第1章 AMQ Streams の概要
AMQ Streams は、OpenShift クラスターで Apache Kafka を実行するプロセスを簡素化します。
本ガイドでは、Kafka コンポーネントの設定方法と、AMQ Streams Operator の使用方法を説明します。手順は、デプロイメントの変更方法や、Cruise Control や分散トレーシングなどの追加機能を導入する方法に関連しています。
AMQ Streams カスタムリソース を使用して、デプロイメントを設定できます。カスタムリソース API リファレンス は、設定で使用できるプロパティーを説明します。
AMQ Streams を使用する方法ステップごとのデプロイメント手順は、『 OpenShift での AMQ Streams のデプロイおよびアップグレード』を参照してください。
1.1. Kafka の機能
Kafka の基盤のデータストリーム処理機能とコンポーネントアーキテクチャーによって以下が提供されます。
- スループットが非常に高く、レイテンシーが低い状態でデータを共有するマイクロサービスおよびその他のアプリケーション。
- メッセージの順序の保証。
- アプリケーションの状態を再構築するためにデータストレージからメッセージを巻き戻し/再生。
- キーバリューログの使用時に古いレコードを削除するメッセージ圧縮。
- クラスター設定での水平スケーラビリティー。
- 耐障害性を制御するデータのレプリケーション。
- 即座にアクセスするために大容量のデータを保持。
1.2. Kafka のユースケース
Kafka の機能は、以下に適しています。
- イベント駆動型のアーキテクチャー。
- アプリケーションの状態変更をイベントのログとしてキャプチャーするイベントソーシング。
- メッセージのブローカー。
- Web サイトアクティビティーの追跡。
- メトリクスによるオペレーションの監視。
- ログの収集および集計。
- 分散システムのログのコミット。
- アプリケーションがリアルタイムでデータに対応できるようにするストリーム処理。
1.3. AMQ Streams による Kafka のサポート
AMQ Streams は、Kafka を OpenShift で実行するためのコンテナーイメージおよび Operator を提供します。AMQ Streams Operator は、AMQ Streams の実行に必要です。AMQ Streams で提供される Operator は、Kafka を効果的に管理するために、専門的なオペレーション情報で目的に合うよう構築されています。
Operator は以下のプロセスを単純化します。
- Kafka クラスターのデプロイおよび実行。
- Kafka コンポーネントのデプロイおよび実行。
- Kafka へアクセスするための設定。
- Kafka へのアクセスをセキュア化。
- Kafka のアップグレード。
- ブローカーの管理。
- トピックの作成および管理。
- ユーザーの作成および管理。
1.4. AMQ Streams の Operator
