6.3. Herramientas
Hay una serie de herramientas disponibles para diagnosticar los problemas de rendimiento en el subsistema de E/S. vmstat proporciona una visión general del rendimiento del sistemas. Las siguientes columnas son las más relevantes para E/S:
si (swap in), so (swap out), bi (block in), bo (block out), y wa (I/O wait time). si y so sirven cuando su espacio swap está en el mismo dispositivo de su partición de datos y como un indicador de presión de memoria general. si y bi son operaciones de lectura, mientras que so y bo son operaciones de escritura. Cada una de estas categorías se reporta en kilobytes. wa es el tiempo inactivo; indica qué porción de la cola de ejecución se bloquea al esperar a que la E/S termine.
El análisis de su sistema con vmstat le dará una idea de si el subsistema de E/S es responsable o no de los problemas de rendimiento. También las columnas
free, buff, y cache son importantes. El valor de la memoria cache que aumenta junto al valor bo, seguido de una caída de la cache y un aumento en free indica que el sistema está realizando escritura diferida e invalidación de memoria cache de página.
Observe que los números de E/S reportados por vmstat son adiciones a todos los dispositivos de E/S. Una vez que hayan determinado que puede haber una brecha de rendimiento en el subsistema de E/S, puede examinar el problema de cerca con iostat, el cual dividirá el reporte de E/S por dispositivo. También puede recuperar un información más detallada, tal como promedio de tamaño de solicitud, el número de lectura y escrituras por segundo y la cantidad de E/S en fusión que en el momento.
Al usar el tamaño de petición y cola promedios (
avgqu-sz), podrá estimar cómo realizar el almacenaje mediante gráficas que genera y al caracterizar el rendimiento de su almacenaje. Algunas generalizaciones aplican: por ejemplo, si el tamaño de solicitud promedio es de 4KB y el tamaño de cola es 1, será poco probable que el rendimiento sea muy efectivo.
Si los números de rendimiento no coinciden con el rendimiento esperado, realice un análisis minucioso con blktrace. El paquete de herramientas blktrace ofrece información detallada sobre el tiempo que gasta en el subsistema de E/S. La salida de blktrace es una serie de archivos de trazado binarios que pueden ser posprocesados por otras herramientas tales como blkparse.
blkparse es la herramienta compañera de blktrace. Lee la salida cruda del trazado y produce una versión textual abreviada.
El siguiente es un ejemplo de salida de blktrace:
8,64 3 1 0.000000000 4162 Q RM 73992 + 8 [fs_mark]
8,64 3 0 0.000012707 0 m N cfq4162S / alloced
8,64 3 2 0.000013433 4162 G RM 73992 + 8 [fs_mark]
8,64 3 3 0.000015813 4162 P N [fs_mark]
8,64 3 4 0.000017347 4162 I R 73992 + 8 [fs_mark]
8,64 3 0 0.000018632 0 m N cfq4162S / insert_request
8,64 3 0 0.000019655 0 m N cfq4162S / add_to_rr
8,64 3 0 0.000021945 0 m N cfq4162S / idle=0
8,64 3 5 0.000023460 4162 U N [fs_mark] 1
8,64 3 0 0.000025761 0 m N cfq workload slice:300
8,64 3 0 0.000027137 0 m N cfq4162S / set_active wl_prio:0 wl_type:2
8,64 3 0 0.000028588 0 m N cfq4162S / fifo=(null)
8,64 3 0 0.000029468 0 m N cfq4162S / dispatch_insert
8,64 3 0 0.000031359 0 m N cfq4162S / dispatched a request
8,64 3 0 0.000032306 0 m N cfq4162S / activate rq, drv=1
8,64 3 6 0.000032735 4162 D R 73992 + 8 [fs_mark]
8,64 1 1 0.004276637 0 C R 73992 + 8 [0]
Como puede ver, la salida es densa y difícil de leer. Puede decir qué procesos son responsables de emitir E/S a su dispositivo, lo cual es útil, pero blkparse puede proporcionar información adicional en un formato fácil de entender en su resumen. La información de resumen blkparse se imprime al final de la salida:
Total (sde):
Reads Queued: 19, 76KiB Writes Queued: 142,183, 568,732KiB
Read Dispatches: 19, 76KiB Write Dispatches: 25,440, 568,732KiB
Reads Requeued: 0 Writes Requeued: 125
Reads Completed: 19, 76KiB Writes Completed: 25,315, 568,732KiB
Read Merges: 0, 0KiB Write Merges: 116,868, 467,472KiB
IO unplugs: 20,087 Timer unplugs: 0
El resumen muestra las tasas de E/S promedio, la actividad de fusión y compara la carga de lectura con la carga de trabajo de escritura. Sin embargo, para la mayoría, la salida de blkparse es demasiado voluminosa. Afortunadamente, hay varias herramientas que ayudan a visualizar los datos.
btt proporciona un análisis de la cantidad de tiempo de E/S utilizado en las diferentes áreas de la pila de E/S. Dichas áreas son:
- Q — Una E/S de bloque está en cola
- G — Obtener solicitudUna nueva E/S de bloque en cola no era candidata para fusionar con ninguna solicitud existente, por lo tanto se asigna una nueva petición de capa de bloque.
