Opérateurs
Travailler avec des opérateurs dans OpenShift Container Platform
Résumé
Chapitre 1. Aperçu des opérateurs
Les opérateurs sont parmi les composants les plus importants d'OpenShift Container Platform. Les opérateurs sont la méthode privilégiée pour conditionner, déployer et gérer les services sur le plan de contrôle. Ils peuvent également offrir des avantages aux applications exécutées par les utilisateurs.
Les opérateurs s'intègrent aux API de Kubernetes et aux outils CLI tels que les commandes kubectl et oc. Ils permettent de surveiller les applications, d'effectuer des contrôles de santé, de gérer les mises à jour over-the-air (OTA) et de s'assurer que les applications restent dans l'état que vous avez spécifié.
Bien que les deux suivent des concepts et des objectifs similaires pour les opérateurs, les opérateurs dans OpenShift Container Platform sont gérés par deux systèmes différents, en fonction de leur objectif :
- Les opérateurs de cluster, qui sont gérés par l'opérateur de version de cluster (CVO), sont installés par défaut pour exécuter les fonctions de cluster.
- Des opérateurs supplémentaires facultatifs, gérés par Operator Lifecycle Manager (OLM), peuvent être mis à la disposition des utilisateurs pour qu'ils les exécutent dans leurs applications.
Avec les opérateurs, vous pouvez créer des applications pour surveiller les services en cours d'exécution dans le cluster. Les opérateurs sont conçus spécifiquement pour vos applications. Les opérateurs mettent en œuvre et automatisent les opérations courantes du jour 1, telles que l'installation et la configuration, ainsi que les opérations du jour 2, telles que la montée et la descente en charge automatique et la création de sauvegardes. Toutes ces activités se trouvent dans un logiciel qui s'exécute au sein de votre cluster.
1.1. Pour les développeurs
En tant que développeur, vous pouvez effectuer les tâches suivantes de l'opérateur :
- Installer le SDK CLI de l'opérateur.
- Créer des opérateurs basés sur Go, des opérateurs basés sur Ansible, des opérateurs basés sur Java et des opérateurs basés sur Helm.
- Utilisez Operator SDK pour créer, tester et déployer un opérateur.
- Installez et abonnez un opérateur à votre espace de noms.
- Créer une application à partir d'un opérateur installé via la console web.
1.2. Pour les administrateurs
En tant qu'administrateur de cluster, vous pouvez effectuer les tâches suivantes de l'opérateur :
- Gérer des catalogues personnalisés
- Autoriser les administrateurs qui ne font pas partie d'un cluster à installer des opérateurs
- Installer un opérateur à partir d'OperatorHub
- Voir le statut de l'opérateur.
- Gérer les conditions de l'opérateur
- Mise à niveau des opérateurs installés
- Supprimer les opérateurs installés
- Configurer la prise en charge du proxy
- Utiliser Operator Lifecycle Manager sur des réseaux restreints
Pour tout savoir sur les opérateurs de clusters fournis par Red Hat, consultez la référence sur les opérateurs de clusters.
1.3. Prochaines étapes
Pour en savoir plus sur les opérateurs, voir Qu'est-ce qu'un opérateur ?
Chapitre 2. Comprendre les opérateurs
2.1. Qu'est-ce qu'un opérateur ?
D'un point de vue conceptuel, Operators prend les connaissances opérationnelles humaines et les encode dans des logiciels qui sont plus facilement partagés avec les consommateurs.
Les opérateurs sont des logiciels qui facilitent la complexité opérationnelle de l'exécution d'un autre logiciel. Ils agissent comme une extension de l'équipe d'ingénierie de l'éditeur du logiciel, en surveillant un environnement Kubernetes (tel que OpenShift Container Platform) et en utilisant son état actuel pour prendre des décisions en temps réel. Les opérateurs avancés sont conçus pour gérer les mises à niveau de manière transparente, réagir automatiquement aux pannes et ne pas prendre de raccourcis, comme sauter un processus de sauvegarde du logiciel pour gagner du temps.
Plus techniquement, les opérateurs sont une méthode de conditionnement, de déploiement et de gestion d'une application Kubernetes.
Une application Kubernetes est une application qui est à la fois déployée sur Kubernetes et gérée à l'aide des API Kubernetes et des outils kubectl ou oc. Pour pouvoir tirer le meilleur parti de Kubernetes, vous avez besoin d'un ensemble d'API cohérentes à étendre afin d'assurer le service et la gestion de vos applications qui s'exécutent sur Kubernetes. Considérez les opérateurs comme le moteur d'exécution qui gère ce type d'application sur Kubernetes.
2.1.1. Pourquoi utiliser des opérateurs ?
Les opérateurs fournissent :
- Répétabilité de l'installation et de la mise à niveau.
- Contrôles constants de l'état de santé de chaque composant du système.
- Mises à jour OTA (Over-the-air) pour les composants OpenShift et le contenu ISV.
- Un lieu où les connaissances des ingénieurs de terrain sont regroupées et diffusées à tous les utilisateurs, et pas seulement à un ou deux d'entre eux.
- Pourquoi déployer sur Kubernetes ?
- Kubernetes (et par extension, OpenShift Container Platform) contient toutes les primitives nécessaires pour construire des systèmes distribués complexes - traitement des secrets, équilibrage de charge, découverte de services, mise à l'échelle automatique - qui fonctionnent sur site et avec des fournisseurs de cloud.
- Pourquoi gérer votre application avec les API de Kubernetes et l'outil
kubectl? -
Ces API sont riches en fonctionnalités, disposent de clients pour toutes les plateformes et s'intègrent au contrôle d'accès et à l'audit du cluster. Un opérateur utilise le mécanisme d'extension de Kubernetes, les définitions de ressources personnalisées (CRD), de sorte que votre objet personnalisé, par exemple
MongoDB, ressemble et agit comme les objets Kubernetes natifs intégrés. - Comment les opérateurs se comparent-ils aux courtiers en services ?
- Un courtier de services est une étape vers la découverte et le déploiement programmatiques d'une application. Cependant, comme il ne s'agit pas d'un processus de longue durée, il ne peut pas exécuter les opérations du deuxième jour comme la mise à niveau, le basculement ou la mise à l'échelle. Les personnalisations et la paramétrisation des paramètres sont fournies au moment de l'installation, contrairement à un opérateur qui surveille constamment l'état actuel de votre cluster. Les services hors cluster conviennent bien à un courtier de services, bien qu'il existe également des opérateurs pour ces services.
2.1.2. Cadre de l'opérateur
L'Operator Framework est une famille d'outils et de capacités permettant d'offrir l'expérience client décrite ci-dessus. Il ne s'agit pas seulement d'écrire du code ; les tests, la livraison et la mise à jour des opérateurs sont tout aussi importants. Les composants de l'Operator Framework sont des outils open source permettant de résoudre ces problèmes :
- SDK de l'opérateur
- L'Operator SDK aide les auteurs d'opérateurs à démarrer, construire, tester et emballer leur propre opérateur en fonction de leur expertise sans avoir besoin de connaître les complexités de l'API Kubernetes.
- Gestionnaire du cycle de vie des opérateurs
- Operator Lifecycle Manager (OLM) contrôle l'installation, la mise à niveau et le contrôle d'accès basé sur les rôles (RBAC) des opérateurs dans un cluster. Déployé par défaut dans OpenShift Container Platform 4.12.
- Registre des opérateurs
- Le registre Operator stocke les versions de service de cluster (CSV) et les définitions de ressources personnalisées (CRD) pour la création dans un cluster et stocke les métadonnées Operator sur les paquets et les canaux. Il s'exécute dans un cluster Kubernetes ou OpenShift pour fournir ces données de catalogue d'opérateurs à OLM.
- OperatorHub
- OperatorHub est une console web permettant aux administrateurs de clusters de découvrir et de sélectionner les opérateurs à installer sur leur cluster. Il est déployé par défaut dans OpenShift Container Platform.
Ces outils sont conçus pour être composables, de sorte que vous pouvez utiliser tous ceux qui vous sont utiles.
2.1.3. Modèle de maturité de l'opérateur
Le niveau de sophistication de la logique de gestion encapsulée dans un opérateur peut varier. En général, cette logique dépend aussi fortement du type de service représenté par l'opérateur.
Il est toutefois possible de généraliser l'échelle de maturité des opérations encapsulées d'un opérateur pour certains ensembles de capacités que la plupart des opérateurs peuvent inclure. À cette fin, le modèle de maturité de l'opérateur ci-après définit cinq phases de maturité pour les opérations génériques du deuxième jour d'un opérateur :
Figure 2.1. Modèle de maturité de l'opérateur
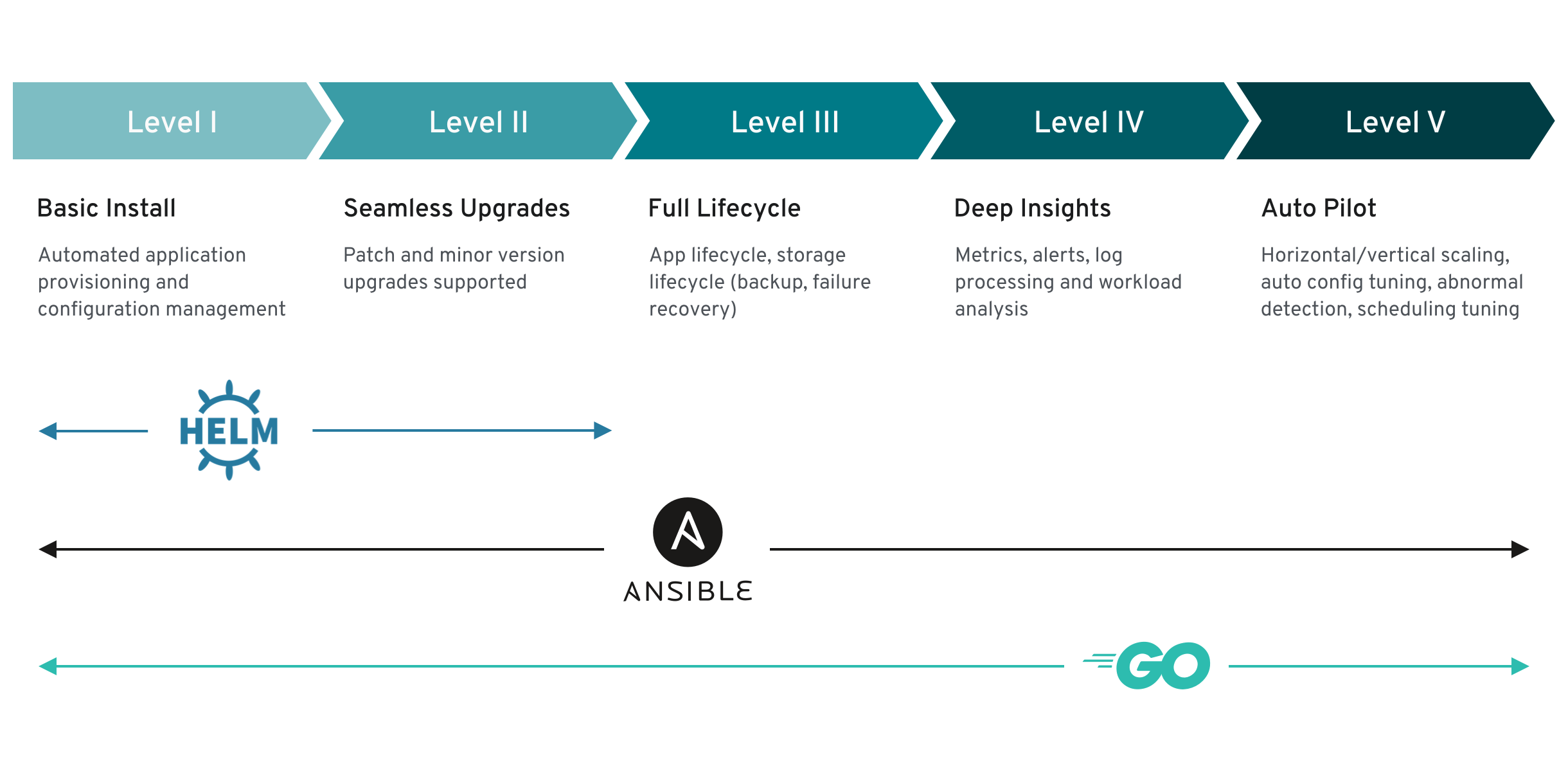
Le modèle ci-dessus montre également comment ces capacités peuvent être développées au mieux grâce aux fonctionnalités Helm, Go et Ansible de l'Operator SDK.
2.2. Format d'emballage du cadre de l'opérateur
Ce guide décrit le format d'emballage pour les opérateurs pris en charge par Operator Lifecycle Manager (OLM) dans OpenShift Container Platform.
2.2.1. Format de l'offre groupée
Le bundle format pour les opérateurs est un format d'empaquetage introduit par le cadre des opérateurs. Pour améliorer l'évolutivité et permettre aux utilisateurs en amont d'héberger leurs propres catalogues, la spécification du format bundle simplifie la distribution des métadonnées des opérateurs.
Un Operator bundle représente une version unique d'un Operator. Les bundle manifests sur disque sont conteneurisés et expédiés en tant que bundle image, qui est une image de conteneur non rinçable qui stocke les manifestes Kubernetes et les métadonnées de l'opérateur. Le stockage et la distribution de l'image de bundle sont ensuite gérés à l'aide d'outils de conteneur existants tels que podman et docker et de registres de conteneurs tels que Quay.
Les métadonnées de l'opérateur peuvent inclure
- Informations qui identifient l'opérateur, par exemple son nom et sa version.
- Informations supplémentaires qui pilotent l'interface utilisateur, par exemple son icône et quelques exemples de ressources personnalisées (CR).
- API requises et fournies.
- Images liées.
Lors du chargement des manifestes dans la base de données du registre des opérateurs, les exigences suivantes sont validées :
- La liasse doit avoir au moins un canal défini dans les annotations.
- Chaque bundle a exactement une version de service de cluster (CSV).
- Si un CSV possède une définition de ressource personnalisée (CRD), cette CRD doit exister dans l'ensemble.
2.2.1.1. Manifestes
Les manifestes de paquets font référence à un ensemble de manifestes Kubernetes qui définissent le déploiement et le modèle RBAC de l'opérateur.
Un bundle comprend un CSV par répertoire et généralement les CRD qui définissent les API propres au CSV dans son répertoire /manifests.
Exemple de présentation du format de la liasse
etcd
├── manifests
│ ├── etcdcluster.crd.yaml
│ └── etcdoperator.clusterserviceversion.yaml
│ └── secret.yaml
│ └── configmap.yaml
└── metadata
└── annotations.yaml
└── dependencies.yamlAutres objets pris en charge
Les types d'objets suivants peuvent également être inclus de manière facultative dans le répertoire /manifests d'une liasse :
Types d'objets optionnels pris en charge
-
ClusterRole -
ClusterRoleBinding -
ConfigMap -
ConsoleCLIDownload -
ConsoleLink -
ConsoleQuickStart -
ConsoleYamlSample -
PodDisruptionBudget -
PriorityClass -
PrometheusRule -
Role -
RoleBinding -
Secret -
Service -
ServiceAccount -
ServiceMonitor -
VerticalPodAutoscaler
Lorsque ces objets facultatifs sont inclus dans une liasse, Operator Lifecycle Manager (OLM) peut les créer à partir de la liasse et gérer leur cycle de vie en même temps que le CSV :
Cycle de vie des objets optionnels
- Lorsque le CSV est supprimé, OLM supprime l'objet facultatif.
Lorsque le CSV est mis à jour :
- Si le nom de l'objet facultatif est le même, OLM le met à jour à sa place.
- Si le nom de l'objet facultatif a changé entre les versions, OLM le supprime et le recrée.
2.2.1.2. Annotations
Une liasse comprend également un fichier annotations.yaml dans son répertoire /metadata. Ce fichier définit des données agrégées de plus haut niveau qui aident à décrire le format et les informations sur la manière dont l'offre groupée doit être ajoutée à un index d'offres groupées :
Exemple annotations.yaml
annotations:
operators.operatorframework.io.bundle.mediatype.v1: "registry+v1"
operators.operatorframework.io.bundle.manifests.v1: "manifests/"
operators.operatorframework.io.bundle.metadata.v1: "metadata/"
operators.operatorframework.io.bundle.package.v1: "test-operator"
operators.operatorframework.io.bundle.channels.v1: "beta,stable"
operators.operatorframework.io.bundle.channel.default.v1: "stable" - 1
- Le type de média ou le format du bundle de l'opérateur. Le format
registry v1signifie qu'il contient un CSV et les objets Kubernetes associés. - 2
- Le chemin dans l'image vers le répertoire qui contient les manifestes de l'opérateur. Cette étiquette est réservée pour une utilisation future et a pour valeur par défaut
manifests/. La valeurmanifests.v1implique que la liasse contient des manifestes d'opérateurs. - 3
- Le chemin dans l'image vers le répertoire qui contient les fichiers de métadonnées sur la liasse. Cette étiquette est réservée pour une utilisation future et a actuellement pour valeur par défaut
metadata/. La valeurmetadata.v1implique que cette liasse a des métadonnées d'opérateur. - 4
- Le nom du paquet de la liasse.
- 5
- La liste des chaînes auxquelles l'offre groupée est abonnée lorsqu'elle est ajoutée à un registre d'opérateur.
- 6
- Le canal par défaut auquel un opérateur doit être abonné lorsqu'il est installé à partir d'un registre.
En cas de non-concordance, c'est le fichier annotations.yaml qui fait foi, car le registre des opérateurs sur le cluster qui s'appuie sur ces annotations n'a accès qu'à ce fichier.
2.2.1.3. Dépendances
Les dépendances d'un Opérateur sont listées dans un fichier dependencies.yaml dans le dossier metadata/ d'un bundle. Ce fichier est facultatif et n'est actuellement utilisé que pour spécifier les dépendances explicites de la version de l'opérateur.
La liste des dépendances contient un champ type pour chaque élément afin de spécifier de quel type de dépendance il s'agit. Les types de dépendances de l'opérateur suivants sont pris en charge :
olm.package-
Ce type indique une dépendance pour une version spécifique de l'opérateur. Les informations sur la dépendance doivent inclure le nom du paquet et la version du paquet au format semver. Par exemple, vous pouvez spécifier une version exacte telle que
0.5.2ou une plage de versions telle que>0.5.1. olm.gvk- Avec ce type, l'auteur peut spécifier une dépendance avec des informations sur le groupe, la version et le type (GVK), de manière similaire à l'utilisation existante des CRD et des API dans un CSV. Il s'agit d'un chemin permettant aux auteurs d'opérateurs de consolider toutes les dépendances, API ou versions explicites, au même endroit.
olm.constraint- Ce type déclare des contraintes génériques sur des propriétés arbitraires de l'opérateur.
Dans l'exemple suivant, des dépendances sont spécifiées pour un opérateur Prometheus et des CRD etcd :
Exemple de fichier dependencies.yaml
dependencies:
- type: olm.package
value:
packageName: prometheus
version: ">0.27.0"
- type: olm.gvk
value:
group: etcd.database.coreos.com
kind: EtcdCluster
version: v1beta22.2.1.4. À propos de l'interface de programmation opm
L'outil CLI opm est fourni par Operator Framework pour être utilisé avec le format Operator bundle. Cet outil vous permet de créer et de maintenir des catalogues d'opérateurs à partir d'une liste de bundles d'opérateurs qui sont similaires à des dépôts de logiciels. Le résultat est une image de conteneur qui peut être stockée dans un registre de conteneurs et ensuite installée sur un cluster.
Un catalogue contient une base de données de pointeurs vers le contenu du manifeste de l'opérateur qui peut être interrogé par le biais d'une API incluse qui est servie lorsque l'image du conteneur est exécutée. Sur OpenShift Container Platform, Operator Lifecycle Manager (OLM) peut référencer l'image dans une source de catalogue, définie par un objet CatalogSource, qui interroge l'image à intervalles réguliers pour permettre des mises à jour fréquentes des opérateurs installés sur le cluster.
-
Voir Outils CLI pour les étapes d'installation du CLI
opm.
2.2.2. Catalogues basés sur des fichiers
File-based catalogs sont la dernière itération du format de catalogue dans Operator Lifecycle Manager (OLM). Il s'agit d'une évolution du format de base de données SQLite, basée sur du texte brut (JSON ou YAML) et une configuration déclarative, et il est entièrement rétrocompatible. L'objectif de ce format est de permettre l'édition, la composabilité et l'extensibilité du catalogue de l'opérateur.
- Édition
Avec les catalogues basés sur des fichiers, les utilisateurs qui interagissent avec le contenu d'un catalogue sont en mesure d'apporter des modifications directes au format et de vérifier que ces modifications sont valides. Comme ce format est du JSON ou du YAML en texte brut, les responsables de catalogues peuvent facilement manipuler les métadonnées des catalogues à la main ou à l'aide d'outils JSON ou YAML largement connus et pris en charge, tels que l'interface de programmation (CLI)
jq.Cette possibilité de modification permet d'utiliser les fonctions suivantes et les extensions définies par l'utilisateur :
- Promouvoir une offre existante auprès d'un nouveau canal
- Changer le canal par défaut d'un paquet
- Algorithmes personnalisés pour l'ajout, la mise à jour et la suppression des bords de mise à niveau
- Composabilité
Les catalogues basés sur des fichiers sont stockés dans une hiérarchie de répertoires arbitraire, ce qui permet de composer des catalogues. Par exemple, considérons deux répertoires distincts de catalogues basés sur des fichiers :
catalogAetcatalogB. Un responsable de catalogue peut créer un nouveau catalogue combiné en créant un nouveau répertoirecatalogCet en y copiantcatalogAetcatalogB.Cette composabilité permet de créer des catalogues décentralisés. Le format permet aux auteurs d'opérateurs de maintenir des catalogues spécifiques aux opérateurs et aux mainteneurs de construire de manière triviale un catalogue composé de catalogues d'opérateurs individuels. Les catalogues basés sur des fichiers peuvent être composés en combinant plusieurs autres catalogues, en extrayant des sous-ensembles d'un catalogue ou en combinant ces deux méthodes.
NoteLes paquets en double et les paquets en double à l'intérieur d'un paquet ne sont pas autorisés. La commande
opm validaterenvoie une erreur si des doublons sont trouvés.Étant donné que les auteurs d'opérateurs connaissent le mieux leur opérateur, ses dépendances et sa compatibilité avec les mises à jour, ils sont en mesure de maintenir leur propre catalogue spécifique à l'opérateur et de contrôler directement son contenu. Avec les catalogues basés sur des fichiers, les auteurs d'opérateurs sont responsables de la construction et de la maintenance de leurs paquets dans un catalogue. Les responsables des catalogues composites, cependant, ne sont responsables que de la conservation des paquets dans leur catalogue et de la publication du catalogue pour les utilisateurs.
- Extensibilité
La spécification de catalogue basée sur les fichiers est une représentation de bas niveau d'un catalogue. Bien qu'il puisse être maintenu directement dans sa forme de bas niveau, les responsables de catalogues peuvent construire des extensions intéressantes qui peuvent être utilisées par leurs propres outils personnalisés pour effectuer n'importe quel nombre de mutations.
Par exemple, un outil pourrait traduire une API de haut niveau, telle que
(mode=semver), en un format de catalogue de bas niveau, basé sur des fichiers, pour les bords de mise à niveau. Ou encore, un responsable de catalogue pourrait avoir besoin de personnaliser toutes les métadonnées des lots en ajoutant une nouvelle propriété aux lots qui répondent à certains critères.Bien que cette extensibilité permette de développer des outils officiels supplémentaires au-dessus des API de bas niveau pour les futures versions d'OpenShift Container Platform, le principal avantage est que les mainteneurs de catalogues disposent également de cette capacité.
À partir d'OpenShift Container Platform 4.11, le catalogue Operator fourni par Red Hat par défaut est publié dans le format de catalogue basé sur des fichiers. Les catalogues Operator fournis par Red Hat par défaut pour OpenShift Container Platform 4.6 à 4.10 sont publiés dans le format de base de données SQLite déprécié.
Les sous-commandes, drapeaux et fonctionnalités de opm liés au format de base de données SQLite sont également obsolètes et seront supprimés dans une prochaine version. Ces fonctionnalités sont toujours prises en charge et doivent être utilisées pour les catalogues qui utilisent le format de base de données SQLite obsolète.
La plupart des sous-commandes et des drapeaux de opm pour travailler avec le format de base de données SQLite, tels que opm index prune, ne fonctionnent pas avec le format de catalogue basé sur des fichiers. Pour plus d'informations sur l'utilisation des catalogues basés sur des fichiers, voir Gestion des catalogues personnalisés et Mise en miroir des images pour une installation déconnectée à l'aide du plugin oc-mirror.
2.2.2.1. Structure du répertoire
Les catalogues basés sur des fichiers peuvent être stockés et chargés à partir de systèmes de fichiers basés sur des répertoires. Le CLI de opm charge le catalogue en parcourant le répertoire racine et en revenant sur les sous-répertoires. Il tente de charger tous les fichiers qu'il trouve et échoue en cas d'erreur.
Les fichiers hors catalogue peuvent être ignorés à l'aide des fichiers .indexignore, qui obéissent aux mêmes règles que les fichiers .gitignore en ce qui concerne les motifs et la priorité.
Exemple de fichier .indexignore
# Ignore everything except non-object .json and .yaml files
**/*
!*.json
!*.yaml
**/objects/*.json
**/objects/*.yamlLes responsables des catalogues ont la possibilité de choisir la disposition qu'ils souhaitent, mais il est recommandé de stocker les blobs de catalogue basés sur les fichiers de chaque paquet dans des sous-répertoires distincts. Chaque fichier individuel peut être au format JSON ou YAML ; il n'est pas nécessaire que tous les fichiers d'un catalogue utilisent le même format.
Structure de base recommandée
catalog
├── packageA
│ └── index.yaml
├── packageB
│ ├── .indexignore
│ ├── index.yaml
│ └── objects
│ └── packageB.v0.1.0.clusterserviceversion.yaml
└── packageC
└── index.jsonCette structure recommandée a la propriété que chaque sous-répertoire de la hiérarchie des répertoires est un catalogue autonome, ce qui rend la composition, la découverte et la navigation dans le catalogue des opérations triviales du système de fichiers. Le catalogue peut également être inclus dans un catalogue parent en le copiant dans le répertoire racine du catalogue parent.
2.2.2.2. Schémas
Les catalogues basés sur des fichiers utilisent un format, basé sur la spécification du langage CUE, qui peut être étendu avec des schémas arbitraires. Le schéma CUE suivant ( _Meta ) définit le format auquel tous les blobs de catalogues basés sur des fichiers doivent adhérer :
_Meta schéma
_Meta: {
// schema is required and must be a non-empty string
schema: string & !=""
// package is optional, but if it's defined, it must be a non-empty string
package?: string & !=""
// properties is optional, but if it's defined, it must be a list of 0 or more properties
properties?: [... #Property]
}
#Property: {
// type is required
type: string & !=""
// value is required, and it must not be null
value: !=null
}
Aucun des schémas CUE énumérés dans la présente spécification ne doit être considéré comme exhaustif. La commande opm validate comporte des validations supplémentaires qu'il est difficile, voire impossible, d'exprimer de manière concise dans le langage CUE.
Un catalogue Operator Lifecycle Manager (OLM) utilise actuellement trois schémas (olm.package, olm.channel, et olm.bundle), qui correspondent aux concepts existants de paquet et de liasse d'OLM.
Chaque paquet d'opérateurs d'un catalogue nécessite exactement un blob olm.package, au moins un blob olm.channel et un ou plusieurs blobs olm.bundle.
Tous les schémas olm.* sont réservés aux schémas définis par OLM. Les schémas personnalisés doivent utiliser un préfixe unique, tel qu'un domaine dont vous êtes propriétaire.
2.2.2.2.1. schéma de l'olm.package
Le schéma olm.package définit les métadonnées d'un opérateur au niveau du paquet. Il s'agit de son nom, de sa description, de son canal par défaut et de son icône.
Exemple 2.1. olm.package schéma
#Package: {
schema: "olm.package"
// Package name
name: string & !=""
// A description of the package
description?: string
// The package's default channel
defaultChannel: string & !=""
// An optional icon
icon?: {
base64data: string
mediatype: string
}
}2.2.2.2.2. schéma olm.channel
Le schéma olm.channel définit un canal à l'intérieur d'un paquet, les entrées de paquet qui sont membres du canal et les bords de mise à niveau pour ces paquets.
Une liasse peut être incluse en tant qu'entrée dans plusieurs blobs olm.channel, mais elle ne peut avoir qu'une seule entrée par canal.
Il est possible que la valeur de remplacement d'une entrée fasse référence à un autre nom de paquet qui ne peut être trouvé dans ce catalogue ou dans un autre catalogue. Cependant, tous les autres invariants du canal doivent rester vrais, comme le fait qu'un canal n'ait pas plusieurs têtes.
Exemple 2.2. olm.channel schéma
#Channel: {
schema: "olm.channel"
package: string & !=""
name: string & !=""
entries: [...#ChannelEntry]
}
#ChannelEntry: {
// name is required. It is the name of an `olm.bundle` that
// is present in the channel.
name: string & !=""
// replaces is optional. It is the name of bundle that is replaced
// by this entry. It does not have to be present in the entry list.
replaces?: string & !=""
// skips is optional. It is a list of bundle names that are skipped by
// this entry. The skipped bundles do not have to be present in the
// entry list.
skips?: [...string & !=""]
// skipRange is optional. It is the semver range of bundle versions
// that are skipped by this entry.
skipRange?: string & !=""
}2.2.2.2.3. schéma olm.bundle
Exemple 2.3. olm.bundle schéma
#Bundle: {
schema: "olm.bundle"
package: string & !=""
name: string & !=""
image: string & !=""
properties: [...#Property]
relatedImages?: [...#RelatedImage]
}
#Property: {
// type is required
type: string & !=""
// value is required, and it must not be null
value: !=null
}
#RelatedImage: {
// image is the image reference
image: string & !=""
// name is an optional descriptive name for an image that
// helps identify its purpose in the context of the bundle
name?: string & !=""
}2.2.2.3. Propriétés
Les propriétés sont des éléments arbitraires de métadonnées qui peuvent être attachés à des schémas de catalogues basés sur des fichiers. Le champ type est une chaîne qui spécifie effectivement la signification sémantique et syntaxique du champ value. La valeur peut être n'importe quel JSON ou YAML arbitraire.
OLM définit une poignée de types de propriétés, en utilisant à nouveau le préfixe réservé olm.*.
2.2.2.3.1. propriété olm.package
La propriété olm.package définit le nom et la version du paquet. Il s'agit d'une propriété obligatoire pour les bundles, et il doit y avoir exactement une de ces propriétés. Le champ packageName doit correspondre au champ de première classe package de la liasse et le champ version doit être une version sémantique valide.
Exemple 2.4. olm.package propriété
#PropertyPackage: {
type: "olm.package"
value: {
packageName: string & !=""
version: string & !=""
}
}2.2.2.3.2. propriété olm.gvk
La propriété olm.gvk définit le groupe/la version/le type (GVK) d'une API Kubernetes fournie par ce bundle. Cette propriété est utilisée par OLM pour résoudre un bundle avec cette propriété en tant que dépendance pour d'autres bundles qui listent le même GVK comme API requise. Le GVK doit respecter les validations GVK de Kubernetes.
Exemple 2.5. olm.gvk propriété
#PropertyGVK: {
type: "olm.gvk"
value: {
group: string & !=""
version: string & !=""
kind: string & !=""
}
}2.2.2.3.3. olm.package.required
La propriété olm.package.required définit le nom du package et la plage de versions d'un autre package requis par cette offre groupée. Pour chaque propriété de paquetage requise qu'une offre énumère, OLM s'assure qu'un opérateur est installé sur le cluster pour le paquetage répertorié et dans la plage de versions requise. Le champ versionRange doit être une plage de versions sémantiques (semver) valide.
Exemple 2.6. olm.package.required propriété
#PropertyPackageRequired: {
type: "olm.package.required"
value: {
packageName: string & !=""
versionRange: string & !=""
}
}2.2.2.3.4. olm.gvk.requis
La propriété olm.gvk.required définit le groupe/la version/le type (GVK) d'une API Kubernetes dont ce bundle a besoin. Pour chaque propriété GVK requise, OLM s'assure qu'il existe un opérateur installé sur le cluster qui la fournit. Le GVK doit respecter les validations GVK de Kubernetes.
Exemple 2.7. olm.gvk.required propriété
#PropertyGVKRequired: {
type: "olm.gvk.required"
value: {
group: string & !=""
version: string & !=""
kind: string & !=""
}
}2.2.2.4. Exemple de catalogue
Avec les catalogues basés sur des fichiers, les responsables des catalogues peuvent se concentrer sur la curation et la compatibilité des opérateurs. Comme les auteurs d'opérateurs ont déjà produit des catalogues spécifiques pour leurs opérateurs, les responsables de catalogues peuvent construire leur catalogue en rendant chaque catalogue d'opérateur dans un sous-répertoire du répertoire racine du catalogue.
Il existe de nombreuses façons de créer un catalogue basé sur des fichiers ; les étapes suivantes décrivent une approche simple :
Maintenir un seul fichier de configuration pour le catalogue, contenant des références d'images pour chaque opérateur du catalogue :
Exemple de fichier de configuration de catalogue
name: community-operators repo: quay.io/community-operators/catalog tag: latest references: - name: etcd-operator image: quay.io/etcd-operator/index@sha256:5891b5b522d5df086d0ff0b110fbd9d21bb4fc7163af34d08286a2e846f6be03 - name: prometheus-operator image: quay.io/prometheus-operator/index@sha256:e258d248fda94c63753607f7c4494ee0fcbe92f1a76bfdac795c9d84101eb317Exécuter un script qui analyse le fichier de configuration et crée un nouveau catalogue à partir de ses références :
Exemple de script
name=$(yq eval '.name' catalog.yaml) mkdir "$name" yq eval '.name + "/" + .references[].name' catalog.yaml | xargs mkdir for l in $(yq e '.name as $catalog | .references[] | .image + "|" + $catalog + "/" + .name + "/index.yaml"' catalog.yaml); do image=$(echo $l | cut -d'|' -f1) file=$(echo $l | cut -d'|' -f2) opm render "$image" > "$file" done opm alpha generate dockerfile "$name" indexImage=$(yq eval '.repo + ":" + .tag' catalog.yaml) docker build -t "$indexImage" -f "$name.Dockerfile" . docker push "$indexImage"
2.2.2.5. Lignes directrices
Les lignes directrices suivantes doivent être prises en compte lors de la gestion de catalogues basés sur des fichiers.
2.2.2.5.1. Paquets immuables
En ce qui concerne le gestionnaire du cycle de vie des opérateurs (OLM), il est généralement conseillé de considérer les images des liasses et leurs métadonnées comme immuables.
Si un bundle cassé a été poussé vers un catalogue, vous devez supposer qu'au moins un de vos utilisateurs a effectué une mise à niveau vers ce bundle. Sur la base de cette hypothèse, vous devez publier une autre liasse avec un bord de mise à niveau à partir de la liasse cassée pour vous assurer que les utilisateurs ayant installé la liasse cassée reçoivent une mise à niveau. OLM ne réinstallera pas une liasse installée si le contenu de cette liasse est mis à jour dans le catalogue.
Toutefois, dans certains cas, il est préférable de modifier les métadonnées du catalogue :
-
Promotion des canaux : Si vous avez déjà publié une offre groupée et que vous décidez par la suite de l'ajouter à un autre canal, vous pouvez ajouter une entrée pour votre offre groupée dans un autre blob
olm.channel. -
Nouveaux bords de mise à niveau : Si vous publiez une nouvelle version de l'offre groupée
1.2.z, par exemple1.2.4, mais que1.3.0est déjà disponible, vous pouvez mettre à jour les métadonnées du catalogue pour1.3.0afin d'ignorer1.2.4.
2.2.2.5.2. Contrôle des sources
Les métadonnées du catalogue doivent être stockées dans le contrôle de la source et considérées comme la source de vérité. Les mises à jour des images du catalogue doivent comprendre les étapes suivantes :
- Mettre à jour le répertoire du catalogue contrôlé par la source avec un nouveau commit.
-
Construire et pousser l'image du catalogue. Utilisez une taxonomie d'étiquetage cohérente, telle que
:latestou:<target_cluster_version>, afin que les utilisateurs puissent recevoir les mises à jour d'un catalogue au fur et à mesure qu'elles sont disponibles.
2.2.2.6. Utilisation du CLI
Pour obtenir des instructions sur la création de catalogues basés sur des fichiers à l'aide de l'interface CLI de opm, reportez-vous à la section Gestion des catalogues personnalisés.
Pour obtenir une documentation de référence sur les commandes CLI de opm relatives à la gestion des catalogues basés sur des fichiers, voir Outils CLI.
2.2.2.7. Automatisation
Les auteurs d'opérateurs et les responsables de catalogues sont encouragés à automatiser la maintenance de leurs catalogues avec des flux de travail CI/CD. Les mainteneurs de catalogues peuvent encore améliorer cela en construisant une automatisation GitOps pour accomplir les tâches suivantes :
- Vérifier que les auteurs de demandes d'extraction (PR) sont autorisés à effectuer les modifications demandées, par exemple en mettant à jour la référence de l'image de leur paquet.
-
Vérifiez que les mises à jour du catalogue passent la commande
opm validate. - Vérifiez que les références du bundle ou de l'image de catalogue mis à jour existent, que les images de catalogue s'exécutent correctement dans un cluster et que les opérateurs de ce package peuvent être installés avec succès.
- Fusionner automatiquement les RP qui ont passé les contrôles précédents.
- Reconstruire et republier automatiquement l'image du catalogue.
2.2.3. RukPak (aperçu technologique)
RukPak est une fonctionnalité d'aperçu technologique uniquement. Les fonctionnalités de l'aperçu technologique ne sont pas prises en charge par les accords de niveau de service (SLA) de production de Red Hat et peuvent ne pas être complètes sur le plan fonctionnel. Red Hat ne recommande pas de les utiliser en production. Ces fonctionnalités offrent un accès anticipé aux fonctionnalités des produits à venir, ce qui permet aux clients de tester les fonctionnalités et de fournir un retour d'information pendant le processus de développement.
Pour plus d'informations sur la portée de l'assistance des fonctionnalités de l'aperçu technologique de Red Hat, voir Portée de l'assistance des fonctionnalités de l'aperçu technologique.
OpenShift Container Platform 4.12 introduit le type platform Operator en tant que fonctionnalité d'aperçu technologique. Le mécanisme de la plateforme Operator s'appuie sur le composant RukPak, également introduit dans OpenShift Container Platform 4.12, et ses ressources pour gérer le contenu.
RukPak se compose d'une série de contrôleurs, appelés provisioners, qui installent et gèrent le contenu sur un cluster Kubernetes. RukPak fournit également deux API principales : Bundle et BundleDeployment. Ces composants travaillent ensemble pour apporter du contenu sur le cluster et l'installer, en générant des ressources au sein du cluster.
Un provisionneur place une surveillance sur les ressources Bundle et BundleDeployment qui font explicitement référence au provisionneur. Pour un ensemble donné, le provisionneur décompresse le contenu de la ressource Bundle sur le cluster. Ensuite, lorsqu'une ressource BundleDeployment fait référence à cet ensemble, le provisionneur installe le contenu de l'ensemble et est responsable de la gestion du cycle de vie de ces ressources.
Deux provisionneurs sont actuellement mis en œuvre et fournis avec RukPak : le plain provisioner qui source et décompresse les paquets plain v0, et le registry provisioner qui source et décompresse les paquets Operator Lifecycle Manager (OLM) registry v1.
2.2.3.1. L'offre groupée
Un objet RukPak Bundle représente un contenu à mettre à la disposition d'autres consommateurs dans le cluster. Tout comme le contenu d'une image de conteneur doit être extrait et décompressé pour que le pod puisse commencer à l'utiliser, les objets Bundle sont utilisés pour référencer le contenu qui pourrait avoir besoin d'être extrait et décompressé. En ce sens, un bundle est une généralisation du concept d'image et peut être utilisé pour représenter n'importe quel type de contenu.
Les paquets ne peuvent rien faire par eux-mêmes ; ils ont besoin d'un provisionneur pour décompresser et rendre leur contenu disponible dans le cluster. Ils peuvent être décompressés sur n'importe quel support de stockage arbitraire, tel qu'un fichier tar.gz dans un répertoire monté dans les pods du provisionneur. Chaque objet Bundle est associé à un champ spec.provisionerClassName qui indique l'objet Provisioner qui surveille et décompresse ce type de paquet particulier.
Exemple Bundle objet configuré pour fonctionner avec le provisionneur ordinaire
apiVersion: core.rukpak.io/v1alpha1
kind: Bundle
metadata:
name: my-bundle
spec:
source:
type: image
image:
ref: my-bundle@sha256:xyz123
provisionerClassName: core-rukpak-io-plainLes paquets sont considérés comme immuables après leur création.
2.2.3.1.1. Immutabilité de l'offre groupée
Une fois qu'un objet Bundle est accepté par le serveur API, l'ensemble est considéré comme un artefact immuable par le reste du système RukPak. Ce comportement renforce la notion qu'un bundle représente un élément de contenu unique et statique à introduire dans le cluster. Un utilisateur peut être certain qu'un bundle particulier pointe vers un ensemble spécifique de manifestes et qu'il ne peut être mis à jour sans créer un nouveau bundle. Cette propriété s'applique aussi bien aux bundles autonomes qu'aux bundles dynamiques créés par un objet BundleTemplate intégré.
L'immuabilité de l'ensemble est assurée par le webhook principal de RukPak. Ce webhook surveille les événements de l'objet Bundle et, pour toute mise à jour d'une liasse, vérifie si le champ spec de la liasse existante est sémantiquement égal à celui de la liasse mise à jour proposée. Si ce n'est pas le cas, la mise à jour est rejetée par le webhook. D'autres champs de l'objet Bundle, tels que metadata ou status, sont mis à jour au cours du cycle de vie de l'offre groupée ; seul le champ spec est considéré comme immuable.
L'application d'un objet Bundle et la tentative de mise à jour de sa spécification devraient échouer. Par exemple, l'exemple suivant crée un bundle :
$ oc apply -f -<<EOF
apiVersion: core.rukpak.io/v1alpha1
kind: Bundle
metadata:
name: combo-tag-ref
spec:
source:
type: git
git:
ref:
tag: v0.0.2
repository: https://github.com/operator-framework/combo
provisionerClassName: core-rukpak-io-plain
EOFExemple de sortie
bundle.core.rukpak.io/combo-tag-ref createdEnsuite, l'application d'un correctif à la liasse pour qu'elle pointe vers une balise plus récente renvoie une erreur :
$ oc patch bundle combo-tag-ref --type='merge' -p '{"spec":{"source":{"git":{"ref":{"tag":"v0.0.3"}}}}}'Exemple de sortie
Error from server (bundle.spec is immutable): admission webhook "vbundles.core.rukpak.io" denied the request: bundle.spec is immutable
Le webhook d'admission du noyau RukPak a rejeté le correctif parce que la spécification de l'ensemble est immuable. La méthode recommandée pour modifier le contenu d'une liasse consiste à créer un nouvel objet Bundle au lieu de le mettre à jour sur place.
Autres considérations sur l'immutabilité
Bien que le champ spec de l'objet Bundle soit immuable, il est toujours possible pour un objet BundleDeployment de pivoter vers une version plus récente du contenu de la liasse sans modifier le champ spec sous-jacent. Ce pivotement involontaire pourrait se produire dans le scénario suivant :
-
Un utilisateur définit une étiquette d'image, une branche Git ou une étiquette Git dans le champ
spec.sourcede l'objetBundle. - La balise image est déplacée vers un nouveau résumé, un utilisateur apporte des modifications à une branche Git, ou un utilisateur supprime et repousse une balise Git sur un commit différent.
- Un utilisateur fait quelque chose qui entraîne la recréation du pod d'unpackage du bundle, comme la suppression du pod d'unpackage.
Si ce scénario se produit, le nouveau contenu de l'étape 2 est décompressé à la suite de l'étape 3. Le déploiement de l'offre groupée détecte les modifications et passe à la version la plus récente du contenu.
Ceci est similaire au comportement d'un pod, où l'une des images de conteneur du pod utilise une balise, la balise est déplacée vers un digest différent, puis à un moment donné dans le futur, le pod existant est reprogrammé sur un nœud différent. À ce moment-là, le nœud extrait la nouvelle image du nouveau résumé et exécute quelque chose de différent sans que l'utilisateur ne le demande explicitement.
Pour être sûr que le contenu sous-jacent de la spécification Bundle ne change pas, utilisez une image basée sur un condensé ou une référence à un commit Git lors de la création de l'offre groupée.
2.2.3.1.2. Paquet simple spec
Un bundle simple dans RukPak est une collection de manifestes YAML Kubernetes statiques et arbitraires dans un répertoire donné.
Le format de liasse simple actuellement mis en œuvre est le format plain v0. Le nom du format de liasse, plain v0, combine le type de liasse (plain) et la version actuelle du schéma (v0).
Le format de la liasse plain v0 est à la version de schéma v0, ce qui signifie qu'il s'agit d'un format expérimental susceptible d'être modifié.
Par exemple, l'illustration suivante montre l'arborescence des fichiers d'un bundle plain v0. Il doit comporter un répertoire manifests/ contenant les ressources Kubernetes nécessaires au déploiement d'une application.
Exemple plain v0 Arborescence des fichiers de la liasse
manifests
├── namespace.yaml
├── cluster_role.yaml
├── role.yaml
├── serviceaccount.yaml
├── cluster_role_binding.yaml
├── role_binding.yaml
└── deployment.yaml
Les manifestes statiques doivent se trouver dans le répertoire manifests/ et contenir au moins une ressource pour que le bundle soit un bundle plain v0 valide que le provisionneur peut décompresser. Le répertoire manifests/ doit également être plat ; tous les manifestes doivent se trouver au niveau supérieur, sans sous-répertoire.
N'incluez pas de contenu dans le répertoire manifests/ d'un paquet ordinaire qui ne soit pas un manifeste statique. Sinon, un échec se produira lors de la création de contenu sur le cluster à partir de ce bundle. Tout fichier qui ne s'appliquerait pas avec succès avec la commande oc apply entraînera une erreur. Les fichiers YAML ou JSON multi-objets sont également valides.
2.2.3.1.3. Spécification de la liasse de registres
Un bundle de registre, ou registry v1 bundle, contient un ensemble de manifestes YAML Kubernetes statiques organisés dans l'ancien format de bundle Operator Lifecycle Manager (OLM).
2.2.3.2. Déploiement groupé
Un objet BundleDeployment modifie l'état d'un cluster Kubernetes en installant et en supprimant des objets. Il est important de vérifier et de faire confiance au contenu qui est installé et de limiter l'accès à l'API BundleDeployment, à l'aide d'un système RBAC, aux seules personnes qui ont besoin de ces autorisations.
L'API RukPak BundleDeployment pointe vers un objet Bundle et indique qu'il doit être actif. Cela permet notamment de pivoter à partir d'anciennes versions d'un ensemble actif. Un objet BundleDeployment peut également inclure une spécification intégrée pour un ensemble souhaité.
Tout comme les pods génèrent des instances d'images de conteneurs, un déploiement de bundle génère une version déployée d'un bundle. Le déploiement d'un bundle peut être considéré comme une généralisation du concept de pod.
Les spécificités de la manière dont un déploiement de bundle apporte des modifications à un cluster basé sur un bundle référencé sont définies par le provisionneur qui est configuré pour surveiller ce déploiement de bundle.
Exemple BundleDeployment objet configuré pour fonctionner avec le provisionneur ordinaire
apiVersion: core.rukpak.io/v1alpha1
kind: BundleDeployment
metadata:
name: my-bundle-deployment
spec:
provisionerClassName: core-rukpak-io-plain
template:
metadata:
labels:
app: my-bundle
spec:
source:
type: image
image:
ref: my-bundle@sha256:xyz123
provisionerClassName: core-rukpak-io-plain2.2.3.3. Provisionneur
Un provisionneur RukPak est un contrôleur qui comprend les API BundleDeployment et Bundle et peut prendre des mesures. Chaque provisionneur se voit attribuer un identifiant unique et est chargé de rapprocher les objets Bundle et BundleDeployment avec un champ spec.provisionerClassName correspondant à cet identifiant particulier.
Par exemple, le "plain provisioner" est capable de décompresser un paquet plain v0 donné sur un cluster et de l'instancier, rendant ainsi le contenu du paquet disponible dans le cluster.
2.3. Cadre de l'opérateur glossaire des termes courants
Cette rubrique fournit un glossaire des termes courants relatifs à l'Operator Framework, y compris Operator Lifecycle Manager (OLM) et Operator SDK.
2.3.1. Termes du cadre commun des opérateurs
2.3.1.1. L'offre groupée
Dans le format bundle, un bundle est une collection d'un CSV d'opérateur, de manifestes et de métadonnées. Ensemble, ils forment une version unique d'un opérateur qui peut être installée sur le cluster.
2.3.1.2. Image de l'offre groupée
Dans le format bundle, un bundle image est une image de conteneur construite à partir de manifestes d'opérateurs et contenant un bundle. Les images de bundle sont stockées et distribuées par des registres de conteneurs spécifiques à l'Open Container Initiative (OCI), tels que Quay.io ou DockerHub.
2.3.1.3. Source du catalogue
Un site catalog source représente un magasin de métadonnées qu'OLM peut interroger pour découvrir et installer des opérateurs et leurs dépendances.
2.3.1.4. Chaîne
Un channel définit un flux de mises à jour pour un opérateur et est utilisé pour déployer des mises à jour pour les abonnés. La tête pointe vers la dernière version de ce canal. Par exemple, un canal stable contient toutes les versions stables d'un opérateur, de la plus ancienne à la plus récente.
Un opérateur peut avoir plusieurs canaux, et un abonnement lié à un certain canal ne recherchera des mises à jour que dans ce canal.
2.3.1.5. Tête de canal
Le site channel head fait référence à la dernière mise à jour connue d'un canal particulier.
2.3.1.6. Version du service de cluster
Un cluster service version (CSV) est un manifeste YAML créé à partir des métadonnées de l'opérateur, qui aide OLM à exécuter l'opérateur dans un cluster. Il s'agit des métadonnées qui accompagnent l'image d'un conteneur Operator, utilisées pour remplir les interfaces utilisateur avec des informations telles que le logo, la description et la version.
Il s'agit également d'une source d'informations techniques nécessaires au fonctionnement de l'opérateur, comme les règles RBAC dont il a besoin et les ressources personnalisées (CR) qu'il gère ou dont il dépend.
2.3.1.7. Dépendance
Un opérateur peut avoir une dépendance dependency à l'égard d'un autre opérateur présent dans le cluster. Par exemple, l'opérateur Vault dépend de l'opérateur etcd pour sa couche de persistance des données.
OLM résout les dépendances en s'assurant que toutes les versions spécifiées des opérateurs et des CRD sont installées sur le cluster pendant la phase d'installation. Cette dépendance est résolue par la recherche et l'installation d'un opérateur dans un catalogue qui satisfait à l'API CRD requise et qui n'est pas lié à des paquets ou à des bundles.
2.3.1.8. Image d'index
Dans le format des bundles, un index image fait référence à une image d'une base de données (un instantané de base de données) qui contient des informations sur les bundles d'opérateurs, y compris les CSV et les CRD de toutes les versions. Cet index peut héberger un historique des opérateurs sur un cluster et être maintenu en ajoutant ou en supprimant des opérateurs à l'aide de l'outil CLI opm.
2.3.1.9. Plan d'installation
Un site install plan est une liste calculée de ressources à créer pour installer ou mettre à niveau automatiquement un CSV.
2.3.1.10. Multitenance
Un tenant dans OpenShift Container Platform est un utilisateur ou un groupe d'utilisateurs qui partagent un accès et des privilèges communs pour un ensemble de charges de travail déployées, généralement représentées par un espace de noms ou un projet. Vous pouvez utiliser les locataires pour fournir un niveau d'isolation entre différents groupes ou équipes.
Lorsqu'un cluster est partagé par plusieurs utilisateurs ou groupes, il est considéré comme un cluster multitenant.
2.3.1.11. Groupe d'opérateurs
Un Operator group configure tous les opérateurs déployés dans le même espace de noms que l'objet OperatorGroup pour qu'ils surveillent leur CR dans une liste d'espaces de noms ou à l'échelle du cluster.
2.3.1.12. Paquet
Dans le format bundle, un package est un répertoire qui contient tout l'historique des versions publiées d'un opérateur pour chaque version. Une version publiée d'un opérateur est décrite dans un manifeste CSV à côté des CRD.
2.3.1.13. Registre
Le site registry est une base de données qui stocke des images de faisceaux d'opérateurs, chacun avec toutes ses versions récentes et historiques dans tous les canaux.
2.3.1.14. Abonnement
Un site subscription permet de maintenir les CSV à jour en suivant un canal dans un paquet.
2.3.1.15. Graphique de mise à jour
Un site update graph relie les versions des CSV entre elles, de la même manière que le graphique de mise à jour de tout autre logiciel. Les opérateurs peuvent être installés de manière séquentielle ou certaines versions peuvent être ignorées. Le graphique de mise à jour ne devrait croître qu'en tête, avec l'ajout de nouvelles versions.
2.4. Gestionnaire du cycle de vie des opérateurs (OLM)
2.4.1. Concepts et ressources du gestionnaire du cycle de vie de l'opérateur
Ce guide fournit une vue d'ensemble des concepts qui régissent Operator Lifecycle Manager (OLM) dans OpenShift Container Platform.
2.4.1.1. Qu'est-ce que l'Operator Lifecycle Manager ?
Operator Lifecycle Manager (OLM) aide les utilisateurs à installer, mettre à jour et gérer le cycle de vie des applications natives Kubernetes (Operators) et de leurs services associés s'exécutant sur leurs clusters OpenShift Container Platform. Il fait partie de l'Operator Framework, une boîte à outils open source conçue pour gérer les opérateurs de manière efficace, automatisée et évolutive.
Figure 2.2. Flux de travail du gestionnaire du cycle de vie de l'opérateur
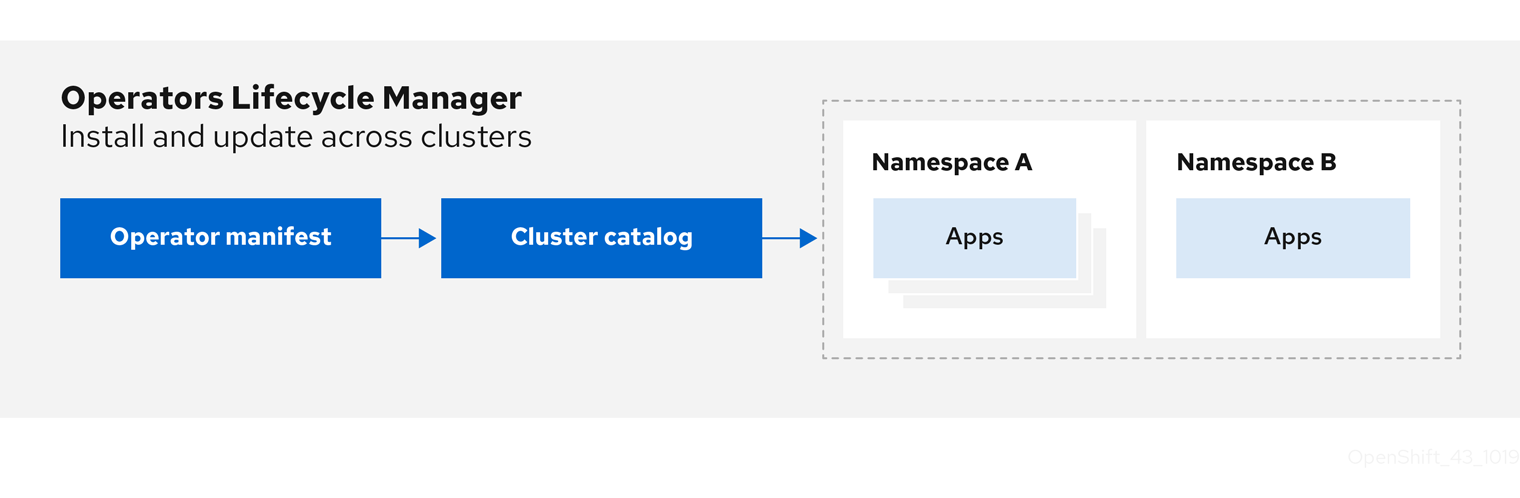
OLM fonctionne par défaut dans OpenShift Container Platform 4.12, ce qui aide les administrateurs de clusters à installer, mettre à niveau et accorder l'accès aux opérateurs fonctionnant sur leur cluster. La console web d'OpenShift Container Platform fournit des écrans de gestion permettant aux administrateurs de cluster d'installer des opérateurs, ainsi que d'accorder à des projets spécifiques l'accès à l'utilisation du catalogue d'opérateurs disponibles sur le cluster.
Pour les développeurs, une expérience en libre-service permet de provisionner et de configurer des instances de bases de données, de surveillance et de services de big data sans avoir à être des experts en la matière, car l'opérateur dispose de ces connaissances.
2.4.1.2. Ressources OLM
Les définitions de ressources personnalisées (CRD) suivantes sont définies et gérées par Operator Lifecycle Manager (OLM) :
| Ressources | Nom court | Description |
|---|---|---|
|
|
| Métadonnées de l'application. Par exemple : nom, version, icône, ressources nécessaires. |
|
|
| Un référentiel de CSV, CRD et paquets qui définissent une application. |
|
|
| Maintient les CSV à jour en suivant un canal dans un paquet. |
|
|
| Liste calculée des ressources à créer pour installer ou mettre à jour automatiquement un CSV. |
|
|
|
Configure tous les opérateurs déployés dans le même espace de noms que l'objet |
|
| - |
Crée un canal de communication entre OLM et un opérateur qu'il gère. Les opérateurs peuvent écrire dans le tableau |
2.4.1.2.1. Version du service de cluster
Un cluster service version (CSV) représente une version spécifique d'un Operator en cours d'exécution sur un cluster OpenShift Container Platform. Il s'agit d'un manifeste YAML créé à partir des métadonnées de l'opérateur qui aide Operator Lifecycle Manager (OLM) à exécuter l'opérateur dans le cluster.
OLM a besoin de ces métadonnées sur un opérateur pour s'assurer qu'il peut être exécuté en toute sécurité sur un cluster et pour fournir des informations sur la manière dont les mises à jour doivent être appliquées lorsque de nouvelles versions de l'opérateur sont publiées. Cela ressemble à l'empaquetage d'un logiciel pour un système d'exploitation traditionnel ; considérez l'étape d'empaquetage pour OLM comme l'étape à laquelle vous créez votre paquet rpm, deb, ou apk.
Un CSV comprend les métadonnées qui accompagnent l'image d'un conteneur d'opérateur, utilisées pour remplir les interfaces utilisateur avec des informations telles que le nom, la version, la description, les étiquettes, le lien vers le référentiel et le logo.
Un CSV est également une source d'informations techniques nécessaires à l'exécution de l'opérateur, telles que les ressources personnalisées (CR) qu'il gère ou dont il dépend, les règles RBAC, les exigences du cluster et les stratégies d'installation. Ces informations indiquent à OLM comment créer les ressources requises et configurer l'opérateur en tant que déploiement.
2.4.1.2.2. Source du catalogue
Un site catalog source représente un magasin de métadonnées, généralement en faisant référence à un site index image stocké dans un registre de conteneurs. Operator Lifecycle Manager (OLM) interroge les sources du catalogue pour découvrir et installer les opérateurs et leurs dépendances. OperatorHub dans la console web d'OpenShift Container Platform affiche également les opérateurs fournis par les sources du catalogue.
Les administrateurs de cluster peuvent consulter la liste complète des opérateurs fournis par une source de catalogue activée sur un cluster en utilisant la page Administration → Cluster Settings → Configuration → OperatorHub de la console web.
Le site spec d'un objet CatalogSource indique comment construire un pod ou comment communiquer avec un service qui sert l'API gRPC du registre des opérateurs.
Exemple 2.8. Exemple d'objet CatalogSource
apiVersion: operators.coreos.com/v1alpha1
kind: CatalogSource
metadata:
generation: 1
name: example-catalog
namespace: openshift-marketplace
annotations:
olm.catalogImageTemplate:
"quay.io/example-org/example-catalog:v{kube_major_version}.{kube_minor_version}.{kube_patch_version}"
spec:
displayName: Example Catalog
image: quay.io/example-org/example-catalog:v1
priority: -400
publisher: Example Org
sourceType: grpc
grpcPodConfig:
securityContextConfig: <security_mode>
nodeSelector:
custom_label: <label>
priorityClassName: system-cluster-critical
tolerations:
- key: "key1"
operator: "Equal"
value: "value1"
effect: "NoSchedule"
updateStrategy:
registryPoll:
interval: 30m0s
status:
connectionState:
address: example-catalog.openshift-marketplace.svc:50051
lastConnect: 2021-08-26T18:14:31Z
lastObservedState: READY
latestImageRegistryPoll: 2021-08-26T18:46:25Z
registryService:
createdAt: 2021-08-26T16:16:37Z
port: 50051
protocol: grpc
serviceName: example-catalog
serviceNamespace: openshift-marketplace- 1
- Nom de l'objet
CatalogSource. Cette valeur est également utilisée comme partie du nom du pod connexe qui est créé dans l'espace de noms demandé. - 2
- Espace de noms dans lequel créer le catalogue. Pour rendre le catalogue disponible à l'échelle du cluster dans tous les espaces de noms, définissez cette valeur sur
openshift-marketplace. Les sources de catalogues fournies par Red Hat par défaut utilisent également l'espace de nomsopenshift-marketplace. Sinon, définissez la valeur sur un espace de noms spécifique pour que l'opérateur ne soit disponible que dans cet espace de noms. - 3
- Facultatif : Pour éviter que les mises à niveau de clusters ne laissent les installations Operator dans un état non pris en charge ou sans chemin de mise à jour continu, vous pouvez activer le changement automatique de la version de l'image d'index de votre catalogue Operator dans le cadre des mises à niveau de clusters.
Définissez l'annotation
olm.catalogImageTemplateavec le nom de votre image d'index et utilisez une ou plusieurs variables de version du cluster Kubernetes comme indiqué lors de la construction du modèle pour la balise d'image. L'annotation remplace le champspec.imageau moment de l'exécution. Voir la section "Modèle d'image pour les sources de catalogue personnalisées" pour plus de détails. - 4
- Nom d'affichage du catalogue dans la console web et la CLI.
- 5
- Image d'index pour le catalogue. En option, peut être omis lors de l'utilisation de l'annotation
olm.catalogImageTemplate, qui définit la spécification d'extraction au moment de l'exécution. - 6
- Poids de la source du catalogue. OLM utilise ce poids pour établir des priorités lors de la résolution des dépendances. Un poids élevé indique que le catalogue est préféré aux catalogues de poids inférieur.
- 7
- Les types de sources sont les suivants :
-
grpcavec une référenceimage: OLM extrait l'image et exécute le pod, qui est censé servir une API conforme. -
grpcavec un champaddress: OLM tente de contacter l'API gRPC à l'adresse indiquée. Ce champ ne doit pas être utilisé dans la plupart des cas. -
configmap: OLM analyse les données de la carte de configuration et exécute un pod qui peut servir l'API gRPC.
-
- 8
- Spécifiez la valeur de
legacyourestricted. Si le champ n'est pas défini, la valeur par défaut estlegacy. Dans une prochaine version d'OpenShift Container Platform, il est prévu que la valeur par défaut soitrestricted. Si votre catalogue ne peut pas s'exécuter avec les autorisationsrestricted, il est recommandé de définir manuellement ce champ surlegacy. - 9
- Facultatif : Pour les sources de catalogue de type
grpc, remplace le sélecteur de nœud par défaut pour le pod qui sert le contenu dansspec.image, s'il est défini. - 10
- Facultatif : Pour les sources de catalogue de type
grpc, remplace le nom de la classe de priorité par défaut pour le pod qui sert le contenu dansspec.image, s'il est défini. Kubernetes fournit les classes de prioritésystem-cluster-criticaletsystem-node-criticalpar défaut. La définition d'un champ vide ("") attribue au pod la priorité par défaut. D'autres classes de priorité peuvent être définies manuellement. - 11
- Facultatif : Pour les sources de catalogue de type
grpc, remplace les tolérances par défaut pour le pod servant le contenu dansspec.image, si elles sont définies. - 12
- Vérifier automatiquement la présence de nouvelles versions à un intervalle donné pour rester à jour.
- 13
- Dernier état observé de la connexion au catalogue. Par exemple :
-
READY: Une connexion est établie avec succès. -
CONNECTING: Une connexion tente de s'établir. -
TRANSIENT_FAILURE: Un problème temporaire s'est produit lors de la tentative d'établissement d'une connexion, tel qu'un dépassement de délai. L'état repassera éventuellement àCONNECTINGet la tentative recommencera.
Pour plus de détails, voir la section États de connectivité dans la documentation gRPC.
-
- 14
- Dernière heure à laquelle le registre du conteneur stockant l'image du catalogue a été interrogé pour s'assurer que l'image est à jour.
- 15
- Informations sur l'état du service de registre des opérateurs du catalogue.
La référence à name d'un objet CatalogSource dans un abonnement indique à OLM où rechercher l'opérateur demandé :
Exemple 2.9. Exemple Subscription objet référençant une source de catalogue
apiVersion: operators.coreos.com/v1alpha1
kind: Subscription
metadata:
name: example-operator
namespace: example-namespace
spec:
channel: stable
name: example-operator
source: example-catalog
sourceNamespace: openshift-marketplace2.4.1.2.2.1. Modèle d'image pour les sources de catalogue personnalisées
La compatibilité de l'opérateur avec le cluster sous-jacent peut être exprimée par une source de catalogue de différentes manières. L'une d'entre elles, utilisée pour les sources de catalogue fournies par défaut par Red Hat, consiste à identifier des balises d'image pour les images d'index qui sont spécifiquement créées pour une version de plateforme particulière, par exemple OpenShift Container Platform 4.12.
Au cours d'une mise à niveau de cluster, la balise d'image d'index pour les sources de catalogue par défaut fournies par Red Hat est mise à jour automatiquement par l'opérateur de version de cluster (CVO) afin que Operator Lifecycle Manager (OLM) tire la version mise à jour du catalogue. Par exemple, lors d'une mise à niveau d'OpenShift Container Platform 4.11 à 4.12, le champ spec.image dans l'objet CatalogSource pour le catalogue redhat-operators est mis à jour de :
registry.redhat.io/redhat/redhat-operator-index:v4.11à :
registry.redhat.io/redhat/redhat-operator-index:v4.12Cependant, l'OVC ne met pas automatiquement à jour les balises d'image pour les catalogues personnalisés. Pour s'assurer que les utilisateurs disposent d'une installation d'Operator compatible et prise en charge après une mise à niveau du cluster, les catalogues personnalisés doivent également être mis à jour pour faire référence à une image d'index mise à jour.
À partir d'OpenShift Container Platform 4.9, les administrateurs de clusters peuvent ajouter l'annotation olm.catalogImageTemplate dans l'objet CatalogSource pour les catalogues personnalisés à une référence d'image qui inclut un modèle. Les variables de version Kubernetes suivantes sont prises en charge pour une utilisation dans le modèle :
-
kube_major_version -
kube_minor_version -
kube_patch_version
Vous devez spécifier la version du cluster Kubernetes et non celle du cluster OpenShift Container Platform, car cette dernière n'est actuellement pas disponible pour le templating.
À condition d'avoir créé et poussé une image d'index avec une balise spécifiant la version Kubernetes mise à jour, la définition de cette annotation permet de modifier automatiquement les versions de l'image d'index dans les catalogues personnalisés après une mise à niveau du cluster. La valeur de l'annotation est utilisée pour définir ou mettre à jour la référence de l'image dans le champ spec.image de l'objet CatalogSource. Cela permet d'éviter que les mises à niveau de cluster ne laissent les installations d'opérateurs dans des états non pris en charge ou sans chemin de mise à jour continu.
Vous devez vous assurer que l'image d'index avec la balise mise à jour, quel que soit le registre dans lequel elle est stockée, est accessible par le cluster au moment de la mise à niveau du cluster.
Exemple 2.10. Exemple de source de catalogue avec un modèle d'image
apiVersion: operators.coreos.com/v1alpha1
kind: CatalogSource
metadata:
generation: 1
name: example-catalog
namespace: openshift-marketplace
annotations:
olm.catalogImageTemplate:
"quay.io/example-org/example-catalog:v{kube_major_version}.{kube_minor_version}"
spec:
displayName: Example Catalog
image: quay.io/example-org/example-catalog:v1.25
priority: -400
publisher: Example Org
Si le champ spec.image et l'annotation olm.catalogImageTemplate sont tous deux définis, le champ spec.image est remplacé par la valeur résolue de l'annotation. Si l'annotation n'aboutit pas à une spécification d'extraction utilisable, la source du catalogue revient à la valeur définie pour spec.image.
Si le champ spec.image n'est pas défini et que l'annotation ne se résout pas en une spécification d'extraction utilisable, OLM interrompt le rapprochement de la source du catalogue et la place dans une condition d'erreur lisible par l'homme.
Pour un cluster OpenShift Container Platform 4.12, qui utilise Kubernetes 1.25, l'annotation olm.catalogImageTemplate dans l'exemple précédent se résout à la référence d'image suivante :
quay.io/example-org/example-catalog:v1.25
Pour les futures versions d'OpenShift Container Platform, vous pouvez créer des images d'index mises à jour pour vos catalogues personnalisés qui ciblent la version Kubernetes ultérieure utilisée par la version ultérieure d'OpenShift Container Platform. Avec l'annotation olm.catalogImageTemplate définie avant la mise à niveau, la mise à niveau du cluster vers la version ultérieure d'OpenShift Container Platform mettrait automatiquement à jour l'image d'index du catalogue.
2.4.1.2.3. Abonnement
Un subscription, défini par un objet Subscription, représente l'intention d'installer un opérateur. C'est la ressource personnalisée qui relie un opérateur à une source de catalogue.
Les abonnements décrivent le canal d'un paquetage d'opérateur auquel il faut s'abonner et s'il faut effectuer les mises à jour automatiquement ou manuellement. S'il est défini sur automatique, l'abonnement permet à Operator Lifecycle Manager (OLM) de gérer et de mettre à jour l'opérateur afin de garantir que la dernière version est toujours en cours d'exécution dans le cluster.
Exemple d'objet Subscription
apiVersion: operators.coreos.com/v1alpha1
kind: Subscription
metadata:
name: example-operator
namespace: example-namespace
spec:
channel: stable
name: example-operator
source: example-catalog
sourceNamespace: openshift-marketplace
Cet objet Subscription définit le nom et l'espace de noms de l'opérateur, ainsi que le catalogue dans lequel les données de l'opérateur peuvent être trouvées. Le canal, tel que alpha, beta, ou stable, permet de déterminer quel flux d'opérateur doit être installé à partir de la source du catalogue.
Les noms des canaux dans un abonnement peuvent varier d'un opérateur à l'autre, mais le système de dénomination doit suivre une convention commune au sein d'un opérateur donné. Par exemple, les noms des canaux peuvent suivre un flux de mises à jour de versions mineures pour l'application fournie par l'opérateur (1.2, 1.3) ou une fréquence de publication (stable, fast).
En plus d'être facilement visible depuis la console web d'OpenShift Container Platform, il est possible d'identifier la disponibilité d'une version plus récente d'un Operator en inspectant l'état de l'abonnement correspondant. La valeur associée au champ currentCSV est la version la plus récente connue par OLM, et installedCSV est la version installée sur le cluster.
2.4.1.2.4. Plan d'installation
Un install plan, défini par un objet InstallPlan, décrit un ensemble de ressources que Operator Lifecycle Manager (OLM) crée pour installer ou mettre à niveau une version spécifique d'un opérateur. La version est définie par une version de service de cluster (CSV).
Pour installer un opérateur, un administrateur de cluster ou un utilisateur ayant reçu des autorisations d'installation d'opérateur doit d'abord créer un objet Subscription. Un abonnement représente l'intention de s'abonner à un flux de versions disponibles d'un opérateur à partir d'une source de catalogue. L'abonnement crée ensuite un objet InstallPlan pour faciliter l'installation des ressources de l'opérateur.
Le plan d'installation doit ensuite être approuvé selon l'une des stratégies d'approbation suivantes :
-
Si le champ
spec.installPlanApprovalde l'abonnement est défini surAutomatic, le plan d'installation est approuvé automatiquement. -
Si le champ
spec.installPlanApprovalde l'abonnement est défini surManual, le plan d'installation doit être approuvé manuellement par un administrateur de cluster ou un utilisateur disposant des autorisations appropriées.
Une fois le plan d'installation approuvé, OLM crée les ressources spécifiées et installe l'opérateur dans l'espace de noms spécifié par l'abonnement.
Exemple 2.11. Exemple d'objet InstallPlan
apiVersion: operators.coreos.com/v1alpha1
kind: InstallPlan
metadata:
name: install-abcde
namespace: operators
spec:
approval: Automatic
approved: true
clusterServiceVersionNames:
- my-operator.v1.0.1
generation: 1
status:
...
catalogSources: []
conditions:
- lastTransitionTime: '2021-01-01T20:17:27Z'
lastUpdateTime: '2021-01-01T20:17:27Z'
status: 'True'
type: Installed
phase: Complete
plan:
- resolving: my-operator.v1.0.1
resource:
group: operators.coreos.com
kind: ClusterServiceVersion
manifest: >-
...
name: my-operator.v1.0.1
sourceName: redhat-operators
sourceNamespace: openshift-marketplace
version: v1alpha1
status: Created
- resolving: my-operator.v1.0.1
resource:
group: apiextensions.k8s.io
kind: CustomResourceDefinition
manifest: >-
...
name: webservers.web.servers.org
sourceName: redhat-operators
sourceNamespace: openshift-marketplace
version: v1beta1
status: Created
- resolving: my-operator.v1.0.1
resource:
group: ''
kind: ServiceAccount
manifest: >-
...
name: my-operator
sourceName: redhat-operators
sourceNamespace: openshift-marketplace
version: v1
status: Created
- resolving: my-operator.v1.0.1
resource:
group: rbac.authorization.k8s.io
kind: Role
manifest: >-
...
name: my-operator.v1.0.1-my-operator-6d7cbc6f57
sourceName: redhat-operators
sourceNamespace: openshift-marketplace
version: v1
status: Created
- resolving: my-operator.v1.0.1
resource:
group: rbac.authorization.k8s.io
kind: RoleBinding
manifest: >-
...
name: my-operator.v1.0.1-my-operator-6d7cbc6f57
sourceName: redhat-operators
sourceNamespace: openshift-marketplace
version: v1
status: Created
...2.4.1.2.5. Groupes d'opérateurs
Un site Operator group, défini par la ressource OperatorGroup, fournit une configuration multitenant aux opérateurs installés dans OLM. Un groupe d'opérateurs sélectionne des espaces de noms cibles dans lesquels générer l'accès RBAC requis pour les opérateurs qui en font partie.
L'ensemble des espaces de noms cibles est fourni par une chaîne délimitée par des virgules, stockée dans l'annotation olm.targetNamespaces d'une version de service de cluster (CSV). Cette annotation est appliquée aux instances CSV des opérateurs membres et est projetée dans leurs déploiements.
Ressources supplémentaires
2.4.1.2.6. Conditions de l'opérateur
Dans le cadre de son rôle de gestion du cycle de vie d'un opérateur, Operator Lifecycle Manager (OLM) déduit l'état d'un opérateur à partir de l'état des ressources Kubernetes qui définissent l'opérateur. Bien que cette approche fournisse un certain niveau d'assurance qu'un opérateur est dans un état donné, il y a de nombreux cas où un opérateur peut avoir besoin de communiquer des informations à OLM qui ne pourraient pas être déduites autrement. Ces informations peuvent alors être utilisées par OLM pour mieux gérer le cycle de vie de l'opérateur.
OLM fournit une définition de ressource personnalisée (CRD) appelée OperatorCondition qui permet aux opérateurs de communiquer des conditions à OLM. Il existe un ensemble de conditions prises en charge qui influencent la gestion de l'opérateur par OLM lorsqu'elles sont présentes dans le tableau Spec.Conditions d'une ressource OperatorCondition.
Par défaut, le tableau Spec.Conditions n'est pas présent dans un objet OperatorCondition jusqu'à ce qu'il soit ajouté par un utilisateur ou à la suite d'une logique d'opérateur personnalisée.
2.4.2. Architecture du gestionnaire du cycle de vie de l'opérateur
Ce guide présente l'architecture des composants de Operator Lifecycle Manager (OLM) dans OpenShift Container Platform.
2.4.2.1. Responsabilités des composantes
Le gestionnaire du cycle de vie des opérateurs (OLM) est composé de deux opérateurs : l'opérateur OLM et l'opérateur de catalogue.
Chacun de ces opérateurs est responsable de la gestion des définitions de ressources personnalisées (CRD) qui constituent la base du cadre OLM :
| Ressources | Nom court | Propriétaire | Description |
|---|---|---|---|
|
|
| OLM | Métadonnées de l'application : nom, version, icône, ressources nécessaires, installation, etc. |
|
|
| Catalogue | Liste calculée des ressources à créer pour installer ou mettre à jour automatiquement un CSV. |
|
|
| Catalogue | Un référentiel de CSV, CRD et paquets qui définissent une application. |
|
|
| Catalogue | Utilisé pour maintenir les CSV à jour en suivant un canal dans un paquet. |
|
|
| OLM |
Configure tous les opérateurs déployés dans le même espace de noms que l'objet |
Chacun de ces opérateurs est également responsable de la création des ressources suivantes :
| Ressources | Propriétaire |
|---|---|
|
| OLM |
|
| |
|
| |
|
| |
|
| Catalogue |
|
|
2.4.2.2. Opérateur OLM
L'opérateur OLM est chargé de déployer les applications définies par les ressources CSV une fois que les ressources requises spécifiées dans le CSV sont présentes dans le cluster.
L'opérateur OLM ne s'occupe pas de la création des ressources nécessaires ; vous pouvez choisir de créer manuellement ces ressources à l'aide du CLI ou de l'opérateur de catalogue. Cette séparation des préoccupations permet aux utilisateurs de s'approprier progressivement la partie du cadre OLM qu'ils choisissent d'exploiter pour leur application.
L'opérateur OLM utilise le flux de travail suivant :
- Surveillez les versions de service de cluster (CSV) dans un espace de noms et vérifiez que les exigences sont respectées.
Si les conditions sont remplies, exécutez la stratégie d'installation pour le CSV.
NoteUn CSV doit être un membre actif d'un groupe d'opérateurs pour que la stratégie d'installation s'exécute.
2.4.2.3. Opérateur de catalogue
L'opérateur de catalogue est responsable de la résolution et de l'installation des versions de service de cluster (CSV) et des ressources requises qu'elles spécifient. Il est également chargé de surveiller les sources du catalogue pour détecter les mises à jour des paquets dans les canaux et de les mettre à niveau, automatiquement si nécessaire, vers les dernières versions disponibles.
Pour suivre un paquet dans un canal, vous pouvez créer un objet Subscription configurant le paquet souhaité, le canal et l'objet CatalogSource que vous souhaitez utiliser pour extraire les mises à jour. Lorsque des mises à jour sont trouvées, un objet InstallPlan approprié est écrit dans l'espace de noms au nom de l'utilisateur.
L'opérateur de catalogue utilise le flux de travail suivant :
- Connectez-vous à chaque source de catalogue dans le cluster.
Rechercher les plans d'installation non résolus créés par un utilisateur et, le cas échéant, les trouver :
- Rechercher le fichier CSV correspondant au nom demandé et l'ajouter en tant que ressource résolue.
- Pour chaque CRD géré ou requis, ajouter le CRD en tant que ressource résolue.
- Pour chaque CRD requis, trouvez le CSV qui le gère.
- Surveillez les plans d'installation résolus et créez toutes les ressources découvertes, si elles ont été approuvées par un utilisateur ou automatiquement.
- Surveillez les sources et les abonnements du catalogue et créez des plans d'installation basés sur ces sources et abonnements.
2.4.2.4. Registre du catalogue
Le registre de catalogue stocke les CSV et les CRD pour la création dans un cluster et stocke les métadonnées sur les paquets et les canaux.
Un site package manifest est une entrée dans le registre du catalogue qui associe une identité de paquet à des ensembles de CSV. Au sein d'un paquet, les canaux pointent vers un CSV particulier. Comme les CSV font explicitement référence au CSV qu'ils remplacent, un manifeste de paquet fournit à l'opérateur de catalogue toutes les informations nécessaires pour mettre à jour un CSV vers la dernière version d'un canal, en passant par chaque version intermédiaire.
2.4.3. Flux de travail du gestionnaire du cycle de vie de l'opérateur
Ce guide décrit le flux de travail de l'Operator Lifecycle Manager (OLM) dans OpenShift Container Platform.
2.4.3.1. Processus d'installation et de mise à niveau de l'opérateur dans OLM
Dans l'écosystème du gestionnaire du cycle de vie des opérateurs (OLM), les ressources suivantes sont utilisées pour résoudre les problèmes d'installation et de mise à niveau des opérateurs :
-
ClusterServiceVersion(CSV) -
CatalogSource -
Subscription
Les métadonnées des opérateurs, définies dans des fichiers CSV, peuvent être stockées dans une collection appelée source de catalogue. OLM utilise les sources du catalogue, qui utilisent l'API du registre des opérateurs, pour rechercher les opérateurs disponibles ainsi que les mises à niveau des opérateurs installés.
Figure 2.3. Vue d'ensemble des sources du catalogue
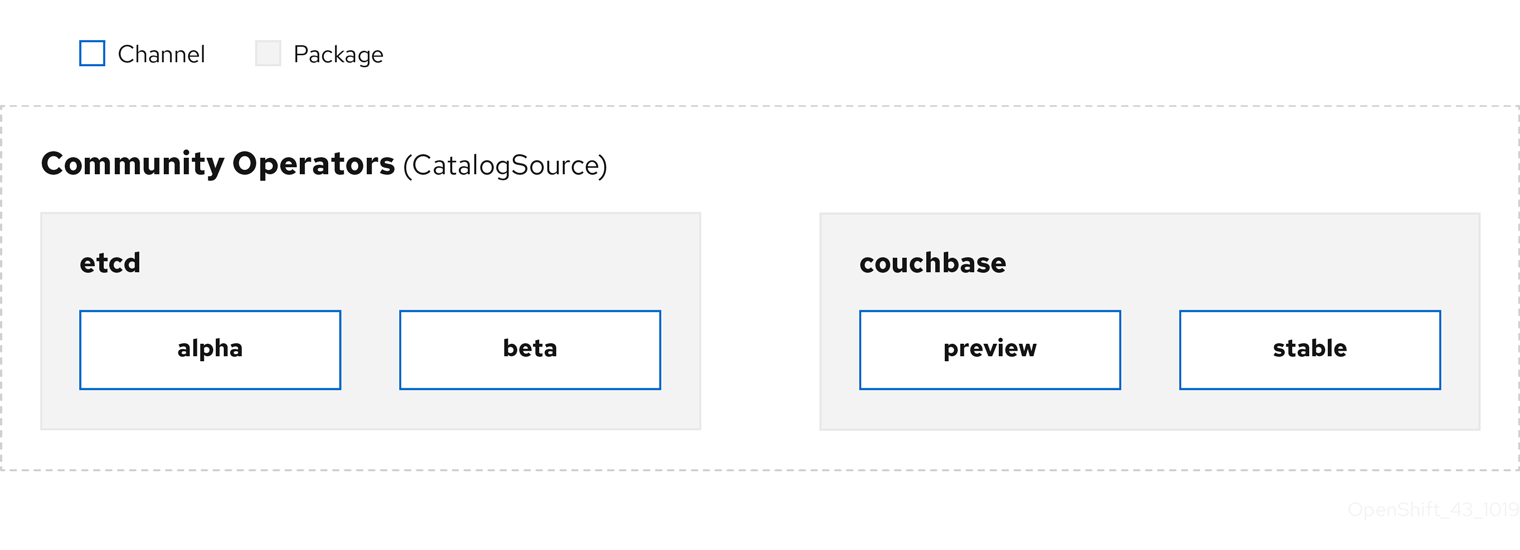
Au sein d'un catalogue source, les opérateurs sont organisés en packages et en flux de mises à jour appelés channels, ce qui devrait être un modèle de mise à jour familier d'OpenShift Container Platform ou d'autres logiciels à cycle de publication continu tels que les navigateurs Web.
Figure 2.4. Paquets et chaînes dans un catalogue source
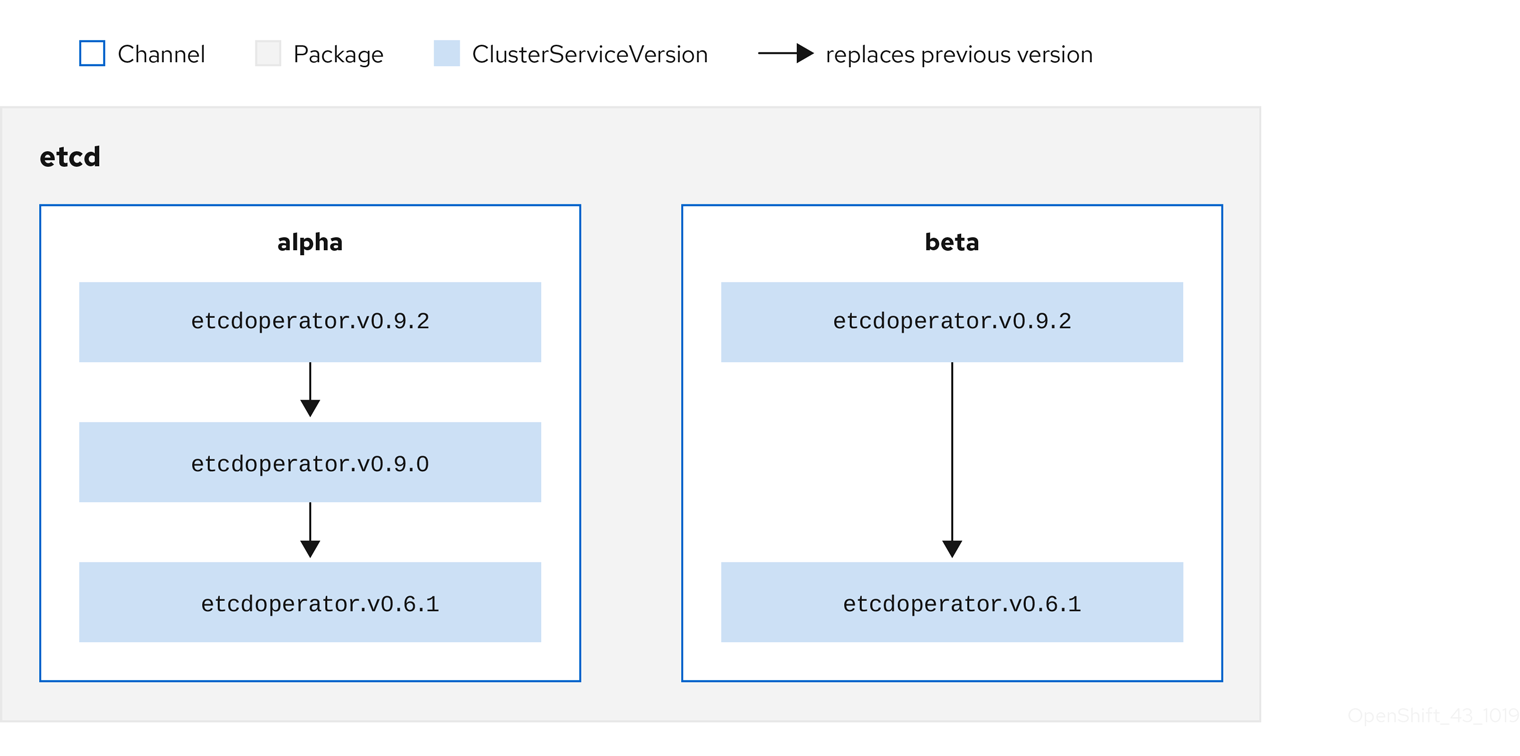
Un utilisateur indique un paquet et un canal particuliers dans une source de catalogue particulière dans un subscription, par exemple un paquet etcd et son canal alpha. Si un abonnement est souscrit pour un paquet qui n'a pas encore été installé dans l'espace de nommage, le dernier opérateur pour ce paquet est installé.
