29.2. Types de topologie de système
Dans l'informatique moderne, l'idée d'une unité centrale est trompeuse, car la plupart des systèmes modernes sont dotés de plusieurs processeurs. La topologie du système est la manière dont ces processeurs sont connectés les uns aux autres et aux autres ressources du système. Cela peut affecter les performances du système et de l'application, ainsi que les considérations de réglage d'un système.
Les deux principaux types de topologie utilisés dans l'informatique moderne sont les suivants :
Symmetric Multi-Processor (SMP) topology- La topologie SMP permet à tous les processeurs d'accéder à la mémoire dans le même laps de temps. Toutefois, comme l'accès partagé et égal à la mémoire oblige intrinsèquement tous les processeurs à effectuer des accès sérialisés à la mémoire, les contraintes de mise à l'échelle des systèmes SMP sont aujourd'hui généralement considérées comme inacceptables. C'est pourquoi pratiquement tous les systèmes de serveurs modernes sont des machines NUMA.
Non-Uniform Memory Access (NUMA) topologyLa topologie NUMA a été développée plus récemment que la topologie SMP. Dans un système NUMA, plusieurs processeurs sont physiquement regroupés sur un socket. Chaque socket dispose d'une zone de mémoire dédiée et de processeurs qui ont un accès local à cette mémoire. Les processeurs d'un même nœud ont un accès rapide à la banque de mémoire de ce nœud et un accès plus lent aux banques de mémoire qui ne se trouvent pas sur leur nœud.
Par conséquent, l'accès à la mémoire non locale entraîne une pénalité en termes de performances. Ainsi, les applications sensibles aux performances sur un système à topologie NUMA devraient accéder à la mémoire qui se trouve sur le même nœud que le processeur qui exécute l'application, et devraient éviter d'accéder à la mémoire distante dans la mesure du possible.
Les applications multithreads sensibles aux performances peuvent bénéficier d'une configuration leur permettant de s'exécuter sur un nœud NUMA spécifique plutôt que sur un processeur spécifique. La pertinence de cette configuration dépend de votre système et des exigences de votre application. Si plusieurs threads d'application accèdent aux mêmes données mises en cache, il peut être judicieux de configurer ces threads pour qu'ils s'exécutent sur le même processeur. Toutefois, si plusieurs threads qui accèdent à des données différentes et les mettent en cache s'exécutent sur le même processeur, chaque thread peut évincer des données mises en cache auxquelles un thread précédent a accédé. Cela signifie que chaque thread "manque" le cache et perd du temps d'exécution en allant chercher les données dans la mémoire et en les replaçant dans le cache. Utilisez l'outil
perfpour vérifier si le nombre de manques dans le cache est excessif.
29.2.1. Affichage des topologies de systèmes
Un certain nombre de commandes permettent de comprendre la topologie d'un système. Cette procédure décrit comment déterminer la topologie du système.
Procédure
Pour afficher une vue d'ensemble de la topologie de votre système :
Copy to Clipboard Copied! Toggle word wrap Toggle overflow Rassembler les informations sur l'architecture de l'unité centrale, telles que le nombre d'unités centrales, de threads, de cœurs, de sockets et de nœuds NUMA :
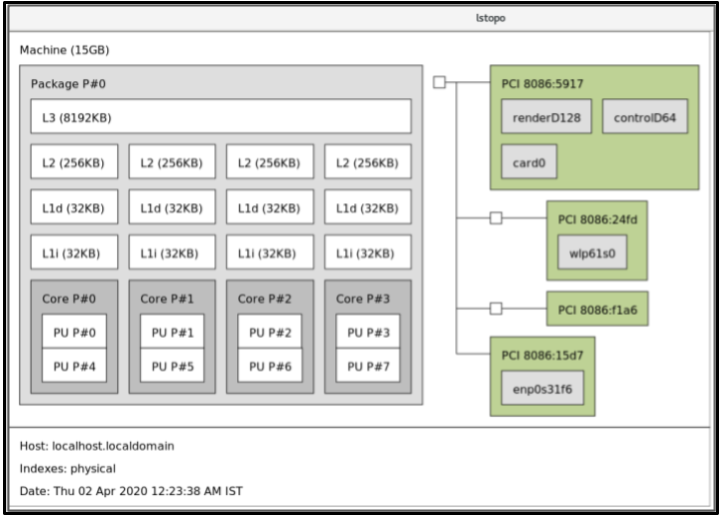
Copy to Clipboard Copied! Toggle word wrap Toggle overflow Pour afficher une représentation graphique de votre système :
dnf install hwloc-gui lstopo
# dnf install hwloc-gui # lstopoCopy to Clipboard Copied! Toggle word wrap Toggle overflow Figure 29.1. La sortie
lstopoPour afficher le texte détaillé :
Copy to Clipboard Copied! Toggle word wrap Toggle overflow