Chapter 2. CRUSH Administration
The CRUSH (Controlled Replication Under Scalable Hashing) algorithm determines how to store and retrieve data by computing data storage locations.
Any sufficiently advanced technology is indistinguishable from magic. | ||
| -- Arthur C. Clarke | ||
2.1. Introducing CRUSH
The CRUSH map for your storage cluster describes your device locations within CRUSH hierarchies and a rule for each hierarchy that determines how Ceph stores data.
The CRUSH map contains at least one hierarchy of nodes and leaves. The nodes of a hierarchy, called "buckets" in Ceph, are any aggregation of storage locations as defined by their type. For example, rows, racks, chassis, hosts, and devices. Each leaf of the hierarchy consists essentially of one of the storage devices in the list of storage devices. A leaf is always contained in one node or "bucket." A CRUSH map also has a list of rules that determine how CRUSH stores and retrieves data.
Storage devices are added to the CRUSH map when adding an OSD to the cluster.
The CRUSH algorithm distributes data objects among storage devices according to a per-device weight value, approximating a uniform probability distribution. CRUSH distributes objects and their replicas or erasure-coding chunks according to the hierarchical cluster map an administrator defines. The CRUSH map represents the available storage devices and the logical buckets that contain them for the rule, and by extension each pool that uses the rule.
To map placement groups to OSDs across failure domains or performance domains, a CRUSH map defines a hierarchical list of bucket types; that is, under types in the generated CRUSH map. The purpose of creating a bucket hierarchy is to segregate the leaf nodes by their failure domains or performance domains or both. Failure domains include hosts, chassis, racks, power distribution units, pods, rows, rooms, and data centers. Performance domains include failure domains and OSDs of a particular configuration. For example, SSDs, SAS drives with SSD journals, SATA drives, and so on. In RHCS 3, devices have the notion of a class, such as hdd, ssd and nvme to more rapidly build CRUSH hierarchies with a class of devices.
With the exception of the leaf nodes representing OSDs, the rest of the hierarchy is arbitrary, and you can define it according to your own needs if the default types do not suit your requirements. We recommend adapting your CRUSH map bucket types to your organization’s hardware naming conventions and using instance names that reflect the physical hardware names. Your naming practice can make it easier to administer the cluster and troubleshoot problems when an OSD or other hardware malfunctions and the administrator needs remote or physical access to the host or other hardware.
In the following example, the bucket hierarchy has four leaf buckets (osd 1-4), two node buckets (host 1-2) and one rack node (rack 1).
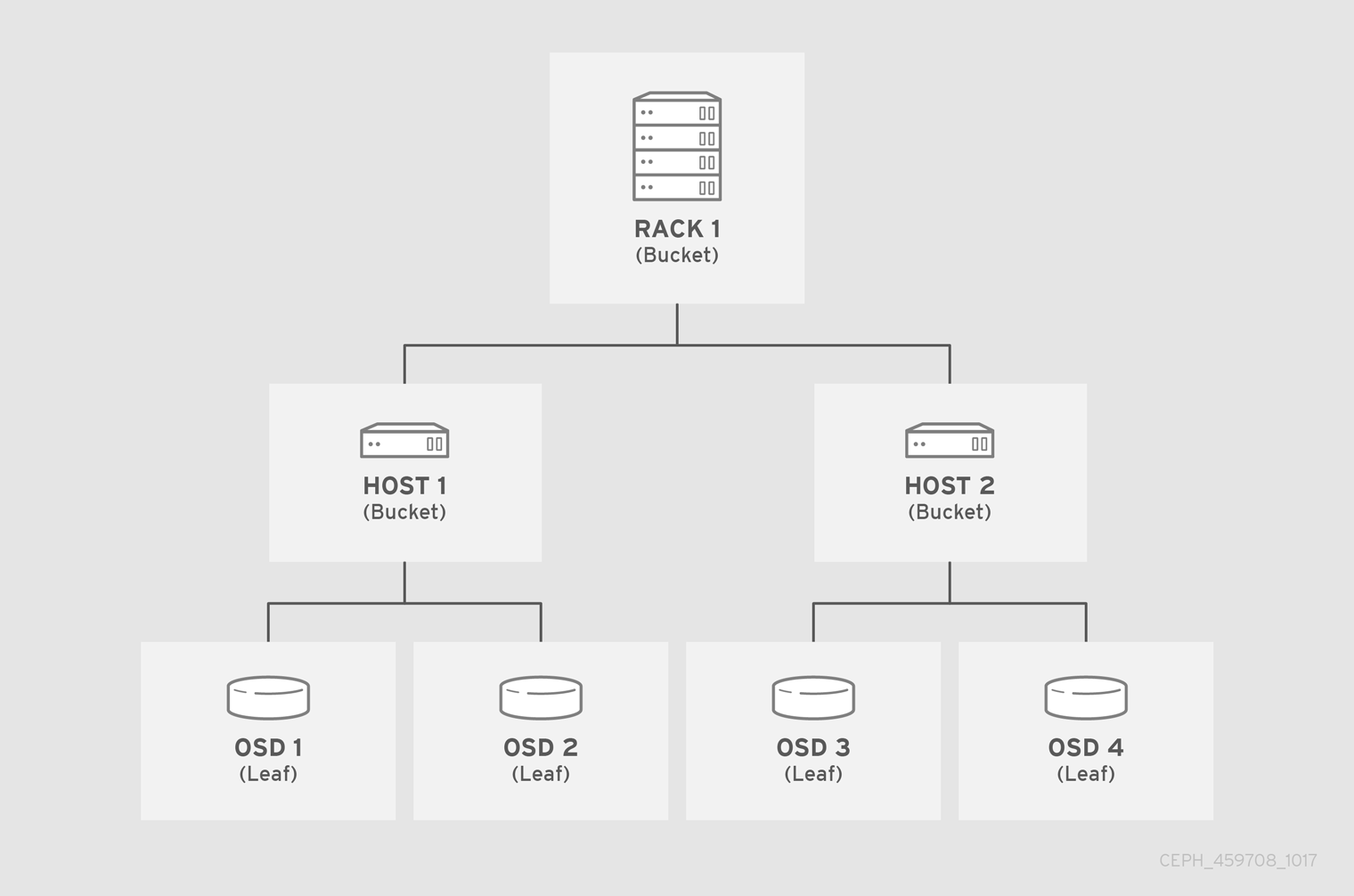
Since leaf nodes reflect storage devices declared under the devices list at the beginning of the CRUSH map, there is no need to declare them as bucket instances. The second lowest bucket type in the hierarchy usually aggregates the devices; that is, it is usually the computer containing the storage media, and uses whatever term administrators prefer to describe it, such as "node", "computer", "server," "host", "machine", and so on. In high density environments, it is increasingly common to see multiple hosts/nodes per card and per chassis. Make sure to account for card and chassis failure too, for example, the need to pull a card or chassis if a node fails can result in bringing down numerous hosts/nodes and their OSDs.
When declaring a bucket instance, specify its type, give it a unique name as a string, assign it an optional unique ID expressed as a negative integer, specify a weight relative to the total capacity or capability of its items, specify the bucket algorithm such as straw, and the hash that is usually 0 reflecting hash algorithm rjenkins1. A bucket can have one or more items. The items can consist of node buckets or leaves. Items can have a weight that reflects the relative weight of the item.
2.1.1. Placing Data Dynamically
Ceph Clients and Ceph OSDs both use the CRUSH map and the CRUSH algorithm.
- Ceph Clients: By distributing CRUSH maps to Ceph clients, CRUSH empowers Ceph clients to communicate with OSDs directly. This means that Ceph clients avoid a centralized object look-up table that could act as a single point of failure, a performance bottleneck, a connection limitation at a centralized look-up server and a physical limit to the storage cluster’s scalability.
- Ceph OSDs: By distributing CRUSH maps to Ceph OSDs, Ceph empowers OSDs to handle replication, backfilling and recovery. This means that the Ceph OSDs handle storage of object replicas (or coding chunks) on behalf of the Ceph client. It also means that Ceph OSDs know enough about the cluster to re-balance the cluster (backfilling) and recover from failures dynamically.