OLM évite délibérément les comparaisons de versions, de sorte que l'opérateur "latest" ou "newest" disponible sur un chemin donné catalog → channel → package ne doit pas nécessairement être le numéro de version le plus élevé. Il doit plutôt être considéré comme la référence head d'un canal, à l'instar d'un dépôt Git.
Chaque CSV a un paramètre replaces qui indique l'opérateur qu'il remplace. Il en résulte un graphe de CSV qui peut être interrogé par OLM et dont les mises à jour peuvent être partagées entre les canaux. Les canaux peuvent être considérés comme des points d'entrée dans le graphe des mises à jour :
Figure 2.5. Graphique OLM des mises à jour des canaux disponibles
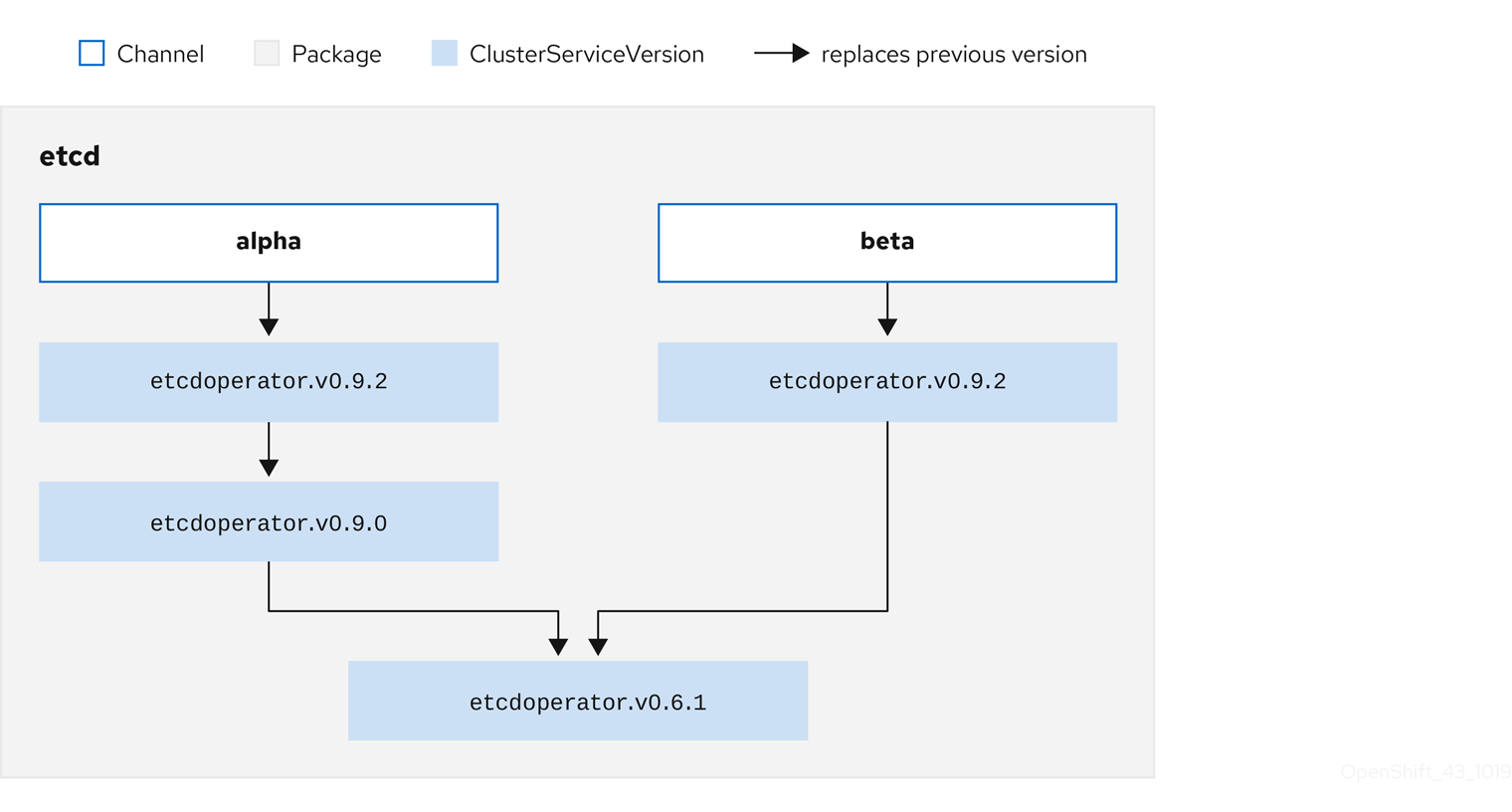
Exemples de chaînes dans un paquet
packageName: example
channels:
- name: alpha
currentCSV: example.v0.1.2
- name: beta
currentCSV: example.v0.1.3
defaultChannel: alpha
Pour qu'OLM puisse demander avec succès des mises à jour, compte tenu d'une source de catalogue, d'un paquet, d'un canal et d'un CSV, un catalogue doit pouvoir renvoyer, sans ambiguïté et de manière déterministe, un CSV unique qui replaces le CSV d'entrée.
2.4.3.1.1. Exemple de chemin de mise à niveau
Pour un exemple de scénario de mise à niveau, considérons un opérateur installé correspondant à la version CSV 0.1.1. OLM interroge la source du catalogue et détecte une mise à niveau dans le canal souscrit avec la nouvelle version CSV 0.1.3 qui remplace une version CSV plus ancienne mais non installée 0.1.2, qui à son tour remplace la version CSV plus ancienne et installée 0.1.1.
OLM remonte de la tête de réseau aux versions précédentes via le champ replaces spécifié dans les CSV pour déterminer le chemin de mise à niveau 0.1.3 → 0.1.2 → 0.1.1; le sens de la flèche indique que la première version remplace la seconde. OLM met à niveau l'opérateur une version à la fois jusqu'à ce qu'il atteigne la tête de canal.
Pour ce scénario, OLM installe la version de l'opérateur 0.1.2 pour remplacer la version existante de l'opérateur 0.1.1. Ensuite, il installe la version de l'opérateur 0.1.3 pour remplacer la version de l'opérateur 0.1.2 précédemment installée. À ce stade, la version de l'opérateur installée 0.1.3 correspond à la tête de canal et la mise à niveau est terminée.
2.4.3.1.2. Sauter des mises à niveau
Le chemin de base pour les mises à niveau dans OLM est le suivant :
- Une source de catalogue est mise à jour avec une ou plusieurs mises à jour d'un opérateur.
- OLM parcourt toutes les versions de l'opérateur jusqu'à la dernière version que contient la source du catalogue.
Cependant, il arrive que cette opération ne soit pas sûre. Dans certains cas, une version publiée d'un opérateur ne doit jamais être installée sur un cluster si ce n'est pas déjà fait, par exemple parce qu'une version introduit une vulnérabilité grave.
Dans ce cas, OLM doit prendre en compte deux états de la grappe et fournir un graphique de mise à jour qui prenne en charge les deux états :
- L'opérateur intermédiaire "bad" a été vu par le cluster et installé.
- L'opérateur intermédiaire "bad" n'a pas encore été installé sur le cluster.
En envoyant un nouveau catalogue et en ajoutant une version skipped, OLM est assuré de toujours recevoir une mise à jour unique, quel que soit l'état du cluster et qu'il ait ou non déjà vu la mauvaise mise à jour.
Exemple de CSV avec la version sautée
apiVersion: operators.coreos.com/v1alpha1
kind: ClusterServiceVersion
metadata:
name: etcdoperator.v0.9.2
namespace: placeholder
annotations:
spec:
displayName: etcd
description: Etcd Operator
replaces: etcdoperator.v0.9.0
skips:
- etcdoperator.v0.9.1Prenons l'exemple suivant : Old CatalogSource et New CatalogSource.
Figure 2.6. Sauter des mises à jour
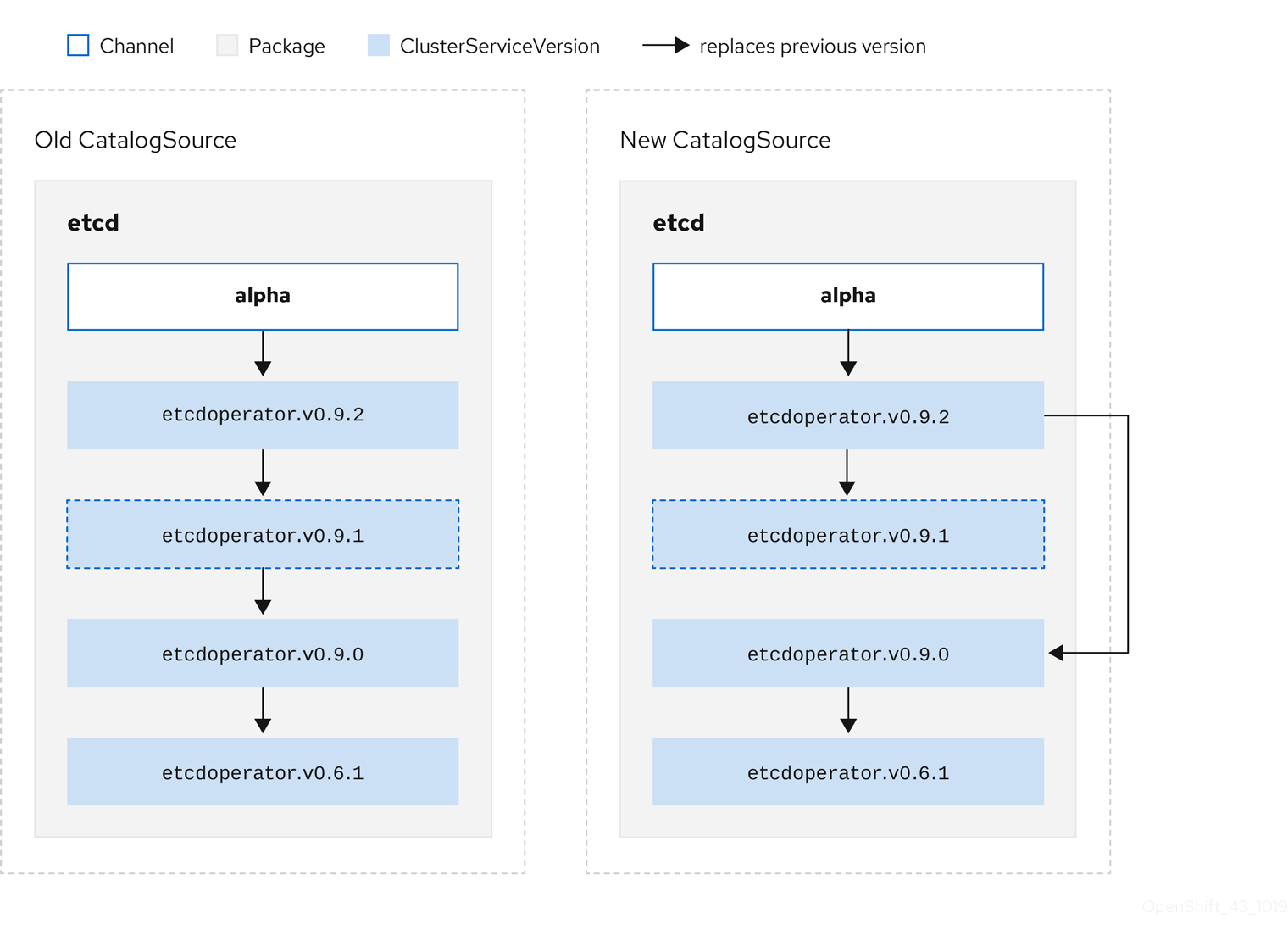
Ce graphique le confirme :
- Tout opérateur trouvé dans Old CatalogSource a un seul remplaçant dans New CatalogSource.
- Tout opérateur trouvé dans New CatalogSource a un seul remplaçant dans New CatalogSource.
- Si la mauvaise mise à jour n'a pas encore été installée, elle ne le sera jamais.
2.4.3.1.3. Remplacement de plusieurs opérateurs
La création de New CatalogSource comme décrit nécessite la publication de CSV qui replace un Opérateur, mais peut skip plusieurs. Ceci peut être réalisé en utilisant l'annotation skipRange:
olm.skipRange : <semver_range>
où <semver_range> a le format de la gamme de versions supporté par la bibliothèque semver.
Lors de la recherche de mises à jour dans les catalogues, si l'en-tête d'un canal comporte une annotation skipRange et que l'opérateur actuellement installé possède un champ de version compris dans la plage, OLM effectue une mise à jour de la dernière entrée du canal.
L'ordre de priorité est le suivant :
-
Tête de chaîne dans la source spécifiée par
sourceNamesur l'abonnement, si les autres critères de saut sont remplis. -
L'opérateur suivant qui remplace l'opérateur actuel, dans la source spécifiée par
sourceName. - Tête de chaîne dans une autre source visible pour l'abonnement, si les autres critères de saut sont remplis.
- L'opérateur suivant qui remplace l'opérateur actuel dans toute source visible par l'abonnement.
Exemple de CSV avec skipRange
apiVersion: operators.coreos.com/v1alpha1
kind: ClusterServiceVersion
metadata:
name: elasticsearch-operator.v4.1.2
namespace: <namespace>
annotations:
olm.skipRange: '>=4.1.0 <4.1.2'2.4.3.1.4. Prise en charge du flux Z
Une version z-stream, ou patch, doit remplacer toutes les versions précédentes de z-stream pour la même version mineure. OLM ne tient pas compte des versions majeures, mineures ou des correctifs, il lui suffit de construire le graphique correct dans un catalogue.
En d'autres termes, OLM doit être capable de prendre un graphique comme dans Old CatalogSource et, comme précédemment, de générer un graphique comme dans New CatalogSource:
Figure 2.7. Remplacement de plusieurs opérateurs
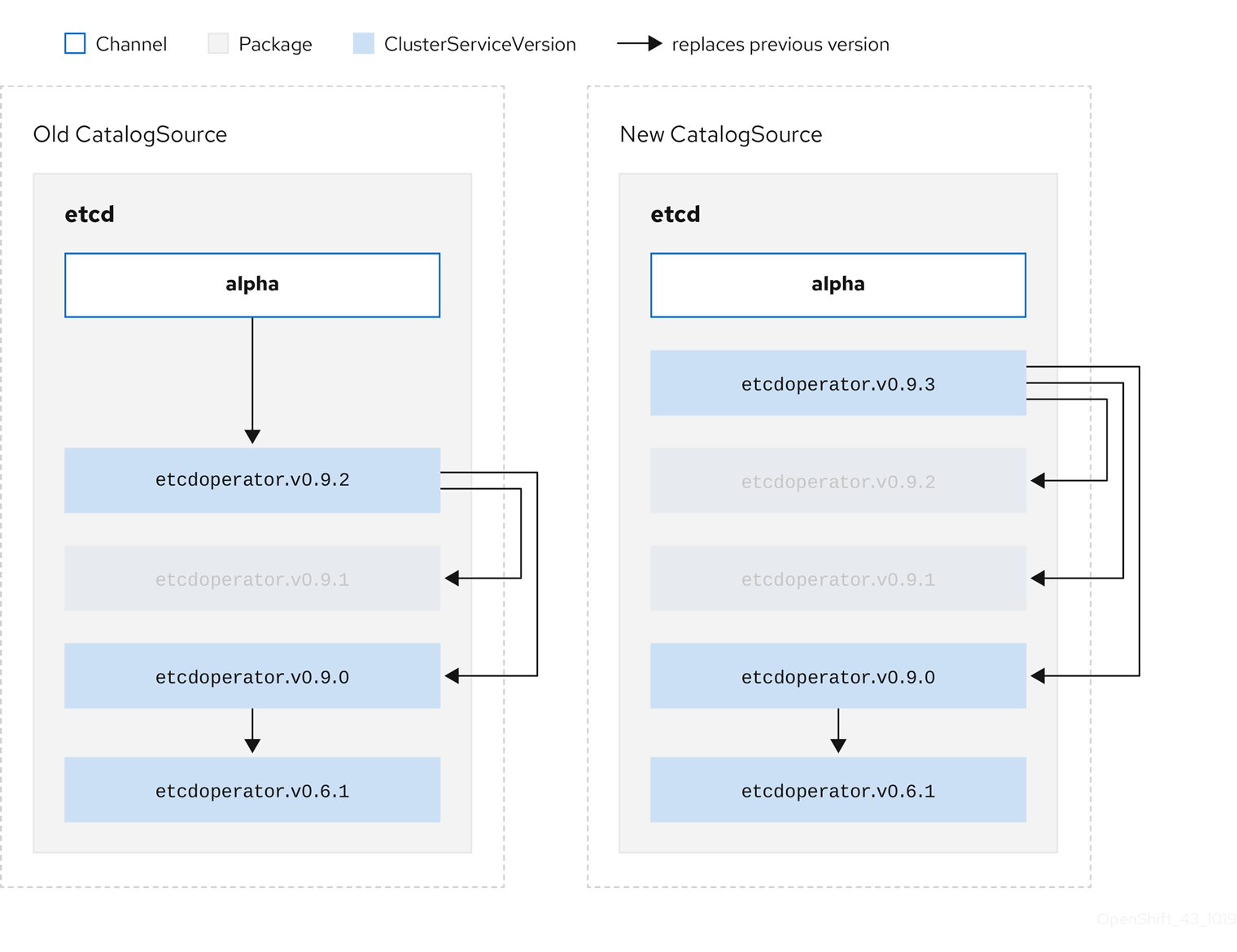
Ce graphique le confirme :
- Tout opérateur trouvé dans Old CatalogSource a un seul remplaçant dans New CatalogSource.
- Tout opérateur trouvé dans New CatalogSource a un seul remplaçant dans New CatalogSource.
- Toute version de z-stream dans Old CatalogSource sera mise à jour avec la dernière version de z-stream dans New CatalogSource.
- Les rejets non disponibles peuvent être considérés comme des nœuds de graphe "virtuels" ; leur contenu n'a pas besoin d'exister, le registre doit simplement répondre comme si le graphe ressemblait à ceci.
2.4.4. Résolution des dépendances de l'Operator Lifecycle Manager
Ce guide présente les cycles de vie de la résolution des dépendances et de la mise à niveau des définitions de ressources personnalisées (CRD) avec Operator Lifecycle Manager (OLM) dans OpenShift Container Platform.
2.4.4.1. À propos de la résolution des dépendances
Le gestionnaire du cycle de vie des opérateurs (OLM) gère la résolution des dépendances et le cycle de vie des mises à jour des opérateurs en cours d'exécution. À bien des égards, les problèmes rencontrés par OLM sont similaires à ceux d'autres gestionnaires de paquets de systèmes ou de langues, tels que yum et rpm.
Cependant, il existe une contrainte que les systèmes similaires n'ont généralement pas et qu'OLM respecte : comme les opérateurs sont toujours en cours d'exécution, OLM s'efforce de garantir que vous ne vous retrouvez jamais avec un ensemble d'opérateurs qui ne fonctionnent pas les uns avec les autres.
Par conséquent, OLM ne doit jamais créer les scénarios suivants :
- Installer un ensemble d'opérateurs nécessitant des API qui ne peuvent être fournies
- Mettre à jour un opérateur de manière à interrompre un autre opérateur qui en dépend
Cela est possible grâce à deux types de données :
| Propriétés | Métadonnées typées sur l'opérateur qui constituent son interface publique dans le résolveur de dépendances. Les exemples incluent le groupe/version/genre (GVK) des API fournies par l'opérateur et la version sémantique (semver) de l'opérateur. |
| Contraintes ou dépendances | Les exigences d'un opérateur qui doivent être satisfaites par d'autres opérateurs qui peuvent ou non avoir déjà été installés sur le cluster cible. Ces exigences agissent comme des requêtes ou des filtres sur tous les opérateurs disponibles et limitent la sélection lors de la résolution des dépendances et de l'installation. Il s'agit par exemple d'exiger qu'une API spécifique soit disponible sur le cluster ou d'attendre l'installation d'un opérateur particulier avec une version particulière. |
OLM convertit ces propriétés et ces contraintes en un système de formules booléennes et les transmet à un solveur SAT, un programme qui établit la satisfiabilité booléenne, qui se charge de déterminer quels opérateurs doivent être installés.
2.4.4.2. Propriétés de l'opérateur
Tous les opérateurs d'un catalogue ont les propriétés suivantes :
olm.package- Inclut le nom du paquet et la version de l'opérateur
olm.gvk- Une propriété unique pour chaque API fournie à partir de la version du service de cluster (CSV)
Des propriétés supplémentaires peuvent également être déclarées directement par l'auteur d'un opérateur en incluant un fichier properties.yaml dans le répertoire metadata/ de l'ensemble Operator.
Exemple de propriété arbitraire
properties:
- type: olm.kubeversion
value:
version: "1.16.0"2.4.4.2.1. Propriétés arbitraires
Les auteurs d'opérateurs peuvent déclarer des propriétés arbitraires dans un fichier properties.yaml dans le répertoire metadata/ du paquet Operator. Ces propriétés sont traduites en une structure de données cartographique qui sert d'entrée au résolveur du gestionnaire du cycle de vie de l'opérateur (OLM) au moment de l'exécution.
Ces propriétés sont opaques pour le résolveur car il ne les comprend pas, mais il peut évaluer les contraintes génériques par rapport à ces propriétés pour déterminer si les contraintes peuvent être satisfaites compte tenu de la liste des propriétés.
Exemple de propriétés arbitraires
properties:
- property:
type: color
value: red
- property:
type: shape
value: square
- property:
type: olm.gvk
value:
group: olm.coreos.io
version: v1alpha1
kind: myresourceCette structure peut être utilisée pour construire une expression CEL (Common Expression Language) pour les contraintes génériques.
Ressources supplémentaires
2.4.4.3. Dépendances des opérateurs
Les dépendances d'un Opérateur sont listées dans un fichier dependencies.yaml dans le dossier metadata/ d'un bundle. Ce fichier est facultatif et n'est actuellement utilisé que pour spécifier les dépendances explicites de la version de l'opérateur.
La liste des dépendances contient un champ type pour chaque élément afin de spécifier de quel type de dépendance il s'agit. Les types de dépendances de l'opérateur suivants sont pris en charge :
olm.package-
Ce type indique une dépendance pour une version spécifique de l'opérateur. Les informations sur la dépendance doivent inclure le nom du paquet et la version du paquet au format semver. Par exemple, vous pouvez spécifier une version exacte telle que
0.5.2ou une plage de versions telle que>0.5.1. olm.gvk- Avec ce type, l'auteur peut spécifier une dépendance avec des informations sur le groupe, la version et le type (GVK), de manière similaire à l'utilisation existante des CRD et des API dans un CSV. Il s'agit d'un chemin permettant aux auteurs d'opérateurs de consolider toutes les dépendances, API ou versions explicites, au même endroit.
olm.constraint- Ce type déclare des contraintes génériques sur des propriétés arbitraires de l'opérateur.
Dans l'exemple suivant, des dépendances sont spécifiées pour un opérateur Prometheus et des CRD etcd :
Exemple de fichier dependencies.yaml
dependencies:
- type: olm.package
value:
packageName: prometheus
version: ">0.27.0"
- type: olm.gvk
value:
group: etcd.database.coreos.com
kind: EtcdCluster
version: v1beta22.4.4.4. Contraintes génériques
Une propriété olm.constraint déclare une contrainte de dépendance d'un type particulier, en distinguant les propriétés sans contrainte et les propriétés avec contrainte. Son champ value est un objet contenant un champ failureMessage qui contient une représentation sous forme de chaîne de caractères du message de la contrainte. Ce message est affiché sous la forme d'un commentaire informatif à l'intention des utilisateurs si la contrainte n'est pas satisfaisable au moment de l'exécution.
Les clés suivantes indiquent les types de contraintes disponibles :
gvk-
Type dont la valeur et l'interprétation sont identiques au type
olm.gvk package-
Type dont la valeur et l'interprétation sont identiques au type
olm.package cel- Une expression en langage d'expression commun (CEL) évaluée au moment de l'exécution par le résolveur du gestionnaire du cycle de vie de l'opérateur (OLM) sur des propriétés arbitraires de l'ensemble et des informations sur les grappes
all,any,not-
Contraintes de conjonction, de disjonction et de négation, respectivement, contenant une ou plusieurs contraintes concrètes, telles que
gvkou une contrainte composée imbriquée
2.4.4.4.1. Contraintes du langage d'expression commun (CEL)
Le type de contrainte cel prend en charge le langage d'expression commun (CEL) en tant que langage d'expression. La structure cel possède un champ rule qui contient la chaîne d'expression CEL évaluée par rapport aux propriétés de l'opérateur au moment de l'exécution afin de déterminer si l'opérateur satisfait à la contrainte.
Exemple de contrainte cel
type: olm.constraint
value:
failureMessage: 'require to have "certified"'
cel:
rule: 'properties.exists(p, p.type == "certified")'
La syntaxe CEL prend en charge un large éventail d'opérateurs logiques, tels que AND et OR. Par conséquent, une expression CEL unique peut comporter plusieurs règles pour plusieurs conditions liées entre elles par ces opérateurs logiques. Ces règles sont évaluées par rapport à un ensemble de données de propriétés différentes provenant d'une liasse ou d'une source donnée, et la sortie est résolue en une liasse ou un opérateur unique qui satisfait à toutes ces règles dans le cadre d'une contrainte unique.
Exemple cel Contrainte avec plusieurs règles
type: olm.constraint
value:
failureMessage: 'require to have "certified" and "stable" properties'
cel:
rule: 'properties.exists(p, p.type == "certified") && properties.exists(p, p.type == "stable")'2.4.4.4.2. Contraintes composées (tout, n'importe quoi, pas)
Les types de contraintes composées sont évalués conformément à leurs définitions logiques.
Voici un exemple de contrainte conjonctive (all) de deux paquets et d'un GVK. C'est-à-dire qu'ils doivent tous être satisfaits par les paquets installés :
Exemple de contrainte all
schema: olm.bundle
name: red.v1.0.0
properties:
- type: olm.constraint
value:
failureMessage: All are required for Red because...
all:
constraints:
- failureMessage: Package blue is needed for...
package:
name: blue
versionRange: '>=1.0.0'
- failureMessage: GVK Green/v1 is needed for...
gvk:
group: greens.example.com
version: v1
kind: Green
Voici un exemple de contrainte disjonctive (any) de trois versions du même GVK. C'est-à-dire qu'au moins l'une d'entre elles doit être satisfaite par les liasses installées :
Exemple de contrainte any
schema: olm.bundle
name: red.v1.0.0
properties:
- type: olm.constraint
value:
failureMessage: Any are required for Red because...
any:
constraints:
- gvk:
group: blues.example.com
version: v1beta1
kind: Blue
- gvk:
group: blues.example.com
version: v1beta2
kind: Blue
- gvk:
group: blues.example.com
version: v1
kind: Blue
Voici un exemple de contrainte de négation (not) d'une version d'un GVK. En d'autres termes, ce kit ne peut être fourni par aucune liasse de l'ensemble des résultats :
Exemple de contrainte not
schema: olm.bundle
name: red.v1.0.0
properties:
- type: olm.constraint
value:
all:
constraints:
- failureMessage: Package blue is needed for...
package:
name: blue
versionRange: '>=1.0.0'
- failureMessage: Cannot be required for Red because...
not:
constraints:
- gvk:
group: greens.example.com
version: v1alpha1
kind: greens
La sémantique de la négation peut sembler peu claire dans le contexte de la contrainte not. Pour clarifier, la négation demande en fait au résolveur de supprimer de l'ensemble des résultats toute solution possible qui inclut un GVK particulier, un paquetage à une version, ou qui satisfait à une contrainte composée enfant.
En corollaire, la contrainte composée not ne doit être utilisée qu'à l'intérieur des contraintes all ou any, car la négation sans sélection préalable d'un ensemble possible de dépendances n'a pas de sens.
2.4.4.4.3. Contraintes composées imbriquées
Une contrainte composée imbriquée, qui contient au moins une contrainte composée fille ainsi que zéro ou plusieurs contraintes simples, est évaluée de bas en haut en suivant les procédures applicables à chaque type de contrainte décrit précédemment.
Voici un exemple de disjonction de conjonctions, où l'une, l'autre ou les deux peuvent satisfaire à la contrainte :
Exemple de contrainte composée imbriquée
schema: olm.bundle
name: red.v1.0.0
properties:
- type: olm.constraint
value:
failureMessage: Required for Red because...
any:
constraints:
- all:
constraints:
- package:
name: blue
versionRange: '>=1.0.0'
- gvk:
group: blues.example.com
version: v1
kind: Blue
- all:
constraints:
- package:
name: blue
versionRange: '<1.0.0'
- gvk:
group: blues.example.com
version: v1beta1
kind: Blue
La taille brute maximale d'un type olm.constraint est de 64 Ko afin de limiter les attaques par épuisement des ressources.
2.4.4.5. Préférences en matière de dépendance
Il peut y avoir plusieurs options qui répondent également à une dépendance d'un opérateur. Le résolveur de dépendances du gestionnaire du cycle de vie des opérateurs (OLM) détermine l'option qui répond le mieux aux exigences de l'opérateur demandé. En tant qu'auteur ou utilisateur d'un opérateur, il peut être important de comprendre comment ces choix sont faits afin que la résolution des dépendances soit claire.
2.4.4.5.1. Priorité au catalogue
Sur le cluster OpenShift Container Platform, OLM lit les sources du catalogue pour savoir quels opérateurs sont disponibles pour l'installation.
Exemple d'objet CatalogSource
apiVersion: "operators.coreos.com/v1alpha1"
kind: "CatalogSource"
metadata:
name: "my-operators"
namespace: "operators"
spec:
sourceType: grpc
grpcPodConfig:
securityContextConfig: <security_mode>
image: example.com/my/operator-index:v1
displayName: "My Operators"
priority: 100- 1
- Spécifiez la valeur de
legacyourestricted. Si le champ n'est pas défini, la valeur par défaut estlegacy. Dans une prochaine version d'OpenShift Container Platform, il est prévu que la valeur par défaut soitrestricted. Si votre catalogue ne peut pas s'exécuter avec les autorisationsrestricted, il est recommandé de définir manuellement ce champ surlegacy.
Un objet CatalogSource possède un champ priority, qui est utilisé par le résolveur pour savoir comment préférer les options pour une dépendance.
Deux règles régissent les préférences en matière de catalogues :
- Les options des catalogues de priorité supérieure sont préférées aux options des catalogues de priorité inférieure.
- Les options du même catalogue que la personne dépendante sont préférées à tout autre catalogue.
2.4.4.5.2. Commande de chaînes
Un paquet Operator dans un catalogue est une collection de canaux de mise à jour auxquels un utilisateur peut s'abonner dans un cluster OpenShift Container Platform. Les canaux peuvent être utilisés pour fournir un flux particulier de mises à jour pour une version mineure (1.2, 1.3) ou une fréquence de publication (stable, fast).
Il est probable qu'une dépendance soit satisfaite par des opérateurs dans le même paquet, mais dans des canaux différents. Par exemple, la version 1.2 d'un opérateur peut exister dans les canaux stable et fast.
Chaque paquet a un canal par défaut, qui est toujours préféré aux autres canaux. Si aucune option du canal par défaut ne peut satisfaire une dépendance, les options des canaux restants sont prises en compte dans l'ordre lexicographique du nom du canal.
2.4.4.5.3. Ordre à l'intérieur d'un canal
Il existe presque toujours plusieurs options pour satisfaire une dépendance au sein d'un même canal. Par exemple, les opérateurs d'un paquet et d'un canal fournissent le même ensemble d'API.
Lorsqu'un utilisateur crée un abonnement, il indique le canal dont il souhaite recevoir les mises à jour. Cela réduit immédiatement la recherche à ce seul canal. Mais à l'intérieur du canal, il est probable que de nombreux opérateurs répondent à une dépendance.
Au sein d'un canal, les nouveaux opérateurs situés plus haut dans le graphe de mise à jour sont privilégiés. Si la tête d'un canal satisfait une dépendance, elle sera essayée en premier.
2.4.4.5.4. Autres contraintes
En plus des contraintes fournies par les dépendances des paquets, OLM inclut des contraintes supplémentaires pour représenter l'état souhaité de l'utilisateur et appliquer les invariants de résolution.
2.4.4.5.4.1. Contrainte d'abonnement
Une contrainte d'abonnement filtre l'ensemble des opérateurs qui peuvent satisfaire un abonnement. Les abonnements sont des contraintes fournies par l'utilisateur au résolveur de dépendances. Elles déclarent l'intention d'installer un nouvel opérateur s'il n'est pas déjà présent sur le cluster, ou de maintenir à jour un opérateur existant.
2.4.4.5.4.2. Contrainte du paquet
Au sein d'un espace de noms, deux opérateurs ne peuvent pas provenir du même paquetage.
2.4.4.6. Améliorations du CRD
OLM met à niveau une définition de ressource personnalisée (CRD) immédiatement si elle appartient à une seule version de service de cluster (CSV). Si une CRD appartient à plusieurs CSV, elle est mise à niveau lorsqu'elle remplit toutes les conditions de compatibilité ascendante suivantes :
- Toutes les versions de service existantes dans le CRD actuel sont présentes dans le nouveau CRD.
- Toutes les instances existantes, ou les ressources personnalisées, qui sont associées aux versions de service du document de référence sont valides lorsqu'elles sont validées par rapport au schéma de validation du nouveau document de référence.
2.4.4.7. Meilleures pratiques en matière de dépendance
Lorsque vous spécifiez des dépendances, vous devez tenir compte de certaines bonnes pratiques.
- Dépendent des API ou d'une gamme de versions spécifiques d'opérateurs
-
Les opérateurs peuvent ajouter ou supprimer des API à tout moment ; spécifiez toujours une dépendance
olm.gvkpour toutes les API dont vos opérateurs ont besoin. L'exception à cette règle est si vous spécifiez des contraintesolm.packageà la place. - Fixer une version minimale
La documentation Kubernetes sur les modifications d'API décrit les modifications autorisées pour les opérateurs de type Kubernetes. Ces conventions de versionnement permettent à un opérateur de mettre à jour une API sans modifier la version de l'API, tant que l'API est rétrocompatible.
Pour les dépendances d'opérateurs, cela signifie que la connaissance de la version de l'API d'une dépendance peut ne pas suffire à garantir que l'opérateur dépendant fonctionne comme prévu.
Par exemple :
-
TestOperator v1.0.0 fournit la version API v1alpha1 de la ressource
MyObject. -
TestOperator v1.0.1 ajoute un nouveau champ
spec.newfieldàMyObject, mais il s'agit toujours de la version 1alpha1.
Votre opérateur peut avoir besoin de la possibilité d'écrire
spec.newfielddans la ressourceMyObject. Une contrainteolm.gvkne suffit pas à OLM pour déterminer que vous avez besoin de TestOperator v1.0.1 et non de TestOperator v1.0.0.Dans la mesure du possible, si un opérateur spécifique qui fournit une API est connu à l'avance, spécifier une contrainte supplémentaire
olm.packagepour fixer un minimum.-
TestOperator v1.0.0 fournit la version API v1alpha1 de la ressource
- Omettre une version maximale ou autoriser une gamme très large
Étant donné que les opérateurs fournissent des ressources à l'échelle du cluster, telles que des services API et des CRD, un opérateur qui spécifie une petite fenêtre pour une dépendance peut limiter inutilement les mises à jour pour d'autres consommateurs de cette dépendance.
Dans la mesure du possible, ne fixez pas de version maximale. Sinon, définissez une plage sémantique très large pour éviter les conflits avec d'autres opérateurs. Par exemple,
>1.0.0 <2.0.0.Contrairement aux gestionnaires de paquets classiques, les auteurs d'opérateurs indiquent explicitement que les mises à jour sont sûres grâce aux canaux d'OLM. Si une mise à jour est disponible pour un abonnement existant, on suppose que l'auteur de l'opérateur indique qu'il peut mettre à jour la version précédente. La définition d'une version maximale pour une dépendance annule le flux de mises à jour de l'auteur en le tronquant inutilement à une limite supérieure particulière.
NoteLes administrateurs de cluster ne peuvent pas remplacer les dépendances définies par l'auteur d'un opérateur.
Toutefois, des versions maximales peuvent et doivent être fixées s'il existe des incompatibilités connues qui doivent être évitées. Des versions spécifiques peuvent être omises à l'aide de la syntaxe de l'intervalle de versions, par exemple
> 1.0.0 !1.2.1.
2.4.4.8. Mises en garde concernant la dépendance
Lorsque vous spécifiez des dépendances, vous devez tenir compte de certaines mises en garde.
- Pas de contraintes composées (AND)
Il n'existe actuellement aucune méthode pour spécifier une relation ET entre les contraintes. En d'autres termes, il n'existe aucun moyen de spécifier qu'un opérateur dépend d'un autre opérateur qui fournit une API donnée et possède la version
>1.1.0.Cela signifie que lorsqu'on spécifie une dépendance telle que :
dependencies: - type: olm.package value: packageName: etcd version: ">3.1.0" - type: olm.gvk value: group: etcd.database.coreos.com kind: EtcdCluster version: v1beta2Il serait possible pour OLM de satisfaire cette exigence avec deux opérateurs : l'un qui fournit EtcdCluster et l'autre qui a la version
>3.1.0. Le fait que cela se produise ou qu'un opérateur satisfaisant les deux contraintes soit sélectionné dépend de l'ordre dans lequel les options potentielles sont visitées. Les préférences en matière de dépendance et les options d'ordre sont bien définies et peuvent faire l'objet d'un raisonnement, mais par prudence, les opérateurs doivent s'en tenir à l'un ou l'autre mécanisme.- Compatibilité entre les espaces de noms
- OLM effectue la résolution des dépendances au niveau de l'espace de noms. Il est possible de se retrouver dans une impasse de mise à jour si la mise à jour d'un opérateur dans un espace de noms pose un problème à un opérateur dans un autre espace de noms, et vice-versa.
2.4.4.9. Exemples de scénarios de résolution des dépendances
Dans les exemples suivants, provider est un opérateur qui "possède" un service de CRD ou d'API.
Exemple : Déclassement d'API dépendantes
A et B sont des API (CRD) :
- Le fournisseur de A dépend de B.
- Le fournisseur de B dispose d'un abonnement.
- Le fournisseur de B se met à jour pour fournir C mais supprime B.
Il en résulte que :
- B n'a plus de fournisseur.
- A ne fonctionne plus.
C'est un cas qu'OLM évite grâce à sa stratégie de mise à jour.
Exemple : Blocage de la version
A et B sont des API :
- Le fournisseur de A a besoin de B.
- Le fournisseur de B a besoin de A.
- Le fournisseur de A se met à jour (fournit A2, exige B2) et supprime A.
- Le fournisseur de B met à jour (fournit B2, exige A2) et supprime B.
Si OLM tente de mettre à jour A sans mettre simultanément à jour B, ou vice-versa, il ne peut pas passer à de nouvelles versions des opérateurs, même si un nouvel ensemble compatible peut être trouvé.
Il s'agit d'un autre cas où OLM empêche la mise en œuvre de sa stratégie de mise à niveau.
2.4.4.10. Colocalisation des opérateurs dans un espace de noms
Le gestionnaire du cycle de vie des opérateurs (OLM) traite les opérateurs gérés par OLM qui sont installés dans le même espace de noms, ce qui signifie que leurs ressources Subscription sont hébergées dans le même espace de noms, comme des opérateurs liés. Même s'ils ne sont pas réellement liés, OLM prend en compte leurs états, tels que leur version et leur politique de mise à jour, lorsque l'un d'entre eux est mis à jour.
Ce comportement par défaut se manifeste de deux manières :
-
InstallPlanles ressources des mises à jour en cours comprennent les ressourcesClusterServiceVersion(CSV) de tous les autres opérateurs qui se trouvent dans le même espace de noms. - Tous les opérateurs d'un même espace de noms partagent la même politique de mise à jour. Par exemple, si un opérateur est réglé sur des mises à jour manuelles, les politiques de mise à jour de tous les autres opérateurs sont également réglées sur le mode manuel.
Ces scénarios peuvent entraîner les problèmes suivants :
- Il devient difficile de raisonner sur les plans d'installation pour les mises à jour d'opérateurs, parce qu'il y a beaucoup plus de ressources définies dans ces plans que le seul opérateur mis à jour.
- Il devient impossible de faire en sorte que certains opérateurs d'un espace de noms soient mis à jour automatiquement tandis que d'autres le sont manuellement, ce que souhaitent souvent les administrateurs de clusters.
Ces problèmes apparaissent généralement parce que, lors de l'installation d'opérateurs avec la console web d'OpenShift Container Platform, le comportement par défaut installe les opérateurs qui prennent en charge le mode d'installation All namespaces dans l'espace de noms global par défaut openshift-operators.
En tant qu'administrateur de cluster, vous pouvez contourner manuellement ce comportement par défaut en utilisant le flux de travail suivant :
- Créer un espace de noms pour l'installation de l'opérateur.
- Créez un custom global Operator group, qui est un groupe d'opérateurs qui surveille tous les espaces de noms. En associant ce groupe d'opérateurs à l'espace de noms que vous venez de créer, vous faites de l'espace de noms d'installation un espace de noms global, ce qui rend les opérateurs qui y sont installés disponibles dans tous les espaces de noms.
- Installer l'opérateur souhaité dans l'espace de noms de l'installation.
Si l'opérateur a des dépendances, celles-ci sont automatiquement installées dans l'espace de noms pré-créé. Par conséquent, les opérateurs dépendants peuvent avoir la même politique de mise à jour et des plans d'installation partagés. Pour une procédure détaillée, voir "Installer des opérateurs globaux dans des espaces de noms personnalisés".
2.4.5. Groupes d'opérateurs
Ce guide décrit l'utilisation des groupes d'opérateurs avec Operator Lifecycle Manager (OLM) dans OpenShift Container Platform.
2.4.5.1. À propos des groupes d'opérateurs
Un site Operator group, défini par la ressource OperatorGroup, fournit une configuration multitenant aux opérateurs installés dans OLM. Un groupe d'opérateurs sélectionne des espaces de noms cibles dans lesquels générer l'accès RBAC requis pour les opérateurs qui en font partie.
L'ensemble des espaces de noms cibles est fourni par une chaîne délimitée par des virgules, stockée dans l'annotation olm.targetNamespaces d'une version de service de cluster (CSV). Cette annotation est appliquée aux instances CSV des opérateurs membres et est projetée dans leurs déploiements.
2.4.5.2. Appartenance à un groupe d'opérateurs
Un opérateur est considéré comme member d'un groupe d'opérateurs si les conditions suivantes sont remplies :
- Le CSV de l'opérateur existe dans le même espace de noms que le groupe d'opérateurs.
- Les modes d'installation figurant dans le CSV de l'opérateur prennent en charge l'ensemble des espaces de noms ciblés par le groupe d'opérateurs.
Un mode d'installation dans un CSV se compose d'un champ InstallModeType et d'un champ booléen Supported. La spécification d'un CSV peut contenir un ensemble de modes d'installation de quatre InstallModeTypes distincts :
| Type de mode d'installation | Description |
|---|---|
|
| L'opérateur peut être membre d'un groupe d'opérateurs qui sélectionne son propre espace de noms. |
|
| L'opérateur peut être membre d'un groupe d'opérateurs qui sélectionne un espace de noms. |
|
| L'opérateur peut être membre d'un groupe d'opérateurs qui sélectionne plusieurs espaces de noms. |
|
|
L'opérateur peut être membre d'un groupe d'opérateurs qui sélectionne tous les espaces de noms (l'ensemble d'espaces de noms cible est la chaîne vide |
Si la spécification d'un CSV omet une entrée de InstallModeType, ce type est considéré comme non pris en charge, sauf si la prise en charge peut être déduite d'une entrée existante qui le prend implicitement en charge.
2.4.5.3. Sélection de l'espace de noms cible
Vous pouvez nommer explicitement l'espace de noms cible d'un groupe d'opérateurs à l'aide du paramètre spec.targetNamespaces:
apiVersion: operators.coreos.com/v1
kind: OperatorGroup
metadata:
name: my-group
namespace: my-namespace
spec:
targetNamespaces:
- my-namespace
Vous pouvez également spécifier un espace de noms en utilisant un sélecteur d'étiquettes avec le paramètre spec.selector:
apiVersion: operators.coreos.com/v1
kind: OperatorGroup
metadata:
name: my-group
namespace: my-namespace
spec:
selector:
cool.io/prod: "true"
L'énumération de plusieurs espaces de noms via spec.targetNamespaces ou l'utilisation d'un sélecteur d'étiquettes via spec.selector n'est pas recommandée, car la prise en charge de plus d'un espace de noms cible dans un groupe d'opérateurs sera probablement supprimée dans une prochaine version.
Si spec.targetNamespaces et spec.selector sont tous deux définis, spec.selector est ignoré. Vous pouvez également omettre spec.selector et spec.targetNamespaces pour spécifier un groupe d'opérateurs global, qui sélectionne tous les espaces de noms :
apiVersion: operators.coreos.com/v1
kind: OperatorGroup
metadata:
name: my-group
namespace: my-namespace
L'ensemble résolu des espaces de noms sélectionnés est indiqué dans le paramètre status.namespaces d'un groupe d'opérateurs. Le paramètre status.namespace d'un groupe d'opérateurs global contient la chaîne vide (""), qui signale à un opérateur consommateur qu'il doit surveiller tous les espaces de noms.
2.4.5.4. Annotations CSV du groupe d'opérateurs
Les CSV membres d'un groupe d'opérateurs ont les annotations suivantes :
| Annotation | Description |
|---|---|
|
| Contient le nom du groupe d'opérateurs. |
|
| Contient l'espace de noms du groupe d'opérateurs. |
|
| Contient une chaîne de caractères délimitée par des virgules qui répertorie la sélection de l'espace de noms cible du groupe d'opérateurs. |
Toutes les annotations, à l'exception de olm.targetNamespaces, sont incluses dans les CSV copiés. L'omission de l'annotation olm.targetNamespaces sur les CSV copiés empêche la duplication des espaces de noms cibles entre les locataires.
2.4.5.5. Annotation des API fournies
Un group/version/kind (GVK) est un identifiant unique pour une API Kubernetes. Les informations sur les GVK fournis par un groupe d'opérateurs sont indiquées dans une annotation olm.providedAPIs. La valeur de l'annotation est une chaîne composée de <kind>.<version>.<group> délimitée par des virgules. Les GVK des CRD et des services API fournis par tous les CSV membres actifs d'un groupe d'opérateurs sont inclus.
Examinez l'exemple suivant d'un objet OperatorGroup avec un seul membre actif CSV qui fournit la ressource PackageManifest:
apiVersion: operators.coreos.com/v1
kind: OperatorGroup
metadata:
annotations:
olm.providedAPIs: PackageManifest.v1alpha1.packages.apps.redhat.com
name: olm-operators
namespace: local
...
spec:
selector: {}
serviceAccount:
metadata:
creationTimestamp: null
targetNamespaces:
- local
status:
lastUpdated: 2019-02-19T16:18:28Z
namespaces:
- local2.4.5.6. Contrôle d'accès basé sur les rôles
Lorsqu'un groupe d'opérateurs est créé, trois rôles de grappe sont générés. Chacun contient une règle d'agrégation unique avec un sélecteur de rôle de cluster défini pour correspondre à une étiquette, comme illustré ci-dessous :
| Rôle de la grappe | Étiquette à faire correspondre |
|---|---|
|
|
|
|
|
|
|
|
|
Les ressources RBAC suivantes sont générées lorsqu'un CSV devient un membre actif d'un groupe d'opérateurs, tant que le CSV surveille tous les espaces de noms avec le mode d'installation AllNamespaces et n'est pas dans un état d'échec avec la raison InterOperatorGroupOwnerConflict:
- Rôles de cluster pour chaque ressource API d'un CRD
- Rôles de cluster pour chaque ressource API d'un service API
- Rôles supplémentaires et liaisons de rôles
| Rôle de la grappe | Paramètres |
|---|---|
|
|
Verbes sur
Étiquettes d'agrégation :
|
|
|
Verbes sur
Étiquettes d'agrégation :
|
|
|
Verbes sur
Étiquettes d'agrégation :
|
|
|
Verbes sur
Étiquettes d'agrégation :
|
| Rôle de la grappe | Paramètres |
|---|---|
|
|
Verbes sur
Étiquettes d'agrégation :
|
|
|
Verbes sur
Étiquettes d'agrégation :
|
|
|
Verbes sur
Étiquettes d'agrégation :
|
Rôles supplémentaires et liaisons de rôles
-
Si le CSV définit exactement un espace de noms cible qui contient
*, un rôle de cluster et une liaison de rôle de cluster correspondante sont générés pour chaque permission définie dans le champpermissionsdu CSV. Toutes les ressources générées reçoivent les étiquettesolm.owner: <csv_name>etolm.owner.namespace: <csv_namespace>. -
Si le CSV not définit exactement un espace de noms cible qui contient
*, tous les rôles et toutes les liaisons de rôles dans l'espace de noms Opérateur avec les étiquettesolm.owner: <csv_name>etolm.owner.namespace: <csv_namespace>sont copiés dans l'espace de noms cible.
2.4.5.7. Copie de fichiers CSV
OLM crée des copies de tous les CSV membres actifs d'un groupe d'opérateurs dans chacun des espaces de noms cibles de ce groupe d'opérateurs. L'objectif d'une copie de CSV est d'indiquer aux utilisateurs d'un espace de noms cible qu'un opérateur spécifique est configuré pour surveiller les ressources créées dans cet espace.
Les CSV copiés ont un motif de statut Copied et sont mis à jour pour correspondre au statut de leur CSV source. L'annotation olm.targetNamespaces est supprimée des CSV copiés avant qu'ils ne soient créés sur le cluster. L'omission de la sélection de l'espace de noms cible évite la duplication des espaces de noms cibles entre les locataires.
Les CSV copiés sont supprimés lorsque le CSV source n'existe plus ou que le groupe d'opérateurs auquel appartient le CSV source ne cible plus l'espace de noms du CSV copié.
Par défaut, le champ disableCopiedCSVs est désactivé. Après avoir activé un champ disableCopiedCSVs, OLM supprime les CSV copiés existants sur un cluster. Lorsqu'un champ disableCopiedCSVs est désactivé, OLM ajoute à nouveau des CSV copiés.
Désactiver le champ
disableCopiedCSVs:$ cat << EOF | oc apply -f - apiVersion: operators.coreos.com/v1 kind: OLMConfig metadata: name: cluster spec: features: disableCopiedCSVs: false EOFActivez le champ
disableCopiedCSVs:$ cat << EOF | oc apply -f - apiVersion: operators.coreos.com/v1 kind: OLMConfig metadata: name: cluster spec: features: disableCopiedCSVs: true EOF
2.4.5.8. Groupes d'opérateurs statiques
Un groupe d'opérateurs est static si son champ spec.staticProvidedAPIs est défini sur true. Par conséquent, OLM ne modifie pas l'annotation olm.providedAPIs d'un groupe d'opérateurs, ce qui signifie qu'elle peut être définie à l'avance. Cela est utile lorsqu'un utilisateur souhaite utiliser un groupe d'opérateurs pour empêcher la contention des ressources dans un ensemble d'espaces de noms, mais qu'il ne dispose pas de CSV membres actifs qui fournissent les API pour ces ressources.
Voici un exemple de groupe d'opérateurs qui protège les ressources Prometheus dans tous les espaces de noms avec l'annotation something.cool.io/cluster-monitoring: "true":
apiVersion: operators.coreos.com/v1
kind: OperatorGroup
metadata:
name: cluster-monitoring
namespace: cluster-monitoring
annotations:
olm.providedAPIs: Alertmanager.v1.monitoring.coreos.com,Prometheus.v1.monitoring.coreos.com,PrometheusRule.v1.monitoring.coreos.com,ServiceMonitor.v1.monitoring.coreos.com
spec:
staticProvidedAPIs: true
selector:
matchLabels:
something.cool.io/cluster-monitoring: "true"2.4.5.9. Intersection des groupes d'opérateurs
Deux groupes d'opérateurs sont considérés comme ayant intersecting provided APIs si l'intersection de leurs ensembles d'espaces de noms cibles n'est pas un ensemble vide et si l'intersection de leurs ensembles d'API fournis, définis par les annotations olm.providedAPIs, n'est pas un ensemble vide.
Un problème potentiel est que les groupes d'opérateurs dont les API fournies se recoupent peuvent être en concurrence pour les mêmes ressources dans l'ensemble des espaces de noms qui se recoupent.
Lors de la vérification des règles d'intersection, l'espace de noms d'un groupe d'opérateurs est toujours inclus dans les espaces de noms cibles sélectionnés.
Règles d'intersection
Chaque fois qu'un membre actif du CSV se synchronise, OLM interroge le cluster pour connaître l'ensemble des API fournies qui se croisent entre le groupe d'opérateurs du CSV et tous les autres. OLM vérifie ensuite si cet ensemble est vide :
Si
trueet les API fournies par le CSV sont un sous-ensemble de celles du groupe d'opérateurs :- Poursuivre la transition.
Si
trueet les API fournies par le CSV sont not un sous-ensemble de celles du groupe d'opérateurs :Si le groupe d'opérateurs est statique :
- Nettoyer les déploiements qui appartiennent au CSV.
-
Le CSV passe à l'état d'échec avec le motif d'état
CannotModifyStaticOperatorGroupProvidedAPIs.
Si le groupe d'opérateurs est not statique :
-
Remplacer l'annotation
olm.providedAPIsdu groupe Operator par l'union de lui-même et des API fournies par le CSV.
-
Remplacer l'annotation
Si
falseet les API fournies par le CSV sont not un sous-ensemble de celles du groupe d'opérateurs :- Nettoyer les déploiements qui appartiennent au CSV.
-
Le CSV passe à l'état d'échec avec le motif d'état
InterOperatorGroupOwnerConflict.
Si
falseet les API fournies par le CSV sont un sous-ensemble de celles du groupe d'opérateurs :Si le groupe d'opérateurs est statique :
- Nettoyer les déploiements qui appartiennent au CSV.
-
Le CSV passe à l'état d'échec avec le motif d'état
CannotModifyStaticOperatorGroupProvidedAPIs.
Si le groupe d'opérateurs est not statique :
-
Remplacer l'annotation
olm.providedAPIsdu groupe Operator par la différence entre lui-même et les API fournies par le CSV.
-
Remplacer l'annotation
Les états de défaillance causés par les groupes d'opérateurs sont non terminaux.
Les actions suivantes sont effectuées à chaque fois qu'un groupe d'opérateurs se synchronise :
- L'ensemble des API fournies par les CSV des membres actifs est calculé à partir du cluster. Les CSV copiés sont ignorés.
-
L'ensemble de clusters est comparé à
olm.providedAPIs, et siolm.providedAPIscontient des API supplémentaires, ces API sont supprimées. - Tous les CSV qui fournissent les mêmes API dans tous les espaces de noms sont remis en file d'attente. Cela permet de notifier aux CSV en conflit dans des groupes qui se croisent que leur conflit a peut-être été résolu, soit par un redimensionnement, soit par la suppression du CSV en conflit.
2.4.5.10. Limites de la gestion d'un opérateur multilocataire
OpenShift Container Platform offre un support limité pour l'installation simultanée de différentes versions d'un opérateur sur le même cluster. Operator Lifecycle Manager (OLM) installe les opérateurs plusieurs fois dans différents espaces de noms. L'une des contraintes est que les versions de l'API de l'opérateur doivent être identiques.
Les opérateurs sont des extensions du plan de contrôle en raison de leur utilisation des objets CustomResourceDefinition (CRD), qui sont des ressources globales dans Kubernetes. Les différentes versions majeures d'un opérateur ont souvent des CRD incompatibles. Cela les rend incompatibles à installer simultanément dans différents espaces de noms sur un cluster.
Tous les locataires, ou espaces de noms, partagent le même plan de contrôle d'un cluster. Par conséquent, les locataires d'un cluster multi-locataires partagent également des CRD globaux, ce qui limite les scénarios dans lesquels différentes instances du même opérateur peuvent être utilisées en parallèle sur le même cluster.
Les scénarios pris en charge sont les suivants :
- Opérateurs de différentes versions qui expédient exactement la même définition de CRD (dans le cas de CRD versionnés, exactement le même ensemble de versions)
- Les opérateurs de différentes versions qui n'expédient pas de CRD, mais dont le CRD est disponible dans un paquet séparé sur OperatorHub
Tous les autres scénarios ne sont pas pris en charge, car l'intégrité des données du cluster ne peut pas être garantie s'il y a plusieurs CRD concurrents ou se chevauchant, provenant de différentes versions de l'opérateur, à réconcilier sur le même cluster.
2.4.5.11. Dépannage des groupes d'opérateurs
L'adhésion
L'espace de noms d'un plan d'installation ne doit contenir qu'un seul groupe d'opérateurs. Lors de la génération d'une version de service de cluster (CSV) dans un espace de noms, un plan d'installation considère qu'un groupe d'opérateurs n'est pas valide dans les cas suivants :
- Aucun groupe d'opérateurs n'existe dans l'espace de noms du plan d'installation.
- Plusieurs groupes d'opérateurs existent dans l'espace de noms du plan d'installation.
- Un nom de compte de service incorrect ou inexistant est spécifié dans le groupe Opérateur.
Si un plan d'installation rencontre un groupe d'opérateurs non valide, le CSV n'est pas généré et la ressource
InstallPlancontinue à s'installer avec un message pertinent. Par exemple, le message suivant est fourni si plusieurs groupes d'opérateurs existent dans le même espace de noms :attenuated service account query failed - more than one operator group(s) are managing this namespace count=2où
count=indique le nombre de groupes d'opérateurs dans l'espace de noms.-
Si les modes d'installation d'une CSV ne prennent pas en charge la sélection de l'espace de noms cible du groupe d'opérateurs dans son espace de noms, la CSV passe à un état d'échec avec la raison
UnsupportedOperatorGroup. Les CSV en état d'échec pour cette raison passent en attente après que la sélection de l'espace de noms cible du groupe d'opérateurs passe à une configuration prise en charge ou que les modes d'installation de la CSV soient modifiés pour prendre en charge la sélection de l'espace de noms cible.
2.4.6. Conditions de l'opérateur
Ce guide explique comment Operator Lifecycle Manager (OLM) utilise les conditions de l'opérateur.
2.4.6.1. À propos des conditions de l'opérateur
Dans le cadre de son rôle de gestion du cycle de vie d'un opérateur, Operator Lifecycle Manager (OLM) déduit l'état d'un opérateur à partir de l'état des ressources Kubernetes qui définissent l'opérateur. Bien que cette approche fournisse un certain niveau d'assurance qu'un opérateur est dans un état donné, il y a de nombreux cas où un opérateur peut avoir besoin de communiquer des informations à OLM qui ne pourraient pas être déduites autrement. Ces informations peuvent alors être utilisées par OLM pour mieux gérer le cycle de vie de l'opérateur.
OLM fournit une définition de ressource personnalisée (CRD) appelée OperatorCondition qui permet aux opérateurs de communiquer des conditions à OLM. Il existe un ensemble de conditions prises en charge qui influencent la gestion de l'opérateur par OLM lorsqu'elles sont présentes dans le tableau Spec.Conditions d'une ressource OperatorCondition.
Par défaut, le tableau Spec.Conditions n'est pas présent dans un objet OperatorCondition jusqu'à ce qu'il soit ajouté par un utilisateur ou à la suite d'une logique d'opérateur personnalisée.
2.4.6.2. Conditions prises en charge
Le gestionnaire du cycle de vie de l'opérateur (OLM) prend en charge les conditions suivantes de l'opérateur.
2.4.6.2.1. État évolutif
La condition Upgradeable Operator empêche le remplacement d'une version de service de cluster (CSV) existante par une version plus récente de la CSV. Cette condition est utile dans les cas suivants
- Un opérateur est sur le point de lancer un processus critique et ne doit pas être mis à niveau tant que le processus n'est pas terminé.
- Un opérateur effectue une migration de ressources personnalisées (CR) qui doit être achevée avant que l'opérateur ne soit prêt à être mis à niveau.
Exemple Upgradeable Condition de l'opérateur
apiVersion: operators.coreos.com/v1
kind: OperatorCondition
metadata:
name: my-operator
namespace: operators
spec:
conditions:
- type: Upgradeable
status: "False"
reason: "migration"
message: "The Operator is performing a migration."
lastTransitionTime: "2020-08-24T23:15:55Z"2.4.7. Mesures du gestionnaire du cycle de vie de l'opérateur
2.4.7.1. Métriques exposées
Operator Lifecycle Manager (OLM) expose certaines ressources spécifiques à OLM pour une utilisation par la pile de surveillance de cluster OpenShift Container Platform basée sur Prometheus.
| Nom | Description |
|---|---|
|
| Nombre de sources du catalogue. |
|
|
État d'une source de catalogue. La valeur |
|
|
Lors du rapprochement d'une version de service de cluster (CSV), présente chaque fois qu'une version CSV est dans un état autre que |
|
| Nombre de CSV enregistrés avec succès. |
|
|
Lors du rapprochement d'un CSV, indique si une version du CSV est dans l'état |
|
| Compte monotone des mises à jour CSV. |
|
| Nombre de plans d'installation. |
|
| Compte monotone des avertissements générés par les ressources, telles que les ressources dépréciées, incluses dans un plan d'installation. |
|
| La durée d'une tentative de résolution de dépendance. |
|
| Nombre d'abonnements. |
|
|
Compte monotone des synchronisations d'abonnements. Inclut les étiquettes |
2.4.8. Gestion des webhooks dans Operator Lifecycle Manager
Les webhooks permettent aux auteurs de l'opérateur d'intercepter, de modifier et d'accepter ou de rejeter des ressources avant qu'elles ne soient enregistrées dans le magasin d'objets et traitées par le contrôleur de l'opérateur. Operator Lifecycle Manager (OLM) peut gérer le cycle de vie de ces webhooks lorsqu'ils sont livrés avec votre opérateur.
Voir Définition des versions de service de cluster (CSV) pour plus de détails sur la manière dont un développeur d'opérateur peut définir des webhooks pour son opérateur, ainsi que sur les considérations à prendre en compte lors de l'exécution sur OLM.
2.5. Comprendre OperatorHub
2.5.1. À propos d'OperatorHub
OperatorHub est l'interface de la console web d'OpenShift Container Platform que les administrateurs de clusters utilisent pour découvrir et installer les opérateurs. En un clic, un opérateur peut être extrait de sa source hors cluster, installé et souscrit sur le cluster, et préparé pour que les équipes d'ingénieurs puissent gérer le produit en libre-service dans les environnements de déploiement à l'aide d'Operator Lifecycle Manager (OLM).
Les administrateurs de clusters peuvent choisir parmi les catalogues regroupés dans les catégories suivantes :
| Catégorie | Description |
|---|---|
| Opérateurs Red Hat | Produits Red Hat emballés et expédiés par Red Hat. Pris en charge par Red Hat. |
| Opérateurs certifiés | Produits des principaux éditeurs de logiciels indépendants (ISV). Red Hat s'associe aux ISV pour emballer et expédier les produits. Pris en charge par l'ISV. |
| Marché Red Hat | Logiciel certifié qui peut être acheté sur Red Hat Marketplace. |
| Opérateurs communautaires | Logiciel optionnel maintenu par les représentants concernés dans le dépôt GitHub redhat-openshift-ecosystem/community-operators-prod/operators. Pas de support officiel. |
| Opérateurs personnalisés | Opérateurs que vous ajoutez vous-même au cluster. Si vous n'avez pas ajouté d'opérateurs personnalisés, la catégorie Custom n'apparaît pas dans la console web de votre OperatorHub. |
Les opérateurs sur OperatorHub sont conditionnés pour fonctionner sur OLM. Cela inclut un fichier YAML appelé version de service de cluster (CSV) contenant tous les CRD, les règles RBAC, les déploiements et les images de conteneurs nécessaires pour installer et exécuter l'opérateur en toute sécurité. Il contient également des informations visibles par l'utilisateur, comme une description de ses fonctionnalités et des versions de Kubernetes prises en charge.
L'Operator SDK peut être utilisé pour aider les développeurs à conditionner leurs opérateurs pour une utilisation sur OLM et OperatorHub. Si vous avez une application commerciale que vous souhaitez rendre accessible à vos clients, incluez-la en utilisant le processus de certification fourni sur le portail Red Hat Partner Connect à l'adresse connect.redhat.com.
2.5.2. Architecture d'OperatorHub
Le composant OperatorHub UI est piloté par l'opérateur Marketplace par défaut sur OpenShift Container Platform dans l'espace de noms openshift-marketplace.
2.5.2.1. Ressource personnalisée OperatorHub
L'opérateur Marketplace gère une ressource personnalisée OperatorHub (CR) nommée cluster qui gère les objets CatalogSource par défaut fournis avec OperatorHub. Vous pouvez modifier cette ressource pour activer ou désactiver les catalogues par défaut, ce qui est utile lors de la configuration d'OpenShift Container Platform dans des environnements réseau restreints.
Exemple OperatorHub ressource personnalisée
apiVersion: config.openshift.io/v1
kind: OperatorHub
metadata:
name: cluster
spec:
disableAllDefaultSources: true
sources: [
{
name: "community-operators",
disabled: false
}
]2.6. Catalogues d'opérateurs fournis par Red Hat
Red Hat fournit plusieurs catalogues d'opérateurs qui sont inclus par défaut dans OpenShift Container Platform.
À partir d'OpenShift Container Platform 4.11, le catalogue Operator fourni par Red Hat par défaut est publié dans le format de catalogue basé sur des fichiers. Les catalogues Operator fournis par Red Hat par défaut pour OpenShift Container Platform 4.6 à 4.10 sont publiés dans le format de base de données SQLite déprécié.
Les sous-commandes, drapeaux et fonctionnalités de opm liés au format de base de données SQLite sont également obsolètes et seront supprimés dans une prochaine version. Ces fonctionnalités sont toujours prises en charge et doivent être utilisées pour les catalogues qui utilisent le format de base de données SQLite obsolète.
La plupart des sous-commandes et des drapeaux de opm pour travailler avec le format de base de données SQLite, tels que opm index prune, ne fonctionnent pas avec le format de catalogue basé sur des fichiers. Pour plus d'informations sur l'utilisation des catalogues basés sur des fichiers, voir Gestion des catalogues personnalisés, Format d'empaquetage d'Operator Framework et Mise en miroir des images pour une installation déconnectée à l'aide du plugin oc-mirror.
2.6.1. À propos des catalogues d'opérateurs
Un catalogue d'opérateurs est un référentiel de métadonnées que le gestionnaire du cycle de vie des opérateurs (OLM) peut interroger pour découvrir et installer des opérateurs et leurs dépendances sur un cluster. OLM installe toujours les opérateurs à partir de la dernière version d'un catalogue.
Une image d'index, basée sur le format Operator bundle, est un instantané conteneurisé d'un catalogue. Il s'agit d'un artefact immuable qui contient la base de données des pointeurs vers un ensemble de contenus du manifeste Operator. Un catalogue peut faire référence à une image d'index afin de trouver la source de son contenu pour OLM sur le cluster.
Au fur et à mesure que les catalogues sont mis à jour, les dernières versions des opérateurs changent et les anciennes versions peuvent être supprimées ou modifiées. En outre, lorsque OLM s'exécute sur un cluster OpenShift Container Platform dans un environnement réseau restreint, il n'est pas en mesure d'accéder aux catalogues directement à partir d'Internet pour en extraire le contenu le plus récent.
En tant qu'administrateur de cluster, vous pouvez créer votre propre image d'index personnalisée, soit basée sur un catalogue fourni par Red Hat, soit à partir de zéro, qui peut être utilisée comme source du contenu du catalogue sur le cluster. La création et la mise à jour de votre propre image d'index fournit une méthode pour personnaliser l'ensemble des opérateurs disponibles sur le cluster, tout en évitant les problèmes d'environnement réseau restreint mentionnés ci-dessus.
Kubernetes déprécie périodiquement certaines API qui sont supprimées dans les versions ultérieures. Par conséquent, les opérateurs ne peuvent pas utiliser les API supprimées à partir de la version d'OpenShift Container Platform qui utilise la version de Kubernetes qui a supprimé l'API.
Si votre cluster utilise des catalogues personnalisés, consultez Contrôle de la compatibilité des opérateurs avec les versions d'OpenShift Container Platform pour plus de détails sur la façon dont les auteurs d'opérateurs peuvent mettre à jour leurs projets afin d'éviter les problèmes de charge de travail et d'empêcher les mises à niveau incompatibles.
La prise en charge de l'ancien site package manifest format pour les opérateurs, y compris les catalogues personnalisés qui utilisaient l'ancien format, est supprimée dans OpenShift Container Platform 4.8 et les versions ultérieures.
Lors de la création d'images de catalogue personnalisées, les versions précédentes d'OpenShift Container Platform 4 nécessitaient l'utilisation de la commande oc adm catalog build, qui a été dépréciée pendant plusieurs versions et est maintenant supprimée. Avec la disponibilité des images d'index fournies par Red Hat à partir d'OpenShift Container Platform 4.6, les créateurs de catalogues doivent utiliser la commande opm index pour gérer les images d'index.
2.6.2. À propos des catalogues d'opérateurs fournis par Red Hat
Les sources de catalogues fournies par Red Hat sont installées par défaut dans l'espace de noms openshift-marketplace, ce qui rend les catalogues disponibles à l'échelle du cluster dans tous les espaces de noms.
Les catalogues d'opérateurs suivants sont distribués par Red Hat :
| Catalogue | Image d'index | Description |
|---|---|---|
|
|
| Produits Red Hat emballés et expédiés par Red Hat. Pris en charge par Red Hat. |
|
|
| Produits des principaux éditeurs de logiciels indépendants (ISV). Red Hat s'associe aux ISV pour emballer et expédier les produits. Pris en charge par l'ISV. |
|
|
| Logiciel certifié qui peut être acheté sur Red Hat Marketplace. |
|
|
| Logiciel maintenu par les représentants concernés dans le dépôt GitHub redhat-openshift-ecosystem/community-operators-prod/operators. Pas de support officiel. |
Au cours d'une mise à niveau de cluster, la balise d'image d'index pour les sources de catalogue par défaut fournies par Red Hat est mise à jour automatiquement par l'opérateur de version de cluster (CVO) afin que Operator Lifecycle Manager (OLM) tire la version mise à jour du catalogue. Par exemple, lors d'une mise à niveau d'OpenShift Container Platform 4.8 à 4.9, le champ spec.image dans l'objet CatalogSource pour le catalogue redhat-operators est mis à jour de :
registry.redhat.io/redhat/redhat-operator-index:v4.8à :
registry.redhat.io/redhat/redhat-operator-index:v4.92.7. Opérateurs dans les clusters multitenants
Le comportement par défaut de l'Operator Lifecycle Manager (OLM) vise à simplifier l'installation de l'opérateur. Cependant, ce comportement peut manquer de flexibilité, en particulier dans les clusters multi-locataires. Pour que plusieurs locataires d'un cluster OpenShift Container Platform puissent utiliser un opérateur, le comportement par défaut d'OLM exige que les administrateurs installent l'opérateur en mode All namespaces, ce qui peut être considéré comme une violation du principe du moindre privilège.
Examinez les scénarios suivants afin de déterminer le processus d'installation de l'opérateur qui convient le mieux à votre environnement et à vos besoins.
2.7.1. Modes d'installation et comportement par défaut de l'opérateur
Lorsque vous installez des opérateurs à l'aide de la console web en tant qu'administrateur, vous avez généralement le choix entre deux modes d'installation, en fonction des capacités de l'opérateur :
- Espace de noms unique
- Installe l'opérateur dans l'espace de noms unique choisi et met à disposition toutes les autorisations demandées par l'opérateur dans cet espace de noms.
- Tous les espaces nominatifs
-
Installe l'opérateur dans l'espace de noms par défaut
openshift-operatorspour qu'il surveille tous les espaces de noms du cluster et qu'il y ait accès. Rend toutes les autorisations demandées par l'opérateur disponibles dans tous les espaces de noms. Dans certains cas, l'auteur d'un opérateur peut définir des métadonnées pour donner à l'utilisateur une deuxième option pour l'espace de noms suggéré par l'opérateur.
Ce choix signifie également que les utilisateurs des espaces de noms concernés ont accès aux API des opérateurs, qui peuvent exploiter les ressources personnalisées (CR) qu'ils possèdent, en fonction de leur rôle dans l'espace de noms :
-
Les rôles
namespace-adminetnamespace-editpeuvent lire/écrire dans les API de l'opérateur, ce qui signifie qu'ils peuvent les utiliser. -
Le rôle
namespace-viewpeut lire les objets CR de cet opérateur.
Pour le mode Single namespace, comme l'opérateur lui-même s'installe dans l'espace de noms choisi, son pod et son compte de service y sont également situés. Pour le mode All namespaces, les privilèges de l'opérateur sont tous automatiquement élevés au rang de rôles de cluster, ce qui signifie que l'opérateur dispose de ces autorisations dans tous les espaces de noms.
2.7.2. Solution recommandée pour les clusters multitenants
Bien qu'il existe un mode d'installation Multinamespace, il n'est pris en charge que par très peu d'opérateurs. Comme solution intermédiaire entre les modes d'installation standard All namespaces et Single namespace, vous pouvez installer plusieurs instances du même opérateur, une pour chaque locataire, en utilisant le flux de travail suivant :
- Créer un espace de noms pour l'opérateur du locataire, distinct de l'espace de noms du locataire.
- Créer un groupe d'opérateurs pour l'opérateur du locataire, limité à l'espace de noms du locataire.
- Installer l'opérateur dans l'espace de noms de l'opérateur du locataire.
Par conséquent, l'opérateur réside dans l'espace de noms de l'opérateur du locataire et surveille l'espace de noms du locataire, mais ni le pod de l'opérateur ni son compte de service ne sont visibles ou utilisables par le locataire.
Cette solution offre une meilleure séparation des locataires, le principe du moindre privilège au prix de l'utilisation des ressources, et une orchestration supplémentaire pour s'assurer que les contraintes sont respectées. Pour une procédure détaillée, voir "Preparing for multiple instances of an Operator for multitenant clusters".
Limites et considérations
Cette solution ne fonctionne que si les contraintes suivantes sont respectées :
- Toutes les instances d'un même opérateur doivent être de la même version.
- L'opérateur ne peut pas dépendre d'autres opérateurs.
- L'opérateur ne peut pas envoyer un webhook de conversion CRD.
Vous ne pouvez pas utiliser différentes versions du même opérateur sur le même cluster. Eventuellement, l'installation d'une autre instance de l'Opérateur serait bloquée lorsqu'elle remplit les conditions suivantes :
- L'instance n'est pas la version la plus récente de l'opérateur.
- L'instance expédie une ancienne révision des CRD qui manque d'informations ou de versions que des révisions plus récentes possèdent et qui sont déjà utilisées sur le cluster.
En tant qu'administrateur, soyez prudent lorsque vous autorisez des administrateurs qui ne font pas partie d'un cluster à installer des opérateurs de manière autonome, comme expliqué dans "Autoriser des administrateurs qui ne font pas partie d'un cluster à installer des opérateurs". Ces locataires ne devraient avoir accès qu'à un catalogue raisonné d'opérateurs dont on sait qu'ils n'ont pas de dépendances. Ces locataires doivent également être contraints d'utiliser la même ligne de version d'un opérateur, afin de s'assurer que les CRD ne changent pas. Cela nécessite l'utilisation de catalogues à l'échelle de l'espace de noms et probablement la désactivation des catalogues globaux par défaut.
2.8. CRDs
2.8.1. Extension de l'API Kubernetes avec des définitions de ressources personnalisées
Les opérateurs utilisent le mécanisme d'extension de Kubernetes, les définitions de ressources personnalisées (CRD), afin que les objets personnalisés gérés par l'opérateur aient la même apparence et le même comportement que les objets Kubernetes intégrés et natifs. Ce guide décrit comment les administrateurs de cluster peuvent étendre leur cluster OpenShift Container Platform en créant et en gérant des CRD.
2.8.1.1. Définitions de ressources personnalisées
Dans l'API Kubernetes, un resource est un point d'extrémité qui stocke une collection d'objets API d'un certain type. Par exemple, la ressource intégrée Pods contient une collection d'objets Pod.
Un objet custom resource definition (CRD) définit un nouveau type d'objet unique, appelé kind, dans le cluster et laisse le serveur API Kubernetes gérer l'ensemble de son cycle de vie.
Custom resource (CR) sont créés à partir des CRD qui ont été ajoutés au cluster par un administrateur du cluster, ce qui permet à tous les utilisateurs du cluster d'ajouter le nouveau type de ressource dans les projets.
Lorsqu'un administrateur de cluster ajoute un nouveau CRD au cluster, le serveur API Kubernetes réagit en créant un nouveau chemin de ressources RESTful accessible à l'ensemble du cluster ou à un seul projet (espace de noms) et commence à servir le CR spécifié.
Les administrateurs de clusters qui souhaitent accorder l'accès au CRD à d'autres utilisateurs peuvent utiliser l'agrégation des rôles de clusters pour accorder l'accès aux utilisateurs ayant les rôles de clusters par défaut admin, edit, ou view. L'agrégation de rôles permet d'insérer des règles personnalisées dans ces rôles. Ce comportement intègre la nouvelle ressource dans la politique RBAC du cluster comme s'il s'agissait d'une ressource intégrée.
Les opérateurs, en particulier, utilisent les CRD en les intégrant à toute politique RBAC requise et à toute autre logique propre au logiciel. Les administrateurs de cluster peuvent également ajouter manuellement des CRD au cluster en dehors du cycle de vie d'un opérateur, les mettant ainsi à la disposition de tous les utilisateurs.
Alors que seuls les administrateurs de clusters peuvent créer des CRD, les développeurs peuvent créer un CR à partir d'un CRD existant s'ils ont les droits de lecture et d'écriture sur celui-ci.
2.8.1.2. Création d'une définition de ressource personnalisée
Pour créer des objets de ressources personnalisées (CR), les administrateurs de clusters doivent d'abord créer une définition de ressources personnalisées (CRD).
Conditions préalables
-
Accès à un cluster OpenShift Container Platform avec des privilèges d'utilisateur
cluster-admin.
Procédure
Pour créer un CRD :
Créez un fichier YAML contenant les types de champs suivants :
Exemple de fichier YAML pour un CRD
apiVersion: apiextensions.k8s.io/v11 kind: CustomResourceDefinition metadata: name: crontabs.stable.example.com2 spec: group: stable.example.com3 versions: name: v14 scope: Namespaced5 names: plural: crontabs6 singular: crontab7 kind: CronTab8 shortNames: - ct9 - 1
- Utilisez l'API
apiextensions.k8s.io/v1. - 2
- Indiquez un nom pour la définition. Ce nom doit être au format
<plural-name>.<group>en utilisant les valeurs des champsgroupetplural. - 3
- Spécifiez un nom de groupe pour l'API. Un groupe API est une collection d'objets logiquement liés. Par exemple, tous les objets de lot tels que
JobouScheduledJobpourraient se trouver dans le groupe API de lot (tel quebatch.api.example.com). Une bonne pratique consiste à utiliser le nom de domaine entièrement qualifié (FQDN) de votre organisation. - 4
- Spécifiez un nom de version à utiliser dans l'URL. Chaque groupe d'API peut exister dans plusieurs versions, par exemple
v1alpha,v1beta,v1. - 5
- Indiquez si les objets personnalisés sont disponibles pour un projet (
Namespaced) ou pour tous les projets du cluster (Cluster). - 6
- Spécifiez le nom pluriel à utiliser dans l'URL. Le champ
pluralest identique à celui d'une ressource dans une URL d'API. - 7
- Spécifiez un nom singulier à utiliser comme alias dans le CLI et pour l'affichage.
- 8
- Spécifie le type d'objets qui peuvent être créés. Le type peut être en CamelCase.
- 9
- Spécifiez une chaîne plus courte pour faire correspondre votre ressource à la CLI.
NotePar défaut, un CRD est géré en grappe et accessible à tous les projets.
Créer l'objet CRD :
oc create -f <nom_du_fichier>.yamlUn nouveau point d'accès à l'API RESTful est créé à l'adresse :
/apis/<spec:group>/<spec:version>/<scope>/*/<names-plural>/...Par exemple, en utilisant le fichier d'exemple, le point final suivant est créé :
/apis/stable.example.com/v1/namespaces/*/crontabs/...Vous pouvez maintenant utiliser cette URL pour créer et gérer des CR. Le type d'objet est basé sur le champ
spec.kindde l'objet CRD que vous avez créé.
2.8.1.3. Création de rôles de cluster pour les définitions de ressources personnalisées
Les administrateurs de clusters peuvent accorder des autorisations à des définitions de ressources personnalisées (CRD) existantes et adaptées aux clusters. Si vous utilisez les rôles de cluster par défaut admin, edit, et view, vous pouvez tirer parti de l'agrégation des rôles de cluster pour leurs règles.
Vous devez attribuer explicitement des autorisations à chacun de ces rôles. Les rôles disposant de plus d'autorisations n'héritent pas des règles des rôles disposant de moins d'autorisations. Si vous attribuez une règle à un rôle, vous devez également attribuer ce verbe aux rôles disposant de plus d'autorisations. Par exemple, si vous accordez l'autorisation get crontabs au rôle view, vous devez également l'accorder aux rôles edit et admin. Le rôle admin ou edit est généralement attribué à l'utilisateur qui a créé un projet à l'aide du modèle de projet.
Conditions préalables
- Créer un CRD.
Procédure
Créer un fichier de définition des rôles de cluster pour le CRD. La définition du rôle de cluster est un fichier YAML qui contient les règles qui s'appliquent à chaque rôle de cluster. Un contrôleur OpenShift Container Platform ajoute les règles que vous spécifiez aux rôles de cluster par défaut.
Exemple de fichier YAML pour la définition d'un rôle de cluster
kind: ClusterRole apiVersion: rbac.authorization.k8s.io/v11 metadata: name: aggregate-cron-tabs-admin-edit2 labels: rbac.authorization.k8s.io/aggregate-to-admin: "true"3 rbac.authorization.k8s.io/aggregate-to-edit: "true"4 rules: - apiGroups: ["stable.example.com"]5 resources: ["crontabs"]6 verbs: ["get", "list", "watch", "create", "update", "patch", "delete", "deletecollection"]7 --- kind: ClusterRole apiVersion: rbac.authorization.k8s.io/v1 metadata: name: aggregate-cron-tabs-view8 labels: # Add these permissions to the "view" default role. rbac.authorization.k8s.io/aggregate-to-view: "true"9 rbac.authorization.k8s.io/aggregate-to-cluster-reader: "true"10 rules: - apiGroups: ["stable.example.com"]11 resources: ["crontabs"]12 verbs: ["get", "list", "watch"]13 - 1
- Utilisez l'API
rbac.authorization.k8s.io/v1. - 2 8
- Spécifiez un nom pour la définition.
- 3
- Spécifiez cette étiquette pour accorder des autorisations au rôle par défaut d'administrateur.
- 4
- Spécifiez cette étiquette pour accorder des autorisations au rôle d'édition par défaut.
- 5 11
- Indiquez le nom du groupe du CRD.
- 6 12
- Indiquez le nom pluriel du CRD auquel ces règles s'appliquent.
- 7 13
- Spécifiez les verbes qui représentent les autorisations accordées au rôle. Par exemple, appliquer les autorisations de lecture et d'écriture aux rôles
admineteditet uniquement l'autorisation de lecture au rôleview. - 9
- Spécifiez cette étiquette pour accorder des autorisations au rôle par défaut
view. - 10
- Spécifiez cette étiquette pour accorder des autorisations au rôle par défaut
cluster-reader.
Créer le rôle de cluster :
oc create -f <nom_du_fichier>.yaml
2.8.1.4. Création de ressources personnalisées à partir d'un fichier
Une fois qu'une définition de ressource personnalisée (CRD) a été ajoutée au cluster, des ressources personnalisées (CR) peuvent être créées à l'aide de l'interface CLI à partir d'un fichier utilisant la spécification CR.
Conditions préalables
- CRD ajouté au cluster par un administrateur de cluster.
Procédure
Créez un fichier YAML pour le CR. Dans l'exemple de définition suivant, les champs personnalisés
cronSpecetimagesont définis dans un CR deKind: CronTab. LeKindprovient du champspec.kindde l'objet CRD :Exemple de fichier YAML pour un CR
apiVersion: "stable.example.com/v1"1 kind: CronTab2 metadata: name: my-new-cron-object3 finalizers:4 - finalizer.stable.example.com spec:5 cronSpec: "* * * * /5" image: my-awesome-cron-image- 1
- Spécifiez le nom du groupe et la version de l'API (nom/version) à partir du CRD.
- 2
- Spécifier le type dans le CRD.
- 3
- Spécifiez un nom pour l'objet.
- 4
- Spécifier les finaliseurs de l'objet, s'il y en a. Les finaliseurs permettent aux contrôleurs de mettre en œuvre des conditions qui doivent être remplies avant que l'objet puisse être supprimé.
- 5
- Spécifier les conditions spécifiques au type d'objet.
Après avoir créé le fichier, créez l'objet :
oc create -f <nom_du_fichier>.yaml
2.8.1.5. Inspection des ressources personnalisées
Vous pouvez inspecter les objets de ressources personnalisées (CR) qui existent dans votre cluster à l'aide de la CLI.
Conditions préalables
- Un objet CR existe dans un espace de noms auquel vous avez accès.
Procédure
Pour obtenir des informations sur un type spécifique de CR, exécutez :
oc get <kind> $ oc get <kind>Par exemple :
$ oc get crontabExemple de sortie
NAME KIND my-new-cron-object CronTab.v1.stable.example.comLes noms de ressources ne sont pas sensibles à la casse et vous pouvez utiliser les formes singulières ou plurielles définies dans le CRD, ainsi que n'importe quel nom court. Par exemple :
$ oc get crontabs$ oc get crontab$ oc get ctVous pouvez également consulter les données YAML brutes d'un CR :
oc get <kind> -o yamlPar exemple :
$ oc get ct -o yamlExemple de sortie
apiVersion: v1 items: - apiVersion: stable.example.com/v1 kind: CronTab metadata: clusterName: "" creationTimestamp: 2017-05-31T12:56:35Z deletionGracePeriodSeconds: null deletionTimestamp: null name: my-new-cron-object namespace: default resourceVersion: "285" selfLink: /apis/stable.example.com/v1/namespaces/default/crontabs/my-new-cron-object uid: 9423255b-4600-11e7-af6a-28d2447dc82b spec: cronSpec: '* * * * /5'1 image: my-awesome-cron-image2
2.8.2. Gestion des ressources à partir de définitions de ressources personnalisées
Ce guide décrit comment les développeurs peuvent gérer les ressources personnalisées (CR) issues des définitions de ressources personnalisées (CRD).
