第2章 デプロイメント設定
本章では、カスタムリソースを使用してサポートされるデプロイメントのさまざまな側面を設定する方法について説明します。
- Kafka クラスター
- Kafka Connect クラスター
- Source2Image がサポートされる Kafka Connect クラスター
- Kafka MirrorMaker
- Kafka Bridge
- Cruise Control
カスタムリソースに適用されるラベルは、Kafka MirrorMaker を構成する OpenShift リソースにも適用されます。そのため、必要に応じてリソースにラベルが適用されるため便利です。
2.1. Kafka クラスターの設定
ここでは、AMQ Streams クラスターで Kafka デプロイメントを設定する方法を説明します。Kafka クラスターは ZooKeeper クラスターとデプロイされます。デプロイメントには、Kafka トピックおよびユーザーを管理する Topic Operator および User Operator も含まれます。
Kafka リソースを使用して Kafka を設定します。設定オプションは、Kafka リソース内の ZooKeeper および Entity Operator でも利用できます。Entity Operator は Topic Operator と User Operator で構成されます。
Kafka リソースの完全なスキーマは 「Kafka スキーマ参照」 に記載されています。
リスナーの設定
クライアントを Kafka ブローカーに接続するためのリスナーを設定します。ブローカーに接続するためのリスナーの設定に関する詳細は、「リスナーの設定」を参照してください。
Kafka へのアクセスの承認
ユーザーが実行するアクションを許可または拒否するように Kafka クラスターを設定できます。Kafka ブローカーへのアクセスをセキュアにするための詳細は、「Kafka へのアクセス管理」を参照してください。
TLS 証明書の管理
Kafka をデプロイする場合、Cluster Operator は自動で TLS 証明書の設定および更新を行い、クラスター内での暗号化および認証を有効にします。必要な場合は、更新期間の終了前にクラスターおよびクライアント CA 証明書を手動で更新できます。クラスターおよびクライアント CA 証明書によって使用される鍵を置き換えることもできます。詳細は、「CA 証明書の手動更新」および「秘密鍵の置換」を参照してください。
その他のリソース
- Apache Kafka の詳細は、Apache Kafka の Web サイト を参照してください。
2.1.1. Kafka の設定
Kafka リソースのプロパティーを使用して、Kafka デプロイメントを設定します。
Kafka の設定に加え、ZooKeeper および AMQ Streams Operator の設定を追加することもできます。ロギングやヘルスチェックなどの一般的な設定プロパティーは、コンポーネントごとに独立して設定されます。
この手順では、可能な設定オプションの一部のみを取り上げますが、特に重要なオプションは次のとおりです。
- リソース要求 (CPU/メモリー)
- 最大および最小メモリー割り当ての JVM オプション
- リスナー (およびクライアントの認証)
- 認証
- ストレージ
- ラックアウェアネス (Rack Awareness)
- メトリクス
- Cruise Control によるクラスターのリバランス
Kafka バージョン
Kafka config の log.message.format.version および inter.broker.protocol.version プロパティーは、指定された Kafka バージョン (spec.kafka.version) によってサポートされるバージョンです。プロパティーは、メッセージに追加されるログ形式のバージョンと、Kafka クラスターで使用される Kafka プロトコルのバージョンを表します。Kafka バージョンのアップグレード時に、これらのプロパティーの更新が必要になります。詳細は、『OpenShift での AMQ Streams のデプロイおよびアップグレード』の「Kafka のアップグレード」を参照してください。
前提条件
- OpenShift クラスター。
- 稼働中の Cluster Operator。
以下をデプロイする手順については、『 OpenShift での AMQ Streams のデプロイおよびアップグレード』を参照してください。
手順
Kafkaリソースのspecプロパティーを編集します。設定可能なプロパティーは以下の例のとおりです。
apiVersion: kafka.strimzi.io/v1beta2 kind: Kafka metadata: name: my-cluster spec: kafka: replicas: 31 version: 2.7.02 logging:3 type: inline loggers: kafka.root.logger.level: "INFO" resources:4 requests: memory: 64Gi cpu: "8" limits: memory: 64Gi cpu: "12" readinessProbe:5 initialDelaySeconds: 15 timeoutSeconds: 5 livenessProbe: initialDelaySeconds: 15 timeoutSeconds: 5 jvmOptions:6 -Xms: 8192m -Xmx: 8192m image: my-org/my-image:latest7 listeners:8 - name: plain9 port: 909210 type: internal11 tls: false12 configuration: useServiceDnsDomain: true13 - name: tls port: 9093 type: internal tls: true authentication:14 type: tls - name: external15 port: 9094 type: route tls: true configuration: brokerCertChainAndKey:16 secretName: my-secret certificate: my-certificate.crt key: my-key.key authorization:17 type: simple config:18 auto.create.topics.enable: "false" offsets.topic.replication.factor: 3 transaction.state.log.replication.factor: 3 transaction.state.log.min.isr: 2 log.message.format.version: 2.7 inter.broker.protocol.version: 2.7 ssl.cipher.suites: "TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384"19 ssl.enabled.protocols: "TLSv1.2" ssl.protocol: "TLSv1.2" storage:20 type: persistent-claim21 size: 10000Gi22 rack:23 topologyKey: topology.kubernetes.io/zone metricsConfig:24 type: jmxPrometheusExporter valueFrom: configMapKeyRef:25 name: my-config-map key: my-key # ... zookeeper:26 replicas: 327 logging:28 type: inline loggers: zookeeper.root.logger: "INFO" resources: requests: memory: 8Gi cpu: "2" limits: memory: 8Gi cpu: "2" jvmOptions: -Xms: 4096m -Xmx: 4096m storage: type: persistent-claim size: 1000Gi metricsConfig: # ... entityOperator:29 tlsSidecar:30 resources: requests: cpu: 200m memory: 64Mi limits: cpu: 500m memory: 128Mi topicOperator: watchedNamespace: my-topic-namespace reconciliationIntervalSeconds: 60 logging:31 type: inline loggers: rootLogger.level: "INFO" resources: requests: memory: 512Mi cpu: "1" limits: memory: 512Mi cpu: "1" userOperator: watchedNamespace: my-topic-namespace reconciliationIntervalSeconds: 60 logging:32 type: inline loggers: rootLogger.level: INFO resources: requests: memory: 512Mi cpu: "1" limits: memory: 512Mi cpu: "1" kafkaExporter:33 # ... cruiseControl:34 # ... tlsSidecar:35 # ...- 1
- レプリカノードの数。クラスターにトピックがすでに定義されている場合は、クラスターをスケーリング できます。
- 2
- Kafka バージョン。アップグレード手順にしたがうと、サポート対象のバージョンに変更できます。
- 3
- ConfigMap にて直接的 (
inline) または間接的 (external) に追加される Kafka のロガーおよびログレベルを指定します。カスタム ConfigMap は、log4j.propertiesキー下に配置する必要があります。Kafkakafka.root.logger.levelロガーでは、ログレベルを INFO、ERROR、WARN、TRACE、DEBUG、FATAL または OFF に設定できます。 - 4
- 5
- コンテナーを再起動するタイミング (liveness) およびコンテナーがトラフィックを許可できるタイミング (readiness) を把握するためのヘルスチェック。
- 6
- Kafka を実行している仮想マシン (VM) のパフォーマンスを最適化するための JVM 設定オプション。
- 7
- 高度な任意設定: 特別な場合のみ推奨されるコンテナーイメージの設定。
- 8
- リスナーは、ブートストラップアドレスでクライアントが Kafka クラスターに接続する方法を設定します。リスナーは、OpenShift クラスター内部または外部からの接続の 内部 または 外部 リスナーとして設定されます。
- 9
- リスナーを識別するための名前。Kafka クラスター内で一意である必要があります。
- 10
- Kafka 内でリスナーによって使用されるポート番号。ポート番号は指定の Kafka クラスター内で一意である必要があります。許可されるポート番号は 9092 以上ですが、すでに Prometheus および JMX によって使用されているポート 9404 および 9999 以外になります。リスナーのタイプによっては、ポート番号は Kafka クライアントに接続するポート番号と同じではない場合があります。
- 11
internalとして指定されたリスナータイプ。外部リスナーの場合はroute、loadbalancer、nodeport、またはingressとして指定。- 12
- 各リスナーの TLS 暗号化を有効にします。デフォルトは
falseです。routeリスナーには TLS 暗号化は必要ありません。 - 13
- クラスターサービスサフィックス (通常は
.cluster.local) を含む完全修飾 DNS 名が割り当てられているかどうかを定義します。 - 14
- 相互 TLS、SCRAM-SHA-512、またはトークンベース OAuth 2.0 として指定される リスナー認証メカニズム。
- 15
- 外部リスナー設定は、
route、loadbalancer、またはnodeportからなど、Kafka クラスターが OpenShift 外部で公開される方法 を指定します。 - 16
- 外部の認証局によって管理される Kafka リスナー証明書 の任意設定。
brokerCertChainAndKeyプロパティーは、サーバー証明書および秘密鍵が含まれるSecretを指定します。TLS による暗号化が有効な任意のリスナーで Kafka リスナー証明書を設定できます。 - 17
- 承認は Kafka ブローカーで簡易、OAUTH2.0、または OPA 承認を有効にします。簡易承認では
AclAuthorizerKafka プラグインが使用されます。 - 18
configによってブローカー設定が指定されます。標準の Apache Kafka 設定が提供されることがあり、AMQ Streams によって直接管理されないプロパティーに限定されます。- 19
- 20
- 21
- 22
- 23
- ラックアウェアネス (Rack awareness) は、異なるラック全体でレプリカを分散するために設定されます。
topologykeyはクラスターノードのラベルと一致する必要があります。 - 24
- Prometheus メトリクス は有効になっています。この例では、メトリクスは Prometheus JMX Exporter (デフォルトのメトリクスエクスポーター) に対して設定されます。
- 25
- Prometheus JMX Exporter 経由でメトリクスを Grafana ダッシュボードにエクスポートする Prometheus ルール。Prometheus JMX Exporter の設定が含まれる ConfigMap を参照することで有効になります。
metricsConfig.valueFrom.configMapKeyRef.key下の空のファイルが含まれる ConfigMap への参照を使用すると、追加設定なしでメトリクスを有効にできます。 - 26
- Kafka 設定と似たプロパティーが含まれる、ZooKeeper 固有の設定。
- 27
- ZooKeeper ノードの数通常、ZooKeeper クラスターまたはアンサンブルは、一般的に 3、5、7 個の奇数個のノードで実行されます。効果的なクォーラムを維持するには、過半数のノードが利用可能である必要があります。ZooKeeper クラスターでクォーラムを損失すると、クライアントへの応答が停止し、Kafka ブローカーが機能しなくなります。AMQ Streams では、 ZooKeeper クラスターの安定性および高可用性が重要になります。
- 28
- 指定された ZooKeeper ロガーおよびログレベル。
- 29
- Topic Operator および User Operator の設定を指定する、Entity Operator 設定。
- 30
- Entity Operator の TLS サイドカー設定。Entity Operator は、ZooKeeper とのセキュアな通信に TLS サイドカーを使用します。
- 31
- 指定された Topic Operator ロガーおよびログレベル。この例では、
inlineロギングが使用されます。 - 32
- 指定された User Operator ロガーおよびログレベル。
- 33
- Kafka Exporter の設定。Kafka Exporter は、特にコンシューマーラグデータなどのメトリクスデータを Kafka ブローカーから抽出する任意のコンポーネントです。
- 34
- Kafka クラスターのリバランス に使用される Cruise Control の任意設定。
- 35
- Cruise Conrol の TLS サイドカーの設定。Cruise Control は、ZooKeeper とのセキュアな通信に TLS サイドカーを使用します。
リソースを作成または更新します。
oc apply -f KAFKA-CONFIG-FILE
2.1.2. Entity Operator の設定
Entity Operator は、実行中の Kafka クラスターで Kafka 関連のエンティティーを管理します。
Entity Operator は以下と構成されます。
- Kafka トピックを管理する Topic Operator
- Kafka ユーザーを管理する User Operator
Cluster Operator は Kafka リソース設定を介して、Kafka クラスターのデプロイ時に、上記の Operator の 1 つまたは両方を含む Entity Operator をデプロイできます。
デプロイされると、デプロイメント設定に応じて、Entity Operator にオペレーターが含まれます。
これらのオペレーターは、Kafka クラスターのトピックおよびユーザーを管理するために自動的に設定されます。
2.1.2.1. Entity Operator の設定プロパティー
Kafka.spec の entityOperator プロパティーを使用して Entity Operator を設定します。
entityOperator プロパティーでは複数のサブプロパティーがサポートされます。
-
tlsSidecar -
topicOperator -
userOperator -
template
tlsSidecar プロパティーには、ZooKeeper との通信に使用される TLS サイドカーコンテナーの設定が含まれます。
template プロパティーには、ラベル、アノテーション、アフィニティー、および容認 (Toleration) などの Entity Operator Pod の設定が含まれます。テンプレートの設定に関する詳細は、「OpenShift リソースのカスタマイズ」 を参照してください。
topicOperator プロパティーには、Topic Operator の設定が含まれます。このオプションがないと、Entity Operator は Topic Operator なしでデプロイされます。
userOperator プロパティーには、User Operator の設定が含まれます。このオプションがないと、Entity Operator は User Operator なしでデプロイされます。
Entity Operator の設定に使用されるプロパティーに関する詳細は「EntityUserOperatorSpec スキーマ参照」を参照してください。
両方の Operator を有効にする基本設定の例
apiVersion: kafka.strimzi.io/v1beta2
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
# ...
zookeeper:
# ...
entityOperator:
topicOperator: {}
userOperator: {}
topicOperator および userOperator に空のオブジェクト ({}) が使用された場合、すべてのプロパティーでデフォルト値が使用されます。
topicOperator および userOperator プロパティーの両方がない場合、Entity Operator はデプロイされません。
2.1.2.2. Topic Operator 設定プロパティー
Topic Operator デプロイメントは、topicOperator オブジェクト内で追加オプションを使用すると設定できます。以下のプロパティーがサポートされます。
watchedNamespace-
User Operator によって
KafkaTopicsが監視される OpenShift namespace。デフォルトは、Kafka クラスターがデプロイされた namespace です。 reconciliationIntervalSeconds-
定期的な調整 (reconciliation) の間隔 (秒単位)。デフォルトは
90です。 zookeeperSessionTimeoutSeconds-
ZooKeeper セッションのタイムアウト (秒単位)。デフォルトは
20です。 topicMetadataMaxAttempts-
Kafka からトピックメタデータの取得を試行する回数。各試行の間隔は、指数バックオフとして定義されます。パーティションまたはレプリカの数によって、トピックの作成に時間がかかる可能性がある場合は、この値を大きくすることを検討してください。デフォルトは
6です。 image-
imageプロパティーを使用すると、使用されるコンテナーイメージを設定できます。カスタムコンテナーイメージの設定に関する詳細は、「image」 を参照してください。 resources-
resourcesプロパティーを使用すると、Topic Operator に割り当てられるリソースの量を設定できます。リソースの要求と制限の設定に関する詳細は、「resources」 を参照してください。 logging-
loggingプロパティーは、Topic Operator のロギングを設定します。詳細は 「logging」 を参照してください。
Topic Operator の設定例
apiVersion: kafka.strimzi.io/v1beta2
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
# ...
zookeeper:
# ...
entityOperator:
# ...
topicOperator:
watchedNamespace: my-topic-namespace
reconciliationIntervalSeconds: 60
# ...2.1.2.3. User Operator 設定プロパティー
User Operator デプロイメントは、userOperator オブジェクト内で追加オプションを使用すると設定できます。以下のプロパティーがサポートされます。
watchedNamespace-
User Operator によって
KafkaUsersが監視される OpenShift namespace。デフォルトは、Kafka クラスターがデプロイされた namespace です。 reconciliationIntervalSeconds-
定期的な調整 (reconciliation) の間隔 (秒単位)。デフォルトは
120です。 zookeeperSessionTimeoutSeconds-
ZooKeeper セッションのタイムアウト (秒単位)。デフォルトは
6です。 image-
imageプロパティーを使用すると、使用されるコンテナーイメージを設定できます。カスタムコンテナーイメージの設定に関する詳細は、「image」 を参照してください。 resources-
resourcesプロパティーを使用すると、User Operator に割り当てられるリソースの量を設定できます。リソースの要求と制限の設定に関する詳細は、「resources」 を参照してください。 logging-
loggingプロパティーは、User Operator のロギングを設定します。詳細は 「logging」 を参照してください。 secretPrefix-
secretPrefixプロパティーは、KafkaUser リソースから作成されたすべての Secret の名前にプレフィックスを追加します。たとえば、STRIMZI_SECRET_PREFIX=kafka-は、すべての Secret 名の前にkafka-を付けます。そのため、my-userという名前の KafkaUser は、kafka-my-userという名前の Secret を作成します。
User Operator の設定例
apiVersion: kafka.strimzi.io/v1beta2
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
# ...
zookeeper:
# ...
entityOperator:
