Questo contenuto non è disponibile nella lingua selezionata.
Chapter 6. Multi-site configuration and administration
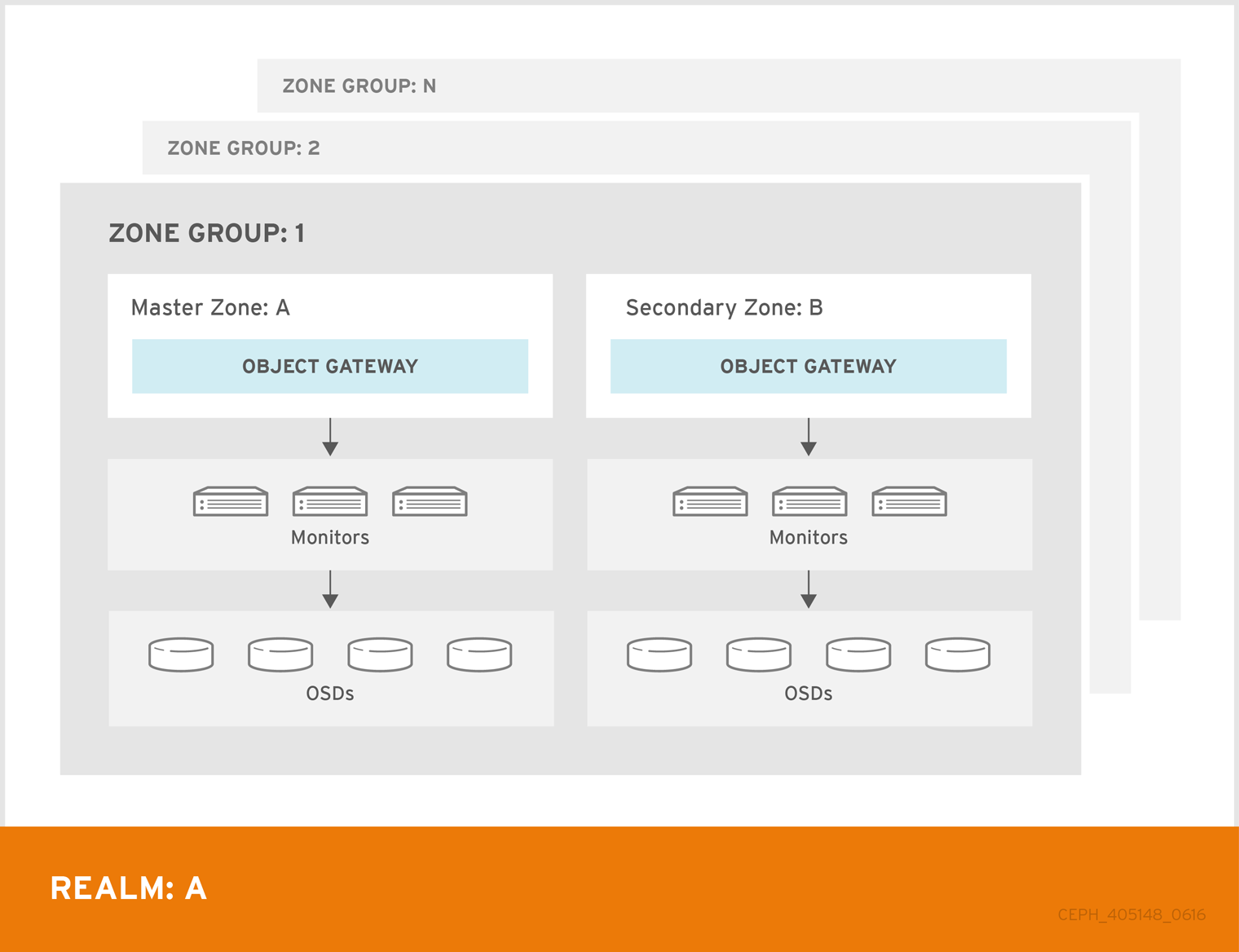
As a storage administrator, you can configure and administer multiple Ceph Object Gateways for a variety of use cases. You can learn what to do during a disaster recovery and failover events. Also, you can learn more about realms, zones, and syncing policies in multi-site Ceph Object Gateway environments.
A single zone configuration typically consists of one zone group containing one zone and one or more ceph-radosgw instances where you may load-balance gateway client requests between the instances. In a single zone configuration, typically multiple gateway instances point to a single Ceph storage cluster. However, Red Hat supports several multi-site configuration options for the Ceph Object Gateway:
-
Multi-zone: A more advanced configuration consists of one zone group and multiple zones, each zone with one or more
ceph-radosgwinstances. Each zone is backed by its own Ceph Storage Cluster. Multiple zones in a zone group provides disaster recovery for the zone group should one of the zones experience a significant failure. Each zone is active and may receive write operations. In addition to disaster recovery, multiple active zones may also serve as a foundation for content delivery networks. - Multi-zone-group: Formerly called 'regions', the Ceph Object Gateway can also support multiple zone groups, each zone group with one or more zones. Objects stored to zone groups within the same realm share a global namespace, ensuring unique object IDs across zone groups and zones.
- Multiple Realms: The Ceph Object Gateway supports the notion of realms, which can be a single zone group or multiple zone groups and a globally unique namespace for the realm. Multiple realms provides the ability to support numerous configurations and namespaces.
Prerequisites
- A healthy running Red Hat Ceph Storage cluster.
- Deployment of the Ceph Object Gateway software.
6.1. Requirements and Assumptions
A multi-site configuration requires at least two Ceph storage clusters, and At least two Ceph object gateway instances, one for each Ceph storage cluster.
This guide assumes at least two Ceph storage clusters in geographically separate locations; however, the configuration can work on the same physical site. This guide also assumes four Ceph object gateway servers named rgw1, rgw2, rgw3 and rgw4 respectively.
A multi-site configuration requires a master zone group and a master zone. Additionally, each zone group requires a master zone. Zone groups might have one or more secondary or non-master zones.
When planning network considerations for multi-site, it is important to understand the relation bandwidth and latency observed on the multi-site synchronization network and the clients ingest rate in direct correlation with the current sync state of the objects owed to the secondary site. The network link between Red Hat Ceph Storage multi-site clusters must be able to handle the ingest into the primary cluster to maintain an effective recovery time on the secondary site. Multi-site synchronization is asynchronous and one of the limitations is the rate at which the sync gateways can process data across the link. An example to look at in terms of network inter-connectivity speed could be 1 GbE or inter-datacenter connectivity, for every 8 TB or cumulative receive data, per client gateway. Thus, if you replicate to two other sites, and ingest 16 TB a day, you need 6 GbE of dedicated bandwidth for multi-site replication.
Red Hat also recommends private Ethernet or Dense wavelength-division multiplexing (DWDM) as a VPN over the internet is not ideal due to the additional overhead incurred.
The master zone within the master zone group of a realm is responsible for storing the master copy of the realm’s metadata, including users, quotas and buckets (created by the radosgw-admin CLI). This metadata gets synchronized to secondary zones and secondary zone groups automatically. Metadata operations executed with the radosgw-admin CLI MUST be executed on a host within the master zone of the master zone group in order to ensure that they get synchronized to the secondary zone groups and zones. Currently, it is possible to execute metadata operations on secondary zones and zone groups, but it is NOT recommended because they WILL NOT be synchronized, leading to fragmented metadata.
For new Ceph Object Gateway deployment in multi-site, it takes around 20 minutes to sync metadata operations to the secondary site.
In the following examples, the rgw1 host will serve as the master zone of the master zone group; the rgw2 host will serve as the secondary zone of the master zone group; the rgw3 host will serve as the master zone of the secondary zone group; and the rgw4 host will serve as the secondary zone of the secondary zone group.
Red Hat recommends to use load balancer and three Ceph Object Gateway daemons to have sync end points with multi-site. For the non-syncing Ceph Object Gateway nodes in a multi-site configuration, which are dedicated for client I/O operations through load balancers, run the ceph config set client.rgw.CLIENT_NODE rgw_run_sync_thread false command to prevent them from performing sync operations, and then restart the Ceph Object Gateway.
Following is a typical configuration file for HAProxy for syncing gateways:
Example
[root@host01 ~]# cat ./haproxy.cfg
global
log 127.0.0.1 local2
chroot /var/lib/haproxy
pidfile /var/run/haproxy.pid
maxconn 7000
user haproxy
group haproxy
daemon
stats socket /var/lib/haproxy/stats
defaults
mode http
log global
option httplog
option dontlognull
option http-server-close
option forwardfor except 127.0.0.0/8
option redispatch
retries 3
timeout http-request 10s
timeout queue 1m
timeout connect 10s
timeout client 30s
timeout server 30s
timeout http-keep-alive 10s
timeout check 10s
timeout client-fin 1s
timeout server-fin 1s
maxconn 6000
listen stats
bind 0.0.0.0:1936
mode http
log global
maxconn 256
clitimeout 10m
srvtimeout 10m
contimeout 10m
timeout queue 10m
# JTH start
stats enable
stats hide-version
stats refresh 30s
stats show-node
## stats auth admin:password
stats uri /haproxy?stats
stats admin if TRUE
frontend main
bind *:5000
acl url_static path_beg -i /static /images /javascript /stylesheets
acl url_static path_end -i .jpg .gif .png .css .js
use_backend static if url_static
default_backend app
maxconn 6000
backend static
balance roundrobin
fullconn 6000
server app8 host01:8080 check maxconn 2000
server app9 host02:8080 check maxconn 2000
server app10 host03:8080 check maxconn 2000
backend app
balance roundrobin
fullconn 6000
server app8 host01:8080 check maxconn 2000
server app9 host02:8080 check maxconn 2000
server app10 host03:8080 check maxconn 20006.2. Pools
Red Hat recommends using the Ceph Placement Group’s per Pool Calculator to calculate a suitable number of placement groups for the pools the radosgw daemon will create. Set the calculated values as defaults in the Ceph configuration database.
Example
[ceph: root@host01 /]# ceph config set osd osd_pool_default_pg_num 32
[ceph: root@host01 /]# ceph config set osd osd_pool_default_pgp_num 32Making this change to the Ceph configuration will use those defaults when the Ceph Object Gateway instance creates the pools. Alternatively, you can create the pools manually.
Pool names particular to a zone follow the naming convention ZONE_NAME.POOL_NAME. For example, a zone named us-east will have the following pools:
-
.rgw.root -
us-east.rgw.control -
us-east.rgw.meta -
us-east.rgw.log -
us-east.rgw.buckets.index -
us-east.rgw.buckets.data -
us-east.rgw.buckets.non-ec -
us-east.rgw.meta:users.keys -
us-east.rgw.meta:users.email -
us-east.rgw.meta:users.swift -
us-east.rgw.meta:users.uid
6.3. Migrating a single site system to multi-site
To migrate from a single site system with a default zone group and zone to a multi-site system, use the following steps:
Create a realm. Replace
REALM_NAMEwith the realm name.Syntax
radosgw-admin realm create --rgw-realm REALM_NAME --defaultRename the default zone and zonegroup. Replace
NEW_ZONE_GROUP_NAMEandNEW_ZONE_NAMEwith the zonegroup and zone name respectively.Syntax
radosgw-admin zonegroup rename --rgw-zonegroup default --zonegroup-new-name NEW_ZONE_GROUP_NAME radosgw-admin zone rename --rgw-zone default --zone-new-name NEW_ZONE_NAME --rgw-zonegroup NEW_ZONE_GROUP_NAMERename the default zonegroup’s
api_name. ReplaceNEW_ZONE_GROUP_NAMEwith the zonegroup name.Syntax
radosgw-admin zonegroup modify --api-name NEW_ZONE_GROUP_NAME --rgw-zonegroup NEW_ZONE_GROUP_NAMEConfigure the primary zonegroup. Replace
NEW_ZONE_GROUP_NAMEwith the zonegroup name andREALM_NAMEwith realm name. ReplaceENDPOINTwith the fully qualified domain names in the zonegroup.Syntax
radosgw-admin zonegroup modify --rgw-realm REALM_NAME --rgw-zonegroup NEW_ZONE_GROUP_NAME --endpoints http://ENDPOINT --master --defaultConfigure the primary zone. Replace
REALM_NAMEwith realm name,NEW_ZONE_GROUP_NAMEwith the zonegroup name,NEW_ZONE_NAMEwith the zone name, andENDPOINTwith the fully qualified domain names in the zonegroup.Syntax
radosgw-admin zone modify --rgw-realm REALM_NAME --rgw-zonegroup NEW_ZONE_GROUP_NAME --rgw-zone NEW_ZONE_NAME --endpoints http://ENDPOINT --master --defaultCreate a system user. Replace
USER_IDwith the username. ReplaceDISPLAY_NAMEwith a display name. It can contain spaces.Syntax
radosgw-admin user create --uid USER_ID --display-name DISPLAY_NAME --access-key ACCESS_KEY --secret SECRET_KEY --systemCommit the updated configuration:
Example
[ceph: root@host01 /]# radosgw-admin period update --commitGrep for the rgw service name
Syntax
ceph orch ls | grep rgwSetup the configurations for realm, zonegroup and the primary zone.
Syntax
ceph config set client.rgw.SERVICE_NAME rgw_realm REALM_NAME ceph config set client.rgw.SERVICE_NAME rgw_zonegroup ZONE_GROUP_NAME ceph config set client.rgw.SERVICE_NAME rgw_zone PRIMARY_ZONE_NAMEExample
[ceph: root@host01 /]# ceph config set client.rgw.rgwsvcid.mons-1.jwgwwp rgw_realm test_realm [ceph: root@host01 /]# ceph config set client.rgw.rgwsvcid.mons-1.jwgwwp rgw_zonegroup us [ceph: root@host01 /]# ceph config set client.rgw.rgwsvcid.mons-1.jwgwwp rgw_zone us-east-1Restart the Ceph Object Gateway:
Example
[ceph: root@host01 /]# systemctl restart ceph-radosgw@rgw.`hostname -s`Syntax
[ceph: root@host01 /]# ceph orch restart _RGW_SERVICE_NAME_Example
[ceph: root@host01 /]# ceph orch restart rgw.rgwsvcid.mons-1.jwgwwp
6.4. Establishing a secondary zone
Zones within a zone group replicate all data to ensure that each zone has the same data. When creating the secondary zone, issue ALL of the radosgw-admin zone operations on a host identified to serve the secondary zone.
