Questo contenuto non è disponibile nella lingua selezionata.
Chapter 8. Message Routing
Abstract
The message routing patterns describe various ways of linking message channels together. This includes various algorithms that can be applied to the message stream (without modifying the body of the message).
8.1. Content-Based Router
Overview
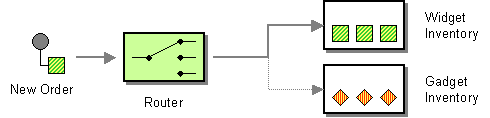
A content-based router, shown in Figure 8.1, “Content-Based Router Pattern”, enables you to route messages to the appropriate destination based on the message contents.
Figure 8.1. Content-Based Router Pattern
Java DSL example
The following example shows how to route a request from an input, seda:a, endpoint to either seda:b, queue:c, or seda:d depending on the evaluation of various predicate expressions:
RouteBuilder builder = new RouteBuilder() {
public void configure() {
from("seda:a").choice()
.when(header("foo").isEqualTo("bar")).to("seda:b")
.when(header("foo").isEqualTo("cheese")).to("seda:c")
.otherwise().to("seda:d");
}
};XML configuration example
The following example shows how to configure the same route in XML:
<camelContext id="buildSimpleRouteWithChoice" xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="seda:a"/>
<choice>
<when>
<xpath>$foo = 'bar'</xpath>
<to uri="seda:b"/>
</when>
<when>
<xpath>$foo = 'cheese'</xpath>
<to uri="seda:c"/>
</when>
<otherwise>
<to uri="seda:d"/>
</otherwise>
</choice>
</route>
</camelContext>8.2. Message Filter
Overview
A message filter is a processor that eliminates undesired messages based on specific criteria. In Apache Camel, the message filter pattern, shown in Figure 8.2, “Message Filter Pattern”, is implemented by the filter() Java DSL command. The filter() command takes a single predicate argument, which controls the filter. When the predicate is true, the incoming message is allowed to proceed, and when the predicate is false, the incoming message is blocked.
Figure 8.2. Message Filter Pattern

Java DSL example
The following example shows how to create a route from endpoint, seda:a, to endpoint, seda:b, that blocks all messages except for those messages whose foo header have the value, bar:
RouteBuilder builder = new RouteBuilder() {
public void configure() {
from("seda:a").filter(header("foo").isEqualTo("bar")).to("seda:b");
}
};
To evaluate more complex filter predicates, you can invoke one of the supported scripting languages, such as XPath, XQuery, or SQL (see Part II, “Routing Expression and Predicate Languages”). The following example defines a route that blocks all messages except for those containing a person element whose name attribute is equal to James:
from("direct:start").
filter().xpath("/person[@name='James']").
to("mock:result");XML configuration example
The following example shows how to configure the route with an XPath predicate in XML (see Part II, “Routing Expression and Predicate Languages”):
<camelContext id="simpleFilterRoute" xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="seda:a"/>
<filter>
<xpath>$foo = 'bar'</xpath>
<to uri="seda:b"/>
</filter>
</route>
</camelContext>
Make sure you put the endpoint you want to filter (for example, <to uri="seda:b"/>) before the closing </filter> tag or the filter will not be applied (in 2.8+, omitting this will result in an error).
Filtering with beans
Here is an example of using a bean to define the filter behavior:
from("direct:start")
.filter().method(MyBean.class, "isGoldCustomer").to("mock:result").end()
.to("mock:end");
public static class MyBean {
public boolean isGoldCustomer(@Header("level") String level) {
return level.equals("gold");
}
}Using stop()
Available as of Camel 2.0
Stop is a special type of filter that filters out all messages. Stop is convenient to use in a content-based router when you need to stop further processing in one of the predicates.
In the following example, we do not want messages with the word Bye in the message body to propagate any further in the route. We prevent this in the when() predicate using .stop().
from("direct:start")
.choice()
.when(bodyAs(String.class).contains("Hello")).to("mock:hello")
.when(bodyAs(String.class).contains("Bye")).to("mock:bye").stop()
.otherwise().to("mock:other")
.end()
.to("mock:result");Knowing if Exchange was filtered or not
Available as of Camel 2.5
The message filter EIP will add a property on the Exchange which states if it was filtered or not.
The property has the key Exchange.FILTER_MATCHED which has the String value of CamelFilterMatched. Its value is a boolean indicating true or false. If the value is true then the Exchange was routed in the filter block.
8.3. Recipient List
Overview
A recipient list, shown in Figure 8.3, “Recipient List Pattern”, is a type of router that sends each incoming message to multiple different destinations. In addition, a recipient list typically requires that the list of recipients be calculated at run time.
Figure 8.3. Recipient List Pattern

Recipient list with fixed destinations
The simplest kind of recipient list is where the list of destinations is fixed and known in advance, and the exchange pattern is InOnly. In this case, you can hardwire the list of destinations into the to() Java DSL command.
The examples given here, for the recipient list with fixed destinations, work only with the InOnly exchange pattern (similar to a pipes and filters pattern). If you want to create a recipient list for exchange patterns with Out messages, use the multicast pattern instead.
Java DSL example
The following example shows how to route an InOnly exchange from a consumer endpoint, queue:a, to a fixed list of destinations:
from("seda:a").to("seda:b", "seda:c", "seda:d");XML configuration example
The following example shows how to configure the same route in XML:
<camelContext id="buildStaticRecipientList" xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="seda:a"/>
<to uri="seda:b"/>
<to uri="seda:c"/>
<to uri="seda:d"/>
</route>
</camelContext>Recipient list calculated at run time
In most cases, when you use the recipient list pattern, the list of recipients should be calculated at runtime. To do this use the recipientList() processor, which takes a list of destinations as its sole argument. Because Apache Camel applies a type converter to the list argument, it should be possible to use most standard Java list types (for example, a collection, a list, or an array). For more details about type converters, see Section 34.3, “Built-In Type Converters”.
The recipients receive a copy of the same exchange instance and Apache Camel executes them sequentially.
Java DSL example
The following example shows how to extract the list of destinations from a message header called recipientListHeader, where the header value is a comma-separated list of endpoint URIs:
from("direct:a").recipientList(header("recipientListHeader").tokenize(","));
In some cases, if the header value is a list type, you might be able to use it directly as the argument to recipientList(). For example:
from("seda:a").recipientList(header("recipientListHeader"));However, this example is entirely dependent on how the underlying component parses this particular header. If the component parses the header as a simple string, this example will not work. The header must be parsed into some type of Java list.
XML configuration example
The following example shows how to configure the preceding route in XML, where the header value is a comma-separated list of endpoint URIs:
<camelContext id="buildDynamicRecipientList" xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="seda:a"/>
<recipientList delimiter=",">
<header>recipientListHeader</header>
</recipientList>
</route>
</camelContext>Sending to multiple recipients in parallel
Available as of Camel 2.2
The recipient list pattern supports parallelProcessing, which is similar to the corresponding feature in the splitter pattern. Use the parallel processing feature to send the exchange to multiple recipients concurrently — for example:
from("direct:a").recipientList(header("myHeader")).parallelProcessing();
In Spring XML, the parallel processing feature is implemented as an attribute on the recipientList tag — for example:
<route>
<from uri="direct:a"/>
<recipientList parallelProcessing="true">
<header>myHeader</header>
</recipientList>
</route>Stop on exception
Available as of Camel 2.2
The recipient list supports the stopOnException feature, which you can use to stop sending to any further recipients, if any recipient fails.
from("direct:a").recipientList(header("myHeader")).stopOnException();And in Spring XML its an attribute on the recipient list tag.
In Spring XML, the stop on exception feature is implemented as an attribute on the recipientList tag — for example:
<route>
<from uri="direct:a"/>
<recipientList stopOnException="true">
<header>myHeader</header>
</recipientList>
</route>
You can combine parallelProcessing and stopOnException in the same route.
Ignore invalid endpoints
Available as of Camel 2.3
The recipient list pattern supports the ignoreInvalidEndpoints option, which enables the recipient list to skip invalid endpoints (the routing slips pattern also supports this option). For example:
from("direct:a").recipientList(header("myHeader")).ignoreInvalidEndpoints();
And in Spring XML, you can enable this option by setting the ignoreInvalidEndpoints attribute on the recipientList tag, as follows
<route>
<from uri="direct:a"/>
<recipientList ignoreInvalidEndpoints="true">
<header>myHeader</header>
</recipientList>
</route>
Consider the case where myHeader contains the two endpoints, direct:foo,xxx:bar. The first endpoint is valid and works. The second is invalid and, therefore, ignored. Apache Camel logs at INFO level whenever an invalid endpoint is encountered.
Using custom AggregationStrategy
Available as of Camel 2.2
You can use a custom AggregationStrategy with the recipient list pattern, which is useful for aggregating replies from the recipients in the list. By default, Apache Camel uses the UseLatestAggregationStrategy aggregation strategy, which keeps just the last received reply. For a more sophisticated aggregation strategy, you can define your own implementation of the AggregationStrategy interface — see Section 8.5, “Aggregator” for details. For example, to apply the custom aggregation strategy, MyOwnAggregationStrategy, to the reply messages, you can define a Java DSL route as follows:
from("direct:a")
.recipientList(header("myHeader")).aggregationStrategy(new MyOwnAggregationStrategy())
.to("direct:b");
In Spring XML, you can specify the custom aggregation strategy as an attribute on the recipientList tag, as follows:
<route>
<from uri="direct:a"/>
<recipientList strategyRef="myStrategy">
<header>myHeader</header>
</recipientList>
<to uri="direct:b"/>
</route>
<bean id="myStrategy" class="com.mycompany.MyOwnAggregationStrategy"/>Using custom thread pool
Available as of Camel 2.2
This is only needed when you use parallelProcessing. By default Camel uses a thread pool with 10 threads. Notice this is subject to change when we overhaul thread pool management and configuration later (hopefully in Camel 2.2).
You configure this just as you would with the custom aggregation strategy.
Using method call as recipient list
You can use a bean integration to provide the recipients, for example:
from("activemq:queue:test").recipientList().method(MessageRouter.class, "routeTo");
Where the MessageRouter bean is defined as follows:
public class MessageRouter {
public String routeTo() {
String queueName = "activemq:queue:test2";
return queueName;
}
}Bean as recipient list
You can make a bean behave as a recipient list by adding the @RecipientList annotation to a methods that returns a list of recipients. For example:
public class MessageRouter {
@RecipientList
public String routeTo() {
String queueList = "activemq:queue:test1,activemq:queue:test2";
return queueList;
}
}
In this case, do not include the recipientList DSL command in the route. Define the route as follows:
from("activemq:queue:test").bean(MessageRouter.class, "routeTo");Using timeout
Available as of Camel 2.5
If you use parallelProcessing, you can configure a total timeout value in milliseconds. Camel will then process the messages in parallel until the timeout is hit. This allows you to continue processing if one message is slow.
In the example below, the recipientlist header has the value, direct:a,direct:b,direct:c, so that the message is sent to three recipients. We have a timeout of 250 milliseconds, which means only the last two messages can be completed within the timeframe. The aggregation therefore yields the string result, BC.
from("direct:start")
.recipientList(header("recipients"), ",")
.aggregationStrategy(new AggregationStrategy() {
public Exchange aggregate(Exchange oldExchange, Exchange newExchange) {
if (oldExchange == null) {
return newExchange;
}
String body = oldExchange.getIn().getBody(String.class);
oldExchange.getIn().setBody(body + newExchange.getIn().getBody(String.class));
return oldExchange;
}
})
.parallelProcessing().timeout(250)
// use end to indicate end of recipientList clause
.end()
.to("mock:result");
from("direct:a").delay(500).to("mock:A").setBody(constant("A"));
from("direct:b").to("mock:B").setBody(constant("B"));
from("direct:c").to("mock:C").setBody(constant("C"));
This timeout feature is also supported by splitter and both multicast and recipientList.
By default if a timeout occurs the AggregationStrategy is not invoked. However you can implement a specialized version
// Java
public interface TimeoutAwareAggregationStrategy extends AggregationStrategy {
/**
* A timeout occurred
*
* @param oldExchange the oldest exchange (is <tt>null</tt> on first aggregation as we only have the new exchange)
* @param index the index
* @param total the total
* @param timeout the timeout value in millis
*/
void timeout(Exchange oldExchange, int index, int total, long timeout);
This allows you to deal with the timeout in the AggregationStrategy if you really need to.
The timeout is total, which means that after X time, Camel will aggregate the messages which has completed within the timeframe. The remainders will be cancelled. Camel will also only invoke the timeout method in the TimeoutAwareAggregationStrategy once, for the first index which caused the timeout.
Apply custom processing to the outgoing messages
Before recipientList sends a message to one of the recipient endpoints, it creates a message replica, which is a shallow copy of the original message. In a shallow copy, the headers and payload of the original message are copied by reference only. Each new copy does not contain its own instance of those elements. As a result, shallow copies of a message are linked and you cannot apply custom processing when routing them to different endpoints.
If you want to perform some custom processing on each message replica before the replica is sent to its endpoint, you can invoke the onPrepare DSL command in the recipientList clause. The onPrepare command inserts a custom processor just after the message has been shallow-copied and just before the message is dispatched to its endpoint. For example, in the following route, the CustomProc processor is invoked on the message replica for each recipient endpoint:
from("direct:start")
.recipientList().onPrepare(new CustomProc());
A common use case for the onPrepare DSL command is to perform a deep copy of some or all elements of a message. This allows each message replica to be modified independently of the others. For example, the following CustomProc processor class performs a deep copy of the message body, where the message body is presumed to be of type, BodyType, and the deep copy is performed by the method, BodyType.deepCopy().
// Java
import org.apache.camel.*;
...
public class CustomProc implements Processor {
public void process(Exchange exchange) throws Exception {
BodyType body = exchange.getIn().getBody(BodyType.class);
// Make a _deep_ copy of of the body object
BodyType clone = BodyType.deepCopy();
exchange.getIn().setBody(clone);
// Headers and attachments have already been
// shallow-copied. If you need deep copies,
// add some more code here.
}
}Options
The recipientList DSL command supports the following options:
| Name | Default Value | Description |
|
|
| Delimiter used if the Expression returned multiple endpoints. |
|
| Refers to an AggregationStrategy to be used to assemble the replies from the recipients, into a single outgoing message from the Section 8.3, “Recipient List”. By default Camel will use the last reply as the outgoing message. | |
|
|
This option can be used to explicitly specify the method name to use, when using POJOs as the | |
|
|
|
This option can be used, when using POJOs as the |
|
|
| Camel 2.2: If enables then sending messages to the recipients occurs concurrently. Note the caller thread will still wait until all messages has been fully processed, before it continues. Its only the sending and processing the replies from the recipients which happens concurrently. |
|
|
|
If enabled, the |
|
| Camel 2.2: Refers to a custom Thread Pool to be used for parallel processing. Notice if you set this option, then parallel processing is automatic implied, and you do not have to enable that option as well. | |
|
|
| Camel 2.2: Whether or not to stop continue processing immediately when an exception occurred. If disable, then Camel will send the message to all recipients regardless if one of them failed. You can deal with exceptions in the AggregationStrategy class where you have full control how to handle that. |
|
|
| Camel 2.3: If an endpoint uri could not be resolved, should it be ignored. Otherwise Camel will thrown an exception stating the endpoint uri is not valid. |
|
|
| Camel 2.5: If enabled then Camel will process replies out-of-order, eg in the order they come back. If disabled, Camel will process replies in the same order as the Expression specified. |
|
|
Camel 2.5: Sets a total timeout specified in millis. If the Section 8.3, “Recipient List” hasn’t been able to send and process all replies within the given timeframe, then the timeout triggers and the Section 8.3, “Recipient List” breaks out and continues. Notice if you provide a AggregationStrategy then the | |
|
| Camel 2.8: Refers to a custom Processor to prepare the copy of the Exchange each recipient will receive. This allows you to do any custom logic, such as deep-cloning the message payload if that’s needed etc. | |
|
|
| Camel 2.8: Whether the unit of work should be shared. See the same option on Section 8.4, “Splitter” for more details. |
|
|
| Camel 2.13.1/2.12.4: Allows to configure the cache size for the ProducerCache which caches producers for reuse in the routing slip. Will by default use the default cache size which is 0. Setting the value to -1 allows to turn off the cache all together. |
Using Exchange Pattern in Recipient List
By default, the Recipient List uses the current exchange pattern. However, there may be few cases where you can send a message to a recipient using a different exchange pattern.
