モニタリング
OpenShift Container Platform でのモニタリングスタックの設定および使用
概要
第1章 モニタリングの概要
1.1. OpenShift Container Platform モニタリングについて
OpenShift Container Platform には、コアプラットフォームコンポーネントのモニタリングを提供する事前に設定され、事前にインストールされた自己更新型のモニタリングスタックが含まれます。また、ユーザー定義プロジェクトのモニタリングを有効 にするオプションもあります。
クラスター管理者は、サポートされている設定で モニタリングスタックを設定 できます。OpenShift Container Platform は、追加設定が不要のモニタリングのベストプラクティスを提供します。
クラスター管理者にクラスターの問題について即時に通知するアラートのセットがデフォルトで含まれます。OpenShift Container Platform Web コンソールのデフォルトのダッシュボードには、クラスターの状態をすぐに理解できるようにするクラスターのメトリクスの視覚的な表示が含まれます。
OpenShift Container Platform Web コンソールを使用して、メトリクスの表示と管理、アラート、および モニタリングダッシュボードの確認 することができます。OpenShift Container Platform は、Prometheus、Alertmanager、および Grafana のような サードパーティーインターフェイス へのアクセスも提供します。
OpenShift Container Platform 4.9 のインストール後に、クラスター管理者はオプションでユーザー定義プロジェクトのモニターリングを有効にできます。この機能を使用することで、クラスター管理者、開発者、および他のユーザーは、サービスと Pod を独自のプロジェクトでモニターする方法を指定できます。クラスター管理者は、ユーザーメトリクスが利用できないことや、Prometheus が モニターリングの問題をトラブルシューティング する際に多くのディスク領域を消費することなど、一般的な問題に対する答えを見つけることができます。
1.2. モニタリングスタックについて
OpenShift Container Platform モニタリングスタックは、Prometheus オープンソースプロジェクトおよびその幅広いエコシステムをベースとしています。モニタリングスタックには、以下のコンポーネントが含まれます。
-
デフォルトのプラットフォームモニタリングコンポーネント。プラットフォームモニタリングコンポーネントのセットは、OpenShift Container Platform のインストール時にデフォルトで
openshift-monitoringプロジェクトにインストールされます。これにより、Kubernetes サービスを含む OpenShift Container Platform のコアコンポーネントのモニタリング機能が提供されます。デフォルトのモニタリングスタックは、クラスターのリモートのヘルスモニタリングも有効にします。これらのコンポーネントは、以下の図の Installed by default (デフォルトのインストール) セクションで説明されています。 -
ユーザー定義のプロジェクトをモニターするためのコンポーネント。オプションでユーザー定義プロジェクトのモニタリングを有効にした後に、追加のモニタリングコンポーネントは
openshift-user-workload-monitoringプロジェクトにインストールされます。これにより、ユーザー定義プロジェクトのモニタリング機能が提供されます。これらのコンポーネントは、以下の図の User (ユーザー) セクションで説明されています。
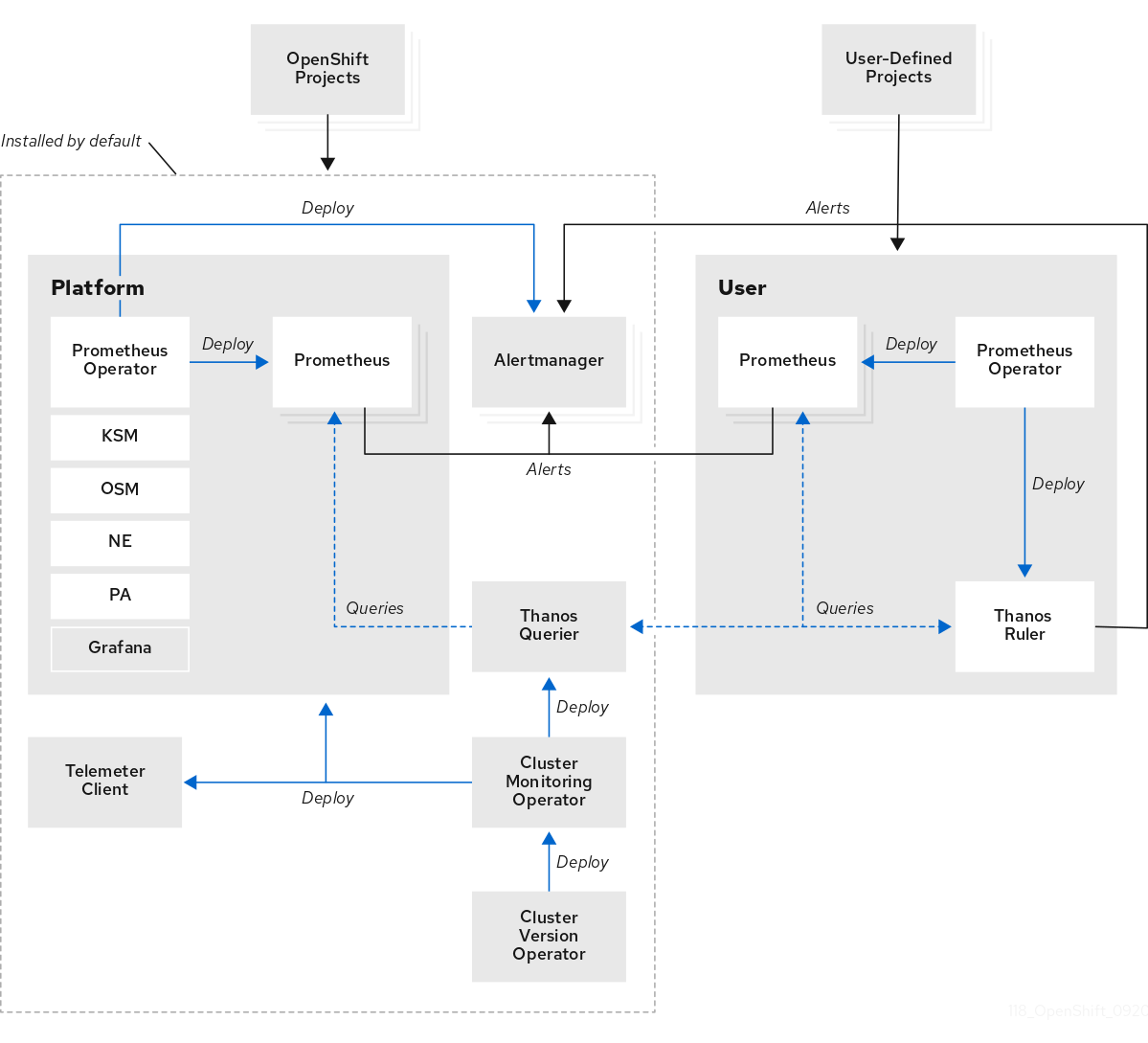
1.2.1. デフォルトのモニタリングコンポーネント
デフォルトで、OpenShift Container Platform 4.9 モニターリングスタックには、以下のコンポーネントが含まれます。
| コンポーネント | 説明 |
|---|---|
| クラスターモニタリング Operator | Cluster Monitoring Operator (CMO) は、モニタリングスタックの中心的なコンポーネントです。Prometheus および Alertmanager インスタンス、Thanos Querier、Telemeter Client、およびメトリクスターゲットをデプロイ、管理、および自動更新します。CMO は Cluster Version Operator (CVO) によってデプロイされます。 |
| Prometheus Operator |
|
| Prometheus | Prometheus は、OpenShift Container Platform モニタリングスタックのベースとなるモニタリングシステムです。Prometheus は Time Series を使用するデータベースであり、メトリクスのルール評価エンジンです。Prometheus は処理のためにアラートを Alertmanager に送信します。 |
| Prometheus アダプター |
Prometheus アダプター (上記の図の PA) は、Prometheus で使用する Kubernetes ノードおよび Pod クエリーを変換します。変換されるリソースメトリクスには、CPU およびメモリーの使用率メトリクスが含まれます。Prometheus アダプターは、Horizontal Pod Autoscaling のクラスターリソースメトリクス API を公開します。Prometheus アダプターは |
| Alertmanager | Alertmanager サービスは、Prometheus から送信されるアラートを処理します。また、Alertmanager は外部の通知システムにアラートを送信します。 |
|
|
|
|
|
OpenShift Container Platform 固有のリソースのメトリクスを追加すると、 |
|
|
|
| Thanos Querier | Thanos Querier は、単一のマルチテナントインターフェイスで、OpenShift Container Platform のコアメトリクスおよびユーザー定義プロジェクトのメトリクスを集約し、オプションでこれらの重複を排除します。 |
| Grafana | Grafana 解析プラットフォームは、メトリクスの分析および可視化のためのダッシュボードを提供します。モニタリングスタックおよびダッシュボードと共に提供される Grafana インスタンスは読み取り専用です。 |
| Telemeter クライアント | Telemeter Client は、クラスターのリモートヘルスモニタリングを容易にするために、プラットフォーム Prometheus インスタンスから Red Hat にデータのサブセクションを送信します。 |
モニターリグスタックのすべてのコンポーネントはスタックによってモニターされ、OpenShift Container Platform の更新時に自動的に更新されます。
1.2.2. デフォルトのモニタリングターゲット
スタック自体のコンポーネントに加え、デフォルトのモニタリングスタックは以下をモニターします。
- CoreDNS
- Elasticsearch(ロギングがインストールされている場合)
- etcd
- Fluentd(ロギングがインストールされている場合)
- HAProxy
- イメージレジストリー
- Kubelets
- Kubernetes API サーバー
- Kubernetes コントローラーマネージャー
- Kubernetes スケジューラー
- Metering(メータリングがインストールされている場合)
- OpenShift API サーバー
- OpenShift Controller Manager
- Operator Lifecycle Manager (OLM)
各 OpenShift Container Platform コンポーネントはそれぞれのモニタリング設定を行います。OpenShift Container Platform コンポーネントのモニタリングに関する問題は、一般的なモニタリングコンポーネントに対してではなく、そのコンポーネントに対して Jira 問題 を開きます。
他の OpenShift Container Platform フレームワークのコンポーネントもメトリクスを公開する場合があります。詳細については、それぞれのドキュメントを参照してください。
1.2.3. ユーザー定義プロジェクトをモニターするためのコンポーネント
OpenShift Container Platform 4.9 には、ユーザー定義プロジェクトでサービスおよび Pod をモニターできるモニターリングスタックのオプションの拡張機能が含まれています。この機能には、以下のコンポーネントが含まれます。
| コンポーネント | 説明 |
|---|---|
| Prometheus Operator |
|
| Prometheus | Prometheus は、ユーザー定義のプロジェクト用にモニタリング機能が提供されるモニタリングシステムです。Prometheus は処理のためにアラートを Alertmanager に送信します。 |
| Thanos Ruler | Thanos Ruler は、別のプロセスとしてデプロイされる Prometheus のルール評価エンジンです。OpenShift Container Platform 4.9 では、Thanos Ruler はユーザー定義プロジェクトのモニターリングについてのルールおよびアラート評価を提供します。 |
上記の表のコンポーネントは、モニタリングがユーザー定義のプロジェクトに対して有効にされた後にデプロイされます。
モニターリグスタックのすべてのコンポーネントはスタックによってモニターされ、OpenShift Container Platform の更新時に自動的に更新されます。
1.2.4. ユーザー定義プロジェクトのターゲットのモニタリング
モニタリングがユーザー定義プロジェクトについて有効にされている場合には、以下をモニターできます。
- ユーザー定義プロジェクトのサービスエンドポイント経由で提供されるメトリクス。
- ユーザー定義プロジェクトで実行される Pod。
1.3. OpenShift Container Platform モニタリングの一般用語集
この用語集では、OpenShift Container Platform アーキテクチャーで使用される一般的な用語を定義します。
- Alertmanager
- Alertmanager は、Prometheus から受信したアラートを処理します。また、Alertmanager は外部の通知システムにアラートを送信します。
- アラートルール
- アラートルールには、クラスター内の特定の状態を示す一連の条件が含まれます。アラートは、これらの条件が true の場合にトリガーされます。アラートルールには、アラートのルーティング方法を定義する重大度を割り当てることができます。
- クラスターモニタリング Operator
- Cluster Monitoring Operator (CMO) は、モニタリングスタックの中心的なコンポーネントです。Thanos Querier、Telemeter Client、メトリクスターゲットなどの Prometheus インスタンスをデプロイおよび管理して、それらが最新であることを確認します。CMO は Cluster Version Operator (CVO) によってデプロイされます。
- Cluster Version Operator
- Cluster Version Operator (CVO) はクラスター Operator のライフサイクルを管理し、その多くはデフォルトで OpenShift Container Platform にインストールされます。
- 設定マップ
-
設定マップは、設定データを Pod に注入する方法を提供します。タイプ
ConfigMapのボリューム内の設定マップに格納されたデータを参照できます。Pod で実行しているアプリケーションは、このデータを使用できます。 - Container
- コンテナーは、ソフトウェアとそのすべての依存関係を含む軽量で実行可能なイメージです。コンテナーは、オペレーティングシステムを仮想化します。そのため、コンテナーはデータセンターからパブリッククラウド、プライベートクラウド、開発者のラップトップなどまで、場所を問わずコンテナーを実行できます。
- カスタムリソース (CR)
- CR は Kubernetes API のエクステンションです。カスタムリソースを作成できます。
- etcd
- etcd は OpenShift Container Platform のキーと値のストアであり、すべてのリソースオブジェクトの状態を保存します。
- Fluentd
- Fluentd は、ノードからログを収集し、そのログを Elasticsearch に送ります。
- Kubelets
- ノード上で実行され、コンテナーマニフェストを読み取ります。定義されたコンテナーが開始され、実行されていることを確認します。
- Kubernetes API サーバー
- Kubernetes API サーバーは、API オブジェクトのデータを検証して設定します。
- Kubernetes コントローラーマネージャー
- Kubernetes コントローラーマネージャーは、クラスターの状態を管理します。
- Kubernetes スケジューラー
- Kubernetes スケジューラーは Pod をノードに割り当てます。
- labels
- ラベルは、Pod などのオブジェクトのサブセットを整理および選択するために使用できるキーと値のペアです。
- メータリング
- メータリングは、異なるデータソースからデータを処理するためのレポートを作成できる汎用のデータ分析ツールです。
- node
- OpenShift Container Platform クラスター内のワーカーマシン。ノードは、仮想マシン (VM) または物理マシンのいずれかです。
- Operator
- OpenShift Container Platform クラスターで Kubernetes アプリケーションをパッケージ化、デプロイ、および管理するための推奨される方法。Operator は、人間による操作に関する知識を取り入れて、簡単にパッケージ化してお客様と共有できるソフトウェアにエンコードします。
- Operator Lifecycle Manager (OLM)
- OLM は、Kubernetes ネイティブアプリケーションのライフサイクルをインストール、更新、および管理するのに役立ちます。OLM は、Operator を効果的かつ自動化されたスケーラブルな方法で管理するために設計されたオープンソースのツールキットです。
- 永続ストレージ
- デバイスがシャットダウンされた後でもデータを保存します。Kubernetes は永続ボリュームを使用して、アプリケーションデータを保存します。
- 永続ボリューム要求 (PVC)
- PVC を使用して、PersistentVolume を Pod にマウントできます。クラウド環境の詳細を知らなくてもストレージにアクセスできます。
- Pod
- Pod は、Kubernetes における最小の論理単位です。Pod には、ワーカーノードで実行される 1 つ以上のコンテナーが含まれます。
- Prometheus
- Prometheus は、OpenShift Container Platform モニタリングスタックのベースとなるモニタリングシステムです。Prometheus は Time Series を使用するデータベースであり、メトリクスのルール評価エンジンです。Prometheus は処理のためにアラートを Alertmanager に送信します。
- Prometheus アダプター
- Prometheus アダプターは、Prometheus で使用するために Kubernetes ノードと Pod のクエリーを変換します。変換されるリソースメトリクスには、CPU およびメモリーの使用率が含まれます。Prometheus アダプターは、Horizontal Pod Autoscaling のクラスターリソースメトリクス API を公開します。
- Prometheus Operator
-
openshift-monitoringプロジェクトの Prometheus Operator(PO) は、プラットフォーム Prometheus インスタンスおよび Alertmanager インスタンスを作成し、設定し、管理します。また、Kubernetes ラベルのクエリーに基づいてモニタリングターゲットの設定を自動生成します。 - サイレンス
- サイレンスをアラートに適用し、アラートの条件が true の場合に通知が送信されることを防ぐことができます。初期通知後はアラートをミュートにして、根本的な問題の解決に取り組むことができます。
- storage
- OpenShift Container Platform は、オンプレミスおよびクラウドプロバイダーの両方で、多くのタイプのストレージをサポートします。OpenShift Container Platform クラスターで、永続データおよび非永続データ用のコンテナーストレージを管理できます。
- Thanos Ruler
- Thanos Ruler は、別のプロセスとしてデプロイされる Prometheus のルール評価エンジンです。OpenShift Container Platform では、Thanos Ruler はユーザー定義プロジェクトをモニタリングするためのルールおよびアラート評価を提供します。
- Web コンソール
- OpenShift Container Platform を管理するためのユーザーインターフェイス (UI)。
1.5. 次のステップ
第2章 モニタリングスタックの設定
OpenShift Container Platform 4 インストールプログラムは、インストール前の少数の設定オプションのみを提供します。ほとんどの OpenShift Container Platform フレームワークコンポーネント (クラスターモニタリングスタックを含む) の設定はインストール後に行われます。
このセクションでは、サポートされている設定内容を説明し、モニタリングスタックの設定方法を示し、いくつかの一般的な設定シナリオを示します。
2.1. 前提条件
- モニタリングスタックには、追加のリソース要件があります。コンピューティングリソースの推奨事項については、Cluster Monitoring Operator のスケーリング を参照し、十分なリソースがあることを確認してください。
2.2. モニタリングのメンテナンスおよびサポート
OpenShift Container Platform モニタリングの設定は、本書で説明されているオプションを使用して行う方法がサポートされている方法です。サポートされていない他の設定は使用しないでください。設定のパラダイムが Prometheus リリース間で変更される可能性があり、このような変更には、設定のすべての可能性が制御されている場合のみ適切に対応できます。本セクションで説明されている設定以外の設定を使用する場合、cluster-monitoring-operator が差分を調整するため、変更内容は失われます。Operator はデフォルトで定義された状態へすべてをリセットします。
2.2.1. モニタリングのサポートに関する考慮事項
以下の変更は明示的にサポートされていません。
-
追加の
ServiceMonitor、PodMonitor、およびPrometheusRuleオブジェクトをopenshift-*およびkube-*プロジェクトに作成します。 openshift-monitoringまたはopenshift-user-workload-monitoringプロジェクトにデプロイされるリソースまたはオブジェクト変更OpenShift Container Platform モニタリングスタックによって作成されるリソースは、後方互換性の保証がないために他のリソースで使用されることは意図されていません。注記Alertmanager 設定は、
openshift-monitoringプロジェクトにシークレットリソースとしてデプロイされます。Alertmanager の追加ルートを設定するには、そのシークレットをデコードし、変更し、その後にエンコードする必要があります。この手順は、前述のステートメントに対してサポートされる例外です。- スタックのリソースの変更。OpenShift Container Platform モニタリングスタックは、そのリソースが常に期待される状態にあることを確認します。これらが変更される場合、スタックはこれらをリセットします。
-
ユーザー定義ワークロードの
openshift-*、およびkube-*プロジェクトへのデプロイ。これらのプロジェクトは Red Hat が提供するコンポーネント用に予約され、ユーザー定義のワークロードに使用することはできません。 - モニタリングスタック Grafana インスタンスの変更。
- カスタム Prometheus インスタンスの OpenShift Container Platform へのインストール。カスタムインスタンスは、Prometheus Operator によって管理される Prometheus カスタムリソース (CR) です。
-
Prometheus Operator での
Probeカスタムリソース定義 (CRD) による現象ベースのモニタリングの有効化。 -
Prometheus Operator での
AlertmanagerConfigCRD を使用した Alertmanager 設定の変更。
メトリクス、記録ルールまたはアラートルールの後方互換性を保証されません。
2.2.2. Operator のモニタリングについてのサポートポリシー
モニタリング Operator により、OpenShift Container Platform モニタリングリソースの設定およびテスト通りに機能することを確認できます。Operator の Cluster Version Operator (CVO) コントロールがオーバーライドされる場合、Operator は設定の変更に対応せず、クラスターオブジェクトの意図される状態を調整したり、更新を受信したりしません。
Operator の CVO コントロールのオーバーライドはデバッグ時に役立ちますが、これはサポートされず、クラスター管理者は個々のコンポーネントの設定およびアップグレードを完全に制御することを前提としています。
Cluster Version Operator のオーバーライド
spec.overrides パラメーターを CVO の設定に追加すると、管理者はコンポーネントについての CVO の動作にオーバーライドの一覧を追加できます。コンポーネントについて spec.overrides[].unmanaged パラメーターを true に設定すると、クラスターのアップグレードがブロックされ、CVO のオーバーライドが設定された後に管理者にアラートが送信されます。
Disabling ownership via cluster version overrides prevents upgrades. Please remove overrides before continuing.CVO のオーバーライドを設定すると、クラスター全体がサポートされていない状態になり、モニタリングスタックをその意図された状態に調整されなくなります。これは Operator に組み込まれた信頼性の機能に影響を与え、更新が受信されなくなります。サポートを継続するには、オーバーライドを削除した後に、報告された問題を再現する必要があります。
2.3. モニタリングスタックの設定の準備
モニタリング設定マップを作成し、更新してモニタリングスタックを設定できます。
2.3.1. クラスターモニタリング設定マップの作成
OpenShift Container Platform のコアモニタリングコンポーネントを設定するには、cluster-monitoring-config ConfigMap オブジェクトを openshift-monitoring プロジェクトに作成する必要があります。
変更を cluster-monitoring-config ConfigMap オブジェクトに保存すると、openshift-monitoring プロジェクトの Pod の一部またはすべてが再デプロイされる可能性があります。これらのコンポーネントが再デプロイするまで時間がかかる場合があります。
前提条件
-
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。 -
OpenShift CLI (
oc) がインストールされている。
手順
cluster-monitoring-configConfigMapオブジェクトが存在するかどうかを確認します。$ oc -n openshift-monitoring get configmap cluster-monitoring-configConfigMapオブジェクトが存在しない場合:以下の YAML マニフェストを作成します。以下の例では、このファイルは
cluster-monitoring-config.yamlという名前です。apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: |設定を適用して
ConfigMapを作成します。$ oc apply -f cluster-monitoring-config.yaml
2.3.2. ユーザー定義のワークロードモニタリング設定マップの作成
ユーザー定義プロジェクトをモニターするコンポーネントを設定するには、user-workload-monitoring-config ConfigMap オブジェクトを openshift-user-workload-monitoring プロジェクトに作成する必要があります。
変更を user-workload-monitoring-config ConfigMap オブジェクトに保存すると、openshift-user-workload-monitoring プロジェクトの Pod の一部またはすべてが再デプロイされる可能性があります。これらのコンポーネントが再デプロイするまで時間がかかる場合があります。ユーザー定義プロジェクトのモニタリングを最初に有効にする前に設定マップを作成し、設定することができます。これにより、Pod を頻繁に再デプロイする必要がなくなります。
前提条件
-
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。 -
OpenShift CLI (