2.1.2. Establishing Failure Domains
Having multiple object replicas or M erasure coding chunks helps prevent data loss, but it is not sufficient to address high availability. By reflecting the underlying physical organization of the Ceph Storage Cluster, CRUSH can model—and thereby address—potential sources of correlated device failures. By encoding the cluster’s topology into the cluster map, CRUSH placement policies can separate object replicas or erasure coding chunks across different failure domains while still maintaining the desired pseudo-random distribution. For example, to address the possibility of concurrent failures, it may be desirable to ensure that data replicas or erasure coding chunks are on devices using different shelves, racks, power supplies, controllers or physical locations. This helps to prevent data loss and allows the cluster to operate in a degraded state.
2.1.3. Establishing Performance Domains
Ceph can support multiple hierarchies to separate one type of hardware performance profile from another type of hardware performance profile. For example, CRUSH can create one hierarchy for hard disk drives and another hierarchy for SSDs. Performance domains—hierarchies that take the performance profile of the underlying hardware into consideration—are increasingly popular due to the need to support different performance characteristics. Operationally, these are just CRUSH maps with more than one root type bucket. Use case examples include:
- VMs: Ceph hosts that serve as a back end to cloud platforms like OpenStack, CloudStack, ProxMox or OpenNebula tend to use the most stable and performant filesystem such as XFS on SAS drives with a partitioned high performance SSD for journaling, because XFS does not journal and write simultaneously. To maintain a consistent performance profile, such use cases should aggregate similar hardware in a CRUSH hierarchy.
- Object Storage: Ceph hosts that serve as an object storage back end for S3 and Swift interfaces may take advantage of less expensive storage media such as SATA drives that may not be suitable for VMs—reducing the cost per gigabyte for object storage, while separating more economical storage hosts from more performant ones intended for storing volumes and images on cloud platforms. HTTP tends to be the bottleneck in object storage systems.
- Cold Storage: Systems designed for cold storage—infrequently accessed data, or data retrieval with relaxed performance requirements—may take advantage of less expensive storage media and erasure coding. However, erasure coding may require a bit of additional RAM and CPU, and thus differ in RAM and CPU requirements from a host used for object storage or VMs.
-
SSD-backed Pools: SSDs are expensive, but they provide significant advantages over hard disk drives. SSDs have no seek time and they provide high total throughput. In addition to using SSDs for journaling, a cluster can support SSD-backed pools. Common use cases include high performance SSD pools. For example, it is possible to map the
.rgw.buckets.indexpool for the Ceph Object Gateway to SSDs instead of SATA drives.
In RHCS 3 and later releases, a CRUSH map supports the notion of a device class. Ceph can discover aspects of a storage device and automatically assign a class such as hdd, ssd or nvme. However, CRUSH is not limited to these defaults. For example, CRUSH hierarchies may also be used to separate different types of workloads. For example, an SSD might be used for a journal or write-ahead log, a bucket index or for raw object storage. CRUSH can support different device classes, such as ssd-bucket-index or ssd-object-storage so Ceph does not use the same storage media for different workloads—making performance more predictable and consistent.
2.1.3.1. Using Different Device Classes in RHCS 2 and Earlier
The notion of device classes does not exist in RHCS 2 and earlier. In order to use different classes of storage drives in RHCS 2 and earlier, such as SSDs and SATA drives, create pools that will point to the SSD and SATA drives. The data going to these pools must be segregated by creating separate root hierarchies for the SSD and SATA drives respectively. The CRUSH map must define one hierarchy for SSDs and one hierarchy for SATA drives. SSDs and SATA drives may reside on the same hosts, or in separate hosts.
Once the two CRUSH hierarchies exist, create separate rules for the SSD and SATA hierarchies and set the respective pools to use the appropriate ruleset.
- NOTE
-
Red Hat does not support the notion of
rulesetin RHCS 3.0 and later releases. See RHCS 2 documentation for details on CRUSH rulesets.
To achieve this, modify the CRUSH map (decompile the CRUSH map to modify—see the Decompile a CRUSH Map section for further details). Create two different root or entry points from which the CRUSH algorithm will go through to store objects. There will be one root for SSD disks and another one for SATA disks. The following example has two SATA disks and two SSD disks on each host, and three hosts in total. In a way, CRUSH thinks there are two different platforms.
CRUSH map example:
##
# OSD SATA DECLARATION
##
host ceph-osd2-sata {
id -2 # do not change unnecessarily
# weight 2.000
alg straw
hash 0 # rjenkins1
item osd.0 weight 1.000
item osd.3 weight 1.000
}
host ceph-osd1-sata {
id -3 # do not change unnecessarily
# weight 2.000
alg straw
hash 0 # rjenkins1
item osd.2 weight 1.000
item osd.5 weight 1.000
}
host ceph-osd0-sata {
id -4 # do not change unnecessarily
# weight 2.000
alg straw
hash 0 # rjenkins1
item osd.1 weight 1.000
item osd.4 weight 1.000
}
##
# OSD SSD DECLARATION
##
host ceph-osd2-ssd {
id -22 # do not change unnecessarily
# weight 2.000
alg straw
hash 0 # rjenkins1
item osd.6 weight 1.000
item osd.9 weight 1.000
}
host ceph-osd1-ssd {
id -23 # do not change unnecessarily
# weight 2.000
alg straw
hash 0 # rjenkins1
item osd.8 weight 1.000
item osd.11 weight 1.000
}
host ceph-osd0-ssd {
id -24 # do not change unnecessarily
# weight 2.000
alg straw
hash 0 # rjenkins1
item osd.7 weight 1.000
item osd.10 weight 1.000
}Create two roots containing the OSDs:
## # SATA ROOT DECLARATION ## root sata { id -1 # do not change unnecessarily # weight 6.000 alg straw hash 0 # rjenkins1 item ceph-osd2-sata weight 2.000 item ceph-osd1-sata weight 2.000 item ceph-osd0-sata weight 2.000 } ## # SATA ROOT DECLARATION ## root ssd { id -21 # do not change unnecessarily # weight 6.000 alg straw hash 0 # rjenkins1 item ceph-osd2-ssd weight 2.000 item ceph-osd1-ssd weight 2.000 item ceph-osd0-ssd weight 2.000 }Create two new rules for the SSDs:
## # SSD RULE DECLARATION ## # rules rule ssd { ruleset 0 type replicated min_size 1 max_size 10 step take ssd step chooseleaf firstn 0 type host step emit } ## # SATA RULE DECLARATION ## rule sata { ruleset 1 type replicated min_size 1 max_size 10 step take sata step chooseleaf firstn 0 type host step emit }Compile and inject the new map:
$ crushtool -c lamap.txt -o lamap.coloc $ sudo ceph osd setcrushmap -i lamap.colocSee the result:
$ sudo ceph osd tree # id weight type name up/down reweight -21 12 root ssd -22 2 host ceph-osd2-ssd 6 1 osd.6 up 1 9 1 osd.9 up 1 -23 2 host ceph-osd1-ssd 8 1 osd.8 up 1 11 1 osd.11 up 1 -24 2 host ceph-osd0-ssd 7 1 osd.7 up 1 10 1 osd.10 up 1 -1 12 root sata -2 2 host ceph-osd2-sata 0 1 osd.0 up 1 3 1 osd.3 up 1 -3 2 host ceph-osd1-sata 2 1 osd.2 up 1 5 1 osd.5 up 1 -4 2 host ceph-osd0-sata 1 1 osd.1 up 1 4 1 osd.4 up 1
Now work on the pools.
Create the pools:
pool
ssd:root@ceph-mon0:~# ceph osd pool create ssd 128 128pool
sata:root@ceph-mon0:~# ceph osd pool create sata 128 128Assign rules to the pools:
Set pool 8 crush_ruleset to 0:
root@ceph-mon0:~# ceph osd pool set ssd crush_ruleset 0Set pool 9 crush_ruleset to 1:
root@ceph-mon0:~# ceph osd pool set sata crush_ruleset 1Result from
ceph osd dump:pool 8 'ssd' replicated size 2 min_size 1 crush_ruleset 0 object_hash rjenkins pg_num 128 pgp_num 128 last_change 116 flags hashpspool stripe_width 0 pool 9 'sata' replicated size 2 min_size 1 crush_ruleset 1 object_hash rjenkins pg_num 128 pgp_num 128 last_change 117 flags hashpspool stripe_width 0
To prevent the moved OSDs from moving back to their default CRUSH locations upon restart of the service, disable updating the CRUSH map on start of the daemon using osd crush update on start = false.