For example, you may have a route that initiates as a InOnly route. Now, If you want to use InOut exchange pattern with a recipient list, you need to configure the exchange pattern directly in the recipient endpoints.
The following example illustrates the route where the new files will start as InOnly and then route to a recipient list. If you want to use InOut with the ActiveMQ (JMS) endpoint, you need to specify this using the exchangePattern equals to InOut option. However, the response form the JMS request or reply will then be continued routed, and thus the response is stored in as a file in the outbox directory.
from("file:inbox")
// the exchange pattern is InOnly initially when using a file route
.recipientList().constant("activemq:queue:inbox?exchangePattern=InOut")
.to("file:outbox");
The InOut exchange pattern must get a response during the timeout. However, it fails if the response is not recieved.
8.4. Splitter
Overview
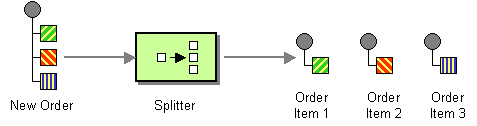
A splitter is a type of router that splits an incoming message into a series of outgoing messages. Each of the outgoing messages contains a piece of the original message. In Apache Camel, the splitter pattern, shown in Figure 8.4, “Splitter Pattern”, is implemented by the split() Java DSL command.
Figure 8.4. Splitter Pattern
The Apache Camel splitter actually supports two patterns, as follows:
- Simple splitter — implements the splitter pattern on its own.
- Splitter/aggregator — combines the splitter pattern with the aggregator pattern, such that the pieces of the message are recombined after they have been processed.
Before the splitter separates the original message into parts, it makes a shallow copy of the original message. In a shallow copy, the headers and payload of the original message are copied as references only. Although the splitter does not itself route the resulting message parts to different endpoints, parts of the split message might undergo secondary routing.
Because the message parts are shallow copies, they remain linked to the original message. As a result, they cannot be modified independently. If you want to apply custom logic to different copies of a message part before routing it to a set of endpoints, you must use the onPrepareRef DSL option in the splitter clause to make a deep copy of the original message. For information about using options, see the section called “Options”.
Java DSL example
The following example defines a route from seda:a to seda:b that splits messages by converting each line of an incoming message into a separate outgoing message:
RouteBuilder builder = new RouteBuilder() {
public void configure() {
from("seda:a")
.split(bodyAs(String.class).tokenize("\n"))
.to("seda:b");
}
};
The splitter can use any expression language, so you can split messages using any of the supported scripting languages, such as XPath, XQuery, or SQL (see Part II, “Routing Expression and Predicate Languages”). The following example extracts bar elements from an incoming message and insert them into separate outgoing messages:
from("activemq:my.queue")
.split(xpath("//foo/bar"))
.to("file://some/directory")XML configuration example
The following example shows how to configure a splitter route in XML, using the XPath scripting language:
<camelContext id="buildSplitter" xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="seda:a"/>
<split>
<xpath>//foo/bar</xpath>
<to uri="seda:b"/>
</split>
</route>
</camelContext>
You can use the tokenize expression in the XML DSL to split bodies or headers using a token, where the tokenize expression is defined using the tokenize element. In the following example, the message body is tokenized using the \n separator character. To use a regular expression pattern, set regex=true in the tokenize element.
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<split>
<tokenize token="\n"/>
<to uri="mock:result"/>
</split>
</route>
</camelContext>Splitting into groups of lines
To split a big file into chunks of 1000 lines, you can define a splitter route as follows in the Java DSL:
from("file:inbox")
.split().tokenize("\n", 1000).streaming()
.to("activemq:queue:order");
The second argument to tokenize specifies the number of lines that should be grouped into a single chunk. The streaming() clause directs the splitter not to read the whole file at once (resulting in much better performance if the file is large).
The same route can be defined in XML DSL as follows:
<route>
<from uri="file:inbox"/>
<split streaming="true">
<tokenize token="\n" group="1000"/>
<to uri="activemq:queue:order"/>
</split>
</route>
The output when using the group option is always of java.lang.String type.
Skip first item
To skip the first item in the message you can use the skipFirst option.
In Java DSL, make the third option in the tokenize parameter true:
from("direct:start")
// split by new line and group by 3, and skip the very first element
.split().tokenize("\n", 3, true).streaming()
.to("mock:group");The same route can be defined in XML DSL as follows:
<route>
<from uri="file:inbox"/>
<split streaming="true">
<tokenize token="\n" group="1000" skipFirst="true" />
<to uri="activemq:queue:order"/>
</split>
</route>Splitter reply
If the exchange that enters the splitter has the InOut message-exchange pattern (that is, a reply is expected), the splitter returns a copy of the original input message as the reply message in the Out message slot. You can override this default behavior by implementing your own aggregation strategy.
Parallel execution
If you want to execute the resulting pieces of the message in parallel, you can enable the parallel processing option, which instantiates a thread pool to process the message pieces. For example:
XPathBuilder xPathBuilder = new XPathBuilder("//foo/bar");
from("activemq:my.queue").split(xPathBuilder).parallelProcessing().to("activemq:my.parts");
You can customize the underlying ThreadPoolExecutor used in the parallel splitter. For example, you can specify a custom executor in the Java DSL as follows:
XPathBuilder xPathBuilder = new XPathBuilder("//foo/bar");
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(8, 16, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue());
from("activemq:my.queue")
.split(xPathBuilder)
.parallelProcessing()
.executorService(threadPoolExecutor)
.to("activemq:my.parts");You can specify a custom executor in the XML DSL as follows:
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:parallel-custom-pool"/>
<split executorServiceRef="threadPoolExecutor">
<xpath>/invoice/lineItems</xpath>
<to uri="mock:result"/>
</split>
</route>
</camelContext>
<bean id="threadPoolExecutor" class="java.util.concurrent.ThreadPoolExecutor">
<constructor-arg index="0" value="8"/>
<constructor-arg index="1" value="16"/>
<constructor-arg index="2" value="0"/>
<constructor-arg index="3" value="MILLISECONDS"/>
<constructor-arg index="4"><bean class="java.util.concurrent.LinkedBlockingQueue"/></constructor-arg>
</bean>Using a bean to perform splitting
As the splitter can use any expression to do the splitting, you can use a bean to perform splitting, by invoking the method() expression. The bean should return an iterable value such as: java.util.Collection, java.util.Iterator, or an array.
The following route defines a method() expression that calls a method on the mySplitterBean bean instance:
from("direct:body")
// here we use a POJO bean mySplitterBean to do the split of the payload
.split()
.method("mySplitterBean", "splitBody")
.to("mock:result");
from("direct:message")
// here we use a POJO bean mySplitterBean to do the split of the message
// with a certain header value
.split()
.method("mySplitterBean", "splitMessage")
.to("mock:result");
Where mySplitterBean is an instance of the MySplitterBean class, which is defined as follows:
public class MySplitterBean {
/**
* The split body method returns something that is iteratable such as a java.util.List.
*
* @param body the payload of the incoming message
* @return a list containing each part split
*/
public List<String> splitBody(String body) {
// since this is based on an unit test you can of couse
// use different logic for splitting as {router} have out
// of the box support for splitting a String based on comma
// but this is for show and tell, since this is java code
// you have the full power how you like to split your messages
List<String> answer = new ArrayList<String>();
String[] parts = body.split(",");
for (String part : parts) {
answer.add(part);
}
return answer;
}
/**
* The split message method returns something that is iteratable such as a java.util.List.
*
* @param header the header of the incoming message with the name user
* @param body the payload of the incoming message
* @return a list containing each part split
*/
public List<Message> splitMessage(@Header(value = "user") String header, @Body String body) {
// we can leverage the Parameter Binding Annotations
// http://camel.apache.org/parameter-binding-annotations.html
// to access the message header and body at same time,
// then create the message that we want, splitter will
// take care rest of them.
// *NOTE* this feature requires {router} version >= 1.6.1
List<Message> answer = new ArrayList<Message>();
String[] parts = header.split(",");
for (String part : parts) {
DefaultMessage message = new DefaultMessage();
message.setHeader("user", part);
message.setBody(body);
answer.add(message);
}
return answer;
}
}
You can use aBeanIOSplitter object with the Splitter EIP to split big payloads by using a stream mode to avoid reading the entire content into memory. The following example shows how to set up a BeanIOSplitter object by using the mapping file, which is loaded from the classpath:
The BeanIOSplitter class is new in Camel 2.18. It is not available in Camel 2.17.
BeanIOSplitter splitter = new BeanIOSplitter();
splitter.setMapping("org/apache/camel/dataformat/beanio/mappings.xml");
splitter.setStreamName("employeeFile");
// Following is a route that uses the beanio data format to format CSV data
// in Java objects:
from("direct:unmarshal")
// Here the message body is split to obtain a message for each row:
.split(splitter).streaming()
.to("log:line")
.to("mock:beanio-unmarshal");The following example adds an error handler:
BeanIOSplitter splitter = new BeanIOSplitter();
splitter.setMapping("org/apache/camel/dataformat/beanio/mappings.xml");
splitter.setStreamName("employeeFile");
splitter.setBeanReaderErrorHandlerType(MyErrorHandler.class);
from("direct:unmarshal")
.split(splitter).streaming()
.to("log:line")
.to("mock:beanio-unmarshal");Exchange properties
The following properties are set on each split exchange:
| header | type | description |
|---|---|---|
|
|
| Apache Camel 2.0: A split counter that increases for each Exchange being split. The counter starts from 0. |
|
|
| Apache Camel 2.0: The total number of Exchanges that was split. This header is not applied for stream based splitting. |
|
|
| Apache Camel 2.4: Whether or not this Exchange is the last. |
Splitter/aggregator pattern
It is a common pattern for the message pieces to be aggregated back into a single exchange, after processing of the individual pieces has completed. To support this pattern, the split() DSL command lets you provide an AggregationStrategy object as the second argument.
Java DSL example
The following example shows how to use a custom aggregation strategy to recombine a split message after all of the message pieces have been processed:
from("direct:start")
.split(body().tokenize("@"), new MyOrderStrategy())
// each split message is then send to this bean where we can process it
.to("bean:MyOrderService?method=handleOrder")
// this is important to end the splitter route as we do not want to do more routing
// on each split message
.end()
// after we have split and handled each message we want to send a single combined
// response back to the original caller, so we let this bean build it for us
// this bean will receive the result of the aggregate strategy: MyOrderStrategy
.to("bean:MyOrderService?method=buildCombinedResponse")AggregationStrategy implementation
The custom aggregation strategy, MyOrderStrategy, used in the preceding route is implemented as follows:
/**
* This is our own order aggregation strategy where we can control
* how each split message should be combined. As we do not want to
* lose any message, we copy from the new to the old to preserve the
* order lines as long we process them
*/
public static class MyOrderStrategy implements AggregationStrategy {
public Exchange aggregate(Exchange oldExchange, Exchange newExchange) {
// put order together in old exchange by adding the order from new exchange
if (oldExchange == null) {
// the first time we aggregate we only have the new exchange,
// so we just return it
return newExchange;
}
String orders = oldExchange.getIn().getBody(String.class);
String newLine = newExchange.getIn().getBody(String.class);
LOG.debug("Aggregate old orders: " + orders);
LOG.debug("Aggregate new order: " + newLine);
// put orders together separating by semi colon
orders = orders + ";" + newLine;
// put combined order back on old to preserve it
oldExchange.getIn().setBody(orders);
// return old as this is the one that has all the orders gathered until now
return oldExchange;
}
}Stream based processing
When parallel processing is enabled, it is theoretically possible for a later message piece to be ready for aggregation before an earlier piece. In other words, the message pieces might arrive at the aggregator out of order. By default, this does not happen, because the splitter implementation rearranges the message pieces back into their original order before passing them into the aggregator.
If you would prefer to aggregate the message pieces as soon as they are ready (and possibly out of order), you can enable the streaming option, as follows:
from("direct:streaming")
.split(body().tokenize(","), new MyOrderStrategy())
.parallelProcessing()
.streaming()
.to("activemq:my.parts")
.end()
.to("activemq:all.parts");You can also supply a custom iterator to use with streaming, as follows:
// Java
import static org.apache.camel.builder.ExpressionBuilder.beanExpression;
...
from("direct:streaming")
.split(beanExpression(new MyCustomIteratorFactory(), "iterator"))
.streaming().to("activemq:my.parts")You cannot use streaming mode in conjunction with XPath. XPath requires the complete DOM XML document in memory.
Stream based processing with XML
If an incoming messages is a very large XML file, you can process the message most efficiently using the tokenizeXML sub-command in streaming mode.
For example, given a large XML file that contains a sequence of order elements, you can split the file into order elements using a route like the following:
from("file:inbox")
.split().tokenizeXML("order").streaming()
.to("activemq:queue:order");You can do the same thing in XML, by defining a route like the following:
<route>
<from uri="file:inbox"/>
<split streaming="true">
<tokenize token="order" xml="true"/>
<to uri="activemq:queue:order"/>
</split>
</route>It is often the case that you need access to namespaces that are defined in one of the enclosing (ancestor) elements of the token elements. You can copy namespace definitions from one of the ancestor elements into the token element, by specifing which element you want to inherit namespace definitions from.
