Chapter 6. Clustering in Web Applications
6.1. Session Replication
6.1.1. About HTTP Session Replication
Session replication ensures that client sessions of distributable applications are not disrupted by failovers of nodes in a cluster. Each node in the cluster shares information about ongoing sessions, and can take over sessions if a node disappears.
Session replication is the mechanism by which mod_cluster, mod_jk, mod_proxy, ISAPI, and NSAPI clusters provide high availability.
6.1.2. Enable Session Replication in Your Application
To take advantage of JBoss EAP High Availability (HA) features and enable clustering of your web application, you must configure your application to be distributable. If your application is not marked as distributable, its sessions will never be distributed.
Make your Application Distributable
Add the
<distributable/>element inside the<web-app>tag of your application’sweb.xmldescriptor file:Example: Minimum Configuration for a Distributable Application
<?xml version="1.0"?> <web-app xmlns="http://java.sun.com/xml/ns/j2ee" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://java.sun.com/xml/ns/j2ee http://java.sun.com/xml/ns/j2ee/web-app_3_0.xsd" version="3.0"> <distributable/> </web-app>Next, if desired, modify the default replication behavior. If you want to change any of the values affecting session replication, you can override them inside a
<replication-config>element inside<jboss-web>in an application’sWEB-INF/jboss-web.xmlfile. For a given element, only include it if you want to override the defaults.Example:
<replication-config>Values<jboss-web xmlns="http://www.jboss.com/xml/ns/javaee" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.jboss.com/xml/ns/javaee http://www.jboss.org/j2ee/schema/jboss-web_10_0.xsd"> <replication-config> <replication-granularity>SESSION</replication-granularity> </replication-config> </jboss-web>
The <replication-granularity> parameter determines the granularity of data that is replicated. It defaults to SESSION, but can be set to ATTRIBUTE to increase performance on sessions where most attributes remain unchanged.
Valid values for <replication-granularity> can be :
-
SESSION: The default value. The entire session object is replicated if any attribute is dirty. This policy is required if an object reference is shared by multiple session attributes. The shared object references are maintained on remote nodes since the entire session is serialized in one unit. -
ATTRIBUTE: This is only for dirty attributes in the session and for some session data, such as the last-accessed timestamp.
Immutable Session Attributes
For JBoss EAP 7, session replication is triggered when the session is mutated or when any mutable attribute of the session is accessed. Session attributes are assumed to be mutable unless one of the following is true:
The value is a known immutable value:
-
null -
java.util.Collections.EMPTY_LIST,EMPTY_MAP,EMPTY_SET
-
The value type is or implements a known immutable type:
-
java.lang.Boolean,Character,Byte,Short,Integer,Long,Float,Double -
java.lang.Class,Enum,StackTraceElement,String -
java.io.File,java.nio.file.Path -
java.math.BigDecimal,BigInteger,MathContext -
java.net.Inet4Address,Inet6Address,InetSocketAddress,URI,URL -
java.security.Permission -
java.util.Currency,Locale,TimeZone,UUID -
java.time.Clock,Duration,Instant,LocalDate,LocalDateTime,LocalTime,MonthDay,Period,Year,YearMonth,ZoneId,ZoneOffset,ZonedDateTime -
java.time.chrono.ChronoLocalDate,Chronology,Era -
java.time.format.DateTimeFormatter,DecimalStyle -
java.time.temporal.TemporalField,TemporalUnit,ValueRange,WeekFields -
java.time.zone.ZoneOffsetTransition,ZoneOffsetTransitionRule,ZoneRules
-
The value type is annotated with:
-
@org.wildfly.clustering.web.annotation.Immutable -
@net.jcip.annotations.Immutable
-
6.2. HTTP Session Passivation and Activation
6.2.1. About HTTP Session Passivation and Activation
Passivation is the process of controlling memory usage by removing relatively unused sessions from memory while storing them in persistent storage.
Activation is when passivated data is retrieved from persisted storage and put back into memory.
Passivation occurs at different times in an HTTP session’s lifetime:
- When the container requests the creation of a new session, if the number of currently active sessions exceeds a configurable limit, the server attempts to passivate some sessions to make room for the new one.
