Chapter 6. Kafka Bridge
This chapter provides an overview of the AMQ Streams Kafka Bridge and helps you get started using its REST API to interact with AMQ Streams.
- To try out the Kafka Bridge in your local environment, see the Section 6.2, “Kafka Bridge quickstart” later in this chapter.
- For detailed configuration steps, see Section 2.5, “Kafka Bridge cluster configuration”.
- To view the API documentation, see the Kafka Bridge API reference.
6.1. Kafka Bridge overview
You can use the AMQ Streams Kafka Bridge as an interface to make specific types of HTTP requests to the Kafka cluster.
6.1.1. Kafka Bridge interface
The Kafka Bridge provides a RESTful interface that allows HTTP-based clients to interact with a Kafka cluster. It offers the advantages of a web API connection to AMQ Streams, without the need for client applications to interpret the Kafka protocol.
The API has two main resources — consumers and topics — that are exposed and made accessible through endpoints to interact with consumers and producers in your Kafka cluster. The resources relate only to the Kafka Bridge, not the consumers and producers connected directly to Kafka.
6.1.1.1. HTTP requests
The Kafka Bridge supports HTTP requests to a Kafka cluster, with methods to:
- Send messages to a topic.
- Retrieve messages from topics.
- Retrieve a list of partitions for a topic.
- Create and delete consumers.
- Subscribe consumers to topics, so that they start receiving messages from those topics.
- Retrieve a list of topics that a consumer is subscribed to.
- Unsubscribe consumers from topics.
- Assign partitions to consumers.
- Commit a list of consumer offsets.
- Seek on a partition, so that a consumer starts receiving messages from the first or last offset position, or a given offset position.
The methods provide JSON responses and HTTP response code error handling. Messages can be sent in JSON or binary formats.
Clients can produce and consume messages without the requirement to use the native Kafka protocol.
Additional resources
- To view the API documentation, including example requests and responses, see the Kafka Bridge API reference.
6.1.2. Supported clients for the Kafka Bridge
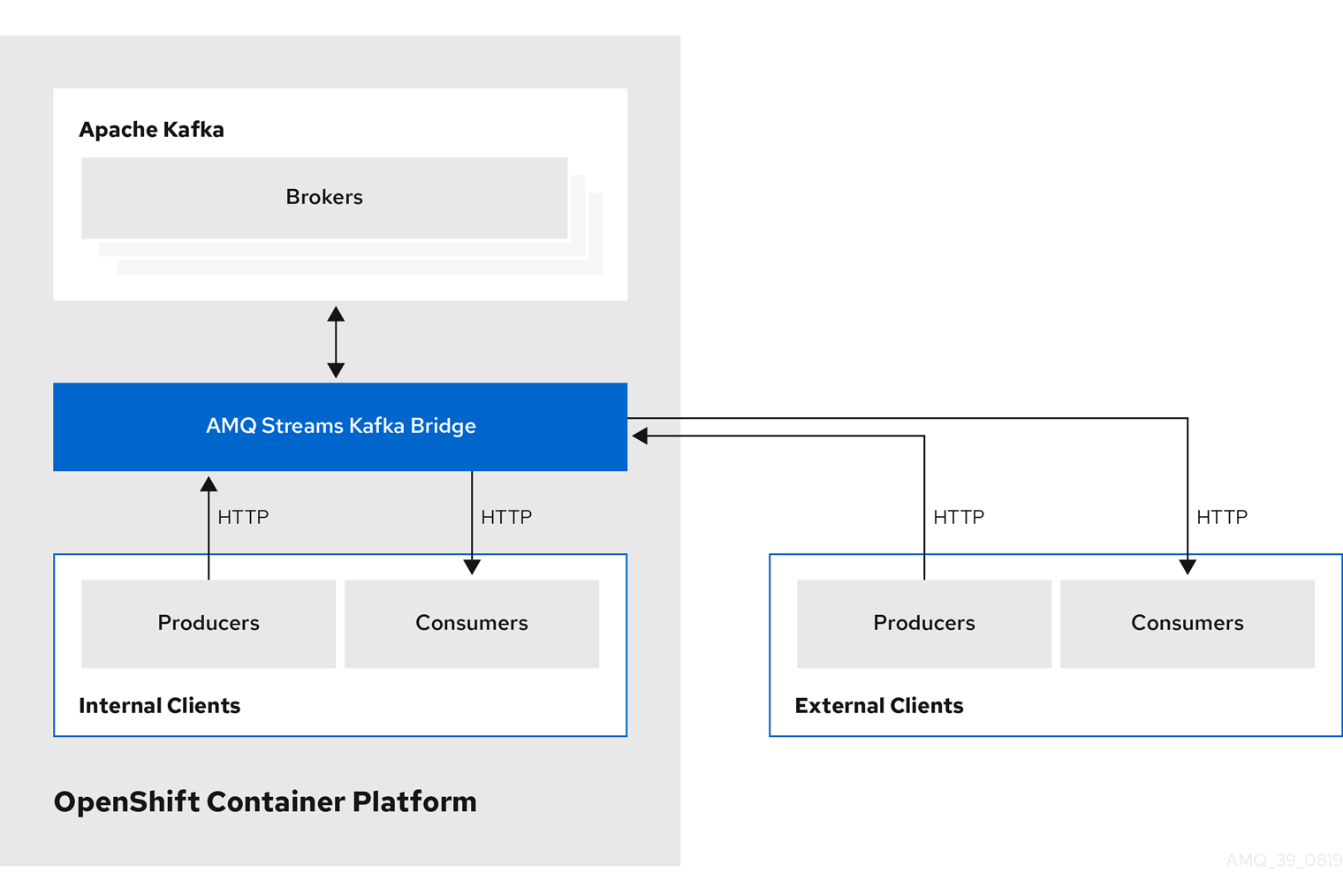
You can use the Kafka Bridge to integrate both internal and external HTTP client applications with your Kafka cluster.
- Internal clients
-