In the Java DSL, you specify the ancestor element as the second argument of tokenizeXML. For example, to inherit namespace definitions from the enclosing orders element:
from("file:inbox")
.split().tokenizeXML("order", "orders").streaming()
.to("activemq:queue:order");
In the XML DSL, you specify the ancestor element using the inheritNamespaceTagName attribute. For example:
<route>
<from uri="file:inbox"/>
<split streaming="true">
<tokenize token="order"
xml="true"
inheritNamespaceTagName="orders"/>
<to uri="activemq:queue:order"/>
</split>
</route>Options
The split DSL command supports the following options:
| Name | Default Value | Description |
|
| Refers to an AggregationStrategy to be used to assemble the replies from the sub-messages, into a single outgoing message from the Section 8.4, “Splitter”. See the section titled What does the splitter return below for whats used by default. | |
|
|
This option can be used to explicitly specify the method name to use, when using POJOs as the | |
|
|
|
This option can be used, when using POJOs as the |
|
|
| If enables then processing the sub-messages occurs concurrently. Note the caller thread will still wait until all sub-messages has been fully processed, before it continues. |
|
|
|
If enabled, the |
|
| Refers to a custom Thread Pool to be used for parallel processing. Notice if you set this option, then parallel processing is automatic implied, and you do not have to enable that option as well. | |
|
|
| Camel 2.2: Whether or not to stop continue processing immediately when an exception occurred. If disable, then Camel continue splitting and process the sub-messages regardless if one of them failed. You can deal with exceptions in the AggregationStrategy class where you have full control how to handle that. |
|
|
| If enabled then Camel will split in a streaming fashion, which means it will split the input message in chunks. This reduces the memory overhead. For example if you split big messages its recommended to enable streaming. If streaming is enabled then the sub-message replies will be aggregated out-of-order, eg in the order they come back. If disabled, Camel will process sub-message replies in the same order as they where splitted. |
|
|
Camel 2.5: Sets a total timeout specified in millis. If the Section 8.3, “Recipient List” hasn’t been able to split and process all replies within the given timeframe, then the timeout triggers and the Section 8.4, “Splitter” breaks out and continues. Notice if you provide an AggregationStrategy then the | |
|
| Camel 2.8: Refers to a custom Processor to prepare the sub-message of the Exchange, before its processed. This allows you to do any custom logic, such as deep-cloning the message payload if that’s needed etc. | |
|
|
| Camel 2.8: Whether the unit of work should be shared. See further below for more details. |
8.5. Aggregator
Overview
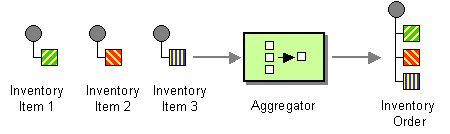
The aggregator pattern, shown in Figure 8.5, “Aggregator Pattern”, enables you to combine a batch of related messages into a single message.
Figure 8.5. Aggregator Pattern
To control the aggregator’s behavior, Apache Camel allows you to specify the properties described in Enterprise Integration Patterns, as follows:
- Correlation expression — Determines which messages should be aggregated together. The correlation expression is evaluated on each incoming message to produce a correlation key. Incoming messages with the same correlation key are then grouped into the same batch. For example, if you want to aggregate all incoming messages into a single message, you can use a constant expression.
- Completeness condition — Determines when a batch of messages is complete. You can specify this either as a simple size limit or, more generally, you can specify a predicate condition that flags when the batch is complete.
- Aggregation algorithm — Combines the message exchanges for a single correlation key into a single message exchange.
For example, consider a stock market data system that receives 30,000 messages per second. You might want to throttle down the message flow if your GUI tool cannot cope with such a massive update rate. The incoming stock quotes can be aggregated together simply by choosing the latest quote and discarding the older prices. (You can apply a delta processing algorithm, if you prefer to capture some of the history.)
The Aggregator now enlists in JMX using a ManagedAggregateProcessorMBean that includes more information. It enables you to use the aggregate controller to control it.
How the aggregator works
Figure 8.6, “Aggregator Implementation” shows an overview of how the aggregator works, assuming it is fed with a stream of exchanges that have correlation keys such as A, B, C, or D.
Figure 8.6. Aggregator Implementation

The incoming stream of exchanges shown in Figure 8.6, “Aggregator Implementation” is processed as follows:
- The correlator is responsible for sorting exchanges based on the correlation key. For each incoming exchange, the correlation expression is evaluated, yielding the correlation key. For example, for the exchange shown in Figure 8.6, “Aggregator Implementation”, the correlation key evaluates to A.
The aggregation strategy is responsible for merging exchanges with the same correlation key. When a new exchange, A, comes in, the aggregator looks up the corresponding aggregate exchange, A', in the aggregation repository and combines it with the new exchange.
Until a particular aggregation cycle is completed, incoming exchanges are continuously aggregated with the corresponding aggregate exchange. An aggregation cycle lasts until terminated by one of the completion mechanisms.
NoteFrom Camel 2.16, the new XSLT Aggregation Strategy allows you to merge two messages with an XSLT file. You can access the
AggregationStrategies.xslt()file from the toolbox.If a completion predicate is specified on the aggregator, the aggregate exchange is tested to determine whether it is ready to be sent to the next processor in the route. Processing continues as follows:
- If complete, the aggregate exchange is processed by the latter part of the route. There are two alternative models for this: synchronous (the default), which causes the calling thread to block, or asynchronous (if parallel processing is enabled), where the aggregate exchange is submitted to an executor thread pool (as shown in Figure 8.6, “Aggregator Implementation”).
- If not complete, the aggregate exchange is saved back to the aggregation repository.
-
In parallel with the synchronous completion tests, it is possible to enable an asynchronous completion test by enabling either the
completionTimeoutoption or thecompletionIntervaloption. These completion tests run in a separate thread and, whenever the completion test is satisfied, the corresponding exchange is marked as complete and starts to be processed by the latter part of the route (either synchronously or asynchronously, depending on whether parallel processing is enabled or not). - If parallel processing is enabled, a thread pool is responsible for processing exchanges in the latter part of the route. By default, this thread pool contains ten threads, but you have the option of customizing the pool (the section called “Threading options”).
Java DSL example
The following example aggregates exchanges with the same StockSymbol header value, using the UseLatestAggregationStrategy aggregation strategy. For a given StockSymbol value, if more than three seconds elapse since the last exchange with that correlation key was received, the aggregated exchange is deemed to be complete and is sent to the mock endpoint.
from("direct:start")
.aggregate(header("id"), new UseLatestAggregationStrategy())
.completionTimeout(3000)
.to("mock:aggregated");XML DSL example
The following example shows how to configure the same route in XML:
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<aggregate strategyRef="aggregatorStrategy"
completionTimeout="3000">
<correlationExpression>
<simple>header.StockSymbol</simple>
</correlationExpression>
<to uri="mock:aggregated"/>
</aggregate>
</route>
</camelContext>
<bean id="aggregatorStrategy"
class="org.apache.camel.processor.aggregate.UseLatestAggregationStrategy"/>Specifying the correlation expression
In the Java DSL, the correlation expression is always passed as the first argument to the aggregate() DSL command. You are not limited to using the Simple expression language here. You can specify a correlation expression using any of the expression languages or scripting languages, such as XPath, XQuery, SQL, and so on.
For exampe, to correlate exchanges using an XPath expression, you could use the following Java DSL route:
from("direct:start")
.aggregate(xpath("/stockQuote/@symbol"), new UseLatestAggregationStrategy())
.completionTimeout(3000)
.to("mock:aggregated");
If the correlation expression cannot be evaluated on a particular incoming exchange, the aggregator throws a CamelExchangeException by default. You can suppress this exception by setting the ignoreInvalidCorrelationKeys option. For example, in the Java DSL:
from(...).aggregate(...).ignoreInvalidCorrelationKeys()
In the XML DSL, you can set the ignoreInvalidCorrelationKeys option is set as an attribute, as follows:
<aggregate strategyRef="aggregatorStrategy"
ignoreInvalidCorrelationKeys="true"
...>
...
</aggregate>Specifying the aggregation strategy
In Java DSL, you can either pass the aggregation strategy as the second argument to the aggregate() DSL command or specify it using the aggregationStrategy() clause. For example, you can use the aggregationStrategy() clause as follows:
from("direct:start")
.aggregate(header("id"))
.aggregationStrategy(new UseLatestAggregationStrategy())
.completionTimeout(3000)
.to("mock:aggregated");
Apache Camel provides the following basic aggregation strategies (where the classes belong to the org.apache.camel.processor.aggregate Java package):
UseLatestAggregationStrategy- Return the last exchange for a given correlation key, discarding all earlier exchanges with this key. For example, this strategy could be useful for throttling the feed from a stock exchange, where you just want to know the latest price of a particular stock symbol.
UseOriginalAggregationStrategy-
Return the first exchange for a given correlation key, discarding all later exchanges with this key. You must set the first exchange by calling
UseOriginalAggregationStrategy.setOriginal()before you can use this strategy. GroupedExchangeAggregationStrategy-
Concatenates all of the exchanges for a given correlation key into a list, which is stored in the
Exchange.GROUPED_EXCHANGEexchange property. See the section called “Grouped exchanges”.
Implementing a custom aggregation strategy
If you want to apply a different aggregation strategy, you can implement one of the following aggregation strategy base interfaces:
org.apache.camel.processor.aggregate.AggregationStrategy- The basic aggregation strategy interface.
org.apache.camel.processor.aggregate.TimeoutAwareAggregationStrategyImplement this interface, if you want your implementation to receive a notification when an aggregation cycle times out. The
timeoutnotification method has the following signature:void timeout(Exchange oldExchange, int index, int total, long timeout)org.apache.camel.processor.aggregate.CompletionAwareAggregationStrategyImplement this interface, if you want your implementation to receive a notification when an aggregation cycle completes normally. The notification method has the following signature:
void onCompletion(Exchange exchange)
For example, the following code shows two different custom aggregation strategies, StringAggregationStrategy and ArrayListAggregationStrategy::
//simply combines Exchange String body values using '' as a delimiter
class StringAggregationStrategy implements AggregationStrategy {
public Exchange aggregate(Exchange oldExchange, Exchange newExchange) {
if (oldExchange == null) {
return newExchange;
}
String oldBody = oldExchange.getIn().getBody(String.class);
String newBody = newExchange.getIn().getBody(String.class);
oldExchange.getIn().setBody(oldBody + "" + newBody);
return oldExchange;
}
}
//simply combines Exchange body values into an ArrayList<Object>
class ArrayListAggregationStrategy implements AggregationStrategy {
public Exchange aggregate(Exchange oldExchange, Exchange newExchange) {
Object newBody = newExchange.getIn().getBody();
ArrayList<Object> list = null;
if (oldExchange == null) {
list = new ArrayList<Object>();
list.add(newBody);
newExchange.getIn().setBody(list);
return newExchange;
} else {
list = oldExchange.getIn().getBody(ArrayList.class);
list.add(newBody);
return oldExchange;
}
}
}
Since Apache Camel 2.0, the AggregationStrategy.aggregate() callback method is also invoked for the very first exchange. On the first invocation of the aggregate method, the oldExchange parameter is null and the newExchange parameter contains the first incoming exchange.
To aggregate messages using the custom strategy class, ArrayListAggregationStrategy, define a route like the following:
from("direct:start")
.aggregate(header("StockSymbol"), new ArrayListAggregationStrategy())
.completionTimeout(3000)
.to("mock:result");You can also configure a route with a custom aggregation strategy in XML, as follows:
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<aggregate strategyRef="aggregatorStrategy"
completionTimeout="3000">
<correlationExpression>
<simple>header.StockSymbol</simple>
</correlationExpression>
<to uri="mock:aggregated"/>
</aggregate>
</route>
</camelContext>
<bean id="aggregatorStrategy" class="com.my_package_name.ArrayListAggregationStrategy"/>Controlling the lifecycle of a custom aggregation strategy
You can implement a custom aggregation strategy so that its lifecycle is aligned with the lifecycle of the enterprise integration pattern that is controlling it. This can be useful for ensuring that the aggregation strategy can shut down gracefully.
To implement an aggregation strategy with lifecycle support, you must implement the org.apache.camel.Service interface (in addition to the AggregationStrategy interface) and provide implementations of the start() and stop() lifecycle methods. For example, the following code example shows an outline of an aggregation strategy with lifecycle support:
// Java
import org.apache.camel.processor.aggregate.AggregationStrategy;
import org.apache.camel.Service;
import java.lang.Exception;
...
class MyAggStrategyWithLifecycleControl
implements AggregationStrategy, Service {
public Exchange aggregate(Exchange oldExchange, Exchange newExchange) {
// Implementation not shown...
...
}
public void start() throws Exception {
// Actions to perform when the enclosing EIP starts up
...
}
public void stop() throws Exception {
// Actions to perform when the enclosing EIP is stopping
...
}
}Exchange properties
The following properties are set on each aggregated exchange:
| Header | Type | Description Aggregated Exchange Properties |
|---|---|---|
|
|
| The total number of exchanges aggregated into this exchange. |
|
|
|
Indicates the mechanism responsible for completing the aggregate exchange. Possible values are: |
The following properties are set on exchanges redelivered by the SQL Component aggregation repository (see the section called “Persistent aggregation repository”):
| Header | Type | Description Redelivered Exchange Properties |
|---|---|---|
|
|
|
Sequence number of the current redelivery attempt (starting at |
Specifying a completion condition
It is mandatory to specify at least one completion condition, which determines when an aggregate exchange leaves the aggregator and proceeds to the next node on the route. The following completion conditions can be specified:
completionPredicate-
Evaluates a predicate after each exchange is aggregated in order to determine completeness. A value of
trueindicates that the aggregate exchange is complete. Alternatively, instead of setting this option, you can define a customAggregationStrategythat implements thePredicateinterface, in which case theAggregationStrategywill be used as the completion predicate. completionSize- Completes the aggregate exchange after the specified number of incoming exchanges are aggregated.
completionTimeout(Incompatible with
completionInterval) Completes the aggregate exchange, if no incoming exchanges are aggregated within the specified timeout.In other words, the timeout mechanism keeps track of a timeout for each correlation key value. The clock starts ticking after the latest exchange with a particular key value is received. If another exchange with the same key value is not received within the specified timeout, the corresponding aggregate exchange is marked complete and sent to the next node on the route.
completionInterval(Incompatible with
completionTimeout) Completes all outstanding aggregate exchanges, after each time interval (of specified length) has elapsed.The time interval is not tailored to each aggregate exchange. This mechanism forces simultaneous completion of all outstanding aggregate exchanges. Hence, in some cases, this mechanism could complete an aggregate exchange immediately after it started aggregating.
completionFromBatchConsumer- When used in combination with a consumer endpoint that supports the batch consumer mechanism, this completion option automatically figures out when the current batch of exchanges is complete, based on information it receives from the consumer endpoint. See the section called “Batch consumer”.
forceCompletionOnStop- When this option is enabled, it forces completion of all outstanding aggregate exchanges when the current route context is stopped.
The preceding completion conditions can be combined arbitrarily, except for the completionTimeout and completionInterval conditions, which cannot be simultaneously enabled. When conditions are used in combination, the general rule is that the first completion condition to trigger is the effective completion condition.
Specifying the completion predicate
You can specify an arbitrary predicate expression that determines when an aggregated exchange is complete. There are two possible ways of evaluating the predicate expression:
- On the latest aggregate exchange — this is the default behavior.
-
On the latest incoming exchange — this behavior is selected when you enable the
eagerCheckCompletionoption.
