Chapter 9. Introducing Metrics
This section describes how to monitor AMQ Streams Kafka, Zookeeper and Kafka Connect clusters using Prometheus to provide monitoring data for example Grafana dashboards.
In order to run the example Grafana dashboards, you must:
The resources referenced in this section are intended as a starting point for setting up monitoring, but they are provided as examples only. If you require further support on configuring and running Prometheus or Grafana in production, try reaching out to their respective communities.
Additional resources
- For more information about Prometheus, see the Prometheus documentation.
- For more information about Grafana, see the Grafana documentation.
- Apache Kafka Monitoring describes JMX metrics exposed by Apache Kafka.
- Zookeeper JMX describes JMX metrics exposed by Apache Zookeeper.
9.1. Example Metrics files
You can find the example metrics configuration files in the examples/metrics directory.
metrics
├── grafana-install
│ ├── grafana.yaml
├── grafana-dashboards
│ ├── strimzi-kafka-connect.json
│ ├── strimzi-kafka.json
│ └── strimzi-zookeeper.json
│ └── strimzi-kafka-exporter.json
├── kafka-connect-metrics.yaml
├── kafka-metrics.yaml
├── prometheus-additional-properties
│ └── prometheus-additional.yaml
├── prometheus-alertmanager-config
│ └── alert-manager-config.yaml
└── prometheus-install
├── alert-manager.yaml
├── prometheus-rules.yaml
├── prometheus.yaml
└── strimzi-service-monitor.yaml - 1
- Installation file for the Grafana image
- 2
- Grafana dashboard configuration
- 3
- Grafana dashboard configuration specific to Kafka Exporter
- 4
- Metrics configuration that defines Prometheus JMX Exporter relabeling rules for Kafka Connect
- 5
- Metrics configuration that defines Prometheus JMX Exporter relabeling rules for Kafka and Zookeeper
- 6
- Configuration to add roles for service monitoring
- 7
- Hook definitions for sending notifications through Alertmanager
- 8
- Resources for deploying and configuring Alertmanager
- 9
- Alerting rules examples for use with Prometheus Alertmanager (deployed with Prometheus)
- 10
- Installation file for the Prometheus image
- 11
- Prometheus job definitions to scrape metrics data
9.2. Prometheus metrics
AMQ Streams uses the Prometheus JMX Exporter to expose JMX metrics from Kafka and Zookeeper using an HTTP endpoint, which is then scraped by the Prometheus server.
9.2.1. Prometheus metrics configuration
AMQ Streams provides example configuration files for Grafana.
Grafana dashboards are dependent on Prometheus JMX Exporter relabeling rules, which are defined for:
-
Kafka and Zookeeper as a
Kafkaresource configuration in the examplekafka-metrics.yamlfile -
Kafka Connect as
KafkaConnectandKafkaConnectS2Iresources in the examplekafka-connect-metrics.yamlfile
A label is a name-value pair. Relabeling is the process of writing a label dynamically. For example, the value of a label may be derived from the name of a Kafka server and client ID.
We show metrics configuration using kafka-metrics.yaml in this section, but the process is the same when configuring Kafka Connect using the kafka-connect-metrics.yaml file.
Additional resources
For more information on the use of relabeling, see Configuration in the Prometheus documentation.
9.2.2. Prometheus metrics deployment options
To apply the example metrics configuration of relabeling rules to your Kafka cluster, do one of the following:
9.2.3. Copying Prometheus metrics configuration to a Kafka resource
To use Grafana dashboards for monitoring, you can copy the example metrics configuration to a Kafka resource.
Procedure
Execute the following steps for each Kafka resource in your deployment.
Update the
Kafkaresource in an editor.oc edit kafka my-cluster-
Copy the example configuration in
kafka-metrics.yamlto your ownKafkaresource definition. - Save the file, exit the editor and wait for the updated resource to be reconciled.
9.2.4. Deploying a Kafka cluster with Prometheus metrics configuration
To use Grafana dashboards for monitoring, you can deploy an example Kafka cluster with metrics configuration.
Procedure
Deploy the Kafka cluster with the metrics configuration:
oc apply -f kafka-metrics.yaml
9.3. Prometheus
Prometheus provides an open source set of components for systems monitoring and alert notification.
We describe here how you can use the CoreOS Prometheus Operator to run and manage a Prometheus server that is suitable for use in production environments, but with the correct configuration you can run any Prometheus server.
