4. Writing Agent Plug-ins: Background
4.1. About the Advanced Management Plug-in System (AMPS) for Agent Plug-ins
- The agent's plug-in container. The plug-in contain runs inside the JBoss ON agent and it provides a manager for all of the deployed resource plug-ins.The plug-in container is what actually manages the lifecycle of the resource plug-ins. The agent starts the plug-in container, and the plug-in container starts the resource plug-ins. The plug-in container also handles all the classloading, threading, and running for resource plug-ins.Plug-in developers never need to interact with the plug-in container. As long as a plug-in is written with the appropriate components and with a valid plug-in descriptor, the agent will be able to manage the resource.
- Domain objects. This defines the individual objects for plug-ins, specifically resources, resource types, and configuration. All of the other elements in AMPS use the domain objects to define resource elements.One of the largest API sets within the domain object is configuration. The configuration API is used anywhere that a set of configuration properties is required, from plug-in configuration settings to connect to a resource to operation arguments.
- The plug-in components. These components define the actual component interfaces that are used by agent plug-ins, well as the facets that plug-ins can support.The plug-in components are the public API.This element within AMPS is the part that plug-in writers use. This contains the interfaces that plug-in writers implement in the resource plug-in.
- Native System. A lot of information require to monitor or manage a resource is available from the operating system information. The native system provides JNI or native access to that operating system information and can pull information from the process table, run external programs, or gather system metrics.
- Resource plug-ins.. JBoss ON has a set of resource plug-ins already defined. Each individual resource plug-in manages a particular product (applications and servers, services, or platforms). These plug-ins are loaded into the agent's plug-in container and implement the plug-in components defined in the API.
Note
4.2. The Breakdown of Agent Plug-in Configuration
rhq-plugin.xml inside the META-INF/ directory).
- A plug-in component file that contains all of the code for the plug-in functionality
- A
*Discovery.javafile that configures the discovery process for the resources defined in the plug-in - A
*EventPoller.javathat defines the events that can be collected by the resource
rhq-plugin.xml plug-in descriptor.
Note
4.2.1. Schema Files
rhq-configuration.xsd file to define the basic configuration options available.
rhq-plugin.xsd file, which extends the rhq-configuration.xsd schema and adds additional elements specifically for resource-related plug-ins.
Note
<xs:annotation> items) in the XSD files themselves.
rhq-configuration.xsd file provides schema which is available for all JBoss ON plug-ins. The rhq-configuration.xsd file is in source/modules/core/client-api/src/main/resources.
rhq-configuration schema relate to setting configuration values for a plug-in, like <simple-property> and <map-property>.
| Element | Description |
|---|---|
| configuration-property | For adding a configuration attribute to a plug-in for user-defined settings. |
| simple-property | For setting a default configuration value. |
| option | For setting whether a property's values come from an enumerated list (false) or can be anything defined by the user (true). |
rhq-configuration.xsd file also defines the most common flags that can be used for the plug-in descriptor, including the required name and optional displayName attributes.
| Attribute | Description |
|---|---|
| name | Required. Gives a unique name for the plug-in. |
| displayName | Gives the name to use for the plug-in in the GUI. If this isn't given, then the name value is used. |
| description | Gives a short description of the plug-in. |
rhq-plugin.xsd provides all of the schema elements specifically for agent plug-ins. The rhq-plugin.xsd file is in the source/modules/core/client-api/src/main/resources directory.
rhq-plugin.xsd file are listed in Table 11, “rhq-plugin.xsd Schema Elements”.
| Element | Description |
|---|---|
| plugin | Contains the root element for the plug-in descriptor. |
| depends | Identifies any other plug-ins which this plug-in requires or extends. |
| platforms, servers, services | Identifies the type for a resource defined within the agent plug-in. <platforms> are top-level elements, but <servers> and <services> are added as children of platforms or other server and service resources. |
| metric | An element within a platform, server, or service which defines metrics which can be collected for that resource type.
Child elements and attributes for this resource element are listed in the
rhq-plugin.xsd file.
Values that form part of a larger data structure, such as an array of values, need to be deconstructed into individual values before they can be monitored.
|
| event | An element within a platform, server, or service which defines whether that resource supports events. There are no other configuration properties with events; the events themselves are culled from the resource's log files. |
| bundle-target | Configures whether and how bundles can be deployed to a resource.
Child elements and attributes for this resource element are listed in the
rhq-plugin.xsd file.
|
| drift-definition | Configures whether and how drift monitoring can be performed for a resource.
Child elements and attributes for this resource element are listed in the
rhq-plugin.xsd file.
|
| resource-configuration | Defines a configuration property for a resource type.
Child elements and attributes for this resource element are listed in the
rhq-plugin.xsd file.
|
| operation | Defines an operation that can be performed on that resource type.
Child elements and attributes for this resource element are listed in the
rhq-plugin.xsd file.
|
| content | Configures what types of packages can be uploaded or deployed on a resource type.
Child elements and attributes for this resource element are listed in the
rhq-plugin.xsd file.
|
rhq-plugin.xsd contain flags that are used within the root element of the plug-in descriptor. These add additional management attributes for controlling the release and updates of agent plug-ins.
| Attribute | Description |
|---|---|
| package | For setting the plug-in package name. |
| version | For setting the version of the plug-in. This must be in an OSGi-compatible format. |
| ampsVersion | For the agent plug-in system version that this plug-in requires. This must be in an OSGi-compatible format. |
| pluginLifecycleListener | For the listener which initializes and shuts down the plug-in. |
| discovery | Sets whether a resource type is detected by discovery scans. This flag may not be necessary for child resources that will be discovered by the parent resource. |
rhq-plugin.xsd file. Each one is described by the text in the <xs:annotation> tags for the item.