For example, if you want to terminate a stream of stock quotes every time you receive an ALERT message (as indicated by the value of a MsgType header in the latest incoming exchange), you can define a route like the following:
from("direct:start")
.aggregate(
header("id"),
new UseLatestAggregationStrategy()
)
.completionPredicate(
header("MsgType").isEqualTo("ALERT")
)
.eagerCheckCompletion()
.to("mock:result");The following example shows how to configure the same route using XML:
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<aggregate strategyRef="aggregatorStrategy"
eagerCheckCompletion="true">
<correlationExpression>
<simple>header.StockSymbol</simple>
</correlationExpression>
<completionPredicate>
<simple>$MsgType = 'ALERT'</simple>
</completionPredicate>
<to uri="mock:result"/>
</aggregate>
</route>
</camelContext>
<bean id="aggregatorStrategy"
class="org.apache.camel.processor.aggregate.UseLatestAggregationStrategy"/>Specifying a dynamic completion timeout
It is possible to specify a dynamic completion timeout, where the timeout value is recalculated for every incoming exchange. For example, to set the timeout value from the timeout header in each incoming exchange, you could define a route as follows:
from("direct:start")
.aggregate(header("StockSymbol"), new UseLatestAggregationStrategy())
.completionTimeout(header("timeout"))
.to("mock:aggregated");You can configure the same route in the XML DSL, as follows:
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<aggregate strategyRef="aggregatorStrategy">
<correlationExpression>
<simple>header.StockSymbol</simple>
</correlationExpression>
<completionTimeout>
<header>timeout</header>
</completionTimeout>
<to uri="mock:aggregated"/>
</aggregate>
</route>
</camelContext>
<bean id="aggregatorStrategy"
class="org.apache.camel.processor.UseLatestAggregationStrategy"/>
You can also add a fixed timeout value and Apache Camel will fall back to use this value, if the dynamic value is null or 0.
Specifying a dynamic completion size
It is possible to specify a dynamic completion size, where the completion size is recalculated for every incoming exchange. For example, to set the completion size from the mySize header in each incoming exchange, you could define a route as follows:
from("direct:start")
.aggregate(header("StockSymbol"), new UseLatestAggregationStrategy())
.completionSize(header("mySize"))
.to("mock:aggregated");And the same example using Spring XML:
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<aggregate strategyRef="aggregatorStrategy">
<correlationExpression>
<simple>header.StockSymbol</simple>
</correlationExpression>
<completionSize>
<header>mySize</header>
</completionSize>
<to uri="mock:aggregated"/>
</aggregate>
</route>
</camelContext>
<bean id="aggregatorStrategy"
class="org.apache.camel.processor.UseLatestAggregationStrategy"/>
You can also add a fixed size value and Apache Camel will fall back to use this value, if the dynamic value is null or 0.
Forcing completion of a single group from within an AggregationStrategy
If you implement a custom AggregationStrategy class, there is a mechanism available to force the completion of the current message group, by setting the Exchange.AGGREGATION_COMPLETE_CURRENT_GROUP exchange property to true on the exchange returned from the AggregationStrategy.aggregate() method. This mechanism only affects the current group: other message groups (with different correlation IDs) are not forced to complete. This mechanism overrides any other completion mechanisms, such as predicate, size, timeout, and so on.
For example, the following sample AggregationStrategy class completes the current group, if the message body size is larger than 5:
// Java
public final class MyCompletionStrategy implements AggregationStrategy {
@Override
public Exchange aggregate(Exchange oldExchange, Exchange newExchange) {
if (oldExchange == null) {
return newExchange;
}
String body = oldExchange.getIn().getBody(String.class) + "+"
+ newExchange.getIn().getBody(String.class);
oldExchange.getIn().setBody(body);
if (body.length() >= 5) {
oldExchange.setProperty(Exchange.AGGREGATION_COMPLETE_CURRENT_GROUP, true);
}
return oldExchange;
}
}Forcing completion of all groups with a special message
It is possible to force completion of all outstanding aggregate messages, by sending a message with a special header to the route. There are two alternative header settings you can use to force completion:
Exchange.AGGREGATION_COMPLETE_ALL_GROUPS-
Set to
true, to force completion of the current aggregation cycle. This message acts purely as a signal and is not included in any aggregation cycle. After processing this signal message, the content of the message is discarded. Exchange.AGGREGATION_COMPLETE_ALL_GROUPS_INCLUSIVE-
Set to
true, to force completion of the current aggregation cycle. This message is included in the current aggregation cycle.
Using AggregateController
The org.apache.camel.processor.aggregate.AggregateController enables you to control the aggregate at runtime using Java or JMX API. This can be used to force completing groups of exchanges, or query the current runtime statistics.
If no custom have been configured, the aggregator provides a default implementation which you can access using the getAggregateController() method. However, it is easy to configure a controller in the route using aggregateController.
private AggregateController controller = new DefaultAggregateController();
from("direct:start")
.aggregate(header("id"), new MyAggregationStrategy()).completionSize(10).id("myAggregator")
.aggregateController(controller)
.to("mock:aggregated");
Also, you can use the API on AggregateControllerto force completion. For example, to complete a group with key foo
int groups = controller.forceCompletionOfGroup("foo");The number return would be the number of groups completed. Following is an API to complete all groups:
int groups = controller.forceCompletionOfAllGroups();Enforcing unique correlation keys
In some aggregation scenarios, you might want to enforce the condition that the correlation key is unique for each batch of exchanges. In other words, when the aggregate exchange for a particular correlation key completes, you want to make sure that no further aggregate exchanges with that correlation key are allowed to proceed. For example, you might want to enforce this condition, if the latter part of the route expects to process exchanges with unique correlation key values.
Depending on how the completion conditions are configured, there might be a risk of more than one aggregate exchange being generated with a particular correlation key. For example, although you might define a completion predicate that is designed to wait until all the exchanges with a particular correlation key are received, you might also define a completion timeout, which could fire before all of the exchanges with that key have arrived. In this case, the late-arriving exchanges could give rise to a second aggregate exchange with the same correlation key value.
For such scenarios, you can configure the aggregator to suppress aggregate exchanges that duplicate previous correlation key values, by setting the closeCorrelationKeyOnCompletion option. In order to suppress duplicate correlation key values, it is necessary for the aggregator to record previous correlation key values in a cache. The size of this cache (the number of cached correlation keys) is specified as an argument to the closeCorrelationKeyOnCompletion() DSL command. To specify a cache of unlimited size, you can pass a value of zero or a negative integer. For example, to specify a cache size of 10000 key values:
from("direct:start")
.aggregate(header("UniqueBatchID"), new MyConcatenateStrategy())
.completionSize(header("mySize"))
.closeCorrelationKeyOnCompletion(10000)
.to("mock:aggregated");
If an aggregate exchange completes with a duplicate correlation key value, the aggregator throws a ClosedCorrelationKeyException exception.
Stream based processing using Simple expressions
You can use Simple language expressions as the token with the tokenizeXML sub-command in streaming mode. Using Simple language expressions will enable support for dynamic tokens.
For example, to use Java to split a sequence of names delineated up by the tag person, you can split the file into name elements using the tokenizeXML bean and a Simple language token.
public void testTokenizeXMLPairSimple() throws Exception {
Expression exp = TokenizeLanguage.tokenizeXML("${header.foo}", null);
Get the input string of names delineated by <person> and set <person> as the token.
exchange.getIn().setHeader("foo", "<person>");
exchange.getIn().setBody("<persons><person>James</person><person>Claus</person><person>Jonathan</person><person>Hadrian</person></persons>");List the names split from the input.
List<?> names = exp.evaluate(exchange, List.class);
assertEquals(4, names.size());
assertEquals("<person>James</person>", names.get(0));
assertEquals("<person>Claus</person>", names.get(1));
assertEquals("<person>Jonathan</person>", names.get(2));
assertEquals("<person>Hadrian</person>", names.get(3));
}Grouped exchanges
You can combine all of the aggregated exchanges in an outgoing batch into a single org.apache.camel.impl.GroupedExchange holder class. To enable grouped exchanges, specify the groupExchanges() option, as shown in the following Java DSL route:
from("direct:start")
.aggregate(header("StockSymbol"))
.completionTimeout(3000)
.groupExchanges()
.to("mock:result");
The grouped exchange sent to mock:result contains the list of aggregated exchanges in the message body. The following line of code shows how a subsequent processor can access the contents of the grouped exchange in the form of a list:
// Java
List<Exchange> grouped = ex.getIn().getBody(List.class);When you enable the grouped exchanges feature, you must not configure an aggregation strategy (the grouped exchanges feature is itself an aggregation strategy).
The old approach of accessing the grouped exchanges from a property on the outgoing exchange is now deprecated and will be removed in a future release.
Batch consumer
The aggregator can work together with the batch consumer pattern to aggregate the total number of messages reported by the batch consumer (a batch consumer endpoint sets the CamelBatchSize, CamelBatchIndex , and CamelBatchComplete properties on the incoming exchange). For example, to aggregate all of the files found by a File consumer endpoint, you could use a route like the following:
from("file://inbox")
.aggregate(xpath("//order/@customerId"), new AggregateCustomerOrderStrategy())
.completionFromBatchConsumer()
.to("bean:processOrder");Currently, the following endpoints support the batch consumer mechanism: File, FTP, Mail, iBatis, and JPA.
Persistent aggregation repository
The default aggregator uses an in-memory only AggregationRepository. If you want to store pending aggregated exchanges persistently, you can use the SQL Component as a persistent aggregation repository. The SQL Component includes a JdbcAggregationRepository that persists aggregated messages on-the-fly, and ensures that you do not lose any messages.
When an exchange has been successfully processed, it is marked as complete when the confirm method is invoked on the repository. This means that if the same exchange fails again, it will be retried until it is successful.
Add a dependency on camel-sql
To use the SQL Component, you must include a dependency on camel-sql in your project. For example, if you are using a Maven pom.xml file:
<dependency>
<groupId>org.apache.camel</groupId>
<artifactId>camel-sql</artifactId>
<version>x.x.x</version>
<!-- use the same version as your Camel core version -->
</dependency>Create the aggregation database tables
You must create separate aggregation and completed database tables for persistence. For example, the following query creates the tables for a database named my_aggregation_repo:
CREATE TABLE my_aggregation_repo (
id varchar(255) NOT NULL,
exchange blob NOT NULL,
constraint aggregation_pk PRIMARY KEY (id)
);
CREATE TABLE my_aggregation_repo_completed (
id varchar(255) NOT NULL,
exchange blob NOT NULL,
constraint aggregation_completed_pk PRIMARY KEY (id)
);
}Configure the aggregation repository
You must also configure the aggregation repository in your framework XML file (for example, Spring or Blueprint):
<bean id="my_repo"
class="org.apache.camel.processor.aggregate.jdbc.JdbcAggregationRepository">
<property name="repositoryName" value="my_aggregation_repo"/>
<property name="transactionManager" ref="my_tx_manager"/>
<property name="dataSource" ref="my_data_source"/>
...
</bean>
The repositoryName, transactionManager, and dataSource properties are required. For details on more configuration options for the persistent aggregation repository, see SQL Component in the Apache Camel Component Reference Guide.
Threading options
As shown in Figure 8.6, “Aggregator Implementation”, the aggregator is decoupled from the latter part of the route, where the exchanges sent to the latter part of the route are processed by a dedicated thread pool. By default, this pool contains just a single thread. If you want to specify a pool with multiple threads, enable the parallelProcessing option, as follows:
from("direct:start")
.aggregate(header("id"), new UseLatestAggregationStrategy())
.completionTimeout(3000)
.parallelProcessing()
.to("mock:aggregated");By default, this creates a pool with 10 worker threads.
If you want to exercise more control over the created thread pool, specify a custom java.util.concurrent.ExecutorService instance using the executorService option (in which case it is unnecessary to enable the parallelProcessing option).
Aggregating into a List
A common aggregation scenario involves aggregating a series of incoming message bodies into a List object. To facilitate this scenario, Apache Camel provides the AbstractListAggregationStrategy abstract class, which you can quickly extend to create an aggregation strategy for this case. Incoming message bodies of type, T, are aggregated into a completed exchange, with a message body of type List<T>.
For example, to aggregate a series of Integer message bodies into a List<Integer> object, you could use an aggregation strategy defined as follows:
import org.apache.camel.processor.aggregate.AbstractListAggregationStrategy;
...
/**
* Strategy to aggregate integers into a List<Integer>.
*/
public final class MyListOfNumbersStrategy extends AbstractListAggregationStrategy<Integer> {
@Override
public Integer getValue(Exchange exchange) {
// the message body contains a number, so just return that as-is
return exchange.getIn().getBody(Integer.class);
}
}Aggregator options
The aggregator supports the following options:
| Option | Default | Description |
|---|---|---|
|
|
Mandatory Expression which evaluates the correlation key to use for aggregation. The Exchange which has the same correlation key is aggregated together. If the correlation key could not be evaluated an Exception is thrown. You can disable this by using the | |
|
|
Mandatory | |
|
|
A reference to lookup the | |
|
|
Number of messages aggregated before the aggregation is complete. This option can be set as either a fixed value or using an Expression which allows you to evaluate a size dynamically - will use | |
|
|
Time in millis that an aggregated exchange should be inactive before its complete. This option can be set as either a fixed value or using an Expression which allows you to evaluate a timeout dynamically - will use | |
|
| A repeating period in millis by which the aggregator will complete all current aggregated exchanges. Camel has a background task which is triggered every period. You cannot use this option together with completionTimeout, only one of them can be used. | |
|
|
Specifies a predicate (of | |
|
|
|
This option is if the exchanges are coming from a Batch Consumer. Then when enabled the Section 8.5, “Aggregator” will use the batch size determined by the Batch Consumer in the message header |
|
|
|
Whether or not to eager check for completion when a new incoming Exchange has been received. This option influences the behavior of the |
|
|
|
If |
|
|
|
If enabled then Camel will group all aggregated Exchanges into a single combined |
|
|
| Whether or not to ignore correlation keys which could not be evaluated to a value. By default Camel will throw an Exception, but you can enable this option and ignore the situation instead. |
|
|
Whether or not late Exchanges should be accepted or not. You can enable this to indicate that if a correlation key has already been completed, then any new exchanges with the same correlation key be denied. Camel will then throw a | |
|
|
| Camel 2.5: Whether or not exchanges which complete due to a timeout should be discarded. If enabled, then when a timeout occurs the aggregated message will not be sent out but dropped (discarded). |
|
|
Allows you to plug in you own implementation of | |
|
|
Reference to lookup a | |
|
|
| When aggregated are completed they are being send out of the aggregator. This option indicates whether or not Camel should use a thread pool with multiple threads for concurrency. If no custom thread pool has been specified then Camel creates a default pool with 10 concurrent threads. |
|
|
If using | |
|
|
Reference to lookup a | |
|
|
If using one of the | |
|
|
Reference to look up a | |
|
| When you stop the Aggregator, this option allows it to complete all pending exchanges from the aggregation repository. | |
|
|
| Turns on optimistic locking, which can be used in combination with an aggregation repository. |
|
| Configures the retry policy for optimistic locking. |
8.6. Resequencer
Overview
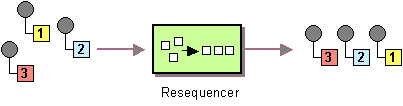
The resequencer pattern, shown in Figure 8.7, “Resequencer Pattern”, enables you to resequence messages according to a sequencing expression. Messages that generate a low value for the sequencing expression are moved to the front of the batch and messages that generate a high value are moved to the back.
Figure 8.7. Resequencer Pattern
Apache Camel supports two resequencing algorithms:
- Batch resequencing — Collects messages into a batch, sorts the messages and sends them to their output.
- Stream resequencing — Re-orders (continuous) message streams based on the detection of gaps between messages.
By default the resequencer does not support duplicate messages and will only keep the last message, in cases where a message arrives with the same message expression. However, in batch mode you can enable the resequencer to allow duplicates.
