9.4. Competing Consumers
Overview
Copy linkLink copied to clipboard!
The competing consumers pattern, shown in Figure 9.3, “Competing Consumers Pattern”, enables multiple consumers to pull messages from the same queue, with the guarantee that each message is consumed once only. This pattern can be used to replace serial message processing with concurrent message processing (bringing a corresponding reduction in response latency).
Figure 9.3. Competing Consumers Pattern
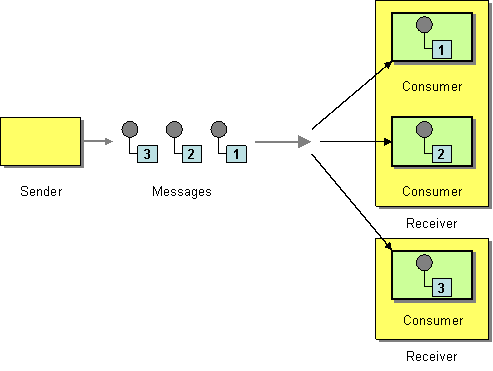
The following components demonstrate the competing consumers pattern:
JMS based competing consumers
Copy linkLink copied to clipboard!
A regular JMS queue implicitly guarantees that each message can only be consumed at once. Hence, a JMS queue automatically supports the competing consumers pattern. For example, you could define three competing consumers that pull messages from the JMS queue,
HighVolumeQ, as follows:
from("jms:HighVolumeQ").to("cxf:bean:replica01");
from("jms:HighVolumeQ").to("cxf:bean:replica02");
from("jms:HighVolumeQ").to("cxf:bean:replica03");
Where the CXF (Web services) endpoints,
replica01, replica02, and replica03, process messages from the HighVolumeQ queue in parallel.
Alternatively, you can set the JMS query option,
concurrentConsumers, to create a thread pool of competing consumers. For example, the following route creates a pool of three competing threads that pick messages from the specified queue:
from("jms:HighVolumeQ?concurrentConsumers=3").to("cxf:bean:replica01");
And the
concurrentConsumers option can also be specified in XML DSL, as follows:
<route>
<from uri="jms:HighVolumeQ?concurrentConsumers=3"/>
<to uri="cxf:bean:replica01"/>
</route>Note
JMS topics cannot support the competing consumers pattern. By definition, a JMS topic is intended to send multiple copies of the same message to different consumers. Therefore, it is not compatible with the competing consumers pattern.
SEDA based competing consumers
Copy linkLink copied to clipboard!
The purpose of the SEDA component is to simplify concurrent processing by breaking the computation into stages. A SEDA endpoint essentially encapsulates an in-memory blocking queue (implemented by
java.util.concurrent.BlockingQueue). Therefore, you can use a SEDA endpoint to break a route into stages, where each stage might use multiple threads. For example, you can define a SEDA route consisting of two stages, as follows:
// Stage 1: Read messages from file system.
from("file://var/messages").to("seda:fanout");
// Stage 2: Perform concurrent processing (3 threads).
from("seda:fanout").to("cxf:bean:replica01");
from("seda:fanout").to("cxf:bean:replica02");
from("seda:fanout").to("cxf:bean:replica03");
Where the first stage contains a single thread that consumes message from a file endpoint,
file://var/messages, and routes them to a SEDA endpoint, seda:fanout. The second stage contains three threads: a thread that routes exchanges to cxf:bean:replica01, a thread that routes exchanges to cxf:bean:replica02, and a thread that routes exchanges to cxf:bean:replica03. These three threads compete to take exchange instances from the SEDA endpoint, which is implemented using a blocking queue. Because the blocking queue uses locking to prevent more than one thread from accessing the queue at a time, you are guaranteed that each exchange instance can only be consumed once.