Este contenido no está disponible en el idioma seleccionado.
Chapter 3. Core Concepts
3.1. Overview
The following topics provide high-level, architectural information on core concepts and objects you will encounter when using OpenShift Container Platform. Many of these objects come from Kubernetes, which is extended by OpenShift Container Platform to provide a more feature-rich development lifecycle platform.
- Containers and images are the building blocks for deploying your applications.
- Pods and services allow for containers to communicate with each other and proxy connections.
- Projects and users provide the space and means for communities to organize and manage their content together.
- Builds and image streams allow you to build working images and react to new images.
- Deployments add expanded support for the software development and deployment lifecycle.
- Routes announce your service to the world.
- Templates allow for many objects to be created at once based on customized parameters.
3.2. Containers and Images
3.2.1. Containers
The basic units of OpenShift Container Platform applications are called containers. Linux container technologies are lightweight mechanisms for isolating running processes so that they are limited to interacting with only their designated resources.
Many application instances can be running in containers on a single host without visibility into each others' processes, files, network, and so on. Typically, each container provides a single service (often called a "micro-service"), such as a web server or a database, though containers can be used for arbitrary workloads.
The Linux kernel has been incorporating capabilities for container technologies for years. More recently the Docker project has developed a convenient management interface for Linux containers on a host. OpenShift Container Platform and Kubernetes add the ability to orchestrate Docker-formatted containers across multi-host installations.
Though you do not directly interact with the Docker CLI or service when using OpenShift Container Platform, understanding their capabilities and terminology is important for understanding their role in OpenShift Container Platform and how your applications function inside of containers. The docker RPM is available as part of RHEL 7, as well as CentOS and Fedora, so you can experiment with it separately from OpenShift Container Platform. Refer to the article Get Started with Docker Formatted Container Images on Red Hat Systems for a guided introduction.
3.2.1.1. Init Containers
A pod can have init containers in addition to application containers. Init containers allow you to reorganize setup scripts and binding code. An init container differs from a regular container in that it always runs to completion. Each init container must complete successfully before the next one is started.
For more information, see Pods and Services.
3.2.2. Images
Containers in OpenShift Container Platform are based on Docker-formatted container images. An image is a binary that includes all of the requirements for running a single container, as well as metadata describing its needs and capabilities.
You can think of it as a packaging technology. Containers only have access to resources defined in the image unless you give the container additional access when creating it. By deploying the same image in multiple containers across multiple hosts and load balancing between them, OpenShift Container Platform can provide redundancy and horizontal scaling for a service packaged into an image.
You can use the Docker CLI directly to build images, but OpenShift Container Platform also supplies builder images that assist with creating new images by adding your code or configuration to existing images.
Because applications develop over time, a single image name can actually refer to many different versions of the "same" image. Each different image is referred to uniquely by its hash (a long hexadecimal number e.g. fd44297e2ddb050ec4f…) which is usually shortened to 12 characters (e.g. fd44297e2ddb).
Image Version Tag Policy
Rather than version numbers, the Docker service allows applying tags (such as v1, v2.1, GA, or the default latest) in addition to the image name to further specify the image desired, so you may see the same image referred to as centos (implying the latest tag), centos:centos7, or fd44297e2ddb.
Do not use the latest tag for any official OpenShift Container Platform images. These are images that start with openshift3/. latest can refer to a number of versions, such as 3.10, or 3.11.
How you tag the images dictates the updating policy. The more specific you are, the less frequently the image will be updated. Use the following to determine your chosen OpenShift Container Platform images policy:
- vX.Y
-
The vX.Y tag points to X.Y.Z-<number>. For example, if the
registry-consoleimage is updated to v3.11, it points to the newest 3.11.Z-<number> tag, such as 3.11.1-8. - X.Y.Z
- Similar to the vX.Y example above, the X.Y.Z tag points to the latest X.Y.Z-<number>. For example, 3.11.1 would point to 3.11.1-8
- X.Y.Z-<number>
- The tag is unique and does not change. When using this tag, the image does not update if an image is updated. For example, the 3.11.1-8 will always point to 3.11.1-8, even if an image is updated.
3.2.3. Container Image Registries
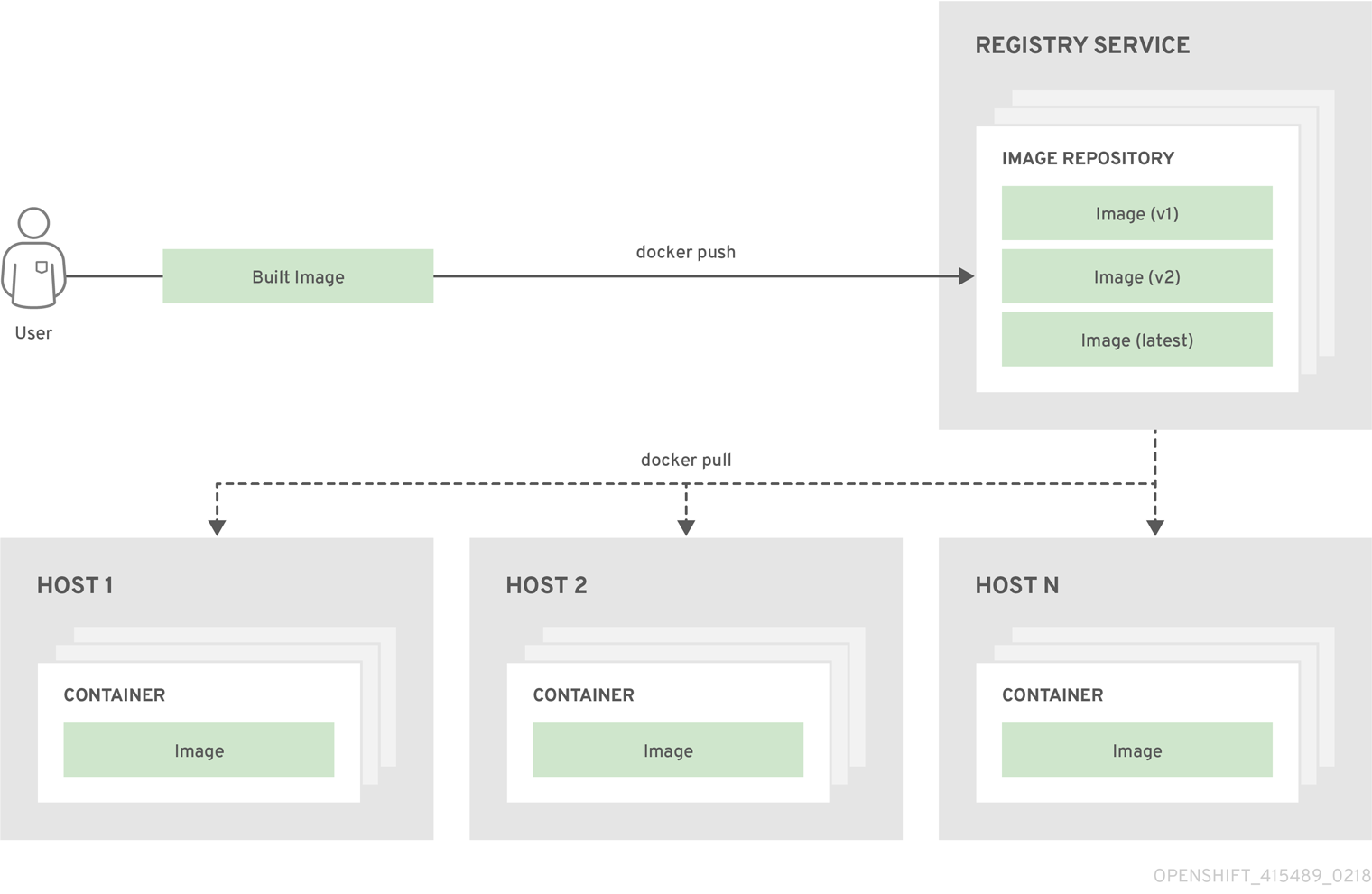
A container image registry is a service for storing and retrieving Docker-formatted container images. A registry contains a collection of one or more image repositories. Each image repository contains one or more tagged images. Docker provides its own registry, the Docker Hub, and you can also use private or third-party registries. Red Hat provides a registry at registry.redhat.io for subscribers. OpenShift Container Platform can also supply its own internal registry for managing custom container images.
