンドを使用してリビジョンのタグの割り当てを解除します。$ kn service update svc --untag candidate--untag Tagは以下の構文を使用します。-
--untagフラグには 1 つの値が必要です。 -
tag文字列は、割り当てを解除する必要のあるサービスのトラフィックブロックの固有のタグを示します。これにより、それぞれのカスタム URL も削除されます。 -
--untagフラグは複数回指定できます。
-
9.1.3.3. トラフィックフラグ操作の優先順位
すべてのトラフィック関連のフラグは、単一の kn service update コマンドを使用して指定できます。kn は、これらのフラグの優先順位を定義します。コマンドの使用時に指定されるフラグの順番は考慮に入れられません。
kn で評価されるフラグの優先順位は以下のとおりです。
-
--untag: このフラグで参照されるすべてのリビジョンはトラフィックブロックから削除されます。 -
--tag: リビジョンはトラフィックブロックで指定されるようにタグ付けされます。 -
--traffic: 参照されるリビジョンには、分割されたトラフィックの一部が割り当てられます。
9.1.3.4. トラフィック分割フラグ
kn は kn service update コマンドの一環として、サービスのトラフィックブロックでのトラフィック操作に対応します。
以下の表は、トラフィック分割フラグ、値の形式、およびフラグが実行する操作の概要を表示しています。Repetition 列は、フラグの特定の値が kn service update コマンドで許可されるかどうかを示します。
| フラグ | 値 | 操作 | 繰り返し |
|---|---|---|---|
|
|
|
| はい |
|
|
|
| はい |
|
|
|
| いいえ |
|
|
|
| はい |
|
|
|
| いいえ |
|
|
|
リビジョンから | はい |
9.2. Knative Serving 自動スケーリングの設定
OpenShift Serverless は、Knative Serving 自動スケーリングシステムを OpenShift Container Platform クラスターで有効にすることで、アクティブでない Pod をゼロにスケーリングする機能など、Pod の自動スケーリングの各種機能を提供します。Knative Serving の自動スケーリングを有効にするには、リビジョンテンプレートで同時実行 (concurrency) およびスケール境界 (scale bound) を設定する必要があります。
リビジョンテンプレートでの制限およびターゲットの設定は、アプリケーションの単一インスタンスに対して行われます。たとえば、target アノテーションを 50 に設定することにより、アプリケーションの各インスタンスが一度に 50 要求を処理できるようアプリケーションをスケーリングするように Autoscaler が設定されます。
9.2.1. Knative Serving 自動スケーリングの同時要求の設定
アプリケーションの各インスタンス (リビジョンコンテナー) によって処理される同時要求の数は、リビジョンテンプレートに target アノテーションまたは containerConcurrency フィールドを追加して指定できます。
以下は、リビジョンテンプレートで使用される target のサンプルです。
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: myapp
spec:
template:
metadata:
annotations:
autoscaling.knative.dev/target: 50
spec:
containers:
- image: myimage
以下は、リビジョンテンプレートで使用される containerConcurrency のサンプルです。
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: myapp
spec:
template:
metadata:
annotations:
spec:
containerConcurrency: 100
containers:
- image: myimage
target と containerConcurrency の両方の値を追加することにより、同時要求の target 数をターゲットとして設定できますが、これにより要求の containerConcurrency 数のハード制限も設定されます。たとえば、target 値が 50 で、containerConcurrency 値が 100 の場合、要求のターゲットに設定された数は 50 になりますが、ハード制限は 100 になります。
containerConcurrency 値が target 値よりも低い場合、実際に処理できる数よりも多くの要求をターゲットとして設定する必要はないため、target 値は小さい値に調整されます。
containerConcurrency は、特定の時点にアプリケーションに到達する要求の数を制限する明らかな必要がある場合にのみ使用する必要があります。containerConcurrency は、アプリケーションで同時実行の制約を実行する必要がある場合にのみ使用することを推奨します。
9.2.1.1. ターゲットアノテーションの使用による同時要求の設定
同時要求数のデフォルトターゲットは 100 ですが、リビジョンテンプレートで autoscaling.knative.dev/target アノテーション値を追加または変更することによってこの値を上書きできます。
以下は、ターゲットを 50 に設定するためにこのアノテーションをリビジョンテンプレートで使用する方法の例を示しています。
autoscaling.knative.dev/target: 509.2.1.2. containerConcurrency フィールドを使用した同時要求の設定
containerConcurrency は、処理される同時要求数にハード制限を設定します。
containerConcurrency: 0 | 1 | 2-N- 0
- 無制限の同時要求を許可します。
- 1
- リビジョンコンテナーの所定インスタンスによって一度に処理される要求は 1 つのみであることを保証します。
- 2 以上
- 同時要求をこの数に制限します。
target アノテーションがない場合、自動スケーリングは、target が containerConcurrency の値と等しい場合のように設定されます。
9.2.2. Knative Serving 自動スケーリングのスケール境界の設定
minScale および maxScale アノテーションは、アプリケーションを提供できる Pod の最小および最大数を設定するために使用できます。これらのアノテーションは、コールドスタートを防いだり、コンピューティングコストをコントロールするために使用できます。
- minScale
-
minScaleアノテーションが設定されていない場合、Pod はゼロ (または、enable-scale-to-zeroがConfigMapでfalseの場合は 1) にスケーリングします。 - maxScale
-
maxScaleアノテーションが設定されていない場合、作成できる Pod の上限はありません。
minScale および maxScale は、リビジョンテンプレートで以下のように設定できます。
spec:
template:
metadata:
annotations:
autoscaling.knative.dev/minScale: "2"
autoscaling.knative.dev/maxScale: "10"
これらのアノテーションをリビジョンテンプレートで使用することで、この設定が PodAutoscaler オブジェクトに伝播します。
これらのアノテーションは、リビジョンの有効期間全体で適用されます。リビジョンがルートで参照されていない場合でも、 minScale によって指定される最小 Pod 数は依然として指定されます。ルーティングできないリビジョンについては、ガべージコレクションの対象になることに留意してください。これにより、Knative はリソースを回収できます。
9.3. OpenShift Serverless を使用したクラスターロギング
9.3.1. クラスターロギング
OpenShift Container Platform クラスター管理者は、いくつかの CLI コマンドを使用してクラスターロギングをデプロイでき、OpenShift Container Platform Web コンソールを使用して Elasticsearch Operator および Cluster Logging Operator をインストールできます。Operator がインストールされている場合、ClusterLogging カスタムリソース (Custom Resource、CR) を作成してクラスターロギング Pod およびクラスターロギングのサポートに必要な他のリソースをスケジュールします。Operator はクラスターロギングのデプロイ、アップグレード、および維持を行います。
クラスターロギングは、instance という名前の ClusterLogging カスタムリソース (CR) を変更することで設定できます。CR は、ログを収集し、保存し、視覚化するために必要なロギングスタックのすべてのコンポーネントを含む完全なクラスターロギングデプロイメントを定義します。Cluster Logging Operator は ClusterLogging カスタムリソースを監視し、ロギングデプロイメントを適宜調整します。
管理者およびアプリケーション開発者は、表示アクセスのあるプロジェクトのログを表示できます。
9.3.2. クラスターロギングのデプロイおよび設定について
OpenShift Container Platform クラスターロギングは、小規模および中規模の OpenShift Container Platform クラスター用に調整されたデフォルト設定で使用されるように設計されています。
以下のインストール方法には、サンプルの ClusterLogging カスタムリソース (CR) が含まれます。これを使用して、クラスターロギングインスタンスを作成し、クラスターロギングのデプロイメントを設定することができます。
デフォルトのクラスターロギングインストールを使用する必要がある場合は、サンプル CR を直接使用できます。
デプロイメントをカスタマイズする必要がある場合、必要に応じてサンプル CR に変更を加えます。以下では、クラスターロギングのインスタンスをインストール時に実行し、インストール後に変更する設定について説明します。ClusterLogging カスタムリソース外で加える変更を含む、各コンポーネントの使用方法については、設定についてのセクションを参照してください。
9.3.2.1. クラスターロギングの設定およびチューニング
クラスターロギング環境は、openshift-logging プロジェクトにデプロイされる ClusterLogging カスタムリソースを変更することによって設定できます。
インストール時またはインストール後に、以下のコンポーネントのいずれかを変更することができます。
- メモリーおよび CPU
-
resourcesブロックを有効なメモリーおよび CPU 値で変更することにより、各コンポーネントの CPU およびメモリーの両方の制限を調整することができます。
spec:
logStore:
elasticsearch:
resources:
limits:
cpu:
memory: 16Gi
requests:
cpu: 500m
memory: 16Gi
type: "elasticsearch"
collection:
logs:
fluentd:
resources:
limits:
cpu:
memory:
requests:
cpu:
memory:
type: "fluentd"
visualization:
kibana:
resources:
limits:
cpu:
memory:
requests:
cpu:
memory:
type: kibana
curation:
curator:
resources:
