Chapter 5. Erasure Code Pools
Ceph storage strategies involve defining data durability requirements. Data durability means the ability to sustain the loss of one or more OSDs without losing data.
Ceph stores data in pools and there are two types of the pools:
- replicated
- erasure-coded
Ceph uses the replicated pools by default, meaning the Ceph copies every object from a primary OSD node to one or more secondary OSDs.
The erasure-coded pools reduces the amount of disk space required to ensure data durability but it is computationally a bit more expensive than replication.
Erasure coding is a method of storing an object in the Ceph storage cluster durably where the erasure code algorithm breaks the object into data chunks (k) and coding chunks (m), and stores those chunks in different OSDs.
In the event of the failure of an OSD, Ceph retrieves the remaining data (k) and coding (m) chunks from the other OSDs and the erasure code algorithm restores the object from those chunks.
Red Hat recommends min_size for erasure-coded pools to be K+2 or more to prevent loss of writes and data.
Erasure coding uses storage capacity more efficiently than replication. The n-replication approach maintains n copies of an object (3x by default in Ceph), whereas erasure coding maintains only k + m chunks. For example, 3 data and 2 coding chunks use 1.5x the storage space of the original object.
While erasure coding uses less storage overhead than replication, the erasure code algorithm uses more RAM and CPU than replication when it accesses or recovers objects. Erasure coding is advantageous when data storage must be durable and fault tolerant, but do not require fast read performance (for example, cold storage, historical records, and so on).
For the mathematical and detailed explanation on how erasure code works in Ceph, see the Erasure Coded I/O section in the Architecture Guide for Red Hat Ceph Storage 3.
Ceph creates a default erasure code profile when initializing a cluster with k=2 and m=1, This mean that Ceph will spread the object data over three OSDs (k+m == 3) and Ceph can lose one of those OSDs without losing data. To know more about erasure code profiling see the Erasure Code Profiles section.
