Ce contenu n'est pas disponible dans la langue sélectionnée.
Chapter 5. Disaster recovery with stretch cluster for OpenShift Data Foundation
Red Hat OpenShift Data Foundation deployment can be stretched between two different geographical locations to provide the storage infrastructure with disaster recovery capabilities. When faced with a disaster, such as one of the two locations is partially or totally not available, OpenShift Data Foundation deployed on the OpenShift Container Platform deployment must be able to survive. This solution is available only for metropolitan spanned data centers with specific latency requirements between the servers of the infrastructure.
The stretch cluster solution is designed for deployments where latencies do not exceed 10 ms maximum round-trip time (RTT) between the zones containing data volumes. For Arbiter nodes follow the latency requirements specified for etcd, see Guidance for Red Hat OpenShift Container Platform Clusters - Deployments Spanning Multiple Sites(Data Centers/Regions). Contact Red Hat Customer Support if you are planning to deploy with higher latencies.
The following diagram shows the simplest deployment for a stretched cluster:
OpenShift nodes and OpenShift Data Foundation daemons
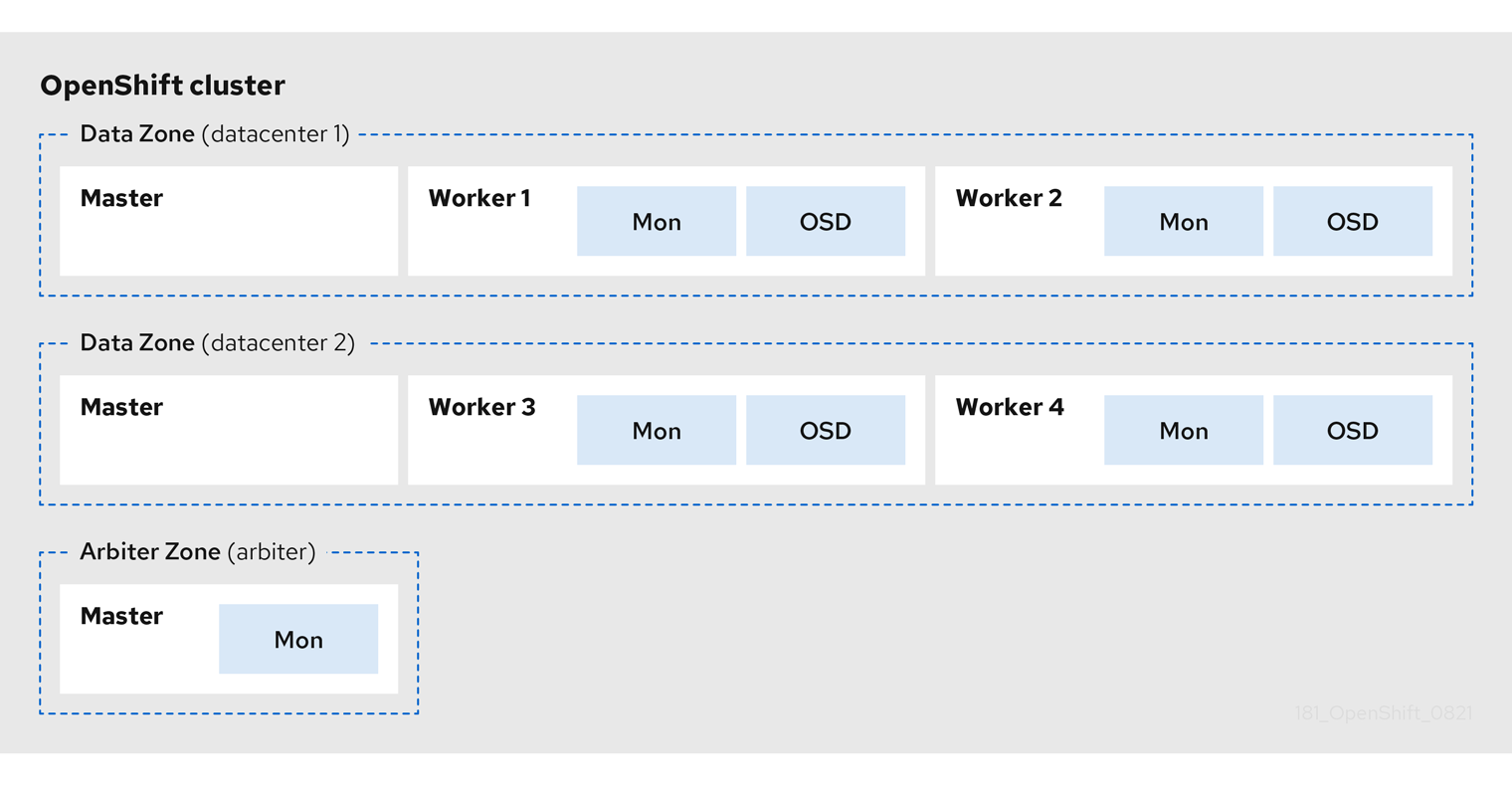
In the diagram the OpenShift Data Foundation monitor pod deployed in the Arbiter zone has a built-in tolerance for the master nodes. The diagram shows the master nodes in each Data Zone which are required for a highly available OpenShift Container Platform control plane. Also, it is important that the OpenShift Container Platform nodes in one of the zones have network connectivity with the OpenShift Container Platform nodes in the other two zones.