4.2.2. Descriptor and Configuration
- The names of the resource types (servers and services) supported by the plug-in
- Any configuration settings that the agent's plug-in components use to connect to the resource
- Any metrics (measurement definitions) to use to monitor the resource; this depends on the type of data issued by the resource itself.
- A set of operations that can be invoked on the resource. This is commonly start and stop operations, but it can include application-specific operations or other actions, like running a script.
- Resource configuration values that can be edited in the actual configuration of the resource.The plug-in configuration tells the components how to connect to the resource. The resource configuration, on the other hand, are settings in the resource itself that can be edited externally.
- Any child resources that are part of the resource hierarchy. For example, a JBoss server has data source services running within them, so the data source services are defined in the JBoss server resource plug-in, as a child resource of the JBoss server.
4.2.2.1. Resource Type, Metadata, and Plug-in Configuration
<plugin> element.
<plugin name="JMX"
displayName="Generic JMX"
package="org.rhq.plugins.jmx"
description="Supports management of JMX MBean Servers via various remoting systems."
ampsVersion="2.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns="urn:xmlns:rhq-plugin"
xmlns:c="urn:xmlns:rhq-configuration">nameanddisplayNamegive the internal and GUI name of the plug-in.ampsVersiongives the version number of the plug-in itself.packagegives the name of the classes used by the components in the plug-in.
<platform>, <server>, or <service>.
<service> resource definitions inside <server> (or other <service>) resource definitions.
<server name="JMX Server" discovery="JMXDiscoveryComponent" class="JMXServerComponent"
description="Generic JMX Server"
supportsManualAdd="true" createDeletePolicy="neither">Important
discoveryidentifies the discovery component used to identify the resource type.classidentifies the plug-in component which contains the actual code of the plug-in.
supportsManualAddallows resources to be added to the inventory by administrators.createDeletePolicysets whether children can be added or removed manually from inventory.
<plugin-configuration>
<c:list-property name="Servers">
<c:map-property name="OneServer">
<c:simple-property name="host"/>
<c:simple-property name="port">
<c:integer-constraint
minimum="0"
maximum="65535"/>
</c:simple-property>
<c:simple-property name="protocol">
<c:property-options>
<c:option value="http" default="true"/>
<c:option value="https"/>
</c:property-options>
</c:simple-property>
</c:map-property>
</c:list-property>
</plugin-configuration><simple-property>, which defines a one key-value pair<map-property>, which defines multiple key-value pairs related to a single entity, following thejava.util.Mapconcept<list-property>, which contains a list of properties
<map-property> and <list-property> define groups of <simple-property> element. Additionally, these properties can be formally grouped together under <group> element. Using a <group> element creates a collapsible configuration ares in the UI.
<c:template name="JDK 5" description="Connect to JDK 5">
<c:simple-property name="type" default="org.mc4j.ems.connection.support.metadata.J2SE5ConnectionTypeDescriptor"/>
<c:simple-property name="connectorAddress" default="service:jmx:rmi:///jndi/rmi://localhost:8999/jmxrmi"/>
</c:template>4.2.2.2. Discovery and Process Scans
<plugin> element has a discovery attribute which identifies the discovery Java file for the resource plug-in. (If there are multiple resources defined in the plug-in, then there will be multiple discovery components.)
/**
* Discovery class
*/
public class testDiscovery implements ResourceDiscoveryComponent
,ManualAddFacet
{
private final Log log = LogFactory.getLog(this.getClass());
/**
* Do the manual add of this one resource
*/
public DiscoveredResourceDetails discoverResource(Configuration pluginConfiguration, ResourceDiscoveryContext context) throws InvalidPluginConfigurationException {
// TODO implement this
DiscoveredResourceDetails detail = null; // new DiscoveredResourceDetails(
// context.getResourceType(), // ResourceType
// );
return detail;
}
} public DiscoveredResourceDetails discoverResource(Configuration pluginConfig,
ResourceDiscoveryContext discoveryContext)
throws InvalidPluginConfigurationException {
// TODO: Connect to the remote JVM to verify the user-specified conn props are valid, and if connecting
// fails, throw an exception.
String resourceKey = pluginConfig.getSimpleValue(CONNECTOR_ADDRESS_CONFIG_PROPERTY, null);
String connectionType = pluginConfig.getSimpleValue(CONNECTION_TYPE, null);
// TODO (ips, 09/04/09): We should connect to the remote JVM in order to obtain its version.
String version = null;
DiscoveredResourceDetails resourceDetails = new DiscoveredResourceDetails(discoveryContext.getResourceType(),
resourceKey, "Java VM", version, connectionType + " [" + resourceKey + "]", pluginConfig, null);
return resourceDetails;
} <process-scan> element and then implemented in the discovery component.
