Este contenido no está disponible en el idioma seleccionado.
Chapter 3. Automatically scaling pods with the Custom Metrics Autoscaler Operator
3.1. Release notes
3.1.1. Custom Metrics Autoscaler Operator release notes
You can review the following release notes to learn about changes in the Custom Metrics Autoscaler Operator version 2.18.1-2. The release notes for the Custom Metrics Autoscaler Operator for Red Hat OpenShift describe new features and enhancements, deprecated features, and known issues.
The Custom Metrics Autoscaler Operator uses the Kubernetes-based Event Driven Autoscaler (KEDA) and is built on top of the OpenShift Dedicated horizontal pod autoscaler (HPA).
The Custom Metrics Autoscaler Operator for Red Hat OpenShift is provided as an installable component, with a distinct release cycle from the core OpenShift Dedicated. The Red Hat OpenShift Container Platform Life Cycle Policy outlines release compatibility.
3.1.1.1. Supported versions
The following table defines the Custom Metrics Autoscaler Operator versions for each OpenShift Dedicated version.
| Version | OpenShift Dedicated version | General availability |
|---|---|---|
| 2.18.1-2 | 4.21 | General availability |
| 2.18.1-2 | 4.20 | General availability |
| 2.18.1-2 | 4.19 | General availability |
| 2.18.1-2 | 4.18 | General availability |
| 2.18.1-2 | 4.17 | General availability |
| 2.18.1-2 | 4.16 | General availability |
| 2.18.1-2 | 4.15 | General availability |
| 2.18.1-2 | 4.14 | General availability |
| 2.18.1-2 | 4.13 | General availability |
| 2.18.1-2 | 4.12 | General availability |
3.1.1.2. Custom Metrics Autoscaler Operator 2.18.1-2 release notes
Issued: 09 February 2026
You can review the following release notes to learn about the bug fixes provided in this release of the Custom Metrics Autoscaler Operator.
This release of the Custom Metrics Autoscaler Operator 2.18.1-2 addresses Common Vulnerabilities and Exposures (CVEs). The following advisory is available for the Custom Metrics Autoscaler Operator: RHSA-2026:2368
Before installing this version of the Custom Metrics Autoscaler Operator, remove any previously installed Technology Preview versions or the community-supported version of Kubernetes-based Event Driven Autoscaler (KEDA).
3.1.2. Release notes for past releases of the Custom Metrics Autoscaler Operator
You can review the following release notes to learn about changes in previous versions of the Custom Metrics Autoscaler Operator.
For the current version, see Custom Metrics Autoscaler Operator release notes.
3.1.2.1. Custom Metrics Autoscaler Operator 2.18 release notes
You can review the following release notes to learn about changes in the 2.18.z releases.
3.1.2.2. Custom Metrics Autoscaler Operator 2.18.1-1 release notes
This release of the Custom Metrics Autoscaler Operator 2.18.1-1, which provides new features and enhancements, deprecated features, and bug fixes for running the Operator in an OpenShift Dedicated cluster, was issued on 15 January 2026. Review the following information to understand important changes in this release.
The following advisory is available for the Custom Metrics Autoscaler Operator: RHBA-2026:0730
Before installing this version of the Custom Metrics Autoscaler Operator, remove any previously installed Technology Preview versions or the community-supported version of Kubernetes-based Event Driven Autoscaler (KEDA).
- New features and enhancements
Note the new features and enhancements in this release:
Forced activation
You can now temporarily force the activation of a scale target by adding the
autoscaling.keda.sh/force-activation: "true"annotation to theScaledObjectcustom resource (CR). (KEDA issue 6903)Excluding labels from being propagated to the HPA
You can now exclude specific labels from being propagated to a Horizontal Pod Autoscaler (HPA) by using the
scaledobject.keda.sh/hpa-excluded-labelsannotation to theScaledObjectorScaledJobCR. (KEDA issue 6849)Pause in scaling down
You can now pause the scaling down of an object without preventing the object from scaling up. (KEDA issue 6902)
Pause in scaling up
You can now pause the scaling up for an object without preventing the object from scaling down. (KEDA issue 7022)
Support for the s390x architecture
The Operator can now run on
s390xarchitecture. Previously it ran onamd64,ppc64le, orarm64. (KEDA issue 6543)Fallback for triggers of
Valuemetric typeFallback is now supported for triggers that use the
Valuemetric type. Previously, fallback was supported for only theAverageValuemetric type. (KEDA issue 6655)Support for even distribution of Kafka partitions
You can now configure a Kafka scaler to scale Kafka consumers by partition count on the topic. This ensures that the partitions are evenly spread across all consumers. (KEDA issue 2581)
The Zap logger has replaced the Kubernetes logger
The Operator now uses the Zap logging library to emit logs. (KEDA issue 5732)
- Deprecated and removed features
-
For the CPU and Memory triggers, the
typesetting, deprecated in an earlier version, is removed. You must usemetricTypeinstead. (KEDA bug 6698)
-
For the CPU and Memory triggers, the
- Bug fixes
- Before this update, a bug in the pending-pod-condition detection logic caused duplicate jobs to be created for scaled jobs that have slow-starting containers. With this release, the logic to properly evaluate each pod individually and correctly identify when a job is no longer pending. (KEDA bug 6698)
-
Before this update, if a deployment object contained an
envFromparameter that included a prefix setting, the prefix was ignored and the environment variable keys were added to the scaler configuration without the prefix. With this release, the prefix is now added to the environment variable key. (KEDA bug 6728) - Before this update, a scale client was not initialized when creating a new scale handler. This was due to a segmentation fault that occurred when accessing an uninitialized scale client in the scale handler during non-static fallback modes for specific scale target types. With this release, the issue is corrected. (KEDA bug 6992)
-
Before this update, if a user created a scaled object, the object had the
Pausedstatus condition ofUnknown. With this release, thePausedcondition is properly set tofalse. (KEDA bug 7011) -
Before this update, after removing the
autoscaling.keda.sh/paused-replicasfrom a scaled object CR, the object could still have thePausedstatus condition oftrue. With this release, this issue has been resolved and the object reports the pause status correctly. (KEDA bug 6982) -
Before this update, when creating a scaled object with the
scaledobject.keda.sh/transfer-hpa-ownershipannotation, the object status might not list the name of the HPA that is taking ownership of the object. With this release, the HPA name is reported correctly. (KEDA bug 6336) -
Before this update, a cron trigger incorrectly prevented scaling the replicas to 0 even if the cron schedule was inactive and the
minReplicaCountvalue is0. This happened because the trigger always reported a metric value of1during its inactive periods. With this release, the cron trigger is now able to return a metric of0, allowing an object to scale to 0. (KEDA bug 6886) -
Before this update, in a Kafka trigger, specifying
sasl:noneresulted in an error, despitenonebeing the default value forsasl. With this release, you can now configuresasl:nonein a Kafka trigger. (KEDA bug 7061) - Before this update, when scaling to 0, the Operator might not check if all scalers are not active. As a result, the Operator could scale an object to 0 even though there were active scalers. With this release, this issue has been resolved. (KEDA issue 6986)
3.1.2.3. Custom Metrics Autoscaler Operator 2.17 release notes
You can review the following release notes to learn about changes in the 2.17.z releases.
3.1.2.3.1. Custom Metrics Autoscaler Operator 2.17.2-2 release notes
Issued: 21 October 2025
This release of the Custom Metrics Autoscaler Operator 2.17.2-2, which is a rebuild of the 2.17.2 version of the Custom Metrics Autoscaler Operator using a newer base image and Go compiler, was issued on 21 October 2025. There are no code changes to the Custom Metrics Autoscaler Operator.
The following advisory is available for the Custom Metrics Autoscaler Operator: RHBA-2025:18914
3.1.2.3.2. Custom Metrics Autoscaler Operator 2.17.2 release notes
Issued: 25 September 2025
This release of the Custom Metrics Autoscaler Operator 2.17.2, which addresses Common Vulnerabilities and Exposures (CVEs), was issued on 25 September 2025. You can review the following release notes to learn about changes in this release.
The following advisory is available for the Custom Metrics Autoscaler Operator: RHSA-2025:16124
Before installing this version of the Custom Metrics Autoscaler Operator, remove any previously installed Technology Preview versions or the community-supported version of Kubernetes-based Event Driven Autoscaler (KEDA).
- New features and enhancements
Note the new features and enhancements in this release:
The KEDA controller is automatically created during installation
The KEDA controller is now automatically created when you install the Custom Metrics Autoscaler Operator. Previously, you needed to manually create the KEDA controller. You can edit the automatically-created KEDA controller, as needed.
Support for the Kubernetes workload trigger
The Cluster Metrics Autoscaler Operator now supports using the Kubernetes workload trigger to scale pods based on the number of pods matching a specific label selector.
Support for bound service account tokens
The Cluster Metrics Autoscaler Operator now supports bound service account tokens. Previously, the Operator supported only legacy service account tokens, which are being phased out in favor of bound service account tokens for security reasons.
- Bug fixes
- Before this update, the KEDA controller did not support volume mounts. As a result, you could not use Kerberos with the Kafka scaler. With this release, the KEDA controller now supports volume mounts. (OCPBUGS-42559)
-
Before this update, the KEDA version in the
keda-operatordeployment object log reported that the Custom Metrics Autoscaler Operator was based on an incorrect KEDA version. With this release, the correct KEDA version is reported in the log. (OCPBUGS-58129)
3.1.2.4. Custom Metrics Autoscaler Operator 2.15 release notes
You can review the following release notes to learn about changes in the 2.15.z releases.
3.1.2.5. Custom Metrics Autoscaler Operator 2.15.1-4 release notes
Issued: 31 March 2025
This release of the Custom Metrics Autoscaler Operator 2.15.1-4, which addresses Common Vulnerabilities and Exposures (CVEs), was issued on 25 September 2025. You can review the following release notes to learn about changes in this release.
The following advisory is available for the Custom Metrics Autoscaler Operator: RHSA-2025:3501
Before installing this version of the Custom Metrics Autoscaler Operator, remove any previously installed Technology Preview versions or the community-supported version of Kubernetes-based Event Driven Autoscaler (KEDA).
- New features and enhancements
Note the new features and enhancements in this release:
CMA multi-arch builds
With this version of the Custom Metrics Autoscaler Operator, you can now install and run the Operator on an ARM64 OpenShift Dedicated cluster.
3.1.2.6. Custom Metrics Autoscaler Operator 2.14 release notes
You can review the following release notes to learn about changes in the 2.14.z releases.
3.1.2.6.1. Custom Metrics Autoscaler Operator 2.14.1-467 release notes
This release of the Custom Metrics Autoscaler Operator 2.14.1-467 provides a CVE and a bug fix for running the Operator in an OpenShift Dedicated cluster. The following advisory is available for the Custom Metrics Autoscaler: RHSA-2024:7348.
Before installing this version of the Custom Metrics Autoscaler Operator, remove any previously installed Technology Preview versions or the community-supported version of Kubernetes-based Event Driven Autoscaler (KEDA).
- Bug fixes
- Before this update, the root file system of the Custom Metrics Autoscaler Operator pod was writable, which is unnecessary and could present security issues. With this release, the pod root file system is read-only, which addresses the potential security issue. (OCPBUGS-37989)
3.1.2.6.2. Custom Metrics Autoscaler Operator 2.14.1-454 release notes
This release of the Custom Metrics Autoscaler Operator 2.14.1-454 provides a CVE, a new feature, and bug fixes for running the Operator in an OpenShift Dedicated cluster. The following advisory is available for the Custom Metrics Autoscaler: RHBA-2024:5865.
Before installing this version of the Custom Metrics Autoscaler Operator, remove any previously installed Technology Preview versions or the community-supported version of Kubernetes-based Event Driven Autoscaler (KEDA).