# ...
userOperator:
watchedNamespace: my-user-namespace
reconciliationIntervalSeconds: 60
# ...2.1.3. Kafka および ZooKeeper のストレージタイプ
Kafka および ZooKeeper はステートフルなアプリケーションであるため、データをディスクに格納する必要があります。AMQ Streams では、3 つのタイプのストレージがサポートされます。
- 一時ストレージ
- 永続ストレージ
- JBOD ストレージ
JBOD ストレージは Kafka でサポートされ、ZooKeeper ではサポートされていません。
Kafka リソースを設定する場合、Kafka ブローカーおよび対応する ZooKeeper ノードによって使用されるストレージのタイプを指定できます。以下のリソースの storage プロパティーを使用して、ストレージタイプを設定します。
-
Kafka.spec.kafka -
Kafka.spec.zookeeper
ストレージタイプは type フィールドで設定されます。
Kafka クラスターをデプロイした後に、ストレージタイプを変更することはできません。
その他のリソース
- 一時ストレージの詳細は、「一時ストレージのスキーマ参照」を参照してください。
- 永続ストレージの詳細は、「永続ストレージのスキーマ参照」を参照してください。
- JBOD ストレージの詳細は、「JBOD スキーマ参照」を参照してください。
-
Kafkaのスキーマに関する詳細は、「Kafkaスキーマ参照」を参照してください。
2.1.3.1. データストレージに関する留意事項
効率的なデータストレージインフラストラクチャーは、AMQ Streams のパフォーマンスを最適化するために不可欠です。
ブロックストレージが必要です。NFS などのファイルストレージは、Kafka では機能しません。
ブロックストレージには、以下などを選択できます。
- Amazon Elastic Block Store (EBS)などのクラウドベースのブロックストレージソリューション。
- ローカルの永続ボリューム。
- ファイバーチャネル や iSCSI などのプロトコルがアクセスする SAN (ストレージネットワークエリア) ボリューム。
AMQ Streams には OpenShift の raw ブロックボリュームは必要ありません。
2.1.3.1.1. ファイルシステム
XFS ファイルシステムを使用するようにストレージシステムを設定することが推奨されます。AMQ Streams は ext4 ファイルシステムとも互換性がありますが、最適化するには追加の設定が必要になることがあります。
2.1.3.1.2. Apache Kafka および ZooKeeper ストレージ
Apache Kafka と ZooKeeper には別々のディスクを使用します。
3 つのタイプのデータストレージがサポートされます。
- 一時データストレージ (開発用のみで推奨されます)
- 永続データストレージ
- JBOD (Just a Bunch of Disks、Kafka のみに適しています)
詳細は「Kafka および ZooKeeper ストレージ」を参照してください。
ソリッドステートドライブ (SSD) は必須ではありませんが、複数のトピックに対してデータが非同期的に送受信される大規模なクラスターで Kafka のパフォーマンスを向上させることができます。SSD は、高速で低レイテンシーのデータアクセスが必要な ZooKeeper で特に有効です。
Kafka と ZooKeeper の両方にデータレプリケーションが組み込まれているため、複製されたストレージのプロビジョニングは必要ありません。
2.1.3.2. 一時ストレージ
一時ストレージは emptyDir ボリュームを使用してデータを保存します。一時ストレージを使用するには、type フィールドを ephemeral に設定します。
emptyDir ボリュームは永続的ではなく、保存されたデータは Pod の再起動時に失われます。新規 Pod の起動後に、クラスターの他のノードからすべてのデータを復元する必要があります。一時ストレージは、単一ノードの ZooKeeper クラスターやレプリケーション係数が 1 の Kafka トピックでの使用には適していません。この設定により、データが失われます。
一時ストレージの例
apiVersion: kafka.strimzi.io/v1beta2
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
# ...
storage:
type: ephemeral
# ...
zookeeper:
# ...
storage:
type: ephemeral
# ...2.1.3.2.1. ログディレクトリー
一時ボリュームは、以下のパスにマウントされるログディレクトリーとして Kafka ブローカーによって使用されます。
/var/lib/kafka/data/kafka-logIDX
IDX は、Kafka ブローカー Pod インデックスです。例: /var/lib/kafka/data/kafka-log0
2.1.3.3. 永続ストレージ
永続ストレージは Persistent Volume Claim (永続ボリューム要求、PVC) を使用して、データを保存するための永続ボリュームをプロビジョニングします。永続ボリューム要求を使用すると、ボリュームのプロビジョニングを行う ストレージクラス に応じて、さまざまなタイプのボリュームをプロビジョニングできます。永続ボリューム要求と使用できるデータタイプには、多くのタイプの SAN ストレージやローカル永続ボリューム などがあります。
永続ストレージを使用するには、type を persistent-claim に設定する必要があります。永続ストレージでは、追加の設定オプションがサポートされます。
id(任意)-
ストレージ ID 番号。このオプションは、JBOD ストレージ宣言で定義されるストレージボリュームには必須です。デフォルトは
0です。 size(必須)- 永続ボリューム要求のサイズを定義します (例: 1000Gi)。
class(任意)- 動的ボリュームプロビジョニングに使用する OpenShift の ストレージクラス。
selector(任意)- 使用する特定の永続ボリュームを選択できます。このようなボリュームを選択するラベルを表す key:value ペアが含まれます。
deleteClaim(任意)-
クラスターのアンデプロイ時に永続ボリューム要求を削除する必要があるかどうかを指定するブール値。デフォルトは
falseです。
既存の AMQ Streams クラスターで永続ボリュームのサイズを増やすことは、永続ボリュームのサイズ変更をサポートする OpenShift バージョンでのみサポートされます。サイズを変更する永続ボリュームには、ボリューム拡張をサポートするストレージクラスを使用する必要があります。ボリューム拡張をサポートしないその他のバージョンの OpenShift およびストレージクラスでは、クラスターをデプロイする前に必要なストレージサイズを決定する必要があります。既存の永続ボリュームのサイズを縮小することはできません。
size が 1000Gi の永続ストレージ設定の例 (抜粋)
# ...
storage:
type: persistent-claim
size: 1000Gi
# ...以下の例は、ストレージクラスの使用例を示しています。
特定のストレージクラスを指定する永続ストレージ設定の例 (抜粋)
# ...
storage:
type: persistent-claim
size: 1Gi
class: my-storage-class
# ...
最後に、selector を使用して特定のラベルが付いた永続ボリュームを選択し、SSD などの必要な機能を提供できます。
セレクターを指定する永続ストレージ設定の例 (抜粋)
# ...
storage:
type: persistent-claim
size: 1Gi
selector:
hdd-type: ssd
deleteClaim: true
# ...2.1.3.3.1. ストレージクラスのオーバーライド
デフォルトのストレージクラスを使用する代わりに、1 つ以上の Kafka ブローカー または ZooKeeper ノードに異なるストレージクラスを指定できます。これは、ストレージクラスが、異なるアベイラビリティーゾーンやデータセンターに制限されている場合などに便利です。この場合、overrides フィールドを使用できます。
以下の例では、デフォルトのストレージクラスの名前は my-storage-class になります。
ストレージクラスのオーバーライドを使用した AMQ Streams クラスターの例
apiVersion: kafka.strimzi.io/v1beta2
kind: Kafka
metadata:
labels:
app: my-cluster
name: my-cluster
namespace: myproject
spec:
# ...
kafka:
replicas: 3
storage:
deleteClaim: true
size: 100Gi
type: persistent-claim
class: my-storage-class
overrides:
- broker: 0
class: my-storage-class-zone-1a
- broker: 1
class: my-storage-class-zone-1b
- broker: 2
class: my-storage-class-zone-1c
# ...
zookeeper:
replicas: 3
storage:
deleteClaim: true
size: 100Gi
type: persistent-claim
class: my-storage-class
overrides:
- broker: 0
class: my-storage-class-zone-1a
- broker: 1
class: my-storage-class-zone-1b
- broker: 2
class: my-storage-class-zone-1c
# ...
overrides プロパティーが設定され、ボリュームによって以下のストレージクラスが使用されます。
-
ZooKeeper ノード 0 の永続ボリュームでは
my-storage-class-zone-1aが使用されます。 -
ZooKeeper ノード 1 の永続ボリュームでは
my-storage-class-zone-1bが使用されます。 -
ZooKeeper ノード 2 の永続ボリュームでは
my-storage-class-zone-1cが使用されます。 -
Kafka ブローカー 0 の永続ボリュームでは
my-storage-class-zone-1aが使用されます。 -
Kafka ブローカー 1 の永続ボリュームでは
my-storage-class-zone-1bが使用されます。 -
Kafka ブローカー 2 の永続ボリュームでは
my-storage-class-zone-1cが使用されます。
現在、overrides プロパティーは、ストレージクラスの設定をオーバーライドするためのみに使用されます。他のストレージ設定フィールドのオーバーライドは現在サポートされていません。ストレージ設定の他のフィールドは現在サポートされていません。
2.1.3.3.2. Persistent Volume Claim (永続ボリューム要求、PVC) の命名
永続ストレージが使用されると、以下の名前で Persistent Volume Claim (永続ボリューム要求、PVC) が作成されます。
data-cluster-name-kafka-idx-
Kafka ブローカー Pod
idxのデータを保存するために使用されるボリュームの永続ボリューム要求です。 data-cluster-name-zookeeper-idx-
ZooKeeper ノード Pod
idxのデータを保存するために使用されるボリュームの永続ボリューム要求です。
2.1.3.3.3. ログディレクトリー
永続ボリュームは、以下のパスにマウントされるログディレクトリーとして Kafka ブローカーによって使用されます。
/var/lib/kafka/data/kafka-logIDX
IDX は、Kafka ブローカー Pod インデックスです。例: /var/lib/kafka/data/kafka-log0
2.1.3.4. 永続ボリュームのサイズ変更
既存の AMQ Streams クラスターによって使用される永続ボリュームのサイズを増やすことで、ストレージ容量を増やすことができます。永続ボリュームのサイズ変更は、JBOD ストレージ設定で 1 つまたは複数の永続ボリュームが使用されるクラスターでサポートされます。
永続ボリュームのサイズを拡張することはできますが、縮小することはできません。永続ボリュームのサイズ縮小は、現在 OpenShift ではサポートされていません。
前提条件
- ボリュームのサイズ変更をサポートする OpenShift クラスター。
- Cluster Operator が稼働している必要があります。
- ボリューム拡張をサポートするストレージクラスを使用して作成された永続ボリュームを使用する Kafka クラスター。
手順
Kafkaリソースで、Kafka クラスター、ZooKeeper クラスター、またはその両方に割り当てられた永続ボリュームのサイズを増やします。-
Kafka クラスターに割り当てられたボリュームサイズを増やすには、
spec.kafka.storageプロパティーを編集します。 ZooKeeper クラスターに割り当てたボリュームサイズを増やすには、
spec.zookeeper.storageプロパティーを編集します。たとえば、ボリュームサイズを
1000Giから2000Giに増やすには、以下のように編集します。apiVersion: kafka.strimzi.io/v1beta2 kind: Kafka metadata: name: my-cluster spec: kafka: # ... storage: type: persistent-claim size: 2000Gi class: my-storage-class # ... zookeeper: # ...
-
Kafka クラスターに割り当てられたボリュームサイズを増やすには、
リソースを作成または更新します。
oc apply -f KAFKA-CONFIG-FILEOpenShift では、Cluster Operator からの要求に応じて、選択された永続ボリュームの容量が増やされます。サイズ変更が完了すると、サイズ変更された永続ボリュームを使用するすべての Pod が Cluster Operator によって再起動されます。これは自動的に行われます。
その他のリソース
OpenShift での永続ボリュームのサイズ変更に関する詳細は、「Resizing Persistent Volumes using Kubernetes」を参照してください。
2.1.3.5. JBOD ストレージの概要
AMQ Streams で、複数のディスクやボリュームのデータストレージ設定である JBOD を使用するように設定できます。JBOD は、Kafka ブローカーのデータストレージを増やす方法の 1 つです。また、パフォーマンスを向上することもできます。
JBOD 設定は 1 つ以上のボリュームによって記述され、各ボリュームは 一時 または 永続 ボリュームのいずれかになります。JBOD ボリューム宣言のルールおよび制約は、一時および永続ストレージのルールおよび制約と同じです。たとえば、永続ストレージのボリュームをプロビジョニング後に縮小することはできません。また、type=ephemeral の場合は sizeLimit の値を変更することはできません。
2.1.3.5.1. JBOD の設定
AMQ Streams で JBOD を使用するには、ストレージ type を jbod に設定する必要があります。volumes プロパティーを使用すると、JBOD ストレージアレイまたは設定を構成するディスクを記述できます。以下は、JBOD 設定例の抜粋になります。
# ...
storage:
type: jbod
volumes:
- id: 0
type: persistent-claim
size: 100Gi
deleteClaim: false
- id: 1
type: persistent-claim
size: 100Gi
deleteClaim: false
# ...id は、JBOD ボリュームの作成後に変更することはできません。
ユーザーは JBOD 設定に対してボリュームを追加または削除できます。
2.1.3.5.2. JBOD および 永続ボリューム要求 (PVC)
永続ストレージを使用して JBOD ボリュームを宣言する場合、永続ボリューム要求 (Persistent Volume Claim、PVC) の命名スキームは以下のようになります。
data-id-cluster-name-kafka-idx-
idは、Kafka ブローカー Podidxのデータを保存するために使用されるボリュームの ID に置き換えます。
2.1.3.5.3. ログディレクトリー
JBOD ボリュームは、以下のパスにマウントされるログディレクトリーとして Kafka ブローカーによって使用されます。
/var/lib/kafka/data-id/kafka-log_idx_-
idは、Kafka ブローカー Podidxのデータを保存するために使用されるボリュームの ID に置き換えます。例:/var/lib/kafka/data-0/kafka-log0
2.1.3.6. JBOD ストレージへのボリュームの追加
この手順では、JBOD ストレージを使用するように設定されている Kafka クラスターにボリュームを追加する方法を説明します。この手順は、他のストレージタイプを使用するように設定されている Kafka クラスターには適用できません。
以前使用され、削除された id の下に新規ボリュームを追加する場合、以前使用された PersistentVolumeClaims が必ず削除されているよう確認する必要があります。
前提条件
- OpenShift クラスター。
- 稼働中の Cluster Operator。
- JBOD ストレージのある Kafka クラスター。
手順
Kafkaリソースのspec.kafka.storage.volumesプロパティーを編集します。新しいボリュームをvolumesアレイに追加します。たとえば、id が2の新しいボリュームを追加します。apiVersion: kafka.strimzi.io/v1beta2 kind: Kafka metadata: name: my-cluster spec: kafka: # ... storage: type: jbod volumes: - id: 0 type: persistent-claim size: 100Gi deleteClaim: false - id: 1 type: persistent-claim size: 100Gi deleteClaim: false - id: 2 type: persistent-claim size: 100Gi deleteClaim: false # ... zookeeper: # ...リソースを作成または更新します。
oc apply -f KAFKA-CONFIG-FILE- 新しいトピックを作成するか、既存のパーティションを新しいディスクに再度割り当てします。
その他のリソース
トピックの再割り当てに関する詳細は 「パーティションの再割り当て」 を参照してください。
2.1.3.7. JBOD ストレージからのボリュームの削除
この手順では、JBOD ストレージを使用するように設定されている Kafka クラスターからボリュームを削除する方法を説明します。この手順は、他のストレージタイプを使用するように設定されている Kafka クラスターには適用できません。JBOD ストレージには、常に 1 つのボリュームが含まれている必要があります。
データの損失を避けるには、ボリュームを削除する前にすべてのパーティションを移動する必要があります。
前提条件
- OpenShift クラスター。
- 稼働中の Cluster Operator。
- 複数のボリュームがある JBOD ストレージのある Kafka クラスター。
手順
- 削除するディスクからすべてのパーティションを再度割り当てます。削除するディスクに割り当てられたままになっているパーティションのデータは削除される可能性があります。
Kafkaリソースのspec.kafka.storage.volumesプロパティーを編集します。volumesアレイから 1 つまたは複数のボリュームを削除します。たとえば、ID が1と2のボリュームを削除します。apiVersion: kafka.strimzi.io/v1beta2 kind: Kafka metadata: name: my-cluster spec: kafka: # ... storage: type: jbod volumes: - id: 0 type: persistent-claim size: 100Gi deleteClaim: false # ... zookeeper: # ...リソースを作成または更新します。
oc apply -f KAFKA-CONFIG-FILE
その他のリソース
トピックの再割り当てに関する詳細は 「パーティションの再割り当て」 を参照してください。
2.1.4. クラスターのスケーリング
2.1.4.1. Kafka クラスターのスケーリング
2.1.4.1.1. ブローカーのクラスターへの追加
トピックのスループットを向上させる主な方法は、そのトピックのパーティション数を増やすことです。これにより、追加のパーティションによってクラスター内の異なるブローカー間でトピックの負荷が共有されます。ただし、各ブローカーが特定のリソース (通常は I/O) によって制約される場合、パーティションを増やしてもスループットは向上しません。代わりに、ブローカーをクラスターに追加する必要があります。
追加のブローカーをクラスターに追加する場合、Kafka ではパーティションは自動的に割り当てられません。既存のブローカーから新規のブローカーに移動するパーティションを決定する必要があります。
すべてのブローカー間でパーティションが再分散されたら、各ブローカーのリソース使用率が低下するはずです。
2.1.4.1.2. クラスターからのブローカーの削除
AMQ Streams では StatefulSets を使用してブローカー Pod を管理されるため、あらゆる Pod を削除できるわけではありません。クラスターから削除できるのは、番号が最も大きい 1 つまたは複数の Pod のみです。たとえば、12 個のブローカーがあるクラスターでは、Pod の名前は cluster-name-kafka-0 から cluster-name-kafka-11 になります。1 つのブローカー分をスケールダウンする場合、cluster-name-kafka-11 が削除されます。
クラスターからブローカーを削除する前に、そのブローカーにパーティションが割り当てられていないことを確認します。また、使用が停止されたブローカーの各パーティションを引き継ぐ、残りのブローカーを決める必要もあります。ブローカーに割り当てられたパーティションがなければ、クラスターを安全にスケールダウンできます。
2.1.4.2. パーティションの再割り当て
現在、Topic Operator はレプリカを別のブローカーに再割当てすることをサポートしないため、ブローカー Pod に直接接続してレプリカをブローカーに再割り当てする必要があります。
ブローカー Pod 内では、kafka-reassign-partitions.sh ユーティリティーを使用してパーティションを別のブローカーに再割り当てできます。
これには、以下の 3 つのモードがあります。
--generate- トピックとブローカーのセットを取り、再割り当て JSON ファイル を生成します。これにより、トピックのパーティションがブローカーに割り当てられます。これはトピック全体で動作するため、一部のトピックのパーティションを再度割り当てする場合は使用できません。
--execute- 再割り当て JSON ファイル を取り、クラスターのパーティションおよびブローカーに適用します。その結果、パーティションを取得したブローカーは、パーティションリーダーのフォロワーになります。新規ブローカーが ISR (In-Sync Replica、同期レプリカ) に参加できたら、古いブローカーはフォロワーではなくなり、そのレプリカが削除されます。
--verify-
--verifyは、--executeステップと同じ 再割り当て JSON ファイル を使用して、ファイル内のすべてのパーティションが目的のブローカーに移動されたかどうかを確認します。再割り当てが完了すると、--verify は有効な スロットル も削除します。スロットルを削除しないと、再割り当てが完了した後もクラスターは影響を受け続けます。
クラスターでは、1 度に 1 つの再割当てのみを実行でき、実行中の再割当てをキャンセルすることはできません。再割り当てをキャンセルする必要がある場合は、割り当てが完了するのを待ってから別の再割り当てを実行し、最初の再割り当ての結果を元に戻します。kafka-reassign-partitions.sh によって、元に戻すための再割り当て JSON が出力の一部として生成されます。大規模な再割り当ては、進行中の再割り当てを停止する必要がある場合に備えて、複数の小さな再割り当てに分割するようにしてください。
2.1.4.2.1. 再割り当て JSON ファイル
再割り当て JSON ファイル には特定の構造があります。
{
"version": 1,
"partitions": [
<PartitionObjects>
]
}ここで <PartitionObjects> は、以下のようなコンマ区切りのオブジェクトリストになります。
{
"topic": <TopicName>,
"partition": <Partition>,
"replicas": [ <AssignedBrokerIds> ]
}
Kafka は "log_dirs" プロパティーもサポートしますが、AMQ Streams では使用しないでください。
以下は、トピック topic-a のパーティション 4 をブローカー 2、4、および 7 に割り当て、トピック topic-b のパーティション 2 をブローカー 1、5、および 7 に割り当てる、再割り当て JSON ファイルの例になります。
{
"version": 1,
"partitions": [
{
"topic": "topic-a",
"partition": 4,
"replicas": [2,4,7]
},
{
"topic": "topic-b",
"partition": 2,
"replicas": [1,5,7]
}
]
}JSON に含まれていないパーティションは変更されません。
2.1.4.2.2. JBOD ボリューム間でのパーティションの再割り当て
Kafka クラスターで JBOD ストレージを使用する場合は、特定のボリュームとログディレクトリー (各ボリュームに単一のログディレクトリーがある) との間でパーティションを再割り当てを選択することができます。パーティションを特定のボリュームに再割り当てするには、再割り当て JSON ファイルで log_dirs オプションを <PartitionObjects> に追加します。
{
"topic": <TopicName>,
"partition": <Partition>,
"replicas": [ <AssignedBrokerIds> ],
"log_dirs": [ <AssignedLogDirs> ]
}
log_dirs オブジェクトに含まれるログディレクトリーの数は、replicas オブジェクトで指定されるレプリカ数と同じである必要があります。値は、ログディレクトリーへの絶対パスか、any キーワードである必要があります。
以下に例を示します。
{
"topic": "topic-a",
"partition": 4,
"replicas": [2,4,7].