AMQ Streams では Operator を使用して Kafka をサポートし、Kafka のコンポーネントおよび依存関係を OpenShift にデプロイして管理します。
Operator は、OpenShift アプリケーションのパッケージ化、デプロイメント、および管理を行う方法です。AMQ Streams Operator は OpenShift の機能を拡張し、Kafka デプロイメントに関連する共通タスクや複雑なタスクを自動化します。Kafka 操作の情報をコードに実装することで、Kafka の管理タスクは簡素化され、必要な手動の作業が少なくなります。
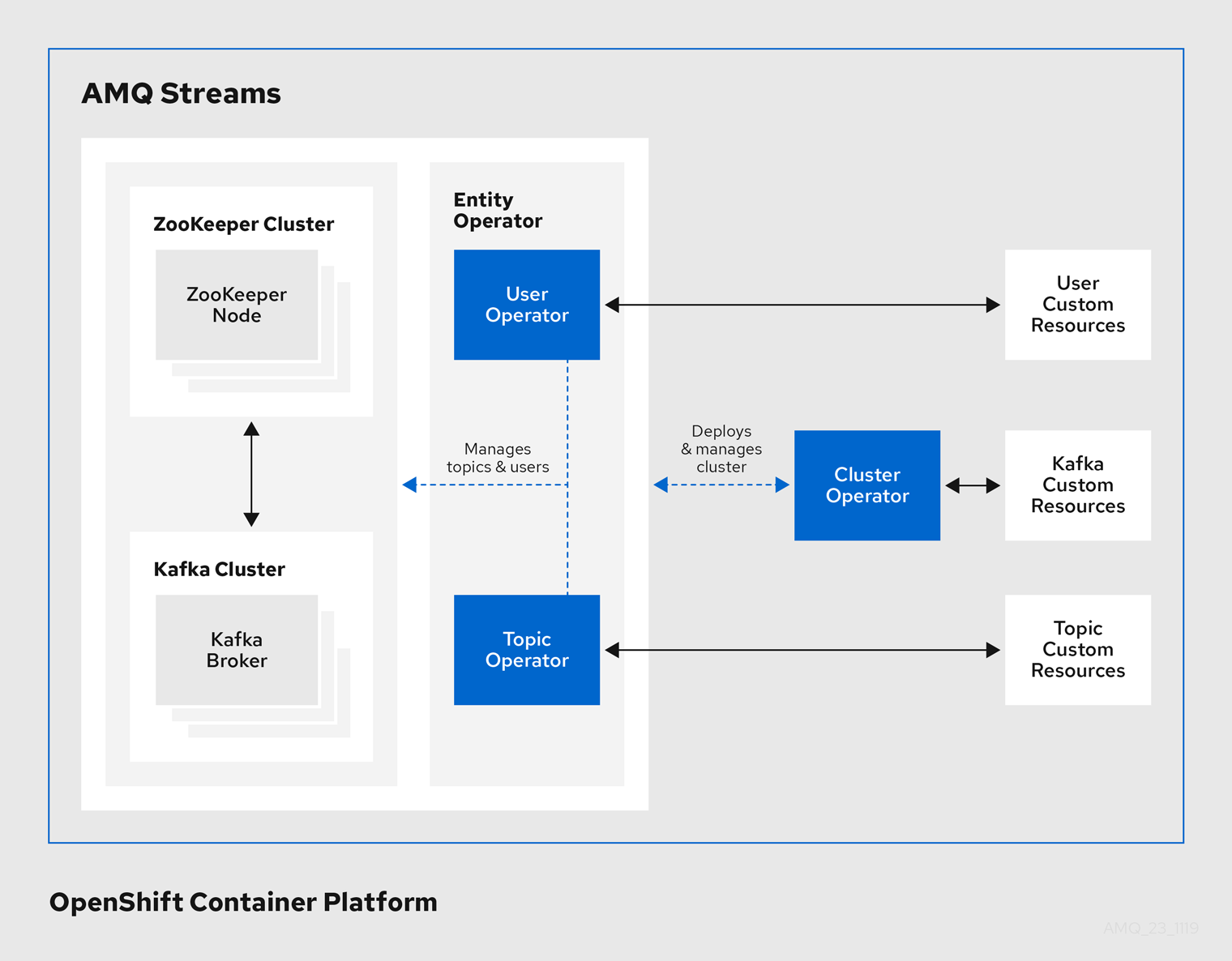
Operator
AMQ Streams は、OpenShift クラスター内で実行中の Kafka クラスターを管理するための Operator を提供します。
- Cluster Operator
- Apache Kafka クラスター、Kafka Connect、Kafka MirrorMaker、Kafka Bridge、Kafka Exporter、および Entity Operator をデプロイおよび管理します。
- Entitiy Operator
- Topic Operator および User Operator を構成します。
- Topic Operator
- Kafka トピックを管理します。
- User Operator
- Kafka ユーザーを管理します。
Cluster Operator は、Kafka クラスターと同時に、Topic Operator および User Operator を Entity Operator 設定の一部としてデプロイできます。
AMQ Streams アーキテクチャー内の Operator
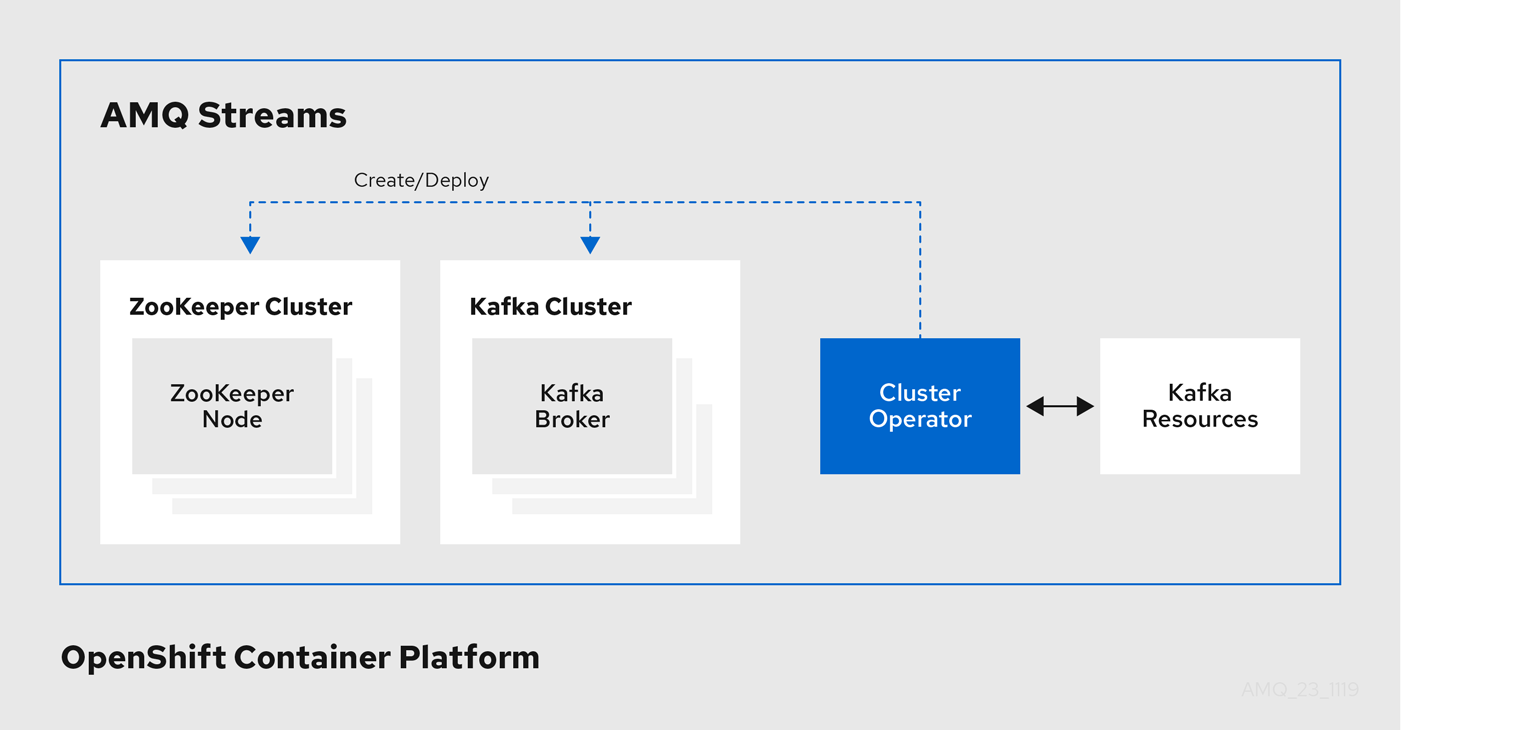
1.4.1. Cluster Operator
AMQ Streams では、Cluster Operator を使用して以下のクラスターをデプロイおよび管理します。
- Kafka (ZooKeeper、Entity Operator、Kafka Exporter、Cruise Control を含む)
- Kafka Connect
- Kafka MirrorMaker
- Kafka Bridge
クラスターのデプロイメントにはカスタムリソースが使用されます。
たとえば、以下のように Kafka クラスターをデプロイします。
-
クラスター設定のある
Kafkaリソースが OpenShift クラスター内で作成されます。 -
Kafkaリソースに宣言された内容を基にして、該当する Kafka クラスターが Cluster Operator によってデプロイされます。
Cluster Operator で以下もデプロイできます (Kafka リソースの設定より)。
-
KafkaTopicカスタムリソースより Operator スタイルのトピック管理を提供する Topic Operator -