5.1. Requirements for enabling stretch cluster
- Ensure you have addressed OpenShift Container Platform requirements for deployments spanning multiple sites. For more information, see knowledgebase article on cluster deployments spanning multiple sites.
- Ensure that you have at least three OpenShift Container Platform master nodes in three different zones. One master node in each of the three zones.
- Ensure that you have at least four OpenShift Container Platform worker nodes evenly distributed across the two Data Zones.
- For stretch clusters on bare metall, use the SSD drive as the root drive for OpenShift Container Platform master nodes.
- Ensure that each node is pre-labeled with its zone label. For more information, see the Applying topology zone labels to OpenShift Container Platform node section.
- The stretch cluster solution is designed for deployments where latencies do not exceed 10 ms between zones. Contact Red Hat Customer Support if you are planning to deploy with higher latencies.
Flexible scaling and Arbiter both cannot be enabled at the same time as they have conflicting scaling logic. With Flexible scaling, you can add one node at a time to your OpenShift Data Foundation cluster. Whereas in an Arbiter cluster, you need to add at least one node in each of the two data zones.
5.2. Applying topology zone labels to OpenShift Container Platform nodes
During a site outage, the zone that has the arbiter function makes use of the arbiter label. These labels are arbitrary and must be unique for the three locations.
For example, you can label the nodes as follows:
topology.kubernetes.io/zone=arbiter for Master0 topology.kubernetes.io/zone=datacenter1 for Master1, Worker1, Worker2 topology.kubernetes.io/zone=datacenter2 for Master2, Worker3, Worker4
To apply the labels to the node:
$ oc label node <NODENAME> topology.kubernetes.io/zone=<LABEL>
<NODENAME>- Is the name of the node
<LABEL>- Is the topology zone label
To validate the labels using the example labels for the three zones:
$ oc get nodes -l topology.kubernetes.io/zone=<LABEL> -o name<LABEL>Is the topology zone label
Alternatively, you can run a single command to see all the nodes with its zone.
$ oc get nodes -L topology.kubernetes.io/zone
The stretch cluster topology zone labels are now applied to the appropriate OpenShift Container Platform nodes to define the three locations.
5.3. Installing Local Storage Operator
Install the Local Storage Operator from the Operator Hub before creating Red Hat OpenShift Data Foundation clusters on local storage devices.
Procedure
- Log in to the OpenShift Web Console.
-
Click Operators
OperatorHub. -
Type
local storagein the Filter by keyword box to find the Local Storage Operator from the list of operators, and click on it. Set the following options on the Install Operator page:
-
Update channel as
stable. - Installation mode as A specific namespace on the cluster.
- Installed Namespace as Operator recommended namespace openshift-local-storage.
- Update approval as Automatic.
-
Update channel as
- Click Install.
Verification steps
- Verify that the Local Storage Operator shows a green tick indicating successful installation.
5.4. Installing Red Hat OpenShift Data Foundation Operator
You can install Red Hat OpenShift Data Foundation Operator using the Red Hat OpenShift Container Platform Operator Hub.
Prerequisites
- Access to an OpenShift Container Platform cluster using an account with cluster-admin and Operator installation permissions.
- You must have at least four worker nodes evenly distributed across two data centers in the Red Hat OpenShift Container Platform cluster.
- For additional resource requirements, see Planning your deployment.
When you need to override the cluster-wide default node selector for OpenShift Data Foundation, you can use the following command in command-line interface to specify a blank node selector for the
openshift-storagenamespace (create openshift-storage namespace in this case):$ oc annotate namespace openshift-storage openshift.io/node-selector=
-
Taint a node as
infrato ensure only Red Hat OpenShift Data Foundation resources are scheduled on that node. This helps you save on subscription costs. For more information, see How to use dedicated worker nodes for Red Hat OpenShift Data Foundation chapter in the Managing and Allocating Storage Resources guide.
Procedure
- Log in to the OpenShift Web Console.
-
Click Operators
OperatorHub. -
Scroll or type
OpenShift Data Foundationinto the Filter by keyword box to search for the OpenShift Data Foundation Operator. - Click Install.
Set the following options on the Install Operator page:
- Update Channel as stable-4.15.