Internal clients are container-based HTTP clients running in the same OpenShift cluster as the Kafka Bridge itself. Internal clients can access the Kafka Bridge on the host and port defined in the
KafkaBridgecustom resource. - External clients
- External clients are HTTP clients running outside the OpenShift cluster in which the Kafka Bridge is deployed and running. External clients can access the Kafka Bridge through an OpenShift Route, a loadbalancer service, or using an Ingress.
HTTP internal and external client integration
6.1.3. Securing the Kafka Bridge
AMQ Streams does not currently provide any encryption, authentication, or authorization for the Kafka Bridge. This means that requests sent from external clients to the Kafka Bridge are:
- Not encrypted, and must use HTTP rather than HTTPS
- Sent without authentication
However, you can secure the Kafka Bridge using other methods, such as:
- OpenShift Network Policies that define which pods can access the Kafka Bridge.
- Reverse proxies with authentication or authorization, for example, OAuth2 proxies.
- API Gateways.
- Ingress or OpenShift Routes with TLS termination.
The Kafka Bridge supports TLS encryption and TLS and SASL authentication when connecting to the Kafka Brokers. Within your OpenShift cluster, you can configure:
- TLS or SASL-based authentication between the Kafka Bridge and your Kafka cluster
- A TLS-encrypted connection between the Kafka Bridge and your Kafka cluster.
For more information, see Section 2.5.1, “Configuring the Kafka Bridge”.
You can use ACLs in Kafka brokers to restrict the topics that can be consumed and produced using the Kafka Bridge.
6.1.4. Accessing the Kafka Bridge outside of OpenShift
After deployment, the AMQ Streams Kafka Bridge can only be accessed by applications running in the same OpenShift cluster. These applications use the kafka-bridge-name-bridge-service Service to access the API.
If you want to make the Kafka Bridge accessible to applications running outside of the OpenShift cluster, you can expose it manually by using one of the following features:
- Services of types LoadBalancer or NodePort
- Ingress resources
- OpenShift Routes
If you decide to create Services, use the following labels in the selector to configure the pods to which the service will route the traffic:
# ...
selector:
strimzi.io/cluster: kafka-bridge-name
strimzi.io/kind: KafkaBridge
#...- 1
- Name of the Kafka Bridge custom resource in your OpenShift cluster.
