Chapter 3. Master/Slave
Abstract
Persistent messages require an additional layer of fault tolerance. In case of a broker failure, persistent messages require that the replacement broker has a copy of all the undelivered messages. Master/slave groups address this requirement by having a standby broker that shares the active broker's data store.
A master/slave group consists of two or more brokers where one master broker is active and one or more slave brokers are on hot standby, ready to take over whenever the master fails or shuts down. All of the brokers store the message and event data processed by the master broker. So, when one of the slaves takes over as the new master broker the integrity of the messaging system is guaranteed.
Red Hat JBoss A-MQ supports two master/slave broker configurations:
- Shared file system—the master and the slaves use a common persistence store that is located on a shared file system
- Shared JDBC database—the masters and the slaves use a common JDBC persistence store
3.1. Shared File System Master/Slave
Copy linkLink copied to clipboard!
Overview
Copy linkLink copied to clipboard!
A shared file system master/slave group works by sharing a common data store that is located on a shared file system. Brokers automatically configure themselves to operate in master mode or slave mode based on their ability to grab an exclusive lock on the underlying data store.
The disadvantage of this configuration is that the shared file system is a single point of failure. This disadvantage can be mitigated by using a storage area network(SAN) with built in high availability(HA) functionality. The SAN will handle replication and fail over of the data store.
Supported network file systems
Copy linkLink copied to clipboard!
The following network file systems (and only these file systems) are supported by JBoss A-MQ:
- NFSv4
- GFS2
File locking requirements
Copy linkLink copied to clipboard!
The shared file system requires an efficient and reliable file locking mechanism to function correctly. Not all SAN file systems are compatible with the configuration needs of the shared file system.
Warning
OCFS2 is incompatible with this master/slave configuration, because mutex file locking from Java is not supported.
Warning
NFSv3 is incompatible with this master/slave configuration. In the event of an abnormal termination of a master broker, which is an NFSv3 client, the NFSv3 server does not time out the lock held by the client. This renders the Red Hat JBoss A-MQ data directory inaccessible. Because of this, the slave broker cannot acquire the lock and therefore cannot start up. In this case, the only way to unblock the master/slave in NFSv3 is to reboot all broker instances.
NFSv4, on the other hand, is compatible with the master/slave configuration, as its design includes timeouts for locks. When an NFSv4 client holding a lock terminates abnormally, NFSv4 automatically releases the lock after thirty seconds, allowing another NFSv4 client to grab it.
It is possible for a slave to grab the lock from the master without the master's knowledge when NFSv4 crashes. This is so because the master broker does not automatically check whether it still has the lock, giving a slave the chance to grab it when the NFSv4 thirty second timeout elapses.
The persistence adapter's lockKeepAlivePeriod attribute enables you to avoid this scenario. Setting the lockKeepAlivePeriod attribute instructs the master to check, at intervals of the specified milliseconds, whether it still has the lock (lock is valid) and that the lock file still exists. If the master discovers the lock is invalid, it tries to regain it. If it fails or the lock file no longer exists, the master shuts down, allowing a slave to try to get the lock and become master. In attempting to get the lock, the slave also checks whether the lock files exists, and if not, assumes the integrity of the store has been compromised and shuts down.
To enable this lock checking mechanism, add the lockKeepAlivePeriod attribute to the
which instructs the master broker to check at five second intervals whether the lock is still valid and that the lock file exists
persistenceAdaptor element in the broker configuration. For example, like this: <kahaDB directory="/sharedFileSystem/sharedBrokerData" lockKeepAlivePeriod="5000" />Initial state
Copy linkLink copied to clipboard!
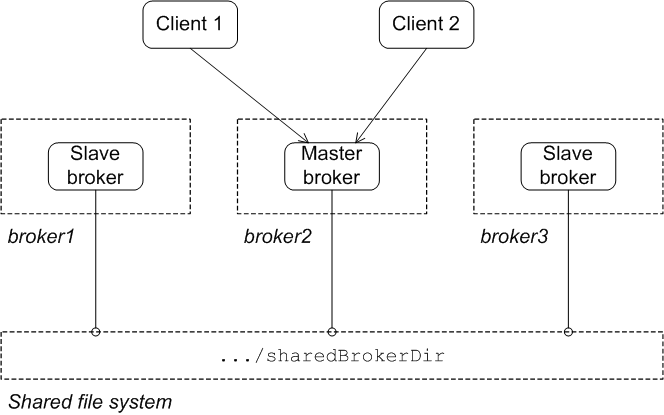
Figure 3.1, “Shared File System Initial State” shows the initial state of a shared file system master/slave group. When all of the brokers are started, one of them grabs the exclusive lock on the broker data store and becomes the master. All of the other brokers remain slaves and pause while waiting for the exclusive lock to free up. Only the master starts its transport connectors, so all of the clients connect to it.
Figure 3.1. Shared File System Initial State
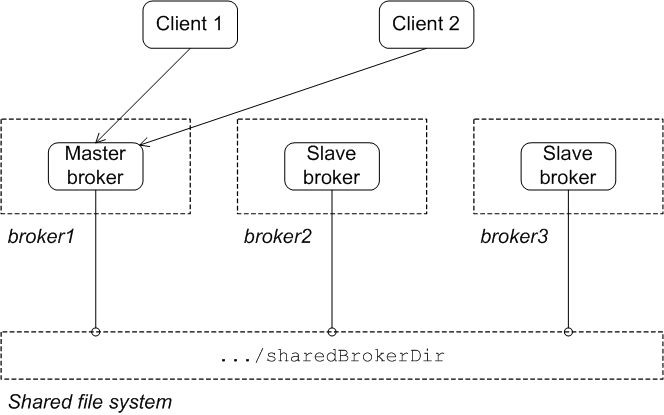
State after failure of the master
Copy linkLink copied to clipboard!
Figure 3.2, “Shared File System after Master Failure” shows the state of the master/slave group after the original master has shut down or failed. As soon as the master gives up the lock (or after a suitable timeout, if the master crashes), the lock on the data store frees up and another broker grabs the lock and gets promoted to master.
Figure 3.2. Shared File System after Master Failure
After the clients lose their connection to the original master, they automatically try all of the other brokers listed in the failover URL. This enables them to find and connect to the new master.
Configuring the brokers
Copy linkLink copied to clipboard!
In the shared file system master/slave configuration, there is nothing special to distinguish a master broker from the slave brokers. The membership of a particular master/slave group is defined by the fact that all of the brokers in the group use the same persistence layer and store their data in the same shared directory.
Example 3.1, “Shared File System Broker Configuration” shows the broker configuration for a shared file system master/slave group that shares a data store located at
/sharedFileSystem/sharedBrokerData and uses the KahaDB persistence store.
All of the brokers in the group must share the same
persistenceAdapter element.
Configuring the clients
Copy linkLink copied to clipboard!
Clients of shared file system master/slave group must be configured with a failover URL that lists the URLs for all of the brokers in the group. Example 3.2, “Client URL for a Shared File System Master/Slave Group” shows the client failover URL for a group that consists of three brokers:
broker1, broker2, and broker3.
For more information about using the failover protocol see Section 2.1.1, “Static Failover”.
Reintroducing a failed node
Copy linkLink copied to clipboard!
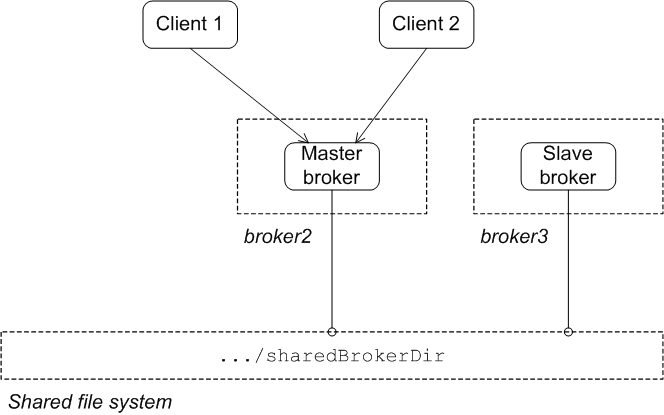
You can restart the failed master at any time and it will rejoin the cluster. It will rejoin as a slave broker because one of the other brokers already owns the exclusive lock on the data store, as shown in Figure 3.3, “Shared File System after Master Restart”.
Figure 3.3. Shared File System after Master Restart