oc) がインストールされている。
手順
user-workload-monitoring-configConfigMapオブジェクトが存在するかどうかを確認します。$ oc -n openshift-user-workload-monitoring get configmap user-workload-monitoring-configuser-workload-monitoring-configConfigMapオブジェクトが存在しない場合:以下の YAML マニフェストを作成します。以下の例では、このファイルは
user-workload-monitoring-config.yamlという名前です。apiVersion: v1 kind: ConfigMap metadata: name: user-workload-monitoring-config namespace: openshift-user-workload-monitoring data: config.yaml: |設定を適用して
ConfigMapを作成します。$ oc apply -f user-workload-monitoring-config.yaml注記user-workload-monitoring-configConfigMapオブジェクトに適用される設定は、クラスター管理者がユーザー定義プロジェクトのモニタリングを有効にしない限りアクティブにされません。
2.4. モニタリングスタックの設定
OpenShift Container Platform 4.9 では、 cluster-monitoring-config または user-workload-monitoring-config ConfigMap オブジェクトを使用してモニターリングスタックを設定できます。設定マップはクラスターモニタリング Operator (CMO) を設定し、その後にスタックのコンポーネントが設定されます。
前提条件
OpenShift Container Platform のコアモニタリングコンポーネントを設定する場合、以下を実行します。
-
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。 -
cluster-monitoring-configConfigMapオブジェクトを作成している。
-
ユーザー定義のプロジェクトをモニターするコンポーネントを設定する場合:
-
cluster-adminロールを持つユーザーとして、またはopenshift-user-workload-monitoringプロジェクトのuser-workload-monitoring-config-editロールを持つユーザーとして、クラスターにアクセスできる。 -
user-workload-monitoring-configConfigMapオブジェクトを作成している。
-
-
OpenShift CLI (
oc) がインストールされている。
手順
ConfigMapオブジェクトを編集します。OpenShift Container Platform のコアモニタリングコンポーネントを設定するには、以下を実行します。
openshift-monitoringプロジェクトでcluster-monitoring-configConfigMapオブジェクトを編集します。$ oc -n openshift-monitoring edit configmap cluster-monitoring-config設定を、
data/config.yamlの下に値とキーのペア<component_name>: <component_configuration>として追加します。apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | <component>: <configuration_for_the_component><component>および<configuration_for_the_component>を随時置き換えます。以下の
ConfigMapオブジェクトの例は、Prometheus の永続ボリューム要求 (PVC) を設定します。これは、OpenShift Container Platform のコアコンポーネントのみをモニターする Prometheus インスタンスに関連します。apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | prometheusK8s:1 volumeClaimTemplate: spec: storageClassName: fast volumeMode: Filesystem resources: requests: storage: 40Gi- 1
- Prometheus コンポーネントを定義し、後続の行はその設定を定義します。
ユーザー定義のプロジェクトをモニターするコンポーネントを設定するには、以下を実行します。
openshift-user-workload-monitoringプロジェクトでuser-workload-monitoring-configConfigMapオブジェクトを編集します。$ oc -n openshift-user-workload-monitoring edit configmap user-workload-monitoring-config設定を、
data/config.yamlの下に値とキーのペア<component_name>: <component_configuration>として追加します。apiVersion: v1 kind: ConfigMap metadata: name: user-workload-monitoring-config namespace: openshift-user-workload-monitoring data: config.yaml: | <component>: <configuration_for_the_component><component>および<configuration_for_the_component>を随時置き換えます。以下の
ConfigMapオブジェクトの例は、Prometheus のデータ保持期間および最小コンテナーリソース要求を設定します。これは、ユーザー定義のプロジェクトのみをモニターする Prometheus インスタンスに関連します。apiVersion: v1 kind: ConfigMap metadata: name: user-workload-monitoring-config namespace: openshift-user-workload-monitoring data: config.yaml: | prometheus:1 retention: 24h2 resources: requests: cpu: 200m3 memory: 2Gi4 注記Prometheus 設定マップコンポーネントは、
cluster-monitoring-configConfigMapオブジェクトでprometheusK8sと呼ばれ、user-workload-monitoring-configConfigMapオブジェクトでprometheusと呼ばれます。
ファイルを保存して、変更を
ConfigMapオブジェクトに適用します。新規設定の影響を受けた Pod は自動的に再起動されます。注記user-workload-monitoring-configConfigMapオブジェクトに適用される設定は、クラスター管理者がユーザー定義プロジェクトのモニタリングを有効にしない限りアクティブにされません。警告変更がモニタリング設定マップに保存されると、関連するプロジェクトの Pod およびその他のリソースが再デプロイされる可能性があります。該当するプロジェクトの実行中のモニタリングプロセスも再起動する可能性があります。
2.5. 設定可能なモニタリングコンポーネント
以下の表は、設定可能なモニタリングコンポーネントと、cluster-monitoring-config および user-workload-monitoring-config ConfigMap オブジェクトでコンポーネントを指定するために使用されるキーを示しています。
| コンポーネント | cluster-monitoring-config 設定マップキー | user-workload-monitoring-config 設定マップキー |
|---|---|---|
| Prometheus Operator |
|
|
| Prometheus |
|
|
| Alertmanager |
| |
| kube-state-metrics |
| |
| openshift-state-metrics |
| |
| Grafana |
| |
| Telemeter クライアント |
| |
| Prometheus アダプター |
| |
| Thanos Querier |
| |
| Thanos Ruler |
|
Prometheus キーは、cluster-monitoring-config ConfigMap で prometheusK8s と呼ばれ、user-workload-monitoring-config ConfigMap オブジェクトで prometheus と呼ばれています。
2.6. モニタリングコンポーネントの異なるノードへの移動
モニタリングスタックコンポーネントのいずれかを指定されたノードに移動できます。
前提条件
OpenShift Container Platform のコアモニタリングコンポーネントを設定する場合、以下を実行します。
-
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。 -
cluster-monitoring-configConfigMapオブジェクトを作成している。
-
ユーザー定義のプロジェクトをモニターするコンポーネントを設定する場合:
-
cluster-adminロールを持つユーザーとして、またはopenshift-user-workload-monitoringプロジェクトのuser-workload-monitoring-config-editロールを持つユーザーとして、クラスターにアクセスできる。 -
user-workload-monitoring-configConfigMapオブジェクトを作成している。
-
-
OpenShift CLI (
oc) がインストールされている。
手順
ConfigMapオブジェクトを編集します。OpenShift Container Platform のコアプロジェクトをモニターするコンポーネントを移行するには、以下を実行します。
openshift-monitoringプロジェクトでcluster-monitoring-configConfigMapオブジェクトを編集します。$ oc -n openshift-monitoring edit configmap cluster-monitoring-configコンポーネントの
nodeSelector制約をdata/config.yamlに指定します。apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | <component>: nodeSelector: <node_key>: <node_value> <node_key>: <node_value> <...><component>を適宜置き換え、<node_key>: <node_value>を、宛先ノードのグループを指定するキーと値のペアのマップに置き換えます。通常は、単一のキーと値のペアのみが使用されます。コンポーネントは、指定されたキーと値のペアのそれぞれをラベルとして持つノードでのみ実行できます。ノードには追加のラベルを持たせることもできます。
重要モニタリングコンポーネントの多くは、高可用性を維持するために、クラスターの異なるノード間で複数の Pod を使用してデプロイされます。モニタリングコンポーネントをラベル付きノードに移動する際には、コンポーネントの耐障害性を維持するために十分な数の一致するノードが利用可能であることを確認します。1 つのラベルのみが指定されている場合は、複数の別々のノードにコンポーネントに関連するすべての Pod を分散するために、十分な数のノードにそのラベルが含まれていることを確認します。または、複数のラベルを指定することもできます。その場合は、それぞれのラベルを個々のノードに関連付けます。
注記nodeSelectorの制約を設定した後もモニタリングコンポーネントがPending状態のままになっている場合は、Pod ログでテイントおよび容認に関連するエラーの有無を確認します。たとえば、OpenShift Container Platform のコアプロジェクトのモニタリングコンポーネントを、
nodename: controlplane1、nodename: worker1、nodename: worker2、およびnodename: worker2のラベルが付けられた特定のノードに移行するには、以下を使用します。apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | prometheusOperator: nodeSelector: nodename: controlplane1 prometheusK8s: nodeSelector: nodename: worker1 nodename: worker2 alertmanagerMain: nodeSelector: nodename: worker1 nodename: worker2 kubeStateMetrics: nodeSelector: nodename: worker1 grafana: nodeSelector: nodename: worker1 telemeterClient: nodeSelector: nodename: worker1 k8sPrometheusAdapter: nodeSelector: nodename: worker1 nodename: worker2 openshiftStateMetrics: nodeSelector: nodename: worker1 thanosQuerier: nodeSelector: nodename: worker1 nodename: worker2
ユーザー定義プロジェクトをモニターするコンポーネントを移動するには、以下を実行します。
openshift-user-workload-monitoringプロジェクトでuser-workload-monitoring-configConfigMapオブジェクトを編集します。$ oc -n openshift-user-workload-monitoring edit configmap user-workload-monitoring-configコンポーネントの
nodeSelector制約をdata/config.yamlに指定します。apiVersion: v1 kind: ConfigMap metadata: name: user-workload-monitoring-config namespace: openshift-user-workload-monitoring data: config.yaml: | <component>: nodeSelector: <node_key>: <node_value> <node_key>: <node_value> <...><component>を適宜置き換え、<node_key>: <node_value>を、宛先ノードを指定するキーと値のペアのマップに置き換えます。通常は、単一のキーと値のペアのみが使用されます。コンポーネントは、指定されたキーと値のペアのそれぞれをラベルとして持つノードでのみ実行できます。ノードには追加のラベルを持たせることもできます。
重要モニタリングコンポーネントの多くは、高可用性を維持するために、クラスターの異なるノード間で複数の Pod を使用してデプロイされます。モニタリングコンポーネントをラベル付きノードに移動する際には、コンポーネントの耐障害性を維持するために十分な数の一致するノードが利用可能であることを確認します。1 つのラベルのみが指定されている場合は、複数の別々のノードにコンポーネントに関連するすべての Pod を分散するために、十分な数のノードにそのラベルが含まれていることを確認します。または、複数のラベルを指定することもできます。その場合は、それぞれのラベルを個々のノードに関連付けます。
注記nodeSelectorの制約を設定した後もモニタリングコンポーネントがPending状態のままになっている場合は、Pod ログでテイントおよび容認に関連するエラーの有無を確認します。たとえば、ユーザー定義プロジェクトのモニタリングコンポーネントを
nodename: worker1、nodename: worker2、およびnodename: worker2のラベルが付けられた特定のワーカーノードに移行するには、以下を使用します。apiVersion: v1 kind: ConfigMap metadata: name: user-workload-monitoring-config namespace: openshift-user-workload-monitoring data: config.yaml: | prometheusOperator: nodeSelector: nodename: worker1 prometheus: nodeSelector: nodename: worker1 nodename: worker2 thanosRuler: nodeSelector: nodename: worker1 nodename: worker2
変更を適用するためにファイルを保存します。新しい設定の影響を受けるコンポーネントは新しいノードに自動的に移動します。
注記user-workload-monitoring-configConfigMapオブジェクトに適用される設定は、クラスター管理者がユーザー定義プロジェクトのモニタリングを有効にしない限りアクティブにされません。警告変更がモニタリング設定マップに保存されると、関連するプロジェクトの Pod およびその他のリソースが再デプロイされる可能性があります。該当するプロジェクトの実行中のモニタリングプロセスも再起動する可能性があります。
2.7. モニタリングコンポーネントへの容認 (Toleration) の割り当て
容認をモニタリングスタックのコンポーネントに割り当て、それらをテイントされたノードに移動することができます。
前提条件
OpenShift Container Platform のコアモニタリングコンポーネントを設定する場合、以下を実行します。
-
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。 -
cluster-monitoring-configConfigMapオブジェクトを作成している。
-
ユーザー定義のプロジェクトをモニターするコンポーネントを設定する場合:
-
cluster-adminロールを持つユーザーとして、またはopenshift-user-workload-monitoringプロジェクトのuser-workload-monitoring-config-editロールを持つユーザーとして、クラスターにアクセスできる。 -
user-workload-monitoring-configConfigMapオブジェクトを作成している。
-
-
OpenShift CLI (
oc) がインストールされている。
手順
ConfigMapオブジェクトを編集します。容認をコア OpenShift Container Platform プロジェクトをモニターするコンポーネントに割り当てるには、以下を実行します。
openshift-monitoringプロジェクトでcluster-monitoring-configConfigMapオブジェクトを編集します。$ oc -n openshift-monitoring edit configmap cluster-monitoring-configコンポーネントの
tolerationsを指定します。apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | <component>: tolerations: <toleration_specification><component>および<toleration_specification>を随時置き換えます。たとえば、
oc adm taint nodes node1 key1=value1:NoScheduleは、キーがkey1で、値がvalue1のnode1にテイントを追加します。これにより、モニタリングコンポーネントがnode1に Pod をデプロイするのを防ぎます。ただし、そのテイントに対して許容値が設定されている場合を除きます。以下の例は、サンプルのテイントを容認するようにalertmanagerMainコンポーネントを設定します。apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | alertmanagerMain: tolerations: - key: "key1" operator: "Equal" value: "value1" effect: "NoSchedule"
ユーザー定義プロジェクトをモニターするコンポーネントに容認を割り当てるには、以下を実行します。
openshift-user-workload-monitoringプロジェクトでuser-workload-monitoring-configConfigMapオブジェクトを編集します。$ oc -n openshift-user-workload-monitoring edit configmap user-workload-monitoring-configコンポーネントの
tolerationsを指定します。apiVersion: v1 kind: ConfigMap metadata: name: user-workload-monitoring-config namespace: openshift-user-workload-monitoring data: config.yaml: | <component>: tolerations: <toleration_specification><component>および<toleration_specification>を随時置き換えます。たとえば、
oc adm taint nodes node1 key1=value1:NoScheduleは、キーがkey1で、値がvalue1のnode1にテイントを追加します。これにより、モニタリングコンポーネントがnode1に Pod をデプロイするのを防ぎます。ただし、そのテイントに対して許容値が設定されている場合を除きます。以下の例では、サンプルのテイントを容認するようにthanosRulerコンポーネントを設定します。apiVersion: v1 kind: ConfigMap metadata: name: user-workload-monitoring-config namespace: openshift-user-workload-monitoring data: config.yaml: | thanosRuler: tolerations: - key: "key1" operator: "Equal" value: "value1" effect: "NoSchedule"
変更を適用するためにファイルを保存します。新しいコンポーネントの配置設定が自動的に適用されます。
注記user-workload-monitoring-configConfigMapオブジェクトに適用される設定は、クラスター管理者がユーザー定義プロジェクトのモニタリングを有効にしない限りアクティブにされません。警告変更がモニタリング設定マップに保存されると、関連するプロジェクトの Pod およびその他のリソースが再デプロイされる可能性があります。該当するプロジェクトの実行中のモニタリングプロセスも再起動する可能性があります。
2.8. 永続ストレージの設定
クラスターモニタリングを永続ストレージと共に実行すると、メトリクスは永続ボリューム (PV) に保存され、Pod の再起動または再作成後も維持されます。これは、メトリクスデータまたはアラートデータをデータ損失から保護する必要がある場合に適しています。実稼働環境では、永続ストレージを設定することを強く推奨します。IO デマンドが高いため、ローカルストレージを使用することが有利になります。
設定可能な推奨のストレージ技術 を参照してください。
2.8.1. 永続ストレージの前提条件
- ディスクが一杯にならないように、十分なローカル永続ストレージを確保します。必要な永続ストレージは Pod 数によって異なります。永続ストレージのシステム要件については、Prometheus データベースのストレージ要件 を参照してください。
- 永続ボリューム要求 (PVC) で要求される永続ボリューム (PV) が利用できる状態にあることを確認する必要があります。各レプリカに 1 つの PV が必要です。Prometheus には 2 つのレプリカがあり、Alertmanager には 3 つのレプリカがあるため、モニタリングスタック全体をサポートするには、合計で 5 つの PV が必要になります。PV は、ローカルストレージ Operator で利用できる必要があります。動的にプロビジョニングされるストレージを有効にすると、この設定は適用されません。
-
永続ボリュームを設定する際に、
volumeModeパラメーターのストレージタイプ値としてFilesystemを使用します。 - 注記
永続ストレージにローカルボリュームを使用する場合は、
LocalVolumeオブジェクトのvolumeMode: Blockで記述される raw ブロックボリュームを使用しないでください。Prometheus は raw ブロックボリュームを使用できません。
2.8.2. ローカ永続ボリューム要求 (PVC) の設定
モニタリングコンポーネントが永続ボリューム (PV) を使用できるようにするには、永続ボリューム要求 (PVC) を設定する必要があります。
前提条件
OpenShift Container Platform のコアモニタリングコンポーネントを設定する場合、以下を実行します。
-
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。 -
cluster-monitoring-configConfigMapオブジェクトを作成している。
-
ユーザー定義のプロジェクトをモニターするコンポーネントを設定する場合:
-
cluster-adminロールを持つユーザーとして、またはopenshift-user-workload-monitoringプロジェクトのuser-workload-monitoring-config-editロールを持つユーザーとして、クラスターにアクセスできる。 -