2.8.2.1. Définitions de ressources personnalisées
Dans l'API Kubernetes, un resource est un point d'extrémité qui stocke une collection d'objets API d'un certain type. Par exemple, la ressource intégrée Pods contient une collection d'objets Pod.
Un objet custom resource definition (CRD) définit un nouveau type d'objet unique, appelé kind, dans le cluster et laisse le serveur API Kubernetes gérer l'ensemble de son cycle de vie.
Custom resource (CR) sont créés à partir des CRD qui ont été ajoutés au cluster par un administrateur du cluster, ce qui permet à tous les utilisateurs du cluster d'ajouter le nouveau type de ressource dans les projets.
Les opérateurs, en particulier, utilisent les CRD en les intégrant à toute politique RBAC requise et à toute autre logique propre au logiciel. Les administrateurs de cluster peuvent également ajouter manuellement des CRD au cluster en dehors du cycle de vie d'un opérateur, les mettant ainsi à la disposition de tous les utilisateurs.
Alors que seuls les administrateurs de clusters peuvent créer des CRD, les développeurs peuvent créer un CR à partir d'un CRD existant s'ils ont les droits de lecture et d'écriture sur celui-ci.
2.8.2.2. Création de ressources personnalisées à partir d'un fichier
Une fois qu'une définition de ressource personnalisée (CRD) a été ajoutée au cluster, des ressources personnalisées (CR) peuvent être créées à l'aide de l'interface CLI à partir d'un fichier utilisant la spécification CR.
Conditions préalables
- CRD ajouté au cluster par un administrateur de cluster.
Procédure
Créez un fichier YAML pour le CR. Dans l'exemple de définition suivant, les champs personnalisés
cronSpecetimagesont définis dans un CR deKind: CronTab. LeKindprovient du champspec.kindde l'objet CRD :Exemple de fichier YAML pour un CR
apiVersion: "stable.example.com/v1"1 kind: CronTab2 metadata: name: my-new-cron-object3 finalizers:4 - finalizer.stable.example.com spec:5 cronSpec: "* * * * /5" image: my-awesome-cron-image- 1
- Spécifiez le nom du groupe et la version de l'API (nom/version) à partir du CRD.
- 2
- Spécifier le type dans le CRD.
- 3
- Spécifiez un nom pour l'objet.
- 4
- Spécifier les finaliseurs de l'objet, s'il y en a. Les finaliseurs permettent aux contrôleurs de mettre en œuvre des conditions qui doivent être remplies avant que l'objet puisse être supprimé.
- 5
- Spécifier les conditions spécifiques au type d'objet.
Après avoir créé le fichier, créez l'objet :
oc create -f <nom_du_fichier>.yaml
2.8.2.3. Inspection des ressources personnalisées
Vous pouvez inspecter les objets de ressources personnalisées (CR) qui existent dans votre cluster à l'aide de la CLI.
Conditions préalables
- Un objet CR existe dans un espace de noms auquel vous avez accès.
Procédure
Pour obtenir des informations sur un type spécifique de CR, exécutez :
oc get <kind> $ oc get <kind>Par exemple :
$ oc get crontabExemple de sortie
NAME KIND my-new-cron-object CronTab.v1.stable.example.comLes noms de ressources ne sont pas sensibles à la casse et vous pouvez utiliser les formes singulières ou plurielles définies dans le CRD, ainsi que n'importe quel nom court. Par exemple :
$ oc get crontabs$ oc get crontab$ oc get ctVous pouvez également consulter les données YAML brutes d'un CR :
oc get <kind> -o yamlPar exemple :
$ oc get ct -o yamlExemple de sortie
apiVersion: v1 items: - apiVersion: stable.example.com/v1 kind: CronTab metadata: clusterName: "" creationTimestamp: 2017-05-31T12:56:35Z deletionGracePeriodSeconds: null deletionTimestamp: null name: my-new-cron-object namespace: default resourceVersion: "285" selfLink: /apis/stable.example.com/v1/namespaces/default/crontabs/my-new-cron-object uid: 9423255b-4600-11e7-af6a-28d2447dc82b spec: cronSpec: '* * * * /5'1 image: my-awesome-cron-image2
Chapitre 3. Tâches de l'utilisateur
3.1. Création d'applications à partir d'opérateurs installés
Ce guide présente aux développeurs un exemple de création d'applications à partir d'un opérateur installé en utilisant la console web d'OpenShift Container Platform.
3.1.1. Création d'un cluster etcd à l'aide d'un opérateur
Cette procédure décrit la création d'un nouveau cluster etcd à l'aide de l'opérateur etcd, géré par Operator Lifecycle Manager (OLM).
Conditions préalables
- Accès à un cluster OpenShift Container Platform 4.12.
- L'opérateur etcd a déjà été installé par un administrateur sur l'ensemble du cluster.
Procédure
-
Créez un nouveau projet dans la console web d'OpenShift Container Platform pour cette procédure. Cet exemple utilise un projet appelé
my-etcd. Naviguez jusqu'à la page Operators → Installed Operators. Les opérateurs qui ont été installés sur la grappe par l'administrateur de la grappe et qui sont disponibles pour être utilisés sont affichés ici sous la forme d'une liste de versions de service de grappe (CSV). Les CSV sont utilisées pour lancer et gérer le logiciel fourni par l'opérateur.
AstuceVous pouvez obtenir cette liste à partir de l'interface de programmation en utilisant :
$ oc get csvSur la page Installed Operators, cliquez sur l'opérateur etcd pour obtenir plus de détails et connaître les actions disponibles.
Comme indiqué sous Provided APIs, cet opérateur met à disposition trois nouveaux types de ressources, dont un pour un etcd Cluster (la ressource
EtcdCluster). Ces objets fonctionnent de la même manière que les objets Kubernetes natifs intégrés, tels queDeploymentouReplicaSet, mais contiennent une logique spécifique à la gestion de etcd.Créer un nouveau cluster etcd :
- Dans la boîte API etcd Cluster, cliquez sur Create instance.
-
L'écran suivant vous permet d'apporter des modifications au modèle minimal de départ d'un objet
EtcdCluster, comme la taille de l'amas. Pour l'instant, cliquez sur Create pour finaliser. Cela déclenche le démarrage par l'opérateur des pods, des services et des autres composants du nouveau cluster etcd.
Cliquez sur le cluster etcd example, puis sur l'onglet Resources pour voir que votre projet contient maintenant un certain nombre de ressources créées et configurées automatiquement par l'Opérateur.
Vérifiez qu'un service Kubernetes a été créé pour vous permettre d'accéder à la base de données depuis d'autres pods de votre projet.
Tous les utilisateurs ayant le rôle
editdans un projet donné peuvent créer, gérer et supprimer des instances d'application (un cluster etcd, dans cet exemple) gérées par des opérateurs qui ont déjà été créés dans le projet, en libre-service, comme dans un service en nuage. Si vous souhaitez donner cette possibilité à d'autres utilisateurs, les administrateurs du projet peuvent ajouter le rôle à l'aide de la commande suivante :$ oc policy add-role-to-user edit <user> -n <target_project>
Vous disposez désormais d'un cluster etcd qui réagit aux pannes et rééquilibre les données lorsque les pods deviennent malsains ou sont migrés entre les nœuds du cluster. Plus important encore, les administrateurs de clusters ou les développeurs disposant d'un accès approprié peuvent désormais facilement utiliser la base de données avec leurs applications.
3.2. Installation des opérateurs dans votre espace de noms
Si un administrateur de cluster a délégué les droits d'installation d'un opérateur à votre compte, vous pouvez installer et souscrire un opérateur à votre espace de noms en libre-service.
3.2.1. Conditions préalables
- Un administrateur de cluster doit ajouter certaines permissions à votre compte utilisateur OpenShift Container Platform pour permettre l'installation d'opérateurs en libre-service dans un espace de noms. Pour plus d'informations, reportez-vous à la section Autoriser les administrateurs autres que les administrateurs de cluster à installer des opérateurs.
3.2.2. A propos de l'installation de l'opérateur avec OperatorHub
OperatorHub est une interface utilisateur permettant de découvrir les opérateurs ; il fonctionne en conjonction avec Operator Lifecycle Manager (OLM), qui installe et gère les opérateurs sur un cluster.
En tant qu'utilisateur disposant des permissions appropriées, vous pouvez installer un opérateur à partir d'OperatorHub en utilisant la console web ou le CLI d'OpenShift Container Platform.
Lors de l'installation, vous devez déterminer les paramètres initiaux suivants pour l'opérateur :
- Mode d'installation
- Choisissez un espace de noms spécifique dans lequel installer l'opérateur.
- Canal de mise à jour
- Si un opérateur est disponible sur plusieurs canaux, vous pouvez choisir le canal auquel vous souhaitez vous abonner. Par exemple, pour déployer à partir du canal stable, s'il est disponible, sélectionnez-le dans la liste.
- Stratégie d'approbation
Vous pouvez choisir des mises à jour automatiques ou manuelles.
Si vous choisissez les mises à jour automatiques pour un opérateur installé, lorsqu'une nouvelle version de cet opérateur est disponible dans le canal sélectionné, Operator Lifecycle Manager (OLM) met automatiquement à jour l'instance en cours d'exécution de votre opérateur sans intervention humaine.
Si vous sélectionnez les mises à jour manuelles, lorsqu'une version plus récente d'un opérateur est disponible, OLM crée une demande de mise à jour. En tant qu'administrateur de cluster, vous devez ensuite approuver manuellement cette demande de mise à jour pour que l'opérateur soit mis à jour avec la nouvelle version.
3.2.3. Installation à partir d'OperatorHub en utilisant la console web
Vous pouvez installer et vous abonner à un opérateur à partir d'OperatorHub en utilisant la console web d'OpenShift Container Platform.
Conditions préalables
- Accès à un cluster OpenShift Container Platform à l'aide d'un compte disposant des permissions d'installation de l'opérateur.
Procédure
- Naviguez dans la console web jusqu'à la page Operators → OperatorHub.
Faites défiler ou tapez un mot-clé dans la case Filter by keyword pour trouver l'opérateur souhaité. Par exemple, tapez
advancedpour trouver l'opérateur Advanced Cluster Management for Kubernetes.Vous pouvez également filtrer les options par Infrastructure Features. Par exemple, sélectionnez Disconnected si vous voulez voir les opérateurs qui travaillent dans des environnements déconnectés, également connus sous le nom d'environnements réseau restreints.
Sélectionnez l'opérateur pour afficher des informations supplémentaires.
NoteLe choix d'un Opérateur communautaire vous avertit que Red Hat ne certifie pas les Opérateurs communautaires ; vous devez accuser réception de cet avertissement avant de continuer.
- Lisez les informations sur l'opérateur et cliquez sur Install.
Sur la page Install Operator:
- Choisissez un espace de noms unique et spécifique dans lequel installer l'Opérateur. L'opérateur ne surveillera et ne pourra être utilisé que dans ce seul espace de noms.
- Sélectionnez une adresse Update Channel (si plusieurs sont disponibles).
- Sélectionnez la stratégie d'approbation Automatic ou Manual, comme décrit précédemment.
Cliquez sur Install pour rendre l'opérateur disponible pour les espaces de noms sélectionnés sur ce cluster OpenShift Container Platform.
Si vous avez sélectionné une stratégie d'approbation Manual, le statut de mise à niveau de l'abonnement reste Upgrading jusqu'à ce que vous examiniez et approuviez le plan d'installation.
Après approbation sur la page Install Plan, le statut de la mise à niveau de l'abonnement passe à Up to date.
- Si vous avez sélectionné une stratégie d'approbation Automatic, le statut du surclassement devrait être résolu à Up to date sans intervention.
Une fois que l'état de mise à niveau de l'abonnement est Up to date, sélectionnez Operators → Installed Operators pour vérifier que la version du service de cluster (CSV) de l'opérateur installé s'affiche finalement. L'adresse Status devrait finalement se résoudre en InstallSucceeded dans l'espace de noms concerné.
NotePour le mode d'installation All namespaces…, le statut se résout en InstallSucceeded dans l'espace de noms
openshift-operators, mais le statut est Copied si vous vérifiez dans d'autres espaces de noms.Si ce n'est pas le cas :
-
Vérifiez les journaux de tous les pods du projet
openshift-operators(ou d'un autre espace de noms pertinent si le mode d'installation A specific namespace… a été sélectionné) sur la page Workloads → Pods qui signalent des problèmes afin de les résoudre.
-
Vérifiez les journaux de tous les pods du projet
3.2.4. Installation à partir d'OperatorHub en utilisant le CLI
Au lieu d'utiliser la console web de OpenShift Container Platform, vous pouvez installer un Operator depuis OperatorHub en utilisant le CLI. Utilisez la commande oc pour créer ou mettre à jour un objet Subscription.
Conditions préalables
- Accès à un cluster OpenShift Container Platform à l'aide d'un compte disposant des permissions d'installation de l'opérateur.
-
Installez la commande
ocsur votre système local.
Procédure
Voir la liste des opérateurs disponibles pour la grappe à partir d'OperatorHub :
$ oc get packagemanifests -n openshift-marketplaceExemple de sortie
NAME CATALOG AGE 3scale-operator Red Hat Operators 91m advanced-cluster-management Red Hat Operators 91m amq7-cert-manager Red Hat Operators 91m ... couchbase-enterprise-certified Certified Operators 91m crunchy-postgres-operator Certified Operators 91m mongodb-enterprise Certified Operators 91m ... etcd Community Operators 91m jaeger Community Operators 91m kubefed Community Operators 91m ...Notez le catalogue de l'opérateur souhaité.
Inspectez l'opérateur de votre choix pour vérifier les modes d'installation pris en charge et les canaux disponibles :
oc describe packagemanifests <operator_name> -n openshift-marketplaceUn groupe d'opérateurs, défini par un objet
OperatorGroup, sélectionne des espaces de noms cibles dans lesquels générer l'accès RBAC requis pour tous les opérateurs dans le même espace de noms que le groupe d'opérateurs.L'espace de noms auquel vous abonnez l'opérateur doit avoir un groupe d'opérateurs qui correspond au mode d'installation de l'opérateur, soit le mode
AllNamespacesouSingleNamespace. Si l'opérateur que vous avez l'intention d'installer utilise le modeAllNamespaces, l'espace de nomsopenshift-operatorsdispose déjà d'un groupe d'opérateurs approprié.Cependant, si l'opérateur utilise le mode
SingleNamespaceet que vous n'avez pas déjà un groupe d'opérateurs approprié en place, vous devez en créer un.NoteLa version console web de cette procédure gère la création des objets
OperatorGroupetSubscriptionautomatiquement dans les coulisses lorsque vous choisissez le modeSingleNamespace.Créez un fichier YAML de l'objet
OperatorGroup, par exempleoperatorgroup.yaml:Exemple d'objet
OperatorGroupapiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: <operatorgroup_name> namespace: <namespace> spec: targetNamespaces: - <namespace>Créer l'objet
OperatorGroup:$ oc apply -f operatorgroup.yaml
Créez un fichier YAML de l'objet
Subscriptionpour abonner un espace de noms à un opérateur, par exemplesub.yaml:Exemple d'objet
SubscriptionapiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: <subscription_name> namespace: openshift-operators1 spec: channel: <channel_name>2 name: <operator_name>3 source: redhat-operators4 sourceNamespace: openshift-marketplace5 config: env:6 - name: ARGS value: "-v=10" envFrom:7 - secretRef: name: license-secret volumes:8 - name: <volume_name> configMap: name: <configmap_name> volumeMounts:9 - mountPath: <directory_name> name: <volume_name> tolerations:10 - operator: "Exists" resources:11 requests: memory: "64Mi" cpu: "250m" limits: memory: "128Mi" cpu: "500m" nodeSelector:12 foo: bar- 1
- Pour l'utilisation du mode d'installation
AllNamespaces, indiquez l'espace de nomsopenshift-operators. Sinon, indiquez l'espace de noms unique correspondant à l'utilisation du mode d'installationSingleNamespace. - 2
- Nom du canal auquel s'abonner.
- 3
- Nom de l'opérateur auquel s'abonner.
- 4
- Nom de la source du catalogue qui fournit l'opérateur.
- 5
- Espace de noms de la source de catalogue. Utilisez
openshift-marketplacepour les sources de catalogue par défaut d'OperatorHub. - 6
- Le paramètre
envdéfinit une liste de variables d'environnement qui doivent exister dans tous les conteneurs du module créé par OLM. - 7
- Le paramètre
envFromdéfinit une liste de sources pour alimenter les variables d'environnement dans le conteneur. - 8
- Le paramètre
volumesdéfinit une liste de volumes qui doivent exister sur le pod créé par OLM. - 9
- Le paramètre
volumeMountsdéfinit une liste de VolumeMounts qui doivent exister dans tous les conteneurs du pod créé par OLM. Si unvolumeMountfait référence à unvolumequi n'existe pas, OLM ne parvient pas à déployer l'opérateur. - 10
- Le paramètre
tolerationsdéfinit une liste de tolérances pour le module créé par OLM. - 11
- Le paramètre
resourcesdéfinit les contraintes de ressources pour tous les conteneurs du module créé par OLM. - 12
- Le paramètre
nodeSelectordéfinit unNodeSelectorpour le module créé par OLM.
Créer l'objet
Subscription:$ oc apply -f sub.yamlA ce stade, OLM connaît l'opérateur sélectionné. Une version de service de cluster (CSV) pour l'opérateur devrait apparaître dans l'espace de noms cible, et les API fournies par l'opérateur devraient être disponibles pour la création.
3.2.5. Installer une version spécifique d'un opérateur
Vous pouvez installer une version spécifique d'un opérateur en définissant la version du service de cluster (CSV) dans un objet Subscription.
Conditions préalables
- Accès à un cluster OpenShift Container Platform à l'aide d'un compte disposant des autorisations d'installation de l'opérateur
-
OpenShift CLI (
oc) installé
Procédure
Créez un fichier YAML de l'objet
Subscriptionqui abonne un espace de noms à un opérateur avec une version spécifique en définissant le champstartingCSV. Définissez le champinstallPlanApprovalsurManualpour empêcher l'opérateur d'effectuer une mise à niveau automatique si une version plus récente existe dans le catalogue.Par exemple, le fichier
sub.yamlsuivant peut être utilisé pour installer Red Hat Quay Operator spécifiquement à la version 3.4.0 :Abonnement avec une version de départ spécifique de l'opérateur
apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: quay-operator namespace: quay spec: channel: quay-v3.4 installPlanApproval: Manual1 name: quay-operator source: redhat-operators sourceNamespace: openshift-marketplace startingCSV: quay-operator.v3.4.02 - 1
- Définissez la stratégie d'approbation sur
Manualau cas où la version spécifiée serait remplacée par une version ultérieure dans le catalogue. Ce plan empêche une mise à niveau automatique vers une version ultérieure et nécessite une approbation manuelle avant que le CSV de départ ne puisse terminer l'installation. - 2
- Définir une version spécifique d'un CSV opérateur.
Créer l'objet
Subscription:$ oc apply -f sub.yaml- Approuver manuellement le plan d'installation en attente pour terminer l'installation de l'opérateur.
Chapitre 4. Tâches de l'administrateur
4.1. Ajouter des opérateurs à une grappe
Grâce à Operator Lifecycle Manager (OLM), les administrateurs de clusters peuvent installer des opérateurs basés sur OLM dans un cluster OpenShift Container Platform.
4.1.1. A propos de l'installation de l'opérateur avec OperatorHub
OperatorHub est une interface utilisateur permettant de découvrir les opérateurs ; il fonctionne en conjonction avec Operator Lifecycle Manager (OLM), qui installe et gère les opérateurs sur un cluster.
En tant qu'utilisateur disposant des permissions appropriées, vous pouvez installer un opérateur à partir d'OperatorHub en utilisant la console web ou le CLI d'OpenShift Container Platform.
Lors de l'installation, vous devez déterminer les paramètres initiaux suivants pour l'opérateur :
- Mode d'installation
- Choisissez un espace de noms spécifique dans lequel installer l'opérateur.
- Canal de mise à jour
- Si un opérateur est disponible sur plusieurs canaux, vous pouvez choisir le canal auquel vous souhaitez vous abonner. Par exemple, pour déployer à partir du canal stable, s'il est disponible, sélectionnez-le dans la liste.
- Stratégie d'approbation
Vous pouvez choisir des mises à jour automatiques ou manuelles.
Si vous choisissez les mises à jour automatiques pour un opérateur installé, lorsqu'une nouvelle version de cet opérateur est disponible dans le canal sélectionné, Operator Lifecycle Manager (OLM) met automatiquement à jour l'instance en cours d'exécution de votre opérateur sans intervention humaine.
Si vous sélectionnez les mises à jour manuelles, lorsqu'une version plus récente d'un opérateur est disponible, OLM crée une demande de mise à jour. En tant qu'administrateur de cluster, vous devez ensuite approuver manuellement cette demande de mise à jour pour que l'opérateur soit mis à jour avec la nouvelle version.
4.1.2. Installation à partir d'OperatorHub en utilisant la console web
Vous pouvez installer et vous abonner à un opérateur à partir d'OperatorHub en utilisant la console web d'OpenShift Container Platform.
Conditions préalables
-
Accès à un cluster OpenShift Container Platform à l'aide d'un compte disposant des autorisations
cluster-admin. - Accès à un cluster OpenShift Container Platform à l'aide d'un compte disposant des permissions d'installation de l'opérateur.
Procédure
- Naviguez dans la console web jusqu'à la page Operators → OperatorHub.
Faites défiler ou tapez un mot-clé dans la case Filter by keyword pour trouver l'opérateur souhaité. Par exemple, tapez
advancedpour trouver l'opérateur Advanced Cluster Management for Kubernetes.Vous pouvez également filtrer les options par Infrastructure Features. Par exemple, sélectionnez Disconnected si vous voulez voir les opérateurs qui travaillent dans des environnements déconnectés, également connus sous le nom d'environnements réseau restreints.
Sélectionnez l'opérateur pour afficher des informations supplémentaires.
NoteLe choix d'un Opérateur communautaire vous avertit que Red Hat ne certifie pas les Opérateurs communautaires ; vous devez accuser réception de cet avertissement avant de continuer.
- Lisez les informations sur l'opérateur et cliquez sur Install.
Sur la page Install Operator:
Sélectionnez l'un des éléments suivants :
-
All namespaces on the cluster (default) installe l'opérateur dans l'espace de noms par défaut
openshift-operatorspour qu'il soit surveillé et mis à la disposition de tous les espaces de noms du cluster. Cette option n'est pas toujours disponible. - A specific namespace on the cluster vous permet de choisir un seul espace de noms spécifique dans lequel installer l'opérateur. L'opérateur ne surveillera et ne pourra être utilisé que dans ce seul espace de noms.
-
All namespaces on the cluster (default) installe l'opérateur dans l'espace de noms par défaut
- Choisissez un espace de noms unique et spécifique dans lequel installer l'Opérateur. L'opérateur ne surveillera et ne pourra être utilisé que dans ce seul espace de noms.
- Sélectionnez une adresse Update Channel (si plusieurs sont disponibles).
- Sélectionnez la stratégie d'approbation Automatic ou Manual, comme décrit précédemment.
Cliquez sur Install pour rendre l'opérateur disponible pour les espaces de noms sélectionnés sur ce cluster OpenShift Container Platform.
Si vous avez sélectionné une stratégie d'approbation Manual, le statut de mise à niveau de l'abonnement reste Upgrading jusqu'à ce que vous examiniez et approuviez le plan d'installation.
Après approbation sur la page Install Plan, le statut de la mise à niveau de l'abonnement passe à Up to date.
- Si vous avez sélectionné une stratégie d'approbation Automatic, le statut du surclassement devrait être résolu à Up to date sans intervention.
Une fois que l'état de mise à niveau de l'abonnement est Up to date, sélectionnez Operators → Installed Operators pour vérifier que la version du service de cluster (CSV) de l'opérateur installé s'affiche finalement. L'adresse Status devrait finalement se résoudre en InstallSucceeded dans l'espace de noms concerné.
NotePour le mode d'installation All namespaces…, le statut se résout en InstallSucceeded dans l'espace de noms
openshift-operators, mais le statut est Copied si vous vérifiez dans d'autres espaces de noms.Si ce n'est pas le cas :
-
Vérifiez les journaux de tous les pods du projet
openshift-operators(ou d'un autre espace de noms pertinent si le mode d'installation A specific namespace… a été sélectionné) sur la page Workloads → Pods qui signalent des problèmes afin de les résoudre.
-
Vérifiez les journaux de tous les pods du projet
4.1.3. Installation à partir d'OperatorHub en utilisant le CLI
Au lieu d'utiliser la console web de OpenShift Container Platform, vous pouvez installer un Operator depuis OperatorHub en utilisant le CLI. Utilisez la commande oc pour créer ou mettre à jour un objet Subscription.
Conditions préalables
- Accès à un cluster OpenShift Container Platform à l'aide d'un compte disposant des permissions d'installation de l'opérateur.
-
Installez la commande
ocsur votre système local.
Procédure
Voir la liste des opérateurs disponibles pour la grappe à partir d'OperatorHub :
$ oc get packagemanifests -n openshift-marketplaceExemple de sortie
NAME CATALOG AGE 3scale-operator Red Hat Operators 91m advanced-cluster-management Red Hat Operators 91m amq7-cert-manager Red Hat Operators 91m ... couchbase-enterprise-certified Certified Operators 91m crunchy-postgres-operator Certified Operators 91m mongodb-enterprise Certified Operators 91m ... etcd Community Operators 91m jaeger Community Operators 91m kubefed Community Operators 91m ...Notez le catalogue de l'opérateur souhaité.
Inspectez l'opérateur de votre choix pour vérifier les modes d'installation pris en charge et les canaux disponibles :
oc describe packagemanifests <operator_name> -n openshift-marketplaceUn groupe d'opérateurs, défini par un objet
OperatorGroup, sélectionne des espaces de noms cibles dans lesquels générer l'accès RBAC requis pour tous les opérateurs dans le même espace de noms que le groupe d'opérateurs.L'espace de noms auquel vous abonnez l'opérateur doit avoir un groupe d'opérateurs qui correspond au mode d'installation de l'opérateur, soit le mode
AllNamespacesouSingleNamespace. Si l'opérateur que vous avez l'intention d'installer utilise le modeAllNamespaces, l'espace de nomsopenshift-operatorsdispose déjà d'un groupe d'opérateurs approprié.Cependant, si l'opérateur utilise le mode
SingleNamespaceet que vous n'avez pas déjà un groupe d'opérateurs approprié en place, vous devez en créer un.NoteLa version console web de cette procédure gère la création des objets
OperatorGroupetSubscriptionautomatiquement dans les coulisses lorsque vous choisissez le modeSingleNamespace.Créez un fichier YAML de l'objet
OperatorGroup, par exempleoperatorgroup.yaml:Exemple d'objet
OperatorGroupapiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: <operatorgroup_name> namespace: <namespace> spec: targetNamespaces: - <namespace>Créer l'objet
OperatorGroup:$ oc apply -f operatorgroup.yaml
Créez un fichier YAML de l'objet
Subscriptionpour abonner un espace de noms à un opérateur, par exemplesub.yaml:Exemple d'objet
SubscriptionapiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: <subscription_name> namespace: openshift-operators1 spec: channel: <channel_name>2 name: <operator_name>3 source: redhat-operators4 sourceNamespace: openshift-marketplace5 config: env:6 - name: ARGS value: "-v=10" envFrom:7 - secretRef: name: license-secret volumes:8 - name: <volume_name> configMap: name: <configmap_name> volumeMounts:9 - mountPath: <directory_name> name: <volume_name> tolerations:10 - operator: "Exists" resources:11 requests: memory: "64Mi" cpu: "250m" limits: memory: "128Mi" cpu: "500m" nodeSelector:12 foo: bar- 1
- Pour l'utilisation du mode d'installation
AllNamespaces, indiquez l'espace de nomsopenshift-operators. Sinon, indiquez l'espace de noms unique correspondant à l'utilisation du mode d'installationSingleNamespace. - 2
- Nom du canal auquel s'abonner.
- 3
- Nom de l'opérateur auquel s'abonner.
- 4
- Nom de la source du catalogue qui fournit l'opérateur.
- 5
- Espace de noms de la source de catalogue. Utilisez
openshift-marketplacepour les sources de catalogue par défaut d'OperatorHub. - 6
- Le paramètre
envdéfinit une liste de variables d'environnement qui doivent exister dans tous les conteneurs du module créé par OLM. - 7
- Le paramètre
envFromdéfinit une liste de sources pour alimenter les variables d'environnement dans le conteneur. - 8
- Le paramètre
volumesdéfinit une liste de volumes qui doivent exister sur le pod créé par OLM. - 9
- Le paramètre
volumeMountsdéfinit une liste de VolumeMounts qui doivent exister dans tous les conteneurs du pod créé par OLM. Si unvolumeMountfait référence à unvolumequi n'existe pas, OLM ne parvient pas à déployer l'opérateur. - 10
- Le paramètre
tolerationsdéfinit une liste de tolérances pour le module créé par OLM. - 11
- Le paramètre
resourcesdéfinit les contraintes de ressources pour tous les conteneurs du module créé par OLM. - 12
- Le paramètre
nodeSelectordéfinit unNodeSelectorpour le module créé par OLM.
Créer l'objet
Subscription:$ oc apply -f sub.yamlA ce stade, OLM connaît l'opérateur sélectionné. Une version de service de cluster (CSV) pour l'opérateur devrait apparaître dans l'espace de noms cible, et les API fournies par l'opérateur devraient être disponibles pour la création.
4.1.4. Installer une version spécifique d'un opérateur
Vous pouvez installer une version spécifique d'un opérateur en définissant la version du service de cluster (CSV) dans un objet Subscription.
Conditions préalables
- Accès à un cluster OpenShift Container Platform à l'aide d'un compte disposant des autorisations d'installation de l'opérateur
-
OpenShift CLI (
oc) installé
Procédure
Créez un fichier YAML de l'objet
Subscriptionqui abonne un espace de noms à un opérateur avec une version spécifique en définissant le champstartingCSV. Définissez le champinstallPlanApprovalsurManualpour empêcher l'opérateur d'effectuer une mise à niveau automatique si une version plus récente existe dans le catalogue.Par exemple, le fichier
sub.yamlsuivant peut être utilisé pour installer Red Hat Quay Operator spécifiquement à la version 3.4.0 :Abonnement avec une version de départ spécifique de l'opérateur
apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: quay-operator namespace: quay spec: channel: quay-v3.4 installPlanApproval: Manual1 name: quay-operator source: redhat-operators sourceNamespace: openshift-marketplace startingCSV: quay-operator.v3.4.02 - 1
- Définissez la stratégie d'approbation sur
Manualau cas où la version spécifiée serait remplacée par une version ultérieure dans le catalogue. Ce plan empêche une mise à niveau automatique vers une version ultérieure et nécessite une approbation manuelle avant que le CSV de départ ne puisse terminer l'installation. - 2
- Définir une version spécifique d'un CSV opérateur.
Créer l'objet
Subscription:$ oc apply -f sub.yaml- Approuver manuellement le plan d'installation en attente pour terminer l'installation de l'opérateur.
4.1.5. Préparer plusieurs instances d'un opérateur pour les clusters multitenants
En tant qu'administrateur de cluster, vous pouvez ajouter plusieurs instances d'un opérateur pour une utilisation dans des clusters multitenant. Il s'agit d'une solution alternative à l'utilisation du mode d'installation standard All namespaces, qui peut être considéré comme une violation du principe du moindre privilège, ou du mode Multinamespace, qui n'est pas largement adopté. Pour plus d'informations, voir "Operators in multitenant clusters".
Dans la procédure suivante, tenant est un utilisateur ou un groupe d'utilisateurs qui partagent un accès et des privilèges communs pour un ensemble de charges de travail déployées. Le tenant Operator est l'instance d'un opérateur qui est destiné à être utilisé uniquement par ce locataire.
Conditions préalables
Toutes les instances de l'opérateur que vous souhaitez installer doivent être de la même version dans un cluster donné.
ImportantPour plus d'informations sur ce point et d'autres limitations, voir "Operators in multitenant clusters".
Procédure
Avant d'installer l'Opérateur, créez un espace de noms pour l'Opérateur du locataire qui soit distinct de l'espace de noms du locataire. Par exemple, si l'espace de noms du locataire est
team1, vous pouvez créer un espace de nomsteam1-operator:Définissez une ressource
Namespaceet enregistrez le fichier YAML, par exempleteam1-operator.yaml:apiVersion: v1 kind: Namespace metadata: name: team1-operatorCréez l'espace de noms en exécutant la commande suivante :
$ oc create -f team1-operator.yaml
Créer un groupe d'opérateurs pour l'opérateur du locataire, limité à l'espace de noms du locataire, avec une seule entrée d'espace de noms dans la liste
spec.targetNamespaces:Définissez une ressource
OperatorGroupet enregistrez le fichier YAML, par exempleteam1-operatorgroup.yaml:apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: team1-operatorgroup namespace: team1-operator spec: targetNamespaces: - team11 - 1
- Définissez uniquement l'espace de noms du locataire dans la liste
spec.targetNamespaces.
Créez le groupe Operator en exécutant la commande suivante :
$ oc create -f team1-operatorgroup.yaml
Prochaines étapes
Installer l'Opérateur dans l'espace de noms de l'Opérateur du locataire. Cette tâche est plus facile à réaliser en utilisant l'OperatorHub dans la console web plutôt que le CLI ; pour une procédure détaillée, voir Installer à partir de l'OperatorHub en utilisant la console web.
NoteUne fois l'installation de l'opérateur terminée, l'opérateur réside dans l'espace de noms de l'opérateur du locataire et surveille l'espace de noms du locataire, mais ni le pod de l'opérateur ni son compte de service ne sont visibles ou utilisables par le locataire.
4.1.6. Installation d'opérateurs globaux dans des espaces de noms personnalisés
Lors de l'installation d'opérateurs avec la console web d'OpenShift Container Platform, le comportement par défaut installe les opérateurs qui prennent en charge le mode d'installation All namespaces dans l'espace de noms global par défaut openshift-operators. Cela peut entraîner des problèmes liés au partage des plans d'installation et des politiques de mise à jour entre tous les opérateurs de l'espace de noms. Pour plus de détails sur ces limitations, voir "Colocation d'opérateurs dans un espace de noms".
En tant qu'administrateur de cluster, vous pouvez contourner manuellement ce comportement par défaut en créant un espace de noms global personnalisé et en utilisant cet espace de noms pour installer votre propre ensemble d'opérateurs et leurs dépendances.
Procédure
Avant d'installer l'opérateur, créez un espace de noms pour l'installation de l'opérateur de votre choix. Cet espace de noms d'installation deviendra l'espace de noms global personnalisé :
Définissez une ressource
Namespaceet enregistrez le fichier YAML, par exempleglobal-operators.yaml:apiVersion: v1 kind: Namespace metadata: name: global-operatorsCréez l'espace de noms en exécutant la commande suivante :
$ oc create -f global-operators.yaml
Créez un global Operator group personnalisé, qui est un groupe d'opérateurs qui surveille tous les espaces de noms :
Définissez une ressource
OperatorGroupet enregistrez le fichier YAML, par exempleglobal-operatorgroup.yaml. Omettez les champsspec.selectoretspec.targetNamespacespour en faire une ressource global Operator group, qui sélectionne tous les espaces de noms :apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: global-operatorgroup namespace: global-operatorsNoteLe site
status.namespacesd'un groupe d'opérateurs global créé contient la chaîne vide (""), qui signale à un opérateur consommateur qu'il doit surveiller tous les espaces de noms.Créez le groupe Operator en exécutant la commande suivante :
$ oc create -f global-operatorgroup.yaml
Prochaines étapes
Installez l'opérateur souhaité dans l'espace de noms d'installation. Cette tâche est plus facile à réaliser en utilisant l'OperatorHub dans la console web plutôt que le CLI ; pour une procédure détaillée, voir Installer à partir de l'OperatorHub en utilisant la console web.
NoteLorsque vous lancez l'installation d'un opérateur, si celui-ci a des dépendances, celles-ci sont également installées automatiquement dans l'espace de noms global personnalisé. Par conséquent, les opérateurs dépendants peuvent avoir la même politique de mise à jour et les mêmes plans d'installation partagés.
4.1.7. Placement en pods des charges de travail des opérateurs
Par défaut, Operator Lifecycle Manager (OLM) place les pods sur des nœuds de travail arbitraires lors de l'installation d'un opérateur ou du déploiement de charges de travail Operand. En tant qu'administrateur, vous pouvez utiliser des projets avec une combinaison de sélecteurs de nœuds, de taints et de tolérances pour contrôler le placement d'opérateurs et d'opérandes sur des nœuds spécifiques.
Le contrôle du placement des charges de travail de l'opérateur et de l'opérande dans le pod est soumis aux conditions préalables suivantes :
-
Déterminez un nœud ou un ensemble de nœuds à cibler pour les modules en fonction de vos besoins. Si elle est disponible, notez une étiquette existante, telle que
node-role.kubernetes.io/app, qui identifie le ou les nœuds. Sinon, ajoutez une étiquette, telle quemyoperator, en utilisant un ensemble de machines de calcul ou en modifiant le nœud directement. Vous utiliserez cette étiquette dans une étape ultérieure comme sélecteur de nœuds dans votre projet. -
Si vous voulez vous assurer que seuls les pods ayant une certaine étiquette sont autorisés à s'exécuter sur les nœuds, tout en dirigeant les charges de travail non liées vers d'autres nœuds, ajoutez une altération au(x) nœud(s) en utilisant un ensemble de machines de calcul ou en modifiant le nœud directement. Utilisez un effet qui garantit que les nouveaux pods qui ne correspondent pas à l'erreur ne peuvent pas être planifiés sur les nœuds. Par exemple, un effet
myoperator:NoSchedulegarantit que les nouveaux modules qui ne correspondent pas à l'effet ne sont pas programmés sur ce nœud, mais que les modules existants sur le nœud sont autorisés à rester. - Créez un projet configuré avec un sélecteur de nœuds par défaut et, si vous avez ajouté une taint, une tolérance correspondante.
À ce stade, le projet que vous avez créé peut être utilisé pour diriger les pods vers les nœuds spécifiés dans les scénarios suivants :
- Pour les cabines d'opérateurs
-
Les administrateurs peuvent créer un objet
Subscriptiondans le projet comme décrit dans la section suivante. En conséquence, les pods de l'opérateur sont placés sur les nœuds spécifiés. - Pour les pods d'opérandes
- En utilisant un opérateur installé, les utilisateurs peuvent créer une application dans le projet, qui place la ressource personnalisée (CR) appartenant à l'opérateur dans le projet. Par conséquent, les pods de l'Opérateur sont placés sur les nœuds spécifiés, à moins que l'Opérateur ne déploie des objets à l'échelle du cluster ou des ressources dans d'autres espaces de noms, auquel cas ce placement de pods personnalisés ne s'applique pas.
4.1.8. Contrôler l'endroit où un opérateur est installé
Par défaut, lorsque vous installez un Operator, OpenShift Container Platform installe le pod Operator sur l'un de vos nœuds de travail de manière aléatoire. Cependant, il peut y avoir des situations où vous voulez que ce pod soit planifié sur un nœud spécifique ou un ensemble de nœuds.
Les exemples suivants décrivent des situations dans lesquelles vous pourriez vouloir planifier un pod opérateur sur un nœud ou un ensemble de nœuds spécifique :
-
Si un opérateur a besoin d'une plateforme particulière, telle que
amd64ouarm64 - Si un opérateur nécessite un système d'exploitation particulier, tel que Linux ou Windows
- Si vous souhaitez que les opérateurs qui travaillent ensemble soient programmés sur le même hôte ou sur des hôtes situés sur le même rack
- Si vous souhaitez que les opérateurs soient dispersés dans l'infrastructure afin d'éviter les temps d'arrêt dus à des problèmes de réseau ou de matériel
Vous pouvez contrôler l'endroit où un pod d'opérateur est installé en ajoutant des contraintes d'affinité de nœud, d'affinité de pod ou d'anti-affinité de pod à l'objet Subscription de l'opérateur. L'affinité de nœud est un ensemble de règles utilisées par le planificateur pour déterminer où un module peut être placé. L'affinité de pod vous permet de vous assurer que des pods liés sont planifiés sur le même nœud. L'anti-affinité de pod vous permet d'empêcher un pod d'être planifié sur un nœud.
Les exemples suivants montrent comment utiliser l'affinité de nœud ou l'anti-affinité de pod pour installer une instance de Custom Metrics Autoscaler Operator sur un nœud spécifique du cluster :
Exemple d'affinité de nœud qui place le pod de l'opérateur sur un nœud spécifique
apiVersion: operators.coreos.com/v1alpha1
kind: Subscription
metadata:
name: openshift-custom-metrics-autoscaler-operator
namespace: openshift-keda
spec:
name: my-package
source: my-operators
sourceNamespace: operator-registries
config:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- ip-10-0-163-94.us-west-2.compute.internal
...- 1
- Une affinité de nœud qui exige que le pod de l'opérateur soit programmé sur un nœud nommé
ip-10-0-163-94.us-west-2.compute.internal.
Exemple d'affinité de nœud qui place le pod de l'opérateur sur un nœud avec une plate-forme spécifique
apiVersion: operators.coreos.com/v1alpha1
kind: Subscription
metadata:
name: openshift-custom-metrics-autoscaler-operator
namespace: openshift-keda
spec:
name: my-package
source: my-operators
sourceNamespace: operator-registries
config:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/arch
operator: In
values:
- arm64
- key: kubernetes.io/os
operator: In
values:
- linux- 1
- Une affinité de nœud qui exige que le pod de l'opérateur soit programmé sur un nœud avec les étiquettes
kubernetes.io/arch=arm64etkubernetes.io/os=linux.
Exemple d'affinité de pod qui place le pod de l'opérateur sur un ou plusieurs nœuds spécifiques
apiVersion: operators.coreos.com/v1alpha1
kind: Subscription
metadata:
name: openshift-custom-metrics-autoscaler-operator
namespace: openshift-keda
spec:
name: my-package
source: my-operators
sourceNamespace: operator-registries
config:
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- test
topologyKey: kubernetes.io/hostname- 1
- Une affinité de pod qui place le pod de l'opérateur sur un nœud qui a des pods avec le label
app=test.
Exemple d'anti-affinité de pods qui empêche le pod Operator d'accéder à un ou plusieurs nœuds spécifiques
apiVersion: operators.coreos.com/v1alpha1
kind: Subscription
metadata:
name: openshift-custom-metrics-autoscaler-operator
namespace: openshift-keda
spec:
name: my-package
source: my-operators
sourceNamespace: operator-registries
config:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: cpu
operator: In
values:
- high
topologyKey: kubernetes.io/hostname
...- 1
- Une anti-affinité de pods qui empêche le pod de l'opérateur d'être planifié sur un nœud qui a des pods avec le label
cpu=high.
Procédure
Pour contrôler l'emplacement d'une nacelle d'opérateur, procédez comme suit :
- Installez l'opérateur comme d'habitude.
- Si nécessaire, assurez-vous que vos nœuds sont étiquetés de manière à répondre correctement à l'affinité.
Modifiez l'objet Operator
Subscriptionpour ajouter une affinité :apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: openshift-custom-metrics-autoscaler-operator namespace: openshift-keda spec: name: my-package source: my-operators sourceNamespace: operator-registries config: affinity:1 nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: kubernetes.io/hostname operator: In values: - ip-10-0-185-229.ec2.internal ...- 1
- Ajoutez un
nodeAffinity, unpodAffinityou unpodAntiAffinity. Reportez-vous à la section Ressources supplémentaires qui suit pour obtenir des informations sur la création d'une affinité.
Vérification
Pour s'assurer que le pod est déployé sur le nœud spécifique, exécutez la commande suivante :
$ oc get pods -o wideExemple de sortie
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES custom-metrics-autoscaler-operator-5dcc45d656-bhshg 1/1 Running 0 50s 10.131.0.20 ip-10-0-185-229.ec2.internal <none> <none>
4.2. Mise à jour des opérateurs installés
En tant qu'administrateur de cluster, vous pouvez mettre à jour les opérateurs qui ont été précédemment installés à l'aide d'Operator Lifecycle Manager (OLM) sur votre cluster OpenShift Container Platform.
4.2.1. Préparation de la mise à jour de l'opérateur
L'abonnement d'un opérateur installé spécifie un canal de mise à jour qui suit et reçoit les mises à jour de l'opérateur. Vous pouvez modifier le canal de mise à jour pour commencer à suivre et à recevoir des mises à jour à partir d'un canal plus récent.
Les noms des canaux de mise à jour dans un abonnement peuvent varier d'un opérateur à l'autre, mais le système de dénomination suit généralement une convention commune au sein d'un opérateur donné. Par exemple, les noms des canaux peuvent correspondre à un flux de mises à jour de versions mineures pour l'application fournie par l'opérateur (1.2, 1.3) ou à une fréquence de publication (stable, fast).
Vous ne pouvez pas changer les opérateurs installés pour un canal plus ancien que le canal actuel.
Red Hat Customer Portal Labs comprend l'application suivante qui aide les administrateurs à préparer la mise à jour de leurs opérateurs :
Vous pouvez utiliser l'application pour rechercher des opérateurs basés sur Operator Lifecycle Manager et vérifier la version disponible de l'opérateur par canal de mise à jour à travers différentes versions d'OpenShift Container Platform. Les opérateurs basés sur la version du cluster ne sont pas inclus.
4.2.2. Changer le canal de mise à jour d'un opérateur
Vous pouvez changer le canal de mise à jour d'un opérateur en utilisant la console web d'OpenShift Container Platform.
Si la stratégie d'approbation de l'abonnement est définie sur Automatic, le processus de mise à jour est lancé dès qu'une nouvelle version de l'opérateur est disponible dans le canal sélectionné. Si la stratégie d'approbation est définie sur Manual, vous devez approuver manuellement les mises à jour en attente.
Conditions préalables
- Un opérateur précédemment installé à l'aide de l'outil Operator Lifecycle Manager (OLM).
Procédure
- Dans la perspective Administrator de la console web, naviguez vers Operators → Installed Operators.
- Cliquez sur le nom de l'opérateur dont vous souhaitez modifier le canal de mise à jour.
- Cliquez sur l'onglet Subscription.
- Cliquez sur le nom du canal de mise à jour sous Channel.
- Cliquez sur le canal de mise à jour le plus récent vers lequel vous souhaitez passer, puis cliquez sur Save.
Pour les abonnements avec une stratégie d'approbation Automatic, la mise à jour commence automatiquement. Retournez à la page Operators → Installed Operators pour suivre la progression de la mise à jour. Une fois la mise à jour terminée, le statut passe à Succeeded et Up to date.
Pour les abonnements avec une stratégie d'approbation Manual, vous pouvez approuver manuellement la mise à jour à partir de l'onglet Subscription.
4.2.3. Approbation manuelle d'une mise à jour de l'opérateur en attente
Si la stratégie d'approbation de l'abonnement d'un opérateur installé est définie sur Manual, lorsque de nouvelles mises à jour sont publiées dans son canal de mise à jour actuel, la mise à jour doit être approuvée manuellement avant que l'installation ne puisse commencer.
Conditions préalables
- Un opérateur précédemment installé à l'aide de l'outil Operator Lifecycle Manager (OLM).
Procédure
- Dans la perspective Administrator de la console web OpenShift Container Platform, naviguez vers Operators → Installed Operators.
- Les opérateurs dont la mise à jour est en cours affichent un statut avec Upgrade available. Cliquez sur le nom de l'opérateur que vous souhaitez mettre à jour.
- Cliquez sur l'onglet Subscription. Toute mise à jour nécessitant une approbation est affichée à côté de Upgrade Status. Par exemple, il peut s'agir de 1 requires approval.
- Cliquez sur 1 requires approval, puis sur Preview Install Plan.
- Examinez les ressources répertoriées comme étant disponibles pour une mise à jour. Lorsque vous êtes satisfait, cliquez sur Approve.
- Retournez à la page Operators → Installed Operators pour suivre la progression de la mise à jour. Une fois la mise à jour terminée, le statut passe à Succeeded et Up to date.
4.3. Suppression d'opérateurs d'une grappe
Ce qui suit décrit comment supprimer les opérateurs qui ont été précédemment installés à l'aide d'Operator Lifecycle Manager (OLM) sur votre cluster OpenShift Container Platform.
4.3.1. Suppression d'opérateurs d'une grappe à l'aide de la console web
Les administrateurs de cluster peuvent supprimer les opérateurs installés dans un espace de noms sélectionné à l'aide de la console web.
Conditions préalables
-
Vous avez accès à la console web d'un cluster OpenShift Container Platform en utilisant un compte avec les permissions
cluster-admin.
Procédure
- Naviguez jusqu'à la page Operators → Installed Operators.
- Faites défiler ou saisissez un mot-clé dans le champ Filter by name pour trouver l'opérateur que vous souhaitez supprimer. Cliquez ensuite dessus.
Sur le côté droit de la page Operator Details, sélectionnez Uninstall Operator dans la liste Actions.
Une boîte de dialogue Uninstall Operator? s'affiche.
Sélectionnez Uninstall pour supprimer l'opérateur, les déploiements de l'opérateur et les pods. Suite à cette action, l'opérateur cesse de fonctionner et ne reçoit plus de mises à jour.
NoteCette action ne supprime pas les ressources gérées par l'opérateur, y compris les définitions de ressources personnalisées (CRD) et les ressources personnalisées (CR). Les tableaux de bord et les éléments de navigation activés par la console Web et les ressources hors cluster qui continuent de fonctionner peuvent nécessiter un nettoyage manuel. Pour les supprimer après la désinstallation de l'opérateur, vous devrez peut-être supprimer manuellement les CRD de l'opérateur.
4.3.2. Suppression d'opérateurs d'une grappe à l'aide de la CLI
Les administrateurs de clusters peuvent supprimer les opérateurs installés dans un espace de noms sélectionné à l'aide de l'interface de ligne de commande.
Conditions préalables
-
Accès à un cluster OpenShift Container Platform à l'aide d'un compte disposant des autorisations
cluster-admin. -
ocinstallée sur le poste de travail.
Procédure
Vérifiez la version actuelle de l'opérateur souscrit (par exemple,
jaeger) dans le champcurrentCSV:$ oc get subscription jaeger -n openshift-operators -o yaml | grep currentCSVExemple de sortie
currentCSV: jaeger-operator.v1.8.2Supprimer l'abonnement (par exemple,
jaeger) :$ oc delete subscription jaeger -n openshift-operatorsExemple de sortie
subscription.operators.coreos.com "jaeger" deletedSupprimez le CSV de l'opérateur dans l'espace de noms cible en utilisant la valeur
currentCSVde l'étape précédente :$ oc delete clusterserviceversion jaeger-operator.v1.8.2 -n openshift-operatorsExemple de sortie
clusterserviceversion.operators.coreos.com "jaeger-operator.v1.8.2" deleted
4.3.3. Actualisation des abonnements défaillants
Dans Operator Lifecycle Manager (OLM), si vous vous abonnez à un opérateur qui fait référence à des images qui ne sont pas accessibles sur votre réseau, vous pouvez trouver des travaux dans l'espace de noms openshift-marketplace qui échouent avec les erreurs suivantes :
Exemple de sortie
ImagePullBackOff for
Back-off pulling image "example.com/openshift4/ose-elasticsearch-operator-bundle@sha256:6d2587129c846ec28d384540322b40b05833e7e00b25cca584e004af9a1d292e"Exemple de sortie
rpc error: code = Unknown desc = error pinging docker registry example.com: Get "https://example.com/v2/": dial tcp: lookup example.com on 10.0.0.1:53: no such hostEn conséquence, l'abonnement est bloqué dans cet état d'échec et l'opérateur est incapable d'installer ou de mettre à niveau.
Vous pouvez actualiser un abonnement défaillant en supprimant l'abonnement, la version du service de cluster (CSV) et d'autres objets connexes. Après avoir recréé l'abonnement, OLM réinstalle la version correcte de l'opérateur.
Conditions préalables
- Vous avez un abonnement défaillant qui ne parvient pas à extraire une image de paquet inaccessible.
- Vous avez confirmé que l'image correcte de la liasse est accessible.
Procédure
Obtenir les noms des objets
SubscriptionetClusterServiceVersionde l'espace de noms dans lequel l'opérateur est installé :$ oc get sub,csv -n <namespace>Exemple de sortie
NAME PACKAGE SOURCE CHANNEL subscription.operators.coreos.com/elasticsearch-operator elasticsearch-operator redhat-operators 5.0 NAME DISPLAY VERSION REPLACES PHASE clusterserviceversion.operators.coreos.com/elasticsearch-operator.5.0.0-65 OpenShift Elasticsearch Operator 5.0.0-65 SucceededSupprimer l'abonnement :
oc delete subscription <subscription_name> -n <namespace> $ oc delete subscription <subscription_name> -n <namespace>Supprimer la version du service de cluster :
$ oc delete csv <csv_name> -n <namespace>Récupère les noms de tous les travaux défaillants et des cartes de configuration correspondantes dans l'espace de noms
openshift-marketplace:$ oc get job,configmap -n openshift-marketplaceExemple de sortie
NAME COMPLETIONS DURATION AGE job.batch/1de9443b6324e629ddf31fed0a853a121275806170e34c926d69e53a7fcbccb 1/1 26s 9m30s NAME DATA AGE configmap/1de9443b6324e629ddf31fed0a853a121275806170e34c926d69e53a7fcbccb 3 9m30sSupprimer le travail :
oc delete job <job_name> -n openshift-marketplaceCela permet de s'assurer que les pods qui tentent d'extraire l'image inaccessible ne sont pas recréés.
Supprimer la carte de configuration :
oc delete configmap <configmap_name> -n openshift-marketplace- Réinstallez l'opérateur en utilisant OperatorHub dans la console web.
Vérification
Vérifiez que l'opérateur a été réinstallé avec succès :
$ oc get sub,csv,installplan -n <namespace>
4.4. Configuration des fonctionnalités d'Operator Lifecycle Manager
Le contrôleur Operator Lifecycle Manager (OLM) est configuré par une ressource personnalisée (CR) OLMConfig nommée cluster. Les administrateurs de clusters peuvent modifier cette ressource pour activer ou désactiver certaines fonctionnalités.
Ce document présente les fonctionnalités actuellement prises en charge par OLM et configurées par la ressource OLMConfig.
4.4.1. Désactivation des CSV copiés
Lorsqu'un opérateur est installé par Operator Lifecycle Manager (OLM), une copie simplifiée de sa version de service de cluster (CSV) est créée dans chaque espace de noms que l'opérateur est configuré pour surveiller. Ces CSV sont connues sous le nom de copied CSVs et indiquent aux utilisateurs les contrôleurs qui réconcilient activement les événements de ressources dans un espace de noms donné.
Lorsque les opérateurs sont configurés pour utiliser le mode d'installation AllNamespaces, au lieu de cibler un seul espace de noms ou un ensemble spécifique d'espaces de noms, un CSV copié est créé dans chaque espace de noms du cluster. Sur les clusters particulièrement grands, avec des espaces de noms et des opérateurs installés pouvant atteindre des centaines ou des milliers, les CSV copiés consomment une quantité insoutenable de ressources, telles que l'utilisation de la mémoire d'OLM, les limites du cluster etcd et la mise en réseau.
Pour prendre en charge ces clusters plus importants, les administrateurs de clusters peuvent désactiver les CSV copiés pour les opérateurs installés en mode AllNamespaces.
Si vous désactivez les CSV copiés, la capacité d'un utilisateur à découvrir des opérateurs dans OperatorHub et CLI est limitée aux opérateurs installés directement dans l'espace de noms de l'utilisateur.
Si un opérateur est configuré pour rapprocher les événements dans l'espace de noms de l'utilisateur mais est installé dans un espace de noms différent, l'utilisateur ne peut pas voir l'opérateur dans OperatorHub ou CLI. Les opérateurs concernés par cette limitation sont toujours disponibles et continuent à rapprocher les événements dans l'espace de noms de l'utilisateur.
Ce comportement se produit pour les raisons suivantes :
- Les CSV copiés identifient les opérateurs disponibles pour un espace de noms donné.
- Le contrôle d'accès basé sur les rôles (RBAC) délimite la capacité de l'utilisateur à voir et à découvrir des opérateurs dans OperatorHub et CLI.
Procédure
Modifiez l'objet
OLMConfignomméclusteret définissez le champspec.features.disableCopiedCSVscomme étanttrue:$ oc apply -f - <<EOF apiVersion: operators.coreos.com/v1 kind: OLMConfig metadata: name: cluster spec: features: disableCopiedCSVs: true1 EOF- 1
- Désactivation des CSV copiés pour le mode d'installation
AllNamespacesOpérateurs
Vérification
Lorsque les CSV copiés sont désactivés, OLM capture ces informations dans un événement de l'espace de noms de l'opérateur :
$ oc get eventsExemple de sortie
LAST SEEN TYPE REASON OBJECT MESSAGE 85s Warning DisabledCopiedCSVs clusterserviceversion/my-csv.v1.0.0 CSV copying disabled for operators/my-csv.v1.0.0Lorsque le champ
spec.features.disableCopiedCSVsest absent ou défini surfalse, OLM recrée les fichiers CSV copiés pour tous les opérateurs installés en modeAllNamespaceset supprime les événements susmentionnés.
Ressources supplémentaires
4.5. Configuration de la prise en charge du proxy dans Operator Lifecycle Manager
Si un proxy global est configuré sur le cluster OpenShift Container Platform, Operator Lifecycle Manager (OLM) configure automatiquement les opérateurs qu'il gère avec le proxy à l'échelle du cluster. Cependant, vous pouvez également configurer les opérateurs installés pour remplacer le proxy global ou injecter un certificat CA personnalisé.
4.5.1. Remplacer les paramètres proxy d'un opérateur
Si un proxy de sortie à l'échelle du cluster est configuré, les opérateurs fonctionnant avec Operator Lifecycle Manager (OLM) héritent des paramètres de proxy à l'échelle du cluster sur leurs déploiements. Les administrateurs de cluster peuvent également remplacer ces paramètres de proxy en configurant l'abonnement d'un opérateur.
Les opérateurs doivent gérer la définition des variables d'environnement pour les paramètres de proxy dans les pods pour tous les opérateurs gérés.
Conditions préalables
-
Accès à un cluster OpenShift Container Platform à l'aide d'un compte disposant des autorisations
cluster-admin.
Procédure
- Naviguez dans la console web jusqu'à la page Operators → OperatorHub.
- Sélectionnez l'opérateur et cliquez sur Install.
Sur la page Install Operator, modifiez l'objet
Subscriptionpour inclure une ou plusieurs des variables d'environnement suivantes dans la sectionspec:-
HTTP_PROXY -
HTTPS_PROXY -
NO_PROXY
Par exemple :
Subscriptionavec des paramètres de proxy qui remplacent ceux de l'objetapiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: etcd-config-test namespace: openshift-operators spec: config: env: - name: HTTP_PROXY value: test_http - name: HTTPS_PROXY value: test_https - name: NO_PROXY value: test channel: clusterwide-alpha installPlanApproval: Automatic name: etcd source: community-operators sourceNamespace: openshift-marketplace startingCSV: etcdoperator.v0.9.4-clusterwideNoteCes variables d'environnement peuvent également être désactivées à l'aide d'une valeur vide afin de supprimer tout paramètre de proxy personnalisé ou à l'échelle de la grappe.
OLM traite ces variables d'environnement comme une unité ; si au moins l'une d'entre elles est définie, les trois sont considérées comme prioritaires et les valeurs par défaut à l'échelle du cluster ne sont pas utilisées pour les déploiements de l'opérateur souscrit.
-
- Cliquez sur Install pour mettre l'opérateur à la disposition des espaces de noms sélectionnés.
Une fois que le CSV de l'opérateur apparaît dans l'espace de noms approprié, vous pouvez vérifier que les variables d'environnement du proxy personnalisé sont définies dans le déploiement. Par exemple, à l'aide de la CLI :
$ oc get deployment -n openshift-operators \ etcd-operator -o yaml \ | grep -i "PROXY" -A 2Exemple de sortie
- name: HTTP_PROXY value: test_http - name: HTTPS_PROXY value: test_https - name: NO_PROXY value: test image: quay.io/coreos/etcd-operator@sha256:66a37fd61a06a43969854ee6d3e21088a98b93838e284a6086b13917f96b0d9c ...
4.5.2. Injection d'un certificat d'autorité de certification personnalisé
Lorsqu'un administrateur de cluster ajoute un certificat d'autorité de certification personnalisé à un cluster à l'aide d'une carte de configuration, l'opérateur de réseau de cluster fusionne les certificats fournis par l'utilisateur et les certificats d'autorité de certification du système en un seul paquet. Vous pouvez injecter ce paquet fusionné dans votre opérateur fonctionnant sur Operator Lifecycle Manager (OLM), ce qui est utile si vous avez un proxy HTTPS de type "man-in-the-middle".
Conditions préalables
-
Accès à un cluster OpenShift Container Platform à l'aide d'un compte disposant des autorisations
cluster-admin. - Certificat CA personnalisé ajouté au cluster à l'aide d'une carte de configuration.
- Opérateur souhaité installé et fonctionnant sur OLM.
Procédure
Créez une carte de configuration vide dans l'espace de noms où l'abonnement de votre opérateur existe et incluez l'étiquette suivante :
apiVersion: v1 kind: ConfigMap metadata: name: trusted-ca1 labels: config.openshift.io/inject-trusted-cabundle: "true"2 Après avoir créé cette carte de configuration, elle est immédiatement remplie avec le contenu des certificats de l'ensemble fusionné.
Mettez à jour votre objet
Subscriptionpour inclure une sectionspec.configqui monte la carte de configurationtrusted-caen tant que volume pour chaque conteneur au sein d'un pod qui nécessite une autorité de certification personnalisée :apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: my-operator spec: package: etcd channel: alpha config:1 selector: matchLabels: <labels_for_pods>2 volumes:3 - name: trusted-ca configMap: name: trusted-ca items: - key: ca-bundle.crt4 path: tls-ca-bundle.pem5 volumeMounts:6 - name: trusted-ca mountPath: /etc/pki/ca-trust/extracted/pem readOnly: true- 1
- Ajouter une section
configsi elle n'existe pas. - 2
- Spécifier des étiquettes pour correspondre aux pods qui appartiennent à l'opérateur.
- 3
- Créez un volume
trusted-ca. - 4
ca-bundle.crtest nécessaire comme clé de la carte de configuration.- 5
tls-ca-bundle.pemest requis comme chemin d'accès à la carte de configuration.- 6
- Créez un montage du volume
trusted-ca.
NoteLes déploiements d'un opérateur peuvent échouer à valider l'autorité et afficher une erreur
x509 certificate signed by unknown authority. Cette erreur peut se produire même après l'injection d'une autorité de certification personnalisée lors de l'utilisation de l'abonnement d'un opérateur. Dans ce cas, vous pouvez définirmountPathcomme/etc/ssl/certspour trusted-ca en utilisant l'abonnement d'un opérateur.
4.6. Visualisation du statut de l'opérateur
Il est important de comprendre l'état du système dans Operator Lifecycle Manager (OLM) pour prendre des décisions et résoudre les problèmes liés aux opérateurs installés. OLM fournit des informations sur les abonnements et les sources de catalogue connexes concernant leur état et les actions effectuées. Cela permet aux utilisateurs de mieux comprendre l'état de santé de leurs opérateurs.
4.6.1. Types de conditions d'abonnement de l'opérateur
Les abonnements peuvent signaler les types de conditions suivants :
| Condition | Description |
|---|---|
|
| Une partie ou la totalité des sources du catalogue à utiliser pour la résolution sont malsaines. |
|
| Il manque un plan d'installation pour un abonnement. |
|
| Un plan d'installation pour un abonnement est en attente d'installation. |
|
| Un plan d'installation pour un abonnement a échoué. |
|
| La résolution des dépendances pour un abonnement a échoué. |
Les opérateurs de cluster OpenShift Container Platform par défaut sont gérés par l'opérateur de version de cluster (CVO) et n'ont pas d'objet Subscription. Les opérateurs d'application sont gérés par Operator Lifecycle Manager (OLM) et ont un objet Subscription.
4.6.2. Visualisation de l'état de l'abonnement de l'opérateur à l'aide de la CLI
Vous pouvez consulter l'état de l'abonnement de l'opérateur à l'aide de l'interface de ligne de commande.
Conditions préalables
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin. -
Vous avez installé l'OpenShift CLI (
oc).
Procédure
Liste des abonnements des opérateurs :
$ oc get subs -n <operator_namespace>Utilisez la commande
oc describepour inspecter une ressourceSubscription:oc describe sub <subscription_name> -n <operator_namespace>Dans la sortie de la commande, recherchez la section
Conditionspour connaître l'état des types de conditions d'abonnement de l'opérateur. Dans l'exemple suivant, le type de conditionCatalogSourcesUnhealthya le statutfalsecar toutes les sources de catalogue disponibles sont saines :Exemple de sortie
Conditions: Last Transition Time: 2019-07-29T13:42:57Z Message: all available catalogsources are healthy Reason: AllCatalogSourcesHealthy Status: False Type: CatalogSourcesUnhealthy
Les opérateurs de cluster OpenShift Container Platform par défaut sont gérés par l'opérateur de version de cluster (CVO) et n'ont pas d'objet Subscription. Les opérateurs d'application sont gérés par Operator Lifecycle Manager (OLM) et ont un objet Subscription.
4.6.3. Visualisation de l'état de la source du catalogue de l'opérateur à l'aide de la CLI
Vous pouvez consulter l'état d'une source du catalogue de l'opérateur à l'aide de l'interface de ligne de commande.
Conditions préalables
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin. -
Vous avez installé l'OpenShift CLI (
oc).
Procédure
Listez les sources de catalogue dans un espace de noms. Par exemple, vous pouvez vérifier l'espace de noms
openshift-marketplace, qui est utilisé pour les sources de catalogue à l'échelle du cluster :$ oc get catalogsources -n openshift-marketplaceExemple de sortie
NAME DISPLAY TYPE PUBLISHER AGE certified-operators Certified Operators grpc Red Hat 55m community-operators Community Operators grpc Red Hat 55m example-catalog Example Catalog grpc Example Org 2m25s redhat-marketplace Red Hat Marketplace grpc Red Hat 55m redhat-operators Red Hat Operators grpc Red Hat 55mLa commande
oc describepermet d'obtenir plus de détails et de connaître l'état d'une source de catalogue :$ oc describe catalogsource example-catalog -n openshift-marketplaceExemple de sortie
Name: example-catalog Namespace: openshift-marketplace ... Status: Connection State: Address: example-catalog.openshift-marketplace.svc:50051 Last Connect: 2021-09-09T17:07:35Z Last Observed State: TRANSIENT_FAILURE Registry Service: Created At: 2021-09-09T17:05:45Z Port: 50051 Protocol: grpc Service Name: example-catalog Service Namespace: openshift-marketplaceDans l'exemple précédent, le dernier état observé est
TRANSIENT_FAILURE. Cet état indique qu'il y a un problème pour établir une connexion pour la source du catalogue.Listez les pods de l'espace de noms dans lequel votre source de catalogue a été créée :
$ oc get pods -n openshift-marketplaceExemple de sortie
NAME READY STATUS RESTARTS AGE certified-operators-cv9nn 1/1 Running 0 36m community-operators-6v8lp 1/1 Running 0 36m marketplace-operator-86bfc75f9b-jkgbc 1/1 Running 0 42m example-catalog-bwt8z 0/1 ImagePullBackOff 0 3m55s redhat-marketplace-57p8c 1/1 Running 0 36m redhat-operators-smxx8 1/1 Running 0 36mLorsqu'une source de catalogue est créée dans un espace de noms, un pod pour la source de catalogue est créé dans cet espace de noms. Dans l'exemple de sortie précédent, le statut du pod
example-catalog-bwt8zestImagePullBackOff. Ce statut indique qu'il y a un problème lors de l'extraction de l'image d'index de la source de catalogue.Utilisez la commande
oc describepour inspecter un pod et obtenir des informations plus détaillées :$ oc describe pod example-catalog-bwt8z -n openshift-marketplaceExemple de sortie
Name: example-catalog-bwt8z Namespace: openshift-marketplace Priority: 0 Node: ci-ln-jyryyg2-f76d1-ggdbq-worker-b-vsxjd/10.0.128.2 ... Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Scheduled 48s default-scheduler Successfully assigned openshift-marketplace/example-catalog-bwt8z to ci-ln-jyryyf2-f76d1-fgdbq-worker-b-vsxjd Normal AddedInterface 47s multus Add eth0 [10.131.0.40/23] from openshift-sdn Normal BackOff 20s (x2 over 46s) kubelet Back-off pulling image "quay.io/example-org/example-catalog:v1" Warning Failed 20s (x2 over 46s) kubelet Error: ImagePullBackOff Normal Pulling 8s (x3 over 47s) kubelet Pulling image "quay.io/example-org/example-catalog:v1" Warning Failed 8s (x3 over 47s) kubelet Failed to pull image "quay.io/example-org/example-catalog:v1": rpc error: code = Unknown desc = reading manifest v1 in quay.io/example-org/example-catalog: unauthorized: access to the requested resource is not authorized Warning Failed 8s (x3 over 47s) kubelet Error: ErrImagePullDans l'exemple précédent, les messages d'erreur indiquent que l'image d'index de la source de catalogue ne parvient pas à être extraite en raison d'un problème d'autorisation. Par exemple, l'image d'index peut être stockée dans un registre qui nécessite des identifiants de connexion.
4.7. Gestion des conditions de l'opérateur
En tant qu'administrateur de cluster, vous pouvez gérer les conditions de l'opérateur en utilisant Operator Lifecycle Manager (OLM).
4.7.1. Remplacer les conditions de l'opérateur
En tant qu'administrateur de grappe, vous pouvez vouloir ignorer une condition d'opérateur prise en charge signalée par un opérateur. Lorsqu'elles sont présentes, les conditions de l'opérateur dans le tableau Spec.Overrides remplacent les conditions dans le tableau Spec.Conditions, ce qui permet aux administrateurs de grappes de traiter les situations où un opérateur signale incorrectement un état à Operator Lifecycle Manager (OLM).
Par défaut, le tableau Spec.Overrides n'est pas présent dans un objet OperatorCondition tant qu'il n'est pas ajouté par un administrateur de cluster. Le tableau Spec.Conditions n'est pas non plus présent tant qu'il n'est pas ajouté par un utilisateur ou qu'il ne résulte pas d'une logique personnalisée de l'opérateur.
Prenons l'exemple d'une version connue d'un opérateur qui communique toujours qu'il n'est pas évolutif. Dans ce cas, vous pourriez vouloir mettre à niveau l'opérateur malgré le fait qu'il communique qu'il n'est pas évolutif. Pour ce faire, il convient de modifier la condition de l'opérateur en ajoutant les conditions type et status au tableau Spec.Overrides de l'objet OperatorCondition.
Conditions préalables
-
Un opérateur avec un objet
OperatorCondition, installé à l'aide d'OLM.
Procédure
Modifiez l'objet
OperatorConditionpour l'opérateur :oc edit operatorcondition <name> $ oc edit operatorcondition <name>Ajouter un tableau
Spec.Overridesà l'objet :Exemple de dérogation à la condition de l'opérateur
apiVersion: operators.coreos.com/v1 kind: OperatorCondition metadata: name: my-operator namespace: operators spec: overrides: - type: Upgradeable1 status: "True" reason: "upgradeIsSafe" message: "This is a known issue with the Operator where it always reports that it cannot be upgraded." conditions: - type: Upgradeable status: "False" reason: "migration" message: "The operator is performing a migration." lastTransitionTime: "2020-08-24T23:15:55Z"- 1
- Permet à l'administrateur du cluster de modifier l'état de préparation de la mise à niveau à
True.
4.7.2. Mise à jour de votre opérateur pour utiliser les conditions de l'opérateur
Operator Lifecycle Manager (OLM) crée automatiquement une ressource OperatorCondition pour chaque ressource ClusterServiceVersion qu'il réconcilie. Tous les comptes de service du CSV se voient accorder le RBAC nécessaire pour interagir avec le site OperatorCondition appartenant à l'opérateur.
Un auteur d'opérateur peut développer son opérateur pour qu'il utilise la bibliothèque operator-lib, de sorte qu'une fois l'opérateur déployé par OLM, il puisse définir ses propres conditions. Pour plus d'informations sur la définition des conditions d'un opérateur en tant qu'auteur d'un opérateur, voir la page Activation des conditions d'un opérateur.
4.7.2.1. Réglage des valeurs par défaut
Dans un souci de compatibilité ascendante, OLM considère l'absence d'une ressource OperatorCondition comme un refus de la condition. Par conséquent, un opérateur qui choisit d'utiliser les conditions de l'opérateur doit définir des conditions par défaut avant que la sonde de disponibilité du pod ne soit définie sur true. L'opérateur dispose ainsi d'un délai de grâce pour mettre à jour la condition dans l'état correct.
4.8. Permettre aux administrateurs qui ne font pas partie d'un cluster d'installer des opérateurs
Les administrateurs de clusters peuvent utiliser Operator groups pour permettre aux utilisateurs ordinaires d'installer des opérateurs.
4.8.1. Comprendre la politique d'installation de l'opérateur
Les opérateurs peuvent nécessiter des privilèges étendus pour fonctionner, et les privilèges requis peuvent changer d'une version à l'autre. Le gestionnaire du cycle de vie des opérateurs (OLM) s'exécute avec les privilèges cluster-admin. Par défaut, les auteurs d'opérateurs peuvent spécifier n'importe quel ensemble d'autorisations dans la version du service de cluster (CSV), et OLM les accorde alors à l'opérateur.
Pour s'assurer qu'un opérateur ne peut pas obtenir de privilèges à l'échelle du cluster et que les utilisateurs ne peuvent pas escalader les privilèges à l'aide d'OLM, les administrateurs de cluster peuvent auditer manuellement les opérateurs avant qu'ils ne soient ajoutés au cluster. Les administrateurs de grappes disposent également d'outils pour déterminer et limiter les actions autorisées lors de l'installation ou de la mise à niveau d'un opérateur à l'aide de comptes de service.
Les administrateurs de clusters peuvent associer un groupe d'opérateurs à un compte de service auquel un ensemble de privilèges est accordé. Le compte de service définit une politique pour les opérateurs afin de s'assurer qu'ils ne s'exécutent que dans des limites prédéterminées en utilisant des règles de contrôle d'accès basées sur les rôles (RBAC). Par conséquent, l'opérateur ne peut rien faire qui ne soit explicitement autorisé par ces règles.
En employant des groupes d'opérateurs, les utilisateurs disposant de privilèges suffisants peuvent installer des opérateurs dont le champ d'application est limité. Par conséquent, un plus grand nombre d'outils de l'Operator Framework peuvent être mis à la disposition d'un plus grand nombre d'utilisateurs en toute sécurité, ce qui offre une expérience plus riche pour la création d'applications avec des opérateurs.
Le contrôle d'accès basé sur les rôles (RBAC) pour les objets Subscription est automatiquement accordé à tout utilisateur ayant le rôle edit ou admin dans un espace de noms. Cependant, le contrôle d'accès basé sur les rôles n'existe pas pour les objets OperatorGroup; c'est cette absence qui empêche les utilisateurs ordinaires d'installer des opérateurs. La pré-installation des groupes d'opérateurs est en fait ce qui donne les privilèges d'installation.
Gardez les points suivants à l'esprit lorsque vous associez un groupe d'opérateurs à un compte de service :
-
Les ressources
APIServiceetCustomResourceDefinitionsont toujours créées par OLM à l'aide du rôlecluster-admin. Un compte de service associé à un groupe Operator ne doit jamais recevoir de privilèges d'écriture sur ces ressources. - Tout opérateur lié à ce groupe d'opérateurs est désormais limité aux autorisations accordées au compte de service spécifié. Si l'opérateur demande des autorisations qui sortent du cadre du compte de service, l'installation échoue avec les erreurs appropriées afin que l'administrateur du cluster puisse dépanner et résoudre le problème.
4.8.1.1. Scénarios d'installation
Pour déterminer si un opérateur peut être installé ou mis à niveau sur une grappe, Operator Lifecycle Manager (OLM) prend en compte les scénarios suivants :
- Un administrateur de cluster crée un nouveau groupe d'opérateurs et spécifie un compte de service. Tous les opérateurs associés à ce groupe d'opérateurs sont installés et s'exécutent avec les privilèges accordés au compte de service.
- Un administrateur de cluster crée un nouveau groupe Operator et ne spécifie aucun compte de service. OpenShift Container Platform maintient la compatibilité ascendante, de sorte que le comportement par défaut demeure et que les installations et les mises à niveau des opérateurs sont autorisées.
- Pour les groupes d'opérateurs existants qui ne spécifient pas de compte de service, le comportement par défaut est conservé et les installations et mises à niveau d'opérateurs sont autorisées.
- Un administrateur de cluster met à jour un groupe d'opérateurs existant et spécifie un compte de service. OLM permet à l'opérateur existant de continuer à fonctionner avec ses privilèges actuels. Lorsqu'un opérateur existant est mis à niveau, il est réinstallé et exécuté avec les privilèges accordés au compte de service, comme n'importe quel nouvel opérateur.
- Un compte de service spécifié par un groupe d'opérateurs est modifié par l'ajout ou la suppression d'autorisations, ou le compte de service existant est remplacé par un nouveau. Lorsque des opérateurs existants sont mis à niveau, ils sont réinstallés et exécutés avec les privilèges accordés au compte de service mis à jour, comme n'importe quel nouvel opérateur.
- Un administrateur de cluster supprime le compte de service d'un groupe Operator. Le comportement par défaut est conservé et les installations et mises à niveau d'opérateurs sont autorisées.
4.8.1.2. Déroulement de l'installation
Lorsqu'un groupe d'opérateurs est lié à un compte de service et qu'un opérateur est installé ou mis à niveau, Operator Lifecycle Manager (OLM) utilise le flux de travail suivant :
-
L'objet
Subscriptionest pris en charge par OLM. - OLM récupère le groupe d'opérateurs lié à cet abonnement.
- OLM détermine que le groupe Opérateur a un compte de service spécifié.
- OLM crée un client adapté au compte de service et utilise ce client pour installer l'opérateur. Cela garantit que toute autorisation demandée par l'opérateur est toujours limitée à celle du compte de service dans le groupe de l'opérateur.
- OLM crée un nouveau compte de service avec les autorisations spécifiées dans le CSV et l'attribue à l'opérateur. L'opérateur s'exécute en tant que compte de service attribué.
4.8.2. Scoping Installations de l'opérateur
Pour fournir des règles de cadrage aux installations et mises à niveau d'opérateurs sur Operator Lifecycle Manager (OLM), associez un compte de service à un groupe d'opérateurs.
Dans cet exemple, un administrateur de cluster peut confiner un ensemble d'opérateurs à un espace de noms désigné.
Procédure
Créer un nouvel espace de noms :
$ cat <<EOF | oc create -f - apiVersion: v1 kind: Namespace metadata: name: scoped EOFAttribuez les autorisations auxquelles vous souhaitez que le(s) opérateur(s) soit(ent) limité(s). Cela implique la création d'un nouveau compte de service, d'un ou de plusieurs rôles pertinents et d'une ou de plusieurs obligations de rôle.
$ cat <<EOF | oc create -f - apiVersion: v1 kind: ServiceAccount metadata: name: scoped namespace: scoped EOFPour simplifier, l'exemple suivant autorise le compte de service à faire tout ce qu'il veut dans l'espace de noms désigné. Dans un environnement de production, vous devriez créer un ensemble d'autorisations plus fines :
$ cat <<EOF | oc create -f - apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: scoped namespace: scoped rules: - apiGroups: ["*"] resources: ["*"] verbs: ["*"] --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: scoped-bindings namespace: scoped roleRef: apiGroup: rbac.authorization.k8s.io kind: Role name: scoped subjects: - kind: ServiceAccount name: scoped namespace: scoped EOFCréer un objet
OperatorGroupdans l'espace de noms désigné. Ce groupe d'opérateurs cible l'espace de noms désigné pour s'assurer que son occupation y est limitée.En outre, les groupes d'opérateurs permettent à un utilisateur de spécifier un compte de service. Indiquez le compte de service créé à l'étape précédente :
$ cat <<EOF | oc create -f - apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: scoped namespace: scoped spec: serviceAccountName: scoped targetNamespaces: - scoped EOFTout opérateur installé dans l'espace de noms désigné est lié à ce groupe d'opérateurs et donc au compte de service spécifié.
Créer un objet
Subscriptiondans l'espace de noms désigné pour installer un opérateur :$ cat <<EOF | oc create -f - apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: etcd namespace: scoped spec: channel: singlenamespace-alpha name: etcd source: <catalog_source_name>1 sourceNamespace: <catalog_source_namespace>2 EOFTout opérateur lié à ce groupe d'opérateurs est limité aux autorisations accordées au compte de service spécifié. Si l'opérateur demande des autorisations qui sont en dehors de la portée du compte de service, l'installation échoue avec les erreurs correspondantes.
4.8.2.1. Permissions fines
Operator Lifecycle Manager (OLM) utilise le compte de service spécifié dans un groupe d'opérateurs pour créer ou mettre à jour les ressources suivantes liées à l'opérateur en cours d'installation :
-
ClusterServiceVersion -
Subscription -
Secret -
ServiceAccount -
Service -
ClusterRoleetClusterRoleBinding -
RoleetRoleBinding
Pour confiner les opérateurs à un espace de noms désigné, les administrateurs de clusters peuvent commencer par accorder les autorisations suivantes au compte de service :
Le rôle suivant est un exemple générique et des règles supplémentaires peuvent être nécessaires en fonction de l'opérateur.
kind: Role
rules:
- apiGroups: ["operators.coreos.com"]
resources: ["subscriptions", "clusterserviceversions"]
verbs: ["get", "create", "update", "patch"]
- apiGroups: [""]
resources: ["services", "serviceaccounts"]
verbs: ["get", "create", "update", "patch"]
- apiGroups: ["rbac.authorization.k8s.io"]
resources: ["roles", "rolebindings"]
verbs: ["get", "create", "update", "patch"]
- apiGroups: ["apps"]
resources: ["deployments"]
verbs: ["list", "watch", "get", "create", "update", "patch", "delete"]
- apiGroups: [""]
resources: ["pods"]
verbs: ["list", "watch", "get", "create", "update", "patch", "delete"]En outre, si un opérateur spécifie un secret d'extraction, les autorisations suivantes doivent également être ajoutées :
kind: ClusterRole
rules:
- apiGroups: [""]
resources: ["secrets"]
verbs: ["get"]
---
kind: Role
rules:
- apiGroups: [""]
resources: ["secrets"]
verbs: ["create", "update", "patch"]- 1
- Nécessaire pour obtenir le secret de l'espace de noms OLM.
4.8.3. Contrôle d'accès au catalogue de l'opérateur
Lorsqu'un catalogue d'opérateurs est créé dans l'espace de noms du catalogue global openshift-marketplace, les opérateurs du catalogue sont mis à la disposition de tous les espaces de noms. Un catalogue créé dans d'autres espaces de noms ne rend ses opérateurs disponibles que dans l'espace de noms du catalogue.
Sur les clusters où des utilisateurs non administrateurs de cluster se sont vu déléguer des privilèges d'installation d'opérateurs, les administrateurs de cluster peuvent souhaiter contrôler ou restreindre davantage l'ensemble des opérateurs que ces utilisateurs sont autorisés à installer. Les actions suivantes permettent d'y parvenir :
- Désactiver tous les catalogues globaux par défaut.
- Permettre la création de catalogues personnalisés dans l'espace de noms où les groupes d'opérateurs pertinents ont été préinstallés.
4.8.4. Dépannage des échecs d'autorisation
Si l'installation d'un opérateur échoue en raison d'un manque de permissions, identifiez les erreurs à l'aide de la procédure suivante.
Procédure
Examinez l'objet
Subscription. Son statut comporte une référence d'objetinstallPlanRefqui pointe vers l'objetInstallPlanqui a tenté de créer le ou les objets[Cluster]Role[Binding]nécessaires à l'opérateur :apiVersion: operators.coreos.com/v1 kind: Subscription metadata: name: etcd namespace: scoped status: installPlanRef: apiVersion: operators.coreos.com/v1 kind: InstallPlan name: install-4plp8 namespace: scoped resourceVersion: "117359" uid: 2c1df80e-afea-11e9-bce3-5254009c9c23Vérifier l'état de l'objet
InstallPlanpour détecter d'éventuelles erreurs :apiVersion: operators.coreos.com/v1 kind: InstallPlan status: conditions: - lastTransitionTime: "2019-07-26T21:13:10Z" lastUpdateTime: "2019-07-26T21:13:10Z" message: 'error creating clusterrole etcdoperator.v0.9.4-clusterwide-dsfx4: clusterroles.rbac.authorization.k8s.io is forbidden: User "system:serviceaccount:scoped:scoped" cannot create resource "clusterroles" in API group "rbac.authorization.k8s.io" at the cluster scope' reason: InstallComponentFailed status: "False" type: Installed phase: FailedLe message d'erreur vous indique :
-
Le type de ressource qu'il n'a pas réussi à créer, y compris le groupe API de la ressource. Dans ce cas, il s'agit de
clusterrolesdans le grouperbac.authorization.k8s.io. - Le nom de la ressource.
-
Le type d'erreur :
is forbiddenindique que l'utilisateur n'a pas les droits suffisants pour effectuer l'opération. - Le nom de l'utilisateur qui a tenté de créer ou de mettre à jour la ressource. Dans ce cas, il s'agit du compte de service spécifié dans le groupe Operator.
Le champ d'application de l'opération :
cluster scopeou non.L'utilisateur peut ajouter l'autorisation manquante au compte de service, puis procéder par itération.
NoteOperator Lifecycle Manager (OLM) ne fournit pas actuellement la liste complète des erreurs du premier coup.
-
Le type de ressource qu'il n'a pas réussi à créer, y compris le groupe API de la ressource. Dans ce cas, il s'agit de
4.9. Gestion des catalogues personnalisés
Les administrateurs de clusters et les responsables du catalogue Operator peuvent créer et gérer des catalogues personnalisés emballés à l'aide du format bundle sur Operator Lifecycle Manager (OLM) dans OpenShift Container Platform.
Kubernetes déprécie périodiquement certaines API qui sont supprimées dans les versions ultérieures. Par conséquent, les opérateurs ne peuvent pas utiliser les API supprimées à partir de la version d'OpenShift Container Platform qui utilise la version de Kubernetes qui a supprimé l'API.
Si votre cluster utilise des catalogues personnalisés, consultez Contrôle de la compatibilité des opérateurs avec les versions d'OpenShift Container Platform pour plus de détails sur la façon dont les auteurs d'opérateurs peuvent mettre à jour leurs projets afin d'éviter les problèmes de charge de travail et d'empêcher les mises à niveau incompatibles.
4.9.1. Conditions préalables
-
Installez le CLI
opm.
4.9.2. Catalogues basés sur des fichiers
File-based catalogs sont la dernière itération du format de catalogue dans Operator Lifecycle Manager (OLM). Il s'agit d'une évolution du format de base de données SQLite, basée sur du texte brut (JSON ou YAML) et une configuration déclarative, et il est entièrement rétrocompatible.
À partir d'OpenShift Container Platform 4.11, le catalogue Operator fourni par Red Hat par défaut est publié dans le format de catalogue basé sur des fichiers. Les catalogues Operator fournis par Red Hat par défaut pour OpenShift Container Platform 4.6 à 4.10 sont publiés dans le format de base de données SQLite déprécié.