- New features and enhancements
Note the new features and enhancements in this release:
Support for the Cron trigger with the Custom Metrics Autoscaler Operator
The Custom Metrics Autoscaler Operator can now use the Cron trigger to scale pods based on an hourly schedule. When your specified time frame starts, the Custom Metrics Autoscaler Operator scales pods to your desired amount. When the time frame ends, the Operator scales back down to the previous level.
For more information, see "Understanding the Cron trigger".
- Bug fixes
-
Before this update, if you made changes to audit configuration parameters in the
KedaControllercustom resource, thekeda-metrics-server-audit-policyconfig map would not get updated. As a consequence, you could not change the audit configuration parameters after the initial deployment of the Custom Metrics Autoscaler. With this release, changes to the audit configuration now render properly in the config map, allowing you to change the audit configuration any time after installation. (OCPBUGS-32521)
-
Before this update, if you made changes to audit configuration parameters in the
3.1.2.7. Custom Metrics Autoscaler Operator 2.13 release notes
You can review the following release notes to learn about changes in the 2.13.z releases.
3.1.2.7.1. Custom Metrics Autoscaler Operator 2.13.1 release notes
This release of the Custom Metrics Autoscaler Operator 2.13.1-421 provides a new feature and a bug fix for running the Operator in an OpenShift Dedicated cluster. The following advisory is available for the Custom Metrics Autoscaler: RHBA-2024:4837.
Before installing this version of the Custom Metrics Autoscaler Operator, remove any previously installed Technology Preview versions or the community-supported version of Kubernetes-based Event Driven Autoscaler (KEDA).
- New features and enhancements
Note the new features and enhancements in this release:
Support for custom certificates with the Custom Metrics Autoscaler Operator
The Custom Metrics Autoscaler Operator can now use custom service CA certificates to connect securely to TLS-enabled metrics sources, such as an external Kafka cluster or an external Prometheus service. By default, the Operator uses automatically-generated service certificates to connect to on-cluster services only. There is a new field in the
KedaControllerobject that allows you to load custom server CA certificates for connecting to external services by using config maps.For more information, see "Custom CA certificates for the Custom Metrics Autoscaler".
- Bug fixes
-
Before this update, the
custom-metrics-autoscalerandcustom-metrics-autoscaler-adapterimages were missing time zone information. As a consequence, scaled objects withcrontriggers failed to work because the controllers were unable to find time zone information. With this release, the image builds are updated to include time zone information. As a result, scaled objects containingcrontriggers now function properly. Scaled objects containingcrontriggers are currently not supported for the custom metrics autoscaler. (OCPBUGS-34018)
-
Before this update, the
3.1.2.8. Custom Metrics Autoscaler Operator 2.12 release notes
You can review the following release notes to learn about changes in the 2.12.z releases.
3.1.2.8.1. Custom Metrics Autoscaler Operator 2.12.1-394 release notes
This release of the Custom Metrics Autoscaler Operator 2.12.1-394 provides a bug fix for running the Operator in an OpenShift Dedicated cluster. The following advisory is available for the Custom Metrics Autoscaler: RHSA-2024:2901.
Before installing this version of the Custom Metrics Autoscaler Operator, remove any previously installed Technology Preview versions or the community-supported version of Kubernetes-based Event Driven Autoscaler (KEDA).
- Bug fixes
-
Before this update, the
protojson.Unmarshalfunction entered into an infinite loop when unmarshaling certain forms of invalid JSON. This condition could occur when unmarshaling into a message that contains agoogle.protobuf.Anyvalue or when theUnmarshalOptions.DiscardUnknownoption is set. With this release, the issue is resolved. (OCPBUGS-30305) -
Before this update, when parsing a multipart form, either explicitly with the
Request.ParseMultipartFormmethod or implicitly with theRequest.FormValue,Request.PostFormValue, orRequest.FormFilemethod, the limits on the total size of the parsed form were not applied to the memory consumed. This could cause memory exhaustion. With this release, the parsing process now correctly limits the maximum size of form lines while reading a single form line. (OCPBUGS-30360) -
Before this update, when following an HTTP redirect to a domain that is not on a matching subdomain or on an exact match of the initial domain, an HTTP client would not forward sensitive headers, such as
AuthorizationorCookie. For example, a redirect fromexample.comtowww.example.comwould forward theAuthorizationheader, but a redirect towww.example.orgwould not forward the header. With this release, the issue is resolved. (OCPBUGS-30365) -
Before this update, verifying a certificate chain that contains a certificate with an unknown public key algorithm caused the certificate verification process to panic. This condition affected all crypto and Transport Layer Security (TLS) clients and servers that set the
Config.ClientAuthparameter to theVerifyClientCertIfGivenorRequireAndVerifyClientCertvalue. The default behavior is for TLS servers to not verify client certificates. With this release, the issue is resolved. (OCPBUGS-30370) -
Before this update, if errors returned from the
MarshalJSONmethod contained user-controlled data, an attacker could have used the data to break the contextual auto-escaping behavior of the HTML template package. This condition would allow for subsequent actions to inject unexpected content into the templates. With this release, the issue is resolved. (OCPBUGS-30397) -
Before this update, the
net/httpandgolang.org/x/net/http2Go packages did not limit the number ofCONTINUATIONframes for an HTTP/2 request. This condition could result in excessive CPU consumption. With this release, the issue is resolved. (OCPBUGS-30894)
-
Before this update, the
3.1.2.8.2. Custom Metrics Autoscaler Operator 2.12.1-384 release notes
This release of the Custom Metrics Autoscaler Operator 2.12.1-384 provides a bug fix for running the Operator in an OpenShift Dedicated cluster. The following advisory is available for the Custom Metrics Autoscaler RHBA-2024:2043.
Before installing this version of the Custom Metrics Autoscaler Operator, remove any previously installed Technology Preview versions or the community-supported version of KEDA.
- Bug fixes
-
Before this update, the
custom-metrics-autoscalerandcustom-metrics-autoscaler-adapterimages were missing time zone information. As a consequence, scaled objects withcrontriggers failed to work because the controllers were unable to find time zone information. With this release, the image builds are updated to include time zone information. As a result, scaled objects containingcrontriggers now function properly. (OCPBUGS-32395)
-
Before this update, the
3.1.2.8.3. Custom Metrics Autoscaler Operator 2.12.1-376 release notes
This release of the Custom Metrics Autoscaler Operator 2.12.1-376 provides security updates and bug fixes for running the Operator in an OpenShift Dedicated cluster. The following advisory is available for the Custom Metrics Autoscaler Operator: RHSA-2024:1812.
Before installing this version of the Custom Metrics Autoscaler Operator, remove any previously installed Technology Preview versions or the community-supported version of KEDA.
- Bug fixes
- Before this update, if invalid values such as nonexistent namespaces were specified in scaled object metadata, the underlying scaler clients would not free, or close, their client descriptors, resulting in a slow memory leak. With this release, the underlying client descriptors close when there are errors, preventing memory from leaking. (OCPBUGS-30145)
-
Before this update, the
ServiceMonitorcustom resource (CR) for thekeda-metrics-apiserverpod was not functioning, because the CR referenced an incorrect metrics port name ofhttp. With this release, theServiceMonitorCR now references the proper port name ofmetrics. As a result, the Service Monitor functions properly. (OCPBUGS-25806)
3.1.2.9. Custom Metrics Autoscaler Operator 2.11 release notes
You can review the following release notes to learn about changes in the 2.11.z releases.
3.1.2.9.1. Custom Metrics Autoscaler Operator 2.11.2-322 release notes
This release of the Custom Metrics Autoscaler Operator 2.11.2-322 provides security updates and bug fixes for running the Operator in an OpenShift Dedicated cluster. The following advisory is available for the Custom Metrics Autoscaler: RHSA-2023:6144.
Before installing this version of the Custom Metrics Autoscaler Operator, remove any previously installed Technology Preview versions or the community-supported version of KEDA.
- Bug fixes
- Before this update, the Custom Metrics Autoscaler Operator version 3.11.2-311 was released without a required volume mount in the Operator deployment, the Custom Metrics Autoscaler Operator pod would restart every 15 minutes. With this release, the required volume mount is added to the Operator deployment. As a result, the Operator no longer restarts every 15 minutes. (OCPBUGS-22361)
3.1.2.9.2. Custom Metrics Autoscaler Operator 2.11.2-311 release notes
This release of the Custom Metrics Autoscaler Operator 2.11.2-311 provides new features and bug fixes for running the Operator in an OpenShift Dedicated cluster. The components of the Custom Metrics Autoscaler Operator 2.11.2-311 were released in RHBA-2023:5981.
Before installing this version of the Custom Metrics Autoscaler Operator, remove any previously installed Technology Preview versions or the community-supported version of KEDA.
- New features and enhancements
Note the new features and enhancements in this release:
Red Hat OpenShift Service on AWS and OpenShift Dedicated are now supported
The Custom Metrics Autoscaler Operator 2.11.2-311 can be installed on Red Hat OpenShift Service on AWS and OpenShift Dedicated managed clusters. Previous versions of the Custom Metrics Autoscaler Operator could be installed only in the
openshift-kedanamespace. This prevented the Operator from being installed on Red Hat OpenShift Service on AWS and OpenShift Dedicated clusters. This version of Custom Metrics Autoscaler allows installation to other namespaces such asopenshift-operatorsorkeda, enabling installation into Red Hat OpenShift Service on AWS and OpenShift Dedicated clusters.
- Bug fixes
-
Before this update, if the Custom Metrics Autoscaler Operator was installed and configured, but not in use, the OpenShift CLI reported the
couldn’t get resource list for external.metrics.k8s.io/v1beta1: Got empty response for: external.metrics.k8s.io/v1beta1error after anyoccommand was entered. The message, although harmless, could have caused confusion. With this release, theGot empty response for: external.metrics…error no longer appears inappropriately. (OCPBUGS-15779) - Before this update, any annotation or label change to objects managed by the Custom Metrics Autoscaler were reverted by Custom Metrics Autoscaler Operator any time the Keda Controller was modified, for example after a configuration change. This caused continuous changing of labels in your objects. With this release, the Custom Metrics Autoscaler now uses its own annotation to manage labels and annotations, and annotation or label are no longer inappropriately reverted. (OCPBUGS-15590)
-
Before this update, if the Custom Metrics Autoscaler Operator was installed and configured, but not in use, the OpenShift CLI reported the
3.1.2.10. Custom Metrics Autoscaler Operator 2.10 release notes
You can review the following release notes to learn about changes in the 2.10.z releases.
3.1.2.10.1. Custom Metrics Autoscaler Operator 2.10.1-267 release notes
This release of the Custom Metrics Autoscaler Operator 2.10.1-267 provides new features and bug fixes for running the Operator in an OpenShift Dedicated cluster. The components of the Custom Metrics Autoscaler Operator 2.10.1-267 were released in RHBA-2023:4089.
Before installing this version of the Custom Metrics Autoscaler Operator, remove any previously installed Technology Preview versions or the community-supported version of KEDA.