The Prometheus server configuration uses service discovery to discover the pods in the cluster from which it gets metrics. For this feature to work correctly, the service account used for running the Prometheus service pod must have access to the API server so it can retrieve the pod list.
For more information, see Discovering services.
9.3.1. Prometheus configuration
AMQ Streams provides example configuration files for the Prometheus server.
A Prometheus image is provided for deployment:
-
prometheus.yaml
Additional Prometheus-related configuration is also provided in the following files:
-
prometheus-additional.yaml -
prometheus-rules.yaml -
strimzi-service-monitor.yaml
For Prometheus to obtain monitoring data:
Then use the configuration files to:
Alerting rules
The prometheus-rules.yaml file provides example alerting rule examples for use with Alertmanager.
9.3.2. Prometheus resources
When you apply the Prometheus configuration, the following resources are created in your OpenShift cluster and managed by the Prometheus Operator:
-
A
ClusterRolethat grants permissions to Prometheus to read the health endpoints exposed by the Kafka and Zookeeper pods, cAdvisor and the kubelet for container metrics. -
A
ServiceAccountfor the Prometheus pods to run under. -
A
ClusterRoleBindingwhich binds theClusterRoleto theServiceAccount. -
A
Deploymentto manage the Prometheus Operator pod. -
A
ServiceMonitorto manage the configuration of the Prometheus pod. -
A
Prometheusto manage the configuration of the Prometheus pod. -
A
PrometheusRuleto manage alerting rules for the Prometheus pod. -
A
Secretto manage additional Prometheus settings. -
A
Serviceto allow applications running in the cluster to connect to Prometheus (for example, Grafana using Prometheus as datasource).
9.3.3. Deploying the Prometheus Operator
To deploy the Prometheus Operator to your Kafka cluster, apply the YAML resource files from the Prometheus CoreOS repository.
Procedure
Download the resource files from the repository and replace the example
namespacewith your own:On Linux, use:
curl -s https://raw.githubusercontent.com/coreos/prometheus-operator/master/example/rbac/prometheus-operator/prometheus-operator-deployment.yaml | sed -e 's/namespace: .\*/namespace: my-namespace/' > prometheus-operator-deployment.yamlcurl -s https://raw.githubusercontent.com/coreos/prometheus-operator/master/example/rbac/prometheus-operator/prometheus-operator-cluster-role.yaml > prometheus-operator-cluster-role.yamlcurl -s https://raw.githubusercontent.com/coreos/prometheus-operator/master/example/rbac/prometheus-operator/prometheus-operator-cluster-role-binding.yaml | sed -e 's/namespace: .*/namespace: my-namespace/' > prometheus-operator-cluster-role-binding.yamlcurl -s https://raw.githubusercontent.com/coreos/prometheus-operator/master/example/rbac/prometheus-operator/prometheus-operator-service-account.yaml | sed -e 's/namespace: .*/namespace: my-namespace/' > prometheus-operator-service-account.yamlOn MacOS, use:
curl -s https://raw.githubusercontent.com/coreos/prometheus-operator/master/example/rbac/prometheus-operator/prometheus-operator-deployment.yaml | sed -e '' 's/namespace: .\*/namespace: my-namespace/' > prometheus-operator-deployment.yamlcurl -s https://raw.githubusercontent.com/coreos/prometheus-operator/master/example/rbac/prometheus-operator/prometheus-operator-cluster-role.yaml > prometheus-operator-cluster-role.yamlcurl -s https://raw.githubusercontent.com/coreos/prometheus-operator/master/example/rbac/prometheus-operator/prometheus-operator-cluster-role-binding.yaml | sed -e '' 's/namespace: .*/namespace: my-namespace/' > prometheus-operator-cluster-role-binding.yamlcurl -s https://raw.githubusercontent.com/coreos/prometheus-operator/master/example/rbac/prometheus-operator/prometheus-operator-service-account.yaml | sed -e '' 's/namespace: .*/namespace: my-namespace/' > prometheus-operator-service-account.yamlNoteIf it is not required, you can manually remove the
spec.template.spec.securityContextproperty from theprometheus-operator-deployment.yamlfile.Deploy the Prometheus Operator:
oc apply -f prometheus-operator-deployment.yaml oc apply -f prometheus-operator-cluster-role.yaml oc apply -f prometheus-operator-cluster-role-binding.yaml oc apply -f prometheus-operator-service-account.yaml
9.3.4. Deploying Prometheus
To deploy Prometheus to your Kafka cluster to obtain monitoring data, apply the example resource file for the Prometheus docker image and the YAML files for Prometheus-related resources.