6.1.5. Requests to the Kafka Bridge
Specify data formats and HTTP headers to ensure valid requests are submitted to the Kafka Bridge.
6.1.5.1. Content Type headers
API request and response bodies are always encoded as JSON.
When performing consumer operations,
POSTrequests must provide the followingContent-Typeheader if there is a non-empty body:Content-Type: application/vnd.kafka.v2+jsonWhen performing producer operations,
POSTrequests must provideContent-Typeheaders specifying the embedded data format of the messages produced. This can be eitherjsonorbinary.Expand Embedded data format Content-Type header JSON
Content-Type: application/vnd.kafka.json.v2+jsonBinary
Content-Type: application/vnd.kafka.binary.v2+json
The embedded data format is set per consumer, as described in the next section.
The Content-Type must not be set if the POST request has an empty body. An empty body can be used to create a consumer with the default values.
6.1.5.2. Embedded data format
The embedded data format is the format of the Kafka messages that are transmitted, over HTTP, from a producer to a consumer using the Kafka Bridge. Two embedded data formats are supported: JSON and binary.
When creating a consumer using the /consumers/groupid endpoint, the POST request body must specify an embedded data format of either JSON or binary. This is specified in the format field, for example:
{
"name": "my-consumer",
"format": "binary",
...
}- 1
- A binary embedded data format.
The embedded data format specified when creating a consumer must match the data format of the Kafka messages it will consume.
If you choose to specify a binary embedded data format, subsequent producer requests must provide the binary data in the request body as Base64-encoded strings. For example, when sending messages using the /topics/topicname endpoint, records.value must be encoded in Base64:
{
"records": [
{
"key": "my-key",
"value": "ZWR3YXJkdGhldGhyZWVsZWdnZWRjYXQ="
},
]
}
Producer requests must also provide a Content-Type header that corresponds to the embedded data format, for example, Content-Type: application/vnd.kafka.binary.v2+json.
6.1.5.3. Message format
When sending messages using the /topics endpoint, you enter the message payload in the request body, in the records parameter.
The records parameter can contain any of these optional fields:
-
Message
headers -
Message
key -
Message
value -
Destination
partition
Example POST request to /topics
curl -X POST \
http://localhost:8080/topics/my-topic \
-H 'content-type: application/vnd.kafka.json.v2+json' \
-d '{
"records": [
{
"key": "my-key",
"value": "sales-lead-0001"
"partition": 2
"headers": [
{
"key": "key1",
"value": "QXBhY2hlIEthZmthIGlzIHRoZSBib21iIQ=="
}
]
},
]
}'- 1
- The header value in binary format and encoded as Base64.
6.1.5.4. Accept headers
After creating a consumer, all subsequent GET requests must provide an Accept header in the following format:
Accept: application/vnd.kafka.EMBEDDED-DATA-FORMAT.v2+json
The EMBEDDED-DATA-FORMAT is either json or binary.
For example, when retrieving records for a subscribed consumer using an embedded data format of JSON, include this Accept header:
Accept: application/vnd.kafka.json.v2+json6.1.6. CORS
Cross-Origin Resource Sharing (CORS) allows you to specify allowed methods and originating URLs for accessing the Kafka cluster in your Kafka Bridge HTTP configuration.
Example CORS configuration for Kafka Bridge
# ...
cors:
allowedOrigins: "https://strimzi.io"
allowedMethods: "GET,POST,PUT,DELETE,OPTIONS,PATCH"
# ...CORS allows for simple and preflighted requests between origin sources on different domains.
Simple requests are suitable for standard requests using GET, HEAD, POST methods.
A preflighted request sends a HTTP OPTIONS request as an initial check that the actual request is safe to send. On confirmation, the actual request is sent. Preflight requests are suitable for methods that require greater safeguards, such as PUT and DELETE, and use non-standard headers.
All requests require an Origin value in their header, which is the source of the HTTP request.
6.1.6.1. Simple request
For example, this simple request header specifies the origin as https://strimzi.io.
Origin: https://strimzi.ioThe header information is added to the request.
curl -v -X GET HTTP-ADDRESS/bridge-consumer/records \
-H 'Origin: https://strimzi.io'\
-H 'content-type: application/vnd.kafka.v2+json'
In the response from the Kafka Bridge, an Access-Control-Allow-Origin header is returned.