- Bug fixes
-
Before this update, the
custom-metrics-autoscalerandcustom-metrics-autoscaler-adapterimages did not contain time zone information. Because of this, scaled objects with cron triggers failed to work because the controllers were unable to find time zone information. With this release, the image builds now include time zone information. As a result, scaled objects containing cron triggers now function properly. (OCPBUGS-15264) -
Before this update, the Custom Metrics Autoscaler Operator would attempt to take ownership of all managed objects, including objects in other namespaces and cluster-scoped objects. Because of this, the Custom Metrics Autoscaler Operator was unable to create the role binding for reading the credentials necessary to be an API server. This caused errors in the
kube-systemnamespace. With this release, the Custom Metrics Autoscaler Operator skips adding theownerReferencefield to any object in another namespace or any cluster-scoped object. As a result, the role binding is now created without any errors. (OCPBUGS-15038) -
Before this update, the Custom Metrics Autoscaler Operator added an
ownerReferencesfield to theopenshift-kedanamespace. While this did not cause functionality problems, the presence of this field could have caused confusion for cluster administrators. With this release, the Custom Metrics Autoscaler Operator does not add theownerReferencefield to theopenshift-kedanamespace. As a result, theopenshift-kedanamespace no longer has a superfluousownerReferencefield. (OCPBUGS-15293) -
Before this update, if you used a Prometheus trigger configured with authentication method other than pod identity, and the
podIdentityparameter was set tonone, the trigger would fail to scale. With this release, the Custom Metrics Autoscaler for OpenShift now properly handles thenonepod identity provider type. As a result, a Prometheus trigger configured with authentication method other than pod identity, and thepodIdentityparameter sset tononenow properly scales. (OCPBUGS-15274)
-
Before this update, the
3.1.2.10.2. Custom Metrics Autoscaler Operator 2.10.1 release notes
This release of the Custom Metrics Autoscaler Operator 2.10.1 provides new features and bug fixes for running the Operator in an OpenShift Dedicated cluster. The components of the Custom Metrics Autoscaler Operator 2.10.1 were released in RHEA-2023:3199.
Before installing this version of the Custom Metrics Autoscaler Operator, remove any previously installed Technology Preview versions or the community-supported version of KEDA.
- New features and enhancements
Note the new features and enhancements in this release:
Custom Metrics Autoscaler Operator general availability
The Custom Metrics Autoscaler Operator is now generally available as of Custom Metrics Autoscaler Operator version 2.10.1.
ImportantScaling by using a scaled job is a Technology Preview feature only. Technology Preview features are not supported with Red Hat production service level agreements (SLAs) and might not be functionally complete. Red Hat does not recommend using them in production. These features provide early access to upcoming product features, enabling customers to test functionality and provide feedback during the development process.
For more information about the support scope of Red Hat Technology Preview features, see Technology Preview Features Support Scope.
Performance metrics
You can now use the Prometheus Query Language (PromQL) to query metrics on the Custom Metrics Autoscaler Operator.
Pausing the custom metrics autoscaling for scaled objects
You can now pause the autoscaling of a scaled object, as needed, and resume autoscaling when ready.
Replica fall back for scaled objects
You can now specify the number of replicas to fall back to if a scaled object fails to get metrics from the source.
Customizable HPA naming for scaled objects
You can now specify a custom name for the horizontal pod autoscaler in scaled objects.
Activation and scaling thresholds
Because the horizontal pod autoscaler (HPA) cannot scale to or from 0 replicas, the Custom Metrics Autoscaler Operator does that scaling, after which the HPA performs the scaling. You can now specify when the HPA takes over autoscaling, based on the number of replicas. This allows for more flexibility with your scaling policies.
3.1.2.11. Custom Metrics Autoscaler Operator 2.8 release notes
You can review the following release notes to learn about changes in the 2.8.z releases.
3.1.2.11.1. Custom Metrics Autoscaler Operator 2.8.2-174 release notes
This release of the Custom Metrics Autoscaler Operator 2.8.2-174 provides new features and bug fixes for running the Operator in an OpenShift Dedicated cluster. The components of the Custom Metrics Autoscaler Operator 2.8.2-174 were released in RHEA-2023:1683.
The Custom Metrics Autoscaler Operator version 2.8.2-174 is a Technology Preview feature.
- New features and enhancements
Note the new features and enhancements in this release:
Operator upgrade support
You can now upgrade from a prior version of the Custom Metrics Autoscaler Operator. See "Changing the update channel for an Operator" in the "Additional resources" for information on upgrading an Operator.
must-gather support
You can now collect data about the Custom Metrics Autoscaler Operator and its components by using the OpenShift Dedicated
must-gathertool. Currently, the process for using themust-gathertool with the Custom Metrics Autoscaler is different from that of other operators. See "Gathering debugging data" in the Additional resources section for more information.
3.1.2.11.2. Custom Metrics Autoscaler Operator 2.8.2 release notes
This release of the Custom Metrics Autoscaler Operator 2.8.2 provides new features and bug fixes for running the Operator in an OpenShift Dedicated cluster. The components of the Custom Metrics Autoscaler Operator 2.8.2 were released in RHSA-2023:1042.
The Custom Metrics Autoscaler Operator version 2.8.2 is a Technology Preview feature.
- New features and enhancements
Note the new features and enhancements in this release:
Audit Logging
You can now gather and view audit logs for the Custom Metrics Autoscaler Operator and its associated components. Audit logs are security-relevant chronological sets of records that document the sequence of activities that have affected the system by individual users, administrators, or other components of the system.
Scale applications based on Apache Kafka metrics
You can now use the KEDA Apache kafka trigger/scaler to scale deployments based on an Apache Kafka topic.
Scale applications based on CPU metrics
You can now use the KEDA CPU trigger/scaler to scale deployments based on CPU metrics.
Scale applications based on memory metrics
You can now use the KEDA memory trigger/scaler to scale deployments based on memory metrics.
3.2. Custom Metrics Autoscaler Operator overview
As a developer, you can use Custom Metrics Autoscaler Operator for Red Hat OpenShift to specify how OpenShift Dedicated should automatically increase or decrease the number of pods for a deployment, stateful set, custom resource, or job based on custom metrics that are not based only on CPU or memory.
The Custom Metrics Autoscaler Operator is an optional Operator, based on the Kubernetes Event Driven Autoscaler (KEDA), that allows workloads to be scaled using additional metrics sources other than pod metrics.
The custom metrics autoscaler currently supports only the Prometheus, CPU, memory, and Apache Kafka metrics.
The Custom Metrics Autoscaler Operator scales your pods up and down based on custom, external metrics from specific applications. Your other applications continue to use other scaling methods. You configure triggers, also known as scalers, which are the source of events and metrics that the custom metrics autoscaler uses to determine how to scale. The custom metrics autoscaler uses a metrics API to convert the external metrics to a form that OpenShift Dedicated can use. The custom metrics autoscaler creates a horizontal pod autoscaler (HPA) that performs the actual scaling.
To use the custom metrics autoscaler, you create a ScaledObject or ScaledJob object for a workload, which is a custom resource (CR) that defines the scaling metadata. You specify the deployment or job to scale, the source of the metrics to scale on (trigger), and other parameters such as the minimum and maximum replica counts allowed.
You can create only one scaled object or scaled job for each workload that you want to scale. Also, you cannot use a scaled object or scaled job and the horizontal pod autoscaler (HPA) on the same workload.
The custom metrics autoscaler, unlike the HPA, can scale to zero. If you set the minReplicaCount value in the custom metrics autoscaler CR to 0, the custom metrics autoscaler scales the workload down from 1 to 0 replicas to or up from 0 replicas to 1. This is known as the activation phase. After scaling up to 1 replica, the HPA takes control of the scaling. This is known as the scaling phase.
Some triggers allow you to change the number of replicas that are scaled by the cluster metrics autoscaler. In all cases, the parameter to configure the activation phase always uses the same phrase, prefixed with activation. For example, if the threshold parameter configures scaling, activationThreshold would configure activation. Configuring the activation and scaling phases allows you more flexibility with your scaling policies. For example, you can configure a higher activation phase to prevent scaling up or down if the metric is particularly low.
The activation value has more priority than the scaling value in case of different decisions for each. For example, if the threshold is set to 10, and the activationThreshold is 50, if the metric reports 40, the scaler is not active and the pods are scaled to zero even if the HPA requires 4 instances.
Figure 3.1. Custom metrics autoscaler workflow
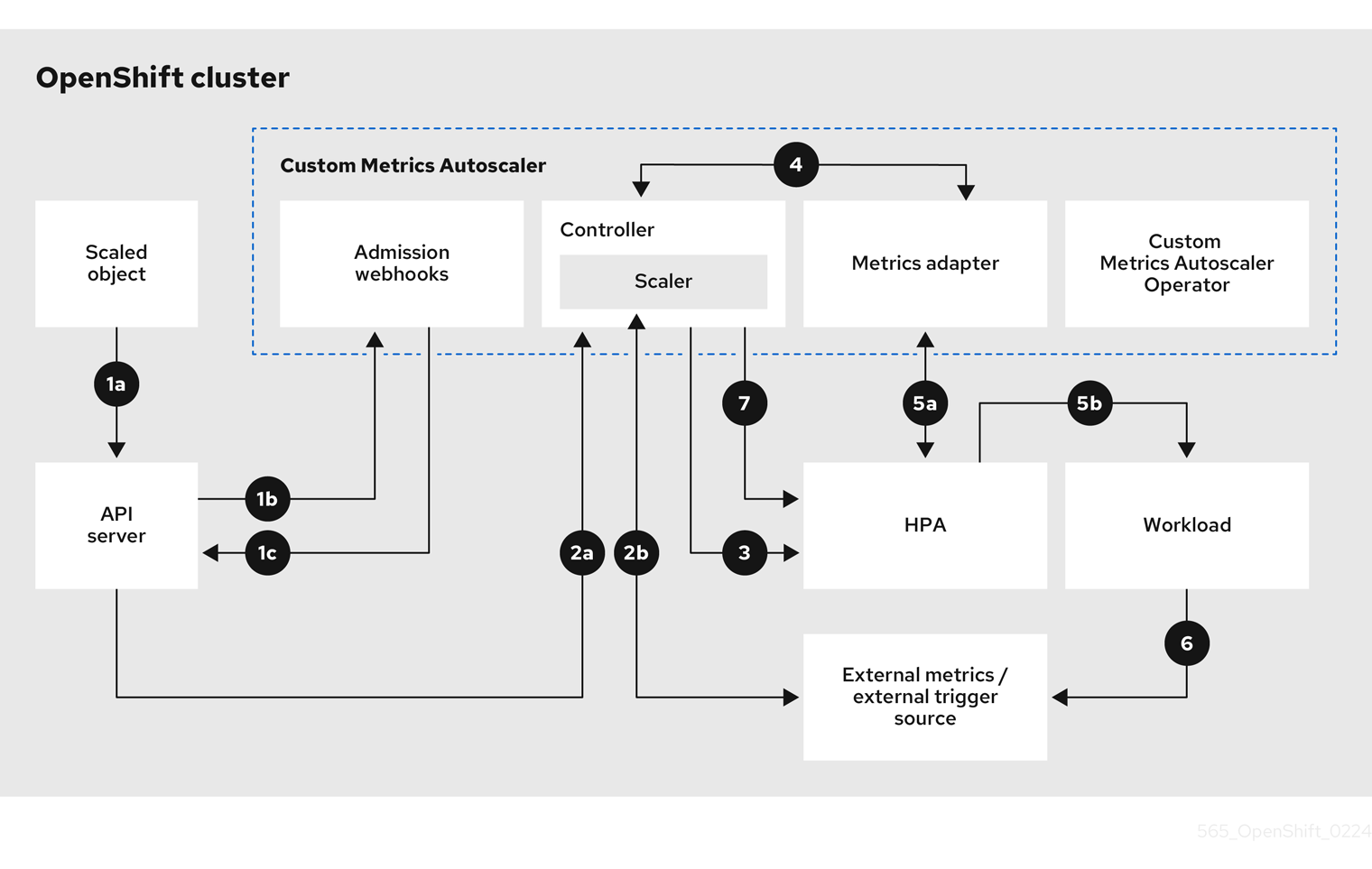
- You create or modify a scaled object custom resource for a workload on a cluster. The object contains the scaling configuration for that workload. Prior to accepting the new object, the OpenShift API server sends it to the custom metrics autoscaler admission webhooks process to ensure that the object is valid. If validation succeeds, the API server persists the object.