The relationship between containers, images, and registries is depicted in the following diagram:
3.3. Pods and Services
3.3.1. Pods
OpenShift Container Platform leverages the Kubernetes concept of a pod, which is one or more containers deployed together on one host, and the smallest compute unit that can be defined, deployed, and managed.
Pods are the rough equivalent of a machine instance (physical or virtual) to a container. Each pod is allocated its own internal IP address, therefore owning its entire port space, and containers within pods can share their local storage and networking.
Pods have a lifecycle; they are defined, then they are assigned to run on a node, then they run until their container(s) exit or they are removed for some other reason. Pods, depending on policy and exit code, may be removed after exiting, or may be retained in order to enable access to the logs of their containers.
OpenShift Container Platform treats pods as largely immutable; changes cannot be made to a pod definition while it is running. OpenShift Container Platform implements changes by terminating an existing pod and recreating it with modified configuration, base image(s), or both. Pods are also treated as expendable, and do not maintain state when recreated. Therefore pods should usually be managed by higher-level controllers, rather than directly by users.
For the maximum number of pods per OpenShift Container Platform node host, see the Cluster Maximums.
Bare pods that are not managed by a replication controller will be not rescheduled upon node disruption.
Below is an example definition of a pod that provides a long-running service, which is actually a part of the OpenShift Container Platform infrastructure: the integrated container image registry. It demonstrates many features of pods, most of which are discussed in other topics and thus only briefly mentioned here:
Pod Object Definition (YAML)
apiVersion: v1
kind: Pod
metadata:
annotations: { ... }
labels:
deployment: docker-registry-1
deploymentconfig: docker-registry
docker-registry: default
generateName: docker-registry-1-
spec:
containers:
- env:
- name: OPENSHIFT_CA_DATA
value: ...
- name: OPENSHIFT_CERT_DATA
value: ...
- name: OPENSHIFT_INSECURE
value: "false"
- name: OPENSHIFT_KEY_DATA
value: ...
- name: OPENSHIFT_MASTER
value: https://master.example.com:8443
image: openshift/origin-docker-registry:v0.6.2
imagePullPolicy: IfNotPresent
name: registry
ports:
- containerPort: 5000
protocol: TCP
resources: {}
securityContext: { ... }
volumeMounts:
- mountPath: /registry
name: registry-storage
- mountPath: /var/run/secrets/kubernetes.io/serviceaccount
name: default-token-br6yz
readOnly: true
dnsPolicy: ClusterFirst
imagePullSecrets:
- name: default-dockercfg-at06w
restartPolicy: Always
serviceAccount: default
volumes:
- emptyDir: {}
name: registry-storage
- name: default-token-br6yz
secret:
secretName: default-token-br6yz- 1
- Pods can be "tagged" with one or more labels, which can then be used to select and manage groups of pods in a single operation. The labels are stored in key/value format in the
metadatahash. One label in this example is docker-registry=default. - 2
- Pods must have a unique name within their namespace. A pod definition may specify the basis of a name with the
generateNameattribute, and random characters will be added automatically to generate a unique name. - 3
containersspecifies an array of container definitions; in this case (as with most), just one.- 4
- Environment variables can be specified to pass necessary values to each container.
- 5
- Each container in the pod is instantiated from its own Docker-formatted container image.
- 6
- The container can bind to ports which will be made available on the pod’s IP.
- 7
- OpenShift Container Platform defines a security context for containers which specifies whether they are allowed to run as privileged containers, run as a user of their choice, and more. The default context is very restrictive but administrators can modify this as needed.
- 8
- The container specifies where external storage volumes should be mounted within the container. In this case, there is a volume for storing the registry’s data, and one for access to credentials the registry needs for making requests against the OpenShift Container Platform API.
- 9
- The pod restart policy with possible values
Always,OnFailure, andNever. The default value isAlways. - 10
- Pods making requests against the OpenShift Container Platform API is a common enough pattern that there is a
serviceAccountfield for specifying which service account user the pod should authenticate as when making the requests. This enables fine-grained access control for custom infrastructure components. - 11
- The pod defines storage volumes that are available to its container(s) to use. In this case, it provides an ephemeral volume for the registry storage and a
secretvolume containing the service account credentials.
This pod definition does not include attributes that are filled by OpenShift Container Platform automatically after the pod is created and its lifecycle begins. The Kubernetes pod documentation has details about the functionality and purpose of pods.
3.3.1.1. Pod Restart Policy
A pod restart policy determines how OpenShift Container Platform responds when containers in that pod exit. The policy applies to all containers in that pod.
The possible values are:
-
Always- Tries restarting a successfully exited container on the pod continuously, with an exponential back-off delay (10s, 20s, 40s) until the pod is restarted. The default isAlways. -
OnFailure- Tries restarting a failed container on the pod with an exponential back-off delay (10s, 20s, 40s) capped at 5 minutes. -
Never- Does not try to restart exited or failed containers on the pod. Pods immediately fail and exit.
Once bound to a node, a pod will never be bound to another node. This means that a controller is necessary in order for a pod to survive node failure:
| Condition | Controller Type | Restart Policy |
|---|---|---|
| Pods that are expected to terminate (such as batch computations) |
| |
| Pods that are expected to not terminate (such as web servers) |
| |
| Pods that need to run one-per-machine | Daemonset | Any |
If a container on a pod fails and the restart policy is set to OnFailure, the pod stays on the node and the container is restarted. If you do not want the container to restart, use a restart policy of Never.
If an entire pod fails, OpenShift Container Platform starts a new pod. Developers need to address the possibility that applications might be restarted in a new pod. In particular, applications need to handle temporary files, locks, incomplete output, and so forth caused by previous runs.
Kubernetes architecture expects reliable endpoints from cloud providers. When a cloud provider is down, the kubelet prevents OpenShift Container Platform from restarting.
If the underlying cloud provider endpoints are not reliable, do not install a cluster using cloud provider integration. Install the cluster as if it was in a no-cloud environment. It is not recommended to toggle cloud provider integration on or off in an installed cluster.
For details on how OpenShift Container Platform uses restart policy with failed containers, see the Example States in the Kubernetes documentation.
3.3.2. Init Containers
An init container is a container in a pod that is started before the pod app containers are started. Init containers can share volumes, perform network operations, and perform computations before the remaining containers start. Init containers can also block or delay the startup of application containers until some precondition is met.
When a pod starts, after the network and volumes are initialized, the init containers are started in order. Each init container must exit successfully before the next is invoked. If an init container fails to start (due to the runtime) or exits with failure, it is retried according to the pod restart policy.
A pod cannot be ready until all init containers have succeeded.
See the Kubernetes documentation for some init container usage examples.
The following example outlines a simple pod which has two init containers. The first init container waits for myservice and the second waits for mydb. Once both containers succeed, the Pod starts.
