CI/CD
Contient des informations sur les builds, les pipelines et GitOps pour OpenShift Container Platform
Résumé
Chapitre 1. Présentation de la plateforme OpenShift Container Platform CI/CD
OpenShift Container Platform est une plateforme Kubernetes prête à l'emploi pour les développeurs, qui permet aux organisations d'automatiser le processus de livraison d'applications grâce aux pratiques DevOps, telles que l'intégration continue (CI) et la livraison continue (CD). Pour répondre aux besoins de votre organisation, OpenShift Container Platform propose les solutions CI/CD suivantes :
- Builds OpenShift
- OpenShift Pipelines
- OpenShift GitOps
1.1. Builds OpenShift
Avec OpenShift Builds, vous pouvez créer des applications cloud-natives en utilisant un processus de construction déclaratif. Vous pouvez définir le processus de construction dans un fichier YAML que vous utilisez pour créer un objet BuildConfig. Cette définition inclut des attributs tels que les déclencheurs de construction, les paramètres d'entrée et le code source. Lors du déploiement, l'objet BuildConfig construit généralement une image exécutable et l'envoie dans un registre d'images de conteneurs.
OpenShift Builds fournit le support extensible suivant pour les stratégies de construction :
- Construction Docker
- Construction de la source à l'image (S2I)
- Construction sur mesure
Pour plus d'informations, voir Comprendre les constructions d'images
1.2. OpenShift Pipelines
OpenShift Pipelines fournit un cadre CI/CD natif Kubernetes pour concevoir et exécuter chaque étape du pipeline CI/CD dans son propre conteneur. Il peut évoluer de manière indépendante pour répondre aux pipelines à la demande avec des résultats prévisibles.
Pour plus d'informations, voir Comprendre les pipelines OpenShift
1.3. OpenShift GitOps
OpenShift GitOps est un opérateur qui utilise Argo CD comme moteur déclaratif de GitOps. Il permet de mettre en place des flux de travail GitOps sur des infrastructures OpenShift et Kubernetes multicluster. En utilisant OpenShift GitOps, les administrateurs peuvent configurer et déployer de manière cohérente l'infrastructure et les applications basées sur Kubernetes à travers les clusters et les cycles de développement.
Pour plus d'informations, voir Comprendre OpenShift GitOps
1.4. Jenkins
Jenkins automatise le processus de construction, de test et de déploiement des applications et des projets. OpenShift Developer Tools fournit une image Jenkins qui s'intègre directement à OpenShift Container Platform. Jenkins peut être déployé sur OpenShift en utilisant les modèles Samples Operator ou la carte certifiée Helm.
Chapitre 2. Constructions
2.1. Comprendre les constructions d'images
2.1.1. Constructions
Une compilation est le processus de transformation des paramètres d'entrée en un objet résultant. Le plus souvent, le processus est utilisé pour transformer les paramètres d'entrée ou le code source en une image exécutable. Un objet BuildConfig est la définition de l'ensemble du processus de construction.
OpenShift Container Platform utilise Kubernetes en créant des conteneurs à partir d'images de construction et en les poussant vers un registre d'images de conteneurs.
Les objets de construction partagent des caractéristiques communes, notamment les entrées pour une construction, la nécessité d'achever un processus de construction, l'enregistrement du processus de construction, la publication des ressources des constructions réussies et la publication de l'état final de la construction. Les constructions tirent parti des restrictions de ressources, en spécifiant des limites sur les ressources telles que l'utilisation de l'unité centrale, l'utilisation de la mémoire et le temps d'exécution de la construction ou du pod.
Le système de construction d'OpenShift Container Platform fournit un support extensible pour les stratégies de construction qui sont basées sur des types sélectionnables spécifiés dans l'API de construction. Il existe trois stratégies de construction principales :
- Construction Docker
- Construction de la source à l'image (S2I)
- Construction sur mesure
Par défaut, les constructions docker et les constructions S2I sont prises en charge.
L'objet résultant d'une compilation dépend du constructeur utilisé pour la créer. Pour les constructions docker et S2I, les objets résultants sont des images exécutables. Pour les constructions personnalisées, les objets résultants sont ce que l'auteur de l'image du constructeur a spécifié.
En outre, la stratégie de construction de pipeline peut être utilisée pour mettre en œuvre des flux de travail sophistiqués :
- Intégration continue
- Déploiement continu
2.1.1.1. Construction Docker
OpenShift Container Platform utilise Buildah pour construire une image de conteneur à partir d'un fichier Docker. Pour plus d'informations sur la construction d'images de conteneurs avec des Dockerfiles, voir la documentation de référence Dockerfile.
Si vous définissez les arguments de construction de Docker en utilisant le tableau buildArgs, voir Comprendre comment ARG et FROM interagissent dans la documentation de référence de Dockerfile.
2.1.1.2. Construction de la source à l'image
Source-to-image (S2I) est un outil permettant de créer des images de conteneurs reproductibles. Il produit des images prêtes à l'emploi en injectant la source d'une application dans une image de conteneur et en assemblant une nouvelle image. La nouvelle image incorpore l'image de base, le constructeur et la source construite et est prête à être utilisée avec la commande buildah run. S2I prend en charge les constructions incrémentielles, qui réutilisent les dépendances téléchargées précédemment, les artefacts construits précédemment, etc.
2.1.1.3. Construction sur mesure
La stratégie de construction personnalisée permet aux développeurs de définir une image de constructeur spécifique responsable de l'ensemble du processus de construction. L'utilisation de votre propre image de constructeur vous permet de personnaliser votre processus de construction.
Une image de construction personnalisée est une image conteneur simple incorporant la logique du processus de construction, par exemple pour construire des RPM ou des images de base.
Les builds personnalisés sont exécutés avec un niveau de privilège élevé et ne sont pas accessibles aux utilisateurs par défaut. Seuls les utilisateurs à qui l'on peut faire confiance en leur accordant des autorisations d'administration de cluster doivent avoir accès à l'exécution des builds personnalisés.
2.1.1.4. Construction d'un pipeline
La stratégie de construction Pipeline est obsolète dans OpenShift Container Platform 4. Des fonctionnalités équivalentes et améliorées sont présentes dans les Pipelines d'OpenShift Container Platform basés sur Tekton.
Les images Jenkins sur OpenShift Container Platform sont entièrement prises en charge et les utilisateurs doivent suivre la documentation utilisateur de Jenkins pour définir leur jenkinsfile dans un travail ou le stocker dans un système de gestion du contrôle de la source.
La stratégie de construction Pipeline permet aux développeurs de définir un pipeline Jenkins qui sera utilisé par le plugin Jenkins pipeline. Le build peut être démarré, surveillé et géré par OpenShift Container Platform de la même manière que n'importe quel autre type de build.
Les flux de travail du pipeline sont définis dans un site jenkinsfile, soit directement intégré dans la configuration de construction, soit fourni dans un dépôt Git et référencé par la configuration de construction.
2.2. Comprendre les configurations de construction
Les sections suivantes définissent le concept de compilation, la configuration de la compilation et décrivent les principales stratégies de compilation disponibles.
2.2.1. BuildConfigs
Une configuration de construction décrit une définition de construction unique et un ensemble de déclencheurs pour la création d'une nouvelle construction. Les configurations de construction sont définies par un BuildConfig, qui est un objet REST pouvant être utilisé dans un POST au serveur API pour créer une nouvelle instance.
Une configuration de construction, ou BuildConfig, est caractérisée par une stratégie de construction et une ou plusieurs sources. La stratégie détermine le processus, tandis que les sources fournissent les données d'entrée.
Selon la façon dont vous choisissez de créer votre application avec OpenShift Container Platform, un BuildConfig est généralement généré automatiquement pour vous si vous utilisez la console web ou le CLI, et il peut être modifié à tout moment. Comprendre les éléments qui composent un BuildConfig et leurs options disponibles peut vous aider si vous choisissez de modifier manuellement votre configuration ultérieurement.
L'exemple suivant BuildConfig entraîne une nouvelle compilation chaque fois qu'une balise d'image de conteneur ou le code source est modifié :
BuildConfig définition de l'objet
kind: BuildConfig
apiVersion: build.openshift.io/v1
metadata:
name: "ruby-sample-build"
spec:
runPolicy: "Serial"
triggers:
-
type: "GitHub"
github:
secret: "secret101"
- type: "Generic"
generic:
secret: "secret101"
-
type: "ImageChange"
source:
git:
uri: "https://github.com/openshift/ruby-hello-world"
strategy:
sourceStrategy:
from:
kind: "ImageStreamTag"
name: "ruby-20-centos7:latest"
output:
to:
kind: "ImageStreamTag"
name: "origin-ruby-sample:latest"
postCommit:
script: "bundle exec rake test"- 1
- Cette spécification crée un nouveau site
BuildConfignomméruby-sample-build. - 2
- Le champ
runPolicyindique si les constructions créées à partir de cette configuration de construction peuvent être exécutées simultanément. La valeur par défaut estSerial, ce qui signifie que les nouvelles constructions sont exécutées séquentiellement et non simultanément. - 3
- Vous pouvez spécifier une liste de déclencheurs qui entraînent la création d'une nouvelle version.
- 4
- La section
sourcedéfinit la source de la construction. Le type de source détermine la source primaire d'entrée, et peut être soitGit, pour pointer vers un dépôt de code,Dockerfile, pour construire à partir d'un fichier Docker en ligne, ouBinary, pour accepter des charges utiles binaires. Il est possible d'avoir plusieurs sources à la fois. Voir la documentation de chaque type de source pour plus de détails. - 5
- La section
strategydécrit la stratégie de construction utilisée pour exécuter la construction. Vous pouvez spécifier une stratégieSource,Docker, ouCustomici. Cet exemple utilise l'image du conteneurruby-20-centos7que Source-to-image (S2I) utilise pour la construction de l'application. - 6
- Une fois que l'image du conteneur est construite avec succès, elle est poussée dans le référentiel décrit dans la section
output. - 7
- La section
postCommitdéfinit un crochet de construction optionnel.
2.3. Création d'intrants de construction
Les sections suivantes présentent une vue d'ensemble des entrées de compilation, des instructions sur la manière d'utiliser les entrées pour fournir du contenu source aux compilations, et sur la manière d'utiliser les environnements de compilation et de créer des secrets.
2.3.1. Construire des intrants
Une entrée de construction fournit un contenu source sur lequel les constructions peuvent opérer. Vous pouvez utiliser les entrées de construction suivantes pour fournir des sources dans OpenShift Container Platform, listées par ordre de priorité :
- Définitions de fichiers Docker en ligne
- Contenu extrait d'images existantes
- Dépôts Git
- Entrées binaires (locales)
- Secrets d'entrée
- Artéfacts externes
Vous pouvez combiner plusieurs entrées dans une seule compilation. Cependant, comme le fichier Dockerfile en ligne est prioritaire, il peut écraser tout autre fichier nommé Dockerfile fourni par une autre entrée. Les entrées binaires (locales) et les dépôts Git sont des entrées mutuellement exclusives.
Vous pouvez utiliser les secrets d'entrée lorsque vous ne souhaitez pas que certaines ressources ou informations d'identification utilisées pendant la construction soient disponibles dans l'image finale de l'application produite par la construction, ou lorsque vous souhaitez consommer une valeur définie dans une ressource secrète. Les artefacts externes peuvent être utilisés pour récupérer des fichiers supplémentaires qui ne sont pas disponibles dans l'un des autres types d'entrée de compilation.
Lorsque vous exécutez une compilation :
- Un répertoire de travail est construit et tout le contenu d'entrée est placé dans le répertoire de travail. Par exemple, le dépôt Git d'entrée est cloné dans le répertoire de travail, et les fichiers spécifiés dans les images d'entrée sont copiés dans le répertoire de travail en utilisant le chemin cible.
-
Le processus de construction change les répertoires en
contextDir, s'il y en a un de défini. - Le fichier Docker en ligne, s'il existe, est écrit dans le répertoire courant.
-
Le contenu du répertoire actuel est fourni au processus de construction pour référence par le fichier Docker, la logique de construction personnalisée ou le script
assemble. Cela signifie que tout contenu d'entrée qui réside en dehors decontextDirest ignoré par le processus de construction.
L'exemple suivant de définition d'une source comprend plusieurs types d'entrée et une explication de la manière dont ils sont combinés. Pour plus de détails sur la définition de chaque type d'entrée, voir les sections spécifiques à chaque type d'entrée.
source:
git:
uri: https://github.com/openshift/ruby-hello-world.git
ref: "master"
images:
- from:
kind: ImageStreamTag
name: myinputimage:latest
namespace: mynamespace
paths:
- destinationDir: app/dir/injected/dir
sourcePath: /usr/lib/somefile.jar
contextDir: "app/dir"
dockerfile: "FROM centos:7\nRUN yum install -y httpd" - 1
- Le référentiel à cloner dans le répertoire de travail pour la construction.
- 2
/usr/lib/somefile.jardemyinputimageest stockée dans<workingdir>/app/dir/injected/dir.- 3
- Le répertoire de travail pour la construction devient
<original_workingdir>/app/dir. - 4
- Un fichier Docker contenant ce contenu est créé à l'adresse
<original_workingdir>/app/dir, remplaçant tout fichier existant portant ce nom.
2.3.2. Source du fichier Docker
Lorsque vous fournissez une valeur dockerfile, le contenu de ce champ est écrit sur le disque dans un fichier nommé dockerfile. Cette opération est effectuée après le traitement des autres sources d'entrée, donc si le référentiel de la source d'entrée contient un Dockerfile dans le répertoire racine, il est remplacé par ce contenu.
La définition de la source fait partie de la section spec du site BuildConfig:
source:
dockerfile: "FROM centos:7\nRUN yum install -y httpd" - 1
- Le champ
dockerfilecontient un fichier Docker en ligne qui est construit.
2.3.3. Source de l'image
Vous pouvez ajouter des fichiers supplémentaires au processus de construction avec des images. Les images d'entrée sont référencées de la même manière que les cibles d'image From et To sont définies. Cela signifie que les images de conteneurs et les balises de flux d'images peuvent être référencées. En conjonction avec l'image, vous devez fournir une ou plusieurs paires de chemins pour indiquer le chemin des fichiers ou des répertoires pour copier l'image et la destination pour les placer dans le contexte de construction.
Le chemin d'accès source peut être n'importe quel chemin d'accès absolu dans l'image spécifiée. La destination doit être un chemin de répertoire relatif. Au moment de la construction, l'image est chargée et les fichiers et répertoires indiqués sont copiés dans le répertoire contextuel du processus de construction. Il s'agit du même répertoire dans lequel le contenu du référentiel source est cloné. Si le chemin source se termine par /., le contenu du répertoire est copié, mais le répertoire lui-même n'est pas créé à la destination.
Les entrées d'images sont spécifiées dans la définition de source de BuildConfig:
source:
git:
uri: https://github.com/openshift/ruby-hello-world.git
ref: "master"
images:
- from:
kind: ImageStreamTag
name: myinputimage:latest
namespace: mynamespace
paths:
- destinationDir: injected/dir
sourcePath: /usr/lib/somefile.jar
- from:
kind: ImageStreamTag
name: myotherinputimage:latest
namespace: myothernamespace
pullSecret: mysecret
paths:
- destinationDir: injected/dir
sourcePath: /usr/lib/somefile.jar- 1
- Un tableau contenant une ou plusieurs images et fichiers d'entrée.
- 2
- Une référence à l'image contenant les fichiers à copier.
- 3
- Un tableau de chemins source/destination.
- 4
- Le répertoire relatif à la racine de construction où le processus de construction peut accéder au fichier.
- 5
- Emplacement du fichier à copier à partir de l'image référencée.
- 6
- Un secret facultatif fourni si des informations d'identification sont nécessaires pour accéder à l'image d'entrée.Note
Si votre cluster utilise un objet
ImageContentSourcePolicypour configurer la mise en miroir du référentiel, vous ne pouvez utiliser que des secrets d'extraction globaux pour les registres mis en miroir. Vous ne pouvez pas ajouter un secret d'extraction à un projet.
Images nécessitant des secrets de tirage
Lorsque vous utilisez une image d'entrée qui nécessite un secret d'extraction, vous pouvez lier le secret d'extraction au compte de service utilisé par la compilation. Par défaut, les builds utilisent le compte de service builder. Le secret d'extraction est automatiquement ajouté à la compilation si le secret contient un identifiant qui correspond au référentiel hébergeant l'image d'entrée. Pour lier un secret d'extraction au compte de service utilisé par la compilation, exécutez :
$ oc secrets link builder dockerhubCette fonctionnalité n'est pas prise en charge pour les constructions utilisant la stratégie personnalisée.
Images sur des registres en miroir nécessitant des secrets d'extraction
Lorsque vous utilisez une image d'entrée provenant d'un registre en miroir, si vous obtenez un message build error: failed to pull image, vous pouvez résoudre l'erreur en utilisant l'une des méthodes suivantes :
- Créez un secret d'entrée contenant les informations d'authentification pour le référentiel de l'image du constructeur et tous les miroirs connus. Dans ce cas, créez un secret d'extraction pour les informations d'identification du registre d'images et de ses miroirs.
-
Utiliser le secret d'entrée comme secret de sortie sur l'objet
BuildConfig.
2.3.4. Source Git
Lorsqu'il est spécifié, le code source est extrait de l'emplacement fourni.
Si vous fournissez un fichier Docker en ligne, il écrase le fichier Docker qui se trouve à l'adresse contextDir du dépôt Git.
La définition de la source fait partie de la section spec du site BuildConfig:
source:
git:
uri: "https://github.com/openshift/ruby-hello-world"
ref: "master"
contextDir: "app/dir"
dockerfile: "FROM openshift/ruby-22-centos7\nUSER example" - 1
- Le champ
gitcontient l'URI du dépôt Git distant du code source. En option, le champrefpermet d'extraire une référence Git spécifique. Un champrefvalide peut être une balise SHA1 ou un nom de branche. - 2
- Le champ
contextDirvous permet de remplacer l'emplacement par défaut dans le référentiel du code source où la compilation recherche le code source de l'application. Si votre application existe dans un sous-répertoire, vous pouvez remplacer l'emplacement par défaut (le dossier racine) à l'aide de ce champ. - 3
- Si le champ facultatif
dockerfileest fourni, il doit s'agir d'une chaîne contenant un Dockerfile qui écrase tout Dockerfile existant dans le référentiel source.
Si le champ ref indique une demande d'extraction, le système utilise une opération git fetch et ensuite la caisse FETCH_HEAD.
Si aucune valeur ref n'est fournie, OpenShift Container Platform effectue un clone superficiel (--depth=1). Dans ce cas, seuls les fichiers associés au commit le plus récent sur la branche par défaut (généralement master) sont téléchargés. Les dépôts se téléchargent ainsi plus rapidement, mais sans l'historique complet des livraisons. Pour effectuer un git clone complet de la branche par défaut d'un dépôt spécifié, définissez ref comme étant le nom de la branche par défaut (par exemple master).
Les opérations de clonage de Git qui passent par un proxy qui effectue un détournement TLS ou un recryptage de la connexion proxy par l'homme du milieu (MITM) ne fonctionnent pas.
2.3.4.1. Utilisation d'un proxy
Si votre dépôt Git n'est accessible qu'à l'aide d'un proxy, vous pouvez définir le proxy à utiliser dans la section source de la configuration de construction. Vous pouvez configurer un proxy HTTP et HTTPS à utiliser. Les deux champs sont facultatifs. Les domaines pour lesquels aucun proxy ne doit être utilisé peuvent également être spécifiés dans le champ NoProxy.
Votre URI source doit utiliser le protocole HTTP ou HTTPS pour que cela fonctionne.
source:
git:
uri: "https://github.com/openshift/ruby-hello-world"
ref: "master"
httpProxy: http://proxy.example.com
httpsProxy: https://proxy.example.com
noProxy: somedomain.com, otherdomain.com
Pour les constructions de la stratégie Pipeline, étant donné les restrictions actuelles du plugin Git pour Jenkins, toutes les opérations Git via le plugin Git n'utilisent pas le proxy HTTP ou HTTPS défini dans le site BuildConfig. Le plugin Git utilise uniquement le proxy configuré dans l'interface utilisateur de Jenkins, dans le panneau Plugin Manager. Ce proxy est ensuite utilisé pour toutes les interactions Git dans Jenkins, pour tous les travaux.
2.3.4.2. Source Clone Secrets
Les modules de construction ont besoin d'accéder à tous les dépôts Git définis comme source pour une construction. Les secrets de clone de source sont utilisés pour fournir au pod constructeur un accès auquel il n'aurait normalement pas accès, comme les dépôts privés ou les dépôts avec des certificats SSL auto-signés ou non fiables.
Les configurations suivantes de clone secret de source sont prises en charge :
- fichier .gitconfig
- Authentification de base
- Authentification par clé SSH
- Autorités de certification de confiance
Vous pouvez également utiliser des combinaisons de ces configurations pour répondre à vos besoins spécifiques.
2.3.4.2.1. Ajout automatique d'un secret de clone de source à une configuration de construction
Lorsqu'un BuildConfig est créé, OpenShift Container Platform peut automatiquement remplir sa référence de secret de clone source. Ce comportement permet aux builds résultants d'utiliser automatiquement les informations d'identification stockées dans le secret référencé pour s'authentifier auprès d'un dépôt Git distant, sans nécessiter de configuration supplémentaire.
Pour utiliser cette fonctionnalité, un secret contenant les informations d'identification du dépôt Git doit exister dans l'espace de noms dans lequel le site BuildConfig est créé ultérieurement. Ce secret doit inclure une ou plusieurs annotations préfixées par build.openshift.io/source-secret-match-uri-. La valeur de chacune de ces annotations est un modèle d'identifiant de ressource uniforme (URI), défini comme suit. Lorsqu'un BuildConfig est créé sans référence à un secret de clone source et que son URI de source Git correspond à un modèle d'URI dans une annotation de secret, OpenShift Container Platform insère automatiquement une référence à ce secret dans le BuildConfig.
Conditions préalables
Un modèle d'URI doit être composé de
-
Un système valide :
*://,git://,http://,https://oussh:// -
Un hôte : *` ou un nom d'hôte ou une adresse IP valide précédé(e) éventuellement de
*. -
Un chemin d'accès :
/*ou/suivi de caractères quelconques comprenant éventuellement des caractères*
Dans tous les cas ci-dessus, le caractère * est interprété comme un joker.
Les modèles d'URI doivent correspondre aux URI de la source Git, qui sont conformes à la norme RFC3986. Ne pas inclure de nom d'utilisateur (ou de mot de passe) dans un modèle d'URI.
Par exemple, si vous utilisez ssh://git@bitbucket.atlassian.com:7999/ATLASSIAN jira.git pour l'URL d'un dépôt git, le secret de la source doit être spécifié comme ssh://bitbucket.atlassian.com:7999/* (et non ssh://git@bitbucket.atlassian.com:7999/*).
$ oc annotate secret mysecret \
'build.openshift.io/source-secret-match-uri-1=ssh://bitbucket.atlassian.com:7999/*'Procédure
Si plusieurs secrets correspondent à l'URI Git d'une BuildConfig particulière, OpenShift Container Platform sélectionne le secret dont la correspondance est la plus longue. Cela permet une surcharge de base, comme dans l'exemple suivant.
Le fragment suivant montre deux secrets de clone source partiels, le premier correspondant à tout serveur du domaine mycorp.com accédé par HTTPS, et le second surpassant l'accès aux serveurs mydev1.mycorp.com et mydev2.mycorp.com:
kind: Secret
apiVersion: v1
metadata:
name: matches-all-corporate-servers-https-only
annotations:
build.openshift.io/source-secret-match-uri-1: https://*.mycorp.com/*
data:
...
---
kind: Secret
apiVersion: v1
metadata:
name: override-for-my-dev-servers-https-only
annotations:
build.openshift.io/source-secret-match-uri-1: https://mydev1.mycorp.com/*
build.openshift.io/source-secret-match-uri-2: https://mydev2.mycorp.com/*
data:
...Ajouter une annotation
build.openshift.io/source-secret-match-uri-à un secret préexistant en utilisant :$ oc annotate secret mysecret \ 'build.openshift.io/source-secret-match-uri-1=https://*.mycorp.com/*'
2.3.4.2.2. Ajout manuel d'un secret de clone source
Les secrets de clone de source peuvent être ajoutés manuellement à une configuration de compilation en ajoutant un champ sourceSecret à la section source à l'intérieur de BuildConfig et en lui attribuant le nom du secret que vous avez créé. Dans cet exemple, il s'agit de basicsecret.
apiVersion: "v1"
kind: "BuildConfig"
metadata:
name: "sample-build"
spec:
output:
to:
kind: "ImageStreamTag"
name: "sample-image:latest"
source:
git:
uri: "https://github.com/user/app.git"
sourceSecret:
name: "basicsecret"
strategy:
sourceStrategy:
from:
kind: "ImageStreamTag"
name: "python-33-centos7:latest"Procédure
Vous pouvez également utiliser la commande oc set build-secret pour définir le secret du clone source sur une configuration de construction existante.
Pour définir le secret du clone source sur une configuration de compilation existante, entrez la commande suivante :
$ oc set build-secret --source bc/sample-build basicsecret
2.3.4.2.3. Création d'un secret à partir d'un fichier .gitconfig
Si le clonage de votre application dépend d'un fichier .gitconfig, vous pouvez créer un secret qui le contient. Ajoutez-le au compte de service builder, puis à votre fichier BuildConfig.
Procédure
-
Pour créer un secret à partir d'un fichier
.gitconfig:
$ oc create secret generic <secret_name> --from-file=<path/to/.gitconfig>
La vérification SSL peut être désactivée si sslVerify=false est défini pour la section http dans votre fichier .gitconfig:
[http]
sslVerify=false2.3.4.2.4. Création d'un secret à partir d'un fichier .gitconfig pour Git sécurisé
Si votre serveur Git est sécurisé par un protocole SSL bidirectionnel et un nom d'utilisateur avec mot de passe, vous devez ajouter les fichiers de certificats à votre compilation de sources et ajouter des références aux fichiers de certificats dans le fichier .gitconfig.
Conditions préalables
- Vous devez avoir des informations d'identification Git.
Procédure
Ajoutez les fichiers de certificats à votre version source et ajoutez des références aux fichiers de certificats dans le fichier .gitconfig.
-
Ajoutez les fichiers
client.crt,cacert.crt, etclient.keyau dossier/var/run/secrets/openshift.io/source/dans le code source de l'application. Dans le fichier
.gitconfigdu serveur, ajoutez la section[http]comme indiqué dans l'exemple suivant :# cat .gitconfigExemple de sortie
[user] name = <name> email = <email> [http] sslVerify = false sslCert = /var/run/secrets/openshift.io/source/client.crt sslKey = /var/run/secrets/openshift.io/source/client.key sslCaInfo = /var/run/secrets/openshift.io/source/cacert.crtCréer le secret :
$ oc create secret generic <secret_name> \ --from-literal=username=<user_name> \1 --from-literal=password=<password> \2 --from-file=.gitconfig=.gitconfig \ --from-file=client.crt=/var/run/secrets/openshift.io/source/client.crt \ --from-file=cacert.crt=/var/run/secrets/openshift.io/source/cacert.crt \ --from-file=client.key=/var/run/secrets/openshift.io/source/client.key
Pour éviter d'avoir à saisir à nouveau votre mot de passe, veillez à spécifier l'image source-image (S2I) dans vos constructions. Cependant, si vous ne pouvez pas cloner le référentiel, vous devez toujours spécifier votre nom d'utilisateur et votre mot de passe pour promouvoir la compilation.
2.3.4.2.5. Création d'un secret à partir du code source authentification de base
L'authentification de base nécessite soit une combinaison de --username et --password, soit un jeton pour s'authentifier auprès du serveur de gestion de la configuration logicielle (SCM).
Conditions préalables
- Nom d'utilisateur et mot de passe pour accéder au référentiel privé.
Procédure
Créez d'abord le secret avant d'utiliser les adresses
--usernameet--passwordpour accéder au dépôt privé :$ oc create secret generic <secret_name> \ --from-literal=username=<user_name> \ --from-literal=password=<password> \ --type=kubernetes.io/basic-authCréer un secret d'authentification de base avec un jeton :
$ oc create secret generic <secret_name> \ --from-literal=password=<token> \ --type=kubernetes.io/basic-auth
2.3.4.2.6. Création d'un secret à partir du code source Authentification par clé SSH
L'authentification basée sur une clé SSH nécessite une clé SSH privée.
Les clés du référentiel sont généralement situées dans le répertoire $HOME/.ssh/ et sont nommées par défaut id_dsa.pub, id_ecdsa.pub, id_ed25519.pub ou id_rsa.pub.
Procédure
Générer les informations d'identification de la clé SSH :
$ ssh-keygen -t ed25519 -C "your_email@example.com"NoteLa création d'une phrase de passe pour la clé SSH empêche OpenShift Container Platform de se construire. Lorsque vous êtes invité à saisir une phrase de passe, laissez-la vide.
Deux fichiers sont créés : la clé publique et la clé privée correspondante (l'une des clés suivantes :
id_dsa,id_ecdsa,id_ed25519ouid_rsa). Une fois ces deux fichiers en place, consultez le manuel de votre système de gestion du contrôle des sources (SCM) pour savoir comment télécharger la clé publique. La clé privée est utilisée pour accéder à votre dépôt privé.Avant d'utiliser la clé SSH pour accéder au référentiel privé, créez le secret :
$ oc create secret generic <secret_name> \ --from-file=ssh-privatekey=<path/to/ssh/private/key> \ --from-file=<path/to/known_hosts> \1 --type=kubernetes.io/ssh-auth- 1
- Facultatif : L'ajout de ce champ permet une vérification stricte de la clé d'hôte du serveur.
AvertissementLe fait d'ignorer le fichier
known_hostslors de la création du secret rend la construction vulnérable à une attaque potentielle de type "man-in-the-middle" (MITM).NoteAssurez-vous que le fichier
known_hostscontient une entrée pour l'hôte de votre code source.
2.3.4.2.7. Création d'un secret à partir d'un code source autorités de certification de confiance
L'ensemble des autorités de certification (CA) Transport Layer Security (TLS) qui sont approuvées lors d'une opération de clonage Git sont intégrées dans les images d'infrastructure OpenShift Container Platform. Si votre serveur Git utilise un certificat auto-signé ou signé par une autorité non approuvée par l'image, vous pouvez créer un secret qui contient le certificat ou désactiver la vérification TLS.
Si vous créez un secret pour le certificat CA, OpenShift Container Platform l'utilise pour accéder à votre serveur Git pendant l'opération de clonage Git. L'utilisation de cette méthode est nettement plus sûre que la désactivation de la vérification SSL de Git, qui accepte tout certificat TLS présenté.
Procédure
Créer un secret avec un fichier de certificat CA.
Si votre autorité de certification utilise des autorités de certification intermédiaires, combinez les certificats de toutes les autorités de certification dans un fichier
ca.crt. Entrez la commande suivante :cat intermediateCA.crt intermediateCA.crt rootCA.crt > ca.crtCréer le secret :
oc create secret generic mycert --from-file=ca.crt=</path/to/file> $ oc create secret generic mycert --from-file=ca.crt=</path/to/file>1 - 1
- Vous devez utiliser le nom de clé
ca.crt.
2.3.4.2.8. Combinaisons secrètes de la source
Vous pouvez combiner les différentes méthodes de création de clones secrets de sources pour répondre à vos besoins spécifiques.
2.3.4.2.8.1. Création d'un secret d'authentification basé sur SSH avec un fichier .gitconfig
Vous pouvez combiner les différentes méthodes de création de secrets de clone source pour répondre à vos besoins spécifiques, par exemple un secret d'authentification basé sur SSH avec un fichier .gitconfig.
Conditions préalables
- Authentification SSH
- fichier .gitconfig
Procédure
Pour créer un secret d'authentification basé sur SSH avec un fichier
.gitconfig, exécutez :$ oc create secret generic <secret_name> \ --from-file=ssh-privatekey=<path/to/ssh/private/key> \ --from-file=<path/to/.gitconfig> \ --type=kubernetes.io/ssh-auth
2.3.4.2.8.2. Création d'un secret combinant un fichier .gitconfig et un certificat CA
Vous pouvez combiner les différentes méthodes de création de secrets de clone source pour répondre à vos besoins spécifiques, par exemple un secret combinant un fichier .gitconfig et un certificat d'autorité de certification (CA).
Conditions préalables
- fichier .gitconfig
- Certificat CA
Procédure
Pour créer un secret combinant un fichier
.gitconfiget un certificat d'autorité de certification, exécutez la commande suivante :$ oc create secret generic <secret_name> \ --from-file=ca.crt=<path/to/certificate> \ --from-file=<path/to/.gitconfig>
2.3.4.2.8.3. Création d'un secret d'authentification de base avec un certificat d'autorité de certification
Vous pouvez combiner les différentes méthodes de création de secrets de clone source pour répondre à vos besoins spécifiques, par exemple un secret combinant une authentification de base et un certificat d'autorité de certification (CA).
Conditions préalables
- Données d'authentification de base
- Certificat CA
Procédure
Créer un secret d'authentification de base avec un certificat CA, exécuter :
$ oc create secret generic <secret_name> \ --from-literal=username=<user_name> \ --from-literal=password=<password> \ --from-file=ca-cert=</path/to/file> \ --type=kubernetes.io/basic-auth
2.3.4.2.8.4. Création d'un secret d'authentification de base avec un fichier .gitconfig
Vous pouvez combiner les différentes méthodes de création de secrets de clone source pour répondre à vos besoins spécifiques, par exemple un secret combinant une authentification de base et un fichier .gitconfig.
Conditions préalables
- Données d'authentification de base
-
.gitconfigfichier
Procédure
Pour créer un secret d'authentification de base avec un fichier
.gitconfig, exécutez :$ oc create secret generic <secret_name> \ --from-literal=username=<user_name> \ --from-literal=password=<password> \ --from-file=</path/to/.gitconfig> \ --type=kubernetes.io/basic-auth
2.3.4.2.8.5. Création d'un secret d'authentification de base avec un fichier .gitconfig et un certificat CA
Vous pouvez combiner les différentes méthodes de création de secrets de clone source pour répondre à vos besoins spécifiques, par exemple un secret combinant une authentification de base, un fichier .gitconfig et un certificat d'autorité de certification (CA).
Conditions préalables
- Données d'authentification de base
-
.gitconfigfichier - Certificat CA
Procédure
Pour créer un secret d'authentification de base avec un fichier
.gitconfiget un certificat CA, exécutez :$ oc create secret generic <secret_name> \ --from-literal=username=<user_name> \ --from-literal=password=<password> \ --from-file=</path/to/.gitconfig> \ --from-file=ca-cert=</path/to/file> \ --type=kubernetes.io/basic-auth
2.3.5. Source binaire (locale)
La diffusion de contenu à partir d'un système de fichiers local vers le constructeur est appelée construction de type Binary. La valeur correspondante de BuildConfig.spec.source.type est Binary pour ces constructions.
Ce type de source est unique en ce sens qu'il est utilisé uniquement en fonction de l'utilisation que vous faites du site oc start-build.
Les constructions de type binaire nécessitent que le contenu soit diffusé à partir du système de fichiers local. Il n'est donc pas possible de déclencher automatiquement une construction de type binaire, comme on le ferait avec un déclencheur de changement d'image. En effet, les fichiers binaires ne peuvent pas être fournis. De même, vous ne pouvez pas lancer de builds de type binaire à partir de la console web.
Pour utiliser les constructions binaires, invoquez oc start-build avec l'une de ces options :
-
--from-file: Le contenu du fichier que vous spécifiez est envoyé sous forme de flux binaire au constructeur. Vous pouvez également spécifier l'URL d'un fichier. Ensuite, le constructeur stocke les données dans un fichier portant le même nom en haut du contexte de construction. -
--from-diret--from-repo: Le contenu est archivé et envoyé sous forme de flux binaire au constructeur. Ensuite, le constructeur extrait le contenu de l'archive dans le répertoire du contexte de construction. Avec--from-dir, vous pouvez également spécifier l'URL d'une archive qui sera extraite. -
--from-archive: L'archive que vous spécifiez est envoyée au constructeur, où elle est extraite dans le répertoire du contexte de construction. Cette option se comporte de la même manière que--from-dir; une archive est créée sur votre hôte en premier, lorsque l'argument de ces options est un répertoire.
Dans chacun des cas énumérés précédemment :
-
Si votre
BuildConfiga déjà un type de sourceBinarydéfini, il est effectivement ignoré et remplacé par ce que le client envoie. -
Si votre
BuildConfiga un type de sourceGitdéfini, il est dynamiquement désactivé, puisqueBinaryetGits'excluent mutuellement et que les données du flux binaire fourni au constructeur sont prioritaires.
Au lieu d'un nom de fichier, vous pouvez transmettre une URL avec un schéma HTTP ou HTTPS à --from-file et --from-archive. Lorsque vous utilisez --from-file avec une URL, le nom du fichier dans l'image du constructeur est déterminé par l'en-tête Content-Disposition envoyé par le serveur web, ou par le dernier composant du chemin URL si l'en-tête n'est pas présent. Aucune forme d'authentification n'est prise en charge et il n'est pas possible d'utiliser un certificat TLS personnalisé ou de désactiver la validation du certificat.
Lors de l'utilisation de oc new-build --binary=true, la commande s'assure que les restrictions associées aux constructions binaires sont appliquées. Le résultat BuildConfig a un type de source de Binary, ce qui signifie que la seule façon valide d'exécuter une compilation pour ce BuildConfig est d'utiliser oc start-build avec l'une des options --from pour fournir les données binaires requises.
Les options Dockerfile et contextDir source ont une signification particulière pour les constructions binaires.
Dockerfile peut être utilisé avec n'importe quelle source de construction binaire. Si Dockerfile est utilisé et que le flux binaire est une archive, son contenu sert de Dockerfile de remplacement pour tout Dockerfile dans l'archive. Si Dockerfile est utilisé avec l'argument --from-file, et que l'argument file est nommé Dockerfile, la valeur de Dockerfile remplace la valeur du flux binaire.
Dans le cas du flux binaire encapsulant le contenu extrait de l'archive, la valeur du champ contextDir est interprétée comme un sous-répertoire de l'archive et, s'il est valide, le constructeur passe à ce sous-répertoire avant d'exécuter la construction.
2.3.6. Secrets d'entrée et cartes de configuration
Pour éviter que le contenu des secrets d'entrée et des cartes de configuration n'apparaisse dans les images de conteneurs de sortie de la construction, utilisez des volumes de construction dans vos stratégies de construction Docker et de construction source-image.
Dans certains cas, les opérations de construction nécessitent des informations d'identification ou d'autres données de configuration pour accéder aux ressources dépendantes, mais il n'est pas souhaitable que ces informations soient placées dans le contrôle de la source. Vous pouvez définir des secrets d'entrée et des cartes de configuration d'entrée à cette fin.
Par exemple, lorsque vous construisez une application Java avec Maven, vous pouvez mettre en place un miroir privé de Maven Central ou JCenter auquel vous accédez par des clés privées. Pour télécharger des bibliothèques à partir de ce miroir privé, vous devez fournir les éléments suivants :
-
Un fichier
settings.xmlconfiguré avec l'URL du miroir et les paramètres de connexion. -
Une clé privée référencée dans le fichier de configuration, telle que
~/.ssh/id_rsa.
Pour des raisons de sécurité, vous ne souhaitez pas exposer vos informations d'identification dans l'image de l'application.
Cet exemple décrit une application Java, mais vous pouvez utiliser la même approche pour ajouter des certificats SSL dans le répertoire /etc/ssl/certs, des clés ou des jetons d'API, des fichiers de licence, etc.
2.3.6.1. Qu'est-ce qu'un secret ?
Le type d'objet Secret fournit un mécanisme pour contenir des informations sensibles telles que les mots de passe, les fichiers de configuration du client OpenShift Container Platform, les fichiers dockercfg, les informations d'identification du référentiel source privé, etc. Les secrets découplent le contenu sensible des pods. Vous pouvez monter des secrets dans des conteneurs à l'aide d'un plugin de volume ou le système peut utiliser des secrets pour effectuer des actions au nom d'un pod.
Définition de l'objet secret YAML
apiVersion: v1
kind: Secret
metadata:
name: test-secret
namespace: my-namespace
type: Opaque
data:
username: dmFsdWUtMQ0K
password: dmFsdWUtMg0KDQo=
stringData:
hostname: myapp.mydomain.com - 1
- Indique la structure des noms et des valeurs des clés du secret.
- 2
- Le format autorisé pour les clés du champ
datadoit respecter les directives de la valeurDNS_SUBDOMAINdans le glossaire des identifiants Kubernetes. - 3
- La valeur associée aux clés de la carte
datadoit être encodée en base64. - 4
- Les entrées de la carte
stringDatasont converties en base64 et sont ensuite déplacées automatiquement vers la cartedata. Ce champ est en écriture seule. La valeur n'est renvoyée que par le champdata. - 5
- La valeur associée aux clés de la carte
stringDataest constituée de chaînes de texte en clair.
2.3.6.1.1. Propriétés des secrets
Les principales propriétés sont les suivantes
- Les données secrètes peuvent être référencées indépendamment de leur définition.
- Les volumes de données secrètes sont sauvegardés par des installations de stockage de fichiers temporaires (tmpfs) et ne s'arrêtent jamais sur un nœud.
- Les données secrètes peuvent être partagées au sein d'un espace de noms.
2.3.6.1.2. Types de secrets
La valeur du champ type indique la structure des noms et des valeurs des clés du secret. Le type peut être utilisé pour imposer la présence de noms d'utilisateur et de clés dans l'objet secret. Si vous ne souhaitez pas de validation, utilisez le type opaque, qui est le type par défaut.
Indiquez l'un des types suivants pour déclencher une validation minimale côté serveur afin de garantir la présence de noms de clés spécifiques dans les données secrètes :
-
kubernetes.io/service-account-token. Utilise un jeton de compte de service. -
kubernetes.io/dockercfg. Utilise le fichier.dockercfgpour les informations d'identification Docker requises. -
kubernetes.io/dockerconfigjson. Utilise le fichier.docker/config.jsonpour les informations d'identification Docker requises. -
kubernetes.io/basic-auth. A utiliser avec l'authentification de base. -
kubernetes.io/ssh-auth. A utiliser avec l'authentification par clé SSH. -
kubernetes.io/tls. A utiliser avec les autorités de certification TLS.
Indiquez type= Opaque si vous ne souhaitez pas de validation, ce qui signifie que le secret ne prétend pas se conformer à une convention pour les noms de clés ou les valeurs. Un secret opaque permet d'utiliser des paires key:value non structurées pouvant contenir des valeurs arbitraires.
Vous pouvez spécifier d'autres types arbitraires, tels que example.com/my-secret-type. Ces types ne sont pas appliqués côté serveur, mais ils indiquent que le créateur du secret avait l'intention de se conformer aux exigences clé/valeur de ce type.
2.3.6.1.3. Mises à jour des secrets
Lorsque vous modifiez la valeur d'un secret, la valeur utilisée par un module déjà en cours d'exécution ne change pas dynamiquement. Pour modifier un secret, vous devez supprimer le module original et en créer un nouveau, dans certains cas avec un PodSpec identique.
La mise à jour d'un secret suit le même processus que le déploiement d'une nouvelle image de conteneur. Vous pouvez utiliser la commande kubectl rolling-update.
La valeur resourceVersion d'un secret n'est pas spécifiée lorsqu'il est référencé. Par conséquent, si un secret est mis à jour au moment où les modules démarrent, la version du secret utilisée pour le module n'est pas définie.
Actuellement, il n'est pas possible de vérifier la version de la ressource d'un objet secret qui a été utilisée lors de la création d'un pod. Il est prévu que les modules communiquent cette information, de sorte qu'un contrôleur puisse redémarrer ceux qui utilisent un ancien resourceVersion. Dans l'intervalle, ne mettez pas à jour les données des secrets existants, mais créez-en de nouveaux avec des noms distincts.
2.3.6.2. Créer des secrets
Vous devez créer un secret avant de créer les modules qui dépendent de ce secret.
Lors de la création de secrets :
- Créer un objet secret avec des données secrètes.
- Mettre à jour le compte de service pod pour autoriser la référence au secret.
-
Créer un pod, qui consomme le secret en tant que variable d'environnement ou en tant que fichier à l'aide d'un volume
secret.
Procédure
La commande create permet de créer un objet secret à partir d'un fichier JSON ou YAML :
$ oc create -f <filename>Par exemple, vous pouvez créer un secret à partir de votre fichier local
.docker/config.json:$ oc create secret generic dockerhub \ --from-file=.dockerconfigjson=<path/to/.docker/config.json> \ --type=kubernetes.io/dockerconfigjsonCette commande génère une spécification JSON du secret nommé
dockerhubet crée l'objet.Définition de l'objet secret opaque YAML
apiVersion: v1 kind: Secret metadata: name: mysecret type: Opaque1 data: username: dXNlci1uYW1l password: cGFzc3dvcmQ=- 1
- Spécifie un secret opaque.
Fichier JSON de configuration Docker Définition de l'objet secret
apiVersion: v1 kind: Secret metadata: name: aregistrykey namespace: myapps type: kubernetes.io/dockerconfigjson1 data: .dockerconfigjson:bm5ubm5ubm5ubm5ubm5ubm5ubm5ubmdnZ2dnZ2dnZ2dnZ2dnZ2dnZ2cgYXV0aCBrZXlzCg==2
2.3.6.3. Utiliser les secrets
Après avoir créé des secrets, vous pouvez créer un pod pour référencer votre secret, obtenir des journaux et supprimer le pod.
Procédure
Créez le pod pour référencer votre secret :
oc create -f <votre_fichier_yaml_>.yamlObtenir les journaux :
$ oc logs secret-example-podSupprimer le pod :
$ oc delete pod secret-example-pod
2.3.6.4. Ajout de secrets d'entrée et de cartes de configuration
Pour fournir des informations d'identification et d'autres données de configuration à une compilation sans les placer dans le contrôle du code source, vous pouvez définir des secrets d'entrée et des cartes de configuration d'entrée.
Dans certains cas, les opérations de construction nécessitent des informations d'identification ou d'autres données de configuration pour accéder aux ressources dépendantes. Pour rendre ces informations disponibles sans les placer dans le contrôle du code source, vous pouvez définir des secrets d'entrée et des cartes de configuration d'entrée.
Procédure
Pour ajouter un secret d'entrée, des cartes de configuration ou les deux à un objet BuildConfig existant :
Créer l'objet
ConfigMap, s'il n'existe pas :$ oc create configmap settings-mvn \ --from-file=settings.xml=<path/to/settings.xml>Cela crée une nouvelle carte de configuration nommée
settings-mvn, qui contient le contenu en texte brut du fichiersettings.xml.AstuceVous pouvez également appliquer le YAML suivant pour créer la carte de configuration :
apiVersion: core/v1 kind: ConfigMap metadata: name: settings-mvn data: settings.xml: | <settings> … # Insert maven settings here </settings>Créer l'objet
Secret, s'il n'existe pas :$ oc create secret generic secret-mvn \ --from-file=ssh-privatekey=<path/to/.ssh/id_rsa> --type=kubernetes.io/ssh-authCela crée un nouveau secret nommé
secret-mvn, qui contient le contenu encodé en base64 de la clé privéeid_rsa.AstuceVous pouvez également appliquer le langage YAML suivant pour créer le secret d'entrée :
apiVersion: core/v1 kind: Secret metadata: name: secret-mvn type: kubernetes.io/ssh-auth data: ssh-privatekey: | # Insert ssh private key, base64 encodedAjoutez la carte de configuration et le secret à la section
sourcede l'objetBuildConfigexistant :source: git: uri: https://github.com/wildfly/quickstart.git contextDir: helloworld configMaps: - configMap: name: settings-mvn secrets: - secret: name: secret-mvn
Pour inclure le secret et la carte de configuration dans un nouvel objet BuildConfig, exécutez la commande suivante :
$ oc new-build \
openshift/wildfly-101-centos7~https://github.com/wildfly/quickstart.git \
--context-dir helloworld --build-secret “secret-mvn” \
--build-config-map "settings-mvn"
Pendant la construction, les fichiers settings.xml et id_rsa sont copiés dans le répertoire où se trouve le code source. Dans les images du constructeur S2I d'OpenShift Container Platform, il s'agit du répertoire de travail de l'image, qui est défini à l'aide de l'instruction WORKDIR dans le fichier Dockerfile. Si vous souhaitez spécifier un autre répertoire, ajoutez un destinationDir à la définition :
source:
git:
uri: https://github.com/wildfly/quickstart.git
contextDir: helloworld
configMaps:
- configMap:
name: settings-mvn
destinationDir: ".m2"
secrets:
- secret:
name: secret-mvn
destinationDir: ".ssh"
Vous pouvez également spécifier le répertoire de destination lors de la création d'un nouvel objet BuildConfig:
$ oc new-build \
openshift/wildfly-101-centos7~https://github.com/wildfly/quickstart.git \
--context-dir helloworld --build-secret “secret-mvn:.ssh” \
--build-config-map "settings-mvn:.m2"
Dans les deux cas, le fichier settings.xml est ajouté au répertoire ./.m2 de l'environnement de construction et la clé id_rsa est ajoutée au répertoire ./.ssh.
2.3.6.5. Stratégie de la source à l'image
Lors de l'utilisation d'une stratégie Source, tous les secrets d'entrée définis sont copiés dans leur destinationDir respectif. Si vous avez laissé destinationDir vide, les secrets sont placés dans le répertoire de travail de l'image du constructeur.
La même règle est utilisée lorsque destinationDir est un chemin relatif. Les secrets sont placés dans les chemins relatifs au répertoire de travail de l'image. Le dernier répertoire du chemin destinationDir est créé s'il n'existe pas dans l'image du constructeur. Tous les répertoires précédents dans le chemin destinationDir doivent exister, sinon une erreur se produit.
Les secrets d'entrée sont ajoutés comme étant inscriptibles dans le monde, ont les permissions 0666 et sont tronqués à la taille zéro après l'exécution du script assemble. Cela signifie que les fichiers secrets existent dans l'image résultante, mais qu'ils sont vides pour des raisons de sécurité.
Les cartes de configuration en entrée ne sont pas tronquées après la fin du script assemble.
2.3.6.6. Stratégie Docker
Lorsque vous utilisez une stratégie Docker, vous pouvez ajouter tous les secrets d'entrée définis dans votre image de conteneur en utilisant les instructions ADD et COPY dans votre fichier Docker.
Si vous ne spécifiez pas destinationDir pour un secret, les fichiers sont copiés dans le même répertoire que celui où se trouve le fichier Docker. Si vous spécifiez un chemin relatif comme destinationDir, alors les secrets sont copiés dans ce répertoire, par rapport à l'emplacement de votre Dockerfile. Cela rend les fichiers secrets disponibles pour l'opération de construction de Docker en tant que partie du répertoire de contexte utilisé pendant la construction.
Exemple de fichier Docker référençant les données des cartes secrètes et de configuration
FROM centos/ruby-22-centos7
USER root
COPY ./secret-dir /secrets
COPY ./config /
# Create a shell script that will output secrets and ConfigMaps when the image is run
RUN echo '#!/bin/sh' > /input_report.sh
RUN echo '(test -f /secrets/secret1 && echo -n "secret1=" && cat /secrets/secret1)' >> /input_report.sh
RUN echo '(test -f /config && echo -n "relative-configMap=" && cat /config)' >> /input_report.sh
RUN chmod 755 /input_report.sh
CMD ["/bin/sh", "-c", "/input_report.sh"]Les utilisateurs suppriment normalement leurs secrets d'entrée de l'image de l'application finale afin que les secrets ne soient pas présents dans le conteneur fonctionnant à partir de cette image. Cependant, les secrets existent toujours dans l'image elle-même, dans la couche où ils ont été ajoutés. Cette suppression fait partie du fichier Docker lui-même.
Pour éviter que le contenu des secrets d'entrée et des cartes de configuration n'apparaisse dans les images du conteneur de sortie de la construction et éviter ce processus de suppression, utilisez plutôt des volumes de construction dans votre stratégie de construction Docker.
2.3.6.7. Stratégie personnalisée
Lors de l'utilisation d'une stratégie personnalisée, tous les secrets d'entrée et les cartes de configuration définis sont disponibles dans le conteneur du constructeur, dans le répertoire /var/run/secrets/openshift.io/build. L'image de compilation personnalisée doit utiliser ces secrets et ces cartes de configuration de manière appropriée. Avec la stratégie personnalisée, vous pouvez définir des secrets comme décrit dans les options de la stratégie personnalisée.
Il n'y a pas de différence technique entre les secrets de stratégie existants et les secrets d'entrée. Cependant, votre image de constructeur peut les distinguer et les utiliser différemment, en fonction du cas d'utilisation de votre construction.
Les secrets d'entrée sont toujours montés dans le répertoire /var/run/secrets/openshift.io/build, ou votre constructeur peut analyser la variable d'environnement $BUILD, qui inclut l'objet de construction complet.
Si un secret d'extraction pour le registre existe à la fois dans l'espace de noms et dans le nœud, les constructions utilisent par défaut le secret d'extraction de l'espace de noms.
2.3.7. Artéfacts externes
Il n'est pas recommandé de stocker des fichiers binaires dans un référentiel de sources. Par conséquent, vous devez définir une construction qui extrait des fichiers supplémentaires, tels que les dépendances Java .jar, au cours du processus de construction. La manière de procéder dépend de la stratégie de compilation que vous utilisez.
Pour une stratégie de construction de Source, vous devez insérer les commandes shell appropriées dans le script assemble:
.s2i/bin/assemble Fichier
#!/bin/sh
APP_VERSION=1.0
wget http://repository.example.com/app/app-$APP_VERSION.jar -O app.jar.s2i/bin/run Fichier
#!/bin/sh
exec java -jar app.jar
Pour une stratégie de construction Docker, vous devez modifier le fichier Docker et invoquer des commandes shell avec l'instructionRUN :
Extrait de Dockerfile
FROM jboss/base-jdk:8
ENV APP_VERSION 1.0
RUN wget http://repository.example.com/app/app-$APP_VERSION.jar -O app.jar
EXPOSE 8080
CMD [ "java", "-jar", "app.jar" ]
Dans la pratique, vous souhaiterez peut-être utiliser une variable d'environnement pour l'emplacement du fichier afin que le fichier spécifique à télécharger puisse être personnalisé à l'aide d'une variable d'environnement définie sur le site BuildConfig, plutôt que de mettre à jour le fichier Dockerfile ou le script assemble.
Vous avez le choix entre différentes méthodes pour définir les variables d'environnement :
-
Utilisation du fichier
.s2i/environment] (uniquement pour une stratégie de construction de source) -
Mise en place
BuildConfig -
Fournir explicitement en utilisant
oc start-build --env(uniquement pour les constructions qui sont déclenchées manuellement)
2.3.8. Utilisation des identifiants Docker pour les registres privés
Vous pouvez fournir aux constructions un fichier .docker/config.json avec des informations d'identification valides pour les registres de conteneurs privés. Cela vous permet de pousser l'image de sortie dans un registre d'images de conteneurs privé ou de tirer une image de construction du registre d'images de conteneurs privé qui nécessite une authentification.
Vous pouvez fournir des informations d'identification pour plusieurs référentiels dans le même registre, chacun avec des informations d'identification spécifiques à ce chemin d'accès au registre.
Pour le registre d'images de conteneurs d'OpenShift Container Platform, cela n'est pas nécessaire car les secrets sont générés automatiquement pour vous par OpenShift Container Platform.
Le fichier .docker/config.json se trouve par défaut dans votre répertoire personnel et a le format suivant :
auths:
index.docker.io/v1/:
auth: "YWRfbGzhcGU6R2labnRib21ifTE="
email: "user@example.com"
docker.io/my-namespace/my-user/my-image:
auth: "GzhYWRGU6R2fbclabnRgbkSp=""
email: "user@example.com"
docker.io/my-namespace:
auth: "GzhYWRGU6R2deesfrRgbkSp=""
email: "user@example.com"
Vous pouvez définir plusieurs registres d'images de conteneurs ou plusieurs référentiels dans le même registre. Vous pouvez également ajouter des entrées d'authentification à ce fichier en exécutant la commande docker login. Le fichier sera créé s'il n'existe pas.
Kubernetes fournit des objets Secret, qui peuvent être utilisés pour stocker la configuration et les mots de passe.
Conditions préalables
-
Vous devez disposer d'un fichier
.docker/config.json.
Procédure
Créez le secret à partir de votre fichier local
.docker/config.json:$ oc create secret generic dockerhub \ --from-file=.dockerconfigjson=<path/to/.docker/config.json> \ --type=kubernetes.io/dockerconfigjsonCette opération génère une spécification JSON du secret nommé
dockerhubet crée l'objet.Ajoutez un champ
pushSecretdans la sectionoutputdeBuildConfiget attribuez-lui le nom dusecretque vous avez créé, c'est-à-diredockerhubdans l'exemple précédent :spec: output: to: kind: "DockerImage" name: "private.registry.com/org/private-image:latest" pushSecret: name: "dockerhub"Vous pouvez utiliser la commande
oc set build-secretpour définir le secret de poussée sur la configuration de construction :$ oc set build-secret --push bc/sample-build dockerhubVous pouvez également lier le secret push au compte de service utilisé par le build au lieu de spécifier le champ
pushSecret. Par défaut, les builds utilisent le compte de servicebuilder. Le secret de poussée est automatiquement ajouté à la compilation si le secret contient un identifiant qui correspond au référentiel hébergeant l'image de sortie de la compilation.$ oc secrets link builder dockerhubTirer l'image du conteneur constructeur d'un registre privé d'images de conteneurs en spécifiant le champ
pullSecret, qui fait partie de la définition de la stratégie de construction :strategy: sourceStrategy: from: kind: "DockerImage" name: "docker.io/user/private_repository" pullSecret: name: "dockerhub"Vous pouvez utiliser la commande
oc set build-secretpour définir le secret d'extraction sur la configuration de construction :$ oc set build-secret --pull bc/sample-build dockerhubNoteCet exemple utilise
pullSecretdans une version Source, mais il est également applicable dans les versions Docker et Custom.Vous pouvez également lier le secret d'extraction au compte de service utilisé par la compilation au lieu de spécifier le champ
pullSecret. Par défaut, les builds utilisent le compte de servicebuilder. Le secret d'extraction est automatiquement ajouté à la compilation si le secret contient un identifiant qui correspond au référentiel hébergeant l'image d'entrée de la compilation. Pour lier le secret d'extraction au compte de service utilisé par la compilation au lieu de spécifier le champpullSecret, exécutez :$ oc secrets link builder dockerhubNoteVous devez spécifier une image
fromdans la spécificationBuildConfigpour bénéficier de cette fonctionnalité. Les constructions de stratégie Docker générées paroc new-buildouoc new-apppeuvent ne pas le faire dans certaines situations.
2.3.9. Construire des environnements
Comme pour les variables d'environnement pod, les variables d'environnement build peuvent être définies en termes de références à d'autres ressources ou variables à l'aide de l'API Downward. Il y a quelques exceptions, qui sont notées.
Vous pouvez également gérer les variables d'environnement définies dans le site BuildConfig à l'aide de la commande oc set env.
Le référencement des ressources du conteneur à l'aide de valueFrom dans les variables d'environnement de construction n'est pas pris en charge, car les références sont résolues avant la création du conteneur.
2.3.9.1. Utiliser les champs de compilation comme variables d'environnement
Vous pouvez injecter des informations sur l'objet de construction en définissant la variable d'environnement fieldPath source à l'adresse JsonPath du champ dont vous souhaitez obtenir la valeur.
La stratégie Jenkins Pipeline ne prend pas en charge la syntaxe valueFrom pour les variables d'environnement.
Procédure
Définissez la source de la variable d'environnement
fieldPathà l'adresseJsonPathdu champ dont vous souhaitez obtenir la valeur :env: - name: FIELDREF_ENV valueFrom: fieldRef: fieldPath: metadata.name
2.3.9.2. Utiliser des secrets comme variables d'environnement
Vous pouvez rendre les valeurs clés des secrets disponibles en tant que variables d'environnement à l'aide de la syntaxe valueFrom.
Cette méthode affiche les secrets en texte brut dans la sortie de la console du pod de construction. Pour éviter cela, utilisez plutôt des secrets d'entrée et des cartes de configuration.
Procédure
Pour utiliser un secret comme variable d'environnement, définissez la syntaxe
valueFrom:apiVersion: build.openshift.io/v1 kind: BuildConfig metadata: name: secret-example-bc spec: strategy: sourceStrategy: env: - name: MYVAL valueFrom: secretKeyRef: key: myval name: mysecret
2.3.10. Service servant les secrets de certificat
Les secrets de certificats de service sont destinés à prendre en charge des applications intergicielles complexes qui nécessitent des certificats prêts à l'emploi. Ils ont les mêmes paramètres que les certificats de serveur générés par l'outil d'administration pour les nœuds et les maîtres.
Procédure
Pour sécuriser la communication avec votre service, demandez au cluster de générer un couple certificat/clé de service signé dans un secret de votre espace de noms.
Définissez l'annotation
service.beta.openshift.io/serving-cert-secret-namesur votre service avec la valeur fixée au nom que vous voulez utiliser pour votre secret.Ensuite, votre
PodSpecpeut monter ce secret. Lorsqu'il est disponible, votre pod s'exécute. Le certificat est bon pour le nom DNS du service interne,<service.name>.<service.namespace>.svc.Le certificat et la clé sont au format PEM et sont stockés respectivement dans
tls.crtettls.key. La paire certificat/clé est automatiquement remplacée lorsqu'elle est proche de l'expiration. La date d'expiration est indiquée dans l'annotationservice.beta.openshift.io/expirysur le secret, qui est au format RFC3339.
Dans la plupart des cas, le nom DNS du service <service.name>.<service.namespace>.svc n'est pas routable de l'extérieur. L'utilisation principale de <service.name>.<service.namespace>.svc est pour la communication à l'intérieur d'un cluster ou d'un service, et avec des itinéraires de re-cryptage.
Les autres pods peuvent faire confiance aux certificats créés par le cluster, qui ne sont signés que pour les noms DNS internes, en utilisant le bundle de l'autorité de certification (CA) dans le fichier /var/run/secrets/kubernetes.io/serviceaccount/service-ca.crt qui est automatiquement monté dans leur pod.
L'algorithme de signature pour cette fonctionnalité est x509.SHA256WithRSA. Pour effectuer une rotation manuelle, supprimez le secret généré. Un nouveau certificat est créé.
2.3.11. Restrictions en matière de secrets
Pour utiliser un secret, un module doit faire référence au secret. Un secret peut être utilisé avec un module de trois façons :
- Pour remplir les variables d'environnement des conteneurs.
- En tant que fichiers dans un volume monté sur un ou plusieurs de ses conteneurs.
- Par kubelet lors de l'extraction des images pour le pod.
Les secrets de type volume écrivent les données dans le conteneur sous forme de fichier en utilisant le mécanisme de volume. imagePullSecrets utilise des comptes de service pour l'injection automatique du secret dans tous les pods d'un espace de noms.
Lorsqu'un modèle contient une définition de secret, le seul moyen pour le modèle d'utiliser le secret fourni est de s'assurer que les sources de volume du secret sont validées et que la référence d'objet spécifiée pointe effectivement vers un objet de type Secret. Par conséquent, un secret doit être créé avant tous les pods qui en dépendent. Le moyen le plus efficace de s'en assurer est de l'injecter automatiquement par l'intermédiaire d'un compte de service.
Les objets API secrets résident dans un espace de noms. Ils ne peuvent être référencés que par les pods de ce même espace de noms.
La taille des secrets individuels est limitée à 1 Mo. Il s'agit de décourager la création de secrets volumineux qui épuiseraient la mémoire de l'apiserver et du kubelet. Cependant, la création d'un certain nombre de secrets plus petits pourrait également épuiser la mémoire.
2.4. Gestion des résultats de la compilation
Les sections suivantes présentent une vue d'ensemble et des instructions pour la gestion des résultats de la compilation.
2.4.1. Production d'un bâtiment
Les constructions qui utilisent la stratégie docker ou source-to-image (S2I) aboutissent à la création d'une nouvelle image de conteneur. L'image est ensuite poussée vers le registre d'images de conteneurs spécifié dans la section output de la spécification Build.
Si le type de sortie est ImageStreamTag, alors l'image sera poussée vers le registre d'images intégré d'OpenShift et étiquetée dans le flux d'images spécifié. Si la sortie est de type DockerImage, alors le nom de la référence de sortie sera utilisé comme spécification docker push. La spécification peut contenir un registre ou sera par défaut DockerHub si aucun registre n'est spécifié. Si la section output de la spécification de construction est vide, alors l'image ne sera pas poussée à la fin de la construction.
Sortie vers un ImageStreamTag
spec:
output:
to:
kind: "ImageStreamTag"
name: "sample-image:latest"Sortie vers une spécification docker Push
spec:
output:
to:
kind: "DockerImage"
name: "my-registry.mycompany.com:5000/myimages/myimage:tag"2.4.2. Variables d'environnement de l'image de sortie
docker et la stratégie source-to-image (S2I) définissent les variables d'environnement suivantes sur les images de sortie :
| Variable | Description |
|---|---|
|
| Nom de la construction |
|
| Espace de noms de la construction |
|
| L'URL source de la construction |
|
| La référence Git utilisée dans la construction |
|
| Source commit utilisé dans la construction |
De plus, toute variable d'environnement définie par l'utilisateur, par exemple celles configurées avec les options S2I] ou docker strategy, fera également partie de la liste des variables d'environnement de l'image de sortie.
2.4.3. Étiquettes de l'image de sortie
docker et les constructions source-to-image (S2I)` définissent les étiquettes suivantes sur les images de sortie :
| Étiquette | Description |
|---|---|
|
| Auteur du commit source utilisé dans le build |
|
| Date du commit source utilisé dans le build |
|
| Hash du commit source utilisé dans le build |
|
| Message du commit source utilisé dans la construction |
|
| Branche ou référence spécifiée dans la source |
|
| URL source pour la construction |
Vous pouvez également utiliser le champ BuildConfig.spec.output.imageLabels pour spécifier une liste d'étiquettes personnalisées qui seront appliquées à chaque image construite à partir de la configuration de construction.
Étiquettes personnalisées à appliquer aux images construites
spec:
output:
to:
kind: "ImageStreamTag"
name: "my-image:latest"
imageLabels:
- name: "vendor"
value: "MyCompany"
- name: "authoritative-source-url"
value: "registry.mycompany.com"2.5. Utiliser des stratégies de construction
Les sections suivantes définissent les principales stratégies de construction prises en charge et expliquent comment les utiliser.
2.5.1. Construction Docker
OpenShift Container Platform utilise Buildah pour construire une image de conteneur à partir d'un fichier Docker. Pour plus d'informations sur la construction d'images de conteneurs avec des Dockerfiles, voir la documentation de référence Dockerfile.
Si vous définissez les arguments de construction de Docker en utilisant le tableau buildArgs, voir Comprendre comment ARG et FROM interagissent dans la documentation de référence de Dockerfile.
2.5.1.1. Remplacer le fichier Dockerfile de l'image
Vous pouvez remplacer l'instruction FROM du fichier Docker par l'instruction from de l'objet BuildConfig. Si le fichier Docker utilise des constructions en plusieurs étapes, l'image de la dernière instruction FROM sera remplacée.
Procédure
Pour remplacer l'instruction FROM du fichier Docker par l'instruction from du fichier BuildConfig.
strategy:
dockerStrategy:
from:
kind: "ImageStreamTag"
name: "debian:latest"2.5.1.2. Utilisation du chemin d'accès au fichier Docker
Par défaut, les constructions Docker utilisent un Dockerfile situé à la racine du contexte spécifié dans le champ BuildConfig.spec.source.contextDir.
Le champ dockerfilePath permet au build d'utiliser un chemin différent pour localiser votre Dockerfile, par rapport au champ BuildConfig.spec.source.contextDir. Il peut s'agir d'un nom de fichier différent du Dockerfile par défaut, comme MyDockerfile, ou d'un chemin vers un Dockerfile dans un sous-répertoire, comme dockerfiles/app1/Dockerfile.
Procédure
Pour utiliser le champ dockerfilePath afin que le build utilise un chemin différent pour localiser votre Dockerfile, définissez :
strategy:
dockerStrategy:
dockerfilePath: dockerfiles/app1/Dockerfile2.5.1.3. Utiliser les variables d'environnement de Docker
Pour rendre les variables d'environnement disponibles au processus de construction de docker et à l'image résultante, vous pouvez ajouter des variables d'environnement à la définition dockerStrategy de la configuration de construction.
Les variables d'environnement qui y sont définies sont insérées sous la forme d'une seule instruction ENV Dockerfile juste après l'instruction FROM, de sorte qu'elles puissent être référencées ultérieurement dans le Dockerfile.
Procédure
Les variables sont définies lors de la construction et restent dans l'image de sortie, elles seront donc également présentes dans tout conteneur qui exécute cette image.
Par exemple, la définition d'un proxy HTTP personnalisé à utiliser lors de la construction et de l'exécution :
dockerStrategy:
...
env:
- name: "HTTP_PROXY"
value: "http://myproxy.net:5187/"
Vous pouvez également gérer les variables d'environnement définies dans la configuration de construction à l'aide de la commande oc set env.
2.5.1.4. Ajouter des arguments de construction de docker
Vous pouvez définir les arguments de construction de docker en utilisant le tableau buildArgs. Les arguments de construction sont transmis à docker lorsqu'une construction est lancée.
Voir Comprendre comment ARG et FROM interagissent dans la documentation de référence Dockerfile.
Procédure
Pour définir les arguments de construction de docker, ajoutez des entrées au tableau buildArgs, qui se trouve dans la définition dockerStrategy de l'objet BuildConfig. Par exemple :
dockerStrategy:
...
buildArgs:
- name: "foo"
value: "bar"
Seuls les champs name et value sont pris en charge. Les paramètres du champ valueFrom sont ignorés.
2.5.1.5. La réduction des couches avec les constructions de dockers
Les constructions Docker créent normalement une couche représentant chaque instruction dans un Dockerfile. En définissant imageOptimizationPolicy sur SkipLayers, on fusionne toutes les instructions en une seule couche au-dessus de l'image de base.
Procédure
Réglez le site
imageOptimizationPolicysurSkipLayers:strategy: dockerStrategy: imageOptimizationPolicy: SkipLayers
2.5.1.6. Utilisation des volumes de construction
Vous pouvez monter des volumes de construction pour permettre aux constructions en cours d'accéder aux informations que vous ne souhaitez pas conserver dans l'image du conteneur de sortie.
Les volumes de construction fournissent des informations sensibles, telles que les références du référentiel, dont l'environnement de construction ou la configuration n'a besoin qu'au moment de la construction. Les volumes de construction sont différents des entrées de construction, dont les données peuvent persister dans l'image du conteneur de sortie.
Les points de montage des volumes de construction, à partir desquels la construction en cours lit les données, sont fonctionnellement similaires aux montages des volumes de pods.
Conditions préalables
Procédure
Dans la définition
dockerStrategyde l'objetBuildConfig, ajoutez tous les volumes de construction au tableauvolumes. Par exemple :spec: dockerStrategy: volumes: - name: secret-mvn1 mounts: - destinationPath: /opt/app-root/src/.ssh2 source: type: Secret3 secret: secretName: my-secret4 - name: settings-mvn5 mounts: - destinationPath: /opt/app-root/src/.m26 source: type: ConfigMap7 configMap: name: my-config8 - name: my-csi-volume9 mounts: - destinationPath: /opt/app-root/src/some_path10 source: type: CSI11 csi: driver: csi.sharedresource.openshift.io12 readOnly: true13 volumeAttributes:14 attribute: value- 1 5 9
- Obligatoire. Un nom unique.
- 2 6 10
- Obligatoire. Le chemin absolu du point de montage. Il ne doit pas contenir
..ou:et ne doit pas entrer en conflit avec le chemin de destination généré par le constructeur./opt/app-root/srcest le répertoire d'accueil par défaut pour de nombreuses images Red Hat S2I. - 3 7 11
- Obligatoire. Le type de source,
ConfigMap,Secret, ouCSI. - 4 8
- Obligatoire. Le nom de la source.
- 12
- Nécessaire. Le pilote qui fournit le volume CSI éphémère.
- 13
- Obligatoire. Cette valeur doit être définie sur
true. Fournit un volume en lecture seule. - 14
- Facultatif. Les attributs de volume du volume CSI éphémère. Consultez la documentation du pilote CSI pour connaître les clés et les valeurs des attributs pris en charge.
Le pilote CSI pour ressources partagées est pris en charge en tant que fonction d'aperçu technologique.
2.5.2. Construction de la source à l'image
Source-to-image (S2I) est un outil permettant de créer des images de conteneurs reproductibles. Il produit des images prêtes à l'emploi en injectant la source d'une application dans une image de conteneur et en assemblant une nouvelle image. La nouvelle image incorpore l'image de base, le constructeur et la source construite et est prête à être utilisée avec la commande buildah run. S2I prend en charge les constructions incrémentielles, qui réutilisent les dépendances téléchargées précédemment, les artefacts construits précédemment, etc.
2.5.2.1. Effectuer des constructions incrémentielles de source à image
Source-to-image (S2I) peut effectuer des constructions incrémentielles, ce qui signifie qu'il réutilise les artefacts des images construites précédemment.
Procédure
Pour créer une construction incrémentielle, créez une stratégie avec la modification suivante de la définition de la stratégie :
strategy: sourceStrategy: from: kind: "ImageStreamTag" name: "incremental-image:latest"1 incremental: true2 - 1
- Spécifiez une image qui prend en charge les constructions incrémentielles. Consultez la documentation de l'image du constructeur pour savoir si elle prend en charge ce comportement.
- 2
- Cette option permet de contrôler si une construction incrémentale est tentée. Si l'image du constructeur ne prend pas en charge les constructions incrémentielles, la construction réussira quand même, mais vous obtiendrez un message indiquant que la construction incrémentielle n'a pas réussi à cause d'un script
save-artifactsmanquant.
2.5.2.2. Remplacer les scripts d'image du constructeur de sources par des scripts d'image du constructeur d'images
Vous pouvez remplacer les scripts source-image (S2I) assemble, run et save-artifacts fournis par l'image de construction.
Procédure
Pour remplacer les scripts S2I assemble, run, et save-artifacts fournis par l'image du constructeur, il faut soit :
-
Fournissez un script
assemble,runousave-artifactsdans le répertoire.s2i/bindu référentiel des sources de votre application. Fournir l'URL d'un répertoire contenant les scripts dans le cadre de la définition de la stratégie. Par exemple :
strategy: sourceStrategy: from: kind: "ImageStreamTag" name: "builder-image:latest" scripts: "http://somehost.com/scripts_directory"1 - 1
- Ce chemin sera complété par
run,assemble, etsave-artifacts. Si l'un ou tous les scripts sont trouvés, ils seront utilisés à la place des scripts du même nom fournis dans l'image.
Les fichiers situés à l'URL scripts sont prioritaires sur les fichiers situés à l'URL .s2i/bin du référentiel source.
2.5.2.3. Variables d'environnement source-image
Il existe deux façons de mettre les variables d'environnement à la disposition du processus de compilation des sources et de l'image qui en résulte. Les fichiers d'environnement et les valeurs d'environnement BuildConfig. Les variables fournies seront présentes lors du processus de construction et dans l'image de sortie.
2.5.2.3.1. Utilisation de fichiers d'environnement source-image
Source build vous permet de définir des valeurs d'environnement, une par ligne, à l'intérieur de votre application, en les spécifiant dans un fichier .s2i/environment dans le dépôt de sources. Les variables d'environnement spécifiées dans ce fichier sont présentes pendant le processus de construction et dans l'image de sortie.
Si vous fournissez un fichier .s2i/environment dans votre dépôt de sources, source-to-image (S2I) lit ce fichier pendant la construction. Cela permet de personnaliser le comportement de la compilation, car le script assemble peut utiliser ces variables.
Procédure
Par exemple, pour désactiver la compilation des actifs pour votre application Rails pendant la construction :
-
Ajouter
DISABLE_ASSET_COMPILATION=truedans le fichier.s2i/environment.
En plus des builds, les variables d'environnement spécifiées sont également disponibles dans l'application en cours d'exécution. Par exemple, pour que l'application Rails démarre en mode development au lieu de production:
-
Ajouter
RAILS_ENV=developmentau fichier.s2i/environment.
La liste complète des variables d'environnement prises en charge est disponible dans la section "Utilisation des images" pour chaque image.
2.5.2.3.2. Utilisation de l'environnement de configuration de la construction source-image
Vous pouvez ajouter des variables d'environnement à la définition sourceStrategy de la configuration de construction. Les variables d'environnement définies à cet endroit sont visibles lors de l'exécution du script assemble et seront définies dans l'image de sortie, ce qui les rend également disponibles pour le script run et le code de l'application.
Procédure
Par exemple, pour désactiver la compilation des actifs pour votre application Rails :
sourceStrategy: ... env: - name: "DISABLE_ASSET_COMPILATION" value: "true"
2.5.2.4. Ignorer les fichiers source à image
Source-to-image (S2I) prend en charge un fichier .s2iignore, qui contient une liste de modèles de fichiers à ignorer. Les fichiers du répertoire de travail de la compilation, tels qu'ils sont fournis par les différentes sources d'entrée, qui correspondent à un modèle trouvé dans le fichier .s2iignore ne seront pas mis à la disposition du script assemble.
2.5.2.5. Créer des images à partir du code source avec source-to-image
Source-to-image (S2I) est un cadre qui facilite l'écriture d'images qui prennent le code source d'une application en entrée et produisent une nouvelle image qui exécute l'application assemblée en sortie.
Le principal avantage de l'utilisation de S2I pour la construction d'images de conteneurs reproductibles est la facilité d'utilisation pour les développeurs. En tant qu'auteur d'une image de construction, vous devez comprendre deux concepts de base pour que vos images offrent les meilleures performances S2I : le processus de construction et les scripts S2I.
2.5.2.5.1. Comprendre le processus de construction de la source à l'image
Le processus de construction se compose des trois éléments fondamentaux suivants, qui sont combinés pour former une image finale du conteneur :
- Sources d'information
- Scripts source-image (S2I)
- Image du constructeur
S2I génère un Dockerfile avec l'image du constructeur comme première instruction FROM. Le fichier Docker généré par S2I est ensuite transmis à Buildah.
2.5.2.5.2. Comment écrire des scripts source-image ?
Vous pouvez écrire des scripts source-image (S2I) dans n'importe quel langage de programmation, à condition que les scripts soient exécutables dans l'image du constructeur. S2I prend en charge plusieurs options fournissant des scripts assemble/run/save-artifacts. Tous ces emplacements sont vérifiés lors de chaque compilation dans l'ordre suivant :
- Un script spécifié dans la configuration de la construction.
-
Un script trouvé dans le répertoire source de l'application
.s2i/bin. -
Un script trouvé à l'URL de l'image par défaut avec l'étiquette
io.openshift.s2i.scripts-url.
L'étiquette io.openshift.s2i.scripts-url spécifiée dans l'image et le script spécifié dans une configuration de compilation peuvent prendre l'une des formes suivantes :
-
image:///path_to_scripts_dirchemin absolu à l'intérieur de l'image vers un répertoire où se trouvent les scripts S2I. -
file:///path_to_scripts_dirchemin d'accès : chemin relatif ou absolu vers un répertoire de l'hôte où se trouvent les scripts S2I. -
http(s)://path_to_scripts_dir: URL d'un répertoire où se trouvent les scripts S2I.
| Le scénario | Description |
|---|---|
|
|
Le script
|
|
|
Le script |
|
|
Le script
Ces dépendances sont rassemblées dans un fichier |
|
|
Le script |
|
|
Le script
Note
L'emplacement suggéré pour placer l'application de test construite par votre script |
Example S2I scripts
Les exemples de scripts S2I suivants sont écrits en Bash. Chaque exemple suppose que le contenu de tar est décompressé dans le répertoire /tmp/s2i.
assemble le scénario :
#!/bin/bash
# restore build artifacts
if [ "$(ls /tmp/s2i/artifacts/ 2>/dev/null)" ]; then
mv /tmp/s2i/artifacts/* $HOME/.
fi
# move the application source
mv /tmp/s2i/src $HOME/src
# build application artifacts
pushd ${HOME}
make all
# install the artifacts
make install
popdrun le scénario :
#!/bin/bash
# run the application
/opt/application/run.shsave-artifacts le scénario :
#!/bin/bash
pushd ${HOME}
if [ -d deps ]; then
# all deps contents to tar stream
tar cf - deps
fi
popdusage le scénario :
#!/bin/bash
# inform the user how to use the image
cat <<EOF
This is a S2I sample builder image, to use it, install
https://github.com/openshift/source-to-image
EOF2.5.2.6. Utilisation des volumes de construction
Vous pouvez monter des volumes de construction pour permettre aux constructions en cours d'accéder aux informations que vous ne souhaitez pas conserver dans l'image du conteneur de sortie.
Les volumes de construction fournissent des informations sensibles, telles que les références du référentiel, dont l'environnement de construction ou la configuration n'a besoin qu'au moment de la construction. Les volumes de construction sont différents des entrées de construction, dont les données peuvent persister dans l'image du conteneur de sortie.
Les points de montage des volumes de construction, à partir desquels la construction en cours lit les données, sont fonctionnellement similaires aux montages des volumes de pods.
Conditions préalables
Procédure
Dans la définition
sourceStrategyde l'objetBuildConfig, ajoutez tous les volumes de construction au tableauvolumes. Par exemple :spec: sourceStrategy: volumes: - name: secret-mvn1 mounts: - destinationPath: /opt/app-root/src/.ssh2 source: type: Secret3 secret: secretName: my-secret4 - name: settings-mvn5 mounts: - destinationPath: /opt/app-root/src/.m26 source: type: ConfigMap7 configMap: name: my-config8 - name: my-csi-volume9 mounts: - destinationPath: /opt/app-root/src/some_path10 source: type: CSI11 csi: driver: csi.sharedresource.openshift.io12 readOnly: true13 volumeAttributes:14 attribute: value
- 1 5 9
- Obligatoire. Un nom unique.
- 2 6 10
- Obligatoire. Le chemin absolu du point de montage. Il ne doit pas contenir
..ou:et ne doit pas entrer en conflit avec le chemin de destination généré par le constructeur./opt/app-root/srcest le répertoire d'accueil par défaut pour de nombreuses images Red Hat S2I. - 3 7 11
- Obligatoire. Le type de source,
ConfigMap,Secret, ouCSI. - 4 8
- Obligatoire. Le nom de la source.
- 12
- Nécessaire. Le pilote qui fournit le volume CSI éphémère.
- 13
- Obligatoire. Cette valeur doit être définie sur
true. Fournit un volume en lecture seule. - 14
- Facultatif. Les attributs de volume du volume CSI éphémère. Consultez la documentation du pilote CSI pour connaître les clés et les valeurs des attributs pris en charge.
Le pilote CSI pour ressources partagées est pris en charge en tant que fonction d'aperçu technologique.
2.5.3. Construction sur mesure
La stratégie de construction personnalisée permet aux développeurs de définir une image de constructeur spécifique responsable de l'ensemble du processus de construction. L'utilisation de votre propre image de constructeur vous permet de personnaliser votre processus de construction.
Une image de construction personnalisée est une image conteneur simple incorporant la logique du processus de construction, par exemple pour construire des RPM ou des images de base.
Les builds personnalisés sont exécutés avec un niveau de privilège élevé et ne sont pas accessibles aux utilisateurs par défaut. Seuls les utilisateurs à qui l'on peut faire confiance en leur accordant des autorisations d'administration de cluster doivent avoir accès à l'exécution des builds personnalisés.
2.5.3.1. Utilisation de l'image FROM pour des constructions personnalisées
Vous pouvez utiliser la section customStrategy.from pour indiquer l'image à utiliser pour la construction personnalisée
Procédure
Définir la section
customStrategy.from:strategy: customStrategy: from: kind: "DockerImage" name: "openshift/sti-image-builder"
2.5.3.2. Utilisation des secrets dans les constructions personnalisées
Outre les secrets pour les sources et les images qui peuvent être ajoutés à tous les types de construction, les stratégies personnalisées permettent d'ajouter une liste arbitraire de secrets au module de construction.
Procédure
Pour monter chaque secret à un emplacement spécifique, modifiez les champs
secretSourceetmountPathdu fichier YAMLstrategy:strategy: customStrategy: secrets: - secretSource:1 name: "secret1" mountPath: "/tmp/secret1"2 - secretSource: name: "secret2" mountPath: "/tmp/secret2"
2.5.3.3. Utilisation de variables d'environnement pour des constructions personnalisées
Pour mettre les variables d'environnement à la disposition du processus de compilation personnalisé, vous pouvez ajouter des variables d'environnement à la définition customStrategy de la configuration de compilation.
Les variables d'environnement qui y sont définies sont transmises au pod qui exécute la construction personnalisée.
Procédure
Définir un proxy HTTP personnalisé à utiliser lors de la construction :
customStrategy: ... env: - name: "HTTP_PROXY" value: "http://myproxy.net:5187/"Pour gérer les variables d'environnement définies dans la configuration de la compilation, entrez la commande suivante :
oc set env <enter_variables> $ oc set env <enter_variables>
2.5.3.4. Utilisation des images personnalisées du constructeur
La stratégie de construction personnalisée d'OpenShift Container Platform vous permet de définir une image de construction spécifique responsable de l'ensemble du processus de construction. Lorsque vous avez besoin d'un build pour produire des artefacts individuels tels que des packages, des JAR, des WAR, des ZIP installables ou des images de base, utilisez une image de constructeur personnalisée à l'aide de la stratégie de build personnalisée.
Une image de construction personnalisée est une image de conteneur simple incorporant la logique du processus de construction, qui est utilisée pour construire des artefacts tels que des RPM ou des images de conteneur de base.
En outre, le constructeur personnalisé permet de mettre en œuvre n'importe quel processus de construction étendu, tel qu'un flux CI/CD qui exécute des tests unitaires ou d'intégration.
2.5.3.4.1. Image personnalisée du constructeur
Lors de son invocation, une image de constructeur personnalisé reçoit les variables d'environnement suivantes avec les informations nécessaires pour procéder à la construction :
| Nom de la variable | Description |
|---|---|
|
|
L'intégralité du JSON sérialisé de la définition de l'objet |
|
| L'URL d'un dépôt Git contenant les sources à construire. |
|
|
Utilise la même valeur que |
|
| Spécifie le sous-répertoire du dépôt Git à utiliser lors de la construction. Uniquement présent s'il est défini. |
|
| La référence Git à construire. |
|
| La version du master OpenShift Container Platform qui a créé cet objet de construction. |
|
| Le registre de l'image du conteneur dans lequel l'image doit être transférée. |
|
| Le nom de l'étiquette de l'image du conteneur pour l'image en cours de construction. |
|
|
Chemin d'accès aux informations d'identification du registre des conteneurs pour l'exécution d'une opération |
2.5.3.4.2. Flux de travail des constructeurs personnalisés
Bien que les auteurs d'images de construction personnalisées aient une certaine flexibilité dans la définition du processus de construction, votre image de construction doit respecter les étapes suivantes nécessaires à l'exécution d'une construction au sein d'OpenShift Container Platform :
-
La définition de l'objet
Buildcontient toutes les informations nécessaires sur les paramètres d'entrée de la construction. - Exécuter le processus de construction.
- Si votre compilation produit une image, poussez-la dans l'emplacement de sortie de la compilation s'il est défini. D'autres emplacements de sortie peuvent être passés avec des variables d'environnement.
2.5.4. Construction d'un pipeline
La stratégie de construction Pipeline est obsolète dans OpenShift Container Platform 4. Des fonctionnalités équivalentes et améliorées sont présentes dans les Pipelines d'OpenShift Container Platform basés sur Tekton.
Les images Jenkins sur OpenShift Container Platform sont entièrement prises en charge et les utilisateurs doivent suivre la documentation utilisateur de Jenkins pour définir leur jenkinsfile dans un travail ou le stocker dans un système de gestion du contrôle de la source.
La stratégie de construction Pipeline permet aux développeurs de définir un pipeline Jenkins qui sera utilisé par le plugin Jenkins pipeline. Le build peut être démarré, surveillé et géré par OpenShift Container Platform de la même manière que n'importe quel autre type de build.
Les flux de travail du pipeline sont définis dans un site jenkinsfile, soit directement intégré dans la configuration de construction, soit fourni dans un dépôt Git et référencé par la configuration de construction.
2.5.4.1. Comprendre les pipelines de la plateforme de conteneurs OpenShift
La stratégie de construction Pipeline est obsolète dans OpenShift Container Platform 4. Des fonctionnalités équivalentes et améliorées sont présentes dans les Pipelines d'OpenShift Container Platform basés sur Tekton.
Les images Jenkins sur OpenShift Container Platform sont entièrement prises en charge et les utilisateurs doivent suivre la documentation utilisateur de Jenkins pour définir leur jenkinsfile dans un travail ou le stocker dans un système de gestion du contrôle de la source.
Les pipelines vous permettent de contrôler la construction, le déploiement et la promotion de vos applications sur OpenShift Container Platform. En combinant la stratégie de construction Jenkins Pipeline, jenkinsfiles, et le langage spécifique au domaine OpenShift Container Platform (DSL) fourni par le plugin client Jenkins, vous pouvez créer des pipelines avancés de construction, de test, de déploiement et de promotion pour n'importe quel scénario.
OpenShift Container Platform Jenkins Sync Plugin
Le plugin Jenkins Sync d'OpenShift Container Platform maintient la configuration et les objets de construction synchronisés avec les travaux et les constructions Jenkins, et fournit les éléments suivants :
- Création dynamique de tâches et d'exécutions dans Jenkins.
- Création dynamique de modèles de pods d'agents à partir de flux d'images, de balises de flux d'images ou de cartes de configuration.
- Injection de variables d'environnement.
- Visualisation du pipeline dans la console web de OpenShift Container Platform.
- Intégration avec le plugin Jenkins Git, qui transmet les informations de commit des builds d'OpenShift Container Platform au plugin Jenkins Git.
- Synchronisation des secrets dans les entrées de justificatifs Jenkins.
OpenShift Container Platform Jenkins Client Plugin
Le plugin client Jenkins d'OpenShift Container Platform est un plugin Jenkins qui vise à fournir une syntaxe de pipeline Jenkins lisible, concise, complète et fluide pour des interactions riches avec un serveur API d'OpenShift Container Platform. Le plugin utilise l'outil de ligne de commande d'OpenShift Container Platform, oc, qui doit être disponible sur les nœuds exécutant le script.
Le plugin Jenkins Client doit être installé sur votre master Jenkins afin que le DSL OpenShift Container Platform soit disponible pour être utilisé dans le site jenkinsfile pour votre application. Ce plugin est installé et activé par défaut lors de l'utilisation de l'image Jenkins d'OpenShift Container Platform.
Pour les Pipelines OpenShift Container Platform dans votre projet, vous devez utiliser la stratégie de construction de Pipeline Jenkins. Cette stratégie utilise par défaut une adresse jenkinsfile à la racine de votre référentiel source, mais fournit également les options de configuration suivantes :
-
Un champ en ligne
jenkinsfiledans votre configuration de construction. -
Un champ
jenkinsfilePathdans votre configuration de construction qui référence l'emplacement dejenkinsfileà utiliser par rapport à la sourcecontextDir.
Le champ facultatif jenkinsfilePath indique le nom du fichier à utiliser, par rapport à la source contextDir. Si contextDir est omis, la valeur par défaut est la racine du référentiel. Si jenkinsfilePath est omis, la valeur par défaut est jenkinsfile.
2.5.4.2. Fournir le fichier Jenkins pour les constructions de pipelines
La stratégie de construction Pipeline est obsolète dans OpenShift Container Platform 4. Des fonctionnalités équivalentes et améliorées sont présentes dans les Pipelines d'OpenShift Container Platform basés sur Tekton.
Les images Jenkins sur OpenShift Container Platform sont entièrement prises en charge et les utilisateurs doivent suivre la documentation utilisateur de Jenkins pour définir leur jenkinsfile dans un travail ou le stocker dans un système de gestion du contrôle de la source.
Le site jenkinsfile utilise la syntaxe standard du langage groovy pour permettre un contrôle précis de la configuration, de la construction et du déploiement de votre application.
Vous pouvez fournir le site jenkinsfile de l'une des manières suivantes :
- Un fichier situé dans votre dépôt de code source.
-
Intégrée dans votre configuration de construction à l'aide du champ
jenkinsfile.
Si vous utilisez la première option, le site jenkinsfile doit être inclus dans le dépôt du code source de vos applications à l'un des endroits suivants :
-
Un fichier nommé
jenkinsfileà la racine de votre référentiel. -
Un fichier nommé
jenkinsfileà la racine de la sourcecontextDirde votre référentiel. -
Un nom de fichier spécifié via le champ
jenkinsfilePathde la sectionJenkinsPipelineStrategyde votre BuildConfig, qui est relatif à la sourcecontextDirsi elle est fournie, sinon il prend par défaut la racine du référentiel.
Le site jenkinsfile est exécuté sur le pod d'agent Jenkins, qui doit disposer des binaires du client OpenShift Container Platform si vous avez l'intention d'utiliser le DSL OpenShift Container Platform.
Procédure
Pour fournir le fichier Jenkins, vous pouvez soit
- Intégrer le fichier Jenkins dans la configuration de construction.
- Inclure dans la configuration de construction une référence au dépôt Git qui contient le fichier Jenkins.
Définition de l'intégration
kind: "BuildConfig"
apiVersion: "v1"
metadata:
name: "sample-pipeline"
spec:
strategy:
jenkinsPipelineStrategy:
jenkinsfile: |-
node('agent') {
stage 'build'
openshiftBuild(buildConfig: 'ruby-sample-build', showBuildLogs: 'true')
stage 'deploy'
openshiftDeploy(deploymentConfig: 'frontend')
}Référence au dépôt Git
kind: "BuildConfig"
apiVersion: "v1"
metadata:
name: "sample-pipeline"
spec:
source:
git:
uri: "https://github.com/openshift/ruby-hello-world"
strategy:
jenkinsPipelineStrategy:
jenkinsfilePath: some/repo/dir/filename - 1
- Le champ facultatif
jenkinsfilePathindique le nom du fichier à utiliser, par rapport à la sourcecontextDir. SicontextDirest omis, la valeur par défaut est la racine du référentiel. SijenkinsfilePathest omis, la valeur par défaut estjenkinsfile.
2.5.4.3. Utilisation de variables d'environnement pour la construction de pipelines
La stratégie de construction Pipeline est obsolète dans OpenShift Container Platform 4. Des fonctionnalités équivalentes et améliorées sont présentes dans les Pipelines d'OpenShift Container Platform basés sur Tekton.
Les images Jenkins sur OpenShift Container Platform sont entièrement prises en charge et les utilisateurs doivent suivre la documentation utilisateur de Jenkins pour définir leur jenkinsfile dans un travail ou le stocker dans un système de gestion du contrôle de la source.
Pour mettre les variables d'environnement à la disposition du processus de construction de Pipeline, vous pouvez ajouter des variables d'environnement à la définition jenkinsPipelineStrategy de la configuration de construction.
Une fois définies, les variables d'environnement seront définies comme paramètres pour tout travail Jenkins associé à la configuration de construction.
Procédure
Pour définir les variables d'environnement à utiliser lors de la construction, éditez le fichier YAML :
jenkinsPipelineStrategy: ... env: - name: "FOO" value: "BAR"
Vous pouvez également gérer les variables d'environnement définies dans la configuration de construction à l'aide de la commande oc set env.
2.5.4.3.1. Mapping entre les variables d'environnement BuildConfig et les paramètres des jobs Jenkins
Lorsqu'un travail Jenkins est créé ou mis à jour en fonction des modifications apportées à la configuration de construction d'une stratégie Pipeline, toutes les variables d'environnement de la configuration de construction sont mises en correspondance avec les définitions des paramètres du travail Jenkins, les valeurs par défaut des définitions des paramètres du travail Jenkins étant les valeurs actuelles des variables d'environnement associées.
Après la création initiale du job Jenkins, vous pouvez encore ajouter des paramètres supplémentaires au job à partir de la console Jenkins. Les noms des paramètres diffèrent des noms des variables d'environnement dans la configuration de la construction. Les paramètres sont pris en compte lors du lancement des builds pour ces travaux Jenkins.
La façon dont vous démarrez la construction d'une tâche Jenkins détermine la façon dont les paramètres sont définis.
-
Si vous démarrez avec
oc start-build, les valeurs des variables d'environnement dans la configuration de construction sont les paramètres définis pour l'instance de travail correspondante. Toute modification apportée aux valeurs par défaut des paramètres à partir de la console Jenkins est ignorée. Les valeurs de la configuration de construction sont prioritaires. Si vous commencez par
oc start-build -e, les valeurs des variables d'environnement spécifiées dans l'option-esont prioritaires.- Si vous spécifiez une variable d'environnement qui ne figure pas dans la configuration de la construction, elle sera ajoutée en tant que définition des paramètres du travail de Jenkins.
-
Toute modification apportée aux paramètres correspondant aux variables d'environnement à partir de la console Jenkins est ignorée. La configuration de construction et ce que vous spécifiez avec
oc start-build -esont prioritaires.
- Si vous démarrez le travail Jenkins avec la console Jenkins, vous pouvez alors contrôler le réglage des paramètres avec la console Jenkins dans le cadre du lancement d'une compilation pour le travail.
Il est recommandé de spécifier dans la configuration de la construction toutes les variables d'environnement possibles à associer aux paramètres du travail. Cela permet de réduire les entrées/sorties sur disque et d'améliorer les performances lors du traitement par Jenkins.
2.5.4.4. Tutoriel de construction d'un pipeline
La stratégie de construction Pipeline est obsolète dans OpenShift Container Platform 4. Des fonctionnalités équivalentes et améliorées sont présentes dans les Pipelines d'OpenShift Container Platform basés sur Tekton.
Les images Jenkins sur OpenShift Container Platform sont entièrement prises en charge et les utilisateurs doivent suivre la documentation utilisateur de Jenkins pour définir leur jenkinsfile dans un travail ou le stocker dans un système de gestion du contrôle de la source.
Cet exemple montre comment créer un pipeline OpenShift Container Platform qui construira, déploiera et vérifiera une application Node.js/MongoDB en utilisant le modèle nodejs-mongodb.json.
Procédure
Créer le master Jenkins :
$ oc project <project_name>Sélectionnez le projet que vous souhaitez utiliser ou créez un nouveau projet à l'aide de
oc new-project <project_name>.$ oc new-app jenkins-ephemeral1 Si vous souhaitez utiliser un stockage persistant, utilisez plutôt
jenkins-persistent.Créez un fichier nommé
nodejs-sample-pipeline.yamlavec le contenu suivant :NoteCela crée un objet
BuildConfigqui utilise la stratégie du pipeline Jenkins pour construire, déployer et mettre à l'échelle l'application d'exempleNode.js/MongoDB.kind: "BuildConfig" apiVersion: "v1" metadata: name: "nodejs-sample-pipeline" spec: strategy: jenkinsPipelineStrategy: jenkinsfile: <pipeline content from below> type: JenkinsPipelineAprès avoir créé un objet
BuildConfigà l'aide d'un objetjenkinsPipelineStrategy, vous indiquez au pipeline ce qu'il doit faire à l'aide d'un objet inlinejenkinsfile:NoteCet exemple ne met pas en place un dépôt Git pour l'application.
Le contenu suivant
jenkinsfileest écrit en Groovy en utilisant le DSL OpenShift Container Platform. Pour cet exemple, incluez du contenu en ligne dans l'objetBuildConfigen utilisant le style littéral YAML, bien que l'inclusion d'unjenkinsfiledans votre référentiel source soit la méthode préférée.def templatePath = 'https://raw.githubusercontent.com/openshift/nodejs-ex/master/openshift/templates/nodejs-mongodb.json'1 def templateName = 'nodejs-mongodb-example'2 pipeline { agent { node { label 'nodejs'3 } } options { timeout(time: 20, unit: 'MINUTES')4 } stages { stage('preamble') { steps { script { openshift.withCluster() { openshift.withProject() { echo "Using project: ${openshift.project()}" } } } } } stage('cleanup') { steps { script { openshift.withCluster() { openshift.withProject() { openshift.selector("all", [ template : templateName ]).delete()5 if (openshift.selector("secrets", templateName).exists()) {6 openshift.selector("secrets", templateName).delete() } } } } } } stage('create') { steps { script { openshift.withCluster() { openshift.withProject() { openshift.newApp(templatePath)7 } } } } } stage('build') { steps { script { openshift.withCluster() { openshift.withProject() { def builds = openshift.selector("bc", templateName).related('builds') timeout(5) {8 builds.untilEach(1) { return (it.object().status.phase == "Complete") } } } } } } } stage('deploy') { steps { script { openshift.withCluster() { openshift.withProject() { def rm = openshift.selector("dc", templateName).rollout() timeout(5) {9 openshift.selector("dc", templateName).related('pods').untilEach(1) { return (it.object().status.phase == "Running") } } } } } } } stage('tag') { steps { script { openshift.withCluster() { openshift.withProject() { openshift.tag("${templateName}:latest", "${templateName}-staging:latest")10 } } } } } } }- 1
- Chemin du modèle à utiliser.
- 1 2
- Nom du modèle qui sera créé.
- 3
- Créer un pod d'agent
node.jssur lequel exécuter ce build. - 4
- Définir un délai de 20 minutes pour ce pipeline.
- 5
- Supprimer tout ce qui porte l'étiquette de ce modèle.
- 6
- Supprimez tous les secrets portant cette étiquette de modèle.
- 7
- Créez une nouvelle application à partir du site
templatePath. - 8
- Attendez jusqu'à cinq minutes que la construction soit terminée.
- 9
- Attendez jusqu'à cinq minutes que le déploiement soit terminé.
- 10
- Si tout le reste a réussi, marquez l'image
$ {templateName}:latestcomme$ {templateName}-staging:latest. Une configuration de construction de pipeline pour l'environnement de mise à l'essai peut surveiller la modification de l'image$ {templateName}-staging:latestet la déployer ensuite dans l'environnement de mise à l'essai.
NoteL'exemple précédent a été écrit en utilisant le style de pipeline déclaratif, mais l'ancien style de pipeline scripté est également pris en charge.
Créez le Pipeline
BuildConfigdans votre cluster OpenShift Container Platform :$ oc create -f nodejs-sample-pipeline.yamlSi vous ne souhaitez pas créer votre propre fichier, vous pouvez utiliser l'exemple du référentiel Origin en exécutant :
$ oc create -f https://raw.githubusercontent.com/openshift/origin/master/examples/jenkins/pipeline/nodejs-sample-pipeline.yaml
Démarrer le pipeline :
$ oc start-build nodejs-sample-pipelineNoteVous pouvez également démarrer votre pipeline avec la console web d'OpenShift Container Platform en naviguant vers la section Builds → Pipeline et en cliquant sur Start Pipeline, ou en visitant la console Jenkins, en naviguant vers le pipeline que vous avez créé et en cliquant sur Build Now.
Une fois le pipeline lancé, vous devriez voir les actions suivantes se dérouler dans votre projet :
- Une instance de travail est créée sur le serveur Jenkins.
- Un module d'agent est lancé, si votre pipeline en nécessite un.
Le pipeline s'exécute sur le pod agent, ou sur le master si aucun agent n'est requis.
-
Toutes les ressources créées précédemment avec l'étiquette
template=nodejs-mongodb-exampleseront supprimées. -
Une nouvelle application et toutes ses ressources associées seront créées à partir du modèle
nodejs-mongodb-example. Une compilation sera lancée à l'aide de
nodejs-mongodb-exampleBuildConfig.- Le pipeline attendra que la construction soit terminée pour déclencher l'étape suivante.
Un déploiement sera lancé à l'aide de la configuration de déploiement
nodejs-mongodb-example.- Le pipeline attendra que le déploiement soit terminé pour déclencher l'étape suivante.
-
Si la construction et le déploiement sont réussis, l'image
nodejs-mongodb-example:latestsera étiquetée commenodejs-mongodb-example:stage.
-
Toutes les ressources créées précédemment avec l'étiquette
Le pod de l'agent est supprimé, s'il était nécessaire pour le pipeline.
NoteLa meilleure façon de visualiser l'exécution du pipeline est de l'afficher dans la console web d'OpenShift Container Platform. Vous pouvez visualiser vos pipelines en vous connectant à la console web et en naviguant vers Builds → Pipelines.
2.5.5. Ajouter des secrets avec la console web
Vous pouvez ajouter un secret à votre configuration de construction afin qu'elle puisse accéder à un dépôt privé.
Procédure
Pour ajouter un secret à votre configuration de construction afin qu'elle puisse accéder à un dépôt privé à partir de la console web d'OpenShift Container Platform :
- Créez un nouveau projet OpenShift Container Platform.
- Créez un secret contenant les informations d'identification permettant d'accéder à un dépôt de code source privé.
- Créer une configuration de construction.
-
Sur la page de l'éditeur de configuration de la construction ou sur la page
create app from builder imagede la console web, définissez le paramètre Source Secret. - Cliquez sur Save.
2.5.6. Permettre de tirer et de pousser
Vous pouvez activer l'extraction vers un registre privé en définissant le secret d'extraction et la poussée en définissant le secret de poussée dans la configuration de la construction.
Procédure
Pour permettre l'extraction vers un registre privé :
- Définir le secret d'extraction dans la configuration de la construction.
Pour activer la poussée :
- Définir le secret de poussée dans la configuration de la construction.
2.6. Constructions d'images personnalisées avec Buildah
Avec OpenShift Container Platform 4.12, un docker socket ne sera pas présent sur les nœuds hôtes. Cela signifie que l'option mount docker socket d'une construction personnalisée n'est pas garantie pour fournir un socket docker accessible pour une utilisation dans une image de construction personnalisée.
Si vous avez besoin de cette capacité pour construire et pousser des images, ajoutez l'outil Buildah à votre image de construction personnalisée et utilisez-le pour construire et pousser l'image dans votre logique de construction personnalisée. Voici un exemple d'exécution de constructions personnalisées à l'aide de Buildah.
L'utilisation de la stratégie de construction personnalisée nécessite des autorisations que les utilisateurs normaux n'ont pas par défaut, car elle permet à l'utilisateur d'exécuter du code arbitraire à l'intérieur d'un conteneur privilégié fonctionnant sur le cluster. Ce niveau d'accès peut être utilisé pour compromettre le cluster et ne doit donc être accordé qu'à des utilisateurs disposant de privilèges administratifs sur le cluster.
2.6.1. Conditions préalables
- Examiner comment accorder des autorisations de construction personnalisée.
2.6.2. Création d'artefacts de construction personnalisés
Vous devez créer l'image que vous souhaitez utiliser comme image de construction personnalisée.
Procédure
En partant d'un répertoire vide, créez un fichier nommé
Dockerfileavec le contenu suivant :FROM registry.redhat.io/rhel8/buildah # In this example, `/tmp/build` contains the inputs that build when this # custom builder image is run. Normally the custom builder image fetches # this content from some location at build time, by using git clone as an example. ADD dockerfile.sample /tmp/input/Dockerfile ADD build.sh /usr/bin RUN chmod a+x /usr/bin/build.sh # /usr/bin/build.sh contains the actual custom build logic that will be run when # this custom builder image is run. ENTRYPOINT ["/usr/bin/build.sh"]Dans le même répertoire, créez un fichier nommé
dockerfile.sample. Ce fichier est inclus dans l'image de construction personnalisée et définit l'image produite par la construction personnalisée :FROM registry.access.redhat.com/ubi8/ubi RUN touch /tmp/buildDans le même répertoire, créez un fichier nommé
build.sh. Ce fichier contient la logique qui est exécutée lors de l'exécution de la version personnalisée :#!/bin/sh # Note that in this case the build inputs are part of the custom builder image, but normally this # is retrieved from an external source. cd /tmp/input # OUTPUT_REGISTRY and OUTPUT_IMAGE are env variables provided by the custom # build framework TAG="${OUTPUT_REGISTRY}/${OUTPUT_IMAGE}" # performs the build of the new image defined by dockerfile.sample buildah --storage-driver vfs bud --isolation chroot -t ${TAG} . # buildah requires a slight modification to the push secret provided by the service # account to use it for pushing the image cp /var/run/secrets/openshift.io/push/.dockercfg /tmp (echo "{ \"auths\": " ; cat /var/run/secrets/openshift.io/push/.dockercfg ; echo "}") > /tmp/.dockercfg # push the new image to the target for the build buildah --storage-driver vfs push --tls-verify=false --authfile /tmp/.dockercfg ${TAG}
2.6.3. Construire une image personnalisée du constructeur
Vous pouvez utiliser OpenShift Container Platform pour construire et pousser des images de constructeur personnalisées à utiliser dans une stratégie personnalisée.
Conditions préalables
- Définissez toutes les données qui seront utilisées pour créer votre nouvelle image de constructeur personnalisé.