- The custom metrics autoscaler controller watches for new or modified scaled objects. When the OpenShift API server notifies the controller of a change, the controller monitors any external trigger sources, also known as data sources, that are specified in the object for changes to the metrics data. One or more scalers request scaling data from the external trigger source. For example, for a Kafka trigger type, the controller uses the Kafka scaler to communicate with a Kafka instance to obtain the data requested by the trigger.
- The controller creates a horizontal pod autoscaler object for the scaled object. As a result, the Horizontal Pod Autoscaler (HPA) Operator starts monitoring the scaling data associated with the trigger. The HPA requests scaling data from the cluster OpenShift API server endpoint.
- The OpenShift API server endpoint is served by the custom metrics autoscaler metrics adapter. When the metrics adapter receives a request for custom metrics, it uses a GRPC connection to the controller to request it for the most recent trigger data received from the scaler.
- The HPA makes scaling decisions based upon the data received from the metrics adapter and scales the workload up or down by increasing or decreasing the replicas.
- As a it operates, a workload can affect the scaling metrics. For example, if a workload is scaled up to handle work in a Kafka queue, the queue size decreases after the workload processes all the work. As a result, the workload is scaled down.
-
If the metrics are in a range specified by the
minReplicaCountvalue, the custom metrics autoscaler controller disables all scaling, and leaves the replica count at a fixed level. If the metrics exceed that range, the custom metrics autoscaler controller enables scaling and allows the HPA to scale the workload. While scaling is disabled, the HPA does not take any action.
3.2.1. Custom CA certificates for the Custom Metrics Autoscaler
By default, the Custom Metrics Autoscaler Operator uses automatically-generated service CA certificates to connect to on-cluster services.
If you want to use off-cluster services that require custom CA certificates, you can add the required certificates to a config map. Then, add the config map to the KedaController custom resource as described in Installing the custom metrics autoscaler. The Operator loads those certificates on start-up and registers them as trusted by the Operator.
The config maps can contain one or more certificate files that contain one or more PEM-encoded CA certificates. Or, you can use separate config maps for each certificate file.
If you later update the config map to add additional certificates, you must restart the keda-operator-* pod for the changes to take effect.
3.3. Installing the custom metrics autoscaler
You can use the OpenShift Dedicated web console to install the Custom Metrics Autoscaler Operator.
The installation creates the following five CRDs:
-
ClusterTriggerAuthentication -
KedaController -
ScaledJob -
ScaledObject -
TriggerAuthentication
The installation process also creates the KedaController custom resource (CR). You can modify the default KedaController CR, if needed. For more information, see "Editing the Keda Controller CR".
If you are installing a Custom Metrics Autoscaler Operator version lower than 2.17.2, you must manually create the Keda Controller CR. You can use the procedure described in "Editing the Keda Controller CR" to create the CR.
3.3.1. Installing the custom metrics autoscaler
You can use the following procedure to install the Custom Metrics Autoscaler Operator.
Prerequisites
You have access to the cluster as a user with the
cluster-adminrole.If your OpenShift Dedicated cluster is in a cloud account that is owned by Red Hat (non-CCS), you must request
cluster-adminprivileges.- Remove any previously-installed Technology Preview versions of the Cluster Metrics Autoscaler Operator.
Remove any versions of the community-based KEDA.
Also, remove the KEDA 1.x custom resource definitions by running the following commands:
$ oc delete crd scaledobjects.keda.k8s.io$ oc delete crd triggerauthentications.keda.k8s.io-
Ensure that the
kedanamespace exists. If not, you must manually create thekedanamespace. Optional: If you need the Custom Metrics Autoscaler Operator to connect to off-cluster services, such as an external Kafka cluster or an external Prometheus service, put any required service CA certificates into a config map. The config map must exist in the same namespace where the Operator is installed. For example:
$ oc create configmap -n openshift-keda thanos-cert --from-file=ca-cert.pem
Procedure
-
In the OpenShift Dedicated web console, click Ecosystem
Software Catalog. - From the list of available Operators, choose Custom Metrics Autoscaler, and click Install.
- On the Install Operator page, ensure that the A specific namespace on the cluster option is selected for Installation Mode.
- For Installed Namespace, click Select a namespace.
Click Select Project:
-
If the
kedanamespace exists, select keda from the list. If the
kedanamespace does not exist:- Select Create Project to open the Create Project window.
-
In the Name field, enter
keda. -
In the Display Name field, enter a descriptive name, such as
keda. - Optional: In the Display Name field, add a description for the namespace.
- Click Create.
-
If the
- Click Install.
Verify the installation by listing the Custom Metrics Autoscaler Operator components:
-
Navigate to Workloads
Pods. -
Select the
kedaproject from the drop-down menu and verify that thecustom-metrics-autoscaler-operator-*pod is running. -
Navigate to Workloads
Deployments to verify that the custom-metrics-autoscaler-operatordeployment is running.
-
Navigate to Workloads
Optional: Verify the installation in the OpenShift CLI (
oc) using the following command:$ oc get all -n kedaExample output
NAME READY STATUS RESTARTS AGE pod/custom-metrics-autoscaler-operator-5fd8d9ffd8-xt4xp 1/1 Running 0 18m NAME READY UP-TO-DATE AVAILABLE AGE deployment.apps/custom-metrics-autoscaler-operator 1/1 1 1 18m NAME DESIRED CURRENT READY AGE replicaset.apps/custom-metrics-autoscaler-operator-5fd8d9ffd8 1 1 1 18m
3.3.2. Editing the Keda Controller CR
You can use the following procedure to modify the KedaController custom resource (CR), which is automatically installed during the installation of the Custom Metrics Autoscaler Operator.
Procedure
-
In the OpenShift Dedicated web console, click Ecosystem
Installed Operators. - Click Custom Metrics Autoscaler.
- On the Operator Details page, click the KedaController tab.
On the KedaController tab, click Create KedaController and edit the file.
kind: KedaController apiVersion: keda.sh/v1alpha1 metadata: name: keda namespace: openshift-keda spec: watchNamespace: ''1 operator: logLevel: info2 logEncoder: console3 caConfigMaps:4 - thanos-cert - kafka-cert volumeMounts:5 - mountPath: /<path_to_directory> name: <name> volumes:6 - name: <volume_name> emptyDir: medium: Memory metricsServer: logLevel: '0'7 auditConfig:8 logFormat: "json" logOutputVolumeClaim: "persistentVolumeClaimName" policy: rules: - level: Metadata omitStages: ["RequestReceived"] omitManagedFields: false lifetime: maxAge: "2" maxBackup: "1" maxSize: "50" serviceAccount: {}- 1
- Specifies a single namespace in which the Custom Metrics Autoscaler Operator scales applications. Leave it blank or leave it empty to scale applications in all namespaces. This field should have a namespace or be empty. The default value is empty.
- 2
- Specifies the level of verbosity for the Custom Metrics Autoscaler Operator log messages. The allowed values are
debug,info,error. The default isinfo. - 3
- Specifies the logging format for the Custom Metrics Autoscaler Operator log messages. The allowed values are
consoleorjson. The default isconsole. - 4
- Optional: Specifies one or more config maps with CA certificates, which the Custom Metrics Autoscaler Operator can use to connect securely to TLS-enabled metrics sources.
- 5
- Optional: Add the container mount path.
- 6
- Optional: Add a
volumesblock to list each projected volume source. - 7
- Specifies the logging level for the Custom Metrics Autoscaler Metrics Server. The allowed values are
0forinfoand4fordebug. The default is0. - 8
- Activates audit logging for the Custom Metrics Autoscaler Operator and specifies the audit policy to use, as described in the "Configuring audit logging" section.
- Click Save to save the changes.
3.4. Understanding custom metrics autoscaler triggers
Triggers, also known as scalers, provide the metrics that the Custom Metrics Autoscaler Operator uses to scale your pods.
The custom metrics autoscaler currently supports the Prometheus, CPU, memory, Apache Kafka, and cron triggers.
You use a ScaledObject or ScaledJob custom resource to configure triggers for specific objects, as described in the sections that follow.
You can configure a certificate authority to use with your scaled objects or for all scalers in the cluster.
3.4.1. Understanding the Prometheus trigger
You can scale pods based on Prometheus metrics, which can use the installed OpenShift Dedicated monitoring or an external Prometheus server as the metrics source. See "Configuring the custom metrics autoscaler to use OpenShift Dedicated monitoring" for information on the configurations required to use the OpenShift Dedicated monitoring as a source for metrics.
If Prometheus is collecting metrics from the application that the custom metrics autoscaler is scaling, do not set the minimum replicas to 0 in the custom resource. If there are no application pods, the custom metrics autoscaler does not have any metrics to scale on.
Example scaled object with a Prometheus target
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: prom-scaledobject
namespace: my-namespace
spec:
# ...
triggers:
- type: prometheus
metadata:
serverAddress: https://thanos-querier.openshift-monitoring.svc.cluster.local:9092
namespace: kedatest
metricName: http_requests_total
threshold: '5'
query: sum(rate(http_requests_total{job="test-app"}[1m]))
authModes: basic
cortexOrgID: my-org
ignoreNullValues: "false"
unsafeSsl: "false"
timeout: 1000 - 1
- Specifies Prometheus as the trigger type.
- 2
- Specifies the address of the Prometheus server. This example uses OpenShift Dedicated monitoring.
- 3
- Optional: Specifies the namespace of the object you want to scale. This parameter is mandatory if using OpenShift Dedicated monitoring as a source for the metrics.
- 4
- Specifies the name to identify the metric in the
external.metrics.k8s.ioAPI. If you are using more than one trigger, all metric names must be unique. - 5
- Specifies the value that triggers scaling. Must be specified as a quoted string value.
- 6
- Specifies the Prometheus query to use.
- 7
- Specifies the authentication method to use. Prometheus scalers support bearer authentication (
bearer), basic authentication (basic), or TLS authentication (tls). You configure the specific authentication parameters in a trigger authentication, as discussed in a following section. As needed, you can also use a secret. - 8
- 9
- Optional: Specifies how the trigger should proceed if the Prometheus target is lost.
-
If
true, the trigger continues to operate if the Prometheus target is lost. This is the default behavior. -
If
false, the trigger returns an error if the Prometheus target is lost.
-
If
- 10
- Optional: Specifies whether the certificate check should be skipped. For example, you might skip the check if you are running in a test environment and using self-signed certificates at the Prometheus endpoint.
-
If
false, the certificate check is performed. This is the default behavior. If
true, the certificate check is not performed.ImportantSkipping the check is not recommended.
-
If
- 11
- Optional: Specifies an HTTP request timeout in milliseconds for the HTTP client used by this Prometheus trigger. This value overrides any global timeout setting.
3.4.1.1. Configuring GPU-based autoscaling with Prometheus and DCGM metrics
You can use the Custom Metrics Autoscaler with NVIDIA Data Center GPU Manager (DCGM) metrics to scale workloads based on GPU utilization. This is particularly useful for AI and machine learning workloads that require GPU resources.
Example scaled object with a Prometheus target for GPU-based autoscaling
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: gpu-scaledobject
namespace: my-namespace
spec:
scaleTargetRef:
kind: Deployment
name: gpu-deployment
minReplicaCount: 1
maxReplicaCount: 5
triggers:
- type: prometheus
metadata:
serverAddress: https://thanos-querier.openshift-monitoring.svc.cluster.local:9092
namespace: my-namespace
metricName: gpu_utilization
threshold: '90'
query: SUM(DCGM_FI_DEV_GPU_UTIL{instance=~".+", gpu=~".+"})
authModes: bearer
authenticationRef:
name: keda-trigger-auth-prometheus- 1
- Specifies the minimum number of replicas to maintain. For GPU workloads, this should not be set to
0to ensure that metrics continue to be collected. - 2
- Specifies the maximum number of replicas allowed during scale-up operations.