- M — Una E/S de bloque se fusiona con una solicitud existente.
- I — Una solicitud se inserta dentro de la cola de dispositivo.
- D — Una solicitud se expide al Dispositivo.
- C — Una solicitud es completada por el controlador.
- P — La cola de dispositivo se tapona para permitir que las solicitudes se acumulen.
- U — La cola de dispositivo se destapona para permitir que las solicitudes acumuladas se envíen al dispositivo.
btt no solamente divide el tiempo utilizado en cada una de las áreas, sino también el tiempo de transición utilizado entre ellas, al igual que:
- Q2Q — tiempo entre solicitudes enviadas a la capa de bloques
- Q2G — tiempo que se tarda desde el momento que una E/S de bloque es puesta en cola hasta el tiempo que obtiene una solicitud asignada.
- G2I — tiempo que se tarda desde que se asigna una solicitud al tiempo que se inserta en la cola del dispositivo.
- Q2M — tiempo que se tarda desde que E/S de un bloque es puesta en cola al tiempo que se fusiona con la solicitud existente.
- I2D — tiempo que se tarda desde que se inserta una solicitud en un dispositivo al tiempo que se emite al dispositivo.
- M2D — tiempo que se tarda desde la fusión de una E/S de bloque con la solicitud de salida hasta la emisión de la solicitud al dispositivo
- D2C — tiempo de servicio de la solicitud por dispositivo
- Q2C — tiempo total utilizado en la capa de bloques para una solicitud
Puede reducir bastante una carga de trabajo de la tabla anterior. Por ejemplo, si Q2Q es mucho mayor que Q2C, significará que la aplicación no está emitiendo una E/S en una rápida sucesión. De esta manera, cualquier problema de rendimiento que se presente no estará relacionado de ninguna manera con el subsistema de E/S. Si D2C es muy alto, entonces significará que el dispositivo se está tardando mucho para servir las solicitudes. Esto puede indicar que el dispositivo esta sobrecargado (lo cual puede ser debido a un recurso compartido), o puede ser debido a que la carga enviada al dispositivo es subóptima. Si Q2G es muy alto, significa que hay muchas solicitudes en cola al mismo tiempo. Esto puede indicar que el almacenamiento no puede sostener la carga de E/S.
Por último, Seekwatcher consume los datos binarios de blktrace y genera un grupo de gráficos, incluidos Dirección de bloques lógicos (LBA), rendimiento, búsquedas por segundo, y Operaciones de E/S por segundo (IOPS).
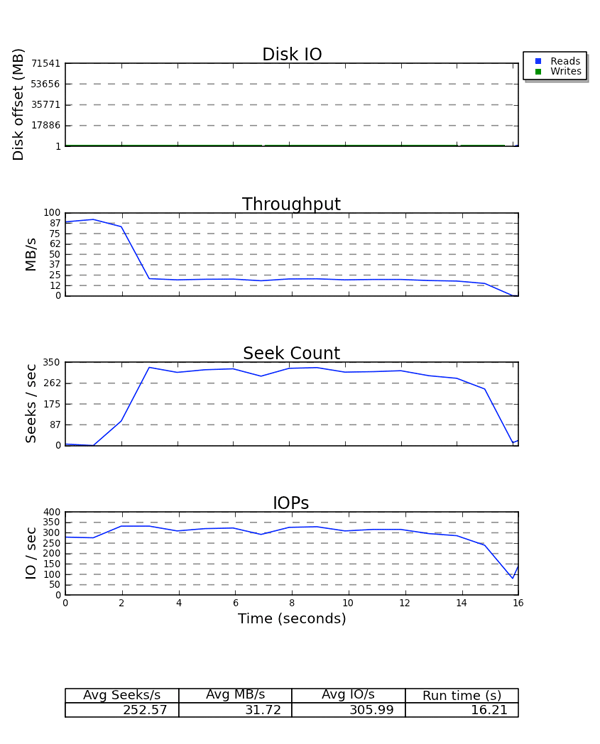
Figura 6.2. Ejemplo de salida de Seekwatcher
Todos los gráficos usan el tiempo como eje X. El gráfico LBA muestra y escribe en diferentes colores. Es interesante observar la relación entre el rendimiento y las gráficas de búsqueda por segundo. Para almacenamiento que es sensible a búsquedas, hay una relación inversa entre los dos gráficos. El gráfico IOPS es útil si por ejemplo, no se está obteniendo el rendimiento esperado de un dispositivo, pero está llegando a sus limitaciones de IOPS.