<process-scan> child element. The <process-scan> element itself is empty, but has two required attributes: name and query. name identifies the specific scan method. query is the attribute that does something. The query is a string written in Process Info Query Language (PIQL). This value is used to search for the process.
process|attribute|match=value,arg|attribute|match=valueps information contains both of those attributes.
jsmith 2035 0.0 -1.5 724712 30616 p7 S+ 9:49PM 0:01.61 java
-Dprogram.name=run.sh -Xms128m -Xmx512m -Dsun.rmi.dgc.client.gcInterval=3600000
-Dsun.rmi.dgc.server.gcInterval=3600000 -Djboss.platform.mbeanserver
-Djava.endorsed.dirs=/devel/jboss-4.0.5.GA/lib/endorsed
-classpath /devel/jboss-4.0.5.GA/bin/run.jar:/lib/tools.jar
org.jboss.Main -c minimalbasename query attribute, with a matching argument, defined in the arg query attribute.
process|attribute|match=value,arg|attribute|match=value
| | |____ |_ |____ |______
| | | | | |
| | | | | |
| | | | | |
| | | | | |
process|basename|match=^java.*,arg|org.jboss.Main|match=.*process|attribute|match=valueprocess|pidfile|match=/etc/product/lock.pidrhq-plugin.xml descriptor file, then the discovery component must be written to implement the scan and process results.
Example 9. Process Scan Method in the Discovery Component
List<ProcessScanResult< autoDiscoveryResults =
context.getAutoDiscoveredProcesses();
for (ProcessScanResult result : autoDiscoveryResults) {
ProcessInfo procInfo = result.getProcessInfo();
....
// as before
DiscoveredResourceDetails detail =
new DiscoveredResourceDetails(
resourceType, key, name, null,
description, childConfig, procInfo
);
result.add(detail);
}<metric> elements in the plug-in descriptor.
<metric displayName="Bytes Sent"
description="Shows the rate that data bytes are sent by the Web service."
property="Bytes Sent/sec"
defaultOn="true"
displayType="summary"
measurementType="trendsup"
units="bytes"/>propertyidentifies the resource monitoring property.measurementTypesets the data type being collected.unitssets the units of the thing being monitored.
MeasurementFacet.
public class testComponent implements ResourceComponent
, MeasurementFacet
, OperationFacetMeasurementReport, with a MeasurementScheduleRequest entity for each type of monitoring data.
public void getValues(MeasurementReport report, Set<MeasurementScheduleRequest> metrics) throws Exception {
String propertyBase = "\\Web Service(_Total)\\";
Pdh pdh = new Pdh();
for (MeasurementScheduleRequest request : metrics) {
double value = pdh.getRawValue(propertyBase + request.getName());
report.addData(new MeasurementDataNumeric(request, value));
}
}Important
<operation> element, implemented in the plug-in Java component through an OperationFacet, and then invoked in a OperationResult method.
4.2.2.3. Events
<event> element, no children, that identifies the logging area by name.
<event name="errorLogEntry" description="an entry in the error log file"/>EventPoller component. This can be in the larger plug-in Java component, but it is usually broken into a separate *EventPoller.java component. The way to implement event polling depends on the resource and the nature of its logging. One of the simplest ways is to call the EventPoller(), then define the event type and set how the event is polled.
public PerfTestEventPoller(ResourceContext resourceContext) {
this.resourceContext = resourceContext;
}
public String getEventType() {
return PERFTEST_EVENT_TYPE;
}
public Set<Event> poll() {
int count = Integer.parseInt(System.getProperty(SYSPROP_EVENTS_COUNT, "1"));
String severityString = System.getProperty(SYSPROP_EVENTS_SEVERITY, EventSeverity.INFO.name());
EventSeverity severity = EventSeverity.valueOf(severityString);
Set<Event> events = new HashSet<Event>(count);
for (int i = 0; i < count; i++) {
Event event = new Event(PERFTEST_EVENT_TYPE, "source.loc", System.currentTimeMillis(), severity, "event #"
+ i);
events.add(event);
}
return events;
}4.2.2.4. Resource Configuration
<resource-configuration> elements. These configuration elements follow the same conventions as the <plugin-configuration> elements. The properties are defined as <simple-property> elements and can be listed (for options), mapped, or organized into groups that are collapsible sections in the UI.
<resource-configuration>
<c:group name="Attributes">
<c:simple-property
name="appBase"
required="true"
readOnly="true"
description="The Application Base directory for this virtual host." />
<c:simple-property
name="autoDeploy"
type="boolean"
description="Does this host deploy new applications dropped in appBase at runtime?" />
<c:simple-property
name="deployOnStartup"
type="boolean"
description="Does this host deploy applications in appBase at startup?" />
<c:simple-property
name="deployXML"
displayName="Deploy XML"
type="boolean"
description="deploy Context XML config files?" />
<c:simple-property
name="unpackWARs"
displayName="Unpack WARs"
type="boolean"
description="Does this Host automatically unpack deployed WAR files?" />
<c:simple-property
name="aliases"
required="false"
type="longString"
description="Aliases assigned to the Host. When editing, each alias must be on a new line. Aliases are automatically lowercased." />
</c:group>
</resource-configuration> public Configuration loadResourceConfiguration() {
Configuration configuration = super.loadResourceConfiguration();
try {
resetConfig(CONFIG_ALIASES, configuration);
} catch (Exception e) {
log.error("Failed to reset role property value", e);
}
return configuration;
} public void updateResourceConfiguration(ConfigurationUpdateReport report) {
Configuration reportConfiguration = report.getConfiguration();
// reserve the new alias settings
PropertySimple newAliases = reportConfiguration.getSimple(CONFIG_ALIASES);
// get the current alias settings
resetConfig(CONFIG_ALIASES, reportConfiguration);
PropertySimple currentAliases = reportConfiguration.getSimple(CONFIG_ALIASES);
// remove the aliases config from the report so they are ignored by the mbean config processing
reportConfiguration.remove(CONFIG_ALIASES);
// perform standard processing on remaining config
super.updateResourceConfiguration(report);
// add back the aliases config so the report is complete
reportConfiguration.put(newAliases);
// if the mbean update failed, return now
if (ConfigurationUpdateStatus.SUCCESS != report.getStatus()) {
return;
}
// try updating the alias settings
try {
consolidateSettings(newAliases, currentAliases, "addAlias", "removeAlias", "alias");
} catch (Exception e) {
newAliases.setErrorMessage(ThrowableUtil.getStackAsString(e));
report.setErrorMessage("Failed setting resource configuration - see property error messages for details");
log.info("Failure setting Tomcat VHost aliases configuration value", e);
}
// If all went well, persist the changes to the Tomcat server.xml
try {
storeConfig();
} catch (Exception e) {
report
.setErrorMessage("Failed to persist configuration change. Changes will not survive Tomcat restart unless a successful Store Configuration operation is performed.");
}
}4.2.3. Lifecycle Listeners
org.rhq.core.pluginapi.plugin.PluginLifecycleListener class allocates global resources needed by plug-in components and cleans up those resources.