Batch resequencing
The batch resequencing algorithm is enabled by default. For example, to resequence a batch of incoming messages based on the value of a timestamp contained in the TimeStamp header, you can define the following route in Java DSL:
from("direct:start").resequence(header("TimeStamp")).to("mock:result");
By default, the batch is obtained by collecting all of the incoming messages that arrive in a time interval of 1000 milliseconds (default batch timeout), up to a maximum of 100 messages (default batch size). You can customize the values of the batch timeout and the batch size by appending a batch() DSL command, which takes a BatchResequencerConfig instance as its sole argument. For example, to modify the preceding route so that the batch consists of messages collected in a 4000 millisecond time window, up to a maximum of 300 messages, you can define the Java DSL route as follows:
import org.apache.camel.model.config.BatchResequencerConfig;
RouteBuilder builder = new RouteBuilder() {
public void configure() {
from("direct:start").resequence(header("TimeStamp")).batch(new BatchResequencerConfig(300,4000L)).to("mock:result");
}
};You can also specify a batch resequencer pattern using XML configuration. The following example defines a batch resequencer with a batch size of 300 and a batch timeout of 4000 milliseconds:
<camelContext id="resequencerBatch" xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start" />
<resequence>
<!--
batch-config can be omitted for default (batch) resequencer settings
-->
<batch-config batchSize="300" batchTimeout="4000" />
<simple>header.TimeStamp</simple>
<to uri="mock:result" />
</resequence>
</route>
</camelContext>Batch options
Table 8.2, “Batch Resequencer Options” shows the options that are available in batch mode only.
| Java DSL | XML DSL | Default | Description |
|---|---|---|---|
|
|
|
|
If |
|
|
|
|
If |
For example, if you want to resequence messages from JMS queues based on JMSPriority, you would need to combine the options, allowDuplicates and reverse, as follows:
from("jms:queue:foo")
// sort by JMSPriority by allowing duplicates (message can have same JMSPriority)
// and use reverse ordering so 9 is first output (most important), and 0 is last
// use batch mode and fire every 3th second
.resequence(header("JMSPriority")).batch().timeout(3000).allowDuplicates().reverse()
.to("mock:result");Stream resequencing
To enable the stream resequencing algorithm, you must append stream() to the resequence() DSL command. For example, to resequence incoming messages based on the value of a sequence number in the seqnum header, you define a DSL route as follows:
from("direct:start").resequence(header("seqnum")).stream().to("mock:result");
The stream-processing resequencer algorithm is based on the detection of gaps in a message stream, rather than on a fixed batch size. Gap detection, in combination with timeouts, removes the constraint of needing to know the number of messages of a sequence (that is, the batch size) in advance. Messages must contain a unique sequence number for which a predecessor and a successor is known. For example a message with the sequence number 3 has a predecessor message with the sequence number 2 and a successor message with the sequence number 4. The message sequence 2,3,5 has a gap because the successor of 3 is missing. The resequencer therefore must retain message 5 until message 4 arrives (or a timeout occurs).
By default, the stream resequencer is configured with a timeout of 1000 milliseconds, and a maximum message capacity of 100. To customize the stream’s timeout and message capacity, you can pass a StreamResequencerConfig object as an argument to stream(). For example, to configure a stream resequencer with a message capacity of 5000 and a timeout of 4000 milliseconds, you define a route as follows:
// Java
import org.apache.camel.model.config.StreamResequencerConfig;
RouteBuilder builder = new RouteBuilder() {
public void configure() {
from("direct:start").resequence(header("seqnum")).
stream(new StreamResequencerConfig(5000, 4000L)).
to("mock:result");
}
};If the maximum time delay between successive messages (that is, messages with adjacent sequence numbers) in a message stream is known, the resequencer’s timeout parameter should be set to this value. In this case, you can guarantee that all messages in the stream are delivered in the correct order to the next processor. The lower the timeout value that is compared to the out-of-sequence time difference, the more likely it is that the resequencer will deliver messages out of sequence. Large timeout values should be supported by sufficiently high capacity values, where the capacity parameter is used to prevent the resequencer from running out of memory.
If you want to use sequence numbers of some type other than long, you would must define a custom comparator, as follows:
// Java
ExpressionResultComparator<Exchange> comparator = new MyComparator();
StreamResequencerConfig config = new StreamResequencerConfig(5000, 4000L, comparator);
from("direct:start").resequence(header("seqnum")).stream(config).to("mock:result");You can also specify a stream resequencer pattern using XML configuration. The following example defines a stream resequencer with a message capacity of 5000 and a timeout of 4000 milliseconds:
<camelContext id="resequencerStream" xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<resequence>
<stream-config capacity="5000" timeout="4000"/>
<simple>header.seqnum</simple>
<to uri="mock:result" />
</resequence>
</route>
</camelContext>Ignore invalid exchanges
The resequencer EIP throws a CamelExchangeException exception, if the incoming exchange is not valid — that is, if the sequencing expression cannot be evaluated for some reason (for example, due to a missing header). You can use the ignoreInvalidExchanges option to ignore these exceptions, which means the resequencer will skip any invalid exchanges.
from("direct:start")
.resequence(header("seqno")).batch().timeout(1000)
// ignore invalid exchanges (they are discarded)
.ignoreInvalidExchanges()
.to("mock:result");Reject old messages
The rejectOld option can be used to prevent messages being sent out of order, regardless of the mechanism used to resequence messages. When the rejectOld option is enabled, the resequencer rejects an incoming message (by throwing a MessageRejectedException exception), if the incoming messages is older (as defined by the current comparator) than the last delivered message.
from("direct:start")
.onException(MessageRejectedException.class).handled(true).to("mock:error").end()
.resequence(header("seqno")).stream().timeout(1000).rejectOld()
.to("mock:result");8.7. Routing Slip
Overview
The routing slip pattern, shown in Figure 8.8, “Routing Slip Pattern”, enables you to route a message consecutively through a series of processing steps, where the sequence of steps is not known at design time and can vary for each message. The list of endpoints through which the message should pass is stored in a header field (the slip), which Apache Camel reads at run time to construct a pipeline on the fly.
Figure 8.8. Routing Slip Pattern
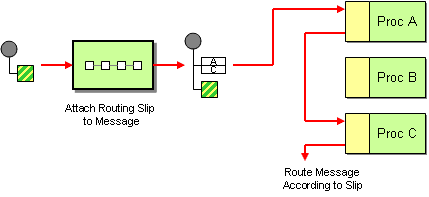
The slip header
The routing slip appears in a user-defined header, where the header value is a comma-separated list of endpoint URIs. For example, a routing slip that specifies a sequence of security tasks — decrypting, authenticating, and de-duplicating a message — might look like the following:
cxf:bean:decrypt,cxf:bean:authenticate,cxf:bean:dedupThe current endpoint property
From Camel 2.5 the Routing Slip will set a property (Exchange.SLIP_ENDPOINT) on the exchange which contains the current endpoint as it advanced though the slip. This enables you to find out how far the exchange has progressed through the slip.
The Section 8.7, “Routing Slip” will compute the slip beforehand which means, the slip is only computed once. If you need to compute the slip on-the-fly then use the Section 8.18, “Dynamic Router” pattern instead.
Java DSL example
The following route takes messages from the direct:a endpoint and reads a routing slip from the aRoutingSlipHeader header:
from("direct:b").routingSlip("aRoutingSlipHeader");You can specify the header name either as a string literal or as an expression.
You can also customize the URI delimiter using the two-argument form of routingSlip(). The following example defines a route that uses the aRoutingSlipHeader header key for the routing slip and uses the # character as the URI delimiter:
from("direct:c").routingSlip("aRoutingSlipHeader", "#");XML configuration example
The following example shows how to configure the same route in XML:
<camelContext id="buildRoutingSlip" xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:c"/>
<routingSlip uriDelimiter="#">
<headerName>aRoutingSlipHeader</headerName>
</routingSlip>
</route>
</camelContext>Ignore invalid endpoints
The Section 8.7, “Routing Slip” now supports ignoreInvalidEndpoints, which the Section 8.3, “Recipient List” pattern also supports. You can use it to skip endpoints that are invalid. For example:
from("direct:a").routingSlip("myHeader").ignoreInvalidEndpoints();
In Spring XML, this feature is enabled by setting the ignoreInvalidEndpoints attribute on the <routingSlip> tag:
<route>
<from uri="direct:a"/>
<routingSlip ignoreInvalidEndpoints="true">
<headerName>myHeader</headerName>
</routingSlip>
</route>
Consider the case where myHeader contains the two endpoints, direct:foo,xxx:bar. The first endpoint is valid and works. The second is invalid and, therefore, ignored. Apache Camel logs at INFO level whenever an invalid endpoint is encountered.
Options
The routingSlip DSL command supports the following options:
| Name | Default Value | Description |
|
|
| Delimiter used if the Expression returned multiple endpoints. |
|
|
| If an endpoint uri could not be resolved, should it be ignored. Otherwise Camel will thrown an exception stating the endpoint uri is not valid. |
|
|
| Camel 2.13.1/2.12.4: Allows to configure the cache size for the ProducerCache which caches producers for reuse in the routing slip. Will by default use the default cache size which is 0. Setting the value to -1 allows to turn off the cache all together. |
8.8. Throttler
Overview
A throttler is a processor that limits the flow rate of incoming messages. You can use this pattern to protect a target endpoint from getting overloaded. In Apache Camel, you can implement the throttler pattern using the throttle() Java DSL command.
Java DSL example
To limit the flow rate to 100 messages per second, define a route as follows:
from("seda:a").throttle(100).to("seda:b");
If necessary, you can customize the time period that governs the flow rate using the timePeriodMillis() DSL command. For example, to limit the flow rate to 3 messages per 30000 milliseconds, define a route as follows:
from("seda:a").throttle(3).timePeriodMillis(30000).to("mock:result");XML configuration example
The following example shows how to configure the preceding route in XML:
<camelContext id="throttleRoute" xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="seda:a"/>
<!-- throttle 3 messages per 30 sec -->
<throttle timePeriodMillis="30000">
<constant>3</constant>
<to uri="mock:result"/>
</throttle>
</route>
</camelContext>Dynamically changing maximum requests per period
Available os of Camel 2.8 Since we use an Expression, you can adjust this value at runtime, for example you can provide a header with the value. At runtime Camel evaluates the expression and converts the result to a java.lang.Long type. In the example below we use a header from the message to determine the maximum requests per period. If the header is absent, then the Section 8.8, “Throttler” uses the old value. So that allows you to only provide a header if the value is to be changed:
<camelContext id="throttleRoute" xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:expressionHeader"/>
<throttle timePeriodMillis="500">
<!-- use a header to determine how many messages to throttle per 0.5 sec -->
<header>throttleValue</header>
<to uri="mock:result"/>
</throttle>
</route>
</camelContext>Asynchronous delaying
The throttler can enable non-blocking asynchronous delaying, which means that Apache Camel schedules a task to be executed in the future. The task is responsible for processing the latter part of the route (after the throttler). This allows the caller thread to unblock and service further incoming messages. For example:
from("seda:a").throttle(100).asyncDelayed().to("seda:b");From Camel 2.17, the Throttler will use the rolling window for time periods that give a better flow of messages. However, It will enhance the performance of a throttler.
Options
The throttle DSL command supports the following options:
| Name | Default Value | Description |
|
| Maximum number of requests per period to throttle. This option must be provided and a positive number. Notice, in the XML DSL, from Camel 2.8 onwards this option is configured using an Expression instead of an attribute. | |
|
|
|
The time period in millis, in which the throttler will allow at most |
|
|
| Camel 2.4: If enabled then any messages which is delayed happens asynchronously using a scheduled thread pool. |
|
|
Camel 2.4: Refers to a custom Thread Pool to be used if | |
|
|
|
Camel 2.4: Is used if |
8.9. Delayer
Overview
A delayer is a processor that enables you to apply a relative time delay to incoming messages.
Java DSL example
You can use the delay() command to add a relative time delay, in units of milliseconds, to incoming messages. For example, the following route delays all incoming messages by 2 seconds:
from("seda:a").delay(2000).to("mock:result");Alternatively, you can specify the time delay using an expression:
from("seda:a").delay(header("MyDelay")).to("mock:result");
The DSL commands that follow delay() are interpreted as sub-clauses of delay(). Hence, in some contexts it is necessary to terminate the sub-clauses of delay() by inserting the end() command. For example, when delay() appears inside an onException() clause, you would terminate it as follows:
from("direct:start")
.onException(Exception.class)
.maximumRedeliveries(2)
.backOffMultiplier(1.5)
.handled(true)
.delay(1000)
.log("Halting for some time")
.to("mock:halt")
.end()
.end()
.to("mock:result");XML configuration example
The following example demonstrates the delay in XML DSL:
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="seda:a"/>
<delay>
<header>MyDelay</header>
</delay>
<to uri="mock:result"/>
</route>
<route>
<from uri="seda:b"/>
<delay>
<constant>1000</constant>
</delay>
<to uri="mock:result"/>
</route>
</camelContext>Creating a custom delay
You can use an expression combined with a bean to determine the delay as follows:
from("activemq:foo").
delay().expression().method("someBean", "computeDelay").
to("activemq:bar");Where the bean class could be defined as follows:
public class SomeBean {
public long computeDelay() {
long delay = 0;
// use java code to compute a delay value in millis
return delay;
}
}Asynchronous delaying
You can let the delayer use non-blocking asynchronous delaying, which means that Apache Camel schedules a task to be executed in the future. The task is responsible for processing the latter part of the route (after the delayer). This allows the caller thread to unblock and service further incoming messages. For example:
from("activemq:queue:foo")
.delay(1000)
.asyncDelayed()
.to("activemq:aDelayedQueue");The same route can be written in the XML DSL, as follows:
<route>
<from uri="activemq:queue:foo"/>
<delay asyncDelayed="true">
<constant>1000</constant>
</delay>
<to uri="activemq:aDealyedQueue"/>
</route>Options
The delayer pattern supports the following options:
| Name | Default Value | Description |
|
|
| Camel 2.4: If enabled then delayed messages happens asynchronously using a scheduled thread pool. |
|
|
Camel 2.4: Refers to a custom Thread Pool to be used if | |
|
|
|
Camel 2.4: Is used if |
8.10. Load Balancer
Overview
The load balancer pattern allows you to delegate message processing to one of several endpoints, using a variety of different load-balancing policies.
Java DSL example
The following route distributes incoming messages between the target endpoints, mock:x, mock:y, mock:z, using a round robin load-balancing policy:
from("direct:start").loadBalance().roundRobin().to("mock:x", "mock:y", "mock:z");XML configuration example
The following example shows how to configure the same route in XML:
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<loadBalance>
<roundRobin/>
<to uri="mock:x"/>
<to uri="mock:y"/>
<to uri="mock:z"/>
</loadBalance>
</route>
</camelContext>Load-balancing policies
The Apache Camel load balancer supports the following load-balancing policies:
Round robin
The round robin load-balancing policy cycles through all of the target endpoints, sending each incoming message to the next endpoint in the cycle. For example, if the list of target endpoints is, mock:x, mock:y, mock:z, then the incoming messages are sent to the following sequence of endpoints: mock:x, mock:y, mock:z, mock:x, mock:y, mock:z, and so on.
You can specify the round robin load-balancing policy in Java DSL, as follows:
from("direct:start").loadBalance().roundRobin().to("mock:x", "mock:y", "mock:z");Alternatively, you can configure the same route in XML, as follows:
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<loadBalance>
<roundRobin/>
<to uri="mock:x"/>
<to uri="mock:y"/>
<to uri="mock:z"/>
</loadBalance>
</route>
</camelContext>Random
The random load-balancing policy chooses the target endpoint randomly from the specified list.