Les sous-commandes, drapeaux et fonctionnalités de opm liés au format de base de données SQLite sont également obsolètes et seront supprimés dans une prochaine version. Ces fonctionnalités sont toujours prises en charge et doivent être utilisées pour les catalogues qui utilisent le format de base de données SQLite obsolète.
La plupart des sous-commandes et des drapeaux de opm pour travailler avec le format de base de données SQLite, tels que opm index prune, ne fonctionnent pas avec le format de catalogue basé sur des fichiers. Pour plus d'informations sur l'utilisation des catalogues basés sur des fichiers, voir Format d'empaquetage d'Operator Framework et Mise en miroir des images pour une installation déconnectée à l'aide du plugin oc-mirror.
4.9.2.1. Création d'une image de catalogue basée sur des fichiers
Vous pouvez créer une image de catalogue qui utilise le format de texte brut file-based catalog (JSON ou YAML), qui remplace le format de base de données SQLite obsolète. L'interface CLI de opm fournit des outils qui permettent d'initialiser un catalogue au format fichier, d'y rendre de nouveaux enregistrements et de valider la validité du catalogue.
Conditions préalables
-
opm -
podmanversion 1.9.3 - Une image de bundle construite et poussée vers un registre qui prend en charge Docker v2-2
Procédure
Initialiser un catalogue pour un catalogue basé sur des fichiers :
Créer un répertoire pour le catalogue :
$ mkdir <nom_de_l'opérateur>-indexCréer un fichier Docker qui peut construire une image de catalogue :
Exemple
<operator_name>-index.Dockerfile# The base image is expected to contain # /bin/opm (with a serve subcommand) and /bin/grpc_health_probe FROM registry.redhat.io/openshift4/ose-operator-registry:v4.9 # Configure the entrypoint and command ENTRYPOINT ["/bin/opm"] CMD ["serve", "/configs"] # Copy declarative config root into image at /configs ADD <operator_name>-index /configs # Set DC-specific label for the location of the DC root directory # in the image LABEL operators.operatorframework.io.index.configs.v1=/configsLe fichier Docker doit se trouver dans le même répertoire parent que le répertoire du catalogue que vous avez créé à l'étape précédente :
Exemple de structure de répertoire
. ├── <operator_name>-index └── <operator_name>-index.DockerfileRemplissez le catalogue avec la définition de votre paquet :
$ opm init <operator_name> \1 --default-channel=preview \2 --description=./README.md \3 --icon=./operator-icon.svg \4 --output yaml \5 > <operator_name>-index/index.yaml6 - 1
- Nom de l'opérateur ou du paquet.
- 2
- Canal que l'abonnement utilisera par défaut s'il n'est pas spécifié.
- 3
- Chemin d'accès au site de l'opérateur
README.mdou à d'autres documents. - 4
- Chemin d'accès à l'icône de l'opérateur.
- 5
- Format de sortie : JSON ou YAML.
- 6
- Chemin d'accès pour la création du fichier de configuration du catalogue.
Cette commande génère un blob de configuration déclarative
olm.packagedans le fichier de configuration du catalogue spécifié.
Ajouter une liasse au catalogue :
$ opm render <registry>/<namespace>/<bundle_image_name>:<tag> \1 --output=yaml \ >> <operator_name>-index/index.yaml2 La commande
opm rendergénère un blob de configuration déclaratif à partir des images de catalogue et de bundle fournies.NoteLes chaînes doivent contenir au moins une liasse.
Ajoutez une entrée de canal pour l'offre groupée. Par exemple, modifiez l'exemple suivant selon vos spécifications et ajoutez-le à votre fichier
<operator_name>-index/index.yaml:Exemple d'entrée de canal
--- schema: olm.channel package: <operator_name> name: preview entries: - name: <operator_name>.v0.1.01 - 1
- Veillez à inclure le point (
.) après<operator_name>mais avantvdans la version. Sinon, l'entrée ne passera pas la commandeopm validate.
Valider le catalogue basé sur les fichiers :
Exécutez la commande
opm validatedans le répertoire du catalogue :$ opm validate <nom_de_l'opérateur>-indexVérifiez que le code d'erreur est bien
0:$ echo $?Exemple de sortie
0
Construire l'image du catalogue :
$ podman build . \ -f <operator_name>-index.Dockerfile \ -t <registry>/<namespace>/<catalog_image_name>:<tag>Pousser l'image du catalogue vers un registre :
Si nécessaire, authentifiez-vous auprès de votre registre cible :
$ podman login <registry>Pousser l'image du catalogue :
$ podman push <registry>/<namespace>/<catalog_image_name>:<tag>
4.9.3. Catalogues basés sur SQLite
Le format de base de données SQLite pour les catalogues d'opérateurs est une fonctionnalité obsolète. La fonctionnalité dépréciée est toujours incluse dans OpenShift Container Platform et continue d'être prise en charge ; cependant, elle sera supprimée dans une prochaine version de ce produit et n'est pas recommandée pour les nouveaux déploiements.
Pour obtenir la liste la plus récente des fonctionnalités majeures qui ont été dépréciées ou supprimées dans OpenShift Container Platform, consultez la section Deprecated and removed features des notes de version d'OpenShift Container Platform.
4.9.3.1. Création d'une image d'index basée sur SQLite
Vous pouvez créer une image d'index basée sur le format de base de données SQLite en utilisant le CLI opm.
Conditions préalables
-
opm -
podmanversion 1.9.3 - Une image de bundle construite et poussée vers un registre qui prend en charge Docker v2-2
Procédure
Commencer un nouvel index :
$ opm index add \ --bundles <registry>/<namespace>/<bundle_image_name>:<tag> \1 --tag <registry>/<namespace>/<index_image_name>:<tag> \2 [--binary-image <registry_base_image>]3 Pousser l'image de l'index vers un registre.
Si nécessaire, authentifiez-vous auprès de votre registre cible :
$ podman login <registry>Appuyez sur l'image d'index :
$ podman push <registry>/<namespace>/<index_image_name>:<tag>
4.9.3.2. Mise à jour d'une image d'index basée sur SQLite
Après avoir configuré OperatorHub pour utiliser une source de catalogue qui fait référence à une image d'index personnalisée, les administrateurs de cluster peuvent maintenir les opérateurs disponibles sur leur cluster à jour en ajoutant des images de bundle à l'image d'index.
Vous pouvez mettre à jour une image d'index existante à l'aide de la commande opm index add.
Conditions préalables
-
opm -
podmanversion 1.9.3 - Une image d'index est construite et poussée vers un registre.
- Une source de catalogue existante référençant l'image d'index.
Procédure
Mettre à jour l'index existant en ajoutant des images de liasses :
$ opm index add \ --bundles <registry>/<namespace>/<new_bundle_image>@sha256:<digest> \1 --from-index <registry>/<namespace>/<existing_index_image>:<existing_tag> \2 --tag <registry>/<namespace>/<existing_index_image>:<updated_tag> \3 --pull-tool podman4 - 1
- L'option
--bundlesspécifie une liste séparée par des virgules d'images supplémentaires à ajouter à l'index. - 2
- Le drapeau
--from-indexspécifie l'index précédemment poussé. - 3
- L'option
--tagspécifie la balise d'image à appliquer à l'image d'index mise à jour. - 4
- L'option
--pull-toolspécifie l'outil utilisé pour extraire les images des conteneurs.
où :
<registry>-
Spécifie le nom d'hôte du registre, par exemple
quay.iooumirror.example.com. <namespace>-
Spécifie l'espace de noms du registre, par exemple
ocs-devouabc. <new_bundle_image>-
Spécifie la nouvelle image de paquet à ajouter au registre, par exemple
ocs-operator. <digest>-
Spécifie l'ID de l'image SHA, ou condensé, de l'image de la liasse, par exemple
c7f11097a628f092d8bad148406aa0e0951094a03445fd4bc0775431ef683a41. <existing_index_image>-
Spécifie l'image précédemment poussée, telle que
abc-redhat-operator-index. <existing_tag>-
Spécifie une balise d'image précédemment poussée, telle que
4.12. <updated_tag>-
Spécifie la balise d'image à appliquer à l'image d'index mise à jour, par exemple
4.12.1.
Example command
$ opm index add \ --bundles quay.io/ocs-dev/ocs-operator@sha256:c7f11097a628f092d8bad148406aa0e0951094a03445fd4bc0775431ef683a41 \ --from-index mirror.example.com/abc/abc-redhat-operator-index:4.12 \ --tag mirror.example.com/abc/abc-redhat-operator-index:4.12.1 \ --pull-tool podmanPousser l'image d'index mise à jour :
$ podman push <registry>/<namespace>/<existing_index_image>:<updated_tag>Une fois que Operator Lifecycle Manager (OLM) a interrogé automatiquement l'image d'index référencée dans la source du catalogue à intervalles réguliers, vérifiez que les nouveaux paquets ont été ajoutés avec succès :
$ oc get packagemanifests -n openshift-marketplace
4.9.3.3. Filtrage d'une image d'index basée sur SQLite
Une image d'index, basée sur le format Operator bundle, est un instantané conteneurisé d'un catalogue d'opérateurs. Vous pouvez filtrer, ou prune, un index de tous les paquets à l'exception d'une liste spécifiée, ce qui crée une copie de l'index source contenant uniquement les opérateurs que vous souhaitez.
Conditions préalables
-
podmanversion 1.9.3 -
grpcurl(outil de ligne de commande tiers) -
opm - Accès à un registre qui prend en charge Docker v2-2
Procédure
S'authentifier avec le registre cible :
$ podman login <target_registry>Déterminez la liste des paquets que vous souhaitez inclure dans votre index élagué.
Exécutez l'image de l'index source que vous souhaitez élaguer dans un conteneur. Par exemple :
$ podman run -p50051:50051 \ -it registry.redhat.io/redhat/redhat-operator-index:v4.12Exemple de sortie
Trying to pull registry.redhat.io/redhat/redhat-operator-index:v4.12... Getting image source signatures Copying blob ae8a0c23f5b1 done ... INFO[0000] serving registry database=/database/index.db port=50051Dans une autre session de terminal, utilisez la commande
grpcurlpour obtenir une liste des paquets fournis par l'index :grpcurl -plaintext localhost:50051 api.Registry/ListPackages > packages.outInspectez le fichier
packages.outet identifiez les noms de paquets de cette liste que vous souhaitez conserver dans votre index élagué. Par exemple :Exemples de listes de paquets
... { "name": "advanced-cluster-management" } ... { "name": "jaeger-product" } ... { { "name": "quay-operator" } ...-
Dans la session de terminal où vous avez exécuté la commande
podman run, appuyez sur Ctrl et C pour arrêter le processus de conteneur.
Exécutez la commande suivante pour élaguer l'index source de tous les paquets, à l'exception des paquets spécifiés :
$ opm index prune \ -f registry.redhat.io/redhat/redhat-operator-index:v4.12 \1 -p advanced-cluster-management,jaeger-product,quay-operator \2 [-i registry.redhat.io/openshift4/ose-operator-registry:v4.9] \3 -t <target_registry>:<port>/<namespace>/redhat-operator-index:v4.124 - 1
- Index pour la taille.
- 2
- Liste de paquets à conserver, séparés par des virgules.
- 3
- Requis uniquement pour les images IBM Power et IBM zSystems : L'image de base Operator Registry avec le tag qui correspond à la version majeure et mineure du cluster OpenShift Container Platform cible.
- 4
- Balise personnalisée pour la nouvelle image d'index en cours de construction.
Exécutez la commande suivante pour transférer la nouvelle image d'index dans votre registre cible :
$ podman push <target_registry>:<port>/<namespace>/redhat-operator-index:v4.12où
<namespace>est un espace de noms existant dans le registre.
4.9.4. Cataloguer les sources et podifier l'admission à la sécurité
Pod security admission a été introduit dans OpenShift Container Platform 4.11 pour garantir les normes de sécurité des pods. Les sources de catalogue construites à l'aide du format de catalogue basé sur SQLite et d'une version de l'outil CLI opm publiée avant OpenShift Container Platform 4.11 ne peuvent pas fonctionner dans le cadre d'une application restreinte de la sécurité des pods.
Dans OpenShift Container Platform 4.12, les espaces de noms n'ont pas de mise en œuvre de la sécurité restreinte des pods par défaut et le mode de sécurité de la source du catalogue par défaut est défini sur legacy.
L'application restreinte par défaut pour tous les espaces de noms est prévue pour être incluse dans une prochaine version d'OpenShift Container Platform. Lorsque l'application restreinte se produit, le contexte de sécurité de la spécification de pod pour les pods de source de catalogue doit correspondre à la norme de sécurité de pod restreinte. Si votre image source de catalogue nécessite une norme de sécurité pod différente, l'étiquette des admissions de sécurité pod pour l'espace de noms doit être explicitement définie.
Si vous ne souhaitez pas exécuter vos pods de source de catalogue basés sur SQLite en tant que restreint, vous n'avez pas besoin de mettre à jour votre source de catalogue dans OpenShift Container Platform 4.12.
Cependant, il est recommandé de prendre des mesures dès maintenant pour s'assurer que vos sources de catalogue s'exécutent dans le cadre de l'application de la sécurité des pods restreints. Si vous ne le faites pas, vos sources de catalogue risquent de ne pas fonctionner dans les prochaines versions d'OpenShift Container Platform.
En tant qu'auteur de catalogue, vous pouvez activer la compatibilité avec l'application de la sécurité des pods restreints en effectuant l'une des actions suivantes :
- Migrez votre catalogue vers le format de catalogue basé sur les fichiers.
-
Mettez à jour votre image de catalogue avec une version de l'outil
opmCLI publiée avec OpenShift Container Platform 4.11 ou une version ultérieure.
Le format de catalogue de base de données SQLite est obsolète, mais toujours pris en charge par Red Hat. Dans une prochaine version, le format de base de données SQLite ne sera pas pris en charge et les catalogues devront migrer vers le format de catalogue basé sur des fichiers. À partir d'OpenShift Container Platform 4.11, le catalogue Operator fourni par Red Hat par défaut est publié dans le format de catalogue basé sur des fichiers. Les catalogues basés sur des fichiers sont compatibles avec l'application de la sécurité des pods restreints.
Si vous ne souhaitez pas mettre à jour l'image du catalogue de votre base de données SQLite ou migrer votre catalogue vers le format de catalogue basé sur des fichiers, vous pouvez configurer votre catalogue pour qu'il s'exécute avec des autorisations élevées.
4.9.4.1. Migration des catalogues de bases de données SQLite vers le format de catalogue basé sur des fichiers
Vous pouvez mettre à jour vos catalogues au format de base de données SQLite, qui est obsolète, au format de catalogue basé sur des fichiers.
Conditions préalables
- Source du catalogue de la base de données SQLite
- Autorisations de l'administrateur du cluster
-
La dernière version de l'outil
opmCLI est disponible avec OpenShift Container Platform 4.12 sur station de travail
Procédure
Migrez le catalogue de votre base de données SQLite vers un catalogue basé sur des fichiers en exécutant la commande suivante :
$ opm migrate <registry_image> <fbc_directory>Générez un fichier Docker pour votre catalogue basé sur les fichiers en exécutant la commande suivante :
$ opm generate dockerfile <fbc_directory> \ --binary-image \ registry.redhat.io/openshift4/ose-operator-registry:v4.12
Prochaines étapes
- Le fichier Docker généré peut être construit, étiqueté et poussé vers votre registre.
4.9.4.2. Reconstruction des images de catalogues de bases de données SQLite
Vous pouvez reconstruire votre image de catalogue de base de données SQLite avec la dernière version de l'outil opm CLI qui est disponible avec votre version d'OpenShift Container Platform.
Conditions préalables
- Source du catalogue de la base de données SQLite
- Autorisations de l'administrateur du cluster
-
La dernière version de l'outil
opmCLI est disponible avec OpenShift Container Platform 4.12 sur station de travail
Procédure
Exécutez la commande suivante pour reconstruire votre catalogue avec une version plus récente de l'outil CLI
opm:$ opm index add --binary-image \ registry.redhat.io/openshift4/ose-operator-registry:v4.12 \ --from-index <your_registry_image> \ --bundles "" -t \<your_registry_image>
4.9.4.3. Configurer les catalogues pour qu'ils s'exécutent avec des autorisations élevées
Si vous ne souhaitez pas mettre à jour votre image de catalogue de base de données SQLite ou migrer votre catalogue vers le format de catalogue basé sur des fichiers, vous pouvez effectuer les actions suivantes pour vous assurer que votre source de catalogue s'exécute lorsque l'application de la sécurité du pod par défaut passe à restreinte :
- Définissez manuellement le mode de sécurité du catalogue sur legacy dans la définition de la source du catalogue. Cette action garantit que votre catalogue s'exécute avec des autorisations héritées, même si le mode de sécurité du catalogue par défaut devient restreint.
- Étiqueter l'espace de noms de la source du catalogue pour l'application de la sécurité de la ligne de base ou du pod privilégié.
Le format de catalogue de base de données SQLite est obsolète, mais toujours pris en charge par Red Hat. Dans une prochaine version, le format de base de données SQLite ne sera plus pris en charge et les catalogues devront migrer vers le format de catalogue basé sur des fichiers. Les catalogues basés sur des fichiers sont compatibles avec l'application de la sécurité des pods restreints.
Conditions préalables
- Source du catalogue de la base de données SQLite
- Autorisations de l'administrateur du cluster
-
Espace de noms cible qui prend en charge l'exécution de pods avec la norme élevée d'admission à la sécurité des pods de
baselineou deprivileged
Procédure
Modifiez la définition de
CatalogSourceen remplaçant l'étiquettespec.grpcPodConfig.securityContextConfigparlegacy, comme le montre l'exemple suivant :Exemple
CatalogSourcedéfinitionapiVersion: operators.coreos.com/v1alpha1 kind: CatalogSource metadata: name: my-catsrc namespace: my-ns spec: sourceType: grpc grpcPodConfig: securityContextConfig: legacy image: my-image:latestAstuceDans OpenShift Container Platform 4.12, le champ
spec.grpcPodConfig.securityContextConfigest défini par défaut surlegacy. Dans une prochaine version d'OpenShift Container Platform, il est prévu que le paramètre par défaut deviennerestricted. Si votre catalogue ne peut pas s'exécuter sous une application restreinte, il est recommandé de définir manuellement ce champ àlegacy.Modifiez votre fichier
<namespace>.yamlpour ajouter les normes d'admission à la sécurité des pods élevés à l'espace de noms de la source de votre catalogue, comme le montre l'exemple suivant :Exemple de fichier
<namespace>.yamlapiVersion: v1 kind: Namespace metadata: ... labels: security.openshift.io/scc.podSecurityLabelSync: "false"1 openshift.io/cluster-monitoring: "true" pod-security.kubernetes.io/enforce: baseline2 name: "<namespace_name>"- 1
- Désactivez la synchronisation des étiquettes de sécurité des pods en ajoutant l'étiquette
security.openshift.io/scc.podSecurityLabelSync=falseà l'espace de noms. - 2
- Appliquez l'étiquette d'admission à la sécurité du pod
pod-security.kubernetes.io/enforce. Définissez l'étiquette surbaselineouprivileged. Utilisez le profil de sécurité du podbaselineà moins que d'autres charges de travail dans l'espace de noms ne nécessitent un profilprivileged.
4.9.5. Ajout d'une source de catalogue à un cluster
L'ajout d'une source de catalogue à un cluster OpenShift Container Platform permet la découverte et l'installation d'opérateurs pour les utilisateurs. Les administrateurs de cluster peuvent créer un objet CatalogSource qui référence une image d'index. OperatorHub utilise des sources de catalogue pour remplir l'interface utilisateur.
Conditions préalables
- Une image d'index est construite et poussée vers un registre.
Procédure
Créez un objet
CatalogSourcequi fait référence à votre image d'index.Modifiez le texte suivant selon vos spécifications et sauvegardez-le sous forme de fichier
catalogSource.yaml:apiVersion: operators.coreos.com/v1alpha1 kind: CatalogSource metadata: name: my-operator-catalog namespace: openshift-marketplace1 annotations: olm.catalogImageTemplate:2 "<registry>/<namespace>/<index_image_name>:v{kube_major_version}.{kube_minor_version}.{kube_patch_version}" spec: sourceType: grpc grpcPodConfig: securityContextConfig: <security_mode>3 image: <registry>/<namespace>/<index_image_name>:<tag>4 displayName: My Operator Catalog publisher: <publisher_name>5 updateStrategy: registryPoll:6 interval: 30m- 1
- Si vous souhaitez que la source du catalogue soit disponible globalement pour les utilisateurs de tous les espaces de noms, spécifiez l'espace de noms
openshift-marketplace. Sinon, vous pouvez spécifier un espace de noms différent pour que le catalogue soit délimité et disponible uniquement pour cet espace de noms. - 2
- Facultatif : Définissez l'annotation
olm.catalogImageTemplateavec le nom de votre image d'index et utilisez une ou plusieurs variables de version du cluster Kubernetes comme indiqué lors de la construction du modèle pour la balise d'image. - 3
- Spécifiez la valeur de
legacyourestricted. Si le champ n'est pas défini, la valeur par défaut estlegacy. Dans une prochaine version d'OpenShift Container Platform, il est prévu que la valeur par défaut soitrestricted. Si votre catalogue ne peut pas s'exécuter avec les autorisationsrestricted, il est recommandé de définir manuellement ce champ surlegacy. - 4
- Spécifiez votre image d'index. Si vous spécifiez une balise après le nom de l'image, par exemple
:v4.12, le pod source du catalogue utilise une politique d'extraction d'image deAlways, ce qui signifie que le pod extrait toujours l'image avant de démarrer le conteneur. Si vous spécifiez un condensé, par exemple@sha256:<id>, la politique d'extraction d'image estIfNotPresent, ce qui signifie que le module n'extrait l'image que si elle n'existe pas déjà sur le nœud. - 5
- Indiquez votre nom ou le nom d'une organisation qui publie le catalogue.
- 6
- Les sources du catalogue peuvent automatiquement vérifier la présence de nouvelles versions pour rester à jour.
Utilisez le fichier pour créer l'objet
CatalogSource:$ oc apply -f catalogSource.yaml
Vérifiez que les ressources suivantes ont bien été créées.
Vérifier les gousses :
$ oc get pods -n openshift-marketplaceExemple de sortie
NAME READY STATUS RESTARTS AGE my-operator-catalog-6njx6 1/1 Running 0 28s marketplace-operator-d9f549946-96sgr 1/1 Running 0 26hVérifier la source du catalogue :
$ oc get catalogsource -n openshift-marketplaceExemple de sortie
NAME DISPLAY TYPE PUBLISHER AGE my-operator-catalog My Operator Catalog grpc 5sVérifier le manifeste du paquet :
$ oc get packagemanifest -n openshift-marketplaceExemple de sortie
NAME CATALOG AGE jaeger-product My Operator Catalog 93s
Vous pouvez maintenant installer les opérateurs à partir de la page OperatorHub de votre console web OpenShift Container Platform.
4.9.6. Accès aux images des opérateurs à partir de registres privés
Si certaines images pertinentes pour les opérateurs gérés par Operator Lifecycle Manager (OLM) sont hébergées dans un registre d'images de conteneurs authentifié, également connu sous le nom de registre privé, OLM et OperatorHub ne peuvent pas extraire les images par défaut. Pour permettre l'accès, vous pouvez créer un secret d'extraction qui contient les informations d'authentification pour le registre. En référençant un ou plusieurs secrets d'extraction dans une source de catalogue, OLM peut se charger de placer les secrets dans l'espace de noms de l'opérateur et du catalogue pour permettre l'installation.
D'autres images requises par un opérateur ou ses opérandes peuvent également nécessiter l'accès à des registres privés. OLM ne gère pas le placement des secrets dans les espaces de noms des locataires cibles pour ce scénario, mais des références d'authentification peuvent être ajoutées au secret d'extraction du cluster global ou aux comptes de service de l'espace de noms individuel pour permettre l'accès requis.
Les types d'images suivants doivent être pris en compte pour déterminer si les opérateurs gérés par OLM disposent d'un accès au tirage approprié :
- Images de l'index
-
Un objet
CatalogSourcepeut faire référence à une image d'index, qui utilise le format Operator bundle et est une source de catalogue conditionnée sous forme d'images conteneurisées hébergées dans des registres d'images. Si une image d'index est hébergée dans un registre privé, un secret peut être utilisé pour permettre l'accès en pull. - Images de l'ensemble
- Les images d'ensemble d'opérateurs sont des métadonnées et des manifestes présentés sous forme d'images conteneurisées qui représentent une version unique d'un opérateur. Si des images d'ensemble référencées dans une source de catalogue sont hébergées dans un ou plusieurs registres privés, un secret peut être utilisé pour permettre l'accès en mode "pull".
- Images des opérateurs et des opérandes
Si un opérateur installé à partir d'une source de catalogue utilise une image privée, que ce soit pour l'image de l'opérateur elle-même ou pour l'une des images d'opérandes qu'elle surveille, l'installation de l'opérateur échouera car le déploiement n'aura pas accès à l'authentification de registre requise. Le fait de référencer des secrets dans une source de catalogue ne permet pas à OLM de placer les secrets dans les espaces de noms des locataires cibles dans lesquels les opérateurs sont installés.
Au lieu de cela, les détails d'authentification peuvent être ajoutés au secret d'extraction du cluster global dans l'espace de noms
openshift-config, qui donne accès à tous les espaces de noms du cluster. Si l'accès à l'ensemble du cluster n'est pas autorisé, le secret d'extraction peut être ajouté aux comptes de servicedefaultdes espaces de noms des locataires cibles.
Conditions préalables
Au moins un des éléments suivants hébergé dans un registre privé :
- Une image d'index ou de catalogue.
- Une image du faisceau d'opérateurs.
- Une image d'opérateur ou d'opérande.
Procédure
Créez un secret pour chaque registre privé requis.
Connectez-vous au registre privé pour créer ou mettre à jour votre fichier d'informations d'identification :
$ podman login <registry>:<port>NoteLe chemin d'accès au fichier des informations d'identification du registre peut varier en fonction de l'outil conteneur utilisé pour se connecter au registre. Pour l'interface de programmation
podman, l'emplacement par défaut est${XDG_RUNTIME_DIR}/containers/auth.json. Pour le CLIdocker, l'emplacement par défaut est/root/.docker/config.json.Il est recommandé d'inclure des informations d'identification pour un seul registre par secret et de gérer les informations d'identification pour plusieurs registres dans des secrets distincts. Plusieurs secrets peuvent être inclus dans un objet
CatalogSourcelors d'étapes ultérieures, et OpenShift Container Platform fusionnera les secrets en un seul fichier d'informations d'identification virtuel à utiliser lors d'une extraction d'image.Un fichier d'informations d'identification de registre peut, par défaut, contenir des informations relatives à plusieurs registres ou à plusieurs référentiels d'un même registre. Vérifiez le contenu actuel de votre fichier. Par exemple :
Fichier stockant les informations d'identification pour plusieurs registres
{ "auths": { "registry.redhat.io": { "auth": "FrNHNydQXdzclNqdg==" }, "quay.io": { "auth": "fegdsRib21iMQ==" }, "https://quay.io/my-namespace/my-user/my-image": { "auth": "eWfjwsDdfsa221==" }, "https://quay.io/my-namespace/my-user": { "auth": "feFweDdscw34rR==" }, "https://quay.io/my-namespace": { "auth": "frwEews4fescyq==" } } }Ce fichier étant utilisé pour créer des secrets dans les étapes suivantes, assurez-vous que vous ne stockez les détails que pour un seul registre par fichier. Pour ce faire, vous pouvez utiliser l'une des méthodes suivantes :
-
Utilisez la commande
podman logout <registry>pour supprimer les informations d'identification des registres supplémentaires jusqu'à ce qu'il ne reste plus que le registre souhaité. Modifiez votre fichier d'informations d'identification du registre et séparez les détails du registre à stocker dans plusieurs fichiers. Par exemple :
Fichier stockant les informations d'identification pour un registre
{ "auths": { "registry.redhat.io": { "auth": "FrNHNydQXdzclNqdg==" } } }Fichier stockant les informations d'identification pour un autre registre
{ "auths": { "quay.io": { "auth": "Xd2lhdsbnRib21iMQ==" } } }
-
Utilisez la commande
Créez un secret dans l'espace de noms
openshift-marketplacequi contient les informations d'authentification pour un registre privé :$ oc create secret generic <secret_name> \ -n openshift-marketplace \ --from-file=.dockerconfigjson=<path/to/registry/credentials> \ --type=kubernetes.io/dockerconfigjsonRépétez cette étape pour créer des secrets supplémentaires pour tout autre registre privé requis, en mettant à jour l'indicateur
--from-filepour spécifier un autre chemin d'accès au fichier d'informations d'identification du registre.
Créer ou mettre à jour un objet
CatalogSourceexistant pour référencer un ou plusieurs secrets :apiVersion: operators.coreos.com/v1alpha1 kind: CatalogSource metadata: name: my-operator-catalog namespace: openshift-marketplace spec: sourceType: grpc secrets:1 - "<secret_name_1>" - "<secret_name_2>" grpcPodConfig: securityContextConfig: <security_mode>2 image: <registry>:<port>/<namespace>/<image>:<tag> displayName: My Operator Catalog publisher: <publisher_name> updateStrategy: registryPoll: interval: 30m- 1
- Ajoutez une section
spec.secretset spécifiez les secrets requis. - 2
- Spécifiez la valeur de
legacyourestricted. Si le champ n'est pas défini, la valeur par défaut estlegacy. Dans une prochaine version d'OpenShift Container Platform, il est prévu que la valeur par défaut soitrestricted. Si votre catalogue ne peut pas s'exécuter avec les autorisationsrestricted, il est recommandé de définir manuellement ce champ surlegacy.
Si des images d'opérateurs ou d'opérandes référencées par un opérateur abonné nécessitent l'accès à un registre privé, vous pouvez soit fournir un accès à tous les espaces de noms du cluster, soit à des espaces de noms de locataires cibles individuels.
Pour permettre l'accès à tous les espaces de noms du cluster, ajoutez des détails d'authentification au secret d'extraction du cluster global dans l'espace de noms
openshift-config.AvertissementLes ressources du cluster doivent s'adapter au nouveau secret de tirage global, ce qui peut limiter temporairement la capacité d'utilisation du cluster.
Extraire le fichier
.dockerconfigjsondu secret d'extraction global :$ oc extract secret/pull-secret -n openshift-config --confirmMettez à jour le fichier
.dockerconfigjsonavec vos informations d'authentification pour le ou les registres privés requis et enregistrez-le dans un nouveau fichier :$ cat .dockerconfigjson | \ jq --compact-output '.auths["<registry>:<port>/<namespace>/"] |= . + {"auth":"<token>"}' \1 > new_dockerconfigjson- 1
- Remplacez
<registry>:<port>/<namespace>par les détails du registre privé et<token>par vos identifiants d'authentification.
Mettre à jour le secret d'extraction global avec le nouveau fichier :
$ oc set data secret/pull-secret -n openshift-config \ --from-file=.dockerconfigjson=new_dockerconfigjson
Pour mettre à jour un espace de noms individuel, ajoutez un secret d'extraction au compte de service de l'opérateur qui a besoin d'un accès dans l'espace de noms du locataire cible.
Recréez le secret que vous avez créé pour
openshift-marketplacedans l'espace de noms du locataire :$ oc create secret generic <secret_name> \ -n <tenant_namespace> \ --from-file=.dockerconfigjson=<path/to/registry/credentials> \ --type=kubernetes.io/dockerconfigjsonVérifiez le nom du compte de service de l'opérateur en effectuant une recherche dans l'espace de noms du locataire :
oc get sa -n <tenant_namespace>1 - 1
- Si l'opérateur a été installé dans un espace de noms particulier, recherchez dans cet espace de noms. Si l'opérateur a été installé dans tous les espaces de noms, recherchez l'espace de noms
openshift-operators.
Exemple de sortie
NAME SECRETS AGE builder 2 6m1s default 2 6m1s deployer 2 6m1s etcd-operator 2 5m18s1 - 1
- Compte de service pour un opérateur etcd installé.
Lier le secret au compte de service de l'opérateur :
$ oc secrets link <operator_sa> \ -n <tenant_namespace> \ <secret_name> \ --for=pull
4.9.7. Disabling the default OperatorHub catalog sources
Les catalogues d'opérateurs que le contenu source fourni par Red Hat et les projets communautaires sont configurés pour OperatorHub par défaut lors d'une installation d'OpenShift Container Platform. En tant qu'administrateur de cluster, vous pouvez désactiver l'ensemble des catalogues par défaut.
Procédure
Disable the sources for the default catalogs by adding
disableAllDefaultSources: trueto theOperatorHubobject:$ oc patch OperatorHub cluster --type json \ -p '[{"op": "add", "path": "/spec/disableAllDefaultSources", "value": true}]'
Alternatively, you can use the web console to manage catalog sources. From the Administration → Cluster Settings → Configuration → OperatorHub page, click the Sources tab, where you can create, delete, disable, and enable individual sources.
4.9.8. Suppression des catalogues personnalisés
En tant qu'administrateur de cluster, vous pouvez supprimer les catalogues d'opérateurs personnalisés qui ont été précédemment ajoutés à votre cluster en supprimant la source de catalogue correspondante.
Procédure
- Dans la perspective Administrator de la console web, naviguez vers Administration → Cluster Settings.
- Cliquez sur l'onglet Configuration, puis sur OperatorHub.
- Cliquez sur l'onglet Sources.
-
Sélectionnez le menu Options
 du catalogue que vous souhaitez supprimer, puis cliquez sur Delete CatalogSource.
du catalogue que vous souhaitez supprimer, puis cliquez sur Delete CatalogSource.
4.10. Utilisation d'Operator Lifecycle Manager sur des réseaux restreints
Pour les clusters OpenShift Container Platform qui sont installés sur des réseaux restreints, également connus sous le nom de disconnected clusters, Operator Lifecycle Manager (OLM) par défaut ne peut pas accéder aux sources OperatorHub fournies par Red Hat et hébergées sur des registres distants, car ces sources distantes nécessitent une connectivité Internet complète.
Cependant, en tant qu'administrateur de cluster, vous pouvez toujours permettre à votre cluster d'utiliser OLM dans un réseau restreint si vous avez un poste de travail qui a un accès complet à l'internet. Le poste de travail, qui nécessite un accès complet à Internet pour extraire le contenu OperatorHub distant, est utilisé pour préparer des miroirs locaux des sources distantes et pousser le contenu vers un registre de miroirs.
Le registre miroir peut être situé sur un hôte bastion, qui nécessite une connectivité à la fois à votre station de travail et au cluster déconnecté, ou sur un hôte complètement déconnecté, ou airgapped, qui nécessite un support amovible pour déplacer physiquement le contenu mis en miroir vers l'environnement déconnecté.
Ce guide décrit la procédure suivante, nécessaire pour activer OLM dans les réseaux restreints :
- Désactiver les sources OperatorHub distantes par défaut pour OLM.
- Utiliser un poste de travail avec un accès complet à l'internet pour créer et pousser des miroirs locaux du contenu d'OperatorHub vers un registre de miroirs.
- Configurez OLM pour qu'il installe et gère des opérateurs à partir de sources locales sur le registre miroir au lieu des sources distantes par défaut.
Après avoir activé OLM dans un réseau restreint, vous pouvez continuer à utiliser votre poste de travail non restreint pour maintenir vos sources OperatorHub locales à jour au fur et à mesure que de nouvelles versions d'opérateurs sont publiées.
Bien qu'OLM puisse gérer des opérateurs à partir de sources locales, la capacité d'un opérateur donné à fonctionner avec succès dans un réseau restreint dépend toujours de l'opérateur lui-même, qui doit répondre aux critères suivants :
-
Dresser la liste des images connexes ou des autres images de conteneurs dont l'opérateur pourrait avoir besoin pour remplir ses fonctions, dans le paramètre
relatedImagesde son objetClusterServiceVersion(CSV). - Référencer toutes les images spécifiées par un condensé (SHA) et non par un tag.
Vous pouvez rechercher des logiciels dans le catalogue de l'écosystème Red Hat pour obtenir une liste des opérateurs Red Hat qui prennent en charge l'exécution en mode déconnecté en filtrant avec les sélections suivantes :
| Type | Application conteneurisée |
| Méthode de déploiement | Opérateur |
| Caractéristiques de l'infrastructure | Déconnecté |
4.10.1. Conditions préalables
-
Connectez-vous à votre cluster OpenShift Container Platform en tant qu'utilisateur disposant des privilèges
cluster-admin. -
Si vous souhaitez élaguer le catalogue par défaut et ne mettre en miroir de manière sélective qu'un sous-ensemble d'opérateurs, installez le CLI
opm.
Si vous utilisez OLM dans un réseau restreint sur des systèmes IBM z, vous devez disposer d'au moins 12 Go dans le répertoire où vous placez votre registre.
4.10.2. Disabling the default OperatorHub catalog sources
Les catalogues d'opérateurs dont le contenu source est fourni par Red Hat et les projets communautaires sont configurés pour OperatorHub par défaut lors d'une installation d'OpenShift Container Platform. Dans un environnement réseau restreint, vous devez désactiver les catalogues par défaut en tant qu'administrateur de cluster. Vous pouvez ensuite configurer OperatorHub pour utiliser des sources de catalogue locales.
Procédure
Disable the sources for the default catalogs by adding
disableAllDefaultSources: trueto theOperatorHubobject:$ oc patch OperatorHub cluster --type json \ -p '[{"op": "add", "path": "/spec/disableAllDefaultSources", "value": true}]'
Alternatively, you can use the web console to manage catalog sources. From the Administration → Cluster Settings → Configuration → OperatorHub page, click the Sources tab, where you can create, delete, disable, and enable individual sources.
4.10.3. Filtrage d'une image d'index basée sur SQLite
Une image d'index, basée sur le format Operator bundle, est un instantané conteneurisé d'un catalogue d'opérateurs. Vous pouvez filtrer, ou prune, un index de tous les paquets à l'exception d'une liste spécifiée, ce qui crée une copie de l'index source contenant uniquement les opérateurs que vous souhaitez.
Lorsque vous configurez Operator Lifecycle Manager (OLM) pour utiliser du contenu mis en miroir sur des clusters OpenShift Container Platform à réseau restreint, utilisez cette méthode d'élagage si vous souhaitez uniquement mettre en miroir un sous-ensemble d'opérateurs à partir des catalogues par défaut.
Pour les étapes de cette procédure, le registre cible est un registre miroir existant qui est accessible par votre station de travail avec un accès réseau illimité. Cet exemple montre également l'élagage de l'image d'index pour le catalogue par défaut redhat-operators, mais le processus est le même pour n'importe quelle image d'index.
Conditions préalables
- Poste de travail avec accès illimité au réseau
-
podmanversion 1.9.3 -
grpcurl(outil de ligne de commande tiers) -
opm - Accès à un registre qui prend en charge Docker v2-2
Procédure
S'authentifier avec
registry.redhat.io:$ podman login registry.redhat.ioS'authentifier avec le registre cible :
$ podman login <target_registry>Déterminez la liste des paquets que vous souhaitez inclure dans votre index élagué.
Exécutez l'image de l'index source que vous souhaitez élaguer dans un conteneur. Par exemple :
$ podman run -p50051:50051 \ -it registry.redhat.io/redhat/redhat-operator-index:v4.12Exemple de sortie
Trying to pull registry.redhat.io/redhat/redhat-operator-index:v4.12... Getting image source signatures Copying blob ae8a0c23f5b1 done ... INFO[0000] serving registry database=/database/index.db port=50051Dans une autre session de terminal, utilisez la commande
grpcurlpour obtenir une liste des paquets fournis par l'index :grpcurl -plaintext localhost:50051 api.Registry/ListPackages > packages.outInspectez le fichier
packages.outet identifiez les noms de paquets de cette liste que vous souhaitez conserver dans votre index élagué. Par exemple :Exemples de listes de paquets
... { "name": "advanced-cluster-management" } ... { "name": "jaeger-product" } ... { { "name": "quay-operator" } ...-
Dans la session de terminal où vous avez exécuté la commande
podman run, appuyez sur Ctrl et C pour arrêter le processus de conteneur.
Exécutez la commande suivante pour élaguer l'index source de tous les paquets, à l'exception des paquets spécifiés :
$ opm index prune \ -f registry.redhat.io/redhat/redhat-operator-index:v4.12 \1 -p advanced-cluster-management,jaeger-product,quay-operator \2 [-i registry.redhat.io/openshift4/ose-operator-registry:v4.9] \3 -t <target_registry>:<port>/<namespace>/redhat-operator-index:v4.124 - 1
- Index pour la taille.
- 2
- Liste de paquets à conserver, séparés par des virgules.
- 3
- Requis uniquement pour les images IBM Power et IBM zSystems : L'image de base Operator Registry avec le tag qui correspond à la version majeure et mineure du cluster OpenShift Container Platform cible.
- 4
- Balise personnalisée pour la nouvelle image d'index en cours de construction.
Exécutez la commande suivante pour transférer la nouvelle image d'index dans votre registre cible :
$ podman push <target_registry>:<port>/<namespace>/redhat-operator-index:v4.12où
<namespace>est un espace de noms existant dans le registre. Par exemple, vous pouvez créer un espace de nomsolm-mirrorpour y transférer tout le contenu mis en miroir.
4.10.4. Miroir d'un catalogue d'opérateurs
Pour obtenir des instructions sur la mise en miroir des catalogues d'opérateurs pour une utilisation avec des clusters déconnectés, voir Installation → Mise en miroir d'images pour une installation déconnectée.
À partir d'OpenShift Container Platform 4.11, le catalogue Operator fourni par Red Hat par défaut est publié dans le format de catalogue basé sur des fichiers. Les catalogues Operator fournis par Red Hat par défaut pour OpenShift Container Platform 4.6 à 4.10 sont publiés dans le format de base de données SQLite déprécié.
Les sous-commandes, drapeaux et fonctionnalités de opm liés au format de base de données SQLite sont également obsolètes et seront supprimés dans une prochaine version. Ces fonctionnalités sont toujours prises en charge et doivent être utilisées pour les catalogues qui utilisent le format de base de données SQLite obsolète.
La plupart des sous-commandes et des drapeaux de opm pour travailler avec le format de base de données SQLite, tels que opm index prune, ne fonctionnent pas avec le format de catalogue basé sur des fichiers. Pour plus d'informations sur l'utilisation des catalogues basés sur des fichiers, voir Format d'empaquetage d'Operator Framework, Gestion des catalogues personnalisés et Mise en miroir des images pour une installation déconnectée à l'aide du plugin oc-mirror.
4.10.5. Ajout d'une source de catalogue à un cluster
L'ajout d'une source de catalogue à un cluster OpenShift Container Platform permet la découverte et l'installation d'opérateurs pour les utilisateurs. Les administrateurs de cluster peuvent créer un objet CatalogSource qui référence une image d'index. OperatorHub utilise des sources de catalogue pour remplir l'interface utilisateur.
Conditions préalables
- Une image d'index est construite et poussée vers un registre.
Procédure
Créez un objet
CatalogSourcequi fait référence à votre image d'index. Si vous avez utilisé la commandeoc adm catalog mirrorpour mettre en miroir votre catalogue vers un registre cible, vous pouvez utiliser le fichiercatalogSource.yamlgénéré dans votre répertoire manifests comme point de départ.Modifiez le texte suivant selon vos spécifications et sauvegardez-le sous forme de fichier
catalogSource.yaml:apiVersion: operators.coreos.com/v1alpha1 kind: CatalogSource metadata: name: my-operator-catalog1 namespace: openshift-marketplace2 spec: sourceType: grpc grpcPodConfig: securityContextConfig: <security_mode>3 image: <registry>/<namespace>/redhat-operator-index:v4.124 displayName: My Operator Catalog publisher: <publisher_name>5 updateStrategy: registryPoll:6 interval: 30m- 1
- Si vous avez mis en miroir le contenu dans des fichiers locaux avant de le télécharger dans un registre, supprimez tous les caractères backslash (
/) du champmetadata.nameafin d'éviter une erreur "invalid resource name" (nom de ressource non valide) lors de la création de l'objet. - 2
- Si vous souhaitez que la source du catalogue soit disponible globalement pour les utilisateurs de tous les espaces de noms, spécifiez l'espace de noms
openshift-marketplace. Sinon, vous pouvez spécifier un espace de noms différent pour que le catalogue soit délimité et disponible uniquement pour cet espace de noms. - 3
- Spécifiez la valeur de
legacyourestricted. Si le champ n'est pas défini, la valeur par défaut estlegacy. Dans une prochaine version d'OpenShift Container Platform, il est prévu que la valeur par défaut soitrestricted. Si votre catalogue ne peut pas s'exécuter avec les autorisationsrestricted, il est recommandé de définir manuellement ce champ surlegacy. - 4
- Spécifiez votre image d'index. Si vous spécifiez une balise après le nom de l'image, par exemple
:v4.12, le pod source du catalogue utilise une politique d'extraction d'image deAlways, ce qui signifie que le pod extrait toujours l'image avant de démarrer le conteneur. Si vous spécifiez un condensé, par exemple@sha256:<id>, la politique d'extraction d'image estIfNotPresent, ce qui signifie que le module n'extrait l'image que si elle n'existe pas déjà sur le nœud. - 5
- Indiquez votre nom ou le nom d'une organisation qui publie le catalogue.
- 6
- Les sources du catalogue peuvent automatiquement vérifier la présence de nouvelles versions pour rester à jour.
Utilisez le fichier pour créer l'objet
CatalogSource:$ oc apply -f catalogSource.yaml
Vérifiez que les ressources suivantes ont bien été créées.
Vérifier les gousses :
$ oc get pods -n openshift-marketplaceExemple de sortie
NAME READY STATUS RESTARTS AGE my-operator-catalog-6njx6 1/1 Running 0 28s marketplace-operator-d9f549946-96sgr 1/1 Running 0 26hVérifier la source du catalogue :
$ oc get catalogsource -n openshift-marketplaceExemple de sortie
NAME DISPLAY TYPE PUBLISHER AGE my-operator-catalog My Operator Catalog grpc 5sVérifier le manifeste du paquet :
$ oc get packagemanifest -n openshift-marketplaceExemple de sortie
NAME CATALOG AGE jaeger-product My Operator Catalog 93s
Vous pouvez maintenant installer les opérateurs à partir de la page OperatorHub de votre console web OpenShift Container Platform.
4.10.6. Mise à jour d'une image d'index basée sur SQLite
Après avoir configuré OperatorHub pour utiliser une source de catalogue qui fait référence à une image d'index personnalisée, les administrateurs de cluster peuvent maintenir les opérateurs disponibles sur leur cluster à jour en ajoutant des images de bundle à l'image d'index.
Vous pouvez mettre à jour une image d'index existante à l'aide de la commande opm index add. Pour les réseaux restreints, le contenu mis à jour doit également être dupliqué sur le cluster.
Conditions préalables
-
opm -
podmanversion 1.9.3 - Une image d'index est construite et poussée vers un registre.
- Une source de catalogue existante référençant l'image d'index.
Procédure
Mettre à jour l'index existant en ajoutant des images de liasses :
$ opm index add \ --bundles <registry>/<namespace>/<new_bundle_image>@sha256:<digest> \1 --from-index <registry>/<namespace>/<existing_index_image>:<existing_tag> \2 --tag <registry>/<namespace>/<existing_index_image>:<updated_tag> \3 --pull-tool podman4 - 1
- L'option
--bundlesspécifie une liste séparée par des virgules d'images supplémentaires à ajouter à l'index. - 2
- Le drapeau
--from-indexspécifie l'index précédemment poussé. - 3
- L'option
--tagspécifie la balise d'image à appliquer à l'image d'index mise à jour. - 4
- L'option
--pull-toolspécifie l'outil utilisé pour extraire les images des conteneurs.
où :
<registry>-
Spécifie le nom d'hôte du registre, par exemple
quay.iooumirror.example.com. <namespace>-
Spécifie l'espace de noms du registre, par exemple
ocs-devouabc. <new_bundle_image>-
Spécifie la nouvelle image de paquet à ajouter au registre, par exemple
ocs-operator. <digest>-
Spécifie l'ID de l'image SHA, ou condensé, de l'image de la liasse, par exemple
c7f11097a628f092d8bad148406aa0e0951094a03445fd4bc0775431ef683a41. <existing_index_image>-
Spécifie l'image précédemment poussée, telle que
abc-redhat-operator-index. <existing_tag>-
Spécifie une balise d'image précédemment poussée, telle que
4.12. <updated_tag>-
Spécifie la balise d'image à appliquer à l'image d'index mise à jour, par exemple
4.12.1.
Example command
$ opm index add \ --bundles quay.io/ocs-dev/ocs-operator@sha256:c7f11097a628f092d8bad148406aa0e0951094a03445fd4bc0775431ef683a41 \ --from-index mirror.example.com/abc/abc-redhat-operator-index:4.12 \ --tag mirror.example.com/abc/abc-redhat-operator-index:4.12.1 \ --pull-tool podmanPousser l'image d'index mise à jour :
$ podman push <registry>/<namespace>/<existing_index_image>:<updated_tag>Suivez à nouveau les étapes de la procédure Mirroring an Operator catalog pour refléter le contenu mis à jour. Cependant, lorsque vous arrivez à l'étape de création de l'objet
ImageContentSourcePolicy(ICSP), utilisez la commandeoc replaceau lieu de la commandeoc create. Par exemple :oc replace -f ./manifests-redhat-operator-index-<random_number>/imageContentSourcePolicy.yamlCette modification est nécessaire car l'objet existe déjà et doit être mis à jour.
NoteNormalement, la commande
oc applypeut être utilisée pour mettre à jour des objets existants qui ont été créés précédemment à l'aide deoc apply. Toutefois, en raison d'un problème connu concernant la taille du champmetadata.annotationsdans les objets ICSP, la commandeoc replacedoit être utilisée pour cette étape.Une fois que Operator Lifecycle Manager (OLM) a interrogé automatiquement l'image d'index référencée dans la source du catalogue à intervalles réguliers, vérifiez que les nouveaux paquets ont été ajoutés avec succès :
$ oc get packagemanifests -n openshift-marketplace
4.11. Catalogage de la source d'ordonnancement des pods
Lorsqu'une source de catalogue Operator Lifecycle Manager (OLM) de type grpc définit une spec.image, l'opérateur de catalogue crée un pod qui sert le contenu de l'image définie. Par défaut, ce pod définit les éléments suivants dans sa spécification :
-
Seul le sélecteur de nœuds
kubernetes.io/os=linux - Pas de nom de classe de priorité
- Aucune tolérance
En tant qu'administrateur, vous pouvez remplacer ces valeurs en modifiant les champs de la section facultative spec.grpcPodConfig de l'objet CatalogSource.
4.11.1. Remplacer le sélecteur de nœuds pour les pods source du catalogue
Prequisites
-
CatalogSourceobjet de type sourcegrpcavecspec.imagedéfini
Procédure
Modifiez l'objet
CatalogSourceet ajoutez ou modifiez la sectionspec.grpcPodConfigpour inclure ce qui suit :grpcPodConfig: nodeSelector: custom_label: <label>où
<label>est l'étiquette du sélecteur de nœud que vous souhaitez que les pods source du catalogue utilisent pour l'ordonnancement.
4.11.2. Remplacer le nom de la classe de priorité pour les pods source du catalogue
Prequisites
-
CatalogSourceobjet de type sourcegrpcavecspec.imagedéfini
Procédure
Modifiez l'objet
CatalogSourceet ajoutez ou modifiez la sectionspec.grpcPodConfigpour inclure ce qui suit :grpcPodConfig: priorityClassName: <priority_class>où
<priority_class>est l'un des suivants :-
Une des classes de priorité par défaut fournies par Kubernetes :
system-cluster-criticalousystem-node-critical -
Un ensemble vide (
"") pour attribuer la priorité par défaut - Une classe de priorité préexistante et définie sur mesure
-
Une des classes de priorité par défaut fournies par Kubernetes :
Auparavant, le seul paramètre d'ordonnancement des pods qui pouvait être remplacé était priorityClassName. Pour ce faire, il suffisait d'ajouter l'annotation operatorframework.io/priorityclass à l'objet CatalogSource. Par exemple :
apiVersion: operators.coreos.com/v1alpha1
kind: CatalogSource
metadata:
name: example-catalog
namespace: namespace: openshift-marketplace
annotations:
operatorframework.io/priorityclass: system-cluster-critical
Si un objet CatalogSource définit à la fois l'annotation et spec.grpcPodConfig.priorityClassName, l'annotation est prioritaire sur le paramètre de configuration.
4.11.3. Dépassement des tolérances pour les pods source du catalogue
Prequisites
-
CatalogSourceobjet de type sourcegrpcavecspec.imagedéfini
Procédure
Modifiez l'objet
CatalogSourceet ajoutez ou modifiez la sectionspec.grpcPodConfigpour inclure ce qui suit :grpcPodConfig: tolerations: - key: "<key_name>" operator: "<operator_type>" value: "<value>" effect: "<effect>"
4.12. Gestion des opérateurs de plateforme (Avant-première technologique)
Un opérateur de plateforme est un opérateur basé sur OLM qui peut être installé pendant ou après les opérations du jour 0 d'un cluster OpenShift Container Platform et qui participe au cycle de vie du cluster. En tant qu'administrateur de cluster, vous pouvez gérer les opérateurs de plateforme en utilisant l'API PlatformOperator.
Le type d'opérateur de plate-forme est une fonctionnalité d'aperçu technologique uniquement. Les fonctionnalités de l'aperçu technologique ne sont pas prises en charge par les accords de niveau de service (SLA) de production de Red Hat et peuvent ne pas être complètes sur le plan fonctionnel. Red Hat ne recommande pas de les utiliser en production. Ces fonctionnalités offrent un accès anticipé aux fonctionnalités des produits à venir, ce qui permet aux clients de tester les fonctionnalités et de fournir un retour d'information pendant le processus de développement.
Pour plus d'informations sur la portée de l'assistance des fonctionnalités de l'aperçu technologique de Red Hat, voir Portée de l'assistance des fonctionnalités de l'aperçu technologique.
4.12.1. À propos des opérateurs de plateforme
Operator Lifecycle Manager (OLM) introduit un nouveau type d'opérateur appelé platform Operators. Un opérateur de plateforme est un opérateur basé sur OLM qui peut être installé pendant ou après les opérations du jour 0 d'un cluster OpenShift Container Platform et qui participe au cycle de vie du cluster. En tant qu'administrateur de cluster, vous pouvez utiliser les opérateurs de plateforme pour personnaliser davantage votre installation OpenShift Container Platform afin de répondre à vos exigences et à vos cas d'utilisation.
En utilisant la fonction existante de capacités de cluster dans OpenShift Container Platform, les administrateurs de cluster peuvent déjà désactiver un sous-ensemble de composants basés sur l'opérateur de version de cluster (CVO) considérés comme non essentiels à la charge utile initiale avant l'installation du cluster. Les opérateurs de plateforme s'inspirent de ce modèle en offrant des options de personnalisation supplémentaires. Grâce au mécanisme de l'opérateur de plateforme, qui s'appuie sur les ressources du composant RukPak, les opérateurs basés sur OLM peuvent désormais être installés au moment de l'installation du cluster et peuvent bloquer le déploiement du cluster si l'opérateur ne parvient pas à s'installer correctement.
Dans OpenShift Container Platform 4.12, cette version Technology Preview se concentre sur le mécanisme de base de la plateforme Operator et construit une base pour étendre le concept dans les prochaines versions. Vous pouvez utiliser l'API PlatformOperator à l'échelle du cluster pour configurer les opérateurs avant ou après la création du cluster sur les clusters qui ont activé l'ensemble de fonctionnalités TechPreviewNoUpgrades.
4.12.1.1. Restrictions relatives à l'aperçu technologique pour les opérateurs de plates-formes
Pendant la version Technology Preview de la fonctionnalité Platform Operators dans OpenShift Container Platform 4.12, les restrictions suivantes déterminent si un Operator peut être installé via le mécanisme Platform Operators :
-
Les manifestes Kubernetes doivent être empaquetés à l'aide du format de paquet Operator Lifecycle Manager (OLM)
registry v1. - L'Opérateur ne peut pas déclarer de dépendances de paquetage ou de groupe/version/genre (GVK).
-
L'opérateur ne peut pas spécifier des modes d'installation de la version du service de cluster (CSV) autres que les modes suivants
AllNamespaces -
L'opérateur ne peut pas spécifier de définitions
WebhookouAPIService. -
Tous les paquets doivent se trouver dans la source du catalogue
redhat-operators.
Après avoir pris en compte ces restrictions, les opérateurs suivants peuvent être installés avec succès :
| 3scale-operator | amq-broker-rhel8 |
| amq-online | amq-streams |
| ansible-cloud-addons-operator | opérateur d'apicastère |
| opérateur de sécurité des conteneurs | eap |
| opérateur d'intégration de fichiers | produit gatekeeper-operator |
| opérateur d'intégration | jws-operator |
| kiali-ossm | node-healthcheck-operator |
| odf-csi-addons-operator | odr-hub-operator |
| openshift-cert-manager-operator | openshift-custom-metrics-autoscaler-operator |
| openshift-gitops-operator | openshift-pipelines-operator-rh |
| opérateur de quai | chapeau rouge-chamel-k |
| rhpam-kogito-operator | service-registry-operator |
| servicemeshoperator | skupper-opérateur |
Les fonctionnalités suivantes ne sont pas disponibles dans le cadre de cet aperçu technologique :
- Mise à jour automatique des paquets de l'opérateur de la plate-forme après le déploiement du cluster
- Extension du mécanisme de l'opérateur de plate-forme pour prendre en charge tout composant optionnel basé sur l'OVE
4.12.2. Conditions préalables
-
Accès à un cluster OpenShift Container Platform à l'aide d'un compte disposant des autorisations
cluster-admin. Le jeu de fonctionnalités
TechPreviewNoUpgradesest activé sur le cluster.AvertissementL'activation de l'ensemble de fonctionnalités
TechPreviewNoUpgradene peut être annulée et empêche les mises à jour mineures de la version. Ces jeux de fonctionnalités ne sont pas recommandés sur les clusters de production.-
Seule la source du catalogue
redhat-operatorsest activée sur le cluster. Il s'agit d'une restriction dans le cadre de la version Technology Preview. -
La commande
ocinstallée sur votre poste de travail.
4.12.3. Installation des opérateurs de plate-forme lors de la création d'un cluster
En tant qu'administrateur de cluster, vous pouvez installer des opérateurs de plateforme en fournissant les manifestes FeatureGate et PlatformOperator lors de la création du cluster.
Procédure
- Choisissez un opérateur de plate-forme parmi l'ensemble des opérateurs basés sur OLM pris en charge. Pour obtenir la liste de cet ensemble et des détails sur les limitations actuelles, voir "Technology Preview restrictions for platform Operators".
-
Sélectionnez une méthode d'installation en grappe et suivez les instructions pour créer un fichier
install-config.yaml. Pour plus de détails sur la préparation d'une installation en grappe, voir "Sélection d'une méthode d'installation en grappe et préparation pour les utilisateurs". Après avoir créé le fichier
install-config.yamlet y avoir apporté les modifications nécessaires, passez au répertoire qui contient le programme d'installation et créez les manifestes :./openshift-install create manifests --dir <installation_directory> $ ./openshift-install create manifests --dir <installation_directory>1 - 1
- For
<installation_directory>, specify the name of the directory that contains theinstall-config.yamlfile for your cluster.
Créez un fichier YAML de l'objet
FeatureGatedans le répertoire<installation_directory>/manifests/qui active l'ensemble de fonctionnalitésTechPreviewNoUpgrade, par exemple un fichierfeature-gate.yaml:Exemple de fichier
feature-gate.yamlapiVersion: config.openshift.io/v1 kind: FeatureGate metadata: annotations: include.release.openshift.io/self-managed-high-availability: "true" include.release.openshift.io/single-node-developer: "true" release.openshift.io/create-only: "true" name: cluster spec: featureSet: TechPreviewNoUpgrade1 - 1
- Activer l'ensemble de fonctions
TechPreviewNoUpgrade.
Créez un fichier YAML de l'objet
PlatformOperatorpour l'opérateur de la plateforme choisie dans le répertoire<installation_directory>/manifests/, par exemple un fichiercert-manager.yamlpour l'opérateur cert-manager de Red Hat OpenShift :Exemple de fichier
cert-manager.yamlapiVersion: platform.openshift.io/v1alpha1 kind: PlatformOperator metadata: name: cert-manager spec: package: name: openshift-cert-manager-operatorLorsque vous êtes prêt à terminer l'installation du cluster, reportez-vous à la méthode d'installation que vous avez choisie et continuez à exécuter la commande
openshift-install create cluster.Lors de la création du cluster, les manifestes fournis sont utilisés pour activer l'ensemble des fonctionnalités de
TechPreviewNoUpgradeet installer la plateforme Operator de votre choix.ImportantL'échec de l'installation de l'opérateur de plate-forme bloque le processus d'installation du cluster.
Vérification
Vérifiez l'état de la plate-forme
cert-managerOperator en exécutant la commande suivante :$ oc get platformoperator cert-manager -o yamlExemple de sortie
... status: activeBundleDeployment: name: cert-manager conditions: - lastTransitionTime: "2022-10-24T17:24:40Z" message: Successfully applied the cert-manager BundleDeployment resource reason: InstallSuccessful status: "True"1 type: Installed- 1
- Attendez que la condition d'état
InstalledsignaleTrue.
Vérifiez que l'opérateur du cluster
platform-operators-aggregatedsignale un étatAvailable=True:$ oc get clusteroperator platform-operators-aggregated -o yamlExemple de sortie
... status: conditions: - lastTransitionTime: "2022-10-24T17:43:26Z" message: All platform operators are in a successful state reason: AsExpected status: "False" type: Progressing - lastTransitionTime: "2022-10-24T17:43:26Z" status: "False" type: Degraded - lastTransitionTime: "2022-10-24T17:43:26Z" message: All platform operators are in a successful state reason: AsExpected status: "True" type: Available
4.12.4. Installation des opérateurs de plate-forme après la création du cluster
En tant qu'administrateur de cluster, vous pouvez installer les opérateurs de plateforme après la création du cluster sur les clusters qui ont activé le jeu de fonctionnalités TechPreviewNoUpgrades en utilisant l'API PlatformOperator à l'échelle du cluster.
Procédure
- Choisissez un opérateur de plate-forme parmi l'ensemble des opérateurs basés sur OLM pris en charge. Pour obtenir la liste de cet ensemble et des détails sur les limitations actuelles, voir "Technology Preview restrictions for platform Operators".
Créez un fichier YAML de l'objet
PlatformOperatorpour l'opérateur de la plateforme choisie, par exemple un fichiercert-manager.yamlpour l'opérateur cert-manager de Red Hat OpenShift :Exemple de fichier
cert-manager.yamlapiVersion: platform.openshift.io/v1alpha1 kind: PlatformOperator metadata: name: cert-manager spec: package: name: openshift-cert-manager-operatorCréez l'objet
PlatformOperatoren exécutant la commande suivante :$ oc apply -f cert-manager.yamlNoteSi le jeu de fonctionnalités
TechPreviewNoUpgradesn'est pas activé dans votre cluster, la création de l'objet échoue avec le message suivant :error: resource mapping not found for name: "cert-manager" namespace: "" from "cert-manager.yaml": no matches for kind "PlatformOperator" in version "platform.openshift.io/v1alpha1" ensure CRDs are installed first
Vérification
Vérifiez l'état de la plate-forme
cert-managerOperator en exécutant la commande suivante :$ oc get platformoperator cert-manager -o yamlExemple de sortie
... status: activeBundleDeployment: name: cert-manager conditions: - lastTransitionTime: "2022-10-24T17:24:40Z" message: Successfully applied the cert-manager BundleDeployment resource reason: InstallSuccessful status: "True"1 type: Installed- 1
- Attendez que la condition d'état
InstalledsignaleTrue.
Vérifiez que l'opérateur du cluster
platform-operators-aggregatedsignale un étatAvailable=True:$ oc get clusteroperator platform-operators-aggregated -o yamlExemple de sortie
... status: conditions: - lastTransitionTime: "2022-10-24T17:43:26Z" message: All platform operators are in a successful state reason: AsExpected status: "False" type: Progressing - lastTransitionTime: "2022-10-24T17:43:26Z" status: "False" type: Degraded - lastTransitionTime: "2022-10-24T17:43:26Z" message: All platform operators are in a successful state reason: AsExpected status: "True" type: Available
4.12.5. Suppression des opérateurs de plate-forme
En tant qu'administrateur de cluster, vous pouvez supprimer des opérateurs de plate-forme existants. Operator Lifecycle Manager (OLM) effectue une suppression en cascade. Tout d'abord, OLM supprime le déploiement du bundle pour l'opérateur de plate-forme, ce qui supprime ensuite tous les objets référencés dans le bundle de type registry v1.
Le gestionnaire d'opérateurs de plate-forme et le provisionneur de déploiement d'offres groupées ne gèrent que les objets référencés dans l'offre groupée, mais pas les objets déployés ultérieurement par les charges de travail de l'offre groupée elles-mêmes. Par exemple, si une charge de travail de l'offre groupée crée un espace de noms et que l'opérateur n'est pas configuré pour le nettoyer avant la suppression de l'opérateur, OLM n'est pas en mesure de supprimer l'espace de noms lors de la suppression de l'opérateur de plate-forme.
Procédure
Obtenez une liste des opérateurs de plate-forme installés et recherchez le nom de l'opérateur que vous souhaitez supprimer :
$ oc get platformoperatorSupprimer la ressource
PlatformOperatorpour l'opérateur choisi, par exemple pour l'opérateur de quai :$ oc delete platformoperator quay-operatorExemple de sortie
platformoperator.platform.openshift.io "quay-operator" deleted
Vérification
Vérifier que l'espace de noms de l'opérateur de plate-forme est finalement supprimé, par exemple pour l'opérateur de quai :
$ oc get ns quay-operator-systemExemple de sortie
Error from server (NotFound): namespaces "quay-operator-system" not foundVérifier que l'opérateur du cluster
platform-operators-aggregatedcontinue à signaler l'étatAvailable=True:$ oc get co platform-operators-aggregatedExemple de sortie
NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE MESSAGE platform-operators-aggregated 4.12.0-0 True False False 70s
Chapitre 5. Développer les opérateurs
5.1. À propos du SDK de l'opérateur
L'Operator Framework est une boîte à outils open source permettant de gérer les applications natives de Kubernetes, appelées Operators, de manière efficace, automatisée et évolutive. Les opérateurs tirent parti de l'extensibilité de Kubernetes pour offrir les avantages de l'automatisation des services en nuage, tels que le provisionnement, la mise à l'échelle, la sauvegarde et la restauration, tout en étant capables de fonctionner partout où Kubernetes peut fonctionner.
Les opérateurs facilitent la gestion d'applications complexes, avec état, au-dessus de Kubernetes. Cependant, écrire un Operator aujourd'hui peut être difficile en raison de défis tels que l'utilisation d'API de bas niveau, l'écriture de boilerplate, et un manque de modularité, ce qui conduit à la duplication.
L'Operator SDK, un composant de l'Operator Framework, fournit une interface de ligne de commande (CLI) que les développeurs d'opérateurs peuvent utiliser pour construire, tester et déployer un opérateur.
Why use the Operator SDK?
Le SDK Operator simplifie ce processus de création d'applications natives de Kubernetes, qui peut nécessiter des connaissances opérationnelles approfondies et spécifiques à l'application. Le SDK Operator ne se contente pas d'abaisser cette barrière, il contribue également à réduire la quantité de code standard nécessaire pour de nombreuses fonctions de gestion courantes, telles que le comptage ou la surveillance.
L'Operator SDK est un cadre qui utilise la bibliothèque controller-runtime pour faciliter l'écriture d'opérateurs en offrant les fonctionnalités suivantes :
- API de haut niveau et abstractions pour écrire la logique opérationnelle de manière plus intuitive
- Outils d'échafaudage et de génération de code pour démarrer rapidement un nouveau projet
- Intégration avec Operator Lifecycle Manager (OLM) pour rationaliser le conditionnement, l'installation et le fonctionnement des opérateurs sur un cluster
- Extensions pour couvrir les cas d'utilisation courants des opérateurs
- Paramètres définis automatiquement dans tout opérateur Go-based généré pour une utilisation sur les clusters où l'opérateur Prometheus est déployé
Les auteurs d'opérateurs ayant un accès d'administrateur de cluster à un cluster basé sur Kubernetes (tel que OpenShift Container Platform) peuvent utiliser le CLI Operator SDK pour développer leurs propres opérateurs basés sur Go, Ansible ou Helm. Kubebuilder est intégré dans le SDK Operator en tant que solution d'échafaudage pour les opérateurs basés sur Go, ce qui signifie que les projets Kubebuilder existants peuvent être utilisés tels quels avec le SDK Operator et continuer à fonctionner.
OpenShift Container Platform 4.12 supporte Operator SDK 1.25.4.
5.1.1. Qu'est-ce qu'un opérateur ?
Pour une vue d'ensemble des concepts et de la terminologie de base des opérateurs, voir Comprendre les opérateurs.
5.1.2. Processus de développement
Le SDK Opérateur fournit le flux de travail suivant pour développer un nouvel opérateur :
- Créez un projet Operator en utilisant l'interface de ligne de commande (CLI) du SDK Operator.
- Définir de nouvelles API de ressources en ajoutant des définitions de ressources personnalisées (CRD).
- Spécifiez les ressources à surveiller en utilisant l'API SDK de l'opérateur.
- Définir la logique de rapprochement de l'opérateur dans un gestionnaire désigné et utiliser l'API SDK de l'opérateur pour interagir avec les ressources.
- Utilisez l'interface CLI du SDK de l'opérateur pour créer et générer les manifestes de déploiement de l'opérateur.
Figure 5.1. Flux de travail de l'opérateur SDK
À un niveau élevé, un opérateur qui utilise le SDK opérateur traite les événements pour les ressources surveillées dans un gestionnaire défini par l'auteur de l'opérateur et prend des mesures pour réconcilier l'état de l'application.
5.2. Installation du SDK CLI de l'opérateur
L'Operator SDK fournit une interface de ligne de commande (CLI) que les développeurs d'opérateurs peuvent utiliser pour créer, tester et déployer un opérateur. Vous pouvez installer l'interface CLI du SDK de l'opérateur sur votre poste de travail afin d'être prêt à créer vos propres opérateurs.
Les auteurs d'opérateurs ayant un accès d'administrateur de cluster à un cluster basé sur Kubernetes, tel que OpenShift Container Platform, peuvent utiliser le CLI Operator SDK pour développer leurs propres opérateurs basés sur Go, Ansible, java ou Helm. Kubebuilder est intégré dans le SDK Operator en tant que solution d'échafaudage pour les opérateurs basés sur Go, ce qui signifie que les projets Kubebuilder existants peuvent être utilisés tels quels avec le SDK Operator et continuer à fonctionner.
OpenShift Container Platform 4.12 supporte Operator SDK 1.25.4.
5.2.1. Installation de l'interface de programmation de l'opérateur sous Linux
Vous pouvez installer l'outil OpenShift SDK CLI sur Linux.
Conditions préalables
- Go v1.19
-
dockerv17.03 ,podmanv1.9.3 , oubuildahv1.7
Procédure
- Naviguez vers le site miroir d'OpenShift.
- A partir du dernier répertoire 4.12, téléchargez la dernière version de l'archive pour Linux.
Décompressez l'archive :
$ tar xvf operator-sdk-v1.25.4-ocp-linux-x86_64.tar.gzRendre le fichier exécutable :
$ chmod +x operator-sdkDéplacez le fichier binaire
operator-sdkextrait dans un répertoire qui se trouve sur votre sitePATH.AstucePour vérifier votre
PATH:$ echo $PATH$ sudo mv ./operator-sdk /usr/local/bin/operator-sdk
Vérification
Après avoir installé le SDK CLI de l'opérateur, vérifiez qu'il est disponible :
$ operator-sdk versionExemple de sortie
operator-sdk version: "v1.25.4-ocp", ...
5.2.2. Installation du SDK CLI de l'opérateur sur macOS
Vous pouvez installer l'outil OpenShift SDK CLI sur macOS.
Conditions préalables
- Go v1.19
-
dockerv17.03 ,podmanv1.9.3 , oubuildahv1.7
Procédure
-
Pour les architectures
amd64etarm64, naviguez vers le site miroir OpenShift pour l'architectureamd64et le site miroir OpenShift pour l'architecturearm64respectivement. - A partir du dernier répertoire 4.12, téléchargez la dernière version de l'archive pour macOS.
Décompressez l'archive Operator SDK pour l'architecture
amd64en exécutant la commande suivante :$ tar xvf operator-sdk-v1.25.4-ocp-darwin-x86_64.tar.gzDécompressez l'archive Operator SDK pour l'architecture
arm64en exécutant la commande suivante :$ tar xvf operator-sdk-v1.25.4-ocp-darwin-aarch64.tar.gzRendez le fichier exécutable en exécutant la commande suivante :
$ chmod +x operator-sdkDéplacez le binaire
operator-sdkextrait dans un répertoire qui se trouve sur votrePATHen exécutant la commande suivante :AstuceVérifiez votre
PATHen exécutant la commande suivante :$ echo $PATH$ sudo mv ./operator-sdk /usr/local/bin/operator-sdk
Vérification
Après avoir installé l'interface de programmation de l'opérateur, vérifiez qu'elle est disponible en exécutant la commande suivante: :
$ operator-sdk versionExemple de sortie
operator-sdk version: "v1.25.4-ocp", ...
5.3. Opérateurs basés sur le Go
5.3.1. Premiers pas avec Operator SDK pour les opérateurs basés sur Go
Pour démontrer les bases de la configuration et de l'exécution d'un opérateur basé sur Go à l'aide des outils et des bibliothèques fournis par le SDK Operator, les développeurs d'opérateurs peuvent construire un exemple d'opérateur basé sur Go pour Memcached, un magasin de valeurs clés distribué, et le déployer dans un cluster.
5.3.1.1. Conditions préalables
- Operator SDK CLI installé
-
OpenShift CLI (
oc) v4.12 installé - Go v1.19
-
Connexion à un cluster OpenShift Container Platform 4.12 avec
ocavec un compte qui a les permissionscluster-admin - Pour permettre au cluster d'extraire l'image, le dépôt où vous avez poussé votre image doit être défini comme public, ou vous devez configurer un secret d'extraction d'image
5.3.1.2. Création et déploiement d'opérateurs basés sur Go
Vous pouvez construire et déployer un simple opérateur basé sur Go pour Memcached en utilisant le SDK Operator.
Procédure
Create a project.
Créez votre répertoire de projet :
$ mkdir memcached-operatorAllez dans le répertoire du projet :
$ cd memcached-operatorExécutez la commande
operator-sdk initpour initialiser le projet :$ operator-sdk init \ --domain=example.com \ --repo=github.com/example-inc/memcached-operatorLa commande utilise par défaut le plugin Go.
Create an API.
Créer une API Memcached simple :
$ operator-sdk create api \ --resource=true \ --controller=true \ --group cache \ --version v1 \ --kind MemcachedBuild and push the Operator image.
Utilisez les cibles par défaut de
Makefilepour construire et pousser votre opérateur. DéfinissezIMGavec une spécification d'extraction pour votre image qui utilise un registre vers lequel vous pouvez pousser :$ make docker-build docker-push IMG=<registry>/<user>/<image_name>:<tag>Run the Operator.
Installer le CRD :
$ make installDéployez le projet sur le cluster. Définissez
IMGsur l'image que vous avez poussée :$ make deploy IMG=<registry>/<user>/<image_name>:<tag>
Create a sample custom resource (CR).
Créer un échantillon de CR :
$ oc apply -f config/samples/cache_v1_memcached.yaml \ -n memcached-operator-systemIl faut s'attendre à ce que le CR réconcilie l'opérateur :
$ oc logs deployment.apps/memcached-operator-controller-manager \ -c manager \ -n memcached-operator-system
Delete a CR
Supprimez un CR en exécutant la commande suivante :
$ oc delete -f config/samples/cache_v1_memcached.yaml -n memcached-operator-systemClean up.
Exécutez la commande suivante pour nettoyer les ressources qui ont été créées dans le cadre de cette procédure :
$ make undeploy
5.3.1.3. Prochaines étapes
- Voir le tutoriel de l'Operator SDK pour les opérateurs basés sur Go pour une description plus approfondie de la construction d'un opérateur basé sur Go.
5.3.2. Didacticiel sur le SDK pour les opérateurs basés sur Go
Les développeurs d'opérateurs peuvent profiter de la prise en charge du langage de programmation Go dans le SDK de l'opérateur pour créer un exemple d'opérateur basé sur Go pour Memcached, un magasin de valeurs clés distribué, et gérer son cycle de vie.
Ce processus est réalisé à l'aide de deux pièces maîtresses du cadre de l'opérateur :
- SDK de l'opérateur
-
L'outil CLI
operator-sdket la bibliothèque APIcontroller-runtime - Gestionnaire du cycle de vie des opérateurs (OLM)
- Installation, mise à niveau et contrôle d'accès basé sur les rôles (RBAC) des opérateurs sur un cluster
Ce tutoriel est plus détaillé que le tutoriel " Getting started with Operator SDK for Go-based Operators" (Démarrer avec Operator SDK pour les opérateurs basés sur Go).
5.3.2.1. Conditions préalables
- Operator SDK CLI installé
-
OpenShift CLI (
oc) v4.12 installé - Go v1.19
-
Connexion à un cluster OpenShift Container Platform 4.12 avec
ocavec un compte qui a les permissionscluster-admin - Pour permettre au cluster d'extraire l'image, le dépôt où vous avez poussé votre image doit être défini comme public, ou vous devez configurer un secret d'extraction d'image
5.3.2.2. Création d'un projet
Utilisez l'interface de programmation Operator SDK pour créer un projet appelé memcached-operator.
Procédure
Créer un répertoire pour le projet :
$ mkdir -p $HOME/projects/memcached-operatorAccédez au répertoire :
$ cd $HOME/projects/memcached-operatorActiver le support pour les modules Go :
$ export GO111MODULE=onExécutez la commande
operator-sdk initpour initialiser le projet :$ operator-sdk init \ --domain=example.com \ --repo=github.com/example-inc/memcached-operatorNoteLa commande
operator-sdk initutilise par défaut le plugin Go.La commande
operator-sdk initgénère un fichiergo.modà utiliser avec les modules Go. Le drapeau--repoest nécessaire lors de la création d'un projet en dehors de$GOPATH/src/, car les fichiers générés nécessitent un chemin de module valide.
5.3.2.2.1. Dossier PROJET
Parmi les fichiers générés par la commande operator-sdk init figure un fichier Kubebuilder PROJECT. Les commandes operator-sdk suivantes, ainsi que la sortie help, qui sont exécutées à partir de la racine du projet, lisent ce fichier et savent que le type de projet est Go. Par exemple :
domain: example.com
layout:
- go.kubebuilder.io/v3
projectName: memcached-operator
repo: github.com/example-inc/memcached-operator
version: "3"
plugins:
manifests.sdk.operatorframework.io/v2: {}
scorecard.sdk.operatorframework.io/v2: {}
sdk.x-openshift.io/v1: {}5.3.2.2.2. À propos du gestionnaire
Le programme principal de l'opérateur est le fichier main.go, qui initialise et exécute le gestionnaire. Ce dernier enregistre automatiquement le schéma pour toutes les définitions d'API de ressources personnalisées (CR) et met en place et exécute les contrôleurs et les webhooks.
Le gestionnaire peut restreindre l'espace de noms que tous les contrôleurs surveillent à la recherche de ressources :
mgr, err := ctrl.NewManager(cfg, manager.Options{Namespace: namespace})
Par défaut, le gestionnaire surveille l'espace de noms dans lequel l'opérateur s'exécute. Pour surveiller tous les espaces de noms, vous pouvez laisser l'option namespace vide :
mgr, err := ctrl.NewManager(cfg, manager.Options{Namespace: ""})
Vous pouvez également utiliser la fonction MultiNamespacedCacheBuilder pour surveiller un ensemble spécifique d'espaces de noms :
var namespaces []string
mgr, err := ctrl.NewManager(cfg, manager.Options{
NewCache: cache.MultiNamespacedCacheBuilder(namespaces),
})5.3.2.2.3. À propos des API multigroupes
Avant de créer une API et un contrôleur, demandez-vous si votre opérateur a besoin de plusieurs groupes d'API. Ce didacticiel couvre le cas par défaut d'une API à groupe unique, mais pour modifier la présentation de votre projet afin de prendre en charge des API à groupes multiples, vous pouvez exécuter la commande suivante :
$ operator-sdk edit --multigroup=true
Cette commande met à jour le fichier PROJECT, qui devrait ressembler à l'exemple suivant :
domain: example.com
layout: go.kubebuilder.io/v3
multigroup: true
...
Pour les projets multi-groupes, les fichiers de type API Go sont créés dans le répertoire apis/<group>/<version>/, et les contrôleurs sont créés dans le répertoire controllers/<group>/. Le fichier Dockerfile est ensuite mis à jour en conséquence.
Ressource supplémentaire
- Pour plus de détails sur la migration vers un projet multi-groupe, voir la documentation de Kubebuilder.
5.3.2.3. Création d'une API et d'un contrôleur
Utilisez le SDK CLI de l'opérateur pour créer une API et un contrôleur de définition de ressources personnalisées (CRD).
Procédure
Exécutez la commande suivante pour créer une API avec le groupe
cache, la versionv1et le typeMemcached:$ operator-sdk create api \ --group=cache \ --version=v1 \ --kind=MemcachedLorsque vous y êtes invité, entrez
ypour créer la ressource et le contrôleur :Create Resource [y/n] y Create Controller [y/n] yExemple de sortie
Writing scaffold for you to edit... api/v1/memcached_types.go controllers/memcached_controller.go ...
Ce processus génère la ressource Memcached API à l'adresse api/v1/memcached_types.go et le contrôleur à l'adresse controllers/memcached_controller.go.
5.3.2.3.1. Définition de l'API
Définir l'API pour la ressource personnalisée (CR) Memcached.
Procédure
Modifiez les définitions du type Go à l'adresse
api/v1/memcached_types.gopour obtenirspecetstatus:// MemcachedSpec defines the desired state of Memcached type MemcachedSpec struct { // +kubebuilder:validation:Minimum=0 // Size is the size of the memcached deployment Size int32 `json:"size"` } // MemcachedStatus defines the observed state of Memcached type MemcachedStatus struct { // Nodes are the names of the memcached pods Nodes []string `json:"nodes"` }Mettre à jour le code généré pour le type de ressource :
$ make generateAstuceAprès avoir modifié un fichier
*_types.go, vous devez exécuter la commandemake generatepour mettre à jour le code généré pour ce type de ressource.La cible Makefile ci-dessus invoque l'utilitaire
controller-genpour mettre à jour le fichierapi/v1/zz_generated.deepcopy.go. Cela permet de s'assurer que les définitions de type de l'API Go implémentent l'interfaceruntime.Objectque tous les types Kind doivent implémenter.
5.3.2.3.2. Générer des manifestes CRD
Une fois l'API définie avec les champs spec et status et les marqueurs de validation de la définition des ressources personnalisées (CRD), vous pouvez générer des manifestes CRD.
Procédure
Exécutez la commande suivante pour générer et mettre à jour les manifestes CRD :
$ make manifestsCette cible Makefile invoque l'utilitaire
controller-genpour générer les manifestes CRD dans le fichierconfig/crd/bases/cache.example.com_memcacheds.yaml.
5.3.2.3.2.1. À propos de la validation de l'OpenAPI
Les schémas OpenAPIv3 sont ajoutés aux manifestes CRD dans le bloc spec.validation lorsque les manifestes sont générés. Ce bloc de validation permet à Kubernetes de valider les propriétés d'une ressource personnalisée Memcached (CR) lors de sa création ou de sa mise à jour.
Des marqueurs, ou annotations, sont disponibles pour configurer les validations de votre API. Ces marqueurs ont toujours un préfixe kubebuilder:validation.
5.3.2.4. Mise en œuvre du contrôleur
Après avoir créé une nouvelle API et un nouveau contrôleur, vous pouvez mettre en œuvre la logique du contrôleur.
Procédure
Pour cet exemple, remplacez le fichier de contrôleur généré
controllers/memcached_controller.gopar l'exemple de mise en œuvre suivant :Exemple 5.1. Exemple
memcached_controller.go/* Copyright 2020. Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. */ package controllers import ( appsv1 "k8s.io/api/apps/v1" corev1 "k8s.io/api/core/v1" "k8s.io/apimachinery/pkg/api/errors" metav1 "k8s.io/apimachinery/pkg/apis/meta/v1" "k8s.io/apimachinery/pkg/types" "reflect" "context" "github.com/go-logr/logr" "k8s.io/apimachinery/pkg/runtime" ctrl "sigs.k8s.io/controller-runtime" "sigs.k8s.io/controller-runtime/pkg/client" cachev1alpha1 "github.com/example/memcached-operator/api/v1alpha1" ) // MemcachedReconciler reconciles a Memcached object type MemcachedReconciler struct { client.Client Log logr.Logger Scheme *runtime.Scheme } // +kubebuilder:rbac:groups=cache.example.com,resources=memcacheds,verbs=get;list;watch;create;update;patch;delete // +kubebuilder:rbac:groups=cache.example.com,resources=memcacheds/status,verbs=get;update;patch // +kubebuilder:rbac:groups=cache.example.com,resources=memcacheds/finalizers,verbs=update // +kubebuilder:rbac:groups=apps,resources=deployments,verbs=get;list;watch;create;update;patch;delete // +kubebuilder:rbac:groups=core,resources=pods,verbs=get;list; // Reconcile is part of the main kubernetes reconciliation loop which aims to // move the current state of the cluster closer to the desired state. // TODO(user): Modify the Reconcile function to compare the state specified by // the Memcached object against the actual cluster state, and then // perform operations to make the cluster state reflect the state specified by // the user. // // For more details, check Reconcile and its Result here: // - https://pkg.go.dev/sigs.k8s.io/controller-runtime@v0.7.0/pkg/reconcile func (r *MemcachedReconciler) Reconcile(ctx context.Context, req ctrl.Request) (ctrl.Result, error) { log := r.Log.WithValues("memcached", req.NamespacedName) // Fetch the Memcached instance memcached := &cachev1alpha1.Memcached{} err := r.Get(ctx, req.NamespacedName, memcached) if err != nil { if errors.IsNotFound(err) { // Request object not found, could have been deleted after reconcile request. // Owned objects are automatically garbage collected. For additional cleanup logic use finalizers. // Return and don't requeue log.Info("Memcached resource not found. Ignoring since object must be deleted") return ctrl.Result{}, nil } // Error reading the object - requeue the request. log.Error(err, "Failed to get Memcached") return ctrl.Result{}, err } // Check if the deployment already exists, if not create a new one found := &appsv1.Deployment{} err = r.Get(ctx, types.NamespacedName{Name: memcached.Name, Namespace: memcached.Namespace}, found) if err != nil && errors.IsNotFound(err) { // Define a new deployment dep := r.deploymentForMemcached(memcached) log.Info("Creating a new Deployment", "Deployment.Namespace", dep.Namespace, "Deployment.Name", dep.Name) err = r.Create(ctx, dep) if err != nil { log.Error(err, "Failed to create new Deployment", "Deployment.Namespace", dep.Namespace, "Deployment.Name", dep.Name) return ctrl.Result{}, err } // Deployment created successfully - return and requeue return ctrl.Result{Requeue: true}, nil } else if err != nil { log.Error(err, "Failed to get Deployment") return ctrl.Result{}, err } // Ensure the deployment size is the same as the spec size := memcached.Spec.Size if *found.Spec.Replicas != size { found.Spec.Replicas = &size err = r.Update(ctx, found) if err != nil { log.Error(err, "Failed to update Deployment", "Deployment.Namespace", found.Namespace, "Deployment.Name", found.Name) return ctrl.Result{}, err } // Spec updated - return and requeue return ctrl.Result{Requeue: true}, nil } // Update the Memcached status with the pod names // List the pods for this memcached's deployment podList := &corev1.PodList{} listOpts := []client.ListOption{ client.InNamespace(memcached.Namespace), client.MatchingLabels(labelsForMemcached(memcached.Name)), } if err = r.List(ctx, podList, listOpts...); err != nil { log.Error(err, "Failed to list pods", "Memcached.Namespace", memcached.Namespace, "Memcached.Name", memcached.Name) return ctrl.Result{}, err } podNames := getPodNames(podList.Items) // Update status.Nodes if needed if !reflect.DeepEqual(podNames, memcached.Status.Nodes) { memcached.Status.Nodes = podNames err := r.Status().Update(ctx, memcached) if err != nil { log.Error(err, "Failed to update Memcached status") return ctrl.Result{}, err } } return ctrl.Result{}, nil } // deploymentForMemcached returns a memcached Deployment object func (r *MemcachedReconciler) deploymentForMemcached(m *cachev1alpha1.Memcached) *appsv1.Deployment { ls := labelsForMemcached(m.Name) replicas := m.Spec.Size dep := &appsv1.Deployment{ ObjectMeta: metav1.ObjectMeta{ Name: m.Name, Namespace: m.Namespace, }, Spec: appsv1.DeploymentSpec{ Replicas: &replicas, Selector: &metav1.LabelSelector{ MatchLabels: ls, }, Template: corev1.PodTemplateSpec{ ObjectMeta: metav1.ObjectMeta{ Labels: ls, }, Spec: corev1.PodSpec{ Containers: []corev1.Container{{ Image: "memcached:1.4.36-alpine", Name: "memcached", Command: []string{"memcached", "-m=64", "-o", "modern", "-v"}, Ports: []corev1.ContainerPort{{ ContainerPort: 11211, Name: "memcached", }}, }}, }, }, }, } // Set Memcached instance as the owner and controller ctrl.SetControllerReference(m, dep, r.Scheme) return dep } // labelsForMemcached returns the labels for selecting the resources // belonging to the given memcached CR name. func labelsForMemcached(name string) map[string]string { return map[string]string{"app": "memcached", "memcached_cr": name} } // getPodNames returns the pod names of the array of pods passed in func getPodNames(pods []corev1.Pod) []string { var podNames []string for _, pod := range pods { podNames = append(podNames, pod.Name) } return podNames } // SetupWithManager sets up the controller with the Manager. func (r *MemcachedReconciler) SetupWithManager(mgr ctrl.Manager) error { return ctrl.NewControllerManagedBy(mgr). For(&cachev1alpha1.Memcached{}). Owns(&appsv1.Deployment{}). Complete(r) }Le contrôleur de l'exemple exécute la logique de rapprochement suivante pour chaque ressource personnalisée (CR)
Memcached:- Créer un déploiement Memcached s'il n'existe pas.
