Capítulo 4. CPU
El término CPU, el cual significa Unidad de procesamiento central, es un nombre equivocado para la mayoría de los sistemas, puesto que central implica única, mientras que la mayoría de los sistemas modernos tienen más de una unidad de procesamiento o núcleo. Físicamente, las CPU vienen en un paquete unido a la placa madre en un socket. Cada socket en la placa madre tiene varias conexiones: a otros sockets de CPU, controladores de memoria, controladores de interrupción, y otros dispositivos periféricos. Un socket para el sistema operativo es una agrupación de varias CPU y recursos asociados. Este concepto es central a la mayoría de nuestras discusiones sobre ajuste de CPU.
Red Hat Enterprise Linux mantiene una riqueza de estadística sobre eventos de CPU de sistemas; estas estadísticas sirven en la planeación de una estrategia de ajuste para mejorar el rendimiento de CPU. Sección 4.1.2, “Ajuste de rendimiento de la CPU” discute algunas de las estadísticas útiles, dónde hallarlas, cómo analizarlas para ajuste de rendimiento.
Topología
Los computadores antes tenían relativamente pocas CPU por sistema que permitían una arquitectura conocida como Multiprocesador simétrico (SMP). Esto significaba que cada CPU en el sistema tenía acceso similar (o simétrico) a la memoria disponible. En años recientes, el conteo por socket de CPU ha aumentado al punto de que el hecho de intentar dar acceso simétrico a todos los RAM en el sistema se ha convertido en algo muy costoso. La mayoría de sistemas de conteo de CPU de alto costo en estos días tienen una arquitectura conocida como Acceso de memoria no uniforme (NUMA) en lugar de SMP.
Los procesadores AMD han tenido este tipo de arquitectura por algún tiempo con sus interconexiones Hyper Transport (HT), mientras que Intel ha comenzado a implementar NUMA en sus diseños de Quick Path Interconnect (QPI). NUMA y SMP se ajustan de forma diferente, ya que usted debe justificar la topología del sistema al asignar recursos para una aplicación.
Hilos
Dentro del sistema operativo de Linux, la unidad de ejecución se conoce como hilo. Los hilos tienen un contexto de registro, una pila, y un segmento de código ejecutable que ejecutan en una CPU. Es trabajo del sistema operativo (SO) programar esos hilos en las CPU disponibles.
El Sistema operativo maximiza el uso de CPU al balancear los hilos a través de núcleos disponibles. Puesto que el SO se interesa principalmente en mantener ocupadas las CPU, no siempre tomará decisiones óptimas con respecto al rendimiento de aplicaciones. Si traslada un hilo de aplicación a una CPU en otro socket empeorará el rendimiento más que si espera a que la CPU actual esté disponible, puesto que las operaciones de memoria pueden desacelerarse a través de sockets. Para obtener aplicaciones de alto rendimiento, es mejor que el diseñador determine dónde se deben colocar los hilos. La Sección 4.2, “Programación de CPU” discute la mejor manera de asignar las CPU y memoria para ejecutar hilos de aplicaciones.
Interrupciones
Uno de los eventos menos obvios (pero, importante) que puede impactar el rendimiento de aplicaciones son las interrupciones (también conocidas como las IRQ en Linux). Estos eventos son manejados por el sistema operativo y utilizados por periféricos para señalar la llegada de datos o la culminación de una operación, tal como una escritura de red o un evento de temporizador.
La forma en que el SO o la CPU que ejecuta el código de aplicaciones maneja una interrupción, no afecta la funcionalidad de la aplicación. Sin embargo, puede impactar el rendimiento de la aplicación. Este capítulo discute algunos consejos sobre prevención de interrupciones de rendimiento de aplicaciones que están impactando de una forma adversa.
4.1. Topología de CPU
Copiar enlaceEnlace copiado en el portapapeles!
4.1.1. Topología de CPU y Numa
Copiar enlaceEnlace copiado en el portapapeles!