To add a additional zones, follow the same procedures as for adding the secondary zone. Use a different zone name.
-
Run the metadata operations, such as user creation and quotas, on a host within the master zone of the master zonegroup. The master zone and the secondary zone can receive bucket operations from the RESTful APIs, but the secondary zone redirects bucket operations to the master zone. If the master zone is down, bucket operations will fail. If you create a bucket using the
radosgw-adminCLI, you must run it on a host within the master zone of the master zone group so that the buckets will synchronize with other zone groups and zones. -
Bucket creation for a particular user is not supported, even if you create a user in the secondary zone with
--yes-i-really-mean-it. -
Creating a user from a non-primary site is successful when using the
--yes-i-really-mean-itflag however the user does not sync to the primary site.
Prerequisites
- At least two running Red Hat Ceph Storage clusters.
- At least two Ceph Object Gateway instances, one for each Red Hat Ceph Storage cluster.
- Root-level access to all the nodes.
- Nodes or containers are added to the storage cluster.
- All Ceph Manager, Monitor, and OSD daemons are deployed.
Procedure
Log into the
cephadmshell:Example
[root@host04 ~]# cephadm shellPull the primary realm configuration from the host:
Syntax
radosgw-admin realm pull --url=URL_TO_PRIMARY_ZONE_GATEWAY --access-key=ACCESS_KEY --secret-key=SECRET_KEYExample
[ceph: root@host04 /]# radosgw-admin realm pull --url=http://10.74.249.26:80 --access-key=LIPEYZJLTWXRKXS9LPJC --secret-key=IsAje0AVDNXNw48LjMAimpCpI7VaxJYSnfD0FFKQPull the primary period configuration from the host:
Syntax
radosgw-admin period pull --url=URL_TO_PRIMARY_ZONE_GATEWAY --access-key=ACCESS_KEY --secret-key=SECRET_KEYExample
[ceph: root@host04 /]# radosgw-admin period pull --url=http://10.74.249.26:80 --access-key=LIPEYZJLTWXRKXS9LPJC --secret-key=IsAje0AVDNXNw48LjMAimpCpI7VaxJYSnfD0FFKQConfigure a secondary zone:
NoteAll zones run in an active-active configuration by default; that is, a gateway client might write data to any zone and the zone will replicate the data to all other zones within the zone group. If the secondary zone should not accept write operations, specify the
--read-onlyflag to create an active-passive configuration between the master zone and the secondary zone. Additionally, provide theaccess_keyandsecret_keyof the generated system user stored in the master zone of the master zone group.Syntax
radosgw-admin zone create --rgw-zonegroup=_ZONE_GROUP_NAME_ \ --rgw-zone=_SECONDARY_ZONE_NAME_ --endpoints=http://_RGW_SECONDARY_HOSTNAME_:_RGW_PRIMARY_PORT_NUMBER_1_ \ --access-key=_SYSTEM_ACCESS_KEY_ --secret=_SYSTEM_SECRET_KEY_ \ [--read-only]Example
[ceph: root@host04 /]# radosgw-admin zone create --rgw-zonegroup=us --rgw-zone=us-east-2 --endpoints=http://rgw2:80 --access-key=LIPEYZJLTWXRKXS9LPJC --secret-key=IsAje0AVDNXNw48LjMAimpCpI7VaxJYSnfD0FFKQOptional: Delete the default zone:
ImportantDo not delete the default zone and its pools if you are using the default zone and zone group to store data.
Example
[ceph: root@host04 /]# radosgw-admin zone rm --rgw-zone=default [ceph: root@host04 /]# ceph osd pool rm default.rgw.log default.rgw.log --yes-i-really-really-mean-it [ceph: root@host04 /]# ceph osd pool rm default.rgw.meta default.rgw.meta --yes-i-really-really-mean-it [ceph: root@host04 /]# ceph osd pool rm default.rgw.control default.rgw.control --yes-i-really-really-mean-it [ceph: root@host04 /]# ceph osd pool rm default.rgw.data.root default.rgw.data.root --yes-i-really-really-mean-it [ceph: root@host04 /]# ceph osd pool rm default.rgw.gc default.rgw.gc --yes-i-really-really-mean-itUpdate the Ceph configuration database:
Syntax
ceph config set client.rgw.SERVICE_NAME rgw_realm REALM_NAME ceph config set client.rgw.SERVICE_NAME rgw_zonegroup ZONE_GROUP_NAME ceph config set client.rgw.SERVICE_NAME rgw_zone SECONDARY_ZONE_NAMEExample
[ceph: root@host04 /]# ceph config set client.rgw.rgwsvcid.mons-1.jwgwwp rgw_realm test_realm [ceph: root@host04 /]# ceph config set client.rgw.rgwsvcid.mons-1.jwgwwp rgw_zonegroup us [ceph: root@host04 /]# ceph config set client.rgw.rgwsvcid.mons-1.jwgwwp rgw_zone us-east-2Commit the changes:
Syntax
radosgw-admin period update --commitExample
[ceph: root@host04 /]# radosgw-admin period update --commitOutside the
cephadmshell, fetch the FSID of the storage cluster and the processes:Example
[root@host04 ~]# systemctl list-units | grep cephStart the Ceph Object Gateway daemon:
Syntax
systemctl start ceph-FSID@DAEMON_NAME systemctl enable ceph-FSID@DAEMON_NAMEExample
[root@host04 ~]# systemctl start ceph-62a081a6-88aa-11eb-a367-001a4a000672@rgw.test_realm.us-east-2.host04.ahdtsw.service [root@host04 ~]# systemctl enable ceph-62a081a6-88aa-11eb-a367-001a4a000672@rgw.test_realm.us-east-2.host04.ahdtsw.service
6.4.1. Configuring the archive zone
Ensure you have a realm before configuring a zone as an archive. Without a realm, you cannot archive data through an archive zone for default zone/zonegroups.
Archive Object data residing on Red Hat Ceph Storage using the Object Storage Archive Zone Feature.
The archive zone uses multi-site replication and S3 object versioning feature in Ceph Object Gateway. The archive zone retains all version of all the objects available, even when deleted in the production file.
The archive zone has a history of versions of S3 objects that can only be eliminated through the gateways that are associated with the archive zone. It captures all the data updates and metadata to consolidate them as versions of S3 objects.
Bucket granular replication to the archive zone can be used after creating an archive zone.
You can control the storage space usage of an archive zone through the bucket Lifecycle policies, where you can define the number of versions you would like to keep for an object.
An archive zone helps protect your data against logical or physical errors. It can save users from logical failures, such as accidentally deleting a bucket in the production zone. It can also save your data from massive hardware failures, like a complete production site failure. Additionally, it provides an immutable copy, which can help build a ransomware protection strategy.
To implement the bucket granular replication, use the sync policies commands for enabling and disabling policies. See Creating a sync policy group and Modifying a sync policy group for more information.
Using the sync policy group procedures is optional and only necessary to use enabling and disabling with bucket granular replication. For using the archive zone without bucket granular replication, it is not necessary to use the sync policy procedures.
If you want to migrate the storage cluster from single site, see Migrating a single site system to multi-site.
Prerequisites
- A running Red Hat Ceph Storage cluster.
- Root-level access to a Ceph Monitor node.
- Installation of the Ceph Object Gateway software.
Procedure
During new zone creation, use the
archivetier to configure the archive zone.Syntax
$ radosgw-admin zone create --rgw-zonegroup={ZONE_GROUP_NAME} --rgw-zone={ZONE_NAME} --endpoints={http://FQDN:PORT},{http://FQDN:PORT} --tier-type=archiveExample
[ceph: root@host01 /]# radosgw-admin zone create --rgw-zonegroup=us --rgw-zone=us-east --endpoints={http://example.com:8080} --tier-type=archiveFrom the archive zone, modify the archive zone to sync from only the primary zone and perform a period update commit.
Syntax
$ radosgw-admin zone modify --rgw-zone archive --sync_from primary --sync_from_all false --sync-from-rm secondary $ radosgw-admin period update --commit
The recommendation is to reduce the max_objs_per_shard to 50K to account for the omap olh entries in the archive zone. This helps in keeping the number of omap entries per bucket index shard object in check to prevent large omap warnings.
For example,
$ ceph config set client.rgw rgw_max_objs_per_shard 500006.4.1.1. Deleting objects in archive zone
You can use an S3 lifecycle policy extension to delete objects within an <ArchiveZone> element.
Archive zone objects can only be deleted using the expiration lifecycle policy rule.
-
If any
<Rule>section contains an<ArchiveZone>element, that rule executes in archive zone and are the ONLY rules which run in an archive zone. -
Rules marked
<ArchiveZone>do NOT execute in non-archive zones.
The rules within the lifecycle policy determine when and what objects to delete. For more information about lifecycle creation and management, see Bucket lifecycle.
Prerequisites
- A running Red Hat Ceph Storage cluster.
- Root-level access to a Ceph Monitor node.
- Installation of the Ceph Object Gateway software.
Procedure
Set the
<ArchiveZone>lifecycle policy rule. For more information about creating a lifecycle policy, see See the Creating a lifecycle management policy section in the Red Hat Ceph Storage Object Gateway Guide for more details.Example
<?xml version="1.0" ?> <LifecycleConfiguration xmlns="http://s3.amazonaws.com/doc/2006-03-01/"> <Rule> <ID>delete-1-days-az</ID> <Filter> <Prefix></Prefix> <ArchiveZone />1 </Filter> <Status>Enabled</Status> <Expiration> <Days>1</Days> </Expiration> </Rule> </LifecycleConfiguration>Optional: See if a specific lifecycle policy contains an archive zone rule.
Syntax
radosgw-admin lc get --bucket BUCKET_NAMEExample
[ceph: root@host01 /]# radosgw-admin lc get --bucket test-bkt { "prefix_map": { "": { "status": true, "dm_expiration": true, "expiration": 0, "noncur_expiration": 2, "mp_expiration": 0, "transitions": {}, "noncur_transitions": {} } }, "rule_map": [ { "id": "Rule 1", "rule": { "id": "Rule 1", "prefix": "", "status": "Enabled", "expiration": { "days": "", "date": "" }, "noncur_expiration": { "days": "2", "date": "" }, "mp_expiration": { "days": "", "date": "" }, "filter": { "prefix": "", "obj_tags": { "tagset": {} }, "archivezone": ""1 }, "transitions": {}, "noncur_transitions": {}, "dm_expiration": true } } ] }If the Ceph Object Gateway user is deleted, the buckets at the archive site owned by that user is inaccessible. Link those buckets to another Ceph Object Gateway user to access the data.
Syntax
radosgw-admin bucket link --uid NEW_USER_ID --bucket BUCKET_NAME --yes-i-really-mean-itExample
[ceph: root@host01 /]# radosgw-admin bucket link --uid arcuser1 --bucket arc1-deleted-da473fbbaded232dc5d1e434675c1068 --yes-i-really-mean-it
6.4.2. Failover and disaster recovery
If the primary zone fails, failover to the secondary zone for disaster recovery.
Prerequisites
- A running Red Hat Ceph Storage cluster.
- Root-level access to a Ceph Monitor node.
- Installation of the Ceph Object Gateway software.
Procedure
Make the secondary zone the primary and default zone. For example:
Syntax
radosgw-admin zone modify --rgw-zone=ZONE_NAME --master --defaultBy default, Ceph Object Gateway runs in an active-active configuration. If the cluster was configured to run in an active-passive configuration, the secondary zone is a read-only zone. Remove the
--read-onlystatus to allow the zone to receive write operations. For example:Syntax
radosgw-admin zone modify --rgw-zone=ZONE_NAME --master --default --read-only=falseUpdate the period to make the changes take effect:
Example
[ceph: root@host01 /]# radosgw-admin period update --commitRestart the Ceph Object Gateway.
NoteUse the output from the
ceph orch pscommand, under theNAMEcolumn, to get the SERVICE_TYPE.ID information.To restart the Ceph Object Gateway on an individual node in the storage cluster:
Syntax
systemctl restart ceph-CLUSTER_ID@SERVICE_TYPE.ID.serviceExample
[root@host01 ~]# systemctl restart ceph-c4b34c6f-8365-11ba-dc31-529020a7702d@rgw.realm.zone.host01.gwasto.serviceTo restart the Ceph Object Gateways on all nodes in the storage cluster:
Syntax
ceph orch restart SERVICE_TYPEExample
[ceph: root@host01 /]# ceph orch restart rgw
If the former primary zone recovers, revert the operation.
From the recovered zone, pull the realm from the current primary zone:
Syntax
radosgw-admin realm pull --url=URL_TO_PRIMARY_ZONE_GATEWAY \ --access-key=ACCESS_KEY --secret=SECRET_KEYMake the recovered zone the primary and default zone:
Syntax
radosgw-admin zone modify --rgw-zone=ZONE_NAME --master --defaultUpdate the period to make the changes take effect:
Example
[ceph: root@host01 /]# radosgw-admin period update --commitRestart the Ceph Object Gateway in the recovered zone:
Syntax
ceph orch restart SERVICE_TYPEExample
[ceph: root@host01 /]# ceph orch restart rgwIf the secondary zone needs to be a read-only configuration, update the secondary zone:
Syntax
radosgw-admin zone modify --rgw-zone=ZONE_NAME --read-only radosgw-admin zone modify --rgw-zone=ZONE_NAME --read-onlyUpdate the period to make the changes take effect:
Example
[ceph: root@host01 /]# radosgw-admin period update --commitRestart the Ceph Object Gateway in the secondary zone:
Syntax
ceph orch restart SERVICE_TYPEExample
[ceph: root@host01 /]# ceph orch restart rgw
6.5. 3-site failover and disaster recovery
Recover your data from different failover and disaster scenarios.