Sample Init Container Pod Object Definition (YAML)
apiVersion: v1
kind: Pod
metadata:
name: myapp-pod
labels:
app: myapp
spec:
containers:
- name: myapp-container
image: busybox
command: ['sh', '-c', 'echo The app is running! && sleep 3600']
initContainers:
- name: init-myservice
image: busybox
command: ['sh', '-c', 'until nslookup myservice; do echo waiting for myservice; sleep 2; done;']
- name: init-mydb
image: busybox
command: ['sh', '-c', 'until nslookup mydb; do echo waiting for mydb; sleep 2; done;']
Each init container has all of the fields of an app container except for readinessProbe. Init containers must exit for pod startup to continue and cannot define readiness other than completion.
Init containers can include activeDeadlineSeconds on the pod and livenessProbe on the container to prevent init containers from failing forever. The active deadline includes init containers.
3.3.3. Services
A Kubernetes service serves as an internal load balancer. It identifies a set of replicated pods in order to proxy the connections it receives to them. Backing pods can be added to or removed from a service arbitrarily while the service remains consistently available, enabling anything that depends on the service to refer to it at a consistent address. The default service clusterIP addresses are from the OpenShift Container Platform internal network and they are used to permit pods to access each other.
To permit external access to the service, additional externalIP and ingressIP addresses that are external to the cluster can be assigned to the service. These externalIP addresses can also be virtual IP addresses that provide highly available access to the service.
Services are assigned an IP address and port pair that, when accessed, proxy to an appropriate backing pod. A service uses a label selector to find all the containers running that provide a certain network service on a certain port.
Like pods, services are REST objects. The following example shows the definition of a service for the pod defined above:
Service Object Definition (YAML)
apiVersion: v1
kind: Service
metadata:
name: docker-registry
spec:
selector:
docker-registry: default
clusterIP: 172.30.136.123
ports:
- nodePort: 0
port: 5000
protocol: TCP
targetPort: 5000 - 1
- The service name docker-registry is also used to construct an environment variable with the service IP that is inserted into other pods in the same namespace. The maximum name length is 63 characters.
- 2
- The label selector identifies all pods with the docker-registry=default label attached as its backing pods.
- 3
- Virtual IP of the service, allocated automatically at creation from a pool of internal IPs.
- 4
- Port the service listens on.
- 5
- Port on the backing pods to which the service forwards connections.
The Kubernetes documentation has more information on services.
3.3.3.1. Service externalIPs
In addition to the cluster’s internal IP addresses, the user can configure IP addresses that are external to the cluster. The administrator is responsible for ensuring that traffic arrives at a node with this IP.
The externalIPs must be selected by the cluster administrators from the externalIPNetworkCIDRs range configured in master-config.yaml file. When master-config.yaml is changed, the master services must be restarted.
Sample externalIPNetworkCIDR /etc/origin/master/master-config.yaml
networkConfig:
externalIPNetworkCIDRs:
- 192.0.1.0.0/24Service externalIPs Definition (JSON)
{
"kind": "Service",
"apiVersion": "v1",
"metadata": {
"name": "my-service"
},
"spec": {
"selector": {
"app": "MyApp"
},
"ports": [
{
"name": "http",
"protocol": "TCP",
"port": 80,
"targetPort": 9376
}
],
"externalIPs" : [
"192.0.1.1"
]
}
}- 1
- List of external IP addresses on which the port is exposed. This list is in addition to the internal IP address list.
3.3.3.2. Service ingressIPs
In non-cloud clusters, externalIP addresses can be automatically assigned from a pool of addresses. This eliminates the need for the administrator manually assigning them.
The pool is configured in /etc/origin/master/master-config.yaml file. After changing this file, restart the master service.
The ingressIPNetworkCIDR is set to 172.29.0.0/16 by default. If the cluster environment is not already using this private range, use the default range or set a custom range.
If you are using high availability, then this range must be less than 256 addresses.
Sample ingressIPNetworkCIDR /etc/origin/master/master-config.yaml
networkConfig:
ingressIPNetworkCIDR: 172.29.0.0/163.3.3.3. Service NodePort
Setting the service type=NodePort will allocate a port from a flag-configured range (default: 30000-32767), and each node will proxy that port (the same port number on every node) into your service.
The selected port will be reported in the service configuration, under spec.ports[*].nodePort.
To specify a custom port just place the port number in the nodePort field. The custom port number must be in the configured range for nodePorts. When 'master-config.yaml' is changed the master services must be restarted.
Sample servicesNodePortRange /etc/origin/master/master-config.yaml
kubernetesMasterConfig:
servicesNodePortRange: ""
The service will be visible as both the <NodeIP>:spec.ports[].nodePort and spec.clusterIp:spec.ports[].port
Setting a nodePort is a privileged operation.
3.3.3.4. Service Proxy Mode
OpenShift Container Platform has two different implementations of the service-routing infrastructure. The default implementation is entirely iptables-based, and uses probabilistic iptables rewriting rules to distribute incoming service connections between the endpoint pods. The older implementation uses a user space process to accept incoming connections and then proxy traffic between the client and one of the endpoint pods.
The iptables-based implementation is much more efficient, but it requires that all endpoints are always able to accept connections; the user space implementation is slower, but can try multiple endpoints in turn until it finds one that works. If you have good readiness checks (or generally reliable nodes and pods), then the iptables-based service proxy is the best choice. Otherwise, you can enable the user space-based proxy when installing, or after deploying the cluster by editing the node configuration file.
3.3.3.5. Headless services
If your application does not need load balancing or single-service IP addresses, you can create a headless service. When you create a headless service, no load-balancing or proxying is done and no cluster IP is allocated for this service. For such services, DNS is automatically configured depending on whether the service has selectors defined or not.
Services with selectors: For headless services that define selectors, the endpoints controller creates Endpoints records in the API and modifies the DNS configuration to return A records (addresses) that point directly to the pods backing the service.
Services without selectors: For headless services that do not define selectors, the endpoints controller does not create Endpoints records. However, the DNS system looks for and configures the following records:
-
For
ExternalNametype services,CNAMErecords. -
For all other service types,
Arecords for any endpoints that share a name with the service.
3.3.3.5.1. Creating a headless service
Creating a headless service is similar to creating a standard service, but you do not declare the ClusterIP address. To create a headless service, add the clusterIP: None parameter value to the service YAML definition.
For example, for a group of pods that you want to be a part of the same cluster or service.
List of Pods
$ oc get pods -o wideExample Output
NAME READY STATUS RESTARTS AGE IP NODE
frontend-1-287hw 1/1 Running 0 7m 172.17.0.3 node_1
frontend-1-68km5 1/1 Running 0 7m 172.17.0.6 node_1You can define the headless service as:
Headless Service Definition
apiVersion: v1
kind: Service
metadata:
labels:
app: ruby-helloworld-sample
template: application-template-stibuild
name: frontend-headless
spec:
clusterIP: None
ports:
- name: web
port: 5432
protocol: TCP
targetPort: 8080
selector:
name: frontend
sessionAffinity: None
type: ClusterIP
status:
loadBalancer: {}Also, headless service does not have any IP address of its own.
$ oc get svcExample Output
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
frontend ClusterIP 172.30.232.77 <none> 5432/TCP 12m
frontend-headless ClusterIP None <none> 5432/TCP 10m3.3.3.5.2. Endpoint discovery by using a headless service
The benefit of using a headless service is that you can discover a pod’s IP address directly. Standard services act as load balancer or proxy and give access to the workload object by using the service name. With headless services, the service name resolves to the set of IP addresses of the pods that are grouped by the service.