KafkaUserカスタムリソースより Operator スタイルのユーザー管理を提供する User Operator
デプロイメントの Entity Operator 内の Topic Operator および User Operator 関数。
Cluster Operator のアーキテクチャー例
1.4.2. Topic Operator
Topic Operator は、OpenShift リソースより Kafka クラスターのトピックを管理する方法を提供します。
Topic Operator のアーキテクチャー例
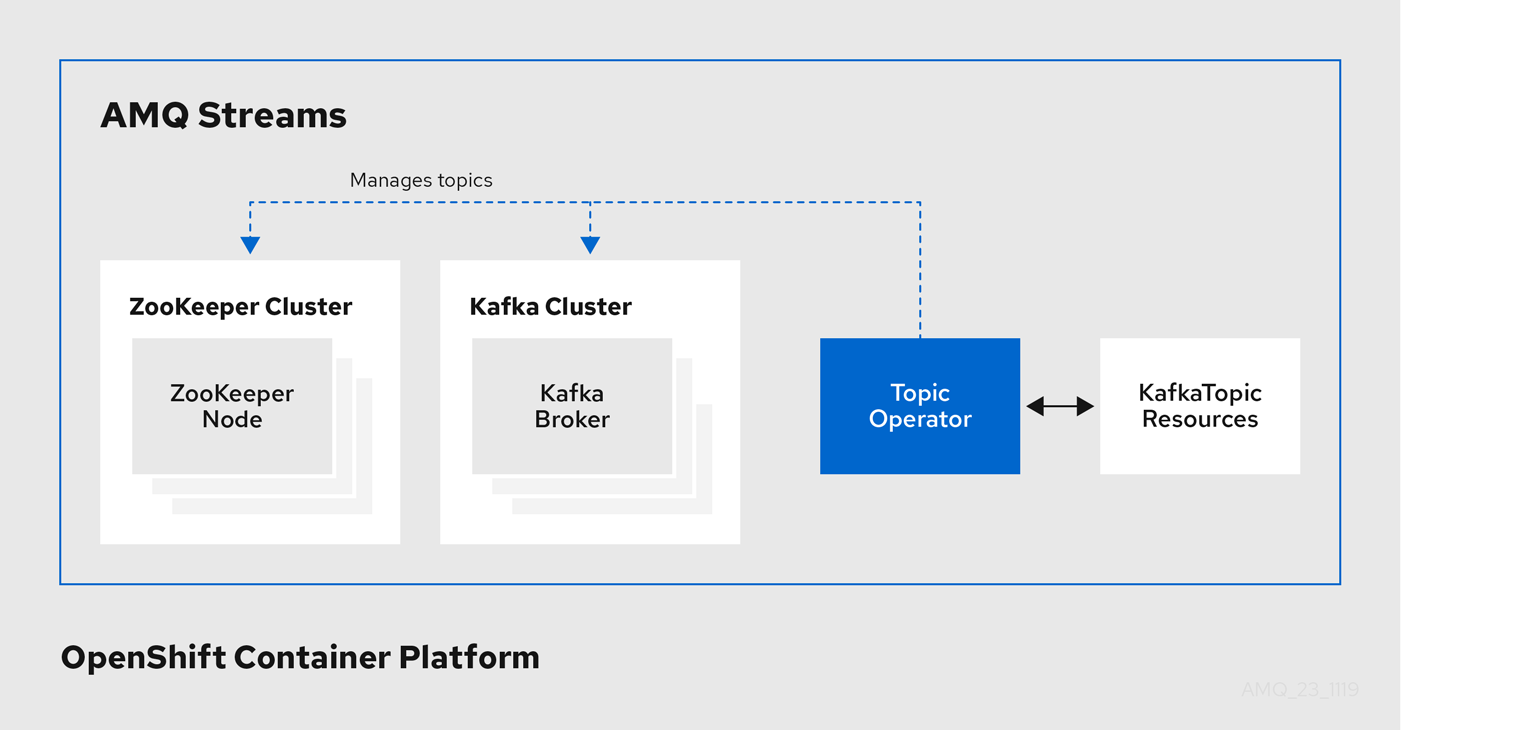
Topic Operator の役割は、対応する Kafka トピックと同期して Kafka トピックを記述する KafkaTopic OpenShift リソースのセットを保持することです。
KafkaTopic とトピックの関係は次のとおりです。
-
KafkaTopicが作成されると、Topic Operator によってトピックが作成されます。 -
KafkaTopicが削除されると、Topic Operator によってトピックが削除されます。 -
KafkaTopicが変更されると、Topick Operator によってトピックが更新されます。
上記と逆になるトピックと KafkaTopic の関係は次のとおりです。
-
トピックが Kafka クラスター内で作成されると、Operator によって
KafkaTopicが作成されます。 -
トピックが Kafka クラスターから削除されると、Operator によって
KafkaTopicが削除されます。 -
トピックが Kafka クラスターで変更されると、Operator によって
KafkaTopicが更新されます。
このため、KafkaTopic をアプリケーションのデプロイメントの一部として宣言でき、トピックの作成は Topic Operator によって行われます。アプリケーションは、必要なトピックからの作成または消費のみに対処する必要があります。
Topic Operator は、各トピックの情報を トピックストア で維持します。トピックストアは、Kafka トピックまたは OpenShift KafkaTopic カスタムリソースからの更新と継続的に同期されます。ローカルのインメモリートピックストアに適用される操作からの更新は、ディスク上のバックアップトピックストアに永続化されます。トピックが再設定されたり、別のブローカーに再割り当てされた場合、KafkaTopic は常に最新の状態になります。
1.4.3. User Operator
User Operator は、Kafka ユーザーが記述される KafkaUser リソースを監視して Kafka クラスターの Kafka ユーザーを管理し、Kafka ユーザーが Kafka クラスターで適切に設定されるようにします。
たとえば、KafkaUser とユーザーの関係は次のようになります。
-