Prerequisites
- A running Red Hat Ceph Storage cluster.
- Root-level access to a Ceph Monitor node.
- Installation of the Ceph Object Gateway software.
Procedure
Make the either the secondary or tertiary zone the primary and default zone. For example:
Syntax
radosgw-admin zone modify --rgw-zone=ZONE_NAME --master --defaultBy default, Ceph Object Gateway runs in an active-active-active configuration. If the cluster was configured to run in an active-passive-passive configuration, the secondary and tertiary zones are read-only zones. Remove the
--read-onlystatus to allow the zone to receive write operations. For example:Syntax
radosgw-admin zone modify --rgw-zone=ZONE_NAME --master --default --read-only=falseUpdate the period to make the changes take effect.
Example
[ceph: root@host01 /]# radosgw-admin period update --commitRestart the Ceph Object Gateway.
NoteUse the output from the
ceph orch pscommand, under theNAMEcolumn, to get the SERVICE_TYPE.ID information.Restart the Ceph Object Gateway on an individual node in the storage cluster.
Syntax
systemctl restart ceph-CLUSTER_ID@SERVICE_TYPE.ID.serviceExample
[root@host01 ~]# systemctl restart ceph-c4b34c6f-8365-11ba-dc31-529020a7702d@rgw.realm.zone.host01.gwasto.serviceRestart the Ceph Object Gateways on all nodes in the storage cluster.
Syntax
ceph orch restart SERVICE_TYPEExample
[ceph: root@host01 /]# ceph orch restart rgwIf the former primary zone recovers, revert the operation.
From the recovered zone, pull the realm from the current primary zone.
Syntax
radosgw-admin realm pull --url=URL_TO_PRIMARY_ZONE_GATEWAY \ --access-key=ACCESS_KEY --secret=SECRET_KEYMake the recovered zone the primary and default zone:
Syntax
radosgw-admin zone modify --rgw-zone=ZONE_NAME --master --defaultUpdate the period to make the changes take effect.
Example
[ceph: root@host01 /]# radosgw-admin period update --commitRestart the Ceph Object Gateway in the recovered zone.
Syntax
ceph orch restart SERVICE_TYPEExample
[ceph: root@host01 /]# ceph orch restart rgwIf the secondary and tertiary zones need to be a read-only configuration, update each zone.
Syntax
radosgw-admin zone modify --rgw-zone=ZONE_NAME --read-only radosgw-admin zone modify --rgw-zone=ZONE_NAME --read-onlyUpdate the period to make the changes take effect.
Example
[ceph: root@host01 /]# radosgw-admin period update --commitRestart the Ceph Object Gateway in the receovered zones.
Syntax
ceph orch restart SERVICE_TYPEExample
[ceph: root@host01 /]# ceph orch restart rgw
6.6. Configuring multiple realms in the same storage cluster
You can configure multiple realms in the same storage cluster. This is a more advanced use case for multi-site. Configuring multiple realms in the same storage cluster enables you to use a local realm to handle local Ceph Object Gateway client traffic, as well as a replicated realm for data that will be replicated to a secondary site.
Red Hat recommends that each realm has its own Ceph Object Gateway.
Prerequisites
- Two running Red Hat Ceph Storage data centers in a storage cluster.
- The access key and secret key for each data center in the storage cluster.
- Root-level access to all the Ceph Object Gateway nodes.
- Each data center has its own local realm. They share a realm that replicates on both sites.
Procedure
Create one local realm on the first data center in the storage cluster:
Syntax
radosgw-admin realm create --rgw-realm=REALM_NAME --defaultExample
[ceph: root@host01 /]# radosgw-admin realm create --rgw-realm=ldc1 --defaultCreate one local master zonegroup on the first data center:
Syntax
radosgw-admin zonegroup create --rgw-zonegroup=ZONE_GROUP_NAME --endpoints=http://RGW_NODE_NAME:80 --rgw-realm=REALM_NAME --master --defaultExample
[ceph: root@host01 /]# radosgw-admin zonegroup create --rgw-zonegroup=ldc1zg --endpoints=http://rgw1:80 --rgw-realm=ldc1 --master --defaultCreate one local zone on the first data center:
Syntax
radosgw-admin zone create --rgw-zonegroup=ZONE_GROUP_NAME --rgw-zone=ZONE_NAME --master --default --endpoints=HTTP_FQDN[,HTTP_FQDN]Example
[ceph: root@host01 /]# radosgw-admin zone create --rgw-zonegroup=ldc1zg --rgw-zone=ldc1z --master --default --endpoints=http://rgw.example.comCommit the period:
Example
[ceph: root@host01 /]# radosgw-admin period update --commitYou can either deploy the Ceph Object Gateway daemons with the appropriate realm and zone or update the configuration database:
Deploy the Ceph Object Gateway using placement specification:
Syntax
ceph orch apply rgw SERVICE_NAME --realm=REALM_NAME --zone=ZONE_NAME --placement="NUMBER_OF_DAEMONS HOST_NAME_1 HOST_NAME_2"Example
[ceph: root@host01 /]# ceph orch apply rgw rgw --realm=ldc1 --zone=ldc1z --placement="1 host01"Update the Ceph configuration database:
Syntax
ceph config set client.rgw.SERVICE_NAME rgw_realm REALM_NAME ceph config set client.rgw.SERVICE_NAME rgw_zonegroup ZONE_GROUP_NAME ceph config set client.rgw.SERVICE_NAME rgw_zone ZONE_NAMEExample
[ceph: root@host01 /]# ceph config set client.rgw.rgwsvcid.mons-1.jwgwwp rgw_realm ldc1 [ceph: root@host01 /]# ceph config set client.rgw.rgwsvcid.mons-1.jwgwwp rgw_zonegroup ldc1zg [ceph: root@host01 /]# ceph config set client.rgw.rgwsvcid.mons-1.jwgwwp rgw_zone ldc1z
Restart the Ceph Object Gateway.
NoteUse the output from the
ceph orch pscommand, under theNAMEcolumn, to get the SERVICE_TYPE.ID information.To restart the Ceph Object Gateway on an individual node in the storage cluster:
Syntax
systemctl restart ceph-CLUSTER_ID@SERVICE_TYPE.ID.serviceExample
[root@host01 ~]# systemctl restart ceph-c4b34c6f-8365-11ba-dc31-529020a7702d@rgw.realm.zone.host01.gwasto.serviceTo restart the Ceph Object Gateways on all nodes in the storage cluster:
Syntax
ceph orch restart SERVICE_TYPEExample
[ceph: root@host01 /]# ceph orch restart rgw
Create one local realm on the second data center in the storage cluster:
Syntax
radosgw-admin realm create --rgw-realm=REALM_NAME --defaultExample
[ceph: root@host04 /]# radosgw-admin realm create --rgw-realm=ldc2 --defaultCreate one local master zonegroup on the second data center:
Syntax
radosgw-admin zonegroup create --rgw-zonegroup=ZONE_GROUP_NAME --endpoints=http://RGW_NODE_NAME:80 --rgw-realm=REALM_NAME --master --defaultExample
[ceph: root@host04 /]# radosgw-admin zonegroup create --rgw-zonegroup=ldc2zg --endpoints=http://rgw2:80 --rgw-realm=ldc2 --master --defaultCreate one local zone on the second data center:
Syntax
radosgw-admin zone create --rgw-zonegroup=ZONE_GROUP_NAME --rgw-zone=ZONE_NAME --master --default --endpoints=HTTP_FQDN[, HTTP_FQDN]Example
[ceph: root@host04 /]# radosgw-admin zone create --rgw-zonegroup=ldc2zg --rgw-zone=ldc2z --master --default --endpoints=http://rgw.example.comCommit the period:
Example
[ceph: root@host04 /]# radosgw-admin period update --commitYou can either deploy the Ceph Object Gateway daemons with the appropriate realm and zone or update the configuration database:
Deploy the Ceph Object Gateway using placement specification:
Syntax
ceph orch apply rgw SERVICE_NAME --realm=REALM_NAME --zone=ZONE_NAME --placement="NUMBER_OF_DAEMONS HOST_NAME_1 HOST_NAME_2"Example
[ceph: root@host01 /]# ceph orch apply rgw rgw --realm=ldc2 --zone=ldc2z --placement="1 host01"Update the Ceph configuration database:
Syntax
ceph config set client.rgw.SERVICE_NAME rgw_realm REALM_NAME ceph config set client.rgw.SERVICE_NAME rgw_zonegroup ZONE_GROUP_NAME ceph config set client.rgw.SERVICE_NAME rgw_zone ZONE_NAMEExample
[ceph: root@host01 /]# ceph config set client.rgw.rgwsvcid.mons-1.jwgwwp rgw_realm ldc2 [ceph: root@host01 /]# ceph config set client.rgw.rgwsvcid.mons-1.jwgwwp rgw_zonegroup ldc2zg [ceph: root@host01 /]# ceph config set client.rgw.rgwsvcid.mons-1.jwgwwp rgw_zone ldc2z
Restart the Ceph Object Gateway.
NoteUse the output from the
ceph orch pscommand, under theNAMEcolumn, to get the SERVICE_TYPE.ID information.To restart the Ceph Object Gateway on individual node in the storage cluster:
Syntax
systemctl restart ceph-CLUSTER_ID@SERVICE_TYPE.ID.serviceExample
[root@host04 ~]# systemctl restart ceph-c4b34c6f-8365-11ba-dc31-529020a7702d@rgw.realm.zone.host01.gwasto.serviceTo restart the Ceph Object Gateways on all nodes in the storage cluster:
Syntax
ceph orch restart SERVICE_TYPEExample
[ceph: root@host04 /]# ceph orch restart rgw
Create a replicated realm on the first data center in the storage cluster:
Syntax
radosgw-admin realm create --rgw-realm=REPLICATED_REALM_1 --defaultExample
[ceph: root@host01 /]# radosgw-admin realm create --rgw-realm=rdc1 --defaultUse the
--defaultflag to make the replicated realm default on the primary site.Create a master zonegroup for the first data center:
Syntax
radosgw-admin zonegroup create --rgw-zonegroup=RGW_ZONE_GROUP --endpoints=http://_RGW_NODE_NAME:80 --rgw-realm=_RGW_REALM_NAME --master --defaultExample
[ceph: root@host01 /]# radosgw-admin zonegroup create --rgw-zonegroup=rdc1zg --endpoints=http://rgw1:80 --rgw-realm=rdc1 --master --defaultCreate a master zone on the first data center:
Syntax
radosgw-admin zone create --rgw-zonegroup=RGW_ZONE_GROUP --rgw-zone=_MASTER_RGW_NODE_NAME --master --default --endpoints=HTTP_FQDN[,HTTP_FQDN]Example
[ceph: root@host01 /]# radosgw-admin zone create --rgw-zonegroup=rdc1zg --rgw-zone=rdc1z --master --default --endpoints=http://rgw.example.comCreate a synchronization user and add the system user to the master zone for multi-site:
Syntax
radosgw-admin user create --uid="SYNCHRONIZATION_USER" --display-name="Synchronization User" --system radosgw-admin zone modify --rgw-zone=RGW_ZONE --access-key=ACCESS_KEY --secret=SECRET_KEYExample
radosgw-admin user create --uid="synchronization-user" --display-name="Synchronization User" --system [ceph: root@host01 /]# radosgw-admin zone modify --rgw-zone=rdc1zg --access-key=3QV0D6ZMMCJZMSCXJ2QJ --secret=VpvQWcsfI9OPzUCpR4kynDLAbqa1OIKqRB6WEnH8Commit the period:
Example
[ceph: root@host01 /]# radosgw-admin period update --commitYou can either deploy the Ceph Object Gateway daemons with the appropriate realm and zone or update the configuration database:
Deploy the Ceph Object Gateway using placement specification:
Syntax
ceph orch apply rgw SERVICE_NAME --realm=REALM_NAME --zone=ZONE_NAME --placement="NUMBER_OF_DAEMONS HOST_NAME_1 HOST_NAME_2"Example
[ceph: root@host01 /]# ceph orch apply rgw rgw --realm=rdc1 --zone=rdc1z --placement="1 host01"Update the Ceph configuration database:
Syntax
ceph config set client.rgw.SERVICE_NAME rgw_realm REALM_NAME ceph config set client.rgw.SERVICE_NAME rgw_zonegroup ZONE_GROUP_NAME ceph config set client.rgw.SERVICE_NAME rgw_zone ZONE_NAMEExample
[ceph: root@host01 /]# ceph config set client.rgw.rgwsvcid.mons-1.jwgwwp rgw_realm rdc1 [ceph: root@host01 /]# ceph config set client.rgw.rgwsvcid.mons-1.jwgwwp rgw_zonegroup rdc1zg [ceph: root@host01 /]# ceph config set client.rgw.rgwsvcid.mons-1.jwgwwp rgw_zone rdc1z
Restart the Ceph Object Gateway.