2.1.3.2. Using Different Device Classes in RHCS 3 and Later
To create performance domains in RHCS 3, use device classes and a single CRUSH hierarchy. Simply add OSDs to the CRUSH hierarchy in the same manner as RHCS 2 using the CLI. Then do the following:
Add a class to each device. For example:
# ceph osd crush set-device-class <class> <osdId> [<osdId>] # ceph osd crush set-device-class hdd osd.0 osd.1 osd.4 osd.5 # ceph osd crush set-device-class ssd osd.2 osd.3 osd.6 osd.7Then, create rules to use the devices.
# ceph osd crush rule create-replicated <rule-name> <root> <failure-domain-type> <class> # ceph osd crush rule create-replicated cold default host hdd # ceph osd crush rule create-replicated hot default host ssdFinally, set pools to use the rules.
ceph osd pool set <poolname> crush_rule <rule-name> ceph osd pool set cold_tier crush_rule cold ceph osd pool set hot_tier crush_rule hot
With RHCS 3 and later, there is no need to manually edit the CRUSH map!
2.2. CRUSH Hierarchies
The CRUSH map is a directed acyclic graph, so it can accommodate multiple hierarchies (for example, performance domains). The easiest way to create and modify a CRUSH hierarchy is with the Ceph CLI; however, you can also decompile a CRUSH map, edit it, recompile it, and activate it.
When declaring a bucket instance with the Ceph CLI, you must specify its type and give it a unique name (string). Ceph automatically assigns a bucket ID, set the algorithm to straw, set the hash to 0 reflecting rjenkins1 and set a weight. When modifying a decompiled CRUSH map, assign the bucket a unique ID expressed as a negative integer (optional), specify a weight relative to the total capacity/capability of its item(s), specify the bucket algorithm (usually straw), and the hash (usually 0, reflecting hash algorithm rjenkins1).
A bucket can have one or more items. The items can consist of node buckets (for example, racks, rows, hosts) or leaves (for example, an OSD disk). Items can have a weight that reflects the relative weight of the item.
When modifying a decompiled CRUSH map, you can declare a node bucket with the following syntax:
[bucket-type] [bucket-name] {
id [a unique negative numeric ID]
weight [the relative capacity/capability of the item(s)]
alg [the bucket type: uniform | list | tree | straw ]
hash [the hash type: 0 by default]
item [item-name] weight [weight]
}For example, using the diagram above, we would define two host buckets and one rack bucket. The OSDs are declared as items within the host buckets:
host node1 {
id -1
alg straw
hash 0
item osd.0 weight 1.00
item osd.1 weight 1.00
}
host node2 {
id -2
alg straw
hash 0
item osd.2 weight 1.00
item osd.3 weight 1.00
}
rack rack1 {
id -3
alg straw
hash 0
item node1 weight 2.00
item node2 weight 2.00
}In the foregoing example, note that the rack bucket does not contain any OSDs. Rather it contains lower level host buckets, and includes the sum total of their weight in the item entry.
2.2.1. CRUSH Location
A CRUSH location is the position of an OSD in terms of the CRUSH map’s hierarchy. When you express a CRUSH location on the command line interface, a CRUSH location specifier takes the form of a list of name/value pairs describing the OSD’s position. For example, if an OSD is in a particular row, rack, chassis and host, and is part of the default CRUSH tree, its crush location could be described as:
root=default row=a rack=a2 chassis=a2a host=a2a1Note:
- The order of the keys does not matter.
-
The key name (left of
=) must be a valid CRUSHtype. By default these includeroot,datacenter,room,row,pod,pdu,rack,chassisandhost. You may edit the CRUSH map to change the types to suit your needs. -
You do not need to specify all the buckets/keys. For example, by default, Ceph automatically sets a
ceph-osddaemon’s location to beroot=default host={HOSTNAME}(based on the output fromhostname -s).
2.2.1.1. Default ceph-crush-location Hook
Upon startup, Ceph gets the CRUSH location of each daemon using the ceph-crush-location tool by default. The ceph-crush-location utility returns the CRUSH location of a given daemon. Its CLI usage consists of:
ceph-crush-location --cluster {cluster-name} --id {ID} --type {daemon-type}
For example, the following command returns the location of OSD.0:
ceph-crush-location --cluster ceph --id 0 --type osd
By default, the ceph-crush-location utility returns a CRUSH location string for a given daemon. The location returned in order of precedence is based on:
-
A
{TYPE}_crush_locationoption in the Ceph configuration file. For example, for OSD daemons,{TYPE}would beosdand the setting would look likeosd_crush_location. -
A
crush_locationoption for a particular daemon in the Ceph configuration file. -
A default of
root=default host=HOSTNAMEwhere the host name is returned by thehostname -scommand.
In a typical deployment scenario, provisioning software (or the system administrator) can simply set the crush_location field in a host’s Ceph configuration file to describe that machine’s location within the datacenter or cluster. This provides location awareness to Ceph daemons and clients alike.
2.2.1.2. Custom Location Hooks
A custom location hook can be used in place of the generic hook for OSD daemon placement in the hierarchy. (On startup, each OSD ensures its position is correct.):
osd_crush_location_hook = /path/to/script
This hook is passed several arguments (below) and should output a single line to stdout with the CRUSH location description.:
ceph-crush-location --cluster {cluster-name} --id {ID} --type {daemon-type}
where the --cluster name is typically 'ceph', the --id is the daemon identifier (the OSD number), and the daemon --type is typically osd.
2.2.2. Adding a Bucket
To add a bucket instance to your CRUSH hierarchy, specify the bucket name and its type. Bucket names must be unique in the CRUSH map.
ceph osd crush add-bucket {name} {type}If you plan to use multiple hierarchies, for example, for different hardware performance profiles, consider naming buckets based on their type of hardware or use case.
For example, you could create a hierarchy for solid state drives (ssd), a hierarchy for SAS disks with SSD journals (hdd-journal), and another hierarchy for SATA drives (hdd):
ceph osd crush add-bucket ssd-root root
ceph osd crush add-bucket hdd-journal-root root
ceph osd crush add-bucket hdd-root rootThe Ceph CLI outputs:
added bucket ssd-root type root to crush map
added bucket hdd-journal-root type root to crush map
added bucket hdd-root type root to crush mapUsing colons (:) in bucket names is not supported.
Add an instance of each bucket type you need for your hierarchy. The following example demonstrates adding buckets for a row with a rack of SSD hosts and a rack of hosts for object storage.
ceph osd crush add-bucket ssd-row1 row
ceph osd crush add-bucket ssd-row1-rack1 rack
ceph osd crush add-bucket ssd-row1-rack1-host1 host
ceph osd crush add-bucket ssd-row1-rack1-host2 host
ceph osd crush add-bucket hdd-row1 row
ceph osd crush add-bucket hdd-row1-rack2 rack
ceph osd crush add-bucket hdd-row1-rack1-host1 host
ceph osd crush add-bucket hdd-row1-rack1-host2 host
ceph osd crush add-bucket hdd-row1-rack1-host3 host
ceph osd crush add-bucket hdd-row1-rack1-host4 hostIf you have already used the Ansible automation application or another tool to add OSDs to your cluster, the host nodes can already be in the CRUSH map.
Once you have completed these steps, view your tree.
ceph osd treeNotice that the hierarchy remains flat. You must move your buckets into hierarchical position after you add them to the CRUSH map.
2.2.3. Moving a Bucket
When you create your initial cluster, Ceph has a default CRUSH map with a root bucket named default and your initial OSD hosts appear under the default bucket. When you add a bucket instance to your CRUSH map, it appears in the CRUSH hierarchy, but it does not necessarily appear under a particular bucket.
To move a bucket instance to a particular location in your CRUSH hierarchy, specify the bucket name and its type. For example:
ceph osd crush move ssd-row1 root=ssd-root
ceph osd crush move ssd-row1-rack1 row=ssd-row1
ceph osd crush move ssd-row1-rack1-host1 rack=ssd-row1-rack1
ceph osd crush move ssd-row1-rack1-host2 rack=ssd-row1-rack1Once you have completed these steps, you can view your tree.
ceph osd tree
You can also use ceph osd crush create-or-move to create a location while moving an OSD.