pluginLifecycleListener attribute in the top-level <plugin> element.
<plugin name="Apache"
displayName="Apache HTTP Server"
description="Management of Apache web servers"
package="org.rhq.plugins.apache"
pluginLifecycleListener="ApachePluginLifecycleListener"
...4.2.4. Plug-in Dependencies: Defining Relationships Between Plug-ins
- Required dependencies are set using the
<depends>element. Just using<depends>means that the required plug-in must be loaded or the other plug-in will fail to load. Adding theuseClassesattribute makes the classes and JAR files for the parent plug-in available to the child plug-in. - An injection plug-in dependency means that a root-level resource runs inside another resource type, and that parent resource is defined as a parent plug-in. This essentially adds a new child to an existing resource type.
- An embedded plug-in dependency means that a new parent resource type is added for an existing child. This can allow the child to be extended to share the new parent's classloader (depending on both plug-ins' configuration) or simply expand discovery.
Important
4.2.4.1. Required Plug-in Dependencies
<depends> element directly under the <plug-in> element defines a parent plug-in that the plug-in depends on and required to be loaded. The <depends> element is what specifies a required dependency. The plug-in will not deploy successfully, unless all <depends> plug-ins are also successfully deployed.
<depends> element can pull in JARs from the parent plug-in by specifying the useClasses attribute. The useClasses option can be set for only one required dependency in a single plug-in descriptor. If no <depends> element has a useClasses attribute, the last <depends> element specified in the plug-in descriptor, by default, has its useClasses attribute to true.
<depends> element is used if the plug-in needs access to another plug-in's classes or if the plug-in should only be deployed when another plug-in is also deployed.
Note
<depends> element, as well as the other configuration.
4.2.4.2. Embedded Plug-in Dependencies
sourcePlugin and sourceType attributes on the resource elements. When a plug-in source is specified, the server or service is copied from the source resource type, which means it has the same metadata as the source, with the exception that the embedded server or service can override the discovery and resource classes and, potentially, have a different name.
4.2.4.3. Injection Plug-in Dependencies
<runs-inside> element. Each parent is an optional dependency.
<runs-inside>
<parent-resource-type name="JMX Server" plugin="JMX" />
<parent-resource-type name="JBoss Server" plugin="JBoss AS" />
</runs-inside>4.2.5. Class Sharing Between Plug-ins
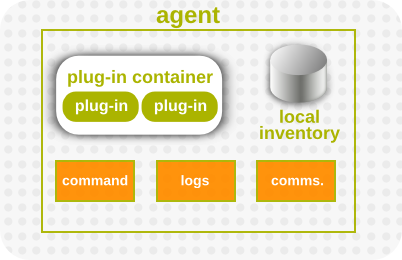
Figure 5. Agent Components, Together
<depends useClasses=""> attribute is set to true. If a plug-in is a direct dependent of another plug-in, and that dependency is defined with <depends useClasses="true">, then that parent plug-in's JAR classes (and all of its parent JARs) are available to the dependent plug-in's classloader.
classLoader="instance" on the resource type and make sure the resource type's discovery component implements the ClassLoaderFacet so it tells the plug-in container where any additional connection classes can be found for the specific version of the specific resource being managed.
classLoader option set to shared. This means that Z1.server resources share their classloaders with their parent resources, and that classloader may be a resource classloader or a plug-in classloader. Every Z1.server resource uses the same classloader.
Example 10. classLoader for Plug-in Z
<plug-in name="Z">
<depends plugin="A" />
<server name="Z1.server" classLoader="shared">
<runs-inside>
<parent-resource-type name="B1.server" plugin="B"/>
<parent-resource-type name="C1.server" plugin="C"/>
</runs-inside>
</server>
<server name="Z2.server" sourcePlugin="D" sourceType="D1" classLoader="instance">
</server>
<server name="Z3.server" classLoader="instance">
</server>
</plugin>classLoader option to instance means that each resource uses its own resource plug-in. However, for Z2.server, the Z2.server plug-in is extended by embedding the values for Plug-in D, so Z2.server resources share their classloaders with their parent plug-in.