NoteUse the output from the
ceph orch pscommand, under theNAMEcolumn, to get the SERVICE_TYPE.ID information.To restart the Ceph Object Gateway on individual node in the storage cluster:
Syntax
systemctl restart ceph-CLUSTER_ID@SERVICE_TYPE.ID.serviceExample
[root@host01 ~]# systemctl restart ceph-c4b34c6f-8365-11ba-dc31-529020a7702d@rgw.realm.zone.host01.gwasto.serviceTo restart the Ceph Object Gateways on all nodes in the storage cluster:
Syntax
ceph orch restart SERVICE_TYPEExample
[ceph: root@host01 /]# ceph orch restart rgw
Pull the replicated realm on the second data center:
Syntax
radosgw-admin realm pull --url=https://tower-osd1.cephtips.com --access-key=ACCESS_KEY --secret-key=SECRET_KEYExample
[ceph: root@host01 /]# radosgw-admin realm pull --url=https://tower-osd1.cephtips.com --access-key=3QV0D6ZMMCJZMSCXJ2QJ --secret-key=VpvQWcsfI9OPzUCpR4kynDLAbqa1OIKqRB6WEnH8Pull the period from the first data center:
Syntax
radosgw-admin period pull --url=https://tower-osd1.cephtips.com --access-key=ACCESS_KEY --secret-key=SECRET_KEYExample
[ceph: root@host01 /]# radosgw-admin period pull --url=https://tower-osd1.cephtips.com --access-key=3QV0D6ZMMCJZMSCXJ2QJ --secret-key=VpvQWcsfI9OPzUCpR4kynDLAbqa1OIKqRB6WEnH8Create the secondary zone on the second data center:
Syntax
radosgw-admin zone create --rgw-zone=RGW_ZONE --rgw-zonegroup=RGW_ZONE_GROUP --endpoints=https://tower-osd4.cephtips.com --access-key=_ACCESS_KEY --secret-key=SECRET_KEYExample
[ceph: root@host04 /]# radosgw-admin zone create --rgw-zone=rdc2z --rgw-zonegroup=rdc1zg --endpoints=https://tower-osd4.cephtips.com --access-key=3QV0D6ZMMCJZMSCXJ2QJ --secret-key=VpvQWcsfI9OPzUCpR4kynDLAbqa1OIKqRB6WEnH8Commit the period:
Example
[ceph: root@host04 /]# radosgw-admin period update --commitYou can either deploy the Ceph Object Gateway daemons with the appropriate realm and zone or update the configuration database:
Deploy the Ceph Object Gateway using placement specification:
Syntax
ceph orch apply rgw SERVICE_NAME --realm=REALM_NAME --zone=ZONE_NAME --placement="NUMBER_OF_DAEMONS HOST_NAME_1 HOST_NAME_2"Example
[ceph: root@host04 /]# ceph orch apply rgw rgw --realm=rdc1 --zone=rdc2z --placement="1 host04"Update the Ceph configuration database:
Syntax
ceph config set client.rgw.SERVICE_NAME rgw_realm REALM_NAME ceph config set client.rgw.SERVICE_NAME rgw_zonegroup ZONE_GROUP_NAME ceph config set client.rgw.SERVICE_NAME rgw_zone ZONE_NAMEExample
[ceph: root@host04 /]# ceph config set client.rgw.rgwsvcid.mons-1.jwgwwp rgw_realm rdc1 [ceph: root@host04 /]# ceph config set client.rgw.rgwsvcid.mons-1.jwgwwp rgw_zonegroup rdc1zg [ceph: root@host04 /]# ceph config set client.rgw.rgwsvcid.mons-1.jwgwwp rgw_zone rdc2z
Restart the Ceph Object Gateway.
NoteUse the output from the
ceph orch pscommand, under theNAMEcolumn, to get the SERVICE_TYPE.ID information.To restart the Ceph Object Gateway on individual node in the storage cluster:
Syntax
systemctl restart ceph-CLUSTER_ID@SERVICE_TYPE.ID.serviceExample
[root@host02 ~]# systemctl restart ceph-c4b34c6f-8365-11ba-dc31-529020a7702d@rgw.realm.zone.host01.gwasto.serviceTo restart the Ceph Object Gateways on all nodes in the storage cluster:
Syntax
ceph orch restart SERVICE_TYPEExample
[ceph: root@host04 /]# ceph orch restart rgw
-
Log in as
rooton the endpoint for the second data center. Verify the synchronization status on the master realm:
Syntax
radosgw-admin sync statusExample
[ceph: root@host04 /]# radosgw-admin sync status realm 59762f08-470c-46de-b2b1-d92c50986e67 (ldc2) zonegroup 7cf8daf8-d279-4d5c-b73e-c7fd2af65197 (ldc2zg) zone 034ae8d3-ae0c-4e35-8760-134782cb4196 (ldc2z) metadata sync no sync (zone is master)-
Log in as
rooton the endpoint for the first data center. Verify the synchronization status for the replication-synchronization realm:
Syntax
radosgw-admin sync status --rgw-realm RGW_REALM_NAMEExample
[ceph: root@host01 /]# radosgw-admin sync status --rgw-realm rdc1 realm 73c7b801-3736-4a89-aaf8-e23c96e6e29d (rdc1) zonegroup d67cc9c9-690a-4076-89b8-e8127d868398 (rdc1zg) zone 67584789-375b-4d61-8f12-d1cf71998b38 (rdc2z) metadata sync syncing full sync: 0/64 shards incremental sync: 64/64 shards metadata is caught up with master data sync source: 705ff9b0-68d5-4475-9017-452107cec9a0 (rdc1z) syncing full sync: 0/128 shards incremental sync: 128/128 shards data is caught up with source realm 73c7b801-3736-4a89-aaf8-e23c96e6e29d (rdc1) zonegroup d67cc9c9-690a-4076-89b8-e8127d868398 (rdc1zg) zone 67584789-375b-4d61-8f12-d1cf71998b38 (rdc2z) metadata sync syncing full sync: 0/64 shards incremental sync: 64/64 shards metadata is caught up with master data sync source: 705ff9b0-68d5-4475-9017-452107cec9a0 (rdc1z) syncing full sync: 0/128 shards incremental sync: 128/128 shards data is caught up with sourceTo store and access data in the local site, create the user for local realm:
Syntax
radosgw-admin user create --uid="LOCAL_USER" --display-name="Local user" --rgw-realm=_REALM_NAME --rgw-zonegroup=ZONE_GROUP_NAME --rgw-zone=ZONE_NAMEExample
[ceph: root@host04 /]# radosgw-admin user create --uid="local-user" --display-name="Local user" --rgw-realm=ldc1 --rgw-zonegroup=ldc1zg --rgw-zone=ldc1zImportantBy default, users are created under the default realm. For the users to access data in the local realm, the
radosgw-admincommand requires the--rgw-realmargument.
6.7. Using multi-site sync policies
As a storage administrator, you can use multi-site sync policies at the bucket level to control data movement between buckets in different zones. These policies are called bucket-granularity sync policies. Previously, all buckets within zones were treated symmetrically. This means that each zone contained a mirror copy of a given bucket, and the copies of buckets were identical in all of the zones. The sync process assumed that the bucket sync source and the bucket sync destination referred to the same bucket.
Bucket sync policies apply to data only, and metadata is synced across all the zones in the multi-site irrespective of the presence of the the bucket sync policies. Objects that were created, modified, or deleted when the bucket sync policy was in allowed or forbidden place, it does not automatically sync when policy takes effect. Run the bucket sync run command to sync these objects.
If there are multiple sync policies defined at zonegroup level, only one policy can be in enabled state at any time. We can toggle between policies if needed
The sync policy supersedes the old zone group coarse configuration (sync_from*). The sync policy can be configured at the zone group level. If it is configured, it replaces the old-style configuration at the zone group level, but it can also be configured at the bucket level.
The bucket sync policies are applicable to the archive zones. The movement from an archive zone is not bidirectional wherein all the objects can be moved from active zone to archive zone. However, you cannot move objects from the archive zone to active zone since archive zone is read-only.
Example for bucket sync policy for zone groups
[ceph: root@host01 /]# radosgw-admin sync info --bucket=buck
{
"sources": [
{
"id": "pipe1",
"source": {
"zone": "us-east",
"bucket": "buck:115b12b3-....4409.1"
},
"dest": {
"zone": "us-west",
"bucket": "buck:115b12b3-....4409.1"
},
...
}
],
"dests": [
{
"id": "pipe1",
"source": {
"zone": "us-west",
"bucket": "buck:115b12b3-....4409.1"
},
"dest": {
"zone": "us-east",
"bucket": "buck:115b12b3-....4409.1"
},
...
},
{
"id": "pipe1",
"source": {
"zone": "us-west",
"bucket": "buck:115b12b3-....4409.1"
},
"dest": {
"zone": "us-west-2",
"bucket": "buck:115b12b3-....4409.1"
},
...
}
],
...
}Prerequisites
- A running Red Hat Ceph Storage cluster.
- Root-level access to a Ceph Monitor node.
- Installation of the Ceph Object Gateway software.
6.7.1. Multi-site sync policy group state
In the sync policy, multiple groups that can contain lists of data-flow configurations can be defined, as well as lists of pipe configurations. The data-flow defines the flow of data between the different zones. It can define symmetrical data flow, in which multiple zones sync data from each other, and it can define directional data flow, in which the data moves in one way from one zone to another.
A pipe defines the actual buckets that can use these data flows, and the properties that are associated with it, such as the source object prefix.
A sync policy group can be in 3 states:
-
enabled— sync is allowed and enabled. -
allowed— sync is allowed. -
forbidden— sync, as defined by this group, is not allowed.
When the zones replicate, you can disable replication for specific buckets using the sync policy. The following are the semantics that need to be followed to resolve the policy conflicts:
| Zonegroup | Bucket | Result |
|---|---|---|
| enabled | enabled | enabled |
| enabled | allowed | enabled |
| enabled | forbidden | disabled |
| allowed | enabled | enabled |
| allowed | allowed | disabled |
| allowed | forbidden | disabled |
| forbidden | enabled | disabled |
| forbidden | allowed | disabled |
| forbidden | forbidden | disabled |
For multiple group polices that are set to reflect for any sync pair (SOURCE_ZONE, SOURCE_BUCKET), (DESTINATION_ZONE, DESTINATION_BUCKET), the following rules are applied in the following order:
-
Even if one sync policy is
forbidden, the sync isdisabled. -
At least one policy should be
enabledfor the sync to beallowed.
Sync states in this group can override other groups.
A policy can be defined at the bucket level. A bucket level sync policy inherits the data flow of the zonegroup policy, and can only define a subset of what the zonegroup allows.
A wildcard zone, and a wildcard bucket parameter in the policy defines all relevant zones, or all relevant buckets. In the context of a bucket policy, it means the current bucket instance. A disaster recovery configuration where entire zones are mirrored does not require configuring anything on the buckets. However, for a fine grained bucket sync it would be better to configure the pipes to be synced by allowing (status=allowed) them at the zonegroup level (for example, by using wildcard). However, enable the specific sync at the bucket level (status=enabled) only. If needed, the policy at the bucket level can limit the data movement to specific relevant zones.
Any changes to the zonegroup policy need to be applied on the zonegroup master zone, and require period update and commit. Changes to the bucket policy need to be applied on the zonegroup master zone. Ceph Object Gateway handles these changes dynamically.
S3 bucket replication API
The S3 bucket replication API is implemented, and allows users to create replication rules between different buckets. Note though that while the AWS replication feature allows bucket replication within the same zone, Ceph Object Gateway does not allow it at the moment. However, the Ceph Object Gateway API also added a Zone array that allows users to select to what zones the specific bucket will be synced.
6.7.2. Retrieving the current policy
You can use the get command to retrieve the current zonegroup sync policy, or a specific bucket policy.
Prerequisites
- A running Red Hat Ceph Storage cluster.
-
Root or
sudoaccess. - The Ceph Object Gateway is installed.
Procedure
Retrieve the current zonegroup sync policy or bucket policy. To retrieve a specific bucket policy, use the
--bucketoption:Syntax
radosgw-admin sync policy get --bucket=BUCKET_NAMEExample
[ceph: root@host01 /]# radosgw-admin sync policy get --bucket=mybucket
6.7.3. Creating a sync policy group
You can create a sync policy group for the current zone group, or for a specific bucket.
When creating a sync policy for bucket granular replication for a sync policy group that has changed from forbidden to enabled, a manual update might be necessary to complete the sync process.
For example, if any data is written to bucket1 when its policy is forbidden, the data might not sync properly across zones after the policy is changed to enabled. To properly sync the changes, run the bucket sync run command on the sync policy. This step is also necessary if the bucket is resharded when the policy is forbidden. In this case the bucket sync run command must also be used after enabling the policy.
Prerequisites
- A running Red Hat Ceph Storage cluster.
-
Root or
sudoaccess. - The Ceph Object Gateway is installed.
- When creating for an archive zone, be sure that the archive zone is created before the sync policy group.
Procedure
Create a sync policy group or a bucket policy. To create a bucket policy, use the
--bucketoption:Syntax
radosgw-admin sync group create --bucket=BUCKET_NAME --group-id=GROUP_ID --status=enabled | allowed | forbiddenExample
[ceph: root@host01 /]# radosgw-admin sync group create --group-id=mygroup1 --status=enabledOptional: Manually complete the sync process for bucket granular replication.
NoteThis step is mandatory when using as part of an archive zone with bucket granular replication if the policy has data written or the bucket was resharded when the policy was
forbidden.Syntax
radosgw-admin bucket sync runExample
[ceph: root@host01 /]# radosgw-admin bucket sync run
6.7.4. Modifying a sync policy group
You can modify an existing sync policy group for the current zone group, or for a specific bucket.
When modifying a sync policy for bucket granular replication for a sync policy group that has changed from forbidden to enabled, a manual update might be necessary in order to complete the sync process.
For example, if any data is written to bucket1 when its policy is forbidden, the data might not sync properly across zones after the policy is changed to enabled. To properly sync the changes, run the bucket sync run command on the sync policy. This step is also necessary if the bucket is resharded when the policy is forbidden. In this case the bucket sync run command must also be used after enabling the policy.
Prerequisites
- A running Red Hat Ceph Storage cluster.
-
Root or
sudoaccess. - The Ceph Object Gateway is installed.
- When modifying for an archive zone, be sure that the archive zone is created before the sync policy group.
Procedure
Modify the sync policy group or a bucket policy. To modify a bucket policy, use the
--bucketoption.Syntax
radosgw-admin sync group modify --bucket=BUCKET_NAME --group-id=GROUP_ID --status=enabled | allowed | forbiddenExample
[ceph: root@host01 /]# radosgw-admin sync group modify --group-id=mygroup1 --status=forbiddenOptional: Manually complete the sync process for bucket granular replication.
