Ce contenu n'est pas disponible dans la langue sélectionnée.
Chapter 1. Introduction to the Ceph File System
As a storage administrator, you can gain an understanding of the features, system components, and limitations to manage a Ceph File System (CephFS) environment.
1.1. Ceph File System features and enhancements
The Ceph File System (CephFS) is a file system compatible with POSIX standards that is built on top of Ceph’s distributed object store, called RADOS (Reliable Autonomic Distributed Object Storage). CephFS provides file access to a Red Hat Ceph Storage cluster, and uses the POSIX semantics wherever possible. For example, in contrast to many other common network file systems like NFS, CephFS maintains strong cache coherency across clients. The goal is for processes using the file system to behave the same when they are on different hosts as when they are on the same host. However, in some cases, CephFS diverges from the strict POSIX semantics.
The Ceph File System has the following features and enhancements:
- Scalability
- The Ceph File System is highly scalable due to horizontal scaling of metadata servers and direct client reads and writes with individual OSD nodes.
- Shared File System
- The Ceph File System is a shared file system so multiple clients can work on the same file system at once.
- Multiple File Systems
- You can have multiple file systems active on one storage cluster. Each CephFS has its own set of pools and its own set of Metadata Server (MDS) ranks. When deploying multiple file systems this requires more running MDS daemons. This can increase metadata throughput, but also increases operational costs. You can also limit client access to certain file systems.
- High Availability
- The Ceph File System provides a cluster of Ceph Metadata Servers (MDS). One is active and others are in standby mode. If the active MDS terminates unexpectedly, one of the standby MDS becomes active. As a result, client mounts continue working through a server failure. This behavior makes the Ceph File System highly available. In addition, you can configure multiple active metadata servers.
- Configurable File and Directory Layouts
- The Ceph File System allows users to configure file and directory layouts to use multiple pools, pool namespaces, and file striping modes across objects.
- POSIX Access Control Lists (ACL)
-
The Ceph File System supports the POSIX Access Control Lists (ACL). ACLs are enabled by default with the Ceph File Systems mounted as kernel clients with kernel version
kernel-3.10.0-327.18.2.el7or newer. To use an ACL with the Ceph File Systems mounted as FUSE clients, you must enable them. - Client Quotas
- The Ceph File System supports setting quotas on any directory in a system. The quota can restrict the number of bytes or the number of files stored beneath that point in the directory hierarchy. CephFS client quotas are enabled by default.
CephFS EC pools are for archival purpose only.
Additional Resources
- See the Management of MDS service using the Ceph Orchestrator section in the Operations Guide to install Ceph Metadata servers.
- See the Deployment of the Ceph File System section in the File System Guide to create Ceph File Systems.
1.2. Ceph File System components
The Ceph File System has two primary components:
- Clients
-
The CephFS clients perform I/O operations on behalf of applications using CephFS, such as
ceph-fusefor FUSE clients andkcephfsfor kernel clients. CephFS clients send metadata requests to an active Metadata Server. In return, the CephFS client learns of the file metadata, and can begin safely caching both metadata and file data. - Metadata Servers (MDS)
The MDS does the following:
- Provides metadata to CephFS clients.
- Manages metadata related to files stored on the Ceph File System.
- Coordinates access to the shared Red Hat Ceph Storage cluster.
- Caches hot metadata to reduce requests to the backing metadata pool store.
- Manages the CephFS clients' caches to maintain cache coherence.
- Replicates hot metadata between active MDS.
- Coalesces metadata mutations to a compact journal with regular flushes to the backing metadata pool.
-
CephFS requires at least one Metadata Server daemon (
ceph-mds) to run.
The diagram below shows the component layers of the Ceph File System.