classLoader option is set to instance and it has no injected or embedded dependencies. When the classLoader option is set to instance, the ResourceDiscoveryComponent implementation can optionally define a ClassLoaderFacet with a method (getAdditionalClasspathUrls) that returns a List<URL> pointing to additional JARs that should be placed in the resource's classloader. When the plug-in container needs to create a classloader for a resource, it checks if the resource's discovery component implements this facet, and, if so, it gets the additional classpath URLs and adds them to the resource classloader when it creates it.
classLoader attribute value and its parent's classLoader attribute value.
| Resource ClassLoader | Parent ClassLoader | ClassLoader Description |
|---|---|---|
| shared | shared | The useClasses value must be set to true so that the resource can access both its classes and the parent classes. |
| instance | shared | The resource primarily needs its own classes, but it may be beneficial for useclasses to be set to true to so that the child can use parent classes. |
| shared | instance | The resource uses only its own classloader. |
| instance | instance | The resource uses only its own classloader. |
4.3. Extended Example: Content Types for Resources
<content> elements. The required properties are set as flags on the main <content> element; any configurable properties, which are set by the user when new packages are uploaded to the resource, are given in <c:simple-property> child elements. For example, this content element in the Platform Resource Plug-in identifies deployable (category) package types for Windows platforms:
<content name="InstalledSoftware" displayName="Installed Software" category="deployable" description="Installed Windows Software">
<configuration>
<c:simple-property name="Publisher"/>
<c:simple-property name="Comments"/>
<c:simple-property name="Contact"/>
<c:simple-property name="HelpLink"/>
<c:simple-property name="HelpTelephone"/>
<c:simple-property name="InstallLocation"/>
<c:simple-property name="InstallSource"/>
<c:simple-property name="EstimatedSize" units="kilobytes"/>
</configuration>
</content>| Attribute | Description | Optional or Required |
|---|---|---|
| Name | The programmatic name of the package type. | Required |
| Display Name | A user interface friendly name of the package type. | Optional |
| Description | Describes the type of content found in packages of this type. | Optional |
| Category | One of four enumerated options:
| Required |
| Discovery Interval | Defines the time between package discovery scans for this type; different package types can be configured with intervals to represent the likelihood of the package inventory changing. | Optional |
| Creation Type Flag | If set to true, a package of this type is used when creating resources of the enclosing resource type. An example of this situation is a Java EAR file. There is an EAR resource type that represents the enterprise application in JBoss ON. Under that resource type, there is a package type defined to represent the EAR file itself. This package type is flagged as a creation type; when creating a new EAR resource, the EAR file must be created at the same time. The default for this attribute is false, as packages will typically not represent the creation of a new resource. | Optional |
| Configuration | The configuration element allows the plug-in to define an open-ended set of attributes about the package type. These values will be populated during package discovery, and if not marked as read only, can be specified by the user at artifact creation time. An example of a property in this configuration element is a Boolean that describes if an EAR file is deployed as exploded or zipped. When EAR files are discovered, this flag will be populated and carry package type specified information. Additionally, when deploying a new EAR file through JBoss ON, this flag can be set to indicate how the package should be deployed on the AS instance. | Optional |
4.4. Extended Example: HTTP Metrics
- Issue a GET or HEAD request to the base URL for the given server.
- Collect both the HTTP return code and the response time as a resource trait.
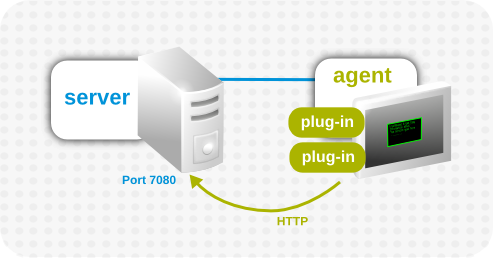
Figure 6. Basic Agent Plug-in Scenario
Note
rhq-plugin.xml file as the plug-in descriptor, which is required for JBoss ON to recognize the plug-in configuration. The plug-in is built as a maven project, so it has a pom.xml file, although that is not a requirement, since any properly configured JAR file can be deployed as an agent plug-in.
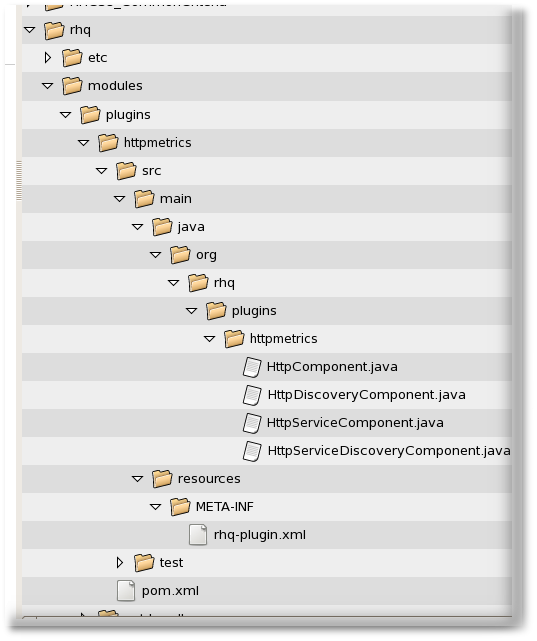
Figure 7. Directory Layout of an Agent Plug-in Project
4.4.1. Looking at the Plug-in Descriptor (rhq-plugin.xml)
Example 11. Basic Plug-in Information
<?xml version="1.0" encoding="UTF-8" ?>
<plugin name="HttpTest"
displayName="HttpTest plugin"
package="org.rhq.plugins.httptest"
version="2.0"
description="Monitoring of http servers"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns="urn:xmlns:rhq-plugin"
xmlns:c="urn:xmlns:rhq-configuration">package attribute identifies the Java package for Java class names that are referenced in the plug-in configuration in the descriptor.