When you look up the DNS A record for a standard service, you get the loadbalanced IP of the service.
$ dig frontend.test A +search +shortExample Output
172.30.232.77But for a headless service, you get the list of IPs of individual pods.
$ dig frontend-headless.test A +search +shortExample Output
172.17.0.3
172.17.0.6
For using a headless service with a StatefulSet and related use cases where you need to resolve DNS for the pod during initialization and termination, set publishNotReadyAddresses to true (the default value is false). When publishNotReadyAddresses is set to true, it indicates that DNS implementations must publish the notReadyAddresses of subsets for the Endpoints associated with the Service.
3.3.4. Labels
Labels are used to organize, group, or select API objects. For example, pods are "tagged" with labels, and then services use label selectors to identify the pods they proxy to. This makes it possible for services to reference groups of pods, even treating pods with potentially different containers as related entities.
Most objects can include labels in their metadata. So labels can be used to group arbitrarily-related objects; for example, all of the pods, services, replication controllers, and deployment configurations of a particular application can be grouped.
Labels are simple key/value pairs, as in the following example:
labels:
key1: value1
key2: value2Consider:
- A pod consisting of an nginx container, with the label role=webserver.
- A pod consisting of an Apache httpd container, with the same label role=webserver.
A service or replication controller that is defined to use pods with the role=webserver label treats both of these pods as part of the same group.
The Kubernetes documentation has more information on labels.
3.3.5. Endpoints
The servers that back a service are called its endpoints, and are specified by an object of type Endpoints with the same name as the service. When a service is backed by pods, those pods are normally specified by a label selector in the service specification, and OpenShift Container Platform automatically creates the Endpoints object pointing to those pods.
In some cases, you may want to create a service but have it be backed by external hosts rather than by pods in the OpenShift Container Platform cluster. In this case, you can leave out the selector field in the service, and create the Endpoints object manually.
Note that OpenShift Container Platform will not let most users manually create an Endpoints object that points to an IP address in the network blocks reserved for pod and service IPs. Only cluster admins or other users with permission to create resources under endpoints/restricted can create such Endpoint objects.
3.4. Projects and Users
3.4.1. Users
Interaction with OpenShift Container Platform is associated with a user. An OpenShift Container Platform user object represents an actor which may be granted permissions in the system by adding roles to them or to their groups.
Several types of users can exist:
| Regular users |
This is the way most interactive OpenShift Container Platform users will be represented. Regular users are created automatically in the system upon first login, or can be created via the API. Regular users are represented with the |
| System users |
Many of these are created automatically when the infrastructure is defined, mainly for the purpose of enabling the infrastructure to interact with the API securely. They include a cluster administrator (with access to everything), a per-node user, users for use by routers and registries, and various others. Finally, there is an |
| Service accounts |
These are special system users associated with projects; some are created automatically when the project is first created, while project administrators can create more for the purpose of defining access to the contents of each project. Service accounts are represented with the |
Every user must authenticate in some way in order to access OpenShift Container Platform. API requests with no authentication or invalid authentication are authenticated as requests by the anonymous system user. Once authenticated, policy determines what the user is authorized to do.
3.4.2. Namespaces
A Kubernetes namespace provides a mechanism to scope resources in a cluster. In OpenShift Container Platform, a project is a Kubernetes namespace with additional annotations.
Namespaces provide a unique scope for:
- Named resources to avoid basic naming collisions.
- Delegated management authority to trusted users.
- The ability to limit community resource consumption.
Most objects in the system are scoped by namespace, but some are excepted and have no namespace, including nodes and users.
The Kubernetes documentation has more information on namespaces.
3.4.3. Projects
A project is a Kubernetes namespace with additional annotations, and is the central vehicle by which access to resources for regular users is managed. A project allows a community of users to organize and manage their content in isolation from other communities. Users must be given access to projects by administrators, or if allowed to create projects, automatically have access to their own projects.
Projects can have a separate name, displayName, and description.
-
The mandatory
nameis a unique identifier for the project and is most visible when using the CLI tools or API. The maximum name length is 63 characters. -
The optional
displayNameis how the project is displayed in the web console (defaults toname). -
The optional
descriptioncan be a more detailed description of the project and is also visible in the web console.
Each project scopes its own set of:
| Objects | Pods, services, replication controllers, etc. |
| Policies | Rules for which users can or cannot perform actions on objects. |
| Constraints | Quotas for each kind of object that can be limited. |
| Service accounts | Service accounts act automatically with designated access to objects in the project. |
Cluster administrators can create projects and delegate administrative rights for the project to any member of the user community. Cluster administrators can also allow developers to create their own projects.
Developers and administrators can interact with projects using the CLI or the web console.
3.4.3.1. Projects provided at installation
OpenShift Container Platform comes with a number of projects out of the box, and projects starting with openshift- are the most essential to users. These projects host master components that run as pods and other infrastructure components. The pods created in these namespaces that have a critical pod annotation are considered critical, and they have guaranteed admission by kubelet. Pods created for master components in these namespaces are already marked as critical.
3.5. Builds and Image Streams
3.5.1. Builds
A build is the process of transforming input parameters into a resulting object. Most often, the process is used to transform input parameters or source code into a runnable image. A BuildConfig object is the definition of the entire build process.
OpenShift Container Platform leverages Kubernetes by creating Docker-formatted containers from build images and pushing them to a container image registry.
Build objects share common characteristics: inputs for a build, the need to complete a build process, logging the build process, publishing resources from successful builds, and publishing the final status of the build. Builds take advantage of resource restrictions, specifying limitations on resources such as CPU usage, memory usage, and build or pod execution time.
The OpenShift Container Platform build system provides extensible support for build strategies that are based on selectable types specified in the build API. There are three primary build strategies available:
By default, Docker builds and S2I builds are supported.
The resulting object of a build depends on the builder used to create it. For Docker and S2I builds, the resulting objects are runnable images. For Custom builds, the resulting objects are whatever the builder image author has specified.
Additionally, the Pipeline build strategy can be used to implement sophisticated workflows:
- continuous integration
- continuous deployment
For a list of build commands, see the Developer’s Guide.
For more information on how OpenShift Container Platform leverages Docker for builds, see the upstream documentation.
3.5.1.1. Docker Build
The Docker build strategy invokes the docker build command, and it therefore expects a repository with a Dockerfile and all required artifacts in it to produce a runnable image.
3.5.1.2. Source-to-Image (S2I) Build
Source-to-Image (S2I) is a tool for building reproducible, Docker-formatted container images. It produces ready-to-run images by injecting application source into a container image and assembling a new image. The new image incorporates the base image (the builder) and built source and is ready to use with the docker run command. S2I supports incremental builds, which re-use previously downloaded dependencies, previously built artifacts, etc.
The advantages of S2I include the following:
| Image flexibility |
S2I scripts can be written to inject application code into almost any existing Docker-formatted container image, taking advantage of the existing ecosystem. Note that, currently, S2I relies on |
| Speed | With S2I, the assemble process can perform a large number of complex operations without creating a new layer at each step, resulting in a fast process. In addition, S2I scripts can be written to re-use artifacts stored in a previous version of the application image, rather than having to download or build them each time the build is run. |
| Patchability | S2I allows you to rebuild the application consistently if an underlying image needs a patch due to a security issue. |
| Operational efficiency | By restricting build operations instead of allowing arbitrary actions, as a Dockerfile would allow, the PaaS operator can avoid accidental or intentional abuses of the build system. |
| Operational security | Building an arbitrary Dockerfile exposes the host system to root privilege escalation. This can be exploited by a malicious user because the entire Docker build process is run as a user with Docker privileges. S2I restricts the operations performed as a root user and can run the scripts as a non-root user. |
| User efficiency |
S2I prevents developers from performing arbitrary |
| Ecosystem | S2I encourages a shared ecosystem of images where you can leverage best practices for your applications. |
| Reproducibility | Produced images can include all inputs including specific versions of build tools and dependencies. This ensures that the image can be reproduced precisely. |
3.5.1.3. Custom Build
The Custom build strategy allows developers to define a specific builder image responsible for the entire build process. Using your own builder image allows you to customize your build process.