- When a web application is deployed and a backup copy of sessions active on other servers is acquired by the newly deploying web application’s session manager, sessions might be passivated.
A session is passivated if the number of active sessions exceeds a configurable maximum.
Sessions are always passivated using a Least Recently Used (LRU) algorithm.
6.2.2. Configure HTTP Session Passivation in Your Application
HTTP session passivation is configured in your application’s WEB-INF/jboss-web.xml and META-INF/jboss-web.xml file.
Example: jboss-web.xml File
<jboss-web xmlns="http://www.jboss.com/xml/ns/javaee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.jboss.com/xml/ns/javaee http://www.jboss.org/j2ee/schema/jboss-web_10_0.xsd">
<max-active-sessions>20</max-active-sessions>
</jboss-web>
The <max-active-sessions> element dictates the maximum number of active sessions allowed, and is used to enable session passivation. If session creation would cause the number of active sessions to exceed <max-active-sessions>, then the oldest session known to the session manager will passivate to make room for the new session.
The total number of sessions in memory includes sessions replicated from other cluster nodes that are not being accessed on this node. Take this into account when setting <max-active-sessions>. The number of sessions replicated from other nodes also depends on whether REPL or DIST cache mode is enabled. In REPL cache mode, each session is replicated to each node. In DIST cache mode, each session is replicated only to the number of nodes specified by the owners parameter. See Configure the Cache Mode in the JBoss EAP Configuration Guide for information on configuring session cache modes. For example, consider an eight node cluster, where each node handles requests from 100 users. With REPL cache mode, each node would store 800 sessions in memory. With DIST cache mode enabled, and the default owners setting of 2, each node stores 200 sessions in memory.
6.3. Public API for Clustering Services
JBoss EAP 7 introduced a refined public clustering API for use by applications. The new services are designed to be lightweight, easily injectable, with no external dependencies.
org.wildfly.clustering.group.GroupThe group service provides a mechanism to view the cluster topology for a JGroups channel, and to be notified when the topology changes.
@Resource(lookup = "java:jboss/clustering/group/channel-name") private Group channelGroup;
org.wildfly.clustering.dispatcher.CommandDispatcherThe
CommandDispatcherFactoryservice provides a mechanism to create a dispatcher for executing commands on nodes in the cluster. The resultingCommandDispatcheris a command-pattern analog to the reflection-basedGroupRpcDispatcherfrom previous JBoss EAP releases.@Resource(lookup = "java:jboss/clustering/dispatcher/channel-name") private CommandDispatcherFactory factory; public void foo() { String context = "Hello world!"; // Exclude node1 and node3 from the executeOnCluster try (CommandDispatcher<String> dispatcher = this.factory.createCommandDispatcher(context)) { dispatcher.executeOnGroup(new StdOutCommand(), node1, node3); } } public static class StdOutCommand implements Command<Void, String> { @Override public Void execute(String context) { System.out.println(context); return null; } }
6.4. HA Singleton Service
A clustered singleton service, also known as a high-availability (HA) singleton, is a service deployed on multiple nodes in a cluster. The service is provided on only one of the nodes. The node running the singleton service is usually called the master node.
When the master node either fails or shuts down, another master is selected from the remaining nodes and the service is restarted on the new master. Other than a brief interval when one master has stopped and another has yet to take over, the service is provided by one, and only one, node.
HA Singleton ServiceBuilder API
JBoss EAP 7 introduced a new public API for building singleton services that simplifies the process significantly.
The SingletonServiceConfigurator implementation installs its services so they will start asynchronously, preventing deadlocking of the Modular Service Container (MSC).
HA Singleton Service Election Policies
If there is a preference for which node should start the HA singleton, you can set the election policy in the ServiceActivator class.
JBoss EAP provides two election policies:
Simple election policy
The simple election policy selects a master node based on the relative age. The required age is configured in the position property, which is the index in the list of available nodes, where:
- position = 0 – refers to the oldest node. This is the default.
- position = 1 – refers to the 2nd oldest, and so on.
Position can also be negative to indicate the youngest nodes.
- position = -1 – refers to the youngest node.
- position = -2 – refers to the 2nd youngest node, and so on.
Random election policy
The random election policy elects a random member to be the provider of a singleton service.