limits:
memory: 200Mi
requests:
cpu: 200m
memory: 200Mi
type: "curator"- Elasticsearch ストレージ
-
storageClassnameおよびsizeパラメーターを使用し、Elasticsearch クラスターの永続ストレージのクラスおよびサイズを設定できます。Cluster Logging Operator は、これらのパラメーターに基づいて、Elasticsearch クラスターの各データノードについてPersistentVolumeClaimを作成します。
spec:
logStore:
type: "elasticsearch"
elasticsearch:
nodeCount: 3
storage:
storageClassName: "gp2"
size: "200G"
この例では、クラスターの各データノードが gp2 ストレージの 200G を要求する PersistentVolumeClaim にバインドされるように指定します。それぞれのプライマリーシャードは単一のレプリカによってサポートされます。
storage ブロックを省略すると、一時ストレージのみを含むデプロイメントになります。
spec:
logStore:
type: "elasticsearch"
elasticsearch:
nodeCount: 3
storage: {}- Elasticsearch レプリケーションポリシー
Elasticsearch シャードをクラスター内のデータノードにレプリケートする方法を定義するポリシーを設定できます。
-
FullRedundancy:各インデックスのシャードはすべてのデータノードに完全にレプリケートされます。 -
MultipleRedundancy:各インデックスのシャードはデータノードの半分に分散します。 -
SingleRedundancy:各シャードの単一コピー。2 つ以上のデータノードが存在する限り、ログは常に利用可能かつ回復可能です。 -
ZeroRedundancy:シャードのコピーはありません。ログは、ノードの停止または失敗時に利用不可になる (または失われる) 可能性があります。
-
- Curator スケジュール
- Curator のスケジュールを cron 形式 で指定します。
spec:
curation:
type: "curator"
resources:
curator:
schedule: "30 3 * * *"9.3.2.2. 変更された ClusterLogging リソースのサンプル
以下は、前述のオプションを使用して変更された ClusterLogging カスタムリソースの例です。
変更された ClusterLogging リソースのサンプル
apiVersion: "logging.openshift.io/v1"
kind: "ClusterLogging"
metadata:
name: "instance"
namespace: "openshift-logging"
spec:
managementState: "Managed"
logStore:
type: "elasticsearch"
elasticsearch:
nodeCount: 3
resources:
limits:
memory: 32Gi
requests:
cpu: 3
memory: 32Gi
storage: {}
redundancyPolicy: "SingleRedundancy"
visualization:
type: "kibana"
kibana:
resources:
limits:
memory: 1Gi
requests:
cpu: 500m
memory: 1Gi
replicas: 1
curation:
type: "curator"
curator:
resources:
limits:
memory: 200Mi
requests:
cpu: 200m
memory: 200Mi
schedule: "*/5 * * * *"
collection:
logs:
type: "fluentd"
fluentd:
resources:
limits:
memory: 1Gi
requests:
cpu: 200m
memory: 1Gi9.3.3. クラスターロギングの使用による Knative Serving コンポーネントのログの検索
手順
Elasticsearch の仮想化ツール Kibana UI を開くには、 以下のコマンドを使用して Kibana ルートを取得します。
$ oc -n openshift-logging get route kibana- ルートの URL を使用して Kibana ダッシュボードに移動し、ログインします。
- インデックスが .all に設定されていることを確認します。インデックスが .all に設定されていない場合、OpenShift システムログのみが一覧表示されます。
knative-servingnamespace を使用してログをフィルターできます。kubernetes.namespace_name:knative-servingを検索ボックスに入力して結果をフィルターします。注記Knative Serving はデフォルトで構造化ロギングを使用します。クラスターロギング Fluentd 設定をカスタマイズしてこれらのログの解析を有効にできます。これにより、ログレベルでのフィルターリングで問題を迅速に特定できます。
9.3.4. クラスターロギングを使用した Knative Serving でデプロイされたサービスのログの検索
OpenShift Container Platform クラスターロギングにより、アプリケーションがコンソールに書き込むログは Elasticsearch で収集されます。以下の手順で、Knative Serving を使用してデプロイされたアプリケーションにこれらの機能を適用する方法の概要を示します。
手順
Kibana URL を見つけます。
$ oc -n cluster-logging get route kibana- URL をブラウザーに入力し、Kibana UI を開きます。
- インデックスが .all に設定されていることを確認します。インデックスが .all に設定されていない場合、OpenShift システムログのみが一覧表示されます。
サービスがデプロイされている Kubernetes namespace を使用してログをフィルターします。フィルターを追加してサービス自体を特定します:
kubernetes.namespace_name:default AND kubernetes.labels.serving_knative_dev\/service:{SERVICE_NAME}注記/configurationまたは/revisionを使用してフィルターすることもできます。kubernetes.container_name:<user-container>を使用して検索を絞り込み、ご使用のアプリケーションで生成されるログのみを表示することができます。それ以外の場合は、queue-proxy からのログが表示されます。注記アプリケーションで JSON ベースの構造化ロギングを使用することで、実稼働環境でのこれらのログの迅速なフィルターを実行できます。
9.4. リビジョン間でのトラフィックの分割
9.4.1. Developer パースペクティブを使用したリビジョン間のトラフィックの分離
サーバーレスアプリケーションの作成後、サーバーレスアプリケーションは Developer パースペクティブの Topology ビューに表示されます。アプリケーションのリビジョンはノードごとに表示され、サーバーレスリソースサービスには、ノードの周りの四角形のマークが付けられます。
コードまたはサービス設定の新たな変更により、指定のタイミングでリビジョン、コードのスナップショットがトリガーされます。サービスの場合、必要に応じてこれを分割し、異なるリビジョンにルーティングして、サービスのリビジョン間のトラフィックを管理することができます。
手順
Topology ビューでアプリケーションの複数のリビジョン間でトラフィックを分割するには、以下を行います。
- 四角形のマークが付けられたサーバーレスリソースサービスをクリックし、その概要をサイドパネルに表示します。
Resources タブをクリックして、サービスの Revisions および Routes の一覧を表示します。
図9.1 Serverless アプリケーション
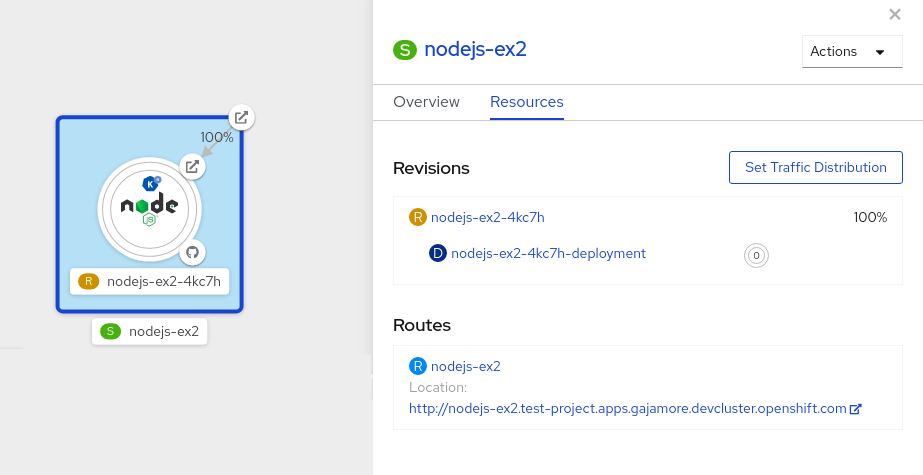
- サイドパネルの上部にある S アイコンで示されるサービスをクリックし、サービスの詳細の概要を確認します。
-
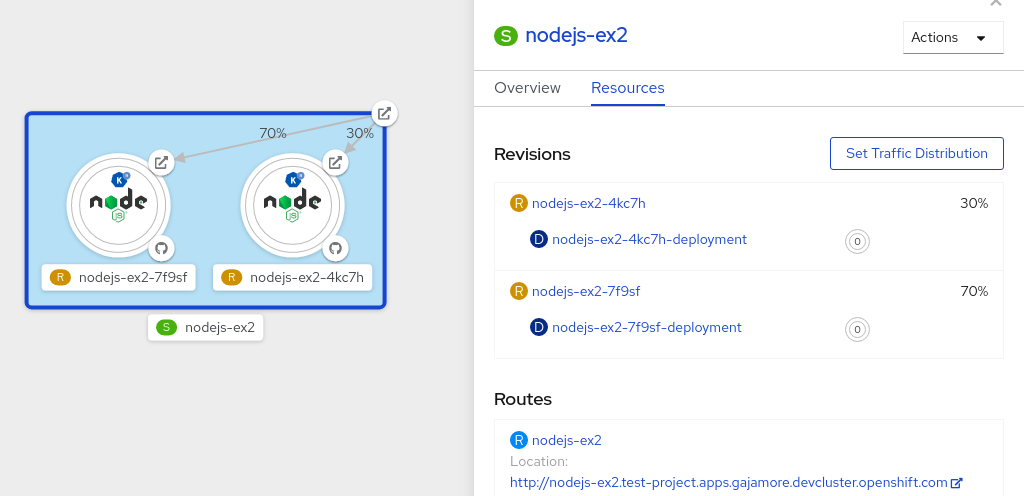
YAML タブをクリックし、YAML エディターでサービス設定を変更し、Save をクリックします。たとえば、
timeoutsecondsを 300 から 301 に変更します。この設定の変更により、新規リビジョンがトリガーされます。Topology ビューでは、最新のリビジョンが表示され、サービスの Resources タブに 2 つのリビジョンが表示されるようになります。 Resources タブで ボタンをクリックして、トラフィック分配ダイアログボックスを表示します。
- Splits フィールドに、2 つのリビジョンのそれぞれの分割されたトラフィックパーセンテージを追加します。
- 2 つのリビジョンのカスタム URL を作成するタグを追加します。
Save をクリックし、Topology ビューで 2 つのリビジョンを表す 2 つのノードを表示します。
図9.2 Serverless アプリケーションのリビジョン
第10章 Knative Eventing
10.1. Knative Eventing でのブローカーの使用
Knative Eventing は、特に指定がない場合は default ブローカーを使用します。
クラスター管理者のパーミッションがある場合は、namespace アノテーションを使用して default ブローカーを自動的に作成できます。
その他のすべてのユーザーは、本書で説明されている手動プロセスを使用してブローカーを作成する必要があります。
10.1.1. ブローカーの手動による作成
ブローカーを作成するには、それぞれの namespace に ServiceAccount を作成し、その ServiceAccount に必要な RBAC パーミッションを付与する必要があります。
前提条件
-
ClusterRoleを含む Knative Eventing がインストールされている。
手順
ServiceAccountオブジェクトを作成します。以下のコマンドを入力して
eventing-broker-ingressオブジェクトを作成します。$ oc -n <namespace> create serviceaccount eventing-broker-ingress以下のコマンドを入力して
eventing-broker-filterオブジェクトを作成します。$ oc -n <namespace> create serviceaccount eventing-broker-filter
RBAC パーミッションを作成したオブジェクトに指定します。
$ oc -n default create rolebinding eventing-broker-ingress \ --clusterrole=eventing-broker-ingress \ --serviceaccount=default:eventing-broker-ingress$ oc -n default create rolebinding eventing-broker-filter \ --clusterrole=eventing-broker-filter \ --serviceaccount=default:eventing-broker-filter以下を含む YAML ファイルを作成し、適用してブローカーを作成します。
apiVersion: eventing.knative.dev/v1beta1 kind: Broker metadata: namespace: default name: default1 - 1