Los primeros procesadores de computadores eran uniprocesadores, es decir que el sistema tenía una sola CPU. La ilusión de procesos en ejecución en paralelo solamente era realizada por el sistema operativo al pasar rápidamente la única CPU de un proceso de ejecución a otro. En la búsqueda por aumentar el rendimiento del sistema, los diseñadores notaron que el aumento de la tasa de reloj para ejecutar instrucciones de una forma más rápida solamente funcionaba hasta cierto punto (por lo general limitaciones en la creación de una onda de reloj estable con la tecnología actual). Para obtener un mayor rendimiento de todo el sistema, los diseñadores le añadieron otra CPU, lo cual permitió dos corrientes de ejecución paralelas. Esta tendencia de añadir procesadores ha continuado con el tiempo.
La mayoría de los primeros sistemas de multiprocesadores fueron diseñados para que cada CPU tuviera la misma ruta para cada ubicación de memoria (por lo general un bus paralelo). Esto permitía a cada CPU acceder a cualquier sitio de memoria en la misma cantidad de tiempo que cualquier otra CPU en el sistema. Este tipo de arquitectura se conoce como Sistema de multiprocesador simétrico (SMP). El SMP es apropiado para pocas CPU, pero si el número de CPU está por encima de cierto punto (de 8 a 16), los trazados paralelos requeridos para permitir igual acceso a memoria, ocuparán demasiado espacio en la placa, y dejarán menos espacio para los periféricos.
Dos nuevos conceptos combinados para permitir un número superior de CPU en un sistema:
- Buses seriales
- Topologías de NUMA
Un bus serial es una ruta de comunicación de un solo cable con una muy alta tasa de reloj, el cual transfiere datos como ráfagas de paquetes. Los diseñadores de hardware comenzaron a usar los buses de seriales como interconexiones de alta velocidad entre varias CPU y entre varias CPU y controladores de memoria y otros periféricos. Es decir que en lugar de requerir entre 32 y 64 trazos en la placa desde cada CPU al subsistema de memoria, había ahora un trazo, lo cual reduce de manera substancial la cantidad de espacio requerido en la placa.
Al mismo tiempo, los diseñadores de hardware empaquetaban más transistores en el mismo espacio para reducir tamaños de circuitos. En lugar de colocar CPU individuales directamente en la placa principal, comenzaban a empacarlas dentro del paquete del procesador como procesadores multinúcleos. Entonces, en lugar de intentar proporcionar igual acceso a memoria desde cada paquete de procesador, los diseñadores recurrieron a una estrategia de Acceso de memoria no uniforme o NUMA, en la que cada combinación de paquete y socket tiene una o más áreas de memoria dedicadas para acceso de alta velocidad. Cada conector también está interconectado a otros sockets para acceso más lento a la otra memoria de los otros sockets.
A manera de ejemplo de NUMA, supongamos que tenemos una placa madre de dos sockets cada una poblada con un paquete quad-core. Es decir, que el número total de CPU en el sistema es ocho; cuatro en cada socket. Cada socket también tiene un banco de memoria conectado de cuatro GB de RAM, para una memoria de sistema total de ocho GB. Para este ejemplo, las CPU 0-3 están en el socket 0 y las CPU 4-7 están en socket 1. Cada socket en este ejemplo también corresponde a un nodo de NUMA.
Podría tomarse tres ciclos de reloj para que CPU 0 acceda a memoria desde banco 0: un ciclo para presentar la dirección al controlador de memoria, un ciclo para configurar acceso al sitio de memoria y un ciclo para leer o escribir al sitio. Sin embargo, podría tomarse seis ciclos de reloj para que CPU4 acceda a memoria desde el mismo sitio; debido a que está en un socket independiente, deberá ir a través de dos controladores de memoria en socket 0. Si la memoria no se impugna en dicha ubicación (es decir, si hay más de una CPU intentando acceder de forma simultánea al mismo sitio), los controladores de memoria necesitarán arbitrar y poner en serie el acceso a la memoria, a fin de que el acceso de memoria se prolongue. Si adiciona consistencia de cache (garantizar que las cache de CPU local contengan los mismos datos para el mismo sitio de memoria), complica el proceso más adelante.