NoteThis step is mandatory when using as part of an archive zone with bucket granular replication if the policy has data written or the bucket was resharded when the policy was
forbidden.Syntax
radosgw-admin bucket sync runExample
[ceph: root@host01 /]# radosgw-admin bucket sync run
6.7.5. Getting a sync policy group
You can use the group get command to show the current sync policy group by group ID, or to show a specific bucket policy.
If the --bucket option is not provided, the groups created at zonegroup level is retrieved and not the groups at the bucket-level.
Prerequisites
- A running Red Hat Ceph Storage cluster.
-
Root or
sudoaccess. - The Ceph Object Gateway is installed.
Procedure
Show the current sync policy group or bucket policy. To show a specific bucket policy, use the
--bucketoption:Syntax
radosgw-admin sync group get --bucket=BUCKET_NAME --group-id=GROUP_IDExample
[ceph: root@host01 /]# radosgw-admin sync group get --group-id=mygroup
6.7.6. Removing a sync policy group
You can use the group remove command to remove the current sync policy group by group ID, or to remove a specific bucket policy.
Prerequisites
- A running Red Hat Ceph Storage cluster.
-
Root or
sudoaccess. - The Ceph Object Gateway is installed.
Procedure
Remove the current sync policy group or bucket policy. To remove a specific bucket policy, use the
--bucketoption:Syntax
radosgw-admin sync group remove --bucket=BUCKET_NAME --group-id=GROUP_IDExample
[ceph: root@host01 /]# radosgw-admin sync group remove --group-id=mygroup
6.7.7. Creating a sync flow
You can create two different types of flows for a sync policy group or for a specific bucket:
- Directional sync flow
- Symmetrical sync flow
The group flow create command creates a sync flow. If you issue the group flow create command for a sync policy group or bucket that already has a sync flow, the command overwrites the existing settings for the sync flow and applies the settings you specify.
| Option | Description | Required/Optional |
|---|---|---|
| --bucket | Name of the bucket to which the sync policy needs to be configured. Used only in bucket-level sync policy. | Optional |
| --group-id | ID of the sync group. | Required |
| --flow-id | ID of the flow. | Required |
| --flow-type | Types of flows for a sync policy group or for a specific bucket - directional or symmetrical. | Required |
| --source-zone | To specify the source zone from which sync should happen. Zone that send data to the sync group. Required if flow type of sync group is directional. | Optional |
| --dest-zone | To specify the destination zone to which sync should happen. Zone that receive data from the sync group. Required if flow type of sync group is directional. | Optional |
| --zones | Zones that part of the sync group. Zones mention will be both sender and receiver zone. Specify zones separated by ",". Required if flow type of sync group is symmetrical. | Optional |
Prerequisites
- A running Red Hat Ceph Storage cluster.
-
Root or
sudoaccess. - The Ceph Object Gateway is installed.
Procedure
Create or update a directional sync flow. To create or update directional sync flow for a specific bucket, use the
--bucketoption.Syntax
radosgw-admin sync group flow create --bucket=BUCKET_NAME --group-id=GROUP_ID --flow-id=FLOW_ID --flow-type=directional --source-zone=SOURCE_ZONE --dest-zone=DESTINATION_ZONECreate or update a symmetrical sync flow. To specify multiple zones for a symmetrical flow type, use a comma-separated list for the
--zonesoption.Syntax
radosgw-admin sync group flow create --bucket=BUCKET_NAME --group-id=GROUP_ID --flow-id=FLOW_ID --flow-type=symmetrical --zones=ZONE_NAME1,ZONE_NAME2zonesare comma-separated lists of all zones that need to be added to the flow.
6.7.8. Removing sync flows and zones
The group flow remove command removes sync flows or zones from a sync policy group or bucket.
For sync policy groups or buckets using directional flows, group flow remove command removes the flow. For sync policy groups or buckets using symmetrical flows, you can use the group flow remove command to remove specified zones from the flow, or to remove the flow.
Prerequisites
- A running Red Hat Ceph Storage cluster.
-
Root or
sudoaccess. - The Ceph Object Gateway is installed.
Procedure
Remove a directional sync flow. To remove the directional sync flow for a specific bucket, use the
--bucketoption.Syntax
radosgw-admin sync group flow remove --bucket=BUCKET_NAME --group-id=GROUP_ID --flow-id=FLOW_ID --flow-type=directional --source-zone=SOURCE_ZONE --dest-zone=DESTINATION_ZONERemove specific zones from a symmetrical sync flow. To remove multiple zones from a symmetrical flow, use a comma-separated list for the
--zonesoption.Syntax
radosgw-admin sync group flow remove --bucket=BUCKET_NAME --group-id=GROUP_ID --flow-id=FLOW_ID --flow-type=symmetrical --zones=ZONE_NAME1,ZONE_NAME2Remove a symmetrical sync flow. To remove the sync flow at the zonegroup level, remove the
--bucketoption.Syntax
radosgw-admin sync group flow remove --group-id=GROUP_ID --flow-id=FLOW_ID --flow-type=symmetrical --zones=ZONE_NAME1,ZONE_NAME2
6.7.9. Creating or modifying a sync group pipe
As a storage administrator, you can define pipes to specify which buckets can use your configured data flows and the properties associated with those data flows.
The sync group pipe create command enables you to create pipes, which are custom sync group data flows between specific buckets or groups of buckets, or between specific zones or groups of zones.
This command uses the following options:
| Option | Description | Required/Optional |
|---|---|---|
| --bucket | Name of the bucket to which sync policy need to be configured. Used only in bucket-level sync policy. | Optional |
| --group-id | ID of the sync group | Required |
| --pipe-id | ID of the pipe | Required |
| --source-zones |
Zones that send data to the sync group. Use single quotes (') for value. Use commas to separate multiple zones. Use the wildcard | Required |
| --source-bucket |
Bucket or buckets that send data to the sync group. If bucket name is not mentioned, then | Optional |
| --source-bucket-id | ID of the source bucket. | Optional |
| --dest-zones |
Zone or zones that receive the sync data. Use single quotes (') for value. Use commas to separate multiple zones. Use the wildcard | Required |
| --dest-bucket |
Bucket or buckets that receive the sync data. If bucket name is not mentioned, then | Optional |
| --dest-bucket-id | ID of the destination bucket. | Optional |
| --prefix |
Bucket prefix. Use the wildcard | Optional |
| --prefix-rm | Do not use bucket prefix for filtering. | Optional |
| --tags-add | Comma-separated list of key=value pairs. | Optional |
| --tags-rm | Removes one or more key=value pairs of tags. | Optional |
| --dest-owner | Destination owner of the objects from source. | Optional |
| --storage-class | Destination storage class for the objects from source. | Optional |
| --mode |
Use | Optional |
| --uid | Used for permissions validation in user mode. Specifies the user ID under which the sync operation will be issued. | Optional |
If you want to enable/disable sync for a specific bucket at a zonegroup level, set the zonegroup level sync policy to enable/disable and create a pipe for each bucket with --source-bucket and --dest-bucket with the same bucket name or with bucket-id, i.e, --source-bucket-id and --dest-bucket-id.
Prerequisites
- A running Red Hat Ceph Storage cluster.
-
Root or
sudoaccess. - The Ceph Object Gateway is installed.
Procedure
Create the sync group pipe. The
createcommand is also used to update a command by creating the sync group pipe with only the relevant options.Syntax
radosgw-admin sync group pipe create --bucket=BUCKET_NAME --group-id=GROUP_ID --pipe-id=PIPE_ID --source-zones='ZONE_NAME','ZONE_NAME2'... --source-bucket=SOURCE_BUCKET --source-bucket-id=SOURCE_BUCKET_ID --dest-zones='ZONE_NAME','ZONE_NAME2'... --dest-bucket=DESTINATION_BUCKET --dest-bucket-id=DESTINATION_BUCKET_ID --prefix=SOURCE_PREFIX --prefix-rm --tags-add=KEY1=VALUE1,KEY2=VALUE2,.. --tags-rm=KEY1=VALUE1,KEY2=VALUE2, ... --dest-owner=OWNER_ID --storage-class=STORAGE_CLASS --mode=USER --uid=USER_ID
6.7.10. Modifying or deleting a sync group pipe
As a storage administrator, you can use the sync group pipe modify command or sync group pipe remove command to modify the sync group pipe by removing certain options. You can also use sync group pipe remove command to remove zones, buckets, or the sync group pipe completely.
Prerequisites
- A running Red Hat Ceph Storage cluster.
-
Root or
sudoaccess. - The Ceph Object Gateway is installed.
Procedure
Modify the sync group pipe options with the
modifyargument.Syntax
radosgw-admin sync group pipe modify --bucket=BUCKET_NAME --group-id=GROUP_ID --pipe-id=PIPE_ID --source-zones='ZONE_NAME','ZONE_NAME2'... --source-bucket=SOURCE_BUCKET1 --source-bucket-id=SOURCE_BUCKET_ID --dest-zones='ZONE_NAME','ZONE_NAME2'... --dest-bucket=DESTINATION_BUCKET1 --dest-bucket-id=_DESTINATION_BUCKET-IDNoteEnsure to put the zones in single quotes ('). The source bucket does not need the quotes.
Example
[root@host01 ~]# radosgw-admin sync group pipe modify --group-id=zonegroup --pipe-id=pipe --dest-zones='primary','secondary','tertiary' --source-zones='primary','secondary','tertiary' --source-bucket=pri-bkt-1 --dest-bucket=pri-bkt-1Modify the sync group pipe options with the
removeargument.Syntax
radosgw-admin sync group pipe remove --bucket=BUCKET_NAME --group-id=GROUP_ID --pipe-id=PIPE_ID --source-zones='ZONE_NAME','ZONE_NAME2'... --source-bucket=SOURCE_BUCKET, --source-bucket-id=SOURCE_BUCKET_ID --dest-zones='ZONE_NAME','ZONE_NAME2'... --dest-bucket=DESTINATION_BUCKET --dest-bucket-id=DESTINATION_BUCKET-IDExample
[root@host01 ~]# radosgw-admin sync group pipe remove --group-id=zonegroup --pipe-id=pipe --dest-zones='primary','secondary','tertiary' --source-zones='primary','secondary','tertiary' --source-bucket=pri-bkt-1 --dest-bucket=pri-bkt-1Delete a sync group pipe.
Syntax
radosgw-admin sync group pipe remove --bucket=BUCKET_NAME --group-id=GROUP_ID --pipe-id=PIPE_IDExample
[root@host01 ~]# radosgw-admin sync group pipe remove -bucket-name=mybuck --group-id=zonegroup --pipe-id=pipe
6.7.11. Obtaining information about sync operations
The sync info command enables you to get information about the expected sync sources and targets, as defined by the sync policy.
When you create a sync policy for a bucket, that policy defines how data moves from that bucket toward a different bucket in a different zone. Creating the policy also creates a list of bucket dependencies that are used as hints whenever that bucket syncs with another bucket. Note that a bucket can refer to another bucket without actually syncing to it, since syncing depends on whether the data flow allows the sync to take place.
Both the --bucket and effective-zone-name parameters are optional. If you invoke the sync info command without specifying any options, the Object Gateway returns all of the sync operations defined by the sync policy in all zones.
Prerequisites
- A running Red Hat Ceph Storage cluster.
-
Root or
sudoaccess. - The Ceph Object Gateway is installed.
- A group sync policy is defined.
Procedure
Get information about sync operations for buckets:
Syntax
radosgw-admin sync info --bucket=BUCKET_NAME --effective-zone-name=ZONE_NAMEGet information about sync operations at the zonegroup level:
Syntax
radosgw-admin sync info
6.8. Using destination parameters
There are 3 types of destination parameters:
- Storage class
- Destination owner translation
- User mode
You can set the destination owner to force a specific destination owner for the objects. You can configure the destination storage class. If you select user mode, you can set only the destination bucket owner. You can set the user ID for the user mode to execute the sync operation for permissions validation.
6.8.1. Destination Params: Storage Class
Configuring Storage class of the destination objects:
Example
[ceph: root@host01 /]# radosgw-admin sync group create --bucket=buck10 \
--group-id=buck10-default --status=enabled
[ceph: root@host01 /]# radosgw-admin sync group pipe create --bucket=buck10 \
--group-id=buck10-default \
--pipe-id=pipe-storage-class \
--source-zones='*' --dest-zones=us-west-2 \
--storage-class=CHEAP_AND_SLOW6.8.2. Destination Params: Destination Owner Translation
Setting the destination objects owner as the destination bucket owner. This requires specifying the uid of the destination bucket:
Example
[ceph: root@host01 /]# radosgw-admin sync group create --bucket=buck11 \
--group-id=buck11-default --status=enabled
[ceph: root@host01 /]# radosgw-admin sync group pipe create --bucket=buck11 \
--group-id=buck11-default --pipe-id=pipe-dest-owner \
--source-zones='*' --dest-zones='*' \
--dest-bucket=buck12 --dest-owner=joe6.8.3. Destination Params: User Mode
User mode makes sure that the user has permissions to both read the objects, and write to the destination bucket. This requires that the uid of the user (which in its context the operation executes) is specified.
Example
[ceph: root@host01 /]# radosgw-admin sync group pipe modify --bucket=buck11 \
--group-id=buck11-default --pipe-id=pipe-dest-owner \
--mode=user --uid=jenny6.9. Bucket granular sync policies
The following features are now supported:
- Greenfield deployment: This release supports new multi-site deployments. To set up bucket granular sync replication, a new zonegroup/zone must be configured at a minimum.
- Brownfield deployment: Migrate or upgrade Ceph Object Gateway multi-site replication configurations to the newly featured Ceph Object Gateway bucket granular sync policy replication.
Ensure that all the nodes in the storage cluster are in the same schema during the upgrade.
- Data flow - directional, symmetrical: Both unidirectional and bi-directional/symmetrical replication can be configured.
In this release, the following features are not supported:
- Source filters
- Storage class
- Destination owner translation
- User mode
When the sync policy of bucket or zonegroup, moves from disabled to enabled state, the below behavioral changes are observed:
Normal scenario:
- Zonegroup level: Data written when the sync policy is disabled catches up as soon as it’s enabled, with no additional steps.