HTTP/1.1 200 OK
Access-Control-Allow-Origin: * - 1
- Returning an asterisk (
*) shows the resource can be accessed by any domain.
6.1.6.2. Preflighted request
An initial preflight request is sent to Kafka Bridge using an OPTIONS method. The HTTP OPTIONS request sends header information to check that Kafka Bridge will allow the actual request.
Here the preflight request checks that a POST request is valid from https://strimzi.io.
OPTIONS /my-group/instances/my-user/subscription HTTP/1.1
Origin: https://strimzi.io
Access-Control-Request-Method: POST
Access-Control-Request-Headers: Content-Type
OPTIONS is added to the header information of the preflight request.
curl -v -X OPTIONS -H 'Origin: https://strimzi.io' \
-H 'Access-Control-Request-Method: POST' \
-H 'content-type: application/vnd.kafka.v2+json'Kafka Bridge responds to the initial request to confirm that the request will be accepted. The response header returns allowed origins, methods and headers.
HTTP/1.1 200 OK
Access-Control-Allow-Origin: https://strimzi.io
Access-Control-Allow-Methods: GET,POST,PUT,DELETE,OPTIONS,PATCH
Access-Control-Allow-Headers: content-typeIf the origin or method is rejected, an error message is returned.
The actual request does not require Access-Control-Request-Method header, as it was confirmed in the preflight request, but it does require the origin header.
curl -v -X POST HTTP-ADDRESS/topics/bridge-topic \
-H 'Origin: https://strimzi.io' \
-H 'content-type: application/vnd.kafka.v2+json'The response shows the originating URL is allowed.
HTTP/1.1 200 OK
Access-Control-Allow-Origin: https://strimzi.ioAdditional resources
Fetch CORS specification
6.1.7. Kafka Bridge API resources
For the full list of REST API endpoints and descriptions, including example requests and responses, see the Kafka Bridge API reference.
6.1.8. Kafka Bridge deployment
You deploy the Kafka Bridge into your OpenShift cluster by using the Cluster Operator.
After the Kafka Bridge is deployed, the Cluster Operator creates Kafka Bridge objects in your OpenShift cluster. Objects include the deployment, service, and pod, each named after the name given in the custom resource for the Kafka Bridge.
Additional resources
- For deployment instructions, see Deploying Kafka Bridge to your OpenShift cluster in the Deploying and Upgrading AMQ Streams on OpenShift guide.
- For detailed information on configuring the Kafka Bridge, see Section 2.5, “Kafka Bridge cluster configuration”
-
For information on configuring the host and port for the
KafkaBridgeresource, see Section 2.5.1, “Configuring the Kafka Bridge”. - For information on integrating external clients, see Section 6.1.4, “Accessing the Kafka Bridge outside of OpenShift”.
6.2. Kafka Bridge quickstart
Use this quickstart to try out the AMQ Streams Kafka Bridge in your local development environment. You will learn how to:
- Deploy the Kafka Bridge to your OpenShift cluster
- Expose the Kafka Bridge service to your local machine by using port-forwarding
- Produce messages to topics and partitions in your Kafka cluster
- Create a Kafka Bridge consumer
- Perform basic consumer operations, such as subscribing the consumer to topics and retrieving the messages that you produced
In this quickstart, HTTP requests are formatted as curl commands that you can copy and paste to your terminal. Access to an OpenShift cluster is required; to run and manage a local OpenShift cluster, use a tool such as Minikube, CodeReady Containers, or MiniShift.
Ensure you have the prerequisites and then follow the tasks in the order provided in this chapter.
About data formats
In this quickstart, you will produce and consume messages in JSON format, not binary. For more information on the data formats and HTTP headers used in the example requests, see Section 6.1.5, “Requests to the Kafka Bridge”.
Prerequisites for the quickstart
- Cluster administrator access to a local or remote OpenShift cluster.
- AMQ Streams is installed.
- A running Kafka cluster, deployed by the Cluster Operator, in an OpenShift namespace.
- The Entity Operator is deployed and running as part of the Kafka cluster.