user-workload-monitoring-configConfigMapオブジェクトを作成している。
-
-
OpenShift CLI (
oc) がインストールされている。
手順
ConfigMapオブジェクトを編集します。OpenShift Container Platform のコアプロジェクトをモニターするコンポーネントの PVC を設定するには、以下を実行します。
openshift-monitoringプロジェクトでcluster-monitoring-configConfigMapオブジェクトを編集します。$ oc -n openshift-monitoring edit configmap cluster-monitoring-configコンポーネントの PVC 設定を
data/config.yamlの下に追加します。apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | <component>: volumeClaimTemplate: spec: storageClassName: <storage_class> resources: requests: storage: <amount_of_storage>volumeClaimTemplateの指定方法については、PersistentVolumeClaims についての Kubernetes ドキュメント を参照してください。以下の例では、OpenShift Container Platform のコアコンポーネントをモニターする Prometheus インスタンスのローカル永続ストレージを要求する PVC を設定します。
apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | prometheusK8s: volumeClaimTemplate: spec: storageClassName: local-storage resources: requests: storage: 40Gi上記の例では、ローカルストレージ Operator によって作成されるストレージクラスは
local-storageと呼ばれます。以下の例では、Alertmanager のローカル永続ストレージを要求する PVC を設定します。
apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | alertmanagerMain: volumeClaimTemplate: spec: storageClassName: local-storage resources: requests: storage: 10Gi
ユーザー定義プロジェクトをモニターするコンポーネントの PVC を設定するには、以下を実行します。
openshift-user-workload-monitoringプロジェクトでuser-workload-monitoring-configConfigMapオブジェクトを編集します。$ oc -n openshift-user-workload-monitoring edit configmap user-workload-monitoring-configコンポーネントの PVC 設定を
data/config.yamlの下に追加します。apiVersion: v1 kind: ConfigMap metadata: name: user-workload-monitoring-config namespace: openshift-user-workload-monitoring data: config.yaml: | <component>: volumeClaimTemplate: spec: storageClassName: <storage_class> resources: requests: storage: <amount_of_storage>volumeClaimTemplateの指定方法については、PersistentVolumeClaims についての Kubernetes ドキュメント を参照してください。以下の例では、ユーザー定義プロジェクトをモニターする Prometheus インスタンスのローカル永続ストレージを要求する PVC を設定します。
apiVersion: v1 kind: ConfigMap metadata: name: user-workload-monitoring-config namespace: openshift-user-workload-monitoring data: config.yaml: | prometheus: volumeClaimTemplate: spec: storageClassName: local-storage resources: requests: storage: 40Gi上記の例では、ローカルストレージ Operator によって作成されるストレージクラスは
local-storageと呼ばれます。以下の例では、Thanos Ruler のローカル永続ストレージを要求する PVC を設定します。
apiVersion: v1 kind: ConfigMap metadata: name: user-workload-monitoring-config namespace: openshift-user-workload-monitoring data: config.yaml: | thanosRuler: volumeClaimTemplate: spec: storageClassName: local-storage resources: requests: storage: 10Gi注記thanosRulerコンポーネントのストレージ要件は、評価されルールの数や、各ルールが生成するサンプル数により異なります。
変更を適用するためにファイルを保存します。新規設定の影響を受けた Pod は自動的に再起動され、新規ストレージ設定が適用されます。
注記user-workload-monitoring-configConfigMapオブジェクトに適用される設定は、クラスター管理者がユーザー定義プロジェクトのモニタリングを有効にしない限りアクティブにされません。警告変更がモニタリング設定マップに保存されると、関連するプロジェクトの Pod およびその他のリソースが再デプロイされる可能性があります。該当するプロジェクトの実行中のモニタリングプロセスも再起動する可能性があります。
2.8.3. 永続ストレージボリュームのサイズ変更
OpenShift Container Platform は、使用される基礎となる StorageClass リソースが永続的なボリュームのサイズ変更をサポートしている場合でも、StatefulSet リソースによって使用される既存の永続的なストレージボリュームのサイズ変更をサポートしません。したがって、既存の永続ボリューム要求 (PVC) の storage フィールドをより大きなサイズで更新しても、この設定は関連する永続ボリューム (PV) に反映されません。
ただし、手動プロセスを使用して PV のサイズを変更することは可能です。Prometheus、Thanos Ruler、Alertmanager などの監視コンポーネントの PV のサイズを変更する場合は、コンポーネントが設定されている適切な設定マップを更新できます。次に、PVC にパッチを適用し、Pod を削除して孤立させます。Pod を孤立させると、StatefulSet リソースがすぐに再作成され、Pod にマウントされたボリュームのサイズが新しい PVC 設定で自動的に更新されます。このプロセス中にサービスの中断は発生しません。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 OpenShift Container Platform のコアモニタリングコンポーネントを設定する場合、以下を実行します。
-
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。 -
cluster-monitoring-configConfigMapオブジェクトを作成している。 - コア OpenShift Container Platform モニタリングコンポーネント用に少なくとも 1 つの PVC を設定しました。
-
ユーザー定義のプロジェクトをモニターするコンポーネントを設定する場合:
-
cluster-adminロールを持つユーザーとして、またはopenshift-user-workload-monitoringプロジェクトのuser-workload-monitoring-config-editロールを持つユーザーとして、クラスターにアクセスできる。 -
user-workload-monitoring-configConfigMapオブジェクトを作成している。 - ユーザー定義プロジェクトを監視するコンポーネント用に少なくとも 1 つの PVC を設定しました。
-
手順
ConfigMapオブジェクトを編集します。OpenShift Container Platform のコアプロジェクトをモニターするコンポーネントの PVC サイズを変更するには、以下を実行します。
openshift-monitoringプロジェクトでcluster-monitoring-configConfigMapオブジェクトを編集します。$ oc -n openshift-monitoring edit configmap cluster-monitoring-configdata/config.yamlの下に、コンポーネントの PVC 設定用の新しいストレージサイズを追加します。apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | <component>:1 volumeClaimTemplate: spec: storageClassName: <storage_class>2 resources: requests: storage: <amount_of_storage>3 以下の例では、コア OpenShift Container Platform コンポーネントをモニターする Prometheus インスタンスのローカル永続ストレージを 100 ギガバイトに設定する PVC を設定します。
apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | prometheusK8s: volumeClaimTemplate: spec: storageClassName: local-storage resources: requests: storage: 100Gi次の例では、Alertmanager のローカル永続ストレージを 40 ギガバイトに設定する PVC を設定します。
apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | alertmanagerMain: volumeClaimTemplate: spec: storageClassName: local-storage resources: requests: storage: 40Gi
ユーザー定義プロジェクトを監視するコンポーネントの PVC のサイズを変更するには:
注記ユーザー定義のプロジェクトを監視する Thanos Ruler および Prometheus インスタンスのボリュームサイズを変更できます。
openshift-user-workload-monitoringプロジェクトでuser-workload-monitoring-configConfigMapオブジェクトを編集します。$ oc -n openshift-user-workload-monitoring edit configmap user-workload-monitoring-configdata/config.yaml下の監視コンポーネントの PVC 設定を更新します。apiVersion: v1 kind: ConfigMap metadata: name: user-workload-monitoring-config namespace: openshift-user-workload-monitoring data: config.yaml: | <component>:1 volumeClaimTemplate: spec: storageClassName: <storage_class>2 resources: requests: storage: <amount_of_storage>3 次の例では、ユーザー定義のプロジェクトを監視する Prometheus インスタンスの PVC サイズを 100 ギガバイトに設定します。
apiVersion: v1 kind: ConfigMap metadata: name: user-workload-monitoring-config namespace: openshift-user-workload-monitoring data: config.yaml: | prometheus: volumeClaimTemplate: spec: storageClassName: local-storage resources: requests: storage: 100Gi次の例では、Thanos Ruler の PVC サイズを 20 ギガバイトに設定します。
apiVersion: v1 kind: ConfigMap metadata: name: user-workload-monitoring-config namespace: openshift-user-workload-monitoring data: config.yaml: | thanosRuler: volumeClaimTemplate: spec: storageClassName: local-storage resources: requests: storage: 20Gi注記thanosRulerコンポーネントのストレージ要件は、評価されルールの数や、各ルールが生成するサンプル数により異なります。
変更を適用するためにファイルを保存します。新規設定の影響を受けた Pod は自動的に再起動します。
警告monitoring config map への変更を保存すると、関連プロジェクトの Pod およびその他のリソースが再デプロイされる場合があります。そのプロジェクトで実行している監視プロセスも再開される可能性があります。
更新されたストレージ要求を使用して、すべての PVC に手動でパッチを適用します。以下の例では、
openshift-monitoringnamespace の Prometheus コンポーネントのストレージサイズを 100Gi に変更します。$ for p in $(oc -n openshift-monitoring get pvc -l app.kubernetes.io/name=prometheus -o jsonpath='{range .items[*]}{.metadata.name} {end}'); do \ oc -n openshift-monitoring patch pvc/${p} --patch '{"spec": {"resources": {"requests": {"storage":"100Gi"}}}}'; \ done--cascade=orphanパラメーターを使用して、基になる StatefulSet を削除します。$ oc delete statefulset -l app.kubernetes.io/name=prometheus --cascade=orphan
2.8.4. Prometheus メトリクスデータの保持期間の変更
デフォルトで、OpenShift Container Platform クラスターモニタリングスタックは、Prometheus データの保持期間を 15 日間に設定します。この保持期間は、データ削除のタイミングを調整するために変更できます。
前提条件
OpenShift Container Platform のコアモニタリングコンポーネントを設定する場合、以下を実行します。
-
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。 -
cluster-monitoring-configConfigMapオブジェクトを作成している。
-
ユーザー定義のプロジェクトをモニターするコンポーネントを設定する場合:
-
cluster-adminロールを持つユーザーとして、またはopenshift-user-workload-monitoringプロジェクトのuser-workload-monitoring-config-editロールを持つユーザーとして、クラスターにアクセスできる。 -
user-workload-monitoring-configConfigMapオブジェクトを作成している。
-
-
OpenShift CLI (
oc) がインストールされている。
手順
ConfigMapオブジェクトを編集します。OpenShift Container Platform のコアプロジェクトをモニターする Prometheus インスタンスの保持時間を変更するには、以下を実行します。
openshift-monitoringプロジェクトでcluster-monitoring-configConfigMapオブジェクトを編集します。$ oc -n openshift-monitoring edit configmap cluster-monitoring-config保持期間の設定を
data/config.yamlに追加します。apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | prometheusK8s: retention: <time_specification><time_specification>を、ms(ミリ秒)、s(秒)、m(分)、h(時間)、d(日)、w(週)、またはy(年) が直後に続く数字に置き換えます。以下の例では、OpenShift Container Platform のコアコンポーネントをモニターする Prometheus インスタンスの保持期間を 24 時間に設定します。
apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | prometheusK8s: retention: 24h
ユーザー定義のプロジェクトをモニターする Prometheus インスタンスの保持時間を変更するには、以下を実行します。
openshift-user-workload-monitoringプロジェクトでuser-workload-monitoring-configConfigMapオブジェクトを編集します。$ oc -n openshift-user-workload-monitoring edit configmap user-workload-monitoring-config保持期間の設定を
data/config.yamlに追加します。apiVersion: v1 kind: ConfigMap metadata: name: user-workload-monitoring-config namespace: openshift-user-workload-monitoring data: config.yaml: | prometheus: retention: <time_specification><time_specification>を、ms(ミリ秒)、s(秒)、m(分)、h(時間)、d(日)、w(週)、またはy(年) が直後に続く数字に置き換えます。以下の例では、ユーザー定義プロジェクトをモニターする Prometheus インスタンスの保持期間を 24 時間に設定します。
apiVersion: v1 kind: ConfigMap metadata: name: user-workload-monitoring-config namespace: openshift-user-workload-monitoring data: config.yaml: | prometheus: retention: 24h
変更を適用するためにファイルを保存します。新規設定の影響を受けた Pod は自動的に再起動されます。
注記user-workload-monitoring-configConfigMapオブジェクトに適用される設定は、クラスター管理者がユーザー定義プロジェクトのモニタリングを有効にしない限りアクティブにされません。警告変更がモニタリング設定マップに保存されると、関連するプロジェクトの Pod およびその他のリソースが再デプロイされる可能性があります。該当するプロジェクトの実行中のモニタリングプロセスも再起動する可能性があります。
2.9. リモート書き込みストレージの設定
リモート書き込みストレージを設定して、Prometheus が取り込んだメトリックをリモートシステムに送信して長期保存できるようにします。これを行っても、Prometheus がメトリクスを保存する方法や期間には影響はありません。
前提条件
OpenShift Container Platform のコアモニタリングコンポーネントを設定する場合、以下を実行します。
-
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。 -
cluster-monitoring-configConfigMapオブジェクトを作成している。
-
ユーザー定義のプロジェクトをモニターするコンポーネントを設定する場合:
-
cluster-adminロールを持つユーザーとして、またはopenshift-user-workload-monitoringプロジェクトのuser-workload-monitoring-config-editロールを持つユーザーとして、クラスターにアクセスできる。 -
user-workload-monitoring-configConfigMapオブジェクトを作成している。
-
-
OpenShift CLI (
oc) がインストールされている。 - リモート書き込み互換性のあるエンドポイント (Thanos) を設定し、エンドポイント URL を把握している。リモート書き込み機能と互換性のないエンドポイントの情報ては、Prometheus リモートエンドポイントおよびストレージについてのドキュメント を参照してください。
リモート書き込みエンドポイントに認証情報を設定している。
Importantセキュリティーリスクを軽減するには、暗号化されていない HTTP を使用するか、認証を使用せずに、エンドポイントにメトリックを送信しないようにします。
手順
openshift-monitoringプロジェクトでcluster-monitoring-configConfigMapオブジェクトを編集します。$ oc -n openshift-monitoring edit configmap cluster-monitoring-config-
data/config.yaml/prometheusK8sにremoteWrite:セクションを追加します。 このセクションにエンドポイント URL および認証情報を追加します。
apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | prometheusK8s: remoteWrite: - url: "https://remote-write.endpoint" <endpoint_authentication_credentials>endpoint_authentication_credentialsの場合には、エンドポイントの認証情報を置き換えます。現時点で、サポートされている認証方法は Basic 認証 (basicAuth) およびクライアント TLS(tlsConfig) 認証です。以下の例では、Basic 認証を設定します。
basicAuth: username: <usernameSecret> password: <passwordSecret><usernameSecret>および<passwordSecret>は随時置き換えます。以下の例では、
nameにremoteWriteAuth、keyにuserとpasswordを指定した Basic 認証です。これらの値には、エンドポイント認証情報が含まれます。apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | prometheusK8s: remoteWrite: - url: "https://remote-write.endpoint" basicAuth: username: name: remoteWriteAuth key: user password: name: remoteWriteAuth key: password以下の例では、クライアント TLS 認証を設定します。
tlsConfig: ca: <caSecret> cert: <certSecret> keySecret: <keySecret>それに応じて、
<caSecret>、<certSecret>および<keySecret>を置き換えます。以下の例では、
name値にselfsigned-mtls-bundle、cakey値にca.crt、certkey値にclient.crt、keySecretkey値にclient.keyを使用した TLS 認証設定を示します。apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | prometheusK8s: remoteWrite: - url: "https://remote-write.endpoint" tlsConfig: ca: secret: name: selfsigned-mtls-bundle key: ca.crt cert: secret: name: selfsigned-mtls-bundle key: client.crt keySecret: name: selfsigned-mtls-bundle key: client.key
認証クレデンシャルの後に、書き込みの再ラベル設定値を追加します。
apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | prometheusK8s: remoteWrite: - url: "https://remote-write.endpoint" <endpoint_authentication_credentials> <write_relabel_configs><write_relabel_configs>は、リモートエンドポイントに送信する必要のあるメトリクスの書き込みラベル一覧に置き換えます。以下の例では、
