第10章 メトリクスの概要
このセクションでは、Prometheus を使用して AMQ Streams Kafka、Zookeeper、および Kafka Connect クラスターを監視し、Grafana ダッシュボードなどのモニタリングデータを提供する方法について説明します。
Prometheus サーバーは、AMQ Streams ディストリビューションの一部としてサポートされません。しかし、メトリクスを公開するために使用される Prometheus エンドポイントと JMX エクスポーターはサポートされます。監視のために Prometheus を AMQ Streams で使用する場合、手順とメトリクス設定ファイルのサンプルが提供されます。
Grafana ダッシュボードのサンプルを実行するには、以下を行う必要があります。
このセクションで参照されるリソースは、まず監視を設定することを目的としており、これらはサンプルとしてのみ提供されます。実稼働環境で Prometheus または Grafana を設定、実行するためにサポートがさらに必要な場合は、それぞれのコミュニティーに連絡してください。
その他のリソース
- Prometheus の詳細は、Prometheus のドキュメントを参照してください。
- Grafana の詳細は、Grafana のドキュメントを参照してください。
- Apache Kafka Monitoring では、Apache Kafka により公開される JMX メトリクスについて解説しています。
- ZooKeeper JMX では、Apache Zookeeper により公開される JMX メトリックについて解説しています。
10.1. メトリクスファイルの例
メトリクス設定のサンプルファイルは、examples/metrics ディレクトリーにあります。
metrics
├── grafana-install
│ ├── grafana.yaml
├── grafana-dashboards
│ ├── strimzi-kafka-connect.json
│ ├── strimzi-kafka.json
│ └── strimzi-zookeeper.json
│ └── strimzi-kafka-exporter.json
├── kafka-connect-metrics.yaml
├── kafka-metrics.yaml
├── prometheus-additional-properties
│ └── prometheus-additional.yaml
├── prometheus-alertmanager-config
│ └── alert-manager-config.yaml
└── prometheus-install
├── alert-manager.yaml
├── prometheus-rules.yaml
├── prometheus.yaml
└── strimzi-service-monitor.yaml - 1
- Grafana イメージのインストールファイル。
- 2
- Grafana ダッシュボードの設定。
- 3
- Kafka Exporter に固有の Grafana ダッシュボード設定。
- 4
- Kafka Connect に対する Prometheus JMX Exporter の再ラベル付けルールを定義するメトリクス設定。
- 5
- Kafka および ZooKeeper に対する Prometheus JMX Exporter の再ラベル付けルールを定義するメトリクス設定。
- 6
- サービス監視のロールを追加する設定。
- 7
- Alertmanager による通知送信のためのフック定義。
- 8
- Alertmanager をデプロイおよび設定するためのリソース。
- 9
- Prometheus Alertmanager と使用するアラートルールの例 (Prometheus とデプロイ)。
- 10
- Prometheus イメージのインストールファイル。
- 11
- メトリクスデータをスクレープする Prometheus ジョブ定義。
10.2. Prometheus メトリクス
AMQ Streams は、Prometheus JMX Exporter を使用して、HTTP エンドポイントを使用する Kafka および ZooKeeper から JMX メトリクスを公開し、さらにメトリクスは Prometheus サーバーによってスクレープされます。
