カーネルの管理、監視、および更新
Red Hat Enterprise Linux 8 上で Linux カーネルを管理するためのガイド
概要
Red Hat ドキュメントへのフィードバック (英語のみ)
Red Hat ドキュメントに関するご意見やご感想をお寄せください。また、改善点があればお知らせください。
Jira からのフィードバック送信 (アカウントが必要)
- Jira の Web サイトにログインします。
- 上部のナビゲーションバーで Create をクリックします。
- Summary フィールドにわかりやすいタイトルを入力します。
- Description フィールドに、ドキュメントの改善に関するご意見を記入してください。ドキュメントの該当部分へのリンクも追加してください。
- ダイアログの下部にある Create をクリックします。
第1章 Linux カーネル
Linux カーネルと、Red Hat が提供および管理する Linux カーネル RPM パッケージ (Red Hat カーネル) を学びます。Red Hat カーネルを最新の状態に保ちます。これにより、オペレーティングシステムに最新のバグ修正、パフォーマンス強化、およびパッチがすべて適用され、新しいハードウェアとの互換性が保たれます。
1.1. カーネルとは
カーネルは Linux オペレーティングシステムのコア部分で、システムリソースを管理し、ハードウェアアプリケーションおよびソフトウェアアプリケーション間のインターフェイスを確立します。
Red Hat カーネルは、アップストリームの Linux メインラインカーネルをベースにしたカスタムカーネルです。Red Hat のエンジニアは、安定性と、最新のテクノロジーおよびハードウェアとの互換性に重点を置き、さらなる開発と強化を行っています。
Red Hat が新しいカーネルバージョンをリリースする前に、カーネルは厳格な品質保証テストをクリアしなければなりません。
Red Hat カーネルは RPM 形式でパッケージ化されているため、YUM パッケージマネージャーにより簡単にアップグレードおよび検証できます。
Red Hat によってコンパイルされていないカーネルは、Red Hat では サポートされていません。
1.2. RPM パッケージ
RPM パッケージは、ファイルのアーカイブと、これらのファイルのインストールと消去に使用されるメタデータで構成されます。具体的には、RPM パッケージには次の要素が含まれています。
- GPG 署名
- GPG 署名は、パッケージの整合性を検証するために使用されます。
- ヘッダー (パッケージのメタデータ)
- RPM パッケージマネージャーは、このメタデータを使用して、パッケージの依存関係、ファイルのインストール先、その他の情報を確認します。
- ペイロード
-
ペイロードは、システムにインストールするファイルを含む
cpioアーカイブです。
RPM パッケージには 2 つの種類があります。いずれも、同じファイル形式とツールを使用しますが、コンテンツが異なるため、目的が異なります。
ソース RPM (SRPM)
SRPM には、ソースコードと、ソースコードをバイナリー RPM にビルドする方法を記述した
specファイルが含まれています。必要に応じて、SRPM にはソースコードへのパッチを含めることができます。バイナリー RPM
バイナリー RPM には、ソースおよびパッチから構築されたバイナリーが含まれます。
1.3. Linux カーネル RPM パッケージの概要
カーネル RPM は、ファイルを含まないメタパッケージで、以下の必須サブパッケージが正しくインストールされるようにします。
kernel-core-
カーネルのバイナリーイメージ、システムをブートストラップするためのすべての
initramfs関連オブジェクト、およびコア機能を確保するための最小限の数のカーネルモジュールを提供します。このサブパッケージ単体は、仮想環境およびクラウド環境で使用して、Red Hat Enterprise Linux 8 カーネルのブート時間を短縮し、ディスクサイズを抑えます。 kernel-modules-
kernel-coreに存在しない残りのカーネルモジュールを提供します。
上記の kernel サブパッケージをいくつか用意することで、特に仮想環境やクラウド環境でのシステム管理者へのメンテナンス面を低減させることを目指します。
オプションのカーネルパッケージの例:
kernel-modules-extra- 希少なハードウェア用のカーネルモジュールを提供します。このモジュールのロードはデフォルトで無効になっています。
kernel-debug- カーネル診断用に多くのデバッグオプションが有効になっているカーネルを提供しますが、これによりパフォーマンスが低下します。
kernel-tools- Linux カーネルを操作するためのツールとサポートドキュメントを提供します。
kernel-devel-
kernelパッケージに対してモジュールをビルドするのに十分なカーネルヘッダーと makefile を提供します。 kernel-abi-stablelists-
RHEL カーネル ABI に関連する情報を提供します。これには、外部 Linux カーネルモジュールが必要とするカーネルシンボルのリストや、強化を支援するための
yumプラグインが含まれます。 kernel-headers- Linux カーネルと、ユーザー空間ライブラリーおよびプログラムとの間のインターフェイスを指定する C ヘッダーファイルが含まれます。ヘッダーファイルは、ほとんどの標準プログラムをビルドするのに必要な構造と定数を定義します。
1.4. カーネルパッケージの内容の表示
リポジトリーをクエリーすると、カーネルパッケージがモジュールなどの特定のファイルを提供しているかどうかを確認できます。ファイルリストを表示するためにパッケージをダウンロードまたはインストールする必要はありません。
dnf ユーティリティーを使用して、たとえば kernel-core、kernel-modules-core、または kernel-modules パッケージのファイルリストをクエリーします。kernel パッケージはファイルを含まないメタパッケージであることに注意してください。
手順
パッケージの利用可能なバージョンをリスト表示します。
yum repoquery <package_name>
$ yum repoquery <package_name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow パッケージ内のファイルをリスト表示します。
yum repoquery -l <package_name>
$ yum repoquery -l <package_name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
1.5. 特定のカーネルバージョンのインストール
yum パッケージマネージャーを使用して新しいカーネルをインストールします。
手順
特定のカーネルバージョンをインストールするには、次のコマンドを実行します。
yum install kernel-5.14.0
# yum install kernel-5.14.0Copy to Clipboard Copied! Toggle word wrap Toggle overflow
1.6. カーネルの更新
yum パッケージマネージャーを使用してカーネルを更新します。
手順
カーネルを更新するには、次のコマンドを入力します。
yum update kernel
# yum update kernelCopy to Clipboard Copied! Toggle word wrap Toggle overflow このコマンドは、カーネルと、利用可能な最新バージョンへのすべての依存関係を更新します。
- システムを再起動して、変更を有効にします。
RHEL 7 から RHEL 8 にアップグレードする場合は、RHEL 7 から RHEL 8 へのアップグレード ドキュメントの関連のセクションを参照してください。
1.7. カーネルのデフォルトとしての設定
grubby コマンドラインツールと GRUB を使用して、特定のカーネルをデフォルトとして設定します。
手順
grubbyツールを使用し、デフォルトとしてカーネルを設定する以下のコマンドを実行し、
grubbyツールを使用してカーネルをデフォルトとして設定します。grubby --set-default $kernel_path
# grubby --set-default $kernel_pathCopy to Clipboard Copied! Toggle word wrap Toggle overflow コマンドは、
.confの接尾辞のないマシン ID を引数として使用します。注記マシン ID は
/boot/loader/entries/ディレクトリーにあります。
id引数を使用し、デフォルトとしてカーネルを設定するid引数を使用してブートエントリーのリストを表示し、任意のカーネルをデフォルトとして設定します。grubby --info ALL | grep id grubby --set-default /boot/vmlinuz-<version>.<architecture>
# grubby --info ALL | grep id # grubby --set-default /boot/vmlinuz-<version>.<architecture>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 注記title引数を使用してブートエントリーのリストを表示するには、# grubby --info=ALL | grep titleコマンドを実行します。
次回の起動時のみ用にデフォルトのカーネルを設定する
次のコマンドを実行し、
grub2-rebootコマンドを使用して、次回の再起動限定でデフォルトのカーネルを設定します。grub2-reboot <index|title|id>
# grub2-reboot <index|title|id>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 警告取り扱いに注意して、次回の起動時限定のデフォルトのカーネルを設定します。新しいカーネル RPM、自己ビルドカーネルをインストールし、エントリーを
/boot/loader/entries/ディレクトリーに手動で追加すると、インデックス値が変更される可能性があります。
第2章 カーネルモジュールの管理
カーネルモジュール、それらの情報を表示する方法、およびカーネルモジュールを使用して基本的な管理タスクを実行する方法を学びます。
2.1. モジュールの紹介
Red Hat Enterprise Linux カーネルはカーネルモジュールを使用して拡張でき、システムを再起動せずにオプションの追加機能を提供します。RHEL 8 では、カーネルモジュールは追加のカーネルコードで、圧縮された <KERNEL_MODULE_NAME>.ko.xz オブジェクトファイルに組み込まれています。
カーネルモジュールにより有効になっている最も一般的な機能は、以下のとおりです。
- 新しいハードウェアのサポートを追加するデバイスドライバー
- GFS2 や NFS などのファイルシステムのサポート
- システムコール
最新のシステムでは、必要に応じて自動的にカーネルモジュールが読み込まれます。ただし、場合によっては、モジュールを手動でロードまたはアンロードする必要があります。
カーネルと同様に、モジュールは動作をカスタマイズするパラメーターを受け入れます。
カーネルツールを使用して、モジュールに対して次のアクションを実行できます。
- 現在実行中のモジュールを検査する。
- カーネルにロードできるモジュールを検査する。
- モジュールが受け入れるパラメーターを検査する。
- 実行中のカーネルにカーネルモジュールをロードおよびアンロードするメカニズムを有効化する。
2.2. カーネルモジュールの依存関係
カーネルモジュールによっては、1 つ以上の他のカーネルモジュールに依存するものもあります。/lib/modules/<KERNEL_VERSION>/modules.dep ファイルには、対応するカーネルバージョンに対するカーネルモジュールの依存関係の完全なリストが含まれます。
depmod
依存関係ファイルは、kmod パッケージに含まれる depmod プログラムによって生成されます。kmod によって提供される多くのユーティリティーは、操作を実行するときにモジュールの依存関係を考慮します。したがって、手動 での依存関係の追跡は、ほとんど必要ありません。
カーネルモジュールのコードは、カーネル空間で無制限モードで実行されます。どのモジュールを読み込んでいるかに注意してください。
weak-modules
depmod に加えて、Red Hat Enterprise Linux は、kmod パッケージの一部である weak-modules スクリプトを提供します。weak-modules は、インストールされているカーネルと kABI 互換性のあるモジュールを決定します。モジュールカーネルの互換性をチェックしている間、weak-modules はモジュールシンボルの依存関係を、それらがビルドされたカーネルの上位リリースから下位リリースへと処理します。カーネルのリリースとは独立して各モジュールを処理します。
2.3. インストール済みカーネルモジュールのリスト表示
grubby --info=ALL コマンドは、!BLS インストールおよび BLS インストールにインストールされたカーネルのインデックスリストを表示します。
手順
以下のコマンドを使用して、インストールされているカーネルをリスト表示します。
grubby --info=ALL | grep title
# grubby --info=ALL | grep titleCopy to Clipboard Copied! Toggle word wrap Toggle overflow インストールされているカーネルのリストは、以下のようになります。
title=Red Hat Enterprise Linux (4.18.0-20.el8.x86_64) 8.0 (Ootpa) title=Red Hat Enterprise Linux (4.18.0-19.el8.x86_64) 8.0 (Ootpa) title=Red Hat Enterprise Linux (4.18.0-12.el8.x86_64) 8.0 (Ootpa) title=Red Hat Enterprise Linux (4.18.0) 8.0 (Ootpa) title=Red Hat Enterprise Linux (0-rescue-2fb13ddde2e24fde9e6a246a942caed1) 8.0 (Ootpa)
title=Red Hat Enterprise Linux (4.18.0-20.el8.x86_64) 8.0 (Ootpa) title=Red Hat Enterprise Linux (4.18.0-19.el8.x86_64) 8.0 (Ootpa) title=Red Hat Enterprise Linux (4.18.0-12.el8.x86_64) 8.0 (Ootpa) title=Red Hat Enterprise Linux (4.18.0) 8.0 (Ootpa) title=Red Hat Enterprise Linux (0-rescue-2fb13ddde2e24fde9e6a246a942caed1) 8.0 (Ootpa)Copy to Clipboard Copied! Toggle word wrap Toggle overflow
これは、GRUB メニューからの grubby-8.40-17 のインストール済みカーネルのリストです。
2.4. 現在読み込み済みカーネルモジュールのリスト表示
現在ロードされているカーネルモジュールを表示します。
前提条件
-
kmodパッケージがインストールされている。
手順
現在読み込み済みのカーネルモジュールの一覧を表示するには、以下のコマンドを実行します。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 上記の例では、以下のようになります。
-
Module列は、現在読み込まれているモジュールの 名前 を示します。 -
Size列は、モジュールごとの メモリー 容量をキロバイト単位で表示します。 -
Used by列には、特定のモジュールに 依存する モジュールの数と、オプションで名前が表示されます。
-
2.5. インストール済みカーネルのリスト表示
grubby ユーティリティーを使用して、システムにインストールされているすべてのカーネルを一覧表示します。
前提条件
- root 権限がある。
手順
インストールされているすべてのカーネルを一覧表示するには、次のコマンドを実行します。
grubby --info=ALL | grep ^kernel
# grubby --info=ALL | grep ^kernel kernel="/boot/vmlinuz-4.18.0-305.10.2.el8_4.x86_64" kernel="/boot/vmlinuz-4.18.0-240.el8.x86_64" kernel="/boot/vmlinuz-0-rescue-41eb2e172d7244698abda79a51778f1b"Copy to Clipboard Copied! Toggle word wrap Toggle overflow
出力には、インストールされているすべてのカーネルのパスとバージョンが表示されます。
2.6. モジュール情報の表示
modinfo コマンドを使用して、指定したカーネルモジュールに関する詳細情報を表示します。
前提条件
-
kmodパッケージがインストールされている。
手順
カーネルモジュールの情報を表示するには、以下を実行します。
modinfo <KERNEL_MODULE_NAME>
$ modinfo <KERNEL_MODULE_NAME>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 以下に例を示します。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow ロードされているかどうかに関係なく、利用可能なすべてのモジュールに関する情報をクエリーできます。
parmエントリーは、ユーザーがモジュールに設定できるパラメーターと、期待される値のタイプを示します。注記カーネルモジュールの名前を入力する際には、
.ko.xz拡張子は名前の末尾に追加しないでください。カーネルモジュール名には拡張子はありません。ただし、対応するファイルには拡張子があります。
2.7. システム実行時のカーネルモジュールのロード
Linux カーネルの機能を拡張する最適な方法は、カーネルモジュールを読み込むことです。modprobe コマンドを使用して、カーネルモジュールを検出し、現在実行しているカーネルに読み込みます。
この手順で説明されている変更は、システムの再起動後は 維持されません。システムの再起動後にも 設定を維持 するようにカーネルモジュールを読み込む方法は、システムの起動時に自動的にカーネルモジュールを読み込む を参照してください。
前提条件
- root 権限がある。
-
kmodパッケージがインストールされている。 - 関連のカーネルモジュールが読み込まれていない。これが当てはまるかどうかを確認するには、現在ロードされているカーネルモジュールのリスト を表示します。
手順
読み込むカーネルモジュールを選択します。
モジュールは
/lib/modules/$(uname -r)/kernel/<SUBSYSTEM>/ディレクトリーにあります。関連するカーネルモジュールを読み込みます。
modprobe <MODULE_NAME>
# modprobe <MODULE_NAME>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 注記カーネルモジュールの名前を入力する際には、
.ko.xz拡張子は名前の末尾に追加しないでください。カーネルモジュール名には拡張子はありません。ただし、対応するファイルには拡張子があります。
検証
必要に応じて、関連モジュールが読み込まれたことを確認します。
lsmod | grep <MODULE_NAME>
$ lsmod | grep <MODULE_NAME>Copy to Clipboard Copied! Toggle word wrap Toggle overflow モジュールが正しく読み込まれた場合、このコマンドは関連するカーネルモジュールを表示します。以下に例を示します。
lsmod | grep serio_raw
$ lsmod | grep serio_raw serio_raw 16384 0Copy to Clipboard Copied! Toggle word wrap Toggle overflow
2.8. システム実行時のカーネルモジュールのアンロード
実行中のカーネルから特定のカーネルモジュールをアンロードするには、modprobe コマンドを使用して、システム実行時に現在ロードされているカーネルからカーネルモジュールを検索してアンロードします。
実行中のシステムで使用されているカーネルモジュールをアンロードしないでください。システムが不安定になったり、動作しなくなったりする可能性があります。
非アクティブなカーネルモジュールのアンロードが完了すると、起動時に自動的にロードされるように定義されているモジュールは、システムの再起動後もアンロードされたままになることはありません。この結果を防ぐ方法については、システムの起動時にカーネルモジュールが自動的に読み込まれないようにするを 参照してください。
前提条件
- root 権限がある。
-
kmodパッケージがインストールされている。
手順
ロードされたすべてのカーネルモジュールをリスト表示します。
lsmod
# lsmodCopy to Clipboard Copied! Toggle word wrap Toggle overflow アンロードするカーネルモジュールを選択します。
カーネルモジュールに依存関係がある場合は、カーネルモジュールをアンロードする前に、これらをアンロードします。依存関係のあるモジュールを識別する方法の詳細は、現在ロードされているカーネルモジュールのリスト表示 および カーネルモジュールの依存関係 を参照してください。
関連するカーネルモジュールをアンロードします。
modprobe -r <MODULE_NAME>
# modprobe -r <MODULE_NAME>Copy to Clipboard Copied! Toggle word wrap Toggle overflow カーネルモジュールの名前を入力する際には、
.ko.xz拡張子は名前の末尾に追加しないでください。カーネルモジュール名には拡張子はありません。ただし、対応するファイルには拡張子があります。
検証
必要に応じて、関連モジュールがアンロードされたことを確認します。
lsmod | grep <MODULE_NAME>
$ lsmod | grep <MODULE_NAME>Copy to Clipboard Copied! Toggle word wrap Toggle overflow モジュールが正常にアンロードされる場合、このコマンドは出力を表示しません。
2.9. 起動プロセスの初期段階でのカーネルモジュールのアンロード
特定の状況では、たとえば、カーネルモジュールにシステムが応答しなくなるコードがあり、ユーザーが不正なカーネルモジュールを永続的に無効にする段階に到達できない場合、起動プロセスの早い段階でカーネルモジュールをアンロードする必要が出てくる場合があります。カーネルモジュールのロードを一時的にブロックするには、ブートローダーを使用します。
ブートシーケンスの続行前に、関連するブートローダーエントリーを編集して、必要なカーネルモジュールをアンロードできます。
この手順で説明されている変更は、システムを再起動すると維持されません。起動プロセス時にカーネルモジュールが自動的に読み込まれないように、denylist にカーネルモジュールを追加する方法は、システムの起動時にカーネルモジュールが自動的にロードされないようにする を参照してください。
前提条件
- なんらかの理由で読み込みを阻止する必要のある、読み込み可能なカーネルモジュールがある。
手順
- システムをブートローダーで起動します。
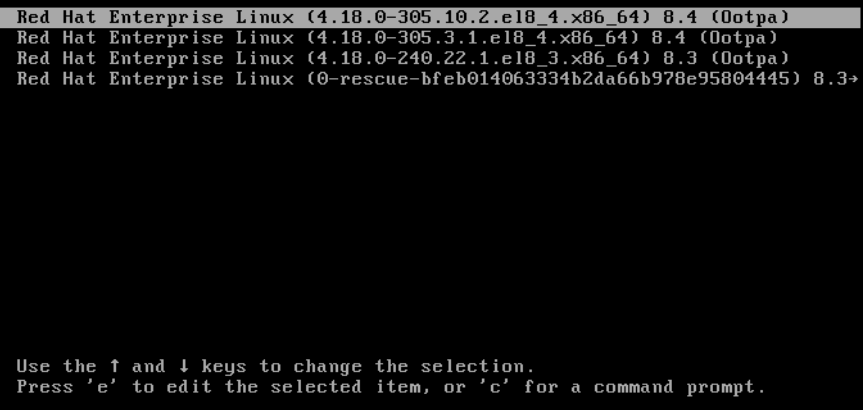
- カーソルキーを使用して、関連するブートローダーエントリーを強調表示します。
e キーを押してエントリーを編集します。
図2.1 カーネルブートメニュー
- カーソルキーを使用して、linux で始まる行に移動します。
modprobe.blacklist=module_nameを行末に追加します。図2.2 カーネルブートエントリー
serio_rawカーネルモジュールは、起動プロセスの初期段階でアンロードする不正なモジュールを示しています。- Ctrl+X を押して、変更した設定を使用して起動します。

検証
システムの起動後、関連するカーネルモジュールがロードされていないことを確認します。
lsmod | grep serio_raw
# lsmod | grep serio_rawCopy to Clipboard Copied! Toggle word wrap Toggle overflow
2.10. システムの起動時にカーネルモジュールを自動的にロードする
起動プロセス中にカーネルモジュールを自動的にロードするように設定します。
前提条件
- root 権限がある。
-
kmodパッケージがインストールされている。
手順
起動プロセス中に読み込むカーネルモジュールを選択します。
モジュールは
/lib/modules/$(uname -r)/kernel/<SUBSYSTEM>/ディレクトリーにあります。モジュールの設定ファイルを作成します。
echo <MODULE_NAME> > /etc/modules-load.d/<MODULE_NAME>.conf
# echo <MODULE_NAME> > /etc/modules-load.d/<MODULE_NAME>.confCopy to Clipboard Copied! Toggle word wrap Toggle overflow 注記カーネルモジュールの名前を入力する際には、
.ko.xz拡張子は名前の末尾に追加しないでください。カーネルモジュール名には拡張子はありません。ただし、対応するファイルには拡張子があります。
検証
再起動後、関連するモジュールがロードされていることを確認します。
lsmod | grep <MODULE_NAME>
$ lsmod | grep <MODULE_NAME>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
この手順で説明している変更は、システムを再起動しても 持続されます。
2.11. システムの起動時にカーネルモジュールが自動的にロードされないようにする
対応するコマンドを使用して、modprobe 設定ファイルにモジュールを一覧表示することで、起動プロセス中にシステムが自動的にカーネルモジュールを読み込むことを阻止できます。
前提条件
-
この手順のコマンドには root 権限が必要です。
su -を使用して root ユーザーに切り替えるか、コマンドの前にsudoを付けます。 -
kmodパッケージがインストールされている。 - 現在のシステム設定に、拒否する予定のカーネルモジュールが必要ないことを確認する。
手順
lsmodコマンドを使用して、現在実行中のカーネルに読み込まれているモジュールを一覧表示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow 出力で、ロードを阻止するモジュールを特定します。
または、
/lib/modules/<KERNEL-VERSION>/kernel/<SUBSYSTEM>/ディレクトリーに読み込まれないようにするアンロードしたカーネルモジュールを特定します。以下に例を示します。ls /lib/modules/4.18.0-477.20.1.el8_8.x86_64/kernel/crypto/
$ ls /lib/modules/4.18.0-477.20.1.el8_8.x86_64/kernel/crypto/ ansi_cprng.ko.xz chacha20poly1305.ko.xz md4.ko.xz serpent_generic.ko.xz anubis.ko.xz cmac.ko.xz…Copy to Clipboard Copied! Toggle word wrap Toggle overflow
拒否リストとして機能する設定ファイルを作成します。
touch /etc/modprobe.d/denylist.conf
# touch /etc/modprobe.d/denylist.confCopy to Clipboard Copied! Toggle word wrap Toggle overflow 任意のテキストエディターで、カーネルへの自動読み込みから除外するモジュール名を
blacklist設定コマンドと組み合わせます。以下に例を示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow blacklistコマンドは、モジュールが、拒否リストにない別のカーネルモジュールの依存関係としてロードされることを阻止しないため、install行も定義する必要があります。この場合、システムはモジュールをインストールする代わりに/bin/falseを実行します。ハッシュ記号で始まる行は、ファイルをより読みやすくするために使用可能なコメントです。注記カーネルモジュールの名前を入力する際には、
.ko.xz拡張子は名前の末尾に追加しないでください。カーネルモジュール名には拡張子はありません。ただし、対応するファイルには拡張子があります。再構築を行う前に、現在の初期 RAM ディスクイメージのバックアップコピーを作成します。
cp /boot/initramfs-$(uname -r).img /boot/initramfs-$(uname -r).bak.$(date +%m-%d-%H%M%S).img
# cp /boot/initramfs-$(uname -r).img /boot/initramfs-$(uname -r).bak.$(date +%m-%d-%H%M%S).imgCopy to Clipboard Copied! Toggle word wrap Toggle overflow または、カーネルモジュールの自動読み込みを阻止するカーネルバージョンに対応する初期 RAM ディスクイメージのバックアップコピーを作成します。
cp /boot/initramfs-<VERSION>.img /boot/initramfs-<VERSION>.img.bak.$(date +%m-%d-%H%M%S)
# cp /boot/initramfs-<VERSION>.img /boot/initramfs-<VERSION>.img.bak.$(date +%m-%d-%H%M%S)Copy to Clipboard Copied! Toggle word wrap Toggle overflow
新しい初期 RAM ディスクイメージを生成して、変更を適用します。
dracut -f -v
# dracut -f -vCopy to Clipboard Copied! Toggle word wrap Toggle overflow システムで現在使用中のものとは異なるカーネルバージョンの初期 RAM ディスクイメージを構築する場合は、ターゲット
initramfsとカーネルバージョンの両方を指定します。dracut -f -v /boot/initramfs-<TARGET-VERSION>.img <CORRESPONDING-TARGET-KERNEL-VERSION>
# dracut -f -v /boot/initramfs-<TARGET-VERSION>.img <CORRESPONDING-TARGET-KERNEL-VERSION>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
システムを再起動します。
reboot
$ rebootCopy to Clipboard Copied! Toggle word wrap Toggle overflow
この手順で説明されている変更は、システムの再起動後も 有効なまま維持されます。重要なカーネルモジュールを誤って拒否リストに指定すると、システムが不安定または操作不能な状態になる可能性があります。
2.12. カスタムカーネルモジュールのコンパイル
ハードウェアおよびソフトウェアレベルで、さまざまな設定による要求に応じて、サンプリングカーネルモジュールを構築できます。
前提条件
kernel-develパッケージ、gccパッケージ、およびelfutils-libelf-develパッケージをインストールしている。dnf install kernel-devel-$(uname -r) gcc elfutils-libelf-devel
# dnf install kernel-devel-$(uname -r) gcc elfutils-libelf-develCopy to Clipboard Copied! Toggle word wrap Toggle overflow - root 権限がある。
-
カスタムカーネルモジュールをコンパイルする
/root/testmodule/ディレクトリーを作成している。
手順
以下の内容で
/root/testmodule/test.cを作成します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow test.cファイルは、カーネルモジュールに主な機能を提供するソースファイルです。このファイルは、組織的な目的で、専用の/root/testmodule/ディレクトリーに作成されています。モジュールをコンパイルすると、/root/testmodule/ディレクトリーには複数のファイルが含まれます。test.cファイルには、システムライブラリーから次のものが含まれます。-
サンプルコードの
printk()機能には、linux/kernel.hヘッダーファイルが必要です。 -
linux/module.hヘッダーファイルには、複数の C ソースファイル間で共有される関数宣言とマクロ定義が含まれています。
-
サンプルコードの
-
次に、
init_module()関数およびcleanup_module()関数に従い、テキストを出力するカーネルロギング機能printk()を起動および終了します。 以下の内容で
/root/testmodule/Makefileを作成します。obj-m := test.o
obj-m := test.oCopy to Clipboard Copied! Toggle word wrap Toggle overflow Makefile には、コンパイラーが
test.oという名前のオブジェクトファイルを生成するための指示が含まれています。obj-mディレクティブは、生成されるtest.koファイルを、読み込み可能なカーネルモジュールとしてコンパイルすることを指定します。あるいは、obj-yディレクティブは、組み込みカーネルモジュールとしてtest.koをビルドするように指示できます。カーネルモジュールをコンパイルします。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow コンパイラーは、各ソースファイル (
test.c) のオブジェクトファイル (test.o) を中間手順として作成してから、それらを最終カーネルモジュール (test.ko) にリンクします。コンパイルが成功すると、
/root/testmodule/には、コンパイル済みカスタムカーネルモジュールに関連する追加ファイルが含まれます。コンパイル済みモジュール自身は、test.koファイルで表されます。
検証
必要に応じて、
/root/testmodule/ディレクトリーのコンテンツを確認します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow カーネルモジュールを
/lib/modules/$(uname -r)/ディレクトリーにコピーします。cp /root/testmodule/test.ko /lib/modules/$(uname -r)/
# cp /root/testmodule/test.ko /lib/modules/$(uname -r)/Copy to Clipboard Copied! Toggle word wrap Toggle overflow モジュールの依存関係のリストを更新します。
depmod -a
# depmod -aCopy to Clipboard Copied! Toggle word wrap Toggle overflow カーネルモジュールを読み込みます。
modprobe -v test
# modprobe -v test insmod /lib/modules/4.18.0-305.el8.x86_64/test.koCopy to Clipboard Copied! Toggle word wrap Toggle overflow カーネルモジュールが正常に読み込まれたことを確認します。
lsmod | grep test
# lsmod | grep test test 16384 0Copy to Clipboard Copied! Toggle word wrap Toggle overflow カーネルリングバッファーから最新のメッセージを読み込みます。
dmesg
# dmesg [74422.545004] Hello World This is a testCopy to Clipboard Copied! Toggle word wrap Toggle overflow
第3章 セキュアブート用のカーネルとモジュールの署名
署名済みカーネルと署名済みカーネルモジュールを使用して、システムのセキュリティーを強化できます。セキュアブートが有効になっている UEFI ベースのビルドシステムでは、プライベートにビルドされたカーネルまたはカーネルモジュールに自己署名できます。さらに、カーネルまたはカーネルモジュールをデプロイするターゲットシステムに公開鍵をインポートすることもできます。
セキュアブートが有効な場合、次のすべてのコンポーネントを秘密鍵で署名し、対応する公開鍵で認証する必要があります。
- UEFI オペレーティングシステムのブートローダー
- Red Hat Enterprise Linux カーネル
- すべてのカーネルモジュール
これらのコンポーネントのいずれかが署名および認証されていない場合、システムは起動プロセスを完了できません。
RHEL 8 には以下が含まれます。
- 署名済みブートローダー
- 署名済みカーネル
- 署名済みカーネルモジュール
さらに、署名済みの第 1 ステージのブートローダーと署名済みカーネルには、Red Hat 公開鍵が組み込まれています。これらの署名された実行可能バイナリーと埋め込みキーにより、RHEL 8 は Microsoft UEFI セキュアブート認証局キーを使用してインストール、起動、実行できるようになります。これらのキーは、UEFI セキュアブートをサポートするシステムの UEFI ファームウェアによって提供されます。
- セキュアブートのサポートは、すべての UEFI ベースのシステムに含まれるわけではありません。
- カーネルモジュールを構築、署名するビルドシステムは、UEFI セキュアブートを有効にする必要がなく、UEFI ベースのシステムである必要すらありません。
3.1. 前提条件
外部でビルドされたカーネルモジュールに署名できるようにするには、次のパッケージからユーティリティーをインストールします。
yum install pesign openssl kernel-devel mokutil keyutils
# yum install pesign openssl kernel-devel mokutil keyutilsCopy to Clipboard Copied! Toggle word wrap Toggle overflow Expand 表3.1 必要なユーティリティー ユーティリティー 提供するパッケージ 使用対象 目的 efikeygenpesignビルドシステム
公開および秘密 X.509 鍵のペアを生成
opensslopensslビルドシステム
暗号化されていない秘密鍵をエクスポートします。
sign-filekernel-develビルドシステム
秘密鍵でカーネルモジュールに署名するために使用する実行ファイル
mokutilmokutilターゲットシステム
公開鍵を手動で登録する際に使用するオプションのユーティリティー
keyctlkeyutilsターゲットシステム
システムキーリングへの公開鍵の表示時に使用するオプションのユーティリティー
3.2. UEFI セキュアブートとは
Unified Extensible Firmware Interface (UEFI) セキュアブートテクノロジーを使用すると、信頼できる鍵によって署名されていないカーネル空間コードの実行を防ぐことができます。システムブートローダーは暗号鍵で署名されています。ファームウェア内の公開鍵のデータベースは、鍵に署名するプロセスを認可します。その後、次のステージのブートローダーとカーネルで署名を検証できます。
UEFI セキュアブートは、以下のようにファームウェアから署名済みドライバーおよびカーネルモジュールへの信頼チェーンを確立します。
-
UEFI 秘密鍵が
shim第 1 ステージブートローダーに署名し、それを公開鍵が認証します。認証局 (CA) は公開鍵に署名します。CA はファームウェアのデータベースに保存されます。 -
shimファイルには、GRUB ブートローダーとカーネルを認証するための Red Hat 公開鍵 Red Hat Secure Boot (CA key 1) が含まれています。 - カーネルには、ドライバーおよびモジュールを認証する公開鍵が含まれます。
セキュアブートは、UEFI 仕様のブートパス検証コンポーネントです。この仕様は、以下を定義します。
- 揮発性ではないストレージでの暗号で保護された UEFI 変数用のプログラミングインターフェイス
- UEFI 変数での信頼できる X.509 ルート証明書の保存
- ブートローダーやドライバーなどの UEFI アプリケーションの検証
- 既知の問題のある証明書およびアプリケーションハッシュを無効にする手順
UEFI セキュアブートは、不正な変更の検出には役立ちますが、以下を行うことは できません。
- 第 2 ステージブートローダーのインストールまたは削除を防止する。
- このような変更について、ユーザーによる明示的な確認を要求する。
- ブートパスの操作を停止する。署名は、ブートローダーのインストールや更新時ではなく、起動時に検証されます。
ブートローダーまたはカーネルがシステムの信頼された鍵で署名されていない場合、セキュアブートにより起動が妨げられます。
3.3. UEFI セキュアブートのサポート
カーネルとロードされたすべてのドライバーが信頼できるキーで署名されている場合、UEFI セキュアブートが有効になっているシステムに RHEL 8 をインストールして実行できます。Red Hat は、関連する Red Hat キーによって署名および認証されたカーネルとドライバーを提供します。
外部でビルドされたカーネルまたはドライバーをロードする場合は、それらにも署名する必要があります。
UEFI セキュアブートによる制限
- システムは、署名が適切に認証された後にのみ、カーネルモードコードを実行します。
- GRUB モジュールの署名および検証を行うインフラストラクチャーがないため、GRUB モジュールの読み込みは無効です。モジュールのロードを許可すると、セキュアブートによって定義されたセキュリティー境界内で信頼できないコードが実行されます。
- Red Hat は、RHEL 8 でサポートされているすべてのモジュールを含む署名済み GRUB バイナリーを提供します。
3.4. X.509 鍵でカーネルモジュールを認証するための要件
RHEL 8 では、カーネルモジュールがロードされると、カーネルはカーネルシステムキーリング (.builtin_trusted_keys) およびカーネルプラットフォームキーリング (.platform) からの公開 X.509 キーに対してモジュールの署名をチェックします。.platform キーリングは、サードパーティーのプラットフォームプロバイダーおよびカスタム公開鍵からの鍵を提供します。カーネルシステムの .blacklist キーリングからの鍵は検証から除外されます。
UEFI セキュアブート機能が有効になっているシステムでカーネルモジュールをロードするには、特定の条件を満たす必要があります。
UEFI セキュアブートが有効な場合、または
module.sig_enforceカーネルパラメーターが指定されている場合:-
署名がシステムキーリング (
.builtin_trusted_keys) およびプラットフォームキーリング (.platform) からの鍵に対して認証されている署名済みのカーネルモジュールだけを読み込みできます。 -
公開鍵は、システムで拒否されたキーのキーリング (
.blacklist) に配置できません。
-
署名がシステムキーリング (
UEFI セキュアブートが無効で
module.sig_enforceカーネルパラメーターが指定されていない場合:- 公開鍵なしで、未署名のカーネルモジュールと署名済みカーネルモジュールを読み込むことができます。
システムが UEFI ベースでない場合、または UEFI セキュアブートが無効になっている場合:
-
カーネルに埋め込まれた鍵のみが
.builtin_trusted_keysおよび.platformに読み込まれます。 - カーネルの再構築なしでキーセットを拡張することはできません。
-
カーネルに埋め込まれた鍵のみが
| モジュールの署名 | 公開鍵ありおよび署名が有効 | UEFI セキュアブートの状態 | sig_enforce | モジュールの読み込み | カーネルのテイント |
|---|---|---|---|---|---|
| 署名なし | - | 有効でない | 有効でない | 成功 | はい |
| 有効でない | 有効 | 失敗 | - | ||
| 有効 | - | 失敗 | - | ||
| 署名あり | いいえ | 有効でない | 有効でない | 成功 | はい |
| 有効でない | 有効 | 失敗 | - | ||
| 有効 | - | 失敗 | - | ||
| 署名あり | はい | 有効でない | 有効でない | 成功 | いいえ |
| 有効でない | 有効 | 成功 | いいえ | ||
| 有効 | - | 成功 | いいえ |
3.5. 公開鍵のソース
カーネルは、起動時に X.509 キーを永続キーストアから以下のキーリングに読み込みます。
-
システムキーリング (
.builtin_trusted_keys) -
.platformキーリング -
システムの
.blacklistキーリング
| X.509 鍵のソース | ユーザーによるキーの追加 | UEFI セキュアブートの状態 | ブート中に読み込まれる鍵 |
|---|---|---|---|
| カーネルに埋め込み | いいえ | - |
|
|
UEFI | 限定的 | 有効でない | いいえ |
| 有効 |
| ||
|
| いいえ | 有効でない | いいえ |
| 有効 |
| ||
| Machine Owner Key (MOK) リスト | はい | 有効でない | いいえ |
| 有効 |
|