2.2.4. Removing a Bucket
To remove a bucket instance from your CRUSH hierarchy, specify the bucket name. For example:
ceph osd crush remove {bucket-name}Or:
ceph osd crush rm {bucket-name}The bucket must be empty in order to remove it.
If you are removing higher level buckets (for example, a root like default), check to see if a pool uses a CRUSH rule that selects that bucket. If so, you need to modify your CRUSH rules; otherwise, peering fails.
2.2.5. Bucket Algorithms
When you create buckets using the Ceph CLI, Ceph sets the algorithm to straw by default. Ceph supports four bucket algorithms, each representing a tradeoff between performance and reorganization efficiency. If you are unsure of which bucket type to use, we recommend using a straw bucket. The bucket algorithms are:
-
Uniform: Uniform buckets aggregate devices with exactly the same weight. For example, when firms commission or decommission hardware, they typically do so with many machines that have exactly the same physical configuration (for example, bulk purchases). When storage devices have exactly the same weight, you can use the
uniformbucket type, which allows CRUSH to map replicas into uniform buckets in constant time. With non-uniform weights, you should use another bucket algorithm. - List: List buckets aggregate their content as linked lists. Based on the RUSH (Replication Under Scalable Hashing) P algorithm, a list is a natural and intuitive choice for an expanding cluster: either an object is relocated to the newest device with some appropriate probability, or it remains on the older devices as before. The result is optimal data migration when items are added to the bucket. Items removed from the middle or tail of the list, however, can result in a significant amount of unnecessary movement, making list buckets most suitable for circumstances in which they never (or very rarely) shrink.
- Tree: Tree buckets use a binary search tree. They are more efficient than list buckets when a bucket contains a larger set of items. Based on the RUSH (Replication Under Scalable Hashing) R algorithm, tree buckets reduce the placement time to O(log n), making them suitable for managing much larger sets of devices or nested buckets.
- Straw (default): List and Tree buckets use a divide and conquer strategy in a way that either gives certain items precedence (for example, those at the beginning of a list) or obviates the need to consider entire subtrees of items at all. That improves the performance of the replica placement process, but can also introduce suboptimal reorganization behavior when the contents of a bucket change due an addition, removal, or re-weighting of an item. The straw bucket type allows all items to fairly “compete” against each other for replica placement through a process analogous to a draw of straws.
2.3. Ceph OSDs in CRUSH
Once you have a CRUSH hierarchy for the OSDs, add OSDs to the CRUSH hierarchy. You can also move or remove OSDs from an existing hierarchy. The Ceph CLI usage has the following values:
- id
- Description
- The numeric ID of the OSD.
- Type
- Integer
- Required
- Yes
- Example
-
0
- name
- Description
- The full name of the OSD.
- Type
- String
- Required
- Yes
- Example
-
osd.0
- weight
- Description
- The CRUSH weight for the OSD.
- Type
- Double
- Required
- Yes
- Example
-
2.0
- root
- Description
- The name of the root bucket of the hierarchy or tree in which the OSD resides.
- Type
- Key-value pair.
- Required
- Yes
- Example
-
root=default,root=replicated_rule, and so on
- bucket-type
- Description
- One or more name-value pairs, where the name is the bucket type and the value is the bucket’s name. You can specify a CRUSH location for an OSD in the CRUSH hierarchy.
- Type
- Key-value pairs.
- Required
- No
- Example
-
datacenter=dc1 room=room1 row=foo rack=bar host=foo-bar-1
2.3.1. Viewing OSDs in CRUSH
The ceph osd crush tree command prints CRUSH buckets and items in a tree view. Use this command to determine a list of OSDs in a particular bucket. It will print output similar to ceph osd tree.
To return additional details, execute the following:
# ceph osd crush tree -f json-prettyThe command returns an output similar to the following:
[
{
"id": -2,
"name": "ssd",
"type": "root",
"type_id": 10,
"items": [
{
"id": -6,
"name": "dell-per630-11-ssd",
"type": "host",
"type_id": 1,
"items": [
{
"id": 6,
"name": "osd.6",
"type": "osd",
"type_id": 0,
"crush_weight": 0.099991,
"depth": 2
}
]
},
{
"id": -7,
"name": "dell-per630-12-ssd",
"type": "host",
"type_id": 1,
"items": [
{
"id": 7,
"name": "osd.7",
"type": "osd",
"type_id": 0,
"crush_weight": 0.099991,
"depth": 2
}
]
},
{
"id": -8,
"name": "dell-per630-13-ssd",
"type": "host",
"type_id": 1,
"items": [
{
"id": 8,
"name": "osd.8",
"type": "osd",
"type_id": 0,
"crush_weight": 0.099991,
"depth": 2
}
]
}
]
},
{
"id": -1,
"name": "default",
"type": "root",
"type_id": 10,
"items": [
{
"id": -3,
"name": "dell-per630-11",
"type": "host",
"type_id": 1,
"items": [
{
"id": 0,
"name": "osd.0",
"type": "osd",
"type_id": 0,
"crush_weight": 0.449997,
"depth": 2
},
{
"id": 3,
"name": "osd.3",
"type": "osd",
"type_id": 0,
"crush_weight": 0.289993,
"depth": 2
}
]
},
{
"id": -4,
"name": "dell-per630-12",
"type": "host",
"type_id": 1,
"items": [
{
"id": 1,
"name": "osd.1",
"type": "osd",
"type_id": 0,
"crush_weight": 0.449997,
"depth": 2
},
{
"id": 4,
"name": "osd.4",
"type": "osd",
"type_id": 0,
"crush_weight": 0.289993,
"depth": 2
}
]
},
{
"id": -5,
"name": "dell-per630-13",
"type": "host",
"type_id": 1,
"items": [
{
"id": 2,
"name": "osd.2",
"type": "osd",
"type_id": 0,
"crush_weight": 0.449997,
"depth": 2
},
{
"id": 5,
"name": "osd.5",
"type": "osd",
"type_id": 0,
"crush_weight": 0.289993,
"depth": 2
}
]
}
]
}
]
In RHCS 3 and later, an OSD object will also have a device_class attribute.
2.3.2. Adding an OSD to CRUSH
Adding an OSD to a CRUSH hierarchy is the final step before you may start an OSD (rendering it up and in) and Ceph assigns placement groups to the OSD.
In RHCS 3, you may also add a device class.
You must prepare an OSD before you add it to the CRUSH hierarchy. Deployment utilities, such the Ansible automation application, performs this step for you. See Adding/Removing OSDs for additional details.
The CRUSH hierarchy is notional, so the ceph osd crush add command allows you to add OSDs to the CRUSH hierarchy wherever you wish. The location you specify should reflect its actual location. If you specify at least one bucket, the command places the OSD into the most specific bucket you specify, and it moves that bucket underneath any other buckets you specify.
To add an OSD to a CRUSH hierarchy:
ceph osd crush add {id-or-name} {weight} [{bucket-type}={bucket-name} ...]If you specify only the root bucket, the command attaches the OSD directly to the root. However, CRUSH rules expect OSDs to be inside of hosts or chassis, and host or chassis should be inside of other buckets reflecting your cluster topology.
The following example adds osd.0 to the hierarchy:
ceph osd crush add osd.0 1.0 root=default datacenter=dc1 room=room1 row=foo rack=bar host=foo-bar-1
You can also use ceph osd crush set or ceph osd crush create-or-move to add an OSD to the CRUSH hierarchy.
2.3.3. Moving an OSD within a CRUSH Hierarchy
If the deployment utility, such as the Ansible automation application added an OSD to the CRUSH map at a sub-optimal CRUSH location, or if your cluster topology changes, you can move an OSD in the CRUSH hierarchy to reflect its actual location.
Moving an OSD in the CRUSH hierarchy means that Ceph will recompute which placement groups get assigned to the OSD, potentially resulting in significant redistribution of data.
To move an OSD within the CRUSH hierarchy:
ceph osd crush set {id-or-name} {weight} root={pool-name} [{bucket-type}={bucket-name} ...]
You can also use ceph osd crush create-or-move to move an OSD within the CRUSH hierarchy.