Procédure
Définissez un objet
BuildConfigqui construira votre image de constructeur personnalisée :$ oc new-build --binary --strategy=docker --name custom-builder-imageDepuis le répertoire dans lequel vous avez créé votre image de compilation personnalisée, exécutez la compilation :
$ oc start-build custom-builder-image --from-dir . -FUne fois la construction terminée, votre nouvelle image de constructeur personnalisé est disponible dans votre projet dans une balise de flux d'images nommée
custom-builder-image:latest.
2.6.4. Utiliser l'image personnalisée du constructeur
Vous pouvez définir un objet BuildConfig qui utilise la stratégie personnalisée en conjonction avec votre image de constructeur personnalisé pour exécuter votre logique de construction personnalisée.
Conditions préalables
- Définir toutes les entrées requises pour la nouvelle image du constructeur personnalisé.
- Créez votre image de constructeur personnalisée.
Procédure
Créez un fichier nommé
buildconfig.yaml. Ce fichier définit l'objetBuildConfigqui est créé dans votre projet et exécuté :kind: BuildConfig apiVersion: build.openshift.io/v1 metadata: name: sample-custom-build labels: name: sample-custom-build annotations: template.alpha.openshift.io/wait-for-ready: 'true' spec: strategy: type: Custom customStrategy: forcePull: true from: kind: ImageStreamTag name: custom-builder-image:latest namespace: <yourproject>1 output: to: kind: ImageStreamTag name: sample-custom:latest- 1
- Indiquez le nom de votre projet.
Créer le site
BuildConfig:$ oc create -f buildconfig.yamlCréez un fichier nommé
imagestream.yaml. Ce fichier définit le flux d'images vers lequel la compilation poussera l'image :kind: ImageStream apiVersion: image.openshift.io/v1 metadata: name: sample-custom spec: {}Créer le flux d'images :
$ oc create -f imagestream.yamlExécutez votre construction personnalisée :
$ oc start-build sample-custom-build -FLorsque la construction s'exécute, elle lance un pod qui exécute l'image du constructeur personnalisé qui a été construite précédemment. Le pod exécute la logique
build.shqui est définie comme le point d'entrée de l'image du constructeur personnalisé. La logiquebuild.shinvoque Buildah pour construire le sitedockerfile.samplequi a été intégré dans l'image de construction personnalisée, puis utilise Buildah pour pousser la nouvelle image vers le sitesample-custom image stream.
2.7. Effectuer et configurer des constructions de base
Les sections suivantes fournissent des instructions pour les opérations de construction de base, y compris le démarrage et l'annulation des constructions, l'édition de BuildConfigs, la suppression de BuildConfigs, l'affichage des détails de la construction et l'accès aux journaux de construction.
2.7.1. Démarrer une construction
Vous pouvez lancer manuellement une nouvelle compilation à partir d'une configuration de compilation existante dans votre projet actuel.
Procédure
Pour lancer manuellement une compilation, entrez la commande suivante :
oc start-build <buildconfig_name>2.7.1.1. Réexécution d'une compilation
Vous pouvez relancer manuellement une compilation en utilisant l'option --from-build.
Procédure
Pour réexécuter manuellement une compilation, entrez la commande suivante :
oc start-build --from-build=<nom_de_la_construction>
2.7.1.2. Journaux de construction en continu
Vous pouvez spécifier l'option --follow pour que les journaux de la compilation soient transmis à stdout.
Procédure
Pour diffuser manuellement les journaux d'une compilation dans
stdout, entrez la commande suivante :oc start-build <buildconfig_name> --follow
2.7.1.3. Définition de variables d'environnement lors du lancement d'une compilation
Vous pouvez spécifier l'option --env pour définir toute variable d'environnement souhaitée pour la construction.
Procédure
Pour spécifier une variable d'environnement souhaitée, entrez la commande suivante :
$ oc start-build <buildconfig_name> --env=<key>=<value>
2.7.1.4. Démarrer une compilation avec les sources
Plutôt que de s'appuyer sur une extraction de source Git ou un fichier Docker pour une construction, vous pouvez également démarrer une construction en poussant directement votre source, qui peut être le contenu d'un répertoire de travail Git ou SVN, un ensemble d'artefacts binaires préconstruits que vous souhaitez déployer, ou un simple fichier. Ceci peut être fait en spécifiant l'une des options suivantes pour la commande start-build:
| Option | Description |
|---|---|
|
| Spécifie un répertoire qui sera archivé et utilisé comme entrée binaire pour la construction. |
|
| Spécifie un fichier unique qui sera le seul fichier dans la source de construction. Le fichier est placé à la racine d'un répertoire vide avec le même nom de fichier que le fichier original fourni. |
|
|
Spécifie un chemin vers un dépôt local à utiliser comme entrée binaire pour une compilation. Ajoutez l'option |
Si vous passez l'une de ces options directement à la compilation, le contenu est transmis à la compilation et remplace les paramètres actuels de la source de la compilation.
Les reconstructions déclenchées par une entrée binaire ne préserveront pas la source sur le serveur, de sorte que les reconstructions déclenchées par des modifications de l'image de base utiliseront la source spécifiée dans la configuration de la construction.
Procédure
Lancez une compilation à partir d'une source en utilisant la commande suivante pour envoyer le contenu d'un dépôt Git local sous forme d'archive à partir de la balise
v2:$ oc start-build hello-world --from-repo=../hello-world --commit=v2
2.7.2. Annulation d'une construction
Vous pouvez annuler une construction à l'aide de la console web ou de la commande CLI suivante.
Procédure
Pour annuler manuellement une construction, entrez la commande suivante :
oc cancel-build <build_name>
2.7.2.1. Annulation de plusieurs constructions
Vous pouvez annuler plusieurs constructions à l'aide de la commande CLI suivante.
Procédure
Pour annuler manuellement plusieurs constructions, entrez la commande suivante :
oc cancel-build <build1_name> <build2_name> <build3_name> $ oc cancel-build <build1_name> <build2_name>
2.7.2.2. Annulation de toutes les constructions
Vous pouvez annuler toutes les constructions à partir de la configuration de la construction avec la commande CLI suivante.
Procédure
Pour annuler toutes les constructions, entrez la commande suivante :
oc cancel-build bc/<buildconfig_name>
2.7.2.3. Annulation de toutes les constructions dans un état donné
Vous pouvez annuler toutes les constructions dans un état donné, tel que new ou pending, tout en ignorant les constructions dans d'autres états.
Procédure
Pour annuler tout ce qui se trouve dans un état donné, entrez la commande suivante :
oc cancel-build bc/<buildconfig_name>
2.7.3. Modifier une BuildConfig
Pour modifier vos configurations de construction, vous utilisez l'option Edit BuildConfig dans la vue Builds de la perspective Developer.
Vous pouvez utiliser l'une des vues suivantes pour modifier un site BuildConfig:
-
Le site Form view vous permet de modifier votre site
BuildConfigà l'aide des champs de formulaire et des cases à cocher standard. -
Le site YAML view vous permet d'éditer votre site
BuildConfigavec un contrôle total sur les opérations.
Vous pouvez passer de Form view à YAML view sans perdre de données. Les données contenues dans le site Form view sont transférées vers le site YAML view et vice versa.
Procédure
-
Dans la vue Builds de la perspective Developer, cliquez sur le menu
 pour voir l'option Edit BuildConfig.
pour voir l'option Edit BuildConfig.
- Cliquez sur Edit BuildConfig pour voir l'option Form view.
Dans la section Git, entrez l'URL du dépôt Git pour la base de code que vous souhaitez utiliser pour créer une application. L'URL est ensuite validée.
Optionnel : Cliquez sur Show Advanced Git Options pour ajouter des détails tels que
- Git Reference pour spécifier une branche, une balise ou un commit qui contient le code que vous voulez utiliser pour construire l'application.
- Context Dir pour spécifier le sous-répertoire qui contient le code que vous voulez utiliser pour construire l'application.
- Source Secret pour créer un site Secret Name avec des informations d'identification permettant d'extraire votre code source d'un dépôt privé.
Dans la section Build from, sélectionnez l'option à partir de laquelle vous souhaitez construire. Vous pouvez utiliser les options suivantes :
- Image Stream tag référence une image pour un flux d'images et une balise donnés. Saisissez le projet, le flux d'images et la balise de l'emplacement à partir duquel vous souhaitez construire et pousser.
- Image Stream image référence une image pour un flux d'images et un nom d'image donnés. Saisissez l'image du flux d'images à partir duquel vous souhaitez construire. Saisissez également le projet, le flux d'images et la balise à utiliser.
- Docker image: L'image Docker est référencée par le biais d'un dépôt d'images Docker. Vous devrez également entrer le projet, le flux d'image et le tag pour faire référence à l'endroit où vous souhaitez pousser.
- Facultatif : dans la section Environment Variables, ajoutez les variables d'environnement associées au projet en utilisant les champs Name et Value. Pour ajouter d'autres variables d'environnement, utilisez Add Value, ou Add from ConfigMap et Secret.
Facultatif : Pour personnaliser davantage votre application, utilisez les options avancées suivantes :
- Déclencheur
- Déclenche la construction d'une nouvelle image lorsque l'image du constructeur change. Ajoutez d'autres déclencheurs en cliquant sur Add Trigger et en sélectionnant Type et Secret.
- Secrets
- Ajoute des secrets pour votre application. Ajoutez d'autres secrets en cliquant sur Add secret et en sélectionnant Secret et Mount point.
- Politique
- Cliquez sur Run policy pour sélectionner la politique d'exécution de la construction. La politique sélectionnée détermine l'ordre dans lequel les builds créés à partir de la configuration de build doivent être exécutés.
- Crochets
- Sélectionnez Run build hooks after image is built pour exécuter des commandes à la fin de la construction et vérifier l'image. Ajoutez Hook type, Command, et Arguments à la commande.
-
Cliquez sur Save pour enregistrer l'adresse
BuildConfig.
2.7.4. Suppression d'une BuildConfig
Vous pouvez supprimer un site BuildConfig à l'aide de la commande suivante.
Procédure
Pour supprimer un site
BuildConfig, entrez la commande suivante :oc delete bc <BuildConfigName> $ oc delete bc <BuildConfigName>Cette opération supprime également toutes les constructions qui ont été instanciées à partir de ce site
BuildConfig.Pour supprimer un site
BuildConfiget conserver les constructions installées à partir du siteBuildConfig, spécifiez l'indicateur--cascade=falselorsque vous entrez la commande suivante :oc delete --cascade=false bc <BuildConfigName>
2.7.5. Voir les détails de la construction
Vous pouvez afficher les détails de la construction à l'aide de la console Web ou de la commande CLI oc describe.
Cette fonction permet d'afficher des informations telles que
- La source de construction.
- La stratégie de construction.
- La destination de la sortie.
- Digest de l'image dans le registre de destination.
- Comment la construction a été créée.
Si la compilation utilise la stratégie Docker ou Source, la sortie oc describe inclut également des informations sur la révision des sources utilisée pour la compilation, y compris l'ID du commit, l'auteur, le committer et le message.
Procédure
Pour afficher les détails de la construction, entrez la commande suivante :
oc describe build <nom_de_la_construction>
2.7.6. Accès aux journaux de construction
Vous pouvez accéder aux journaux de construction à l'aide de la console web ou de l'interface de programmation.
Procédure
Pour diffuser les journaux en utilisant directement la compilation, entrez la commande suivante :
oc describe build <nom_de_la_construction>
2.7.6.1. Accès aux journaux de BuildConfig
Vous pouvez accéder aux journaux de BuildConfig à l'aide de la console Web ou de la CLI.
Procédure
Pour diffuser les journaux de la dernière version pour une
BuildConfig, entrez la commande suivante :oc logs -f bc/<buildconfig_name>
2.7.6.2. Accès aux journaux BuildConfig pour une version donnée de la construction
Vous pouvez accéder aux journaux d'une version donnée pour une BuildConfig en utilisant la console web ou le CLI.
Procédure
Pour diffuser les journaux d'une version donnée pour une
BuildConfig, entrez la commande suivante :oc logs --version=<number> bc/<buildconfig_name>
2.7.6.3. Activation de la verbosité des journaux
Vous pouvez activer une sortie plus verbeuse en transmettant la variable d'environnement BUILD_LOGLEVEL dans le cadre de sourceStrategy ou dockerStrategy dans BuildConfig.
Un administrateur peut définir la verbosité de construction par défaut pour l'ensemble de l'instance d'OpenShift Container Platform en configurant env/BUILD_LOGLEVEL. Cette valeur par défaut peut être remplacée en spécifiant BUILD_LOGLEVEL dans un BuildConfig donné. Vous pouvez spécifier une priorité plus élevée sur la ligne de commande pour les constructions non binaires en passant --build-loglevel à oc start-build.
Les niveaux de journalisation disponibles pour les compilations de sources sont les suivants :
| Niveau 0 |
Produit la sortie des conteneurs exécutant le script |
| Niveau 1 | Produit des informations de base sur le processus exécuté. |
| Niveau 2 | Produit des informations très détaillées sur le processus exécuté. |
| Niveau 3 | Produit des informations très détaillées sur le processus exécuté, ainsi qu'une liste du contenu de l'archive. |
| Niveau 4 | Produit actuellement les mêmes informations que le niveau 3. |
| Niveau 5 | Produit tout ce qui est mentionné dans les niveaux précédents et fournit en plus des messages docker push. |
Procédure
Pour obtenir une sortie plus verbeuse, transmettez la variable d'environnement
BUILD_LOGLEVELà l'adressesourceStrategyoudockerStrategyà l'adresseBuildConfig:sourceStrategy: ... env: - name: "BUILD_LOGLEVEL" value: "2"1 - 1
- Ajustez cette valeur au niveau d'enregistrement souhaité.
2.8. Déclenchement et modification des constructions
Les sections suivantes décrivent comment déclencher des builds et modifier des builds à l'aide de crochets de build.
2.8.1. Construire des déclencheurs
Lors de la définition d'un site BuildConfig, vous pouvez définir des déclencheurs pour contrôler les circonstances dans lesquelles le site BuildConfig doit être exécuté. Les déclencheurs de construction suivants sont disponibles :
- Crochet Web
- Changement d'image
- Changement de configuration
2.8.1.1. Déclencheurs de webhook
Les déclencheurs Webhook vous permettent de déclencher une nouvelle construction en envoyant une demande au point d'extrémité API de OpenShift Container Platform. Vous pouvez définir ces déclencheurs en utilisant GitHub, GitLab, Bitbucket ou Generic webhooks.
Actuellement, les webhooks d'OpenShift Container Platform ne supportent que les versions analogues de l'événement push pour chacun des systèmes de gestion de code source (SCM) basés sur Git. Tous les autres types d'événements sont ignorés.
Lorsque les événements push sont traités, l'hôte du plan de contrôle d'OpenShift Container Platform confirme si la référence de la branche à l'intérieur de l'événement correspond à la référence de la branche dans le BuildConfig correspondant. Si c'est le cas, il vérifie alors la référence exacte du commit noté dans l'événement webhook sur le build d'OpenShift Container Platform. S'ils ne correspondent pas, aucun build n'est déclenché.
oc new-app et oc new-build créent automatiquement les déclencheurs GitHub et Generic webhook, mais tous les autres déclencheurs webhook nécessaires doivent être ajoutés manuellement. Vous pouvez ajouter manuellement des déclencheurs en définissant des déclencheurs.
Pour tous les webhooks, vous devez définir un secret avec une clé nommée WebHookSecretKey et la valeur à fournir lors de l'invocation du webhook. La définition du webhook doit ensuite faire référence au secret. Le secret garantit l'unicité de l'URL, empêchant ainsi d'autres personnes de déclencher la construction. La valeur de la clé est comparée au secret fourni lors de l'invocation du webhook.
Par exemple, voici un webhook GitHub avec une référence à un secret nommé mysecret:
type: "GitHub"
github:
secretReference:
name: "mysecret"
Le secret est alors défini comme suit. Notez que la valeur du secret est codée en base64, comme c'est le cas pour tout champ data d'un objet Secret.
- kind: Secret
apiVersion: v1
metadata:
name: mysecret
creationTimestamp:
data:
WebHookSecretKey: c2VjcmV0dmFsdWUx2.8.1.1.1. Utiliser les webhooks de GitHub
Les webhooks de GitHub gèrent l'appel fait par GitHub lorsqu'un dépôt est mis à jour. Lors de la définition du déclencheur, vous devez spécifier un secret, qui fait partie de l'URL que vous fournissez à GitHub lors de la configuration du webhook.
Exemple de définition d'un webhook GitHub :
type: "GitHub"
github:
secretReference:
name: "mysecret"
Le secret utilisé dans la configuration du déclencheur du webhook n'est pas le même que le champ secret que vous rencontrez lors de la configuration du webhook dans l'interface utilisateur de GitHub. Le premier sert à rendre l'URL du webhook unique et difficile à prédire, le second est un champ de chaîne optionnel utilisé pour créer un condensé hexagonal HMAC du corps, qui est envoyé en tant qu'en-tête X-Hub-Signature.
L'URL du payload est renvoyée en tant qu'URL du Webhook GitHub par la commande oc describe (voir Afficher les URL du Webhook), et est structurée comme suit :
Exemple de sortie
https://<openshift_api_host:port>/apis/build.openshift.io/v1/namespaces/<namespace>/buildconfigs/<name>/webhooks/<secret>/githubConditions préalables
-
Créer un site
BuildConfigà partir d'un dépôt GitHub.
Procédure
Pour configurer un GitHub Webhook :
Après avoir créé un site
BuildConfigà partir d'un dépôt GitHub, exécutez :$ oc describe bc/<name-of-your-BuildConfig>Cela génère un webhook GitHub URL qui ressemble à :
Exemple de sortie
<https://api.starter-us-east-1.openshift.com:443/apis/build.openshift.io/v1/namespaces/<namespace>/buildconfigs/<name>/webhooks/<secret>/github- Copiez et collez cette URL dans GitHub, à partir de la console web de GitHub.
- Dans votre dépôt GitHub, sélectionnez Add Webhook à partir de Settings → Webhooks.
- Collez l'URL dans le champ Payload URL.
-
Changez le Content Type de la valeur par défaut de GitHub
application/x-www-form-urlencodedàapplication/json. Cliquez sur Add webhook.
Vous devriez voir un message de GitHub indiquant que votre webhook a été configuré avec succès.
Désormais, lorsque vous apportez une modification à votre dépôt GitHub, une nouvelle construction démarre automatiquement, et une fois la construction réussie, un nouveau déploiement démarre.
NoteGogs supporte le même format de charge utile de webhook que GitHub. Par conséquent, si vous utilisez un serveur Gogs, vous pouvez définir un déclencheur webhook GitHub sur votre
BuildConfiget le déclencher également par votre serveur Gogs.
Avec un fichier contenant une charge utile JSON valide, tel que
payload.json, vous pouvez déclencher manuellement le webhook aveccurl:$ curl -H \N "X-GitHub-Event : push\N" -H "Content-Type : application/json" -k -X POST --data-binary @payload.json https://<openshift_api_host:port>/apis/build.openshift.io/v1/namespaces/<namespace>/buildconfigs/<name>/webhooks/<secret>/githubL'argument
-kn'est nécessaire que si votre serveur API ne dispose pas d'un certificat correctement signé.
2.8.1.1.2. Utiliser les webhooks de GitLab
Les webhooks de GitLab gèrent l'appel fait par GitLab lorsqu'un dépôt est mis à jour. Comme pour les déclencheurs GitHub, vous devez spécifier un secret. L'exemple suivant est une définition YAML d'un déclencheur dans le fichier BuildConfig:
type: "GitLab"
gitlab:
secretReference:
name: "mysecret"
L'URL de la charge utile est renvoyée en tant qu'URL de GitLab Webhook par la commande oc describe, et est structurée comme suit :
Exemple de sortie
https://<openshift_api_host:port>/apis/build.openshift.io/v1/namespaces/<namespace>/buildconfigs/<name>/webhooks/<secret>/gitlabProcédure
Pour configurer un GitLab Webhook :
Décrire le site
BuildConfigpour obtenir l'URL du webhook :$ oc describe bc <name>-
Copiez l'URL du webhook en remplaçant
<secret>par votre valeur secrète. - Suivez les instructions d'installation de GitLab pour coller l'URL du webhook dans les paramètres de votre dépôt GitLab.
Avec un fichier contenant une charge utile JSON valide, tel que
payload.json, vous pouvez déclencher manuellement le webhook aveccurl:$ curl -H "X-GitLab-Event : Push Hook" -H "Content-Type : application/json" -k -X POST --data-binary @payload.json https://<openshift_api_host:port>/apis/build.openshift.io/v1/namespaces/<namespace>/buildconfigs/<name>/webhooks/<secret>/gitlabL'argument
-kn'est nécessaire que si votre serveur API ne dispose pas d'un certificat correctement signé.
2.8.1.1.3. Utiliser les webhooks Bitbucket
Les webhooks Bitbucket gèrent l'appel fait par Bitbucket lorsqu'un référentiel est mis à jour. Comme pour les triggers précédents, vous devez spécifier un secret. L'exemple suivant est une définition YAML d'un déclencheur dans le fichier BuildConfig:
type: "Bitbucket"
bitbucket:
secretReference:
name: "mysecret"
L'URL de la charge utile est renvoyée en tant qu'URL de Bitbucket Webhook par la commande oc describe, et est structurée comme suit :
Exemple de sortie
https://<openshift_api_host:port>/apis/build.openshift.io/v1/namespaces/<namespace>/buildconfigs/<name>/webhooks/<secret>/bitbucketProcédure
Pour configurer un Webhook Bitbucket :
Décrivez le "BuildConfig" pour obtenir l'URL du webhook :
$ oc describe bc <name>-
Copiez l'URL du webhook en remplaçant
<secret>par votre valeur secrète. - Suivez les instructions de configuration de Bitbucket pour coller l'URL du webhook dans les paramètres de votre référentiel Bitbucket.
Avec un fichier contenant une charge utile JSON valide, tel que
payload.json, vous pouvez déclencher manuellement le webhook aveccurl:$ curl -H \N "X-Event-Key : repo:push" -H "Content-Type : application/json" -k -X POST --data-binary @payload.json https://<openshift_api_host:port>/apis/build.openshift.io/v1/namespaces/<namespace>/buildconfigs/<name>/webhooks/<secret>/bitbucketL'argument
-kn'est nécessaire que si votre serveur API ne dispose pas d'un certificat correctement signé.
2.8.1.1.4. Utilisation de webhooks génériques
Les webhooks génériques sont invoqués à partir de n'importe quel système capable de faire une requête web. Comme pour les autres webhooks, vous devez spécifier un secret, qui fait partie de l'URL que l'appelant doit utiliser pour déclencher la compilation. Le secret garantit l'unicité de l'URL, empêchant ainsi d'autres personnes de déclencher la création. Voici un exemple de définition de déclencheur YAML dans BuildConfig:
type: "Generic"
generic:
secretReference:
name: "mysecret"
allowEnv: true - 1
- La valeur
truepermet à un webhook générique de transmettre des variables d'environnement.
Procédure
Pour configurer l'appelant, fournissez au système appelant l'URL du point de terminaison générique du webhook pour votre construction :
Exemple de sortie
https://<openshift_api_host:port>/apis/build.openshift.io/v1/namespaces/<namespace>/buildconfigs/<name>/webhooks/<secret>/genericL'appelant doit invoquer le webhook en tant qu'opération
POST.Pour invoquer manuellement le webhook, vous pouvez utiliser
curl:$ curl -X POST -k https://<openshift_api_host:port>/apis/build.openshift.io/v1/namespaces/<namespace>/buildconfigs/<name>/webhooks/<secret>/genericLe verbe HTTP doit être défini sur
POST. L'indicateur insecure-kest spécifié pour ignorer la validation du certificat. Ce deuxième indicateur n'est pas nécessaire si votre cluster dispose de certificats correctement signés.Le point d'accès peut accepter une charge utile facultative au format suivant :
git: uri: "<url to git repository>" ref: "<optional git reference>" commit: "<commit hash identifying a specific git commit>" author: name: "<author name>" email: "<author e-mail>" committer: name: "<committer name>" email: "<committer e-mail>" message: "<commit message>" env:1 - name: "<variable name>" value: "<variable value>"- 1
- Comme pour les variables d'environnement de
BuildConfig, les variables d'environnement définies ici sont mises à la disposition de votre compilation. Si ces variables entrent en conflit avec les variables d'environnement deBuildConfig, ces dernières sont prioritaires. Par défaut, les variables d'environnement transmises par webhook sont ignorées. Définissez le champallowEnvàtruedans la définition du webhook pour activer ce comportement.
Pour transmettre cette charge utile à l'aide de
curl, définissez-la dans un fichier nommépayload_file.yamlet exécutez :$ curl -H "Content-Type : application/yaml" --data-binary @payload_file.yaml -X POST -k https://<openshift_api_host:port>/apis/build.openshift.io/v1/namespaces/<namespace>/buildconfigs/<name>/webhooks/<secret>/genericLes arguments sont les mêmes que dans l'exemple précédent, avec l'ajout d'un en-tête et d'une charge utile. L'argument
-Hdéfinit l'en-têteContent-Typeenapplication/yamlouapplication/jsonen fonction du format de votre charge utile. L'argument--data-binaryest utilisé pour envoyer une charge utile binaire avec les nouvelles lignes intactes avec la requêtePOST.
OpenShift Container Platform permet aux builds d'être déclenchées par le webhook générique même si une charge utile de requête invalide est présentée, par exemple, un type de contenu invalide, un contenu non analysable ou invalide, et ainsi de suite. Ce comportement est maintenu pour des raisons de compatibilité ascendante. Si une charge utile non valide est présentée, OpenShift Container Platform renvoie un avertissement au format JSON dans le cadre de sa réponse HTTP 200 OK.
2.8.1.1.5. Affichage des URL des webhooks
Vous pouvez utiliser la commande suivante pour afficher les URL de webhook associées à une configuration de construction. Si la commande n'affiche aucune URL de webhook, aucun déclencheur de webhook n'est défini pour cette configuration.
Procédure
-
Pour afficher les URL des webhooks associés à un site
BuildConfig, exécutez :
$ oc describe bc <name>2.8.1.2. Utilisation des déclencheurs de changement d'image
En tant que développeur, vous pouvez configurer votre compilation pour qu'elle s'exécute automatiquement chaque fois qu'une image de base est modifiée.
Vous pouvez utiliser des déclencheurs de changement d'image pour lancer automatiquement votre compilation lorsqu'une nouvelle version d'une image en amont est disponible. Par exemple, si une compilation est basée sur une image RHEL, vous pouvez déclencher l'exécution de cette compilation chaque fois que l'image RHEL change. Ainsi, l'image de l'application s'exécute toujours sur la dernière image de base RHEL.
Les flux d'images qui pointent vers des images de conteneurs dans les registres de conteneurs v1 ne déclenchent une compilation qu'une seule fois, lorsque la balise du flux d'images devient disponible, et non lors des mises à jour ultérieures de l'image. Cela est dû à l'absence d'images identifiables de manière unique dans les registres de conteneurs v1.
Procédure
Définissez une adresse
ImageStreamqui pointe vers l'image en amont que vous souhaitez utiliser comme déclencheur :kind: "ImageStream" apiVersion: "v1" metadata: name: "ruby-20-centos7"Cela définit le flux d'images lié à un référentiel d'images de conteneurs situé à l'adresse
<system-registry>/<namespace>/ruby-20-centos7. Le site<system-registry>est défini comme un service portant le nomdocker-registryet fonctionnant dans OpenShift Container Platform.Si un flux d'images est l'image de base pour la compilation, définissez le champ
fromdans la stratégie de compilation pour qu'il pointe vers l'imageImageStream:strategy: sourceStrategy: from: kind: "ImageStreamTag" name: "ruby-20-centos7:latest"Dans ce cas, la définition
sourceStrategyconsomme la baliselatestdu flux d'images nomméruby-20-centos7situé dans cet espace de noms.Définir une construction avec un ou plusieurs déclencheurs qui pointent vers
ImageStreams:type: "ImageChange"1 imageChange: {} type: "ImageChange"2 imageChange: from: kind: "ImageStreamTag" name: "custom-image:latest"- 1
- Un déclencheur de changement d'image qui surveille les objets
ImageStreametTagtels que définis par le champfromde la stratégie de construction. L'objetimageChangedoit être vide. - 2
- Un déclencheur de changement d'image qui surveille un flux d'images arbitraire. La partie
imageChange, dans ce cas, doit inclure un champfromqui fait référence auImageStreamTagà surveiller.
Lors de l'utilisation d'un déclencheur de changement d'image pour le flux d'image de la stratégie, le build généré est fourni avec un tag docker immuable qui pointe vers la dernière image correspondant à ce tag. Cette nouvelle référence d'image est utilisée par la stratégie lorsqu'elle s'exécute pour la construction.
Pour les autres déclencheurs de changement d'image qui ne font pas référence au flux d'images de la stratégie, une nouvelle construction est lancée, mais la stratégie de construction n'est pas mise à jour avec une référence d'image unique.
Comme cet exemple comporte un déclencheur de changement d'image pour la stratégie, la compilation résultante est la suivante :
strategy:
sourceStrategy:
from:
kind: "DockerImage"
name: "172.30.17.3:5001/mynamespace/ruby-20-centos7:<immutableid>"Cela garantit que la construction déclenchée utilise la nouvelle image qui vient d'être poussée dans le dépôt, et que la construction peut être relancée à tout moment avec les mêmes données.
Vous pouvez mettre en pause un déclencheur de changement d'image pour permettre plusieurs changements sur le flux d'images référencé avant qu'une compilation ne soit lancée. Vous pouvez également attribuer la valeur true à l'attribut paused lors de l'ajout initial d'un ImageChangeTrigger à un BuildConfig afin d'empêcher le déclenchement immédiat d'une compilation.
type: "ImageChange"
imageChange:
from:
kind: "ImageStreamTag"
name: "custom-image:latest"
paused: true
En plus de définir le champ image pour tous les types Strategy, pour les constructions personnalisées, la variable d'environnement OPENSHIFT_CUSTOM_BUILD_BASE_IMAGE est vérifiée. Si elle n'existe pas, elle est créée avec la référence d'image immuable. Si elle existe, elle est mise à jour avec la référence d'image immuable.
Si une compilation est déclenchée par un webhook ou une demande manuelle, la compilation créée utilise le <immutableid> résolu à partir du ImageStream référencé par le Strategy. Cela garantit que les compilations sont effectuées en utilisant des balises d'image cohérentes pour faciliter la reproduction.
2.8.1.3. Identifier l'élément déclencheur d'un changement d'image lors d'une construction
En tant que développeur, si vous avez des déclencheurs de changement d'image, vous pouvez identifier le changement d'image qui a déclenché la dernière compilation. Cela peut s'avérer utile pour le débogage ou le dépannage des constructions.
Exemple BuildConfig
apiVersion: build.openshift.io/v1
kind: BuildConfig
metadata:
name: bc-ict-example
namespace: bc-ict-example-namespace
spec:
# ...
triggers:
- imageChange:
from:
kind: ImageStreamTag
name: input:latest
namespace: bc-ict-example-namespace
- imageChange:
from:
kind: ImageStreamTag
name: input2:latest
namespace: bc-ict-example-namespace
type: ImageChange
status:
imageChangeTriggers:
- from:
name: input:latest
namespace: bc-ict-example-namespace
lastTriggerTime: "2021-06-30T13:47:53Z"
lastTriggeredImageID: image-registry.openshift-image-registry.svc:5000/bc-ict-example-namespace/input@sha256:0f88ffbeb9d25525720bfa3524cb1bf0908b7f791057cf1acfae917b11266a69
- from:
name: input2:latest
namespace: bc-ict-example-namespace
lastTriggeredImageID: image-registry.openshift-image-registry.svc:5000/bc-ict-example-namespace/input2@sha256:0f88ffbeb9d25525720bfa3524cb2ce0908b7f791057cf1acfae917b11266a69
lastVersion: 1Cet exemple omet les éléments qui ne sont pas liés aux déclencheurs de changement d'image.
Conditions préalables
- Vous avez configuré plusieurs déclencheurs de changement d'image. Ces déclencheurs ont déclenché une ou plusieurs constructions.
Procédure
Dans
buildConfig.status.imageChangeTriggerspour identifier le sitelastTriggerTimequi a l'horodatage le plus récent.Le présent
ImageChangeTriggerStatusEnsuite, vous utilisez le `name` et le `namespace` de cette compilation pour trouver le trigger de changement d'image correspondant dans `buildConfig.spec.triggers`.-
Sous
imageChangeTriggers, comparez les horodatages pour identifier le dernier
Déclencheurs de changement d'image
Dans votre configuration de construction, buildConfig.spec.triggers est un tableau de politiques de déclenchement de construction, BuildTriggerPolicy.
Chaque site BuildTriggerPolicy possède un champ type et un ensemble de champs pointeurs. Chaque champ pointeur correspond à l'une des valeurs autorisées pour le champ type. Ainsi, vous ne pouvez attribuer à BuildTriggerPolicy qu'un seul champ de pointeurs.
Pour les déclencheurs de changement d'image, la valeur de type est ImageChange. Ensuite, le champ imageChange est le pointeur vers un objet ImageChangeTrigger, qui possède les champs suivants :
-
lastTriggeredImageID: Ce champ, qui n'apparaît pas dans l'exemple, est obsolète dans OpenShift Container Platform 4.8 et sera ignoré dans une prochaine version. Il contient la référence de l'image résolue pour leImageStreamTaglorsque le dernier build a été déclenché à partir de ceBuildConfig. -
paused: Vous pouvez utiliser ce champ, qui n'apparaît pas dans l'exemple, pour désactiver temporairement ce déclencheur de changement d'image particulier. -
from: Ce champ permet de référencer le siteImageStreamTagqui pilote ce déclencheur de changement d'image. Son type est le type de base de Kubernetes,OwnerReference.
The from field has the following fields of note: kind: For image change triggers, the only supported value is ImageStreamTag. namespace: You use this field to specify the namespace of the ImageStreamTag. ** name: You use this field to specify the ImageStreamTag.
Statut du déclencheur de changement d'image
Dans votre configuration de construction, buildConfig.status.imageChangeTriggers est un tableau d'éléments ImageChangeTriggerStatus. Chaque élément ImageChangeTriggerStatus comprend les éléments from, lastTriggeredImageID et lastTriggerTime présentés dans l'exemple précédent.
Le site ImageChangeTriggerStatus qui contient la version la plus récente de lastTriggerTime a déclenché la version la plus récente. Vous utilisez ses name et namespace pour identifier le déclencheur de changement d'image dans buildConfig.spec.triggers qui a déclenché la compilation.
Le site lastTriggerTime dont l'horodatage est le plus récent correspond au site ImageChangeTriggerStatus de la dernière version. Ce ImageChangeTriggerStatus a les mêmes name et namespace que le déclencheur de changement d'image dans buildConfig.spec.triggers qui a déclenché la construction.
2.8.1.4. Déclencheurs de changement de configuration
Un déclencheur de changement de configuration permet de lancer automatiquement une compilation dès qu'un nouveau site BuildConfig est créé.
Voici un exemple de définition de déclencheur YAML dans la base de données BuildConfig:
type: "ConfigChange"
Les déclencheurs de changement de configuration ne fonctionnent actuellement que lors de la création d'un nouveau site BuildConfig. Dans une prochaine version, les déclencheurs de changement de configuration pourront également lancer une construction à chaque fois qu'un site BuildConfig sera mis à jour.
2.8.1.4.1. Réglage manuel des déclencheurs
Les déclencheurs peuvent être ajoutés et supprimés des configurations de construction à l'aide de oc set triggers.
Procédure
Pour définir un déclencheur GitHub webhook sur une configuration de construction, utilisez :
$ oc set triggers bc <name> --from-githubPour définir un déclencheur de changement d'image, utilisez :
$ oc set triggers bc <name> --from-image='<image>'Pour supprimer un déclencheur, ajoutez
--remove:$ oc set triggers bc <name> --from-bitbucket --remove
Lorsqu'un déclencheur de webhook existe déjà, le fait de l'ajouter à nouveau régénère le secret du webhook.
Pour plus d'informations, consultez la documentation d'aide avec en exécutant :
$ oc set triggers --help2.8.2. Construire des crochets
Les crochets de construction permettent d'injecter un comportement dans le processus de construction.
Le champ postCommit d'un objet BuildConfig exécute des commandes à l'intérieur d'un conteneur temporaire qui exécute l'image de sortie de la compilation. Le hook est exécuté immédiatement après que la dernière couche de l'image a été validée et avant que l'image ne soit poussée vers un registre.
Le répertoire de travail actuel est défini comme étant le répertoire de l'image WORKDIR, qui est le répertoire de travail par défaut de l'image du conteneur. Pour la plupart des images, c'est là que se trouve le code source.
Le hook échoue si le script ou la commande renvoie un code de sortie non nul ou si le démarrage du conteneur temporaire échoue. Lorsque le hook échoue, il marque la compilation comme ayant échoué et l'image n'est pas poussée vers un registre. La raison de l'échec peut être vérifiée en consultant les journaux de construction.
Les crochets de construction peuvent être utilisés pour exécuter des tests unitaires afin de vérifier l'image avant que la construction ne soit considérée comme terminée et que l'image ne soit mise à disposition dans un registre. Si tous les tests réussissent et que le programme d'exécution des tests renvoie le code de sortie 0, la compilation est considérée comme réussie. En cas d'échec d'un test, la compilation est considérée comme un échec. Dans tous les cas, le journal de construction contient la sortie du programme d'essai, qui peut être utilisée pour identifier les tests qui ont échoué.
Le hook postCommit n'est pas seulement limité à l'exécution de tests, mais peut également être utilisé pour d'autres commandes. Comme il s'exécute dans un conteneur temporaire, les modifications apportées par le crochet ne persistent pas, ce qui signifie que l'exécution du crochet ne peut pas affecter l'image finale. Ce comportement permet, entre autres, l'installation et l'utilisation de dépendances de test qui sont automatiquement supprimées et ne sont pas présentes dans l'image finale.
2.8.2.1. Configurer les crochets de compilation après livraison
Il existe différentes façons de configurer le crochet de post-construction. Tous les formulaires des exemples suivants sont équivalents et s'exécutent à l'adresse bundle exec rake test --verbose.
Procédure
Script shell :
postCommit: script: "bundle exec rake test --verbose"La valeur
scriptest un script shell à exécuter avec/bin/sh -ic. Utilisez cette valeur lorsqu'un script shell est approprié pour exécuter le crochet de compilation. Par exemple, pour exécuter des tests unitaires comme ci-dessus. Pour contrôler le point d'entrée de l'image, ou si l'image n'a pas/bin/sh, utilisezcommandet/ouargs.NoteLe drapeau supplémentaire
-ia été introduit pour améliorer l'expérience de travail avec les images CentOS et RHEL, et pourrait être supprimé dans une prochaine version.Comme point d'entrée de l'image :
postCommit: command: ["/bin/bash", "-c", "bundle exec rake test --verbose"]Dans cette forme,
commandest la commande à exécuter, qui remplace le point d'entrée de l'image dans la forme exec, comme documenté dans la référence Dockerfile. Ceci est nécessaire si l'image n'a pas/bin/sh, ou si vous ne voulez pas utiliser un shell. Dans tous les autres cas, l'utilisation descriptpeut être plus pratique.Commande avec arguments :
postCommit: command: ["bundle", "exec", "rake", "test"] args: ["--verbose"]Cette forme est équivalente à l'ajout des arguments à
command.
Fournir simultanément script et command crée un crochet de construction invalide.
2.8.2.2. Utiliser l'interface de commande pour définir les crochets de compilation après livraison
La commande oc set build-hook peut être utilisée pour définir le crochet de compilation pour une configuration de compilation.
Procédure
Pour définir une commande comme crochet de construction post-commit :
$ oc set build-hook bc/mybc \ --post-commit \ --command \ -- bundle exec rake test --verbosePour définir un script comme crochet de compilation post-commit :
$ oc set build-hook bc/mybc --post-commit --script="bundle exec rake test --verbose"
2.9. Effectuer des constructions avancées
Les sections suivantes fournissent des instructions pour les opérations de construction avancées, notamment la définition des ressources de construction et de la durée maximale, l'affectation des constructions aux nœuds, l'enchaînement des constructions, l'élagage des constructions et les stratégies d'exécution des constructions.
2.9.1. Définition des ressources de construction
Par défaut, les constructions sont réalisées par des pods utilisant des ressources non liées, telles que la mémoire et le processeur. Ces ressources peuvent être limitées.
Procédure
Vous pouvez limiter l'utilisation des ressources de deux manières :
- Limiter l'utilisation des ressources en spécifiant des limites de ressources dans les limites du conteneur par défaut d'un projet.
Limit resource use by specifying resource limits as part of the build configuration. ** In the following example, each of the
resources,cpu, andmemoryparameters are optional:apiVersion: "v1" kind: "BuildConfig" metadata: name: "sample-build" spec: resources: limits: cpu: "100m"1 memory: "256Mi"2 Toutefois, si un quota a été défini pour votre projet, l'un des deux éléments suivants est nécessaire :
Un ensemble de sections
resourcesavec unrequestsexplicite :resources: requests:1 cpu: "100m" memory: "256Mi"- 1
- L'objet
requestscontient la liste des ressources correspondant à la liste des ressources du quota.
Une plage de limites définie dans votre projet, où les valeurs par défaut de l'objet
LimitRanges'appliquent aux pods créés pendant le processus de construction.Dans le cas contraire, la création d'un build pod échouera, car le quota n'aura pas été atteint.
2.9.2. Définition de la durée maximale
Lors de la définition d'un objet BuildConfig, vous pouvez définir sa durée maximale en définissant le champ completionDeadlineSeconds. Ce champ est spécifié en secondes et n'est pas défini par défaut. S'il n'est pas défini, aucune durée maximale n'est imposée.
La durée maximale est calculée à partir du moment où un pod de construction est planifié dans le système, et définit la durée pendant laquelle il peut être actif, y compris le temps nécessaire à l'extraction de l'image du constructeur. Après avoir atteint le délai spécifié, la construction est interrompue par OpenShift Container Platform.
Procédure
Pour définir la durée maximale, spécifiez
completionDeadlineSecondsdans votreBuildConfig. L'exemple suivant montre la partie d'unBuildConfigspécifiant le champcompletionDeadlineSecondspour 30 minutes :spec: completionDeadlineSeconds: 1800
Ce paramètre n'est pas pris en charge par l'option Stratégie de pipeline.
2.9.3. Assigner des constructions à des nœuds spécifiques
Les builds peuvent être ciblés pour s'exécuter sur des nœuds spécifiques en spécifiant des étiquettes dans le champ nodeSelector d'une configuration de build. La valeur nodeSelector est un ensemble de paires clé-valeur qui sont associées aux étiquettes Node lors de la planification du module de construction.
La valeur nodeSelector peut également être contrôlée par des valeurs par défaut et des valeurs de remplacement à l'échelle du cluster. Les valeurs par défaut ne seront appliquées que si la configuration de construction ne définit aucune paire clé-valeur pour nodeSelector et ne définit pas non plus une valeur de carte explicitement vide pour nodeSelector:{}. Les valeurs de remplacement remplaceront les valeurs dans la configuration de construction sur une base clé par clé.
Si l'adresse NodeSelector spécifiée ne peut être associée à un nœud portant ces étiquettes, la construction reste indéfiniment dans l'état Pending.
Procédure
Attribuez des builds à exécuter sur des nœuds spécifiques en attribuant des étiquettes dans le champ
nodeSelectorde l'adresseBuildConfig, par exemple :apiVersion: "v1" kind: "BuildConfig" metadata: name: "sample-build" spec: nodeSelector:1 key1: value1 key2: value2- 1
- Les constructions associées à cette configuration de construction ne s'exécuteront que sur les nœuds portant les étiquettes
key1=value2etkey2=value2.
2.9.4. Constructions en chaîne
Pour les langages compilés tels que Go, C, C et Java, l'inclusion des dépendances nécessaires à la compilation dans l'image de l'application peut augmenter la taille de l'image ou introduire des vulnérabilités qui peuvent être exploitées.
Pour éviter ces problèmes, il est possible d'enchaîner deux compilations. Une compilation qui produit l'artefact compilé, et une seconde qui place cet artefact dans une image séparée qui exécute l'artefact.
Dans l'exemple suivant, une compilation source-image (S2I) est combinée avec une compilation docker pour compiler un artefact qui est ensuite placé dans une image d'exécution séparée.
Bien que cet exemple enchaîne une construction S2I et une construction docker, la première construction peut utiliser n'importe quelle stratégie qui produit une image contenant les artefacts souhaités, et la seconde construction peut utiliser n'importe quelle stratégie qui peut consommer du contenu d'entrée à partir d'une image.
La première compilation prend la source de l'application et produit une image contenant un fichier WAR. L'image est poussée vers le flux d'images artifact-image. Le chemin de l'artefact de sortie dépend du script assemble du constructeur S2I utilisé. Dans le cas présent, l'artefact est envoyé à /wildfly/standalone/deployments/ROOT.war.
apiVersion: build.openshift.io/v1
kind: BuildConfig
metadata:
name: artifact-build
spec:
output:
to:
kind: ImageStreamTag
name: artifact-image:latest
source:
git:
uri: https://github.com/openshift/openshift-jee-sample.git
ref: "master"
strategy:
sourceStrategy:
from:
kind: ImageStreamTag
name: wildfly:10.1
namespace: openshift
La deuxième version utilise l'image source avec un chemin vers le fichier WAR à l'intérieur de l'image de sortie de la première version. Une page dockerfile copie le fichier WAR dans une image d'exécution.
apiVersion: build.openshift.io/v1
kind: BuildConfig
metadata:
name: image-build
spec:
output:
to:
kind: ImageStreamTag
name: image-build:latest
source:
dockerfile: |-
FROM jee-runtime:latest
COPY ROOT.war /deployments/ROOT.war
images:
- from:
kind: ImageStreamTag
name: artifact-image:latest
paths:
- sourcePath: /wildfly/standalone/deployments/ROOT.war
destinationDir: "."
strategy:
dockerStrategy:
from:
kind: ImageStreamTag
name: jee-runtime:latest
triggers:
- imageChange: {}
type: ImageChange- 1
fromspécifie que la construction de docker doit inclure la sortie de l'image du flux d'imagesartifact-image, qui était la cible de la construction précédente.- 2
pathsspécifie les chemins de l'image cible à inclure dans la construction actuelle de Docker.- 3
- L'image d'exécution est utilisée comme image source pour la construction de docker.
Le résultat de cette configuration est que l'image de sortie de la deuxième compilation n'a pas besoin de contenir les outils de compilation nécessaires pour créer le fichier WAR. De plus, comme la deuxième compilation contient un déclencheur de changement d'image, chaque fois que la première compilation est exécutée et produit une nouvelle image avec l'artefact binaire, la deuxième compilation est automatiquement déclenchée pour produire une image d'exécution qui contient cet artefact. Par conséquent, les deux compilations se comportent comme une seule compilation avec deux étapes.
2.9.5. Taille des constructions
Par défaut, les versions qui ont terminé leur cycle de vie sont conservées indéfiniment. Vous pouvez limiter le nombre de versions antérieures conservées.
Procédure
Limitez le nombre de constructions précédentes qui sont conservées en fournissant une valeur entière positive pour
successfulBuildsHistoryLimitoufailedBuildsHistoryLimitdans votreBuildConfig, par exemple :apiVersion: "v1" kind: "BuildConfig" metadata: name: "sample-build" spec: successfulBuildsHistoryLimit: 21 failedBuildsHistoryLimit: 22 Déclencher l'élagage de la construction par l'une des actions suivantes :
- Mise à jour d'une configuration de construction.
- Attente de la fin du cycle de vie d'une construction.
Les constructions sont triées en fonction de leur date de création, les plus anciennes étant élaguées en premier.
Les administrateurs peuvent élaguer manuellement les constructions à l'aide de la commande d'élagage d'objets 'oc adm'.
2.9.6. Politique d'exécution de la construction
La politique d'exécution de la construction décrit l'ordre dans lequel les constructions créées à partir de la configuration de la construction doivent être exécutées. Pour ce faire, il suffit de modifier la valeur du champ runPolicy dans la section spec de la spécification Build.
Il est également possible de modifier la valeur de runPolicy pour les configurations de construction existantes :
-
Si l'on remplace
ParallelparSerialouSerialLatestOnlyet que l'on déclenche une nouvelle construction à partir de cette configuration, la nouvelle construction attendra que toutes les constructions parallèles soient terminées, car la construction en série ne peut s'exécuter que seule. -
Changer
SerialenSerialLatestOnlyet déclencher un nouveau build provoque l'annulation de tous les builds existants dans la file d'attente, à l'exception du build en cours d'exécution et du build créé le plus récemment. La version la plus récente s'exécute ensuite.
2.10. Utilisation des abonnements Red Hat dans les constructions
Utilisez les sections suivantes pour exécuter des builds intitulés sur OpenShift Container Platform.
2.10.1. Création d'une balise de flux d'images pour l'image de base universelle de Red Hat
Pour utiliser les abonnements Red Hat dans une compilation, vous créez une balise de flux d'images pour référencer l'image de base universelle (UBI).
Pour que l'UBI soit disponible à l'adresse in every project dans le cluster, vous devez ajouter la balise de flux d'images à l'espace de noms openshift. Sinon, pour le rendre disponible à l'adresse in a specific project, vous devez ajouter la balise de flux d'images à ce projet.
L'avantage d'utiliser des balises de flux d'images de cette manière est que cela permet d'accéder à l'UBI sur la base des informations d'identification registry.redhat.io dans le secret d'installation sans exposer le secret d'installation à d'autres utilisateurs. C'est plus pratique que de demander à chaque développeur d'installer des secrets d'installation avec des informations d'identification registry.redhat.io dans chaque projet.
Procédure
Pour créer un site
ImageStreamTagdans l'espace de nomsopenshift, afin qu'il soit disponible pour les développeurs de tous les projets, entrez :$ oc tag --source=docker registry.redhat.io/ubi8/ubi:latest ubi:latest -n openshiftAstuceVous pouvez également appliquer le YAML suivant pour créer un
ImageStreamTagdans l'espace de nomsopenshift:apiVersion: image.openshift.io/v1 kind: ImageStream metadata: name: ubi namespace: openshift spec: tags: - from: kind: DockerImage name: registry.redhat.io/ubi8/ubi:latest name: latest referencePolicy: type: SourcePour créer un site
ImageStreamTagdans un seul projet, entrez :$ oc tag --source=docker registry.redhat.io/ubi8/ubi:latest ubi:latestAstuceVous pouvez également appliquer le YAML suivant pour créer un site
ImageStreamTagdans un seul projet :apiVersion: image.openshift.io/v1 kind: ImageStream metadata: name: ubi spec: tags: - from: kind: DockerImage name: registry.redhat.io/ubi8/ubi:latest name: latest referencePolicy: type: Source
2.10.2. Ajouter des droits d'abonnement en tant que secret de construction
Les constructions qui utilisent les abonnements Red Hat pour installer le contenu doivent inclure les clés de droits en tant que secret de construction.
Conditions préalables
Vous devez avoir accès aux droits de Red Hat par le biais de votre abonnement. Le secret des droits est automatiquement créé par l'opérateur Insights.
Lorsque vous effectuez un Entitlement Build à l'aide de Red Hat Enterprise Linux (RHEL) 7, vous devez avoir les instructions suivantes dans votre Dockerfile avant d'exécuter les commandes yum:
RUN rm /etc/rhsm-hostProcédure
Ajouter le secret etc-pki-entitlement comme volume de construction dans la stratégie Docker de la configuration de construction :
strategy: dockerStrategy: from: kind: ImageStreamTag name: ubi:latest volumes: - name: etc-pki-entitlement mounts: - destinationPath: /etc/pki/entitlement source: type: Secret secret: secretName: etc-pki-entitlement
2.10.3. Exécuter des builds avec le gestionnaire d'abonnements
2.10.3.1. Constructions Docker à l'aide du gestionnaire d'abonnement
Les constructions de stratégies Docker peuvent utiliser le gestionnaire d'abonnement pour installer le contenu de l'abonnement.
Conditions préalables
Les clés de droits doivent être ajoutées en tant que volumes de stratégie de construction.
Procédure
Utilisez le fichier Docker suivant comme exemple pour installer du contenu avec le gestionnaire d'abonnement :
FROM registry.redhat.io/ubi8/ubi:latest
RUN dnf search kernel-devel --showduplicates && \
dnf install -y kernel-devel2.10.4. Exécuter des builds avec des abonnements Red Hat Satellite
2.10.4.1. Ajout de configurations Red Hat Satellite aux constructions
Les constructions qui utilisent Red Hat Satellite pour installer du contenu doivent fournir des configurations appropriées pour obtenir du contenu à partir des dépôts Satellite.
Conditions préalables
Vous devez fournir ou créer un fichier de configuration du dépôt compatible avec
yumqui télécharge le contenu de votre instance Satellite.Exemple de configuration du référentiel
[test-<name>] name=test-<number> baseurl = https://satellite.../content/dist/rhel/server/7/7Server/x86_64/os enabled=1 gpgcheck=0 sslverify=0 sslclientkey = /etc/pki/entitlement/...-key.pem sslclientcert = /etc/pki/entitlement/....pem
Procédure
Créez un site
ConfigMapcontenant le fichier de configuration du référentiel Satellite :$ oc create configmap yum-repos-d --from-file /path/to/satellite.repoAjouter la configuration du référentiel satellite et la clé d'habilitation en tant que volumes de construction :
strategy: dockerStrategy: from: kind: ImageStreamTag name: ubi:latest volumes: - name: yum-repos-d mounts: - destinationPath: /etc/yum.repos.d source: type: ConfigMap configMap: name: yum-repos-d - name: etc-pki-entitlement mounts: - destinationPath: /etc/pki/entitlement source: type: Secret secret: secretName: etc-pki-entitlement
2.10.4.2. Constructions Docker à l'aide d'abonnements Red Hat Satellite
Les constructions de stratégie Docker peuvent utiliser les dépôts Red Hat Satellite pour installer le contenu de l'abonnement.
Conditions préalables
- Vous avez ajouté les clés d'habilitation et les configurations du référentiel satellite en tant que volumes de construction.
Procédure
Utilisez le fichier Docker suivant comme exemple pour installer du contenu avec Satellite :
FROM registry.redhat.io/ubi8/ubi:latest
RUN dnf search kernel-devel --showduplicates && \
dnf install -y kernel-devel2.11. Sécuriser les constructions par la stratégie
Les builds dans OpenShift Container Platform sont exécutés dans des conteneurs privilégiés. En fonction de la stratégie de construction utilisée, si vous avez des privilèges, vous pouvez exécuter des constructions pour escalader leurs permissions sur le cluster et les nœuds hôtes. En tant que mesure de sécurité, elle limite les personnes autorisées à exécuter des builds et la stratégie utilisée pour ces builds. Les builds personnalisés sont intrinsèquement moins sûrs que les builds source, car ils peuvent exécuter n'importe quel code dans un conteneur privilégié, et sont désactivés par défaut. Accordez les permissions de construction de docker avec prudence, car une vulnérabilité dans la logique de traitement de Dockerfile pourrait entraîner l'octroi de privilèges sur le nœud hôte.
Par défaut, tous les utilisateurs qui peuvent créer des builds sont autorisés à utiliser les stratégies de build docker et Source-to-image (S2I). Les utilisateurs disposant de privilèges d'administrateur de cluster peuvent activer la stratégie de build personnalisée, comme indiqué dans la section restreignant les stratégies de build à un utilisateur de manière globale.
Vous pouvez contrôler qui peut construire et quelles stratégies de construction ils peuvent utiliser en utilisant une politique d'autorisation. Chaque stratégie de construction a une sous-ressource de construction correspondante. Un utilisateur doit avoir l'autorisation de créer un build et l'autorisation de créer sur la sous-ressource de la stratégie de build pour créer des builds utilisant cette stratégie. Des rôles par défaut sont fournis pour accorder l'autorisation de création sur la sous-ressource de la stratégie de construction.
| Stratégie | Sous-ressource | Rôle |
|---|---|---|
| Docker | builds/docker | system:build-strategy-docker |
| De la source à l'image | builds/source | system:build-strategy-source |
| Sur mesure | constructions/personnalisées | système:construire-stratégie-personnalisée |
| JenkinsPipeline | builds/jenkinspipeline | système:construire-stratégie-jenkinspipeline |
2.11.1. Désactiver l'accès à une stratégie de construction au niveau mondial
Pour empêcher l'accès à une stratégie de construction particulière au niveau mondial, connectez-vous en tant qu'utilisateur disposant de privilèges d'administrateur de cluster, supprimez le rôle correspondant du groupe system:authenticated et appliquez l'annotation rbac.authorization.kubernetes.io/autoupdate: "false" pour les protéger contre les modifications entre les redémarrages de l'API. L'exemple suivant montre la désactivation de la stratégie de construction Docker.
Procédure
Appliquez l'annotation
rbac.authorization.kubernetes.io/autoupdate:$ oc edit clusterrolebinding system:build-strategy-docker-bindingExemple de sortie
apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: annotations: rbac.authorization.kubernetes.io/autoupdate: "false"1 creationTimestamp: 2018-08-10T01:24:14Z name: system:build-strategy-docker-binding resourceVersion: "225" selfLink: /apis/rbac.authorization.k8s.io/v1/clusterrolebindings/system%3Abuild-strategy-docker-binding uid: 17b1f3d4-9c3c-11e8-be62-0800277d20bf roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: system:build-strategy-docker subjects: - apiGroup: rbac.authorization.k8s.io kind: Group name: system:authenticated- 1
- Changez la valeur de l'annotation
rbac.authorization.kubernetes.io/autoupdateen"false".
Supprimer le rôle :
$ oc adm policy remove-cluster-role-from-group system:build-strategy-docker system:authenticatedAssurez-vous que les sous-ressources de la stratégie de construction sont également supprimées de ces rôles :
$ oc edit clusterrole admin$ oc edit clusterrole editPour chaque rôle, indiquez les sous-ressources qui correspondent à la ressource de la stratégie à désactiver.
Désactiver la stratégie de construction de docker pour admin:
kind: ClusterRole metadata: name: admin ... - apiGroups: - "" - build.openshift.io resources: - buildconfigs - buildconfigs/webhooks - builds/custom1 - builds/source verbs: - create - delete - deletecollection - get - list - patch - update - watch ...- 1
- Ajoutez
builds/custometbuilds/sourcepour désactiver globalement les constructions de dockers pour les utilisateurs ayant le rôle admin.
2.11.2. Restreindre les stratégies de construction aux utilisateurs au niveau mondial
Vous pouvez autoriser un ensemble d'utilisateurs spécifiques à créer des builds avec une stratégie particulière.
Conditions préalables
- Désactiver l'accès global à la stratégie de construction.
Procédure
Attribuez le rôle correspondant à la stratégie de construction à un utilisateur spécifique. Par exemple, pour ajouter le rôle de cluster
system:build-strategy-dockerà l'utilisateurdevuser:$ oc adm policy add-cluster-role-to-user system:build-strategy-docker devuserAvertissementAccorder à un utilisateur l'accès au niveau du cluster à la sous-ressource
builds/dockersignifie que l'utilisateur peut créer des builds avec la stratégie docker dans n'importe quel projet dans lequel il peut créer des builds.
2.11.3. Restreindre les stratégies de construction à un utilisateur au sein d'un projet
De la même manière que vous attribuez le rôle de stratégie de construction à un utilisateur de manière globale, vous pouvez autoriser un ensemble d'utilisateurs spécifiques au sein d'un projet à créer des constructions à l'aide d'une stratégie particulière.
Conditions préalables
- Désactiver l'accès global à la stratégie de construction.
Procédure
Attribuer le rôle correspondant à la stratégie de construction à un utilisateur spécifique au sein d'un projet. Par exemple, pour ajouter le rôle
system:build-strategy-dockerdans le projetdevprojectà l'utilisateurdevuser:$ oc adm policy add-role-to-user system:build-strategy-docker devuser -n devproject
2.12. Construire des ressources de configuration
La procédure suivante permet de configurer les paramètres de construction.
2.12.1. Construire les paramètres de configuration du contrôleur
La ressource build.config.openshift.io/cluster offre les paramètres de configuration suivants.
| Paramètres | Description |
|---|---|
|
|
Contient des informations à l'échelle du cluster sur la manière de gérer les builds. Le nom canonique, et le seul valide, est
|
|
| Contrôle les informations par défaut pour les constructions.
Vous pouvez remplacer les valeurs en définissant les variables d'environnement
Les valeurs qui ne sont pas définies ici sont héritées de DefaultProxy.
|
|
|
|
|
| Contrôle les paramètres d'annulation des constructions.
|
|
|
|
2.12.2. Configuration des paramètres de construction
Vous pouvez configurer les paramètres de construction en modifiant la ressource build.config.openshift.io/cluster.
Procédure
Modifier la ressource
build.config.openshift.io/cluster:$ oc edit build.config.openshift.io/clusterVoici un exemple de ressource
build.config.openshift.io/cluster:apiVersion: config.openshift.io/v1 kind: Build1 metadata: annotations: release.openshift.io/create-only: "true" creationTimestamp: "2019-05-17T13:44:26Z" generation: 2 name: cluster resourceVersion: "107233" selfLink: /apis/config.openshift.io/v1/builds/cluster uid: e2e9cc14-78a9-11e9-b92b-06d6c7da38dc spec: buildDefaults:2 defaultProxy:3 httpProxy: http://proxy.com httpsProxy: https://proxy.com noProxy: internal.com env:4 - name: envkey value: envvalue gitProxy:5 httpProxy: http://gitproxy.com httpsProxy: https://gitproxy.com noProxy: internalgit.com imageLabels:6 - name: labelkey value: labelvalue resources:7 limits: cpu: 100m memory: 50Mi requests: cpu: 10m memory: 10Mi buildOverrides:8 imageLabels:9 - name: labelkey value: labelvalue nodeSelector:10 selectorkey: selectorvalue tolerations:11 - effect: NoSchedule key: node-role.kubernetes.io/builds operator: Exists- 1
Build: Contient des informations à l'échelle du cluster sur la manière de gérer les builds. Le nom canonique, et le seul valide, estcluster.- 2
buildDefaults: Contrôle les informations par défaut pour les constructions.- 3
defaultProxy: Contient les paramètres proxy par défaut pour toutes les opérations de construction, y compris l'extraction ou la poussée d'images et le téléchargement de sources.- 4
env: Un ensemble de variables d'environnement par défaut qui sont appliquées à la compilation si les variables spécifiées n'existent pas sur la compilation.- 5
gitProxy: Contient les paramètres du proxy pour les opérations Git uniquement. S'ils sont définis, ils remplacent tous les paramètres de proxy pour toutes les commandes Git, telles quegit clone.- 6
imageLabels: Une liste d'étiquettes qui sont appliquées à l'image résultante. Vous pouvez remplacer une étiquette par défaut en fournissant une étiquette portant le même nom dans l'adresseBuildConfig.- 7
resources: Définit les ressources nécessaires à l'exécution de la construction.- 8
buildOverrides: Contrôle les paramètres d'annulation des constructions.- 9
imageLabels: Une liste d'étiquettes qui sont appliquées à l'image résultante. Si vous avez fourni une étiquette dansBuildConfigavec le même nom qu'une étiquette dans cette table, votre étiquette sera écrasée.- 10
nodeSelector: Un sélecteur qui doit être vrai pour que le module de construction tienne sur un nœud.- 11
tolerations: Une liste de tolérances qui remplace toutes les tolérances existantes définies sur un module de construction.
2.13. Dépannage des constructions
Utilisez les éléments suivants pour résoudre les problèmes de construction.
2.13.1. Résoudre les refus d'accès aux ressources
Si votre demande d'accès aux ressources est refusée :
- Enjeu
- Une construction échoue avec :
requested access to the resource is denied- Résolution
- Vous avez dépassé l'un des quotas d'images définis pour votre projet. Vérifiez votre quota actuel et vérifiez les limites appliquées et l'espace de stockage utilisé :
$ oc describe quota2.13.2. Échec de la génération du certificat de service
Si votre demande d'accès aux ressources est refusée :
- Enjeu
-
Si la génération d'un certificat de service échoue avec (l'annotation
service.beta.openshift.io/serving-cert-generation-errordu service contient) :
Exemple de sortie
secret/ssl-key references serviceUID 62ad25ca-d703-11e6-9d6f-0e9c0057b608, which does not match 77b6dd80-d716-11e6-9d6f-0e9c0057b60- Résolution
-
Le service qui a généré le certificat n'existe plus, ou a un autre
serviceUID. Vous devez forcer la régénération des certificats en supprimant l'ancien secret et en effaçant les annotations suivantes sur le service :service.beta.openshift.io/serving-cert-generation-erroretservice.beta.openshift.io/serving-cert-generation-error-num:
oc delete secret <secret_name>oc annotate service <service_name> service.beta.openshift.io/serving-cert-generation-error-oc annotate service <service_name> service.beta.openshift.io/serving-cert-generation-error-num-
La commande de suppression d'une annotation comporte une adresse - après le nom de l'annotation à supprimer.
2.14. Mise en place d'autorités de certification de confiance supplémentaires pour les constructions
Utilisez les sections suivantes pour configurer des autorités de certification (AC) supplémentaires qui seront approuvées par les builds lors de l'extraction d'images à partir d'un registre d'images.
La procédure exige qu'un administrateur de cluster crée un site ConfigMap et ajoute des autorités de certification supplémentaires en tant que clés dans le site ConfigMap.
-
Le site
ConfigMapdoit être créé dans l'espace de nomsopenshift-config. domainest la clé dans le siteConfigMapetvalueest le certificat codé en PEM.-
Chaque autorité de certification doit être associée à un domaine. Le format du domaine est
hostname[..port].
-
Chaque autorité de certification doit être associée à un domaine. Le format du domaine est
-
Le nom
ConfigMapdoit être défini dans le champspec.additionalTrustedCAde la ressourceimage.config.openshift.io/clustercluster scoped configuration.
2.14.1. Ajout d'autorités de certification au cluster
La procédure suivante permet d'ajouter des autorités de certification (AC) à la grappe afin de les utiliser lors de l'envoi et du retrait d'images.
Conditions préalables
-
Vous devez avoir accès aux certificats publics du registre, généralement un fichier
hostname/ca.crtsitué dans le répertoire/etc/docker/certs.d/.
Procédure
Créez un site
ConfigMapdans l'espace de nomsopenshift-configcontenant les certificats approuvés pour les registres qui utilisent des certificats auto-signés. Pour chaque fichier CA, assurez-vous que la clé deConfigMapest le nom d'hôte du registre au formathostname[..port]:$ oc create configmap registry-cas -n openshift-config \ --from-file=myregistry.corp.com..5000=/etc/docker/certs.d/myregistry.corp.com:5000/ca.crt \ --from-file=otherregistry.com=/etc/docker/certs.d/otherregistry.com/ca.crtMettre à jour la configuration de l'image du cluster :
$ oc patch image.config.openshift.io/cluster --patch '{"spec":{"additionalTrustedCA":{"name":"registry-cas"}}}' --type=merge
Chapitre 3. Pipelines
3.1. Notes de mise à jour de Red Hat OpenShift Pipelines
Red Hat OpenShift Pipelines est une expérience CI/CD cloud-native basée sur le projet Tekton qui fournit :
- Définitions standard de pipeline natif Kubernetes (CRDs).
- Pipelines sans serveur, sans frais de gestion des serveurs de CI.
- Extensibilité pour construire des images en utilisant n'importe quel outil Kubernetes, comme S2I, Buildah, JIB et Kaniko.
- Portabilité sur n'importe quelle distribution Kubernetes.
- CLI puissant pour interagir avec les pipelines.
- Expérience utilisateur intégrée avec la perspective Developer de la console web OpenShift Container Platform.
Pour une vue d'ensemble de Red Hat OpenShift Pipelines, voir Comprendre OpenShift Pipelines.
3.1.1. Matrice de compatibilité et de soutien
Certaines fonctionnalités de cette version sont actuellement en avant-première technologique. Ces fonctionnalités expérimentales ne sont pas destinées à être utilisées en production.
Dans le tableau, les caractéristiques sont marquées par les statuts suivants :
| TP | Avant-première technologique |
| GA | Disponibilité générale |
| Version de Red Hat OpenShift Pipelines | Version du composant | Version d'OpenShift | Statut de soutien | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Opérateur | Pipelines | Déclencheurs | CLI | Catalogue | Chaînes | Hub | Les pipelines en tant que code | ||
| 1.10 | 0.44.x | 0.23.x | 0.30.x | NA | 0.15.x (TP) | 1.12.x (TP) | 0.17.x (GA) | 4.11, 4.12, 4.13 (prévus) | GA |
| 1.9 | 0.41.x | 0.22.x | 0.28.x | NA | 0.13.x (TP) | 1.11.x (TP) | 0.15.x (GA) | 4.11, 4.12, 4.13 (prévus) | GA |
| 1.8 | 0.37.x | 0.20.x | 0.24.x | NA | 0.9.0 (TP) | 1.8.x (TP) | 0.10.x (TP) | 4.10, 4.11, 4.12 | GA |
| 1.7 | 0.33.x | 0.19.x | 0.23.x | 0.33 | 0.8.0 (TP) | 1.7.0 (TP) | 0.5.x (TP) | 4.9, 4.10, 4.11 | GA |
| 1.6 | 0.28.x | 0.16.x | 0.21.x | 0.28 | N/A | N/A | N/A | 4.9 | GA |
| 1.5 | 0.24.x | 0.14.x (TP) | 0.19.x | 0.24 | N/A | N/A | N/A | 4.8 | GA |
| 1.4 | 0.22.x | 0.12.x (TP) | 0.17.x | 0.22 | N/A | N/A | N/A | 4.7 | GA |
En outre, la prise en charge de l'exécution de Red Hat OpenShift Pipelines sur du matériel ARM est dans l'aperçu technologique.
Pour toute question ou commentaire, vous pouvez envoyer un courriel à l'équipe produit à l'adresse pipelines-interest@redhat.com.
3.1.2. Rendre l'open source plus inclusif
Red Hat s'engage à remplacer les termes problématiques dans son code, sa documentation et ses propriétés Web. Nous commençons par ces quatre termes : master, slave, blacklist et whitelist. En raison de l'ampleur de cette entreprise, ces changements seront mis en œuvre progressivement au cours de plusieurs versions à venir. Pour plus de détails, voir le message de notre directeur technique Chris Wright.
3.1.3. Notes de version pour Red Hat OpenShift Pipelines General Availability 1.10
Avec cette mise à jour, Red Hat OpenShift Pipelines General Availability (GA) 1.10 est disponible sur OpenShift Container Platform 4.11 et les versions ultérieures.
3.1.3.1. Nouvelles fonctionnalités
En plus des corrections et des améliorations de stabilité, les sections suivantes mettent en évidence les nouveautés de Red Hat OpenShift Pipelines 1.10.
3.1.3.1.1. Pipelines
-
Avec cette mise à jour, vous pouvez spécifier des variables d'environnement dans un modèle de pod
PipelineRunouTaskRunpour remplacer ou ajouter les variables configurées dans une tâche ou une étape. Vous pouvez également spécifier des variables d'environnement dans un modèle de module par défaut afin d'utiliser ces variables globalement pour tous les modulesPipelineRunsetTaskRuns. Cette mise à jour ajoute également une nouvelle configuration par défaut nomméeforbidden-envspour filtrer les variables d'environnement lors de la propagation à partir des modèles de pods. Avec cette mise à jour, les tâches personnalisées dans les pipelines sont activées par défaut.
NotePour désactiver cette mise à jour, définissez l'indicateur
enable-custom-taskssurfalsedans la ressource personnaliséefeature-flagsconfig.-
Cette mise à jour prend en charge la version de l'API
v1beta1.CustomRunpour les tâches personnalisées. Cette mise à jour ajoute la prise en charge du rapprochement
PipelineRunpour la création d'une exécution personnalisée. Par exemple, la version personnalisée deTaskRunscréée à partir dePipelineRunspeut désormais utiliser la version de l'APIv1beta1.CustomRunau lieu dev1alpha1.Run, si l'indicateur de fonctionnalitécustom-task-versionest défini surv1beta1, au lieu de la valeur par défautv1alpha1.NoteVous devez mettre à jour le contrôleur de tâches personnalisé pour qu'il écoute la version de l'API
*v1beta1.CustomRunau lieu de*v1alpha1.Runafin de répondre aux demandesv1beta1.CustomRun.-
Cette mise à jour ajoute un nouveau champ
retriesaux spécificationsv1beta1.TaskRunetv1.TaskRun.
3.1.3.1.2. Déclencheurs
-
Avec cette mise à jour, les déclencheurs prennent en charge la création des objets
Pipelines,Tasks,PipelineRuns, etTaskRunsde la versionv1de l'API ainsi que des objetsCustomRunde la versionv1beta1de l'API. Avec cette mise à jour, GitHub Interceptor bloque l'exécution d'un déclencheur de demande d'extraction à moins qu'il ne soit invoqué par un propriétaire ou accompagné d'un commentaire configurable de la part d'un propriétaire.
NotePour activer ou désactiver cette mise à jour, définissez la valeur du paramètre
githubOwnerssurtrueoufalsedans le fichier de configuration de GitHub Interceptor.-
Avec cette mise à jour, GitHub Interceptor a la possibilité d'ajouter une liste délimitée par des virgules de tous les fichiers qui ont été modifiés pour les événements push et pull request. La liste des fichiers modifiés est ajoutée à la propriété
changed_filesde la charge utile de l'événement dans le champ des extensions de premier niveau. -
Cette mise à jour modifie le site
MinVersionde TLS entls.VersionTLS12afin que les déclencheurs s'exécutent sur OpenShift Container Platform lorsque le mode Federal Information Processing Standards (FIPS) est activé.
3.1.3.1.3. CLI
-
Cette mise à jour ajoute la possibilité de transmettre un fichier CSI (Container Storage Interface) en tant qu'espace de travail au moment du démarrage d'une application
Task,ClusterTaskouPipeline. -
Cette mise à jour ajoute la prise en charge de l'API
v1à toutes les commandes CLI associées aux ressources task, pipeline, pipeline run et task run. Tekton CLI fonctionne avec les APIv1beta1etv1pour ces ressources. -
Cette mise à jour ajoute la prise en charge d'un paramètre de type d'objet dans les commandes
startetdescribe.
3.1.3.1.4. Opérateur
-
Cette mise à jour ajoute un paramètre
default-forbidden-envdans les propriétés optionnelles du pipeline. Ce paramètre inclut des variables d'environnement interdites qui ne doivent pas être propagées si elles sont fournies par des modèles de pods. -
Cette mise à jour ajoute la prise en charge des logos personnalisés dans l'interface utilisateur du Tekton Hub. Pour ajouter un logo personnalisé, définissez la valeur du paramètre
customLogoà l'URI codée en base64 du logo dans le Tekton Hub CR. - Cette mise à jour augmente le numéro de version de la tâche git-clone à 0.9.
3.1.3.1.5. Chaînes Tekton
-
Cette mise à jour ajoute des annotations et des étiquettes aux attestations
PipelineRunetTaskRun. -
Cette mise à jour ajoute un nouveau format appelé
slsa/v1, qui génère la même provenance que celle générée lors d'une demande au formatin-toto. - Avec cette mise à jour, les fonctionnalités de Sigstore sont retirées des fonctionnalités expérimentales.
-
Avec cette mise à jour, la fonction
predicate.materialsinclut l'URI de l'image et les informations de résumé de toutes les étapes et barres latérales d'un objetTaskRun.
3.1.3.1.6. Hub Tekton
-
Cette mise à jour prend en charge l'installation, la mise à niveau ou la rétrogradation des ressources Tekton de la version de l'API
v1sur le cluster. - Cette mise à jour permet d'ajouter un logo personnalisé à la place du logo du Tekton Hub dans l'interface utilisateur.
-
Cette mise à jour étend les fonctionnalités de la commande
tkn hub installen ajoutant un drapeau--type artifact, qui récupère les ressources de l'Artifact Hub et les installe sur votre cluster. - Cette mise à jour ajoute des informations sur le niveau de support, le catalogue et l'organisation en tant qu'étiquettes pour les ressources installées depuis Artifact Hub sur votre cluster.
3.1.3.1.7. Les pipelines en tant que code
-
Cette mise à jour améliore la prise en charge des webhooks entrants. Pour une application GitHub installée sur le cluster OpenShift Container Platform, vous n'avez pas besoin de fournir la spécification
git_providerpour un webhook entrant. Au lieu de cela, Pipelines as Code détecte le secret et l'utilise pour le webhook entrant. - Avec cette mise à jour, vous pouvez utiliser le même jeton pour récupérer des tâches distantes du même hôte sur GitHub avec une branche autre que celle par défaut.
-
Avec cette mise à jour, Pipelines as Code supporte les modèles Tekton
v1. Vous pouvez avoir des modèlesv1etv1beta1, que Pipelines as Code lit pour la génération de PR. Le PR est créé en tant quev1sur le cluster. -
Avant cette mise à jour, l'interface utilisateur de la console OpenShift utilisait un modèle d'exécution de pipeline codé en dur comme modèle de secours lorsqu'un modèle d'exécution n'était pas trouvé dans l'espace de noms OpenShift. Cette mise à jour de la carte de configuration
pipelines-as-codefournit un nouveau modèle d'exécution de pipeline par défaut nommépipelines-as-code-template-defaultpour la console à utiliser. - Avec cette mise à jour, Pipelines as Code supporte le statut minimal de Tekton Pipelines 0.44.0.
-
Avec cette mise à jour, Pipelines as Code supporte l'API Tekton
v1, ce qui signifie que Pipelines as Code est maintenant compatible avec Tekton v0.44 et plus. - Avec cette mise à jour, vous pouvez configurer des tableaux de bord de console personnalisés en plus de la configuration d'une console pour OpenShift et des tableaux de bord Tekton pour k8s.
-
Avec cette mise à jour, Pipelines as Code détecte l'installation d'une application GitHub initiée à l'aide de la commande
tkn pac create repoet ne nécessite pas de webhook GitHub si elle a été installée globalement. -
Avant cette mise à jour, s'il y avait une erreur sur une exécution de
PipelineRunet non sur les tâches attachées àPipelineRun, Pipelines as Code ne signalait pas correctement l'échec. Avec cette mise à jour, Pipelines as Code signale correctement l'erreur sur les contrôles GitHub lorsqu'unPipelineRunn'a pas pu être créé. -
Avec cette mise à jour, Pipelines as Code inclut une variable
target_namespace, qui s'étend à l'espace de noms en cours d'exécution oùPipelineRunest exécuté. - Avec cette mise à jour, Pipelines as Code vous permet de contourner les questions d'entreprise de GitHub dans l'application CLI bootstrap GitHub.
- Avec cette mise à jour, Pipelines as Code ne signale pas d'erreurs lorsque le référentiel CR n'a pas été trouvé.
- Avec cette mise à jour, Pipelines as Code signale une erreur si plusieurs exécutions de pipeline portant le même nom ont été trouvées.
3.1.3.2. Changements en cours
-
Avec cette mise à jour, la version précédente de la commande
tknn'est pas compatible avec Red Hat OpenShift Pipelines 1.10. -
Cette mise à jour supprime la prise en charge des ressources de pipeline
ClusteretCloudEventdans Tekton CLI. Vous ne pouvez pas créer de ressources de pipeline en utilisant la commandetkn pipelineresource create. De plus, les ressources de pipeline ne sont plus prises en charge dans la commandestartd'une tâche, d'une tâche de cluster ou d'un pipeline. -
Cette mise à jour supprime
tektonen tant que format de provenance des chaînes Tekton.
3.1.3.3. Fonctionnalités obsolètes et supprimées
-
Dans Red Hat OpenShift Pipelines 1.10, les commandes
ClusterTasksont désormais obsolètes et devraient être supprimées dans une prochaine version. La commandetkn task createest également obsolète avec cette mise à jour. -
Dans Red Hat OpenShift Pipelines 1.10, les drapeaux
-iet-oqui étaient utilisés avec la commandetkn task startsont désormais obsolètes car l'APIv1ne prend pas en charge les ressources de pipeline. -
Dans Red Hat OpenShift Pipelines 1.10, l'indicateur
-rqui était utilisé avec la commandetkn pipeline startest obsolète car l'APIv1ne prend pas en charge les ressources de pipeline. -
La mise à jour Red Hat OpenShift Pipelines 1.10 définit le paramètre
openshiftDefaultEmbeddedStatusàbothavecfulletminimalstatut intégré. Le drapeau permettant de modifier le statut intégré par défaut est également obsolète et sera supprimé. De plus, le statut intégré par défaut du pipeline sera modifié enminimaldans une prochaine version.
3.1.3.4. Problèmes connus
Cette mise à jour inclut les changements suivants, incompatibles avec le passé :
-
Suppression de la grappe
PipelineResources -
Suppression du nuage
PipelineResources
-
Suppression de la grappe
Si la fonctionnalité de mesure des pipelines ne fonctionne pas après une mise à niveau du cluster, exécutez la commande suivante en guise de solution de contournement :
$ oc get tektoninstallersets.operator.tekton.dev | awk '/pipeline-main-static/ {print $1}' | xargs oc delete tektoninstallersets- Avec cette mise à jour, l'utilisation de bases de données externes, telles que Crunchy PostgreSQL, n'est pas prise en charge sur IBM Power, IBM zSystems et IBM® LinuxONE. Utilisez plutôt la base de données par défaut du Tekton Hub.
3.1.3.5. Problèmes corrigés
-
Avant cette mise à jour, la commande
opc pacgénérait une erreur d'exécution au lieu d'afficher un message d'aide. Cette mise à jour corrige la commandeopc pacpour qu'elle affiche le message d'aide. -
Avant cette mise à jour, l'exécution de la commande
tkn pac create reponécessitait les détails du webhook pour créer un dépôt. Avec cette mise à jour, la commandetkn-pac create repone configure pas de webhook lorsque votre application GitHub est installée. -
Avant cette mise à jour, Pipelines as Code ne signalait pas d'erreur de création d'une exécution de pipeline lorsque Tekton Pipelines rencontrait des problèmes lors de la création de la ressource
PipelineRun. Par exemple, une tâche inexistante dans un pipeline n'affichait aucun statut. Avec cette mise à jour, Pipelines as Code affiche le message d'erreur approprié provenant de Tekton Pipelines ainsi que la tâche manquante. - Cette mise à jour corrige la redirection de la page de l'interface utilisateur après une authentification réussie. Désormais, vous êtes redirigé vers la même page que celle où vous avez tenté de vous connecter au Tekton Hub.
-
Cette mise à jour corrige la commande
listavec ces drapeaux,--all-namespaceset--output=yaml, pour une tâche en grappe, une tâche individuelle et un pipeline. -
Cette mise à jour supprime la barre oblique à la fin de l'URL de
repo.spec.urlafin qu'elle corresponde à l'URL provenant de GitHub. -
Avant cette mise à jour, la fonction
marshalJSONn'affichait pas de liste d'objets. Avec cette mise à jour, la fonctionmarshalJSONgère la liste d'objets. - Avec cette mise à jour, Pipelines as Code vous permet de contourner les questions d'entreprise de GitHub dans l'application CLI bootstrap GitHub.
- Cette mise à jour corrige la vérification des collaborateurs GitHub lorsque votre dépôt a plus de 100 utilisateurs.
-
Avec cette mise à jour, les commandes
signetverifypour une tâche ou un pipeline fonctionnent désormais sans fichier de configuration kubernetes. - Avec cette mise à jour, Tekton Operator nettoie les tâches cron d'élagage restantes si l'élagage a été ignoré sur un espace de noms.
-
Avant cette mise à jour, l'objet API
ConfigMapn'était pas mis à jour avec une valeur configurée par l'utilisateur pour l'intervalle de rafraîchissement du catalogue. Cette mise à jour corrige l'APICATALOG_REFRESH_INTERVALdans le Tekon Hub CR. Cette mise à jour corrige la réconciliation de
PipelineRunStatuslors de la modification de l'indicateur de fonctionnalitéEmbeddedStatus. Cette mise à jour réinitialise les paramètres suivants :-
Les paramètres
status.runsetstatus.taskrunsànilavecminimal EmbeddedStatus -
Le paramètre
status.childReferencesànilavecfull EmbeddedStatus
-
Les paramètres
-
Cette mise à jour ajoute une configuration de conversion au CRD
ResolutionRequest. Cette mise à jour configure correctement la conversion de la requêtev1alpha1.ResolutionRequestvers la requêtev1beta1.ResolutionRequest. - Cette mise à jour vérifie la présence d'espaces de travail en double associés à une tâche de pipeline.
- Cette mise à jour corrige la valeur par défaut de l'activation des résolveurs dans le code.
-
Cette mise à jour corrige la conversion des noms
TaskRefetPipelineRefà l'aide d'un résolveur.
3.1.4. Notes de version pour Red Hat OpenShift Pipelines General Availability 1.9
Avec cette mise à jour, Red Hat OpenShift Pipelines General Availability (GA) 1.9 est disponible sur OpenShift Container Platform 4.11 et les versions ultérieures.
3.1.4.1. Nouvelles fonctionnalités
En plus des corrections et des améliorations de stabilité, les sections suivantes mettent en évidence les nouveautés de Red Hat OpenShift Pipelines 1.9.
3.1.4.1.1. Pipelines
- Avec cette mise à jour, vous pouvez spécifier les paramètres du pipeline et les résultats sous forme de tableaux et de dictionnaires d'objets.
- Cette mise à jour prend en charge l'interface de stockage de conteneurs (CSI) et les volumes projetés pour votre espace de travail.
-
Avec cette mise à jour, vous pouvez spécifier les paramètres
stdoutConfigetstderrConfiglors de la définition des étapes du pipeline. La définition de ces paramètres permet de capturer la sortie standard et l'erreur standard, associées aux étapes, dans des fichiers locaux. -
Avec cette mise à jour, vous pouvez ajouter des variables dans le gestionnaire d'événements
steps[].onError, par exemple,$(params.CONTINUE). -
Avec cette mise à jour, vous pouvez utiliser le résultat de la tâche
finallydans la définitionPipelineResults. Par exemple,$(finally.<pipelinetask-name>.result.<result-name>), où<pipelinetask-name>désigne le nom de la tâche du pipeline et<result-name>le nom du résultat. - Cette mise à jour prend en charge les besoins en ressources au niveau des tâches pour l'exécution d'une tâche.
- Avec cette mise à jour, vous n'avez pas besoin de recréer les paramètres qui sont partagés, sur la base de leurs noms, entre un pipeline et les tâches définies. Cette mise à jour fait partie d'une fonctionnalité de l'avant-première pour les développeurs.
- Cette mise à jour ajoute la prise en charge de la résolution à distance, comme les résolveurs intégrés de git, cluster, bundle et hub.
3.1.4.1.2. Déclencheurs
-
Cette mise à jour ajoute le CRD
Interceptorpour définirNamespacedInterceptor. Vous pouvez utiliserNamespacedInterceptordans la sectionkindde la référence aux intercepteurs dans les déclencheurs ou dans la spécificationEventListener. -
Cette mise à jour permet à
CloudEvents. - Avec cette mise à jour, vous pouvez configurer le numéro de port du webhook lors de la définition d'un déclencheur.
-
Cette mise à jour permet d'utiliser le déclencheur
eventIDcomme entrée dansTriggerBinding. Cette mise à jour prend en charge la validation et la rotation des certificats pour le serveur
ClusterInterceptor.-
Les déclencheurs effectuent la validation des certificats pour les intercepteurs principaux et transmettent un nouveau certificat à
ClusterInterceptorlorsque son certificat expire.
-
Les déclencheurs effectuent la validation des certificats pour les intercepteurs principaux et transmettent un nouveau certificat à
3.1.4.1.3. CLI
-
Cette mise à jour permet d'afficher les annotations dans la commande
describe. -
Cette mise à jour permet d'afficher le pipeline, les tâches et le délai d'attente dans la commande
pr describe. -
Cette mise à jour ajoute des drapeaux permettant d'indiquer le pipeline, les tâches et le délai d'attente dans la commande
pipeline start. -
Cette mise à jour permet d'indiquer la présence d'un espace de travail, optionnel ou obligatoire, dans la commande
described'une tâche et d'un pipeline. -
Cette mise à jour ajoute le drapeau
timestampspour afficher les journaux avec un horodatage. -
Cette mise à jour ajoute un nouvel indicateur
--ignore-running-pipelinerun, qui ignore la suppression deTaskRunassociée àPipelineRun. -
Cette mise à jour ajoute la prise en charge des commandes expérimentales. Cette mise à jour ajoute également des sous-commandes expérimentales,
signetverifyà l'outil CLItkn. - Cette mise à jour permet d'utiliser la fonction d'achèvement de l'interpréteur de commandes Z (Zsh) sans générer de fichiers.
Cette mise à jour introduit un nouvel outil CLI appelé
opc. Il est prévu qu'une prochaine version remplace l'outil CLItknparopc.Important-
Le nouvel outil CLI
opcest une fonctionnalité de l'aperçu technologique. -
opcremplaceratknavec des fonctionnalités supplémentaires spécifiques à Red Hat OpenShift Pipelines, qui ne s'intègrent pas nécessairement danstkn.
-
Le nouvel outil CLI
3.1.4.1.4. Opérateur
Avec cette mise à jour, Pipelines as Code est installé par défaut. Vous pouvez désactiver Pipelines as Code en utilisant le drapeau
-p:$ oc patch tektonconfig config --type="merge" -p '{"spec": {"platforms": {"openshift":{"pipelinesAsCode": {"enable": false}}}}}'-
Avec cette mise à jour, vous pouvez également modifier les configurations de Pipelines as Code dans le CRD
TektonConfig. - Avec cette mise à jour, si vous désactivez la perspective développeur, l'opérateur n'installe pas les ressources personnalisées liées à la console développeur.
-
Cette mise à jour inclut le support de
ClusterTriggerBindingpour Bitbucket Server et Bitbucket Cloud et vous aide à réutiliser unTriggerBindingsur l'ensemble de votre cluster.
3.1.4.1.5. Résolveurs
Resolvers est une fonctionnalité d'aperçu technologique uniquement. Les fonctionnalités de l'aperçu technologique ne sont pas prises en charge par les accords de niveau de service (SLA) de production de Red Hat et peuvent ne pas être complètes sur le plan fonctionnel. Red Hat ne recommande pas de les utiliser en production. Ces fonctionnalités offrent un accès anticipé aux fonctionnalités des produits à venir, ce qui permet aux clients de tester les fonctionnalités et de fournir un retour d'information pendant le processus de développement.
Pour plus d'informations sur la portée de l'assistance des fonctionnalités de l'aperçu technologique de Red Hat, voir Portée de l'assistance des fonctionnalités de l'aperçu technologique.
Avec cette mise à jour, vous pouvez configurer les résolveurs de pipeline dans le CRD
TektonConfig. Vous pouvez activer ou désactiver ces résolveurs de pipeline :enable-bundles-resolver,enable-cluster-resolver,enable-git-resolver, etenable-hub-resolver.apiVersion: operator.tekton.dev/v1alpha1 kind: TektonConfig metadata: name: config spec: pipeline: enable-bundles-resolver: true enable-cluster-resolver: true enable-git-resolver: true enable-hub-resolver: true ...Vous pouvez également fournir des configurations spécifiques au résolveur dans
TektonConfig. Par exemple, vous pouvez définir les champs suivants dans le formatmap[string]stringpour définir des configurations pour des résolveurs individuels :apiVersion: operator.tekton.dev/v1alpha1 kind: TektonConfig metadata: name: config spec: pipeline: bundles-resolver-config: default-service-account: pipelines cluster-resolver-config: default-namespace: test git-resolver-config: server-url: localhost.com hub-resolver-config: default-tekton-hub-catalog: tekton ...
3.1.4.1.6. Chaînes Tekton
Tekton Chains est une fonctionnalité d'aperçu technologique uniquement. Les fonctionnalités de l'aperçu technologique ne sont pas prises en charge par les accords de niveau de service (SLA) de production de Red Hat et peuvent ne pas être complètes sur le plan fonctionnel. Red Hat ne recommande pas de les utiliser en production. Ces fonctionnalités offrent un accès anticipé aux fonctionnalités des produits à venir, ce qui permet aux clients de tester les fonctionnalités et de fournir un retour d'information pendant le processus de développement.
Pour plus d'informations sur la portée de l'assistance des fonctionnalités de l'aperçu technologique de Red Hat, voir Portée de l'assistance des fonctionnalités de l'aperçu technologique.
-
Avant cette mise à jour, seules les images de l'Open Container Initiative (OCI) étaient prises en charge en tant que sorties de
TaskRundans l'agent de provenance in-toto. Cette mise à jour ajoute les métadonnées de provenance in-toto en tant que sorties avec ces suffixes,ARTIFACT_URIetARTIFACT_DIGEST. -
Avant cette mise à jour, seules les attestations
TaskRunétaient prises en charge. Cette mise à jour ajoute la prise en charge des attestationsPipelineRun. -
Cette mise à jour ajoute la prise en charge des chaînes Tekton pour obtenir le paramètre
imgPullSecretà partir du modèle de pod. Cette mise à jour vous aide à configurer l'authentification du référentiel en fonction de chaque exécution de pipeline ou de tâche sans modifier le compte de service.
3.1.4.1.7. Hub Tekton
Tekton Hub est une fonctionnalité d'aperçu technologique uniquement. Les fonctionnalités de l'aperçu technologique ne sont pas prises en charge par les accords de niveau de service (SLA) de production de Red Hat et peuvent ne pas être complètes sur le plan fonctionnel. Red Hat ne recommande pas de les utiliser en production. Ces fonctionnalités offrent un accès anticipé aux fonctionnalités des produits à venir, ce qui permet aux clients de tester les fonctionnalités et de fournir un retour d'information pendant le processus de développement.
Pour plus d'informations sur la portée de l'assistance des fonctionnalités de l'aperçu technologique de Red Hat, voir Portée de l'assistance des fonctionnalités de l'aperçu technologique.
Avec cette mise à jour, en tant qu'administrateur, vous pouvez utiliser une base de données externe, telle que Crunchy PostgreSQL avec Tekton Hub, au lieu d'utiliser la base de données par défaut de Tekton Hub. Cette mise à jour vous permet d'effectuer les actions suivantes :
- Spécifier les coordonnées d'une base de données externe à utiliser avec Tekton Hub
- Désactiver la base de données Tekton Hub par défaut déployée par l'Opérateur
Cette mise à jour supprime la dépendance de
config.yamlà l'égard des dépôts Git externes et déplace les données de configuration complètes dans l'APIConfigMap. Cette mise à jour permet à l'administrateur d'effectuer les actions suivantes :- Ajoutez les données de configuration, telles que les catégories, les catalogues, les scopes et les defaultScopes dans la ressource personnalisée Tekton Hub.
- Modifier les données de configuration du Tekton Hub sur le cluster. Toutes les modifications sont conservées lors des mises à jour de l'opérateur.
- Mettre à jour la liste des catalogues pour Tekton Hub
Modifier les catégories pour Tekton Hub
NoteSi vous n'ajoutez pas de données de configuration, vous pouvez utiliser les données par défaut de l'API
ConfigMappour les configurations du Tekton Hub.
3.1.4.1.8. Les pipelines en tant que code
-
Cette mise à jour ajoute la prise en charge de la limite de concurrence dans le CRD
Repositorypour définir le nombre maximum dePipelineRunsen cours d'exécution pour un référentiel à la fois. LesPipelineRunsprovenant d'une requête pull ou d'un événement push sont mis en file d'attente dans l'ordre alphabétique. -
Cette mise à jour ajoute une nouvelle commande
tkn pac logspour afficher les journaux du dernier pipeline exécuté pour un dépôt. Cette mise à jour prend en charge la correspondance d'événement avancée sur le chemin de fichier pour les requêtes push et pull vers GitHub et GitLab. Par exemple, vous pouvez utiliser le langage d'expression commun (CEL) pour lancer un pipeline uniquement si le chemin d'accès d'un fichier markdown dans le répertoire
docsa changé.... annotations: pipelinesascode.tekton.dev/on-cel-expression: | event == "pull_request" && "docs/*.md".pathChanged()-
Avec cette mise à jour, vous pouvez référencer un pipeline distant dans l'objet
pipelineRef:à l'aide d'annotations. -
Avec cette mise à jour, vous pouvez configurer automatiquement de nouveaux dépôts GitHub avec Pipelines as Code, qui met en place un espace de noms et crée un CRD
Repositorypour votre dépôt GitHub. -
Avec cette mise à jour, Pipelines as Code génère des métriques pour
PipelineRunsavec des informations sur les fournisseurs. Cette mise à jour apporte les améliorations suivantes au plugin
tkn-pac:- Détecte correctement les pipelines en cours d'exécution
- Correction de l'affichage de la durée lorsqu'il n'y a pas d'heure d'achèvement de l'échec
-
Affiche un extrait d'erreur et met en évidence le modèle d'expression régulière de l'erreur dans la commande
tkn-pac describe -
Ajoute le commutateur
use-real-timeaux commandestkn-pac lsettkn-pac describe -
Importe la documentation des journaux de
tkn-pac -
Affiche
pipelineruntimeoutcomme un échec dans les commandestkn-pac lsettkn-pac describe. -
Afficher un échec spécifique de l'exécution d'un pipeline avec l'option
--target-pipelinerun.
- Avec cette mise à jour, vous pouvez voir les erreurs de votre pipeline sous la forme d'un commentaire du système de contrôle de version (VCS) ou d'un petit extrait dans les contrôles GitHub.
- Avec cette mise à jour, Pipelines as Code peut optionnellement détecter les erreurs dans les tâches si elles sont d'un format simple et ajouter ces tâches en tant qu'annotations dans GitHub. Cette mise à jour fait partie d'un aperçu pour les développeurs.
Cette mise à jour ajoute les nouvelles commandes suivantes :
-
tkn-pac webhook add: Ajoute un webhook aux paramètres du référentiel du projet et met à jour la cléwebhook.secretdans l'objetk8s Secretexistant sans mettre à jour le référentiel. -
tkn-pac webhook update-token: Met à jour le jeton de fournisseur pour un objetk8s Secretexistant sans mettre à jour le référentiel.
-
-
Cette mise à jour améliore les fonctionnalités de la commande
tkn-pac create repo, qui crée et configure des webhooks pour GitHub, GitLab et BitbucketCloud, ainsi que la création de dépôts. -
Avec cette mise à jour, la commande
tkn-pac describeaffiche les cinquante derniers événements dans un ordre trié. -
Cette mise à jour ajoute l'option
--lastà la commandetkn-pac logs. -
Avec cette mise à jour, la commande
tkn-pac resolvedemande un jeton lors de la détection d'ungit_auth_secretdans le modèle de fichier. - Avec cette mise à jour, Pipelines as Code cache les secrets dans les extraits de journaux pour éviter d'exposer des secrets dans l'interface GitHub.
-
Avec cette mise à jour, les secrets générés automatiquement pour
git_auth_secretsont une référence propriétaire avecPipelineRun. Les secrets sont nettoyés en même temps quePipelineRun, et non après l'exécution du pipeline. -
Cette mise à jour ajoute la possibilité d'annuler l'exécution d'un pipeline à l'aide du commentaire
/cancel. Avant cette mise à jour, le champ d'application du jeton GitHub apps n'était pas défini et les jetons étaient utilisés pour chaque installation de référentiel. Avec cette mise à jour, vous pouvez définir la portée du jeton GitHub apps sur le référentiel cible en utilisant les paramètres suivants :
-
secret-github-app-token-scoped: Le jeton d'application est limité au référentiel cible, et non à tous les référentiels auxquels l'installation de l'application a accès. -
secret-github-app-scope-extra-repos: Personnalise le champ d'application du jeton d'application avec un propriétaire ou un dépôt supplémentaire.
-
- Avec cette mise à jour, vous pouvez utiliser Pipelines as Code avec vos propres dépôts Git hébergés sur GitLab.
- Avec cette mise à jour, vous pouvez accéder aux détails de l'exécution du pipeline sous la forme d'événements kubernetes dans votre espace de noms. Ces détails vous aident à résoudre les erreurs de pipeline sans avoir besoin d'accéder aux espaces de noms des administrateurs.
- Cette mise à jour supporte l'authentification des URLs dans les Pipelines en tant que résolveur de code avec le fournisseur Git.
-
Avec cette mise à jour, vous pouvez définir le nom du catalogue du concentrateur en utilisant un paramètre dans la carte de configuration
pipelines-as-code. -
Cette mise à jour permet de définir les limites maximales et par défaut du paramètre
max-keep-run. - Cette mise à jour ajoute des documents sur la façon d'injecter des certificats SSL (Secure Sockets Layer) personnalisés dans Pipelines as Code pour vous permettre de vous connecter à l'instance du fournisseur avec des certificats personnalisés.
-
Avec cette mise à jour, la définition de la ressource
PipelineRuncomporte l'URL du journal en tant qu'annotation. Par exemple, la commandetkn-pac describeaffiche le lien du journal lors de la description d'une ressourcePipelineRun. -
Avec cette mise à jour, les journaux de
tkn-pacaffichent le nom du dépôt, au lieu du nom dePipelineRun.
3.1.4.2. Changements en cours
-
Avec cette mise à jour, le type de définition de ressource personnalisée (CRD)
Conditionsa été supprimé. Il est possible d'utiliser le typeWhenExpressionsà la place. -
Avec cette mise à jour, la prise en charge des ressources de pipeline de l'API
tekton.dev/v1alpha1, telles que Pipeline, PipelineRun, Task, Clustertask et TaskRun, a été supprimée. -
Avec cette mise à jour, la commande
tkn-pac setupa été supprimée. A la place, utilisez la commandetkn-pac webhook addpour ajouter un webhook à un référentiel Git existant. Et utilisez la commandetkn-pac webhook update-tokenpour mettre à jour le jeton d'accès du fournisseur personnel pour un objet Secret existant dans le référentiel Git. -
Avec cette mise à jour, un espace de noms qui exécute un pipeline avec les paramètres par défaut n'applique pas le label
pod-security.kubernetes.io/enforce:privilegedà une charge de travail.
3.1.4.3. Fonctionnalités obsolètes et supprimées
-
Dans la version 1.9.0 de Red Hat OpenShift Pipelines,
ClusterTasksest déprécié et il est prévu de le supprimer dans une prochaine version. Comme alternative, vous pouvez utiliserCluster Resolver. -
Dans la version 1.9.0 de Red Hat OpenShift Pipelines, l'utilisation des champs
triggersetnamespaceSelectordans une seule spécificationEventListenerest dépréciée et il est prévu de la supprimer dans une prochaine version. Vous pouvez utiliser ces champs dans différentes spécificationsEventListeneravec succès. -
Dans la version 1.9.0 de Red Hat OpenShift Pipelines, la commande
tkn pipelinerun describen'affiche pas les délais d'attente pour la ressourcePipelineRun. -
Dans la version 1.9.0 de Red Hat OpenShift Pipelines, la ressource personnalisée (CR) PipelineResource` est obsolète. La CR
PipelineResourceétait une fonctionnalité Tech Preview et faisait partie de l'APItekton.dev/v1alpha1. - Dans la version 1.9.0 de Red Hat OpenShift Pipelines, les paramètres d'image personnalisée des tâches de cluster sont obsolètes. Comme alternative, vous pouvez copier une tâche de cluster et utiliser votre image personnalisée dans celle-ci.
3.1.4.4. Problèmes connus
-
Les cartes de configuration
chains-secretetchains-configsont supprimées après la désinstallation de Red Hat OpenShift Pipelines Operator. Comme elles contiennent des données d'utilisateur, elles doivent être conservées et non supprimées.
Lorsque vous exécutez le jeu de commandes
tkn pacsous Windows, vous pouvez recevoir le message d'erreur suivant :Command finished with error: not supported by Windows.Solution de contournement : Définissez la variable d'environnement
NO_COLORsurtrue.L'exécution de la commande
tkn pac resolve -f <filename> | oc create -fpeut ne pas donner les résultats escomptés si la commandetkn pac resolveutilise une valeur de paramètre modélisée pour fonctionner.Solution : Pour atténuer ce problème, enregistrez la sortie de
tkn pac resolvedans un fichier temporaire en exécutant la commandetkn pac resolve -f <filename> -o tempfile.yaml, puis la commandeoc create -f tempfile.yaml. Par exemple,tkn pac resolve -f <filename> -o /tmp/pull-request-resolved.yaml && oc create -f /tmp/pull-request-resolved.yaml.
3.1.4.5. Problèmes corrigés
- Avant cette mise à jour, après avoir remplacé un tableau vide, le tableau original renvoyait une chaîne vide, ce qui rendait les paramètres qu'il contenait invalides. Avec cette mise à jour, ce problème est résolu et le tableau original retourne une chaîne vide.
- Avant cette mise à jour, si des secrets en double étaient présents dans un compte de service pour une exécution de pipeline, cela entraînait un échec dans la création du module de tâches. Avec cette mise à jour, ce problème est résolu et le module de tâches est créé avec succès même si des secrets en double sont présents dans un compte de service.
-
Avant cette mise à jour, en consultant le champ
spec.StatusMessagedu TaskRun, les utilisateurs ne pouvaient pas savoir si leTaskRunavait été annulé par l'utilisateur ou par unPipelineRunqui en faisait partie. Avec cette mise à jour, ce problème est résolu et les utilisateurs peuvent distinguer le statut deTaskRunen regardant le champspec.StatusMessagede la TaskRun. - Avant cette mise à jour, la validation du webhook était supprimée lors de la suppression d'anciennes versions d'objets invalides. Avec cette mise à jour, ce problème est résolu.
Avant cette mise à jour, si vous définissiez le paramètre
timeouts.pipelinesur0, vous ne pouviez pas définir les paramètrestimeouts.tasksoutimeouts.finally. Cette mise à jour résout le problème. Désormais, lorsque vous définissez la valeur du paramètretimeouts.pipeline, vous pouvez définir la valeur du paramètre "timeouts.tasks" ou du paramètretimeouts.finally. Par exemple :yaml kind: PipelineRun spec: timeouts: pipeline: "0" # No timeout tasks: "0h3m0s"- Avant cette mise à jour, une condition de course pouvait se produire si un autre outil mettait à jour des étiquettes ou des annotations sur un PipelineRun ou un TaskRun. Avec cette mise à jour, ce problème est résolu et vous pouvez fusionner les étiquettes ou les annotations.
- Avant cette mise à jour, les clés de journal n'avaient pas les mêmes clés que dans les contrôleurs de pipeline. Avec cette mise à jour, ce problème a été résolu et les clés des journaux ont été mises à jour pour correspondre au flux de journaux des contrôleurs de pipeline. Les clés des journaux sont passées de "ts" à "timestamp", de "level" à "severity" et de "message" à "msg".
- Avant cette mise à jour, si un PipelineRun était supprimé avec un statut inconnu, un message d'erreur n'était pas généré. Avec cette mise à jour, ce problème est résolu et un message d'erreur est généré.
-
Avant cette mise à jour, il était nécessaire d'utiliser le fichier
kubeconfigpour accéder aux commandes de l'offre groupée telles quelistetpush. Avec cette mise à jour, ce problème a été résolu et le fichierkubeconfign'est plus nécessaire pour accéder aux commandes de l'offre groupée. - Avant cette mise à jour, si le PipelineRun parent était en cours d'exécution pendant la suppression des TaskRuns, les TaskRuns étaient supprimées. Avec cette mise à jour, ce problème est résolu et les TaskRuns ne sont pas supprimées si le PipelineRun parent est en cours d'exécution.
- Avant cette mise à jour, si l'utilisateur tentait de construire une grappe avec plus d'objets que le contrôleur de pipeline ne le permettait, l'interface de programmation Tekton n'affichait pas de message d'erreur. Avec cette mise à jour, ce problème est résolu et la CLI Tekton affiche un message d'erreur si l'utilisateur tente de construire une grappe avec plus d'objets que la limite autorisée dans le contrôleur de pipeline.
-
Avant cette mise à jour, si des espaces de noms étaient supprimés du cluster, l'opérateur ne supprimait pas les espaces de noms des sujets
ClusterInterceptor ClusterRoleBinding. Avec cette mise à jour, ce problème a été résolu et l'opérateur supprime les espaces de noms des sujetsClusterInterceptor ClusterRoleBinding. -
Avant cette mise à jour, l'installation par défaut de Red Hat OpenShift Pipelines Operator avait pour résultat que la ressource de liaison de rôle
pipelines-scc-rolebinding security context constraint(SCC) restait dans le cluster. Avec cette mise à jour, l'installation par défaut de Red Hat OpenShift Pipelines Operator entraîne la suppression de la ressource de liaison de rôlepipelines-scc-rolebinding security context constraint(SCC) du cluster.