- この例では、
defaultという名前を使用していますが、これを他の有効な名前に置き換えることができます。
10.1.2. namespace アノテーションを使用したブローカーの自動作成
クラスター管理者のパーミッションがある場合は、namespace にアノテーションを付けることでブローカーを自動的に作成できます。
前提条件
- Knative Eventing がインストールされている。
- OpenShift Container Platform のクラスター管理者パーミッション。
手順
以下のコマンドを入力して namespace にアノテーションを付けます。
$ oc label namespace default knative-eventing-injection=enabled1 $ oc -n default get broker default- 1
defaultを必要な namespace に置き換えます。
以下の例で示されている行は、
defaultという名前のブローカーをdefaultnamespace に自動的に作成します。
アノテーションによって作成されたブローカーは、アノテーションを削除しても削除されません。これらは手動で削除する必要があります。
10.1.3. namespace アノテーションを使用して作成されたブローカーの削除
選択した namespace(この例では
defaultnamespace) から挿入されたブローカーを削除します。$ oc -n default delete broker default
10.2. チャネルの使用
イベントソースから Knative Eventing チャネルにイベントをシンクすることができます。チャネルは、単一のイベント転送および永続レイヤーを定義するカスタムリソース (CR) です。イベントがチャネルに送信された後に、これらのイベントはサブスクリプションを使用して複数の Knative サービスに送信できます。
チャネルインスタンスのデフォルト設定は default-ch-webhook ConfigMap で定義されます。ただし、開発者はサポートされているチャネルオブジェクトをインスタンス化することで、独自のチャネルを直接作成できます。
10.2.1. サポートされているチャネルタイプ
現時点で、OpenShift Serverless は Knative Eventing テクノロジープレビューの一部として InMemoryChannel タイプのチャネルの使用のみをサポートします。
10.2.2. デフォルトの InMemoryChannel 設定の使用
InMemoryChannel は開発での使用のみを目的としているため、実稼働環境では使用できません。
以下は、InMemoryChannel タイプのチャネルの制限です。
- イベントの永続性は利用できません。Pod がダウンすると、その Pod のイベントが失われます。
- InMemoryChannel タイプのチャネルはイベントの順序を実装しないため、チャネルで同時に受信される 2 つのイベントはいずれの順序でもサブスクライバーに配信できます。
-
サブスクライバーがイベントを拒否する場合、再配信は試行されません。代わりに、拒否されたイベントは、シンクが存在する場合は
deadLetterSinkに送信されます。これが存在しない場合にはドロップされます。イベント配信およびチャネルのdeadLetterSink設定についての詳細は、 サブスクリプションの使用によるチャネルからシンクへのイベント送信 を参照してください。
Knative Eventing のインストール時に、以下のカスタムリソース定義 (CRD) が自動的に作成されます。
apiVersion: v1
kind: ConfigMap
metadata:
namespace: knative-eventing
name: config-br-default-channel
data:
channelTemplateSpec: |
apiVersion: messaging.knative.dev/v1
kind: InMemoryChannelクラスターのデフォルト設定を使用したチャネルの作成
汎用 Channel カスタムオブジェクトを作成します。
apiVersion: messaging.knative.dev/v1 kind: Channel metadata: name: example-channel namespace: defaultChannel オブジェクトが作成されると、変更用の受付 Webhook はデフォルトのチャネル実装に基づいて Channel オブジェクトの
spec.channelTemplateプロパティーのセットを追加します。apiVersion: messaging.knative.dev/v1 kind: Channel metadata: name: example-channel namespace: default spec: channelTemplate: apiVersion: messaging.knative.dev/v1 kind: InMemoryChannel
チャネルコントローラーは、その後に spec.channelTemplate 設定に基づいてサポートするチャネルインスタンスを作成します。spec.channelTemplate プロパティーは作成後に変更できません。それらは、ユーザーではなくデフォルトのチャネルメカニズムで設定されるためです。
このメカニズムが使用される場合、汎用チャネル、および InMemoryChannel タイプのチャネルなど 2 つのオブジェクトが作成されます。
汎用チャネルは、サブスクリプションを InMemoryChannel にコピーするプロキシーとして機能し、サポートする InMemoryChannel タイプのチャネルのステータスを反映するようにそのステータスを設定します。
この例のチャネルはデフォルトの namespace で作成されるため、チャネルはクラスターのデフォルト (InMemoryChannel) を使用します。
10.3. サブスクリプションの使用によるチャネルからシンクへのイベント送信
サブスクリプションは、Channel からイベントシンクにイベントを配信します。
10.3.1. サブスクリプションの作成
サブスクリプションを作成して、サービスまたは他のイベントシンクをチャネルに接続できます。
Knative Eventing はテクノロジープレビュー機能としてご利用いただけます。InMemoryChannel タイプは開発での使用のみを目的として提供されるため、実稼働環境では使用できません。
前提条件
- Knative Serving および Eventing を含む OpenShift Serverless を Container Platform クラスターにインストールしている必要があります。クラスター管理者がこれをインストールできます。
- 使用する必要のある既存のシンクがない場合は、サーバーレスアプリケーションの作成および管理 についてのドキュメントを参照して、シンクとして使用する Service を作成します。
- サブスクリプションを接続するためのチャネルが必要です。Knative Eventing でのチャネルの使用 について参照してください。
手順
以下を含む YAML ファイルを作成して、チャネルをサービスに接続するために Subscription オブジェクトを作成します。
apiVersion: messaging.knative.dev/v1beta1 kind: Subscription metadata: name: my-subscription1 namespace: default spec: channel:2 apiVersion: messaging.knative.dev/v1beta1 kind: Channel name: example-channel delivery:3 deadLetterSink: ref: apiVersion: serving.knative.dev/v1 kind: Service name: error-handler subscriber:4 ref: apiVersion: serving.knative.dev/v1 kind: Service name: event-display- 1
- サブスクリプションの名前。
- 2
- サブスクリプションが接続するチャネルの設定。
- 3
- イベント配信の設定。これは、サブスクリプションに対してサブスクライバーに配信できないイベントに何が発生するかについて示します。これが設定されると、使用できないイベントが
deadLetterSinkに送信されます。イベントがドロップされると、イベントの再配信は試行されず、エラーのログがシステムに記録されます。deadLetterSink値は Destination である必要があります。 - 4
- サブスクライバーの設定。これは、イベントがチャネルから送信されるイベントシンクです。
以下を入力して YAML ファイルを適用します。
$ oc apply -f <FILENAME>
10.4. トリガーの使用
チャネルまたはブローカーに送信されたすべてのイベントは、デフォルトでそのチャネルまたはブローカーのすべてのサブスクライバーに送信されます。
トリガーを使用すると、チャネルまたはブローカーからイベントをフィルターできるため、サブスクライバーは定義された基準に基づくイベントのサブセットのみを受け取ることができます。
Knative CLI は、トリガーの作成および管理に使用できる kn trigger コマンドのセットを提供します。
10.4.1. 前提条件
トリガーを使用する前に、以下が必要になります。
-
Knative Eventing および
knがインストールされている。 defaultブローカーまたは作成したブローカーのいずれかの利用可能なブローカー。defaultブローカーは、Knative Eventing でのブローカーの使用 の説明に従うか、またはトリガーの作成時に--inject-brokerフラグを使用して作成できます。このフラグの使用方法については、以下の手順で説明します。- Knative サービスなどの利用可能なイベントコンシューマー。
10.4.2. kn を使用したトリガーの作成
手順
トリガーを作成するには、以下のコマンドを入力します。
$ kn trigger create <TRIGGER-NAME> --broker <BROKER-NAME> --filter <KEY=VALUE> --sink <SINK>
トリガーを作成し、またブローカー挿入を使用して default ブローカーを作成するには、以下のコマンドを入力します。
$ kn trigger create <TRIGGER-NAME> --inject-broker --filter <KEY=VALUE> --sink <SINK>トリガー YAML の例:
apiVersion: eventing.knative.dev/v1alpha1
kind: Trigger
metadata:
name: trigger-example
spec:
broker: default
subscriber:
ref:
apiVersion: serving.knative.dev/v1
kind: Service
name: my-service 10.4.3. kn を使用したトリガーの一覧表示
kn trigger list コマンドは利用可能なトリガーの一覧を出力します。
手順
利用可能なトリガーの一覧を出力するには、以下のコマンドを入力します。
$ kn trigger list出力例:
$ kn trigger list NAME BROKER SINK AGE CONDITIONS READY REASON email default svc:edisplay 4s 5 OK / 5 True ping default svc:edisplay 32s 5 OK / 5 TrueJSON 形式でトリガーの一覧を出力するには、以下のコマンドを入力します。
$ kn trigger list -o json
10.4.4. kn を使用したトリガーの記述
kn trigger describe コマンドは、トリガーについての情報を出力します。
手順