.builtin_trusted_keys- 起動時にビルドされるキーリング
- 信頼できる公開鍵を提供します。
-
キーを表示するには、
root権限が必要です。
.platform- 起動時にビルドされるキーリング
- サードパーティーのプラットフォームプロバイダーからの鍵とカスタムの公開鍵を提供します。
-
キーを表示するには、
root権限が必要です。
.blacklist- 失効した X.509 キーを含むキーリング
-
公開鍵が
.builtin_trusted_keysにある場合でも、.blacklistからの鍵で署名されたモジュールは認証に失敗します。
- UEFI セキュアブート
db - 署名データベース
- UEFI アプリケーション、UEFI ドライバー、およびブートローダーのキー (ハッシュ) を保存します。
- キーはマシンにロードできます。
- UEFI セキュアブート
dbx - 失効した署名データベース
- キーがロードされるのを防ぎます。
-
このデータベースからの失効したキーは、
.blacklistキーリングに追加されます。
3.6. 公開鍵と秘密鍵の生成
セキュアブート対応システムでカスタムカーネルまたはカスタムカーネルモジュールを使用するには、X.509 の公開鍵と秘密鍵のペアを生成する必要があります。生成された秘密鍵を使用して、カーネルまたはカーネルモジュールに署名できます。また、対応する公開鍵をセキュアブートの Machine Owner Key (MOK) に追加することで、署名済みのカーネルまたはカーネルモジュールを検証できます。
強力なセキュリティー対策とアクセスポリシーを適用して、秘密鍵の内容を保護します。悪用すれば、この鍵は、一致する公開鍵で認証されるシステムのセキュリティーに危害を与えるために使用できます。
手順
X.509 の公開鍵と秘密鍵のペアを作成します。
カスタムカーネル モジュール に署名するだけの場合:
efikeygen --dbdir /etc/pki/pesign \ --self-sign \ --module \ --common-name 'CN=Organization signing key' \ --nickname 'Custom Secure Boot key'# efikeygen --dbdir /etc/pki/pesign \ --self-sign \ --module \ --common-name 'CN=Organization signing key' \ --nickname 'Custom Secure Boot key'Copy to Clipboard Copied! Toggle word wrap Toggle overflow カスタム カーネル に署名する場合:
efikeygen --dbdir /etc/pki/pesign \ --self-sign \ --kernel \ --common-name 'CN=Organization signing key' \ --nickname 'Custom Secure Boot key'# efikeygen --dbdir /etc/pki/pesign \ --self-sign \ --kernel \ --common-name 'CN=Organization signing key' \ --nickname 'Custom Secure Boot key'Copy to Clipboard Copied! Toggle word wrap Toggle overflow RHEL システムが FIPS モードを実行している場合:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 注記FIPS モードでは、
efikeygenが PKI データベース内でデフォルトの "NSS Certificate DB" トークンを検索できるように、--tokenオプションを使用する必要があります。公開鍵と秘密鍵は
/etc/pki/pesign/ディレクトリーに保存されます。
セキュリティー上、署名鍵の有効期間内にカーネルとカーネルモジュールに署名することが推奨されます。ただし、sign-file ユーティリティーは警告を表示せず、キーは有効期限に関係なく RHEL 8 で使用できます。
3.7. システムキーリングの出力例
keyutils パッケージからの keyctl ユーティリティーを使用して、システムのキーリングの鍵に関する情報を表示できます。
前提条件
- root 権限がある。
-
keyutilsパッケージからkeyctlユーティリティーをインストールしました。
例3.1 キーリング出力
以下は、UEFI セキュアブートが有効になっている RHEL 8 システムからの .builtin_trusted_keys、.platform、および .blacklist キーリングの短縮された出力例です。
この例の .builtin_trusted_keys キーリングは、UEFI セキュアブート db キーからの 2 つのキー、および shim ブートローダーに組み込まれている Red Hat Secure Boot (CA key 1) の追加を表しています。
例3.2 カーネルコンソール出力
以下の例は、カーネルコンソールの出力を示しています。このメッセージでは、UEFI セキュアブートに関連するソースの鍵を特定します。これらには、UEFI セキュアブート db、組み込みの shim、および MOK リストが含まれます。
3.8. 公開鍵を MOK リストに追加してターゲットシステムに公開鍵を登録する
カーネルまたはカーネルモジュールへのアクセスのために、システム上で公開鍵を認証し、それをターゲットシステムのプラットフォームキーリング (.platform) に登録する必要があります。セキュアブートが有効な UEFI ベースのシステムで RHEL 8 を起動すると、カーネルが db 鍵データベースから公開鍵をインポートし、dbx データベースから失効した鍵を除外します。
Machine Owner Key (MOK) 機能を使用すると、UEFI セキュアブートキーデータベースを拡張できます。セキュアブートが有効な UEFI 対応システムで RHEL 8 を起動すると、セキュアブートデータベースの鍵とともに、MOK リストの鍵がプラットフォームキーリング (.platform) に追加されます。MOK リストの鍵も、同じ方法でセキュアかつ永続的に保存されますが、これはセキュアブートデータベースとは別の機能です。
MOK 機能は、shim、MokManager、GRUB、および UEFI ベースのシステムでセキュアな鍵管理と認証を可能にする mokutil ユーティリティーによってサポートされています。
システムでカーネルモジュールの認証サービスを取得するには、ファクトリーファームウェアイメージで公開鍵を UEFI セキュアブート鍵データベースに組み入れるようシステムベンダーに要求することを検討してください。
前提条件
- 公開鍵と秘密鍵のペアを生成し、公開鍵の有効期限を知っています。詳細は、公開鍵と秘密鍵のペアの生成 を参照してください。
手順
公開鍵を
sb_cert.cerファイルにエクスポートします。certutil -d /etc/pki/pesign \ -n 'Custom Secure Boot key' \ -Lr \ > sb_cert.cer# certutil -d /etc/pki/pesign \ -n 'Custom Secure Boot key' \ -Lr \ > sb_cert.cerCopy to Clipboard Copied! Toggle word wrap Toggle overflow 公開鍵を MOK リストにインポートします。
mokutil --import sb_cert.cer
# mokutil --import sb_cert.cerCopy to Clipboard Copied! Toggle word wrap Toggle overflow - この MOK 登録要求の新しいパスワードを入力してください。
マシンを再起動します。
shimブートローダーは、保留中の MOK キー登録要求を認識し、MokManager.efiを起動して、UEFI コンソールから登録を完了できるようにします。Enroll MOKを選択し、プロンプトが表示されたら、この要求に関連付けたパスワードを入力し、登録を確認します。公開鍵が MOK リストに永続的に追加されます。
キーが MOK リストに追加されると、UEFI セキュアブートが有効になっている場合は、このブートおよび後続のブートで
.platformキーリングに自動的に伝達されます。
3.9. 秘密鍵でカーネルに署名する
UEFI セキュアブート機能が有効になっている場合は、署名済みカーネルをロードすると、システムのセキュリティーを強化できます。
前提条件
- 公開鍵と秘密鍵のペアを生成し、公開鍵の有効期限を知っています。詳細は、公開鍵と秘密鍵のペアの生成 を参照してください。
- ターゲットシステムに公開鍵を登録しています。詳細は、公開鍵を MOK リストに追加して、ターゲットシステムに公開鍵を登録する を参照してください。
- 署名に使用できる ELF 形式のカーネルイメージがあります。
手順
x64 アーキテクチャーの場合:
署名済みイメージを作成します。
pesign --certificate 'Custom Secure Boot key' \ --in vmlinuz-version \ --sign \ --out vmlinuz-version.signed# pesign --certificate 'Custom Secure Boot key' \ --in vmlinuz-version \ --sign \ --out vmlinuz-version.signedCopy to Clipboard Copied! Toggle word wrap Toggle overflow versionをvmlinuzファイルのバージョン接尾辞に置き換え、Custom Secure Boot keyを以前に選択した名前に置き換えます。オプション: 署名を確認します。
pesign --show-signature \ --in vmlinuz-version.signed# pesign --show-signature \ --in vmlinuz-version.signedCopy to Clipboard Copied! Toggle word wrap Toggle overflow 未署名イメージを署名済みイメージで上書きします。
mv vmlinuz-version.signed vmlinuz-version
# mv vmlinuz-version.signed vmlinuz-versionCopy to Clipboard Copied! Toggle word wrap Toggle overflow
64 ビット ARM アーキテクチャーの場合:
vmlinuzファイルを解凍します。zcat vmlinuz-version > vmlinux-version
# zcat vmlinuz-version > vmlinux-versionCopy to Clipboard Copied! Toggle word wrap Toggle overflow 署名済みイメージを作成します。
pesign --certificate 'Custom Secure Boot key' \ --in vmlinux-version \ --sign \ --out vmlinux-version.signed# pesign --certificate 'Custom Secure Boot key' \ --in vmlinux-version \ --sign \ --out vmlinux-version.signedCopy to Clipboard Copied! Toggle word wrap Toggle overflow オプション: 署名を確認します。
pesign --show-signature \ --in vmlinux-version.signed# pesign --show-signature \ --in vmlinux-version.signedCopy to Clipboard Copied! Toggle word wrap Toggle overflow vmlinuxファイルを圧縮します。gzip --to-stdout vmlinux-version.signed > vmlinuz-version
# gzip --to-stdout vmlinux-version.signed > vmlinuz-versionCopy to Clipboard Copied! Toggle word wrap Toggle overflow 圧縮されていない
vmlinuxファイルを削除します。rm vmlinux-version*
# rm vmlinux-version*Copy to Clipboard Copied! Toggle word wrap Toggle overflow
3.10. 秘密鍵で GRUB ビルドに署名する
UEFI セキュアブート機能が有効になっているシステムでは、カスタムの既存の秘密鍵で GRUB ビルドに署名できます。カスタム GRUB ビルドを使用している場合、またはシステムから Microsoft トラストアンカーを削除した場合は、これを行う必要があります。
前提条件
- 公開鍵と秘密鍵のペアを生成し、公開鍵の有効期限を知っています。詳細は、公開鍵と秘密鍵のペアの生成 を参照してください。
- ターゲットシステムに公開鍵を登録しています。詳細は、公開鍵を MOK リストに追加して、ターゲットシステムに公開鍵を登録する を参照してください。
- 署名に使用できる GRUB EFI バイナリーがあります。
手順
x64 アーキテクチャーの場合:
署名済み GRUB EFI バイナリーを作成します。
pesign --in /boot/efi/EFI/redhat/grubx64.efi \ --out /boot/efi/EFI/redhat/grubx64.efi.signed \ --certificate 'Custom Secure Boot key' \ --sign# pesign --in /boot/efi/EFI/redhat/grubx64.efi \ --out /boot/efi/EFI/redhat/grubx64.efi.signed \ --certificate 'Custom Secure Boot key' \ --signCopy to Clipboard Copied! Toggle word wrap Toggle overflow Custom Secure Boot keyを以前に選択した名前に置き換えます。オプション: 署名を確認します。
pesign --in /boot/efi/EFI/redhat/grubx64.efi.signed \ --show-signature# pesign --in /boot/efi/EFI/redhat/grubx64.efi.signed \ --show-signatureCopy to Clipboard Copied! Toggle word wrap Toggle overflow 署名されていないバイナリーを署名済みバイナリーで上書きします。
mv /boot/efi/EFI/redhat/grubx64.efi.signed \ /boot/efi/EFI/redhat/grubx64.efi# mv /boot/efi/EFI/redhat/grubx64.efi.signed \ /boot/efi/EFI/redhat/grubx64.efiCopy to Clipboard Copied! Toggle word wrap Toggle overflow
64 ビット ARM アーキテクチャーの場合:
署名済み GRUB EFI バイナリーを作成します。
pesign --in /boot/efi/EFI/redhat/grubaa64.efi \ --out /boot/efi/EFI/redhat/grubaa64.efi.signed \ --certificate 'Custom Secure Boot key' \ --sign# pesign --in /boot/efi/EFI/redhat/grubaa64.efi \ --out /boot/efi/EFI/redhat/grubaa64.efi.signed \ --certificate 'Custom Secure Boot key' \ --signCopy to Clipboard Copied! Toggle word wrap Toggle overflow Custom Secure Boot keyを以前に選択した名前に置き換えます。オプション: 署名を確認します。
pesign --in /boot/efi/EFI/redhat/grubaa64.efi.signed \ --show-signature# pesign --in /boot/efi/EFI/redhat/grubaa64.efi.signed \ --show-signatureCopy to Clipboard Copied! Toggle word wrap Toggle overflow 署名されていないバイナリーを署名済みバイナリーで上書きします。
mv /boot/efi/EFI/redhat/grubaa64.efi.signed \ /boot/efi/EFI/redhat/grubaa64.efi# mv /boot/efi/EFI/redhat/grubaa64.efi.signed \ /boot/efi/EFI/redhat/grubaa64.efiCopy to Clipboard Copied! Toggle word wrap Toggle overflow
3.11. 秘密鍵を使用したカーネルモジュールの署名
UEFI セキュアブートメカニズムが有効になっている場合は、署名済みカーネルモジュールをロードすることでシステムのセキュリティーを強化できます。
署名済みカーネルモジュールは、UEFI セキュアブートが無効になっているシステムまたは非 UEFI システムでもロードできます。そのため、カーネルモジュールの署名済みバージョンと未署名バージョンの両方を提供する必要はありません。
前提条件
- 公開鍵と秘密鍵のペアを生成し、公開鍵の有効期限を知っています。詳細は、公開鍵と秘密鍵のペアの生成 を参照してください。
- ターゲットシステムに公開鍵を登録しています。詳細は、公開鍵を MOK リストに追加して、ターゲットシステムに公開鍵を登録する を参照してください。
- ELF イメージ形式で署名できるカーネルモジュールがある。
手順
公開鍵を
sb_cert.cerファイルにエクスポートします。certutil -d /etc/pki/pesign \ -n 'Custom Secure Boot key' \ -Lr \ > sb_cert.cer# certutil -d /etc/pki/pesign \ -n 'Custom Secure Boot key' \ -Lr \ > sb_cert.cerCopy to Clipboard Copied! Toggle word wrap Toggle overflow NSS データベースからキーを PKCS #12 ファイルとして抽出します。
pk12util -o sb_cert.p12 \ -n 'Custom Secure Boot key' \ -d /etc/pki/pesign# pk12util -o sb_cert.p12 \ -n 'Custom Secure Boot key' \ -d /etc/pki/pesignCopy to Clipboard Copied! Toggle word wrap Toggle overflow - 前のコマンドのプロンプトが表示されたら、秘密鍵を暗号化する新しいパスワードを入力します。
暗号化されていない秘密鍵をエクスポートします。
openssl pkcs12 \ -in sb_cert.p12 \ -out sb_cert.priv \ -nocerts \ -nodes# openssl pkcs12 \ -in sb_cert.p12 \ -out sb_cert.priv \ -nocerts \ -nodesCopy to Clipboard Copied! Toggle word wrap Toggle overflow 重要暗号化されていない秘密鍵を安全に保管してください。
カーネルモジュールに署名します。次のコマンドは、カーネルモジュールファイル内の ELF イメージに署名を直接追加します。
/usr/src/kernels/$(uname -r)/scripts/sign-file \ sha256 \ sb_cert.priv \ sb_cert.cer \ my_module.ko# /usr/src/kernels/$(uname -r)/scripts/sign-file \ sha256 \ sb_cert.priv \ sb_cert.cer \ my_module.koCopy to Clipboard Copied! Toggle word wrap Toggle overflow
これでカーネルモジュールの読み込み準備が完了しました。
RHEL 8 では、キーペアの有効期限が重要です。鍵に有効期限はありませんが、カーネルモジュールはその署名鍵の有効期間内に署名する必要があります。sign-file ユーティリティーでは、これに関する警告は表示されません。たとえば、2019 でのみ有効な鍵を使用して、その鍵で 2019 で署名されたカーネルモジュールを認証できます。ただし、ユーザーはこの鍵を使用して 2020 でカーネルモジュールに署名することはできません。
検証
カーネルモジュールの署名に関する情報を表示します。
modinfo my_module.ko | grep signer
# modinfo my_module.ko | grep signer signer: Your Name KeyCopy to Clipboard Copied! Toggle word wrap Toggle overflow 生成時に入力した名前が署名に記載されていることを確認します。
注記この追加された署名は ELF イメージセクションには含まれず、また ELF イメージの正式な一部ではありません。したがって、
readelfなどのユーティリティーは、カーネルモジュールの署名を表示できません。モジュールをロードします。
insmod my_module.ko
# insmod my_module.koCopy to Clipboard Copied! Toggle word wrap Toggle overflow モジュールを削除 (アンロード) します。
modprobe -r my_module.ko
# modprobe -r my_module.koCopy to Clipboard Copied! Toggle word wrap Toggle overflow
3.12. 署名済みカーネルモジュールの読み込み
公開鍵をシステムキーリング (.builtin_trusted_keys) と MOK リストに登録し、秘密鍵でカーネルモジュールに署名したら、modprobe コマンドを使用してそれらをロードできます。
前提条件
- 公開鍵と秘密鍵のペアを生成した。詳細は、公開鍵と秘密鍵のペアの生成 を参照してください。
- 公開鍵をシステムのキーリングに登録している。詳細は、公開鍵を MOK リストに追加して、ターゲットシステムに公開鍵を登録する を参照してください。
- 秘密鍵でカーネルモジュールに署名している。詳細は、秘密鍵を使用したカーネルモジュールの署名 を参照してください。
/lib/modules/$(uname -r)/extra/ディレクトリーを作成するkernel-modules-extraパッケージをインストールします。yum -y install kernel-modules-extra
# yum -y install kernel-modules-extraCopy to Clipboard Copied! Toggle word wrap Toggle overflow
手順
公開鍵がシステムキーリング上にあることを確認します。
keyctl list %:.platform
# keyctl list %:.platformCopy to Clipboard Copied! Toggle word wrap Toggle overflow カーネルモジュールを必要なカーネルの
extra/ディレクトリーにコピーします。cp my_module.ko /lib/modules/$(uname -r)/extra/
# cp my_module.ko /lib/modules/$(uname -r)/extra/Copy to Clipboard Copied! Toggle word wrap Toggle overflow モジュールの依存関係のリストを更新します。
depmod -a
# depmod -aCopy to Clipboard Copied! Toggle word wrap Toggle overflow カーネルモジュールを読み込みます。
modprobe -v my_module
# modprobe -v my_moduleCopy to Clipboard Copied! Toggle word wrap Toggle overflow オプション: 起動時にモジュールをロードするには、
/etc/modules-loaded.d/my_module.confファイルに追加します。echo "my_module" > /etc/modules-load.d/my_module.conf
# echo "my_module" > /etc/modules-load.d/my_module.confCopy to Clipboard Copied! Toggle word wrap Toggle overflow
検証
モジュールが正常にロードされたことを確認します。
lsmod | grep my_module
# lsmod | grep my_moduleCopy to Clipboard Copied! Toggle word wrap Toggle overflow
第4章 カーネルコマンドラインパラメーターの設定
カーネルコマンドラインパラメーターを使用すると、起動時に Red Hat Enterprise Linux カーネルの特定の側面の動作を変更できます。システム管理者は、起動時に設定されるオプションを制御します。特定のカーネル動作は起動時にのみ設定できることに注意してください。
カーネルコマンドラインパラメーターを変更してシステムの動作を変更すると、システムに悪影響を及ぼす可能性があります。変更を実稼働環境にデプロイする前に必ずテストしてください。詳細なガイダンスは、Red Hat Support チームまでご連絡ください。
4.1. カーネルコマンドラインパラメーターとは
カーネルコマンドラインパラメーターを使用すると、デフォルト値を上書きしたり、特定のハードウェア設定を指定したりできます。ブート時に、次の機能を設定できます。
- Red Hat Enterprise Linux カーネル
- 初期 RAM ディスク
- ユーザー領域機能
デフォルトでは、GRUB ブートローダーを使用するシステムのカーネルコマンドラインパラメーターは、カーネルブートエントリーごとに /boot/grub2/grubenv ファイルの kernelopts 変数で定義されます。
IBM Z では、zipl ブートローダーは環境変数に対応していないため、カーネルコマンドラインパラメーターはブートエントリー設定ファイルに保存されます。したがって、kernelopts 環境変数は使用できません。
grubby ユーティリティーを使用すると、ブートローダー設定ファイルを操作できます。grubby を使用すると、次のアクションを実行できます。
- デフォルトのブートエントリーの変更
- GRUB メニューエントリーに対する引数の追加または削除
4.2. ブートエントリーについて
ブートエントリーは、設定ファイルに保存され、特定のカーネルバージョンに関連付けられたオプションのコレクションです。実際には、ブートエントリーは、システムにカーネルがインストールされているのと同じ数だけあります。ブートエントリー設定ファイルは、/boot/loader/entries/ ディレクトリーにあります。
6f9cc9cb7d7845d49698c9537337cedc-4.18.0-5.el8.x86_64.conf
6f9cc9cb7d7845d49698c9537337cedc-4.18.0-5.el8.x86_64.conf
上記のファイル名は、/etc/machine-id ファイルに保存されているマシン ID と、カーネルバージョンから構成されます。
ブートエントリー設定ファイルには、カーネルバージョン、初期 ramdisk イメージ、およびカーネルのコマンドラインパラメーターを含む kernelopts 環境変数に関する情報が含まれています。設定ファイルには次の内容を含めることができます。
kernelopts 環境変数は /boot/grub2/grubenv ファイルで定義されます。
4.3. すべてのブートエントリーでカーネルコマンドラインパラメーターの変更
システム上のすべてのブートエントリーのカーネルコマンドラインパラメーターを変更します。
前提条件
-
grubbyユーティリティーがシステムにインストールされている。 -
ziplユーティリティーが IBM Z システムにインストールされている。
手順
パラメーターを追加するには、以下を行います。
grubby --update-kernel=ALL --args="<NEW_PARAMETER>"
# grubby --update-kernel=ALL --args="<NEW_PARAMETER>"Copy to Clipboard Copied! Toggle word wrap Toggle overflow GRUB ブートローダーを使用するシステムの場合は、
/boot/grub2/grubenvのkernelopts変数に新しいカーネルパラメーターを追加して、ファイルを更新します。IBM Z で、ブートメニューを更新します。
zipl
# ziplCopy to Clipboard Copied! Toggle word wrap Toggle overflow
パラメーターを削除するには、次のコマンドを実行します。
grubby --update-kernel=ALL --remove-args="<PARAMETER_TO_REMOVE>"
# grubby --update-kernel=ALL --remove-args="<PARAMETER_TO_REMOVE>"Copy to Clipboard Copied! Toggle word wrap Toggle overflow IBM Z で、ブートメニューを更新します。
zipl
# ziplCopy to Clipboard Copied! Toggle word wrap Toggle overflow
新しくインストールされたカーネルは、以前に設定されたカーネルからカーネルコマンドラインパラメーターを継承します。
4.4. 1 つのブートエントリーでカーネルコマンドラインパラメーターの変更
システム上の単一のブートエントリーのカーネルコマンドラインパラメーターを変更します。
前提条件
-
grubbyおよびziplユーティリティーがシステムにインストールされている。
手順
パラメーターを追加するには、以下を行います。
grubby --update-kernel=/boot/vmlinuz-$(uname -r) --args="<NEW_PARAMETER>"
# grubby --update-kernel=/boot/vmlinuz-$(uname -r) --args="<NEW_PARAMETER>"Copy to Clipboard Copied! Toggle word wrap Toggle overflow IBM Z で、ブートメニューを更新します。
grubby --args="<NEW_PARAMETER> --update-kernel=ALL --zipl
# grubby --args="<NEW_PARAMETER> --update-kernel=ALL --ziplCopy to Clipboard Copied! Toggle word wrap Toggle overflow
パラメーターを削除するには、次のコマンドを実行します。
grubby --update-kernel=/boot/vmlinuz-$(uname -r) --remove-args="<PARAMETER_TO_REMOVE>"
# grubby --update-kernel=/boot/vmlinuz-$(uname -r) --remove-args="<PARAMETER_TO_REMOVE>"Copy to Clipboard Copied! Toggle word wrap Toggle overflow IBM Z で、ブートメニューを更新します。
grubby --args="<PARAMETER_TO_REMOVE> --update-kernel=ALL --zipl
# grubby --args="<PARAMETER_TO_REMOVE> --update-kernel=ALL --ziplCopy to Clipboard Copied! Toggle word wrap Toggle overflow
grub.cfg ファイルを使用するシステムでは、デフォルトで、カーネルブートエントリーごとに options パラメーターがあり、これは kernelopts 変数に設定されます。この変数は、/boot/grub2/grubenv 設定ファイルで定義されます。
GRUB システムの場合:
-
すべてのブートエントリーに対してカーネルコマンドラインパラメーターを変更する場合には、
grubbyユーティリティーは/boot/grub2/grubenvファイルのkernelopts変数を更新します。 -
1 つのブートエントリーのカーネルコマンドラインパラメーターが変更されると、
kernelopts変数の拡張やカーネルパラメーターの変更が行われ、得られた値は各ブートエントリーの/boot/loader/entries/<RELEVANT_KERNEL_BOOT_ENTRY.conf>ファイルに保存されます。
zIPL システムの場合:
-
grubbyは、個別のカーネルブートエントリーのカーネルコマンドラインパラメーターを変更して、/boot/loader/entries/<ENTRY>.confファイルに保存します。
4.5. 起動時の一時的なカーネルコマンドラインパラメーターの変更
1 回の起動プロセス中にのみカーネルパラメーターを変更することで、カーネルメニューエントリーを一時的に変更します。
この手順は単一ブートにのみ適用され、変更は永続的に行われません。
手順
- GRUB ブートメニューを起動します。
- 起動するカーネルを選択します。
- e キーを押してカーネルパラメーターを編集します。
-
カーソルを下に移動してカーネルコマンドラインを見つけます。カーネルコマンドラインは、64 ビット IBM Power シリーズおよび x86-64 BIOS ベースのシステムの場合は
linuxで始まり、UEFI システムの場合はlinuxefiで始まります。 カーソルを行の最後に移動します。
注記行の最初に移動するには Ctrl+a を押します。行の最後に移動するには Ctrl+e を押します。システムによっては、Home キーおよび End キーも機能する場合があります。
必要に応じてカーネルパラメーターを編集します。たとえば、緊急モードでシステムを実行するには、
linux行の最後にemergencyパラメーターを追加します。linux ($root)/vmlinuz-4.18.0-348.12.2.el8_5.x86_64 root=/dev/mapper/rhel-root ro crashkernel=auto resume=/dev/mapper/rhel-swap rd.lvm.lv=rhel/root rd.lvm.lv=rhel/swap rhgb quiet emergency
linux ($root)/vmlinuz-4.18.0-348.12.2.el8_5.x86_64 root=/dev/mapper/rhel-root ro crashkernel=auto resume=/dev/mapper/rhel-swap rd.lvm.lv=rhel/root rd.lvm.lv=rhel/swap rhgb quiet emergencyCopy to Clipboard Copied! Toggle word wrap Toggle overflow システムメッセージを有効にするには、
rhgbおよびquietパラメーターを削除します。- Ctrl+x を押して、選択したカーネルと変更したコマンドラインパラメーターで起動します。
Esc キーを押してコマンドラインの編集を終了すると、ユーザーの加えた変更はすべて破棄されます。
4.6. シリアルコンソール接続を有効にする GRUB 設定
シリアルコンソールは、ネットワークがダウンしている場合にヘッドレスサーバーまたは埋め込みシステムに接続する際に便利です。あるいは、セキュリティールールを回避し、別のシステムへのログインアクセスを取得する必要がある場合などです。
シリアルコンソール接続を使用するように、デフォルトの GRUB 設定の一部を設定する必要があります。
前提条件
- root 権限がある。
手順
/etc/default/grubファイルに以下の 2 つの行を追加します。GRUB_TERMINAL="serial" GRUB_SERIAL_COMMAND="serial --speed=9600 --unit=0 --word=8 --parity=no --stop=1"
GRUB_TERMINAL="serial" GRUB_SERIAL_COMMAND="serial --speed=9600 --unit=0 --word=8 --parity=no --stop=1"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 最初の行は、グラフィカルターミナルを無効にします。
GRUB_TERMINALキーは、GRUB_TERMINAL_INPUTおよびGRUB_TERMINAL_OUTPUTの値を上書きします。2 行目は、ボーレート (
--speed)、パリティー、および他の値を使用中の環境とハードウェアに適合するように調整します。以下のログファイルのようなタスクには、115200 のように非常に高いボーレートが推奨されます。GRUB 設定ファイルを更新します。
BIOS ベースのマシンの場合:
grub2-mkconfig -o /boot/grub2/grub.cfg
# grub2-mkconfig -o /boot/grub2/grub.cfgCopy to Clipboard Copied! Toggle word wrap Toggle overflow UEFI ベースのマシンの場合:
grub2-mkconfig -o /boot/efi/EFI/redhat/grub.cfg
# grub2-mkconfig -o /boot/efi/EFI/redhat/grub.cfgCopy to Clipboard Copied! Toggle word wrap Toggle overflow
- システムを再起動して、変更を有効にします。
第5章 実行時のカーネルパラメーターの設定
システム管理者は、実行時に Red Hat Enterprise Linux カーネルの動作のさまざまな側面を変更できます。sysctl コマンドを使用し、/etc/sysctl.d/ および /proc/sys/ ディレクトリー内の設定ファイルを変更して、実行時にカーネルパラメーターを設定します。
プロダクションシステムでカーネルパラメーターを設定するには、慎重なプランニングが必要です。計画外の変更を行うと、カーネルが不安定になり、システムの再起動が必要になる場合があります。カーネル値を変更する前に、有効なオプションを使用していることを確認してください。
IBM DB2 でのカーネルのチューニングに関する詳細は、Tuning Red Hat Enterprise Linux for IBM DB2 を参照してください。
5.1. カーネルパラメーターとは
カーネルパラメーターは、システムの実行中に調整できる調整可能な値です。変更を有効にするために、システムを再起動したりカーネルを再コンパイルしたりする必要がないことに注意してください。
以下を使用してカーネルパラメーターに対応できます。
-
sysctlコマンド -
/proc/sys/ディレクトリーにマウントされている仮想ファイルシステム -
/etc/sysctl.d/ディレクトリー内の設定ファイル
調整可能パラメーターは、カーネルサブシステムでクラスに分割されます。Red Hat Enterprise Linux には、以下の調整可能のクラスがあります。
| 調整パラメーターのクラス | サブシステム |
|---|---|
|
| 実行ドメインおよびパーソナリティー |
|
| 暗号化インターフェイス |
|
| カーネルのデバッグインターフェイス |
|
| デバイス固有の情報 |
|
| グローバルおよび特定のファイルシステムの設定項目 |
|
| グローバルなカーネルの設定項目 |
|
| ネットワークの設定項目 |
|
| Sun Remote Procedure Call (NFS) |
|
| ユーザー名前空間の制限 |
|
| メモリー、バッファー、およびキャッシュのチューニングと管理 |
5.2. sysctl でカーネルパラメーターの一時的な設定
sysctl コマンドを使用して、実行時に一時的にカーネルパラメーターを設定します。このコマンドは、調整可能パラメーターのリスト表示およびフィルタリングにも便利です。
前提条件
- root 権限がある。
手順
すべてのパラメーターとその値をリストします。
sysctl -a
# sysctl -a# sysctl -aCopy to Clipboard Copied! Toggle word wrap Toggle overflow 注記# sysctl -aコマンドは、ランタイム時およびシステムの起動時に調整できるカーネルパラメーターを表示します。パラメーターを一時的に設定するには、次のように入力します。
sysctl <TUNABLE_CLASS>.<PARAMETER>=<TARGET_VALUE>
# sysctl <TUNABLE_CLASS>.<PARAMETER>=<TARGET_VALUE>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 上記のサンプルコマンドは、システムの実行中にパラメーター値を変更します。この変更は、再起動なしですぐに適用されます。
注記変更は、システムの再起動後にデフォルトに戻ります。
5.3. sysctl を使用したカーネルパラメーターの永続的な設定
sysctl コマンドを使用して、カーネルパラメーターを永続的に設定します。
前提条件
- root 権限がある。
手順
すべてのパラメーターをリストします。
sysctl -a
# sysctl -a# sysctl -aCopy to Clipboard Copied! Toggle word wrap Toggle overflow このコマンドは、実行時に設定できるカーネルパラメーターをすべて表示します。
パラメーターを永続的に設定します。
sysctl -w <TUNABLE_CLASS>.<PARAMETER>=<TARGET_VALUE> >> /etc/sysctl.conf
# sysctl -w <TUNABLE_CLASS>.<PARAMETER>=<TARGET_VALUE> >> /etc/sysctl.confCopy to Clipboard Copied! Toggle word wrap Toggle overflow サンプルコマンドは、調整可能な値を変更して、
/etc/sysctl.confファイルに書き込みます。これにより、カーネルパラメーターのデフォルト値が上書きされます。変更は、再起動なしで即座に永続的に反映されます。
カーネルパラメーターを永続的に変更するには、/etc/sysctl.d/ ディレクトリーの設定ファイルを手動で変更することもできます。
5.4. /etc/sysctl.d/ の設定ファイルでカーネルパラメーターの調整
カーネルパラメーターを永続的に設定するには、/etc/sysctl.d/ ディレクトリー内の設定ファイルを手動で変更する必要があります。
前提条件
- root 権限がある。
手順
/etc/sysctl.d/に新しい設定ファイルを作成します。vim /etc/sysctl.d/<some_file.conf>
# vim /etc/sysctl.d/<some_file.conf># vim /etc/sysctl.d/<some_file.conf>Copy to Clipboard Copied! Toggle word wrap Toggle overflow カーネルパラメーターを 1 行に 1 つずつ含めます。
<TUNABLE_CLASS>.<PARAMETER>=<TARGET_VALUE> <TUNABLE_CLASS>.<PARAMETER>=<TARGET_VALUE>
<TUNABLE_CLASS>.<PARAMETER>=<TARGET_VALUE><TUNABLE_CLASS>.<PARAMETER>=<TARGET_VALUE><TUNABLE_CLASS>.<PARAMETER>=<TARGET_VALUE><TUNABLE_CLASS>.<PARAMETER>=<TARGET_VALUE><TUNABLE_CLASS>.<PARAMETER>=<TARGET_VALUE><TUNABLE_CLASS>.<PARAMETER>=<TARGET_VALUE><TUNABLE_CLASS>.<PARAMETER>=<TARGET_VALUE> <TUNABLE_CLASS>.<PARAMETER>=<TARGET_VALUE><TUNABLE_CLASS>.<PARAMETER>=<TARGET_VALUE><TUNABLE_CLASS>.<PARAMETER>=<TARGET_VALUE><TUNABLE_CLASS>.<PARAMETER>=<TARGET_VALUE><TUNABLE_CLASS>.<PARAMETER>=<TARGET_VALUE><TUNABLE_CLASS>.<PARAMETER>=<TARGET_VALUE><TUNABLE_CLASS>.<PARAMETER>=<TARGET_VALUE>Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 設定ファイルを保存します。
マシンを再起動して、変更を有効にします。
または、再起動せずに変更を適用します。
sysctl -p /etc/sysctl.d/<some_file.conf>
# sysctl -p /etc/sysctl.d/<some_file.conf># sysctl -p /etc/sysctl.d/<some_file.conf>Copy to Clipboard Copied! Toggle word wrap Toggle overflow このコマンドにより、以前に作成した設定ファイルから値を読み取ることができます。
5.5. /proc/sys/ でカーネルパラメーターの一時的な設定
/proc/sys/ 仮想ファイルシステムディレクトリー内のファイルを使用して、一時的にカーネルパラメーターを設定します。
前提条件
- root 権限がある。
手順
設定するカーネルパラメーターを特定します。