my_metricという単一のメトリックを転送する方法を紹介します。apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | prometheusK8s: remoteWrite: - url: "https://remote-write.endpoint" writeRelabelConfigs: - sourceLabels: [__name__] regex: 'my_metric' action: keep書き込み再ラベル設定オプションについては、Prometheus relabel_config documentation を参照してください。
必要な場合は、以下のように
nameおよびnamespacemetadataの値を変更して、ユーザー定義のプロジェクトをモニターする Prometheus インスタンスのリモート書き込みを設定します。apiVersion: v1 kind: ConfigMap metadata: name: user-workload-monitoring-config namespace: openshift-user-workload-monitoring data: config.yaml: | prometheus: remoteWrite: - url: "https://remote-write.endpoint" <endpoint_authentication_credentials> <write_relabel_configs>注記Prometheus 設定マップコンポーネントは、
cluster-monitoring-configConfigMapオブジェクトでprometheusK8sと呼ばれ、user-workload-monitoring-configConfigMapオブジェクトでprometheusと呼ばれます。ファイルを保存して、変更を
ConfigMapオブジェクトに適用します。新規設定の影響を受けた Pod は自動的に再起動します。注記user-workload-monitoring-configConfigMapオブジェクトに適用される設定は、クラスター管理者がユーザー定義プロジェクトのモニタリングを有効にしない限りアクティブにされません。警告モニタリング
ConfigMapオブジェクトへの変更を保存すると、関連するプロジェクトの Pod およびその他のリソースが再デプロイされる可能性があります。また、変更を保存すると、そのプロジェクトで実行中のモニタリングプロセスも再起動する可能性があります。
2.10. ユーザー定義プロジェクトでバインドされていないメトリクス属性の影響の制御
開発者は、キーと値のペアの形式でメトリクスの属性を定義するためにラベルを作成できます。使用できる可能性のあるキーと値のペアの数は、属性について使用できる可能性のある値の数に対応します。数が無制限の値を持つ属性は、バインドされていない属性と呼ばれます。たとえば、customer_id 属性は、使用できる値が無限にあるため、バインドされていない属性になります。
割り当てられるキーと値のペアにはすべて、一意の時系列があります。ラベルに多数のバインドされていない値を使用すると、作成される時系列の数が指数関数的に増加する可能性があります。これは Prometheus のパフォーマンスに影響する可能性があり、多くのディスク領域を消費する可能性があります。
クラスター管理者は、以下の手段を使用して、ユーザー定義プロジェクトでのバインドされていないメトリクス属性の影響を制御できます。
- ユーザー定義プロジェクトで、ターゲット収集ごとに 受け入れ可能なサンプル数を制限 します。
- ターゲットを収集できない場合や、収集サンプルのしきい値に達する際に実行される アラートを作成 します。
収集サンプルを制限すると、多くのバインドされていない属性をラベルに追加して問題が発生するのを防ぐことができます。さらに開発者は、メトリクスに定義するバインドされていない 属性の数を制限することにより、根本的な原因を防ぐことができます。使用可能な値の制限されたセットにバインドされる属性を使用すると、可能なキーと値のペアの組み合わせの数が減ります。
2.10.1. ユーザー定義プロジェクトの収集サンプル制限の設定
ユーザー定義プロジェクトで、ターゲット収集ごとに受け入れ可能なサンプル数を制限できます。
サンプル制限を設定すると、制限に達した後にそのターゲット収集についての追加のサンプルデータは取り込まれません。
前提条件
-
cluster-adminロールを持つユーザーとして、またはopenshift-user-workload-monitoringプロジェクトのuser-workload-monitoring-config-editロールを持つユーザーとして、クラスターにアクセスできる。 -
user-workload-monitoring-configConfigMapオブジェクトを作成している。 -
OpenShift CLI (
oc) がインストールされている。
手順
openshift-user-workload-monitoringプロジェクトでuser-workload-monitoring-configConfigMapオブジェクトを編集します。$ oc -n openshift-user-workload-monitoring edit configmap user-workload-monitoring-configenforcedSampleLimit設定をdata/config.yamlに追加し、ユーザー定義プロジェクトのターゲットの収集ごとに受け入れ可能なサンプルの数を制限できます。apiVersion: v1 kind: ConfigMap metadata: name: user-workload-monitoring-config namespace: openshift-user-workload-monitoring data: config.yaml: | prometheus: enforcedSampleLimit: 500001 - 1
- このパラメーターが指定されている場合は、値が必要です。この
enforcedSampleLimitの例では、ユーザー定義プロジェクトのターゲット収集ごとに受け入れ可能なサンプル数を 50,000 に制限します。
変更を適用するためにファイルを保存します。制限は自動的に適用されます。
注記user-workload-monitoring-configConfigMapオブジェクトに適用される設定は、クラスター管理者がユーザー定義プロジェクトのモニタリングを有効にしない限りアクティブにされません。警告変更が
user-workload-monitoring-configConfigMapオブジェクトに保存されると、openshift-user-workload-monitoringプロジェクトの Pod および他のリソースは再デプロイされる可能性があります。該当するプロジェクトの実行中のモニタリングプロセスも再起動する可能性があります。
2.10.2. 収集サンプルアラートの作成
以下の場合に通知するアラートを作成できます。
-
ターゲットを収集できず、指定された
forの期間利用できない -
指定された
forの期間、収集サンプルのしきい値に達するか、またはこの値を上回る
前提条件
-
cluster-adminロールを持つユーザーとして、またはopenshift-user-workload-monitoringプロジェクトのuser-workload-monitoring-config-editロールを持つユーザーとして、クラスターにアクセスできる。 - ユーザー定義プロジェクトのモニタリングを有効にしている。
-
user-workload-monitoring-configConfigMapオブジェクトを作成している。 -
enforcedSampleLimitを使用して、ユーザー定義プロジェクトのターゲット収集ごとに受け入れ可能なサンプル数を制限している。 -
OpenShift CLI (
oc) がインストールされている。
手順
ターゲットがダウンし、実行されたサンプル制限に近づく際に通知するアラートを指定して YAML ファイルを作成します。この例のファイルは
monitoring-stack-alerts.yamlという名前です。apiVersion: monitoring.coreos.com/v1 kind: PrometheusRule metadata: labels: prometheus: k8s role: alert-rules name: monitoring-stack-alerts1 namespace: ns12 spec: groups: - name: general.rules rules: - alert: TargetDown3 annotations: message: '{{ printf "%.4g" $value }}% of the {{ $labels.job }}/{{ $labels.service }} targets in {{ $labels.namespace }} namespace are down.'4 expr: 100 * (count(up == 0) BY (job, namespace, service) / count(up) BY (job, namespace, service)) > 10 for: 10m5 labels: severity: warning6 - alert: ApproachingEnforcedSamplesLimit7 annotations: message: '{{ $labels.container }} container of the {{ $labels.pod }} pod in the {{ $labels.namespace }} namespace consumes {{ $value | humanizePercentage }} of the samples limit budget.'8 expr: scrape_samples_scraped/50000 > 0.89 for: 10m10 labels: severity: warning11 - 1
- アラートルールの名前を定義します。
- 2
- アラートルールをデプロイするユーザー定義のプロジェクトを指定します。
- 3
TargetDownアラートは、forの期間にターゲットを収集できないか、または利用できない場合に実行されます。- 4
TargetDownアラートが実行される場合に出力されるメッセージ。- 5
- アラートが実行される前に、
TargetDownアラートの条件がこの期間中 true である必要があります。 - 6
TargetDownアラートの重大度を定義します。- 7
ApproachingEnforcedSamplesLimitアラートは、指定されたforの期間に定義された収集サンプルのしきい値に達するか、またはこの値を上回る場合に実行されます。- 8
ApproachingEnforcedSamplesLimitアラートの実行時に出力されるメッセージ。- 9
ApproachingEnforcedSamplesLimitアラートのしきい値。この例では、ターゲット収集ごとのサンプル数が実行されたサンプル制限50000の 80% を超えるとアラートが実行されます。アラートが実行される前に、forの期間も経過している必要があります。式scrape_samples_scraped/<number> > <threshold>の<number>はuser-workload-monitoring-configConfigMapオブジェクトで定義されるenforcedSampleLimit値に一致する必要があります。- 10
- アラートが実行される前に、
ApproachingEnforcedSamplesLimitアラートの条件がこの期間中 true である必要があります。 - 11
ApproachingEnforcedSamplesLimitアラートの重大度を定義します。
設定をユーザー定義プロジェクトに適用します。
$ oc apply -f monitoring-stack-alerts.yaml
第3章 外部 alertmanager インスタンスの設定
OpenShift Container Platform モニタリングスタックには、Prometheus からのアラートのルートなど、ローカルの Alertmanager インスタンスが含まれます。openshift-monitoring または user-workload-monitoring-config プロジェクトのいずれかで cluster-monitoring-config 設定マップを設定して外部 Alertmanager インスタンスを追加できます。
複数のクラスターに同じ外部 Alertmanager 設定を追加し、クラスターごとにローカルインスタンスを無効にする場合には、単一の外部 Alertmanager インスタンスを使用して複数のクラスターのアラートルーティングを管理できます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 openshift-monitoringプロジェクトで OpenShift Container Platform のコアモニタリングコンポーネントを設定する場合:-
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。 -
cluster-monitoring-configConfigMap を作成している。
-
ユーザー定義のプロジェクトをモニターするコンポーネントを設定する場合:
-
cluster-adminロールを持つユーザーとして、またはopenshift-user-workload-monitoringプロジェクトのuser-workload-monitoring-config-editロールを持つユーザーとして、クラスターにアクセスできる。 -
user-workload-monitoring-configConfigMap オブジェクトを作成している。
-
手順
ConfigMapオブジェクトを編集します。OpenShift Container Platform のコアプロジェクトのルーティングアラート用に追加の Alertmanager を設定するには、以下を実行します。
openshift-monitoringプロジェクトでcluster-monitoring-configConfigMap を編集します。$ oc -n openshift-monitoring edit configmap cluster-monitoring-config-
data/config.yaml/prometheusK8sにadditionalAlertmanagerConfigs:セクションを追加します。 このセクションに別の Alertmanager 設定の詳細情報を追加します。
apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | prometheusK8s: additionalAlertmanagerConfigs: - <alertmanager_specification><alertmanager_specification>は、追加の Alertmanager インスタンスの認証およびその他の設定の詳細を置き換えます。現時点で、サポートされている認証方法はベアラートークン (bearerToken) およびクライアント TLS(tlsConfig) です。以下の設定マップは、クライアント TLS 認証でベアラートークンを使用して追加の Alertmanager を設定します。apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | prometheusK8s: additionalAlertmanagerConfigs: - scheme: https pathPrefix: / timeout: "30s" apiVersion: v1 bearerToken: name: alertmanager-bearer-token key: token tlsConfig: key: name: alertmanager-tls key: tls.key cert: name: alertmanager-tls key: tls.crt ca: name: alertmanager-tls key: tls.ca staticConfigs: - external-alertmanager1-remote.com - external-alertmanager1-remote2.com
ユーザー定義プロジェクトでルーティングアラート用に追加の Alertmanager インスタンスを設定するには、以下を実行します。
openshift-user-workload-monitoringプロジェクトでuser-workload-monitoring-config設定マップを編集します。$ oc -n openshift-user-workload-monitoring edit configmap user-workload-monitoring-config-
data/config.yaml/の下に<component>/additionalAlertmanagerConfigs:セクションを追加します。 このセクションに別の Alertmanager 設定の詳細情報を追加します。
apiVersion: v1 kind: ConfigMap metadata: name: user-workload-monitoring-config namespace: openshift-user-workload-monitoring data: config.yaml: | <component>: additionalAlertmanagerConfigs: - <alertmanager_specification><component>には、サポート対象の外部 Alertmanager コンポーネント (prometheusまたはthanosRuler)2 つの内、いずれかに置き換えます。<alertmanager_specification>は、追加の Alertmanager インスタンスの認証およびその他の設定の詳細を置き換えます。現時点で、サポートされている認証方法はベアラートークン (bearerToken) およびクライアント TLS(tlsConfig) です。以下の設定マップは、ベアラートークンおよびクライアント TLS 認証を指定した Thanos Ruler を使用して追加の Alertmanager を設定します。apiVersion: v1 kind: ConfigMap metadata: name: user-workload-monitoring-config namespace: openshift-user-workload-monitoring data: config.yaml: | thanosRuler: additionalAlertmanagerConfigs: - scheme: https pathPrefix: / timeout: "30s" apiVersion: v1 bearerToken: name: alertmanager-bearer-token key: token tlsConfig: key: name: alertmanager-tls key: tls.key cert: name: alertmanager-tls key: tls.crt ca: name: alertmanager-tls key: tls.ca staticConfigs: - external-alertmanager1-remote.com - external-alertmanager1-remote2.com注記user-workload-monitoring-configConfigMapオブジェクトに適用される設定は、クラスター管理者がユーザー定義プロジェクトのモニタリングを有効にしない限りアクティブにされません。
-
ファイルを保存して、変更を
ConfigMapオブジェクトに適用します。新しいコンポーネントの配置設定が自動的に適用されます。
3.1. 追加ラベルの時系列 (time series) およびアラートへの割り当て
Prometheus の外部ラベル機能を使用して、カスタムラベルを、Prometheus から出るすべての時系列およびアラートに割り当てることができます。
前提条件
OpenShift Container Platform のコアモニタリングコンポーネントを設定する場合、以下を実行します。
-
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。 -
cluster-monitoring-configConfigMapオブジェクトを作成している。
-
ユーザー定義のプロジェクトをモニターするコンポーネントを設定する場合:
-
cluster-adminロールを持つユーザーとして、またはopenshift-user-workload-monitoringプロジェクトのuser-workload-monitoring-config-editロールを持つユーザーとして、クラスターにアクセスできる。 -
user-workload-monitoring-configConfigMapオブジェクトを作成している。
-
-
OpenShift CLI (
oc) がインストールされている。
手順
ConfigMapオブジェクトを編集します。カスタムラベルを、OpenShift Container Platform のコアプロジェクトをモニターする Prometheus インスタンスから出るすべての時系列およびアラートに割り当てるには、以下を実行します。
openshift-monitoringプロジェクトでcluster-monitoring-configConfigMapオブジェクトを編集します。$ oc -n openshift-monitoring edit configmap cluster-monitoring-configdata/config.yamlの下にすべてのメトリクスについて追加する必要のあるラベルのマップを定義します。apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | prometheusK8s: externalLabels: <key>: <value>1 - 1
<key>: <value>をキーと値のペアのマップに置き換えます。ここで、<key>は新規ラベルの一意の名前で、<value>はその値になります。
警告prometheusまたはprometheus_replicaは予約され、上書きされるため、これらをキー名として使用しないでください。たとえば、リージョンおよび環境に関するメタデータをすべての時系列およびアラートに追加するには、以下を使用します。
apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | prometheusK8s: externalLabels: region: eu environment: prod
カスタムラベルを、ユーザー定義のプロジェクトをモニターする Prometheus インスタンスから出るすべての時系列およびアラートに割り当てるには、以下を実行します。
openshift-user-workload-monitoringプロジェクトでuser-workload-monitoring-configConfigMapオブジェクトを編集します。$ oc -n openshift-user-workload-monitoring edit configmap user-workload-monitoring-configdata/config.yamlの下にすべてのメトリクスについて追加する必要のあるラベルのマップを定義します。apiVersion: v1 kind: ConfigMap metadata: name: user-workload-monitoring-config namespace: openshift-user-workload-monitoring data: config.yaml: | prometheus: externalLabels: <key>: <value>1 - 1
<key>: <value>をキーと値のペアのマップに置き換えます。ここで、<key>は新規ラベルの一意の名前で、<value>はその値になります。
警告prometheusまたはprometheus_replicaは予約され、上書きされるため、これらをキー名として使用しないでください。注記openshift-user-workload-monitoringプロジェクトでは、Prometheus はメトリクスを処理し、Thanos Ruler はアラートおよび記録ルールを処理します。user-workload-monitoring-configConfigMapオブジェクトでprometheusのexternalLabelsを設定すると、すべてのルールではなく、メトリクスの外部ラベルのみが設定されます。たとえば、リージョンおよび環境に関するメタデータをすべての時系列およびユーザー定義プロジェクトに関連するアラートに追加するには、以下を使用します。
apiVersion: v1 kind: ConfigMap metadata: name: user-workload-monitoring-config namespace: openshift-user-workload-monitoring data: config.yaml: | prometheus: externalLabels: region: eu environment: prod
変更を適用するためにファイルを保存します。新しい設定は自動的に適用されます。
注記user-workload-monitoring-configConfigMapオブジェクトに適用される設定は、クラスター管理者がユーザー定義プロジェクトのモニタリングを有効にしない限りアクティブにされません。警告変更がモニタリング設定マップに保存されると、関連するプロジェクトの Pod およびその他のリソースが再デプロイされる可能性があります。該当するプロジェクトの実行中のモニタリングプロセスも再起動する可能性があります。
3.2. モニタリングコンポーネントのログレベルの設定
Alertmanager、Prometheus Operator、Prometheus、Alertmanager および Thanos Querier および Thanos Ruler のログレベルを設定できます。
cluster-monitoring-config および user-workload-monitoring-configConfigMap オブジェクトの該当するコンポーネントには、以下のログレベルを適用することができます。