2.3.4. Removing an OSD from a CRUSH Hierarchy
Removing an OSD from a CRUSH hierarchy is the first step when you want to remove an OSD from your cluster. When you remove the OSD from the CRUSH map, CRUSH recomputes which OSDs get the placement groups and data re-balances accordingly. See Adding/Removing OSDs for additional details.
To remove an OSD from the CRUSH map of a running cluster, execute the following:
ceph osd crush remove {name}2.4. Device Classes
Ceph’s CRUSH map provides extraordinary flexibility in controlling data placement. This is one of Ceph’s greatest strengths. Early Ceph deployments used hard disk drives almost exclusively. Today, Ceph clusters are frequently built with multiple types of storage devices: HDD, SSD, NVMe, or even various classes of the foregoing. For example, it is common in Ceph Object Gateway deployments to have storage policies where clients can store data on slower HDDs and other storage policies for storing data on fast SSDs. Ceph Object Gateway deployments may even have a pool backed by fast SSDs for bucket indices. Additionally, OSD nodes also frequently have SSDs used exclusively for journals or write-ahead logs that do NOT appear in the CRUSH map. These complex hardware scenarios historically required manually editing the CRUSH map, which can be time-consuming and tedious. In RHCS 3, Red Hat has added a new 'device class', which dramatically simplifies creating CRUSH hierarchies, In RHCS 3 and beyond, it is no longer required to have different CRUSH hierarchies for different classes of storage devices.
CRUSH rules work in terms of the CRUSH hierarchy. However, if different classes of storage devices reside in the same hosts, the process became more complicated—requiring users to create multiple CRUSH hierarchies for each class of device, and then disable the osd crush update on start option that automates much of the CRUSH hierarchy management. Device classes eliminate this tediousness by telling the CRUSH rule what class of device to use, dramatically simplifying CRUSH management tasks.
In RHCS 3 and later, the ceph osd tree command has a column reflecting a device class.
The following sections detail device class usage. See Using Different Device Classes in RHCS 3 and Later and CRUSH Storage Strategy Examples for additional examples.
2.4.1. Setting a Device Class
To set a device class for an OSD, execute the following:
# ceph osd crush set-device-class <class> <osdId> [<osdId>...]For example:
# ceph osd crush set-device-class hdd osd.0 osd.1
# ceph osd crush set-device-class ssd osd.2 osd.3
# ceph osd crush set-device-class bucket-index osd.4
Ceph may assign a class to a device automatically. However, class names are simply arbitrary strings. There is no requirement to adhere to hdd, ssd or nvme. In the foregoing example, a device class named bucket-index may indicate an SSD device that a Ceph Object Gatway pool uses exclusively bucket index workloads. To change a device class that was already set, use ceph osd crush rm-device-class first.
2.4.2. Removing a Device Class
To remove a device class for an OSD, execute the following:
# ceph osd crush rm-device-class <class> <osdId> [<osdId>...]For example:
# ceph osd crush rm-device-class hdd osd.0 osd.1
# ceph osd crush rm-device-class ssd osd.2 osd.3
# ceph osd crush rm-device-class bucket-index osd.42.4.3. Renaming a Device Class
To rename a device class for all OSDs that use that class, execute the following:
# ceph osd crush class rename <oldName> <newName>For example:
# ceph osd crush class rename hdd sas15k2.4.4. Listing Device Classes
To list device classes in the CRUSH map, execute the following:
# ceph osd crush class lsThe output will look something like this:
[
"hdd",
"ssd",
"bucket-index"
]2.4.5. Listing OSDs of a Device Class
To list all OSDs that belong to a particular class, execute the following:
# ceph osd crush class ls-osd <class>For example:
# ceph osd crush class ls-osd hddThe output is simply a list of OSD numbers. For example:
0
1
2
3
4
5
62.4.6. Listing CRUSH Rules by Class
To list all crush rules that reference the same class, execute the following:
# ceph osd crush rule ls-by-class <class>For example:
# ceph osd crush rule ls-by-class hdd2.5. CRUSH Weights
The CRUSH algorithm assigns a weight value in terabytes (by convention) per OSD device with the objective of approximating a uniform probability distribution for write requests that assign new data objects to PGs and PGs to OSDs. For this reason, as a best practice, we recommend creating CRUSH hierarchies with devices of the same type and size, and assigning the same weight. We also recommend using devices with the same I/O and throughput characteristics so that you will also have uniform performance characteristics in your CRUSH hierarchy, even though performance characteristics do not affect data distribution.
Since using uniform hardware is not always practical, you may incorporate OSD devices of different sizes and use a relative weight so that Ceph will distribute more data to larger devices and less data to smaller devices.
2.5.1. Set an OSD’s Weight in Terabytes
To set an OSD CRUSH weight in Terabytes within the CRUSH map, execute the following command
ceph osd crush reweight {name} {weight}Where:
- name
- Description
- The full name of the OSD.
- Type
- String
- Required
- Yes
- Example
-
osd.0
- weight
- Description
-
The CRUSH weight for the OSD. This should be the size of the OSD in Terabytes, where
1.0is 1 Terabyte. - Type
- Double
- Required
- Yes
- Example
-
2.0
This setting is used when creating an OSD or adjusting the CRUSH weight immediately after adding the OSD. It usually does not change over the life of the OSD.
2.5.2. Set a Bucket’s OSD Weights
Using ceph osd crush reweight can be time-consuming. You can set (or reset) all Ceph OSD weights under a bucket (row, rack, node, and so on) by executing:
osd crush reweight-subtree <name>Where,
name is the name of the CRUSH bucket.
2.5.3. Set an OSD’s in Weight
For the purposes of ceph osd in and ceph osd out, an OSD is either in the cluster or out of the cluster. That is how a monitor records an OSD’s status. However, even though an OSD is in the cluster, it may be experiencing a malfunction such that you do not want to rely on it as much until you fix it (for example, replace a storage drive, change out a controller, and so on).
You can increase or decrease the in weight of a particular OSD (that is, without changing its weight in Terabytes) by executing:
ceph osd reweight {id} {weight}Where:
-
idis the OSD number. -
weightis a range from 0.0-1.0, where0is notinthe cluster (that is, it does not have any PGs assigned to it) and 1.0 isinthe cluster (that is, the OSD receives the same number of PGs as other OSDs).
2.5.4. Set an OSD’s Weight by Utilization
CRUSH is designed to approximate a uniform probability distribution for write requests that assign new data objects PGs and PGs to OSDs. However, a cluster may become imbalanced anyway. This can happen for a number of reasons. For example:
- Multiple Pools: You can assign multiple pools to a CRUSH hierarchy, but the pools may have different numbers of placement groups, size (number of replicas to store), and object size characteristics.
-
Custom Clients: Ceph clients such as block device, object gateway and filesystem shard data from their clients and stripe the data as objects across the cluster as uniform-sized smaller RADOS objects. So except for the foregoing scenario, CRUSH usually achieves its goal. However, there is another case where a cluster can become imbalanced: namely, using
libradosto store data without normalizing the size of objects. This scenario can lead to imbalanced clusters (for example, storing 100 1MB objects and 10 4MB objects will make a few OSDs have more data than the others). - Probability: A uniform distribution will result in some OSDs with more PGs and some with less. For clusters with a large number of OSDs, the statistical outliers will be further out.
You can reweight OSDs by utilization by executing the following:
ceph osd reweight-by-utilization [threshold] [weight_change_amount] [number_of_OSDs] [--no-increasing]For example:
ceph osd test-reweight-by-utilization 110 .5 4 --no-increasingWhere:
-
thresholdis a percentage of utilization such that OSDs facing higher data storage loads will receive a lower weight and thus fewer PGs assigned to them. The default value is120, reflecting 120%. Any value from100+is a valid threshold. Optional. -
weight_change_amountis the amount to change the weight. Valid values are greater than0.0 - 1.0. The default value is0.05. Optional. -
number_of_OSDsis the maximum number of OSDs to reweight. For large clusters, limiting the number of OSDs to reweight prevents significant rebalancing. Optional. -
no-increasingis off by default. Increasing the osd weight is allowed when using thereweight-by-utilizationortest-reweight-by-utilizationcommands. If this option is used with these commands, it prevent the increasing the OSD weight, even if the OSD is underutilized. Optional.