10.2.1. Prometheus メトリクスの設定
AMQ Streams には、Grafana の設定ファイルのサンプルが含まれています。
Grafana ダッシュボードは、以下に対して定義される Prometheus JMX Exporter の再ラベル付けルールに依存します。
-
kafka-metrics.yamlサンプルファイルで、Kafkaリソース設定とする Kafka および ZooKeeper。 -
サンプル
kafka-connect-metrics.yamlファイルで、KafkaConnectおよびKafkaConnectS2Iリソースとする Kafka Connect。
ラベルは名前と値のペアです。再ラベル付けは、ラベルを動的に書き込むプロセスです。たとえば、ラベルの値は Kafka サーバーおよびクライアント ID の名前から派生されます。
このセクションでは、kafka-metrics.yaml を使用してメトリクス設定を説明しますが、このプロセスは kafka-connect-metrics.yaml ファイルを使用して Kafka Connect を設定する場合と同じです。
その他のリソース
再ラベル付けの使用方法の詳細は、Prometheus ドキュメントの「Configuration」を参照してください。
10.2.2. Prometheus メトリクスのデプロイメントオプション
再ラベル付けルールのメトリクス設定例を Kafka クラスターに適用するには、以下のいずれかを行います。
10.2.3. Prometheus メトリクス設定の Kafka リソースへのコピー
Grafana ダッシュボードを監視に使用するには、メトリクス設定サンプルを Kafka リソースにコピーします。
手順
デプロイメントの Kafka リソースごとに以下の手順を実行します。
エディターで
Kafkaリソースを更新します。oc edit kafka my-cluster-
kafka-metrics.yamlの設定例を、ユーザーのKafkaリソース定義にコピーします。 - ファイルを保存し、エディターを終了して更新したリソースが調整されるのを待ちます。
10.2.4. Prometheus メトリクス設定での Kafka クラスターのデプロイメント
Grafana ダッシュボードを監視に使用するには、メトリクス設定でサンプル Kafka クラスターをデプロイできます。
手順
メトリクス設定で Kafka クラスターをデプロイします。
oc apply -f kafka-metrics.yaml
10.3. Prometheus
Prometheus では、システム監視とアラート通知のオープンソースのコンポーネントセットが提供されます。
ここでは、CoreOS Prometheus Operator を使用して、実稼働環境での使用に適している Prometheus サーバーを実行および管理する方法を説明します。正しい設定を使用すれば、すべての Prometheus サーバーを実行できます。
Prometheus サーバーの設定では、サービス検出を使用して、メトリクス取得元のクラスター内にある Pod を検出します。この機能が正しく機能するには、Prometheus サービス Pod の稼働に使用されるサービスアカウントで API サーバーにアクセスし、Pod リストを取得できる必要があります。
詳細は、「Discovering services」を参照してください。
10.3.1. Prometheus の設定
AMQ Streams では、Prometheus サーバーの設定ファイルのサンプル が提供されます。
デプロイメント用に Prometheus イメージが提供されます。
-
prometheus.yaml
Prometheus 関連の追加設定も、以下のファイルに含まれています。
-
prometheus-additional.yaml -
prometheus-rules.yaml -
strimzi-service-monitor.yaml
Prometheus で監視データを取得するには以下を行います。
次に、設定ファイルを使用して以下を行います。
アラートルール
prometheus-rules.yaml ファイルには、Alertmanager で使用するアラートルールのサンプルが含まれています。
10.3.2. Prometheus リソース