-
debug:デバッグ、情報、警告、およびエラーメッセージをログに記録します。 -
info:情報、警告およびエラーメッセージをログに記録します。 -
warn:警告およびエラーメッセージのみをログに記録します。 -
error:エラーメッセージのみをログに記録します。
デフォルトのログレベルは info です。
前提条件
openshift-monitoringプロジェクトで Alertmanager、Prometheus Operator、Prometheus、または Thanos Querier のログレベルを設定する場合には、以下を実行します。-
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。 -
cluster-monitoring-configConfigMapオブジェクトを作成している。
-
openshift-user-workload-monitoringプロジェクトで Prometheus Operator、Prometheus、または Thanos Ruler のログレベルを設定する場合には、以下を実行します。-
cluster-adminロールを持つユーザーとして、またはopenshift-user-workload-monitoringプロジェクトのuser-workload-monitoring-config-editロールを持つユーザーとして、クラスターにアクセスできる。 -
user-workload-monitoring-configConfigMapオブジェクトを作成している。
-
-
OpenShift CLI (
oc) がインストールされている。
手順
ConfigMapオブジェクトを編集します。openshift-monitoringプロジェクトのコンポーネントのログレベルを設定するには、以下を実行します。openshift-monitoringプロジェクトでcluster-monitoring-configConfigMapオブジェクトを編集します。$ oc -n openshift-monitoring edit configmap cluster-monitoring-configコンポーネントの
logLevel: <log_level>をdata/config.yamlの下に追加します。apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | <component>:1 logLevel: <log_level>2
openshift-user-workload-monitoringプロジェクトのコンポーネントのログレベルを設定するには、以下を実行します。openshift-user-workload-monitoringプロジェクトでuser-workload-monitoring-configConfigMapオブジェクトを編集します。$ oc -n openshift-user-workload-monitoring edit configmap user-workload-monitoring-configコンポーネントの
logLevel: <log_level>をdata/config.yamlの下に追加します。apiVersion: v1 kind: ConfigMap metadata: name: user-workload-monitoring-config namespace: openshift-user-workload-monitoring data: config.yaml: | <component>:1 logLevel: <log_level>2
変更を適用するためにファイルを保存します。ログレベルの変更を適用する際に、コンポーネントの Pod は自動的に再起動します。
注記user-workload-monitoring-configConfigMapオブジェクトに適用される設定は、クラスター管理者がユーザー定義プロジェクトのモニタリングを有効にしない限りアクティブにされません。警告変更がモニタリング設定マップに保存されると、関連するプロジェクトの Pod およびその他のリソースが再デプロイされる可能性があります。該当するプロジェクトの実行中のモニタリングプロセスも再起動する可能性があります。
関連するプロジェクトでデプロイメントまたは Pod 設定を確認し、ログレベルが適用されていることを確認します。以下の例では、
openshift-user-workload-monitoringプロジェクトのprometheus-operatorデプロイメントでログレベルを確認します。$ oc -n openshift-user-workload-monitoring get deploy prometheus-operator -o yaml | grep "log-level"出力例
- --log-level=debugコンポーネントの Pod が実行中であることを確認します。以下の例は、
openshift-user-workload-monitoringプロジェクトの Pod のステータスを一覧表示します。$ oc -n openshift-user-workload-monitoring get pods注記認識されない
loglevel値がConfigMapオブジェクトに含まれる場合、コンポーネントの Pod が正常に再起動されない可能性があります。
3.3. デフォルトの Grafana デプロイメントの無効化
デフォルトでは、読み取り専用の Grafana インスタンスは、クラスターメトリクスを表示するダッシュボードのコレクションと共にデプロイされます。Grafana インスタンスは、ユーザー側で設定できません。
Grafana デプロイメントを無効にすると、関連するリソースがクラスターから削除されます。これらのダッシュボードを必要とせずに、クラスターのリソースを節約するには、以下を行うことができます。ただし、引き続き Web コンソールに含まれるメトリクスおよびダッシュボードを表示できます。Grafana はいつでも再度有効化することができます。
前提条件
-
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。 -
cluster-monitoring-configConfigMapオブジェクトを作成している。 -
OpenShift CLI (
oc) がインストールされている。
手順
openshift-monitoringプロジェクトでcluster-monitoring-configConfigMapオブジェクトを編集します。$ oc -n openshift-monitoring edit configmap cluster-monitoring-configgrafanaコンポーネントのenabled: falseをdata/config.yamlの下に追加します。apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | grafana: enabled: false変更を適用するためにファイルを保存します。リソースは、変更を適用したら、自動的に削除されます。
警告この変更により、Prometheus および Thanos Querier など、一部のコンポーネントが生成されます。これにより、永続ストレージの設定のセクションの手順が完了していない場合に、収集されたメトリクスが失われる可能性があります。
Grafana Pod が実行されていないことを確認します。以下の例は、
openshift-monitoringプロジェクトの Pod のステータスを一覧表示します。$ oc -n openshift-monitoring get pods注記これらの Pod を終了するまでに数分かかる場合があります。
3.4. ローカル Alertmanager の無効化
Prometheus インスタンスからのアラートをルーティングするローカル Alertmanager は、OpenShift ContainerPlatform モニタリングスタックの openshift-monitoring プロジェクトではデフォルトで有効になっています。
ローカル Alertmanager を必要としない場合、openshift-monitoring プロジェクトで cluster-monitoring-config 設定マップを指定して無効にできます。
前提条件
-
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。 -
cluster-monitoring-configConfigMap を作成している。 -
OpenShift CLI (
oc) がインストールされている。
手順
openshift-monitoringプロジェクトでcluster-monitoring-configConfigMap を編集します。$ oc -n openshift-monitoring edit configmap cluster-monitoring-configdata/config.yamlの下に、alertmanagerMainコンポーネントのenabled: falseを追加します。apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | alertmanagerMain: enabled: false- 変更を適用するためにファイルを保存します。Alertmanager インスタンスは、この変更を適用すると自動的に無効にされます。
3.5. 次のステップ
- ユーザー定義プロジェクトのモニタリングの有効化
- リモート正常性レポート を確認し、必要な場合はこれをオプトアウトします。
第4章 ユーザー定義プロジェクトのモニタリングの有効化
OpenShift Container Platform 4.9 では、デフォルトのプラットフォームのモニターリングに加えて、ユーザー定義プロジェクトのモニターリングを有効にできます。追加のモニタリングソリューションなしに、OpenShift Container Platform で独自のプロジェクトをモニターできるようになりました。この新機能を使用することで、コアプラットフォームコンポーネントとユーザー定義プロジェクトのモニタリングが一元化されます。
Operator Lifecycle Manager (OLM) を使用してインストールされた Prometheus Operator のバージョンは、ユーザー定義のモニタリングと互換性がありません。そのため、OLM Prometheus Operator によって管理される Prometheus カスタムリソース (CR) としてインストールされるカスタム Prometheus インスタンスは OpenShift Container Platform ではサポートされていません。
4.1. ユーザー定義プロジェクトのモニタリングの有効化
クラスター管理者は、クラスターモニタリング ConfigMap オブジェクト に enableUserWorkload: true フィールドを設定し、ユーザー定義プロジェクトのモニタリングを有効にできます。
OpenShift Container Platform 4.9 では、ユーザー定義プロジェクトのモニターリングを有効にする前に、カスタム Prometheus インスタンスを削除する必要があります。
OpenShift Container Platform のユーザー定義プロジェクトのモニターリングを有効にするには、cluster-admin ロールを持つユーザーとしてクラスターにアクセスできる必要があります。これにより、クラスター管理者は任意で、ユーザー定義のプロジェクトをモニターするコンポーネントを設定するパーミッションをユーザーに付与できます。
前提条件
-
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。 -
OpenShift CLI (
oc) がインストールされている。 -
cluster-monitoring-configConfigMapオブジェクトを作成している。 オプションで
user-workload-monitoring-configConfigMapをopenshift-user-workload-monitoringプロジェクトに作成している。ユーザー定義プロジェクトをモニターするコンポーネントのConfigMapに設定オプションを追加できます。注記設定の変更を
user-workload-monitoring-configConfigMapに保存するたびに、openshift-user-workload-monitoringプロジェクトの Pod が再デプロイされます。これらのコンポーネントが再デプロイするまで時間がかかる場合があります。ユーザー定義プロジェクトのモニタリングを最初に有効にする前にConfigMapオブジェクトを作成し、設定することができます。これにより、Pod を頻繁に再デプロイする必要がなくなります。
手順
cluster-monitoring-configConfigMapオブジェクトを編集します。$ oc -n openshift-monitoring edit configmap cluster-monitoring-configenableUserWorkload: trueをdata/config.yamlの下に追加します。apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | enableUserWorkload: true1 - 1
trueに設定すると、enableUserWorkloadパラメーターはクラスター内のユーザー定義プロジェクトのモニタリングを有効にします。
変更を適用するためにファイルを保存します。ユーザー定義プロジェクトのモニタリングは自動的に有効になります。
警告変更が
cluster-monitoring-configConfigMapオブジェクトに保存されると、openshift-monitoringプロジェクトの Pod および他のリソースは再デプロイされる可能性があります。該当するプロジェクトの実行中のモニタリングプロセスも再起動する可能性があります。prometheus-operator、prometheus-user-workloadおよびthanos-ruler-user-workloadPod がopenshift-user-workload-monitoringプロジェクトで実行中であることを確認します。Pod が起動するまでに少し時間がかかる場合があります。$ oc -n openshift-user-workload-monitoring get pod出力例
NAME READY STATUS RESTARTS AGE prometheus-operator-6f7b748d5b-t7nbg 2/2 Running 0 3h prometheus-user-workload-0 4/4 Running 1 3h prometheus-user-workload-1 4/4 Running 1 3h thanos-ruler-user-workload-0 3/3 Running 0 3h thanos-ruler-user-workload-1 3/3 Running 0 3h
4.2. ユーザーに対するユーザー定義のプロジェクトをモニターするパーミッションの付与
クラスター管理者は、すべての OpenShift Container Platform のコアプロジェクトおよびユーザー定義プロジェクトをモニターできます。
クラスター管理者は、開発者およびその他のユーザーに、独自のプロジェクトをモニターするパーミッションを付与できます。特権は、以下のモニタリングロールのいずれかを割り当てることで付与されます。
-
monitoring-rules-view ロールは、プロジェクトの
PrometheusRuleカスタムリソースへの読み取りアクセスを提供します。 -
monitoring-rules-edit ロールは、プロジェクトの
PrometheusRuleカスタムリソースを作成し、変更し、削除するパーミッションをユーザーに付与します。 -
monitoring-edit ロールは、
monitoring-rules-editロールと同じ特権を付与します。さらに、ユーザーはサービスまたは Pod の新規の収集 ターゲットを作成できます。このロールを使用すると、ServiceMonitorおよびPodMonitorリソースを作成し、変更し、削除することもできます。
また、ユーザー定義のプロジェクトをモニターするコンポーネントを設定するパーミッションをユーザーに付与することもできます。
-
openshift-user-workload-monitoringプロジェクトの user-workload-monitoring-config-edit ロールにより、user-workload-monitoring-configConfigMapオブジェクトを編集できます。このロールを使用して、ConfigMapオブジェクトを編集し、ユーザー定義のワークロードのモニター用に Prometheus、Prometheus Operator および Thanos Ruler を設定できます。
このセクションでは、OpenShift Container Platform Web コンソールまたは CLI を使用してこれらのロールを割り当てる方法について説明します。
4.2.1. Web コンソールを使用したユーザーパーミッションの付与
OpenShift Container Platform Web コンソールを使用して、独自のプロジェクトをモニターするパーミッションをユーザーに付与できます。
前提条件
-
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。 - ロールを割り当てるユーザーアカウントがすでに存在している。
手順
- OpenShift Container Platform Web コンソールの Administrator パースペクティブで、User Management → Role Bindings → Create Binding に移動します。
- Binding Typeで、Namespace Role Binding タイプを選択します。
- Name フィールドに、ロールバインディングの名前を入力します。
Namespace フィールドで、アクセスを付与するユーザー定義プロジェクトを選択します。
重要モニタリングロールは、Namespace フィールドで適用するプロジェクトにバインドされます。この手順を使用してユーザーに付与するパーミッションは、選択されたプロジェクトにのみ適用されます。
-
Role Name 一覧で、
monitoring-rules-view、monitoring-rules-edit、またはmonitoring-editを選択します。 - Subject セクションで、User を選択します。
- Subject Name フィールドにユーザーの名前を入力します。
- Create を選択して、ロールバインディングを適用します。
4.2.2. CLI を使用したユーザーパーミッションの付与
OpenShift CLI (oc) を使用して、独自のプロジェクトをモニターするパーミッションをユーザーに付与できます。
前提条件
-
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。 - ロールを割り当てるユーザーアカウントがすでに存在している。
-
OpenShift CLI (
oc) がインストールされている。
手順
プロジェクトのユーザーにモニタリングロールを割り当てます。
$ oc policy add-role-to-user <role> <user> -n <namespace>1 - 1
<role>をmonitoring-rules-view、monitoring-rules-edit、またはmonitoring-editに置き換えます。
重要選択したすべてのロールは、クラスター管理者が特定のプロジェクトにバインドする必要があります。
たとえば、
<role>をmonitoring-editに、<user>をjohnsmithに、<namespace>をns1に置き換えます。これにより、ユーザーjohnsmithに、メトリクスコレクションをセットアップし、ns1namespace にアラートルールを作成するパーミッションが割り当てられます。
4.3. ユーザーに対するユーザー定義プロジェクトのモニタリングを設定するためのパーミッションの付与
ユーザーに対して、ユーザー定義プロジェクトのモニタリングを設定するためのパーミッションを付与できます。
前提条件
-
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。 - ロールを割り当てるユーザーアカウントがすでに存在している。
-
OpenShift CLI (
oc) がインストールされている。
手順
user-workload-monitoring-config-editロールをopenshift-user-workload-monitoringプロジェクトのユーザーに割り当てます。$ oc -n openshift-user-workload-monitoring adm policy add-role-to-user \ user-workload-monitoring-config-edit <user> \ --role-namespace openshift-user-workload-monitoring
4.4. カスタムアプリケーションについてのクラスター外からのメトリクスへのアクセス
独自のサービスをモニタリングする際に、コマンドラインから Prometheus 統計をクエリーする方法を説明します。クラスター外からモニタリングデータにアクセスするには、thanos-querier ルートを使用します。
前提条件
- 独自のサービスをデプロイしている。ユーザー定義プロジェクトのモニタリングの有効化手順に従ってください。
手順
トークンを展開して Prometheus に接続します。
$ SECRET=`oc get secret -n openshift-user-workload-monitoring | grep prometheus-user-workload-token | head -n 1 | awk '{print $1 }'`$ TOKEN=`echo $(oc get secret $SECRET -n openshift-user-workload-monitoring -o json | jq -r '.data.token') | base64 -d`ルートホストを展開します。
$ THANOS_QUERIER_HOST=`oc get route thanos-querier -n openshift-monitoring -o json | jq -r '.spec.host'`コマンドラインで独自のサービスのメトリクスをクエリーします。以下に例を示します。
$ NAMESPACE=ns1$ curl -X GET -kG "https://$THANOS_QUERIER_HOST/api/v1/query?" --data-urlencode "query=up{namespace='$NAMESPACE'}" -H "Authorization: Bearer $TOKEN"出力には、アプリケーション Pod が起動していた期間が表示されます。
出力例
{"status":"success","data":{"resultType":"vector","result":[{"metric":{"__name__":"up","endpoint":"web","instance":"10.129.0.46:8080","job":"prometheus-example-app","namespace":"ns1","pod":"prometheus-example-app-68d47c4fb6-jztp2","service":"prometheus-example-app"},"value":[1591881154.748,"1"]}]}}
4.5. モニタリングからのユーザー定義のプロジェクトを除く
ユーザー定義のプロジェクトは、ユーザーワークロード監視から除外できます。これを実行するには、単に openshift.io/user-monitoring ラベルに false を指定して、プロジェクトの namespace に追加します。
手順
ラベルをプロジェクト namespace に追加します。
$ oc label namespace my-project 'openshift.io/user-monitoring=false'モニタリングを再度有効にするには、namespace からラベルを削除します。
$ oc label namespace my-project 'openshift.io/user-monitoring-'注記プロジェクトにアクティブな監視ターゲットがあった場合、ラベルを追加した後、Prometheus がそれらのスクレイピングを停止するまでに数分かかる場合があります。
4.6. ユーザー定義プロジェクトのモニタリングの無効化
ユーザー定義プロジェクトのモニタリングを有効にした後に、クラスターモニタリング ConfigMap オブジェクトに enableUserWorkload: false を設定してこれを再度無効にできます。
または、enableUserWorkload: true を削除して、ユーザー定義プロジェクトのモニタリングを無効にできます。
手順
cluster-monitoring-configConfigMapオブジェクトを編集します。$ oc -n openshift-monitoring edit configmap cluster-monitoring-configdata/config.yamlでenableUserWorkload:をfalseに設定します。apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | enableUserWorkload: false
- 変更を適用するためにファイルを保存します。ユーザー定義プロジェクトのモニタリングは自動的に無効になります。
prometheus-operator、prometheus-user-workloadおよびthanos-ruler-user-workloadPod がopenshift-user-workload-monitoringプロジェクトで終了していることを確認します。これには少し時間がかかる場合があります。$ oc -n openshift-user-workload-monitoring get pod出力例
No resources found in openshift-user-workload-monitoring project.