Bucket level: Data written when the sync policy is disabled does not catch up when the policy is enabled. In this case, either one of the below two workarounds can be applied:
- Writing new data to the bucket re-synchronizes the old data.
-
Executing
bucket sync runcommand syncs all the old data.
When you want to toggle from the sync policy to the legacy policy, you need to first run the sync init command followed by the radosgw-admin bucket sync run command to sync all the objects.
Reshard scenario:
-
Zonegroup level: Any reshard that happens when the policy is
disabled, sync gets stuck after the policy isenabledagain. New objects also do not sync at this point. Run thebucket sync runcommand as a workaround. -
Bucket level: If any bucket is resharded when the policy is
disabled, sync gets stuck after the policy is enabled again. New objects also do not sync at this point. Run thebucket sync runcommand as a workaround.
When the policy is set to enabled for the zonegroup and the policy is set to enabled or allowed for the bucket, the pipe configuration takes effect from zonegroup level and not at the bucket level. This is a known issue BZ#2240719.
6.9.1. Setting bi-directional policy for zonegroups
Zonegroup sync policies are created with the new sync policy engine. Any change to the zonegroup sync policy requires a period update and a commit.
In the below example, create a group policy and define a data flow for the movement of data from one zone to another. Configure a pipe for the zonegroups to define the buckets that can use this data flow. The system in the below examples include 3 zones: us-east (the master zone), us-west, and us-west-2.
Prerequisites
- A running Red Hat Ceph Storage cluster.
- The Ceph Object Gateway is installed.
Procedure
Create a new sync group with the status set to allowed.
Example
[ceph: root@host01 /]# radosgw-admin sync group create --group-id=group1 --status=allowedNoteUntil a fully configured zonegroup replication policy is created, it is recommended to set the --status to
allowed, to prevent the replication from starting.Create a flow policy for the newly created group with the --flow-type set as
symmetricalto enable bi-directional replication.Example
[ceph: root@host01 /]# radosgw-admin sync group flow create --group-id=group1 \ --flow-id=flow-mirror --flow-type=symmetrical \ --zones=us-east,us-westCreate a new pipe called
pipe.Example
[ceph: root@host01 /]# radosgw-admin sync group pipe create --group-id=group1 \ --pipe-id=pipe1 --source-zones='*' \ --source-bucket='*' --dest-zones='*' \ --dest-bucket='*'NoteUse the * wildcard for zones to include all zones set in the previous flow policy, and * for buckets to replicate all existing buckets in the zones.
After configuring the bucket sync policy, set the --status to enabled.
Example
[ceph: root@host01 /]# radosgw-admin sync group modify --group-id=group1 --status=enabledUpdate and commit the new period.
Example
[ceph: root@host01 /]# radosgw-admin period update --commitNoteUpdating and committing the period is mandatory for a zonegroup policy.
Optional: Check the sync source, and destination for a specific bucket. All buckets in zones us-east and us-west replicates bi-directionally.
Example
[ceph: root@host01 /]# radosgw-admin sync info -bucket buck { "sources": [ { "id": "pipe1", "source": { "zone": "us-east", "bucket": "buck:115b12b3-....4409.1" }, "dest": { "zone": "us-west", "bucket": "buck:115b12b3-....4409.1" }, ... } ], "dests": [ { "id": "pipe1", "source": { "zone": "us-west", "bucket": "buck:115b12b3-....4409.1" }, "dest": { "zone": "us-east", "bucket": "buck:115b12b3-....4409.1" }, ... } ], ... }The id field in the above output reflects the pipe rule that generated that entry. A single rule can generate multiple sync entries as seen in the below example.
6.9.2. Setting directional policy for zonegroups
Set the policy for zone groups uni directionally with the sync policy engine.
In the following example, create a group policy and configure the data flow for the movement of data from one zone to another. Also, configure a pipe for the zonegroups to define the buckets that can use this data flow. The system in the following examples includes 3 zones: us-east (the primary zone), us-west (secondary zone), and us-west-2 (backup zone). Here, us-west-2 is a replica of us-west, but data is not replicated back from it.
Prerequisites
- A running Red Hat Ceph Storage cluster.
- The Ceph Object Gateway is installed.
Procedure
On the primary zone, create a new sync group with the status set to allowed.
Syntax
radosgw-admin sync group create --group-id=GROUP_ID --status=allowedExample
[ceph: root@host01 /]# radosgw-admin sync group create --group-id=group1 --status=allowedNoteUntil a fully configured zonegroup replication policy is created, it is recommended to set the
--statustoallowed, to prevent the replication from starting.Create the flow.
Syntax
radosgw-admin sync group flow create --group-id=GROUP_ID --flow-id=FLOW_ID --flow-type=directional --source-zone=SOURCE_ZONE_NAME --dest-zone=DESTINATION_ZONE_NAMEExample
[ceph: root@host01 /]# radosgw-admin sync group flow create --group-id=group1 --flow-id=us-west-backup --flow-type=directional --source-zone=us-west --dest-zone=us-west-2Create the pipe.
Syntax
radosgw-admin sync group pipe create --group-id=GROUP_ID --pipe-id=PIPE_ID --source-zones='SOURCE_ZONE_NAME' --dest-zones='DESTINATION_ZONE_NAME'Example
[ceph: root@host01 /]# radosgw-admin sync group pipe create --group-id=group1 --pipe-id=pipe1 --source-zones='us-west' --dest-zones='us-west-2'Update and commit the new period.
Example
[ceph: root@host01 /]# radosgw-admin period update --commitNoteUpdating and committing the period is mandatory for a zonegroup policy.
Verify source and destination of zonegroup using sync info in both the sites.
Syntax
radosgw-admin sync info
6.9.3. Setting directional policy for buckets
Set the policy for buckets uni directionally with the sync policy engine.
In the following example, create a group policy and configure the data flow for the movement of data from one zone to another. Also, configure a pipe for the zonegroups to define the buckets that can use this data flow. The system in the following examples includes 3 zones: us-east (the primary zone), us-west (secondary zone), and us-west-2 (backup zone). Here, us-west-2 is a replica of us-west, but data is not replicated back from it.
The difference between setting the directional policy for zonegroups and buckets is that you need to specify the --bucket option.
Prerequisites
- A running Red Hat Ceph Storage cluster.
- The Ceph Object Gateway is installed.
Procedure
On the primary zone, create a new sync group with the status set to allowed.
Syntax
radosgw-admin sync group create --group-id=GROUP_ID --status=allowed --bucket=BUCKET_NAMEExample
[ceph: root@host01 /]# radosgw-admin sync group create --group-id=group1 --status=allowed --bucket=buckNoteUntil a fully configured zonegroup replication policy is created, it is recommended to set the
--statustoallowed, to prevent the replication from starting.Create the flow.
Syntax
radosgw-admin sync group flow create --bucket-name=BUCKET_NAME --group-id=GROUP_ID --flow-id=FLOW_ID --flow-type=directional --source-zone=SOURCE_ZONE_NAME --dest-zone=DESTINATION_ZONE_NAMEExample
[ceph: root@host01 /]# radosgw-admin sync group flow create --bucket-name=buck --group-id=group1 --flow-id=us-west-backup --flow-type=directional --source-zone=us-west --dest-zone=us-west-2Create the pipe.
Syntax
radosgw-admin sync group pipe create --group-id=GROUP_ID --bucket-name=BUCKET_NAME --pipe-id=PIPE_ID --source-zones='SOURCE_ZONE_NAME' --dest-zones='DESTINATION_ZONE_NAME'Example
[ceph: root@host01 /]# radosgw-admin sync group pipe create --group-id=group1 --bucket-name=buck --pipe-id=pipe1 --source-zones='us-west' --dest-zones='us-west-2'Verify source and destination of zonegroup using sync info in both the sites.
Syntax
radosgw-admin sync info --bucket-name=BUCKET_NAME
6.9.4. Setting bi-directional policy for buckets
The data flow for the bucket-level policy is inherited from the zonegroup policy. The data flow and pipes need not be changed for the bucket-level policy, as the bucket-level policy flow and pipes are only be a subset of the flow defined in the zonegroup policy.
- A bucket-level policy can enable pipes that are not enabled, except forbidden, at the zonegroup policy.
- Bucket-level policies do not require period updates.
Prerequisites
- A running Red Hat Ceph Storage cluster.
- The Ceph Object Gateway is installed.
- A sync flow is created.
Procedure
Set the zonegroup policy
--statustoallowedto permit per-bucket replication.Example
[ceph: root@host01 /]# radosgw-admin sync group modify --group-id=group1 --status=allowedUpdate the period after modifying the zonegroup policy.
Example
[ceph: root@host01 /]# radosgw-admin period update --commitCreate a sync group for the bucket we want to synchronize to and set
--statustoenabled.Example
[ceph: root@host01 /]# radosgw-admin sync group create --bucket=buck \ --group-id=buck-default --status=enabledCreate a pipe for the group that was created in the previous step. The flow is inherited from the zonegroup level policy where data flow is symmetrical.
Example
[ceph: root@host01 /]# radosgw-admin sync group pipe create --bucket=buck \ --group-id=buck-default --pipe-id=pipe1 \ --source-zones='*' --dest-zones='*'NoteUse wildcards * to specify the source and destination zones for the bucket replication.
Optional: To retrieve information about the expected bucket sync sources and targets, as defined by the sync policy, run the
radosgw-admin bucket sync infocommand with the--bucketflag.Example
[ceph: root@host01 /]# radosgw-admin bucket sync info --bucket buck realm 33157555-f387-44fc-b4b4-3f9c0b32cd66 (india) zonegroup 594f1f63-de6f-4e1e-90b6-105114d7ad55 (shared) zone ffaa5ba4-c1bd-4c17-b176-2fe34004b4c5 (primary) bucket :buck[ffaa5ba4-c1bd-4c17-b176-2fe34004b4c5.16191.1] source zone e0e75beb-4e28-45ff-8d48-9710de06dcd0 bucket :buck[ffaa5ba4-c1bd-4c17-b176-2fe34004b4c5.16191.1]Optional: To retrieve information about the expected sync sources and targets, as defined by the sync policy, run the
radosgw-admin sync infocommand with the --bucket flag.Example
[ceph: root@host01 /]# radosgw-admin sync info --bucket buck { "id": "pipe1", "source": { "zone": "secondary", "bucket": "buck:ffaa5ba4-c1bd-4c17-b176-2fe34004b4c5.16191.1" }, "dest": { "zone": "primary", "bucket": "buck:ffaa5ba4-c1bd-4c17-b176-2fe34004b4c5.16191.1" }, "params": { "source": { "filter": { "tags": [] } }, "dest": {}, "priority": 0, "mode": "system", "user": "" } }, { "id": "pipe1", "source": { "zone": "primary", "bucket": "buck:ffaa5ba4-c1bd-4c17-b176-2fe34004b4c5.16191.1" }, "dest": { "zone": "secondary", "bucket": "buck:ffaa5ba4-c1bd-4c17-b176-2fe34004b4c5.16191.1" }, "params": { "source": { "filter": { "tags": [] } }, "dest": {}, "priority": 0, "mode": "system", "user": "" } }
6.9.5. Syncing between buckets
You can sync data between the source and destination buckets across zones, but not within the same zone. Note that internally, data is still pulled from the source at the destination zone.
A wildcard bucket name means that the current bucket is in the context of the bucket sync policy.
There are two types of syncing between buckets:
- Syncing from a bucket - You need to specify the source bucket.
- Syncing to a bucket - You need to specify the destination bucket.
Prerequisites
- A running Red Hat Ceph Storage cluster.
- The Ceph Object Gateway is installed.
Syncing from a different bucket
Create a sync group to pull data from a bucket of another zone.
Syntax
radosgw-admin sync group create --bucket=BUCKET_NAME --group-id=GROUP_ID --status=enabledExample
[ceph: root@host01 /]# radosgw-admin sync group create --bucket=buck4 --group-id=buck4-default --status=enabledPull data.
Syntax
radosgw-admin sync group pipe create --bucket-name=BUCKET_NAME --group-id=GROUP_ID --pipe-id=PIPE_ID --source-zones=SOURCE_ZONE_NAME --source-bucket=SOURCE_BUCKET_NAME --dest-zones=DESTINATION_ZONE_NAMEExample
[ceph: root@host01 /]# radosgw-admin sync group pipe create --bucket=buck4 \ --group-id=buck4-default --pipe-id=pipe1 \ --source-zones='*' --source-bucket=buck5 \ --dest-zones='*'In this example, you can see that the source bucket is
buck5.Optional: Sync from buckets in specific zones.
Example
[ceph: root@host01 /]# radosgw-admin sync group pipe modify --bucket=buck4 \ --group-id=buck4-default --pipe-id=pipe1 \ --source-zones=us-west --source-bucket=buck5 \ --dest-zones='*'Check sync status.
Syntax
radosgw-admin sync info --bucket-name=BUCKET_NAMEExample
[ceph: root@host01 /]# radosgw-admin sync info --bucket=buck4 { "sources": [], "dests": [], "hints": { "sources": [], "dests": [ "buck4:115b12b3-....14433.2" ] }, "resolved-hints-1": { "sources": [], "dests": [ { "id": "pipe1", "source": { "zone": "us-west", "bucket": "buck5" }, "dest": { "zone": "us-east", "bucket": "buck4:115b12b3-....14433.2" }, ... }, { "id": "pipe1", "source": { "zone": "us-west", "bucket": "buck5" }, "dest": { "zone": "us-west-2", "bucket": "buck4:115b12b3-....14433.2" }, ... } ] }, "resolved-hints": { "sources": [], "dests": [] }Note that there are
resolved-hints, which means that the bucketbuck5found aboutbuck4syncing from it indirectly, and not from its own policy. The policy forbuck5itself is empty.
Syncing to a different bucket
Create a sync group.