Configure only the .rgw.buckets pool as erasure-coded and all other Ceph Object Gateway pools as replicated, otherwise an attempt to create a new bucket fails with the following error:
set_req_state_err err_no=95 resorting to 500
The reason for this is that erasure-coded pools do not support the omap operations and certain Ceph Object Gateway metadata pools require the omap support.
5.1. Creating a Sample Erasure-coded Pool
The simplest erasure coded pool is equivalent to RAID5 and requires at least three hosts:
$ ceph osd pool create ecpool 50 50 erasure
pool 'ecpool' created
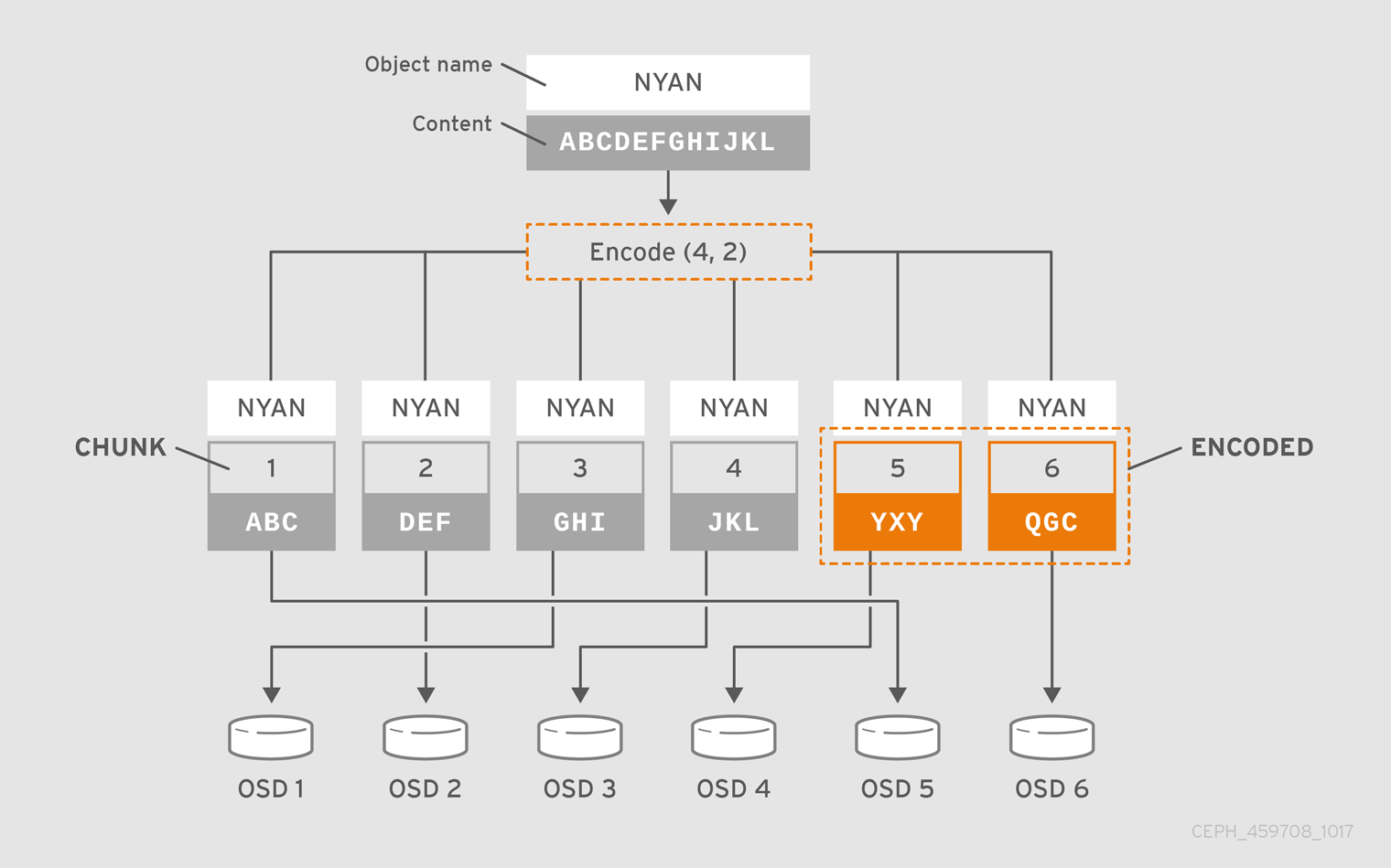
$ echo ABCDEFGHI | rados --pool ecpool put NYAN -
$ rados --pool ecpool get NYAN -
ABCDEFGHIThe 50 in pool create stands for the number of placement groups.
5.2. Erasure Code Profiles
Ceph defines an erasure-coded pool with a profile. Ceph uses a profile when creating an erasure-coded pool and the associated CRUSH rule.
Ceph creates a default erasure code profile when initializing a cluster and it provides the same level of redundancy as two copies in a replicated pool. However, it uses 25% less storage capacity. The default profiles defines k=2 and m=1, meaning Ceph will spread the object data over three OSDs (k+m=3) and Ceph can lose one of those OSDs without losing data.
The default erasure code profile can sustain the loss of a single OSD. It is equivalent to a replicated pool with a size two, but requires 1.5 TB instead of 2 TB to store 1 TB of data. To display the default profile use the following command:
$ ceph osd erasure-code-profile get default
directory=.libs
k=2
m=1
plugin=jerasure
crush-failure-domain=host
technique=reed_sol_vanYou can create a new profile to improve redundancy without increasing raw storage requirements. For instance, a profile with k=8 and m=4 can sustain the loss of four (m=4) OSDs by distributing an object on 12 (k+m=12) OSDs. Ceph divides the object into 8 chunks and computes 4 coding chunks for recovery. For example, if the object size is 8 MB, each data chunk is 1 MB and each coding chunk has the same size as the data chunk, that is also 1 MB. The object will not be lost even if four OSDs fail simultaneously.