HA Singleton Service Preferences
An HA singleton service election policy may optionally specify one or more preferred servers. This preferred server, when available, will be the master for all singleton applications under that policy.
You can define the preferences either through the node name or through the outbound socket binding name.
Node preferences always take precedence over the results of an election policy.
By default, JBoss EAP high availability configurations provide a simple election policy named default with no preferred server. You can set the preference by creating a custom policy and defining the preferred server.
Quorum
A potential issue with a singleton service arises when there is a network partition. In this situation, also known as the split-brain scenario, subsets of nodes cannot communicate with each other. Each set of servers consider all servers from the other set failed and continue to work as the surviving cluster. This might result in data consistency issues.
JBoss EAP allows you to specify a quorum in the election policy to prevent the split-brain scenario. The quorum specifies a minimum number of nodes to be present before a singleton provider election can take place.
A typical deployment scenario uses a quorum of N/2 + 1, where N is the anticipated cluster size. This value can be updated at runtime, and will immediately affect any active singleton services.
HA Singleton Service Election Listener
After electing a new primary singleton service provider, any registered SingletonElectionListener is triggered, notifying every member of the cluster about the new primary provider. The following example illustrates the usage of SingletonElectionListener:
public class MySingletonElectionListener implements SingletonElectionListener {
@Override
public void elected(List<Node> candidates, Node primary) {
// ...
}
}
public class MyServiceActivator implements ServiceActivator {
@Override
public void activate(ServiceActivatorContext context) {
String containerName = "foo";
SingletonElectionPolicy policy = new MySingletonElectionPolicy();
SingletonElectionListener listener = new MySingletonElectionListener();
int quorum = 3;
ServiceName name = ServiceName.parse("my.service.name");
// Use a SingletonServiceConfiguratorFactory backed by default cache of "foo" container
Supplier<SingletonServiceConfiguratorFactory> factory = new ActiveServiceSupplier<SingletonServiceConfiguratorFactory>(context.getServiceRegistry(), ServiceName.parse(SingletonDefaultCacheRequirement.SINGLETON_SERVICE_CONFIGURATOR_FACTORY.resolve(containerName)));
ServiceBuilder<?> builder = factory.get().createSingletonServiceConfigurator(name)
.electionListener(listener)
.electionPolicy(policy)
.requireQuorum(quorum)
.build(context.getServiceTarget());
Service service = new MyService();
builder.setInstance(service).install();
}
}Create an HA Singleton Service Application
The following is an abbreviated example of the steps required to create and deploy an application as a cluster-wide singleton service. This example demonstrates a querying service that regularly queries a singleton service to get the name of the node on which it is running.
To see the singleton behavior, you must deploy the application to at least two servers. It is transparent whether the singleton service is running on the same node or whether the value is obtained remotely.
Create the
SingletonServiceclass. ThegetValue()method, which is called by the querying service, provides information about the node on which it is running.class SingletonService implements Service { private Logger LOG = Logger.getLogger(this.getClass()); private Node node; private Supplier<Group> groupSupplier; private Consumer<Node> nodeConsumer; SingletonService(Supplier<Group> groupSupplier, Consumer<Node> nodeConsumer) { this.groupSupplier = groupSupplier; this.nodeConsumer = nodeConsumer; } @Override public void start(StartContext context) { this.node = this.groupSupplier.get().getLocalMember(); this.nodeConsumer.accept(this.node); LOG.infof("Singleton service is started on node '%s'.", this.node); } @Override public void stop(StopContext context) { LOG.infof("Singleton service is stopping on node '%s'.", this.node); this.node = null; } }Create the querying service. It calls the
getValue()method of the singleton service to get the name of the node on which it is running, and then writes the result to the server log.class QueryingService implements Service { private Logger LOG = Logger.getLogger(this.getClass()); private ScheduledExecutorService executor; @Override public void start(StartContext context) throws { LOG.info("Querying service is starting."); executor = Executors.newSingleThreadScheduledExecutor(); executor.scheduleAtFixedRate(() -> { Supplier<Node> node = new PassiveServiceSupplier<>(context.getController().getServiceContainer(), SingletonServiceActivator.SINGLETON_SERVICE_NAME); if (node.get() != null) { LOG.infof("Singleton service is running on this (%s) node.", node.get()); } else { LOG.infof("Singleton service is not running on this node."); } }, 5, 5, TimeUnit.SECONDS); } @Override public void stop(StopContext context) { LOG.info("Querying service is stopping."); executor.shutdown(); } }Implement the