Prometheus 設定を適用すると、以下のリソースが OpenShift クラスターに作成され、Prometheus Operator によって管理されます。
-
ClusterRole。コンテナーメトリクスのために Kafka と ZooKeeper の Pod、cAdvisor および kubelet によって公開される health エンドポイントを読み取る権限を Prometheus に付与します。 -
ServiceAccount。これで Prometheus Pod が実行されます。 -
ClusterRoleBinding。ClusterRoleをServiceAccountにバインドします。 -
Deployment。Prometheus Operator Pod を管理します。 -
ServiceMonitor。Prometheus Pod の設定を管理します。 -
Prometheus。Prometheus Pod の設定を管理します。 -
PrometheusRule。Prometheus Pod のアラートルールを管理します。 -
Secret。Prometheus の追加設定を管理します。 -
Service。クラスターで稼働するアプリケーションが Prometheus に接続できるようにします (例: Prometheus をデータソースとして使用する Grafana)。
10.3.3. Prometheus Operator のデプロイメント
Prometheus Operator を Kafka クラスターにデプロイするには、Prometheus CoreOS リポジトリー から YAML リソースファイルを適用します。
手順
リポジトリーからリソースファイルをダウンロードし、サンプルの
namespaceを独自の namespace に置き換えます。Linux の場合は、以下を使用します。
curl -s https://raw.githubusercontent.com/coreos/prometheus-operator/master/example/rbac/prometheus-operator/prometheus-operator-deployment.yaml | sed -e 's/namespace: .\*/namespace: my-namespace/' > prometheus-operator-deployment.yamlcurl -s https://raw.githubusercontent.com/coreos/prometheus-operator/master/example/rbac/prometheus-operator/prometheus-operator-cluster-role.yaml > prometheus-operator-cluster-role.yamlcurl -s https://raw.githubusercontent.com/coreos/prometheus-operator/master/example/rbac/prometheus-operator/prometheus-operator-cluster-role-binding.yaml | sed -e 's/namespace: .*/namespace: my-namespace/' > prometheus-operator-cluster-role-binding.yamlcurl -s https://raw.githubusercontent.com/coreos/prometheus-operator/master/example/rbac/prometheus-operator/prometheus-operator-service-account.yaml | sed -e 's/namespace: .*/namespace: my-namespace/' > prometheus-operator-service-account.yamlMacOS の場合は、以下を使用します。