You can specify the random load-balancing policy in Java DSL, as follows:
from("direct:start").loadBalance().random().to("mock:x", "mock:y", "mock:z");Alternatively, you can configure the same route in XML, as follows:
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<loadBalance>
<random/>
<to uri="mock:x"/>
<to uri="mock:y"/>
<to uri="mock:z"/>
</loadBalance>
</route>
</camelContext>Sticky
The sticky load-balancing policy directs the In message to an endpoint that is chosen by calculating a hash value from a specified expression. The advantage of this load-balancing policy is that expressions of the same value are always sent to the same server. For example, by calculating the hash value from a header that contains a username, you ensure that messages from a particular user are always sent to the same target endpoint. Another useful approach is to specify an expression that extracts the session ID from an incoming message. This ensures that all messages belonging to the same session are sent to the same target endpoint.
You can specify the sticky load-balancing policy in Java DSL, as follows:
from("direct:start").loadBalance().sticky(header("username")).to("mock:x", "mock:y", "mock:z");Alternatively, you can configure the same route in XML, as follows:
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<loadBalance>
<sticky>
<correlationExpression>
<simple>header.username</simple>
</correlationExpression>
</sticky>
<to uri="mock:x"/>
<to uri="mock:y"/>
<to uri="mock:z"/>
</loadBalance>
</route>
</camelContext>When you add the sticky option to the failover load balancer, the load balancer starts from the last known good endpoint.
Topic
The topic load-balancing policy sends a copy of each In message to all of the listed destination endpoints (effectively broadcasting the message to all of the destinations, like a JMS topic).
You can use the Java DSL to specify the topic load-balancing policy, as follows:
from("direct:start").loadBalance().topic().to("mock:x", "mock:y", "mock:z");Alternatively, you can configure the same route in XML, as follows:
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<loadBalance>
<topic/>
<to uri="mock:x"/>
<to uri="mock:y"/>
<to uri="mock:z"/>
</loadBalance>
</route>
</camelContext>Failover
Available as of Apache Camel 2.0 The failover load balancer is capable of trying the next processor in case an Exchange failed with an exception during processing. You can configure the failover with a list of specific exceptions that trigger failover. If you do not specify any exceptions, failover is triggered by any exception. The failover load balancer uses the same strategy for matching exceptions as the onException exception clause.
If you use streaming, you should enable Stream Caching when using the failover load balancer. This is needed so the stream can be re-read when failing over.
The failover load balancer supports the following options:
| Option | Type | Default | Description |
|
|
|
|
Camel 2.3: Specifies whether to use the
For example, the |
|
|
|
|
Camel 2.3: Specifies the maximum number of attempts to fail over to a new endpoint. The value, |
|
|
|
|
Camel 2.3: Specifies whether the |
The following example is configured to fail over, only if an IOException exception is thrown:
from("direct:start")
// here we will load balance if IOException was thrown
// any other kind of exception will result in the Exchange as failed
// to failover over any kind of exception we can just omit the exception
// in the failOver DSL
.loadBalance().failover(IOException.class)
.to("direct:x", "direct:y", "direct:z");You can optionally specify multiple exceptions to fail over, as follows:
// enable redelivery so failover can react
errorHandler(defaultErrorHandler().maximumRedeliveries(5));
from("direct:foo")
.loadBalance()
.failover(IOException.class, MyOtherException.class)
.to("direct:a", "direct:b");You can configure the same route in XML, as follows:
<route errorHandlerRef="myErrorHandler">
<from uri="direct:foo"/>
<loadBalance>
<failover>
<exception>java.io.IOException</exception>
<exception>com.mycompany.MyOtherException</exception>
</failover>
<to uri="direct:a"/>
<to uri="direct:b"/>
</loadBalance>
</route>The following example shows how to fail over in round robin mode:
from("direct:start")
// Use failover load balancer in stateful round robin mode,
// which means it will fail over immediately in case of an exception
// as it does NOT inherit error handler. It will also keep retrying, as
// it is configured to retry indefinitely.
.loadBalance().failover(-1, false, true)
.to("direct:bad", "direct:bad2", "direct:good", "direct:good2");You can configure the same route in XML, as follows:
<route>
<from uri="direct:start"/>
<loadBalance>
<!-- failover using stateful round robin,
which will keep retrying the 4 endpoints indefinitely.
You can set the maximumFailoverAttempt to break out after X attempts -->
<failover roundRobin="true"/>
<to uri="direct:bad"/>
<to uri="direct:bad2"/>
<to uri="direct:good"/>
<to uri="direct:good2"/>
</loadBalance>
</route>
If you want to failover to the next endpoint as soon as possible, you can disable the inheritErrorHandler by configuring inheritErrorHandler=false. By disabling the Error Handler you can ensure that it does not intervene. This allows the failover load balancer to handle failover as soon as possible. If you also enable the roundRobin mode, then it keeps retrying until it successes. You can then configure the maximumFailoverAttempts option to a high value to let it eventually exhaust and fail.
Weighted round robin and weighted random
In many enterprise environments, where server nodes of unequal processing power are hosting services, it is usually preferable to distribute the load in accordance with the individual server processing capacities. A weighted round robin algorithm or a weighted random algorithm can be used to address this problem.
The weighted load balancing policy allows you to specify a processing load distribution ratio for each server with respect to the others. You can specify this value as a positive processing weight for each server. A larger number indicates that the server can handle a larger load. The processing weight is used to determine the payload distribution ratio of each processing endpoint with respect to the others.
The parameters that can be used are described in the following table:
| Option | Type | Default | Description |
|---|---|---|---|
|
|
|
|
The default value for round-robin is |
|
|
|
|
The |
The following Java DSL examples show how to define a weighted round-robin route and a weighted random route:
// Java
// round-robin
from("direct:start")
.loadBalance().weighted(true, "4:2:1" distributionRatioDelimiter=":")
.to("mock:x", "mock:y", "mock:z");
//random
from("direct:start")
.loadBalance().weighted(false, "4,2,1")
.to("mock:x", "mock:y", "mock:z");You can configure the round-robin route in XML, as follows:
<!-- round-robin -->
<route>
<from uri="direct:start"/>
<loadBalance>
<weighted roundRobin="true" distributionRatio="4:2:1" distributionRatioDelimiter=":" />
<to uri="mock:x"/>
<to uri="mock:y"/>
<to uri="mock:z"/>
</loadBalance>
</route>Custom Load Balancer
You can use a custom load balancer (eg your own implementation) also.
An example using Java DSL:
from("direct:start")
// using our custom load balancer
.loadBalance(new MyLoadBalancer())
.to("mock:x", "mock:y", "mock:z");And the same example using XML DSL:
<!-- this is the implementation of our custom load balancer -->
<bean id="myBalancer" class="org.apache.camel.processor.CustomLoadBalanceTest$MyLoadBalancer"/>
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<loadBalance>
<!-- refer to my custom load balancer -->
<custom ref="myBalancer"/>
<!-- these are the endpoints to balancer -->
<to uri="mock:x"/>
<to uri="mock:y"/>
<to uri="mock:z"/>
</loadBalance>
</route>
</camelContext>Notice in the XML DSL above we use <custom> which is only available in Camel 2.8 onwards. In older releases you would have to do as follows instead:
<loadBalance ref="myBalancer">
<!-- these are the endpoints to balancer -->
<to uri="mock:x"/>
<to uri="mock:y"/>
<to uri="mock:z"/>
</loadBalance>
To implement a custom load balancer you can extend some support classes such as LoadBalancerSupport and SimpleLoadBalancerSupport. The former supports the asynchronous routing engine, and the latter does not. Here is an example:
public static class MyLoadBalancer extends LoadBalancerSupport {
public boolean process(Exchange exchange, AsyncCallback callback) {
String body = exchange.getIn().getBody(String.class);
try {
if ("x".equals(body)) {
getProcessors().get(0).process(exchange);
} else if ("y".equals(body)) {
getProcessors().get(1).process(exchange);
} else {
getProcessors().get(2).process(exchange);
}
} catch (Throwable e) {
exchange.setException(e);
}
callback.done(true);
return true;
}
}Circuit Breaker
The Circuit Breaker load balancer is a stateful pattern that is used to monitor all calls for certain exceptions. Initially, the Circuit Breaker is in closed state and passes all messages. If there are failures and the threshold is reached, it moves to open state and rejects all calls until halfOpenAfter timeout is reached. After the timeout, if there is a new call, the Circuit Breaker passes all the messages. If the result is success, the Circuit Breaker moves to a closed state, if not, it moves back to open state.
Java DSL example:
from("direct:start").loadBalance()
.circuitBreaker(2, 1000L, MyCustomException.class)
.to("mock:result");Spring XML example:
<camelContext id="camel" xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<loadBalance>
<circuitBreaker threshold="2" halfOpenAfter="1000">
<exception>MyCustomException</exception>
</circuitBreaker>
<to uri="mock:result"/>
</loadBalance>
</route>
</camelContext>8.11. Hystrix
Overview
Available as of Camel 2.18.
The Hystrix pattern lets an application integrate with Netflix Hystrix, which can provide a circuit breaker in Camel routes. Hystrix is a latency and fault tolerance library designed to
- Isolate points of access to remote systems, services and third-party libraries
- Stop cascading failure
- Enable resilience in complex distributed systems where failure is inevitable
If you use maven then add the following dependency to your pom.xml file to use Hystrix:
<dependency>
<groupId>org.apache.camel</groupId>
<artifactId>camel-hystrix</artifactId>
<version>x.x.x</version>
<!-- Specify the same version as your Camel core version. -->
</dependency>Java DSL example
Below is an example route that shows a Hystrix endpoint that protects against slow operation by falling back to the in-lined fallback route. By default, the timeout request is just 1000ms so the HTTP endpoint has to be fairly quick to succeed.
from("direct:start")
.hystrix()
.to("http://fooservice.com/slow")
.onFallback()
.transform().constant("Fallback message")
.end()
.to("mock:result");XML configuration example
Following is the same example but in XML:
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<hystrix>
<to uri="http://fooservice.com/slow"/>
<onFallback>
<transform>
<constant>Fallback message</constant>
</transform>
</onFallback>
</hystrix>
<to uri="mock:result"/>
</route>
</camelContext>Using the Hystrix fallback feature
The onFallback() method is for local processing where you can transform a message or call a bean or something else as the fallback. If you need to call an external service over the network then you should use the onFallbackViaNetwork() method, which runs in an independent HystrixCommand object that uses its own thread pool so it does not exhaust the first command object.
Hystrix configuration examples
Hystrix has many options as listed in the next section. The example below shows the Java DSL for setting the execution timeout to 5 seconds rather than the default 1 second and for letting the circuit breaker wait 10 seconds rather than 5 seconds (the default) before attempting a request again when the state was tripped to be open.
from("direct:start")
.hystrix()
.hystrixConfiguration()
.executionTimeoutInMilliseconds(5000).circuitBreakerSleepWindowInMilliseconds(10000)
.end()
.to("http://fooservice.com/slow")
.onFallback()
.transform().constant("Fallback message")
.end()
.to("mock:result");Following is the same example but in XML:
<camelContext xmlns="http://camel.apache.org/schema/spring">
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<hystrix>
<hystrixConfiguration executionTimeoutInMilliseconds="5000" circuitBreakerSleepWindowInMilliseconds="10000"/>
<to uri="http://fooservice.com/slow"/>
<onFallback>
<transform>
<constant>Fallback message</constant>
</transform>
</onFallback>
</hystrix>
<to uri="mock:result"/>
</route>
</camelContext> You can also configure Hystrix globally and then refer to that
configuration. For example:<camelContext xmlns="http://camel.apache.org/schema/spring">
<!-- This is a shared config that you can refer to from all Hystrix patterns. -->
<hystrixConfiguration id="sharedConfig" executionTimeoutInMilliseconds="5000" circuitBreakerSleepWindowInMilliseconds="10000"/>
<route>
<from uri="direct:start"/>
<hystrix hystrixConfigurationRef="sharedConfig">
<to uri="http://fooservice.com/slow"/>
<onFallback>
<transform>
<constant>Fallback message</constant>
</transform>
</onFallback>
</hystrix>
<to uri="mock:result"/>
</route>
</camelContext>Options
Ths Hystrix component supports the following options. Hystrix provides the default values.
| Name | Default Value | Type | Description |
|---|---|---|---|
|
|
| Boolean | Determines whether a circuit breaker will be used to track health and to short-circuit requests if it trips. |
|
|
| Integer | Sets the error percentage at or above which the circuit should trip open and start short-circuiting requests to fallback logic. |
|
|
| Boolean | A value of true forces the circuit breaker into a closed state in which it allows requests regardless of the error percentage. |
|
|
| Boolean | A value of true forces the circuit breaker into an open (tripped) state in which it rejects all requests. |
|
|
| Integer | Sets the minimum number of requests in a rolling window that will trip the circuit. |
|
|
| Integer | Sets the amount of time, after tripping the circuit, to reject requests. After this time elapses, request attempts are allowed to determine if the circuit should again be closed. |
|
| Node ID | String | Identifies the Hystrix command. You cannot configure this option. it is always the node ID to make the command unique. |
|
|
| Integer |
Sets the core thread-pool size. This is the maximum number of |
|
|
| Integer |
Sets the maximum number of requests that a |
|
|
| String |
Indicates which of these isolation strategies |
|
|
| Boolean |
Indicates whether the |
|
|
| Integer | Sets the timeout in milliseconds for execution completion. |
|
|
| Boolean |
Indicates whether the execution of |
|
|
| Boolean |
Determines whether a call to |
|
|
| Integer |
Sets the maximum number of requests that a |
|
|
| String | Identifies the Hystrix group being used to correlate statistics and circuit breaker properties. |
|
|
| Integer | Sets the keep-alive time, in minutes. |
|
|
| Integer |
Sets the maximum queue size of the |
|
|
| Integer | Sets the time to wait, in milliseconds, between allowing health snapshots to be taken. Health snapshots calculate success and error percentages and affect circuit breaker status. |
|
|
| Integer | Sets the maximum number of execution times that are kept per bucket. If more executions occur during the time they will wrap around and start over-writing at the beginning of the bucket. |
|
|
| Boolean | Indicates whether execution latency should be tracked. The latency is calculated as a percentile. A value of false causes summary statistics (mean, percentiles) to be returned as -1. |
|
|
| Integer |
Sets the number of buckets the |
|
|
| Integer | Sets the duration of the rolling window in which execution times are kept to allow for percentile calculations, in milliseconds. |
|
|
| Integer | Sets the number of buckets the rolling statistical window is divided into. |
|
|
| Integer |
This option and the following options apply to capturing metrics from |
|
|
| Integer |
Sets the queue size rejection threshold — an artificial maximum queue size at which rejections occur even ifý |
|
|
| Boolean |
Indicates whether |
|
|
| String | Defines which thread-pool this command should run in. By default this is using the same key as the group key. |
|
|
| Integer | Sets the number of buckets the rolling statistical window is divided into. |
|
|
| Integer | Sets the duration of the statistical rolling window, in milliseconds. This is how long metrics are kept for the thread pool. |
8.12. Service Call
Overview
Available as of Camel 2.18.
The service call pattern lets you call remote services in a distributed system. The service to call is looked up in a service registry such as Kubernetes, Consul, etcd or Zookeeper. The pattern separates the configuration of the service registry from the calling of the service.