ls -l /proc/sys/<TUNABLE_CLASS>/
# ls -l /proc/sys/<TUNABLE_CLASS>/# ls -l /proc/sys/<TUNABLE_CLASS>/Copy to Clipboard Copied! Toggle word wrap Toggle overflow コマンドが返した書き込み可能なファイルは、カーネルの設定に使用できます。読み取り専用権限を持つファイルは、現在の設定に関するフィードバックを提供します。
カーネルパラメーターにターゲットの値を割り当てます。
echo <TARGET_VALUE> > /proc/sys/<TUNABLE_CLASS>/<PARAMETER>
# echo <TARGET_VALUE> > /proc/sys/<TUNABLE_CLASS>/<PARAMETER># echo <TARGET_VALUE> > /proc/sys/<TUNABLE_CLASS>/<PARAMETER>Copy to Clipboard Copied! Toggle word wrap Toggle overflow コマンドを使用して適用された設定の変更は永続的なものではなく、システムを再起動すると消えてしまいます。
検証
新しく設定したカーネルパラメーターの値を確認します。
cat /proc/sys/<TUNABLE_CLASS>/<PARAMETER>
# cat /proc/sys/<TUNABLE_CLASS>/<PARAMETER># cat /proc/sys/<TUNABLE_CLASS>/<PARAMETER>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
第6章 GRUB メニューを一時的に変更する
GRUB メニューエントリーを変更したり、現在のブートにのみ適用される引数をカーネルに渡したりできます。ブートローダーメニューで選択したメニューエントリーでは、次のことができます。
- e キーを押して、メニューエントリーエディターインターフェイスを表示します。
- 変更を破棄し、Esc キーを押して標準メニューインターフェイスを再ロードします。
- c キーを押してコマンドラインを読み込みます。
- 関連する GRUB コマンドを入力し、Enter キーを押して入力します。
- Tab キーを押して、コンテキストに基づいてコマンドを完了します。
- Ctrl+a キーの組み合わせを押して、行の先頭に移動します。
- Ctrl+e キーの組み合わせを押して、行末に移動します。
次の手順では、1 回の起動プロセス中に GRUB メニューを変更する方法について説明します。
6.1. GRUB について
GNU GRand Unified Bootloader (GRUB) を使用して、次のアクションを実行できます。
- システムの起動時にロードするオペレーティングシステムまたはカーネルを選択します。
- カーネルに引数を渡します。
GRUB で起動する場合は、メニューインターフェイスまたはコマンドラインインターフェイス (GRUB command shell) のいずれかを使用できます。システムを起動すると、メニューインターフェイスが表示されます。

c キーを押すとコマンドラインに切り替えることができます。

exit と入力して Enter キーを押すと、メニューインターフェイスに戻ることができます。
GRUB BLS ファイル
ブートローダーメニューエントリーは、ブートローダー仕様 (BLS) ファイルとして定義されます。このファイル形式は、ブートローダー設定ファイルを操作することなく、ドロップインディレクトリー内の各ブートオプションのブートローダー設定を管理します。grubby ユーティリティーは、これらの BLS ファイルを編集できます。
GRUB 設定ファイル
/boot/grub2/grub.cfg 設定ファイルは、メニューエントリーを定義しません。
6.3. レスキューモードでの起動
レスキューモードは、便利なシングルユーザー環境を提供し、通常の起動プロセスを完了できない状況においてシステムの修復を可能にします。レスキューモードでは、システムはすべてのローカルファイルシステムをマウントし、いくつかの重要なシステムサービスを開始しようとします。ただし、ネットワークインターフェイスをアクティブにしたり、より多くのユーザーが同時にシステムにログインしたりすることはできません。
手順
- GRUB ブート画面で、e キーを押して編集します。
Linux行の末尾に次のパラメーターを追加します。systemd.unit=rescue.target
systemd.unit=rescue.targetCopy to Clipboard Copied! Toggle word wrap Toggle overflow Ctrl+x を押して、レスキューモードで起動します。


6.4. 緊急モードでの起動
緊急モードは、可能な限り最小限の環境を提供し、システムがレスキューモードに入れない状態でもシステムの修復を可能にします。
緊急モードでは、システムは次のことを行います。
-
rootファイルシステムを読み取り専用にマウントします - いくつかの重要なサービスを開始します
ただし、システムは次のことを 行いません。
- 他のローカルファイルシステムのマウントを試みる
- ネットワークインターフェイスをアクティブにする
手順
- GRUB ブート画面で、e キーを押して編集します。
Linux行の末尾に次のパラメーターを追加します。systemd.unit=emergency.target
systemd.unit=emergency.targetCopy to Clipboard Copied! Toggle word wrap Toggle overflow Ctrl+x を押して緊急モードで起動します。


6.5. デバッグシェルのブート
systemd デバッグシェルは、起動プロセスの非常に早い段階でシェルプロンプトを提供します。デバッグシェルに入ったら、systemctl list-jobs や systemctl list-units などの systemctl コマンドを使用して、systemd 関連の起動問題の原因を検索できます。
手順
- GRUB ブート画面で、e キーを押して編集します。
Linux行の末尾に次のパラメーターを追加します。systemd.debug-shell
systemd.debug-shellCopy to Clipboard Copied! Toggle word wrap Toggle overflow オプション:
debugオプションを追加します。注記カーネルコマンドラインに
debugオプションを追加すると、ログメッセージの数が増加します。systemdでは、カーネルコマンドラインオプションのdebugが、systemd.log_level=debugのショートカットになりました。- Ctrl+x を押して、デバッグシェルを起動します。

デバッグシェルを永続的に有効にすると、使用に認証が必要ないため、セキュリティー上のリスクが生じます。デバッグセッションが終了したら無効にすることを推奨します。
6.6. デバッグシェルへの接続
起動プロセス中に、systemd-debug-generator は TTY9 でデバッグシェルを設定します。
前提条件
- デバッグシェルが正常に起動しました。デバッグシェルのブート を参照してください。
手順
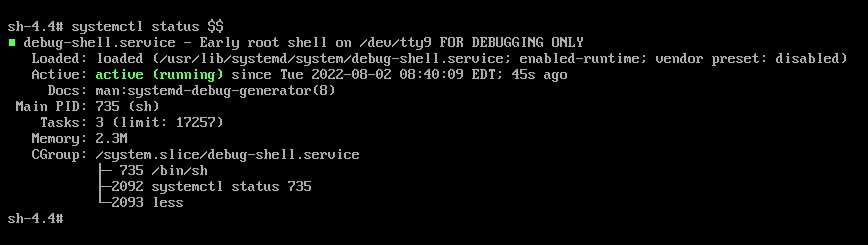
Ctrl+Alt+F9 を押してデバッグシェルに接続します。
仮想マシンを使用している場合は、このキーの組み合わせを送信するには、仮想化アプリケーションからのサポートが必要です。たとえば、Virtual Machine Manager を使用している場合は、メニューから → を選択します。
- デバッグシェルは認証を必要としないため、TTY9 で次のようなプロンプトが表示されます。
sh-4.4#
sh-4.4#検証
以下のようなコマンドを入力します。
systemctl status $$
sh-4.4# systemctl status $$Copy to Clipboard Copied! Toggle word wrap Toggle overflow - デフォルトのシェルに戻るには、ブートが成功した場合に Ctrl+Alt+F1 を押します。
6.7. インストールディスクを使用した root パスワードのリセット
root パスワードを忘れた場合や紛失した場合は、リセットできます。
手順
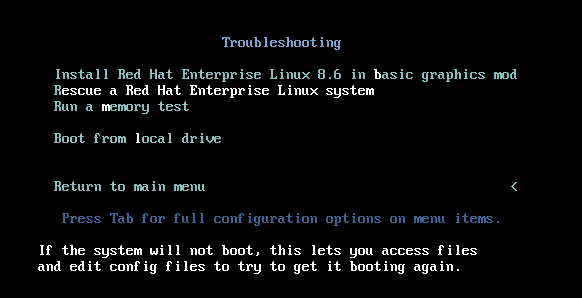
- インストールソースからホストを起動します。
インストールメディアのブートメニューで、
Troubleshootingを選択します。Troubleshooting メニューで
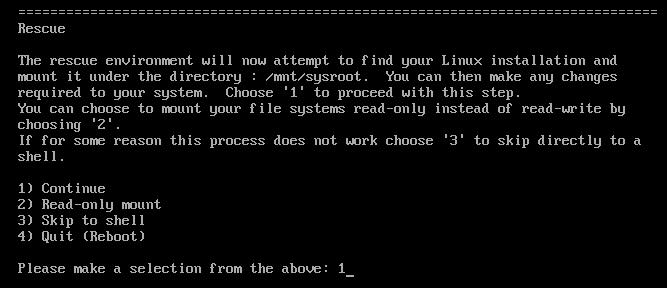
Rescue a Red Hat Enterprise Linux systemオプションを選択します。Rescue メニューで
1を選択し、Enter キーを押して続行します。以下のようにファイルシステム
rootを変更します。chroot /mnt/sysimage
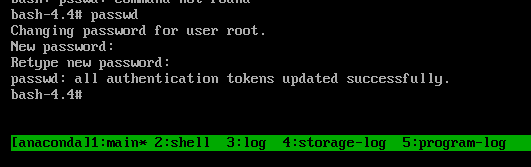
sh-4.4# chroot /mnt/sysimageCopy to Clipboard Copied! Toggle word wrap Toggle overflow passwdコマンドを入力し、コマンドラインに表示される指示にしたがってrootパスワードを変更します。時間がかかるディスクの SELinux の再ラベルを防ぐために、
autorelableファイルを削除します。rm -f /.autorelabel
sh-4.4# rm -f /.autorelabelCopy to Clipboard Copied! Toggle word wrap Toggle overflow -
exitコマンドを入力して、chroot環境を終了します。 -
exitコマンドを再び実行して初期化を再開し、システム起動を完了します。


6.8. rd.break を使用した root パスワードのリセット
root パスワードを忘れた場合や紛失した場合は、リセットできます。
手順
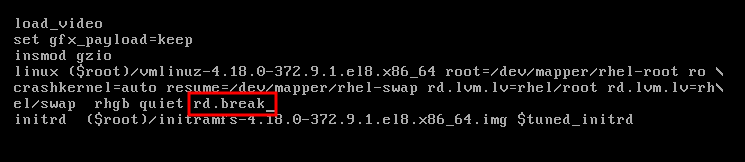
- システムを起動し、GRUB ブート画面で e キーを押して編集を行います。
Linux行の末尾にrd.breakパラメーターを追加します。Ctrl+x を押して変更したパラメーターでシステムを起動します。
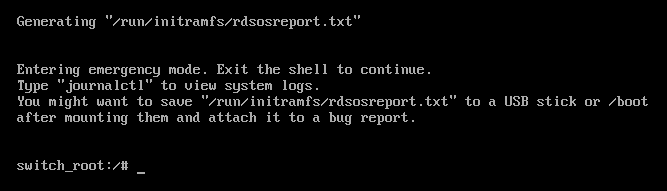
ファイルシステムを書き込み可能で再マウントします。
switch_root:/# mount -o remount,rw /sysroot
switch_root:/# mount -o remount,rw /sysrootCopy to Clipboard Copied! Toggle word wrap Toggle overflow ファイルシステムの
rootを変更します。switch_root:/# chroot /sysroot
switch_root:/# chroot /sysrootCopy to Clipboard Copied! Toggle word wrap Toggle overflow passwdコマンドを入力し、コマンドラインに表示される指示に従います。次回のシステム起動時にすべてのファイルにラベルを付け直します。
touch /.autorelabel
sh-4.4# touch /.autorelabelCopy to Clipboard Copied! Toggle word wrap Toggle overflow ファイルシステムを 読み取り専用 で再マウントします。
mount -o remount,ro /
sh-4.4# mount -o remount,ro /Copy to Clipboard Copied! Toggle word wrap Toggle overflow -
exitコマンドを入力して、chroot環境を終了します。 exitコマンドを再び実行して初期化を再開し、システム起動を完了します。注記SELinux の再ラベル付けプロセスには時間がかかる場合があります。プロセスが完了すると、システムが自動的に再起動します。
enforcing=0 オプションを追加すると、時間のかかる SELinux の再ラベル付けプロセスを省略できます。
手順
linux行の最後にrd.breakパラメーターを追加するときは、enforcing=0も追加します。rd.break enforcing=0
rd.break enforcing=0Copy to Clipboard Copied! Toggle word wrap Toggle overflow /etc/shadowファイルの SELinux セキュリティーコンテキストを復元します。restorecon /etc/shadow
# restorecon /etc/shadowCopy to Clipboard Copied! Toggle word wrap Toggle overflow SELinux ポリシーの適用をオンに戻し、オンになっていることを確認します。
setenforce 1 getenforce
# setenforce 1 # getenforce EnforcingCopy to Clipboard Copied! Toggle word wrap Toggle overflow
手順 3 で enforcing=0 オプションを追加した場合は、手順 8 で touch /.autorelabel コマンドの入力を省略できることに注意してください。
第7章 GRUB ブートローダーに永続的な変更を加える
grubby ツールを使用して、GRUB で永続的な変更を行います。
7.1. 前提条件
- システムに RHEL が正常にインストールされました。
- root 権限がある。
7.2. デフォルトのカーネルの一覧表示
デフォルトのカーネルを一覧表示すると、デフォルトのカーネルのファイル名およびインデックス番号を見つけて、GRUB ブートローダーに永続的な変更を加えることができます。
手順
- デフォルトカーネルのファイル名を取得するには、次のように入力します。
grubby --default-kernel
# grubby --default-kernel
/boot/vmlinuz-4.18.0-372.9.1.el8.x86_64- デフォルトカーネルのインデックス番号を取得するには、次のように入力します。
grubby --default-index
# grubby --default-index
07.4. カーネル引数の編集
既存のカーネル引数の値を変更できます。たとえば、仮想コンソール (画面) のフォントとサイズを変更できます。
手順
仮想コンソールのフォントを、サイズが
32のlatarcyrheb-sunに変更します。grubby --args=vconsole.font=latarcyrheb-sun32 --update-kernel /boot/vmlinuz-4.18.0-372.9.1.el8.x86_64
# grubby --args=vconsole.font=latarcyrheb-sun32 --update-kernel /boot/vmlinuz-4.18.0-372.9.1.el8.x86_64Copy to Clipboard Copied! Toggle word wrap Toggle overflow
7.6. 新しいブートエントリーの追加
ブートローダーメニューエントリーに新しいブートエントリーを追加できます。
手順
すべてのカーネル引数をデフォルトカーネルからこの新しいカーネルエントリーにコピーします。
grubby --add-kernel=new_kernel --title="entry_title" --initrd="new_initrd" --copy-default
# grubby --add-kernel=new_kernel --title="entry_title" --initrd="new_initrd" --copy-defaultCopy to Clipboard Copied! Toggle word wrap Toggle overflow 利用可能なブートエントリーのリストを取得します。
ls -l /boot/loader/entries/*
# ls -l /boot/loader/entries/* -rw-r--r--. 1 root root 408 May 27 06:18 /boot/loader/entries/67db13ba8cdb420794ef3ee0a8313205-0-rescue.conf -rw-r--r--. 1 root root 536 Jun 30 07:53 /boot/loader/entries/67db13ba8cdb420794ef3ee0a8313205-4.18.0-372.9.1.el8.x86_64.conf -rw-r--r-- 1 root root 336 Aug 15 15:12 /boot/loader/entries/d88fa2c7ff574ae782ec8c4288de4e85-4.18.0-193.el8.x86_64.confCopy to Clipboard Copied! Toggle word wrap Toggle overflow 新たなブートエントリーを作成します。たとえば、4.18.0-193.el8.x86_64 カーネルの場合は、次のようにコマンドを発行します。
grubby --grub2 --add-kernel=/boot/vmlinuz-4.18.0-193.el8.x86_64 --title="Red Hat Enterprise 8 Test" --initrd=/boot/initramfs-4.18.0-193.el8.x86_64.img --copy-default
# grubby --grub2 --add-kernel=/boot/vmlinuz-4.18.0-193.el8.x86_64 --title="Red Hat Enterprise 8 Test" --initrd=/boot/initramfs-4.18.0-193.el8.x86_64.img --copy-defaultCopy to Clipboard Copied! Toggle word wrap Toggle overflow
検証
新しく追加されたブートエントリーが、使用可能なブートエントリーのリストに表示されていることを確認します。
ls -l /boot/loader/entries/*
# ls -l /boot/loader/entries/* -rw-r--r--. 1 root root 408 May 27 06:18 /boot/loader/entries/67db13ba8cdb420794ef3ee0a8313205-0-rescue.conf -rw-r--r--. 1 root root 536 Jun 30 07:53 /boot/loader/entries/67db13ba8cdb420794ef3ee0a8313205-4.18.0-372.9.1.el8.x86_64.conf -rw-r--r-- 1 root root 287 Aug 16 15:17 /boot/loader/entries/d88fa2c7ff574ae782ec8c4288de4e85-4.18.0-193.el8.x86_64.0~custom.conf -rw-r--r-- 1 root root 287 Aug 16 15:29 /boot/loader/entries/d88fa2c7ff574ae782ec8c4288de4e85-4.18.0-193.el8.x86_64.confCopy to Clipboard Copied! Toggle word wrap Toggle overflow
7.7. grubby でデフォルトのブートエントリーを変更する
grubby ツールを使用すると、デフォルトのブートエントリーを変更できます。
手順
- デフォルトのカーネルとして指定されたカーネルに永続的な変更を加えるには、次のように入力します。
grubby --set-default /boot/vmlinuz-4.18.0-372.9.1.el8.x86_64
# grubby --set-default /boot/vmlinuz-4.18.0-372.9.1.el8.x86_64
The default is /boot/loader/entries/67db13ba8cdb420794ef3ee0a8313205-4.18.0-372.9.1.el8.x86_64.conf with index 0 and kernel /boot/vmlinuz-4.18.0-372.9.1.el8.x86_647.9. 現在および将来のカーネルのデフォルトカーネルオプションの変更
kernelopts 変数を使用すると、現在および将来のカーネルのデフォルトカーネルオプションを変更できます。
手順
kernelopts変数を使用してカーネルパラメーターをリスト表示します。grub2-editenv - list | grep kernelopts
# grub2-editenv - list | grep kernelopts kernelopts=root=/dev/mapper/rhel-root ro crashkernel=auto resume=/dev/mapper/rhel-swap rd.lvm.lv=rhel/root rd.lvm.lv=rhel/swap rhgb quietCopy to Clipboard Copied! Toggle word wrap Toggle overflow カーネルのコマンドラインパラメーターを変更します。パラメーターを追加、削除、または変更できます。たとえば、
debugパラメーターを追加するには、次のように入力します。grub2-editenv - set "$(grub2-editenv - list | grep kernelopts) <debug>"
# grub2-editenv - set "$(grub2-editenv - list | grep kernelopts) <debug>"Copy to Clipboard Copied! Toggle word wrap Toggle overflow オプション:
kerneloptsに新しく追加されたパラメーターを確認します。grub2-editenv - list | grep kernelopts
# grub2-editenv - list | grep kernelopts kernelopts=root=/dev/mapper/rhel-root ro crashkernel=auto resume=/dev/mapper/rhel-swap rd.lvm.lv=rhel/root rd.lvm.lv=rhel/swap rhgb quiet debugCopy to Clipboard Copied! Toggle word wrap Toggle overflow - システムを再起動して、変更を有効にします。
代わりに、grubby コマンドを使用して、現在および将来のカーネルに引数を渡すこともできます。
grubby --update-kernel ALL --args="<PARAMETER>"
# grubby --update-kernel ALL --args="<PARAMETER>"第9章 GRUB の再インストール
GRUB ブートローダーを再インストールすると、GRUB の誤ったインストール、ファイルの欠落、またはシステムの破損によってよく発生する一部の問題を修正できます。これらの問題は、不足しているファイルを復元し、ブート情報を更新することで解決できます。
GRUB を再インストールする理由:
- GRUB ブートローダーパッケージをアップグレードする。
- 別のドライブにブート情報を追加する。
- インストール済みのオペレーティングシステムを制御するために、ユーザーが GRUB ブートローダーを必要としている。ただし、一部のオペレーティングシステムには独自のブートローダーがインストールされており、GRUB を再インストールすると、目的のオペレーティングシステムに制御権限が戻されます。
GRUB は、ファイルが破損していない場合にのみファイルを復元します。
9.1. BIOS ベースマシンへの GRUB の再インストール
BIOS ベースのシステムに GRUB ブートローダーを再インストールできます。GRUB パッケージを更新した後は必ず GRUB を再インストールしてください。
これにより、既存の GRUB が上書きされ、新しい GRUB がインストールされます。インストール中にシステムでデータの破損やブートクラッシュが発生しないようにしてください。
手順
GRUB がインストールされているデバイスに GRUB を再インストールします。たとえば、
sdaがデバイスの場合は、以下のようになります。grub2-install /dev/sda
# grub2-install /dev/sdaCopy to Clipboard Copied! Toggle word wrap Toggle overflow システムを再起動して、変更を有効にします。
reboot
# rebootCopy to Clipboard Copied! Toggle word wrap Toggle overflow
9.2. UEFI ベースマシンへの GRUB の再インストール
UEFI ベースのシステムに GRUB ブートローダーを再インストールできます。
インストール中にシステムでデータの破損やブートクラッシュが発生しないようにしてください。
手順
grub2-efiおよびshimブートローダーファイルを再インストールします。yum reinstall grub2-efi shim
# yum reinstall grub2-efi shimCopy to Clipboard Copied! Toggle word wrap Toggle overflow システムを再起動して、変更を有効にします。
reboot
# rebootCopy to Clipboard Copied! Toggle word wrap Toggle overflow
9.3. IBM Power マシンへの GRUB の再インストール
IBM Power システムの Power PC Reference Platform (PReP) ブートパーティションに GRUB ブートローダーを再インストールできます。GRUB パッケージを更新した後は必ず GRUB を再インストールしてください。
これにより、既存の GRUB が上書きされ、新しい GRUB がインストールされます。インストール中にシステムでデータの破損やブートクラッシュが発生しないようにしてください。
手順
GRUB が格納されているディスクパーティションを特定します。
bootlist -m normal -o
# bootlist -m normal -o sda1Copy to Clipboard Copied! Toggle word wrap Toggle overflow ディスクパーティションに GRUB を再インストールします。
grub2-install partition
# grub2-install partitionCopy to Clipboard Copied! Toggle word wrap Toggle overflow partitionは、識別された GRUB パーティション (/dev/sda1など) に置き換えます。システムを再起動して、変更を有効にします。
reboot
# rebootCopy to Clipboard Copied! Toggle word wrap Toggle overflow
9.4. GRUB のリセット
GRUB をリセットすると、すべての GRUB 設定ファイルとシステム設定が完全に削除され、ブートローダーが再インストールされます。すべての設定をデフォルト値にリセットして、破損したファイルや無効な設定によって発生した障害を修正できます。
次の手順では、ユーザーが行ったすべてのカスタマイズが削除されます。
手順
設定ファイルを削除します。
rm /etc/grub.d/* rm /etc/sysconfig/grub
# rm /etc/grub.d/* # rm /etc/sysconfig/grubCopy to Clipboard Copied! Toggle word wrap Toggle overflow パッケージを再インストールします。
BIOS ベースのマシンの場合:
yum reinstall grub2-tools
# yum reinstall grub2-toolsCopy to Clipboard Copied! Toggle word wrap Toggle overflow UEFI ベースのマシンの場合:
yum reinstall grub2-efi shim grub2-tools grub2-common
# yum reinstall grub2-efi shim grub2-tools grub2-commonCopy to Clipboard Copied! Toggle word wrap Toggle overflow
変更を有効にするために
grub.cfgファイルを再ビルドします。BIOS ベースのマシンの場合:
grub2-mkconfig -o /boot/grub2/grub.cfg
# grub2-mkconfig -o /boot/grub2/grub.cfgCopy to Clipboard Copied! Toggle word wrap Toggle overflow UEFI ベースのマシンの場合:
grub2-mkconfig -o /boot/efi/EFI/redhat/grub.cfg
# grub2-mkconfig -o /boot/efi/EFI/redhat/grub.cfgCopy to Clipboard Copied! Toggle word wrap Toggle overflow
-
GRUB の再インストール 手順に従って、
/boot/パーティションに GRUB を復元します。
第10章 GRUB をパスワードで保護する
GRUB をパスワードで保護するには、次の 2 つの方法があります。
- メニューエントリーの修正にはパスワードが必要ですが、既存のメニューエントリーの起動には必要ありません。
- メニューエントリーを変更したり、既存のメニューエントリーを起動したりするには、パスワードが必要です。
第11章 仮想化環境でカーネルパニックのパラメーターを無効のままにする
RHEL 8 に仮想マシンを設定する場合は、仮想マシンで偽ソフトロックアップが発生する可能性があるため、カーネルパラメーター softlockup_panic および nmi_watchdog を有効にしないでください。また、カーネルパニックは必要ありません。
以下のセクションで、このアドバイスの背後にある理由を見つけてください。
11.1. ソフトロックアップとは
ソフトロックアップは、通常、タスクが再スケジュールされずに CPU のカーネル領域で実行しているときにバグによって生じる状況です。また、このタスクは、その他のタスクがその特定の CPU で実行することを許可しません。これにより、警告が、システムコンソールを介してユーザーに表示されます。この問題は、ソフトロックアップの発生 (fire) とも呼ばれます。
11.2. カーネルパニックを制御するパラメーター
ソフトロックの検出時にシステムの動作を制御する、以下のカーネルパラメーターを設定できます。
softlockup_panicソフトロックアップが検出されたときにカーネルでパニックを発生させるどうかを制御します。
Expand タイプ 値 効果 整数
0
カーネルが、ソフトロックアップでパニックにならない
整数
1
カーネルが、ソフトロックアップでパニックになる
RHEL 8 では、この値はデフォルトで 0 です。
システムでパニックを発生させるには、その前にハードロックアップを検出する必要があります。検出は、
nmi_watchdogパラメーターで制御されます。nmi_watchdogロックアップ検出メカニズム (
watchdogs) がアクティブかどうかを制御します。このパラメーターは整数型です。Expand 値 効果 0
ロックアップ検出を無効にする
1
ロックアップ検出を有効にする
ハードロックアップ検出は、各 CPU で割り込みに応答する機能を監視します。
watchdog_threshウォッチドッグの
hrtimer、NMI イベント、およびソフトロックアップまたはハードロックアップのしきい値を制御します。Expand デフォルトのしきい値 ソフトロックアップのしきい値 10 秒
2 *
watchdog_threshこのパラメーターをゼロに設定すると、ロックアップ検出を無効にします。
11.3. 仮想化環境で誤ったソフトロックアップ
物理ホスト上で発生する ソフトロックアップ は、通常、カーネルまたはハードウェアのバグを表します。仮想化環境のゲストオペレーティングシステムで同じ現象が発生すると、誤った警告が表示される可能性があります。
ホストのワークロードが重い場合や、メモリーなどの特定のリソースに対する競合が激しい場合は、誤ったソフトロックアップが発生する可能性があります。これは、ホストがゲスト CPU のスケジューリングを 20 秒超中断する場合に起こります。ゲスト CPU がホスト上で再度実行されるようにスケジュールされると、時間のジャンプ が発生し、それによって期限が来たタイマーが作動します。タイマーには、ゲスト CPU のソフトロックアップを報告できる hrtimer ウォッチドッグも含まれます。
仮想化環境でのソフトロックアップは誤りである可能性があります。ソフトロックアップがゲスト CPU に報告する際にシステムパニックをトリガーするカーネルパラメーターを有効にしないでください。
ゲストのソフトロックアップを理解するには、ホストがゲストをタスクとしてスケジュールしてから、ゲストが独自のタスクをスケジュールしていることを理解することが重要になります。
第12章 データベースサーバーのカーネルパラメーターの調整
データベースサーバーとデータベースの効率的な操作を確保するには、必要なカーネルパラメーターのセットを設定する必要があります。
12.1. データベースサーバーの概要
データベースサーバーは、データベース管理システム (DBMS) の機能を提供するサービスです。DBMS は、データベース管理のためのユーティリティーを提供し、エンドユーザー、アプリケーション、およびデータベースと対話します。
Red Hat Enterprise Linux 8 は、以下のデータベース管理システムを提供します。
- MariaDB 10.3
- MariaDB 10.5 - RHEL 8.4 以降で利用できます。
- MariaDB 10.11 - RHEL 8.10 以降で利用可能
- MySQL 8.0
- PostgreSQL 10
- PostgreSQL 9.6
- PostgreSQL 12 - RHEL 8.1.1 以降で利用できます。
- PostgreSQL 13 - RHEL 8.4 以降で利用できます。
- PostgreSQL 15 - RHEL 8.8 以降で利用できます。
- PostgreSQL 16 - RHEL 8.10 以降で利用可能
12.2. データベースアプリケーションのパフォーマンスに影響するパラメーター
次のカーネルパラメーターは、データベースアプリケーションのパフォーマンスに影響します。
- fs.aio-max-nr
サーバー上でシステムが処理できる非同期 I/O 操作の最大数を定義します。
注記fs.aio-max-nrパラメーターを増やしても、aio の制限以上を追加することはありません。- fs.file-max
システムが同時にサポートするファイルハンドル (開いているファイルに割り当てられた一時ファイル名または ID) の最大数を定義します。
カーネルは、アプリケーションからファイルハンドルが要求されるたびに、ファイルハンドルを動的に割り当てます。ただし、アプリケーションによってこれらのファイルハンドルが解放されても、カーネルはそれらを解放しません。代わりにこれらのファイルハンドルをリサイクルします。現在使用されているファイルハンドルの数が少ない場合でも、割り当てられたファイルハンドルの合計数は時間の経過とともに増加します。
kernel.shmall-
システム全体で使用できる共有メモリーページの合計を定義します。メインメモリー全体を使用するには、
kernel.shmallパラメーターの値が、メインメモリーの合計サイズ以下である必要があります。 kernel.shmmax- Linux プロセスが仮想アドレス空間に割り当てることができる 1 つの共有メモリーセグメントの最大サイズをバイト単位で定義します。
kernel.shmmni- データベースサーバーが処理できる共有メモリーセグメントの最大数を定義します。
net.ipv4.ip_local_port_range- システムは、ポート番号を指定せずにデータベースサーバーに接続するプログラムにこのポート範囲を使用します。
net.core.rmem_default- TCP (Transmission Control Protocol) を介してデフォルトの受信ソケットメモリーを定義します。
net.core.rmem_max- TCP (Transmission Control Protocol) による最大受信ソケットメモリーを定義します。
net.core.wmem_default- TCP (Transmission Control Protocol) によるデフォルトの送信ソケットメモリーを定義します。
net.core.wmem_max- TCP (Transmission Control Protocol) による最大送信ソケットメモリーを定義します。
vm.dirty_bytes/vm.dirty_ratio-
ダーティーデータを生成しているプロセスが
write()関数内でディスクへの書き出しを開始する、ダーティー化可能なメモリーのしきい値を、バイト単位またはパーセンテージ単位で定義します。
一度に指定できるのは、vm.dirty_bytes または vm.dirty_ratio の いずれか です。
vm.dirty_background_bytes/vm.dirty_background_ratio- カーネルがハードディスクにダーティーデータを積極的に書き出し始める、ダーティー化可能なメモリーのしきい値を、バイト単位またはパーセンテージ単位で定義します。
一度に指定できるのは、vm.dirty_background_bytes または vm.dirty_background_ratio の いずれか です。
vm.dirty_writeback_centisecsハードディスクへのダーティーデータの書き込みを行うカーネルスレッドの起動を定期的に行う間隔を定義します。
このカーネルパラメーターは、100 分の 1 秒単位で測定されます。
vm.dirty_expire_centisecs古くなったダーティーデータが、ハードディスクに書き込まれるまでの時間を定義します。
このカーネルパラメーターは、100 分の 1 秒単位で測定されます。
第13章 カーネルロギングの使用
ログファイルは、カーネル、サービス、システム上で実行されているアプリケーションなど、システムに関するメッセージを提供します。syslog サービスは、Red Hat Enterprise Linux でのロギング用にネイティブサポートを提供します。さまざまなユーティリティーがこのシステムを使用してイベントを記録し、ログファイルにまとめます。このファイルは、オペレーティングシステムの監査や問題のトラブルシューティングに役に立ちます。
13.1. カーネルリングバッファーとは
起動プロセス中、コンソールはシステム起動の初期段階に関する重要な情報を提供します。先に出力されたメッセージが失われないように、カーネルはリングバッファーを利用します。このバッファーは、カーネルコード内の printk() 関数により生成されるブートメッセージなど、すべてのメッセージを格納します。次に、カーネルリングバッファーからのメッセージは、syslog サービスなどの永続ストレージのログファイルに読み込まれ、保存されます。
リングバッファーは、固定サイズの循環データ構造で、カーネルにハードコーディングされています。ユーザーは、dmesg コマンドまたは /var/log/boot.log ファイル介して、カーネルリングバッファーに保存されているデータを表示できます。リングバッファーが満杯になると、新しいデータにより古いデータが上書きされます。
13.2. ログレベルおよびカーネルロギングにおける printk のロール
カーネルが報告する各メッセージには、メッセージの重要性を定義するログレベルが関連付けられています。カーネルリングバッファーは、カーネルリングバッファーとは で説明されているように、すべてのログレベルのカーネルメッセージを収集します。バッファーからコンソールに出力されるメッセージを定義するのは kernel.printk パラメーターです。
ログレベルの値は、以下の順序で分類されます。
- 0
- カーネルの緊急事態。システムが利用できません。
- 1
- カーネルアラート。すぐに対処する必要があります。
- 2
- 重大な問題があると見なされるカーネルの状態。
- 3
- 一般的なカーネルのエラー状態。
- 4
- 一般的なカーネルの警告状態。
- 5
- 正常だが重要な状態に関するカーネル通知。
- 6
- カーネル情報メッセージ。
- 7
- カーネルのデバッグレベルのメッセージ。
デフォルトでは、RHEL 8 の kernel.printk には次の値があります。
sysctl kernel.printk
# sysctl kernel.printk
kernel.printk = 7 4 1 7この 4 つの値は、順に以下を定義します。
- コンソールログレベル。コンソールに出力されるメッセージの最低優先度を定義します。
- 明示的なログレベルが付いていないメッセージのデフォルトのログレベル。
- コンソールのログレベルに、可能な限り低いログレベル設定を設定します。
起動時のコンソールのログレベルのデフォルト値を設定します。
これらの各値は、エラーメッセージを処理するさまざまなルールを定義します。
デフォルトの 7 4 1 7 printk 値を使用することで、カーネルアクティビティーのデバッグを改善できます。ただし、シリアルコンソールと組み合わせると、この printk 設定により激しい I/O バーストが発生し、RHEL システムが一時的に応答しなくなる可能性があります。通常 4 4 1 7 に printk 値を設定するとこのような状況を回避できますが、代わりに追加のデバッグ情報が失われてしまいます。
また、quiet、debug などの特定のカーネルコマンドラインパラメーターにより、デフォルトの kernel.printk 値が変更される点に注意してください。
第14章 kdump のインストール
新しいバージョンの RHEL 8 インストールでは、kdump サービスはデフォルトでインストールされ、アクティブ化されます。
14.1. kdump とは
kdump は、クラッシュダンプメカニズムを提供し、クラッシュダンプまたは vmcore ダンプファイルを生成するサービスです。vmcore には、分析およびトラブルシューティング用のシステムメモリーの内容が含まれています。kdump は、kexec システムコールを使用して、再起動せずに 2 番目のカーネルである capture kernel を起動します。このカーネルはクラッシュしたカーネルのメモリーの内容をキャプチャーし、ファイルに保存します。この別のカーネルは、システムメモリーの予約部分で使用できます。
カーネルクラッシュダンプは、システム障害時に利用できる唯一の情報になります。したがって、ミッションクリティカルな環境では、kdump を稼働させることが重要です。Red Hat は、通常のカーネル更新サイクルで kexec-tools を定期的に更新してテストすることを推奨します。これは、新しいカーネル機能をインストールするときに重要です。
マシンに複数のカーネルがある場合は、インストールされているすべてのカーネルに対して、または指定したカーネルに対してのみ kdump を有効にできます。kdump をインストールすると、システムによってデフォルトの /etc/kdump.conf ファイルが作成されます。/etc/kdump.conf にはデフォルトの最小 kdump 設定が含まれています。これを編集して kdump 設定をカスタマイズできます。
14.2. Anaconda を使用した kdump のインストール
Anaconda インストーラーでは、対話式インストール時に kdump 設定用のグラフィカルインターフェイス画面が表示されます。kdump を有効にして、必要な量のメモリーを予約できます。
手順
Anaconda インストーラーで、KDUMP をクリックして
kdumpを有効にします。- メモリー予約をカスタマイズする必要がある場合は、Kdump Memory Reservation で Manual を選択します。
KDUMP > Memory To Be Reserved (MB) で、
kdumpに必要なメモリー予約を設定します。


14.3. コマンドラインで kdump のインストール
カスタムの キックスタート インストールなどのインストール方法では、kdump がデフルトでインストールまたは有効化 されない 場合があります。その場合、次の手順で kdump を有効にできます。
前提条件
- アクティブな RHEL サブスクリプションがある。
-
システムの CPU アーキテクチャー用の
kexec-toolsパッケージを含むリポジトリーがある。 -
kdump設定とターゲットの要件をすべて満たしている。詳細は サポートされている kdump 設定とターゲット を参照してください。
手順
システムに
kdumpがインストールされているかどうかを確認します。rpm -q kexec-tools
# rpm -q kexec-toolsCopy to Clipboard Copied! Toggle word wrap Toggle overflow このパッケージがインストールされている場合は以下を出力します。
kexec-tools-2.0.17-11.el8.x86_64
kexec-tools-2.0.17-11.el8.x86_64Copy to Clipboard Copied! Toggle word wrap Toggle overflow このパッケージがインストールされていない場合は以下を出力します
package kexec-tools is not installed
package kexec-tools is not installedCopy to Clipboard Copied! Toggle word wrap Toggle overflow kdumpおよび必要なパッケージをインストールします。dnf install kexec-tools
# dnf install kexec-toolsCopy to Clipboard Copied! Toggle word wrap Toggle overflow
kernel-3.10.0-693.el7 以降では、Intel IOMMU ドライバーが kdump でサポートされます。kernel-3.10.0-514[.XYZ].el7 以前のバージョンでは、応答しないキャプチャーカーネルを防ぐために、Intel IOMMU が無効化されていることを確認する必要があります。
第15章 コマンドラインで kdump の設定