SingletonServiceActivatorclass to build and install both the singleton service and the querying service.public class SingletonServiceActivator implements ServiceActivator { private final Logger LOG = Logger.getLogger(SingletonServiceActivator.class); static final ServiceName SINGLETON_SERVICE_NAME = ServiceName.parse("org.jboss.as.quickstarts.ha.singleton.service"); private static final ServiceName QUERYING_SERVICE_NAME = ServiceName.parse("org.jboss.as.quickstarts.ha.singleton.service.querying"); @Override public void activate(ServiceActivatorContext serviceActivatorContext) { SingletonPolicy policy = new ActiveServiceSupplier<SingletonPolicy>( serviceActivatorContext.getServiceRegistry(), ServiceName.parse(SingletonDefaultRequirement.POLICY.getName())).get(); ServiceTarget target = serviceActivatorContext.getServiceTarget(); ServiceBuilder<?> builder = policy.createSingletonServiceConfigurator(SINGLETON_SERVICE_NAME).build(target); Consumer<Node> member = builder.provides(SINGLETON_SERVICE_NAME); Supplier<Group> group = builder.requires(ServiceName.parse("org.wildfly.clustering.default-group")); builder.setInstance(new SingletonService(group, member)).install(); serviceActivatorContext.getServiceTarget() .addService(QUERYING_SERVICE_NAME, new QueryingService()) .setInitialMode(ServiceController.Mode.ACTIVE) .install(); serviceActivatorContext.getServiceTarget().addService(QUERYING_SERVICE_NAME).setInstance(new QueryingService()).install(); LOG.info("Singleton and querying services activated."); } }-
Create a file in the
META-INF/services/directory namedorg.jboss.msc.service.ServiceActivatorthat contains the name of theServiceActivatorclass, for example,org.jboss.as.quickstarts.ha.singleton.service.SingletonServiceActivator.
See the ha-singleton-service quickstart that ships with JBoss EAP for the complete working example. This quickstart also provides a second example that demonstrates a singleton service that is installed with a backup service. The backup service is running on all nodes that are not elected to be running the singleton service. Finally, this quickstart also demonstrates how to configure a few different election policies.
6.5. HA singleton deployments
You can deploy your application as a singleton deployment. When deployed to a group of clustered servers, a singleton deployment only deploys on a single node at any given time. If the node on which the deployment is active stops or fails, the deployment automatically starts on another node.
A singleton deployment can be deployed on multiple nodes in the following situations:
- A group of clustered servers on a given node cannot establish a connection due to a configuration issue or a network issue.
A non-HA configuration is used, such as the following configuration files:
-
A
standalone.xmlconfiguration, which supports the Java EE 8 Web Profile, or astandalone-full.xmlconfiguration, which supports the Java EE 8 Full Platform profile. -
A
domain.xmlconfiguration, which consists of either default domain profiles or full-domain profiles.
-
A
Non-HA configurations do not have the singleton subsystem enabled by default. If you use this default configuration, the singleton-deployment.xml file is ignored to promote a successful deployment of an application.
However, using a non-HA configuration can cause errors for the jboss-all.xml descriptor file. To avoid these errors, add the single deployment to the singleton-deployment.xml descriptor. You can then deploy the application using any profile type.
The policies for controlling HA singleton behavior are managed by a new singleton subsystem. A deployment can either specify a specific singleton policy or use the default subsystem policy.
A deployment identifies itself as a singleton deployment by using a META-INF/singleton-deployment.xml deployment descriptor, which is applied to an existing deployment as a deployment overlay. Alternatively, the requisite singleton configuration can be embedded within an existing jboss-all.xml file.
Defining or choosing a singleton deployment
To define a deployment as a singleton deployment, include a META-INF/singleton-deployment.xml descriptor in your application archive.
If a Maven WAR plug-in already exists, you can migrate the plug-in to the META-INF directory: **/src/main/webapp/META-INF.