Maven users must add a dependency for the service registry to be used. Possibilities include:
-
camel-consul -
camel-etcd -
camel-kubenetes -
camel-ribbon
Syntax for calling a service
To call a service, refer to the name of the service as shown below:
from("direct:start")
.serviceCall("foo")
.to("mock:result");The following example shows the XML DSL for calling a service:
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<serviceCall name="foo"/>
<to uri="mock:result"/>
</route>
</camelContext>
In these examples, Camel uses the component that integrates with the service registry to look up a service with the name foo. The lookup returns a set of IP:PORT pairs that refer to a list of active servers that host the remote service. Camel then randomly selects from that list the server to use and builds a Camel URI with the chosen IP and PORT number.
By default, Camel uses the HTTP component. In the example above, the call resolves to a Camel URI that is called by a dynamic toD endpoint as shown below:
toD("http://IP:PORT")<toD uri="http:IP:port"/>
You can use URI parameters to call the service, for example, beer=yes:
serviceCall("foo?beer=yes")<serviceCall name="foo?beer=yes"/>You can also provide a context path, for example:
serviceCall("foo/beverage?beer=yes")<serviceCall name="foo/beverage?beer=yes"/>Translating service names to URIs
As you can see, the service name resolves to a Camel endpoint URI. Following are a few more examples. The → shows the resolution of the Camel URI):
serviceCall("myService") -> http://hostname:port
serviceCall("myService/foo") -> http://hostname:port/foo
serviceCall("http:myService/foo") -> http:hostname:port/foo<serviceCall name="myService"/> -> http://hostname:port
<serviceCall name="myService/foo"/> -> http://hostname:port/foo
<serviceCall name="http:myService/foo"/> -> http:hostname:port/foo
To fully control the resolved URI, provide an additional URI parameter that specifies the desired Camel URI. In the specified URI, you can use the service name, which resolves to IP:PORT. Here are some examples:
serviceCall("myService", "http:myService.host:myService.port/foo") -> http:hostname:port/foo
serviceCall("myService", "netty4:tcp:myService?connectTimeout=1000") -> netty:tcp:hostname:port?connectTimeout=1000<serviceCall name="myService" uri="http:myService.host:myService.port/foo"/> -> http:hostname:port/foo
<serviceCall name="myService" uri="netty4:tcp:myService?connectTimeout=1000"/> -> netty:tcp:hostname:port?connectTimeout=1000
The examples above call a service named myService. The second parameter controls the value of the resolved URI. Notice that the first example uses serviceName.host and serviceName.port to refer to either the IP or the PORT. If you specify just serviceName then it resolves to IP:PORT.
Configuring the component that calls the service
By default, Camel uses the HTTP component to call the service. You can configure the use of a different component, such as HTTP4 or Netty4 HTTP, as in the following example:
KubernetesConfigurationDefinition config = new KubernetesConfigurationDefinition();
config.setComponent("netty4-http");
// Register the service call configuration:
context.setServiceCallConfiguration(config);
from("direct:start")
.serviceCall("foo")
.to("mock:result");Following is an example in XML DSL:
<camelContext xmlns="http://camel.apache.org/schema/spring">
<kubernetesConfiguration id="kubernetes" component="netty4-http"/>
<route>
<from uri="direct:start"/>
<serviceCall name="foo"/>
<to uri="mock:result"/>
</route>
</camelContext>Service call options when using Kubernetes
A Kubernetes implementation supports the following options:
| Option | Default Value | Description |
|
| Kubernetes API version when using client lookup. | |
|
| Sets the Certificate Authority data when using client lookup. | |
|
| Sets the Certificate Authority data that are loaded from the file when using client lookup. | |
|
| Sets the Client Certificate data when using client lookup. | |
|
| Sets the Client Certificate data that are loaded from the file when using client lookup. | |
|
| Sets the Client Keystore algorithm, such as RSA, when using client lookup. | |
|
| Sets the Client Keystore data when using client lookup. | |
|
| Sets the Client Keystore data that are loaded from the file when using client lookup. | |
|
| Sets the Client Keystore passphrase when using client lookup. | |
|
|
Sets the DNS domain to use for | |
|
|
| The choice of strategy used to look up the service. The lookup strategies include:
|
|
| The URL for the Kubernetes master when using client lookup. | |
|
|
The Kubernetes namespace to use. By default the namespace’s name is taken from the environment variable | |
|
| Sets the OAUTH token for authentication (instead of username/password) when using client lookup. | |
|
| Sets the password for authentication when using client lookup. | |
|
| false | Sets whether to turn on trust certificate check when using client lookup. |
|
| Sets the username for authentication when using client lookup. |
8.13. Multicast
Overview
The multicast pattern, shown in Figure 8.9, “Multicast Pattern”, is a variation of the recipient list with a fixed destination pattern, which is compatible with the InOut message exchange pattern. This is in contrast to recipient list, which is only compatible with the InOnly exchange pattern.
Figure 8.9. Multicast Pattern
Multicast with a custom aggregation strategy
Whereas the multicast processor receives multiple Out messages in response to the original request (one from each of the recipients), the original caller is only expecting to receive a single reply. Thus, there is an inherent mismatch on the reply leg of the message exchange, and to overcome this mismatch, you must provide a custom aggregation strategy to the multicast processor. The aggregation strategy class is responsible for aggregating all of the Out messages into a single reply message.
Consider the example of an electronic auction service, where a seller offers an item for sale to a list of buyers. The buyers each put in a bid for the item, and the seller automatically selects the bid with the highest price. You can implement the logic for distributing an offer to a fixed list of buyers using the multicast() DSL command, as follows:
from("cxf:bean:offer").multicast(new HighestBidAggregationStrategy()).
to("cxf:bean:Buyer1", "cxf:bean:Buyer2", "cxf:bean:Buyer3");
Where the seller is represented by the endpoint, cxf:bean:offer, and the buyers are represented by the endpoints, cxf:bean:Buyer1, cxf:bean:Buyer2, cxf:bean:Buyer3. To consolidate the bids received from the various buyers, the multicast processor uses the aggregation strategy, HighestBidAggregationStrategy. You can implement the HighestBidAggregationStrategy in Java, as follows:
// Java
import org.apache.camel.processor.aggregate.AggregationStrategy;
import org.apache.camel.Exchange;
public class HighestBidAggregationStrategy implements AggregationStrategy {
public Exchange aggregate(Exchange oldExchange, Exchange newExchange) {
float oldBid = oldExchange.getOut().getHeader("Bid", Float.class);
float newBid = newExchange.getOut().getHeader("Bid", Float.class);
return (newBid > oldBid) ? newExchange : oldExchange;
}
}
Where it is assumed that the buyers insert the bid price into a header named, Bid. For more details about custom aggregation strategies, see Section 8.5, “Aggregator”.
Parallel processing
By default, the multicast processor invokes each of the recipient endpoints one after another (in the order listed in the to() command). In some cases, this might cause unacceptably long latency. To avoid these long latency times, you have the option of enabling parallel processing by adding the parallelProcessing() clause. For example, to enable parallel processing in the electronic auction example, define the route as follows:
from("cxf:bean:offer")
.multicast(new HighestBidAggregationStrategy())
.parallelProcessing()
.to("cxf:bean:Buyer1", "cxf:bean:Buyer2", "cxf:bean:Buyer3");Where the multicast processor now invokes the buyer endpoints, using a thread pool that has one thread for each of the endpoints.
If you want to customize the size of the thread pool that invokes the buyer endpoints, you can invoke the executorService() method to specify your own custom executor service. For example:
from("cxf:bean:offer")
.multicast(new HighestBidAggregationStrategy())
.executorService(MyExecutor)
.to("cxf:bean:Buyer1", "cxf:bean:Buyer2", "cxf:bean:Buyer3");Where MyExecutor is an instance of java.util.concurrent.ExecutorService type.
When the exchange has an InOut pattern, an aggregation strategy is used to aggregate reply messages. The default aggregation strategy takes the latest reply message and discards earlier replies. For example, in the following route, the custom strategy, MyAggregationStrategy, is used to aggregate the replies from the endpoints, direct:a, direct:b, and direct:c:
from("direct:start")
.multicast(new MyAggregationStrategy())
.parallelProcessing()
.timeout(500)
.to("direct:a", "direct:b", "direct:c")
.end()
.to("mock:result");XML configuration example
The following example shows how to configure a similar route in XML, where the route uses a custom aggregation strategy and a custom thread executor:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="
http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-3.0.xsd
http://camel.apache.org/schema/spring http://camel.apache.org/schema/spring/camel-spring.xsd
">
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="cxf:bean:offer"/>
<multicast strategyRef="highestBidAggregationStrategy"
parallelProcessing="true"
threadPoolRef="myThreadExcutor">
<to uri="cxf:bean:Buyer1"/>
<to uri="cxf:bean:Buyer2"/>
<to uri="cxf:bean:Buyer3"/>
</multicast>
</route>
</camelContext>
<bean id="highestBidAggregationStrategy" class="com.acme.example.HighestBidAggregationStrategy"/>
<bean id="myThreadExcutor" class="com.acme.example.MyThreadExcutor"/>
</beans>
Where both the parallelProcessing attribute and the threadPoolRef attribute are optional. It is only necessary to set them if you want to customize the threading behavior of the multicast processor.
Apply custom processing to the outgoing messages
The multicast pattern copies the source Exchange and multicasts the copy. By default, the router makes a shallow copy of the source message. In a shallow copy, the headers and payload of the original message are copied by reference only, so that resulting copies of the original message are linked. Because shallow copies of a multicast message are linked, you’re unable to apply custom processing if the message body is mutable. Custom processing that you apply to a copy sent to one endpoint are also applied to copies sent to every other endpoint.
Although the multicast syntax allows you to invoke the process DSL command in the multicast clause, this does not make sense semantically and it does not have the same effect as onPrepare (in fact, in this context, the process DSL command has no effect).
Using onPrepare to execute custom logic when preparing messages
If you want to apply custom processing to each message replica before it is sent to its endpoint, you can invoke the onPrepare DSL command in the multicast clause. The onPrepare command inserts a custom processor just after the message has been shallow-copied and just before the message is dispatched to its endpoint. For example, in the following route, the CustomProc processor is invoked on the message sent to direct:a and the CustomProc processor is also invoked on the message sent to direct:b.
from("direct:start")
.multicast().onPrepare(new CustomProc())
.to("direct:a").to("direct:b");
A common use case for the onPrepare DSL command is to perform a deep copy of some or all elements of a message. For example, the following CustomProc processor class performs a deep copy of the message body, where the message body is presumed to be of type, BodyType, and the deep copy is performed by the method, BodyType.deepCopy().
// Java
import org.apache.camel.*;
...
public class CustomProc implements Processor {
public void process(Exchange exchange) throws Exception {
BodyType body = exchange.getIn().getBody(BodyType.class);
// Make a _deep_ copy of of the body object
BodyType clone = BodyType.deepCopy();
exchange.getIn().setBody(clone);
// Headers and attachments have already been
// shallow-copied. If you need deep copies,
// add some more code here.
}
}
You can use onPrepare to implement any kind of custom logic that you want to execute before the Exchange is multicast.
It is recommended practice to design for immutable objects.
For example if you have a mutable message body as this Animal class:
public class Animal implements Serializable {
private int id;
private String name;
public Animal() {
}
public Animal(int id, String name) {
this.id = id;
this.name = name;
}
public Animal deepClone() {
Animal clone = new Animal();
clone.setId(getId());
clone.setName(getName());
return clone;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public String toString() {
return id + " " + name;
}
}Then we can create a deep clone processor which clones the message body:
public class AnimalDeepClonePrepare implements Processor {
public void process(Exchange exchange) throws Exception {
Animal body = exchange.getIn().getBody(Animal.class);
// do a deep clone of the body which wont affect when doing multicasting
Animal clone = body.deepClone();
exchange.getIn().setBody(clone);
}
}
Then we can use the AnimalDeepClonePrepare class in the multicast route using the onPrepare option as shown:
from("direct:start")
.multicast().onPrepare(new AnimalDeepClonePrepare()).to("direct:a").to("direct:b");And the same example in XML DSL
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<!-- use on prepare with multicast -->
<multicast onPrepareRef="animalDeepClonePrepare">
<to uri="direct:a"/>
<to uri="direct:b"/>
</multicast>
</route>
<route>
<from uri="direct:a"/>
<process ref="processorA"/>
<to uri="mock:a"/>
</route>
<route>
<from uri="direct:b"/>
<process ref="processorB"/>
<to uri="mock:b"/>
</route>
</camelContext>
<!-- the on prepare Processor which performs the deep cloning -->
<bean id="animalDeepClonePrepare" class="org.apache.camel.processor.AnimalDeepClonePrepare"/>
<!-- processors used for the last two routes, as part of unit test -->
<bean id="processorA" class="org.apache.camel.processor.MulticastOnPrepareTest$ProcessorA"/>
<bean id="processorB" class="org.apache.camel.processor.MulticastOnPrepareTest$ProcessorB"/>Options
The multicast DSL command supports the following options:
| Name | Default Value | Description |
|
| Refers to an AggregationStrategy to be used to assemble the replies from the multicasts, into a single outgoing message from the multicast. By default Camel will use the last reply as the outgoing message. | |
|
|
This option can be used to explicitly specify the method name to use, when using POJOs as the | |
|
|
|
This option can be used, when using POJOs as the |
|
|
| If enabled, sending messages to the multicasts occurs concurrently. Note the caller thread will still wait until all messages has been fully processed, before it continues. Its only the sending and processing the replies from the multicasts which happens concurrently. |
|
|
|
If enabled, the |
|
| Refers to a custom Thread Pool to be used for parallel processing. Notice if you set this option, then parallel processing is automatic implied, and you do not have to enable that option as well. | |
|
|
| Camel 2.2: Whether or not to stop continue processing immediately when an exception occurred. If disable, then Camel will send the message to all multicasts regardless if one of them failed. You can deal with exceptions in the AggregationStrategy class where you have full control how to handle that. |
|
|
| If enabled then Camel will process replies out-of-order, eg in the order they come back. If disabled, Camel will process replies in the same order as multicasted. |
|
|
Camel 2.5: Sets a total timeout specified in milliseconds. If the multicast hasn’t been able to send and process all replies within the given timeframe, then the timeout triggers and the multicast breaks out and continues. Notice if you provide a TimeoutAwareAggregationStrategy then the | |
|
| Camel 2.8: Refers to a custom Processor to prepare the copy of the Exchange each multicast will receive. This allows you to do any custom logic, such as deep-cloning the message payload if that’s needed etc. | |
|
|
| Camel 2.8: Whether the unit of work should be shared. See the same option on Section 8.4, “Splitter” for more details. |
8.14. Composed Message Processor
Composed Message Processor
The composed message processor pattern, as shown in Figure 8.10, “Composed Message Processor Pattern”, allows you to process a composite message by splitting it up, routing the sub-messages to appropriate destinations, and then re-aggregating the responses back into a single message.