-
Avant cette mise à jour, Pipelines as Code ne recevait pas les valeurs mises à jour de l'objet Pipelines as Code
ConfigMap. Avec cette mise à jour, ce problème est résolu et l'objet Pipelines as CodeConfigMaprecherche toute nouvelle modification. -
Avant cette mise à jour, le contrôleur de Pipelines as Code n'attendait pas que l'étiquette
tekton.dev/pipelinesoit mise à jour et ajoutait l'étiquettecheckrun id, ce qui provoquait des conditions de concurrence. Avec cette mise à jour, le contrôleur de Pipelines as Code attend que l'étiquettetekton.dev/pipelinesoit mise à jour et ajoute ensuite l'étiquettecheckrun id, ce qui permet d'éviter les problèmes de concurrence. -
Avant cette mise à jour, la commande
tkn-pac create repone remplaçait pas une commandePipelineRunsi elle existait déjà dans le dépôt git. Avec cette mise à jour, la commandetkn-pac createest corrigée pour remplacer une commandePipelineRunsi elle existe dans le dépôt git, ce qui résout le problème avec succès. -
Avant cette mise à jour, la commande
tkn pac describen'affichait pas les raisons de chaque message. Avec cette mise à jour, ce problème est corrigé et la commandetkn pac describeaffiche les motifs pour chaque message. -
Avant cette mise à jour, une demande d'extraction échouait si l'utilisateur dans l'annotation fournissait des valeurs en utilisant une forme de regex, par exemple,
refs/head/rel-*. La demande d'extraction échouait parce qu'il manquaitrefs/headsdans sa branche de base. Avec cette mise à jour, le préfixe est ajouté et on vérifie qu'il correspond. Cela résout le problème et la demande d'extraction est acceptée.
3.1.4.6. Notes de version pour Red Hat OpenShift Pipelines General Availability 1.9.1
Avec cette mise à jour, Red Hat OpenShift Pipelines General Availability (GA) 1.9.1 est disponible sur OpenShift Container Platform 4.11 et les versions ultérieures.
3.1.4.7. Problèmes corrigés
-
Avant cette mise à jour, la commande
tkn pac repo listne fonctionnait pas sous Microsoft Windows. Cette mise à jour corrige le problème et vous pouvez désormais exécuter la commandetkn pac repo listsous Microsoft Windows. - Avant cette mise à jour, l'observateur de Pipelines as Code ne recevait pas tous les événements de changement de configuration. Avec cette mise à jour, l'observateur de Pipelines as Code a été mis à jour, et maintenant l'observateur de Pipelines as Code ne manque pas les événements de changement de configuration.
-
Avant cette mise à jour, les pods créés par Pipelines as Code, tels que
TaskRunsouPipelineRunsne pouvaient pas accéder aux certificats personnalisés exposés par l'utilisateur dans le cluster. Cette mise à jour corrige le problème et vous pouvez maintenant accéder aux certificats personnalisés à partir des podsTaskRunsouPipelineRunsdans le cluster. -
Avant cette mise à jour, sur un cluster activé avec FIPS, l'intercepteur
tekton-triggers-core-interceptorscore utilisé dans la ressourceTriggerne fonctionnait pas après que l'opérateur Pipelines ait été mis à niveau vers la version 1.9. Cette mise à jour résout le problème. Désormais, OpenShift utilise MInTLS 1.2 pour tous ses composants. Par conséquent, l'intercepteur centraltekton-triggers-core-interceptorsest mis à jour vers la version 1.2 de TLS et sa fonctionnalité fonctionne correctement. Avant cette mise à jour, lors de l'utilisation d'un pipeline avec un registre d'images interne à OpenShift, l'URL de l'image devait être codée en dur dans la définition du pipeline. Par exemple, l'URL de l'image devait être codée en dur dans la définition de l'exécution du pipeline :
... - name: IMAGE_NAME value: 'image-registry.openshift-image-registry.svc:5000/<test_namespace>/<test_pipelinerun>' ...Lors de l'utilisation d'une exécution de pipeline dans le contexte de Pipelines as Code, ces valeurs codées en dur empêchaient les définitions d'exécution de pipeline d'être utilisées dans différents clusters et espaces de noms.
Avec cette mise à jour, vous pouvez utiliser les variables de modèle dynamiques au lieu de coder en dur les valeurs des espaces de noms et des noms d'exécutions de pipeline pour généraliser les définitions d'exécutions de pipeline. Par exemple :
... - name: IMAGE_NAME value: 'image-registry.openshift-image-registry.svc:5000/{{ target_namespace }}/$(context.pipelineRun.name)' ...- Avant cette mise à jour, Pipelines as Code utilisait le même jeton GitHub pour récupérer une tâche distante disponible dans le même hôte uniquement sur la branche GitHub par défaut. Cette mise à jour résout le problème. Désormais, Pipelines as Code utilise le même jeton GitHub pour récupérer une tâche distante à partir de n'importe quelle branche GitHub.
3.1.4.8. Problèmes connus
La valeur de
CATALOG_REFRESH_INTERVAL, un champ de l'objet Hub APIConfigMaputilisé dans le Tekton Hub CR, n'est pas mise à jour avec une valeur personnalisée fournie par l'utilisateur.Solution de contournement : Aucune. Vous pouvez suivre le problème SRVKP-2854.
3.1.4.9. Changements en cours
- Avec cette mise à jour, un problème de mauvaise configuration de l'OLM a été introduit, ce qui empêche la mise à niveau de la plateforme OpenShift Container. Ce problème sera corrigé dans une prochaine version.
3.1.4.10. Notes de version pour Red Hat OpenShift Pipelines General Availability 1.9.2
Avec cette mise à jour, Red Hat OpenShift Pipelines General Availability (GA) 1.9.2 est disponible sur OpenShift Container Platform 4.11 et les versions ultérieures.
3.1.4.11. Problèmes corrigés
- Avant cette mise à jour, un problème de mauvaise configuration OLM avait été introduit dans la version précédente, ce qui empêchait la mise à niveau d'OpenShift Container Platform. Avec cette mise à jour, ce problème de mauvaise configuration a été corrigé.
3.1.5. Notes de mise à jour pour Red Hat OpenShift Pipelines General Availability 1.8
Avec cette mise à jour, Red Hat OpenShift Pipelines General Availability (GA) 1.8 est disponible sur OpenShift Container Platform 4.10, 4.11 et 4.12.
3.1.5.1. Nouvelles fonctionnalités
En plus des corrections et des améliorations de stabilité, les sections suivantes mettent en évidence les nouveautés de Red Hat OpenShift Pipelines 1.8.
3.1.5.1.1. Pipelines
-
Avec cette mise à jour, vous pouvez exécuter Red Hat OpenShift Pipelines GA 1.8 et plus sur un cluster OpenShift Container Platform qui fonctionne sur du matériel ARM. Cela inclut la prise en charge des ressources
ClusterTasket de l'outil CLItkn.
L'exécution de Red Hat OpenShift Pipelines sur du matériel ARM est une fonctionnalité d'aperçu technologique uniquement. Les fonctionnalités de l'aperçu technologique ne sont pas prises en charge par les accords de niveau de service (SLA) de production de Red Hat et peuvent ne pas être complètes sur le plan fonctionnel. Red Hat ne recommande pas de les utiliser en production. Ces fonctionnalités offrent un accès anticipé aux fonctionnalités des produits à venir, ce qui permet aux clients de tester les fonctionnalités et de fournir un retour d'information pendant le processus de développement.
Pour plus d'informations sur la portée de l'assistance des fonctionnalités de l'aperçu technologique de Red Hat, voir Portée de l'assistance des fonctionnalités de l'aperçu technologique.
-
Cette mise à jour met en œuvre les dérogations
StepetSidecarpour les ressourcesTaskRun. Cette mise à jour ajoute les statuts minimaux
TaskRunetRundans les statutsPipelineRun.Pour activer cette fonctionnalité, dans la définition de la ressource personnalisée
TektonConfig, dans la sectionpipeline, vous devez définir le champenable-api-fieldssuralpha.Avec cette mise à jour, la fonctionnalité d'arrêt gracieux des exécutions de pipeline passe d'une fonctionnalité alpha à une fonctionnalité stable. Par conséquent, le statut
PipelineRunCancelled, précédemment déprécié, reste déprécié et devrait être supprimé dans une prochaine version.Cette fonctionnalité étant disponible par défaut, il n'est plus nécessaire de donner au champ
pipeline.enable-api-fieldsla valeuralphadans la définition de la ressource personnaliséeTektonConfig.Avec cette mise à jour, vous pouvez spécifier l'espace de travail pour une tâche de pipeline en utilisant le nom de l'espace de travail. Cette modification facilite la spécification d'un espace de travail partagé pour une paire de ressources
PipelineetPipelineTask. Vous pouvez également continuer à mapper les espaces de travail de manière explicite.Pour activer cette fonctionnalité, dans la définition de la ressource personnalisée
TektonConfig, dans la sectionpipeline, vous devez définir le champenable-api-fieldssuralpha.- Avec cette mise à jour, les paramètres des spécifications intégrées sont propagés sans mutations.
-
Avec cette mise à jour, vous pouvez spécifier les métadonnées requises d'une ressource
Taskréférencée par une ressourcePipelineRunen utilisant des annotations et des étiquettes. Ainsi, les métadonnées deTaskqui dépendent du contexte d'exécution sont disponibles pendant l'exécution du pipeline. -
Cette mise à jour ajoute la prise en charge des types d'objets ou de dictionnaires dans les valeurs
paramsetresults. Cette modification affecte la compatibilité ascendante et rompt parfois la compatibilité descendante, comme l'utilisation d'un client antérieur avec une version plus récente de Red Hat OpenShift Pipelines. Cette mise à jour modifie la structure deArrayOrStruct, ce qui affecte les projets qui utilisent l'API du langage Go en tant que bibliothèque. -
Cette mise à jour ajoute une valeur
SkippingReasonau champSkippedTasksdes champs de statutPipelineRunafin que les utilisateurs sachent pourquoi une tâche de pipeline donnée a été ignorée. Cette mise à jour prend en charge une fonctionnalité alpha qui permet d'utiliser un type
arraypour émettre des résultats à partir d'un objetTask. Le type de résultat passe destringàArrayOrString. Par exemple, une tâche peut spécifier un type pour produire un résultat sous forme de tableau :kind: Task apiVersion: tekton.dev/v1beta1 metadata: name: write-array annotations: description: | A simple task that writes array spec: results: - name: array-results type: array description: The array results ...En outre, vous pouvez exécuter un script de tâche pour remplir les résultats avec un tableau :
$ echo -n "[\"hello\",\"world\"]" | tee $(results.array-results.path)Pour activer cette fonctionnalité, dans la définition de la ressource personnalisée
TektonConfig, dans la sectionpipeline, vous devez définir le champenable-api-fieldssuralpha.Cette fonctionnalité est en cours de réalisation et fait partie du TEP-0076.
3.1.5.1.2. Déclencheurs
Cette mise à jour fait passer le champ
TriggerGroupsde la spécificationEventListenerd'une fonctionnalité alpha à une fonctionnalité stable. Ce champ permet de spécifier un ensemble d'intercepteurs avant de sélectionner et d'exécuter un groupe de déclencheurs.Cette fonctionnalité étant disponible par défaut, il n'est plus nécessaire de donner au champ
pipeline.enable-api-fieldsla valeuralphadans la définition de la ressource personnaliséeTektonConfig.-
Avec cette mise à jour, la ressource
Triggerprend en charge les connexions sécurisées de bout en bout en exécutant le serveurClusterInterceptorà l'aide de HTTPS.
3.1.5.1.3. CLI
-
Avec cette mise à jour, vous pouvez utiliser la commande
tkn taskrun exportpour exporter une exécution de tâche en direct d'un cluster vers un fichier YAML, que vous pouvez utiliser pour importer l'exécution de tâche vers un autre cluster. -
Avec cette mise à jour, vous pouvez ajouter l'option
-o nameà la commandetkn pipeline startafin d'afficher le nom de l'exécution du pipeline dès son démarrage. -
Cette mise à jour ajoute une liste des plugins disponibles à la sortie de la commande
tkn --help. -
Avec cette mise à jour, lors de la suppression d'un pipeline ou d'une tâche, vous pouvez utiliser à la fois les drapeaux
--keepet--keep-since. -
Avec cette mise à jour, vous pouvez utiliser
Cancelledcomme valeur du champspec.statusplutôt que la valeur obsolètePipelineRunCancelled.
3.1.5.1.4. Opérateur
- Avec cette mise à jour, en tant qu'administrateur, vous pouvez configurer votre instance locale de Tekton Hub pour qu'elle utilise une base de données personnalisée plutôt que la base de données par défaut.
Avec cette mise à jour, en tant qu'administrateur de cluster, si vous activez votre instance locale de Tekton Hub, celle-ci rafraîchit périodiquement la base de données afin que les changements dans le catalogue apparaissent dans la console web de Tekton Hub. Vous pouvez ajuster la période entre les rafraîchissements.
Auparavant, pour ajouter les tâches et les pipelines du catalogue à la base de données, vous deviez effectuer cette tâche manuellement ou configurer un travail cron pour le faire à votre place.
- Avec cette mise à jour, vous pouvez installer et faire fonctionner une instance de Tekton Hub avec une configuration minimale. De cette façon, vous pouvez commencer à travailler avec vos équipes pour décider des personnalisations supplémentaires qu'elles pourraient souhaiter.
-
Cette mise à jour ajoute
GIT_SSL_CAINFOà la tâchegit-cloneafin que vous puissiez cloner des dépôts sécurisés.
3.1.5.1.5. Chaînes Tekton
Tekton Chains est une fonctionnalité d'aperçu technologique uniquement. Les fonctionnalités de l'aperçu technologique ne sont pas prises en charge par les accords de niveau de service (SLA) de production de Red Hat et peuvent ne pas être complètes sur le plan fonctionnel. Red Hat ne recommande pas de les utiliser en production. Ces fonctionnalités offrent un accès anticipé aux fonctionnalités des produits à venir, ce qui permet aux clients de tester les fonctionnalités et de fournir un retour d'information pendant le processus de développement.
Pour plus d'informations sur la portée de l'assistance des fonctionnalités de l'aperçu technologique de Red Hat, voir Portée de l'assistance des fonctionnalités de l'aperçu technologique.
- Avec cette mise à jour, vous pouvez vous connecter à un coffre-fort en utilisant OIDC plutôt qu'un jeton statique. Cette modification signifie que Spire peut générer l'identifiant OIDC afin que seules les charges de travail de confiance soient autorisées à se connecter à l'espace de stockage. En outre, vous pouvez transmettre l'adresse de l'espace de stockage en tant que valeur de configuration plutôt que de l'injecter en tant que variable d'environnement.
-
La carte de configuration
chains-configpour Tekton Chains dans l'espace de nomsopenshift-pipelinesest automatiquement réinitialisée par défaut après la mise à jour de Red Hat OpenShift Pipelines Operator car la mise à jour directe de la carte de configuration n'est pas prise en charge lors de l'installation à l'aide de Red Hat OpenShift Pipelines Operator. Cependant, avec cette mise à jour, vous pouvez configurer les chaînes Tekton en utilisant la ressource personnaliséeTektonChain. Cette fonctionnalité permet à votre configuration de persister après la mise à jour, contrairement à la carte de configurationchains-config, qui est écrasée lors des mises à jour.
3.1.5.1.6. Hub Tekton
Tekton Hub est une fonctionnalité d'aperçu technologique uniquement. Les fonctionnalités de l'aperçu technologique ne sont pas prises en charge par les accords de niveau de service (SLA) de production de Red Hat et peuvent ne pas être complètes sur le plan fonctionnel. Red Hat ne recommande pas de les utiliser en production. Ces fonctionnalités offrent un accès anticipé aux fonctionnalités des produits à venir, ce qui permet aux clients de tester les fonctionnalités et de fournir un retour d'information pendant le processus de développement.
Pour plus d'informations sur la portée de l'assistance des fonctionnalités de l'aperçu technologique de Red Hat, voir Portée de l'assistance des fonctionnalités de l'aperçu technologique.
Avec cette mise à jour, si vous installez une nouvelle instance de Tekton Hub en utilisant l'Opérateur, le login Tekton Hub est désactivé par défaut. Pour activer les fonctions de connexion et de notation, vous devez créer le secret API Hub lors de l'installation de Tekton Hub.
NoteÉtant donné que la connexion Tekton Hub était activée par défaut dans Red Hat OpenShift Pipelines 1.7, si vous mettez à niveau l'opérateur, la connexion est activée par défaut dans Red Hat OpenShift Pipelines 1.8. Pour désactiver cette connexion, voir Désactivation de la connexion Tekton Hub après la mise à niveau d'OpenShift Pipelines 1.7.x -→ 1.8.x
Avec cette mise à jour, en tant qu'administrateur, vous pouvez configurer votre instance locale de Tekton Hub pour utiliser une base de données PostgreSQL 13 personnalisée plutôt que la base de données par défaut. Pour ce faire, créez une ressource
Secretnomméetekton-hub-db. Par exemple :apiVersion: v1 kind: Secret metadata: name: tekton-hub-db labels: app: tekton-hub-db type: Opaque stringData: POSTGRES_HOST: <hostname> POSTGRES_DB: <database_name> POSTGRES_USER: <user_name> POSTGRES_PASSWORD: <user_password> POSTGRES_PORT: <listening_port_number>- Avec cette mise à jour, vous n'avez plus besoin de vous connecter à la console web Tekton Hub pour ajouter des ressources du catalogue à la base de données. Désormais, ces ressources sont automatiquement ajoutées lorsque l'API Tekton Hub est lancée pour la première fois.
- Cette mise à jour actualise automatiquement le catalogue toutes les 30 minutes en appelant le job API d'actualisation du catalogue. Cet intervalle est configurable par l'utilisateur.
3.1.5.1.7. Les pipelines en tant que code
Pipelines as Code (PAC) est une fonctionnalité d'aperçu technologique uniquement. Les fonctionnalités de l'aperçu technologique ne sont pas prises en charge par les accords de niveau de service (SLA) de production de Red Hat et peuvent ne pas être complètes sur le plan fonctionnel. Red Hat ne recommande pas de les utiliser en production. Ces fonctionnalités offrent un accès anticipé aux fonctionnalités des produits à venir, ce qui permet aux clients de tester les fonctionnalités et de fournir un retour d'information pendant le processus de développement.
Pour plus d'informations sur la portée de l'assistance des fonctionnalités de l'aperçu technologique de Red Hat, voir Portée de l'assistance des fonctionnalités de l'aperçu technologique.
-
Avec cette mise à jour, en tant que développeur, vous recevez une notification de l'outil CLI
tkn-pacsi vous essayez d'ajouter un référentiel dupliqué à une exécution de Pipelines as Code. Lorsque vous entreztkn pac create repository, chaque référentiel doit avoir une URL unique. Cette notification permet également d'éviter les exploits de détournement. -
Avec cette mise à jour, en tant que développeur, vous pouvez utiliser la nouvelle commande
tkn-pac setup clipour ajouter un dépôt Git à Pipelines as Code en utilisant le mécanisme de webhook. Ainsi, vous pouvez utiliser Pipelines as Code même lorsque l'utilisation de GitHub Apps n'est pas possible. Cette fonctionnalité inclut la prise en charge des dépôts sur GitHub, GitLab et BitBucket. Avec cette mise à jour, Pipelines as Code prend en charge l'intégration de GitLab avec des fonctionnalités telles que les suivantes :
- ACL (Access Control List) sur le projet ou le groupe
-
/ok-to-testle soutien des utilisateurs autorisés -
/retestle soutien.
Avec cette mise à jour, vous pouvez effectuer un filtrage avancé des pipelines avec le langage d'expression commun (CEL). Avec CEL, vous pouvez faire correspondre des exécutions de pipeline avec différents événements du fournisseur Git en utilisant des annotations dans la ressource
PipelineRun. Par exemple :... annotations: pipelinesascode.tekton.dev/on-cel-expression: | event == "pull_request" && target_branch == "main" && source_branch == "wip"-
Auparavant, en tant que développeur, vous ne pouviez avoir qu'une seule exécution de pipeline dans votre répertoire
.tektonpour chaque événement Git, tel qu'une pull request. Avec cette mise à jour, vous pouvez avoir plusieurs exécutions de pipeline dans votre répertoire.tekton. La console web affiche l'état et les rapports des exécutions. Les exécutions de pipeline fonctionnent en parallèle et renvoient des rapports à l'interface du fournisseur Git. -
Avec cette mise à jour, vous pouvez tester ou retester un pipeline en commentant
/testou/retestsur une pull request. Vous pouvez également spécifier le pipeline par son nom. Par exemple, vous pouvez saisir/test <pipelinerun_name>ou/retest <pipelinerun-name>. -
Avec cette mise à jour, vous pouvez supprimer une ressource personnalisée du référentiel et ses secrets associés en utilisant la nouvelle commande
tkn-pac delete repository.
3.1.5.2. Changements en cours
Cette mise à jour modifie le niveau de métrique par défaut des ressources
TaskRunetPipelineRunpour les valeurs suivantes :apiVersion: v1 kind: ConfigMap metadata: name: config-observability namespace: tekton-pipelines labels: app.kubernetes.io/instance: default app.kubernetes.io/part-of: tekton-pipelines data: _example: | ... metrics.taskrun.level: "task" metrics.taskrun.duration-type: "histogram" metrics.pipelinerun.level: "pipeline" metrics.pipelinerun.duration-type: "histogram"-
Avec cette mise à jour, si une annotation ou un label est présent à la fois dans les ressources
PipelineetPipelineRun, la valeur du typeRunest prioritaire. Il en va de même si une annotation ou un label est présent dans les ressourcesTasketTaskRun. -
Dans Red Hat OpenShift Pipelines 1.8, le champ
PipelineRun.Spec.ServiceAccountNames, précédemment déprécié, a été supprimé. Utilisez le champPipelineRun.Spec.TaskRunSpecsà la place. -
Dans Red Hat OpenShift Pipelines 1.8, le champ
TaskRun.Status.ResourceResults.ResourceRef, précédemment déprécié, a été supprimé. Utilisez le champTaskRun.Status.ResourceResults.ResourceNameà la place. -
Dans Red Hat OpenShift Pipelines 1.8, le type de ressource
Conditions, précédemment déprécié, a été supprimé. Supprimez la ressourceConditionsdes définitions de ressourcesPipelinequi l'incluent. Utilisez les expressionswhendans les définitionsPipelineRunà la place.
-
Pour les chaînes Tekton, le format
tekton-provenancea été supprimé dans cette version. Utilisez plutôt le formatin-totoen définissant"artifacts.taskrun.format": "in-toto"dans la ressource personnaliséeTektonChain.
Red Hat OpenShift Pipelines 1.7.x était livré avec Pipelines as Code 0.5.x. La mise à jour actuelle est livrée avec Pipelines as Code 0.10.x. Ce changement crée une nouvelle route dans l'espace de noms
openshift-pipelinespour le nouveau contrôleur. Vous devez mettre à jour cette route dans les applications GitHub ou les webhooks qui utilisent Pipelines as Code. Pour récupérer la route, utilisez la commande suivante :$ oc get route -n openshift-pipelines pipelines-as-code-controller \ --template='https://{{ .spec.host }}'-
Avec cette mise à jour, Pipelines as Code renomme les clés secrètes par défaut pour la définition de ressource personnalisée (CRD)
Repository. Dans votre CRD, remplaceztokenparprovider.token, et remplacezsecretparwebhook.secret. -
Avec cette mise à jour, Pipelines as Code remplace une variable de modèle spéciale par une variable qui prend en charge des exécutions de pipeline multiples pour des dépôts privés. Dans vos exécutions du pipeline, remplacez
secret: pac-git-basic-auth-{{repo_owner}}-{{repo_name}}parsecret: {{ git_auth_secret }}. Avec cette mise à jour, Pipelines as Code met à jour les commandes suivantes dans l'outil CLI
tkn-pac:-
Remplacer
tkn pac repository createpartkn pac create repository. -
Remplacer
tkn pac repository deletepartkn pac delete repository. -
Remplacer
tkn pac repository listpartkn pac list.
-
Remplacer
3.1.5.3. Fonctionnalités obsolètes et supprimées
À partir d'OpenShift Container Platform 4.11, les canaux
previewetstablepour l'installation et la mise à jour de Red Hat OpenShift Pipelines Operator sont supprimés. Pour installer et mettre à niveau l'opérateur, utilisez le canalpipelines-<version>approprié ou le canallatestpour la version stable la plus récente. Par exemple, pour installer la version1.8.xd'OpenShift Pipelines Operator, utilisez le canalpipelines-1.8.NoteDans OpenShift Container Platform 4.10 et les versions antérieures, vous pouvez utiliser les canaux
previewetstablepour installer et mettre à niveau l'opérateur.La prise en charge de la version de l'API
tekton.dev/v1alpha1, qui était obsolète dans Red Hat OpenShift Pipelines GA 1.6, devrait être supprimée dans la prochaine version Red Hat OpenShift Pipelines GA 1.9.Ce changement affecte le composant pipeline, qui comprend les ressources
TaskRun,PipelineRun,Task,Pipeline, et les ressources similairestekton.dev/v1alpha1. Comme alternative, mettez à jour les ressources existantes pour utiliserapiVersion: tekton.dev/v1beta1comme décrit dans Migrating From Tekton v1alpha1 to Tekton v1beta1.Les corrections de bogues et l'assistance pour la version de l'API
tekton.dev/v1alpha1ne sont fournies que jusqu'à la fin du cycle de vie actuel de l'AG 1.8.ImportantPour Tekton Operator, la version de l'API
operator.tekton.dev/v1alpha1est not deprecated. Il n'est pas nécessaire de modifier cette valeur.-
Dans Red Hat OpenShift Pipelines 1.8, la ressource personnalisée (CR)
PipelineResourceest disponible mais n'est plus prise en charge. La CRPipelineResourceétait une fonctionnalité Tech Preview et faisait partie de l'APItekton.dev/v1alpha1, qui a été dépréciée et qu'il est prévu de supprimer dans la prochaine version Red Hat OpenShift Pipelines GA 1.9. -
Dans Red Hat OpenShift Pipelines 1.8, la ressource personnalisée (CR)
Conditionest supprimée. La CRConditionfaisait partie de l'APItekton.dev/v1alpha1, qui a été dépréciée et devrait être supprimée dans la prochaine version de Red Hat OpenShift Pipelines GA 1.9. -
Dans Red Hat OpenShift Pipelines 1.8, l'image
gcr.iopourgsutila été supprimée. Cette suppression pourrait interrompre les clusters avec les ressourcesPipelinequi dépendent de cette image. Les corrections de bugs et l'assistance sont fournies uniquement jusqu'à la fin du cycle de vie de Red Hat OpenShift Pipelines 1.7.
-
Dans Red Hat OpenShift Pipelines 1.8, les champs
PipelineRun.Status.TaskRunsetPipelineRun.Status.Runssont dépréciés et devraient être supprimés dans une prochaine version. Voir TEP-0100 : Embedded TaskRuns and Runs Status in PipelineRuns. Dans Red Hat OpenShift Pipelines 1.8, l'état
pipelineRunCancelledest déprécié et il est prévu de le supprimer dans une prochaine version. La terminaison gracieuse des objetsPipelineRunest maintenant promue d'une fonctionnalité alpha à une fonctionnalité stable (voir TEP-0058 : Terminaison gracieuse de l'exécution du pipeline). (Voir TEP-0058 : Graceful Pipeline Run Termination.) Comme alternative, vous pouvez utiliser l'étatCancelled, qui remplace l'étatpipelineRunCancelled.Vous n'avez pas besoin de modifier vos ressources
PipelineetTask. Si vous avez des outils qui annulent les exécutions de pipeline, vous devez les mettre à jour dans la prochaine version. Ce changement affecte également les outils tels que le CLI, les extensions de l'IDE, etc., afin qu'ils prennent en charge les nouveaux statutsPipelineRun.Cette fonctionnalité étant disponible par défaut, il n'est plus nécessaire de donner au champ
pipeline.enable-api-fieldsla valeuralphadans la définition de la ressource personnaliséeTektonConfig.Dans Red Hat OpenShift Pipelines 1.8, le champ
timeoutdansPipelineRuna été déprécié. À la place, utilisez le champPipelineRun.Timeouts, qui est maintenant passé d'une fonctionnalité alpha à une fonctionnalité stable.Cette fonctionnalité étant disponible par défaut, il n'est plus nécessaire de donner au champ
pipeline.enable-api-fieldsla valeuralphadans la définition de la ressource personnaliséeTektonConfig.-
Dans Red Hat OpenShift Pipelines 1.8, les conteneurs
initsont omis des calculs de demande par défaut de l'objetLimitRange.
3.1.5.4. Problèmes connus
Le pipeline
s2i-nodejsne peut pas utiliser le flux d'imagesnodejs:14-ubi8-minimalpour effectuer des constructions source-image (S2I). L'utilisation de ce flux d'images produit un messageerror building at STEP "RUN /usr/libexec/s2i/assemble": exit status 127.Solution de contournement : Utilisez
nodejs:14-ubi8plutôt que le flux d'imagesnodejs:14-ubi8-minimal.
Lorsque vous exécutez des tâches de cluster Maven et Jib-Maven, l'image de conteneur par défaut n'est prise en charge que sur l'architecture Intel (x86). Par conséquent, les tâches échoueront sur les clusters ARM, IBM Power Systems (ppc64le), IBM Z et LinuxONE (s390x).
Solution de contournement : Spécifiez une image personnalisée en définissant la valeur du paramètre
MAVEN_IMAGEsurmaven:3.6.3-adoptopenjdk-11.AstuceAvant d'installer des tâches basées sur le catalogue Tekton sur ARM, IBM Power Systems (ppc64le), IBM Z et LinuxONE (s390x) en utilisant
tkn hub, vérifiez si la tâche peut être exécutée sur ces plates-formes. Pour vérifier sippc64leets390xsont répertoriés dans la section "Platforms" des informations sur la tâche, vous pouvez exécuter la commande suivante :tkn hub info task <name>-
Sur ARM, IBM Power Systems, IBM Z et LinuxONE, la tâche
s2i-dotnetcluster n'est pas prise en charge.
-
Le mappage implicite des paramètres transmet incorrectement les paramètres des définitions de premier niveau
PipelineouPipelineRunaux tâchestaskRef. Le mappage ne doit se faire qu'à partir d'une ressource de premier niveau vers des tâches avec des spécifications en lignetaskSpec. Ce problème n'affecte que les clusters où cette fonctionnalité a été activée en définissant le champenable-api-fieldssuralphadans la sectionpipelinede la définition de la ressource personnaliséeTektonConfig.
3.1.5.5. Problèmes corrigés
- Avant cette mise à jour, les métriques pour les exécutions de pipeline dans la vue Développeur de la console web étaient incomplètes et obsolètes. Avec cette mise à jour, le problème a été corrigé de sorte que les métriques sont correctes.
-
Avant cette mise à jour, si un pipeline avait deux tâches parallèles qui échouaient et que l'une d'entre elles avait
retries=2, les tâches finales ne s'exécutaient jamais, et le pipeline s'arrêtait et ne s'exécutait pas. Par exemple, la tâchepipelines-operator-subscriptionéchouait par intermittence avec le message d'erreur suivant :Unable to connect to the server: EOF. Avec cette mise à jour, le problème a été corrigé de sorte que les tâches finales s'exécutent toujours. -
Avant cette mise à jour, si l'exécution d'un pipeline s'arrêtait en raison de l'échec d'une tâche, les autres tâches risquaient de ne pas être relancées. Par conséquent, aucune tâche
finallyn'était programmée, ce qui entraînait un blocage du pipeline. Cette mise à jour résout le problème. Les objetsTaskRunsetRunpeuvent réessayer lorsqu'une exécution du pipeline s'est arrêtée, même par arrêt gracieux, afin que les exécutions du pipeline puissent se terminer. -
Cette mise à jour modifie la façon dont les besoins en ressources sont calculés lorsqu'un ou plusieurs objets
LimitRangesont présents dans l'espace de noms où un objetTaskRunexiste. Le planificateur prend désormais en compte les conteneursstepet exclut tous les autres conteneurs d'applications, tels que les conteneurs sidecar, lors de la prise en compte des demandes provenant d'objetsLimitRange. -
Avant cette mise à jour, dans certaines conditions, le paquetage flag pouvait analyser incorrectement une sous-commande suivant immédiatement un double tiret de terminaison de drapeau,
--. Dans ce cas, il exécutait la sous-commande du point d'entrée plutôt que la commande réelle. Cette mise à jour corrige ce problème d'analyse des drapeaux afin que le point d'entrée exécute la commande correcte. -
Avant cette mise à jour, le contrôleur pouvait générer plusieurs paniques si l'extraction d'une image échouait ou si son statut d'extraction était incomplet. Cette mise à jour corrige le problème en vérifiant la valeur
step.ImageIDplutôt que la valeurstatus.TaskSpec. -
Avant cette mise à jour, l'annulation d'une exécution de pipeline contenant une tâche personnalisée non planifiée produisait une erreur
PipelineRunCouldntCancel. Cette mise à jour corrige ce problème. Vous pouvez annuler une exécution de pipeline contenant une tâche personnalisée non planifiée sans produire cette erreur. Avant cette mise à jour, si le
<NAME>dans$params["<NAME>"]ou$params['<NAME>']contenait un point (.), toute partie du nom à droite du point n'était pas extraite. Par exemple, à partir de$params["org.ipsum.lorem"], seulorgétait extrait.Cette mise à jour corrige le problème de sorte que
$paramsrécupère la valeur complète. Par exemple,$params["org.ipsum.lorem"]et$params['org.ipsum.lorem']sont valides et la valeur complète de<NAME>,org.ipsum.lorem, est extraite.Il génère également une erreur si
<NAME>n'est pas entouré de guillemets simples ou doubles. Par exemple,$params.org.ipsum.loremn'est pas valide et génère une erreur de validation.
-
Avec cette mise à jour, les ressources
Triggerprennent en charge les intercepteurs personnalisés et garantissent que le port du service d'interception personnalisé est le même que celui du fichier de définitionClusterInterceptor.
-
Avant cette mise à jour, la commande
tkn versionpour les chaînes Tekton et les composants Operator ne fonctionnait pas correctement. Cette mise à jour corrige le problème de sorte que la commande fonctionne correctement et renvoie des informations sur la version de ces composants. -
Avant cette mise à jour, si vous exécutiez une commande
tkn pr delete --ignore-runninget qu'un pipeline n'avait pas de valeurstatus.condition, l'outil CLItkngénérait une erreur de pointeur nul (NPE). Cette mise à jour corrige le problème de sorte que l'outil CLI génère désormais une erreur et ignore correctement les exécutions de pipeline qui sont toujours en cours. -
Avant cette mise à jour, si vous utilisiez les commandes
tkn pr delete --keep <value>outkn tr delete --keep <value>et que le nombre d'exécutions de pipeline ou de tâches était inférieur à la valeur, la commande ne renvoyait pas d'erreur comme prévu. Cette mise à jour corrige le problème de sorte que la commande renvoie correctement une erreur dans ces conditions. -
Avant cette mise à jour, si vous utilisiez les commandes
tkn pr deleteoutkn tr deleteavec les drapeaux-pou-tet le drapeau--ignore-running, les commandes supprimaient incorrectement les ressources en cours d'exécution ou en attente. Cette mise à jour corrige le problème de sorte que ces commandes ignorent correctement les ressources en cours d'exécution ou en attente.
-
Avec cette mise à jour, vous pouvez configurer les chaînes Tekton en utilisant la ressource personnalisée
TektonChain. Cette fonctionnalité permet à votre configuration de persister après la mise à jour, contrairement à la carte de configurationchains-config, qui est écrasée lors des mises à jour. -
Avec cette mise à jour, les ressources
ClusterTaskne s'exécutent plus en tant que root par défaut, à l'exception des tâches de clusterbuildahets2i. -
Avant cette mise à jour, les tâches sur Red Hat OpenShift Pipelines 1.7.1 échouaient lors de l'utilisation de
initcomme premier argument suivi de deux arguments ou plus. Avec cette mise à jour, les drapeaux sont analysés correctement, et les exécutions de tâches sont réussies. Avant cette mise à jour, l'installation de Red Hat OpenShift Pipelines Operator sur OpenShift Container Platform 4.9 et 4.10 échouait en raison d'une liaison de rôle non valide, avec le message d'erreur suivant :
error updating rolebinding openshift-operators-prometheus-k8s-read-binding: RoleBinding.rbac.authorization.k8s.io "openshift-operators-prometheus-k8s-read-binding" is invalid: roleRef: Invalid value: rbac.RoleRef{APIGroup:"rbac.authorization.k8s.io", Kind:"Role", Name:"openshift-operator-read"}: cannot change roleRefCette mise à jour corrige le problème de sorte que l'échec ne se produise plus.
-
Auparavant, la mise à niveau de Red Hat OpenShift Pipelines Operator entraînait la recréation du compte de service
pipeline, ce qui signifiait que les secrets liés au compte de service étaient perdus. Cette mise à jour corrige ce problème. Lors des mises à niveau, l'Opérateur ne recrée plus le compte de servicepipeline. Par conséquent, les secrets liés au compte de servicepipelinepersistent après les mises à niveau, et les ressources (tâches et pipelines) continuent de fonctionner correctement. -
Avec cette mise à jour, les pods Pipelines as Code s'exécutent sur les nœuds d'infrastructure si les paramètres du nœud d'infrastructure sont configurés dans la ressource personnalisée (CR)
TektonConfig. Auparavant, avec l'élagueur de ressources, chaque opérateur d'espace de noms créait une commande qui s'exécutait dans un conteneur distinct. Cette conception consommait trop de ressources dans les grappes comportant un grand nombre d'espaces de noms. Par exemple, pour exécuter une seule commande, une grappe de 1000 espaces de noms produisait 1000 conteneurs dans un pod.
Cette mise à jour corrige le problème. Elle transmet la configuration basée sur l'espace de noms à la tâche afin que toutes les commandes s'exécutent en boucle dans un conteneur.
-
Dans Tekton Chains, vous devez définir un secret appelé
signing-secretspour contenir la clé utilisée pour signer les tâches et les images. Cependant, avant cette mise à jour, la mise à jour de Red Hat OpenShift Pipelines Operator réinitialisait ou écrasait ce secret, et la clé était perdue. Cette mise à jour corrige ce problème. Désormais, si le secret est configuré après l'installation de Tekton Chains via l'Opérateur, le secret persiste et n'est pas écrasé par les mises à jour. Avant cette mise à jour, toutes les tâches de construction de S2I échouaient avec une erreur similaire au message suivant :
Error: error writing "0 0 4294967295\n" to /proc/22/uid_map: write /proc/22/uid_map: operation not permitted time="2022-03-04T09:47:57Z" level=error msg="error writing \"0 0 4294967295\\n\" to /proc/22/uid_map: write /proc/22/uid_map: operation not permitted" time="2022-03-04T09:47:57Z" level=error msg="(unable to determine exit status)"Avec cette mise à jour, la contrainte de contexte de sécurité (SCC) de
pipelines-sccest compatible avec la capacité deSETFCAPnécessaire pour les tâches de cluster deBuildahetS2I. Par conséquent, les tâches de constructionBuildahetS2Ipeuvent être exécutées avec succès.Pour exécuter avec succès la tâche de cluster
Buildahet les tâches de constructionS2Ipour les applications écrites dans différents langages et frameworks, ajoutez l'extrait suivant pour les objetsstepsappropriés tels quebuildetpush:securityContext: capabilities: add: ["SETFCAP"]- Avant cette mise à jour, l'installation de Red Hat OpenShift Pipelines Operator prenait plus de temps que prévu. Cette mise à jour optimise certains paramètres afin d'accélérer le processus d'installation.
-
Avec cette mise à jour, les tâches des clusters Buildah et S2I comportent moins d'étapes que dans les versions précédentes. Certaines étapes ont été regroupées en une seule afin de mieux fonctionner avec les objets
ResourceQuotaetLimitRangeet de ne pas nécessiter plus de ressources que nécessaire. -
Cette mise à jour met à jour les versions de Buildah, de l'outil CLI
tknet de l'outil CLIskopeodans les tâches en grappe. -
Avant cette mise à jour, l'opérateur échouait lors de la création de ressources RBAC si un espace de noms était dans l'état
Terminating. Avec cette mise à jour, l'opérateur ignore les espaces de noms dans l'étatTerminatinget crée les ressources RBAC. -
Avant cette mise à jour, les pods pour les cronjobs prune n'étaient pas planifiés sur les nœuds d'infrastructure, comme prévu. Au lieu de cela, ils étaient planifiés sur les nœuds de travail ou n'étaient pas planifiés du tout. Avec cette mise à jour, ces types de pods peuvent désormais être planifiés sur les nœuds d'infrastructure s'ils sont configurés dans la ressource personnalisée (CR)
TektonConfig.
3.1.5.6. Notes de version pour Red Hat OpenShift Pipelines General Availability 1.8.1
Avec cette mise à jour, Red Hat OpenShift Pipelines General Availability (GA) 1.8.1 est disponible sur OpenShift Container Platform 4.10, 4.11 et 4.12.
3.1.5.6.1. Problèmes connus
Par défaut, les conteneurs ont des permissions restreintes pour une sécurité accrue. Les permissions restreintes s'appliquent à tous les pods contrôleurs dans l'Opérateur Red Hat OpenShift Pipelines, ainsi qu'à certaines tâches de cluster. En raison des permissions restreintes, la tâche de cluster
git-cloneéchoue dans certaines configurations.Solution de contournement : Aucune. Vous pouvez suivre le problème SRVKP-2634.
Lorsque les ensembles d'installation sont dans un état d'échec, l'état de la ressource personnalisée
TektonConfigest incorrectement affiché commeTrueau lieu deFalse.Exemple : Échec de l'installation des jeux
$ oc get tektoninstallerset NAME READY REASON addon-clustertasks-nx5xz False Error addon-communityclustertasks-cfb2p True addon-consolecli-ftrb8 True addon-openshift-67dj2 True addon-pac-cf7pz True addon-pipelines-fvllm True addon-triggers-b2wtt True addon-versioned-clustertasks-1-8-hqhnw False Error pipeline-w75ww True postpipeline-lrs22 True prepipeline-ldlhw True rhosp-rbac-4dmgb True trigger-hfg64 True validating-mutating-webhoook-28rf7 TrueExemple : Statut incorrect
TektonConfig$ oc get tektonconfig config NAME VERSION READY REASON config 1.8.1 True
3.1.5.6.2. Problèmes corrigés
-
Avant cette mise à jour, l'élagueur supprimait les tâches des pipelines en cours d'exécution et affichait l'avertissement suivant :
some tasks were indicated completed without ancestors being done. Avec cette mise à jour, l'élagueur conserve les tâches qui font partie des pipelines en cours d'exécution. -
Avant cette mise à jour,
pipeline-1.8était le canal par défaut pour l'installation de Red Hat OpenShift Pipelines Operator 1.8.x. Avec cette mise à jour,latestest le canal par défaut. - Avant cette mise à jour, les pods contrôleurs de Pipelines as Code n'avaient pas accès aux certificats exposés par l'utilisateur. Avec cette mise à jour, Pipelines as Code peut désormais accéder aux routes et aux dépôts Git protégés par un certificat auto-signé ou personnalisé.
- Avant cette mise à jour, la tâche échouait avec des erreurs RBAC après la mise à niveau de Red Hat OpenShift Pipelines 1.7.2 à 1.8.0. Avec cette mise à jour, les tâches s'exécutent avec succès sans aucune erreur RBAC.
-
Avant cette mise à jour, à l'aide de l'outil CLI
tkn, vous ne pouviez pas supprimer les exécutions de tâches et les exécutions de pipeline qui contenaient un objetresultdont le type étaitarray. Avec cette mise à jour, vous pouvez utiliser l'outil CLItknpour supprimer les exécutions de tâches et les exécutions de pipeline qui contiennent un objetresultdont le type estarray. -
Avant cette mise à jour, si une spécification de pipeline contenait une tâche avec un paramètre
ENV_VARSde typearray, l'exécution du pipeline échouait avec l'erreur suivante :invalid input params for task func-buildpacks: param types don’t match the user-specified type: [ENV_VARS]. Avec cette mise à jour, les exécutions de pipeline avec de telles spécifications de pipeline et de tâche n'échouent pas. -
Avant cette mise à jour, les administrateurs de grappes ne pouvaient pas fournir de fichier
config.jsonà la tâche de grappeBuildahpour accéder à un registre de conteneurs. Avec cette mise à jour, les administrateurs de clusters peuvent fournir un fichierconfig.jsonà la tâche de clusterBuildahen utilisant l'espace de travaildockerconfig.
3.1.5.7. Notes de version pour Red Hat OpenShift Pipelines General Availability 1.8.2
Avec cette mise à jour, Red Hat OpenShift Pipelines General Availability (GA) 1.8.2 est disponible sur OpenShift Container Platform 4.10, 4.11 et 4.12.
3.1.5.7.1. Problèmes corrigés
-
Avant cette mise à jour, la tâche
git-cloneéchouait lors du clonage d'un référentiel à l'aide de clés SSH. Avec cette mise à jour, le rôle de l'utilisateur non root dans la tâchegit-initest supprimé, et le programme SSH recherche les clés correctes dans le répertoire$HOME/.ssh/.
3.1.6. Notes de version pour Red Hat OpenShift Pipelines General Availability 1.7
Avec cette mise à jour, Red Hat OpenShift Pipelines General Availability (GA) 1.7 est disponible sur OpenShift Container Platform 4.9, 4.10 et 4.11.
3.1.6.1. Nouvelles fonctionnalités
En plus des corrections et des améliorations de stabilité, les sections suivantes mettent en évidence les nouveautés de Red Hat OpenShift Pipelines 1.7.
3.1.6.1.1. Pipelines
Avec cette mise à jour,
pipelines-<version>est le canal par défaut pour installer Red Hat OpenShift Pipelines Operator. Par exemple, le canal par défaut pour installer la version1.7d'OpenShift Pipelines Operator estpipelines-1.7. Les administrateurs de cluster peuvent également utiliser le canallatestpour installer la version stable la plus récente de l'Opérateur.NoteLes canaux
previewetstableseront dépréciés et supprimés dans une prochaine version.Lorsque vous exécutez une commande dans un espace de noms utilisateur, votre conteneur s'exécute en tant que
root(user id0) mais dispose de privilèges d'utilisateur sur l'hôte. Avec cette mise à jour, pour exécuter des pods dans l'espace de noms utilisateur, vous devez passer les annotations attendues par CRI-O.-
Pour ajouter ces annotations pour tous les utilisateurs, exécutez la commande
oc edit clustertask buildahet modifiez la tâche de clusterbuildah. - Pour ajouter les annotations à un espace de noms spécifique, exportez la tâche de cluster en tant que tâche vers cet espace de noms.
-
Pour ajouter ces annotations pour tous les utilisateurs, exécutez la commande
Avant cette mise à jour, si certaines conditions n'étaient pas remplies, l'expression
whensautait un objetTasket ses tâches dépendantes. Avec cette mise à jour, vous pouvez étendre l'expressionwhenpour garder l'objetTaskuniquement, et non ses tâches dépendantes. Pour activer cette mise à jour, définissez l'indicateurscope-when-expressions-to-tasksurtruedans le CRDTektonConfig.NoteL'indicateur
scope-when-expressions-to-taskest obsolète et sera supprimé dans une prochaine version. En tant que meilleure pratique pour OpenShift Pipelines, utilisez les expressionswhenlimitées à l'élément gardéTaskuniquement.-
Avec cette mise à jour, vous pouvez utiliser la substitution de variables dans le champ
subPathd'un espace de travail au sein d'une tâche. Avec cette mise à jour, vous pouvez référencer les paramètres et les résultats en utilisant une notation entre crochets avec des guillemets simples ou doubles. Avant cette mise à jour, vous ne pouviez utiliser que la notation par points. Par exemple, les éléments suivants sont désormais équivalents :
$(param.myparam),$(param['myparam']), et$(param["myparam"]).Vous pouvez utiliser des guillemets simples ou doubles pour entourer les noms de paramètres qui contiennent des caractères problématiques, tels que
".". Par exemple,$(param['my.param'])et$(param["my.param"]).
-
Avec cette mise à jour, vous pouvez inclure le paramètre
onErrord'une étape dans la définition de la tâche sans activer l'indicateurenable-api-fields.
3.1.6.1.2. Déclencheurs
-
Avec cette mise à jour, la carte de configuration
feature-flag-triggersdispose d'un nouveau champlabels-exclusion-pattern. Vous pouvez définir la valeur de ce champ par une expression régulière (regex). Le contrôleur filtre les étiquettes qui correspondent au motif de l'expression régulière et les empêche de se propager de l'auditeur d'événements vers les ressources créées pour l'auditeur d'événements. -
Avec cette mise à jour, le champ
TriggerGroupsest ajouté à la spécificationEventListener. Ce champ permet de spécifier un ensemble d'intercepteurs à exécuter avant de sélectionner et d'exécuter un groupe de déclencheurs. Pour activer cette fonctionnalité, dans la définition de la ressource personnaliséeTektonConfig, dans la sectionpipeline, vous devez définir le champenable-api-fieldssuralpha. -
Avec cette mise à jour, les ressources
Triggerprennent en charge les exécutions personnalisées définies par un modèleTriggerTemplate. -
Avec cette mise à jour, les déclencheurs prennent en charge l'émission d'événements Kubernetes à partir d'un pod
EventListener. -
Avec cette mise à jour, les mesures de comptage sont disponibles pour les objets suivants :
ClusterInteceptor,EventListener,TriggerTemplate,ClusterTriggerBinding, etTriggerBinding. -
Cette mise à jour ajoute la spécification
ServicePortà la ressource Kubernetes. Vous pouvez utiliser cette spécification pour modifier le port qui expose le service d'écoute d'événements. Le port par défaut est8080. -
Avec cette mise à jour, vous pouvez utiliser le champ
targetURIdans la spécificationEventListenerpour envoyer des événements cloud pendant le traitement des déclencheurs. Pour activer cette fonctionnalité, dans la définition de la ressource personnaliséeTektonConfig, dans la sectionpipeline, vous devez définir le champenable-api-fieldssuralpha. -
Avec cette mise à jour, l'objet
tekton-triggers-eventlistener-rolesa maintenant un verbepatch, en plus du verbecreatequi existe déjà. -
Avec cette mise à jour, le paramètre
securityContext.runAsUserest supprimé du déploiement de l'écouteur d'événements.
3.1.6.1.3. CLI
Avec cette mise à jour, la commande
tkn [pipeline | pipelinerun] exportexporte un pipeline ou une exécution de pipeline sous la forme d'un fichier YAML. Par exemple, il est possible d'exporter un pipeline ou une exécution de pipeline sous forme de fichier YAML :Exporter un pipeline nommé
test_pipelinedans l'espace de nomsopenshift-pipelines:$ tkn pipeline export test_pipeline -n openshift-pipelinesExporter un pipeline nommé
test_pipeline_rundans l'espace de nomsopenshift-pipelines:$ tkn pipelinerun export test_pipeline_run -n openshift-pipelines
-
Avec cette mise à jour, l'option
--graceest ajoutée à l'optiontkn pipelinerun cancel. Utilisez l'option--gracepour mettre fin à l'exécution d'un pipeline de manière gracieuse au lieu de forcer la fin. Pour activer cette fonctionnalité, dans la définition de la ressource personnaliséeTektonConfig, dans la sectionpipeline, vous devez définir le champenable-api-fieldsàalpha. Cette mise à jour ajoute les versions Operator et Chains à la sortie de la commande
tkn version.ImportantTekton Chains est une fonctionnalité de l'aperçu technologique.
-
Avec cette mise à jour, la commande
tkn pipelinerun describeaffiche toutes les exécutions de tâches annulées, lorsque vous annulez une exécution de pipeline. Avant cette correction, une seule tâche était affichée. -
Avec cette mise à jour, vous pouvez ne pas fournir les spécifications de l'espace de travail optionnel lorsque vous exécutez la commande
tkn [t | p | ct] startskips avec l'option--skip-optional-workspace. Vous pouvez également ne pas le faire en mode interactif. Avec cette mise à jour, vous pouvez utiliser la commande
tkn chainspour gérer les chaînes Tekton. Vous pouvez également utiliser l'option--chains-namespacepour spécifier l'espace de noms dans lequel vous souhaitez installer les chaînes Tekton.ImportantTekton Chains est une fonctionnalité de l'aperçu technologique.
3.1.6.1.4. Opérateur
Avec cette mise à jour, vous pouvez utiliser l'opérateur Red Hat OpenShift Pipelines pour installer et déployer Tekton Hub et Tekton Chains.
ImportantLes chaînes Tekton et le déploiement de Tekton Hub sur un cluster sont des fonctionnalités de l'aperçu technologique.
Avec cette mise à jour, vous pouvez trouver et utiliser Pipelines as Code (PAC) en tant qu'option supplémentaire.
ImportantPipelines as Code est une fonctionnalité de l'aperçu technologique.
Avec cette mise à jour, vous pouvez désormais désactiver l'installation des tâches de cluster communautaire en définissant le paramètre
communityClusterTaskssurfalse. Par exemple :... spec: profile: all targetNamespace: openshift-pipelines addon: params: - name: clusterTasks value: "true" - name: pipelineTemplates value: "true" - name: communityClusterTasks value: "false" ...Avec cette mise à jour, vous pouvez désactiver l'intégration de Tekton Hub avec la perspective Developer en définissant l'indicateur
enable-devconsole-integrationdans la ressource personnaliséeTektonConfigsurfalse. Par exemple :... hub: params: - name: enable-devconsole-integration value: "true" ...-
Avec cette mise à jour, la carte de configuration
operator-config.yamlpermet à la sortie de la commandetkn versiond'afficher la version de l'opérateur. -
Avec cette mise à jour, la version des tâches
argocd-task-sync-and-waitest modifiée env0.2. -
Avec cette mise à jour du CRD
TektonConfig, la commandeoc get tektonconfigaffiche la version de l'OPerator. - Avec cette mise à jour, le moniteur de service est ajouté aux mesures des déclencheurs.
3.1.6.1.5. Hub
Le déploiement de Tekton Hub sur un cluster est une fonctionnalité de l'aperçu technologique.
Tekton Hub vous aide à découvrir, rechercher et partager des tâches et des pipelines réutilisables pour vos flux de travail CI/CD. Une instance publique de Tekton Hub est disponible sur hub.tekton.dev.
Depuis Red Hat OpenShift Pipelines 1.7, les administrateurs de clusters peuvent également installer et déployer une instance personnalisée de Tekton Hub sur les clusters d'entreprise. Vous pouvez créer un catalogue avec des tâches réutilisables et des pipelines spécifiques à votre organisation.
3.1.6.1.6. Chaînes
Tekton Chains est une fonctionnalité de l'aperçu technologique.
Tekton Chains est un contrôleur de définition de ressources personnalisées (CRD) de Kubernetes. Vous pouvez l'utiliser pour gérer la sécurité de la chaîne logistique des tâches et des pipelines créés à l'aide de Red Hat OpenShift Pipelines.
Par défaut, Tekton Chains surveille les exécutions de tâches dans votre cluster OpenShift Container Platform. Chains prend des instantanés des exécutions de tâches terminées, les convertit en un ou plusieurs formats de charge utile standard, et signe et stocke tous les artefacts.
Tekton Chains prend en charge les fonctionnalités suivantes :
-
Vous pouvez signer les exécutions de tâches, les résultats des exécutions de tâches et les images de registre OCI avec des types de clés cryptographiques et des services tels que
cosign. -
Vous pouvez utiliser des formats d'attestation tels que
in-toto. - Vous pouvez stocker en toute sécurité des signatures et des artefacts signés en utilisant le référentiel OCI comme backend de stockage.
3.1.6.1.7. Les pipelines en tant que code (PAC)
Pipelines as Code est une fonctionnalité de l'aperçu technologique.
Avec Pipelines as Code, les administrateurs de clusters et les utilisateurs disposant des privilèges requis peuvent définir des modèles de pipelines dans le cadre de dépôts Git de code source. Lorsqu'elle est déclenchée par un push de code source ou une pull request pour le dépôt Git configuré, la fonctionnalité exécute le pipeline et signale son état.
Pipelines as Code prend en charge les fonctionnalités suivantes :
- Statut de la demande d'extraction. Lors de l'itération sur une demande d'extraction, le statut et le contrôle de la demande d'extraction sont exercés sur la plateforme hébergeant le dépôt Git.
- GitHub vérifie l'API pour définir le statut d'une exécution de pipeline, y compris les recontrôles.
- Événements GitHub relatifs aux demandes d'extraction et aux livraisons.
-
Actions de demande d'extraction dans les commentaires, telles que
/retest. - Filtrage des événements Git et pipeline séparé pour chaque événement.
- Résolution automatique des tâches dans OpenShift Pipelines pour les tâches locales, Tekton Hub, et les URLs distantes.
- Utilisation des blobs et des objets de l'API GitHub pour récupérer les configurations.
-
Liste de contrôle d'accès (ACL) sur une organisation GitHub, ou en utilisant un fichier de type Prow
OWNER. -
Le plugin
tkn pacpour l'outil CLItkn, que vous pouvez utiliser pour gérer les dépôts de Pipelines as Code et le bootstrapping. - Prise en charge de l'application GitHub, de GitHub Webhook, du serveur Bitbucket et de Bitbucket Cloud.
3.1.6.2. Fonctionnalités obsolètes
-
Changement radical : Cette mise à jour supprime les champs
disable-working-directory-overwriteetdisable-home-env-overwritede la ressource personnalisée (CR)TektonConfig. Par conséquent, la CRTektonConfigne définit plus automatiquement la variable d'environnement$HOMEet le paramètreworkingDir. Vous pouvez toujours définir la variable d'environnement$HOMEet le paramètreworkingDiren utilisant les champsenvetworkingDirdans la définition de ressource personnalisée (CRD)Task.
-
Le type de définition de ressource personnalisée (CRD)
Conditionsest obsolète et devrait être supprimé dans une prochaine version. Utilisez plutôt l'expression recommandéeWhen.
-
Changement radical : La ressource
Triggersvalide les modèles et génère une erreur si vous ne spécifiez pas les valeursEventListeneretTriggerBinding.
3.1.6.3. Problèmes connus
Lorsque vous exécutez des tâches de cluster Maven et Jib-Maven, l'image de conteneur par défaut n'est prise en charge que sur l'architecture Intel (x86). Par conséquent, les tâches échoueront sur les clusters ARM, IBM Power Systems (ppc64le), IBM Z et LinuxONE (s390x). Pour contourner le problème, vous pouvez spécifier une image personnalisée en définissant la valeur du paramètre
MAVEN_IMAGEsurmaven:3.6.3-adoptopenjdk-11.AstuceAvant d'installer des tâches basées sur le catalogue Tekton sur ARM, IBM Power Systems (ppc64le), IBM Z et LinuxONE (s390x) en utilisant
tkn hub, vérifiez si la tâche peut être exécutée sur ces plates-formes. Pour vérifier sippc64leets390xsont répertoriés dans la section "Platforms" des informations sur la tâche, vous pouvez exécuter la commande suivante :tkn hub info task <name>-
Sur IBM Power Systems, IBM Z et LinuxONE, la tâche
s2i-dotnetcluster n'est pas prise en charge. Vous ne pouvez pas utiliser le flux d'images
nodejs:14-ubi8-minimalcar cela génère les erreurs suivantes :STEP 7: RUN /usr/libexec/s2i/assemble /bin/sh: /usr/libexec/s2i/assemble: No such file or directory subprocess exited with status 127 subprocess exited with status 127 error building at STEP "RUN /usr/libexec/s2i/assemble": exit status 127 time="2021-11-04T13:05:26Z" level=error msg="exit status 127"
-
Le mappage implicite des paramètres transmet incorrectement les paramètres des définitions de premier niveau
PipelineouPipelineRunaux tâchestaskRef. Le mappage ne doit se faire qu'à partir d'une ressource de premier niveau vers des tâches avec des spécifications en lignetaskSpec. Ce problème n'affecte que les clusters où cette fonctionnalité a été activée en définissant le champenable-api-fieldssuralphadans la sectionpipelinede la définition de la ressource personnaliséeTektonConfig.
3.1.6.4. Problèmes corrigés
-
Avec cette mise à jour, si des métadonnées telles que
labelsetannotationssont présentes dans les définitions des objetsPipelineetPipelineRun, les valeurs du typePipelineRunsont prioritaires. Vous pouvez observer un comportement similaire pour les objetsTasketTaskRun. -
Avec cette mise à jour, si le champ
timeouts.tasksou le champtimeouts.finallyest défini sur0, le champtimeouts.pipelineest également défini sur0. -
Avec cette mise à jour, l'indicateur
-xset est supprimé des scripts qui n'utilisent pas de shebang. Cette correction réduit les risques de fuite de données lors de l'exécution des scripts. -
Avec cette mise à jour, tout caractère backslash présent dans les noms d'utilisateur des identifiants Git est échappé par un backslash supplémentaire dans le fichier
.gitconfig.
-
Avec cette mise à jour, la propriété
finalizerde l'objetEventListenern'est pas nécessaire pour nettoyer les logs et les cartes de configuration. - Avec cette mise à jour, le client HTTP par défaut associé au serveur d'écoute des événements est supprimé et un client HTTP personnalisé est ajouté. En conséquence, les délais d'attente ont été améliorés.
- Avec cette mise à jour, le rôle de cluster Déclencheurs fonctionne désormais avec les références de propriétaires.
- Avec cette mise à jour, la condition de course dans l'écouteur d'événements ne se produit pas lorsque plusieurs intercepteurs renvoient des extensions.
-
Avec cette mise à jour, la commande
tkn pr deleten'efface pas les pipelines exécutés avec l'indicateurignore-running.
- Avec cette mise à jour, les pods de l'opérateur ne continuent pas à redémarrer lorsque vous modifiez les paramètres d'un add-on.
-
Avec cette mise à jour, le pod
tkn serveCLI est planifié sur les nœuds infra, s'il n'est pas configuré dans les ressources personnalisées d'abonnement et de configuration. - Avec cette mise à jour, les tâches de cluster avec les versions spécifiées ne sont pas supprimées lors de la mise à niveau.
3.1.6.5. Notes de version pour Red Hat OpenShift Pipelines General Availability 1.7.1
Avec cette mise à jour, Red Hat OpenShift Pipelines General Availability (GA) 1.7.1 est disponible sur OpenShift Container Platform 4.9, 4.10 et 4.11.
3.1.6.5.1. Problèmes corrigés
- Avant cette mise à jour, la mise à niveau de Red Hat OpenShift Pipelines Operator supprimait les données de la base de données associée à Tekton Hub et installait une nouvelle base de données. Avec cette mise à jour, une mise à niveau de l'Opérateur préserve les données.
- Avant cette mise à jour, seuls les administrateurs de cluster pouvaient accéder aux métriques de pipeline dans la console OpenShift Container Platform. Avec cette mise à jour, les utilisateurs ayant d'autres rôles dans le cluster peuvent également accéder aux métriques du pipeline.
-
Avant cette mise à jour, les exécutions de pipeline échouaient pour les pipelines contenant des tâches qui émettent des messages de fin volumineux. Les exécutions de pipeline échouaient parce que la taille totale des messages de fin de tous les conteneurs dans un pod ne peut pas dépasser 12 KB. Avec cette mise à jour, les conteneurs d'initialisation
place-toolsetstep-initqui utilisent la même image sont fusionnés pour réduire le nombre de conteneurs en cours d'exécution dans le pod de chaque tâche. La solution réduit le risque d'échec des exécutions du pipeline en minimisant le nombre de conteneurs en cours d'exécution dans le pod d'une tâche. Cependant, elle ne supprime pas la limitation de la taille maximale autorisée d'un message de fin. -
Avant cette mise à jour, les tentatives d'accès aux URL de ressources directement depuis la console web Tekton Hub entraînaient une erreur Nginx
404. Avec cette mise à jour, l'image de la console web Tekton Hub est corrigée pour permettre l'accès aux URLs des ressources directement depuis la console web Tekton Hub. - Avant cette mise à jour, la tâche d'élagage des ressources créait un conteneur distinct pour chaque espace de noms afin d'élaguer les ressources. Avec cette mise à jour, la tâche d'élagage des ressources exécute les commandes pour tous les espaces de noms en boucle dans un seul conteneur.
3.1.6.6. Notes de mise à jour pour Red Hat OpenShift Pipelines General Availability 1.7.2
Avec cette mise à jour, Red Hat OpenShift Pipelines General Availability (GA) 1.7.2 est disponible sur OpenShift Container Platform 4.9, 4.10, et la version à venir.
3.1.6.6.1. Problèmes connus
-
La carte de configuration
chains-configpour les chaînes Tekton dans l'espace de nomsopenshift-pipelinesest automatiquement réinitialisée par défaut après la mise à niveau de Red Hat OpenShift Pipelines Operator. Actuellement, il n'y a pas de solution de contournement pour ce problème.
3.1.6.6.2. Problèmes corrigés
-
Avant cette mise à jour, les tâches sur OpenShift Pipelines 1.7.1 échouaient lors de l'utilisation de
initcomme premier argument, suivi de deux arguments ou plus. Avec cette mise à jour, les drapeaux sont analysés correctement et les tâches sont exécutées avec succès. Avant cette mise à jour, l'installation de Red Hat OpenShift Pipelines Operator sur OpenShift Container Platform 4.9 et 4.10 échouait en raison d'une liaison de rôle non valide, avec le message d'erreur suivant :
error updating rolebinding openshift-operators-prometheus-k8s-read-binding: RoleBinding.rbac.authorization.k8s.io "openshift-operators-prometheus-k8s-read-binding" is invalid: roleRef: Invalid value: rbac.RoleRef{APIGroup:"rbac.authorization.k8s.io", Kind:"Role", Name:"openshift-operator-read"}: cannot change roleRefAvec cette mise à jour, l'opérateur Red Hat OpenShift Pipelines s'installe avec des espaces de noms de liaison de rôle distincts pour éviter les conflits avec l'installation d'autres opérateurs.
Avant cette mise à jour, la mise à niveau de l'opérateur entraînait la réinitialisation de la clé secrète
signing-secretspour les chaînes Tekton à sa valeur par défaut. Avec cette mise à jour, la clé secrète personnalisée persiste après la mise à niveau de l'opérateur.NoteLa mise à niveau vers Red Hat OpenShift Pipelines 1.7.2 réinitialise la clé. Cependant, lorsque vous mettez à niveau vers des versions ultérieures, la clé est censée persister.
Avant cette mise à jour, toutes les tâches de construction de S2I échouaient avec une erreur similaire au message suivant :
Error: error writing "0 0 4294967295\n" to /proc/22/uid_map: write /proc/22/uid_map: operation not permitted time="2022-03-04T09:47:57Z" level=error msg="error writing \"0 0 4294967295\\n\" to /proc/22/uid_map: write /proc/22/uid_map: operation not permitted" time="2022-03-04T09:47:57Z" level=error msg="(unable to determine exit status)"Avec cette mise à jour, la contrainte de contexte de sécurité (SCC) de
pipelines-sccest compatible avec la capacité deSETFCAPnécessaire pour les tâches de cluster deBuildahetS2I. Par conséquent, les tâches de constructionBuildahetS2Ipeuvent être exécutées avec succès.Pour exécuter avec succès la tâche de cluster
Buildahet les tâches de constructionS2Ipour les applications écrites dans différents langages et frameworks, ajoutez l'extrait suivant pour les objetsstepsappropriés tels quebuildetpush:securityContext: capabilities: add: ["SETFCAP"]
3.1.6.7. Notes de version pour Red Hat OpenShift Pipelines General Availability 1.7.3
Avec cette mise à jour, Red Hat OpenShift Pipelines General Availability (GA) 1.7.3 est disponible sur OpenShift Container Platform 4.9, 4.10 et 4.11.
3.1.6.7.1. Problèmes corrigés
-
Avant cette mise à jour, l'opérateur échouait lors de la création de ressources RBAC si un espace de noms était dans l'état
Terminating. Avec cette mise à jour, l'opérateur ignore les espaces de noms dans l'étatTerminatinget crée les ressources RBAC. -
Auparavant, la mise à niveau de Red Hat OpenShift Pipelines Operator entraînait la recréation du compte de service
pipeline, ce qui signifiait que les secrets liés au compte de service étaient perdus. Cette mise à jour corrige ce problème. Lors des mises à niveau, l'Opérateur ne recrée plus le compte de servicepipeline. Par conséquent, les secrets liés au compte de servicepipelinepersistent après les mises à niveau, et les ressources (tâches et pipelines) continuent de fonctionner correctement.
3.1.7. Notes de mise à jour pour Red Hat OpenShift Pipelines General Availability 1.6
Avec cette mise à jour, Red Hat OpenShift Pipelines General Availability (GA) 1.6 est disponible sur OpenShift Container Platform 4.9.
3.1.7.1. Nouvelles fonctionnalités
En plus des corrections et des améliorations de la stabilité, les sections suivantes mettent en évidence les nouveautés de Red Hat OpenShift Pipelines 1.6.
-
Avec cette mise à jour, vous pouvez configurer la commande
startd'un pipeline ou d'une tâche pour qu'elle renvoie une chaîne formatée YAML ou JSON en utilisant l'option--output <string>, où<string>estyamloujson. Sinon, sans l'option--output, la commandestartrenvoie un message convivial difficile à analyser par d'autres programmes. Le renvoi d'une chaîne au format YAML ou JSON est utile pour les environnements d'intégration continue (CI). Par exemple, après la création d'une ressource, vous pouvez utiliseryqoujqpour analyser le message au format YAML ou JSON concernant la ressource et attendre que cette ressource soit terminée sans utiliser l'optionshowlog. -
Avec cette mise à jour, vous pouvez vous authentifier auprès d'un registre en utilisant le fichier d'authentification
auth.jsonde Podman. Par exemple, vous pouvez utilisertkn bundle pushpour pousser vers un registre distant en utilisant Podman au lieu de Docker CLI. -
Avec cette mise à jour, si vous utilisez la commande
tkn [taskrun | pipelinerun] delete --all, vous pouvez conserver les exécutions datant de moins d'un certain nombre de minutes en utilisant la nouvelle option--keep-since <minutes>. Par exemple, pour conserver les exécutions datant de moins de cinq minutes, vous devez saisirtkn [taskrun | pipelinerun] delete -all --keep-since 5. -
Avec cette mise à jour, lorsque vous supprimez des exécutions de tâches ou des exécutions de pipeline, vous pouvez utiliser les options
--parent-resourceet--keep-sinceen même temps. Par exemple, la commandetkn pipelinerun delete --pipeline pipelinename --keep-since 5préserve les exécutions de pipeline dont la ressource parente est nomméepipelinenameet dont l'ancienneté est inférieure ou égale à cinq minutes. Les commandestkn tr delete -t <taskname> --keep-since 5ettkn tr delete --clustertask <taskname> --keep-since 5fonctionnent de la même manière pour les exécutions de tâches. -
Cette mise à jour ajoute la prise en charge des ressources de déclenchement pour qu'elles fonctionnent avec les ressources
v1beta1.
-
Cette mise à jour ajoute une option
ignore-runningaux commandestkn pipelinerun deleteettkn taskrun delete. -
Cette mise à jour ajoute une sous-commande
createaux commandestkn taskettkn clustertask. -
Avec cette mise à jour, lorsque vous utilisez la commande
tkn pipelinerun delete --all, vous pouvez utiliser la nouvelle option--label <string>pour filtrer les parcours du pipeline par étiquette. Vous pouvez également utiliser l'option--labelavec=et==comme opérateurs d'égalité, ou!=comme opérateur d'inégalité. Par exemple, les commandestkn pipelinerun delete --all --label asdfettkn pipelinerun delete --all --label==asdfsuppriment toutes deux toutes les séries de pipelines portant le labelasdf. - Avec cette mise à jour, vous pouvez récupérer la version des composants Tekton installés à partir de la carte de configuration ou, si la carte de configuration n'est pas présente, à partir du contrôleur de déploiement.
-
Avec cette mise à jour, les déclencheurs prennent en charge les cartes de configuration
feature-flagsetconfig-defaultspour configurer les drapeaux des fonctionnalités et définir les valeurs par défaut, respectivement. -
Cette mise à jour ajoute une nouvelle métrique,
eventlistener_event_count, que vous pouvez utiliser pour compter les événements reçus par la ressourceEventListener. Cette mise à jour ajoute les types d'API
v1beta1Go. Avec cette mise à jour, les déclencheurs prennent désormais en charge la version de l'APIv1beta1.Avec la version actuelle, les fonctionnalités de
v1alpha1sont désormais obsolètes et seront supprimées dans une prochaine version. Commencez à utiliser les fonctionnalités dev1beta1à la place.
Dans la version actuelle, l'exécution automatique des ressources est activée par défaut. En outre, vous pouvez configurer l'exécution automatique des tâches et des pipelines pour chaque espace de noms séparément, en utilisant les nouvelles annotations suivantes :
-
operator.tekton.dev/prune.schedule: Si la valeur de cette annotation est différente de la valeur spécifiée dans la définition de la ressource personnaliséeTektonConfig, un nouveau travail cron est créé dans cet espace de noms. -
operator.tekton.dev/prune.skip: Lorsqu'il est défini surtrue, l'espace de noms pour lequel il est configuré ne sera pas élagué. -
operator.tekton.dev/prune.resources: Cette annotation accepte une liste de ressources séparées par des virgules. Pour élaguer une seule ressource, telle qu'une exécution de pipeline, définissez cette annotation à"pipelinerun". Pour élaguer plusieurs ressources, telles qu'une exécution de tâche et une exécution de pipeline, définissez cette annotation à"taskrun, pipelinerun". -
operator.tekton.dev/prune.keep: Utilisez cette annotation pour conserver une ressource sans l'élaguer. operator.tekton.dev/prune.keep-since: Cette annotation permet de conserver les ressources en fonction de leur âge. La valeur de cette annotation doit être égale à l'âge de la ressource en minutes. Par exemple, pour conserver les ressources qui ont été créées il y a cinq jours au maximum, définissezkeep-sincesur7200.NoteLes annotations
keepetkeep-sinces'excluent mutuellement. Pour toute ressource, vous ne devez configurer qu'une seule d'entre elles.-
operator.tekton.dev/prune.strategy: Fixer la valeur de cette annotation àkeepoukeep-since.
-
-
Les administrateurs peuvent désactiver la création du compte de service
pipelinepour l'ensemble du cluster, et empêcher l'escalade des privilèges par une mauvaise utilisation du SCC associé, qui est très similaire àanyuid. -
Vous pouvez désormais configurer les drapeaux de fonctionnalité et les composants en utilisant la ressource personnalisée (CR)
TektonConfiget les CR pour les composants individuels, tels queTektonPipelineetTektonTriggers. Ce niveau de granularité permet de personnaliser et de tester des fonctionnalités alpha telles que le Tekton OCI bundle pour des composants individuels. -
Vous pouvez désormais configurer le champ optionnel
Timeoutspour la ressourcePipelineRun. Par exemple, vous pouvez configurer des délais séparément pour l'exécution d'un pipeline, l'exécution de chaque tâche et les tâchesfinally. -
Les pods générés par la ressource
TaskRundéfinissent désormais le champactiveDeadlineSecondsdes pods. Cela permet à OpenShift de les considérer comme terminés, et vous permet d'utiliser l'objet spécifiquement scopedResourceQuotapour les pods. - Vous pouvez utiliser les cartes de configuration pour éliminer les balises de métriques ou les types d'étiquettes sur une exécution de tâche, une exécution de pipeline, une tâche et un pipeline. En outre, vous pouvez configurer différents types de métriques pour mesurer la durée, tels qu'un histogramme, une jauge ou la dernière valeur.
-
Vous pouvez définir les demandes et les limites d'un pod de manière cohérente, car Tekton prend désormais entièrement en charge l'objet
LimitRangeen tenant compte des champsMin,Max,DefaultetDefaultRequest. Les fonctionnalités alpha suivantes sont introduites :
L'exécution d'un pipeline peut maintenant s'arrêter après l'exécution des tâches
finally, plutôt que d'arrêter directement l'exécution de toutes les tâches comme c'était le cas auparavant. Cette mise à jour ajoute les valeursspec.statussuivantes :-
StoppedRunFinallyarrêtera les tâches en cours d'exécution une fois qu'elles seront terminées, puis exécutera les tâchesfinally. -
CancelledRunFinallyannulera immédiatement les tâches en cours, puis exécutera les tâchesfinally. Cancelledconservera le comportement antérieur fourni par le statutPipelineRunCancelled.NoteLe statut
Cancelledremplace le statutPipelineRunCancelled, qui est obsolète et qui sera supprimé dans la versionv1.
-
-
Vous pouvez désormais utiliser la commande
oc debugpour mettre une tâche en mode débogage, ce qui met l'exécution en pause et vous permet d'inspecter des étapes spécifiques d'un module. -
Lorsque vous attribuez la valeur
continueau champonErrord'une étape, le code de sortie de l'étape est enregistré et transmis aux étapes suivantes. Toutefois, l'exécution de la tâche n'échoue pas et l'exécution des autres étapes de la tâche se poursuit. Pour conserver le comportement existant, vous pouvez attribuer au champonErrorla valeurstopAndFail. - Les tâches peuvent désormais accepter plus de paramètres qu'elles n'en utilisent réellement. Lorsque l'option alpha est activée, les paramètres peuvent se propager implicitement aux spécifications intégrées. Par exemple, une tâche intégrée peut accéder aux paramètres de son pipeline parent, sans définir explicitement chaque paramètre pour la tâche.
-
Si vous activez l'indicateur pour les caractéristiques alpha, les conditions des expressions
Whenne s'appliqueront qu'à la tâche à laquelle elle est directement associée, et non aux dépendances de la tâche. Pour appliquer les expressionsWhenà la tâche associée et à ses dépendances, vous devez associer l'expression à chaque tâche dépendante séparément. Notez qu'à l'avenir, ce sera le comportement par défaut des expressionsWhendans toutes les nouvelles versions API de Tekton. Le comportement par défaut existant sera supprimé en faveur de cette mise à jour.
La version actuelle vous permet de configurer la sélection des nœuds en spécifiant les valeurs
nodeSelectorettolerationsdans la ressource personnalisée (CR)TektonConfig. L'opérateur ajoute ces valeurs à tous les déploiements qu'il crée.-
Pour configurer la sélection des nœuds pour le contrôleur de l'opérateur et le déploiement des webhooks, vous devez modifier les champs
config.nodeSelectoretconfig.tolerationsdans la spécification deSubscriptionCR, après avoir installé l'opérateur. -
Pour déployer le reste des pods du plan de contrôle d'OpenShift Pipelines sur un nœud d'infrastructure, mettez à jour le CR
TektonConfigavec les champsnodeSelectorettolerations. Les modifications sont ensuite appliquées à tous les pods créés par Operator.
-
Pour configurer la sélection des nœuds pour le contrôleur de l'opérateur et le déploiement des webhooks, vous devez modifier les champs
3.1.7.2. Fonctionnalités obsolètes
-
Dans le CLI 0.21.0, la prise en charge de toutes les ressources
v1alpha1pour les commandesclustertask,task,taskrun,pipeline, etpipelinerunest obsolète. Ces ressources sont désormais obsolètes et seront supprimées dans une prochaine version.
Dans la version 0.16.0 de Tekton Triggers, l'étiquette redondante
statusest supprimée des métriques de la ressourceEventListener.ImportantChangement radical : Le label
statusa été supprimé de la métriqueeventlistener_http_duration_seconds_*. Supprimez les requêtes basées sur le labelstatus.-
Avec la version actuelle, les fonctionnalités de
v1alpha1sont désormais obsolètes et seront supprimées dans une prochaine version. Avec cette mise à jour, vous pouvez commencer à utiliser les types d'APIv1beta1Go à la place. Les déclencheurs prennent désormais en charge la version de l'APIv1beta1. Avec la version actuelle, la ressource
EventListenerenvoie une réponse avant que les déclencheurs ne terminent leur traitement.ImportantChangement de rupture : Avec cette modification, la ressource
EventListenerne répond plus avec un code d'état201 Createdlorsqu'elle crée des ressources. Au lieu de cela, elle répond avec un code de réponse202 Accepted.La version actuelle supprime le champ
podTemplatede la ressourceEventListener.ImportantChangement radical : Le champ
podTemplate, qui a été supprimé dans le cadre de #1100, a été supprimé.La version actuelle supprime le champ
replicas, obsolète, de la spécification de la ressourceEventListener.ImportantChangement radical : Le champ
replicas, obsolète, a été supprimé.
Dans Red Hat OpenShift Pipelines 1.6, les valeurs de
HOME="/tekton/home"etworkingDir="/workspace"sont supprimées de la spécification des objetsStep.Au lieu de cela, Red Hat OpenShift Pipelines définit
HOMEetworkingDiraux valeurs définies par les conteneurs exécutant les objetsStep. Vous pouvez remplacer ces valeurs dans la spécification de vos objetsStep.Pour utiliser l'ancien comportement, vous pouvez remplacer les champs
disable-working-directory-overwriteetdisable-home-env-overwritede la CRTektonConfigparfalse:apiVersion: operator.tekton.dev/v1alpha1 kind: TektonConfig metadata: name: config spec: pipeline: disable-working-directory-overwrite: false disable-home-env-overwrite: false ...ImportantLes champs
disable-working-directory-overwriteetdisable-home-env-overwritede la CRTektonConfigsont désormais obsolètes et seront supprimés dans une prochaine version.
3.1.7.3. Problèmes connus
-
Lorsque vous exécutez des tâches de cluster Maven et Jib-Maven, l'image de conteneur par défaut n'est prise en charge que sur l'architecture Intel (x86). Par conséquent, les tâches échoueront sur les clusters IBM Power Systems (ppc64le), IBM Z et LinuxONE (s390x). Pour contourner ce problème, vous pouvez spécifier une image personnalisée en définissant la valeur du paramètre
MAVEN_IMAGEsurmaven:3.6.3-adoptopenjdk-11. -
Sur IBM Power Systems, IBM Z et LinuxONE, la tâche
s2i-dotnetcluster n'est pas prise en charge. -
Avant d'installer des tâches basées sur le catalogue Tekton sur IBM Power Systems (ppc64le), IBM Z et LinuxONE (s390x) à l'aide de
tkn hub, vérifiez si la tâche peut être exécutée sur ces plates-formes. Pour vérifier sippc64leets390xsont listés dans la section "Platforms" des informations sur la tâche, vous pouvez exécuter la commande suivante :tkn hub info task <name> Vous ne pouvez pas utiliser le flux d'images
nodejs:14-ubi8-minimalcar cela génère les erreurs suivantes :STEP 7: RUN /usr/libexec/s2i/assemble /bin/sh: /usr/libexec/s2i/assemble: No such file or directory subprocess exited with status 127 subprocess exited with status 127 error building at STEP "RUN /usr/libexec/s2i/assemble": exit status 127 time="2021-11-04T13:05:26Z" level=error msg="exit status 127"
3.1.7.4. Problèmes corrigés
-
La commande
tkn hubest désormais prise en charge sur les systèmes IBM Power, IBM Z et LinuxONE.
-
Avant cette mise à jour, le terminal n'était pas disponible après que l'utilisateur ait exécuté une commande
tkn, et l'exécution du pipeline était terminée, même siretriesétait spécifié. La spécification d'un délai d'attente dans l'exécution de la tâche ou du pipeline n'avait aucun effet. Cette mise à jour corrige le problème afin que le terminal soit disponible après l'exécution de la commande. -
Avant cette mise à jour, l'exécution de
tkn pipelinerun delete --allsupprimait toutes les ressources. Cette mise à jour empêche la suppression des ressources en cours d'exécution. -
Avant cette mise à jour, l'utilisation de la commande
tkn version --component=<component>ne renvoyait pas la version du composant. Cette mise à jour corrige le problème de sorte que cette commande renvoie la version du composant. -
Avant cette mise à jour, lorsque vous utilisiez la commande
tkn pr logs, elle affichait les journaux de sortie des pipelines dans le mauvais ordre des tâches. Cette mise à jour résout le problème de sorte que les journaux dePipelineRunssont répertoriés dans l'ordre d'exécution approprié deTaskRun.
-
Avant cette mise à jour, la modification de la spécification d'un pipeline en cours d'exécution pouvait empêcher l'exécution du pipeline de s'arrêter lorsqu'elle était terminée. Cette mise à jour corrige le problème en ne récupérant la définition qu'une seule fois et en utilisant ensuite la spécification stockée dans l'état pour la vérification. Cette modification réduit la probabilité d'une condition de course lorsqu'un
PipelineRunou unTaskRunfait référence à unPipelineou unTaskqui change pendant l'exécution. -
Whenles valeurs d'expression peuvent désormais contenir des références à des paramètres de type tableau, comme par exemple :values: [$(params.arrayParam[*])].
3.1.7.5. Notes de version pour Red Hat OpenShift Pipelines General Availability 1.6.1
3.1.7.5.1. Problèmes connus
Après la mise à niveau vers Red Hat OpenShift Pipelines 1.6.1 à partir d'une version plus ancienne, OpenShift Pipelines peut entrer dans un état incohérent dans lequel vous ne pouvez pas effectuer d'opérations (créer/supprimer/appliquer) sur les ressources Tekton (tâches et pipelines). Par exemple, lors de la suppression d'une ressource, vous pouvez rencontrer l'erreur suivante :
Error from server (InternalError): Internal error occurred: failed calling webhook "validation.webhook.pipeline.tekton.dev": Post "https://tekton-pipelines-webhook.openshift-pipelines.svc:443/resource-validation?timeout=10s": service "tekton-pipelines-webhook" not found.
3.1.7.5.2. Problèmes corrigés
La variable d'environnement
SSL_CERT_DIR(/tekton-custom-certs) définie par Red Hat OpenShift Pipelines ne remplacera pas les répertoires système par défaut suivants par des fichiers de certificats :-
/etc/pki/tls/certs -
/etc/ssl/certs -
/system/etc/security/cacerts
-
- L'Horizontal Pod Autoscaler peut gérer le nombre de répliques des déploiements contrôlés par Red Hat OpenShift Pipelines Operator. À partir de cette version, si le compte est modifié par un utilisateur final ou un agent sur le cluster, Red Hat OpenShift Pipelines Operator ne réinitialisera pas le compte de répliques des déploiements qu'il gère. Cependant, les répliques seront réinitialisées lorsque vous mettrez à niveau le Red Hat OpenShift Pipelines Operator.
-
Le pod qui sert le CLI
tknsera désormais programmé sur des nœuds, en fonction du sélecteur de nœuds et des limites de tolérance spécifiées dans la ressource personnaliséeTektonConfig.
3.1.7.6. Notes de version pour Red Hat OpenShift Pipelines General Availability 1.6.2
3.1.7.6.1. Problèmes connus
-
Lorsque vous créez un nouveau projet, la création du compte de service
pipelineest retardée, et la suppression des tâches de cluster et des modèles de pipeline existants prend plus de 10 minutes.
3.1.7.6.2. Problèmes corrigés
-
Avant cette mise à jour, plusieurs instances d'ensembles d'installation Tekton étaient créées pour un pipeline après la mise à niveau vers Red Hat OpenShift Pipelines 1.6.1 à partir d'une version plus ancienne. Avec cette mise à jour, l'opérateur s'assure qu'une seule instance de chaque type de
TektonInstallerSetexiste après une mise à niveau. - Avant cette mise à jour, tous les réconciliateurs de l'Opérateur utilisaient la version du composant pour décider de la recréation des ressources lors d'une mise à niveau vers Red Hat OpenShift Pipelines 1.6.1 à partir d'une version plus ancienne. Par conséquent, les ressources dont la version des composants n'a pas changé lors de la mise à niveau n'ont pas été recréées. Avec cette mise à jour, l'opérateur utilise la version de l'opérateur au lieu de la version du composant pour décider de la recréation des ressources lors d'une mise à niveau.
- Avant cette mise à jour, le service pipelines webhook était absent du cluster après une mise à jour. Cela était dû à un blocage de la mise à jour sur les cartes de configuration. Avec cette mise à jour, un mécanisme est ajouté pour désactiver la validation du webhook si les cartes de configuration sont absentes dans le cluster. Par conséquent, le service pipelines webhook persiste dans le cluster après une mise à jour.
- Avant cette mise à jour, les tâches cron pour l'élagage automatique étaient recréées après tout changement de configuration de l'espace de noms. Avec cette mise à jour, les tâches cron pour l'élagage automatique ne sont recréées que s'il y a un changement d'annotation pertinent dans l'espace de noms.
La version amont de Tekton Pipelines est révisée en
v0.28.3, qui comporte les corrections suivantes :-
Correction des objets
PipelineRunouTaskRunpour permettre la propagation des étiquettes ou des annotations. Pour les paramètres implicites :
-
Ne pas appliquer les paramètres de
PipelineSpecà l'objetTaskRefs. -
Désactive le comportement param implicite pour les objets
Pipeline.
-
Ne pas appliquer les paramètres de
-
Correction des objets
3.1.7.7. Notes de version pour Red Hat OpenShift Pipelines General Availability 1.6.3
3.1.7.7.1. Problèmes corrigés
Avant cette mise à jour, l'Opérateur Red Hat OpenShift Pipelines installait des politiques de sécurité de pods à partir de composants tels que Pipelines et Triggers. Cependant, les politiques de sécurité de pods livrées dans le cadre des composants ont été dépréciées dans une version antérieure. Avec cette mise à jour, l'opérateur arrête d'installer des politiques de sécurité de pods à partir de composants. Par conséquent, les chemins de mise à niveau suivants sont concernés :
- La mise à jour d'OpenShift Pipelines 1.6.1 ou 1.6.2 vers OpenShift Pipelines 1.6.3 supprime les politiques de sécurité des pods, y compris celles des composants Pipelines et Triggers.
La mise à niveau d'OpenShift Pipelines 1.5.x vers 1.6.3 conserve les politiques de sécurité des pods installées à partir des composants. En tant qu'administrateur de cluster, vous pouvez les supprimer manuellement.
NoteLorsque vous mettez à niveau vers des versions ultérieures, l'Opérateur Red Hat OpenShift Pipelines supprimera automatiquement toutes les politiques de sécurité de pods obsolètes.
- Avant cette mise à jour, seuls les administrateurs de cluster pouvaient accéder aux métriques de pipeline dans la console OpenShift Container Platform. Avec cette mise à jour, les utilisateurs ayant d'autres rôles dans le cluster peuvent également accéder aux métriques du pipeline.
- Avant cette mise à jour, des problèmes de contrôle d'accès basé sur les rôles (RBAC) avec l'opérateur OpenShift Pipelines causaient des problèmes de mise à niveau ou d'installation de composants. Cette mise à jour améliore la fiabilité et la cohérence de l'installation de divers composants Red Hat OpenShift Pipelines.
-
Avant cette mise à jour, le fait de définir les champs
clusterTasksetpipelineTemplatessurfalsedans le CRTektonConfigralentissait la suppression des tâches en grappe et des modèles de pipeline. Cette mise à jour améliore la vitesse de gestion du cycle de vie des ressources Tekton telles que les tâches de cluster et les modèles de pipeline.
3.1.7.8. Notes de version pour Red Hat OpenShift Pipelines General Availability 1.6.4
3.1.7.8.1. Problèmes connus
Après la mise à niveau de Red Hat OpenShift Pipelines 1.5.2 vers 1.6.4, l'accès aux routes d'écoute d'événements renvoie une erreur
503.Solution : Modifiez le port cible dans le fichier YAML pour la route de l'écouteur d'événements.
Extraire le nom de la route pour l'espace de noms concerné.
$ oc get route -n <namespace>Editer l'itinéraire pour modifier la valeur du champ
targetPort.$ oc edit route -n <namespace> <el-route_name>Exemple : Route d'écoute d'événements existante
... spec: host: el-event-listener-q8c3w5-test-upgrade1.apps.ve49aws.aws.ospqa.com port: targetPort: 8000 to: kind: Service name: el-event-listener-q8c3w5 weight: 100 wildcardPolicy: None ...Exemple : Modification de l'itinéraire de l'auditeur d'événements
... spec: host: el-event-listener-q8c3w5-test-upgrade1.apps.ve49aws.aws.ospqa.com port: targetPort: http-listener to: kind: Service name: el-event-listener-q8c3w5 weight: 100 wildcardPolicy: None ...
3.1.7.8.2. Problèmes corrigés
-
Avant cette mise à jour, l'opérateur échouait lors de la création de ressources RBAC si un espace de noms était dans l'état
Terminating. Avec cette mise à jour, l'opérateur ignore les espaces de noms dans l'étatTerminatinget crée les ressources RBAC. - Avant cette mise à jour, les tâches échouaient ou redémarraient en raison de l'absence d'annotation spécifiant la version du contrôleur Tekton associé. Avec cette mise à jour, l'inclusion des annotations appropriées est automatisée et les tâches s'exécutent sans échec ni redémarrage.
3.1.8. Notes de mise à jour pour Red Hat OpenShift Pipelines General Availability 1.5
Red Hat OpenShift Pipelines General Availability (GA) 1.5 est désormais disponible sur OpenShift Container Platform 4.8.
3.1.8.1. Matrice de compatibilité et de soutien
Certaines fonctionnalités de cette version sont actuellement en avant-première technologique. Ces fonctionnalités expérimentales ne sont pas destinées à être utilisées en production.
Dans le tableau, les caractéristiques sont marquées par les statuts suivants :
| TP | Avant-première technologique |
| GA | Disponibilité générale |
Notez l'étendue de l'assistance suivante sur le portail client de Red Hat pour ces fonctionnalités :
| Fonctionnalité | Version | Statut de soutien |
|---|---|---|
| Pipelines | 0.24 | GA |
| CLI | 0.19 | GA |
| Catalogue | 0.24 | GA |
| Déclencheurs | 0.14 | TP |
| Ressources en gazoducs | - | TP |
Pour toute question ou commentaire, vous pouvez envoyer un courriel à l'équipe produit à l'adresse pipelines-interest@redhat.com.
3.1.8.2. Nouvelles fonctionnalités
En plus des corrections et des améliorations de la stabilité, les sections suivantes mettent en évidence les nouveautés de Red Hat OpenShift Pipelines 1.5.
Les exécutions de pipelines et de tâches seront automatiquement élaguées par une tâche cron dans l'espace de noms cible. La tâche cron utilise la variable d'environnement
IMAGE_JOB_PRUNER_TKNpour obtenir la valeur detkn image. Avec cette amélioration, les champs suivants sont introduits dans la ressource personnaliséeTektonConfig:... pruner: resources: - pipelinerun - taskrun schedule: "*/5 * * * *" # cron schedule keep: 2 # delete all keeping n ...Dans OpenShift Container Platform, vous pouvez personnaliser l'installation du composant Tekton Add-ons en modifiant les valeurs des nouveaux paramètres
clusterTasksetpipelinesTemplatesdans la ressource personnaliséeTektonConfig:apiVersion: operator.tekton.dev/v1alpha1 kind: TektonConfig metadata: name: config spec: profile: all targetNamespace: openshift-pipelines addon: params: - name: clusterTasks value: "true" - name: pipelineTemplates value: "true" ...La personnalisation est possible si vous créez le module complémentaire à l'aide de
TektonConfigou directement à l'aide de Tekton Add-ons. Toutefois, si les paramètres ne sont pas transmis, le contrôleur ajoute des paramètres avec des valeurs par défaut.Note-
Si le module complémentaire est créé à l'aide de la ressource personnalisée
TektonConfiget que vous modifiez ultérieurement les valeurs des paramètres dans la ressource personnaliséeAddon, les valeurs de la ressource personnaliséeTektonConfigremplacent les modifications. -
Vous ne pouvez définir la valeur du paramètre
pipelinesTemplatessurtrueque si la valeur du paramètreclusterTasksesttrue.
-
Si le module complémentaire est créé à l'aide de la ressource personnalisée
Le paramètre
enableMetricsest ajouté à la ressource personnaliséeTektonConfig. Vous pouvez l'utiliser pour désactiver le moniteur de service, qui fait partie de Tekton Pipelines pour OpenShift Container Platform.apiVersion: operator.tekton.dev/v1alpha1 kind: TektonConfig metadata: name: config spec: profile: all targetNamespace: openshift-pipelines pipeline: params: - name: enableMetrics value: "true" ...- Les métriques OpenCensus d'Eventlistener, qui capturent les métriques au niveau du processus, sont ajoutées.
- Les déclencheurs disposent désormais d'un sélecteur d'étiquettes ; vous pouvez configurer les déclencheurs d'un auditeur d'événements à l'aide d'étiquettes.
La définition de la ressource personnalisée
ClusterInterceptorpour l'enregistrement des intercepteurs a été ajoutée, ce qui vous permet d'enregistrer de nouveaux typesInterceptorque vous pouvez ajouter. En outre, les modifications suivantes ont été apportées :-
Dans les spécifications du déclencheur, vous pouvez configurer les intercepteurs à l'aide d'une nouvelle API qui comprend un champ
refpour faire référence à un intercepteur de cluster. En outre, vous pouvez utiliser le champparamspour ajouter des paramètres qui seront transmis aux intercepteurs pour traitement. -
Les intercepteurs intégrés CEL, GitHub, GitLab et BitBucket ont été migrés. Ils sont mis en œuvre à l'aide de la nouvelle définition de ressource personnalisée
ClusterInterceptor. -
Les intercepteurs de base sont migrés vers le nouveau format et tous les nouveaux déclencheurs créés à l'aide de l'ancienne syntaxe passent automatiquement à la nouvelle syntaxe basée sur
refouparams.
-
Dans les spécifications du déclencheur, vous pouvez configurer les intercepteurs à l'aide d'une nouvelle API qui comprend un champ
-
Pour désactiver le préfixe du nom de la tâche ou de l'étape lors de l'affichage des journaux, utilisez l'option
--prefixpour les commandeslog. -
Pour afficher la version d'un composant spécifique, utilisez le nouvel indicateur
--componentdans la commandetkn version. -
La commande
tkn hub check-upgradea été ajoutée et d'autres commandes ont été révisées pour être basées sur la version du pipeline. En outre, les noms des catalogues sont affichés dans la sortie de la commandesearch. -
La prise en charge des espaces de travail optionnels a été ajoutée à la commande
start. -
Si les plugins ne sont pas présents dans le répertoire
plugins, ils sont recherchés dans le chemin courant. La commande
tkn start [task | clustertask | pipeline]démarre de manière interactive et demande la valeurparams, même si les paramètres par défaut sont spécifiés. Pour arrêter les invites interactives, passez le drapeau--use-param-defaultsau moment de l'invocation de la commande. Par exemple :$ tkn pipeline start build-and-deploy \ -w name=shared-workspace,volumeClaimTemplateFile=https://raw.githubusercontent.com/openshift/pipelines-tutorial/pipelines-1.9/01_pipeline/03_persistent_volume_claim.yaml \ -p deployment-name=pipelines-vote-api \ -p git-url=https://github.com/openshift/pipelines-vote-api.git \ -p IMAGE=image-registry.openshift-image-registry.svc:5000/pipelines-tutorial/pipelines-vote-api \ --use-param-defaults-
Le champ
versionest ajouté dans la commandetkn task describe. -
L'option permettant de sélectionner automatiquement des ressources telles que
TriggerTemplate, ouTriggerBinding, ouClusterTriggerBinding, ouEventlistener, est ajoutée dans la commandedescribe, si une seule est présente. -
Dans la commande
tkn pr describe, une section pour les tâches ignorées a été ajoutée. -
La prise en charge du site
tkn clustertask logsa été ajoutée. -
La fusion YAML et la variable de
config.yamlsont supprimées. En outre, le fichierrelease.yamlpeut désormais être utilisé plus facilement par des outils tels quekustomizeetytt. - La prise en charge des noms de ressources contenant le caractère point (".") a été ajoutée.
-
Le tableau
hostAliasesde la spécificationPodTemplateest ajouté à l'annulation de la résolution des noms d'hôtes au niveau du pod. Il est obtenu en modifiant le fichier/etc/hosts. -
Une variable
$(tasks.status)est introduite pour accéder à l'état d'exécution global des tâches. - Un point d'entrée binaire pour Windows a été ajouté.
3.1.8.3. Fonctionnalités obsolètes
Dans les expressions
when, la prise en charge des champs écrits en PascalCase est supprimée. Les expressionswhenne prennent en charge que les champs écrits en minuscules.NoteSi vous avez appliqué un pipeline avec des expressions
whendans Tekton Pipelinesv0.16(Operatorv1.2.x), vous devez le réappliquer.Lorsque vous mettez à niveau Red Hat OpenShift Pipelines Operator vers
v1.5, les tâches de clusteropenshift-clientetopenshift-client-v-1-5-0ont le paramètreSCRIPT. Cependant, le paramètreARGSet la ressourcegitsont supprimés de la spécification de la tâche de clusteropenshift-client. Il s'agit d'un changement radical, et seules les tâches de cluster qui n'ont pas de version spécifique dans le champnamede la ressourceClusterTasksont mises à niveau de manière transparente.Pour éviter que le pipeline ne s'interrompe, utilisez le paramètre
SCRIPTaprès la mise à niveau, car il déplace les valeurs précédemment spécifiées dans le paramètreARGSvers le paramètreSCRIPTde la tâche de cluster. Par exemple :... - name: deploy params: - name: SCRIPT value: oc rollout status <deployment-name> runAfter: - build taskRef: kind: ClusterTask name: openshift-client ...Lorsque vous mettez à niveau Red Hat OpenShift Pipelines Operator
v1.4versv1.5, les noms de profil dans lesquels la ressource personnaliséeTektonConfigest installée changent désormais.Expand Tableau 3.3. Profils pour TektonConfig ressource personnalisée Profils dans les pipelines 1.5 Profil correspondant dans Pipelines 1.4 Installation des composants Tekton Tous (default profile)
Tous (default profile)
Pipelines, déclencheurs, modules complémentaires
De base
Défaut
Pipelines, déclencheurs
Lite
De base
Pipelines
NoteSi vous avez utilisé
profile: alldans l'instanceconfigde la ressource personnaliséeTektonConfig, aucune modification n'est nécessaire dans la spécification de la ressource.Toutefois, si l'opérateur installé est dans le profil Default ou Basic avant la mise à niveau, vous devez modifier l'instance
configde la ressource personnaliséeTektonConfigaprès la mise à niveau. Par exemple, si la configuration étaitprofile: basicavant la mise à niveau, assurez-vous qu'elle estprofile: liteaprès la mise à niveau vers Pipelines 1.5.Les champs
disable-home-env-overwriteetdisable-working-dir-overwritesont désormais obsolètes et seront supprimés dans une prochaine version. Pour cette version, la valeur par défaut de ces drapeaux est fixée àtruepour des raisons de compatibilité ascendante.NoteDans la prochaine version (Red Hat OpenShift Pipelines 1.6), la variable d'environnement
HOMEne sera pas automatiquement définie à/tekton/home, et le répertoire de travail par défaut ne sera pas défini à/workspacepour les exécutions de tâches. Ces valeurs par défaut entrent en conflit avec toute valeur définie par l'image Dockerfile de l'étape.-
Les champs
ServiceTypeetpodTemplatesont supprimés de la spécificationEventListener. - Le compte de service du contrôleur ne demande plus l'autorisation de lister et de surveiller les espaces de noms à l'échelle du cluster.
Le statut de la ressource
EventListenerest assorti d'une nouvelle condition appeléeReady.NoteÀ l'avenir, les autres conditions d'état de la ressource
EventListenerseront supprimées au profit de la condition d'étatReady.-
Les champs
eventListeneretnamespacede la réponseEventListenersont obsolètes. Utilisez plutôt le champeventListenerUID. Le champ
replicasest obsolète dans la spécificationEventListener. Le champspec.replicasest déplacé versspec.resources.kubernetesResource.replicasdans la spécificationKubernetesResource.NoteLe champ
replicassera supprimé dans une prochaine version.-
L'ancienne méthode de configuration des intercepteurs de base est obsolète. Cependant, elle continue de fonctionner jusqu'à ce qu'elle soit supprimée dans une prochaine version. À la place, les intercepteurs d'une ressource
Triggersont désormais configurés à l'aide d'une nouvelle syntaxe basée surrefetparams. Le webhook par défaut qui en résulte passe automatiquement de l'ancienne syntaxe à la nouvelle syntaxe pour les nouveaux déclencheurs. -
Utilisez
rbac.authorization.k8s.io/v1au lieu de l'ancienrbac.authorization.k8s.io/v1beta1pour la ressourceClusterRoleBinding. -
Dans les rôles de grappe, l'accès en écriture à l'échelle de la grappe à des ressources telles que
serviceaccounts,secrets,configmaps, etlimitrangesest supprimé. En outre, l'accès aux ressources telles quedeployments,statefulsets, etdeployment/finalizersest supprimé pour l'ensemble de la grappe. -
La définition de la ressource personnalisée
imagedans le groupecaching.internal.knative.devn'est plus utilisée par Tekton et est exclue de cette version.
3.1.8.4. Problèmes connus
La tâche cluster git-cli est construite à partir de l'image de base alpine/git, qui attend
/rootcomme répertoire personnel de l'utilisateur. Cependant, cela n'est pas explicitement défini dans la tâche de clustergit-cli.Dans Tekton, le répertoire d'accueil par défaut est remplacé par
/tekton/homeà chaque étape d'une tâche, sauf indication contraire. Cet écrasement de la variable d'environnement$HOMEde l'image de base entraîne l'échec de la tâche de clustergit-cli.Ce problème devrait être corrigé dans les prochaines versions. Pour Red Hat OpenShift Pipelines 1.5 et les versions antérieures, vous pouvez use any one of the following workarounds pour éviter l'échec de la tâche de cluster
git-cli:Définissez la variable d'environnement
$HOMEdans les étapes, afin qu'elle ne soit pas écrasée.-
[OPTIONNEL] Si vous avez installé Red Hat OpenShift Pipelines à l'aide de l'Opérateur, clonez la tâche de cluster
git-clidans une tâche séparée. Cette approche garantit que l'Opérateur n'écrase pas les modifications apportées à la tâche de cluster. -
Exécutez la commande
oc edit clustertasks git-cli. Ajouter la variable d'environnement
HOMEau YAML de l'étape :... steps: - name: git env: - name: HOME value: /root image: $(params.BASE_IMAGE) workingDir: $(workspaces.source.path) ...AvertissementPour Red Hat OpenShift Pipelines installé par l'Opérateur, si vous ne clonez pas la tâche de cluster
git-clidans une tâche séparée avant de modifier la variable d'environnementHOME, les modifications sont écrasées lors de la réconciliation de l'Opérateur.
-
[OPTIONNEL] Si vous avez installé Red Hat OpenShift Pipelines à l'aide de l'Opérateur, clonez la tâche de cluster
Désactive l'écrasement de la variable d'environnement
HOMEdans la carte de configurationfeature-flags.-
Exécutez la commande
oc edit -n openshift-pipelines configmap feature-flags. Fixer la valeur de l'indicateur
disable-home-env-overwriteàtrue.Avertissement- Si vous avez installé Red Hat OpenShift Pipelines à l'aide de l'Opérateur, les modifications sont écrasées lors de la réconciliation de l'Opérateur.
-
La modification de la valeur par défaut de l'indicateur
disable-home-env-overwritepeut perturber d'autres tâches et des tâches en grappe, car elle modifie le comportement par défaut de toutes les tâches.
-
Exécutez la commande
Utilisez un compte de service différent pour la tâche de cluster
git-cli, car l'écrasement de la variable d'environnementHOMEse produit lorsque le compte de service par défaut pour les pipelines est utilisé.- Créer un nouveau compte de service.
- Liez votre secret Git au compte de service que vous venez de créer.
- Utiliser le compte de service lors de l'exécution d'une tâche ou d'un pipeline.
-
Sur IBM Power Systems, IBM Z et LinuxONE, la tâche
s2i-dotnetcluster et la commandetkn hubne sont pas prises en charge. -
Lorsque vous exécutez des tâches de cluster Maven et Jib-Maven, l'image de conteneur par défaut n'est prise en charge que sur l'architecture Intel (x86). Par conséquent, les tâches échoueront sur les clusters IBM Power Systems (ppc64le), IBM Z et LinuxONE (s390x). Pour contourner ce problème, vous pouvez spécifier une image personnalisée en définissant la valeur du paramètre
MAVEN_IMAGEsurmaven:3.6.3-adoptopenjdk-11.
3.1.8.5. Problèmes corrigés
-
Les expressions
whendans les tâchesdagne sont pas autorisées à spécifier la variable de contexte accédant à l'état d'exécution ($(tasks.<pipelineTask>.status)) d'une autre tâche. -
Utilisez les UID des propriétaires plutôt que les noms des propriétaires, car cela permet d'éviter les conditions de course créées par la suppression d'un PVC
volumeClaimTemplate, dans les situations où une ressourcePipelineRunest rapidement supprimée puis recréée. -
Un nouveau fichier Docker est ajouté pour
pullrequest-initpour l'imagebuild-basedéclenchée par des utilisateurs non root. -
Lorsqu'un pipeline ou une tâche est exécuté avec l'option
-fet que leparamdans sa définition n'a pas detypedéfini, une erreur de validation est générée au lieu de l'échec silencieux du pipeline ou de l'exécution de la tâche. -
Pour les commandes
tkn start [task | pipeline | clustertask], la description de l'indicateur--workspaceest désormais cohérente. - Lors de l'analyse des paramètres, si un tableau vide est rencontré, l'aide interactive correspondante est affichée sous la forme d'une chaîne vide.