KafkaUserが作成されると、User Operator によって記述されるユーザーが作成されます。 -
KafkaUserが削除されると、User Operator によって記述されるユーザーが削除されます。 -
KafkaUserが変更されると、User Operator によって記述されるユーザーが更新されます。
User Operator は Topic Operator とは異なり、Kafka クラスターからの変更は OpenShift リソースと同期されません。アプリケーションで直接 Kafka トピックを Kafka で作成することは可能ですが、ユーザーが User Operator と同時に直接 Kafka クラスターで管理されることは想定されません。
User Operator では、アプリケーションのデプロイメントの一部として KafkaUser リソースを宣言できます。ユーザーの認証および承認メカニズムを指定できます。たとえば、ユーザーがブローカーへのアクセスを独占しないようにするため、Kafka リソースの使用を制御する ユーザークォータ を設定することもできます。
ユーザーが作成されると、ユーザークレデンシャルが Secret に作成されます。アプリケーションはユーザーとそのクレデンシャルを使用して、認証やメッセージの生成または消費を行う必要があります。
User Operator は 認証のクレデンシャルを管理する他に、KafkaUser 宣言にユーザーのアクセス権限の記述を含めることで承認も管理します。
1.5. AMQ Streams のカスタムリソース
AMQ Streams を使用した Kafka コンポーネントの OpenShift クラスターへのデプロイメントは、カスタムリソースの適用により高度な設定が可能です。カスタムリソースは、OpenShift リソースを拡張するために CRD (カスタムリソース定義、Custom Resource Definition) によって追加される API のインスタンスとして作成されます。
CRD は、OpenShift クラスターでカスタムリソースを記述するための設定手順として機能し、デプロイメントで使用する Kafka コンポーネントごとに AMQ Streams で提供されます。CRD およびカスタムリソースは YAML ファイルとして定義されます。YAML ファイルのサンプルは AMQ Streams ディストリビューションに同梱されています。
また、CRD を使用すると、CLI へのアクセスや設定検証などのネイティブ OpenShift 機能を AMQ Streams リソースで活用することもできます。
1.5.1. AMQ Streams カスタムリソースの例
AMQ Streams 固有リソースのインスタンス化および管理に使用されるスキーマを定義するため、CRD をクラスターに 1 度インストールする必要があります。
CRD をインストールして新規カスタムリソースタイプをクラスターに追加した後に、その仕様に基づいてリソースのインスタンスを作成できます。