6.2.1. Deploying the Kafka Bridge to your OpenShift cluster
AMQ Streams includes a YAML example that specifies the configuration of the AMQ Streams Kafka Bridge. Make some minimal changes to this file and then deploy an instance of the Kafka Bridge to your OpenShift cluster.
Procedure
Edit the
examples/bridge/kafka-bridge.yamlfile.apiVersion: kafka.strimzi.io/v1alpha1 kind: KafkaBridge metadata: name: quickstart1 spec: replicas: 1 bootstrapServers: <cluster-name>-kafka-bootstrap:90922 http: port: 8080- 1
- When the Kafka Bridge is deployed,
-bridgeis appended to the name of the deployment and other related resources. In this example, the Kafka Bridge deployment is namedquickstart-bridgeand the accompanying Kafka Bridge service is namedquickstart-bridge-service. - 2
- In the
bootstrapServersproperty, enter the name of the Kafka cluster as the<cluster-name>.
Deploy the Kafka Bridge to your OpenShift cluster:
oc apply -f examples/bridge/kafka-bridge.yamlA
quickstart-bridgedeployment, service, and other related resources are created in your OpenShift cluster.Verify that the Kafka Bridge was successfully deployed:
oc get deploymentsNAME READY UP-TO-DATE AVAILABLE AGE quickstart-bridge 1/1 1 1 34m my-cluster-connect 1/1 1 1 24h my-cluster-entity-operator 1/1 1 1 24h #...
What to do next
After deploying the Kafka Bridge to your OpenShift cluster, expose the Kafka Bridge service to your local machine.
Additional resources
- For more detailed information about configuring the Kafka Bridge, see Section 2.5, “Kafka Bridge cluster configuration”.
6.2.2. Exposing the Kafka Bridge service to your local machine
Next, use port forwarding to expose the AMQ Streams Kafka Bridge service to your local machine on http://localhost:8080.
Port forwarding is only suitable for development and testing purposes.
Procedure
List the names of the pods in your OpenShift cluster:
oc get pods -o name pod/kafka-consumer # ... pod/quickstart-bridge-589d78784d-9jcnr pod/strimzi-cluster-operator-76bcf9bc76-8dnfmConnect to the
quickstart-bridgepod on port8080:oc port-forward pod/quickstart-bridge-589d78784d-9jcnr 8080:8080 &NoteIf port 8080 on your local machine is already in use, use an alternative HTTP port, such as
8008.
API requests are now forwarded from port 8080 on your local machine to port 8080 in the Kafka Bridge pod.
6.2.3. Producing messages to topics and partitions
Next, produce messages to topics in JSON format by using the topics endpoint. You can specify destination partitions for messages in the request body, as shown here. The partitions endpoint provides an alternative method for specifying a single destination partition for all messages as a path parameter.
Procedure
In a text editor, create a YAML definition for a Kafka topic with three partitions.
apiVersion: kafka.strimzi.io/v1beta1 kind: KafkaTopic metadata: name: bridge-quickstart-topic labels: strimzi.io/cluster: <kafka-cluster-name>1 spec: partitions: 32 replicas: 1 config: retention.ms: 7200000 segment.bytes: 1073741824-
Save the file to the
examples/topicdirectory asbridge-quickstart-topic.yaml. Create the topic in your OpenShift cluster:
oc apply -f examples/topic/bridge-quickstart-topic.yamlUsing the Kafka Bridge, produce three messages to the topic you created:
curl -X POST \ http://localhost:8080/topics/bridge-quickstart-topic \ -H 'content-type: application/vnd.kafka.json.v2+json' \ -d '{ "records": [ { "key": "my-key", "value": "sales-lead-0001" }, { "value": "sales-lead-0002", "partition": 2 }, { "value": "sales-lead-0003" } ] }'-
sales-lead-0001is sent to a partition based on the hash of the key. -
sales-lead-0002is sent directly to partition 2. -
sales-lead-0003is sent to a partition in thebridge-quickstart-topictopic using a round-robin method.