"log_dirs": [ "/var/lib/kafka/data-0/kafka-log2", "/var/lib/kafka/data-0/kafka-log4", "/var/lib/kafka/data-0/kafka-log7" ]
}2.1.4.3. 再割り当て JSON ファイルの生成
この手順では、kafka-reassign-partitions.sh ツールを使用して、指定のトピックセットすべてのパーティションを再割り当てする再割り当て JSON ファイルを生成する方法を説明します。
前提条件
- 稼働中の Cluster Operator。
-
Kafkaリソース - パーティションを再割り当てするトピックセット。
手順
移動するトピックを一覧表示する
topics.jsonという名前の JSON ファイルを準備します。これには、以下の構造が必要です。{ "version": 1, "topics": [ <TopicObjects> ] }ここで <TopicObjects> は、以下のようなコンマ区切りのオブジェクトリストになります。
{ "topic": <TopicName> }たとえば、
topic-aとtopic-bのすべてのパーティションを再割り当てするには、以下のようなtopics.jsonファイルを準備する必要があります。{ "version": 1, "topics": [ { "topic": "topic-a"}, { "topic": "topic-b"} ] }topics.jsonファイルをブローカー Pod の 1 つにコピーします。cat topics.json | oc exec -c kafka <BrokerPod> -i -- \ /bin/bash -c \ 'cat > /tmp/topics.json'kafka-reassign-partitions.shコマンドを使用して、再割り当て JSON を生成します。oc exec <BrokerPod> -c kafka -it -- \ bin/kafka-reassign-partitions.sh --bootstrap-server localhost:9092 \ --topics-to-move-json-file /tmp/topics.json \ --broker-list <BrokerList> \ --generateたとえば、
topic-aおよびtopic-bのすべてのパーティションをブローカー4および7に移動する場合は、以下を実行します。oc exec <BrokerPod> -c kafka -it -- \ bin/kafka-reassign-partitions.sh --bootstrap-server localhost:9092 \ --topics-to-move-json-file /tmp/topics.json \ --broker-list 4,7 \ --generate
2.1.4.4. 手動による再割り当て JSON ファイルの作成
特定のパーティションを移動したい場合は、再割り当て JSON ファイルを手動で作成できます。
2.1.4.5. 再割り当てスロットル
パーティションの再割り当てには、ブローカーの間で大量のデータを転送する必要があるため、処理が遅くなる可能性があります。クライアントへの悪影響を防ぐため、再割り当て処理をスロットルで調整することができます。これにより、再割り当ての完了に時間がかかる可能性があります。
- スロットルが低すぎると、新たに割り当てられたブローカーは公開されるレコードに遅れずに対応することはできず、再割り当ては永久に完了しません。
- スロットルが高すぎると、クライアントに影響します。
たとえば、プロデューサーの場合は、承認待ちが通常のレイテンシーよりも大きくなる可能性があります。コンシューマーの場合は、ポーリング間のレイテンシーが大きいことが原因でスループットが低下する可能性があります。
2.1.4.6. Kafka クラスターのスケールアップ
この手順では、Kafka クラスターでブローカーの数を増やす方法を説明します。
前提条件
- 既存の Kafka クラスター。
-
拡大されたクラスターでパーティションをブローカーに再割り当てする方法が記述される
reassignment.jsonというファイル名の 再割り当て JSON ファイル。
手順
-
Kafka.spec.kafka.replicas設定オプションを増やして、新しいブローカーを必要なだけ追加します。 - 新しいブローカー Pod が起動したことを確認します。
後でコマンドを実行するブローカー Pod に
reassignment.jsonファイルをコピーします。cat reassignment.json | \ oc exec broker-pod -c kafka -i -- /bin/bash -c \ 'cat > /tmp/reassignment.json'以下に例を示します。
cat reassignment.json | \ oc exec my-cluster-kafka-0 -c kafka -i -- /bin/bash -c \ 'cat > /tmp/reassignment.json'同じブローカー Pod から
kafka-reassign-partitions.shコマンドラインツールを使用して、パーティションの再割り当てを実行します。oc exec broker-pod -c kafka -it -- \ bin/kafka-reassign-partitions.sh --bootstrap-server localhost:9092 \ --reassignment-json-file /tmp/reassignment.json \ --executeレプリケーションをスロットルで調整する場合、
--throttleとブローカー間のスロットル率 (バイト/秒単位) を渡すこともできます。以下に例を示します。oc exec my-cluster-kafka-0 -c kafka -it -- \ bin/kafka-reassign-partitions.sh --bootstrap-server localhost:9092 \ --reassignment-json-file /tmp/reassignment.json \ --throttle 5000000 \ --executeこのコマンドは、2 つの再割り当て JSON オブジェクトを出力します。最初の JSON オブジェクトには、移動されたパーティションの現在の割り当てが記録されます。後で再割り当てを元に戻す必要がある場合に備え、この値をローカルファイル (Pod のファイル以外) に保存します。2 つ目の JSON オブジェクトは、再割り当て JSON ファイルに渡した目的の再割り当てです。
再割り当ての最中にスロットルを変更する必要がある場合は、同じコマンドラインに別のスロットル率を指定して実行します。以下に例を示します。
oc exec my-cluster-kafka-0 -c kafka -it -- \ bin/kafka-reassign-partitions.sh --bootstrap-server localhost:9092 \ --reassignment-json-file /tmp/reassignment.json \ --throttle 10000000 \ --executeブローカー Pod のいずれかから
kafka-reassign-partitions.shコマンドラインツールを使用して、再割り当てが完了したかどうかを定期的に確認します。これは先ほどの手順と同じコマンドですが、--executeオプションの代わりに--verifyオプションを使用します。oc exec broker-pod -c kafka -it -- \ bin/kafka-reassign-partitions.sh --bootstrap-server localhost:9092 \ --reassignment-json-file /tmp/reassignment.json \ --verify例:
oc exec my-cluster-kafka-0 -c kafka -it -- \ bin/kafka-reassign-partitions.sh --bootstrap-server localhost:9092 \ --reassignment-json-file /tmp/reassignment.json \ --verify-
--verifyコマンドによって、移動した各パーティションが正常に完了したことが報告されると、再割り当ては終了します。この最終的な--verifyによって、結果的に再割り当てスロットルも削除されます。割り当てを元のブローカーに戻すために JSON ファイルを保存した場合は、ここでそのファイルを削除できます。
2.1.4.7. Kafka クラスターのスケールダウン
この手順では、Kafka クラスターでブローカーの数を減らす方法を説明します。
前提条件
- 既存の Kafka クラスター。
-
最も番号の大きい
Pod(s)のブローカーが削除された後にクラスターのブローカーにパーティションを再割り当てする方法が記述されている、reassignment.jsonという名前の 再割り当て JSON ファイル。
手順
後でコマンドを実行するブローカー Pod に
reassignment.jsonファイルをコピーします。cat reassignment.json | \ oc exec broker-pod -c kafka -i -- /bin/bash -c \ 'cat > /tmp/reassignment.json'以下に例を示します。
cat reassignment.json | \ oc exec my-cluster-kafka-0 -c kafka -i -- /bin/bash -c \ 'cat > /tmp/reassignment.json'同じブローカー Pod から
kafka-reassign-partitions.shコマンドラインツールを使用して、パーティションの再割り当てを実行します。oc exec broker-pod -c kafka -it -- \ bin/kafka-reassign-partitions.sh --bootstrap-server localhost:9092 \ --reassignment-json-file /tmp/reassignment.json \ --executeレプリケーションをスロットルで調整する場合、
--throttleとブローカー間のスロットル率 (バイト/秒単位) を渡すこともできます。以下に例を示します。oc exec my-cluster-kafka-0 -c kafka -it -- \ bin/kafka-reassign-partitions.sh --bootstrap-server localhost:9092 \ --reassignment-json-file /tmp/reassignment.json \ --throttle 5000000 \ --executeこのコマンドは、2 つの再割り当て JSON オブジェクトを出力します。最初の JSON オブジェクトには、移動されたパーティションの現在の割り当てが記録されます。後で再割り当てを元に戻す必要がある場合に備え、この値をローカルファイル (Pod のファイル以外) に保存します。2 つ目の JSON オブジェクトは、再割り当て JSON ファイルに渡した目的の再割り当てです。
再割り当ての最中にスロットルを変更する必要がある場合は、同じコマンドラインに別のスロットル率を指定して実行します。以下に例を示します。
oc exec my-cluster-kafka-0 -c kafka -it -- \ bin/kafka-reassign-partitions.sh --bootstrap-server localhost:9092 \ --reassignment-json-file /tmp/reassignment.json \ --throttle 10000000 \ --executeブローカー Pod のいずれかから
kafka-reassign-partitions.shコマンドラインツールを使用して、再割り当てが完了したかどうかを定期的に確認します。これは先ほどの手順と同じコマンドですが、--executeオプションの代わりに--verifyオプションを使用します。oc exec broker-pod -c kafka -it -- \ bin/kafka-reassign-partitions.sh --bootstrap-server localhost:9092 \ --reassignment-json-file /tmp/reassignment.json \ --verify例:
oc exec my-cluster-kafka-0 -c kafka -it -- \ bin/kafka-reassign-partitions.sh --bootstrap-server localhost:9092 \ --reassignment-json-file /tmp/reassignment.json \ --verify-
--verifyコマンドによって、移動した各パーティションが正常に完了したことが報告されると、再割り当ては終了します。この最終的な--verifyによって、結果的に再割り当てスロットルも削除されます。割り当てを元のブローカーに戻すために JSON ファイルを保存した場合は、ここでそのファイルを削除できます。 すべてのパーティションの再割り当てが終了すると、削除されるブローカーはクラスター内のいずれのパーティションにも対応しないはずです。これは、ブローカーのデータログディレクトリーにライブパーティションのログが含まれていないことを確認すると検証できます。ブローカーのログディレクトリーに、拡張正規表現
\.[a-z0-9]-delete$と一致しないディレクトリーが含まれる場合、ブローカーにライブパーティションがあるため、停止してはなりません。これを確認するには、以下のコマンドを実行します。
oc exec my-cluster-kafka-0 -c kafka -it -- \ /bin/bash -c \ "ls -l /var/lib/kafka/kafka-log_<N>_ | grep -E '^d' | grep -vE '[a-zA-Z0-9.-]+\.[a-z0-9]+-delete$'"N は削除された
Pod(s)の数に置き換えます。上記のコマンドによって出力が生成される場合、ブローカーにはライブパーティションがあります。この場合、再割り当てが終了していないか、再割り当て JSON ファイルが適切ではありません。
-
ブローカーにライブパーティションがないことが確認できたら、
KafkaリソースのKafka.spec.kafka.replicasを編集できます。これにより、StatefulSetがスケールダウンされ、番号が最も大きいブローカーPod(s)が削除されます。
2.1.5. ローリングアップデートのメンテナンス時間枠
メンテナンス時間枠によって、Kafka および ZooKeeper クラスターの特定のローリングアップデートが便利な時間に開始されるようにスケジュールできます。
2.1.5.1. メンテナンス時間枠の概要
ほとんどの場合、Cluster Operator は対応する Kafka リソースの変更に対応するために Kafka または ZooKeeper クラスターのみを更新します。これにより、Kafka リソースの変更を適用するタイミングを計画し、Kafka クライアントアプリケーションへの影響を最小限に抑えることができます。
ただし、Kafka リソースの変更がなくても Kafka および ZooKeeper クラスターの更新が発生することがあります。たとえば、Cluster Operator によって管理される CA (認証局) 証明書が期限切れ直前である場合にローリング再起動の実行が必要になります。
サービスの 可用性 は Pod のローリング再起動による影響を受けないはずですが (ブローカーおよびトピックの設定が適切である場合)、Kafka クライアントアプリケーションの パフォーマンス は影響を受ける可能性があります。メンテナンス時間枠によって、Kafka および ZooKeeper クラスターのこのような自発的なアップデートが便利な時間に開始されるようにスケジュールできます。メンテナンス時間枠がクラスターに設定されていない場合は、予測できない高負荷が発生する期間など、不便な時間にこのような自発的なローリングアップデートが行われる可能性があります。
2.1.5.2. メンテナンス時間枠の定義
Kafka.spec.maintenanceTimeWindows プロパティーに文字列の配列を入力して、メンテナンス時間枠を設定します。各文字列は、UTC (協定世界時、Coordinated Universal Time) であると解釈される cron 式 です。UTC は実用的にはグリニッジ標準時と同じです。
以下の例では、日、月、火、水、および木曜日の午前 0 時に開始し、午前 1 時 59 分 (UTC) に終わる、単一のメンテナンス時間枠が設定されます。
# ...
maintenanceTimeWindows:
- "* * 0-1 ? * SUN,MON,TUE,WED,THU *"