kdump 用メモリーは、システムの起動時に予約されます。システムの Grand Unified Bootloader (GRUB) 設定ファイルでメモリーサイズを設定できます。メモリーサイズは、設定ファイルで指定された crashkernel= 値と、システムの物理メモリーのサイズによって異なります。
15.1. kdump サイズの見積もり
kdump 環境を計画および構築するときは、クラッシュダンプファイルに必要な容量を把握することが重要です。
makedumpfile --mem-usage コマンドは、クラッシュダンプファイルに必要な容量を推定します。また、メモリー使用量に関するレポートを生成します。このレポートは、ダンプレベルと、除外しても問題ないページを決定するのに役立ちます。
手順
次のコマンドを入力して、メモリー使用量に関するレポートを生成します。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
makedumpfile --mem-usage は、必要なメモリーをページ単位で報告します。つまり、カーネルページサイズを元に、使用するメモリーのサイズを計算する必要があります。
デフォルトでは、RHEL カーネルは、AMD64 および Intel 64 の CPU アーキテクチャーで 4KB のサイズのページを使用し、IBM POWER アーキテクチャーで 64KB のサイズのページを使用します。
15.2. メモリー使用量の設定
kdump のメモリー予約は、システムの起動中に行われます。メモリーサイズは、システムの GRUB (Grand Unified Bootloader) 設定で設定されます。メモリーサイズは、設定ファイルで指定された crashkernel= オプションの値と、システムの物理メモリーのサイズにより異なります。
crashkernel= オプションはさまざまな方法で定義できます。crashkernel= 値を指定するか、auto オプションを設定できます。crashkernel=auto パラメーターは、システムの物理メモリーの合計量に基づいて、メモリーを自動的に予約します。これを設定すると、カーネルは、キャプチャーカーネルに必要な適切な量のメモリーを自動的に予約します。これにより、OOM (Out-of-Memory) エラーの回避に役立ちます。
kdump の自動メモリー割り当ては、システムのハードウェアアーキテクチャーと利用可能なメモリーサイズによって異なります。
たとえば、AMD64 および Intel 64 の場合には、crashkernel=auto パラメーターは、利用可能なメモリーが 1GB を超える場合にのみ機能します。64 ビット ARM アーキテクチャーと IBM Power Systems には、2 GB 以上の使用可能なメモリーが必要です。
システムに、自動割り当ての最小メモリーしきい値より少ないメモリーしかない場合は、手動で予約メモリーの量を設定できます。
前提条件
- システムの root 権限がある。
-
kdump設定とターゲットの要件をすべて満たしている。詳細は サポートされている kdump 設定とターゲット を参照してください。
手順
crashkernel=オプションを準備してください。たとえば、128 MB のメモリーを予約するには、以下を使用します。
crashkernel=128M
crashkernel=128MCopy to Clipboard Copied! Toggle word wrap Toggle overflow または、インストールされているメモリーの合計量に応じて、予約メモリーサイズを変数に設定できます。変数へのメモリー予約の構文は
crashkernel=<range1>:<size1>,<range2>:<size2>です。以下に例を示します。crashkernel=512M-2G:64M,2G-:128M
crashkernel=512M-2G:64M,2G-:128MCopy to Clipboard Copied! Toggle word wrap Toggle overflow システムメモリーの合計量が 512 MB - 2 GB の範囲にある場合、64 MB のメモリーを予約します。メモリーの合計量が 2 GB を超える場合、メモリー予約は 128 MB になります。
予約メモリーのオフセット。
一部のシステムでは、
crashkernelの予約が早い段階で行われるため、特定の固定オフセットでメモリーを予約する必要があります。また、特別な用途のために、さらに多くのメモリーの予約が必要になることもあります。オフセットを定義すると、予約メモリーはそこから開始されます。予約メモリーをオフセットするには、以下の構文を使用します。crashkernel=128M@16M
crashkernel=128M@16MCopy to Clipboard Copied! Toggle word wrap Toggle overflow この例では、
kdumpは 16 MB (物理アドレス0x01000000) から始まる 128 MB のメモリーを予約します。offset パラメーターを 0 に設定するか、完全に省略すると、kdumpは予約メモリーを自動的にオフセットします。変数のメモリー予約を設定する場合は、この構文を使用することもできます。その場合、オフセットは常に最後に指定されます。以下に例を示します。crashkernel=512M-2G:64M,2G-:128M@16M
crashkernel=512M-2G:64M,2G-:128M@16MCopy to Clipboard Copied! Toggle word wrap Toggle overflow
crashkernel=オプションをブートローダー設定に適用します。grubby --update-kernel=ALL --args="crashkernel=<value>"
# grubby --update-kernel=ALL --args="crashkernel=<value>"Copy to Clipboard Copied! Toggle word wrap Toggle overflow <value>は、前のステップで準備したcrashkernel=オプションの値に置き換えます。
15.3. kdump ターゲットの設定
クラッシュダンプは通常、ローカルファイルシステムにファイルとして保存され、デバイスに直接書き込まれます。必要に応じて、NFS または SSH プロトコルを使用して、ネットワーク経由でクラッシュダンプを送信できます。クラッシュダンプファイルを保存するオプションは、一度に 1 つだけ設定できます。デフォルトの動作では、ローカルファイルシステムの /var/crash/ ディレクトリーに保存されます。
前提条件
- システムの root 権限がある。
-
kdump設定とターゲットの要件をすべて満たしている。詳細は サポートされている kdump 設定とターゲット を参照してください。
手順
ローカルファイルシステムの
/var/crash/ディレクトリーにクラッシュダンプファイルを保存するには、/etc/kdump.confファイルを変更して、パスを指定します。path /var/crash
path /var/crashCopy to Clipboard Copied! Toggle word wrap Toggle overflow path /var/crashオプションは、kdumpがクラッシュダンプファイルを保存するファイルシステムへのパスを表します。注記-
/etc/kdump.confファイルでダンプターゲットを指定すると、path は指定されたダンプ出力先に対する相対パスになります。 -
/etc/kdump.confファイルでダンプターゲットを指定しない場合、パスはルートディレクトリーからの 絶対 パスを表します。
現在のシステムにマウントされているファイルシステムに応じて、ダンプターゲットと調整されたダンプパスが自動的に設定されます。
-
kdumpによって生成されるクラッシュダンプファイルと付随するファイルを保護するには、ユーザー権限や SELinux コンテキストなど、ターゲットの宛先ディレクトリーの属性を適切に設定する必要があります。さらに、次のようにkdump.confファイルでkdump_post.shなどのスクリプトを定義することもできます。kdump_post <path_to_kdump_post.sh>
kdump_post <path_to_kdump_post.sh>Copy to Clipboard Copied! Toggle word wrap Toggle overflow kdump_postディレクティブは、kdumpがクラッシュダンプの取得と指定の保存先への保存を完了した 後に 実行されるシェルスクリプトまたはコマンドを指定するものです。このメカニズムを使用すると、kdumpの機能を拡張して、ファイル権限の調整などの操作を実行できます。-
kdumpターゲット設定
*grep -v ^# /etc/kdump.conf | grep -v ^$*
# *grep -v ^# /etc/kdump.conf | grep -v ^$*
ext4 /dev/mapper/vg00-varcrashvol
path /var/crash
core_collector makedumpfile -c --message-level 1 -d 31
ダンプターゲットが指定されています (ext4 /dev/mapper/vg00-varcrashvol)。そのため、ダンプターゲットは /var/crash にマウントされます。path オプションも /var/crash に設定されています。したがって、kdump は、vmcore ファイルを /var/crash/var/crash ディレクトリーに保存します。
クラッシュダンプを保存するローカルディレクトリーを変更するには、
rootユーザーとして/etc/kdump.conf設定ファイルを編集します。-
#path /var/crashの行頭にあるハッシュ記号 (#) を削除します。 値を対象のディレクトリーパスに置き換えます。以下に例を示します。
path /usr/local/cores
path /usr/local/coresCopy to Clipboard Copied! Toggle word wrap Toggle overflow 重要RHEL 8 では、障害を回避するために、
kdumpsystemdサービスの起動時に、pathディレクティブを使用してkdumpターゲットとして定義されたディレクトリーが存在している必要があります。以前のバージョンの RHEL とは異なり、サービス起動時にディレクトリーが存在しない場合、ディレクトリーは自動的に作成されなくなりました。
-
ファイルを別のパーティションに書き込むには、
/etc/kdump.conf設定ファイルを編集します。必要に応じて
#ext4の行頭にあるハッシュ記号 (#) を削除します。-
デバイス名 (
#ext4 /dev/vg/lv_kdump行) -
ファイルシステムラベル (
#0ext4 LABEL=/boot行) -
UUID (
#ext4 UUID=03138356-5e61-4ab3-b58e-27507ac41937の行)
-
デバイス名 (
ファイルシステムタイプとデバイス名、ラベル、または UUID を必要な値に変更します。UUID 値を指定するための正しい構文は、
UUID="correct-uuid"とUUID=correct-uuidの両方です。以下に例を示します。ext4 UUID=03138356-5e61-4ab3-b58e-27507ac41937
ext4 UUID=03138356-5e61-4ab3-b58e-27507ac41937Copy to Clipboard Copied! Toggle word wrap Toggle overflow 重要LABEL=またはUUID=を使用してストレージデバイスを指定することを推奨します。/dev/sda3などのディスクデバイス名は、再起動した場合に一貫性が保証されません。IBM Z ハードウェアで Direct Access Storage Device (DASD) を使用する場合は、
kdumpに進む前に、ダンプデバイスが/etc/dasd.confで正しく指定されていることを確認してください。
クラッシュダンプを直接書き込むには、
/etc/kdump.conf設定ファイルを修正します。-
#raw /dev/vg/lv_kdumpの行頭にあるハッシュ記号 (#) を削除します。 値を対象のデバイス名に置き換えます。以下に例を示します。
raw /dev/sdb1
raw /dev/sdb1Copy to Clipboard Copied! Toggle word wrap Toggle overflow
-
NFSプロトコルを使用してクラッシュダンプをリモートマシンに保存するには、次の手順を実行します。-
#nfs my.server.com:/export/tmpの行頭にあるハッシュ記号 (#) を削除します。 値を、正しいホスト名およびディレクトリーパスに置き換えます。以下に例を示します。
nfs penguin.example.com:/export/cores
nfs penguin.example.com:/export/coresCopy to Clipboard Copied! Toggle word wrap Toggle overflow 変更を有効にするには、
kdumpサービスを再起動します。sudo systemctl restart kdump.service
sudo systemctl restart kdump.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow 注記NFS ディレクティブを使用して NFS ターゲットを指定すると、
kdump.serviceが自動的に NFS ターゲットをマウントしてディスク容量をチェックしようとします。NFS ターゲットを事前にマウントする必要はありません。kdump.serviceがターゲットをマウントしないようにするには、kdump.confでdracut_args --mountディレクティブを使用します。これにより、kdump.serviceが--mount引数を使用してdracutユーティリティーを呼び出して NFS ターゲットを指定できるようになります。
-
SSH プロトコルを使用してクラッシュダンプをリモートマシンに保存するには、次の手順を実行します。
-
#ssh user@my.server.comの行頭にあるハッシュ記号 (#) を削除します。 - 値を正しいユーザー名およびホスト名に置き換えます。
SSH キーを設定に含めます。
-
#sshkey /root/.ssh/kdump_id_rsaの行頭にあるハッシュ記号 (#) を削除します。 値を、ダンプ先のサーバー上の正しいキーの場所に変更します。以下に例を示します。
ssh john@penguin.example.com sshkey /root/.ssh/mykey
ssh john@penguin.example.com sshkey /root/.ssh/mykeyCopy to Clipboard Copied! Toggle word wrap Toggle overflow
-
-
15.4. kdump コアコレクターの設定
kdump では、core_collector を使用してクラッシュダンプイメージをキャプチャーします。RHEL では、makedumpfile ユーティリティーがデフォルトのコアコレクターです。これは、以下に示すプロセスによりダンプファイルを縮小するのに役立ちます。
- クラッシュダンプファイルのサイズを圧縮し、さまざまなダンプレベルを使用して必要なページのみをコピーする
- 不要なクラッシュダンプページを除外する
- クラッシュダンプに含めるページタイプをフィルタリングする
クラッシュダンプファイルの圧縮は、RHEL 7 以降ではデフォルトで有効になっています。
クラッシュダンプファイルの圧縮をカスタマイズする必要がある場合は、以下の手順に従います。
構文
core_collector makedumpfile -l --message-level 1 -d 31
core_collector makedumpfile -l --message-level 1 -d 31オプション
-
-c、-l、または-p:zlib(-cオプションの場合)、lzo(-lオプションの場合)、またはsnappy(-pオプションの場合) のいずれかを使用して、ページごとに圧縮ダンプファイルの形式を指定します。 -
-d(dump_level): ページを除外して、ダンプファイルにコピーされないようにします。 -
--message-level: メッセージタイプを指定します。このオプションでmessage_levelを指定すると、出力の表示量を制限できます。たとえば、message_levelで 7 を指定すると、一般的なメッセージとエラーメッセージを出力します。message_levelの最大値は 31 です。
前提条件
- システムの root 権限がある。
-
kdump設定とターゲットの要件をすべて満たしている。詳細は サポートされている kdump 設定とターゲット を参照してください。
手順
-
rootとして、/etc/kdump.conf設定ファイルを編集し、#core_collector makedumpfile -l --message-level 1 -d 31の先頭からハッシュ記号 ("#") を削除します。 - 次のコマンドを入力して、クラッシュダンプファイルの圧縮を有効にします。
core_collector makedumpfile -l --message-level 1 -d 31
core_collector makedumpfile -l --message-level 1 -d 31
-l オプションにより、dump の圧縮ファイル形式を指定します。-d オプションで、ダンプレベルを 31 に指定します。--message-level オプションで、メッセージレベルを 1 に指定します。
また、-c オプションおよび -p オプションを使用した以下の例を検討してください。
-cを使用してクラッシュダンプファイルを圧縮するには、次のコマンドを実行します。core_collector makedumpfile -c -d 31 --message-level 1
core_collector makedumpfile -c -d 31 --message-level 1Copy to Clipboard Copied! Toggle word wrap Toggle overflow -pを使用してクラッシュダンプファイルを圧縮するには、次のコマンドを実行します。core_collector makedumpfile -p -d 31 --message-level 1
core_collector makedumpfile -p -d 31 --message-level 1Copy to Clipboard Copied! Toggle word wrap Toggle overflow
15.5. kdump のデフォルト障害応答の設定
デフォルトでは、設定したターゲットの場所で kdump がクラッシュダンプファイルの作成に失敗すると、システムが再起動し、ダンプがプロセス内で失われます。デフォルトの失敗応答を変更し、コアダンプをプライマリーターゲットに保存できない場合に別の操作を実行するように kdump を設定できます。追加のアクションは次のとおりです。
dump_to_rootfs-
コアダンプを
rootファイルシステムに保存します。 reboot- システムを再起動します。コアダンプは失われます。
halt- システムを停止します。コアダンプは失われます。
poweroff- システムの電源を切ります。コアダンプは失われます。
shell-
initramfs内からシェルセッションを実行します。コアダンプを手動で記録できます。 final_action-
kdumpの成功後、またはシェルまたはdump_to_rootfsの失敗アクションの完了時に、reboot、haltおよびpoweroffなどの追加操作を有効にします。デフォルトはrebootです。 failure_action-
カーネルクラッシュでダンプが失敗する可能性がある場合に実行するアクションを指定します。デフォルトは
rebootです。
前提条件
- root 権限
-
kdump設定とターゲットの要件をすべて満たしている。詳細は サポートされている kdump 設定とターゲット を参照してください。
手順
-
rootユーザーとして、/etc/kdump.conf設定ファイルの#failure_action行の先頭からハッシュ記号 (#) を削除します。 値を必要なアクションに置き換えます。
failure_action poweroff
failure_action poweroffCopy to Clipboard Copied! Toggle word wrap Toggle overflow
15.6. kdump の設定ファイル
kdump カーネルの設定ファイルは /etc/sysconfig/kdump です。このファイルは、kdump カーネルコマンドラインパラメーターを制御します。ほとんどの設定では、デフォルトオプションを使用します。ただし、シナリオによっては、kdump カーネルの動作を制御するために特定のパラメーターを変更する必要があります。たとえば、KDUMP_COMMANDLINE_APPEND オプションを変更して kdump カーネルコマンドラインを追加して詳細なデバッグ出力を取得したり、KDUMP_COMMANDLINE_REMOVE オプションを変更して kdump コマンドラインから引数を削除したりします。
KDUMP_COMMANDLINE_REMOVE現在の
kdumpコマンドラインから引数を削除します。これにより、kdumpエラーやkdumpカーネルの起動失敗の原因となるパラメーターが削除されます。これらのパラメーターは、以前のKDUMP_COMMANDLINEプロセスから解析されるか、/proc/cmdlineファイルから継承されたものである場合があります。この変数が設定されていない場合は、
/proc/cmdlineファイルからすべての値が継承されます。このオプションを設定すると、問題のデバッグに役立つ情報も提供されます。特定の引数を削除するには、以下のようにして
KDUMP_COMMANDLINE_REMOVEに追加します。
KDUMP_COMMANDLINE_REMOVE="hugepages hugepagesz slub_debug quiet log_buf_len swiotlb"
# KDUMP_COMMANDLINE_REMOVE="hugepages hugepagesz slub_debug quiet log_buf_len swiotlb"KDUMP_COMMANDLINE_APPENDこのオプションは、現在のコマンドラインに引数を追加します。この引数は、以前の
KDUMP_COMMANDLINE_REMOVE変数によって解析されたものである場合があります。kdumpカーネルの場合は、mce、cgroup、numa、hest_disableなどの特定のモジュールを無効にすると、カーネルエラーを防ぐのに役立ちます。これらのモジュールは、kdump用に予約されているカーネルメモリーの大部分を消費したり、kdumpカーネルの起動失敗を引き起こしたりする可能性があります。kdumpカーネルコマンドラインでメモリーcgroupを無効にするには、以下のコマンドを実行します。
KDUMP_COMMANDLINE_APPEND="cgroup_disable=memory"
KDUMP_COMMANDLINE_APPEND="cgroup_disable=memory"15.7. kdump 設定のテスト
kdump を設定したら、システムクラッシュを手動でテストして、定義した kdump ターゲットに vmcore ファイルが生成されていることを確認する必要があります。vmcore ファイルは、新しく起動したカーネルのコンテキストからキャプチャーされます。したがって、vmcore にはカーネルクラッシュをデバッグするための重要な情報が含まれています。
アクティブな実稼働システムでは kdump をテストしないでください。kdump をテストするコマンドにより、カーネルがクラッシュし、データが失われます。システムアーキテクチャーに応じて、十分なメンテナンス時間を必ず確保してください。kdump のテストでは時間のかかる再起動が数回必要になる場合があります。
kdump のテスト中に vmcore ファイルが生成されない場合は、kdump のテストを成功させるために、再度テストを実行する前に問題を特定して修正してください。
手動でシステムを変更した場合は、システム変更の最後に kdump 設定をテストする必要があります。たとえば、次のいずれかの変更を行った場合は、kdump のパフォーマンスが最適になるように、kdump の設定をテストしてください。
- パッケージのアップグレード。
- ハードウェアレベルの変更 (ストレージやネットワークの変更など)。
- ファームウェアのアップグレード。
- サードパーティーのモジュールを含む新規のインストールおよびアプリケーションのアップグレード。
- ホットプラグメカニズムを使用した、このメカニズムをサポートするハードウェアへのメモリーの追加。
-
/etc/kdump.confファイルまたは/etc/sysconfig/kdumpファイルに対する変更。
前提条件
- システムの root 権限がある。
-
重要なデータがすべて保存されている。
kdumpをテストするコマンドにより、カーネルがクラッシュし、データが失われます。 - システムアーキテクチャーに応じて、十分なマシンメンテナンス時間が確保されている。
手順
kdumpサービスを有効にします。kdumpctl restart
# kdumpctl restartCopy to Clipboard Copied! Toggle word wrap Toggle overflow kdumpctlを使用してkdumpサービスのステータスを確認します。kdumpctl status
# kdumpctl status kdump:Kdump is operationalCopy to Clipboard Copied! Toggle word wrap Toggle overflow 必要に応じて
systemctlコマンドを使用すると、出力がsystemdジャーナルに印刷されます。カーネルクラッシュを開始して、
kdumpの設定をテストします。sysrq-triggerキーの組み合わせによりカーネルがクラッシュし、必要に応じてシステムが再起動します。echo c > /proc/sysrq-trigger
# echo c > /proc/sysrq-triggerCopy to Clipboard Copied! Toggle word wrap Toggle overflow カーネルの再起動時に、
/etc/kdump.confファイルで指定した場所にaddress-YYYY-MM-DD-HH:MM:SS/vmcoreファイルが作成されます。デフォルトは/var/crash/です。
15.8. システムクラッシュ後に kdump によって生成されるファイル
システムがクラッシュすると、kdump サービスは、カーネルメモリーをダンプファイル (vmcore) にキャプチャーします。また、トラブルシューティングと事後分析に役立つ追加の診断ファイルを生成します。
kdump によって生成されるファイル:
-
vmcore- クラッシュ時のシステムメモリーを含む主なカーネルメモリーダンプファイル。これには、kdump設定で指定されているcore_collectorプログラムの設定に従ってデータが追加されます。デフォルトでは、カーネルデータ構造、プロセス情報、スタックトレース、およびその他の診断情報が含まれます。 -
vmcore-dmesg.txt- パニックになったプライマリーカーネルからのカーネルリングバッファーログ (dmesg) の内容。 -
kexec-dmesg.log-vmcoreデータを収集するセカンダリーのkexecカーネルの実行に基づくカーネルおよびシステムログメッセージが含まれます。
15.9. kdump サービスの有効化および無効化
kdump 機能は、特定のカーネルまたはインストールされているすべてのカーネルで有効または無効にするように設定できます。kdump 機能を定期的にテストし、正しく動作することを検証する必要があります。
前提条件
- システムの root 権限がある。
-
kdumpの設定とターゲットの要件をすべて満たしている。サポートされている kdump 設定とターゲット を参照してください。 -
kdumpをインストールするためのすべての設定が、要件に応じてセットアップされている。
手順
multi-user.targetのkdumpサービスを有効にします。systemctl enable kdump.service
# systemctl enable kdump.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow 現在のセッションでサービスを起動します。
systemctl start kdump.service
# systemctl start kdump.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow kdumpサービスを停止します。systemctl stop kdump.service
# systemctl stop kdump.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow kdumpサービスを無効にします。systemctl disable kdump.service
# systemctl disable kdump.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow
kptr_restrict=1 をデフォルトとして設定することが推奨されます。kptr_restrict がデフォルトで (1) に設定されている場合、Kernel Address Space Layout (KASLR) が有効かどうかに関係なく、kdumpctl サービスがクラッシュカーネルをロードします。
kptr_restrict が 1 に設定されておらず、KASLR が有効になっている場合は、/proc/kore ファイルの内容がすべてゼロとして生成されます。kdumpctl サービスは、/proc/kcore ファイルにアクセスしてクラッシュカーネルを読み込むことができません。kexec-kdump-howto.txt ファイルには、kptr_restrict=1 に設定することを推奨する警告メッセージが表示されます。kdumpctl サービスが必ずクラッシュカーネルを読み込むように、sysctl.conf ファイルで次の内容を確認します。
-
sysctl.confファイルでのカーネルのkptr_restrict=1設定
15.10. カーネルドライバーが kdump を読み込まないようにする設定
/etc/sysconfig/kdump 設定ファイルに KDUMP_COMMANDLINE_APPEND= 変数を追加することで、キャプチャーカーネルが特定のカーネルドライバーをロードしないように制御できます。この方法を使用すると、kdump 初期 RAM ディスクイメージ initramfs が、指定されたカーネルモジュールをロードするのを防ぐことができます。これにより、メモリー不足 (OOM) killer エラーやその他のクラッシュカーネル障害を防ぐことができます。
次のいずれかの設定オプションを使用して、KDUMP_COMMANDLINE_APPEND= 変数を追加できます。
-
rd.driver.blacklist=<modules> -
modprobe.blacklist=<modules>
前提条件
- システムの root 権限がある。
手順
現在実行中のカーネルに読み込まれるモジュールのリストを表示します。ロードをブロックするカーネルモジュールを選択します。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow /etc/sysconfig/kdumpファイルのKDUMP_COMMANDLINE_APPEND=変数を更新します。以下に例を示します。KDUMP_COMMANDLINE_APPEND="rd.driver.blacklist=hv_vmbus,hv_storvsc,hv_utils,hv_netvsc,hid-hyperv"
KDUMP_COMMANDLINE_APPEND="rd.driver.blacklist=hv_vmbus,hv_storvsc,hv_utils,hv_netvsc,hid-hyperv"Copy to Clipboard Copied! Toggle word wrap Toggle overflow modprobe.blacklist=<modules>設定オプションを使用した以下の例も検討してください。KDUMP_COMMANDLINE_APPEND="modprobe.blacklist=emcp modprobe.blacklist=bnx2fc modprobe.blacklist=libfcoe modprobe.blacklist=fcoe"
KDUMP_COMMANDLINE_APPEND="modprobe.blacklist=emcp modprobe.blacklist=bnx2fc modprobe.blacklist=libfcoe modprobe.blacklist=fcoe"Copy to Clipboard Copied! Toggle word wrap Toggle overflow kdumpサービスを再起動します。systemctl restart kdump
# systemctl restart kdumpCopy to Clipboard Copied! Toggle word wrap Toggle overflow
15.11. 暗号化されたディスクがあるシステムでの kdump の実行
LUKS 暗号化パーティションを実行すると、システムで利用可能なメモリーが一定量必要になります。システムが必要なメモリー量を下回ると、cryptsetup ユーティリティーがパーティションのマウントに失敗します。その結果、2 番目のカーネル (キャプチャーカーネル) で、暗号化したターゲットの場所に vmcore ファイルをキャプチャーできませんでした。
kdumpctl estimate コマンドは、kdump に必要なメモリー容量を予測できます。kdumpctl estimate は、推奨の crashkernel 値を出力します。この値は kdump に必要な最適なメモリーサイズです。
推奨の crashkernel 値は、現在のカーネルサイズ、カーネルモジュール、initramfs、および暗号化したターゲットメモリー要件に基づいて計算されます。
カスタムの crashkernel= オプションを使用している場合、kdumpctl estimate は LUKS required size 値を出力します。この値は、LUKS 暗号化ターゲットに必要なメモリーサイズです。
手順
crashkernel=の推定値を出力します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow -
crashkernel=の値を増やして、必要なメモリー量を設定します。 - システムを再起動します。
それでも kdump がダンプファイルを暗号化したターゲットに保存できない場合は、必要に応じて crashkernel= を増やしてください。
第16章 Web コンソールで kdump の設定
RHEL 8 Web コンソールを使用して、kdump 設定をセットアップおよびテストできます。Web コンソールでは、起動時に kdump サービスを有効にすることができます。Web コンソールを使用すると、kdump 用に予約されたメモリーを設定し、vmcore の保存場所を非圧縮形式または圧縮形式で選択できます。
16.1. Web コンソールで kdump メモリーの使用量およびターゲットの場所を設定
RHEL Web コンソールインターフェイスを使用して、kdump カーネルのメモリー予約を設定し、vmcore ダンプファイルをキャプチャーするターゲットの場所を指定することもできます。
前提条件
- Web コンソールがインストールされており、アクセス可能である。詳細は、Web コンソールのインストール を参照してください。
手順
-
Web コンソールで、 タブを開き、Kernel crash dump スイッチをオンに設定して
kdumpサービスを起動します。 ターミナルで
kdumpのメモリー使用量を設定します。以下に例を示します。sudo grubby --update-kernel ALL --args crashkernel=512M
$ sudo grubby --update-kernel ALL --args crashkernel=512MCopy to Clipboard Copied! Toggle word wrap Toggle overflow 変更を適用するにはシステムを再起動します。
- Kernel dump タブで、Crash dump location フィールドの末尾にある Edit をクリックします。
vmcoreダンプファイルを保存するターゲットディレクトリーを指定します。- ローカルファイルシステムの場合は、ドロップダウンメニューから Local Filesystem を選択します。
SSH プロトコルを使用したリモートシステムの場合は、ドロップダウンメニューから Remote over SSH を選択し、次のフィールドを指定します。
- Server フィールドに、リモートサーバーのアドレスを入力します。
- SSH key フィールドに、SSH キーの場所を入力します。
- Directory フィールドに、ターゲットディレクトリーを入力します。
NFS プロトコルを使用したリモートシステムの場合は、ドロップダウンメニューから Remote over NFS を選択し、次のフィールドを指定します。
- Server フィールドに、リモートサーバーのアドレスを入力します。
- Export フィールドに、NFS サーバーの共有フォルダーの場所を入力します。
Directory フィールドに、ターゲットディレクトリーを入力します。
注記Compression チェックボックスをオンにすると、
vmcoreファイルのサイズを削減できます。
オプション: View automation script をクリッ自動化スクリプトを表示します。
生成されたスクリプトを含むウィンドウが開きます。シェルスクリプトと Ansible Playbook 生成オプションのタブを参照できます。
オプション: Copy to clipboard をクリックして、スクリプトをコピーします。
このスクリプトを使用すると、複数のマシンに同じ設定を適用できます。
検証
- をクリックします。
Test kdump settings の下にある Crash system をクリックします。
警告システムクラッシュを開始すると、カーネルの動作が停止し、システムがクラッシュしてデータが失われます。
第17章 kdump の有効化
RHEL 8 システムの場合、特定のカーネルまたはインストールされているすべてのカーネルで、kdump 機能を有効または無効にするように設定できます。ただし、kdump 機能を定期的にテストし、その動作状態を検証する必要があります。
17.1. インストールされているすべてのカーネルでの kdump の有効化
kdump サービスは、kexec ツールのインストール後に kdump.service を有効にすることで起動します。マシンにインストールされているすべてのカーネルに対して、kdump を有効にして起動できます。
前提条件
- 管理者権限がある。
手順
インストールされているすべてのカーネルに
crashkernel=コマンドラインパラメーターを追加します。grubby --update-kernel=ALL --args="crashkernel=xxM"
# grubby --update-kernel=ALL --args="crashkernel=xxM"Copy to Clipboard Copied! Toggle word wrap Toggle overflow xxMは必要なメモリー (メガバイト単位) です。システムを再起動します。
reboot
# rebootCopy to Clipboard Copied! Toggle word wrap Toggle overflow kdumpサービスを有効にします。systemctl enable --now kdump.service
# systemctl enable --now kdump.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow
検証
kdumpが実行されていることを確認します。systemctl status kdump.service
# systemctl status kdump.service ○ kdump.service - Crash recovery kernel arming Loaded: loaded (/usr/lib/systemd/system/kdump.service; enabled; vendor preset: disabled) Active: active (live)Copy to Clipboard Copied! Toggle word wrap Toggle overflow
17.2. 特定のインストール済みカーネルでの kdump の有効化
マシン上の特定カーネルに対して、kdump を有効にできます。
前提条件
- 管理者権限がある。
手順
マシンにインストールされているカーネルをリスト表示します。
ls -a /boot/vmlinuz-*
# ls -a /boot/vmlinuz-* /boot/vmlinuz-0-rescue-2930657cd0dc43c2b75db480e5e5b4a9 /boot/vmlinuz-4.18.0-330.el8.x86_64 /boot/vmlinuz-4.18.0-330.rt7.111.el8.x86_64Copy to Clipboard Copied! Toggle word wrap Toggle overflow 特定の
kdumpカーネルを、システムの Grand Unified Bootloader (GRUB) 設定に追加します。以下に例を示します。
grubby --update-kernel=vmlinuz-4.18.0-330.el8.x86_64 --args="crashkernel=xxM"
# grubby --update-kernel=vmlinuz-4.18.0-330.el8.x86_64 --args="crashkernel=xxM"Copy to Clipboard Copied! Toggle word wrap Toggle overflow xxMは必要なメモリー予約 (メガバイト単位) です。kdumpを有効にします。systemctl enable --now kdump.service
# systemctl enable --now kdump.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow
検証
kdumpが実行されていることを確認します。systemctl status kdump.service
# systemctl status kdump.service ○ kdump.service - Crash recovery kernel arming Loaded: loaded (/usr/lib/systemd/system/kdump.service; enabled; vendor preset: disabled) Active: active (live)Copy to Clipboard Copied! Toggle word wrap Toggle overflow
17.3. kdump サービスの無効化
kdump.service を停止し、RHEL 8 システムでのサービスの起動を無効にすることができます。
前提条件
-
kdump設定とターゲットの要件をすべて満たしている。詳細は サポートされている kdump 設定とターゲット を参照してください。 -
kdumpのインストール用のオプションがすべて、要件に応じて設定されている。詳細は、kdump のインストール を参照してください。
手順
現在のセッションで
kdumpを停止するには、以下のコマンドを実行します。systemctl stop kdump.service
# systemctl stop kdump.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow kdumpを無効にするには、以下を行います。systemctl disable kdump.service
# systemctl disable kdump.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow
kptr_restrict=1 をデフォルトとして設定することが推奨されます。kptr_restrict がデフォルトで (1) に設定されている場合、Kernel Address Space Layout (KASLR) が有効かどうかに関係なく、kdumpctl サービスがクラッシュカーネルをロードします。
kptr_restrict が 1 に設定されておらず、KASLR が有効になっている場合は、/proc/kore ファイルの内容がすべてゼロとして生成されます。kdumpctl サービスは、/proc/kcore ファイルにアクセスしてクラッシュカーネルを読み込むことができません。kexec-kdump-howto.txt ファイルには、kptr_restrict=1 に設定することを推奨する警告メッセージが表示されます。kdumpctl サービスが必ずクラッシュカーネルを読み込むように、sysctl.conf ファイルで次の内容を確認します。
-
sysctl.confファイルでのカーネルのkptr_restrict=1設定
第18章 サポートされている kdump 設定とターゲット
kdump メカニズムは、カーネルクラッシュが発生したときにクラッシュダンプファイルを生成する Linux カーネルの機能です。カーネルダンプファイルには、カーネルクラッシュの根本原因を分析して特定するのに役立つ重要な情報が含まれています。クラッシュの原因は、ハードウェアの問題やサードパーティーのカーネルモジュールの問題など、さまざまな要因が考えられます。
提供された情報と手順を使用することで、次のアクションを実行できます。
- RHEL 8 システムでサポートされている設定とターゲットを特定します。
- kdump を設定します。
- kdump 操作を確認します。
18.1. kdump メモリー要件
kdump がカーネルクラッシュダンプをキャプチャーし、さらなる分析のために保存するには、システムメモリーの一部をキャプチャーカーネル用に永続的に予約しておく必要があります。予約されている場合、システムメモリーのこの部分はメインカーネルでは使用できません。
メモリー要件は、特定のシステムパラメーターによって異なります。主な要因は、システムのハードウェアアーキテクチャーです。Intel 64 や AMD64 (別称: x86_64 ) などの正確なマシンアーキテクチャーを識別し、それを標準出力に出力するには、次のコマンドを使用します。
uname -m
$ uname -m$ uname -m