A Custom builder image is a plain Docker-formatted container image embedded with build process logic, for example for building RPMs or base images. The openshift/origin-custom-docker-builder image is available on the Docker Hub registry as an example implementation of a Custom builder image.
3.5.1.4. Pipeline Build
The Pipeline build strategy allows developers to define a Jenkins pipeline for execution by the Jenkins pipeline plugin. The build can be started, monitored, and managed by OpenShift Container Platform in the same way as any other build type.
Pipeline workflows are defined in a Jenkinsfile, either embedded directly in the build configuration, or supplied in a Git repository and referenced by the build configuration.
The first time a project defines a build configuration using a Pipeline strategy, OpenShift Container Platform instantiates a Jenkins server to execute the pipeline. Subsequent Pipeline build configurations in the project share this Jenkins server.
For more details on how the Jenkins server is deployed and how to configure or disable the autoprovisioning behavior, see Configuring Pipeline Execution.
The Jenkins server is not automatically removed, even if all Pipeline build configurations are deleted. It must be manually deleted by the user.
For more information about Jenkins Pipelines, see the Jenkins documentation.
3.5.2. Image Streams
An image stream and its associated tags provide an abstraction for referencing container images from within OpenShift Container Platform. The image stream and its tags allow you to see what images are available and ensure that you are using the specific image you need even if the image in the repository changes.
Image streams do not contain actual image data, but present a single virtual view of related images, similar to an image repository.
You can configure Builds and Deployments to watch an image stream for notifications when new images are added and react by performing a Build or Deployment, respectively.
For example, if a Deployment is using a certain image and a new version of that image is created, a Deployment could be automatically performed to pick up the new version of the image.
However, if the image stream tag used by the Deployment or Build is not updated, then even if the container image in the container image registry is updated, the Build or Deployment will continue using the previous (presumably known good) image.
The source images can be stored in any of the following:
- OpenShift Container Platform’s integrated registry
-
An external registry, for example
registry.redhat.ioorhub.docker.com - Other image streams in the OpenShift Container Platform cluster
When you define an object that references an image stream tag (such as a Build or Deployment configuration), you point to an image stream tag, not the Docker repository. When you Build or Deploy your application, OpenShift Container Platform queries the Docker repository using the image stream tag to locate the associated ID of the image and uses that exact image.
The image stream metadata is stored in the etcd instance along with other cluster information.
The following image stream contains two tags: 34 which points to a Python v3.4 image and 35 which points to a Python v3.5 image:
$ oc describe is pythonExample Output
Name: python
Namespace: imagestream
Created: 25 hours ago
Labels: app=python
Annotations: openshift.io/generated-by=OpenShiftWebConsole
openshift.io/image.dockerRepositoryCheck=2017-10-03T19:48:00Z
Docker Pull Spec: docker-registry.default.svc:5000/imagestream/python
Image Lookup: local=false
Unique Images: 2
Tags: 2
34
tagged from centos/python-34-centos7
* centos/python-34-centos7@sha256:28178e2352d31f240de1af1370be855db33ae9782de737bb005247d8791a54d0
14 seconds ago
35
tagged from centos/python-35-centos7
* centos/python-35-centos7@sha256:2efb79ca3ac9c9145a63675fb0c09220ab3b8d4005d35e0644417ee552548b10
7 seconds agoUsing image streams has several significant benefits:
- You can tag, rollback a tag, and quickly deal with images, without having to re-push using the command line.
- You can trigger Builds and Deployments when a new image is pushed to the registry. Also, OpenShift Container Platform has generic triggers for other resources (such as Kubernetes objects).
- You can mark a tag for periodic re-import. If the source image has changed, that change is picked up and reflected in the image stream, which triggers the Build and/or Deployment flow, depending upon the Build or Deployment configuration.
- You can share images using fine-grained access control and quickly distribute images across your teams.
- If the source image changes, the image stream tag will still point to a known-good version of the image, ensuring that your application will not break unexpectedly.
- You can configure security around who can view and use the images through permissions on the image stream objects.
- Users that lack permission to read or list images on the cluster level can still retrieve the images tagged in a project using image streams.
For a curated set of image streams, see the OpenShift Image Streams and Templates library.
When using image streams, it is important to understand what the image stream tag is pointing to and how changes to tags and images can affect you. For example:
-
If your image stream tag points to a container image tag, you need to understand how that container image tag is updated. For example, a container image tag
docker.io/ruby:2.5points to a v2.5 ruby image, but a container image tagdocker.io/ruby:latestchanges with major versions. So, the container image tag that a image stream tag points to can tell you how stable the image stream tag is. - If your image stream tag follows another image stream tag instead of pointing directly to a container image tag, it is possible that the image stream tag might be updated to follow a different image stream tag in the future. This change might result in picking up an incompatible version change.
3.5.2.1. Important terms
- Docker repository
A collection of related container images and tags identifying them. For example, the OpenShift Jenkins images are in a Docker repository:
docker.io/openshift/jenkins-2-centos7- Container registry
A content server that can store and service images from Docker repositories. For example:
registry.redhat.io- container image
- A specific set of content that can be run as a container. Usually associated with a particular tag within a Docker repository.
- container image tag
- A label applied to a container image in a repository that distinguishes a specific image. For example, here 3.6.0 is a tag:
docker.io/openshift/jenkins-2-centos7:3.6.0A container image tag can be updated to point to new container image content at any time.
- container image ID
- A SHA (Secure Hash Algorithm) code that can be used to pull an image. For example:
docker.io/openshift/jenkins-2-centos7@sha256:ab312bda324A SHA image ID cannot change. A specific SHA identifier always references the exact same container image content.
- Image stream
- An OpenShift Container Platform object that contains pointers to any number of Docker-formatted container images identified by tags. You can think of an image stream as equivalent to a Docker repository.
- Image stream tag
- A named pointer to an image in an image stream. An image stream tag is similar to a container image tag. See Image Stream Tag below.
- Image stream image
- An image that allows you to retrieve a specific container image from a particular image stream where it is tagged. An image stream image is an API resource object that pulls together some metadata about a particular image SHA identifier. See Image Stream Images below.
- Image stream trigger
- A trigger that causes a specific action when an image stream tag changes. For example, importing can cause the value of the tag to change, which causes a trigger to fire when there are Deployments, Builds, or other resources listening for those. See Image Stream Triggers below.
3.5.2.2. Configuring Image Streams
An image stream object file contains the following elements.
See the Developer Guide for details on managing images and image streams.