# ...
実際には、必要な CA 証明書の更新が設定されたメンテナンス時間枠内で完了できるように、Kafka リソースの Kafka.spec.clusterCa.renewalDays および Kafka.spec.clientsCa.renewalDays プロパティーとともにメンテナンス期間を設定する必要があります。
AMQ Streams では、指定の期間にしたがってメンテナンス操作を正確にスケジュールしません。その代わりに、調整ごとにメンテナンス期間が現在「オープン」であるかどうかを確認します。これは、特定の時間枠内でのメンテナンス操作の開始が、最大で Cluster Operator の調整が行われる間隔の長さ分、遅れる可能性があることを意味します。したがって、メンテナンス時間枠は最低でもその間隔の長さにする必要があります。
その他のリソース
- Cluster Operator 設定についての詳細は、「Cluster Operator の設定」 を参照してください。
2.1.5.3. メンテナンス時間枠の設定
サポートされるプロセスによってトリガーされるローリングアップデートのメンテナンス時間枠を設定できます。
前提条件
- OpenShift クラスターが必要です。
- Cluster Operator が稼働している必要があります。
手順
KafkaリソースでmaintenanceTimeWindowsプロパティーを追加または編集します。たとえば、0800 から 1059 までと、1400 から 1559 までのメンテナンスを可能にするには、以下のようにmaintenanceTimeWindowsを設定します。apiVersion: kafka.strimzi.io/v1beta2 kind: Kafka metadata: name: my-cluster spec: kafka: # ... zookeeper: # ... maintenanceTimeWindows: - "* * 8-10 * * ?" - "* * 14-15 * * ?"リソースを作成または更新します。
oc apply -f KAFKA-CONFIG-FILE
その他のリソース
ローリングアップデートの実行:
2.1.6. ターミナルからの ZooKeeper への接続
ほとんどの Kafka CLI ツールは Kafka に直接接続できます。したがって、通常の状況では ZooKeeper に接続する必要はありません。ZooKeeper サービスは暗号化および認証でセキュア化され、AMQ Streams の一部でない外部アプリケーションでの使用は想定されていません。
しかし、ZooKeeper への接続を必要とする Kafka CLI ツールを使用する場合は、ZooKeeper コンテナー内でターミナルを使用し、ZooKeeper アドレスとして localhost:12181 に接続できます。
前提条件
- OpenShift クラスターが利用できる必要があります。
- Kafka クラスターが稼働している必要があります。
- Cluster Operator が稼働している必要があります。
手順
OpenShift コンソールを使用してターミナルを開くか、CLI から
execコマンドを実行します。以下に例を示します。
oc exec -ti my-cluster-zookeeper-0 -- bin/kafka-topics.sh --list --zookeeper localhost:12181必ず
localhost:12181を使用してください。ZooKeeper に対して Kafka コマンドを実行できるようになりました。
2.1.7. Kafka ノードの手動による削除
この手順では、OpenShift アノテーションを使用して既存の Kafka ノードを削除する方法を説明します。Kafka ノードの削除するには、Kafka ブローカーが稼働している Pod と、関連する PersistentVolumeClaim の両方を削除します (クラスターが永続ストレージでデプロイされた場合)。削除後、Pod と関連する PersistentVolumeClaim は自動的に再作成されます。
PersistentVolumeClaim を削除すると、データが永久に失われる可能性があります。以下の手順は、ストレージで問題が発生した場合にのみ実行してください。
前提条件
以下を実行する方法については、『 OpenShift での AMQ Streams のデプロイおよびアップグレード』を参照してください。
手順
削除する
Podの名前を見つけます。たとえば、クラスターの名前が cluster-name の場合、Pod の名前は cluster-name-kafka-index になります。index はゼロで始まり、レプリカーの合計数で終わる値です。
OpenShift で
Podリソースにアノテーションを付けます。oc annotateを使用します。oc annotate pod cluster-name-kafka-index strimzi.io/delete-pod-and-pvc=true- 基盤となる永続ボリューム要求 (Persistent Volume Claim) でアノテーションが付けられた Pod が削除され、再作成されるときに、次の調整の実行を待ちます。
2.1.8. ZooKeeper ノードの手動による削除
この手順では、OpenShift アノテーションを使用して既存の ZooKeeper ノードを削除する方法を説明します。ZooKeeper ノードの削除するには、ZooKeeper が稼働している Pod と、関連する PersistentVolumeClaim の両方を削除します (クラスターが永続ストレージでデプロイされた場合)。削除後、Pod と関連する PersistentVolumeClaim は自動的に再作成されます。
PersistentVolumeClaim を削除すると、データが永久に失われる可能性があります。以下の手順は、ストレージで問題が発生した場合にのみ実行してください。
前提条件
以下を実行する方法については、『 OpenShift での AMQ Streams のデプロイおよびアップグレード』を参照してください。
手順
削除する
Podの名前を見つけます。たとえば、クラスターの名前が cluster-name の場合、Pod の名前は cluster-name-zookeeper-index になります。index はゼロで始まり、レプリカーの合計数で終わる値です。
OpenShift で
Podリソースにアノテーションを付けます。oc annotateを使用します。oc annotate pod cluster-name-zookeeper-index strimzi.io/delete-pod-and-pvc=true- 基盤となる永続ボリューム要求 (Persistent Volume Claim) でアノテーションが付けられた Pod が削除され、再作成されるときに、次の調整の実行を待ちます。
2.1.9. Kafka クラスターリソースのリスト
以下のリソースは、OpenShift クラスターの Cluster Operator によって作成されます。
共有リソース
cluster-name-cluster-ca- クラスター通信の暗号化に使用されるクラスター CA プライベートキーのあるシークレット。
cluster-name-cluster-ca-cert- クラスター CA 公開鍵のあるシークレット。このキーは、Kafka ブローカーのアイデンティティーの検証に使用できます。
cluster-name-clients-ca- ユーザー証明書に署名するために使用されるクライアント CA 秘密鍵のあるシークレット。
cluster-name-clients-ca-cert- クライアント CA 公開鍵のあるシークレット。このキーは、Kafka ユーザーのアイデンティティーの検証に使用できます。
cluster-name-cluster-operator-certs- Kafka および ZooKeeper と通信するための Cluster Operator キーのあるシークレット。
ZooKeeper ノード
cluster-name-zookeeper- ZooKeeper ノード Pod の管理を担当する StatefulSet。
cluster-name-zookeeper-idx- Zookeeper StatefulSet によって作成された Pod。
cluster-name-zookeeper-nodes- DNS が ZooKeeper Pod の IP アドレスを直接解決するのに必要なヘッドレスサービス。
cluster-name-zookeeper-client- Kafka ブローカーがクライアントとして ZooKeeper ノードに接続するために使用するサービス。
cluster-name-zookeeper-config- ZooKeeper 補助設定が含まれ、ZooKeeper ノード Pod によってボリュームとしてマウントされる ConfigMap。
cluster-name-zookeeper-nodes- ZooKeeper ノードキーがあるシークレット。
cluster-name-zookeeper- Zookeeper ノードで使用されるサービスアカウント。
cluster-name-zookeeper- ZooKeeper ノードに設定された Pod の Disruption Budget。
cluster-name-network-policy-zookeeper- ZooKeeper サービスへのアクセスを管理するネットワークポリシー。
data-cluster-name-zookeeper-idx-
ZooKeeper ノード Pod
idxのデータを保存するために使用されるボリュームの永続ボリューム要求です。このリソースは、データを保存するために永続ボリュームのプロビジョニングに永続ストレージが選択された場合のみ作成されます。
Kafka ブローカー
cluster-name-kafka- Kafka ブローカー Pod の管理を担当する StatefulSet。
cluster-name-kafka-idx- Kafka StatefulSet によって作成された Pod。
cluster-name-kafka-brokers- DNS が Kafka ブローカー Pod の IP アドレスを直接解決するのに必要なサービス。
cluster-name-kafka-bootstrap- サービスは、OpenShift クラスター内から接続する Kafka クライアントのブートストラップサーバーとして使用できます。
cluster-name-kafka-external-bootstrap-
OpenShift クラスター外部から接続するクライアントのブートストラップサービス。このリソースは、外部リスナーが有効な場合にのみ作成されます。リスナー名が
externalで、ポートが9094である場合に、古いサービス名は後方互換性を維持するために使用されます。 cluster-name-kafka-pod-id-
トラフィックを OpenShift クラスターの外部から個別の Pod にルーティングするために使用されるサービス。このリソースは、外部リスナーが有効な場合にのみ作成されます。リスナー名が
externalで、ポートが9094である場合に、古いサービス名は後方互換性を維持するために使用されます。 cluster-name-kafka-external-bootstrap-
OpenShift クラスターの外部から接続するクライアントのブートストラップルート。このリソースは、外部リスナーが有効になっていて、タイプ
routeに設定されている場合にのみ作成されます。リスナー名がexternalで、ポートが9094である場合に、古いルート名は後方互換性を維持するために使用されます。 cluster-name-kafka-pod-id-
OpenShift クラスターの外部から個別の Pod へのトラフィックに対するルート。このリソースは、外部リスナーが有効になっていて、タイプ
routeに設定されている場合にのみ作成されます。リスナー名がexternalで、ポートが9094である場合に、古いルート名は後方互換性を維持するために使用されます。 cluster-name-kafka-listener-name-bootstrap- OpenShift クラスター外部から接続するクライアントのブートストラップサービス。このリソースは、外部リスナーが有効な場合にのみ作成されます。新しいサービス名はその他すべての外部リスナーに使用されます。
cluster-name-kafka-listener-name-pod-id- トラフィックを OpenShift クラスターの外部から個別の Pod にルーティングするために使用されるサービス。このリソースは、外部リスナーが有効な場合にのみ作成されます。新しいサービス名はその他すべての外部リスナーに使用されます。
cluster-name-kafka-listener-name-bootstrap-
OpenShift クラスターの外部から接続するクライアントのブートストラップルート。このリソースは、外部リスナーが有効になっていて、タイプ
routeに設定されている場合にのみ作成されます。新しいルート名はその他すべての外部リスナーに使用されます。 cluster-name-kafka-listener-name-pod-id-
OpenShift クラスターの外部から個別の Pod へのトラフィックに対するルート。このリソースは、外部リスナーが有効になっていて、タイプ
routeに設定されている場合にのみ作成されます。新しいルート名はその他すべての外部リスナーに使用されます。 cluster-name-kafka-config- Kafka 補助設定が含まれ、Kafka ブローカー Pod によってボリュームとしてマウントされる ConfigMap。
cluster-name-kafka-brokers- Kafka ブローカーキーのあるシークレット。
cluster-name-kafka- Kafka ブローカーによって使用されるサービスアカウント。
cluster-name-kafka- Kafka ブローカーに設定された Pod の Disruption Budget。
cluster-name-network-policy-kafka- Kafka サービスへのアクセスを管理するネットワークポリシー。
strimzi-namespace-name-cluster-name-kafka-init- Kafka ブローカーによって使用されるクラスターロールバインディング。
cluster-name-jmx- Kafka ブローカーポートのセキュア化に使用される JMX ユーザー名およびパスワードのあるシークレット。このリソースは、Kafka で JMX が有効になっている場合にのみ作成されます。
data-cluster-name-kafka-idx-
Kafka ブローカー Pod
idxのデータを保存するために使用されるボリュームの永続ボリューム要求です。このリソースは、データを保存するために永続ボリュームのプロビジョニングに永続ストレージが選択された場合のみ作成されます。 data-id-cluster-name-kafka-idx-
Kafka ブローカー Pod
idxのデータを保存するために使用されるボリュームidの永続ボリューム要求です。このリソースは、永続ボリュームをプロビジョニングしてデータを保存するときに、JBOD ボリュームに永続ストレージが選択された場合のみ作成されます。
Entitiy Operator
これらのリソースは、Cluster Operator を使用して Entity Operator がデプロイされる場合にのみ作成されます。
cluster-name-entity-operator- Topic および User Operator とのデプロイメント。
cluster-name-entity-operator-random-string- Entity Operator デプロイメントによって作成された Pod。
cluster-name-entity-topic-operator-config- Topic Operator の補助設定のある ConfigMap。
cluster-name-entity-user-operator-config- User Operator の補助設定のある ConfigMap。
cluster-name-entity-operator-certs- Kafka および ZooKeeper と通信するための Entity Operator キーのあるシークレット。
cluster-name-entity-operator- Entity Operator によって使用されるサービスアカウント。
strimzi-cluster-name-entity-topic-operator- Entity Topic Operator によって使用されるロールバインディング。
strimzi-cluster-name-entity-user-operator- Entity User Operator によって使用されるロールバインディング。
Kafka Exporter
これらのリソースは、Cluster Operator を使用して Kafka Exporter がデプロイされる場合にのみ作成されます。
cluster-name-kafka-exporter- Kafka Exporter でのデプロイメント。
cluster-name-kafka-exporter-random-string- Kafka Exporter デプロイメントによって作成された Pod。
cluster-name-kafka-exporter- コンシューマーラグメトリクスの収集に使用されるサービス。
cluster-name-kafka-exporter- Kafka Exporter によって使用されるサービスアカウント。
Cruise Control
これらのリソースは、Cluster Operator を使用して Cruise Control がデプロイされた場合のみ作成されます。
cluster-name-cruise-control- Cruise Control でのデプロイメント。
cluster-name-cruise-control-random-string- Cruise Control デプロイメントによって作成された Pod。
cluster-name-cruise-control-config- Cruise Control の補助設定が含まれ、Cruise Control Pod によってボリュームとしてマウントされる ConfigMap。
cluster-name-cruise-control-certs- Kafka および ZooKeeper と通信するための Cruise Control キーのあるシークレット。
cluster-name-cruise-control- Cruise Control との通信に使用されるサービス。
cluster-name-cruise-control- Cruise Control によって使用されるサービスアカウント。
cluster-name-network-policy-cruise-control- Cruise Control サービスへのアクセスを管理するネットワークポリシー。
2.2. Kafka Connect/S2I クラスターの設定
ここでは、AMQ Streams クラスターにて Kafka Connect や S2I (Source-to-Image) のある Kafka Connect デプロイメントを設定する方法を説明します。
Kafka Connect は、コネクタープラグインを使用して Kafka ブローカーと他のシステムの間でデータをストリーミングする統合ツールです。Kafka Connect は、Kafka と、データベースなどの外部データソースまたはターゲットと統合するためのフレームワークを提供し、コネクターを使用してデータをインポートまたはエクスポートします。コネクターは、必要な接続設定を提供するプラグインです。
Kafka Connect を使用している場合は、KafkaConnect または KafkaConnectS2I リソースを設定します。S2I (Source-to-Image) フレームワークを使用して Kafka Connect をデプロイする場合は、KafkaConnectS2I リソースを使用します。
-
KafkaConnectリソースの完全なスキーマは 「KafkaConnectスキーマ参照」 に記載されています。 -
KafkaConnectS2Iリソースの完全なスキーマは 「KafkaConnectS2Iスキーマ参照」 に記載されています。
build 設定が KafkaConnect リソースに導入されたため、AMQ Streams はデータコネクションに必要なコネクタープラグインでコンテナーイメージを自動的にビルドできるようになりました。そのため、S2I (Source-to-Image) 対応の Kafka Connect のサポートが非推奨になりました。この変更に備えるため、Kafka Connect S2I インスタンスを Kafka Connect インスタンスに移行できます。
その他のリソース
2.2.1. Kafka Connect の設定
Kafka Connect を使用して、Kafka クラスターへの外部データ接続を設定します。
KafkaConnect または KafkaConnectS2I リソースのプロパティーを使用して、Kafka Connect デプロイメントを設定します。この手順の例は、KafkaConnect リソースの場合ですが、プロパティーは KafkaConnectS2I リソースと同じです。
Kafka Connector の設定
KafkaConnect リソースを使用すると、Kafka Connect のコネクターインスタンスを OpenShift ネイティブに作成および管理できます。
Kafka Connect 設定では、strimzi.io/use-connector-resources アノテーションを追加して、Kafka Connect クラスターの KafkaConnectors を有効にします。AMQ Streams がデータコネクションに必要なコネクタープラグインでコンテナーイメージを自動的にビルドするために、build 設定を追加することもできます。Kafka Connect コネクターの外部設定は、externalConfiguration プロパティーを使用して指定されます。
コネクターを管理するには、Kafka Connect REST API を使用するか、KafkaConnector カスタムリソースを使用します。KafkaConnector リソースは、リンク先の Kafka Connect クラスターと同じ namespace にデプロイする必要があります。これらの方法を使用して、コネクターを作成、再割り当て、または削除するための詳細は、『OpenShift での AMQ Streams のデプロイおよびアップグレード』の「コネクターの作成および管理」を参照してください。
コネクター設定は、HTTP リクエストの一部として Kafka Connect に渡され、Kafka 自体に保存されます。ConfigMap およびシークレットは、設定やデータの保存に使用される標準的な OpenShift リソースです。ConfigMap およびシークレットを使用してコネクターの特定の要素を設定できます。その後、HTTP REST コマンドで設定値を参照できます。これにより、必要な場合は設定が分離され、よりセキュアになります。この方法は、ユーザー名、パスワード、証明書などの機密性の高いデータに適用されます。
前提条件
- OpenShift クラスター。
- 稼働中の Cluster Operator。
以下を実行する方法については、『 OpenShift での AMQ Streams のデプロイおよびアップグレード』を参照してください。
手順
KafkaConnectまたはKafkaConnectS2Iリソースのspecプロパティーを編集します。設定可能なプロパティーは以下の例のとおりです。
apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaConnect1 metadata: name: my-connect-cluster annotations: strimzi.io/use-connector-resources: "true"2 spec: replicas: 33 authentication:4 type: tls certificateAndKey: certificate: source.crt key: source.key secretName: my-user-source bootstrapServers: my-cluster-kafka-bootstrap:90925 tls:6 trustedCertificates: - secretName: my-cluster-cluster-cert certificate: ca.crt - secretName: my-cluster-cluster-cert certificate: ca2.crt config:7 group.id: my-connect-cluster offset.storage.topic: my-connect-cluster-offsets config.storage.topic: my-connect-cluster-configs status.storage.topic: my-connect-cluster-status key.converter: org.apache.kafka.connect.json.JsonConverter value.converter: org.apache.kafka.connect.json.JsonConverter key.converter.schemas.enable: true value.converter.schemas.enable: true config.storage.replication.factor: 3 offset.storage.replication.factor: 3 status.storage.replication.factor: 3 build:8 output:9 type: docker image: my-registry.io/my-org/my-connect-cluster:latest pushSecret: my-registry-credentials plugins:10 - name: debezium-postgres-connector artifacts: - type: tgz url: https://repo1.maven.org/maven2/io/debezium/debezium-connector-postgres/1.3.1.Final/debezium-connector-postgres-1.3.1.Final-plugin.tar.gz sha512sum: 962a12151bdf9a5a30627eebac739955a4fd95a08d373b86bdcea2b4d0c27dd6e1edd5cb548045e115e33a9e69b1b2a352bee24df035a0447cb820077af00c03 - name: camel-telegram artifacts: - type: tgz url: https://repo.maven.apache.org/maven2/org/apache/camel/kafkaconnector/camel-telegram-kafka-connector/0.7.0/camel-telegram-kafka-connector-0.7.0-package.tar.gz sha512sum: a9b1ac63e3284bea7836d7d24d84208c49cdf5600070e6bd1535de654f6920b74ad950d51733e8020bf4187870699819f54ef5859c7846ee4081507f48873479 externalConfiguration:11 env: - name: AWS_ACCESS_KEY_ID valueFrom: secretKeyRef: name: aws-creds key: awsAccessKey - name: AWS_SECRET_ACCESS_KEY valueFrom: secretKeyRef: name: aws-creds key: awsSecretAccessKey resources:12 requests: cpu: "1" memory: 2Gi limits: cpu: "2" memory: 2Gi logging:13 type: inline loggers: log4j.rootLogger: "INFO" readinessProbe:14 initialDelaySeconds: 15 timeoutSeconds: 5 livenessProbe: initialDelaySeconds: 15 timeoutSeconds: 5 metricsConfig:15 type: jmxPrometheusExporter valueFrom: configMapKeyRef: name: my-config-map key: my-key jvmOptions:16 "-Xmx": "1g" "-Xms": "1g" image: my-org/my-image:latest17 rack: topologyKey: topology.kubernetes.io/zone18 template:19 pod: affinity: podAntiAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: application operator: In values: - postgresql - mongodb topologyKey: "kubernetes.io/hostname" connectContainer:20 env: - name: JAEGER_SERVICE_NAME value: my-jaeger-service - name: JAEGER_AGENT_HOST value: jaeger-agent-name - name: JAEGER_AGENT_PORT value: "6831"- 1
- 必要に応じて、
KafkaConnectまたはKafkaConnectS2Iを使用します。 - 2
- Kafka Connect クラスターの KafkaConnectors を有効にします。
- 3
- 4
- OAuth ベアラートークン、SASL ベースの SCRAM-SHA-512 または PLAIN メカニズムを使用し、ここで示された TLS メカニズム を使用する、Kafka Connect クラスターの認証。デフォルトでは、Kafka Connect はプレーンテキスト接続を使用して Kafka ブローカーに接続します。
- 5
- Kafka Connect クラスターに接続するためのブートストラップサーバー。
- 6
- クラスターの TLS 証明書が X.509 形式で保存されるキー名のある TLS による暗号化。複数の証明書が同じシークレットに保存されている場合は、複数回リストできます。
- 7
- ワーカー の Kafka Connect 設定 (コネクターではない)。標準の Apache Kafka 設定が提供されることがありますが、AMQ Streams によって直接管理されないプロパティーに限定されます。
- 8
- コネクタープラグインで自動的にコンテナーイメージをビルドするためのビルド設定プロパティー。
- 9
- (必須) 新しいイメージがプッシュされるコンテナーレジストリーの設定。
- 10
- (必須) 新しいコンテナーイメージに追加するコネクタープラグインとそれらのアーティファクトの一覧。各プラグインは、1 つ以上の
artifactで設定する必要があります。 - 11
- ここで示す環境変数や、ボリュームを使用した Kafka コネクターの外部設定
- 12
- 13
- ConfigMap にて直接的 (
inline) または間接的 (external) に追加される Kafka Connect のロガーおよびログレベルを指定します。カスタム ConfigMap は、log4j.propertiesまたはlog4j2.propertiesキー下に配置する必要があります。Kafka Connectlog4j.rootLoggerロガーでは、ログレベルを INFO、ERROR、WARN、TRACE、DEBUG、FATAL または OFF に設定できます。 - 14
- コンテナーを再起動するタイミング (liveness) およびコンテナーがトラフィックを許可できるタイミング (readiness) を把握するためのヘルスチェック。
- 15
- Prometheus メトリクス。この例では、Prometheus JMX エクスポーターの設定が含まれる ConfigMap を参照して有効になります。
metricsConfig.valueFrom.configMapKeyRef.key下の空のファイルが含まれる ConfigMap への参照を使用すると、追加設定なしでメトリクスを有効にできます。 - 16
- Kafka Connect を実行している仮想マシン (VM) のパフォーマンスを最適化するための JVM 設定オプション。
- 17
- 高度な任意設定: 特別な場合のみ推奨されるコンテナーイメージの設定。
- 18
- ラックアウェアネス (Rack awareness) は、異なるラック全体でレプリカを分散するために設定されます。
topologykeyはクラスターノードのラベルと一致する必要があります。 - 19
- テンプレートのカスタマイズ。ここでは、Pod は非アフィニティーでスケジュールされるため、Pod は同じホスト名のノードではスケジュールされません。
- 20
- 環境変数は、Jaeger を使用した分散トレーシングにも設定 されます。
リソースを作成または更新します。
oc apply -f KAFKA-CONNECT-CONFIG-FILE- Kafka Connect の承認が有効である場合、Kafka Connect ユーザーを設定し、Kafka Connect のコンシューマーグループおよびトピックへのアクセスを有効にします。
2.2.2. 複数インスタンスの Kafka Connect 設定
Kafka Connect のインスタンスを複数実行している場合は、以下の config プロパティーのデフォルト設定を変更する必要があります。
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaConnect
metadata:
name: my-connect
spec:
# ...
config:
group.id: connect-cluster
offset.storage.topic: connect-cluster-offsets
config.storage.topic: connect-cluster-configs
status.storage.topic: connect-cluster-status
# ...
# ...
これら 3 つのトピックの値は、同じ group.id を持つすべての Kafka Connect インスタンスで同じする必要があります。
デフォルト設定を変更しないと、同じ Kafka クラスターに接続する各 Kafka Connect インスタンスは同じ値でデプロイされます。その結果、事実上はすべてのインスタンスが結合されてクラスターで実行され、同じトピックが使用されます。
複数の Kafka Connect クラスターが同じトピックの使用を試みると、Kafka Connect は想定どおりに動作せず、エラーが生成されます。
複数の Kafka Connect インスタンスを実行する場合は、インスタンスごとにこれらのプロパティーの値を変更してください。
2.2.3. Kafka Connect のユーザー承認の設定
この手順では、Kafka Connect のユーザーアクセスを承認する方法を説明します。
Kafka でいかなるタイプの承認が使用される場合、Kafka Connect ユーザーは Kafka Connect のコンシューマーグループおよび内部トピックへの読み書きアクセス権限が必要になります。
コンシューマーグループおよび内部トピックのプロパティーは AMQ Streams によって自動設定されますが、 KafkaConnect または KafkaConnectS2I リソースの spec で明示的に指定することもできます。
KafkaConnect リソースの設定プロパティーの例
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaConnect
metadata:
name: my-connect
spec:
# ...
config:
group.id: my-connect-cluster
offset.storage.topic: my-connect-cluster-offsets
config.storage.topic: my-connect-cluster-configs
status.storage.topic: my-connect-cluster-status
# ...
# ...
この手順では、simple 承認の使用時にアクセス権限が付与される方法を説明します。
簡易 (simple) 承認は、Kafka AclAuthorizer プラグインによって処理される ACL ルールを使用し、適切なレベルのアクセス権限が提供されます。簡易 (simple) 承認を使用するように KafkaUser リソースを設定するための詳細は、「AclRule スキーマ参照」を参照してください。
複数のインスタンスを実行している場合、コンシューマーグループとトピックのデフォルト値は異なります。
前提条件
- OpenShift クラスター。
- 稼働中の Cluster Operator。
手順
KafkaUserリソースのauthorizationプロパティーを編集し、アクセス権限をユーザーに付与します。以下の例では、
literalの名前の値を使用して Kafka Connect トピックおよびコンシューマーグループにアクセス権限が設定されます。Expand プロパティー 名前 offset.storage.topicconnect-cluster-offsetsstatus.storage.topicconnect-cluster-statusconfig.storage.topicconnect-cluster-configsgroupconnect-clusterapiVersion: kafka.strimzi.io/v1beta2 kind: KafkaUser metadata: name: my-user labels: strimzi.io/cluster: my-cluster spec: # ... authorization: type: simple acls: # access to offset.storage.topic - resource: type: topic name: connect-cluster-offsets patternType: literal operation: Write host: "*" - resource: type: topic name: connect-cluster-offsets patternType: literal operation: Create host: "*" - resource: type: topic name: connect-cluster-offsets patternType: literal operation: Describe host: "*" - resource: type: topic name: connect-cluster-offsets patternType: literal operation: Read host: "*" # access to status.storage.topic - resource: type: topic name: connect-cluster-status patternType: literal operation: Write host: "*" - resource: type: topic name: connect-cluster-status patternType: literal operation: Create host: "*" - resource: type: topic name: connect-cluster-status patternType: literal operation: Describe host: "*" - resource: type: topic name: connect-cluster-status patternType: literal operation: Read host: "*" # access to config.storage.topic - resource: type: topic name: connect-cluster-configs patternType: literal operation: Write host: "*" - resource: type: topic name: connect-cluster-configs patternType: literal operation: Create host: "*" - resource: type: topic name: connect-cluster-configs patternType: literal operation: Describe host: "*" - resource: type: topic name: connect-cluster-configs patternType: literal operation: Read host: "*" # consumer group - resource: type: group name: connect-cluster patternType: literal operation: Read host: "*"リソースを作成または更新します。
oc apply -f KAFKA-USER-CONFIG-FILE
2.2.4. Kafka コネクターの再起動の実行
この手順では、OpenShift アノテーションを使用して Kafka コネクターの再起動を手動でトリガーする方法を説明します。
前提条件
- Cluster Operator が稼働している必要があります。
手順
再起動する Kafka コネクターを制御する
KafkaConnectorカスタムリソースの名前を見つけます。oc get KafkaConnectorコネクターを再起動するには、OpenShift で
KafkaConnectorリソースにアノテーションを付けます。以下はoc annotateを使用した例になります。oc annotate KafkaConnector KAFKACONNECTOR-NAME strimzi.io/restart=true次の調整が発生するまで待ちます (デフォルトでは 2 分ごとです)。
アノテーションが調整プロセスで検出されれば、Kafka コネクターは再起動されます。Kafka Connect が再起動リクエストを受け入れると、アノテーションは
KafkaConnectorカスタムリソースから削除されます。
その他のリソース
- 『OpenShift での AMQ Streams のデプロイおよびアップグレード』の「コネクターの作成および管理」。
2.2.5. Kafka コネクタータスクの再起動の実行
この手順では、OpenShift アノテーションを使用して Kafka コネクタータスクの再起動を手動でトリガーする方法を説明します。
前提条件
- Cluster Operator が稼働している必要があります。
手順
再起動する Kafka コネクタータスクを制御する
KafkaConnectorカスタムリソースの名前を見つけます。oc get KafkaConnectorKafkaConnectorカスタムリソースから再起動するタスクの ID を検索します。タスク ID は 0 から始まる負の値ではない整数です。oc describe KafkaConnector KAFKACONNECTOR-NAMEコネクタータスクを再起動するには、OpenShift で
KafkaConnectorリソースにアノテーションを付けます。たとえば、oc annotateを使用してタスク 0 を再起動します。oc annotate KafkaConnector KAFKACONNECTOR-NAME strimzi.io/restart-task=0次の調整が発生するまで待ちます (デフォルトでは 2 分ごとです)。
アノテーションが調整プロセスで検出されれば、Kafka コネクタータスクは再起動されます。Kafka Connect が再起動リクエストを受け入れると、アノテーションは
KafkaConnectorカスタムリソースから削除されます。
その他のリソース
- 『OpenShift での AMQ Streams のデプロイおよびアップグレード』の「コネクターの作成および管理」。
2.2.6. S2I を使用する Kafka Connect から Kafka Connect への移行
S2I を使用する Kafka Connect と KafkaConnectS2I リソースのサポートは非推奨になりました。これは、データ接続に必要なコネクタープラグインでコンテナーイメージを自動的にビルドするために使用される KafkaConnect リソースに build 設定プロパティーが導入されたためです。
この手順では、S2I インスタンスのある Kafka Connect を標準の Kafka Connect インスタンスに移行する方法を説明します。これには、KafkaConnectS2I リソースに代わる、新しい KafkaConnect カスタムリソースを設定します。設定後、KafkaConnectS2I リソースは削除されます。
移行プロセスでは、KafkaConnectS2I インスタンスが削除された時点から、新しい KafkaConnect インスタンスが正常にデプロイされるまで、ダウンタイムが発生します。この間、コネクターは実行されず、データは処理されません。ただし、変更後に停止した時点からコネクターが続行されるはずです。
前提条件
-
S2I を使用する Kafka Connect が
KafkaConnectS2I設定を使用してデプロイされている。 - S2I を使用する Kafka Connect が、S2I ビルドを使用して追加されたコネクターでイメージを使用している。
-
シンクおよびソースコネクターインスタンスは
KafkaConnectorリソースまたは Kafka Connect REST API を使用して作成された。
手順
-
KafkaconnectS2Iリソースに使用される名前と同じ名前を使用して、新しいKafkaConnectカスタムリソースを作成します。 -
KafkaConnectS2IリソースプロパティーをKafkaConnectリソースにコピーします。 指定した場合は、同じ
spec.configプロパティーを使用するようにしてください。-
group.id -
offset.storage.topic -
config.storage.topic status.storage.topicこれらのプロパティーが指定されていない場合は、デフォルトが使用されます。この場合は、
KafkaConnectリソース設定にも指定しません。
次に、
KafkaConnectリソース固有の設定を新しいリソースに追加します。-
build設定を追加して、Kafka Connect デプロイメントに追加するすべてのコネクターおよびその他のライブラリーを設定します。注記この代わりに、コネクターで新しいイメージを手動でビルドし、
.spec.imageプロパティーを使用して指定することもできます。古い
KafkaConnectS2Iリソースを削除します。oc delete -f MY-KAFKA-CONNECT-S2I-CONFIG-FILEMY-KAFKA-CONNECT-S2I-CONFIG-FILE を、
KafkaConnectS2Iリソース設定が含まれるファイルの名前に置き換えます。代わりに、リソースの名前を指定できます。
oc delete kafkaconnects2i MY-KAFKA-CONNECT-S2IMY-KAFKA-CONNECT-S2I を
KafkaConnectS2Iリソースの名前に置き換えます。S2I を使用する Kafka Connect のデプロイメントと Pod が削除されるまで待ちます。
警告他のリソースを削除する必要はありません。
新しい
KafkaConnectリソースをデプロイします。oc apply -f MY-KAFKA-CONNECT-CONFIG-FILEMY-KAFKA-CONNECT-CONFIG-FILE を、新しい
KafkaConnectリソース設定が含まれるファイルの名前に置き換えます。新しいイメージのビルド、デプロイメントの作成、および Pod の起動が行われるまで待ちます。
Kafka Connect コネクターの管理に
KafkaConnectorリソースを使用している場合は、予想されるコネクターがすべて存在し、稼働していることを確認します。oc get kctr --selector strimzi.io/cluster=MY-KAFKA-CONNECT-CLUSTER -o nameMY-KAFKA-CONNECT-CLUSTER は、Kafka Connect クラスターの名前に置き換えます。
コネクターは Kafka Connect ストレージより自動的に復元されます。Kafka Connect REST API を使用してコネクターを管理している場合でも、手作業で再作成する必要はありません。
2.2.7. Kafka Connect クラスターリソースの一覧
以下のリソースは、OpenShift クラスターの Cluster Operator によって作成されます。
- connect-cluster-name-connect
- Kafka Connect ワーカーノード Pod の作成を担当するデプロイメント。
- connect-cluster-name-connect-api
- Kafka Connect クラスターを管理するために REST インターフェースを公開するサービス。
- connect-cluster-name-config
- Kafka Connect 補助設定が含まれ、Kafka ブローカー Pod によってボリュームとしてマウントされる ConfigMap。
- connect-cluster-name-connect
- Kafka Connect ワーカーノードに設定された Pod の Disruption Budget。
2.2.8. Kafka Connect (S2I) クラスターリソースの一覧
以下のリソースは、OpenShift クラスターの Cluster Operator によって作成されます。
- connect-cluster-name-connect-source
- 新たにビルドされた Docker イメージのベースイメージとして使用される ImageStream。
- connect-cluster-name-connect
- あたらしい Kafka Connect Docker イメージのビルドを担当する BuildConfig。
- connect-cluster-name-connect
- 新たにビルドされた Docker イメージがプッシュされる ImageStream。
- connect-cluster-name-connect
- Kafka Connect ワーカーノード Pod の作成を担当する DeploymentConfig。
- connect-cluster-name-connect-api
- Kafka Connect クラスターを管理するために REST インターフェースを公開するサービス。
- connect-cluster-name-config
- Kafka Connect 補助設定が含まれ、Kafka ブローカー Pod によってボリュームとしてマウントされる ConfigMap。
- connect-cluster-name-connect
- Kafka Connect ワーカーノードに設定された Pod の Disruption Budget。
2.2.9. 変更データキャプチャーのための Debezium との統合
Red Hat Debezium は分散型の変更データキャプチャー (change data capture) プラットフォームです。データベースの行レベルの変更をキャプチャーして、変更イベントレコードを作成し、Kafka トピックへレコードをストリーミングします。Debezium は Apache Kafka に構築されます。AMQ Streams で Debezium をデプロイおよび統合できます。AMQ Streams のデプロイ後に、Kafka Connect で Debezium をコネクター設定としてデプロイします。Debezium は変更イベントレコードを OpenShift 上の AMQ Streams に渡します。アプリケーションは 変更イベントストリーム を読み取りでき、変更イベントが発生した順にアクセスできます。
Debezium には、以下を含む複数の用途があります。
- データレプリケーション。
- キャッシュの更新およびインデックスの検索。
- モノリシックアプリケーションの簡素化。
- データ統合。
- ストリーミングクエリーの有効化。
データベースの変更をキャプチャーするには、Debezium データベースコネクターで Kafka Connect をデプロイします。KafkaConnector リソースを設定し、コネクターインスタンスを定義します。
AMQ Streams で Debezium をデプロイするための詳細は、「製品ドキュメント」を参照してください。Debezium のドキュメントの 1 つ が『Getting Started with Debezium』で、このガイドはデータベース更新の変更イベントレコードの表示に必要なサービスおよびコネクターの設定方法を説明します。
2.3. Kafka MirrorMaker クラスターの設定
本章では、Kafka クラスター間でデータを複製するために AMQ Streams クラスターで Kafka MirrorMaker デプロイメントを設定する方法を説明します。
AMQ Streams では、MirrorMaker または MirrorMaker 2.0 を使用できます。MirrorMaker 2.0 は最新バージョンで、Kafka クラスター間でより効率的にデータをミラーリングする方法を提供します。
MirrorMaker を使用している場合は、KafkaMirrorMaker リソースを設定します。
以下の手順は、リソースの設定方法を示しています。
KafkaMirrorMaker リソースの完全なスキーマは、「KafkaMirrorMaker スキーマ参照」に記載されています。
2.3.1. Kafka MirrorMaker の設定
KafkaMirrorMaker リソースのプロパティーを使用して、Kafka MirrorMaker デプロイメントを設定します。
TLS または SASL 認証を使用して、プロデューサーおよびコンシューマーのアクセス制御を設定できます。この手順では、コンシューマーおよびプロデューサー側で TLS による暗号化および認証を使用する設定を説明します。
前提条件
以下を実行する方法については、『 OpenShift での AMQ Streams のデプロイおよびアップグレード』を参照してください。
- ソースおよびターゲットの Kafka クラスターが使用できる必要があります。
手順
KafkaMirrorMakerリソースのspecプロパティーを編集します。設定可能なプロパティーは以下の例のとおりです。
apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaMirrorMaker metadata: name: my-mirror-maker spec: replicas: 31 consumer: bootstrapServers: my-source-cluster-kafka-bootstrap:90922 groupId: "my-group"3 numStreams: 24 offsetCommitInterval: 1200005 tls:6 trustedCertificates: - secretName: my-source-cluster-ca-cert certificate: ca.crt authentication:7 type: tls certificateAndKey: secretName: my-source-secret certificate: public.crt key: private.key config:8 max.poll.records: 100 receive.buffer.bytes: 32768 ssl.cipher.suites: "TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384"9 ssl.enabled.protocols: "TLSv1.2" ssl.protocol: "TLSv1.2" ssl.endpoint.identification.algorithm: HTTPS10 producer: bootstrapServers: my-target-cluster-kafka-bootstrap:9092 abortOnSendFailure: false11 tls: trustedCertificates: - secretName: my-target-cluster-ca-cert certificate: ca.crt authentication: type: tls certificateAndKey: secretName: my-target-secret certificate: public.crt key: private.key config: compression.type: gzip batch.size: 8192 ssl.cipher.suites: "TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384"12 ssl.enabled.protocols: "TLSv1.2" ssl.protocol: "TLSv1.2" ssl.endpoint.identification.algorithm: HTTPS13 whitelist: "my-topic|other-topic"14 resources:15 requests: cpu: "1" memory: 2Gi limits: cpu: "2" memory: 2Gi logging:16 type: inline loggers: mirrormaker.root.logger: "INFO" readinessProbe:17 initialDelaySeconds: 15 timeoutSeconds: 5 livenessProbe: initialDelaySeconds: 15 timeoutSeconds: 5 metricsConfig:18 type: jmxPrometheusExporter valueFrom: configMapKeyRef: name: my-config-map key: my-key jvmOptions:19 "-Xmx": "1g" "-Xms": "1g" image: my-org/my-image:latest20 template:21 pod: affinity: podAntiAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: application operator: In values: - postgresql - mongodb topologyKey: "kubernetes.io/hostname" connectContainer:22 env: - name: JAEGER_SERVICE_NAME value: my-jaeger-service - name: JAEGER_AGENT_HOST value: jaeger-agent-name - name: JAEGER_AGENT_PORT value: "6831" tracing:23 type: jaeger- 1
- 2
- コンシューマーおよびプロデューサーのブートストラップサーバー。
- 3
- 4
- 5
- 6
- コンシューマーまたはプロデューサーの TLS 証明書が X.509 形式で保存される、キー名のある TLS による暗号化。複数の証明書が同じシークレットに保存されている場合は、複数回リストできます。
- 7
- OAuth ベアラートークン、SASL ベースの SCRAM-SHA-512 または PLAIN メカニズムを使用し、ここで示された TLS メカニズム を使用する、コンシューマーおよびプロデューサーの認証。
- 8
- 9
- TLS バージョンの特定の 暗号スイート と実行される外部リスナーの SSL プロパティー。
- 10
HTTPSに設定して ホスト名の検証を有効にします。空の文字列を指定すると検証が無効になります。- 11
abortOnSendFailureプロパティー がtrueに設定された場合、Kafka MirrorMaker が終了し、メッセージの送信失敗後にコンテナーが再起動します。- 12
- TLS バージョンの特定の 暗号スイート と実行される外部リスナーの SSL プロパティー。
- 13
HTTPSに設定して ホスト名の検証を有効にします。空の文字列を指定すると検証が無効になります。- 14
- ソースからターゲット Kafka クラスターにミラーリングされたトピックの 許可リスト。
- 15
- 16
- ConfigMap より直接的 (
inline) または間接的 (external) に追加されたロガーおよびログレベルを指定します。カスタム ConfigMap は、log4j.propertiesまたはlog4j2.propertiesキー下に配置する必要があります。MirrorMaker にはmirrormaker.root.loggerと呼ばれる単一のロガーがあります。ログレベルは INFO、ERROR、WARN、TRACE、DEBUG、FATAL、または OFF に設定できます。 - 17
- コンテナーを再起動するタイミング (liveness) およびコンテナーがトラフィックを許可できるタイミング (readiness) を把握するためのヘルスチェック。
- 18
- Prometheus メトリクス。この例では、Prometheus JMX エクスポーターの設定が含まれる ConfigMap を参照して有効になります。
metricsConfig.valueFrom.configMapKeyRef.key下の空のファイルが含まれる ConfigMap への参照を使用すると、追加設定なしでメトリクスを有効にできます。 - 19
- Kafka MirrorMaker を実行している仮想マシン (VM) のパフォーマンスを最適化するための JVM 設定オプション。
- 20
- 高度な任意設定: 特別な場合のみ推奨されるコンテナーイメージの設定。
- 21
- テンプレートのカスタマイズ。ここでは、Pod は非アフィニティーでスケジュールされるため、Pod は同じホスト名のノードではスケジュールされません。
- 22
- 環境変数は、Jaeger を使用した分散トレーシングにも設定 されます。
- 23
警告abortOnSendFailureプロパティーがfalseに設定されると、プロデューサーはトピックの次のメッセージを送信しようとします。失敗したメッセージは再送されないため、元のメッセージが失われる可能性があります。リソースを作成または更新します。
oc apply -f <your-file>
2.3.2. Kafka MirrorMaker クラスターリソースの一覧
以下のリソースは、OpenShift クラスターの Cluster Operator によって作成されます。
- <mirror-maker-name>-mirror-maker
- Kafka MirrorMaker Pod の作成を担当するデプロイメント。
- <mirror-maker-name>-config
- Kafka MirrorMaker の補助設定が含まれ、Kafka ブローカー Pod によってボリュームとしてマウントされる ConfigMap。
- <mirror-maker-name>-mirror-maker
- Kafka MirrorMaker ワーカーノードに設定された Pod の Disruption Budget。
2.4. Kafka MirrorMaker 2.0 クラスターの設定
ここでは、AMQ Streams クラスターで Kafka MirrorMaker 2.0 デプロイメントを設定する方法を説明します。
MirrorMaker 2.0 は、データセンター内またはデータセンター全体の 2 台以上の Kafka クラスター間でデータを複製するために使用されます。
クラスター全体のデータレプリケーションでは、以下が必要な状況がサポートされます。
- システム障害時のデータの復旧
- 分析用のデータの集計
- 特定のクラスターへのデータアクセスの制限
- レイテンシーを改善するための特定場所でのデータのプロビジョニング
MirrorMaker 2.0 を使用している場合は、KafkaMirrorMaker2 リソースを設定します。
MirrorMaker 2.0 では、クラスターの間でデータを複製する全く新しい方法が導入されました。
その結果、リソースの設定は MirrorMaker の以前のバージョンとは異なります。MirrorMaker 2.0 の使用を選択した場合、現在、レガシーサポートがないため、リソースを手作業で新しい形式に変換する必要があります。
MirrorMaker 2.0 によってデータが複製される方法は、以下に説明されています。
以下の手順では、MirrorMaker 2.0 に対してリソースが設定される方法について取り上げます。
KafkaMirrorMaker2 リソースの完全なスキーマは、「KafkaMirrorMaker2 スキーマ参照」に記載されています。
2.4.1. MirrorMaker 2.0 のデータレプリケーション
MirrorMaker 2.0 はソースの Kafka クラスターからメッセージを消費して、ターゲットの Kafka クラスターに書き込みます。
MirrorMaker 2.0 は以下を使用します。
- ソースクラスターからデータを消費するソースクラスターの設定。
- データをターゲットクラスターに出力するターゲットクラスターの設定。
MirrorMaker 2.0 は Kafka Connect フレームワークをベースとし、コネクターによってクラスター間のデータ転送が管理されます。MirrorMaker 2.0 の MirrorSourceConnector は、ソースクラスターからターゲットクラスターにトピックを複製します。
あるクラスターから別のクラスターにデータを ミラーリング するプロセスは非同期です。推奨されるパターンは、ソース Kafka クラスターとともにローカルでメッセージが作成され、ターゲットの Kafka クラスターの近くでリモートで消費されることです。
MirrorMaker 2.0 は、複数のソースクラスターで使用できます。
図2.1 2 つのクラスターにおけるレプリケーション
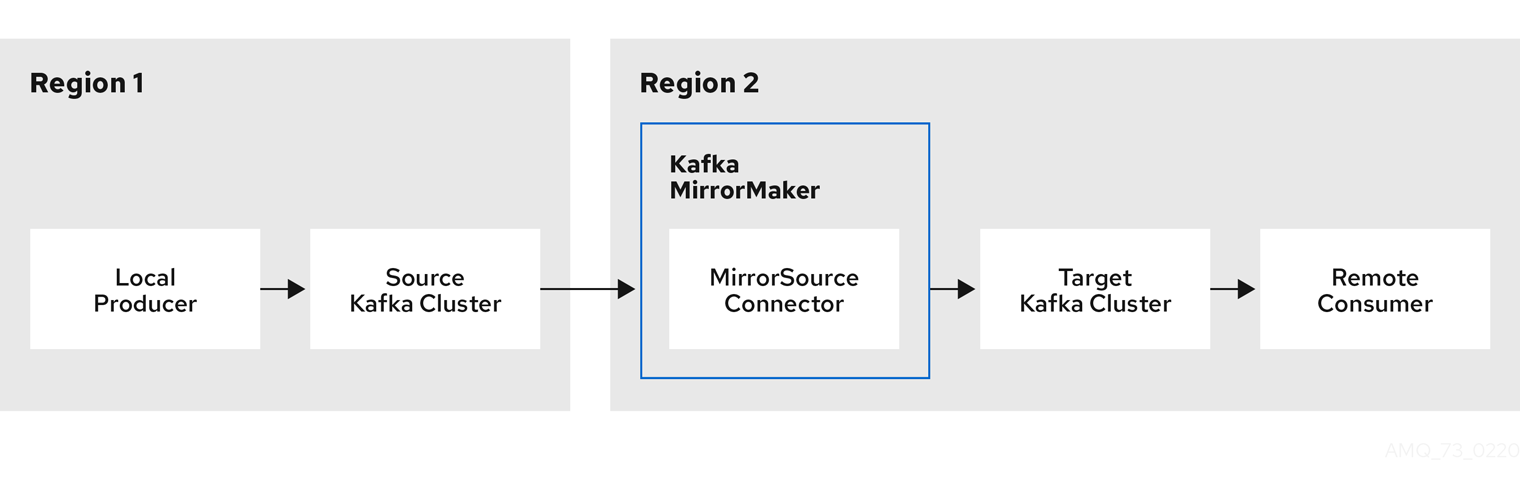
デフォルトでは、ソースクラスターの新規トピックのチェックは 10 分ごとに行われます。refresh.topics.interval.seconds を KafkaMirrorMaker2 リソースのソースコネクター設定に追加することで、頻度を変更できます。ただし、操作の頻度が増えると、全体的なパフォーマンスに影響する可能性があります。
2.4.2. クラスターの設定
active/passive または active/active クラスター設定で MirrorMaker 2.0 を使用できます。
- active/active 設定では、両方のクラスターがアクティブで、同じデータを同時に提供します。これは、地理的に異なる場所で同じデータをローカルで利用可能にする場合に便利です。
- active/passive 設定では、アクティブなクラスターからのデータはパッシブなクラスターで複製され、たとえば、システム障害時のデータ復旧などでスタンバイ状態を維持します。
プロデューサーとコンシューマーがアクティブなクラスターのみに接続することを前提とします。
MirrorMaker 2.0 クラスターは、ターゲットの宛先ごとに必要です。
2.4.2.1. 双方向レプリケーション (active/active)
MirrorMaker 2.0 アーキテクチャーでは、active/active クラスター設定で双方向レプリケーションがサポートされます。
各クラスターは、 source および remote トピックの概念を使用して、別のクラスターのデータを複製します。同じトピックが各クラスターに保存されるため、リモートトピックの名前がソースクラスターを表すように自動的に MirrorMaker 2.0 によって変更されます。元のクラスターの名前の先頭には、トピックの名前が追加されます。
図2.2 トピックの名前変更
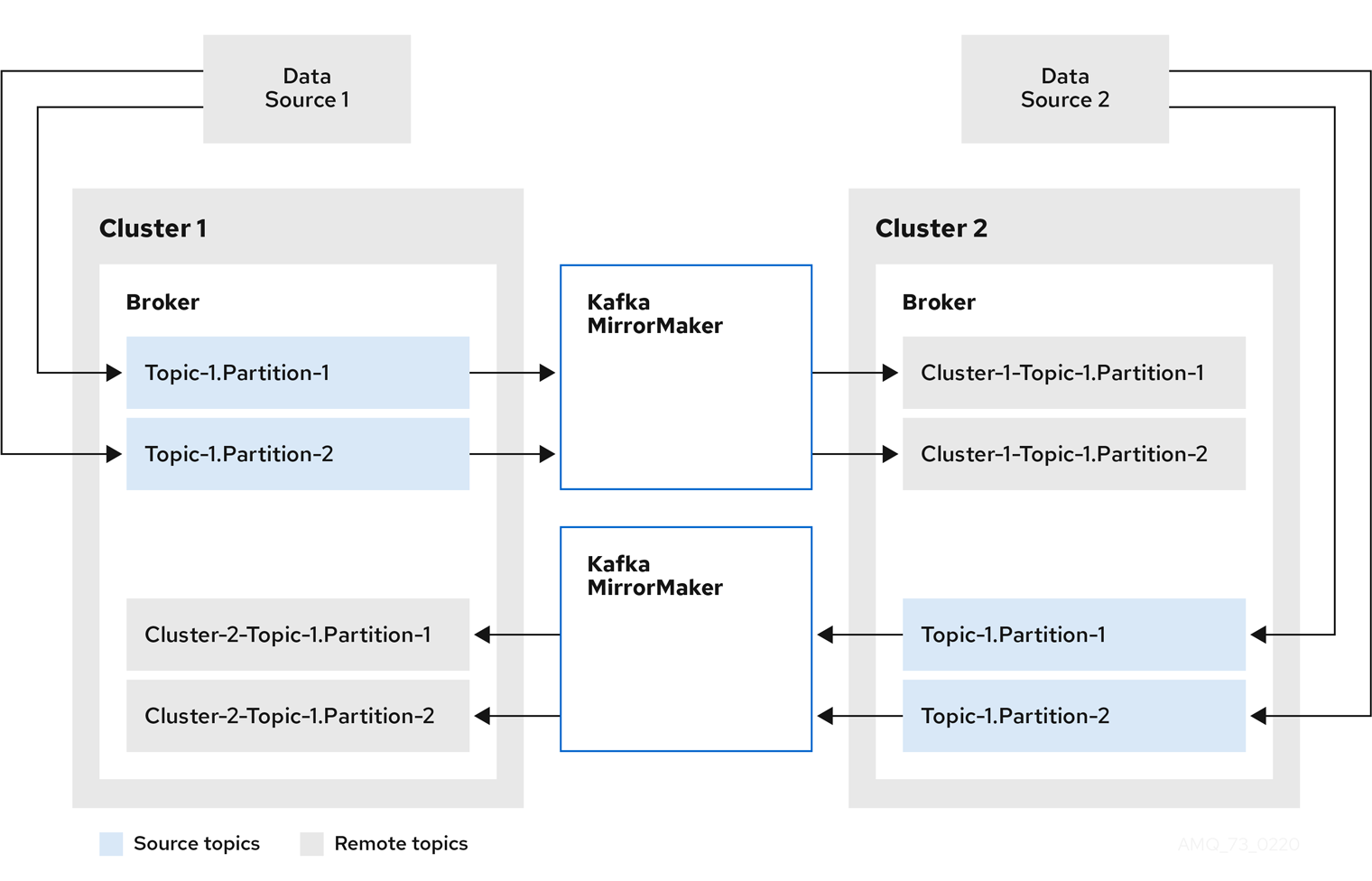
ソースクラスターにフラグを付けると、トピックはそのクラスターに複製されません。
remote トピックを介したレプリケーションの概念は、データの集約が必要なアーキテクチャーの設定に役立ちます。コンシューマーは、同じクラスター内でソースおよびリモートトピックにサブスクライブできます。これに個別の集約クラスターは必要ありません。
2.4.2.2. 一方向レプリケーション (active/passive)
MirrorMaker 2.0 アーキテクチャーでは、active/passive クラスター設定でー方向レプリケーションがサポートされます。
active/passiveのクラスター設定を使用してバックアップを作成したり、データを別のクラスターに移行したりできます。この場合、リモートトピックの名前を自動的に変更したくないことがあります。
IdentityReplicationPolicy を KafkaMirrorMaker2 リソースのソースコネクター設定に追加することで、名前の自動変更をオーバーライドできます。この設定が適用されると、トピックには元の名前が保持されます。
2.4.2.3. トピック設定の同期
トピック設定は、ソースクラスターとターゲットクラスター間で自動的に同期化されます。設定プロパティーを同期化することで、リバランスの必要性が軽減されます。
2.4.2.4. データの整合性
MirrorMaker 2.0 は、ソーストピックを監視し、設定変更をリモートトピックに伝播して、不足しているパーティションを確認および作成します。MirrorMaker 2.0 のみがリモートトピックに書き込みできます。
2.4.2.5. オフセットの追跡
MirrorMaker 2.0 では、内部トピックを使用してコンシューマーグループのオフセットを追跡します。
- オフセット同期 トピックは、複製されたトピックパーティションのソースおよびターゲットオフセットをレコードメタデータからマッピングします。
- チェックポイント トピックは、各コンシューマーグループの複製されたトピックパーティションのソースおよびターゲットクラスターで最後にコミットされたオフセットをマッピングします。
チェックポイント トピックのオフセットは、設定によって事前定義された間隔で追跡されます。両方のトピックは、フェイルオーバー時に正しいオフセットの位置からレプリケーションの完全復元を可能にします。
MirrorMaker 2.0 は、MirrorCheckpointConnector を使用して、オフセット追跡の チェックポイントを生成します。
2.4.2.6. コンシューマーグループオフセットの同期
__consumer_offsets トピックには、各コンシューマーグループのコミットされたオフセットに関する情報が保存されます。オフセットの同期は、ソースクラスターのコンシューマーグループのコンシューマーオフセットをターゲットクラスターのコンシューマーオフセットに定期的に転送します。
オフセットの同期は、特に active/passive 設定で便利です。アクティブなクラスターがダウンした場合、コンシューマーアプリケーションはパッシブ (スタンバイ) クラスターに切り替え、最後に転送されたオフセットの位置からピックアップできます。
トピックオフセットの同期を使用するには、以下を行います。
-
sync.group.offsets.enabledをKafkaMirrorMaker2リソースのチェックポイントコネクター設定に追加し、プロパティーをtrueに設定して同期を有効にします。同期はデフォルトで無効になっています。 -
IdentityReplicationPolicyをソースおよびチェックポイントコネクター設定に追加し、ターゲットクラスターのトピックが元の名前を保持するようにします。
トピックオフセットの同期を機能させるため、ターゲットクラスターのコンシューマーグループは、ソースクラスターのグループと同じ ID を使用できません。
同期を有効にすると、ソースクラスターからオフセットの同期が定期的に行われます。sync.group.offsets.interval.seconds および emit.checkpoints.interval.seconds をチェックポイントコネクター設定に追加すると、頻度を変更できます。これらのプロパティーは、コンシューマーグループのオフセットが同期される頻度 (秒単位) と、オフセットを追跡するためにチェックポイントが生成される頻度を指定します。両方のプロパティーのデフォルトは 60 秒です。refresh.groups.interval.seconds プロパティーを使用して、新規コンシューマーグループをチェックする頻度を変更することもできます。デフォルトでは 10 分ごとに実行されます。
同期は時間ベースであるため、コンシューマーによってパッシブクラスターへ切り替えられると、一部のメッセージが重複する可能性があります。
2.4.2.7. 接続性チェック
ハートビート 内部トピックによって、クラスター間の接続性が確認されます。
ハートビート トピックは、ソースクラスターから複製されます。
ターゲットクラスターは、トピックを使用して以下を確認します。
- クラスター間の接続を管理するコネクターが稼働している。
- ソースクラスターが利用可能である。
MirrorMaker 2.0 は MirrorHeartbeatConnector を使用して、これらのチェックを実行する ハートビート を生成します。
2.4.3. ACL ルールの同期
User Operator を使用して いない 場合は、ACL でリモートトピックにアクセスできます。
User Operator なしで AclAuthorizer が使用されている場合、ブローカーへのアクセスを管理する ACL ルールはリモートトピックにも適用されます。ソーストピックを読み取りできるユーザーは、そのリモートトピックを読み取りできます。
OAuth 2.0 での承認は、このようなリモートトピックへのアクセスをサポートしません。
2.4.4. MirrorMaker 2.0 を使用した Kafka クラスター間でのデータの同期
MirrorMaker 2.0 を使用して、設定を介して Kafka クラスター間のデータを同期します。
設定では以下を指定する必要があります。
- 各 Kafka クラスター
- TLS 認証を含む各クラスターの接続情報
レプリケーションのフローおよび方向
- クラスター対クラスター
- トピック対トピック
KafkaMirrorMaker2 リソースのプロパティーを使用して、Kafka MirrorMaker 2.0 デプロイメントを設定します。
従来のバージョンの MirrorMaker は継続してサポートされます。従来のバージョンに設定したリソースを使用する場合は、MirrorMaker 2.0 でサポートされる形式に更新する必要があります。
MirrorMaker 2.0 によって、レプリケーション係数などのプロパティーのデフォルト設定値が提供されます。デフォルトに変更がない最小設定の例は以下のようになります。
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaMirrorMaker2
metadata:
name: my-mirror-maker2
spec:
version: 2.7.0
connectCluster: "my-cluster-target"
clusters:
- alias: "my-cluster-source"
bootstrapServers: my-cluster-source-kafka-bootstrap:9092
- alias: "my-cluster-target"
bootstrapServers: my-cluster-target-kafka-bootstrap:9092
mirrors:
- sourceCluster: "my-cluster-source"
targetCluster: "my-cluster-target"
sourceConnector: {}TLS または SASL 認証を使用して、ソースおよびターゲットクラスターのアクセス制御を設定できます。この手順では、ソースおよびターゲットクラスターに対して TLS による暗号化および認証を使用する設定を説明します。
前提条件
以下を実行する方法については、『 OpenShift での AMQ Streams のデプロイおよびアップグレード』を参照してください。