Los procesadores de alta gama más recientes de Intel (Xeon) y AMD (Opteron) tienen topologías de NUMA. Los procesadores AMD usan una interconexión conocida como HyperTransport o HT, mientras que Intel usa una llamada QuickPath Interconnect u QPI. Las interconexiones difieren en la forma como se conectan físicamente a otras interconexiones, memoria, y dispositivos periféricos, pero en efecto son un interruptor que permite acceso transparente a un dispositivo conectado. En este caso, transparente se refiere a que no se requiere API de programación especial para usar la interconexión, no es una opción "sin costo" alguno.
Puesto que las arquitecturas del sistema son tan diversas, no es práctico caracterizar de forma específica la multa de rendimiento impuesta por acceder a memoria no-local. Decimos que cada salto o 'hop' a través de una interconexión impone al menos alguna multa de rendimiento constante por salto, por lo tanto al referirnos a ubicación de memoria que está a dos interconexiones de la CPU actual se impone por la menos 2N + tiempo de ciclo de memoria unidades para acceder tiempo, donde N es la multa por salto.
Dada la multa de rendimiento, las aplicaciones sensibles a rendimiento deben evitar con regularidad el acceso a la memoria remota en un sistema de topología de NUMA. La aplicación debe configurarse para que permanezca en un nodo determinado y asigne memoria desde dicho nodo.
Para hacerlo, hay algunas cosas que las aplicaciones deben saber:
- ¿Qué significa topología del sistema?
- ¿En dónde se está ejecutando la aplicación?
- ¿En dónde se encuentra el banco de memoria más cercano?
4.1.2. Ajuste de rendimiento de la CPU
Copiar enlaceEnlace copiado en el portapapeles!
Lea esta sección para entender cómo ajustar para obtener mejor rendimiento de CPU y para una introducción de varias herramientas que ayudan en el proceso.
NUMA se utilizaba en un principio, para conectar un procesador único a varios bancos de memoria. Debido que los fabricantes de CPU refinaron los procesos y encogieron los tamaños, los núcleos de CPU múltiples pudieron incluirse en un paquete. Dichos núcleos de CPU eran agrupados para que cada vez que se accediera a una memoria de banco local y cache, se pudieran compartir entre los núcleos; sin embargo, cada 'salto' a través de una núcleo , memoria y una cache, trae como consecuencia poco rendimiento.
El sistema de ejemplo en Figura 4.1, “El acceso de memoria remota y local en topología de NUMA” contiene dos nodos NUMA. Cada nodo tiene cuatro CPU, un banco de memoria y un controlador de memoria. Cualquier CPU en un nodo tiene acceso directo al banco de memoria en ese nodo. Al seguir las flechas en Nodo 1, los pasos son los siguientes:
- Una CPU (0-3) presenta la dirección de memoria para el controlador local.
- El controlador de memoria configura el acceso a la dirección de memoria.
- La CPU realiza operaciones de lectura y escritura en esa dirección de memoria.
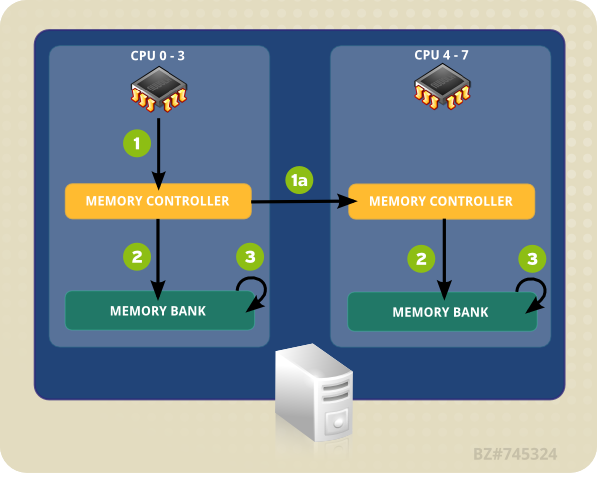
Figura 4.1. El acceso de memoria remota y local en topología de NUMA
Sin embargo, si una CPU en un nodo necesita código de acceso que reside en el banco de memoria de un NUMA diferente, la ruta que debe tomar será menos directa:
- Una CPU (0-3) presenta la dirección de memoria remota para el controlador de memoria local.