openshift-user-workload-monitoring プロジェクトの user-workload-monitoring-config ConfigMap オブジェクトは、ユーザー定義プロジェクトのモニタリングが無効にされている場合は自動的に削除されません。これにより、ConfigMap で作成した可能性のあるカスタム設定を保持されます。
4.7. 次のステップ
第5章 メトリックの管理
メトリクスを使用すると、クラスターコンポーネントおよび独自のワークロードのパフォーマンスをモニターできます。
5.1. メトリクスについて
OpenShift Container Platform 4.9 では、クラスターコンポーネントはサービスエンドポイントで公開されるメトリクスを収集することによりモニターされます。ユーザー定義プロジェクトのメトリクスのコレクションを設定することもできます。
Prometheus クライアントライブラリーをアプリケーションレベルで使用することで、独自のワークロードに指定するメトリクスを定義できます。
OpenShift Container Platform では、メトリクスは /metrics の正規名の下に HTTP サービスエンドポイント経由で公開されます。curl クエリーを http://<endpoint>/metrics に対して実行して、サービスの利用可能なすべてのメトリクスを一覧表示できます。たとえば、prometheus-example-app サンプルサービスへのルートを公開し、以下を実行して利用可能なすべてのメトリクスを表示できます。
$ curl http://<example_app_endpoint>/metrics出力例
# HELP http_requests_total Count of all HTTP requests
# TYPE http_requests_total counter
http_requests_total{code="200",method="get"} 4
http_requests_total{code="404",method="get"} 2
# HELP version Version information about this binary
# TYPE version gauge
version{version="v0.1.0"} 15.2. ユーザー定義プロジェクトのメトリクスコレクションの設定
ServiceMonitor リソースを作成して、ユーザー定義プロジェクトのサービスエンドポイントからメトリクスを収集できます。これは、アプリケーションが Prometheus クライアントライブラリーを使用してメトリクスを /metrics の正規の名前に公開していることを前提としています。
このセクションでは、ユーザー定義のプロジェクトでサンプルサービスをデプロイし、次にサービスのモニター方法を定義する ServiceMonitor リソースを作成する方法を説明します。
5.2.1. サンプルサービスのデプロイ
ユーザー定義のプロジェクトでサービスのモニタリングをテストするには、サンプルサービスをデプロイすることができます。
手順
-
サービス設定の YAML ファイルを作成します。この例では、
prometheus-example-app.yamlという名前です。 以下のデプロイメントおよびサービス設定の詳細をファイルに追加します。
apiVersion: v1 kind: Namespace metadata: name: ns1 --- apiVersion: apps/v1 kind: Deployment metadata: labels: app: prometheus-example-app name: prometheus-example-app namespace: ns1 spec: replicas: 1 selector: matchLabels: app: prometheus-example-app template: metadata: labels: app: prometheus-example-app spec: containers: - image: ghcr.io/rhobs/prometheus-example-app:0.4.1 imagePullPolicy: IfNotPresent name: prometheus-example-app --- apiVersion: v1 kind: Service metadata: labels: app: prometheus-example-app name: prometheus-example-app namespace: ns1 spec: ports: - port: 8080 protocol: TCP targetPort: 8080 name: web selector: app: prometheus-example-app type: ClusterIPこの設定は、
prometheus-example-appという名前のサービスをユーザー定義のns1プロジェクトにデプロイします。このサービスは、カスタムversionメトリクスを公開します。設定をクラスターに適用します。
$ oc apply -f prometheus-example-app.yamlサービスをデプロイするには多少時間がかかります。
Pod が実行中であることを確認できます。
$ oc -n ns1 get pod出力例
NAME READY STATUS RESTARTS AGE prometheus-example-app-7857545cb7-sbgwq 1/1 Running 0 81m
5.2.2. サービスのモニター方法の指定
サービスが公開するメトリクスを使用するには、OpenShift Container モニタリングを、/metrics エンドポイントからメトリクスを収集できるように設定する必要があります。これは、サービスのモニタリング方法を指定する ServiceMonitor カスタムリソース定義、または Pod のモニタリング方法を指定する PodMonitor CRD を使用して実行できます。前者の場合は Service オブジェクトが必要ですが、後者の場合は不要です。これにより、Prometheus は Pod によって公開されるメトリクスエンドポイントからメトリクスを直接収集することができます。
この手順では、ユーザー定義プロジェクトでサービスの ServiceMonitor リソースを作成する方法を説明します。
前提条件
-
cluster-adminロールまたはmonitoring-editロールを持つユーザーとしてクラスターにアクセスできる。 - ユーザー定義プロジェクトのモニタリングを有効にしている。
この例では、
prometheus-example-appサンプルサービスをns1プロジェクトにデプロイしている。注記prometheus-example-appサンプルサービスは TLS 認証をサポートしません。
手順
-
ServiceMonitorリソース設定の YAML ファイルを作成します。この例では、ファイルはexample-app-service-monitor.yamlという名前です。 以下の
ServiceMonitorリソース設定の詳細を追加します。apiVersion: monitoring.coreos.com/v1 kind: ServiceMonitor metadata: labels: k8s-app: prometheus-example-monitor name: prometheus-example-monitor namespace: ns1 spec: endpoints: - interval: 30s port: web scheme: http selector: matchLabels: app: prometheus-example-appこれは、
prometheus-example-appサンプルサービスによって公開されるメトリクスを収集するServiceMonitorリソースを定義します。これにはversionメトリクスが含まれます。注記ユーザー定義の namespace の
ServiceMonitorリソースは、同じ namespace のサービスのみを検出できます。つまり、ServiceMonitorリソースのnamespaceSelectorフィールドは常に無視されます。設定をクラスターに適用します。
$ oc apply -f example-app-service-monitor.yamlServiceMonitorをデプロイするのに多少時間がかかります。ServiceMonitorリソースが実行中であることを確認できます。$ oc -n ns1 get servicemonitor出力例
NAME AGE prometheus-example-monitor 81m
5.3. メトリクスのクエリー
OpenShift Container Platform モニタリングダッシュボードでは、Prometheus のクエリー言語 (PromQL) クエリーを実行し、プロットに可視化されるメトリクスを検査できます。この機能により、クラスターの状態と、モニターしているユーザー定義のワークロードに関する情報が提供されます。
クラスター管理者 は、すべての OpenShift Container Platform のコアプロジェクトおよびユーザー定義プロジェクトのメトリックをクエリーできます。
開発者 として、メトリックのクエリー時にプロジェクト名を指定する必要があります。選択したプロジェクトのメトリックを表示するには、必要な権限が必要です。
5.3.1. クラスター管理者としてのすべてのプロジェクトのメトリックのクエリー
クラスター管理者またはすべてのプロジェクトの表示パーミッションを持つユーザーとして、メトリクス UI ですべてのデフォルト OpenShift Container Platform およびユーザー定義プロジェクトのメトリクスにアクセスできます。
クラスター管理者のみが、OpenShift Container Platform Monitoring で提供されるサードパーティーの UI にアクセスできます。
前提条件
-
cluster-adminロールまたはすべてのプロジェクトの表示パーミッションを持つユーザーとしてクラスターにアクセスできる。 -
OpenShift CLI (
oc) がインストールされている。
手順
- OpenShift Container Platform Web コンソール内の Administrator パースペクティブで、Observe → Metrics を選択します。
- Insert Metric at Cursor を選択し、事前に定義されたクエリーの一覧を表示します。
- カスタムクエリーを作成するには、Prometheus クエリー言語 (PromQL) のクエリーを Expression フィールドに追加します。
- 複数のクエリーを追加するには、Add Query を選択します。
-
クエリーを削除するには、クエリーの横にある
 を選択してから Delete query を選択します。
を選択してから Delete query を選択します。
-
クエリーの実行を無効にするには、クエリーの横にある
を選択してから Disable query を選択します。
Run Queries を選択し、作成したクエリーを実行します。クエリーからのメトリクスはプロットで可視化されます。クエリーが無効な場合、UI にはエラーメッセージが表示されます。
注記大量のデータで動作するクエリーは、時系列グラフの描画時にタイムアウトするか、またはブラウザーをオーバーロードする可能性があります。これを回避するには、Hide graph を選択し、メトリックテーブルのみを使用してクエリーを調整します。次に、使用できるクエリーを確認した後に、グラフを描画できるようにプロットを有効にします。
- オプション: ページ URL には、実行したクエリーが含まれます。このクエリーのセットを再度使用できるようにするには、この URL を保存します。
5.3.2. 開発者が行うユーザー定義プロジェクトのメトリクスのクエリー
ユーザー定義のプロジェクトのメトリックには、開発者またはプロジェクトの表示パーミッションを持つユーザーとしてアクセスできます。
Developer パースペクティブには、選択したプロジェクトの事前に定義された CPU、メモリー、帯域幅、およびネットワークパケットのクエリーが含まれます。また、プロジェクトの CPU、メモリー、帯域幅、ネットワークパケットおよびアプリケーションメトリックについてカスタム Prometheus Query Language (PromQL) クエリーを実行することもできます。
開発者は Developer パースペクティブのみを使用でき、Administrator パースペクティブは使用できません。開発者は、1 度に 1 つのプロジェクトのメトリクスのみをクエリーできます。開発者はコアプラットフォームコンポーネント用の OpenShift Container Platform モニタリングで提供されるサードパーティーの UI にアクセスできません。その代わりとして、ユーザー定義プロジェクトにメトリクス UI を使用します。
前提条件
- 開発者として、またはメトリクスで表示しているプロジェクトの表示パーミッションを持つユーザーとしてクラスターへのアクセスがある。
- ユーザー定義プロジェクトのモニタリングを有効にしている。
- ユーザー定義プロジェクトにサービスをデプロイしている。
-
サービスのモニター方法を定義するために、サービスの
ServiceMonitorカスタムリソース定義 (CRD) を作成している。
手順
- OpenShift Container Platform Web コンソールの Developer パースペクティブから、Observe → Metrics を選択します。
- Project: 一覧でメトリックで表示するプロジェクトを選択します。
Select Query 一覧からクエリーを選択するか、Show PromQL を選択してカスタム PromQL クエリーを実行します。
注記Developer パースペクティブでは、1 度に 1 つのクエリーのみを実行できます。
5.3.3. 視覚化されたメトリクスの使用
クエリーの実行後に、メトリクスが対話式プロットに表示されます。プロットの X 軸は時間を表し、Y 軸はメトリクスの値を表します。各メトリクスは、グラフ上の色付きの線で表示されます。プロットを対話的に操作し、メトリクスを参照できます。
手順
Administrator パースペクティブで、以下を行います。
最初に、有効な全クエリーの全メトリクスがプロットに表示されます。表示されるメトリクスを選択できます。
注記デフォルトでは、クエリーテーブルに、すべてのメトリクスとその現在の値を一覧表示する拡張ビューが表示されます。˅ を選択すると、クエリーの拡張ビューを最小にすることができます。
-
クエリーからすべてのメトリクスを非表示にするには、クエリーの
をクリックし、Hide all series をクリックします。
- 特定のメトリクスを非表示にするには、クエリーテーブルに移動し、メトリクス名の横にある色の付いた四角をクリックします。
-
クエリーからすべてのメトリクスを非表示にするには、クエリーの
プロットをズームアップし、時間範囲を変更するには、以下のいずれかを行います。
- プロットを水平にクリックし、ドラッグして、時間範囲を視覚的に選択します。
- 左上隅のメニューを使用して、時間範囲を選択します。
- 時間の範囲をリセットするには、Reset Zoom を選択します。
- 特定の時点のすべてのクエリーの出力を表示するには、その時点のプロットにてマウスのカーソルを保持します。クエリーの出力はポップアップに表示されます。
- プロットを非表示にするには、Hide Graph を選択します。
Developer パースペクティブ:
プロットをズームアップし、時間範囲を変更するには、以下のいずれかを行います。
- プロットを水平にクリックし、ドラッグして、時間範囲を視覚的に選択します。
- 左上隅のメニューを使用して、時間範囲を選択します。
- 時間の範囲をリセットするには、Reset Zoom を選択します。
- 特定の時点のすべてのクエリーの出力を表示するには、その時点のプロットにてマウスのカーソルを保持します。クエリーの出力はポップアップに表示されます。
5.4. 次のステップ
第6章 アラートの管理
OpenShift Container Platform 4.9 では、アラート UI を使用してアラート、サイレンス、およびアラートルールを管理できます。
- アラートルールアラートルールには、クラスター内の特定の状態を示す一連の条件が含まれます。アラートは、これらの条件が true の場合にトリガーされます。アラートルールには、アラートのルーティング方法を定義する重大度を割り当てることができます。
- Alertsアラートは、アラートルールで定義された条件が true の場合に発生します。アラートは、一連の状況が OpenShift Container Platform クラスター内で明確であることを示す通知を提供します。
- サイレンス。サイレンスをアラートに適用し、アラートの条件が true の場合に通知が送信されることを防ぐことができます。初期通知後はアラートをミュートにして、根本的な問題の解決に取り組むことができます。
アラート UI で利用可能なアラート、サイレンス、およびアラートルールは、アクセス可能なプロジェクトに関連付けられます。たとえば、cluster-admin 権限でログインしている場合は、すべてのアラート、サイレンス、およびアラートルールにアクセスできます。
管理者以外のユーザーは、次のユーザーロールが割り当てられていれば、アラートを作成して無効にすることができます。
-
Alertmanager へのアクセスを許可する
cluster-monitoring-viewロール -
monitoring-alertmanager-editロール。これにより、Web コンソールの Administrator パースペクティブでアラートを作成して無効にできます。 -
monitoring-rules-editロール。これにより、Web コンソールの Developer パースペクティブでアラートを作成して無効にできます。
6.1. Administrator および Developer パースペクティブでのアラート UI へのアクセス
アラート UI は、OpenShift Container Platform Web コンソールの Administrator パースペクティブおよび Developer パースペクティブからアクセスできます。
- Administrator パースペクティブで、Observe → Alerting を選択します。このパースペクティブのアラート UI の主なページには、Alerts、Silences、および Alerting Rules という 3 つのページがあります。
- Developer パースペクティブで、Observe → <project_name> → Alerts を選択します。このパースペクティブのアラートでは、サイレンスおよびアラートルールはすべて Alerts ページで管理されます。Alerts ページに表示される結果は、選択されたプロジェクトに固有のものです。
Developer パースペクティブでは、Project: 一覧からアクセスできる OpenShift Container Platform のコアプロジェクトおよびユーザー定義プロジェクトを選択できます。ただし、cluster-admin 権限がない場合、OpenShift Container Platform のコアプロジェクトに関連するアラート、サイレンス、およびアラートルールは表示されません。
6.2. アラート、サイレンスおよびアラートルールの検索およびフィルター
アラート UI に表示されるアラート、サイレンス、およびアラートルールをフィルターできます。このセクションでは、利用可能なフィルターオプションのそれぞれについて説明します。
アラートフィルターについて
Administrator パースペクティブでは、アラート UI の Alerts ページに、デフォルトの OpenShift Container Platform プロジェクトおよびユーザー定義プロジェクトに関連するアラートの詳細が提供されます。このページには、各アラートの重大度、状態、およびソースの概要が含まれます。アラートが現在の状態に切り替わった時間も表示されます。
アラートの状態、重大度、およびソースでフィルターできます。デフォルトでは、Firing の Platform アラートのみが表示されます。以下では、それぞれのアラートフィルターオプションについて説明します。
Alert State フィルター:
-
Firingアラート条件が true で、オプションの
forの期間を経過しているためにアラートが実行されます。アラートは、条件が true である限り継続して実行されます。 - Pendingアラートはアクティブですが、アラート実行前のアラートルールに指定される期間待機します。
- Silencedアラートは定義された期間についてサイレンスにされるようになりました。定義するラベルセレクターのセットに基づいてアラートを一時的にミュートします。一覧表示される値または正規表現のすべてに一致するアラートについては通知は送信されません。
-
Firingアラート条件が true で、オプションの
Severity フィルター:
- Criticalアラートをトリガーした状態は重大な影響を与える可能性があります。このアラートには、実行時に早急な対応が必要となり、通常は個人または緊急対策チーム (Critical Response Team) に送信先が設定されます。
- Warningアラートは、問題の発生を防ぐために注意が必要になる可能性のある問題についての警告通知を提供します。通常、警告は早急な対応を要さないレビュー用にチケットシステムにルート指定されます。
- Infoアラートは情報提供のみを目的として提供されます。
- Noneアラートには重大度が定義されていません。
- また、ユーザー定義プロジェクトに関連するアラートの重大度の定義を作成することもできます。
Source フィルター:
- Platformプラットフォームレベルのアラートは、デフォルトの OpenShift Container Platform プロジェクトにのみ関連します。これらのプロジェクトは OpenShift Container Platform のコア機能を提供します。
- Userユーザーアラートはユーザー定義のプロジェクトに関連します。これらのアラートはユーザーによって作成され、カスタマイズ可能です。ユーザー定義のワークロードモニタリングはインストール後に有効にでき、独自のワークロードへの可観測性を提供します。
サイレンスフィルターについて
Administrator パースペクティブでは、アラート UI の Silences ページには、デフォルトの OpenShift Container Platform およびユーザー定義プロジェクトのアラートに適用されるサイレンスについての詳細が示されます。このページには、それぞれのサイレンスの状態の概要とサイレンスが終了する時間の概要が含まれます。
サイレンス状態でフィルターを実行できます。デフォルトでは、Active および Pending のサイレンスのみが表示されます。以下は、それぞれのサイレンス状態のフィルターオプションについて説明しています。
Silence State フィルター:
- Activeサイレンスはアクティブで、アラートはサイレンスが期限切れになるまでミュートされます。
- Pendingサイレンスがスケジュールされており、アクティブな状態ではありません。
- Expiredアラートの条件が true の場合、サイレンスが期限切れになり、通知が送信されます。
アラートルールフィルターについて
Administrator パースペクティブでは、アラート UI の Alerting Rules ページには、デフォルトの OpenShift Container Platform およびユーザー定義プロジェクトに関連するアラートルールの詳細が示されます。このページには、各アラートルールの状態、重大度およびソースの概要が含まれます。
アラート状態、重大度、およびソースを使用してアラートルールをフィルターできます。デフォルトでは、プラットフォームのアラートルールのみが表示されます。以下では、それぞれのアラートルールのフィルターオプションを説明します。
Alert State フィルター:
-
Firingアラート条件が true で、オプションの
forの期間を経過しているためにアラートが実行されます。アラートは、条件が true である限り継続して実行されます。 - Pendingアラートはアクティブですが、アラート実行前のアラートルールに指定される期間待機します。