クラスターの設定によりますが、インストールには通常、クラスター管理者権限が必要です。
カスタムリソースの管理は、AMQ Streams 管理者のみが行えます。詳細は、『OpenShift での AMQ Streams のデプロイおよびアップグレード』の「AMQ Streams の管理者の指名」を参照してください。
kind:Kafka などの新しい kind リソースは、OpenShift クラスター内で CRD によって定義されます。
Kubernetes API サーバーを使用すると、kind を基にしたカスタムリソースの作成が可能になり、カスタムリソースが OpenShift クラスターに追加されたときにカスタムリソースの検証および格納方法を CRD から判断します。
CRD が削除されると、そのタイプのカスタムタイプも削除されます。さらに、Pod や Statefulset などのカスタムリソースによって作成されたリソースも削除されます。
AMQ Streams 固有の各カスタムリソースは、リソースの kind の CRD によって定義されるスキーマに準拠します。AMQ Streams コンポーネントのカスタムリソースには、specで定義される共通の設定プロパティーがあります。
CRD とカスタムリソースの関係を理解するため、Kafka トピックの CRD の例を見てみましょう。
Kafka トピックの CRD
apiVersion: kafka.strimzi.io/v1beta2
kind: CustomResourceDefinition
metadata:
name: kafkatopics.kafka.strimzi.io
labels:
app: strimzi
spec:
group: kafka.strimzi.io
versions:
v1beta2
scope: Namespaced
names:
# ...
singular: kafkatopic
plural: kafkatopics
shortNames:
- kt
additionalPrinterColumns:
# ...
subresources:
status: {}
validation:
openAPIV3Schema:
properties:
spec:
type: object
properties:
partitions:
type: integer
minimum: 1
replicas:
type: integer
minimum: 1
maximum: 32767
# ...- 1
- CRD を識別するためのトピック CRD、その名前および名前のメタデータ。
- 2
- この CRD に指定された項目には、トピックの API にアクセスするため URL に使用されるグルShortNameープ (ドメイン) 名、複数名、およびサポートされるスキーマバージョンが含まれます。他の名前は、CLI のインスタンスリソースを識別するために使用されます。例:
oc get kafkatopic my-topicまたはoc get kafkatopics - 3
- ShortName は CLI コマンドで使用できます。たとえば、