トリガーについての情報を出力するには、以下のコマンドを入力します。
$ kn trigger describe <TRIGGER-NAME>出力例:
$ kn trigger describe ping
Name: ping
Namespace: default
Labels: eventing.knative.dev/broker=default
Annotations: eventing.knative.dev/creator=kube:admin, eventing.knative.dev/lastModifier=kube:admin
Age: 2m
Broker: default
Filter:
type: dev.knative.event
Sink:
Name: edisplay
Namespace: default
Resource: Service (serving.knative.dev/v1)
Conditions:
OK TYPE AGE REASON
++ Ready 2m
++ BrokerReady 2m
++ DependencyReady 2m
++ Subscribed 2m
++ SubscriberResolved 2m10.4.5. kn を使用したトリガーの削除
手順
トリガーを削除するには、以下のコマンドを入力します。
$ kn trigger delete <TRIGGER-NAME>10.4.6. kn を使用したトリガーの更新
特定のフラグを指定して kn trigger update コマンドを使用して、トリガーの属性を迅速に更新できます。
手順
トリガーを更新するには、以下のコマンドを入力します。
$ kn trigger update NAME --filter KEY=VALUE --sink SINK [flags]
トリガーを、受信イベントに一致するイベント属性をフィルターするように更新できます (例: type=knative.dev.event)。以下に例を示します。
$ kn trigger update mytrigger --filter type=knative.dev.event
トリガーからフィルター属性を削除することもできます。たとえば、キー type を使用してフィルター属性を削除できます。
$ kn trigger update mytrigger --filter type-
以下の例は、トリガーのシンクを svc:new-service に更新する方法を示しています。
$ kn trigger update mytrigger --sink svc:new-service10.4.7. トリガーを使用したイベントのフィルター
以下のトリガーの例では、type: dev.knative.samples.helloworld 属性のあるイベントのみがイベントコンシューマーに到達します。
$ kn trigger create foo --broker default --filter type=dev.knative.samples.helloworld --sink svc:mysvc複数の属性を使用してイベントをフィルターすることもできます。以下の例は、type、source、および extension 属性を使用してイベントをフィルターする方法を示しています。
$ kn trigger create foo --broker default --sink svc:mysvc \
--filter type=dev.knative.samples.helloworld \
--filter source=dev.knative.samples/helloworldsource \
--filter myextension=my-extension-value10.5. SinkBinding の使用
SinkBinding は、イベントプロデューサーまたは イベントソース を Knative サービスやアプリケーションなどのイベントコンシューマーまたは イベントシンク に接続するために使用されます。
以下の手順では、どちらの場合も YAML ファイルを作成する必要があります。
サンプルで使用されたもので YAML ファイルの名前を変更する場合は、必ず対応する CLI コマンドを更新する必要があります。
10.5.1. Knative CLI (kn) による SinkBinding の使用
以下に、kn コマンドを使用して SinkBinding インスタンスを作成し、管理し、削除するために必要な手順を説明します。
前提条件
- Knative Serving および Eventing がインストールされている。
-
knCLI がインストールされている。
手順
SinkBinding が正しく設定されていることを確認するには、受信メッセージをダンプする Knative イベント表示サービスまたはイベントシンクを作成します。
$ kn service create event-display --image quay.io/openshift-knative/knative-eventing-sources-event-display:latestイベントをサービスに転送する SinkBinding を作成します。
$ kn source binding create bind-heartbeat --subject Job:batch/v1:app=heartbeat-cron --sink svc:event-displayCronJob を作成します。
heartbeats-cronjob.yamlという名前のファイルを作成し、以下のサンプルコードをこれにコピーします。apiVersion: batch/v1beta1 kind: CronJob metadata: name: heartbeat-cron spec: spec: # Run every minute schedule: "* * * * *" jobTemplate: metadata: labels: app: heartbeat-cron spec: template: spec: restartPolicy: Never containers: - name: single-heartbeat image: quay.io/openshift-knative/knative-eventing-sources-heartbeats:latest args: - --period=1 env: - name: ONE_SHOT value: "true" - name: POD_NAME valueFrom: fieldRef: fieldPath: metadata.name - name: POD_NAMESPACE valueFrom: fieldRef: fieldPath: metadata.namespaceheartbeats-cronjob.yamlファイルを作成した後に、以下を入力してこれを適用します。$ oc apply --filename heartbeats-cronjob.yaml
以下のコマンドを入力し、出力を検査して、コントローラーが正しくマップされていることを確認します。
$ kn source binding describe bind-heartbeat出力例
Name: bind-heartbeat Namespace: demo-2 Annotations: sources.knative.dev/creator=minikube-user, sources.knative.dev/lastModifier=minikub ... Age: 2m Subject: Resource: job (batch/v1) Selector: app: heartbeat-cron Sink: Name: event-display Resource: Service (serving.knative.dev/v1) Conditions: OK TYPE AGE REASON ++ Ready 2m
検証手順
メッセージダンパー機能ログを確認して、Kubernetes イベントが Knative イベントシンクに送信されていることを確認できます。
以下のコマンドを入力して、メッセージダンパー機能ログを表示します。
$ oc get pods$ oc logs $(oc get pod -o name | grep event-display) -c user-container出力例
☁️ cloudevents.Event Validation: valid Context Attributes, specversion: 1.0 type: dev.knative.eventing.samples.heartbeat source: https://knative.dev/eventing-contrib/cmd/heartbeats/#event-test/mypod id: 2b72d7bf-c38f-4a98-a433-608fbcdd2596 time: 2019-10-18T15:23:20.809775386Z contenttype: application/json Extensions, beats: true heart: yes the: 42 Data, { "id": 1, "label": "" }
10.5.2. YAML メソッドでの SinkBinding の使用
以下に、SinkBinding インスタンスを作成し、管理し、削除するために必要な手順を説明します。
前提条件
- Knative Serving および Eventing がインストールされている。
手順
SinkBinding が正しく設定されていることを確認するには、受信メッセージをログにダンプする Knative イベント表示サービスまたはイベントシンクを作成します。
以下のサンプル YAML を
service.yamlという名前のファイルにコピーします。apiVersion: serving.knative.dev/v1 kind: Service metadata: name: event-display spec: template: spec: containers: - image: quay.io/openshift-knative/knative-eventing-sources-event-display:latestservice.yamlファイルを作成した後に、以下を入力してこれを適用します。$ oc apply -f service.yaml
イベントをサービスに転送する SinkBinding を作成します。
sinkbinding.yamlという名前のファイルを作成し、以下のサンプルコードをこれにコピーします。apiVersion: sources.knative.dev/v1alpha1 kind: SinkBinding metadata: name: bind-heartbeat spec: subject: apiVersion: batch/v1 kind: Job1 selector: matchLabels: app: heartbeat-cron sink: ref: apiVersion: serving.knative.dev/v1 kind: Service name: event-display
- 1
- この例では、ラベル
app: heartbeat-cronを指定したジョブがイベントシンクにバインドされます。sinkbinding.yamlファイルを作成した後に、以下を入力してこれを適用します。$ oc apply -f sinkbinding.yaml
CronJob を作成します。