Executing reweight-by-utilization is recommended and somewhat inevitable for large clusters. Utilization rates may change over time, and as your cluster size or hardware changes, the weightings may need to be updated to reflect changing utilization. If you elect to reweight by utilization, you may need to re-run this command as utilization, hardware or cluster size change.
Executing this or other weight commands that assign a weight will override the weight assigned by this command (for example, osd reweight-by-utilization, osd crush weight, osd weight, in or out).
2.5.5. Set an OSD’s Weight by PG Distribution
In CRUSH hierarchies with a smaller number of OSDs, it’s possible for some OSDs to get more PGs than other OSDs, resulting in a higher load. You can reweight OSDs by PG distribution to address this situation by executing the following:
osd reweight-by-pg <poolname>Where:
-
poolnameis the name of the pool. Ceph will examine how the pool assigns PGs to OSDs and reweight the OSDs according to this pool’s PG distribution. Note that multiple pools could be assigned to the same CRUSH hierarchy. Reweighting OSDs according to one pool’s distribution could have unintended effects for other pools assigned to the same CRUSH hierarchy if they do not have the same size (number of replicas) and PGs.
2.5.6. Recalculate a CRUSH Tree’s Weights
CRUSH tree buckets should be the sum of their leaf weights. If you manually edit the CRUSH map weights, you should execute the following to ensure that the CRUSH bucket tree accurately reflects the sum of the leaf OSDs under the bucket.
osd crush reweight-all2.6. Primary Affinity
When a Ceph Client reads or writes data, it always contacts the primary OSD in the acting set. For set [2, 3, 4], osd.2 is the primary. Sometimes an OSD is not well suited to act as a primary compared to other OSDs (for example, it has a slow disk or a slow controller). To prevent performance bottlenecks (especially on read operations) while maximizing utilization of your hardware, you can set a Ceph OSD’s primary affinity so that CRUSH is less likely to use the OSD as a primary in an acting set. :
ceph osd primary-affinity <osd-id> <weight>
Primary affinity is 1 by default (that is, an OSD may act as a primary). You may set the OSD primary range from 0-1, where 0 means that the OSD may NOT be used as a primary and 1 means that an OSD may be used as a primary. When the weight is < 1, it is less likely that CRUSH will select the Ceph OSD Daemon to act as a primary.
2.7. CRUSH Rules
CRUSH rules define how a Ceph client selects buckets and the primary OSD within them to store object, and how the primary OSD selects buckets and the secondary OSDs to store replicas or coding chunks. For example, you might create a rule that selects a pair of target OSDs backed by SSDs for two object replicas, and another rule that select three target OSDs backed by SAS drives in different data centers for three replicas.
A rule takes the following form:
rule <rulename> {
ruleset <ruleset>
type [ replicated | raid4 ]
min_size <min-size>
max_size <max-size>
step take <bucket-type> [class <class-name>]
step [choose|chooseleaf] [firstn|indep] <N> <bucket-type>
step emit
}- ruleset
- Description
- (Deprecated) A means of classifying a rule as belonging to a set of rules. Activated by setting the ruleset in a pool. Supported in RHCS 2 and earlier releases. Not supported in RHCS 3 and later releases.
- Purpose
- A component of the rule mask.
- Type
- Integer
- Required
- Yes
- Default
-
0
- type
- Description
- Describes a rule for either a storage drive (replicated) or a RAID.
- Purpose
- A component of the rule mask.
- Type
- String
- Required
- Yes
- Default
-
replicated - Valid Values
-
Currently only
replicated
- min_size
- Description
- If a pool makes fewer replicas than this number, CRUSH will not select this rule.
- Type
- Integer
- Purpose
- A component of the rule mask.
- Required
- Yes
- Default
-
1
- max_size
- Description
- If a pool makes more replicas than this number, CRUSH will not select this rule.
- Type
- Integer
- Purpose
- A component of the rule mask.
- Required
- Yes
- Default
-
10
- step take <bucket-name> [class <class-name>]
- Description
- Takes a bucket name, and begins iterating down the tree. May take a device class name in RHCS 3 and later.
- Purpose
- A component of the rule.
- Required
- Yes
- Example
-
step take datastep take data class ssd
- step choose firstn <num> type <bucket-type>
- Description
Selects the number of buckets of the given type. The number is usually the number of replicas in the pool (that is, pool size).
-
If
<num> == 0, choosepool-num-replicasbuckets (all available). -
If
<num> > 0 && < pool-num-replicas, choose that many buckets. -
If
<num> < 0, it meanspool-num-replicas - {num}.
-
If
- Purpose
- A component of the rule.
- Prerequisite
-
Follows
step takeorstep choose. - Example
-
step choose firstn 1 type row
- step chooseleaf firstn <num> type <bucket-type>
- Description
Selects a set of buckets of
{bucket-type}and chooses a leaf node from the subtree of each bucket in the set of buckets. The number of buckets in the set is usually the number of replicas in the pool (that is, pool size).-
If
<num> == 0, choosepool-num-replicasbuckets (all available). -
If
<num> > 0 && < pool-num-replicas, choose that many buckets. -
If
<num> < 0, it meanspool-num-replicas - <num>.
-
If
- Purpose
- A component of the rule. Usage removes the need to select a device using two steps.
- Prerequisite
-
Follows
step takeorstep choose. - Example
-
step chooseleaf firstn 0 type row
- step emit
- Description
- Outputs the current value and empties the stack. Typically used at the end of a rule, but may also be used to pick from different trees in the same rule.
- Purpose
- A component of the rule.
- Prerequisite
-
Follows
step choose. - Example
-
step emit
- firstn versus indep
- Description
-
Controls the replacement strategy CRUSH uses when OSDs are marked down in the CRUSH map. If this rule is to be used with replicated pools it should be
firstnand if it is for erasure-coded pools it should beindep. - Example
-
You have a PG stored on OSDs 1, 2, 3, 4, 5 in which 3 goes down.. In the first scenario, with the
firstnmode, CRUSH adjusts its calculation to select 1 and 2, then selects 3 but discovers it is down, so it retries and selects 4 and 5, and then goes on to select a new OSD 6. The final CRUSH mapping change is from 1, 2, 3, 4, 5 to 1, 2, 4, 5, 6. In the second scenario, withindepmode on an erasure-coded pool, CRUSH attempts to select the failed OSD 3, tries again and picks out 6, for a final transformation from 1, 2, 3, 4, 5 to 1, 2, 6, 4, 5.
A given CRUSH rule can be assigned to multiple pools, but it is not possible for a single pool to have multiple CRUSH rules.
2.7.1. Listing Rules
To list CRUSH rules from the command line, execute the following:
ceph osd crush rule list
ceph osd crush rule ls2.7.2. Dumping a Rule
To dump the contents of a specific CRUSH rule, execute the following:
ceph osd crush rule dump {name}2.7.3. Adding a Simple Rule
To add a CRUSH rule, you must specify a rule name, the root node of the hierarchy you wish to use, the type of bucket you want to replicate across (for example, 'rack', 'row', and so on and the mode for choosing the bucket.
ceph osd crush rule create-simple {rulename} {root} {bucket-type} {firstn|indep}
Ceph will create a rule with chooseleaf and 1 bucket of the type you specify.
For example:
ceph osd crush rule create-simple deleteme default host firstnCreate the following rule:
{ "rule_id": 1,
"rule_name": "deleteme",
"ruleset": 1,
"type": 1,
"min_size": 1,
"max_size": 10,
"steps": [
{ "op": "take",
"item": -1,
"item_name": "default"},
{ "op": "chooseleaf_firstn",
"num": 0,
"type": "host"},
{ "op": "emit"}]}
The ruleset is not supported in RHCS 3 and later releases. It is only present for backward compatibility for RHCS 2 and earlier releases of Ceph.
2.7.4. Adding a Replicated Rule
To create a CRUSH rule for a replicated pool, execute the following:
# ceph osd crush rule create-replicated <name> <root> <failure-domain> <class>Where:
-
<name>: The name of the rule. -
<root>: The root of the CRUSH hierarchy. -
<failure-domain>: The failure domain. For example:hostorrack. -
<class>: The storage device class. For example:hddorssd. RHCS 3 and later only.