-
If the request is successful, the Kafka Bridge returns an
offsetsarray, along with a200code and acontent-typeheader ofapplication/vnd.kafka.v2+json. For each message, theoffsetsarray describes:- The partition that the message was sent to
The current message offset of the partition
Example response
#... { "offsets":[ { "partition":0, "offset":0 }, { "partition":2, "offset":0 }, { "partition":0, "offset":1 } ] }
What to do next
After producing messages to topics and partitions, create a Kafka Bridge consumer.
Additional resources
- POST /topics/{topicname} in the API reference documentation.
- POST /topics/{topicname}/partitions/{partitionid} in the API reference documentation.
6.2.4. Creating a Kafka Bridge consumer
Before you can perform any consumer operations in the Kafka cluster, you must first create a consumer by using the consumers endpoint. The consumer is referred to as a Kafka Bridge consumer.
Procedure
Create a Kafka Bridge consumer in a new consumer group named
bridge-quickstart-consumer-group:curl -X POST http://localhost:8080/consumers/bridge-quickstart-consumer-group \ -H 'content-type: application/vnd.kafka.v2+json' \ -d '{ "name": "bridge-quickstart-consumer", "auto.offset.reset": "earliest", "format": "json", "enable.auto.commit": false, "fetch.min.bytes": 512, "consumer.request.timeout.ms": 30000 }'-
The consumer is named
bridge-quickstart-consumerand the embedded data format is set asjson. - Some basic configuration settings are defined.
The consumer will not commit offsets to the log automatically because the
enable.auto.commitsetting isfalse. You will commit the offsets manually later in this quickstart.If the request is successful, the Kafka Bridge returns the consumer ID (
instance_id) and base URL (base_uri) in the response body, along with a200code.Example response
#... { "instance_id": "bridge-quickstart-consumer", "base_uri":"http://<bridge-name>-bridge-service:8080/consumers/bridge-quickstart-consumer-group/instances/bridge-quickstart-consumer" }
-
The consumer is named
-
Copy the base URL (
base_uri) to use in the other consumer operations in this quickstart.
What to do next
Now that you have created a Kafka Bridge consumer, you can subscribe it to topics.
Additional resources
- POST /consumers/{groupid} in the API reference documentation.
6.2.5. Subscribing a Kafka Bridge consumer to topics
After you have created a Kafka Bridge consumer, subscribe it to one or more topics by using the subscription endpoint. Once subscribed, the consumer starts receiving all messages that are produced to the topic.
Procedure
Subscribe the consumer to the
bridge-quickstart-topictopic that you created earlier, in Producing messages to topics and partitions:curl -X POST http://localhost:8080/consumers/bridge-quickstart-consumer-group/instances/bridge-quickstart-consumer/subscription \ -H 'content-type: application/vnd.kafka.v2+json' \ -d '{ "topics": [ "bridge-quickstart-topic" ] }'The
topicsarray can contain a single topic (as shown here) or multiple topics. If you want to subscribe the consumer to multiple topics that match a regular expression, you can use thetopic_patternstring instead of thetopicsarray.If the request is successful, the Kafka Bridge returns a
204(No Content) code only.
What to do next
After subscribing a Kafka Bridge consumer to topics, you can retrieve messages from the consumer.
Additional resources
- POST /consumers/{groupid}/instances/{name}/subscription in the API reference documentation.
6.2.6. Retrieving the latest messages from a Kafka Bridge consumer
Next, retrieve the latest messages from the Kafka Bridge consumer by requesting data from the records endpoint. In production, HTTP clients can call this endpoint repeatedly (in a loop).
Procedure
- Produce additional messages to the Kafka Bridge consumer, as described in Producing messages to topics and partitions.
Submit a
GETrequest to therecordsendpoint:curl -X GET http://localhost:8080/consumers/bridge-quickstart-consumer-group/instances/bridge-quickstart-consumer/records \ -H 'accept: application/vnd.kafka.json.v2+json'After creating and subscribing to a Kafka Bridge consumer, a first GET request will return an empty response because the poll operation starts a rebalancing process to assign partitions.
Repeat step two to retrieve messages from the Kafka Bridge consumer.