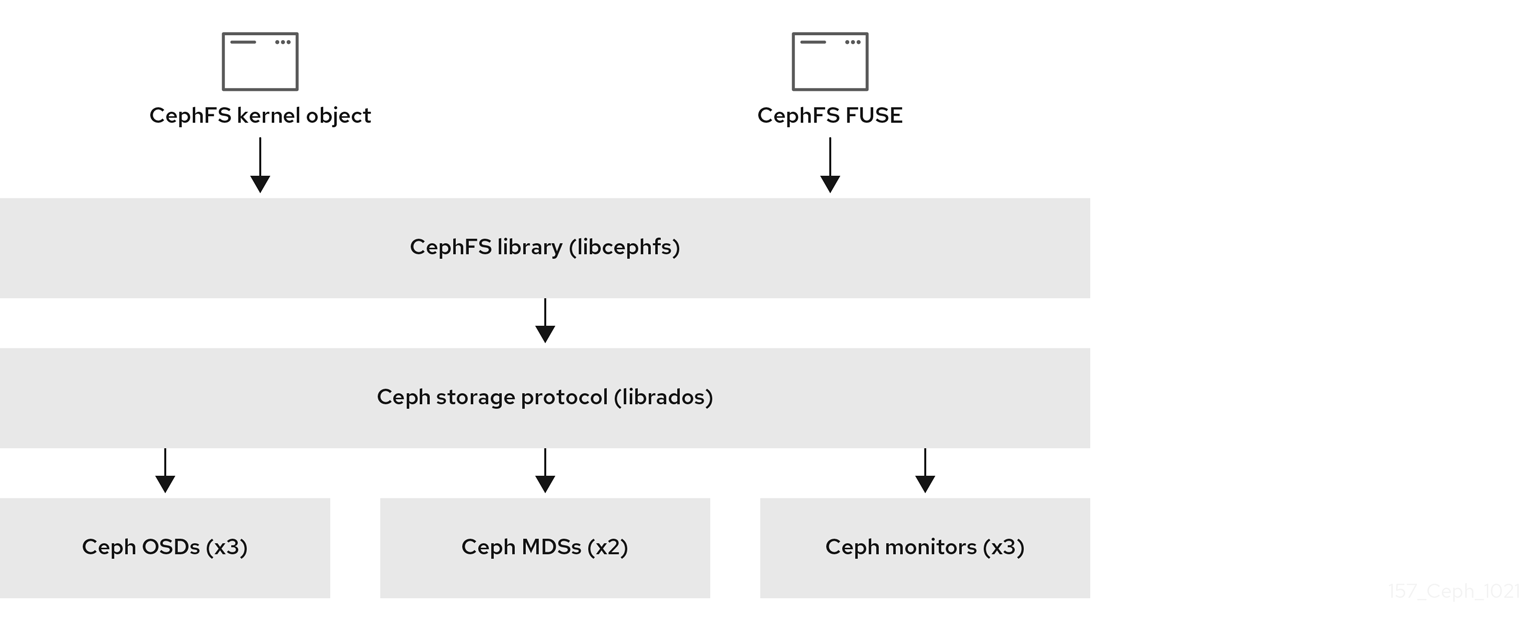
The bottom layer represents the underlying core storage cluster components:
-
Ceph OSDs (
ceph-osd) where the Ceph File System data and metadata are stored. -
Ceph Metadata Servers (
ceph-mds) that manages Ceph File System metadata. -
Ceph Monitors (
ceph-mon) that manages the master copy of the cluster map.
The Ceph Storage protocol layer represents the Ceph native librados library for interacting with the core storage cluster.
The CephFS library layer includes the CephFS libcephfs library that works on top of librados and represents the Ceph File System.
The top layer represents two types of Ceph clients that can access the Ceph File Systems.
The diagram below shows more details on how the Ceph File System components interact with each other.
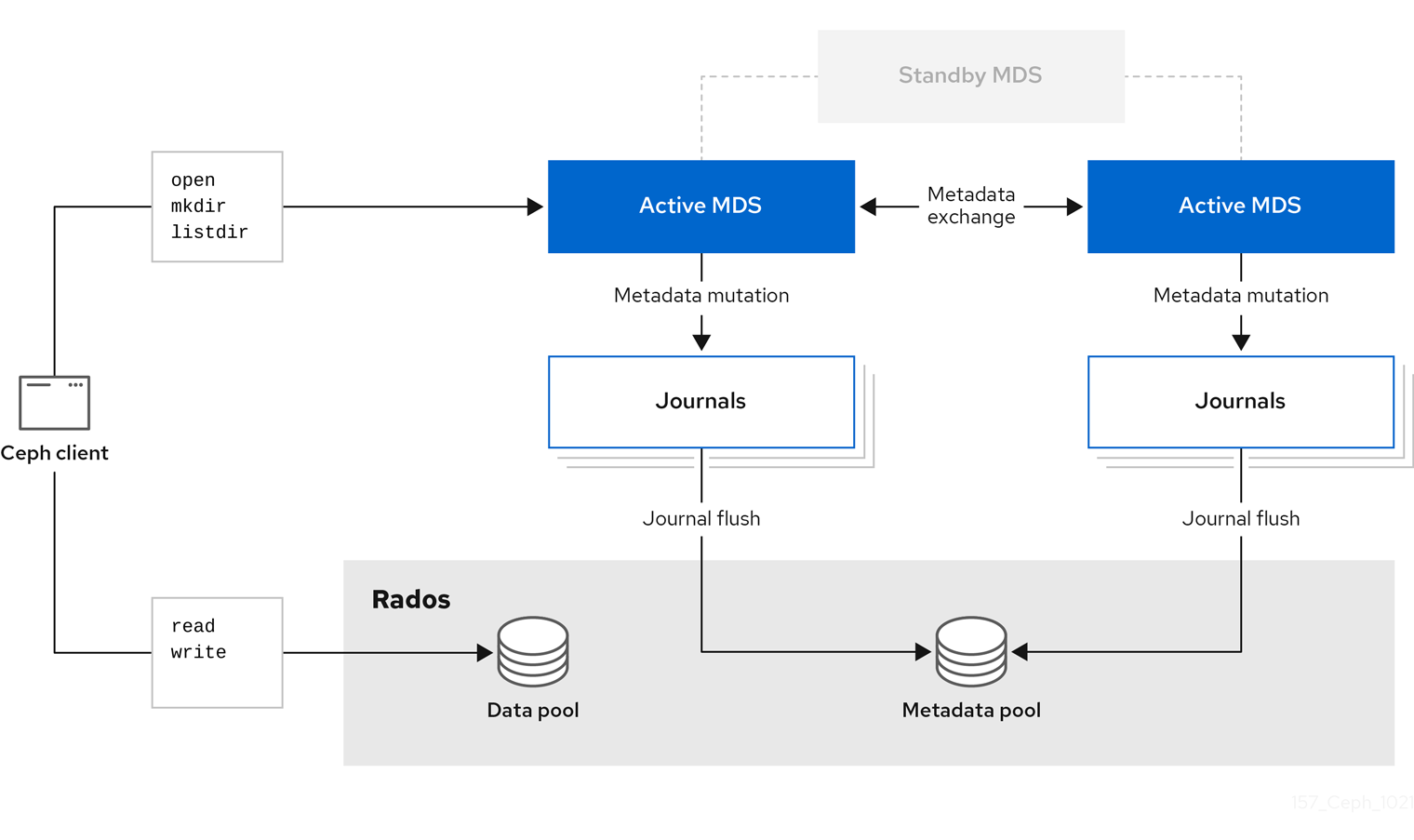
Additional Resources
- See the Management of MDS service using the Ceph Orchestrator section in the File System Guide to install Ceph Metadata servers.
- See the Deployment of the Ceph File System section in the Red Hat Ceph Storage File System Guide to create Ceph File Systems.
1.3. Ceph File System and SELinux
Starting with Red Hat Enterprise Linux 8.3 and Red Hat Ceph Storage 4.2, support for using Security-Enhanced Linux (SELinux) on Ceph File Systems (CephFS) environments is available. You can now set any SELinux file type with CephFS, along with assigning a particular SELinux type on individual files. This support applies to the Ceph File System Metadata Server (MDS), the CephFS File System in User Space (FUSE) clients, and the CephFS kernel clients.
Additional Resources
- See the Using SELinux on Red Hat Enterprise Linux 8 for more information about SELinux.
1.4. Ceph File System limitations and the POSIX standards
The Ceph File System diverges from the strict POSIX semantics in the following ways:
-
If a client’s attempt to write a file fails, the write operations are not necessarily atomic. That is, the client might call the