Procedure
If an application is deployed in an EAR file, move the
singleton-deployment.xmldescriptor or thesingleton-deploymentelement, which is located within thejboss-all.xmlfile, to the top-level of theMETA-INFdirectory.Example: Singleton deployment descriptor
<?xml version="1.0" encoding="UTF-8"?> <singleton-deployment xmlns="urn:jboss:singleton-deployment:1.0"/>
To add an application deployment as a WAR file or a JAR file, move the
singleton-deployment.xmldescriptor to the top-level of the/META-INFdirectory in the application archive.Example: Singleton deployment descriptor with a specific singleton policy
<?xml version="1.0" encoding="UTF-8"?> <singleton-deployment policy="my-new-policy" xmlns="urn:jboss:singleton-deployment:1.0"/>
Optional: To define the
singleton-deploymentin ajboss-all.xmlfile, move thejboss-all.xmldescriptor to the top-level of the/META-INFdirectory in the application archive.Example: Defining
singleton-deploymentinjboss-all.xml<?xml version="1.0" encoding="UTF-8"?> <jboss xmlns="urn:jboss:1.0"> <singleton-deployment xmlns="urn:jboss:singleton-deployment:1.0"/> </jboss>Optional: Use a singleton policy to define the
singleton-deploymentin thejboss-all.xmlfile. Move thejboss-all.xmldescriptor to the top-level of the/META-INFdirectory in the application archive.Example: Defining
singleton-deploymentinjboss-all.xmlwith a specific singleton policy<?xml version="1.0" encoding="UTF-8"?> <jboss xmlns="urn:jboss:1.0"> <singleton-deployment policy="my-new-policy" xmlns="urn:jboss:singleton-deployment:1.0"/> </jboss>
Creating a Singleton Deployment
JBoss EAP provides two election policies:
Simple election policy
The
simple-election-policychooses a specific member, indicated by thepositionattribute, on which a given application will be deployed. Thepositionattribute determines the index of the node to be elected from a list of candidates sorted by descending age, where0indicates the oldest node,1indicates the second oldest node,-1indicates the youngest node,-2indicates the second youngest node, and so on. If the specified position exceeds the number of candidates, a modulus operation is applied.Example: Create a New Singleton Policy with a
simple-election-policyand Position Set to-1, Using the Management CLIbatch /subsystem=singleton/singleton-policy=my-new-policy:add(cache-container=server) /subsystem=singleton/singleton-policy=my-new-policy/election- policy=simple:add(position=-1) run-batch
NoteTo set the newly created policy
my-new-policyas the default, run this command:/subsystem=singleton:write-attribute(name=default, value=my-new-policy)
Example: Configure a
simple-election-policywith Position Set to-1Usingstandalone-ha.xml<subsystem xmlns="urn:jboss:domain:singleton:1.0"> <singleton-policies default="my-new-policy"> <singleton-policy name="my-new-policy" cache-container="server"> <simple-election-policy position="-1"/> </singleton-policy> </singleton-policies> </subsystem>Random election policy
The
random-election-policychooses a random member on which a given application will be deployed.Example: Creating a New Singleton Policy with a
random-election-policy, Using the Management CLIbatch /subsystem=singleton/singleton-policy=my-other-new-policy:add(cache-container=server) /subsystem=singleton/singleton-policy=my-other-new-policy/election-policy=random:add() run-batch
Example: Configure a
random-election-policyUsingstandalone-ha.xml<subsystem xmlns="urn:jboss:domain:singleton:1.0"> <singleton-policies default="my-other-new-policy"> <singleton-policy name="my-other-new-policy" cache-container="server"> <random-election-policy/> </singleton-policy> </singleton-policies> </subsystem>NoteThe
default-cacheattribute of thecache-containerneeds to be defined before trying to add the policy. Without this, if you are using a custom cache container, you might end up getting error messages.
Preferences
Additionally, any singleton election policy can indicate a preference for one or more members of a cluster. Preferences can be defined either by using the node name or by using the outbound socket binding name. Node preferences always take precedent over the results of an election policy.