The deployment process creates a ClusterRoleBinding and discovers an Alertmanager instance in the namespace specified for the deployment.
By default, the Prometheus Operator only supports jobs that include an endpoints role for service discovery. Targets are discovered and scraped for each endpoint port address. For endpoint discovery, the port address may be derived from service (role: service) or pod (role: pod) discovery.
Prerequisites
- Check the example alerting rules provided
Procedure
Modify the Prometheus installation file (
prometheus.yaml) according to the namespace Prometheus is going to be installed in:On Linux, use:
sed -i 's/namespace: .*/namespace: my-namespace/' prometheus.yamlOn MacOS, use:
sed -i '' 's/namespace: .*/namespace: my-namespace/' prometheus.yaml-
Edit the
ServiceMonitorresource instrimzi-service-monitor.yamlto define Prometheus jobs that will scrape the metrics data. To use another role:
Create a
Secretresource:oc create secret generic additional-scrape-configs --from-file=prometheus-additional.yaml-
Edit the
additionalScrapeConfigsproperty in theprometheus.yamlfile to include the name of theSecretand the YAML file (prometheus-additional.yaml) that contains the additional configuration.
Edit the
prometheus-rules.yamlfile that creates sample alert notification rules:On Linux, use:
sed -i 's/namespace: .*/namespace: my-namespace/' prometheus-rules.yamlOn MacOS, use:
sed -i '' 's/namespace: .*/namespace: my-namespace/' prometheus-rules.yamlDeploy the Prometheus resources:
oc apply -f strimzi-service-monitor.yaml oc apply -f prometheus-rules.yaml oc apply -f prometheus.yaml
9.4. Prometheus Alertmanager
Prometheus Alertmanager is a plugin for handling alerts and routing them to a notification service. Alertmanager supports an essential aspect of monitoring, which is to be notified of conditions that indicate potential issues based on alerting rules.
9.4.1. Alertmanager configuration
AMQ Streams provides example configuration files for Prometheus Alertmanager.
A configuration file defines the resources for deploying Alertmanager:
-
alert-manager.yaml
An additional configuration file provides the hook definitions for sending notifications from your Kafka cluster.
-
alert-manager-config.yaml
For Alertmanger to handle Prometheus alerts, use the configuration files to:
9.4.2. Alerting rules
Alerting rules provide notifications about specific conditions observed in the metrics. Rules are declared on the Prometheus server, but Prometheus Alertmanager is responsible for alert notifications.
Prometheus alerting rules describe conditions using PromQL expressions that are continuously evaluated.
When an alert expression becomes true, the condition is met and the Prometheus server sends alert data to the Alertmanager. Alertmanager then sends out a notification using the communication method configured for its deployment.
Alertmanager can be configured to use email, chat messages or other notification methods.
Additional resources
For more information about setting up alerting rules, see Configuration in the Prometheus documentation.
9.4.3. Alerting rule examples
Example alerting rules for Kafka and Zookeeper metrics are provided with AMQ Streams for use in a Prometheus deployment.
General points about the alerting rule definitions:
-
A
forproperty is used with the rules to determine the period of time a condition must persist before an alert is triggered. -
A tick is a basic Zookeeper time unit, which is measured in milliseconds and configured using the
tickTimeparameter ofKafka.spec.zookeeper.config. For example, if ZookeepertickTime=3000, 3 ticks (3 x 3000) equals 9000 milliseconds. -
The availability of the
ZookeeperRunningOutOfSpacemetric and alert is dependent on the OpenShift configuration and storage implementation used. Storage implementations for certain platforms may not be able to supply the information on available space required for the metric to provide an alert.