- La solicitud de CPU para la dirección de memoria remota se pasa a un controlador de memoria remota, local al nodo que contiene la dirección de memoria.
- El controlador de memoria remota configura el acceso a la dirección de memoria remota.
- La CPU realiza operaciones de lectura y escritura en esa dirección de memoria remota.
Cada acción necesita pasar por controladores de memoria múltiple, por lo tanto el acceso puede tomar más de dos veces siempre y cuando intente acceder direcciones de memoria remota. El rendimiento primario tiene que ver con un sistema multinúcleos, para garantizar que la información viaje de forma tan eficiente como sea posible, a través de la ruta más rápida y corta.
Para configurar una aplicación para obtener un rendimiento de CPU óptimo, debe saber:
- la topología de los componentes del sistema (cómo se conectan sus componentes),
- el núcleo en el cual se ejecuta la aplicación, y
- la ubicación del banco de memoria más cercano.
Red Hat Enterprise Linux 6 se distribuye con un número de herramientas para ayudarlo a encontrar información y a ajustar su sistema. Las siguientes secciones ofrecen una visión general de las herramientas útiles para ajustar el rendimiento de CPU.
4.1.2.1. Configuración de afinidad de CPU con taskset
Copiar enlaceEnlace copiado en el portapapeles!
taskset recupera y establece la afinidad de CPU de un proceso en ejecución (por el ID de proceso). También puede servir para lanzar un proceso con una afinidad de CPU determinada, la cual vincula los procesos especificados a una CPU especificada o una serie de CPU. No obstante, taskset no garantiza la asignación de memoria local. Si requiere beneficios de rendimiento adicional de memoria local, recomendamos numactl en taskset; consulte la Sección 4.1.2.2, “Control de la política NUMA con numactl” para obtener mayor información.
La afinidad de CPU se representa como una máscara de bits. El orden más bajo de bits corresponde a la primera CPU lógica, y el más alto corresponde a la última CPU lógica. Estas máscaras suelen ser hexadecimales, por lo tanto
0x00000001 representa procesador 0, y 0x00000003 representa procesador 0 y 1.
Para establecer la afinidad de CPU de un proceso en ejecución, ejecute el siguiente comando, remplace máscara por la máscara del procesador o procesadores a la que desea vincular el proceso y pid por el ID del proceso cuya afinidad desea cambiar:
# taskset -p máscara pid
Para lanzar un proceso con una determinada afinidad, ejecute el siguiente comando, remplace máscara por la máscara del procesador o procesadores a la que desea vincular su proceso, y programa por el programa, opciones y argumentos del programa que desea ejecutar.
# taskset mask -- program
En lugar de especificar los procesadores como una máscara de bits, puede también usar la opción
-c para proporcionar una lista delimitada por comas o un rango de procesadores, como:
# taskset -c 0,5,7-9 -- myprogram
Para mayor información sobre taskset, consulte la página de manual:
man taskset.
4.1.2.2. Control de la política NUMA con numactl
Copiar enlaceEnlace copiado en el portapapeles!
numactl ejecuta procesos con programación especificada o política de ubicación de memoria. La política seleccionada se establece para este proceso y todos sus hijos. numactl también puede establecer política persistente para segmentos o archivos de memoria compartida y establece afinidad de CPU y afinidad de memoria de un proceso. Utiliza el sistema de archivos /sys para determinar la topología del sistema.
El sistema de archivos
/sys contiene información sobre cómo se conectan las CPU, la memoria y los dispositivos periféricos mediante interconexiones NUMA. En particular, el directorio /sys/devices/system/cpu contiene información sobre cómo se conectan las CPU de un sistema a otro. El directorio /sys/devices/system/node contiene información sobre los nodos NUMA en el sistema, y las distancias relativas entre dichos nodos.
En un sistema NUMA, entre mayor sea la distancia entre un procesador y un banco de memoria, más lento será el acceso del procesador a dicho banco de memoria. Las aplicaciones sensibles al rendimiento deben, por lo tanto, configurarse para que puedan asignar memoria desde el banco de memoria más cercano posible.