The most important parameters of the profile are k, m and crush-failure-domain, because they define the storage overhead and the data durability.
Choosing the correct profile is important because you cannot change the profile after you create the pool. To modify a profile, you must create a new pool with a different profile and migrate the objects from the old pool to the new pool.
For instance, if the desired architecture must sustain the loss of two racks with a storage overhead of 40% overhead, the following profile can be defined:
$ ceph osd erasure-code-profile set myprofile \
k=4 \
m=2 \
crush-failure-domain=rack
$ ceph osd pool create ecpool 12 12 erasure *myprofile*
$ echo ABCDEFGHIJKL | rados --pool ecpool put NYAN -
$ rados --pool ecpool get NYAN -
ABCDEFGHIJKLThe primary OSD will divide the NYAN object into four (k=4) data chunks and create two additional chunks (m=2). The value of m defines how many OSDs can be lost simultaneously without losing any data. The crush-failure-domain=rack will create a CRUSH rule that ensures no two chunks are stored in the same rack.
Red Hat supports the following erasure coding values for k, and m:
- k=8 m=3
- k=8 m=4
- k=4 m=2
If the number of OSDs lost equals the number of coding chunks (m), some placement groups in the erasure coding pool will go into incomplete state. If the number of OSDs lost is less than m, no placement groups will go into incomplete state. In either situation, no data loss will occur. If placement groups are in incomplete state, temporarily reducing min_size of an erasure coded pool will allow recovery.
5.2.1. OSD erasure-code-profile Set
To create a new erasure code profile:
ceph osd erasure-code-profile set <name> \
[<directory=directory>] \
[<plugin=plugin>] \
[<stripe_unit=stripe_unit>] \
[<crush-device-class>]\
[<crush-failure-domain>]\
[<key=value> ...] \
[--force]Where:
- directory
- Description
- Set the directory name from which the erasure code plug-in is loaded.
- Type
- String
- Required
- No.
- Default
-
/usr/lib/ceph/erasure-code
- plugin
- Description
- Use the erasure code plug-in to compute coding chunks and recover missing chunks. See the Erasure Code Plug-ins section for details.
- Type
- String
- Required
- No.
- Default
-
jerasure
- stripe_unit
- Description
-
The amount of data in a data chunk, per stripe. For example, a profile with 2 data chunks and
stripe_unit=4Kwould put the range 0-4K in chunk 0, 4K-8K in chunk 1, then 8K-12K in chunk 0 again. This should be a multiple of 4K for best performance. The default value is taken from the monitor config optionosd_pool_erasure_code_stripe_unitwhen a pool is created. The stripe_width of a pool using this profile will be the number of data chunks multiplied by thisstripe_unit. - Type
- String
- Required
- No.
- Default
-
4K
- crush-device-class
- Description
-
The device class, such as
hddorssd. Available only in RHCS 3 and later. - Type
- String
- Required
- No
- Default
-
none, meaning CRUSH uses all devices regardless of class.
- crush-failure-domain
- Description
-
The failure domain, such as
hostorrack. - Type
- String
- Required
- No
- Default
-
host
- key
- Description
- The semantic of the remaining key-value pairs is defined by the erasure code plug-in.
- Type
- String
- Required
- No.
- --force
- Description
- Override an existing profile by the same name.
- Type
- String
- Required
- No.
5.2.2. OSD erasure-code-profile Remove
To remove an erasure code profile:
ceph osd erasure-code-profile rm <name>If the profile is referenced by a pool, the deletion will fail.
5.2.3. OSD erasure-code-profile Get
To display an erasure code profile:
ceph osd erasure-code-profile get <name>5.2.4. OSD erasure-code-profile List
To list the names of all erasure code profiles:
ceph osd erasure-code-profile ls5.3. Erasure Coding with Overwrites (Technology Preview)
By default, erasure coded pools only work with the Ceph Object Gateway, which performs full object writes and appends. With Red Hat Ceph Storage 3, partial writes for an erasure coded pool can be enabled on a per-pool basis.