Image Stream Object Definition
apiVersion: v1
kind: ImageStream
metadata:
annotations:
openshift.io/generated-by: OpenShiftNewApp
creationTimestamp: 2017-09-29T13:33:49Z
generation: 1
labels:
app: ruby-sample-build
template: application-template-stibuild
name: origin-ruby-sample
namespace: test
resourceVersion: "633"
selflink: /oapi/v1/namespaces/test/imagestreams/origin-ruby-sample
uid: ee2b9405-c68c-11e5-8a99-525400f25e34
spec: {}
status:
dockerImageRepository: 172.30.56.218:5000/test/origin-ruby-sample
tags:
- items:
- created: 2017-09-02T10:15:09Z
dockerImageReference: 172.30.56.218:5000/test/origin-ruby-sample@sha256:47463d94eb5c049b2d23b03a9530bf944f8f967a0fe79147dd6b9135bf7dd13d
generation: 2
image: sha256:909de62d1f609a717ec433cc25ca5cf00941545c83a01fb31527771e1fab3fc5
- created: 2017-09-29T13:40:11Z
dockerImageReference: 172.30.56.218:5000/test/origin-ruby-sample@sha256:909de62d1f609a717ec433cc25ca5cf00941545c83a01fb31527771e1fab3fc5
generation: 1
image: sha256:47463d94eb5c049b2d23b03a9530bf944f8f967a0fe79147dd6b9135bf7dd13d
tag: latest - 1
- The name of the image stream.
- 2
- Docker repository path where new images can be pushed to add/update them in this image stream.
- 3
- The SHA identifier that this image stream tag currently references. Resources that reference this image stream tag use this identifier.
- 4
- The SHA identifier that this image stream tag previously referenced. Can be used to rollback to an older image.
- 5
- The image stream tag name.
For a sample build configuration that references an image stream, see What Is a BuildConfig? in the Strategy stanza of the configuration.
For a sample deployment configuration that references an image stream, see Creating a Deployment Configuration in the Strategy stanza of the configuration.
3.5.2.3. Image Stream Images
An image stream image points from within an image stream to a particular image ID.
Image stream images allow you to retrieve metadata about an image from a particular image stream where it is tagged.
Image stream image objects are automatically created in OpenShift Container Platform whenever you import or tag an image into the image stream. You should never have to explicitly define an image stream image object in any image stream definition that you use to create image streams.
The image stream image consists of the image stream name and image ID from the repository, delimited by an @ sign:
<image-stream-name>@<image-id>To refer to the image in the image stream object example above, the image stream image looks like:
origin-ruby-sample@sha256:47463d94eb5c049b2d23b03a9530bf944f8f967a0fe79147dd6b9135bf7dd13d3.5.2.4. Image Stream Tags
An image stream tag is a named pointer to an image in an image stream. It is often abbreviated as istag. An image stream tag is used to reference or retrieve an image for a given image stream and tag.
Image stream tags can reference any local or externally managed image. It contains a history of images represented as a stack of all images the tag ever pointed to. Whenever a new or existing image is tagged under particular image stream tag, it is placed at the first position in the history stack. The image previously occupying the top position will be available at the second position, and so forth. This allows for easy rollbacks to make tags point to historical images again.
The following image stream tag is from the image stream object example above:
Image Stream Tag with Two Images in its History
tags:
- items:
- created: 2017-09-02T10:15:09Z
dockerImageReference: 172.30.56.218:5000/test/origin-ruby-sample@sha256:47463d94eb5c049b2d23b03a9530bf944f8f967a0fe79147dd6b9135bf7dd13d
generation: 2
image: sha256:909de62d1f609a717ec433cc25ca5cf00941545c83a01fb31527771e1fab3fc5
- created: 2017-09-29T13:40:11Z
dockerImageReference: 172.30.56.218:5000/test/origin-ruby-sample@sha256:909de62d1f609a717ec433cc25ca5cf00941545c83a01fb31527771e1fab3fc5
generation: 1
image: sha256:47463d94eb5c049b2d23b03a9530bf944f8f967a0fe79147dd6b9135bf7dd13d
tag: latestImage stream tags can be permanent tags or tracking tags.
- Permanent tags are version-specific tags that point to a particular version of an image, such as Python 3.5.
Tracking tags are reference tags that follow another image stream tag and could be updated in the future to change which image they follow, much like a symlink. Note that these new levels are not guaranteed to be backwards-compatible.
For example, the
latestimage stream tags that ship with OpenShift Container Platform are tracking tags. This means consumers of thelatestimage stream tag will be updated to the newest level of the framework provided by the image when a new level becomes available. Alatestimage stream tag tov3.10could be changed tov3.11at any time. It is important to be aware that theselatestimage stream tags behave differently than the Dockerlatesttag. Thelatestimage stream tag, in this case, does not point to the latest image in the Docker repository. It points to another image stream tag, which might not be the latest version of an image. For example, if thelatestimage stream tag points tov3.10of an image, when the3.11version is released, thelatesttag is not automatically updated tov3.11, and remains atv3.10until it is manually updated to point to av3.11image stream tag.NoteTracking tags are limited to a single image stream and cannot reference other image streams.
You can create your own image stream tags for your own needs. See the Recommended Tagging Conventions.
The image stream tag is composed of the name of the image stream and a tag, separated by a colon:
<image stream name>:<tag>
For example, to refer to the sha256:47463d94eb5c049b2d23b03a9530bf944f8f967a0fe79147dd6b9135bf7dd13d image in the image stream object example above, the image stream tag would be:
origin-ruby-sample:latest3.5.2.5. Image Stream Change Triggers
Image stream triggers allow your Builds and Deployments to be automatically invoked when a new version of an upstream image is available.
For example, Builds and Deployments can be automatically started when an image stream tag is modified. This is achieved by monitoring that particular image stream tag and notifying the Build or Deployment when a change is detected.
The ImageChange trigger results in a new replication controller whenever the content of an image stream tag changes (when a new version of the image is pushed).
An ImageChange Trigger
triggers:
- type: "ImageChange"
imageChangeParams:
automatic: true
from:
kind: "ImageStreamTag"
name: "origin-ruby-sample:latest"
namespace: "myproject"
containerNames:
- "helloworld"- 1
- If the
imageChangeParams.automaticfield is set tofalse, the trigger is disabled.
With the above example, when the latest tag value of the origin-ruby-sample image stream changes and the new image value differs from the current image specified in the deployment configuration’s helloworld container, a new replication controller is created using the new image for the helloworld container.
If an ImageChange trigger is defined on a deployment configuration (with a ConfigChange trigger and automatic=false, or with automatic=true) and the ImageStreamTag pointed by the ImageChange trigger does not exist yet, then the initial deployment process will automatically start as soon as an image is imported or pushed by a build to the ImageStreamTag.
3.5.2.6. Image Stream Mappings
When the integrated registry receives a new image, it creates and sends an image stream mapping to OpenShift Container Platform, providing the image’s project, name, tag, and image metadata.
Configuring image stream mappings is an advanced feature.
This information is used to create a new image (if it does not already exist) and to tag the image into the image stream. OpenShift Container Platform stores complete metadata about each image, such as commands, entry point, and environment variables. Images in OpenShift Container Platform are immutable and the maximum name length is 63 characters.
See the Developer Guide for details on manually tagging images.