下記の最小メモリー要件のリストを使用して、利用可能な最新バージョンで kdump 用のメモリーを自動的に予約するための適切なメモリーサイズを設定できます。メモリーサイズは、システムのアーキテクチャーと利用可能な物理メモリーの合計によって異なります。
| アーキテクチャー | 使用可能なメモリー | 最小予約メモリー |
|---|---|---|
|
AMD64 と Intel 64 ( | 1 GB から 4 GB | 192 MB のメモリー |
| 4 GB から 64 GB | 256 MB のメモリー | |
| 64 GB 以上 | 512 MB のメモリー | |
|
64 ビット ARM アーキテクチャー ( | 2 GB 以上 | 480 MB のメモリー |
|
IBM Power Systems ( | 2 GB から 4 GB | 384 MB のメモリー |
| 4 GB から 16 GB | 512 MB のメモリー | |
| 16 GB から 64 GB | 1 GB のメモリー | |
| 64 GB から 128 GB | 2 GB のメモリー | |
| 128 GB 以上 | 4 GB のメモリー | |
|
IBM Z ( | 1 GB から 4 GB | 192 MB のメモリー |
| 4 GB から 64 GB | 256 MB のメモリー | |
| 64 GB 以上 | 512 MB のメモリー |
多くのシステムでは、kdump は必要なメモリー量を予測して、自動的に予約できます。この動作はデフォルトで有効になっていますが、利用可能な合計メモリーサイズが一定以上搭載されているシステムに限られます。この自動割り当て動作に必要なメモリーサイズはシステムのアーキテクチャーによって異なります。
システムのメモリー合計量に基づく予約メモリーの自動設定は、ベストエフォート予測です。実際に必要なメモリーは、I/O デバイスなどの他の要因によって異なる場合があります。十分なメモリーを使用しないと、カーネルパニックが発生したときに、デバッグカーネルがキャプチャーカーネルとして起動できなくなる可能性があります。この問題を回避するには、クラッシュカーネルメモリーを十分に増やしてください。
18.2. メモリー自動予約の最小しきい値
kexec-tools ユーティリティーは、デフォルトで、crashkernel コマンドラインパラメーターを設定し、kdump 用に一定量のメモリーを予約します。ただし、一部のシステムでは、ブートローダー設定ファイルで crashkernel=auto パラメーターを使用するか、グラフィカル設定ユーティリティーでこのオプションを有効にすることで、kdump 用のメモリーを割り当てることが可能です。この自動予約を機能させるには、システムで一定量の合計メモリーが使用可能である必要があります。メモリー要件はシステムのアーキテクチャーによって異なります。システムのメモリーが指定のしきい値よりも小さい場合は、メモリーを手動で設定する必要があります。
| アーキテクチャー | 必要なメモリー |
|---|---|
|
AMD64 と Intel 64 ( | 2 GB |
|
IBM Power Systems ( | 2 GB |
|
IBM Z ( | 4 GB |
起動コマンドラインの crashkernel=auto オプションは、RHEL 9 以降のリリースでは対応しなくなりました。
18.3. サポートしている kdump のダンプ出力先
カーネルクラッシュが発生すると、オペレーティングシステムは、設定したダンプ出力先またはデフォルトのダンプ出力先にダンプファイルを保存します。ダンプファイルは、デバイスに直接保存することも、ローカルファイルシステムにファイルとして保存することも、ネットワーク経由で送信することもできます。以下に示すダンプ出力先のリストを使用すると、kdump で現在サポートされているダンプ出力先とサポートされていないダンプ出力先を把握できます。
| ダンプ出力先の種類 | 対応しているダンプ出力先 | 対応していないダンプ出力先 |
|---|---|---|
| 物理ストレージ |
|
|
| ネットワーク |
|
|
| ハイパーバイザー |
| |
| ファイルシステム | ext[234]、XFS、および NFS ファイルシステム。 |
|
| ファームウェア |
|
18.4. 対応している kdump のフィルターレベル
ダンプファイルのサイズを削減するために、kdump は makedumpfile コアコレクターを使用してデータを圧縮し、さらに不要な情報を除外します。たとえば、-8 レベルを使用すると、hugepages および hugetlbfs ページを削除できます。makedumpfile が現在サポートしているレベルは `kdump` のフィルタリングレベル の表で確認できます。
| オプション | 説明 |
|---|---|
|
| ゼロページ |
|
| キャッシュページ |
|
| キャッシュプライベート |
|
| ユーザーページ |
|
| フリーページ |
18.5. 対応しているデフォルトの障害応答
デフォルトでは、kdump がコアダンプを作成できない場合、オペレーティングシステムが再起動します。ただし、コアダンプをプライマリーターゲットに保存できない場合に別の操作を実行するように kdump を設定できます。
| オプション | 説明 |
|---|---|
|
| root ファイルシステムにコアダンプの保存を試行します。ネットワーク上のダンプ出力先と併用する場合に特に便利なオプションです。ネットワーク上のダンプ出力先にアクセスできない場合、ローカルにコアダンプを保存するよう kdump の設定を行います。システムは、後で再起動します。 |
|
| システムを再起動します。コアダンプは失われます。 |
|
| システムを停止します。コアダンプは失われます。 |
|
| システムの電源を切ります。コアダンプは失われます。 |
|
| initramfs 内から shell セッションを実行して、ユーザーが手動でコアダンプを記録できるようにします。 |
|
|
|
18.6. final_action パラメーターの使用
kdump が成功した場合、または kdump が設定されたターゲットでの vmcore ファイルの保存に失敗した場合は、final_action パラメーターを使用して、reboot、halt、poweroff などの追加操作を実行できます。final_action パラメーターが指定されていない場合、デフォルトの応答は reboot です。
手順
final_actionを設定するには、/etc/kdump.confファイルを編集して、次のいずれかのオプションを追加します。-
final_action reboot -
final_action halt -
final_action poweroff
-
変更を有効にするには、
kdumpサービスを再起動します。kdumpctl restart
# kdumpctl restartCopy to Clipboard Copied! Toggle word wrap Toggle overflow
18.7. failure_action パラメーターの使用
failure_action パラメーターは、カーネルがクラッシュした場合にダンプが失敗したときに実行するアクションを指定します。failure_action のデフォルトのアクションは、システムを再起動する reboot です。
このパラメーターは、実行する以下のアクションを認識します。
reboot- ダンプが失敗した後、システムを再起動します。
dump_to_rootfs- 非ルートダンプターゲットが設定されている場合、ダンプファイルをルートファイルシステムに保存します。
halt- システムを停止します。
poweroff- システムで実行中の操作を停止します。
shell-
initramfs内でシェルセッションを開始します。このセッションから、追加のリカバリーアクションを手動で実行できます。
手順
ダンプが失敗した場合に実行するアクションを設定するには、
/etc/kdump.confファイルを編集して、failure_actionオプションの 1 つを指定します。-
failure_action reboot -
failure_action halt -
failure_action poweroff -
failure_action shell -
failure_action dump_to_rootfs
-
変更を有効にするには、
kdumpサービスを再起動します。kdumpctl restart
# kdumpctl restartCopy to Clipboard Copied! Toggle word wrap Toggle overflow
第19章 ファームウェア支援ダンプの仕組み
ファームウェア支援ダンプ (fadump) は、IBM POWER システムの kdump メカニズムの代わりに提供されるダンプ取得メカニズムです。kexec および kdump のメカニズムは、AMD64 および Intel 64 システムでコアダンプを取得する際に役立ちます。ただし、ミニシステムやメインフレームコンピューターなどの一部のハードウェアでは、オンボードファームウェアを使用してメモリー領域を分離し、クラッシュ分析で重要なデータが誤って上書きされることを防ぎます。fadump ユーティリティーは、fadump メカニズムと IBM POWER システム上の RHEL とのインテグレーション向けに最適化されています。
19.1. IBM PowerPC ハードウェアにおけるファームウェア支援ダンプ
fadump ユーティリティーは、PCI デバイスおよび I/O デバイスが搭載され、完全にリセットされたシステムから vmcore ファイルをキャプチャーします。この仕組みでは、クラッシュするとファームウェアを使用してメモリー領域を保存し、kdump ユーザー空間スクリプトをもう一度使用して vmcore ファイルを保存します。このメモリー領域には、ブートメモリー、システムレジスター、およびハードウェアのページテーブルエントリー (PTE) を除く、すべてのシステムメモリーコンテンツが含まれます。
fadump メカニズムは、パーティションを再起動し、新規カーネルを使用して以前のカーネルクラッシュからのデータをダンプすることで従来のダンプタイプに比べて信頼性が向上されています。fadump には、IBM POWER6 プロセッサーベースまたはそれ以降バージョンのハードウェアプラットフォームが必要です。
PowerPC 固有のハードウェアのリセット方法など、fadump メカニズムの詳細は、/usr/share/doc/kexec-tools/fadump-howto.txt ファイルを参照してください。
保持されないメモリー領域はブートメモリーと呼ばれており、この領域はクラッシュ後にカーネルを正常に起動するのに必要なメモリー容量です。デフォルトのブートメモリーサイズは、256 MB または全システム RAM の 5% のいずれか大きい方です。
kexec で開始されたイベントとは異なり、fadump メカニズムでは実稼働用のカーネルを使用してクラッシュダンプを復元します。PowerPC ハードウェアは、クラッシュ後の起動時に、デバイスノード /proc/device-tree/rtas/ibm.kernel-dump が proc ファイルシステム (procfs) で利用できるようにします。fadump-aware kdump スクリプトでは、保存された vmcore があるかを確認してから、システムの再起動を正常に完了させます。
19.2. ファームウェア支援ダンプメカニズムの有効化
IBM POWER システムのクラッシュダンプ機能は、ファームウェア支援ダンプ (fadump) メカニズムを有効にすることで強化できます。
セキュアブート環境では、GRUB ブートローダーは、Real Mode Area (RMA) と呼ばれるブートメモリー領域を割り当てます。RMA のサイズは 512 MB で、ブートコンポーネント間で分割されます。コンポーネントがサイズ割り当てを超えると、GRUB はメモリー不足 (OOM) エラーで失敗します。
RHEL 8.7 および 8.6 バージョンのセキュアブート環境では、ファームウェア支援ダンプ (fadump) メカニズムを有効にしないでください。GRUB2 ブートローダーが次のエラーで失敗します。
error: ../../grub-core/kern/mm.c:376:out of memory. Press any key to continue…
error: ../../grub-core/kern/mm.c:376:out of memory.
Press any key to continue…
システムは、fadump 設定のためにデフォルトの initramfs サイズを増やした場合にのみ回復可能です。
システムを回復するための回避策については、記事 System boot ends in GRUB Out of Memory (OOM) を参照してください。
手順
-
kdumpのインストールと設定 fadump=onカーネルオプションを有効にします。grubby --update-kernel=ALL --args="fadump=on"
# grubby --update-kernel=ALL --args="fadump=on"Copy to Clipboard Copied! Toggle word wrap Toggle overflow オプション: デフォルトを使用する代わりに、予約済みのブートメモリーを指定する場合は、
crashkernel=xxMオプションを有効にします。ここで、xxは必要なメモリーの量 (メガバイト単位) です。grubby --update-kernel=ALL --args="crashkernel=xxM fadump=on"
# grubby --update-kernel=ALL --args="crashkernel=xxM fadump=on"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 重要ブート設定オプションを指定するときは、実行する前にすべてのブート設定オプションをテストしてください。
kdumpカーネルの起動に失敗した場合は、crashkernel=引数に指定した値を徐々に増やして、適切な値を設定します。
19.3. IBM Z ハードウェアにおけるファームウェア支援ダンプの仕組み
IBM Z システムは、以下のファームウェア支援ダンプメカニズムをサポートします。
-
スタンドアロンダンプ (sadump) -
VMDUMP
IBM Z システムでは、kdump インフラストラクチャーはサポート対象で、使用されています。ただし、IBM Z のファームウェア支援ダンプ (fadump) 方式のいずれかを使用すると、次のような利点があります。
-
システムコンソールは
sadumpメカニズムを開始および制御し、それをIPLブート可能なデバイスに保存します。 -
VMDUMPメカニズムはsadumpに似ています。このツールもシステムコンソールから開始しますが、ハードウェアから生成されたダンプを取得して解析用にシステムにコピーします。 -
(他のハードウェアベースのダンプメカニズムと同様に) これらの手法では、(
kdumpサービスが開始される前の) 起動初期段階におけるマシンの状態をキャプチャーできます。 -
VMDUMPには、ダンプファイルを Red Hat Enterprise Linux システムに受信するメカニズムが含まれていますが、VMDUMPの設定と制御は IBM Z ハードウェアコンソールから管理されます。
19.4. Fujitsu PRIMEQUEST システムにおける sadump の使用
Fujitsu sadump メカニズムは、kdump が正常に完了できない場合に fallback ダンプキャプチャーを提供します。システム管理ボード (MMB) インターフェイスから sadump を手動で呼び出すことができます。MMB を使用して、Intel 64 または AMD 64 サーバーの場合と同様に kdump を設定し、sadump を有効にします。
手順
sadumpに対してkdumpが予想どおりに起動するように/etc/sysctl.confファイルで以下の行を追加または編集します。kernel.panic=0 kernel.unknown_nmi_panic=1
kernel.panic=0 kernel.unknown_nmi_panic=1Copy to Clipboard Copied! Toggle word wrap Toggle overflow 警告特に、
kdumpの後にシステムが再起動しないようにする必要があります。kdumpがvmcoreファイルの保存に失敗した後にシステムが再起動すると、sadumpを呼び出すことができなくなります。/etc/kdump.confのfailure_actionパラメーターをhaltまたはshellとして適切に設定します。failure_action shell
failure_action shellCopy to Clipboard Copied! Toggle word wrap Toggle overflow
第20章 コアダンプの分析
システムクラッシュの原因を確認するには、crash ユーティリティーを使用します。これにより、GNU Debugger (GDB) に似たインタラクティブなプロンプトが提供されます。crash を使用すると、kdump、netdump、diskdump、または xendump によって作成されたコアダンプと実行中の Linux システムを分析できます。あるいは、Kernel Oops Analyzer または Kdump Helper ツールを使用することもできます。
20.1. crash ユーティリティーのインストール
crash ユーティリティーをインストールするために必要なパッケージと手順を説明します。RHEL 8 システムでは、crash ユーティリティーがデフォルトでインストールされていない可能性があります。crash は、システムの実行中、またはカーネルクラッシュが発生してコアダンプファイルが作成された後に、システムの状態を対話的に分析するためのツールです。コアダンプファイルは、vmcore ファイルとも呼ばれます。
手順
関連するリポジトリーを有効にします。
subscription-manager repos --enable baseos repository
# subscription-manager repos --enable baseos repositoryCopy to Clipboard Copied! Toggle word wrap Toggle overflow subscription-manager repos --enable appstream repository
# subscription-manager repos --enable appstream repositoryCopy to Clipboard Copied! Toggle word wrap Toggle overflow subscription-manager repos --enable rhel-8-for-x86_64-baseos-debug-rpms
# subscription-manager repos --enable rhel-8-for-x86_64-baseos-debug-rpmsCopy to Clipboard Copied! Toggle word wrap Toggle overflow crashパッケージをインストールします。yum install crash
# yum install crashCopy to Clipboard Copied! Toggle word wrap Toggle overflow kernel-debuginfoパッケージをインストールします。yum install kernel-debuginfo
# yum install kernel-debuginfoCopy to Clipboard Copied! Toggle word wrap Toggle overflow パッケージ
kernel-debuginfoは実行中のカーネルに対応し、ダンプ分析に必要なデータを提供します。
20.2. crash ユーティリティーの実行および終了
crash ユーティリティーは、kdump を分析するための強力なツールです。クラッシュダンプファイルに対して crash を実行すると、クラッシュ時のシステムの状態を把握し、問題の根本原因を特定し、カーネル関連の問題をトラブルシューティングできます。
前提条件
-
現在実行しているカーネルを特定します (
4.18.0-5.el8.x86_64など)。
手順
crashユーティリティーを起動するには、次の 2 つの必要なパラメーターを渡します。-
debug-info (圧縮解除された vmlinuz イメージ) (特定の
kernel-debuginfoパッケージに含まれる/usr/lib/debug/lib/modules/4.18.0-5.el8.x86_64/vmlinuxなど) 実際の vmcore ファイル (例:
/var/crash/127.0.0.1-2018-10-06-14:05:33/vmcore)結果として生じる
crashコマンドは次のようになります。crash /usr/lib/debug/lib/modules/4.18.0-5.el8.x86_64/vmlinux /var/crash/127.0.0.1-2018-10-06-14:05:33/vmcore
# crash /usr/lib/debug/lib/modules/4.18.0-5.el8.x86_64/vmlinux /var/crash/127.0.0.1-2018-10-06-14:05:33/vmcoreCopy to Clipboard Copied! Toggle word wrap Toggle overflow kdumpで取得したのと同じ <kernel> のバージョンを使用します。例20.1 crash ユーティリティーの実行
以下の例は、4.18.0-5.el8.x86_64 カーネルを使用して、2018 年 10 月 6 日 (14:05 PM) に作成されたコアダンプの分析を示しています。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
-
debug-info (圧縮解除された vmlinuz イメージ) (特定の
対話型プロンプトを終了して
crashを停止するには、exitまたはqと入力します。crash> exit ~]#
crash> exit ~]#Copy to Clipboard Copied! Toggle word wrap Toggle overflow
crash コマンドは、ライブシステムをデバッグするための強力なツールとして利用することもできます。ただし、システムレベルの問題を回避するために注意して使用する必要があります。
20.3. crash ユーティリティーのさまざまなインジケーターの表示
crash ユーティリティーを使用して、カーネルメッセージバッファー、バックトレース、プロセスステータス、仮想メモリー情報、開いているファイルなど、さまざまなインジケータを表示します。
メッセージバッファーの表示
カーネルメッセージバッファーを表示するには、対話式プロンプトで
logコマンドを入力します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow このコマンドの使用方法の詳細を参照するには、
help logと入力してください。注記カーネルメッセージバッファーには、システムクラッシュに関する最も重要な情報が含まれています。カーネルメッセージバッファーは、常に最初に
vmcore-dmesg.txtファイルにダンプされます。たとえば、ターゲットロケーションに十分なスペースがないために完全なvmcoreファイルを取得できなかった場合は、カーネルメッセージバッファーから必要な情報を取得できます。デフォルトでは、vmcore-dmesg.txtは/var/crash/ディレクトリーに格納されます。
バックトレースの表示
カーネルスタックトレースを表示するには、
btコマンドを使用します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow bt <pid>を入力して特定のプロセスのバックトレースを表示するか、help btを実行して、btの使用の詳細を表示します。
プロセスの状態表示
システム内のプロセスの状態を表示するには、
psコマンドを使用します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow ps <pid>を使用して、単一プロセスのステータスを表示します。psの詳細な使用方法は、help ps を使用します。
仮想メモリー情報の表示
基本的な仮想メモリー情報を表示するには、対話式プロンプトで
vmコマンドを入力します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow vm <pid>を実行して、1 つのプロセスの情報を表示するか、help vmを実行して、vmの使用方法を表示します。
オープンファイルの表示
オープンファイルの情報を表示するには、
filesコマンドを実行します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow files <pid>を実行して、選択した 1 つのプロセスによって開かれたファイルを表示するか、help filesを実行して、filesの使用方法を表示します。
20.4. Kernel Oops Analyzer の使用
Kernel Oops Analyzer ツールは、ナレッジベースの既知の問題と oops メッセージを比較することで、クラッシュダンプを分析します。
前提条件
-
oopsメッセージは、Kernel Oops Analyzer にフィードするために保護されています。
手順
- Kernel Oops Analyzer ツールにアクセスします。
カーネルクラッシュの問題を診断するには、
vmcoreに生成されたカーネルの oops ログをアップロードします。-
あるいは、テキストメッセージまたは
vmcore-dmesg.txtを入力として提供することで、カーネルクラッシュの問題を診断することもできます。
-
あるいは、テキストメッセージまたは
-
DETECTをクリックして、makedumpfileからの情報に基づくoopsメッセージを既知のソリューションと比較します。
20.5. Kdump Helper ツール
Kdump ヘルパーツールは、提供された情報を使用して kdump を設定するのに役立ちます。Kdump Helper は、ユーザーの設定に基づいて設定スクリプトを生成します。サーバーでスクリプトを開始して実行すると、kdump サービスが設定されます。
第21章 early kdump を使用した起動時間クラッシュの取得
early kdump は、kdump メカニズムの機能です。システムサービスが起動する前の起動プロセス初期段階でシステムまたはカーネルのクラッシュが発生した場合に、vmcore ファイルをキャプチャーします。early kdump はクラッシュカーネルとクラッシュカーネルの initramfs を早い段階でメモリーにロードします。
カーネルクラッシュは、kdump サービスが起動する前のブート初期段階で発生することがあります。その場合、kdump はクラッシュしたカーネルメモリーの内容をキャプチャーして保存できません。そのため、トラブルシューティングにとって重要なクラッシュ関連の重大な情報が失われます。この問題に対処するには、kdump サービスの一部である early kdump 機能を使用できます。
21.1. early kdump の有効化
early kdump 機能は、初期クラッシュの vmcore 情報をキャプチャーするため、十分に早めにロードされるように、クラッシュカーネルと初期 RAM ディスクイメージ (initramfs) をセットアップします。これにより、初期のブートカーネルクラッシュに関する情報が失われるリスクを排除できます。
前提条件
- アクティブな RHEL サブスクリプションがある。
-
システムの CPU アーキテクチャー用の
kexec-toolsパッケージを含むリポジトリーがある。 -
kdumpの設定とターゲットの要件を満たしている詳細は、サポートされている kdump 設定とターゲット を参照してください。
手順
kdumpサービスが有効でアクティブであることを確認します。systemctl is-enabled kdump.service && systemctl is-active kdump.service
# systemctl is-enabled kdump.service && systemctl is-active kdump.service enabled activeCopy to Clipboard Copied! Toggle word wrap Toggle overflow kdumpが有効ではなく、実行されていない場合は、必要な設定をすべて設定し、kdumpサービスが有効化されていることを確認します。起動カーネルの
initramfsイメージを、early kdump機能で再構築します。dracut -f --add earlykdump
# dracut -f --add earlykdumpCopy to Clipboard Copied! Toggle word wrap Toggle overflow rd.earlykdumpカーネルコマンドラインパラメーターを追加します。grubby --update-kernel=/boot/vmlinuz-$(uname -r) --args="rd.earlykdump"
# grubby --update-kernel=/boot/vmlinuz-$(uname -r) --args="rd.earlykdump"Copy to Clipboard Copied! Toggle word wrap Toggle overflow システムを再起動して変更を反映します。
reboot
# rebootCopy to Clipboard Copied! Toggle word wrap Toggle overflow
検証
rd.earlykdumpが正常に追加され、early kdump機能が有効になっていることを確認します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow
第22章 カーネルライブパッチでパッチの適用
Red Hat Enterprise Linux カーネルのライブパッチソリューションを使用すると、再起動やプロセスの再起動を行わずに実行中のカーネルにパッチを適用できます。
このソリューションでは、システム管理者は以下を行うことができます。
- 重大なセキュリティーパッチをカーネルに即座に適用することが可能。
- 長時間実行しているタスクの完了、ユーザーのログオフ、スケジュールダウンタイムを待つ必要がない。
- システムのアップタイムをより制御し、セキュリティーや安定性を犠牲にしない。
カーネルライブパッチを使用すると、セキュリティーパッチに必要な再起動の回数を減らすことができます。ただし、すべての重大または重要な CVE に対処できるわけではないことに注意してください。ライブパッチの範囲の詳細は、Red Hat ナレッジベースソリューション Is live kernel patch (kpatch) supported in Red Hat Enterprise Linux? を参照してください。
カーネルのライブパッチとその他のカーネルサブコンポーネントの間には、いくつかの非互換性が存在します。カーネルのライブパッチを使用する前に、kpatch の制限 を慎重に確認してください。
カーネルのライブパッチ更新のサポート頻度の詳細は、以下を参照してください。
22.1. kpatch の制限
-
kpatch機能を使用すると、システムをすぐに再起動する必要のない、簡単なセキュリティーおよびバグ修正の更新を適用できます。 -
パッチのロード中またはロード後に
SystemTapまたはkprobeツールを使用しないでください。プローブが削除されるまでパッチは有効にならない可能性があります。
22.2. サードパーティーのライブパッチサポート
kpatch ユーティリティーは、Red Hat リポジトリー提供の RPM モジュールを含む、Red Hat がサポートする唯一のカーネルライブパッチユーティリティーです。Red Hat はサードパーティーが提供するライブパッチをサポートしていません。
サードパーティーソフトウェアのサポートポリシーの詳細は、As a customer how does Red Hat support me when I use third party components? を参照してください。
22.3. カーネルライブパッチへのアクセス
カーネルモジュール (kmod) はカーネルのライブパッチ機能を実装し、RPM パッケージとして提供されます。
すべてのお客様は、通常のチャンネルから提供されるカーネルライブパッチにアクセスできます。ただし、延長サポートサービスにサブスクライブしていないお客様は、次のマイナーリリースが利用可能になると、現行のマイナーリリースに対する新しいパッチへのアクセスを失うことになります。たとえば、標準のサブスクリプションを購入しているお客様は、RHEL 8.3 カーネルがリリースされるまで RHEL 8.2 カーネルのライブパッチのみを行うことができます。
カーネルのライブパッチのコンポーネントは、以下のようになります。
- カーネルパッチモジュール
- カーネルライブパッチの配信メカニズム
- パッチが適用されるカーネル専用に構築されたカーネルモジュール。
- パッチモジュールには、カーネルに必要な修正のコードが含まれます。
-
パッチモジュールは、
livepatchカーネルサブシステムに登録され、置換する元の関数と置換関数へのポインターを指定します。カーネルパッチモジュールは RPM として提供されます。 -
命名規則は、
kpatch_<kernel version>_<kpatch version>_<kpatch release>です。名前の "kernel version" 部分の ドット は、アンダースコア に置き換えます。
kpatchユーティリティー- パッチモジュールを管理するためのコマンドラインユーティリティー。
kpatchサービス-
multiuser.targetで必要なsystemdサービス。このターゲットは、システムの起動時にカーネルパッチをロードします。 kpatch-dnfパッケージ- RPM パッケージ形式で配信される DNF プラグイン。このプラグインは、カーネルライブパッチへの自動サブスクリプションを管理します。
22.4. カーネルのライブパッチ適用のプロセス
kpatch カーネルパッチソリューションは、livepatch カーネルサブシステムを使用して、古い関数を更新された関数にリダイレクトします。システムにライブカーネルパッチを適用すると、次のプロセスがトリガーされます。
-
カーネルパッチモジュールは、
/var/lib/kpatch/ディレクトリーにコピーされ、次回の起動時にsystemdを介して、カーネルへの再適用として登録されます。 -
kpatchモジュールは実行中のカーネルにロードされ、新しい関数は新しいコードのメモリー内のロケーションへのポインターとともにftraceメカニズムに登録されます。
カーネルがパッチを適用した関数にアクセスすると、ftrace メカニズムによって関数がリダイレクトされ、元の関数がバイパスされてカーネルが関数のパッチを適用したバージョンに誘導されます。
図22.1 カーネルライブパッチの仕組み
22.5. 現在インストールされているカーネルをライブパッチストリームにサブスクライブする手順
カーネルパッチモジュールは RPM パッケージに含まれ、パッチが適用されたカーネルバージョンに固有のものとなります。各 RPM パッケージは時間とともに累積的に更新されます。
以下の手順では、指定のカーネルに対して、今後の累積パッチ更新をすべてサブスクライブする方法を説明します。ライブパッチは累積的であるため、特定のカーネルにデプロイされている個々のパッチを選択できません。
Red Hat は、Red Hat がサポートするシステムに適用されたサードパーティーのライブパッチをサポートしません。
前提条件
- root 権限がある。
手順
オプション: カーネルのバージョンを確認します。
uname -r
# uname -r 4.18.0-94.el8.x86_64Copy to Clipboard Copied! Toggle word wrap Toggle overflow カーネルのバージョンに一致するライブパッチパッケージを検索します。
yum search $(uname -r)
# yum search $(uname -r)Copy to Clipboard Copied! Toggle word wrap Toggle overflow ライブパッチパッケージをインストールします。
yum install "kpatch-patch = $(uname -r)"
# yum install "kpatch-patch = $(uname -r)"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 上記のコマンドでは、特定カーネルにのみに最新の累積パッチをインストールし、適用します。
ライブパッチパッケージのバージョンが 1-1 以上である場合には、パッケージにパッチモジュールが含まれます。この場合、ライブパッチパッケージのインストール時に、カーネルにパッチが自動的に適用されます。
カーネルパッチモジュールは、今後の再起動時に
systemdシステムおよびサービスマネージャーにより読み込まれる/var/lib/kpatch/ディレクトリーにもインストールされます。注記指定のカーネルに利用可能なライブパッチがない場合は、空のライブパッチパッケージがインストールされます。空のライブパッチパッケージには、kpatch_version-kpatch_release 0-0 (例:
kpatch-patch-4_18_0-94-0-0.el8.x86_64.rpm) が含まれます。空の RPM のインストールを行うと、指定のカーネルの将来のすべてのライブパッチにシステムがサブスクライブされます。
検証
インストールされているすべてのカーネルにパッチが当てられていることを確認します。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow この出力は、カーネルパッチモジュールがカーネルに読み込まれていることを示しています。このカーネルには、
kpatch-patch-4_18_0-94-1-1.el8.x86_64.rpmパッケージで修正された最新のパッチが当てられています。注記kpatch listコマンドを入力しても、空のライブパッチパッケージが返されません。代わりにrpm -qa | grep kpatchコマンドを使用します。rpm -qa | grep kpatch
# rpm -qa | grep kpatch kpatch-patch-4_18_0-477_21_1-0-0.el8_8.x86_64 kpatch-dnf-0.9.7_0.4-2.el8.noarch kpatch-0.9.7-2.el8.noarchCopy to Clipboard Copied! Toggle word wrap Toggle overflow
22.6. ライブパッチストリームに新しいカーネルを自動的にサブスクライブする手順
kpatch-dnf YUM プラグインを使用して、カーネルパッチモジュール (別称: カーネルライブパッチ) が提供する修正にシステムをサブスクライブできます。このプラグインは、現在システムが使用するカーネルと、今後インストールされる カーネルの 自動 サブスクリプションを有効にします。
前提条件
- root 権限がある。
手順
オプション: インストールされているすべてのカーネルと現在実行中のカーネルを確認します。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow kpatch-dnfプラグインをインストールします。yum install kpatch-dnf
# yum install kpatch-dnfCopy to Clipboard Copied! Toggle word wrap Toggle overflow カーネルライブパッチの自動サブスクリプションを有効にします。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow このコマンドは、現在インストールされているすべてのカーネルをサブスクライブして、カーネルライブパッチを受け取ります。このコマンドは、インストールされている全カーネルに、最新の累積パッチ (存在する場合) をインストールして適用します。
カーネルを更新すると、新しいカーネルのインストールプロセス中にライブパッチが自動的にインストールされます。
カーネルパッチモジュールは、今後の再起動時に
systemdシステムおよびサービスマネージャーにより読み込まれる/var/lib/kpatch/ディレクトリーにもインストールされます。注記指定のカーネルに利用可能なライブパッチがない場合は、空のライブパッチパッケージがインストールされます。空のライブパッチパッケージには、kpatch_version-kpatch_release 0-0 (例:
kpatch-patch-4_18_0-240-0-0.el8.x86_64.rpm) が含まれます。空の RPM のインストールを行うと、指定のカーネルの将来のすべてのライブパッチにシステムがサブスクライブされます。
検証
インストールされているすべてのカーネルにパッチが適用されていることを確認します。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow この出力から、実行中のカーネルとインストールされている他のカーネル両方に
kpatch-patch-4_18_0-240_10_1-0-1.rpmとkpatch-patch-4_18_0-240_15_1-0-1.rpmパッケージそれぞれからの修正が適用されたことが分かります。注記kpatch listコマンドを入力しても、空のライブパッチパッケージが返されません。代わりにrpm -qa | grep kpatchコマンドを使用します。rpm -qa | grep kpatch
# rpm -qa | grep kpatch kpatch-patch-4_18_0-477_21_1-0-0.el8_8.x86_64 kpatch-dnf-0.9.7_0.4-2.el8.noarch kpatch-0.9.7-2.el8.noarchCopy to Clipboard Copied! Toggle word wrap Toggle overflow
22.7. ライブパッチストリームへの自動サブスクリプションの無効化
カーネルパッチモジュールが提供する修正にシステムをサブスクライブする場合、サブスクリプションは 自動的 です。この機能を無効にして、kpatch-patch パッケージの自動インストールを無効化できます。
前提条件
- root 権限がある。
手順
オプション: インストールされているすべてのカーネルと現在実行中のカーネルを確認します。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow カーネルライブパッチへの自動サブスクリプションを無効にします。
yum kpatch manual
# yum kpatch manual Updating Subscription Management repositories.Copy to Clipboard Copied! Toggle word wrap Toggle overflow
検証
成功した出力を確認できます。
yum kpatch status
# yum kpatch status ... Updating Subscription Management repositories. Last metadata expiration check: 0:30:41 ago on Tue Jun 14 15:59:26 2022. Kpatch update setting: manualCopy to Clipboard Copied! Toggle word wrap Toggle overflow
22.8. カーネルパッチモジュールの更新
カーネルパッチモジュールは、RPM パッケージを通じて配信および適用されます。累積的なカーネルパッチモジュールを更新するプロセスは、他の RPM パッケージの更新と同様です。
前提条件
- 現在インストールされているカーネルをライブパッチストリームにサブスクライブする手順 に従って、システムがライブパッチストリームにサブスクライブされている。
手順
現在のカーネルの新しい累積バージョンを更新します。
yum update "kpatch-patch = $(uname -r)"
# yum update "kpatch-patch = $(uname -r)"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 上記のコマンドは、現在実行中のカーネルに利用可能な更新を自動的にインストールし、適用します。これには、新たにリリースされた累計なライブパッチが含まれます。
もしくは、インストールしたすべてのカーネルパッチモジュールを更新します。
yum update "kpatch-patch"
# yum update "kpatch-patch"Copy to Clipboard Copied! Toggle word wrap Toggle overflow
システムが同じカーネルで再起動すると、kpatch.service systemd サービスにより、再度カーネルにライブパッチが自動的に適用されます。
22.9. ライブパッチパッケージの削除
ライブパッチパッケージを削除して、Red Hat Enterprise Linux カーネルライブパッチソリューションを無効にします。
前提条件
- root 権限がある。
- ライブパッチパッケージがインストールされている。
手順
ライブパッチパッケージを選択します。
yum list installed | grep kpatch-patch
# yum list installed | grep kpatch-patch kpatch-patch-4_18_0-94.x86_64 1-1.el8 @@commandline …Copy to Clipboard Copied! Toggle word wrap Toggle overflow 出力例には、インストールしたライブパッチパッケージがリストされます。
ライブパッチパッケージを削除します。
yum remove kpatch-patch-4_18_0-94.x86_64
# yum remove kpatch-patch-4_18_0-94.x86_64Copy to Clipboard Copied! Toggle word wrap Toggle overflow ライブパッチパッケージが削除されると、カーネルは次回の再起動までパッチが当てられたままになりますが、カーネルパッチモジュールはディスクから削除されます。今後の再起動では、対応するカーネルにはパッチが適用されなくなります。
- システムを再起動します。
ライブパッチパッケージが削除されたことを確認します。
yum list installed | grep kpatch-patch