- ソースおよびターゲットの Kafka クラスターが使用できる必要があります。
手順
KafkaMirrorMaker2リソースのspecプロパティーを編集します。設定可能なプロパティーは以下の例のとおりです。
apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaMirrorMaker2 metadata: name: my-mirror-maker2 spec: version: 2.7.01 replicas: 32 connectCluster: "my-cluster-target"3 clusters:4 - alias: "my-cluster-source"5 authentication:6 certificateAndKey: certificate: source.crt key: source.key secretName: my-user-source type: tls bootstrapServers: my-cluster-source-kafka-bootstrap:90927 tls:8 trustedCertificates: - certificate: ca.crt secretName: my-cluster-source-cluster-ca-cert - alias: "my-cluster-target"9 authentication:10 certificateAndKey: certificate: target.crt key: target.key secretName: my-user-target type: tls bootstrapServers: my-cluster-target-kafka-bootstrap:909211 config:12 config.storage.replication.factor: 1 offset.storage.replication.factor: 1 status.storage.replication.factor: 1 ssl.cipher.suites: "TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384"13 ssl.enabled.protocols: "TLSv1.2" ssl.protocol: "TLSv1.2" ssl.endpoint.identification.algorithm: HTTPS14 tls:15 trustedCertificates: - certificate: ca.crt secretName: my-cluster-target-cluster-ca-cert mirrors:16 - sourceCluster: "my-cluster-source"17 targetCluster: "my-cluster-target"18 sourceConnector:19 config: replication.factor: 120 offset-syncs.topic.replication.factor: 121 sync.topic.acls.enabled: "false"22 refresh.topics.interval.seconds: 6023 replication.policy.separator: ""24 replication.policy.class: "io.strimzi.kafka.connect.mirror.IdentityReplicationPolicy"25 heartbeatConnector:26 config: heartbeats.topic.replication.factor: 127 checkpointConnector:28 config: checkpoints.topic.replication.factor: 129 refresh.groups.interval.seconds: 60030 sync.group.offsets.enabled: true31 sync.group.offsets.interval.seconds: 6032 emit.checkpoints.interval.seconds: 6033 replication.policy.class: "io.strimzi.kafka.connect.mirror.IdentityReplicationPolicy" topicsPattern: ".*"34 groupsPattern: "group1|group2|group3"35 resources:36 requests: cpu: "1" memory: 2Gi limits: cpu: "2" memory: 2Gi logging:37 type: inline loggers: connect.root.logger.level: "INFO" readinessProbe:38 initialDelaySeconds: 15 timeoutSeconds: 5 livenessProbe: initialDelaySeconds: 15 timeoutSeconds: 5 jvmOptions:39 "-Xmx": "1g" "-Xms": "1g" image: my-org/my-image:latest40 template:41 pod: affinity: podAntiAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: application operator: In values: - postgresql - mongodb topologyKey: "kubernetes.io/hostname" connectContainer:42 env: - name: JAEGER_SERVICE_NAME value: my-jaeger-service - name: JAEGER_AGENT_HOST value: jaeger-agent-name - name: JAEGER_AGENT_PORT value: "6831" tracing: type: jaeger43 externalConfiguration:44 env: - name: AWS_ACCESS_KEY_ID valueFrom: secretKeyRef: name: aws-creds key: awsAccessKey - name: AWS_SECRET_ACCESS_KEY valueFrom: secretKeyRef: name: aws-creds key: awsSecretAccessKey- 1
- 常に同じになる Kafka Connect と Mirror Maker 2.0 の バージョン。
- 2
- 3
- Kafka Connect の Kafka クラスターエイリアス。ターゲット Kafka クラスターを指定する必要があります。Kafka クラスターは、その内部トピックのために Kafka Connect によって使用されます。
- 4
- 同期される Kafka クラスターの 指定。
- 5
- ソースの Kafka クラスターの クラスターエイリアス。
- 6
- 7
- ソース Kafka クラスターに接続するための ブートストラップサーバー。
- 8
- ソース Kafka クラスターの TLS 証明書が X.509 形式で保存されるキー名のある TLS による暗号化。複数の証明書が同じシークレットに保存されている場合は、複数回リストできます。
- 9
- ターゲット Kafka クラスターの クラスターエイリアス。
- 10
- ターゲット Kafka クラスターの認証は、ソース Kafka クラスターと同様に設定されます。
- 11
- ターゲット Kafka クラスターに接続するための ブートストラップサーバー。
- 12
- Kafka Connect の設定。標準の Apache Kafka 設定が提供されることがありますが、AMQ Streams によって直接管理されないプロパティーに限定されます。
- 13
- TLS バージョンの特定の 暗号スイート と実行される外部リスナーの SSL プロパティー。
- 14
HTTPSに設定して ホスト名の検証を有効にします。空の文字列を指定すると検証が無効になります。- 15
- ターゲット Kafka クラスターの TLS による暗号化は、ソース Kafka クラスターと同様に設定されます。
- 16
- 17
- MirrorMaker 2.0 コネクターによって使用されるソースクラスターの クラスターエイリアス。
- 18
- MirrorMaker 2.0 コネクターによって使用されるターゲットクラスターの クラスターエイリアス。
- 19
- リモートトピックを作成する
MirrorSourceConnectorの設定。デフォルトの設定オプションはconfigによって上書きされます。 - 20
- ターゲットクラスターで作成されるミラーリングされたトピックのレプリケーション係数。
- 21
- ソースおよびターゲットクラスターのオフセットをマップする
MirrorSourceConnectoroffset-syncs内部トピックのレプリケーション係数。 - 22
- ACL ルールの同期 が有効になっていると、同期されたトピックに ACL が適用されます。デフォルトは
trueです。 - 23
- 新規トピックのチェック頻度を変更する任意設定。デフォルトでは 10 分毎にチェックされます。
- 24
- リモートトピック名の変更に使用する区切り文字を定義します。
- 25
- リモートトピック名の自動変更をオーバーライドするポリシーを追加します。その名前の前にソースクラスターの名前を追加する代わりに、トピックが元の名前を保持します。このオプションの設定は、active/passive バックアップおよびデータ移行に役立ちます。トピックオフセットの同期を設定するには、このプロパティーも
checkpointConnector.configに設定する必要があります。 - 26
- 接続性チェックを実行する
MirrorHeartbeatConnectorの設定。デフォルトの設定オプションはconfigによって上書きされます。 - 27
- ターゲットクラスターで作成されたハートビートトピックのレプリケーション係数。
- 28
- オフセットを追跡する
MirrorCheckpointConnectorの設定。デフォルトの設定オプションはconfigによって上書きされます。 - 29
- ターゲットクラスターで作成されたチェックポイントトピックのレプリケーション係数。
- 30
- 新規コンシューマーグループのチェック頻度を変更する任意設定。デフォルトでは 10 分毎にチェックされます。
- 31
- コンシューマーグループのオフセットを同期する任意設定。これは、active/passive 設定でのリカバリーに便利です。同期はデフォルトでは有効になっていません。
- 32
- コンシューマーグループオフセットの同期が有効な場合は、同期の頻度を調整できます。
- 33
- オフセット追跡のチェック頻度を調整します。オフセット同期の頻度を変更する場合、これらのチェックの頻度も調整する必要がある場合があります。
- 34
- 正規表現パターンとして定義されたソースクラスターからのトピックレプリケーション。ここで、すべてのトピックを要求します。
- 35
- 正規表現パターンとして定義されたソースクラスターからのコンシューマーグループレプリケーション。ここで、3 つのコンシューマーグループを名前で要求します。コンマ区切りリストを使用できます。
- 36
- 37
- ConfigMap にて直接的 (
inline) または間接的 (external) に追加される Kafka Connect のロガーおよびログレベルを指定します。カスタム ConfigMap は、log4j.propertiesまたはlog4j2.propertiesキー下に配置する必要があります。Kafka Connectlog4j.rootLoggerロガーでは、ログレベルを INFO、ERROR、WARN、TRACE、DEBUG、FATAL または OFF に設定できます。 - 38
- コンテナーを再起動するタイミング (liveness) およびコンテナーがトラフィックを許可できるタイミング (readiness) を把握するためのヘルスチェック。
- 39
- Kafka MirrorMaker を実行している仮想マシン (VM) のパフォーマンスを最適化するための JVM 設定オプション。
- 40
- 高度な任意設定: 特別な場合のみ推奨されるコンテナーイメージの設定。
- 41
- テンプレートのカスタマイズ。ここでは、Pod は非アフィニティーでスケジュールされるため、Pod は同じホスト名のノードではスケジュールされません。
- 42
- 環境変数は、Jaeger を使用した分散トレーシングにも設定 されます。
- 43
- 44
- 環境変数として Kafka MirrorMaker にマウントされた OpenShift Secret の外部設定。
リソースを作成または更新します。
oc apply -f MIRRORMAKER-CONFIGURATION-FILE
2.4.5. Kafka MirrorMaker 2.0 コネクターの再起動の実行
この手順では、OpenShift アノテーションを使用して Kafka MirrorMaker 2.0 コネクターの再起動を手動でトリガーする方法を説明します。
前提条件
- Cluster Operator が稼働している必要があります。
手順
再起動する Kafka MirrorMaker 2.0 コネクターを制御する
KafkaMirrorMaker2カスタムリソースの名前を見つけます。oc get KafkaMirrorMaker2KafkaMirrorMaker2カスタムリソースから再起動される Kafka MirrorMaker 2.0 コネクターの名前を見つけます。oc describe KafkaMirrorMaker2 KAFKAMIRRORMAKER-2-NAMEコネクターを再起動するには、OpenShift で
KafkaMirrorMaker2リソースにアノテーションを付けます。以下の例では、my-source->my-target.MirrorSourceConnectorという名前のコネクターがoc annotateによって再起動されます。oc annotate KafkaMirrorMaker2 KAFKAMIRRORMAKER-2-NAME "strimzi.io/restart-connector=my-source->my-target.MirrorSourceConnector"次の調整が発生するまで待ちます (デフォルトでは 2 分ごとです)。
アノテーションが調整プロセスで検出されれば、Kafka MirrorMaker 2.0 コネクターは再起動されます。再起動リクエストが許可されると、アノテーションは
KafkaMirrorMaker2カスタムリソースから削除されます。
その他のリソース
2.4.6. Kafka MirrorMaker 2.0 コネクタータスクの再起動の実行
この手順では、OpenShift アノテーションを使用して Kafka MirrorMaker 2.0 コネクタータスクの再起動を手動でトリガーする方法を説明します。
前提条件
- Cluster Operator が稼働している必要があります。
手順
再起動する Kafka MirrorMaker 2.0 コネクターを制御する
KafkaMirrorMaker2カスタムリソースの名前を見つけます。oc get KafkaMirrorMaker2KafkaMirrorMaker2カスタムリソースから再起動される Kafka MirrorMaker 2.0 コネクターの名前と、タスクの ID を見つけます。タスク ID は 0 から始まる負の値ではない整数です。oc describe KafkaMirrorMaker2 KAFKAMIRRORMAKER-2-NAMEコネクタータスクを再起動するには、OpenShift で
KafkaMirrorMaker2リソースにアノテーションを付けます。以下の例では、my-source->my-target.MirrorSourceConnectorという名前のコネクターのタスク 0 がoc annotateによって再起動されます。oc annotate KafkaMirrorMaker2 KAFKAMIRRORMAKER-2-NAME "strimzi.io/restart-connector-task=my-source->my-target.MirrorSourceConnector:0"次の調整が発生するまで待ちます (デフォルトでは 2 分ごとです)。
アノテーションが調整プロセスで検出されれば、Kafka MirrorMaker 2.0 コネクタータスクは再起動されます。再起動タスクリクエストが許可されると、アノテーションは
KafkaMirrorMaker2カスタムリソースから削除されます。
その他のリソース
2.5. Kafka Bridge クラスターの設定
ここでは、AMQ Streams クラスターで Kafka Bridge デプロイメントを設定する方法を説明します。
Kafka Bridge では、HTTP ベースのクライアントと Kafka クラスターを統合するための API が提供されます。
Kafka Bridge を使用している場合は、KafkaBridge リソースを設定します。
KafkaBridge リソースの完全なスキーマは 「KafkaBridge スキーマ参照」 に記載されています。
2.5.1. Kafka Bridge の設定
Kafka Bridge を使用した Kafka クラスターへの HTTP ベースのリクエスト
KafkaBridge リソースのプロパティーを使用して、Kafka Bridge デプロイメントを設定します。
クライアントのコンシューマーリクエストが異なる Kafka Bridge インスタンスによって処理された場合に発生する問題を防ぐには、アドレスベースのルーティングを利用して、要求が適切な Kafka Bridge インスタンスにルーティングされるようにする必要があります。また、独立した各 Kafka Bridge インスタンスにレプリカが必要です。Kafka Bridge インスタンスには、別のインスタンスと共有されない独自の状態があります。
前提条件
- OpenShift クラスター。
- 稼働中の Cluster Operator。
以下を実行する方法については、『 OpenShift での AMQ Streams のデプロイおよびアップグレード』を参照してください。
手順
KafkaBridgeリソースのspecプロパティーを編集します。設定可能なプロパティーは以下の例のとおりです。
apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaBridge metadata: name: my-bridge spec: replicas: 31 bootstrapServers: my-cluster-kafka-bootstrap:90922 tls:3 trustedCertificates: - secretName: my-cluster-cluster-cert certificate: ca.crt - secretName: my-cluster-cluster-cert certificate: ca2.crt authentication:4 type: tls certificateAndKey: secretName: my-secret certificate: public.crt key: private.key http:5 port: 8080 cors:6 allowedOrigins: "https://strimzi.io" allowedMethods: "GET,POST,PUT,DELETE,OPTIONS,PATCH" consumer:7 config: auto.offset.reset: earliest producer:8 config: delivery.timeout.ms: 300000 resources:9 requests: cpu: "1" memory: 2Gi limits: cpu: "2" memory: 2Gi logging:10 type: inline loggers: logger.bridge.level: "INFO" # enabling DEBUG just for send operation logger.send.name: "http.openapi.operation.send" logger.send.level: "DEBUG" jvmOptions:11 "-Xmx": "1g" "-Xms": "1g" readinessProbe:12 initialDelaySeconds: 15 timeoutSeconds: 5 livenessProbe: initialDelaySeconds: 15 timeoutSeconds: 5 image: my-org/my-image:latest13 template:14 pod: affinity: podAntiAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: application operator: In values: - postgresql - mongodb topologyKey: "kubernetes.io/hostname" bridgeContainer:15 env: - name: JAEGER_SERVICE_NAME value: my-jaeger-service - name: JAEGER_AGENT_HOST value: jaeger-agent-name - name: JAEGER_AGENT_PORT value: "6831"- 1