The Kafka Bridge returns an array of messages — describing the topic name, key, value, partition, and offset — in the response body, along with a
200code. Messages are retrieved from the latest offset by default.HTTP/1.1 200 OK content-type: application/vnd.kafka.json.v2+json #... [ { "topic":"bridge-quickstart-topic", "key":"my-key", "value":"sales-lead-0001", "partition":0, "offset":0 }, { "topic":"bridge-quickstart-topic", "key":null, "value":"sales-lead-0003", "partition":0, "offset":1 }, #...NoteIf an empty response is returned, produce more records to the consumer as described in Producing messages to topics and partitions, and then try retrieving messages again.
What to do next
After retrieving messages from a Kafka Bridge consumer, try committing offsets to the log.
Additional resources
- GET /consumers/{groupid}/instances/{name}/records in the API reference documentation.
6.2.7. Commiting offsets to the log
Next, use the offsets endpoint to manually commit offsets to the log for all messages received by the Kafka Bridge consumer. This is required because the Kafka Bridge consumer that you created earlier, in Creating a Kafka Bridge consumer, was configured with the enable.auto.commit setting as false.
Procedure
Commit offsets to the log for the
bridge-quickstart-consumer:curl -X POST http://localhost:8080/consumers/bridge-quickstart-consumer-group/instances/bridge-quickstart-consumer/offsetsBecause no request body is submitted, offsets are committed for all the records that have been received by the consumer. Alternatively, the request body can contain an array (OffsetCommitSeekList) that specifies the topics and partitions that you want to commit offsets for.
If the request is successful, the Kafka Bridge returns a
204code only.
What to do next
After committing offsets to the log, try out the endpoints for seeking to offsets.
Additional resources
- POST /consumers/{groupid}/instances/{name}/offsets in the API reference documentation.
6.2.8. Seeking to offsets for a partition
Next, use the positions endpoints to configure the Kafka Bridge consumer to retrieve messages for a partition from a specific offset, and then from the latest offset. This is referred to in Apache Kafka as a seek operation.
Procedure
Seek to a specific offset for partition 0 of the
quickstart-bridge-topictopic:curl -X POST http://localhost:8080/consumers/bridge-quickstart-consumer-group/instances/bridge-quickstart-consumer/positions \ -H 'content-type: application/vnd.kafka.v2+json' \ -d '{ "offsets": [ { "topic": "bridge-quickstart-topic", "partition": 0, "offset": 2 } ] }'If the request is successful, the Kafka Bridge returns a
204code only.Submit a
GETrequest to therecordsendpoint:curl -X GET http://localhost:8080/consumers/bridge-quickstart-consumer-group/instances/bridge-quickstart-consumer/records \ -H 'accept: application/vnd.kafka.json.v2+json'The Kafka Bridge returns messages from the offset that you seeked to.
Restore the default message retrieval behavior by seeking to the last offset for the same partition. This time, use the positions/end endpoint.
curl -X POST http://localhost:8080/consumers/bridge-quickstart-consumer-group/instances/bridge-quickstart-consumer/positions/end \ -H 'content-type: application/vnd.kafka.v2+json' \ -d '{ "partitions": [ { "topic": "bridge-quickstart-topic", "partition": 0 } ] }'If the request is successful, the Kafka Bridge returns another
204code.
You can also use the positions/beginning endpoint to seek to the first offset for one or more partitions.
What to do next
In this quickstart, you have used the AMQ Streams Kafka Bridge to perform several common operations on a Kafka cluster. You can now delete the Kafka Bridge consumer that you created earlier.
Additional resources
- POST /consumers/{groupid}/instances/{name}/positions in the API reference documentation.
- POST /consumers/{groupid}/instances/{name}/positions/beginning in the API reference documentation.
- POST /consumers/{groupid}/instances/{name}/positions/end in the API reference documentation.
6.2.9. Deleting a Kafka Bridge consumer
Finally, delete the Kafa Bridge consumer that you used throughout this quickstart.
Procedure
Delete the Kafka Bridge consumer by sending a
DELETErequest to the instances endpoint.curl -X DELETE http://localhost:8080/consumers/bridge-quickstart-consumer-group/instances/bridge-quickstart-consumerIf the request is successful, the Kafka Bridge returns a
204code only.
Additional resources
- DELETE /consumers/{groupid}/instances/{name} in the API reference documentation.