Kafka alerting rules
UnderReplicatedPartitions-
Gives the number of partitions for which the current broker is the lead replica but which have fewer replicas than the
min.insync.replicasconfigured for their topic. This metric provides insights about brokers that host the follower replicas. Those followers are not keeping up with the leader. Reasons for this could include being (or having been) offline, and over-throttled interbroker replication. An alert is raised when this value is greater than zero, providing information on the under-replicated partitions for each broker. AbnormalControllerState- Indicates whether the current broker is the controller for the cluster. The metric can be 0 or 1. During the life of a cluster, only one broker should be the controller and the cluster always needs to have an active controller. Having two or more brokers saying that they are controllers indicates a problem. If the condition persists, an alert is raised when the sum of all the values for this metric on all brokers is not equal to 1, meaning that there is no active controller (the sum is 0) or more than one controller (the sum is greater than 1).
UnderMinIsrPartitionCount-
Indicates that the minimum number of in-sync replicas (ISRs) for a lead Kafka broker, specified using
min.insync.replicas, that must acknowledge a write operation has not been reached. The metric defines the number of partitions that the broker leads for which the in-sync replicas count is less than the minimum in-sync. An alert is raised when this value is greater than zero, providing information on the partition count for each broker that did not achieve the minimum number of acknowledgments. OfflineLogDirectoryCount- Indicates the number of log directories which are offline (for example, due to a hardware failure) so that the broker cannot store incoming messages anymore. An alert is raised when this value is greater than zero, providing information on the number of offline log directories for each broker.
KafkaRunningOutOfSpace-
Indicates the remaining amount of disk space that can be used for writing data. An alert is raised when this value is lower than 5GiB, providing information on the disk that is running out of space for each persistent volume claim. The threshold value may be changed in
prometheus-rules.yaml.
Zookeeper alerting rules
AvgRequestLatency- Indicates the amount of time it takes for the server to respond to a client request. An alert is raised when this value is greater than 10 (ticks), providing the actual value of the average request latency for each server.
OutstandingRequests- Indicates the number of queued requests in the server. This value goes up when the server receives more requests than it can process. An alert is raised when this value is greater than 10, providing the actual number of outstanding requests for each server.
ZookeeperRunningOutOfSpace- Indicates the remaining amount of disk space that can be used for writing data to Zookeeper. An alert is raised when this value is lower than 5GiB., providing information on the disk that is running out of space for each persistent volume claim.
9.4.4. Deploying Alertmanager
To deploy Alertmanager, apply the example configuration files.
The sample configuration provided with AMQ Streams configures the Alertmanager to send notifications to a Slack channel.
The following resources are defined on deployment:
-
An
Alertmanagerto manage the Alertmanager pod. -
A
Secretto manage the configuration of the Alertmanager. -
A
Serviceto provide an easy to reference hostname for other services to connect to Alertmanager (such as Prometheus).
Procedure
Create a
Secretresource from the Alertmanager configuration file (alert-manager-config.yaml):oc create secret generic alertmanager-alertmanager --from-file=alert-manager-config.yamlUpdate the
alert-manager-config.yamlfile to replace the:-
slack_api_urlproperty with the actual value of the Slack API URL related to the application for the Slack workspace -
channelproperty with the actual Slack channel on which to send notifications
-
Deploy Alertmanager:
oc apply -f alert-manager.yaml
9.5. Grafana
Grafana provides visualizations of Prometheus metrics.
You can deploy and enable the example Grafana dashboards provided with AMQ Streams.
9.5.1. Grafana configuration
AMQ Streams provides example dashboard configuration files for Grafana.
A Grafana docker image is provided for deployment:
-
grafana.yaml
Example dashboards are also provided as JSON files:
-
strimzi-kafka.json -
strimzi-kafka-connect.json -
strimzi-zookeeper.json
The example dashboards are a good starting point for monitoring key metrics, but they do not represent all available metrics. You may need to modify the example dashboards or add other metrics, depending on your infrastructure.
For Grafana to present the dashboards, use the configuration files to:
9.5.2. Deploying Grafana
To deploy Grafana to provide visualizations of Prometheus metrics, apply the example configuration file.
Prerequisites
Procedure
Deploy Grafana:
oc apply -f grafana.yaml- Enable the Grafana dashboards.
9.5.3. Enabling the example Grafana dashboards
Set up a Prometheus data source and example dashboards to enable Grafana for monitoring.
No alert notification rules are defined.
When accessing a dashboard, you can use the port-forward command to forward traffic from the Grafana pod to the host.
For example, you can access the Grafana user interface by:
-
Running
oc port-forward grafana-1-fbl7s 3000:3000 -
Pointing a browser to
http://localhost:3000
The name of the Grafana pod is different for each user.