Syntax
radosgw-admin sync group create --bucket=BUCKET_NAME --group-id=GROUP_ID --status=enabledExample
[ceph: root@host01 /]# radosgw-admin sync group create --bucket=buck6 \ --group-id=buck6-default --status=enabledPush data.
Syntax
radosgw-admin sync group pipe create --bucket-name=BUCKET_NAME --group-id=GROUP_ID --pipe-id=PIPE_ID --source-zones=SOURCE_ZONE_NAME --dest-zones=DESTINATION_ZONE_NAME --dest-bucket=DESTINATION_BUCKET_NAMEExample
[ceph: root@host01 /]# radosgw-admin sync group pipe create --bucket=buck6 \ --group-id=buck6-default --pipe-id=pipe1 \ --source-zones='*' --dest-zones='*' --dest-bucket=buck5In this example, you can see that the destination bucket is
buck5.Optional: Sync to buckets in specific zones.
Example
[ceph: root@host01 /]# radosgw-admin sync group pipe modify --bucket=buck6 \ --group-id=buck6-default --pipe-id=pipe1 \ --source-zones='*' --dest-zones='us-west' --dest-bucket=buck5Check sync status.
Syntax
radosgw-admin sync info --bucket-name=BUCKET_NAMEExample
[ceph: root@host01 /]# radosgw-admin sync info --bucket buck5 { "sources": [], "dests": [ { "id": "pipe1", "source": { "zone": "us-west", "bucket": "buck6:c7887c5b-f6ff-4d5f-9736-aa5cdb4a15e8.20493.4" }, "dest": { "zone": "us-east", "bucket": "buck5" }, "params": { "source": { "filter": { "tags": [] } }, "dest": {}, "priority": 0, "mode": "system", "user": "s3cmd" } }, ], "hints": { "sources": [], "dests": [ "buck5" ] }, "resolved-hints-1": { "sources": [], "dests": [] }, "resolved-hints": { "sources": [], "dests": [] } }
6.9.6. Filtering objects
Filter objects within the bucket with prefixes and tags. You can set object filter at zonegroup level policy as well. If the --bucket option is used, then it is set at bucket level for a bucket.
In the following example, sync from buck1 bucket from one zone is synced to buck1 bucket in another zone with the objects that start with the prefix foo/. Similarly, you can filter objects that have tags such as color=blue. Prefixes and tags can be combined, in which objects need to have both in the order to be synced. The priority parameter can also be passed, and it is used to determine when multiple different rules are there that are matches. This configuration determines that rules to be used.
- If the tag in sync policy has more than one tags, while syncing objects, it sync objects that match at least one tag, the key value pair. Objects might not match all the tag sets.
- If the prefix and tag is set, then to sync the object to another zone, the objects must have prefix and any one tag should match. Only then, it syncs with each other.
Prerequisites
- At least two running Red Hat Ceph Storage clusters.
- The Ceph Object Gateway is installed.
- Buckets are created.
Procedure
Create a new sync group. If you want to create at the bucket level, use the
--bucketoption.Syntax
radosgw-admin sync group create --bucket=BUCKET_NAME --group-id=GROUP_ID --status=enabledExample
[ceph: root@host01 /]# radosgw-admin sync group create --bucket=buck1 --group-id=buck8-default --status=enabledSync between buckets where the object matches the tags. The flow is inherited from the zonegroup level policy where data flow is symmetrical.
Syntax
radosgw-admin sync group pipe create --bucket=BUCKET_NAME --group-id=GROUP_ID --pipe-id=PIPE_ID --tags-add=KEY1=VALUE1,KEY2=VALUE2 --source-zones='ZONE_NAME1','ZONE_NAME2' --dest-zones='ZONE_NAME1','ZONE_NAME2'Example
[ceph: root@host01 /]# radosgw-admin sync group pipe create --bucket=buck1 \ --group-id=buck1-default --pipe-id=pipe-tags \ --tags-add=color=blue,color=red --source-zones='*' \ --dest-zones='*'Sync between buckets where the object matches the prefix. The flow is inherited from the zonegroup level policy where data flow is symmetrical.
Syntax
radosgw-admin sync group pipe create --bucket=BUCKET_NAME --group-id=GROUP_ID --pipe-id=PIPE_ID --prefix=PREFIX --source-zones='ZONE_NAME1','ZONE_NAME2' --dest-zones='ZONE_NAME1','ZONE_NAME2'Example
[ceph: root@host01 /]# radosgw-admin sync group pipe create --bucket=buck1 \ --group-id=buck1-default --pipe-id=pipe-prefix \ --prefix=foo/ --source-zones='*' --dest-zones='*' \Check the updated sync.
Syntax
radosgw-admin sync info --bucket=BUCKET_NAMEExample
[ceph: root@host01 /]# radosgw-admin sync info --bucket=buck1NoteIn the example, only two different destinations and no sources reflect, one each for configuration. When the sync process happens, it selects the relevant rule for each object it syncs.
6.9.7. Disabling policy between buckets
You can disable the policy between buckets along with sync information with the forbidden or allowed state.
See the Multi-site sync policy group state for the different combinations that can used for zonegroup and bucket level sync policies.
In certain cases, to interrupt the replication between two buckets, you can set the group policy for the bucket to be forbidden. You can also disable policy at zonegroup level, if the sync that is set does not happen for any of the buckets.
You can also create a sync policy in disabled state with allowed or forbidden state using the radosgw-admin sync group create command.
Prerequisites
- A running Red Hat Ceph Storage cluster.
- The Ceph Object Gateway is installed.
Procedure
Run the
sync group modifycommand to change the status from allowed to forbidden.Example
[ceph: root@host01 /]# radosgw-admin sync group modify --group-id buck-default --status forbidden --bucket buck { "groups": [ { "id": "buck-default", "data_flow": {}, "pipes": [ { "id": "pipe1", "source": { "bucket": "*", "zones": [ "*" ] }, "dest": { "bucket": "*", "zones": [ "*" ] }, "params": { "source": { "filter": { "tags": [] } }, "dest": {}, "priority": 0, "mode": "system", } } ], "status": "forbidden" } ] }In this example, the replication of the bucket
buckis interrupted between zonesus-eastandus-west.NoteNo update and commit for the period is required as this is a bucket sync policy.
Optional: Run
sync info commandcommand to check the status of the sync for bucketbuck.Example
[ceph: root@host01 /]# radosgw-admin sync info --bucket buck { "sources": [], "dests": [], "hints": { "sources": [], "dests": [] }, "resolved-hints-1": { "sources": [], "dests": [] }, "resolved-hints": { "sources": [], "dests": [] } }NoteThere are no source and destination targets as the replication is interrupted.
6.10. Multi-site Ceph Object Gateway command line usage
As a storage administrator, you can have a good understanding of how to use the Ceph Object Gateway in a multi-site environment. You can learn how to better manage the realms, zone groups, and zones in a multi-site environment.
Prerequisites
- A running Red Hat Ceph Storage.
- Deployment of the Ceph Object Gateway software.
- Access to a Ceph Object Gateway node or container.
6.10.1. Realms
A realm represents a globally unique namespace consisting of one or more zonegroups containing one or more zones, and zones containing buckets, which in turn contain objects. A realm enables the Ceph Object Gateway to support multiple namespaces and their configuration on the same hardware.
A realm contains the notion of periods. Each period represents the state of the zone group and zone configuration in time. Each time you make a change to a zonegroup or zone, update the period and commit it.
Red Hat recommends creating realms for new clusters.
6.10.1.1. Creating a realm
To create a realm, use the realm create command and specify the realm name.
Procedure
Create a realm.
Syntax
radosgw-admin realm create --rgw-realm=REALM_NAMEExample
[ceph: root@host01 /]# radosgw-admin realm create --rgw-realm=test_realmImportantDo not use the realm with the
--defaultflag if the data and metadata are stored in thedefault.rgw.dataanddefault.rgw.indexpools. If a new realm is set as the default and these pools contain important data, theradosgw-adminutility can fail to manage this data properly.Only use the
--defaultflag if necessary to specify the realm as the default and if you do not need the existing data or metadata in thedefault.rgwpools. If the existing data or metadata is needed, either migrate the default configuration to a multi-site or realm setup or avoid setting the new realm as the default. For more information about migrating to a multi-site, see Migrating a single site system to multi-site. By specifying--default, the realm is called implicitly with eachradosgw-admincall unless--rgw-realmand the realm name are explicitly provided.Optional: Change the default realm.
Syntax
radosgw-admin realm default --rgw-realm=REALM_NAMEExample
[ceph: root@host01 /]# radosgw-admin realm default --rgw-realm=test_realm1
6.10.1.2. Making a Realm the Default
One realm in the list of realms should be the default realm. There may be only one default realm. If there is only one realm and it wasn’t specified as the default realm when it was created, make it the default realm. Alternatively, to change which realm is the default, run the following command:
[ceph: root@host01 /]# radosgw-admin realm default --rgw-realm=test_realm
When the realm is default, the command line assumes --rgw-realm=REALM_NAME as an argument.
6.10.1.3. Deleting a Realm
To delete a realm, run the realm delete command and specify the realm name.
Syntax
radosgw-admin realm delete --rgw-realm=REALM_NAMEExample
[ceph: root@host01 /]# radosgw-admin realm delete --rgw-realm=test_realm6.10.1.4. Getting a realm
To get a realm, run the realm get command and specify the realm name.
Syntax
radosgw-admin realm get --rgw-realm=REALM_NAMEExample
[ceph: root@host01 /]# radosgw-admin realm get --rgw-realm=test_realm >filename.jsonThe CLI will echo a JSON object with the realm properties.
{
"id": "0a68d52e-a19c-4e8e-b012-a8f831cb3ebc",
"name": "test_realm",
"current_period": "b0c5bbef-4337-4edd-8184-5aeab2ec413b",
"epoch": 1
}
Use > and an output file name to output the JSON object to a file.
6.10.1.5. Setting a realm
To set a realm, run the realm set command, specify the realm name, and --infile= with an input file name.
Syntax
radosgw-admin realm set --rgw-realm=REALM_NAME --infile=IN_FILENAMEExample
[ceph: root@host01 /]# radosgw-admin realm set --rgw-realm=test_realm --infile=filename.json6.10.1.6. Listing realms
To list realms, run the realm list command:
Example
[ceph: root@host01 /]# radosgw-admin realm list6.10.1.7. Listing Realm Periods
To list realm periods, run the realm list-periods command.
Example
[ceph: root@host01 /]# radosgw-admin realm list-periods6.10.1.8. Pulling a Realm
To pull a realm from the node containing the master zone group and master zone to a node containing a secondary zone group or zone, run the realm pull command on the node that will receive the realm configuration.
Syntax
radosgw-admin realm pull --url=URL_TO_MASTER_ZONE_GATEWAY--access-key=ACCESS_KEY --secret=SECRET_KEY6.10.1.9. Renaming a Realm
A realm is not part of the period. Consequently, renaming the realm is only applied locally, and will not get pulled with realm pull.
When renaming a realm with multiple zones, run the command on each zone.
Procedure
Rename the realm.
Syntax
radosgw-admin realm rename --rgw-realm=REALM_NAME --realm-new-name=NEW_REALM_NAMENoteDo NOT use
realm setto change thenameparameter. That changes the internal name only. Specifying--rgw-realmwould still use the old realm name.Example
[ceph: root@host01 /]# radosgw-admin realm rename --rgw-realm=test_realm --realm-new-name=test_realm2Commit the changes.
Syntax
radosgw-admin period update --commitExample
[ceph: root@host01 /]# radosgw-admin period update --commit
6.10.2. Zone Groups
The Ceph Object Gateway supports multi-site deployments and a global namespace by using the notion of zone groups. Formerly called a region, a zone group defines the geographic location of one or more Ceph Object Gateway instances within one or more zones.
Configuring zone groups differs from typical configuration procedures, because not all of the settings end up in a Ceph configuration file. You can list zone groups, get a zone group configuration, and set a zone group configuration.
The radosgw-admin zonegroup operations can be performed on any node within the realm, because the step of updating the period propagates the changes throughout the cluster. However, radosgw-admin zone operations MUST be performed on a host within the zone.
6.10.2.1. Creating a Zone Group
Creating a zone group consists of specifying the zone group name. Creating a zone assumes it will live in the default realm unless --rgw-realm=REALM_NAME is specified. If the zonegroup is the master zonegroup, specify the --master flag.
Do not create the zone group with the --default flag if the data and metadata are stored in the default.rgw.data and default.rgw.index pools. If a new zone group is set as the default and these pools contain important data, the radosgw-admin utility can fail to manage this data properly.
Only use the --default flag if necessary to specify the zone group as the default and if you do not need the existing data or metadata in the default.rgw pools. If the existing data or metadata is needed, either migrate the default configuration to a multi-site or zone group setup or avoid setting the new zone group as the default. For more information about migrating to a multi-site, see Migrating a single site system to multi-site. By specifying --default, the zone group is called implicitly with each radosgw-admin call unless --rgw-zonegroup and the zone group name are explicitly provided.
Procedure
Create a zone group.
Syntax
radosgw-admin zonegroup create --rgw-zonegroup=ZONE_GROUP_NAME [--rgw-realm=REALM_NAME] [--master]Example
[ceph: root@host01 /]# radosgw-admin zonegroup create --rgw-zonegroup=zonegroup1 --rgw-realm=test_realm --defaultOptional: Change a zone group setting.
Syntax
zonegroup modify --rgw-zonegroup=ZONE_GROUP_NAMEExample
[ceph: root@host01 /]# radosgw-admin zonegroup modify --rgw-zonegroup=zonegroup1Optional: Change the default zone group.
Syntax
radosgw-admin zonegroup default --rgw-zonegroup=ZONE_GROUP_NAMEExample
[ceph: root@host01 /]# radosgw-admin zonegroup default --rgw-zonegroup=zonegroup2Commit the change.