Using erasure coded pools with overwrites allows Ceph Block Devices and CephFS store their data in an erasure coded pool:
Syntax
ceph osd pool set <erasure_coded_pool_name> allow_ec_overwrites trueExample
$ ceph osd pool set ec_pool allow_ec_overwrites trueEnabling erasure coded pools with overwrites can only reside in a pool using BlueStore OSDs. Since BlueStore’s checksumming is used to detect bitrot or other corruption during deep scrubs. Using FileStore with erasure coded overwrites is unsafe, and yields lower performance when compared to BlueStore.
Erasure coded pools do not support omap. To use erasure coded pools with Ceph Block Devices and CephFS, store the data in an erasure coded pool, and the metadata in a replicated pool.
For Ceph Block Devices, use the --data-pool option during image creation:
Syntax
rbd create --size <image_size>M|G|T --data-pool <erasure_coded_pool_name> <replicated_pool_name>/<image_name>Example
$ rbd create --size 1G --data-pool ec_pool rep_pool/image01If using erasure coded pools for CephFS, then setting the overwrites must be done in a file layout.
5.4. Erasure Code Plugins
Ceph supports erasure coding with a plug-in architecture, which means you can create erasure coded pools using different types of algorithms. Ceph supports:
- Jerasure (Default)
- Locally Repairable
- ISA (Intel only)
The following sections describe these plug-ins in greater detail.
5.4.1. Jerasure Erasure Code Plugin
The jerasure plug-in is the most generic and flexible plug-in. It is also the default for Ceph erasure coded pools.
The jerasure plug-in encapsulates the JerasureH library. For detailed information about the parameters, see the jerasure documentation.
To create a new erasure code profile using the jerasure plug-in, run the following command:
ceph osd erasure-code-profile set <name> \
plugin=jerasure \
k=<data-chunks> \
m=<coding-chunks> \
technique=<reed_sol_van|reed_sol_r6_op|cauchy_orig|cauchy_good|liberation|blaum_roth|liber8tion> \
[crush-root=<root>] \
[crush-failure-domain=<bucket-type>] \
[directory=<directory>] \
[--force]Where:
- k
- Description
- Each object is split in data-chunks parts, each stored on a different OSD.
- Type
- Integer
- Required
- Yes.
- Example
-
4
- m
- Description
- Compute coding chunks for each object and store them on different OSDs. The number of coding chunks is also the number of OSDs that can be down without losing data.
- Type
- Integer
- Required
- Yes.
- Example
- 2
- technique
- Description
- The more flexible technique is reed_sol_van; it is enough to set k and m. The cauchy_good technique can be faster but you need to chose the packetsize carefully. All of reed_sol_r6_op, liberation, blaum_roth, liber8tion are RAID6 equivalents in the sense that they can only be configured with m=2.
- Type
- String
- Required
- No.
- Valid Setttings
-
reed_sol_vanreed_sol_r6_opcauchy_origcauchy_goodliberationblaum_rothliber8tion - Default
-
reed_sol_van
- packetsize
- Description
- The encoding will be done on packets of bytes size at a time. Choosing the correct packet size is difficult. The jerasure documentation contains extensive information on this topic.
- Type
- Integer
- Required
- No.
- Default
-
2048
- crush-root
- Description
- The name of the CRUSH bucket used for the first step of the rule. For instance step take default.
- Type
- String
- Required
- No.
- Default
- default
- crush-failure-domain
- Description
- Ensure that no two chunks are in a bucket with the same failure domain. For instance, if the failure domain is host no two chunks will be stored on the same host. It is used to create a rule step such as step chooseleaf host.
- Type
- String
- Required
- No.