- 3
- Specifies the GPU utilization percentage threshold that triggers scaling. When the average GPU utilization exceeds 90%, the autoscaler scales up the deployment.
- 4
- Specifies a Prometheus query using NVIDIA DCGM metrics to monitor GPU utilization across all GPU devices. The
DCGM_FI_DEV_GPU_UTILmetric provides GPU utilization percentages.
3.4.1.2. Configuring the custom metrics autoscaler to use OpenShift Dedicated monitoring
You can use the installed OpenShift Dedicated Prometheus monitoring as a source for the metrics used by the custom metrics autoscaler. However, there are some additional configurations you must perform.
For your scaled objects to be able to read the OpenShift Dedicated Prometheus metrics, you must use a trigger authentication or a cluster trigger authentication in order to provide the authentication information required. The following procedure differs depending on which trigger authentication method you use. For more information on trigger authentications, see "Understanding custom metrics autoscaler trigger authentications".
These steps are not required for an external Prometheus source.
You must perform the following tasks, as described in this section:
- Create a service account.
- Create the trigger authentication.
- Create a role.
- Add that role to the service account.
- Reference the token in the trigger authentication object used by Prometheus.
Prerequisites
- OpenShift Dedicated monitoring must be installed.
- Monitoring of user-defined workloads must be enabled in OpenShift Dedicated monitoring, as described in the Creating a user-defined workload monitoring config map section.
- The Custom Metrics Autoscaler Operator must be installed.
Procedure
Change to the appropriate project:
$ oc project <project_name>1 - 1
- Specifies one of the following projects:
- If you are using a trigger authentication, specify the project with the object you want to scale.
-
If you are using a cluster trigger authentication, specify the
openshift-kedaproject.
Create a service account if your cluster does not have one:
Create a
service accountobject by using the following command:$ oc create serviceaccount thanos1 - 1
- Specifies the name of the service account.
Create a trigger authentication with the service account token:
Create a YAML file similar to the following:
apiVersion: keda.sh/v1alpha1 kind: <authentication_method>1 metadata: name: keda-trigger-auth-prometheus spec: boundServiceAccountToken:2 - parameter: bearerToken3 serviceAccountName: thanos4 - 1
- Specifies one of the following trigger authentication methods:
-
If you are using a trigger authentication, specify
TriggerAuthentication. This example configures a trigger authentication. -
If you are using a cluster trigger authentication, specify
ClusterTriggerAuthentication.
-
If you are using a trigger authentication, specify
- 2
- Specifies that this trigger authentication uses a bound service account token for authorization when connecting to the metrics endpoint.
- 3
- Specifies the authentication parameter to supply by using the token. Here, the example uses bearer authentication.
- 4
- Specifies the name of the service account to use.
Create the CR object:
$ oc create -f <file-name>.yaml
Create a role for reading Thanos metrics:
Create a YAML file with the following parameters:
apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: thanos-metrics-reader rules: - apiGroups: - "" resources: - pods verbs: - get - apiGroups: - metrics.k8s.io resources: - pods - nodes verbs: - get - list - watchCreate the CR object:
$ oc create -f <file-name>.yaml
Create a role binding for reading Thanos metrics:
Create a YAML file similar to the following:
apiVersion: rbac.authorization.k8s.io/v1 kind: <binding_type>1 metadata: name: thanos-metrics-reader2 namespace: my-project3 roleRef: apiGroup: rbac.authorization.k8s.io kind: Role name: thanos-metrics-reader subjects: - kind: ServiceAccount name: thanos4 namespace: <namespace_name>5 - 1
- Specifies one of the following object types:
-
If you are using a trigger authentication, specify
RoleBinding. -
If you are using a cluster trigger authentication, specify
ClusterRoleBinding.
-
If you are using a trigger authentication, specify
- 2
- Specifies the name of the role you created.
- 3
- Specifies one of the following projects:
- If you are using a trigger authentication, specify the project with the object you want to scale.
-
If you are using a cluster trigger authentication, specify the
openshift-kedaproject.
- 4
- Specifies the name of the service account to bind to the role.
- 5
- Specifies the project where you previously created the service account.
Create the CR object:
$ oc create -f <file-name>.yaml
You can now deploy a scaled object or scaled job to enable autoscaling for your application, as described in "Understanding how to add custom metrics autoscalers". To use OpenShift Dedicated monitoring as the source, in the trigger, or scaler, you must include the following parameters:
-
triggers.typemust beprometheus -
triggers.metadata.serverAddressmust behttps://thanos-querier.openshift-monitoring.svc.cluster.local:9092 -
triggers.metadata.authModesmust bebearer -
triggers.metadata.namespacemust be set to the namespace of the object to scale -
triggers.authenticationRefmust point to the trigger authentication resource specified in the previous step
3.4.2. Understanding the CPU trigger
You can scale pods based on CPU metrics. This trigger uses cluster metrics as the source for metrics.
The custom metrics autoscaler scales the pods associated with an object to maintain the CPU usage that you specify. The autoscaler increases or decreases the number of replicas between the minimum and maximum numbers to maintain the specified CPU utilization across all pods. The memory trigger considers the memory utilization of the entire pod. If the pod has multiple containers, the memory trigger considers the total memory utilization of all containers in the pod.
-
This trigger cannot be used with the
ScaledJobcustom resource. -
When using a memory trigger to scale an object, the object does not scale to
0, even if you are using multiple triggers.
Example scaled object with a CPU target
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: cpu-scaledobject
namespace: my-namespace
spec:
# ...
triggers:
- type: cpu
metricType: Utilization
metadata:
value: '60'
minReplicaCount: 1 - 1
- Specifies CPU as the trigger type.
- 2
- Specifies the type of metric to use, either
UtilizationorAverageValue. - 3
- Specifies the value that triggers scaling. Must be specified as a quoted string value.
-
When using
Utilization, the target value is the average of the resource metrics across all relevant pods, represented as a percentage of the requested value of the resource for the pods. -
When using
AverageValue, the target value is the average of the metrics across all relevant pods.
-
When using
- 4
- Specifies the minimum number of replicas when scaling down. For a CPU trigger, enter a value of
1or greater, because the HPA cannot scale to zero if you are using only CPU metrics.
3.4.3. Understanding the memory trigger
You can scale pods based on memory metrics. This trigger uses cluster metrics as the source for metrics.
The custom metrics autoscaler scales the pods associated with an object to maintain the average memory usage that you specify. The autoscaler increases and decreases the number of replicas between the minimum and maximum numbers to maintain the specified memory utilization across all pods. The memory trigger considers the memory utilization of entire pod. If the pod has multiple containers, the memory utilization is the sum of all of the containers.
-
This trigger cannot be used with the
ScaledJobcustom resource. -
When using a memory trigger to scale an object, the object does not scale to
0, even if you are using multiple triggers.
Example scaled object with a memory target
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: memory-scaledobject
namespace: my-namespace
spec:
# ...
triggers:
- type: memory
metricType: Utilization
metadata:
value: '60'
containerName: api - 1
- Specifies memory as the trigger type.
- 2
- Specifies the type of metric to use, either
UtilizationorAverageValue. - 3
- Specifies the value that triggers scaling. Must be specified as a quoted string value.
-
When using
Utilization, the target value is the average of the resource metrics across all relevant pods, represented as a percentage of the requested value of the resource for the pods. -
When using
AverageValue, the target value is the average of the metrics across all relevant pods.
-
When using
- 4
- Optional: Specifies an individual container to scale, based on the memory utilization of only that container, rather than the entire pod. In this example, only the container named
apiis to be scaled.
3.4.4. Understanding the Kafka trigger
You can scale pods based on an Apache Kafka topic or other services that support the Kafka protocol. The custom metrics autoscaler does not scale higher than the number of Kafka partitions, unless you set the allowIdleConsumers parameter to true in the scaled object or scaled job.
If the number of consumer groups exceeds the number of partitions in a topic, the extra consumer groups remain idle. To avoid this, by default the number of replicas does not exceed:
- The number of partitions on a topic, if a topic is specified
- The number of partitions of all topics in the consumer group, if no topic is specified
-
The
maxReplicaCountspecified in scaled object or scaled job CR
You can use the allowIdleConsumers parameter to disable these default behaviors.
Example scaled object with a Kafka target
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: kafka-scaledobject
namespace: my-namespace
spec:
# ...
triggers:
- type: kafka
metadata:
topic: my-topic
bootstrapServers: my-cluster-kafka-bootstrap.openshift-operators.svc:9092
consumerGroup: my-group
lagThreshold: '10'
activationLagThreshold: '5'
offsetResetPolicy: latest
allowIdleConsumers: true
scaleToZeroOnInvalidOffset: false
excludePersistentLag: false
version: '1.0.0'
partitionLimitation: '1,2,10-20,31'
tls: enable - 1
- Specifies Kafka as the trigger type.
- 2
- Specifies the name of the Kafka topic on which Kafka is processing the offset lag.
- 3
- Specifies a comma-separated list of Kafka brokers to connect to.
- 4
- Specifies the name of the Kafka consumer group used for checking the offset on the topic and processing the related lag.
- 5
- Optional: Specifies the average target value that triggers scaling. Must be specified as a quoted string value. The default is
5. - 6
- Optional: Specifies the target value for the activation phase. Must be specified as a quoted string value.
- 7
- Optional: Specifies the Kafka offset reset policy for the Kafka consumer. The available values are:
latestandearliest. The default islatest. - 8
- Optional: Specifies whether the number of Kafka replicas can exceed the number of partitions on a topic.
-
If
true, the number of Kafka replicas can exceed the number of partitions on a topic. This allows for idle Kafka consumers. -
If
false, the number of Kafka replicas cannot exceed the number of partitions on a topic. This is the default.
-
If
- 9
- Specifies how the trigger behaves when a Kafka partition does not have a valid offset.
-
If
true, the consumers are scaled to zero for that partition. -
If
false, the scaler keeps a single consumer for that partition. This is the default.
-
If
- 10
- Optional: Specifies whether the trigger includes or excludes partition lag for partitions whose current offset is the same as the current offset of the previous polling cycle.
-
If
true, the scaler excludes partition lag in these partitions. -
If
false, the trigger includes all consumer lag in all partitions. This is the default.
-
If
- 11
- Optional: Specifies the version of your Kafka brokers. Must be specified as a quoted string value. The default is
1.0.0. - 12
- Optional: Specifies a comma-separated list of partition IDs to scope the scaling on. If set, only the listed IDs are considered when calculating lag. Must be specified as a quoted string value. The default is to consider all partitions.
- 13
- Optional: Specifies whether to use TSL client authentication for Kafka. The default is
disable. For information on configuring TLS, see "Understanding custom metrics autoscaler trigger authentications".
3.4.5. Understanding the Cron trigger
You can scale pods based on a time range.
When the time range starts, the custom metrics autoscaler scales the pods associated with an object from the configured minimum number of pods to the specified number of desired pods. At the end of the time range, the pods are scaled back to the configured minimum. The time period must be configured in cron format.
The following example scales the pods associated with this scaled object from 0 to 100 from 6:00 AM to 6:30 PM India Standard Time.
Example scaled object with a Cron trigger
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: cron-scaledobject
namespace: default
spec:
scaleTargetRef:
name: my-deployment
minReplicaCount: 0
maxReplicaCount: 100
cooldownPeriod: 300
triggers:
- type: cron
metadata:
timezone: Asia/Kolkata
start: "0 6 * * *"
end: "30 18 * * *"
desiredReplicas: "100" - 1
- Specifies the minimum number of pods to scale down to at the end of the time frame.