heartbeats-cronjob.yamlという名前のファイルを作成し、以下のサンプルコードをこれにコピーします。apiVersion: batch/v1beta1 kind: CronJob metadata: name: heartbeat-cron spec: spec: # Run every minute schedule: "* * * * *" jobTemplate: metadata: labels: app: heartbeat-cron spec: template: spec: restartPolicy: Never containers: - name: single-heartbeat image: quay.io/openshift-knative/knative-eventing-sources-heartbeats:latest args: - --period=1 env: - name: ONE_SHOT value: "true" - name: POD_NAME valueFrom: fieldRef: fieldPath: metadata.name - name: POD_NAMESPACE valueFrom: fieldRef: fieldPath: metadata.namespaceheartbeats-cronjob.yamlファイルを作成した後に、以下を入力してこれを適用します。$ oc apply -f heartbeats-cronjob.yaml
以下のコマンドを入力し、出力を検査して、コントローラーが正しくマップされていることを確認します。
$ oc get sinkbindings.sources.knative.dev bind-heartbeat -oyaml出力例
spec: sink: ref: apiVersion: serving.knative.dev/v1 kind: Service name: event-display namespace: default subject: apiVersion: batch/v1 kind: Job namespace: default selector: matchLabels: app: heartbeat-cron
検証手順
メッセージダンパー機能ログを確認して、Kubernetes イベントが Knative イベントシンクに送信されていることを確認できます。
以下のコマンドを入力して、メッセージダンパー機能ログを表示します。
$ oc get pods$ oc logs $(oc get pod -o name | grep event-display) -c user-container出力例
☁️ cloudevents.Event Validation: valid Context Attributes, specversion: 1.0 type: dev.knative.eventing.samples.heartbeat source: https://knative.dev/eventing-contrib/cmd/heartbeats/#event-test/mypod id: 2b72d7bf-c38f-4a98-a433-608fbcdd2596 time: 2019-10-18T15:23:20.809775386Z contenttype: application/json Extensions, beats: true heart: yes the: 42 Data, { "id": 1, "label": "" }
第11章 イベントソース
11.1. イベントソースの使用
イベントソース は、イベントプロデューサーをイベント シンク またはコンシューマーにリンクするオブジェクトです。シンクには、イベントソースからイベントを受信する Knative サービス、チャネルまたはブローカーを使用できます。
現時点で、OpenShift Serverless は以下のイベントソースタイプをサポートします。
- ApiServerSource
- シンクを Kubernetes API サーバーに接続します。
- PingSource
- 一定のペイロードを使用して ping イベントを定期的に送信します。これはタイマーとして使用できます。
シンクバインディング もサポートされます。これにより、シンクを使用して Deployment、 Job、または StatefulSet などのコア Kubernetes リソースを接続できます。
OpenShift Container Platform Web コンソール、kn CLI を使用するか、または YAML ファイルを適用して Developer パースペクティブで Knative イベントソースを作成したり、管理したりできます。
11.1.1. 前提条件
- Knative Serving および Eventing を含む OpenShift Serverless を Container Platform クラスターにインストールしている必要があります。クラスター管理者がこれをインストールできます。
11.1.2. イベントソースの作成
- ApiServerSource オブジェクトを作成します。
- PingSource オブジェクトを作成します。
11.1.3. 追加リソース
- OpenShift Serverless を使用した Eventing ワークフローの詳細は、Knative Eventing アーキテクチャー について参照してください。
11.2. Knative CLI を使用したイベントソースおよびイベントソースタイプの一覧表示
kn CLI を使用して、Knative Eventing で使用するために利用できるイベントソースまたはイベントソースのタイプを一覧表示し、管理できます。
現在、kn は以下のイベントソースタイプの管理をサポートします。
- API サーバーソース
-
APIServerSourceオブジェクトを作成して、シンクを Kubernetes API サーバーに接続します。 - Ping ソース
-
一定のペイロードを使用して ping イベントを定期的に送信します。これはタイマーとして使用でき、
PingSourceオブジェクトとして作成されます。
11.2.1. Knative CLI の使用による利用可能なイベントソースタイプの一覧表示
以下のコマンドを使用して、ターミナルに利用可能なイベントソースタイプを一覧表示できます。
$ kn source list-typesこのコマンドのデフォルト出力は以下のようになります。
TYPE NAME DESCRIPTION
ApiServerSource apiserversources.sources.knative.dev Watch and send Kubernetes API events to a sink
PingSource pingsources.sources.knative.dev Periodically send ping events to a sink
SinkBinding sinkbindings.sources.knative.dev Binding for connecting a PodSpecable to a sink利用可能なイベントソースタイプを YAML 形式で一覧表示することもできます。
$ kn source list-types -o yaml11.2.2. Knative CLI の使用による利用可能なイベントリソースの一覧表示
以下のコマンドを使用して、ターミナルに利用可能なイベントソースを一覧表示できます。
$ kn source list出力例
NAME TYPE RESOURCE SINK READY
a1 ApiServerSource apiserversources.sources.knative.dev svc:eshow2 True
b1 SinkBinding sinkbindings.sources.knative.dev svc:eshow3 False
p1 PingSource pingsources.sources.knative.dev svc:eshow1 True
--type フラグを使用して、特定タイプのイベントソースのみを一覧表示できます。
$ kn source list --type PingSource出力例
NAME TYPE RESOURCE SINK READY
p1 PingSource pingsources.sources.knative.dev svc:eshow1 True11.2.3. 次のステップ
- API サーバーソースの使用 についてのドキュメントを参照してください。
- ping ソースの使用 についてのドキュメントを参照してください。
11.3. API サーバーソースの使用
API サーバーソースは、Knative サービスなどのイベントシンクを Kubernetes API サーバーに接続するために使用できるイベントソースです。API サーバーソースは Kubernetes イベントを監視し、それらを Knative Eventing ブローカーに転送します。
以下の手順では、どちらの場合も YAML ファイルを作成する必要があります。
サンプルで使用されたもので YAML ファイルの名前を変更する場合は、必ず対応する CLI コマンドを更新する必要があります。
11.3.1. Knative CLI での API サーバーソースの使用
以下のセクションでは、kn コマンドを使用して ApiServerSource オブジェクトを作成するために必要な手順を説明します。
前提条件
- Knative Serving および Eventing がクラスターにインストールされている。
-
API サーバーソースがインストールされるのと同じ namespace に
defaultブローカーを作成している必要があります。 -
knCLI がインストールされている。
手順
ApiServerSourceオブジェクトのサービスアカウント、ロール、およびロールバインディングを作成します。authentication.yamlという名前のファイルを作成し、以下のサンプルコードをこれにコピーして、これを実行できます。apiVersion: v1 kind: ServiceAccount metadata: name: events-sa namespace: default1 --- apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: event-watcher namespace: default2 rules: - apiGroups: - "" resources: - events verbs: - get - list - watch --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: k8s-ra-event-watcher namespace: default3 roleRef: apiGroup: rbac.authorization.k8s.io kind: Role name: event-watcher subjects: - kind: ServiceAccount name: events-sa namespace: default4 注記適切なパーミッションを持つ既存のサービスアカウントを再利用する必要がある場合、そのサービスアカウントの
authentication.yamlファイルを変更する必要があります。サービスアカウント、ロールバインディング、およびクラスターバインディングを作成します。
$ oc apply -f authentication.yamlブローカーをイベントシンクとして使用する
ApiServerSourceオブジェクトを作成します。$ kn source apiserver create <event_source_name> --sink broker:<broker_name> --resource "event:v1" --service-account <service_account_name> --mode Resource受信メッセージをログにダンプする Knative サービスを作成します。
$ kn service create <service_name> --image quay.io/openshift-knative/knative-eventing-sources-event-display:latestdefaultブローカーからサービスにイベントをフィルターするトリガーを作成します。$ kn trigger create <trigger_name> --sink svc:<service_name>デフォルト namespace で Pod を起動してイベントを作成します。
$ oc create deployment hello-node --image=quay.io/openshift-knative/knative-eventing-sources-event-display以下のコマンドを入力し、生成される出力を検査して、コントローラーが正しくマップされていることを確認します。