- Silencedアラートは定義された期間についてサイレンスにされるようになりました。定義するラベルセレクターのセットに基づいてアラートを一時的にミュートします。一覧表示される値または正規表現のすべてに一致するアラートについては通知は送信されません。
- Not Firingアラートは実行されません。
-
Firingアラート条件が true で、オプションの
Severity フィルター:
- Criticalアラートルールで定義される状態は重大な影響を与える可能性があります。true の場合、これらの状態には早急な対応が必要です。通常、ルールに関連するアラートは個別または緊急対策チーム (Critical Response Team) に送信先が設定されます。
- Warningアラートルールで定義される状態は、問題の発生を防ぐために注意を要する場合があります。通常、ルールに関連するアラートは早急な対応を要さないレビュー用にチケットシステムにルート指定されます。
- Infoアラートルールは情報アラートのみを提供します。
- Noneアラートルールには重大度が定義されていません。
- ユーザー定義プロジェクトに関連するアラートルールのカスタム重大度定義を作成することもできます。
Source フィルター:
- Platformプラットフォームレベルのアラートルールは、デフォルトの OpenShift Container Platform プロジェクトにのみ関連します。これらのプロジェクトは OpenShift Container Platform のコア機能を提供します。
- Userユーザー定義のワークロードアラートルールは、ユーザー定義プロジェクトに関連します。これらのアラートルールはユーザーによって作成され、カスタマイズ可能です。ユーザー定義のワークロードモニタリングはインストール後に有効にでき、独自のワークロードへの可観測性を提供します。
Developer パースペクティブでのアラート、サイレンスおよびアラートルールの検索およびフィルター
Developer パースペクティブのアラート UI の Alerts ページでは、選択されたプロジェクトに関連するアラートとサイレンスを組み合わせたビューを提供します。規定するアラートルールへのリンクが表示されるアラートごとに提供されます。
このビューでは、アラートの状態と重大度でフィルターを実行できます。デフォルトで、プロジェクトへのアクセスパーミッションがある場合は、選択されたプロジェクトのすべてのアラートが表示されます。これらのフィルターは Administrator パースペクティブについて記載されているフィルターと同じです。
6.3. アラート、サイレンスおよびアラートルールについての情報の取得
アラート UI は、アラートおよびそれらを規定するアラートルールおよびサイレンスについての詳細情報を提供します。
前提条件
- 開発者として、またはメトリクスで表示しているプロジェクトの表示パーミッションを持つユーザーとしてクラスターへのアクセスがある。
手順
Administrator パースペクティブでアラートについての情報を取得するには、以下を実行します。
- OpenShift Container Platform Web コンソールを開き、Observe → Alerting → Alerts ページに移動します。
- オプション: 検索一覧で Name フィールドを使用し、アラートを名前で検索します。
- オプション: Filter 一覧でフィルターを選択し、アラートを状態、重大度およびソースでフィルターします。
- オプション: 1 つ以上の Name、Severity、State、および Source 列ヘッダーをクリックし、アラートを並べ替えます。
Alert Details ページに移動するためにアラートの名前を選択します。このページには、アラートの時系列データを示すグラフが含まれます。また、以下を含むアラートについての情報も含まれます。
- アラートの説明
- アラートに関連付けられたメッセージ
- アラートに割り当てられるラベル
- アラートを規定するアラートルールへのリンク
- アラートが存在する場合のアラートのサイレンス
Administrator パースペクティブでサイレンスについての情報を取得するには、以下を実行します。
- Observe → Alerting → Silences ページに移動します。
- オプション: Search by name フィールドを使用し、サイレンスを名前でフィルターします。
- オプション: Filter 一覧でフィルターを選択し、サイレンスをフィルターします。デフォルトでは、Active および Pending フィルターが適用されます。
- オプション: 1 つ以上の Name、Firing Alerts、および State 列ヘッダーをクリックしてサイレンスを並べ替えます。
Silence Details ページに移動するサイレンスの名前を選択します。このページには、以下の詳細が含まれます。
- アラート仕様
- 開始時間
- 終了時間
- サイレンス状態
- 発生するアラートの数および一覧
Administrator パースペクティブでアラートルールについての情報を取得するには、以下を実行します。
- Observe → Alerting → Alerting Rules ページに移動します。
- オプション: Filter 一覧でフィルターを選択し、アラートルールを状態、重大度およびソースでフィルターします。
- オプション: 1 つ以上の Name、Severity、Alert State、および Source 列ヘッダーをクリックし、アラートルールを並べ替えます。
アラートルールの名前を選択し、Alerting Rule Details ページに移動します。このページには、アラートルールに関する以下の情報が含まれます。
- アラートルール名、重大度、および説明
- アラートを発生させるための条件を定義する式
- アラートを発生させるための条件が true である期間
- アラートルールに規定される各アラートのグラフ。アラートを発生させる際に使用する値が表示されます。
- アラートルールで規定されるすべてのアラートについての表
Developer パースペクティブでアラート、サイレンス、およびアラートルールについての情報を取得するには、以下を実行します。
- Observe → <project_name> → Alerts ページに移動します。
アラート、サイレンス、またはアラートルールの詳細を表示します。
- Alert Details を表示するには、アラート名の左側で > を選択し、一覧でアラートを選択します。
Silence Details を表示するには、Alert Details ページの Silenced By セクションでサイレンスを選択します。Silence Details ページには、以下の情報が含まれます。
- アラート仕様
- 開始時間
- 終了時間
- サイレンス状態
- 発生するアラートの数および一覧
-
Alerting Rule Details を表示するには、Alerts ページのアラートの右側にある
メニューの View Alerting Rule を選択します。
選択したプロジェクトに関連するアラート、サイレンスおよびアラートルールのみが Developer パースペクティブに表示されます。
6.4. アラートルールの管理
OpenShift Container Platform モニタリングには、デフォルトのアラートルールのセットが同梱されます。クラスター管理者は、デフォルトのアラートルールを表示できます。
OpenShift Container Platform 4.9 では、ユーザー定義プロジェクトでアラートルールを作成し、表示し、編集し、削除することができます。
アラートルールについての考慮事項
- デフォルトのアラートルールは OpenShift Container Platform クラスター用に使用され、それ以外の目的では使用されません。
- 一部のアラートルールには、複数の意図的に同じ名前が含まれます。それらは同じイベントについてのアラートを送信しますが、それぞれ異なるしきい値、重大度およびそれらの両方が設定されます。
- 抑制 (inhibition) ルールは、高い重大度のアラートが実行される際に実行される低い重大度のアラートの通知を防ぎます。
6.4.1. ユーザー定義プロジェクトのアラートの最適化
アラートルールの作成時に以下の推奨事項を考慮して、独自のプロジェクトのアラートを最適化できます。
- プロジェクト用に作成するアラートルールの数を最小限にします。影響を与える条件についてユーザーに通知するアラートルールを作成します。影響を与えない条件について数多くのアラートを生成すると、関連性のあるアラートを認識することはより困難になります。
- 原因ではなく現象についてのアラートルールを作成します。根本的な原因に関係なく状態について通知するアラートルールを作成します。次に、原因を調査できます。アラートルールのそれぞれが特定の原因にのみ関連する場合に、さらに多くのアラートルールが必要になります。そのため、いくつかの原因は見落される可能性があります。
- アラートルールを作成する前にプランニングを行います。重要な現象と、その発生時に実行するアクションを決定します。次に、現象別にアラートルールをビルドします。
- クリアなアラートメッセージングを提供します。アラートメッセージに現象および推奨されるアクションを記載します。
- アラートルールに重大度レベルを含めます。アラートの重大度は、報告される現象が生じた場合に取るべき対応によって異なります。たとえば、現象に個人または緊急対策チーム (Critical Response Team) による早急な対応が必要な場合、重大アラートをトリガーする必要があります。
アラートルーティングを最適化します。ルールがデフォルトの OpenShift Container Platform メトリクスをクエリーしない場合には、
openshift-user-workload-monitoringプロジェクトの Prometheus インスタンスにアラートルールを直接デプロイします。これにより、アラートルールの待ち時間が短縮され、モニタリングコンポーネントへの負荷が最小限に抑えられます。警告ユーザー定義プロジェクトのデフォルトの OpenShift Container Platform メトリクスは、CPU およびメモリーの使用状況、帯域幅の統計、およびパケットレートについての情報を提供します。ルールを
openshift-user-workload-monitoringプロジェクトの Prometheus インスタンスに直接ロート指定する場合、これらのメトリクスをアラートルールに含めることはできません。アラートルールの最適化は、ドキュメントを参照し、モニタリング用のアーキテクチャーの全体像を把握している場合にのみ使用してください。
6.4.2. ユーザー定義プロジェクトのアラートルールの作成
ユーザー定義のプロジェクトについてアラートルールを作成できます。これらのアラートルールは、選択したメトリクスの値に基づいてアラートを実行します。
前提条件
- ユーザー定義プロジェクトのモニタリングを有効にしている。
-
アラートルールを作成する必要のある namespace の
monitoring-rules-editロールを持つユーザーとしてログインします。 -
OpenShift CLI (
oc) がインストールされている。
手順
-
アラートルールの YAML ファイルを作成します。この例では、
example-app-alerting-rule.yamlという名前です。 アラートルール設定を YAML ファイルに追加します。以下に例を示します。
注記アラートルールの作成時に、同じ名前のルールが別のプロジェクトにある場合に、プロジェクトのラベルがこのアラートルールに対して適用されます。
apiVersion: monitoring.coreos.com/v1 kind: PrometheusRule metadata: name: example-alert namespace: ns1 spec: groups: - name: example rules: - alert: VersionAlert expr: version{job="prometheus-example-app"} == 0この設定により、
example-alertという名前のアラートルールが作成されます。アラートルールは、サンプルサービスによって公開されるversionメトリクスが0になるとアラートを実行します。重要ユーザー定義のアラートルールには、独自のプロジェクトおよびクラスターメトリクスのメトリクスを含めることができます。別のユーザー定義プロジェクトのメトリクスを含めることはできません。
たとえば、ユーザー定義プロジェクトの
ns1のアラートルールには、ns1、および CPU およびメモリーメトリクスなどのクラスターメトリクスなどを含めることができます。ただし、ルールにはns2からのメトリクスを含めることはできません。さらに、
openshift-*コア OpenShift Container Platform プロジェクトのアラートルールは作成できません。デフォルトで OpenShift Container Platform モニタリングはこれらのプロジェクトのアラートルールのセットを提供します。設定ファイルをクラスターに適用します。
$ oc apply -f example-app-alerting-rule.yamlアラートルールの作成には多少時間がかかります。
6.4.3. プラットフォームメトリクスをクエリーしないアラートルールの待ち時間の短縮
ユーザー定義プロジェクトのアラートルールがデフォルトのクラスターメトリクスをクエリーしない場合、openshift-user-workload-monitoring プロジェクトの Prometheus インスタンスにルールを直接デプロイすることができます。これにより、Thanos Ruler が必要でない場合にこれをバイパスすることで、アラートルールの待ち時間が短縮されます。これは、モニタリングコンポーネントの全体的な負荷を最小限に抑えるのに役立ちます。
ユーザー定義プロジェクトのデフォルトの OpenShift Container Platform メトリクスは、CPU およびメモリーの使用状況、帯域幅の統計、およびパケットレートについての情報を提供します。ルールを openshift-user-workload-monitoring プロジェクトの Prometheus インスタンスに直接デプロイする場合、これらのメトリクスをアラートルールに含めることはできません。本セクションで説明した手順は、ドキュメントを参照し、モニタリング用のアーキテクチャーの全体像を把握している場合にのみ使用してください。
前提条件
- ユーザー定義プロジェクトのモニタリングを有効にしている。
-
アラートルールを作成する必要のある namespace の
monitoring-rules-editロールを持つユーザーとしてログインします。 -
OpenShift CLI (
oc) がインストールされている。
手順
-
アラートルールの YAML ファイルを作成します。この例では、
example-app-alerting-rule.yamlという名前です。 キーが
openshift.io/prometheus-rule-evaluation-scopeで、値がleaf-prometheusのラベルが含まれる YAML ファイルにアラートルール設定を追加します。以下に例を示します。apiVersion: monitoring.coreos.com/v1 kind: PrometheusRule metadata: name: example-alert namespace: ns1 labels: openshift.io/prometheus-rule-evaluation-scope: leaf-prometheus spec: groups: - name: example rules: - alert: VersionAlert expr: version{job="prometheus-example-app"} == 0
そのラベルがある場合、アラートルールは openshift-user-workload-monitoring プロジェクトの Prometheus インスタンスにデプロイされます。ラベルが存在しない場合、アラートルールは Theanos Ruler にデプロイされます。
設定ファイルをクラスターに適用します。
$ oc apply -f example-app-alerting-rule.yamlアラートルールの作成には多少時間がかかります。
- OpenShift Container Platform 4.9 モニターリングアーキテクチャーに関する詳細は、Monitoring overview を参照してください。
6.4.4. ユーザー定義プロジェクトのアラートルールへのアクセス
ユーザー定義プロジェクトのアラートルールを一覧表示するには、プロジェクトの monitoring-rules-view ロールが割り当てられている必要があります。
前提条件
- ユーザー定義プロジェクトのモニタリングを有効にしている。
-
プロジェクトの
monitoring-rules-viewロールを持つユーザーとしてログインしている。 -
OpenShift CLI (
oc) がインストールされている。
手順
<project>でアラートルールを一覧表示できます。$ oc -n <project> get prometheusruleアラートルールの設定を一覧表示するには、以下を実行します。
$ oc -n <project> get prometheusrule <rule> -o yaml
6.4.5. 単一ビューでのすべてのプロジェクトのアラートルールの一覧表示
クラスター管理者は、OpenShift Container Platform のコアプロジェクトおよびユーザー定義プロジェクトのアラートルールを単一ビューで一覧表示できます。
前提条件
-
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。 -
OpenShift CLI (
oc) がインストールされている。
手順
- Administrator パースペクティブで、Observe → Alerting → Alerting Rules に移動します。
Filter ドロップダウンメニューで、Platform および User ソースを選択します。
注記Platform ソースはデフォルトで選択されます。
6.4.6. ユーザー定義プロジェクトのアラートルールの削除
ユーザー定義プロジェクトのアラートルールを削除できます。
前提条件
- ユーザー定義プロジェクトのモニタリングを有効にしている。
-
アラートルールを作成する必要のある namespace の
monitoring-rules-editロールを持つユーザーとしてログインします。 -
OpenShift CLI (
oc) がインストールされている。
手順
<namespace>のルール<foo>を削除するには、以下を実行します。$ oc -n <namespace> delete prometheusrule <foo>
6.5. サイレンスの管理
アラートの発生時にアラートについての通知の受信を停止するためにサイレンスを作成できます。根本的な問題を解決する際に、初回の通知後にアラートをサイレンスにすることが役に立つ場合があります。
サイレンスの作成時に、サイレンスをすぐにアクティブにするか、または後にアクティブにするかを指定する必要があります。また、サイレンスの有効期限を設定する必要もあります。
既存のサイレンスを表示し、編集し、期限切れにすることができます。
6.5.1. アラートをサイレンスにする
特定のアラート、または定義する仕様に一致するアラートのいずれかをサイレンスにすることができます。
前提条件
-
あなたはクラスター管理者であり、
cluster-adminクラスターロールを持つユーザーとしてクラスターにアクセスできます。 あなたは非管理者ユーザーであり、次のユーザーロールを持つユーザーとしてクラスターにアクセスできます。
-
Alertmanager へのアクセスを許可する
cluster-monitoring-viewクラスターロール。 -
monitoring-alertmanager-editロール。これにより、Web コンソールの Administrator パースペクティブでアラートを作成して無効にできます。 -
monitoring-rules-editロール。これにより、Web コンソールの Developer パースペクティブでアラートを作成して無効にできます。
-
Alertmanager へのアクセスを許可する
手順
特定のアラートをサイレンスにするには、以下を実行します。
Administrator パースペクティブで、以下を行います。
- OpenShift Container Platform Web コンソールの Observe → Alerting → Alerts ページに移動します。
-
サイレンスにする必要のあるアラートについて、右側の列で
を選択し、Silence Alert を選択します。Silence Alert フォームは、選択したアラートの事前に設定された仕様と共に表示されます。
- オプション: サイレンスを変更します。
- サイレンスを作成する前にコメントを追加する必要があります。
- サイレンスを作成するには、Silence を選択します。
Developer パースペクティブ:
- OpenShift Container Platform Web コンソールの Observe → <project_name> → Alerts ページに移動します。
- アラート名の左側にある > を選択して、アラートの詳細を展開します。拡張されたビューでアラートの名前を選択し、アラートの Alert Details ページを開きます。
- Silence Alert を選択します。Silence Alert フォームが、選択したアラートの事前に設定された仕様と共に表示されます。
- オプション: サイレンスを変更します。
- サイレンスを作成する前にコメントを追加する必要があります。
- サイレンスを作成するには、Silence を選択します。
Administrator パースペクティブにアラート仕様を作成してアラートのセットをサイレンスにするには、以下を実行します。
- OpenShift Container Platform Web コンソールの Observe → Alerting → Silences ページに移動します。
- Create Silence を選択します。
- Create Silence フォームで、アラートのスケジュール、期間、およびラベルの詳細を設定します。また、サイレンスのコメントを追加する必要もあります。
- 直前の手順で入力したラベルセクターに一致するアラートのサイレンスを作成するには、Silence を選択します。
6.5.2. サイレンスの編集
サイレンスは編集することができます。 これにより、既存のサイレンスが期限切れとなり、変更された設定で新規のサイレンスが作成されます。
手順
Administrator パースペクティブでサイレンスを編集するには、以下を実行します。
- Observe → Alerting → Silences ページに移動します。
変更するサイレンスについて、最後の列の
を選択し、Edit silence を選択します。
または、サイレンスについて Silence Details ページで Actions → Edit Silence を選択できます。
- Edit Silence ページで変更を入力し、Silence を選択します。これにより、既存のサイレンスが期限切れとなり、選択された設定でサイレンスが作成されます。
Developer パースペクティブでサイレンスを編集するには、以下を実行します。
- Observe → <project_name> → Alerts ページに移動します。
- アラート名の左側にある > を選択して、アラートの詳細を展開します。拡張されたビューでアラートの名前を選択し、アラートの Alert Details ページを開きます。
- そのページの Silenced By セクションでサイレンスの名前を選択し、サイレンスの Silence Details ページに移動します。
- Silence Details ページに移動するサイレンスの名前を選択します。
- サイレンスについて、Silence Details ページで Actions → Edit Silence を選択します。
- Edit Silence ページで変更を入力し、Silence を選択します。これにより、既存のサイレンスが期限切れとなり、選択された設定でサイレンスが作成されます。