- 2
- Specifies the maximum number of replicas when scaling up. This value should be the same as
desiredReplicas. The default is100. - 3
- Specifies a Cron trigger.
- 4
- Specifies the timezone for the time frame. This value must be from the IANA Time Zone Database.
- 5
- Specifies the start of the time frame.
- 6
- Specifies the end of the time frame.
- 7
- Specifies the number of pods to scale to between the start and end of the time frame. This value should be the same as
maxReplicaCount.
3.4.6. Understanding the Kubernetes workload trigger
You can scale pods based on the number of pods matching a specific label selector.
The Custom Metrics Autoscaler Operator tracks the number of pods with a specific label that are in the same namespace, then calculates a relation based on the number of labeled pods to the pods for the scaled object. Using this relation, the Custom Metrics Autoscaler Operator scales the object according to the scaling policy in the ScaledObject or ScaledJob specification.
The pod counts includes pods with a Succeeded or Failed phase.
For example, if you have a frontend deployment and a backend deployment. You can use a kubernetes-workload trigger to scale the backend deployment based on the number of frontend pods. If number of frontend pods goes up, the Operator would scale the backend pods to maintain the specified ratio. In this example, if there are 10 pods with the app=frontend pod selector, the Operator scales the backend pods to 5 in order to maintain the 0.5 ratio set in the scaled object.
Example scaled object with a Kubernetes workload trigger
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: workload-scaledobject
namespace: my-namespace
spec:
triggers:
- type: kubernetes-workload
metadata:
podSelector: 'app=frontend'
value: '0.5'
activationValue: '3.1' - 1
- Specifies a Kubernetes workload trigger.
- 2
- Specifies one or more pod selectors and/or set-based selectors, separated with commas, to use to get the pod count.
- 3
- Specifies the target relation between the scaled workload and the number of pods that match the selector. The relation is calculated following the following formula:
relation = (pods that match the selector) / (scaled workload pods) - 4
- Optional: Specifies the target value for scaler activation phase. The default is
0.
3.5. Understanding custom metrics autoscaler trigger authentications
A trigger authentication allows you to include authentication information in a scaled object or a scaled job that can be used by the associated containers. You can use trigger authentications to pass OpenShift Dedicated secrets, platform-native pod authentication mechanisms, environment variables, and so on.
You define a TriggerAuthentication object in the same namespace as the object that you want to scale. That trigger authentication can be used only by objects in that namespace.
Alternatively, to share credentials between objects in multiple namespaces, you can create a ClusterTriggerAuthentication object that can be used across all namespaces.
Trigger authentications and cluster trigger authentication use the same configuration. However, a cluster trigger authentication requires an additional kind parameter in the authentication reference of the scaled object.
Example trigger authentication that uses a bound service account token
kind: TriggerAuthentication
apiVersion: keda.sh/v1alpha1
metadata:
name: secret-triggerauthentication
namespace: my-namespace
spec:
boundServiceAccountToken:
- parameter: bearerToken
serviceAccountName: thanos Example cluster trigger authentication that uses a bound service account token
kind: ClusterTriggerAuthentication
apiVersion: keda.sh/v1alpha1
metadata:
name: bound-service-account-token-triggerauthentication
spec:
boundServiceAccountToken:
- parameter: bearerToken
serviceAccountName: thanos Example trigger authentication that uses a secret for Basic authentication
kind: TriggerAuthentication
apiVersion: keda.sh/v1alpha1
metadata:
name: secret-triggerauthentication
namespace: my-namespace
spec:
secretTargetRef:
- parameter: username
name: my-basic-secret
key: username
- parameter: password
name: my-basic-secret
key: password- 1
- Specifies the namespace of the object you want to scale.
- 2
- Specifies that this trigger authentication uses a secret for authorization when connecting to the metrics endpoint.
- 3
- Specifies the authentication parameter to supply by using the secret.
- 4
- Specifies the name of the secret to use. See the following example secret for Basic authentication.
- 5
- Specifies the key in the secret to use with the specified parameter.
Example secret for Basic authentication
apiVersion: v1
kind: Secret
metadata:
name: my-basic-secret
namespace: default
data:
username: "dXNlcm5hbWU="
password: "cGFzc3dvcmQ="- 1
- User name and password to supply to the trigger authentication. The values in the
datastanza must be base-64 encoded.
Example trigger authentication that uses a secret for CA details
kind: TriggerAuthentication
apiVersion: keda.sh/v1alpha1
metadata:
name: secret-triggerauthentication
namespace: my-namespace
spec:
secretTargetRef:
- parameter: key
name: my-secret
key: client-key.pem
- parameter: ca
name: my-secret
key: ca-cert.pem - 1
- Specifies the namespace of the object you want to scale.
- 2
- Specifies that this trigger authentication uses a secret for authorization when connecting to the metrics endpoint.
- 3
- Specifies the type of authentication to use.
- 4
- Specifies the name of the secret to use.
- 5
- Specifies the key in the secret to use with the specified parameter.
- 6
- Specifies the authentication parameter for a custom CA when connecting to the metrics endpoint.
- 7
- Specifies the name of the secret to use. See the following example secret with certificate authority (CA) details.
- 8
- Specifies the key in the secret to use with the specified parameter.
Example secret with certificate authority (CA) details
apiVersion: v1
kind: Secret
metadata:
name: my-secret
namespace: my-namespace
data:
ca-cert.pem: LS0tLS1CRUdJTiBDRVJUSUZJQ0FURS0tLS0...
client-cert.pem: LS0tLS1CRUdJTiBDRVJUSUZJQ0FURS0...
client-key.pem: LS0tLS1CRUdJTiBQUklWQVRFIEtFWS0t...Example trigger authentication that uses a bearer token
kind: TriggerAuthentication
apiVersion: keda.sh/v1alpha1
metadata:
name: token-triggerauthentication
namespace: my-namespace
spec:
secretTargetRef:
- parameter: bearerToken
name: my-secret
key: bearerToken - 1
- Specifies the namespace of the object you want to scale.
- 2
- Specifies that this trigger authentication uses a secret for authorization when connecting to the metrics endpoint.
- 3
- Specifies the type of authentication to use.
- 4
- Specifies the name of the secret to use. See the following example secret for a bearer token.
- 5
- Specifies the key in the token to use with the specified parameter.
Example secret for a bearer token
apiVersion: v1
kind: Secret
metadata:
name: my-secret
namespace: my-namespace
data:
bearerToken: "<bearer_token>" - 1
- Specifies a bearer token to use with bearer authentication. The value must be base-64 encoded.
Example trigger authentication that uses an environment variable
kind: TriggerAuthentication
apiVersion: keda.sh/v1alpha1
metadata:
name: env-var-triggerauthentication
namespace: my-namespace
spec:
env:
- parameter: access_key
name: ACCESS_KEY
containerName: my-container - 1
- Specifies the namespace of the object you want to scale.
- 2
- Specifies that this trigger authentication uses environment variables for authorization when connecting to the metrics endpoint.
- 3
- Specify the parameter to set with this variable.
- 4
- Specify the name of the environment variable.
- 5
- Optional: Specify a container that requires authentication. The container must be in the same resource as referenced by
scaleTargetRefin the scaled object.
Example trigger authentication that uses pod authentication providers
kind: TriggerAuthentication
apiVersion: keda.sh/v1alpha1
metadata:
name: pod-id-triggerauthentication
namespace: my-namespace
spec:
podIdentity:
provider: aws-eks Additional resources
3.5.1. Using trigger authentications
You use trigger authentications and cluster trigger authentications by using a custom resource to create the authentication, then add a reference to a scaled object or scaled job.
Prerequisites
- The Custom Metrics Autoscaler Operator must be installed.
- If you are using a bound service account token, the service account must exist.
If you are using a bound service account token, a role-based access control (RBAC) object that enables the Custom Metrics Autoscaler Operator to request service account tokens from the service account must exist.
apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: keda-operator-token-creator namespace: <namespace_name>1 rules: - apiGroups: - "" resources: - serviceaccounts/token verbs: - create resourceNames: - thanos2 --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: keda-operator-token-creator-binding namespace: <namespace_name>3 roleRef: apiGroup: rbac.authorization.k8s.io kind: Role name: keda-operator-token-creator subjects: - kind: ServiceAccount name: keda-operator namespace: openshift-keda-
If you are using a secret, the
Secretobject must exist.
Procedure
Create the
TriggerAuthenticationorClusterTriggerAuthenticationobject.Create a YAML file that defines the object:
Example trigger authentication with a bound service account token
kind: TriggerAuthentication apiVersion: keda.sh/v1alpha1 metadata: name: prom-triggerauthentication namespace: my-namespace1 spec: boundServiceAccountToken:2 - parameter: token serviceAccountName: thanos3 Create the
TriggerAuthenticationobject:$ oc create -f <filename>.yaml
Create or edit a
ScaledObjectYAML file that uses the trigger authentication:Create a YAML file that defines the object by running the following command:
Example scaled object with a trigger authentication
apiVersion: keda.sh/v1alpha1 kind: ScaledObject metadata: name: scaledobject namespace: my-namespace spec: scaleTargetRef: name: example-deployment maxReplicaCount: 100 minReplicaCount: 0 pollingInterval: 30 triggers: - type: prometheus metadata: serverAddress: https://thanos-querier.openshift-monitoring.svc.cluster.local:9092 namespace: kedatest # replace <NAMESPACE> metricName: http_requests_total threshold: '5' query: sum(rate(http_requests_total{job="test-app"}[1m])) authModes: "basic" authenticationRef: name: prom-triggerauthentication1 kind: TriggerAuthentication2 Example scaled object with a cluster trigger authentication
apiVersion: keda.sh/v1alpha1 kind: ScaledObject metadata: name: scaledobject namespace: my-namespace spec: scaleTargetRef: name: example-deployment maxReplicaCount: 100 minReplicaCount: 0 pollingInterval: 30 triggers: - type: prometheus metadata: serverAddress: https://thanos-querier.openshift-monitoring.svc.cluster.local:9092 namespace: kedatest # replace <NAMESPACE> metricName: http_requests_total threshold: '5' query: sum(rate(http_requests_total{job="test-app"}[1m])) authModes: "basic" authenticationRef: name: prom-cluster-triggerauthentication1 kind: ClusterTriggerAuthentication2 Create the scaled object by running the following command:
$ oc apply -f <filename>
3.6. Understanding how to add custom metrics autoscalers
To add a custom metrics autoscaler, create a ScaledObject custom resource for a deployment, stateful set, or custom resource. Create a ScaledJob custom resource for a job.
You can create only one scaled object for each workload that you want to scale. Also, you cannot use a scaled object and the horizontal pod autoscaler (HPA) on the same workload.
3.6.1. Adding a custom metrics autoscaler to a workload
You can create a custom metrics autoscaler for a workload that is created by a Deployment, StatefulSet, or custom resource object.
Prerequisites
- The Custom Metrics Autoscaler Operator must be installed.
If you use a custom metrics autoscaler for scaling based on CPU or memory:
Your cluster administrator must have properly configured cluster metrics. You can use the
oc describe PodMetrics <pod-name>command to determine if metrics are configured. If metrics are configured, the output appears similar to the following, with CPU and Memory displayed under Usage.$ oc describe PodMetrics openshift-kube-scheduler-ip-10-0-135-131.ec2.internalExample output
Name: openshift-kube-scheduler-ip-10-0-135-131.ec2.internal Namespace: openshift-kube-scheduler Labels: <none> Annotations: <none> API Version: metrics.k8s.io/v1beta1 Containers: Name: wait-for-host-port Usage: Memory: 0 Name: scheduler Usage: Cpu: 8m Memory: 45440Ki Kind: PodMetrics Metadata: Creation Timestamp: 2019-05-23T18:47:56Z Self Link: /apis/metrics.k8s.io/v1beta1/namespaces/openshift-kube-scheduler/pods/openshift-kube-scheduler-ip-10-0-135-131.ec2.internal Timestamp: 2019-05-23T18:47:56Z Window: 1m0s Events: <none>The pods associated with the object you want to scale must include specified memory and CPU limits. For example:
Example pod spec
apiVersion: v1 kind: Pod # ... spec: containers: - name: app image: images.my-company.example/app:v4 resources: limits: memory: "128Mi" cpu: "500m" # ...