write()system call on a file opened with theO_SYNCflag with an 8MB buffer and then terminates unexpectedly and the write operation can be only partially applied. Almost all file systems, even local file systems, have this behavior. - In situations when the write operations occur simultaneously, a write operation that exceeds object boundaries is not necessarily atomic. For example, writer A writes "aa|aa" and writer B writes "bb|bb" simultaneously, where "|" is the object boundary, and "aa|bb" is written rather than the proper "aa|aa" or "bb|bb".
-
POSIX includes the
telldir()andseekdir()system calls that allow you to obtain the current directory offset and seek back to it. Because CephFS can fragment directories at any time, it is difficult to return a stable integer offset for a directory. As such, calling theseekdir()system call to a non-zero offset might often work but is not guaranteed to do so. Callingseekdir()to offset 0 will always work. This is equivalent to therewinddir()system call. -
Sparse files propagate incorrectly to the
st_blocksfield of thestat()system call. CephFS does not explicitly track parts of a file that are allocated or written to, because thest_blocksfield is always populated by the quotient of file size divided by block size. This behavior causes utilities, such asdu, to overestimate used space. -
When the
mmap()system call maps a file into memory on multiple hosts, write operations are not coherently propagated to caches of other hosts. That is, if a page is cached on host A, and then updated on host B, host A page is not coherently invalidated. -
CephFS clients present a hidden
.snapdirectory that is used to access, create, delete, and rename snapshots. Although this directory is excluded from thereaddir()system call, any process that tries to create a file or directory with the same name returns an error. The name of this hidden directory can be changed at mount time with the-o snapdirname=.<new_name>option or by using theclient_snapdirconfiguration option.
Additional Resources
- See the Management of MDS service using the Ceph Orchestrator section in the File System Guide to install Ceph Metadata servers.
- See the Deployment of the Ceph File System section in the Red Hat Ceph Storage File System Guide to create Ceph File Systems.