Example: Indicate Preference in the Existing Singleton Policy Using the Management CLI
/subsystem=singleton/singleton-policy=foo/election-policy=simple:list-add(name=name-preferences, value=nodeA) /subsystem=singleton/singleton-policy=bar/election-policy=random:list-add(name=socket-binding-preferences, value=binding1)
Example: Create a New Singleton Policy with a simple-election-policy and name-preferences, Using the Management CLI
batch /subsystem=singleton/singleton-policy=my-new-policy:add(cache-container=server) /subsystem=singleton/singleton-policy=my-new-policy/election-policy=simple:add(name-preferences=[node1, node2, node3, node4]) run-batch
To set the newly created policy my-new-policy as the default, run this command:
/subsystem=singleton:write-attribute(name=default, value=my-new-policy)
Example: Configure a random-election-policy with socket-binding-preferences Using standalone-ha.xml
<subsystem xmlns="urn:jboss:domain:singleton:1.0">
<singleton-policies default="my-other-new-policy">
<singleton-policy name="my-other-new-policy" cache-container="server">
<random-election-policy>
<socket-binding-preferences>binding1 binding2 binding3 binding4</socket-binding-preferences>
</random-election-policy>
</singleton-policy>
</singleton-policies>
</subsystem>
Define a Quorum
Network partitions are particularly problematic for singleton deployments, since they can trigger multiple singleton providers for the same deployment to run at the same time. To defend against this scenario, a singleton policy can define a quorum that requires a minimum number of nodes to be present before a singleton provider election can take place. A typical deployment scenario uses a quorum of N/2 + 1, where N is the anticipated cluster size. This value can be updated at runtime, and will immediately affect any singleton deployments using the respective singleton policy.
Example: Quorum Declaration in the standalone-ha.xml File
<subsystem xmlns="urn:jboss:domain:singleton:1.0">
<singleton-policies default="default">
<singleton-policy name="default" cache-container="server" quorum="4">
<simple-election-policy/>
</singleton-policy>
</singleton-policies>
</subsystem>
Example: Quorum Declaration Using the Management CLI
/subsystem=singleton/singleton-policy=foo:write-attribute(name=quorum, value=3)
See the ha-singleton-deployment quickstart that ships with JBoss EAP for a complete working example of a service packaged in an application as a cluster-wide singleton using singleton deployments.
Determine the Primary Singleton Service Provider Using the CLI
The singleton subsystem exposes a runtime resource for each singleton deployment or service created from a particular singleton policy. This helps you determine the primary singleton provider using the CLI.
You can view the name of the cluster member currently acting as the singleton provider. For example:
/subsystem=singleton/singleton-policy=default/deployment=singleton.jar:read-attribute(name=primary-provider)
{
"outcome" => "success",
"result" => "node1"
}You can also view the names of the nodes on which the singleton deployment or service is installed. For example:
/subsystem=singleton/singleton-policy=default/deployment=singleton.jar:read-attribute(name=providers)
{
"outcome" => "success",
"result" => [
"node1",
"node2"
]
}6.6. Apache mod_cluster-manager Application
6.6.1. About mod_cluster-manager Application
The mod_cluster-manager application is an administration web page, which is available on Apache HTTP Server. It is used for monitoring the connected worker nodes and performing various administration tasks, such as enabling or disabling contexts, and configuring the load-balancing properties of worker nodes in a cluster.
Exploring mod_cluster-manager Application
The mod_cluster-manager application can be used for performing various administration tasks on worker nodes.