Procedure
Create a YAML file similar to the following. Only the name
<2>, object name<4>, and object kind<5>are required:Example scaled object
apiVersion: keda.sh/v1alpha1 kind: ScaledObject metadata: annotations: autoscaling.keda.sh/paused-replicas: "0"1 name: scaledobject2 namespace: my-namespace spec: scaleTargetRef: apiVersion: apps/v13 name: example-deployment4 kind: Deployment5 envSourceContainerName: .spec.template.spec.containers[0]6 cooldownPeriod: 2007 maxReplicaCount: 1008 minReplicaCount: 09 metricsServer:10 auditConfig: logFormat: "json" logOutputVolumeClaim: "persistentVolumeClaimName" policy: rules: - level: Metadata omitStages: "RequestReceived" omitManagedFields: false lifetime: maxAge: "2" maxBackup: "1" maxSize: "50" fallback:11 failureThreshold: 3 replicas: 6 behavior: static12 pollingInterval: 3013 advanced: restoreToOriginalReplicaCount: false14 horizontalPodAutoscalerConfig: name: keda-hpa-scale-down15 behavior:16 scaleDown: stabilizationWindowSeconds: 300 policies: - type: Percent value: 100 periodSeconds: 15 triggers: - type: prometheus17 metadata: serverAddress: https://thanos-querier.openshift-monitoring.svc.cluster.local:9092 namespace: kedatest metricName: http_requests_total threshold: '5' query: sum(rate(http_requests_total{job="test-app"}[1m])) authModes: basic authenticationRef:18 name: prom-triggerauthentication kind: TriggerAuthentication- 1
- Optional: Specifies that the Custom Metrics Autoscaler Operator is to scale the replicas to the specified value and stop autoscaling, as described in the "Pausing the custom metrics autoscaler for a workload" section.
- 2
- Specifies a name for this custom metrics autoscaler.
- 3
- Optional: Specifies the API version of the target resource. The default is
apps/v1. - 4
- Specifies the name of the object that you want to scale.
- 5
- Specifies the
kindasDeployment,StatefulSetorCustomResource. - 6
- Optional: Specifies the name of the container in the target resource, from which the custom metrics autoscaler gets environment variables holding secrets and so forth. The default is
.spec.template.spec.containers[0]. - 7
- Optional. Specifies the period in seconds to wait after the last trigger is reported before scaling the deployment back to
0if theminReplicaCountis set to0. The default is300. - 8
- Optional: Specifies the maximum number of replicas when scaling up. The default is
100. - 9
- Optional: Specifies the minimum number of replicas when scaling down.
- 10
- Optional: Specifies the parameters for audit logs. as described in the "Configuring audit logging" section.
- 11
- Optional: Specifies the number of replicas to fall back to if a scaler fails to get metrics from the source for the number of times defined by the
failureThresholdparameter. For more information on fallback behavior, see the KEDA documentation. - 12
- Optional: Specifies the replica count to be used if a fallback occurs. Enter one of the following options or omit the parameter:
-
Enter
staticto use the number of replicas specified by thefallback.replicasparameter. This is the default. -
Enter
currentReplicasto maintain the current number of replicas. -
Enter
currentReplicasIfHigherto maintain the current number of replicas, if that number is higher than thefallback.replicasparameter. If the current number of replicas is lower than thefallback.replicasparameter, use thefallback.replicasvalue. -
Enter
currentReplicasIfLowerto maintain the current number of replicas, if that number is lower than thefallback.replicasparameter. If the current number of replicas is higher than thefallback.replicasparameter, use thefallback.replicasvalue.
-
Enter
- 13
- Optional: Specifies the interval in seconds to check each trigger on. The default is
30. - 14
- Optional: Specifies whether to scale back the target resource to the original replica count after the scaled object is deleted. The default is
false, which keeps the replica count as it is when the scaled object is deleted. - 15
- Optional: Specifies a name for the horizontal pod autoscaler. The default is
keda-hpa-{scaled-object-name}. - 16
- Optional: Specifies a scaling policy to use to control the rate to scale pods up or down, as described in the "Scaling policies" section.
- 17
- Specifies the trigger to use as the basis for scaling, as described in the "Understanding the custom metrics autoscaler triggers" section. This example uses OpenShift Dedicated monitoring.
- 18
- Optional: Specifies a trigger authentication or a cluster trigger authentication. For more information, see Understanding the custom metrics autoscaler trigger authentication in the Additional resources section.
-
Enter
TriggerAuthenticationto use a trigger authentication. This is the default. -
Enter
ClusterTriggerAuthenticationto use a cluster trigger authentication.
-
Enter
Create the custom metrics autoscaler by running the following command:
$ oc create -f <filename>.yaml
Verification
View the command output to verify that the custom metrics autoscaler was created:
$ oc get scaledobject <scaled_object_name>Example output
NAME SCALETARGETKIND SCALETARGETNAME MIN MAX TRIGGERS AUTHENTICATION READY ACTIVE FALLBACK AGE scaledobject apps/v1.Deployment example-deployment 0 50 prometheus prom-triggerauthentication True True True 17sNote the following fields in the output:
-
TRIGGERS: Indicates the trigger, or scaler, that is being used. -
AUTHENTICATION: Indicates the name of any trigger authentication being used. READY: Indicates whether the scaled object is ready to start scaling:-
If
True, the scaled object is ready. -
If
False, the scaled object is not ready because of a problem in one or more of the objects you created.
-
If
ACTIVE: Indicates whether scaling is taking place:-
If
True, scaling is taking place. -
If
False, scaling is not taking place because there are no metrics or there is a problem in one or more of the objects you created.
-
If
FALLBACK: Indicates whether the custom metrics autoscaler is able to get metrics from the source-
If
False, the custom metrics autoscaler is getting metrics. -
If
True, the custom metrics autoscaler is getting metrics because there are no metrics or there is a problem in one or more of the objects you created.
-
If
-
3.7. Pausing the custom metrics autoscaler for a scaled object
You can pause and restart the autoscaling of a workload, as needed.
For example, you might want to pause autoscaling before performing cluster maintenance or to avoid resource starvation by removing non-mission-critical workloads.
3.7.1. Pausing a custom metrics autoscaler
You can pause the autoscaling of a scaled object by adding the autoscaling.keda.sh/paused-replicas annotation to the custom metrics autoscaler for that scaled object. The custom metrics autoscaler scales the replicas for that workload to the specified value and pauses autoscaling until the annotation is removed.
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
annotations:
autoscaling.keda.sh/paused-replicas: "4"
# ...Procedure
Use the following command to edit the
ScaledObjectCR for your workload:$ oc edit ScaledObject scaledobjectAdd the
autoscaling.keda.sh/paused-replicasannotation with any value:apiVersion: keda.sh/v1alpha1 kind: ScaledObject metadata: annotations: autoscaling.keda.sh/paused-replicas: "4"1 creationTimestamp: "2023-02-08T14:41:01Z" generation: 1 name: scaledobject namespace: my-project resourceVersion: '65729' uid: f5aec682-acdf-4232-a783-58b5b82f5dd0- 1
- Specifies that the Custom Metrics Autoscaler Operator is to scale the replicas to the specified value and stop autoscaling.
3.7.2. Restarting the custom metrics autoscaler for a scaled object
You can restart a paused custom metrics autoscaler by removing the autoscaling.keda.sh/paused-replicas annotation for that ScaledObject.
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
annotations:
autoscaling.keda.sh/paused-replicas: "4"
# ...Procedure
Use the following command to edit the
ScaledObjectCR for your workload:$ oc edit ScaledObject scaledobjectRemove the
autoscaling.keda.sh/paused-replicasannotation.apiVersion: keda.sh/v1alpha1 kind: ScaledObject metadata: annotations: autoscaling.keda.sh/paused-replicas: "4"1 creationTimestamp: "2023-02-08T14:41:01Z" generation: 1 name: scaledobject namespace: my-project resourceVersion: '65729' uid: f5aec682-acdf-4232-a783-58b5b82f5dd0- 1
- Remove this annotation to restart a paused custom metrics autoscaler.
3.8. Gathering audit logs
You can gather audit logs, which are a security-relevant chronological set of records documenting the sequence of activities that have affected the system by individual users, administrators, or other components of the system.
For example, audit logs can help you understand where an autoscaling request is coming from. This is key information when backends are getting overloaded by autoscaling requests made by user applications and you need to determine which is the troublesome application.
3.8.1. Configuring audit logging
You can configure auditing for the Custom Metrics Autoscaler Operator by editing the KedaController custom resource. The logs are sent to an audit log file on a volume that is secured by using a persistent volume claim in the KedaController CR.
Prerequisites
- The Custom Metrics Autoscaler Operator must be installed.
Procedure
Edit the
KedaControllercustom resource to add theauditConfigstanza:kind: KedaController apiVersion: keda.sh/v1alpha1 metadata: name: keda namespace: keda spec: # ... metricsServer: # ... auditConfig: logFormat: "json"1 logOutputVolumeClaim: "pvc-audit-log"2 policy: rules:3 - level: Metadata omitStages: "RequestReceived"4 omitManagedFields: false5 lifetime:6 maxAge: "2" maxBackup: "1" maxSize: "50"- 1
- Specifies the output format of the audit log, either
legacyorjson. - 2
- Specifies an existing persistent volume claim for storing the log data. All requests coming to the API server are logged to this persistent volume claim. If you leave this field empty, the log data is sent to stdout.
- 3
- Specifies which events should be recorded and what data they should include:
-
None: Do not log events. -
Metadata: Log only the metadata for the request, such as user, timestamp, and so forth. Do not log the request text and the response text. This is the default. -
Request: Log only the metadata and the request text but not the response text. This option does not apply for non-resource requests. -
RequestResponse: Log event metadata, request text, and response text. This option does not apply for non-resource requests.
-
- 4
- Specifies stages for which no event is created.
- 5
- Specifies whether to omit the managed fields of the request and response bodies from being written to the API audit log, either
trueto omit the fields orfalseto include the fields. - 6
- Specifies the size and lifespan of the audit logs.
-
maxAge: The maximum number of days to retain audit log files, based on the timestamp encoded in their filename. -
maxBackup: The maximum number of audit log files to retain. Set to0to retain all audit log files. -
maxSize: The maximum size in megabytes of an audit log file before it gets rotated.
-
Verification
View the audit log file directly:
Obtain the name of the
keda-metrics-apiserver-*pod:oc get pod -n kedaExample output
NAME READY STATUS RESTARTS AGE custom-metrics-autoscaler-operator-5cb44cd75d-9v4lv 1/1 Running 0 8m20s keda-metrics-apiserver-65c7cc44fd-rrl4r 1/1 Running 0 2m55s keda-operator-776cbb6768-zpj5b 1/1 Running 0 2m55sView the log data by using a command similar to the following:
$ oc logs keda-metrics-apiserver-<hash>|grep -i metadata1 - 1
- Optional: You can use the
grepcommand to specify the log level to display:Metadata,Request,RequestResponse.