$ kn source apiserver describe testevents出力例
Name: testevents Namespace: default Annotations: sources.knative.dev/creator=developer, sources.knative.dev/lastModifier=developer Age: 3m ServiceAccountName: events-sa Mode: Resource Sink: Name: default Namespace: default Kind: Broker (eventing.knative.dev/v1alpha1) Resources: Kind: event (v1) Controller: false Conditions: OK TYPE AGE REASON ++ Ready 3m ++ Deployed 3m ++ SinkProvided 3m ++ SufficientPermissions 3m ++ EventTypesProvided 3m
検証手順
メッセージダンパー機能ログを確認して、Kubernetes イベントが Knative に送信されていることを確認できます。
Pod を取得します。
$ oc get podsPod のメッセージダンパー機能ログを表示します。
$ oc logs $(oc get pod -o name | grep event-display) -c user-container出力例
☁️ cloudevents.Event Validation: valid Context Attributes, specversion: 1.0 type: dev.knative.apiserver.resource.update datacontenttype: application/json ... Data, { "apiVersion": "v1", "involvedObject": { "apiVersion": "v1", "fieldPath": "spec.containers{hello-node}", "kind": "Pod", "name": "hello-node", "namespace": "default", ..... }, "kind": "Event", "message": "Started container", "metadata": { "name": "hello-node.159d7608e3a3572c", "namespace": "default", .... }, "reason": "Started", ... }
11.3.2. Knative CLI を使用した API サーバーソースの削除
本セクションでは、kn コマンドおよび oc コマンドを使用して ApiServerSource オブジェクト、トリガー、サービス、サービスアカウント、クラスターロール、およびクラスターバインディングを削除するために使用される手順について説明します。
前提条件
-
knCLI がインストールされていること。
手順
トリガーを削除します。
$ kn trigger delete <trigger_name>サービスを削除します。
$ kn service delete <service_name>API サーバーソースを削除します。
$ kn source apiserver delete <source_name>- サービスアカウント、クラスターロール、およびクラスターバインディングを削除します。
$ oc delete -f authentication.yaml11.3.3. YAML ファイルを使用した API サーバーソースの作成
以下では、YAML ファイルを使用して ApiServerSource オブジェクトを作成するために必要な手順を説明します。
前提条件
- Knative Serving および Eventing がクラスターにインストールされている。
-
defaultブローカーを、ApiServerSourceオブジェクトで定義されるものと同じ namespace に作成している。
手順
API サーバーソースのサービスアカウント、ロールおよびロールバインディングを作成するには、
authentication.yamlという名前のファイルを作成し、以下のサンプルコードをこれにコピーします。apiVersion: v1 kind: ServiceAccount metadata: name: events-sa namespace: default1 --- apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: event-watcher namespace: default2 rules: - apiGroups: - "" resources: - events verbs: - get - list - watch --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: k8s-ra-event-watcher namespace: default3 roleRef: apiGroup: rbac.authorization.k8s.io kind: Role name: event-watcher subjects: - kind: ServiceAccount name: events-sa namespace: default4 注記適切なパーミッションを持つ既存のサービスアカウントを再利用する必要がある場合、そのサービスアカウントの
authentication.yamlを変更する必要があります。authentication.yamlファイルを作成した後に、これを適用します。$ oc apply -f authentication.yamlApiServerSourceオブジェクトを作成するには、k8s-events.yamlという名前のファイルを作成し、以下のサンプルコードをこれにコピーします。apiVersion: sources.knative.dev/v1alpha1 kind: ApiServerSource metadata: name: testevents spec: serviceAccountName: events-sa mode: Resource resources: - apiVersion: v1 kind: Event sink: ref: apiVersion: eventing.knative.dev/v1beta1 kind: Broker name: defaultk8s-events.yamlファイルを作成した後に、これを適用します。$ oc apply -f k8s-events.yamlAPI サーバーソースが正しく設定されていることを確認するには、受信メッセージをログにダンプする Knative サービスを作成します。
以下のサンプル YAML を
service.yamlという名前のファイルにコピーします。apiVersion: serving.knative.dev/v1 kind: Service metadata: name: event-display namespace: default spec: template: spec: containers: - image: quay.io/openshift-knative/knative-eventing-sources-event-display:v0.13.2service.yamlファイルを作成した後に、これを適用します。$ oc apply -f service.yamlイベントを直前の手順で作成したサービスにフィルターする
defaultブローカーからトリガーを作成するには、trigger.yamlという名前のファイルを作成し、以下のサンプルコードをこれにコピーします。apiVersion: eventing.knative.dev/v1alpha1 kind: Trigger metadata: name: event-display-trigger namespace: default spec: subscriber: ref: apiVersion: serving.knative.dev/v1 kind: Service name: event-displaytrigger.yamlファイルを作成した後に、これを適用します。$ oc apply -f trigger.yamlイベントを作成するには、
defaultnamespace で Pod を起動します。$ oc create deployment hello-node --image=quay.io/openshift-knative/knative-eventing-sources-event-displayコントローラーが正しくマップされていることを確認するには、以下のコマンドを入力し、出力を検査します。
$ oc get apiserversource.sources.knative.dev testevents -o yaml出力例
apiVersion: sources.knative.dev/v1alpha1 kind: ApiServerSource metadata: annotations: creationTimestamp: "2020-04-07T17:24:54Z" generation: 1 name: testevents namespace: default resourceVersion: "62868" selfLink: /apis/sources.knative.dev/v1alpha1/namespaces/default/apiserversources/testevents2 uid: 1603d863-bb06-4d1c-b371-f580b4db99fa spec: mode: Resource resources: - apiVersion: v1 controller: false controllerSelector: apiVersion: "" kind: "" name: "" uid: "" kind: Event labelSelector: {} serviceAccountName: events-sa sink: ref: apiVersion: eventing.knative.dev/v1beta1 kind: Broker name: default
検証手順
Kubernetes イベントが Knative に送信されていることを確認するには、メッセージダンパー機能ログを確認します。
Pod を取得します。
$ oc get podsPod のメッセージダンパー機能ログを表示します。
$ oc logs $(oc get pod -o name | grep event-display) -c user-container出力例
☁️ cloudevents.Event Validation: valid Context Attributes, specversion: 1.0 type: dev.knative.apiserver.resource.update datacontenttype: application/json ... Data, { "apiVersion": "v1", "involvedObject": { "apiVersion": "v1", "fieldPath": "spec.containers{hello-node}", "kind": "Pod", "name": "hello-node", "namespace": "default", ..... }, "kind": "Event", "message": "Started container", "metadata": { "name": "hello-node.159d7608e3a3572c", "namespace": "default", .... }, "reason": "Started", ... }
11.3.4. API サーバーソースの削除
本セクションでは、YAML ファイルを削除して、ApiServerSource オブジェクト、トリガー、サービス、サービスアカウント、クラスターロール、およびクラスターバインディングを削除する方法について説明します。