Example 12. Server Definition
<server name="HttpCheck"
description="Httpserver pinging"
discovery="HttpDiscoveryComponent"
class="HttpComponent">.java files and classes. The supportsManualAdd option sells JBoss ON that the HTTP services can be added manually through the UI, which is important for administration.
Example 13. Service Definition
<service name="HttpServiceCheck"
discovery="HttpServiceDiscoveryComponent"
class="HttpServiceComponent"
description="One remote Http Server"
supportsManualAdd="true"<service> element defines the plug-in properties that are configured through the UI. This can be simple (setting a simple string for the URL).
Example 14. Simple Configuration Properties
<plugin-configuration>
<c:simple-property name="url"
type="string"
required="true" />
</plugin-configuration>Example 15. Complex Configuration Properties
<plugin-configuration>
<c:list-property name="Servers">
<c:map-property name="OneServer">
<c:simple-property name="host"/>
<c:simple-property name="port">
<c:integer-constraint
minimum="0"
maximum="65535"/>
</c:simple-property>
<c:simple-property name="protocol">
<c:property-options>
<c:option value="http" default="true"/>
<c:option value="https"/>
</c:property-options>
</c:simple-property>
</c:map-property>
</c:list-property>
</plugin-configuration><service> element contains the metrics that are configured for the HTTP Metrics plug-in. The first metric, for the response time, collects a numeric data type. The status metric collects a trait data type. (JBoss ON is intelligent enough to only store changed traits to conserve space.)
Example 16. Defined Metrics
<metric property="responseTime"
displayName="Response Time"
measurementType="dynamic"
units="milliseconds"
displayType="summary"/>
<metric property="status"
displayName="Status Code"
data type="trait"
displayType="summary"/>
</service>
</server>
</plugin>| Attribute | Description |
|---|---|
| property | Gives the unique name of this metric. The name can also be obtained in the code using the getName() call. |
| description | Gives a human readable description of the metric. |
| displayName | Gives the name that gets displayed in the JBoss ON UI. |
| data type | Sets the type of metric, such as numeric or trait. |
| units | The measurement units to use for numerical data type. |
| displayType | If the value is set to summary, the metric is displayed in the indicator charts and collected by default. |
| defaultOn | Sets whether the metric collected by default. |
| measurementType | Sets what characteristics the numerical values have. The options are trends up, trends down, or dynamic. For both trends metrics, the system automatically creates additional per minute metrics.
Values that form part of a larger data structure, such as an array of values, need to be deconstructed into individual values before they can be monitored.
|
4.4.2. Looking at the Discovery Components (HttpDiscoveryComponent.java and HttpServiceDiscoveryComponent.java)
HttpDiscoveryComponent.java, discovers the HTTP metrics server. The discovery component is called by the InventoryManager in the agent to discover resources. This can be done by a process table scan, querying the MBeanServer, or other means. Whatever the method, the most important thing is that the discovery component returns the same unique key each time for the same resource. The DiscoveryComponent needs to implement org.rhq.core.pluginapi.inventory.ResourceDiscoveryComponent and you need to implement discoverResources().
Example 17. HttpDiscoveryComponent.java
public class HttpDiscoveryComponent implements
ResourceDiscoveryComponent
{
public Set discoverResources(ResourceDiscoveryContext context)
throws InvalidPluginConfigurationException, Exception
{
Set<DiscoveredResourceDetails> result =
new HashSet<DiscoveredResourceDetails>();
String key = "http://localhost:7080/"; // Jon server
String name = key;
String description = "Http server at " + key;
Configuration configuration = null;
ResourceType resourceType = context.getResourceType();
DiscoveredResourceDetails detail =
new DiscoveredResourceDetails(resourceType,
key, name, null, description,
configuration, null
);
result.add(detail);
return result;
}HttpServiceDiscoveryComponent.java) relies on information passed through the GUI to configure its resources, rather than a discovery scan. The initial definition in the Java file is similar to the one for the server discovery, but this definition has an additional List<Configuration> childConfigs which processes the information that is passed through the UI. This pulls the information for the required url information supplied by the user.
Example 18. Service Discovery
public class HttpServiceDiscoveryComponent
implements ResourceDiscoveryComponent<HttpServiceComponent>;
{
public Set<DiscoveredResourceDetails> discoverResources
(ResourceDiscoveryContext<HttpServiceComponent> context)
throws InvalidPluginConfigurationException, Exception
{
Set<DiscoveredResourceDetails> result =
new HashSet<DiscoveredResourceDetails>();
ResourceType resourceType = context.getResourceType();
List<Configuration> childConfigs =
context.getPluginConfigurations();
for (Configuration childConfig : childConfigs) {
String key = childConfig.getSimpleValue("url", null);
if (key == null)
throw new InvalidPluginConfigurationException(
"No URL provided");Example 19. Listing HTTP URL Resources
String name = key;
String description = "Http server at " + key;
DiscoveredResourceDetails detail =
new DiscoveredResourceDetails(
resourceType, key, name, null,
description, childConfig, null
);
result.add(detail);
}
return result;
}4.4.3. Looking at the Plug-in Components (HttpComponent.java and HttpServiceComponent.java)
HttpComponent.java), the plug-in is pretty simple. The component only implements placeholder methods from the ResourceComponent interface to set the server availability. Setting the availability to UP automatically allows the resource component to start.
