Capítulo 1. Sinopsis de adición del equilibrador de carga
Nota
A partir de Red Hat Enterprise Linux 6.6, Red Hat proporciona soporte para HAProxy y keepalived además del software del equilibrador de carga Piranha. Para obtener más información sobre cómo configurar un sistema Red Hat Enterprise Linux con HAProxy y keepalived, consulte la documentación de administración del equilibrador de carga para Red Hat Enterprise Linux 7.
La adición del equilibrador de carga es una serie de componentes de software integrados que proporcionan Servidores virtuales de Linux (LVS) para balanceo de carga IP, a través de un conjunto de servidores reales. La adición del equilibrador de carga se ejecuta en un enrutador LVS activo y también como un enrutador LVS de respaldo. El enrutador LVS activo tiene dos roles:
- Balancear la carga a través de los servidores reales.
- Revisar la integridad de los servicios en cada servidor real.
El enrutador LVS de respaldo sondea el estado del enrutador LVS activo y toma el control de sus tareas en caso de que falle.
Este capítulo proporciona una visión general de los componentes y funciones de la adición del equilibrador de carga. Consta de las siguientes secciones:
1.1. Configuración básica de una adición del equilibrador de carga
Copiar enlaceEnlace copiado en el portapapeles!
Figura 1.1, “ Configuración básica de una adición del equilibrador de carga” muestra una adición simple del equilibrador de carga de dos capas. En la primera capa hay un enrutador activo y un enrutador LVS de respaldo. Cada enrutador LVS tiene dos interfaces de red, una interfaz en la Internet y la otra en una red privada, lo cual permite regular el tráfico entre las dos redes. En este ejemplo, el enrutador activo utiliza Traducción de acceso de redes o NAT para dirigir el tráfico desde la Internet a un número variable de servidores reales en la segunda capa, la cual a su vez proporciona los servicios necesarios. Por lo tanto, los servidores reales en este ejemplo, se conectan a una red privada dedicada y pasan todo el tráfico que va y viene a través del enrutador LVS activo. Para el mundo exterior, los servidores aparecen como una entidad.
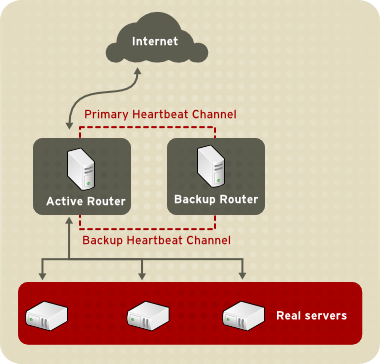
Figura 1.1. Configuración básica de una adición del equilibrador de carga
Las solicitudes de servicios que llegan al enrutador LVS se dirigen a la dirección IP virtual o VIP. Esta es una dirección enrutable públicamente, que el administrador del sitio asocia con un nombre de dominio totalmente calificado, tal como www.example.com, y se asigna a uno o más servidores virtuales. Un servidor virtual es un servicio configurado para escuchar en una IP virtual específica. Consulte la Sección 4.6, “SERVIDORES VIRTUALES” para obtener más información sobre cómo configurar un servidor virtual mediante Piranha Configuration Tool. Una dirección VIP migra desde un enrutador LVS a otro durante una conmutación, manteniendo así una presencia en esa dirección IP (conocidas también direcciones IP flotantes).
Las direcciones VIP pueden tener alias que se dirijan al mismo dispositivo que conecta al enrutador LVS a la Internet. Por ejemplo, si eth0 está conectado a la Internet, puede haber varios servidores virtuales con alias para
eth0:1. Alternativamente, cada servidor virtual puede asociarse con un dispositivo por servicio. Por ejemplo, el tráfico HTTP puede ser manejado en eth0:1 y el tráfico FTP puede ser manejado en eth0:2.
Solo un enrutador LVS está activo a la vez. El rol del enrutador activo es redirigir la solicitud del servicio desde la dirección IP virtual al servidor real. La redirección está basada en uno de ocho algoritmos de balance de carga descritos más adelante en la Sección 1.3, “Sinopsis de programación de la adición del equilibrador de carga ”.
Asimismo, el enrutador activo sondea de forma dinámica la salud de los servicios específicos en los servidores reales mediante un script de envío y espera. Para ayudar en la detección de la salud de servicios que requieren datos dinámicos, tal como HTTPS o SSL, el administrador puede llamar ejecutables externos. Si un servicio en un servidor real no funciona, el enrutador activo deja de enviar tareas a dicho servidor hasta que vuelva a la operación normal.
El enrutador de respaldo cumple el rol de un sistema en espera. El enrutador LVS intercambia periódicamente mensajes denominados pulsos, a través de la interfaz pública externa primaria y de la interfaz privada en caso de procesos de recuperación contra fallos. Si el nodo de respaldo no recibe un pulso dentro de un intervalo de tiempo determinado, inicia un proceso de conmutación y asume el rol del enrutador LVS activo. Durante el proceso de conmutación, el enrutador de respaldo toma las direcciones VIP servidas por el enrutador fallido mediante una técnica llamada suplantación de identidad ARP — en donde el enrutador LVS de respaldo se anuncia como el servidor de destino para los paquetes IP dirigidos al nodo fallido. Cuando el nodo fallido retorna al servicio activo, el nodo de respaldo asume nuevamente su rol de asistente de respaldo en caliente.
La configuración simple de dos capas utilizada en Figura 1.1, “ Configuración básica de una adición del equilibrador de carga” es la mejor para servir datos que no cambian con frecuencia — como por ejemplo, las páginas web estáticas — porque los servidores individuales reales no sincronizan automáticamente los datos entre cada nodo.
1.1.1. Replicación de datos y la compartición de datos entre servidores reales
Copiar enlaceEnlace copiado en el portapapeles!
Ya que no hay un componente incorporado en la adición del equilibrador de carga para compartir los datos entre los servidores reales, el administrador tiene dos opciones básicas:
- Sincronizar los datos a través del grupo de servidores reales.
- Añadir una tercera capa a la topología para el acceso de datos compartidos.
La primera opción es la preferida en aquellos servidores que no aceptan que un gran número de usuarios cargue o cambie datos en los servidores reales. Si la configuración permite una gran cantidad de usuarios, tales como un sitio web de comercio electrónico, es preferible adicionar una nueva capa.
1.1.1.1. Cómo configurar servidores reales para sincronizar datos
Copiar enlaceEnlace copiado en el portapapeles!
Hay varias formas en las que un administrador puede sincronizar datos a través del grupo de servidores reales. Por ejemplo, los scripts de shell pueden emplearse para que, si un ingeniero de la red actualiza una página, la página se envíe simultáneamente a todos los usuarios. También el administrador del sistema puede usar programas tales como
rsync para replicar los datos cambiados a través de todos los nodos en el intervalo establecido.
Sin embargo, este tipo de sincronización de datos no funciona de forma óptima, si la configuración se sobrecarga constantemente al subir archivos o emitir transacciones de base de datos. Para una configuración con una carga alta, la solución ideal es una topología de tres partes.