oc get kafkatopicの代わりにoc get ktを略名として使用できます。 - 4
- カスタムリソースで
getコマンドを使用する場合に示される情報。 - 5
- リソースの スキーマ参照 に記載されている CRD の現在のステータス。
- 6
- openAPIV3Schema 検証によって、トピックカスタムリソースの作成が検証されます。たとえば、トピックには 1 つ以上のパーティションと 1 つのレプリカが必要です。
ファイル名に、インデックス番号とそれに続く「Crd」が含まれるため、AMQ Streams インストールファイルと提供される CRD YAML ファイルを識別できます。
KafkaTopic カスタムリソースに該当する例は次のとおりです。
Kafka トピックカスタムリソース
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaTopic
metadata:
name: my-topic
labels:
strimzi.io/cluster: my-cluster
spec:
partitions: 1
replicas: 1
config:
retention.ms: 7200000
segment.bytes: 1073741824
status:
conditions:
lastTransitionTime: "2019-08-20T11:37:00.706Z"
status: "True"
type: Ready
observedGeneration: 1
/ ...- 1
kindおよびapiVersionによって、インスタンスであるカスタムリソースの CRD が特定されます。- 2
- トピックまたはユーザーが属する Kafka クラスターの名前 (
Kafkaリソースの名前と同じ) を定義する、KafkaTopicおよびKafkaUserリソースのみに適用可能なラベル。 - 3
- 指定内容には、トピックのパーティション数およびレプリカ数や、トピック自体の設定パラメーターが示されています。この例では、メッセージがトピックに保持される期間や、ログのセグメントファイルサイズが指定されています。
- 4
KafkaTopicリソースのステータス条件。lastTransitionTimeでtype条件がReadyに変更されています。
プラットフォーム CLI からカスタムリソースをクラスターに適用できます。カスタムリソースが作成されると、Kubernetes API の組み込みリソースと同じ検証が使用されます。
KafkaTopic の作成後、Topic Operator は通知を受け取り、該当する Kafka トピックが AMQ Streams で作成されます。
1.6. リスナーの設定
リスナーは、Kafka ブローカーへの接続に使用されます。
AMQ Streams は、Kafka リソース経由でリスナーを設定するプロパティーと汎用 GenericKafkaListener スキーマを提供します。
GenericKafkaListener は、柔軟なリスナー設定を実現します。