Las aplicaciones sensibles de rendimiento también deben configurarse para ejecutar un conjunto de núcleos, en particular, aplicaciones multihilos. Debido a que la memoria cache de primer nivel suele ser pequeña, si múltiples hilos se ejecutan en un núcleo, cada hilo en potencia desalojará datos en cache accedidos por un hilo previo. Cuando el sistema operativo intenta realizar multitareas entre estos hilos, y los hilos que continúan desalojando los datos en cache del otro, se consume un gran porcentaje de su tiempo de ejecución en el remplazo de línea de cache. Este problema se conoce como hiperpaginación de cache. Por lo tanto, se recomienda vincular una aplicación multihilos a un nodo, en lugar de vinculoarla a un núcleo individual, ya que esto permite a los hilos compartir líneas cache en múltiples niveles (primero-, segundo-, y último nivel de cache) y minimizar la necesidad para las operaciones de llenado de cache. Sin embargo, la vinculación de una aplicación a un núcleo individual puede funcionar si todos los hilos acceden a los mismos datos guardados en cache.
numactl le permite vincular una aplicación a un núcleo particular o nodo de NUMA y asignar la memoria asociada con un núcleo o conjunto de núcleos a una aplicación. Algunas opciones útiles proporcionadas por numactl son:
--show- Despliega lo parámetros de política NUMA del proceso actual. Este parámetro no requiere parámetros adicionales y puede ser utilizado como tal:
numactl --show. --hardware- Despliega un inventario de los nodos disponibles en el sistema
--membind- Solamente asigna memoria desde los nodos especificados. Cuando está en uso, la asignación de memoria fallará en estos nodos si es insuficiente. El uso para este parámetro es
numactl --membind=nodos programa, where nodos es la lista de nodos de la cual desea asignar memoria y programa es el programa cuyos requerimientos de memoria deberían asignarse desde ese nodo. Los números de nodos puede otorgarse como una lista delimitada por comas, un rango o una combinación de los dos. Para obtener mayor información sobre numactl, consulte la página de manual:man numactl. --cpunodebind- Solamente ejecute un comando (y sus procesos hijos) en las CPU pertenecientes al nodo especificado. El uso para este parámetro es
numactl --cpunodebind=nodos programa, donde nodos es la lista de nodos a cuyas CPU será vinculado el programa especificado (programa). Los números de nodos pueden presentarse como una lista delimitada por comas, un rango o combinación de dos. Para mayor información sobre numactl, consulte la página de manual:man numactl. --physcpubind- Solamente ejecute un comando (y sus procesos hijos) en las CPU especificadas. El uso para este parámetro es
numactl --physcpubind=cpu program, donde cpu es una lista delimitada por comas de los números de CPU como aparecen en los campos de/proc/cpuinfo, y programa es el programa que debe ejecutarse solo en esas CPU. Las CPU también pueden especificarse con relación a lacpusetactual. Para obtener mayor información sobre numactl, consulte la página de manual:man numactl. --localalloc- Especifica que la memoria siempre debe asignarse en el nodo actual
--preferred- Donde sea posible, la memoria es asignada en el nodo especificado. Si la memoria no puede asignarse en el nodo especificado, se conmutará a otros nodos. Esta opción toma únicamente un nodo individual, así:
numactl --preferred=nodo. Para obtener mayor información sobre numactl, por favor consulte la página de manual:man numactl.
La biblioteca libnuma incluida en el paquete numactl, ofrece una interfaz de programación sencilla para la política de NUMA soportada por el kernel. Se utiliza para ajuste minucioso más que la herramienta numactl. Para mayor información, consulte la página de manual:
man numa(3).
4.1.3. numastat
Copiar enlaceEnlace copiado en el portapapeles!
Importante
La herramienta numastat fue escrita en script de Perl por Andi Kleen y reescrita para Red Hat Enterprise Linux 6.4.