手順
トリガーを削除します。
$ oc delete -f trigger.yamlサービスを削除します。
$ oc delete -f service.yamlAPI サーバーソースを削除します。
$ oc delete -f k8s-events.yamlサービスアカウント、クラスターロール、およびクラスターバインディングを削除します。
$ oc delete -f authentication.yaml
11.4. ping ソースの使用
ping ソースは、一定のペイロードを使用して ping イベントをイベントコンシューマーに定期的に送信するために使用されます。ping ソースを使用すると、以下の例のようにタイマーと同様にイベントの送信をスケジュールできます。
ping ソースの例
apiVersion: sources.knative.dev/v1alpha2
kind: PingSource
metadata:
name: test-ping-source
spec:
schedule: "*/2 * * * *"
jsonData: '{"message": "Hello world!"}'
sink:
ref:
apiVersion: serving.knative.dev/v1
kind: Service
name: event-display11.4.1. Knative CLI を使用した ping ソースの作成
以下のセクションでは、kn CLI を使用して基本的な PingSource オブジェクトを作成し、検証し、削除する方法を説明します。
前提条件
- Knative Serving および Eventing がインストールされている。
-
knCLI がインストールされている。
手順
ping ソースが機能していることを確認するには、受信メッセージをサービスのログにダンプする単純な Knative サービスを作成します。
$ kn service create event-display \ --image quay.io/openshift-knative/knative-eventing-sources-event-display:latest要求する必要のある ping イベントのセットごとに、
PingSourceをイベントコンシューマーと同じ namespace に作成します。$ kn source ping create test-ping-source \ --schedule "*/2 * * * *" \ --data '{"message": "Hello world!"}' \ --sink svc:event-display以下のコマンドを入力し、出力を検査して、コントローラーが正しくマップされていることを確認します。
$ kn source ping describe test-ping-source出力例
Name: test-ping-source Namespace: default Annotations: sources.knative.dev/creator=developer, sources.knative.dev/lastModifier=developer Age: 15s Schedule: */2 * * * * Data: {"message": "Hello world!"} Sink: Name: event-display Namespace: default Resource: Service (serving.knative.dev/v1) Conditions: OK TYPE AGE REASON ++ Ready 8s ++ Deployed 8s ++ SinkProvided 15s ++ ValidSchedule 15s ++ EventTypeProvided 15s ++ ResourcesCorrect 15s
検証手順
シンク Pod のログを確認して、Kubernetes イベントが Knative イベントに送信されていることを確認できます。
デフォルトで、Knative サービスは、トラフィックが 60 秒以内に受信されない場合に Pod を終了します。本書の例では、新たに作成される Pod で各メッセージが確認されるように 2 分ごとにメッセージを送信する PingSource オブジェクトを作成します。
作成された新規 Pod を監視します。
$ watch oc get podsCtrl+Cを使用して Pod の監視をキャンセルし、作成された Pod のログを確認します。$ oc logs $(oc get pod -o name | grep event-display) -c user-container出力例
☁️ cloudevents.Event Validation: valid Context Attributes, specversion: 1.0 type: dev.knative.sources.ping source: /apis/v1/namespaces/default/pingsources/test-ping-source id: 99e4f4f6-08ff-4bff-acf1-47f61ded68c9 time: 2020-04-07T16:16:00.000601161Z datacontenttype: application/json Data, { "message": "Hello world!" }
11.4.1.1. ping ソースの削除
PingSourceオブジェクトを削除します。$ kn delete pingsources.sources.knative.dev test-ping-sourceevent-displayサービスを削除します。$ kn delete service.serving.knative.dev event-display
11.4.2. YAML ファイルを使用した ping ソースの作成
以下のセクションでは、YAML ファイルを使用して基本的な ping ソースを作成し、検証し、削除する方法を説明します。
前提条件
- Knative Serving および Eventing がインストールされている。
以下の手順では、YAML ファイルを作成する必要があります。
サンプルで使用されたもので YAML ファイルの名前を変更する場合は、必ず対応する CLI コマンドを更新する必要があります。
手順
ping ソースが機能していることを確認するには、受信メッセージをサービスのログにダンプする単純な Knative サービスを作成します。
サンプル YAML を
service.yamlという名前のファイルにコピーします。apiVersion: serving.knative.dev/v1 kind: Service metadata: name: event-display spec: template: spec: containers: - image: quay.io/openshift-knative/knative-eventing-sources-event-display:latestservice.yamlファイルを適用します。$ oc apply --filename service.yaml
要求する必要のある ping イベントのセットごとに、
PingSourceオブジェクトをイベントコンシューマーと同じ namespace に作成します。サンプル YAML を
ping-source.yamlという名前のファイルにコピーします。apiVersion: sources.knative.dev/v1alpha2 kind: PingSource metadata: name: test-ping-source spec: schedule: "*/2 * * * *" jsonData: '{"message": "Hello world!"}' sink: ref: apiVersion: serving.knative.dev/v1 kind: Service name: event-displayping-source.yamlファイルを適用します。$ oc apply --filename ping-source.yaml
以下のコマンドを入力し、出力を検査して、コントローラーが正しくマップされていることを確認します。
$ oc get pingsource.sources.knative.dev test-ping-source -oyaml出力例
apiVersion: sources.knative.dev/v1alpha2 kind: PingSource metadata: annotations: sources.knative.dev/creator: developer sources.knative.dev/lastModifier: developer creationTimestamp: "2020-04-07T16:11:14Z" generation: 1 name: test-ping-source namespace: default resourceVersion: "55257" selfLink: /apis/sources.knative.dev/v1alpha2/namespaces/default/pingsources/test-ping-source uid: 3d80d50b-f8c7-4c1b-99f7-3ec00e0a8164 spec: jsonData: '{ value: "hello" }' schedule: '*/2 * * * *' sink: ref: apiVersion: serving.knative.dev/v1 kind: Service name: event-display namespace: default
検証手順
シンク Pod のログを確認して、Kubernetes イベントが Knative イベントに送信されていることを確認できます。
デフォルトで、Knative サービスは、トラフィックが 60 秒以内に受信されない場合に Pod を終了します。本書の例では、新たに作成される Pod で各メッセージが確認されるように 2 分ごとにメッセージを送信する PingSource オブジェクトを作成します。
作成された新規 Pod を監視します。
$ watch oc get podsCtrl+Cを使用して Pod の監視をキャンセルし、作成された Pod のログを確認します。$ oc logs $(oc get pod -o name | grep event-display) -c user-container出力例
☁️ cloudevents.Event Validation: valid Context Attributes, specversion: 1.0 type: dev.knative.sources.ping source: /apis/v1/namespaces/default/pingsources/test-ping-source id: 042ff529-240e-45ee-b40c-3a908129853e time: 2020-04-07T16:22:00.000791674Z datacontenttype: application/json Data, { "message": "Hello world!" }
11.4.2.1. PingSource の削除
以下のコマンドを入力してサービスを削除します。
$ oc delete --filename service.yaml以下のコマンドを入力して
PingSourceオブジェクトを削除します。$ oc delete --filename ping-source.yaml
第12章 OpenShift Serverless でのメータリングの使用
クラスター管理者として、メータリングを使用して OpenShift Serverless クラスターで実行されている内容を分析できます。
OpenShift Container Platform のメータリングについての詳細は、メータリングの概要 を参照してください。
12.1. メータリングのインストール
OpenShift Container Platform でのメータリングのインストールについての詳細は、メータリングのインストール を参照してください。