-
Assurez-vous que la taille du déploiement est la même que celle spécifiée par la spécification CR de
Memcached. -
Mettre à jour l'état de
MemcachedCR avec les noms des podsmemcached.
Les sous-sections suivantes expliquent comment le contrôleur de l'exemple de mise en œuvre surveille les ressources et comment la boucle de rapprochement est déclenchée. Vous pouvez sauter ces sous-sections pour passer directement à l'exécution de l'opérateur.
5.3.2.4.1. Ressources surveillées par le contrôleur
La fonction SetupWithManager() dans controllers/memcached_controller.go spécifie comment le contrôleur est construit pour surveiller un CR et d'autres ressources qui sont détenues et gérées par ce contrôleur.
import (
...
appsv1 "k8s.io/api/apps/v1"
...
)
func (r *MemcachedReconciler) SetupWithManager(mgr ctrl.Manager) error {
return ctrl.NewControllerManagedBy(mgr).
For(&cachev1.Memcached{}).
Owns(&appsv1.Deployment{}).
Complete(r)
}
NewControllerManagedBy() fournit un constructeur de contrôleurs qui permet différentes configurations de contrôleurs.
For(&cachev1.Memcached{}) spécifie le type Memcached en tant que ressource primaire à surveiller. Pour chaque événement d'ajout, de mise à jour ou de suppression d'un type Memcached, la boucle de rapprochement reçoit un argument de rapprochement Request, composé d'un espace de noms et d'une clé de nom, pour cet objet Memcached.
Owns(&appsv1.Deployment{}) spécifie le type Deployment comme ressource secondaire à surveiller. Pour chaque événement d'ajout, de mise à jour ou de suppression du type Deployment, le gestionnaire d'événements associe chaque événement à une demande de rapprochement pour le propriétaire du déploiement. Dans ce cas, le propriétaire est l'objet Memcached pour lequel le déploiement a été créé.
5.3.2.4.2. Configurations du contrôleur
Vous pouvez initialiser un contrôleur en utilisant de nombreuses autres configurations utiles. Par exemple, il est possible d'initialiser un contrôleur en utilisant de nombreuses autres configurations utiles :
Définissez le nombre maximum de rapprochements simultanés pour le contrôleur en utilisant l'option
MaxConcurrentReconciles, dont la valeur par défaut est1:func (r *MemcachedReconciler) SetupWithManager(mgr ctrl.Manager) error { return ctrl.NewControllerManagedBy(mgr). For(&cachev1.Memcached{}). Owns(&appsv1.Deployment{}). WithOptions(controller.Options{ MaxConcurrentReconciles: 2, }). Complete(r) }- Filtrer les événements de veille à l'aide de prédicats.
-
Choisissez le type de EventHandler pour modifier la façon dont un événement de surveillance se traduit en demandes de rapprochement pour la boucle de rapprochement. Pour les relations entre opérateurs qui sont plus complexes que les ressources primaires et secondaires, vous pouvez utiliser le gestionnaire
EnqueueRequestsFromMapFuncpour transformer un événement de surveillance en un ensemble arbitraire de demandes de rapprochement.
Pour plus de détails sur ces configurations et d'autres, voir les GoDocs sur les constructeurs et les contrôleurs en amont.
5.3.2.4.3. Boucle de réconciliation
Chaque contrôleur possède un objet de rapprochement avec une méthode Reconcile() qui met en œuvre la boucle de rapprochement. La boucle de rapprochement reçoit l'argument Request, qui est une clé d'espace de noms et de noms utilisée pour trouver l'objet de ressource primaire, Memcached, à partir du cache :
import (
ctrl "sigs.k8s.io/controller-runtime"
cachev1 "github.com/example-inc/memcached-operator/api/v1"
...
)
func (r *MemcachedReconciler) Reconcile(ctx context.Context, req ctrl.Request) (ctrl.Result, error) {
// Lookup the Memcached instance for this reconcile request
memcached := &cachev1.Memcached{}
err := r.Get(ctx, req.NamespacedName, memcached)
...
}En fonction des valeurs de retour, du résultat et de l'erreur, la demande peut être remise en file d'attente et la boucle de rapprochement peut être déclenchée à nouveau :
// Reconcile successful - don't requeue
return ctrl.Result{}, nil
// Reconcile failed due to error - requeue
return ctrl.Result{}, err
// Requeue for any reason other than an error
return ctrl.Result{Requeue: true}, nil
Vous pouvez également paramétrer le site Result.RequeueAfter pour qu'il relance la demande après un délai de grâce :
import "time"
// Reconcile for any reason other than an error after 5 seconds
return ctrl.Result{RequeueAfter: time.Second*5}, nil
Vous pouvez renvoyer Result avec RequeueAfter pour réconcilier périodiquement un CR.
Pour en savoir plus sur les réconciliateurs, les clients et l'interaction avec les événements de ressources, consultez la documentation de l 'API Controller Runtime Client.
5.3.2.4.4. Permissions et manifestes RBAC
Le contrôleur a besoin de certaines autorisations RBAC pour interagir avec les ressources qu'il gère. Ces autorisations sont spécifiées à l'aide de marqueurs RBAC, tels que les suivants :
// +kubebuilder:rbac:groups=cache.example.com,resources=memcacheds,verbs=get;list;watch;create;update;patch;delete
// +kubebuilder:rbac:groups=cache.example.com,resources=memcacheds/status,verbs=get;update;patch
// +kubebuilder:rbac:groups=cache.example.com,resources=memcacheds/finalizers,verbs=update
// +kubebuilder:rbac:groups=apps,resources=deployments,verbs=get;list;watch;create;update;patch;delete
// +kubebuilder:rbac:groups=core,resources=pods,verbs=get;list;
func (r *MemcachedReconciler) Reconcile(ctx context.Context, req ctrl.Request) (ctrl.Result, error) {
...
}
Le manifeste de l'objet ClusterRole à l'adresse config/rbac/role.yaml est généré à partir des marqueurs précédents à l'aide de l'utilitaire controller-gen chaque fois que la commande make manifests est exécutée.
5.3.2.5. Activation de la prise en charge du proxy
Les auteurs d'opérateurs peuvent développer des opérateurs qui prennent en charge les proxys réseau. Les administrateurs de clusters configurent la prise en charge du proxy pour les variables d'environnement qui sont gérées par Operator Lifecycle Manager (OLM). Pour prendre en charge les clusters proxy, votre opérateur doit inspecter l'environnement à la recherche des variables proxy standard suivantes et transmettre les valeurs aux opérateurs :
-
HTTP_PROXY -
HTTPS_PROXY -
NO_PROXY
Ce tutoriel utilise HTTP_PROXY comme variable d'environnement.
Conditions préalables
- Un cluster dont le proxy de sortie à l'échelle du cluster est activé.
Procédure
Modifiez le fichier
controllers/memcached_controller.gopour y inclure les éléments suivants :Importez le paquet
proxyà partir de laoperator-libbibliothèque :import ( ... "github.com/operator-framework/operator-lib/proxy" )Ajoutez la fonction d'aide
proxy.ReadProxyVarsFromEnvà la boucle de rapprochement et ajoutez les résultats aux environnements Operand :for i, container := range dep.Spec.Template.Spec.Containers { dep.Spec.Template.Spec.Containers[i].Env = append(container.Env, proxy.ReadProxyVarsFromEnv()...) } ...
Définissez la variable d'environnement sur le déploiement de l'opérateur en ajoutant ce qui suit au fichier
config/manager/manager.yaml:containers: - args: - --leader-elect - --leader-election-id=ansible-proxy-demo image: controller:latest name: manager env: - name: "HTTP_PROXY" value: "http_proxy_test"
5.3.2.6. Fonctionnement de l'opérateur
Vous pouvez utiliser l'interface de programmation de l'opérateur SDK de trois manières différentes pour créer et exécuter votre opérateur :
- Exécuter localement en dehors du cluster comme un programme Go.
- Exécuter en tant que déploiement sur le cluster.
- Regroupez votre opérateur et utilisez Operator Lifecycle Manager (OLM) pour le déployer sur le cluster.
Avant d'exécuter votre opérateur basé sur Go en tant que déploiement sur OpenShift Container Platform ou en tant que bundle utilisant OLM, assurez-vous que votre projet a été mis à jour pour utiliser les images prises en charge.
5.3.2.6.1. Exécution locale en dehors du cluster
Vous pouvez exécuter votre projet Operator en tant que programme Go en dehors du cluster. Ceci est utile pour le développement afin d'accélérer le déploiement et les tests.
Procédure
Exécutez la commande suivante pour installer les définitions de ressources personnalisées (CRD) dans le cluster configuré dans votre fichier
~/.kube/configet exécutez l'opérateur localement :$ make install runExemple de sortie
... 2021-01-10T21:09:29.016-0700 INFO controller-runtime.metrics metrics server is starting to listen {"addr": ":8080"} 2021-01-10T21:09:29.017-0700 INFO setup starting manager 2021-01-10T21:09:29.017-0700 INFO controller-runtime.manager starting metrics server {"path": "/metrics"} 2021-01-10T21:09:29.018-0700 INFO controller-runtime.manager.controller.memcached Starting EventSource {"reconciler group": "cache.example.com", "reconciler kind": "Memcached", "source": "kind source: /, Kind="} 2021-01-10T21:09:29.218-0700 INFO controller-runtime.manager.controller.memcached Starting Controller {"reconciler group": "cache.example.com", "reconciler kind": "Memcached"} 2021-01-10T21:09:29.218-0700 INFO controller-runtime.manager.controller.memcached Starting workers {"reconciler group": "cache.example.com", "reconciler kind": "Memcached", "worker count": 1}
5.3.2.6.2. Exécution en tant que déploiement sur le cluster
Vous pouvez exécuter votre projet Operator en tant que déploiement sur votre cluster.
Conditions préalables
- Préparez votre opérateur basé sur Go à fonctionner sur OpenShift Container Platform en mettant à jour le projet pour utiliser les images prises en charge
Procédure
Exécutez les commandes
makesuivantes pour construire et pousser l'image de l'opérateur. Modifiez l'argumentIMGdans les étapes suivantes pour référencer un référentiel auquel vous avez accès. Vous pouvez obtenir un compte pour stocker des conteneurs sur des sites de dépôt tels que Quay.io.Construire l'image :
$ make docker-build IMG=<registry>/<user>/<image_name>:<tag>NoteLe fichier Docker généré par le SDK pour l'Operator fait explicitement référence à
GOARCH=amd64pourgo build. Cette référence peut être modifiée enGOARCH=$TARGETARCHpour les architectures non-AMD64. Docker définira automatiquement la variable d'environnement à la valeur spécifiée par–platform. Avec Buildah, il faudra utiliser–build-argà cette fin. Pour plus d'informations, voir Architectures multiples.Transférer l'image dans un référentiel :
$ make docker-push IMG=<registry>/<user>/<image_name>:<tag>NoteLe nom et la balise de l'image, par exemple
IMG=<registry>/<user>/<image_name>:<tag>, dans les deux commandes peuvent également être définis dans votre Makefile. Modifiez la valeur deIMG ?= controller:latestpour définir votre nom d'image par défaut.
Exécutez la commande suivante pour déployer l'opérateur :
$ make deploy IMG=<registry>/<user>/<image_name>:<tag>Par défaut, cette commande crée un espace de noms avec le nom de votre projet Operator sous la forme
<project_name>-systemet est utilisé pour le déploiement. Cette commande installe également les manifestes RBAC à partir deconfig/rbac.Exécutez la commande suivante pour vérifier que l'opérateur fonctionne :
oc get deployment -n <nom_du_projet>-systèmeExemple de sortie
NAME READY UP-TO-DATE AVAILABLE AGE <project_name>-controller-manager 1/1 1 1 8m
5.3.2.6.3. Regroupement d'un opérateur et déploiement avec Operator Lifecycle Manager
5.3.2.6.3.1. Regroupement d'un opérateur
Le format Operator bundle est la méthode d'emballage par défaut pour Operator SDK et Operator Lifecycle Manager (OLM). Vous pouvez préparer votre Operator pour une utilisation sur OLM en utilisant Operator SDK pour construire et pousser votre projet Operator en tant qu'image groupée.
Conditions préalables
- Operator SDK CLI installé sur un poste de développement
-
OpenShift CLI (
oc) v4.12 installé - Projet d'opérateur initialisé à l'aide de l'Operator SDK
- Si votre opérateur est basé sur Go, votre projet doit être mis à jour pour utiliser les images prises en charge pour fonctionner sur OpenShift Container Platform
Procédure
Exécutez les commandes
makesuivantes dans le répertoire de votre projet Operator pour construire et pousser votre image Operator. Modifiez l'argumentIMGdans les étapes suivantes pour référencer un référentiel auquel vous avez accès. Vous pouvez obtenir un compte pour stocker des conteneurs sur des sites de dépôt tels que Quay.io.Construire l'image :
$ make docker-build IMG=<registry>/<user>/<operator_image_name>:<tag>NoteLe fichier Docker généré par le SDK pour l'Operator fait explicitement référence à
GOARCH=amd64pourgo build. Cette référence peut être modifiée enGOARCH=$TARGETARCHpour les architectures non-AMD64. Docker définira automatiquement la variable d'environnement à la valeur spécifiée par–platform. Avec Buildah, il faudra utiliser–build-argà cette fin. Pour plus d'informations, voir Architectures multiples.Transférer l'image dans un référentiel :
$ make docker-push IMG=<registry>/<user>/<operator_image_name>:<tag>
Créez votre manifeste Operator bundle en exécutant la commande
make bundle, qui invoque plusieurs commandes, dont les sous-commandes Operator SDKgenerate bundleetbundle validate:$ make bundle IMG=<registry>/<user>/<operator_image_name>:<tag>Les manifestes de l'offre groupée d'un opérateur décrivent la manière d'afficher, de créer et de gérer une application. La commande
make bundlecrée les fichiers et répertoires suivants dans votre projet Operator :-
Un répertoire bundle manifests nommé
bundle/manifestsqui contient un objetClusterServiceVersion -
Un répertoire de métadonnées de la liasse nommé
bundle/metadata -
Toutes les définitions de ressources personnalisées (CRD) dans un répertoire
config/crd -
Un fichier Docker
bundle.Dockerfile
Ces fichiers sont ensuite automatiquement validés à l'aide de
operator-sdk bundle validateafin de s'assurer que la représentation du paquet sur le disque est correcte.-
Un répertoire bundle manifests nommé
Construisez et poussez votre image de bundle en exécutant les commandes suivantes. OLM consomme les liasses d'opérateurs à l'aide d'une image d'index, qui fait référence à une ou plusieurs images de liasses.
Créez l'image de l'ensemble. Définissez
BUNDLE_IMGavec les détails du registre, de l'espace de noms de l'utilisateur et de la balise d'image où vous avez l'intention de pousser l'image :$ make bundle-build BUNDLE_IMG=<registry>/<user>/<bundle_image_name>:<tag>Pousser l'image de la liasse :
$ docker push <registry>/<user>/<bundle_image_name>:<tag>
5.3.2.6.3.2. Déploiement d'un opérateur avec Operator Lifecycle Manager
Operator Lifecycle Manager (OLM) vous aide à installer, mettre à jour et gérer le cycle de vie des opérateurs et de leurs services associés sur un cluster Kubernetes. OLM est installé par défaut sur OpenShift Container Platform et s'exécute en tant qu'extension Kubernetes afin que vous puissiez utiliser la console web et l'OpenShift CLI (oc) pour toutes les fonctions de gestion du cycle de vie des opérateurs sans outils supplémentaires.
Le format Operator bundle est la méthode d'emballage par défaut pour Operator SDK et OLM. Vous pouvez utiliser Operator SDK pour exécuter rapidement une image de bundle sur OLM afin de vous assurer qu'elle fonctionne correctement.
Conditions préalables
- Operator SDK CLI installé sur un poste de développement
- L'image de l'ensemble de l'opérateur est construite et poussée vers un registre
-
OLM installé sur un cluster basé sur Kubernetes (v1.16.0 ou version ultérieure si vous utilisez
apiextensions.k8s.io/v1CRD, par exemple OpenShift Container Platform 4.12) -
Connexion au cluster avec
ocen utilisant un compte avec les permissions decluster-admin - Si votre opérateur est basé sur Go, votre projet doit être mis à jour pour utiliser les images prises en charge pour fonctionner sur OpenShift Container Platform
Procédure
Saisissez la commande suivante pour exécuter l'opérateur sur le cluster :
$ operator-sdk run bundle \1 -n <namespace> \2 <registry>/<user>/<bundle_image_name>:<tag>3 - 1
- La commande
run bundlecrée un catalogue de fichiers valide et installe le paquet Operator sur votre cluster à l'aide d'OLM. - 2
- Facultatif : Par défaut, la commande installe l'opérateur dans le projet actif dans votre fichier
~/.kube/config. Vous pouvez ajouter l'option-npour définir un espace de noms différent pour l'installation. - 3
- Si vous ne spécifiez pas d'image, la commande utilise
quay.io/operator-framework/opm:latestcomme image d'index par défaut. Si vous spécifiez une image, la commande utilise l'image du paquet elle-même comme image d'index.
ImportantDepuis OpenShift Container Platform 4.11, la commande
run bundleprend en charge par défaut le format de catalogue basé sur des fichiers pour les catalogues Operator. Le format de base de données SQLite déprécié pour les catalogues Operator continue d'être pris en charge ; cependant, il sera supprimé dans une prochaine version. Il est recommandé aux auteurs d'Operator de migrer leurs flux de travail vers le format de catalogue basé sur des fichiers.Cette commande permet d'effectuer les actions suivantes :
- Créez une image d'index faisant référence à votre image de liasse. L'image d'index est opaque et éphémère, mais elle reflète fidèlement la manière dont un paquet serait ajouté à un catalogue en production.
- Créez une source de catalogue qui pointe vers votre nouvelle image d'index, ce qui permet à OperatorHub de découvrir votre opérateur.
-
Déployez votre opérateur sur votre cluster en créant un site
OperatorGroup,Subscription,InstallPlan, et toutes les autres ressources nécessaires, y compris RBAC.
5.3.2.7. Création d'une ressource personnalisée
Une fois votre opérateur installé, vous pouvez le tester en créant une ressource personnalisée (CR) qui est maintenant fournie sur le cluster par l'opérateur.
Conditions préalables
-
Exemple Memcached Operator, qui fournit le CR
Memcached, installé sur un cluster
Procédure
Passez à l'espace de noms dans lequel votre opérateur est installé. Par exemple, si vous avez déployé l'opérateur à l'aide de la commande
make deploy:$ oc project memcached-operator-systemModifiez l'exemple de manifeste
MemcachedCR à l'adresseconfig/samples/cache_v1_memcached.yamlpour qu'il contienne la spécification suivante :apiVersion: cache.example.com/v1 kind: Memcached metadata: name: memcached-sample ... spec: ... size: 3Créer le CR :
$ oc apply -f config/samples/cache_v1_memcached.yamlAssurez-vous que l'opérateur
Memcachedcrée le déploiement pour l'échantillon de CR avec la taille correcte :$ oc get deploymentsExemple de sortie
NAME READY UP-TO-DATE AVAILABLE AGE memcached-operator-controller-manager 1/1 1 1 8m memcached-sample 3/3 3 3 1mVérifiez l'état des pods et du CR pour confirmer que l'état est mis à jour avec les noms des pods Memcached.
Vérifier les gousses :
$ oc get podsExemple de sortie
NAME READY STATUS RESTARTS AGE memcached-sample-6fd7c98d8-7dqdr 1/1 Running 0 1m memcached-sample-6fd7c98d8-g5k7v 1/1 Running 0 1m memcached-sample-6fd7c98d8-m7vn7 1/1 Running 0 1mVérifier l'état de la CR :
$ oc get memcached/memcached-sample -o yamlExemple de sortie
apiVersion: cache.example.com/v1 kind: Memcached metadata: ... name: memcached-sample ... spec: size: 3 status: nodes: - memcached-sample-6fd7c98d8-7dqdr - memcached-sample-6fd7c98d8-g5k7v - memcached-sample-6fd7c98d8-m7vn7
Mettre à jour la taille du déploiement.
Mettre à jour le fichier
config/samples/cache_v1_memcached.yamlpour modifier le champspec.sizedans le CRMemcachedde3à5:$ oc patch memcached memcached-sample \ -p '{"spec":{"size": 5}}' \ --type=mergeConfirmez que l'opérateur modifie la taille du déploiement :
$ oc get deploymentsExemple de sortie
NAME READY UP-TO-DATE AVAILABLE AGE memcached-operator-controller-manager 1/1 1 1 10m memcached-sample 5/5 5 5 3m
Supprimez le CR en exécutant la commande suivante :
$ oc delete -f config/samples/cache_v1_memcached.yamlNettoyer les ressources qui ont été créées dans le cadre de ce tutoriel.
Si vous avez utilisé la commande
make deploypour tester l'opérateur, exécutez la commande suivante :$ make undeploySi vous avez utilisé la commande
operator-sdk run bundlepour tester l'opérateur, exécutez la commande suivante :$ operator-sdk cleanup <nom_du_projet>
5.3.3. Présentation du projet pour les opérateurs basés à Go
Le CLI operator-sdk peut générer, ou scaffold, un certain nombre de paquets et de fichiers pour chaque projet Operator.
5.3.3.1. Présentation d'un projet basé sur Go
Les projets Operator basés sur Go, le type par défaut, générés à l'aide de la commande operator-sdk init contiennent les fichiers et répertoires suivants :
| Fichier ou répertoire | Objectif |
|---|---|
|
|
Programme principal de l'opérateur. Il instancie un nouveau gestionnaire qui enregistre toutes les définitions de ressources personnalisées (CRD) dans le répertoire |
|
|
Arborescence de répertoires qui définit les API des CRD. Vous devez modifier les fichiers |
|
|
Implémentations de contrôleurs. Modifiez les fichiers |
|
| Manifestes Kubernetes utilisés pour déployer votre contrôleur sur un cluster, y compris les CRD, RBAC et les certificats. |
|
| Cibles utilisées pour construire et déployer votre contrôleur. |
|
| Instructions utilisées par un moteur de conteneur pour construire votre opérateur. |
|
| Les manifestes Kubernetes pour l'enregistrement des CRD, la configuration du RBAC et le déploiement de l'opérateur en tant que déploiement. |
5.3.4. Mise à jour des projets Operator basés sur Go pour les nouvelles versions du SDK Operator
OpenShift Container Platform 4.12 supporte Operator SDK 1.25.4. Si vous avez déjà le CLI 1.22.0 installé sur votre station de travail, vous pouvez mettre à jour le CLI vers 1.25.4 en installant la dernière version.
Cependant, pour que vos projets Operator existants restent compatibles avec Operator SDK 1.25.4, des étapes de mise à jour sont nécessaires pour les ruptures associées introduites depuis la version 1.22.0. Vous devez effectuer les étapes de mise à jour manuellement dans tous vos projets Operator qui ont été précédemment créés ou maintenus avec la version 1.22.0.
5.3.4.1. Mise à jour des projets Operator basés sur Go pour Operator SDK 1.25.4
La procédure suivante met à jour un projet Go-based Operator existant pour le rendre compatible avec la version 1.25.4.
Conditions préalables
- Operator SDK 1.25.4 installé
- Un projet Operator créé ou maintenu avec Operator SDK 1.22.0
Procédure
Apportez les modifications suivantes au fichier
config/default/manager_auth_proxy_patch.yaml:apiVersion: apps/v1 kind: Deployment metadata: name: controller-manager namespace: system spec: template: spec: containers: - name: kube-rbac-proxy image: registry.redhat.io/openshift4/ose-kube-rbac-proxy:v4.121 args: - "--secure-listen-address=0.0.0.0:8443" - "--upstream=http://127.0.0.1:8080/" - "--logtostderr=true" - "--v=0" ...- 1
- Mettre à jour la version de la balise de
v4.11àv4.12.
Apportez les modifications suivantes à votre site
Makefile:Pour activer la prise en charge des architectures multiples, ajoutez la cible
docker-buildxà votre projetMakefile:Exemple
Makefile# PLATFORMS defines the target platforms for the manager image be build to provide support to multiple # architectures. (i.e. make docker-buildx IMG=myregistry/mypoperator:0.0.1). To use this option you need to: # - able to use docker buildx . More info: https://docs.docker.com/build/buildx/ # - have enable BuildKit, More info: https://docs.docker.com/develop/develop-images/build_enhancements/ # - be able to push the image for your registry (i.e. if you do not inform a valid value via IMG=<myregistry/image:<tag>> than the export will fail) # To properly provided solutions that supports more than one platform you should use this option. PLATFORMS ?= linux/arm64,linux/amd64,linux/s390x,linux/ppc64le .PHONY: docker-buildx docker-buildx: test ## Build and push docker image for the manager for cross-platform support # copy existing Dockerfile and insert --platform=${BUILDPLATFORM} into Dockerfile.cross, and preserve the original Dockerfile sed -e '1 s/\(^FROM\)/FROM --platform=\$$\{BUILDPLATFORM\}/; t' -e ' 1,// s//FROM --platform=\$$\{BUILDPLATFORM\}/' Dockerfile > Dockerfile.cross - docker buildx create --name project-v3-builder docker buildx use project-v3-builder - docker buildx build --push --platform=$(PLATFORMS) --tag ${IMG} -f Dockerfile.cross - docker buildx rm project-v3-builder rm Dockerfile.crossMettez à jour l'échafaudage de votre projet pour prendre en charge les modifications apportées à
kubebuilder, comme le montre l'exemple suivant :Ancienne
Makefile.PHONY: test test: manifests generate fmt vet envtest ## Run tests. KUBEBUILDER_ASSETS="$(shell $(ENVTEST) use $(ENVTEST_K8S_VERSION) -p path)" go test ./... -coverprofile cover.outNouveau
Makefile.PHONY: test test: manifests generate fmt vet envtest ## Run tests. KUBEBUILDER_ASSETS="$(shell $(ENVTEST) use $(ENVTEST_K8S_VERSION) -p path)" go test $(go list ./... | grep -v /test/) -coverprofile cover.outPour s'assurer que les cibles de
Makefilene téléchargent pas des binaires déjà présents dans votre chemin binaire, apportez les modifications suivantes à votre fichierMakefile:Ancienne
MakefileKUSTOMIZE_INSTALL_SCRIPT ?= "https://raw.githubusercontent.com/kubernetes-sigs/kustomize/master/hack/install_kustomize.sh" .PHONY: kustomize kustomize: $(KUSTOMIZE) ## Download kustomize locally if necessary. $(KUSTOMIZE): $(LOCALBIN) { curl -s $(KUSTOMIZE_INSTALL_SCRIPT) | bash -s -- $(subst v,,$(KUSTOMIZE_VERSION)) $(LOCALBIN); } .PHONY: controller-gen controller-gen: $(CONTROLLER_GEN) ## Download controller-gen locally if necessary. $(CONTROLLER_GEN): $(LOCALBIN) test -s $(LOCALBIN)/controller-gen || GOBIN=$(LOCALBIN) go install sigs.k8s.io/controller-tools/cmd/controller-gen@$(CONTROLLER_TOOLS_VERSION GOBIN=$(LOCALBIN) go install sigs.k8s.io/controller-tools/cmd/controller-gen@$(CONTROLLER_TOOLS_VERSION) .PHONY: envtest envtest: $(ENVTEST) ## Download envtest-setup locally if necessary. $(ENVTEST): $(LOCALBIN) GOBIN=$(LOCALBIN) go install sigs.k8s.io/controller-runtime/tools/setup-envtest@latestNouveau
MakefileKUSTOMIZE_INSTALL_SCRIPT ?= "https://raw.githubusercontent.com/kubernetes-sigs/kustomize/master/hack/install_kustomize.sh" .PHONY: kustomize kustomize: $(KUSTOMIZE) ## Download kustomize locally if necessary. $(KUSTOMIZE): $(LOCALBIN) test -s $(LOCALBIN)/kustomize || { curl -s $(KUSTOMIZE_INSTALL_SCRIPT) | bash -s -- $(subst v,,$(KUSTOMIZE_VERSION)) $(LOCALBIN); }1 .PHONY: controller-gen controller-gen: $(CONTROLLER_GEN) ## Download controller-gen locally if necessary. $(CONTROLLER_GEN): $(LOCALBIN) test -s $(LOCALBIN)/controller-gen || GOBIN=$(LOCALBIN) go install sigs.k8s.io/controller-tools/cmd/controller-gen@$(CONTROLLER_TOOLS_VERSION)2 .PHONY: envtest envtest: $(ENVTEST) ## Download envtest-setup locally if necessary. $(ENVTEST): $(LOCALBIN) test -s $(LOCALBIN)/setup-envtest || GOBIN=$(LOCALBIN) go install sigs.k8s.io/controller-runtime/tools/setup-envtest@latest3 Mettez à jour
controller-toolsvers la versionv0.9.2comme indiqué dans l'exemple suivant :Exemple `Makefile
## Tool Versions KUSTOMIZE_VERSION ?= v3.8.7 CONTROLLER_TOOLS_VERSION ?= v0.9.21 - 1
- Mise à jour de la version
v0.9.0versv0.9.2.
Pour appliquer les changements à votre
Makefileet reconstruire votre Opérateur, entrez la commande suivante :$ make
Pour mettre à jour Go et ses dépendances, apportez les modifications suivantes à votre fichier
go.mod:go 1.191 require ( github.com/onsi/ginkgo/v2 v2.1.42 github.com/onsi/gomega v1.19.03 k8s.io/api v0.25.04 k8s.io/apimachinery v0.25.05 k8s.io/client-go v0.25.06 sigs.k8s.io/controller-runtime v0.13.07 )- 1
- Mise à jour de la version
1.18vers1.19. - 2
- Mise à jour de la version
v1.16.5versv2.1.4. - 3
- Mise à jour de la version
v1.18.1versv1.19.0. - 4
- Mise à jour de la version
v0.24.0versv0.25.0. - 5
- Mise à jour de la version
v0.24.0versv0.25.0. - 6
- Mise à jour de la version
v0.24.0versv0.25.0. - 7
- Mise à jour de la version
v0.12.1versv0.13.0.
Pour télécharger les versions mises à jour, nettoyer les dépendances et appliquer les changements dans votre fichier
go.mod, exécutez la commande suivante :$ go mod tidy
5.4. Opérateurs basés sur Ansible
5.4.1. Démarrer avec Operator SDK pour les opérateurs basés sur Ansible
Le SDK Operator comprend des options permettant de générer un projet Operator qui exploite les playbooks et modules Ansible existants pour déployer des ressources Kubernetes en tant qu'application unifiée, sans avoir à écrire de code Go.
Pour démontrer les bases de la configuration et de l'exécution d'un opérateur basé sur Ansible à l'aide des outils et des bibliothèques fournis par le SDK Operator, les développeurs d'opérateurs peuvent construire un exemple d'opérateur basé sur Ansible pour Memcached, un magasin de valeurs clés distribué, et le déployer sur un cluster.
5.4.1.1. Conditions préalables
- Operator SDK CLI installé
-
OpenShift CLI (
oc) v4.12 installé - Ansible v2.9.0
- Ansible Runner v2.0.2
- Ansible Runner HTTP Event Emitter plugin v1.0.0
- Python 3.8.6
- Client OpenShift Python v0.12.0
-
Connexion à un cluster OpenShift Container Platform 4.12 avec
ocavec un compte qui a les permissionscluster-admin - Pour permettre au cluster d'extraire l'image, le dépôt où vous avez poussé votre image doit être défini comme public, ou vous devez configurer un secret d'extraction d'image
5.4.1.2. Créer et déployer des opérateurs basés sur Ansible
Vous pouvez construire et déployer un simple opérateur Ansible pour Memcached en utilisant le SDK de l'opérateur.
Procédure
Create a project.
Créez votre répertoire de projet :
$ mkdir memcached-operatorAllez dans le répertoire du projet :
$ cd memcached-operatorExécutez la commande
operator-sdk initavec le pluginansiblepour initialiser le projet :$ operator-sdk init \ --plugins=ansible \ --domain=example.com
Create an API.
Créer une API Memcached simple :
$ operator-sdk create api \ --group cache \ --version v1 \ --kind Memcached \ --generate-role1 - 1
- Génère un rôle Ansible pour l'API.
Build and push the Operator image.
Utilisez les cibles par défaut de
Makefilepour construire et pousser votre opérateur. DéfinissezIMGavec une spécification d'extraction pour votre image qui utilise un registre vers lequel vous pouvez pousser :$ make docker-build docker-push IMG=<registry>/<user>/<image_name>:<tag>Run the Operator.
Installer le CRD :
$ make installDéployez le projet sur le cluster. Définissez
IMGsur l'image que vous avez poussée :$ make deploy IMG=<registry>/<user>/<image_name>:<tag>
Create a sample custom resource (CR).
Créer un échantillon de CR :
$ oc apply -f config/samples/cache_v1_memcached.yaml \ -n memcached-operator-systemIl faut s'attendre à ce que le CR réconcilie l'opérateur :
$ oc logs deployment.apps/memcached-operator-controller-manager \ -c manager \ -n memcached-operator-systemExemple de sortie
... I0205 17:48:45.881666 7 leaderelection.go:253] successfully acquired lease memcached-operator-system/memcached-operator {"level":"info","ts":1612547325.8819902,"logger":"controller-runtime.manager.controller.memcached-controller","msg":"Starting EventSource","source":"kind source: cache.example.com/v1, Kind=Memcached"} {"level":"info","ts":1612547325.98242,"logger":"controller-runtime.manager.controller.memcached-controller","msg":"Starting Controller"} {"level":"info","ts":1612547325.9824686,"logger":"controller-runtime.manager.controller.memcached-controller","msg":"Starting workers","worker count":4} {"level":"info","ts":1612547348.8311093,"logger":"runner","msg":"Ansible-runner exited successfully","job":"4037200794235010051","name":"memcached-sample","namespace":"memcached-operator-system"}
Delete a CR
Supprimez un CR en exécutant la commande suivante :
$ oc delete -f config/samples/cache_v1_memcached.yaml -n memcached-operator-systemClean up.
Exécutez la commande suivante pour nettoyer les ressources qui ont été créées dans le cadre de cette procédure :
$ make undeploy
5.4.1.3. Prochaines étapes
- Voir le tutoriel Operator SDK pour les opérateurs basés sur An sible pour une présentation plus approfondie de la construction d'un opérateur basé sur Ansible.
5.4.2. Tutoriel sur le SDK pour les opérateurs basés sur Ansible
Les développeurs d'opérateurs peuvent profiter de la prise en charge d'Ansible dans le SDK Operator pour construire un exemple d'opérateur basé sur Ansible pour Memcached, un magasin de valeurs clés distribué, et gérer son cycle de vie. Ce tutoriel décrit le processus suivant :
- Créer un déploiement Memcached
-
Veillez à ce que la taille du déploiement soit la même que celle spécifiée par la spécification de ressource personnalisée (CR) de
Memcached -
Mettre à jour le statut du CR
Memcacheden utilisant le rédacteur de statut avec les noms des podsmemcached
Ce processus est réalisé en utilisant deux pièces maîtresses du cadre de l'opérateur :
- SDK de l'opérateur
-
L'outil CLI
operator-sdket la bibliothèque APIcontroller-runtime - Gestionnaire du cycle de vie des opérateurs (OLM)
- Installation, mise à niveau et contrôle d'accès basé sur les rôles (RBAC) des opérateurs sur un cluster
Ce tutoriel est plus détaillé que le tutoriel Getting started with Operator SDK for Ansible-based Operators (Démarrer avec Operator SDK pour les opérateurs basés sur Ansible).
5.4.2.1. Conditions préalables
- Operator SDK CLI installé
-
OpenShift CLI (
oc) v4.12 installé - Ansible v2.9.0
- Ansible Runner v2.0.2
- Ansible Runner HTTP Event Emitter plugin v1.0.0
- Python 3.8.6
- Client OpenShift Python v0.12.0
-
Connexion à un cluster OpenShift Container Platform 4.12 avec
ocavec un compte qui a les permissionscluster-admin - Pour permettre au cluster d'extraire l'image, le dépôt où vous avez poussé votre image doit être défini comme public, ou vous devez configurer un secret d'extraction d'image
5.4.2.2. Création d'un projet
Utilisez l'interface de programmation Operator SDK pour créer un projet appelé memcached-operator.
Procédure
Créer un répertoire pour le projet :
$ mkdir -p $HOME/projects/memcached-operatorAccédez au répertoire :
$ cd $HOME/projects/memcached-operatorExécutez la commande
operator-sdk initavec le pluginansiblepour initialiser le projet :$ operator-sdk init \ --plugins=ansible \ --domain=example.com
5.4.2.2.1. Dossier PROJET
Parmi les fichiers générés par la commande operator-sdk init figure un fichier Kubebuilder PROJECT. Les commandes operator-sdk suivantes, ainsi que la sortie help, qui sont exécutées à partir de la racine du projet, lisent ce fichier et savent que le type de projet est Ansible. Par exemple :
domain: example.com
layout: ansible.sdk.operatorframework.io/v1
projectName: memcached-operator
version: 35.4.2.3. Création d'une API
Utilisez le SDK CLI de l'opérateur pour créer une API Memcached.
Procédure
Exécutez la commande suivante pour créer une API avec le groupe
cache, la versionv1et le typeMemcached:$ operator-sdk create api \ --group cache \ --version v1 \ --kind Memcached \ --generate-role1 - 1
- Génère un rôle Ansible pour l'API.
Après avoir créé l'API, votre projet Operator est mis à jour avec la structure suivante :
- Memcached CRD
-
Inclut un exemple de ressource
Memcached - Gestionnaire
Programme qui réconcilie l'état de la grappe avec l'état désiré en utilisant :
- Un réconciliateur, soit un rôle Ansible, soit un playbook
-
Un fichier
watches.yaml, qui connecte la ressourceMemcachedau rôle Ansiblememcached
5.4.2.4. Modifier le gestionnaire
Mettez à jour votre projet Operator pour fournir la logique de rapprochement, sous la forme d'un rôle Ansible, qui s'exécute chaque fois qu'une ressource Memcached est créée, mise à jour ou supprimée.
Procédure
Mettez à jour le fichier
roles/memcached/tasks/main.ymlavec la structure suivante :--- - name: start memcached community.kubernetes.k8s: definition: kind: Deployment apiVersion: apps/v1 metadata: name: '{{ ansible_operator_meta.name }}-memcached' namespace: '{{ ansible_operator_meta.namespace }}' spec: replicas: "{{size}}" selector: matchLabels: app: memcached template: metadata: labels: app: memcached spec: containers: - name: memcached command: - memcached - -m=64 - -o - modern - -v image: "docker.io/memcached:1.4.36-alpine" ports: - containerPort: 11211Ce rôle
memcachedgarantit l'existence d'un déploiementmemcachedet définit la taille du déploiement.Définissez des valeurs par défaut pour les variables utilisées dans votre rôle Ansible en modifiant le fichier
roles/memcached/defaults/main.yml:--- # defaults file for Memcached size: 1Mettez à jour l'exemple de ressource
Memcacheddans le fichierconfig/samples/cache_v1_memcached.yamlavec la structure suivante :apiVersion: cache.example.com/v1 kind: Memcached metadata: name: memcached-sample spec: size: 3Les paires clé-valeur de la spécification des ressources personnalisées (CR) sont transmises à Ansible en tant que variables supplémentaires.
Les noms de toutes les variables dans le champ spec sont convertis en snake case, c'est-à-dire en minuscules avec un trait de soulignement, par l'opérateur avant d'exécuter Ansible. Par exemple, serviceAccount dans la spécification devient service_account dans Ansible.
Vous pouvez désactiver cette conversion en définissant l'option snakeCaseParameters sur false dans votre fichier watches.yaml. Il est recommandé d'effectuer une validation de type dans Ansible sur les variables afin de s'assurer que votre application reçoit les données attendues.
5.4.2.5. Activation de la prise en charge du proxy
Les auteurs d'opérateurs peuvent développer des opérateurs qui prennent en charge les proxys réseau. Les administrateurs de clusters configurent la prise en charge du proxy pour les variables d'environnement qui sont gérées par Operator Lifecycle Manager (OLM). Pour prendre en charge les clusters proxy, votre opérateur doit inspecter l'environnement à la recherche des variables proxy standard suivantes et transmettre les valeurs aux opérateurs :
-
HTTP_PROXY -
HTTPS_PROXY -
NO_PROXY
Ce tutoriel utilise HTTP_PROXY comme variable d'environnement.
Conditions préalables
- Un cluster dont le proxy de sortie à l'échelle du cluster est activé.
Procédure
Ajoutez les variables d'environnement au déploiement en mettant à jour le fichier
roles/memcached/tasks/main.ymlavec ce qui suit :... env: - name: HTTP_PROXY value: '{{ lookup("env", "HTTP_PROXY") | default("", True) }}' - name: http_proxy value: '{{ lookup("env", "HTTP_PROXY") | default("", True) }}' ...Définissez la variable d'environnement sur le déploiement de l'opérateur en ajoutant ce qui suit au fichier
config/manager/manager.yaml:containers: - args: - --leader-elect - --leader-election-id=ansible-proxy-demo image: controller:latest name: manager env: - name: "HTTP_PROXY" value: "http_proxy_test"
5.4.2.6. Fonctionnement de l'opérateur
Vous pouvez utiliser l'interface de programmation de l'opérateur SDK de trois manières différentes pour créer et exécuter votre opérateur :
- Exécuter localement en dehors du cluster comme un programme Go.
- Exécuter en tant que déploiement sur le cluster.
- Regroupez votre opérateur et utilisez Operator Lifecycle Manager (OLM) pour le déployer sur le cluster.
5.4.2.6.1. Exécution locale en dehors du cluster
Vous pouvez exécuter votre projet Operator en tant que programme Go en dehors du cluster. Ceci est utile pour le développement afin d'accélérer le déploiement et les tests.
Procédure
Exécutez la commande suivante pour installer les définitions de ressources personnalisées (CRD) dans le cluster configuré dans votre fichier
~/.kube/configet exécutez l'opérateur localement :$ make install runExemple de sortie
... {"level":"info","ts":1612589622.7888272,"logger":"ansible-controller","msg":"Watching resource","Options.Group":"cache.example.com","Options.Version":"v1","Options.Kind":"Memcached"} {"level":"info","ts":1612589622.7897573,"logger":"proxy","msg":"Starting to serve","Address":"127.0.0.1:8888"} {"level":"info","ts":1612589622.789971,"logger":"controller-runtime.manager","msg":"starting metrics server","path":"/metrics"} {"level":"info","ts":1612589622.7899997,"logger":"controller-runtime.manager.controller.memcached-controller","msg":"Starting EventSource","source":"kind source: cache.example.com/v1, Kind=Memcached"} {"level":"info","ts":1612589622.8904517,"logger":"controller-runtime.manager.controller.memcached-controller","msg":"Starting Controller"} {"level":"info","ts":1612589622.8905244,"logger":"controller-runtime.manager.controller.memcached-controller","msg":"Starting workers","worker count":8}
5.4.2.6.2. Exécution en tant que déploiement sur le cluster
Vous pouvez exécuter votre projet Operator en tant que déploiement sur votre cluster.
Procédure
Exécutez les commandes
makesuivantes pour construire et pousser l'image de l'opérateur. Modifiez l'argumentIMGdans les étapes suivantes pour référencer un référentiel auquel vous avez accès. Vous pouvez obtenir un compte pour stocker des conteneurs sur des sites de dépôt tels que Quay.io.Construire l'image :
$ make docker-build IMG=<registry>/<user>/<image_name>:<tag>NoteLe fichier Docker généré par le SDK pour l'Operator fait explicitement référence à
GOARCH=amd64pourgo build. Cette référence peut être modifiée enGOARCH=$TARGETARCHpour les architectures non-AMD64. Docker définira automatiquement la variable d'environnement à la valeur spécifiée par–platform. Avec Buildah, il faudra utiliser–build-argà cette fin. Pour plus d'informations, voir Architectures multiples.Transférer l'image dans un référentiel :
$ make docker-push IMG=<registry>/<user>/<image_name>:<tag>NoteLe nom et la balise de l'image, par exemple
IMG=<registry>/<user>/<image_name>:<tag>, dans les deux commandes peuvent également être définis dans votre Makefile. Modifiez la valeur deIMG ?= controller:latestpour définir votre nom d'image par défaut.
Exécutez la commande suivante pour déployer l'opérateur :
$ make deploy IMG=<registry>/<user>/<image_name>:<tag>Par défaut, cette commande crée un espace de noms avec le nom de votre projet Operator sous la forme
<project_name>-systemet est utilisé pour le déploiement. Cette commande installe également les manifestes RBAC à partir deconfig/rbac.Exécutez la commande suivante pour vérifier que l'opérateur fonctionne :
oc get deployment -n <nom_du_projet>-systèmeExemple de sortie
NAME READY UP-TO-DATE AVAILABLE AGE <project_name>-controller-manager 1/1 1 1 8m
5.4.2.6.3. Regroupement d'un opérateur et déploiement avec Operator Lifecycle Manager
5.4.2.6.3.1. Regroupement d'un opérateur
Le format Operator bundle est la méthode d'emballage par défaut pour Operator SDK et Operator Lifecycle Manager (OLM). Vous pouvez préparer votre Operator pour une utilisation sur OLM en utilisant Operator SDK pour construire et pousser votre projet Operator en tant qu'image groupée.
Conditions préalables
- Operator SDK CLI installé sur un poste de développement
-
OpenShift CLI (
oc) v4.12 installé - Projet d'opérateur initialisé à l'aide de l'Operator SDK
Procédure
Exécutez les commandes
makesuivantes dans le répertoire de votre projet Operator pour construire et pousser votre image Operator. Modifiez l'argumentIMGdans les étapes suivantes pour référencer un référentiel auquel vous avez accès. Vous pouvez obtenir un compte pour stocker des conteneurs sur des sites de dépôt tels que Quay.io.Construire l'image :
$ make docker-build IMG=<registry>/<user>/<operator_image_name>:<tag>NoteLe fichier Docker généré par le SDK pour l'Operator fait explicitement référence à
GOARCH=amd64pourgo build. Cette référence peut être modifiée enGOARCH=$TARGETARCHpour les architectures non-AMD64. Docker définira automatiquement la variable d'environnement à la valeur spécifiée par–platform. Avec Buildah, il faudra utiliser–build-argà cette fin. Pour plus d'informations, voir Architectures multiples.Transférer l'image dans un référentiel :
$ make docker-push IMG=<registry>/<user>/<operator_image_name>:<tag>
Créez votre manifeste Operator bundle en exécutant la commande
make bundle, qui invoque plusieurs commandes, dont les sous-commandes Operator SDKgenerate bundleetbundle validate:$ make bundle IMG=<registry>/<user>/<operator_image_name>:<tag>Les manifestes de l'offre groupée d'un opérateur décrivent la manière d'afficher, de créer et de gérer une application. La commande
make bundlecrée les fichiers et répertoires suivants dans votre projet Operator :-
Un répertoire bundle manifests nommé
bundle/manifestsqui contient un objetClusterServiceVersion -
Un répertoire de métadonnées de la liasse nommé
bundle/metadata -
Toutes les définitions de ressources personnalisées (CRD) dans un répertoire
config/crd -
Un fichier Docker
bundle.Dockerfile
Ces fichiers sont ensuite automatiquement validés à l'aide de
operator-sdk bundle validateafin de s'assurer que la représentation du paquet sur le disque est correcte.-
Un répertoire bundle manifests nommé
Construisez et poussez votre image de bundle en exécutant les commandes suivantes. OLM consomme les liasses d'opérateurs à l'aide d'une image d'index, qui fait référence à une ou plusieurs images de liasses.
Créez l'image de l'ensemble. Définissez
BUNDLE_IMGavec les détails du registre, de l'espace de noms de l'utilisateur et de la balise d'image où vous avez l'intention de pousser l'image :$ make bundle-build BUNDLE_IMG=<registry>/<user>/<bundle_image_name>:<tag>Pousser l'image de la liasse :
$ docker push <registry>/<user>/<bundle_image_name>:<tag>
5.4.2.6.3.2. Déploiement d'un opérateur avec Operator Lifecycle Manager
Operator Lifecycle Manager (OLM) vous aide à installer, mettre à jour et gérer le cycle de vie des opérateurs et de leurs services associés sur un cluster Kubernetes. OLM est installé par défaut sur OpenShift Container Platform et s'exécute en tant qu'extension Kubernetes afin que vous puissiez utiliser la console web et l'OpenShift CLI (oc) pour toutes les fonctions de gestion du cycle de vie des opérateurs sans outils supplémentaires.
Le format Operator bundle est la méthode d'emballage par défaut pour Operator SDK et OLM. Vous pouvez utiliser Operator SDK pour exécuter rapidement une image de bundle sur OLM afin de vous assurer qu'elle fonctionne correctement.
Conditions préalables
- Operator SDK CLI installé sur un poste de développement
- L'image de l'ensemble de l'opérateur est construite et poussée vers un registre
-
OLM installé sur un cluster basé sur Kubernetes (v1.16.0 ou version ultérieure si vous utilisez
apiextensions.k8s.io/v1CRD, par exemple OpenShift Container Platform 4.12) -
Connexion au cluster avec
ocen utilisant un compte avec les permissions decluster-admin
Procédure
Saisissez la commande suivante pour exécuter l'opérateur sur le cluster :
$ operator-sdk run bundle \1 -n <namespace> \2 <registry>/<user>/<bundle_image_name>:<tag>3 - 1
- La commande
run bundlecrée un catalogue de fichiers valide et installe le paquet Operator sur votre cluster à l'aide d'OLM. - 2
- Facultatif : Par défaut, la commande installe l'opérateur dans le projet actif dans votre fichier
~/.kube/config. Vous pouvez ajouter l'option-npour définir un espace de noms différent pour l'installation. - 3
- Si vous ne spécifiez pas d'image, la commande utilise
quay.io/operator-framework/opm:latestcomme image d'index par défaut. Si vous spécifiez une image, la commande utilise l'image du paquet elle-même comme image d'index.
ImportantDepuis OpenShift Container Platform 4.11, la commande
run bundleprend en charge par défaut le format de catalogue basé sur des fichiers pour les catalogues Operator. Le format de base de données SQLite déprécié pour les catalogues Operator continue d'être pris en charge ; cependant, il sera supprimé dans une prochaine version. Il est recommandé aux auteurs d'Operator de migrer leurs flux de travail vers le format de catalogue basé sur des fichiers.Cette commande permet d'effectuer les actions suivantes :
- Créez une image d'index faisant référence à votre image de liasse. L'image d'index est opaque et éphémère, mais elle reflète fidèlement la manière dont un paquet serait ajouté à un catalogue en production.
- Créez une source de catalogue qui pointe vers votre nouvelle image d'index, ce qui permet à OperatorHub de découvrir votre opérateur.
-
Déployez votre opérateur sur votre cluster en créant un site
OperatorGroup,Subscription,InstallPlan, et toutes les autres ressources nécessaires, y compris RBAC.
5.4.2.7. Création d'une ressource personnalisée
Une fois votre opérateur installé, vous pouvez le tester en créant une ressource personnalisée (CR) qui est maintenant fournie sur le cluster par l'opérateur.
Conditions préalables
-
Exemple Memcached Operator, qui fournit le CR
Memcached, installé sur un cluster
Procédure
Passez à l'espace de noms dans lequel votre opérateur est installé. Par exemple, si vous avez déployé l'opérateur à l'aide de la commande
make deploy:$ oc project memcached-operator-systemModifiez l'exemple de manifeste
MemcachedCR à l'adresseconfig/samples/cache_v1_memcached.yamlpour qu'il contienne la spécification suivante :apiVersion: cache.example.com/v1 kind: Memcached metadata: name: memcached-sample ... spec: ... size: 3Créer le CR :
$ oc apply -f config/samples/cache_v1_memcached.yamlAssurez-vous que l'opérateur
Memcachedcrée le déploiement pour l'échantillon de CR avec la taille correcte :$ oc get deploymentsExemple de sortie
NAME READY UP-TO-DATE AVAILABLE AGE memcached-operator-controller-manager 1/1 1 1 8m memcached-sample 3/3 3 3 1mVérifiez l'état des pods et du CR pour confirmer que l'état est mis à jour avec les noms des pods Memcached.
Vérifier les gousses :
$ oc get podsExemple de sortie
NAME READY STATUS RESTARTS AGE memcached-sample-6fd7c98d8-7dqdr 1/1 Running 0 1m memcached-sample-6fd7c98d8-g5k7v 1/1 Running 0 1m memcached-sample-6fd7c98d8-m7vn7 1/1 Running 0 1mVérifier l'état de la CR :
$ oc get memcached/memcached-sample -o yamlExemple de sortie
apiVersion: cache.example.com/v1 kind: Memcached metadata: ... name: memcached-sample ... spec: size: 3 status: nodes: - memcached-sample-6fd7c98d8-7dqdr - memcached-sample-6fd7c98d8-g5k7v - memcached-sample-6fd7c98d8-m7vn7
Mettre à jour la taille du déploiement.
Mettre à jour le fichier
config/samples/cache_v1_memcached.yamlpour modifier le champspec.sizedans le CRMemcachedde3à5:$ oc patch memcached memcached-sample \ -p '{"spec":{"size": 5}}' \ --type=mergeConfirmez que l'opérateur modifie la taille du déploiement :
$ oc get deploymentsExemple de sortie
NAME READY UP-TO-DATE AVAILABLE AGE memcached-operator-controller-manager 1/1 1 1 10m memcached-sample 5/5 5 5 3m
Supprimez le CR en exécutant la commande suivante :
$ oc delete -f config/samples/cache_v1_memcached.yamlNettoyer les ressources qui ont été créées dans le cadre de ce tutoriel.
Si vous avez utilisé la commande
make deploypour tester l'opérateur, exécutez la commande suivante :$ make undeploySi vous avez utilisé la commande
operator-sdk run bundlepour tester l'opérateur, exécutez la commande suivante :$ operator-sdk cleanup <nom_du_projet>
5.4.3. Présentation du projet pour les opérateurs basés sur Ansible
Le CLI operator-sdk peut générer, ou scaffold, un certain nombre de paquets et de fichiers pour chaque projet Operator.
5.4.3.1. Mise en place d'un projet basé sur Ansible
Les projets Operator basés sur Ansible générés à l'aide de la commande operator-sdk init --plugins ansible contiennent les répertoires et fichiers suivants :
| Fichier ou répertoire | Objectif |
|---|---|
|
| Fichier Docker pour construire l'image du conteneur pour l'opérateur. |
|
| Cibles pour la construction, la publication et le déploiement de l'image du conteneur qui contient le binaire de l'opérateur, et cibles pour l'installation et la désinstallation de la définition des ressources personnalisées (CRD). |
|
| Fichier YAML contenant des informations sur les métadonnées de l'opérateur. |
|
|
Fichiers CRD de base et paramètres du fichier |
|
|
Rassemble tous les manifestes d'opérateurs pour le déploiement. Utilisé par la commande |
|
| Déploiement du gestionnaire de contrôleur. |
|
|
|
|
| Rôle et liaison de rôle pour l'élection du leader et le proxy d'authentification. |
|
| Exemple de ressources créées pour les CRD. |
|
| Exemples de configurations à tester. |
|
| Un sous-répertoire pour les playbooks à exécuter. |
|
| Sous-répertoire dans lequel l'arbre des rôles doit être exécuté. |
|
|
Groupe/version/genre (GVK) des ressources à surveiller, et la méthode d'invocation Ansible. Les nouvelles entrées sont ajoutées à l'aide de la commande |
|
| Fichier YAML contenant les collections Ansible et les dépendances de rôle à installer lors d'une compilation. |
|
| Scénarios moléculaires pour tester de bout en bout votre rôle et votre opérateur. |
5.4.4. Mise à jour des projets pour les nouvelles versions du SDK de l'opérateur
OpenShift Container Platform 4.12 supporte Operator SDK 1.25.4. Si vous avez déjà le CLI 1.22.0 installé sur votre station de travail, vous pouvez mettre à jour le CLI vers 1.25.4 en installant la dernière version.
Cependant, pour que vos projets Operator existants restent compatibles avec Operator SDK 1.25.4, des étapes de mise à jour sont nécessaires pour les ruptures associées introduites depuis la version 1.22.0. Vous devez effectuer les étapes de mise à jour manuellement dans tous vos projets Operator qui ont été précédemment créés ou maintenus avec la version 1.22.0.
5.4.4.1. Mise à jour des projets Operator basés sur Ansible pour Operator SDK 1.25.4
La procédure suivante met à jour un projet d'opérateur existant basé sur Ansible pour le rendre compatible avec la version 1.25.4.
Conditions préalables
- Operator SDK 1.25.4 installé
- Un projet Operator créé ou maintenu avec Operator SDK 1.22.0
Procédure
Apportez les modifications suivantes au fichier
config/default/manager_auth_proxy_patch.yaml:apiVersion: apps/v1 kind: Deployment metadata: name: controller-manager namespace: system spec: template: spec: containers: - name: kube-rbac-proxy image: registry.redhat.io/openshift4/ose-kube-rbac-proxy:v4.121 args: - "--secure-listen-address=0.0.0.0:8443" - "--upstream=http://127.0.0.1:8080/" - "--logtostderr=true" - "--v=0" ...- 1
- Mettre à jour la version de la balise de
v4.11àv4.12.
Apportez les modifications suivantes à votre site
Makefile:Pour activer la prise en charge des architectures multiples, ajoutez la cible
docker-buildxà votre projetMakefile:Exemple
Makefile# PLATFORMS defines the target platforms for the manager image be build to provide support to multiple # architectures. (i.e. make docker-buildx IMG=myregistry/mypoperator:0.0.1). To use this option you need to: # - able to use docker buildx . More info: https://docs.docker.com/build/buildx/ # - have enable BuildKit, More info: https://docs.docker.com/develop/develop-images/build_enhancements/ # - be able to push the image for your registry (i.e. if you do not inform a valid value via IMG=<myregistry/image:<tag>> than the export will fail) # To properly provided solutions that supports more than one platform you should use this option. PLATFORMS ?= linux/arm64,linux/amd64,linux/s390x,linux/ppc64le .PHONY: docker-buildx docker-buildx: test ## Build and push docker image for the manager for cross-platform support # copy existing Dockerfile and insert --platform=${BUILDPLATFORM} into Dockerfile.cross, and preserve the original Dockerfile sed -e '1 s/\(^FROM\)/FROM --platform=\$$\{BUILDPLATFORM\}/; t' -e ' 1,// s//FROM --platform=\$$\{BUILDPLATFORM\}/' Dockerfile > Dockerfile.cross - docker buildx create --name project-v3-builder docker buildx use project-v3-builder - docker buildx build --push --platform=$(PLATFORMS) --tag ${IMG} -f Dockerfile.cross - docker buildx rm project-v3-builder rm Dockerfile.crossPour permettre la prise en charge des architectures
arm64dans votre projet Operator, apportez les modifications suivantes à votre projetMakefile:Ancienne
MakefileOS := $(shell uname -s | tr '[:upper:]' '[:lower:]') ARCH := $(shell uname -m | sed 's/x86_64/amd64/')Nouveau
MakefileOS := $(shell uname -s | tr '[:upper:]' '[:lower:]') ARCH := $(shell uname -m | sed 's/x86_64/amd64/' | sed 's/aarch64/arm64/')Mettez à jour la version de Kustomize à
v4.5.5comme indiqué dans l'exemple suivant :Ancienne
Makefile.PHONY: kustomize KUSTOMIZE = $(shell pwd)/bin/kustomize kustomize: ## Download kustomize locally if necessary. ifeq (,$(wildcard $(KUSTOMIZE))) ifeq (,$(shell which kustomize 2>/dev/null)) @{ \ set -e ;\ mkdir -p $(dir $(KUSTOMIZE)) ;\ curl -sSLo - https://github.com/kubernetes-sigs/kustomize/releases/download/kustomize/v3.8.7/kustomize_v3.8.7_$(OS)_$(ARCH).tar.gz | \ tar xzf - -C bin/ ;\ } elseNouveau
Makefile.PHONY: kustomize KUSTOMIZE = $(shell pwd)/bin/kustomize kustomize: ## Download kustomize locally if necessary. ifeq (,$(wildcard $(KUSTOMIZE))) ifeq (,$(shell which kustomize 2>/dev/null)) @{ \ set -e ;\ mkdir -p $(dir $(KUSTOMIZE)) ;\ curl -sSLo - https://github.com/kubernetes-sigs/kustomize/releases/download/kustomize/v4.5.5/kustomize_v4.5.5_$(OS)_$(ARCH).tar.gz | \1 tar xzf - -C bin/ ;\ } else- 1
- Mise à jour de la version
v3.8.7versv4.5.5.
ImportantLa version de Kustomize
4.0.0a supprimé le plugingo-getteret a introduit des changements qui ne sont pas compatibles avec les versions antérieures. Les projets d'opérateurs qui s'appuient sur des versions antérieures de Kustomize pourraient ne pas fonctionner avec les nouvelles versions.Pour appliquer les changements à votre
Makefileet reconstruire votre Opérateur, entrez la commande suivante :$ make
Mettez à jour votre fichier
config/default/kustomizations.yamlcomme indiqué dans les exemples suivants :Exemple de fichier
kustomizations.yaml# Adds namespace to all resources. namespace: memcached-operator-system # Value of this field is prepended to the # names of all resources, e.g. a deployment named # "wordpress" becomes "alices-wordpress". # Note that it should also match with the prefix (text before '-') of the namespace # field above. namePrefix: memcached-operator- # Labels to add to all resources and selectors. #labels:1 #- includeSelectors: true2 # pairs: # someName: someValue resources:3 - ../crd - ../rbac - ../managerMettez à jour votre fichier
molecule/default/kustomize.ymlen y apportant les modifications suivantes :Exemple de fichier
molecule/default/kustomize.yml--- - name: Build kustomize testing overlay # load_restrictor must be set to none so we can load patch files from the default overlay command: '{{ kustomize }} build --load-restrictor LoadRestrictionsNone'1 args: chdir: '{{ config_dir }}/testing' register: resources changed_when: false- 1
- Remplacer
--load_restrictor none .par--load-restrictor LoadRestrictionNone.
5.4.5. Prise en charge d'Ansible dans Operator SDK
5.4.5.1. Fichiers de ressources personnalisés
Les opérateurs utilisent le mécanisme d'extension de Kubernetes, les définitions de ressources personnalisées (CRD), de sorte que votre ressource personnalisée (CR) ressemble et agit comme les objets Kubernetes natifs intégrés.
Le format de fichier CR est un fichier de ressources Kubernetes. L'objet comporte des champs obligatoires et facultatifs :
| Field | Description |
|---|---|
|
| Version du CR à créer. |
|
| Il s'agit en quelque sorte de la CR à créer. |
|
| Métadonnées spécifiques à Kubernetes à créer. |
|
| Liste clé-valeur des variables qui sont transmises à Ansible. Ce champ est vide par défaut. |
|
|
Résume l'état actuel de l'objet. Pour les opérateurs basés sur Ansible, la sous-ressource |
|
| Annotations spécifiques à Kubernetes à ajouter au CR. |
La liste suivante d'annotations CR modifie le comportement de l'opérateur :
| Annotation | Description |
|---|---|
|
|
Spécifie l'intervalle de réconciliation pour le CR. Cette valeur est analysée à l'aide du paquet Golang standard |
Exemple d'annotation d'opérateur basée sur Ansible
apiVersion: "test1.example.com/v1alpha1"
kind: "Test1"
metadata:
name: "example"
annotations:
ansible.operator-sdk/reconcile-period: "30s"5.4.5.2. fichier watches.yaml
Un group/version/kind (GVK) est un identifiant unique pour une API Kubernetes. Le fichier watches.yaml contient une liste de correspondances entre des ressources personnalisées (CR), identifiées par leur GVK, et un rôle ou un playbook Ansible. L'opérateur attend ce fichier de mappage dans un emplacement prédéfini à l'adresse /opt/ansible/watches.yaml.
| Field | Description |
|---|---|
|
| Groupe de CR à suivre. |
|
| Version de la CR à regarder. |
|
| Une sorte de CR à regarder |
|
|
Chemin d'accès au rôle Ansible ajouté au conteneur. Par exemple, si votre répertoire |
|
|
Chemin d'accès au playbook Ansible ajouté au conteneur. Ce playbook est censé être un moyen d'appeler des rôles. Ce champ s'exclut mutuellement avec le champ |
|
| L'intervalle de réconciliation, c'est-à-dire la fréquence à laquelle le rôle ou le livre de jeu est exécuté, pour un CR donné. |
|
|
Lorsque la valeur est |
Exemple de fichier watches.yaml
- version: v1alpha1
group: test1.example.com
kind: Test1
role: /opt/ansible/roles/Test1
- version: v1alpha1
group: test2.example.com
kind: Test2
playbook: /opt/ansible/playbook.yml
- version: v1alpha1
group: test3.example.com
kind: Test3
playbook: /opt/ansible/test3.yml
reconcilePeriod: 0
manageStatus: false5.4.5.2.1. Options avancées
Les fonctions avancées peuvent être activées en les ajoutant à votre fichier watches.yaml par GVK. Elles peuvent être placées sous les champs group, version, kind et playbook ou role.
Certaines caractéristiques peuvent être modifiées par ressource à l'aide d'une annotation sur le CR. Les options qui peuvent être remplacées ont l'annotation spécifiée ci-dessous.
| Fonctionnalité | Clé YAML | Description | Annotation pour l'annulation | Valeur par défaut |
|---|---|---|---|---|
| Période de réconciliation |
| Délai entre deux rapprochements pour un CR donné. |
|
|
| Gérer le statut |
|
Permet à l'opérateur de gérer la section |
| |
| Surveiller les ressources dépendantes |
| Permet à l'opérateur de surveiller dynamiquement les ressources créées par Ansible. |
| |
| Surveiller les ressources gérées par les clusters |
| Permet à l'opérateur de surveiller les ressources de type cluster qui sont créées par Ansible. |
| |
| Artéfacts de coureur maximum |
| Gère le nombre de répertoires d'artefacts qu'Ansible Runner conserve dans le conteneur Operator pour chaque ressource individuelle. |
|
|
Exemple de fichier watches.yml avec des options avancées
- version: v1alpha1
group: app.example.com
kind: AppService
playbook: /opt/ansible/playbook.yml
maxRunnerArtifacts: 30
reconcilePeriod: 5s
manageStatus: False
watchDependentResources: False5.4.5.3. Variables supplémentaires envoyées à Ansible
Des variables supplémentaires peuvent être envoyées à Ansible, qui sont ensuite gérées par l'opérateur. La section spec de la ressource personnalisée (CR) transmet les paires clé-valeur en tant que variables supplémentaires. Cela équivaut à des variables supplémentaires transmises à la commande ansible-playbook.
L'opérateur transmet également des variables supplémentaires dans le champ meta pour le nom du CR et l'espace de noms du CR.
Pour l'exemple de CR suivant :
apiVersion: "app.example.com/v1alpha1"
kind: "Database"
metadata:
name: "example"
spec:
message: "Hello world 2"
newParameter: "newParam"La structure transmise à Ansible en tant que variables supplémentaires est la suivante :
{ "meta": {
"name": "<cr_name>",
"namespace": "<cr_namespace>",
},
"message": "Hello world 2",
"new_parameter": "newParam",
"_app_example_com_database": {
<full_crd>
},
}
Les champs message et newParameter sont définis au niveau supérieur en tant que variables supplémentaires, et meta fournit les métadonnées pertinentes pour le CR, telles que définies dans l'opérateur. Les champs meta sont accessibles en utilisant la notation par points dans Ansible, par exemple :
---
- debug:
msg: "name: {{ ansible_operator_meta.name }}, {{ ansible_operator_meta.namespace }}"5.4.5.4. Répertoire Ansible Runner
Ansible Runner conserve des informations sur les exécutions d'Ansible dans le conteneur. Il se trouve à l'adresse /tmp/ansible-operator/runner/<group>/<version>/<kind>/<namespace>/<name>.
5.4.6. Collection Kubernetes pour Ansible
Pour gérer le cycle de vie de votre application sur Kubernetes à l'aide d'Ansible, vous pouvez utiliser la collection Kubernetes pour Ansible. Cette collection de modules Ansible permet à un développeur d'exploiter ses fichiers de ressources Kubernetes existants écrits en YAML ou d'exprimer la gestion du cycle de vie dans Ansible natif.
L'un des plus grands avantages de l'utilisation d'Ansible en conjonction avec les fichiers de ressources Kubernetes existants est la possibilité d'utiliser Jinja templating afin que vous puissiez personnaliser les ressources avec la simplicité de quelques variables dans Ansible.
Cette section détaille l'utilisation de la collection Kubernetes. Pour commencer, installez la collection sur votre poste de travail local et testez-la à l'aide d'un playbook avant de passer à son utilisation au sein d'un Operator.
5.4.6.1. Installation de la collection Kubernetes pour Ansible
Vous pouvez installer la Kubernetes Collection for Ansible sur votre poste de travail local.
Procédure
Installer Ansible 2.9 :
$ sudo dnf install ansibleInstallez le paquetage client OpenShift python:
$ pip3 install openshiftInstallez la collection Kubernetes en utilisant l'une des méthodes suivantes :
Vous pouvez installer la collection directement depuis Ansible Galaxy :
$ ansible-galaxy collection install community.kubernetesSi vous avez déjà initialisé votre Opérateur, il se peut que vous ayez un fichier
requirements.ymlau niveau supérieur de votre projet. Ce fichier spécifie les dépendances Ansible qui doivent être installées pour que votre opérateur fonctionne. Par défaut, ce fichier installe la collectioncommunity.kubernetesainsi que la collectionoperator_sdk.util, qui fournit des modules et des plugins pour les fonctions spécifiques à l'opérateur.Pour installer les modules dépendants du fichier
requirements.yml:$ ansible-galaxy collection install -r requirements.yml
5.4.6.2. Tester la collection Kubernetes localement
Les développeurs de l'opérateur peuvent exécuter le code Ansible à partir de leur machine locale, au lieu d'exécuter et de reconstruire l'opérateur à chaque fois.
Conditions préalables
- Initialiser un projet Operator basé sur Ansible et créer une API qui a un rôle Ansible généré en utilisant le SDK Operator
- Installer la collection Kubernetes pour Ansible
Procédure
Dans le répertoire de votre projet Operator basé sur Ansible, modifiez le fichier
roles/<kind>/tasks/main.ymlavec la logique Ansible que vous souhaitez. Le répertoireroles/<kind>/est créé lorsque vous utilisez l'indicateur--generate-rolelors de la création d'une API. Le remplaçable<kind>correspond au type que vous avez spécifié pour l'API.L'exemple suivant crée et supprime une carte de configuration en fonction de la valeur d'une variable nommée
state:--- - name: set ConfigMap example-config to {{ state }} community.kubernetes.k8s: api_version: v1 kind: ConfigMap name: example-config namespace: default1 state: "{{ state }}" ignore_errors: true2 Modifiez le fichier
roles/<kind>/defaults/main.ymlpour questatesoit remplacé parpresentpar défaut :--- state: presentCréez un playbook Ansible en créant un fichier
playbook.ymldans le niveau supérieur de votre répertoire de projet, et incluez votre rôle<kind>:--- - hosts: localhost roles: - <kind>Exécutez le manuel de jeu :
$ ansible-playbook playbook.ymlExemple de sortie
[WARNING]: provided hosts list is empty, only localhost is available. Note that the implicit localhost does not match 'all' PLAY [localhost] ******************************************************************************** TASK [Gathering Facts] ******************************************************************************** ok: [localhost] TASK [memcached : set ConfigMap example-config to present] ******************************************************************************** changed: [localhost] PLAY RECAP ******************************************************************************** localhost : ok=2 changed=1 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0Vérifiez que la carte de configuration a été créée :
$ oc get configmapsExemple de sortie
NAME DATA AGE example-config 0 2m1sExécutez à nouveau le manuel de jeu en remplaçant
stateparabsent:$ ansible-playbook playbook.yml --extra-vars state=absentExemple de sortie
[WARNING]: provided hosts list is empty, only localhost is available. Note that the implicit localhost does not match 'all' PLAY [localhost] ******************************************************************************** TASK [Gathering Facts] ******************************************************************************** ok: [localhost] TASK [memcached : set ConfigMap example-config to absent] ******************************************************************************** changed: [localhost] PLAY RECAP ******************************************************************************** localhost : ok=2 changed=1 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0Vérifiez que la carte de configuration a été supprimée :
$ oc get configmaps
5.4.6.3. Prochaines étapes
- Voir Utiliser Ansible à l'intérieur d'un opérateur pour plus de détails sur le déclenchement de votre logique Ansible personnalisée à l'intérieur d'un opérateur lorsqu'une ressource personnalisée (CR) est modifiée.
5.4.7. Utiliser Ansible à l'intérieur d'un opérateur
Après vous être familiarisé avec l'utilisation locale de Kubernetes Collection pour Ansible, vous pouvez déclencher la même logique Ansible à l'intérieur d'un opérateur lorsqu'une ressource personnalisée (CR) change. Cet exemple associe un rôle Ansible à une ressource Kubernetes spécifique que l'opérateur surveille. Ce mappage est effectué dans le fichier watches.yaml.
5.4.7.1. Fichiers de ressources personnalisés
Les opérateurs utilisent le mécanisme d'extension de Kubernetes, les définitions de ressources personnalisées (CRD), de sorte que votre ressource personnalisée (CR) ressemble et agit comme les objets Kubernetes natifs intégrés.
Le format de fichier CR est un fichier de ressources Kubernetes. L'objet comporte des champs obligatoires et facultatifs :
| Field | Description |
|---|---|
|
| Version du CR à créer. |
|
| Il s'agit en quelque sorte de la CR à créer. |
|
| Métadonnées spécifiques à Kubernetes à créer. |
|
| Liste clé-valeur des variables qui sont transmises à Ansible. Ce champ est vide par défaut. |
|
|
Résume l'état actuel de l'objet. Pour les opérateurs basés sur Ansible, la sous-ressource |
|
| Annotations spécifiques à Kubernetes à ajouter au CR. |
La liste suivante d'annotations CR modifie le comportement de l'opérateur :
| Annotation | Description |
|---|---|
|
|
Spécifie l'intervalle de réconciliation pour le CR. Cette valeur est analysée à l'aide du paquet Golang standard |
Exemple d'annotation d'opérateur basée sur Ansible
apiVersion: "test1.example.com/v1alpha1"
kind: "Test1"
metadata:
name: "example"
annotations:
ansible.operator-sdk/reconcile-period: "30s"5.4.7.2. Tester localement un opérateur basé sur Ansible
Vous pouvez tester la logique à l'intérieur d'un Operator basé sur Ansible qui s'exécute localement en utilisant la commande make run à partir du répertoire de premier niveau de votre projet Operator. La cible Makefile make run exécute localement le binaire ansible-operator, qui lit le fichier watches.yaml et utilise votre fichier ~/.kube/config pour communiquer avec un cluster Kubernetes, tout comme le font les modules k8s.
Vous pouvez personnaliser le chemin des rôles en définissant la variable d'environnement ANSIBLE_ROLES_PATH ou en utilisant le drapeau ansible-roles-path. Si le rôle n'est pas trouvé dans la valeur ANSIBLE_ROLES_PATH, l'opérateur le cherche dans {{current directory}}/roles.
Conditions préalables
- Ansible Runner v2.0.2
- Ansible Runner HTTP Event Emitter plugin v1.0.0
- Effectuer les étapes précédentes pour tester la collection Kubernetes localement
Procédure
Installez votre définition de ressource personnalisée (CRD) et les définitions de contrôle d'accès basé sur les rôles (RBAC) appropriées pour votre ressource personnalisée (CR) :
$ make installExemple de sortie
/usr/bin/kustomize build config/crd | kubectl apply -f - customresourcedefinition.apiextensions.k8s.io/memcacheds.cache.example.com createdExécutez la commande
make run:$ make runExemple de sortie
/home/user/memcached-operator/bin/ansible-operator run {"level":"info","ts":1612739145.2871568,"logger":"cmd","msg":"Version","Go Version":"go1.15.5","GOOS":"linux","GOARCH":"amd64","ansible-operator":"v1.10.1","commit":"1abf57985b43bf6a59dcd18147b3c574fa57d3f6"} ... {"level":"info","ts":1612739148.347306,"logger":"controller-runtime.metrics","msg":"metrics server is starting to listen","addr":":8080"} {"level":"info","ts":1612739148.3488882,"logger":"watches","msg":"Environment variable not set; using default value","envVar":"ANSIBLE_VERBOSITY_MEMCACHED_CACHE_EXAMPLE_COM","default":2} {"level":"info","ts":1612739148.3490262,"logger":"cmd","msg":"Environment variable not set; using default value","Namespace":"","envVar":"ANSIBLE_DEBUG_LOGS","ANSIBLE_DEBUG_LOGS":false} {"level":"info","ts":1612739148.3490646,"logger":"ansible-controller","msg":"Watching resource","Options.Group":"cache.example.com","Options.Version":"v1","Options.Kind":"Memcached"} {"level":"info","ts":1612739148.350217,"logger":"proxy","msg":"Starting to serve","Address":"127.0.0.1:8888"} {"level":"info","ts":1612739148.3506632,"logger":"controller-runtime.manager","msg":"starting metrics server","path":"/metrics"} {"level":"info","ts":1612739148.350784,"logger":"controller-runtime.manager.controller.memcached-controller","msg":"Starting EventSource","source":"kind source: cache.example.com/v1, Kind=Memcached"} {"level":"info","ts":1612739148.5511978,"logger":"controller-runtime.manager.controller.memcached-controller","msg":"Starting Controller"} {"level":"info","ts":1612739148.5512562,"logger":"controller-runtime.manager.controller.memcached-controller","msg":"Starting workers","worker count":8}L'opérateur surveillant désormais les événements de votre CR, la création d'un CR déclenchera l'exécution de votre rôle Ansible.
NotePrenons l'exemple d'un manifeste
config/samples/<gvk>.yamlCR :apiVersion: <group>.example.com/v1alpha1 kind: <kind> metadata: name: "<kind>-sample"Comme le champ
specn'est pas défini, Ansible est invoqué sans variables supplémentaires. Le passage de variables supplémentaires d'un CR à Ansible est abordé dans une autre section. Il est important de définir des valeurs par défaut raisonnables pour l'opérateur.Créez une instance de votre CR avec la variable par défaut
statefixée àpresent:$ oc apply -f config/samples/<gvk>.yamlVérifiez que la carte de configuration
example-configa été créée :$ oc get configmapsExemple de sortie
NAME STATUS AGE example-config Active 3sModifiez votre fichier
config/samples/<gvk>.yamlpour que le champstatesoit remplacé parabsent. Par exemple :apiVersion: cache.example.com/v1 kind: Memcached metadata: name: memcached-sample spec: state: absentAppliquez les modifications :
$ oc apply -f config/samples/<gvk>.yamlConfirmez que la carte de configuration est supprimée :
$ oc get configmap
5.4.7.3. Test d'un opérateur basé sur Ansible sur le cluster
Après avoir testé votre logique Ansible personnalisée localement à l'intérieur d'un opérateur, vous pouvez tester l'opérateur à l'intérieur d'un pod sur un cluster OpenShift Container Platform, ce qui est préférable pour une utilisation en production.
Vous pouvez exécuter votre projet Operator en tant que déploiement sur votre cluster.
Procédure
Exécutez les commandes
makesuivantes pour construire et pousser l'image de l'opérateur. Modifiez l'argumentIMGdans les étapes suivantes pour référencer un référentiel auquel vous avez accès. Vous pouvez obtenir un compte pour stocker des conteneurs sur des sites de dépôt tels que Quay.io.Construire l'image :
$ make docker-build IMG=<registry>/<user>/<image_name>:<tag>NoteLe fichier Docker généré par le SDK pour l'Operator fait explicitement référence à
GOARCH=amd64pourgo build. Cette référence peut être modifiée enGOARCH=$TARGETARCHpour les architectures non-AMD64. Docker définira automatiquement la variable d'environnement à la valeur spécifiée par–platform. Avec Buildah, il faudra utiliser–build-argà cette fin. Pour plus d'informations, voir Architectures multiples.Transférer l'image dans un référentiel :
$ make docker-push IMG=<registry>/<user>/<image_name>:<tag>NoteLe nom et la balise de l'image, par exemple
IMG=<registry>/<user>/<image_name>:<tag>, dans les deux commandes peuvent également être définis dans votre Makefile. Modifiez la valeur deIMG ?= controller:latestpour définir votre nom d'image par défaut.
Exécutez la commande suivante pour déployer l'opérateur :
$ make deploy IMG=<registry>/<user>/<image_name>:<tag>Par défaut, cette commande crée un espace de noms avec le nom de votre projet Operator sous la forme
<project_name>-systemet est utilisé pour le déploiement. Cette commande installe également les manifestes RBAC à partir deconfig/rbac.Exécutez la commande suivante pour vérifier que l'opérateur fonctionne :
oc get deployment -n <nom_du_projet>-systèmeExemple de sortie
NAME READY UP-TO-DATE AVAILABLE AGE <project_name>-controller-manager 1/1 1 1 8m
5.4.7.4. Journaux Ansible
Les opérateurs basés sur Ansible fournissent des journaux sur l'exécution d'Ansible, ce qui peut être utile pour déboguer vos tâches Ansible. Les journaux peuvent également contenir des informations détaillées sur les aspects internes de l'opérateur et ses interactions avec Kubernetes.
5.4.7.4.1. Visualisation des journaux Ansible
Conditions préalables
- Opérateur basé sur Ansible fonctionnant comme un déploiement sur un cluster
Procédure
Pour afficher les journaux d'un opérateur basé sur Ansible, exécutez la commande suivante :
$ oc logs deployment/<project_name>-controller-manager \ -c manager \1 -n <namespace>2 Exemple de sortie
{"level":"info","ts":1612732105.0579333,"logger":"cmd","msg":"Version","Go Version":"go1.15.5","GOOS":"linux","GOARCH":"amd64","ansible-operator":"v1.10.1","commit":"1abf57985b43bf6a59dcd18147b3c574fa57d3f6"} {"level":"info","ts":1612732105.0587437,"logger":"cmd","msg":"WATCH_NAMESPACE environment variable not set. Watching all namespaces.","Namespace":""} I0207 21:08:26.110949 7 request.go:645] Throttling request took 1.035521578s, request: GET:https://172.30.0.1:443/apis/flowcontrol.apiserver.k8s.io/v1alpha1?timeout=32s {"level":"info","ts":1612732107.768025,"logger":"controller-runtime.metrics","msg":"metrics server is starting to listen","addr":"127.0.0.1:8080"} {"level":"info","ts":1612732107.768796,"logger":"watches","msg":"Environment variable not set; using default value","envVar":"ANSIBLE_VERBOSITY_MEMCACHED_CACHE_EXAMPLE_COM","default":2} {"level":"info","ts":1612732107.7688773,"logger":"cmd","msg":"Environment variable not set; using default value","Namespace":"","envVar":"ANSIBLE_DEBUG_LOGS","ANSIBLE_DEBUG_LOGS":false} {"level":"info","ts":1612732107.7688901,"logger":"ansible-controller","msg":"Watching resource","Options.Group":"cache.example.com","Options.Version":"v1","Options.Kind":"Memcached"} {"level":"info","ts":1612732107.770032,"logger":"proxy","msg":"Starting to serve","Address":"127.0.0.1:8888"} I0207 21:08:27.770185 7 leaderelection.go:243] attempting to acquire leader lease memcached-operator-system/memcached-operator... {"level":"info","ts":1612732107.770202,"logger":"controller-runtime.manager","msg":"starting metrics server","path":"/metrics"} I0207 21:08:27.784854 7 leaderelection.go:253] successfully acquired lease memcached-operator-system/memcached-operator {"level":"info","ts":1612732107.7850506,"logger":"controller-runtime.manager.controller.memcached-controller","msg":"Starting EventSource","source":"kind source: cache.example.com/v1, Kind=Memcached"} {"level":"info","ts":1612732107.8853772,"logger":"controller-runtime.manager.controller.memcached-controller","msg":"Starting Controller"} {"level":"info","ts":1612732107.8854098,"logger":"controller-runtime.manager.controller.memcached-controller","msg":"Starting workers","worker count":4}
5.4.7.4.2. L'activation de l'intégralité d'Ansible génère des logs
Vous pouvez définir la variable d'environnement ANSIBLE_DEBUG_LOGS à True pour permettre de vérifier le résultat complet d'Ansible dans les journaux, ce qui peut être utile lors du débogage.