Procedure
Access the Grafana user interface using
admin/admincredentials.On the initial view choose to reset the password.

Click the Add data source button.
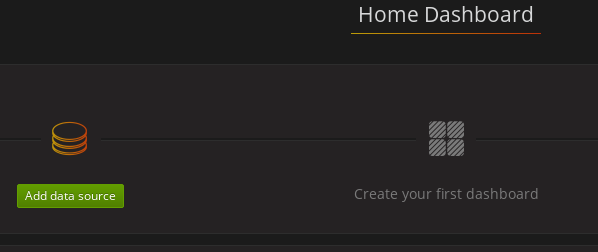
Add Prometheus as a data source.
- Specify a name
- Add Prometheus as the type
- Specify the connection string to the Prometheus server (http://prometheus-operated:9090) in the URL field
Click Add to test the connection to the data source.
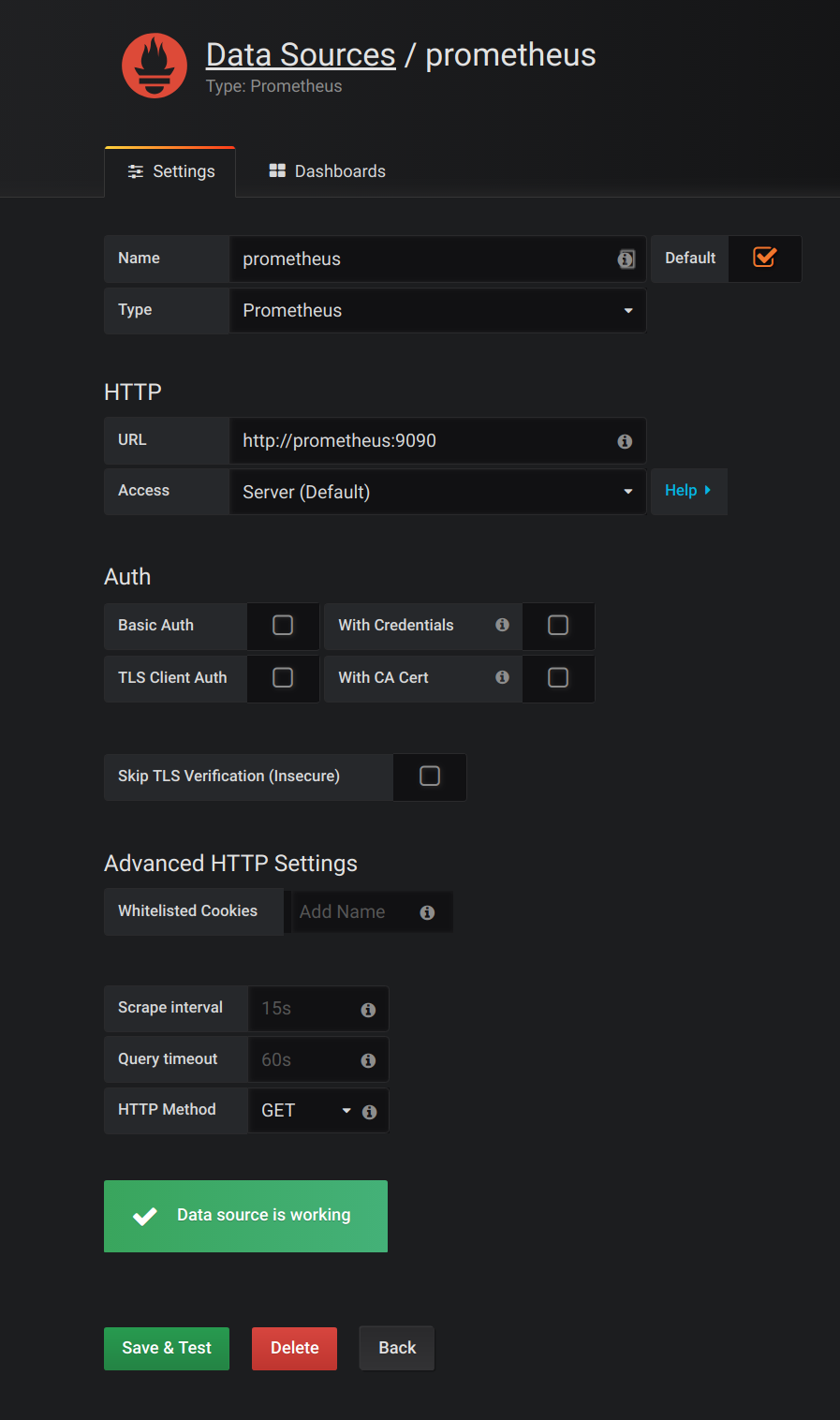
Click Dashboards, then Import to open the Import Dashboard window and import the example dashboards (or paste the JSON).