3.1.9. Notes de mise à jour pour Red Hat OpenShift Pipelines General Availability 1.4
Red Hat OpenShift Pipelines General Availability (GA) 1.4 est désormais disponible sur OpenShift Container Platform 4.7.
En plus des canaux stable et preview Operator, Red Hat OpenShift Pipelines Operator 1.4.0 est livré avec les canaux dépréciés ocp-4.6, ocp-4.5, et ocp-4.4. Ces canaux dépréciés et leur prise en charge seront supprimés dans la prochaine version de Red Hat OpenShift Pipelines.
3.1.9.1. Matrice de compatibilité et de soutien
Certaines fonctionnalités de cette version sont actuellement en avant-première technologique. Ces fonctionnalités expérimentales ne sont pas destinées à être utilisées en production.
Dans le tableau, les caractéristiques sont marquées par les statuts suivants :
| TP | Avant-première technologique |
| GA | Disponibilité générale |
Notez l'étendue de l'assistance suivante sur le portail client de Red Hat pour ces fonctionnalités :
| Fonctionnalité | Version | Statut de soutien |
|---|---|---|
| Pipelines | 0.22 | GA |
| CLI | 0.17 | GA |
| Catalogue | 0.22 | GA |
| Déclencheurs | 0.12 | TP |
| Ressources en gazoducs | - | TP |
Pour toute question ou commentaire, vous pouvez envoyer un courriel à l'équipe produit à l'adresse pipelines-interest@redhat.com.
3.1.9.2. Nouvelles fonctionnalités
En plus des corrections et des améliorations de la stabilité, les sections suivantes mettent en évidence les nouveautés de Red Hat OpenShift Pipelines 1.4.
Les tâches personnalisées présentent les améliorations suivantes :
- Les résultats du pipeline peuvent désormais faire référence aux résultats produits par les tâches personnalisées.
- Les tâches personnalisées peuvent désormais utiliser des espaces de travail, des comptes de service et des modèles de pods pour créer des tâches personnalisées plus complexes.
La tâche
finallyprésente les améliorations suivantes :-
Les expressions
whensont prises en charge dans les tâchesfinally, ce qui permet une exécution gardée efficace et une réutilisation améliorée des tâches. Une tâche
finallypeut être configurée pour consommer les résultats de n'importe quelle tâche au sein du même pipeline.NoteLa prise en charge des expressions
whenet des tâchesfinallyn'est pas disponible dans la console Web d'OpenShift Container Platform 4.7.
-
Les expressions
-
La prise en charge de plusieurs secrets du type
dockercfgoudockerconfigjsona été ajoutée pour l'authentification au moment de l'exécution. -
La fonctionnalité de prise en charge de la vérification éparse avec la tâche
git-clonea été ajoutée. Cela vous permet de ne cloner qu'un sous-ensemble du référentiel en tant que copie locale et de limiter la taille des référentiels clonés. - Vous pouvez créer des exécutions de pipeline dans un état d'attente sans les démarrer. Dans les clusters fortement sollicités, cela permet aux opérateurs de contrôler l'heure de démarrage des opérations de pipeline.
-
Veillez à définir manuellement la variable d'environnement
SYSTEM_NAMESPACEpour le contrôleur ; elle était auparavant définie par défaut. -
Un utilisateur non-root est maintenant ajouté à l'image build-base de pipelines afin que
git-initpuisse cloner des dépôts en tant qu'utilisateur non-root. - La prise en charge de la validation des dépendances entre les ressources résolues avant le début de l'exécution d'un pipeline a été ajoutée. Toutes les variables de résultat du pipeline doivent être valides, et les espaces de travail optionnels d'un pipeline ne peuvent être transmis qu'aux tâches qui s'y attendent pour que le pipeline commence à fonctionner.
- Le contrôleur et le webhook s'exécutent en tant que groupe non root, et leurs capacités superflues ont été supprimées pour les rendre plus sûrs.
-
Vous pouvez utiliser la commande
tkn pr logspour voir les flux de journaux pour les exécutions de tâches répétées. -
Vous pouvez utiliser l'option
--clustertaskde la commandetkn tr deletepour supprimer toutes les exécutions de tâches associées à une tâche de cluster particulière. -
La possibilité d'utiliser le service Knative avec la ressource
EventListenerest ajoutée par l'introduction d'un nouveau champcustomResource. - Un message d'erreur s'affiche lorsque la charge utile d'un événement n'utilise pas le format JSON.
-
Les intercepteurs de contrôle de source tels que GitLab, BitBucket et GitHub utilisent désormais la nouvelle interface de type
InterceptorRequestouInterceptorResponse. -
Une nouvelle fonction CEL
marshalJSONest implémentée pour vous permettre d'encoder un objet JSON ou un tableau en une chaîne de caractères. -
Un gestionnaire HTTP pour servir le CEL et les intercepteurs centraux de contrôle de source a été ajouté. Il regroupe quatre intercepteurs principaux dans un seul serveur HTTP qui est déployé dans l'espace de noms
tekton-pipelines. L'objetEventListenertransmet les événements à l'intercepteur via le serveur HTTP. Chaque intercepteur est disponible sur un chemin différent. Par exemple, l'intercepteur CEL est disponible sur le chemin/cel. La contrainte de contexte de sécurité (SCC)
pipelines-sccest utilisée avec le compte de service par défautpipelinepour les pipelines. Ce nouveau compte de service est similaire àanyuid, mais avec une différence mineure telle que définie dans le YAML pour SCC de OpenShift Container Platform 4.7 :fsGroup: type: MustRunAs
3.1.9.3. Fonctionnalités obsolètes
-
Le sous-type
build-gcsdans le stockage des ressources du pipeline et l'imagegcs-fetcherne sont pas pris en charge. -
Dans le champ
taskRundes tâches en grappe, l'étiquettetekton.dev/taskest supprimée. -
Pour les webhooks, la valeur
v1beta1correspondant au champadmissionReviewVersionsest supprimée. -
L'image d'aide
creds-initpour la construction et le déploiement est supprimée. Dans la spécification et la liaison des déclencheurs, le champ obsolète
template.nameest supprimé au profit detemplate.ref. Vous devez mettre à jour toutes les définitions deeventListenerpour utiliser le champref.NoteLa mise à niveau d'OpenShift Pipelines 1.3.x et des versions antérieures vers OpenShift Pipelines 1.4.0 interrompt les auditeurs d'événements en raison de l'indisponibilité du champ
template.name. Dans ce cas, utilisez OpenShift Pipelines 1.4.1 pour bénéficier du champtemplate.namerestauré.-
Pour les ressources/objets personnalisés
EventListener, les champsPodTemplateetServiceTypesont obsolètes au profit deResource. - Le style de spécification "embedded bindings", obsolète, a été supprimé.
-
Le champ
specest supprimé du champtriggerSpecBinding. - La représentation de l'ID de l'événement passe d'une chaîne aléatoire de cinq caractères à un UUID.
3.1.9.4. Problèmes connus
- Sur le site Developer, les fonctionnalités de métriques et de déclencheurs de pipeline ne sont disponibles que sur OpenShift Container Platform 4.7.6 ou les versions ultérieures.
-
Sur les systèmes IBM Power, IBM Z et LinuxONE, la commande
tkn hubn'est pas prise en charge. -
Lorsque vous exécutez les tâches Maven et Jib Maven sur des clusters IBM Power Systems (ppc64le), IBM Z et LinuxONE (s390x), définissez la valeur du paramètre
MAVEN_IMAGEsurmaven:3.6.3-adoptopenjdk-11. Les déclencheurs génèrent une erreur résultant d'une mauvaise gestion du format JSON, si vous avez la configuration suivante dans la liaison du déclencheur :
params: - name: github_json value: $(body)Pour résoudre le problème :
-
Si vous utilisez les déclencheurs v0.11.0 et plus, utilisez la fonction
marshalJSONCEL, qui prend un objet ou un tableau JSON et renvoie l'encodage JSON de cet objet ou de ce tableau sous la forme d'une chaîne. Si vous utilisez une version plus ancienne des déclencheurs, ajoutez l'annotation suivante dans le modèle de déclencheur :
annotations: triggers.tekton.dev/old-escape-quotes: "true"
-
Si vous utilisez les déclencheurs v0.11.0 et plus, utilisez la fonction
- Lors de la mise à jour d'OpenShift Pipelines 1.3.x vers 1.4.x, vous devez recréer les routes.
3.1.9.5. Problèmes corrigés
-
Auparavant, l'étiquette
tekton.dev/taskavait été supprimée de l'exécution des tâches en grappe et l'étiquettetekton.dev/clusterTaskavait été introduite. Les problèmes résultant de ce changement sont résolus en corrigeant les commandesclustertask describeetdelete. De plus, la fonctionlastrunpour les tâches est modifiée, afin de résoudre le problème de l'étiquettetekton.dev/taskappliquée aux tâches et aux tâches en grappe dans les anciennes versions des pipelines. -
Lors d'une opération interactive
tkn pipeline start pipelinename, unPipelineResourceest créé de manière interactive. La commandetkn p startimprime l'état de la ressource si l'état de la ressource n'est pasnil. -
Auparavant, l'étiquette
tekton.dev/task=nameétait supprimée des exécutions de tâches créées à partir de tâches en grappe. Ce correctif modifie la commandetkn clustertask startavec l'indicateur--lastpour vérifier la présence de l'étiquettetekton.dev/task=namedans les exécutions de tâches créées. -
Lorsqu'une tâche utilise une spécification de tâche en ligne, l'exécution de la tâche correspondante est désormais intégrée dans le pipeline lorsque vous exécutez la commande
tkn pipeline describe, et le nom de la tâche est renvoyé comme étant intégré. -
La commande
tkn versionpermet d'afficher la version de l'outil CLI Tekton installé, sanskubeConfiguration namespaceconfiguré ni accès à un cluster. -
Si un argument est inattendu ou si plusieurs arguments sont utilisés, la commande
tkn completiongénère une erreur. -
Auparavant, les exécutions de pipeline avec les tâches
finallyimbriquées dans une spécification de pipeline perdaient ces tâchesfinally, lorsqu'elles étaient converties en versionv1alpha1et restaurées en versionv1beta1. Cette erreur survenant lors de la conversion a été corrigée afin d'éviter toute perte potentielle de données. Les exécutions de pipeline avec les tâchesfinallyimbriquées dans une spécification de pipeline sont désormais sérialisées et stockées sur la version alpha, pour être désérialisées ultérieurement. -
Auparavant, il y avait une erreur dans la génération de pods lorsqu'un compte de service avait le champ
secretscomme{}. L'exécution de la tâche échouait avecCouldntGetTaskparce que la requête GET avec un nom secret vide renvoyait une erreur, indiquant que le nom de la ressource pouvait ne pas être vide. Ce problème est corrigé en évitant d'utiliser un nom secret vide dans la requête GETkubeclient. -
Les pipelines avec les versions de l'API
v1beta1peuvent maintenant être demandés avec la versionv1alpha1, sans perdre les tâchesfinally. L'application de la versionv1alpha1renvoyée stockera la ressource en tant quev1beta1, la sectionfinallyétant rétablie dans son état d'origine. -
Auparavant, un champ
selfLinknon défini dans le contrôleur provoquait une erreur dans les clusters Kubernetes v1.20. Comme solution temporaire, le champ sourceCloudEventest défini à une valeur qui correspond à l'URI source actuel, sans la valeur du champselfLinkauto-remplie. -
Auparavant, un nom secret comportant des points, tel que
gcr.io, entraînait l'échec de la création d'une exécution de tâche. Cela était dû au fait que le nom secret était utilisé en interne dans le cadre d'un nom de montage de volume. Le nom de montage du volume est conforme à l'étiquette DNS RFC1123 et interdit les points dans le nom. Ce problème est résolu en remplaçant le point par un tiret, ce qui permet d'obtenir un nom lisible. -
Les variables contextuelles sont désormais validées dans les tâches
finally. -
Auparavant, lorsque l'outil de rapprochement des tâches recevait une tâche qui n'avait pas fait l'objet d'une mise à jour de statut contenant le nom du module qu'elle avait créé, l'outil de rapprochement des tâches répertoriait les modules associés à la tâche. Il utilise les étiquettes de l'exécution de la tâche, qui ont été propagées dans le module, pour trouver le module. La modification de ces étiquettes pendant l'exécution de la tâche a eu pour effet que le code n'a pas trouvé le module existant. Par conséquent, des modules en double ont été créés. Ce problème est résolu en modifiant le réconciliateur de tâches pour qu'il n'utilise que l'étiquette
tekton.dev/taskRuncontrôlée par Tekton lors de la recherche de la nacelle. - Auparavant, lorsqu'un pipeline acceptait un espace de travail optionnel et le transmettait à une tâche du pipeline, l'outil de réconciliation de l'exécution du pipeline s'arrêtait avec une erreur si l'espace de travail n'était pas fourni, même si une liaison d'espace de travail manquante est un état valide pour un espace de travail optionnel. Ce problème est corrigé en s'assurant que le réconciliateur d'exécution de pipeline n'échoue pas à créer une exécution de tâche, même si un espace de travail optionnel n'est pas fourni.
- L'ordre trié des statuts d'étape correspond à l'ordre des conteneurs d'étape.
-
Auparavant, le statut d'exécution de la tâche était défini sur
unknownlorsqu'un module rencontrait la raisonCreateContainerConfigError, ce qui signifiait que la tâche et le pipeline s'exécutaient jusqu'à ce que le module s'arrête. Ce problème est résolu en définissant le statut d'exécution de la tâche surfalse, de sorte que la tâche soit considérée comme ayant échoué lorsque le module rencontre la raisonCreateContainerConfigError. -
Auparavant, les résultats du pipeline étaient résolus lors de la première réconciliation, après l'achèvement de l'exécution du pipeline. Cela pouvait faire échouer la résolution et entraîner l'écrasement de la condition
Succeededde l'exécution du pipeline. En conséquence, les informations sur l'état final étaient perdues, ce qui risquait de perturber les services qui surveillaient les conditions de l'exécution du pipeline. Ce problème est résolu en déplaçant la résolution des résultats du pipeline à la fin d'une réconciliation, lorsque le pipeline est placé dans une conditionSucceededouTrue. - La variable d'état d'exécution est désormais validée. Cela évite de valider les résultats de la tâche tout en validant les variables de contexte pour accéder à l'état d'exécution.
- Auparavant, un résultat de pipeline contenant une variable non valide était ajouté à l'exécution du pipeline avec l'expression littérale de la variable intacte. Il était donc difficile d'évaluer si les résultats étaient correctement remplis. Ce problème est résolu en filtrant les résultats de l'exécution de la chaîne de production qui font référence à des exécutions de tâches qui ont échoué. Désormais, un résultat de pipeline qui contient une variable non valide ne sera pas du tout émis par le pipeline.
-
La commande
tkn eventlistener describea été corrigée pour éviter les plantages en l'absence de modèle. Elle affiche également les détails des références des déclencheurs. -
Les mises à niveau d'OpenShift Pipelines 1.3.x et des versions antérieures vers OpenShift Pipelines 1.4.0 interrompent les auditeurs d'événements en raison de l'indisponibilité de
template.name. Dans OpenShift Pipelines 1.4.1,template.namea été restauré pour éviter d'interrompre les auditeurs d'événements dans les déclencheurs. -
Dans OpenShift Pipelines 1.4.1, la ressource personnalisée
ConsoleQuickStarta été mise à jour pour s'aligner sur les capacités et le comportement d'OpenShift Container Platform 4.7.
3.1.10. Notes de publication pour Red Hat OpenShift Pipelines Technology Preview 1.3
3.1.10.1. Nouvelles fonctionnalités
Red Hat OpenShift Pipelines Technology Preview (TP) 1.3 est maintenant disponible sur OpenShift Container Platform 4.7. Red Hat OpenShift Pipelines TP 1.3 est mis à jour pour prendre en charge :
- Tekton Pipelines 0.19.0
-
Tekton
tknCLI 0.15.0 - Tekton Triggers 0.10.2
- tâches en grappe basées sur le catalogue Tekton 0.19.0
- IBM Power Systems sur OpenShift Container Platform 4.7
- IBM Z et LinuxONE sur OpenShift Container Platform 4.7
En plus des corrections et des améliorations de stabilité, les sections suivantes mettent en évidence les nouveautés de Red Hat OpenShift Pipelines 1.3.
3.1.10.1.1. Pipelines
- Les tâches qui construisent des images, telles que les tâches S2I et Buildah, émettent désormais une URL de l'image construite qui inclut l'image SHA.
-
Les conditions dans les tâches du pipeline qui font référence à des tâches personnalisées ne sont pas autorisées car la définition des ressources personnalisées (CRD) de
Conditiona été supprimée. -
L'expansion des variables est désormais ajoutée dans le CRD
Taskpour les champs suivants :spec.steps[].imagePullPolicyetspec.sidecar[].imagePullPolicy. -
Vous pouvez désactiver le mécanisme d'authentification intégré dans Tekton en définissant le drapeau de fonctionnalité
disable-creds-initsurtrue. -
Résolu lorsque les expressions sont maintenant listées dans les sections
Skipped TasksetTask Runsdans le champStatusde la configurationPipelineRun. -
La commande
git initpeut désormais cloner des sous-modules récursifs. -
L'auteur d'un CR
Taskpeut désormais spécifier un délai pour une étape dans la spécificationTask. -
Vous pouvez maintenant baser l'image du point d'entrée sur l'image
distroless/static:nonrootet lui donner un mode pour se copier vers la destination, sans dépendre de la présence de la commandecpdans l'image de base. -
Vous pouvez désormais utiliser l'indicateur de configuration
require-git-ssh-secret-known-hostspour interdire l'omission d'hôtes connus dans le secret SSH de Git. Lorsque la valeur de l'indicateur esttrue, vous devez inclure le champknown_hostdans le secret SSH de Git. La valeur par défaut de l'indicateur estfalse. - Le concept d'espaces de travail optionnels est désormais introduit. Une tâche ou un pipeline peut déclarer un espace de travail optionnel et modifier conditionnellement son comportement en fonction de sa présence. Une tâche ou un pipeline peut également omettre cet espace de travail, modifiant ainsi le comportement de la tâche ou du pipeline. Les espaces de travail par défaut de l'exécution de la tâche ne sont pas ajoutés à la place d'un espace de travail optionnel omis.
- L'initialisation des identifiants dans Tekton détecte désormais un identifiant SSH utilisé avec une URL non-SSH, et vice versa dans les ressources du pipeline Git, et enregistre un avertissement dans les conteneurs d'étapes.
- Le contrôleur d'exécution des tâches émet un avertissement si l'affinité spécifiée par le modèle de pod est remplacée par l'assistant d'affinité.
- Le réconciliateur d'exécution des tâches enregistre désormais des mesures pour les événements du nuage qui sont émis une fois l'exécution d'une tâche terminée. Cela inclut les tentatives.
3.1.10.1.2. L'interface de programmation des pipelines
-
La prise en charge de
--no-headers flagest maintenant ajoutée aux commandes suivantes :tkn condition list,tkn triggerbinding list,tkn eventlistener list,tkn clustertask list,tkn clustertriggerbinding list. -
Lorsqu'elles sont utilisées ensemble, les options
--lastou--usesont prioritaires sur les options--prefix-nameet--timeout. -
La commande
tkn eventlistener logsa été ajoutée pour afficher les journaux deEventListener. -
Les commandes de
tekton hubsont désormais intégrées dans le CLI detkn. -
L'option
--nocolourest désormais remplacée par--no-color. -
L'indicateur
--all-namespacesest ajouté aux commandes suivantes :tkn triggertemplate list,tkn condition list,tkn triggerbinding list,tkn eventlistener list.
3.1.10.1.3. Déclencheurs
-
Vous pouvez maintenant spécifier vos informations sur les ressources dans le modèle
EventListener. -
Il est désormais obligatoire pour les comptes de service
EventListenerd'avoir les verbeslistetwatch, en plus du verbegetpour toutes les ressources de déclenchement. Cela vous permet d'utiliserListerspour récupérer des données des ressourcesEventListener,Trigger,TriggerBinding,TriggerTemplateetClusterTriggerBinding. Vous pouvez utiliser cette fonctionnalité pour créer un objetSinkau lieu de spécifier plusieurs informateurs, et faire directement des appels au serveur API. -
Une nouvelle interface
Interceptora été ajoutée pour prendre en charge les corps d'événements d'entrée immuables. Les intercepteurs peuvent désormais ajouter des données ou des champs à un nouveau champextensionset ne peuvent pas modifier les corps d'entrée, ce qui les rend immuables. L'intercepteur CEL utilise cette nouvelle interfaceInterceptor. -
Un champ
namespaceSelectorest ajouté à la ressourceEventListener. Il permet de spécifier les espaces de noms à partir desquels la ressourceEventListenerpeut récupérer l'objetTriggerpour traiter les événements. Pour utiliser le champnamespaceSelector, le compte de service de la ressourceEventListenerdoit avoir un rôle de cluster. -
La ressource
EventListenerprend désormais en charge la connexion sécurisée de bout en bout avec le moduleeventlistener. -
The escaping parameters behavior in the
TriggerTemplatesresource by replacing"with\"is now removed. -
Un nouveau champ
resources, prenant en charge les ressources Kubernetes, est introduit dans le cadre de la spécificationEventListener. - Une nouvelle fonctionnalité pour l'intercepteur CEL, avec la prise en charge des majuscules et minuscules des chaînes ASCII, a été ajoutée.
-
Vous pouvez intégrer des ressources
TriggerBindingen utilisant les champsnameetvaluedans un déclencheur ou un récepteur d'événements. -
La configuration de
PodSecurityPolicyest mise à jour pour fonctionner dans des environnements restreints. Elle garantit que les conteneurs doivent être exécutés en tant que non-root. En outre, le contrôle d'accès basé sur les rôles pour l'utilisation de la politique de sécurité du pod est déplacé de l'échelle du cluster à l'échelle de l'espace de noms. Cela garantit que les déclencheurs ne peuvent pas utiliser d'autres politiques de sécurité de pods qui ne sont pas liées à un espace de noms. -
La prise en charge des modèles de déclenchement intégrés a été ajoutée. Vous pouvez utiliser le champ
namepour faire référence à un modèle incorporé ou incorporer le modèle dans le champspec.
3.1.10.2. Fonctionnalités obsolètes
-
Les modèles de pipeline qui utilisent les CRD
PipelineResourcessont désormais obsolètes et seront supprimés dans une prochaine version. -
Le champ
template.nameest obsolète en faveur du champtemplate.refet sera supprimé dans une prochaine version. -
L'abréviation
-cpour la commande--checka été supprimée. En outre, les drapeaux globauxtknsont ajoutés à la commandeversion.
3.1.10.3. Problèmes connus
-
Les superpositions CEL ajoutent des champs à une nouvelle fonction de niveau supérieur
extensions, au lieu de modifier le corps de l'événement entrant. Les ressourcesTriggerBindingpeuvent accéder aux valeurs de cette nouvelle fonctionextensionsà l'aide de la syntaxe$(extensions.<key>). Mettez à jour votre liaison pour utiliser la syntaxe$(extensions.<key>)au lieu de la syntaxe$(body.<overlay-key>). -
The escaping parameters behavior by replacing
"with\"is now removed. If you need to retain the old escaping parameters behavior add thetekton.dev/old-escape-quotes: true"annotation to yourTriggerTemplatespecification. -
Vous pouvez intégrer des ressources
TriggerBindingen utilisant les champsnameetvalueà l'intérieur d'un déclencheur ou d'un récepteur d'événements. Toutefois, vous ne pouvez pas spécifier les champsnameetrefpour une seule liaison. Utilisez le champrefpour faire référence à une ressourceTriggerBindinget le champnamepour les liaisons intégrées. -
Un intercepteur ne peut pas tenter de référencer une ressource
secreten dehors de l'espace de noms d'une ressourceEventListener. Vous devez inclure des secrets dans l'espace de noms de la ressource `EventListener`. -
Dans les déclencheurs 0.9.0 et ultérieurs, si un paramètre
TriggerBindingbasé sur le corps ou l'en-tête est manquant ou malformé dans la charge utile d'un événement, les valeurs par défaut sont utilisées au lieu d'afficher une erreur. -
Les tâches et les pipelines créés avec des objets
WhenExpressionavec Tekton Pipelines 0.16.x doivent être réappliqués pour fixer leurs annotations JSON. - Lorsqu'un pipeline accepte un espace de travail optionnel et le donne à une tâche, l'exécution du pipeline se bloque si l'espace de travail n'est pas fourni.
- Pour utiliser la tâche Buildah cluster dans un environnement déconnecté, assurez-vous que le fichier Docker utilise un flux d'images interne comme image de base, puis utilisez-le de la même manière que n'importe quelle tâche S2I cluster.
3.1.10.4. Problèmes corrigés
-
Les extensions ajoutées par un intercepteur CEL sont transmises aux intercepteurs de webhook en ajoutant le champ
Extensionsdans le corps de l'événement. -
Le délai d'inactivité des lecteurs de journaux est désormais configurable à l'aide du champ
LogOptions. Toutefois, le comportement par défaut, à savoir un délai d'attente de 10 secondes, est conservé. -
La commande
logignore l'indicateur--followlorsque l'exécution d'une tâche ou d'un pipeline est terminée, et lit les journaux disponibles au lieu des journaux en direct. -
Les références aux ressources Tekton suivantes :
EventListener,TriggerBinding,ClusterTriggerBinding,Condition, etTriggerTemplatesont désormais normalisées et rendues cohérentes dans tous les messages destinés aux utilisateurs dans les commandestkn. -
Auparavant, si vous lanciez une exécution de tâche ou de pipeline annulée avec les drapeaux
--use-taskrun <canceled-task-run-name>,--use-pipelinerun <canceled-pipeline-run-name>ou--last, la nouvelle exécution était annulée. Ce bogue est maintenant corrigé. -
La commande
tkn pr desca été améliorée afin de garantir qu'elle n'échoue pas en cas d'exécution d'un pipeline avec des conditions. -
Lorsque vous supprimez une exécution de tâche à l'aide de la commande
tkn tr deleteavec l'option--tasket qu'il existe une tâche de cluster portant le même nom, les exécutions de tâches de la tâche de cluster sont également supprimées. Pour contourner ce problème, filtrez les exécutions de tâches en utilisant le champTaskRefKind. -
La commande
tkn triggertemplate describen'affichait qu'une partie de la valeurapiVersiondans la sortie. Par exemple, seultriggers.tekton.devétait affiché au lieu detriggers.tekton.dev/v1alpha1. Ce bogue est maintenant corrigé. - Dans certaines conditions, le webhook ne parvenait pas à acquérir un bail et ne fonctionnait pas correctement. Ce bogue est maintenant corrigé.
- Les pipelines avec des expressions when créés dans la version 0.16.3 peuvent maintenant être exécutés dans la version 0.17.1 et les versions ultérieures. Après une mise à jour, il n'est pas nécessaire de réappliquer les définitions de pipelines créées dans les versions précédentes, car les premières lettres des annotations, qu'elles soient en majuscules ou en minuscules, sont désormais prises en charge.
-
Par défaut, le champ
leader-election-haest maintenant activé pour la haute disponibilité. Lorsque l'indicateur du contrôleurdisable-haest défini surtrue, il désactive la prise en charge de la haute disponibilité. - Les problèmes de duplication des événements cloud sont désormais résolus. Les événements cloud ne sont désormais envoyés que lorsqu'une condition modifie l'état, la raison ou le message.
-
Lorsqu'un nom de compte de service est absent d'une spécification
PipelineRunouTaskRun, le contrôleur utilise le nom de compte de service de la carte de configurationconfig-defaults. Si le nom du compte de service est également absent de la carte de configurationconfig-defaults, le contrôleur lui attribue désormais la valeurdefaultdans la spécification. - La validation de la compatibilité avec l'assistant d'affinité est désormais prise en charge lorsque la même revendication de volume persistant est utilisée pour plusieurs espaces de travail, mais avec des sous-chemins différents.
3.1.11. Notes de version pour Red Hat OpenShift Pipelines Technology Preview 1.2
3.1.11.1. Nouvelles fonctionnalités
Red Hat OpenShift Pipelines Technology Preview (TP) 1.2 est maintenant disponible sur OpenShift Container Platform 4.6. Red Hat OpenShift Pipelines TP 1.2 est mis à jour pour prendre en charge :
- Tekton Pipelines 0.16.3
-
Tekton
tknCLI 0.13.1 - Tekton Triggers 0.8.1
- tâches en grappe basées sur le catalogue Tekton 0.16
- IBM Power Systems sur OpenShift Container Platform 4.6
- IBM Z et LinuxONE sur OpenShift Container Platform 4.6
En plus des corrections et des améliorations de stabilité, les sections suivantes mettent en évidence les nouveautés de Red Hat OpenShift Pipelines 1.2.
3.1.11.1.1. Pipelines
Cette version de Red Hat OpenShift Pipelines ajoute la prise en charge d'une installation déconnectée.
NoteLes installations dans des environnements restreints ne sont actuellement pas prises en charge sur les systèmes IBM Power, IBM Z et LinuxONE.
-
Vous pouvez désormais utiliser le champ
when, au lieu de la ressourceconditions, pour exécuter une tâche uniquement lorsque certains critères sont remplis. Les composants clés des ressourcesWhenExpressionsontInput,OperatoretValues. Si toutes les expressions when évaluentTrue, la tâche est exécutée. Si l'une des expressions when évalueFalse, la tâche est ignorée. - Les statuts des étapes sont désormais mis à jour en cas d'annulation ou de dépassement du délai d'exécution d'une tâche.
-
La prise en charge de Git Large File Storage (LFS) est désormais disponible pour construire l'image de base utilisée par
git-init. -
Vous pouvez désormais utiliser le champ
taskSpecpour spécifier des métadonnées, telles que des étiquettes et des annotations, lorsqu'une tâche est intégrée dans un pipeline. -
Les événements "cloud" sont désormais pris en charge par le pipeline. Les tentatives avec
backoffsont désormais activées pour les événements cloud envoyés par la ressource pipeline d'événements cloud. -
Vous pouvez désormais définir une configuration
Workspacepar défaut pour tout espace de travail qu'une ressourceTaskdéclare, mais qu'une ressourceTaskRunne fournit pas explicitement. -
L'interpolation des variables de l'espace de noms est prise en charge pour l'espace de noms
PipelineRunet l'espace de nomsTaskRun. -
La validation des objets
TaskRunest désormais ajoutée pour vérifier qu'il n'y a pas plus d'un espace de travail de réclamation de volume persistant utilisé lorsqu'une ressourceTaskRunest associée à un assistant d'affinité. Si plus d'un espace de travail de réclamation de volume persistant est utilisé, l'exécution de la tâche échoue avec une conditionTaskRunValidationFailed. Notez que par défaut, l'assistant Affinity est désactivé dans Red Hat OpenShift Pipelines, vous devrez donc activer l'assistant pour l'utiliser.
3.1.11.1.2. L'interface de programmation des pipelines
Les commandes
tkn task describe,tkn taskrun describe,tkn clustertask describe,tkn pipeline describe, ettkn pipelinerun describemaintenant :-
Sélectionne automatiquement les ressources
Task,TaskRun,ClusterTask,PipelineetPipelineRun, respectivement, si une seule d'entre elles est présente. -
Affichez les résultats des ressources
Task,TaskRun,ClusterTask,PipelineetPipelineRundans leurs sorties respectives. -
Afficher les espaces de travail déclarés dans les ressources
Task,TaskRun,ClusterTask,PipelineetPipelineRundans leurs sorties, respectivement.
-
Sélectionne automatiquement les ressources
-
Vous pouvez désormais utiliser l'option
--prefix-nameavec la commandetkn clustertask startpour spécifier un préfixe pour le nom d'une exécution de tâche. -
La commande
tkn clustertask startest désormais compatible avec le mode interactif. -
Vous pouvez désormais spécifier les propriétés
PodTemplateprises en charge par les pipelines à l'aide de définitions de fichiers locaux ou distants pour les objetsTaskRunetPipelineRun. -
Vous pouvez maintenant utiliser l'option
--use-params-defaultsavec la commandetkn clustertask startpour utiliser les valeurs par défaut définies dans la configurationClusterTasket créer l'exécution de la tâche. -
Le drapeau
--use-param-defaultsde la commandetkn pipeline startinvite désormais à passer en mode interactif si les valeurs par défaut n'ont pas été spécifiées pour certains paramètres.
3.1.11.1.3. Déclencheurs
-
La fonction du langage d'expression commun (CEL) appelée
parseYAMLa été ajoutée pour analyser une chaîne YAML en une carte de chaînes. - Les messages d'erreur pour l'analyse des expressions CEL ont été améliorés pour les rendre plus granulaires lors de l'évaluation des expressions et lors de l'analyse du corps du crochet pour créer l'environnement d'évaluation.
- La prise en charge du marshaling des valeurs booléennes et des cartes est désormais possible si elles sont utilisées comme valeurs d'expressions dans un mécanisme de recouvrement CEL.
Les champs suivants ont été ajoutés à l'objet
EventListener:-
Le champ
replicaspermet à l'auditeur d'événements d'exécuter plus d'un pod en spécifiant le nombre de répliques dans le fichier YAML. -
Le champ
NodeSelectorpermet à l'objetEventListenerde programmer le pod d'écoute d'événements sur un nœud spécifique.
-
Le champ
-
Les intercepteurs de webhook peuvent désormais analyser l'en-tête
EventListener-Request-URLpour extraire les paramètres de l'URL de la requête originale gérée par l'écouteur d'événements. - Les annotations de l'écouteur d'événements peuvent maintenant être propagées au déploiement, aux services et aux autres pods. Notez que les annotations personnalisées sur les services ou le déploiement sont écrasées, et doivent donc être ajoutées aux annotations de l'écouteur d'événements afin qu'elles soient propagées.
-
La validation correcte des répliques dans la spécification
EventListenerest maintenant disponible pour les cas où un utilisateur spécifie les valeursspec.replicascommenegativeouzero. -
Vous pouvez désormais spécifier l'objet
TriggerCRDdans la spécificationEventListeneren tant que référence en utilisant le champTriggerRefpour créer l'objetTriggerCRDséparément et le lier ensuite dans la spécificationEventListener. -
La validation et les valeurs par défaut de l'objet
TriggerCRDsont désormais disponibles.
3.1.11.2. Fonctionnalités obsolètes
-
$(params)sont désormais supprimés de la ressourcetriggertemplateet remplacés par$(tt.params)afin d'éviter toute confusion entre les paramètres des ressourcesresourcetemplateettriggertemplate. -
La référence
ServiceAccountdu niveau d'authentification optionnel basé surEventListenerTriggerest passée d'une référence d'objet à une chaîneServiceAccountName. Cela garantit que la référenceServiceAccountse trouve dans le même espace de noms que l'objetEventListenerTrigger. -
La définition de ressource personnalisée (CRD)
Conditionsest désormais obsolète ; utilisez la CRDWhenExpressionsà la place. -
L'objet
PipelineRun.Spec.ServiceAccountNamesest obsolète et remplacé par l'objetPipelineRun.Spec.TaskRunSpec[].ServiceAccountName.
3.1.11.3. Problèmes connus
- Cette version de Red Hat OpenShift Pipelines ajoute la prise en charge d'une installation déconnectée. Cependant, certaines images utilisées par les tâches de cluster doivent être mises en miroir pour qu'elles fonctionnent dans des clusters déconnectés.
-
Les pipelines dans l'espace de noms
openshiftne sont pas supprimés après la désinstallation de Red Hat OpenShift Pipelines Operator. Utilisez la commandeoc delete pipelines -n openshift --allpour supprimer les pipelines. La désinstallation de Red Hat OpenShift Pipelines Operator ne supprime pas les écouteurs d'événements.
En guise de solution de contournement, supprimer les CRD
EventListeneretPod:Modifier l'objet
EventListeneravec les finaliseursforegroundDeletion:$ oc patch el/<eventlistener_name> -p '{"metadata":{"finalizers" :[\N-"foregroundDeletion"]}}' --type=mergePar exemple :
$ oc patch el/github-listener-interceptor -p '{"metadata":{"finalizers":["foregroundDeletion"]}}' --type=mergeSupprimer le CRD
EventListener:$ oc patch crd/eventlisteners.triggers.tekton.dev -p '{"metadata":{"finalizers":[]}}' --type=merge
Lorsque vous exécutez une tâche d'image de conteneur multiarchitecture sans spécification de commande sur un cluster IBM Power Systems (ppc64le) ou IBM Z (s390x), la ressource
TaskRunéchoue avec l'erreur suivante :Error executing command: fork/exec /bin/bash: exec format errorComme solution de contournement, utilisez une image de conteneur spécifique à l'architecture ou spécifiez le résumé sha256 pour qu'il pointe vers l'architecture correcte. Pour obtenir le condensé sha256, entrez :
$ skopeo inspect --raw <image_name>| jq '.manifests[] | select(.platform.architecture == "<architecture>") | .digest'
3.1.11.4. Problèmes corrigés
- Une validation syntaxique simple pour vérifier le filtre CEL, les superpositions dans le validateur Webhook et les expressions dans l'intercepteur a été ajoutée.
- Les déclencheurs n'écrasent plus les annotations définies sur les objets de déploiement et de service sous-jacents.
-
Auparavant, un écouteur d'événements pouvait cesser d'accepter des événements. Ce correctif ajoute un délai d'inactivité de 120 secondes pour le puits
EventListenerafin de résoudre ce problème. -
Auparavant, l'annulation de l'exécution d'un pipeline avec un état
Failed(Canceled)donnait un message de réussite. Ce problème a été corrigé et un message d'erreur est désormais affiché. -
La commande
tkn eventlistener listfournit désormais l'état des récepteurs d'événements répertoriés, ce qui vous permet d'identifier facilement ceux qui sont disponibles. -
Des messages d'erreur cohérents sont désormais affichés pour les commandes
triggers listettriggers describelorsque les déclencheurs ne sont pas installés ou lorsqu'une ressource ne peut être trouvée. -
Auparavant, un grand nombre de connexions inactives s'accumulaient lors de la livraison d'événements dans le nuage. Le paramètre
DisableKeepAlives: truea été ajouté à la configuration decloudeventclientpour résoudre ce problème. Ainsi, une nouvelle connexion est établie pour chaque événement en nuage. -
Auparavant, le code
creds-initécrivait des fichiers vides sur le disque même si les informations d'identification d'un type donné n'étaient pas fournies. Ce correctif modifie le codecreds-initpour qu'il écrive des fichiers uniquement pour les informations d'identification qui ont été effectivement montées à partir de secrets correctement annotés.
3.1.12. Notes de publication pour Red Hat OpenShift Pipelines Technology Preview 1.1
3.1.12.1. Nouvelles fonctionnalités
Red Hat OpenShift Pipelines Technology Preview (TP) 1.1 est maintenant disponible sur OpenShift Container Platform 4.5. Red Hat OpenShift Pipelines TP 1.1 est mis à jour pour prendre en charge :
- Tekton Pipelines 0.14.3
-
Tekton
tknCLI 0.11.0 - Tekton Triggers 0.6.1
- tâches en grappe basées sur le catalogue Tekton 0.14
En plus des corrections et des améliorations de stabilité, les sections suivantes mettent en évidence les nouveautés de Red Hat OpenShift Pipelines 1.1.
3.1.12.1.1. Pipelines
- Les espaces de travail peuvent désormais être utilisés à la place des ressources de pipeline. Il est recommandé d'utiliser les espaces de travail dans OpenShift Pipelines, car les ressources de pipeline sont difficiles à déboguer, limitées dans leur portée et rendent les tâches moins réutilisables. Pour plus de détails sur les espaces de travail, voir la section Comprendre OpenShift Pipelines.
La prise en charge de l'espace de travail pour les modèles de demande en volume a été ajoutée :
- Le modèle de demande de volume pour une exécution de pipeline et une exécution de tâche peut désormais être ajouté en tant que source de volume pour les espaces de travail. Le contrôleur tekton crée alors une demande de volume persistante (PVC) en utilisant le modèle qui est vu comme un PVC pour toutes les exécutions de tâches dans le pipeline. Ainsi, il n'est pas nécessaire de définir la configuration du PVC à chaque fois qu'il lie un espace de travail qui s'étend sur plusieurs tâches.
- L'aide à la recherche du nom du PVC lorsqu'un modèle de demande de volume est utilisé comme source de volume est désormais disponible en utilisant la substitution de variable.
Soutien à l'amélioration des audits :
-
Le champ
PipelineRun.Statuscontient désormais l'état de chaque tâche exécutée dans le pipeline et la spécification du pipeline utilisée pour instancier une exécution du pipeline afin de surveiller la progression de l'exécution du pipeline. -
Les résultats des pipelines ont été ajoutés à la spécification des pipelines et au statut
PipelineRun. -
Le champ
TaskRun.Statuscontient désormais la spécification exacte de la tâche utilisée pour instancier la ressourceTaskRun.
-
Le champ
- Prise en charge de l'application du paramètre par défaut aux conditions.
-
Une exécution de tâche créée en référençant une tâche de cluster ajoute désormais l'étiquette
tekton.dev/clusterTaskau lieu de l'étiquettetekton.dev/task. -
Le rédacteur de la configuration kube ajoute maintenant les configurations
ClientKeyDataetClientCertificateDatadans la structure de la ressource pour permettre le remplacement du cluster de type de ressource pipeline avec la tâche kubeconfig-creator. -
Les noms des cartes de configuration
feature-flagsetconfig-defaultssont désormais personnalisables. - La prise en charge du réseau hôte dans le modèle de pod utilisé par l'exécution de la tâche est désormais disponible.
- Un assistant d'affinité est maintenant disponible pour prendre en charge l'affinité des nœuds dans les exécutions de tâches qui partagent le volume de l'espace de travail. Par défaut, cette fonctionnalité est désactivée sur OpenShift Pipelines.
-
Le modèle de pod a été mis à jour pour spécifier
imagePullSecretsafin d'identifier les secrets que le runtime du conteneur doit utiliser pour autoriser les extractions d'images de conteneurs lors du démarrage d'un pod. - Prise en charge de l'émission d'événements d'avertissement par le contrôleur d'exécution des tâches si ce dernier ne parvient pas à mettre à jour l'exécution des tâches.
- Des étiquettes k8s standard ou recommandées ont été ajoutées à toutes les ressources pour identifier les ressources appartenant à une application ou à un composant.
-
Le processus
Entrypointest maintenant informé des signaux et ces signaux sont ensuite propagés à l'aide d'un groupe PID dédié du processusEntrypoint. - Le modèle de pod peut désormais être défini au niveau d'une tâche au moment de l'exécution en utilisant les spécifications d'exécution de la tâche.
Prise en charge de l'émission d'événements Kubernetes :
-
Le contrôleur émet maintenant des événements pour des événements supplémentaires du cycle de vie de l'exécution de la tâche -
taskrun startedettaskrun running. - Le contrôleur d'exécution des pipelines émet désormais un événement à chaque fois qu'un pipeline démarre.
-
Le contrôleur émet maintenant des événements pour des événements supplémentaires du cycle de vie de l'exécution de la tâche -
- En plus des événements Kubernetes par défaut, la prise en charge des événements cloud pour les exécutions de tâches est désormais disponible. Le contrôleur peut être configuré pour envoyer tous les événements d'exécution de tâches, tels que la création, le démarrage et l'échec, en tant qu'événements cloud.
-
Prise en charge de l'utilisation de la variable
$context.<task|taskRun|pipeline|pipelineRun>.namepour référencer le nom approprié lors de l'exécution d'un pipeline ou d'une tâche. - La validation des paramètres d'exécution du pipeline est désormais disponible pour s'assurer que tous les paramètres requis par le pipeline sont fournis par l'exécution du pipeline. Cela permet également aux opérations de pipelines de fournir des paramètres supplémentaires en plus des paramètres requis.
-
Vous pouvez désormais spécifier des tâches au sein d'un pipeline qui seront toujours exécutées avant que le pipeline ne se termine, soit après avoir terminé toutes les tâches avec succès, soit après l'échec d'une tâche du pipeline, en utilisant le champ
finallydans le fichier YAML du pipeline. -
La tâche
git-cloneest maintenant disponible.
3.1.12.1.2. L'interface de programmation des pipelines
-
La commande
tkn evenlistener describeprend désormais en charge les déclencheurs intégrés. - Support pour recommander des sous-commandes et faire des suggestions si une sous-commande incorrecte est utilisée.
-
La commande
tkn task describesélectionne désormais automatiquement la tâche si une seule tâche est présente dans le pipeline. -
Vous pouvez désormais lancer une tâche en utilisant des valeurs de paramètres par défaut en spécifiant l'indicateur
--use-param-defaultsdans la commandetkn task start. -
Vous pouvez désormais spécifier un modèle de demande de volume pour les exécutions de pipeline ou de tâches en utilisant l'option
--workspaceavec les commandestkn pipeline startoutkn task start. -
La commande
tkn pipelinerun logsaffiche désormais les journaux des dernières tâches énumérées dans la sectionfinally. -
La prise en charge du mode interactif a été ajoutée à la commande
tkn task startet à la sous-commandedescribepour les ressourcestknsuivantes :pipeline,pipelinerun,task,taskrun,clustertask, etpipelineresource. -
La commande
tkn versionaffiche désormais la version des déclencheurs installés dans le cluster. -
La commande
tkn pipeline describeaffiche désormais les valeurs des paramètres et les délais spécifiés pour les tâches utilisées dans le pipeline. -
Prise en charge de l'option
--lastpour les commandestkn pipelinerun describeettkn taskrun describeafin de décrire l'exécution la plus récente du pipeline ou de la tâche, respectivement. -
La commande
tkn pipeline describeaffiche désormais les conditions applicables aux tâches du pipeline. -
Vous pouvez désormais utiliser les drapeaux
--no-headerset--all-namespacesavec la commandetkn resource list.
3.1.12.1.3. Déclencheurs
Les fonctions suivantes du langage d'expression commun (CEL) sont désormais disponibles :
-
parseURLpour analyser et extraire des parties d'une URL -
parseJSONpour analyser les types de valeurs JSON intégrés dans une chaîne de caractères dans le champpayloaddu webhookdeployment
-
- Un nouvel intercepteur pour les webhooks de Bitbucket a été ajouté.
-
Les auditeurs d'événements affichent désormais les champs
Address URLetAvailable statuscomme champs supplémentaires lorsqu'ils sont listés avec la commandekubectl get. -
les paramètres des modèles de déclenchement utilisent désormais la syntaxe
$(tt.params.<paramName>)au lieu de$(params.<paramName>)afin de réduire la confusion entre les paramètres des modèles de déclenchement et ceux des modèles de ressources. -
Vous pouvez désormais ajouter
tolerationsdans le CRDEventListenerpour vous assurer que les auditeurs d'événements sont déployés avec la même configuration même si tous les nœuds sont altérés en raison de problèmes de sécurité ou de gestion. -
Vous pouvez maintenant ajouter une sonde de préparation pour l'événement Deployment à l'adresse
URL/live. -
La prise en charge de l'intégration des spécifications
TriggerBindingdans les déclencheurs d'écoute d'événements a été ajoutée. -
Les ressources de déclenchement sont maintenant annotées avec les étiquettes recommandées
app.kubernetes.io.
3.1.12.2. Fonctionnalités obsolètes
Les éléments suivants sont obsolètes dans cette version :
-
Les drapeaux
--namespaceou-npour toutes les commandes de l'ensemble du cluster, y compris les commandesclustertasketclustertriggerbinding, sont obsolètes. Ils seront supprimés dans une prochaine version. -
Le champ
namedanstriggers.bindingsau sein d'une liste d'événements a été abandonné au profit du champrefet sera supprimé dans une prochaine version. -
L'interpolation de variables dans les modèles de déclenchement à l'aide de
$(params)a été abandonnée au profit de$(tt.params)afin de réduire la confusion avec la syntaxe d'interpolation des variables du pipeline. La syntaxe$(params.<paramName>)sera supprimée dans une prochaine version. -
L'étiquette
tekton.dev/taskest obsolète pour les tâches en grappe. -
Le champ
TaskRun.Status.ResourceResults.ResourceRefest obsolète et sera supprimé. -
Les sous-commandes
tkn pipeline create,tkn task createettkn resource create -font été supprimées. -
La validation des espaces de noms a été supprimée des commandes
tkn. -
Le délai d'attente par défaut de
1het l'indicateur-tpour la commandetkn ct startont été supprimés. -
La tâche
s2ia été supprimée.
3.1.12.3. Problèmes connus
- Les conditions ne favorisent pas les espaces de travail.
-
L'option
--workspaceet le mode interactif ne sont pas pris en charge pour la commandetkn clustertask start. -
La prise en charge de la compatibilité ascendante pour la syntaxe
$(params.<paramName>)vous oblige à utiliser des modèles de déclencheurs avec des paramètres spécifiques aux pipelines, car le webhook du déclencheur n'est pas en mesure de différencier les paramètres des déclencheurs de ceux des pipelines. -
Les métriques de pipeline indiquent des valeurs incorrectes lorsque vous exécutez une requête promQL pour
tekton_taskrun_countettekton_taskrun_duration_seconds_count. -
les exécutions de pipeline et les exécutions de tâches continuent d'être dans les états
RunningetRunning(Pending)respectivement, même lorsqu'un nom de PVC non existant est donné à un espace de travail.
3.1.12.4. Problèmes corrigés
-
Auparavant, la commande
tkn task delete <name> --trssupprimait à la fois la tâche et la tâche de cluster si le nom de la tâche et de la tâche de cluster était le même. Avec cette correction, la commande ne supprime que les exécutions de tâches créées par la tâche<name>. -
Auparavant, la commande
tkn pr delete -p <name> --keep 2ne tenait pas compte de l'indicateur-plorsqu'elle était utilisée avec l'indicateur--keepet supprimait toutes les exécutions du pipeline, à l'exception des deux dernières. Avec cette correction, la commande ne supprime que les exécutions de pipeline créées par le pipeline<name>, à l'exception des deux dernières. -
La sortie de
tkn triggertemplate describeaffiche désormais les modèles de ressources sous forme de tableau au lieu du format YAML. -
Auparavant, la tâche de cluster
buildahéchouait lorsqu'un nouvel utilisateur était ajouté à un conteneur. Avec cette correction, le problème a été résolu.
3.1.13. Notes de publication pour Red Hat OpenShift Pipelines Technology Preview 1.0
3.1.13.1. Nouvelles fonctionnalités
Red Hat OpenShift Pipelines Technology Preview (TP) 1.0 est maintenant disponible sur OpenShift Container Platform 4.4. Red Hat OpenShift Pipelines TP 1.0 est mis à jour pour prendre en charge :
- Tekton Pipelines 0.11.3
-
Tekton
tknCLI 0.9.0 - Tekton Triggers 0.4.0
- tâches en grappe basées sur le catalogue Tekton 0.11
En plus des corrections et des améliorations de la stabilité, les sections suivantes mettent en évidence les nouveautés de Red Hat OpenShift Pipelines 1.0.
3.1.13.1.1. Pipelines
- Prise en charge de la version v1beta1 de l'API.
- Prise en charge d'une plage de limites améliorée. Auparavant, la plage de limites était spécifiée exclusivement pour l'exécution de la tâche et l'exécution du pipeline. Désormais, il n'est plus nécessaire de spécifier explicitement la plage de limites. La plage de limites minimale de l'espace de noms est utilisée.
- Prise en charge du partage des données entre les tâches à l'aide des résultats et des paramètres des tâches.
-
Les pipelines peuvent désormais être configurés pour ne pas écraser la variable d'environnement
HOMEet le répertoire de travail des étapes. -
À l'instar des tâches,
sidecarsprend désormais en charge le mode script. -
Vous pouvez désormais spécifier un nom de planificateur différent dans la ressource d'exécution de la tâche
podTemplate. - Prise en charge de la substitution de variables à l'aide de la notation en tableau étoilé.
- Le contrôleur Tekton peut désormais être configuré pour surveiller un espace de noms individuel.
- Un nouveau champ de description est désormais ajouté à la spécification des pipelines, des tâches, des tâches en grappe, des ressources et des conditions.
- Ajout de paramètres proxy aux ressources du pipeline Git.
3.1.13.1.2. L'interface de programmation des pipelines
-
La sous-commande
describeest désormais ajoutée pour les ressourcestknsuivantes :EventListener,Condition,TriggerTemplate,ClusterTask, etTriggerSBinding. -
La prise en charge de
v1beta1a été ajoutée aux ressources suivantes, ainsi que la compatibilité ascendante pourv1alpha1:ClusterTask,Task,Pipeline,PipelineRun, etTaskRun. Les commandes suivantes peuvent désormais lister les résultats de tous les espaces de noms en utilisant l'option
--all-namespaces:tkn task list,tkn pipeline list,tkn taskrun list,tkn pipelinerun listLa sortie de ces commandes est également améliorée pour afficher des informations sans en-tête à l'aide de l'option
--no-headers.-
Vous pouvez maintenant démarrer un pipeline en utilisant les valeurs de paramètres par défaut en spécifiant l'indicateur
--use-param-defaultsdans la commandetkn pipelines start. -
La prise en charge de l'espace de travail est désormais ajoutée aux commandes
tkn pipeline startettkn task start. -
Une nouvelle commande
clustertriggerbindinga été ajoutée avec les sous-commandes suivantes :describe,delete, etlist. -
Vous pouvez désormais lancer directement un pipeline à l'aide d'un fichier local ou distant
yaml. -
La sous-commande
describeaffiche désormais une sortie améliorée et détaillée. Avec l'ajout de nouveaux champs, tels quedescription,timeout,param description, etsidecar status, la sortie de la commande fournit désormais des informations plus détaillées sur une ressourcetknspécifique. -
La commande
tkn task logaffiche désormais les journaux directement si une seule tâche est présente dans l'espace de noms.
3.1.13.1.3. Déclencheurs
-
Les déclencheurs peuvent désormais créer des ressources de pipeline
v1alpha1etv1beta1. -
Prise en charge de la nouvelle fonction d'interception du langage d'expression commun (CEL) -
compareSecret. Cette fonction compare en toute sécurité les chaînes de caractères aux secrets contenus dans les expressions CEL. - Prise en charge de l'authentification et de l'autorisation au niveau du déclencheur de l'auditeur d'événements.
3.1.13.2. Fonctionnalités obsolètes
Les éléments suivants sont obsolètes dans cette version :
La variable d'environnement
$HOMEet la variableworkingDirdans la spécificationStepssont obsolètes et pourraient être modifiées dans une version ultérieure. Actuellement, dans un conteneurStep, les variablesHOMEetworkingDirsont remplacées par les variables/tekton/homeet/workspace, respectivement.Dans une version ultérieure, ces deux champs ne seront pas modifiés et prendront les valeurs définies dans l'image du conteneur et dans le YAML
Task. Pour cette version, utilisez les drapeauxdisable-home-env-overwriteetdisable-working-directory-overwritepour désactiver l'écrasement des variablesHOMEetworkingDir.-
Les commandes suivantes sont obsolètes et pourraient être supprimées dans une prochaine version :
tkn pipeline create,tkn task create. -
L'indicateur
-fde la commandetkn resource createest désormais obsolète. Il pourrait être supprimé dans une prochaine version. -
L'indicateur
-tet l'indicateur--timeout(avec le format des secondes) pour la commandetkn clustertask createsont désormais obsolètes. Seul le format durée est désormais pris en charge, par exemple1h30s. Ces drapeaux obsolètes pourraient être supprimés dans une prochaine version.
3.1.13.3. Problèmes connus
- Si vous effectuez une mise à niveau à partir d'une ancienne version de Red Hat OpenShift Pipelines, vous devez supprimer vos déploiements existants avant d'effectuer la mise à niveau vers Red Hat OpenShift Pipelines version 1.0. Pour supprimer un déploiement existant, vous devez d'abord supprimer les ressources personnalisées, puis désinstaller l'opérateur Red Hat OpenShift Pipelines. Pour plus de détails, consultez la section sur la désinstallation de Red Hat OpenShift Pipelines.
-
La soumission des mêmes tâches
v1alpha1plus d'une fois entraîne une erreur. Utilisez la commandeoc replaceau lieu deoc applylorsque vous soumettez à nouveau une tâchev1alpha1. La tâche
buildahcluster ne fonctionne pas lorsqu'un nouvel utilisateur est ajouté à un conteneur.Lors de l'installation de l'Opérateur, l'indicateur
--storage-driverpour la tâche de clusterbuildahn'est pas spécifié, et l'indicateur prend donc sa valeur par défaut. Dans certains cas, cela entraîne un mauvais paramétrage du pilote de stockage. Lorsqu'un nouvel utilisateur est ajouté, le pilote de stockage incorrect entraîne l'échec de la tâche de clusterbuildahavec l'erreur suivante :useradd: /etc/passwd.8: lock file already used useradd: cannot lock /etc/passwd; try again later.Pour contourner le problème, définissez manuellement la valeur de l'indicateur
--storage-driveràoverlaydans le fichierbuildah-task.yaml:Connectez-vous à votre cluster en tant que
cluster-admin:$ oc login -u <login> -p <password> https://openshift.example.com:6443Utilisez la commande
oc editpour éditer la tâche de clusterbuildah:$ oc edit clustertask buildahLa version actuelle du fichier YAML de
buildahclustertask s'ouvre dans l'éditeur défini par votre variable d'environnementEDITOR.Sous le champ
Steps, localisez le champcommandsuivant :command: ['buildah', 'bud', '--format=$(params.FORMAT)', '--tls-verify=$(params.TLSVERIFY)', '--layers', '-f', '$(params.DOCKERFILE)', '-t', '$(resources.outputs.image.url)', '$(params.CONTEXT)']Remplacer le champ
commandpar le champ suivant :command: ['buildah', '--storage-driver=overlay', 'bud', '--format=$(params.FORMAT)', '--tls-verify=$(params.TLSVERIFY)', '--no-cache', '-f', '$(params.DOCKERFILE)', '-t', '$(params.IMAGE)', '$(params.CONTEXT)']- Enregistrez le fichier et quittez.
Vous pouvez également modifier le fichier YAML de la tâche de cluster
buildahdirectement sur la console web en naviguant vers Pipelines → Cluster Tasks → buildah. Sélectionnez Edit Cluster Task dans le menu Actions et remplacez le champcommandcomme indiqué dans la procédure précédente.
3.1.13.4. Problèmes corrigés
-
Auparavant, la tâche
DeploymentConfigdéclenchait une nouvelle construction de déploiement même lorsqu'une construction d'image était déjà en cours. Cela entraînait l'échec du déploiement du pipeline. Avec cette correction, la commandedeploy taskest maintenant remplacée par la commandeoc rollout statusqui attend que le déploiement en cours se termine. -
La prise en charge du paramètre
APP_NAMEest désormais ajoutée dans les modèles de pipeline. -
Auparavant, le modèle de pipeline pour Java S2I ne parvenait pas à rechercher l'image dans le registre. Avec cette correction, l'image est recherchée en utilisant les ressources existantes du pipeline d'images au lieu du paramètre
IMAGE_NAMEfourni par l'utilisateur. - Toutes les images d'OpenShift Pipelines sont désormais basées sur les Red Hat Universal Base Images (UBI).
-
Auparavant, lorsque le pipeline était installé dans un espace de noms autre que
tekton-pipelines, la commandetkn versionaffichait la version du pipeline sous la formeunknown. Avec cette correction, la commandetkn versionaffiche désormais la version correcte du pipeline dans n'importe quel espace de noms. -
L'indicateur
-cn'est plus pris en charge pour la commandetkn version. - Les utilisateurs non-administrateurs peuvent maintenant lister les liens de déclenchement des clusters.
-
La fonction de l'écouteur d'événement
CompareSecretest maintenant corrigée pour l'intercepteur CEL. -
Les sous-commandes
list,describe, etstartpour les tâches et les tâches en grappe affichent désormais correctement la sortie dans le cas où une tâche et une tâche en grappe ont le même nom. - Auparavant, l'opérateur OpenShift Pipelines modifiait les contraintes de contexte de sécurité (SCC) privilégiées, ce qui provoquait une erreur lors de la mise à niveau du cluster. Cette erreur est maintenant corrigée.
-
Dans l'espace de noms
tekton-pipelines, les délais d'exécution de toutes les tâches et de tous les pipelines sont désormais fixés à la valeur du champdefault-timeout-minutesà l'aide de la carte de configuration. - Auparavant, la section des pipelines dans la console web n'était pas affichée pour les utilisateurs non-administrateurs. Ce problème est désormais résolu.
3.2. Comprendre les pipelines OpenShift
Red Hat OpenShift Pipelines est une solution cloud-native d'intégration et de livraison continues (CI/CD) basée sur les ressources Kubernetes. Elle utilise les blocs de construction Tekton pour automatiser les déploiements sur plusieurs plateformes en faisant abstraction des détails de mise en œuvre sous-jacents. Tekton introduit un certain nombre de définitions de ressources personnalisées (CRD) standard pour définir les pipelines CI/CD qui sont portables à travers les distributions Kubernetes.
3.2.1. Caractéristiques principales
- Red Hat OpenShift Pipelines est un système CI/CD sans serveur qui exécute des pipelines avec toutes les dépendances requises dans des conteneurs isolés.
- Red Hat OpenShift Pipelines est conçu pour les équipes décentralisées qui travaillent sur une architecture basée sur les microservices.
- Red Hat OpenShift Pipelines utilise des définitions de pipeline CI/CD standard qui sont faciles à étendre et à intégrer aux outils Kubernetes existants, ce qui vous permet d'évoluer à la demande.
- Vous pouvez utiliser Red Hat OpenShift Pipelines pour construire des images avec des outils Kubernetes tels que Source-to-Image (S2I), Buildah, Buildpacks et Kaniko qui sont portables sur n'importe quelle plateforme Kubernetes.
- Vous pouvez utiliser la console OpenShift Container Platform Developer pour créer des ressources Tekton, consulter les journaux d'exécution des pipelines et gérer les pipelines dans vos espaces de noms OpenShift Container Platform.
3.2.2. Concepts des pipelines OpenShift
Ce guide fournit une vue détaillée des différents concepts de pipelines.
3.2.2.1. Tâches
Task les ressources sont les éléments constitutifs d'un pipeline et consistent en des étapes exécutées de manière séquentielle. Il s'agit essentiellement d'une fonction d'entrées et de sorties. Une tâche peut être exécutée individuellement ou dans le cadre d'un pipeline. Les tâches sont réutilisables et peuvent être utilisées dans plusieurs pipelines.
Steps sont une série de commandes qui sont exécutées séquentiellement par la tâche et qui permettent d'atteindre un objectif spécifique, tel que la construction d'une image. Chaque tâche s'exécute en tant que pod, et chaque étape s'exécute en tant que conteneur au sein de ce pod. Comme les étapes s'exécutent dans le même module, elles peuvent accéder aux mêmes volumes pour les fichiers de mise en cache, les cartes de configuration et les secrets.
L'exemple suivant illustre la tâche apply-manifests.
apiVersion: tekton.dev/v1beta1
kind: Task
metadata:
name: apply-manifests
spec:
workspaces:
- name: source
params:
- name: manifest_dir
description: The directory in source that contains yaml manifests
type: string
default: "k8s"
steps:
- name: apply
image: image-registry.openshift-image-registry.svc:5000/openshift/cli:latest
workingDir: /workspace/source
command: ["/bin/bash", "-c"]
args:
- |-
echo Applying manifests in $(params.manifest_dir) directory
oc apply -f $(params.manifest_dir)
echo -----------------------------------Cette tâche démarre le pod et exécute un conteneur à l'intérieur de ce pod en utilisant l'image spécifiée pour exécuter les commandes spécifiées.
À partir d'OpenShift Pipelines 1.6, les valeurs par défaut suivantes du fichier YAML de l'étape sont supprimées :
-
La variable d'environnement
HOMEn'indique pas par défaut le répertoire/tekton/home -
Le champ
workingDirne renvoie pas par défaut au répertoire/workspace
Au lieu de cela, le conteneur de l'étape définit la variable d'environnement HOME et le champ workingDir. Toutefois, vous pouvez remplacer les valeurs par défaut en spécifiant les valeurs personnalisées dans le fichier YAML de l'étape.
À titre de mesure temporaire, pour maintenir la compatibilité ascendante avec les anciennes versions d'OpenShift Pipelines, vous pouvez définir les champs suivants dans la définition de la ressource personnalisée TektonConfig à false:
spec:
pipeline:
disable-working-directory-overwrite: false
disable-home-env-overwrite: false3.2.2.2. Quand l'expression
Les expressions When protègent l'exécution des tâches en définissant des critères pour l'exécution des tâches au sein d'un pipeline. Elles contiennent une liste de composants qui permet à une tâche de s'exécuter uniquement lorsque certains critères sont remplis. Les expressions When sont également prises en charge dans l'ensemble final des tâches spécifiées à l'aide du champ finally dans le fichier YAML du pipeline.
Les éléments clés d'une expression when sont les suivants :
-
input: Spécifie des entrées statiques ou des variables telles qu'un paramètre, un résultat de tâche et un état d'exécution. Vous devez saisir une entrée valide. Si vous ne saisissez pas d'entrée valide, sa valeur prend par défaut la forme d'une chaîne vide. -
operator: Spécifie la relation d'une entrée avec un ensemble devalues. Saisissezinounotincomme valeurs d'opérateur. -
values: Spécifie un tableau de valeurs de chaînes de caractères. Entrez un tableau non vide de valeurs statiques ou de variables telles que des paramètres, des résultats et un état lié d'un espace de travail.
Les expressions when déclarées sont évaluées avant l'exécution de la tâche. Si la valeur d'une expression when est True, la tâche est exécutée. Si la valeur d'une expression when est False, la tâche est ignorée.
Vous pouvez utiliser les expressions when dans différents cas d'utilisation. Par exemple, si :
- Le résultat d'une tâche précédente est conforme aux attentes.
- Un fichier dans un dépôt Git a été modifié dans les commits précédents.
- Une image existe dans le registre.
- Un espace de travail est disponible en option.
L'exemple suivant montre les expressions when pour une exécution de pipeline. Le pipeline n'exécutera la tâche create-file que si les critères suivants sont remplis : le paramètre path est README.md, et la tâche echo-file-exists n'est exécutée que si le résultat exists de la tâche check-file est yes.
apiVersion: tekton.dev/v1beta1
kind: PipelineRun
metadata:
generateName: guarded-pr-
spec:
serviceAccountName: 'pipeline'
pipelineSpec:
params:
- name: path
type: string
description: The path of the file to be created
workspaces:
- name: source
description: |
This workspace is shared among all the pipeline tasks to read/write common resources
tasks:
- name: create-file
when:
- input: "$(params.path)"
operator: in
values: ["README.md"]
workspaces:
- name: source
workspace: source
taskSpec:
workspaces:
- name: source
description: The workspace to create the readme file in
steps:
- name: write-new-stuff
image: ubuntu
script: 'touch $(workspaces.source.path)/README.md'
- name: check-file
params:
- name: path
value: "$(params.path)"
workspaces:
- name: source
workspace: source
runAfter:
- create-file
taskSpec:
params:
- name: path
workspaces:
- name: source
description: The workspace to check for the file
results:
- name: exists
description: indicates whether the file exists or is missing
steps:
- name: check-file
image: alpine
script: |
if test -f $(workspaces.source.path)/$(params.path); then
printf yes | tee /tekton/results/exists
else
printf no | tee /tekton/results/exists
fi
- name: echo-file-exists
when:
- input: "$(tasks.check-file.results.exists)"
operator: in
values: ["yes"]
taskSpec:
steps:
- name: echo
image: ubuntu
script: 'echo file exists'
...
- name: task-should-be-skipped-1
when:
- input: "$(params.path)"
operator: notin
values: ["README.md"]
taskSpec:
steps:
- name: echo
image: ubuntu
script: exit 1
...
finally:
- name: finally-task-should-be-executed
when:
- input: "$(tasks.echo-file-exists.status)"
operator: in
values: ["Succeeded"]
- input: "$(tasks.status)"
operator: in
values: ["Succeeded"]
- input: "$(tasks.check-file.results.exists)"
operator: in
values: ["yes"]
- input: "$(params.path)"
operator: in
values: ["README.md"]
taskSpec:
steps:
- name: echo
image: ubuntu
script: 'echo finally done'
params:
- name: path
value: README.md
workspaces:
- name: source
volumeClaimTemplate:
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 16Mi- 1
- Spécifie le type d'objet Kubernetes. Dans cet exemple,
PipelineRun. - 2
- Tâche
create-fileutilisée dans le pipeline. - 3
whenqui spécifie d'exécuter la tâcheecho-file-existsuniquement si le résultatexistsde la tâchecheck-fileestyes.- 4
whenqui spécifie d'ignorer la tâchetask-should-be-skipped-1uniquement si le paramètrepathestREADME.md.- 5
whenexpression qui spécifie d'exécuter la tâchefinally-task-should-be-executedseulement si le statut d'exécution de la tâcheecho-file-existset le statut de la tâche estSucceeded, le résultatexistsde la tâchecheck-fileestyes, et le paramètrepathestREADME.md.
La page Pipeline Run details de la console web de OpenShift Container Platform montre l'état des tâches et des expressions de temps comme suit :
- Tous les critères sont remplis : Les tâches et le symbole de l'expression "quand", représenté par un losange, sont verts.
- L'un des critères n'est pas respecté : La tâche est ignorée. Les tâches ignorées et le symbole de l'expression "quand" sont grisés.
- Aucun des critères n'est rempli : La tâche est ignorée. Les tâches ignorées et le symbole de l'expression "quand" sont grisés.
- L'exécution de la tâche échoue : Les tâches qui échouent et le symbole de l'expression "quand" sont en rouge.
3.2.2.3. Enfin, les tâches
Les tâches finally sont le dernier ensemble de tâches spécifiées à l'aide du champ finally dans le fichier YAML du pipeline. Une tâche finally exécute toujours les tâches du pipeline, que les exécutions du pipeline soient réussies ou non. Les tâches finally sont exécutées en parallèle après l'exécution de toutes les tâches du pipeline, avant que le pipeline correspondant ne se termine.
Vous pouvez configurer une tâche finally pour qu'elle consomme les résultats de n'importe quelle tâche du même pipeline. Cette approche ne modifie pas l'ordre d'exécution de cette tâche finale. Elle est exécutée en parallèle avec d'autres tâches finales après l'exécution de toutes les tâches non finales.
L'exemple suivant montre un extrait de code du pipeline clone-cleanup-workspace. Ce code clone le référentiel dans un espace de travail partagé et nettoie l'espace de travail. Après avoir exécuté les tâches du pipeline, la tâche cleanup spécifiée dans la section finally du fichier YAML du pipeline nettoie l'espace de travail.
apiVersion: tekton.dev/v1beta1
kind: Pipeline
metadata:
name: clone-cleanup-workspace
spec:
workspaces:
- name: git-source
tasks:
- name: clone-app-repo
taskRef:
name: git-clone-from-catalog
params:
- name: url
value: https://github.com/tektoncd/community.git
- name: subdirectory
value: application
workspaces:
- name: output
workspace: git-source
finally:
- name: cleanup
taskRef:
name: cleanup-workspace
workspaces:
- name: source
workspace: git-source
- name: check-git-commit
params:
- name: commit
value: $(tasks.clone-app-repo.results.commit)
taskSpec:
params:
- name: commit
steps:
- name: check-commit-initialized
image: alpine
script: |
if [[ ! $(params.commit) ]]; then
exit 1
fi- 1
- Nom unique de la canalisation.
- 2
- L'espace de travail partagé où le dépôt git est cloné.
- 3
- La tâche de clonage du référentiel d'application dans l'espace de travail partagé.
- 4
- La tâche de nettoyage de l'espace de travail partagé.
- 5
- Une référence à la tâche qui doit être exécutée lors de l'exécution de la tâche.
- 6
- Volume de stockage partagé dont une tâche d'un pipeline a besoin au moment de l'exécution pour recevoir des données d'entrée ou fournir des données de sortie.
- 7
- Liste des paramètres requis pour une tâche. Si un paramètre n'a pas de valeur implicite par défaut, vous devez définir explicitement sa valeur.
- 8
- Définition des tâches intégrées.
3.2.2.4. Exécution des tâches
Un site TaskRun instancie une tâche à exécuter avec des entrées, des sorties et des paramètres d'exécution spécifiques sur un cluster. Il peut être invoqué seul ou dans le cadre d'une exécution de pipeline pour chaque tâche d'un pipeline.
Une tâche consiste en une ou plusieurs étapes qui exécutent des images de conteneur, et chaque image de conteneur effectue un travail de construction spécifique. Une exécution de tâche exécute les étapes d'une tâche dans l'ordre spécifié, jusqu'à ce que toutes les étapes s'exécutent avec succès ou qu'un échec se produise. Un TaskRun est automatiquement créé par un PipelineRun pour chaque tâche d'un pipeline.
L'exemple suivant montre une tâche qui exécute la tâche apply-manifests avec les paramètres d'entrée appropriés :
apiVersion: tekton.dev/v1beta1
kind: TaskRun
metadata:
name: apply-manifests-taskrun
spec:
serviceAccountName: pipeline
taskRef:
kind: Task
name: apply-manifests
workspaces:
- name: source
persistentVolumeClaim:
claimName: source-pvc- 1
- La tâche exécute la version de l'API
v1beta1. - 2
- Spécifie le type d'objet Kubernetes. Dans cet exemple,
TaskRun. - 3
- Nom unique permettant d'identifier l'exécution de cette tâche.
- 4
- Définition de l'exécution de la tâche. Pour cette exécution de tâche, la tâche et l'espace de travail requis sont spécifiés.
- 5
- Nom de la référence de tâche utilisée pour cette exécution de tâche. Cette tâche exécute la tâche
apply-manifests. - 6
- Espace de travail utilisé par l'exécution de la tâche.
3.2.2.5. Pipelines
Un site Pipeline est un ensemble de ressources Task disposées dans un ordre d'exécution spécifique. Elles sont exécutées pour construire des flux de travail complexes qui automatisent la construction, le déploiement et la livraison d'applications. Vous pouvez définir un flux de travail CI/CD pour votre application à l'aide de pipelines contenant une ou plusieurs tâches.
Une définition de ressource Pipeline se compose d'un certain nombre de champs ou d'attributs qui, ensemble, permettent au pipeline d'atteindre un objectif spécifique. Chaque définition de ressource Pipeline doit contenir au moins une ressource Task, qui reçoit des données d'entrée spécifiques et produit des données de sortie spécifiques. La définition du pipeline peut également inclure Conditions, Workspaces, Parameters, ou Resources en fonction des exigences de l'application.
L'exemple suivant montre le pipeline build-and-deploy, qui construit une image d'application à partir d'un dépôt Git en utilisant la ressource buildah ClusterTask :
apiVersion: tekton.dev/v1beta1
kind: Pipeline
metadata:
name: build-and-deploy
spec:
workspaces:
- name: shared-workspace
params:
- name: deployment-name
type: string
description: name of the deployment to be patched
- name: git-url
type: string
description: url of the git repo for the code of deployment
- name: git-revision
type: string
description: revision to be used from repo of the code for deployment
default: "pipelines-1.9"
- name: IMAGE
type: string
description: image to be built from the code
tasks:
- name: fetch-repository
taskRef:
name: git-clone
kind: ClusterTask
workspaces:
- name: output
workspace: shared-workspace
params:
- name: url
value: $(params.git-url)
- name: subdirectory
value: ""
- name: deleteExisting
value: "true"
- name: revision
value: $(params.git-revision)
- name: build-image
taskRef:
name: buildah
kind: ClusterTask
params:
- name: TLSVERIFY
value: "false"
- name: IMAGE
value: $(params.IMAGE)
workspaces:
- name: source
workspace: shared-workspace
runAfter:
- fetch-repository
- name: apply-manifests
taskRef:
name: apply-manifests
workspaces:
- name: source
workspace: shared-workspace
runAfter:
- build-image
- name: update-deployment
taskRef:
name: update-deployment
workspaces:
- name: source
workspace: shared-workspace
params:
- name: deployment
value: $(params.deployment-name)
- name: IMAGE
value: $(params.IMAGE)
runAfter:
- apply-manifests- 1
- Version de l'API du pipeline
v1beta1. - 2
- Spécifie le type d'objet Kubernetes. Dans cet exemple,
Pipeline. - 3
- Nom unique de cette canalisation.
- 4
- Spécifie la définition et la structure du pipeline.
- 5
- Espaces de travail utilisés pour toutes les tâches du pipeline.
- 6
- Paramètres utilisés pour toutes les tâches du pipeline.
- 7
- Spécifie la liste des tâches utilisées dans le pipeline.
- 8
- La tâche
build-image, qui utilise la tâchebuildahClusterTaskpour construire des images d'application à partir d'un dépôt Git donné. - 9
- Task
apply-manifests, qui utilise une tâche définie par l'utilisateur portant le même nom. - 10
- Spécifie l'ordre dans lequel les tâches sont exécutées dans un pipeline. Dans cet exemple, la tâche
apply-manifestsn'est exécutée qu'une fois la tâchebuild-imageterminée.
L'opérateur Red Hat OpenShift Pipelines installe la tâche de cluster Buildah et crée le compte de service pipeline avec des permissions suffisantes pour construire et pousser une image. La tâche Buildah cluster peut échouer si elle est associée à un compte de service différent avec des autorisations insuffisantes.
3.2.2.6. Exécution du pipeline
Un site PipelineRun est un type de ressource qui lie un pipeline, des espaces de travail, des informations d'identification et un ensemble de valeurs de paramètres spécifiques à un scénario pour exécuter le flux de travail CI/CD.
Un site PipelineRun est l'instance en cours d'exécution d'un pipeline. Il instancie un pipeline pour l'exécuter avec des entrées, des sorties et des paramètres d'exécution spécifiques sur un cluster. Il crée également une exécution de tâche pour chaque tâche de l'exécution du pipeline.
Le pipeline exécute les tâches de manière séquentielle jusqu'à ce qu'elles soient terminées ou qu'une tâche échoue. Le champ status suit la progression de chaque tâche et la stocke à des fins de contrôle et d'audit.
L'exemple suivant exécute le pipeline build-and-deploy avec les ressources et les paramètres appropriés :
apiVersion: tekton.dev/v1beta1
kind: PipelineRun
metadata:
name: build-deploy-api-pipelinerun
spec:
pipelineRef:
name: build-and-deploy
params:
- name: deployment-name
value: vote-api
- name: git-url
value: https://github.com/openshift-pipelines/vote-api.git
- name: IMAGE
value: image-registry.openshift-image-registry.svc:5000/pipelines-tutorial/vote-api
workspaces:
- name: shared-workspace
volumeClaimTemplate:
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 500Mi- 1
- Exécution du pipeline Version de l'API
v1beta1. - 2
- Le type d'objet Kubernetes. Dans cet exemple,
PipelineRun. - 3
- Nom unique permettant d'identifier cette canalisation.
- 4
- Nom du pipeline à exécuter. Dans cet exemple,
build-and-deploy. - 5
- La liste des paramètres nécessaires à l'exécution du pipeline.
- 6
- Espace de travail utilisé par le pipeline.
3.2.2.7. Espaces de travail
Il est recommandé d'utiliser des espaces de travail au lieu des CR PipelineResource dans Red Hat OpenShift Pipelines, car les CR PipelineResource sont difficiles à déboguer, limités dans leur portée et rendent les tâches moins réutilisables.
Les espaces de travail déclarent les volumes de stockage partagés dont une tâche d'un pipeline a besoin au moment de l'exécution pour recevoir des données d'entrée ou fournir des données de sortie. Au lieu de spécifier l'emplacement réel des volumes, les espaces de travail vous permettent de déclarer le système de fichiers ou les parties du système de fichiers qui seraient nécessaires au moment de l'exécution. Une tâche ou un pipeline déclare l'espace de travail et vous devez fournir les détails de l'emplacement spécifique du volume. Celui-ci est ensuite monté dans cet espace de travail lors de l'exécution d'une tâche ou d'un pipeline. Cette séparation entre la déclaration de volume et les volumes de stockage au moment de l'exécution rend les tâches réutilisables, flexibles et indépendantes de l'environnement de l'utilisateur.
Avec les espaces de travail, vous pouvez
- Stocker les entrées et sorties des tâches
- Partager des données entre les tâches
- Utilisez-le comme point de montage pour les informations d'identification contenues dans les secrets
- L'utiliser comme point de montage pour les configurations contenues dans les cartes de configuration
- L'utiliser comme point de montage pour les outils communs partagés par une organisation
- Créer un cache d'artefacts de construction qui accélère les travaux
Vous pouvez spécifier des espaces de travail dans les sites TaskRun ou PipelineRun en utilisant :
- Une carte de configuration ou un secret en lecture seule
- Une revendication de volume persistant existante partagée avec d'autres tâches
- Une demande de volume persistante à partir d'un modèle de demande de volume fourni
-
Une adresse
emptyDirqui est rejetée à la fin de l'exécution de la tâche
L'exemple suivant montre un extrait de code du pipeline build-and-deploy, qui déclare un espace de travail shared-workspace pour les tâches build-image et apply-manifests telles que définies dans le pipeline.
apiVersion: tekton.dev/v1beta1
kind: Pipeline
metadata:
name: build-and-deploy
spec:
workspaces:
- name: shared-workspace
params:
...
tasks:
- name: build-image
taskRef:
name: buildah
kind: ClusterTask
params:
- name: TLSVERIFY
value: "false"
- name: IMAGE
value: $(params.IMAGE)
workspaces:
- name: source
workspace: shared-workspace
runAfter:
- fetch-repository
- name: apply-manifests
taskRef:
name: apply-manifests
workspaces:
- name: source
workspace: shared-workspace
runAfter:
- build-image
...- 1
- Liste des espaces de travail partagés entre les tâches définies dans le pipeline. Un pipeline peut définir autant d'espaces de travail que nécessaire. Dans cet exemple, un seul espace de travail nommé
shared-workspaceest déclaré. - 2
- Définition des tâches utilisées dans le pipeline. Cet extrait définit deux tâches,
build-imageetapply-manifests, qui partagent un espace de travail commun. - 3
- Liste des espaces de travail utilisés dans la tâche
build-image. Une définition de tâche peut inclure autant d'espaces de travail que nécessaire. Toutefois, il est recommandé qu'une tâche utilise au maximum un espace de travail accessible en écriture. - 4
- Nom qui identifie de manière unique l'espace de travail utilisé dans la tâche. Cette tâche utilise un espace de travail nommé
source. - 5
- Nom de l'espace de travail du pipeline utilisé par la tâche. Notez que l'espace de travail
sourceutilise à son tour l'espace de travail du pipeline nomméshared-workspace. - 6
- Liste des espaces de travail utilisés dans la tâche
apply-manifests. Notez que cette tâche partage l'espace de travailsourceavec la tâchebuild-image.
Les espaces de travail aident les tâches à partager des données et vous permettent de spécifier un ou plusieurs volumes dont chaque tâche du pipeline a besoin pendant son exécution. Vous pouvez créer une demande de volume persistant ou fournir un modèle de demande de volume qui crée une demande de volume persistant pour vous.
L'extrait de code suivant de l'exécution du pipeline build-deploy-api-pipelinerun utilise un modèle de demande de volume pour créer une demande de volume persistante afin de définir le volume de stockage de l'espace de travail shared-workspace utilisé dans le pipeline build-and-deploy.
apiVersion: tekton.dev/v1beta1
kind: PipelineRun
metadata:
name: build-deploy-api-pipelinerun
spec:
pipelineRef:
name: build-and-deploy
params:
...
workspaces:
- name: shared-workspace
volumeClaimTemplate:
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 500Mi- 1
- Spécifie la liste des espaces de travail du pipeline pour lesquels la liaison de volume sera fournie lors de l'exécution du pipeline.
- 2
- Le nom de l'espace de travail dans le pipeline pour lequel le volume est fourni.
- 3
- Spécifie un modèle de revendication de volume qui crée une revendication de volume persistante pour définir le volume de stockage de l'espace de travail.
3.2.2.8. Déclencheurs
Utilisez Triggers en conjonction avec les pipelines pour créer un système CI/CD à part entière où les ressources Kubernetes définissent l'ensemble de l'exécution CI/CD. Les déclencheurs capturent les événements externes, tels qu'une demande d'extraction Git, et les traitent pour en extraire des informations clés. La mise en correspondance de ces données d'événement avec un ensemble de paramètres prédéfinis déclenche une série de tâches qui peuvent ensuite créer et déployer des ressources Kubernetes et instancier le pipeline.
Par exemple, vous définissez un flux de travail CI/CD à l'aide de Red Hat OpenShift Pipelines pour votre application. Le pipeline doit démarrer pour que toute nouvelle modification prenne effet dans le référentiel de l'application. Les déclencheurs automatisent ce processus en capturant et en traitant tout événement de changement et en déclenchant une exécution du pipeline qui déploie la nouvelle image avec les dernières modifications.
Les déclencheurs sont constitués des principales ressources suivantes, qui fonctionnent ensemble pour former un système CI/CD réutilisable, découplé et autonome :
La ressource
TriggerBindingextrait les champs d'une charge utile d'événement et les stocke en tant que paramètres.L'exemple suivant montre un extrait de code de la ressource
TriggerBinding, qui extrait les informations relatives au dépôt Git de la charge utile de l'événement reçu :apiVersion: triggers.tekton.dev/v1beta11 kind: TriggerBinding2 metadata: name: vote-app3 spec: params:4 - name: git-repo-url value: $(body.repository.url) - name: git-repo-name value: $(body.repository.name) - name: git-revision value: $(body.head_commit.id)- 1
- La version API de la ressource
TriggerBinding. Dans cet exemple,v1beta1. - 2
- Spécifie le type d'objet Kubernetes. Dans cet exemple,
TriggerBinding. - 3
- Nom unique pour identifier la ressource
TriggerBinding. - 4
- Liste des paramètres qui seront extraits de la charge utile de l'événement reçu et transmis à la ressource
TriggerTemplate. Dans cet exemple, l'URL, le nom et la révision du dépôt Git sont extraits du corps de l'événement.
La ressource
TriggerTemplatesert de norme pour la façon dont les ressources doivent être créées. Elle spécifie la manière dont les données paramétrées de la ressourceTriggerBindingdoivent être utilisées. Un modèle de déclenchement reçoit des données de la liaison de déclenchement, puis effectue une série d'actions qui aboutissent à la création de nouvelles ressources de pipeline et au lancement d'un nouveau cycle de pipeline.L'exemple suivant montre un extrait de code d'une ressource
TriggerTemplate, qui crée un pipeline en utilisant les informations du dépôt Git reçues de la ressourceTriggerBindingque vous venez de créer :apiVersion: triggers.tekton.dev/v1beta11 kind: TriggerTemplate2 metadata: name: vote-app3 spec: params:4 - name: git-repo-url description: The git repository url - name: git-revision description: The git revision default: pipelines-1.9 - name: git-repo-name description: The name of the deployment to be created / patched resourcetemplates:5 - apiVersion: tekton.dev/v1beta1 kind: PipelineRun metadata: name: build-deploy-$(tt.params.git-repo-name)-$(uid) spec: serviceAccountName: pipeline pipelineRef: name: build-and-deploy params: - name: deployment-name value: $(tt.params.git-repo-name) - name: git-url value: $(tt.params.git-repo-url) - name: git-revision value: $(tt.params.git-revision) - name: IMAGE value: image-registry.openshift-image-registry.svc:5000/pipelines-tutorial/$(tt.params.git-repo-name) workspaces: - name: shared-workspace volumeClaimTemplate: spec: accessModes: - ReadWriteOnce resources: requests: storage: 500Mi- 1
- La version API de la ressource
TriggerTemplate. Dans cet exemple,v1beta1. - 2
- Spécifie le type d'objet Kubernetes. Dans cet exemple,
TriggerTemplate. - 3
- Nom unique pour identifier la ressource
TriggerTemplate. - 4
- Paramètres fournis par la ressource
TriggerBinding. - 5
- Liste des modèles qui spécifient la manière dont les ressources doivent être créées en utilisant les paramètres reçus par les ressources
TriggerBindingouEventListener.
La ressource
Triggercombine les ressourcesTriggerBindingetTriggerTemplateet, éventuellement, le processeur d'événementsinterceptors.Les intercepteurs traitent tous les événements pour une plateforme spécifique qui s'exécute avant la ressource
TriggerBinding. Vous pouvez utiliser les intercepteurs pour filtrer les données utiles, vérifier les événements, définir et tester les conditions de déclenchement et mettre en œuvre d'autres traitements utiles. Les intercepteurs utilisent le secret pour la vérification des événements. Une fois que les données de l'événement passent par un intercepteur, elles sont transmises au déclencheur avant que vous ne transmettiez les données de la charge utile à la liaison du déclencheur. Vous pouvez également utiliser un intercepteur pour modifier le comportement du déclencheur associé référencé dans la spécificationEventListener.L'exemple suivant montre un extrait de code d'une ressource
Trigger, nomméevote-trigger, qui connecte les ressourcesTriggerBindingetTriggerTemplate, ainsi que le processeur d'événementsinterceptors.apiVersion: triggers.tekton.dev/v1beta11 kind: Trigger2 metadata: name: vote-trigger3 spec: serviceAccountName: pipeline4 interceptors: - ref: name: "github"5 params:6 - name: "secretRef" value: secretName: github-secret secretKey: secretToken - name: "eventTypes" value: ["push"] bindings: - ref: vote-app7 template:8 ref: vote-app --- apiVersion: v1 kind: Secret9 metadata: name: github-secret type: Opaque stringData: secretToken: "1234567"- 1
- La version API de la ressource
Trigger. Dans cet exemple,v1beta1. - 2
- Spécifie le type d'objet Kubernetes. Dans cet exemple,
Trigger. - 3
- Nom unique pour identifier la ressource
Trigger. - 4
- Nom du compte de service à utiliser.
- 5
- Nom de l'intercepteur à référencer. Dans cet exemple,
github. - 6
- Paramètres souhaités à spécifier.
- 7
- Nom de la ressource
TriggerBindingà connecter à la ressourceTriggerTemplate. - 8
- Nom de la ressource
TriggerTemplateà connecter à la ressourceTriggerBinding. - 9
- Secret à utiliser pour vérifier les événements.
La ressource
EventListenerfournit un point de terminaison, ou un puits d'événements, qui écoute les événements HTTP entrants avec une charge utile JSON. Elle extrait les paramètres de l'événement de chaque ressourceTriggerBinding, puis traite ces données pour créer des ressources Kubernetes comme spécifié par la ressourceTriggerTemplatecorrespondante. La ressourceEventListenereffectue également un traitement léger des événements ou un filtrage de base sur la charge utile à l'aide de l'événementinterceptors, qui identifie le type de charge utile et le modifie éventuellement. Actuellement, les déclencheurs de pipeline prennent en charge cinq types d'intercepteurs : Webhook Interceptors, GitHub Interceptors, GitLab Interceptors, Bitbucket Interceptors, et Common Expression Language (CEL) Interceptors.L'exemple suivant montre une ressource
EventListenerqui fait référence à la ressourceTriggernomméevote-trigger.apiVersion: triggers.tekton.dev/v1beta11 kind: EventListener2 metadata: name: vote-app3 spec: serviceAccountName: pipeline4 triggers: - triggerRef: vote-trigger5 - 1
- La version API de la ressource
EventListener. Dans cet exemple,v1beta1. - 2
- Spécifie le type d'objet Kubernetes. Dans cet exemple,
EventListener. - 3
- Nom unique pour identifier la ressource
EventListener. - 4
- Nom du compte de service à utiliser.
- 5
- Nom de la ressource
Triggerréférencée par la ressourceEventListener.
3.3. Installation d'OpenShift Pipelines
Ce guide guide les administrateurs de cluster à travers le processus d'installation de Red Hat OpenShift Pipelines Operator sur un cluster OpenShift Container Platform.
Conditions préalables
-
Vous avez accès à un cluster OpenShift Container Platform en utilisant un compte avec des permissions
cluster-admin. -
Vous avez installé
ocCLI. -
Vous avez installé OpenShift Pipelines (
tkn) CLI sur votre système local. - Votre cluster a la capacité Marketplace activée ou la source du catalogue Red Hat Operator configurée manuellement.
3.3.1. Installation de l'opérateur Red Hat OpenShift Pipelines dans la console web
Vous pouvez installer Red Hat OpenShift Pipelines en utilisant l'Opérateur listé dans le OperatorHub de OpenShift Container Platform. Lorsque vous installez l'Opérateur Red Hat OpenShift Pipelines, les ressources personnalisées (CR) requises pour la configuration des pipelines sont automatiquement installées avec l'Opérateur.
La définition de ressource personnalisée (CRD) par défaut de l'opérateur config.operator.tekton.dev est désormais remplacée par tektonconfigs.operator.tekton.dev. En outre, l'opérateur fournit les CRD supplémentaires suivants pour gérer individuellement les composants OpenShift Pipelines : tektonpipelines.operator.tekton.dev, tektontriggers.operator.tekton.dev et tektonaddons.operator.tekton.dev.
Si OpenShift Pipelines est déjà installé sur votre cluster, l'installation existante est mise à niveau de manière transparente. L'opérateur remplacera l'instance de config.operator.tekton.dev sur votre cluster par une instance de tektonconfigs.operator.tekton.dev et des objets supplémentaires des autres CRD si nécessaire.
Si vous avez modifié manuellement votre installation existante, par exemple en changeant l'espace de noms cible dans l'instance CRD config.operator.tekton.dev en apportant des modifications au champ resource name - cluster, le chemin de mise à niveau n'est pas fluide. Dans de tels cas, le flux de travail recommandé est de désinstaller votre installation et de réinstaller Red Hat OpenShift Pipelines Operator.
L'Opérateur Red Hat OpenShift Pipelines offre désormais la possibilité de choisir les composants que vous souhaitez installer en spécifiant des profils dans le cadre de la CR TektonConfig. Le CR TektonConfig est automatiquement installé lors de l'installation de l'Opérateur. Les profils pris en charge sont les suivants :
- Lite : Cette option n'installe que les pipelines Tekton.
- Basique : Ceci installe les Pipelines Tekton et les Déclencheurs Tekton.
-
All : Il s'agit du profil par défaut utilisé lors de l'installation de
TektonConfigCR. Ce profil installe tous les composants Tekton : Tekton Pipelines, Tekton Triggers, Tekton Addons (qui incluent les ressourcesClusterTasks,ClusterTriggerBindings,ConsoleCLIDownload,ConsoleQuickStartetConsoleYAMLSample).
Procédure
- Dans la perspective Administrator de la console web, naviguez vers Operators → OperatorHub.
-
Utilisez la boîte Filter by keyword pour rechercher
Red Hat OpenShift PipelinesOperator dans le catalogue. Cliquez sur la tuile Red Hat OpenShift Pipelines Operator. - Lisez la brève description de l'opérateur sur la page Red Hat OpenShift Pipelines Operator. Cliquez sur Install.
Sur la page Install Operator:
-
Sélectionnez All namespaces on the cluster (default) pour l'espace de noms Installation Mode. Ce mode installe l'opérateur dans l'espace de noms par défaut
openshift-operators, ce qui permet à l'opérateur de surveiller tous les espaces de noms du cluster et d'y avoir accès. - Sélectionnez Automatic pour la stratégie d'approbation Approval Strategy. Cela garantit que les futures mises à niveau de l'opérateur sont gérées automatiquement par le gestionnaire du cycle de vie de l'opérateur (OLM). Si vous sélectionnez la stratégie d'approbation Manual, OLM crée une demande de mise à jour. En tant qu'administrateur de cluster, vous devez ensuite approuver manuellement la demande de mise à jour OLM pour mettre à jour l'opérateur vers la nouvelle version.
Sélectionnez un site Update Channel.
-
Le canal
latestpermet l'installation de la version stable la plus récente de Red Hat OpenShift Pipelines Operator. Actuellement, il s'agit du canal par défaut pour l'installation de Red Hat OpenShift Pipelines Operator. Pour installer une version spécifique de Red Hat OpenShift Pipelines Operator, les administrateurs de clusters peuvent utiliser le canal
pipelines-<version>correspondant. Par exemple, pour installer la version1.8.xde Red Hat OpenShift Pipelines Operator, vous pouvez utiliser le canalpipelines-1.8.NoteÀ partir d'OpenShift Container Platform 4.11, les canaux
previewetstablepour l'installation et la mise à niveau de Red Hat OpenShift Pipelines Operator ne sont pas disponibles. Cependant, dans OpenShift Container Platform 4.10 et les versions antérieures, vous pouvez utiliser les canauxpreviewetstablepour installer et mettre à niveau l'Opérateur.
-
Le canal
-
Sélectionnez All namespaces on the cluster (default) pour l'espace de noms Installation Mode. Ce mode installe l'opérateur dans l'espace de noms par défaut
Cliquez sur Install. Vous verrez l'opérateur sur la page Installed Operators.
NoteL'opérateur est installé automatiquement dans l'espace de noms
openshift-operators.Vérifiez que le site Status est défini sur Succeeded Up to date pour confirmer la réussite de l'installation de Red Hat OpenShift Pipelines Operator.
AvertissementLe statut de réussite peut être Succeeded Up to date même si l'installation d'autres composants est en cours. Il est donc important de vérifier l'installation manuellement dans le terminal.
Vérifiez que tous les composants de Red Hat OpenShift Pipelines Operator ont été installés avec succès. Connectez-vous au cluster sur le terminal et exécutez la commande suivante :
$ oc get tektonconfig configExemple de sortie
NAME VERSION READY REASON config 1.9.2 TrueSi la condition READY est True, l'opérateur et ses composants ont été installés avec succès.
De plus, vérifiez les versions des composants en exécutant la commande suivante :
$ oc get tektonpipeline,tektontrigger,tektonaddon,pacExemple de sortie
NAME VERSION READY REASON tektonpipeline.operator.tekton.dev/pipeline v0.41.1 True NAME VERSION READY REASON tektontrigger.operator.tekton.dev/trigger v0.22.2 True NAME VERSION READY REASON tektonaddon.operator.tekton.dev/addon 1.9.2 True NAME VERSION READY REASON openshiftpipelinesascode.operator.tekton.dev/pipelines-as-code v0.15.5 True
3.3.2. Installer l'opérateur OpenShift Pipelines à l'aide du CLI
Vous pouvez installer Red Hat OpenShift Pipelines Operator depuis OperatorHub en utilisant le CLI.
Procédure
Créez un fichier YAML d'objet d'abonnement pour abonner un espace de noms à l'opérateur Red Hat OpenShift Pipelines, par exemple,
sub.yaml:Exemple d'abonnement
apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: openshift-pipelines-operator namespace: openshift-operators spec: channel: <channel name>1 name: openshift-pipelines-operator-rh2 source: redhat-operators3 sourceNamespace: openshift-marketplace4 - 1
- Le nom du canal de l'opérateur. Le canal
pipelines-<version>est le canal par défaut. Par exemple, le canal par défaut pour Red Hat OpenShift Pipelines Operator version1.7estpipelines-1.7. Le canallatestpermet l'installation de la version stable la plus récente de l'Opérateur Red Hat OpenShift Pipelines. - 2
- Nom de l'opérateur auquel s'abonner.
- 3
- Nom de la CatalogSource qui fournit l'opérateur.
- 4
- Espace de noms du CatalogSource. Utilisez
openshift-marketplacepour les CatalogSources par défaut d'OperatorHub.
Créer l'objet Abonnement :
$ oc apply -f sub.yamlL'opérateur Red Hat OpenShift Pipelines est désormais installé dans l'espace de noms cible par défaut
openshift-operators.
3.3.3. Opérateur Red Hat OpenShift Pipelines dans un environnement restreint
L'opérateur Red Hat OpenShift Pipelines permet de prendre en charge l'installation de pipelines dans un environnement réseau restreint.
L'opérateur installe un webhook proxy qui définit les variables d'environnement proxy dans les conteneurs du pod créé par tekton-controllers sur la base de l'objet proxy cluster. Il définit également les variables d'environnement proxy dans les ressources TektonPipelines, TektonTriggers, Controllers, Webhooks, et Operator Proxy Webhook.
Par défaut, le proxy webhook est désactivé pour l'espace de noms openshift-pipelines. Pour le désactiver pour tout autre espace de noms, vous pouvez ajouter l'étiquette operator.tekton.dev/disable-proxy: true à l'objet namespace.
3.3.4. Désactiver la création automatique de ressources RBAC
L'installation par défaut de Red Hat OpenShift Pipelines Operator crée plusieurs ressources de contrôle d'accès basé sur les rôles (RBAC) pour tous les espaces de noms dans le cluster, à l'exception des espaces de noms correspondant au modèle d'expression régulière ^(openshift|kube)-*. Parmi ces ressources RBAC, la ressource de liaison de rôle pipelines-scc-rolebinding security context constraint (SCC) est un problème de sécurité potentiel, car le SCC pipelines-scc associé possède le privilège RunAsAny.
Pour désactiver la création automatique de ressources RBAC à l'échelle du cluster après l'installation de Red Hat OpenShift Pipelines Operator, les administrateurs de cluster peuvent définir le paramètre createRbacResource sur false dans la ressource personnalisée (CR) TektonConfig au niveau du cluster.
Exemple TektonConfig CR
apiVersion: operator.tekton.dev/v1alpha1
kind: TektonConfig
metadata:
name: config
spec:
params:
- name: createRbacResource
value: "false"
profile: all
targetNamespace: openshift-pipelines
addon:
params:
- name: clusterTasks
value: "true"
- name: pipelineTemplates
value: "true"
...
En tant qu'administrateur de cluster ou utilisateur disposant des privilèges appropriés, lorsque vous désactivez la création automatique de ressources RBAC pour tous les espaces de noms, la ressource par défaut ClusterTask ne fonctionne pas. Pour que la ressource ClusterTask fonctionne, vous devez créer manuellement les ressources RBAC pour chaque espace de noms prévu.
3.4. Désinstallation d'OpenShift Pipelines
Les administrateurs de cluster peuvent désinstaller Red Hat OpenShift Pipelines Operator en effectuant les étapes suivantes :
- Supprimez les ressources personnalisées (CR) qui ont été ajoutées par défaut lors de l'installation de Red Hat OpenShift Pipelines Operator.
Supprimer les CR des composants optionnels, tels que les chaînes Tekton, qui dépendent de l'opérateur.
ImportantSi vous désinstallez l'Opérateur sans supprimer les CR des composants optionnels, vous ne pourrez pas les supprimer ultérieurement.
- Désinstallez l'opérateur Red Hat OpenShift Pipelines.
Désinstaller uniquement l'Opérateur ne supprimera pas les composants Red Hat OpenShift Pipelines créés par défaut lors de l'installation de l'Opérateur.
3.4.1. Suppression des composants Red Hat OpenShift Pipelines et des ressources personnalisées
Supprimez les ressources personnalisées (CR) créées par défaut lors de l'installation de Red Hat OpenShift Pipelines Operator.
Procédure
- Dans la perspective Administrator de la console web, naviguez vers Administration → Custom Resource Definition.
-
Tapez
config.operator.tekton.devdans la boîte Filter by name pour rechercher les CR de Red Hat OpenShift Pipelines Operator. - Cliquez sur CRD Config pour voir la page Custom Resource Definition Details.
Cliquez sur le menu déroulant Actions et sélectionnez Delete Custom Resource Definition.
NoteLa suppression des CR supprimera les composants Red Hat OpenShift Pipelines, et toutes les tâches et les pipelines sur le cluster seront perdus.
- Cliquez sur Delete pour confirmer la suppression des CR.
Répétez la procédure pour trouver et supprimer les CR des composants optionnels tels que les chaînes Tekton, avant de désinstaller l'opérateur. Si vous désinstallez l'opérateur sans retirer les CR des composants optionnels, vous ne pourrez pas les retirer ultérieurement.
3.4.2. Désinstallation de l'opérateur Red Hat OpenShift Pipelines
Procédure
-
À partir de la page Operators → OperatorHub, utilisez la boîte Filter by keyword pour rechercher
Red Hat OpenShift Pipelines Operator. - Cliquez sur la tuile OpenShift Pipelines Operator. La tuile Opérateur indique qu'elle est installée.
- Dans la page du descripteur OpenShift Pipelines Operator, cliquez sur Uninstall.
3.5. Créer des solutions CI/CD pour les applications à l'aide d'OpenShift Pipelines
Avec Red Hat OpenShift Pipelines, vous pouvez créer une solution CI/CD personnalisée pour construire, tester et déployer votre application.
Pour créer un pipeline CI/CD complet et autonome pour une application, effectuez les tâches suivantes :
- Créez des tâches personnalisées ou installez des tâches réutilisables existantes.
- Créez et définissez le pipeline de livraison pour votre application.
Fournissez un volume de stockage ou un système de fichiers attaché à un espace de travail pour l'exécution du pipeline, en utilisant l'une des approches suivantes :
- Spécifier un modèle de revendication de volume qui crée une revendication de volume persistante
- Spécifier une revendication de volume persistant
-
Créer un objet
PipelineRunpour instancier et invoquer le pipeline. - Ajouter des déclencheurs pour capturer les événements dans le référentiel source.
Cette section utilise l'exemple pipelines-tutorial pour démontrer les tâches précédentes. L'exemple utilise une application simple qui se compose des éléments suivants
-
Une interface frontale,
pipelines-vote-ui, dont le code source se trouve dans le dépôt Gitpipelines-vote-uiGit. -
Une interface back-end,
pipelines-vote-api, dont le code source se trouve dans le dépôt Gitpipelines-vote-apiGit. -
Les tâches
apply-manifestsetupdate-deploymentdans le dépôtpipelines-tutorialGit.
3.5.1. Conditions préalables
- Vous avez accès à un cluster OpenShift Container Platform.
- Vous avez installé OpenShift Pipelines à l'aide de l'opérateur Red Hat OpenShift Pipelines Operator répertorié dans l'OpenShift OperatorHub. Une fois installé, il s'applique à l'ensemble du cluster.
- Vous avez installé OpenShift Pipelines CLI.
-
Vous avez forké le front-end
pipelines-vote-uiet back-endpipelines-vote-apiÀ l'aide de votre identifiant GitHub, et vous disposez d'un accès administrateur à ces dépôts. -
Facultatif : vous avez cloné le dépôt
pipelines-tutorialDépôt Git.
3.5.2. Création d'un projet et vérification de votre compte de service de gazoduc
Procédure
Connectez-vous à votre cluster OpenShift Container Platform :
$ oc login -u <login> -p <password> https://openshift.example.com:6443Créez un projet pour l'exemple d'application. Pour cet exemple de flux de travail, créez le projet
pipelines-tutorial:$ oc new-project pipelines-tutorialNoteSi vous créez un projet avec un nom différent, veillez à mettre à jour les URL des ressources utilisées dans l'exemple avec le nom de votre projet.
Consulter le compte de service
pipeline:Red Hat OpenShift Pipelines Operator ajoute et configure un compte de service nommé
pipelinequi dispose de suffisamment d'autorisations pour construire et pousser une image. Ce compte de service est utilisé par l'objetPipelineRun.$ oc get serviceaccount pipeline
3.5.3. Création de tâches de pipeline
Procédure
Installez les ressources de tâches
apply-manifestsetupdate-deploymentà partir du référentielpipelines-tutorial, qui contient une liste de tâches réutilisables pour les pipelines :$ oc create -f https://raw.githubusercontent.com/openshift/pipelines-tutorial/pipelines-1.9/01_pipeline/01_apply_manifest_task.yaml $ oc create -f https://raw.githubusercontent.com/openshift/pipelines-tutorial/pipelines-1.9/01_pipeline/02_update_deployment_task.yamlUtilisez la commande
tkn task listpour répertorier les tâches que vous avez créées :$ tkn task listLa sortie vérifie que les ressources de tâches
apply-manifestsetupdate-deploymentont été créées :NAME DESCRIPTION AGE apply-manifests 1 minute ago update-deployment 48 seconds agoUtilisez la commande
tkn clustertasks listpour dresser la liste des tâches de cluster supplémentaires installées par l'opérateur, telles quebuildahets2i-python:NotePour utiliser la tâche
buildahcluster dans un environnement restreint, vous devez vous assurer que le fichier Docker utilise un flux d'images interne comme image de base.$ tkn clustertasks listLa liste des ressources
ClusterTaskinstallées par l'opérateur s'affiche :NAME DESCRIPTION AGE buildah 1 day ago git-clone 1 day ago s2i-python 1 day ago tkn 1 day ago
Dans Red Hat OpenShift Pipelines 1.10, la fonctionnalité de tâche de cluster est dépréciée et il est prévu de la supprimer dans une prochaine version.
3.5.4. Assemblage d'un pipeline
Un pipeline représente un flux CI/CD et est défini par les tâches à exécuter. Il est conçu pour être générique et réutilisable dans de multiples applications et environnements.
Un pipeline spécifie la manière dont les tâches interagissent entre elles et leur ordre d'exécution à l'aide des paramètres from et runAfter. Il utilise le champ workspaces pour spécifier un ou plusieurs volumes dont chaque tâche du pipeline a besoin pendant son exécution.
Dans cette section, vous allez créer un pipeline qui récupère le code source de l'application sur GitHub, puis le construit et le déploie sur OpenShift Container Platform.