- Installation Mode as A specific namespace on the cluster.
-
Installed Namespace as Operator recommended namespace openshift-storage. If Namespace
openshift-storagedoes not exist, it is created during the operator installation. Select Approval Strategy as Automatic or Manual.
If you select Automatic updates, then the Operator Lifecycle Manager (OLM) automatically upgrades the running instance of your Operator without any intervention.
If you selected Manual updates, then the OLM creates an update request. As a cluster administrator, you must then manually approve that update request to update the Operator to a newer version.
- Ensure that the Enable option is selected for the Console plugin.
- Click Install.
Verification steps
-
After the operator is successfully installed, a pop-up with a message,
Web console update is availableappears on the user interface. Click Refresh web console from this pop-up for the console changes to reflect. In the Web Console:
- Navigate to Installed Operators and verify that the OpenShift Data Foundation Operator shows a green tick indicating successful installation.
- Navigate to Storage and verify if the Data Foundation dashboard is available.
Next steps
5.5. Creating OpenShift Data Foundation cluster
Prerequisites
- Ensure that you have met all the requirements in Requirements for enabling stretch cluster section.
Procedure
In the OpenShift Web Console, click Operators
Installed Operators to view all the installed operators. Ensure that the Project selected is
openshift-storage.- Click on the OpenShift Data Foundation operator and then click Create StorageSystem.
- In the Backing storage page, select the Create a new StorageClass using the local storage devices option.
Click Next.
ImportantYou are prompted to install the Local Storage Operator if it is not already installed. Click Install, and follow the procedure as described in Installing Local Storage Operator.
In the Create local volume set page, provide the following information:
Enter a name for the LocalVolumeSet and the StorageClass.
By default, the local volume set name appears for the storage class name. You can change the name.
Choose one of the following:
Disks on all nodes
Uses the available disks that match the selected filters on all the nodes.
Disks on selected nodes
Uses the available disks that match the selected filters only on selected nodes.
ImportantIf the nodes selected do not match the OpenShift Data Foundation cluster requirement of an aggregated 30 CPUs and 72 GiB of RAM, a minimal cluster is deployed.
For minimum starting node requirements, see the Resource requirements section in the Planning guide.
-
Select
SSDorNVMeto build a supported configuration. You can selectHDDsfor unsupported test installations. Expand the Advanced section and set the following options:
Volume Mode
Block is selected by default.
Device Type
Select one or more device types from the dropdown list.
Disk Size
Set a minimum size of 100GB for the device and maximum available size of the device that needs to be included.
Maximum Disks Limit
This indicates the maximum number of PVs that can be created on a node. If this field is left empty, then PVs are created for all the available disks on the matching nodes.
Click Next.
A pop-up to confirm the creation of LocalVolumeSet is displayed.
- Click Yes to continue.
In the Capacity and nodes page, configure the following:
Available raw capacity is populated with the capacity value based on all the attached disks associated with the storage class. This takes some time to show up.
The Selected nodes list shows the nodes based on the storage class.
Select Enable arbiter checkbox if you want to use the stretch clusters. This option is available only when all the prerequisites for arbiter are fulfilled and the selected nodes are populated. For more information, see Arbiter stretch cluster requirements in Requirements for enabling stretch cluster.
Select the arbiter zone from the dropdown list.
Choose a performance profile for Configure performance.
You can also configure the performance profile after the deployment using the Configure performance option from the options menu of the StorageSystems tab.
ImportantBefore selecting a resource profile, make sure to check the current availability of resources within the cluster. Opting for a higher resource profile in a cluster with insufficient resources might lead to installation failures. For more information about resource requirements, see Resource requirement for performance profiles.
- Click Next.
Optional: In the Security and network page, configure the following based on your requirement:
- To enable encryption, select Enable data encryption for block and file storage.
Select one of the following Encryption level:
- Cluster-wide encryption to encrypt the entire cluster (block and file).
- StorageClass encryption to create encrypted persistent volume (block only) using encryption enabled storage class.
Optional: Select the Connect to an external key management service checkbox. This is optional for cluster-wide encryption.
- From the Key Management Service Provider drop-down list, either select Vault or Thales CipherTrust Manager (using KMIP). If you selected Vault, go to the next step. If you selected Thales CipherTrust Manager (using KMIP), go to step iii.
Select an Authentication Method.
- Using Token authentication method
- Enter a unique Connection Name, host Address of the Vault server ('https://<hostname or ip>'), Port number and Token.
Expand Advanced Settings to enter additional settings and certificate details based on your
Vaultconfiguration:- Enter the Key Value secret path in the Backend Path that is dedicated and unique to OpenShift Data Foundation.
- Optional: Enter TLS Server Name and Vault Enterprise Namespace.
- Upload the respective PEM encoded certificate file to provide the CA Certificate, Client Certificate and Client Private Key .