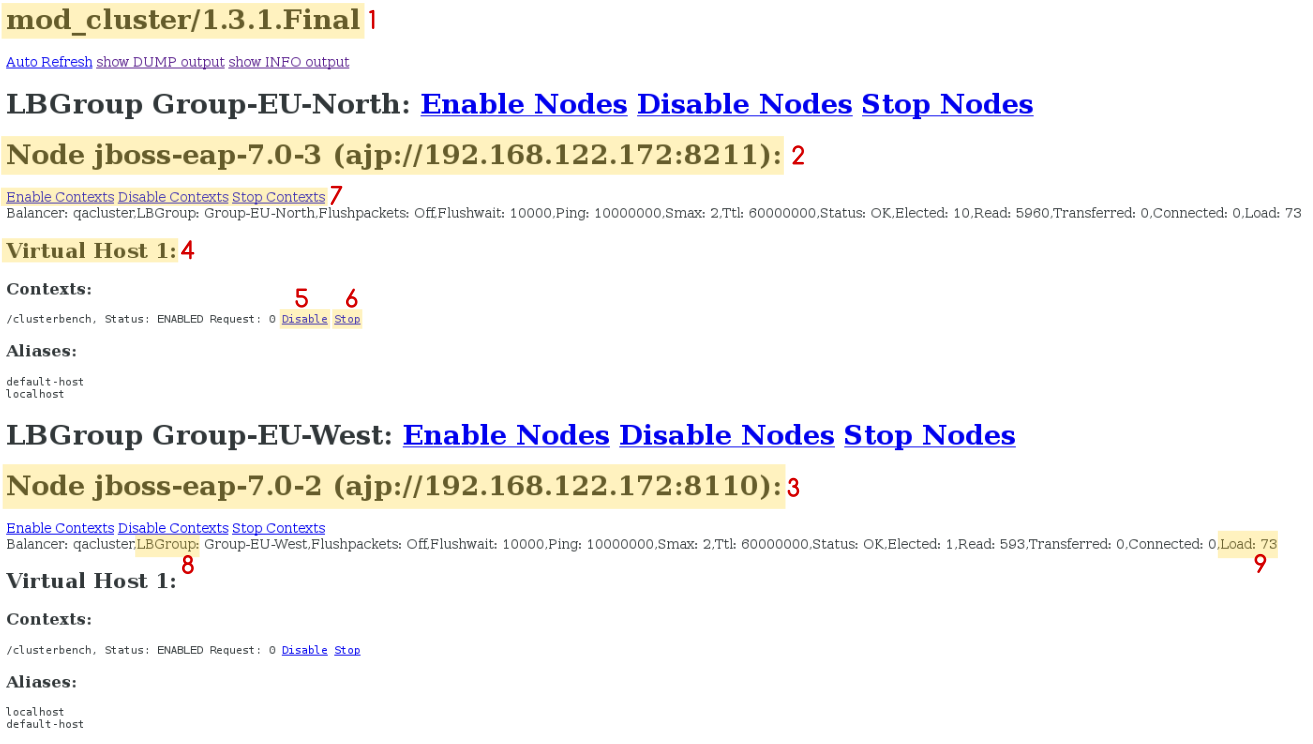 Figure - mod_cluster Administration Web Page
Figure - mod_cluster Administration Web Page
- [1] mod_cluster/1.3.1.Final: The version of the mod_cluster native library.
- [2] ajp://192.168.122.204:8099: The protocol used (either AJP, HTTP, or HTTPS), hostname or IP address of the worker node, and the port.
- [3] jboss-eap-7.0-2: The worker node’s JVMRoute.
- [4] Virtual Host 1: The virtual host(s) configured on the worker node.
- [5] Disable: An administration option that can be used to disable the creation of new sessions on the particular context. However, the ongoing sessions do not get disabled and remain intact.
-
[6] Stop: An administration option that can be used to stop the routing of session requests to the context. The remaining sessions will fail over to another node unless the
sticky-session-forceproperty is set totrue. - [7] Enable Contexts Disable Contexts Stop Contexts: The operations that can be performed on the whole node. Selecting one of these options affects all the contexts of a node in all its virtual hosts.
[8] Load balancing group (LBGroup): The
load-balancing-groupproperty is set in themodclustersubsystem in JBoss EAP configuration to group all worker nodes into custom load balancing groups. Load balancing group (LBGroup) is an informational field that gives information about all set load balancing groups. If this field is not set, then all worker nodes are grouped into a single default load balancing group.NoteThis is only an informational field and thus cannot be used to set
load-balancing-groupproperty. The property has to be set inmodclustersubsystem in JBoss EAP configuration.[9] Load (value): The load factor on the worker node. The load factors are evaluated as below:
-load > 0 : A load factor with value 1 indicates that the worker node is overloaded. A load factor of 100 denotes a free and not-loaded node. -load = 0 : A load factor of value 0 indicates that the worker node is in standby mode. This means that no session requests will be routed to this node until and unless the other worker nodes are unavailable. -load = -1 : A load factor of value -1 indicates that the worker node is in an error state. -load = -2 : A load factor of value -2 indicates that the worker node is undergoing CPing/CPong and is in a transition state.