Le pipeline effectue les tâches suivantes pour l'application back-end pipelines-vote-api et l'application front-end pipelines-vote-ui:
-
Clone le code source de l'application à partir du dépôt Git en se référant aux paramètres
git-urletgit-revision. -
Construit l'image du conteneur à l'aide de la tâche de cluster
buildah. -
Pousse l'image dans le registre d'images OpenShift en se référant au paramètre
image. -
Déploie la nouvelle image sur OpenShift Container Platform en utilisant les tâches
apply-manifestsetupdate-deployment.
Procédure
Copiez le contenu du fichier YAML de l'exemple de pipeline suivant et enregistrez-le :
apiVersion: tekton.dev/v1beta1 kind: Pipeline metadata: name: build-and-deploy spec: workspaces: - name: shared-workspace params: - name: deployment-name type: string description: name of the deployment to be patched - name: git-url type: string description: url of the git repo for the code of deployment - name: git-revision type: string description: revision to be used from repo of the code for deployment default: "pipelines-1.9" - name: IMAGE type: string description: image to be built from the code tasks: - name: fetch-repository taskRef: name: git-clone kind: ClusterTask workspaces: - name: output workspace: shared-workspace params: - name: url value: $(params.git-url) - name: subdirectory value: "" - name: deleteExisting value: "true" - name: revision value: $(params.git-revision) - name: build-image taskRef: name: buildah kind: ClusterTask params: - name: IMAGE value: $(params.IMAGE) workspaces: - name: source workspace: shared-workspace runAfter: - fetch-repository - name: apply-manifests taskRef: name: apply-manifests workspaces: - name: source workspace: shared-workspace runAfter: - build-image - name: update-deployment taskRef: name: update-deployment params: - name: deployment value: $(params.deployment-name) - name: IMAGE value: $(params.IMAGE) runAfter: - apply-manifestsLa définition du pipeline fait abstraction des spécificités du référentiel source Git et des registres d'images. Ces détails sont ajoutés à l'adresse
paramslorsqu'un pipeline est déclenché et exécuté.Créer le pipeline :
oc create -f <pipeline-yaml-fichier-nom.yaml>Vous pouvez également exécuter le fichier YAML directement à partir du dépôt Git :
$ oc create -f https://raw.githubusercontent.com/openshift/pipelines-tutorial/pipelines-1.9/01_pipeline/04_pipeline.yamlUtilisez la commande
tkn pipeline listpour vérifier que le pipeline est ajouté à l'application :$ tkn pipeline listLa sortie vérifie que le pipeline
build-and-deploya été créé :NAME AGE LAST RUN STARTED DURATION STATUS build-and-deploy 1 minute ago --- --- --- ---
3.5.5. Miroir d'images pour l'exécution de pipelines dans un environnement restreint
Pour exécuter OpenShift Pipelines dans un cluster déconnecté ou un cluster provisionné dans un environnement restreint, assurez-vous que l'opérateur d'échantillons est configuré pour un réseau restreint, ou qu'un administrateur de cluster a créé un cluster avec un registre en miroir.
La procédure suivante utilise l'exemple pipelines-tutorial pour créer un pipeline pour une application dans un environnement restreint à l'aide d'un cluster avec un registre miroir. Pour que l'exemple pipelines-tutorial fonctionne dans un environnement restreint, vous devez mettre en miroir les images de constructeur respectives du registre miroir pour l'interface frontale, pipelines-vote-ui; l'interface dorsale, pipelines-vote-api; et le registre cli.
Procédure
Miroir de l'image du constructeur à partir du registre des miroirs pour l'interface frontale,
pipelines-vote-ui.Vérifiez que la balise images requise n'est pas importée :
$ oc describe imagestream python -n openshiftExemple de sortie
Name: python Namespace: openshift [...] 3.8-ubi8 (latest) tagged from registry.redhat.io/ubi8/python-38:latest prefer registry pullthrough when referencing this tag Build and run Python 3.8 applications on UBI 8. For more information about using this builder image, including OpenShift considerations, see https://github.com/sclorg/s2i-python-container/blob/master/3.8/README.md. Tags: builder, python Supports: python:3.8, python Example Repo: https://github.com/sclorg/django-ex.git [...]Mettez en miroir la balise d'image prise en charge dans le registre privé :
$ oc image mirror registry.redhat.io/ubi8/python-38:latest <mirror-registry>:<port>/ubi8/python-38Importer l'image :
$ oc tag <mirror-registry>:<port>/ubi8/python-38 python:latest --scheduled -n openshiftVous devez périodiquement réimporter l'image. L'option
--scheduledpermet de réimporter automatiquement l'image.Vérifier que les images avec le tag donné ont été importées :
$ oc describe imagestream python -n openshiftExemple de sortie
Name: python Namespace: openshift [...] latest updates automatically from registry <mirror-registry>:<port>/ubi8/python-38 * <mirror-registry>:<port>/ubi8/python-38@sha256:3ee3c2e70251e75bfeac25c0c33356add9cc4abcbc9c51d858f39e4dc29c5f58 [...]
Miroir de l'image du constructeur à partir du registre des miroirs pour l'interface back-end,
pipelines-vote-api.Vérifiez que la balise images requise n'est pas importée :
$ oc describe imagestream golang -n openshiftExemple de sortie
Name: golang Namespace: openshift [...] 1.14.7-ubi8 (latest) tagged from registry.redhat.io/ubi8/go-toolset:1.14.7 prefer registry pullthrough when referencing this tag Build and run Go applications on UBI 8. For more information about using this builder image, including OpenShift considerations, see https://github.com/sclorg/golang-container/blob/master/README.md. Tags: builder, golang, go Supports: golang Example Repo: https://github.com/sclorg/golang-ex.git [...]Mettez en miroir la balise d'image prise en charge dans le registre privé :
$ oc image mirror registry.redhat.io/ubi8/go-toolset:1.14.7 <mirror-registry>:<port>/ubi8/go-toolsetImporter l'image :
$ oc tag <mirror-registry>:<port>/ubi8/go-toolset golang:latest --scheduled -n openshiftVous devez périodiquement réimporter l'image. L'option
--scheduledpermet de réimporter automatiquement l'image.Vérifier que les images avec le tag donné ont été importées :
$ oc describe imagestream golang -n openshiftExemple de sortie
Name: golang Namespace: openshift [...] latest updates automatically from registry <mirror-registry>:<port>/ubi8/go-toolset * <mirror-registry>:<port>/ubi8/go-toolset@sha256:59a74d581df3a2bd63ab55f7ac106677694bf612a1fe9e7e3e1487f55c421b37 [...]
Miroir de l'image du constructeur à partir du registre des miroirs pour le site
cli.Vérifiez que la balise images requise n'est pas importée :
$ oc describe imagestream cli -n openshiftExemple de sortie
Name: cli Namespace: openshift [...] latest updates automatically from registry quay.io/openshift-release-dev/ocp-v4.0-art-dev@sha256:65c68e8c22487375c4c6ce6f18ed5485915f2bf612e41fef6d41cbfcdb143551 * quay.io/openshift-release-dev/ocp-v4.0-art-dev@sha256:65c68e8c22487375c4c6ce6f18ed5485915f2bf612e41fef6d41cbfcdb143551 [...]Mettez en miroir la balise d'image prise en charge dans le registre privé :
$ oc image mirror quay.io/openshift-release-dev/ocp-v4.0-art-dev@sha256:65c68e8c22487375c4c6ce6f18ed5485915f2bf612e41fef6d41cbfcdb143551 <mirror-registry>:<port>/openshift-release-dev/ocp-v4.0-art-dev:latestImporter l'image :
$ oc tag <mirror-registry>:<port>/openshift-release-dev/ocp-v4.0-art-dev cli:latest --scheduled -n openshiftVous devez périodiquement réimporter l'image. L'option
--scheduledpermet de réimporter automatiquement l'image.Vérifier que les images avec le tag donné ont été importées :
$ oc describe imagestream cli -n openshiftExemple de sortie
Name: cli Namespace: openshift [...] latest updates automatically from registry <mirror-registry>:<port>/openshift-release-dev/ocp-v4.0-art-dev * <mirror-registry>:<port>/openshift-release-dev/ocp-v4.0-art-dev@sha256:65c68e8c22487375c4c6ce6f18ed5485915f2bf612e41fef6d41cbfcdb143551 [...]
3.5.6. Gestion d'un pipeline
Une ressource PipelineRun démarre un pipeline et le lie aux ressources Git et image qui doivent être utilisées pour l'invocation spécifique. Elle crée et démarre automatiquement les ressources TaskRun pour chaque tâche du pipeline.
Procédure
Démarrer le pipeline pour l'application back-end :
$ tkn pipeline start build-and-deploy \ -w name=shared-workspace,volumeClaimTemplateFile=https://raw.githubusercontent.com/openshift/pipelines-tutorial/pipelines-1.9/01_pipeline/03_persistent_volume_claim.yaml \ -p deployment-name=pipelines-vote-api \ -p git-url=https://github.com/openshift/pipelines-vote-api.git \ -p IMAGE='image-registry.openshift-image-registry.svc:5000/$(context.pipelineRun.namespace)/pipelines-vote-api' \ --use-param-defaultsLa commande précédente utilise un modèle de demande de volume, qui crée une demande de volume persistante pour l'exécution du pipeline.
Pour suivre la progression de l'exécution du pipeline, entrez la commande suivante: :
$ tkn pipelinerun logs <pipelinerun_id> -fLe <pipelinerun_id> de la commande ci-dessus est l'identifiant du site
PipelineRunqui a été renvoyé dans la sortie de la commande précédente.Démarrer le pipeline pour l'application frontale :
$ tkn pipeline start build-and-deploy \ -w name=shared-workspace,volumeClaimTemplateFile=https://raw.githubusercontent.com/openshift/pipelines-tutorial/pipelines-1.9/01_pipeline/03_persistent_volume_claim.yaml \ -p deployment-name=pipelines-vote-ui \ -p git-url=https://github.com/openshift/pipelines-vote-ui.git \ -p IMAGE='image-registry.openshift-image-registry.svc:5000/$(context.pipelineRun.namespace)/pipelines-vote-ui' \ --use-param-defaultsPour suivre la progression de l'exécution du pipeline, entrez la commande suivante :
$ tkn pipelinerun logs <pipelinerun_id> -fLe <pipelinerun_id> de la commande ci-dessus est l'identifiant du site
PipelineRunqui a été renvoyé dans la sortie de la commande précédente.Après quelques minutes, utilisez la commande
tkn pipelinerun listpour vérifier que le pipeline s'est déroulé correctement en listant toutes les exécutions du pipeline :$ tkn pipelinerun listLa sortie répertorie les exécutions du pipeline :
NAME STARTED DURATION STATUS build-and-deploy-run-xy7rw 1 hour ago 2 minutes Succeeded build-and-deploy-run-z2rz8 1 hour ago 19 minutes SucceededObtenir l'itinéraire de la demande :
$ oc get route pipelines-vote-ui --template='http://{{.spec.host}}'Notez la sortie de la commande précédente. Vous pouvez accéder à l'application en utilisant cette route.
Pour réexécuter le dernier pipeline, en utilisant les ressources du pipeline et le compte de service du pipeline précédent, exécutez :
$ tkn pipeline start build-and-deploy --last
3.5.7. Ajouter des déclencheurs à un pipeline
Les déclencheurs permettent aux pipelines de répondre aux événements GitHub externes, tels que les événements "push" et les "pull requests". Après avoir assemblé et démarré un pipeline pour l'application, ajoutez les ressources TriggerBinding, TriggerTemplate, Trigger, et EventListener pour capturer les événements GitHub.
Procédure
Copiez le contenu de l'exemple de fichier YAML
TriggerBindingsuivant et enregistrez-le :apiVersion: triggers.tekton.dev/v1beta1 kind: TriggerBinding metadata: name: vote-app spec: params: - name: git-repo-url value: $(body.repository.url) - name: git-repo-name value: $(body.repository.name) - name: git-revision value: $(body.head_commit.id)Créer la ressource
TriggerBinding:oc create -f <triggerbinding-yaml-file-name.yaml>Vous pouvez également créer la ressource
TriggerBindingdirectement à partir du dépôt Gitpipelines-tutorial:$ oc create -f https://raw.githubusercontent.com/openshift/pipelines-tutorial/pipelines-1.9/03_triggers/01_binding.yamlCopiez le contenu de l'exemple de fichier YAML
TriggerTemplatesuivant et enregistrez-le :apiVersion: triggers.tekton.dev/v1beta1 kind: TriggerTemplate metadata: name: vote-app spec: params: - name: git-repo-url description: The git repository url - name: git-revision description: The git revision default: pipelines-1.9 - name: git-repo-name description: The name of the deployment to be created / patched resourcetemplates: - apiVersion: tekton.dev/v1beta1 kind: PipelineRun metadata: generateName: build-deploy-$(tt.params.git-repo-name)- spec: serviceAccountName: pipeline pipelineRef: name: build-and-deploy params: - name: deployment-name value: $(tt.params.git-repo-name) - name: git-url value: $(tt.params.git-repo-url) - name: git-revision value: $(tt.params.git-revision) - name: IMAGE value: image-registry.openshift-image-registry.svc:5000/$(context.pipelineRun.namespace)/$(tt.params.git-repo-name) workspaces: - name: shared-workspace volumeClaimTemplate: spec: accessModes: - ReadWriteOnce resources: requests: storage: 500MiLe modèle spécifie un modèle de réclamation de volume pour créer une réclamation de volume persistante afin de définir le volume de stockage de l'espace de travail. Par conséquent, il n'est pas nécessaire de créer une demande de volume persistant pour assurer le stockage des données.
Créer la ressource
TriggerTemplate:oc create -f <triggertemplate-nom-de-fichier-yaml.yaml>Vous pouvez également créer la ressource
TriggerTemplatedirectement à partir du dépôt Gitpipelines-tutorial:$ oc create -f https://raw.githubusercontent.com/openshift/pipelines-tutorial/pipelines-1.9/03_triggers/02_template.yamlCopiez le contenu de l'exemple de fichier YAML
Triggersuivant et enregistrez-le :apiVersion: triggers.tekton.dev/v1beta1 kind: Trigger metadata: name: vote-trigger spec: serviceAccountName: pipeline bindings: - ref: vote-app template: ref: vote-appCréer la ressource
Trigger:oc create -f <trigger-yaml-file-name.yaml>Vous pouvez également créer la ressource
Triggerdirectement à partir du dépôt Gitpipelines-tutorial:$ oc create -f https://raw.githubusercontent.com/openshift/pipelines-tutorial/pipelines-1.9/03_triggers/03_trigger.yamlCopiez le contenu de l'exemple de fichier YAML
EventListenersuivant et enregistrez-le :apiVersion: triggers.tekton.dev/v1beta1 kind: EventListener metadata: name: vote-app spec: serviceAccountName: pipeline triggers: - triggerRef: vote-triggerSi vous n'avez pas défini de ressource personnalisée pour le déclencheur, ajoutez la spécification de liaison et de modèle au fichier YAML
EventListener, au lieu de vous référer au nom du déclencheur :apiVersion: triggers.tekton.dev/v1beta1 kind: EventListener metadata: name: vote-app spec: serviceAccountName: pipeline triggers: - bindings: - ref: vote-app template: ref: vote-appCréez la ressource
EventListeneren suivant les étapes suivantes :Pour créer une ressource
EventListenerà l'aide d'une connexion HTTPS sécurisée :Ajouter une étiquette pour activer la connexion HTTPS sécurisée à la ressource
Eventlistener:oc label namespace <ns-name> operator.tekton.dev/enable-annotation=enabledCréer la ressource
EventListener:oc create -f <eventlistener-yaml-file-name.yaml>Vous pouvez également créer la ressource
EvenListenerdirectement à partir du dépôt Gitpipelines-tutorial:$ oc create -f https://raw.githubusercontent.com/openshift/pipelines-tutorial/pipelines-1.9/03_triggers/04_event_listener.yamlCréer une route avec la terminaison TLS re-encrypt :
$ oc create route reencrypt --service=<svc-name> --cert=tls.crt --key=tls.key --ca-cert=ca.crt --hostname=<hostname>Vous pouvez également créer un fichier YAML de terminaison TLS réencryptée pour créer un itinéraire sécurisé.
Exemple Ré-encrypter le YAML de terminaison TLS de la route sécurisée
apiVersion: route.openshift.io/v1 kind: Route metadata: name: route-passthrough-secured1 spec: host: <hostname> to: kind: Service name: frontend2 tls: termination: reencrypt3 key: [as in edge termination] certificate: [as in edge termination] caCertificate: [as in edge termination] destinationCACertificate: |-4 -----BEGIN CERTIFICATE----- [...] -----END CERTIFICATE------ 1 2
- Le nom de l'objet, qui est limité à 63 caractères.
- 3
- Le champ
terminationest défini surreencrypt. C'est le seul champ obligatoire detls. - 4
- Nécessaire pour le rechiffrement.
destinationCACertificatespécifie un certificat d'autorité de certification pour valider le certificat du point de terminaison, sécurisant ainsi la connexion entre le routeur et les modules de destination. Si le service utilise un certificat de signature de service, ou si l'administrateur a spécifié un certificat d'autorité de certification par défaut pour le routeur et que le service dispose d'un certificat signé par cette autorité de certification, ce champ peut être omis.
Voir
oc create route reencrypt --helppour plus d'options.
Pour créer une ressource
EventListenerà l'aide d'une connexion HTTP non sécurisée :-
Créer la ressource
EventListener. Exposer le service
EventListeneren tant que route OpenShift Container Platform pour le rendre accessible au public :$ oc expose svc el-vote-app
-
Créer la ressource
3.5.8. Configuration des auditeurs d'événements pour desservir plusieurs espaces de noms
Vous pouvez sauter cette section si vous souhaitez créer un pipeline CI/CD de base. Cependant, si votre stratégie de déploiement implique plusieurs espaces de noms, vous pouvez configurer les auditeurs d'événements pour qu'ils desservent plusieurs espaces de noms.
Pour améliorer la réutilisation des objets EvenListener, les administrateurs de clusters peuvent les configurer et les déployer en tant qu'auditeurs d'événements multi-locataires desservant plusieurs espaces de noms.
Procédure
Configurer l'autorisation de récupération à l'échelle du cluster pour l'écouteur d'événements.
Définissez un nom de compte de service à utiliser dans les objets
ClusterRoleBindingetEventListener. Par exemple,el-sa.Exemple
ServiceAccount.yamlapiVersion: v1 kind: ServiceAccount metadata: name: el-sa ---Dans la section
rulesdu fichierClusterRole.yaml, définissez les autorisations appropriées pour que chaque déploiement d'écouteur d'événements fonctionne à l'échelle du cluster.Exemple
ClusterRole.yamlkind: ClusterRole apiVersion: rbac.authorization.k8s.io/v1 metadata: name: el-sel-clusterrole rules: - apiGroups: ["triggers.tekton.dev"] resources: ["eventlisteners", "clustertriggerbindings", "clusterinterceptors", "triggerbindings", "triggertemplates", "triggers"] verbs: ["get", "list", "watch"] - apiGroups: [""] resources: ["configmaps", "secrets"] verbs: ["get", "list", "watch"] - apiGroups: [""] resources: ["serviceaccounts"] verbs: ["impersonate"] ...Configurez la liaison des rôles de cluster avec le nom de compte de service et le nom de rôle de cluster appropriés.
Exemple
ClusterRoleBinding.yamlapiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: el-mul-clusterrolebinding subjects: - kind: ServiceAccount name: el-sa namespace: default roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: el-sel-clusterrole ...
Dans le paramètre
specde l'écouteur d'événements, ajoutez le nom du compte de service, par exempleel-sa. Remplissez le paramètrenamespaceSelectoravec les noms des espaces de noms que l'écouteur d'événements est censé servir.Exemple
EventListener.yamlapiVersion: triggers.tekton.dev/v1beta1 kind: EventListener metadata: name: namespace-selector-listener spec: serviceAccountName: el-sa namespaceSelector: matchNames: - default - foo ...Créez un compte de service avec les autorisations nécessaires, par exemple
foo-trigger-sa. Utilisez-le pour lier les rôles des déclencheurs.Exemple
ServiceAccount.yamlapiVersion: v1 kind: ServiceAccount metadata: name: foo-trigger-sa namespace: foo ...Exemple
RoleBinding.yamlapiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: triggercr-rolebinding namespace: foo subjects: - kind: ServiceAccount name: foo-trigger-sa namespace: foo roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: tekton-triggers-eventlistener-roles ...Créez un déclencheur avec le modèle de déclencheur, la liaison de déclencheur et le nom du compte de service appropriés.
Exemple
Trigger.yamlapiVersion: triggers.tekton.dev/v1beta1 kind: Trigger metadata: name: trigger namespace: foo spec: serviceAccountName: foo-trigger-sa interceptors: - ref: name: "github" params: - name: "secretRef" value: secretName: github-secret secretKey: secretToken - name: "eventTypes" value: ["push"] bindings: - ref: vote-app template: ref: vote-app ...
3.5.9. Création de webhooks
Webhooks sont des messages HTTP POST qui sont reçus par les auditeurs d'événements chaque fois qu'un événement configuré se produit dans votre référentiel. La charge utile de l'événement est ensuite mise en correspondance avec des liaisons de déclenchement et traitée par des modèles de déclenchement. Les modèles de déclenchement finissent par lancer une ou plusieurs exécutions de pipeline, conduisant à la création et au déploiement de ressources Kubernetes.
Dans cette section, vous allez configurer une URL webhook sur vos dépôts Git forkés pipelines-vote-ui et pipelines-vote-api. Cette URL pointe vers la route de service EventListener accessible au public.
L'ajout de webhooks nécessite des droits d'administration sur le référentiel. Si vous n'avez pas d'accès administratif à votre référentiel, contactez votre administrateur système pour ajouter des webhooks.
Procédure
Obtenir l'URL du webhook :
Pour une connexion HTTPS sécurisée :
$ echo "URL: $(oc get route el-vote-app --template='https://{{.spec.host}}')"Pour une connexion HTTP (non sécurisée) :
$ echo "URL: $(oc get route el-vote-app --template='http://{{.spec.host}}')"Notez l'URL obtenue dans le résultat.
Configurer manuellement les webhooks sur le référentiel frontal :
-
Ouvrez le dépôt Git frontal
pipelines-vote-uidans votre navigateur. - Cliquez sur Settings → Webhooks → Add Webhook
Sur la page Webhooks/Add Webhook:
- Entrez l'URL du webhook de l'étape 1 dans le champ Payload URL
- Sélectionnez application/json pour le Content type
- Spécifiez le secret dans le champ Secret
- Assurez-vous que le site Just the push event est sélectionné
- Sélectionner Active
- Cliquez sur Add Webhook
-
Ouvrez le dépôt Git frontal
-
Répétez l'étape 2 pour le référentiel back-end
pipelines-vote-api.
3.5.10. Déclenchement de l'exécution d'un pipeline
Chaque fois qu'un événement push se produit dans le dépôt Git, le webhook configuré envoie une charge utile d'événement à la route de service EventListener exposée publiquement. Le service EventListener de l'application traite la charge utile et la transmet aux paires de ressources TriggerBinding et TriggerTemplate correspondantes. La ressource TriggerBinding extrait les paramètres, et la ressource TriggerTemplate utilise ces paramètres et spécifie la manière dont les ressources doivent être créées. Cela peut entraîner la reconstruction et le redéploiement de l'application.
Dans cette section, vous poussez un commit vide dans le dépôt frontal pipelines-vote-ui, ce qui déclenche l'exécution du pipeline.
Procédure
Depuis le terminal, clonez votre dépôt Git forké
pipelines-vote-ui:$ git clone git@github.com:<your GitHub ID>/pipelines-vote-ui.git -b pipelines-1.9Pousser un commit vide :
$ git commit -m "empty-commit" --allow-empty && git push origin pipelines-1.9Vérifier si l'exécution du pipeline a été déclenchée :
$ tkn pipelinerun listRemarquez qu'une nouvelle canalisation a été mise en place.
3.5.11. Permettre la surveillance des auditeurs d'événements pour les déclencheurs des projets définis par l'utilisateur
En tant qu'administrateur de cluster, pour rassembler les métriques des auditeurs d'événements pour le service Triggers dans un projet défini par l'utilisateur et les afficher dans la console Web de OpenShift Container Platform, vous pouvez créer un moniteur de service pour chaque auditeur d'événements. Lors de la réception d'une requête HTTP, les auditeurs d'événements du service Triggers renvoient trois métriques -eventlistener_http_duration_seconds, eventlistener_event_count et eventlistener_triggered_resources.
Conditions préalables
- Vous vous êtes connecté à la console web de OpenShift Container Platform.
- Vous avez installé l'opérateur Red Hat OpenShift Pipelines.
- Vous avez activé la surveillance pour les projets définis par l'utilisateur.
Procédure
Pour chaque auditeur d'événements, créez un moniteur de service. Par exemple, pour afficher les mesures de l'auditeur d'événements
github-listenerdans l'espace de nomstest, créez le moniteur de services suivant :apiVersion: monitoring.coreos.com/v1 kind: ServiceMonitor metadata: labels: app.kubernetes.io/managed-by: EventListener app.kubernetes.io/part-of: Triggers eventlistener: github-listener annotations: networkoperator.openshift.io/ignore-errors: "" name: el-monitor namespace: test spec: endpoints: - interval: 10s port: http-metrics jobLabel: name namespaceSelector: matchNames: - test selector: matchLabels: app.kubernetes.io/managed-by: EventListener app.kubernetes.io/part-of: Triggers eventlistener: github-listener ...Testez le moniteur de service en envoyant une requête à l'écouteur d'événements. Par exemple, envoyez un commit vide :
$ git commit -m "empty-commit" --allow-empty && git push origin main- Sur la console web d'OpenShift Container Platform, naviguez vers Administrator → Observe → Metrics.
-
Pour afficher une mesure, effectuez une recherche à partir de son nom. Par exemple, pour afficher les détails de la métrique
eventlistener_http_resourcespour l'auditeur d'événementsgithub-listener, effectuez une recherche à l'aide du mot-cléeventlistener_http_resources.
3.5.12. Configurer les capacités de demande d'extraction dans GitHub Interceptor
Avec GitHub Interceptor, vous pouvez créer une logique qui valide et filtre les webhooks de GitHub. Par exemple, vous pouvez valider l'origine du webhook et filtrer les événements entrants en fonction de critères spécifiques. Lorsque vous utilisez GitHub Interceptor pour filtrer les données d'événements, vous pouvez spécifier les types d'événements qu'Interceptor peut accepter dans un champ. Dans Red Hat OpenShift Pipelines, vous pouvez utiliser les capacités suivantes de GitHub Interceptor :
- Filtrer les événements de demande d'extraction en fonction des fichiers qui ont été modifiés
- Valider les pull requests en fonction des propriétaires GitHub configurés
3.5.12.1. Filtrer les pull requests avec GitHub Interceptor
Vous pouvez filtrer les événements GitHub en fonction des fichiers qui ont été modifiés pour les événements push et pull. Cela vous permet d'exécuter un pipeline uniquement pour les changements pertinents dans votre dépôt Git. GitHub Interceptor ajoute une liste délimitée par des virgules de tous les fichiers qui ont été modifiés et utilise CEL Interceptor pour filtrer les événements entrants sur la base des fichiers modifiés. La liste des fichiers modifiés est ajoutée à la propriété changed_files de la charge utile de l'événement dans le champ de niveau supérieur extensions.
Prérequis
- Vous avez installé l'opérateur Red Hat OpenShift Pipelines.
Procédure
Effectuez l'une des étapes suivantes :
Pour un dépôt GitHub public, définissez la valeur du paramètre
addChangedFilesàtruedans le fichier de configuration YAML illustré ci-dessous :apiVersion: triggers.tekton.dev/v1beta1 kind: EventListener metadata: name: github-add-changed-files-pr-listener spec: triggers: - name: github-listener interceptors: - ref: name: "github" kind: ClusterInterceptor apiVersion: triggers.tekton.dev params: - name: "secretRef" value: secretName: github-secret secretKey: secretToken - name: "eventTypes" value: ["pull_request", "push"] - name: "addChangedFiles" value: enabled: true - ref: name: cel params: - name: filter value: extensions.changed_files.matches('controllers/') ...Pour un dépôt GitHub privé, définissez la valeur du paramètre
addChangedFilesàtrueet fournissez les détails du jeton d'accès,secretNameetsecretKeydans le fichier de configuration YAML illustré ci-dessous :apiVersion: triggers.tekton.dev/v1beta1 kind: EventListener metadata: name: github-add-changed-files-pr-listener spec: triggers: - name: github-listener interceptors: - ref: name: "github" kind: ClusterInterceptor apiVersion: triggers.tekton.dev params: - name: "secretRef" value: secretName: github-secret secretKey: secretToken - name: "eventTypes" value: ["pull_request", "push"] - name: "addChangedFiles" value: enabled: true personalAccessToken: secretName: github-pat secretKey: token - ref: name: cel params: - name: filter value: extensions.changed_files.matches('controllers/') ...
- Sauvegarder le fichier de configuration.
3.5.12.2. Valider les pull requests avec GitHub Interceptors
Vous pouvez utiliser GitHub Interceptor pour valider le traitement des pull requests en fonction des propriétaires GitHub configurés pour un dépôt. Cette validation permet d'éviter l'exécution inutile d'un objet PipelineRun ou TaskRun. GitHub Interceptor ne traite une demande d'extraction que si le nom d'utilisateur est répertorié comme propriétaire ou si un commentaire configurable est émis par un propriétaire du dépôt. Par exemple, lorsque vous commentez /ok-to-test sur une demande d'extraction en tant que propriétaire, un objet PipelineRun ou TaskRun est déclenché.
Les propriétaires sont configurés dans un fichier OWNERS à la racine du référentiel.
Conditions préalables
- Vous avez installé l'opérateur Red Hat OpenShift Pipelines.
Procédure
- Créer une valeur de chaîne secrète.
- Configurez le webhook GitHub avec cette valeur.
-
Créez un secret Kubernetes nommé
secretRefqui contient votre valeur secrète. - Transmettez le secret Kubernetes comme référence à votre GitHub Interceptor.
-
Créez un fichier
ownerset ajoutez la liste des approbateurs dans la sectionapprovers. Effectuez l'une des étapes suivantes :
Pour un dépôt GitHub public, définissez la valeur du paramètre
githubOwnersàtruedans le fichier de configuration YAML illustré ci-dessous :apiVersion: triggers.tekton.dev/v1beta1 kind: EventListener metadata: name: github-owners-listener spec: triggers: - name: github-listener interceptors: - ref: name: "github" kind: ClusterInterceptor apiVersion: triggers.tekton.dev params: - name: "secretRef" value: secretName: github-secret secretKey: secretToken - name: "eventTypes" value: ["pull_request", "issue_comment"] - name: "githubOwners" value: enabled: true checkType: none ...Pour un dépôt GitHub privé, définissez la valeur du paramètre
githubOwnersàtrueet fournissez les détails du jeton d'accès,secretNameetsecretKeydans le fichier de configuration YAML illustré ci-dessous :apiVersion: triggers.tekton.dev/v1beta1 kind: EventListener metadata: name: github-owners-listener spec: triggers: - name: github-listener interceptors: - ref: name: "github" kind: ClusterInterceptor apiVersion: triggers.tekton.dev params: - name: "secretRef" value: secretName: github-secret secretKey: secretToken - name: "eventTypes" value: ["pull_request", "issue_comment"] - name: "githubOwners" value: enabled: true personalAccessToken: secretName: github-token secretKey: secretToken checkType: all ...NoteLe paramètre
checkTypeest utilisé pour spécifier les propriétaires GitHub qui ont besoin d'une authentification. Vous pouvez lui donner la valeurorgMembers,repoMembers, ouall.
- Sauvegarder le fichier de configuration.
3.6. Gestion des tâches en grappe non versionnées et versionnées
En tant qu'administrateur de cluster, l'installation de Red Hat OpenShift Pipelines Operator crée des variantes de chaque tâche de cluster par défaut connues sous le nom de versioned cluster tasks (VCT) et non-versioned cluster tasks (NVCT). Par exemple, l'installation de Red Hat OpenShift Pipelines Operator v1.7 crée une buildah-1-7-0 VCT et une buildah NVCT.
NVCT et VCT ont les mêmes métadonnées, le même comportement et les mêmes spécifications, y compris params, workspaces, et steps. Cependant, ils se comportent différemment lorsque vous les désactivez ou que vous mettez à niveau l'opérateur.
Dans Red Hat OpenShift Pipelines 1.10, la fonctionnalité de tâche de cluster est dépréciée et il est prévu de la supprimer dans une prochaine version.
3.6.1. Différences entre les tâches en grappe non versionnées et versionnées
Les tâches de cluster non-versionnées et versionnées ont des conventions d'appellation différentes. De plus, l'opérateur Red Hat OpenShift Pipelines les met à jour différemment.
| Tâche en grappe non versionnée | Tâche en grappe versionnée | |
|---|---|---|
| Nomenclature |
Le NVCT ne contient que le nom de la tâche de cluster. Par exemple, le nom du NVCT de Buildah installé avec Operator v1.7 est |
Le VCT contient le nom de la tâche de cluster, suivi de la version comme suffixe. Par exemple, le nom du VCT de Buildah installé avec Operator v1.7 est |
| Mise à niveau | Lorsque vous mettez à niveau l'Opérateur, il met à jour la tâche de cluster non versionnée avec les dernières modifications. Le nom de la tâche NVCT reste inchangé. |
La mise à niveau de l'opérateur installe la dernière version du VCT et conserve la version précédente. La dernière version d'un VCT correspond à l'Opérateur mis à jour. Par exemple, l'installation de l'Opérateur 1.7 installe |
3.6.2. Avantages et inconvénients des tâches en grappe non versionnées et versionnées
Avant d'adopter les tâches de cluster versionnées ou non versionnées comme standard dans les environnements de production, les administrateurs de cluster peuvent prendre en compte leurs avantages et leurs inconvénients.
| Tâche en grappe | Avantages | Inconvénients |
|---|---|---|
| Tâche en grappe sans version (NVCT) |
| Si vous déployez des pipelines qui utilisent NVCT, ils risquent de s'interrompre après une mise à niveau d'Operator si les tâches de cluster mises à niveau automatiquement ne sont pas rétrocompatibles. |
| Tâche en grappe versionnée (VCT) |
|
|
3.6.3. Désactivation des tâches en grappe non versionnées et versionnées
En tant qu'administrateur de cluster, vous pouvez désactiver les tâches de cluster que l'OpenShift Pipelines Operator a installées.
Procédure
Pour supprimer toutes les tâches en grappe non versionnées et les dernières tâches en grappe versionnées, modifiez la définition de ressource personnalisée (CRD)
TektonConfiget définissez le paramètreclusterTasksdansspec.addon.paramssurfalse.Exemple
TektonConfigCRapiVersion: operator.tekton.dev/v1alpha1 kind: TektonConfig metadata: name: config spec: params: - name: createRbacResource value: "false" profile: all targetNamespace: openshift-pipelines addon: params: - name: clusterTasks value: "false" ...Lorsque vous désactivez les tâches de cluster, l'opérateur supprime du cluster toutes les tâches de cluster non versionnées et uniquement la dernière version des tâches de cluster versionnées.
NoteLa réactivation des tâches de cluster installe les tâches de cluster non révisées.
Facultatif : Pour supprimer les versions antérieures des tâches de cluster versionnées, utilisez l'une des méthodes suivantes :
Pour supprimer des tâches de cluster à version antérieure, utilisez la commande
oc delete clustertasksuivie du nom de la tâche de cluster à version. Par exemple :$ oc delete clustertask buildah-1-6-0Pour supprimer toutes les tâches de cluster versionnées créées par une ancienne version de l'Opérateur, vous pouvez supprimer l'ensemble d'installation correspondant. Par exemple, vous pouvez supprimer l'ensemble d'installation correspondant :
$ oc delete tektoninstallerset versioned-clustertask-1-6-k98asImportantSi vous supprimez une ancienne tâche en grappe versionnée, vous ne pouvez pas la restaurer. Vous ne pouvez restaurer que les tâches de cluster versionnées et non versionnées que la version actuelle de l'opérateur a créées.
3.7. Utiliser Tekton Hub avec OpenShift Pipelines
Tekton Hub est une fonctionnalité d'aperçu technologique uniquement. Les fonctionnalités de l'aperçu technologique ne sont pas prises en charge par les accords de niveau de service (SLA) de production de Red Hat et peuvent ne pas être complètes sur le plan fonctionnel. Red Hat ne recommande pas de les utiliser en production. Ces fonctionnalités offrent un accès anticipé aux fonctionnalités des produits à venir, ce qui permet aux clients de tester les fonctionnalités et de fournir un retour d'information pendant le processus de développement.
Pour plus d'informations sur la portée de l'assistance des fonctionnalités de l'aperçu technologique de Red Hat, voir Portée de l'assistance des fonctionnalités de l'aperçu technologique.
Tekton Hub vous aide à découvrir, rechercher et partager des tâches et des pipelines réutilisables pour vos flux de travail CI/CD. Une instance publique de Tekton Hub est disponible sur hub.tekton.dev. Les administrateurs de clusters peuvent également installer et déployer une instance personnalisée de Tekton Hub en modifiant les configurations dans la ressource personnalisée (CR) TektonHub.
3.7.1. Installation et déploiement de Tekton Hub sur un cluster OpenShift Container Platform
Tekton Hub est un composant optionnel ; les administrateurs de clusters ne peuvent pas l'installer en utilisant la ressource personnalisée (CR) TektonConfig. Pour installer et gérer Tekton Hub, utilisez la CR TektonHub.
Vous pouvez installer Tekton Hub sur votre cluster en utilisant deux modes :
- Without autorisation de connexion et évaluation des artefacts du centre Tekton
- with autorisation de connexion et évaluation des artefacts du centre Tekton
Si vous utilisez Github Enterprise ou Gitlab Enterprise, installez et déployez Tekton Hub dans le même réseau que le serveur d'entreprise. Par exemple, si le serveur d'entreprise fonctionne derrière un VPN, déployez Tekton Hub sur un cluster qui est également derrière le VPN.
3.7.1.1. Installation du Tekton Hub sans login et rating
Vous pouvez installer Tekton Hub sur votre cluster automatiquement avec la configuration par défaut. Lorsque vous utilisez la configuration par défaut, Tekton Hub ne prend pas en charge la connexion avec autorisation et les évaluations pour les artefacts Tekton Hub.
Conditions préalables
-
Assurez-vous que Red Hat OpenShift Pipelines Operator est installé dans l'espace de noms par défaut
openshift-pipelinessur le cluster.
Procédure
Créez un CR
TektonHubsimilaire à l'exemple suivant.apiVersion: operator.tekton.dev/v1alpha1 kind: TektonHub metadata: name: hub spec: targetNamespace: openshift-pipelines1 db: # Optional: If you want to use custom database secret: tekton-hub-db # Name of db secret should be `tekton-hub-db` categories: # Optional: If you want to use custom categories - Automation - Build Tools - CLI - Cloud - Code Quality - ... catalogs: # Optional: If you want to use custom catalogs - name: tekton org: tektoncd type: community provider: github url: https://github.com/tektoncd/catalog revision: main scopes: # Optional: If you want to add new users - name: agent:create users: [abc, qwe, pqr] - name: catalog:refresh users: [abc, qwe, pqr] - name: config:refresh users: [abc, qwe, pqr] default: # Optional: If you want to add custom default scopes scopes: - rating:read - rating:write api: catalogRefreshInterval: 30m2 - 1
- L'espace de noms dans lequel Tekton Hub doit être installé ; la valeur par défaut est
openshift-pipelines. - 2
- Intervalle de temps après lequel le catalogue se rafraîchit automatiquement. Les unités de temps prises en charge sont les secondes (
s), les minutes (m), les heures (h), les jours (d) et les semaines (w). L'intervalle par défaut est de 30 minutes.
NoteSi vous ne fournissez pas de valeurs personnalisées pour les champs facultatifs dans le CR
TektonHub, les valeurs par défaut configurées dans la carte de configuration de l'API Tekton Hub sont utilisées.Appliquer la CR
TektonHub.$ oc apply -f <tekton-hub-cr>.yamlVérifiez l'état de l'installation. Le CR
TektonHubpeut prendre un certain temps avant d'atteindre un état stable.$ oc get tektonhub.operator.tekton.devExemple de sortie
NAME VERSION READY REASON APIURL UIURL hub v1.9.0 True https://api.route.url/ https://ui.route.url/
3.7.1.2. Installation du Tekton Hub avec login et rating
Vous pouvez installer Tekton Hub sur votre cluster avec une configuration personnalisée qui prend en charge la connexion avec autorisation et les évaluations pour les artefacts Tekton Hub.
Conditions préalables
-
Assurez-vous que Red Hat OpenShift Pipelines Operator est installé dans l'espace de noms par défaut
openshift-pipelinessur le cluster.
Procédure
Créez une application OAuth avec votre hébergeur de référentiel Git, et notez l'identifiant et le secret du client. Les hébergeurs supportés sont GitHub, GitLab et BitBucket.
-
Pour une application GitHub OAuth, définissez l'URL de la page d'accueil et l'URL de rappel de l'autorisation comme
<auth-route>. -
Pour une application GitLab OAuth, définissez l'adresse
REDIRECT_URIcomme<auth-route>/auth/gitlab/callback. -
Pour une application BitBucket OAuth, définissez l'adresse
Callback URLcomme<auth-route>.
-
Pour une application GitHub OAuth, définissez l'URL de la page d'accueil et l'URL de rappel de l'autorisation comme
Modifiez le fichier
<tekton_hub_root>/config/02-api/20-api-secret.yamlpour y inclure les secrets de l'API Tekton Hub. Par exemple :apiVersion: v1 kind: Secret metadata: name: tekton-hub-api namespace: openshift-pipelines type: Opaque stringData: GH_CLIENT_ID:1 GH_CLIENT_SECRET:2 GL_CLIENT_ID:3 GL_CLIENT_SECRET:4 BB_CLIENT_ID:5 BB_CLIENT_SECRET:6 JWT_SIGNING_KEY:7 ACCESS_JWT_EXPIRES_IN:8 REFRESH_JWT_EXPIRES_IN:9 AUTH_BASE_URL:10 GHE_URL:11 GLE_URL:12 - 1
- L'identifiant du client de l'application GitHub OAuth.
- 2
- Le secret du client de l'application OAuth de GitHub.
- 3
- L'identifiant du client de l'application GitLab OAuth.
- 4
- Le secret du client de l'application OAuth de GitLab.
- 5
- L'identifiant du client de l'application BitBucket OAuth.
- 6
- Le secret du client de l'application BitBucket OAuth.
- 7
- Chaîne longue et aléatoire utilisée pour signer le jeton Web JSON (JWT) créé pour les utilisateurs.
- 8
- Ajoutez la limite de temps après laquelle le jeton d'accès expire. Par exemple,
1m, où m représente les minutes. Les unités de temps prises en charge sont les secondes (s), les minutes (m), les heures (h), les jours (d) et les semaines (w). - 9
- Ajoutez la limite de temps après laquelle le jeton de rafraîchissement expire. Par exemple,
1m, oùmindique les minutes. Les unités de temps prises en charge sont les secondes (s), les minutes (m), les heures (h), les jours (d) et les semaines (w). Assurez-vous que le délai d'expiration défini pour le rafraîchissement du jeton est supérieur au délai d'expiration défini pour l'accès au jeton. - 10
- URL de la route pour l'application OAuth.
- 11
- URL de GitHub Enterprise, si vous vous authentifiez à l'aide de GitHub Enterprise. Ne fournissez pas l'URL du catalogue comme valeur de ce champ.
- 12
- URL de GitLab Enterprise, si vous vous authentifiez avec GitLab Enterprise. Ne fournissez pas l'URL du catalogue comme valeur pour ce champ.
NoteVous pouvez supprimer les champs inutilisés pour les fournisseurs de services d'hébergement de référentiel Git qui ne sont pas pertinents pour votre déploiement.
Créez un CR
TektonHubsimilaire à l'exemple suivant.apiVersion: operator.tekton.dev/v1alpha1 kind: TektonHub metadata: name: hub spec: targetNamespace: openshift-pipelines1 db:2 secret: tekton-hub-db3 categories:4 - Automation - Build Tools - CLI - Cloud - Code Quality ... catalogs:5 - name: tekton org: tektoncd type: community provider: github url: https://github.com/tektoncd/catalog revision: main scopes:6 - name: agent:create users: [<username>] - name: catalog:refresh users: [<username>] - name: config:refresh users: [<username>] default:7 scopes: - rating:read - rating:write api: catalogRefreshInterval: 30m8 - 1
- L'espace de noms dans lequel Tekton Hub doit être installé ; la valeur par défaut est
openshift-pipelines. - 2
- Facultatif : Base de données personnalisée, telle qu'une base de données Crunchy Postgres.
- 3
- Le nom du secret de la base de données doit être
tekton-hub-db. - 4
- Facultatif : Catégories personnalisées pour les tâches et les pipelines dans Tekton Hub.
- 5
- En option : Catalogues personnalisés pour Tekton Hub.
- 6
- Optionnel : Utilisateurs supplémentaires. Vous pouvez mentionner plusieurs utilisateurs, tels que
[<username_1>, <username_2>, <username_3>]. - 7
- Facultatif : Portées par défaut personnalisées.
- 8
- Intervalle de temps après lequel le catalogue se rafraîchit automatiquement. Les unités de temps prises en charge sont les secondes (
s), les minutes (m), les heures (h), les jours (d) et les semaines (w). L'intervalle par défaut est de 30 minutes.
NoteSi vous ne fournissez pas de valeurs personnalisées pour les champs facultatifs dans le CR
TektonHub, les valeurs par défaut configurées dans la carte de configuration de l'API Tekton Hub sont utilisées.Appliquer la CR
TektonHub.$ oc apply -f <tekton-hub-cr>.yamlVérifiez l'état de l'installation. Le CR
TektonHubpeut prendre un certain temps avant d'atteindre un état stable.$ oc get tektonhub.operator.tekton.devExemple de sortie
NAME VERSION READY REASON APIURL UIURL hub v1.9.0 True https://api.route.url/ https://ui.route.url/
3.7.2. Optionnel : Utiliser une base de données personnalisée dans Tekton Hub
Les administrateurs de clusters peuvent utiliser une base de données personnalisée avec Tekton Hub, au lieu de la base de données PostgreSQL par défaut installée par l'Opérateur. Vous pouvez associer une base de données personnalisée au moment de l'installation, et l'utiliser avec les interfaces db-migration, api, et ui fournies par Tekton Hub. Vous pouvez également associer une base de données personnalisée à Tekton Hub même après l'installation de la base de données par défaut.
Procédure
Créez un secret nommé
tekton-hub-dbdans l'espace de noms cible avec les clés suivantes :-
POSTGRES_HOST -
POSTGRES_DB -
POSTGRES_USER -
POSTGRES_PASSWORD POSTGRES_PORTExemple : Secrets de base de données personnalisés
apiVersion: v1 kind: Secret metadata: name: tekton-hub-db labels: app: tekton-hub-db type: Opaque stringData: POSTGRES_HOST: <The name of the host of the database> POSTGRES_DB: <Name of the database> POSTGRES_USER: <The name of user account> POSTGRES_PASSWORD: <The password of user account> POSTGRES_PORT: <The port that the database is listening on> ...NoteL'espace de noms cible par défaut est
openshift-pipelines.
-
Dans le CR
TektonHub, définissez la valeur de l'attribut secret de la base de données surtekton-hub-db.Exemple : Ajout d'un secret de base de données personnalisé
apiVersion: operator.tekton.dev/v1alpha1 kind: TektonHub metadata: name: hub spec: targetNamespace: openshift-pipelines db: secret: tekton-hub-db api: hubConfigUrl: https://raw.githubusercontent.com/tektoncd/hub/main/config.yaml catalogRefreshInterval: 30m ...Utilisez la mise à jour de
TektonHubCR pour associer la base de données personnalisée à Tekton Hub.Si vous associez la base de données personnalisée au moment de l'installation de Tekton Hub sur votre cluster, appliquez la mise à jour de
TektonHubCR.$ oc apply -f <tekton-hub-cr>.yamlSi vous associez la base de données personnalisée une fois l'installation de Tekton Hub terminée, remplacez la CR
TektonHubexistante par la CRTektonHubmise à jour.$ oc replace -f <tekton-hub-cr>.yaml
Vérifiez l'état de l'installation. Le CR
TektonHubpeut prendre un certain temps avant d'atteindre un état stable.$ oc get tektonhub.operator.tekton.devExemple de sortie
NAME VERSION READY REASON APIURL UIURL hub v1.9.0 True https://api.route.url/ https://ui.route.url/
3.7.2.1. Facultatif : Installation de la base de données Crunchy Postgres et du Tekton Hub
Les administrateurs de clusters peuvent installer la base de données Crunchy Postgres et configurer Tekton Hub pour l'utiliser à la place de la base de données par défaut.
Conditions préalables
- Installez l'opérateur Crunchy Postgres depuis le Hub de l'opérateur.
- Créer une instance Postgres qui initie une base de données Postgres Crunchy.
Procédure
Entrez dans le pod Crunchy Postgres.
Exemple : Entrer dans la nacelle
test-instance1-m7hh-0$ oc exec -it -n openshift-operators test-instance1-m7hh-0 -- /bin/sh Defaulting container name to database. Use 'oc describe pod/test-instance1-m7hh-0 -n openshift-operators' to see all of the containers in this pod. sh-4.4$ psql -U postgres psql (14.4) Type "help" for help.Trouvez le fichier
pg_hba.conf.postgres=# SHOW hba_file; hba_file -------------------------- /pgdata/pg14/pg_hba.conf (1 row) postgres=#- Quitter la base de données.
Vérifiez que le fichier
pg_hba.confcontient l'entréehost all all 0.0.0.0/0 md5, nécessaire pour accéder à toutes les connexions entrantes. En outre, ajoutez l'entrée à la fin du fichierpg_hba.conf.Exemple :
pg_hba.conffilesh-4.4$ cat /pgdata/pg14/pg_hba.conf # Do not edit this file manually! # It will be overwritten by Patroni! local all "postgres" peer hostssl replication "_crunchyrepl" all cert hostssl "postgres" "_crunchyrepl" all cert host all "_crunchyrepl" all reject hostssl all all all md5 host all all 0.0.0.0/0 md5Enregistrez le fichier
pg_hba.confet rechargez la base de données.sh-4.4$ psql -U postgres psql (14.4) Type "help" for help. postgres=# SHOW hba_file; hba_file -------------------------- /pgdata/pg14/pg_hba.conf (1 row) postgres=# SELECT pg_reload_conf(); pg_reload_conf ---------------- t (1 row)- Quitter la base de données.
Décoder la valeur secrète de l'hôte Crunchy Postgres.
Exemple : Décoder la valeur secrète d'un hôte Crunchy Postgres
$ echo 'aGlwcG8tcHJpbWFyeS5vcGVuc2hpZnQtb3BlcmF0b3JzLnN2YyA=' | base64 --decode test-primary.openshift-operators.svcCréez un secret nommé
tekton-hub-dbdans l'espace de noms cible avec les clés suivantes :-
POSTGRES_HOST -
POSTGRES_DB -
POSTGRES_USER -
POSTGRES_PASSWORD POSTGRES_PORTExemple : Secrets de base de données personnalisés
apiVersion: v1 kind: Secret metadata: name: tekton-hub-db labels: app: tekton-hub-db type: Opaque stringData: POSTGRES_HOST: test-primary.openshift-operators.svc POSTGRES_DB: test POSTGRES_USER: test POSTGRES_PASSWORD: woXOisU5>ocJiTF7y{{;1[Q( POSTGRES_PORT: '5432' ...
NoteL'espace de noms cible par défaut est
openshift-pipelines.-
Dans le CR
TektonHub, définissez la valeur de l'attribut secret de la base de données surtekton-hub-db.Exemple : Ajout d'un secret de base de données personnalisé
apiVersion: operator.tekton.dev/v1alpha1 kind: TektonHub metadata: name: hub spec: targetNamespace: openshift-pipelines db: secret: tekton-hub-db ...Utilisez la mise à jour de
TektonHubCR pour associer la base de données personnalisée à Tekton Hub.$ oc apply -f <tekton-hub-cr>.yamlVérifiez l'état de l'installation. Le CR
TektonHubpeut prendre un certain temps avant d'atteindre un état stable.$ oc get tektonhub.operator.tekton.devExemple de sortie
NAME VERSION READY REASON APIURL UIURL hub v1.9.0 True https://api.route.url/ https://ui.route.url/
3.7.2.2. Optionnel : Migrer les données du Tekton Hub vers une base de données Postgres Crunchy existante
Tekton Hub supporte l'utilisation de Crunchy Postgres comme base de données personnalisée. Pour un Tekton Hub préinstallé avec une base de données par défaut, les administrateurs de cluster peuvent utiliser Crunchy Postgres comme base de données personnalisée après avoir migré les données du Tekton Hub de la base de données interne ou par défaut vers la base de données externe Crunchy Postgres.
Procédure
Décharge les données existantes de la base de données interne ou par défaut dans un fichier dans le pod.
Exemple : Vider les données
$ pg_dump -Ft -h localhost -U postgres hub -f /tmp/hub.dumpCopiez le fichier contenant le vidage des données sur votre système local.
Format de la commande
$ oc cp -n <namespace> <podName>:<path-to-hub.dump> <path-to-local-system>
$ oc cp -n openshift-pipelines tekton-hub-db-7d6d888c67-p7mdr:/tmp/hub.dump /home/test_user/Downloads/hub.dumpCopiez le fichier qui contient le dumping de données du système local vers le pod qui exécute la base de données externe Crunchy Postgres.
Format de la commande
$ oc cp -n <namespace> <path-to-local-system> <podName>:<path-to-hub.dump>
$ oc cp -n openshift-operators /home/test_user/Downloads/hub.dump test-instance1-spnz-0:/tmp/hub.dump- Restaurer les données de la base de données Crunchy Postgres. format .command
$ pg_restore -d <nom-de-la-base-de-données> -h localhost -U postgres <chemin-où-le-fichier-est-copié>Exemple
$ pg_restore -d test -h localhost -U postgres /tmp/hub.dumpAccédez au pod Crunchy Postgres. Exemple : Accéder au pod
test-instance1-m7hh-0$ oc exec -it -n openshift-operators test-instance1-m7hh-0 -- /bin/sh Defaulting container name to database. Use 'oc describe pod/test-instance1-m7hh-0 -n openshift-operators' to see all of the containers in this pod. sh-4.4$ psql -U postgres psql (14.4) Type "help" for help.Trouvez le fichier
pg_hba.conf.postgres=# SHOW hba_file; hba_file -------------------------- /pgdata/pg14/pg_hba.conf (1 row) postgres=#- Quitter la base de données.
Vérifiez si le fichier
pg_hba.confcontient l'entréehost all all 0.0.0.0/0 md5, qui est nécessaire pour accéder à toutes les connexions entrantes. Si nécessaire, ajoutez l'entrée à la fin du fichierpg_hba.conf.Exemple :
pg_hba.conffilesh-4.4$ cat /pgdata/pg14/pg_hba.conf # Do not edit this file manually! # It will be overwritten by Patroni! local all "postgres" peer hostssl replication "_crunchyrepl" all cert hostssl "postgres" "_crunchyrepl" all cert host all "_crunchyrepl" all reject hostssl all all all md5 host all all 0.0.0.0/0 md5Enregistrez le fichier
pg_hba.confet rechargez la base de données.sh-4.4$ psql -U postgres psql (14.4) Type "help" for help. postgres=# SHOW hba_file; hba_file -------------------------- /pgdata/pg14/pg_hba.conf (1 row) postgres=# SELECT pg_reload_conf(); pg_reload_conf ---------------- t (1 row)- Quitter la base de données.
Vérifiez qu'un secret nommé
tekton-hub-dbdans l'espace de noms cible possède les clés suivantes :-
POSTGRES_HOST -
POSTGRES_DB -
POSTGRES_USER -
POSTGRES_PASSWORD POSTGRES_PORTExemple : Secrets de base de données personnalisés
apiVersion: v1 kind: Secret metadata: name: tekton-hub-db labels: app: tekton-hub-db type: Opaque stringData: POSTGRES_HOST: test-primary.openshift-operators.svc POSTGRES_DB: test POSTGRES_USER: test POSTGRES_PASSWORD: woXOisU5>ocJiTF7y{{;1[Q( POSTGRES_PORT: '5432' ...NoteLa valeur du champ
POSTGRES_HOSTest encodée comme un secret. Vous pouvez décoder la valeur de l'hôte Crunchy Postgres en utilisant l'exemple suivant.exemple : Décoder la valeur secrète d'un hôte Crunchy Postgres
$ echo 'aGlwcG8tcHJpbWFyeS5vcGVuc2hpZnQtb3BlcmF0b3JzLnN2YyA=' | base64 --decode test-primary.openshift-operators.svc
-
Vérifiez que dans la CR
TektonHub, la valeur de l'attribut secret de la base de données esttekton-hub-db.Exemple : TektonHub CR avec le nom du secret de la base de données
apiVersion: operator.tekton.dev/v1alpha1 kind: TektonHub metadata: name: hub spec: targetNamespace: openshift-pipelines db: secret: tekton-hub-db ...Pour associer la base de données externe Crunchy Postgres à Tekton Hub, remplacez tout CR
TektonHubexistant par le CRTektonHubmis à jour.$ oc replace -f <updated-tekton-hub-cr>.yamlVérifiez l'état du Tekton Hub. La mise à jour de
TektonHubCR peut prendre un certain temps avant d'atteindre un état stable.$ oc get tektonhub.operator.tekton.devExemple de sortie
NAME VERSION READY REASON APIURL UIURL hub v1.9.0 True https://api.route.url/ https://ui.route.url/
3.7.3. Mise à jour du Tekton Hub avec des catégories et des catalogues personnalisés
Les administrateurs de clusters peuvent mettre à jour Tekton Hub avec des catégories, des catalogues, des portées et des portées par défaut personnalisés qui reflètent le contexte de leur organisation.
Procédure
Facultatif : Modifiez les champs
categories,catalogs,scopes, etdefault:scopesdans le Tekton Hub CR.NoteLes informations par défaut pour les catégories, le catalogue, les champs d'application et les champs d'application par défaut sont tirées de la carte de configuration de l'API Tekton Hub. Si vous fournissez des valeurs personnalisées dans le CR
TektonHub, elles remplacent les valeurs par défaut.Appliquer le moyeu Tekton CR.
$ oc apply -f <tekton-hub-cr>.yamlObserver l'état du moyeu Tekton.
$ oc get tektonhub.operator.tekton.devExemple de sortie
NAME VERSION READY REASON APIURL UIURL hub v1.9.0 True https://api.route.url https://ui.route.url
3.7.4. Modifier l'intervalle de rafraîchissement du catalogue de Tekton Hub
L'intervalle de rafraîchissement du catalogue par défaut pour Tekton Hub est de 30 minutes. Les administrateurs de cluster peuvent modifier l'intervalle de rafraîchissement automatique du catalogue en modifiant la valeur du champ catalogRefreshInterval dans le CR TektonHub.
Procédure
Modifier la valeur du champ
catalogRefreshIntervaldans le CRTektonHub.apiVersion: operator.tekton.dev/v1alpha1 kind: TektonHub metadata: name: hub spec: targetNamespace: openshift-pipelines1 api: catalogRefreshInterval: 30m2 - 1
- L'espace de noms dans lequel Tekton Hub est installé ; la valeur par défaut est
openshift-pipelines. - 2
- Intervalle de temps après lequel le catalogue se rafraîchit automatiquement. Les unités de temps prises en charge sont les secondes (
s), les minutes (m), les heures (h), les jours (d) et les semaines (w). L'intervalle par défaut est de 30 minutes.
Appliquer la CR
TektonHub.$ oc apply -f <tekton-hub-cr>.yamlVérifiez l'état de l'installation. Le CR
TektonHubpeut prendre un certain temps avant d'atteindre un état stable.$ oc get tektonhub.operator.tekton.devExemple de sortie
NAME VERSION READY REASON APIURL UIURL hub v1.9.0 True https://api.route.url/ https://ui.route.url/
3.7.5. Ajout de nouveaux utilisateurs dans la configuration du Tekton Hub
Les administrateurs de clusters peuvent ajouter de nouveaux utilisateurs à Tekton Hub avec différents champs d'application.
Procédure
Modifiez le CR
TektonHubpour ajouter de nouveaux utilisateurs avec des champs d'application différents.... scopes: - name: agent:create users: [<username_1>, <username_2>]1 - name: catalog:refresh users: [<username_3>, <username_4>] - name: config:refresh users: [<username_5>, <username_6>] default: scopes: - rating:read - rating:write ...- 1
- Les noms d'utilisateur enregistrés auprès du fournisseur de services d'hébergement du dépôt Git.
NoteUn nouvel utilisateur qui se connecte au Tekton Hub pour la première fois n'aura que le champ d'application par défaut. Pour activer des champs d'application supplémentaires, assurez-vous que le nom d'utilisateur de l'utilisateur est ajouté dans le champ
scopesdu CRTektonHub.Appliquer la mise à jour de
TektonHubCR.$ oc apply -f <tekton-hub-cr>.yamlVérifiez l'état du Tekton Hub. La mise à jour de
TektonHubCR peut prendre un certain temps avant d'atteindre un état stable.$ oc get tektonhub.operator.tekton.devExemple de sortie
NAME VERSION READY REASON APIURL UIURL hub v1.9.0 True https://api.route.url/ https://ui.route.url/Actualiser la configuration.
$ curl -X POST -H "Authorization: <access-token>" \1 --header "Content-Type: application/json" \ --data '{"force": true} \ <api-route>/system/config/refresh- 1
- Le jeton JWT.
3.7.6. Désactivation de l'autorisation Tekton Hub après la mise à niveau de Red Hat OpenShift Pipelines Operator de 1.7 à 1.8
Lorsque vous installez Tekton Hub avec Red Hat OpenShift Pipelines Operator 1.8, l'autorisation de connexion et les évaluations pour les artefacts Tekton Hub sont désactivées pour l'installation par défaut. Cependant, lorsque vous mettez à niveau l'Opérateur de 1.7 à 1.8, l'instance de Tekton Hub sur votre cluster ne désactive pas automatiquement l'autorisation de connexion et les évaluations.
Pour désactiver l'autorisation de connexion et les évaluations pour Tekton Hub après avoir mis à jour l'Opérateur de 1.7 à 1.8, suivez les étapes de la procédure suivante.
Conditions préalables
-
Assurez-vous que Red Hat OpenShift Pipelines Operator est installé dans l'espace de noms par défaut
openshift-pipelinessur le cluster.
Procédure
Supprimez le secret API Tekton Hub existant que vous avez créé lors de l'installation manuelle de Tekton Hub pour Operator 1.7.
oc delete secret tekton-hub-api -n <targetNamespace>1 - 1
- L'espace de noms commun pour le secret de l'API Tekton Hub et le CR Tekton Hub. Par défaut, l'espace de noms cible est
openshift-pipelines.
Supprimer l'objet
TektonInstallerSetpour l'API Tekton Hub.$ oc get tektoninstallerset -o name | grep tekton-hub-api | xargs oc deleteNoteAprès la suppression, l'Opérateur crée automatiquement un nouveau jeu d'installation Tekton Hub API.
Attendez et vérifiez l'état du Tekton Hub. Passez aux étapes suivantes lorsque la colonne
READYafficheTrue.$ oc get tektonhub hubExemple de sortie
NAME VERSION READY REASON APIURL UIURL hub 1.8.0 True https://tekton-hub-api-openshift-pipelines.apps.example.com https://tekton-hub-ui-openshift-pipelines.apps.example.comSupprimer l'objet
ConfigMappour l'interface utilisateur du Tekton Hub.$ oc delete configmap tekton-hub-ui -n <targetNamespace>1 - 1
- L'espace de noms commun pour l'interface utilisateur du Tekton Hub et le Tekton Hub CR. Par défaut, l'espace de noms cible est
openshift-pipelines.
Supprimer l'objet
TektonInstallerSetpour l'interface utilisateur du Tekton Hub.$ oc get tektoninstallerset -o name | grep tekton-hub-ui | xargs oc deleteNoteAprès la suppression, l'Opérateur crée automatiquement un nouveau jeu d'installation Tekton Hub UI.
Attendez et vérifiez l'état du Tekton Hub. Passez aux étapes suivantes lorsque la colonne
READYafficheTrue.$ oc get tektonhub hubExemple de sortie
NAME VERSION READY REASON APIURL UIURL hub 1.8.0 True https://tekton-hub-api-openshift-pipelines.apps.example.com https://tekton-hub-ui-openshift-pipelines.apps.example.com
3.8. Utiliser les pipelines comme du code
Avec Pipelines as Code, les administrateurs de clusters et les utilisateurs disposant des privilèges requis peuvent définir des modèles de pipelines dans le cadre de dépôts Git de code source. Lorsqu'elle est déclenchée par un push de code source ou une pull request pour le dépôt Git configuré, la fonctionnalité exécute le pipeline et signale son état.
3.8.1. Caractéristiques principales
Pipelines as Code prend en charge les fonctionnalités suivantes :
- Statut et contrôle des pull requests sur la plateforme hébergeant le dépôt Git.
- API GitHub Checks pour définir le statut d'une exécution de pipeline, y compris les rechecks.
- Événements GitHub relatifs aux demandes d'extraction et aux livraisons.
-
Actions de demande d'extraction dans les commentaires, telles que
/retest. - Filtrage des événements Git et pipeline séparé pour chaque événement.
- Résolution automatique des tâches dans OpenShift Pipelines, y compris les tâches locales, Tekton Hub et les URL distantes.
- Récupération des configurations à l'aide de l'API GitHub blobs et objets.
-
Liste de contrôle d'accès (ACL) sur une organisation GitHub, ou en utilisant un fichier de type Prow
OWNER. -
Le plugin
tkn pacCLI pour gérer le bootstrapping et les pipelines en tant que dépôts de code. - Prise en charge de GitHub App, GitHub Webhook, Bitbucket Server et Bitbucket Cloud.
3.8.2. Installation de Pipelines as Code sur une plateforme de conteneurs OpenShift
Pipelines as Code est installé dans l'espace de noms openshift-pipelines lorsque vous installez l'opérateur Red Hat OpenShift Pipelines. Pour plus de détails, voir Installing OpenShift Pipelines dans la section Additional resources.
Pour désactiver l'installation par défaut des pipelines en tant que code avec l'opérateur, définissez la valeur du paramètre enable sur false dans la ressource personnalisée TektonConfig.
...
spec:
platforms:
openshift:
pipelinesAsCode:
enable: false
settings:
application-name: Pipelines as Code CI
auto-configure-new-github-repo: "false"
bitbucket-cloud-check-source-ip: "true"
hub-catalog-name: tekton
hub-url: https://api.hub.tekton.dev/v1
remote-tasks: "true"
secret-auto-create: "true"
...En option, vous pouvez exécuter la commande suivante :
$ oc patch tektonconfig config --type="merge" -p '{"spec": {"platforms": {"openshift":{"pipelinesAsCode": {"enable": false}}}}}'
Pour activer l'installation par défaut de Pipelines as Code avec Red Hat OpenShift Pipelines Operator, définissez la valeur du paramètre enable sur true dans la ressource personnalisée TektonConfig:
...
spec:
platforms:
openshift:
pipelinesAsCode:
enable: true
settings:
application-name: Pipelines as Code CI
auto-configure-new-github-repo: "false"
bitbucket-cloud-check-source-ip: "true"
hub-catalog-name: tekton
hub-url: https://api.hub.tekton.dev/v1
remote-tasks: "true"
secret-auto-create: "true"
...En option, vous pouvez exécuter la commande suivante :
$ oc patch tektonconfig config --type="merge" -p '{"spec": {"platforms": {"openshift":{"pipelinesAsCode": {"enable": true}}}}}'3.8.3. Installation de Pipelines as Code CLI
Les administrateurs de clusters peuvent utiliser les outils CLI tkn pac et opc sur des machines locales ou en tant que conteneurs pour les tests. Les outils tkn pac et opc CLI sont installés automatiquement lorsque vous installez tkn CLI pour Red Hat OpenShift Pipelines.
Vous pouvez installer les binaires tkn pac et opc version 1.10.0 pour les plateformes supportées :
3.8.4. Utiliser Pipelines as Code avec un hébergeur de dépôts Git
Après avoir installé Pipelines as Code, les administrateurs de clusters peuvent configurer un fournisseur de services d'hébergement de dépôts Git. Actuellement, les services suivants sont pris en charge :
- Application GitHub
- GitHub Webhook
- GitLab
- Serveur Bitbucket
- Bitbucket Cloud
GitHub App est le service recommandé pour l'utilisation de Pipelines as Code.
3.8.5. Utiliser les pipelines comme du code avec une application GitHub
Les GitHub Apps agissent comme un point d'intégration avec Red Hat OpenShift Pipelines et apportent l'avantage des flux de travail basés sur Git à OpenShift Pipelines. Les administrateurs de cluster peuvent configurer une seule application GitHub pour tous les utilisateurs du cluster. Pour que les applications GitHub fonctionnent avec Pipelines as Code, assurez-vous que le webhook de l'application GitHub pointe vers la route d'écoute d'événements de Pipelines as Code (ou le point d'arrivée) qui écoute les événements GitHub.
3.8.5.1. Configuration d'une application GitHub
Les administrateurs de cluster peuvent créer une application GitHub en exécutant la commande suivante :
$ tkn pac bootstrap github-app
Si le plugin tkn pac CLI n'est pas installé, vous pouvez créer l'application GitHub manuellement.
Procédure
Pour créer et configurer manuellement une application GitHub pour Pipelines as Code, procédez comme suit :
- Connectez-vous à votre compte GitHub.
- Allez sur Settings → Developer settings → GitHub Apps, et cliquez sur New GitHub App.
Fournissez les informations suivantes dans le formulaire de l'application GitHub :
-
GitHub Application Name:
OpenShift Pipelines - Homepage URL: URL de la console OpenShift
-
Webhook URL: La route ou l'URL d'entrée de Pipelines as Code. Vous pouvez la trouver en exécutant la commande
echo https://$(oc get route -n openshift-pipelines pipelines-as-code-controller -o jsonpath='{.spec.host}'). -
Webhook secret: Un secret arbitraire. Vous pouvez générer un secret en exécutant la commande
openssl rand -hex 20.
-
GitHub Application Name:
Sélectionnez le site suivant : Repository permissions:
-
Checks:
Read & Write -
Contents:
Read & Write -
Issues:
Read & Write -
Metadata:
Read-only -
Pull request:
Read & Write
-
Checks:
Sélectionnez le site suivant : Organization permissions:
-
Members:
Readonly -
Plan:
Readonly
-
Members:
Sélectionnez le site suivant : User permissions:
- Check run
- Issue comment
- Pull request
- Push
- Cliquez sur Create GitHub App.
- Sur la page Details de l'application GitHub nouvellement créée, notez l'adresse App ID affichée en haut.
- Dans la section Private keys, cliquez sur Generate Private key pour générer et télécharger automatiquement une clé privée pour l'application GitHub. Conservez la clé privée en toute sécurité afin de pouvoir la consulter et l'utiliser ultérieurement.
- Installez l'application créée sur un référentiel que vous souhaitez utiliser avec Pipelines as Code.
3.8.5.2. Configurer Pipelines as Code pour accéder à une application GitHub
Pour configurer Pipelines as Code afin d'accéder à l'application GitHub nouvellement créée, exécutez la commande suivante :
$ oc -n openshift-pipelines create secret generic pipelines-as-code-secret \
--from-literal github-private-key="$(cat <PATH_PRIVATE_KEY>)" \
--from-literal github-application-id="<APP_ID>" \
--from-literal webhook.secret="<WEBHOOK_SECRET>" Pipelines as Code fonctionne automatiquement avec GitHub Enterprise en détectant le jeu d'en-têtes de GitHub Enterprise et en l'utilisant pour l'URL d'autorisation de l'API de GitHub Enterprise.
3.8.5.3. Créer une application GitHub dans une perspective d'administrateur
En tant qu'administrateur de cluster, vous pouvez configurer votre application GitHub avec le cluster OpenShift Container Platform pour utiliser Pipelines as Code. Cette configuration vous permet d'exécuter un ensemble de tâches nécessaires au déploiement de la construction.
Conditions préalables
Vous avez installé l'opérateur Red Hat OpenShift Pipelines pipelines-1.9 à partir du Operator Hub.
Procédure
- Dans la perspective de l'administrateur, accédez à Pipelines à l'aide du volet de navigation.
- Cliquez sur Setup GitHub App sur la page Pipelines.
-
Saisissez le nom de votre application GitHub. Par exemple,
pipelines-ci-clustername-testui. - Cliquez sur Setup.
- Saisissez votre mot de passe Git lorsque le navigateur vous le demande.
-
Cliquez sur Create GitHub App for <username>, où
<username>est votre nom d'utilisateur GitHub.
Vérification
Après la création réussie de l'application GitHub, la console web d'OpenShift Container Platform s'ouvre et affiche les détails de l'application.
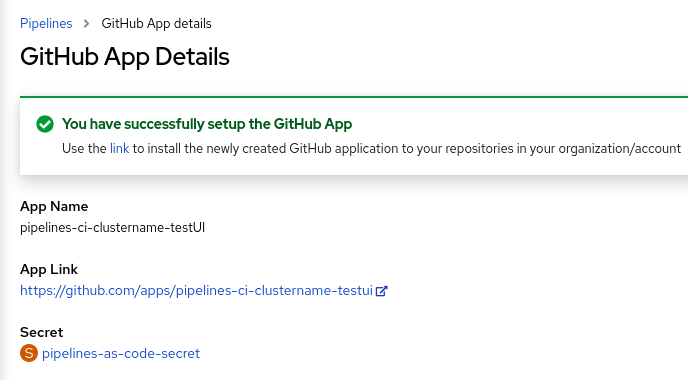
Les détails de l'application GitHub sont enregistrés en tant que secret dans l'espace de noms openShift-pipelines.
Pour afficher les détails tels que le nom, le lien et le secret associés aux applications GitHub, naviguez jusqu'à Pipelines et cliquez sur View GitHub App.
3.8.6. Utiliser les pipelines comme du code avec GitHub Webhook
Utilisez Pipelines as Code avec GitHub Webhook sur votre dépôt si vous ne pouvez pas créer une application GitHub. Cependant, l'utilisation de Pipelines as Code avec GitHub Webhook ne vous donne pas accès à l'API GitHub Check Runs. Le statut des tâches est ajouté en tant que commentaires sur la demande d'extraction et n'est pas disponible sous l'onglet Checks.
Pipelines as Code avec GitHub Webhook ne prend pas en charge les commentaires GitOps tels que /retest et /ok-to-test. Pour redémarrer l'intégration continue (CI), créez un nouveau commit dans le dépôt. Par exemple, pour créer un nouveau commit sans aucune modification, vous pouvez utiliser la commande suivante :
git --amend -a --no-edit && git push --force-with-lease <origin> <branchname>Conditions préalables
- Assurez-vous que Pipelines as Code est installé sur le cluster.
Pour l'autorisation, créez un jeton d'accès personnel sur GitHub.
Pour générer un jeton sécurisé et précis, limitez son champ d'application à un référentiel spécifique et accordez les autorisations suivantes :
Expand Tableau 3.7. Permissions pour les jetons à granularité fine Nom Accès Administration
Lecture seule
Métadonnées
Lecture seule
Contenu
Lecture seule
Statuts d'engagement
Lire et écrire
Demande de retrait
Lire et écrire
Crochets Web
Lire et écrire
Pour utiliser des jetons classiques, définissez la portée comme
public_repopour les dépôts publics etrepopour les dépôts privés. En outre, prévoyez une courte période d'expiration du jeton et notez le jeton dans un autre emplacement.NoteSi vous souhaitez configurer le webhook à l'aide du CLI
tkn pac, ajoutez la portéeadmin:repo_hook.
Procédure
Configurez le webhook et créez une ressource personnalisée (CR)
Repository.Pour configurer un webhook et créer un CR
Repositoryautomatically à l'aide de l'outil CLItkn pac, utilisez la commande suivante :$ tkn pac create repoExemple de sortie interactive
? Enter the Git repository url (default: https://github.com/owner/repo): ? Please enter the namespace where the pipeline should run (default: repo-pipelines): ! Namespace repo-pipelines is not found ? Would you like me to create the namespace repo-pipelines? Yes ✓ Repository owner-repo has been created in repo-pipelines namespace ✓ Setting up GitHub Webhook for Repository https://github.com/owner/repo 👀 I have detected a controller url: https://pipelines-as-code-controller-openshift-pipelines.apps.example.com ? Do you want me to use it? Yes ? Please enter the secret to configure the webhook for payload validation (default: sJNwdmTifHTs): sJNwdmTifHTs ℹ ️You now need to create a GitHub personal access token, please checkout the docs at https://docs.github.com/en/authentication/keeping-your-account-and-data-secure/creating-a-personal-access-token for the required scopes ? Please enter the GitHub access token: **************************************** ✓ Webhook has been created on repository owner/repo 🔑 Webhook Secret owner-repo has been created in the repo-pipelines namespace. 🔑 Repository CR owner-repo has been updated with webhook secret in the repo-pipelines namespace ℹ Directory .tekton has been created. ✓ We have detected your repository using the programming language Go. ✓ A basic template has been created in /home/Go/src/github.com/owner/repo/.tekton/pipelinerun.yaml, feel free to customize it.Pour configurer un webhook et créer un
RepositoryCR manually, procédez comme suit :Sur votre cluster OpenShift, extrayez l'URL publique du contrôleur Pipelines as Code.
$ echo https://$(oc get route -n pipelines-as-code pipelines-as-code-controller -o jsonpath='{.spec.host}')Sur votre dépôt ou organisation GitHub, effectuez les étapes suivantes :
- Allez sur Settings -> Webhooks et cliquez sur Add webhook.
- Définissez l'adresse Payload URL sur l'URL publique du contrôleur Pipelines as Code.
- Sélectionnez le type de contenu application/json.
Ajoutez un secret pour le webhook et notez-le dans un autre emplacement. Avec
opensslinstallé sur votre machine locale, générez un secret aléatoire.$ openssl rand -hex 20- Cliquez sur Let me select individual events et sélectionnez les événements suivants : Commit comments, Issue comments, Pull request, et Pushes.
- Cliquez sur Add webhook.
Sur votre cluster OpenShift, créez un objet
Secretavec le jeton d'accès personnel et le secret du webhook.$ oc -n target-namespace create secret generic github-webhook-config \ --from-literal provider.token="<GITHUB_PERSONAL_ACCESS_TOKEN>" \ --from-literal webhook.secret="<WEBHOOK_SECRET>"Créer un CR
Repository.Exemple :
RepositoryCRapiVersion: "pipelinesascode.tekton.dev/v1alpha1" kind: Repository metadata: name: my-repo namespace: target-namespace spec: url: "https://github.com/owner/repo" git_provider: secret: name: "github-webhook-config" key: "provider.token" # Set this if you have a different key in your secret webhook_secret: name: "github-webhook-config" key: "webhook.secret" # Set this if you have a different key for your secretNotePipelines as Code suppose que l'objet OpenShift
Secretet le CRRepositorysont dans le même espace de noms.
Facultatif : Pour un CR
Repositoryexistant, ajoutez plusieurs secrets GitHub Webhook ou fournissez un substitut pour un secret supprimé.Ajoutez un webhook à l'aide de l'outil CLI
tkn pac.Exemple : Webhook supplémentaire à l'aide de la CLI de
tkn pac$ tkn pac webhook add -n repo-pipelinesExemple de sortie interactive
✓ Setting up GitHub Webhook for Repository https://github.com/owner/repo 👀 I have detected a controller url: https://pipelines-as-code-controller-openshift-pipelines.apps.example.com ? Do you want me to use it? Yes ? Please enter the secret to configure the webhook for payload validation (default: AeHdHTJVfAeH): AeHdHTJVfAeH ✓ Webhook has been created on repository owner/repo 🔑 Secret owner-repo has been updated with webhook secert in the repo-pipelines namespace.-
Mettre à jour la clé
webhook.secretdans l'objet OpenShiftSecretexistant.
Facultatif : Pour un CR
Repositoryexistant, mettez à jour le jeton d'accès personnel.Mettez à jour le jeton d'accès personnel à l'aide de l'outil CLI
tkn pac.Exemple : Mise à jour du jeton d'accès personnel à l'aide du CLI
tkn pac$ tkn pac webhook update-token -n repo-pipelinesExemple de sortie interactive
? Please enter your personal access token: **************************************** 🔑 Secret owner-repo has been updated with new personal access token in the repo-pipelines namespace.Vous pouvez également mettre à jour le jeton d'accès personnel en modifiant le CR
Repository.Trouvez le nom du secret sur le site
RepositoryCR.... spec: git_provider: secret: name: "github-webhook-config" ...Utilisez la commande
oc patchpour mettre à jour les valeurs de$NEW_TOKENdans l'espace de noms$target_namespace.$ oc -n $target_namespace patch secret github-webhook-config -p "{\"data\": {\"provider.token\": \"$(echo -n $NEW_TOKEN|base64 -w0)\"}}"
3.8.7. Utiliser les pipelines comme du code avec GitLab
Si votre organisation ou votre projet utilise GitLab comme plateforme préférée, vous pouvez utiliser Pipelines as Code pour votre référentiel avec un webhook sur GitLab.
Conditions préalables
- Assurez-vous que Pipelines as Code est installé sur le cluster.
Pour l'autorisation, générez un jeton d'accès personnel en tant que responsable du projet ou de l'organisation sur GitLab.
Note-
Si vous souhaitez configurer le webhook à l'aide du CLI
tkn pac, ajoutez la portéeadmin:repo_hookau jeton. - L'utilisation d'un jeton pour un projet spécifique ne peut pas fournir un accès API à une demande de fusion (MR) envoyée à partir d'un dépôt forké. Dans de tels cas, Pipelines as Code affiche le résultat d'un pipeline en tant que commentaire sur la MR.
-
Si vous souhaitez configurer le webhook à l'aide du CLI
Procédure
Configurez le webhook et créez une ressource personnalisée (CR)
Repository.Pour configurer un webhook et créer un CR
Repositoryautomatically à l'aide de l'outil CLItkn pac, utilisez la commande suivante :$ tkn pac create repoExemple de sortie interactive
? Enter the Git repository url (default: https://gitlab.com/owner/repo): ? Please enter the namespace where the pipeline should run (default: repo-pipelines): ! Namespace repo-pipelines is not found ? Would you like me to create the namespace repo-pipelines? Yes ✓ Repository repositories-project has been created in repo-pipelines namespace ✓ Setting up GitLab Webhook for Repository https://gitlab.com/owner/repo ? Please enter the project ID for the repository you want to be configured, project ID refers to an unique ID (e.g. 34405323) shown at the top of your GitLab project : 17103 👀 I have detected a controller url: https://pipelines-as-code-controller-openshift-pipelines.apps.example.com ? Do you want me to use it? Yes ? Please enter the secret to configure the webhook for payload validation (default: lFjHIEcaGFlF): lFjHIEcaGFlF ℹ ️You now need to create a GitLab personal access token with `api` scope ℹ ️Go to this URL to generate one https://gitlab.com/-/profile/personal_access_tokens, see https://is.gd/rOEo9B for documentation ? Please enter the GitLab access token: ************************** ? Please enter your GitLab API URL:: https://gitlab.com ✓ Webhook has been created on your repository 🔑 Webhook Secret repositories-project has been created in the repo-pipelines namespace. 🔑 Repository CR repositories-project has been updated with webhook secret in the repo-pipelines namespace ℹ Directory .tekton has been created. ✓ A basic template has been created in /home/Go/src/gitlab.com/repositories/project/.tekton/pipelinerun.yaml, feel free to customize it.Pour configurer un webhook et créer un
RepositoryCR manually, procédez comme suit :Sur votre cluster OpenShift, extrayez l'URL publique du contrôleur Pipelines as Code.
$ echo https://$(oc get route -n pipelines-as-code pipelines-as-code-controller -o jsonpath='{.spec.host}')Sur votre projet GitLab, effectuez les étapes suivantes :
- Utilisez la barre latérale gauche pour aller à Settings -> Webhooks.
- Définissez l'adresse URL sur l'URL publique du contrôleur Pipelines as Code.
Ajoutez un secret pour le webhook et notez-le dans un autre emplacement. Avec
opensslinstallé sur votre machine locale, générez un secret aléatoire.$ openssl rand -hex 20- Cliquez sur Let me select individual events et sélectionnez les événements suivants : Commit comments, Issue comments, Pull request, et Pushes.
- Cliquez sur Save changes.
Sur votre cluster OpenShift, créez un objet
Secretavec le jeton d'accès personnel et le secret du webhook.$ oc -n target-namespace create secret generic gitlab-webhook-config \ --from-literal provider.token="<GITLAB_PERSONAL_ACCESS_TOKEN>" \ --from-literal webhook.secret="<WEBHOOK_SECRET>"Créer un CR
Repository.Exemple :
RepositoryCRapiVersion: "pipelinesascode.tekton.dev/v1alpha1" kind: Repository metadata: name: my-repo namespace: target-namespace spec: url: "https://gitlab.com/owner/repo"1 git_provider: secret: name: "gitlab-webhook-config" key: "provider.token" # Set this if you have a different key in your secret webhook_secret: name: "gitlab-webhook-config" key: "webhook.secret" # Set this if you have a different key for your secret- 1
- Actuellement, Pipelines as Code ne détecte pas automatiquement les instances privées pour GitLab. Dans ce cas, spécifiez l'URL de l'API sous la spécification
git_provider.url. En général, vous pouvez utiliser la spécificationgit_provider.urlpour remplacer manuellement l'URL de l'API.
Note-
Pipelines as Code suppose que l'objet OpenShift
Secretet le CRRepositorysont dans le même espace de noms.
Facultatif : Pour un CR
Repositoryexistant, ajoutez plusieurs secrets GitLab Webhook ou fournissez un substitut pour un secret supprimé.Ajoutez un webhook à l'aide de l'outil CLI
tkn pac.Exemple : Ajout d'un webhook supplémentaire à l'aide du CLI
tkn pac$ tkn pac webhook add -n repo-pipelinesExemple de sortie interactive
✓ Setting up GitLab Webhook for Repository https://gitlab.com/owner/repo 👀 I have detected a controller url: https://pipelines-as-code-controller-openshift-pipelines.apps.example.com ? Do you want me to use it? Yes ? Please enter the secret to configure the webhook for payload validation (default: AeHdHTJVfAeH): AeHdHTJVfAeH ✓ Webhook has been created on repository owner/repo 🔑 Secret owner-repo has been updated with webhook secert in the repo-pipelines namespace.-
Mettre à jour la clé
webhook.secretdans l'objet OpenShiftSecretexistant.
Facultatif : Pour un CR
Repositoryexistant, mettez à jour le jeton d'accès personnel.Mettez à jour le jeton d'accès personnel à l'aide de l'outil CLI
tkn pac.Exemple : Mise à jour du jeton d'accès personnel à l'aide du CLI
tkn pac$ tkn pac webhook update-token -n repo-pipelinesExemple de sortie interactive
? Please enter your personal access token: **************************************** 🔑 Secret owner-repo has been updated with new personal access token in the repo-pipelines namespace.Vous pouvez également mettre à jour le jeton d'accès personnel en modifiant le CR
Repository.Trouvez le nom du secret sur le site
RepositoryCR.... spec: git_provider: secret: name: "gitlab-webhook-config" ...Utilisez la commande
oc patchpour mettre à jour les valeurs de$NEW_TOKENdans l'espace de noms$target_namespace.$ oc -n $target_namespace patch secret gitlab-webhook-config -p "{\"data\": {\"provider.token\": \"$(echo -n $NEW_TOKEN|base64 -w0)\"}}"
Ressources complémentaires
3.8.8. Utiliser les pipelines comme du code avec Bitbucket Cloud
Si votre organisation ou votre projet utilise Bitbucket Cloud comme plateforme préférée, vous pouvez utiliser Pipelines as Code pour votre référentiel avec un webhook sur Bitbucket Cloud.
Conditions préalables
- Assurez-vous que Pipelines as Code est installé sur le cluster.
Créer un mot de passe pour l'application sur Bitbucket Cloud.
Cochez les cases suivantes pour ajouter les autorisations appropriées au jeton :
-
Compte :
Email,Read -
Adhésion à l'espace de travail :
Read,Write -
Projets :
Read,Write -
Questions :
Read,Write Demandes d'extension :
Read,WriteNote-
Si vous souhaitez configurer le webhook à l'aide du CLI
tkn pac, ajoutez les autorisationsWebhooks:ReadetWriteau jeton. - Une fois généré, sauvegardez une copie du mot de passe ou du jeton dans un autre endroit.
-
Si vous souhaitez configurer le webhook à l'aide du CLI
-
Compte :
Procédure
Configurez le webhook et créez un CR
Repository.Pour configurer un webhook et créer un CR
Repositoryautomatically à l'aide de l'outil CLItkn pac, utilisez la commande suivante :$ tkn pac create repoExemple de sortie interactive
? Enter the Git repository url (default: https://bitbucket.org/workspace/repo): ? Please enter the namespace where the pipeline should run (default: repo-pipelines): ! Namespace repo-pipelines is not found ? Would you like me to create the namespace repo-pipelines? Yes ✓ Repository workspace-repo has been created in repo-pipelines namespace ✓ Setting up Bitbucket Webhook for Repository https://bitbucket.org/workspace/repo ? Please enter your bitbucket cloud username: <username> ℹ ️You now need to create a Bitbucket Cloud app password, please checkout the docs at https://is.gd/fqMHiJ for the required permissions ? Please enter the Bitbucket Cloud app password: ************************************ 👀 I have detected a controller url: https://pipelines-as-code-controller-openshift-pipelines.apps.example.com ? Do you want me to use it? Yes ✓ Webhook has been created on repository workspace/repo 🔑 Webhook Secret workspace-repo has been created in the repo-pipelines namespace. 🔑 Repository CR workspace-repo has been updated with webhook secret in the repo-pipelines namespace ℹ Directory .tekton has been created. ✓ A basic template has been created in /home/Go/src/bitbucket/repo/.tekton/pipelinerun.yaml, feel free to customize it.Pour configurer un webhook et créer un
RepositoryCR manually, procédez comme suit :Sur votre cluster OpenShift, extrayez l'URL publique du contrôleur Pipelines as Code.
$ echo https://$(oc get route -n pipelines-as-code pipelines-as-code-controller -o jsonpath='{.spec.host}')Sur Bitbucket Cloud, effectuez les étapes suivantes :
- Utilisez le volet de navigation gauche de votre référentiel Bitbucket Cloud pour aller sur Repository settings -> Webhooks et cliquez sur Add webhook.
- Définir un site Title. Par exemple, "Pipelines as Code".
- Définissez l'adresse URL sur l'URL publique du contrôleur Pipelines as Code.
- Sélectionnez ces événements : Repository: Push, Pull Request: Created, Pull Request: Updated, et Pull Request: Comment created.
- Cliquez sur Save.
Sur votre cluster OpenShift, créez un objet
Secretavec le mot de passe de l'application dans l'espace de noms cible.$ oc -n target-namespace create secret generic bitbucket-cloud-token \ --from-literal provider.token="<BITBUCKET_APP_PASSWORD>"Créer un CR
Repository.Exemple :
RepositoryCRapiVersion: "pipelinesascode.tekton.dev/v1alpha1" kind: Repository metadata: name: my-repo namespace: target-namespace spec: url: "https://bitbucket.com/workspace/repo" branch: "main" git_provider: user: "<BITBUCKET_USERNAME>"1 secret: name: "bitbucket-cloud-token"2 key: "provider.token" # Set this if you have a different key in your secret
Note-
Les commandes
tkn pac createettkn pac bootstrapne sont pas prises en charge sur Bitbucket Cloud. Bitbucket Cloud ne prend pas en charge les secrets des webhooks. Pour sécuriser la charge utile et empêcher le détournement de l'IC, Pipelines as Code récupère la liste des adresses IP de Bitbucket Cloud et s'assure que les réceptions de webhook proviennent uniquement de ces adresses IP.
-
Pour désactiver le comportement par défaut, définissez
bitbucket-cloud-check-source-ip keycommefalsedans la carte de configuration de Pipelines as Code pour l'espace de nomspipelines-as-code. -
Pour autoriser d'autres adresses IP ou réseaux sûrs, ajoutez-les sous forme de valeurs séparées par des virgules à la clé
bitbucket-cloud-additional-source-ipdans la carte de configuration Pipelines as Code pour l'espace de nomspipelines-as-code.
-
Pour désactiver le comportement par défaut, définissez
Facultatif : Pour un CR
Repositoryexistant, ajoutez plusieurs secrets Bitbucket Cloud Webhook ou fournissez un substitut pour un secret supprimé.Ajoutez un webhook à l'aide de l'outil CLI
tkn pac.Exemple : Ajout d'un webhook supplémentaire à l'aide du CLI
tkn pac$ tkn pac webhook add -n repo-pipelinesExemple de sortie interactive
✓ Setting up Bitbucket Webhook for Repository https://bitbucket.org/workspace/repo ? Please enter your bitbucket cloud username: <username> 👀 I have detected a controller url: https://pipelines-as-code-controller-openshift-pipelines.apps.example.com ? Do you want me to use it? Yes ✓ Webhook has been created on repository workspace/repo 🔑 Secret workspace-repo has been updated with webhook secret in the repo-pipelines namespace.NoteUtilisez l'option
[-n <namespace>]avec la commandetkn pac webhook adduniquement lorsque le CRRepositoryexiste dans un espace de noms autre que l'espace de noms par défaut.-
Mettre à jour la clé
webhook.secretdans l'objet OpenShiftSecretexistant.
Facultatif : Pour un CR
Repositoryexistant, mettez à jour le jeton d'accès personnel.Mettez à jour le jeton d'accès personnel à l'aide de l'outil CLI
tkn pac.Exemple : Mise à jour du jeton d'accès personnel à l'aide du CLI
tkn pac$ tkn pac webhook update-token -n repo-pipelinesExemple de sortie interactive
? Please enter your personal access token: **************************************** 🔑 Secret owner-repo has been updated with new personal access token in the repo-pipelines namespace.NoteUtilisez l'option
[-n <namespace>]avec la commandetkn pac webhook update-tokenuniquement lorsque le CRRepositoryexiste dans un espace de noms autre que l'espace de noms par défaut.Vous pouvez également mettre à jour le jeton d'accès personnel en modifiant le CR
Repository.Trouvez le nom du secret sur le site
RepositoryCR.... spec: git_provider: user: "<BITBUCKET_USERNAME>" secret: name: "bitbucket-cloud-token" key: "provider.token" ...Utilisez la commande
oc patchpour mettre à jour les valeurs de$passworddans l'espace de noms$target_namespace.$ oc -n $target_namespace patch secret bitbucket-cloud-token -p "{\"data\": {\"provider.token\": \"$(echo -n $NEW_TOKEN|base64 -w0)\"}}"
3.8.9. Utiliser les pipelines comme du code avec Bitbucket Server
Si votre organisation ou votre projet utilise Bitbucket Server comme plateforme préférée, vous pouvez utiliser Pipelines as Code pour votre référentiel avec un webhook sur Bitbucket Server.
Conditions préalables
- Assurez-vous que Pipelines as Code est installé sur le cluster.
Générer un jeton d'accès personnel en tant que gestionnaire du projet sur le serveur Bitbucket, et enregistrer une copie de ce jeton dans un autre emplacement.
Note-
Le jeton doit avoir les autorisations
PROJECT_ADMINetREPOSITORY_ADMIN. - Le token doit avoir accès aux dépôts forkés dans les pull requests.
-
Le jeton doit avoir les autorisations
Procédure
Sur votre cluster OpenShift, extrayez l'URL publique du contrôleur Pipelines as Code.
$ echo https://$(oc get route -n pipelines-as-code pipelines-as-code-controller -o jsonpath='{.spec.host}')Sur le serveur Bitbucket, effectuez les étapes suivantes :
- Utilisez le volet de navigation gauche de votre référentiel Bitbucket Data Center pour aller sur Repository settings -> Webhooks et cliquez sur Add webhook.
- Définir un site Title. Par exemple, "Pipelines as Code".
- Définissez l'adresse URL sur l'URL publique du contrôleur Pipelines as Code.
Ajoutez un secret pour le webhook et sauvegardez-en une copie dans un autre emplacement. Si
opensslest installé sur votre machine locale, générez un secret aléatoire à l'aide de la commande suivante :$ openssl rand -hex 20Sélectionnez les événements suivants :
- Repository: Push
- Repository: Modified
- Pull Request: Opened
- Pull Request: Source branch updated
- Pull Request: Comment added
- Cliquez sur Save.
Sur votre cluster OpenShift, créez un objet
Secretavec le mot de passe de l'application dans l'espace de noms cible.$ oc -n target-namespace create secret generic bitbucket-server-webhook-config \ --from-literal provider.token="<PERSONAL_TOKEN>" \ --from-literal webhook.secret="<WEBHOOK_SECRET>"Créer un CR
Repository.Exemple :
RepositoryCR--- apiVersion: "pipelinesascode.tekton.dev/v1alpha1" kind: Repository metadata: name: my-repo namespace: target-namespace spec: url: "https://bitbucket.com/workspace/repo" git_provider: url: "https://bitbucket.server.api.url/rest"1 user: "<BITBUCKET_USERNAME>"2 secret:3 name: "bitbucket-server-webhook-config" key: "provider.token" # Set this if you have a different key in your secret webhook_secret: name: "bitbucket-server-webhook-config" key: "webhook.secret" # Set this if you have a different key for your secret- 1
- Assurez-vous que vous avez la bonne URL de l'API du serveur Bitbucket sans le suffixe
/api/v1.0. En général, l'installation par défaut a un suffixe/rest. - 2
- Vous ne pouvez faire référence à un utilisateur que par l'adresse
ACCOUNT_IDdans un fichier propriétaire. - 3
- Pipelines as Code suppose que le secret mentionné dans la spécification
git_provider.secretet la CRRepositoryse trouve dans le même espace de noms.
NoteLes commandes
tkn pac createettkn pac bootstrapne sont pas prises en charge par le serveur Bitbucket.
Ressources complémentaires
3.8.10. Interfacer Pipelines as Code avec des certificats personnalisés
Pour configurer Pipelines as Code avec un dépôt Git accessible avec un certificat personnalisé ou signé de manière privée, vous pouvez exposer le certificat à Pipelines as Code.
Procédure
-
Si vous avez installé Pipelines as Code à l'aide de l'Opérateur Red Hat OpenShift Pipelines, vous pouvez ajouter votre certificat personnalisé au cluster à l'aide de l'objet
Proxy. L'Opérateur expose le certificat dans tous les composants et charges de travail de Red Hat OpenShift Pipelines, y compris Pipelines as Code.
Ressources complémentaires
3.8.11. Utilisation de Repository CRD avec Pipelines as Code
La ressource personnalisée (CR) Repository a les fonctions principales suivantes :
- Informer Pipelines as Code sur le traitement d'un événement à partir d'une URL.
- Informer Pipelines as Code de l'espace de noms pour l'exécution des pipelines.
- Référence un secret d'API, un nom d'utilisateur ou une URL d'API nécessaire pour les plates-formes du fournisseur Git lors de l'utilisation des méthodes webhook.
- Fournit le dernier état d'exécution du pipeline pour un référentiel.
Vous pouvez utiliser le CLI tkn pac ou d'autres méthodes alternatives pour créer un CR Repository dans l'espace de noms cible. Par exemple, vous pouvez créer un CR à l'intérieur de l'espace de noms cible :
cat <<EOF|kubectl create -n my-pipeline-ci -f-
apiVersion: "pipelinesascode.tekton.dev/v1alpha1"
kind: Repository
metadata:
name: project-repository
spec:
url: "https://github.com/<repository>/<project>"
EOF- 1
my-pipeline-ciest l'espace de noms cible.
Chaque fois qu'il y a un événement provenant de l'URL tel que https://github.com/<repository>/<project>pipelines as Code l'identifie et commence à vérifier le contenu du référentiel <repository>/<project> pour que l'exécution des pipelines corresponde au contenu du répertoire .tekton/.
-
Vous devez créer le CRD
Repositorydans le même espace de noms que celui où les pipelines associés au référentiel de code source seront exécutés ; il ne peut pas cibler un espace de noms différent. -
Si plusieurs CRD
Repositorycorrespondent au même événement, Pipelines as Code ne traitera que le plus ancien. Si vous avez besoin de faire correspondre un espace de noms spécifique, ajoutez l'annotationpipelinesascode.tekton.dev/target-namespace: "<mynamespace>". Ce ciblage explicite empêche un acteur malveillant d'exécuter un pipeline dans un espace de noms auquel il n'a pas accès.
3.8.11.1. Fixer des limites de concurrence dans le CRD Repository
Vous pouvez utiliser la spécification concurrency_limit dans le CRD Repository pour définir le nombre maximum d'exécutions simultanées du pipeline pour un référentiel.
...
spec:
concurrency_limit: <number>
...Si plusieurs séries de pipelines correspondent à un événement, les séries de pipelines qui correspondent à l'événement commencent dans l'ordre alphabétique.
Par exemple, si vous avez trois projets de pipeline dans le répertoire .tekton et que vous créez une demande d'extraction avec un concurrency_limit de 1 dans la configuration du référentiel, tous les projets de pipeline sont exécutés dans l'ordre alphabétique. À tout moment, un seul pipeline est en cours d'exécution, tandis que les autres sont en file d'attente.
3.8.12. Utiliser les pipelines comme résolveur de code
Le résolveur de Pipelines as Code permet de s'assurer qu'un pipeline en cours d'exécution n'entre pas en conflit avec d'autres.
Pour diviser votre pipeline et votre cycle de pipeline, stockez les fichiers dans le répertoire .tekton/ ou ses sous-répertoires.
Si Pipelines as Code observe une exécution de pipeline avec une référence à une tâche ou à un pipeline dans un fichier YAML situé dans le répertoire .tekton/, Pipelines as Code résout automatiquement la tâche référencée pour fournir une exécution de pipeline unique avec une spécification intégrée dans un objet PipelineRun.
Si Pipelines as Code ne peut pas résoudre les tâches référencées dans la définition Pipeline ou PipelineSpec, l'exécution échoue avant d'appliquer tout changement au cluster. Vous pouvez voir le problème sur votre plateforme Git et dans les événements de l'espace de noms cible où se trouve le CR Repository.
Le résolveur passe à la résolution s'il observe les types de tâches suivants :
- Une référence à une tâche de cluster.
- Une tâche ou un ensemble de tâches.
-
Une tâche personnalisée avec une version de l'API qui n'a pas de préfixe
tekton.dev/.
Le résolveur utilise ces tâches littéralement, sans aucune transformation.
Pour tester votre pipeline en local avant de l'envoyer dans une pull request, utilisez la commande tkn pac resolve.
Vous pouvez également référencer des pipelines et des tâches à distance.
3.8.12.1. Utiliser les annotations de tâches à distance avec Pipelines as Code
Pipelines as Code prend en charge la récupération de tâches ou de pipelines distants en utilisant des annotations dans l'exécution d'un pipeline. Si vous faites référence à une tâche distante dans une exécution de pipeline, ou à un pipeline dans un objet PipelineRun ou PipelineSpec, le résolveur de Pipelines as Code l'inclut automatiquement. S'il y a une erreur lors de la récupération des tâches distantes ou de leur analyse, Pipelines as Code arrête le traitement des tâches.
Pour inclure des tâches à distance, reportez-vous aux exemples d'annotation suivants :
Référencement des tâches à distance dans Tekton Hub
Référencer une seule tâche à distance dans Tekton Hub.
... pipelinesascode.tekton.dev/task: "git-clone"1 ...- 1
- Pipelines as Code inclut la dernière version de la tâche du Tekton Hub.
Référencement de plusieurs tâches à distance à partir de Tekton Hub
... pipelinesascode.tekton.dev/task: "[git-clone, golang-test, tkn]" ...Référencez plusieurs tâches à distance à partir du Tekton Hub en utilisant le suffixe
-<NUMBER>.... pipelinesascode.tekton.dev/task: "git-clone" pipelinesascode.tekton.dev/task-1: "golang-test" pipelinesascode.tekton.dev/task-2: "tkn"1 ...- 1
- Par défaut, Pipelines as Code interprète la chaîne comme la dernière tâche à récupérer dans le Tekton Hub.
Référence une version spécifique d'une tâche à distance à partir du Tekton Hub.
... pipelinesascode.tekton.dev/task: "[git-clone:0.1]"1 ...- 1
- Se réfère à la version
0.1de la tâche à distancegit-clonedu Tekton Hub.
Tâches à distance à l'aide d'URL
...
pipelinesascode.tekton.dev/task: "<https://remote.url/task.yaml>"
...- 1
- L'URL publique de la tâche distante.Note
Si vous utilisez GitHub et que l'URL de la tâche distante utilise le même hôte que le CRD
Repository, Pipelines as Code utilise le jeton GitHub et récupère l'URL à l'aide de l'API GitHub.Par exemple, si vous avez une URL de dépôt similaire à
https://github.com/<organization>/<repository>et que l'URL HTTP distante fait référence à un blob GitHub similaire àhttps://github.com/<organization>/<repository>/blob/<mainbranch>/<path>/<file>pipelines as Code récupère les fichiers de définition de tâches de ce référentiel privé avec le jeton GitHub App.Lorsque vous travaillez sur un dépôt public GitHub, Pipelines as Code agit de la même manière pour une URL brute GitHub telle que
https://raw.githubusercontent.com/<organization>/<repository>/<mainbranch>/<path>/<file>.- Les jetons GitHub App sont limités au propriétaire ou à l'organisation où se trouve le dépôt. Lorsque vous utilisez la méthode GitHub webhook, vous pouvez récupérer n'importe quel dépôt privé ou public dans n'importe quelle organisation où le jeton personnel est autorisé.
Référencer une tâche à partir d'un fichier YAML dans votre référentiel
...
pipelinesascode.tekton.dev/task: "<share/tasks/git-clone.yaml>"
...- 1
- Chemin relatif vers le fichier local contenant la définition de la tâche.
3.8.12.2. Utiliser des annotations de pipeline à distance avec Pipelines as Code
Vous pouvez partager une définition de pipeline entre plusieurs référentiels en utilisant l'annotation de pipeline distant.
...
pipelinesascode.tekton.dev/pipeline: "<https://git.provider/raw/pipeline.yaml>"
...- 1
- À la définition du pipeline distant. Vous pouvez également fournir des emplacements pour des fichiers à l'intérieur du même référentiel.
Vous ne pouvez faire référence qu'à une seule définition de pipeline à l'aide de l'annotation.
3.8.13. Création d'un pipeline à l'aide de Pipelines as Code
Pour exécuter des pipelines en utilisant Pipelines as Code, vous pouvez créer des définitions ou des modèles de pipelines sous forme de fichiers YAML dans le répertoire .tekton/ du référentiel. Vous pouvez référencer des fichiers YAML dans d'autres référentiels à l'aide d'URL distantes, mais l'exécution des pipelines n'est déclenchée que par des événements dans le référentiel contenant le répertoire .tekton/.
Le résolveur Pipelines as Code regroupe les exécutions de pipelines avec toutes les tâches en une seule exécution de pipeline sans dépendances externes.
-
Pour les pipelines, utilisez au moins un pipeline exécuté avec une spécification ou un objet
Pipelineséparé. - Pour les tâches, intégrer la spécification de la tâche dans un pipeline ou la définir séparément en tant qu'objet "tâche".
Paramétrer les commits et les URL
Vous pouvez spécifier les paramètres de votre livraison et de votre URL en utilisant des variables dynamiques et extensibles au format {{<var>}}. Actuellement, vous pouvez utiliser les variables suivantes :
-
{{repo_owner}}: Le propriétaire du référentiel. -
{{repo_name}}: Le nom du référentiel. -
{{repo_url}}: L'URL complète du dépôt. -
{{revision}}: Révision SHA complète d'un commit. -
{{sender}}: Le nom d'utilisateur ou l'identifiant du compte de l'expéditeur du commit. -
{{source_branch}}: Le nom de la branche d'où provient l'événement. -
{{target_branch}}: Le nom de la branche ciblée par l'événement. Pour les événements "push", c'est la même chose quesource_branch. -
{{pull_request_number}}: Le numéro de la demande de retrait ou de fusion, défini uniquement pour un type d'événementpull_request. -
{{git_auth_secret}}: Le nom secret qui est généré automatiquement avec le jeton du fournisseur Git pour l'extraction des dépôts privés.
Correspondance entre un événement et une exécution de pipeline
Vous pouvez faire correspondre différents événements du fournisseur Git avec chaque pipeline en utilisant des annotations spéciales sur l'exécution du pipeline. S'il y a plusieurs pipelines correspondant à un événement, Pipelines as Code les exécute en parallèle et envoie les résultats au fournisseur Git dès qu'un pipeline se termine.