# yum list installed | grep kpatch-patchCopy to Clipboard Copied! Toggle word wrap Toggle overflow パッケージが正常に削除された場合、このコマンドでは何も出力されません。
検証
カーネルライブパッチソリューションが無効になっていることを確認します。
kpatch list
# kpatch list Loaded patch modules:Copy to Clipboard Copied! Toggle word wrap Toggle overflow この出力例では、現在読み込まれているパッチモジュールがないため、カーネルにパッチが適用されておらず、ライブパッチソリューションがアクティブでないことが示されています。
現在、Red Hat はシステムの再起動なしで、ライブパッチを元に戻すことはサポートしていません。ご不明な点がございましたら、サポートチームまでお問い合わせください。
22.10. カーネルパッチモジュールのアンインストール
Red Hat Enterprise Linux カーネルライブパッチソリューションが、以降の起動時にカーネルパッチモジュールを適用しないようにします。
前提条件
- root 権限がある。
- ライブパッチパッケージがインストールされている。
- カーネルパッチモジュールがインストールされ、ロードされている。
手順
カーネルパッチモジュールを選択します。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 選択したカーネルパッチモジュールをアンインストールします。
kpatch uninstall kpatch_4_18_0_94_1_1
# kpatch uninstall kpatch_4_18_0_94_1_1 uninstalling kpatch_4_18_0_94_1_1 (4.18.0-94.el8.x86_64)Copy to Clipboard Copied! Toggle word wrap Toggle overflow アンインストールしたカーネルモジュールが読み込まれていることに注意してください。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 選択したモジュールをアンインストールすると、カーネルは次回の再起動までパッチが当てられますが、カーネルパッチモジュールはディスクから削除されます。
- システムを再起動します。
検証
カーネルパッチモジュールがアンインストールされていることを確認します。
kpatch list
# kpatch list Loaded patch modules: …Copy to Clipboard Copied! Toggle word wrap Toggle overflow この出力例では、カーネルパッチモジュールがロードまたはインストールされていないことが示されています。そのため、カーネルにパッチが適用されておらず、カーネルライブパッチソリューションがアクティブではありません。
22.11. kpatch.service の無効化
Red Hat Enterprise Linux カーネルライブパッチソリューションが、以降の起動時にすべてのカーネルパッチモジュールをグローバルに適用しないようにします。
前提条件
- root 権限がある。
- ライブパッチパッケージがインストールされている。
- カーネルパッチモジュールがインストールされ、ロードされている。
手順
kpatch.serviceが有効化されていることを確認します。systemctl is-enabled kpatch.service
# systemctl is-enabled kpatch.service enabledCopy to Clipboard Copied! Toggle word wrap Toggle overflow kpatch.serviceを無効にします。systemctl disable kpatch.service
# systemctl disable kpatch.service Removed /etc/systemd/system/multi-user.target.wants/kpatch.service.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 適用されたカーネルモジュールが依然としてロードされていることに注意してください。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
- システムを再起動します。
オプション:
kpatch.serviceのステータスを確認します。systemctl status kpatch.service
# systemctl status kpatch.service ● kpatch.service - "Apply kpatch kernel patches" Loaded: loaded (/usr/lib/systemd/system/kpatch.service; disabled; vendor preset: disabled) Active: inactive (dead)Copy to Clipboard Copied! Toggle word wrap Toggle overflow 出力例は、
kpatch.serviceが無効になっていることを証明しています。したがって、カーネルのライブパッチソリューションはアクティブではありません。カーネルパッチモジュールがアンロードされたことを確認します。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 上記の出力例では、カーネルパッチモジュールがインストールされていても、カーネルにパッチが適用されていないことを示しています。
現在、Red Hat はシステムの再起動なしで、ライブパッチを元に戻すことはサポートしていません。ご不明な点がございましたら、サポートチームまでお問い合わせください。
第23章 コントロールグループを使用したアプリケーションのシステムリソース制限の設定
コントロールグループ (cgroups) カーネル機能を使用すると、アプリケーションのリソース使用状況を制御して、より効率的に使用できます。
cgroups は、以下のタスクで使用できます。
- システムリソース割り当ての制限を設定します。
- 特定のプロセスへのハードウェアリソースの割り当てにおける優先順位を設定する。
- 特定のプロセスをハードウェアリソースの取得から分離する。
23.1. コントロールグループの概要
コントロールグループ の Linux カーネル機能を使用して、プロセスを階層的に順序付けされたグループ (cgroups) に編成できます。階層 (コントロールグループツリー) は、デフォルトで /sys/fs/cgroup/ ディレクトリーにマウントされている cgroups 仮想ファイルシステムに構造を提供して定義します。
systemd サービスマネージャーは、cgroups を使用して、管理するすべてのユニットとサービスを整理します。/sys/fs/cgroup/ ディレクトリーのサブディレクトリーを作成および削除することで、cgroups の階層を手動で管理できます。
続いて、カーネルのリソースコントローラーは、cgroups 内のプロセスのシステムリソースを制限、優先順位付け、または割り当てることで、これらのプロセスの動作を変更します。これらのリソースには以下が含まれます。
- CPU 時間
- メモリー
- ネットワーク帯域幅
- これらのリソースの組み合わせ
cgroups の主なユースケースは、システムプロセスを集約し、アプリケーションとユーザー間でハードウェアリソースを分割することです。これにより、環境の効率、安定性、およびセキュリティーを強化できます。
- コントロールグループ 1
コントロールグループバージョン 1 (
cgroups-v1) はリソースごとのコントローラー階層を提供します。CPU、メモリー、I/O などのリソースごとに、独自のコントロールグループ階層があります。異なるコントロールグループ階層を組み合わせることで、1 つのコントローラーが別のコントローラーと連携してそれぞれのリソースを管理できるようになります。ただし、2 つのコントローラーが異なるプロセス階層に属している場合、連携が制限されます。cgroups-v1コントローラーは長期間にわたって開発されたため、コントロールファイルの動作と命名に一貫性がありません。- コントロールグループ 2
Control groups version 2 (
cgroups-v2) は、すべてのリソースコントローラーがマウントされる単一のコントロールグループ階層を提供します。コントロールファイルの動作と命名は、さまざまなコントローラーにおいて一貫性があります。
注記cgroups-v2は、RHEL 8.2 以降のバージョンで完全にサポートされています。詳細は Control Group v2 is now fully supported in RHEL 8 を参照してください。
23.2. カーネルリソースコントローラーの概要
カーネルリソースコントローラーは、コントロールグループの機能を有効化します。RHEL 8 は、コントロールグループバージョン 1 (cgroups-v1) および コントロールグループバージョン 2 (cgroups-v2) のさまざまなコントローラーをサポートします。
コントロールグループサブシステムとも呼ばれるリソースコントローラーは、1 つのリソース (CPU 時間、メモリー、ネットワーク帯域幅、ディスク I/O など) を表すカーネルサブシステムです。Linux カーネルは、systemd サービスマネージャーによって自動的にマウントされるリソースコントローラーの範囲を提供します。現在マウントされているリソースコントローラーの一覧は、/proc/cgroups ファイルで確認できます。
cgroups-v1 で利用可能なコントローラー
blkio- ブロックデバイスへの入出力アクセスを制限します。
cpu-
コントロールグループのタスク用の Completely Fair Scheduler (CFS) パラメーターを調整します。
cpuコントローラーは、同じマウント上のcpuacctコントローラーとともにマウントされます。 cpuacct-
コントロールグループ内のタスクが使用する CPU リソースに関する自動レポートを作成します。
cpuacctコントローラーは、同じマウント上のcpuコントローラーとともにマウントされます。 cpuset- コントロールグループタスクが、指定された CPU のサブセットでのみ実行されるように制限し、指定されたメモリーノードでのみメモリーを使用するようにタスクに指示します。
devices- コントロールグループ内のタスクのデバイスへのアクセスを制御します。
freezer- コントロールグループ内のタスクを一時停止または再開します。
memory- コントロールグループ内のタスクによるメモリー使用の制限を設定し、それらのタスクが使用したメモリーリソースに関する自動レポートを生成します。
net_cls-
特定のコントロールグループタスクから発信されたパケットを識別するために Linux トラフィックコントローラー (
tcコマンド) を有効化するクラス識別子 (classid) でネットワークパケットをタグ付けします。net_clsのサブシステムnet_filter(iptables) でも、このタグを使用して、そのようなパケットに対するアクションを実行することができます。net_filterは、ファイアウォール識別子 (fwid) でネットワークソケットをタグ付けします。これにより、Linux ファイアウォールは、(iptablesコマンドを使用して) 特定のコントロールグループタスクから発信されたパケットを識別できるようになります。 net_prio- ネットワークトラフィックの優先度を設定します。
pids- コントロールグループ内の複数のプロセスとその子プロセスに制限を設定します。
perf_event-
perfパフォーマンス監視およびレポートユーティリティーにより、監視するタスクをグループ化します。 rdma- コントロールグループ内の Remote Direct Memory Access/InfiniBand 固有リソースに制限を設定します。
hugetlb- コントロールグループ内のタスクによる大容量の仮想メモリーページの使用を制限します。
cgroups-v2 で利用可能なコントローラー
io- ブロックデバイスへの入出力アクセスを制限します。
memory- コントロールグループ内のタスクによるメモリー使用の制限を設定し、それらのタスクが使用したメモリーリソースに関する自動レポートを生成します。
pids- コントロールグループ内の複数のプロセスとその子プロセスに制限を設定します。
rdma- コントロールグループ内の Remote Direct Memory Access/InfiniBand 固有リソースに制限を設定します。
cpu- コントロールグループのタスクの Completely Fair Scheduler (CFS) パラメーターを調整し、コントロールグループのタスクで使用される CPU リソースに関する自動レポートを作成します。
cpuset-
コントロールグループタスクが、指定された CPU のサブセットでのみ実行されるように制限し、指定されたメモリーノードでのみメモリーを使用するようにタスクに指示します。新しいパーティション機能により、コア機能 (
cpus{,.effective},mems{,.effective}) のみがサポートされます。 perf_event-
perfパフォーマンス監視およびレポートユーティリティーにより、監視するタスクをグループ化します。perf_eventは v2 階層で自動的に有効になります。
リソースコントローラーは、cgroups-v1 階層または cgroups-v 2 階層のいずれかで使用できますが、両方を同時に使用することはできません。
23.3. 名前空間の概要
名前空間は、ソフトウェアオブジェクトを整理および識別するための個別の空間を作成するものです。これにより、オブジェクトが相互に影響を及ぼすことがなくなります。その結果、各ソフトウェアオブジェクトが同じシステムを共有しているにもかかわらず、独自のリソースセット (マウントポイント、ネットワークデバイス、ホスト名など) が各オブジェクトに格納されます。
名前空間を使用する最も一般的なテクノロジーの 1 つとしてコンテナーが挙げられます。
特定のグローバルリソースへの変更は、その名前空間のプロセスにのみ表示され、残りのシステムまたは他の名前空間には影響しません。
プロセスがどの名前空間に所属するかを確認するには、/proc/<PID>/ns/ ディレクトリーのシンボリックリンクを確認します。
| 名前空間 | 分離 |
|---|---|
| Mount | マウントポイント |
| UTS | ホスト名および NIS ドメイン名 |
| IPC | System V IPC、POSIX メッセージキュー |
| PID | プロセス ID |
| Network | ネットワークデバイス、スタック、ポートなど。 |
| User | ユーザーおよびグループ ID |
| Control groups | コントロールグループの root ディレクトリー |
23.4. cgroups-v1 を使用したアプリケーションへの CPU 制限の設定
コントロールグループバージョン 1 (cgroups-v1) を使用してアプリケーションに対する CPU 制限を設定するには、/sys/fs/ 仮想ファイルシステムを使用します。
前提条件
- root 権限がある。
- CPU 消費制限の対象とするアプリケーションがシステムにインストールされている。
cgroups-v1コントローラーがマウントされていることを確認している。Copy to Clipboard Copied! Toggle word wrap Toggle overflow
手順
CPU 消費を制限するアプリケーションのプロセス ID (PID) を特定します。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow PID 6955を持つsha1sumサンプルアプリケーションが、大量の CPU リソースを消費しています。cpuリソースコントローラーディレクトリーにサブディレクトリーを作成します。mkdir /sys/fs/cgroup/cpu/Example/
# mkdir /sys/fs/cgroup/cpu/Example/Copy to Clipboard Copied! Toggle word wrap Toggle overflow このディレクトリーはコントロールグループを表します。ここに特定のプロセスを配置して、そのプロセスに特定の CPU 制限を適用できます。同時に、いくつかの
cgroups-v1インターフェイスファイルとcpuコントローラー固有のファイルがディレクトリーに作成されます。オプション: 新しく作成されたコントロールグループを確認します。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow cpuacct.usage、cpu.cfs._period_usなどのファイルは、Exampleコントロールグループ内のプロセスに設定できる特定の設定や制限を表しています。ファイル名の先頭に、それが属するコントロールグループコントローラーの名前が付いていることに注意してください。デフォルトでは、新しく作成されたコントロールグループは、システムの CPU リソース全体へのアクセスを制限なしで継承します。
コントロールグループの CPU 制限を設定します。
echo "1000000" > /sys/fs/cgroup/cpu/Example/cpu.cfs_period_us echo "200000" > /sys/fs/cgroup/cpu/Example/cpu.cfs_quota_us
# echo "1000000" > /sys/fs/cgroup/cpu/Example/cpu.cfs_period_us # echo "200000" > /sys/fs/cgroup/cpu/Example/cpu.cfs_quota_usCopy to Clipboard Copied! Toggle word wrap Toggle overflow -
cpu.cfs_period_usファイルは、コントロールグループの CPU リソースへのアクセスを再割り当てする必要がある頻度を表します。期間はマイクロ秒 (µs、"us") 単位です。上限は 1,000,000 マイクロ秒、下限は 1,000 マイクロ秒です。 cpu.cfs_quota_usファイルは、コントロールグループ内のすべてのプロセスが 1 つの期間 (cpu.cfs_period_usで定義) 中にまとめて実行できる合計時間をマイクロ秒単位で表します。コントロールグループ内のプロセスが 1 つの期間中にクォータで指定された時間をすべて使い果たすと、そのプロセスは残り期間にわたってスロットリングされ、次の期間まで実行できなくなります。下限は 1000 マイクロ秒です。上記のコマンド例は、CPU 時間制限を設定して、
Exampleコントロールグループでまとめられているすべてのプロセスは、1 秒ごと (cpu.cfs_period_usに定義されている) に、0.2 秒間だけ (cpu.cfs_quota_usに定義されている) 実行できるようにしています。
-
オプション: 制限を確認します。
cat /sys/fs/cgroup/cpu/Example/cpu.cfs_period_us /sys/fs/cgroup/cpu/Example/cpu.cfs_quota_us 1000000 200000
# cat /sys/fs/cgroup/cpu/Example/cpu.cfs_period_us /sys/fs/cgroup/cpu/Example/cpu.cfs_quota_us 1000000 200000Copy to Clipboard Copied! Toggle word wrap Toggle overflow アプリケーションの PID を
Exampleコントロールグループに追加します。echo "6955" > /sys/fs/cgroup/cpu/Example/cgroup.procs
# echo "6955" > /sys/fs/cgroup/cpu/Example/cgroup.procsCopy to Clipboard Copied! Toggle word wrap Toggle overflow このコマンドによって、特定のアプリケーションが
Exampleコントロールグループのメンバーとなり、Exampleコントロールグループに設定された CPU 制限を超えないようになります。PID はシステム内の既存のプロセスを表す必要があります。このPID 6955は、プロセスsha1sum /dev/zero &に割り当てられており、cpuコントローラーの使用例を示すために使用されています。
検証
アプリケーションが指定のコントロールグループで実行されていることを確認します。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow アプリケーションのプロセスは、アプリケーションのプロセスに CPU 制限を適用する
Exampleコントロールグループで実行されます。スロットルしたアプリケーションの現在の CPU 使用率を特定します。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow PID 6955の CPU 消費が 99% から 20% に減少していることに注意してください。
cpu.cfs_period_us および cpu.cfs_quota_us に対応する cgroups-v2 は、cpu.max ファイルです。cpu.max ファイルは、cpu コントローラーから入手できます。
第24章 cgroups-v2 を使用したアプリケーションへの CPU 時間配分の制御
一部のアプリケーションが CPU 時間を多く使用し過ぎて、環境全体の健全性に悪影響を与える場合があります。アプリケーションを コントロールグループバージョン 2 (cgroups-v2) に配置し、それらのコントロールグループの CPU 制限を設定できます。その結果、アプリケーションの CPU 消費を調整できます。
ユーザーには、コントロールグループに割り当てられる CPU 時間の配分を調整する方法が 2 つあります。
24.1. cgroups-v2 のマウント
RHEL 8 は、システムの起動プロセス中に、デフォルトで cgroup-v1 仮想ファイルシステムをマウントします。cgroup-v2 機能を使用してアプリケーションのリソースを制限するには、システムを手動で設定します。システムリソースの使用を制御するには、systemd を使用します。特別な場合にのみ、cgroups 仮想ファイルシステムを手動で設定する必要があります。たとえば、cgroup-v2 階層に同等のものがない cgroup-v1 コントローラーを使用する必要がある場合などです。
前提条件
- root 権限がある。
手順
systemdシステムおよびサービスマネージャーによるシステムブート中に、デフォルトでcgroups-v2をマウントするようにシステムを設定します。grubby --update-kernel=/boot/vmlinuz-$(uname -r) --args="systemd.unified_cgroup_hierarchy=1"
# grubby --update-kernel=/boot/vmlinuz-$(uname -r) --args="systemd.unified_cgroup_hierarchy=1"Copy to Clipboard Copied! Toggle word wrap Toggle overflow これにより、必要なカーネルコマンドラインパラメーターが現在のブートエントリーに追加されます。
systemd.unified_cgroup_hierarchy=1パラメーターをすべてのカーネルブートエントリーに追加するには、次の手順に従います。grubby --update-kernel=ALL --args="systemd.unified_cgroup_hierarchy=1"
# grubby --update-kernel=ALL --args="systemd.unified_cgroup_hierarchy=1"Copy to Clipboard Copied! Toggle word wrap Toggle overflow - システムを再起動して、変更を有効にします。
検証
cgroups-v2ファイルシステムがマウントされていることを確認します。mount -l | grep cgroup
# mount -l | grep cgroup cgroup2 on /sys/fs/cgroup type cgroup2 (rw,nosuid,nodev,noexec,relatime,seclabel,nsdelegate)Copy to Clipboard Copied! Toggle word wrap Toggle overflow cgroups-v2ファイルシステムが/sys/fs/cgroup/ディレクトリーに正常にマウントされました。/sys/fs/cgroup/ディレクトリーの内容を確認します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow /sys/fs/cgroup/ディレクトリー (root control group とも呼ばれる) は、デフォルトで、インターフェイスファイル (cgroupで始まる) とcpuset.cpus.effectiveなどのコントローラー固有のファイルを提供します。さらに、/sys/fs/cgroup/init.scope、/sys/fs/cgroup/system.slice、および/sys/fs/cgroup/user.sliceなど、systemdに関連するディレクトリーがいくつかあります。
24.2. CPU 時間配分のための cgroup の準備
アプリケーションの CPU 消費を制御するには、特定の CPU コントローラーを有効にして専用のコントロールグループを作成する必要があります。cgroup ファイルの組織的な明確さを維持するために、/sys/fs/cgroup/ root コントロールグループ内に少なくとも 2 つのレベルの子コントロールグループを作成することが推奨されます。
前提条件
- root 権限がある。
- 制御するプロセスの PID を把握している。
-
cgroups-v2ファイルシステムをマウントしている。詳細は、cgroups-v2 のマウント を参照してください。
手順
CPU 消費を制限するアプリケーションのプロセス ID (PID) を特定します。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow この出力例は、
PID 34578および34579(sha1sumの 2 つの例示的なアプリケーション) が大量のリソース、つまり CPU を消費していることを示しています。いずれもcgroups-v2機能の管理を示すために使用されるサンプルアプリケーションです。cpuおよびcpusetコントローラーが/sys/fs/cgroup/cgroup.controllersファイルで利用可能であることを確認します。cat /sys/fs/cgroup/cgroup.controllers cpuset cpu io memory hugetlb pids rdma
# cat /sys/fs/cgroup/cgroup.controllers cpuset cpu io memory hugetlb pids rdmaCopy to Clipboard Copied! Toggle word wrap Toggle overflow CPU 関連のコントローラーを有効にします。
echo "+cpu" >> /sys/fs/cgroup/cgroup.subtree_control echo "+cpuset" >> /sys/fs/cgroup/cgroup.subtree_control
# echo "+cpu" >> /sys/fs/cgroup/cgroup.subtree_control # echo "+cpuset" >> /sys/fs/cgroup/cgroup.subtree_controlCopy to Clipboard Copied! Toggle word wrap Toggle overflow これらのコマンドにより、
/sys/fs/cgroup/ルートコントロールグループ直下のサブグループに対してcpuおよびcpusetコントローラーが有効になります。サブグループ で指定した各プロセスに対して、基準に基づいてコントロールチェックを適用できます。任意のレベルで
cgroup.subtree_controlファイルを確認して、直下の子グループで有効にできるコントローラーを識別できます。注記デフォルトでは、ルートコントロールグループの
/sys/fs/cgroup/cgroup.subtree_controlファイルにはmemoryとpidsコントローラーが含まれます。/sys/fs/cgroup/Example/ディレクトリーを作成します。mkdir /sys/fs/cgroup/Example/
# mkdir /sys/fs/cgroup/Example/Copy to Clipboard Copied! Toggle word wrap Toggle overflow /sys/fs/cgroup/Example/ディレクトリーはサブグループを定義します。また、前の手順では、このサブグループのcpuコントローラーおよびcpusetコントローラーを有効にしました。/sys/fs/cgroup/Example/ディレクトリーを作成すると、cgroups-v2インターフェイスファイルとcpuおよびcpusetのコントローラー固有のファイルがディレクトリーに自動的に作成されます。/sys/fs/cgroup/Example/ディレクトリーは、memoryおよびpidsコントローラー用のコントローラー固有のファイルも提供します。オプション: 新しく作成された子コントロールグループを確認します。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 出力例には、
cpuset.cpusやcpu.maxなどのファイルが表示されます。これらのファイルは、cpusetコントローラーおよびcpuコントローラーに固有のものです。cpusetおよびcpuコントローラーは、/sys/fs/cgroup/cgroup.subtree_controlファイルを使用して、ルート (/sys/fs/cgroup/) の直下のサブコントローラーグループに対して手動で有効にされます。ディレクトリーには
cgroup.procsまたはcgroup.controllersなどの一般的なcgroupコントロールインターフェイスファイルがありますが、これは有効なコントローラーに関係なく、すべてのコントロールグループに共通のものです。memory.highおよびpids.maxなどのファイルは、memoryおよびpidsコントローラーに関連し、ルートコントロールグループ (/sys/fs/cgroup/) にあり、常にデフォルトで有効になります。デフォルトでは、新しく作成されたサブグループは、制限なしで、システムのすべての CPU およびメモリーリソースへのアクセスを継承します。
/sys/fs/cgroup/Example/の CPU 関連のコントローラーを有効にし、CPU にのみ関連するコントローラーを取得します。echo "+cpu" >> /sys/fs/cgroup/Example/cgroup.subtree_control echo "+cpuset" >> /sys/fs/cgroup/Example/cgroup.subtree_control
# echo "+cpu" >> /sys/fs/cgroup/Example/cgroup.subtree_control # echo "+cpuset" >> /sys/fs/cgroup/Example/cgroup.subtree_controlCopy to Clipboard Copied! Toggle word wrap Toggle overflow これらのコマンドにより、直下のサブコントロールグループに、(
memoryまたはpidsコントローラーではなく) CPU 時間の配分の調整に関係するコントローラー だけが設定されるようになります。/sys/fs/cgroup/Example/tasks/ディレクトリーを作成します。mkdir /sys/fs/cgroup/Example/tasks/
# mkdir /sys/fs/cgroup/Example/tasks/Copy to Clipboard Copied! Toggle word wrap Toggle overflow /sys/fs/cgroup/Example/tasks/ディレクトリーは、cpuおよびcpusetコントローラーにのみ関連するファイルを持つサブグループを定義します。オプション: 別の子コントロールグループを検査します。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow CPU 時間を制御するプロセスが同じ CPU で競合していることを確認します。
echo "1" > /sys/fs/cgroup/Example/tasks/cpuset.cpus
# echo "1" > /sys/fs/cgroup/Example/tasks/cpuset.cpusCopy to Clipboard Copied! Toggle word wrap Toggle overflow これにより、
Example/tasks子コントロールグループに配置するプロセスが、同じ CPU 上で競合するようになります。この設定は、cpuコントローラーをアクティベートするのに重要です。重要cpuコントローラーは、関連する子コントロールグループに、単一の CPU 上で時間を競合するプロセスが少なくとも 2 つある場合にのみアクティブになります。
検証
オプション: 直下の子 cgroups に対して CPU 関連コントローラーが有効になっていることを確認します。
cat /sys/fs/cgroup/cgroup.subtree_control /sys/fs/cgroup/Example/cgroup.subtree_control cpuset cpu memory pids cpuset cpu
# cat /sys/fs/cgroup/cgroup.subtree_control /sys/fs/cgroup/Example/cgroup.subtree_control cpuset cpu memory pids cpuset cpuCopy to Clipboard Copied! Toggle word wrap Toggle overflow オプション:CPU 時間を制御するプロセスが同じ CPU で競合していることを確認します。
cat /sys/fs/cgroup/Example/tasks/cpuset.cpus 1
# cat /sys/fs/cgroup/Example/tasks/cpuset.cpus 1Copy to Clipboard Copied! Toggle word wrap Toggle overflow
24.3. CPU 帯域幅の調整によるアプリケーションへの CPU 時間配分の制御
特定の cgroup ツリーの下にあるアプリケーションへの CPU 時間の配分を調整するには、cpu コントローラーの関連ファイルに値を割り当てる必要があります。
前提条件
- root 権限がある。
- CPU 時間の配分を制御する 2 つ以上のアプリケーションがある。
- CPU 時間配分のための cgroup の準備 に記載するように、該当するアプリケーションが同じ CPU の CPU 時間を取り合っていることを確認している。
-
cgroups-v2 のマウント で説明されているように、
cgroups-v2ファイルシステムをマウントしている。 -
CPU 時間配分のための cgroup の準備 で説明されているのと同様に、親コントロールグループとサブコントロールグループの両方に、
cpuおよびcpusetコントローラーを有効にしている。 以下の例のように、
/sys/fs/cgroup/ルートコントロールグループ内に 2 つのレベルの サブコントロールグループ を作成していること。… ├── Example │ ├── tasks …
… ├── Example │ ├── tasks …Copy to Clipboard Copied! Toggle word wrap Toggle overflow
手順
コントロールグループ内のリソース制限を実現するために CPU 帯域幅を設定します。
echo "200000 1000000" > /sys/fs/cgroup/Example/tasks/cpu.max
# echo "200000 1000000" > /sys/fs/cgroup/Example/tasks/cpu.maxCopy to Clipboard Copied! Toggle word wrap Toggle overflow 最初の値は、一定の期間にサブグループにある全プロセスをまとめて実行できる許容される時間クォータ (マイクロ秒単位) です。2 番目の値は期間の長さを指定します。
一期間中にコントロールグループ内のプロセスが全体としてこのクォータで指定した時間を使い切ってしまうと、残りの時間がスロットルされて、次の期間まで実行できなくなります。
このコマンドは、
/sys/fs/cgroup/Example/tasksサブグループの全プロセスが 1 秒ごとに 0.2 秒間のみ CPU で実行されるように、CPU 時間の配分の制御を設定します。つまり、毎秒 5 分の 1 です。オプション: 時間クォータを確認します。
cat /sys/fs/cgroup/Example/tasks/cpu.max 200000 1000000
# cat /sys/fs/cgroup/Example/tasks/cpu.max 200000 1000000Copy to Clipboard Copied! Toggle word wrap Toggle overflow アプリケーションの PID を
Example/tasksサブグループに追加します。echo "34578" > /sys/fs/cgroup/Example/tasks/cgroup.procs echo "34579" > /sys/fs/cgroup/Example/tasks/cgroup.procs
# echo "34578" > /sys/fs/cgroup/Example/tasks/cgroup.procs # echo "34579" > /sys/fs/cgroup/Example/tasks/cgroup.procsCopy to Clipboard Copied! Toggle word wrap Toggle overflow サンプルコマンドは、必要なアプリケーションが
Example/tasks子グループのメンバーになり、この子グループに設定された CPU 時間配分を超えないようにします。
検証
アプリケーションが指定のコントロールグループで実行されていることを確認します。
cat /proc/34578/cgroup /proc/34579/cgroup 0::/Example/tasks 0::/Example/tasks
# cat /proc/34578/cgroup /proc/34579/cgroup 0::/Example/tasks 0::/Example/tasksCopy to Clipboard Copied! Toggle word wrap Toggle overflow 上記の出力は、
Example/tasksサブグループで実行される指定されたアプリケーションのプロセスを示しています。スロットリングされたアプリケーションの現在の CPU 使用率を確認します。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow PID 34578およびPID 34579の CPU 使用率が 10% に減少していることが分かります。Example/tasksサブグループは、そのプロセスをまとめて 20% の CPU 時間に調整します。コントロールグループにプロセスが 2 つあるため、各プロセスは CPU 時間の 10% を使用できます。
24.4. CPU の重みの調整によるアプリケーションへの CPU 時間配分の制御
特定の cgroup ツリーの下にあるアプリケーションへの CPU 時間の配分を調整するには、cpu コントローラーの関連ファイルに値を割り当てる必要があります。
前提条件
- root 権限がある。
- CPU 時間の配分を制御するアプリケーションがある。
- CPU 時間配分のための cgroup の準備 に記載するように、該当するアプリケーションが同じ CPU の CPU 時間を取り合っていることを確認している。
-
cgroups-v2 のマウント で説明されているように、
cgroups-v2ファイルシステムをマウントしている。 次の例のように、
/sys/fs/cgroup/root control group 内に、child control groups グループの 2 階層を作成しました。Copy to Clipboard Copied! Toggle word wrap Toggle overflow -
CPU 時間配分のための cgroup の準備 で説明されているのと同様に、親コントロールグループとサブコントロールグループに、
cpuおよびcpusetコントローラーを有効にしている。
手順
コントロールグループ内のリソース制限を実現するために、希望する CPU の重みを設定します。
echo "150" > /sys/fs/cgroup/Example/g1/cpu.weight echo "100" > /sys/fs/cgroup/Example/g2/cpu.weight echo "50" > /sys/fs/cgroup/Example/g3/cpu.weight
# echo "150" > /sys/fs/cgroup/Example/g1/cpu.weight # echo "100" > /sys/fs/cgroup/Example/g2/cpu.weight # echo "50" > /sys/fs/cgroup/Example/g3/cpu.weightCopy to Clipboard Copied! Toggle word wrap Toggle overflow アプリケーションの PID を
g1、g2、およびg3サブグループに追加します。echo "33373" > /sys/fs/cgroup/Example/g1/cgroup.procs echo "33374" > /sys/fs/cgroup/Example/g2/cgroup.procs echo "33377" > /sys/fs/cgroup/Example/g3/cgroup.procs
# echo "33373" > /sys/fs/cgroup/Example/g1/cgroup.procs # echo "33374" > /sys/fs/cgroup/Example/g2/cgroup.procs # echo "33377" > /sys/fs/cgroup/Example/g3/cgroup.procsCopy to Clipboard Copied! Toggle word wrap Toggle overflow 上記のコマンドの例は、目的のアプリケーションが
Example/g*/子 cgroup のメンバーになり、それらの cgroup の設定に従って CPU 時間を分散させることを保証します。実行中のプロセスを持つサブ cgroups(
g1、g2、g3) の重みは、親 cgroup のレベルで合算されます (例)。その後、CPU リソースはそれぞれの重みに基づいて相対的に配分されます。その結果、すべてのプロセスが同時に実行されると、カーネルはそれぞれの cgroup の
cpu.weightファイルに基づいて、それぞれのプロセスに比例配分の CPU 時間を割り当てます。Expand サブ cgroup cpu.weightファイルCPU 時間の割り当て g1
150
約 50% (150/300)
g2
100
約 33% (100/300)
g3
50
約 16% (50/300)
cpu.weightコントローラーファイルの値はパーセンテージではありません。1 つのプロセスが実行を停止し、cgroup
g2が実行中のプロセスのない状態になると、計算では cgroupg2が省略され、cgroupsg1およびg3の重みだけが考慮されます。Expand サブ cgroup cpu.weightファイルCPU 時間の割り当て g1
150
約 75% (150/200)
g3
50
約 25% (50/200)
重要子 cgroup に複数の実行中のプロセスがある場合、cgroup に割り当てられた CPU 時間が、そのメンバープロセス間で均等に分配されます。
検証
アプリケーションが指定のコントロールグループで実行されていることを確認します。
cat /proc/33373/cgroup /proc/33374/cgroup /proc/33377/cgroup 0::/Example/g1 0::/Example/g2 0::/Example/g3
# cat /proc/33373/cgroup /proc/33374/cgroup /proc/33377/cgroup 0::/Example/g1 0::/Example/g2 0::/Example/g3Copy to Clipboard Copied! Toggle word wrap Toggle overflow コマンド出力は、
Example/g*/サブ cgroups で実行される指定されたアプリケーションのプロセスを示しています。スロットリングされたアプリケーションの現在の CPU 使用率を確認します。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 注記わかりやすくするために、すべてのプロセスを単一の CPU 上で実行しています。CPU の重みは、複数の CPU で使用される場合にも、同じ原則を適用します。
PID 33373、PID 33374、およびPID 33377の CPU リソースが、それぞれの子 cgroups に割り当てた 150、100、および 50 の重みに基づいて割り当てられていることに注意してください。重みは、各アプリケーションの CPU 時間の約 50%、33%、および 16% の配分に対応します。
第25章 systemd によるコントロールグループバージョン 1 の使用
cgroup は、systemd システムとサービスマネージャー、およびそれらが提供するユーティリティーを使用して管理できます。これは、cgroups 管理の推奨される方法でもあります。
25.1. コントロールグループバージョン 1 における systemd のロール
RHEL 8 では、cgroup 階層のシステムを systemd ユニットツリーにバインドすることにより、リソース管理設定をプロセスレベルからアプリケーションレベルに移行します。したがって、システムリソースは、systemctl コマンドを使用するか、systemd ユニットファイルを変更して管理できます。
デフォルトでは、systemd システムおよびサービスマネージャーは、slice、scope、および service ユニットを使用して、コントロールグループ内のプロセスを整理および構造化します。systemctl コマンドは、カスタム slices を作成することで、この構造をさらに変更できます。また、systemd は、重要なカーネルリソースコントローラーの階層を /sys/fs/cgroup/ ディレクトリーに自動的にマウントします。