Syntax
radosgw-admin period update --commitExample
[ceph: root@host01 /]# radosgw-admin period update --commit
6.10.2.2. Making a Zone Group the Default
One zonegroup in the list of zonegroups should be the default zonegroup. There may be only one default zonegroup. If there is only one zonegroup and it wasn’t specified as the default zonegroup when it was created, make it the default zonegroup. Alternatively, to change which zonegroup is the default, run the following command:
Example
[ceph: root@host01 /]# radosgw-admin zonegroup default --rgw-zonegroup=us
When the zonegroup is the default, the command line assumes --rgw-zonegroup=ZONE_GROUP_NAME as an argument.
Then, update the period:
[ceph: root@host01 /]# radosgw-admin period update --commit6.10.2.3. Adding a Zone to a Zone Group
To add a zone to a zonegroup, you MUST run this command on a host that will be in the zone. To add a zone to a zonegroup, run the following command:
Syntax
radosgw-admin zonegroup add --rgw-zonegroup=ZONE_GROUP_NAME --rgw-zone=ZONE_NAMEThen, update the period:
Example
[ceph: root@host01 /]# radosgw-admin period update --commit6.10.2.4. Removing a Zone from a Zone Group
To remove a zone from a zonegroup, run the following command:
Syntax
radosgw-admin zonegroup remove --rgw-zonegroup=ZONE_GROUP_NAME --rgw-zone=ZONE_NAMEThen, update the period:
Example
[ceph: root@host01 /]# radosgw-admin period update --commit6.10.2.5. Renaming a Zone Group
To rename a zonegroup, run the following command:
Syntax
radosgw-admin zonegroup rename --rgw-zonegroup=ZONE_GROUP_NAME --zonegroup-new-name=NEW_ZONE_GROUP_NAMEThen, update the period:
Example
[ceph: root@host01 /]# radosgw-admin period update --commit6.10.2.6. Deleting a Zone group
To delete a zonegroup, run the following command:
Syntax
radosgw-admin zonegroup delete --rgw-zonegroup=ZONE_GROUP_NAMEThen, update the period:
Example
[ceph: root@host01 /]# radosgw-admin period update --commit6.10.2.7. Listing Zone Groups
A Ceph cluster contains a list of zone groups. To list the zone groups, run the following command:
[ceph: root@host01 /]# radosgw-admin zonegroup list
The radosgw-admin returns a JSON formatted list of zone groups.
{
"default_info": "90b28698-e7c3-462c-a42d-4aa780d24eda",
"zonegroups": [
"us"
]
}6.10.2.8. Getting a Zone Group
To view the configuration of a zone group, run the following command:
Syntax
radosgw-admin zonegroup get [--rgw-zonegroup=ZONE_GROUP_NAME]The zone group configuration looks like this:
{
"id": "90b28698-e7c3-462c-a42d-4aa780d24eda",
"name": "us",
"api_name": "us",
"is_master": "true",
"endpoints": [
"http:\/\/rgw1:80"
],
"hostnames": [],
"hostnames_s3website": [],
"master_zone": "9248cab2-afe7-43d8-a661-a40bf316665e",
"zones": [
{
"id": "9248cab2-afe7-43d8-a661-a40bf316665e",
"name": "us-east",
"endpoints": [
"http:\/\/rgw1"
],
"log_meta": "true",
"log_data": "true",
"bucket_index_max_shards": 11,
"read_only": "false"
},
{
"id": "d1024e59-7d28-49d1-8222-af101965a939",
"name": "us-west",
"endpoints": [
"http:\/\/rgw2:80"
],
"log_meta": "false",
"log_data": "true",
"bucket_index_max_shards": 11,
"read_only": "false"
}
],
"placement_targets": [
{
"name": "default-placement",
"tags": []
}
],
"default_placement": "default-placement",
"realm_id": "ae031368-8715-4e27-9a99-0c9468852cfe"
}6.10.2.9. Setting a Zone Group
Defining a zone group consists of creating a JSON object, specifying at least the required settings:
-
name: The name of the zone group. Required. -
api_name: The API name for the zone group. Optional. is_master: Determines if the zone group is the master zone group. Required.Note: You can only have one master zone group.
-
endpoints: A list of all the endpoints in the zone group. For example, you may use multiple domain names to refer to the same zone group. Remember to escape the forward slashes (\/). You may also specify a port (fqdn:port) for each endpoint. Optional. -
hostnames: A list of all the hostnames in the zone group. For example, you may use multiple domain names to refer to the same zone group. Optional. Thergw dns namesetting will automatically be included in this list. You should restart the gateway daemon(s) after changing this setting. master_zone: The master zone for the zone group. Optional. Uses the default zone if not specified.NoteYou can only have one master zone per zone group.
-
zones: A list of all zones within the zone group. Each zone has a name (required), a list of endpoints (optional), and whether or not the gateway will log metadata and data operations (false by default). -
placement_targets: A list of placement targets (optional). Each placement target contains a name (required) for the placement target and a list of tags (optional) so that only users with the tag can use the placement target (i.e., the user’splacement_tagsfield in the user info). -
default_placement: The default placement target for the object index and object data. Set todefault-placementby default. You may also set a per-user default placement in the user info for each user.
To set a zone group, create a JSON object consisting of the required fields, save the object to a file, for example, zonegroup.json; then, run the following command:
Example
[ceph: root@host01 /]# radosgw-admin zonegroup set --infile zonegroup.json
Where zonegroup.json is the JSON file you created.
The default zone group is_master setting is true by default. If you create a new zone group and want to make it the master zone group, you must either set the default zone group is_master setting to false, or delete the default zone group.
Finally, update the period:
Example
[ceph: root@host01 /]# radosgw-admin period update --commit6.10.2.10. Setting a Zone Group Map
Setting a zone group map consists of creating a JSON object consisting of one or more zone groups, and setting the master_zonegroup for the cluster. Each zone group in the zone group map consists of a key/value pair, where the key setting is equivalent to the name setting for an individual zone group configuration, and the val is a JSON object consisting of an individual zone group configuration.
You may only have one zone group with is_master equal to true, and it must be specified as the master_zonegroup at the end of the zone group map. The following JSON object is an example of a default zone group map.
{
"zonegroups": [
{
"key": "90b28698-e7c3-462c-a42d-4aa780d24eda",
"val": {
"id": "90b28698-e7c3-462c-a42d-4aa780d24eda",
"name": "us",
"api_name": "us",
"is_master": "true",
"endpoints": [
"http:\/\/rgw1:80"
],
"hostnames": [],
"hostnames_s3website": [],
"master_zone": "9248cab2-afe7-43d8-a661-a40bf316665e",
"zones": [
{
"id": "9248cab2-afe7-43d8-a661-a40bf316665e",
"name": "us-east",
"endpoints": [
"http:\/\/rgw1"
],
"log_meta": "true",
"log_data": "true",
"bucket_index_max_shards": 11,
"read_only": "false"
},
{
"id": "d1024e59-7d28-49d1-8222-af101965a939",
"name": "us-west",
"endpoints": [
"http:\/\/rgw2:80"
],
"log_meta": "false",
"log_data": "true",
"bucket_index_max_shards": 11,
"read_only": "false"
}
],
"placement_targets": [
{
"name": "default-placement",
"tags": []
}
],
"default_placement": "default-placement",
"realm_id": "ae031368-8715-4e27-9a99-0c9468852cfe"
}
}
],
"master_zonegroup": "90b28698-e7c3-462c-a42d-4aa780d24eda",
"bucket_quota": {
"enabled": false,
"max_size_kb": -1,
"max_objects": -1
},
"user_quota": {
"enabled": false,
"max_size_kb": -1,
"max_objects": -1
}
}To set a zone group map, run the following command:
Example
[ceph: root@host01 /]# radosgw-admin zonegroup-map set --infile zonegroupmap.json
Where zonegroupmap.json is the JSON file you created. Ensure that you have zones created for the ones specified in the zone group map. Finally, update the period.
Example
[ceph: root@host01 /]# radosgw-admin period update --commit6.10.3. Zones
Ceph Object Gateway supports the notion of zones. A zone defines a logical group consisting of one or more Ceph Object Gateway instances.
Configuring zones differs from typical configuration procedures, because not all of the settings end up in a Ceph configuration file. You can list zones, get a zone configuration, and set a zone configuration.
All radosgw-admin zone operations MUST be issued on a host that operates or will operate within the zone.
6.10.3.1. Creating a Zone
To create a zone, specify a zone name. If it is a master zone, specify the --master option. Only one zone in a zone group can be a master zone. To add the zone to a zonegroup, specify the --rgw-zonegroup option with the zonegroup name.
Zones must be created on a Ceph Object Gateway node that will be within the zone.
Do not create the zone with the --default flag if the data and metadata are stored in the default.rgw.data and default.rgw.index pools. If a new zone is set as the default and these pools contain important data, the radosgw-admin utility can fail to manage this data properly.
Only use the --default flag if necessary to specify the zone as the default and if you do not need the existing data or metadata in the default.rgw pools. If the existing data or metadata is needed, either migrate the default configuration to a multi-site or zone setup or avoid setting the new zone as the default. For more information about migrating to a multi-site, see Migrating a single site system to multi-site. By specifying --default, the zone is called implicitly with each radosgw-admin call unless --rgw-zone and the zone name are explicitly provided.
Procedure
Create the zone.
Syntax
radosgw-admin zone create --rgw-zone=ZONE_NAME \ [--zonegroup=ZONE_GROUP_NAME]\ [--endpoints=ENDPOINT_PORT [,<endpoint:port>] \ [--master] [--default] \ --access-key ACCESS_KEY --secret SECRET_KEYCommit the change.
Syntax
radosgw-admin period update --commitExample
[ceph: root@host01 /]# radosgw-admin period update --commit
6.10.3.2. Deleting a zone
To delete a zone, first remove it from the zonegroup.
Procedure
Remove the zone from the zonegroup:
Syntax
radosgw-admin zonegroup remove --rgw-zonegroup=ZONE_GROUP_NAME\ --rgw-zone=ZONE_NAMEUpdate the period:
Example
[ceph: root@host01 /]# radosgw-admin period update --commitDelete the zone:
ImportantThis procedure MUST be used on a host within the zone.
Syntax
radosgw-admin zone delete --rgw-zone=ZONE_NAMEUpdate the period:
Example
[ceph: root@host01 /]# radosgw-admin period update --commitImportantDo not delete a zone without removing it from a zone group first. Otherwise, updating the period will fail.
If the pools for the deleted zone will not be used anywhere else, consider deleting the pools. Replace DELETED_ZONE_NAME in the example below with the deleted zone’s name.
Once Ceph deletes the zone pools, it deletes all of the data within them in an unrecoverable manner. Only delete the zone pools if Ceph clients no longer need the pool contents.
In a multi-realm cluster, deleting the .rgw.root pool along with the zone pools will remove ALL the realm information for the cluster. Ensure that .rgw.root does not contain other active realms before deleting the .rgw.root pool.
Syntax
ceph osd pool delete DELETED_ZONE_NAME.rgw.control DELETED_ZONE_NAME.rgw.control --yes-i-really-really-mean-it
ceph osd pool delete DELETED_ZONE_NAME.rgw.data.root DELETED_ZONE_NAME.rgw.data.root --yes-i-really-really-mean-it
ceph osd pool delete DELETED_ZONE_NAME.rgw.log DELETED_ZONE_NAME.rgw.log --yes-i-really-really-mean-it
ceph osd pool delete DELETED_ZONE_NAME.rgw.users.uid DELETED_ZONE_NAME.rgw.users.uid --yes-i-really-really-mean-itAfter deleting the pools, restart the RGW process.
6.10.3.3. Modifying a Zone
To modify a zone, specify the zone name and the parameters you wish to modify.
Zones should be modified on a Ceph Object Gateway node that will be within the zone.
Syntax
radosgw-admin zone modify [options]
--access-key=<key>
--secret/--secret-key=<key>
--master
--default
--endpoints=<list>Then, update the period:
Example
[ceph: root@host01 /]# radosgw-admin period update --commit6.10.3.4. Listing Zones
As root, to list the zones in a cluster, run the following command:
Example
[ceph: root@host01 /]# radosgw-admin zone list6.10.3.5. Getting a Zone
As root, to get the configuration of a zone, run the following command:
Syntax
radosgw-admin zone get [--rgw-zone=ZONE_NAME]
The default zone looks like this:
{ "domain_root": ".rgw",
"control_pool": ".rgw.control",
"gc_pool": ".rgw.gc",
"log_pool": ".log",
"intent_log_pool": ".intent-log",
"usage_log_pool": ".usage",
"user_keys_pool": ".users",
"user_email_pool": ".users.email",
"user_swift_pool": ".users.swift",
"user_uid_pool": ".users.uid",
"system_key": { "access_key": "", "secret_key": ""},
"placement_pools": [
{ "key": "default-placement",
"val": { "index_pool": ".rgw.buckets.index",
"data_pool": ".rgw.buckets"}
}
]
}6.10.3.6. Setting a Zone
Configuring a zone involves specifying a series of Ceph Object Gateway pools. For consistency, we recommend using a pool prefix that is the same as the zone name. See the Pools chapter in the Red Hat Ceph Storage Storage Strategies Guide for details on configuring pools.
Zones should be set on a Ceph Object Gateway node that will be within the zone.
To set a zone, create a JSON object consisting of the pools, save the object to a file, for example, zone.json; then, run the following command, replacing ZONE_NAME with the name of the zone:
Example
[ceph: root@host01 /]# radosgw-admin zone set --rgw-zone=test-zone --infile zone.json
Where zone.json is the JSON file you created.
Then, as root, update the period:
Example
[ceph: root@host01 /]# radosgw-admin period update --commit6.10.3.7. Renaming a Zone
To rename a zone, specify the zone name and the new zone name. Issue the following command on a host within the zone:
Syntax
radosgw-admin zone rename --rgw-zone=ZONE_NAME --zone-new-name=NEW_ZONE_NAMEThen, update the period:
Example
[ceph: root@host01 /]# radosgw-admin period update --commit