- Click Save and skip to step iv.
- Using Kubernetes authentication method
- Enter a unique Vault Connection Name, host Address of the Vault server ('https://<hostname or ip>'), Port number and Role name.
Expand Advanced Settings to enter additional settings and certificate details based on your
Vaultconfiguration:- Enter the Key Value secret path in the Backend Path that is dedicated and unique to OpenShift Data Foundation.
- Optional: Enter TLS Server Name and Authentication Path if applicable.
- Upload the respective PEM encoded certificate file to provide the CA Certificate, Client Certificate and Client Private Key .
- Click Save and skip to step iv.
To use Thales CipherTrust Manager (using KMIP) as the KMS provider, follow the steps below:
- Enter a unique Connection Name for the Key Management service within the project.
In the Address and Port sections, enter the IP of Thales CipherTrust Manager and the port where the KMIP interface is enabled. For example:
- Address: 123.34.3.2
- Port: 5696
- Upload the Client Certificate, CA certificate, and Client Private Key.
- If StorageClass encryption is enabled, enter the Unique Identifier to be used for encryption and decryption generated above.
-
The TLS Server field is optional and used when there is no DNS entry for the KMIP endpoint. For example,
kmip_all_<port>.ciphertrustmanager.local.
Network is set to Default (OVN) if you are using a single network.
You can switch to Custom (Multus) if you are using multiple network interfaces and then choose any one of the following:
- Select a Public Network Interface from the dropdown.
- Select a Cluster Network Interface from the dropdown.
NoteIf you are using only one additional network interface, select the single
NetworkAttachementDefinition, that is,ocs-public-clusterfor the Public Network Interface, and leave the Cluster Network Interface blank.- Click Next.
- In the Data Protection page, click Next.
In the Review and create page, review the configuration details.
To modify any configuration settings, click Back to go back to the previous configuration page.
- Click Create StorageSystem.
Verification steps
To verify the final Status of the installed storage cluster:
-
In the OpenShift Web Console, navigate to Installed Operators
OpenShift Data Foundation Storage System ocs-storagecluster-storagesystem Resources. -
Verify that the
StatusofStorageClusterisReadyand has a green tick mark next to it.
-
In the OpenShift Web Console, navigate to Installed Operators
For arbiter mode of deployment:
-
In the OpenShift Web Console, navigate to Installed Operators
OpenShift Data Foundation Storage System ocs-storagecluster-storagesystem Resources ocs-storagecluster. In the YAML tab, search for the
arbiterkey in thespecsection and ensureenableis set totrue.spec: arbiter: enable: true [..] nodeTopologies: arbiterLocation: arbiter #arbiter zone storageDeviceSets: - config: {} count: 1 [..] replica: 4 status: conditions: [..] failureDomain: zone
-
In the OpenShift Web Console, navigate to Installed Operators
- To verify that all the components for OpenShift Data Foundation are successfully installed, see Verifying your OpenShift Data Foundation installation.
5.6. Verifying OpenShift Data Foundation deployment
To verify that OpenShift Data Foundation is deployed correctly:
5.6.1. Verifying the state of the pods
Procedure
-
Click Workloads
Pods from the OpenShift Web Console. Select
openshift-storagefrom the Project drop-down list.NoteIf the Show default projects option is disabled, use the toggle button to list all the default projects.
For more information about the expected number of pods for each component and how it varies depending on the number of nodes, see Table 5.1, “Pods corresponding to OpenShift Data Foundation cluster”.
-
Click the Running and Completed tabs to verify that the following pods are in
RunningandCompletedstate:
| Component | Corresponding pods |
|---|---|
| OpenShift Data Foundation Operator |
|
| Rook-ceph Operator |
(1 pod on any worker node) |
| Multicloud Object Gateway |
|
| MON |
(5 pods are distributed across 3 zones, 2 per data-center zones and 1 in arbiter zone) |
| MGR |
(2 pods on any storage node) |
| MDS |
(2 pods are distributed across 2 data-center zones) |
| RGW |
(2 pods are distributed across 2 data-center zones) |
| CSI |
|
| rook-ceph-crashcollector |
(1 pod on each storage node and 1 pod in arbiter zone) |
| OSD |
|
5.6.2. Verifying the OpenShift Data Foundation cluster is healthy
Procedure
-
In the OpenShift Web Console, click Storage
Data Foundation. - In the Status card of the Overview tab, click Storage System and then click the storage system link from the pop up that appears.
- In the Status card of the Block and File tab, verify that the Storage Cluster has a green tick.
- In the Details card, verify that the cluster information is displayed.
For more information on the health of the OpenShift Data Foundation cluster using the Block and File dashboard, see Monitoring OpenShift Data Foundation.