systemd の 3 つのユニットタイプは、リソース制御に使用します。
Service - ユニット設定ファイルに従って
systemdが起動したプロセスまたはプロセスのグループ。サービスは、指定したプロセスをカプセル化して、1 つのセットとして起動および停止できるようにします。サービスの名前は以下の方法で指定されます。<name>.service
<name>.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow スコープ - 外部で作成されたプロセスのグループ。スコープは、
fork()関数を介して任意のプロセスで開始および停止されたプロセスをカプセル化し、ランタイム時にsystemdで登録します。たとえば、ユーザーセッション、コンテナー、および仮想マシンはスコープとして処理されます。スコープの名前は以下のように指定されます。<name>.scope
<name>.scopeCopy to Clipboard Copied! Toggle word wrap Toggle overflow スライス - 階層的に編成されたユニットのグループ。スライスは、スコープおよびサービスを配置する階層を編成します。実際のプロセスは、スコープまたはサービスに含まれます。スライスユニットの名前はすべて、階層内の場所へのパスに対応します。ハイフン (-) 文字は、
-.sliceルートスライスからのスライスへのパスコンポーネントの区切り文字として機能します。次の例では、プロセスを含むサービスとスコープは、独自のプロセスを持たないスライスに配置されます。<parent-name>.slice
<parent-name>.sliceCopy to Clipboard Copied! Toggle word wrap Toggle overflow parent-name.sliceはparent.sliceのサブスライスで、これは-.sliceroot スライスのサブスライスです。parent-name.sliceには、parent-name-name2.sliceという名前の独自のサブスライスを指定できます。
サービス、スコープ、スライス ユニットは、コントロールグループ階層のオブジェクトに直接マッピングされます。これらのユニットがアクティブになると、ユニット名から構築されるグループパスを制御するように直接マッピングされます。
コントロールグループ階層の例
プロセスを含むサービスとスコープは、独自のプロセスを持たないスライスに配置されます。
25.2. 一時的なコントロールグループの作成
一時的な cgroups は、ランタイム時にユニット (サービスまたはスコープ) が消費するリソースに制限を設定します。
手順
一時的なコントロールグループを作成するには、以下の形式で
systemd-runコマンドを使用します。systemd-run --unit=<name> --slice=<name>.slice <command>
# systemd-run --unit=<name> --slice=<name>.slice <command>Copy to Clipboard Copied! Toggle word wrap Toggle overflow このコマンドは、一時的なサービスまたはスコープユニットを作成し、開始し、そのユニットでカスタムコマンドを実行します。
-
--unit=<name>オプションは、ユニットに名前を指定します。--unitが指定されていないと、名前は自動的に生成されます。 -
--slice=<name>.sliceオプションは、サービスまたはスコープユニットを指定のスライスのメンバーにします。<name>.sliceは、既存のスライスの名前 (systemctl -t sliceの出力に表示) に置き換えるか、一意の名前を指定して新規スライスを作成します。デフォルトでは、サービスおよびスコープはsystem.sliceのメンバーとして作成されます。 <command>は、サービスまたはスコープユニットに入力するコマンドに置き換えます。以下のような、サービスまたはスコープが正常に作成され開始したことを確認するメッセージが表示されます。
Running as unit <name>.service
# Running as unit <name>.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow
-
オプション: ランタイム情報を収集するため、プロセスが終了した後もユニットを実行したままにします。
systemd-run --unit=<name> --slice=<name>.slice --remain-after-exit <command>
# systemd-run --unit=<name> --slice=<name>.slice --remain-after-exit <command>Copy to Clipboard Copied! Toggle word wrap Toggle overflow このコマンドは、一時的なサービスユニットを作成して起動し、そのユニットでカスタムコマンドを実行します。
--remain-after-exitオプションを使用すると、プロセスの終了後もサービスが実行し続けます。
25.3. 永続的なコントロールグループの作成
永続的なコントロールグループをサービスに割り当てるには、そのユニット設定ファイルを編集する必要があります。自動的に開始されたサービスを管理するために、システムの再起動後も設定は保持されます。
手順
永続的なコントロールグループを作成するには、以下のように入力します。
systemctl enable <name>.service
# systemctl enable <name>.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow このコマンドは、
/usr/lib/systemd/system/ディレクトリーにユニット設定ファイルを自動的に作成し、デフォルトでは、<name>.serviceをsystem.sliceユニットに割り当てます。
25.4. コマンドラインでのメモリーリソース制御の設定
コマンドラインでコマンドを実行することは、プロセスグループのハードウェアリソースへのアクセスの制限を設定したり、優先順位を付けたり、制御したりする方法の 1 つです。
手順
サービスのメモリー使用量を制限するには、以下を実行します。
systemctl set-property example.service MemoryMax=1500K
# systemctl set-property example.service MemoryMax=1500KCopy to Clipboard Copied! Toggle word wrap Toggle overflow このコマンドは、
example.serviceサービスが所属するコントロールグループで実行されるプロセスに対して、1,500 KB のメモリー制限を割り当てます。この設定バリアントのMemoryMaxパラメーターは/etc/systemd/system.control/example.service.d/50-MemoryMax.confファイルで定義され、/sys/fs/cgroup/memory/system.slice/example.service/memory.limit_in_bytesファイルの値を制御します。必要に応じて、サービスのメモリー使用量を一時的に制限するには、以下を実行します。
systemctl set-property --runtime example.service MemoryMax=1500K
# systemctl set-property --runtime example.service MemoryMax=1500KCopy to Clipboard Copied! Toggle word wrap Toggle overflow このコマンドは、メモリー制限を
example.serviceサービスに即座に割り当てます。MemoryMaxパラメーターは、次回起動時まで/run/systemd/system.control/example.service.d/50-MemoryMax.confファイルで定義されます。再起動すると、/run/systemd/system.control/ディレクトリー全体とMemoryMaxが削除されます。
50-MemoryMax.conf ファイルは、メモリー制限を 4096 バイトの倍数 (AMD64 および Intel 64 に固有のカーネルページサイズ) として保存します。実際のバイト数は、CPU アーキテクチャーによって異なります。
25.5. ユニットファイルを使用したメモリーリソース制御の設定
各永続的なユニットは systemd システムおよびサービスマネージャーによって監視され、/usr/lib/systemd/system/ ディレクトリーにユニット設定ファイルがあります。永続ユニットのリソース制御設定を変更するには、テキストエディターで手動で、またはコマンドラインからユニット設定ファイルを変更します。
プロセスのグループのハードウェアリソースに対するアクセス権限を設定して優先順位を付け、制御する方法の 1 つとして、ユニットファイルを手動で変更する方法があります。
手順
サービスのメモリー使用量を制限するには、以下のように
/usr/lib/systemd/system/example.serviceファイルを変更します。… [Service] MemoryMax=1500K …
… [Service] MemoryMax=1500K …Copy to Clipboard Copied! Toggle word wrap Toggle overflow この設定は、
example.serviceが属するコントロールグループで実行されるプロセスの最大メモリー消費量を制限します。注記測定単位のキロバイト、メガバイト、ギガバイト、またはテラバイトを指定するには、接尾辞 K、M、G、または T を使用します。
すべてのユニット設定ファイルを再読み込みします。
systemctl daemon-reload
# systemctl daemon-reloadCopy to Clipboard Copied! Toggle word wrap Toggle overflow サービスを再起動します。
systemctl restart example.service
# systemctl restart example.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow - システムを再起動します。
検証
変更が有効になったことを確認します。
cat /sys/fs/cgroup/memory/system.slice/example.service/memory.limit_in_bytes 1536000
# cat /sys/fs/cgroup/memory/system.slice/example.service/memory.limit_in_bytes 1536000Copy to Clipboard Copied! Toggle word wrap Toggle overflow メモリー消費量は約 1,500 KB に制限されました。
注記memory.limit_in_bytesファイルは、メモリー制限を 4096 バイトの倍数 (AMD64 および Intel 64 に固有のカーネルページサイズ) として保存します。実際のバイト数は、CPU アーキテクチャーによって異なります。
25.6. 一時的なコントロールグループの削除
systemd システムおよびサービスマネージャーを使用して、プロセスのグループのハードウェアリソースへのアクセスを制限して優先順位を付け、制御する必要がなくなった場合に、一時的なコントロールグループ (cgroup) を削除できます。
一時的な cgroups は、サービスまたはスコープユニットに含まれる全プロセスが完了すると、自動的に解放されます。
手順
サービスユニットの全プロセスを停止するには、以下を実行します。
systemctl stop <name>.service
# systemctl stop <name>.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow ユニットプロセスを 1 つ以上終了するには、以下を実行します。
systemctl kill <name>.service --kill-who=PID,… --signal=<signal>
# systemctl kill <name>.service --kill-who=PID,… --signal=<signal>Copy to Clipboard Copied! Toggle word wrap Toggle overflow このコマンドは
--kill-whoオプションを使用して、コントロールグループから終了するプロセスを選択します。複数のプロセスを同時に強制終了するには、PID のコンマ区切りのリストを指定します。--signalオプションは、指定されたプロセスに送信する POSIX シグナルのタイプを決定します。デフォルトのシグナルは SIGTERM です。
25.7. 永続的なコントロールグループの削除
systemd システムおよびサービスマネージャーを使用して、プロセスのグループのハードウェアリソースへのアクセスを制限して優先順位を付け、制御する必要がなくなった場合に、永続的なコントロールグループおよび永続コントロールグループ (cgroup) を削除できます。
永続的な cgroups は、サービスまたはスコープユニットが停止または無効化されてその設定ファイルが削除されると解放されます。
手順
サービスユニットを停止します。
systemctl stop <name>.service
# systemctl stop <name>.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow サービスユニットを無効にします。
systemctl disable <name>.service
# systemctl disable <name>.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow 関連するユニット設定ファイルを削除します。
rm /usr/lib/systemd/system/<name>.service
# rm /usr/lib/systemd/system/<name>.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow すべてのユニット設定ファイルを再度読み込み、変更を有効にします。
systemctl daemon-reload
# systemctl daemon-reloadCopy to Clipboard Copied! Toggle word wrap Toggle overflow
25.8. systemd ユニットのリスト表示
systemd システムおよびサービスマネージャーを使用して、そのユニットをリスト表示します。
手順
systemctlユーティリティーを使用して、システム上のすべてのアクティブなユニットをリスト表示します。ターミナルは、次の例のような出力を返します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow UNIT- コントロールグループ階層内のユニットの位置も反映するユニットの名前です。リソース制御に関連するユニットは、スライス、スコープ および サービス です。
LOAD- ユニット設定ファイルが正しく読み込まれたかどうかを示します。ユニットファイルのロードに失敗した場合、フィールドには loaded ではなく error 状態が表示されます。ユニットの読み込みの状態は他に stub, merged, and masked などがあります。
ACTIVE-
ユニットのアクティベーションの状態 (概要レベル)。こちらは
SUBを一般化したものです。 SUB- ユニットのアクティベーションの状態 (詳細レベル)。許容値の範囲は、ユニットタイプによって異なります。
DESCRIPTION- ユニットのコンテンツおよび機能の説明。
すべてのアクティブなユニットと非アクティブなユニットをリスト表示します。
systemctl --all
# systemctl --allCopy to Clipboard Copied! Toggle word wrap Toggle overflow 出力の情報量を限定します。
systemctl --type service,masked
# systemctl --type service,maskedCopy to Clipboard Copied! Toggle word wrap Toggle overflow --typeオプションでは、サービス および スライス などのユニットタイプのコンマ区切りのリスト、または 読み込み済み、マスク済み などのユニットの読み込み状態が必要です。
25.9. systemd cgroups 階層の表示
コントロールグループ (cgroups) の階層と、特定の cgroups で実行しているプロセスを表示します。
手順
systemd-cglsコマンドを使用して、システム上のcgroups階層全体を表示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow この出力例では
cgroups階層全体を返します。この階層は、slices で形成される最も高いレベルです。systemd-cgls <resource_controller>コマンドを使用して、リソースコントローラーによってフィルター処理されたcgroups階層を表示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow この出力例では、選択したコントローラーと対話するサービスのリストを表示します。
systemctl status <system_unit>コマンドを使用して、特定のユニットとcgroups階層のその部分に関する詳細情報を表示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow
25.10. リソースコントローラーの表示
リソースコントローラーを使用するプロセスを識別します。
手順
プロセスが対話するリソースコントローラーを表示し、
cat proc/<PID>/cgroupコマンドを実行します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow 出力例は、
example.serviceユニットに属するプロセスPID 11269のものです。プロセスが、systemdユニットファイルの仕様で定義されている正しいコントロールグループに配置されたことを確認できます。注記デフォルトでは、デフォルトのリソースコントローラーがすべて自動的にマウントされるため、リソースコントローラーのリストにある項目とその順序は、
systemdが起動するすべてのユニットで同じになります。
25.11. リソース消費の監視
現在実行中のコントロールグループ (cgroups) とそのリソース消費のリストをリアルタイムで表示します。
手順
systemd-cgtopコマンドを使用して、現在実行中のcgroupsの動的アカウントを表示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow この出力例では、現在実行中の
cgroupsが、リソースの使用状況 (CPU、メモリー、ディスク I/O 負荷) 別に表示されています。デフォルトでは 1 秒ごとにリストが更新されます。そのため、コントロールグループごとに、実際のリソースの使用状況に関する動的な見解が得られるようになります。
第26章 cgroups-v2 と systemd を使用したリソース管理の設定
systemd スイートの主な機能は、サービスの管理と監視です。そのため、systemd は、起動プロセス中に適切なサービスが適切なタイミングおよび正しい順序で起動するようにします。サービスの実行時には、スムーズに実行して基盤のハードウェアプラットフォームを最適に使用する必要があります。したがって、systemd はリソース管理ポリシーを定義する機能や、さまざまなオプションを調整する機能も備えており、これらによってサービスのパフォーマンスを改善します。
26.1. 前提条件
- Linux cgroup サブシステムの基本知識。
26.2. リソース配分モデルの概要
リソース管理では、systemd はコントロールグループバージョン 2 (cgroups-v2) インターフェイスを使用します。
デフォルトでは、RHEL 8 は cgroups-v1 を使用します。したがって、cgroups-v2 を有効にして、systemd がリソース管理に cgroups-v2 インターフェイスを使用できるようにする必要があります。cgroups-v2 を有効にする方法の詳細は、cgroups-v2 のマウント を参照してください。
システムリソースの配分を変更するには、以下のリソース配分モデルの 1 つまたは複数を適用できます。
- 重み
リソースは、すべてのサブグループの重みを合計し、すべての重みの合計と比較した各サブグループの重みに基づいて、各サブグループにリソースの一部を与えることによって配分されます。
たとえば、
cgroupsが 10 個あり、それぞれの重みが 100 の場合には、合計は 1000 で、各cgroupはリソースの 10 分の 1 を受け取ります。重みは通常、ステートレスリソースの配分に使用されます。コントロールグループの重みを調整するには、CPUWeight= オプションを使用します。
- 制限
cgroupは、設定したリソースの量だけ使用できますが、リソースをオーバーコミットすることもできます。そのため、サブグループ制限の合計は、親cgroupの制限を超える可能性があります。コントロールグループの制限を調整するには、MemoryMax= オプションを使用します。
- 保護
cgroupに、保護するリソース量を設定できます。リソースの使用量が保護するリソース量を下回る場合でも、カーネルは、このcgroupにペナルティーを課さず、同じリソースを取得しようとしている他のcgroupを優先しません。オーバーコミットも可能です。コントロールグループの保護リソース量を調整するには、MemoryLow= オプションを使用します。
- 割り当て
- リアルタイムの予算など、上限のあるリソースの特定の量を排他的に割り当てます。オーバーコミットが可能です。
26.3. systemd を使用した CPU リソースの割り当て
systemd が管理するシステムでは、各システムサービスは対象の cgroup で起動します。CPU cgroup コントローラーのサポートを有効にすると、システムはプロセスごとのディストリビューションではなく、CPU リソースのサービス対応ディストリビューションを使用します。サービス対応ディストリビューションでは、同じサービスを使用するプロセスの数に関係なく、各サービスはシステム上で実行されている他のすべてのサービスと比較してほぼ同じ量の CPU 時間を受け取ります。
特定のサービスで多くの CPU リソースが必要な場合は、サービスの CPU 時間割り当てポリシーを変更することでリソースを付与できます。
手順
systemd の使用時に CPU 時間割り当てポリシーオプションを設定するには、以下を実行します。
選択したサービスで、CPU 時間割り当てポリシーオプションに割り当てた値を確認します。
systemctl show --property <CPU time allocation policy option> <service name>
$ systemctl show --property <CPU time allocation policy option> <service name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow root として、CPU 時間割り当てポリシーのオプションで必要な値を設定します。
systemctl set-property <service name> <CPU time allocation policy option>=<value>
# systemctl set-property <service name> <CPU time allocation policy option>=<value>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
cgroup プロパティーは、プロパティーの設定直後に適用されます。したがって、サービスを再起動する必要はありません。
検証
サービスに必要な CPU 時間割り当てポリシーオプションの値が正常に変更されたかどうかを確認するには、以下のコマンドを実行します。
systemctl show --property <CPU time allocation policy option> <service name>
$ systemctl show --property <CPU time allocation policy option> <service name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
26.4. systemd の CPU 時間割り当てポリシーオプション
最も頻繁に使用される CPU 時間割り当てポリシーオプションは、次のとおりです。
CPUWeight=特定のサービスに対して、他の全サービスよりも 優先度を高く 割り当てます。1 - 10,000 の範囲から値を選択できます。デフォルト値は 100 です。
たとえば、他の全サービスと比べて 2 倍の CPU を
httpd.serviceに割り当てるには、値をCPUWeight=200に設定します。CPUWeight=は、利用可能な CPU リソースが枯渇した場合にのみ適用されることに注意してください。CPUQuota=絶対 CPU 時間のクォータ をサービスに割り当てます。このオプションの値は、利用可能な CPU 時間合計に対してサービスが受け取る CPU 時間の最大比率 (例:
CPUQuota=30%) を指定します。CPUQuota=は、重みや制限など、特定のリソース配分モデルの制限値を表すことに注意してください。CPUQuota=の詳細は、システムのsystemd.resource-control(5)man ページを参照してください。
26.5. systemd を使用したメモリーリソースの割り当て
systemd を使用してメモリーリソースを割り当てるには、次のいずれかのメモリー設定オプションを使用します。
-
MemoryMin -
MemoryLow -
MemoryHigh -
MemoryMax -
MemorySwapMax
手順
systemd の使用時にメモリー割り当て設定オプションを指定するには、以下を実行します。
選択したサービスで、メモリー割り当て設定オプションに割り当てた値を確認します。
systemctl show --property <memory allocation configuration option> <service name>
$ systemctl show --property <memory allocation configuration option> <service name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow rootとして、メモリー割り当ての設定オプションで必要な値を設定します。systemctl set-property <service name> <memory allocation configuration option>=<value>
# systemctl set-property <service name> <memory allocation configuration option>=<value>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
cgroup プロパティーは、プロパティーの設定直後に適用されます。したがって、サービスを再起動する必要はありません。
検証
サービスのメモリー割り当て設定オプションの必要な値が正常に変更されたかどうかを確認するには、次のように入力します。
systemctl show --property <memory allocation configuration option> <service name>
$ systemctl show --property <memory allocation configuration option> <service name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
26.6. systemd のメモリー割り当て設定オプション
systemd を使用してシステムメモリー割り当てを設定する場合には、以下のオプションを使用できます。
MemoryMin- ハードメモリーの保護。メモリー使用量が指定された制限を下回る場合には、cgroup メモリーは解放されません。
MemoryLow- ソフトメモリーの保護。メモリー使用量が指定された制限を下回り、保護されていない cgroup からメモリーが解放されなかった場合のみ、cgroup のメモリーを解放できます。
MemoryHigh- メモリースロットルの制限。メモリー使用量が指定された制限を超えると、cgroup のプロセスにスロットリングが適用され、解放への圧力が高まります。
MemoryMax-
メモリー使用量の絶対上限。キロバイト (K)、メガバイト (M)、ギガバイト (G)、テラバイト (T) の接尾辞 (例:
MemoryMax=1G) を使用できます。 MemorySwapMax- swap の使用量のハード制限。
メモリーの上限を超えると、OOM (Out-of-memory) killer は実行中のサービスを停止します。これを回避するには、OOMScoreAdjust= の値を減らして、メモリーの耐性を高めます。
26.7. systemd を使用した I/O 帯域幅の設定
RHEL 8 で特定のサービスのパフォーマンスを改善するには、systemd を使用してそのサービスに I/O 帯域幅リソースを割り当てることができます。
これには、以下の I/O 設定オプションを使用できます。
- IOWeight
- IODeviceWeight
- IOReadBandwidthMax
- IOWriteBandwidthMax
- IOReadIOPSMax
- IOWriteIOPSMax
手順
systemd を使用して I/O 帯域幅設定 オプションを設定するには、以下を実行します。
選択したサービスで、I/O 帯域幅設定オプションに割り当てた値を確認します。
systemctl show --property <I/O bandwidth configuration option> <service name>
$ systemctl show --property <I/O bandwidth configuration option> <service name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow rootとして、I/O 帯域幅の設定オプションで必要な値を設定します。systemctl set-property <service name> <I/O bandwidth configuration option>=<value>
# systemctl set-property <service name> <I/O bandwidth configuration option>=<value>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
cgroup プロパティーが設定されると、すぐに適用されます。したがって、サービスを再起動する必要はありません。
検証
サービスの I/O 帯域幅設定オプションの必要な値が正常に変更されたかどうかを確認するには、次のように入力します。
systemctl show --property <I/O bandwidth configuration option> <service name>
$ systemctl show --property <I/O bandwidth configuration option> <service name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
26.8. systemd の I/O 帯域幅設定オプション
systemd を使用してブロックレイヤー I/O ポリシーを管理するには、次の設定オプションを使用できます。
IOWeight- デフォルトの I/O 加重を設定します。加重の値をベースとして使用し、他のサービスと比べ、実際に受け取る I/O 帯域幅を計算します。
IODeviceWeight特定のブロックデバイスの I/O 加重を設定します。
注記加重ベースのオプションは、ブロックデバイスが CFQ I/O スケジューラーを使用している場合にのみサポートされます。デバイスが Multi-Queue Block I/O キューメカニズムを使用する場合は、オプションのサポートはありません。
たとえば、IODeviceWeight=/dev/disk/by-id/dm-name-rhel-root 200 などです。
IOReadBandwidthMax、IOWriteBandwidthMaxデバイスまたはマウントポイントごとの絶対帯域幅を設定します。
たとえば、
IOWriteBandwith=/var/log 5Mなどです。注記systemdは、ファイルシステムからデバイスへの変換を自動的に処理します。IOReadIOPSMax、IOWriteIOPSMax- 1 秒あたりの I/O 処理数 (IOPS) の絶対帯域幅を設定します。
26.9. systemd を使用した CPUSET コントローラーの設定
systemd リソース管理 API で、サービスが使用できる CPU および NUMA ノードのセットに制限を設定できます。この制限により、プロセスによって使用されるシステムリソースへのアクセスを制限します。要求された設定は、cpuset.cpus および cpuset.mems ファイルに書き込まれます。
ただし、親 cgroup が cpus または mems のいずれかを制限するため、要求された設定が使用されない可能性があります。現在の設定にアクセスするために、cpuset.cpus.effective および cpuset.mems.effective ファイルがユーザーにエクスポートされます。
手順
AllowedCPUsを設定するには、以下を実行します。systemctl set-property <service name>.service AllowedCPUs=<value>
# systemctl set-property <service name>.service AllowedCPUs=<value>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 以下に例を示します。
systemctl set-property <service name>.service AllowedCPUs=0-5
# systemctl set-property <service name>.service AllowedCPUs=0-5Copy to Clipboard Copied! Toggle word wrap Toggle overflow AllowedMemoryNodesを設定するには、以下を実行します。systemctl set-property <service name>.service AllowedMemoryNodes=<value>
# systemctl set-property <service name>.service AllowedMemoryNodes=<value>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 以下に例を示します。
systemctl set-property <service name>.service AllowedMemoryNodes=0
# systemctl set-property <service name>.service AllowedMemoryNodes=0Copy to Clipboard Copied! Toggle word wrap Toggle overflow
第27章 systemd を使用した CPU のアフィニティーおよび NUMA ポリシーの設定
CPU 管理、メモリー管理、および I/O 帯域幅オプションで、利用可能なリソースを分割します。
27.1. systemd を使用した CPU アフィニティーの設定
CPU アフィニティーの設定は、特定のプロセスにアクセスできる CPU を一部だけに制限する場合に役立ちます。実際には、CPU スケジューラーでは、プロセスのアフィニティーマスク上にない CPU で実行するプロセスはスケジューリングされません。
デフォルトの CPU アフィニティーマスクは、systemd が管理するすべてのサービスに適用されます。
特定の systemd サービスの CPU アフィニティーマスクを設定するには、systemd の /etc/systemd/system.conf でユニットファイルオプションとマネージャー設定オプション両方として CPUAffinity= を指定します。
CPUAffinity= ユニットファイルのオプション では、CPU または CPU 範囲のリストを設定し、アフィニティーマスクとしてマージして使用されます。/etc/systemd/system.conf ファイルの CPUAffinity オプション は、プロセス ID 番号 (PID) 1 と、PID1 でフォークされた全プロセスにアフィニティーマスクを定義します。これにより、各サービスで CPUAffinity を上書きできます。
特定の systemd サービスの CPU アフィニティーマスクを設定したら、システムを再起動して変更を適用する必要があります。
手順
CPUAffinity ユニットファイル オプションを使用して、特定の systemd サービスの CPU アフィニティーマスクを設定するには、次の手順を実行します。
選択したサービスで
CPUAffinityユニットファイルオプションの値を確認します。systemctl show --property <CPU affinity configuration option> <service name>
$ systemctl show --property <CPU affinity configuration option> <service name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow root として、アフィニティーマスクとして使用する CPU 範囲の
CPUAffinityユニットファイルで必要な値を設定します。systemctl set-property <service name> CPUAffinity=<value>
# systemctl set-property <service name> CPUAffinity=<value>Copy to Clipboard Copied! Toggle word wrap Toggle overflow サービスを再起動して変更を適用します。
systemctl restart <service name>
# systemctl restart <service name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
manager configuration オプションを使用して特定の systemd サービスの CPU アフィニティーマスクを設定するには、以下を実行します。
/etc/systemd/system.confファイルを編集します。vi /etc/systemd/system.conf
# vi /etc/systemd/system.confCopy to Clipboard Copied! Toggle word wrap Toggle overflow -
CPUAffinity=オプションを検索して、CPU 数を設定します。 - 編集したファイルを保存し、サーバーを再起動して変更を適用します。
27.2. systemd を使用した NUMA ポリシーの設定
Non-Uniform Memory Access (NUMA) は、コンピューターメモリーのサブシステム設計で、この設計ではメモリーのアクセス時間は、プロセッサーからの物理メモリーの場所により異なります。
CPU に近いメモリーは、別の CPU のローカルにあるメモリーや、一連の CPU 間で共有されているメモリーと比べ、レイテンシーが低くなっています (外部メモリー)。
Linux カーネルでは、NUMA ポリシーを使用して、カーネルがプロセス用に物理メモリーを割り当てる場所 (例: NUMA ノード) を制御します。
systemd は、サービスのメモリー割り当てポリシーを制御するためのユニットファイルオプション NUMAPolicy および NUMAMask を提供します。
手順
NUMAPolicy ユニットファイルオプションで NUMA メモリーポリシーを設定するには以下を実行します。
選択したサービスで
NUMAPolicyユニットファイルオプションの値を確認します。systemctl show --property <NUMA policy configuration option> <service name>
$ systemctl show --property <NUMA policy configuration option> <service name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow root として、
NUMAPolicyユニットファイルオプションに必要なポリシータイプを設定します。systemctl set-property <service name> NUMAPolicy=<value>
# systemctl set-property <service name> NUMAPolicy=<value>Copy to Clipboard Copied! Toggle word wrap Toggle overflow サービスを再起動して変更を適用します。
systemctl restart <service name>
# systemctl restart <service name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
[Manager] 設定オプションを使用してグローバルな NUMAPolicy を設定するには、以下を実行します。
-
/etc/systemd/system.confファイルで [Manager] セクションにあるNUMAPolicyオプションを検索します。 - ポリシータイプを編集してファイルを保存します。
systemd設定をリロードします。systemd daemon-reload
# systemd daemon-reloadCopy to Clipboard Copied! Toggle word wrap Toggle overflow - サーバーを再起動します。
bind などの厳密な NUMA ポリシーを設定する場合は、CPUAffinity= ユニットファイルオプションも適切に設定されていることを確認してください。
27.3. systemd の NUMA ポリシー設定オプション
Systemd で以下のオプションを指定して、NUMA ポリシーを設定します。
NUMAPolicy実行したプロセスの NUMA メモリーポリシーを制御します。次のポリシータイプを使用できます。
- default
- preferred
- bind
- interleave
- local
NUMAMask選択した NUMA ポリシーに関連付けられた NUMA ノードリストを制御します。
次のポリシーには
NUMAMaskオプションを指定する必要がないことに注意してください。- default
- local
優先ポリシーの場合、このリストで指定できるのは単一の NUMA ノードのみです。
第28章 BPF Compiler Collection を使用したシステムパフォーマンスの分析
BPF Compiler Collection (BCC) は、Berkeley Packet Filter (BPF) の機能を組み合わせてシステムパフォーマンスを分析します。BPF を使用すると、カーネル内でカスタムプログラムを安全に実行して、パフォーマンス監視、トレース、およびデバッグ用のシステムイベントとデータにアクセスできます。BCC は、ユーザーがシステムから重要な詳細情報を抽出するための BPF プログラムの開発とデプロイを、ツールとライブラリーを使用して簡素化します。
28.1. bcc-tools パッケージのインストール
bcc-tools パッケージをインストールします。これにより、依存関係として BPF Compiler Collection (BCC) ライブラリーもインストールされます。
手順
bcc-toolsをインストールします。yum install bcc-tools
# yum install bcc-toolsCopy to Clipboard Copied! Toggle word wrap Toggle overflow BCC ツールは、
/usr/share/bcc/tools/ディレクトリーにインストールされます。
検証
インストールされたツールを検査します。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow リスト内の
docディレクトリーには、各ツールのドキュメントがあります。
28.2. bcc-tools でパフォーマンスの分析
BPF Compiler Collection (BCC) ライブラリーから事前に作成された特定のプログラムを使用して、システムパフォーマンスをイベントごとに効率的かつセキュアに分析します。BCC ライブラリーで事前作成されたプログラムセットは、追加プログラム作成の例として使用できます。
前提条件
- bcc-tools パッケージがインストールされている
- root 権限がある。
手順
execsnoopを使用してシステムプロセスを調べる-
1 つのターミナルで
execsnoopプログラムを実行します。
/usr/share/bcc/tools/execsnoop
# /usr/share/bcc/tools/execsnoopCopy to Clipboard Copied! Toggle word wrap Toggle overflow lsコマンドの短期的なプロセスを作成するために、別のターミナルで次のように入力します。ls /usr/share/bcc/tools/doc/
$ ls /usr/share/bcc/tools/doc/Copy to Clipboard Copied! Toggle word wrap Toggle overflow execsnoopを実行している端末に、次のような出力が表示されます。PCOMM PID PPID RET ARGS ls 8382 8287 0 /usr/bin/ls --color=auto /usr/share/bcc/tools/doc/ ...