curl -s https://raw.githubusercontent.com/coreos/prometheus-operator/master/example/rbac/prometheus-operator/prometheus-operator-deployment.yaml | sed -e '' 's/namespace: .\*/namespace: my-namespace/' > prometheus-operator-deployment.yamlcurl -s https://raw.githubusercontent.com/coreos/prometheus-operator/master/example/rbac/prometheus-operator/prometheus-operator-cluster-role.yaml > prometheus-operator-cluster-role.yamlcurl -s https://raw.githubusercontent.com/coreos/prometheus-operator/master/example/rbac/prometheus-operator/prometheus-operator-cluster-role-binding.yaml | sed -e '' 's/namespace: .*/namespace: my-namespace/' > prometheus-operator-cluster-role-binding.yamlcurl -s https://raw.githubusercontent.com/coreos/prometheus-operator/master/example/rbac/prometheus-operator/prometheus-operator-service-account.yaml | sed -e '' 's/namespace: .*/namespace: my-namespace/' > prometheus-operator-service-account.yaml注記これが必要ない場合は、
spec.template.spec.securityContextプロパティーをprometheus-operator-deployment.yamlファイルから手動で削除できます。Prometheus Operator をデプロイします。
oc apply -f prometheus-operator-deployment.yaml oc apply -f prometheus-operator-cluster-role.yaml oc apply -f prometheus-operator-cluster-role-binding.yaml oc apply -f prometheus-operator-service-account.yaml
10.3.4. Prometheus のデプロイメント
Prometheus を Kafka クラスターにデプロイして監視データを取得するには、Prometheus Docker イメージのリソースサンプルファイルと Prometheus 関連リソースの YAML ファイルを適用します。
デプロイメントプロセスでは、ClusterRoleBinding が作成され、デプロイメントのために指定された namespace で Alertmanager インスタンスが検出されます。
Prometheus Operator はデフォルトでは、endpoints ロールが含まれるジョブのみをサービス検出でサポートします。ターゲットは、エンドポイントのポートアドレスごとに検出およびスクレープされます。エンドポイントの検出では、ポートアドレスはサービス (role: service) または Pod (role: pod) の検出から派生する可能性があります。
前提条件
- 提供されるアラートルールのサンプルを確認します。
手順
Prometheus のインストール先となる namespace に従い、Prometheus インストールファイル (
prometheus.yaml) を変更します。Linux の場合は、以下を使用します。
sed -i 's/namespace: .*/namespace: my-namespace/' prometheus.yamlMacOS の場合は、以下を使用します。
sed -i '' 's/namespace: .*/namespace: my-namespace/' prometheus.yaml-
ServiceMonitorリソースをstrimzi-service-monitor.yamlで編集し、メトリクスデータをスクレープする Prometheus ジョブを定義します。 別のロールを使用するには、以下を実行します。
