2.5. Considerations for Configuring HA Services
You can create a cluster to suit your needs for high availability by configuring HA (high-availability) services. The key component for HA service management in a Red Hat cluster,
rgmanager, implements cold failover for off-the-shelf applications. In a Red Hat cluster, an application is configured with other cluster resources to form an HA service that can fail over from one cluster node to another with no apparent interruption to cluster clients. HA-service failover can occur if a cluster node fails or if a cluster system administrator moves the service from one cluster node to another (for example, for a planned outage of a cluster node).
To create an HA service, you must configure it in the cluster configuration file. An HA service comprises cluster resources. Cluster resources are building blocks that you create and manage in the cluster configuration file — for example, an IP address, an application initialization script, or a Red Hat GFS shared partition.
An HA service can run on only one cluster node at a time to maintain data integrity. You can specify failover priority in a failover domain. Specifying failover priority consists of assigning a priority level to each node in a failover domain. The priority level determines the failover order — determining which node that an HA service should fail over to. If you do not specify failover priority, an HA service can fail over to any node in its failover domain. Also, you can specify if an HA service is restricted to run only on nodes of its associated failover domain. (When associated with an unrestricted failover domain, an HA service can start on any cluster node in the event no member of the failover domain is available.)
Figure 2.1, “Web Server Cluster Service Example” shows an example of an HA service that is a web server named "content-webserver". It is running in cluster node B and is in a failover domain that consists of nodes A, B, and D. In addition, the failover domain is configured with a failover priority to fail over to node D before node A and to restrict failover to nodes only in that failover domain. The HA service comprises these cluster resources:
- IP address resource — IP address 10.10.10.201.
- An application resource named "httpd-content" — a web server application init script
/etc/init.d/httpd(specifyinghttpd). - A file system resource — Red Hat GFS named "gfs-content-webserver".
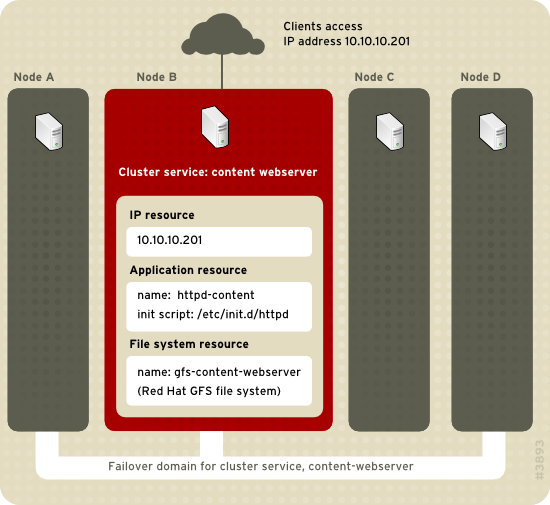
Figure 2.1. Web Server Cluster Service Example
Clients access the HA service through the IP address 10.10.10.201, enabling interaction with the web server application, httpd-content. The httpd-content application uses the gfs-content-webserver file system. If node B were to fail, the content-webserver HA service would fail over to node D. If node D were not available or also failed, the service would fail over to node A. Failover would occur with minimal service interruption to the cluster clients. For example, in an HTTP service, certain state information may be lost (like session data). The HA service would be accessible from another cluster node via the same IP address as it was before failover.
Note
For more information about HA services and failover domains, refer to Red Hat Cluster Suite Overview. For information about configuring failover domains, refer to Section 3.7, “Configuring a Failover Domain” (using Conga) or Section 5.6, “Configuring a Failover Domain” (using
system-config-cluster).
An HA service is a group of cluster resources
configured into a coherent entity that provides specialized services
to clients. An HA service is represented as a resource tree in the
cluster configuration file,
/etc/cluster/cluster.conf (in each cluster
node). In the cluster configuration file, each resource tree is an XML
representation that specifies each resource, its attributes, and its
relationship among other resources in the resource tree (parent,
child, and sibling relationships).Note
Because an HA service consists of resources organized into a
hierarchical tree, a service is sometimes referred to as a
resource tree or resource
group. Both phrases are synonymous with
HA service.
At the root of each resource tree is a special type of resource
— a service resource. Other types of resources comprise
the rest of a service, determining its
characteristics. Configuring an HA service consists of
creating a service resource, creating subordinate cluster
resources, and organizing them into a coherent entity that
conforms to hierarchical restrictions of the service.
Red Hat Cluster supports the following HA services:
- Apache
- Application (Script)
- LVM (HA LVM)
- MySQL
- NFS
- Open LDAP
- Oracle
- PostgreSQL 8
- Samba
Note
Red Hat Enterprise Linux 5 does not support running Clustered Samba in an active/active configuration, in which Samba serves the same shared file system from multiple nodes. Red Hat Enterprise Linux 5 does support running Samba in a cluster in active/passive mode, with failover from one node to the other nodes in a cluster. Note that if failover occurs, locking states are lost and active connections to Samba are severed so that the clients must reconnect. - SAP
- Tomcat 5
There are two major considerations to take into account when configuring an HA service:
- The types of resources needed to create a service
- Parent, child, and sibling relationships among resources
The types of resources and the hierarchy of resources depend on the type of service you are configuring.
The types of cluster resources are listed in Appendix C, HA Resource Parameters. Information about parent, child, and sibling relationships among resources is described in Appendix D, HA Resource Behavior.