5.6.3. Verifying the Multicloud Object Gateway is healthy
Procedure
-
In the OpenShift Web Console, click Storage
Data Foundation. In the Status card of the Overview tab, click Storage System and then click the storage system link from the pop up that appears.
- In the Status card of the Object tab, verify that both Object Service and Data Resiliency have a green tick.
- In the Details card, verify that the MCG information is displayed.
For more information on the health of the OpenShift Data Foundation cluster using the object service dashboard, see Monitoring OpenShift Data Foundation.
The Multicloud Object Gateway only has a single copy of the database (NooBaa DB). This means if NooBaa DB PVC gets corrupted and we are unable to recover it, can result in total data loss of applicative data residing on the Multicloud Object Gateway. Because of this, Red Hat recommends taking a backup of NooBaa DB PVC regularly. If NooBaa DB fails and cannot be recovered, then you can revert to the latest backed-up version. For instructions on backing up your NooBaa DB, follow the steps in this knowledgabase article.
5.6.4. Verifying that the specific storage classes exist
Procedure
-
Click Storage
Storage Classes from the left pane of the OpenShift Web Console. Verify that the following storage classes are created with the OpenShift Data Foundation cluster creation:
-
ocs-storagecluster-ceph-rbd -
ocs-storagecluster-cephfs -
openshift-storage.noobaa.io -
ocs-storagecluster-ceph-rgw
-
5.7. Install Zone Aware Sample Application
Deploy a zone aware sample application to validate whether an OpenShift Data Foundation, stretch cluster setup is configured correctly.
With latency between the data zones, you can expect to see performance degradation compared to an OpenShift cluster with low latency between nodes and zones (for example, all nodes in the same location). The rate of or amount of performance degradation depends on the latency between the zones and on the application behavior using the storage (such as heavy write traffic). Ensure that you test the critical applications with stretch cluster configuration to ensure sufficient application performance for the required service levels.
A ReadWriteMany (RWX) Persistent Volume Claim (PVC) is created using the ocs-storagecluster-cephfs storage class. Multiple pods use the newly created RWX PVC at the same time. The application used is called File Uploader.
Demonstration on how an application is spread across topology zones so that it is still available in the event of a site outage:
This demonstration is possible since this application shares the same RWX volume for storing files. It works for persistent data access as well because Red Hat OpenShift Data Foundation is configured as a stretched cluster with zone awareness and high availability.
Create a new project.
$ oc new-project my-shared-storage
Deploy the example PHP application called file-uploader.
$ oc new-app openshift/php:latest~https://github.com/mashetty330/openshift-php-upload-demo --name=file-uploader
Example Output:
Found image 4f2dcc0 (9 days old) in image stream "openshift/php" under tag "7.2-ubi8" for "openshift/php:7.2- ubi8" Apache 2.4 with PHP 7.2 ----------------------- PHP 7.2 available as container is a base platform for building and running various PHP 7.2 applications and frameworks. PHP is an HTML-embedded scripting language. PHP attempts to make it easy for developers to write dynamically generated web pages. PHP also offers built-in database integration for several commercial and non-commercial database management systems, so writing a database-enabled webpage with PHP is fairly simple. The most common use of PHP coding is probably as a replacement for CGI scripts. Tags: builder, php, php72, php-72 * A source build using source code from https://github.com/christianh814/openshift-php-upload-demo will be cr eated * The resulting image will be pushed to image stream tag "file-uploader:latest" * Use 'oc start-build' to trigger a new build --> Creating resources ... imagestream.image.openshift.io "file-uploader" created buildconfig.build.openshift.io "file-uploader" created deployment.apps "file-uploader" created service "file-uploader" created --> Success Build scheduled, use 'oc logs -f buildconfig/file-uploader' to track its progress. Application is not exposed. You can expose services to the outside world by executing one or more of the commands below: 'oc expose service/file-uploader' Run 'oc status' to view your app.View the build log and wait until the application is deployed.