Mientras que el comando predeterminado (
numastat, sin opciones ni parámetros) mantiene una compatibilidad estricta con la versión anterior a la herramienta, observe que las provisiones de iones o parámetros para este comando cambia de forma significativa tanto el contenido de salida como el formato.
numastat despliega estadísticas de memoria (tal como asignación de golpes y pérdidas) fpara procesos y sistema operativo en un NUMA por nodo. Ahora al ejecutar
numastat se despliega de forma predeterminada el número de páginas de memoria ocupadas por las siguientes categorías de eventos para cada nodo.
El rendimiento óptimo de CPU se indica mediante los valores bajos de
numa_miss y numa_foreign.
Esta versión actualizada de numastat también muestra si la memoria de proceso se extiende a través de un sistema o si se centraliza en nodos específicos mediante numactl.
La referencia cruzada de salida numastat con la salida por CPU de top para verificar que los hilos de procesos se ejecuten en los mismos nodos a los que se asigna la memoria.
Categorías de trazado predeterminado
- numa_hit
- El número de asignaciones intentadas en este nodo que no fueron exitosas.
- numa_miss
- El número de asignaciones designadas a otro nodo que fueron asignadas en este nodo debido a baja memoria en el nodo designado. Cada evento
numa_misstiene un evento correspondientenuma_foreignen otro nodo. - numa_foreign
- El número de asignaciones que destinadas inicialmente para este nodo que fueron asignadas a otro nodo. Cada evento
numa_foreigntiene un eventonuma_misscorrespondiente en otro nodo. - interleave_hit
- El número de asignaciones de políticas de intercalación intentadas en este nodo que fueron exitosas.
- local_node
- El número de veces que un proceso en este nodo asignó memoria correctamente en este nodo.
- other_node
- El número de veces que un proceso en este nodo asigna memoria correctamente en este nodo.
Al suplir cualquiera de las siguientes opciones cambian las unidades desplegadas a MB de memoria (redondeando a dos decimales), y otras conductas numastat específicas como se describe a continuación.
-c- De forma horizontal condensa la tabla de información desplegada. Es útil en sistemas con un gran número de nodos NUMA, pero la anchura de columnas y el espacio entre columnas son, de alguna manera, predecibles. Cuando se utiliza esta opción, la cantidad de memoria se redondea al megabyte más cercano.
-m- Muestra la información de uso de memoria en todo el sistema en una base por nodo, similar a la información que se encuentra en
/proc/meminfo. -n- Muestra la misma información que la original de
numastat(numa_hit, numa_miss, numa_foreign, interleave_hit, local_node, and other_node), con un formato actualizado, mediante MB como la unidad de medida -p patrón- Muestra información de memoria por nodo para un patrón específico. Si el valor para el patrón consta de dígitos, numastat supone que es un identificador de procesos numérico. De lo contrario, numastat busca líneas de comando de procesos para el patrón especificado.Se asume que los argumentos de línea de comandos ingresados después del valor de la opción
-psean patrones adicionales para ser filtrados. Los patrones adicionales expanden el filtro, en lugar de estrecharlo. -s- Clasifica los datos desplegados en orden descendente para que los que consumen más memoria (según la columna
total) estén en la lista de primeros.También puede especificar un nodo, y la tabla será organizada según la columna de nodo. Al usar esta opción, el valor de nodo debe ir acompañado de la opción-sinmediatamente, como se muestra aquí:numastat -s2No incluya el espacio en blanco entre la opción y su valor. -v- Muestra información más detallada. Es decir, información del proceso para múltiples procesos desplegará información detallada para cada proceso.
-V- Despliega información sobre la versión de numastat.
-z- Omite las filas y columnas de tabla con valores de cero únicamente. Observe que los valores cercanos a cero se redondean a cero para propósitos de despliegue y no serán omitidos de la salida desplegada.
4.1.4. Daemon de administración de afinidad NUMA (numad)
Copiar enlaceEnlace copiado en el portapapeles!
numad es un daemon de administración de afinidad NUMA. Monitoriza la topología de NUMA y el uso de recursos dentro de un sistema con el fin de mejorar de forma dinámica la asignación de recursos y administración de NUMA (y por ende, el rendimiento del sistema).