For example:
$ oc logs keda-metrics-apiserver-65c7cc44fd-rrl4r|grep -i metadataExample output
... {"kind":"Event","apiVersion":"audit.k8s.io/v1","level":"Metadata","auditID":"4c81d41b-3dab-4675-90ce-20b87ce24013","stage":"ResponseComplete","requestURI":"/healthz","verb":"get","user":{"username":"system:anonymous","groups":["system:unauthenticated"]},"sourceIPs":["10.131.0.1"],"userAgent":"kube-probe/1.28","responseStatus":{"metadata":{},"code":200},"requestReceivedTimestamp":"2023-02-16T13:00:03.554567Z","stageTimestamp":"2023-02-16T13:00:03.555032Z","annotations":{"authorization.k8s.io/decision":"allow","authorization.k8s.io/reason":""}} ...
Alternatively, you can view a specific log:
Use a command similar to the following to log into the
keda-metrics-apiserver-*pod:$ oc rsh pod/keda-metrics-apiserver-<hash> -n kedaFor example:
$ oc rsh pod/keda-metrics-apiserver-65c7cc44fd-rrl4r -n kedaChange to the
/var/audit-policy/directory:sh-4.4$ cd /var/audit-policy/List the available logs:
sh-4.4$ lsExample output
log-2023.02.17-14:50 policy.yamlView the log, as needed:
sh-4.4$ cat <log_name>/<pvc_name>|grep -i <log_level>1 - 1
- Optional: You can use the
grepcommand to specify the log level to display:Metadata,Request,RequestResponse.
For example:
sh-4.4$ cat log-2023.02.17-14:50/pvc-audit-log|grep -i RequestExample output
... {"kind":"Event","apiVersion":"audit.k8s.io/v1","level":"Request","auditID":"63e7f68c-04ec-4f4d-8749-bf1656572a41","stage":"ResponseComplete","requestURI":"/openapi/v2","verb":"get","user":{"username":"system:aggregator","groups":["system:authenticated"]},"sourceIPs":["10.128.0.1"],"responseStatus":{"metadata":{},"code":304},"requestReceivedTimestamp":"2023-02-17T13:12:55.035478Z","stageTimestamp":"2023-02-17T13:12:55.038346Z","annotations":{"authorization.k8s.io/decision":"allow","authorization.k8s.io/reason":"RBAC: allowed by ClusterRoleBinding \"system:discovery\" of ClusterRole \"system:discovery\" to Group \"system:authenticated\""}} ...
3.9. Gathering debugging data
When opening a support case, it is helpful to provide debugging information about your cluster to Red Hat Support.
To help troubleshoot your issue, provide the following information:
-
Data gathered using the
must-gathertool. - The unique cluster ID.
You can use the must-gather tool to collect data about the Custom Metrics Autoscaler Operator and its components, including the following items:
-
The
kedanamespace and its child objects. - The Custom Metric Autoscaler Operator installation objects.
- The Custom Metric Autoscaler Operator CRD objects.
3.9.1. Gathering debugging data
The following command runs the must-gather tool for the Custom Metrics Autoscaler Operator:
$ oc adm must-gather --image="$(oc get packagemanifests openshift-custom-metrics-autoscaler-operator \
-n openshift-marketplace \
-o jsonpath='{.status.channels[?(@.name=="stable")].currentCSVDesc.annotations.containerImage}')"
The standard OpenShift Dedicated must-gather command, oc adm must-gather, does not collect Custom Metrics Autoscaler Operator data.
Prerequisites
-
You are logged in to OpenShift Dedicated as a user with the
dedicated-adminrole. -
The OpenShift Dedicated CLI (
oc) installed.
Procedure
-
Navigate to the directory where you want to store the
must-gatherdata. Perform one of the following:
To get only the Custom Metrics Autoscaler Operator
must-gatherdata, use the following command:$ oc adm must-gather --image="$(oc get packagemanifests openshift-custom-metrics-autoscaler-operator \ -n openshift-marketplace \ -o jsonpath='{.status.channels[?(@.name=="stable")].currentCSVDesc.annotations.containerImage}')"The custom image for the
must-gathercommand is pulled directly from the Operator package manifests, so that it works on any cluster where the Custom Metric Autoscaler Operator is available.To gather the default
must-gatherdata in addition to the Custom Metric Autoscaler Operator information:Use the following command to obtain the Custom Metrics Autoscaler Operator image and set it as an environment variable:
$ IMAGE="$(oc get packagemanifests openshift-custom-metrics-autoscaler-operator \ -n openshift-marketplace \ -o jsonpath='{.status.channels[?(@.name=="stable")].currentCSVDesc.annotations.containerImage}')"Use the
oc adm must-gatherwith the Custom Metrics Autoscaler Operator image:$ oc adm must-gather --image-stream=openshift/must-gather --image=${IMAGE}
Example 3.1. Example must-gather output for the Custom Metric Autoscaler
└── keda ├── apps │ ├── daemonsets.yaml │ ├── deployments.yaml │ ├── replicasets.yaml │ └── statefulsets.yaml ├── apps.openshift.io │ └── deploymentconfigs.yaml ├── autoscaling │ └── horizontalpodautoscalers.yaml ├── batch │ ├── cronjobs.yaml │ └── jobs.yaml ├── build.openshift.io │ ├── buildconfigs.yaml │ └── builds.yaml ├── core │ ├── configmaps.yaml │ ├── endpoints.yaml │ ├── events.yaml │ ├── persistentvolumeclaims.yaml │ ├── pods.yaml │ ├── replicationcontrollers.yaml │ ├── secrets.yaml │ └── services.yaml ├── discovery.k8s.io │ └── endpointslices.yaml ├── image.openshift.io │ └── imagestreams.yaml ├── k8s.ovn.org │ ├── egressfirewalls.yaml │ └── egressqoses.yaml ├── keda.sh │ ├── kedacontrollers │ │ └── keda.yaml │ ├── scaledobjects │ │ └── example-scaledobject.yaml │ └── triggerauthentications │ └── example-triggerauthentication.yaml ├── monitoring.coreos.com │ └── servicemonitors.yaml ├── networking.k8s.io │ └── networkpolicies.yaml ├── keda.yaml ├── pods │ ├── custom-metrics-autoscaler-operator-58bd9f458-ptgwx │ │ ├── custom-metrics-autoscaler-operator │ │ │ └── custom-metrics-autoscaler-operator │ │ │ └── logs │ │ │ ├── current.log │ │ │ ├── previous.insecure.log │ │ │ └── previous.log │ │ └── custom-metrics-autoscaler-operator-58bd9f458-ptgwx.yaml │ ├── custom-metrics-autoscaler-operator-58bd9f458-thbsh │ │ └── custom-metrics-autoscaler-operator │ │ └── custom-metrics-autoscaler-operator │ │ └── logs │ ├── keda-metrics-apiserver-65c7cc44fd-6wq4g │ │ ├── keda-metrics-apiserver │ │ │ └── keda-metrics-apiserver │ │ │ └── logs │ │ │ ├── current.log │ │ │ ├── previous.insecure.log │ │ │ └── previous.log │ │ └── keda-metrics-apiserver-65c7cc44fd-6wq4g.yaml │ └── keda-operator-776cbb6768-fb6m5 │ ├── keda-operator │ │ └── keda-operator │ │ └── logs │ │ ├── current.log │ │ ├── previous.insecure.log │ │ └── previous.log │ └── keda-operator-776cbb6768-fb6m5.yaml ├── policy │ └── poddisruptionbudgets.yaml └── route.openshift.io └── routes.yamlCreate a compressed file from the
must-gatherdirectory that was created in your working directory. For example, on a computer that uses a Linux operating system, run the following command:$ tar cvaf must-gather.tar.gz must-gather.local.5421342344627712289/1 - 1
- Replace
must-gather-local.5421342344627712289/with the actual directory name.
- Attach the compressed file to your support case on the Red Hat Customer Portal.
3.10. Viewing Operator metrics
The Custom Metrics Autoscaler Operator exposes ready-to-use metrics that it pulls from the on-cluster monitoring component. You can query the metrics by using the Prometheus Query Language (PromQL) to analyze and diagnose issues. All metrics are reset when the controller pod restarts.
3.10.1. Accessing performance metrics
You can access the metrics and run queries by using the OpenShift Dedicated web console.
Procedure
- Select the Administrator perspective in the OpenShift Dedicated web console.
-
Select Observe
Metrics. - To create a custom query, add your PromQL query to the Expression field.
- To add multiple queries, select Add Query.
3.10.1.1. Provided Operator metrics
The Custom Metrics Autoscaler Operator exposes the following metrics, which you can view by using the OpenShift Dedicated web console.
| Metric name | Description |
|---|---|
|
|
Whether the particular scaler is active or inactive. A value of |
|
| The current value for each scaler’s metric, which is used by the Horizontal Pod Autoscaler (HPA) in computing the target average. |
|
| The latency of retrieving the current metric from each scaler. |
|
| The number of errors that have occurred for each scaler. |
|
| The total number of errors encountered for all scalers. |
|
| The number of errors that have occurred for each scaled obejct. |
|
| The total number of Custom Metrics Autoscaler custom resources in each namespace for each custom resource type. |
|
| The total number of triggers by trigger type. |
Custom Metrics Autoscaler Admission webhook metrics
The Custom Metrics Autoscaler Admission webhook also exposes the following Prometheus metrics.
| Metric name | Description |
|---|---|
|
| The number of scaled object validations. |
|
| The number of validation errors. |
3.11. Removing the Custom Metrics Autoscaler Operator
You can remove the custom metrics autoscaler from your OpenShift Dedicated cluster. After removing the Custom Metrics Autoscaler Operator, remove other components associated with the Operator to avoid potential issues.
Delete the KedaController custom resource (CR) first. If you do not delete the KedaController CR, OpenShift Dedicated can hang when you delete the keda project. If you delete the Custom Metrics Autoscaler Operator before deleting the CR, you are not able to delete the CR.
3.11.1. Uninstalling the Custom Metrics Autoscaler Operator
Use the following procedure to remove the custom metrics autoscaler from your OpenShift Dedicated cluster.
Prerequisites
- The Custom Metrics Autoscaler Operator must be installed.
Procedure
-
In the OpenShift Dedicated web console, click Ecosystem
Installed Operators. - Switch to the keda project.
Remove the
KedaControllercustom resource.- Find the CustomMetricsAutoscaler Operator and click the KedaController tab.
- Find the custom resource, and then click Delete KedaController.
- Click Uninstall.
Remove the Custom Metrics Autoscaler Operator:
-
Click Ecosystem
Installed Operators. -
Find the CustomMetricsAutoscaler Operator and click the Options menu
 and select Uninstall Operator.
and select Uninstall Operator.
- Click Uninstall.
-
Click Ecosystem
Optional: Use the OpenShift CLI to remove the custom metrics autoscaler components:
Delete the custom metrics autoscaler CRDs:
-
clustertriggerauthentications.keda.sh -
kedacontrollers.keda.sh -
scaledjobs.keda.sh -
scaledobjects.keda.sh -
triggerauthentications.keda.sh
$ oc delete crd clustertriggerauthentications.keda.sh kedacontrollers.keda.sh scaledjobs.keda.sh scaledobjects.keda.sh triggerauthentications.keda.shDeleting the CRDs removes the associated roles, cluster roles, and role bindings. However, there might be a few cluster roles that must be manually deleted.
-
List any custom metrics autoscaler cluster roles:
$ oc get clusterrole | grep keda.shDelete the listed custom metrics autoscaler cluster roles. For example:
$ oc delete clusterrole.keda.sh-v1alpha1-adminList any custom metrics autoscaler cluster role bindings:
$ oc get clusterrolebinding | grep keda.shDelete the listed custom metrics autoscaler cluster role bindings. For example:
$ oc delete clusterrolebinding.keda.sh-v1alpha1-admin
Delete the custom metrics autoscaler project:
$ oc delete project kedaDelete the Cluster Metric Autoscaler Operator:
$ oc delete operator/openshift-custom-metrics-autoscaler-operator.keda