- Default
-
host
- directory
- Description
- Set the directory name from which the erasure code plug-in is loaded.
- Type
- String
- Required
- No.
- Default
-
/usr/lib/ceph/erasure-code
- --force
- Description
- Override an existing profile by the same name.
- Type
- String
- Required
- No.
5.4.2. Locally Repairable Erasure Code (LRC) Plugin
With the jerasure plug-in, when Ceph stores an erasure-coded object on multiple OSDs, recovering from the loss of one OSD requires reading from all the others. For instance if you configure jerasure with k=8 and m=4, losing one OSD requires reading from the eleven others to repair.
The lrc erasure code plug-in creates local parity chunks to be able to recover using fewer OSDs. For instance if you configure lrc with k=8, m=4 and l=4, it will create an additional parity chunk for every four OSDs. When Ceph loses a single OSD, it can recover the object data with only four OSDs instead of eleven.
Although it is probably not an interesting use case when all hosts are connected to the same switch, you can actually observe reduced bandwidth usage between racks when using the lrc erasure code plug-in.
$ ceph osd erasure-code-profile set LRCprofile \
plugin=lrc \
k=4 m=2 l=3 \
crush-failure-domain=host
$ ceph osd pool create lrcpool 12 12 erasure LRCprofileIn 1.2 version, you can only observe reduced bandwidth if the primary OSD is in the same rack as the lost chunk.:
$ ceph osd erasure-code-profile set LRCprofile \
plugin=lrc \
k=4 m=2 l=3 \
crush-locality=rack \
crush-failure-domain=host
$ ceph osd pool create lrcpool 12 12 erasure LRCprofile5.4.2.1. Create an LRC Profile
To create a new LRC erasure code profile, run the following command:
ceph osd erasure-code-profile set <name> \
plugin=lrc \
k=<data-chunks> \
m=<coding-chunks> \
l=<locality> \
[crush-root=<root>] \
[crush-locality=<bucket-type>] \
[crush-failure-domain=<bucket-type>] \
[directory=<directory>] \
[--force]Where:
- k
- Description
- Each object is split in data-chunks parts, each stored on a different OSD.
- Type
- Integer
- Required
- Yes.
- Example
-
4
- m
- Description
- Compute coding chunks for each object and store them on different OSDs. The number of coding chunks is also the number of OSDs that can be down without losing data.
- Type
- Integer
- Required
- Yes.
- Example
-
2
- l
- Description
- Group the coding and data chunks into sets of size locality. For instance, for k=4 and m=2, when locality=3 two groups of three are created. Each set can be recovered without reading chunks from another set.
- Type
- Integer
- Required
- Yes.
- Example
-
3
- crush-root
- Description
- The name of the crush bucket used for the first step of the rule. For instance step take default.
- Type
- String
- Required
- No.
- Default
- default
- crush-locality
- Description
- The type of the crush bucket in which each set of chunks defined by l will be stored. For instance, if it is set to rack, each group of l chunks will be placed in a different rack. It is used to create a rule step such as step choose rack. If it is not set, no such grouping is done.
- Type
- String
- Required
- No.
- crush-failure-domain
- Description
- Ensure that no two chunks are in a bucket with the same failure domain. For instance, if the failure domain is host no two chunks will be stored on the same host. It is used to create a rule step such as step chooseleaf host.
- Type
- String
- Required
- No.
- Default
-
host
- directory
- Description
- Set the directory name from which the erasure code plug-in is loaded.
- Type
- String
- Required
- No.
- Default
-
/usr/lib/ceph/erasure-code
- --force
- Description
- Override an existing profile by the same name.
- Type
- String
- Required
- No.
5.4.2.2. Create a Low-level LRC Profile
The sum of k and m must be a multiple of the l parameter. The low level configuration parameters do not impose such a restriction and it may be more convenient to use it for specific purposes. It is for instance possible to define two groups, one with 4 chunks and another with 3 chunks. It is also possible to recursively define locality sets, for instance data centers and racks into data centers. The k/m/l are implemented by generating a low level configuration.