Procédure
Modifiez les fichiers
config/manager/manager.yamletconfig/default/manager_auth_proxy_patch.yamlpour y inclure la configuration suivante :containers: - name: manager env: - name: ANSIBLE_DEBUG_LOGS value: "True"
5.4.7.4.3. Activation de la débogage verbose dans les journaux
Lors du développement d'un opérateur basé sur Ansible, il peut être utile d'activer un débogage supplémentaire dans les journaux.
Procédure
Ajoutez l'annotation
ansible.sdk.operatorframework.io/verbosityà votre ressource personnalisée pour activer le niveau de verbosité que vous souhaitez. Par exemple :apiVersion: "cache.example.com/v1alpha1" kind: "Memcached" metadata: name: "example-memcached" annotations: "ansible.sdk.operatorframework.io/verbosity": "4" spec: size: 4
5.4.8. Gestion personnalisée de l'état des ressources
5.4.8.1. À propos de l'état des ressources personnalisées dans les opérateurs basés sur Ansible
Les opérateurs basés sur Ansible mettent automatiquement à jour les sous-ressources des ressources personnalisées (CR) status avec des informations génériques sur l'exécution précédente d'Ansible. Cela inclut le nombre de tâches réussies et échouées, ainsi que les messages d'erreur pertinents, comme indiqué :
status:
conditions:
- ansibleResult:
changed: 3
completion: 2018-12-03T13:45:57.13329
failures: 1
ok: 6
skipped: 0
lastTransitionTime: 2018-12-03T13:45:57Z
message: 'Status code was -1 and not [200]: Request failed: <urlopen error [Errno
113] No route to host>'
reason: Failed
status: "True"
type: Failure
- lastTransitionTime: 2018-12-03T13:46:13Z
message: Running reconciliation
reason: Running
status: "True"
type: Running
Les opérateurs basés sur Ansible permettent également aux auteurs d'opérateurs de fournir des valeurs d'état personnalisées avec le module Ansible k8s_status, qui est inclus dans la collectionoperator_sdk.util . Cela permet à l'auteur de mettre à jour le site status à partir d'Ansible avec n'importe quelle paire clé-valeur.
Par défaut, les opérateurs basés sur Ansible incluent toujours la sortie générique de l'exécution Ansible, comme indiqué ci-dessus. Si vous préférez que votre application not mette à jour l'état avec la sortie Ansible, vous pouvez suivre l'état manuellement à partir de votre application.
5.4.8.2. Suivi manuel du statut des ressources personnalisées
Vous pouvez utiliser la collection operator_sdk.util pour modifier votre opérateur basé sur Ansible afin de suivre manuellement l'état des ressources personnalisées (CR) à partir de votre application.
Conditions préalables
- Projet Operator basé sur Ansible créé en utilisant le SDK Operator
Procédure
Mettre à jour le fichier
watches.yamlavec un champmanageStatusdéfini commefalse:- version: v1 group: api.example.com kind: <kind> role: <role> manageStatus: falseUtilisez le module Ansible
operator_sdk.util.k8s_statuspour mettre à jour la sous-ressource. Par exemple, pour mettre à jour la clétestet la valeurdata,operator_sdk.utilpeut être utilisé comme indiqué :- operator_sdk.util.k8s_status: api_version: app.example.com/v1 kind: <kind> name: "{{ ansible_operator_meta.name }}" namespace: "{{ ansible_operator_meta.namespace }}" status: test: dataVous pouvez déclarer des collections dans le fichier
meta/main.ymlpour le rôle, qui est inclus pour les opérateurs basés sur Ansible :collections: - operator_sdk.utilAprès avoir déclaré les collections dans le méta-rôle, vous pouvez invoquer directement le module
k8s_status:k8s_status: ... status: key1: value1
5.5. Opérateurs à la barre
5.5.1. Premiers pas avec Operator SDK pour les opérateurs basés sur Helm
Le SDK Operator comprend des options permettant de générer un projet Operator qui exploite les cartes Helm existantes pour déployer des ressources Kubernetes en tant qu'application unifiée, sans avoir à écrire de code Go.
Pour démontrer les bases de la configuration et de l'exécution d'un opérateur basé sur Helm à l'aide des outils et des bibliothèques fournis par le SDK Operator, les développeurs d'opérateurs peuvent construire un exemple d'opérateur basé sur Helm pour Nginx et le déployer dans un cluster.
5.5.1.1. Conditions préalables
- Operator SDK CLI installé
-
OpenShift CLI (
oc) v4.12 installé -
Connexion à un cluster OpenShift Container Platform 4.12 avec
ocavec un compte qui a les permissionscluster-admin - Pour permettre au cluster d'extraire l'image, le dépôt où vous avez poussé votre image doit être défini comme public, ou vous devez configurer un secret d'extraction d'image
5.5.1.2. Création et déploiement d'opérateurs basés sur Helm
Vous pouvez construire et déployer un simple opérateur basé sur Helm pour Nginx en utilisant le SDK de l'opérateur.
Procédure
Create a project.
Créez votre répertoire de projet :
$ mkdir nginx-operatorAllez dans le répertoire du projet :
$ cd nginx-operatorExécutez la commande
operator-sdk initavec le pluginhelmpour initialiser le projet :$ operator-sdk init \ --plugins=helm
Create an API.
Créer une API Nginx simple :
$ operator-sdk create api \ --group demo \ --version v1 \ --kind NginxCette API utilise le modèle de graphique intégré de Helm de la commande
helm create.Build and push the Operator image.
Utilisez les cibles par défaut de
Makefilepour construire et pousser votre opérateur. DéfinissezIMGavec une spécification d'extraction pour votre image qui utilise un registre vers lequel vous pouvez pousser :$ make docker-build docker-push IMG=<registry>/<user>/<image_name>:<tag>Run the Operator.
Installer le CRD :
$ make installDéployez le projet sur le cluster. Définissez
IMGsur l'image que vous avez poussée :$ make deploy IMG=<registry>/<user>/<image_name>:<tag>
Add a security context constraint (SCC).
Le compte de service Nginx nécessite un accès privilégié pour fonctionner dans OpenShift Container Platform. Ajoutez le SCC suivant au compte de service pour le pod
nginx-sample:$ oc adm policy add-scc-to-user \ anyuid system:serviceaccount:nginx-operator-system:nginx-sampleCreate a sample custom resource (CR).
Créer un échantillon de CR :
$ oc apply -f config/samples/demo_v1_nginx.yaml \ -n nginx-operator-systemIl faut s'attendre à ce que le CR réconcilie l'opérateur :
$ oc logs deployment.apps/nginx-operator-controller-manager \ -c manager \ -n nginx-operator-system
Delete a CR
Supprimez un CR en exécutant la commande suivante :
$ oc delete -f config/samples/cache_v1_memcached.yaml -n memcached-operator-systemClean up.
Exécutez la commande suivante pour nettoyer les ressources qui ont été créées dans le cadre de cette procédure :
$ make undeploy
5.5.1.3. Prochaines étapes
- Voir le tutoriel du SDK pour les opérateurs basés sur Hel m pour une description plus détaillée de la construction d'un opérateur basé sur Helm.
5.5.2. Didacticiel sur le SDK pour les opérateurs basés sur Helm
Les développeurs d'opérateurs peuvent profiter de la prise en charge de Helm dans le SDK de l'opérateur pour construire un exemple d'opérateur basé sur Helm pour Nginx et gérer son cycle de vie. Ce tutoriel décrit le processus suivant :
- Créer un déploiement Nginx
-
Veillez à ce que la taille du déploiement soit la même que celle spécifiée par la spécification de ressource personnalisée (CR) de
Nginx -
Mettre à jour le statut du CR
Nginxen utilisant le rédacteur de statut avec les noms des podsnginx
Ce processus est réalisé à l'aide de deux pièces maîtresses du cadre de l'opérateur :
- SDK de l'opérateur
-
L'outil CLI
operator-sdket la bibliothèque APIcontroller-runtime - Gestionnaire du cycle de vie des opérateurs (OLM)
- Installation, mise à niveau et contrôle d'accès basé sur les rôles (RBAC) des opérateurs sur un cluster
Ce tutoriel est plus détaillé que le tutoriel " Getting started with Operator SDK for Helm-based Operators" (Démarrer avec Operator SDK pour les opérateurs basés sur le Helm).
5.5.2.1. Conditions préalables
- Operator SDK CLI installé
-
OpenShift CLI (
oc) v4.12 installé -
Connexion à un cluster OpenShift Container Platform 4.12 avec
ocavec un compte qui a les permissionscluster-admin - Pour permettre au cluster d'extraire l'image, le dépôt où vous avez poussé votre image doit être défini comme public, ou vous devez configurer un secret d'extraction d'image
5.5.2.2. Création d'un projet
Utilisez l'interface de programmation Operator SDK pour créer un projet appelé nginx-operator.
Procédure
Créer un répertoire pour le projet :
$ mkdir -p $HOME/projects/nginx-operatorAccédez au répertoire :
$ cd $HOME/projects/nginx-operatorExécutez la commande
operator-sdk initavec le pluginhelmpour initialiser le projet :$ operator-sdk init \ --plugins=helm \ --domain=example.com \ --group=demo \ --version=v1 \ --kind=NginxNotePar défaut, le plugin
helminitialise un projet à l'aide d'un diagramme Helm standard. Vous pouvez utiliser des drapeaux supplémentaires, tels que le drapeau--helm-chart, pour initialiser un projet à l'aide d'un diagramme Helm existant.La commande
initcrée le projetnginx-operatorspécifiquement pour observer une ressource avec la version de l'APIexample.com/v1et le typeNginx.-
Pour les projets basés sur Helm, la commande
initgénère les règles RBAC dans le fichierconfig/rbac/role.yamlen se basant sur les ressources qui seraient déployées par le manifeste par défaut de la carte. Vérifiez que les règles générées dans ce fichier répondent aux exigences de permission de l'opérateur.
5.5.2.2.1. Cartes existantes du gouvernail
Au lieu de créer votre projet avec un diagramme Helm standard, vous pouvez utiliser un diagramme existant, provenant de votre système de fichiers local ou d'un dépôt de diagrammes distant, en utilisant les drapeaux suivants :
-
--helm-chart -
--helm-chart-repo -
--helm-chart-version
Si l'option --helm-chart est spécifiée, les options --group, --version et --kind deviennent facultatives. S'ils ne sont pas définis, les valeurs par défaut suivantes sont utilisées :
| Drapeau | Valeur |
|---|---|
|
|
|
|
|
|
|
|
|
|
| Déduit du graphique spécifié |
Si l'indicateur --helm-chart spécifie une archive de graphique locale, par exemple example-chart-1.2.0.tgz, ou un répertoire, le graphique est validé et décompressé ou copié dans le projet. Dans le cas contraire, le SDK Operator tente de récupérer la carte à partir d'un référentiel distant.
Si l'URL d'un référentiel personnalisé n'est pas spécifiée par l'option --helm-chart-repo, les formats de référence graphique suivants sont pris en charge :
| Format | Description |
|---|---|
|
|
Récupérer la carte Helm nommée |
|
| Récupère l'archive graphique de Helm à l'URL spécifiée. |
Si une URL de référentiel personnalisée est spécifiée par --helm-chart-repo, le format de référence graphique suivant est pris en charge :
| Format | Description |
|---|---|
|
|
Récupère le graphique Helm nommé |
Si l'option --helm-chart-version n'est pas activée, l'Operator SDK récupère la dernière version disponible de la carte Helm. Sinon, il récupère la version spécifiée. L'option --helm-chart-version n'est pas utilisée lorsque la carte spécifiée avec l'option --helm-chart fait référence à une version spécifique, par exemple lorsqu'il s'agit d'un chemin d'accès local ou d'une URL.
Pour plus de détails et d'exemples, exécutez :
$ operator-sdk init --plugins helm --help5.5.2.2.2. Dossier PROJET
Parmi les fichiers générés par la commande operator-sdk init figure un fichier Kubebuilder PROJECT. Les commandes operator-sdk suivantes, ainsi que la sortie help, qui sont exécutées à partir de la racine du projet, lisent ce fichier et savent que le type de projet est Helm. Par exemple :
domain: example.com
layout: helm.sdk.operatorframework.io/v1
projectName: helm-operator
resources:
- group: demo
kind: Nginx
version: v1
version: 35.5.2.3. Comprendre la logique de l'opérateur
Dans cet exemple, le projet nginx-operator exécute la logique de rapprochement suivante pour chaque ressource personnalisée (CR) Nginx:
- Créer un déploiement Nginx s'il n'existe pas.
- Créer un service Nginx s'il n'existe pas.
- Créer une entrée Nginx si elle est activée et n'existe pas.
-
Assurez-vous que le déploiement, le service et l'entrée optionnelle correspondent à la configuration souhaitée, telle que spécifiée par la CR
Nginx, par exemple le nombre de répliques, l'image et le type de service.
Par défaut, le projet nginx-operator surveille les événements relatifs aux ressources Nginx, comme indiqué dans le fichier watches.yaml, et exécute les mises à jour Helm à l'aide du diagramme spécifié :
# Use the 'create api' subcommand to add watches to this file.
- group: demo
version: v1
kind: Nginx
chart: helm-charts/nginx
# +kubebuilder:scaffold:watch5.5.2.3.1. Exemple de tableau de bord
Lorsqu'un projet Helm Operator est créé, le SDK Operator crée un exemple de diagramme Helm qui contient un ensemble de modèles pour une version simple de Nginx.
Dans cet exemple, des modèles sont disponibles pour les ressources de déploiement, de service et d'entrée, ainsi qu'un modèle NOTES.txt, que les développeurs de diagrammes Helm utilisent pour transmettre des informations utiles sur une version.
Si vous n'êtes pas encore familiarisé avec les graphiques Helm, consultez la documentation du développeur Helm.
5.5.2.3.2. Modifier les spécifications des ressources personnalisées
Helm utilise un concept appelé valeurs pour personnaliser les valeurs par défaut d'un graphique Helm, qui sont définies dans le fichier values.yaml.
Vous pouvez remplacer ces valeurs par défaut en définissant les valeurs souhaitées dans la spécification des ressources personnalisées (CR). Vous pouvez utiliser le nombre de répliques comme exemple.
Procédure
Le fichier
helm-charts/nginx/values.yamlcontient une valeur appeléereplicaCountdéfinie par défaut sur1. Pour avoir deux instances Nginx dans votre déploiement, votre spécification CR doit contenirreplicaCount: 2.Modifiez le fichier
config/samples/demo_v1_nginx.yamlpour définirreplicaCount: 2:apiVersion: demo.example.com/v1 kind: Nginx metadata: name: nginx-sample ... spec: ... replicaCount: 2De même, le port de service par défaut est défini sur
80. Pour utiliser8080, modifiez le fichierconfig/samples/demo_v1_nginx.yamlpour définirspec.port: 8080, ce qui ajoute la priorité sur le port de service :apiVersion: demo.example.com/v1 kind: Nginx metadata: name: nginx-sample spec: replicaCount: 2 service: port: 8080
L'opérateur Helm applique l'intégralité de la spécification comme s'il s'agissait du contenu d'un fichier de valeurs, tout comme la commande helm install -f ./overrides.yaml.
5.5.2.4. Activation de la prise en charge du proxy
Les auteurs d'opérateurs peuvent développer des opérateurs qui prennent en charge les proxys réseau. Les administrateurs de clusters configurent la prise en charge du proxy pour les variables d'environnement qui sont gérées par Operator Lifecycle Manager (OLM). Pour prendre en charge les clusters proxy, votre opérateur doit inspecter l'environnement à la recherche des variables proxy standard suivantes et transmettre les valeurs aux opérateurs :
-
HTTP_PROXY -
HTTPS_PROXY -
NO_PROXY
Ce tutoriel utilise HTTP_PROXY comme variable d'environnement.
Conditions préalables
- Un cluster dont le proxy de sortie à l'échelle du cluster est activé.
Procédure
Modifiez le fichier
watches.yamlpour y inclure les dérogations basées sur une variable d'environnement en ajoutant le champoverrideValues:... - group: demo.example.com version: v1alpha1 kind: Nginx chart: helm-charts/nginx overrideValues: proxy.http: $HTTP_PROXY ...Ajouter la valeur
proxy.httpdans le fichierhelmcharts/nginx/values.yaml:... proxy: http: "" https: "" no_proxy: ""Pour vous assurer que le modèle de graphique prend en charge l'utilisation des variables, modifiez le modèle de graphique dans le fichier
helm-charts/nginx/templates/deployment.yamlpour qu'il contienne les éléments suivants :containers: - name: {{ .Chart.Name }} securityContext: - toYaml {{ .Values.securityContext | nindent 12 }} image: "{{ .Values.image.repository }}:{{ .Values.image.tag | default .Chart.AppVersion }}" imagePullPolicy: {{ .Values.image.pullPolicy }} env: - name: http_proxy value: "{{ .Values.proxy.http }}"Définissez la variable d'environnement sur le déploiement de l'opérateur en ajoutant ce qui suit au fichier
config/manager/manager.yaml:containers: - args: - --leader-elect - --leader-election-id=ansible-proxy-demo image: controller:latest name: manager env: - name: "HTTP_PROXY" value: "http_proxy_test"
5.5.2.5. Fonctionnement de l'opérateur
Vous pouvez utiliser l'interface de programmation de l'opérateur SDK de trois manières différentes pour créer et exécuter votre opérateur :
- Exécuter localement en dehors du cluster comme un programme Go.
- Exécuter en tant que déploiement sur le cluster.
- Regroupez votre opérateur et utilisez Operator Lifecycle Manager (OLM) pour le déployer sur le cluster.
5.5.2.5.1. Exécution locale en dehors du cluster
Vous pouvez exécuter votre projet Operator en tant que programme Go en dehors du cluster. Ceci est utile pour le développement afin d'accélérer le déploiement et les tests.
Procédure
Exécutez la commande suivante pour installer les définitions de ressources personnalisées (CRD) dans le cluster configuré dans votre fichier
~/.kube/configet exécutez l'opérateur localement :$ make install runExemple de sortie
... {"level":"info","ts":1612652419.9289865,"logger":"controller-runtime.metrics","msg":"metrics server is starting to listen","addr":":8080"} {"level":"info","ts":1612652419.9296563,"logger":"helm.controller","msg":"Watching resource","apiVersion":"demo.example.com/v1","kind":"Nginx","namespace":"","reconcilePeriod":"1m0s"} {"level":"info","ts":1612652419.929983,"logger":"controller-runtime.manager","msg":"starting metrics server","path":"/metrics"} {"level":"info","ts":1612652419.930015,"logger":"controller-runtime.manager.controller.nginx-controller","msg":"Starting EventSource","source":"kind source: demo.example.com/v1, Kind=Nginx"} {"level":"info","ts":1612652420.2307851,"logger":"controller-runtime.manager.controller.nginx-controller","msg":"Starting Controller"} {"level":"info","ts":1612652420.2309358,"logger":"controller-runtime.manager.controller.nginx-controller","msg":"Starting workers","worker count":8}
5.5.2.5.2. Exécution en tant que déploiement sur le cluster
Vous pouvez exécuter votre projet Operator en tant que déploiement sur votre cluster.
Procédure
Exécutez les commandes
makesuivantes pour construire et pousser l'image de l'opérateur. Modifiez l'argumentIMGdans les étapes suivantes pour référencer un référentiel auquel vous avez accès. Vous pouvez obtenir un compte pour stocker des conteneurs sur des sites de dépôt tels que Quay.io.Construire l'image :
$ make docker-build IMG=<registry>/<user>/<image_name>:<tag>NoteLe fichier Docker généré par le SDK pour l'Operator fait explicitement référence à
GOARCH=amd64pourgo build. Cette référence peut être modifiée enGOARCH=$TARGETARCHpour les architectures non-AMD64. Docker définira automatiquement la variable d'environnement à la valeur spécifiée par–platform. Avec Buildah, il faudra utiliser–build-argà cette fin. Pour plus d'informations, voir Architectures multiples.Transférer l'image dans un référentiel :
$ make docker-push IMG=<registry>/<user>/<image_name>:<tag>NoteLe nom et la balise de l'image, par exemple
IMG=<registry>/<user>/<image_name>:<tag>, dans les deux commandes peuvent également être définis dans votre Makefile. Modifiez la valeur deIMG ?= controller:latestpour définir votre nom d'image par défaut.
Exécutez la commande suivante pour déployer l'opérateur :
$ make deploy IMG=<registry>/<user>/<image_name>:<tag>Par défaut, cette commande crée un espace de noms avec le nom de votre projet Operator sous la forme
<project_name>-systemet est utilisé pour le déploiement. Cette commande installe également les manifestes RBAC à partir deconfig/rbac.Exécutez la commande suivante pour vérifier que l'opérateur fonctionne :
oc get deployment -n <nom_du_projet>-systèmeExemple de sortie
NAME READY UP-TO-DATE AVAILABLE AGE <project_name>-controller-manager 1/1 1 1 8m
5.5.2.5.3. Regroupement d'un opérateur et déploiement avec Operator Lifecycle Manager
5.5.2.5.3.1. Regroupement d'un opérateur
Le format Operator bundle est la méthode d'emballage par défaut pour Operator SDK et Operator Lifecycle Manager (OLM). Vous pouvez préparer votre Operator pour une utilisation sur OLM en utilisant Operator SDK pour construire et pousser votre projet Operator en tant qu'image groupée.
Conditions préalables
- Operator SDK CLI installé sur un poste de développement
-
OpenShift CLI (
oc) v4.12 installé - Projet d'opérateur initialisé à l'aide de l'Operator SDK
Procédure
Exécutez les commandes
makesuivantes dans le répertoire de votre projet Operator pour construire et pousser votre image Operator. Modifiez l'argumentIMGdans les étapes suivantes pour référencer un référentiel auquel vous avez accès. Vous pouvez obtenir un compte pour stocker des conteneurs sur des sites de dépôt tels que Quay.io.Construire l'image :
$ make docker-build IMG=<registry>/<user>/<operator_image_name>:<tag>NoteLe fichier Docker généré par le SDK pour l'Operator fait explicitement référence à
GOARCH=amd64pourgo build. Cette référence peut être modifiée enGOARCH=$TARGETARCHpour les architectures non-AMD64. Docker définira automatiquement la variable d'environnement à la valeur spécifiée par–platform. Avec Buildah, il faudra utiliser–build-argà cette fin. Pour plus d'informations, voir Architectures multiples.Transférer l'image dans un référentiel :
$ make docker-push IMG=<registry>/<user>/<operator_image_name>:<tag>
Créez votre manifeste Operator bundle en exécutant la commande
make bundle, qui invoque plusieurs commandes, dont les sous-commandes Operator SDKgenerate bundleetbundle validate:$ make bundle IMG=<registry>/<user>/<operator_image_name>:<tag>Les manifestes de l'offre groupée d'un opérateur décrivent la manière d'afficher, de créer et de gérer une application. La commande
make bundlecrée les fichiers et répertoires suivants dans votre projet Operator :-
Un répertoire bundle manifests nommé
bundle/manifestsqui contient un objetClusterServiceVersion -
Un répertoire de métadonnées de la liasse nommé
bundle/metadata -
Toutes les définitions de ressources personnalisées (CRD) dans un répertoire
config/crd -
Un fichier Docker
bundle.Dockerfile
Ces fichiers sont ensuite automatiquement validés à l'aide de
operator-sdk bundle validateafin de s'assurer que la représentation du paquet sur le disque est correcte.-
Un répertoire bundle manifests nommé
Construisez et poussez votre image de bundle en exécutant les commandes suivantes. OLM consomme les liasses d'opérateurs à l'aide d'une image d'index, qui fait référence à une ou plusieurs images de liasses.
Créez l'image de l'ensemble. Définissez
BUNDLE_IMGavec les détails du registre, de l'espace de noms de l'utilisateur et de la balise d'image où vous avez l'intention de pousser l'image :$ make bundle-build BUNDLE_IMG=<registry>/<user>/<bundle_image_name>:<tag>Pousser l'image de la liasse :
$ docker push <registry>/<user>/<bundle_image_name>:<tag>
5.5.2.5.3.2. Déploiement d'un opérateur avec Operator Lifecycle Manager
Operator Lifecycle Manager (OLM) vous aide à installer, mettre à jour et gérer le cycle de vie des opérateurs et de leurs services associés sur un cluster Kubernetes. OLM est installé par défaut sur OpenShift Container Platform et s'exécute en tant qu'extension Kubernetes afin que vous puissiez utiliser la console web et l'OpenShift CLI (oc) pour toutes les fonctions de gestion du cycle de vie des opérateurs sans outils supplémentaires.
Le format Operator bundle est la méthode d'emballage par défaut pour Operator SDK et OLM. Vous pouvez utiliser Operator SDK pour exécuter rapidement une image de bundle sur OLM afin de vous assurer qu'elle fonctionne correctement.
Conditions préalables
- Operator SDK CLI installé sur un poste de développement
- L'image de l'ensemble de l'opérateur est construite et poussée vers un registre
-
OLM installé sur un cluster basé sur Kubernetes (v1.16.0 ou version ultérieure si vous utilisez
apiextensions.k8s.io/v1CRD, par exemple OpenShift Container Platform 4.12) -
Connexion au cluster avec
ocen utilisant un compte avec les permissions decluster-admin
Procédure
Saisissez la commande suivante pour exécuter l'opérateur sur le cluster :
$ operator-sdk run bundle \1 -n <namespace> \2 <registry>/<user>/<bundle_image_name>:<tag>3 - 1
- La commande
run bundlecrée un catalogue de fichiers valide et installe le paquet Operator sur votre cluster à l'aide d'OLM. - 2
- Facultatif : Par défaut, la commande installe l'opérateur dans le projet actif dans votre fichier
~/.kube/config. Vous pouvez ajouter l'option-npour définir un espace de noms différent pour l'installation. - 3
- Si vous ne spécifiez pas d'image, la commande utilise
quay.io/operator-framework/opm:latestcomme image d'index par défaut. Si vous spécifiez une image, la commande utilise l'image du paquet elle-même comme image d'index.
ImportantDepuis OpenShift Container Platform 4.11, la commande
run bundleprend en charge par défaut le format de catalogue basé sur des fichiers pour les catalogues Operator. Le format de base de données SQLite déprécié pour les catalogues Operator continue d'être pris en charge ; cependant, il sera supprimé dans une prochaine version. Il est recommandé aux auteurs d'Operator de migrer leurs flux de travail vers le format de catalogue basé sur des fichiers.Cette commande permet d'effectuer les actions suivantes :
- Créez une image d'index faisant référence à votre image de liasse. L'image d'index est opaque et éphémère, mais elle reflète fidèlement la manière dont un paquet serait ajouté à un catalogue en production.
- Créez une source de catalogue qui pointe vers votre nouvelle image d'index, ce qui permet à OperatorHub de découvrir votre opérateur.
-
Déployez votre opérateur sur votre cluster en créant un site
OperatorGroup,Subscription,InstallPlan, et toutes les autres ressources nécessaires, y compris RBAC.
5.5.2.6. Création d'une ressource personnalisée
Une fois votre opérateur installé, vous pouvez le tester en créant une ressource personnalisée (CR) qui est maintenant fournie sur le cluster par l'opérateur.
Conditions préalables
-
Exemple Nginx Operator, qui fournit le CR
Nginx, installé sur un cluster
Procédure
Passez à l'espace de noms dans lequel votre opérateur est installé. Par exemple, si vous avez déployé l'opérateur à l'aide de la commande
make deploy:$ oc project nginx-operator-systemModifiez l'exemple de manifeste
NginxCR à l'adresseconfig/samples/demo_v1_nginx.yamlpour qu'il contienne la spécification suivante :apiVersion: demo.example.com/v1 kind: Nginx metadata: name: nginx-sample ... spec: ... replicaCount: 3Le compte de service Nginx nécessite un accès privilégié pour fonctionner dans OpenShift Container Platform. Ajoutez la contrainte de contexte de sécurité (SCC) suivante au compte de service du pod
nginx-sample:$ oc adm policy add-scc-to-user \ anyuid system:serviceaccount:nginx-operator-system:nginx-sampleCréer le CR :
$ oc apply -f config/samples/demo_v1_nginx.yamlAssurez-vous que l'opérateur
Nginxcrée le déploiement pour l'échantillon de CR avec la taille correcte :$ oc get deploymentsExemple de sortie
NAME READY UP-TO-DATE AVAILABLE AGE nginx-operator-controller-manager 1/1 1 1 8m nginx-sample 3/3 3 3 1mVérifiez le statut des pods et du CR pour confirmer que le statut est mis à jour avec les noms des pods Nginx.
Vérifier les gousses :
$ oc get podsExemple de sortie
NAME READY STATUS RESTARTS AGE nginx-sample-6fd7c98d8-7dqdr 1/1 Running 0 1m nginx-sample-6fd7c98d8-g5k7v 1/1 Running 0 1m nginx-sample-6fd7c98d8-m7vn7 1/1 Running 0 1mVérifier l'état de la CR :
$ oc get nginx/nginx-sample -o yamlExemple de sortie
apiVersion: demo.example.com/v1 kind: Nginx metadata: ... name: nginx-sample ... spec: replicaCount: 3 status: nodes: - nginx-sample-6fd7c98d8-7dqdr - nginx-sample-6fd7c98d8-g5k7v - nginx-sample-6fd7c98d8-m7vn7
Mettre à jour la taille du déploiement.
Mettre à jour le fichier
config/samples/demo_v1_nginx.yamlpour modifier le champspec.sizedans le CRNginxde3à5:$ oc patch nginx nginx-sample \ -p '{"spec":{"replicaCount": 5}}' \ --type=mergeConfirmez que l'opérateur modifie la taille du déploiement :
$ oc get deploymentsExemple de sortie
NAME READY UP-TO-DATE AVAILABLE AGE nginx-operator-controller-manager 1/1 1 1 10m nginx-sample 5/5 5 5 3m
Supprimez le CR en exécutant la commande suivante :
$ oc delete -f config/samples/demo_v1_nginx.yamlNettoyer les ressources qui ont été créées dans le cadre de ce tutoriel.
Si vous avez utilisé la commande
make deploypour tester l'opérateur, exécutez la commande suivante :$ make undeploySi vous avez utilisé la commande
operator-sdk run bundlepour tester l'opérateur, exécutez la commande suivante :$ operator-sdk cleanup <nom_du_projet>
5.5.3. Présentation du projet pour les opérateurs à la barre
Le CLI operator-sdk peut générer, ou scaffold, un certain nombre de paquets et de fichiers pour chaque projet Operator.
5.5.3.1. Présentation du projet à partir de la barre
Les projets Operator basés sur Helm et générés à l'aide de la commande operator-sdk init --plugins helm contiennent les répertoires et fichiers suivants :
| Fichiers/dossiers | Objectif |
|---|---|
|
| Personnaliser les manifestes pour déployer l'opérateur sur un cluster Kubernetes. |
|
|
La carte du gouvernail est initialisée par la commande |
|
|
Utilisé pour construire l'image de l'opérateur avec la commande |
|
| Groupe/version/genre (GVK) et emplacement de la carte du gouvernail. |
|
| Objectifs utilisés pour gérer le projet. |
|
| Fichier YAML contenant des informations sur les métadonnées de l'opérateur. |
5.5.4. Mise à jour des projets basés sur Helm pour les nouvelles versions du SDK Operator
OpenShift Container Platform 4.12 supporte Operator SDK 1.25.4. Si vous avez déjà le CLI 1.22.0 installé sur votre station de travail, vous pouvez mettre à jour le CLI vers 1.25.4 en installant la dernière version.
Cependant, pour que vos projets Operator existants restent compatibles avec Operator SDK 1.25.4, des étapes de mise à jour sont nécessaires pour les ruptures associées introduites depuis la version 1.22.0. Vous devez effectuer les étapes de mise à jour manuellement dans tous vos projets Operator qui ont été précédemment créés ou maintenus avec la version 1.22.0.
5.5.4.1. Mise à jour des projets d'opérateurs basés sur Helm pour Operator SDK 1.25.4
La procédure suivante permet de mettre à jour un projet d'opérateur basé sur Helm pour le rendre compatible avec la version 1.25.4.
Conditions préalables
- Operator SDK 1.25.4 installé
- Un projet Operator créé ou maintenu avec Operator SDK 1.22.0
Procédure
Apportez les modifications suivantes au fichier
config/default/manager_auth_proxy_patch.yaml:apiVersion: apps/v1 kind: Deployment metadata: name: controller-manager namespace: system spec: template: spec: containers: - name: kube-rbac-proxy image: registry.redhat.io/openshift4/ose-kube-rbac-proxy:v4.121 args: - "--secure-listen-address=0.0.0.0:8443" - "--upstream=http://127.0.0.1:8080/" - "--logtostderr=true" - "--v=0" ...- 1
- Mettre à jour la version de la balise de
v4.11àv4.12.
Apportez les modifications suivantes à votre site
Makefile:Pour activer la prise en charge des architectures multiples, ajoutez la cible
docker-buildxà votre projetMakefile:Exemple
Makefile# PLATFORMS defines the target platforms for the manager image be build to provide support to multiple # architectures. (i.e. make docker-buildx IMG=myregistry/mypoperator:0.0.1). To use this option you need to: # - able to use docker buildx . More info: https://docs.docker.com/build/buildx/ # - have enable BuildKit, More info: https://docs.docker.com/develop/develop-images/build_enhancements/ # - be able to push the image for your registry (i.e. if you do not inform a valid value via IMG=<myregistry/image:<tag>> than the export will fail) # To properly provided solutions that supports more than one platform you should use this option. PLATFORMS ?= linux/arm64,linux/amd64,linux/s390x,linux/ppc64le .PHONY: docker-buildx docker-buildx: test ## Build and push docker image for the manager for cross-platform support # copy existing Dockerfile and insert --platform=${BUILDPLATFORM} into Dockerfile.cross, and preserve the original Dockerfile sed -e '1 s/\(^FROM\)/FROM --platform=\$$\{BUILDPLATFORM\}/; t' -e ' 1,// s//FROM --platform=\$$\{BUILDPLATFORM\}/' Dockerfile > Dockerfile.cross - docker buildx create --name project-v3-builder docker buildx use project-v3-builder - docker buildx build --push --platform=$(PLATFORMS) --tag ${IMG} -f Dockerfile.cross - docker buildx rm project-v3-builder rm Dockerfile.crossPour permettre la prise en charge des architectures
arm64dans votre projet Operator, apportez les modifications suivantes à votre projetMakefile:Ancienne
MakefileOS := $(shell uname -s | tr '[:upper:]' '[:lower:]') ARCH := $(shell uname -m | sed 's/x86_64/amd64/')Nouveau
MakefileOS := $(shell uname -s | tr '[:upper:]' '[:lower:]') ARCH := $(shell uname -m | sed 's/x86_64/amd64/' | sed 's/aarch64/arm64/')Mettez à jour la version de Kustomize à
v4.5.5comme indiqué dans l'exemple suivant :Ancienne
Makefile.PHONY: kustomize KUSTOMIZE = $(shell pwd)/bin/kustomize kustomize: ## Download kustomize locally if necessary. ifeq (,$(wildcard $(KUSTOMIZE))) ifeq (,$(shell which kustomize 2>/dev/null)) @{ \ set -e ;\ mkdir -p $(dir $(KUSTOMIZE)) ;\ curl -sSLo - https://github.com/kubernetes-sigs/kustomize/releases/download/kustomize/v3.8.7/kustomize_v3.8.7_$(OS)_$(ARCH).tar.gz | \ tar xzf - -C bin/ ;\ } elseNouveau
Makefile.PHONY: kustomize KUSTOMIZE = $(shell pwd)/bin/kustomize kustomize: ## Download kustomize locally if necessary. ifeq (,$(wildcard $(KUSTOMIZE))) ifeq (,$(shell which kustomize 2>/dev/null)) @{ \ set -e ;\ mkdir -p $(dir $(KUSTOMIZE)) ;\ curl -sSLo - https://github.com/kubernetes-sigs/kustomize/releases/download/kustomize/v4.5.5/kustomize_v4.5.5_$(OS)_$(ARCH).tar.gz | \1 tar xzf - -C bin/ ;\ } else- 1
- Mise à jour de la version
v3.8.7versv4.5.5.
ImportantLa version de Kustomize
4.0.0a supprimé le plugingo-getteret a introduit des changements qui ne sont pas compatibles avec les versions antérieures. Les projets d'opérateurs qui s'appuient sur des versions antérieures de Kustomize pourraient ne pas fonctionner avec les nouvelles versions.Pour appliquer les changements à votre
Makefileet reconstruire votre Opérateur, entrez la commande suivante :$ make
Mettez à jour votre fichier
config/default/kustomizations.yamlcomme indiqué dans les exemples suivants :Exemple de fichier
kustomizations.yaml# Adds namespace to all resources. namespace: memcached-operator-system # Value of this field is prepended to the # names of all resources, e.g. a deployment named # "wordpress" becomes "alices-wordpress". # Note that it should also match with the prefix (text before '-') of the namespace # field above. namePrefix: memcached-operator- # Labels to add to all resources and selectors. #labels:1 #- includeSelectors: true2 # pairs: # someName: someValue resources:3 - ../crd - ../rbac - ../manager
5.5.5. Prise en charge de Helm dans Operator SDK
5.5.5.1. Tableaux de bord
L'une des options du SDK Operator pour générer un projet Operator comprend l'exploitation d'un diagramme Helm existant pour déployer des ressources Kubernetes en tant qu'application unifiée, sans avoir à écrire de code Go. De tels opérateurs basés sur Helm sont conçus pour exceller dans les applications sans état qui nécessitent très peu de logique lors du déploiement, car les changements doivent être appliqués aux objets Kubernetes qui sont générés dans le cadre du diagramme. Cela peut sembler restrictif, mais peut être suffisant pour un nombre surprenant de cas d'utilisation, comme le montre la prolifération des diagrammes Helm construits par la communauté Kubernetes.
La fonction principale d'un opérateur est de lire un objet personnalisé qui représente votre instance d'application et de faire en sorte que son état souhaité corresponde à ce qui est en cours d'exécution. Dans le cas d'un opérateur basé sur Helm, le champ spec de l'objet est une liste d'options de configuration qui sont généralement décrites dans le fichier Helm values.yaml. Au lieu de définir ces valeurs avec des drapeaux à l'aide de la CLI Helm (par exemple, helm install -f values.yaml), vous pouvez les exprimer dans une ressource personnalisée (CR), qui, en tant qu'objet Kubernetes natif, permet de bénéficier des avantages du RBAC qui lui est appliqué et d'une piste d'audit.
Pour un exemple de CR simple appelé Tomcat:
apiVersion: apache.org/v1alpha1
kind: Tomcat
metadata:
name: example-app
spec:
replicaCount: 2
La valeur replicaCount, 2 dans le cas présent, est propagée dans le modèle de graphique où le texte suivant est utilisé :
{{ .Values.replicaCount }}
Une fois qu'un opérateur est construit et déployé, vous pouvez déployer une nouvelle instance d'une application en créant une nouvelle instance d'un CR, ou répertorier les différentes instances en cours d'exécution dans tous les environnements à l'aide de la commande oc:
$ oc get Tomcats --all-namespacesIl n'est pas nécessaire d'utiliser l'interface de programmation Helm ou d'installer Tiller ; les opérateurs basés sur Helm importent le code du projet Helm. Tout ce que vous avez à faire est d'avoir une instance de l'opérateur en cours d'exécution et d'enregistrer le CR avec une définition de ressource personnalisée (CRD). Parce qu'il obéit au RBAC, vous pouvez plus facilement empêcher les changements de production.
5.5.6. Tutoriel sur le SDK pour les opérateurs du gouvernail hybride
Le support standard de l'opérateur basé sur Helm dans le SDK de l'opérateur a des fonctionnalités limitées par rapport au support de l'opérateur basé sur Go et Ansible qui a atteint la capacité de pilotage automatique (niveau V) dans le modèle de maturité de l'opérateur.
L'opérateur hybride Helm améliore les capacités du support existant basé sur Helm grâce aux API Go. Avec cette approche hybride de Helm et Go, le SDK de l'Opérateur permet aux auteurs de l'Opérateur d'utiliser le processus suivant :
- Générer une structure par défaut pour, ou scaffold, une API Go dans le même projet que Helm.
-
Configurer le réconciliateur Helm dans le fichier
main.godu projet, à l'aide des bibliothèques fournies par l'Opérateur Helm Hybride.
L'opérateur Hybrid Helm est une fonctionnalité d'aperçu technologique uniquement. Les fonctionnalités de l'aperçu technologique ne sont pas prises en charge par les accords de niveau de service (SLA) de production de Red Hat et peuvent ne pas être complètes sur le plan fonctionnel. Red Hat ne recommande pas leur utilisation en production. Ces fonctionnalités offrent un accès anticipé aux fonctionnalités des produits à venir, ce qui permet aux clients de tester les fonctionnalités et de fournir un retour d'information pendant le processus de développement.
Pour plus d'informations sur la portée de l'assistance des fonctionnalités de l'aperçu technologique de Red Hat, voir Portée de l'assistance des fonctionnalités de l'aperçu technologique.
Ce tutoriel décrit le processus suivant à l'aide de l'opérateur de pilotage hybride :
-
Créer un déploiement
Memcachedà travers une carte Helm si elle n'existe pas -
Assurez-vous que la taille du déploiement est la même que celle spécifiée par
Memcachedcustom resource (CR) spec -
Créer un déploiement
MemcachedBackupen utilisant l'API Go
5.5.6.1. Conditions préalables
- Operator SDK CLI installé
-
OpenShift CLI (
oc) v4.12 installé -
Connexion à un cluster OpenShift Container Platform 4.12 avec
ocavec un compte qui a les permissionscluster-admin - Pour permettre au cluster d'extraire l'image, le dépôt où vous avez poussé votre image doit être défini comme public, ou vous devez configurer un secret d'extraction d'image
5.5.6.2. Création d'un projet
Utilisez l'interface de programmation Operator SDK pour créer un projet appelé memcached-operator.
Procédure
Créer un répertoire pour le projet :
$ mkdir -p $HOME/github.com/example/memcached-operatorAccédez au répertoire :
$ cd $HOME/github.com/example/memcached-operatorExécutez la commande
operator-sdk initpour initialiser le projet. Utilisez un domaine deexample.compour que tous les groupes API soient<group>.example.com:$ operator-sdk init \ --plugins=hybrid.helm.sdk.operatorframework.io \ --project-version="3" \ --domain example.com \ --repo=github.com/example/memcached-operatorLa commande
initgénère les règles RBAC dans le fichierconfig/rbac/role.yamlen se basant sur les ressources qui seraient déployées par les manifestes par défaut de la carte. Vérifiez que les règles générées dans le fichierconfig/rbac/role.yamlrépondent aux exigences de permission de votre opérateur.
Ressources supplémentaires
- Cette procédure crée une structure de projet compatible avec les API Helm et Go. Pour en savoir plus sur la structure du répertoire du projet, voir Disposition du projet.
5.5.6.3. Création d'une API Helm
Utilisez le SDK CLI de l'opérateur pour créer une API Helm.
Procédure
Exécutez la commande suivante pour créer une API Helm avec le groupe
cache, la versionv1et le typeMemcached:$ operator-sdk create api \ --plugins helm.sdk.operatorframework.io/v1 \ --group cache \ --version v1 \ --kind Memcached
Cette procédure configure également votre projet Operator pour qu'il observe la ressource Memcached avec la version d'API v1 et met en place un modèle de graphique Helm. Au lieu de créer le projet à partir du modèle de graphique Helm fourni par le SDK Operator, vous pouvez utiliser un graphique existant de votre système de fichiers local ou d'un référentiel de graphiques distant.
Pour plus de détails et d'exemples sur la création d'une API Helm basée sur des graphiques existants ou nouveaux, exécutez la commande suivante :
$ operator-sdk create api --plugins helm.sdk.operatorframework.io/v1 --helpRessources supplémentaires
5.5.6.3.1. Logique de l'opérateur pour l'API Helm
Par défaut, votre projet Operator scaffolded observe les événements de ressources Memcached comme indiqué dans le fichier watches.yaml et exécute les releases Helm en utilisant le diagramme spécifié.
Exemple 5.2. Exemple de fichier watches.yaml
# Use the 'create api' subcommand to add watches to this file.
- group: cache.my.domain
version: v1
kind: Memcached
chart: helm-charts/memcached
#+kubebuilder:scaffold:watchRessources supplémentaires
- Pour une documentation détaillée sur la personnalisation de la logique de l'opérateur de barre par le biais du tableau, voir Comprendre la logique de l'opérateur.
5.5.6.3.2. Configurations personnalisées du réconciliateur Helm à l'aide des bibliothèques API fournies
L'un des inconvénients des opérateurs existants basés sur Helm est l'impossibilité de configurer le réconciliateur Helm, car il n'est pas pris en compte par les utilisateurs. Pour qu'un opérateur basé sur Helm puisse atteindre la capacité de mise à niveau transparente (niveau II et suivants) qui réutilise une carte Helm déjà existante, un hybride entre les types Go et Helm Operator apporte une valeur ajoutée.
Les API fournies dans la bibliothèque helm-operator-plugins permettent aux auteurs d'opérateurs d'effectuer les configurations suivantes :
- Personnaliser la cartographie des valeurs en fonction de l'état de la grappe
- Exécuter du code dans des événements spécifiques en configurant l'enregistreur d'événements du réconciliateur
- Personnaliser le journal du réconciliateur
-
Configurer les annotations
Install,Upgrade, etUninstallpour permettre aux actions de Helm d'être configurées en fonction des annotations trouvées dans les ressources personnalisées surveillées par le réconciliateur -
Configurer le réconciliateur pour qu'il fonctionne avec les crochets
PreetPost
Les configurations ci-dessus peuvent être effectuées dans le fichier main.go:
Exemple de fichier main.go
// Operator's main.go
// With the help of helpers provided in the library, the reconciler can be
// configured here before starting the controller with this reconciler.
reconciler := reconciler.New(
reconciler.WithChart(*chart),
reconciler.WithGroupVersionKind(gvk),
)
if err := reconciler.SetupWithManager(mgr); err != nil {
panic(fmt.Sprintf("unable to create reconciler: %s", err))
}5.5.6.4. Création d'une API Go
Utilisez le SDK CLI de l'opérateur pour créer une API Go.
Procédure
Exécutez la commande suivante pour créer une API Go avec le groupe
cache, la versionv1et le typeMemcachedBackup:$ operator-sdk create api \ --group=cache \ --version v1 \ --kind MemcachedBackup \ --resource \ --controller \ --plugins=go/v3Lorsque vous y êtes invité, entrez
ypour créer à la fois la ressource et le contrôleur :$ Create Resource [y/n] y Create Controller [y/n] y
Cette procédure génère la ressource MemcachedBackup API à l'adresse api/v1/memcachedbackup_types.go et le contrôleur à l'adresse controllers/memcachedbackup_controller.go.
5.5.6.4.1. Définition de l'API
Définir l'API pour la ressource personnalisée (CR) MemcachedBackup.
Représentez cette API Go en définissant le type MemcachedBackup, qui aura un champ MemcachedBackupSpec.Size pour définir la quantité d'instances de sauvegarde Memcached (CR) à déployer, et un champ MemcachedBackupStatus.Nodes pour stocker les noms des pods d'un CR.
Le champ Node est utilisé pour illustrer un exemple de champ Status.
Procédure
Définir l'API pour le CR
MemcachedBackupen modifiant les définitions de type Go dans le fichierapi/v1/memcachedbackup_types.gopour obtenir les typesspecetstatus:Exemple 5.3. Exemple de fichier
api/v1/memcachedbackup_types.go// MemcachedBackupSpec defines the desired state of MemcachedBackup type MemcachedBackupSpec struct { // INSERT ADDITIONAL SPEC FIELDS - desired state of cluster // Important: Run "make" to regenerate code after modifying this file //+kubebuilder:validation:Minimum=0 // Size is the size of the memcached deployment Size int32 `json:"size"` } // MemcachedBackupStatus defines the observed state of MemcachedBackup type MemcachedBackupStatus struct { // INSERT ADDITIONAL STATUS FIELD - define observed state of cluster // Important: Run "make" to regenerate code after modifying this file // Nodes are the names of the memcached pods Nodes []string `json:"nodes"` }Mettre à jour le code généré pour le type de ressource :
$ make generateAstuceAprès avoir modifié un fichier
*_types.go, vous devez exécuter la commandemake generatepour mettre à jour le code généré pour ce type de ressource.Une fois l'API définie avec les champs
specetstatuset les marqueurs de validation CRD, générer et mettre à jour les manifestes CRD :$ make manifests
Cette cible Makefile invoque l'utilitaire controller-gen pour générer les manifestes CRD dans le fichier config/crd/bases/cache.my.domain_memcachedbackups.yaml.
5.5.6.4.2. Mise en œuvre du contrôleur
Le contrôleur de ce tutoriel effectue les actions suivantes :
-
Créez un déploiement
Memcacheds'il n'existe pas. -
Assurez-vous que la taille du déploiement est la même que celle spécifiée par la spécification CR de
Memcached. -
Mettre à jour l'état de
MemcachedCR avec les noms des podsmemcached.
Pour une explication détaillée sur la manière de configurer le contrôleur pour qu'il effectue les actions mentionnées ci-dessus, voir Mise en œuvre du contrôleur dans le tutoriel SDK de l'opérateur pour les opérateurs standard basés sur Go.
5.5.6.4.3. Différences dans main.go
Pour les opérateurs standard basés sur Go et l'opérateur hybride Helm, le fichier main.go gère l'échafaudage, l'initialisation et l'exécution du programme pour l'API Go Manager pour l'API Go. Pour l'opérateur Helm hybride, cependant, le fichier main.go expose également la logique de chargement du fichier watches.yaml et de configuration du réconciliateur Helm.
Exemple 5.4. Exemple de fichier main.go
...
for _, w := range ws {
// Register controller with the factory
reconcilePeriod := defaultReconcilePeriod
if w.ReconcilePeriod != nil {
reconcilePeriod = w.ReconcilePeriod.Duration
}
maxConcurrentReconciles := defaultMaxConcurrentReconciles
if w.MaxConcurrentReconciles != nil {
maxConcurrentReconciles = *w.MaxConcurrentReconciles
}
r, err := reconciler.New(
reconciler.WithChart(*w.Chart),
reconciler.WithGroupVersionKind(w.GroupVersionKind),
reconciler.WithOverrideValues(w.OverrideValues),
reconciler.SkipDependentWatches(w.WatchDependentResources != nil && !*w.WatchDependentResources),
reconciler.WithMaxConcurrentReconciles(maxConcurrentReconciles),
reconciler.WithReconcilePeriod(reconcilePeriod),
reconciler.WithInstallAnnotations(annotation.DefaultInstallAnnotations...),
reconciler.WithUpgradeAnnotations(annotation.DefaultUpgradeAnnotations...),
reconciler.WithUninstallAnnotations(annotation.DefaultUninstallAnnotations...),
)
...
Le gestionnaire est initialisé avec les conciliateurs Helm et Go:
Exemple 5.5. Exemple de conciliateurs Helm et Go
...
// Setup manager with Go API
if err = (&controllers.MemcachedBackupReconciler{
Client: mgr.GetClient(),
Scheme: mgr.GetScheme(),
}).SetupWithManager(mgr); err != nil {
setupLog.Error(err, "unable to create controller", "controller", "MemcachedBackup")
os.Exit(1)
}
...
// Setup manager with Helm API
for _, w := range ws {
...
if err := r.SetupWithManager(mgr); err != nil {
setupLog.Error(err, "unable to create controller", "controller", "Helm")
os.Exit(1)
}
setupLog.Info("configured watch", "gvk", w.GroupVersionKind, "chartPath", w.ChartPath, "maxConcurrentReconciles", maxConcurrentReconciles, "reconcilePeriod", reconcilePeriod)
}
// Start the manager
if err := mgr.Start(ctrl.SetupSignalHandler()); err != nil {
setupLog.Error(err, "problem running manager")
os.Exit(1)
}5.5.6.4.4. Permissions et manifestes RBAC
Le contrôleur nécessite certaines autorisations de contrôle d'accès basé sur les rôles (RBAC) pour interagir avec les ressources qu'il gère. Pour l'API Go, ces autorisations sont spécifiées à l'aide de marqueurs RBAC, comme le montre le didacticiel Operator SDK pour les opérateurs standard basés sur Go.
Pour l'API Helm, les permissions sont échafaudées par défaut dans roles.yaml. Actuellement, cependant, en raison d'un problème connu lorsque l'API Go est scaffoldée, les permissions pour l'API Helm sont écrasées. En raison de ce problème, assurez-vous que les autorisations définies dans roles.yaml correspondent à vos besoins.
Ce problème connu fait l'objet d'un suivi sur https://github.com/operator-framework/helm-operator-plugins/issues/142.
Voici un exemple de role.yaml pour un opérateur Memcached :
Exemple 5.6. Exemple de conciliateurs Helm et Go
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: manager-role
rules:
- apiGroups:
- ""
resources:
- namespaces
verbs:
- get
- apiGroups:
- apps
resources:
- deployments
- daemonsets
- replicasets
- statefulsets
verbs:
- create
- delete
- get
- list
- patch
- update
- watch
- apiGroups:
- cache.my.domain
resources:
- memcachedbackups
verbs:
- create
- delete
- get
- list
- patch
- update
- watch
- apiGroups:
- cache.my.domain
resources:
- memcachedbackups/finalizers
verbs:
- create
- delete
- get
- list
- patch
- update
- watch
- apiGroups:
- ""
resources:
- pods
- services
- services/finalizers
- endpoints
- persistentvolumeclaims
- events
- configmaps
- secrets
- serviceaccounts
verbs:
- create
- delete
- get
- list
- patch
- update
- watch
- apiGroups:
- cache.my.domain
resources:
- memcachedbackups/status
verbs:
- get
- patch
- update
- apiGroups:
- policy
resources:
- events
- poddisruptionbudgets
verbs:
- create
- delete
- get
- list
- patch
- update
- watch
- apiGroups:
- cache.my.domain
resources:
- memcacheds
- memcacheds/status
- memcacheds/finalizers
verbs:
- create
- delete
- get
- list
- patch
- update
- watchRessources supplémentaires
5.5.6.5. Exécution locale en dehors du cluster
Vous pouvez exécuter votre projet Operator en tant que programme Go en dehors du cluster. Ceci est utile pour le développement afin d'accélérer le déploiement et les tests.
Procédure
Exécutez la commande suivante pour installer les définitions de ressources personnalisées (CRD) dans le cluster configuré dans votre fichier
~/.kube/configet exécutez l'opérateur localement :$ make install run
5.5.6.6. Exécution en tant que déploiement sur le cluster
Vous pouvez exécuter votre projet Operator en tant que déploiement sur votre cluster.
Procédure
Exécutez les commandes
makesuivantes pour construire et pousser l'image de l'opérateur. Modifiez l'argumentIMGdans les étapes suivantes pour référencer un référentiel auquel vous avez accès. Vous pouvez obtenir un compte pour stocker des conteneurs sur des sites de dépôt tels que Quay.io.Construire l'image :
$ make docker-build IMG=<registry>/<user>/<image_name>:<tag>NoteLe fichier Docker généré par le SDK pour l'Operator fait explicitement référence à
GOARCH=amd64pourgo build. Cette référence peut être modifiée enGOARCH=$TARGETARCHpour les architectures non-AMD64. Docker définira automatiquement la variable d'environnement à la valeur spécifiée par–platform. Avec Buildah, il faudra utiliser–build-argà cette fin. Pour plus d'informations, voir Architectures multiples.Transférer l'image dans un référentiel :
$ make docker-push IMG=<registry>/<user>/<image_name>:<tag>NoteLe nom et la balise de l'image, par exemple
IMG=<registry>/<user>/<image_name>:<tag>, dans les deux commandes peuvent également être définis dans votre Makefile. Modifiez la valeur deIMG ?= controller:latestpour définir votre nom d'image par défaut.
Exécutez la commande suivante pour déployer l'opérateur :
$ make deploy IMG=<registry>/<user>/<image_name>:<tag>Par défaut, cette commande crée un espace de noms avec le nom de votre projet Operator sous la forme
<project_name>-systemet est utilisé pour le déploiement. Cette commande installe également les manifestes RBAC à partir deconfig/rbac.Exécutez la commande suivante pour vérifier que l'opérateur fonctionne :
oc get deployment -n <nom_du_projet>-systèmeExemple de sortie
NAME READY UP-TO-DATE AVAILABLE AGE <project_name>-controller-manager 1/1 1 1 8m
5.5.6.7. Créer des ressources personnalisées
Une fois votre opérateur installé, vous pouvez le tester en créant des ressources personnalisées (CR) qui sont désormais fournies sur le cluster par l'opérateur.
Procédure
Passez à l'espace de noms dans lequel votre opérateur est installé :
$ oc project <nom_du_projet>-systèmeMettez à jour l'exemple de manifeste
MemcachedCR dans le fichierconfig/samples/cache_v1_memcached.yamlen remplaçant le champreplicaCountpar3:Exemple 5.7. Exemple de fichier
config/samples/cache_v1_memcached.yamlapiVersion: cache.my.domain/v1 kind: Memcached metadata: name: memcached-sample spec: # Default values copied from <project_dir>/helm-charts/memcached/values.yaml affinity: {} autoscaling: enabled: false maxReplicas: 100 minReplicas: 1 targetCPUUtilizationPercentage: 80 fullnameOverride: "" image: pullPolicy: IfNotPresent repository: nginx tag: "" imagePullSecrets: [] ingress: annotations: {} className: "" enabled: false hosts: - host: chart-example.local paths: - path: / pathType: ImplementationSpecific tls: [] nameOverride: "" nodeSelector: {} podAnnotations: {} podSecurityContext: {} replicaCount: 3 resources: {} securityContext: {} service: port: 80 type: ClusterIP serviceAccount: annotations: {} create: true name: "" tolerations: []Créer le CR
Memcached:$ oc apply -f config/samples/cache_v1_memcached.yamlAssurez-vous que l'opérateur Memcached crée le déploiement pour l'exemple de CR avec la taille correcte :
$ oc get podsExemple de sortie
NAME READY STATUS RESTARTS AGE memcached-sample-6fd7c98d8-7dqdr 1/1 Running 0 18m memcached-sample-6fd7c98d8-g5k7v 1/1 Running 0 18m memcached-sample-6fd7c98d8-m7vn7 1/1 Running 0 18mMettez à jour l'exemple de manifeste
MemcachedBackupCR dans le fichierconfig/samples/cache_v1_memcachedbackup.yamlen mettant à jour le fichiersizeen2:Exemple 5.8. Exemple de fichier
config/samples/cache_v1_memcachedbackup.yamlapiVersion: cache.my.domain/v1 kind: MemcachedBackup metadata: name: memcachedbackup-sample spec: size: 2Créer le CR
MemcachedBackup:$ oc apply -f config/samples/cache_v1_memcachedbackup.yamlAssurez-vous que le nombre de pods
memcachedbackupest le même que celui spécifié dans le CR :$ oc get podsExemple de sortie
NAME READY STATUS RESTARTS AGE memcachedbackup-sample-8649699989-4bbzg 1/1 Running 0 22m memcachedbackup-sample-8649699989-mq6mx 1/1 Running 0 22m-
Vous pouvez mettre à jour les
specdans chacun des CR ci-dessus, puis les appliquer à nouveau. Le contrôleur procède à une nouvelle réconciliation et s'assure que la taille des pods est conforme à ce qui est spécifié dans le sitespecdes CR respectifs. Nettoyer les ressources qui ont été créées dans le cadre de ce tutoriel :
Supprimer la ressource
Memcached:$ oc delete -f config/samples/cache_v1_memcached.yamlSupprimer la ressource
MemcachedBackup:$ oc delete -f config/samples/cache_v1_memcachedbackup.yamlSi vous avez utilisé la commande
make deploypour tester l'opérateur, exécutez la commande suivante :$ make undeploy
5.5.6.8. Schéma du projet
L'échafaudage de l'opérateur hybride Helm est personnalisé pour être compatible avec les API Helm et Go.
| Fichiers/dossiers | Objectif |
|---|---|
|
|
Instructions utilisées par un moteur de conteneur pour construire votre image d'opérateur avec la commande |
|
| Fichier de construction avec des cibles d'aide pour vous aider à travailler avec votre projet. |
|
| Fichier YAML contenant des informations sur les métadonnées de l'opérateur. Représente la configuration du projet et est utilisé pour suivre les informations utiles pour le CLI et les plugins. |
|
|
Contient des binaires utiles tels que |
|
| Contient les fichiers de configuration, y compris tous les manifestes Kustomize, pour lancer votre projet Operator sur un cluster. Les plugins peuvent l'utiliser pour fournir des fonctionnalités. Par exemple, pour que le SDK Operator vous aide à créer votre bundle Operator, le CLI recherche les CRD et CR qui sont échafaudés dans ce répertoire.
|
|
| Contient la définition de l'API Go. |
|
| Contient les contrôleurs de l'API Go. |
|
| Contient des fichiers utilitaires, tels que le fichier utilisé pour structurer l'en-tête de licence pour les fichiers de votre projet. |
|
|
Programme principal de l'opérateur. Installe un nouveau gestionnaire qui enregistre toutes les définitions de ressources personnalisées (CRD) dans le répertoire |
|
|
Contient les graphiques Helm qui peuvent être spécifiés en utilisant la commande |
|
| Contient le groupe/la version/l'espèce (GVK) et l'emplacement de la carte Helm. Utilisé pour configurer les montres Helm. |
5.5.7. Mise à jour des projets basés sur Hybrid Helm pour les nouvelles versions du SDK Operator
OpenShift Container Platform 4.12 supporte Operator SDK 1.25.4. Si vous avez déjà le CLI 1.22.0 installé sur votre station de travail, vous pouvez mettre à jour le CLI vers 1.25.4 en installant la dernière version.
Cependant, pour que vos projets Operator existants restent compatibles avec Operator SDK 1.25.4, des étapes de mise à jour sont nécessaires pour les ruptures associées introduites depuis la version 1.22.0. Vous devez effectuer les étapes de mise à jour manuellement dans tous vos projets Operator qui ont été précédemment créés ou maintenus avec la version 1.22.0.
5.5.7.1. Mise à jour des projets d'opérateurs hybrides basés sur Helm pour Operator SDK 1.25.4
La procédure suivante permet de mettre à jour un projet d'opérateur hybride basé sur Helm pour le rendre compatible avec la version 1.25.4.
Conditions préalables
- Operator SDK 1.25.4 installé
- Un projet Operator créé ou maintenu avec Operator SDK 1.22.0
Procédure
Apportez les modifications suivantes au fichier
config/default/manager_auth_proxy_patch.yaml:apiVersion: apps/v1 kind: Deployment metadata: name: controller-manager namespace: system spec: template: spec: containers: - name: kube-rbac-proxy image: registry.redhat.io/openshift4/ose-kube-rbac-proxy:v4.121 args: - "--secure-listen-address=0.0.0.0:8443" - "--upstream=http://127.0.0.1:8080/" - "--logtostderr=true" - "--v=0" ...- 1
- Mettre à jour la version de la balise de
v4.11àv4.12.
Apportez les modifications suivantes à votre site
Makefile:Pour activer la prise en charge des architectures multiples, ajoutez la cible
docker-buildxà votre projetMakefile:Exemple
Makefile# PLATFORMS defines the target platforms for the manager image be build to provide support to multiple # architectures. (i.e. make docker-buildx IMG=myregistry/mypoperator:0.0.1). To use this option you need to: # - able to use docker buildx . More info: https://docs.docker.com/build/buildx/ # - have enable BuildKit, More info: https://docs.docker.com/develop/develop-images/build_enhancements/ # - be able to push the image for your registry (i.e. if you do not inform a valid value via IMG=<myregistry/image:<tag>> than the export will fail) # To properly provided solutions that supports more than one platform you should use this option. PLATFORMS ?= linux/arm64,linux/amd64,linux/s390x,linux/ppc64le .PHONY: docker-buildx docker-buildx: test ## Build and push docker image for the manager for cross-platform support # copy existing Dockerfile and insert --platform=${BUILDPLATFORM} into Dockerfile.cross, and preserve the original Dockerfile sed -e '1 s/\(^FROM\)/FROM --platform=\$$\{BUILDPLATFORM\}/; t' -e ' 1,// s//FROM --platform=\$$\{BUILDPLATFORM\}/' Dockerfile > Dockerfile.cross - docker buildx create --name project-v3-builder docker buildx use project-v3-builder - docker buildx build --push --platform=$(PLATFORMS) --tag ${IMG} -f Dockerfile.cross - docker buildx rm project-v3-builder rm Dockerfile.crossPour appliquer les changements à votre
Makefileet reconstruire votre Opérateur, entrez la commande suivante :$ make
Pour mettre à jour Go et ses dépendances, apportez les modifications suivantes à votre fichier
go.mod:go 1.191 require ( github.com/onsi/ginkgo/v2 v2.1.42 github.com/onsi/gomega v1.19.03 k8s.io/api v0.25.04 k8s.io/apimachinery v0.25.05 k8s.io/client-go v0.25.06 sigs.k8s.io/controller-runtime v0.13.07 )- 1
- Mise à jour de la version
1.18vers1.19. - 2
- Mise à jour de la version
v1.16.5versv2.1.4. - 3
- Mise à jour de la version
v1.18.1versv1.19.0. - 4
- Mise à jour de la version
v0.24.0versv0.25.0. - 5
- Mise à jour de la version
v0.24.0versv0.25.0. - 6
- Mise à jour de la version
v0.24.0versv0.25.0. - 7
- Mise à jour de la version
v0.12.1versv0.13.0.
Pour télécharger les versions mises à jour, nettoyer les dépendances et appliquer les changements dans votre fichier
go.mod, exécutez la commande suivante :$ go mod tidy
5.6. Opérateurs basés sur Java
5.6.1. Premiers pas avec Operator SDK pour les opérateurs basés sur Java
Le SDK de l'opérateur basé sur Java est une fonctionnalité d'aperçu technologique uniquement. Les fonctionnalités de l'aperçu technologique ne sont pas prises en charge par les accords de niveau de service (SLA) de production de Red Hat et peuvent ne pas être complètes sur le plan fonctionnel. Red Hat ne recommande pas de les utiliser en production. Ces fonctionnalités offrent un accès anticipé aux fonctionnalités des produits à venir, ce qui permet aux clients de tester les fonctionnalités et de fournir un retour d'information pendant le processus de développement.
Pour plus d'informations sur la portée de l'assistance des fonctionnalités de l'aperçu technologique de Red Hat, voir Portée de l'assistance des fonctionnalités de l'aperçu technologique.
Pour démontrer les bases de la configuration et de l'exécution d'un opérateur Java à l'aide des outils et des bibliothèques fournis par le SDK Operator, les développeurs d'opérateurs peuvent créer un exemple d'opérateur Java pour Memcached, un magasin de valeurs clés distribué, et le déployer dans une grappe.
5.6.1.1. Conditions préalables
- Operator SDK CLI installé
-
OpenShift CLI (
oc) v4.12 installé - Java v11
- Maven v3.6.3
-
Connexion à un cluster OpenShift Container Platform 4.12 avec
ocavec un compte qui a les permissionscluster-admin - Pour permettre au cluster d'extraire l'image, le dépôt où vous avez poussé votre image doit être défini comme public, ou vous devez configurer un secret d'extraction d'image
5.6.1.2. Création et déploiement d'opérateurs basés sur Java
Vous pouvez construire et déployer un simple opérateur basé sur Java pour Memcached en utilisant le SDK de l'opérateur.
Procédure
Create a project.
Créez votre répertoire de projet :
$ mkdir memcached-operatorAllez dans le répertoire du projet :
$ cd memcached-operatorExécutez la commande
operator-sdk initavec le pluginquarkuspour initialiser le projet :$ operator-sdk init \ --plugins=quarkus \ --domain=example.com \ --project-name=memcached-operator
Create an API.
Créer une API Memcached simple :
$ operator-sdk create api \ --plugins quarkus \ --group cache \ --version v1 \ --kind MemcachedBuild and push the Operator image.
Utilisez les cibles par défaut de
Makefilepour construire et pousser votre opérateur. DéfinissezIMGavec une spécification d'extraction pour votre image qui utilise un registre vers lequel vous pouvez pousser :$ make docker-build docker-push IMG=<registry>/<user>/<image_name>:<tag>Run the Operator.
Installer le CRD :
$ make installDéployez le projet sur le cluster. Définissez
IMGsur l'image que vous avez poussée :$ make deploy IMG=<registry>/<user>/<image_name>:<tag>
Create a sample custom resource (CR).
Créer un échantillon de CR :
$ oc apply -f config/samples/cache_v1_memcached.yaml \ -n memcached-operator-systemIl faut s'attendre à ce que le CR réconcilie l'opérateur :
$ oc logs deployment.apps/memcached-operator-controller-manager \ -c manager \ -n memcached-operator-system
Delete a CR
Supprimez un CR en exécutant la commande suivante :
$ oc delete -f config/samples/cache_v1_memcached.yaml -n memcached-operator-systemClean up.
Exécutez la commande suivante pour nettoyer les ressources qui ont été créées dans le cadre de cette procédure :
$ make undeploy
5.6.1.3. Prochaines étapes
- Voir le tutoriel du SDK Operator pour les opérateurs basés sur Java pour une présentation plus approfondie de la construction d'un opérateur basé sur Java.
5.6.2. Didacticiel sur le SDK pour les opérateurs basés sur Java
Le SDK de l'opérateur basé sur Java est une fonctionnalité d'aperçu technologique uniquement. Les fonctionnalités de l'aperçu technologique ne sont pas prises en charge par les accords de niveau de service (SLA) de production de Red Hat et peuvent ne pas être complètes sur le plan fonctionnel. Red Hat ne recommande pas de les utiliser en production. Ces fonctionnalités offrent un accès anticipé aux fonctionnalités des produits à venir, ce qui permet aux clients de tester les fonctionnalités et de fournir un retour d'information pendant le processus de développement.
Pour plus d'informations sur la portée de l'assistance des fonctionnalités de l'aperçu technologique de Red Hat, voir Portée de l'assistance des fonctionnalités de l'aperçu technologique.
Les développeurs d'opérateurs peuvent tirer parti de la prise en charge du langage de programmation Java dans l'Operator SDK pour créer un exemple d'opérateur basé sur Java pour Memcached, un magasin de valeurs clés distribué, et gérer son cycle de vie.
Ce processus est réalisé à l'aide de deux pièces maîtresses du cadre de l'opérateur :
- SDK de l'opérateur
-
L'outil CLI
operator-sdket la bibliothèque APIjava-operator-sdk - Gestionnaire du cycle de vie des opérateurs (OLM)
- Installation, mise à niveau et contrôle d'accès basé sur les rôles (RBAC) des opérateurs sur un cluster
Ce tutoriel est plus détaillé que le tutoriel " Getting started with Operator SDK for Java-based Operators" (Démarrer avec Operator SDK pour les opérateurs basés sur Java).
5.6.2.1. Conditions préalables
- Operator SDK CLI installé
-
OpenShift CLI (
oc) v4.12 installé - Java v11
- Maven v3.6.3
-
Connexion à un cluster OpenShift Container Platform 4.12 avec
ocavec un compte qui a les permissionscluster-admin - Pour permettre au cluster d'extraire l'image, le dépôt où vous avez poussé votre image doit être défini comme public, ou vous devez configurer un secret d'extraction d'image
5.6.2.2. Création d'un projet
Utilisez l'interface de programmation Operator SDK pour créer un projet appelé memcached-operator.
Procédure
Créer un répertoire pour le projet :
$ mkdir -p $HOME/projects/memcached-operatorAccédez au répertoire :
$ cd $HOME/projects/memcached-operatorExécutez la commande
operator-sdk initavec le pluginquarkuspour initialiser le projet :$ operator-sdk init \ --plugins=quarkus \ --domain=example.com \ --project-name=memcached-operator
5.6.2.2.1. Dossier PROJET
Parmi les fichiers générés par la commande operator-sdk init figure un fichier Kubebuilder PROJECT. Les commandes operator-sdk suivantes, ainsi que la sortie help, qui sont exécutées à partir de la racine du projet, lisent ce fichier et savent que le type de projet est Java. Par exemple :
domain: example.com
layout:
- quarkus.javaoperatorsdk.io/v1-alpha
projectName: memcached-operator
version: "3"5.6.2.3. Création d'une API et d'un contrôleur
Utilisez le SDK CLI de l'opérateur pour créer une API et un contrôleur de définition de ressources personnalisées (CRD).
Procédure
Exécutez la commande suivante pour créer une API :
$ operator-sdk create api \ --plugins=quarkus \1 --group=cache \2 --version=v1 \3 --kind=Memcached4
Vérification
Exécutez la commande
treepour visualiser la structure du fichier :$ treeExemple de sortie
. ├── Makefile ├── PROJECT ├── pom.xml └── src └── main ├── java │ └── com │ └── example │ ├── Memcached.java │ ├── MemcachedReconciler.java │ ├── MemcachedSpec.java │ └── MemcachedStatus.java └── resources └── application.properties 6 directories, 8 files
5.6.2.3.1. Définition de l'API
Définir l'API pour la ressource personnalisée (CR) Memcached.
Procédure
Modifiez les fichiers suivants qui ont été générés dans le cadre du processus
create api:Mettez à jour les attributs suivants dans le fichier
MemcachedSpec.javapour définir l'état souhaité du CRMemcached:public class MemcachedSpec { private Integer size; public Integer getSize() { return size; } public void setSize(Integer size) { this.size = size; } }Mettez à jour les attributs suivants dans le fichier
MemcachedStatus.javapour définir l'état observé de la CRMemcached:NoteL'exemple ci-dessous illustre un champ d'état de nœud. Il est recommandé d'utiliser des propriétés d'état typiques dans la pratique.
import java.util.ArrayList; import java.util.List; public class MemcachedStatus { // Add Status information here // Nodes are the names of the memcached pods private List<String> nodes; public List<String> getNodes() { if (nodes == null) { nodes = new ArrayList<>(); } return nodes; } public void setNodes(List<String> nodes) { this.nodes = nodes; } }Mettre à jour le fichier
Memcached.javapour définir le Schema for Memcached APIs qui s'étend aux fichiersMemcachedSpec.javaetMemcachedStatus.java.@Version("v1") @Group("cache.example.com") public class Memcached extends CustomResource<MemcachedSpec, MemcachedStatus> implements Namespaced {}
5.6.2.3.2. Générer des manifestes CRD
Une fois l'API définie à l'aide des fichiers MemcachedSpec et MemcachedStatus, vous pouvez générer des manifestes CRD.
Procédure
Exécutez la commande suivante à partir du répertoire
memcached-operatorpour générer le CRD :$ mvn clean install
Vérification
Vérifiez le contenu du CRD dans le fichier
target/kubernetes/memcacheds.cache.example.com-v1.ymlcomme indiqué dans l'exemple suivant :$ cat target/kubernetes/memcacheds.cache.example.com-v1.yamlExemple de sortie
# Generated by Fabric8 CRDGenerator, manual edits might get overwritten! apiVersion: apiextensions.k8s.io/v1 kind: CustomResourceDefinition metadata: name: memcacheds.cache.example.com spec: group: cache.example.com names: kind: Memcached plural: memcacheds singular: memcached scope: Namespaced versions: - name: v1 schema: openAPIV3Schema: properties: spec: properties: size: type: integer type: object status: properties: nodes: items: type: string type: array type: object type: object served: true storage: true subresources: status: {}
5.6.2.3.3. Création d'une ressource personnalisée
Après avoir généré les manifestes CRD, vous pouvez créer la ressource personnalisée (CR).
Procédure
Créer un CR Memcached appelé
memcached-sample.yaml:apiVersion: cache.example.com/v1 kind: Memcached metadata: name: memcached-sample spec: # Add spec fields here size: 1
5.6.2.4. Mise en œuvre du contrôleur
Après avoir créé une nouvelle API et un nouveau contrôleur, vous pouvez mettre en œuvre la logique du contrôleur.
Procédure
Ajoutez la dépendance suivante au fichier
pom.xml:<dependency> <groupId>commons-collections</groupId> <artifactId>commons-collections</artifactId> <version>3.2.2</version> </dependency>Pour cet exemple, remplacez le fichier de contrôleur généré
MemcachedReconciler.javapar l'exemple de mise en œuvre suivant :Exemple 5.9. Exemple
MemcachedReconciler.javapackage com.example; import io.fabric8.kubernetes.client.KubernetesClient; import io.javaoperatorsdk.operator.api.reconciler.Context; import io.javaoperatorsdk.operator.api.reconciler.Reconciler; import io.javaoperatorsdk.operator.api.reconciler.UpdateControl; import io.fabric8.kubernetes.api.model.ContainerBuilder; import io.fabric8.kubernetes.api.model.ContainerPortBuilder; import io.fabric8.kubernetes.api.model.LabelSelectorBuilder; import io.fabric8.kubernetes.api.model.ObjectMetaBuilder; import io.fabric8.kubernetes.api.model.OwnerReferenceBuilder; import io.fabric8.kubernetes.api.model.Pod; import io.fabric8.kubernetes.api.model.PodSpecBuilder; import io.fabric8.kubernetes.api.model.PodTemplateSpecBuilder; import io.fabric8.kubernetes.api.model.apps.Deployment; import io.fabric8.kubernetes.api.model.apps.DeploymentBuilder; import io.fabric8.kubernetes.api.model.apps.DeploymentSpecBuilder; import org.apache.commons.collections.CollectionUtils; import java.util.HashMap; import java.util.List; import java.util.Map; import java.util.stream.Collectors; public class MemcachedReconciler implements Reconciler<Memcached> { private final KubernetesClient client; public MemcachedReconciler(KubernetesClient client) { this.client = client; } // TODO Fill in the rest of the reconciler @Override public UpdateControl<Memcached> reconcile( Memcached resource, Context context) { // TODO: fill in logic Deployment deployment = client.apps() .deployments() .inNamespace(resource.getMetadata().getNamespace()) .withName(resource.getMetadata().getName()) .get(); if (deployment == null) { Deployment newDeployment = createMemcachedDeployment(resource); client.apps().deployments().create(newDeployment); return UpdateControl.noUpdate(); } int currentReplicas = deployment.getSpec().getReplicas(); int requiredReplicas = resource.getSpec().getSize(); if (currentReplicas != requiredReplicas) { deployment.getSpec().setReplicas(requiredReplicas); client.apps().deployments().createOrReplace(deployment); return UpdateControl.noUpdate(); } List<Pod> pods = client.pods() .inNamespace(resource.getMetadata().getNamespace()) .withLabels(labelsForMemcached(resource)) .list() .getItems(); List<String> podNames = pods.stream().map(p -> p.getMetadata().getName()).collect(Collectors.toList()); if (resource.getStatus() == null || !CollectionUtils.isEqualCollection(podNames, resource.getStatus().getNodes())) { if (resource.getStatus() == null) resource.setStatus(new MemcachedStatus()); resource.getStatus().setNodes(podNames); return UpdateControl.updateResource(resource); } return UpdateControl.noUpdate(); } private Map<String, String> labelsForMemcached(Memcached m) { Map<String, String> labels = new HashMap<>(); labels.put("app", "memcached"); labels.put("memcached_cr", m.getMetadata().getName()); return labels; } private Deployment createMemcachedDeployment(Memcached m) { Deployment deployment = new DeploymentBuilder() .withMetadata( new ObjectMetaBuilder() .withName(m.getMetadata().getName()) .withNamespace(m.getMetadata().getNamespace()) .build()) .withSpec( new DeploymentSpecBuilder() .withReplicas(m.getSpec().getSize()) .withSelector( new LabelSelectorBuilder().withMatchLabels(labelsForMemcached(m)).build()) .withTemplate( new PodTemplateSpecBuilder() .withMetadata( new ObjectMetaBuilder().withLabels(labelsForMemcached(m)).build()) .withSpec( new PodSpecBuilder() .withContainers( new ContainerBuilder() .withImage("memcached:1.4.36-alpine") .withName("memcached") .withCommand("memcached", "-m=64", "-o", "modern", "-v") .withPorts( new ContainerPortBuilder() .withContainerPort(11211) .withName("memcached") .build()) .build()) .build()) .build()) .build()) .build(); deployment.addOwnerReference(m); return deployment; } }Le contrôleur de l'exemple exécute la logique de rapprochement suivante pour chaque ressource personnalisée (CR)
Memcached:- Crée un déploiement Memcached s'il n'existe pas.
-
Veille à ce que la taille du déploiement corresponde à la taille spécifiée par la spécification
MemcachedCR. -
Met à jour l'état de
MemcachedCR avec les noms des podsmemcached.
Les sous-sections suivantes expliquent comment le contrôleur de l'exemple de mise en œuvre surveille les ressources et comment la boucle de rapprochement est déclenchée. Vous pouvez sauter ces sous-sections pour passer directement à l'exécution de l'opérateur.
5.6.2.4.1. Boucle de réconciliation
Chaque contrôleur possède un objet de rapprochement avec une méthode
Reconcile()qui met en œuvre la boucle de rapprochement. L'argumentDeploymentest transmis à la boucle de rapprochement, comme le montre l'exemple suivant :Deployment deployment = client.apps() .deployments() .inNamespace(resource.getMetadata().getNamespace()) .withName(resource.getMetadata().getName()) .get();Comme le montre l'exemple suivant, si le site
Deploymentestnull, le déploiement doit être créé. Après avoir crééDeployment, vous pouvez déterminer si un rapprochement est nécessaire. Si la réconciliation n'est pas nécessaire, renvoyez la valeur deUpdateControl.noUpdate(), sinon renvoyez la valeur de `UpdateControl.updateStatus(resource) :if (deployment == null) { Deployment newDeployment = createMemcachedDeployment(resource); client.apps().deployments().create(newDeployment); return UpdateControl.noUpdate(); }Après avoir obtenu le site
Deployment, obtenez les répliques actuelles et requises, comme le montre l'exemple suivant :int currentReplicas = deployment.getSpec().getReplicas(); int requiredReplicas = resource.getSpec().getSize();Si
currentReplicasne correspond pas àrequiredReplicas, vous devez mettre à jourDeployment, comme le montre l'exemple suivant :if (currentReplicas != requiredReplicas) { deployment.getSpec().setReplicas(requiredReplicas); client.apps().deployments().createOrReplace(deployment); return UpdateControl.noUpdate(); }L'exemple suivant montre comment obtenir la liste des pods et leurs noms :
List<Pod> pods = client.pods() .inNamespace(resource.getMetadata().getNamespace()) .withLabels(labelsForMemcached(resource)) .list() .getItems(); List<String> podNames = pods.stream().map(p -> p.getMetadata().getName()).collect(Collectors.toList());Vérifiez si des ressources ont été créées et vérifiez les podnames avec les ressources Memcached. En cas de non-concordance dans l'une ou l'autre de ces conditions, procédez à une réconciliation comme indiqué dans l'exemple suivant :
if (resource.getStatus() == null || !CollectionUtils.isEqualCollection(podNames, resource.getStatus().getNodes())) { if (resource.getStatus() == null) resource.setStatus(new MemcachedStatus()); resource.getStatus().setNodes(podNames); return UpdateControl.updateResource(resource); }
5.6.2.4.2. Définir labelsForMemcached
labelsForMemcached est un utilitaire qui renvoie une carte des étiquettes à attacher aux ressources :
private Map<String, String> labelsForMemcached(Memcached m) {
Map<String, String> labels = new HashMap<>();
labels.put("app", "memcached");
labels.put("memcached_cr", m.getMetadata().getName());
return labels;
}5.6.2.4.3. Définir le createMemcachedDeployment
La méthode createMemcachedDeployment utilise la classe DeploymentBuilder de fabric8:
private Deployment createMemcachedDeployment(Memcached m) {
Deployment deployment = new DeploymentBuilder()
.withMetadata(
new ObjectMetaBuilder()
.withName(m.getMetadata().getName())
.withNamespace(m.getMetadata().getNamespace())
.build())
.withSpec(
new DeploymentSpecBuilder()
.withReplicas(m.getSpec().getSize())
.withSelector(
new LabelSelectorBuilder().withMatchLabels(labelsForMemcached(m)).build())
.withTemplate(
new PodTemplateSpecBuilder()
.withMetadata(
new ObjectMetaBuilder().withLabels(labelsForMemcached(m)).build())
.withSpec(
new PodSpecBuilder()
.withContainers(
new ContainerBuilder()
.withImage("memcached:1.4.36-alpine")
.withName("memcached")
.withCommand("memcached", "-m=64", "-o", "modern", "-v")
.withPorts(
new ContainerPortBuilder()
.withContainerPort(11211)
.withName("memcached")
.build())
.build())
.build())
.build())
.build())
.build();
deployment.addOwnerReference(m);
return deployment;
}5.6.2.5. Fonctionnement de l'opérateur
Vous pouvez utiliser l'interface de programmation de l'opérateur SDK de trois manières différentes pour créer et exécuter votre opérateur :
- Exécuter localement en dehors du cluster comme un programme Go.
- Exécuter en tant que déploiement sur le cluster.
- Regroupez votre opérateur et utilisez Operator Lifecycle Manager (OLM) pour le déployer sur le cluster.
5.6.2.5.1. Exécution locale en dehors du cluster
Vous pouvez exécuter votre projet Operator en tant que programme Go en dehors du cluster. Ceci est utile pour le développement afin d'accélérer le déploiement et les tests.
Procédure
Exécutez la commande suivante pour compiler l'Opérateur :
$ mvn clean installExemple de sortie
[INFO] ------------------------------------------------------------------------ [INFO] BUILD SUCCESS [INFO] ------------------------------------------------------------------------ [INFO] Total time: 11.193 s [INFO] Finished at: 2021-05-26T12:16:54-04:00 [INFO] ------------------------------------------------------------------------Exécutez la commande suivante pour installer le CRD dans l'espace de noms par défaut :
$ oc apply -f target/kubernetes/memcacheds.cache.example.com-v1.ymlExemple de sortie
customresourcedefinition.apiextensions.k8s.io/memcacheds.cache.example.com createdCréez un fichier appelé
rbac.yamlcomme indiqué dans l'exemple suivant :apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: memcached-operator-admin subjects: - kind: ServiceAccount name: memcached-quarkus-operator-operator namespace: default roleRef: kind: ClusterRole name: cluster-admin apiGroup: ""Exécutez la commande suivante pour accorder les privilèges de
cluster-adminàmemcached-quarkus-operator-operatoren appliquant le fichierrbac.yaml:$ oc apply -f rbac.yamlSaisissez la commande suivante pour lancer l'opérateur :
$ java -jar target/quarkus-app/quarkus-run.jarNoteLa commande
javalancera l'opérateur et restera active jusqu'à ce que vous mettiez fin au processus. Vous aurez besoin d'un autre terminal pour exécuter le reste de ces commandes.Appliquez le fichier
memcached-sample.yamlà l'aide de la commande suivante :$ kubectl apply -f memcached-sample.yamlExemple de sortie
memcached.cache.example.com/memcached-sample created
Vérification
Exécutez la commande suivante pour confirmer que le module a démarré :
$ oc get allExemple de sortie
NAME READY STATUS RESTARTS AGE pod/memcached-sample-6c765df685-mfqnz 1/1 Running 0 18s
5.6.2.5.2. Exécution en tant que déploiement sur le cluster
Vous pouvez exécuter votre projet Operator en tant que déploiement sur votre cluster.