The following image stream mapping example results in an image being tagged as test/origin-ruby-sample:latest:
Image Stream Mapping Object Definition
apiVersion: v1
kind: ImageStreamMapping
metadata:
creationTimestamp: null
name: origin-ruby-sample
namespace: test
tag: latest
image:
dockerImageLayers:
- name: sha256:5f70bf18a086007016e948b04aed3b82103a36bea41755b6cddfaf10ace3c6ef
size: 0
- name: sha256:ee1dd2cb6df21971f4af6de0f1d7782b81fb63156801cfde2bb47b4247c23c29
size: 196634330
- name: sha256:5f70bf18a086007016e948b04aed3b82103a36bea41755b6cddfaf10ace3c6ef
size: 0
- name: sha256:5f70bf18a086007016e948b04aed3b82103a36bea41755b6cddfaf10ace3c6ef
size: 0
- name: sha256:ca062656bff07f18bff46be00f40cfbb069687ec124ac0aa038fd676cfaea092
size: 177723024
- name: sha256:63d529c59c92843c395befd065de516ee9ed4995549f8218eac6ff088bfa6b6e
size: 55679776
- name: sha256:92114219a04977b5563d7dff71ec4caa3a37a15b266ce42ee8f43dba9798c966
size: 11939149
dockerImageMetadata:
Architecture: amd64
Config:
Cmd:
- /usr/libexec/s2i/run
Entrypoint:
- container-entrypoint
Env:
- RACK_ENV=production
- OPENSHIFT_BUILD_NAMESPACE=test
- OPENSHIFT_BUILD_SOURCE=https://github.com/openshift/ruby-hello-world.git
- EXAMPLE=sample-app
- OPENSHIFT_BUILD_NAME=ruby-sample-build-1
- PATH=/opt/app-root/src/bin:/opt/app-root/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
- STI_SCRIPTS_URL=image:///usr/libexec/s2i
- STI_SCRIPTS_PATH=/usr/libexec/s2i
- HOME=/opt/app-root/src
- BASH_ENV=/opt/app-root/etc/scl_enable
- ENV=/opt/app-root/etc/scl_enable
- PROMPT_COMMAND=. /opt/app-root/etc/scl_enable
- RUBY_VERSION=2.2
ExposedPorts:
8080/tcp: {}
Labels:
build-date: 2015-12-23
io.k8s.description: Platform for building and running Ruby 2.2 applications
io.k8s.display-name: 172.30.56.218:5000/test/origin-ruby-sample:latest
io.openshift.build.commit.author: Ben Parees <bparees@users.noreply.github.com>
io.openshift.build.commit.date: Wed Jan 20 10:14:27 2016 -0500
io.openshift.build.commit.id: 00cadc392d39d5ef9117cbc8a31db0889eedd442
io.openshift.build.commit.message: 'Merge pull request #51 from php-coder/fix_url_and_sti'
io.openshift.build.commit.ref: master
io.openshift.build.image: centos/ruby-22-centos7@sha256:3a335d7d8a452970c5b4054ad7118ff134b3a6b50a2bb6d0c07c746e8986b28e
io.openshift.build.source-location: https://github.com/openshift/ruby-hello-world.git
io.openshift.builder-base-version: 8d95148
io.openshift.builder-version: 8847438ba06307f86ac877465eadc835201241df
io.openshift.s2i.scripts-url: image:///usr/libexec/s2i
io.openshift.tags: builder,ruby,ruby22
io.s2i.scripts-url: image:///usr/libexec/s2i
license: GPLv2
name: CentOS Base Image
vendor: CentOS
User: "1001"
WorkingDir: /opt/app-root/src
Container: 86e9a4a3c760271671ab913616c51c9f3cea846ca524bf07c04a6f6c9e103a76
ContainerConfig:
AttachStdout: true
Cmd:
- /bin/sh
- -c
- tar -C /tmp -xf - && /usr/libexec/s2i/assemble
Entrypoint:
- container-entrypoint
Env:
- RACK_ENV=production
- OPENSHIFT_BUILD_NAME=ruby-sample-build-1
- OPENSHIFT_BUILD_NAMESPACE=test
- OPENSHIFT_BUILD_SOURCE=https://github.com/openshift/ruby-hello-world.git
- EXAMPLE=sample-app
- PATH=/opt/app-root/src/bin:/opt/app-root/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
- STI_SCRIPTS_URL=image:///usr/libexec/s2i
- STI_SCRIPTS_PATH=/usr/libexec/s2i
- HOME=/opt/app-root/src
- BASH_ENV=/opt/app-root/etc/scl_enable
- ENV=/opt/app-root/etc/scl_enable
- PROMPT_COMMAND=. /opt/app-root/etc/scl_enable
- RUBY_VERSION=2.2
ExposedPorts:
8080/tcp: {}
Hostname: ruby-sample-build-1-build
Image: centos/ruby-22-centos7@sha256:3a335d7d8a452970c5b4054ad7118ff134b3a6b50a2bb6d0c07c746e8986b28e
OpenStdin: true
StdinOnce: true
User: "1001"
WorkingDir: /opt/app-root/src
Created: 2016-01-29T13:40:00Z
DockerVersion: 1.8.2.fc21
Id: 9d7fd5e2d15495802028c569d544329f4286dcd1c9c085ff5699218dbaa69b43
Parent: 57b08d979c86f4500dc8cad639c9518744c8dd39447c055a3517dc9c18d6fccd
Size: 441976279
apiVersion: "1.0"
kind: DockerImage
dockerImageMetadataVersion: "1.0"
dockerImageReference: 172.30.56.218:5000/test/origin-ruby-sample@sha256:47463d94eb5c049b2d23b03a9530bf944f8f967a0fe79147dd6b9135bf7dd13d3.5.2.7. Working with Image Streams
The following sections describe how to use image streams and image stream tags. For more information on working with image streams, see Managing Images.
3.5.2.7.1. Getting Information about Image Streams
To get general information about the image stream and detailed information about all the tags it is pointing to, use the following command:
$ oc describe is/<image-name>For example:
$ oc describe is/pythonExample Output
Name: python
Namespace: default
Created: About a minute ago
Labels: <none>
Annotations: openshift.io/image.dockerRepositoryCheck=2017-10-02T17:05:11Z
Docker Pull Spec: docker-registry.default.svc:5000/default/python
Image Lookup: local=false
Unique Images: 1
Tags: 1
3.5
tagged from centos/python-35-centos7
* centos/python-35-centos7@sha256:49c18358df82f4577386404991c51a9559f243e0b1bdc366df25
About a minute agoTo get all the information available about particular image stream tag:
$ oc describe istag/<image-stream>:<tag-name>For example:
$ oc describe istag/python:latestExample Output
Image Name: sha256:49c18358df82f4577386404991c51a9559f243e0b1bdc366df25
Docker Image: centos/python-35-centos7@sha256:49c18358df82f4577386404991c51a9559f243e0b1bdc366df25
Name: sha256:49c18358df82f4577386404991c51a9559f243e0b1bdc366df25
Created: 2 minutes ago
Image Size: 251.2 MB (first layer 2.898 MB, last binary layer 72.26 MB)
Image Created: 2 weeks ago
Author: <none>
Arch: amd64
Entrypoint: container-entrypoint
Command: /bin/sh -c $STI_SCRIPTS_PATH/usage
Working Dir: /opt/app-root/src
User: 1001
Exposes Ports: 8080/tcp
Docker Labels: build-date=20170801More information is output than shown.
3.5.2.7.2. Adding Additional Tags to an Image Stream
To add a tag that points to one of the existing tags, you can use the oc tag command:
oc tag <image-name:tag> <image-name:tag>For example:
$ oc tag python:3.5 python:latestExample Output
Tag python:latest set to python@sha256:49c18358df82f4577386404991c51a9559f243e0b1bdc366df25.
Use the oc describe command to confirm the image stream has two tags, one (3.5) pointing at the external container image and another tag (latest) pointing to the same image because it was created based on the first tag.