The lrc erasure code plug-in recursively applies erasure code techniques so that recovering from the loss of some chunks only requires a subset of the available chunks, most of the time.
For instance, when three coding steps are described as:
chunk nr 01234567
step 1 _cDD_cDD
step 2 cDDD____
step 3 ____cDDDwhere c are coding chunks calculated from the data chunks D, the loss of chunk 7 can be recovered with the last four chunks. And the loss of chun 2 chunk can be recovered with the first four chunks.
The miminal testing scenario is strictly equivalent to using the default erasure-code profile. The DD implies K=2, the c implies M=1 and uses the jerasure plug-in by default.
$ ceph osd erasure-code-profile set LRCprofile \
plugin=lrc \
mapping=DD_ \
layers='[ [ "DDc", "" ] ]'
$ ceph osd pool create lrcpool 12 12 erasure LRCprofileThe lrc plug-in is particularly useful for reducing inter-rack bandwidth usage. Although it is probably not an interesting use case when all hosts are connected to the same switch, reduced bandwidth usage can actually be observed. It is equivalent to k=4, m=2 and l=3 although the layout of the chunks is different:
$ ceph osd erasure-code-profile set LRCprofile \
plugin=lrc \
mapping=__DD__DD \
layers='[
[ "_cDD_cDD", "" ],
[ "cDDD____", "" ],
[ "____cDDD", "" ],
]'
$ ceph osd pool create lrcpool 12 12 erasure LRCprofileIn Firefly the reduced bandwidth will only be observed if the primary OSD is in the same rack as the lost chunk.:
$ ceph osd erasure-code-profile set LRCprofile \
plugin=lrc \
mapping=__DD__DD \
layers='[
[ "_cDD_cDD", "" ],
[ "cDDD____", "" ],
[ "____cDDD", "" ],
]' \
crush-steps='[
[ "choose", "rack", 2 ],
[ "chooseleaf", "host", 4 ],
]'
$ ceph osd pool create lrcpool 12 12 erasure LRCprofileLRC now uses jerasure as the default EC backend. It is possible to specify the EC backend and algorithm on a per layer basis using the low level configuration. The second argument in layers='[ [ "DDc", "" ] ]' is actually an erasure code profile to be used for this level. The example below specifies the ISA backend with the Cauchy technique to be used in the lrcpool.:
$ ceph osd erasure-code-profile set LRCprofile \
plugin=lrc \
mapping=DD_ \
layers='[ [ "DDc", "plugin=isa technique=cauchy" ] ]'
$ ceph osd pool create lrcpool 12 12 erasure LRCprofileYou could also use a different erasure code profile for for each layer.:
$ ceph osd erasure-code-profile set LRCprofile \
plugin=lrc \
mapping=__DD__DD \
layers='[
[ "_cDD_cDD", "plugin=isa technique=cauchy" ],
[ "cDDD____", "plugin=isa" ],
[ "____cDDD", "plugin=jerasure" ],
]'
$ ceph osd pool create lrcpool 12 12 erasure LRCprofile5.4.3. Controlling CRUSH Placement
The default CRUSH rule provides OSDs that are on different hosts. For instance:
chunk nr 01234567
step 1 _cDD_cDD
step 2 cDDD____
step 3 ____cDDDneeds exactly 8 OSDs, one for each chunk. If the hosts are in two adjacent racks, the first four chunks can be placed in the first rack and the last four in the second rack. Recovering from the loss of a single OSD does not require using bandwidth between the two racks.
For instance:
crush-steps='[ [ "choose", "rack", 2 ], [ "chooseleaf", "host", 4 ] ]'will create a rule that will select two crush buckets of type rack and for each of them choose four OSDs, each of them located in different bucket of type host.
The rule can also be created manually for finer control.