Example 20. Server Availability After Discovery
public AvailabilityType getAvailability() {
return AvailabilityType.UP;
}HttpServiceComponent.java) is more complex because it must carry out the operations defined in the plug-in descriptor.
<metric> element in the descriptor to the MeasurementFacet.
MeasurementFacet implements the following method:
getValues(MeasurementReport report, Set metrics)MeasurementReport passed in is where the monitoring results are added. The metrics value is a list of metrics for which data should be gathered. All of this information can be defined in the <metrics> element or in the UI configuration.
public class HttpComponent implements ResourceComponent,
MeasurementFacet
{
URL url; // remote server url
long time; // response time from last collection
String status; // Status code from last collectiongetValues() method from the MeasurementFacet must be implemented, but that's not the first step to take. A resource cannot be discovered if the resource is down, so the first step is to set a start value to start the service from ResourceContext and give it an availability of UP.
Example 21. Service Resource Availability
public void start(ResourceContext context)
throws InvalidPluginConfigurationException, Exception
{
url = new URL(context.getResourceKey());
// Provide an initial status, so
// getAvailability() returns up
status = "200";
}getValues() can be implemented. This actually collects the monitoring data from the given URLs.
Example 22. Implementing getValues()
public void getValues(MeasurementReport report,
Set<MeasurementScheduleRequest> metrics)
throws Exception
{
getData();
// Loop over the incoming requests and
// fill in the requested data
for (MeasurementScheduleRequest request : metrics)
{
if (request.getName().equals("responseTime")) {
report.addData(new MeasurementDataNumeric(
request, new Double(time)));
} else if (request.getName().equals("status")) {
report.addData(new MeasurementDataTrait
(request, status));
}
}
}getData() method in the MeasurementFacet loops the incoming request to see which metric is wanted and then to supply the collected value. Depending on the type of data, the data may be to be wrapped into the correct MeasurementData* class.
Example 23. Implementing getData()
private void getData()
{
HttpURLConnection con = null;
int code = 0;
try {
con = (HttpURLConnection) url.openConnection();
con.setConnectTimeout(1000);
long now = System.currentTimeMillis();
con.connect();
code = con.getResponseCode();
long t2 = System.currentTimeMillis();
time = t2 - now;
} catch (Exception e) {
e.printStackTrace();
}
if (con != null)
con.disconnect();
status = String.valueOf(code);
}4.5. Examples: Embedded and Injected Plug-in Dependencies
4.5.1. Simple Dependency: JBoss AS and JMX Plug-ins
<depends> tag. This means that the required plug-in has to be deployed successfully before the plug-in which requires it can be deployed. A simple example of this is JBoss AS, which has a JMX server running inside it. The JBoss AS plug-in for JBoss ON, then, sets a dependency on the JMX plug-in.
Example 24. JMX Plug-in Descriptor
<plugin name="JMX">
<server name="JMX Server" discovery="JMXDiscoveryComponent" class="JMXServerComponent">
...
</server>
</plugin>useClasses argument is set to true), but the JBoss AS plug-in descriptor does not actually define or use any source types related to or referencing the JMX plug-in.
Example 25. JBoss AS Plug-in Descriptor
<plugin name="JBossAS">
<depends plugin="JMX" useClasses="true"/>
<server name="JBossAS Server" discovery="JBossASDiscoveryComponent" class="JBossASServerComponent">
...
</server>
</plugin>Important
useClasses=true.
Note
4.5.2. Embedded Dependency: JVM MBeanServer and JBoss AS
Example 26. JMX Plug-in Descriptor
<plugin name="JMX">
<server name="JMX Server" discovery="JMXDiscoveryComponent" class="JMXServerComponent">
<service name="VM Memory System"
discovery="MBeanResourceDiscoveryComponent"
class="MBeanResourceComponent"
description="The memory system of the Java virtual machine">
...
</service>
...
</server>
</plugin><server> definition pulls in the sourcePlugin and sourceType attributes. The reason for this is to run a second JMX discovery scan, this one using the org.rhq.plugins.jmx.EmbeddedJMXServerDiscoveryComponent class to run a special discovery scan looking for a JVM embedded in a JBoss AS instance. The sourcePlugin and sourceType attributes, then, copy the resource type and give it a unique name so that any embedded JVMs are treated as different resource types than standalone JVMs.
Example 27. JBoss AS Plug-in Descriptor
<plugin name="JBossAS">
<depends plugin="JMX" useClasses="true"/>
<server name="JBossAS Server" discovery="JBossASDiscoveryComponent" class="JBossASServerComponent">
<server name="JBoss AS JVM"
description="JVM of the JBossAS"
sourcePlugin="JMX"
sourceType="JMX Server"
discovery="org.rhq.plugins.jmx.EmbeddedJMXServerDiscoveryComponent"
class="org.rhq.plugins.jmx.JMXServerComponent">
...
</server>
...
</server>
</plugin>4.5.3. Injected Dependency: Hibernate with JVM and JBoss AS
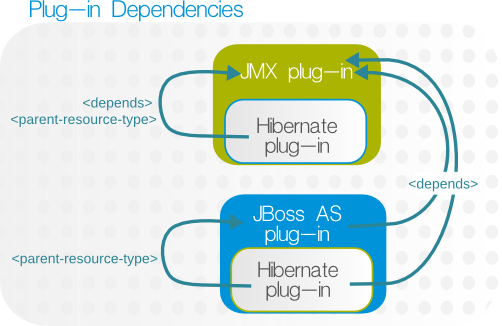
Figure 8. Hibernate, JMX, and JBoss AS Dependencies
Example 28. JMX Plug-in Descriptor
<plugin name="JMX">
<server name="JMX Server" discovery="JMXDiscoveryComponent" class="JMXServerComponent">
...