After importing the dashboards, the Grafana dashboard homepage presents Kafka and Zookeeper dashboards.
When the Prometheus server has been collecting metrics for a AMQ Streams cluster for some time, the dashboards are populated.
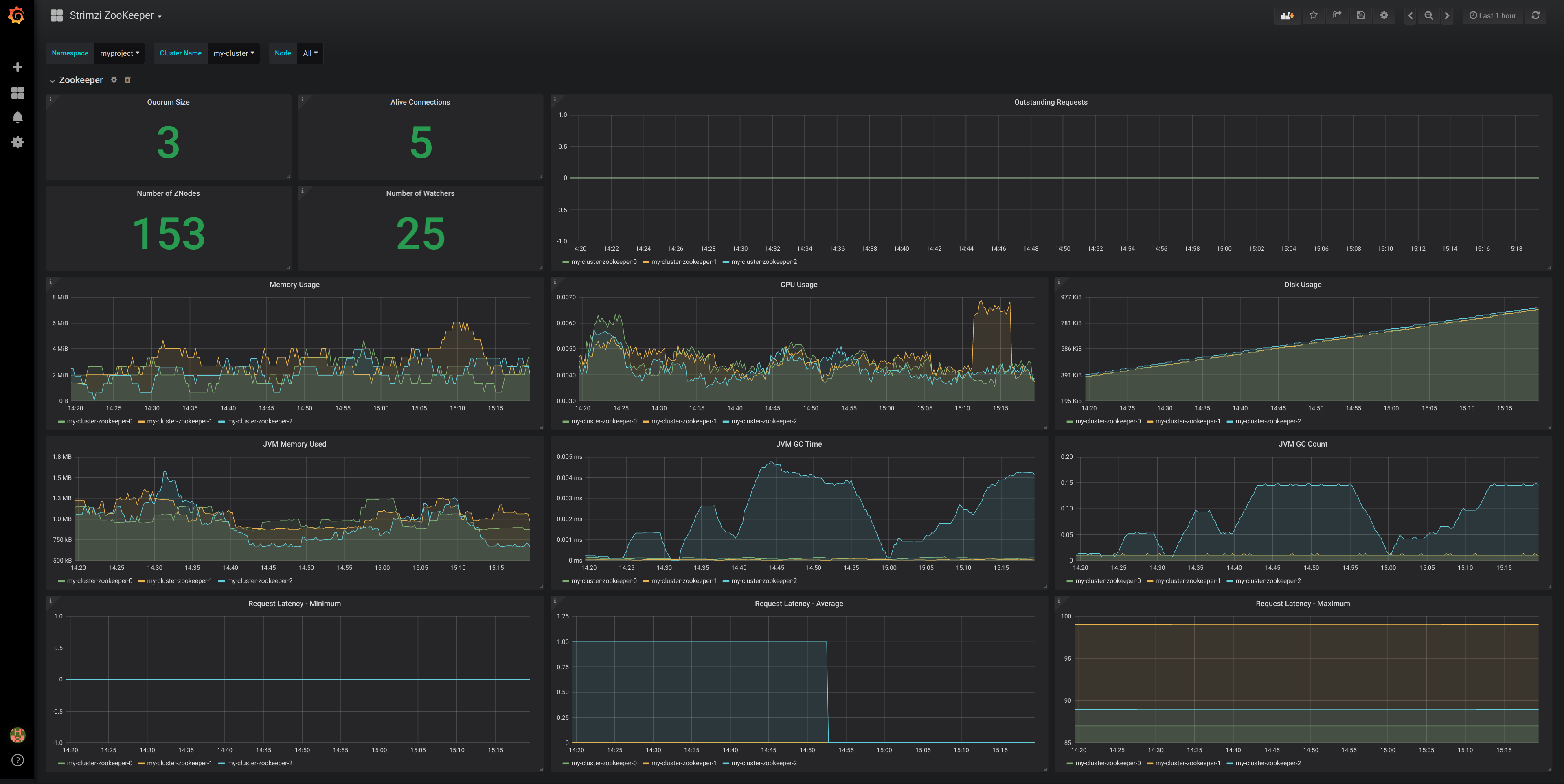
Figure 9.1. Kafka dashboard
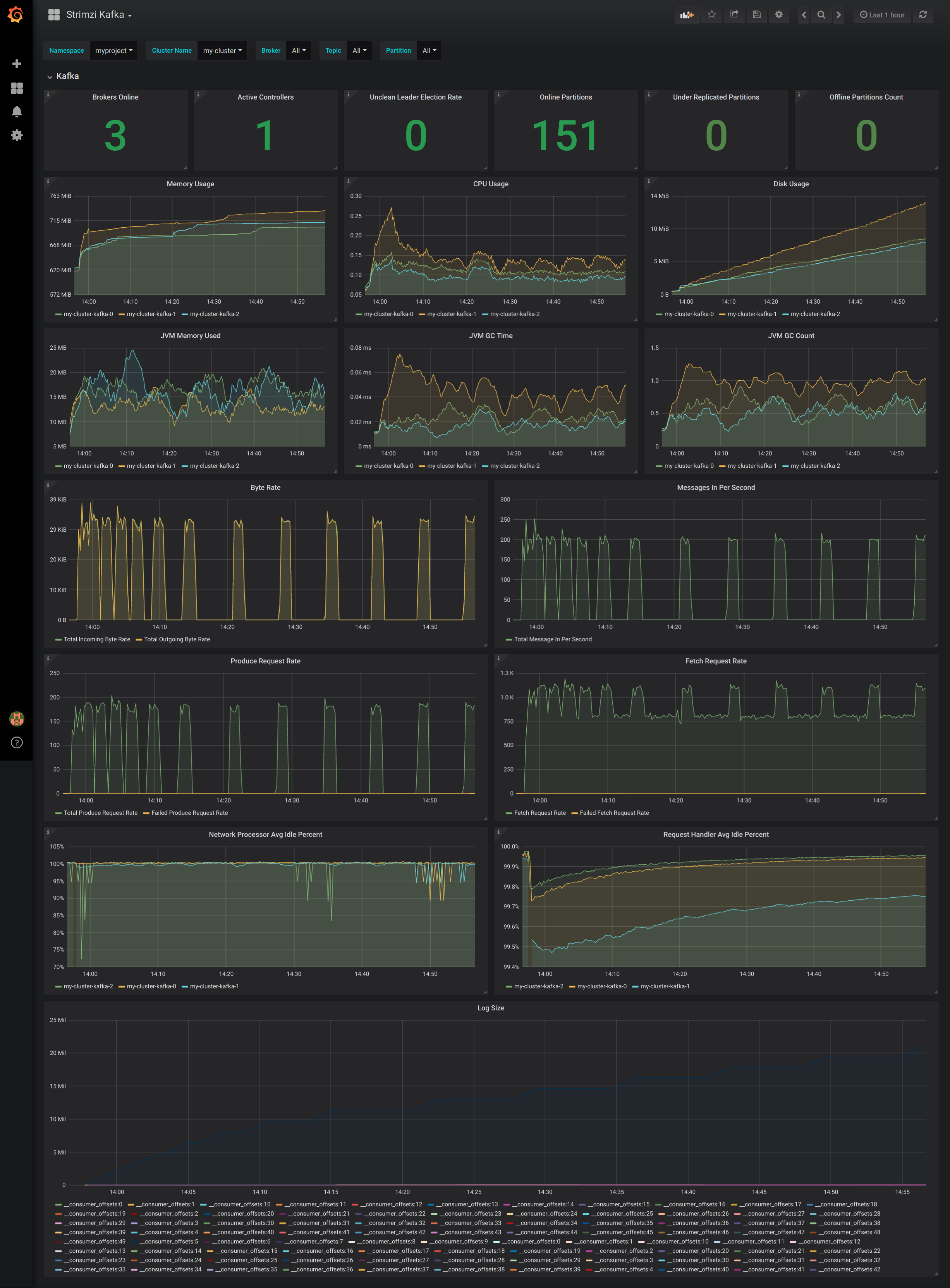
Figure 9.2. Zookeeper dashboard