5.5. ISA Erasure Code Plugin
The isa plug-in is encapsulates the ISA library. It only runs on Intel processors.
To create a new erasure code profile using the isa plug-in, run the following command:
ceph osd erasure-code-profile set <name> \
plugin=isa \
technique=<reed_sol_van|cauchy> \
[k=<data-chunks>] \
[m=<coding-chunks>] \
[crush-root=<root>] \
[crush-failure-domain=<bucket-type>] \
[directory=<directory>] \
[--force]Where:
- technique
- Description
- The ISA plug-in comes in two Reed Solomon forms. If reed_sol_van is set, it is Vandermonde, if cauchy is set, it is Cauchy.
- Type
- String
- Required
- No.
- Valid Settings
-
reed_sol_vancauchy - Default
-
reed_sol_van
- k
- Description
- Each object is split in data-chunks parts, each stored on a different OSD.
- Type
- Integer
- Required
- No.
- Default
-
7
- m
- Description
- Compute coding chunks for each object and store them on different OSDs. The number of coding chunks is also the number of OSDs that can be down without losing data.
- Type
- Integer
- Required
- No.
- Default
-
3
- crush-root
- Description
- The name of the crush bucket used for the first step of the rule. For intance step take default.
- Type
- String
- Required
- No.
- Default
- default
- crush-failure-domain
- Description
- Ensure that no two chunks are in a bucket with the same failure domain. For instance, if the failure domain is host no two chunks will be stored on the same host. It is used to create a rule step such as step chooseleaf host.
- Type
- String
- Required
- No.
- Default
-
host
- directory
- Description
- Set the directory name from which the erasure code plug-in is loaded.
- Type
- String
- Required
- No.
- Default
-
/usr/lib/ceph/erasure-code
- --force
- Description
- Override an existing profile by the same name.
- Type
- String
- Required
- No.
5.6. Pyramid Erasure Code
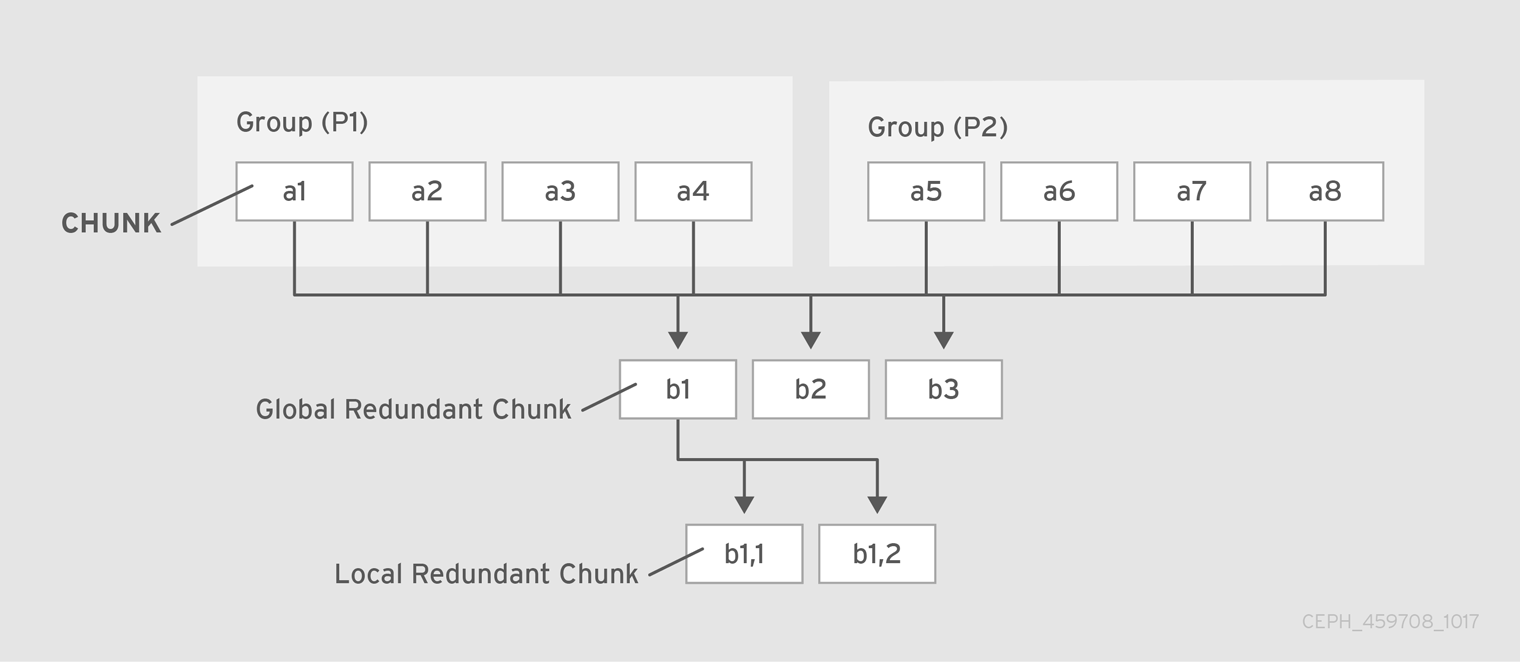
Pyramid erasure code is basically an improved algorithm based on the original erasure code algorithm to improve the access and recovery of data. It is simply a derivation of any existing MDS (Maximum Distance Separable) code like Reed-Solomon for any given (n, k) where k is the original number of data chunks and n is the total number of data chunks after the coding process. As Pyramid code is based on standard MDS code, it has the same encoding/decoding approach. A pyramid coded data pool has the same write overhead and same recovery ability of arbitrary failures like a normal erasure coded pool. The only advantage of pyramid code is that it significantly reduces the read overhead in comparison to normal erasure code.