For example:
# ceph osd crush rule create-replicated fast default host ssd2.7.5. Adding an Erasure Code Rule
To add a CRUSH rule for use with an erasure coded pool, you may specify a rule name and an erasure code profile.
ceph osd crush rule create-erasure {rulename} {profilename}2.7.6. Removing a Rule
To remove a rule, execute the following and specify the CRUSH rule name:
ceph osd crush rule rm {name}2.8. CRUSH Tunables
The Ceph project has grown exponentially with many changes and many new features. Beginning with the first commercially supported major release of Ceph, v0.48 (Argonaut), Ceph provides the ability to adjust certain parameters of the CRUSH algorithm, that is, the settings are not frozen in the source code.
A few important points to consider:
- Adjusting CRUSH values may result in the shift of some PGs between storage nodes. If the Ceph cluster is already storing a lot of data, be prepared for some fraction of the data to move.
-
The
ceph-osdandceph-mondaemons will start requiring the feature bits of new connections as soon as they receive an updated map. However, already-connected clients are effectively grandfathered in, and will misbehave if they do not support the new feature. Make sure when you upgrade your Ceph Storage Cluster daemons that you also update your Ceph clients. -
If the CRUSH tunables are set to non-legacy values and then later changed back to the legacy values,
ceph-osddaemons will not be required to support the feature. However, the OSD peering process requires examining and understanding old maps. Therefore, you should not run old versions of theceph-osddaemon if the cluster has previously used non-legacy CRUSH values, even if the latest version of the map has been switched back to using the legacy defaults.
2.8.1. The Evolution of CRUSH Tunables
Ceph clients and daemons prior to version 0.48 do not detect for tunables and are not compatible with version 0.48 and beyond, you must upgrade. The ability to adjust tunable CRUSH values has also evolved with major Ceph releases.
Legacy Values
Legacy values deployed in newer clusters with CRUSH Tunables may misbehave. Issues include:
- In Hierarchies with a small number of devices in the leaf buckets, some PGs map to fewer than the desired number of replicas. This commonly happens for hierarchies with "host" nodes with a small number (1-3) of OSDs nested beneath each one.
- For large clusters, some small percentages of PGs map to less than the desired number of OSDs. This is more prevalent when there are several layers of the hierarchy. For example, row, rack, host, osd.
- When some OSDs are marked out, the data tends to get redistributed to nearby OSDs instead of across the entire hierarchy.
Red Hat strongly encourage upgrading both Ceph clients and Ceph daemons to major supported releases to take advantage of CRUSH tunables. Red Hat recommends that all cluster daemons and clients use the same release version.
Argonaut (Legacy)
This is the first commercially supported release of Ceph.
Version Requirements:
- Ceph 0.48, 0.49 and later
- Linux kernel 3.6 or later, including the RBD kernel clients
Supported CRUSH Tunables:
-
choose_local_tries: Number of local retries. Legacy value is 2, optimal value is 0. -
choose_local_fallback_tries: Legacy value is 5, optimal value is 0. -
choose_total_tries: Total number of attempts to choose an item. Legacy value was 19, subsequent testing indicates that a value of 50 is more appropriate for typical clusters. For extremely large clusters, a larger value might be necessary.
-
Bobtail
Version Requirements:
- Ceph 0.55, 0.56.x and later
- Linux kernel 3.9 or later, including the RBD kernel clients
Supported CRUSH Tunable:
-
chooseleaf_descend_once: Whether a recursive chooseleaf attempt will retry, or only try once and allow the original placement to retry. Legacy default is 0, optimal value is 1.
-
Firefly
This is the first Red Hat supported version of Ceph.
Version Requirements:
- Red Hat Ceph Storage 1.2.3 and later
- Red Hat Enterprise Linux 7.1 or later, including the RBD kernel clients
Supported CRUSH Tunables:
-
chooseleaf_vary_r: Whether a recursive chooseleaf attempt will start with a non-zero value of r, based on how many attempts the parent has already made. Legacy default is 0, but with this value CRUSH is sometimes unable to find a mapping. The optimal value, in terms of computational cost and correctness is 1. However, for legacy clusters that have lots of existing data, changing from 0 to 1 will cause a lot of data to move; a value of 4 or 5 will allow CRUSH to find a valid mapping but will make less data move. -
straw_calc_version: There were some problems with the internal weights calculated and stored in the CRUSH map for straw buckets. Specifically, when there were items with a CRUSH weight of 0 or both a mix of weights and some duplicated weights CRUSH would distribute data incorrectly, that is, not in proportion to the weights. A value of 0 preserves the old, broken internal weight calculation; a value of 1 fixes the behavior. Setting thestraw_calc_versionto 1 and then adjusting a straw bucket, by either adding, removing, reweighting an item, or by using the reweight-all command, can trigger a small to moderate amount of data movement if the cluster has hit one of the problematic conditions. This tunable option is special because it has absolutely no impact concerning the required kernel version on the client side.
-
Hammer
The hammer tunable profile does not affect the mapping of existing CRUSH maps simply by changing the tunable profile, but a new bucket type, straw2 is now supported.
Version Requirements:
- Red Hat Ceph Storage 1.3 and later
- Red Hat Enterprise Linux 7.1 or later, including the RBD kernel clients
New Bucket Type:
-
The new
straw2bucket type fixes several limitations in the original straw bucket. Specifically, the old straw buckets would change some mappings that should have changed when a weight was adjusted, while straw2 buckets achieves the original goal of only changing mappings to or from the bucket item whose weight has changed. Thestraw2bucket is the default for any newly created buckets. Changing a bucket type from straw to straw2 will result in a reasonably small amount of data movement, depending on how much the bucket item weights vary from each other. When the weights are all the same no data will move, and when item weights vary significantly there will be more movement.
-
The new
Jewel
Red Hat Ceph Storage 2 is supported on Red Hat Enterprise Linux 7.2 or above, but the jewel tunable profile is only supported on Red Hat Enterprise Linux 7.3 or above. The jewel tunable profile improves the overall behavior of CRUSH, such that it significantly reduces mapping changes when an OSD is marked out of the cluster.
Version Requirements:
- Red Hat Ceph Storage 2 and later
- Red Hat Enterprise Linux 7.3 or later, including the RBD kernel clients and the CephFS kernel clients
Supported CRUSH Tunable:
-
chooseleaf_stable: Whether a recursive chooseleaf attempt will use a better value for an inner loop that greatly reduces the number of mapping changes when an OSD is marked out. The legacy value is 0, while the new value of 1 uses the new approach. Changing this value on an existing cluster will result in a very large amount of data movement as almost every PG mapping is likely to change.
-
2.8.2. Tuning CRUSH
Before you tune CRUSH, you should ensure that all Ceph clients and all Ceph daemons use the same version. If you have recently upgraded, ensure that you have restarted daemons and reconnected clients.
The simplest way to adjust the CRUSH tunables is by changing to a known profile. Those are:
-
legacy: The legacy behavior from v0.47 (pre-Argonaut) and earlier. -
argonaut: The legacy values supported by v0.48 (Argonaut) release. -
bobtail: The values supported by the v0.56 (Bobtail) release. -
firefly: The values supported by the v0.80 (Firefly) release. -
hammer: The values supported by the v0.94 (Hammer) release. -
jewel: The values supported by the v10.0.2 (Jewel) release. -
optimal: The current best values. -
default: The current default values for a new cluster.
You can select a profile on a running cluster with the command:
# ceph osd crush tunables <profile>This may result in some data movement.
Generally, you should set the CRUSH tunables after you upgrade, or if you receive a warning. Starting with version v0.74, Ceph will issue a health warning if the CRUSH tunables are not set to their optimal values, the optimal values are the default as of v0.73. To make this warning go away, you have two options:
Adjust the tunables on the existing cluster. Note that this will result in some data movement (possibly as much as 10%). This is the preferred route, but should be taken with care on a production cluster where the data movement may affect performance. You can enable optimal tunables with:
# ceph osd crush tunables optimalIf things go poorly (for example, too much load) and not very much progress has been made, or there is a client compatibility problem (old kernel cephfs or rbd clients, or pre-bobtail librados clients), you can switch back to an earlier profile:
# ceph osd crush tunables <profile>For example, to restore the pre-v0.48 (Argonaut) values, execute:
# ceph osd crush tunables legacyYou can make the warning go away without making any changes to CRUSH by adding the following option to the
[mon]section of theceph.conffile:mon warn on legacy crush tunables = falseFor the change to take effect, restart the monitors, or apply the option to running monitors with:
# ceph tell mon.\* injectargs --no-mon-warn-on-legacy-crush-tunables
2.8.3. Tuning CRUSH, The Hard Way
If you can ensure that all clients are running recent code, you can adjust the tunables by extracting the CRUSH map, modifying the values, and reinjecting it into the cluster.
