Ce contenu n'est pas disponible dans la langue sélectionnée.
Chapter 9. Configuring a deployment
Configure and manage a Streams for Apache Kafka deployment to your precise needs using Streams for Apache Kafka custom resources. Streams for Apache Kafka provides example custom resources with each release, allowing you to configure and create instances of supported Kafka components. Fine-tune your deployment by configuring custom resources to include additional features according to your specific requirements. For specific areas of configuration, namely metrics, logging, and external configuration for Kafka Connect connectors, you can also use ConfigMap resources. By using a ConfigMap resource to incorporate configuration, you centralize maintenance. You can also use configuration providers to load configuration from external sources, which we recommend for supplying the credentials for Kafka Connect connector configuration.
Use custom resources to configure and create instances of the following components:
- Kafka clusters
- Kafka Connect clusters
- Kafka MirrorMaker
- Kafka Bridge
- Cruise Control
You can also use custom resource configuration to manage your instances or modify your deployment to introduce additional features. This might include configuration that supports the following:
- Specifying node pools
- Securing client access to Kafka brokers
- Accessing Kafka brokers from outside the cluster
- Creating topics
- Creating users (clients)
- Controlling feature gates
- Changing logging frequency
- Allocating resource limits and requests
- Introducing features, such as Streams for Apache Kafka Drain Cleaner, Cruise Control, or distributed tracing.
The Streams for Apache Kafka Custom Resource API Reference describes the properties you can use in your configuration.
Labels applied to a custom resource are also applied to the OpenShift resources making up its cluster. This provides a convenient mechanism for resources to be labeled as required.
Applying changes to a custom resource configuration file
You add configuration to a custom resource using spec properties. After adding the configuration, you can use oc to apply the changes to a custom resource configuration file:
oc apply -f <kafka_configuration_file>
9.1. Using example configuration files
Further enhance your deployment by incorporating additional supported configuration. Example configuration files are provided with the downloadable release artifacts from the Streams for Apache Kafka software downloads page.
The example files include only the essential properties and values for custom resources by default. You can download and apply the examples using the oc command-line tool. The examples can serve as a starting point when building your own Kafka component configuration for deployment.
If you installed Streams for Apache Kafka using the Operator, you can still download the example files and use them to upload configuration.
The release artifacts include an examples directory that contains the configuration examples.
Example configuration files provided with Streams for Apache Kafka
examples ├── user 1 ├── topic 2 ├── security 3 │ ├── tls-auth │ ├── scram-sha-512-auth │ └── keycloak-authorization ├── mirror-maker 4 ├── metrics 5 ├── kafka 6 │ └── nodepools 7 ├── cruise-control 8 ├── connect 9 └── bridge 10
- 1
KafkaUsercustom resource configuration, which is managed by the User Operator.- 2
KafkaTopiccustom resource configuration, which is managed by Topic Operator.- 3
- Authentication and authorization configuration for Kafka components. Includes example configuration for TLS and SCRAM-SHA-512 authentication. The Red Hat Single Sign-On example includes
Kafkacustom resource configuration and a Red Hat Single Sign-On realm specification. You can use the example to try Red Hat Single Sign-On authorization services. There is also an example with enabledoauthauthentication andkeycloakauthorization metrics. - 4
Kafkacustom resource configuration for a deployment of Mirror Maker. Includes example configuration for replication policy and synchronization frequency.- 5
- Metrics configuration, including Prometheus installation and Grafana dashboard files.
- 6
Kafkacustom resource configuration for a deployment of Kafka. Includes example configuration for an ephemeral or persistent single or multi-node deployment.- 7
KafkaNodePoolconfiguration for Kafka nodes in a Kafka cluster. Includes example configuration for nodes in clusters that use KRaft (Kafka Raft metadata) mode or ZooKeeper.- 8
Kafkacustom resource with a deployment configuration for Cruise Control. IncludesKafkaRebalancecustom resources to generate optimization proposals from Cruise Control, with example configurations to use the default or user optimization goals.- 9
KafkaConnectandKafkaConnectorcustom resource configuration for a deployment of Kafka Connect. Includes example configurations for a single or multi-node deployment.- 10
KafkaBridgecustom resource configuration for a deployment of Kafka Bridge.
9.2. Configuring Kafka
Update the spec properties of the Kafka custom resource to configure your Kafka deployment.
As well as configuring Kafka, you can add configuration for ZooKeeper and the Streams for Apache Kafka Operators. Common configuration properties, such as logging and healthchecks, are configured independently for each component.
Configuration options that are particularly important include the following:
- Resource requests (CPU / Memory)
- JVM options for maximum and minimum memory allocation
- Listeners for connecting clients to Kafka brokers (and authentication of clients)
- Authentication
- Storage
- Rack awareness
- Metrics
- Cruise Control for cluster rebalancing
- Metadata version for KRaft-based Kafka clusters
- Inter-broker protocol version for ZooKeeper-based Kafka clusters
The .spec.kafka.metadataVersion property or the inter.broker.protocol.version property in config must be a version supported by the specified Kafka version (spec.kafka.version). The property represents the Kafka metadata or inter-broker protocol version used in a Kafka cluster. If either of these properties is not set in the configuration, the Cluster Operator updates the version to the default for the Kafka version used.
The oldest supported metadata version is 3.3. Using a metadata version that is older than the Kafka version might cause some features to be disabled.
For a deeper understanding of the Kafka cluster configuration options, refer to the Streams for Apache Kafka Custom Resource API Reference.
Managing TLS certificates
When deploying Kafka, the Cluster Operator automatically sets up and renews TLS certificates to enable encryption and authentication within your cluster. If required, you can manually renew the cluster and clients CA certificates before their renewal period starts. You can also replace the keys used by the cluster and clients CA certificates. For more information, see Renewing CA certificates manually and Replacing private keys.
Example Kafka custom resource configuration
apiVersion: kafka.strimzi.io/v1beta2
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
replicas: 3 1
version: 3.7.0 2
logging: 3
type: inline
loggers:
kafka.root.logger.level: INFO
resources: 4
requests:
memory: 64Gi
cpu: "8"
limits:
memory: 64Gi
cpu: "12"
readinessProbe: 5
initialDelaySeconds: 15
timeoutSeconds: 5
livenessProbe:
initialDelaySeconds: 15
timeoutSeconds: 5
jvmOptions: 6
-Xms: 8192m
-Xmx: 8192m
image: my-org/my-image:latest 7
listeners: 8
- name: plain 9
port: 9092 10
type: internal 11
tls: false 12
configuration:
useServiceDnsDomain: true 13
- name: tls
port: 9093
type: internal
tls: true
authentication: 14
type: tls
- name: external1 15
port: 9094
type: route
tls: true
configuration:
brokerCertChainAndKey: 16
secretName: my-secret
certificate: my-certificate.crt
key: my-key.key
authorization: 17
type: simple
config: 18
auto.create.topics.enable: "false"
offsets.topic.replication.factor: 3
transaction.state.log.replication.factor: 3
transaction.state.log.min.isr: 2
default.replication.factor: 3
min.insync.replicas: 2
inter.broker.protocol.version: "3.7"
storage: 19
type: persistent-claim 20
size: 10000Gi
rack: 21
topologyKey: topology.kubernetes.io/zone
metricsConfig: 22
type: jmxPrometheusExporter
valueFrom:
configMapKeyRef: 23
name: my-config-map
key: my-key
# ...
zookeeper: 24
replicas: 3 25
logging: 26
type: inline
loggers:
zookeeper.root.logger: INFO
resources:
requests:
memory: 8Gi
cpu: "2"
limits:
memory: 8Gi
cpu: "2"
jvmOptions:
-Xms: 4096m
-Xmx: 4096m
storage:
type: persistent-claim
size: 1000Gi
metricsConfig:
# ...
entityOperator: 27
tlsSidecar: 28
resources:
requests:
cpu: 200m
memory: 64Mi
limits:
cpu: 500m
memory: 128Mi
topicOperator:
watchedNamespace: my-topic-namespace
reconciliationIntervalSeconds: 60
logging: 29
type: inline
loggers:
rootLogger.level: INFO
resources:
requests:
memory: 512Mi
cpu: "1"
limits:
memory: 512Mi
cpu: "1"
userOperator:
watchedNamespace: my-topic-namespace
reconciliationIntervalSeconds: 60
logging: 30
type: inline
loggers:
rootLogger.level: INFO
resources:
requests:
memory: 512Mi
cpu: "1"
limits:
memory: 512Mi
cpu: "1"
kafkaExporter: 31
# ...
cruiseControl: 32
# ...
- 1
- The number of replica nodes.
- 2
- Kafka version, which can be changed to a supported version by following the upgrade procedure.
- 3
- Kafka loggers and log levels added directly (
inline) or indirectly (external) through a ConfigMap. A custom Log4j configuration must be placed under thelog4j.propertieskey in the ConfigMap. For the Kafkakafka.root.logger.levellogger, you can set the log level to INFO, ERROR, WARN, TRACE, DEBUG, FATAL or OFF. - 4
- Requests for reservation of supported resources, currently
cpuandmemory, and limits to specify the maximum resources that can be consumed. - 5
- Healthchecks to know when to restart a container (liveness) and when a container can accept traffic (readiness).
- 6
- JVM configuration options to optimize performance for the Virtual Machine (VM) running Kafka.
- 7
- ADVANCED OPTION: Container image configuration, which is recommended only in special situations.
- 8
- Listeners configure how clients connect to the Kafka cluster via bootstrap addresses. Listeners are configured as internal or external listeners for connection from inside or outside the OpenShift cluster.
- 9
- Name to identify the listener. Must be unique within the Kafka cluster.
- 10
- Port number used by the listener inside Kafka. The port number has to be unique within a given Kafka cluster. Allowed port numbers are 9092 and higher with the exception of ports 9404 and 9999, which are already used for Prometheus and JMX. Depending on the listener type, the port number might not be the same as the port number that connects Kafka clients.
- 11
- Listener type specified as
internalorcluster-ip(to expose Kafka using per-brokerClusterIPservices), or for external listeners, asroute(OpenShift only),loadbalancer,nodeportoringress(Kubernetes only). - 12
- Enables or disables TLS encryption for each listener. For
routeandingresstype listeners, TLS encryption must always be enabled by setting it totrue. - 13
- Defines whether the fully-qualified DNS names including the cluster service suffix (usually
.cluster.local) are assigned. - 14
- Listener authentication mechanism specified as mTLS, SCRAM-SHA-512, or token-based OAuth 2.0.
- 15
- External listener configuration specifies how the Kafka cluster is exposed outside OpenShift, such as through a
route,loadbalancerornodeport. - 16
- Optional configuration for a Kafka listener certificate managed by an external CA (certificate authority). The
brokerCertChainAndKeyspecifies aSecretthat contains a server certificate and a private key. You can configure Kafka listener certificates on any listener with enabled TLS encryption. - 17
- Authorization enables simple, OAUTH 2.0, or OPA authorization on the Kafka broker. Simple authorization uses the
AclAuthorizerandStandardAuthorizerKafka plugins. - 18
- Broker configuration. Standard Apache Kafka configuration may be provided, restricted to those properties not managed directly by Streams for Apache Kafka.
- 19
- Storage size for persistent volumes may be increased and additional volumes may be added to JBOD storage.
- 20
- Persistent storage has additional configuration options, such as a storage
idandclassfor dynamic volume provisioning. - 21
- Rack awareness configuration to spread replicas across different racks, data centers, or availability zones. The
topologyKeymust match a node label containing the rack ID. The example used in this configuration specifies a zone using the standardtopology.kubernetes.io/zonelabel. - 22
- Prometheus metrics enabled. In this example, metrics are configured for the Prometheus JMX Exporter (the default metrics exporter).
- 23
- Rules for exporting metrics in Prometheus format to a Grafana dashboard through the Prometheus JMX Exporter, which are enabled by referencing a ConfigMap containing configuration for the Prometheus JMX exporter. You can enable metrics without further configuration using a reference to a ConfigMap containing an empty file under
metricsConfig.valueFrom.configMapKeyRef.key. - 24
- ZooKeeper-specific configuration, which contains properties similar to the Kafka configuration.
- 25
- The number of ZooKeeper nodes. ZooKeeper clusters or ensembles usually run with an odd number of nodes, typically three, five, or seven. The majority of nodes must be available in order to maintain an effective quorum. If the ZooKeeper cluster loses its quorum, it will stop responding to clients and the Kafka brokers will stop working. Having a stable and highly available ZooKeeper cluster is crucial for Streams for Apache Kafka.
- 26
- ZooKeeper loggers and log levels.
- 27
- Entity Operator configuration, which specifies the configuration for the Topic Operator and User Operator.
- 28
- Entity Operator TLS sidecar configuration. Entity Operator uses the TLS sidecar for secure communication with ZooKeeper.
- 29
- Specified Topic Operator loggers and log levels. This example uses
inlinelogging. - 30
- Specified User Operator loggers and log levels.
- 31
- Kafka Exporter configuration. Kafka Exporter is an optional component for extracting metrics data from Kafka brokers, in particular consumer lag data. For Kafka Exporter to be able to work properly, consumer groups need to be in use.
- 32
- Optional configuration for Cruise Control, which is used to rebalance the Kafka cluster.
9.2.1. Setting limits on brokers using the Kafka Static Quota plugin
Use the Kafka Static Quota plugin to set throughput and storage limits on brokers in your Kafka cluster. You enable the plugin and set limits by configuring the Kafka resource. You can set a byte-rate threshold and storage quotas to put limits on the clients interacting with your brokers.
You can set byte-rate thresholds for producer and consumer bandwidth. The total limit is distributed across all clients accessing the broker. For example, you can set a byte-rate threshold of 40 MBps for producers. If two producers are running, they are each limited to a throughput of 20 MBps.
Storage quotas throttle Kafka disk storage limits between a soft limit and hard limit. The limits apply to all available disk space. Producers are slowed gradually between the soft and hard limit. The limits prevent disks filling up too quickly and exceeding their capacity. Full disks can lead to issues that are hard to rectify. The hard limit is the maximum storage limit.
For JBOD storage, the limit applies across all disks. If a broker is using two 1 TB disks and the quota is 1.1 TB, one disk might fill and the other disk will be almost empty.
Prerequisites
- The Cluster Operator that manages the Kafka cluster is running.
Procedure
Add the plugin properties to the
configof theKafkaresource.The plugin properties are shown in this example configuration.
Example Kafka Static Quota plugin configuration
apiVersion: kafka.strimzi.io/v1beta2 kind: Kafka metadata: name: my-cluster spec: kafka: # ... config: client.quota.callback.class: io.strimzi.kafka.quotas.StaticQuotaCallback 1 client.quota.callback.static.produce: 1000000 2 client.quota.callback.static.fetch: 1000000 3 client.quota.callback.static.storage.soft: 400000000000 4 client.quota.callback.static.storage.hard: 500000000000 5 client.quota.callback.static.storage.check-interval: 5 6- 1
- Loads the Kafka Static Quota plugin.
- 2
- Sets the producer byte-rate threshold. 1 MBps in this example.
- 3
- Sets the consumer byte-rate threshold. 1 MBps in this example.
- 4
- Sets the lower soft limit for storage. 400 GB in this example.
- 5
- Sets the higher hard limit for storage. 500 GB in this example.
- 6
- Sets the interval in seconds between checks on storage. 5 seconds in this example. You can set this to 0 to disable the check.
Update the resource.
oc apply -f <kafka_configuration_file>
Additional resources
9.2.2. Default ZooKeeper configuration values
When deploying ZooKeeper with Streams for Apache Kafka, some of the default configuration set by Streams for Apache Kafka differs from the standard ZooKeeper defaults. This is because Streams for Apache Kafka sets a number of ZooKeeper properties with values that are optimized for running ZooKeeper within an OpenShift environment.
The default configuration for key ZooKeeper properties in Streams for Apache Kafka is as follows:
| Property | Default value | Description |
|---|---|---|
|
| 2000 | The length of a single tick in milliseconds, which determines the length of a session timeout. |
|
| 5 | The maximum number of ticks that a follower is allowed to fall behind the leader in a ZooKeeper cluster. |
|
| 2 | The maximum number of ticks that a follower is allowed to be out of sync with the leader in a ZooKeeper cluster. |
|
| 1 |
Enables the |
|
| false | Flag to disable the ZooKeeper admin server. The admin server is not used by Streams for Apache Kafka. |
Modifying these default values as zookeeper.config in the Kafka custom resource may impact the behavior and performance of your ZooKeeper cluster.
9.2.3. Deleting Kafka nodes using annotations
This procedure describes how to delete an existing Kafka node by using an OpenShift annotation. Deleting a Kafka node consists of deleting both the Pod on which the Kafka broker is running and the related PersistentVolumeClaim (if the cluster was deployed with persistent storage). After deletion, the Pod and its related PersistentVolumeClaim are recreated automatically.
Deleting a PersistentVolumeClaim can cause permanent data loss and the availability of your cluster cannot be guaranteed. The following procedure should only be performed if you have encountered storage issues.
Prerequisites
- A running Cluster Operator
Procedure
Find the name of the
Podthat you want to delete.Kafka broker pods are named
<cluster_name>-kafka-<index_number>, where<index_number>starts at zero and ends at the total number of replicas minus one. For example,my-cluster-kafka-0.Use
oc annotateto annotate thePodresource in OpenShift:oc annotate pod <cluster_name>-kafka-<index_number> strimzi.io/delete-pod-and-pvc="true"
- Wait for the next reconciliation, when the annotated pod with the underlying persistent volume claim will be deleted and then recreated.
9.2.4. Deleting ZooKeeper nodes using annotations
This procedure describes how to delete an existing ZooKeeper node by using an OpenShift annotation. Deleting a ZooKeeper node consists of deleting both the Pod on which ZooKeeper is running and the related PersistentVolumeClaim (if the cluster was deployed with persistent storage). After deletion, the Pod and its related PersistentVolumeClaim are recreated automatically.
Deleting a PersistentVolumeClaim can cause permanent data loss and the availability of your cluster cannot be guaranteed. The following procedure should only be performed if you have encountered storage issues.
Prerequisites
- A running Cluster Operator
Procedure
Find the name of the
Podthat you want to delete.ZooKeeper pods are named
<cluster_name>-zookeeper-<index_number>, where<index_number>starts at zero and ends at the total number of replicas minus one. For example,my-cluster-zookeeper-0.Use
oc annotateto annotate thePodresource in OpenShift:oc annotate pod <cluster_name>-zookeeper-<index_number> strimzi.io/delete-pod-and-pvc="true"
- Wait for the next reconciliation, when the annotated pod with the underlying persistent volume claim will be deleted and then recreated.
9.3. Configuring node pools
Update the spec properties of the KafkaNodePool custom resource to configure a node pool deployment.
A node pool refers to a distinct group of Kafka nodes within a Kafka cluster. Each pool has its own unique configuration, which includes mandatory settings for the number of replicas, roles, and storage allocation.
Optionally, you can also specify values for the following properties:
-
resourcesto specify memory and cpu requests and limits -
templateto specify custom configuration for pods and other OpenShift resources -
jvmOptionsto specify custom JVM configuration for heap size, runtime and other options
The Kafka resource represents the configuration for all nodes in the Kafka cluster. The KafkaNodePool resource represents the configuration for nodes only in the node pool. If a configuration property is not specified in KafkaNodePool, it is inherited from the Kafka resource. Configuration specified in the KafkaNodePool resource takes precedence if set in both resources. For example, if both the node pool and Kafka configuration includes jvmOptions, the values specified in the node pool configuration are used. When -Xmx: 1024m is set in KafkaNodePool.spec.jvmOptions and -Xms: 512m is set in Kafka.spec.kafka.jvmOptions, the node uses the value from its node pool configuration.
Properties from Kafka and KafkaNodePool schemas are not combined. To clarify, if KafkaNodePool.spec.template includes only podSet.metadata.labels, and Kafka.spec.kafka.template includes podSet.metadata.annotations and pod.metadata.labels, the template values from the Kafka configuration are ignored since there is a template value in the node pool configuration.
For a deeper understanding of the node pool configuration options, refer to the Streams for Apache Kafka Custom Resource API Reference.
Example configuration for a node pool in a cluster using KRaft mode
apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaNodePool metadata: name: kraft-dual-role 1 labels: strimzi.io/cluster: my-cluster 2 spec: replicas: 3 3 roles: 4 - controller - broker storage: 5 type: jbod volumes: - id: 0 type: persistent-claim size: 100Gi deleteClaim: false resources: 6 requests: memory: 64Gi cpu: "8" limits: memory: 64Gi cpu: "12"
- 1
- Unique name for the node pool.
- 2
- The Kafka cluster the node pool belongs to. A node pool can only belong to a single cluster.
- 3
- Number of replicas for the nodes.
- 4
- Roles for the nodes in the node pool. In this example, the nodes have dual roles as controllers and brokers.
- 5
- Storage specification for the nodes.
- 6
- Requests for reservation of supported resources, currently
cpuandmemory, and limits to specify the maximum resources that can be consumed.
The configuration for the Kafka resource must be suitable for KRaft mode. Currently, KRaft mode has a number of limitations.
Example configuration for a node pool in a cluster using ZooKeeper
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaNodePool
metadata:
name: pool-a
labels:
strimzi.io/cluster: my-cluster
spec:
replicas: 3
roles:
- broker 1
storage:
type: jbod
volumes:
- id: 0
type: persistent-claim
size: 100Gi
deleteClaim: false
resources:
requests:
memory: 64Gi
cpu: "8"
limits:
memory: 64Gi
cpu: "12"
- 1
- Roles for the nodes in the node pool, which can only be
brokerwhen using Kafka with ZooKeeper.
9.3.1. Assigning IDs to node pools for scaling operations
This procedure describes how to use annotations for advanced node ID handling by the Cluster Operator when performing scaling operations on node pools. You specify the node IDs to use, rather than the Cluster Operator using the next ID in sequence. Management of node IDs in this way gives greater control.
To add a range of IDs, you assign the following annotations to the KafkaNodePool resource:
-
strimzi.io/next-node-idsto add a range of IDs that are used for new brokers -
strimzi.io/remove-node-idsto add a range of IDs for removing existing brokers
You can specify an array of individual node IDs, ID ranges, or a combination of both. For example, you can specify the following range of IDs: [0, 1, 2, 10-20, 30] for scaling up the Kafka node pool. This format allows you to specify a combination of individual node IDs (0, 1, 2, 30) as well as a range of IDs (10-20).
In a typical scenario, you might specify a range of IDs for scaling up and a single node ID to remove a specific node when scaling down.
In this procedure, we add the scaling annotations to node pools as follows:
-
pool-ais assigned a range of IDs for scaling up -
pool-bis assigned a range of IDs for scaling down
During the scaling operation, IDs are used as follows:
- Scale up picks up the lowest available ID in the range for the new node.
- Scale down removes the node with the highest available ID in the range.
If there are gaps in the sequence of node IDs assigned in the node pool, the next node to be added is assigned an ID that fills the gap.
The annotations don’t need to be updated after every scaling operation. Any unused IDs are still valid for the next scaling event.
The Cluster Operator allows you to specify a range of IDs in either ascending or descending order, so you can define them in the order the nodes are scaled. For example, when scaling up, you can specify a range such as [1000-1999], and the new nodes are assigned the next lowest IDs: 1000, 1001, 1002, 1003, and so on. Conversely, when scaling down, you can specify a range like [1999-1000], ensuring that nodes with the next highest IDs are removed: 1003, 1002, 1001, 1000, and so on.
If you don’t specify an ID range using the annotations, the Cluster Operator follows its default behavior for handling IDs during scaling operations. Node IDs start at 0 (zero) and run sequentially across the Kafka cluster. The next lowest ID is assigned to a new node. Gaps to node IDs are filled across the cluster. This means that they might not run sequentially within a node pool. The default behavior for scaling up is to add the next lowest available node ID across the cluster; and for scaling down, it is to remove the node in the node pool with the highest available node ID. The default approach is also applied if the assigned range of IDs is misformatted, the scaling up range runs out of IDs, or the scaling down range does not apply to any in-use nodes.
Prerequisites
- The Cluster Operator must be deployed.
-
(Optional) Use the
reserved.broker-max.idconfiguration property to extend the allowable range for node IDs within your node pools.
By default, Apache Kafka restricts node IDs to numbers ranging from 0 to 999. To use node ID values greater than 999, add the reserved.broker-max.id configuration property to the Kafka custom resource and specify the required maximum node ID value.
In this example, the maximum node ID is set at 10000. Node IDs can then be assigned up to that value.
Example configuration for the maximum node ID number
apiVersion: kafka.strimzi.io/v1beta2
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
config:
reserved.broker.max.id: 10000
# ...
Procedure
Annotate the node pool with the IDs to use when scaling up or scaling down, as shown in the following examples.
IDs for scaling up are assigned to node pool
pool-a:Assigning IDs for scaling up
oc annotate kafkanodepool pool-a strimzi.io/next-node-ids="[0,1,2,10-20,30]"
The lowest available ID from this range is used when adding a node to
pool-a.IDs for scaling down are assigned to node pool
pool-b:Assigning IDs for scaling down
oc annotate kafkanodepool pool-b strimzi.io/remove-node-ids="[60-50,9,8,7]"
The highest available ID from this range is removed when scaling down
pool-b.NoteIf you want to remove a specific node, you can assign a single node ID to the scaling down annotation:
oc annotate kafkanodepool pool-b strimzi.io/remove-node-ids="[3]".You can now scale the node pool.
For more information, see the following:
On reconciliation, a warning is given if the annotations are misformatted.
After you have performed the scaling operation, you can remove the annotation if it’s no longer needed.
Removing the annotation for scaling up
oc annotate kafkanodepool pool-a strimzi.io/next-node-ids-
Removing the annotation for scaling down
oc annotate kafkanodepool pool-b strimzi.io/remove-node-ids-
9.3.2. Impact on racks when moving nodes from node pools
If rack awareness is enabled on a Kafka cluster, replicas can be spread across different racks, data centers, or availability zones. When moving nodes from node pools, consider the implications on the cluster topology, particularly regarding rack awareness. Removing specific pods from node pools, especially out of order, may break the cluster topology or cause an imbalance in distribution across racks. An imbalance can impact both the distribution of nodes themselves and the partition replicas within the cluster. An uneven distribution of nodes and partitions across racks can affect the performance and resilience of the Kafka cluster.
Plan the removal of nodes strategically to maintain the required balance and resilience across racks. Use the strimzi.io/remove-node-ids annotation to move nodes with specific IDs with caution. Ensure that configuration to spread partition replicas across racks and for clients to consume from the closest replicas is not broken.
Use Cruise Control and the KafkaRebalance resource with the RackAwareGoal to make sure that replicas remain distributed across different racks.
9.3.3. Adding nodes to a node pool
This procedure describes how to scale up a node pool to add new nodes. Currently, scale up is only possible for broker-only node pools containing nodes that run as dedicated brokers.
In this procedure, we start with three nodes for node pool pool-a:
Kafka nodes in the node pool
NAME READY STATUS RESTARTS my-cluster-pool-a-0 1/1 Running 0 my-cluster-pool-a-1 1/1 Running 0 my-cluster-pool-a-2 1/1 Running 0
Node IDs are appended to the name of the node on creation. We add node my-cluster-pool-a-3, which has a node ID of 3.
During this process, the ID of the node that holds the partition replicas changes. Consider any dependencies that reference the node ID.
Prerequisites
- The Cluster Operator must be deployed.
- Cruise Control is deployed with Kafka.
(Optional) For scale up operations, you can specify the node IDs to use in the operation.
If you have assigned a range of node IDs for the operation, the ID of the node being added is determined by the sequence of nodes given. If you have assigned a single node ID, a node is added with the specified ID. Otherwise, the lowest available node ID across the cluster is used.
Procedure
Create a new node in the node pool.
For example, node pool
pool-ahas three replicas. We add a node by increasing the number of replicas:oc scale kafkanodepool pool-a --replicas=4
Check the status of the deployment and wait for the pods in the node pool to be created and ready (
1/1).oc get pods -n <my_cluster_operator_namespace>
Output shows four Kafka nodes in the node pool
NAME READY STATUS RESTARTS my-cluster-pool-a-0 1/1 Running 0 my-cluster-pool-a-1 1/1 Running 0 my-cluster-pool-a-2 1/1 Running 0 my-cluster-pool-a-3 1/1 Running 0
Reassign the partitions after increasing the number of nodes in the node pool.
After scaling up a node pool, use the Cruise Control
add-brokersmode to move partition replicas from existing brokers to the newly added brokers.Using Cruise Control to reassign partition replicas
apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaRebalance metadata: # ... spec: mode: add-brokers brokers: [3]
We are reassigning partitions to node
my-cluster-pool-a-3. The reassignment can take some time depending on the number of topics and partitions in the cluster.
9.3.4. Removing nodes from a node pool
This procedure describes how to scale down a node pool to remove nodes. Currently, scale down is only possible for broker-only node pools containing nodes that run as dedicated brokers.
In this procedure, we start with four nodes for node pool pool-a:
Kafka nodes in the node pool
NAME READY STATUS RESTARTS my-cluster-pool-a-0 1/1 Running 0 my-cluster-pool-a-1 1/1 Running 0 my-cluster-pool-a-2 1/1 Running 0 my-cluster-pool-a-3 1/1 Running 0
Node IDs are appended to the name of the node on creation. We remove node my-cluster-pool-a-3, which has a node ID of 3.
During this process, the ID of the node that holds the partition replicas changes. Consider any dependencies that reference the node ID.
Prerequisites
- The Cluster Operator must be deployed.
- Cruise Control is deployed with Kafka.
(Optional) For scale down operations, you can specify the node IDs to use in the operation.
If you have assigned a range of node IDs for the operation, the ID of the node being removed is determined by the sequence of nodes given. If you have assigned a single node ID, the node with the specified ID is removed. Otherwise, the node with the highest available ID in the node pool is removed.
Procedure
Reassign the partitions before decreasing the number of nodes in the node pool.
Before scaling down a node pool, use the Cruise Control
remove-brokersmode to move partition replicas off the brokers that are going to be removed.Using Cruise Control to reassign partition replicas
apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaRebalance metadata: # ... spec: mode: remove-brokers brokers: [3]
We are reassigning partitions from node
my-cluster-pool-a-3. The reassignment can take some time depending on the number of topics and partitions in the cluster.After the reassignment process is complete, and the node being removed has no live partitions, reduce the number of Kafka nodes in the node pool.
For example, node pool
pool-ahas four replicas. We remove a node by decreasing the number of replicas:oc scale kafkanodepool pool-a --replicas=3
Output shows three Kafka nodes in the node pool
NAME READY STATUS RESTARTS my-cluster-pool-b-kafka-0 1/1 Running 0 my-cluster-pool-b-kafka-1 1/1 Running 0 my-cluster-pool-b-kafka-2 1/1 Running 0
9.3.5. Moving nodes between node pools
This procedure describes how to move nodes between source and target Kafka node pools without downtime. You create a new node on the target node pool and reassign partitions to move data from the old node on the source node pool. When the replicas on the new node are in-sync, you can delete the old node.
In this procedure, we start with two node pools:
-
pool-awith three replicas is the target node pool -
pool-bwith four replicas is the source node pool
We scale up pool-a, and reassign partitions and scale down pool-b, which results in the following:
-
pool-awith four replicas -
pool-bwith three replicas
During this process, the ID of the node that holds the partition replicas changes. Consider any dependencies that reference the node ID.
Prerequisites
- The Cluster Operator must be deployed.
- Cruise Control is deployed with Kafka.
(Optional) For scale up and scale down operations, you can specify the range of node IDs to use.
If you have assigned node IDs for the operation, the ID of the node being added or removed is determined by the sequence of nodes given. Otherwise, the lowest available node ID across the cluster is used when adding nodes; and the node with the highest available ID in the node pool is removed.
Procedure
Create a new node in the target node pool.
For example, node pool
pool-ahas three replicas. We add a node by increasing the number of replicas:oc scale kafkanodepool pool-a --replicas=4
Check the status of the deployment and wait for the pods in the node pool to be created and ready (
1/1).oc get pods -n <my_cluster_operator_namespace>
Output shows four Kafka nodes in the source and target node pools
NAME READY STATUS RESTARTS my-cluster-pool-a-0 1/1 Running 0 my-cluster-pool-a-1 1/1 Running 0 my-cluster-pool-a-4 1/1 Running 0 my-cluster-pool-a-7 1/1 Running 0 my-cluster-pool-b-2 1/1 Running 0 my-cluster-pool-b-3 1/1 Running 0 my-cluster-pool-b-5 1/1 Running 0 my-cluster-pool-b-6 1/1 Running 0
Node IDs are appended to the name of the node on creation. We add node
my-cluster-pool-a-7, which has a node ID of7.Reassign the partitions from the old node to the new node.
Before scaling down the source node pool, use the Cruise Control
remove-brokersmode to move partition replicas off the brokers that are going to be removed.Using Cruise Control to reassign partition replicas
apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaRebalance metadata: # ... spec: mode: remove-brokers brokers: [6]
We are reassigning partitions from node
my-cluster-pool-b-6. The reassignment can take some time depending on the number of topics and partitions in the cluster.After the reassignment process is complete, reduce the number of Kafka nodes in the source node pool.
For example, node pool
pool-bhas four replicas. We remove a node by decreasing the number of replicas:oc scale kafkanodepool pool-b --replicas=3
The node with the highest ID (
6) within the pool is removed.Output shows three Kafka nodes in the source node pool
NAME READY STATUS RESTARTS my-cluster-pool-b-kafka-2 1/1 Running 0 my-cluster-pool-b-kafka-3 1/1 Running 0 my-cluster-pool-b-kafka-5 1/1 Running 0
9.3.6. Changing node pool roles
Node pools can be used with Kafka clusters that operate in KRaft mode (using Kafka Raft metadata) or use ZooKeeper for metadata management. If you are using KRaft mode, you can specify roles for all nodes in the node pool to operate as brokers, controllers, or both. If you are using ZooKeeper, nodes must be set as brokers only.
In certain circumstances you might want to change the roles assigned to a node pool. For example, you may have a node pool that contains nodes that perform dual broker and controller roles, and then decide to split the roles between two node pools. In this case, you create a new node pool with nodes that act only as brokers, and then reassign partitions from the dual-role nodes to the new brokers. You can then switch the old node pool to a controller-only role.
You can also perform the reverse operation by moving from node pools with controller-only and broker-only roles to a node pool that contains nodes that perform dual broker and controller roles. In this case, you add the broker role to the existing controller-only node pool, reassign partitions from the broker-only nodes to the dual-role nodes, and then delete the broker-only node pool.
When removing broker roles in the node pool configuration, keep in mind that Kafka does not automatically reassign partitions. Before removing the broker role, ensure that nodes changing to controller-only roles do not have any assigned partitions. If partitions are assigned, the change is prevented. No replicas must be left on the node before removing the broker role. The best way to reassign partitions before changing roles is to apply a Cruise Control optimization proposal in remove-brokers mode. For more information, see Section 19.6, “Generating optimization proposals”.
9.3.7. Transitioning to separate broker and controller roles
This procedure describes how to transition to using node pools with separate roles. If your Kafka cluster is using a node pool with combined controller and broker roles, you can transition to using two node pools with separate roles. To do this, rebalance the cluster to move partition replicas to a node pool with a broker-only role, and then switch the old node pool to a controller-only role.
In this procedure, we start with node pool pool-a, which has controller and broker roles:
Dual-role node pool
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaNodePool
metadata:
name: pool-a
labels:
strimzi.io/cluster: my-cluster
spec:
replicas: 3
roles:
- controller
- broker
storage:
type: jbod
volumes:
- id: 0
type: persistent-claim
size: 20Gi
deleteClaim: false
# ...
The node pool has three nodes:
Kafka nodes in the node pool
NAME READY STATUS RESTARTS my-cluster-pool-a-0 1/1 Running 0 my-cluster-pool-a-1 1/1 Running 0 my-cluster-pool-a-2 1/1 Running 0
Each node performs a combined role of broker and controller. We create a second node pool called pool-b, with three nodes that act as brokers only.
During this process, the ID of the node that holds the partition replicas changes. Consider any dependencies that reference the node ID.
Procedure
Create a node pool with a
brokerrole.Example node pool configuration
apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaNodePool metadata: name: pool-b labels: strimzi.io/cluster: my-cluster spec: replicas: 3 roles: - broker storage: type: jbod volumes: - id: 0 type: persistent-claim size: 100Gi deleteClaim: false # ...The new node pool also has three nodes. If you already have a broker-only node pool, you can skip this step.
-
Apply the new
KafkaNodePoolresource to create the brokers. Check the status of the deployment and wait for the pods in the node pool to be created and ready (
1/1).oc get pods -n <my_cluster_operator_namespace>
Output shows pods running in two node pools
NAME READY STATUS RESTARTS my-cluster-pool-a-0 1/1 Running 0 my-cluster-pool-a-1 1/1 Running 0 my-cluster-pool-a-2 1/1 Running 0 my-cluster-pool-b-3 1/1 Running 0 my-cluster-pool-b-4 1/1 Running 0 my-cluster-pool-b-5 1/1 Running 0
Node IDs are appended to the name of the node on creation.
Use the Cruise Control
remove-brokersmode to reassign partition replicas from the dual-role nodes to the newly added brokers.Using Cruise Control to reassign partition replicas
apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaRebalance metadata: # ... spec: mode: remove-brokers brokers: [0, 1, 2]
The reassignment can take some time depending on the number of topics and partitions in the cluster.
NoteIf nodes changing to controller-only roles have any assigned partitions, the change is prevented. The
status.conditionsof theKafkaresource provide details of events preventing the change.Remove the
brokerrole from the node pool that originally had a combined role.Dual-role nodes switched to controllers
apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaNodePool metadata: name: pool-a labels: strimzi.io/cluster: my-cluster spec: replicas: 3 roles: - controller storage: type: jbod volumes: - id: 0 type: persistent-claim size: 20Gi deleteClaim: false # ...- Apply the configuration change so that the node pool switches to a controller-only role.
9.3.8. Transitioning to dual-role nodes
This procedure describes how to transition from separate node pools with broker-only and controller-only roles to using a dual-role node pool. If your Kafka cluster is using node pools with dedicated controller and broker nodes, you can transition to using a single node pool with both roles. To do this, add the broker role to the controller-only node pool, rebalance the cluster to move partition replicas to the dual-role node pool, and then delete the old broker-only node pool.
In this procedure, we start with two node pools pool-a, which has only the controller role and pool-b which has only the broker role:
Single role node pools
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaNodePool
metadata:
name: pool-a
labels:
strimzi.io/cluster: my-cluster
spec:
replicas: 3
roles:
- controller
storage:
type: jbod
volumes:
- id: 0
type: persistent-claim
size: 100Gi
deleteClaim: false
# ...
---
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaNodePool
metadata:
name: pool-b
labels:
strimzi.io/cluster: my-cluster
spec:
replicas: 3
roles:
- broker
storage:
type: jbod
volumes:
- id: 0
type: persistent-claim
size: 100Gi
deleteClaim: false
# ...
The Kafka cluster has six nodes:
Kafka nodes in the node pools
NAME READY STATUS RESTARTS my-cluster-pool-a-0 1/1 Running 0 my-cluster-pool-a-1 1/1 Running 0 my-cluster-pool-a-2 1/1 Running 0 my-cluster-pool-b-3 1/1 Running 0 my-cluster-pool-b-4 1/1 Running 0 my-cluster-pool-b-5 1/1 Running 0
The pool-a nodes perform the role of controller. The pool-b nodes perform the role of broker.
During this process, the ID of the node that holds the partition replicas changes. Consider any dependencies that reference the node ID.
Procedure
Edit the node pool
pool-aand add thebrokerrole to it.Example node pool configuration
apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaNodePool metadata: name: pool-a labels: strimzi.io/cluster: my-cluster spec: replicas: 3 roles: - controller - broker storage: type: jbod volumes: - id: 0 type: persistent-claim size: 100Gi deleteClaim: false # ...Check the status and wait for the pods in the node pool to be restarted and ready (
1/1).oc get pods -n <my_cluster_operator_namespace>
Output shows pods running in two node pools
NAME READY STATUS RESTARTS my-cluster-pool-a-0 1/1 Running 0 my-cluster-pool-a-1 1/1 Running 0 my-cluster-pool-a-2 1/1 Running 0 my-cluster-pool-b-3 1/1 Running 0 my-cluster-pool-b-4 1/1 Running 0 my-cluster-pool-b-5 1/1 Running 0
Node IDs are appended to the name of the node on creation.
Use the Cruise Control
remove-brokersmode to reassign partition replicas from the broker-only nodes to the dual-role nodes.Using Cruise Control to reassign partition replicas
apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaRebalance metadata: # ... spec: mode: remove-brokers brokers: [3, 4, 5]
The reassignment can take some time depending on the number of topics and partitions in the cluster.
Remove the
pool-bnode pool that has the old broker-only nodes.oc delete kafkanodepool pool-b -n <my_cluster_operator_namespace>
9.3.9. Managing storage using node pools
Storage management in Streams for Apache Kafka is usually straightforward, and requires little change when set up, but there might be situations where you need to modify your storage configurations. Node pools simplify this process, because you can set up separate node pools that specify your new storage requirements.
In this procedure we create and manage storage for a node pool called pool-a containing three nodes. We show how to change the storage class (volumes.class) that defines the type of persistent storage it uses. You can use the same steps to change the storage size (volumes.size).
We strongly recommend using block storage. Streams for Apache Kafka is only tested for use with block storage.
Prerequisites
- The Cluster Operator must be deployed.
- Cruise Control is deployed with Kafka.
- For storage that uses persistent volume claims for dynamic volume allocation, storage classes are defined and available in the OpenShift cluster that correspond to the storage solutions you need.
Procedure
Create the node pool with its own storage settings.
For example, node pool
pool-auses JBOD storage with persistent volumes:apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaNodePool metadata: name: pool-a labels: strimzi.io/cluster: my-cluster spec: replicas: 3 storage: type: jbod volumes: - id: 0 type: persistent-claim size: 500Gi class: gp2-ebs # ...Nodes in
pool-aare configured to use Amazon EBS (Elastic Block Store) GP2 volumes.-
Apply the node pool configuration for
pool-a. Check the status of the deployment and wait for the pods in
pool-ato be created and ready (1/1).oc get pods -n <my_cluster_operator_namespace>
Output shows three Kafka nodes in the node pool
NAME READY STATUS RESTARTS my-cluster-pool-a-0 1/1 Running 0 my-cluster-pool-a-1 1/1 Running 0 my-cluster-pool-a-2 1/1 Running 0
To migrate to a new storage class, create a new node pool with the required storage configuration:
apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaNodePool metadata: name: pool-b labels: strimzi.io/cluster: my-cluster spec: roles: - broker replicas: 3 storage: type: jbod volumes: - id: 0 type: persistent-claim size: 1Ti class: gp3-ebs # ...Nodes in
pool-bare configured to use Amazon EBS (Elastic Block Store) GP3 volumes.-
Apply the node pool configuration for
pool-b. -
Check the status of the deployment and wait for the pods in
pool-bto be created and ready. Reassign the partitions from
pool-atopool-b.When migrating to a new storage configuration, use the Cruise Control
remove-brokersmode to move partition replicas off the brokers that are going to be removed.Using Cruise Control to reassign partition replicas
apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaRebalance metadata: # ... spec: mode: remove-brokers brokers: [0, 1, 2]
We are reassigning partitions from
pool-a. The reassignment can take some time depending on the number of topics and partitions in the cluster.After the reassignment process is complete, delete the old node pool:
oc delete kafkanodepool pool-a
9.3.10. Managing storage affinity using node pools
In situations where storage resources, such as local persistent volumes, are constrained to specific worker nodes, or availability zones, configuring storage affinity helps to schedule pods to use the right nodes.
Node pools allow you to configure affinity independently. In this procedure, we create and manage storage affinity for two availability zones: zone-1 and zone-2.
You can configure node pools for separate availability zones, but use the same storage class. We define an all-zones persistent storage class representing the storage resources available in each zone.
We also use the .spec.template.pod properties to configure the node affinity and schedule Kafka pods on zone-1 and zone-2 worker nodes.
The storage class and affinity is specified in node pools representing the nodes in each availability zone:
-
pool-zone-1 -
pool-zone-2.
Prerequisites
- The Cluster Operator must be deployed.
- If you are not familiar with the concepts of affinity, see the Kubernetes node and pod affinity documentation.
Procedure
Define the storage class for use with each availability zone:
apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: name: all-zones provisioner: kubernetes.io/my-storage parameters: type: ssd volumeBindingMode: WaitForFirstConsumer
Create node pools representing the two availability zones, specifying the
all-zonesstorage class and the affinity for each zone:Node pool configuration for zone-1
apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaNodePool metadata: name: pool-zone-1 labels: strimzi.io/cluster: my-cluster spec: replicas: 3 storage: type: jbod volumes: - id: 0 type: persistent-claim size: 500Gi class: all-zones template: pod: affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: topology.kubernetes.io/zone operator: In values: - zone-1 # ...Node pool configuration for zone-2
apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaNodePool metadata: name: pool-zone-2 labels: strimzi.io/cluster: my-cluster spec: replicas: 4 storage: type: jbod volumes: - id: 0 type: persistent-claim size: 500Gi class: all-zones template: pod: affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: topology.kubernetes.io/zone operator: In values: - zone-2 # ...- Apply the node pool configuration.
Check the status of the deployment and wait for the pods in the node pools to be created and ready (
1/1).oc get pods -n <my_cluster_operator_namespace>
Output shows 3 Kafka nodes in
pool-zone-1and 4 Kafka nodes inpool-zone-2NAME READY STATUS RESTARTS my-cluster-pool-zone-1-kafka-0 1/1 Running 0 my-cluster-pool-zone-1-kafka-1 1/1 Running 0 my-cluster-pool-zone-1-kafka-2 1/1 Running 0 my-cluster-pool-zone-2-kafka-3 1/1 Running 0 my-cluster-pool-zone-2-kafka-4 1/1 Running 0 my-cluster-pool-zone-2-kafka-5 1/1 Running 0 my-cluster-pool-zone-2-kafka-6 1/1 Running 0
9.3.11. Migrating existing Kafka clusters to use Kafka node pools
This procedure describes how to migrate existing Kafka clusters to use Kafka node pools. After you have updated the Kafka cluster, you can use the node pools to manage the configuration of nodes within each pool.
Currently, replica and storage configuration in the KafkaNodePool resource must also be present in the Kafka resource. The configuration is ignored when node pools are being used.
Prerequisites
Procedure
Create a new
KafkaNodePoolresource.-
Name the resource
kafka. -
Point a
strimzi.io/clusterlabel to your existingKafkaresource. - Set the replica count and storage configuration to match your current Kafka cluster.
-
Set the roles to
broker.
Example configuration for a node pool used in migrating a Kafka cluster
apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaNodePool metadata: name: kafka labels: strimzi.io/cluster: my-cluster spec: replicas: 3 roles: - broker storage: type: jbod volumes: - id: 0 type: persistent-claim size: 100Gi deleteClaim: falseWarningTo preserve cluster data and the names of its nodes and resources, the node pool name must be
kafka, and thestrimzi.io/clusterlabel must match the Kafka resource name. Otherwise, nodes and resources are created with new names, including the persistent volume storage used by the nodes. Consequently, your previous data may not be available.-
Name the resource
Apply the
KafkaNodePoolresource:oc apply -f <node_pool_configuration_file>
By applying this resource, you switch Kafka to using node pools.
There is no change or rolling update and resources are identical to how they were before.
Enable support for node pools in the
Kafkaresource using thestrimzi.io/node-pools: enabledannotation.Example configuration for a node pool in a cluster using ZooKeeper
apiVersion: kafka.strimzi.io/v1beta2 kind: Kafka metadata: name: my-cluster annotations: strimzi.io/node-pools: enabled spec: kafka: # ... zookeeper: # ...Apply the
Kafkaresource:oc apply -f <kafka_configuration_file>
There is no change or rolling update. The resources remain identical to how they were before.
-
Remove the replicated properties from the
Kafkacustom resource. When theKafkaNodePoolresource is in use, you can remove the properties that you copied to theKafkaNodePoolresource, such as the.spec.kafka.replicasand.spec.kafka.storageproperties.
Reversing the migration
To revert to managing Kafka nodes using only Kafka custom resources:
-
If you have multiple node pools, consolidate them into a single
KafkaNodePoolnamedkafkawith node IDs from 0 to N (where N is the number of replicas). -
Ensure that the
.spec.kafkaconfiguration in theKafkaresource matches theKafkaNodePoolconfiguration, including storage, resources, and replicas. -
Disable support for node pools in the
Kafkaresource using thestrimzi.io/node-pools: disabledannotation. -
Delete the Kafka node pool named
kafka.
9.4. Configuring the Entity Operator
Use the entityOperator property in Kafka.spec to configure the Entity Operator. The Entity Operator is responsible for managing Kafka-related entities in a running Kafka cluster. It comprises the following operators:
- Topic Operator to manage Kafka topics
- User Operator to manage Kafka users
By configuring the Kafka resource, the Cluster Operator can deploy the Entity Operator, including one or both operators. Once deployed, the operators are automatically configured to handle the topics and users of the Kafka cluster.
Each operator can only monitor a single namespace. For more information, see Section 1.2.1, “Watching Streams for Apache Kafka resources in OpenShift namespaces”.
The entityOperator property supports several sub-properties:
-
tlsSidecar -
topicOperator -
userOperator -
template
The tlsSidecar property contains the configuration of the TLS sidecar container, which is used to communicate with ZooKeeper.
The template property contains the configuration of the Entity Operator pod, such as labels, annotations, affinity, and tolerations. For more information on configuring templates, see Section 9.16, “Customizing OpenShift resources”.
The topicOperator property contains the configuration of the Topic Operator. When this option is missing, the Entity Operator is deployed without the Topic Operator.
The userOperator property contains the configuration of the User Operator. When this option is missing, the Entity Operator is deployed without the User Operator.
For more information on the properties used to configure the Entity Operator, see the EntityOperatorSpec schema reference.
Example of basic configuration enabling both operators
apiVersion: kafka.strimzi.io/v1beta2
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
# ...
zookeeper:
# ...
entityOperator:
topicOperator: {}
userOperator: {}
If an empty object ({}) is used for the topicOperator and userOperator, all properties use their default values.
When both topicOperator and userOperator properties are missing, the Entity Operator is not deployed.
9.4.1. Configuring the Topic Operator
Use topicOperator properties in Kafka.spec.entityOperator to configure the Topic Operator.
If you are using unidirectional topic management, which is enabled by default, the following properties are not used and are ignored: Kafka.spec.entityOperator.topicOperator.zookeeperSessionTimeoutSeconds and Kafka.spec.entityOperator.topicOperator.topicMetadataMaxAttempts. For more information on unidirectional topic management, refer to Section 10.1, “Topic management modes”.
The following properties are supported:
watchedNamespace-
The OpenShift namespace in which the Topic Operator watches for
KafkaTopicresources. Default is the namespace where the Kafka cluster is deployed. reconciliationIntervalSeconds-
The interval between periodic reconciliations in seconds. Default
120. zookeeperSessionTimeoutSeconds-
The ZooKeeper session timeout in seconds. Default
18. topicMetadataMaxAttempts-
The number of attempts at getting topic metadata from Kafka. The time between each attempt is defined as an exponential back-off. Consider increasing this value when topic creation might take more time due to the number of partitions or replicas. Default
6. image-
The
imageproperty can be used to configure the container image which is used. To learn more, refer to the information provided on configuring theimageproperty`. resources-
The
resourcesproperty configures the amount of resources allocated to the Topic Operator. You can specify requests and limits formemoryandcpuresources. The requests should be enough to ensure a stable performance of the operator. logging-
The
loggingproperty configures the logging of the Topic Operator. To learn more, refer to the information provided on Topic Operator logging.
Example Topic Operator configuration
apiVersion: kafka.strimzi.io/v1beta2
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
# ...
zookeeper:
# ...
entityOperator:
# ...
topicOperator:
watchedNamespace: my-topic-namespace
reconciliationIntervalSeconds: 60
resources:
requests:
cpu: "1"
memory: 500Mi
limits:
cpu: "1"
memory: 500Mi
# ...
9.4.2. Configuring the User Operator
Use userOperator properties in Kafka.spec.entityOperator to configure the User Operator. The following properties are supported:
watchedNamespace-
The OpenShift namespace in which the User Operator watches for
KafkaUserresources. Default is the namespace where the Kafka cluster is deployed. reconciliationIntervalSeconds-
The interval between periodic reconciliations in seconds. Default
120. image-
The
imageproperty can be used to configure the container image which will be used. To learn more, refer to the information provided on configuring theimageproperty`. resources-
The
resourcesproperty configures the amount of resources allocated to the User Operator. You can specify requests and limits formemoryandcpuresources. The requests should be enough to ensure a stable performance of the operator. logging-
The
loggingproperty configures the logging of the User Operator. To learn more, refer to the information provided on User Operator logging. secretPrefix-
The
secretPrefixproperty adds a prefix to the name of all Secrets created from the KafkaUser resource. For example,secretPrefix: kafka-would prefix all Secret names withkafka-. So a KafkaUser namedmy-userwould create a Secret namedkafka-my-user.
Example User Operator configuration
apiVersion: kafka.strimzi.io/v1beta2
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
# ...
zookeeper:
# ...
entityOperator:
# ...
userOperator:
watchedNamespace: my-user-namespace
reconciliationIntervalSeconds: 60
resources:
requests:
cpu: "1"
memory: 500Mi
limits:
cpu: "1"
memory: 500Mi
# ...
9.5. Configuring the Cluster Operator
Use environment variables to configure the Cluster Operator. Specify the environment variables for the container image of the Cluster Operator in its Deployment configuration file. You can use the following environment variables to configure the Cluster Operator. If you are running Cluster Operator replicas in standby mode, there are additional environment variables for enabling leader election.
Kafka, Kafka Connect, and Kafka MirrorMaker support multiple versions. Use their STRIMZI_<COMPONENT_NAME>_IMAGES environment variables to configure the default container images used for each version. The configuration provides a mapping between a version and an image. The required syntax is whitespace or comma-separated <version> = <image> pairs, which determine the image to use for a given version. For example, 3.7.0=registry.redhat.io/amq-streams/kafka-37-rhel9:2.7.0. Theses default images are overridden if image property values are specified in the configuration of a component. For more information on image configuration of components, see the Streams for Apache Kafka Custom Resource API Reference.
The Deployment configuration file provided with the Streams for Apache Kafka release artifacts is install/cluster-operator/060-Deployment-strimzi-cluster-operator.yaml.
STRIMZI_NAMESPACEA comma-separated list of namespaces that the operator operates in. When not set, set to empty string, or set to
*, the Cluster Operator operates in all namespaces.The Cluster Operator deployment might use the downward API to set this automatically to the namespace the Cluster Operator is deployed in.
Example configuration for Cluster Operator namespaces
env: - name: STRIMZI_NAMESPACE valueFrom: fieldRef: fieldPath: metadata.namespaceSTRIMZI_FULL_RECONCILIATION_INTERVAL_MS- Optional, default is 120000 ms. The interval between periodic reconciliations, in milliseconds.
STRIMZI_OPERATION_TIMEOUT_MS- Optional, default 300000 ms. The timeout for internal operations, in milliseconds. Increase this value when using Streams for Apache Kafka on clusters where regular OpenShift operations take longer than usual (due to factors such as prolonged download times for container images, for example).
STRIMZI_ZOOKEEPER_ADMIN_SESSION_TIMEOUT_MS-
Optional, default 10000 ms. The session timeout for the Cluster Operator’s ZooKeeper admin client, in milliseconds. Increase the value if ZooKeeper requests from the Cluster Operator are regularly failing due to timeout issues. There is a maximum allowed session time set on the ZooKeeper server side via the
maxSessionTimeoutconfig. By default, the maximum session timeout value is 20 times the defaulttickTime(whose default is 2000) at 40000 ms. If you require a higher timeout, change themaxSessionTimeoutZooKeeper server configuration value. STRIMZI_OPERATIONS_THREAD_POOL_SIZE- Optional, default 10. The worker thread pool size, which is used for various asynchronous and blocking operations that are run by the Cluster Operator.
STRIMZI_OPERATOR_NAME- Optional, defaults to the pod’s hostname. The operator name identifies the Streams for Apache Kafka instance when emitting OpenShift events.
STRIMZI_OPERATOR_NAMESPACEThe name of the namespace where the Cluster Operator is running. Do not configure this variable manually. Use the downward API.
env: - name: STRIMZI_OPERATOR_NAMESPACE valueFrom: fieldRef: fieldPath: metadata.namespaceSTRIMZI_OPERATOR_NAMESPACE_LABELSOptional. The labels of the namespace where the Streams for Apache Kafka Cluster Operator is running. Use namespace labels to configure the namespace selector in network policies. Network policies allow the Streams for Apache Kafka Cluster Operator access only to the operands from the namespace with these labels. When not set, the namespace selector in network policies is configured to allow access to the Cluster Operator from any namespace in the OpenShift cluster.
env: - name: STRIMZI_OPERATOR_NAMESPACE_LABELS value: label1=value1,label2=value2STRIMZI_LABELS_EXCLUSION_PATTERNOptional, default regex pattern is
^app.kubernetes.io/(?!part-of).*. The regex exclusion pattern used to filter labels propagation from the main custom resource to its subresources. The labels exclusion filter is not applied to labels in template sections such asspec.kafka.template.pod.metadata.labels.env: - name: STRIMZI_LABELS_EXCLUSION_PATTERN value: "^key1.*"STRIMZI_CUSTOM_<COMPONENT_NAME>_LABELSOptional. One or more custom labels to apply to all the pods created by the custom resource of the component. The Cluster Operator labels the pods when the custom resource is created or is next reconciled.
Labels can be applied to the following components:
-
KAFKA -
KAFKA_CONNECT -
KAFKA_CONNECT_BUILD -
ZOOKEEPER -
ENTITY_OPERATOR -
KAFKA_MIRROR_MAKER2 -
KAFKA_MIRROR_MAKER -
CRUISE_CONTROL -
KAFKA_BRIDGE -
KAFKA_EXPORTER
-
STRIMZI_CUSTOM_RESOURCE_SELECTOROptional. The label selector to filter the custom resources handled by the Cluster Operator. The operator will operate only on those custom resources that have the specified labels set. Resources without these labels will not be seen by the operator. The label selector applies to
Kafka,KafkaConnect,KafkaBridge,KafkaMirrorMaker, andKafkaMirrorMaker2resources.KafkaRebalanceandKafkaConnectorresources are operated only when their corresponding Kafka and Kafka Connect clusters have the matching labels.env: - name: STRIMZI_CUSTOM_RESOURCE_SELECTOR value: label1=value1,label2=value2STRIMZI_KAFKA_IMAGES-
Required. The mapping from the Kafka version to the corresponding image containing a Kafka broker for that version. For example
3.6.0=registry.redhat.io/amq-streams/kafka-36-rhel9:2.7.0, 3.7.0=registry.redhat.io/amq-streams/kafka-37-rhel9:2.7.0. STRIMZI_KAFKA_CONNECT_IMAGES-
Required. The mapping from the Kafka version to the corresponding image of Kafka Connect for that version. For example
3.6.0=registry.redhat.io/amq-streams/kafka-36-rhel9:2.7.0, 3.7.0=registry.redhat.io/amq-streams/kafka-37-rhel9:2.7.0. STRIMZI_KAFKA_MIRROR_MAKER2_IMAGES-
Required. The mapping from the Kafka version to the corresponding image of MirrorMaker 2 for that version. For example
3.6.0=registry.redhat.io/amq-streams/kafka-36-rhel9:2.7.0, 3.7.0=registry.redhat.io/amq-streams/kafka-37-rhel9:2.7.0. - (Deprecated)
STRIMZI_KAFKA_MIRROR_MAKER_IMAGES -
Required. The mapping from the Kafka version to the corresponding image of MirrorMaker for that version. For example
3.6.0=registry.redhat.io/amq-streams/kafka-36-rhel9:2.7.0, 3.7.0=registry.redhat.io/amq-streams/kafka-37-rhel9:2.7.0. STRIMZI_DEFAULT_TOPIC_OPERATOR_IMAGE-
Optional. The default is
registry.redhat.io/amq-streams/strimzi-rhel9-operator:2.7.0. The image name to use as the default when deploying the Topic Operator if no image is specified as theKafka.spec.entityOperator.topicOperator.imagein theKafkaresource. STRIMZI_DEFAULT_USER_OPERATOR_IMAGE-
Optional. The default is
registry.redhat.io/amq-streams/strimzi-rhel9-operator:2.7.0. The image name to use as the default when deploying the User Operator if no image is specified as theKafka.spec.entityOperator.userOperator.imagein theKafkaresource. STRIMZI_DEFAULT_TLS_SIDECAR_ENTITY_OPERATOR_IMAGE-
Optional. The default is
registry.redhat.io/amq-streams/kafka-37-rhel9:2.7.0. The image name to use as the default when deploying the sidecar container for the Entity Operator if no image is specified as theKafka.spec.entityOperator.tlsSidecar.imagein theKafkaresource. The sidecar provides TLS support. STRIMZI_DEFAULT_KAFKA_EXPORTER_IMAGE-
Optional. The default is
registry.redhat.io/amq-streams/kafka-37-rhel9:2.7.0. The image name to use as the default when deploying the Kafka Exporter if no image is specified as theKafka.spec.kafkaExporter.imagein theKafkaresource. STRIMZI_DEFAULT_CRUISE_CONTROL_IMAGE-
Optional. The default is
registry.redhat.io/amq-streams/kafka-37-rhel9:2.7.0. The image name to use as the default when deploying Cruise Control if no image is specified as theKafka.spec.cruiseControl.imagein theKafkaresource. STRIMZI_DEFAULT_KAFKA_BRIDGE_IMAGE-
Optional. The default is
registry.redhat.io/amq-streams/bridge-rhel9:2.7.0. The image name to use as the default when deploying the Kafka Bridge if no image is specified as theKafka.spec.kafkaBridge.imagein theKafkaresource. STRIMZI_DEFAULT_KAFKA_INIT_IMAGE-
Optional. The default is
registry.redhat.io/amq-streams/strimzi-rhel9-operator:2.7.0. The image name to use as the default for the Kafka initializer container if no image is specified in thebrokerRackInitImageof theKafkaresource or theclientRackInitImageof the Kafka Connect resource. The init container is started before the Kafka cluster for initial configuration work, such as rack support. STRIMZI_IMAGE_PULL_POLICY-
Optional. The
ImagePullPolicythat is applied to containers in all pods managed by the Cluster Operator. The valid values areAlways,IfNotPresent, andNever. If not specified, the OpenShift defaults are used. Changing the policy will result in a rolling update of all your Kafka, Kafka Connect, and Kafka MirrorMaker clusters. STRIMZI_IMAGE_PULL_SECRETS-
Optional. A comma-separated list of
Secretnames. The secrets referenced here contain the credentials to the container registries where the container images are pulled from. The secrets are specified in theimagePullSecretsproperty for all pods created by the Cluster Operator. Changing this list results in a rolling update of all your Kafka, Kafka Connect, and Kafka MirrorMaker clusters. STRIMZI_KUBERNETES_VERSIONOptional. Overrides the OpenShift version information detected from the API server.
Example configuration for OpenShift version override
env: - name: STRIMZI_KUBERNETES_VERSION value: | major=1 minor=16 gitVersion=v1.16.2 gitCommit=c97fe5036ef3df2967d086711e6c0c405941e14b gitTreeState=clean buildDate=2019-10-15T19:09:08Z goVersion=go1.12.10 compiler=gc platform=linux/amd64KUBERNETES_SERVICE_DNS_DOMAINOptional. Overrides the default OpenShift DNS domain name suffix.
By default, services assigned in the OpenShift cluster have a DNS domain name that uses the default suffix
cluster.local.For example, for broker kafka-0:
<cluster-name>-kafka-0.<cluster-name>-kafka-brokers.<namespace>.svc.cluster.local
The DNS domain name is added to the Kafka broker certificates used for hostname verification.
If you are using a different DNS domain name suffix in your cluster, change the
KUBERNETES_SERVICE_DNS_DOMAINenvironment variable from the default to the one you are using in order to establish a connection with the Kafka brokers.STRIMZI_CONNECT_BUILD_TIMEOUT_MS- Optional, default 300000 ms. The timeout for building new Kafka Connect images with additional connectors, in milliseconds. Consider increasing this value when using Streams for Apache Kafka to build container images containing many connectors or using a slow container registry.
STRIMZI_NETWORK_POLICY_GENERATIONOptional, default
true. Network policy for resources. Network policies allow connections between Kafka components.Set this environment variable to
falseto disable network policy generation. You might do this, for example, if you want to use custom network policies. Custom network policies allow more control over maintaining the connections between components.STRIMZI_DNS_CACHE_TTL-
Optional, default
30. Number of seconds to cache successful name lookups in local DNS resolver. Any negative value means cache forever. Zero means do not cache, which can be useful for avoiding connection errors due to long caching policies being applied. STRIMZI_POD_SET_RECONCILIATION_ONLY-
Optional, default
false. When set totrue, the Cluster Operator reconciles only theStrimziPodSetresources and any changes to the other custom resources (Kafka,KafkaConnect, and so on) are ignored. This mode is useful for ensuring that your pods are recreated if needed, but no other changes happen to the clusters. STRIMZI_FEATURE_GATES- Optional. Enables or disables the features and functionality controlled by feature gates.
STRIMZI_POD_SECURITY_PROVIDER_CLASS-
Optional. Configuration for the pluggable
PodSecurityProviderclass, which can be used to provide the security context configuration for Pods and containers.
9.5.1. Restricting access to the Cluster Operator using network policy
Use the STRIMZI_OPERATOR_NAMESPACE_LABELS environment variable to establish network policy for the Cluster Operator using namespace labels.
The Cluster Operator can run in the same namespace as the resources it manages, or in a separate namespace. By default, the STRIMZI_OPERATOR_NAMESPACE environment variable is configured to use the downward API to find the namespace the Cluster Operator is running in. If the Cluster Operator is running in the same namespace as the resources, only local access is required and allowed by Streams for Apache Kafka.
If the Cluster Operator is running in a separate namespace to the resources it manages, any namespace in the OpenShift cluster is allowed access to the Cluster Operator unless network policy is configured. By adding namespace labels, access to the Cluster Operator is restricted to the namespaces specified.
Network policy configured for the Cluster Operator deployment
#...
env:
# ...
- name: STRIMZI_OPERATOR_NAMESPACE_LABELS
value: label1=value1,label2=value2
#...
9.5.2. Setting periodic reconciliation of custom resources
Use the STRIMZI_FULL_RECONCILIATION_INTERVAL_MS variable to set the time interval for periodic reconciliations by the Cluster Operator. Replace its value with the required interval in milliseconds.
Reconciliation period configured for the Cluster Operator deployment
#...
env:
# ...
- name: STRIMZI_FULL_RECONCILIATION_INTERVAL_MS
value: "120000"
#...
The Cluster Operator reacts to all notifications about applicable cluster resources received from the OpenShift cluster. If the operator is not running, or if a notification is not received for any reason, resources will get out of sync with the state of the running OpenShift cluster. In order to handle failovers properly, a periodic reconciliation process is executed by the Cluster Operator so that it can compare the state of the resources with the current cluster deployments in order to have a consistent state across all of them.
Additional resources
9.5.3. Pausing reconciliation of custom resources using annotations
Sometimes it is useful to pause the reconciliation of custom resources managed by Streams for Apache Kafka operators, so that you can perform fixes or make updates. If reconciliations are paused, any changes made to custom resources are ignored by the operators until the pause ends.
If you want to pause reconciliation of a custom resource, set the strimzi.io/pause-reconciliation annotation to true in its configuration. This instructs the appropriate operator to pause reconciliation of the custom resource. For example, you can apply the annotation to the KafkaConnect resource so that reconciliation by the Cluster Operator is paused.
You can also create a custom resource with the pause annotation enabled. The custom resource is created, but it is ignored.
Prerequisites
- The Streams for Apache Kafka Operator that manages the custom resource is running.
Procedure
Annotate the custom resource in OpenShift, setting
pause-reconciliationtotrue:oc annotate <kind_of_custom_resource> <name_of_custom_resource> strimzi.io/pause-reconciliation="true"
For example, for the
KafkaConnectcustom resource:oc annotate KafkaConnect my-connect strimzi.io/pause-reconciliation="true"
Check that the status conditions of the custom resource show a change to
ReconciliationPaused:oc describe <kind_of_custom_resource> <name_of_custom_resource>
The
typecondition changes toReconciliationPausedat thelastTransitionTime.Example custom resource with a paused reconciliation condition type
apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaConnect metadata: annotations: strimzi.io/pause-reconciliation: "true" strimzi.io/use-connector-resources: "true" creationTimestamp: 2021-03-12T10:47:11Z #... spec: # ... status: conditions: - lastTransitionTime: 2021-03-12T10:47:41.689249Z status: "True" type: ReconciliationPaused
Resuming from pause
-
To resume reconciliation, you can set the annotation to
false, or remove the annotation.
Additional resources
9.5.4. Running multiple Cluster Operator replicas with leader election
The default Cluster Operator configuration enables leader election to run multiple parallel replicas of the Cluster Operator. One replica is elected as the active leader and operates the deployed resources. The other replicas run in standby mode. When the leader stops or fails, one of the standby replicas is elected as the new leader and starts operating the deployed resources.
By default, Streams for Apache Kafka runs with a single Cluster Operator replica that is always the leader replica. When a single Cluster Operator replica stops or fails, OpenShift starts a new replica.
Running the Cluster Operator with multiple replicas is not essential. But it’s useful to have replicas on standby in case of large-scale disruptions caused by major failure. For example, suppose multiple worker nodes or an entire availability zone fails. This failure might cause the Cluster Operator pod and many Kafka pods to go down at the same time. If subsequent pod scheduling causes congestion through lack of resources, this can delay operations when running a single Cluster Operator.
9.5.4.1. Enabling leader election for Cluster Operator replicas
Configure leader election environment variables when running additional Cluster Operator replicas. The following environment variables are supported:
STRIMZI_LEADER_ELECTION_ENABLED-
Optional, disabled (
false) by default. Enables or disables leader election, which allows additional Cluster Operator replicas to run on standby.
Leader election is disabled by default. It is only enabled when applying this environment variable on installation.
STRIMZI_LEADER_ELECTION_LEASE_NAME-
Required when leader election is enabled. The name of the OpenShift
Leaseresource that is used for the leader election. STRIMZI_LEADER_ELECTION_LEASE_NAMESPACERequired when leader election is enabled. The namespace where the OpenShift
Leaseresource used for leader election is created. You can use the downward API to configure it to the namespace where the Cluster Operator is deployed.env: - name: STRIMZI_LEADER_ELECTION_LEASE_NAMESPACE valueFrom: fieldRef: fieldPath: metadata.namespaceSTRIMZI_LEADER_ELECTION_IDENTITYRequired when leader election is enabled. Configures the identity of a given Cluster Operator instance used during the leader election. The identity must be unique for each operator instance. You can use the downward API to configure it to the name of the pod where the Cluster Operator is deployed.
env: - name: STRIMZI_LEADER_ELECTION_IDENTITY valueFrom: fieldRef: fieldPath: metadata.nameSTRIMZI_LEADER_ELECTION_LEASE_DURATION_MS- Optional, default 15000 ms. Specifies the duration the acquired lease is valid.
STRIMZI_LEADER_ELECTION_RENEW_DEADLINE_MS- Optional, default 10000 ms. Specifies the period the leader should try to maintain leadership.
STRIMZI_LEADER_ELECTION_RETRY_PERIOD_MS- Optional, default 2000 ms. Specifies the frequency of updates to the lease lock by the leader.
9.5.4.2. Configuring Cluster Operator replicas
To run additional Cluster Operator replicas in standby mode, you will need to increase the number of replicas and enable leader election. To configure leader election, use the leader election environment variables.
To make the required changes, configure the following Cluster Operator installation files located in install/cluster-operator/:
- 060-Deployment-strimzi-cluster-operator.yaml
- 022-ClusterRole-strimzi-cluster-operator-role.yaml
- 022-RoleBinding-strimzi-cluster-operator.yaml
Leader election has its own ClusterRole and RoleBinding RBAC resources that target the namespace where the Cluster Operator is running, rather than the namespace it is watching.
The default deployment configuration creates a Lease resource called strimzi-cluster-operator in the same namespace as the Cluster Operator. The Cluster Operator uses leases to manage leader election. The RBAC resources provide the permissions to use the Lease resource. If you use a different Lease name or namespace, update the ClusterRole and RoleBinding files accordingly.
Prerequisites
-
You need an account with permission to create and manage
CustomResourceDefinitionand RBAC (ClusterRole, andRoleBinding) resources.
Procedure
Edit the Deployment resource that is used to deploy the Cluster Operator, which is defined in the 060-Deployment-strimzi-cluster-operator.yaml file.
Change the
replicasproperty from the default (1) to a value that matches the required number of replicas.Increasing the number of Cluster Operator replicas
apiVersion: apps/v1 kind: Deployment metadata: name: strimzi-cluster-operator labels: app: strimzi spec: replicas: 3Check that the leader election
envproperties are set.If they are not set, configure them.
To enable leader election,
STRIMZI_LEADER_ELECTION_ENABLEDmust be set totrue(default).In this example, the name of the lease is changed to
my-strimzi-cluster-operator.Configuring leader election environment variables for the Cluster Operator
# ... spec containers: - name: strimzi-cluster-operator # ... env: - name: STRIMZI_LEADER_ELECTION_ENABLED value: "true" - name: STRIMZI_LEADER_ELECTION_LEASE_NAME value: "my-strimzi-cluster-operator" - name: STRIMZI_LEADER_ELECTION_LEASE_NAMESPACE valueFrom: fieldRef: fieldPath: metadata.namespace - name: STRIMZI_LEADER_ELECTION_IDENTITY valueFrom: fieldRef: fieldPath: metadata.nameFor a description of the available environment variables, see Section 9.5.4.1, “Enabling leader election for Cluster Operator replicas”.
If you specified a different name or namespace for the
Leaseresource used in leader election, update the RBAC resources.(optional) Edit the
ClusterRoleresource in the022-ClusterRole-strimzi-cluster-operator-role.yamlfile.Update
resourceNameswith the name of theLeaseresource.Updating the ClusterRole references to the lease
apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: strimzi-cluster-operator-leader-election labels: app: strimzi rules: - apiGroups: - coordination.k8s.io resourceNames: - my-strimzi-cluster-operator # ...(optional) Edit the
RoleBindingresource in the022-RoleBinding-strimzi-cluster-operator.yamlfile.Update
subjects.nameandsubjects.namespacewith the name of theLeaseresource and the namespace where it was created.Updating the RoleBinding references to the lease
apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: strimzi-cluster-operator-leader-election labels: app: strimzi subjects: - kind: ServiceAccount name: my-strimzi-cluster-operator namespace: myproject # ...Deploy the Cluster Operator:
oc create -f install/cluster-operator -n myproject
Check the status of the deployment:
oc get deployments -n myproject
Output shows the deployment name and readiness
NAME READY UP-TO-DATE AVAILABLE strimzi-cluster-operator 3/3 3 3
READYshows the number of replicas that are ready/expected. The deployment is successful when theAVAILABLEoutput shows the correct number of replicas.
9.5.5. Configuring Cluster Operator HTTP proxy settings
If you are running a Kafka cluster behind a HTTP proxy, you can still pass data in and out of the cluster. For example, you can run Kafka Connect with connectors that push and pull data from outside the proxy. Or you can use a proxy to connect with an authorization server.
Configure the Cluster Operator deployment to specify the proxy environment variables. The Cluster Operator accepts standard proxy configuration (HTTP_PROXY, HTTPS_PROXY and NO_PROXY) as environment variables. The proxy settings are applied to all Streams for Apache Kafka containers.
The format for a proxy address is http://<ip_address>:<port_number>. To set up a proxy with a name and password, the format is http://<username>:<password>@<ip-address>:<port_number>.
Prerequisites
-
You need an account with permission to create and manage
CustomResourceDefinitionand RBAC (ClusterRole, andRoleBinding) resources.
Procedure
To add proxy environment variables to the Cluster Operator, update its
Deploymentconfiguration (install/cluster-operator/060-Deployment-strimzi-cluster-operator.yaml).Example proxy configuration for the Cluster Operator
apiVersion: apps/v1 kind: Deployment spec: # ... template: spec: serviceAccountName: strimzi-cluster-operator containers: # ... env: # ... - name: "HTTP_PROXY" value: "http://proxy.com" 1 - name: "HTTPS_PROXY" value: "https://proxy.com" 2 - name: "NO_PROXY" value: "internal.com, other.domain.com" 3 # ...Alternatively, edit the
Deploymentdirectly:oc edit deployment strimzi-cluster-operator
If you updated the YAML file instead of editing the
Deploymentdirectly, apply the changes:oc create -f install/cluster-operator/060-Deployment-strimzi-cluster-operator.yaml
Additional resources
9.5.6. Disabling FIPS mode using Cluster Operator configuration
Streams for Apache Kafka automatically switches to FIPS mode when running on a FIPS-enabled OpenShift cluster. Disable FIPS mode by setting the FIPS_MODE environment variable to disabled in the deployment configuration for the Cluster Operator. With FIPS mode disabled, Streams for Apache Kafka automatically disables FIPS in the OpenJDK for all components. With FIPS mode disabled, Streams for Apache Kafka is not FIPS compliant. The Streams for Apache Kafka operators, as well as all operands, run in the same way as if they were running on an OpenShift cluster without FIPS enabled.
Procedure
To disable the FIPS mode in the Cluster Operator, update its
Deploymentconfiguration (install/cluster-operator/060-Deployment-strimzi-cluster-operator.yaml) and add theFIPS_MODEenvironment variable.Example FIPS configuration for the Cluster Operator
apiVersion: apps/v1 kind: Deployment spec: # ... template: spec: serviceAccountName: strimzi-cluster-operator containers: # ... env: # ... - name: "FIPS_MODE" value: "disabled" 1 # ...- 1
- Disables the FIPS mode.
Alternatively, edit the
Deploymentdirectly:oc edit deployment strimzi-cluster-operator
If you updated the YAML file instead of editing the
Deploymentdirectly, apply the changes:oc apply -f install/cluster-operator/060-Deployment-strimzi-cluster-operator.yaml
9.6. Configuring Kafka Connect
Update the spec properties of the KafkaConnect custom resource to configure your Kafka Connect deployment.
Use Kafka Connect to set up external data connections to your Kafka cluster. Use the properties of the KafkaConnect resource to configure your Kafka Connect deployment.
For a deeper understanding of the Kafka Connect cluster configuration options, refer to the Streams for Apache Kafka Custom Resource API Reference.
KafkaConnector configuration
KafkaConnector resources allow you to create and manage connector instances for Kafka Connect in an OpenShift-native way.
In your Kafka Connect configuration, you enable KafkaConnectors for a Kafka Connect cluster by adding the strimzi.io/use-connector-resources annotation. You can also add a build configuration so that Streams for Apache Kafka automatically builds a container image with the connector plugins you require for your data connections. External configuration for Kafka Connect connectors is specified through the externalConfiguration property.
To manage connectors, you can use use KafkaConnector custom resources or the Kafka Connect REST API. KafkaConnector resources must be deployed to the same namespace as the Kafka Connect cluster they link to. For more information on using these methods to create, reconfigure, or delete connectors, see Adding connectors.
Connector configuration is passed to Kafka Connect as part of an HTTP request and stored within Kafka itself. ConfigMaps and Secrets are standard OpenShift resources used for storing configurations and confidential data. You can use ConfigMaps and Secrets to configure certain elements of a connector. You can then reference the configuration values in HTTP REST commands, which keeps the configuration separate and more secure, if needed. This method applies especially to confidential data, such as usernames, passwords, or certificates.
Handling high volumes of messages
You can tune the configuration to handle high volumes of messages. For more information, see Handling high volumes of messages.
Example KafkaConnect custom resource configuration
apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaConnect 1 metadata: name: my-connect-cluster annotations: strimzi.io/use-connector-resources: "true" 2 spec: replicas: 3 3 authentication: 4 type: tls certificateAndKey: certificate: source.crt key: source.key secretName: my-user-source bootstrapServers: my-cluster-kafka-bootstrap:9092 5 tls: 6 trustedCertificates: - secretName: my-cluster-cluster-cert certificate: ca.crt - secretName: my-cluster-cluster-cert certificate: ca2.crt config: 7 group.id: my-connect-cluster offset.storage.topic: my-connect-cluster-offsets config.storage.topic: my-connect-cluster-configs status.storage.topic: my-connect-cluster-status key.converter: org.apache.kafka.connect.json.JsonConverter value.converter: org.apache.kafka.connect.json.JsonConverter key.converter.schemas.enable: true value.converter.schemas.enable: true config.storage.replication.factor: 3 offset.storage.replication.factor: 3 status.storage.replication.factor: 3 build: 8 output: 9 type: docker image: my-registry.io/my-org/my-connect-cluster:latest pushSecret: my-registry-credentials plugins: 10 - name: connector-1 artifacts: - type: tgz url: <url_to_download_connector_1_artifact> sha512sum: <SHA-512_checksum_of_connector_1_artifact> - name: connector-2 artifacts: - type: jar url: <url_to_download_connector_2_artifact> sha512sum: <SHA-512_checksum_of_connector_2_artifact> externalConfiguration: 11 env: - name: AWS_ACCESS_KEY_ID valueFrom: secretKeyRef: name: aws-creds key: awsAccessKey - name: AWS_SECRET_ACCESS_KEY valueFrom: secretKeyRef: name: aws-creds key: awsSecretAccessKey resources: 12 requests: cpu: "1" memory: 2Gi limits: cpu: "2" memory: 2Gi logging: 13 type: inline loggers: log4j.rootLogger: INFO readinessProbe: 14 initialDelaySeconds: 15 timeoutSeconds: 5 livenessProbe: initialDelaySeconds: 15 timeoutSeconds: 5 metricsConfig: 15 type: jmxPrometheusExporter valueFrom: configMapKeyRef: name: my-config-map key: my-key jvmOptions: 16 "-Xmx": "1g" "-Xms": "1g" image: my-org/my-image:latest 17 rack: topologyKey: topology.kubernetes.io/zone 18 template: 19 pod: affinity: podAntiAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: application operator: In values: - postgresql - mongodb topologyKey: "kubernetes.io/hostname" connectContainer: 20 env: - name: OTEL_SERVICE_NAME value: my-otel-service - name: OTEL_EXPORTER_OTLP_ENDPOINT value: "http://otlp-host:4317" tracing: type: opentelemetry 21
- 1
- Use
KafkaConnect. - 2
- Enables KafkaConnectors for the Kafka Connect cluster.
- 3
- The number of replica nodes for the workers that run tasks.
- 4
- Authentication for the Kafka Connect cluster, specified as mTLS, token-based OAuth, SASL-based SCRAM-SHA-256/SCRAM-SHA-512, or PLAIN. By default, Kafka Connect connects to Kafka brokers using a plain text connection.
- 5
- Bootstrap server for connection to the Kafka cluster.
- 6
- TLS encryption with key names under which TLS certificates are stored in X.509 format for the cluster. If certificates are stored in the same secret, it can be listed multiple times.
- 7
- Kafka Connect configuration of workers (not connectors). Standard Apache Kafka configuration may be provided, restricted to those properties not managed directly by Streams for Apache Kafka.
- 8
- Build configuration properties for building a container image with connector plugins automatically.
- 9
- (Required) Configuration of the container registry where new images are pushed.
- 10
- (Required) List of connector plugins and their artifacts to add to the new container image. Each plugin must be configured with at least one
artifact. - 11
- External configuration for connectors using environment variables, as shown here, or volumes. You can also use configuration provider plugins to load configuration values from external sources.
- 12
- Requests for reservation of supported resources, currently
cpuandmemory, and limits to specify the maximum resources that can be consumed. - 13
- Specified Kafka Connect loggers and log levels added directly (
inline) or indirectly (external) through a ConfigMap. A custom Log4j configuration must be placed under thelog4j.propertiesorlog4j2.propertieskey in the ConfigMap. For the Kafka Connectlog4j.rootLoggerlogger, you can set the log level to INFO, ERROR, WARN, TRACE, DEBUG, FATAL or OFF. - 14
- Healthchecks to know when to restart a container (liveness) and when a container can accept traffic (readiness).
- 15
- Prometheus metrics, which are enabled by referencing a ConfigMap containing configuration for the Prometheus JMX exporter in this example. You can enable metrics without further configuration using a reference to a ConfigMap containing an empty file under
metricsConfig.valueFrom.configMapKeyRef.key. - 16
- JVM configuration options to optimize performance for the Virtual Machine (VM) running Kafka Connect.
- 17
- ADVANCED OPTION: Container image configuration, which is recommended only in special situations.
- 18
- SPECIALIZED OPTION: Rack awareness configuration for the deployment. This is a specialized option intended for a deployment within the same location, not across regions. Use this option if you want connectors to consume from the closest replica rather than the leader replica. In certain cases, consuming from the closest replica can improve network utilization or reduce costs . The
topologyKeymust match a node label containing the rack ID. The example used in this configuration specifies a zone using the standardtopology.kubernetes.io/zonelabel. To consume from the closest replica, enable theRackAwareReplicaSelectorin the Kafka broker configuration. - 19
- Template customization. Here a pod is scheduled with anti-affinity, so the pod is not scheduled on nodes with the same hostname.
- 20
- Environment variables are set for distributed tracing.
- 21
- Distributed tracing is enabled by using OpenTelemetry.
9.6.1. Configuring Kafka Connect for multiple instances
By default, Streams for Apache Kafka configures the group ID and names of the internal topics used by Kafka Connect. When running multiple instances of Kafka Connect, you must change these default settings using the following config properties:
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaConnect
metadata:
name: my-connect
spec:
config:
group.id: my-connect-cluster 1
offset.storage.topic: my-connect-cluster-offsets 2
config.storage.topic: my-connect-cluster-configs 3
status.storage.topic: my-connect-cluster-status 4
# ...
# ...
Values for the three topics must be the same for all instances with the same group.id.
Unless you modify these default settings, each instance connecting to the same Kafka cluster is deployed with the same values. In practice, this means all instances form a cluster and use the same internal topics.
Multiple instances attempting to use the same internal topics will cause unexpected errors, so you must change the values of these properties for each instance.
9.6.2. Configuring Kafka Connect user authorization
When using authorization in Kafka, a Kafka Connect user requires read/write access to the cluster group and internal topics of Kafka Connect. This procedure outlines how access is granted using simple authorization and ACLs.
Properties for the Kafka Connect cluster group ID and internal topics are configured by Streams for Apache Kafka by default. Alternatively, you can define them explicitly in the spec of the KafkaConnect resource. This is useful when configuring Kafka Connect for multiple instances, as the values for the group ID and topics must differ when running multiple Kafka Connect instances.
Simple authorization uses ACL rules managed by the Kafka AclAuthorizer and StandardAuthorizer plugins to ensure appropriate access levels. For more information on configuring a KafkaUser resource to use simple authorization, see the AclRule schema reference.
Prerequisites
- An OpenShift cluster
- A running Cluster Operator
Procedure
Edit the
authorizationproperty in theKafkaUserresource to provide access rights to the user.Access rights are configured for the Kafka Connect topics and cluster group using
literalname values. The following table shows the default names configured for the topics and cluster group ID.Table 9.2. Names for the access rights configuration Property Name offset.storage.topicconnect-cluster-offsetsstatus.storage.topicconnect-cluster-statusconfig.storage.topicconnect-cluster-configsgroupconnect-clusterIn this example configuration, the default names are used to specify access rights. If you are using different names for a Kafka Connect instance, use those names in the ACLs configuration.
Example configuration for simple authorization
apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaUser metadata: name: my-user labels: strimzi.io/cluster: my-cluster spec: # ... authorization: type: simple acls: # access to offset.storage.topic - resource: type: topic name: connect-cluster-offsets patternType: literal operations: - Create - Describe - Read - Write host: "*" # access to status.storage.topic - resource: type: topic name: connect-cluster-status patternType: literal operations: - Create - Describe - Read - Write host: "*" # access to config.storage.topic - resource: type: topic name: connect-cluster-configs patternType: literal operations: - Create - Describe - Read - Write host: "*" # cluster group - resource: type: group name: connect-cluster patternType: literal operations: - Read host: "*"Create or update the resource.
oc apply -f KAFKA-USER-CONFIG-FILE
9.6.3. Manually stopping or pausing Kafka Connect connectors
If you are using KafkaConnector resources to configure connectors, use the state configuration to either stop or pause a connector. In contrast to the paused state, where the connector and tasks remain instantiated, stopping a connector retains only the configuration, with no active processes. Stopping a connector from running may be more suitable for longer durations than just pausing. While a paused connector is quicker to resume, a stopped connector has the advantages of freeing up memory and resources.
The state configuration replaces the (deprecated) pause configuration in the KafkaConnectorSpec schema, which allows pauses on connectors. If you were previously using the pause configuration to pause connectors, we encourage you to transition to using the state configuration only to avoid conflicts.
Prerequisites
- The Cluster Operator is running.
Procedure
Find the name of the
KafkaConnectorcustom resource that controls the connector you want to pause or stop:oc get KafkaConnector
Edit the
KafkaConnectorresource to stop or pause the connector.Example configuration for stopping a Kafka Connect connector
apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaConnector metadata: name: my-source-connector labels: strimzi.io/cluster: my-connect-cluster spec: class: org.apache.kafka.connect.file.FileStreamSourceConnector tasksMax: 2 config: file: "/opt/kafka/LICENSE" topic: my-topic state: stopped # ...Change the
stateconfiguration tostoppedorpaused. The default state for the connector when this property is not set isrunning.Apply the changes to the
KafkaConnectorconfiguration.You can resume the connector by changing
statetorunningor removing the configuration.
Alternatively, you can expose the Kafka Connect API and use the stop and pause endpoints to stop a connector from running. For example, PUT /connectors/<connector_name>/stop. You can then use the resume endpoint to restart it.
9.6.4. Manually restarting Kafka Connect connectors
If you are using KafkaConnector resources to manage connectors, use the strimzi.io/restart annotation to manually trigger a restart of a connector.
Prerequisites
- The Cluster Operator is running.
Procedure
Find the name of the
KafkaConnectorcustom resource that controls the Kafka connector you want to restart:oc get KafkaConnector
Restart the connector by annotating the
KafkaConnectorresource in OpenShift:oc annotate KafkaConnector <kafka_connector_name> strimzi.io/restart="true"
The
restartannotation is set totrue.Wait for the next reconciliation to occur (every two minutes by default).
The Kafka connector is restarted, as long as the annotation was detected by the reconciliation process. When Kafka Connect accepts the restart request, the annotation is removed from the
KafkaConnectorcustom resource.
9.6.5. Manually restarting Kafka Connect connector tasks
If you are using KafkaConnector resources to manage connectors, use the strimzi.io/restart-task annotation to manually trigger a restart of a connector task.
Prerequisites
- The Cluster Operator is running.
Procedure
Find the name of the
KafkaConnectorcustom resource that controls the Kafka connector task you want to restart:oc get KafkaConnector
Find the ID of the task to be restarted from the
KafkaConnectorcustom resource:oc describe KafkaConnector <kafka_connector_name>
Task IDs are non-negative integers, starting from 0.
Use the ID to restart the connector task by annotating the
KafkaConnectorresource in OpenShift:oc annotate KafkaConnector <kafka_connector_name> strimzi.io/restart-task="0"
In this example, task
0is restarted.Wait for the next reconciliation to occur (every two minutes by default).
The Kafka connector task is restarted, as long as the annotation was detected by the reconciliation process. When Kafka Connect accepts the restart request, the annotation is removed from the
KafkaConnectorcustom resource.
9.7. Configuring Kafka MirrorMaker 2
Update the spec properties of the KafkaMirrorMaker2 custom resource to configure your MirrorMaker 2 deployment. MirrorMaker 2 uses source cluster configuration for data consumption and target cluster configuration for data output.
MirrorMaker 2 is based on the Kafka Connect framework, connectors managing the transfer of data between clusters.
You configure MirrorMaker 2 to define the Kafka Connect deployment, including the connection details of the source and target clusters, and then run a set of MirrorMaker 2 connectors to make the connection.
MirrorMaker 2 supports topic configuration synchronization between the source and target clusters. You specify source topics in the MirrorMaker 2 configuration. MirrorMaker 2 monitors the source topics. MirrorMaker 2 detects and propagates changes to the source topics to the remote topics. Changes might include automatically creating missing topics and partitions.
In most cases you write to local topics and read from remote topics. Though write operations are not prevented on remote topics, they should be avoided.
The configuration must specify:
- Each Kafka cluster
- Connection information for each cluster, including authentication
The replication flow and direction
- Cluster to cluster
- Topic to topic
For a deeper understanding of the Kafka MirrorMaker 2 cluster configuration options, refer to the Streams for Apache Kafka Custom Resource API Reference.
MirrorMaker 2 resource configuration differs from the previous version of MirrorMaker, which is now deprecated. There is currently no legacy support, so any resources must be manually converted into the new format.
Default configuration
MirrorMaker 2 provides default configuration values for properties such as replication factors. A minimal configuration, with defaults left unchanged, would be something like this example:
Minimal configuration for MirrorMaker 2
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaMirrorMaker2
metadata:
name: my-mirror-maker2
spec:
version: 3.7.0
connectCluster: "my-cluster-target"
clusters:
- alias: "my-cluster-source"
bootstrapServers: my-cluster-source-kafka-bootstrap:9092
- alias: "my-cluster-target"
bootstrapServers: my-cluster-target-kafka-bootstrap:9092
mirrors:
- sourceCluster: "my-cluster-source"
targetCluster: "my-cluster-target"
sourceConnector: {}
You can configure access control for source and target clusters using mTLS or SASL authentication. This procedure shows a configuration that uses TLS encryption and mTLS authentication for the source and target cluster.
You can specify the topics and consumer groups you wish to replicate from a source cluster in the KafkaMirrorMaker2 resource. You use the topicsPattern and groupsPattern properties to do this. You can provide a list of names or use a regular expression. By default, all topics and consumer groups are replicated if you do not set the topicsPattern and groupsPattern properties. You can also replicate all topics and consumer groups by using ".*" as a regular expression. However, try to specify only the topics and consumer groups you need to avoid causing any unnecessary extra load on the cluster.
Handling high volumes of messages
You can tune the configuration to handle high volumes of messages. For more information, see Handling high volumes of messages.
Example KafkaMirrorMaker2 custom resource configuration
apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaMirrorMaker2 metadata: name: my-mirror-maker2 spec: version: 3.7.0 1 replicas: 3 2 connectCluster: "my-cluster-target" 3 clusters: 4 - alias: "my-cluster-source" 5 authentication: 6 certificateAndKey: certificate: source.crt key: source.key secretName: my-user-source type: tls bootstrapServers: my-cluster-source-kafka-bootstrap:9092 7 tls: 8 trustedCertificates: - certificate: ca.crt secretName: my-cluster-source-cluster-ca-cert - alias: "my-cluster-target" 9 authentication: 10 certificateAndKey: certificate: target.crt key: target.key secretName: my-user-target type: tls bootstrapServers: my-cluster-target-kafka-bootstrap:9092 11 config: 12 config.storage.replication.factor: 1 offset.storage.replication.factor: 1 status.storage.replication.factor: 1 tls: 13 trustedCertificates: - certificate: ca.crt secretName: my-cluster-target-cluster-ca-cert mirrors: 14 - sourceCluster: "my-cluster-source" 15 targetCluster: "my-cluster-target" 16 sourceConnector: 17 tasksMax: 10 18 autoRestart: 19 enabled: true config replication.factor: 1 20 offset-syncs.topic.replication.factor: 1 21 sync.topic.acls.enabled: "false" 22 refresh.topics.interval.seconds: 60 23 replication.policy.class: "org.apache.kafka.connect.mirror.IdentityReplicationPolicy" 24 heartbeatConnector: 25 autoRestart: enabled: true config: heartbeats.topic.replication.factor: 1 26 replication.policy.class: "org.apache.kafka.connect.mirror.IdentityReplicationPolicy" checkpointConnector: 27 autoRestart: enabled: true config: checkpoints.topic.replication.factor: 1 28 refresh.groups.interval.seconds: 600 29 sync.group.offsets.enabled: true 30 sync.group.offsets.interval.seconds: 60 31 emit.checkpoints.interval.seconds: 60 32 replication.policy.class: "org.apache.kafka.connect.mirror.IdentityReplicationPolicy" topicsPattern: "topic1|topic2|topic3" 33 groupsPattern: "group1|group2|group3" 34 resources: 35 requests: cpu: "1" memory: 2Gi limits: cpu: "2" memory: 2Gi logging: 36 type: inline loggers: connect.root.logger.level: INFO readinessProbe: 37 initialDelaySeconds: 15 timeoutSeconds: 5 livenessProbe: initialDelaySeconds: 15 timeoutSeconds: 5 jvmOptions: 38 "-Xmx": "1g" "-Xms": "1g" image: my-org/my-image:latest 39 rack: topologyKey: topology.kubernetes.io/zone 40 template: 41 pod: affinity: podAntiAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: application operator: In values: - postgresql - mongodb topologyKey: "kubernetes.io/hostname" connectContainer: 42 env: - name: OTEL_SERVICE_NAME value: my-otel-service - name: OTEL_EXPORTER_OTLP_ENDPOINT value: "http://otlp-host:4317" tracing: type: opentelemetry 43 externalConfiguration: 44 env: - name: AWS_ACCESS_KEY_ID valueFrom: secretKeyRef: name: aws-creds key: awsAccessKey - name: AWS_SECRET_ACCESS_KEY valueFrom: secretKeyRef: name: aws-creds key: awsSecretAccessKey
- 1
- The Kafka Connect and MirrorMaker 2 version, which will always be the same.
- 2
- The number of replica nodes for the workers that run tasks.
- 3
- Kafka cluster alias for Kafka Connect, which must specify the target Kafka cluster. The Kafka cluster is used by Kafka Connect for its internal topics.
- 4
- Specification for the Kafka clusters being synchronized.
- 5
- Cluster alias for the source Kafka cluster.
- 6
- Authentication for the source cluster, specified as mTLS, token-based OAuth, SASL-based SCRAM-SHA-256/SCRAM-SHA-512, or PLAIN.
- 7
- Bootstrap server for connection to the source Kafka cluster.
- 8
- TLS encryption with key names under which TLS certificates are stored in X.509 format for the source Kafka cluster. If certificates are stored in the same secret, it can be listed multiple times.
- 9
- Cluster alias for the target Kafka cluster.
- 10
- Authentication for the target Kafka cluster is configured in the same way as for the source Kafka cluster.
- 11
- Bootstrap server for connection to the target Kafka cluster.
- 12
- Kafka Connect configuration. Standard Apache Kafka configuration may be provided, restricted to those properties not managed directly by Streams for Apache Kafka.
- 13
- TLS encryption for the target Kafka cluster is configured in the same way as for the source Kafka cluster.
- 14
- MirrorMaker 2 connectors.
- 15
- Cluster alias for the source cluster used by the MirrorMaker 2 connectors.
- 16
- Cluster alias for the target cluster used by the MirrorMaker 2 connectors.
- 17
- Configuration for the
MirrorSourceConnectorthat creates remote topics. Theconfigoverrides the default configuration options. - 18
- The maximum number of tasks that the connector may create. Tasks handle the data replication and run in parallel. If the infrastructure supports the processing overhead, increasing this value can improve throughput. Kafka Connect distributes the tasks between members of the cluster. If there are more tasks than workers, workers are assigned multiple tasks. For sink connectors, aim to have one task for each topic partition consumed. For source connectors, the number of tasks that can run in parallel may also depend on the external system. The connector creates fewer than the maximum number of tasks if it cannot achieve the parallelism.
- 19
- Enables automatic restarts of failed connectors and tasks. By default, the number of restarts is indefinite, but you can set a maximum on the number of automatic restarts using the
maxRestartsproperty. - 20
- Replication factor for mirrored topics created at the target cluster.
- 21
- Replication factor for the
MirrorSourceConnectoroffset-syncsinternal topic that maps the offsets of the source and target clusters. - 22
- When ACL rules synchronization is enabled, ACLs are applied to synchronized topics. The default is
true. This feature is not compatible with the User Operator. If you are using the User Operator, set this property tofalse. - 23
- Optional setting to change the frequency of checks for new topics. The default is for a check every 10 minutes.
- 24
- Adds a policy that overrides the automatic renaming of remote topics. Instead of prepending the name with the name of the source cluster, the topic retains its original name. This optional setting is useful for active/passive backups and data migration. The property must be specified for all connectors. For bidirectional (active/active) replication, use the
DefaultReplicationPolicyclass to automatically rename remote topics and specify thereplication.policy.separatorproperty for all connectors to add a custom separator. - 25
- Configuration for the
MirrorHeartbeatConnectorthat performs connectivity checks. Theconfigoverrides the default configuration options. - 26
- Replication factor for the heartbeat topic created at the target cluster.
- 27
- Configuration for the
MirrorCheckpointConnectorthat tracks offsets. Theconfigoverrides the default configuration options. - 28
- Replication factor for the checkpoints topic created at the target cluster.
- 29
- Optional setting to change the frequency of checks for new consumer groups. The default is for a check every 10 minutes.
- 30
- Optional setting to synchronize consumer group offsets, which is useful for recovery in an active/passive configuration. Synchronization is not enabled by default.
- 31
- If the synchronization of consumer group offsets is enabled, you can adjust the frequency of the synchronization.
- 32
- Adjusts the frequency of checks for offset tracking. If you change the frequency of offset synchronization, you might also need to adjust the frequency of these checks.
- 33
- Topic replication from the source cluster defined as a comma-separated list or regular expression pattern. The source connector replicates the specified topics. The checkpoint connector tracks offsets for the specified topics. Here we request three topics by name.
- 34
- Consumer group replication from the source cluster defined as a comma-separated list or regular expression pattern. The checkpoint connector replicates the specified consumer groups. Here we request three consumer groups by name.
- 35
- Requests for reservation of supported resources, currently
cpuandmemory, and limits to specify the maximum resources that can be consumed. - 36
- Specified Kafka Connect loggers and log levels added directly (
inline) or indirectly (external) through a ConfigMap. A custom Log4j configuration must be placed under thelog4j.propertiesorlog4j2.propertieskey in the ConfigMap. For the Kafka Connectlog4j.rootLoggerlogger, you can set the log level to INFO, ERROR, WARN, TRACE, DEBUG, FATAL or OFF. - 37
- Healthchecks to know when to restart a container (liveness) and when a container can accept traffic (readiness).
- 38
- JVM configuration options to optimize performance for the Virtual Machine (VM) running Kafka MirrorMaker.
- 39
- ADVANCED OPTION: Container image configuration, which is recommended only in special situations.
- 40
- SPECIALIZED OPTION: Rack awareness configuration for the deployment. This is a specialized option intended for a deployment within the same location, not across regions. Use this option if you want connectors to consume from the closest replica rather than the leader replica. In certain cases, consuming from the closest replica can improve network utilization or reduce costs . The
topologyKeymust match a node label containing the rack ID. The example used in this configuration specifies a zone using the standardtopology.kubernetes.io/zonelabel. To consume from the closest replica, enable theRackAwareReplicaSelectorin the Kafka broker configuration. - 41
- Template customization. Here a pod is scheduled with anti-affinity, so the pod is not scheduled on nodes with the same hostname.
- 42
- Environment variables are set for distributed tracing.
- 43
- Distributed tracing is enabled by using OpenTelemetry.
- 44
- External configuration for an OpenShift Secret mounted to Kafka MirrorMaker as an environment variable. You can also use configuration provider plugins to load configuration values from external sources.
9.7.1. Configuring active/active or active/passive modes
You can use MirrorMaker 2 in active/passive or active/active cluster configurations.
- active/active cluster configuration
- An active/active configuration has two active clusters replicating data bidirectionally. Applications can use either cluster. Each cluster can provide the same data. In this way, you can make the same data available in different geographical locations. As consumer groups are active in both clusters, consumer offsets for replicated topics are not synchronized back to the source cluster.
- active/passive cluster configuration
- An active/passive configuration has an active cluster replicating data to a passive cluster. The passive cluster remains on standby. You might use the passive cluster for data recovery in the event of system failure.
The expectation is that producers and consumers connect to active clusters only. A MirrorMaker 2 cluster is required at each target destination.
9.7.1.1. Bidirectional replication (active/active)
The MirrorMaker 2 architecture supports bidirectional replication in an active/active cluster configuration.
Each cluster replicates the data of the other cluster using the concept of source and remote topics. As the same topics are stored in each cluster, remote topics are automatically renamed by MirrorMaker 2 to represent the source cluster. The name of the originating cluster is prepended to the name of the topic.
Figure 9.1. Topic renaming
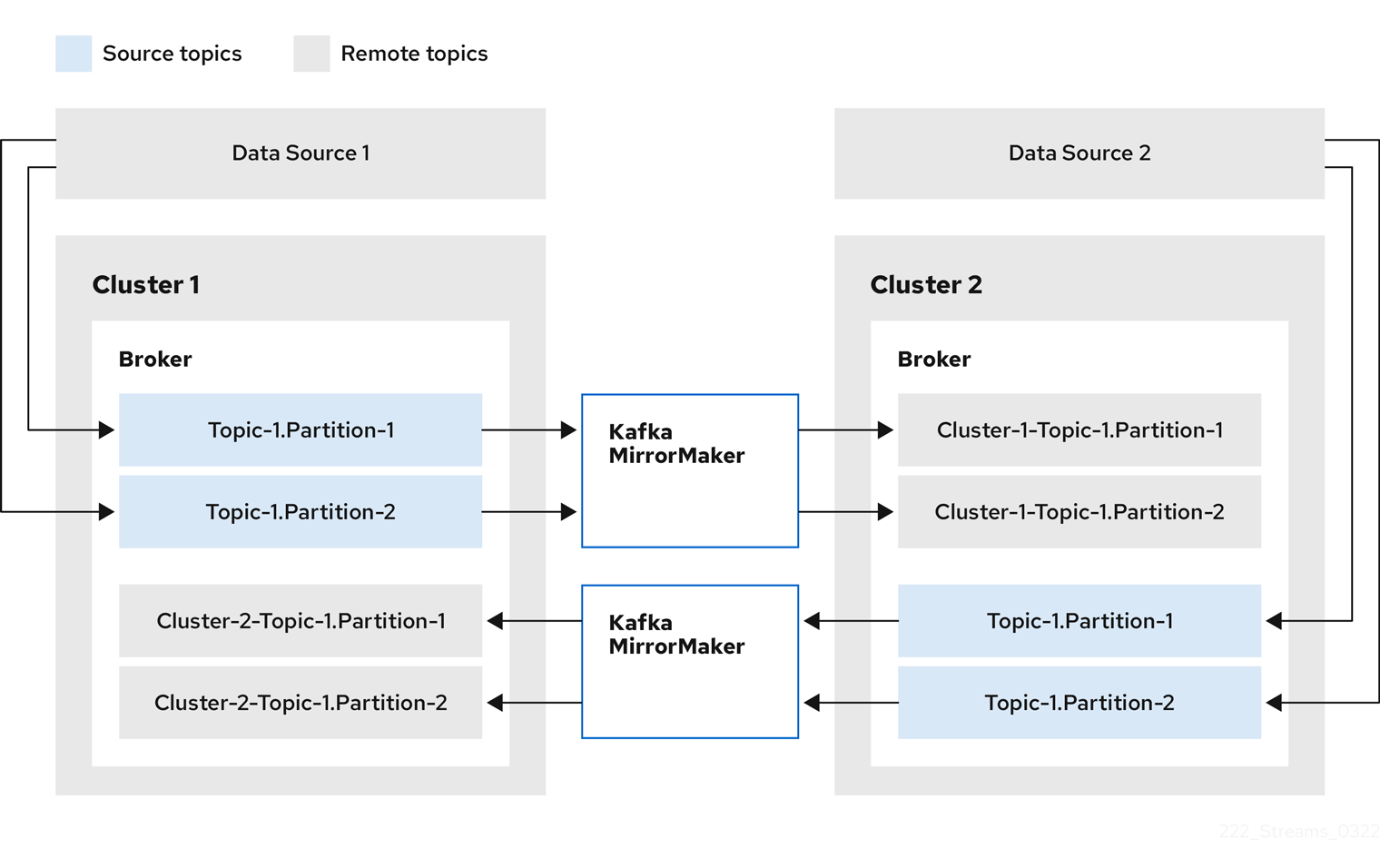
By flagging the originating cluster, topics are not replicated back to that cluster.
The concept of replication through remote topics is useful when configuring an architecture that requires data aggregation. Consumers can subscribe to source and remote topics within the same cluster, without the need for a separate aggregation cluster.
9.7.1.2. Unidirectional replication (active/passive)
The MirrorMaker 2 architecture supports unidirectional replication in an active/passive cluster configuration.
You can use an active/passive cluster configuration to make backups or migrate data to another cluster. In this situation, you might not want automatic renaming of remote topics.
You can override automatic renaming by adding IdentityReplicationPolicy to the source connector configuration. With this configuration applied, topics retain their original names.
9.7.2. Configuring MirrorMaker 2 for multiple instances
By default, Streams for Apache Kafka configures the group ID and names of the internal topics used by the Kafka Connect framework that MirrorMaker 2 runs on. When running multiple instances of MirrorMaker 2, and they share the same connectCluster value, you must change these default settings using the following config properties:
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaMirrorMaker2
metadata:
name: my-mirror-maker2
spec:
connectCluster: "my-cluster-target"
clusters:
- alias: "my-cluster-target"
config:
group.id: my-connect-cluster 1
offset.storage.topic: my-connect-cluster-offsets 2
config.storage.topic: my-connect-cluster-configs 3
status.storage.topic: my-connect-cluster-status 4
# ...
# ...
Values for the three topics must be the same for all instances with the same group.id.
The connectCluster setting specifies the alias of the target Kafka cluster used by Kafka Connect for its internal topics. As a result, modifications to the connectCluster, group ID, and internal topic naming configuration are specific to the target Kafka cluster. You don’t need to make changes if two MirrorMaker 2 instances are using the same source Kafka cluster or in an active-active mode where each MirrorMaker 2 instance has a different connectCluster setting and target cluster.
However, if multiple MirrorMaker 2 instances share the same connectCluster, each instance connecting to the same target Kafka cluster is deployed with the same values. In practice, this means all instances form a cluster and use the same internal topics.
Multiple instances attempting to use the same internal topics will cause unexpected errors, so you must change the values of these properties for each instance.
9.7.3. Configuring MirrorMaker 2 connectors
Use MirrorMaker 2 connector configuration for the internal connectors that orchestrate the synchronization of data between Kafka clusters.
MirrorMaker 2 consists of the following connectors:
MirrorSourceConnector-
The source connector replicates topics from a source cluster to a target cluster. It also replicates ACLs and is necessary for the
MirrorCheckpointConnectorto run. MirrorCheckpointConnector- The checkpoint connector periodically tracks offsets. If enabled, it also synchronizes consumer group offsets between the source and target cluster.
MirrorHeartbeatConnector- The heartbeat connector periodically checks connectivity between the source and target cluster.
The following table describes connector properties and the connectors you configure to use them.
| Property | sourceConnector | checkpointConnector | heartbeatConnector |
|---|---|---|---|
| ✓ | ✓ | ✓ |
| ✓ | ✓ | ✓ |
| ✓ | ✓ | ✓ |
| ✓ | ✓ | |
| ✓ | ✓ | |
| ✓ | ✓ | |
| ✓ | ||
| ✓ | ||
| ✓ | ||
| ✓ | ||
| ✓ | ||
| ✓ | ||
| ✓ | ||
| ✓ | ||
| ✓ | ||
| ✓ | ||
| ✓ | ||
| ✓ | ||
| ✓ | ||
| ✓ | ||
| ✓ | ||
| ✓ | ||
| ✓ | ||
| ✓ | ||
| ✓ | ||
| ✓ | ||
| ✓ | ||
| ✓ |
9.7.3.1. Changing the location of the consumer group offsets topic
MirrorMaker 2 tracks offsets for consumer groups using internal topics.
offset-syncstopic-
The
offset-syncstopic maps the source and target offsets for replicated topic partitions from record metadata. checkpointstopic-
The
checkpointstopic maps the last committed offset in the source and target cluster for replicated topic partitions in each consumer group.
As they are used internally by MirrorMaker 2, you do not interact directly with these topics.
MirrorCheckpointConnector emits checkpoints for offset tracking. Offsets for the checkpoints topic are tracked at predetermined intervals through configuration. Both topics enable replication to be fully restored from the correct offset position on failover.
The location of the offset-syncs topic is the source cluster by default. You can use the offset-syncs.topic.location connector configuration to change this to the target cluster. You need read/write access to the cluster that contains the topic. Using the target cluster as the location of the offset-syncs topic allows you to use MirrorMaker 2 even if you have only read access to the source cluster.
9.7.3.2. Synchronizing consumer group offsets
The __consumer_offsets topic stores information on committed offsets for each consumer group. Offset synchronization periodically transfers the consumer offsets for the consumer groups of a source cluster into the consumer offsets topic of a target cluster.
Offset synchronization is particularly useful in an active/passive configuration. If the active cluster goes down, consumer applications can switch to the passive (standby) cluster and pick up from the last transferred offset position.
To use topic offset synchronization, enable the synchronization by adding sync.group.offsets.enabled to the checkpoint connector configuration, and setting the property to true. Synchronization is disabled by default.
When using the IdentityReplicationPolicy in the source connector, it also has to be configured in the checkpoint connector configuration. This ensures that the mirrored consumer offsets will be applied for the correct topics.
Consumer offsets are only synchronized for consumer groups that are not active in the target cluster. If the consumer groups are in the target cluster, the synchronization cannot be performed and an UNKNOWN_MEMBER_ID error is returned.
If enabled, the synchronization of offsets from the source cluster is made periodically. You can change the frequency by adding sync.group.offsets.interval.seconds and emit.checkpoints.interval.seconds to the checkpoint connector configuration. The properties specify the frequency in seconds that the consumer group offsets are synchronized, and the frequency of checkpoints emitted for offset tracking. The default for both properties is 60 seconds. You can also change the frequency of checks for new consumer groups using the refresh.groups.interval.seconds property, which is performed every 10 minutes by default.
Because the synchronization is time-based, any switchover by consumers to a passive cluster will likely result in some duplication of messages.
If you have an application written in Java, you can use the RemoteClusterUtils.java utility to synchronize offsets through the application. The utility fetches remote offsets for a consumer group from the checkpoints topic.
9.7.3.3. Deciding when to use the heartbeat connector
The heartbeat connector emits heartbeats to check connectivity between source and target Kafka clusters. An internal heartbeat topic is replicated from the source cluster, which means that the heartbeat connector must be connected to the source cluster. The heartbeat topic is located on the target cluster, which allows it to do the following:
- Identify all source clusters it is mirroring data from
- Verify the liveness and latency of the mirroring process
This helps to make sure that the process is not stuck or has stopped for any reason. While the heartbeat connector can be a valuable tool for monitoring the mirroring processes between Kafka clusters, it’s not always necessary to use it. For example, if your deployment has low network latency or a small number of topics, you might prefer to monitor the mirroring process using log messages or other monitoring tools. If you decide not to use the heartbeat connector, simply omit it from your MirrorMaker 2 configuration.
9.7.3.4. Aligning the configuration of MirrorMaker 2 connectors
To ensure that MirrorMaker 2 connectors work properly, make sure to align certain configuration settings across connectors. Specifically, ensure that the following properties have the same value across all applicable connectors:
-
replication.policy.class -
replication.policy.separator -
offset-syncs.topic.location -
topic.filter.class
For example, the value for replication.policy.class must be the same for the source, checkpoint, and heartbeat connectors. Mismatched or missing settings cause issues with data replication or offset syncing, so it’s essential to keep all relevant connectors configured with the same settings.
9.7.4. Configuring MirrorMaker 2 connector producers and consumers
MirrorMaker 2 connectors use internal producers and consumers. If needed, you can configure these producers and consumers to override the default settings.
For example, you can increase the batch.size for the source producer that sends topics to the target Kafka cluster to better accommodate large volumes of messages.
Producer and consumer configuration options depend on the MirrorMaker 2 implementation, and may be subject to change.
The following tables describe the producers and consumers for each of the connectors and where you can add configuration.
| Type | Description | Configuration |
|---|---|---|
| Producer | Sends topic messages to the target Kafka cluster. Consider tuning the configuration of this producer when it is handling large volumes of data. |
|
| Producer |
Writes to the |
|
| Consumer | Retrieves topic messages from the source Kafka cluster. |
|
| Type | Description | Configuration |
|---|---|---|
| Producer | Emits consumer offset checkpoints. |
|
| Consumer |
Loads the |
|
You can set offset-syncs.topic.location to target to use the target Kafka cluster as the location of the offset-syncs topic.
| Type | Description | Configuration |
|---|---|---|
| Producer | Emits heartbeats. |
|
The following example shows how you configure the producers and consumers.
Example configuration for connector producers and consumers
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaMirrorMaker2
metadata:
name: my-mirror-maker2
spec:
version: 3.7.0
# ...
mirrors:
- sourceCluster: "my-cluster-source"
targetCluster: "my-cluster-target"
sourceConnector:
tasksMax: 5
config:
producer.override.batch.size: 327680
producer.override.linger.ms: 100
producer.request.timeout.ms: 30000
consumer.fetch.max.bytes: 52428800
# ...
checkpointConnector:
config:
producer.override.request.timeout.ms: 30000
consumer.max.poll.interval.ms: 300000
# ...
heartbeatConnector:
config:
producer.override.request.timeout.ms: 30000
# ...
9.7.5. Specifying a maximum number of data replication tasks
Connectors create the tasks that are responsible for moving data in and out of Kafka. Each connector comprises one or more tasks that are distributed across a group of worker pods that run the tasks. Increasing the number of tasks can help with performance issues when replicating a large number of partitions or synchronizing the offsets of a large number of consumer groups.
Tasks run in parallel. Workers are assigned one or more tasks. A single task is handled by one worker pod, so you don’t need more worker pods than tasks. If there are more tasks than workers, workers handle multiple tasks.
You can specify the maximum number of connector tasks in your MirrorMaker configuration using the tasksMax property. Without specifying a maximum number of tasks, the default setting is a single task.
The heartbeat connector always uses a single task.
The number of tasks that are started for the source and checkpoint connectors is the lower value between the maximum number of possible tasks and the value for tasksMax. For the source connector, the maximum number of tasks possible is one for each partition being replicated from the source cluster. For the checkpoint connector, the maximum number of tasks possible is one for each consumer group being replicated from the source cluster. When setting a maximum number of tasks, consider the number of partitions and the hardware resources that support the process.
If the infrastructure supports the processing overhead, increasing the number of tasks can improve throughput and latency. For example, adding more tasks reduces the time taken to poll the source cluster when there is a high number of partitions or consumer groups.
Increasing the number of tasks for the source connector is useful when you have a large number of partitions.
Increasing the number of tasks for the source connector
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaMirrorMaker2
metadata:
name: my-mirror-maker2
spec:
# ...
mirrors:
- sourceCluster: "my-cluster-source"
targetCluster: "my-cluster-target"
sourceConnector:
tasksMax: 10
# ...
Increasing the number of tasks for the checkpoint connector is useful when you have a large number of consumer groups.
Increasing the number of tasks for the checkpoint connector
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaMirrorMaker2
metadata:
name: my-mirror-maker2
spec:
# ...
mirrors:
- sourceCluster: "my-cluster-source"
targetCluster: "my-cluster-target"
checkpointConnector:
tasksMax: 10
# ...
By default, MirrorMaker 2 checks for new consumer groups every 10 minutes. You can adjust the refresh.groups.interval.seconds configuration to change the frequency. Take care when adjusting lower. More frequent checks can have a negative impact on performance.
9.7.5.1. Checking connector task operations
If you are using Prometheus and Grafana to monitor your deployment, you can check MirrorMaker 2 performance. The example MirrorMaker 2 Grafana dashboard provided with Streams for Apache Kafka shows the following metrics related to tasks and latency.
- The number of tasks
- Replication latency
- Offset synchronization latency
Additional resources
9.7.6. Synchronizing ACL rules for remote topics
When using MirrorMaker 2 with Streams for Apache Kafka, it is possible to synchronize ACL rules for remote topics. However, this feature is only available if you are not using the User Operator.
If you are using type: simple authorization without the User Operator, the ACL rules that manage access to brokers also apply to remote topics. This means that users who have read access to a source topic can also read its remote equivalent.
OAuth 2.0 authorization does not support access to remote topics in this way.
9.7.7. Securing a Kafka MirrorMaker 2 deployment
This procedure describes in outline the configuration required to secure a MirrorMaker 2 deployment.
You need separate configuration for the source Kafka cluster and the target Kafka cluster. You also need separate user configuration to provide the credentials required for MirrorMaker to connect to the source and target Kafka clusters.
For the Kafka clusters, you specify internal listeners for secure connections within an OpenShift cluster and external listeners for connections outside the OpenShift cluster.
You can configure authentication and authorization mechanisms. The security options implemented for the source and target Kafka clusters must be compatible with the security options implemented for MirrorMaker 2.
After you have created the cluster and user authentication credentials, you specify them in your MirrorMaker configuration for secure connections.
In this procedure, the certificates generated by the Cluster Operator are used, but you can replace them by installing your own certificates. You can also configure your listener to use a Kafka listener certificate managed by an external CA (certificate authority).
Before you start
Before starting this procedure, take a look at the example configuration files provided by Streams for Apache Kafka. They include examples for securing a deployment of MirrorMaker 2 using mTLS or SCRAM-SHA-512 authentication. The examples specify internal listeners for connecting within an OpenShift cluster.
The examples also provide the configuration for full authorization, including the ACLs that allow user operations on the source and target Kafka clusters.
When configuring user access to source and target Kafka clusters, ACLs must grant access rights to internal MirrorMaker 2 connectors and read/write access to the cluster group and internal topics used by the underlying Kafka Connect framework in the target cluster. If you’ve renamed the cluster group or internal topics, such as when configuring MirrorMaker 2 for multiple instances, use those names in the ACLs configuration.
Simple authorization uses ACL rules managed by the Kafka AclAuthorizer and StandardAuthorizer plugins to ensure appropriate access levels. For more information on configuring a KafkaUser resource to use simple authorization, see the AclRule schema reference.
Prerequisites
- Streams for Apache Kafka is running
- Separate namespaces for source and target clusters
The procedure assumes that the source and target Kafka clusters are installed to separate namespaces. If you want to use the Topic Operator, you’ll need to do this. The Topic Operator only watches a single cluster in a specified namespace.
By separating the clusters into namespaces, you will need to copy the cluster secrets so they can be accessed outside the namespace. You need to reference the secrets in the MirrorMaker configuration.
Procedure
Configure two
Kafkaresources, one to secure the source Kafka cluster and one to secure the target Kafka cluster.You can add listener configuration for authentication and enable authorization.
In this example, an internal listener is configured for a Kafka cluster with TLS encryption and mTLS authentication. Kafka
simpleauthorization is enabled.Example source Kafka cluster configuration with TLS encryption and mTLS authentication
apiVersion: kafka.strimzi.io/v1beta2 kind: Kafka metadata: name: my-source-cluster spec: kafka: version: 3.7.0 replicas: 1 listeners: - name: tls port: 9093 type: internal tls: true authentication: type: tls authorization: type: simple config: offsets.topic.replication.factor: 1 transaction.state.log.replication.factor: 1 transaction.state.log.min.isr: 1 default.replication.factor: 1 min.insync.replicas: 1 inter.broker.protocol.version: "3.7" storage: type: jbod volumes: - id: 0 type: persistent-claim size: 100Gi deleteClaim: false zookeeper: replicas: 1 storage: type: persistent-claim size: 100Gi deleteClaim: false entityOperator: topicOperator: {} userOperator: {}Example target Kafka cluster configuration with TLS encryption and mTLS authentication
apiVersion: kafka.strimzi.io/v1beta2 kind: Kafka metadata: name: my-target-cluster spec: kafka: version: 3.7.0 replicas: 1 listeners: - name: tls port: 9093 type: internal tls: true authentication: type: tls authorization: type: simple config: offsets.topic.replication.factor: 1 transaction.state.log.replication.factor: 1 transaction.state.log.min.isr: 1 default.replication.factor: 1 min.insync.replicas: 1 inter.broker.protocol.version: "3.7" storage: type: jbod volumes: - id: 0 type: persistent-claim size: 100Gi deleteClaim: false zookeeper: replicas: 1 storage: type: persistent-claim size: 100Gi deleteClaim: false entityOperator: topicOperator: {} userOperator: {}Create or update the
Kafkaresources in separate namespaces.oc apply -f <kafka_configuration_file> -n <namespace>
The Cluster Operator creates the listeners and sets up the cluster and client certificate authority (CA) certificates to enable authentication within the Kafka cluster.
The certificates are created in the secret
<cluster_name>-cluster-ca-cert.Configure two
KafkaUserresources, one for a user of the source Kafka cluster and one for a user of the target Kafka cluster.-
Configure the same authentication and authorization types as the corresponding source and target Kafka cluster. For example, if you used
tlsauthentication and thesimpleauthorization type in theKafkaconfiguration for the source Kafka cluster, use the same in theKafkaUserconfiguration. - Configure the ACLs needed by MirrorMaker 2 to allow operations on the source and target Kafka clusters.
Example source user configuration for mTLS authentication
apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaUser metadata: name: my-source-user labels: strimzi.io/cluster: my-source-cluster spec: authentication: type: tls authorization: type: simple acls: # MirrorSourceConnector - resource: # Not needed if offset-syncs.topic.location=target type: topic name: mm2-offset-syncs.my-target-cluster.internal operations: - Create - DescribeConfigs - Read - Write - resource: # Needed for every topic which is mirrored type: topic name: "*" operations: - DescribeConfigs - Read # MirrorCheckpointConnector - resource: type: cluster operations: - Describe - resource: # Needed for every group for which offsets are synced type: group name: "*" operations: - Describe - resource: # Not needed if offset-syncs.topic.location=target type: topic name: mm2-offset-syncs.my-target-cluster.internal operations: - ReadExample target user configuration for mTLS authentication
apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaUser metadata: name: my-target-user labels: strimzi.io/cluster: my-target-cluster spec: authentication: type: tls authorization: type: simple acls: # cluster group - resource: type: group name: mirrormaker2-cluster operations: - Read # access to config.storage.topic - resource: type: topic name: mirrormaker2-cluster-configs operations: - Create - Describe - DescribeConfigs - Read - Write # access to status.storage.topic - resource: type: topic name: mirrormaker2-cluster-status operations: - Create - Describe - DescribeConfigs - Read - Write # access to offset.storage.topic - resource: type: topic name: mirrormaker2-cluster-offsets operations: - Create - Describe - DescribeConfigs - Read - Write # MirrorSourceConnector - resource: # Needed for every topic which is mirrored type: topic name: "*" operations: - Create - Alter - AlterConfigs - Write # MirrorCheckpointConnector - resource: type: cluster operations: - Describe - resource: type: topic name: my-source-cluster.checkpoints.internal operations: - Create - Describe - Read - Write - resource: # Needed for every group for which the offset is synced type: group name: "*" operations: - Read - Describe # MirrorHeartbeatConnector - resource: type: topic name: heartbeats operations: - Create - Describe - WriteNoteYou can use a certificate issued outside the User Operator by setting
typetotls-external. For more information, see theKafkaUserSpecschema reference.-
Configure the same authentication and authorization types as the corresponding source and target Kafka cluster. For example, if you used
Create or update a
KafkaUserresource in each of the namespaces you created for the source and target Kafka clusters.oc apply -f <kafka_user_configuration_file> -n <namespace>
The User Operator creates the users representing the client (MirrorMaker), and the security credentials used for client authentication, based on the chosen authentication type.
The User Operator creates a new secret with the same name as the
KafkaUserresource. The secret contains a private and public key for mTLS authentication. The public key is contained in a user certificate, which is signed by the clients CA.Configure a
KafkaMirrorMaker2resource with the authentication details to connect to the source and target Kafka clusters.Example MirrorMaker 2 configuration with TLS encryption and mTLS authentication
apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaMirrorMaker2 metadata: name: my-mirror-maker-2 spec: version: 3.7.0 replicas: 1 connectCluster: "my-target-cluster" clusters: - alias: "my-source-cluster" bootstrapServers: my-source-cluster-kafka-bootstrap:9093 tls: 1 trustedCertificates: - secretName: my-source-cluster-cluster-ca-cert certificate: ca.crt authentication: 2 type: tls certificateAndKey: secretName: my-source-user certificate: user.crt key: user.key - alias: "my-target-cluster" bootstrapServers: my-target-cluster-kafka-bootstrap:9093 tls: 3 trustedCertificates: - secretName: my-target-cluster-cluster-ca-cert certificate: ca.crt authentication: 4 type: tls certificateAndKey: secretName: my-target-user certificate: user.crt key: user.key config: # -1 means it will use the default replication factor configured in the broker config.storage.replication.factor: -1 offset.storage.replication.factor: -1 status.storage.replication.factor: -1 mirrors: - sourceCluster: "my-source-cluster" targetCluster: "my-target-cluster" sourceConnector: config: replication.factor: 1 offset-syncs.topic.replication.factor: 1 sync.topic.acls.enabled: "false" heartbeatConnector: config: heartbeats.topic.replication.factor: 1 checkpointConnector: config: checkpoints.topic.replication.factor: 1 sync.group.offsets.enabled: "true" topicsPattern: "topic1|topic2|topic3" groupsPattern: "group1|group2|group3"- 1
- The TLS certificates for the source Kafka cluster. If they are in a separate namespace, copy the cluster secrets from the namespace of the Kafka cluster.
- 2
- The user authentication for accessing the source Kafka cluster using the TLS mechanism.
- 3
- The TLS certificates for the target Kafka cluster.
- 4
- The user authentication for accessing the target Kafka cluster.
Create or update the
KafkaMirrorMaker2resource in the same namespace as the target Kafka cluster.oc apply -f <mirrormaker2_configuration_file> -n <namespace_of_target_cluster>
9.7.8. Manually stopping or pausing MirrorMaker 2 connectors
If you are using KafkaMirrorMaker2 resources to configure internal MirrorMaker connectors, use the state configuration to either stop or pause a connector. In contrast to the paused state, where the connector and tasks remain instantiated, stopping a connector retains only the configuration, with no active processes. Stopping a connector from running may be more suitable for longer durations than just pausing. While a paused connector is quicker to resume, a stopped connector has the advantages of freeing up memory and resources.
The state configuration replaces the (deprecated) pause configuration in the KafkaMirrorMaker2ConnectorSpec schema, which allows pauses on connectors. If you were previously using the pause configuration to pause connectors, we encourage you to transition to using the state configuration only to avoid conflicts.
Prerequisites
- The Cluster Operator is running.
Procedure
Find the name of the
KafkaMirrorMaker2custom resource that controls the MirrorMaker 2 connector you want to pause or stop:oc get KafkaMirrorMaker2
Edit the
KafkaMirrorMaker2resource to stop or pause the connector.Example configuration for stopping a MirrorMaker 2 connector
apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaMirrorMaker2 metadata: name: my-mirror-maker2 spec: version: 3.7.0 replicas: 3 connectCluster: "my-cluster-target" clusters: # ... mirrors: - sourceCluster: "my-cluster-source" targetCluster: "my-cluster-target" sourceConnector: tasksMax: 10 autoRestart: enabled: true state: stopped # ...Change the
stateconfiguration tostoppedorpaused. The default state for the connector when this property is not set isrunning.Apply the changes to the
KafkaMirrorMaker2configuration.You can resume the connector by changing
statetorunningor removing the configuration.
Alternatively, you can expose the Kafka Connect API and use the stop and pause endpoints to stop a connector from running. For example, PUT /connectors/<connector_name>/stop. You can then use the resume endpoint to restart it.
9.7.9. Manually restarting MirrorMaker 2 connectors
Use the strimzi.io/restart-connector annotation to manually trigger a restart of a MirrorMaker 2 connector.
Prerequisites
- The Cluster Operator is running.
Procedure
Find the name of the
KafkaMirrorMaker2custom resource that controls the Kafka MirrorMaker 2 connector you want to restart:oc get KafkaMirrorMaker2
Find the name of the Kafka MirrorMaker 2 connector to be restarted from the
KafkaMirrorMaker2custom resource:oc describe KafkaMirrorMaker2 <mirrormaker_cluster_name>
Use the name of the connector to restart the connector by annotating the
KafkaMirrorMaker2resource in OpenShift:oc annotate KafkaMirrorMaker2 <mirrormaker_cluster_name> "strimzi.io/restart-connector=<mirrormaker_connector_name>"
In this example, connector
my-connectorin themy-mirror-maker-2cluster is restarted:oc annotate KafkaMirrorMaker2 my-mirror-maker-2 "strimzi.io/restart-connector=my-connector"
Wait for the next reconciliation to occur (every two minutes by default).
The MirrorMaker 2 connector is restarted, as long as the annotation was detected by the reconciliation process. When MirrorMaker 2 accepts the request, the annotation is removed from the
KafkaMirrorMaker2custom resource.
9.7.10. Manually restarting MirrorMaker 2 connector tasks
Use the strimzi.io/restart-connector-task annotation to manually trigger a restart of a MirrorMaker 2 connector.
Prerequisites
- The Cluster Operator is running.
Procedure
Find the name of the
KafkaMirrorMaker2custom resource that controls the MirrorMaker 2 connector task you want to restart:oc get KafkaMirrorMaker2
Find the name of the connector and the ID of the task to be restarted from the
KafkaMirrorMaker2custom resource:oc describe KafkaMirrorMaker2 <mirrormaker_cluster_name>
Task IDs are non-negative integers, starting from 0.
Use the name and ID to restart the connector task by annotating the
KafkaMirrorMaker2resource in OpenShift:oc annotate KafkaMirrorMaker2 <mirrormaker_cluster_name> "strimzi.io/restart-connector-task=<mirrormaker_connector_name>:<task_id>"
In this example, task
0for connectormy-connectorin themy-mirror-maker-2cluster is restarted:oc annotate KafkaMirrorMaker2 my-mirror-maker-2 "strimzi.io/restart-connector-task=my-connector:0"
Wait for the next reconciliation to occur (every two minutes by default).
The MirrorMaker 2 connector task is restarted, as long as the annotation was detected by the reconciliation process. When MirrorMaker 2 accepts the request, the annotation is removed from the
KafkaMirrorMaker2custom resource.
9.8. Configuring Kafka MirrorMaker (deprecated)
Update the spec properties of the KafkaMirrorMaker custom resource to configure your Kafka MirrorMaker deployment.
You can configure access control for producers and consumers using TLS or SASL authentication. This procedure shows a configuration that uses TLS encryption and mTLS authentication on the consumer and producer side.
For a deeper understanding of the Kafka MirrorMaker cluster configuration options, refer to the Streams for Apache Kafka Custom Resource API Reference.
Kafka MirrorMaker 1 (referred to as just MirrorMaker in the documentation) has been deprecated in Apache Kafka 3.0.0 and will be removed in Apache Kafka 4.0.0. As a result, the KafkaMirrorMaker custom resource which is used to deploy Kafka MirrorMaker 1 has been deprecated in Streams for Apache Kafka as well. The KafkaMirrorMaker resource will be removed from Streams for Apache Kafka when we adopt Apache Kafka 4.0.0. As a replacement, use the KafkaMirrorMaker2 custom resource with the IdentityReplicationPolicy.
Example KafkaMirrorMaker custom resource configuration
apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaMirrorMaker metadata: name: my-mirror-maker spec: replicas: 3 1 consumer: bootstrapServers: my-source-cluster-kafka-bootstrap:9092 2 groupId: "my-group" 3 numStreams: 2 4 offsetCommitInterval: 120000 5 tls: 6 trustedCertificates: - secretName: my-source-cluster-ca-cert certificate: ca.crt authentication: 7 type: tls certificateAndKey: secretName: my-source-secret certificate: public.crt key: private.key config: 8 max.poll.records: 100 receive.buffer.bytes: 32768 producer: bootstrapServers: my-target-cluster-kafka-bootstrap:9092 abortOnSendFailure: false 9 tls: trustedCertificates: - secretName: my-target-cluster-ca-cert certificate: ca.crt authentication: type: tls certificateAndKey: secretName: my-target-secret certificate: public.crt key: private.key config: compression.type: gzip batch.size: 8192 include: "my-topic|other-topic" 10 resources: 11 requests: cpu: "1" memory: 2Gi limits: cpu: "2" memory: 2Gi logging: 12 type: inline loggers: mirrormaker.root.logger: INFO readinessProbe: 13 initialDelaySeconds: 15 timeoutSeconds: 5 livenessProbe: initialDelaySeconds: 15 timeoutSeconds: 5 metricsConfig: 14 type: jmxPrometheusExporter valueFrom: configMapKeyRef: name: my-config-map key: my-key jvmOptions: 15 "-Xmx": "1g" "-Xms": "1g" image: my-org/my-image:latest 16 template: 17 pod: affinity: podAntiAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: application operator: In values: - postgresql - mongodb topologyKey: "kubernetes.io/hostname" mirrorMakerContainer: 18 env: - name: OTEL_SERVICE_NAME value: my-otel-service - name: OTEL_EXPORTER_OTLP_ENDPOINT value: "http://otlp-host:4317" tracing: 19 type: opentelemetry
- 1
- The number of replica nodes.
- 2
- Bootstrap servers for consumer and producer.
- 3
- Group ID for the consumer.
- 4
- The number of consumer streams.
- 5
- The offset auto-commit interval in milliseconds.
- 6
- TLS encryption with key names under which TLS certificates are stored in X.509 format for consumer or producer. If certificates are stored in the same secret, it can be listed multiple times.
- 7
- Authentication for consumer or producer, specified as mTLS, token-based OAuth, SASL-based SCRAM-SHA-256/SCRAM-SHA-512, or PLAIN.
- 8
- Kafka configuration options for consumer and producer.
- 9
- If the
abortOnSendFailureproperty is set totrue, Kafka MirrorMaker will exit and the container will restart following a send failure for a message. - 10
- A list of included topics mirrored from source to target Kafka cluster.
- 11
- Requests for reservation of supported resources, currently
cpuandmemory, and limits to specify the maximum resources that can be consumed. - 12
- Specified loggers and log levels added directly (
inline) or indirectly (external) through a ConfigMap. A custom Log4j configuration must be placed under thelog4j.propertiesorlog4j2.propertieskey in the ConfigMap. MirrorMaker has a single logger calledmirrormaker.root.logger. You can set the log level to INFO, ERROR, WARN, TRACE, DEBUG, FATAL or OFF. - 13
- Healthchecks to know when to restart a container (liveness) and when a container can accept traffic (readiness).
- 14
- Prometheus metrics, which are enabled by referencing a ConfigMap containing configuration for the Prometheus JMX exporter in this example. You can enable metrics without further configuration using a reference to a ConfigMap containing an empty file under
metricsConfig.valueFrom.configMapKeyRef.key. - 15
- JVM configuration options to optimize performance for the Virtual Machine (VM) running Kafka MirrorMaker.
- 16
- ADVANCED OPTION: Container image configuration, which is recommended only in special situations.
- 17
- Template customization. Here a pod is scheduled with anti-affinity, so the pod is not scheduled on nodes with the same hostname.
- 18
- Environment variables are set for distributed tracing.
- 19
- Distributed tracing is enabled by using OpenTelemetry.Warning
With the
abortOnSendFailureproperty set tofalse, the producer attempts to send the next message in a topic. The original message might be lost, as there is no attempt to resend a failed message.
9.9. Configuring the Kafka Bridge
Update the spec properties of the KafkaBridge custom resource to configure your Kafka Bridge deployment.
In order to prevent issues arising when client consumer requests are processed by different Kafka Bridge instances, address-based routing must be employed to ensure that requests are routed to the right Kafka Bridge instance. Additionally, each independent Kafka Bridge instance must have a replica. A Kafka Bridge instance has its own state which is not shared with another instances.
For a deeper understanding of the Kafka Bridge cluster configuration options, refer to the Streams for Apache Kafka Custom Resource API Reference.
Example KafkaBridge custom resource configuration
apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaBridge metadata: name: my-bridge spec: replicas: 3 1 bootstrapServers: <cluster_name>-cluster-kafka-bootstrap:9092 2 tls: 3 trustedCertificates: - secretName: my-cluster-cluster-cert certificate: ca.crt - secretName: my-cluster-cluster-cert certificate: ca2.crt authentication: 4 type: tls certificateAndKey: secretName: my-secret certificate: public.crt key: private.key http: 5 port: 8080 cors: 6 allowedOrigins: "https://strimzi.io" allowedMethods: "GET,POST,PUT,DELETE,OPTIONS,PATCH" consumer: 7 config: auto.offset.reset: earliest producer: 8 config: delivery.timeout.ms: 300000 resources: 9 requests: cpu: "1" memory: 2Gi limits: cpu: "2" memory: 2Gi logging: 10 type: inline loggers: logger.bridge.level: INFO # enabling DEBUG just for send operation logger.send.name: "http.openapi.operation.send" logger.send.level: DEBUG jvmOptions: 11 "-Xmx": "1g" "-Xms": "1g" readinessProbe: 12 initialDelaySeconds: 15 timeoutSeconds: 5 livenessProbe: initialDelaySeconds: 15 timeoutSeconds: 5 image: my-org/my-image:latest 13 template: 14 pod: affinity: podAntiAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: application operator: In values: - postgresql - mongodb topologyKey: "kubernetes.io/hostname" bridgeContainer: 15 env: - name: OTEL_SERVICE_NAME value: my-otel-service - name: OTEL_EXPORTER_OTLP_ENDPOINT value: "http://otlp-host:4317" tracing: type: opentelemetry 16
- 1
- The number of replica nodes.
- 2
- Bootstrap server for connection to the target Kafka cluster. Use the name of the Kafka cluster as the <cluster_name>.
- 3
- TLS encryption with key names under which TLS certificates are stored in X.509 format for the source Kafka cluster. If certificates are stored in the same secret, it can be listed multiple times.
- 4
- Authentication for the Kafka Bridge cluster, specified as mTLS, token-based OAuth, SASL-based SCRAM-SHA-256/SCRAM-SHA-512, or PLAIN. By default, the Kafka Bridge connects to Kafka brokers without authentication.
- 5
- HTTP access to Kafka brokers.
- 6
- CORS access specifying selected resources and access methods. Additional HTTP headers in requests describe the origins that are permitted access to the Kafka cluster.
- 7
- Consumer configuration options.
- 8
- Producer configuration options.
- 9
- Requests for reservation of supported resources, currently
cpuandmemory, and limits to specify the maximum resources that can be consumed. - 10
- Specified Kafka Bridge loggers and log levels added directly (
inline) or indirectly (external) through a ConfigMap. A custom Log4j configuration must be placed under thelog4j.propertiesorlog4j2.propertieskey in the ConfigMap. For the Kafka Bridge loggers, you can set the log level to INFO, ERROR, WARN, TRACE, DEBUG, FATAL or OFF. - 11
- JVM configuration options to optimize performance for the Virtual Machine (VM) running the Kafka Bridge.
- 12
- Healthchecks to know when to restart a container (liveness) and when a container can accept traffic (readiness).
- 13
- Optional: Container image configuration, which is recommended only in special situations.
- 14
- Template customization. Here a pod is scheduled with anti-affinity, so the pod is not scheduled on nodes with the same hostname.
- 15
- Environment variables are set for distributed tracing.
- 16
- Distributed tracing is enabled by using OpenTelemetry.
Additional resources
9.10. Configuring Kafka and ZooKeeper storage
Streams for Apache Kafka provides flexibility in configuring the data storage options of Kafka and ZooKeeper.
The supported storage types are:
- Ephemeral (Recommended for development only)
- Persistent
- JBOD (Kafka only; not available for ZooKeeper)
- Tiered storage (Early access)
To configure storage, you specify storage properties in the custom resource of the component. The storage type is set using the storage.type property. When using node pools, you can specify storage configuration unique to each node pool used in a Kafka cluster. The same storage properties available to the Kafka resource are also available to the KafkaNodePool pool resource.
Tiered storage provides more flexibility for data management by leveraging the parallel use of storage types with different characteristics. For example, tiered storage might include the following:
- Higher performance and higher cost block storage
- Lower performance and lower cost object storage
Tiered storage is an early access feature in Kafka. To configure tiered storage, you specify tieredStorage properties. Tiered storage is configured only at the cluster level using the Kafka custom resource.
The storage-related schema references provide more information on the storage configuration properties:
The storage type cannot be changed after a Kafka cluster is deployed.
9.10.1. Data storage considerations
For Streams for Apache Kafka to work well, an efficient data storage infrastructure is essential. We strongly recommend using block storage. Streams for Apache Kafka is only tested for use with block storage. File storage, such as NFS, is not tested and there is no guarantee it will work.
Choose one of the following options for your block storage:
- A cloud-based block storage solution, such as Amazon Elastic Block Store (EBS)
- Persistent storage using local persistent volumes
- Storage Area Network (SAN) volumes accessed by a protocol such as Fibre Channel or iSCSI
Streams for Apache Kafka does not require OpenShift raw block volumes.
9.10.1.1. File systems
Kafka uses a file system for storing messages. Streams for Apache Kafka is compatible with the XFS and ext4 file systems, which are commonly used with Kafka. Consider the underlying architecture and requirements of your deployment when choosing and setting up your file system.
For more information, refer to Filesystem Selection in the Kafka documentation.
9.10.1.2. Disk usage
Use separate disks for Apache Kafka and ZooKeeper.
Solid-state drives (SSDs), though not essential, can improve the performance of Kafka in large clusters where data is sent to and received from multiple topics asynchronously. SSDs are particularly effective with ZooKeeper, which requires fast, low latency data access.
You do not need to provision replicated storage because Kafka and ZooKeeper both have built-in data replication.
9.10.2. Ephemeral storage
Ephemeral data storage is transient. All pods on a node share a local ephemeral storage space. Data is retained for as long as the pod that uses it is running. The data is lost when a pod is deleted. Although a pod can recover data in a highly available environment.
Because of its transient nature, ephemeral storage is only recommended for development and testing.
Ephemeral storage uses emptyDir volumes to store data. An emptyDir volume is created when a pod is assigned to a node. You can set the total amount of storage for the emptyDir using the sizeLimit property .
Ephemeral storage is not suitable for single-node ZooKeeper clusters or Kafka topics with a replication factor of 1.
To use ephemeral storage, you set the storage type configuration in the Kafka or ZooKeeper resource to ephemeral. If you are using node pools, you can also specify ephemeral in the storage configuration of individual node pools.
Example ephemeral storage configuration
apiVersion: kafka.strimzi.io/v1beta2
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
storage:
type: ephemeral
# ...
zookeeper:
storage:
type: ephemeral
# ...
9.10.2.1. Mount path of Kafka log directories
The ephemeral volume is used by Kafka brokers as log directories mounted into the following path:
/var/lib/kafka/data/kafka-logIDX
Where IDX is the Kafka broker pod index. For example /var/lib/kafka/data/kafka-log0.
9.10.3. Persistent storage
Persistent data storage retains data in the event of system disruption. For pods that use persistent data storage, data is persisted across pod failures and restarts. Because of its permanent nature, persistent storage is recommended for production environments.
To use persistent storage in Streams for Apache Kafka, you specify persistent-claim in the storage configuration of the Kafka or ZooKeeper resources. If you are using node pools, you can also specify persistent-claim in the storage configuration of individual node pools.
You configure the resource so that pods use Persistent Volume Claims (PVCs) to make storage requests on persistent volumes (PVs). PVs represent storage volumes that are created on demand and are independent of the pods that use them. The PVC requests the amount of storage required when a pod is being created. The underlying storage infrastructure of the PV does not need to be understood. If a PV matches the storage criteria, the PVC is bound to the PV.
You have two options for specifying the storage type:
storage.type: persistent-claim-
If you choose
persistent-claimas the storage type, a single persistent storage volume is defined. storage.type: jbod-
When you select
jbodas the storage type, you have the flexibility to define an array of persistent storage volumes using unique IDs.
In a production environment, it is recommended to configure the following:
-
For Kafka or node pools, set
storage.typetojbodwith one or more persistent volumes. -
For ZooKeeper, set
storage.typeaspersistent-claimfor a single persistent volume.
Persistent storage also has the following configuration options:
id(optional)-
A storage identification number. This option is mandatory for storage volumes defined in a JBOD storage declaration. Default is
0. size(required)- The size of the persistent volume claim, for example, "1000Gi".
class(optional)- PVCs can request different types of persistent storage by specifying a StorageClass. Storage classes define storage profiles and dynamically provision PVs based on that profile. If a storage class is not specified, the storage class marked as default in the OpenShift cluster is used. Persistent storage options might include SAN storage types or local persistent volumes.
selector(optional)- Configuration to specify a specific PV. Provides key:value pairs representing the labels of the volume selected.
deleteClaim(optional)-
Boolean value to specify whether the PVC is deleted when the cluster is uninstalled. Default is
false.
Increasing the size of persistent volumes in an existing Streams for Apache Kafka cluster is only supported in OpenShift versions that support persistent volume resizing. The persistent volume to be resized must use a storage class that supports volume expansion. For other versions of OpenShift and storage classes that do not support volume expansion, you must decide the necessary storage size before deploying the cluster. Decreasing the size of existing persistent volumes is not possible.
Example persistent storage configuration for Kafka and ZooKeeper
apiVersion: kafka.strimzi.io/v1beta2
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
storage:
type: jbod
volumes:
- id: 0
type: persistent-claim
size: 100Gi
deleteClaim: false
- id: 1
type: persistent-claim
size: 100Gi
deleteClaim: false
- id: 2
type: persistent-claim
size: 100Gi
deleteClaim: false
# ...
zookeeper:
storage:
type: persistent-claim
size: 1000Gi
# ...
Example persistent storage configuration with specific storage class
# ... storage: type: persistent-claim size: 500Gi class: my-storage-class # ...
Use a selector to specify a labeled persistent volume that provides certain features, such as an SSD.
Example persistent storage configuration with selector
# ...
storage:
type: persistent-claim
size: 1Gi
selector:
hdd-type: ssd
deleteClaim: true
# ...
9.10.3.1. Storage class overrides
Instead of using the default storage class, you can specify a different storage class for one or more Kafka or ZooKeeper nodes. This is useful, for example, when storage classes are restricted to different availability zones or data centers. You can use the overrides field for this purpose.
In this example, the default storage class is named my-storage-class:
Example storage configuration with class overrides
apiVersion: kafka.strimzi.io/v1beta2
kind: Kafka
metadata:
labels:
app: my-cluster
name: my-cluster
namespace: myproject
spec:
# ...
kafka:
replicas: 3
storage:
type: jbod
volumes:
- id: 0
type: persistent-claim
size: 100Gi
deleteClaim: false
class: my-storage-class
overrides:
- broker: 0
class: my-storage-class-zone-1a
- broker: 1
class: my-storage-class-zone-1b
- broker: 2
class: my-storage-class-zone-1c
# ...
# ...
zookeeper:
replicas: 3
storage:
deleteClaim: true
size: 100Gi
type: persistent-claim
class: my-storage-class
overrides:
- broker: 0
class: my-storage-class-zone-1a
- broker: 1
class: my-storage-class-zone-1b
- broker: 2
class: my-storage-class-zone-1c
# ...
As a result of the configured overrides property, the volumes use the following storage classes:
-
The persistent volumes of ZooKeeper node 0 use
my-storage-class-zone-1a. -
The persistent volumes of ZooKeeper node 1 use
my-storage-class-zone-1b. -
The persistent volumes of ZooKeeper node 2 use
my-storage-class-zone-1c. -
The persistent volumes of Kafka broker 0 use
my-storage-class-zone-1a. -
The persistent volumes of Kafka broker 1 use
my-storage-class-zone-1b. -
The persistent volumes of Kafka broker 2 use
my-storage-class-zone-1c.
The overrides property is currently used only to override the storage class. Overrides for other storage configuration properties is not currently supported.
9.10.3.2. PVC resources for persistent storage
When persistent storage is used, it creates PVCs with the following names:
data-cluster-name-kafka-idx-
PVC for the volume used for storing data for the Kafka broker pod
idx. data-cluster-name-zookeeper-idx-
PVC for the volume used for storing data for the ZooKeeper node pod
idx.
9.10.3.3. Mount path of Kafka log directories
The persistent volume is used by the Kafka brokers as log directories mounted into the following path:
/var/lib/kafka/data/kafka-logIDX
Where IDX is the Kafka broker pod index. For example /var/lib/kafka/data/kafka-log0.
9.10.4. Resizing persistent volumes
Persistent volumes used by a cluster can be resized without any risk of data loss, as long as the storage infrastructure supports it. Following a configuration update to change the size of the storage, Streams for Apache Kafka instructs the storage infrastructure to make the change. Storage expansion is supported in Streams for Apache Kafka clusters that use persistent-claim volumes.
Storage reduction is only possible when using multiple disks per broker. You can remove a disk after moving all partitions on the disk to other volumes within the same broker (intra-broker) or to other brokers within the same cluster (intra-cluster).
You cannot decrease the size of persistent volumes because it is not currently supported in OpenShift.
Prerequisites
- An OpenShift cluster with support for volume resizing.
- The Cluster Operator is running.
- A Kafka cluster using persistent volumes created using a storage class that supports volume expansion.
Procedure
Edit the
Kafkaresource for your cluster.Change the
sizeproperty to increase the size of the persistent volume allocated to a Kafka cluster, a ZooKeeper cluster, or both.-
For Kafka clusters, update the
sizeproperty underspec.kafka.storage. -
For ZooKeeper clusters, update the
sizeproperty underspec.zookeeper.storage.
Kafka configuration to increase the volume size to
2000GiapiVersion: kafka.strimzi.io/v1beta2 kind: Kafka metadata: name: my-cluster spec: kafka: # ... storage: type: persistent-claim size: 2000Gi class: my-storage-class # ... zookeeper: # ...-
For Kafka clusters, update the
Create or update the resource:
oc apply -f <kafka_configuration_file>OpenShift increases the capacity of the selected persistent volumes in response to a request from the Cluster Operator. When the resizing is complete, the Cluster Operator restarts all pods that use the resized persistent volumes. This happens automatically.
Verify that the storage capacity has increased for the relevant pods on the cluster:
oc get pv
Kafka broker pods with increased storage
NAME CAPACITY CLAIM pvc-0ca459ce-... 2000Gi my-project/data-my-cluster-kafka-2 pvc-6e1810be-... 2000Gi my-project/data-my-cluster-kafka-0 pvc-82dc78c9-... 2000Gi my-project/data-my-cluster-kafka-1
The output shows the names of each PVC associated with a broker pod.
Additional resources
- For more information about resizing persistent volumes in OpenShift, see Resizing Persistent Volumes using Kubernetes.
9.10.5. JBOD storage
JBOD storage allows you to configure your Kafka cluster to use multiple disks or volumes. This approach provides increased data storage capacity for Kafka brokers, and can lead to performance improvements. A JBOD configuration is defined by one or more volumes, each of which can be either ephemeral or persistent. The rules and constraints for JBOD volume declarations are the same as those for ephemeral and persistent storage. For example, you cannot decrease the size of a persistent storage volume after it has been provisioned, nor can you change the value of sizeLimit when the type is ephemeral.
JBOD storage is supported for Kafka only, not for ZooKeeper.
To use JBOD storage, you set the storage type configuration in the Kafka resource to jbod. If you are using node pools, you can also specify jbod in the storage configuration of individual node pools.
The volumes property allows you to describe the disks that make up your JBOD storage array or configuration.
Example JBOD storage configuration
apiVersion: kafka.strimzi.io/v1beta2
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
storage:
type: jbod
volumes:
- id: 0
type: persistent-claim
size: 100Gi
deleteClaim: false
- id: 1
type: persistent-claim
size: 100Gi
deleteClaim: false
# ...
The IDs cannot be changed once the JBOD volumes are created. You can add or remove volumes from the JBOD configuration.
9.10.5.1. PVC resource for JBOD storage
When persistent storage is used to declare JBOD volumes, it creates a PVC with the following name:
data-id-cluster-name-kafka-idx-
PVC for the volume used for storing data for the Kafka broker pod
idx. Theidis the ID of the volume used for storing data for Kafka broker pod.
9.10.5.2. Mount path of Kafka log directories
The JBOD volumes are used by Kafka brokers as log directories mounted into the following path:
/var/lib/kafka/data-id/kafka-logidx
Where id is the ID of the volume used for storing data for Kafka broker pod idx. For example /var/lib/kafka/data-0/kafka-log0.
9.10.6. Adding volumes to JBOD storage
This procedure describes how to add volumes to a Kafka cluster configured to use JBOD storage. It cannot be applied to Kafka clusters configured to use any other storage type.
When adding a new volume under an id which was already used in the past and removed, you have to make sure that the previously used PersistentVolumeClaims have been deleted.
Prerequisites
- An OpenShift cluster
- A running Cluster Operator
- A Kafka cluster with JBOD storage
Procedure
Edit the
spec.kafka.storage.volumesproperty in theKafkaresource. Add the new volumes to thevolumesarray. For example, add the new volume with id2:apiVersion: kafka.strimzi.io/v1beta2 kind: Kafka metadata: name: my-cluster spec: kafka: # ... storage: type: jbod volumes: - id: 0 type: persistent-claim size: 100Gi deleteClaim: false - id: 1 type: persistent-claim size: 100Gi deleteClaim: false - id: 2 type: persistent-claim size: 100Gi deleteClaim: false # ... zookeeper: # ...Create or update the resource:
oc apply -f <kafka_configuration_file>Create new topics or reassign existing partitions to the new disks.
TipCruise Control is an effective tool for reassigning partitions. To perform an intra-broker disk balance, you set
rebalanceDisktotrueunder theKafkaRebalance.spec.
9.10.7. Removing volumes from JBOD storage
This procedure describes how to remove volumes from Kafka cluster configured to use JBOD storage. It cannot be applied to Kafka clusters configured to use any other storage type. The JBOD storage always has to contain at least one volume.
To avoid data loss, you have to move all partitions before removing the volumes.
Prerequisites
- An OpenShift cluster
- A running Cluster Operator
- A Kafka cluster with JBOD storage with two or more volumes
Procedure
Reassign all partitions from the disks which are you going to remove. Any data in partitions still assigned to the disks which are going to be removed might be lost.
TipYou can use the
kafka-reassign-partitions.shtool to reassign the partitions.Edit the
spec.kafka.storage.volumesproperty in theKafkaresource. Remove one or more volumes from thevolumesarray. For example, remove the volumes with ids1and2:apiVersion: kafka.strimzi.io/v1beta2 kind: Kafka metadata: name: my-cluster spec: kafka: # ... storage: type: jbod volumes: - id: 0 type: persistent-claim size: 100Gi deleteClaim: false # ... zookeeper: # ...Create or update the resource:
oc apply -f <kafka_configuration_file>
9.10.8. Tiered storage (early access)
Tiered storage introduces a flexible approach to managing Kafka data whereby log segments are moved to a separate storage system. For example, you can combine the use of block storage on brokers for frequently accessed data and offload older or less frequently accessed data from the block storage to more cost-effective, scalable remote storage solutions, such as Amazon S3, without compromising data accessibility and durability.
Tiered storage is an early access Kafka feature, which is also available in Streams for Apache Kafka. Due to its current limitations, it is not recommended for production environments.
Tiered storage requires an implementation of Kafka’s RemoteStorageManager interface to handle communication between Kafka and the remote storage system, which is enabled through configuration of the Kafka resource. Streams for Apache Kafka uses Kafka’s TopicBasedRemoteLogMetadataManager for Remote Log Metadata Management (RLMM) when custom tiered storage is enabled. The RLMM manages the metadata related to remote storage.
To use custom tiered storage, do the following:
- Include a tiered storage plugin for Kafka in the Streams for Apache Kafka image by building a custom container image. The plugin must provide the necessary functionality for a Kafka cluster managed by Streams for Apache Kafka to interact with the tiered storage solution.
-
Configure Kafka for tiered storage using
tieredStorageproperties in theKafkaresource. Specify the class name and path for the customRemoteStorageManagerimplementation, as well as any additional configuration. - If required, specify RLMM-specific tiered storage configuration.
Example custom tiered storage configuration for Kafka
apiVersion: kafka.strimzi.io/v1beta2
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
tieredStorage:
type: custom 1
remoteStorageManager: 2
className: com.example.kafka.tiered.storage.s3.S3RemoteStorageManager
classPath: /opt/kafka/plugins/tiered-storage-s3/*
config:
storage.bucket.name: my-bucket 3
# ...
config:
rlmm.config.remote.log.metadata.topic.replication.factor: 1 4
# ...
- 1
- The
typemust be set tocustom. - 2
- The configuration for the custom
RemoteStorageManagerimplementation, including class name and path. - 3
- Configuration to pass to the custom
RemoteStorageManagerimplementation, which Streams for Apache Kafka automatically prefixes withrsm.config.. - 4
- Tiered storage configuration to pass to the RLMM, which requires an
rlmm.config.prefix. For more information on tiered storage configuration, see the Apache Kafka documentation.
9.11. Configuring CPU and memory resource limits and requests
By default, the Streams for Apache Kafka Cluster Operator does not specify CPU and memory resource requests and limits for its deployed operands. Ensuring an adequate allocation of resources is crucial for maintaining stability and achieving optimal performance in Kafka. The ideal resource allocation depends on your specific requirements and use cases.
It is recommended to configure CPU and memory resources for each container by setting appropriate requests and limits.
9.12. Configuring pod scheduling
To avoid performance degradation caused by resource conflicts between applications scheduled on the same OpenShift node, you can schedule Kafka pods separately from critical workloads. This can be achieved by either selecting specific nodes or dedicating a set of nodes exclusively for Kafka.
9.12.1. Specifying affinity, tolerations, and topology spread constraints
Use affinity, tolerations and topology spread constraints to schedule the pods of kafka resources onto nodes. Affinity, tolerations and topology spread constraints are configured using the affinity, tolerations, and topologySpreadConstraint properties in following resources:
-
Kafka.spec.kafka.template.pod -
Kafka.spec.zookeeper.template.pod -
Kafka.spec.entityOperator.template.pod -
KafkaConnect.spec.template.pod -
KafkaBridge.spec.template.pod -
KafkaMirrorMaker.spec.template.pod -
KafkaMirrorMaker2.spec.template.pod
The format of the affinity, tolerations, and topologySpreadConstraint properties follows the OpenShift specification. The affinity configuration can include different types of affinity:
- Pod affinity and anti-affinity
- Node affinity
Additional resources
9.12.1.1. Use pod anti-affinity to avoid critical applications sharing nodes
Use pod anti-affinity to ensure that critical applications are never scheduled on the same disk. When running a Kafka cluster, it is recommended to use pod anti-affinity to ensure that the Kafka brokers do not share nodes with other workloads, such as databases.
9.12.1.2. Use node affinity to schedule workloads onto specific nodes
The OpenShift cluster usually consists of many different types of worker nodes. Some are optimized for CPU heavy workloads, some for memory, while other might be optimized for storage (fast local SSDs) or network. Using different nodes helps to optimize both costs and performance. To achieve the best possible performance, it is important to allow scheduling of Streams for Apache Kafka components to use the right nodes.
OpenShift uses node affinity to schedule workloads onto specific nodes. Node affinity allows you to create a scheduling constraint for the node on which the pod will be scheduled. The constraint is specified as a label selector. You can specify the label using either the built-in node label like beta.kubernetes.io/instance-type or custom labels to select the right node.
9.12.1.3. Use node affinity and tolerations for dedicated nodes
Use taints to create dedicated nodes, then schedule Kafka pods on the dedicated nodes by configuring node affinity and tolerations.
Cluster administrators can mark selected OpenShift nodes as tainted. Nodes with taints are excluded from regular scheduling and normal pods will not be scheduled to run on them. Only services which can tolerate the taint set on the node can be scheduled on it. The only other services running on such nodes will be system services such as log collectors or software defined networks.
Running Kafka and its components on dedicated nodes can have many advantages. There will be no other applications running on the same nodes which could cause disturbance or consume the resources needed for Kafka. That can lead to improved performance and stability.
9.12.2. Configuring pod anti-affinity to schedule each Kafka broker on a different worker node
Many Kafka brokers or ZooKeeper nodes can run on the same OpenShift worker node. If the worker node fails, they will all become unavailable at the same time. To improve reliability, you can use podAntiAffinity configuration to schedule each Kafka broker or ZooKeeper node on a different OpenShift worker node.
Prerequisites
- An OpenShift cluster
- A running Cluster Operator
Procedure
Edit the
affinityproperty in the resource specifying the cluster deployment. To make sure that no worker nodes are shared by Kafka brokers or ZooKeeper nodes, use thestrimzi.io/namelabel. Set thetopologyKeytokubernetes.io/hostnameto specify that the selected pods are not scheduled on nodes with the same hostname. This will still allow the same worker node to be shared by a single Kafka broker and a single ZooKeeper node. For example:apiVersion: kafka.strimzi.io/v1beta2 kind: Kafka spec: kafka: # ... template: pod: affinity: podAntiAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: strimzi.io/name operator: In values: - CLUSTER-NAME-kafka topologyKey: "kubernetes.io/hostname" # ... zookeeper: # ... template: pod: affinity: podAntiAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: strimzi.io/name operator: In values: - CLUSTER-NAME-zookeeper topologyKey: "kubernetes.io/hostname" # ...Where
CLUSTER-NAMEis the name of your Kafka custom resource.If you even want to make sure that a Kafka broker and ZooKeeper node do not share the same worker node, use the
strimzi.io/clusterlabel. For example:apiVersion: kafka.strimzi.io/v1beta2 kind: Kafka spec: kafka: # ... template: pod: affinity: podAntiAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: strimzi.io/cluster operator: In values: - CLUSTER-NAME topologyKey: "kubernetes.io/hostname" # ... zookeeper: # ... template: pod: affinity: podAntiAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: strimzi.io/cluster operator: In values: - CLUSTER-NAME topologyKey: "kubernetes.io/hostname" # ...Where
CLUSTER-NAMEis the name of your Kafka custom resource.Create or update the resource.
oc apply -f <kafka_configuration_file>
9.12.3. Configuring pod anti-affinity in Kafka components
Pod anti-affinity configuration helps with the stability and performance of Kafka brokers. By using podAntiAffinity, OpenShift will not schedule Kafka brokers on the same nodes as other workloads. Typically, you want to avoid Kafka running on the same worker node as other network or storage intensive applications such as databases, storage or other messaging platforms.
Prerequisites
- An OpenShift cluster
- A running Cluster Operator
Procedure
Edit the
affinityproperty in the resource specifying the cluster deployment. Use labels to specify the pods which should not be scheduled on the same nodes. ThetopologyKeyshould be set tokubernetes.io/hostnameto specify that the selected pods should not be scheduled on nodes with the same hostname. For example:apiVersion: kafka.strimzi.io/v1beta2 kind: Kafka spec: kafka: # ... template: pod: affinity: podAntiAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: application operator: In values: - postgresql - mongodb topologyKey: "kubernetes.io/hostname" # ... zookeeper: # ...Create or update the resource.
This can be done using
oc apply:oc apply -f <kafka_configuration_file>
9.12.4. Configuring node affinity in Kafka components
Prerequisites
- An OpenShift cluster
- A running Cluster Operator
Procedure
Label the nodes where Streams for Apache Kafka components should be scheduled.
This can be done using
oc label:oc label node NAME-OF-NODE node-type=fast-networkAlternatively, some of the existing labels might be reused.
Edit the
affinityproperty in the resource specifying the cluster deployment. For example:apiVersion: kafka.strimzi.io/v1beta2 kind: Kafka spec: kafka: # ... template: pod: affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: node-type operator: In values: - fast-network # ... zookeeper: # ...Create or update the resource.
This can be done using
oc apply:oc apply -f <kafka_configuration_file>
9.12.5. Setting up dedicated nodes and scheduling pods on them
Prerequisites
- An OpenShift cluster
- A running Cluster Operator
Procedure
- Select the nodes which should be used as dedicated.
- Make sure there are no workloads scheduled on these nodes.
Set the taints on the selected nodes:
This can be done using
oc adm taint:oc adm taint node NAME-OF-NODE dedicated=Kafka:NoScheduleAdditionally, add a label to the selected nodes as well.
This can be done using
oc label:oc label node NAME-OF-NODE dedicated=KafkaEdit the
affinityandtolerationsproperties in the resource specifying the cluster deployment.For example:
apiVersion: kafka.strimzi.io/v1beta2 kind: Kafka spec: kafka: # ... template: pod: tolerations: - key: "dedicated" operator: "Equal" value: "Kafka" effect: "NoSchedule" affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: dedicated operator: In values: - Kafka # ... zookeeper: # ...Create or update the resource.
This can be done using
oc apply:oc apply -f <kafka_configuration_file>
9.13. Configuring logging levels
Configure logging levels in the custom resources of Kafka components and Streams for Apache Kafka operators. You can specify the logging levels directly in the spec.logging property of the custom resource. Or you can define the logging properties in a ConfigMap that’s referenced in the custom resource using the configMapKeyRef property.
The advantages of using a ConfigMap are that the logging properties are maintained in one place and are accessible to more than one resource. You can also reuse the ConfigMap for more than one resource. If you are using a ConfigMap to specify loggers for Streams for Apache Kafka Operators, you can also append the logging specification to add filters.
You specify a logging type in your logging specification:
-
inlinewhen specifying logging levels directly -
externalwhen referencing a ConfigMap
Example inline logging configuration
# ...
logging:
type: inline
loggers:
kafka.root.logger.level: INFO
# ...
Example external logging configuration
# ...
logging:
type: external
valueFrom:
configMapKeyRef:
name: my-config-map
key: my-config-map-key
# ...
Values for the name and key of the ConfigMap are mandatory. Default logging is used if the name or key is not set.
9.13.1. Logging options for Kafka components and operators
For more information on configuring logging for specific Kafka components or operators, see the following sections.
Kafka component logging
Operator logging
9.13.2. Creating a ConfigMap for logging
To use a ConfigMap to define logging properties, you create the ConfigMap and then reference it as part of the logging definition in the spec of a resource.
The ConfigMap must contain the appropriate logging configuration.
-
log4j.propertiesfor Kafka components, ZooKeeper, and the Kafka Bridge -
log4j2.propertiesfor the Topic Operator and User Operator
The configuration must be placed under these properties.
In this procedure a ConfigMap defines a root logger for a Kafka resource.
Procedure
Create the ConfigMap.
You can create the ConfigMap as a YAML file or from a properties file.
ConfigMap example with a root logger definition for Kafka:
kind: ConfigMap apiVersion: v1 metadata: name: logging-configmap data: log4j.properties: kafka.root.logger.level="INFO"If you are using a properties file, specify the file at the command line:
oc create configmap logging-configmap --from-file=log4j.properties
The properties file defines the logging configuration:
# Define the logger kafka.root.logger.level="INFO" # ...
Define external logging in the
specof the resource, setting thelogging.valueFrom.configMapKeyRef.nameto the name of the ConfigMap andlogging.valueFrom.configMapKeyRef.keyto the key in this ConfigMap.# ... logging: type: external valueFrom: configMapKeyRef: name: logging-configmap key: log4j.properties # ...Create or update the resource.
oc apply -f <kafka_configuration_file>
9.13.3. Configuring Cluster Operator logging
Cluster Operator logging is configured through a ConfigMap named strimzi-cluster-operator. A ConfigMap containing logging configuration is created when installing the Cluster Operator. This ConfigMap is described in the file install/cluster-operator/050-ConfigMap-strimzi-cluster-operator.yaml. You configure Cluster Operator logging by changing the data.log4j2.properties values in this ConfigMap.
To update the logging configuration, you can edit the 050-ConfigMap-strimzi-cluster-operator.yaml file and then run the following command:
oc create -f install/cluster-operator/050-ConfigMap-strimzi-cluster-operator.yaml
Alternatively, edit the ConfigMap directly:
oc edit configmap strimzi-cluster-operator
With this ConfigMap, you can control various aspects of logging, including the root logger level, log output format, and log levels for different components. The monitorInterval setting, determines how often the logging configuration is reloaded. You can also control the logging levels for the Kafka AdminClient, ZooKeeper ZKTrustManager, Netty, and the OkHttp client. Netty is a framework used in Streams for Apache Kafka for network communication, and OkHttp is a library used for making HTTP requests.
If the ConfigMap is missing when the Cluster Operator is deployed, the default logging values are used.
If the ConfigMap is accidentally deleted after the Cluster Operator is deployed, the most recently loaded logging configuration is used. Create a new ConfigMap to load a new logging configuration.
Do not remove the monitorInterval option from the ConfigMap.
9.13.4. Adding logging filters to Streams for Apache Kafka operators
If you are using a ConfigMap to configure the (log4j2) logging levels for Streams for Apache Kafka operators, you can also define logging filters to limit what’s returned in the log.
Logging filters are useful when you have a large number of logging messages. Suppose you set the log level for the logger as DEBUG (rootLogger.level="DEBUG"). Logging filters reduce the number of logs returned for the logger at that level, so you can focus on a specific resource. When the filter is set, only log messages matching the filter are logged.
Filters use markers to specify what to include in the log. You specify a kind, namespace and name for the marker. For example, if a Kafka cluster is failing, you can isolate the logs by specifying the kind as Kafka, and use the namespace and name of the failing cluster.
This example shows a marker filter for a Kafka cluster named my-kafka-cluster.
Basic logging filter configuration
rootLogger.level="INFO" appender.console.filter.filter1.type=MarkerFilter 1 appender.console.filter.filter1.onMatch=ACCEPT 2 appender.console.filter.filter1.onMismatch=DENY 3 appender.console.filter.filter1.marker=Kafka(my-namespace/my-kafka-cluster) 4
You can create one or more filters. Here, the log is filtered for two Kafka clusters.
Multiple logging filter configuration
appender.console.filter.filter1.type=MarkerFilter appender.console.filter.filter1.onMatch=ACCEPT appender.console.filter.filter1.onMismatch=DENY appender.console.filter.filter1.marker=Kafka(my-namespace/my-kafka-cluster-1) appender.console.filter.filter2.type=MarkerFilter appender.console.filter.filter2.onMatch=ACCEPT appender.console.filter.filter2.onMismatch=DENY appender.console.filter.filter2.marker=Kafka(my-namespace/my-kafka-cluster-2)
Adding filters to the Cluster Operator
To add filters to the Cluster Operator, update its logging ConfigMap YAML file (install/cluster-operator/050-ConfigMap-strimzi-cluster-operator.yaml).
Procedure
Update the
050-ConfigMap-strimzi-cluster-operator.yamlfile to add the filter properties to the ConfigMap.In this example, the filter properties return logs only for the
my-kafka-clusterKafka cluster:kind: ConfigMap apiVersion: v1 metadata: name: strimzi-cluster-operator data: log4j2.properties: #... appender.console.filter.filter1.type=MarkerFilter appender.console.filter.filter1.onMatch=ACCEPT appender.console.filter.filter1.onMismatch=DENY appender.console.filter.filter1.marker=Kafka(my-namespace/my-kafka-cluster)Alternatively, edit the
ConfigMapdirectly:oc edit configmap strimzi-cluster-operator
If you updated the YAML file instead of editing the
ConfigMapdirectly, apply the changes by deploying the ConfigMap:oc create -f install/cluster-operator/050-ConfigMap-strimzi-cluster-operator.yaml
Adding filters to the Topic Operator or User Operator
To add filters to the Topic Operator or User Operator, create or edit a logging ConfigMap.
In this procedure a logging ConfigMap is created with filters for the Topic Operator. The same approach is used for the User Operator.
Procedure
Create the ConfigMap.
You can create the ConfigMap as a YAML file or from a properties file.
In this example, the filter properties return logs only for the
my-topictopic:kind: ConfigMap apiVersion: v1 metadata: name: logging-configmap data: log4j2.properties: rootLogger.level="INFO" appender.console.filter.filter1.type=MarkerFilter appender.console.filter.filter1.onMatch=ACCEPT appender.console.filter.filter1.onMismatch=DENY appender.console.filter.filter1.marker=KafkaTopic(my-namespace/my-topic)If you are using a properties file, specify the file at the command line:
oc create configmap logging-configmap --from-file=log4j2.properties
The properties file defines the logging configuration:
# Define the logger rootLogger.level="INFO" # Set the filters appender.console.filter.filter1.type=MarkerFilter appender.console.filter.filter1.onMatch=ACCEPT appender.console.filter.filter1.onMismatch=DENY appender.console.filter.filter1.marker=KafkaTopic(my-namespace/my-topic) # ...
Define external logging in the
specof the resource, setting thelogging.valueFrom.configMapKeyRef.nameto the name of the ConfigMap andlogging.valueFrom.configMapKeyRef.keyto the key in this ConfigMap.For the Topic Operator, logging is specified in the
topicOperatorconfiguration of theKafkaresource.spec: # ... entityOperator: topicOperator: logging: type: external valueFrom: configMapKeyRef: name: logging-configmap key: log4j2.properties- Apply the changes by deploying the Cluster Operator:
create -f install/cluster-operator -n my-cluster-operator-namespace
Additional resources
9.14. Using ConfigMaps to add configuration
Add specific configuration to your Streams for Apache Kafka deployment using ConfigMap resources. ConfigMaps use key-value pairs to store non-confidential data. Configuration data added to ConfigMaps is maintained in one place and can be reused amongst components.
ConfigMaps can only store the following types of configuration data:
- Logging configuration
- Metrics configuration
- External configuration for Kafka Connect connectors
You can’t use ConfigMaps for other areas of configuration.
When you configure a component, you can add a reference to a ConfigMap using the configMapKeyRef property.
For example, you can use configMapKeyRef to reference a ConfigMap that provides configuration for logging. You might use a ConfigMap to pass a Log4j configuration file. You add the reference to the logging configuration.
Example ConfigMap for logging
# ...
logging:
type: external
valueFrom:
configMapKeyRef:
name: my-config-map
key: my-config-map-key
# ...
To use a ConfigMap for metrics configuration, you add a reference to the metricsConfig configuration of the component in the same way.
ExternalConfiguration properties make data from a ConfigMap (or Secret) mounted to a pod available as environment variables or volumes. You can use external configuration data for the connectors used by Kafka Connect. The data might be related to an external data source, providing the values needed for the connector to communicate with that data source.
For example, you can use the configMapKeyRef property to pass configuration data from a ConfigMap as an environment variable.
Example ConfigMap providing environment variable values
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaConnect
metadata:
name: my-connect
spec:
# ...
externalConfiguration:
env:
- name: MY_ENVIRONMENT_VARIABLE
valueFrom:
configMapKeyRef:
name: my-config-map
key: my-key
If you are using ConfigMaps that are managed externally, use configuration providers to load the data in the ConfigMaps.
9.14.1. Naming custom ConfigMaps
Streams for Apache Kafka creates its own ConfigMaps and other resources when it is deployed to OpenShift. The ConfigMaps contain data necessary for running components. The ConfigMaps created by Streams for Apache Kafka must not be edited.
Make sure that any custom ConfigMaps you create do not have the same name as these default ConfigMaps. If they have the same name, they will be overwritten. For example, if your ConfigMap has the same name as the ConfigMap for the Kafka cluster, it will be overwritten when there is an update to the Kafka cluster.
Additional resources
9.15. Loading configuration values from external sources
Use configuration providers to load configuration data from external sources. The providers operate independently of Streams for Apache Kafka. You can use them to load configuration data for all Kafka components, including producers and consumers. You reference the external source in the configuration of the component and provide access rights. The provider loads data without needing to restart the Kafka component or extracting files, even when referencing a new external source. For example, use providers to supply the credentials for the Kafka Connect connector configuration. The configuration must include any access rights to the external source.
9.15.1. Enabling configuration providers
You can enable one or more configuration providers using the config.providers properties in the spec configuration of a component.
Example configuration to enable a configuration provider
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaConnect
metadata:
name: my-connect
annotations:
strimzi.io/use-connector-resources: "true"
spec:
# ...
config:
# ...
config.providers: env
config.providers.env.class: org.apache.kafka.common.config.provider.EnvVarConfigProvider
# ...
- KubernetesSecretConfigProvider
- Loads configuration data from OpenShift secrets. You specify the name of the secret and the key within the secret where the configuration data is stored. This provider is useful for storing sensitive configuration data like passwords or other user credentials.
- KubernetesConfigMapConfigProvider
- Loads configuration data from OpenShift config maps. You specify the name of the config map and the key within the config map where the configuration data is stored. This provider is useful for storing non-sensitive configuration data.
- EnvVarConfigProvider
- Loads configuration data from environment variables. You specify the name of the environment variable where the configuration data is stored. This provider is useful for configuring applications running in containers, for example, to load certificates or JAAS configuration from environment variables mapped from secrets.
- FileConfigProvider
- Loads configuration data from a file. You specify the path to the file where the configuration data is stored. This provider is useful for loading configuration data from files that are mounted into containers.
- DirectoryConfigProvider
- Loads configuration data from files within a directory. You specify the path to the directory where the configuration files are stored. This provider is useful for loading multiple configuration files and for organizing configuration data into separate files.
To use KubernetesSecretConfigProvider and KubernetesConfigMapConfigProvider, which are part of the OpenShift Configuration Provider plugin, you must set up access rights to the namespace that contains the configuration file.
You can use the other providers without setting up access rights. You can supply connector configuration for Kafka Connect or MirrorMaker 2 in this way by doing the following:
- Mount config maps or secrets into the Kafka Connect pod as environment variables or volumes
-
Enable
EnvVarConfigProvider,FileConfigProvider, orDirectoryConfigProviderin the Kafka Connect or MirrorMaker 2 configuration -
Pass connector configuration using the
externalConfigurationproperty in thespecof theKafkaConnectorKafkaMirrorMaker2resource
Using providers help prevent the passing of restricted information through the Kafka Connect REST interface. You can use this approach in the following scenarios:
- Mounting environment variables with the values a connector uses to connect and communicate with a data source
- Mounting a properties file with values that are used to configure Kafka Connect connectors
- Mounting files in a directory that contains values for the TLS truststore and keystore used by a connector
A restart is required when using a new Secret or ConfigMap for a connector, which can disrupt other connectors.
Additional resources
9.15.2. Loading configuration values from secrets or config maps
Use the KubernetesSecretConfigProvider to provide configuration properties from a secret or the KubernetesConfigMapConfigProvider to provide configuration properties from a config map.
In this procedure, a config map provides configuration properties for a connector. The properties are specified as key values of the config map. The config map is mounted into the Kafka Connect pod as a volume.
Prerequisites
- A Kafka cluster is running.
- The Cluster Operator is running.
- You have a config map containing the connector configuration.
Example config map with connector properties
apiVersion: v1 kind: ConfigMap metadata: name: my-connector-configuration data: option1: value1 option2: value2
Procedure
Configure the
KafkaConnectresource.-
Enable the
KubernetesConfigMapConfigProvider
The specification shown here can support loading values from config maps and secrets.
Example Kafka Connect configuration to use config maps and secrets
apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaConnect metadata: name: my-connect annotations: strimzi.io/use-connector-resources: "true" spec: # ... config: # ... config.providers: secrets,configmaps 1 config.providers.configmaps.class: io.strimzi.kafka.KubernetesConfigMapConfigProvider 2 config.providers.secrets.class: io.strimzi.kafka.KubernetesSecretConfigProvider 3 # ...- 1
- The alias for the configuration provider is used to define other configuration parameters. The provider parameters use the alias from
config.providers, taking the formconfig.providers.${alias}.class. - 2
KubernetesConfigMapConfigProviderprovides values from config maps.- 3
KubernetesSecretConfigProviderprovides values from secrets.
-
Enable the
Create or update the resource to enable the provider.
oc apply -f <kafka_connect_configuration_file>
Create a role that permits access to the values in the external config map.
Example role to access values from a config map
apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: connector-configuration-role rules: - apiGroups: [""] resources: ["configmaps"] resourceNames: ["my-connector-configuration"] verbs: ["get"] # ...
The rule gives the role permission to access the
my-connector-configurationconfig map.Create a role binding to permit access to the namespace that contains the config map.
Example role binding to access the namespace that contains the config map
apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: connector-configuration-role-binding subjects: - kind: ServiceAccount name: my-connect-connect namespace: my-project roleRef: kind: Role name: connector-configuration-role apiGroup: rbac.authorization.k8s.io # ...
The role binding gives the role permission to access the
my-projectnamespace.The service account must be the same one used by the Kafka Connect deployment. The service account name format is
<cluster_name>-connect, where<cluster_name>is the name of theKafkaConnectcustom resource.Reference the config map in the connector configuration.
Example connector configuration referencing the config map
apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaConnector metadata: name: my-connector labels: strimzi.io/cluster: my-connect spec: # ... config: option: ${configmaps:my-project/my-connector-configuration:option1} # ... # ...The placeholder structure is
configmaps:<path_and_file_name>:<property>.KubernetesConfigMapConfigProviderreads and extracts theoption1property value from the external config map.
9.15.3. Loading configuration values from environment variables
Use the EnvVarConfigProvider to provide configuration properties as environment variables. Environment variables can contain values from config maps or secrets.
In this procedure, environment variables provide configuration properties for a connector to communicate with Amazon AWS. The connector must be able to read the AWS_ACCESS_KEY_ID and AWS_SECRET_ACCESS_KEY. The values of the environment variables are derived from a secret mounted into the Kafka Connect pod.
The names of user-defined environment variables cannot start with KAFKA_ or STRIMZI_.
Prerequisites
- A Kafka cluster is running.
- The Cluster Operator is running.
- You have a secret containing the connector configuration.
Example secret with values for environment variables
apiVersion: v1 kind: Secret metadata: name: aws-creds type: Opaque data: awsAccessKey: QUtJQVhYWFhYWFhYWFhYWFg= awsSecretAccessKey: Ylhsd1lYTnpkMjl5WkE=
Procedure
Configure the
KafkaConnectresource.-
Enable the
EnvVarConfigProvider -
Specify the environment variables using the
externalConfigurationproperty.
Example Kafka Connect configuration to use external environment variables
apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaConnect metadata: name: my-connect annotations: strimzi.io/use-connector-resources: "true" spec: # ... config: # ... config.providers: env 1 config.providers.env.class: org.apache.kafka.common.config.provider.EnvVarConfigProvider 2 # ... externalConfiguration: env: - name: AWS_ACCESS_KEY_ID 3 valueFrom: secretKeyRef: name: aws-creds 4 key: awsAccessKey 5 - name: AWS_SECRET_ACCESS_KEY valueFrom: secretKeyRef: name: aws-creds key: awsSecretAccessKey # ...- 1
- The alias for the configuration provider is used to define other configuration parameters. The provider parameters use the alias from
config.providers, taking the formconfig.providers.${alias}.class. - 2
EnvVarConfigProviderprovides values from environment variables.- 3
- The environment variable takes a value from the secret.
- 4
- The name of the secret containing the environment variable.
- 5
- The name of the key stored in the secret.
NoteThe
secretKeyRefproperty references keys in a secret. If you are using a config map instead of a secret, use theconfigMapKeyRefproperty.-
Enable the
Create or update the resource to enable the provider.
oc apply -f <kafka_connect_configuration_file>
Reference the environment variable in the connector configuration.
Example connector configuration referencing the environment variable
apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaConnector metadata: name: my-connector labels: strimzi.io/cluster: my-connect spec: # ... config: option: ${env:AWS_ACCESS_KEY_ID} option: ${env:AWS_SECRET_ACCESS_KEY} # ... # ...The placeholder structure is
env:<environment_variable_name>.EnvVarConfigProviderreads and extracts the environment variable values from the mounted secret.
9.15.4. Loading configuration values from a file within a directory
Use the FileConfigProvider to provide configuration properties from a file within a directory. Files can be config maps or secrets.
In this procedure, a file provides configuration properties for a connector. A database name and password are specified as properties of a secret. The secret is mounted to the Kafka Connect pod as a volume. Volumes are mounted on the path /opt/kafka/external-configuration/<volume-name>.
Prerequisites
- A Kafka cluster is running.
- The Cluster Operator is running.
- You have a secret containing the connector configuration.
Example secret with database properties
apiVersion: v1 kind: Secret metadata: name: mysecret type: Opaque stringData: connector.properties: |- 1 dbUsername: my-username 2 dbPassword: my-password
Procedure
Configure the
KafkaConnectresource.-
Enable the
FileConfigProvider -
Specify the file using the
externalConfigurationproperty.
Example Kafka Connect configuration to use an external property file
apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaConnect metadata: name: my-connect spec: # ... config: config.providers: file 1 config.providers.file.class: org.apache.kafka.common.config.provider.FileConfigProvider 2 #... externalConfiguration: volumes: - name: connector-config 3 secret: secretName: mysecret 4- 1
- The alias for the configuration provider is used to define other configuration parameters.
- 2
FileConfigProviderprovides values from properties files. The parameter uses the alias fromconfig.providers, taking the formconfig.providers.${alias}.class.- 3
- The name of the volume containing the secret.
- 4
- The name of the secret.
-
Enable the
Create or update the resource to enable the provider.
oc apply -f <kafka_connect_configuration_file>
Reference the file properties in the connector configuration as placeholders.
Example connector configuration referencing the file
apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaConnector metadata: name: my-source-connector labels: strimzi.io/cluster: my-connect-cluster spec: class: io.debezium.connector.mysql.MySqlConnector tasksMax: 2 config: database.hostname: 192.168.99.1 database.port: "3306" database.user: "${file:/opt/kafka/external-configuration/connector-config/mysecret:dbUsername}" database.password: "${file:/opt/kafka/external-configuration/connector-config/mysecret:dbPassword}" database.server.id: "184054" #...The placeholder structure is
file:<path_and_file_name>:<property>.FileConfigProviderreads and extracts the database username and password property values from the mounted secret.
9.15.5. Loading configuration values from multiple files within a directory
Use the DirectoryConfigProvider to provide configuration properties from multiple files within a directory. Files can be config maps or secrets.
In this procedure, a secret provides the TLS keystore and truststore user credentials for a connector. The credentials are in separate files. The secrets are mounted into the Kafka Connect pod as volumes. Volumes are mounted on the path /opt/kafka/external-configuration/<volume-name>.
Prerequisites
- A Kafka cluster is running.
- The Cluster Operator is running.
- You have a secret containing the user credentials.
Example secret with user credentials
apiVersion: v1
kind: Secret
metadata:
name: my-user
labels:
strimzi.io/kind: KafkaUser
strimzi.io/cluster: my-cluster
type: Opaque
data:
ca.crt: <public_key> # Public key of the clients CA
user.crt: <user_certificate> # Public key of the user
user.key: <user_private_key> # Private key of the user
user.p12: <store> # PKCS #12 store for user certificates and keys
user.password: <password_for_store> # Protects the PKCS #12 store
The my-user secret provides the keystore credentials (user.crt and user.key) for the connector.
The <cluster_name>-cluster-ca-cert secret generated when deploying the Kafka cluster provides the cluster CA certificate as truststore credentials (ca.crt).
Procedure
Configure the
KafkaConnectresource.-
Enable the
DirectoryConfigProvider -
Specify the files using the
externalConfigurationproperty.
Example Kafka Connect configuration to use external property files
apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaConnect metadata: name: my-connect spec: # ... config: config.providers: directory 1 config.providers.directory.class: org.apache.kafka.common.config.provider.DirectoryConfigProvider 2 #... externalConfiguration: volumes: 3 - name: cluster-ca 4 secret: secretName: my-cluster-cluster-ca-cert 5 - name: my-user secret: secretName: my-user 6- 1
- The alias for the configuration provider is used to define other configuration parameters.
- 2
DirectoryConfigProviderprovides values from files in a directory. The parameter uses the alias fromconfig.providers, taking the formconfig.providers.${alias}.class.- 3
- The names of the volumes containing the secrets.
- 4
- The name of the secret for the cluster CA certificate to supply truststore configuration.
- 5
- The name of the secret for the user to supply keystore configuration.
-
Enable the
Create or update the resource to enable the provider.
oc apply -f <kafka_connect_configuration_file>
Reference the file properties in the connector configuration as placeholders.
Example connector configuration referencing the files
apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaConnector metadata: name: my-source-connector labels: strimzi.io/cluster: my-connect-cluster spec: class: io.debezium.connector.mysql.MySqlConnector tasksMax: 2 config: # ... database.history.producer.security.protocol: SSL database.history.producer.ssl.truststore.type: PEM database.history.producer.ssl.truststore.certificates: "${directory:/opt/kafka/external-configuration/cluster-ca:ca.crt}" database.history.producer.ssl.keystore.type: PEM database.history.producer.ssl.keystore.certificate.chain: "${directory:/opt/kafka/external-configuration/my-user:user.crt}" database.history.producer.ssl.keystore.key: "${directory:/opt/kafka/external-configuration/my-user:user.key}" #...The placeholder structure is
directory:<path>:<file_name>.DirectoryConfigProviderreads and extracts the credentials from the mounted secrets.
9.16. Customizing OpenShift resources
A Streams for Apache Kafka deployment creates OpenShift resources, such as Deployment, Pod, and Service resources. These resources are managed by Streams for Apache Kafka operators. Only the operator that is responsible for managing a particular OpenShift resource can change that resource. If you try to manually change an operator-managed OpenShift resource, the operator will revert your changes back.
Changing an operator-managed OpenShift resource can be useful if you want to perform certain tasks, such as the following:
-
Adding custom labels or annotations that control how
Podsare treated by Istio or other services -
Managing how
Loadbalancer-type Services are created by the cluster
To make the changes to an OpenShift resource, you can use the template property within the spec section of various Streams for Apache Kafka custom resources.
Here is a list of the custom resources where you can apply the changes:
-
Kafka.spec.kafka -
Kafka.spec.zookeeper -
Kafka.spec.entityOperator -
Kafka.spec.kafkaExporter -
Kafka.spec.cruiseControl -
KafkaNodePool.spec -
KafkaConnect.spec -
KafkaMirrorMaker.spec -
KafkaMirrorMaker2.spec -
KafkaBridge.spec -
KafkaUser.spec
For more information about these properties, see the Streams for Apache Kafka Custom Resource API Reference.
The Streams for Apache Kafka Custom Resource API Reference provides more details about the customizable fields.
In the following example, the template property is used to modify the labels in a Kafka broker’s pod.
Example template customization
apiVersion: kafka.strimzi.io/v1beta2
kind: Kafka
metadata:
name: my-cluster
labels:
app: my-cluster
spec:
kafka:
# ...
template:
pod:
metadata:
labels:
mylabel: myvalue
# ...
9.16.1. Customizing the image pull policy
Streams for Apache Kafka allows you to customize the image pull policy for containers in all pods deployed by the Cluster Operator. The image pull policy is configured using the environment variable STRIMZI_IMAGE_PULL_POLICY in the Cluster Operator deployment. The STRIMZI_IMAGE_PULL_POLICY environment variable can be set to three different values:
Always- Container images are pulled from the registry every time the pod is started or restarted.
IfNotPresent- Container images are pulled from the registry only when they were not pulled before.
Never- Container images are never pulled from the registry.
Currently, the image pull policy can only be customized for all Kafka, Kafka Connect, and Kafka MirrorMaker clusters at once. Changing the policy will result in a rolling update of all your Kafka, Kafka Connect, and Kafka MirrorMaker clusters.
Additional resources
9.16.2. Applying a termination grace period
Apply a termination grace period to give a Kafka cluster enough time to shut down cleanly.
Specify the time using the terminationGracePeriodSeconds property. Add the property to the template.pod configuration of the Kafka custom resource.
The time you add will depend on the size of your Kafka cluster. The OpenShift default for the termination grace period is 30 seconds. If you observe that your clusters are not shutting down cleanly, you can increase the termination grace period.
A termination grace period is applied every time a pod is restarted. The period begins when OpenShift sends a term (termination) signal to the processes running in the pod. The period should reflect the amount of time required to transfer the processes of the terminating pod to another pod before they are stopped. After the period ends, a kill signal stops any processes still running in the pod.
The following example adds a termination grace period of 120 seconds to the Kafka custom resource. You can also specify the configuration in the custom resources of other Kafka components.
Example termination grace period configuration
apiVersion: kafka.strimzi.io/v1beta2
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
# ...
template:
pod:
terminationGracePeriodSeconds: 120
# ...
# ...