Secretリソースを作成します。oc create secret generic additional-scrape-configs --from-file=prometheus-additional.yaml-
prometheus.yamlファイルでadditionalScrapeConfigsプロパティーを編集し、Secretの名前と、追加の設定が含まれる YAML ファイル (prometheus-additional.yaml) を追加します。
Prometheus リソースをデプロイします。
oc apply -f strimzi-service-monitor.yaml oc apply -f prometheus-rules.yaml oc apply -f prometheus.yaml
10.4. Prometheus Alertmanager
Prometheus Alertmanager は、アラートを処理して通知サービスにルーティングするためのプラグインです。Alertmanager は、アラートルールを基にして潜在的な問題と見られる状態を通知し、監視で必要な条件に対応します。
10.4.1. Alertmanager の設定
AMQ Streams には、Prometheus Alertmanager の設定ファイルのサンプルが含まれます。
設定ファイルは、Alertmanager をデプロイするためのリソースを定義します。
-
alert-manager.yaml
追加の設定ファイルには、Kafka クラスターから通知を送信するためのフック定義が含まれます。
-
alert-manager-config.yaml
Alertmanger で Prometheus アラートの処理を可能にするには、設定ファイルを使用して以下を行います。
10.4.2. アラートルール
アラートルールによって、メトリクスで監視される特定条件についての通知が提供されます。ルールは Prometheus サーバーで宣言されますが、アラート通知は Prometheus Alertmanager で対応します。
Prometheus アラートルールでは、継続的に評価される PromQL 表現を使用して条件が記述されます。
アラート表現が true になると、条件が満たされ、Prometheus サーバーからアラートデータが Alertmanager に送信されます。次に Alertmanager は、そのデプロイメントに設定された通信方法を使用して通知を送信します。
Alertmanager は、電子メール、チャットメッセージなどの通知方法を使用するように設定できます。
その他のリソース
アラートルールの設定についての詳細は、Prometheus ドキュメントの「Configuration」を参照してください。
10.4.3. アラートルールの例
Kafka および ZooKeeper メトリクスのアラートルールのサンプルは AMQ Streams に含まれており、Prometheus デプロイメントで使用できます。
アラートルールの定義に関する一般的な留意点:
-
forプロパティーはルールと併用され、アラートがトリガーされる前に条件が維持されなければならない期間を決定します。 -
ティック (tick) は ZooKeeper の基本的な時間単位です。ミリ秒単位で測定され、
Kafka.spec.zookeeper.configのtickTimeパラメーターを使用して設定されます。たとえば、ZooKeeper でtickTime=3000の場合、3 ティック (3 x 3000) は 9000 ミリ秒と等しくなります。 -
ZookeeperRunningOutOfSpaceメトリクスおよびアラートを利用できるかどうかは、使用される OpenShift 設定およびストレージ実装によります。特定のプラットフォームのストレージ実装では、メトリクスによるアラートの提供に必要な利用可能な領域について情報が提供されない場合があります。
Kafka アラートルール
UnderReplicatedPartitions-
現在のブローカーがリードレプリカでありながら、パーティションのトピックに設定された