Procédure
Exécutez les commandes
makesuivantes pour construire et pousser l'image de l'opérateur. Modifiez l'argumentIMGdans les étapes suivantes pour référencer un référentiel auquel vous avez accès. Vous pouvez obtenir un compte pour stocker des conteneurs sur des sites de dépôt tels que Quay.io.Construire l'image :
$ make docker-build IMG=<registry>/<user>/<image_name>:<tag>NoteLe fichier Docker généré par le SDK pour l'Operator fait explicitement référence à
GOARCH=amd64pourgo build. Cette référence peut être modifiée enGOARCH=$TARGETARCHpour les architectures non-AMD64. Docker définira automatiquement la variable d'environnement à la valeur spécifiée par–platform. Avec Buildah, il faudra utiliser–build-argà cette fin. Pour plus d'informations, voir Architectures multiples.Transférer l'image dans un référentiel :
$ make docker-push IMG=<registry>/<user>/<image_name>:<tag>NoteLe nom et la balise de l'image, par exemple
IMG=<registry>/<user>/<image_name>:<tag>, dans les deux commandes peuvent également être définis dans votre Makefile. Modifiez la valeur deIMG ?= controller:latestpour définir votre nom d'image par défaut.
Exécutez la commande suivante pour installer le CRD dans l'espace de noms par défaut :
$ oc apply -f target/kubernetes/memcacheds.cache.example.com-v1.ymlExemple de sortie
customresourcedefinition.apiextensions.k8s.io/memcacheds.cache.example.com createdCréez un fichier appelé
rbac.yamlcomme indiqué dans l'exemple suivant :apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: memcached-operator-admin subjects: - kind: ServiceAccount name: memcached-quarkus-operator-operator namespace: default roleRef: kind: ClusterRole name: cluster-admin apiGroup: ""ImportantLe fichier
rbac.yamlsera appliqué à une étape ultérieure.Exécutez la commande suivante pour déployer l'opérateur :
$ make deploy IMG=<registry>/<user>/<image_name>:<tag>Exécutez la commande suivante pour accorder les privilèges de
cluster-adminàmemcached-quarkus-operator-operatoren appliquant le fichierrbac.yamlcréé à l'étape précédente :$ oc apply -f rbac.yamlExécutez la commande suivante pour vérifier que l'opérateur fonctionne :
$ oc get all -n defaultExemple de sortie
NAME READY UP-TO-DATE AVAILABLE AGE pod/memcached-quarkus-operator-operator-7db86ccf58-k4mlm 0/1 Running 0 18sExécutez la commande suivante pour appliquer le
memcached-sample.yamlet créer le podmemcached-sample:$ oc apply -f memcached-sample.yamlExemple de sortie
memcached.cache.example.com/memcached-sample created
Vérification
Exécutez la commande suivante pour confirmer le démarrage des pods :
$ oc get allExemple de sortie
NAME READY STATUS RESTARTS AGE pod/memcached-quarkus-operator-operator-7b766f4896-kxnzt 1/1 Running 1 79s pod/memcached-sample-6c765df685-mfqnz 1/1 Running 0 18s
5.6.2.5.3. Regroupement d'un opérateur et déploiement avec Operator Lifecycle Manager
5.6.2.5.3.1. Regroupement d'un opérateur
Le format Operator bundle est la méthode d'emballage par défaut pour Operator SDK et Operator Lifecycle Manager (OLM). Vous pouvez préparer votre Operator pour une utilisation sur OLM en utilisant Operator SDK pour construire et pousser votre projet Operator en tant qu'image groupée.
Conditions préalables
- Operator SDK CLI installé sur un poste de développement
-
OpenShift CLI (
oc) v4.12 installé - Projet d'opérateur initialisé à l'aide de l'Operator SDK
Procédure
Exécutez les commandes
makesuivantes dans le répertoire de votre projet Operator pour construire et pousser votre image Operator. Modifiez l'argumentIMGdans les étapes suivantes pour référencer un référentiel auquel vous avez accès. Vous pouvez obtenir un compte pour stocker des conteneurs sur des sites de dépôt tels que Quay.io.Construire l'image :
$ make docker-build IMG=<registry>/<user>/<operator_image_name>:<tag>NoteLe fichier Docker généré par le SDK pour l'Operator fait explicitement référence à
GOARCH=amd64pourgo build. Cette référence peut être modifiée enGOARCH=$TARGETARCHpour les architectures non-AMD64. Docker définira automatiquement la variable d'environnement à la valeur spécifiée par–platform. Avec Buildah, il faudra utiliser–build-argà cette fin. Pour plus d'informations, voir Architectures multiples.Transférer l'image dans un référentiel :
$ make docker-push IMG=<registry>/<user>/<operator_image_name>:<tag>
Créez votre manifeste Operator bundle en exécutant la commande
make bundle, qui invoque plusieurs commandes, dont les sous-commandes Operator SDKgenerate bundleetbundle validate:$ make bundle IMG=<registry>/<user>/<operator_image_name>:<tag>Les manifestes de l'offre groupée d'un opérateur décrivent la manière d'afficher, de créer et de gérer une application. La commande
make bundlecrée les fichiers et répertoires suivants dans votre projet Operator :-
Un répertoire bundle manifests nommé
bundle/manifestsqui contient un objetClusterServiceVersion -
Un répertoire de métadonnées de la liasse nommé
bundle/metadata -
Toutes les définitions de ressources personnalisées (CRD) dans un répertoire
config/crd -
Un fichier Docker
bundle.Dockerfile
Ces fichiers sont ensuite automatiquement validés à l'aide de
operator-sdk bundle validateafin de s'assurer que la représentation du paquet sur le disque est correcte.-
Un répertoire bundle manifests nommé
Construisez et poussez votre image de bundle en exécutant les commandes suivantes. OLM consomme les liasses d'opérateurs à l'aide d'une image d'index, qui fait référence à une ou plusieurs images de liasses.
Créez l'image de l'ensemble. Définissez
BUNDLE_IMGavec les détails du registre, de l'espace de noms de l'utilisateur et de la balise d'image où vous avez l'intention de pousser l'image :$ make bundle-build BUNDLE_IMG=<registry>/<user>/<bundle_image_name>:<tag>Pousser l'image de la liasse :
$ docker push <registry>/<user>/<bundle_image_name>:<tag>
5.6.2.5.3.2. Déploiement d'un opérateur avec Operator Lifecycle Manager
Operator Lifecycle Manager (OLM) vous aide à installer, mettre à jour et gérer le cycle de vie des opérateurs et de leurs services associés sur un cluster Kubernetes. OLM est installé par défaut sur OpenShift Container Platform et s'exécute en tant qu'extension Kubernetes afin que vous puissiez utiliser la console web et l'OpenShift CLI (oc) pour toutes les fonctions de gestion du cycle de vie des opérateurs sans outils supplémentaires.
Le format Operator bundle est la méthode d'emballage par défaut pour Operator SDK et OLM. Vous pouvez utiliser Operator SDK pour exécuter rapidement une image de bundle sur OLM afin de vous assurer qu'elle fonctionne correctement.
Conditions préalables
- Operator SDK CLI installé sur un poste de développement
- L'image de l'ensemble de l'opérateur est construite et poussée vers un registre
-
OLM installé sur un cluster basé sur Kubernetes (v1.16.0 ou version ultérieure si vous utilisez
apiextensions.k8s.io/v1CRD, par exemple OpenShift Container Platform 4.12) -
Connexion au cluster avec
ocen utilisant un compte avec les permissions decluster-admin
Procédure
Saisissez la commande suivante pour exécuter l'opérateur sur le cluster :
$ operator-sdk run bundle \1 -n <namespace> \2 <registry>/<user>/<bundle_image_name>:<tag>3 - 1
- La commande
run bundlecrée un catalogue de fichiers valide et installe le paquet Operator sur votre cluster à l'aide d'OLM. - 2
- Facultatif : Par défaut, la commande installe l'opérateur dans le projet actif dans votre fichier
~/.kube/config. Vous pouvez ajouter l'option-npour définir un espace de noms différent pour l'installation. - 3
- Si vous ne spécifiez pas d'image, la commande utilise
quay.io/operator-framework/opm:latestcomme image d'index par défaut. Si vous spécifiez une image, la commande utilise l'image du paquet elle-même comme image d'index.
ImportantDepuis OpenShift Container Platform 4.11, la commande
run bundleprend en charge par défaut le format de catalogue basé sur des fichiers pour les catalogues Operator. Le format de base de données SQLite déprécié pour les catalogues Operator continue d'être pris en charge ; cependant, il sera supprimé dans une prochaine version. Il est recommandé aux auteurs d'Operator de migrer leurs flux de travail vers le format de catalogue basé sur des fichiers.Cette commande permet d'effectuer les actions suivantes :
- Créez une image d'index faisant référence à votre image de liasse. L'image d'index est opaque et éphémère, mais elle reflète fidèlement la manière dont un paquet serait ajouté à un catalogue en production.
- Créez une source de catalogue qui pointe vers votre nouvelle image d'index, ce qui permet à OperatorHub de découvrir votre opérateur.
-
Déployez votre opérateur sur votre cluster en créant un site
OperatorGroup,Subscription,InstallPlan, et toutes les autres ressources nécessaires, y compris RBAC.
5.6.3. Présentation du projet pour les opérateurs basés sur Java
Le SDK de l'opérateur basé sur Java est une fonctionnalité d'aperçu technologique uniquement. Les fonctionnalités de l'aperçu technologique ne sont pas prises en charge par les accords de niveau de service (SLA) de production de Red Hat et peuvent ne pas être complètes sur le plan fonctionnel. Red Hat ne recommande pas de les utiliser en production. Ces fonctionnalités offrent un accès anticipé aux fonctionnalités des produits à venir, ce qui permet aux clients de tester les fonctionnalités et de fournir un retour d'information pendant le processus de développement.
Pour plus d'informations sur la portée de l'assistance des fonctionnalités de l'aperçu technologique de Red Hat, voir Portée de l'assistance des fonctionnalités de l'aperçu technologique.
Le CLI operator-sdk peut générer, ou scaffold, un certain nombre de paquets et de fichiers pour chaque projet Operator.
5.6.3.1. Mise en page de projet basée sur Java
Les projets Operator basés sur Java générés par la commande operator-sdk init contiennent les fichiers et répertoires suivants :
| Fichier ou répertoire | Objectif |
|---|---|
|
| Fichier contenant les dépendances nécessaires à l'exécution de l'opérateur. |
|
|
Répertoire qui contient les fichiers représentant l'API. Si le domaine est |
|
| Fichier Java qui définit les implémentations du contrôleur. |
|
| Fichier Java qui définit l'état souhaité du CR Memcached. |
|
| Fichier Java qui définit l'état observé du CR Memcached. |
|
| Fichier Java qui définit le schéma des API de Memcached. |
|
| Répertoire contenant les fichiers yaml du CRD. |
5.6.4. Mise à jour des projets pour les nouvelles versions du SDK de l'opérateur
OpenShift Container Platform 4.12 supporte Operator SDK 1.25.4. Si vous avez déjà le CLI 1.22.0 installé sur votre station de travail, vous pouvez mettre à jour le CLI vers 1.25.4 en installant la dernière version.
Cependant, pour que vos projets Operator existants restent compatibles avec Operator SDK 1.25.4, des étapes de mise à jour sont nécessaires pour les ruptures associées introduites depuis la version 1.22.0. Vous devez effectuer les étapes de mise à jour manuellement dans tous vos projets Operator qui ont été précédemment créés ou maintenus avec la version 1.22.0.
5.6.4.1. Mise à jour des projets Operator basés sur Java pour Operator SDK 1.25.4
La procédure suivante permet de mettre à jour un projet d'opérateur Java existant pour le rendre compatible avec la version 1.25.4.
Conditions préalables
- Operator SDK 1.25.4 installé
- Un projet Operator créé ou maintenu avec Operator SDK 1.22.0
Procédure
Apportez les modifications suivantes au fichier
config/default/manager_auth_proxy_patch.yaml:apiVersion: apps/v1 kind: Deployment metadata: name: controller-manager namespace: system spec: template: spec: containers: - name: kube-rbac-proxy image: registry.redhat.io/openshift4/ose-kube-rbac-proxy:v4.121 args: - "--secure-listen-address=0.0.0.0:8443" - "--upstream=http://127.0.0.1:8080/" - "--logtostderr=true" - "--v=0" ...- 1
- Mettre à jour la version de la balise de
v4.11àv4.12.
Apportez les modifications suivantes à votre site
Makefile:Pour activer la prise en charge des architectures multiples, ajoutez la cible
docker-buildxà votre projetMakefile:Exemple
Makefile# PLATFORMS defines the target platforms for the manager image be build to provide support to multiple # architectures. (i.e. make docker-buildx IMG=myregistry/mypoperator:0.0.1). To use this option you need to: # - able to use docker buildx . More info: https://docs.docker.com/build/buildx/ # - have enable BuildKit, More info: https://docs.docker.com/develop/develop-images/build_enhancements/ # - be able to push the image for your registry (i.e. if you do not inform a valid value via IMG=<myregistry/image:<tag>> than the export will fail) # To properly provided solutions that supports more than one platform you should use this option. PLATFORMS ?= linux/arm64,linux/amd64,linux/s390x,linux/ppc64le .PHONY: docker-buildx docker-buildx: test ## Build and push docker image for the manager for cross-platform support # copy existing Dockerfile and insert --platform=${BUILDPLATFORM} into Dockerfile.cross, and preserve the original Dockerfile sed -e '1 s/\(^FROM\)/FROM --platform=\$$\{BUILDPLATFORM\}/; t' -e ' 1,// s//FROM --platform=\$$\{BUILDPLATFORM\}/' Dockerfile > Dockerfile.cross - docker buildx create --name project-v3-builder docker buildx use project-v3-builder - docker buildx build --push --platform=$(PLATFORMS) --tag ${IMG} -f Dockerfile.cross - docker buildx rm project-v3-builder rm Dockerfile.crossPour appliquer les changements à votre
Makefileet reconstruire votre Opérateur, entrez la commande suivante :$ make
5.7. Définition des versions de service de cluster (CSV)
Un cluster service version (CSV), défini par un objet ClusterServiceVersion, est un manifeste YAML créé à partir des métadonnées de l'opérateur qui aide Operator Lifecycle Manager (OLM) à exécuter l'opérateur dans un cluster. Il s'agit des métadonnées qui accompagnent l'image d'un conteneur Operator, utilisées pour remplir les interfaces utilisateur avec des informations telles que le logo, la description et la version. Il s'agit également d'une source d'informations techniques nécessaires au fonctionnement de l'opérateur, comme les règles RBAC dont il a besoin et les ressources personnalisées (CR) qu'il gère ou dont il dépend.
L'Operator SDK comprend le générateur CSV qui permet de générer un CSV pour le projet Operator en cours, personnalisé à l'aide des informations contenues dans les manifestes YAML et les fichiers source de l'Operator.
Une commande générant des CSV supprime la responsabilité des auteurs d'opérateurs ayant une connaissance approfondie d'OLM pour que leur opérateur interagisse avec OLM ou publie des métadonnées dans le registre du catalogue. En outre, comme la spécification CSV est susceptible d'évoluer au fil du temps avec la mise en œuvre de nouvelles fonctionnalités Kubernetes et OLM, le SDK de l'opérateur est équipé pour étendre facilement son système de mise à jour afin de gérer les nouvelles fonctionnalités CSV à l'avenir.
5.7.1. Comment fonctionne la génération de CSV
Les manifestes de l'offre groupée Operator, qui comprennent des versions de service de cluster (CSV), décrivent comment afficher, créer et gérer une application avec Operator Lifecycle Manager (OLM). Le générateur CSV du SDK Operator, appelé par la sous-commande generate bundle, est la première étape vers la publication de votre Operator dans un catalogue et son déploiement avec OLM. La sous-commande nécessite certains manifestes d'entrée pour construire un manifeste CSV ; toutes les entrées sont lues lorsque la commande est invoquée, ainsi qu'une base CSV, pour générer ou régénérer un CSV de manière autonome.
En règle générale, la sous-commande generate kustomize manifests est exécutée en premier pour générer les bases Kustomize en entrée qui sont consommées par la sous-commande generate bundle. Cependant, l'Operator SDK fournit la commande make bundle, qui automatise plusieurs tâches, y compris l'exécution des sous-commandes suivantes dans l'ordre :
-
generate kustomize manifests -
generate bundle -
bundle validate
5.7.1.1. Fichiers et ressources générés
La commande make bundle crée les fichiers et répertoires suivants dans votre projet Operator :
-
Un répertoire bundle manifests nommé
bundle/manifestsqui contient un objetClusterServiceVersion(CSV) -
Un répertoire de métadonnées de la liasse nommé
bundle/metadata -
Toutes les définitions de ressources personnalisées (CRD) dans un répertoire
config/crd -
Un fichier Docker
bundle.Dockerfile
Les ressources suivantes sont généralement incluses dans un CSV :
- Rôle
- Définit les autorisations de l'opérateur au sein d'un espace de noms.
- ClusterRole
- Définit les autorisations de l'opérateur à l'échelle du cluster.
- Déploiement
- Définit la manière dont l'opérande d'un opérateur est exécuté dans les modules.
- CustomResourceDefinition (CRD)
- Définit les ressources personnalisées que votre opérateur réconcilie.
- Exemples de ressources personnalisées
- Exemples de ressources respectant les spécifications d'un CRD particulier.
5.7.1.2. Gestion des versions
L'option --version de la sous-commande generate bundle fournit une version sémantique de votre bundle lors de sa création et de la mise à jour d'un bundle existant.
En définissant la variable VERSION dans votre Makefile, l'indicateur --version est automatiquement invoqué en utilisant cette valeur lorsque la sous-commande generate bundle est exécutée par la commande make bundle. La version du CSV est la même que celle de l'opérateur, et un nouveau CSV est généré lors de la mise à niveau des versions de l'opérateur.
5.7.2. Champs CSV définis manuellement
De nombreux champs CSV ne peuvent pas être remplis à l'aide de manifestes génériques générés qui ne sont pas spécifiques à Operator SDK. Ces champs sont principalement des métadonnées écrites par l'homme sur l'opérateur et diverses définitions de ressources personnalisées (CRD).
Les auteurs d'opérateurs doivent modifier directement leur fichier YAML de version de service de cluster (CSV), en ajoutant des données personnalisées aux champs obligatoires suivants. Le SDK de l'opérateur émet un avertissement lors de la génération du fichier CSV lorsqu'il détecte un manque de données dans l'un des champs obligatoires.
Les tableaux suivants détaillent les champs CSV définis manuellement qui sont obligatoires et ceux qui sont facultatifs.
| Field | Description |
|---|---|
|
|
Un nom unique pour ce CSV. La version de l'opérateur doit être incluse dans le nom pour garantir l'unicité, par exemple |
|
|
Le niveau de capacité selon le modèle de maturité de l'opérateur. Les options comprennent |
|
| Un nom public pour identifier l'opérateur. |
|
| Brève description de la fonctionnalité de l'opérateur. |
|
| Mots clés décrivant l'opérateur. |
|
|
Entités humaines ou organisationnelles assurant la maintenance de l'opérateur, avec un |
|
|
Le fournisseur de l'opérateur (généralement une organisation), avec une adresse |
|
| Paires clé-valeur à utiliser par les éléments internes de l'opérateur. |
|
|
Version sémantique de l'opérateur, par exemple |
|
|
Tous les CRD que l'opérateur utilise. Ce champ est rempli automatiquement par le SDK de l'opérateur si des fichiers YAML de CRD sont présents sur
|
| Field | Description |
|---|---|
|
| Le nom du CSV remplacé par ce CSV. |
|
|
URL (par exemple, sites web et documentation) relatifs à l'opérateur ou à l'application gérée, chacun avec |
|
| Sélecteurs permettant à l'opérateur d'associer des ressources dans un cluster. |
|
|
Une icône codée en base64 unique à l'opérateur, placée dans un champ |
|
|
Le niveau de maturité atteint par le logiciel dans cette version. Les options comprennent |
Pour plus de détails sur les données que chaque champ ci-dessus doit contenir, voir la spécification CSV.
Plusieurs champs YAML nécessitant actuellement une intervention de l'utilisateur peuvent potentiellement être analysés à partir du code de l'opérateur.
5.7.2.1. Annotations des métadonnées de l'opérateur
Les développeurs d'opérateurs peuvent définir manuellement certaines annotations dans les métadonnées d'une version de service de cluster (CSV) pour activer des fonctionnalités ou mettre en évidence des capacités dans les interfaces utilisateur (UI), telles que OperatorHub.
Le tableau suivant énumère les annotations de métadonnées de l'opérateur qui peuvent être définies manuellement à l'aide des champs metadata.annotations.
| Field | Description |
|---|---|
|
| Fournir des modèles de définition de ressources personnalisées (CRD) avec un ensemble minimal de configurations. Les interfaces utilisateur compatibles pré-remplissent ce modèle pour que les utilisateurs puissent le personnaliser davantage. |
|
|
Spécifiez une seule ressource personnalisée requise en ajoutant l'annotation |
|
| Définir un espace de noms suggéré où l'opérateur doit être déployé. |
|
| Caractéristiques de l'infrastructure prises en charge par l'opérateur. Les utilisateurs peuvent visualiser et filtrer ces caractéristiques lorsqu'ils découvrent des opérateurs via OperatorHub dans la console web. Valeurs valides, sensibles à la casse :
Important
The use of FIPS Validated / Modules in Process cryptographic libraries is only supported on OpenShift Container Platform deployments on the
|
|
|
Tableau libre permettant d'énumérer les abonnements spécifiques nécessaires à l'utilisation de l'opérateur. Par exemple, |
|
| Masque les CRD dans l'interface utilisateur qui ne sont pas destinés à être manipulés par l'utilisateur. |
Exemples de cas d'utilisation
L'opérateur prend en charge les services déconnectés et les services proxy
operators.openshift.io/infrastructure-features: '["disconnected", "proxy-aware"]'L'opérateur a besoin d'une licence OpenShift Container Platform
operators.openshift.io/valid-subscription: '["OpenShift Container Platform"]'L'opérateur a besoin d'une licence 3scale
operators.openshift.io/valid-subscription: '["3Scale Commercial License", "Red Hat Managed Integration"]'L'opérateur prend en charge le mode déconnecté et le mode proxy, et nécessite une licence OpenShift Container Platform
operators.openshift.io/infrastructure-features: '["disconnected", "proxy-aware"]'
operators.openshift.io/valid-subscription: '["OpenShift Container Platform"]'5.7.3. Permettre à votre opérateur de s'adapter à des environnements réseau restreints
En tant qu'auteur d'un opérateur, votre opérateur doit répondre à des exigences supplémentaires pour fonctionner correctement dans un réseau restreint, ou dans un environnement déconnecté.
Exigences de l'opérateur pour la prise en charge du mode déconnecté
- Remplacer les références d'images codées en dur par des variables d'environnement.
Dans la version du service de cluster (CSV) de votre Opérateur :
- Dressez la liste des related images ou des autres images de conteneurs dont votre opérateur pourrait avoir besoin pour remplir ses fonctions.
- Référencer toutes les images spécifiées par un condensé (SHA) et non par un tag.
- Toutes les dépendances de votre opérateur doivent également pouvoir fonctionner en mode déconnecté.
- Votre opérateur ne doit pas nécessiter de ressources hors cluster.
Conditions préalables
- Un projet d'opérateur avec un fichier CSV. La procédure suivante utilise l'opérateur Memcached comme exemple pour les projets basés sur Go, Ansible et Helm.
Procédure
Définir une variable d'environnement pour les références d'images supplémentaires utilisées par l'opérateur dans le fichier
config/manager/manager.yaml:Exemple 5.10. Exemple de fichier
config/manager/manager.yaml... spec: ... spec: ... containers: - command: - /manager ... env: - name: <related_image_environment_variable>1 value: "<related_image_reference_with_tag>"2 Remplacez les références d'images codées en dur par des variables d'environnement dans le fichier correspondant au type de projet de l'opérateur :
Pour les projets Operator basés sur Go, ajoutez la variable d'environnement au fichier
controllers/memcached_controller.gocomme indiqué dans l'exemple suivant :Exemple 5.11. Exemple de fichier
controllers/memcached_controller.go// deploymentForMemcached returns a memcached Deployment object ... Spec: corev1.PodSpec{ Containers: []corev1.Container{{ - Image: "memcached:1.4.36-alpine",1 + Image: os.Getenv("<related_image_environment_variable>"),2 Name: "memcached", Command: []string{"memcached", "-m=64", "-o", "modern", "-v"}, Ports: []corev1.ContainerPort{{ ...NoteLa fonction
os.Getenvrenvoie une chaîne vide si une variable n'est pas définie. Définissez la variable<related_image_environment_variable>avant de modifier le fichier.Pour les projets Operator basés sur Ansible, ajoutez la variable d'environnement au fichier
roles/memcached/tasks/main.ymlcomme indiqué dans l'exemple suivant :Exemple 5.12. Exemple de fichier
roles/memcached/tasks/main.ymlspec: containers: - name: memcached command: - memcached - -m=64 - -o - modern - -v - image: "docker.io/memcached:1.4.36-alpine"1 + image: "{{ lookup('env', '<related_image_environment_variable>') }}"2 ports: - containerPort: 11211 ...Pour les projets d'opérateurs basés sur Helm, ajoutez le champ
overrideValuesau fichierwatches.yamlcomme indiqué dans l'exemple suivant :Exemple 5.13. Exemple de fichier
watches.yaml... - group: demo.example.com version: v1alpha1 kind: Memcached chart: helm-charts/memcached overrideValues:1 relatedImage: ${<related_image_environment_variable>}2 Ajoutez la valeur du champ
overrideValuesau fichierhelm-charts/memchached/values.yamlcomme indiqué dans l'exemple suivant :Exemple de fichier
helm-charts/memchached/values.yaml... relatedImage: ""Modifiez le modèle de graphique dans le fichier
helm-charts/memcached/templates/deployment.yamlcomme indiqué dans l'exemple suivant :Exemple 5.14. Exemple de fichier
helm-charts/memcached/templates/deployment.yamlcontainers: - name: {{ .Chart.Name }} securityContext: - toYaml {{ .Values.securityContext | nindent 12 }} image: "{{ .Values.image.pullPolicy }} env:1 - name: related_image2 value: "{{ .Values.relatedImage }}"3
Ajoutez la définition de la variable
BUNDLE_GEN_FLAGSà votreMakefileen y apportant les modifications suivantes :Exemple
MakefileBUNDLE_GEN_FLAGS ?= -q --overwrite --version $(VERSION) $(BUNDLE_METADATA_OPTS) # USE_IMAGE_DIGESTS defines if images are resolved via tags or digests # You can enable this value if you would like to use SHA Based Digests # To enable set flag to true USE_IMAGE_DIGESTS ?= false ifeq ($(USE_IMAGE_DIGESTS), true) BUNDLE_GEN_FLAGS += --use-image-digests endif ... - $(KUSTOMIZE) build config/manifests | operator-sdk generate bundle -q --overwrite --version $(VERSION) $(BUNDLE_METADATA_OPTS)1 + $(KUSTOMIZE) build config/manifests | operator-sdk generate bundle $(BUNDLE_GEN_FLAGS)2 ...Pour mettre à jour l'image de votre opérateur en utilisant un condensé (SHA) et non une balise, exécutez la commande
make bundleet remplacezUSE_IMAGE_DIGESTSpartrue:$ make bundle USE_IMAGE_DIGESTS=trueAjouter l'annotation
disconnected, qui indique que l'opérateur travaille dans un environnement déconnecté :metadata: annotations: operators.openshift.io/infrastructure-features: '["disconnected"]'Les opérateurs peuvent être filtrés dans OperatorHub grâce à cette fonctionnalité de l'infrastructure.
5.7.4. Permettre à votre opérateur de s'adapter à de multiples architectures et systèmes d'exploitation
Operator Lifecycle Manager (OLM) suppose que tous les opérateurs s'exécutent sur des hôtes Linux. Cependant, en tant qu'auteur d'un opérateur, vous pouvez spécifier si votre opérateur prend en charge la gestion des charges de travail sur d'autres architectures, si des nœuds de travail sont disponibles dans le cluster OpenShift Container Platform.
Si votre opérateur prend en charge des variantes autres que AMD64 et Linux, vous pouvez ajouter des étiquettes à la version du service de cluster (CSV) qui fournit à l'opérateur la liste des variantes prises en charge. Les étiquettes indiquant les architectures et les systèmes d'exploitation pris en charge sont définies comme suit :
labels:
operatorframework.io/arch.<arch>: supported
operatorframework.io/os.<os>: supported
Seules les étiquettes de la tête de canal du canal par défaut sont prises en compte pour le filtrage des manifestes de paquetage par étiquette. Cela signifie, par exemple, qu'il est possible de fournir une architecture supplémentaire à un opérateur dans le canal autre que celui par défaut, mais que cette architecture n'est pas disponible pour le filtrage dans l'API PackageManifest.
Si un CSV ne comporte pas d'étiquette os, il est traité par défaut comme s'il comportait l'étiquette de support Linux suivante :
labels:
operatorframework.io/os.linux: supported
Si un CSV ne comporte pas d'étiquette arch, il est traité par défaut comme s'il comportait l'étiquette de prise en charge AMD64 suivante :
labels:
operatorframework.io/arch.amd64: supportedSi un opérateur prend en charge plusieurs architectures de nœuds ou systèmes d'exploitation, vous pouvez également ajouter plusieurs étiquettes.
Conditions préalables
- Un projet d'opérateur avec un CSV.
- Pour pouvoir répertorier plusieurs architectures et systèmes d'exploitation, l'image de l'opérateur référencée dans le CSV doit être une image de la liste des manifestes.
- Pour que l'opérateur fonctionne correctement dans des environnements de réseaux restreints ou déconnectés, l'image référencée doit également être spécifiée à l'aide d'un condensé (SHA) et non d'une balise.
Procédure
Ajoutez une étiquette à l'adresse
metadata.labelsde votre CSV pour chaque architecture et système d'exploitation pris en charge par votre opérateur :labels: operatorframework.io/arch.s390x: supported operatorframework.io/os.zos: supported operatorframework.io/os.linux: supported1 operatorframework.io/arch.amd64: supported2
5.7.4.1. Architecture et système d'exploitation pour les opérateurs
Les chaînes suivantes sont prises en charge dans Operator Lifecycle Manager (OLM) sur OpenShift Container Platform lors de l'étiquetage ou du filtrage des opérateurs qui prennent en charge plusieurs architectures et systèmes d'exploitation :
| Architecture | String |
|---|---|
| AMD64 |
|
| IBM Power |
|
| IBM zSystems |
|
| Système d'exploitation | String |
|---|---|
| Linux |
|
| z/OS |
|
Différentes versions d'OpenShift Container Platform et d'autres distributions basées sur Kubernetes peuvent prendre en charge un ensemble différent d'architectures et de systèmes d'exploitation.
5.7.5. Définition d'un espace de noms suggéré
Certains opérateurs doivent être déployés dans un espace de noms spécifique, ou avec des ressources auxiliaires dans des espaces de noms spécifiques, pour fonctionner correctement. S'il est résolu à partir d'un abonnement, Operator Lifecycle Manager (OLM) définit par défaut les ressources de l'espace de noms d'un opérateur dans l'espace de noms de son abonnement.
En tant qu'auteur d'un Opérateur, vous pouvez exprimer un espace de noms cible souhaité dans le cadre de votre version de service de cluster (CSV) afin de garder le contrôle sur les espaces de noms finaux des ressources installées pour leurs Opérateurs. Lorsque vous ajoutez l'opérateur à un cluster en utilisant OperatorHub, cela permet à la console web de remplir automatiquement l'espace de noms suggéré pour l'administrateur du cluster pendant le processus d'installation.
Procédure
Dans votre CSV, définissez l'annotation
operatorframework.io/suggested-namespacesur l'espace de noms suggéré :metadata: annotations: operatorframework.io/suggested-namespace: <namespace>1 - 1
- Définissez l'espace de noms suggéré.
5.7.6. Activation des conditions de l'opérateur
Le gestionnaire du cycle de vie des opérateurs (OLM) fournit aux opérateurs un canal pour communiquer des états complexes qui influencent le comportement d'OLM lors de la gestion de l'opérateur. Par défaut, OLM crée une définition de ressource personnalisée (CRD) OperatorCondition lorsqu'il installe un opérateur. En fonction des conditions définies dans la ressource personnalisée (CR) OperatorCondition, le comportement d'OLM change en conséquence.
Pour prendre en charge les conditions de l'opérateur, celui-ci doit pouvoir lire le CR OperatorCondition créé par OLM et être en mesure d'effectuer les tâches suivantes :
- Obtenir la condition spécifique.
- Définir l'état d'une condition spécifique.
Pour ce faire, il suffit d'utiliser la bibliothèque operator-lib library. L'auteur d'un opérateur peut fournir un clientcontroller-runtime dans son opérateur pour que la bibliothèque puisse accéder au CR OperatorCondition appartenant à l'opérateur dans le cluster.
La bibliothèque fournit une interface générique Conditions, qui possède les méthodes suivantes pour Get et Set une conditionType dans la CR OperatorCondition:
Get-
Pour obtenir la condition spécifique, la bibliothèque utilise la fonction
client.Getdecontroller-runtime, qui nécessite unObjectKeyde typetypes.NamespacedNameprésent dansconditionAccessor. Set-
Pour mettre à jour le statut de la condition spécifique, la bibliothèque utilise la fonction
client.Updatedecontroller-runtime. Une erreur se produit si le siteconditionTypen'est pas présent dans le CRD.
L'opérateur n'est autorisé à modifier que la sous-ressource status du CR. Les opérateurs peuvent soit supprimer, soit mettre à jour le tableau status.conditions pour y inclure la condition. Pour plus de détails sur le format et la description des champs présents dans les conditions, voir les GoDocs des conditions en amont.
Operator SDK v1.10.1 supporte operator-lib v0.3.0.
Conditions préalables
- Un projet Operator généré à l'aide du SDK Operator.
Procédure
Pour activer les conditions de l'opérateur dans votre projet d'opérateur :
Dans le fichier
go.modde votre projet Operator, ajoutezoperator-framework/operator-libcomme bibliothèque requise :module github.com/example-inc/memcached-operator go 1.15 require ( k8s.io/apimachinery v0.19.2 k8s.io/client-go v0.19.2 sigs.k8s.io/controller-runtime v0.7.0 operator-framework/operator-lib v0.3.0 )Écrivez votre propre constructeur dans votre logique d'opérateur qui aboutira aux résultats suivants :
-
Accepte un client
controller-runtime. -
Accepte un
conditionType. -
Renvoie une interface
Conditionpour mettre à jour ou ajouter des conditions.
Comme OLM prend actuellement en charge la condition
Upgradeable, vous pouvez créer une interface comportant des méthodes permettant d'accéder à la conditionUpgradeable. Par exemple, vous pouvez créer une interface avec des méthodes permettant d'accéder à la condition :import ( ... apiv1 "github.com/operator-framework/api/pkg/operators/v1" ) func NewUpgradeable(cl client.Client) (Condition, error) { return NewCondition(cl, "apiv1.OperatorUpgradeable") } cond, err := NewUpgradeable(cl);Dans cet exemple, le constructeur
NewUpgradeableest utilisé pour créer une variablecondde typeCondition. La variablecondpossède à son tour les méthodesGetetSet, qui peuvent être utilisées pour traiter la condition OLMUpgradeable.-
Accepte un client
5.7.7. Définition des webhooks
Les webhooks permettent aux auteurs de l'opérateur d'intercepter, de modifier et d'accepter ou de rejeter des ressources avant qu'elles ne soient enregistrées dans le magasin d'objets et traitées par le contrôleur de l'opérateur. Operator Lifecycle Manager (OLM) peut gérer le cycle de vie de ces webhooks lorsqu'ils sont livrés avec votre opérateur.
La ressource CSV (Cluster Service Version) d'un opérateur peut inclure une section webhookdefinitions pour définir les types de webhooks suivants :
- Admission des webhooks (validation et mutation)
- Crochets web de conversion
Procédure
Ajoutez une section
webhookdefinitionsà la sectionspecdu CSV de votre opérateur et incluez toutes les définitions de webhooks utilisant untypedeValidatingAdmissionWebhook,MutatingAdmissionWebhookouConversionWebhook. L'exemple suivant contient les trois types de webhooks :CSV contenant des webhooks
apiVersion: operators.coreos.com/v1alpha1 kind: ClusterServiceVersion metadata: name: webhook-operator.v0.0.1 spec: customresourcedefinitions: owned: - kind: WebhookTest name: webhooktests.webhook.operators.coreos.io1 version: v1 install: spec: deployments: - name: webhook-operator-webhook ... ... ... strategy: deployment installModes: - supported: false type: OwnNamespace - supported: false type: SingleNamespace - supported: false type: MultiNamespace - supported: true type: AllNamespaces webhookdefinitions: - type: ValidatingAdmissionWebhook2 admissionReviewVersions: - v1beta1 - v1 containerPort: 443 targetPort: 4343 deploymentName: webhook-operator-webhook failurePolicy: Fail generateName: vwebhooktest.kb.io rules: - apiGroups: - webhook.operators.coreos.io apiVersions: - v1 operations: - CREATE - UPDATE resources: - webhooktests sideEffects: None webhookPath: /validate-webhook-operators-coreos-io-v1-webhooktest - type: MutatingAdmissionWebhook3 admissionReviewVersions: - v1beta1 - v1 containerPort: 443 targetPort: 4343 deploymentName: webhook-operator-webhook failurePolicy: Fail generateName: mwebhooktest.kb.io rules: - apiGroups: - webhook.operators.coreos.io apiVersions: - v1 operations: - CREATE - UPDATE resources: - webhooktests sideEffects: None webhookPath: /mutate-webhook-operators-coreos-io-v1-webhooktest - type: ConversionWebhook4 admissionReviewVersions: - v1beta1 - v1 containerPort: 443 targetPort: 4343 deploymentName: webhook-operator-webhook generateName: cwebhooktest.kb.io sideEffects: None webhookPath: /convert conversionCRDs: - webhooktests.webhook.operators.coreos.io5 ...
5.7.7.1. Considérations sur les webhooks pour OLM
Lorsque vous déployez un opérateur avec des webhooks à l'aide d'Operator Lifecycle Manager (OLM), vous devez définir les éléments suivants :
-
Le champ
typedoit être défini surValidatingAdmissionWebhook,MutatingAdmissionWebhook, ouConversionWebhook, sinon le CSV sera placé dans une phase d'échec. -
Le fichier CSV doit contenir un déploiement dont le nom est équivalent à la valeur fournie dans le champ
deploymentNamedu fichierwebhookdefinition.
Lorsque le webhook est créé, OLM veille à ce qu'il n'agisse que sur les espaces de noms qui correspondent au groupe d'opérateurs dans lequel l'opérateur est déployé.
Contraintes de l'autorité de certification
OLM est configuré pour fournir à chaque déploiement une seule autorité de certification (CA). La logique qui génère et monte l'autorité de certification dans le déploiement était à l'origine utilisée par la logique du cycle de vie du service API. En conséquence :
-
Le fichier du certificat TLS est monté sur le déploiement à l'adresse
/apiserver.local.config/certificates/apiserver.crt. -
Le fichier de clés TLS est monté sur le déploiement à l'adresse
/apiserver.local.config/certificates/apiserver.key.
Contraintes liées aux règles d'admission des webhooks
Pour éviter qu'un opérateur ne configure le cluster dans un état irrécupérable, OLM place le CSV dans la phase d'échec si les règles définies dans un webhook d'admission interceptent l'une des demandes suivantes :
- Des demandes qui ciblent tous les groupes
-
Demandes ciblant le groupe
operators.coreos.com -
Demandes ciblant les ressources
ValidatingWebhookConfigurationsouMutatingWebhookConfigurations
Contraintes de conversion des webhooks
OLM place le CSV dans la phase d'échec si la définition d'un webhook de conversion ne respecte pas les contraintes suivantes :
-
Les CSV comportant un webhook de conversion ne peuvent prendre en charge que le mode d'installation
AllNamespaces. -
Le champ
spec.preserveUnknownFieldsdu CRD ciblé par le webhook de conversion doit avoir la valeurfalseounil. - Le webhook de conversion défini dans le CSV doit cibler un CRD appartenant à l'entreprise.
- Il ne peut y avoir qu'un seul webhook de conversion sur l'ensemble du cluster pour un CRD donné.
5.7.8. Comprendre les définitions de ressources personnalisées (CRD)
Il existe deux types de définitions de ressources personnalisées (CRD) que votre opérateur peut utiliser : celles qu'il utilise à l'adresse owned et celles dont il dépend à l'adresse required.
5.7.8.1. CRD détenus
Les définitions de ressources personnalisées (CRD) appartenant à votre opérateur constituent la partie la plus importante de votre CSV. Elles établissent le lien entre votre opérateur et les règles RBAC requises, la gestion des dépendances et d'autres concepts Kubernetes.
Il est courant que votre opérateur utilise plusieurs CRD pour relier des concepts, tels que la configuration de la base de données de premier niveau dans un objet et une représentation des ensembles de répliques dans un autre. Chacun d'entre eux doit être répertorié dans le fichier CSV.
| Field | Description | Obligatoire/facultatif |
|---|---|---|
|
| Le nom complet de votre CRD. | Exigée |
|
| La version de cet objet API. | Exigée |
|
| Le nom lisible par machine de votre CRD. | Exigée |
|
|
Une version lisible de votre nom de CRD, par exemple | Exigée |
|
| Une brève description de l'utilisation de ce CRD par l'opérateur ou une description de la fonctionnalité fournie par le CRD. | Exigée |
|
|
Le groupe API auquel appartient ce CRD, par exemple | En option |
|
|
Vos CRD possèdent un ou plusieurs types d'objets Kubernetes. Ceux-ci sont répertoriés dans la section Il est recommandé de ne répertorier que les objets qui sont importants pour un être humain, et non pas une liste exhaustive de tout ce que vous orchestrez. Par exemple, ne listez pas les cartes de configuration qui stockent un état interne qui n'est pas censé être modifié par un utilisateur. | En option |
|
| Ces descripteurs sont un moyen d'indiquer aux interfaces utilisateur certaines entrées ou sorties de votre opérateur qui sont les plus importantes pour l'utilisateur final. Si votre CRD contient le nom d'un secret ou d'une carte de configuration que l'utilisateur doit fournir, vous pouvez le spécifier ici. Ces éléments sont liés et mis en évidence dans les interfaces utilisateur compatibles. Il existe trois types de descripteurs :
Tous les descripteurs acceptent les champs suivants :
Voir également le projet openshift/console pour plus d'informations sur les descripteurs en général. | En option |
L'exemple suivant décrit un CRD MongoDB Standalone qui nécessite une entrée utilisateur sous la forme d'un secret et d'une carte de configuration, et qui orchestre des services, des ensembles avec état, des pods et des cartes de configuration :
Exemple de CRD détenu
- displayName: MongoDB Standalone
group: mongodb.com
kind: MongoDbStandalone
name: mongodbstandalones.mongodb.com
resources:
- kind: Service
name: ''
version: v1
- kind: StatefulSet
name: ''
version: v1beta2
- kind: Pod
name: ''
version: v1
- kind: ConfigMap
name: ''
version: v1
specDescriptors:
- description: Credentials for Ops Manager or Cloud Manager.
displayName: Credentials
path: credentials
x-descriptors:
- 'urn:alm:descriptor:com.tectonic.ui:selector:core:v1:Secret'
- description: Project this deployment belongs to.
displayName: Project
path: project
x-descriptors:
- 'urn:alm:descriptor:com.tectonic.ui:selector:core:v1:ConfigMap'
- description: MongoDB version to be installed.
displayName: Version
path: version
x-descriptors:
- 'urn:alm:descriptor:com.tectonic.ui:label'
statusDescriptors:
- description: The status of each of the pods for the MongoDB cluster.
displayName: Pod Status
path: pods
x-descriptors:
- 'urn:alm:descriptor:com.tectonic.ui:podStatuses'
version: v1
description: >-
MongoDB Deployment consisting of only one host. No replication of
data.5.7.8.2. CRDs requis
Le recours à d'autres CRD obligatoires est totalement facultatif et n'existe que pour réduire la portée des opérateurs individuels et fournir un moyen de composer plusieurs opérateurs ensemble pour résoudre un cas d'utilisation de bout en bout.
Par exemple, un opérateur peut configurer une application et installer un cluster etcd (provenant d'un opérateur etcd) pour le verrouillage distribué et une base de données Postgres (provenant d'un opérateur Postgres) pour le stockage des données.
Operator Lifecycle Manager (OLM) vérifie que les CRD et les opérateurs disponibles dans le cluster répondent à ces exigences. Si des versions appropriées sont trouvées, les opérateurs sont démarrés dans l'espace de noms souhaité et un compte de service est créé pour chaque opérateur afin de créer, surveiller et modifier les ressources Kubernetes requises.
| Field | Description | Obligatoire/facultatif |
|---|---|---|
|
| Le nom complet du CRD dont vous avez besoin. | Exigée |
|
| La version de cet objet API. | Exigée |
|
| Le type d'objet Kubernetes. | Exigée |
|
| Une version du CRD lisible par l'homme. | Exigée |
|
| Un résumé de la manière dont le composant s'intègre dans votre architecture globale. | Exigée |
Exemple de CRD requis
required:
- name: etcdclusters.etcd.database.coreos.com
version: v1beta2
kind: EtcdCluster
displayName: etcd Cluster
description: Represents a cluster of etcd nodes.5.7.8.3. Améliorations du CRD
OLM met à niveau une définition de ressource personnalisée (CRD) immédiatement si elle appartient à une seule version de service de cluster (CSV). Si une CRD appartient à plusieurs CSV, elle est mise à niveau lorsqu'elle remplit toutes les conditions de compatibilité ascendante suivantes :
- Toutes les versions de service existantes dans le CRD actuel sont présentes dans le nouveau CRD.
- Toutes les instances existantes, ou les ressources personnalisées, qui sont associées aux versions de service du document de référence sont valides lorsqu'elles sont validées par rapport au schéma de validation du nouveau document de référence.
5.7.8.3.1. Ajouter une nouvelle version du CRD
Procédure
Pour ajouter une nouvelle version d'un CRD à votre opérateur :
Ajoutez une nouvelle entrée dans la ressource CRD sous la section
versionsde votre CSV.Par exemple, si le CRD actuel a une version
v1alpha1et que vous souhaitez ajouter une nouvelle versionv1beta1et la marquer comme la nouvelle version de stockage, ajoutez une nouvelle entrée pourv1beta1:versions: - name: v1alpha1 served: true storage: false - name: v1beta11 served: true storage: true- 1
- Nouvelle entrée.
Veillez à ce que la version de référence du CRD dans la section
ownedde votre CSV soit mise à jour si le CSV a l'intention d'utiliser la nouvelle version :customresourcedefinitions: owned: - name: cluster.example.com version: v1beta11 kind: cluster displayName: Cluster- 1
- Mettre à jour le site
version.
- Transférez le CRD et le CSV mis à jour vers votre bundle.
5.7.8.3.2. Déclassement ou suppression d'une version du CRD
Operator Lifecycle Manager (OLM) ne permet pas de supprimer immédiatement une version en service d'une définition de ressource personnalisée (CRD). Au lieu de cela, une version obsolète du CRD doit d'abord être désactivée en définissant le champ served du CRD sur false. Ensuite, la version non servante peut être supprimée lors de la mise à niveau ultérieure du CRD.
Procédure
Déclasser et supprimer une version spécifique d'un CRD :
Marquez la version obsolète comme n'étant pas utile pour indiquer que cette version n'est plus utilisée et qu'elle peut être supprimée lors d'une mise à jour ultérieure. Par exemple :
versions: - name: v1alpha1 served: false1 storage: true- 1
- Régler sur
false.
Passer de la version
storageà une version de service si la version à supprimer est actuellement la versionstorage. Par exemple :versions: - name: v1alpha1 served: false storage: false1 - name: v1beta1 served: true storage: true2 NotePour supprimer d'un CRD une version spécifique qui est ou était la version
storage, cette version doit être supprimée destoredVersiondans le statut du CRD. OLM tentera de le faire pour vous s'il détecte qu'une version stockée n'existe plus dans le nouveau CRD.- Mettre à jour le CRD avec les modifications ci-dessus.
Lors des cycles de mise à niveau ultérieurs, la version qui ne sert pas peut être complètement supprimée du document de référence. Par exemple :
versions: - name: v1beta1 served: true storage: true-
Veillez à ce que la version du CRD de référence dans la section
ownedde votre CSV soit mise à jour en conséquence si cette version est retirée du CRD.
5.7.8.4. Modèles de CRD
Les utilisateurs de votre opérateur doivent savoir quelles options sont obligatoires ou facultatives. Vous pouvez fournir des modèles pour chacune de vos définitions de ressources personnalisées (CRD) avec un ensemble minimum de configurations sous la forme d'une annotation nommée alm-examples. Les interfaces utilisateur compatibles rempliront ce modèle à l'avance pour que les utilisateurs puissent le personnaliser davantage.
L'annotation consiste en une liste du type, par exemple, le nom du CRD et les adresses metadata et spec correspondantes de l'objet Kubernetes.
L'exemple complet suivant fournit des modèles pour EtcdCluster, EtcdBackup et EtcdRestore:
metadata:
annotations:
alm-examples: >-
[{"apiVersion":"etcd.database.coreos.com/v1beta2","kind":"EtcdCluster","metadata":{"name":"example","namespace":"default"},"spec":{"size":3,"version":"3.2.13"}},{"apiVersion":"etcd.database.coreos.com/v1beta2","kind":"EtcdRestore","metadata":{"name":"example-etcd-cluster"},"spec":{"etcdCluster":{"name":"example-etcd-cluster"},"backupStorageType":"S3","s3":{"path":"<full-s3-path>","awsSecret":"<aws-secret>"}}},{"apiVersion":"etcd.database.coreos.com/v1beta2","kind":"EtcdBackup","metadata":{"name":"example-etcd-cluster-backup"},"spec":{"etcdEndpoints":["<etcd-cluster-endpoints>"],"storageType":"S3","s3":{"path":"<full-s3-path>","awsSecret":"<aws-secret>"}}}]5.7.8.5. Masquage des objets internes
Il est courant que les opérateurs utilisent des définitions de ressources personnalisées (CRD) en interne pour accomplir une tâche. Ces objets ne sont pas destinés à être manipulés par les utilisateurs et peuvent prêter à confusion pour les utilisateurs de l'opérateur. Par exemple, un opérateur de base de données peut avoir un CRD Replication qui est créé chaque fois qu'un utilisateur crée un objet Base de données avec replication: true.
En tant qu'auteur d'un opérateur, vous pouvez masquer dans l'interface utilisateur les CRD qui ne sont pas destinés à être manipulés par l'utilisateur en ajoutant l'annotation operators.operatorframework.io/internal-objects à la version du service de cluster (CSV) de votre opérateur.
Procédure
-
Avant de marquer l'un de vos CRD comme interne, assurez-vous que les informations de débogage ou la configuration éventuellement nécessaires pour gérer l'application sont reflétées dans le statut ou le bloc
specde votre CR, si cela s'applique à votre opérateur. Ajoutez l'annotation
operators.operatorframework.io/internal-objectsau CSV de votre opérateur pour spécifier les objets internes à cacher dans l'interface utilisateur :Annotation d'un objet interne
apiVersion: operators.coreos.com/v1alpha1 kind: ClusterServiceVersion metadata: name: my-operator-v1.2.3 annotations: operators.operatorframework.io/internal-objects: '["my.internal.crd1.io","my.internal.crd2.io"]'1 ...- 1
- Définir tout CRD interne comme un tableau de chaînes de caractères.
5.7.8.6. Initialisation des ressources personnalisées requises
Un opérateur peut exiger de l'utilisateur qu'il instancie une ressource personnalisée avant que l'opérateur ne soit pleinement fonctionnel. Cependant, il peut être difficile pour un utilisateur de déterminer ce qui est nécessaire ou comment définir la ressource.
En tant que développeur Operator, vous pouvez spécifier une seule ressource personnalisée requise en ajoutant operatorframework.io/initialization-resource à la version du service de cluster (CSV) lors de l'installation d'Operator. Vous êtes alors invité à créer la ressource personnalisée à l'aide d'un modèle fourni dans la CSV. L'annotation doit inclure un modèle qui contient une définition YAML complète nécessaire pour initialiser la ressource lors de l'installation.
Si cette annotation est définie, après avoir installé l'opérateur à partir de la console web d'OpenShift Container Platform, l'utilisateur est invité à créer la ressource en utilisant le modèle fourni dans le CSV.
Procédure
Ajoutez l'annotation
operatorframework.io/initialization-resourceau CSV de votre opérateur pour spécifier une ressource personnalisée requise. Par exemple, l'annotation suivante exige la création d'une ressourceStorageClusteret fournit une définition YAML complète :Annotation de la ressource d'initialisation
apiVersion: operators.coreos.com/v1alpha1 kind: ClusterServiceVersion metadata: name: my-operator-v1.2.3 annotations: operatorframework.io/initialization-resource: |- { "apiVersion": "ocs.openshift.io/v1", "kind": "StorageCluster", "metadata": { "name": "example-storagecluster" }, "spec": { "manageNodes": false, "monPVCTemplate": { "spec": { "accessModes": [ "ReadWriteOnce" ], "resources": { "requests": { "storage": "10Gi" } }, "storageClassName": "gp2" } }, "storageDeviceSets": [ { "count": 3, "dataPVCTemplate": { "spec": { "accessModes": [ "ReadWriteOnce" ], "resources": { "requests": { "storage": "1Ti" } }, "storageClassName": "gp2", "volumeMode": "Block" } }, "name": "example-deviceset", "placement": {}, "portable": true, "resources": {} } ] } } ...
5.7.9. Comprendre vos services API
Comme pour les CRD, il existe deux types de services API que votre opérateur peut utiliser : owned et required.
5.7.9.1. Services API propres
Lorsqu'un CSV possède un service API, il est responsable de la description du déploiement de l'extension api-server qui le soutient et du groupe/version/genre (GVK) qu'il fournit.
Un service API est identifié de manière unique par le groupe/la version qu'il fournit et peut être listé plusieurs fois pour indiquer les différents types de services qu'il est censé fournir.
| Field | Description | Obligatoire/facultatif |
|---|---|---|
|
|
Groupe que le service API fournit, par exemple | Exigée |
|
|
Version du service API, par exemple | Exigée |
|
| Type de service que le service API est censé fournir. | Exigée |
|
| Le nom pluriel du service API fourni. | Exigée |
|
|
Nom du déploiement défini par votre CSV qui correspond à votre service API (requis pour les services API détenus). Pendant la phase d'attente du CSV, l'opérateur OLM recherche sur le site | Exigée |
|
|
Une version lisible du nom de votre service API, par exemple | Exigée |
|
| Une brève description de la manière dont ce service API est utilisé par l'opérateur ou une description de la fonctionnalité fournie par le service API. | Exigée |
|
| Vos services API possèdent un ou plusieurs types d'objets Kubernetes. Ceux-ci sont répertoriés dans la section des ressources afin d'informer vos utilisateurs des objets dont ils pourraient avoir besoin pour dépanner ou pour se connecter à l'application, comme le service ou la règle d'entrée qui expose une base de données. Il est recommandé de ne répertorier que les objets qui sont importants pour un être humain, et non pas une liste exhaustive de tout ce que vous orchestrez. Par exemple, ne listez pas les cartes de configuration qui stockent un état interne qui n'est pas censé être modifié par un utilisateur. | En option |
|
| Essentiellement la même chose que pour les CRD détenus. | En option |
5.7.9.1.1. Création d'une ressource de service API
Le gestionnaire du cycle de vie de l'opérateur (OLM) est chargé de créer ou de remplacer le service et les ressources du service API pour chaque service API unique appartenant à l'opérateur :
-
Les sélecteurs de pods de service sont copiés à partir du déploiement CSV correspondant au champ
DeploymentNamede la description du service API. - Une nouvelle paire clé/certificat d'autorité de certification est générée pour chaque installation et le paquet d'autorités de certification codé en base64 est incorporé dans la ressource de service API correspondante.
5.7.9.1.2. Service API servant des certificats
OLM se charge de la génération d'une paire clé/certificat de service lors de l'installation d'un service API appartenant à l'utilisateur. Le certificat de service a un nom commun (CN) contenant le nom d'hôte de la ressource Service générée et est signé par la clé privée de la liasse CA intégrée dans la ressource de service API correspondante.
Le certificat est stocké en tant que secret de type kubernetes.io/tls dans l'espace de noms du déploiement, et un volume nommé apiservice-cert est automatiquement ajouté à la section des volumes du déploiement dans le CSV correspondant au champ DeploymentName de la description du service API.
S'il n'existe pas encore, un montage de volume avec un nom correspondant est également ajouté à tous les conteneurs de ce déploiement. Cela permet aux utilisateurs de définir un montage de volume avec le nom attendu pour répondre à toute exigence de chemin d'accès personnalisé. Le chemin du montage de volume généré est par défaut /apiserver.local.config/certificates et tous les montages de volume existants ayant le même chemin sont remplacés.
5.7.9.2. Required API services
OLM s'assure que tous les CSV requis disposent d'un service API disponible et que tous les GVK attendus peuvent être découverts avant de tenter l'installation. Cela permet à un CSV de s'appuyer sur des types spécifiques fournis par des services API qu'il ne possède pas.
| Field | Description | Obligatoire/facultatif |
|---|---|---|
|
|
Groupe que le service API fournit, par exemple | Exigée |
|
|
Version du service API, par exemple | Exigée |
|
| Type de service que le service API est censé fournir. | Exigée |
|
|
Une version lisible du nom de votre service API, par exemple | Exigée |
|
| Une brève description de la manière dont ce service API est utilisé par l'opérateur ou une description de la fonctionnalité fournie par le service API. | Exigée |
5.8. Travailler avec des images groupées
Vous pouvez utiliser l'Operator SDK pour emballer, déployer et mettre à niveau les opérateurs dans le format bundle à utiliser sur Operator Lifecycle Manager (OLM).
5.8.1. Regroupement d'un opérateur
Le format Operator bundle est la méthode d'emballage par défaut pour Operator SDK et Operator Lifecycle Manager (OLM). Vous pouvez préparer votre Operator pour une utilisation sur OLM en utilisant Operator SDK pour construire et pousser votre projet Operator en tant qu'image groupée.
Conditions préalables
- Operator SDK CLI installé sur un poste de développement
-
OpenShift CLI (
oc) v4.12 installé - Projet d'opérateur initialisé à l'aide de l'Operator SDK
- Si votre opérateur est basé sur Go, votre projet doit être mis à jour pour utiliser les images prises en charge pour fonctionner sur OpenShift Container Platform
Procédure
Exécutez les commandes
makesuivantes dans le répertoire de votre projet Operator pour construire et pousser votre image Operator. Modifiez l'argumentIMGdans les étapes suivantes pour référencer un référentiel auquel vous avez accès. Vous pouvez obtenir un compte pour stocker des conteneurs sur des sites de dépôt tels que Quay.io.Construire l'image :
$ make docker-build IMG=<registry>/<user>/<operator_image_name>:<tag>NoteLe fichier Docker généré par le SDK pour l'Operator fait explicitement référence à
GOARCH=amd64pourgo build. Cette référence peut être modifiée enGOARCH=$TARGETARCHpour les architectures non-AMD64. Docker définira automatiquement la variable d'environnement à la valeur spécifiée par–platform. Avec Buildah, il faudra utiliser–build-argà cette fin. Pour plus d'informations, voir Architectures multiples.Transférer l'image dans un référentiel :
$ make docker-push IMG=<registry>/<user>/<operator_image_name>:<tag>
Créez votre manifeste Operator bundle en exécutant la commande
make bundle, qui invoque plusieurs commandes, dont les sous-commandes Operator SDKgenerate bundleetbundle validate:$ make bundle IMG=<registry>/<user>/<operator_image_name>:<tag>Les manifestes de l'offre groupée d'un opérateur décrivent la manière d'afficher, de créer et de gérer une application. La commande
make bundlecrée les fichiers et répertoires suivants dans votre projet Operator :-
Un répertoire bundle manifests nommé
bundle/manifestsqui contient un objetClusterServiceVersion -
Un répertoire de métadonnées de la liasse nommé
bundle/metadata -
Toutes les définitions de ressources personnalisées (CRD) dans un répertoire
config/crd -
Un fichier Docker
bundle.Dockerfile
Ces fichiers sont ensuite automatiquement validés à l'aide de
operator-sdk bundle validateafin de s'assurer que la représentation du paquet sur le disque est correcte.-
Un répertoire bundle manifests nommé
Construisez et poussez votre image de bundle en exécutant les commandes suivantes. OLM consomme les liasses d'opérateurs à l'aide d'une image d'index, qui fait référence à une ou plusieurs images de liasses.
Créez l'image de l'ensemble. Définissez
BUNDLE_IMGavec les détails du registre, de l'espace de noms de l'utilisateur et de la balise d'image où vous avez l'intention de pousser l'image :$ make bundle-build BUNDLE_IMG=<registry>/<user>/<bundle_image_name>:<tag>Pousser l'image de la liasse :
$ docker push <registry>/<user>/<bundle_image_name>:<tag>
5.8.2. Déploiement d'un opérateur avec Operator Lifecycle Manager
Operator Lifecycle Manager (OLM) vous aide à installer, mettre à jour et gérer le cycle de vie des opérateurs et de leurs services associés sur un cluster Kubernetes. OLM est installé par défaut sur OpenShift Container Platform et s'exécute en tant qu'extension Kubernetes afin que vous puissiez utiliser la console web et l'OpenShift CLI (oc) pour toutes les fonctions de gestion du cycle de vie des opérateurs sans outils supplémentaires.
Le format Operator bundle est la méthode d'emballage par défaut pour Operator SDK et OLM. Vous pouvez utiliser Operator SDK pour exécuter rapidement une image de bundle sur OLM afin de vous assurer qu'elle fonctionne correctement.
Conditions préalables
- Operator SDK CLI installé sur un poste de développement
- L'image de l'ensemble de l'opérateur est construite et poussée vers un registre
-
OLM installé sur un cluster basé sur Kubernetes (v1.16.0 ou version ultérieure si vous utilisez
apiextensions.k8s.io/v1CRD, par exemple OpenShift Container Platform 4.12) -
Connexion au cluster avec
ocen utilisant un compte avec les permissions decluster-admin - Si votre opérateur est basé sur Go, votre projet doit être mis à jour pour utiliser les images prises en charge pour fonctionner sur OpenShift Container Platform
Procédure
Saisissez la commande suivante pour exécuter l'opérateur sur le cluster :
$ operator-sdk run bundle \1 -n <namespace> \2 <registry>/<user>/<bundle_image_name>:<tag>3 - 1
- La commande
run bundlecrée un catalogue de fichiers valide et installe le paquet Operator sur votre cluster à l'aide d'OLM. - 2
- Facultatif : Par défaut, la commande installe l'opérateur dans le projet actif dans votre fichier
~/.kube/config. Vous pouvez ajouter l'option-npour définir un espace de noms différent pour l'installation. - 3
- Si vous ne spécifiez pas d'image, la commande utilise
quay.io/operator-framework/opm:latestcomme image d'index par défaut. Si vous spécifiez une image, la commande utilise l'image du paquet elle-même comme image d'index.
ImportantDepuis OpenShift Container Platform 4.11, la commande
run bundleprend en charge par défaut le format de catalogue basé sur des fichiers pour les catalogues Operator. Le format de base de données SQLite déprécié pour les catalogues Operator continue d'être pris en charge ; cependant, il sera supprimé dans une prochaine version. Il est recommandé aux auteurs d'Operator de migrer leurs flux de travail vers le format de catalogue basé sur des fichiers.Cette commande permet d'effectuer les actions suivantes :
- Créez une image d'index faisant référence à votre image de liasse. L'image d'index est opaque et éphémère, mais elle reflète fidèlement la manière dont un paquet serait ajouté à un catalogue en production.
- Créez une source de catalogue qui pointe vers votre nouvelle image d'index, ce qui permet à OperatorHub de découvrir votre opérateur.
-
Déployez votre opérateur sur votre cluster en créant un site
OperatorGroup,Subscription,InstallPlan, et toutes les autres ressources nécessaires, y compris RBAC.
5.8.3. Publication d'un catalogue contenant un opérateur groupé
Pour installer et gérer les opérateurs, Operator Lifecycle Manager (OLM) exige que les bundles d'opérateurs soient répertoriés dans une image d'index, qui est référencée par un catalogue sur le cluster. En tant qu'auteur d'un opérateur, vous pouvez utiliser le SDK de l'opérateur pour créer un index contenant le bundle de votre opérateur et toutes ses dépendances. Ceci est utile pour tester sur des clusters distants et pour publier dans les registres de conteneurs.
L'Operator SDK utilise le CLI opm pour faciliter la création d'images d'index. Il n'est pas nécessaire d'avoir une expérience de la commande opm. Pour les cas d'utilisation avancés, la commande opm peut être utilisée directement au lieu de l'Operator SDK.
Conditions préalables
- Operator SDK CLI installé sur un poste de développement
- L'image de l'ensemble de l'opérateur est construite et poussée vers un registre
-
OLM installé sur un cluster basé sur Kubernetes (v1.16.0 ou version ultérieure si vous utilisez
apiextensions.k8s.io/v1CRD, par exemple OpenShift Container Platform 4.12) -
Connexion au cluster avec
ocen utilisant un compte avec les permissions decluster-admin
Procédure
Exécutez la commande suivante
makedans le répertoire de votre projet Operator pour créer une image d'indexation contenant votre bundle Operator :$ make catalog-build CATALOG_IMG=<registry>/<user>/<index_image_name>:<tag>où l'argument
CATALOG_IMGfait référence à un dépôt auquel vous avez accès. Vous pouvez obtenir un compte pour stocker des conteneurs sur des sites de dépôt tels que Quay.io.Pousser l'image de l'index construit vers un référentiel :
$ make catalog-push CATALOG_IMG=<registry>/<user>/<index_image_name>:<tag>AstuceVous pouvez utiliser les commandes Operator SDK
makeensemble si vous préférez effectuer plusieurs actions en séquence à la fois. Par exemple, si vous n'avez pas encore construit d'image bundle pour votre projet Operator, vous pouvez construire et pousser à la fois une image bundle et une image index avec la syntaxe suivante :$ make bundle-build bundle-push catalog-build catalog-push \ BUNDLE_IMG=<bundle_image_pull_spec> \ CATALOG_IMG=<index_image_pull_spec>Vous pouvez également définir le champ
IMAGE_TAG_BASEdans votreMakefileen fonction d'un référentiel existant :IMAGE_TAG_BASE=quay.io/example/my-operatorVous pouvez ensuite utiliser la syntaxe suivante pour construire et pousser des images avec des noms générés automatiquement, tels que
quay.io/example/my-operator-bundle:v0.0.1pour l'image bundle etquay.io/example/my-operator-catalog:v0.0.1pour l'image index :$ make bundle-build bundle-push catalog-build catalog-pushDéfinissez un objet
CatalogSourcequi fait référence à l'image d'index que vous venez de générer, puis créez l'objet à l'aide de la commandeoc applyou de la console web :Exemple
CatalogSourceYAMLapiVersion: operators.coreos.com/v1alpha1 kind: CatalogSource metadata: name: cs-memcached namespace: default spec: displayName: My Test publisher: Company sourceType: grpc grpcPodConfig: securityContextConfig: <security_mode>1 image: quay.io/example/memcached-catalog:v0.0.12 updateStrategy: registryPoll: interval: 10m- 1
- Spécifiez la valeur de
legacyourestricted. Si le champ n'est pas défini, la valeur par défaut estlegacy. Dans une prochaine version d'OpenShift Container Platform, il est prévu que la valeur par défaut soitrestricted. Si votre catalogue ne peut pas s'exécuter avec les autorisationsrestricted, il est recommandé de définir manuellement ce champ surlegacy. - 2
- Définissez
imagecomme la spécification de tirage d'image que vous avez utilisée précédemment avec l'argumentCATALOG_IMG.
Vérifier la source du catalogue :
$ oc get catalogsourceExemple de sortie
NAME DISPLAY TYPE PUBLISHER AGE cs-memcached My Test grpc Company 4h31m
Vérification
Installez l'opérateur à l'aide de votre catalogue :
Définissez un objet
OperatorGroupet créez-le à l'aide de la commandeoc applyou de la console web :Exemple
OperatorGroupYAMLapiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: my-test namespace: default spec: targetNamespaces: - defaultDéfinissez un objet
Subscriptionet créez-le à l'aide de la commandeoc applyou de la console web :Exemple
SubscriptionYAMLapiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: catalogtest namespace: default spec: channel: "alpha" installPlanApproval: Manual name: catalog source: cs-memcached sourceNamespace: default startingCSV: memcached-operator.v0.0.1
Vérifiez que l'opérateur installé fonctionne :
Vérifier le groupe d'opérateurs :
$ oc get ogExemple de sortie
NAME AGE my-test 4h40mVérifiez la version du service de cluster (CSV) :
$ oc get csvExemple de sortie
NAME DISPLAY VERSION REPLACES PHASE memcached-operator.v0.0.1 Test 0.0.1 SucceededVérifier la présence de l'opérateur dans les nacelles :
$ oc get podsExemple de sortie
NAME READY STATUS RESTARTS AGE 9098d908802769fbde8bd45255e69710a9f8420a8f3d814abe88b68f8ervdj6 0/1 Completed 0 4h33m catalog-controller-manager-7fd5b7b987-69s4n 2/2 Running 0 4h32m cs-memcached-7622r 1/1 Running 0 4h33m
5.8.4. Test d'une mise à niveau d'un opérateur sur Operator Lifecycle Manager
Vous pouvez rapidement tester la mise à niveau de votre opérateur en utilisant l'intégration d'Operator Lifecycle Manager (OLM) dans le SDK de l'opérateur, sans avoir à gérer manuellement les images d'index et les sources de catalogue.
La sous-commande run bundle-upgrade automatise le déclenchement de la mise à niveau d'un opérateur installé vers une version ultérieure en spécifiant une image de bundle pour la version ultérieure.
Conditions préalables
-
Opérateur installé avec OLM soit par la sous-commande
run bundle, soit par l'installation traditionnelle d'OLM - Une image de paquet qui représente une version ultérieure de l'opérateur installé
Procédure
Si votre opérateur n'a pas encore été installé avec OLM, installez la version antérieure soit en utilisant la sous-commande
run bundle, soit en procédant à une installation traditionnelle d'OLM.NoteSi la version précédente de l'ensemble a été installée traditionnellement à l'aide d'OLM, l'ensemble plus récent vers lequel vous souhaitez effectuer la mise à niveau ne doit pas exister dans l'image d'index référencée par la source du catalogue. Sinon, l'exécution de la sous-commande
run bundle-upgradeentraînera l'échec du pod de registre, car l'ensemble plus récent est déjà référencé par l'index qui fournit le package et la version du service de cluster (CSV).Par exemple, vous pouvez utiliser la sous-commande
run bundlesuivante pour un opérateur Memcached en spécifiant l'image du bundle précédent :$ operator-sdk run bundle <registry>/<user>/memcached-operator:v0.0.1Exemple de sortie
INFO[0006] Creating a File-Based Catalog of the bundle "quay.io/demo/memcached-operator:v0.0.1" INFO[0008] Generated a valid File-Based Catalog INFO[0012] Created registry pod: quay-io-demo-memcached-operator-v1-0-1 INFO[0012] Created CatalogSource: memcached-operator-catalog INFO[0012] OperatorGroup "operator-sdk-og" created INFO[0012] Created Subscription: memcached-operator-v0-0-1-sub INFO[0015] Approved InstallPlan install-h9666 for the Subscription: memcached-operator-v0-0-1-sub INFO[0015] Waiting for ClusterServiceVersion "my-project/memcached-operator.v0.0.1" to reach 'Succeeded' phase INFO[0015] Waiting for ClusterServiceVersion ""my-project/memcached-operator.v0.0.1" to appear INFO[0026] Found ClusterServiceVersion "my-project/memcached-operator.v0.0.1" phase: Pending INFO[0028] Found ClusterServiceVersion "my-project/memcached-operator.v0.0.1" phase: Installing INFO[0059] Found ClusterServiceVersion "my-project/memcached-operator.v0.0.1" phase: Succeeded INFO[0059] OLM has successfully installed "memcached-operator.v0.0.1"Mettez à niveau l'opérateur installé en spécifiant l'image du paquet pour la version la plus récente de l'opérateur :
$ operator-sdk run bundle-upgrade <registry>/<user>/memcached-operator:v0.0.2Exemple de sortie
INFO[0002] Found existing subscription with name memcached-operator-v0-0-1-sub and namespace my-project INFO[0002] Found existing catalog source with name memcached-operator-catalog and namespace my-project INFO[0008] Generated a valid Upgraded File-Based Catalog INFO[0009] Created registry pod: quay-io-demo-memcached-operator-v0-0-2 INFO[0009] Updated catalog source memcached-operator-catalog with address and annotations INFO[0010] Deleted previous registry pod with name "quay-io-demo-memcached-operator-v0-0-1" INFO[0041] Approved InstallPlan install-gvcjh for the Subscription: memcached-operator-v0-0-1-sub INFO[0042] Waiting for ClusterServiceVersion "my-project/memcached-operator.v0.0.2" to reach 'Succeeded' phase INFO[0019] Found ClusterServiceVersion "my-project/memcached-operator.v0.0.2" phase: Pending INFO[0042] Found ClusterServiceVersion "my-project/memcached-operator.v0.0.2" phase: InstallReady INFO[0043] Found ClusterServiceVersion "my-project/memcached-operator.v0.0.2" phase: Installing INFO[0044] Found ClusterServiceVersion "my-project/memcached-operator.v0.0.2" phase: Succeeded INFO[0044] Successfully upgraded to "memcached-operator.v0.0.2"Nettoyer les opérateurs installés :
$ operator-sdk cleanup memcached-operator
5.8.5. Contrôle de la compatibilité des opérateurs avec les versions d'OpenShift Container Platform
Kubernetes déprécie périodiquement certaines API qui sont supprimées dans les versions ultérieures. Si votre opérateur utilise une API obsolète, il se peut qu'il ne fonctionne plus après la mise à niveau du cluster OpenShift Container Platform vers la version de Kubernetes dans laquelle l'API a été supprimée.
En tant qu'auteur d'un Operator, il est fortement recommandé de consulter le Deprecated API Migration Guide dans la documentation Kubernetes et de maintenir vos projets Operator à jour afin d'éviter d'utiliser des API dépréciées et supprimées. Idéalement, vous devriez mettre à jour votre Operator avant la sortie d'une future version d'OpenShift Container Platform qui rendrait l'Operator incompatible.
Lorsqu'une API est supprimée d'une version d'OpenShift Container Platform, les opérateurs fonctionnant sur cette version de cluster qui utilisent encore les API supprimées ne fonctionneront plus correctement. En tant qu'auteur d'un opérateur, vous devez planifier la mise à jour de vos projets d'opérateurs pour tenir compte de la dépréciation et de la suppression des API afin d'éviter les interruptions pour les utilisateurs de votre opérateur.
Vous pouvez consulter les alertes d'événements de vos opérateurs pour savoir s'il existe des avertissements concernant les API actuellement utilisées. Les alertes suivantes se déclenchent lorsqu'elles détectent une API en cours d'utilisation qui sera supprimée dans la prochaine version :
APIRemovedInNextReleaseInUse- APIs qui seront supprimées dans la prochaine version d'OpenShift Container Platform.
APIRemovedInNextEUSReleaseInUse- APIs qui seront supprimées dans la prochaine version d'OpenShift Container Platform Extended Update Support (EUS).
Si un administrateur de cluster a installé votre Operator, avant de passer à la version suivante d'OpenShift Container Platform, il doit s'assurer qu'une version de votre Operator compatible avec la version suivante du cluster est installée. Bien qu'il soit recommandé de mettre à jour vos projets Operator pour ne plus utiliser les API dépréciées ou supprimées, si vous avez toujours besoin de publier vos bundles Operator avec des API supprimées pour continuer à les utiliser sur des versions antérieures d'OpenShift Container Platform, assurez-vous que le bundle est configuré en conséquence.
La procédure suivante permet d'éviter que les administrateurs n'installent des versions de votre opérateur sur une version incompatible d'OpenShift Container Platform. Ces étapes empêchent également les administrateurs de passer à une version plus récente d'OpenShift Container Platform qui est incompatible avec la version de votre opérateur actuellement installée sur leur cluster.
Cette procédure est également utile lorsque vous savez que la version actuelle de votre Opérateur ne fonctionnera pas bien, pour une raison quelconque, sur une version spécifique d'OpenShift Container Platform. En définissant les versions de cluster où l'Opérateur doit être distribué, vous vous assurez que l'Opérateur n'apparaît pas dans un catalogue d'une version de cluster qui est en dehors de la plage autorisée.
Les opérateurs qui utilisent des API obsolètes peuvent avoir un impact négatif sur les charges de travail critiques lorsque les administrateurs de clusters passent à une version future d'OpenShift Container Platform où l'API n'est plus prise en charge. Si votre opérateur utilise des API obsolètes, vous devez configurer les paramètres suivants dans votre projet d'opérateur dès que possible.
Conditions préalables
- Un projet existant de l'opérateur
Procédure
Si vous savez qu'un bundle spécifique de votre Operator n'est pas pris en charge et ne fonctionnera pas correctement sur OpenShift Container Platform après une certaine version de cluster, configurez la version maximale d'OpenShift Container Platform avec laquelle votre Operator est compatible. Dans la version de service de cluster (CSV) de votre projet Operator, définissez l'annotation
olm.maxOpenShiftVersionpour empêcher les administrateurs de mettre à niveau leur cluster avant de mettre à niveau l'Operator installé vers une version compatible :ImportantVous ne devez utiliser l'annotation
olm.maxOpenShiftVersionque si la version de votre Operator bundle ne peut pas fonctionner dans les versions ultérieures. Sachez que les administrateurs de clusters ne peuvent pas mettre à niveau leurs clusters avec votre solution installée. Si vous ne fournissez pas de version ultérieure et un chemin de mise à niveau valide, les administrateurs de clusters peuvent désinstaller votre Operator et mettre à jour la version du cluster.Exemple de CSV avec
olm.maxOpenShiftVersionannotationapiVersion: operators.coreos.com/v1alpha1 kind: ClusterServiceVersion metadata: annotations: "olm.properties": '[{"type": "olm.maxOpenShiftVersion", "value": "<cluster_version>"}]'1 - 1
- Indiquez la version de cluster maximale d'OpenShift Container Platform avec laquelle votre opérateur est compatible. Par exemple, la définition de
valuesur4.9empêche les mises à niveau de cluster vers des versions d'OpenShift Container Platform postérieures à 4.9 lorsque ce bundle est installé sur un cluster.
Si votre bundle est destiné à être distribué dans un catalogue Operator fourni par Red Hat, configurez les versions compatibles d'OpenShift Container Platform pour votre Operator en définissant les propriétés suivantes. Cette configuration garantit que votre Operator est uniquement inclus dans les catalogues qui ciblent des versions compatibles d'OpenShift Container Platform :
NoteCette étape n'est valable que pour la publication d'opérateurs dans les catalogues fournis par Red Hat. Si votre offre groupée est uniquement destinée à être distribuée dans un catalogue personnalisé, vous pouvez ignorer cette étape. Pour plus de détails, voir "Catalogues d'opérateurs fournis par Red Hat".
Définissez l'annotation
com.redhat.openshift.versionsdans le fichierbundle/metadata/annotations.yamlde votre projet :Exemple de fichier
bundle/metadata/annotations.yamlavec les versions compatiblescom.redhat.openshift.versions : "v4.7-v4.9"1 - 1
- Définir une gamme ou une version unique.
Pour éviter que votre bundle ne soit transféré vers une version incompatible d'OpenShift Container Platform, assurez-vous que l'image d'index est générée avec l'étiquette
com.redhat.openshift.versionsappropriée dans l'image du bundle de votre Operator. Par exemple, si votre projet a été généré en utilisant le SDK Operator, mettez à jour le fichierbundle.Dockerfile:Exemple
bundle.Dockerfileavec versions compatiblesLABEL com.redhat.openshift.versions="<versions>"1 - 1
- Définir une plage ou une version unique, par exemple,
v4.7-v4.9. Ce paramètre définit les versions de cluster dans lesquelles l'opérateur doit être distribué, et l'opérateur n'apparaît pas dans le catalogue d'une version de cluster qui se situe en dehors de la plage.
Vous pouvez désormais regrouper une nouvelle version de votre opérateur et publier la version mise à jour dans un catalogue en vue de sa distribution.
5.9. Respecter l'admission à la sécurité des pods
Pod security admission est une implémentation des standards de sécurité des pods de Kubernetes. L'admission de sécurité des pods restreint le comportement des pods. Les pods qui ne sont pas conformes à l'admission de sécurité des pods définie globalement ou au niveau de l'espace de noms ne sont pas admis dans le cluster et ne peuvent pas s'exécuter.
Si votre projet Operator ne nécessite pas d'autorisations accrues pour s'exécuter, vous pouvez vous assurer que vos charges de travail s'exécutent dans des espaces de noms définis au niveau de sécurité du pod restricted. Si votre projet Operator nécessite des autorisations d'escalade pour s'exécuter, vous devez définir les configurations de contexte de sécurité suivantes :
- Niveau d'admission à la sécurité du pod autorisé pour l'espace de noms de l'opérateur
- Les contraintes de contexte de sécurité (SCC) autorisées pour le compte de service de la charge de travail
Pour plus d'informations, voir Comprendre et gérer l'admission à la sécurité des pods.
5.9.1. Synchronisation des contraintes du contexte de sécurité avec les normes de sécurité des pods
OpenShift Container Platform inclut l'admission de sécurité des pods Kubernetes. Globalement, le profil privileged est appliqué et le profil restricted est utilisé pour les avertissements et les audits.
En plus de la configuration globale du contrôle d'admission à la sécurité des pods, il existe un contrôleur qui applique les étiquettes de contrôle d'admission à la sécurité des pods warn et audit aux espaces de noms en fonction des autorisations SCC des comptes de service qui se trouvent dans un espace de noms donné.
La synchronisation de l'admission à la sécurité des pods est désactivée en permanence pour les espaces de noms définis comme faisant partie de la charge utile du cluster. Vous pouvez activer la synchronisation de l'admission à la sécurité des pods sur d'autres espaces de noms si nécessaire. Si un opérateur est installé dans un espace de noms openshift-* créé par l'utilisateur, la synchronisation est activée par défaut après la création d'une version de service de cluster (CSV) dans l'espace de noms.
Le contrôleur examine les autorisations de l'objet ServiceAccount pour utiliser les contraintes de contexte de sécurité dans chaque espace de noms. Les contraintes de contexte de sécurité (SCC) sont converties en profils de sécurité de pods en fonction de leurs valeurs de champ ; le contrôleur utilise ces profils traduits. Les étiquettes d'admission à la sécurité des modules warn et audit sont définies sur le profil de sécurité de module le plus privilégié trouvé dans l'espace de noms afin d'éviter les avertissements et la journalisation d'audit lors de la création des modules.
L'étiquetage de l'espace de nommage est basé sur la prise en compte des privilèges du compte de service local de l'espace de nommage.
L'application directe des pods peut utiliser les privilèges SCC de l'utilisateur qui exécute le pod. Cependant, les privilèges de l'utilisateur ne sont pas pris en compte lors de l'étiquetage automatique.
5.9.2. Veiller à ce que les charges de travail de l'opérateur s'exécutent dans des espaces de noms définis au niveau de sécurité "restricted pod"
Pour que votre projet Operator puisse fonctionner dans une grande variété de déploiements et d'environnements, configurez les charges de travail de l'Operator pour qu'elles s'exécutent dans des espaces de noms définis au niveau de sécurité du pod restricted.
Vous devez laisser le champ runAsUser vide. Si votre image nécessite un utilisateur spécifique, elle ne peut pas être exécutée avec des contraintes de contexte de sécurité restreintes (SCC) et une application restreinte de la sécurité des pods.
Procédure
Pour configurer les charges de travail de l'opérateur afin qu'elles s'exécutent dans des espaces de noms définis au niveau de sécurité du pod
restricted, modifiez la définition de l'espace de noms de votre opérateur comme dans les exemples suivants :ImportantIl est recommandé de définir le profil seccomp dans la définition de l'espace de noms de votre opérateur. Cependant, la définition du profil seccomp n'est pas prise en charge dans OpenShift Container Platform 4.10.
Pour les projets Operator qui doivent fonctionner uniquement sur OpenShift Container Platform 4.11 et plus, modifiez la définition de l'espace de noms de votre Operator comme dans l'exemple suivant :
Exemple de fichier
config/manager/manager.yaml... spec: securityContext: seccompProfile: type: RuntimeDefault1 runAsNonRoot: true containers: - name: <operator_workload_container> securityContext: allowPrivilegeEscalation: false capabilities: drop: - ALL ...- 1
- En définissant le type de profil seccomp sur
RuntimeDefault, le SCC utilise par défaut le profil de sécurité pod de l'espace de noms.
Pour les projets Operator qui doivent également fonctionner dans OpenShift Container Platform 4.10, modifiez la définition de l'espace de noms de votre Operator comme dans l'exemple suivant :
Exemple de fichier
config/manager/manager.yaml... spec: securityContext:1 runAsNonRoot: true containers: - name: <operator_workload_container> securityContext: allowPrivilegeEscalation: false capabilities: drop: - ALL ...- 1
- En laissant le type de profil seccomp non défini, votre projet Operator peut fonctionner dans OpenShift Container Platform 4.10.
5.9.3. Gestion de l'admission à la sécurité des pods pour les charges de travail de l'opérateur qui nécessitent des autorisations accrues
Si votre projet d'opérateur nécessite des autorisations élargies pour fonctionner, vous devez modifier la version du service de cluster (CSV) de votre opérateur.
Procédure
Définissez la configuration du contexte de sécurité au niveau d'autorisation requis dans le CSV de votre opérateur, comme dans l'exemple suivant :
Exemple
<operator_name>.clusterserviceversion.yamlfichier avec les privilèges d'un administrateur de réseau... containers: - name: my-container securityContext: allowPrivilegeEscalation: false capabilities: add: - "NET_ADMIN" ...Définissez les privilèges du compte de service qui permettent aux charges de travail de votre opérateur d'utiliser les contraintes de contexte de sécurité (SCC) requises, comme dans l'exemple suivant :
Exemple de fichier
<operator_name>.clusterserviceversion.yaml... install: spec: clusterPermissions: - rules: - apiGroups: - security.openshift.io resourceNames: - privileged resources: - securitycontextconstraints verbs: - use serviceAccountName: default ...Modifiez la description CSV de votre opérateur pour expliquer pourquoi votre projet d'opérateur nécessite des autorisations accrues, comme dans l'exemple suivant :
Exemple de fichier
<operator_name>.clusterserviceversion.yaml... spec: apiservicedefinitions:{} ... description: The <operator_name> requires a privileged pod security admission label set on the Operator's namespace. The Operator's agents require escalated permissions to restart the node if the node needs remediation.
5.10. Valider les opérateurs à l'aide de la carte de score
En tant qu'auteur de l'opérateur, vous pouvez utiliser l'outil de scorecard dans le SDK de l'opérateur pour effectuer les tâches suivantes :
- Validez que votre projet Operator ne contient pas d'erreurs de syntaxe et qu'il est correctement empaqueté
- Examinez les suggestions d'amélioration de votre opérateur
5.10.1. A propos de l'outil carte de score
Alors que la sous-commande Operator SDK bundle validate peut valider le contenu et la structure des répertoires de bundle locaux et des images de bundle distantes, vous pouvez utiliser la commande scorecard pour exécuter des tests sur votre Operator sur la base d'un fichier de configuration et d'images de test. Ces tests sont mis en œuvre dans des images de test qui sont configurées et construites pour être exécutées par le scorecard.