Según la carga de trabajo del sistema, numad puede proporcionar un punto de referencia de mejoras de rendimiento hasta de 50%. Para obtener estas ganancias, numad accede de forma periódica a la información desde el sistema de archivos
/proc para monitorizar los recursos del sistema disponibles por nodo. En daemon intenta entonces colocar los procesos importantes en nodos de NUMA que tienen alineada suficiente memoria y recursos de CPU para óptimo rendimiento de NUMA. El umbral actual para administración de procesos es de por lo menos 50% de una CPU y al menos 300 MB de memoria. numad intenta mantener un nivel de utilización de recursos y re-equilibrar las asignaciones cuando sea necesario al trasladar los procesos entre nodos de NUMA.
numad también proporciona un servicio de consejería de pre-colocación que puede ser solicitado por varios sistemas de administración de trabajo para asistir en la vinculación inicial de CPU y recursos de memoria para sus procesos. Este servicio de pre-colocación está disponible independiente de si numad se esta ejecutando o no, como un daemon en el sistema. Para mayor información sobre el uso de la opción
-w para consejo de pre-colocación, consulte la página de manual: man numad.
4.1.4.1. Se beneficia de numad
Copiar enlaceEnlace copiado en el portapapeles!
numad se beneficia principalmente de sistemas con procesos de larga ejecución que consumen cantidades importantes de recursos, en particular, cuando dichos procesos hacen parte de un subconjunto del total de recursos del sistema.
numad también puede beneficiarse de las aplicaciones que consumen valor de recursos de múltiples nodos de NUMA. Sin embargo, los beneficios que numad proporciona decrecen a medida que decrece el porcentaje de recursos consumidos en un sistema.
numad es poco probable mejorar el rendimiento de procesos cuando los procesos se ejecutan por unos pocos minutos o cuando no consumen muchos recursos.También es poco probable que los sistemas con patrones de acceso de memoria continua, tales como base de datos en-memoria, se beneficien del uso de numad.
4.1.4.2. Modos de operación
Copiar enlaceEnlace copiado en el portapapeles!
Nota
Las estadísticas de conteo de memoria de Kernel pueden contradecirse después de grandes cantidades de fusión. Como tal, numad se puede confundir cuando el daemon KSM fusiona grandes cantidades de memoria. El daemon KSM será más consciente de NUMA en futuros lanzamientos. Sin embargo, actualmente, si su sistema tiene una gran cantidad de memoria libre, podrá realizar un rendimiento superior al apagar y desactivar el daemon KSM.
numad sirve de dos formas:
- como un servicio
- como un ejecutable
4.1.4.2.1. Uso de numad como un servicio
Copiar enlaceEnlace copiado en el portapapeles!
Mientras el servicio de numad se ejecuta, intentará ajustar de forma dinámica el sistema basado en su carga de trabajo.
Para iniciar el servicio, ejecute:
# service numad start
Para hacer que el servicio sea persistente a través de reinicios, ejecute:
# chkconfig numad on4.1.4.2.2. Uso de numad como un ejecutable
Copiar enlaceEnlace copiado en el portapapeles!
Para usar numad como un ejecutable, ejecute:
# numad
numad se ejecutará hasta que se detenga. Mientras se ejecuta, sus actividades se registran en
/var/log/numad.log.
Para restringir la administración de numad a un proceso específico, inícielo con las siguientes opciones.
# numad -S 0 -p pid-p pid- Añade el pid especificado a una lista de inclusión explícita. El proceso especificado no será administrado, sino hasta cuando alcance el umbral de importancia del proceso de numad.
-S modo- El parámetro
-Sespecifica el tipo de proceso que escanea. Al establecerlo a0limita la administración de numad a proceso incluidos de forma explícita.
Para detener numad, ejecute:
# numad -i 0
La detención de numad no retira los cambios que ha hecho para mejorar afinidad de NUMA. Si el sistema usa cambios de forma significativa, al ejecutar numad otra vez, ajustará la afinidad para mejorar rendimiento bajo las nuevas condiciones.
Para obtener mayor información sobre opciones disponibles de numad, consulte la página de manual de numad:
man numad.