</server>
</plugin>Example 29. JBoss AS Plug-in Descriptor
<plugin name="JBoss AS">
<depends plugin="JMX" useClasses="true"/>
<server name="JBossAS Server" discovery="JBossASDiscoveryComponent" class="JBossASServerComponent">
...
</server>
</plugin><depends> element. The Hibernate plug-in then defines what resource types could operate as its parents by running a discovery scan (specifically for the Hibernate Statistics resource) against potential parent types. The list of parent resource types is contained in the <runs-inside> element, and each potential parent is identified by name and plug-in type in <parent-resource-type> elements.
Example 30. Hibernate Plug-in Descriptor
<depends plugin="JMX" useClasses="true"/>
<service name="Hibernate Statistics"
discovery="org.rhq.plugins.jmx.MBeanResourceDiscoveryComponent" class="StatisticsComponent">
<runs-inside>
<parent-resource-type name="JMX Server" plugin="JMX"/>
<parent-resource-type name="JBossAS Server" plugin="JBossAS"/>
</runs-inside>
...
</service>
</plugin>4.6. Extended Example: Drift Monitoring
- fileSystem, which is any directory on the machine local to the resource
- pluginConfiguration, which is defined property in the resource plug-in, like a home directory
- resourceConfiguration, a resource configuration property
- measurementTrait, a trait that is gathered about the resource
/etc/, the elements in the drift definition are:
Value name: fileSystem
Value context: /etcExample 31. Base Directory Only
<drift-definition name="Template-File System"
description="Monitor the file system for drift. Definitions should set a more specific base directory as the file system root is not recommended.">
<basedir>
<value-context>fileSystem</value-context>
<value-name>/</value-name>
</basedir>
</drift-definition>Example 32. Included Paths and Patterns
<drift-definition name="Template-Base Files"
description="Monitor base application server files for drift. It defines monitoring for some standard sub-directories of the HOME directory. Note, it is not recommeded to monitor all files for an application server. There are many files, and many temp files.">
<basedir>
<value-context>pluginConfiguration</value-context>
<value-name>homeDir</value-name>
</basedir>
<includes>
<include path="bin" pattern="*/*.sh" />
<include path="lib" />
<include path="client" />
</includes>
</drift-definition>Note
4.7. Extended Example: Provisioning and Content Deployments (Bundles)
- fileSystem, which is any directory on the machine local to the resource
- pluginConfiguration, which is defined property in the resource plug-in, like a home directory
- resourceConfiguration, a resource configuration property
- measurementTrait, a trait that is gathered about the resource
Example 33. A Single Bundle Base Directory
<bundle-target>
<destination-base-dir name="Root File System" description="The top root directory on the platform (/)" >
<value-context>fileSystem</value-context>
<value-name>/</value-name>
</destination-base-dir>
</bundle-target> <destination-base-dir>, are presented to users as options when they are provisioning a bundle. Users can deploy a bundle to any, user-defined directory beneath that base directory, but they cannot deploy to a location outside that directory. If users will reasonably want to provision content to multiple directories, then each directory needs to be added to the <bundle-target> definition.
Example 34. Multiple Bundle Base Directories
<bundle-target>
<destination-base-dir name="Install Directory" description="The top directory where the JBossAS Server is installed. ">
<value-context>pluginConfiguration</value-context>
<value-name>homeDir</value-name>
</destination-base-dir>
<destination-base-dir name="Profile Directory" description="The profile configuration directory.">
<value-context>pluginConfiguration</value-context>
<value-name>serverHomeDir</value-name>
</destination-base-dir>
</bundle-target>Note
4.8. Extended Example: Asynchronous Availability Checks
Note
getAvailability().
AvailabilityCollectorRunnable class.
Example 35. Part 1: The Collector
public class YourResourceComponent implements ResourceComponent {
// your component needs this data member - it is your availability collector
private AvailabilityCollectorRunnable availCollector;Example 36. Part 2: Start the Availability Collector
public void start(ResourceContext context) {
availCollector = resourceContext.createAvailabilityCollectorRunnable(new AvailabilityFacet() {
public AvailabilityType getAvailability() {
// Perform the actual check to see if the managed resource is up or not
// This method is not on a timer and can return the availability in any amount of time
// that it needs to take.
return ...AvailabilityType...;
}
}, 60000L); // 1 minute - the minimum interval allowed
// Now that you've created your availability collector, start it to assign it a thread in the pool.
availCollector.start();
// ... and the rest of your component's start method goes here ...
}
public void stop() {
// Stop your availability collector to cancel the collector and kill its thread.
availCollector.stop();
// ... and the rest of your component's stop method goes here ...
}getAvailability() method. When the async availability collector is created, then the getAvailability() method needs to return the last known results stored in the collector rather than attempting to run a new availability scan.
getAvailability() method.
Example 37. Part 2: Return the Last Known Availability
public AvailabilityType getAvailability() {
// This method quickly returns the last known availability that was recorded
// by the availability collector.
return availCollector.getLastKnownAvailability();
}
}