$ oc logs -f bc/file-uploader -n my-shared-storage
Example Output:
Cloning "https://github.com/christianh814/openshift-php-upload-demo" ... [...] Generating dockerfile with builder image image-registry.openshift-image-regis try.svc:5000/openshift/php@sha256:d97466f33999951739a76bce922ab17088885db610c 0e05b593844b41d5494ea STEP 1: FROM image-registry.openshift-image-registry.svc:5000/openshift/php@s ha256:d97466f33999951739a76bce922ab17088885db610c0e05b593844b41d5494ea STEP 2: LABEL "io.openshift.build.commit.author"="Christian Hernandez <christ ian.hernandez@yahoo.com>" "io.openshift.build.commit.date"="Sun Oct 1 1 7:15:09 2017 -0700" "io.openshift.build.commit.id"="288eda3dff43b02f7f7 b6b6b6f93396ffdf34cb2" "io.openshift.build.commit.ref"="master" " io.openshift.build.commit.message"="trying to modularize" "io.openshift .build.source-location"="https://github.com/christianh814/openshift-php-uploa d-demo" "io.openshift.build.image"="image-registry.openshift-image-regi stry.svc:5000/openshift/php@sha256:d97466f33999951739a76bce922ab17088885db610 c0e05b593844b41d5494ea" STEP 3: ENV OPENSHIFT_BUILD_NAME="file-uploader-1" OPENSHIFT_BUILD_NAMESP ACE="my-shared-storage" OPENSHIFT_BUILD_SOURCE="https://github.com/christ ianh814/openshift-php-upload-demo" OPENSHIFT_BUILD_COMMIT="288eda3dff43b0 2f7f7b6b6b6f93396ffdf34cb2" STEP 4: USER root STEP 5: COPY upload/src /tmp/src STEP 6: RUN chown -R 1001:0 /tmp/src STEP 7: USER 1001 STEP 8: RUN /usr/libexec/s2i/assemble ---> Installing application source... => sourcing 20-copy-config.sh ... ---> 17:24:39 Processing additional arbitrary httpd configuration provide d by s2i ... => sourcing 00-documentroot.conf ... => sourcing 50-mpm-tuning.conf ... => sourcing 40-ssl-certs.sh ... STEP 9: CMD /usr/libexec/s2i/run STEP 10: COMMIT temp.builder.openshift.io/my-shared-storage/file-uploader-1:3 b83e447 Getting image source signatures [...]The command prompt returns out of the tail mode after you see
Push successful.NoteThe new-app command deploys the application directly from the git repository and does not use the OpenShift template, hence the OpenShift route resource is not created by default. You need to create the route manually.
Scaling the application
Scale the application to four replicas and expose its services to make the application zone aware and available.
$ oc expose svc/file-uploader -n my-shared-storage
$ oc scale --replicas=4 deploy/file-uploader -n my-shared-storage
$ oc get pods -o wide -n my-shared-storage
You should have four file-uploader pods in a few minutes. Repeat the above command until there are 4 file-uploader pods in the
Runningstatus.Create a PVC and attach it into an application.
$ oc set volume deploy/file-uploader --add --name=my-shared-storage \ -t pvc --claim-mode=ReadWriteMany --claim-size=10Gi \ --claim-name=my-shared-storage --claim-class=ocs-storagecluster-cephfs \ --mount-path=/opt/app-root/src/uploaded \ -n my-shared-storage
This command:
- Creates a PVC.
- Updates the application deployment to include a volume definition.
- Updates the application deployment to attach a volume mount into the specified mount-path.
- Creates a new deployment with the four application pods.
Check the result of adding the volume.
$ oc get pvc -n my-shared-storage
Example Output:
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE my-shared-storage Bound pvc-5402cc8a-e874-4d7e-af76-1eb05bd2e7c7 10Gi RWX ocs-storagecluster-cephfs 52s
Notice the
ACCESS MODEis set to RWX.All the four
file-uploaderpods are using the same RWX volume. Without this access mode, OpenShift does not attempt to attach multiple pods to the same Persistent Volume (PV) reliably. If you attempt to scale up the deployments that are using ReadWriteOnce (RWO) PV, the pods may get colocated on the same node.
5.7.1. Scaling the application after installation
Procedure
Scale the application to four replicas and expose its services to make the application zone aware and available.
$ oc expose svc/file-uploader -n my-shared-storage
$ oc scale --replicas=4 deploy/file-uploader -n my-shared-storage
$ oc get pods -o wide -n my-shared-storage
You should have four file-uploader pods in a few minutes. Repeat the above command until there are 4 file-uploader pods in the
Runningstatus.Create a PVC and attach it into an application.
$ oc set volume deploy/file-uploader --add --name=my-shared-storage \ -t pvc --claim-mode=ReadWriteMany --claim-size=10Gi \ --claim-name=my-shared-storage --claim-class=ocs-storagecluster-cephfs \ --mount-path=/opt/app-root/src/uploaded \ -n my-shared-storage
This command:
- Creates a PVC.
- Updates the application deployment to include a volume definition.
- Updates the application deployment to attach a volume mount into the specified mount-path.
- Creates a new deployment with the four application pods.
Check the result of adding the volume.
$ oc get pvc -n my-shared-storage
Example Output:
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE my-shared-storage Bound pvc-5402cc8a-e874-4d7e-af76-1eb05bd2e7c7 10Gi RWX ocs-storagecluster-cephfs 52s
Notice the
ACCESS MODEis set to RWX.All the four
file-uploaderpods are using the same RWX volume. Without this access mode, OpenShift does not attempt to attach multiple pods to the same Persistent Volume (PV) reliably. If you attempt to scale up the deployments that are using ReadWriteOnce (RWO) PV, the pods may get colocated on the same node.
5.7.2. Modify Deployment to be Zone Aware
Currently, the file-uploader Deployment is not zone aware and can schedule all the pods in the same zone. In this case, if there is a site outage then the application is unavailable. For more information, see Controlling pod placement by using pod topology spread constraints.
Add the pod placement rule in the application deployment configuration to make the application zone aware.
Run the following command, and review the output:
$ oc get deployment file-uploader -o yaml -n my-shared-storage | less
Example Output:
[...] spec: progressDeadlineSeconds: 600 replicas: 4 revisionHistoryLimit: 10 selector: matchLabels: deployment: file-uploader strategy: rollingUpdate: maxSurge: 25% maxUnavailable: 25% type: RollingUpdate template: metadata: annotations: openshift.io/generated-by: OpenShiftNewApp creationTimestamp: null labels: deployment: file-uploader spec: # <-- Start inserted lines after here containers: # <-- End inserted lines before here - image: image-registry.openshift-image-registry.svc:5000/my-shared-storage/file-uploader@sha256:a458ea62f990e431ad7d5f84c89e2fa27bdebdd5e29c5418c70c56eb81f0a26b imagePullPolicy: IfNotPresent name: file-uploader [...]Edit the deployment to use the topology zone labels.
$ oc edit deployment file-uploader -n my-shared-storage
Add add the following new lines between the
StartandEnd(shown in the output in the previous step):[...] spec: topologySpreadConstraints: - labelSelector: matchLabels: deployment: file-uploader maxSkew: 1 topologyKey: topology.kubernetes.io/zone whenUnsatisfiable: DoNotSchedule - labelSelector: matchLabels: deployment: file-uploader maxSkew: 1 topologyKey: kubernetes.io/hostname whenUnsatisfiable: ScheduleAnyway nodeSelector: node-role.kubernetes.io/worker: "" containers: [...]Example output:
deployment.apps/file-uploader edited
Scale down the deployment to zero pods and then back to four pods. This is needed because the deployment changed in terms of pod placement.
- Scaling down to zero pods
$ oc scale deployment file-uploader --replicas=0 -n my-shared-storage
Example output:
deployment.apps/file-uploader scaled
- Scaling up to four pods
$ oc scale deployment file-uploader --replicas=4 -n my-shared-storage
Example output:
deployment.apps/file-uploader scaled
Verify that the four pods are spread across the four nodes in datacenter1 and datacenter2 zones.
$ oc get pods -o wide -n my-shared-storage | egrep '^file-uploader'| grep -v build | awk '{print $7}' | sort | uniq -cExample output:
1 perf1-mz8bt-worker-d2hdm 1 perf1-mz8bt-worker-k68rv 1 perf1-mz8bt-worker-ntkp8 1 perf1-mz8bt-worker-qpwsr
Search for the zone labels used.
$ oc get nodes -L topology.kubernetes.io/zone | grep datacenter | grep -v master
Example output:
perf1-mz8bt-worker-d2hdm Ready worker 35d v1.20.0+5fbfd19 datacenter1 perf1-mz8bt-worker-k68rv Ready worker 35d v1.20.0+5fbfd19 datacenter1 perf1-mz8bt-worker-ntkp8 Ready worker 35d v1.20.0+5fbfd19 datacenter2 perf1-mz8bt-worker-qpwsr Ready worker 35d v1.20.0+5fbfd19 datacenter2
Use the file-uploader web application using your browser to upload new files.
Find the route that is created.
$ oc get route file-uploader -n my-shared-storage -o jsonpath --template="http://{.spec.host}{'\n'}"Example Output:
http://file-uploader-my-shared-storage.apps.cluster-ocs4-abdf.ocs4-abdf.sandbox744.opentlc.com
Point your browser to the web application using the route in the previous step.
The web application lists all the uploaded files and offers the ability to upload new ones as well as you download the existing data. Right now, there is nothing.
Select an arbitrary file from your local machine and upload it to the application.
- Click Choose file to select an arbitrary file.
Click Upload.
Figure 5.1. A simple PHP-based file upload tool
- Click List uploaded files to see the list of all currently uploaded files.
The OpenShift Container Platform image registry, ingress routing, and monitoring services are not zone aware.
5.8. Recovering OpenShift Data Foundation stretch cluster
Given that the stretch cluster disaster recovery solution is to provide resiliency in the face of a complete or partial site outage, it is important to understand the different methods of recovery for applications and their storage.
How the application is architected determines how soon it becomes available again on the active zone.
There are different methods of recovery for applications and their storage depending on the site outage. The recovery time depends on the application architecture. The different methods of recovery are as follows:
5.8.1. Understanding zone failure
For the purpose of this section, zone failure is considered as a failure where all OpenShift Container Platform, master and worker nodes in a zone are no longer communicating with the resources in the second data zone (for example, powered down nodes). If communication between the data zones is still partially working (intermittently up or down), the cluster, storage, and network admins should disconnect the communication path between the data zones for recovery to succeed.
When you install the sample application, power off the OpenShift Container Platform nodes (at least the nodes with OpenShift Data Foundation devices) to test the failure of a data zone in order to validate that your file-uploader application is available, and you can upload new files.
5.8.2. Recovering zone-aware HA applications with RWX storage
Applications that are deployed with topologyKey: topology.kubernetes.io/zone have one or more replicas scheduled in each data zone, and are using shared storage, that is, ReadWriteMany (RWX) CephFS volume, terminate themselves in the failed zone after few minutes and new pods are rolled in and stuck in pending state until the zones are recovered.
An example of this type of application is detailed in the Install Zone Aware Sample Application section.
During zone recovery if application pods go into CrashLoopBackOff (CLBO) state with permission denied error while mounting the CephFS volume, then restart the nodes where the pods are scheduled. Wait for some time and then check if the pods are running again.
5.8.3. Recovering HA applications with RWX storage
Applications that are using topologyKey: kubernetes.io/hostname or no topology configuration have no protection against all of the application replicas being in the same zone.
This can happen even with podAntiAffinity and topologyKey: kubernetes.io/hostname in the Pod spec because this anti-affinity rule is host-based and not zone-based.
If this happens and all replicas are located in the zone that fails, the application using ReadWriteMany (RWX) storage takes 6-8 minutes to recover on the active zone. This pause is for the OpenShift Container Platform nodes in the failed zone to become NotReady (60 seconds) and then for the default pod eviction timeout to expire (300 seconds).
5.8.4. Recovering applications with RWO storage
Applications that use ReadWriteOnce (RWO) storage have a known behavior described in this Kubernetes issue. Because of this issue, if there is a data zone failure, any application pods in that zone mounting RWO volumes (for example, cephrbd based volumes) are stuck with Terminating status after 6-8 minutes and are not re-created on the active zone without manual intervention.
Check the OpenShift Container Platform nodes with a status of NotReady. There may be an issue that prevents the nodes from communicating with the OpenShift control plane. However, the nodes may still be performing I/O operations against Persistent Volumes (PVs).
If two pods are concurrently writing to the same RWO volume, there is a risk of data corruption. Ensure that processes on the NotReady node are either terminated or blocked until they are terminated.
Example solutions:
- Use an out of band management system to power off a node, with confirmation, to ensure process termination.
Withdraw a network route that is used by nodes at a failed site to communicate with storage.
NoteBefore restoring service to the failed zone or nodes, confirm that all the pods with PVs have terminated successfully.
To get the Terminating pods to recreate on the active zone, you can either force delete the pod or delete the finalizer on the associated PV. Once one of these two actions are completed, the application pod should recreate on the active zone and successfully mount its RWO storage.
- Force deleting the pod
Force deletions do not wait for confirmation from the kubelet that the pod has been terminated.
$ oc delete pod <PODNAME> --grace-period=0 --force --namespace <NAMESPACE>
<PODNAME>- Is the name of the pod
<NAMESPACE>- Is the project namespace
- Deleting the finalizer on the associated PV
Find the associated PV for the Persistent Volume Claim (PVC) that is mounted by the Terminating pod and delete the finalizer using the
oc patchcommand.$ oc patch -n openshift-storage pv/<PV_NAME> -p '{"metadata":{"finalizers":[]}}' --type=merge<PV_NAME>Is the name of the PV
An easy way to find the associated PV is to describe the Terminating pod. If you see a multi-attach warning, it should have the PV names in the warning (for example,
pvc-0595a8d2-683f-443b-aee0-6e547f5f5a7c).$ oc describe pod <PODNAME> --namespace <NAMESPACE>
<PODNAME>- Is the name of the pod
<NAMESPACE>Is the project namespace
Example output:
[...] Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Scheduled 4m5s default-scheduler Successfully assigned openshift-storage/noobaa-db-pg-0 to perf1-mz8bt-worker-d2hdm Warning FailedAttachVolume 4m5s attachdetach-controller Multi-Attach error for volume "pvc-0595a8d2-683f-443b-aee0-6e547f5f5a7c" Volume is already exclusively attached to one node and can't be attached to another
5.8.5. Recovering StatefulSet pods
Pods that are part of a StatefulSet have a similar issue as pods mounting ReadWriteOnce (RWO) volumes. More information is referenced in the Kubernetes resource StatefulSet considerations.
To get the pods part of a StatefulSet to re-create on the active zone after 6-8 minutes you need to force delete the pod with the same requirements (that is, OpenShift Container Platform node powered off or communication disconnected) as pods with RWO volumes.