- 2
- ターゲット Kafka クラスターに接続するための ブートストラップサーバー。
- 3
- ソース Kafka クラスターの TLS 証明書が X.509 形式で保存されるキー名のある TLS による暗号化。複数の証明書が同じシークレットに保存されている場合は、複数回リストできます。
- 4
- OAuth ベアラートークン、SASL ベースの SCRAM-SHA-512 または PLAIN メカニズムを使用し、ここで示された TLS メカニズム を使用する、Kafka Bridge クラスターの認証。デフォルトでは、Kafka Bridge は認証なしで Kafka ブローカーに接続します。
- 5
- Kafka ブローカーへの HTTP アクセス。
- 6
- 選択されたリソースおよびアクセスメソッドを指定する CORS アクセス。リクエストの追加の HTTP ヘッダーには Kafka クラスターへのアクセスが許可されるオリジンが記述されています。
- 7
- コンシューマー設定 オプション。
- 8
- プロデューサー設定 オプション。
- 9
- 10
- ConfigMap にて直接的 (
inline) または間接的 (external) に追加される Kafka Bridge のロガーおよびログレベルを指定します。カスタム ConfigMap は、log4j.propertiesまたはlog4j2.propertiesキー下に配置する必要があります。Kafka Bridge ロガーでは、ログレベルを INFO、ERROR、WARN、TRACE、DEBUG、FATAL または OFF に設定できます。 - 11
- Kafka Bridge を実行している仮想マシン (VM) のパフォーマンスを最適化するための JVM 設定オプション。
- 12
- コンテナーを再起動するタイミング (liveness) およびコンテナーがトラフィックを許可できるタイミング (readiness) を把握するためのヘルスチェック。
- 13
- 高度な任意設定: 特別な場合のみ推奨されるコンテナーイメージの設定。
- 14
- テンプレートのカスタマイズ。ここでは、Pod は非アフィニティーでスケジュールされるため、Pod は同じホスト名のノードではスケジュールされません。
- 15
- 環境変数は、Jaeger を使用した分散トレーシングにも設定 されます。
リソースを作成または更新します。
oc apply -f KAFKA-BRIDGE-CONFIG-FILE
2.5.2. Kafka Bridge クラスターリソースのリスト
以下のリソースは、OpenShift クラスターの Cluster Operator によって作成されます。
- bridge-cluster-name-bridge
- Kafka Bridge ワーカーノード Pod の作成を担当するデプロイメント。
- bridge-cluster-name-bridge-service
- Kafka Bridge クラスターの REST インターフェースを公開するサービス。
- bridge-cluster-name-bridge-config
- Kafka Bridge の補助設定が含まれ、Kafka ブローカー Pod によってボリュームとしてマウントされる ConfigMap。
- bridge-cluster-name-bridge
- Kafka Bridge ワーカーノードに設定された Pod の Disruption Budget。
2.6. OpenShift リソースのカスタマイズ
AMQ Streams では、AMQ Streams の operator によって管理される Deployments、StatefulSets、Pods、および Services などの複数の OpenShift リソースが作成されます。特定の OpenShift リソースの管理を担当する operator のみがそのリソースを変更できます。operator によって管理される OpenShift リソースを手動で変更しようとすると、operator はその変更を元に戻します。
しかし、operator が管理する OpenShift リソースの変更は、以下のような特定のタスクを実行する場合に役立ちます。
-
Podsが Istio またはその他のサービスによって処理される方法を制御するカスタムラベルまたはアノテーションを追加する場合。 -
Loadbalancerタイプのサービスがクラスターによって作成される方法を管理する場合。
このような変更は、AMQ Streams カスタムリソースの template プロパティーを使用して追加します。template プロパティーは以下のリソースでサポートされます。API リファレンスは、カスタマイズ可能フィールドに関する詳細を提供します。
Kafka.spec.kafka-
「
KafkaClusterTemplateスキーマ参照」 を参照 Kafka.spec.zookeeper-
「
ZookeeperClusterTemplateスキーマ参照」 を参照 Kafka.spec.entityOperator-
「
EntityOperatorTemplateスキーマ参照」 を参照 Kafka.spec.kafkaExporter-
「
KafkaExporterTemplateスキーマ参照」 を参照 Kafka.spec.cruiseControl-
「
CruiseControlTemplateスキーマ参照」 を参照 KafkaConnect.spec-
「
KafkaConnectTemplateスキーマ参照」 を参照 KafkaConnectS2I.spec-
「
KafkaConnectTemplateスキーマ参照」 を参照 KafkaMirrorMaker.spec-
「
KafkaMirrorMakerTemplateスキーマ参照」 を参照 KafkaMirrorMaker2.spec-
「
KafkaConnectTemplateスキーマ参照」 を参照 KafkaBridge.spec-
「
KafkaBridgeTemplateスキーマ参照」 を参照 KafkaUser.spec-
「
KafkaUserTemplateスキーマ参照」 を参照
以下の例では、template プロパティーを使用して Kafka ブローカーの StatefulSet のラベルを変更します。
テンプレートのカスタマイズ例
apiVersion: kafka.strimzi.io/v1beta2
kind: Kafka
metadata:
name: my-cluster
labels:
app: my-cluster
spec:
kafka:
# ...
template:
statefulset:
metadata:
labels:
mylabel: myvalue
# ...2.6.1. イメージプルポリシーのカスタマイズ
AMQ Streams では、Cluster Operator によってデプロイされたすべての Pod のコンテナーのイメージプルポリシーをカスタマイズできます。イメージプルポリシーは、Cluster Operator デプロイメントの環境変数 STRIMZI_IMAGE_PULL_POLICY を使用して設定されます。STRIMZI_IMAGE_PULL_POLICY 環境変数に設定できる値は 3 つあります。
Always- Pod が起動または再起動されるたびにコンテナーイメージがレジストリーからプルされます。
IfNotPresent- 以前プルされたことのないコンテナーイメージのみがレジストリーからプルされます。
Never- コンテナーイメージはレジストリーからプルされることはありません。
現在、イメージプルポリシーはすべての Kafka、Kafka Connect、および Kafka MirrorMaker クラスターに対してのみ 1 度にカスタマイズできます。ポリシーを変更すると、すべての Kafka、Kafka Connect、および Kafka MirrorMaker クラスターのローリングアップデートが実行されます。
その他のリソース
- Cluster Operator の設定に関する詳細は、「Cluster Operator の使用」 を参照してください。
- イメージプルポリシーに関する詳細は、「Disruptions」を参照してください。
2.7. Pod スケジューリングの設定
2 つのアプリケーションが同じ OpenShift ノードにスケジュールされた場合、両方のアプリケーションがディスク I/O のように同じリソースを使用し、パフォーマンスに影響する可能性があります。これにより、パフォーマンスが低下する可能性があります。ノードを他の重要なワークロードと共有しないように Kafka Pod をスケジュールする場合、適切なノードを使用したり、Kafka 専用のノードのセットを使用すると、このような問題を適切に回避できます。
2.7.1. アフィニティー、容認 (Toleration)、およびトポロジー分散制約の指定
アフィニティー、容認 (Toleration)、およびトポロジー分散制約を使用して、kafka リソースの Pod をノードにスケジュールします。アフィニティー、容認 (Toleration)、およびトポロジー分散制約は、以下のリソースの affinity、tolerations、および topologySpreadConstraint プロパティーを使用して設定されます。
-
Kafka.spec.kafka.template.pod -
Kafka.spec.zookeeper.template.pod -
Kafka.spec.entityOperator.template.pod -
KafkaConnect.spec.template.pod -
KafkaConnectS2I.spec.template.pod -
KafkaBridge.spec.template.pod -
KafkaMirrorMaker.spec.template.pod -
KafkaMirrorMaker2.spec.template.pod
affinity、tolerations、および topologySpreadConstraint プロパティーの形式は、OpenShift の仕様に準拠します。アフィニティー設定には、さまざまなタイプのアフィニティーを含めることができます。
- Pod のアフィニティーおよび非アフィニティー
- ノードのアフィニティー
OpenShift 1.16 および 1.17 では、topologySpreadConstraint のサポートはデフォルトで無効になっています。topologySpreadConstraint を使用するには、Kubernetes API サーバーおよびスケジューラーで EvenPodsSpread フィーチャーゲートを有効にする必要があります。
その他のリソース
2.7.1.1. Pod の非アフィニティーを使用して重要なアプリケーションがノードを共有しないようにする
Pod の非アフィニティーを使用して、重要なアプリケーションが同じディスクにスケジュールされないようにします。Kafka クラスターの実行時に、Pod の非アフィニティーを使用して、Kafka ブローカーがデータベースなどの他のワークロードとノードを共有しないようにすることが推奨されます。
2.7.1.2. ノードのアフィニティーを使用したワークロードの特定ノードへのスケジュール
OpenShift クラスターは、通常多くの異なるタイプのワーカーノードで構成されます。ワークロードが非常に大きい環境の CPU に対して最適化されたものもあれば、メモリー、ストレージ (高速のローカル SSD)、または ネットワークに対して最適化されたものもあります。異なるノードを使用すると、コストとパフォーマンスの両面で最適化しやすくなります。最適なパフォーマンスを実現するには、AMQ Streams コンポーネントのスケジューリングで適切なノードを使用できるようにすることが重要です。
OpenShift はノードのアフィニティーを使用してワークロードを特定のノードにスケジュールします。ノードのアフィニティーにより、Pod がスケジュールされるノードにスケジューリングの制約を作成できます。制約はラベルセレクターとして指定されます。beta.kubernetes.io/instance-type などの組み込みノードラベルまたはカスタムラベルのいずれかを使用してラベルを指定すると、適切なノードを選択できます。
2.7.1.3. 専用ノードへのノードのアフィニティーと容認 (Toleration) の使用
テイントを使用して専用ノードを作成し、ノードのアフィニティーおよび容認 (Toleration) を設定して専用ノードに Kafka Pod をスケジュールします。
クラスター管理者は、選択した OpenShift ノードをテイントとしてマーク付けできます。テイントのあるノードは、通常のスケジューリングから除外され、通常の Pod はそれらのノードでの実行はスケジュールされません。ノードに設定されたテイントを許容できるサービスのみをスケジュールできます。このようなノードで実行されるその他のサービスは、ログコレクターやソフトウェア定義のネットワークなどのシステムサービスのみです。
専用のノードで Kafka とそのコンポーネントを実行する利点は多くあります。障害の原因になったり、Kafka に必要なリソースを消費するその他のアプリケーションが同じノードで実行されません。これにより、パフォーマンスと安定性が向上します。
2.7.2. Kafka コンポーネントでの Pod の非アフィニティーの設定
前提条件
- OpenShift クラスター。
- 稼働中の Cluster Operator。
手順
クラスターデプロイメントを指定するリソースの
affinityプロパティーを編集します。ラベルを使用して、同じノードでスケジュールすべきでない Pod を指定します。topologyKeyをkubernetes.io/hostnameに設定し、選択した Pod が同じホスト名のノードでスケジュールされてはならないことを指定する必要があります。以下に例を示します。apiVersion: kafka.strimzi.io/v1beta2 kind: Kafka spec: kafka: # ... template: pod: affinity: podAntiAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: application operator: In values: - postgresql - mongodb topologyKey: "kubernetes.io/hostname" # ... zookeeper: # ...リソースを作成または更新します。
oc applyを使用してこれを行うことができます。oc apply -f KAFKA-CONFIG-FILE
2.7.3. Kafka コンポーネントでのノードのアフィニティーの設定
前提条件
- OpenShift クラスター。
- 稼働中の Cluster Operator。
手順
AMQ Streams コンポーネントをスケジュールする必要のあるノードにラベルを付けます。
oc labelを使用してこれを行うことができます。oc label node NAME-OF-NODE node-type=fast-networkまたは、既存のラベルによっては再利用が可能です。
クラスターデプロイメントを指定するリソースの
affinityプロパティーを編集します。以下に例を示します。apiVersion: kafka.strimzi.io/v1beta2 kind: Kafka spec: kafka: # ... template: pod: affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: node-type operator: In values: - fast-network # ... zookeeper: # ...リソースを作成または更新します。
oc applyを使用してこれを行うことができます。oc apply -f KAFKA-CONFIG-FILE
2.7.4. 専用ノードの設定と Pod のスケジューリング
前提条件
- OpenShift クラスター。
- 稼働中の Cluster Operator。
手順
- 専用ノードとして使用するノードを選択します。
- これらのノードにスケジュールされているワークロードがないことを確認します。
選択したノードにテイントを設定します。
oc adm taintを使用してこれを行うことができます。oc adm taint node NAME-OF-NODE dedicated=Kafka:NoScheduleさらに、選択したノードにラベルも追加します。
oc labelを使用してこれを行うことができます。oc label node NAME-OF-NODE dedicated=Kafkaクラスターデプロイメントを指定するリソースの
affinityおよびtolerationsプロパティーを編集します。以下に例を示します。
apiVersion: kafka.strimzi.io/v1beta2 kind: Kafka spec: kafka: # ... template: pod: tolerations: - key: "dedicated" operator: "Equal" value: "Kafka" effect: "NoSchedule" affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: dedicated operator: In values: - Kafka # ... zookeeper: # ...リソースを作成または更新します。
oc applyを使用してこれを行うことができます。oc apply -f KAFKA-CONFIG-FILE
2.8. 外部ロギング
リソースのロギングレベルを設定する場合、リソース YAML の spec.logging プロパティーで直接 インライン で指定できます。
spec:
# ...
logging:
type: inline
loggers:
kafka.root.logger.level: "INFO"または external ロギングを指定することもできます。
spec:
# ...
logging:
type: external
valueFrom:
configMapKeyRef:
name: customConfigMap
key: keyInConfigMap
外部ロギングでは、ロギングプロパティーは ConfigMap に定義されます。ConfigMap の名前は spec.logging.valueFrom.configMapKeyRef.name プロパティーで参照されます。spec.logging.valueFrom.configMapKeyRef.name および spec.logging.valueFrom.configMapKeyRef.key プロパティーは必須です。name または key が設定されていない場合、デフォルトのロギングが使用されます。
ConfigMap を使用する利点は、ロギングプロパティーが 1 カ所で維持され、複数のリソースにアクセスできることです。
2.8.1. ロギングの ConfigMap の作成
ConfigMap を使用してロギングプロパティーを定義するには、ConfigMap を作成してから、リソースの spec にあるロギング定義の一部としてそれを参照します。
ConfigMap には適切なロギング設定が含まれる必要があります。
-
Kafka コンポーネント、ZooKeeper、および Kafka Bridge の
log4j.properties。 -
Topic Operator および User Operator の
log4j2.properties。
設定はこれらのプロパティーの配下に配置する必要があります。
ここでは、ConfigMap によって Kafka リソースのルートロガーが定義される方法を実証します。
手順
ConfigMap を作成します。
ConfigMap を YAML ファイルとして作成するか、コマンドラインで
ocを使用してプロパティーファイルから Config Map を作成します。Kafka のルートロガー定義が含まれる ConfigMap の例:
kind: ConfigMap apiVersion: kafka.strimzi.io/v1beta2 metadata: name: logging-configmap data: log4j.properties: kafka.root.logger.level="INFO"プロパティーファイルを使用してコマンドラインから作成します。
oc create configmap logging-configmap --from-file=log4j.propertiesプロパティーファイルではロギング設定が定義されます。
# Define the logger kafka.root.logger.level="INFO" # ...logging.valueFrom.configMapKeyRef.nameを ConfigMap の名前に設定し、logging.valueFrom.configMapKeyRef.keyをこの ConfigMap のキーに設定し、リソースのspecで 外部 ロギングを定義します。spec: # ... logging: type: external valueFrom: configMapKeyRef: name: customConfigMap key: keyInConfigMapリソースを作成または更新します。
oc apply -f kafka.yaml