For JBoss EAP 7.3, it is also possible to use Undertow as load balancer.
6.7. The distributable-web subsystem for Distributable Web Session Configurations
The distributable-web subsystem facilitates flexible and distributable web session configurations. The subsystem defines a set of distributable web session management profiles. One of these profiles is designated as the default profile. It defines the default behavior of a distributable web application. For example:
[standalone@embedded /] /subsystem=distributable-web:read-attribute(name=default-session-management)
{
"outcome" => "success",
"result" => "default"
}The default session management stores web session data within an Infinispan cache as the following example illustrates:
[standalone@embedded /] /subsystem=distributable-web/infinispan-session-management=default:read-resource
{
"outcome" => "success",
"result" => {
"cache" => undefined,
"cache-container" => "web",
"granularity" => "SESSION",
"affinity" => {"primary-owner" => undefined}
}
}The attributes used in this example and the possible values are:
-
cache: A cache within the associated cache-container. The web application’s cache is based on the configuration of this cache. If undefined, the default cache of the associated cache container is used. -
cache-container: A cache-container defined in theInfinispansubsystem into which session data is stored. granularity: Defines how the session manager maps a session into individual cache entries. The possible values are:-
SESSION: Stores all session attributes within a single cache entry. More expensive than theATTRIBUTEgranularity, but preserves any cross-attribute object references. -
ATTRIBUTE: Stores each session attribute within a separate cache entry. More efficient than theSESSIONgranularity, but does not preserve any cross-attribute object references.
-
affinity: Defines the affinity that a web request must have for a server. The affinity of the associated web session determines the algorithm for generating the route to be appended onto the session ID. The possible values are:-
affinity=none: Web requests do not have any affinity to any node. Use this if web session state is not maintained within the application server. -
affinity=local: Web requests have an affinity to the server that last handled a request for a session. This option corresponds to the sticky session behavior. -
affinity=primary-owner: Web requests have an affinity to the primary owner of a session. This is the default affinity for this distributed session manager. Behaves the same asaffinity=localif the backing cache is not distributed or replicated. -
affinity=ranked: Web requests have an affinity for the first available member in a list that include the primary and the backup owners, and for the member that last handled a session. -
affinity=ranked delimiter: The delimiter used to separate the individual routes within the encoded session identifier. -
Affinity=ranked max routes: The maximum number of routes to encode into the session identifier.
-
You must enable ranked session affinity in your load balancer to have session affinity with multiple, ordered routes. For more information, see Enabling Ranked Session Affinity in Your Load Balancer in the Configuration Guide for JBoss EAP.
You can override the default distributable session management behavior by referencing a session management profile by name or by providing a deployment-specific session management configuration. For more information, see Overide Default Distributable Session Management Behavior.
6.7.1. Storing Web Session Data In a Remote Red Hat Data Grid
The distributable-web subsystem can be configured to store web session data in a remote Red Hat Data Grid cluster using the HotRod protocol. Storing web session data in a remote cluster allows the cache layer to scale independently of the application servers.
Example configuration:
[standalone@embedded /]/subsystem=distributable-web/hotrod-session-management=ExampleRemoteSessionStore:add(remote-cache-container=datagrid, cache-configuration=__REMOTE_CACHE_CONFIG_NAME__, granularity=ATTRIBUTE)
{
"outcome" => "success"
}The attributes used in this example and the possible values are:
-
remote-cache-container: The remote cache container defined in theInfinispansubsystem to store the web session data. cache-configuration: Name of the cache configuration in Red Hat Data Grid cluster. The newly created deployment-specific caches are based on this configuration.If a remote cache configuration matching the name is not found, a new cache configuration is created in the remote container.
granularity: Defines how the session manager maps a session into individual cache entries. The possible values are:-
SESSION: Stores all session attributes within a single cache entry. More expensive than theATTRIBUTEgranularity, but preserves any cross-attribute object references. -
ATTRIBUTE: Stores each session attribute within a separate cache entry. More efficient than theSESSIONgranularity, but does not preserve any cross-attribute object references.
-