Correspondance entre un événement "pull" et une exécution de pipeline
Vous pouvez utiliser l'exemple suivant pour faire correspondre le pipeline pipeline-pr-main avec un événement pull_request qui cible la branche main:
...
metadata:
name: pipeline-pr-main
annotations:
pipelinesascode.tekton.dev/on-target-branch: "[main]"
pipelinesascode.tekton.dev/on-event: "[pull_request]"
...- 1
- Vous pouvez spécifier plusieurs branches en ajoutant des entrées séparées par des virgules. Par exemple,
"[main, release-nightly]". En outre, vous pouvez spécifier ce qui suit :-
Références complètes à des branches telles que
"refs/heads/main" -
Globs avec pattern matching tels que
"refs/heads/\*" -
Tags tels que
"refs/tags/1.\*"
-
Références complètes à des branches telles que
Correspondance entre un événement "push" et une exécution du pipeline
Vous pouvez utiliser l'exemple suivant pour faire correspondre le pipeline pipeline-push-on-main avec un événement push ciblant la branche refs/heads/main:
...
metadata:
name: pipeline-push-on-main
annotations:
pipelinesascode.tekton.dev/on-target-branch: "[refs/heads/main]"
pipelinesascode.tekton.dev/on-event: "[push]"
...- 1
- Vous pouvez spécifier plusieurs branches en ajoutant des entrées séparées par des virgules. Par exemple,
"[main, release-nightly]". En outre, vous pouvez spécifier ce qui suit :-
Références complètes à des branches telles que
"refs/heads/main" -
Globs avec pattern matching tels que
"refs/heads/\*" -
Tags tels que
"refs/tags/1.\*"
-
Références complètes à des branches telles que
Correspondance avancée des événements
Pipelines as Code prend en charge l'utilisation du filtrage basé sur le langage d'expression commun (CEL) pour une correspondance avancée des événements. Si vous avez l'annotation pipelinesascode.tekton.dev/on-cel-expression dans votre pipeline, Pipelines as Code utilise l'expression CEL et saute l'annotation on-target-branch. Par rapport à la simple correspondance de l'annotation on-target-branch, les expressions CEL permettent un filtrage complexe et la négation.
Pour utiliser le filtrage basé sur la CEL avec Pipelines as Code, examinez les exemples d'annotations suivants :
Correspondre à un événement
pull_requestciblant la branchemainet provenant de la branchewip:... pipelinesascode.tekton.dev/on-cel-expression: | event == "pull_request" && target_branch == "main" && source_branch == "wip" ...Pour n'exécuter un pipeline que si le chemin d'accès a changé, vous pouvez utiliser la fonction suffixe de
.pathChangedavec un motif global :... pipelinesascode.tekton.dev/on-cel-expression: | event == "pull_request" && "docs/\*.md".pathChanged()1 ...- 1
- Correspond à tous les fichiers markdown du répertoire
docs.
Pour correspondre à toutes les pull requests commençant par le titre
[DOWNSTREAM]:... pipelinesascode.tekton.dev/on-cel-expression: | event == "pull_request && event_title.startsWith("[DOWNSTREAM]") ...Pour lancer un pipeline sur un événement
pull_request, mais ignorer la brancheexperimental:... pipelinesascode.tekton.dev/on-cel-expression: | event == "pull_request" && target_branch != experimental" ...
Pour un filtrage avancé basé sur la CEL lors de l'utilisation de Pipelines as Code, vous pouvez utiliser les champs et les fonctions de suffixe suivants :
-
event: Un événementpushoupull_request. -
target_branch: La branche cible. -
source_branch: La branche d'origine d'un événementpull_request. Pour les événementspush, c'est la même chose quetarget_branch. -
event_title: Correspond au titre de l'événement, tel que le titre du commit pour un événementpush, et le titre d'une demande d'extraction ou de fusion pour un événementpull_request. Actuellement, seuls GitHub, Gitlab et Bitbucket Cloud sont des fournisseurs pris en charge. -
.pathChanged: Une fonction de suffixe à une chaîne de caractères. La chaîne peut être un glob d'un chemin pour vérifier si le chemin a changé. Actuellement, seuls GitHub et Gitlab sont pris en charge en tant que fournisseurs.
Utilisation du jeton temporaire de l'application GitHub pour les opérations de l'API Github
Vous pouvez utiliser le jeton d'installation temporaire généré par Pipelines as Code from GitHub App pour accéder à l'API GitHub. La valeur du jeton est stockée dans la variable dynamique temporaire {{git_auth_secret}} générée pour les dépôts privés dans la clé git-provider-token.
Par exemple, pour ajouter un commentaire à une pull request, vous pouvez utiliser la tâche github-add-comment de Tekton Hub en utilisant une annotation Pipelines as Code :
...
pipelinesascode.tekton.dev/task: "github-add-comment"
...
Vous pouvez ensuite ajouter une tâche à la section tasks ou aux tâches finally dans la définition de l'exécution du pipeline :
[...]
tasks:
- name:
taskRef:
name: github-add-comment
params:
- name: REQUEST_URL
value: "{{ repo_url }}/pull/{{ pull_request_number }}"
- name: COMMENT_OR_FILE
value: "Pipelines as Code IS GREAT!"
- name: GITHUB_TOKEN_SECRET_NAME
value: "{{ git_auth_secret }}"
- name: GITHUB_TOKEN_SECRET_KEY
value: "git-provider-token"
...- 1
- En utilisant les variables dynamiques, vous pouvez réutiliser ce modèle de snippet pour n'importe quelle demande d'extraction de n'importe quel dépôt.
Sur GitHub Apps, le jeton d'installation généré est disponible pendant 8 heures et limité au dépôt d'où proviennent les événements, sauf configuration différente sur le cluster.
Ressources complémentaires
3.8.14. Exécution d'un pipeline à l'aide de Pipelines as Code
Avec la configuration par défaut, Pipelines as Code exécute tout pipeline exécuté dans le répertoire .tekton/ de la branche par défaut du référentiel, lorsque des événements spécifiés tels que pull request ou push se produisent sur le référentiel. Par exemple, si un pipeline exécuté sur la branche par défaut a l'annotation pipelinesascode.tekton.dev/on-event: "[pull_request]", il sera exécuté à chaque fois qu'un événement de demande d'extraction (pull request) se produit.
Dans le cas d'une pull request ou d'une merge request, Pipelines as Code exécute également des pipelines à partir de branches autres que la branche par défaut, si les conditions suivantes sont remplies par l'auteur de la pull request :
- L'auteur est le propriétaire du dépôt.
- L'auteur est un collaborateur du dépôt.
- L'auteur est un membre public de l'organisation du dépôt.
-
L'auteur de la demande d'extraction est listé dans un fichier
OWNERsitué dans la racine du dépôt de la branchemaincomme défini dans la configuration GitHub pour le dépôt. De plus, l'auteur de la demande d'extraction est ajouté à la sectionapproversoureviewers. Par exemple, si un auteur est listé dans la sectionapprovers, alors une demande d'extraction soulevée par cet auteur démarre l'exécution du pipeline.
...
approvers:
- approved
...
Si l'auteur de la demande d'extraction ne répond pas aux exigences, un autre utilisateur qui répond aux exigences peut commenter /ok-to-test sur la demande d'extraction et lancer l'exécution du pipeline.
Exécution du pipeline
Une exécution de pipeline s'exécute toujours dans l'espace de noms du CRD Repository associé au référentiel qui a généré l'événement.
Vous pouvez observer l'exécution de votre pipeline à l'aide de l'outil CLI tkn pac.
Pour suivre l'exécution de la dernière opération de pipeline, utilisez l'exemple suivant :
$ tkn pac logs -n <my-pipeline-ci> -L1 - 1
my-pipeline-ciest l'espace de noms pour le CRDRepository.
Pour suivre l'exécution d'un pipeline de manière interactive, utilisez l'exemple suivant :
$ tkn pac logs -n <my-pipeline-ci>1 - 1
my-pipeline-ciest l'espace de noms pour le CRDRepository. Si vous souhaitez visualiser un pipeline autre que le dernier, vous pouvez utiliser la commandetkn pac logspour sélectionner unPipelineRunattaché au référentiel :
Si vous avez configuré Pipelines as Code avec une application GitHub, Pipelines as Code affiche une URL dans l'onglet Checks de l'application GitHub. Vous pouvez cliquer sur l'URL et suivre l'exécution du pipeline.
Redémarrage d'un pipeline
Vous pouvez redémarrer un pipeline qui n'a pas connu d'événements, comme l'envoi d'un nouveau commit sur votre branche ou l'ouverture d'une pull request. Sur une application GitHub, allez dans l'onglet Checks et cliquez sur Re-run.
Si vous ciblez une demande d'extraction ou de fusion, utilisez les commentaires suivants à l'intérieur de votre demande d'extraction pour redémarrer toutes les exécutions du pipeline ou certaines d'entre elles :
-
Le commentaire
/retestredémarre toutes les exécutions du pipeline. -
Le commentaire
/retest <pipelinerun-name>permet de redémarrer l'exécution d'un pipeline spécifique. -
Le commentaire
/cancelannule toutes les exécutions du pipeline. -
Le commentaire
/cancel <pipelinerun-name>permet d'annuler une opération de pipeline spécifique.
Les résultats des commentaires sont visibles sous l'onglet Checks d'une application GitHub.
3.8.15. Suivi de l'état d'exécution des pipelines à l'aide de Pipelines as Code
Selon le contexte et les outils pris en charge, vous pouvez surveiller l'état d'un pipeline de différentes manières.
Statut des applications GitHub
À la fin de l'exécution d'un pipeline, l'état est ajouté dans les onglets Check avec des informations limitées sur la durée de chaque tâche de votre pipeline et la sortie de la commande tkn pipelinerun describe.
Extrait d'erreur du journal
Lorsque Pipelines as Code détecte une erreur dans l'une des tâches d'un pipeline, un petit extrait constitué des 3 dernières lignes de la décomposition de la première tâche défaillante est affiché.
Pipelines as Code évite les fuites de secrets en examinant l'exécution du pipeline et en remplaçant les valeurs secrètes par des caractères cachés. Cependant, Pipelines as Code ne peut pas cacher les secrets provenant des espaces de travail et de la source envFrom.
Annotations pour les extraits d'erreurs du journal
Dans la carte de configuration de Pipelines as Code, si vous définissez le paramètre error-detection-from-container-logs à true, Pipelines as Code détecte les erreurs à partir des journaux du conteneur et les ajoute en tant qu'annotations sur la demande d'extraction où l'erreur s'est produite.
Cette fonctionnalité est en avant-première technologique.
Actuellement, Pipelines as Code ne prend en charge que les cas simples où l'erreur ressemble à une sortie makefile ou grep du format suivant :
<filename>:<line>:<column> : <error message>
Vous pouvez personnaliser l'expression régulière utilisée pour détecter les erreurs dans le champ error-detection-simple-regexp. L'expression régulière utilise des groupes nommés pour donner de la flexibilité sur la façon de spécifier la correspondance. Les groupes nécessaires à la correspondance sont le nom de fichier, la ligne et l'erreur. Vous pouvez voir la carte de configuration de Pipelines as Code pour l'expression régulière par défaut.
Par défaut, Pipelines as Code analyse uniquement les 50 dernières lignes des journaux de conteneurs. Vous pouvez augmenter cette valeur dans le champ error-detection-max-number-of-lines ou définir -1 pour un nombre illimité de lignes. Cependant, de telles configurations peuvent augmenter l'utilisation de la mémoire de l'observateur.
Statut du webhook
Pour le webhook, lorsque l'événement est une demande d'extraction, le statut est ajouté en tant que commentaire sur la demande d'extraction ou de fusion.
Défaillances
Si un espace de noms correspond à un CRD Repository, Pipelines as Code émet ses messages de journal d'échec dans les événements Kubernetes à l'intérieur de l'espace de noms.
Statut associé au référentiel CRD
Les 5 derniers messages d'état d'un pipeline sont stockés dans la ressource personnalisée Repository.
$ oc get repo -n <pipelines-as-code-ci>NAME URL NAMESPACE SUCCEEDED REASON STARTTIME COMPLETIONTIME
pipelines-as-code-ci https://github.com/openshift-pipelines/pipelines-as-code pipelines-as-code-ci True Succeeded 59m 56m
En utilisant la commande tkn pac describe, vous pouvez extraire l'état des exécutions associées à votre référentiel et à ses métadonnées.
Notifications
Pipelines as Code ne gère pas les notifications. Si vous avez besoin de notifications, utilisez la fonctionnalité finally de Pipelines.
3.8.16. Utiliser des dépôts privés avec Pipelines as Code
Pipelines as Code prend en charge les dépôts privés en créant ou en mettant à jour un secret dans l'espace de noms cible avec le jeton d'utilisateur. La tâche git-clone de Tekton Hub utilise le jeton d'utilisateur pour cloner les dépôts privés.
Chaque fois que Pipelines as Code crée un nouveau pipeline dans l'espace de noms cible, il crée ou met à jour un secret au format pac-gitauth-<REPOSITORY_OWNER>-<REPOSITORY_NAME>-<RANDOM_STRING>.
Vous devez référencer le secret avec l'espace de travail basic-auth dans vos définitions d'exécution et de pipeline, qui est ensuite transmis à la tâche git-clone.
...
workspace:
- name: basic-auth
secret:
secretName: "{{ git_auth_secret }}"
...
Dans le pipeline, vous pouvez faire référence à l'espace de travail basic-auth pour réutiliser la tâche git-clone:
...
workspaces:
- name basic-auth
params:
- name: repo_url
- name: revision
...
tasks:
workspaces:
- name: basic-auth
workspace: basic-auth
...
tasks:
- name: git-clone-from-catalog
taskRef:
name: git-clone
params:
- name: url
value: $(params.repo_url)
- name: revision
value: $(params.revision)
...- 1
- La tâche
git-clonerécupère l'espace de travailbasic-authet l'utilise pour cloner le dépôt privé.
Vous pouvez modifier cette configuration en attribuant à l'indicateur secret-auto-create la valeur false ou true, comme indiqué dans la carte de configuration Pipelines as Code.
Ressources complémentaires
3.8.17. Nettoyage de l'exécution d'un pipeline à l'aide de Pipelines as Code
Il peut y avoir de nombreuses exécutions de pipelines dans un espace de noms d'utilisateurs. En définissant l'annotation max-keep-runs, vous pouvez configurer Pipelines as Code pour qu'il conserve un nombre limité d'exécutions de pipelines correspondant à un événement. Par exemple :
...
pipelinesascode.tekton.dev/max-keep-runs: "<max_number>"
...- 1
- Pipelines as Code commence à faire le ménage dès la fin d'une exécution réussie, en ne conservant que le nombre maximum d'exécutions du pipeline configuré à l'aide de l'annotation.Note
- Pipelines as Code ne nettoie pas les pipelines en cours d'exécution mais nettoie les pipelines en cours d'exécution dont l'état est inconnu.
- Pipelines as Code ne nettoie pas une demande d'extraction qui a échoué.
3.8.18. Utiliser un webhook entrant avec Pipelines as Code
En utilisant une URL de webhook entrant et un secret partagé, vous pouvez lancer l'exécution d'un pipeline dans un référentiel.
Pour utiliser les webhooks entrants, spécifiez ce qui suit dans la section spec du CRD Repository:
- L'URL du webhook entrant qui correspond à Pipelines as Code.
Le fournisseur Git et le jeton d'utilisateur. Actuellement, Pipelines as Code prend en charge
github,gitlab, etbitbucket-cloud.NoteLors de l'utilisation d'URLs de webhooks entrants dans le contexte de l'application GitHub, vous devez spécifier le jeton.
- Les branches cibles et un secret pour l'URL du webhook entrant.
Exemple : Repository CRD avec webhook entrant
apiVersion: "pipelinesascode.tekton.dev/v1alpha1"
kind: Repository
metadata:
name: repo
namespace: ns
spec:
url: "https://github.com/owner/repo"
git_provider:
type: github
secret:
name: "owner-token"
incoming:
- targets:
- main
secret:
name: repo-incoming-secret
type: webhook-urlExemple : Le secret repo-incoming-secret pour le webhook entrant
apiVersion: v1
kind: Secret
metadata:
name: repo-incoming-secret
namespace: ns
type: Opaque
stringData:
secret: <very-secure-shared-secret>
Pour déclencher l'exécution d'un pipeline situé dans le répertoire .tekton d'un dépôt Git, utilisez la commande suivante :
$ curl -X POST 'https://control.pac.url/incoming?secret=very-secure-shared-secret&repository=repo&branch=main&pipelinerun=target_pipelinerun'
Pipelines as Code fait correspondre l'URL entrant et le traite comme un événement push. Cependant, Pipelines as Code ne signale pas l'état des exécutions du pipeline déclenchées par cette commande.
Pour obtenir un rapport ou une notification, ajoutez-les directement à votre pipeline à l'aide d'une tâche finally. Vous pouvez également inspecter le CRD Repository à l'aide de l'outil CLI tkn pac.
3.8.19. Personnaliser la configuration de Pipelines as Code
Pour personnaliser Pipelines as Code, les administrateurs de clusters peuvent configurer les paramètres suivants à l'aide de la carte de configuration pipelines-as-code dans l'espace de noms pipelines-as-code:
| Paramètres | Description | Défaut |
|---|---|---|
|
| Le nom de l'application. Par exemple, le nom affiché dans les étiquettes GitHub Checks. |
|
|
|
Le nombre de jours pendant lesquels les exécutions du pipeline sont conservées dans l'espace de noms
Notez que ce paramètre | NA |
|
| Indique si un secret doit être automatiquement créé à l'aide du jeton généré dans l'application GitHub. Ce secret peut ensuite être utilisé avec des dépôts privés. |
|
|
| Lorsque cette option est activée, elle autorise les tâches à distance à partir des annotations d'exécution du pipeline. |
|
|
| L'URL de base pour l'API Tekton Hub. | |
|
| Le nom du catalogue Tekton Hub. |
|
|
|
L'URL du tableau de bord Tekton Hub. Pipelines as Code utilise cette URL pour générer une URL | NA |
|
| Indique s'il faut sécuriser les demandes de service en interrogeant les plages d'IP pour un Bitbucket public. La modification de la valeur par défaut du paramètre peut entraîner un problème de sécurité. |
|
|
| Indique s'il faut fournir un ensemble supplémentaire de plages ou de réseaux IP, séparés par des virgules. | NA |
|
|
Limite maximale de la valeur | NA |
|
|
Limite par défaut de la valeur de | NA |
|
| Configure automatiquement les nouveaux dépôts GitHub. Pipelines as Code met en place un espace de noms et crée une ressource personnalisée pour votre dépôt. Ce paramètre n'est pris en charge qu'avec les applications GitHub. |
|
|
|
Configure un modèle pour générer automatiquement l'espace de noms pour votre nouveau dépôt, si |
|
|
| Active ou désactive l'affichage d'un extrait de journal pour les tâches qui ont échoué, avec une erreur dans un pipeline. Vous pouvez désactiver ce paramètre en cas de fuite de données de votre pipeline. |
|
3.8.20. Référence de la commande Pipelines as Code
L'outil CLI tkn pac offre les possibilités suivantes :
- Installation et configuration de Bootstrap Pipelines as Code.
- Créer un nouveau dépôt Pipelines as Code.
- Liste de tous les dépôts de Pipelines as Code.
- Décrire un référentiel Pipelines as Code et les exécutions associées.
- Générer un simple pipeline pour commencer.
- Résoudre un pipeline comme s'il avait été exécuté par Pipelines as Code.
Vous pouvez utiliser les commandes correspondant aux capacités à des fins de test et d'expérimentation, sans avoir à modifier le dépôt Git contenant le code source de l'application.
3.8.20.1. Syntaxe de base
$ tkn pac [command or options] [arguments]3.8.20.2. Options globales
$ tkn pac --help3.8.20.3. Commandes d'utilitaires
3.8.20.3.1. amorçage
| Commandement | Description |
|---|---|
|
| Installe et configure Pipelines as Code pour les fournisseurs de services d'hébergement de dépôts Git, tels que GitHub et GitHub Enterprise. |
|
| Installe la version de nuit de Pipelines as Code. |
|
| Remplace l'URL de la route OpenShift.
Par défaut, Si vous n'avez pas de cluster OpenShift Container Platform, il vous demande l'URL publique qui pointe vers le point d'entrée. |
|
|
Créez une application GitHub et des secrets dans l'espace de noms |
3.8.20.3.2. dépôt
| Commandement | Description |
|---|---|
|
| Crée un nouveau référentiel Pipelines as Code et un espace de noms basé sur le modèle d'exécution du pipeline. |
|
| Liste tous les Pipelines en tant que dépôts de code et affiche le dernier état des exécutions associées. |
|
| Décrit un référentiel Pipelines as Code et les exécutions associées. |
3.8.20.3.3. générer
| Commandement | Description |
|---|---|
|
| Génère une simple exécution de pipeline. Lorsqu'il est exécuté à partir du répertoire contenant le code source, il détecte automatiquement les informations Git actuelles. En outre, il utilise la capacité de détection de la langue de base et ajoute des tâches supplémentaires en fonction de la langue.
Par exemple, s'il détecte un fichier |
3.8.20.3.4. résoudre
| Commandement | Description |
|---|---|
|
| Exécute un pipeline comme s'il appartenait au service Pipelines as Code on. |
|
|
Affiche l'état d'un pipeline en cours d'exécution qui utilise le modèle dans Combiné à une installation Kubernetes fonctionnant sur votre machine locale, vous pouvez observer l'exécution du pipeline sans générer de nouveau commit. Si vous exécutez la commande à partir d'un dépôt de code source, elle tente de détecter les informations Git actuelles et de résoudre automatiquement les paramètres tels que la révision ou la branche actuelle. |
|
| Exécute un pipeline en remplaçant les valeurs par défaut des paramètres dérivés du référentiel Git.
L'option
Vous pouvez remplacer les informations recueillies par défaut dans le référentiel Git en spécifiant des valeurs de paramètres à l'aide de l'option |
3.9. Travailler avec Red Hat OpenShift Pipelines en utilisant la perspective du développeur
Vous pouvez utiliser la perspective Developer de la console web d'OpenShift Container Platform pour créer des pipelines CI/CD pour votre processus de livraison de logiciels.
Dans la perspective de Developer:
- Utilisez l'option Add → Pipeline → Pipeline builder pour créer des pipelines personnalisés pour votre application.
- Utilisez l'option Add → From Git pour créer des pipelines à l'aide de modèles de pipelines et de ressources installés par l'opérateur lors de la création d'une application sur OpenShift Container Platform.
Après avoir créé les pipelines pour votre application, vous pouvez visualiser et interagir visuellement avec les pipelines déployés dans la vue Pipelines. Vous pouvez également utiliser la vue Topology pour interagir avec les pipelines créés à l'aide de l'option From Git. Vous devez appliquer des étiquettes personnalisées aux pipelines créés à l'aide de l'option Pipeline builder pour les voir dans la vue Topology.
Conditions préalables
- Vous avez accès à un cluster OpenShift Container Platform et vous êtes passé à la perspective Developer .
- L'opérateur OpenShift Pipelines est installé dans votre cluster.
- Vous êtes un administrateur de cluster ou un utilisateur disposant d'autorisations de création et de modification.
- Vous avez créé un projet.
3.9.1. Construire des pipelines à l'aide du constructeur de pipelines
Dans la perspective Developer de la console, vous pouvez utiliser l'option Add → Pipeline → Pipeline builder pour :
- Configurer les pipelines à l'aide de Pipeline builder ou de YAML view.
- Construire un flux de pipeline en utilisant des tâches existantes et des tâches de cluster. Lorsque vous installez OpenShift Pipelines Operator, il ajoute des tâches de cluster de pipeline réutilisables à votre cluster.
Dans Red Hat OpenShift Pipelines 1.10, la fonctionnalité de tâche de cluster est dépréciée et il est prévu de la supprimer dans une prochaine version.
- Spécifiez le type de ressources nécessaires à l'exécution du pipeline et, le cas échéant, ajoutez des paramètres supplémentaires au pipeline.
- Référencer ces ressources du pipeline dans chacune des tâches du pipeline en tant que ressources d'entrée et de sortie.
- Si nécessaire, faites référence à tout paramètre supplémentaire ajouté au pipeline dans la tâche. Les paramètres d'une tâche sont pré-remplis en fonction des spécifications de la tâche.
- Utilisez les snippets et les échantillons réutilisables installés par l'opérateur pour créer des pipelines détaillés.
- Recherchez et ajoutez des tâches à partir de votre instance Tekton Hub locale configurée.
Dans la perspective du développeur, vous pouvez créer un pipeline personnalisé en utilisant votre propre ensemble de tâches. Pour rechercher, installer et mettre à jour vos tâches directement à partir de la console du développeur, votre administrateur de cluster doit installer et déployer une instance locale de Tekton Hub et lier ce hub au cluster OpenShift Container Platform. Pour plus de détails, voir Using Tekton Hub with OpenShift Pipelines dans la section Additional resources. Si vous ne déployez pas d'instance Tekton Hub locale, par défaut, vous ne pouvez accéder qu'aux tâches du cluster, aux tâches de l'espace de noms et aux tâches Tekton Hub publiques.
Procédure
- Dans la vue Add de la perspective Developer, cliquez sur la tuile Pipeline pour voir la page Pipeline builder.
Configurez le pipeline à l'aide de la vue Pipeline builder ou de la vue YAML view.
NoteLa vue Pipeline builder prend en charge un nombre limité de champs, tandis que la vue YAML view prend en charge tous les champs disponibles. En option, vous pouvez également utiliser les snippets et échantillons réutilisables installés par l'opérateur pour créer des pipelines détaillés.
Figure 3.1. Vue YAML
Configurez votre pipeline en utilisant Pipeline builder:
- Dans le champ Name, saisissez un nom unique pour la canalisation.
Dans la section Tasks:
- Cliquez sur Add task.
- Recherchez une tâche à l'aide du champ de recherche rapide et sélectionnez la tâche requise dans la liste affichée.
Cliquez sur Add ou Install and add. Dans cet exemple, utilisez la tâche s2i-nodejs.
NoteLa liste de recherche contient toutes les tâches du Tekton Hub et les tâches disponibles dans le cluster. De plus, si une tâche est déjà installée, la liste affichera Add pour ajouter la tâche, tandis qu'elle affichera Install and add pour installer et ajouter la tâche. Elle affichera Update and add si vous ajoutez la même tâche avec une version mise à jour.
Pour ajouter des tâches séquentielles au pipeline :
- Cliquez sur l'icône plus à droite ou à gauche de la tâche → cliquez sur Add task.
- Recherchez une tâche à l'aide du champ de recherche rapide et sélectionnez la tâche requise dans la liste affichée.
Cliquez sur Add ou Install and add.
Figure 3.2. Constructeur de pipelines

Pour ajouter une tâche finale :
- Cliquez sur Add finally task → Cliquez sur Add task.
- Recherchez une tâche à l'aide du champ de recherche rapide et sélectionnez la tâche requise dans la liste affichée.
- Cliquez sur Add ou Install and add.
Dans la section Resources, cliquez sur Add Resources pour spécifier le nom et le type de ressources pour l'exécution du pipeline. Ces ressources sont ensuite utilisées par les tâches du pipeline en tant qu'entrées et sorties. Pour cet exemple :
-
Ajoutez une ressource d'entrée. Dans le champ Name, saisissez
Source, puis dans la liste déroulante Resource Type, sélectionnez Git. Ajoutez une ressource de sortie. Dans le champ Name, saisissez
Img, puis dans la liste déroulante Resource Type, sélectionnez Image.NoteUne icône rouge apparaît à côté de la tâche si une ressource est manquante.
-
Ajoutez une ressource d'entrée. Dans le champ Name, saisissez
- Facultatif : Le site Parameters pour une tâche est pré-rempli sur la base des spécifications de la tâche. Si nécessaire, utilisez le lien Add Parameters dans la section Parameters pour ajouter des paramètres supplémentaires.
- Dans la section Workspaces, cliquez sur Add workspace et saisissez un nom d'espace de travail unique dans le champ Name. Vous pouvez ajouter plusieurs espaces de travail au pipeline.
Dans la section Tasks, cliquez sur la tâche s2i-nodejs pour afficher le panneau latéral contenant les détails de la tâche. Dans le panneau latéral de la tâche, spécifiez les ressources et les paramètres de la tâche s2i-nodejs:
- Si nécessaire, dans la section Parameters, ajoutez des paramètres aux paramètres par défaut, en utilisant la syntaxe $(params.<param-name>).
-
Dans la section Image, saisissez
Imgcomme spécifié dans la section Resources. - Sélectionnez un espace de travail dans la liste déroulante source sous la section Workspaces.
- Ajouter des ressources, des paramètres et des espaces de travail à la tâche openshift-client.
- Cliquez sur Create pour créer et visualiser le pipeline dans la page Pipeline Details.
- Cliquez sur le menu déroulant Actions puis sur Start, pour voir la page Start Pipeline.
- La section Workspaces répertorie les espaces de travail que vous avez créés précédemment. Utilisez le menu déroulant correspondant pour spécifier la source de volume de votre espace de travail. Vous disposez des options suivantes : Empty Directory, Config Map, Secret, PersistentVolumeClaim, ou VolumeClaimTemplate.
3.9.2. Créer des pipelines OpenShift avec des applications
Pour créer des pipelines en même temps que des applications, utilisez l'option From Git dans la vue Add de la perspective Developer. Vous pouvez afficher toutes les conduites disponibles et sélectionner celles que vous souhaitez utiliser pour créer des applications lors de l'importation de votre code ou du déploiement d'une image.
L'intégration au Tekton Hub est activée par défaut et vous pouvez voir les tâches du Tekton Hub qui sont prises en charge par votre cluster. Les administrateurs peuvent désactiver l'intégration au Tekton Hub et les tâches du Tekton Hub ne seront plus affichées. Vous pouvez également vérifier si une URL de webhook existe pour un pipeline généré. Des webhooks par défaut sont ajoutés pour les pipelines créés à l'aide du flux Add et l'URL est visible dans le panneau latéral des ressources sélectionnées dans la vue Topologie.
3.9.3. Ajouter un dépôt GitHub contenant des pipelines
Dans la perspective du développeur, vous pouvez ajouter votre dépôt GitHub contenant des pipelines au cluster OpenShift Container Platform. Cela vous permet d'exécuter des pipelines et des tâches à partir de votre dépôt GitHub sur le cluster lorsque des événements Git pertinents, tels que des demandes push ou pull, sont déclenchés.
Vous pouvez ajouter des dépôts GitHub publics et privés.
Conditions préalables
- Assurez-vous que votre administrateur de cluster a configuré les applications GitHub requises dans la perspective de l'administrateur.
Procédure
- Dans la perspective du développeur, choisissez l'espace de noms ou le projet dans lequel vous souhaitez ajouter votre dépôt GitHub.
- Naviguez vers Pipelines en utilisant le volet de navigation de gauche.
- Cliquez sur Create → Repository à droite de la page Pipelines.
- Saisissez votre Git Repo URL et la console récupère automatiquement le nom du dépôt.
Cliquez sur Show configuration options. Par défaut, une seule option s'affiche Setup a webhook. Si vous avez configuré une application GitHub, deux options s'affichent :
- Use GitHub App: Sélectionnez cette option pour installer votre application GitHub dans votre référentiel.
- Setup a webhook: Sélectionnez cette option pour ajouter un webhook à votre application GitHub.
Configurez un webhook en utilisant l'une des options suivantes dans la section Secret:
Configurer un webhook à l'aide de Git access token:
- Saisissez votre code d'accès personnel.
Cliquez sur Generate correspondant au champ Webhook secret pour générer un nouveau secret webhook.
 Note
NoteVous pouvez cliquer sur le lien situé sous le champ Git access token si vous n'avez pas de jeton d'accès personnel et que vous souhaitez en créer un nouveau.
Configurer un webhook à l'aide de Git access token secret:
Sélectionnez un secret dans votre espace de noms dans la liste déroulante. En fonction du secret sélectionné, un secret de webhook est automatiquement généré.

Ajoutez les détails secrets du webhook à votre dépôt GitHub :
- Copiez le site webhook URL et accédez aux paramètres de votre dépôt GitHub.
- Cliquez sur Webhooks → Add webhook.
- Copiez l'adresse Webhook URL depuis la console de développement et collez-la dans le champ Payload URL des paramètres du dépôt GitHub.
- Sélectionnez le site Content type.
- Copiez l'adresse Webhook secret depuis la console de développement et collez-la dans le champ Secret des paramètres du dépôt GitHub.
- Sélectionnez l'une des options SSL verification.
- Sélectionnez les événements qui déclencheront ce webhook.
- Cliquez sur Add webhook.
- Retournez à la console du développeur et cliquez sur Add.
- Lisez les détails des étapes à suivre et cliquez sur Close.
- Affichez les détails du référentiel que vous venez de créer.
3.9.4. Interagir avec les pipelines en utilisant la perspective du développeur
La vue Pipelines de la perspective Developer répertorie toutes les pipelines d'un projet, avec les détails suivants :
- L'espace de noms dans lequel le pipeline a été créé
- Le dernier passage du pipeline
- Le statut des tâches dans l'exécution du pipeline
- L'état de l'exécution du pipeline
- L'heure de création de la dernière exécution du pipeline
Procédure
- Dans la vue Pipelines de la perspective Developer, sélectionnez un projet dans la liste déroulante Project pour voir les pipelines de ce projet.
Cliquez sur le pipeline souhaité pour afficher la page Pipeline details.
Par défaut, l'onglet Details affiche une représentation visuelle de toutes les tâches
serial,parallel,finallyetwhendu pipeline. Les tâches et les tâchesfinallysont listées dans la partie inférieure droite de la page.Pour afficher les détails de la tâche, cliquez sur les tâches répertoriées Tasks et Finally. En outre, vous pouvez effectuer les opérations suivantes :
- Utilisez les fonctions de zoom avant, zoom arrière, adaptation à l'écran et réinitialisation de la vue à l'aide des icônes standard affichées dans le coin inférieur gauche de la visualisation Pipeline details.
- Modifier le facteur de zoom de la visualisation du pipeline à l'aide de la molette de la souris.
Survolez les tâches pour en voir les détails.
Figure 3.3. Détails du pipeline

Facultatif : Sur la page Pipeline details, cliquez sur l'onglet Metrics pour obtenir les informations suivantes sur les pipelines :
- Pipeline Success Ratio
- Number of Pipeline Runs
- Pipeline Run Duration
Task Run Duration
Vous pouvez utiliser ces informations pour améliorer le flux de travail du pipeline et éliminer les problèmes dès le début du cycle de vie du pipeline.
- Facultatif : Cliquez sur l'onglet YAML pour modifier le fichier YAML du pipeline.
En option, cliquez sur l'onglet pour voir les exécutions terminées ou échouées du pipeline : Cliquez sur l'onglet Pipeline Runs pour afficher les exécutions terminées, en cours ou échouées du pipeline.
L'onglet Pipeline Runs fournit des détails sur l'exécution du pipeline, l'état de la tâche et un lien pour déboguer les exécutions de pipeline qui ont échoué. Utiliser le menu Options
pour arrêter un pipeline en cours d'exécution, pour réexécuter un pipeline en utilisant les mêmes paramètres et ressources que ceux de l'exécution précédente du pipeline, ou pour supprimer un pipeline en cours d'exécution.
Cliquez sur l'exécution de pipeline requise pour afficher la page Pipeline Run details. Par défaut, l'onglet Details affiche une représentation visuelle de toutes les tâches en série, tâches en parallèle, tâches
finallyet expressions dans le pipeline. Les résultats des exécutions réussies sont affichés dans le volet Pipeline Run results au bas de la page. En outre, vous ne pourrez voir que les tâches du Tekton Hub qui sont prises en charge par le cluster. Lorsque vous regardez une tâche, vous pouvez cliquer sur le lien situé à côté pour accéder à la documentation de la tâche.NoteLa section Details de la page Pipeline Run Details affiche un Log Snippet de l'échec de l'exécution du pipeline. Log Snippet fournit un message d'erreur général et un extrait du journal. Un lien vers la section Logs permet d'accéder rapidement aux détails de l'échec de l'exécution.
Sur la page Pipeline Run details, cliquez sur l'onglet Task Runs pour voir les exécutions terminées, en cours et échouées de la tâche.
L'onglet Task Runs fournit des informations sur l'exécution de la tâche avec les liens vers sa tâche et son pod, ainsi que le statut et la durée de l'exécution de la tâche. Utiliser le menu Options
pour supprimer une tâche.
Cliquez sur l'exécution de la tâche requise pour afficher la page Task Run details. Les résultats des exécutions réussies sont affichés dans le volet Task Run results au bas de la page.
NoteLa section Details de la page Task Run details affiche une Log Snippet de l'échec de l'exécution de la tâche. Log Snippet fournit un message d'erreur général et un extrait du journal. Un lien vers la section Logs permet d'accéder rapidement aux détails de l'échec de l'exécution de la tâche.
- Cliquez sur l'onglet Parameters pour afficher les paramètres définis dans le pipeline. Vous pouvez également ajouter ou modifier des paramètres supplémentaires, si nécessaire.
- Cliquez sur l'onglet Resources pour voir les ressources définies dans le pipeline. Vous pouvez également ajouter ou modifier des ressources supplémentaires, si nécessaire.
3.9.5. Utilisation d'un modèle de pipeline personnalisé pour créer et déployer une application à partir d'un dépôt Git
En tant qu'administrateur de cluster, pour créer et déployer une application à partir d'un dépôt Git, vous pouvez utiliser des modèles de pipeline personnalisés qui remplacent les modèles de pipeline par défaut fournis par Red Hat OpenShift Pipelines 1.5 et les versions ultérieures.
Cette fonctionnalité n'est pas disponible dans Red Hat OpenShift Pipelines 1.4 et les versions antérieures.
Conditions préalables
Assurez-vous que Red Hat OpenShift Pipelines 1.5 ou une version ultérieure est installé et disponible dans tous les espaces de noms.
Procédure
- Connectez-vous à la console web d'OpenShift Container Platform en tant qu'administrateur de cluster.
Dans la perspective Administrator, utilisez le panneau de navigation gauche pour aller à la section Pipelines.
-
Dans le menu déroulant Project, sélectionnez le projet openshift. Cela garantit que les étapes suivantes seront effectuées dans l'espace de noms
openshift. Dans la liste des pipelines disponibles, sélectionnez celui qui convient à la construction et au déploiement de votre application. Par exemple, si votre application nécessite un environnement d'exécution
node.js, sélectionnez le pipeline s2i-nodejs.NoteNe modifiez pas le modèle de pipeline par défaut. Il pourrait devenir incompatible avec l'interface utilisateur et le back-end.
- Sous l'onglet YAML du pipeline sélectionné, cliquez sur Download et enregistrez le fichier YAML sur votre machine locale. Si votre fichier de configuration personnalisé échoue, vous pouvez utiliser cette copie pour restaurer une configuration fonctionnelle.
-
Dans le menu déroulant Project, sélectionnez le projet openshift. Cela garantit que les étapes suivantes seront effectuées dans l'espace de noms
Désactiver (supprimer) les modèles de pipeline par défaut :
- Utilisez le panneau de navigation gauche pour aller à Operators → Installed Operators.
- Cliquez sur Red Hat OpenShift Pipelines → Tekton Configuration tab → config → YAML tab.
Pour désactiver (supprimer) les modèles de pipeline par défaut dans l'espace de noms
openshift, définissez le paramètrepipelineTemplatesàfalsedans la ressource personnalisée YAMLTektonConfig, et enregistrez-la.apiVersion: operator.tekton.dev/v1alpha1 kind: TektonConfig metadata: name: config spec: profile: all targetNamespace: openshift-pipelines addon: params: - name: clusterTasks value: "true" - name: pipelineTemplates value: "false" ...NoteSi vous supprimez manuellement les modèles de pipeline par défaut, l'opérateur rétablit les valeurs par défaut lors d'une mise à niveau.
AvertissementEn tant qu'administrateur de cluster, vous pouvez désactiver l'installation des modèles de pipeline par défaut dans la configuration de l'opérateur. Cependant, une telle configuration supprime tous les modèles de pipeline par défaut, et pas seulement celui que vous souhaitez personnaliser.
Créer un modèle de pipeline personnalisé :
- Utilisez le panneau de navigation de gauche pour accéder à la section Pipelines.
- Dans la liste déroulante Create, sélectionnez Pipeline.
Créez le pipeline requis dans l'espace de noms
openshift. Donnez-lui un nom différent de celui par défaut (par exemple,custom-nodejs). Vous pouvez utiliser le modèle de pipeline par défaut téléchargé comme point de départ et le personnaliser.NoteComme
openshiftest l'espace de noms par défaut utilisé par les modèles de pipeline installés par l'opérateur, vous devez créer le modèle de pipeline personnalisé dans l'espace de nomsopenshift. Lorsqu'une application utilise un modèle de pipeline, celui-ci est automatiquement copié dans l'espace de noms du projet concerné.Sous l'onglet Details du pipeline créé, assurez-vous que les Labels du modèle personnalisé correspondent aux étiquettes du pipeline par défaut. Le modèle de pipeline personnalisé doit comporter les étiquettes correctes pour l'exécution, le type et la stratégie de l'application. Par exemple, les étiquettes requises pour une application
node.jsdéployée sur OpenShift Container Platform sont les suivantes :... pipeline.openshift.io/runtime: nodejs pipeline.openshift.io/type: openshift ...NoteVous ne pouvez utiliser qu'un seul modèle de pipeline pour chaque combinaison d'environnement d'exécution et de type de déploiement.
- Dans la perspective Developer, utilisez l'option Add → Git Repository → From Git pour sélectionner le type d'application que vous souhaitez créer et déployer. En fonction de la durée d'exécution requise et du type d'application, votre modèle personnalisé est automatiquement sélectionné.
3.9.6. Démarrage des pipelines à partir de la vue Pipelines
Après avoir créé un pipeline, vous devez le démarrer pour exécuter les tâches incluses dans la séquence définie. Vous pouvez lancer un pipeline à partir de la vue Pipelines, de la page Pipeline Details ou de la vue Topology.
Procédure
Pour démarrer un pipeline à partir de la vue Pipelines:
-
Dans la vue Pipelines de la perspective Developer, cliquez sur le lien Options
à côté d'un pipeline et sélectionnez Start.
La boîte de dialogue Start Pipeline affiche Git Resources et Image Resources en fonction de la définition du pipeline.
NotePour les pipelines créés à l'aide de l'option From Git, la boîte de dialogue Start Pipeline affiche également un champ
APP_NAMEdans la section Parameters, et tous les champs de la boîte de dialogue sont pré-remplis par le modèle de pipeline.- Si vous disposez de ressources dans votre espace de noms, les champs Git Resources et Image Resources sont préremplis avec ces ressources. Si nécessaire, utilisez les menus déroulants pour sélectionner ou créer les ressources requises et personnaliser l'instance d'exécution du pipeline.
Facultatif : Modifiez le site Advanced Options pour ajouter les informations d'identification qui authentifient le serveur Git privé spécifié ou le registre d'images.
- Sous Advanced Options, cliquez sur Show Credentials Options et sélectionnez Add Secret.
Dans la section Create Source Secret, indiquez ce qui suit :
- Une adresse unique Secret Name pour le secret.
- Dans la section Designated provider to be authenticated, indiquez le fournisseur à authentifier dans le champ Access to et la base Server URL.
Sélectionnez le site Authentication Type et fournissez les informations d'identification :
Pour le champ Authentication Type
Image Registry Credentials, indiquez le Registry Server Address que vous souhaitez authentifier et fournissez vos informations d'identification dans les champs Username, Password et Email.Sélectionnez Add Credentials si vous souhaitez spécifier un Registry Server Address supplémentaire.
-
Pour le site Authentication Type
Basic Authentication, indiquez les valeurs des champs UserName et Password or Token. Pour le champ Authentication Type
SSH Keys, indiquez la valeur du champ SSH Private Key.NotePour l'authentification de base et l'authentification SSH, vous pouvez utiliser des annotations telles que :
-
tekton.dev/git-0: https://github.com -
tekton.dev/git-1: https://gitlab.com.
-
- Cochez la case pour ajouter le secret.
Vous pouvez ajouter plusieurs secrets en fonction du nombre de ressources dans votre pipeline.
- Cliquez sur Start pour démarrer le pipeline.
La page PipelineRun details affiche le pipeline en cours d'exécution. Après le démarrage du pipeline, les tâches et les étapes de chaque tâche sont exécutées. Vous pouvez :
- Utilisez les fonctions de zoom avant, zoom arrière, adaptation à l'écran et réinitialisation de l'affichage à l'aide des icônes standard, qui se trouvent dans le coin inférieur gauche de la visualisation de la page PipelineRun details.
- Modifiez le facteur de zoom de la visualisation pipelinerun à l'aide de la molette de la souris. À certains facteurs de zoom, la couleur de fond des tâches change pour indiquer l'état d'erreur ou d'avertissement.
- Survolez les tâches pour en voir les détails, tels que le temps nécessaire à l'exécution de chaque étape, le nom de la tâche et son statut.
- Survolez l'insigne des tâches pour voir le nombre total de tâches et les tâches accomplies.
- Cliquez sur une tâche pour voir les journaux de chaque étape de la tâche.
- Cliquez sur l'onglet Logs pour consulter les journaux relatifs à la séquence d'exécution des tâches. Vous pouvez également développer le volet et télécharger les journaux individuellement ou en masse, en utilisant le bouton correspondant.
Cliquez sur l'onglet Events pour voir le flux d'événements générés par l'exécution d'un pipeline.
Vous pouvez utiliser les onglets Task Runs, Logs, et Events pour faciliter le débogage d'un pipeline ou d'une tâche dont l'exécution a échoué.
Figure 3.4. Détails de l'exécution du pipeline

3.9.7. Démarrer des pipelines à partir de la vue Topologie
Pour les pipelines créés à l'aide de l'option From Git, vous pouvez utiliser la vue Topology pour interagir avec les pipelines après leur démarrage :
Pour voir les pipelines créés à l'aide de Pipeline builder dans la vue Topology, personnalisez les étiquettes des pipelines pour les relier à la charge de travail de l'application.
Procédure
- Cliquez sur Topology dans le panneau de navigation de gauche.
- Cliquez sur l'application pour afficher Pipeline Runs dans le panneau latéral.
Dans Pipeline Runs, cliquez sur Start Last Run pour lancer une nouvelle canalisation avec les mêmes paramètres et ressources que la précédente. Cette option est désactivée si aucun pipeline n'a été lancé. Vous pouvez également démarrer un pipeline lors de sa création.
Figure 3.5. Pipelines dans la vue Topologie
Sur la page Topology, survolez la gauche de l'application pour voir l'état d'avancement de son pipeline. Après l'ajout d'un pipeline, une icône en bas à gauche indique qu'il existe un pipeline associé.
3.9.8. Interagir avec les pipelines à partir de la vue topologique
Le panneau latéral du nœud d'application de la page Topology affiche l'état de l'exécution d'un pipeline et vous pouvez interagir avec lui.
- Si un pipeline ne démarre pas automatiquement, le panneau latéral affiche un message indiquant que le pipeline ne peut pas être démarré automatiquement et qu'il doit donc être démarré manuellement.
- Si une canalisation est créée mais que l'utilisateur ne l'a pas démarrée, son état n'est pas démarré. Lorsque l'utilisateur clique sur l'icône d'état Not started, la boîte de dialogue de démarrage s'ouvre dans la vue Topology.
- Si le pipeline n'a pas de configuration de compilation ou de compilation, la section Builds n'est pas visible. S'il y a un pipeline et une configuration de construction, la section Builds section est visible.
- Le panneau latéral affiche une page Log Snippet lorsqu'une exécution de pipeline échoue dans le cadre d'une exécution de tâche spécifique. Vous pouvez consulter le message Log Snippet dans la section Pipeline Runs, sous l'onglet Resources. Il fournit un message d'erreur général et un extrait du journal. Un lien vers la section Logs permet d'accéder rapidement aux détails de l'échec de l'exécution.
3.9.9. Modification des pipelines
Vous pouvez éditer les pipelines de votre cluster en utilisant la perspective Developer de la console web :
Procédure
- Dans la vue Pipelines de la perspective Developer, sélectionnez la canalisation que vous souhaitez modifier pour en voir les détails. Dans la page Pipeline Details, cliquez sur Actions et sélectionnez Edit Pipeline.
Sur la page Pipeline builder, vous pouvez effectuer les tâches suivantes :
- Ajouter des tâches, des paramètres ou des ressources supplémentaires au pipeline.
- Cliquez sur la tâche que vous souhaitez modifier pour afficher les détails de la tâche dans le panneau latéral et modifier les détails requis de la tâche, tels que le nom d'affichage, les paramètres et les ressources.
- Pour supprimer la tâche, cliquez sur la tâche et, dans le panneau latéral, cliquez sur Actions et sélectionnez Remove Task.
- Cliquez sur Save pour enregistrer le pipeline modifié.
3.9.10. Suppression des pipelines
Vous pouvez supprimer les pipelines de votre cluster en utilisant la perspective Developer de la console web.
Procédure
-
Dans la vue Pipelines de la perspective Developer, cliquez sur le lien Options
à côté d'une ligne de conduite et sélectionnez Delete Pipeline.
- Dans la demande de confirmation Delete Pipeline, cliquez sur Delete pour confirmer la suppression.
3.10. Réduire la consommation de ressources d'OpenShift Pipelines
Si vous utilisez des clusters dans des environnements multi-locataires, vous devez contrôler la consommation des ressources de CPU, de mémoire et de stockage pour chaque projet et objet Kubernetes. Cela permet d'éviter qu'une application consomme trop de ressources et affecte les autres applications.
Pour définir les limites de ressources finales qui sont définies sur les pods résultants, Red Hat OpenShift Pipelines utilise les limites de quotas de ressources et les plages de limites du projet dans lequel ils sont exécutés.
Pour limiter la consommation de ressources dans votre projet, vous pouvez :
- Définir et gérer des quotas de ressources pour limiter la consommation globale de ressources.
- Utilisez les plages de limites pour restreindre la consommation de ressources pour des objets spécifiques, tels que les pods, les images, les flux d'images et les réclamations de volumes persistants.
3.10.1. Comprendre la consommation de ressources dans les pipelines
Chaque tâche consiste en un certain nombre d'étapes à exécuter dans un ordre particulier défini dans le champ steps de la ressource Task. Chaque tâche s'exécute comme un pod, et chaque étape s'exécute comme un conteneur au sein de ce pod.
Les étapes sont exécutées une par une. Le module qui exécute la tâche ne demande que les ressources nécessaires à l'exécution d'une seule image de conteneur (étape) de la tâche à la fois, et ne stocke donc pas de ressources pour toutes les étapes de la tâche.
Le champ Resources de la spécification steps spécifie les limites de la consommation de ressources. Par défaut, les demandes de ressources pour l'unité centrale, la mémoire et le stockage éphémère sont réglées sur les valeurs BestEffort (zéro) ou sur les minimums fixés par les plages de limites dans ce projet.
Exemple de configuration des demandes et des limites de ressources pour une étape
spec:
steps:
- name: <step_name>
resources:
requests:
memory: 2Gi
cpu: 600m
limits:
memory: 4Gi
cpu: 900m
Lorsque le paramètre LimitRange et les valeurs minimales pour les demandes de ressources de conteneur sont spécifiés dans le projet dans lequel le pipeline et les exécutions de tâches sont exécutés, Red Hat OpenShift Pipelines examine toutes les valeurs LimitRange dans le projet et utilise les valeurs minimales au lieu de zéro.
Exemple de configuration des paramètres de la plage de limites au niveau d'un projet
apiVersion: v1
kind: LimitRange
metadata:
name: <limit_container_resource>
spec:
limits:
- max:
cpu: "600m"
memory: "2Gi"
min:
cpu: "200m"
memory: "100Mi"
default:
cpu: "500m"
memory: "800Mi"
defaultRequest:
cpu: "100m"
memory: "100Mi"
type: Container
...3.10.2. Atténuer la surconsommation de ressources dans les pipelines
Lorsque vous avez défini des limites de ressources pour les conteneurs de votre pod, OpenShift Container Platform additionne les limites de ressources demandées lorsque tous les conteneurs s'exécutent simultanément.
Pour consommer la quantité minimale de ressources nécessaires à l'exécution d'une étape à la fois dans la tâche invoquée, Red Hat OpenShift Pipelines demande le maximum de CPU, de mémoire et de stockage éphémère comme spécifié dans l'étape qui nécessite la plus grande quantité de ressources. Cela garantit que les besoins en ressources de toutes les étapes sont satisfaits. Les demandes autres que les valeurs maximales sont fixées à zéro.
Toutefois, ce comportement peut entraîner une utilisation des ressources plus importante que nécessaire. Si vous utilisez des quotas de ressources, cela peut également conduire à des pods non ordonnançables.
Prenons l'exemple d'une tâche à deux étapes qui utilise des scripts et qui ne définit pas de limites de ressources ni de demandes. Le pod résultant a deux conteneurs init (l'un pour la copie du point d'entrée, l'autre pour l'écriture des scripts) et deux conteneurs, un pour chaque étape.
OpenShift Container Platform utilise la plage de limites définie pour le projet afin de calculer les demandes de ressources requises et les limites. Pour cet exemple, définissez la plage de limites suivante dans le projet :
apiVersion: v1
kind: LimitRange
metadata:
name: mem-min-max-demo-lr
spec:
limits:
- max:
memory: 1Gi
min:
memory: 500Mi
type: ContainerDans ce scénario, chaque conteneur init utilise une demande de mémoire de 1Gi (la limite maximale de la plage de limites), et chaque conteneur utilise une demande de mémoire de 500Mi. Ainsi, la demande totale de mémoire pour le pod est de 2Gi.
Si la même plage de limites est utilisée avec une tâche de dix étapes, la demande finale de mémoire est de 5Gi, ce qui est supérieur à ce dont chaque étape a réellement besoin, c'est-à-dire 500Mi (puisque chaque étape s'exécute l'une après l'autre).
Ainsi, pour réduire la consommation de ressources, vous pouvez :
- Réduire le nombre d'étapes d'une tâche donnée en regroupant différentes étapes en une étape plus importante, en utilisant la fonction de script et la même image. Cela permet de réduire la ressource minimale requise.
- Répartir les étapes qui sont relativement indépendantes les unes des autres et qui peuvent s'exécuter seules dans plusieurs tâches au lieu d'une seule. Cela réduit le nombre d'étapes dans chaque tâche, ce qui diminue la demande pour chaque tâche, et le planificateur peut alors les exécuter lorsque les ressources sont disponibles.
3.11. Définir un quota de ressources de calcul pour OpenShift Pipelines
Un objet ResourceQuota dans Red Hat OpenShift Pipelines contrôle la consommation totale de ressources par espace de noms. Vous pouvez l'utiliser pour limiter la quantité d'objets créés dans un espace de noms, en fonction du type d'objet. En outre, vous pouvez spécifier un quota de ressources de calcul pour limiter la quantité totale de ressources de calcul consommées dans un espace de noms.
Cependant, vous pourriez vouloir limiter la quantité de ressources de calcul consommées par les pods résultant de l'exécution d'un pipeline, plutôt que de définir des quotas pour l'ensemble de l'espace de noms. Actuellement, Red Hat OpenShift Pipelines ne vous permet pas de spécifier directement le quota de ressources de calcul pour un pipeline.
3.11.1. Approches alternatives pour limiter la consommation de ressources de calcul dans OpenShift Pipelines
Pour obtenir un certain degré de contrôle sur l'utilisation des ressources informatiques par un pipeline, il convient d'envisager les approches alternatives suivantes :
Définir les demandes et les limites de ressources pour chaque étape d'une tâche.
Exemple : Définir les demandes et les limites de ressources pour chaque étape d'une tâche.
... spec: steps: - name: step-with-limts resources: requests: memory: 1Gi cpu: 500m limits: memory: 2Gi cpu: 800m ...-
Définissez des limites de ressources en spécifiant des valeurs pour l'objet
LimitRange. Pour plus d'informations surLimitRange, reportez-vous à la section Limiter la consommation de ressources avec des plages de limites. - Réduire la consommation de ressources du pipeline.
- Définir et gérer des quotas de ressources par projet.
- Idéalement, le quota de ressources de calcul pour un pipeline devrait correspondre à la quantité totale de ressources de calcul consommées par les pods fonctionnant simultanément dans un pipeline. Cependant, les pods qui exécutent les tâches consomment des ressources de calcul en fonction du cas d'utilisation. Par exemple, une tâche de construction Maven peut nécessiter différentes ressources de calcul pour les différentes applications qu'elle construit. Par conséquent, vous ne pouvez pas prédéterminer les quotas de ressources de calcul pour les tâches d'un pipeline générique. Pour une meilleure prévisibilité et un meilleur contrôle de l'utilisation des ressources de calcul, utilisez des pipelines personnalisés pour différentes applications.
Lors de l'utilisation de Red Hat OpenShift Pipelines dans un espace de noms configuré avec un objet ResourceQuota, les pods résultant des exécutions de tâches et des exécutions de pipelines peuvent échouer avec une erreur, telle que : failed quota: <quota name> must specify cpu, memory.
Pour éviter cette erreur, effectuez l'une des opérations suivantes :
- (Recommandé) Spécifiez une plage de limites pour l'espace de noms.
- Définir explicitement les demandes et les limites pour tous les conteneurs.
Pour plus d'informations, reportez-vous à la question et à la résolution.
Si votre cas d'utilisation n'est pas couvert par ces approches, vous pouvez mettre en œuvre une solution de contournement en utilisant un quota de ressources pour une classe de priorité.
3.11.2. Spécifier le quota de ressources des pipelines en utilisant la classe de priorité
Un objet PriorityClass associe les noms des classes de priorité aux valeurs entières qui indiquent leurs priorités relatives. Les valeurs les plus élevées augmentent la priorité d'une classe. Après avoir créé une classe de priorité, vous pouvez créer des modules qui spécifient le nom de la classe de priorité dans leurs spécifications. En outre, vous pouvez contrôler la consommation de ressources système d'un pod en fonction de sa priorité.
La spécification d'un quota de ressources pour un pipeline est similaire à la définition d'un quota de ressources pour le sous-ensemble de pods créés par l'exécution d'un pipeline. Les étapes suivantes fournissent un exemple de solution de contournement en spécifiant un quota de ressources basé sur la classe de priorité.
Procédure
Créer une classe de priorité pour un pipeline.
Exemple : Classe de priorité pour un pipeline
apiVersion: scheduling.k8s.io/v1 kind: PriorityClass metadata: name: pipeline1-pc value: 1000000 description: "Priority class for pipeline1"Créer un quota de ressources pour un pipeline.
Exemple : Quota de ressources pour un pipeline
apiVersion: v1 kind: ResourceQuota metadata: name: pipeline1-rq spec: hard: cpu: "1000" memory: 200Gi pods: "10" scopeSelector: matchExpressions: - operator : In scopeName: PriorityClass values: ["pipeline1-pc"]Vérifier l'utilisation du quota de ressources pour le pipeline.
Exemple : Vérifier l'utilisation des quotas de ressources pour le pipeline
$ oc describe quotaExemple de sortie
Name: pipeline1-rq Namespace: default Resource Used Hard -------- ---- ---- cpu 0 1k memory 0 200Gi pods 0 10Comme les pods ne sont pas en cours d'exécution, le quota est inutilisé.
Créer les pipelines et les tâches.
Exemple : YAML pour le pipeline
apiVersion: tekton.dev/v1alpha1 kind: Pipeline metadata: name: maven-build spec: workspaces: - name: local-maven-repo resources: - name: app-git type: git tasks: - name: build taskRef: name: mvn resources: inputs: - name: source resource: app-git params: - name: GOALS value: ["package"] workspaces: - name: maven-repo workspace: local-maven-repo - name: int-test taskRef: name: mvn runAfter: ["build"] resources: inputs: - name: source resource: app-git params: - name: GOALS value: ["verify"] workspaces: - name: maven-repo workspace: local-maven-repo - name: gen-report taskRef: name: mvn runAfter: ["build"] resources: inputs: - name: source resource: app-git params: - name: GOALS value: ["site"] workspaces: - name: maven-repo workspace: local-maven-repoExemple : YAML pour une tâche dans le pipeline
apiVersion: tekton.dev/v1alpha1 kind: Task metadata: name: mvn spec: workspaces: - name: maven-repo inputs: params: - name: GOALS description: The Maven goals to run type: array default: ["package"] resources: - name: source type: git steps: - name: mvn image: gcr.io/cloud-builders/mvn workingDir: /workspace/source command: ["/usr/bin/mvn"] args: - -Dmaven.repo.local=$(workspaces.maven-repo.path) - "$(inputs.params.GOALS)" priorityClassName: pipeline1-pcNoteVeiller à ce que toutes les tâches du pipeline appartiennent à la même classe de priorité.
Créer et lancer l'exécution du pipeline.
Exemple : YAML pour l'exécution d'un pipeline
apiVersion: tekton.dev/v1alpha1 kind: PipelineRun metadata: generateName: petclinic-run- spec: pipelineRef: name: maven-build resources: - name: app-git resourceSpec: type: git params: - name: url value: https://github.com/spring-projects/spring-petclinicUne fois les pods créés, vérifiez l'utilisation du quota de ressources pour l'exécution du pipeline.
Exemple : Vérifier l'utilisation des quotas de ressources pour le pipeline
$ oc describe quotaExemple de sortie
Name: pipeline1-rq Namespace: default Resource Used Hard -------- ---- ---- cpu 500m 1k memory 10Gi 200Gi pods 1 10La sortie indique que vous pouvez gérer le quota de ressources combiné pour tous les pods fonctionnant simultanément et appartenant à une classe de priorité, en spécifiant le quota de ressources par classe de priorité.
3.12. Élagage automatique de l'exécution des tâches et de l'exécution du pipeline
Les objets TaskRun et PipelineRun périmés et leurs instances exécutées occupent des ressources physiques qui peuvent être utilisées pour les exécutions actives. Pour éviter ce gaspillage, Red Hat OpenShift Pipelines fournit des annotations que les administrateurs de clusters peuvent utiliser pour élaguer automatiquement les objets inutilisés et leurs instances dans divers espaces de noms.
- À partir de Red Hat OpenShift Pipelines 1.6, l'élagage automatique est activé par défaut.
- La configuration de l'élagage automatique par la spécification d'annotations affecte l'ensemble de l'espace de noms. Vous ne pouvez pas procéder à un élagage automatique sélectif des exécutions de tâches individuelles et des exécutions de pipeline dans un espace de noms.
3.12.1. Configuration par défaut de l'élagueur
La configuration par défaut pour l'élagage périodique des ressources associées à l'exécution d'un pipeline est la suivante :
apiVersion: operator.tekton.dev/v1alpha1
kind: TektonConfig
metadata:
name: config
...
spec:
pruner:
keep: 100
resources:
- pipelinerun
schedule: 0 8 * * *
...Vous pouvez remplacer la configuration par défaut de l'élagueur pour un espace de noms en utilisant les annotations sur l'espace de noms.
3.12.2. Annotations pour l'élagage automatique des tâches et des pipelines
Pour élaguer automatiquement les ressources associées aux exécutions de tâches et de pipelines dans un espace de noms, vous pouvez définir les annotations suivantes dans l'espace de noms :
-
operator.tekton.dev/prune.schedule: Si la valeur de cette annotation est différente de la valeur spécifiée dans la définition de la ressource personnaliséeTektonConfig, un nouveau travail cron est créé dans cet espace de noms. -
operator.tekton.dev/prune.skip: Lorsqu'il est défini surtrue, l'espace de noms pour lequel il est configuré n'est pas élagué. -
operator.tekton.dev/prune.resources: Cette annotation accepte une liste de ressources séparées par des virgules. Pour élaguer une seule ressource, telle qu'une exécution de pipeline, définissez cette annotation à"pipelinerun". Pour élaguer plusieurs ressources, telles qu'une exécution de tâche et une exécution de pipeline, définissez cette annotation à"taskrun, pipelinerun". -
operator.tekton.dev/prune.keep: Utilisez cette annotation pour conserver une ressource sans l'élaguer. operator.tekton.dev/prune.keep-since: Cette annotation permet de conserver les ressources en fonction de leur âge. La valeur de cette annotation doit être égale à l'âge de la ressource en minutes. Par exemple, pour conserver les ressources qui ont été créées il y a cinq jours au maximum, définissezkeep-sincesur7200.NoteLes annotations
keepetkeep-sinces'excluent mutuellement. Pour toute ressource, vous ne devez configurer qu'une seule d'entre elles.-
operator.tekton.dev/prune.strategy: Fixer la valeur de cette annotation àkeepoukeep-since.
Prenons l'exemple des annotations suivantes, qui conservent toutes les exécutions de tâches et de pipelines créées au cours des cinq derniers jours et suppriment les ressources les plus anciennes :
Exemple d'élagage automatique des annotations
...
annotations:
operator.tekton.dev/prune.resources: "taskrun, pipelinerun"
operator.tekton.dev/prune.keep-since: 7200
...3.12.3. Ressources complémentaires
- Pour plus d'informations sur l'élagage manuel de divers objets, voir Élaguer des objets pour récupérer des ressources.
3.13. Utiliser les pods dans un contexte de sécurité privilégié
La configuration par défaut d'OpenShift Pipelines 1.3.x et des versions ultérieures ne vous permet pas d'exécuter des pods avec un contexte de sécurité privilégié, si les pods résultent de l'exécution d'un pipeline ou d'une tâche. Pour de tels pods, le compte de service par défaut est pipeline, et la contrainte de contexte de sécurité (SCC) associée au compte de service pipeline est pipelines-scc. La SCC pipelines-scc est similaire à la SCC anyuid, mais avec des différences mineures telles que définies dans le fichier YAML pour la SCC des pipelines :
Exemple pipelines-scc.yaml snippet
apiVersion: security.openshift.io/v1
kind: SecurityContextConstraints
...
allowedCapabilities:
- SETFCAP
...
fsGroup:
type: MustRunAs
...
En outre, la tâche de cluster Buildah, livrée avec OpenShift Pipelines, utilise vfs comme pilote de stockage par défaut.
3.13.1. Exécution des pods d'exécution de pipeline et d'exécution de tâches avec un contexte de sécurité privilégié
Procédure
Pour exécuter un pod (résultant de l'exécution d'un pipeline ou d'une tâche) avec le contexte de sécurité privileged, procédez aux modifications suivantes :
Configurez le compte d'utilisateur ou le compte de service associé pour qu'il dispose d'une CSC explicite. Vous pouvez effectuer la configuration en utilisant l'une des méthodes suivantes :
Exécutez la commande suivante :
$ oc adm policy add-scc-to-user <scc-name> -z <service-account-name>Vous pouvez également modifier les fichiers YAML pour
RoleBinding, etRoleouClusterRole:Exemple d'objet
RoleBindingapiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: service-account-name1 namespace: default roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: pipelines-scc-clusterrole2 subjects: - kind: ServiceAccount name: pipeline namespace: defaultExemple d'objet
ClusterRoleapiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: pipelines-scc-clusterrole1 rules: - apiGroups: - security.openshift.io resourceNames: - nonroot resources: - securitycontextconstraints verbs: - use- 1
- Remplacer par un rôle de cluster approprié en fonction de la liaison de rôle que vous utilisez.
NoteLa meilleure pratique consiste à créer une copie des fichiers YAML par défaut et à apporter des modifications au fichier dupliqué.
-
Si vous n'utilisez pas le pilote de stockage
vfs, configurez le compte de service associé à l'exécution de la tâche ou du pipeline pour qu'il ait un SCC privilégié, et définissez le contexte de sécurité commeprivileged: true.
3.13.2. Exécution d'un pipeline et d'une tâche à l'aide d'un SCC personnalisé et d'un compte de service personnalisé
Lors de l'utilisation de la contrainte de contexte de sécurité (SCC) pipelines-scc associée au compte de service par défaut pipelines, les pods d'exécution de pipeline et d'exécution de tâche peuvent être confrontés à des dépassements de délai. Cela se produit parce que dans la SCC par défaut pipelines-scc, le paramètre fsGroup.type est défini sur MustRunAs.
Pour plus d'informations sur les délais d'attente des pods, voir BZ#1995779.
Pour éviter les délais d'attente des pods, vous pouvez créer un SCC personnalisé avec le paramètre fsGroup.type défini sur RunAsAny, et l'associer à un compte de service personnalisé.
La meilleure pratique consiste à utiliser un SCC et un compte de service personnalisés pour les exécutions de pipeline et les exécutions de tâches. Cette approche permet une plus grande flexibilité et n'interrompt pas les exécutions lorsque les valeurs par défaut sont modifiées lors d'une mise à niveau.
Procédure
Définir une CSC personnalisée avec le paramètre
fsGroup.typefixé àRunAsAny:Exemple : CCN personnalisé
apiVersion: security.openshift.io/v1 kind: SecurityContextConstraints metadata: annotations: kubernetes.io/description: my-scc is a close replica of anyuid scc. pipelines-scc has fsGroup - RunAsAny. name: my-scc allowHostDirVolumePlugin: false allowHostIPC: false allowHostNetwork: false allowHostPID: false allowHostPorts: false allowPrivilegeEscalation: true allowPrivilegedContainer: false allowedCapabilities: null defaultAddCapabilities: null fsGroup: type: RunAsAny groups: - system:cluster-admins priority: 10 readOnlyRootFilesystem: false requiredDropCapabilities: - MKNOD runAsUser: type: RunAsAny seLinuxContext: type: MustRunAs supplementalGroups: type: RunAsAny volumes: - configMap - downwardAPI - emptyDir - persistentVolumeClaim - projected - secretCréer le SCC personnalisé :
Exemple : Créer le site
my-sccSCC$ oc create -f my-scc.yamlCréer un compte de service personnalisé :
Exemple : Créer un compte de service
fsgroup-runasany$ oc create serviceaccount fsgroup-runasanyAssocier le SCC personnalisé au compte de service personnalisé :
Exemple : Associer le CCN
my-sccau compte de servicefsgroup-runasany$ oc adm policy add-scc-to-user my-scc -z fsgroup-runasanySi vous souhaitez utiliser le compte de service personnalisé pour des tâches privilégiées, vous pouvez associer le
privilegedSCC au compte de service personnalisé en exécutant la commande suivante :Exemple : Associer le CCN
privilegedau compte de servicefsgroup-runasany$ oc adm policy add-scc-to-user privileged -z fsgroup-runasanyUtilisez le compte de service personnalisé dans l'exécution du pipeline et l'exécution de la tâche :
Exemple : Pipeline exécuter YAML avec
fsgroup-runasanycompte de service personnaliséapiVersion: tekton.dev/v1beta1 kind: PipelineRun metadata: name: <pipeline-run-name> spec: pipelineRef: name: <pipeline-cluster-task-name> serviceAccountName: 'fsgroup-runasany'Exemple : Exécution d'une tâche YAML avec le compte de service personnalisé
fsgroup-runasanyapiVersion: tekton.dev/v1beta1 kind: TaskRun metadata: name: <task-run-name> spec: taskRef: name: <cluster-task-name> serviceAccountName: 'fsgroup-runasany'
3.14. Sécuriser les webhooks avec des écouteurs d'événements
En tant qu'administrateur, vous pouvez sécuriser les webhooks à l'aide d'écouteurs d'événements. Après avoir créé un espace de noms, vous activez HTTPS pour la ressource Eventlistener en ajoutant l'étiquette operator.tekton.dev/enable-annotation=enabled à l'espace de noms. Ensuite, vous créez une ressource Trigger et un itinéraire sécurisé à l'aide de la terminaison TLS recryptée.
Les déclencheurs dans Red Hat OpenShift Pipelines prennent en charge les connexions HTTP non sécurisées et HTTPS sécurisées à la ressource Eventlistener. HTTPS sécurise les connexions à l'intérieur et à l'extérieur du cluster.
Red Hat OpenShift Pipelines exécute un pod tekton-operator-proxy-webhook qui surveille les étiquettes dans l'espace de noms. Lorsque vous ajoutez l'étiquette à l'espace de noms, le webhook définit l'annotation service.beta.openshift.io/serving-cert-secret-name=<secret_name> sur l'objet EventListener. Cette annotation crée à son tour des secrets et les certificats requis.
service.beta.openshift.io/serving-cert-secret-name=<secret_name>
En outre, vous pouvez monter le secret créé dans le pod Eventlistener pour sécuriser la demande.
3.14.1. Fournir une connexion sécurisée avec les routes OpenShift
Pour créer une route avec la terminaison TLS recryptée, exécutez :
$ oc create route reencrypt --service=<svc-name> --cert=tls.crt --key=tls.key --ca-cert=ca.crt --hostname=<hostname>Vous pouvez également créer un fichier YAML de terminaison TLS recrypté pour créer un itinéraire sécurisé.
Exemple de recryptage du YAML de terminaison TLS pour créer une route sécurisée
apiVersion: route.openshift.io/v1
kind: Route
metadata:
name: route-passthrough-secured
spec:
host: <hostname>
to:
kind: Service
name: frontend
tls:
termination: reencrypt
key: [as in edge termination]
certificate: [as in edge termination]
caCertificate: [as in edge termination]
destinationCACertificate: |-
-----BEGIN CERTIFICATE-----
[...]
-----END CERTIFICATE------ 1 2
- Le nom de l'objet, qui est limité à 63 caractères.
- 3
- Le champ de terminaison est fixé à
reencrypt. Il s'agit du seul champ TLS obligatoire. - 4
- Il est nécessaire pour le recryptage. Le champ
destinationCACertificatespécifie un certificat CA pour valider le certificat du point final, sécurisant ainsi la connexion entre le routeur et les pods de destination. Vous pouvez omettre ce champ dans l'un ou l'autre des scénarios suivants :- Le service utilise un certificat de signature de service.
- L'administrateur spécifie un certificat d'autorité de certification par défaut pour le routeur, et le service dispose d'un certificat signé par cette autorité de certification.
Vous pouvez exécuter la commande oc create route reencrypt --help pour afficher d'autres options.
3.14.2. Création d'un exemple de ressource EventListener à l'aide d'une connexion HTTPS sécurisée
Cette section utilise l'exemple pipelines-tutorial pour démontrer la création d'un exemple de ressource EventListener à l'aide d'une connexion HTTPS sécurisée.
Procédure
Créer la ressource
TriggerBindingà partir du fichier YAML disponible dans le dépôt pipelines-tutorial :$ oc create -f https://raw.githubusercontent.com/openshift/pipelines-tutorial/master/03_triggers/01_binding.yamlCréer la ressource
TriggerTemplateà partir du fichier YAML disponible dans le dépôt pipelines-tutorial :$ oc create -f https://raw.githubusercontent.com/openshift/pipelines-tutorial/master/03_triggers/02_template.yamlCréez la ressource
Triggerdirectement à partir du référentiel pipelines-tutorial :$ oc create -f https://raw.githubusercontent.com/openshift/pipelines-tutorial/master/03_triggers/03_trigger.yamlCréer une ressource
EventListeneren utilisant une connexion HTTPS sécurisée :Ajouter une étiquette pour activer la connexion HTTPS sécurisée à la ressource
Eventlistener:oc label namespace <ns-name> operator.tekton.dev/enable-annotation=enabledCréer la ressource
EventListenerà partir du fichier YAML disponible dans le dépôt pipelines-tutorial :$ oc create -f https://raw.githubusercontent.com/openshift/pipelines-tutorial/master/03_triggers/04_event_listener.yamlCréez une route avec la terminaison TLS recryptée :
$ oc create route reencrypt --service=<svc-name> --cert=tls.crt --key=tls.key --ca-cert=ca.crt --hostname=<hostname>
3.15. Authentification des pipelines avec git secret
Un secret Git consiste en des informations d'identification permettant d'interagir de manière sécurisée avec un dépôt Git, et est souvent utilisé pour automatiser l'authentification. Dans Red Hat OpenShift Pipelines, vous pouvez utiliser les secrets Git pour authentifier les exécutions de pipeline et les exécutions de tâches qui interagissent avec un dépôt Git pendant l'exécution.
Une exécution de pipeline ou une exécution de tâche accède aux secrets par le biais du compte de service associé. OpenShift Pipelines prend en charge l'utilisation des secrets Git en tant qu'annotations (paires clé-valeur) pour l'authentification de base et l'authentification basée sur SSH.
3.15.1. Sélection des diplômes
L'exécution d'un pipeline ou d'une tâche peut nécessiter plusieurs authentifications pour accéder à différents dépôts Git. Annotez chaque secret avec les domaines où OpenShift Pipelines peut utiliser ses informations d'identification.
Une clé d'annotation de credential pour les secrets Git doit commencer par tekton.dev/git-, et sa valeur est l'URL de l'hôte pour lequel vous voulez qu'OpenShift Pipelines utilise ce credential.
Dans l'exemple suivant, OpenShift Pipelines utilise un secret basic-auth, qui repose sur un nom d'utilisateur et un mot de passe, pour accéder aux dépôts à github.com et gitlab.com.
Exemple : Plusieurs informations d'identification pour l'authentification de base
apiVersion: v1
kind: Secret
metadata:
annotations:
tekton.dev/git-0: github.com
tekton.dev/git-1: gitlab.com
type: kubernetes.io/basic-auth
stringData:
username:
password:
Vous pouvez également utiliser un secret ssh-auth (clé privée) pour accéder à un dépôt Git.
Exemple : Clé privée pour l'authentification basée sur SSH
apiVersion: v1
kind: Secret
metadata:
annotations:
tekton.dev/git-0: https://github.com
type: kubernetes.io/ssh-auth
stringData:
ssh-privatekey: - 1
- Le contenu du fichier de clé privée SSH.
3.15.2. Configuration de l'authentification de base pour Git
Pour qu'un pipeline puisse récupérer des ressources dans des référentiels protégés par mot de passe, vous devez configurer l'authentification de base pour ce pipeline.
Pour configurer l'authentification de base pour un pipeline, mettez à jour les fichiers secret.yaml, serviceaccount.yaml, et run.yaml avec les informations d'identification du secret Git pour le référentiel spécifié. Lorsque vous avez terminé ce processus, OpenShift Pipelines peut utiliser ces informations pour récupérer les ressources de pipeline spécifiées.
Pour GitHub, l'authentification par mot de passe simple est obsolète. Utilisez plutôt un jeton d'accès personnel.
Procédure
Dans le fichier
secret.yaml, spécifiez le nom d'utilisateur et le mot de passe ou le jeton d'accès personnel GitHub pour accéder au dépôt Git cible.apiVersion: v1 kind: Secret metadata: name: basic-user-pass1 annotations: tekton.dev/git-0: https://github.com type: kubernetes.io/basic-auth stringData: username:2 password:3 Dans le fichier
serviceaccount.yaml, associez le secret au compte de service approprié.apiVersion: v1 kind: ServiceAccount metadata: name: build-bot1 secrets: - name: basic-user-pass2 Dans le fichier
run.yaml, associez le compte de service à une exécution de tâche ou de pipeline.Associer le compte de service à l'exécution d'une tâche :
apiVersion: tekton.dev/v1beta1 kind: TaskRun metadata: name: build-push-task-run-21 spec: serviceAccountName: build-bot2 taskRef: name: build-push3 Associer le compte de service à une ressource
PipelineRun:apiVersion: tekton.dev/v1beta1 kind: PipelineRun metadata: name: demo-pipeline1 namespace: default spec: serviceAccountName: build-bot2 pipelineRef: name: demo-pipeline3
Appliquez les modifications.
$ oc apply --filename secret.yaml,serviceaccount.yaml,run.yaml
3.15.3. Configuration de l'authentification SSH pour Git
Pour qu'un pipeline puisse récupérer des ressources à partir de référentiels configurés avec des clés SSH, vous devez configurer l'authentification basée sur SSH pour ce pipeline.
Pour configurer l'authentification basée sur SSH pour un pipeline, mettez à jour les fichiers secret.yaml, serviceaccount.yaml, et run.yaml avec les informations d'identification de la clé privée SSH pour le référentiel spécifié. Lorsque vous avez terminé ce processus, OpenShift Pipelines peut utiliser ces informations pour récupérer les ressources de pipeline spécifiées.
Envisagez d'utiliser l'authentification SSH plutôt que l'authentification de base.
Procédure
-
Générer une clé privée SSH ou copier une clé privée existante, qui est généralement disponible dans le fichier
~/.ssh/id_rsa. Dans le fichier
secret.yaml, définissez la valeur dessh-privatekeycomme étant le contenu du fichier de clé privée SSH, et définissez la valeur deknown_hostscomme étant le contenu du fichier d'hôtes connus.apiVersion: v1 kind: Secret metadata: name: ssh-key1 annotations: tekton.dev/git-0: github.com type: kubernetes.io/ssh-auth stringData: ssh-privatekey:2 known_hosts:3 ImportantSi vous omettez la clé privée, OpenShift Pipelines accepte la clé publique de n'importe quel serveur.
-
Facultatif : Pour spécifier un port SSH personnalisé, ajoutez
:<port number>à la fin de la valeurannotation. Par exemple,tekton.dev/git-0: github.com:2222. Dans le fichier
serviceaccount.yaml, associez le secretssh-keyau compte de servicebuild-bot.apiVersion: v1 kind: ServiceAccount metadata: name: build-bot1 secrets: - name: ssh-key2 Dans le fichier
run.yaml, associez le compte de service à une exécution de tâche ou de pipeline.Associer le compte de service à l'exécution d'une tâche :
apiVersion: tekton.dev/v1beta1 kind: TaskRun metadata: name: build-push-task-run-21 spec: serviceAccountName: build-bot2 taskRef: name: build-push3 Associer le compte de service à un pipeline :
apiVersion: tekton.dev/v1beta1 kind: PipelineRun metadata: name: demo-pipeline1 namespace: default spec: serviceAccountName: build-bot2 pipelineRef: name: demo-pipeline3
Appliquez les modifications.
$ oc apply --filename secret.yaml,serviceaccount.yaml,run.yaml
3.15.4. Utiliser l'authentification SSH dans les tâches de type git
Lorsque vous invoquez des commandes Git, vous pouvez utiliser l'authentification SSH directement dans les étapes d'une tâche. L'authentification SSH ignore la variable $HOME et utilise uniquement le répertoire personnel de l'utilisateur spécifié dans le fichier /etc/passwd. Chaque étape d'une tâche doit donc établir un lien symbolique entre le répertoire /tekton/home/.ssh et le répertoire personnel de l'utilisateur associé.
Cependant, les liens symboliques explicites ne sont pas nécessaires lorsque vous utilisez une ressource de pipeline du type git, ou la tâche git-clone disponible dans le catalogue Tekton.
Pour un exemple d'utilisation de l'authentification SSH dans les tâches de type git, voir authenticating-git-commands.yaml.
3.15.5. Utiliser des secrets en tant qu'utilisateur non root
Il se peut que vous deviez utiliser des secrets en tant qu'utilisateur non root dans certains cas, par exemple :
- Les utilisateurs et les groupes que les conteneurs utilisent pour exécuter des tâches sont choisis au hasard par la plateforme.
- Les étapes d'une tâche définissent un contexte de sécurité non racine.
- Une tâche spécifie un contexte de sécurité global non racine, qui s'applique à toutes les étapes d'une tâche.
Dans de tels scénarios, il convient de prendre en compte les aspects suivants de l'exécution des tâches et des pipelines en tant qu'utilisateur non root :
-
L'authentification SSH pour Git exige que l'utilisateur ait un répertoire personnel valide configuré dans le répertoire
/etc/passwd. La spécification d'un UID qui n'a pas de répertoire personnel valide entraîne l'échec de l'authentification. -
L'authentification SSH ignore la variable d'environnement
$HOME. Vous devez donc créer un lien symbolique entre les fichiers secrets appropriés du répertoire$HOMEdéfini par OpenShift Pipelines (/tekton/home) et le répertoire personnel valide de l'utilisateur non root.
En outre, pour configurer l'authentification SSH dans un contexte de sécurité non root, reportez-vous à l'exemple d'authentification des commandes git.
3.15.6. Limitation de l'accès secret à des étapes spécifiques
Par défaut, les secrets pour OpenShift Pipelines sont stockés dans le répertoire $HOME/tekton/home, et sont disponibles pour toutes les étapes d'une tâche.
Pour limiter un secret à des étapes spécifiques, utilisez la définition du secret pour spécifier un volume et montez le volume dans des étapes spécifiques.
3.16. Utilisation de Tekton Chains pour OpenShift Pipelines Sécurité de la chaîne d'approvisionnement
Tekton Chains est une fonctionnalité d'aperçu technologique uniquement. Les fonctionnalités de l'aperçu technologique ne sont pas prises en charge par les accords de niveau de service (SLA) de production de Red Hat et peuvent ne pas être complètes sur le plan fonctionnel. Red Hat ne recommande pas de les utiliser en production. Ces fonctionnalités offrent un accès anticipé aux fonctionnalités des produits à venir, ce qui permet aux clients de tester les fonctionnalités et de fournir un retour d'information pendant le processus de développement.
Pour plus d'informations sur la portée de l'assistance des fonctionnalités de l'aperçu technologique de Red Hat, voir Portée de l'assistance des fonctionnalités de l'aperçu technologique.
Tekton Chains est un contrôleur de définition de ressources personnalisées (CRD) de Kubernetes. Vous pouvez l'utiliser pour gérer la sécurité de la chaîne logistique des tâches et des pipelines créés à l'aide de Red Hat OpenShift Pipelines.
Par défaut, Tekton Chains observe toutes les exécutions de tâches dans votre cluster OpenShift Container Platform. Lorsque les exécutions de tâches sont terminées, Tekton Chains prend un instantané des exécutions de tâches. Il convertit ensuite l'instantané en un ou plusieurs formats de charge utile standard, et enfin signe et stocke tous les artefacts.
Pour capturer des informations sur l'exécution des tâches, Tekton Chains utilise les objets Result et PipelineResource. Lorsque ces objets ne sont pas disponibles, Tekton Chains utilise les URL et les extraits qualifiés des images OCI.
L'objet PipelineResource est obsolète et sera supprimé dans une prochaine version ; pour une utilisation manuelle, l'objet Results est recommandé.
3.16.1. Caractéristiques principales
-
Vous pouvez signer les exécutions de tâches, les résultats des exécutions de tâches et les images de registre OCI avec des types de clés cryptographiques et des services tels que
cosign. -
Vous pouvez utiliser des formats d'attestation tels que
in-toto. - Vous pouvez stocker en toute sécurité des signatures et des artefacts signés en utilisant le référentiel OCI comme backend de stockage.
3.16.2. Installation des chaînes Tekton à l'aide de l'opérateur Red Hat OpenShift Pipelines
Les administrateurs de clusters peuvent utiliser la ressource personnalisée (CR) TektonChain pour installer et gérer les chaînes Tekton.
Tekton Chains est un composant optionnel de Red Hat OpenShift Pipelines. Actuellement, vous ne pouvez pas l'installer en utilisant le CR TektonConfig.
Conditions préalables
-
Assurez-vous que Red Hat OpenShift Pipelines Operator est installé dans l'espace de noms
openshift-pipelinessur votre cluster.
Procédure
Créez le
TektonChainCR pour votre cluster OpenShift Container Platform.apiVersion: operator.tekton.dev/v1alpha1 kind: TektonChain metadata: name: chain spec: targetNamespace: openshift-pipelinesAppliquer la CR
TektonChain.$ oc apply -f TektonChain.yaml1 - 1
- Remplacer par le nom de fichier du CR
TektonChain.
Vérifier l'état de l'installation.
$ oc get tektonchains.operator.tekton.dev
3.16.3. Configuration des chaînes Tekton
Tekton Chains utilise un objet ConfigMap nommé chains-config dans l'espace de noms openshift-pipelines pour la configuration.
Pour configurer les chaînes Tekton, utilisez l'exemple suivant :
Exemple : Configuration des chaînes Tekton
$ oc patch configmap chains-config -n openshift-pipelines -p='{"data":{"artifacts.oci.storage" : \N- "\N", \N- "artifacts.taskrun.format\N":\N- "tekton\N", \N- "artifacts.taskrun.storage\N" : \N- "tekton\N" }}'- 1
- Utiliser une combinaison de paires clé-valeur prises en charge dans la charge utile JSON.
3.16.3.1. Touches prises en charge pour la configuration des chaînes Tekton
Les administrateurs de grappes peuvent utiliser diverses clés et valeurs prises en charge pour configurer les spécifications relatives aux exécutions de tâches, aux images OCI et au stockage.
3.16.3.1.1. Touches prises en charge pour l'exécution des tâches
| Touches prises en charge | Description | Valeurs prises en charge | Valeurs par défaut |
|---|---|---|---|
|
| Format dans lequel sont stockées les charges utiles de l'exécution des tâches. |
|
|
|
|
Le backend de stockage pour les signatures d'exécution de tâches. Vous pouvez spécifier plusieurs backends sous la forme d'une liste séparée par des virgules, par exemple |
|
|
|
| Le backend de signature pour signer les charges utiles de l'exécution des tâches. |
|
|
3.16.3.1.2. Clés prises en charge pour l'OCI
| Touches prises en charge | Description | Valeurs prises en charge | Valeurs par défaut |
|---|---|---|---|
|
| Format de stockage des données utiles OCI. |
|
|
|
|
Le backend de stockage pour les signatures OCI. Vous pouvez spécifier plusieurs backends sous la forme d'une liste séparée par des virgules, comme |
|
|
|
| Le backend de signature pour signer les données utiles de l'OCI. |
|
|
3.16.3.1.3. Clés de stockage prises en charge
| Touches prises en charge | Description | Valeurs prises en charge | Valeurs par défaut |
|---|---|---|---|
|
| Le référentiel OCI pour stocker les signatures OCI. | Actuellement, les Chains ne supportent que le registre interne OpenShift OCI ; d'autres options populaires telles que Quay ne sont pas supportées. |
3.16.4. Signer des secrets dans les chaînes Tekton
Les administrateurs de clusters peuvent générer une paire de clés et utiliser Tekton Chains pour signer des artefacts à l'aide d'un secret Kubernetes. Pour que les chaînes Tekton fonctionnent, une clé privée et un mot de passe pour les clés cryptées doivent exister en tant que partie du secret Kubernetes signing-secrets, dans l'espace de noms openshift-pipelines.
Actuellement, Tekton Chains prend en charge les systèmes de signature x509 et cosign.
N'utilisez qu'un seul des schémas de signature pris en charge.
3.16.4.1. Signature à l'aide de x509
Pour utiliser le schéma de signature x509 avec les chaînes Tekton, stockez la clé privée x509.pem du type ed25519 ou ecdsa dans le secret Kubernetes signing-secrets. Veillez à ce que la clé soit stockée sous la forme d'un fichier PKCS8 PEM non chiffré (BEGIN PRIVATE KEY).
3.16.4.2. Signer en utilisant la cosignature
Pour utiliser le schéma de signature cosign avec les chaînes Tekton :
- Installer la cosignature.
Générer les paires de clés
cosign.keyetcosign.pub.$ cosign generate-key-pair k8s://openshift-pipelines/signing-secretsCosign vous demande un mot de passe et crée un secret Kubernetes.
-
Stockez la clé privée chiffrée
cosign.keyet le mot de passe de déchiffrementcosign.passworddans le secret Kubernetessigning-secrets. Veillez à ce que la clé privée soit stockée sous la forme d'un fichier PEM crypté de typeENCRYPTED COSIGN PRIVATE KEY.
3.16.4.3. Signature de dépannage
Si les secrets de signature sont déjà renseignés, vous risquez d'obtenir l'erreur suivante :
Error from server (AlreadyExists): secrets "signing-secrets" already existsPour résoudre l'erreur :
Supprimer les secrets :
$ oc delete secret signing-secrets -n openshift-pipelines- Recréer les paires de clés et les stocker dans les secrets en utilisant le schéma de signature de votre choix.
3.16.5. S'authentifier auprès d'un registre OCI
Avant d'envoyer des signatures à un registre OCI, les administrateurs de clusters doivent configurer Tekton Chains pour qu'il s'authentifie auprès du registre. Le contrôleur Tekton Chains utilise le même compte de service que celui sous lequel la tâche s'exécute. Pour configurer un compte de service avec les informations d'identification nécessaires pour envoyer des signatures à un registre OCI, procédez comme suit :
Procédure
Définissez l'espace de noms et le nom du compte de service Kubernetes.
$ export NAMESPACE=<namespace>1 $ export SERVICE_ACCOUNT_NAME=<service_account>2 Créez un secret Kubernetes.
$ oc create secret registry-credentials \ --from-file=.dockerconfigjson \1 --type=kubernetes.io/dockerconfigjson \ -n $NAMESPACE- 1
- Remplacer par le chemin d'accès à votre fichier de configuration Docker. Le chemin par défaut est
~/.docker/config.json.
Donner au compte de service l'accès au secret.
$ oc patch serviceaccount $SERVICE_ACCOUNT_NAME \ -p "{\"imagePullSecrets\": [{\"name\": \"registry-credentials\"}]}" -n $NAMESPACESi vous corrigez le compte de service
pipelinepar défaut que Red Hat OpenShift Pipelines attribue à toutes les exécutions de tâches, l'opérateur Red Hat OpenShift Pipelines remplacera le compte de service. En tant que meilleure pratique, vous pouvez effectuer les étapes suivantes :Créez un compte de service distinct à affecter aux tâches exécutées par l'utilisateur.
oc create serviceaccount <service_account_name> $ oc create serviceaccount <service_account_name>Associez le compte de service aux exécutions de tâches en définissant la valeur du champ
serviceaccountnamedans le modèle d'exécution de tâches.apiVersion: tekton.dev/v1beta1 kind: TaskRun metadata: name: build-push-task-run-2 spec: serviceAccountName: build-bot1 taskRef: name: build-push ...- 1
- Remplacer par le nom du compte de service nouvellement créé.
3.16.5.1. Création et vérification des signatures d'exécution des tâches sans authentification supplémentaire
Pour vérifier les signatures des exécutions de tâches à l'aide des chaînes Tekton sans authentification supplémentaire, effectuez les tâches suivantes :
- Créez une paire de clés x509 chiffrée et enregistrez-la en tant que secret Kubernetes.
- Configurer le stockage de Tekton Chains.
- Créer une tâche, la signer et stocker la signature et la charge utile sous forme d'annotations sur la tâche elle-même.
- Récupérer la signature et la charge utile de l'exécution de la tâche signée.
- Vérifier la signature de l'exécution de la tâche.
Conditions préalables
Assurez-vous que les éléments suivants sont installés sur le cluster :
- Opérateur Red Hat OpenShift Pipelines
- Chaînes Tekton
- Cosignature
Procédure
Créez une paire de clés x509 chiffrée et enregistrez-la en tant que secret Kubernetes :
$ cosign generate-key-pair k8s://openshift-pipelines/signing-secretsFournissez un mot de passe lorsque vous y êtes invité. Cosign stocke la clé privée résultante en tant que partie du secret Kubernetes
signing-secretsdans l'espace de nomsopenshift-pipelines.Dans la configuration des chaînes Tekton, désactivez le stockage OCI et définissez le stockage et le format de l'exécution de la tâche sur
tekton.$ oc patch configmap chains-config -n openshift-pipelines -p='{"data":{"artifacts.oci.storage": "", "artifacts.taskrun.format":"tekton", "artifacts.taskrun.storage": "tekton"}}'Redémarrez le contrôleur Tekton Chains pour vous assurer que la configuration modifiée est appliquée.
$ oc delete po -n openshift-pipelines -l app=tekton-chains-controllerCréer une exécution de tâche.
$ oc create -f https://raw.githubusercontent.com/tektoncd/chains/main/examples/taskruns/task-output-image.yaml1 taskrun.tekton.dev/build-push-run-output-image-qbjvh created- 1
- Remplacer par l'URI ou le chemin d'accès au fichier qui pointe vers l'exécution de la tâche.
Vérifiez l'état d'avancement des étapes et attendez la fin du processus.
$ tkn tr describe --last [...truncated output...] NAME STATUS ∙ create-dir-builtimage-9467f Completed ∙ git-source-sourcerepo-p2sk8 Completed ∙ build-and-push Completed ∙ echo Completed ∙ image-digest-exporter-xlkn7 CompletedRécupérer la signature et la charge utile de l'objet stocké sous forme d'annotations codées
base64:$ export TASKRUN_UID=$(tkn tr describe --last -o jsonpath='{.metadata.uid}') $ tkn tr describe --last -o jsonpath="{.metadata.annotations.chains\.tekton\.dev/signature-taskrun-$TASKRUN_UID}" > signature $ tkn tr describe --last -o jsonpath="{.metadata.annotations.chains\.tekton\.dev/payload-taskrun-$TASKRUN_UID}" | base64 -d > payloadVérifier la signature.
$ cosign verify-blob --key k8s://openshift-pipelines/signing-secrets --signature ./signature ./payload Verified OK
3.16.6. Utilisation des chaînes Tekton pour signer et vérifier l'image et la provenance
Les administrateurs de clusters peuvent utiliser les chaînes Tekton pour signer et vérifier les images et les provenances, en effectuant les tâches suivantes :
- Créez une paire de clés x509 chiffrée et enregistrez-la en tant que secret Kubernetes.
- Configurer l'authentification pour le registre OCI afin de stocker les images, les signatures d'images et les attestations d'images signées.
- Configurer les chaînes Tekton pour qu'elles génèrent et signent la provenance.
- Créer une image avec Kaniko lors d'une exécution de tâches.
- Vérifier l'image et la provenance signées.
Conditions préalables
Assurez-vous que les éléments suivants sont installés sur le cluster :
- Opérateur Red Hat OpenShift Pipelines
- Chaînes Tekton
- Cosignature
- Rekor
- jq
Procédure
Créez une paire de clés x509 chiffrée et enregistrez-la en tant que secret Kubernetes :
$ cosign generate-key-pair k8s://openshift-pipelines/signing-secretsFournissez un mot de passe lorsque vous y êtes invité. Cosign stocke la clé privée résultante dans le secret Kubernetes
signing-secretsdans l'espace de nomsopenshift-pipelineset écrit la clé publique dans le fichier localcosign.pub.Configurer l'authentification pour le registre d'images.
- Pour configurer le contrôleur Tekton Chains afin qu'il transmette des signatures à un registre OCI, utilisez les informations d'identification associées au compte de service de l'exécution de la tâche. Pour plus d'informations, voir la section "Authentification auprès d'un registre OCI".
Pour configurer l'authentification pour une tâche Kaniko qui construit et pousse l'image vers le registre, créez un secret Kubernetes du fichier docker
config.jsoncontenant les informations d'identification requises.$ oc create secret generic <docker_config_secret_name> \1 --from-file <path_to_config.json>2
Configurez les chaînes Tekton en définissant les paramètres
artifacts.taskrun.format,artifacts.taskrun.storageettransparency.enableddans l'objetchains-config:$ oc patch configmap chains-config -n openshift-pipelines -p='{"data":{"artifacts.taskrun.format": "in-toto"}}' $ oc patch configmap chains-config -n openshift-pipelines -p='{"data":{"artifacts.taskrun.storage": "oci"}}' $ oc patch configmap chains-config -n openshift-pipelines -p='{"data":{"transparency.enabled": "true"}}'Lancez la tâche Kaniko.
Appliquez la tâche Kaniko au cluster.
$ oc apply -f examples/kaniko/kaniko.yaml1 - 1
- Remplacer par l'URI ou le chemin d'accès à votre tâche Kaniko.
Définir les variables d'environnement appropriées.
$ export REGISTRY=<url_of_registry>1 $ export DOCKERCONFIG_SECRET_NAME=<name_of_the_secret_in_docker_config_json>2 Lancez la tâche Kaniko.
$ tkn task start --param IMAGE=$REGISTRY/kaniko-chains --use-param-defaults --workspace name=source,emptyDir="" --workspace name=dockerconfig,secret=$DOCKERCONFIG_SECRET_NAME kaniko-chainsObservez les journaux de cette tâche jusqu'à ce que toutes les étapes soient terminées. Une fois l'authentification réussie, l'image finale sera poussée sur
$REGISTRY/kaniko-chains.
Attendez une minute pour permettre à Tekton Chains de générer la provenance et de la signer, puis vérifiez la disponibilité de l'annotation
chains.tekton.dev/signed=truelors de l'exécution de la tâche.$ oc get tr <task_run_name> \1 -o json | jq -r .metadata.annotations { "chains.tekton.dev/signed": "true", ... }- 1
- Remplacer par le nom de l'exécution de la tâche.
Vérifier l'image et l'attestation.
$ cosign verify --key cosign.pub $REGISTRY/kaniko-chains $ cosign verify-attestation --key cosign.pub $REGISTRY/kaniko-chainsTrouver la provenance de l'image dans Rekor.
- Obtenir le résumé de l'image $REGISTRY/kaniko-chains. Vous pouvez le rechercher lors de l'exécution de la tâche, ou extraire l'image pour en extraire le condensé.
Recherchez dans Rekor toutes les entrées qui correspondent à l'extrait
sha256de l'image.$ rekor-cli search --sha <image_digest>1 <uuid_1>2 <uuid_2>3 ...Le résultat de la recherche affiche les UUID des entrées correspondantes. L'un de ces UUID contient l'attestation.
Vérifier l'attestation.
$ rekor-cli get --uuid <uuid> --format json | jq -r .Attestation | base64 --decode | jq
3.17. Visualiser les logs du pipeline en utilisant l'opérateur de logging d'OpenShift
Les journaux générés par l'exécution des pipelines, des tâches et des événements sont stockés dans leurs pods respectifs. Il est utile d'examiner et d'analyser les journaux à des fins de dépannage et d'audit.
Cependant, le fait de conserver les pods indéfiniment entraîne une consommation inutile de ressources et un encombrement des espaces de noms.
Pour éliminer toute dépendance sur les pods pour la visualisation des logs du pipeline, vous pouvez utiliser l'OpenShift Elasticsearch Operator et l'OpenShift Logging Operator. Ces opérateurs vous permettent de visualiser les logs du pipeline en utilisant la pile Elasticsearch Kibana, même après avoir supprimé les pods qui contenaient les logs.
3.17.1. Conditions préalables
Avant d'essayer d'afficher les journaux de pipeline dans un tableau de bord Kibana, vérifiez les points suivants :
- Les étapes sont effectuées par un administrateur de cluster.
- Les journaux d'exécution des pipelines et des tâches sont disponibles.
- L'OpenShift Elasticsearch Operator et l'OpenShift Logging Operator sont installés.
3.17.2. Visualisation des journaux de pipeline dans Kibana
Pour afficher les journaux de pipeline dans la console web Kibana :
Procédure
- Connectez-vous à la console web d'OpenShift Container Platform en tant qu'administrateur de cluster.
- En haut à droite de la barre de menu, cliquez sur l'icône grid → Observability → Logging. La console web Kibana s'affiche.
Créer un modèle d'index :
- Dans le panneau de navigation gauche de la console web Kibana, cliquez sur Management.
- Cliquez sur Create index pattern.
-
Sous Step 1 of 2: Define index pattern → Index pattern, entrez un modèle et cliquez sur
*et cliquez sur Next Step. - Sous Step 2 of 2: Configure settings → Time filter field name, sélectionnez @timestamp dans le menu déroulant et cliquez sur Create index pattern.
Ajouter un filtre :
- Dans le panneau de navigation gauche de la console web Kibana, cliquez sur Discover.
Cliquez sur Add a filter → Edit Query DSL.
Note- Pour chacun des exemples de filtres suivants, modifiez la requête et cliquez sur Save.
- Les filtres sont appliqués l'un après l'autre.
Filtrer les conteneurs liés aux pipelines :
Exemple de requête pour filtrer les conteneurs de pipelines
{ "query": { "match": { "kubernetes.flat_labels": { "query": "app_kubernetes_io/managed-by=tekton-pipelines", "type": "phrase" } } } }Filtrer tous les conteneurs qui ne sont pas des conteneurs
place-tools. Pour illustrer l'utilisation des menus déroulants graphiques au lieu d'éditer le DSL de la requête, considérons l'approche suivante :Figure 3.6. Exemple de filtrage à l'aide des champs déroulants

Filtre
pipelinerundans les étiquettes à mettre en évidence :Exemple de requête pour filtrer
pipelinerundans les étiquettes pour les mettre en évidence{ "query": { "match": { "kubernetes.flat_labels": { "query": "tekton_dev/pipelineRun=", "type": "phrase" } } } }Filtre
pipelinedans les étiquettes à mettre en évidence :Exemple de requête pour filtrer
pipelinedans les étiquettes pour les mettre en évidence{ "query": { "match": { "kubernetes.flat_labels": { "query": "tekton_dev/pipeline=", "type": "phrase" } } } }
Dans la liste Available fields, sélectionnez les champs suivants :
-
kubernetes.flat_labels messageAssurez-vous que les champs sélectionnés sont affichés dans la liste Selected fields.
-
Les journaux sont affichés dans le champ message.
Figure 3.7. Messages filtrés

3.18. Construction non privilégiée d'images de conteneurs à l'aide de Buildah
L'exécution d'OpenShift Pipelines en tant qu'utilisateur root sur un conteneur peut exposer les processus du conteneur et l'hôte à d'autres ressources potentiellement malveillantes. Vous pouvez réduire ce type d'exposition en exécutant la charge de travail en tant qu'utilisateur non root spécifique dans le conteneur. Pour sécuriser les builds non privilégiés des images de conteneurs en utilisant Buildah, vous pouvez effectuer les étapes suivantes :
- Définir le compte de service personnalisé (SA) et la contrainte de contexte de sécurité (SCC).
-
Configurez Buildah pour qu'il utilise l'utilisateur
buildavec l'identifiant1000. - Lancez une exécution de tâche avec une carte de configuration personnalisée ou intégrez-la à une exécution de pipeline.
3.18.1. Configuration d'un compte de service personnalisé et d'une contrainte de contexte de sécurité
La SA par défaut pipeline permet d'utiliser un identifiant d'utilisateur en dehors de la plage de l'espace de noms. Pour réduire la dépendance à l'égard de la SA par défaut, vous pouvez définir une SA et un SCC personnalisés avec le rôle de cluster et les liaisons de rôle nécessaires pour l'utilisateur build avec l'identifiant 1000.
Procédure
Créez un SA et un SCC personnalisés avec le rôle de cluster et les liaisons de rôle nécessaires.
Exemple : SA et SCC personnalisés pour l'identifiant utilisé
1000apiVersion: v1 kind: ServiceAccount metadata: name: pipelines-sa-userid-10001 --- kind: SecurityContextConstraints metadata: annotations: name: pipelines-scc-userid-10002 allowHostDirVolumePlugin: false allowHostIPC: false allowHostNetwork: false allowHostPID: false allowHostPorts: false allowPrivilegeEscalation: false allowPrivilegedContainer: false allowedCapabilities: null apiVersion: security.openshift.io/v1 defaultAddCapabilities: null fsGroup: type: MustRunAs groups: - system:cluster-admins priority: 10 readOnlyRootFilesystem: false requiredDropCapabilities: - MKNOD runAsUser:3 type: MustRunAs uid: 1000 seLinuxContext: type: MustRunAs supplementalGroups: type: RunAsAny users: [] volumes: - configMap - downwardAPI - emptyDir - persistentVolumeClaim - projected - secret --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: pipelines-scc-userid-1000-clusterrole4 rules: - apiGroups: - security.openshift.io resourceNames: - pipelines-scc-userid-1000 resources: - securitycontextconstraints verbs: - use --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: pipelines-scc-userid-1000-rolebinding5 roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: pipelines-scc-userid-1000-clusterrole subjects: - kind: ServiceAccount name: pipelines-sa-userid-1000
- 1
- Définir une SA personnalisée.
- 2
- Définir un SCC personnalisé créé sur la base de privilèges restreints, avec le champ
runAsUsermodifié. - 3
- Restreindre tout pod rattaché au SCC personnalisé par l'intermédiaire de la SA personnalisée à s'exécuter sous l'identité de l'utilisateur
1000. - 4
- Définir un rôle de cluster qui utilise le SCC personnalisé.
- 5
- Lier le rôle de cluster qui utilise le SCC personnalisé à la SA personnalisée.
3.18.2. Configuration de Buildah pour l'utilisation de build user
Vous pouvez définir une tâche Buildah pour utiliser l'utilisateur build avec l'identifiant 1000.
Procédure
Créez une copie de la tâche de cluster
buildahen tant que tâche ordinaire.$ tkn task create --from=buildahModifiez la tâche
buildahcopiée.$ oc edit task buildahExemple : Tâche Buildah modifiée avec l'utilisateur
buildapiVersion: tekton.dev/v1beta1 kind: Task metadata: name: buildah-as-user spec: description: >- Buildah task builds source into a container image and then pushes it to a container registry. Buildah Task builds source into a container image using Project Atomic's Buildah build tool.It uses Buildah's support for building from Dockerfiles, using its buildah bud command.This command executes the directives in the Dockerfile to assemble a container image, then pushes that image to a container registry. params: - name: IMAGE description: Reference of the image buildah will produce. - name: BUILDER_IMAGE description: The location of the buildah builder image. default: registry.redhat.io/rhel8/buildah@sha256:99cae35f40c7ec050fed3765b2b27e0b8bbea2aa2da7c16408e2ca13c60ff8ee - name: STORAGE_DRIVER description: Set buildah storage driver default: vfs - name: DOCKERFILE description: Path to the Dockerfile to build. default: ./Dockerfile - name: CONTEXT description: Path to the directory to use as context. default: . - name: TLSVERIFY description: Verify the TLS on the registry endpoint (for push/pull to a non-TLS registry) default: "true" - name: FORMAT description: The format of the built container, oci or docker default: "oci" - name: BUILD_EXTRA_ARGS description: Extra parameters passed for the build command when building images. default: "" - description: Extra parameters passed for the push command when pushing images. name: PUSH_EXTRA_ARGS type: string default: "" - description: Skip pushing the built image name: SKIP_PUSH type: string default: "false" results: - description: Digest of the image just built. name: IMAGE_DIGEST type: string workspaces: - name: source steps: - name: build securityContext: runAsUser: 10001 image: $(params.BUILDER_IMAGE) workingDir: $(workspaces.source.path) script: | echo "Running as USER ID `id`"2 buildah --storage-driver=$(params.STORAGE_DRIVER) bud \ $(params.BUILD_EXTRA_ARGS) --format=$(params.FORMAT) \ --tls-verify=$(params.TLSVERIFY) --no-cache \ -f $(params.DOCKERFILE) -t $(params.IMAGE) $(params.CONTEXT) [[ "$(params.SKIP_PUSH)" == "true" ]] && echo "Push skipped" && exit 0 buildah --storage-driver=$(params.STORAGE_DRIVER) push \ $(params.PUSH_EXTRA_ARGS) --tls-verify=$(params.TLSVERIFY) \ --digestfile $(workspaces.source.path)/image-digest $(params.IMAGE) \ docker://$(params.IMAGE) cat $(workspaces.source.path)/image-digest | tee /tekton/results/IMAGE_DIGEST volumeMounts: - name: varlibcontainers mountPath: /home/build/.local/share/containers volumeMounts: - name: varlibcontainers mountPath: /home/build/.local/share/containers volumes: - name: varlibcontainers emptyDir: {}
3.18.3. Démarrage d'une tâche avec une carte de configuration personnalisée ou d'un pipeline
Après avoir défini la tâche de cluster Buildah personnalisée, vous pouvez créer un objet TaskRun qui construit une image en tant qu'utilisateur build avec l'identifiant d'utilisateur 1000. En outre, vous pouvez intégrer l'objet TaskRun dans un objet PipelineRun.
Procédure
Créez un objet
TaskRunavec des objets personnalisésConfigMapetDockerfile.Exemple : Une tâche qui exécute Buildah en tant qu'identifiant de l'utilisateur
1000apiVersion: v1 data: Dockerfile: | ARG BASE_IMG=registry.access.redhat.com/ubi8/ubi FROM $BASE_IMG AS buildah-runner RUN dnf -y update && \ dnf -y install git && \ dnf clean all CMD git kind: ConfigMap metadata: name: dockerfile1 --- apiVersion: tekton.dev/v1beta1 kind: TaskRun metadata: name: buildah-as-user-1000 spec: serviceAccountName: pipelines-sa-userid-1000 params: - name: IMAGE value: image-registry.openshift-image-registry.svc:5000/test/buildahuser taskRef: kind: Task name: buildah-as-user workspaces: - configMap: name: dockerfile2 name: source(Facultatif) Créer un pipeline et un cycle de pipeline correspondant.
Exemple : Une canalisation et un tronçon de canalisation correspondant
apiVersion: tekton.dev/v1beta1 kind: Pipeline metadata: name: pipeline-buildah-as-user-1000 spec: params: - name: IMAGE - name: URL workspaces: - name: shared-workspace - name: sslcertdir optional: true tasks: - name: fetch-repository1 taskRef: name: git-clone kind: ClusterTask workspaces: - name: output workspace: shared-workspace params: - name: url value: $(params.URL) - name: subdirectory value: "" - name: deleteExisting value: "true" - name: buildah taskRef: name: buildah-as-user2 runAfter: - fetch-repository workspaces: - name: source workspace: shared-workspace - name: sslcertdir workspace: sslcertdir params: - name: IMAGE value: $(params.IMAGE) --- apiVersion: tekton.dev/v1beta1 kind: PipelineRun metadata: name: pipelinerun-buildah-as-user-1000 spec: serviceAccountName: pipelines-sa-userid-1000 params: - name: URL value: https://github.com/openshift/pipelines-vote-api - name: IMAGE value: image-registry.openshift-image-registry.svc:5000/test/buildahuser taskRef: kind: Pipeline name: pipeline-buildah-as-user-1000 workspaces: - name: shared-workspace3 volumeClaimTemplate: spec: accessModes: - ReadWriteOnce resources: requests: storage: 100Mi- 1
- Utilisez la tâche de cluster
git-clonepour récupérer la source contenant un fichier Docker et le construire à l'aide de la tâche Buildah modifiée. - 2
- Se référer à la tâche Buildah modifiée.
- 3
- Partager les données entre la tâche
git-cloneet la tâche Buildah modifiée à l'aide d'une revendication de volume persistant (PVC) créée automatiquement par le contrôleur.
- Lancer l'exécution de la tâche ou du pipeline.
3.18.4. Limites des versions non privilégiées
Le processus de construction sans privilège fonctionne avec la plupart des objets Dockerfile. Cependant, certaines limitations connues peuvent entraîner l'échec de la construction :
-
L'utilisation de l'option
--mount=type=cachepeut échouer en raison de problèmes de permissions non nécessaires. Pour plus d'informations, voir cet article. -
L'utilisation de l'option
--mount=type=secretéchoue car le montage des ressources nécessite des capacités supplémentaires qui ne sont pas fournies par le SCC personnalisé.
Ressources complémentaires
Chapitre 4. GitOps
4.1. Notes de mise à jour de Red Hat OpenShift GitOps
Red Hat OpenShift GitOps est un moyen déclaratif de mettre en œuvre le déploiement continu pour les applications natives du cloud. Red Hat OpenShift GitOps assure la cohérence des applications lorsque vous les déployez sur différents clusters dans différents environnements, tels que : développement, staging et production. Red Hat OpenShift GitOps vous aide à automatiser les tâches suivantes :
- Veiller à ce que les grappes aient des états similaires pour la configuration, la surveillance et le stockage
- Récupérer ou recréer des clusters à partir d'un état connu
- Appliquer ou inverser les changements de configuration à plusieurs clusters OpenShift Container Platform
- Associer une configuration modèle à différents environnements
- Promouvoir les applications sur l'ensemble des clusters, de la phase d'essai à la production
Pour une vue d'ensemble de Red Hat OpenShift GitOps, voir Comprendre OpenShift GitOps.
4.1.1. Matrice de compatibilité et de soutien
Certaines fonctionnalités de cette version sont actuellement en avant-première technologique. Ces fonctionnalités expérimentales ne sont pas destinées à être utilisées en production.
Dans le tableau, les caractéristiques sont marquées par les statuts suivants :
- TP: Technology Preview
- GA: General Availability
- NA: Not Applicable
| OpenShift GitOps | Component Versions | OpenShift Versions | ||||||
|---|---|---|---|---|---|---|---|---|
| Version |
| Helm | Kustomize | Argo CD | ApplicationSet | Dex | RH SSO | |
| 1.8.0 | 0.0,47 TP | 3.10.0 GA | 4.5.7 GA | 2.6.3 GA | NA | 2.35.1 GA | 7.5.1 GA | 4.10-4.12 |
| 1.7.0 | 0.0,46 TP | 3.10.0 GA | 4.5.7 GA | 2.5.4 GA | NA | 2.35.1 GA | 7.5.1 GA | 4.10-4.12 |
| 1.6.0 | 0.0,46 TP | 3.8.1 GA | 4.4.1 GA | 2.4,5 GA | GA et inclus dans la composante ArgoCD | 2.30.3 GA | 7.5.1 GA | 4.8-4.11 |
| 1.5.0 | 0.0.42 TP | 3.8.0 GA | 4.4.1 GA | 2.3.3 GA | 0.4.1 TP | 2.30.3 GA | 7.5.1 GA | 4.8-4.11 |
| 1.4.0 | 0.0.41 TP | 3.7.1 GA | 4.2.0 GA | 2.2.2 GA | 0.2.0 TP | 2.30,0 GA | 7.4.0 GA | 4.7-4.10 |
| 1.3.0 | 0.0.40 TP | 3.6.0 GA | 4.2.0 GA | 2.1.2 GA | 0.2.0 TP | 2.28,0 GA | 7.4.0 GA | 4.7-4.9, 4.6 avec soutien limité de l'AG |
| 1.2.0 | 0.0.38 TP | 3.5.0 GA | 3.9.4 GA | 2.0,5 GA | 0.1.0 TP | NA | 7.4.0 GA | 4.8 |
| 1.1.0 | 0.0.32 TP | 3.5.0 GA | 3.9.4 GA | 2.0,0 GA | NA | NA | NA | 4.7 |
-
kamest l'interface de ligne de commande (CLI) du Gestionnaire d'applications Red Hat OpenShift GitOps. - RH SSO est l'abréviation de Red Hat SSO.
4.1.1.1. Caractéristiques de l'aperçu technologique
Les fonctionnalités mentionnées dans le tableau suivant sont actuellement en avant-première technologique (TP). Ces fonctionnalités expérimentales ne sont pas destinées à être utilisées en production.
| Fonctionnalité | TP dans les versions de Red Hat OpenShift GitOps | GA dans Red Hat OpenShift GitOps versions |
|---|---|---|
| Stratégie de déploiement progressif d'ApplicationSet | 1.8.0 | NA |
| Sources multiples pour une demande | 1.8.0 | NA |
| Applications du CD Argo dans des espaces nominatifs autres que ceux des avions de contrôle | 1.7.0 | NA |
| Contrôleur de notifications Argo CD | 1.6.0 | NA |
| La page Red Hat OpenShift GitOps Environments dans la perspective Developer de la console web OpenShift Container Platform | 1.1.0 | NA |
4.1.2. Rendre l'open source plus inclusif
Red Hat s'engage à remplacer les termes problématiques dans son code, sa documentation et ses propriétés Web. Nous commençons par ces quatre termes : master, slave, blacklist et whitelist. En raison de l'ampleur de cette entreprise, ces changements seront mis en œuvre progressivement au cours de plusieurs versions à venir. Pour plus de détails, voir le message de notre directeur technique Chris Wright.
4.1.3. Notes de version pour Red Hat OpenShift GitOps 1.8.2
Red Hat OpenShift GitOps 1.8.2 est maintenant disponible sur OpenShift Container Platform 4.10, 4.11, et 4.12.
4.1.3.1. Problèmes corrigés
Les problèmes suivants ont été résolus dans la version actuelle :
Avant cette mise à jour, lorsque vous configuriez Dex en utilisant le paramètre
.spec.dexet que vous essayiez de vous connecter à l'interface utilisateur d'Argo CD en utilisant l'option LOG IN VIA OPENSHIFT, vous ne pouviez pas vous connecter. Cette mise à jour corrige le problème.ImportantLe paramètre
spec.dexdans la CR ArgoCD est obsolète. Dans une prochaine version de Red Hat OpenShift GitOps v1.9, il est prévu de supprimer la configuration de Dex à l'aide du paramètrespec.dexdans la CR ArgoCD. Envisagez d'utiliser le paramètre.spec.ssoà la place. Voir "Activer ou désactiver Dex en utilisant .spec.sso". GITOPS-2761-
Avant cette mise à jour, le cluster et les pods CLI
kamne démarraient pas avec une nouvelle installation de Red Hat OpenShift GitOps v1.8.0 sur le cluster OpenShift Container Platform 4.10. Cette mise à jour corrige le problème et maintenant tous les pods fonctionnent comme prévu. GITOPS-2762
4.1.4. Notes de version pour Red Hat OpenShift GitOps 1.8.1
Red Hat OpenShift GitOps 1.8.1 est maintenant disponible sur OpenShift Container Platform 4.10, 4.11, et 4.12.
4.1.4.1. Mise à jour des errata
4.1.4.1.1. RHSA-2023:1452 - Avis de mise à jour de sécurité de Red Hat OpenShift GitOps 1.8.1
Publié : 2023-03-23
La liste des correctifs de sécurité inclus dans cette version est documentée dans l'avis RHSA-2023:1452.
Si vous avez installé Red Hat OpenShift GitOps Operator, exécutez la commande suivante pour afficher les images de conteneurs dans cette version :
$ oc describe deployment gitops-operator-controller-manager -n openshift-operators4.1.5. Notes de version pour Red Hat OpenShift GitOps 1.8.0
Red Hat OpenShift GitOps 1.8.0 est maintenant disponible sur OpenShift Container Platform 4.10, 4.11, et 4.12.
4.1.5.1. Nouvelles fonctionnalités
La version actuelle apporte les améliorations suivantes :
Avec cette mise à jour, vous pouvez ajouter la prise en charge de la fonctionnalité ApplicationSet Progressive Rollout Strategy. Grâce à cette fonctionnalité, vous pouvez améliorer la ressource ApplicationSet d'ArgoCD pour intégrer une stratégie de déploiement pour une mise à jour progressive des ressources d'application après avoir modifié la spécification de l'ApplicationSet ou les modèles d'application. Lorsque vous activez cette fonctionnalité, les applications sont mises à jour dans un ordre déclaratif au lieu d'être mises à jour simultanément. GITOPS-956
ImportantApplicationSet Progressive Rollout Strategy est une fonctionnalité de l'aperçu technologique.
-
Avec cette mise à jour, la page Application environments dans la perspective Developer de la console web OpenShift Container Platform est découplée de l'interface de ligne de commande (CLI) Red Hat OpenShift GitOps Application Manager,
kam. Vous n'avez pas besoin d'utiliser l'interface de ligne de commandekampour générer des manifestes d'environnement d'application pour que les environnements apparaissent dans la perspective Developer de la console web d'OpenShift Container Platform. Vous pouvez utiliser vos propres manifestes, mais les environnements doivent toujours être représentés par des espaces de noms. De plus, des étiquettes et des annotations spécifiques sont toujours nécessaires. GITOPS-1785 Avec cette mise à jour, Red Hat OpenShift GitOps Operator et
kamCLI sont maintenant disponibles pour l'architecture ARM sur OpenShift Container Platform. GITOPS-1688Importantspec.sso.provider: keycloakn'est pas encore pris en charge sur ARM.-
Avec cette mise à jour, vous pouvez activer la surveillance de la charge de travail pour des instances Argo CD spécifiques en définissant la valeur de l'indicateur
.spec.monitoring.enabledsurtrue. En conséquence, l'opérateur crée un objetPrometheusRulequi contient des règles d'alerte pour chaque composant Argo CD. Ces règles d'alerte déclenchent une alerte lorsque le nombre de répliques du composant correspondant s'éloigne de l'état souhaité pendant un certain temps. L'opérateur n'écrase pas les modifications apportées à l'objetPrometheusRulepar les utilisateurs. GITOPS-2459 Avec cette mise à jour, vous pouvez passer des arguments de commande au déploiement du serveur repo en utilisant le CD CR d'Argo. GITOPS-2445
Par exemple :
apiVersion: argoproj.io/v1alpha1 kind: ArgoCD metadata: name: example-argocd spec: repo: extraRepoCommandArgs: - --max.combined.directory.manifests.size - 10M
4.1.5.2. Problèmes corrigés
Les problèmes suivants ont été résolus dans la version actuelle :
Avant cette mise à jour, la variable d'environnement
ARGOCD_GIT_MODULES_ENABLEDne pouvait être définie que sur le podopenshift-gitops-repo-serveret non sur le podApplicationSet Controller. Par conséquent, lors de l'utilisation du générateur Git, les sous-modules Git étaient clonés lors de la génération des applications enfants car la variable était absente de l'environnementApplicationSet Controller. De plus, si les informations d'identification requises pour cloner ces sous-modules n'étaient pas configurées dans ArgoCD, la génération de l'application échouait. Cette mise à jour corrige le problème ; vous pouvez maintenant ajouter des variables d'environnement telles queArgoCD_GIT_MODULES_ENABLEDau podApplicationSet Controlleren utilisant le CD CR d'Argo. Le podApplicationSet Controllergénère alors avec succès des applications enfants à partir du référentiel cloné et aucun sous-module n'est cloné dans le processus. GITOPS-2399Par exemple :
apiVersion: argoproj.io/v1alpha1 kind: ArgoCD metadata: name: example-argocd labels: example: basic spec: applicationSet: env: - name: ARGOCD_GIT_MODULES_ENABLED value: "true"-
Avant cette mise à jour, lors de l'installation de Red Hat OpenShift GitOps Operator v1.7.0, le fichier de configuration par défaut
argocd-cm.ymlcréé pour l'authentification de Dex contenait le secret client encodé en base64 au format d'une pairekey:value. Cette mise à jour corrige ce problème en ne stockant pas le secret client dans le fichier de configuration par défautargocd-cm.yml. Au lieu de cela, le secret client se trouve maintenant dans un objetargocd-secret, et vous pouvez le référencer dans la carte de configuration en tant que nom de secret. GITOPS-2570
4.1.5.3. Problèmes connus
-
Lorsque vous déployez des applications en utilisant vos manifestes sans utiliser la CLI
kamet que vous visualisez les applications dans la page Application environments dans la perspective Developer de la console web OpenShift Container Platform, l'URL Argo CD de l'application correspondante ne charge pas la page comme prévu à partir de l'icône Argo CD dans la carte. GITOPS-2736
4.1.6. Notes de version pour Red Hat OpenShift GitOps 1.7.3
Red Hat OpenShift GitOps 1.7.3 est maintenant disponible sur OpenShift Container Platform 4.10, 4.11, et 4.12.
4.1.6.1. Mise à jour des errata
4.1.6.1.1. RHSA-2023:1454 - Avis de mise à jour de sécurité de Red Hat OpenShift GitOps 1.7.3
Publié : 2023-03-23
La liste des correctifs de sécurité inclus dans cette version est documentée dans l'avis RHSA-2023:1454.
Si vous avez installé Red Hat OpenShift GitOps Operator, exécutez la commande suivante pour afficher les images de conteneurs dans cette version :
$ oc describe deployment gitops-operator-controller-manager -n openshift-operators4.1.7. Notes de version pour Red Hat OpenShift GitOps 1.7.1
Red Hat OpenShift GitOps 1.7.1 est maintenant disponible sur OpenShift Container Platform 4.10, 4.11, et 4.12.
4.1.7.1. Mise à jour des errata
4.1.7.1.1. RHSA-2023:0467 - Avis de mise à jour de sécurité de Red Hat OpenShift GitOps 1.7.1
Publié : 2023-01-25
La liste des correctifs de sécurité inclus dans cette version est documentée dans l'avis RHSA-2023:0467.
Si vous avez installé Red Hat OpenShift GitOps Operator, exécutez la commande suivante pour afficher les images de conteneurs dans cette version :
$ oc describe deployment gitops-operator-controller-manager -n openshift-operators4.1.8. Notes de version pour Red Hat OpenShift GitOps 1.7.0
Red Hat OpenShift GitOps 1.7.0 est maintenant disponible sur OpenShift Container Platform 4.10, 4.11, et 4.12.
4.1.8.1. Nouvelles fonctionnalités
La version actuelle apporte les améliorations suivantes :
- Avec cette mise à jour, vous pouvez ajouter des variables d'environnement au contrôleur de notifications. GITOPS-2313
-
Avec cette mise à jour, la paire clé-valeur nodeSelector
"kubernetes.io/os": "linux"par défaut est ajoutée à toutes les charges de travail de manière à ce qu'elles ne soient planifiées que sur des nœuds Linux. De plus, tous les sélecteurs de nœuds personnalisés sont ajoutés au sélecteur par défaut et sont prioritaires s'ils ont la même clé. GITOPS-2215 -
Avec cette mise à jour, vous pouvez définir des sélecteurs de nœuds personnalisés dans les charges de travail Operator en éditant leur ressource personnalisée
GitopsService. GITOPS-2164 -
Avec cette mise à jour, vous pouvez utiliser le mode de correspondance des politiques RBAC pour sélectionner l'une des options suivantes :
glob(par défaut) etregex.GITOPS-1975 Avec cette mise à jour, vous pouvez personnaliser le comportement des ressources en utilisant les sous-clés supplémentaires suivantes :
Expand Sous-clé Forme de la clé Champ mappé en argocd-cm contrôles de santé des ressources
resource.customizations.health.<group_kind>
ressources.personnalisations.santé
ressourceIgnoreDifferences
resource.customizations.ignoreDifferences.<group_kind>
resource.customizations.ignoreDifferences
actions sur les ressources
resource.customizations.actions.<group_kind>
resource.customizations.actions
NoteDans les prochaines versions, il est possible de supprimer l'ancienne méthode de personnalisation du comportement des ressources en utilisant uniquement resourceCustomization et non les sous-clés.
- Avec cette mise à jour, pour utiliser la page Environments dans la perspective Developer, vous devez effectuer une mise à jour si vous utilisez une version de Red Hat OpenShift GitOps antérieure à 1.7 et OpenShift Container Platform 4.15 ou supérieure. GITOPS-2415
Avec cette mise à jour, vous pouvez créer des applications, qui sont gérées par la même instance de plan de contrôle Argo CD, dans n'importe quel espace de noms dans le même cluster. En tant qu'administrateur, effectuez les actions suivantes pour activer cette mise à jour :
-
Ajoutez l'espace de noms à l'attribut
.spec.sourceNamespacespour une instance Argo CD en cluster qui gère l'application. Ajoutez l'espace de noms à l'attribut
.spec.sourceNamespacesde la ressource personnaliséeAppProjectassociée à l'application.
-
Ajoutez l'espace de noms à l'attribut
Les applications Argo CD dans les espaces de noms du plan de contrôle ne sont qu'une fonctionnalité de l'aperçu technologique. Les fonctionnalités de l'aperçu technologique ne sont pas prises en charge par les accords de niveau de service (SLA) de production de Red Hat et peuvent ne pas être complètes sur le plan fonctionnel. Red Hat ne recommande pas de les utiliser en production. Ces fonctionnalités offrent un accès anticipé aux fonctionnalités des produits à venir, ce qui permet aux clients de tester les fonctionnalités et de fournir un retour d'information pendant le processus de développement.
Pour plus d'informations sur la portée de l'assistance des fonctionnalités de l'aperçu technologique de Red Hat, voir Portée de l'assistance des fonctionnalités de l'aperçu technologique.
Avec cette mise à jour, Argo CD prend en charge la fonctionnalité Server-Side Apply, qui aide les utilisateurs à effectuer les tâches suivantes :
- Gérer les ressources volumineuses qui sont trop grandes pour la taille d'annotation autorisée de 262144 octets.
Patch d'une ressource existante qui n'est pas gérée ou déployée par Argo CD.
Vous pouvez configurer cette fonction au niveau de l'application ou de la ressource. GITOPS-2340
4.1.8.2. Problèmes corrigés
Les problèmes suivants ont été résolus dans la version actuelle :
-
Avant cette mise à jour, les versions Red Hat OpenShift GitOps étaient affectées par un problème d'échec des pods Dex avec l'erreur
CreateContainerConfigErrorlorsque le SCCanyuidétait assigné au compte de service Dex. Cette mise à jour corrige le problème en assignant un identifiant d'utilisateur par défaut au conteneur Dex. GITOPS-2235 -
Avant cette mise à jour, Red Hat OpenShift GitOps utilisait le RHSSO (Keycloak) via OIDC en plus de Dex. Cependant, avec un correctif de sécurité récent, le certificat de RHSSO ne pouvait pas être validé lorsqu'il était configuré avec un certificat non signé par l'une des autorités de certification bien connues. Cette mise à jour corrige le problème ; vous pouvez maintenant fournir un certificat personnalisé pour vérifier le certificat TLS du KeyCloak lors de la communication avec lui. En outre, vous pouvez ajouter
rootCAau champ.spec.keycloak.rootCAde la ressource personnalisée Argo CD. L'opérateur réconcilie ces changements et met à jour la carte de configurationoidc.config in argocd-cmavec le certificat racine encodé PEM. GITOPS-2214
Exemple de CD Argo avec configuration Keycloak :
apiVersion: argoproj.io/v1alpha1
kind: ArgoCD
metadata:
name: example-argocd
spec:
sso:
keycloak:
rootCA: '<PEM encoded root certificate>'
provider: keycloak
.......
.......-
Avant cette mise à jour, les contrôleurs d'application redémarraient plusieurs fois en raison de l'absence de réponse des sondes de réactivité. Cette mise à jour corrige le problème en supprimant la sonde de réactivité dans le contrôleur d'application
statefulset. GITOPS-2153
4.1.8.3. Problèmes connus
-
Avant cette mise à jour, l'opérateur ne réconciliait pas les paramètres
mountsatokenetServiceAccountpour le serveur de dépôt. Bien que cela ait été corrigé, la suppression du compte de service ne rétablit pas la valeur par défaut. GITOPS-1873 -
Solution de contournement : Définissez manuellement le compte de service
spec.repo.serviceaccountfield to thedefault. GITOPS-2452
4.1.9. Notes de version pour Red Hat OpenShift GitOps 1.6.4
Red Hat OpenShift GitOps 1.6.4 est maintenant disponible sur OpenShift Container Platform 4.8, 4.9, 4.10, et 4.11.
4.1.9.1. Problèmes corrigés
- Avant cette mise à jour, toutes les versions d'Argo CD v1.8.2 et ultérieures étaient vulnérables à un bogue d'autorisation inapproprié. En conséquence, Argo CD acceptait des jetons pour des utilisateurs qui n'étaient pas censés accéder au cluster. Ce problème est maintenant corrigé. CVE-2023-22482
4.1.10. Notes de version pour Red Hat OpenShift GitOps 1.6.2
Red Hat OpenShift GitOps 1.6.2 est désormais disponible sur OpenShift Container Platform 4.8, 4.9, 4.10 et 4.11.
4.1.10.1. Nouvelles fonctionnalités
-
Cette version supprime la variable d'environnement
DISABLE_DEXdu fichier CSVopenshift-gitops-operator. Par conséquent, cette variable d'environnement n'est plus définie lorsque vous effectuez une nouvelle installation de Red Hat OpenShift GitOps. GITOPS-2360
4.1.10.2. Problèmes corrigés
Les problèmes suivants ont été résolus dans la version actuelle :
- Avant cette mise à jour, le contrôle de santé de l'abonnement était marqué degraded pour InstallPlan manquant lorsque plus de 5 opérateurs étaient installés dans un projet. Cette mise à jour corrige le problème. GITOPS-2018
- Avant cette mise à jour, l'opérateur Red Hat OpenShift GitOps spammerait le cluster avec un avertissement d'avis de dépréciation chaque fois qu'il détectait qu'une instance Argo CD utilisait des champs dépréciés. Cette mise à jour corrige ce problème et ne montre qu'un seul événement d'avertissement pour chaque instance qui détecte un champ. GITOPS-2230
- Depuis OpenShift Container Platform 4.12, l'installation de la console est optionnelle. Ce correctif met à jour le Red Hat OpenShift GitOps Operator afin d'éviter les erreurs avec l'Operator si la console n'est pas installée. GITOPS-2352
4.1.11. Notes de version pour Red Hat OpenShift GitOps 1.6.1
Red Hat OpenShift GitOps 1.6.1 est maintenant disponible sur OpenShift Container Platform 4.8, 4.9, 4.10, et 4.11.
4.1.11.1. Problèmes corrigés
Les problèmes suivants ont été résolus dans la version actuelle :
-
Avant cette mise à jour, dans un grand nombre d'applications, les contrôleurs d'application étaient redémarrés plusieurs fois en raison de l'absence de réponse des sondes de réactivité. Cette mise à jour corrige le problème en supprimant la sonde de réactivité dans l'objet
StatefulSetdu contrôleur d'application. GITOPS-2153 Avant cette mise à jour, le certificat RHSSO ne pouvait pas être validé lorsqu'il était configuré avec un certificat qui n'était pas signé par les autorités de certification. Cette mise à jour corrige le problème et vous pouvez désormais fournir un certificat personnalisé qui sera utilisé pour vérifier le certificat TLS du Keycloak lors de la communication avec celui-ci. Vous pouvez ajouter le site
rootCAau champ de la ressource personnalisée Argo CD.spec.keycloak.rootCA. L'opérateur réconcilie ce changement et met à jour le champoidc.configdans le champargocd-cmConfigMapavec le certificat racine codé en PEM. GITOPS-2214NoteRedémarrez le serveur Argo CD après avoir mis à jour le champ
.spec.keycloak.rootCA.Par exemple :
apiVersion: argoproj.io/v1alpha1 kind: ArgoCD metadata: name: example-argocd labels: example: basic spec: sso: provider: keycloak keycloak: rootCA: | ---- BEGIN CERTIFICATE ---- This is a dummy certificate Please place this section with appropriate rootCA ---- END CERTIFICATE ---- server: route: enabled: true- Avant cette mise à jour, un espace de noms de terminaison géré par Argo CD bloquait la création de rôles et d'autres configurations d'autres espaces de noms gérés. Cette mise à jour corrige ce problème. GITOPS-2277
-
Avant cette mise à jour, les pods Dex ne démarraient pas avec
CreateContainerConfigErrorlorsqu'un SCC deanyuidétait attribué à la ressource DexServiceAccount. Cette mise à jour corrige ce problème en assignant un identifiant utilisateur par défaut au conteneur Dex. GITOPS-2235
4.1.12. Notes de version pour Red Hat OpenShift GitOps 1.6.0
Red Hat OpenShift GitOps 1.6.0 est maintenant disponible sur OpenShift Container Platform 4.8, 4.9, 4.10, et 4.11.
4.1.12.1. Nouvelles fonctionnalités
La version actuelle apporte les améliorations suivantes :
-
Auparavant, le contrôleur Argo CD
ApplicationSetétait une fonctionnalité de prévisualisation technologique (TP). Avec cette mise à jour, il s'agit d'une fonctionnalité de disponibilité générale (GA). GITOPS-1958 -
Avec cette mise à jour, les dernières versions de Red Hat OpenShift GitOps sont disponibles sur
latestet sur les canaux basés sur les versions. Pour obtenir ces mises à jour, mettez à jour le paramètrechanneldans le fichier YAML de l'objetSubscription: changez sa valeur destableàlatestou à un canal basé sur la version tel quegitops-1.6. GITOPS-1791 -
Avec cette mise à jour, les paramètres du champ
spec.ssoqui contrôlaient les configurations de porte-clés sont déplacés vers.spec.sso.keycloak. Les paramètres du champ.spec.dexont été ajoutés à.spec.sso.dex. Commencez à utiliser.spec.sso.providerpour activer ou désactiver Dex. Les paramètres de.spec.dexsont obsolètes et devraient être supprimés dans la version 1.9, de même que les champsDISABLE_DEXet.spec.ssopour la configuration du keycloak. GITOPS-1983 -
Avec cette mise à jour, le contrôleur de notifications Argo CD est disponible en tant que charge de travail optionnelle qui peut être activée ou désactivée en utilisant le paramètre
.spec.notifications.enableddans la ressource personnalisée Argo CD. Le contrôleur de notifications Argo CD est disponible en tant que fonctionnalité d'aperçu technique. GITOPS-1917
Le contrôleur Argo CD Notifications est une fonctionnalité d'aperçu technologique uniquement. Les fonctionnalités de l'aperçu technologique ne sont pas prises en charge par les accords de niveau de service (SLA) de production de Red Hat et peuvent ne pas être complètes sur le plan fonctionnel. Red Hat ne recommande pas leur utilisation en production. Ces fonctionnalités offrent un accès anticipé aux fonctionnalités des produits à venir, ce qui permet aux clients de tester les fonctionnalités et de fournir un retour d'information pendant le processus de développement.
Pour plus d'informations sur la portée de l'assistance des fonctionnalités de l'aperçu technologique de Red Hat, voir Portée de l'assistance des fonctionnalités de l'aperçu technologique.
- Avec cette mise à jour, les exclusions de ressources pour les exécutions du pipeline Tekton et les exécutions de tâches sont ajoutées par défaut. Argo CD élague ces ressources par défaut. Ces exclusions de ressources sont ajoutées aux nouvelles instances Argo CD qui sont créées à partir de OpenShift Container Platform. Si les instances sont créées à partir de la CLI, les ressources ne sont pas ajoutées. GITOPS-1876
-
Avec cette mise à jour, vous pouvez sélectionner la méthode de suivi utilisée par Argo CD en définissant le paramètre
resourceTrackingMethoddans la spécification de l'opérande. GITOPS-1862 -
Avec cette mise à jour, vous pouvez ajouter des entrées au configMap
argocd-cmen utilisant le champextraConfigde la ressource personnalisée Red Hat OpenShift GitOps Argo CD. Les entrées spécifiées sont rapprochées de la carte de configurationconfig-cmsans validations. GITOPS-1964 - Avec cette mise à jour, sur OpenShift Container Platform 4.11, la page Red Hat OpenShift GitOps Environments dans la perspective Developer montre l'historique des déploiements réussis des environnements d'application, ainsi que des liens vers la révision pour chaque déploiement. GITOPS-1269
- Avec cette mise à jour, vous pouvez gérer des ressources avec Argo CD qui sont également utilisées comme ressources modèles ou "source" par un opérateur. GITOPS-982
- Avec cette mise à jour, l'opérateur configurera désormais les charges de travail Argo CD avec les permissions correctes pour satisfaire l'admission de sécurité des pods qui a été activée pour Kubernetes 1.24. GITOPS-2026
- Avec cette mise à jour, les plugins de gestion de la configuration 2.0 sont pris en charge. Vous pouvez utiliser la ressource personnalisée Argo CD pour spécifier des conteneurs de barre latérale pour le serveur repo. GITOPS-776
- Avec cette mise à jour, toutes les communications entre les composants du CD Argo et le cache Redis sont correctement sécurisées en utilisant un cryptage TLS moderne. GITOPS-720
- Cette version de Red Hat OpenShift GitOps ajoute la prise en charge d'IBM Z et IBM Power sur OpenShift Container Platform 4.10. Actuellement, les installations dans des environnements restreints ne sont pas prises en charge sur IBM Z et IBM Power.
4.1.12.2. Problèmes corrigés
Les problèmes suivants ont été résolus dans la version actuelle :
-
Avant cette mise à jour, le site
system:serviceaccount:argocd:gitops-argocd-application-controllerne pouvait pas créer la ressource "prometheusrules" dans le groupe d'APImonitoring.coreos.comdans l'espace de nomswebapps-dev. Cette mise à jour corrige ce problème et Red Hat OpenShift GitOps est maintenant capable de gérer toutes les ressources du groupe d'APImonitoring.coreos.com. GITOPS-1638 -
Avant cette mise à jour, lors de la réconciliation des permissions des clusters, si un secret appartenait à une instance de configuration de cluster, il était supprimé. Cette mise à jour corrige ce problème. Maintenant, le champ
namespacesdu secret est supprimé au lieu du secret. GITOPS-1777 -
Avant cette mise à jour, si vous installiez la variante HA d'Argo CD par l'intermédiaire de l'opérateur, ce dernier créait l'objet Redis
StatefulSetavec les règlespodAffinityau lieu des règlespodAntiAffinity. Cette mise à jour corrige ce problème et l'Opérateur crée maintenant l'objet RedisStatefulSetavec les règlespodAntiAffinity. GITOPS-1645 -
Avant cette mise à jour, Argo CD ApplicationSet avait trop de processus
sshZombie. Cette mise à jour corrige ce problème : elle ajoute tini, un simple daemon init qui crée des processus et récolte des zombies, au contrôleur ApplicationSet. Cela garantit que le signalSIGTERMest correctement transmis au processus en cours d'exécution, l'empêchant ainsi d'être un processus zombie. GITOPS-2108
4.1.12.3. Problèmes connus
Red Hat OpenShift GitOps Operator peut utiliser RHSSO (KeyCloak) via OIDC en plus de Dex. Cependant, avec l'application d'un correctif de sécurité récent, le certificat de RHSSO ne peut pas être validé dans certains scénarios. GITOPS-2214
En guise de solution de contournement, désactivez la validation TLS pour le point de terminaison OIDC (Keycloak/RHSSO) dans la spécification ArgoCD.
spec:
extraConfig:
oidc.tls.insecure.skip.verify: "true"
...4.1.13. Notes de version pour Red Hat OpenShift GitOps 1.5.9
Red Hat OpenShift GitOps 1.5.9 est maintenant disponible sur OpenShift Container Platform 4.8, 4.9, 4.10, et 4.11.
4.1.13.1. Problèmes corrigés
- Avant cette mise à jour, toutes les versions d'Argo CD v1.8.2 et ultérieures étaient vulnérables à un bogue d'autorisation inapproprié. En conséquence, Argo CD acceptait des jetons pour des utilisateurs qui n'étaient peut-être pas autorisés à accéder au cluster. Ce problème est maintenant corrigé. CVE-2023-22482
4.1.14. Notes de version pour Red Hat OpenShift GitOps 1.5.7
Red Hat OpenShift GitOps 1.5.7 est maintenant disponible sur OpenShift Container Platform 4.8, 4.9, 4.10, et 4.11.
4.1.14.1. Problèmes corrigés
Les problèmes suivants ont été résolus dans la version actuelle :
- Depuis OpenShift Container Platform 4.12, l'installation de la console est optionnelle. Ce correctif met à jour le Red Hat OpenShift GitOps Operator pour éviter les erreurs avec l'Operator si la console n'est pas installée. GITOPS-2353
4.1.15. Notes de version pour Red Hat OpenShift GitOps 1.5.6
Red Hat OpenShift GitOps 1.5.6 est maintenant disponible sur OpenShift Container Platform 4.8, 4.9, 4.10, et 4.11.
4.1.15.1. Problèmes corrigés
Les problèmes suivants ont été résolus dans la version actuelle :
-
Avant cette mise à jour, dans un grand nombre d'applications, les contrôleurs d'application étaient redémarrés plusieurs fois en raison de l'absence de réponse des sondes de réactivité. Cette mise à jour corrige le problème en supprimant la sonde de réactivité dans l'objet
StatefulSetdu contrôleur d'application. GITOPS-2153 Avant cette mise à jour, le certificat RHSSO ne pouvait pas être validé lorsqu'il était configuré avec un certificat qui n'était pas signé par les autorités de certification. Cette mise à jour corrige le problème et vous pouvez désormais fournir un certificat personnalisé qui sera utilisé pour vérifier le certificat TLS du Keycloak lors de la communication avec celui-ci. Vous pouvez ajouter le site
rootCAau champ de la ressource personnalisée Argo CD.spec.keycloak.rootCA. L'opérateur réconcilie ce changement et met à jour le champoidc.configdans le champargocd-cmConfigMapavec le certificat racine codé en PEM. GITOPS-2214NoteRedémarrez le serveur Argo CD après avoir mis à jour le champ
.spec.keycloak.rootCA.Par exemple :
apiVersion: argoproj.io/v1alpha1 kind: ArgoCD metadata: name: example-argocd labels: example: basic spec: sso: provider: keycloak keycloak: rootCA: | ---- BEGIN CERTIFICATE ---- This is a dummy certificate Please place this section with appropriate rootCA ---- END CERTIFICATE ---- server: route: enabled: true- Avant cette mise à jour, un espace de noms de terminaison géré par Argo CD bloquait la création de rôles et d'autres configurations d'autres espaces de noms gérés. Cette mise à jour corrige ce problème. GITOPS-2278
-
Avant cette mise à jour, les pods Dex ne démarraient pas avec
CreateContainerConfigErrorlorsqu'un SCC deanyuidétait attribué à la ressource DexServiceAccount. Cette mise à jour corrige ce problème en assignant un identifiant utilisateur par défaut au conteneur Dex. GITOPS-2235
4.1.16. Notes de version pour Red Hat OpenShift GitOps 1.5.5
Red Hat OpenShift GitOps 1.5.5 est maintenant disponible sur OpenShift Container Platform 4.8, 4.9, 4.10, et 4.11.
4.1.16.1. Nouvelles fonctionnalités
La version actuelle apporte les améliorations suivantes :
- Avec cette mise à jour, le CD Argo fourni a été mis à jour à la version 2.3.7.
4.1.16.2. Problèmes corrigés
Les problèmes suivants ont été résolus dans la version actuelle :
-
Avant cette mise à jour, les pods
redis-ha-haproxyd'une instance ArgoCD échouaient lorsque des SCC plus restrictifs étaient présents dans le cluster. Cette mise à jour corrige le problème en mettant à jour le contexte de sécurité dans les charges de travail. GITOPS-2034
4.1.16.3. Problèmes connus
Red Hat OpenShift GitOps Operator peut utiliser RHSSO (KeyCloak) avec OIDC et Dex. Cependant, avec l'application d'un correctif de sécurité récent, l'opérateur ne peut pas valider le certificat RHSSO dans certains scénarios. GITOPS-2214
En guise de solution de contournement, désactivez la validation TLS pour le point de terminaison OIDC (Keycloak/RHSSO) dans la spécification ArgoCD.
apiVersion: argoproj.io/v1alpha1 kind: ArgoCD metadata: name: example-argocd spec: extraConfig: "admin.enabled": "true" ...
4.1.17. Notes de version pour Red Hat OpenShift GitOps 1.5.4
Red Hat OpenShift GitOps 1.5.4 est maintenant disponible sur OpenShift Container Platform 4.8, 4.9, 4.10, et 4.11.
4.1.17.1. Problèmes corrigés
Les problèmes suivants ont été résolus dans la version actuelle :
-
Avant cette mise à jour, Red Hat OpenShift GitOps utilisait une ancienne version de la balise d'image REDIS 5. Cette mise à jour corrige le problème et met à jour la balise d'image
rhel8/redis-5. GITOPS-2037
4.1.18. Notes de version pour Red Hat OpenShift GitOps 1.5.3
Red Hat OpenShift GitOps 1.5.3 est maintenant disponible sur OpenShift Container Platform 4.8, 4.9, 4.10, et 4.11.
4.1.18.1. Problèmes corrigés
Les problèmes suivants ont été résolus dans la version actuelle :
- Avant cette mise à jour, toutes les versions non corrigées d'Argo CD v1.0.0 et ultérieures étaient vulnérables à un bogue de script intersite. En conséquence, un utilisateur non autorisé pouvait injecter un lien javascript dans l'interface utilisateur. Ce problème est maintenant corrigé. CVE-2022-31035
- Avant cette mise à jour, toutes les versions d'Argo CD v0.11.0 et ultérieures étaient vulnérables à de multiples attaques lorsque la connexion SSO était initiée à partir du CLI d'Argo CD ou de l'interface utilisateur. Ce problème est maintenant corrigé. CVE-2022-31034
- Avant cette mise à jour, toutes les versions non corrigées d'Argo CD v0.7 et ultérieures étaient vulnérables à un bogue de consommation de mémoire. En conséquence, un utilisateur non autorisé pouvait planter le serveur de dépôt d'Argo CD. Ce problème est maintenant corrigé. CVE-2022-31016
- Avant cette mise à jour, toutes les versions non corrigées d'Argo CD v1.3.0 et ultérieures étaient vulnérables à un bogue de suivi de lien symbolique. En conséquence, un utilisateur non autorisé ayant un accès en écriture au référentiel pouvait faire fuir des fichiers YAML sensibles du serveur de référentiel d'Argo CD. Ce problème est maintenant corrigé. CVE-2022-31036
4.1.19. Notes de version pour Red Hat OpenShift GitOps 1.5.2
Red Hat OpenShift GitOps 1.5.2 est maintenant disponible sur OpenShift Container Platform 4.8, 4.9, 4.10, et 4.11.
4.1.19.1. Problèmes corrigés
Les problèmes suivants ont été résolus dans la version actuelle :
-
Avant cette mise à jour, les images référencées par le site
redhat-operator-indexétaient manquantes. Ce problème est maintenant corrigé. GITOPS-2036
4.1.20. Notes de version pour Red Hat OpenShift GitOps 1.5.1
Red Hat OpenShift GitOps 1.5.1 est maintenant disponible sur OpenShift Container Platform 4.8, 4.9, 4.10, et 4.11.
4.1.20.1. Problèmes corrigés
Les problèmes suivants ont été résolus dans la version actuelle :
- Avant cette mise à jour, si l'accès anonyme à Argo CD était activé, un utilisateur non authentifié pouvait créer un jeton JWT et obtenir un accès complet à l'instance d'Argo CD. Ce problème est maintenant corrigé. CVE-2022-29165
- Avant cette mise à jour, un utilisateur non authentifié pouvait afficher des messages d'erreur sur l'écran de connexion lorsque le SSO était activé. Ce problème est maintenant corrigé. CVE-2022-24905
- Avant cette mise à jour, toutes les versions non corrigées d'Argo CD v0.7.0 et ultérieures étaient vulnérables à un bogue de suivi de lien symbolique. En conséquence, un utilisateur non autorisé ayant un accès en écriture au référentiel pouvait faire fuir des fichiers sensibles depuis le serveur de référentiel d'Argo CD. Ce problème est maintenant corrigé. CVE-2022-24904
4.1.21. Notes de version pour Red Hat OpenShift GitOps 1.5.0
Red Hat OpenShift GitOps 1.5.0 est maintenant disponible sur OpenShift Container Platform 4.8, 4.9, 4.10, et 4.11.
4.1.21.1. Nouvelles fonctionnalités
La version actuelle apporte les améliorations suivantes :
- Cette amélioration met à jour Argo CD vers la version 2.3.3. GITOPS-1708
- Cette amélioration met à jour Dex vers la version 2.30.3. GITOPS-1850
- Cette amélioration met à jour Helm vers la version 3.8.0. GITOPS-1709
- Cette amélioration met à jour Kustomize vers la version 4.4.1. GITOPS-1710
- Cette amélioration permet de passer à la version 0.4.1 de l'Application Set.
- Avec cette mise à jour, un nouveau canal du nom de latest a été ajouté qui fournit la dernière version de Red Hat OpenShift GitOps. Pour GitOps v1.5.0, l'Opérateur est poussé vers gitops-1.5, le canal latest et le canal existant stable. A partir de GitOps v1.6, toutes les dernières versions seront poussées uniquement sur le canal latest et non plus sur le canal stable. GITOPS-1791
-
Avec cette mise à jour, le nouveau CSV ajoute l'annotation
olm.skipRange: '>=1.0.0 <1.5.0'. Par conséquent, toutes les versions précédentes seront ignorées. L'opérateur passe directement à la version 1.5.0. GITOPS-1787 Avec cette mise à jour, l'opérateur met à jour Red Hat Single Sign-On (RH-SSO) vers la version v7.5.1 incluant les améliorations suivantes :
-
Vous pouvez vous connecter à Argo CD en utilisant les identifiants OpenShift, y compris l'identifiant
kube:admin. - Le RH-SSO prend en charge et configure les instances Argo CD pour le contrôle d'accès basé sur les rôles (RBAC) à l'aide des groupes OpenShift.
Le RH-SSO respecte les variables d'environnement
HTTP_Proxy. Vous pouvez utiliser RH-SSO comme SSO pour Argo CD fonctionnant derrière un proxy.
-
Vous pouvez vous connecter à Argo CD en utilisant les identifiants OpenShift, y compris l'identifiant
Avec cette mise à jour, un nouveau champ URL
.hostest ajouté au champ.statusde l'opérande Argo CD. Lorsqu'une route ou une entrée est activée avec la priorité donnée à la route, le nouveau champ URL affiche la route. Si aucune URL n'est fournie par la route ou l'entrée, le champ.hostn'est pas affiché.Lorsque la route ou l'entrée est configurée, mais que le contrôleur correspondant n'est pas configuré correctement et n'est pas dans l'état
Readyou ne propage pas son URL, la valeur du champ.status.hostdans l'opérande indiquePendingau lieu d'afficher l'URL. Cela affecte l'état général de l'opérande en le rendantPendingau lieu deAvailable. GITOPS-654
4.1.21.2. Problèmes corrigés
Les problèmes suivants ont été résolus dans la version actuelle :
- Avant cette mise à jour, les règles RBAC spécifiques à AppProjects n'autorisaient pas l'utilisation de virgules dans le champ sujet du rôle, ce qui empêchait les liaisons avec le compte LDAP. Cette mise à jour corrige le problème et vous pouvez maintenant spécifier des liaisons de rôles complexes dans les règles RBAC spécifiques à AppProject. GITOPS-1771
-
Avant cette mise à jour, lorsqu'une ressource
DeploymentConfigest mise à l'échelle à0, Argo CD l'affichait dans un état progressing avec un message d'état de santé à "replication controller is waiting for pods to run". Cette mise à jour corrige le cas particulier et la vérification de l'état de santé indique maintenant l'état de santé correct de la ressourceDeploymentConfig. GITOPS-1738 -
Avant cette mise à jour, le certificat TLS dans la carte de configuration
argocd-tls-certs-cmétait supprimé par Red Hat OpenShift GitOps à moins que le certificat n'ait été configuré dans le champArgoCDCR specificationtls.initialCerts. Ce problème est maintenant corrigé. GITOPS-1725 -
Avant cette mise à jour, lors de la création d'un espace de noms avec le label
managed-by, de nombreuses ressourcesRoleBindingétaient créées sur le nouvel espace de noms. Cette mise à jour corrige le problème et maintenant Red Hat OpenShift GitOps supprime les ressourcesRoleetRoleBindingnon pertinentes créées par les versions précédentes. GITOPS-1550 -
Avant cette mise à jour, le certificat TLS de la route en mode pass-through n'avait pas de nom d'autorité de certification. Par conséquent, Firefox 94 et les versions ultérieures ne parvenaient pas à se connecter à l'interface utilisateur d'Argo CD avec le code d'erreur SEC_ERROR_BAD_DER. Cette mise à jour corrige le problème. Vous devez supprimer les secrets
<openshift-gitops-ca>et les laisser se recréer. Ensuite, vous devez supprimer les secrets<openshift-gitops-tls>. Après que Red Hat OpenShift GitOps l'ait recréé, l'interface utilisateur Argo CD est à nouveau accessible par Firefox. GITOPS-1548
4.1.21.3. Problèmes connus
-
Le champ Argo CD
.status.hostn'est pas mis à jour lorsqu'une ressourceIngressest utilisée à la place d'une ressourceRoutesur les clusters OpenShift. GITOPS-1920
4.1.22. Notes de version pour Red Hat OpenShift GitOps 1.4.13
Red Hat OpenShift GitOps 1.4.13 est maintenant disponible sur OpenShift Container Platform 4.7, 4.8, 4.9, et 4.10.
4.1.22.1. Problèmes corrigés
Les problèmes suivants ont été résolus dans la version actuelle :
- Depuis OpenShift Container Platform 4.12, l'installation de la console est optionnelle. Ce correctif met à jour le Red Hat OpenShift GitOps Operator afin d'éviter les erreurs avec l'Operator si la console n'est pas installée. GITOPS-2354
4.1.23. Notes de version pour Red Hat OpenShift GitOps 1.4.12
Red Hat OpenShift GitOps 1.4.12 est maintenant disponible sur OpenShift Container Platform 4.7, 4.8, 4.9, et 4.10.
4.1.23.1. Problèmes corrigés
Les problèmes suivants ont été résolus dans la version actuelle :
-
Avant cette mise à jour, dans un grand nombre d'applications, les contrôleurs d'application étaient redémarrés plusieurs fois en raison de l'absence de réponse des sondes de réactivité. Cette mise à jour corrige le problème en supprimant la sonde de réactivité dans l'objet
StatefulSetdu contrôleur d'application. GITOPS-2153 Avant cette mise à jour, le certificat RHSSO ne pouvait pas être validé lorsqu'il était configuré avec un certificat qui n'était pas signé par les autorités de certification. Cette mise à jour corrige le problème et vous pouvez désormais fournir un certificat personnalisé qui sera utilisé pour vérifier le certificat TLS du Keycloak lors de la communication avec celui-ci. Vous pouvez ajouter le site
rootCAau champ de la ressource personnalisée Argo CD.spec.keycloak.rootCA. L'opérateur réconcilie ce changement et met à jour le champoidc.configdans le champargocd-cmConfigMapavec le certificat racine codé en PEM. GITOPS-2214NoteRedémarrez le serveur Argo CD après avoir mis à jour le champ
.spec.keycloak.rootCA.Par exemple :
apiVersion: argoproj.io/v1alpha1 kind: ArgoCD metadata: name: example-argocd labels: example: basic spec: sso: provider: keycloak keycloak: rootCA: | ---- BEGIN CERTIFICATE ---- This is a dummy certificate Please place this section with appropriate rootCA ---- END CERTIFICATE ---- server: route: enabled: true- Avant cette mise à jour, un espace de noms de terminaison géré par Argo CD bloquait la création de rôles et d'autres configurations d'autres espaces de noms gérés. Cette mise à jour corrige ce problème. GITOPS-2276
-
Avant cette mise à jour, les pods Dex ne démarraient pas avec
CreateContainerConfigErrorlorsqu'un SCC deanyuidétait attribué à la ressource DexServiceAccount. Cette mise à jour corrige ce problème en assignant un identifiant utilisateur par défaut au conteneur Dex. GITOPS-2235
4.1.24. Notes de version pour Red Hat OpenShift GitOps 1.4.11
Red Hat OpenShift GitOps 1.4.11 est maintenant disponible sur OpenShift Container Platform 4.7, 4.8, 4.9, et 4.10.
4.1.24.1. Nouvelles fonctionnalités
La version actuelle apporte les améliorations suivantes :
- Avec cette mise à jour, le CD Argo fourni a été mis à jour à la version 2.2.12.
4.1.24.2. Problèmes corrigés
Les problèmes suivants ont été résolus dans la version actuelle :
-
Avant cette mise à jour, les pods
redis-ha-haproxyd'une instance ArgoCD échouaient lorsque des SCC plus restrictifs étaient présents dans le cluster. Cette mise à jour corrige le problème en mettant à jour le contexte de sécurité dans les charges de travail. GITOPS-2034
4.1.24.3. Problèmes connus
Red Hat OpenShift GitOps Operator peut utiliser RHSSO (KeyCloak) avec OIDC et Dex. Cependant, avec l'application d'un correctif de sécurité récent, l'opérateur ne peut pas valider le certificat RHSSO dans certains scénarios. GITOPS-2214
En guise de solution de contournement, désactivez la validation TLS pour le point de terminaison OIDC (Keycloak/RHSSO) dans la spécification ArgoCD.
apiVersion: argoproj.io/v1alpha1 kind: ArgoCD metadata: name: example-argocd spec: extraConfig: "admin.enabled": "true" ...
4.1.25. Notes de version pour Red Hat OpenShift GitOps 1.4.6
Red Hat OpenShift GitOps 1.4.6 est maintenant disponible sur OpenShift Container Platform 4.7, 4.8, 4.9, et 4.10.
4.1.25.1. Problèmes corrigés
Le problème suivant a été résolu dans la version actuelle :
- Les images de base sont mises à jour vers la dernière version afin d'éviter le lien avec la faille OpenSSL : (CVE-2022-0778).
Pour installer la version actuelle de Red Hat OpenShift GitOps 1.4 et recevoir d'autres mises à jour tout au long du cycle de vie du produit, rendez-vous sur le canal GitOps-1.4.
4.1.26. Notes de version pour Red Hat OpenShift GitOps 1.4.5
Red Hat OpenShift GitOps 1.4.5 est maintenant disponible sur OpenShift Container Platform 4.7, 4.8, 4.9, et 4.10.
4.1.26.1. Problèmes corrigés
Vous devriez mettre à niveau directement vers Red Hat OpenShift GitOps v1.4.5 à partir de Red Hat OpenShift GitOps v1.4.3. N'utilisez pas Red Hat OpenShift GitOps v1.4.4 dans un environnement de production. Les problèmes majeurs qui affectaient Red Hat OpenShift GitOps v1.4.4 sont corrigés dans Red Hat OpenShift GitOps 1.4.5.
Le problème suivant a été résolu dans la version actuelle :
-
Avant cette mise à jour, les pods Argo CD étaient bloqués à l'état
ErrImagePullBackOff. Le message d'erreur suivant s'affichait :
reason: ErrImagePull
message: >-
rpc error: code = Unknown desc = reading manifest
sha256:ff4ad30752cf0d321cd6c2c6fd4490b716607ea2960558347440f2f370a586a8
in registry.redhat.io/openshift-gitops-1/argocd-rhel8: StatusCode:
404, <HTML><HEAD><TITLE>Error</TITLE></HEAD><BODY>Ce problème est maintenant corrigé. GITOPS-1848
4.1.27. Notes de version pour Red Hat OpenShift GitOps 1.4.3
Red Hat OpenShift GitOps 1.4.3 est maintenant disponible sur OpenShift Container Platform 4.7, 4.8, 4.9, et 4.10.
4.1.27.1. Problèmes corrigés
Le problème suivant a été résolu dans la version actuelle :
-
Avant cette mise à jour, le certificat TLS dans la carte de configuration
argocd-tls-certs-cmétait supprimé par Red Hat OpenShift GitOps à moins que le certificat n'ait été configuré dans le champtls.initialCertsde la spécification ArgoCD CR. Cette mise à jour corrige ce problème. GITOPS-1725
4.1.28. Notes de version pour Red Hat OpenShift GitOps 1.4.2
Red Hat OpenShift GitOps 1.4.2 est maintenant disponible sur OpenShift Container Platform 4.7, 4.8, 4.9, et 4.10.
4.1.28.1. Problèmes corrigés
Le problème suivant a été résolu dans la version actuelle :
-
Avant cette mise à jour, les ressources Route restaient bloquées dans l'état de santé
Progressingsi plusieursIngressétaient attachés à la route. Cette mise à jour corrige la vérification de l'état de santé et signale l'état de santé correct des ressources Route. GITOPS-1751
4.1.29. Notes de version pour Red Hat OpenShift GitOps 1.4.1
Red Hat OpenShift GitOps 1.4.1 est maintenant disponible sur OpenShift Container Platform 4.7, 4.8, 4.9, et 4.10.
4.1.29.1. Problèmes corrigés
Le problème suivant a été résolu dans la version actuelle :
Red Hat OpenShift GitOps Operator v1.4.0 a introduit une régression qui supprime les champs de description de
specpour les CRD suivants :-
argoproj.io_applications.yaml -
argoproj.io_appprojects.yaml argoproj.io_argocds.yamlAvant cette mise à jour, lorsque vous créiez une ressource
AppProjectà l'aide de la commandeoc create, la synchronisation de la ressource échouait en raison de l'absence de champs de description. Cette mise à jour rétablit les champs de description manquants dans les CRDs précédents. GITOPS-1721
-
4.1.30. Notes de version pour Red Hat OpenShift GitOps 1.4.0
Red Hat OpenShift GitOps 1.4.0 est maintenant disponible sur OpenShift Container Platform 4.7, 4.8, 4.9, et 4.10.
4.1.30.1. Nouvelles fonctionnalités
La version actuelle apporte les améliorations suivantes.
-
Cette amélioration met à jour le Red Hat OpenShift GitOps Application Manager CLI (
kam) vers la version 0.0.41. GITOPS-1669 - Cette amélioration permet de mettre à niveau Argo CD vers la version 2.2.2. GITOPS-1532
- Cette amélioration met à jour Helm vers la version 3.7.1. GITOPS-1530
-
Cette amélioration ajoute l'état de santé des éléments
DeploymentConfig,Route, etOLM Operatorau tableau de bord Argo CD et à la console web OpenShift Container Platform. Ces informations vous aident à surveiller l'état de santé général de votre application. GITOPS-655, GITOPS-915, GITOPS-916, GITOPS-1110 -
Avec cette mise à jour, vous pouvez spécifier le nombre de répliques souhaitées pour les composants
argocd-serveretargocd-repo-serveren définissant les attributs.spec.server.replicaset.spec.repo.replicasdans la ressource personnalisée Argo CD, respectivement. Si vous configurez le pod autoscaler horizontal (HPA) pour les composantsargocd-server, il est prioritaire sur les attributs de la ressource personnalisée Argo CD. GITOPS-1245 En tant qu'utilisateur administratif, lorsque vous donnez à Argo CD l'accès à un espace de noms en utilisant l'étiquette
argocd.argoproj.io/managed-by, il assume les privilèges d'administrateur d'espace de noms. Ces privilèges posent un problème aux administrateurs qui fournissent des espaces de noms à des non-administrateurs, tels que des équipes de développement, car ils permettent à ces derniers de modifier des objets tels que les stratégies de réseau.Avec cette mise à jour, les administrateurs peuvent configurer un rôle de cluster commun pour tous les espaces de noms gérés. Dans les liaisons de rôles pour le contrôleur d'application Argo CD, l'opérateur fait référence à la variable d'environnement
CONTROLLER_CLUSTER_ROLE. Dans les liaisons de rôles pour le serveur Argo CD, l'opérateur se réfère à la variable d'environnementSERVER_CLUSTER_ROLE. Si ces variables d'environnement contiennent des rôles personnalisés, l'opérateur ne crée pas le rôle d'administrateur par défaut. Au lieu de cela, il utilise le rôle personnalisé existant pour tous les espaces de noms gérés. GITOPS-1290-
Avec cette mise à jour, la page Environments dans la perspective OpenShift Container Platform Developer affiche une icône de cœur brisé pour indiquer les ressources dégradées, à l'exception de celles dont le statut est
Progressing,Missing, etUnknown. La console affiche une icône jaune pour indiquer les ressources désynchronisées. GITOPS-1307
4.1.30.2. Problèmes corrigés
Les problèmes suivants ont été résolus dans la version actuelle :
-
Avant cette mise à jour, lorsque la route vers le CLI de Red Hat OpenShift GitOps Application Manager (
kam) était accessible sans spécifier de chemin d'accès dans l'URL, une page par défaut sans aucune information utile était affichée à l'utilisateur. Cette mise à jour corrige le problème afin que la page par défaut affiche des liens de téléchargement pour le CLIkam. GITOPS-923 - Avant cette mise à jour, la définition d'un quota de ressources dans l'espace de noms de la ressource personnalisée Argo CD pouvait entraîner l'échec de la configuration de l'instance Red Hat SSO (RH SSO). Cette mise à jour corrige ce problème en définissant une demande minimale de ressources pour les pods de déploiement RH SSO. GITOPS-1297
-
Avant cette mise à jour, si vous changiez le niveau de journal pour la charge de travail
argocd-repo-server, l'opérateur ne rapprochait pas ce paramètre. La solution consistait à supprimer la ressource de déploiement afin que l'opérateur la recrée avec le nouveau niveau de journalisation. Avec cette mise à jour, le niveau de journal est correctement réconcilié pour les charges de travailargocd-repo-serverexistantes. GITOPS-1387 -
Avant cette mise à jour, si l'opérateur gérait une instance Argo CD dans laquelle il manquait le champ
.datadans le secretargocd-secret, l'opérateur de cette instance se plantait. Cette mise à jour corrige le problème de sorte que l'opérateur ne se bloque pas lorsque le champ.dataest manquant. Au lieu de cela, le secret se régénère et la ressourcegitops-operator-controller-managerest redéployée. GITOPS-1402 -
Avant cette mise à jour, le service
gitopsserviceétait annoté comme un objet interne. Cette mise à jour supprime l'annotation afin que vous puissiez mettre à jour ou supprimer l'instance Argo CD par défaut et exécuter les charges de travail GitOps sur les nœuds d'infrastructure en utilisant l'interface utilisateur. GITOPS-1429
4.1.30.3. Problèmes connus
Voici les problèmes connus dans la version actuelle :
Si vous migrez du fournisseur d'authentification Dex vers le fournisseur Keycloak, il se peut que vous rencontriez des problèmes de connexion avec Keycloak.
Pour éviter ce problème, lors de la migration, désinstallez Dex en supprimant la section
.spec.dexde la ressource personnalisée du CD Argo. Laissez quelques minutes à Dex pour se désinstaller complètement. Ensuite, installez Keycloak en ajoutant.spec.sso.provider: keycloakà la ressource personnalisée du CD Argo.En guise de solution, désinstallez Keycloak en supprimant
.spec.sso.provider: keycloak. Réinstallez-le ensuite. GITOPS-1450, GITOPS-1331
4.1.31. Notes de version pour Red Hat OpenShift GitOps 1.3.7
Red Hat OpenShift GitOps 1.3.7 est maintenant disponible sur OpenShift Container Platform 4.7, 4.8, 4.9, et 4.6 avec un support GA limité.
4.1.31.1. Problèmes corrigés
Le problème suivant a été résolu dans la version actuelle :
- Avant cette mise à jour, une faille a été découverte dans OpenSSL. Cette mise à jour corrige le problème en mettant à jour les images de base vers la dernière version afin d'éviter la faille OpenSSL. (CVE-2022-0778).
Pour installer la version actuelle de Red Hat OpenShift GitOps 1.3 et recevoir d'autres mises à jour tout au long du cycle de vie du produit, rendez-vous sur le canal GitOps-1.3.
4.1.32. Notes de version pour Red Hat OpenShift GitOps 1.3.6
Red Hat OpenShift GitOps 1.3.6 est maintenant disponible sur OpenShift Container Platform 4.7, 4.8, 4.9, et 4.6 avec un support GA limité.
4.1.32.1. Problèmes corrigés
Les problèmes suivants ont été résolus dans la version actuelle :
- Dans Red Hat OpenShift GitOps, un contrôle d'accès incorrect permet une élévation des privilèges de l'administrateur (CVE-2022-1025). Cette mise à jour corrige le problème.
- Une faille de traversée de chemin permet la fuite de fichiers hors limites (CVE-2022-24731). Cette mise à jour corrige le problème.
- Une faille de traversée de chemin et un contrôle d'accès incorrect permettent la fuite de fichiers hors limites (CVE-2022-24730). Cette mise à jour corrige le problème.
4.1.33. Notes de version pour Red Hat OpenShift GitOps 1.3.2
Red Hat OpenShift GitOps 1.3.2 est maintenant disponible sur OpenShift Container Platform 4.7, 4.8, 4.9, et 4.6 avec un support GA limité.
4.1.33.1. Nouvelles fonctionnalités
En plus des corrections et des améliorations de stabilité, les sections suivantes soulignent les nouveautés de Red Hat OpenShift GitOps 1.3.2 :
- Mise à jour du CD Argo vers la version 2.1.8
- Mise à jour de Dex vers la version 2.30.0
4.1.33.2. Problèmes corrigés
Les problèmes suivants ont été résolus dans la version actuelle :
-
Auparavant, dans l'interface OperatorHub sous la section Infrastructure Features, lorsque vous filtrez par
Disconnected, l'Opérateur Red Hat OpenShift GitOps n'apparaissait pas dans les résultats de la recherche, car l'Opérateur n'avait pas l'annotation associée dans son fichier CSV. Avec cette mise à jour, l'annotationDisconnected Clustera été ajoutée à l'Opérateur Red Hat OpenShift GitOps en tant que fonctionnalité d'infrastructure. GITOPS-1539 Lors de l'utilisation d'une instance Argo CD
Namespace-scoped, par exemple, une instance Argo CD qui n'est pas cadrée sur All Namepsaces dans un cluster, Red Hat OpenShift GitOps maintient dynamiquement une liste d'espaces de noms gérés. Ces espaces de noms incluent l'étiquetteargocd.argoproj.io/managed-by. Cette liste d'espaces de noms est stockée dans un cache à Argo CD → Settings → Clusters → "in-cluster" → NAMESPACES. Avant cette mise à jour, si vous supprimiez l'un de ces espaces de noms, l'opérateur l'ignorait et l'espace de noms restait dans la liste. Ce comportement brisait CONNECTION STATE dans cette configuration de cluster, et toutes les tentatives de synchronisation aboutissaient à des erreurs. Par exemple :Le compte de service Argo n'a pas <random_verb> sur <random_resource_type> dans l'espace de noms <the_namespace_you_deleted>.Ce bogue est corrigé. GITOPS-1521
- Avec cette mise à jour, l'opérateur GitOps de Red Hat OpenShift a été annoté avec le niveau de capacité Deep Insights. GITOPS-1519
-
Auparavant, l'opérateur CD Argo gérait lui-même le champ
resource.exclusionmais ignorait le champresource.inclusion. Cela empêchait le champresource.inclusionconfiguré dans le CRArgo CDde se générer dans la carte de configurationargocd-cm. Ce bogue est corrigé. GITOPS-1518
4.1.34. Notes de version pour Red Hat OpenShift GitOps 1.3.1
Red Hat OpenShift GitOps 1.3.1 est maintenant disponible sur OpenShift Container Platform 4.7, 4.8, 4.9, et 4.6 avec un support GA limité.
4.1.34.1. Problèmes corrigés
- Si vous passez à la version 1.3.0, l'opérateur ne renvoie pas une tranche ordonnée de variables d'environnement. En conséquence, le réconciliateur échoue, ce qui entraîne la recréation fréquente de pods Argo CD dans les clusters OpenShift Container Platform fonctionnant derrière un proxy. Cette mise à jour corrige le problème afin que les pods Argo CD ne soient pas recréés. GITOPS-1489
4.1.35. Notes de version pour Red Hat OpenShift GitOps 1.3
Red Hat OpenShift GitOps 1.3 est maintenant disponible sur OpenShift Container Platform 4.7, 4.8, 4.9, et 4.6 avec un support GA limité.
4.1.35.1. Nouvelles fonctionnalités
En plus des corrections et des améliorations de stabilité, les sections suivantes soulignent les nouveautés de Red Hat OpenShift GitOps 1.3.0 :
-
Pour une nouvelle installation de la version 1.3.0, Dex est automatiquement configuré. Vous pouvez vous connecter à l'instance Argo CD par défaut dans l'espace de noms
openshift-gitopsen utilisant les informations d'identification OpenShift oukubeadmin. En tant qu'administrateur, vous pouvez désactiver l'installation de Dex après l'installation de l'opérateur, ce qui supprimera le déploiement de Dex de l'espace de nomsopenshift-gitops. - L'instance Argo CD par défaut installée par l'opérateur ainsi que les contrôleurs qui l'accompagnent peuvent désormais s'exécuter sur les nœuds d'infrastructure du cluster grâce à un simple basculement de configuration.
- Les communications internes dans Argo CD peuvent maintenant être sécurisées en utilisant TLS et les certificats du cluster OpenShift. Les routes d'Argo CD peuvent désormais exploiter les certificats du cluster OpenShift en plus d'utiliser des gestionnaires de certificats externes tels que le cert-manager.
- Utilisez la page Environments améliorée dans la perspective Developer de la console 4.9 pour obtenir des informations sur les environnements GitOps.
-
Vous pouvez désormais accéder aux contrôles de santé personnalisés dans Argo CD pour les ressources
DeploymentConfig, les ressourcesRouteet les opérateurs installés à l'aide d'OLM. L'Opérateur GitOps est maintenant conforme aux conventions de nommage recommandées par la dernière version de l'Operator-SDK :
-
Le préfixe
gitops-operator-est ajouté à toutes les ressources -
Le compte de service est renommé en
gitops-operator-controller-manager
-
Le préfixe
4.1.35.2. Problèmes corrigés
Les problèmes suivants ont été résolus dans la version actuelle :
- Auparavant, si vous configuriez un nouvel espace de noms à gérer par une nouvelle instance d'Argo CD, il était immédiatement Out Of Sync en raison des nouveaux rôles et liens créés par l'opérateur pour gérer ce nouvel espace de noms. Ce comportement est corrigé. GITOPS-1384
4.1.35.3. Problèmes connus
Lors de la migration du fournisseur d'authentification Dex vers le fournisseur Keycloak, il se peut que vous rencontriez des problèmes de connexion avec Keycloak. GITOPS-1450
Pour éviter ce problème, lors de la migration, désinstallez Dex en supprimant la section
.spec.dexqui se trouve dans la ressource personnalisée du CD Argo. Laissez quelques minutes à Dex pour se désinstaller complètement, puis procédez à l'installation de Keycloak en ajoutant.spec.sso.provider: keycloakà la ressource personnalisée du CD Argo.En guise de solution, désinstallez Keycloak en supprimant
.spec.sso.provider: keycloak, puis réinstallez-le.
4.1.36. Notes de version pour Red Hat OpenShift GitOps 1.2.2
Red Hat OpenShift GitOps 1.2.2 est maintenant disponible sur OpenShift Container Platform 4.8.
4.1.36.1. Problèmes corrigés
Le problème suivant a été résolu dans la version actuelle :
- Toutes les versions d'Argo CD sont vulnérables à un bogue de traversée de chemin qui permet de passer des valeurs arbitraires à consommer par les graphiques Helm. Cette mise à jour corrige l'erreur CVE-2022-24348 gitops, la traversée de chemin et le déréférencement des liens symboliques lors du passage des fichiers de valeurs Helm. GITOPS-1756
4.1.37. Notes de version pour Red Hat OpenShift GitOps 1.2.1
Red Hat OpenShift GitOps 1.2.1 est maintenant disponible sur OpenShift Container Platform 4.8.
4.1.37.1. Matrice de soutien
Certaines fonctionnalités de cette version sont actuellement en avant-première technologique. Ces fonctionnalités expérimentales ne sont pas destinées à être utilisées en production.
Aperçu de la technologie Fonctionnalités Support Champ d'application
Dans le tableau ci-dessous, les caractéristiques sont marquées par les statuts suivants :
- TP: Technology Preview
- GA: General Availability
Notez l'étendue de l'assistance suivante sur le portail client de Red Hat pour ces fonctionnalités :
| Fonctionnalité | Red Hat OpenShift GitOps 1.2.1 |
|---|---|
| CD Argo | GA |
| Argo CD ApplicationSet | TP |
|
Red Hat OpenShift GitOps Application Manager CLI ( | TP |
4.1.37.2. Problèmes corrigés
Les problèmes suivants ont été résolus dans la version actuelle :
-
Auparavant, d'énormes pics de mémoire étaient observés sur le contrôleur d'application au démarrage. L'indicateur
--kubectl-parallelism-limitpour le contrôleur d'application est maintenant fixé à 10 par défaut, mais cette valeur peut être remplacée en spécifiant un nombre pour.spec.controller.kubeParallelismLimitdans la spécification Argo CD CR. GITOPS-1255 -
Les dernières API de déclenchement ont provoqué des échecs de construction de Kubernetes en raison d'entrées dupliquées dans le kustomization.yaml lors de l'utilisation de la commande
kam bootstrap. Les composants Pipelines et Tekton triggers ont été mis à jour respectivement en v0.24.2 et v0.14.2 pour résoudre ce problème. GITOPS-1273 - Les rôles et les liens RBAC persistants sont désormais automatiquement supprimés de l'espace de noms cible lorsque l'instance Argo CD de l'espace de noms source est supprimée. GITOPS-1228
- Auparavant, lors du déploiement d'une instance d'Argo CD dans un espace de noms, l'instance d'Argo CD modifiait l'étiquette "managed-by" pour en faire son propre espace de noms. Cette correction rend les espaces de noms non étiquetés tout en s'assurant que les rôles RBAC et les liaisons nécessaires sont créés et supprimés pour l'espace de noms. GITOPS-1247
- Auparavant, les limites par défaut des demandes de ressources sur les charges de travail d'Argo CD, en particulier pour le serveur repo et le contrôleur d'application, s'avéraient très restrictives. Le quota de ressources existant a été supprimé et la limite de mémoire par défaut a été augmentée à 1024M dans le serveur repo. Veuillez noter que ce changement n'affectera que les nouvelles installations ; les charges de travail des instances Argo CD existantes ne seront pas affectées. GITOPS-1274
4.1.38. Notes de version pour Red Hat OpenShift GitOps 1.2
Red Hat OpenShift GitOps 1.2 est maintenant disponible sur OpenShift Container Platform 4.8.
4.1.38.1. Matrice de soutien
Certaines fonctionnalités de cette version sont actuellement en avant-première technologique. Ces fonctionnalités expérimentales ne sont pas destinées à être utilisées en production.
Aperçu de la technologie Fonctionnalités Support Champ d'application
Dans le tableau ci-dessous, les caractéristiques sont marquées par les statuts suivants :
- TP: Technology Preview
- GA: General Availability
Notez l'étendue de l'assistance suivante sur le portail client de Red Hat pour ces fonctionnalités :
| Fonctionnalité | Red Hat OpenShift GitOps 1.2 |
|---|---|
| CD Argo | GA |
| Argo CD ApplicationSet | TP |
|
Red Hat OpenShift GitOps Application Manager CLI ( | TP |
4.1.38.2. Nouvelles fonctionnalités
En plus des corrections et des améliorations de stabilité, les sections suivantes soulignent les nouveautés de Red Hat OpenShift GitOps 1.2 :
-
Si vous n'avez pas d'accès en lecture ou en écriture à l'espace de noms openshift-gitops, vous pouvez maintenant utiliser la variable d'environnement
DISABLE_DEFAULT_ARGOCD_INSTANCEdans l'opérateur GitOps et définir la valeurTRUEpour empêcher l'instance Argo CD par défaut de démarrer dans l'espace de nomsopenshift-gitops. -
Les demandes et les limites de ressources sont maintenant configurées dans les charges de travail Argo CD. Le quota de ressources est activé dans l'espace de noms
openshift-gitops. Par conséquent, les charges de travail hors bande déployées manuellement dans l'espace de noms openshift-gitops doivent être configurées avec des demandes et des limites de ressources et le quota de ressources peut devoir être augmenté. L'authentification Argo CD est maintenant intégrée avec Red Hat SSO et elle est automatiquement configurée avec OpenShift 4 Identity Provider sur le cluster. Cette fonctionnalité est désactivée par défaut. Pour activer Red Hat SSO, ajoutez la configuration SSO dans
ArgoCDCR comme indiqué ci-dessous. Actuellement,keycloakest le seul fournisseur pris en charge.apiVersion: argoproj.io/v1alpha1 kind: ArgoCD metadata: name: example-argocd labels: example: basic spec: sso: provider: keycloak server: route: enabled: trueVous pouvez désormais définir des noms d'hôtes à l'aide d'étiquettes d'itinéraires afin de prendre en charge la répartition des routeurs. La prise en charge de la définition d'étiquettes sur les routes
server(serveur argocd),grafanaetprometheusest désormais disponible. Pour définir des étiquettes sur une route, ajoutezlabelssous la configuration de la route pour un serveur dans le CRArgoCD.Exemple
ArgoCDCR YAML pour définir les étiquettes sur le serveur argocdapiVersion: argoproj.io/v1alpha1 kind: ArgoCD metadata: name: example-argocd labels: example: basic spec: server: route: enabled: true labels: key1: value1 key2: value2-
L'opérateur GitOps accorde désormais automatiquement des permissions aux instances Argo CD pour gérer les ressources dans les espaces de noms cibles en appliquant des étiquettes. Les utilisateurs peuvent étiqueter l'espace de noms cible avec l'étiquette
argocd.argoproj.io/managed-by: <source-namespace>, oùsource-namespaceest l'espace de noms où l'instance argocd est déployée.
4.1.38.3. Problèmes corrigés
Les problèmes suivants ont été résolus dans la version actuelle :
-
Auparavant, si un utilisateur créait des instances supplémentaires d'Argo CD gérées par l'instance de cluster par défaut dans l'espace de noms openshift-gitops, l'application responsable de la nouvelle instance d'Argo CD restait bloquée dans un état
OutOfSync. Ce problème a été résolu en ajoutant une référence au propriétaire dans le secret du cluster. GITOPS-1025
4.1.38.4. Problèmes connus
Voici les problèmes connus dans Red Hat OpenShift GitOps 1.2 :
-
Lorsqu'une instance de CD Argo est supprimée de l'espace de noms source, les étiquettes
argocd.argoproj.io/managed-bydans les espaces de noms cibles ne sont pas supprimées. GITOPS-1228 Le quota de ressources a été activé dans l'espace de noms openshift-gitops dans Red Hat OpenShift GitOps 1.2. Cela peut affecter les charges de travail hors bande déployées manuellement et les charges de travail déployées par l'instance Argo CD par défaut dans l'espace de noms
openshift-gitops. Lorsque vous mettez à niveau Red Hat OpenShift GitOpsv1.1.2versv1.2, ces charges de travail doivent être configurées avec des demandes et des limites de ressources. S'il y a des charges de travail supplémentaires, le quota de ressources dans l'espace de noms openshift-gitops doit être augmenté.Quota de ressources actuel pour l'espace de noms
openshift-gitops.Expand Resource Requests Limits UNITÉ CENTRALE
6688m
13750m
Mémoire
4544Mi
9070Mi
Vous pouvez utiliser la commande suivante pour mettre à jour les limites du processeur.
$ oc patch resourcequota openshift-gitops-compute-resources -n openshift-gitops --type='json' -p='[{"op": "replace", "path": "/spec/hard/limits.cpu", "value":"9000m"}]'Vous pouvez utiliser la commande suivante pour mettre à jour les demandes de CPU.
$ oc patch resourcequota openshift-gitops-compute-resources -n openshift-gitops --type='json' -p='[{"op": "replace", "path": "/spec/hard/cpu", "value":"7000m"}]Vous pouvez remplacer le chemin dans les commandes ci-dessus de
cpuàmemorypour mettre à jour la mémoire.
4.1.39. Notes de version pour Red Hat OpenShift GitOps 1.1
Red Hat OpenShift GitOps 1.1 est maintenant disponible sur OpenShift Container Platform 4.7.
4.1.39.1. Matrice de soutien
Certaines fonctionnalités de cette version sont actuellement en avant-première technologique. Ces fonctionnalités expérimentales ne sont pas destinées à être utilisées en production.
Aperçu de la technologie Fonctionnalités Support Champ d'application
Dans le tableau ci-dessous, les caractéristiques sont marquées par les statuts suivants :
- TP: Technology Preview
- GA: General Availability
Notez l'étendue de l'assistance suivante sur le portail client de Red Hat pour ces fonctionnalités :
| Fonctionnalité | Red Hat OpenShift GitOps 1.1 |
|---|---|
| CD Argo | GA |
| Argo CD ApplicationSet | TP |
|
Red Hat OpenShift GitOps Application Manager CLI ( | TP |
4.1.39.2. Nouvelles fonctionnalités
En plus des corrections et des améliorations de stabilité, les sections suivantes soulignent les nouveautés de Red Hat OpenShift GitOps 1.1 :
-
La fonctionnalité
ApplicationSetest maintenant ajoutée (Technology Preview). La fonctionnalitéApplicationSetpermet à la fois l'automatisation et une plus grande flexibilité lors de la gestion des applications Argo CD sur un grand nombre de clusters et au sein de monorepos. Elle rend également possible l'utilisation en libre-service sur les clusters Kubernetes multitenant. - Argo CD est désormais intégré à la pile de journalisation des clusters et aux fonctions de surveillance et d'alerte d'OpenShift Container Platform.
- Argo CD auth est désormais intégré à OpenShift Container Platform.
- Le contrôleur d'applications Argo CD prend désormais en charge la mise à l'échelle horizontale.
- Les serveurs Argo CD Redis prennent désormais en charge la haute disponibilité (HA).
4.1.39.3. Problèmes corrigés
Les problèmes suivants ont été résolus dans la version actuelle :
- Auparavant, Red Hat OpenShift GitOps ne fonctionnait pas comme prévu dans une configuration de serveur proxy avec des paramètres de proxy global actifs. Ce problème est corrigé et maintenant Argo CD est configuré par l'opérateur Red Hat OpenShift GitOps en utilisant des noms de domaine entièrement qualifiés (FQDN) pour les pods afin de permettre la communication entre les composants. GITOPS-703
-
Le backend Red Hat OpenShift GitOps s'appuie sur le paramètre de requête
?ref=dans l'URL Red Hat OpenShift GitOps pour effectuer des appels API. Auparavant, ce paramètre n'était pas lu à partir de l'URL, ce qui faisait que le backend considérait toujours la référence par défaut. Ce problème est corrigé et le backend Red Hat OpenShift GitOps extrait désormais le paramètre de requête de référence de l'URL Red Hat OpenShift GitOps et utilise uniquement la référence par défaut lorsqu'il n'y a pas de référence d'entrée fournie. GITOPS-817 -
Auparavant, le backend Red Hat OpenShift GitOps ne parvenait pas à trouver le dépôt GitLab valide. Ceci était dû au fait que le backend Red Hat OpenShift GitOps recherchait
maincomme référence de branche, au lieu demasterdans le dépôt GitLab. Ce problème est maintenant corrigé. GITOPS-768 -
La page Environments dans la perspective Developer de la console web OpenShift Container Platform affiche maintenant la liste des applications et le nombre d'environnements. Cette page affiche également un lien Argo CD qui vous dirige vers la page Argo CD Applications qui répertorie toutes les applications. La page Argo CD Applications contient LABELS (par exemple,
app.kubernetes.io/name=appName) qui vous aide à filtrer uniquement les applications de votre choix. GITOPS-544
4.1.39.4. Problèmes connus
Voici les problèmes connus dans Red Hat OpenShift GitOps 1.1 :
- Red Hat OpenShift GitOps ne supporte pas Helm v2 et ksonnet.
- L'opérateur Red Hat SSO (RH SSO) n'est pas pris en charge dans les clusters déconnectés. Par conséquent, l'intégration de Red Hat OpenShift GitOps Operator et RH SSO n'est pas prise en charge dans les clusters déconnectés.
- Lorsque vous supprimez une application Argo CD à partir de la console web d'OpenShift Container Platform, l'application Argo CD est supprimée dans l'interface utilisateur, mais les déploiements sont toujours présents dans le cluster. Comme solution de contournement, supprimez l'application Argo CD à partir de la console Argo CD. GITOPS-830
4.1.39.5. Rupture du changement
4.1.39.5.1. Mise à jour de Red Hat OpenShift GitOps v1.0.1
Lorsque vous mettez à niveau Red Hat OpenShift GitOps v1.0.1 vers v1.1, l'opérateur Red Hat OpenShift GitOps renomme l'instance Argo CD par défaut créée dans l'espace de noms openshift-gitops de argocd-cluster à openshift-gitops.
Il s'agit d'un changement radical qui nécessite que les étapes suivantes soient effectuées manuellement, avant la mise à jour :
Allez dans la console web de OpenShift Container Platform et copiez le contenu du fichier
argocd-cm.ymlconfig map dans l'espace de nomsopenshift-gitopsdans un fichier local. Le contenu peut ressembler à l'exemple suivant :Exemple argocd config map YAML
kind: ConfigMap apiVersion: v1 metadata: selfLink: /api/v1/namespaces/openshift-gitops/configmaps/argocd-cm resourceVersion: '112532' name: argocd-cm uid: f5226fbc-883d-47db-8b53-b5e363f007af creationTimestamp: '2021-04-16T19:24:08Z' managedFields: ... namespace: openshift-gitops labels: app.kubernetes.io/managed-by: argocd-cluster app.kubernetes.io/name: argocd-cm app.kubernetes.io/part-of: argocd data: ""1 admin.enabled: 'true' statusbadge.enabled: 'false' resource.exclusions: | - apiGroups: - tekton.dev clusters: - '*' kinds: - TaskRun - PipelineRun ga.trackingid: '' repositories: | - type: git url: https://github.com/user-name/argocd-example-apps ga.anonymizeusers: 'false' help.chatUrl: '' url: >- https://argocd-cluster-server-openshift-gitops.apps.dev-svc-4.7-041614.devcluster.openshift.com ""2 help.chatText: '' kustomize.buildOptions: '' resource.inclusions: '' repository.credentials: '' users.anonymous.enabled: 'false' configManagementPlugins: '' application.instanceLabelKey: ''-
Supprimer l'instance par défaut de
argocd-cluster. -
Modifiez le nouveau fichier de configuration
argocd-cm.ymlpour restaurer manuellement l'ensemble de la sectiondata. Remplacez la valeur URL dans l'entrée de la carte de configuration par le nouveau nom d'instance
openshift-gitops. Par exemple, dans l'exemple précédent, remplacez la valeur URL par la valeur URL suivante :url: >- https://openshift-gitops-server-openshift-gitops.apps.dev-svc-4.7-041614.devcluster.openshift.com- Connectez-vous au cluster Argo CD et vérifiez que les configurations précédentes sont présentes.
4.2. Comprendre OpenShift GitOps
4.2.1. À propos de GitOps
GitOps est un moyen déclaratif de mettre en œuvre le déploiement continu pour les applications natives du cloud. Vous pouvez utiliser GitOps pour créer des processus reproductibles pour gérer les clusters et les applications OpenShift Container Platform dans des environnements Kubernetes multi-clusters. GitOps gère et automatise les déploiements complexes à un rythme rapide, ce qui permet de gagner du temps lors des cycles de déploiement et de mise en production.
Le flux de travail de GitOps fait passer une application par les étapes de développement, de test, de mise à l'essai et de production. GitOps déploie une nouvelle application ou met à jour une application existante. Vous n'avez donc qu'à mettre à jour le référentiel, GitOps automatise tout le reste.
GitOps est un ensemble de pratiques qui utilisent les requêtes Git pour gérer les configurations de l'infrastructure et des applications. Dans GitOps, le dépôt Git est la seule source de vérité pour la configuration des systèmes et des applications. Ce dépôt Git contient une description déclarative de l'infrastructure dont vous avez besoin dans votre environnement spécifique et contient un processus automatisé pour faire correspondre votre environnement à l'état décrit. Il contient également l'état complet du système, de sorte que la trace des changements apportés à l'état du système est visible et vérifiable. L'utilisation de GitOps permet de résoudre les problèmes liés à la prolifération des configurations d'infrastructures et d'applications.
GitOps définit l'infrastructure et les applications sous forme de code. Il utilise ensuite ce code pour gérer plusieurs espaces de travail et clusters afin de simplifier la création de configurations d'infrastructures et d'applications. En suivant les principes du code, vous pouvez stocker la configuration des clusters et des applications dans des référentiels Git, puis suivre le flux de travail Git pour appliquer ces référentiels aux clusters de votre choix. Vous pouvez appliquer les principes fondamentaux du développement et de la maintenance de logiciels dans un dépôt Git à la création et à la gestion de vos fichiers de configuration de clusters et d'applications.
4.2.2. À propos de Red Hat OpenShift GitOps
Red Hat OpenShift GitOps assure la cohérence des applications lorsque vous les déployez sur différents clusters dans différents environnements, tels que : développement, staging et production. Red Hat OpenShift GitOps organise le processus de déploiement autour des référentiels de configuration et en fait l'élément central. Il dispose toujours d'au moins deux référentiels :
- Dépôt d'applications avec le code source
- Référentiel de configuration de l'environnement qui définit l'état souhaité de l'application
Ces référentiels contiennent une description déclarative de l'infrastructure dont vous avez besoin dans votre environnement spécifique. Ils contiennent également un processus automatisé permettant de faire correspondre votre environnement à l'état décrit.
Red Hat OpenShift GitOps utilise Argo CD pour maintenir les ressources du cluster. Argo CD est un outil déclaratif open-source pour l'intégration et le déploiement continus (CI/CD) d'applications. Red Hat OpenShift GitOps implémente Argo CD en tant que contrôleur afin qu'il surveille continuellement les définitions et les configurations d'applications définies dans un dépôt Git. Ensuite, Argo CD compare l'état spécifié de ces configurations avec leur état réel sur le cluster.
Argo CD signale toutes les configurations qui s'écartent de l'état spécifié. Ces rapports permettent aux administrateurs de resynchroniser automatiquement ou manuellement les configurations vers l'état défini. Par conséquent, Argo CD vous permet de fournir des ressources globales personnalisées, comme les ressources utilisées pour configurer les clusters OpenShift Container Platform.
4.2.2.1. Caractéristiques principales
Red Hat OpenShift GitOps vous aide à automatiser les tâches suivantes :
- Veiller à ce que les grappes aient des états similaires pour la configuration, la surveillance et le stockage
- Appliquer ou inverser les changements de configuration à plusieurs clusters OpenShift Container Platform
- Associer une configuration modèle à différents environnements
- Promouvoir les applications sur l'ensemble des clusters, de la phase d'essai à la production
4.3. Installation de Red Hat OpenShift GitOps
Red Hat OpenShift GitOps utilise Argo CD pour gérer des ressources spécifiques aux clusters, y compris les opérateurs de clusters, les opérateurs optionnels du gestionnaire de cycle de vie des opérateurs (OLM) et la gestion des utilisateurs.
Conditions préalables
- Vous avez accès à la console web de OpenShift Container Platform.
-
Vous êtes connecté en tant qu'utilisateur avec le rôle
cluster-admin. - Vous êtes connecté au cluster OpenShift Container Platform en tant qu'administrateur.
- Votre cluster a la capacité Marketplace activée ou la source du catalogue Red Hat Operator configurée manuellement.
Si vous avez déjà installé la version communautaire de l'Opérateur Argo CD, supprimez l'Opérateur Argo CD Community avant d'installer l'Opérateur Red Hat OpenShift GitOps.
Ce guide explique comment installer Red Hat OpenShift GitOps Operator sur un cluster OpenShift Container Platform et se connecter à l'instance Argo CD.
4.3.1. Installation de Red Hat OpenShift GitOps Operator dans la console web
Procédure
- Ouvrez la perspective Administrator de la console web et naviguez vers Operators → OperatorHub dans le menu de gauche.
Recherchez
OpenShift GitOps, cliquez sur la tuile Red Hat OpenShift GitOps, puis sur Install.Red Hat OpenShift GitOps sera installé dans tous les espaces de noms du cluster.
Après l'installation de Red Hat OpenShift GitOps Operator, il configure automatiquement une instance Argo CD prête à l'emploi qui est disponible dans l'espace de noms openshift-gitops, et une icône Argo CD est affichée dans la barre d'outils de la console. Vous pouvez créer des instances Argo CD ultérieures pour vos applications sous vos projets.
4.3.2. Installation de Red Hat OpenShift GitOps Operator à l'aide du CLI
Vous pouvez installer Red Hat OpenShift GitOps Operator depuis OperatorHub en utilisant le CLI.
Procédure
Créez un fichier YAML d'objet d'abonnement pour abonner un espace de noms à Red Hat OpenShift GitOps, par exemple,
sub.yaml:Exemple d'abonnement
apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: openshift-gitops-operator namespace: openshift-operators spec: channel: latest1 installPlanApproval: Automatic name: openshift-gitops-operator2 source: redhat-operators3 sourceNamespace: openshift-marketplace4 - 1
- Indiquez le nom du canal à partir duquel vous souhaitez abonner l'opérateur.
- 2
- Indiquez le nom de l'opérateur auquel vous souhaitez vous abonner.
- 3
- Indiquez le nom du CatalogSource qui fournit l'opérateur.
- 4
- L'espace de noms du CatalogSource. Utilisez
openshift-marketplacepour les CatalogSources par défaut d'OperatorHub.
Appliquez le site
Subscriptionà la grappe :$ oc apply -f openshift-gitops-sub.yamlUne fois l'installation terminée, assurez-vous que tous les pods de l'espace de noms
openshift-gitopssont en cours d'exécution :$ oc get pods -n openshift-gitopsExemple de sortie
NAME READY STATUS RESTARTS AGE cluster-b5798d6f9-zr576 1/1 Running 0 65m kam-69866d7c48-8nsjv 1/1 Running 0 65m openshift-gitops-application-controller-0 1/1 Running 0 53m openshift-gitops-applicationset-controller-6447b8dfdd-5ckgh 1/1 Running 0 65m openshift-gitops-redis-74bd8d7d96-49bjf 1/1 Running 0 65m openshift-gitops-repo-server-c999f75d5-l4rsg 1/1 Running 0 65m openshift-gitops-server-5785f7668b-wj57t 1/1 Running 0 53m
4.3.3. Connexion à l'instance d'Argo CD en utilisant le compte administrateur d'Argo CD
Red Hat OpenShift GitOps Operator crée automatiquement une instance Argo CD prête à l'emploi qui est disponible dans l'espace de noms openshift-gitops.
Conditions préalables
- Vous avez installé Red Hat OpenShift GitOps Operator dans votre cluster.
Procédure
- Dans la perspective Administrator de la console web, naviguez vers Operators → Installed Operators pour vérifier que Red Hat OpenShift GitOps Operator est installé.
-
Naviguez jusqu'à l'icône de menu
 menu → OpenShift GitOps → Cluster Argo CD. La page de connexion de l'interface utilisateur d'Argo CD s'affiche dans une nouvelle fenêtre.
menu → OpenShift GitOps → Cluster Argo CD. La page de connexion de l'interface utilisateur d'Argo CD s'affiche dans une nouvelle fenêtre.
Obtenir le mot de passe de l'instance Argo CD :
- Dans le panneau gauche de la console, utilisez le sélecteur de perspective pour passer à la perspective Developer.
-
Utilisez la liste déroulante Project et sélectionnez le projet
openshift-gitops. - Utilisez le panneau de navigation de gauche pour accéder à la page Secrets.
- Sélectionnez l'instance openshift-gitops-cluster pour afficher le mot de passe.
Copier le mot de passe.
NotePour vous connecter avec vos identifiants OpenShift Container Platform, sélectionnez l'option
LOG IN VIA OPENSHIFTdans l'interface utilisateur d'Argo CD.
-
Utilisez ce mot de passe et
admincomme nom d'utilisateur pour vous connecter à l'interface utilisateur d'Argo CD dans la nouvelle fenêtre.
Vous ne pouvez pas créer deux CD CR Argo dans le même espace de noms.
4.4. Désinstallation d'OpenShift GitOps
La désinstallation de Red Hat OpenShift GitOps Operator est un processus en deux étapes :
- Supprimez les instances Argo CD qui ont été ajoutées sous l'espace de noms par défaut de l'opérateur Red Hat OpenShift GitOps.
- Désinstallez l'opérateur Red Hat OpenShift GitOps.
La désinstallation de l'opérateur ne supprimera pas les instances de CD Argo créées.
4.4.1. Suppression des instances du CD Argo
Supprimer les instances du CD Argo ajoutées à l'espace de noms de l'opérateur GitOps.
Procédure
- Dans le site Terminal, tapez la commande suivante :
$ oc delete gitopsservice cluster -n openshift-gitopsVous ne pouvez pas supprimer un cluster Argo CD à partir de l'interface de la console web.
Une fois la commande exécutée avec succès, toutes les instances d'Argo CD seront supprimées de l'espace de noms openshift-gitops.
Supprimez toute autre instance de CD Argo dans d'autres espaces de noms à l'aide de la même commande :
oc delete gitopsservice cluster -n <namespace>4.4.2. Désinstallation de l'opérateur GitOps
Procédure
-
À partir de la page Operators → OperatorHub, utilisez la boîte Filter by keyword pour rechercher la tuile
Red Hat OpenShift GitOps Operator. - Cliquez sur la tuile Red Hat OpenShift GitOps Operator. La tuile Opérateur indique qu'elle est installée.
- Dans la page du descripteur Red Hat OpenShift GitOps Operator, cliquez sur Uninstall.
4.5. Mise en place d'une instance Argo CD
Par défaut, Red Hat OpenShift GitOps installe une instance d'Argo CD dans l'espace de noms openshift-gitops avec des permissions supplémentaires pour gérer certaines ressources du cluster. Pour gérer les configurations du cluster ou déployer des applications, vous pouvez installer et déployer une nouvelle instance d'Argo CD. Par défaut, toute nouvelle instance dispose d'autorisations pour gérer les ressources uniquement dans l'espace de noms où elle est déployée.
4.5.1. Installation du CD Argo
Pour gérer les configurations de cluster ou déployer des applications, vous pouvez installer et déployer une nouvelle instance d'Argo CD.
Procédure
- Connectez-vous à la console web de OpenShift Container Platform.
- Cliquez sur Operators → Installed Operators.
- Créez ou sélectionnez le projet dans lequel vous voulez installer l'instance d'Argo CD dans le menu déroulant Project.
- Sélectionnez OpenShift GitOps Operator parmi les opérateurs installés et choisissez l'onglet Argo CD.
Cliquez sur Create pour configurer les paramètres :
- Saisissez le Name de l'instance. Par défaut, l'adresse Name est fixée à argocd.
- Créez une route OS externe pour accéder au serveur Argo CD. Cliquez sur Server → Route et cochez Enabled.
- Pour ouvrir l'interface web d'Argo CD, cliquez sur la route en naviguant vers Networking → Routes → <instance name>-server dans le projet où l'instance d'Argo CD est installée.
4.5.2. Activation des répliques pour le serveur Argo CD et le serveur repo
Les charges de travail d'Argo CD-server et d'Argo CD-repo-server sont sans état. Pour mieux répartir vos charges de travail entre les pods, vous pouvez augmenter le nombre de réplicas du serveur Argo CD et du serveur Argo CD-repo. Cependant, si un autoscaler horizontal est activé sur le serveur Argo CD, il remplace le nombre de réplicas que vous avez défini.
Procédure
Définissez les paramètres
replicaspour les spécificationsrepoetserveren fonction du nombre de répliques que vous souhaitez exécuter :Exemple de ressource personnalisée Argo CD
apiVersion: argoproj.io/v1alpha1 kind: ArgoCD metadata: name: example-argocd labels: example: repo spec: repo: replicas: <number_of_replicas> server: replicas: <number_of_replicas> route: enabled: true path: / tls: insecureEdgeTerminationPolicy: Redirect termination: passthrough wildcardPolicy: None
4.5.3. Déployer des ressources dans un autre espace de noms
Pour permettre à Argo CD de gérer des ressources dans d'autres espaces de noms que celui où il est installé, configurez l'espace de noms cible avec une étiquette argocd.argoproj.io/managed-by.
Procédure
Configurer l'espace de noms :
$ oc label namespace <namespace> \ argocd.argoproj.io/managed-by=<namespace>1 - 1
- L'espace de noms dans lequel Argo CD est installé.
4.5.4. Personnalisation du lien de la console Argo CD
Dans un cluster multi-locataires, les utilisateurs peuvent avoir à gérer plusieurs instances d'Argo CD. Par exemple, après avoir installé une instance d'Argo CD dans votre espace de noms, vous pouvez trouver une instance d'Argo CD différente attachée au lien de la console Argo CD, au lieu de votre propre instance d'Argo CD, dans le lanceur d'application de la console.
Vous pouvez personnaliser le lien de la console Argo CD en définissant la variable d'environnement DISABLE_DEFAULT_ARGOCD_CONSOLELINK:
-
Lorsque vous définissez
DISABLE_DEFAULT_ARGOCD_CONSOLELINKsurtrue, le lien de la console Argo CD est définitivement supprimé. -
Lorsque vous définissez
DISABLE_DEFAULT_ARGOCD_CONSOLELINKsurfalseou que vous utilisez la valeur par défaut, le lien de la console Argo CD est temporairement supprimé et visible à nouveau lorsque l'itinéraire Argo CD est réconcilié.
Conditions préalables
- Vous vous êtes connecté au cluster OpenShift Container Platform en tant qu'administrateur.
- Vous avez installé l'opérateur Red Hat OpenShift GitOps.
Procédure
- Dans la perspective Administrator, naviguez vers Administration → CustomResourceDefinitions.
- Trouvez le CRD Subscription et cliquez pour l'ouvrir.
- Sélectionnez l'onglet Instances et cliquez sur l'abonnement openshift-gitops-operator.
Sélectionnez l'onglet YAML et effectuez votre personnalisation :
Pour activer ou désactiver le lien de la console Argo CD, modifiez la valeur de
DISABLE_DEFAULT_ARGOCD_CONSOLELINKsi nécessaire :apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: openshift-gitops-operator spec: config: env: - name: DISABLE_DEFAULT_ARGOCD_CONSOLELINK value: 'true'
4.6. Configurer un cluster OpenShift en déployant une application avec des configurations de cluster
Avec Red Hat OpenShift GitOps, vous pouvez configurer Argo CD pour synchroniser récursivement le contenu d'un répertoire Git avec une application qui contient des configurations personnalisées pour votre cluster.
Conditions préalables
- Red Hat OpenShift GitOps est installé dans votre cluster.
- Connexion à l'instance Argo CD.
4.6.1. Exécution de l'instance Argo CD au niveau du cluster
L'instance Argo CD par défaut et les contrôleurs qui l'accompagnent, installés par l'opérateur Red Hat OpenShift GitOps, peuvent désormais fonctionner sur les nœuds d'infrastructure du cluster en définissant un simple basculement de configuration.
Procédure
Étiqueter les nœuds existants :
$ oc label node <node-name> node-role.kubernetes.io/infra=""Facultatif : si nécessaire, vous pouvez également appliquer des taints et isoler les charges de travail sur les nœuds d'infrastructure et empêcher d'autres charges de travail d'être planifiées sur ces nœuds :
$ oc adm taint nodes -l node-role.kubernetes.io/infra \ infra=reserved:NoSchedule infra=reserved:NoExecuteAjoutez la bascule
runOnInfradans la ressource personnaliséeGitOpsService:apiVersion: pipelines.openshift.io/v1alpha1 kind: GitopsService metadata: name: cluster spec: runOnInfra: trueFacultatif : si des taints ont été ajoutés aux nœuds, ajoutez
tolerationsà la ressource personnaliséeGitOpsService, par exemple :spec: runOnInfra: true tolerations: - effect: NoSchedule key: infra value: reserved - effect: NoExecute key: infra value: reserved-
Vérifiez que les charges de travail de l'espace de noms
openshift-gitopssont désormais planifiées sur les nœuds d'infrastructure en affichant Pods → Pod details pour n'importe quel module dans l'interface utilisateur de la console.
Tous les nodeSelectors et tolerations ajoutés manuellement à la ressource personnalisée Argo CD par défaut sont remplacés par la bascule et tolerations dans la ressource personnalisée GitOpsService.
4.6.2. Créer une application en utilisant le tableau de bord du CD Argo
Argo CD fournit un tableau de bord qui vous permet de créer des applications.
Cet exemple de flux de travail vous guide dans le processus de configuration d'Argo CD pour synchroniser de manière récursive le contenu du répertoire cluster avec l'application cluster-configs. Le répertoire définit les configurations de cluster de la console web d'OpenShift Container Platform qui ajoutent un lien vers Red Hat Developer Blog - Kubernetes sous l'icône de menu
![]() dans la console web, et définit un espace de noms
dans la console web, et définit un espace de noms spring-petclinic sur le cluster.
Procédure
- Dans le tableau de bord Argo CD, cliquez sur NEW APP pour ajouter une nouvelle application Argo CD.
Pour ce flux de travail, créez une application cluster-configs avec les configurations suivantes :
- Nom de l'application
-
cluster-configs - Projet
-
default - Politique de synchronisation
-
Manual - URL du référentiel
-
https://github.com/redhat-developer/openshift-gitops-getting-started - Révision
-
HEAD - Chemin d'accès
-
cluster - Destination
-
https://kubernetes.default.svc - Espace de noms
-
spring-petclinic - Récurrence des répertoires
-
checked
- Cliquez sur CREATE pour créer votre application.
- Ouvrez la perspective Administrator de la console web et naviguez vers Administration → Namespaces dans le menu de gauche.
-
Recherchez et sélectionnez l'espace de noms, puis entrez
argocd.argoproj.io/managed-by=openshift-gitopsdans le champ Label afin que l'instance d'Argo CD dans l'espace de nomsopenshift-gitopspuisse gérer votre espace de noms.
4.6.3. Création d'une application à l'aide de l'outil oc
Vous pouvez créer des applications Argo CD dans votre terminal en utilisant l'outil oc.
Procédure
Télécharger l'exemple d'application:
$ git clone git@github.com:redhat-developer/openshift-gitops-getting-started.gitCréer l'application :
$ oc create -f openshift-gitops-getting-started/argo/app.yamlExécutez la commande
oc getpour examiner l'application créée :$ oc get application -n openshift-gitopsAjoutez une étiquette à l'espace de noms dans lequel votre application est déployée afin que l'instance Argo CD dans l'espace de noms
openshift-gitopspuisse la gérer :$ oc label namespace spring-petclinic argocd.argoproj.io/managed-by=openshift-gitops
4.6.4. Synchroniser votre application avec votre dépôt Git
Procédure
- Dans le tableau de bord Argo CD, remarquez que l'application cluster-configs Argo CD a les statuts Missing et OutOfSync. Parce que l'application a été configurée avec une politique de synchronisation manuelle, Argo CD ne la synchronise pas automatiquement.
- Cliquez sur SYNC sur la tuile cluster-configs, examinez les changements, puis cliquez sur SYNCHRONIZE. Argo CD détectera automatiquement tout changement dans le référentiel Git. Si les configurations sont modifiées, Argo CD changera l'état de cluster-configs en OutOfSync. Vous pouvez modifier la politique de synchronisation d'Argo CD pour appliquer automatiquement les modifications de votre référentiel Git au cluster.
- Remarquez que l'application cluster-configs Argo CD a maintenant les statuts Healthy et Synced. Cliquez sur la tuile cluster-configs pour vérifier les détails des ressources synchronisées et leur statut sur le cluster.
-
Naviguez vers la console web OpenShift Container Platform et cliquez sur l'icône de menu
pour vérifier qu'un lien vers le site Red Hat Developer Blog - Kubernetes est maintenant présent.
Naviguez jusqu'à la page Project et recherchez l'espace de noms
spring-petclinicpour vérifier qu'il a été ajouté au cluster.Les configurations de votre cluster ont été synchronisées avec succès sur le cluster.
4.6.5. Autorisations intégrées pour la configuration des clusters
Par défaut, l'instance Argo CD dispose d'autorisations pour gérer des ressources spécifiques à la grappe, telles que les opérateurs de grappe, les opérateurs OLM facultatifs et la gestion des utilisateurs.
Argo CD n'a pas les permissions d'administrateur de cluster.
Permissions pour l'instance Argo CD :
| Resources | Descriptions |
| Groupes de ressources | Configurer l'utilisateur ou l'administrateur |
|
| Opérateurs optionnels gérés par OLM |
|
| Groupes, utilisateurs et leurs autorisations |
|
| Opérateurs du plan de contrôle gérés par l'OVE utilisés pour configurer la configuration de la construction à l'échelle de la grappe, la configuration du registre et les politiques du planificateur |
|
| Stockage |
|
| Personnalisation de la console |
4.6.6. Ajout de permissions pour la configuration de la grappe
Vous pouvez accorder des autorisations à une instance Argo CD pour gérer la configuration du cluster. Créez un rôle de cluster avec des autorisations supplémentaires, puis créez une nouvelle liaison de rôle de cluster pour associer le rôle de cluster à un compte de service.
Procédure
- Connectez-vous à la console web de OpenShift Container Platform en tant qu'administrateur.
Dans la console web, sélectionnez User Management → Roles → Create Role. Utilisez le modèle YAML
ClusterRolesuivant pour ajouter des règles afin de spécifier les autorisations supplémentaires.apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: secrets-cluster-role rules: - apiGroups: [""] resources: ["secrets"] verbs: ["*"]- Cliquez sur Create pour ajouter le rôle de cluster.
- Créez maintenant le binding du rôle de cluster. Dans la console web, sélectionnez User Management → Role Bindings → Create Binding.
- Sélectionnez All Projects dans la liste déroulante Project.
- Cliquez sur Create binding.
- Sélectionnez Binding type comme Cluster-wide role binding (ClusterRoleBinding).
- Saisissez une valeur unique pour le site RoleBinding name.
- Sélectionnez le rôle de cluster nouvellement créé ou un rôle de cluster existant dans la liste déroulante.
Sélectionnez le site Subject comme ServiceAccount et fournissez ensuite les sites Subject namespace et name.
-
Subject namespace:
openshift-gitops -
Subject name:
openshift-gitops-argocd-application-controller
-
Subject namespace:
Cliquez sur Create. Le fichier YAML de l'objet
ClusterRoleBindingest le suivant :kind: ClusterRoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: name: cluster-role-binding subjects: - kind: ServiceAccount name: openshift-gitops-argocd-application-controller namespace: openshift-gitops roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: admin
4.7. Déployer une application Spring Boot avec Argo CD
Avec Argo CD, vous pouvez déployer vos applications sur le cluster OpenShift soit en utilisant le tableau de bord Argo CD, soit en utilisant l'outil oc.
Conditions préalables
- Red Hat OpenShift GitOps est installé dans votre cluster.
- Connexion à l'instance Argo CD.
4.7.1. Créer une application en utilisant le tableau de bord du CD Argo
Argo CD fournit un tableau de bord qui vous permet de créer des applications.
Cet exemple de flux de travail vous guide dans le processus de configuration d'Argo CD pour synchroniser de manière récursive le contenu du répertoire cluster avec l'application cluster-configs. Le répertoire définit les configurations de cluster de la console web d'OpenShift Container Platform qui ajoutent un lien vers Red Hat Developer Blog - Kubernetes sous l'icône de menu
![]() dans la console web, et définit un espace de noms
dans la console web, et définit un espace de noms spring-petclinic sur le cluster.
Procédure
- Dans le tableau de bord Argo CD, cliquez sur NEW APP pour ajouter une nouvelle application Argo CD.
Pour ce flux de travail, créez une application cluster-configs avec les configurations suivantes :
- Nom de l'application
-
cluster-configs - Projet
-
default - Politique de synchronisation
-
Manual - URL du référentiel
-
https://github.com/redhat-developer/openshift-gitops-getting-started - Révision
-
HEAD - Chemin d'accès
-
cluster - Destination
-
https://kubernetes.default.svc - Espace de noms
-
spring-petclinic - Récurrence des répertoires
-
checked
Pour ce flux de travail, créez une application spring-petclinic avec les configurations suivantes :
- Nom de l'application
-
spring-petclinic - Projet
-
default - Politique de synchronisation
-
Automatic - URL du référentiel
-
https://github.com/redhat-developer/openshift-gitops-getting-started - Révision
-
HEAD - Chemin d'accès
-
app - Destination
-
https://kubernetes.default.svc - Espace de noms
-
spring-petclinic
- Cliquez sur CREATE pour créer votre application.
- Ouvrez la perspective Administrator de la console web et naviguez vers Administration → Namespaces dans le menu de gauche.
-
Recherchez et sélectionnez l'espace de noms, puis entrez
argocd.argoproj.io/managed-by=openshift-gitopsdans le champ Label afin que l'instance d'Argo CD dans l'espace de nomsopenshift-gitopspuisse gérer votre espace de noms.
4.7.2. Création d'une application à l'aide de l'outil oc
Vous pouvez créer des applications Argo CD dans votre terminal en utilisant l'outil oc.
Procédure
Télécharger l'exemple d'application:
$ git clone git@github.com:redhat-developer/openshift-gitops-getting-started.gitCréer l'application :
$ oc create -f openshift-gitops-getting-started/argo/app.yaml$ oc create -f openshift-gitops-getting-started/argo/app.yamlExécutez la commande
oc getpour examiner l'application créée :$ oc get application -n openshift-gitopsAjoutez une étiquette à l'espace de noms dans lequel votre application est déployée afin que l'instance Argo CD dans l'espace de noms
openshift-gitopspuisse la gérer :$ oc label namespace spring-petclinic argocd.argoproj.io/managed-by=openshift-gitops$ oc label namespace spring-petclinic argocd.argoproj.io/managed-by=openshift-gitops
4.7.3. Vérification du comportement d'auto-réparation d'Argo CD
Argo CD surveille en permanence l'état des applications déployées, détecte les différences entre les manifestes spécifiés dans Git et les changements en cours dans le cluster, puis les corrige automatiquement. Ce comportement est appelé "auto-réparation".
Vous pouvez tester et observer le comportement d'auto-guérison dans Argo CD.
Conditions préalables
-
L'exemple d'application
app-spring-petclinicest déployé et configuré.
Procédure
-
Dans le tableau de bord d'Argo CD, vérifiez que votre application a le statut
Synced. -
Cliquez sur la tuile
app-spring-petclinicdans le tableau de bord Argo CD pour afficher les ressources d'application déployées dans le cluster. - Dans la console web de OpenShift Container Platform, naviguez vers la perspective Developer.
Modifier le déploiement de Spring PetClinic et valider les changements dans le répertoire
app/du dépôt Git. Argo CD déploiera automatiquement les changements sur le cluster.- Forker le dépôt OpenShift GitOps getting started.
-
Dans le fichier
deployment.yaml, remplacez la valeurfailureThresholdpar5. Dans le cluster de déploiement, exécutez la commande suivante pour vérifier la valeur modifiée du champ
failureThreshold:$ oc edit deployment spring-petclinic -n spring-petclinic
Testez le comportement d'autoréparation en modifiant le déploiement sur le cluster et en l'augmentant à deux pods tout en observant l'application dans la console web d'OpenShift Container Platform.
Exécutez la commande suivante pour modifier le déploiement :
$ oc scale deployment spring-petclinic --replicas 2 -n spring-petclinic- Dans la console web d'OpenShift Container Platform, remarquez que le déploiement passe à deux pods et redescend immédiatement à un pod. Argo CD a détecté une différence dans le référentiel Git et a guéri automatiquement l'application sur le cluster OpenShift Container Platform.
- Dans le tableau de bord Argo CD, cliquez sur la tuile app-spring-petclinic → APP DETAILS → EVENTS. L'onglet EVENTS affiche les événements suivants : Argo CD a détecté des ressources de déploiement désynchronisées sur le cluster et a resynchronisé le référentiel Git pour corriger la situation.
4.8. Opérateur CD Argo
La ressource personnalisée ArgoCD est une ressource personnalisée Kubernetes (CRD) qui décrit l'état souhaité pour un cluster Argo CD donné qui vous permet de configurer les composants qui constituent un cluster Argo CD.
4.8.1. Outil CLI d'Argo CD
L'outil Argo CD CLI est un outil utilisé pour configurer Argo CD via la ligne de commande. Red Hat OpenShift GitOps ne prend pas en charge ce binaire. Utilisez la console OpenShift pour configurer Argo CD.
4.8.2. Propriétés des ressources personnalisées d'Argo CD
La ressource personnalisée du CD Argo est constituée des propriétés suivantes :
| Name | Description | Default | Properties |
|
|
Le nom de la clé |
| |
|
|
|
|
|
|
| Ajouter un plugin de gestion de la configuration. |
| |
|
| Options du contrôleur d'application Argo CD. |
|
|
|
| Désactive l'utilisateur administrateur intégré. |
| |
|
| Utiliser un identifiant de suivi Google Analytics. |
| |
|
| Activer les noms d'utilisateur hachés envoyés à Google Analytics. |
| |
|
| Options de grande disponibilité. |
|
|
|
| URL pour obtenir de l'aide par chat (il s'agit généralement de votre canal Slack pour l'assistance). | ||
|
| Le texte qui apparaît dans une zone de texte pour obtenir de l'aide sur le chat. |
| |
|
|
L'image du conteneur pour tous les composants d'Argo CD. Elle remplace la variable d'environnement |
| |
|
| Options de configuration de l'entrée. |
| |
|
| Dépôts Git initiaux pour configurer Argo CD à utiliser lors de la création du cluster. |
| |
|
| Options de configuration du contrôleur de notifications. |
|
|
|
| Modèles d'identifiants du référentiel Git à configurer pour qu'Argo CD les utilise lors de la création du cluster. |
| |
|
| Hôtes SSH initiaux connus pour Argo CD à utiliser lors de la création du cluster. |
| |
|
|
Les options de construction et les paramètres à utiliser avec |
| |
|
| La configuration OIDC comme alternative à Dex. |
| |
|
|
Ajouter le |
| |
|
| Options de configuration de Prometheus. |
|
|
|
| Options de configuration RBAC. |
|
|
|
| Options de configuration de Redis. |
|
|
|
| Personnaliser le comportement des ressources. |
| |
|
| Ignorer complètement des classes entières de groupes de ressources. |
| |
|
| La configuration permet de déterminer les groupes de ressources ou les types de ressources qui sont appliqués. |
| |
|
| Options de configuration du serveur Argo CD. |
|
|
|
| Options d'authentification unique. |
|
|
|
| Activer le badge d'état de la demande. |
| |
|
| Options de configuration de TLS. |
|
|
|
| Activer l'accès des utilisateurs anonymes. |
| |
|
| La balise à utiliser avec l'image du conteneur pour tous les composants du CD Argo. | Dernière version du CD Argo | |
|
| Ajouter un message de bannière d'interface utilisateur. |
|
|
4.8.3. Propriétés du serveur Repo
Les propriétés suivantes sont disponibles pour configurer le composant serveur Repo :
| Name | Default | Description |
|
|
| Les ressources informatiques du conteneur. |
|
|
|
Si le jeton |
|
|
|
Le nom du site |
|
|
| Si l'on veut imposer une vérification TLS stricte à tous les composants lorsqu'ils communiquent avec le serveur repo. |
|
|
| Fournisseur à utiliser pour configurer TLS le certificat gRPC TLS du serveur repo (un de : openshift). Actuellement disponible uniquement pour OpenShift. |
|
|
|
L'image du conteneur pour le serveur Argo CD Repo. Elle remplace la variable d'environnement |
|
|
même que | Le tag à utiliser avec le serveur Argo CD Repo. |
|
|
| Le niveau de journalisation utilisé par le serveur Argo CD Repo. Les options valides sont debug, info, error et warn. |
|
|
| Le format de journal à utiliser par le serveur Argo CD Repo. Les options valides sont text ou json. |
|
|
| Délai d'exécution en secondes pour les outils de rendu (par exemple Helm, Kustomize). |
|
|
| Environnement à définir pour les charges de travail du serveur de référentiel. |
|
|
|
Le nombre de répliques pour le serveur Argo CD Repo. Doit être supérieur ou égal à |
4.8.4. Activation des notifications avec l'instance Argo CD
Pour activer ou désactiver le contrôleur de notifications Argo CD, définissez un paramètre dans la ressource personnalisée Argo CD. Par défaut, les notifications sont désactivées. Pour activer les notifications, définissez le paramètre enabled sur true dans le fichier .yaml:
Procédure
-
Réglez le paramètre
enabledsurtrue:
apiVersion: argoproj.io/v1alpha1
kind: ArgoCD
metadata:
name: example-argocd
spec:
notifications:
enabled: true4.9. Suivi des informations sur l'état des ressources et des déploiements d'applications
La page Red Hat OpenShift GitOps Environments dans la perspective Developer de la console web OpenShift Container Platform montre une liste des déploiements réussis des environnements d'application, ainsi que des liens vers la révision pour chaque déploiement.
La page Application environments dans la perspective Developer de la console web OpenShift Container Platform affiche l'état de santé des ressources de l'application, telles que les routes, l'état de synchronisation, la configuration du déploiement et l'historique du déploiement.
Les pages des environnements dans la perspective Developer de la console web d'OpenShift Container Platform sont découplées de l'interface de ligne de commande (CLI) de Red Hat OpenShift GitOps Application Manager, kam. Vous n'avez pas besoin d'utiliser kam pour générer des manifestes d'environnement d'application pour que les environnements apparaissent dans la perspective Developer de la console web d'OpenShift Container Platform. Vous pouvez utiliser vos propres manifestes, mais les environnements doivent toujours être représentés par des espaces de noms. En outre, des étiquettes et des annotations spécifiques sont toujours nécessaires.
4.9.1. Vérification des informations sur la santé
L'opérateur Red Hat OpenShift GitOps installera le service backend GitOps dans l'espace de noms openshift-gitops.
Conditions préalables
- L'opérateur Red Hat OpenShift GitOps est installé à partir de OperatorHub.
- Assurez-vous que vos applications sont synchronisées par Argo CD.
Procédure
- Cliquez sur Environments sous la perspective Developer. La page Environments affiche la liste des applications ainsi que leur Environment status.
- Survolez les icônes sous la colonne Environment status pour voir l'état de la synchronisation de tous les environnements.
- Cliquez sur le nom de l'application dans la liste pour afficher les détails d'une application spécifique.
Dans la page Application environments, si la section Resources sous l'onglet Overview affiche des icônes, survolez les icônes pour obtenir des détails sur l'état.
- Un cœur brisé indique que des problèmes de ressources ont dégradé les performances de l'application.
- Un signe jaune indique que des problèmes de ressources ont retardé les données sur l'état de l'application.
- Pour consulter l'historique du déploiement d'une application, cliquez sur l'onglet Deployment History. La page comprend des détails tels que Last deployment, Description (message de validation), Environment, Author et Revision.
4.10. Configuration du SSO pour Argo CD à l'aide de Dex
Après l'installation de Red Hat OpenShift GitOps Operator, Argo CD crée automatiquement un utilisateur avec les permissions admin. Pour gérer plusieurs utilisateurs, les administrateurs de cluster peuvent utiliser Argo CD pour configurer l'authentification unique (SSO).
Le paramètre spec.dex dans la CR ArgoCD est obsolète. Dans une prochaine version de Red Hat OpenShift GitOps v1.9, il est prévu de supprimer la configuration de Dex à l'aide du paramètre spec.dex dans la CR ArgoCD. Pensez à utiliser le paramètre .spec.sso à la place.
4.10.1. Activation du connecteur Dex OpenShift OAuth
Dex utilise les utilisateurs et les groupes définis dans OpenShift en vérifiant le serveur OAuth fourni par la plateforme. L'exemple suivant montre les propriétés de Dex ainsi que des exemples de configuration :
apiVersion: argoproj.io/v1alpha1
kind: ArgoCD
metadata:
name: example-argocd
labels:
example: openshift-oauth
spec:
dex:
openShiftOAuth: true
groups:
- default
rbac:
defaultPolicy: 'role:readonly'
policy: |
g, cluster-admins, role:admin
scopes: '[groups]'- 1
- La propriété
openShiftOAuthdéclenche la configuration automatique par l'Opérateur du serveur intégré OpenShiftOAuthlorsque la valeur est définie surtrue. - 2
- La propriété
groupspermet aux utilisateurs du ou des groupes spécifiés de se connecter. - 3
- La propriété de la politique RBAC attribue le rôle d'administrateur dans le cluster Argo CD aux utilisateurs du groupe OpenShift
cluster-admins.
4.10.1.1. Mapper les utilisateurs à des rôles spécifiques
Argo CD ne peut pas mapper les utilisateurs à des rôles spécifiques s'ils ont un rôle direct ClusterRoleBinding. Vous pouvez changer manuellement le rôle comme role:admin sur SSO via OpenShift.
Procédure
Créer un groupe nommé
cluster-admins.$ oc adm groups new cluster-adminsAjouter l'utilisateur au groupe.
$ oc adm groups add-users cluster-admins USERAppliquer le site
cluster-adminClusterRoleau groupe :$ oc adm policy add-cluster-role-to-group cluster-admin cluster-admins
4.10.2. Désactivation de Dex
Dex est installé par défaut pour toutes les instances Argo CD créées par l'Opérateur. Vous pouvez configurer Red Hat OpenShift GitOps pour utiliser Dex comme fournisseur d'authentification SSO en définissant le paramètre .spec.dex.
Dans Red Hat OpenShift GitOps v1.6.0, DISABLE_DEX est déprécié et devrait être supprimé dans Red Hat OpenShift GitOps v1.9.0. Pensez à utiliser le paramètre .spec.sso.dex à la place. Voir "Activer ou désactiver Dex en utilisant .spec.sso".
Procédure
Définissez la variable environnementale
DISABLE_DEXàtruedans la ressource YAML de l'opérateur :... spec: config: env: - name: DISABLE_DEX value: "true" ...
4.10.3. Activation ou désactivation de Dex à l'aide de .spec.sso
Vous pouvez configurer Red Hat OpenShift GitOps pour utiliser Dex comme fournisseur d'authentification SSO en définissant le paramètre .spec.sso.
Procédure
Pour activer Dex, définissez le paramètre
.spec.sso.provider: dexdans la ressource YAML de l'opérateur :... spec: sso: provider: dex dex: openShiftOAuth: true ...-
Pour désactiver dex, supprimez l'élément
spec.ssode la ressource personnalisée Argo CD ou spécifiez un fournisseur SSO différent.
4.11. Configuration du SSO pour Argo CD à l'aide de Keycloak
Après l'installation de Red Hat OpenShift GitOps Operator, Argo CD crée automatiquement un utilisateur avec les permissions admin. Pour gérer plusieurs utilisateurs, les administrateurs de cluster peuvent utiliser Argo CD pour configurer l'authentification unique (SSO).
Conditions préalables
- Red Hat SSO est installé sur le cluster.
- Red Hat OpenShift GitOps Operator est installé sur le cluster.
- Le CD Argo est installé sur le cluster.
4.11.1. Configuration d'un nouveau client dans Keycloak
Dex est installé par défaut pour toutes les instances Argo CD créées par l'Opérateur. Cependant, vous pouvez supprimer la configuration Dex et ajouter Keycloak à la place pour vous connecter à Argo CD en utilisant vos informations d'identification OpenShift. Keycloak agit comme un courtier d'identité entre Argo CD et OpenShift.
Procédure
Pour configurer Keycloak, procédez comme suit :
Supprimer la configuration Dex en supprimant le paramètre
.spec.sso.dexde la ressource personnalisée (CR) Argo CD, et enregistrer la CR :dex: openShiftOAuth: true resources: limits: cpu: memory: requests: cpu: memory:-
Réglez la valeur du paramètre
providersurkeycloakdans l'Argo CD CR. Configurez Keycloak en effectuant l'une des étapes suivantes :
Pour une connexion sécurisée, définissez la valeur du paramètre
rootCAcomme indiqué dans l'exemple suivant :apiVersion: argoproj.io/v1alpha1 kind: ArgoCD metadata: name: example-argocd labels: example: basic spec: sso: provider: keycloak keycloak: rootCA: "<PEM-encoded-root-certificate>"1 server: route: enabled: true- 1
- Un certificat personnalisé utilisé pour vérifier le certificat TLS du Keycloak.
L'opérateur rapproche les modifications du paramètre
.spec.keycloak.rootCAet met à jour le paramètreoidc.configavec le certificat racine codé PEM dans la carte de configurationargocd-cm.Pour une connexion non sécurisée, laissez la valeur du paramètre
rootCAvide et utilisez le paramètreoidc.tls.insecure.skip.verifycomme indiqué ci-dessous :apiVersion: argoproj.io/v1alpha1 kind: ArgoCD metadata: name: example-argocd labels: example: basic spec: extraConfig: oidc.tls.insecure.skip.verify: "true" sso: provider: keycloak keycloak: rootCA: ""
L'instance de Keycloak s'installe et fonctionne en 2 à 3 minutes.
4.11.2. Se connecter à Keycloak
Connectez-vous à la console Keycloak pour gérer les identités ou les rôles et définir les permissions attribuées aux différents rôles.
Conditions préalables
- La configuration par défaut de Dex est supprimée.
- Votre Argo CD CR doit être configuré pour utiliser le fournisseur SSO Keycloak.
Procédure
Obtenir l'URL de la route Keycloak pour la connexion :
$ oc -n argocd get route keycloak NAME HOST/PORT PATH SERVICES PORT TERMINATION WILDCARD keycloak keycloak-default.apps.ci-ln-******.origin-ci-int-aws.dev.**.com keycloak <all> reencrypt NoneObtenir le nom du pod Keycloak qui stocke le nom d'utilisateur et le mot de passe en tant que variables d'environnement :
$ oc -n argocd get pods NAME READY STATUS RESTARTS AGE keycloak-1-2sjcl 1/1 Running 0 45mObtenir le nom d'utilisateur de Keycloak :
$ oc -n argocd exec keycloak-1-2sjcl -- "env" | grep SSO_ADMIN_USERNAME SSO_ADMIN_USERNAME=Cqid54IhObtenir le mot de passe Keycloak :
$ oc -n argocd exec keycloak-1-2sjcl -- "env" | grep SSO_ADMIN_PASSWORD SSO_ADMIN_PASSWORD=GVXxHifH
Sur la page de connexion, cliquez sur LOG IN VIA KEYCLOAK.
NoteL'option LOGIN VIA KEYCLOAK n'apparaît qu'une fois que l'instance de Keycloak est prête.
Cliquez sur Login with OpenShift.
NoteLa connexion à l'aide de
kubeadminn'est pas prise en charge.- Saisissez les informations d'identification OpenShift pour vous connecter.
Optionnel : Par défaut, tout utilisateur connecté à Argo CD a un accès en lecture seule. Vous pouvez gérer l'accès au niveau de l'utilisateur en mettant à jour la carte de configuration
argocd-rbac-cm:policy.csv: <name>, <email>, role:admin
4.11.3. Désinstallation de Keycloak
Vous pouvez supprimer les ressources Keycloak et les configurations correspondantes en supprimant le champ SSO du fichier de ressources personnalisées (CR) du CD Argo. Une fois le champ SSO supprimé, les valeurs du fichier ressemblent à ce qui suit :
apiVersion: argoproj.io/v1alpha1
kind: ArgoCD
metadata:
name: example-argocd
labels:
example: basic
spec:
server:
route:
enabled: trueUne application Keycloak créée à l'aide de cette méthode n'est actuellement pas persistante. Les configurations supplémentaires créées dans le domaine Keycloak d'Argo CD sont supprimées lorsque le serveur redémarre.
4.12. Configuration d'Argo CD RBAC
Par défaut, si vous êtes connecté à Argo CD en utilisant RHSSO, vous êtes un utilisateur en lecture seule. Vous pouvez modifier et gérer l'accès au niveau de l'utilisateur.
4.12.1. Configuration de l'accès au niveau de l'utilisateur
Pour gérer et modifier l'accès au niveau de l'utilisateur, configurez la section RBAC dans la ressource personnalisée d'Argo CD.
Procédure
Modifiez la ressource personnalisée
argocd:$ oc edit argocd [argocd-instance-name] -n [namespace]Sortie
metadata ... ... rbac: policy: 'g, rbacsystem:cluster-admins, role:admin' scopes: '[groups]'Ajoutez la configuration
policyà la sectionrbacet ajoutez lesname,emailetrolede l'utilisateur :metadata ... ... rbac: policy: <name>, <email>, role:<admin> scopes: '[groups]'
Actuellement, RHSSO ne peut pas lire les informations de groupe des utilisateurs de Red Hat OpenShift GitOps. Par conséquent, configurez le RBAC au niveau de l'utilisateur.
4.12.2. Modifier les demandes/limites de ressources du RHSSO
Par défaut, le conteneur RHSSO est créé avec des demandes de ressources et des limitations. Vous pouvez modifier et gérer les demandes de ressources.
| Resource | Requests | Limits |
|---|---|---|
| UNITÉ CENTRALE | 500 | 1000m |
| Mémoire | 512 Mi | 1024 Mi |
Procédure
Modifier les exigences de ressources par défaut en corrigeant le CD CR Argo :
$ oc -n openshift-gitops patch argocd openshift-gitops --type='json' -p='[{"op": "add", "path": "/spec/sso", "value": {"provider": "keycloak", "resources": {"requests": {"cpu": "512m", "memory": "512Mi"}, "limits": {"cpu": "1024m", "memory": "1024Mi"}} }}]'RHSSO créé par Red Hat OpenShift GitOps ne conserve que les modifications apportées par l'opérateur. Si le RHSSO redémarre, toute configuration supplémentaire créée par l'administrateur dans le RHSSO est supprimée.
4.13. Configuration des quotas ou des demandes de ressources
Avec la ressource personnalisée Argo CD, vous pouvez créer, mettre à jour et supprimer les demandes et les limites de ressources pour les charges de travail Argo CD.
4.13.1. Configuration des charges de travail avec demandes et limites de ressources
Vous pouvez créer des charges de travail de ressources personnalisées Argo CD avec des demandes et des limites de ressources. Cela est nécessaire lorsque vous souhaitez déployer l'instance Argo CD dans un espace de noms configuré avec des quotas de ressources.
L'instance Argo CD suivante déploie les charges de travail Argo CD telles que Application Controller, ApplicationSet Controller, Dex, Redis,Repo Server, et Server avec des demandes et des limites de ressources. Vous pouvez également créer d'autres charges de travail avec des exigences de ressources de la même manière.
apiVersion: argoproj.io/v1alpha1
kind: ArgoCD
metadata:
name: example
spec:
server:
resources:
limits:
cpu: 500m
memory: 256Mi
requests:
cpu: 125m
memory: 128Mi
route:
enabled: true
applicationSet:
resources:
limits:
cpu: '2'
memory: 1Gi
requests:
cpu: 250m
memory: 512Mi
repo:
resources:
limits:
cpu: '1'
memory: 512Mi
requests:
cpu: 250m
memory: 256Mi
dex:
resources:
limits:
cpu: 500m
memory: 256Mi
requests:
cpu: 250m
memory: 128Mi
redis:
resources:
limits:
cpu: 500m
memory: 256Mi
requests:
cpu: 250m
memory: 128Mi
controller:
resources:
limits:
cpu: '2'
memory: 2Gi
requests:
cpu: 250m
memory: 1Gi4.13.2. Mise à jour de l'instance d'Argo CD pour actualiser les besoins en ressources
Vous pouvez mettre à jour les besoins en ressources pour tout ou partie des charges de travail après l'installation.
Procédure
Mettre à jour les demandes de ressources Application Controller d'une instance Argo CD dans l'espace de noms Argo CD.
oc -n argocd patch argocd example --type='json' -p='[{"op": "replace", "path": "/spec/controller/resources/requests/cpu", "value":"1"}]'
oc -n argocd patch argocd example --type='json' -p='[{"op": "replace", "path": "/spec/controller/resources/requests/memory", "value":"512Mi"}]'4.13.3. Suppression des demandes de ressources
Vous pouvez également supprimer les exigences en matière de ressources pour tout ou partie de vos charges de travail après l'installation.
Procédure
Supprimer les demandes de ressources Application Controller d'une instance Argo CD dans l'espace de noms Argo CD.
oc -n argocd patch argocd example --type='json' -p='[{"op": "remove", "path": "/spec/controller/resources/requests/cpu"}]'
oc -n argocd argocd patch argocd example --type='json' -p='[{"op": "remove", "path": "/spec/controller/resources/requests/memory"}]'4.14. Suivi des charges de travail des ressources personnalisées d'Argo CD
Avec Red Hat OpenShift GitOps, vous pouvez surveiller la disponibilité des charges de travail des ressources personnalisées Argo CD pour des instances Argo CD spécifiques. En surveillant les charges de travail des ressources personnalisées Argo CD, vous disposez des dernières informations sur l'état de vos instances Argo CD en activant des alertes pour elles. Lorsque les pods de charge de travail des composants tels que le contrôleur d'application, le serveur repo ou le serveur de l'instance Argo CD correspondante sont incapables de démarrer pour certaines raisons et qu'il y a une dérive entre le nombre de répliques prêtes et le nombre de répliques souhaitées pendant une certaine période de temps, l'opérateur déclenche alors les alertes.
Vous pouvez activer et désactiver le paramètre de surveillance des charges de travail des ressources personnalisées d'Argo CD.
Conditions préalables
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin. - Red Hat OpenShift GitOps est installé dans votre cluster.
-
La pile de surveillance est configurée dans votre cluster dans le projet
openshift-monitoring. De plus, l'instance Argo CD se trouve dans un espace de noms que vous pouvez surveiller via Prometheus. -
Le service
kube-state-metricsest en cours d'exécution dans votre cluster. Facultatif : Si vous activez la surveillance d'une instance Argo CD déjà présente dans un projet défini par l'utilisateur, assurez-vous que la surveillance est activée pour les projets définis par l'utilisateur dans votre cluster.
NoteSi vous souhaitez activer la surveillance d'une instance Argo CD dans un espace de noms qui n'est pas surveillé par la pile par défaut
openshift-monitoring, par exemple, tout espace de noms qui ne commence pas paropenshift-*, vous devez activer la surveillance de la charge de travail de l'utilisateur dans votre cluster. Cette action permet à la pile de surveillance de récupérer la PrometheusRule créée.
4.14.1. Activation de la surveillance des charges de travail des ressources personnalisées d'Argo CD
Par défaut, la configuration de la surveillance des charges de travail des ressources personnalisées d'Argo CD est définie sur false.
Avec Red Hat OpenShift GitOps, vous pouvez activer la surveillance de la charge de travail pour des instances Argo CD spécifiques. Par conséquent, l'opérateur crée un objet PrometheusRule qui contient des règles d'alerte pour toutes les charges de travail gérées par les instances Argo CD spécifiques. Ces règles d'alerte déclenchent le déclenchement d'une alerte lorsque le nombre de répliques du composant correspondant s'est écarté de l'état souhaité pendant un certain temps. L'opérateur n'écrase pas les modifications apportées à l'objet PrometheusRule par les utilisateurs.
Procédure
Fixe la valeur du champ
.spec.monitoring.enabledàtruesur une instance de CD Argo donnée :Exemple de ressource personnalisée Argo CD
apiVersion: argoproj.io/v1alpha1 kind: ArgoCD metadata: name: example-argocd labels: example: repo spec: ... monitoring: enabled: true ...Vérifier si une règle d'alerte est incluse dans la PrometheusRule créée par l'opérateur :
Exemple de règle d'alerte
apiVersion: monitoring.coreos.com/v1 kind: PrometheusRule metadata: name: argocd-component-status-alert namespace: openshift-gitops spec: groups: - name: ArgoCDComponentStatus rules: ... - alert: ApplicationSetControllerNotReady1 annotations: message: >- applicationSet controller deployment for Argo CD instance in namespace "default" is not running expr: >- kube_statefulset_status_replicas{statefulset="openshift-gitops-application-controller statefulset", namespace="openshift-gitops"} != kube_statefulset_status_replicas_ready{statefulset="openshift-gitops-application-controller statefulset", namespace="openshift-gitops"} for: 1m labels: severity: critical- 1
- Règle d'alerte dans PrometheusRule qui vérifie si les charges de travail créées par les instances Argo CD s'exécutent comme prévu.
4.14.2. Désactivation de la surveillance des charges de travail des ressources personnalisées d'Argo CD
Vous pouvez désactiver la surveillance de la charge de travail pour des instances Argo CD spécifiques. La désactivation de la surveillance de la charge de travail supprime la PrometheusRule créée.
Procédure
Fixe la valeur du champ
.spec.monitoring.enabledàfalsesur une instance de CD Argo donnée :Exemple de ressource personnalisée Argo CD
apiVersion: argoproj.io/v1alpha1 kind: ArgoCD metadata: name: example-argocd labels: example: repo spec: ... monitoring: enabled: false ...
4.15. Exécution des charges de travail du plan de contrôle GitOps sur des nœuds d'infrastructure
Vous pouvez utiliser les nœuds d'infrastructure pour éviter des coûts de facturation supplémentaires par rapport au nombre d'abonnements.
Vous pouvez utiliser OpenShift Container Platform pour exécuter certaines charges de travail sur les nœuds d'infrastructure installés par Red Hat OpenShift GitOps Operator. Cela comprend les charges de travail qui sont installées par Red Hat OpenShift GitOps Operator par défaut dans l'espace de noms openshift-gitops, y compris l'instance Argo CD par défaut dans cet espace de noms.
Toutes les autres instances d'Argo CD installées dans les espaces de noms des utilisateurs ne peuvent pas être exécutées sur les nœuds d'infrastructure.
4.15.1. Déplacer les charges de travail GitOps vers des nœuds d'infrastructure
Vous pouvez déplacer les charges de travail par défaut installées par Red Hat OpenShift GitOps vers les nœuds d'infrastructure. Les charges de travail qui peuvent être déplacées sont les suivantes :
-
kam deployment -
cluster deployment(service d'arrière-plan) -
openshift-gitops-applicationset-controller deployment -
openshift-gitops-dex-server deployment -
openshift-gitops-redis deployment -
openshift-gitops-redis-ha-haproxy deployment -
openshift-gitops-repo-sever deployment -
openshift-gitops-server deployment -
openshift-gitops-application-controller statefulset -
openshift-gitops-redis-server statefulset
Procédure
Étiqueter les nœuds existants en tant qu'infrastructure en exécutant la commande suivante :
$ oc label node <node-name> node-role.kubernetes.io/infra=Modifiez la ressource personnalisée (CR)
GitOpsServicepour ajouter le sélecteur de nœud d'infrastructure :$ oc edit gitopsservice -n openshift-gitopsDans le fichier CR
GitOpsService, ajoutez le champrunOnInfraà la sectionspecet attribuez-lui la valeurtrue. Ce champ déplace les charges de travail de l'espace de nomsopenshift-gitopsvers les nœuds d'infrastructure :apiVersion: pipelines.openshift.io/v1alpha1 kind: GitopsService metadata: name: cluster spec: runOnInfra: trueFacultatif : Appliquez des taches et isolez les charges de travail sur les nœuds d'infrastructure et empêchez d'autres charges de travail de se programmer sur ces nœuds.
$ oc adm taint nodes -l node-role.kubernetes.io/infra infra=reserved:NoSchedule infra=reserved:NoExecuteFacultatif : si vous appliquez des taches aux nœuds, vous pouvez ajouter des tolérances dans le CR
GitOpsService:spec: runOnInfra: true tolerations: - effect: NoSchedule key: infra value: reserved - effect: NoExecute key: infra value: reserved
Pour vérifier que les charges de travail sont planifiées sur les nœuds d'infrastructure dans l'espace de noms Red Hat OpenShift GitOps, cliquez sur n'importe quel nom de pod et assurez-vous que les adresses Node selector et Tolerations ont été ajoutées.
Tout ajout manuel de Node selectors et Tolerations dans le CR Argo CD par défaut sera remplacé par la bascule et les tolérances dans le CR GitOpsService.
4.16. Exigences de dimensionnement pour l'opérateur GitOps
La page des exigences de dimensionnement affiche les exigences de dimensionnement pour l'installation de Red Hat OpenShift GitOps sur OpenShift Container Platform. Elle fournit également les détails de dimensionnement pour l'instance ArgoCD par défaut qui est instanciée par l'opérateur GitOps.
4.16.1. Exigences de dimensionnement pour GitOps
Red Hat OpenShift GitOps est un moyen déclaratif de mettre en œuvre le déploiement continu pour les applications cloud-natives. Grâce à GitOps, vous pouvez définir et configurer les besoins en CPU et en mémoire de votre application.
Chaque fois que vous installez l'Opérateur Red Hat OpenShift GitOps, les ressources de l'espace de noms sont installées dans les limites définies. Si l'installation par défaut ne définit aucune limite ou demande, l'Opérateur échoue dans l'espace de noms avec des quotas. Sans ressources suffisantes, le cluster ne peut pas planifier les pods liés à ArgoCD. Le tableau suivant détaille les demandes de ressources et les limites pour les charges de travail par défaut :
| Charge de travail | Demandes de l'unité centrale | Limites de l'unité centrale | Demandes de mémoire | Limites de la mémoire |
|---|---|---|---|---|
| argocd-application-controller | 1 | 2 | 1024M | 2048M |
| applicationset-contrôleur | 1 | 2 | 512M | 1024M |
| serveur argocd | 0.125 | 0.5 | 128M | 256M |
| serveur argocd-repo | 0.5 | 1 | 256M | 1024M |
| argocd-redis | 0.25 | 0.5 | 128M | 256M |
| argocd-dex | 0.25 | 0.5 | 128M | 256M |
| HAProxy | 0.25 | 0.5 | 128M | 256M |
En option, vous pouvez également utiliser la ressource personnalisée ArgoCD avec la commande oc pour voir les détails et les modifier :
oc edit argocd <name of argo cd> -n namespace4.17. Résolution des problèmes dans Red Hat OpenShift GitOps
Lorsque vous travaillez avec Red Hat OpenShift GitOps, vous pouvez rencontrer des problèmes liés à la performance, à la surveillance, à la configuration et à d'autres aspects. Cette section vous aide à comprendre ces problèmes et fournit des solutions pour les résoudre.
4.17.1. Problème : Redémarrage automatique pendant la synchronisation du CD Argo avec les configurations de la machine
Dans Red Hat OpenShift Container Platform, les nœuds sont mis à jour automatiquement par le biais de Red Hat OpenShift Machine Config Operator (MCO). Un Machine Config Operator (MCO) est une ressource personnalisée utilisée par le cluster pour gérer le cycle de vie complet de ses nœuds.
Lorsqu'une ressource MCO est créée ou mise à jour dans un cluster, le MCO récupère la mise à jour, effectue les changements nécessaires sur les nœuds sélectionnés et redémarre les nœuds de manière gracieuse en cordonant, drainant et redémarrant ces nœuds. Il s'occupe de tout, du noyau au kubelet.
Cependant, les interactions entre le MCO et le workflow GitOps peuvent introduire des problèmes de performance majeurs et d'autres comportements indésirables. Cette section montre comment faire en sorte que le MCO et l'outil d'orchestration Argo CD GitOps fonctionnent bien ensemble.
4.17.1.1. Solution : Améliorer les performances des configurations de machines et d'Argo CD
Lorsque vous utilisez un opérateur de configuration de machine dans le cadre d'un flux de travail GitOps, la séquence suivante peut produire des performances sous-optimales :
- Argo CD lance un travail de synchronisation automatisé après un commit dans le dépôt Git qui contient les ressources de l'application.
- Si Argo CD remarque une configuration de machine nouvelle ou mise à jour pendant que l'opération de synchronisation est en cours, MCO prend en compte la modification de la configuration de la machine et commence à redémarrer les nœuds pour appliquer la modification.
- Si un nœud de redémarrage dans le cluster contient le contrôleur d'application Argo CD, le contrôleur d'application se termine et la synchronisation de l'application est interrompue.
Comme le MCO redémarre les nœuds dans un ordre séquentiel et que les charges de travail du CD Argo peuvent être reprogrammées à chaque redémarrage, la synchronisation peut prendre un certain temps avant d'être terminée. Il en résulte un comportement indéfini jusqu'à ce que le MCO ait redémarré tous les nœuds concernés par les configurations de machines dans le cadre de la synchronisation.
Chapitre 5. Jenkins
5.1. Configuration des images Jenkins
OpenShift Container Platform fournit une image de conteneur pour exécuter Jenkins. Cette image fournit une instance de serveur Jenkins, qui peut être utilisée pour mettre en place un flux de base pour les tests, l'intégration et la livraison en continu.
L'image est basée sur les images de base universelles de Red Hat (UBI).
OpenShift Container Platform suit la version LTS de Jenkins. OpenShift Container Platform fournit une image qui contient Jenkins 2.x.
Les images Jenkins d'OpenShift Container Platform sont disponibles sur Quay.io ou registry.redhat.io.
Par exemple :
$ podman pull registry.redhat.io/ocp-tools-4/jenkins-rhel8:<image_tag>Pour utiliser ces images, vous pouvez soit y accéder directement à partir de ces registres, soit les pousser dans votre registre d'images de conteneurs OpenShift Container Platform. En outre, vous pouvez créer un flux d'images qui pointe vers l'image, soit dans votre registre d'images de conteneurs, soit à l'emplacement externe. Vos ressources OpenShift Container Platform peuvent alors référencer le flux d'images.
Mais pour des raisons pratiques, OpenShift Container Platform fournit des flux d'images dans l'espace de noms openshift pour l'image de base de Jenkins ainsi que pour les images d'exemple d'agent fournies pour l'intégration d'OpenShift Container Platform avec Jenkins.
5.1.1. Configuration et personnalisation
Vous pouvez gérer l'authentification Jenkins de deux manières :
- L'authentification OAuth de OpenShift Container Platform fournie par le plugin OpenShift Container Platform Login.
- Authentification standard fournie par Jenkins.
5.1.1.1. OpenShift Container Platform Authentification OAuth
L'authentification OAuth est activée en configurant les options sur le panneau Configure Global Security dans l'interface utilisateur Jenkins, ou en définissant la variable d'environnement OPENSHIFT_ENABLE_OAUTH sur Jenkins Deployment configuration à une valeur autre que false. Cela active le plugin OpenShift Container Platform Login, qui récupère les informations de configuration à partir des données de pod ou en interagissant avec le serveur API OpenShift Container Platform.
Les informations d'identification valides sont contrôlées par le fournisseur d'identité d'OpenShift Container Platform.
Jenkins prend en charge l'accès par navigateur et hors navigateur.
Les utilisateurs valides sont automatiquement ajoutés à la matrice d'autorisation Jenkins lors de la connexion, où les rôles OpenShift Container Platform dictent les permissions Jenkins spécifiques que les utilisateurs ont. Les rôles utilisés par défaut sont les rôles prédéfinis admin, edit, et view. Le plugin de connexion exécute des requêtes self-SAR contre ces rôles dans le projet ou l'espace de noms dans lequel Jenkins est exécuté.
Les utilisateurs ayant le rôle admin disposent des autorisations traditionnelles des utilisateurs administratifs de Jenkins. Les utilisateurs ayant le rôle edit ou view ont progressivement moins d'autorisations.
Les rôles par défaut de OpenShift Container Platform admin, edit, et view et les permissions Jenkins attribuées à ces rôles dans l'instance Jenkins sont configurables.
Lorsque Jenkins est exécuté dans un pod OpenShift Container Platform, le plugin de connexion recherche une carte de configuration nommée openshift-jenkins-login-plugin-config dans l'espace de noms dans lequel Jenkins est exécuté.
Si ce plugin trouve et peut lire cette carte de configuration, vous pouvez définir le rôle pour les mappages de permissions Jenkins. Spécifiquement :
- Le plugin de connexion traite les paires de clés et de valeurs dans la carte de configuration comme des mappings de permission Jenkins vers des mappings de rôles OpenShift Container Platform.
- La clé est l'identifiant court du groupe de permission Jenkins et l'identifiant court de la permission Jenkins, ces deux éléments étant séparés par un trait d'union.
-
Si vous souhaitez ajouter l'autorisation
Overall Jenkins Administerà un rôle OpenShift Container Platform, la clé doit êtreOverall-Administer. - Pour avoir une idée des groupes de permissions et des ID de permissions disponibles, allez sur la page d'autorisation de la matrice dans la console Jenkins et les ID des groupes et des permissions individuelles dans le tableau qu'ils fournissent.
- La valeur de la paire clé/valeur est la liste des rôles OpenShift Container Platform auxquels la permission doit s'appliquer, chaque rôle étant séparé par une virgule.
-
Si vous souhaitez ajouter l'autorisation
Overall Jenkins Administeraux rôles par défautadminetedit, ainsi qu'à un nouveau rôle Jenkins que vous avez créé, la valeur de la cléOverall-Administerseraadmin,edit,jenkins.
L'utilisateur admin qui est pré-rempli dans l'image Jenkins d'OpenShift Container Platform avec des privilèges administratifs ne reçoit pas ces privilèges lorsque OpenShift Container Platform OAuth est utilisé. Pour accorder ces permissions, l'administrateur du cluster OpenShift Container Platform doit explicitement définir cet utilisateur dans le fournisseur d'identité OpenShift Container Platform et lui attribuer le rôle admin.
Les autorisations des utilisateurs Jenkins qui sont stockées peuvent être modifiées après la création initiale des utilisateurs. Le plugin OpenShift Container Platform Login interroge le serveur API OpenShift Container Platform pour les permissions et met à jour les permissions stockées dans Jenkins pour chaque utilisateur avec les permissions récupérées d'OpenShift Container Platform. Si l'interface utilisateur Jenkins est utilisée pour mettre à jour les permissions d'un utilisateur Jenkins, les changements de permissions sont écrasés la prochaine fois que le plugin interroge OpenShift Container Platform.
Vous pouvez contrôler la fréquence de l'interrogation à l'aide de la variable d'environnement OPENSHIFT_PERMISSIONS_POLL_INTERVAL. L'intervalle d'interrogation par défaut est de cinq minutes.
La manière la plus simple de créer un nouveau service Jenkins utilisant l'authentification OAuth est d'utiliser un modèle.
5.1.1.2. Authentification Jenkins
L'authentification Jenkins est utilisée par défaut si l'image est exécutée directement, sans utiliser de modèle.
Lors du premier démarrage de Jenkins, la configuration est créée avec l'utilisateur et le mot de passe de l'administrateur. Les informations d'identification de l'utilisateur par défaut sont admin et password. Configurez le mot de passe par défaut en définissant la variable d'environnement JENKINS_PASSWORD lorsque vous utilisez, et uniquement lorsque vous utilisez, l'authentification standard de Jenkins.
Procédure
Créez une application Jenkins qui utilise l'authentification Jenkins standard :
$ oc new-app -e \ JENKINS_PASSWORD=<password> \ ocp-tools-4/jenkins-rhel8
5.1.2. Variables d'environnement Jenkins
Le serveur Jenkins peut être configuré avec les variables d'environnement suivantes :
| Variable | Définition | Exemples de valeurs et de réglages |
|---|---|---|
|
|
Détermine si le plugin OpenShift Container Platform Login gère l'authentification lors de la connexion à Jenkins. Pour l'activer, réglez-le à |
Par défaut : |
|
|
Le mot de passe de l'utilisateur |
Par défaut : |
|
|
Ces valeurs contrôlent la taille maximale du tas de la JVM Jenkins. Si Par défaut, la taille maximale du tas de la JVM Jenkins est fixée à 50 % de la limite de mémoire du conteneur, sans plafond. |
|
|
|
Ces valeurs contrôlent la taille initiale du tas de la JVM Jenkins. Si Par défaut, la JVM définit la taille initiale du tas. |
|
|
| S'il est défini, il spécifie un nombre entier de cœurs utilisés pour dimensionner le nombre de threads internes de la JVM. |
Exemple de réglage : |
|
| Spécifie les options à appliquer à toutes les JVM s'exécutant dans ce conteneur. Il n'est pas recommandé de remplacer cette valeur. |
Par défaut : |
|
| Spécifie les paramètres de collecte des déchets de la JVM Jenkins. Il n'est pas recommandé de remplacer cette valeur. |
Par défaut : |
|
| Spécifie des options supplémentaires pour la JVM Jenkins. Ces options sont ajoutées à toutes les autres options, y compris les options Java ci-dessus, et peuvent être utilisées pour les remplacer si nécessaire. Séparez chaque option supplémentaire par un espace ; si une option contient des caractères d'espacement, échappez-les avec une barre oblique inverse. |
Exemples de paramètres : |
|
| Spécifie les arguments pour Jenkins. | |
|
|
Spécifie les plugins Jenkins supplémentaires à installer lors de la première exécution du conteneur ou lorsque |
Exemple de réglage : |
|
| Spécifie l'intervalle en millisecondes pendant lequel le plugin OpenShift Container Platform Login interroge OpenShift Container Platform sur les permissions associées à chaque utilisateur défini dans Jenkins. |
Valeur par défaut : |
|
|
Lors de l'exécution de cette image avec un volume persistant (PV) OpenShift Container Platform pour le répertoire de configuration Jenkins, le transfert de la configuration de l'image vers le PV n'est effectué que lors du premier démarrage de l'image, car le PV est attribué lors de la création de la réclamation de volume persistant (PVC). Si vous créez une image personnalisée qui étend cette image et met à jour la configuration dans l'image personnalisée après le démarrage initial, la configuration n'est pas copiée à moins que vous ne définissiez cette variable d'environnement à |
Par défaut : |
|
|
Lors de l'exécution de cette image avec un PV OpenShift Container Platform pour le répertoire de configuration Jenkins, le transfert des plugins de l'image vers le PV n'est effectué que lors du premier démarrage de l'image car le PV est attribué lors de la création du PVC. Si vous créez une image personnalisée qui étend cette image et met à jour les plugins dans l'image personnalisée après le démarrage initial, les plugins ne sont pas copiés à moins que vous ne définissiez cette variable d'environnement sur |
Par défaut : |
|
|
Lors de l'exécution de cette image avec un PVC OpenShift Container Platform pour le répertoire de configuration Jenkins, cette variable d'environnement permet au fichier journal des erreurs fatales de persister lorsqu'une erreur fatale se produit. Le fichier d'erreurs fatales est enregistré à l'adresse |
Par défaut : |
|
|
La définition de cette valeur remplace l'image utilisée pour le conteneur |
Par défaut : |
|
|
La définition de cette valeur remplace l'image utilisée pour le conteneur |
Par défaut : |
|
| La définition de cette valeur permet de contrôler le fonctionnement de la JVM lorsqu'elle est exécutée sur un nœud FIPS. Pour plus d'informations, voir Configurer OpenJDK 11 en mode FIPS. |
Par défaut : |
5.1.3. Fournir à Jenkins un accès à l'ensemble des projets
Si vous voulez exécuter Jenkins ailleurs que dans votre projet, vous devez fournir un jeton d'accès à Jenkins pour qu'il puisse accéder à votre projet.
Procédure
Identifiez le secret du compte de service qui dispose des autorisations appropriées pour accéder au projet auquel Jenkins doit accéder :
$ oc describe serviceaccount jenkinsExemple de sortie
Name: default Labels: <none> Secrets: { jenkins-token-uyswp } { jenkins-dockercfg-xcr3d } Tokens: jenkins-token-izv1u jenkins-token-uyswpDans ce cas, le secret est nommé
jenkins-token-uyswp.Récupérer le jeton du secret :
$ oc describe secret <nom du secret ci-dessus>Exemple de sortie
Name: jenkins-token-uyswp Labels: <none> Annotations: kubernetes.io/service-account.name=jenkins,kubernetes.io/service-account.uid=32f5b661-2a8f-11e5-9528-3c970e3bf0b7 Type: kubernetes.io/service-account-token Data ==== ca.crt: 1066 bytes token: eyJhbGc..<content cut>....wRALe paramètre token contient la valeur du token dont Jenkins a besoin pour accéder au projet.
5.1.4. Points de montage inter-volumes Jenkins
L'image Jenkins peut être exécutée avec des volumes montés pour permettre un stockage persistant de la configuration :
-
/var/lib/jenkinsest le répertoire de données dans lequel Jenkins stocke les fichiers de configuration, y compris les définitions de tâches.
5.1.5. Personnalisation de l'image Jenkins grâce à la méthode "source-to-image
Pour personnaliser l'image Jenkins officielle d'OpenShift Container Platform, vous pouvez utiliser l'image en tant que source-to-image (S2I).
Vous pouvez utiliser S2I pour copier vos définitions de tâches Jenkins personnalisées, ajouter des plugins supplémentaires ou remplacer le fichier config.xml fourni par votre propre configuration.
Pour inclure vos modifications dans l'image Jenkins, vous devez disposer d'un dépôt Git avec la structure de répertoire suivante :
plugins- Ce répertoire contient les plugins binaires Jenkins que vous souhaitez copier dans Jenkins.
plugins.txt- Ce fichier liste les plugins que vous souhaitez installer en utilisant la syntaxe suivante :
pluginId:pluginVersionconfiguration/jobs- Ce répertoire contient les définitions des tâches de Jenkins.
configuration/config.xml- Ce fichier contient votre configuration Jenkins personnalisée.
Le contenu du répertoire configuration/ est copié dans le répertoire /var/lib/jenkins/, de sorte que vous pouvez également y inclure des fichiers supplémentaires, tels que credentials.xml.
L'exemple de configuration de construction personnalise l'image Jenkins dans OpenShift Container Platform
apiVersion: build.openshift.io/v1
kind: BuildConfig
metadata:
name: custom-jenkins-build
spec:
source:
git:
uri: https://github.com/custom/repository
type: Git
strategy:
sourceStrategy:
from:
kind: ImageStreamTag
name: jenkins:2
namespace: openshift
type: Source
output:
to:
kind: ImageStreamTag
name: custom-jenkins:latest- 1
- Le paramètre
sourcedéfinit le dépôt Git source avec la disposition décrite ci-dessus. - 2
- Le paramètre
strategydéfinit l'image originale de Jenkins à utiliser comme image source pour la construction. - 3
- Le paramètre
outputdéfinit l'image Jenkins personnalisée résultante que vous pouvez utiliser dans les configurations de déploiement à la place de l'image Jenkins officielle.
5.1.6. Configuration du plugin Jenkins Kubernetes
L'image OpenShift Jenkins inclut le plugin Kubernetes préinstallé pour Jenkins afin que les agents Jenkins puissent être provisionnés dynamiquement sur plusieurs hôtes de conteneurs en utilisant Kubernetes et OpenShift Container Platform.
Pour utiliser le plugin Kubernetes, OpenShift Container Platform fournit une image OpenShift Agent Base qui peut être utilisée comme agent Jenkins.
OpenShift Container Platform 4.11 déplace les images OpenShift Jenkins et OpenShift Agent Base vers le dépôt ocp-tools-4 à l'adresse registry.redhat.io afin que Red Hat puisse produire et mettre à jour les images en dehors du cycle de vie d'OpenShift Container Platform. Auparavant, ces images se trouvaient dans la charge utile d'installation d'OpenShift Container Platform et dans le dépôt openshift4 à l'adresse registry.redhat.io.
Les images OpenShift Jenkins Maven et NodeJS Agent ont été supprimées de la charge utile OpenShift Container Platform 4.11. Red Hat ne produit plus ces images et elles ne sont pas disponibles dans le dépôt ocp-tools-4 à l'adresse registry.redhat.io. Red Hat maintient les versions 4.10 et antérieures de ces images pour toutes les corrections de bogues importantes ou les CVE de sécurité, en suivant la politique de cycle de vie d'OpenShift Container Platform.
Pour plus d'informations, voir le lien "Changements importants pour OpenShift Jenkins images" dans la section suivante "Ressources supplémentaires".
Les images des agents Maven et Node.js sont automatiquement configurées en tant qu'images de modèle de pod Kubernetes dans la configuration d'image Jenkins de la plateforme OpenShift Container pour le plugin Kubernetes. Cette configuration comprend des étiquettes pour chaque image que vous pouvez appliquer à tous vos travaux Jenkins sous leur paramètre Restrict where this project can be run. Si le label est appliqué, les travaux s'exécutent sous un pod OpenShift Container Platform exécutant l'image d'agent correspondante.
Dans OpenShift Container Platform 4.10 et plus, le modèle recommandé pour exécuter des agents Jenkins à l'aide du plugin Kubernetes est d'utiliser des modèles de pods avec les conteneurs jnlp et sidecar. Le conteneur jnlp utilise l'image de l'agent Jenkins Base d'OpenShift Container Platform pour faciliter le lancement d'un pod séparé pour votre construction. L'image du conteneur sidecar contient les outils nécessaires pour construire dans une langue particulière au sein du pod séparé qui a été lancé. De nombreuses images de conteneurs du Red Hat Container Catalog sont référencées dans les flux d'images d'exemple dans l'espace de noms openshift. L'image Jenkins d'OpenShift Container Platform possède un modèle de pod nommé java-build avec des conteneurs sidecar qui démontrent cette approche. Ce modèle de pod utilise la dernière version de Java fournie par le flux d'images java dans l'espace de noms openshift.
L'image Jenkins permet également l'auto-découverte et l'auto-configuration d'images d'agents supplémentaires pour le plugin Kubernetes.
Avec le plugin de synchronisation OpenShift Container Platform, au démarrage de Jenkins, l'image Jenkins recherche dans le projet qu'elle exécute, ou dans les projets listés dans la configuration du plugin, les éléments suivants :
-
Flux d'images dont l'étiquette
roleest définie surjenkins-agent. -
Balises de flux d'images avec l'annotation
rolefixée àjenkins-agent. -
Config maps with the
rolelabel set tojenkins-agent.
Lorsque l'image Jenkins trouve un flux d'images avec l'étiquette appropriée, ou une balise de flux d'images avec l'annotation appropriée, elle génère la configuration du plugin Kubernetes correspondant. De cette façon, vous pouvez affecter vos travaux Jenkins à l'exécution d'un pod utilisant l'image de conteneur fournie par le flux d'images.
Les références de nom et d'image du flux d'images ou de la balise de flux d'images sont mises en correspondance avec les champs de nom et d'image dans le modèle de pod du plugin Kubernetes. Vous pouvez contrôler le champ label du modèle de pod de plugin Kubernetes en définissant une annotation sur l'objet flux d'images ou balise de flux d'images avec la clé agent-label. Sinon, le nom est utilisé comme étiquette.
Ne vous connectez pas à la console Jenkins pour modifier la configuration du modèle de pod. Si vous le faites après la création du modèle de pod, et que le plugin OpenShift Container Platform Sync détecte que l'image associée au flux d'images ou à la balise de flux d'images a changé, il remplace le modèle de pod et écrase ces changements de configuration. Vous ne pouvez pas fusionner une nouvelle configuration avec la configuration existante.
Envisagez l'approche de la carte de configuration si vous avez des besoins de configuration plus complexes.
Lorsqu'elle trouve une carte de configuration avec l'étiquette appropriée, l'image Jenkins suppose que toutes les valeurs de la charge utile de données clé-valeur de la carte de configuration contiennent un langage de balisage extensible (XML) cohérent avec le format de configuration pour Jenkins et les modèles de pods du plugin Kubernetes. L'un des principaux avantages des cartes de configuration par rapport aux flux d'images et aux balises de flux d'images est que vous pouvez contrôler tous les paramètres du modèle de pod plugin Kubernetes.
Exemple de carte de configuration pour jenkins-agent
kind: ConfigMap
apiVersion: v1
metadata:
name: jenkins-agent
labels:
role: jenkins-agent
data:
template1: |-
<org.csanchez.jenkins.plugins.kubernetes.PodTemplate>
<inheritFrom></inheritFrom>
<name>template1</name>
<instanceCap>2147483647</instanceCap>
<idleMinutes>0</idleMinutes>
<label>template1</label>
<serviceAccount>jenkins</serviceAccount>
<nodeSelector></nodeSelector>
<volumes/>
<containers>
<org.csanchez.jenkins.plugins.kubernetes.ContainerTemplate>
<name>jnlp</name>
<image>openshift/jenkins-agent-maven-35-centos7:v3.10</image>
<privileged>false</privileged>
<alwaysPullImage>true</alwaysPullImage>
<workingDir>/tmp</workingDir>
<command></command>
<args>${computer.jnlpmac} ${computer.name}</args>
<ttyEnabled>false</ttyEnabled>
<resourceRequestCpu></resourceRequestCpu>
<resourceRequestMemory></resourceRequestMemory>
<resourceLimitCpu></resourceLimitCpu>
<resourceLimitMemory></resourceLimitMemory>
<envVars/>
</org.csanchez.jenkins.plugins.kubernetes.ContainerTemplate>
</containers>
<envVars/>
<annotations/>
<imagePullSecrets/>
<nodeProperties/>
</org.csanchez.jenkins.plugins.kubernetes.PodTemplate>
L'exemple suivant montre deux conteneurs qui référencent des flux d'images dans l'espace de noms openshift. L'un des conteneurs gère le contrat JNLP pour lancer des pods en tant qu'agents Jenkins. L'autre conteneur utilise une image contenant des outils de construction de code dans un langage de codage particulier :
kind: ConfigMap
apiVersion: v1
metadata:
name: jenkins-agent
labels:
role: jenkins-agent
data:
template2: |-
<org.csanchez.jenkins.plugins.kubernetes.PodTemplate>
<inheritFrom></inheritFrom>
<name>template2</name>
<instanceCap>2147483647</instanceCap>
<idleMinutes>0</idleMinutes>
<label>template2</label>
<serviceAccount>jenkins</serviceAccount>
<nodeSelector></nodeSelector>
<volumes/>
<containers>
<org.csanchez.jenkins.plugins.kubernetes.ContainerTemplate>
<name>jnlp</name>
<image>image-registry.openshift-image-registry.svc:5000/openshift/jenkins-agent-base-rhel8:latest</image>
<privileged>false</privileged>
<alwaysPullImage>true</alwaysPullImage>
<workingDir>/home/jenkins/agent</workingDir>
<command></command>
<args>\$(JENKINS_SECRET) \$(JENKINS_NAME)</args>
<ttyEnabled>false</ttyEnabled>
<resourceRequestCpu></resourceRequestCpu>
<resourceRequestMemory></resourceRequestMemory>
<resourceLimitCpu></resourceLimitCpu>
<resourceLimitMemory></resourceLimitMemory>
<envVars/>
</org.csanchez.jenkins.plugins.kubernetes.ContainerTemplate>
<org.csanchez.jenkins.plugins.kubernetes.ContainerTemplate>
<name>java</name>
<image>image-registry.openshift-image-registry.svc:5000/openshift/java:latest</image>
<privileged>false</privileged>
<alwaysPullImage>true</alwaysPullImage>
<workingDir>/home/jenkins/agent</workingDir>
<command>cat</command>
<args></args>
<ttyEnabled>true</ttyEnabled>
<resourceRequestCpu></resourceRequestCpu>
<resourceRequestMemory></resourceRequestMemory>
<resourceLimitCpu></resourceLimitCpu>
<resourceLimitMemory></resourceLimitMemory>
<envVars/>
</org.csanchez.jenkins.plugins.kubernetes.ContainerTemplate>
</containers>
<envVars/>
<annotations/>
<imagePullSecrets/>
<nodeProperties/>
</org.csanchez.jenkins.plugins.kubernetes.PodTemplate>Ne vous connectez pas à la console Jenkins pour modifier la configuration du modèle de pod. Si vous le faites après la création du modèle de pod, et que le plugin OpenShift Container Platform Sync détecte que l'image associée au flux d'images ou à la balise de flux d'images a changé, il remplace le modèle de pod et écrase ces changements de configuration. Vous ne pouvez pas fusionner une nouvelle configuration avec la configuration existante.
Envisagez l'approche de la carte de configuration si vous avez des besoins de configuration plus complexes.
Une fois installé, le plugin OpenShift Container Platform Sync surveille le serveur API d'OpenShift Container Platform pour les mises à jour des flux d'images, des balises de flux d'images et des cartes de configuration et ajuste la configuration du plugin Kubernetes.
Les règles suivantes s'appliquent :
-
La suppression de l'étiquette ou de l'annotation de la carte de configuration, du flux d'images ou de la balise de flux d'images supprime toute
PodTemplateexistante de la configuration du plugin Kubernetes. - Si ces objets sont supprimés, la configuration correspondante est supprimée du plugin Kubernetes.
-
Si vous créez des objets
ConfigMap,ImageStream, ouImageStreamTagcorrectement étiquetés ou annotés, ou si vous ajoutez des étiquettes après leur création initiale, cela entraîne la création d'unPodTemplatedans la configuration de Kubernetes-plugin. -
Dans le cas du formulaire
PodTemplateby config map, les modifications apportées aux données de la config map pourPodTemplatesont appliquées aux paramètres dePodTemplatedans la configuration du plugin Kubernetes. Les modifications remplacent également toutes les modifications apportées àPodTemplatevia l'interface utilisateur Jenkins entre les modifications apportées à la carte de configuration.
Pour utiliser une image de conteneur comme agent Jenkins, l'image doit exécuter l'agent comme point d'entrée. Pour plus de détails, voir la documentation officielle de Jenkins.
Ressources complémentaires
5.1.7. Permissions Jenkins
Si, dans la carte de configuration, l'élément <serviceAccount> du modèle XML de pod est le compte de service OpenShift Container Platform utilisé pour le pod résultant, les informations d'identification du compte de service sont montées dans le pod. Les permissions sont associées au compte de service et contrôlent quelles opérations contre le maître OpenShift Container Platform sont autorisées à partir du pod.
Considérons le scénario suivant avec des comptes de service utilisés pour le pod, qui est lancé par le plugin Kubernetes qui s'exécute dans l'image Jenkins d'OpenShift Container Platform.
Si vous utilisez le modèle d'exemple pour Jenkins fourni par OpenShift Container Platform, le compte de service jenkins est défini avec le rôle edit pour le projet dans lequel Jenkins s'exécute, et le pod Jenkins maître a ce compte de service monté.
Les deux modèles de pods Maven et NodeJS par défaut qui sont injectés dans la configuration Jenkins sont également configurés pour utiliser le même compte de service que le maître Jenkins.
- Tous les modèles de pods qui sont automatiquement découverts par le plugin de synchronisation d'OpenShift Container Platform parce que leurs flux d'images ou leurs balises de flux d'images ont l'étiquette ou les annotations requises sont configurés pour utiliser le compte de service principal Jenkins comme compte de service.
-
Pour les autres façons de fournir une définition de modèle de pod dans Jenkins et le plugin Kubernetes, vous devez spécifier explicitement le compte de service à utiliser. Ces autres moyens incluent la console Jenkins, le pipeline DSL
podTemplatefourni par le plugin Kubernetes, ou l'étiquetage d'une carte de configuration dont les données sont la configuration XML d'un modèle de pod. -
Si vous ne spécifiez pas de valeur pour le compte de service, le compte de service
defaultest utilisé. - Assurez-vous que le compte de service utilisé a les permissions, les rôles, etc. nécessaires définis dans OpenShift Container Platform pour manipuler les projets que vous choisissez de manipuler à l'intérieur du pod.
5.1.8. Création d'un service Jenkins à partir d'un modèle
Les modèles fournissent des champs de paramètres pour définir toutes les variables d'environnement avec des valeurs par défaut prédéfinies. OpenShift Container Platform fournit des modèles pour faciliter la création d'un nouveau service Jenkins. Les modèles Jenkins doivent être enregistrés dans le projet par défaut openshift par votre administrateur de cluster lors de la configuration initiale du cluster.
Les deux modèles disponibles définissent tous deux une configuration de déploiement et un service. Les modèles diffèrent par leur stratégie de stockage, qui détermine si le contenu de Jenkins persiste après le redémarrage d'un pod.
Un pod peut être redémarré lorsqu'il est déplacé vers un autre nœud ou lorsqu'une mise à jour de la configuration de déploiement déclenche un redéploiement.
-
jenkins-ephemeralutilise un stockage éphémère. Au redémarrage du pod, toutes les données sont perdues. Ce modèle n'est utile que pour le développement ou les tests. -
jenkins-persistentutilise un volume persistant (PV). Les données survivent à un redémarrage du pod.
Pour utiliser un magasin PV, l'administrateur du cluster doit définir un pool PV dans le déploiement d'OpenShift Container Platform.
Après avoir sélectionné le modèle que vous souhaitez, vous devez l'instancier pour pouvoir utiliser Jenkins.
Procédure
Créez une nouvelle application Jenkins en utilisant l'une des méthodes suivantes :
UN PV :
$ oc new-app jenkins-persistentOu un volume de type
emptyDirdont la configuration ne persiste pas lors des redémarrages de pods :$ oc new-app jenkins-ephemeral
Avec les deux modèles, vous pouvez lancer oc describe sur eux pour voir tous les paramètres disponibles pour la surcharge.
Par exemple :
$ oc describe jenkins-ephemeral5.1.9. Utilisation du plugin Jenkins Kubernetes
Dans l'exemple suivant, l'objet openshift-jee-sample BuildConfig provoque le provisionnement dynamique d'un pod d'agent Maven Jenkins. Le pod clone du code source Java, construit un fichier WAR et provoque l'exécution d'un second BuildConfig, openshift-jee-sample-docker. Le second BuildConfig place le nouveau fichier WAR dans une image de conteneur.
OpenShift Container Platform 4.11 a supprimé les images OpenShift Jenkins Maven et NodeJS Agent de son payload. Red Hat ne produit plus ces images et elles ne sont pas disponibles dans le dépôt ocp-tools-4 à l'adresse registry.redhat.io. Red Hat maintient les versions 4.10 et antérieures de ces images pour toutes les corrections de bogues importantes ou les CVE de sécurité, en suivant la politique de cycle de vie de OpenShift Container Platform.
Pour plus d'informations, voir le lien "Changements importants pour OpenShift Jenkins images" dans la section suivante "Ressources supplémentaires".
Exemple de BuildConfig qui utilise le plugin Jenkins Kubernetes
kind: List
apiVersion: v1
items:
- kind: ImageStream
apiVersion: image.openshift.io/v1
metadata:
name: openshift-jee-sample
- kind: BuildConfig
apiVersion: build.openshift.io/v1
metadata:
name: openshift-jee-sample-docker
spec:
strategy:
type: Docker
source:
type: Docker
dockerfile: |-
FROM openshift/wildfly-101-centos7:latest
COPY ROOT.war /wildfly/standalone/deployments/ROOT.war
CMD $STI_SCRIPTS_PATH/run
binary:
asFile: ROOT.war
output:
to:
kind: ImageStreamTag
name: openshift-jee-sample:latest
- kind: BuildConfig
apiVersion: build.openshift.io/v1
metadata:
name: openshift-jee-sample
spec:
strategy:
type: JenkinsPipeline
jenkinsPipelineStrategy:
jenkinsfile: |-
node("maven") {
sh "git clone https://github.com/openshift/openshift-jee-sample.git ."
sh "mvn -B -Popenshift package"
sh "oc start-build -F openshift-jee-sample-docker --from-file=target/ROOT.war"
}
triggers:
- type: ConfigChangeIl est également possible d'outrepasser la spécification du pod de l'agent Jenkins créé dynamiquement. L'exemple suivant est une modification de l'exemple précédent, qui surcharge la mémoire du conteneur et spécifie une variable d'environnement.
Exemple de BuildConfig qui utilise le plugin Jenkins Kubernetes, en spécifiant la limite de mémoire et la variable d'environnement
kind: BuildConfig
apiVersion: build.openshift.io/v1
metadata:
name: openshift-jee-sample
spec:
strategy:
type: JenkinsPipeline
jenkinsPipelineStrategy:
jenkinsfile: |-
podTemplate(label: "mypod",
cloud: "openshift",
inheritFrom: "maven",
containers: [
containerTemplate(name: "jnlp",
image: "openshift/jenkins-agent-maven-35-centos7:v3.10",
resourceRequestMemory: "512Mi",
resourceLimitMemory: "512Mi",
envVars: [
envVar(key: "CONTAINER_HEAP_PERCENT", value: "0.25")
])
]) {
node("mypod") {
sh "git clone https://github.com/openshift/openshift-jee-sample.git ."
sh "mvn -B -Popenshift package"
sh "oc start-build -F openshift-jee-sample-docker --from-file=target/ROOT.war"
}
}
triggers:
- type: ConfigChange- 1
- Un nouveau modèle de pod appelé
mypodest défini dynamiquement. Le nom du nouveau modèle de pod est référencé dans la strophe du nœud. - 2
- La valeur
clouddoit être réglée suropenshift. - 3
- Le nouveau modèle de pod peut hériter sa configuration d'un modèle de pod existant. Dans ce cas, il hérite du modèle de pod Maven qui est prédéfini par OpenShift Container Platform.
- 4
- Cet exemple remplace les valeurs du conteneur préexistant et doit être spécifié par son nom. Toutes les images de l'agent Jenkins livrées avec OpenShift Container Platform utilisent le nom de conteneur
jnlp. - 5
- Spécifiez à nouveau le nom de l'image du conteneur. Il s'agit d'un problème connu.
- 6
- Une demande de mémoire de
512 Miest spécifiée. - 7
- Une limite de mémoire de
512 Miest spécifiée. - 8
- Une variable d'environnement
CONTAINER_HEAP_PERCENT, avec la valeur0.25, est spécifiée. - 9
- La strophe de nœud fait référence au nom du modèle de pod défini.
Par défaut, le pod est supprimé lorsque la construction est terminée. Ce comportement peut être modifié avec le plugin ou dans un fichier Jenkins du pipeline.
Upstream Jenkins a récemment introduit un format déclaratif YAML pour définir un DSL de pipeline podTemplate en ligne avec vos pipelines. Un exemple de ce format, utilisant le modèle de pod java-builder défini dans l'image Jenkins de OpenShift Container Platform :
def nodeLabel = 'java-buidler'
pipeline {
agent {
kubernetes {
cloud 'openshift'
label nodeLabel
yaml """
apiVersion: v1
kind: Pod
metadata:
labels:
worker: ${nodeLabel}
spec:
containers:
- name: jnlp
image: image-registry.openshift-image-registry.svc:5000/openshift/jenkins-agent-base-rhel8:latest
args: ['\$(JENKINS_SECRET)', '\$(JENKINS_NAME)']
- name: java
image: image-registry.openshift-image-registry.svc:5000/openshift/java:latest
command:
- cat
tty: true
"""
}
}
options {
timeout(time: 20, unit: 'MINUTES')
}
stages {
stage('Build App') {
steps {
container("java") {
sh "mvn --version"
}
}
}
}
}Ressources complémentaires
5.1.10. Besoins en mémoire de Jenkins
Lorsqu'il est déployé par les modèles Jenkins Ephemeral ou Jenkins Persistent fournis, la limite de mémoire par défaut est de 1 Gi.
Par défaut, tous les autres processus qui s'exécutent dans le conteneur Jenkins ne peuvent pas utiliser plus de 512 MiB de mémoire. S'ils ont besoin de plus de mémoire, le conteneur s'arrête. Il est donc fortement recommandé que les pipelines exécutent des commandes externes dans un conteneur d'agent dans la mesure du possible.
Et si les quotas de Project le permettent, voir les recommandations de la documentation Jenkins sur ce qu'un maître Jenkins devrait avoir du point de vue de la mémoire. Ces recommandations préconisent d'allouer encore plus de mémoire au maître Jenkins.
Il est recommandé de spécifier les valeurs de demande et de limite de mémoire sur les conteneurs d'agents créés par le plugin Jenkins Kubernetes. Les administrateurs peuvent définir des valeurs par défaut pour chaque image d'agent via la configuration de Jenkins. Les paramètres de demande et de limite de mémoire peuvent également être modifiés pour chaque conteneur.
Vous pouvez augmenter la quantité de mémoire disponible pour Jenkins en remplaçant le paramètre MEMORY_LIMIT lors de l'instanciation du modèle Jenkins Ephemeral ou Jenkins Persistent.
5.2. Agent Jenkins
OpenShift Container Platform fournit une image de base à utiliser en tant qu'agent Jenkins.
L'image de base des agents Jenkins présente les caractéristiques suivantes :
-
Il contient à la fois les outils nécessaires, Java sans tête, le client Jenkins JNLP, et les outils utiles, notamment
git,tar,zip, etnss, entre autres. - Établit l'agent JNLP comme point d'entrée.
-
Inclut l'outil client
ocpour invoquer des opérations en ligne de commande à partir des travaux Jenkins. -
Fournit des fichiers Docker pour les images Red Hat Enterprise Linux (RHEL) et
localdev.
Utilisez une version de l'image de l'agent qui est appropriée pour votre version d'OpenShift Container Platform. L'intégration d'une version du client oc qui n'est pas compatible avec la version d'OpenShift Container Platform peut entraîner un comportement inattendu.
L'image Jenkins d'OpenShift Container Platform définit également le modèle de pod java-builder suivant pour illustrer la façon dont vous pouvez utiliser l'image de l'agent avec le plugin Jenkins Kubernetes.
The java-builder pod template employs two containers: * A jnlp container that uses the OpenShift Container Platform Base agent image and handles the JNLP contract for starting and stopping Jenkins agents. * A java container that uses the java OpenShift Container Platform Sample ImageStream, which contains the various Java binaries, including the Maven binary mvn, for building code.
5.2.1. Images de l'agent Jenkins
Les images de l'agent Jenkins d'OpenShift Container Platform sont disponibles sur Quay.io ou registry.redhat.io.
Les images Jenkins sont disponibles via le Red Hat Registry :
$ docker pull registry.redhat.io/ocp-tools-4/jenkins-rhel8:<image_tag>$ docker pull registry.redhat.io/ocp-tools-4/jenkins-agent-base-rhel8:<image_tag>Pour utiliser ces images, vous pouvez soit y accéder directement depuis Quay.io ou registry.redhat.io, soit les pousser dans votre registre d'images de conteneurs OpenShift Container Platform.
5.2.2. Variables d'environnement de l'agent Jenkins
Chaque conteneur d'agent Jenkins peut être configuré avec les variables d'environnement suivantes.
| Variable | Définition | Exemples de valeurs et de réglages |
|---|---|---|
|
|
Ces valeurs contrôlent la taille maximale du tas de la JVM Jenkins. Si Par défaut, la taille maximale du tas de la JVM Jenkins est fixée à 50 % de la limite de mémoire du conteneur, sans plafond. |
|
|
|
Ces valeurs contrôlent la taille initiale du tas de la JVM Jenkins. Si Par défaut, la JVM définit la taille initiale du tas. |
|
|
| S'il est défini, il spécifie un nombre entier de cœurs utilisés pour dimensionner le nombre de threads internes de la JVM. |
Exemple de réglage : |
|
| Spécifie les options à appliquer à toutes les JVM s'exécutant dans ce conteneur. Il n'est pas recommandé de remplacer cette valeur. |
Par défaut : |
|
| Spécifie les paramètres de collecte des déchets de la JVM Jenkins. Il n'est pas recommandé de remplacer cette valeur. |
Par défaut : |
|
| Spécifie des options supplémentaires pour la JVM Jenkins. Ces options sont ajoutées à toutes les autres options, y compris les options Java ci-dessus, et peuvent être utilisées pour les remplacer, si nécessaire. Séparez chaque option supplémentaire par un espace et si une option contient des caractères d'espacement, échappez-les avec une barre oblique inverse. |
Exemple de paramètres : |
|
|
Spécifie la version de Java à utiliser pour exécuter l'agent dans son conteneur. Deux versions de Java sont installées dans l'image de base du conteneur : |
La valeur par défaut est
Exemple de réglage : |
5.2.3. Besoins en mémoire de l'agent Jenkins
Une JVM est utilisée dans tous les agents Jenkins pour héberger l'agent Jenkins JNLP ainsi que pour exécuter toutes les applications Java telles que javac, Maven ou Gradle.
Par défaut, la JVM de l'agent JNLP de Jenkins utilise 50% de la limite de mémoire du conteneur pour son tas. Cette valeur peut être modifiée par la variable d'environnement CONTAINER_HEAP_PERCENT. Elle peut également être plafonnée à une limite supérieure ou être entièrement supprimée.
Par défaut, tout autre processus exécuté dans le conteneur de l'agent Jenkins, comme les scripts shell ou les commandes oc exécutées à partir des pipelines, ne peut pas utiliser plus de la limite de mémoire restante de 50 % sans provoquer un kill OOM.
Par défaut, chaque processus JVM supplémentaire qui s'exécute dans un conteneur d'agent Jenkins utilise jusqu'à 25 % de la limite de mémoire du conteneur pour son tas. Il peut être nécessaire d'ajuster cette limite pour de nombreuses charges de travail de construction.
5.2.4. Agent Jenkins Gradle builds
L'hébergement des builds Gradle dans l'agent Jenkins sur OpenShift Container Platform présente des complications supplémentaires car, en plus de l'agent JNLP de Jenkins et des JVM Gradle, Gradle génère une troisième JVM pour exécuter les tests s'ils sont spécifiés.
Les paramètres suivants sont suggérés comme point de départ pour exécuter des builds Gradle dans un agent Jenkins à mémoire limitée sur OpenShift Container Platform. Vous pouvez modifier ces paramètres selon vos besoins.
-
Assurez-vous que le démon Gradle à longue durée de vie est désactivé en ajoutant
org.gradle.daemon=falseau fichiergradle.properties. -
Désactivez l'exécution parallèle de la compilation en vous assurant que
org.gradle.parallel=truen'est pas défini dans le fichiergradle.propertieset que--paralleln'est pas défini en tant qu'argument de ligne de commande. -
Pour éviter que les compilations Java ne s'exécutent en dehors du processus, définissez
java { options.fork = false }dans le fichierbuild.gradle. -
Désactiver plusieurs processus de test supplémentaires en s'assurant que
test { maxParallelForks = 1 }est défini dans le fichierbuild.gradle. -
Remplacer les paramètres de mémoire de la JVM Gradle par les variables d'environnement
GRADLE_OPTS,JAVA_OPTSouJAVA_TOOL_OPTIONS. -
Définissez la taille maximale du tas et les arguments de la JVM pour n'importe quelle JVM de test Gradle en définissant les paramètres
maxHeapSizeetjvmArgsdansbuild.gradle, ou par le biais de l'argument de ligne de commande-Dorg.gradle.jvmargs.
5.2.5. Rétention des pods de l'agent Jenkins
Les pods de l'agent Jenkins sont supprimés par défaut une fois la construction terminée ou arrêtée. Ce comportement peut être modifié par le paramètre de rétention des pods du plugin Kubernetes. La rétention des pods peut être définie pour toutes les constructions Jenkins, avec des dérogations pour chaque modèle de pod. Les comportements suivants sont pris en charge :
-
Alwaysconserve le pod de construction quel que soit le résultat de la construction. -
Defaultutilise la valeur du plugin, qui est uniquement le modèle de pod. -
Neversupprime toujours le pod. -
On Failureconserve le pod s'il échoue pendant la construction.
Vous pouvez modifier la rétention des pods dans le fichier Jenkins du pipeline :
podTemplate(label: "mypod",
cloud: "openshift",
inheritFrom: "maven",
podRetention: onFailure(),
containers: [
...
]) {
node("mypod") {
...
}
}- 1
- Les valeurs autorisées pour
podRetentionsontnever(),onFailure(),always()etdefault().
Les pods conservés peuvent continuer à fonctionner et à être comptabilisés dans les quotas de ressources.
5.3. Migration de Jenkins vers OpenShift Pipelines ou Tekton
Vous pouvez migrer vos flux de travail CI/CD de Jenkins vers Red Hat OpenShift Pipelines, une expérience CI/CD cloud-native basée sur le projet Tekton.
5.3.1. Comparaison des concepts de Jenkins et d'OpenShift Pipelines
Vous pouvez consulter et comparer les termes équivalents suivants utilisés dans Jenkins et OpenShift Pipelines.
5.3.1.1. Terminologie Jenkins
Jenkins propose des pipelines déclaratifs et scénarisés qui sont extensibles à l'aide de bibliothèques partagées et de plugins. Voici quelques termes de base de Jenkins :
- Pipeline: Automatise l'ensemble du processus de construction, de test et de déploiement des applications en utilisant la syntaxe Groovy.
- Node: Une machine capable d'orchestrer ou d'exécuter un pipeline scénarisé.
- Stage: Un sous-ensemble conceptuellement distinct de tâches effectuées dans un pipeline. Les plugins ou les interfaces utilisateurs utilisent souvent ce bloc pour afficher l'état ou la progression des tâches.
- Step: Une tâche unique qui spécifie l'action exacte à effectuer, soit en utilisant une commande, soit en utilisant un script.
5.3.1.2. Terminologie d'OpenShift Pipelines
OpenShift Pipelines utilise la syntaxe YAML pour les pipelines déclaratifs et se compose de tâches. Voici quelques termes de base dans OpenShift Pipelines :
- Pipeline: Un ensemble de tâches en série, en parallèle ou les deux.
- Task: Une séquence d'étapes sous forme de commandes, de binaires ou de scripts.
- PipelineRun: Exécution d'un pipeline avec une ou plusieurs tâches.
TaskRun: Exécution d'une tâche comportant une ou plusieurs étapes.
NoteVous pouvez lancer un PipelineRun ou un TaskRun avec un ensemble d'entrées telles que des paramètres et des espaces de travail, et l'exécution se traduit par un ensemble de sorties et d'artefacts.
Workspace: Dans OpenShift Pipelines, les espaces de travail sont des blocs conceptuels qui servent les objectifs suivants :
- Stockage des données d'entrée, des données de sortie et des éléments de construction.
- Espace commun pour partager les données entre les tâches.
- Points de montage pour les informations d'identification contenues dans les secrets, les configurations contenues dans les cartes de configuration et les outils communs partagés par une organisation.
NoteDans Jenkins, il n'y a pas d'équivalent direct des espaces de travail d'OpenShift Pipelines. Vous pouvez considérer le nœud de contrôle comme un espace de travail, car il stocke le référentiel de code cloné, l'historique de construction et les artefacts. Lorsqu'un travail est assigné à un nœud différent, le code cloné et les artefacts générés sont stockés dans ce nœud, mais le nœud de contrôle conserve l'historique de construction.
5.3.1.3. Cartographie des concepts
Les éléments constitutifs de Jenkins et d'OpenShift Pipelines ne sont pas équivalents, et une comparaison spécifique ne fournit pas une correspondance techniquement précise. Les termes et concepts suivants de Jenkins et OpenShift Pipelines sont en corrélation générale :
| Jenkins | OpenShift Pipelines |
|---|---|
| Pipeline | Pipeline et PipelineRun |
| Stade | Tâche |
| Étape | Une étape dans une tâche |
5.3.2. Migrer un exemple de pipeline de Jenkins vers OpenShift Pipelines
Vous pouvez utiliser les exemples équivalents suivants pour vous aider à migrer vos pipelines de construction, de test et de déploiement de Jenkins vers OpenShift Pipelines.
5.3.2.1. Pipeline Jenkins
Considérons un pipeline Jenkins écrit en Groovy pour construire, tester et déployer :
pipeline {
agent any
stages {
stage('Build') {
steps {
sh 'make'
}
}
stage('Test'){
steps {
sh 'make check'
junit 'reports/**/*.xml'
}
}
stage('Deploy') {
steps {
sh 'make publish'
}
}
}
}5.3.2.2. OpenShift Pipelines pipeline
Pour créer un pipeline dans OpenShift Pipelines équivalent au pipeline Jenkins précédent, vous créez les trois tâches suivantes :
Exemple build fichier de définition YAML de la tâche
apiVersion: tekton.dev/v1beta1
kind: Task
metadata:
name: myproject-build
spec:
workspaces:
- name: source
steps:
- image: my-ci-image
command: ["make"]
workingDir: $(workspaces.source.path)Exemple test fichier de définition YAML de la tâche
apiVersion: tekton.dev/v1beta1
kind: Task
metadata:
name: myproject-test
spec:
workspaces:
- name: source
steps:
- image: my-ci-image
command: ["make check"]
workingDir: $(workspaces.source.path)
- image: junit-report-image
script: |
#!/usr/bin/env bash
junit-report reports/**/*.xml
workingDir: $(workspaces.source.path)Exemple deploy fichier de définition YAML de la tâche
apiVersion: tekton.dev/v1beta1
kind: Task
metadata:
name: myprojectd-deploy
spec:
workspaces:
- name: source
steps:
- image: my-deploy-image
command: ["make deploy"]
workingDir: $(workspaces.source.path)Vous pouvez combiner les trois tâches de manière séquentielle pour former un pipeline dans OpenShift Pipelines :
Exemple : Pipelines OpenShift pour la construction, les tests et le déploiement
apiVersion: tekton.dev/v1beta1
kind: Pipeline
metadata:
name: myproject-pipeline
spec:
workspaces:
- name: shared-dir
tasks:
- name: build
taskRef:
name: myproject-build
workspaces:
- name: source
workspace: shared-dir
- name: test
taskRef:
name: myproject-test
workspaces:
- name: source
workspace: shared-dir
- name: deploy
taskRef:
name: myproject-deploy
workspaces:
- name: source
workspace: shared-dir5.3.3. Migration des plugins Jenkins vers les tâches Tekton Hub
Vous pouvez étendre les capacités de Jenkins en utilisant des plugins. Pour obtenir une extensibilité similaire dans OpenShift Pipelines, utilisez l'une des tâches disponibles dans Tekton Hub.
Par exemple, considérons la tâche git-clone dans Tekton Hub, qui correspond au plugin git pour Jenkins.
Exemple : git-clone task from Tekton Hub
apiVersion: tekton.dev/v1beta1
kind: Pipeline
metadata:
name: demo-pipeline
spec:
params:
- name: repo_url
- name: revision
workspaces:
- name: source
tasks:
- name: fetch-from-git
taskRef:
name: git-clone
params:
- name: url
value: $(params.repo_url)
- name: revision
value: $(params.revision)
workspaces:
- name: output
workspace: source5.3.4. Étendre les capacités d'OpenShift Pipelines à l'aide de tâches et de scripts personnalisés
Dans OpenShift Pipelines, si vous ne trouvez pas la bonne tâche dans Tekton Hub, ou si vous avez besoin d'un plus grand contrôle sur les tâches, vous pouvez créer des tâches et des scripts personnalisés pour étendre les capacités d'OpenShift Pipelines.
Exemple : Une tâche personnalisée pour exécuter la commande maven test
apiVersion: tekton.dev/v1beta1
kind: Task
metadata:
name: maven-test
spec:
workspaces:
- name: source
steps:
- image: my-maven-image
command: ["mvn test"]
workingDir: $(workspaces.source.path)Exemple : Exécuter un script shell personnalisé en indiquant son chemin d'accès
...
steps:
image: ubuntu
script: |
#!/usr/bin/env bash
/workspace/my-script.sh
...Exemple : Exécuter un script Python personnalisé en l'écrivant dans le fichier YAML
...
steps:
image: python
script: |
#!/usr/bin/env python3
print(“hello from python!”)
...5.3.5. Comparaison des modèles d'exécution de Jenkins et d'OpenShift Pipelines
Jenkins et OpenShift Pipelines offrent des fonctions similaires mais sont différents en termes d'architecture et d'exécution.
| Jenkins | OpenShift Pipelines |
|---|---|
| Jenkins dispose d'un nœud contrôleur. Jenkins exécute des pipelines et des étapes de manière centralisée, ou orchestre des tâches exécutées sur d'autres nœuds. | OpenShift Pipelines est sans serveur et distribué, et il n'y a pas de dépendance centrale pour l'exécution. |
| Les conteneurs sont lancés par le nœud contrôleur de Jenkins via le pipeline. | OpenShift Pipelines adopte une approche "container-first", où chaque étape s'exécute en tant que conteneur dans un pod (équivalent aux nœuds dans Jenkins). |
| L'extensibilité est obtenue par l'utilisation de plugins. | L'extensibilité est obtenue en utilisant les tâches du Tekton Hub ou en créant des tâches et des scripts personnalisés. |
5.3.6. Exemples de cas d'utilisation courants
Jenkins et OpenShift Pipelines offrent tous deux des fonctionnalités pour les cas d'utilisation CI/CD les plus courants, tels que
- Compilation, construction et déploiement d'images à l'aide d'Apache Maven
- Extension des capacités de base à l'aide de plugins
- Réutilisation des bibliothèques partageables et des scripts personnalisés
5.3.6.1. Exécuter un pipeline Maven dans Jenkins et OpenShift Pipelines
Vous pouvez utiliser Maven dans les flux de travail Jenkins et OpenShift Pipelines pour compiler, construire et déployer des images. Pour faire correspondre votre flux de travail Jenkins existant à OpenShift Pipelines, considérez les exemples suivants :
Exemple : Compiler et construire une image et la déployer sur OpenShift en utilisant Maven dans Jenkins
#!/usr/bin/groovy
node('maven') {
stage 'Checkout'
checkout scm
stage 'Build'
sh 'cd helloworld && mvn clean'
sh 'cd helloworld && mvn compile'
stage 'Run Unit Tests'
sh 'cd helloworld && mvn test'
stage 'Package'
sh 'cd helloworld && mvn package'
stage 'Archive artifact'
sh 'mkdir -p artifacts/deployments && cp helloworld/target/*.war artifacts/deployments'
archive 'helloworld/target/*.war'
stage 'Create Image'
sh 'oc login https://kubernetes.default -u admin -p admin --insecure-skip-tls-verify=true'
sh 'oc new-project helloworldproject'
sh 'oc project helloworldproject'
sh 'oc process -f helloworld/jboss-eap70-binary-build.json | oc create -f -'
sh 'oc start-build eap-helloworld-app --from-dir=artifacts/'
stage 'Deploy'
sh 'oc new-app helloworld/jboss-eap70-deploy.json' }Exemple : Compiler et construire une image et la déployer sur OpenShift en utilisant Maven dans OpenShift Pipelines.
apiVersion: tekton.dev/v1beta1
kind: Pipeline
metadata:
name: maven-pipeline
spec:
workspaces:
- name: shared-workspace
- name: maven-settings
- name: kubeconfig-dir
optional: true
params:
- name: repo-url
- name: revision
- name: context-path
tasks:
- name: fetch-repo
taskRef:
name: git-clone
workspaces:
- name: output
workspace: shared-workspace
params:
- name: url
value: "$(params.repo-url)"
- name: subdirectory
value: ""
- name: deleteExisting
value: "true"
- name: revision
value: $(params.revision)
- name: mvn-build
taskRef:
name: maven
runAfter:
- fetch-repo
workspaces:
- name: source
workspace: shared-workspace
- name: maven-settings
workspace: maven-settings
params:
- name: CONTEXT_DIR
value: "$(params.context-path)"
- name: GOALS
value: ["-DskipTests", "clean", "compile"]
- name: mvn-tests
taskRef:
name: maven
runAfter:
- mvn-build
workspaces:
- name: source
workspace: shared-workspace
- name: maven-settings
workspace: maven-settings
params:
- name: CONTEXT_DIR
value: "$(params.context-path)"
- name: GOALS
value: ["test"]
- name: mvn-package
taskRef:
name: maven
runAfter:
- mvn-tests
workspaces:
- name: source
workspace: shared-workspace
- name: maven-settings
workspace: maven-settings
params:
- name: CONTEXT_DIR
value: "$(params.context-path)"
- name: GOALS
value: ["package"]
- name: create-image-and-deploy
taskRef:
name: openshift-client
runAfter:
- mvn-package
workspaces:
- name: manifest-dir
workspace: shared-workspace
- name: kubeconfig-dir
workspace: kubeconfig-dir
params:
- name: SCRIPT
value: |
cd "$(params.context-path)"
mkdir -p ./artifacts/deployments && cp ./target/*.war ./artifacts/deployments
oc new-project helloworldproject
oc project helloworldproject
oc process -f jboss-eap70-binary-build.json | oc create -f -
oc start-build eap-helloworld-app --from-dir=artifacts/
oc new-app jboss-eap70-deploy.json5.3.6.2. Étendre les capacités de base de Jenkins et d'OpenShift Pipelines à l'aide de plugins
Jenkins a l'avantage de disposer d'un vaste écosystème composé de nombreux plugins développés au fil des ans par sa vaste base d'utilisateurs. Vous pouvez rechercher et parcourir les plugins dans l'index des plugins Jenkins.
OpenShift Pipelines dispose également de nombreuses tâches développées et contribuées par la communauté et les utilisateurs professionnels. Un catalogue public des tâches réutilisables d'OpenShift Pipelines est disponible dans le Tekton Hub.
En outre, OpenShift Pipelines intègre de nombreux plugins de l'écosystème Jenkins dans ses capacités de base. Par exemple, l'autorisation est une fonction critique à la fois dans Jenkins et dans OpenShift Pipelines. Alors que Jenkins garantit l'autorisation en utilisant le plugin Role-based Authorization Strategy, OpenShift Pipelines utilise le système intégré de contrôle d'accès basé sur les rôles d'OpenShift.
5.3.6.3. Partager du code réutilisable dans Jenkins et OpenShift Pipelines
Les bibliothèques partagées Jenkins fournissent du code réutilisable pour certaines parties des pipelines Jenkins. Les bibliothèques sont partagées entre les fichiers Jenkins afin de créer des pipelines hautement modulaires sans répétition de code.
Bien qu'il n'y ait pas d'équivalent direct des bibliothèques partagées de Jenkins dans OpenShift Pipelines, vous pouvez obtenir des flux de travail similaires en utilisant des tâches du Tekton Hub en combinaison avec des tâches et des scripts personnalisés.
5.4. Changements importants dans les images OpenShift Jenkins
OpenShift Container Platform 4.11 déplace les images OpenShift Jenkins et OpenShift Agent Base vers le dépôt ocp-tools-4 à l'adresse registry.redhat.io. Elle supprime également les images OpenShift Jenkins Maven et NodeJS Agent de son payload :
-
OpenShift Container Platform 4.11 déplace les images OpenShift Jenkins et OpenShift Agent Base vers le dépôt
ocp-tools-4à l'adresseregistry.redhat.ioafin que Red Hat puisse produire et mettre à jour les images en dehors du cycle de vie d'OpenShift Container Platform. Auparavant, ces images se trouvaient dans la charge utile d'installation d'OpenShift Container Platform et dans le dépôtopenshift4à l'adresseregistry.redhat.io. -
OpenShift Container Platform 4.10 a déprécié les images OpenShift Jenkins Maven et NodeJS Agent. OpenShift Container Platform 4.11 supprime ces images de sa charge utile. Red Hat ne produit plus ces images et elles ne sont pas disponibles dans le dépôt
ocp-tools-4à l'adresseregistry.redhat.io. Red Hat maintient les versions 4.10 et antérieures de ces images pour toutes les corrections de bogues importantes ou les CVE de sécurité, en suivant la politique de cycle de vie d'OpenShift Container Platform.
Ces changements supportent la recommandation d'OpenShift Container Platform 4.10 d'utiliser plusieurs Pod Templates avec le plugin Jenkins Kubernetes.
5.4.1. Relocalisation des images OpenShift Jenkins
OpenShift Container Platform 4.11 apporte des changements significatifs à l'emplacement et à la disponibilité d'images OpenShift Jenkins spécifiques. En outre, vous pouvez configurer quand et comment mettre à jour ces images.
Qu'est-ce qui reste inchangé dans les images OpenShift Jenkins ?
-
Le Cluster Samples Operator gère les objets
ImageStreametTemplatepour faire fonctionner les images OpenShift Jenkins. -
Par défaut, l'objet Jenkins
DeploymentConfigdu modèle de pod Jenkins déclenche un redéploiement lorsque l'image Jenkins change. Par défaut, cette image est référencée par la balisejenkins:2image stream de Jenkins image stream dans l'espace de nomsopenshiftdans le fichier YAMLImageStreamdans la charge utile de l'opérateur Samples. -
Si vous mettez à jour OpenShift Container Platform 4.10 et antérieures vers 4.11, les modèles de pods dépréciés
mavenetnodejssont toujours dans la configuration de l'image par défaut. -
Si vous mettez à jour OpenShift Container Platform 4.10 et précédentes vers 4.11, les flux d'images
jenkins-agent-mavenetjenkins-agent-nodejsexistent toujours dans votre cluster. Pour maintenir ces flux d'images, consultez la section suivante : " Que se passe-t-il avec les flux d'imagesjenkins-agent-mavenetjenkins-agent-nodejsdans l'espace de nomsopenshift?
Quels sont les changements dans la matrice de support de l'image OpenShift Jenkins ?
Chaque nouvelle image du dépôt ocp-tools-4 dans le registre registry.redhat.io prend en charge plusieurs versions d'OpenShift Container Platform. Lorsque Red Hat met à jour l'une de ces nouvelles images, elle est simultanément disponible pour toutes les versions. Cette disponibilité est idéale lorsque Red Hat met à jour une image en réponse à un avis de sécurité. Dans un premier temps, ce changement s'applique à OpenShift Container Platform 4.11 et aux versions ultérieures. Il est prévu que ce changement s'applique éventuellement à OpenShift Container Platform 4.9 et aux versions ultérieures.
Auparavant, chaque image Jenkins ne prenait en charge qu'une seule version d'OpenShift Container Platform et Red Hat pouvait mettre à jour ces images de manière séquentielle au fil du temps.
Quels sont les ajouts apportés aux objets ImageStream et ImageStreamTag de OpenShift Jenkins et Jenkins Agent Base ?
En passant d'un flux d'images in-payload à un flux d'images qui fait référence à des images non-payload, OpenShift Container Platform peut définir des balises de flux d'images supplémentaires. Red Hat a créé une série de nouvelles balises de flux d'images pour compléter les balises de flux d'images "value": "jenkins:2" et "value": "image-registry.openshift-image-registry.svc:5000/openshift/jenkins-agent-base-rhel8:latest" existantes dans OpenShift Container Platform 4.10 et les versions antérieures. Ces nouvelles balises de flux d'images répondent à certaines demandes d'amélioration de la gestion des flux d'images liés à Jenkins.
A propos des nouvelles balises de flux d'images :
ocp-upgrade-redeploy-
Pour mettre à jour votre image Jenkins lorsque vous mettez à jour OpenShift Container Platform, utilisez cette balise image stream dans votre configuration de déploiement Jenkins. Cette balise de flux d'images correspond à la balise de flux d'images existante
2du flux d'imagesjenkinset à la balise de flux d'imageslatestdu flux d'imagesjenkins-agent-base-rhel8. Elle utilise une balise d'image spécifique à un seul SHA ou résumé d'image. Lorsque l'imageocp-tools-4change, comme pour les avis de sécurité de Jenkins, Red Hat Engineering met à jour la charge utile Cluster Samples Operator. user-maintained-upgrade-redeploy-
Pour redéployer manuellement Jenkins après avoir mis à jour OpenShift Container Platform, utilisez cette balise de flux d'images dans votre configuration de déploiement Jenkins. Cette balise de flux d'images utilise l'indicateur de version d'image le moins spécifique disponible. Lorsque vous redéployez Jenkins, exécutez la commande suivante :
$ oc import-image jenkins:user-maintained-upgrade-redeploy -n openshift. Lorsque vous exécutez cette commande, le contrôleur de la plate-forme OpenShift ContainerImageStreamaccède au registre d'imagesregistry.redhat.ioet stocke toutes les images mises à jour dans l'emplacement du registre d'images OpenShift pour cet objet JenkinsImageStreamTag. Dans le cas contraire, si vous n'exécutez pas cette commande, votre configuration de déploiement Jenkins ne déclenche pas de redéploiement. scheduled-upgrade-redeploy- Pour redéployer automatiquement la dernière version de l'image Jenkins lorsqu'elle est publiée, utilisez cette balise de flux d'images dans votre configuration de déploiement Jenkins. Cette balise de flux d'images utilise la fonction d'importation périodique des balises de flux d'images du contrôleur de flux d'images d'OpenShift Container Platform, qui vérifie les modifications apportées à l'image de référence. Si l'image change, par exemple en raison d'un récent avis de sécurité Jenkins, OpenShift Container Platform déclenche un redéploiement de votre configuration de déploiement Jenkins. Voir "Configuration de l'importation périodique des balises de flux d'images" dans le document suivant "Ressources supplémentaires"
Que se passe-t-il avec les flux d'images jenkins-agent-maven et jenkins-agent-nodejs dans l'espace de noms openshift?
Les images OpenShift Jenkins Maven et NodeJS Agent pour OpenShift Container Platform ont été dépréciées en 4.10, et sont supprimées du payload d'installation d'OpenShift Container Platform en 4.11. Elles n'ont pas d'alternatives définies dans le référentiel ocp-tools-4. Cependant, vous pouvez contourner ce problème en utilisant le modèle de sidecar décrit dans la rubrique "Jenkins agent" mentionnée dans la section suivante "Ressources supplémentaires".
Cependant, le Cluster Samples Operator ne supprime pas les flux d'images jenkins-agent-maven et jenkins-agent-nodejs créés par des versions antérieures, qui pointent vers les balises des images payantes OpenShift Container Platform respectives sur registry.redhat.io. Par conséquent, vous pouvez extraire les mises à jour de ces images en exécutant les commandes suivantes :
$ oc import-image jenkins-agent-nodejs -n openshift$ oc import-image jenkins-agent-maven -n openshift5.4.2. Personnalisation de la balise Jenkins image stream
Pour remplacer le comportement de mise à niveau par défaut et contrôler la manière dont l'image Jenkins est mise à niveau, vous définissez la valeur de la balise de flux d'images que vos configurations de déploiement Jenkins utilisent.
Le comportement de mise à niveau par défaut est celui qui existait lorsque l'image Jenkins faisait partie de la charge utile d'installation. Les noms des balises de flux d'images, 2 et ocp-upgrade-redeploy, dans le fichier de flux d'images jenkins-rhel.json utilisent des références d'images spécifiques à SHA. Par conséquent, lorsque ces balises sont mises à jour avec un nouveau SHA, le contrôleur de changement d'image d'OpenShift Container Platform redéploie automatiquement la configuration de déploiement Jenkins à partir des modèles associés, tels que jenkins-ephemeral.json ou jenkins-persistent.json.
Pour les nouveaux déploiements, afin de remplacer cette valeur par défaut, vous devez modifier la valeur de JENKINS_IMAGE_STREAM_TAG dans le modèle Jenkins jenkins-ephemeral.json. Par exemple, remplacez le 2 dans "value": "jenkins:2" par l'une des balises de flux d'images suivantes :
-
ocp-upgrade-redeployla valeur par défaut, met à jour votre image Jenkins lorsque vous mettez à jour OpenShift Container Platform. -
user-maintained-upgrade-redeployvous oblige à redéployer manuellement Jenkins en exécutant$ oc import-image jenkins:user-maintained-upgrade-redeploy -n openshiftaprès la mise à jour d'OpenShift Container Platform. -
scheduled-upgrade-redeployvérifie périodiquement que la combinaison<image>:<tag>donnée n'a pas été modifiée et met à jour l'image lorsqu'elle l'est. Le contrôleur de changement d'image extrait l'image modifiée et redéploie la configuration de déploiement Jenkins fournie par les modèles. Pour plus d'informations sur cette politique d'importation planifiée, voir la section "Ajouter des balises aux flux d'images" dans la section suivante "Ressources supplémentaires"
Pour remplacer la valeur de mise à niveau actuelle pour les déploiements existants, modifiez les valeurs des variables d'environnement qui correspondent à ces paramètres de modèle.
Conditions préalables
- Vous utilisez OpenShift Jenkins sur OpenShift Container Platform 4.12.
- Vous connaissez l'espace de noms dans lequel OpenShift Jenkins est déployé.
Procédure
Définir la valeur de la balise de flux d'images, en remplaçant
<namespace>par l'espace de noms où OpenShift Jenkins est déployé et<image_stream_tag>par une balise de flux d'images :Exemple
$ oc patch dc jenkins -p '{"spec":{"triggers" :[{"type":"ImageChange",{"imageChangeParams":{"automatic":true,{"containerNames" :[\N "jenkins"],{"from" :{"kind":\N "ImageStreamTag",\N "namespace":\N"<namespace>",\N "name":\N "jenkins:<image_stream_tag>"}}]}}''AstuceAlternativement, pour éditer le YAML de configuration du déploiement de Jenkins, entrez
$ oc edit dc/jenkins -n <namespace>et mettez à jour la lignevalue: 'jenkins:<image_stream_tag>'.
Legal Notice
Copyright © Red Hat
OpenShift documentation is licensed under the Apache License 2.0 (https://www.apache.org/licenses/LICENSE-2.0).
Modified versions must remove all Red Hat trademarks.
Portions adapted from https://github.com/kubernetes-incubator/service-catalog/ with modifications by Red Hat.
Red Hat, Red Hat Enterprise Linux, the Red Hat logo, the Shadowman logo, JBoss, OpenShift, Fedora, the Infinity logo, and RHCE are trademarks of Red Hat, Inc., registered in the United States and other countries.
Linux® is the registered trademark of Linus Torvalds in the United States and other countries.
Java® is a registered trademark of Oracle and/or its affiliates.
XFS® is a trademark of Silicon Graphics International Corp. or its subsidiaries in the United States and/or other countries.
MySQL® is a registered trademark of MySQL AB in the United States, the European Union and other countries.
Node.js® is an official trademark of the OpenJS Foundation.
The OpenStack® Word Mark and OpenStack logo are either registered trademarks/service marks or trademarks/service marks of the OpenStack Foundation, in the United States and other countries and are used with the OpenStack Foundation’s permission. We are not affiliated with, endorsed or sponsored by the OpenStack Foundation, or the OpenStack community.
All other trademarks are the property of their respective owners.