このコンテンツは選択した言語では利用できません。
14.2. MapReduceTask Distributed Execution
MapReduceTask is a distributed task that allows a large-scale computation to be transparently parallelized across Red Hat JBoss Data Grid cluster nodes. MapReduceTask can be instantiated with a reference to a cache containing data that is used as input for this task. JBoss Data Grid's execution environment can migrate and execute instances of provided
Mapper and Reducer seamlessly across JBoss Data Grid nodes.
MapReduceTask distributed execution distributes the reduce phase execution. Previously, the reduce phase was performed on a single master task node. This limitation has been removed, and the reduce phase execution can now be distributed across the cluster also. The distribution of reduce phase is achieved by relying on consistent hashing.
It is still possible to use MapReduceTask with the reduce phase performed on a single node, and this is recommended for smaller input tasks.
Distributed Execution of the MapReduceTask occurs in three phases:
- Mapping phase.
- Outgoing Key and Outgoing Value Migration.
- Reduce phase.
- Map Phase
- MapReduceTask hashes task input keys and groups them by the execution node that they are hashed to. After key node mapping, MapReduceTask sends a map function and inputs keys to each node. The map function is invoked using given keys and locally loaded corresponding values.Results are collected with a Red Hat JBoss Data Grid supplied Collector, and the combine phase is initiated. A Combiner, if specified, takes KOut keys and immediately invokes the reduce phase on keys. The result of mapping phase executed on each node is KOut/VOut map. There is one resulting map per execution node per launched MapReduceTask.
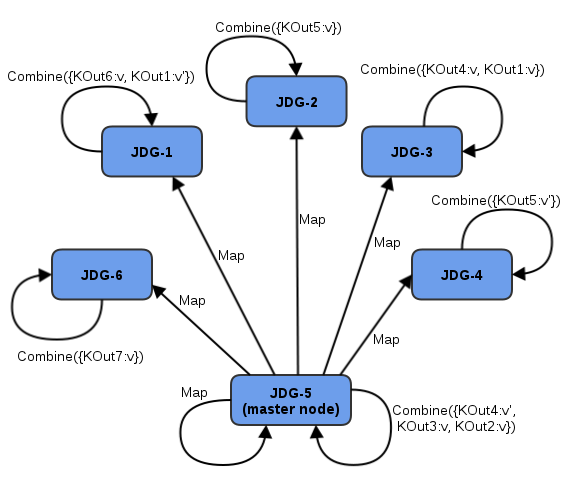
Figure 14.1. Map Phase
- Intermediate KOut/VOut migration phase
- In order to proceed with reduce phase, all intermediate keys and values must be grouped by intermediate KOut keys. As map phases around the cluster can produce identical intermediate keys, all identical intermediate keys and their values must be grouped before reduce is executed on any particular intermediate key.At the end of the combine phase, each intermediate KOut key is hashed and migrated with its VOut values to the JBoss Data Grid node where keys KOut are hashed to. This is achieved using a temporary distributed cache and underlying consistent hashing mechanism.
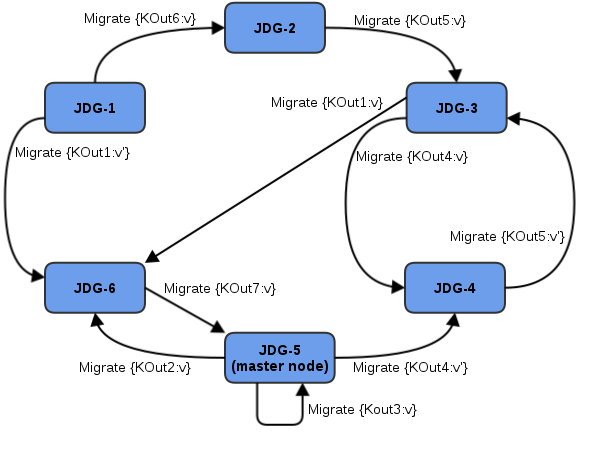
Figure 14.2. Kout/VOut Migration
Once Map and Combine phase have finished execution, a list of KOut keys is returned to a master node and it is initiating MapReduceTask. VOut values are not returned as they are not required at the master task node. MapReduceTask is ready to start with reduce phase. - Reduce Phase
- To complete reduce phase, MapReduceTask groups KOut keys by execution node N they are hashed to. For each node and its grouped input KOut keys, MapReduceTask sends a reduce command to a node where KOut keys are hashed. Once the reduce command is executed on the target execution node, it locates the temporary cache belonging to MapReduce task. For each KOut key, the reduce command obtains a list of VOut values, wraps it with an Iterator, and invokes reduce on it.
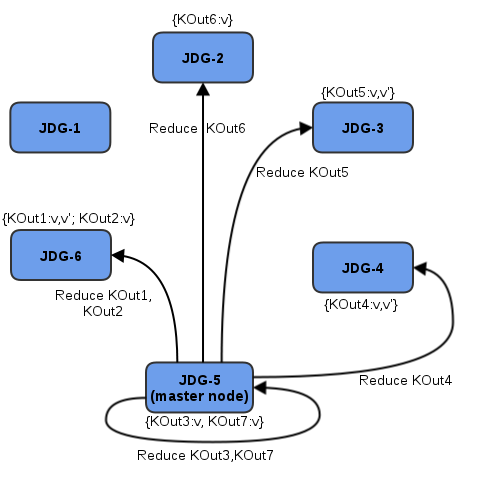
Figure 14.3. Reduce Phase
The result of each reduce is a map where each key is KOut and value is VOut. Each JBoss Data Grid execution node returns one map with KOut/VOut result values. As all initiated reduce commands return to a calling node, MapReduceTask combines all resulting maps into a map and returns the map as a result of MapReduceTask.Distributed reduce phase is enabled by using a MapReduceTask constructor specifying the cache to use as input data for the task and boolean parameterdistributeReducePhaseset totrue. For more information, see the Map/Reduce section of the Red Hat JBoss Data Grid API Documentation.