Le scorecard suppose qu'il est exécuté avec un accès à un cluster Kubernetes configuré, tel que OpenShift Container Platform. Le scorecard exécute chaque test dans un pod, à partir duquel les journaux du pod sont agrégés et les résultats des tests sont envoyés à la console. Le scorecard intègre des tests de base et des tests OLM (Operator Lifecycle Manager) et fournit également un moyen d'exécuter des définitions de test personnalisées.
Flux de travail du tableau de bord
- Créer toutes les ressources requises par les ressources personnalisées (RC) et l'opérateur
- Créer un conteneur proxy dans le déploiement de l'opérateur pour enregistrer les appels au serveur API et exécuter les tests
- Examiner les paramètres dans les CR
Les tests du tableau de bord ne font aucune supposition quant à l'état de l'opérateur testé. La création d'opérateurs et de CR pour un opérateur dépasse le champ d'application du tableau de bord lui-même. Les tests du tableau de bord peuvent toutefois créer toutes les ressources dont ils ont besoin si les tests sont conçus pour la création de ressources.
scorecard syntaxe de la commande
$ operator-sdk scorecard <bundle_dir_ou_image> [flags] (drapeaux)Le tableau de bord requiert un argument de position pour le chemin d'accès au disque de votre groupe d'opérateurs ou le nom d'une image de groupe.
Pour plus d'informations sur les drapeaux, cliquez ici :
$ operator-sdk scorecard -h5.10.2. Configuration du tableau de bord
L'outil scorecard utilise une configuration qui vous permet de configurer des plugins internes, ainsi que plusieurs options de configuration globales. Les tests sont pilotés par un fichier de configuration nommé config.yaml, qui est généré par la commande make bundle, située dans votre répertoire bundle/:
./bundle
...
└── tests
└── scorecard
└── config.yamlExemple de fichier de configuration d'un scorecard
kind: Configuration
apiversion: scorecard.operatorframework.io/v1alpha3
metadata:
name: config
stages:
- parallel: true
tests:
- image: quay.io/operator-framework/scorecard-test:v1.25.4
entrypoint:
- scorecard-test
- basic-check-spec
labels:
suite: basic
test: basic-check-spec-test
- image: quay.io/operator-framework/scorecard-test:v1.25.4
entrypoint:
- scorecard-test
- olm-bundle-validation
labels:
suite: olm
test: olm-bundle-validation-testLe fichier de configuration définit chaque test que le scorecard peut exécuter. Les champs suivants du fichier de configuration du scorecard définissent le test comme suit :
| Champ de configuration | Description |
|---|---|
|
| Nom de l'image du conteneur de test qui met en œuvre un test |
|
| Commande et arguments invoqués dans l'image de test pour exécuter un test |
|
| Étiquettes personnalisées ou définies dans le tableau de bord permettant de sélectionner les tests à effectuer |
5.10.3. Tests de cartes de pointage intégrés
Le tableau de bord est livré avec des tests prédéfinis qui sont organisés en suites : la suite de tests de base et la suite Operator Lifecycle Manager (OLM).
| Test | Description | Nom court |
|---|---|---|
| Existence d'un bloc de spécifications |
Ce test vérifie que toutes les ressources personnalisées (CR) créées dans le cluster disposent d'un bloc |
|
| Test | Description | Nom court |
|---|---|---|
| Validation de l'offre groupée | Ce test valide les manifestes de la liasse trouvés dans la liasse qui est passée dans le scorecard. Si le contenu de la liasse contient des erreurs, le résultat du test comprend le journal du validateur ainsi que les messages d'erreur de la bibliothèque de validation. |
|
| Les API fournies sont validées |
Ce test permet de vérifier que les définitions de ressources personnalisées (CRD) pour les CR fournis contiennent une section de validation et qu'il existe une validation pour chaque champ |
|
| Les CRD possédés ont des ressources répertoriées |
Ce test vérifie que les CRD de chaque CR fourni via l'option |
|
| Champs spécifiques avec descripteurs |
Ce test permet de vérifier que chaque champ des sections CRs |
|
| Champs d'état avec descripteurs |
Ce test permet de vérifier que chaque champ des sections CRs |
|
5.10.4. Exécution de l'outil de tableau de bord
Un ensemble de fichiers Kustomize par défaut est généré par le SDK de l'opérateur après l'exécution de la commande init. Le fichier par défaut bundle/tests/scorecard/config.yaml qui est généré peut être immédiatement utilisé pour exécuter l'outil de scorecard avec votre opérateur, ou vous pouvez modifier ce fichier selon les spécifications de votre test.
Conditions préalables
- Projet d'opérateur généré à l'aide de l'Operator SDK
Procédure
Générer ou régénérer les manifestes et les métadonnées de vos bundles pour votre opérateur :
$ make bundleCette commande ajoute automatiquement des annotations de scorecard aux métadonnées de votre bundle, qui sont utilisées par la commande
scorecardpour exécuter les tests.Exécutez le tableau de bord en fonction du chemin d'accès au disque de votre groupe d'opérateurs ou du nom d'une image de groupe :
$ operator-sdk scorecard <bundle_dir_or_image>
5.10.5. Résultats du tableau de bord
L'option --output de la commande scorecard spécifie le format de sortie des résultats de la carte de score : text ou json.
Exemple 5.15. Exemple d'extrait de sortie JSON
{
"apiVersion": "scorecard.operatorframework.io/v1alpha3",
"kind": "TestList",
"items": [
{
"kind": "Test",
"apiVersion": "scorecard.operatorframework.io/v1alpha3",
"spec": {
"image": "quay.io/operator-framework/scorecard-test:v1.25.4",
"entrypoint": [
"scorecard-test",
"olm-bundle-validation"
],
"labels": {
"suite": "olm",
"test": "olm-bundle-validation-test"
}
},
"status": {
"results": [
{
"name": "olm-bundle-validation",
"log": "time=\"2020-06-10T19:02:49Z\" level=debug msg=\"Found manifests directory\" name=bundle-test\ntime=\"2020-06-10T19:02:49Z\" level=debug msg=\"Found metadata directory\" name=bundle-test\ntime=\"2020-06-10T19:02:49Z\" level=debug msg=\"Getting mediaType info from manifests directory\" name=bundle-test\ntime=\"2020-06-10T19:02:49Z\" level=info msg=\"Found annotations file\" name=bundle-test\ntime=\"2020-06-10T19:02:49Z\" level=info msg=\"Could not find optional dependencies file\" name=bundle-test\n",
"state": "pass"
}
]
}
}
]
}Exemple 5.16. Exemple d'extrait de texte
--------------------------------------------------------------------------------
Image: quay.io/operator-framework/scorecard-test:v1.25.4
Entrypoint: [scorecard-test olm-bundle-validation]
Labels:
"suite":"olm"
"test":"olm-bundle-validation-test"
Results:
Name: olm-bundle-validation
State: pass
Log:
time="2020-07-15T03:19:02Z" level=debug msg="Found manifests directory" name=bundle-test
time="2020-07-15T03:19:02Z" level=debug msg="Found metadata directory" name=bundle-test
time="2020-07-15T03:19:02Z" level=debug msg="Getting mediaType info from manifests directory" name=bundle-test
time="2020-07-15T03:19:02Z" level=info msg="Found annotations file" name=bundle-test
time="2020-07-15T03:19:02Z" level=info msg="Could not find optional dependencies file" name=bundle-test
La spécification du format de sortie correspond à la présentation du type Test de la présentation du type.
5.10.6. Sélection des tests
Les tests du tableau de bord sont sélectionnés en associant l'indicateur CLI --selector à un ensemble de chaînes d'étiquettes. Si aucun drapeau de sélection n'est fourni, tous les tests contenus dans le fichier de configuration du tableau de bord sont exécutés.
Les tests sont exécutés en série, les résultats étant agrégés par le tableau de bord et écrits sur la sortie standard, ou stdout.
Procédure
Pour sélectionner un seul test, par exemple
basic-check-spec-test, spécifiez le test en utilisant l'indicateur--selector:$ operator-sdk scorecard <bundle_dir_or_image> \ -o text \ --selector=test=basic-check-spec-testPour sélectionner une série de tests, par exemple
olm, indiquez une étiquette utilisée par tous les tests OLM :$ operator-sdk scorecard <bundle_dir_or_image> \ -o text \ --selector=suite=olmPour sélectionner plusieurs tests, spécifiez les noms des tests à l'aide de l'indicateur
selectoren utilisant la syntaxe suivante :$ operator-sdk scorecard <bundle_dir_or_image> \ -o text \ --selector='test in (basic-check-spec-test,olm-bundle-validation-test)'
5.10.7. Permettre des tests en parallèle
En tant qu'auteur d'un opérateur, vous pouvez définir des étapes distinctes pour vos tests à l'aide du fichier de configuration du tableau de bord. Les étapes s'exécutent séquentiellement dans l'ordre où elles sont définies dans le fichier de configuration. Une étape contient une liste de tests et un paramètre configurable parallel.
Par défaut, ou lorsqu'une étape définit explicitement parallel à false, les tests d'une étape sont exécutés séquentiellement dans l'ordre où ils sont définis dans le fichier de configuration. L'exécution des tests un par un est utile pour garantir que deux tests n'interagissent pas et n'entrent pas en conflit l'un avec l'autre.
Toutefois, si les tests sont conçus pour être totalement isolés, ils peuvent être parallélisés.
Procédure
Pour exécuter un ensemble de tests isolés en parallèle, incluez-les dans la même étape et fixez
parallelàtrue:apiVersion: scorecard.operatorframework.io/v1alpha3 kind: Configuration metadata: name: config stages: - parallel: true1 tests: - entrypoint: - scorecard-test - basic-check-spec image: quay.io/operator-framework/scorecard-test:v1.25.4 labels: suite: basic test: basic-check-spec-test - entrypoint: - scorecard-test - olm-bundle-validation image: quay.io/operator-framework/scorecard-test:v1.25.4 labels: suite: olm test: olm-bundle-validation-test- 1
- Permet de réaliser des tests en parallèle
Tous les tests d'une étape parallèle sont exécutés simultanément, et Scorecard attend qu'ils soient tous terminés avant de passer à l'étape suivante. Vos tests peuvent ainsi s'exécuter beaucoup plus rapidement.
5.10.8. Tests personnalisés des cartes de pointage
L'outil de tableau de bord peut exécuter des tests personnalisés qui respectent ces conventions obligatoires :
- Les tests sont mis en œuvre dans une image conteneur
- Les tests acceptent un point d'entrée comprenant une commande et des arguments
-
Les tests produisent la carte de score
v1alpha3au format JSON, sans journalisation superflue dans la sortie du test -
Les tests peuvent obtenir le contenu du paquet à un point de montage partagé de
/bundle - Les tests peuvent accéder à l'API Kubernetes à l'aide d'une connexion client dans le cluster
Il est possible d'écrire des tests personnalisés dans d'autres langages de programmation si l'image de test suit les lignes directrices ci-dessus.
L'exemple suivant montre une image de test personnalisée écrite en Go :
Exemple 5.17. Exemple de test de scorecard personnalisé
// Copyright 2020 The Operator-SDK Authors
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
package main
import (
"encoding/json"
"fmt"
"log"
"os"
scapiv1alpha3 "github.com/operator-framework/api/pkg/apis/scorecard/v1alpha3"
apimanifests "github.com/operator-framework/api/pkg/manifests"
)
// This is the custom scorecard test example binary
// As with the Redhat scorecard test image, the bundle that is under
// test is expected to be mounted so that tests can inspect the
// bundle contents as part of their test implementations.
// The actual test is to be run is named and that name is passed
// as an argument to this binary. This argument mechanism allows
// this binary to run various tests all from within a single
// test image.
const PodBundleRoot = "/bundle"
func main() {
entrypoint := os.Args[1:]
if len(entrypoint) == 0 {
log.Fatal("Test name argument is required")
}
// Read the pod's untar'd bundle from a well-known path.
cfg, err := apimanifests.GetBundleFromDir(PodBundleRoot)
if err != nil {
log.Fatal(err.Error())
}
var result scapiv1alpha3.TestStatus
// Names of the custom tests which would be passed in the
// `operator-sdk` command.
switch entrypoint[0] {
case CustomTest1Name:
result = CustomTest1(cfg)
case CustomTest2Name:
result = CustomTest2(cfg)
default:
result = printValidTests()
}
// Convert scapiv1alpha3.TestResult to json.
prettyJSON, err := json.MarshalIndent(result, "", " ")
if err != nil {
log.Fatal("Failed to generate json", err)
}
fmt.Printf("%s\n", string(prettyJSON))
}
// printValidTests will print out full list of test names to give a hint to the end user on what the valid tests are.
func printValidTests() scapiv1alpha3.TestStatus {
result := scapiv1alpha3.TestResult{}
result.State = scapiv1alpha3.FailState
result.Errors = make([]string, 0)
result.Suggestions = make([]string, 0)
str := fmt.Sprintf("Valid tests for this image include: %s %s",
CustomTest1Name,
CustomTest2Name)
result.Errors = append(result.Errors, str)
return scapiv1alpha3.TestStatus{
Results: []scapiv1alpha3.TestResult{result},
}
}
const (
CustomTest1Name = "customtest1"
CustomTest2Name = "customtest2"
)
// Define any operator specific custom tests here.
// CustomTest1 and CustomTest2 are example test functions. Relevant operator specific
// test logic is to be implemented in similarly.
func CustomTest1(bundle *apimanifests.Bundle) scapiv1alpha3.TestStatus {
r := scapiv1alpha3.TestResult{}
r.Name = CustomTest1Name
r.State = scapiv1alpha3.PassState
r.Errors = make([]string, 0)
r.Suggestions = make([]string, 0)
almExamples := bundle.CSV.GetAnnotations()["alm-examples"]
if almExamples == "" {
fmt.Println("no alm-examples in the bundle CSV")
}
return wrapResult(r)
}
func CustomTest2(bundle *apimanifests.Bundle) scapiv1alpha3.TestStatus {
r := scapiv1alpha3.TestResult{}
r.Name = CustomTest2Name
r.State = scapiv1alpha3.PassState
r.Errors = make([]string, 0)
r.Suggestions = make([]string, 0)
almExamples := bundle.CSV.GetAnnotations()["alm-examples"]
if almExamples == "" {
fmt.Println("no alm-examples in the bundle CSV")
}
return wrapResult(r)
}
func wrapResult(r scapiv1alpha3.TestResult) scapiv1alpha3.TestStatus {
return scapiv1alpha3.TestStatus{
Results: []scapiv1alpha3.TestResult{r},
}
}5.11. Validation des paquets d'opérateurs
En tant qu'auteur d'un Operator, vous pouvez exécuter la commande bundle validate dans le SDK Operator pour valider le contenu et le format d'un Operator bundle. Vous pouvez exécuter la commande sur une image de liasse Operator distante ou sur un répertoire de liasse Operator local.
5.11.1. À propos de la commande bundle validate
Alors que la commande Operator SDK scorecard permet d'exécuter des tests sur votre Operator à partir d'un fichier de configuration et d'images de test, la sous-commande bundle validate permet de valider le contenu et la structure des répertoires de paquets locaux et des images de paquets distants.
bundle validate syntaxe de la commande
$ operator-sdk bundle validate <bundle_dir_or_image> <flags>
La commande bundle validate s'exécute automatiquement lorsque vous construisez votre bundle à l'aide de la commande make bundle.
Les images de l'offre groupée sont extraites d'un registre distant et construites localement avant d'être validées. Les répertoires locaux des offres groupées doivent contenir les métadonnées et les manifestes de l'opérateur. Les métadonnées et les manifestes de l'offre groupée doivent avoir une structure similaire à celle de l'offre groupée suivante :
Exemple de présentation de la liasse
./bundle
├── manifests
│ ├── cache.my.domain_memcacheds.yaml
│ └── memcached-operator.clusterserviceversion.yaml
└── metadata
└── annotations.yaml
Les tests de l'offre groupée passent la validation et se terminent par un code de sortie de 0 si aucune erreur n'est détectée.
Exemple de sortie
INFO[0000] All validation tests have completed successfully
Les tests échouent à la validation et se terminent par un code de sortie de 1 si des erreurs sont détectées.
Exemple de sortie
ERRO[0000] Error: Value cache.example.com/v1alpha1, Kind=Memcached: CRD "cache.example.com/v1alpha1, Kind=Memcached" is present in bundle "" but not defined in CSV
Les tests de l'offre groupée qui génèrent des avertissements peuvent toujours passer la validation avec un code de sortie de 0 tant qu'aucune erreur n'est détectée. Les tests n'échouent qu'en cas d'erreur.
Exemple de sortie
WARN[0000] Warning: Value : (memcached-operator.v0.0.1) annotations not found
INFO[0000] All validation tests have completed successfully
Pour plus d'informations sur la sous-commande bundle validate, exécutez :
$ operator-sdk bundle validate -h5.11.2. Tests de validation des paquets intégrés
L'Operator SDK est livré avec des validateurs prédéfinis organisés en suites. Si vous exécutez la commande bundle validate sans spécifier de validateur, le test par défaut s'exécute. Le test par défaut vérifie qu'une offre groupée respecte les spécifications définies par la communauté Operator Framework. Pour plus d'informations, voir "Bundle format".
Vous pouvez exécuter des validateurs optionnels pour tester des problèmes tels que la compatibilité avec OperatorHub ou des API Kubernetes obsolètes. Les validateurs optionnels s'exécutent toujours en plus du test par défaut.
bundle validate syntaxe de la commande pour les suites de tests optionnelles
$ operator-sdk bundle validate <bundle_dir_or_image>
--select-optional <test_label>| Nom | Description | Étiquette |
|---|---|---|
| Cadre de l'opérateur | Ce validateur teste un paquet Operator par rapport à l'ensemble des validateurs fournis par Operator Framework. |
|
| OperatorHub | Ce validateur teste la compatibilité d'un paquet Operator avec OperatorHub. |
|
| Bonnes pratiques | Ce validateur vérifie si une offre groupée d'opérateurs est conforme aux bonnes pratiques définies par le cadre des opérateurs. Il vérifie les problèmes, tels qu'une description CRD vide ou des ressources OLM (Operator Lifecycle Manager) non prises en charge. |
|
5.11.3. Exécution de la commande bundle validate
Le validateur par défaut exécute un test chaque fois que vous entrez la commande bundle validate. Vous pouvez lancer des validateurs optionnels à l'aide de l'option --select-optional. Les validateurs optionnels exécutent des tests en plus du test par défaut.
Conditions préalables
- Projet d'opérateur généré à l'aide de l'Operator SDK
Procédure
Si vous souhaitez exécuter le validateur par défaut dans un répertoire local, entrez la commande suivante à partir du répertoire de votre projet Operator :
$ operator-sdk bundle validate ./bundleSi vous souhaitez exécuter le validateur par défaut sur une image de regroupement d'opérateurs distante, entrez la commande suivante :
$ operator-sdk bundle validate \ <bundle_registry>/<bundle_image_name>:<tag>où :
- <bundle_registry>
-
Spécifie le registre dans lequel le bundle est hébergé, par exemple
quay.io/example. - <nom_de_l'image_de_l'ensemble>
-
Spécifie le nom de l'image de la liasse, par exemple
memcached-operator. - <tag>
Spécifie l'étiquette de l'image de la liasse, par exemple
v1.25.4.NoteSi vous souhaitez valider une image de l'ensemble Operator, vous devez héberger votre image dans un registre distant. Le SDK Operator extrait l'image et la construit localement avant d'exécuter les tests. La commande
bundle validatene prend pas en charge les tests d'images groupées locales.
Si vous souhaitez exécuter un validateur supplémentaire par rapport à une liasse d'opérateurs, entrez la commande suivante :
$ operator-sdk bundle validate \ <bundle_dir_or_image> \ --select-optional <test_label>où :
- <bundle_dir_ou_image>
-
Spécifie le répertoire de la liasse locale ou l'image de la liasse distante, telle que
~/projects/memcachedouquay.io/example/memcached-operator:v1.25.4. - <test_label>
Spécifie le nom du validateur que vous souhaitez exécuter, par exemple
name=good-practices.Exemple de sortie
ERRO[0000] Error: Value apiextensions.k8s.io/v1, Kind=CustomResource: unsupported media type registry+v1 for bundle object WARN[0000] Warning: Value k8sevent.v0.0.1: owned CRD "k8sevents.k8s.k8sevent.com" has an empty description
5.12. Détection et prise en charge des clusters à haute disponibilité ou à nœud unique
Un cluster OpenShift Container Platform peut être configuré en mode haute disponibilité (HA), qui utilise plusieurs nœuds, ou en mode non-HA, qui utilise un seul nœud. Un cluster à nœud unique, également connu sous le nom d'OpenShift à nœud unique, est susceptible d'avoir des contraintes de ressources plus conservatrices. Par conséquent, il est important que les opérateurs installés sur un cluster à nœud unique puissent s'adapter en conséquence et continuer à bien fonctionner.
En accédant à l'API du mode de haute disponibilité du cluster fournie dans OpenShift Container Platform, les auteurs d'opérateurs peuvent utiliser le SDK de l'opérateur pour permettre à leur opérateur de détecter la topologie de l'infrastructure d'un cluster, que ce soit en mode HA ou non HA. Il est possible de développer une logique d'opérateur personnalisée qui utilise la topologie de cluster détectée pour basculer automatiquement les besoins en ressources, à la fois pour l'opérateur et pour tous les opérateurs ou charges de travail qu'il gère, vers un profil qui correspond le mieux à la topologie.
5.12.1. À propos de l'API du mode de haute disponibilité des clusters
OpenShift Container Platform fournit une API de mode de haute disponibilité de cluster qui peut être utilisée par les opérateurs pour aider à détecter la topologie de l'infrastructure. L'API Infrastructure contient des informations sur l'infrastructure à l'échelle du cluster. Les opérateurs gérés par Operator Lifecycle Manager (OLM) peuvent utiliser l'API Infrastructure s'ils ont besoin de configurer un Operand ou une charge de travail gérée différemment en fonction du mode de haute disponibilité.
Dans l'API Infrastructure, le statut infrastructureTopology exprime les attentes pour les services d'infrastructure qui ne s'exécutent pas sur les nœuds du plan de contrôle, généralement indiqués par un sélecteur de nœud pour une valeur role autre que master. Le statut controlPlaneTopology exprime les attentes pour les opérandes qui s'exécutent normalement sur les nœuds du plan de contrôle.
Le paramètre par défaut pour l'un ou l'autre état est HighlyAvailable, ce qui représente le comportement des opérateurs dans les clusters à plusieurs nœuds. Le paramètre SingleReplica est utilisé dans les clusters à nœud unique, également connus sous le nom d'OpenShift à nœud unique, et indique que les opérateurs ne doivent pas configurer leurs Operands pour un fonctionnement en haute disponibilité.
Le programme d'installation d'OpenShift Container Platform définit les champs d'état controlPlaneTopology et infrastructureTopology en fonction du nombre de répliques du cluster lors de sa création, conformément aux règles suivantes :
-
Lorsque le nombre de répliques du plan de contrôle est inférieur à 3, l'état
controlPlaneTopologyest défini surSingleReplica. Dans le cas contraire, il est défini surHighlyAvailable. -
Lorsque le nombre de répliques de travailleurs est égal à 0, les nœuds du plan de contrôle sont également configurés en tant que travailleurs. Par conséquent, l'état
infrastructureTopologysera le même que l'étatcontrolPlaneTopology. -
Lorsque le nombre de répliques de travailleurs est égal à 1, la valeur de
infrastructureTopologyest fixée àSingleReplica. Dans le cas contraire, il est défini surHighlyAvailable.
5.12.2. Exemple d'utilisation de l'API dans les projets d'opérateurs
En tant qu'auteur d'Operator, vous pouvez mettre à jour votre projet Operator pour accéder à l'API d'infrastructure en utilisant des constructions Kubernetes normales et la bibliothèque controller-runtime, comme le montrent les exemples suivants :
controller-runtime exemple de bibliothèque
// Simple query
nn := types.NamespacedName{
Name: "cluster",
}
infraConfig := &configv1.Infrastructure{}
err = crClient.Get(context.Background(), nn, infraConfig)
if err != nil {
return err
}
fmt.Printf("using crclient: %v\n", infraConfig.Status.ControlPlaneTopology)
fmt.Printf("using crclient: %v\n", infraConfig.Status.InfrastructureTopology)Exemple de construction de Kubernetes
operatorConfigInformer := configinformer.NewSharedInformerFactoryWithOptions(configClient, 2*time.Second)
infrastructureLister = operatorConfigInformer.Config().V1().Infrastructures().Lister()
infraConfig, err := configClient.ConfigV1().Infrastructures().Get(context.Background(), "cluster", metav1.GetOptions{})
if err != nil {
return err
}
// fmt.Printf("%v\n", infraConfig)
fmt.Printf("%v\n", infraConfig.Status.ControlPlaneTopology)
fmt.Printf("%v\n", infraConfig.Status.InfrastructureTopology)5.13. Configuration de la surveillance intégrée avec Prometheus
Ce guide décrit la prise en charge de la surveillance intégrée fournie par le SDK Operator à l'aide de l'opérateur Prometheus et détaille l'utilisation pour les auteurs d'opérateurs basés sur Go et Ansible.
5.13.1. Assistance à l'opérateur Prometheus
Prometheus est une boîte à outils open-source de surveillance des systèmes et d'alerte. L'opérateur Prometheus crée, configure et gère des clusters Prometheus fonctionnant sur des clusters basés sur Kubernetes, tels que OpenShift Container Platform.
Des fonctions d'aide existent par défaut dans le SDK de l'opérateur pour configurer automatiquement les métriques dans tout opérateur Go généré pour une utilisation sur les clusters où l'opérateur Prometheus est déployé.
5.13.2. Exposition de mesures personnalisées pour les opérateurs basés sur Go
En tant qu'auteur d'un opérateur, vous pouvez publier des mesures personnalisées en utilisant le registre Prometheus global de la bibliothèque controller-runtime/pkg/metrics.
Conditions préalables
- Opérateur basé sur Go généré à l'aide de l'Operator SDK
- Prometheus Operator, qui est déployé par défaut sur les clusters d'OpenShift Container Platform
Procédure
Dans votre projet Operator SDK, décompressez la ligne suivante dans le fichier
config/default/kustomization.yaml:../prometheusCréez une classe de contrôleur personnalisée pour publier des mesures supplémentaires à partir de l'opérateur. L'exemple suivant déclare les collecteurs
widgetsetwidgetFailuresen tant que variables globales, puis les enregistre avec la fonctioninit()dans le package du contrôleur :Exemple 5.18.
controllers/memcached_controller_test_metrics.gofichierpackage controllers import ( "github.com/prometheus/client_golang/prometheus" "sigs.k8s.io/controller-runtime/pkg/metrics" ) var ( widgets = prometheus.NewCounter( prometheus.CounterOpts{ Name: "widgets_total", Help: "Number of widgets processed", }, ) widgetFailures = prometheus.NewCounter( prometheus.CounterOpts{ Name: "widget_failures_total", Help: "Number of failed widgets", }, ) ) func init() { // Register custom metrics with the global prometheus registry metrics.Registry.MustRegister(widgets, widgetFailures) }Record to these collectors from any part of the reconcile loop in the
maincontroller class, which determines the business logic for the metric :Exemple 5.19.
controllers/memcached_controller.gofichierfunc (r *MemcachedReconciler) Reconcile(ctx context.Context, req ctrl.Request) (ctrl.Result, error) { ... ... // Add metrics widgets.Inc() widgetFailures.Inc() return ctrl.Result{}, nil }Construire et pousser l'opérateur :
$ make docker-build docker-push IMG=<registry>/<user>/<image_name>:<tag>Déployer l'opérateur :
$ make deploy IMG=<registry>/<user>/<image_name>:<tag>Créer des définitions de rôle et de liaison de rôle pour permettre au moniteur de service de l'opérateur d'être scanné par l'instance Prometheus du cluster OpenShift Container Platform.
Les rôles doivent être attribués de manière à ce que les comptes de service disposent des autorisations nécessaires pour analyser les métriques de l'espace de noms :
Exemple 5.20.
config/prometheus/role.yamlrôleapiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: prometheus-k8s-role namespace: <operator_namespace> rules: - apiGroups: - "" resources: - endpoints - pods - services - nodes - secrets verbs: - get - list - watchExemple 5.21.
config/prometheus/rolebinding.yamll'obligation de rôleapiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: prometheus-k8s-rolebinding namespace: memcached-operator-system roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: prometheus-k8s-role subjects: - kind: ServiceAccount name: prometheus-k8s namespace: openshift-monitoringAppliquer les rôles et les liaisons de rôles pour l'opérateur déployé :
$ oc apply -f config/prometheus/role.yaml$ oc apply -f config/prometheus/rolebinding.yamlDéfinissez les étiquettes pour l'espace de noms que vous souhaitez analyser, ce qui active la surveillance du cluster OpenShift pour cet espace de noms :
$ oc label namespace <operator_namespace> openshift.io/cluster-monitoring="true"
Vérification
-
Interroger et visualiser les métriques dans la console web d'OpenShift Container Platform. Vous pouvez utiliser les noms définis dans la classe de contrôleur personnalisé, par exemple
widgets_totaletwidget_failures_total.
5.13.3. Exposer des métriques personnalisées pour les opérateurs basés sur Ansible
En tant qu'auteur d'opérateurs créant des opérateurs basés sur Ansible, vous pouvez utiliser le module osdk_metrics de l'Operator SDK pour exposer des métriques personnalisées d'opérateurs et d'opérandes, émettre des événements et prendre en charge la journalisation.
Conditions préalables
- Opérateur basé sur Ansible généré à l'aide de l'Operator SDK
- Prometheus Operator, qui est déployé par défaut sur les clusters d'OpenShift Container Platform
Procédure
Générer un opérateur basé sur Ansible. Cet exemple utilise un domaine
testmetrics.com:$ operator-sdk init \ --plugins=ansible \ --domain=testmetrics.comCréez une API
metrics. Cet exemple utilise unkindnomméTestmetrics:$ operator-sdk create api \ --group metrics \ --version v1 \ --kind Testmetrics \ --generate-roleModifiez le fichier
roles/testmetrics/tasks/main.ymlet utilisez le moduleosdk_metricspour créer des mesures personnalisées pour votre projet Operator :Exemple 5.22. Exemple de fichier
roles/testmetrics/tasks/main.yml--- # tasks file for Memcached - name: start k8sstatus k8s: definition: kind: Deployment apiVersion: apps/v1 metadata: name: '{{ ansible_operator_meta.name }}-memcached' namespace: '{{ ansible_operator_meta.namespace }}' spec: replicas: "{{size}}" selector: matchLabels: app: memcached template: metadata: labels: app: memcached spec: containers: - name: memcached command: - memcached - -m=64 - -o - modern - -v image: "docker.io/memcached:1.4.36-alpine" ports: - containerPort: 11211 - osdk_metric: name: my_thing_counter description: This metric counts things counter: {} - osdk_metric: name: my_counter_metric description: Add 3.14 to the counter counter: increment: yes - osdk_metric: name: my_gauge_metric description: Create my gauge and set it to 2. gauge: set: 2 - osdk_metric: name: my_histogram_metric description: Observe my histogram histogram: observe: 2 - osdk_metric: name: my_summary_metric description: Observe my summary summary: observe: 2
Vérification
Exécutez votre opérateur sur un cluster. Par exemple, pour utiliser la méthode "run as a deployment" :
Construire l'image de l'opérateur et l'envoyer dans un registre :
$ make docker-build docker-push IMG=<registry>/<user>/<image_name>:<tag>Installer l'opérateur sur un cluster :
$ make installDéployer l'opérateur :
$ make deploy IMG=<registry>/<user>/<image_name>:<tag>
Créer une ressource personnalisée (CR)
Testmetrics:Définir les spécifications du CR :
Exemple 5.23. Exemple de fichier
config/samples/metrics_v1_testmetrics.yamlapiVersion: metrics.testmetrics.com/v1 kind: Testmetrics metadata: name: testmetrics-sample spec: size: 1Créer l'objet :
$ oc create -f config/samples/metrics_v1_testmetrics.yaml
Obtenez les détails de la capsule :
$ oc get podsExemple de sortie
NAME READY STATUS RESTARTS AGE ansiblemetrics-controller-manager-<id> 2/2 Running 0 149m testmetrics-sample-memcached-<id> 1/1 Running 0 147mObtenir les détails du point de terminaison :
$ oc get epExemple de sortie
NAME ENDPOINTS AGE ansiblemetrics-controller-manager-metrics-service 10.129.2.70:8443 150mDemander un jeton de mesure personnalisé :
$ token=`oc create token prometheus-k8s -n openshift-monitoring`Vérifier les valeurs des métriques :
Vérifier la valeur de
my_counter_metric:$ oc exec ansiblemetrics-controller-manager-<id> -- curl -k -H "Authoriza tion: Bearer $token" 'https://10.129.2.70:8443/metrics' | grep my_counterExemple de sortie
HELP my_counter_metric Add 3.14 to the counter TYPE my_counter_metric counter my_counter_metric 2Vérifier la valeur de
my_gauge_metric:$ oc exec ansiblemetrics-controller-manager-<id> -- curl -k -H "Authoriza tion: Bearer $token" 'https://10.129.2.70:8443/metrics' | grep gaugeExemple de sortie
HELP my_gauge_metric Create my gauge and set it to 2.Vérifiez les valeurs
my_histogram_metricetmy_summary_metric:$ oc exec ansiblemetrics-controller-manager-<id> -- curl -k -H "Authoriza tion: Bearer $token" 'https://10.129.2.70:8443/metrics' | grep ObserveExemple de sortie
HELP my_histogram_metric Observe my histogram HELP my_summary_metric Observe my summary
5.14. Configuration de l'élection du chef de file
Au cours du cycle de vie d'un opérateur, il est possible que plusieurs instances fonctionnent à un moment donné, par exemple lors du déploiement d'une mise à niveau de l'opérateur. Dans un tel scénario, il est nécessaire d'éviter les conflits entre les multiples instances de l'opérateur en utilisant l'élection d'un chef de file. Cela permet de s'assurer qu'une seule instance leader s'occupe de la réconciliation tandis que les autres instances sont inactives mais prêtes à prendre le relais lorsque le leader se retire.
Il est possible de choisir entre deux implémentations différentes de l'élection du chef, chacune ayant ses propres avantages :
- Leader pour la vie
-
Le pod leader n'abandonne son rôle de leader que lorsqu'il est supprimé, en utilisant le ramassage des ordures. Cette implémentation exclut la possibilité que deux instances fonctionnent par erreur en tant que leaders, un état également connu sous le nom de "split brain" (cerveau divisé). Toutefois, cette méthode peut entraîner un retard dans l'élection d'un nouveau leader. Par exemple, lorsque le pod leader se trouve sur un nœud qui ne répond pas ou qui est partitionné, le système de gestion de l'instance peut être modifié
pod-eviction-timeoutdicte le temps nécessaire pour que le pod leader soit supprimé du nœud et se retire, avec une valeur par défaut de5m. Voir la documentation Leader-for-life Go pour plus d'informations. - Chef de file avec bail
- Le pod leader renouvelle périodiquement le bail du leader et abandonne le leadership lorsqu'il ne peut pas renouveler le bail. Cette implémentation permet une transition plus rapide vers un nouveau leader lorsque le leader existant est isolé, mais il y a une possibilité de "split brain" dans certaines situations. Voir la documentation Leader-with-lease Go pour plus d'informations.
Par défaut, le SDK Operator active l'implémentation Leader-for-life. Consultez la documentation Go relative aux deux approches afin de déterminer les compromis les plus judicieux pour votre cas d'utilisation.
5.14.1. Exemples d'élections de chefs d'opérateurs
Les exemples suivants illustrent la manière d'utiliser les deux options d'élection du chef de file pour un opérateur, le chef de file à vie et le chef de file avec bail.
5.14.1.1. Élection du leader à vie
Avec l'implémentation de l'élection Leader-for-life, un appel à leader.Become() bloque l'Opérateur qui retente sa chance jusqu'à ce qu'il puisse devenir le leader en créant la carte de configuration nommée memcached-operator-lock:
import (
...
"github.com/operator-framework/operator-sdk/pkg/leader"
)
func main() {
...
err = leader.Become(context.TODO(), "memcached-operator-lock")
if err != nil {
log.Error(err, "Failed to retry for leader lock")
os.Exit(1)
}
...
}
Si l'opérateur n'est pas en cours d'exécution dans un cluster, leader.Become() renvoie simplement sans erreur pour sauter l'élection du leader puisqu'il ne peut pas détecter le nom de l'opérateur.
5.14.1.2. Élection du chef de file avec bail
La mise en œuvre de l'option Leader-with-lease peut être activée à l'aide des options du gestionnaire pour l'élection du leader :
import (
...
"sigs.k8s.io/controller-runtime/pkg/manager"
)
func main() {
...
opts := manager.Options{
...
LeaderElection: true,
LeaderElectionID: "memcached-operator-lock"
}
mgr, err := manager.New(cfg, opts)
...
}
Lorsque l'opérateur n'est pas exécuté dans un cluster, le gestionnaire renvoie une erreur au démarrage car il ne peut pas détecter l'espace de noms de l'opérateur pour créer la carte de configuration pour l'élection du chef. Vous pouvez remplacer cet espace de noms en définissant l'option LeaderElectionNamespace pour le gestionnaire.
5.15. Utilitaire d'élagage d'objets pour les opérateurs basés sur Go
L'utilitaire d'élagage operator-lib permet aux opérateurs basés sur Go de nettoyer, ou d'élaguer, les objets lorsqu'ils ne sont plus nécessaires. Les auteurs d'opérateurs peuvent également utiliser l'utilitaire pour créer des crochets et des stratégies personnalisés.
5.15.1. À propos de l'utilitaire d'élagage operator-lib
Les objets, tels que les jobs ou les pods, sont créés dans le cadre normal du cycle de vie de l'opérateur. Si l'administrateur du cluster ou l'opérateur ne supprime pas ces objets, ils peuvent rester dans le cluster et consommer des ressources.
Auparavant, les options suivantes étaient disponibles pour élaguer les objets inutiles :
- Les auteurs d'opérateurs ont dû créer une solution d'élagage unique pour leurs opérateurs.
- Les administrateurs de clusters devaient nettoyer les objets eux-mêmes.
L'utilitaire d'élagage operator-lib supprime les objets d'un cluster Kubernetes pour un espace de noms donné. La bibliothèque a été ajoutée à la version 0.9.0 de la bibliothèqueoperator-lib dans le cadre de l'Operator Framework.
5.15.2. Configuration de l'utilitaire d'élagage
L'utilitaire d'élagage operator-lib est écrit en Go et comprend des stratégies d'élagage courantes pour les opérateurs basés sur Go.
Exemple de configuration
cfg = Config{
log: logf.Log.WithName("prune"),
DryRun: false,
Clientset: client,
LabelSelector: "app=<operator_name>",
Resources: []schema.GroupVersionKind{
{Group: "", Version: "", Kind: PodKind},
},
Namespaces: []string{"default"},
Strategy: StrategyConfig{
Mode: MaxCountStrategy,
MaxCountSetting: 1,
},
PreDeleteHook: myhook,
}Le fichier de configuration de l'utilitaire d'élagage définit les actions d'élagage à l'aide des champs suivants :
| Champ de configuration | Description |
|---|---|
|
| Logger utilisé pour gérer les messages de la bibliothèque. |
|
|
Booléen qui détermine si les ressources doivent être supprimées. S'il vaut |
|
| Client-go Kubernetes ClientSet utilisé pour les appels à l'API Kubernetes. |
|
| Expression du sélecteur de label Kubernetes utilisée pour trouver les ressources à élaguer. |
|
|
Types de ressources Kubernetes. |
|
| Liste des espaces de noms Kubernetes pour rechercher des ressources. |
|
| Stratégie d'élagage à exécuter. |
|
|
|
|
|
Valeur entière pour |
|
|
Go |
|
| Carte des valeurs qui peuvent être transmises à une fonction de stratégie personnalisée. |
|
| Facultatif : Fonction Go à appeler avant d'élaguer une ressource. |
|
| Facultatif : Fonction Go qui met en œuvre une stratégie d'élagage personnalisée |
Exécution de l'élagage
Vous pouvez appeler l'action d'élagage en exécutant la fonction execute sur la configuration d'élagage.
err := cfg.Execute(ctx)Vous pouvez également appeler une action d'élagage en utilisant un paquet cron ou en appelant l'utilitaire d'élagage avec un événement déclencheur.
5.16. Migration des projets de manifestes de paquets vers le format bundle
La prise en charge de l'ancienne version de package manifest format pour les opérateurs est supprimée dans OpenShift Container Platform 4.8 et les versions ultérieures. Si vous avez un projet Operator qui a été initialement créé à l'aide du format package manifest, vous pouvez utiliser le SDK Operator pour migrer le projet vers le format bundle. Le format bundle est le format d'emballage préféré pour Operator Lifecycle Manager (OLM) à partir d'OpenShift Container Platform 4.6.
5.16.1. À propos de la migration des formats d'emballage
La commande Operator SDK pkgman-to-bundle permet de migrer les manifestes de paquets d'Operator Lifecycle Manager (OLM) vers des paquets. La commande prend un répertoire de manifestes de paquets en entrée et génère des bundles pour chacune des versions de manifestes présentes dans le répertoire d'entrée. Vous pouvez également créer des images de bundle pour chacun des bundles générés.
Par exemple, considérons le répertoire packagemanifests/ suivant pour un projet au format "package manifest" :
Exemple de format de manifeste de paquet
packagemanifests/
└── etcd
├── 0.0.1
│ ├── etcdcluster.crd.yaml
│ └── etcdoperator.clusterserviceversion.yaml
├── 0.0.2
│ ├── etcdbackup.crd.yaml
│ ├── etcdcluster.crd.yaml
│ ├── etcdoperator.v0.0.2.clusterserviceversion.yaml
│ └── etcdrestore.crd.yaml
└── etcd.package.yaml
Après avoir exécuté la migration, les bundles suivants sont générés dans le répertoire bundle/:
Exemple de présentation du format de la liasse
bundle/
├── bundle-0.0.1
│ ├── bundle.Dockerfile
│ ├── manifests
│ │ ├── etcdcluster.crd.yaml
│ │ ├── etcdoperator.clusterserviceversion.yaml
│ ├── metadata
│ │ └── annotations.yaml
│ └── tests
│ └── scorecard
│ └── config.yaml
└── bundle-0.0.2
├── bundle.Dockerfile
├── manifests
│ ├── etcdbackup.crd.yaml
│ ├── etcdcluster.crd.yaml
│ ├── etcdoperator.v0.0.2.clusterserviceversion.yaml
│ ├── etcdrestore.crd.yaml
├── metadata
│ └── annotations.yaml
└── tests
└── scorecard
└── config.yamlSur la base de cette présentation générée, les images des deux liasses sont également créées avec les noms suivants :
-
quay.io/example/etcd:0.0.1 -
quay.io/example/etcd:0.0.2
5.16.2. Migration d'un projet de manifeste de paquetage au format bundle
Les auteurs d'opérateurs peuvent utiliser le SDK Operator pour migrer un projet Operator au format manifeste de paquetage vers un projet au format bundle.
Conditions préalables
- Operator SDK CLI installé
- Projet d'opérateur initialement généré à l'aide de l'Operator SDK dans le format du manifeste de paquetage
Procédure
Utilisez le SDK Operator pour migrer votre projet de manifeste de paquetage vers le format de paquetage et générer des images de paquetage :
$ operator-sdk pkgman-to-bundle <package_manifests_dir> \1 [--output-dir <directory>] \2 --image-tag-base <image_name_base>3 - 1
- Indiquez l'emplacement du répertoire des manifestes du projet, par exemple
packagemanifests/oumanifests/. - 2
- Facultatif : Par défaut, les paquets générés sont écrits localement sur le disque dans le répertoire
bundle/. Vous pouvez utiliser l'option--output-dirpour spécifier un autre emplacement. - 3
- Définissez l'indicateur
--image-tag-basepour fournir la base du nom de l'image, par exemplequay.io/example/etcd, qui sera utilisée pour les paquets. Fournissez le nom sans balise, car la balise des images sera définie en fonction de la version de l'offre groupée. Par exemple, les noms des images de l'offre groupée complète sont générés au format<image_name_base>:<bundle_version>.
Vérification
Vérifiez que l'image générée s'exécute correctement :
$ operator-sdk run bundle <bundle_image_name>:<tag>Exemple de sortie
INFO[0025] Successfully created registry pod: quay-io-my-etcd-0-9-4 INFO[0025] Created CatalogSource: etcd-catalog INFO[0026] OperatorGroup "operator-sdk-og" created INFO[0026] Created Subscription: etcdoperator-v0-9-4-sub INFO[0031] Approved InstallPlan install-5t58z for the Subscription: etcdoperator-v0-9-4-sub INFO[0031] Waiting for ClusterServiceVersion "default/etcdoperator.v0.9.4" to reach 'Succeeded' phase INFO[0032] Waiting for ClusterServiceVersion "default/etcdoperator.v0.9.4" to appear INFO[0048] Found ClusterServiceVersion "default/etcdoperator.v0.9.4" phase: Pending INFO[0049] Found ClusterServiceVersion "default/etcdoperator.v0.9.4" phase: Installing INFO[0064] Found ClusterServiceVersion "default/etcdoperator.v0.9.4" phase: Succeeded INFO[0065] OLM has successfully installed "etcdoperator.v0.9.4"
5.17. Référence CLI du SDK de l'opérateur
L'interface de ligne de commande (CLI) de l'Operator SDK est un kit de développement conçu pour faciliter l'écriture d'opérateurs.
Syntaxe du CLI du SDK de l'opérateur
$ operator-sdk <command> [<subcommand>] [<argument>] [<flags>]Les auteurs d'opérateurs ayant un accès d'administrateur de cluster à un cluster basé sur Kubernetes (tel que OpenShift Container Platform) peuvent utiliser le CLI Operator SDK pour développer leurs propres opérateurs basés sur Go, Ansible ou Helm. Kubebuilder est intégré dans le SDK Operator en tant que solution d'échafaudage pour les opérateurs basés sur Go, ce qui signifie que les projets Kubebuilder existants peuvent être utilisés tels quels avec le SDK Operator et continuer à fonctionner.
5.17.1. liasse
La commande operator-sdk bundle gère les métadonnées du faisceau d'opérateurs.
5.17.1.1. valider
La sous-commande bundle validate valide une liasse d'opérateurs.
| Drapeau | Description |
|---|---|
|
|
Aide pour la sous-commande |
|
|
Outil permettant d'extraire et de décompresser les images de la liasse. Il n'est utilisé que lors de la validation d'une image de paquet. Les options disponibles sont |
|
| Liste de tous les validateurs optionnels disponibles. Lorsqu'il est défini, aucun validateur n'est exécuté. |
|
|
Sélecteur d'étiquettes pour sélectionner les validateurs optionnels à exécuter. Lorsqu'il est exécuté avec l'option |
5.17.2. nettoyage
La commande operator-sdk cleanup détruit et supprime les ressources créées pour un opérateur déployé avec la commande run.
| Drapeau | Description |
|---|---|
|
|
Aide pour la sous-commande |
|
|
Chemin d'accès au fichier |
|
| S'il est présent, l'espace de noms dans lequel la requête CLI doit être exécutée. |
|
|
Temps d'attente pour que la commande se termine avant d'échouer. La valeur par défaut est |
5.17.3. achèvement
La commande operator-sdk completion génère des compléments d'information sur l'interpréteur de commandes afin d'accélérer et de faciliter l'exécution des commandes de l'interface de programmation.
| Sous-commande | Description |
|---|---|
|
| Générer des complétions bash. |
|
| Générer des complétions zsh. |
| Drapeau | Description |
|---|---|
|
| Utilisation help output. |
Par exemple :
$ operator-sdk completion bashExemple de sortie
# bash completion for operator-sdk -*- shell-script -*-
...
# ex: ts=4 sw=4 et filetype=sh5.17.4. créer
La commande operator-sdk create est utilisée pour créer, ou scaffold, une API Kubernetes.
5.17.4.1. api
La sous-commande create api permet d'échafauder une API Kubernetes. La sous-commande doit être exécutée dans un projet qui a été initialisé avec la commande init.
| Drapeau | Description |
|---|---|
|
|
Aide pour la sous-commande |
5.17.5. générer
La commande operator-sdk generate invoque un générateur spécifique pour générer du code ou des manifestes.
5.17.5.1. liasse
La sous-commande generate bundle génère un ensemble de manifestes de bundle, de métadonnées et un fichier bundle.Dockerfile pour votre projet Operator.
En règle générale, vous exécutez d'abord la sous-commande generate kustomize manifests pour générer les bases Kustomize utilisées par la sous-commande generate bundle. Cependant, vous pouvez utiliser la commande make bundle dans un projet initialisé pour automatiser l'exécution de ces commandes dans l'ordre.
| Drapeau | Description |
|---|---|
|
|
Liste séparée par des virgules des canaux auxquels le paquet appartient. La valeur par défaut est |
|
|
Répertoire racine pour les manifestes |
|
| Le canal par défaut de la liasse. |
|
|
Répertoire racine pour les manifestes de l'opérateur, tels que les déploiements et RBAC. Ce répertoire est différent du répertoire transmis à l'indicateur |
|
|
Aide pour |
|
|
Répertoire à partir duquel lire une offre groupée existante. Ce répertoire est le parent du répertoire |
|
|
Répertoire contenant les bases de Kustomize et un fichier |
|
| Générer des manifestes de paquets. |
|
| Générer les métadonnées du bundle et le fichier Docker. |
|
| Répertoire dans lequel écrire le bundle. |
|
|
Remplacer les métadonnées du bundle et le fichier Docker s'ils existent. La valeur par défaut est |
|
| Nom du paquet pour la liasse. |
|
| Fonctionne en mode silencieux. |
|
| Rédiger un manifeste de liasse pour la sortie standard. |
|
| Version sémantique de l'opérateur dans la liasse générée. À définir uniquement lors de la création d'une nouvelle liasse ou de la mise à niveau de l'opérateur. |
5.17.5.2. personnaliser
La sous-commande generate kustomize contient des sous-commandes qui génèrent des données de personnalisation pour l'opérateur.
5.17.5.2.1. manifestes
La sous-commande generate kustomize manifests génère ou régénère des bases Kustomize et un fichier kustomization.yaml dans le répertoire config/manifests, qui sont utilisés pour construire des manifestes de bundle par d'autres commandes Operator SDK. Cette commande demande interactivement les métadonnées de l'interface utilisateur, un composant important des bases de manifeste, par défaut, à moins qu'une base n'existe déjà ou que vous n'ayez activé l'option --interactive=false.
| Drapeau | Description |
|---|---|
|
| Répertoire racine pour les définitions des types d'API. |
|
|
Aide pour |
|
| Répertoire contenant les fichiers Kustomize existants. |
|
|
Lorsque la valeur est |
|
| Répertoire où écrire les fichiers Kustomize. |
|
| Nom du paquet. |
|
| Fonctionne en mode silencieux. |
5.17.6. init
La commande operator-sdk init initialise un projet Operator et génère, ou scaffolds, un répertoire de projet par défaut pour le plugin donné.
Cette commande écrit les fichiers suivants :
- Fichier de licence type
-
PROJECTavec le domaine et le référentiel -
Makefilepour construire le projet -
go.modavec les dépendances du projet -
kustomization.yamlfichier pour personnaliser les manifestes - Fichier correctif pour la personnalisation des images des manifestes des gestionnaires
- Fichier correctif pour l'activation des métriques Prometheus
-
main.gopour exécuter
| Drapeau | Description |
|---|---|
|
|
Aide pour la commande |
|
|
Nom et éventuellement version du plugin avec lequel le projet doit être initialisé. Les plugins disponibles sont |
|
|
Version du projet. Les valeurs disponibles sont |
5.17.7. courir
La commande operator-sdk run propose des options qui permettent de lancer l'opérateur dans différents environnements.
5.17.7.1. liasse
La sous-commande run bundle déploie un opérateur au format bundle avec Operator Lifecycle Manager (OLM).
| Drapeau | Description |
|---|---|
|
|
Image d'index dans laquelle injecter un bundle. L'image par défaut est |
|
|
Mode d'installation pris en charge par la version du service de cluster (CSV) de l'opérateur, par exemple |
|
|
Délai d'installation. La valeur par défaut est |
|
|
Chemin d'accès au fichier |
|
| S'il est présent, l'espace de noms dans lequel la requête CLI doit être exécutée. |
|
|
Aide pour la sous-commande |
5.17.7.2. mise à niveau groupée
La sous-commande run bundle-upgrade met à niveau un opérateur précédemment installé au format bundle avec Operator Lifecycle Manager (OLM).
| Drapeau | Description |
|---|---|
|
|
Délai de mise à niveau. La valeur par défaut est |
|
|
Chemin d'accès au fichier |
|
| S'il est présent, l'espace de noms dans lequel la requête CLI doit être exécutée. |
|
|
Aide pour la sous-commande |
5.17.8. carte de pointage
La commande operator-sdk scorecard exécute l'outil scorecard pour valider un bundle Operator et fournir des suggestions d'amélioration. La commande prend un argument, soit une image de l'offre groupée, soit un répertoire contenant les manifestes et les métadonnées. Si l'argument contient une balise image, l'image doit être présente à distance.
| Drapeau | Description |
|---|---|
|
|
Chemin d'accès au fichier de configuration de la carte de score. Le chemin par défaut est |
|
|
Aide pour la commande |
|
|
Chemin d'accès au fichier |
|
| Liste des tests disponibles pour exécution. |
|
| Espace de noms dans lequel les images de test doivent être exécutées. |
|
|
Format de sortie des résultats. Les valeurs disponibles sont |
|
| Sélecteur d'étiquettes pour déterminer les tests à effectuer. |
|
|
Compte de service à utiliser pour les tests. La valeur par défaut est |
|
| Désactiver le nettoyage des ressources après l'exécution des tests. |
|
|
Nombre de secondes à attendre pour que les tests soient terminés, par exemple |
Chapitre 6. Référence des opérateurs de clusters
Ce guide de référence indexe le site cluster Operators fourni par Red Hat qui sert de base architecturale à OpenShift Container Platform. Les opérateurs de cluster sont installés par défaut, sauf indication contraire, et sont gérés par l'opérateur de version de cluster (CVO). Pour plus de détails sur l'architecture du plan de contrôle, voir Opérateurs dans OpenShift Container Platform.
Les administrateurs de clusters peuvent afficher les opérateurs de clusters dans la console web d'OpenShift Container Platform à partir de la page Administration → Cluster Settings.
Les opérateurs de cluster ne sont pas gérés par Operator Lifecycle Manager (OLM) et OperatorHub. OLM et OperatorHub font partie de l'Operator Framework utilisé dans OpenShift Container Platform pour l'installation et l'exécution d'opérateurs optionnels.
Certains des opérateurs de cluster suivants peuvent être désactivés avant l'installation. Pour plus d'informations, voir Capacités des clusters.
6.1. Opérateur Cluster Baremetal
L'opérateur de cluster baremetal est une fonctionnalité optionnelle de cluster qui peut être désactivée par les administrateurs de cluster lors de l'installation. Pour plus d'informations sur les fonctionnalités optionnelles des clusters, voir \N "Cluster capabilities" sur Installing.
Objectif
The Cluster Baremetal Operator (CBO) deploys all the components necessary to take a bare-metal server to a fully functioning worker node ready to run OpenShift Container Platform compute nodes. The CBO ensures that the metal3 deployment, which consists of the Bare Metal Operator (BMO) and Ironic containers, runs on one of the control plane nodes within the OpenShift Container Platform cluster. The CBO also listens for OpenShift Container Platform updates to resources that it watches and takes appropriate action.
Projet
6.2. Relais d'événements Bare Metal
Objectif
OpenShift Bare Metal Event Relay gère le cycle de vie du Bare Metal Event Relay. Le relais d'événements Bare Metal vous permet de configurer les types d'événements de cluster qui sont surveillés à l'aide des événements matériels Redfish.
Objets de configuration
Vous pouvez utiliser cette commande pour modifier la configuration après l'installation : par exemple, le port webhook. Vous pouvez éditer les objets de configuration avec :
$ oc -n [namespace] edit cm hw-event-proxy-operator-manager-configapiVersion: controller-runtime.sigs.k8s.io/v1alpha1
kind: ControllerManagerConfig
health:
healthProbeBindAddress: :8081
metrics:
bindAddress: 127.0.0.1:8080
webhook:
port: 9443
leaderElection:
leaderElect: true
resourceName: 6e7a703c.redhat-cne.orgProjet
CRD
Le proxy permet aux applications fonctionnant sur des clusters "bare-metal" de répondre rapidement aux changements et aux défaillances du matériel Redfish, tels que les dépassements de seuils de température, les pannes de ventilateur, les pertes de disque, les coupures de courant et les pannes de mémoire, signalés à l'aide du CR HardwareEvent.
hardwareevents.event.redhat-cne.org:
- Champ d'application : Espace nominatif
- CR : HardwareEvent
- Validation : Oui
6.3. Opérateur de certificats dans le nuage
Objectif
Le Cloud Credential Operator (CCO) gère les informations d'identification des fournisseurs de cloud en tant que définitions de ressources personnalisées (CRD) de Kubernetes. Le CCO se synchronise sur CredentialsRequest custom resources (CRs) pour permettre aux composants d'OpenShift Container Platform de demander des informations d'identification de fournisseur de cloud avec les autorisations spécifiques requises pour le fonctionnement du cluster.
En définissant différentes valeurs pour le paramètre credentialsMode dans le fichier install-config.yaml, le CCO peut être configuré pour fonctionner dans plusieurs modes différents. Si aucun mode n'est spécifié ou si le paramètre credentialsMode est défini comme une chaîne vide (""), l'OCC fonctionne dans son mode par défaut.
Projet
openshift-cloud-credential-operator
CRDs
credentialsrequests.cloudcredential.openshift.io- Champ d'application : Espace nominatif
-
CR :
CredentialsRequest - Validation : Oui
Objets de configuration
Aucune configuration n'est nécessaire.
Ressources supplémentaires
6.4. Opérateur d'authentification de cluster
Objectif
L'opérateur d'authentification de cluster installe et maintient la ressource personnalisée Authentication dans un cluster et peut être visualisé avec :
$ oc get clusteroperator authentication -o yamlProjet
6.5. Opérateur Cluster Autoscaler
Objectif
Le Cluster Autoscaler Operator gère les déploiements de l'OpenShift Cluster Autoscaler à l'aide du fournisseur cluster-api.
Projet
CRDs
-
ClusterAutoscaler: Il s'agit d'une ressource unique qui contrôle l'instance de configuration autoscaler pour le cluster. L'opérateur ne répond qu'à la ressourceClusterAutoscalernomméedefaultdans l'espace de noms géré, la valeur de la variable d'environnementWATCH_NAMESPACE. -
MachineAutoscaler: Cette ressource cible un groupe de nœuds et gère les annotations permettant d'activer et de configurer l'autoscaling pour ce groupe, la taille deminetmax. Actuellement, seuls les objetsMachineSetpeuvent être ciblés.
6.6. Cluster Cloud Controller Manager Operator
Objectif
Cet opérateur n'est entièrement pris en charge que pour Microsoft Azure Stack Hub.
Il est disponible en avant-première technologique pour Alibaba Cloud, Amazon Web Services (AWS), Google Cloud Platform (GCP), IBM Cloud, IBM Cloud Power VS, Microsoft Azure, Red Hat OpenStack Platform (RHOSP) et VMware vSphere.
Le Cluster Cloud Controller Manager Operator gère et met à jour les gestionnaires de contrôleurs de nuages déployés sur OpenShift Container Platform. L'opérateur est basé sur le cadre Kubebuilder et les bibliothèques controller-runtime. Il est installé via le Cluster Version Operator (CVO). Il est installé via le Cluster Version Operator (CVO).
Il contient les éléments suivants :
- Opérateur
- Observateur de la configuration du nuage
Par défaut, l'opérateur expose les mesures Prometheus via le service metrics.
Projet
6.7. Opérateur CAPI de groupe
Cet opérateur est disponible en tant qu'aperçu technologique pour Amazon Web Services (AWS) et Google Cloud Platform (GCP).
Objectif
L'Opérateur CAPI Cluster maintient le cycle de vie des ressources API Cluster. Cet opérateur est responsable de toutes les tâches administratives liées au déploiement du projet Cluster API au sein d'un cluster OpenShift Container Platform.
Projet
CRDs
awsmachines.infrastructure.cluster.x-k8s.io- Champ d'application : Espace nominatif
-
CR :
awsmachine - Validation : Non
gcpmachines.infrastructure.cluster.x-k8s.io- Champ d'application : Espace nominatif
-
CR :
gcpmachine - Validation : Non
awsmachinetemplates.infrastructure.cluster.x-k8s.io- Champ d'application : Espace nominatif
-
CR :
awsmachinetemplate - Validation : Non
gcpmachinetemplates.infrastructure.cluster.x-k8s.io- Champ d'application : Espace nominatif
-
CR :
gcpmachinetemplate - Validation : Non
6.8. Opérateur de configuration de cluster
Objectif
L'opérateur de configuration de cluster effectue les tâches suivantes liées à config.openshift.io:
- Crée des CRD.
- Rend les ressources personnalisées initiales.
- Gère les migrations.
Projet
6.9. Cluster CSI Snapshot Controller Operator
L'opérateur de contrôleur de cliché CSI de cluster est une fonctionnalité de cluster optionnelle qui peut être désactivée par les administrateurs de cluster lors de l'installation. Pour plus d'informations sur les capacités optionnelles des clusters, voir \N "Cluster capabilities" sur Installing.
Objectif
The Cluster CSI Snapshot Controller Operator installs and maintains the CSI Snapshot Controller. The CSI Snapshot Controller is responsible for watching the VolumeSnapshot CRD objects and manages the creation and deletion lifecycle of volume snapshots.
Projet
6.10. Opérateur de registre d'images de grappes
Objectif
Le Cluster Image Registry Operator gère une instance unique du registre d'images OpenShift. Il gère toute la configuration du registre, y compris la création du stockage.
Lors du démarrage initial, l'opérateur crée une instance de ressource image-registry par défaut en fonction de la configuration détectée dans le cluster. Cette instance indique le type de stockage en nuage à utiliser en fonction du fournisseur de nuage.
Si les informations disponibles sont insuffisantes pour définir une ressource image-registry complète, une ressource incomplète est définie et l'opérateur met à jour l'état de la ressource en indiquant les informations manquantes.
L'opérateur de registre d'images de cluster s'exécute dans l'espace de noms openshift-image-registry et gère également l'instance de registre à cet emplacement. Toutes les ressources de configuration et de charge de travail pour le registre résident dans cet espace de noms.
Projet
6.11. Opérateur de l'approbateur de la machine à grappes
Objectif
L'opérateur d'approbation des machines de cluster approuve automatiquement les CSR demandés pour un nouveau nœud de travail après l'installation du cluster.
Pour le nœud du plan de contrôle, le service approve-csr du nœud de démarrage approuve automatiquement tous les CSR pendant la phase de démarrage du cluster.
Projet
6.12. Opérateur de suivi de groupe
Objectif
L'opérateur de surveillance des clusters gère et met à jour la pile de surveillance des clusters basée sur Prometheus et déployée au-dessus d'OpenShift Container Platform.
Projet
CRDs
alertmanagers.monitoring.coreos.com- Champ d'application : Espace nominatif
-
CR :
alertmanager - Validation : Oui
prometheuses.monitoring.coreos.com- Champ d'application : Espace nominatif
-
CR :
prometheus - Validation : Oui
prometheusrules.monitoring.coreos.com- Champ d'application : Espace nominatif
-
CR :
prometheusrule - Validation : Oui
servicemonitors.monitoring.coreos.com- Champ d'application : Espace nominatif
-
CR :
servicemonitor - Validation : Oui
Objets de configuration
$ oc -n openshift-monitoring edit cm cluster-monitoring-config6.13. Opérateur de réseau en grappe
Objectif
L'opérateur de réseau de cluster installe et met à niveau les composants de réseau sur un cluster OpenShift Container Platform.
6.14. Opérateur d'échantillons groupés
L'opérateur d'échantillonnage de cluster est une fonctionnalité de cluster optionnelle qui peut être désactivée par les administrateurs de cluster lors de l'installation. Pour plus d'informations sur les fonctionnalités optionnelles des clusters, voir "Cluster capabilities" sur Installing.
Objectif
The Cluster Samples Operator manages the sample image streams and templates stored in the openshift namespace.
On initial start up, the Operator creates the default samples configuration resource to initiate the creation of the image streams and templates. The configuration object is a cluster scoped object with the key cluster and type configs.samples.
The image streams are the Red Hat Enterprise Linux CoreOS (RHCOS)-based OpenShift Container Platform image streams pointing to images on registry.redhat.io. Similarly, the templates are those categorized as OpenShift Container Platform templates.
Le déploiement de Cluster Samples Operator est contenu dans l'espace de noms openshift-cluster-samples-operator. Au démarrage, le secret d'installation est utilisé par la logique d'importation de flux d'images dans le registre d'images OpenShift et le serveur API pour s'authentifier auprès de registry.redhat.io. Un administrateur peut créer des secrets supplémentaires dans l'espace de noms openshift s'il modifie le registre utilisé pour les exemples de flux d'images. S'ils sont créés, ces secrets contiennent le contenu d'un config.json pour docker nécessaire pour faciliter l'importation d'images.
L'image de l'opérateur d'échantillons de clusters contient des définitions de flux d'images et de modèles pour la version d'OpenShift Container Platform associée. Une fois que l'opérateur d'échantillons de clusters a créé un échantillon, il ajoute une annotation qui indique la version d'OpenShift Container Platform avec laquelle il est compatible. L'opérateur utilise cette annotation pour s'assurer que chaque échantillon correspond à la version compatible. Les échantillons qui ne font pas partie de son inventaire sont ignorés, tout comme les échantillons ignorés.
Les modifications apportées aux échantillons gérés par l'opérateur sont autorisées tant que l'annotation de la version n'est pas modifiée ou supprimée. Cependant, lors d'une mise à niveau, l'annotation de la version changeant, ces modifications peuvent être remplacées car l'échantillon est mis à jour avec la version la plus récente. Les images Jenkins font partie de la charge utile de l'installation et sont directement marquées dans les flux d'images.
La ressource échantillons comprend un finalisateur, qui nettoie les éléments suivants lors de leur suppression :
- Flux d'images gérés par l'opérateur
- Modèles gérés par l'opérateur
- Ressources de configuration générées par l'opérateur
- Ressources sur l'état des clusters
Lors de la suppression de la ressource d'échantillons, l'opérateur de cluster d'échantillons recrée la ressource en utilisant la configuration par défaut.
Projet
6.15. Opérateur de stockage en grappe
L'opérateur de stockage en grappe est une fonctionnalité de grappe optionnelle qui peut être désactivée par les administrateurs de grappe lors de l'installation. Pour plus d'informations sur les fonctionnalités optionnelles des clusters, voir "Cluster capabilities" sur Installing.
Objectif
The Cluster Storage Operator sets OpenShift Container Platform cluster-wide storage defaults. It ensures a default storageclass exists for OpenShift Container Platform clusters. It also installs Container Storage Interface (CSI) drivers which enable your cluster to use various storage backends.
Projet
opérateur de stockage en grappe
Configuration
Aucune configuration n'est nécessaire.
Notes
- The storage class that the Operator creates can be made non-default by editing its annotation, but this storage class cannot be deleted as long as the Operator runs.
6.16. Opérateur de version de cluster
Objectif
Les opérateurs de cluster gèrent des domaines spécifiques de la fonctionnalité du cluster. L'opérateur de version de cluster (CVO) gère le cycle de vie des opérateurs de cluster, dont beaucoup sont installés par défaut dans OpenShift Container Platform.
L'OVE vérifie également avec le service de mise à jour OpenShift pour voir les mises à jour valides et les chemins de mise à jour basés sur les versions actuelles des composants et les informations dans le graphique.
Projet
6.17. Opérateur de console
L'opérateur de console est une fonctionnalité optionnelle de la grappe qui peut être désactivée par les administrateurs de la grappe lors de l'installation. Si vous désactivez l'opérateur de console lors de l'installation, votre grappe est toujours prise en charge et peut être mise à niveau. Pour plus d'informations sur les fonctionnalités optionnelles des clusters, voir "Cluster capabilities" à l'adresse Installing.
Objectif
The Console Operator installs and maintains the OpenShift Container Platform web console on a cluster. The Console Operator is installed by default and automatically maintains a console.
Projet
6.18. Opérateur d'ensemble de machine à plan de contrôle
Cet opérateur est disponible pour Amazon Web Services (AWS), Microsoft Azure et VMware vSphere.
Objectif
Le Control Plane Machine Set Operator automatise la gestion des ressources des machines du plan de contrôle au sein d'un cluster OpenShift Container Platform.
Projet
cluster-control-plane-machine-set-operator
CRDs
controlplanemachineset.machine.openshift.io- Champ d'application : Espace nominatif
-
CR :
ControlPlaneMachineSet - Validation : Oui
Ressources supplémentaires
6.19. Opérateur DNS
Objectif
L'opérateur DNS déploie et gère CoreDNS pour fournir un service de résolution de noms aux pods qui permet la découverte de services Kubernetes basés sur le DNS dans OpenShift Container Platform.
L'opérateur crée un déploiement par défaut fonctionnel basé sur la configuration du cluster.
-
Le domaine de cluster par défaut est
cluster.local. - La configuration du CoreDNS Corefile ou du plugin Kubernetes n'est pas encore prise en charge.
L'opérateur DNS gère CoreDNS comme un ensemble de démons Kubernetes exposé comme un service avec une IP statique. CoreDNS fonctionne sur tous les nœuds du cluster.
Projet
6.20. cluster etcd Opérateur
Objectif
L'opérateur de cluster etcd automatise la mise à l'échelle du cluster etcd, permet la surveillance et les mesures du cluster etcd et simplifie les procédures de reprise après sinistre.
Projet
CRDs
etcds.operator.openshift.io- Champ d'application : Groupement d'entreprises
-
CR :
etcd - Validation : Oui
Objets de configuration
$ oc edit etcd cluster6.21. Opérateur d'entrée
Objectif
L'opérateur d'entrée configure et gère le routeur OpenShift Container Platform.
Projet
CRDs
clusteringresses.ingress.openshift.io- Champ d'application : Espace nominatif
-
CR :
clusteringresses - Validation : Non
Objets de configuration
Configuration du cluster
-
Nom du type :
clusteringresses.ingress.openshift.io -
Nom de l'instance :
default Voir la commande :
$ oc get clusteringresses.ingress.openshift.io -n openshift-ingress-operator default -o yaml
-
Nom du type :
Notes
L'opérateur d'entrée configure le routeur dans le projet openshift-ingress et crée le déploiement pour le routeur :
$ oc get deployment -n openshift-ingress
L'opérateur d'entrée utilise l'adresse clusterNetwork[].cidr de l'état network/cluster pour déterminer le mode (IPv4, IPv6 ou double pile) dans lequel le contrôleur d'entrée géré (routeur) doit fonctionner. Par exemple, si clusterNetwork ne contient qu'un cidr v6, le contrôleur d'entrée fonctionne en mode IPv6 uniquement.
Dans l'exemple suivant, les contrôleurs d'entrée gérés par l'opérateur d'entrée fonctionneront en mode IPv4 uniquement, car il n'existe qu'un seul réseau de cluster, qui est un réseau IPv4 cidr:
$ oc get network/cluster -o jsonpath='{.status.clusterNetwork[*]}'Exemple de sortie
map[cidr:10.128.0.0/14 hostPrefix:23]6.22. Opérateur Insights
L'opérateur Insights est une fonctionnalité optionnelle de la grappe qui peut être désactivée par les administrateurs de la grappe lors de l'installation. Pour plus d'informations sur les capacités optionnelles des clusters, voir \N "Cluster capabilities" sur Installing.
Objectif
The Insights Operator gathers OpenShift Container Platform configuration data and sends it to Red Hat. The data is used to produce proactive insights recommendations about potential issues that a cluster might be exposed to. These insights are communicated to cluster administrators through Insights Advisor on console.redhat.com.
Projet
Configuration
Aucune configuration n'est nécessaire.
Notes
Insights Operator complements OpenShift Container Platform Telemetry.
6.23. Opérateur de serveur API Kubernetes
Objectif
L'opérateur du serveur API Kubernetes gère et met à jour le serveur API Kubernetes déployé au-dessus d'OpenShift Container Platform. L'opérateur est basé sur le cadre OpenShift Container Platform library-go et il est installé à l'aide de l'opérateur de version de cluster (CVO).
Projet
openshift-kube-apiserver-operator
CRDs
kubeapiservers.operator.openshift.io- Champ d'application : Groupement d'entreprises
-
CR :
kubeapiserver - Validation : Oui
Objets de configuration
$ oc edit kubeapiserver6.24. Opérateur Kubernetes Controller Manager
Objectif
L'opérateur du gestionnaire de contrôleur Kubernetes gère et met à jour le gestionnaire de contrôleur Kubernetes déployé au-dessus d'OpenShift Container Platform. L'opérateur est basé sur le cadre OpenShift Container Platform library-go et il est installé via l'opérateur de version de cluster (CVO).
Il contient les éléments suivants :
- Opérateur
- Rendu du manifeste Bootstrap
- Installateur basé sur des pods statiques
- Observateur de la configuration
Par défaut, l'opérateur expose les mesures Prometheus via le service metrics.
Projet
6.25. Opérateur de l'ordonnanceur Kubernetes
Objectif
Le Kubernetes Scheduler Operator gère et met à jour le Kubernetes Scheduler déployé au-dessus d'OpenShift Container Platform. L'opérateur est basé sur le cadre OpenShift Container Platform library-go et il est installé avec le Cluster Version Operator (CVO).
L'opérateur du planificateur Kubernetes contient les composants suivants :
- Opérateur
- Rendu du manifeste Bootstrap
- Installateur basé sur des pods statiques
- Observateur de la configuration
Par défaut, l'opérateur expose les métriques Prometheus par l'intermédiaire du service de métrologie.
Projet
cluster-kube-scheduler-operator
Configuration
La configuration du planificateur Kubernetes est le résultat d'une fusion :
- une configuration par défaut.
-
une configuration observée du spec
schedulers.config.openshift.io.
Il s'agit dans tous les cas de configurations éparses, de bribes JSON invalidées qui sont fusionnées pour former une configuration valide à la fin.
6.26. Opérateur de migration de version de stockage Kubernetes
Objectif
L'opérateur Kubernetes Storage Version Migrator détecte les changements de la version de stockage par défaut, crée des demandes de migration pour les types de ressources lorsque la version de stockage change, et traite les demandes de migration.
Projet
6.27. Opérateur API machine
Objectif
L'opérateur API Machine gère le cycle de vie des définitions de ressources personnalisées (CRD), des contrôleurs et des objets RBAC à usage spécifique qui étendent l'API Kubernetes. Il déclare l'état souhaité des machines dans un cluster.
Projet
CRDs
-
MachineSet -
Machine -
MachineHealthCheck
6.28. Machine Config Operator
Objectif
L'opérateur de configuration des machines gère et applique la configuration et les mises à jour du système d'exploitation de base et de l'exécution des conteneurs, y compris tout ce qui se trouve entre le noyau et le kubelet.
Il y a quatre composantes :
-
machine-config-server: Fournit la configuration d'Ignition aux nouvelles machines qui rejoignent le cluster. -
machine-config-controller: Coordonne la mise à niveau des machines vers les configurations souhaitées définies par un objetMachineConfig. Des options sont fournies pour contrôler la mise à niveau d'ensembles de machines individuellement. -
machine-config-daemon: Applique la nouvelle configuration de la machine pendant la mise à jour. Valide et vérifie l'état de la machine par rapport à la configuration demandée. -
machine-config: Fournit une source complète de configuration de la machine lors de l'installation, du premier démarrage et des mises à jour d'une machine.
Currently, there is no supported way to block or restrict the machine config server endpoint. The machine config server must be exposed to the network so that newly-provisioned machines, which have no existing configuration or state, are able to fetch their configuration. In this model, the root of trust is the certificate signing requests (CSR) endpoint, which is where the kubelet sends its certificate signing request for approval to join the cluster. Because of this, machine configs should not be used to distribute sensitive information, such as secrets and certificates.
To ensure that the machine config server endpoints, ports 22623 and 22624, are secured in bare metal scenarios, customers must configure proper network policies.
Ressources supplémentaires
Projet
6.29. Opérateur de marché
L'opérateur de place de marché est une fonctionnalité optionnelle de la grappe qui peut être désactivée par les administrateurs de la grappe si elle n'est pas nécessaire. Pour plus d'informations sur les capacités optionnelles des clusters, voir \N "Cluster capabilities" sur Installing.
Objectif
The Marketplace Operator simplifies the process for bringing off-cluster Operators to your cluster by using a set of default Operator Lifecycle Manager (OLM) catalogs on the cluster. When the Marketplace Operator is installed, it creates the openshift-marketplace namespace. OLM ensures catalog sources installed in the openshift-marketplace namespace are available for all namespaces on the cluster.
Projet
6.30. Opérateur de réglage des nœuds
Objectif
L'opérateur d'optimisation des nœuds vous aide à gérer l'optimisation au niveau des nœuds en orchestrant le démon TuneD et à obtenir des performances à faible latence en utilisant le contrôleur de profil de performance. La majorité des applications à hautes performances nécessitent un certain niveau de réglage du noyau. Le Node Tuning Operator offre une interface de gestion unifiée aux utilisateurs de sysctls au niveau des nœuds et plus de flexibilité pour ajouter des réglages personnalisés en fonction des besoins de l'utilisateur.
L'opérateur gère le démon TuneD conteneurisé pour OpenShift Container Platform en tant qu'ensemble de démons Kubernetes. Il s'assure que la spécification de réglage personnalisé est transmise à tous les démons TuneD conteneurisés s'exécutant dans le cluster dans le format que les démons comprennent. Les démons s'exécutent sur tous les nœuds du cluster, un par nœud.
Les paramètres de niveau nœud appliqués par le démon TuneD conteneurisé sont annulés lors d'un événement qui déclenche un changement de profil ou lorsque le démon TuneD conteneurisé se termine de manière élégante en recevant et en gérant un signal de fin.
L'opérateur de réglage des nœuds utilise le contrôleur de profil de performance pour mettre en œuvre un réglage automatique afin d'obtenir des performances de faible latence pour les applications OpenShift Container Platform. L'administrateur du cluster configure un profil de performance pour définir des paramètres au niveau du nœud, tels que les suivants :
- Mise à jour du noyau vers kernel-rt.
- Choix des unités centrales de traitement pour l'entretien ménager.
- Choix des unités centrales pour l'exécution des charges de travail.
Actuellement, la désactivation de l'équilibrage de la charge du CPU n'est pas prise en charge par cgroup v2. Par conséquent, il se peut que vous n'obteniez pas le comportement souhaité des profils de performance si vous avez activé cgroup v2. L'activation de cgroup v2 n'est pas recommandée si vous utilisez des profils de performance.
L'opérateur Node Tuning fait partie de l'installation standard d'OpenShift Container Platform à partir de la version 4.1.
Dans les versions antérieures d'OpenShift Container Platform, l'opérateur Performance Addon était utilisé pour mettre en œuvre un réglage automatique afin d'obtenir des performances de faible latence pour les applications OpenShift. Dans OpenShift Container Platform 4.11 et les versions ultérieures, cette fonctionnalité fait partie de l'opérateur Node Tuning.
Projet
opérateur de réglage des nœuds de cluster
Ressources supplémentaires
6.31. Opérateur de serveur API OpenShift
Objectif
L'opérateur OpenShift API Server installe et maintient le site openshift-apiserver sur un cluster.
Projet
CRDs
openshiftapiservers.operator.openshift.io- Champ d'application : Groupement d'entreprises
-
CR :
openshiftapiserver - Validation : Oui
6.32. Opérateur du gestionnaire de contrôleur OpenShift
Objectif
L'opérateur OpenShift Controller Manager installe et maintient la ressource personnalisée OpenShiftControllerManager dans un cluster et peut être visualisé avec :
$ oc get clusteroperator openshift-controller-manager -o yaml
Le custom resource definitino (CRD) openshiftcontrollermanagers.operator.openshift.io peut être visualisé dans un cluster avec :
$ oc get crd openshiftcontrollermanagers.operator.openshift.io -o yamlProjet
6.33. Gestionnaire du cycle de vie des opérateurs Opérateurs
Objectif
Operator Lifecycle Manager (OLM) aide les utilisateurs à installer, mettre à jour et gérer le cycle de vie des applications natives Kubernetes (Operators) et de leurs services associés s'exécutant sur leurs clusters OpenShift Container Platform. Il fait partie de l'Operator Framework, une boîte à outils open source conçue pour gérer les opérateurs de manière efficace, automatisée et évolutive.
Figure 6.1. Flux de travail du gestionnaire du cycle de vie de l'opérateur
OLM fonctionne par défaut dans OpenShift Container Platform 4.12, ce qui aide les administrateurs de clusters à installer, mettre à niveau et accorder l'accès aux opérateurs fonctionnant sur leur cluster. La console web d'OpenShift Container Platform fournit des écrans de gestion permettant aux administrateurs de cluster d'installer des opérateurs, ainsi que d'accorder à des projets spécifiques l'accès à l'utilisation du catalogue d'opérateurs disponibles sur le cluster.
Pour les développeurs, une expérience en libre-service permet de provisionner et de configurer des instances de bases de données, de surveillance et de services de big data sans avoir à être des experts en la matière, car l'opérateur dispose de ces connaissances.
CRDs
Le gestionnaire du cycle de vie des opérateurs (OLM) est composé de deux opérateurs : l'opérateur OLM et l'opérateur de catalogue.
Chacun de ces opérateurs est responsable de la gestion des définitions de ressources personnalisées (CRD) qui constituent la base du cadre OLM :
| Ressources | Nom court | Propriétaire | Description |
|---|---|---|---|
|
|
| OLM | Métadonnées de l'application : nom, version, icône, ressources nécessaires, installation, etc. |
|
|
| Catalogue | Liste calculée des ressources à créer pour installer ou mettre à jour automatiquement un CSV. |
|
|
| Catalogue | Un référentiel de CSV, CRD et paquets qui définissent une application. |
|
|
| Catalogue | Utilisé pour maintenir les CSV à jour en suivant un canal dans un paquet. |
|
|
| OLM |
Configure tous les opérateurs déployés dans le même espace de noms que l'objet |
Chacun de ces opérateurs est également responsable de la création des ressources suivantes :
| Ressources | Propriétaire |
|---|---|
|
| OLM |
|
| |
|
| |
|
| |
|
| Catalogue |
|
|
Opérateur OLM
L'opérateur OLM est chargé de déployer les applications définies par les ressources CSV une fois que les ressources requises spécifiées dans le CSV sont présentes dans le cluster.
L'opérateur OLM ne s'occupe pas de la création des ressources nécessaires ; vous pouvez choisir de créer manuellement ces ressources à l'aide du CLI ou de l'opérateur de catalogue. Cette séparation des préoccupations permet aux utilisateurs de s'approprier progressivement la partie du cadre OLM qu'ils choisissent d'exploiter pour leur application.
L'opérateur OLM utilise le flux de travail suivant :
- Surveillez les versions de service de cluster (CSV) dans un espace de noms et vérifiez que les exigences sont respectées.
Si les conditions sont remplies, exécutez la stratégie d'installation pour le CSV.
NoteUn CSV doit être un membre actif d'un groupe d'opérateurs pour que la stratégie d'installation s'exécute.
Opérateur de catalogue
L'opérateur de catalogue est responsable de la résolution et de l'installation des versions de service de cluster (CSV) et des ressources requises qu'elles spécifient. Il est également chargé de surveiller les sources du catalogue pour détecter les mises à jour des paquets dans les canaux et de les mettre à niveau, automatiquement si nécessaire, vers les dernières versions disponibles.
Pour suivre un paquet dans un canal, vous pouvez créer un objet Subscription configurant le paquet souhaité, le canal et l'objet CatalogSource que vous souhaitez utiliser pour extraire les mises à jour. Lorsque des mises à jour sont trouvées, un objet InstallPlan approprié est écrit dans l'espace de noms au nom de l'utilisateur.
L'opérateur de catalogue utilise le flux de travail suivant :
- Connectez-vous à chaque source de catalogue dans le cluster.
Rechercher les plans d'installation non résolus créés par un utilisateur et, le cas échéant, les trouver :
- Rechercher le fichier CSV correspondant au nom demandé et l'ajouter en tant que ressource résolue.
- Pour chaque CRD géré ou requis, ajouter le CRD en tant que ressource résolue.
- Pour chaque CRD requis, trouvez le CSV qui le gère.
- Surveillez les plans d'installation résolus et créez toutes les ressources découvertes, si elles ont été approuvées par un utilisateur ou automatiquement.
- Surveillez les sources et les abonnements du catalogue et créez des plans d'installation basés sur ces sources et abonnements.
Registre du catalogue
Le registre de catalogue stocke les CSV et les CRD pour la création dans un cluster et stocke les métadonnées sur les paquets et les canaux.
Un site package manifest est une entrée dans le registre du catalogue qui associe une identité de paquet à des ensembles de CSV. Au sein d'un paquet, les canaux pointent vers un CSV particulier. Comme les CSV font explicitement référence au CSV qu'ils remplacent, un manifeste de paquet fournit à l'opérateur de catalogue toutes les informations nécessaires pour mettre à jour un CSV vers la dernière version d'un canal, en passant par chaque version intermédiaire.
Ressources supplémentaires
- Pour plus d'informations, voir les sections relatives à la compréhension du gestionnaire du cycle de vie des opérateurs (OLM).
6.34. OpenShift Service CA Operator
Objectif
L'OpenShift Service CA Operator frappe et gère les certificats de service pour les services Kubernetes.
Projet
6.35. opérateur vSphere Problem Detector
Objectif
The vSphere Problem Detector Operator checks clusters that are deployed on vSphere for common installation and misconfiguration issues that are related to storage.
L'opérateur vSphere Problem Detector n'est lancé par l'opérateur de stockage en cluster que lorsque ce dernier détecte que le cluster est déployé sur vSphere.
Configuration
Aucune configuration n'est nécessaire.
Notes
- L'opérateur prend en charge les installations d'OpenShift Container Platform sur vSphere.
-
L'opérateur utilise le site
vsphere-cloud-credentialspour communiquer avec vSphere. - L'opérateur effectue des contrôles liés au stockage.
Legal Notice
Copyright © Red Hat
OpenShift documentation is licensed under the Apache License 2.0 (https://www.apache.org/licenses/LICENSE-2.0).
Modified versions must remove all Red Hat trademarks.
Portions adapted from https://github.com/kubernetes-incubator/service-catalog/ with modifications by Red Hat.
Red Hat, Red Hat Enterprise Linux, the Red Hat logo, the Shadowman logo, JBoss, OpenShift, Fedora, the Infinity logo, and RHCE are trademarks of Red Hat, Inc., registered in the United States and other countries.
Linux® is the registered trademark of Linus Torvalds in the United States and other countries.
Java® is a registered trademark of Oracle and/or its affiliates.
XFS® is a trademark of Silicon Graphics International Corp. or its subsidiaries in the United States and/or other countries.
MySQL® is a registered trademark of MySQL AB in the United States, the European Union and other countries.
Node.js® is an official trademark of the OpenJS Foundation.
The OpenStack® Word Mark and OpenStack logo are either registered trademarks/service marks or trademarks/service marks of the OpenStack Foundation, in the United States and other countries and are used with the OpenStack Foundation’s permission. We are not affiliated with, endorsed or sponsored by the OpenStack Foundation, or the OpenStack community.
All other trademarks are the property of their respective owners.