Let’s take an example of a (11, 8) erasure coded pool and apply the pyramid code approach on it. We will convert the (11, 8) erasure coded pool into a (12, 8) Pyramid coded pool. The erasure coded pool has 8 data chunks and 11 - 8 = 3 redundant chunks. The Pyramid Code separates the 8 data chunks into 2 equal size groups, say P1 = {a1, a2, a3, a4} and P2 = {a5, a6, a7, a8}. It keeps two of the redundant chunks from the erasure code unchanged (say b2 and b3). These two chunks are now called global redundant chunks, because they cover all the 8 data chunks. Next, a new redundant chunk is computed for group P1, which is denoted as group (or local) redundant chunk b1,1. The computation is done as if computing b1 in the original erasure code, except for setting all the data chunks in P2 to 0. Similarly, a group redundant chunks b1,2 is computed for P2. The group redundant chunks are only affected by data chunks in the corresponding groups and not by other groups at all. The group redundant chunks can be interpreted as the projection of the original redundant chunk in the erasure code onto each group i.e, b1,1 + b1,2 = b1. So, in this approach, when one data chunk fails, it can be recovered using a read overhead of 4 instead of 8 for the normal erasure coded pool. For instance, if a3 in P1 fails and a1 is the primary OSD in charge of scrubbing, it can use a1, a2, a4 and b1,1 to recover a3 instead of reading from P2. Reading all chunks is only required when more than one chunk goes missing in the same group.
This Pyramid code has the same write overhead as the original erasure code. Whenever any data chunk is updated, the Pyramid Code needs to update 3 redundant chunks (both b2, b3, plus either b1,1 or b1,2), while the erasure code also updates 3 redundant chunks (b1, b2 and b3). Also, it can recover 3 arbitrary erasures same as the normal erasure code. The only benefit is lesser read overhead as mentioned above which comes at the cost of using one additional redundant chunk. So, Pyramid code trades storage space for access efficiency.
The below diagram shows the constructed pyramid code: