Ce contenu n'est pas disponible dans la langue sélectionnée.
Chapter 7. Handling large message sizes
Kafka’s default batch size for messages is 1MB, which is optimal for maximum throughput in most use cases. Kafka can accommodate larger batches at a reduced throughput, assuming adequate disk capacity.
Large message sizes can be handled in four ways:
- Brokers, producers, and consumers are configured to accommodate larger message sizes.
- Producer-side message compression writes compressed messages to the log.
- Reference-based messaging sends only a reference to data stored in some other system in the message’s payload.
- Inline messaging splits messages into chunks that use the same key, which are then combined on output using a stream-processor like Kafka Streams.
Unless you are handling very large messages, the configuration approach is recommended. The reference-based messaging and message compression options cover most other situations. With any of these options, care must be taken to avoid introducing performance issues.
7.1. Configuring Kafka components to handle larger messages
Large messages can impact system performance and introduce complexities in message processing. If they cannot be avoided, there are configuration options available. To handle larger messages efficiently and prevent blocks in the message flow, consider adjusting the following configurations:
Adjusting the maximum record batch size:
-
Set
message.max.bytesat the broker level to support larger record batch sizes for all topics. -
Set
max.message.bytesat the topic level to support larger record batch sizes for individual topics.
-
Set
-
Increasing the maximum size of messages fetched by each partition follower (
replica.fetch.max.bytes). -
Increasing the batch size (
batch.size) for producers to increase the size of message batches sent in a single produce request. -
Configuring a higher maximum request size for producers (
max.request.size) and consumers (fetch.max.bytes) to accommodate larger record batches. -
Setting a higher maximum limit (
max.partition.fetch.bytes) on how much data is returned to consumers for each partition.
Ensure that the maximum size for batch requests is at least as large as message.max.bytes to accommodate the largest record batch size.
Example broker configuration
message.max.bytes: 10000000 replica.fetch.max.bytes: 10485760
Example producer configuration
batch.size: 327680 max.request.size: 10000000
Example consumer configuration
fetch.max.bytes: 10000000 max.partition.fetch.bytes: 10485760
It’s also possible to configure the producers and consumers used by other Kafka components like Kafka Bridge, Kafka Connect, and MirrorMaker 2 to handle larger messages more effectively.
- Kafka Bridge
Configure the Kafka Bridge using specific producer and consumer configuration properties:
-
producer.configfor producers -
consumer.configfor consumers
Example Kafka Bridge configuration
apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaBridge metadata: name: my-bridge spec: # ... producer: config: batch.size: 327680 max.request.size: 10000000 consumer: config: fetch.max.bytes: 10000000 max.partition.fetch.bytes: 10485760 # ...-
- Kafka Connect
For Kafka Connect, configure the source and sink connectors responsible for sending and retrieving messages using prefixes for producer and consumer configuration properties:
-
producer.overridefor the producer used by the source connector to send messages to a Kafka cluster -
consumerfor the consumer used by the sink connector to retrieve messages from a Kafka cluster
Example Kafka Connect source connector configuration
apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaConnector metadata: name: my-source-connector labels: strimzi.io/cluster: my-connect-cluster spec: # ... config: producer.override.batch.size: 327680 producer.override.max.request.size: 10000000 # ...Example Kafka Connect sink connector configuration
apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaConnector metadata: name: my-sink-connector labels: strimzi.io/cluster: my-connect-cluster spec: # ... config: consumer.fetch.max.bytes: 10000000 consumer.max.partition.fetch.bytes: 10485760 # ...-
- MirrorMaker 2
For MirrorMaker 2, configure the source connector responsible for retrieving messages from the source Kafka cluster using prefixes for producer and consumer configuration properties:
-
producer.overridefor the runtime Kafka Connect producer used to replicate data to the target Kafka cluster -
consumerfor the consumer used by the sink connector to retrieve messages from the source Kafka cluster
Example MirrorMaker 2 source connector configuration
apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaMirrorMaker2 metadata: name: my-mirror-maker2 spec: # ... mirrors: - sourceCluster: "my-cluster-source" targetCluster: "my-cluster-target" sourceConnector: tasksMax: 2 config: producer.override.batch.size: 327680 producer.override.max.request.size: 10000000 consumer.fetch.max.bytes: 10000000 consumer.max.partition.fetch.bytes: 10485760 # ...-
7.2. Producer-side compression
For producer configuration, you specify a compression.type, such as Gzip, which is then applied to batches of data generated by the producer. Using the broker configuration compression.type=producer (default), the broker retains whatever compression the producer used. Whenever producer and topic compression do not match, the broker has to compress batches again prior to appending them to the log, which impacts broker performance.
Compression also adds additional processing overhead on the producer and decompression overhead on the consumer, but includes more data in a batch, so is often beneficial to throughput when message data compresses well.
Combine producer-side compression with fine-tuning of the batch size to facilitate optimum throughput. Using metrics helps to gauge the average batch size needed.
7.3. Reference-based messaging
Reference-based messaging is useful for data replication when you do not know how big a message will be. The external data store must be fast, durable, and highly available for this configuration to work. Data is written to the data store and a reference to the data is returned. The producer sends a message containing the reference to Kafka. The consumer gets the reference from the message and uses it to fetch the data from the data store.
7.4. Reference-based messaging flow

As the message passing requires more trips, end-to-end latency will increase. Another significant drawback of this approach is there is no automatic clean up of the data in the external system when the Kafka message gets cleaned up. A hybrid approach would be to only send large messages to the data store and process standard-sized messages directly.
Inline messaging
Inline messaging is complex, but it does not have the overhead of depending on external systems like reference-based messaging.
The producing client application has to serialize and then chunk the data if the message is too big. The producer then uses the Kafka ByteArraySerializer or similar to serialize each chunk again before sending it. The consumer tracks messages and buffers chunks until it has a complete message. The consuming client application receives the chunks, which are assembled before deserialization. Complete messages are delivered to the rest of the consuming application in order according to the offset of the first or last chunk for each set of chunked messages.
The consumer should commit its offset only after receiving and processing all message chunks to ensure accurate tracking of message delivery and prevent duplicates during rebalancing. Chunks might be spread across segments. Consumer-side handling should cover the possibility that a chunk becomes unavailable if a segment is subsequently deleted.
Figure 7.1. Inline messaging flow
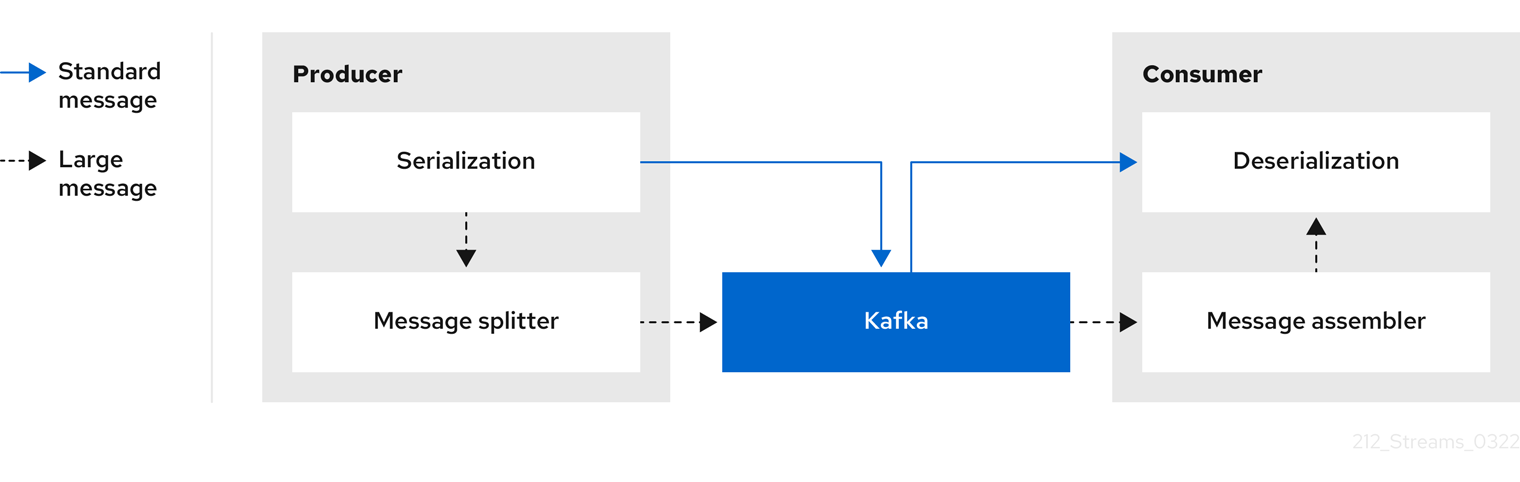
Inline messaging has a performance overhead on the consumer side because of the buffering required, particularly when handling a series of large messages in parallel. The chunks of large messages can become interleaved, so that it is not always possible to commit when all the chunks of a message have been consumed if the chunks of another large message in the buffer are incomplete. For this reason, the buffering is usually supported by persisting message chunks or by implementing commit logic.