$ oc describe is/pythonExample Output
Name: python
Namespace: default
Created: 5 minutes ago
Labels: <none>
Annotations: openshift.io/image.dockerRepositoryCheck=2017-10-02T17:05:11Z
Docker Pull Spec: docker-registry.default.svc:5000/default/python
Image Lookup: local=false
Unique Images: 1
Tags: 2
latest
tagged from python@sha256:49c18358df82f4577386404991c51a9559f243e0b1bdc366df25
* centos/python-35-centos7@sha256:49c18358df82f4577386404991c51a9559f243e0b1bdc366df25
About a minute ago
3.5
tagged from centos/python-35-centos7
* centos/python-35-centos7@sha256:49c18358df82f4577386404991c51a9559f243e0b1bdc366df25
5 minutes ago3.5.2.7.3. Adding Tags for an External Image
Use the oc tag command for all tag-related operations, such as adding tags pointing to internal or external images:
$ oc tag <repositiory/image> <image-name:tag>
For example, this command maps the docker.io/python:3.6.0 image to the 3.6 tag in the python image stream.
$ oc tag docker.io/python:3.6.0 python:3.6Example Output
Tag python:3.6 set to docker.io/python:3.6.0.If the external image is secured, you will need to create a secret with credentials for accessing that registry. See Importing Images from Private Registries for more details.
3.5.2.7.4. Updating an Image Stream Tag
To update a tag to reflect another tag in an image stream:
$ oc tag <image-name:tag> <image-name:latest>
For example, the following updates the latest tag to reflect the 3.6 tag in an image stream:
$ oc tag python:3.6 python:latestExample Output
Tag python:latest set to python@sha256:438208801c4806548460b27bd1fbcb7bb188273d13871ab43f.3.5.2.7.5. Removing Image Stream Tags from an Image Stream
To remove old tags from an image stream:
$ oc tag -d <image-name:tag>For example:
$ oc tag -d python:3.5Example Output
Deleted tag default/python:3.5.3.5.2.7.6. Configuring Periodic Importing of Tags
When working with an external container image registry, to periodically re-import an image (such as, to get latest security updates), use the --scheduled flag:
$ oc tag <repositiory/image> <image-name:tag> --scheduledFor example:
$ oc tag docker.io/python:3.6.0 python:3.6 --scheduledExample Output
Tag python:3.6 set to import docker.io/python:3.6.0 periodically.This command causes OpenShift Container Platform to periodically update this particular image stream tag. This period is a cluster-wide setting set to 15 minutes by default.
To remove the periodic check, re-run above command but omit the --scheduled flag. This will reset its behavior to default.
$ oc tag <repositiory/image> <image-name:tag>3.6. Deployments
3.6.1. Replication controllers
A replication controller ensures that a specified number of replicas of a pod are running at all times. If pods exit or are deleted, the replication controller acts to instantiate more up to the defined number. Likewise, if there are more running than desired, it deletes as many as necessary to match the defined amount.
A replication controller configuration consists of:
- The number of replicas desired (which can be adjusted at runtime).
- A pod definition to use when creating a replicated pod.
- A selector for identifying managed pods.
A selector is a set of labels assigned to the pods that are managed by the replication controller. These labels are included in the pod definition that the replication controller instantiates. The replication controller uses the selector to determine how many instances of the pod are already running in order to adjust as needed.
The replication controller does not perform auto-scaling based on load or traffic, as it does not track either. Rather, this would require its replica count to be adjusted by an external auto-scaler.
A replication controller is a core Kubernetes object called ReplicationController.
The following is an example ReplicationController definition:
apiVersion: v1
kind: ReplicationController
metadata:
name: frontend-1
spec:
replicas: 1
selector:
name: frontend
template:
metadata:
labels:
name: frontend
spec:
containers:
- image: openshift/hello-openshift
name: helloworld
ports:
- containerPort: 8080
protocol: TCP
restartPolicy: Always3.6.2. Replica set
Similar to a replication controller, a replica set ensures that a specified number of pod replicas are running at any given time. The difference between a replica set and a replication controller is that a replica set supports set-based selector requirements whereas a replication controller only supports equality-based selector requirements.
Only use replica sets if you require custom update orchestration or do not require updates at all, otherwise, use Deployments. Replica sets can be used independently, but are used by deployments to orchestrate pod creation, deletion, and updates. Deployments manage their replica sets automatically, provide declarative updates to pods, and do not have to manually manage the replica sets that they create.
A replica set is a core Kubernetes object called ReplicaSet.
The following is an example ReplicaSet definition:
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: frontend-1
labels:
tier: frontend
spec:
replicas: 3
selector:
matchLabels:
tier: frontend
matchExpressions:
- {key: tier, operator: In, values: [frontend]}
template:
metadata:
labels:
tier: frontend
spec:
containers:
- image: openshift/hello-openshift
name: helloworld
ports:
- containerPort: 8080
protocol: TCP
restartPolicy: Always- 1
- A label query over a set of resources. The result of
matchLabelsandmatchExpressionsare logically conjoined. - 2
- Equality-based selector to specify resources with labels that match the selector.
- 3
- Set-based selector to filter keys. This selects all resources with key equal to
tierand value equal tofrontend.
3.6.3. Jobs
A job is similar to a replication controller, in that its purpose is to create pods for specified reasons. The difference is that replication controllers are designed for pods that will be continuously running, whereas jobs are for one-time pods. A job tracks any successful completions and when the specified amount of completions have been reached, the job itself is completed.
The following example computes π to 2000 places, prints it out, then completes:
apiVersion: extensions/v1
kind: Job
metadata:
name: pi
spec:
selector:
matchLabels:
app: pi
template:
metadata:
name: pi
labels:
app: pi
spec:
containers:
- name: pi
image: perl
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
restartPolicy: NeverSee the Jobs topic for more information on how to use jobs.
3.6.4. Deployments and Deployment Configurations
Building on replication controllers, OpenShift Container Platform adds expanded support for the software development and deployment lifecycle with the concept of deployments. In the simplest case, a deployment just creates a new replication controller and lets it start up pods. However, OpenShift Container Platform deployments also provide the ability to transition from an existing deployment of an image to a new one and also define hooks to be run before or after creating the replication controller.
The OpenShift Container Platform DeploymentConfig object defines the following details of a deployment:
-
The elements of a
ReplicationControllerdefinition. - Triggers for creating a new deployment automatically.
- The strategy for transitioning between deployments.
- Life cycle hooks.
Each time a deployment is triggered, whether manually or automatically, a deployer pod manages the deployment (including scaling down the old replication controller, scaling up the new one, and running hooks). The deployment pod remains for an indefinite amount of time after it completes the deployment in order to retain its logs of the deployment. When a deployment is superseded by another, the previous replication controller is retained to enable easy rollback if needed.
For detailed instructions on how to create and interact with deployments, refer to Deployments.
Here is an example DeploymentConfig definition with some omissions and callouts:
apiVersion: v1
kind: DeploymentConfig
metadata:
name: frontend
spec:
replicas: 5
selector:
name: frontend
template: { ... }
triggers:
- type: ConfigChange
- imageChangeParams:
automatic: true
containerNames:
- helloworld
from:
kind: ImageStreamTag
name: hello-openshift:latest
type: ImageChange
strategy:
type: Rolling - 1
- A
ConfigChangetrigger causes a new deployment to be created any time the replication controller template changes. - 2
- An
ImageChangetrigger causes a new deployment to be created each time a new version of the backing image is available in the named image stream. - 3
- The default
Rollingstrategy makes a downtime-free transition between deployments.
3.7. Templates
3.7.1. Overview
A template describes a set of objects that can be parameterized and processed to produce a list of objects for creation by OpenShift Container Platform. The objects to create can include anything that users have permission to create within a project, for example services, build configurations, and deployment configurations. A template may also define a set of labels to apply to every object defined in the template.
See the template guide for details about creating and using templates.