12.2. Knative Serving メータリングのデータソース
以下のサンプルデータソースは、Knative Serving を OpenShift Container Platform メータリングで使用する方法を示します。
12.2.1. Knative Serving での CPU 使用状況のデータソース
このサンプルデータソースは、レポート期間における Knative サービスごとに使用される累積された CPU の秒数を示します。
サンプル YAML
apiVersion: metering.openshift.io/v1
kind: ReportDataSource
metadata:
name: knative-service-cpu-usage
spec:
prometheusMetricsImporter:
query: >
sum
by(namespace,
label_serving_knative_dev_service,
label_serving_knative_dev_revision)
(
label_replace(rate(container_cpu_usage_seconds_total{container!="POD",container!="",pod!=""}[1m]), "pod", "$1", "pod", "(.*)")
*
on(pod, namespace)
group_left(label_serving_knative_dev_service, label_serving_knative_dev_revision)
kube_pod_labels{label_serving_knative_dev_service!=""}
)12.2.2. Knative Serving でのメモリー使用状況のデータソース
このサンプルデータソースは、レポート期間における Knative サービスごとの平均メモリー消費量を示します。
サンプル YAML
apiVersion: metering.openshift.io/v1
kind: ReportDataSource
metadata:
name: knative-service-memory-usage
spec:
prometheusMetricsImporter:
query: >
sum
by(namespace,
label_serving_knative_dev_service,
label_serving_knative_dev_revision)
(
label_replace(container_memory_usage_bytes{container!="POD", container!="",pod!=""}, "pod", "$1", "pod", "(.*)")
*
on(pod, namespace)
group_left(label_serving_knative_dev_service, label_serving_knative_dev_revision)
kube_pod_labels{label_serving_knative_dev_service!=""}
)12.2.3. Knative Serving メータリングのデータソースの適用
手順
ReportDataSourcesリソースを YAML ファイルとして適用します。$ oc apply -f <datasource_name>.yamlコマンドの例
$ oc apply -f knative-service-memory-usage.yaml
12.3. Knative Serving メータリングのクエリー
以下のクエリーサンプルのリソースは、サンプルのデータソースを参照します。
12.3.1. Knative Serving での CPU 使用状況のクエリー
サンプル YAML
apiVersion: metering.openshift.io/v1
kind: ReportQuery
metadata:
name: knative-service-cpu-usage
spec:
inputs:
- name: ReportingStart
type: time
- name: ReportingEnd
type: time
- default: knative-service-cpu-usage
name: KnativeServiceCpuUsageDataSource
type: ReportDataSource
columns:
- name: period_start
type: timestamp
unit: date
- name: period_end
type: timestamp
unit: date
- name: namespace
type: varchar
unit: kubernetes_namespace
- name: service
type: varchar
- name: data_start
type: timestamp
unit: date
- name: data_end
type: timestamp
unit: date
- name: service_cpu_seconds
type: double
unit: cpu_core_seconds
query: |
SELECT
timestamp '{| default .Report.ReportingStart .Report.Inputs.ReportingStart| prestoTimestamp |}' AS period_start,
timestamp '{| default .Report.ReportingEnd .Report.Inputs.ReportingEnd | prestoTimestamp |}' AS period_end,
labels['namespace'] as project,
labels['label_serving_knative_dev_service'] as service,
min("timestamp") as data_start,
max("timestamp") as data_end,
sum(amount * "timeprecision") AS service_cpu_seconds
FROM {| dataSourceTableName .Report.Inputs.KnativeServiceCpuUsageDataSource |}
WHERE "timestamp" >= timestamp '{| default .Report.ReportingStart .Report.Inputs.ReportingStart | prestoTimestamp |}'
AND "timestamp" < timestamp '{| default .Report.ReportingEnd .Report.Inputs.ReportingEnd | prestoTimestamp |}'
GROUP BY labels['namespace'],labels['label_serving_knative_dev_service']12.3.2. Knative Serving でのメモリー使用状況のクエリー
サンプル YAML
apiVersion: metering.openshift.io/v1
kind: ReportQuery
metadata:
name: knative-service-memory-usage
spec:
inputs:
- name: ReportingStart
type: time
- name: ReportingEnd
type: time
- default: knative-service-memory-usage
name: KnativeServiceMemoryUsageDataSource
type: ReportDataSource
columns:
- name: period_start
type: timestamp
unit: date
- name: period_end
type: timestamp
unit: date
- name: namespace
type: varchar
unit: kubernetes_namespace
- name: service
type: varchar
- name: data_start
type: timestamp
unit: date
- name: data_end
type: timestamp
unit: date
- name: service_usage_memory_byte_seconds
type: double
unit: byte_seconds
query: |
SELECT
timestamp '{| default .Report.ReportingStart .Report.Inputs.ReportingStart| prestoTimestamp |}' AS period_start,
timestamp '{| default .Report.ReportingEnd .Report.Inputs.ReportingEnd | prestoTimestamp |}' AS period_end,
labels['namespace'] as project,
labels['label_serving_knative_dev_service'] as service,
min("timestamp") as data_start,
max("timestamp") as data_end,
sum(amount * "timeprecision") AS service_usage_memory_byte_seconds
FROM {| dataSourceTableName .Report.Inputs.KnativeServiceMemoryUsageDataSource |}
WHERE "timestamp" >= timestamp '{| default .Report.ReportingStart .Report.Inputs.ReportingStart | prestoTimestamp |}'
AND "timestamp" < timestamp '{| default .Report.ReportingEnd .Report.Inputs.ReportingEnd | prestoTimestamp |}'
GROUP BY labels['namespace'],labels['label_serving_knative_dev_service']12.3.3. Knative Serving メータリングのクエリーの適用
クエリーを YAML ファイルとして適用します。
$ oc apply -f <query_name>.yamlコマンドの例
$ oc apply -f knative-service-memory-usage.yaml
12.4. Knative Serving のメータリングレポート
Report リソースを作成し、Knative Serving に対してメータリングレポートを実行できます。レポートを実行する前に、レポート期間の開始日と終了日を指定するために、Report リソース内で入力パラメーターを変更する必要があります。
レポート YAML の例
apiVersion: metering.openshift.io/v1
kind: Report
metadata:
name: knative-service-cpu-usage
spec:
reportingStart: '2019-06-01T00:00:00Z'
reportingEnd: '2019-06-30T23:59:59Z'
query: knative-service-cpu-usage
runImmediately: true12.4.1. メータリングレポートの実行
これを YAML ファイルとして適用してレポートを実行します。
$ oc apply -f <report_name>.yamlレポートをチェックします。
$ oc get report出力例
NAME QUERY SCHEDULE RUNNING FAILED LAST REPORT TIME AGE knative-service-cpu-usage knative-service-cpu-usage Finished 2019-06-30T23:59:59Z 10h