min.insync.replicasよりも複製数が少ないパーティションの数が示されます。このメトリクスにより、フォロワーレプリカをホストするブローカーの詳細が提供されます。リーダーからこれらのフォロワーへの複製が追い付いていません。その理由として、現在または過去にオフライン状態になっていたり、過剰なスロットリングが適用されたブローカー間の複製であることが考えられます。この値がゼロより大きい場合にアラートが発生し、複製の数が最低数未満であるパーティションの情報がブローカー別に通知されます。 AbnormalControllerState- 現在のブローカーがクラスターのコントローラーであるかどうかを示します。メトリクスは 0 または 1 です。クラスターのライフサイクルでは、1 つのブローカーのみかコントローラーとなるはずで、クラスターには常にアクティブなコントローラーが存在する必要があります。複数のブローカーがコントローラーであることが示される場合は問題になります。そのような状態が続くと、すべてのブローカーのこのメトリクスの合計値が 1 でない場合にアラートが発生します。合計値が 0 であればアクティブなコントローラーがなく、合計値が 1 を超えればコントローラーが複数あることを意味します。
UnderMinIsrPartitionCount-
書き込み操作の完了を通知しなければならないリード Kafka ブローカーの ISR (In-Sync レプリカ) が最小数 (
min.insync.replicasを使用して指定) に達していないことを示します。このメトリクスでは、ブローカーがリードし、In-Sync レプリカの数が最小数に達していない、パーティションの数が定義されます。この値がゼロより大きい場合にアラートが発生し、完了通知 (ack) が最少数未満であった各ブローカーのパーティション数に関する情報が提供されます。 OfflineLogDirectoryCount- ハードウェア障害などの理由によりオフライン状態であるログディレクトリーの数を示します。そのため、ブローカーは受信メッセージを保存できません。この値がゼロより大きい場合にアラートが発生し、各ブローカーのオフライン状態であるログディレクトリーの数に関する情報が提供されます。
KafkaRunningOutOfSpace-
データの書き込みに使用できる残りのディスク容量を示します。この値が 5GiB 未満になるとアラートが発生し、永続ボリューム要求 (Persistent Volume Claim、PVC) ごとに容量不足のディスクに関する情報が提供されます。しきい値は
prometheus-rules.yamlで変更できます。
ZooKeeper アラートルール
AvgRequestLatency- サーバーがクライアントリクエストに応答するまでの時間を示します。この値が 10 (tick) を超えるとアラートが発生し、各サーバーの平均リクエストレイテンシーの実際の値が通知されます。
OutstandingRequests- サーバーでキューに置かれたリクエストの数を示します。この値は、サーバーが処理能力を超えるリクエストを受信すると上昇します。この値が 10 よりも大きい場合にアラートが発生し、各サーバーの未処理のリクエスト数が通知されます。
ZookeeperRunningOutOfSpace- このメトリクスは、ZooKeeper へのデータ書き込みに使用できる残りのディスク容量を示します。この値が 5GiB 未満になるとアラートが発生し、永続ボリューム要求 (Persistent Volume Claim、PVC) ごとに容量不足のディスクに関する情報が提供されます。
10.4.4. Alertmanager のデプロイメント
Alertmanager をデプロイするには、設定ファイルのサンプルを適用します。
AMQ Streams に含まれる設定サンプルでは、Slack チャネルに通知を送信するように Alertmanager を設定します。
デプロイメントで以下のリソースが定義されます。
-
Alertmanager。Alertmanager Pod を管理します。 -
Secret。Alertmanager の設定を管理します。 -
Service。参照しやすいホスト名を提供し、他のサービスが Alertmanager に接続できるようにします (Prometheus など)。
手順
Alertmanager 設定ファイル (
alert-manager-config.yaml) からSecretリソースを作成します。oc create secret generic alertmanager-alertmanager --from-file=alertmanager.yaml=alert-manager-config.yamlalert-manager-config.yamlファイルを更新し、以下を行います。-
slack_api_urlプロパティーを、Slack ワークスペースのアプリケーションに関連する Slack API URL の実際の値に置き換えます。 -
channelプロパティーを、通知が送信される実際の Slack チャネルに置き換えます。
-
Alertmanager をデプロイします。
oc apply -f alert-manager.yaml
10.5. Grafana
Grafana では、Prometheus メトリクスを視覚化できます。
AMQ Streams で提供される Grafana ダッシュボードサンプルをデプロイして有効化できます。
10.5.1. Grafana の設定
AMQ Streams には、Grafana のダッシュボード設定ファイルのサンプル が含まれています。
Grafana Docker イメージがデプロイメント用に提供されます。
-
grafana.yaml
ダッシュボードのサンプルも JSON ファイルで提供されます。
-
strimzi-kafka.json -
strimzi-kafka-connect.json -
strimzi-zookeeper.json
ダッシュボードのサンプルは、主なメトリクスの監視を開始するための雛形として使用できますが、使用できるすべてのメトリックスを対象としていません。使用するインフラストラクチャーに応じて、ダッシュボードのサンプルの編集や、他のメトリクスの追加が必要な場合もあります。
Grafana でダッシュボードを表示するには、設定ファイルを使用して以下を行います。
10.5.2. Grafana のデプロイメント
Grafana をデプロイして Prometheus メトリクスを視覚化するには、設定ファイルのサンプルを適用します。
前提条件
手順
Grafana をデプロイします。
oc apply -f grafana.yaml- Grafana ダッシュボードを有効にします。
10.5.3. Grafana ダッシュボードサンプルの有効化
Prometheus データソースおよびダッシュボードのサンプルを設定し、監視用に Grafana を有効にします。
アラート通知ルールは定義されていません。
ダッシュボードにアクセスする場合、port-forward コマンドを使用して Grafana Pod からホストにトラフィックを転送できます。
たとえば、以下のように Grafana ユーザーインターフェースにアクセスできます。
-
oc port-forward svc/grafana 3000:3000を実行します。 -
ブラウザーで
http://localhost:3000を指定します。
Grafana Pod の名前はユーザーごとに異なります。
手順
admin/adminクレデンシャルを使用して、Grafana ユーザーインターフェースにアクセスします。最初のビューで、パスワードのリセットを選択します。

Add data source ボタンをクリックします。
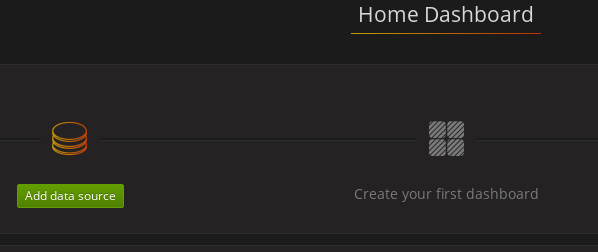
Prometheus をデータソースとして追加します。
- 名前を指定します。
- Prometheus をタイプとして追加します。
- URL フィールドに、Prometheus サーバーへ接続する URL (http://prometheus-operated:9090) を指定します。
Add をクリックしてデータソースへの接続をテストします。
Dashboards、Import の順にクリックして、Import Dashboard ウィンドウを開き、ダッシュボードのサンプルをインポートします (または JSON を貼り付けます)。
ダッシュボードをインポートしたら、Grafana ダッシュボードのホームページに Kafka および ZooKeeper ダッシュボードが表示されます。
Prometheus サーバーが AMQ Streams クラスターのメトリクスを収集すると、それがダッシュボードに反映されます。
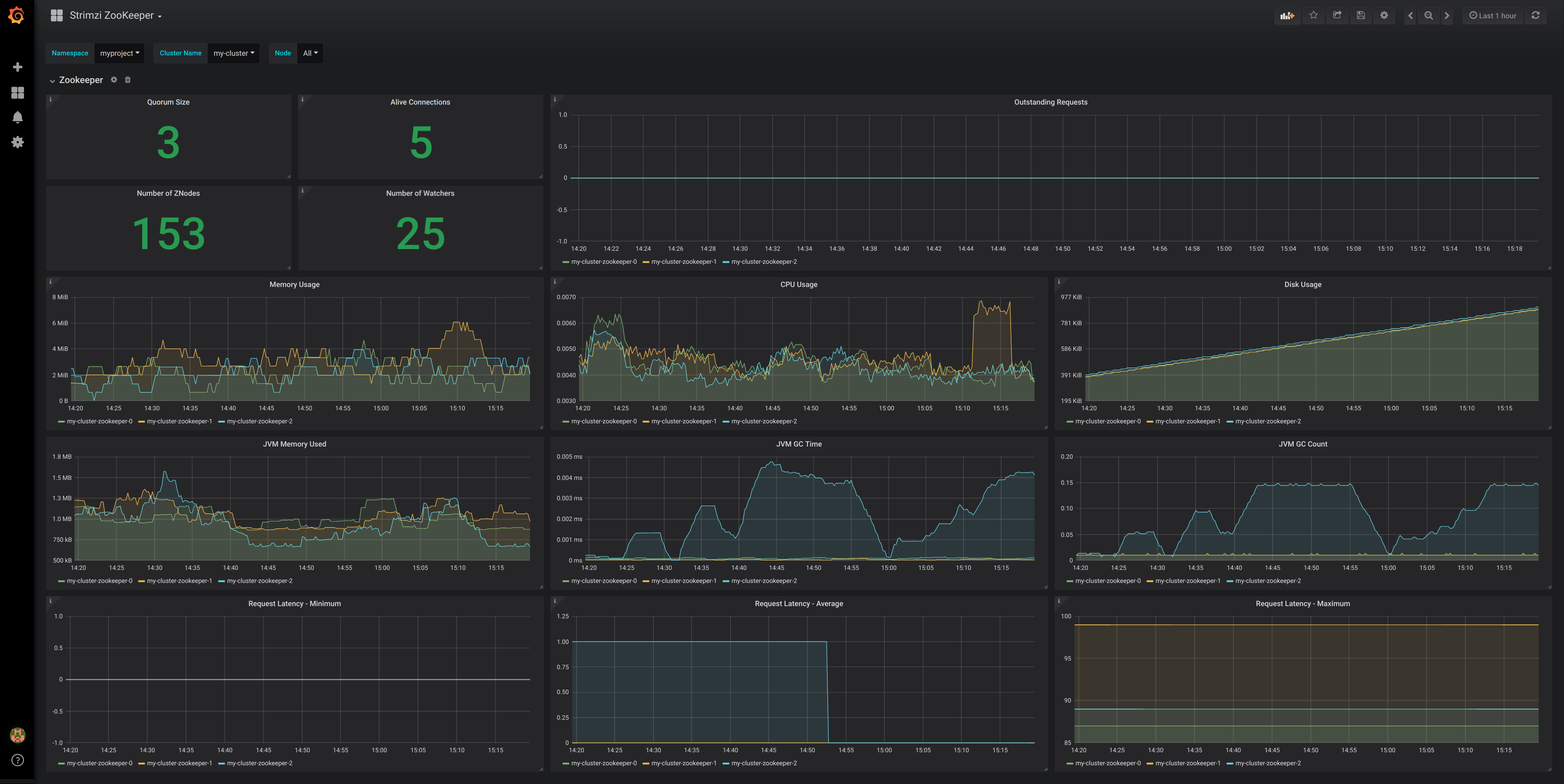
図10.1 Kafka ダッシュボード
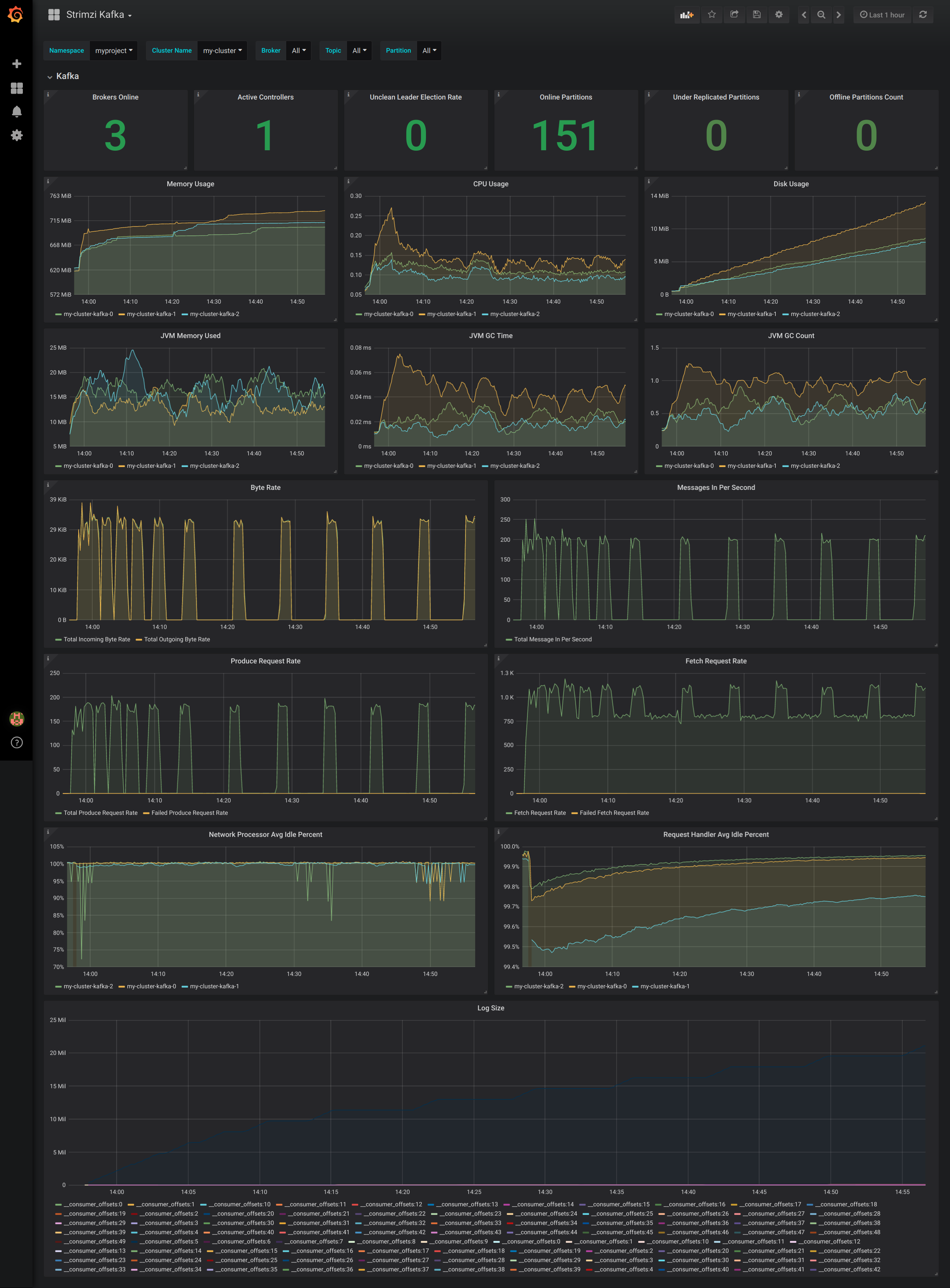
図10.2 ZooKeeper ダッシュボード