Figure 8.10. Composed Message Processor Pattern
Java DSL example
The following example checks that a multipart order can be filled, where each part of the order requires a check to be made at a different inventory:
// split up the order so individual OrderItems can be validated by the appropriate bean
from("direct:start")
.split().body()
.choice()
.when().method("orderItemHelper", "isWidget")
.to("bean:widgetInventory")
.otherwise()
.to("bean:gadgetInventory")
.end()
.to("seda:aggregate");
// collect and re-assemble the validated OrderItems into an order again
from("seda:aggregate")
.aggregate(new MyOrderAggregationStrategy())
.header("orderId")
.completionTimeout(1000L)
.to("mock:result");XML DSL example
The preceding route can also be written in XML DSL, as follows:
<route>
<from uri="direct:start"/>
<split>
<simple>body</simple>
<choice>
<when>
<method bean="orderItemHelper" method="isWidget"/>
<to uri="bean:widgetInventory"/>
</when>
<otherwise>
<to uri="bean:gadgetInventory"/>
</otherwise>
</choice>
<to uri="seda:aggregate"/>
</split>
</route>
<route>
<from uri="seda:aggregate"/>
<aggregate strategyRef="myOrderAggregatorStrategy" completionTimeout="1000">
<correlationExpression>
<simple>header.orderId</simple>
</correlationExpression>
<to uri="mock:result"/>
</aggregate>
</route>Processing steps
Processing starts by splitting the order, using a Section 8.4, “Splitter”. The Section 8.4, “Splitter” then sends individual OrderItems to a Section 8.1, “Content-Based Router”, which routes messages based on the item type. Widget items get sent for checking in the widgetInventory bean and gadget items get sent to the gadgetInventory bean. Once these OrderItems have been validated by the appropriate bean, they are sent on to the Section 8.5, “Aggregator” which collects and re-assembles the validated OrderItems into an order again.
Each received order has a header containing an order ID. We make use of the order ID during the aggregation step: the .header("orderId") qualifier on the aggregate() DSL command instructs the aggregator to use the header with the key, orderId, as the correlation expression.
For full details, check the ComposedMessageProcessorTest.java example source at camel-core/src/test/java/org/apache/camel/processor.
8.15. Scatter-Gather
Scatter-Gather
The scatter-gather pattern, as shown in Figure 8.11, “Scatter-Gather Pattern”, enables you to route messages to a number of dynamically specified recipients and re-aggregate the responses back into a single message.
Figure 8.11. Scatter-Gather Pattern

Dynamic scatter-gather example
The following example outlines an application that gets the best quote for beer from several different vendors. The examples uses a dynamic Section 8.3, “Recipient List” to request a quote from all vendors and an Section 8.5, “Aggregator” to pick the best quote out of all the responses. The routes for this application are defined as follows:
<camelContext id="camel" xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<recipientList>
<header>listOfVendors</header>
</recipientList>
</route>
<route>
<from uri="seda:quoteAggregator"/>
<aggregate strategyRef="aggregatorStrategy" completionTimeout="1000">
<correlationExpression>
<header>quoteRequestId</header>
</correlationExpression>
<to uri="mock:result"/>
</aggregate>
</route>
</camelContext>
In the first route, the Section 8.3, “Recipient List” looks at the listOfVendors header to obtain the list of recipients. Hence, the client that sends messages to this application needs to add a listOfVendors header to the message. Example 8.1, “Messaging Client Sample” shows some sample code from a messaging client that adds the relevant header data to outgoing messages.
Example 8.1. Messaging Client Sample
Map<String, Object> headers = new HashMap<String, Object>();
headers.put("listOfVendors", "bean:vendor1, bean:vendor2, bean:vendor3");
headers.put("quoteRequestId", "quoteRequest-1");
template.sendBodyAndHeaders("direct:start", "<quote_request item=\"beer\"/>", headers);
The message would be distributed to the following endpoints: bean:vendor1, bean:vendor2, and bean:vendor3. These beans are all implemented by the following class:
public class MyVendor {
private int beerPrice;
@Produce(uri = "seda:quoteAggregator")
private ProducerTemplate quoteAggregator;
public MyVendor(int beerPrice) {
this.beerPrice = beerPrice;
}
public void getQuote(@XPath("/quote_request/@item") String item, Exchange exchange) throws Exception {
if ("beer".equals(item)) {
exchange.getIn().setBody(beerPrice);
quoteAggregator.send(exchange);
} else {
throw new Exception("No quote available for " + item);
}
}
}
The bean instances, vendor1, vendor2, and vendor3, are instantiated using Spring XML syntax, as follows:
<bean id="aggregatorStrategy" class="org.apache.camel.spring.processor.scattergather.LowestQuoteAggregationStrategy"/>
<bean id="vendor1" class="org.apache.camel.spring.processor.scattergather.MyVendor">
<constructor-arg>
<value>1</value>
</constructor-arg>
</bean>
<bean id="vendor2" class="org.apache.camel.spring.processor.scattergather.MyVendor">
<constructor-arg>
<value>2</value>
</constructor-arg>
</bean>
<bean id="vendor3" class="org.apache.camel.spring.processor.scattergather.MyVendor">
<constructor-arg>
<value>3</value>
</constructor-arg>
</bean>
Each bean is initialized with a different price for beer (passed to the constructor argument). When a message is sent to each bean endpoint, it arrives at the MyVendor.getQuote method. This method does a simple check to see whether this quote request is for beer and then sets the price of beer on the exchange for retrieval at a later step. The message is forwarded to the next step using POJO Producing (see the @Produce annotation).
At the next step, we want to take the beer quotes from all vendors and find out which one was the best (that is, the lowest). For this, we use an Section 8.5, “Aggregator” with a custom aggregation strategy. The Section 8.5, “Aggregator” needs to identify which messages are relevant to the current quote, which is done by correlating messages based on the value of the quoteRequestId header (passed to the correlationExpression). As shown in Example 8.1, “Messaging Client Sample”, the correlation ID is set to quoteRequest-1 (the correlation ID should be unique). To pick the lowest quote out of the set, you can use a custom aggregation strategy like the following:
public class LowestQuoteAggregationStrategy implements AggregationStrategy {
public Exchange aggregate(Exchange oldExchange, Exchange newExchange) {
// the first time we only have the new exchange
if (oldExchange == null) {
return newExchange;
}
if (oldExchange.getIn().getBody(int.class) < newExchange.getIn().getBody(int.class)) {
return oldExchange;
} else {
return newExchange;
}
}
}Static scatter-gather example
You can specify the recipients explicitly in the scatter-gather application by employing a static Section 8.3, “Recipient List”. The following example shows the routes you would use to implement a static scatter-gather scenario:
from("direct:start").multicast().to("seda:vendor1", "seda:vendor2", "seda:vendor3");
from("seda:vendor1").to("bean:vendor1").to("seda:quoteAggregator");
from("seda:vendor2").to("bean:vendor2").to("seda:quoteAggregator");
from("seda:vendor3").to("bean:vendor3").to("seda:quoteAggregator");
from("seda:quoteAggregator")
.aggregate(header("quoteRequestId"), new LowestQuoteAggregationStrategy()).to("mock:result")8.16. Loop
Loop
The loop pattern enables you to process a message multiple times. It is used mainly for testing.
By default, the loop uses the same exchange throughout the looping. The result from the previous iteration is used for the next (see Section 5.4, “Pipes and Filters”). From Camel 2.8 on you can enable copy mode instead. See the options table for details.
Exchange properties
On each loop iteration, two exchange properties are set, which can optionally be read by any processors included in the loop.
| Property | Description |
|---|---|
|
| Apache Camel 2.0: Total number of loops |
|
| Apache Camel 2.0: Index of the current iteration (0 based) |
Java DSL examples
The following examples show how to take a request from the direct:x endpoint and then send the message repeatedly to mock:result. The number of loop iterations is specified either as an argument to loop() or by evaluating an expression at run time, where the expression must evaluate to an int (or else a RuntimeCamelException is thrown).
The following example passes the loop count as a constant:
from("direct:a").loop(8).to("mock:result");The following example evaluates a simple expression to determine the loop count:
from("direct:b").loop(header("loop")).to("mock:result");The following example evaluates an XPath expression to determine the loop count:
from("direct:c").loop().xpath("/hello/@times").to("mock:result");XML configuration example
You can configure the same routes in Spring XML.
The following example passes the loop count as a constant:
<route>
<from uri="direct:a"/>
<loop>
<constant>8</constant>
<to uri="mock:result"/>
</loop>
</route>The following example evaluates a simple expression to determine the loop count:
<route>
<from uri="direct:b"/>
<loop>
<header>loop</header>
<to uri="mock:result"/>
</loop>
</route>Using copy mode
Now suppose we send a message to direct:start endpoint containing the letter A. The output of processing this route will be that, each mock:loop endpoint will receive AB as message.
from("direct:start")
// instruct loop to use copy mode, which mean it will use a copy of the input exchange
// for each loop iteration, instead of keep using the same exchange all over
.loop(3).copy()
.transform(body().append("B"))
.to("mock:loop")
.end()
.to("mock:result");
However if we do not enable copy mode then mock:loop will receive AB, ABB, ABBB messages.
from("direct:start")
// by default loop will keep using the same exchange so on the 2nd and 3rd iteration its
// the same exchange that was previous used that are being looped all over
.loop(3)
.transform(body().append("B"))
.to("mock:loop")
.end()
.to("mock:result");The equivalent example in XML DSL in copy mode is as follows:
<route>
<from uri="direct:start"/>
<!-- enable copy mode for loop eip -->
<loop copy="true">
<constant>3</constant>
<transform>
<simple>${body}B</simple>
</transform>
<to uri="mock:loop"/>
</loop>
<to uri="mock:result"/>
</route>Options
The loop DSL command supports the following options:
| Name | Default Value | Description |
|
|
|
Camel 2.8: Whether or not copy mode is used. If |
Do While Loop
You can perform the loop until a condition is met using a do while loop. The condition will either be true or false.
In DSL, the command is LoopDoWhile. The following example will perform the loop until the message body length is 5 characters or less:
from("direct:start")
.loopDoWhile(simple("${body.length} <= 5"))
.to("mock:loop")
.transform(body().append("A"))
.end()
.to("mock:result");
In XML, the command is loop doWhile. The following example also performs the loop until the message body length is 5 characters or less:
<route>
<from uri="direct:start"/>
<loop doWhile="true">
<simple>${body.length} <= 5</simple>
<to uri="mock:loop"/>
<transform>
<simple>A${body}</simple>
</transform>
</loop>
<to uri="mock:result"/>
</route>8.17. Sampling
Sampling Throttler
A sampling throttler allows you to extract a sample of exchanges from the traffic through a route. It is configured with a sampling period during which only a single exchange is allowed to pass through. All other exchanges will be stopped.
By default, the sample period is 1 second.
Java DSL example
Use the sample() DSL command to invoke the sampler as follows:
// Sample with default sampling period (1 second)
from("direct:sample")
.sample()
.to("mock:result");
// Sample with explicitly specified sample period
from("direct:sample-configured")
.sample(1, TimeUnit.SECONDS)
.to("mock:result");
// Alternative syntax for specifying sampling period
from("direct:sample-configured-via-dsl")
.sample().samplePeriod(1).timeUnits(TimeUnit.SECONDS)
.to("mock:result");
from("direct:sample-messageFrequency")
.sample(10)
.to("mock:result");
from("direct:sample-messageFrequency-via-dsl")
.sample().sampleMessageFrequency(5)
.to("mock:result");Spring XML example
In Spring XML, use the sample element to invoke the sampler, where you have the option of specifying the sampling period using the samplePeriod and units attributes:
<route>
<from uri="direct:sample"/>
<sample samplePeriod="1" units="seconds">
<to uri="mock:result"/>
</sample>
</route>
<route>
<from uri="direct:sample-messageFrequency"/>
<sample messageFrequency="10">
<to uri="mock:result"/>
</sample>
</route>
<route>
<from uri="direct:sample-messageFrequency-via-dsl"/>
<sample messageFrequency="5">
<to uri="mock:result"/>
</sample>
</route>Options
The sample DSL command supports the following options:
| Name | Default Value | Description |
|
| Samples the message every N’th message. You can only use either frequency or period. | |
|
|
| Samples the message every N’th period. You can only use either frequency or period. |
|
|
|
Time unit as an enum of |
8.18. Dynamic Router
Dynamic Router
The Dynamic Router pattern, as shown in Figure 8.12, “Dynamic Router Pattern”, enables you to route a message consecutively through a series of processing steps, where the sequence of steps is not known at design time. The list of endpoints through which the message should pass is calculated dynamically at run time. Each time the message returns from an endpoint, the dynamic router calls back on a bean to discover the next endpoint in the route.
Figure 8.12. Dynamic Router Pattern
In Camel 2.5 we introduced a dynamicRouter in the DSL, which is like a dynamic Section 8.7, “Routing Slip” that evaluates the slip on-the-fly.
You must ensure that the expression used for the dynamicRouter (such as a bean), returns null to indicate the end. Otherwise, the dynamicRouter continues in an endless loop.
Dynamic Router in Camel 2.5 onwards
From Camel 2.5, the Section 8.18, “Dynamic Router” updates the exchange property, Exchange.SLIP_ENDPOINT, with the current endpoint as it advances through the slip. This enables you to find out how far the exchange has progressed through the slip. (It’s a slip because the Section 8.18, “Dynamic Router” implementation is based on Section 8.7, “Routing Slip”).
Java DSL
In Java DSL you can use the dynamicRouter as follows:
from("direct:start")
// use a bean as the dynamic router
.dynamicRouter(bean(DynamicRouterTest.class, "slip"));Which will leverage a bean integration to compute the slip on-the-fly, which could be implemented as follows:
// Java
/**
* Use this method to compute dynamic where we should route next.
*
* @param body the message body
* @return endpoints to go, or <tt>null</tt> to indicate the end
*/
public String slip(String body) {
bodies.add(body);
invoked++;
if (invoked == 1) {
return "mock:a";
} else if (invoked == 2) {
return "mock:b,mock:c";
} else if (invoked == 3) {
return "direct:foo";
} else if (invoked == 4) {
return "mock:result";
}
// no more so return null
return null;
}
The preceding example is not thread safe. You would have to store the state on the Exchange to ensure thread safety.
Spring XML
The same example in Spring XML would be:
<bean id="mySlip" class="org.apache.camel.processor.DynamicRouterTest"/>
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<dynamicRouter>
<!-- use a method call on a bean as dynamic router -->
<method ref="mySlip" method="slip"/>
</dynamicRouter>
</route>
<route>
<from uri="direct:foo"/>
<transform><constant>Bye World</constant></transform>
<to uri="mock:foo"/>
</route>
</camelContext>Options
The dynamicRouter DSL command supports the following options:
| Name | Default Value | Description |
|
|
| Delimiter used if the Part II, “Routing Expression and Predicate Languages” returned multiple endpoints. |
|
|
| If an endpoint uri could not be resolved, should it be ignored. Otherwise Camel will thrown an exception stating the endpoint uri is not valid. |
@DynamicRouter annotation
You can also use the @DynamicRouter annotation. For example:
// Java
public class MyDynamicRouter {
@Consume(uri = "activemq:foo")
@DynamicRouter
public String route(@XPath("/customer/id") String customerId, @Header("Location") String location, Document body) {
// query a database to find the best match of the endpoint based on the input parameteres
// return the next endpoint uri, where to go. Return null to indicate the end.
}
}
The route method is invoked repeatedly as the message progresses through the slip. The idea is to return the endpoint URI of the next destination. Return null to indicate the end. You can return multiple endpoints if you like, just as the Section 8.7, “Routing Slip”, where each endpoint is separated by a delimiter.