Extract the latest CRUSH map:
ceph osd getcrushmap -o /tmp/crushAdjust tunables. These values appear to offer the best behavior for both large and small clusters we tested with. You will need to additionally specify the
--enable-unsafe-tunablesargument tocrushtoolfor this to work. Please use this option with extreme care.:crushtool -i /tmp/crush --set-choose-local-tries 0 --set-choose-local-fallback-tries 0 --set-choose-total-tries 50 -o /tmp/crush.newReinject modified map:
ceph osd setcrushmap -i /tmp/crush.new
2.8.4. Legacy Values
For reference, the legacy values for the CRUSH tunables can be set with:
crushtool -i /tmp/crush --set-choose-local-tries 2 --set-choose-local-fallback-tries 5 --set-choose-total-tries 19 --set-chooseleaf-descend-once 0 --set-chooseleaf-vary-r 0 -o /tmp/crush.legacy
Again, the special --enable-unsafe-tunables option is required. Further, as noted above, be careful running old versions of the ceph-osd daemon after reverting to legacy values as the feature bit is not perfectly enforced.
2.9. Editing a CRUSH Map
Generally, modifying your CRUSH map at runtime with the Ceph CLI is more convenient than editing the CRUSH map manually. However, there are times when you may choose to edit it, such as changing the default bucket types, or using a bucket algorithm other than straw.
To edit an existing CRUSH map:
- Get the CRUSH map.
- Decompile the CRUSH map.
- Edit at least one of devices, and Buckets and rules.
- Recompile the CRUSH map.
- Set the CRUSH map.
To activate a CRUSH Map rule for a specific pool, identify the common rule number and specify that rule number for the pool when creating the pool.
2.9.1. Getting a CRUSH Map
To get the CRUSH map for your cluster, execute the following:
ceph osd getcrushmap -o {compiled-crushmap-filename}Ceph will output (-o) a compiled CRUSH map to the file name you specified. Since the CRUSH map is in a compiled form, you must decompile it first before you can edit it.
2.9.2. Decompiling a CRUSH Map
To decompile a CRUSH map, execute the following:
crushtool -d {compiled-crushmap-filename} -o {decompiled-crushmap-filename}Ceph will decompile (-d) the compiled CRUSH map and output (-o) it to the file name you specified.
2.9.3. Compiling a CRUSH Map
To compile a CRUSH map, execute the following:
crushtool -c {decompiled-crush-map-filename} -o {compiled-crush-map-filename}Ceph will store a compiled CRUSH map to the file name you specified.
2.9.4. Setting a CRUSH Map
To set the CRUSH map for your cluster, execute the following:
ceph osd setcrushmap -i {compiled-crushmap-filename}Ceph will input the compiled CRUSH map of the file name you specified as the CRUSH map for the cluster.
2.10. CRUSH Storage Strategy Examples
Suppose you want to have most pools default to OSDs backed by large hard drives, but have some pools mapped to OSDs backed by fast solid-state drives (SSDs). CRUSH can handle these scenarios easily.
RHCS 2 and Earlier
In RHCS 2 and earlier releases, it’s possible to have multiple independent CRUSH hierarchies within the same CRUSH map to reflect different performance domains. Define two hierarchies with two different root nodes—one for hard disks (for example, "root platter") and one for SSDs (for example, "root ssd") as shown below:
device 0 osd.0
device 1 osd.1
device 2 osd.2
device 3 osd.3
device 4 osd.4
device 5 osd.5
device 6 osd.6
device 7 osd.7
host ceph-osd-ssd-server-1 {
id -1
alg straw
hash 0
item osd.0 weight 1.00
item osd.1 weight 1.00
}
host ceph-osd-ssd-server-2 {
id -2
alg straw
hash 0
item osd.2 weight 1.00
item osd.3 weight 1.00
}
host ceph-osd-platter-server-1 {
id -3
alg straw
hash 0
item osd.4 weight 1.00
item osd.5 weight 1.00
}
host ceph-osd-platter-server-2 {
id -4
alg straw
hash 0
item osd.6 weight 1.00
item osd.7 weight 1.00
}
root platter {
id -5
alg straw
hash 0
item ceph-osd-platter-server-1 weight 2.00
item ceph-osd-platter-server-2 weight 2.00
}
root ssd {
id -6
alg straw
hash 0
item ceph-osd-ssd-server-1 weight 2.00
item ceph-osd-ssd-server-2 weight 2.00
}
rule data {
ruleset 0
type replicated
min_size 2
max_size 2
step take platter
step chooseleaf firstn 0 type host
step emit
}
rule metadata {
ruleset 1
type replicated
min_size 0
max_size 10
step take platter
step chooseleaf firstn 0 type host
step emit
}
rule rbd {
ruleset 2
type replicated
min_size 0
max_size 10
step take platter
step chooseleaf firstn 0 type host
step emit
}
rule platter {
ruleset 3
type replicated
min_size 0
max_size 10
step take platter
step chooseleaf firstn 0 type host
step emit
}
rule ssd {
ruleset 4
type replicated
min_size 0
max_size 4
step take ssd
step chooseleaf firstn 0 type host
step emit
}
rule ssd-primary {
ruleset 5
type replicated
min_size 5
max_size 10
step take ssd
step chooseleaf firstn 1 type host
step emit
step take platter
step chooseleaf firstn -1 type host
step emit
}You can then set a pool to use the SSD rule by executing:
ceph osd pool set <poolname> crush_ruleset 4- NOTE
-
Red Hat does not support the
rulesetandcrush_rulesetsettings in RHCS 3 and later releases.
Your SSD pool can serve as the fast storage pool. Similarly, you could use the ssd-primary rule to cause each placement group in the pool to be placed with an SSD as the primary and platters as the replicas.
RHCS 3 and Later
In RHCS 3 and later releases, use device classes. The process is much simpler: add a class to each device. For example:
# ceph osd crush set-device-class <class> <osdId> [<osdId>]
# ceph osd crush set-device-class hdd osd.0 osd.1 osd.4 osd.5
# ceph osd crush set-device-class ssd osd.2 osd.3 osd.6 osd.7Then, create rules to use the devices.
# ceph osd crush rule create-replicated <rule-name> <root> <failure-domain-type> <device-class>:
# ceph osd crush rule create-replicated cold default host hdd
# ceph osd crush rule create-replicated hot default host ssdFinally, set pools to use the rules.
ceph osd pool set <poolname> crush_rule <rule-name>
ceph osd pool set cold crush_rule hdd
ceph osd pool set hot crush_rule ssdThere is no need to manually edit the CRUSH map, because one hierarchy can serve multiple classes of devices. Compared to the foregoing example for RHCS 2, the CRUSH map is much simpler for RHCS 3 when using device classes.
device 0 osd.0 class hdd
device 1 osd.1 class hdd
device 2 osd.2 class ssd
device 3 osd.3 class ssd
device 4 osd.4 class hdd
device 5 osd.5 class hdd
device 6 osd.6 class ssd
device 7 osd.7 class ssd
host ceph-osd-server-1 {
id -1
alg straw
hash 0
item osd.0 weight 1.00
item osd.1 weight 1.00
item osd.2 weight 1.00
item osd.3 weight 1.00
}
host ceph-osd-server-2 {
id -2
alg straw
hash 0
item osd.4 weight 1.00
item osd.5 weight 1.00
item osd.6 weight 1.00
item osd.7 weight 1.00
}
root default {
id -3
alg straw
hash 0
item ceph-osd-server-1 weight 4.00
item ceph-osd-server-2 weight 4.00
}
rule cold {
ruleset 0
type replicated
min_size 2
max_size 11
step take default class hdd
step chooseleaf firstn 0 type host
step emit
}
rule hot {
ruleset 1
type replicated
min_size 2
max_size 11
step take default class ssd
step chooseleaf firstn 0 type host
step emit
}