プロパティーを指定して、OpenShift クラスター内で接続する 内部 リスナーを設定したり、OpenShift クラスター外部で接続する外部 リスナーを設定したりできます。
汎用リスナーの設定
各リスナーは、Kafka リソースの配列として定義されます。
リスナーの設定に関する詳細は、「GenericKafkaListener スキーマ参照」を参照してください。
汎用リスナー設定は、非推奨 である KafkaListeners スキーマ参照 を使用した従来のリスナー設定の代わりに使用します。ただし、後方互換性によって、以前の形式を新しい形式に変換 することができます。
KafkaListeners スキーマは plain、tls、および external リスナーのサブプロパティーを使用し、それぞれに固定ポートを使用します。スキーマのアーキテクチャー固有の制限により、3 つのリスナーのみを設定でき、設定オプションはリスナーのタイプに制限されます。
GenericKafkaListener スキーマでは、名前とポートが一意であれば、必要なリスナーをいくつでも設定できます。
たとえば、異なる認証メカニズムを必要とするネットワークからのアクセスを処理する場合などに、複数の外部リスナーを設定することがあります。また、OpenShift ネットワークを外部ネットワークに参加させる必要があることがあります。この場合、OpenShift サービスの DNS ドメイン (通常は .cluster.local) が使用されないように、useServiceDnsDomain プロパティーを使用して内部リスナーを設定できます。
Kafka ブローカーへのアクセスをセキュアにするためのリスナー設定
リスナーを設定して、認証を使用したセキュアな接続を確立できます。Kafka ブローカーへのアクセスをセキュアにするための詳細は、「Kafka へのアクセス管理」を参照してください。
OpenShift 外部のクライアントアクセスに対する外部リスナーの設定
ロードバランサーなどの指定された接続メカニズムを使用して、OpenShift 環境外部のクライアントアクセスに対して外部リスナーを設定できます。外部クライアントを接続するための設定オプションの詳細は、「外部リスナーの設定」を参照してください。
リスナー証明書
TLS 暗号化が有効になっている TLS リスナーまたは外部リスナーの、Kafka リスナー証明書 と呼ばれる独自のサーバー証明書を提供できます。詳細は「Kafka リスナー証明書」を参照してください。
1.7. 本書の表記慣例
置き換え可能なテキスト
本書では、置き換え可能なテキストは、monospace フォントのイタリック体、大文字、およびハイフンで記載されています。
たとえば、以下のコードでは MY-NAMESPACE を namespace の名前に置き換えます。
sed -i 's/namespace: .*/namespace: MY-NAMESPACE/' install/cluster-operator/*RoleBinding*.yaml