6.5.3. 有効期限切れにするサイレンス
サイレンスは有効期限切れにすることができます。サイレンスはいったん期限切れになると、永久に無効にされます。
手順
Administrator パースペクティブでサイレンスを期限切れにするには、以下を実行します。
- Observe → Alerting → Silences ページに移動します。
変更するサイレンスについて、最後の列の
を選択し、Expire silence を選択します。
または、サイレンスの Silence Details ページで Actions → Expire Silence を選択できます。
Developer パースペクティブでサイレンスを期限切れにするには、以下を実行します。
- Observe → <project_name> → Alerts ページに移動します。
- アラート名の左側にある > を選択して、アラートの詳細を展開します。拡張されたビューでアラートの名前を選択し、アラートの Alert Details ページを開きます。
- そのページの Silenced By セクションでサイレンスの名前を選択し、サイレンスの Silence Details ページに移動します。
- Silence Details ページに移動するサイレンスの名前を選択します。
- サイレンスの Silence Details ページで Actions → Expire Silence を選択します。
6.6. 外部システムへの通知の送信
OpenShift Container Platform 4.9 では、実行するアラートをアラート UI で表示できます。アラートは、デフォルトでは通知システムに送信されるように設定されません。以下のレシーバータイプにアラートを送信するように OpenShift Container Platform を設定できます。
- PagerDuty
- Webhook
- Slack
レシーバーへのアラートのルートを指定することにより、障害が発生する際に適切なチームに通知をタイムリーに送信できます。たとえば、重大なアラートには早急な対応が必要となり、通常は個人または緊急対策チーム (Critical Response Team) に送信先が設定されます。重大ではない警告通知を提供するアラートは、早急な対応を要さないレビュー用にチケットシステムにルート指定される可能性があります。
Watchdog アラートの使用によるアラートが機能することの確認
OpenShift Container Platform モニタリングには、継続的に実行される Watchdog アラートが含まれます。Alertmanager は、Watchdog のアラート通知を設定された通知プロバイダーに繰り返し送信します。通常、プロバイダーは Watchdog アラートの受信を停止する際に管理者に通知するように設定されます。このメカニズムは、Alertmanager と通知プロバイダー間の通信に関連する問題を迅速に特定するのに役立ちます。
6.6.1. アラートレシーバーの設定
アラートレシーバーを設定して、クラスターについての重要な問題について把握できるようにします。
前提条件
-
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。
手順
Administrator パースペクティブで、Administration → Cluster Settings → Configuration → Alertmanager に移動します。
注記または、通知ドロワーで同じページに移動することもできます。OpenShift Container Platform Web コンソールの右上にあるベルのアイコンを選択し、AlertmanagerReceiverNotConfigured アラートで Configure を選択します。
- ページの Receivers セクションで Create Receiver を選択します。
- Create Receiver フォームで、Receiver Name を追加し、一覧から Receiver Type を選択します。
レシーバー設定を編集します。
PagerDuty receiver の場合:
- 統合のタイプを選択し、PagerDuty 統合キーを追加します。
- PagerDuty インストールの URL を追加します。
- クライアントおよびインシデントの詳細または重大度の指定を編集する場合は、Show advanced configuration を選択します。
Webhook receiver の場合:
- HTTP POST リクエストを送信するエンドポイントを追加します。
- デフォルトオプションを編集して解決したアラートを receiver に送信する場合は、Show advanced configuration を選択します。
メール receiver の場合:
- 通知を送信するメールアドレスを追加します。
- SMTP 設定の詳細を追加します。これには、通知の送信先のアドレス、メールの送信に使用する smarthost およびポート番号、SMTP サーバーのホスト名、および認証情報を含む詳細情報が含まれます。
- TLS が必要であるかどうかについて選択します。
- デフォルトオプションを編集して解決済みのアラートが receiver に送信されないようにしたり、メール通知設定の本体を編集する必要がある場合は、Show advanced configuration を選択します。
Slack receiver の場合:
- Slack Webhook の URL を追加します。
- 通知を送信する Slack チャネルまたはユーザー名を追加します。
- デフォルトオプションを編集して解決済みのアラートが receiver に送信されないようにしたり、アイコンおよびユーザー設定を編集する必要がある場合は、Show advanced configuration を選択します。チャネル名とユーザー名を検索し、これらをリンクするかどうかについて選択することもできます。
デフォルトでは、実行されるすべてのセレクターに一致するラベルを持つアラートは receiver に送信されます。実行されるアラートのラベルの値を、それらが receiver に送信される前の状態に完全に一致させる必要がある場合は、以下を実行します。
- ルーティングラベル名と値をフォームの Routing Labels セクションに追加します。
- 正規表現を使用する場合は Regular Expression を選択します。
- Add Label を選択して、さらにルーティングラベルを追加します。
- Create を選択して receiver を作成します。
6.7. カスタム Alertmanager 設定の適用
alertmanager-main シークレットを openshift-monitoring プロジェクト内で編集して、デフォルトの Alertmanager 設定を上書きできます。
前提条件
-
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。
手順
CLI で Alertmanager 設定を変更するには、以下を実行します。
現在アクティブな Alertmanager 設定をファイル
alertmanager.yamlに出力します。$ oc -n openshift-monitoring get secret alertmanager-main --template='{{ index .data "alertmanager.yaml" }}' | base64 --decode > alertmanager.yamlalertmanager.yamlで設定を編集します。global: resolve_timeout: 5m route: group_wait: 30s group_interval: 5m repeat_interval: 12h receiver: default routes: - matchers: - "alertname=Watchdog" repeat_interval: 5m receiver: watchdog - matchers: - "service=<your_service>"1 routes: - matchers: - <your_matching_rules>2 receiver: <receiver>3 receivers: - name: default - name: watchdog - name: <receiver> # <receiver_configuration>注記matchersキー名を使用して、ノードの照合でアラートが満たす必要のあるマッチャーを指定します。matchまたはmatch_reキー名は使用しないでください。どちらも非推奨であり、今後のリリースで削除される予定です。さらに、禁止ルールを定義する場合は、
target_matchersキー名を使用してターゲットマッチャーを示し、source_matchersキー 名を使用してソースマッチャーを示します。target_match、target_match_re、source_match、またはsource_match_reキー名は使用しないでください。これらは非推奨であり、今後のリリースで削除される予定です。以下の Alertmanager 設定例は、PagerDuty をアラートレシーバーとして設定します。
global: resolve_timeout: 5m route: group_wait: 30s group_interval: 5m repeat_interval: 12h receiver: default routes: - matchers: - "alertname=Watchdog" repeat_interval: 5m receiver: watchdog - matchers: - "service=example-app" routes: - matchers: - "severity=critical" receiver: team-frontend-page receivers: - name: default - name: watchdog - name: team-frontend-page pagerduty_configs: - service_key: "your-key"この設定では、
example-appサービスで実行される重大度がcriticalのアラートは、team-frontend-pagereceiver を使用して送信されます。通常、これらのタイプのアラートは、個別または緊急対策チーム (Critical Response Team) に送信先が設定されます。新規設定をファイルで適用します。
$ oc -n openshift-monitoring create secret generic alertmanager-main --from-file=alertmanager.yaml --dry-run=client -o=yaml | oc -n openshift-monitoring replace secret --filename=-
OpenShift Container Platform Web コンソールから Alertmanager 設定を変更するには、以下を実行します。
- Web コンソールの Administration → Cluster Settings → Configuration → Alertmanager → YAML ページに移動します。
- YAML 設定ファイルを変更します。
- Save を選択します。
6.8. 次のステップ
第7章 モニタリングダッシュボードの確認
OpenShift Container Platform 4.9 は、クラスターコンポーネントおよびユーザー定義のワークロードの状態を理解するのに役立つ包括的なモニターリングダッシュボードのセットを提供します。
Administrator パースペクティブを使用して、以下を含む OpenShift Container Platform のコアコンポーネントのダッシュボードにアクセスします。
- API パフォーマンス
- etcd
- Kubernetes コンピュートリソース
- Kubernetes ネットワークリソース
- Prometheus
- クラスターおよびノードのパフォーマンスに関連する USE メソッドダッシュボード
図7.1 Administrator パースペクティブのダッシュボードの例
Developer パースペクティブを使用して、選択されたプロジェクトの以下のアプリケーションメトリクスを提供する Kubernetes コンピュートリソースダッシュボードにアクセスします。
- CPU usage (CPU の使用率)
- メモリー使用量
- 帯域幅に関する情報
- パケットレート情報
図7.2 Developer パースペクティブのダッシュボードの例
Developer パースペクティブでは、1 度に 1 つのプロジェクトのみのダッシュボードを表示できます。
7.1. クラスター管理者としてのモニタリングダッシュボードの確認
Administrator パースペクティブでは、OpenShift Container Platform クラスターのコアコンポーネントに関連するダッシュボードを表示できます。
前提条件
-
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。
手順
- OpenShift Container Platform Web コンソールの Administrator パースペクティブで、Observe → Dashboards に移動します。
- Dashboard 一覧でダッシュボードを選択します。etcd や Prometheus ダッシュボードなどの一部のダッシュボードは、選択時に追加のサブメニューを生成します。
必要に応じて、Time Range 一覧でグラフの時間範囲を選択します。
- 事前定義済みの期間を選択します。
時間範囲 一覧で カスタムの時間範囲 を選択して、カスタムの時間範囲を設定します。
- From および To の日付と時間を入力または選択します。
- Save をクリックして、カスタムの時間範囲を保存します。
- オプション: Refresh Interval を選択します。
- 特定の項目についての詳細情報を表示するには、ダッシュボードの各グラフにカーソルを合わせます。
7.2. 開発者としてのモニタリングダッシュボードの確認
Developer パースペクティブを使用して、選択したプロジェクトの Kubernetes コンピュートリソースダッシュボードを表示します。
前提条件
- 開発者またはユーザーとしてクラスターにアクセスできる。
- ダッシュボードを表示するプロジェクトの表示パーミッションがある。
手順
- OpenShift Container Platform Web コンソールの Developer パースペクティブで、Observe → Dashboard に移動します。
- Project: ドロップダウンリストからプロジェクトを選択します。
Dashboard ドロップダウンリストからダッシュボードを選択し、フィルターされたメトリクスを表示します。
注記すべてのダッシュボードは、Kubernetes / Compute Resources / Namespace(Pod) を除く、選択時に追加のサブメニューを生成します。
必要に応じて、Time Range 一覧でグラフの時間範囲を選択します。
- 事前定義済みの期間を選択します。
時間範囲 一覧で カスタムの時間範囲 を選択して、カスタムの時間範囲を設定します。
- From および To の日付と時間を入力または選択します。
- Save をクリックして、カスタムの時間範囲を保存します。
- オプション: Refresh Interval を選択します。
- 特定の項目についての詳細情報を表示するには、ダッシュボードの各グラフにカーソルを合わせます。
7.3. 次のステップ
第8章 サードパーティーの UI へのアクセス
統合メトリクス、アラート、およびダッシュボード UI は OpenShift Container Platform Web コンソールで提供されます。これらの統合 UI の使用方法についての詳細は、以下のドキュメントを参照してください。
OpenShift Container Platform は、Prometheus、Alertmanager、および Grafana サードパーティーインターフェイスへのアクセスも提供します。追加のプラットフォームコンポーネントのダッシュボードは、OpenShift Container Platform Web コンソールの Monitoring → Dashboards に含まれます。
サードパーティーのモニタリングインターフェイスへのデフォルトのアクセスは今後の OpenShift Container Platform リリースで削除される可能性があります。その場合、ポート転送を使用してそれらにアクセスする必要があります。
OpenShift Container Platform モニタリングスタックおよびダッシュボードと共に提供される Grafana インスタンスは読み取り専用です。Grafana ダッシュボードには、Kubernetes および cluster-monitoring メトリクスのみが含まれます。
8.1. Web コンソールを使用したサードパーティーのモニタリング UI へのアクセス
OpenShift Container Platform Web コンソールを使用して Alertmanager、Grafana、Prometheus、および Thanos Querier Web UI にアクセスできます。
前提条件
-
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。
手順
Administrator パースペクティブで、Networking → Routes に移動します。
注記Developer パースペクティブから、サードパーティーの Alertmanager、Grafana、Prometheus、および Thanos Querier UI にアクセスすることはできません。代わりに Developer パースペクティブの Metrics UI リンクを使用します。これには、選択したプロジェクトの事前に定義された CPU、メモリー、帯域幅、およびネットワークパケットのクエリーが含まれます。
-
Project: 一覧で
openshift-monitoringプロジェクトを選択します。 サードパーティーのモニタリング UI にアクセスします。
-
alertmanager-main行の URL を選択し、Alertmanager UI のログインページを開きます。 -
grafana行の URL を選択し、Grafana UI のログインページを開きます。 -
prometheus-k8s行の URL を選択し、Prometheus UI のログインページを開きます。 -
thanos-querier行の URL を選択し、Thanos Querier UI のログインページを開きます。
-
- Log in with OpenShift を選択し、OpenShift Container Platform 認証情報を使用してログインします。
8.2. CLI の使用によるサードパーティーのモニタリング UI へのアクセス
OpenShift CLI (oc) ツールを使用して、Prometheus、Alertmanager、および Grafana Web UI の URL を取得できます。
前提条件
-
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。 -
OpenShift CLI (
oc) がインストールされている。
手順
以下を実行して、
openshift-monitoringプロジェクトのルートを一覧表示します。$ oc -n openshift-monitoring get routes出力例
NAME HOST/PORT ... alertmanager-main alertmanager-main-openshift-monitoring.apps._url_.openshift.com ... grafana grafana-openshift-monitoring.apps._url_.openshift.com ... prometheus-k8s prometheus-k8s-openshift-monitoring.apps._url_.openshift.com ... thanos-querier thanos-querier-openshift-monitoring.apps._url_.openshift.com ...-
Web ブラウザーを使用して
HOST/PORTルートに移動します。 - Log in with OpenShift を選択し、OpenShift Container Platform 認証情報を使用してログインします。
モニタリングルートは Cluster Monitoring Operator によって管理され、ユーザーが変更することはできません。
第9章 モニタリング関連の問題のトラブルシューティング
9.2. Prometheus が大量のディスク領域を消費している理由の特定
開発者は、キーと値のペアの形式でメトリクスの属性を定義するためにラベルを作成できます。使用できる可能性のあるキーと値のペアの数は、属性について使用できる可能性のある値の数に対応します。数が無制限の値を持つ属性は、バインドされていない属性と呼ばれます。たとえば、customer_id 属性は、使用できる値が無限にあるため、バインドされていない属性になります。
割り当てられるキーと値のペアにはすべて、一意の時系列があります。ラベルに多数のバインドされていない値を使用すると、作成される時系列の数が指数関数的に増加する可能性があります。これは Prometheus のパフォーマンスに影響する可能性があり、多くのディスク領域を消費する可能性があります。
Prometheus が多くのディスクを消費する場合、以下の手段を使用できます。
- 収集される 収集サンプルの数を確認 します。
- Prometheus UI での時系列データベース (TSDB) のステータスを確認 して、最も多くの時系列ラベルを作成するラベルについて確認できます。これには、クラスター管理者の権限が必要です。
ユーザー定義メトリクスに割り当てられるバインドされていない属性の数を減らすことで、作成される一意の時系列の数を減らします。
注記使用可能な値の制限されたセットにバインドされる属性を使用すると、可能なキーと値のペアの組み合わせの数が減ります。
- ユーザー定義プロジェクト間で 収集可能なサンプル数の数に制限を適用します。これには、クラスター管理者の権限が必要です。
前提条件
-
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。 -
OpenShift CLI (
oc) がインストールされている。
手順
- Administrator パースペクティブで、Observe → Metrics に移動します。
Expression フィールドで、以下の Prometheus Query Language (PromQL) クエリーを実行します。これにより、収集サンプルの数が最も多い 10 メトリクスが返されます。
topk(10,count by (job)({__name__=~".+"}))予想されるよりも多くの収集サンプルを持つメトリクスに割り当てられたバインドされていないラベル値の数を調査します。
- メトリクスがユーザー定義のプロジェクトに関連する場合、ワークロードに割り当てられたメトリクスのキーと値のペアを確認します。これらのライブラリーは、アプリケーションレベルで Prometheus クライアントライブラリーを使用して実装されます。ラベルで参照されるバインドされていない属性の数の制限を試行します。
- メトリクスが OpenShift Container Platform のコアプロジェクトに関連する場合、Red Hat サポートケースを Red Hat カスタマーポータル で作成してください。
Prometheus UI で TSDB ステータスを確認します。
- Administrator パースペクティブで、Networking → Routes に移動します。
-
Project: 一覧で
openshift-monitoringプロジェクトを選択します。 -
prometheus-k8s行の URL を選択し、Prometheus UI のログインページを開きます。 - Log in with OpenShift を選択し、OpenShift Container Platform 認証情報を使用してログインします。
- Prometheus UI で、Status → TSDB Status に移動します。