PCOMM PID PPID RET ARGS ls 8382 8287 0 /usr/bin/ls --color=auto /usr/share/bcc/tools/doc/ ...Copy to Clipboard Copied! Toggle word wrap Toggle overflow execsnoopプログラムは、システムリソースを消費する新しいプロセスごとに 1 つの行を出力します。また、lsなどの非常に短期間に実行されるプログラムのプロセスを検出します。なお、ほとんどの監視ツールはそれらを登録しません。execsnoop出力には以下のフィールドが表示されます。
-
1 つのターミナルで
- PCOMM
-
親プロセス名。(
ls) - PID
-
プロセス ID。(
8382) - PPID
-
親プロセス ID。(
8287) - RET
-
exec()システムコールの戻り値 (0)。プログラムコードを新規プロセスに読み込みます。 - ARGS
- 引数を使用して起動したプログラムの場所。
execsnoop の詳細、例、オプションについては、/usr/share/bcc/tools/doc/execsnoop_example.txt ファイルを参照してください。
exec() の詳細は、exec(3) man ページを参照してください。
opensnoopを使用して、コマンドにより開かれるファイルを追跡する-
1 つのターミナルで
opensnoopプログラムを実行し、unameコマンドのプロセスによってのみ開かれたファイルを出力します。
/usr/share/bcc/tools/opensnoop -n uname
# /usr/share/bcc/tools/opensnoop -n unameCopy to Clipboard Copied! Toggle word wrap Toggle overflow 別のターミナルで、特定のファイルを開くコマンドを入力します。
uname
$ unameCopy to Clipboard Copied! Toggle word wrap Toggle overflow opensnoopを実行している端末は、以下のような出力を表示します。PID COMM FD ERR PATH 8596 uname 3 0 /etc/ld.so.cache 8596 uname 3 0 /lib64/libc.so.6 8596 uname 3 0 /usr/lib/locale/locale-archive ...
PID COMM FD ERR PATH 8596 uname 3 0 /etc/ld.so.cache 8596 uname 3 0 /lib64/libc.so.6 8596 uname 3 0 /usr/lib/locale/locale-archive ...Copy to Clipboard Copied! Toggle word wrap Toggle overflow opensnoopプログラムは、システム全体でopen()システム呼び出しを監視し、unameが開こうとしたファイルごとに出力行を出力します。opensnoop出力には、以下のフィールドが表示されます。- PID
-
プロセス ID。(
8596) - COMM
-
プロセス名。(
uname) - FD
-
ファイルの記述子。開いたファイルを参照するために
open()が返す値です。(3) - ERR
- すべてのエラー。
- PATH
-
open()で開こうとしたファイルの場所。
コマンドが、存在しないファイルを読み込もうとすると、
FDコラムは-1を返し、ERRコラムは関連するエラーに対応する値を出力します。その結果、opensnoopは、適切に動作しないアプリケーションの特定に役立ちます。
-
1 つのターミナルで
opensnoop の詳細、例、オプションについては、/usr/share/bcc/tools/doc/opensnoop_example.txt ファイルを参照してください。
open() の詳細は、open(2) man ページを参照してください。
biotopを使用して、ディスク上で I/O 操作を実行している上位のプロセスを監視する-
1 つのターミナルで
biotopプログラムを引数30を指定して実行し、30 秒間のサマリーを生成します。
/usr/share/bcc/tools/biotop 30
# /usr/share/bcc/tools/biotop 30Copy to Clipboard Copied! Toggle word wrap Toggle overflow 注記引数を指定しないと、デフォルトでは 1 秒ごとに出力画面が更新されます。
別のターミナルで、次のコマンドを入力して、ローカルハードディスクデバイスからコンテンツを読み取り、出力を
/dev/zeroファイルに書き込みます。dd if=/dev/vda of=/dev/zero
# dd if=/dev/vda of=/dev/zeroCopy to Clipboard Copied! Toggle word wrap Toggle overflow この手順では、
biotopを示す特定の I/O トラフィックを生成します。biotopを実行している端末は、以下のような出力を表示します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow biotop出力には、以下のフィールドが表示されます。
-
1 つのターミナルで
- PID
-
プロセス ID。(
9568) - COMM
-
プロセス名。(
dd) - DISK
-
読み取り操作を実行するディスク。(
vda) - I/O
- 実行された読み取り操作の数。(16294)
- Kbytes
- 読み取り操作によって読み取られたキロバイト数。(14,440,636)
- AVGms
- 読み取り操作の平均 I/O 時間。(3.69)
biotop の詳細、例、およびオプションについては、/usr/share/bcc/tools/doc/biotop_example.txt ファイルを参照してください。
dd の詳細は、dd(1) man ページを参照してください。
xfsslower を使用して、予想以上に遅いファイルシステム操作を明らかにする
xfsslower は、XFS ファイルシステムによる読み取り操作、書き込み操作、開く操作、または同期操作 (fsync) の実行に費やされた時間を測定します。1 引数を指定すると、1 ms よりも遅い操作のみが表示されます。
1 つのターミナルで
xfsslowerプログラムを実行します。/usr/share/bcc/tools/xfsslower 1
# /usr/share/bcc/tools/xfsslower 1Copy to Clipboard Copied! Toggle word wrap Toggle overflow 注記引数を指定しないと、
xfsslowerはデフォルトで 10 ms よりも低速な操作を表示します。別のターミナルで、
vimエディターでテキストファイルを作成するコマンドを入力して、XFS ファイルシステムとのやり取りを開始します。vim text
$ vim textCopy to Clipboard Copied! Toggle word wrap Toggle overflow 前の手順でファイルを保存すると、
xfsslowerを実行しているターミナルに次のような内容が表示されます。Copy to Clipboard Copied! Toggle word wrap Toggle overflow 各行は、特定のしきい値よりも時間がかかったファイルシステム内の操作を表しています。
xfsslowerは、操作に想定以上に時間がかかるなど、ファイルシステムで発生し得る問題を検出します。xfsslower出力には、以下のフィールドが表示されます。- COMM
-
プロセス名。(
b’bash') - T
操作の種類。(
R)- Read
- Write
- Sync
- OFF_KB
- ファイルオフセット (KB)。(0)
- FILENAME
- 読み取り、書き込み、または同期されるファイル。
xfsslower の詳細、例、およびオプションについては、/usr/share/bcc/tools/doc/xfsslower_example.txt ファイルを参照してください。
fsync の詳細は、fsync(2) man ページを参照してください。
第29章 カーネル整合性サブシステムによるセキュリティーの強化
カーネル整合性サブシステムのコンポーネントを使用して、システムの保護を強化できます。関連するコンポーネントとその設定の詳細をご覧ください。
29.1. カーネル整合性サブシステム
整合性サブシステムは、ファイルの改ざんを検出し、読み込まれたポリシーに従ってアクセスを拒否することで、システムの整合性を保護します。また、アクセスログも収集するため、リモート側でリモートアテステーションを通じてシステムの整合性を検証することもできます。カーネル整合性サブシステムには、Integrity Measurement Architecture (IMA) と Extended Verification Module (EVM) が含まれています。
IMA と EVM の概要
整合性測定アーキテクチャー (IMA) は、ファイルコンテンツの整合性を維持します。次の 3 つの機能を備えています。これらは IMA ポリシーを通じて有効にできます。
IMA 測定- ファイルコンテンツのハッシュまたは署名を収集し、測定値をカーネルに保存します。TPM が利用可能な場合、各測定値によって TPM PCR が拡張されます。これにより、アテステーションクォートを使用したリモートアテステーションが可能になります。
IMA-Appraisal- IMA-Appraisal (IMA 評価): 計算されたファイルハッシュを既知の適切な参照値と比較するか、security.ima 属性に保存されている署名を検証することによって、ファイルの整合性を検証します。検証に失敗した場合、システムはアクセスを拒否します。
IMA-Audit- IMA-Audit (IMA 監査): 計算されたファイルコンテンツのハッシュまたは署名をシステム監査ログに保存します。
拡張検証モジュール (EVM) は、security.ima や security.selinux などのシステムセキュリティーに関連する拡張属性を含むファイルメタデータを保護します。EVM は、これらのセキュリティー属性の参照ハッシュまたは HMAC を security.evm に保存し、それを使用してファイルメタデータが悪意を持って変更されたかどうかを検出します。
29.2. 信頼できる鍵および暗号化された鍵
信頼できる鍵 および 暗号化鍵 は、システムセキュリティーを強化する上で重要な要素です。
信頼できる鍵と暗号化された鍵は、カーネルキーリングサービスを使用するカーネルが生成する可変長の対称鍵です。たとえば、Extended Verification Module (EVM) が実行中のシステムの整合性を検証および確認できるように、キーの整合性を検証できます。ユーザーレベルのプログラムがアクセス可能なのは、暗号化された ブロブ の形式での鍵のみです。
- 信頼できる鍵
信頼できる鍵は、鍵の作成と暗号化 (保護) の両方に使用される Trusted Platform Module (TPM) チップを必要とします。各 TPM には、ストレージルートキーと呼ばれるマスターラッピングキーがあります。これは TPM 自体に保存されます。
注記Red Hat Enterprise Linux 8 は、TPM 1.2 と TPM 2.0 の両方をサポートしています。詳細は、Red Hat ナレッジベースソリューション Is Trusted Platform Module (TPM) supported by Red Hat? を参照してください。
TPM 2.0 チップのステータスを確認できます。
cat /sys/class/tpm/tpm0/tpm_version_major 2
$ cat /sys/class/tpm/tpm0/tpm_version_major 2Copy to Clipboard Copied! Toggle word wrap Toggle overflow TPM 2.0 チップを有効にし、マシンのファームウェアの設定を通じて TPM 2.0 デバイスを管理することもできます。
さらに、TPM の platform configuration register (PCR) 値の特定セットを使用して、信頼できる鍵を保護できます。PCR には、ファームウェア、ブートローダー、およびオペレーティングシステムを反映する整合性管理値のセットが含まれます。PCR でシールされたキーは、暗号化されたシステム上の TPM によってのみ復号化できます。ただし、PCR でシールされた信頼できるキーをキーリングにロードすると、それに関連付けられた PCR 値が検証されます。検証後、新しいカーネルの起動をサポートするためなどに、新しい PCR 値または将来の PCR 値でキーを更新できます。また、単一のキーを、それぞれ異なる PCR 値を持つ複数のブロブとして保存することもできます。
- 暗号化鍵
- 暗号化鍵はカーネル Advanced Encryption Standard (AES) を使用するため、TPM を必要としません。これにより、暗号化鍵は信頼できる鍵よりも高速になります。暗号化鍵は、カーネルが生成した乱数を使用して作成され、ユーザー空間のブロブへのエクスポート時に マスターキー により暗号化されます。
マスターキーは信頼できる鍵か、ユーザーキーのいずれかです。マスターキーが信頼されていない場合、暗号化されたキーのセキュリティーは、暗号化に使用されたユーザーキーによって決まります。
29.3. 信頼できる鍵での作業
keyctl ユーティリティーを使用して、信頼できる鍵を作成、エクスポート、ロード、更新することにより、システムのセキュリティーを向上できます。
前提条件
64 ビット ARM アーキテクチャーおよび IBM Z の場合、
trustedカーネルモジュールがロードされます。modprobe trusted
# modprobe trustedCopy to Clipboard Copied! Toggle word wrap Toggle overflow カーネルモジュールをロードする方法の詳細は、システムランタイム時のカーネルモジュールの読み込み を参照してください。
- Trusted Platform Module (TPM) が有効でアクティブである。カーネル整合性サブシステム および 信頼できる鍵および暗号化鍵 を参照してください。
Red Hat Enterprise Linux 8 は、TPM 1.2 と TPM 2.0 の両方をサポートしています。TPM 1.2 を使用する場合は、手順 1 をスキップします。
手順
次のユーティリティーのいずれかを使用して、永続ハンドル (たとえば、81000001) を持つ SHA-256 プライマリーストレージキーを使用して 2048 ビット RSA キーを作成します。
tss2パッケージを使用する場合:TPM_DEVICE=/dev/tpm0 tsscreateprimary -hi o -st TPM_DEVICE=/dev/tpm0 tssevictcontrol -hi o -ho 80000000 -hp 81000001
# TPM_DEVICE=/dev/tpm0 tsscreateprimary -hi o -st Handle 80000000 # TPM_DEVICE=/dev/tpm0 tssevictcontrol -hi o -ho 80000000 -hp 81000001Copy to Clipboard Copied! Toggle word wrap Toggle overflow tpm2-toolsパッケージを使用する場合:Copy to Clipboard Copied! Toggle word wrap Toggle overflow
信頼できるキーを作成します。
keyctl add trusted <NAME> "new <KEY_LENGTH> keyhandle=<PERSISTENT-HANDLE> [options]" <KEYRING>の構文の TPM 2.0 を使用します。この例では、永続ハンドルは 81000001 です。keyctl add trusted kmk "new 32 keyhandle=0x81000001" @u
# keyctl add trusted kmk "new 32 keyhandle=0x81000001" @u 642500861Copy to Clipboard Copied! Toggle word wrap Toggle overflow このコマンドは、
kmkという名前の信頼できる鍵を32バイト (256 ビット) の長さで作成し、ユーザーキーリング (@u) に配置します。鍵の長さは 32 から 128 バイト (256 から 1024 ビット) です。keyctl add trusted <NAME> "new <KEY_LENGTH>" <KEYRING>の構文の TPM 1.2 を使用します。keyctl add trusted kmk "new 32" @u
# keyctl add trusted kmk "new 32" @uCopy to Clipboard Copied! Toggle word wrap Toggle overflow
カーネルキーリングの現在の構造を一覧表示します。
keyctl show
# keyctl show Session Keyring -3 --alswrv 500 500 keyring: ses 97833714 --alswrv 500 -1 \ keyring: uid.1000 642500861 --alswrv 500 500 \ trusted: kmkCopy to Clipboard Copied! Toggle word wrap Toggle overflow 信頼できる鍵のシリアル番号を使用して、鍵をユーザー空間のブロブにエクスポートします。
keyctl pipe 642500861 > kmk.blob
# keyctl pipe 642500861 > kmk.blobCopy to Clipboard Copied! Toggle word wrap Toggle overflow このコマンドは、
pipeサブコマンドとkmkのシリアル番号を使用します。ユーザー空間のブロブから信頼できる鍵をロードします。
keyctl add trusted kmk "load `cat kmk.blob`" @u 268728824
# keyctl add trusted kmk "load `cat kmk.blob`" @u 268728824Copy to Clipboard Copied! Toggle word wrap Toggle overflow TPM で保護された信頼できる鍵 (
kmk) を使用するセキュアな暗号化鍵を作成します。keyctl add encrypted <NAME> "new [FORMAT] <KEY_TYPE>:<PRIMARY_KEY_NAME> <KEY_LENGTH>" <KEYRING> という構文に従います。keyctl add encrypted encr-key "new trusted:kmk 32" @u
# keyctl add encrypted encr-key "new trusted:kmk 32" @u 159771175Copy to Clipboard Copied! Toggle word wrap Toggle overflow
29.4. 暗号化鍵での作業
暗号化鍵を管理することで、Trusted Platform Module (TPM) が使用できないシステムのシステムセキュリティーを向上できます。
暗号化されたキーは、信頼できるプライマリーキーによってシールされていない限り、暗号化に使用されるユーザープライマリーキー (乱数キー) のセキュリティーレベルを継承します。したがって、プライマリーユーザーキーを安全に、できれば起動プロセスの早い段階でロードすることを強く推奨します。
前提条件
64 ビット ARM アーキテクチャーおよび IBM Z の場合、
encrypted-keysカーネルモジュールがロードされます。modprobe encrypted-keys
# modprobe encrypted-keysCopy to Clipboard Copied! Toggle word wrap Toggle overflow カーネルモジュールをロードする方法の詳細は、システムランタイム時のカーネルモジュールの読み込み を参照してください。
手順
ランダムな数列を使用してユーザーキーを生成します。
keyctl add user kmk-user "$(dd if=/dev/urandom bs=1 count=32 2>/dev/null)" @u
# keyctl add user kmk-user "$(dd if=/dev/urandom bs=1 count=32 2>/dev/null)" @u 427069434Copy to Clipboard Copied! Toggle word wrap Toggle overflow このコマンドは、
kmk-userという名前のユーザーキーを生成し、プライマリーキー として動作させ、このユーザーキーを使用して実際の暗号化鍵を保護します。前の手順で取得したプライマリーキーを使用して、暗号化鍵を生成します。
keyctl add encrypted encr-key "new user:kmk-user 32" @u
# keyctl add encrypted encr-key "new user:kmk-user 32" @u 1012412758Copy to Clipboard Copied! Toggle word wrap Toggle overflow
検証
指定したユーザーキーリングにあるすべての鍵をリスト表示します。
keyctl list @u
# keyctl list @u 2 keys in keyring: 427069434: --alswrv 1000 1000 user: kmk-user 1012412758: --alswrv 1000 1000 encrypted: encr-keyCopy to Clipboard Copied! Toggle word wrap Toggle overflow
29.5. IMA と EVM の有効化
Integrity Measurement Architecture (IMA) と Extended Verification Module (EVM) を有効にして設定することで、オペレーティングシステムのセキュリティーを向上できます。
必ず IMA と一緒に EVM を有効にしてください。
EVM を単独で有効にすることもできますが、EVM 評価は IMA 評価ルールによってのみトリガーされます。したがって、SELinux 属性などのファイルメタデータが EVM によって保護されません。ファイルメタデータがオフラインで改ざんされた場合、EVM はファイルメタデータの変更を防ぐことしかできません。ファイルの実行などのファイルアクセスは妨げません。
前提条件
セキュアブートが一時的に無効になっている。
注記セキュアブートが有効になっている場合、
ima_appraise=fixカーネルコマンドラインパラメーターが機能しません。securityfsファイルシステムが/sys/kernel/security/ディレクトリーにマウントされており、/sys/kernel/security/integrity/ima/ディレクトリーが存在している。mountコマンドを使用して、securityfsがマウントされている場所を確認できます。mount
# mount ... securityfs on /sys/kernel/security type securityfs (rw,nosuid,nodev,noexec,relatime) ...Copy to Clipboard Copied! Toggle word wrap Toggle overflow systemdサービスマネージャーに、ブート時に IMA と EVM をサポートするパッチが適用されている。次のコマンドを使用して確認します。grep <options> pattern <files>
# grep <options> pattern <files>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 以下に例を示します。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 手順
現在のブートエントリーの fix モードで IMA と EVM を有効にし、次のカーネルコマンドラインパラメーターを追加することで、ユーザーが IMA 測定値を収集および更新できるようにします。
grubby --update-kernel=/boot/vmlinuz-$(uname -r) --args="ima_policy=appraise_tcb ima_appraise=fix evm=fix"
# grubby --update-kernel=/boot/vmlinuz-$(uname -r) --args="ima_policy=appraise_tcb ima_appraise=fix evm=fix"Copy to Clipboard Copied! Toggle word wrap Toggle overflow このコマンドは、現在のブートエントリーの 修正 モードで IMA と EVM を有効にし、IMA 測定値を収集および更新します。
ima_policy=appraise_tcbカーネルコマンドラインパラメーターにより、カーネルは、デフォルトの TCB (Trusted Computing Base) 測定ポリシーと評価手順を使用するようになります。評価手順では、以前の測定と現在の測定が一致しないファイルへのアクセスを禁止します。- 再起動して変更を適用します。
オプション: カーネルコマンドラインに追加されたパラメーターを確認します。
cat /proc/cmdline BOOT_IMAGE=(hd0,msdos1)/vmlinuz-4.18.0-167.el8.x86_64 root=/dev/mapper/rhel-root ro crashkernel=auto resume=/dev/mapper/rhel-swap rd.lvm.lv=rhel/root rd.lvm.lv=rhel/swap rhgb quiet ima_policy=appraise_tcb ima_appraise=fix evm=fix
# cat /proc/cmdline BOOT_IMAGE=(hd0,msdos1)/vmlinuz-4.18.0-167.el8.x86_64 root=/dev/mapper/rhel-root ro crashkernel=auto resume=/dev/mapper/rhel-swap rd.lvm.lv=rhel/root rd.lvm.lv=rhel/swap rhgb quiet ima_policy=appraise_tcb ima_appraise=fix evm=fixCopy to Clipboard Copied! Toggle word wrap Toggle overflow カーネルマスターキーを作成して、EVM 鍵を保護します。
keyctl add user kmk "$(dd if=/dev/urandom bs=1 count=32 2> /dev/null)" @u
# keyctl add user kmk "$(dd if=/dev/urandom bs=1 count=32 2> /dev/null)" @u 748544121Copy to Clipboard Copied! Toggle word wrap Toggle overflow kmkは、すべてカーネル領域メモリー内に保持されます。kmkの 32 バイトの Long 値は、/dev/urandomファイルの乱数バイト数から生成し、ユーザーの (@u) キーリングに配置します。鍵のシリアル番号は、前の出力の 1 行目にあります。kmkに基づいて暗号化された EVM 鍵を作成します。keyctl add encrypted evm-key "new user:kmk 64" @u
# keyctl add encrypted evm-key "new user:kmk 64" @u 641780271Copy to Clipboard Copied! Toggle word wrap Toggle overflow kmkを使用して 64 バイトの long 型ユーザーキー (evm-key) を生成してユーザー (@u) のキーリングに配置します。鍵のシリアル番号は、前の出力の 1 行目にあります。重要ユーザーキーの名前は evm-key (EVM サブシステムが想定して使用している名前) にする必要があります。
エクスポートする鍵のディレクトリーを作成します。
mkdir -p /etc/keys/
# mkdir -p /etc/keys/Copy to Clipboard Copied! Toggle word wrap Toggle overflow kmkを検索し、その暗号化されていない値を新しいディレクトリーにエクスポートします。keyctl pipe $(keyctl search @u user kmk) > /etc/keys/kmk
# keyctl pipe $(keyctl search @u user kmk) > /etc/keys/kmkCopy to Clipboard Copied! Toggle word wrap Toggle overflow evm-keyを検索し、その暗号化された値を新しいディレクトリーにエクスポートします。keyctl pipe $(keyctl search @u encrypted evm-key) > /etc/keys/evm-key
# keyctl pipe $(keyctl search @u encrypted evm-key) > /etc/keys/evm-keyCopy to Clipboard Copied! Toggle word wrap Toggle overflow evm-keyは、すでにカーネルのマスターキーにより暗号化されています。オプション: 新しく作成されたキーを表示します。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow オプション: システムの再起動後など、鍵がキーリングから削除されている場合は、新しいものを作成する代わりに、すでにエクスポートされている
kmkとevm-keyをインポートできます。kmkをインポートします。keyctl add user kmk "$(cat /etc/keys/kmk)" @u 451342217
# keyctl add user kmk "$(cat /etc/keys/kmk)" @u 451342217Copy to Clipboard Copied! Toggle word wrap Toggle overflow evm-keyをインポートします。keyctl add encrypted evm-key "load $(cat /etc/keys/evm-key)" @u 924537557
# keyctl add encrypted evm-key "load $(cat /etc/keys/evm-key)" @u 924537557Copy to Clipboard Copied! Toggle word wrap Toggle overflow
EVM をアクティブ化します。
echo 1 > /sys/kernel/security/evm
# echo 1 > /sys/kernel/security/evmCopy to Clipboard Copied! Toggle word wrap Toggle overflow システム全体のラベルを付け直します。
find / -fstype xfs -type f -uid 0 -exec head -n 1 '{}' >/dev/null \;# find / -fstype xfs -type f -uid 0 -exec head -n 1 '{}' >/dev/null \;Copy to Clipboard Copied! Toggle word wrap Toggle overflow 警告システムのラベルを変更せずに IMA と EVM を有効にすると、システム上のファイルの大部分にアクセスできなくなる可能性があります。
検証
EVM が初期化されていることを確認します。
dmesg | tail -1
# dmesg | tail -1 […] evm: key initializedCopy to Clipboard Copied! Toggle word wrap Toggle overflow
29.6. Integrity Measurement Architecture によるファイルのハッシュの収集
測定 フェーズでは、ファイルハッシュを作成し、そのファイルの拡張属性 (xattrs) としてファイルハッシュを保存できます。ファイルハッシュを使用すると、RSA ベースのデジタル署名またはハッシュベースのメッセージ認証コード (HMAC-SHA1) のいずれかを生成し、拡張属性に対するオフライン改ざん攻撃を防ぐことができます。
前提条件
- IMA と EVM が有効になっている。詳細は、Integrity Measurement Architecture と Extended Verification Module を参照してください。
- 有効な信頼できる鍵または暗号化鍵が、カーネルキーリングに保存されている。
-
ima-evm-utils、attr、およびkeyutilsパッケージがインストールされている。
手順
テストファイルを作成します。
echo <Test_text> > test_file
# echo <Test_text> > test_fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow IMA と EVM は、
test_fileサンプルファイルにハッシュ値が割り当てられ、その拡張属性として格納されていることを確認します。ファイルの拡張属性を検査します。
getfattr -m . -d test_file file: test_file
# getfattr -m . -d test_file # file: test_file security.evm=0sAnDIy4VPA0HArpPO/EqiutnNyBql security.ima=0sAQOEDeuUnWzwwKYk+n66h/vby3eDCopy to Clipboard Copied! Toggle word wrap Toggle overflow 出力例には、IMA および EVM ハッシュ値と SELinux コンテキストを含む拡張属性が示されています。EVM は、他の属性に関連する
security.evm拡張属性を追加します。この時点で、security.evmでevmctlユーティリティーを使用して、RSA ベースのデジタル署名またはハッシュベースのメッセージ認証コード (HMAC-SHA1) を生成できます。
第30章 RHEL システムロールを使用したカーネルパラメーターの永続的な設定
kernel_settings RHEL システムロールを使用すると、複数のクライアントにカーネルパラメーターを同時に設定できます。同時設定には次の利点があります。
- 効率的な入力設定を持つ使いやすいインターフェイスを提供します。
- すべてのカーネルパラメーターを 1 か所で保持します。
コントロールマシンから kernel_settings ロールを実行すると、カーネルパラメーターはすぐに管理システムに適用され、再起動後も維持されます。
RHEL チャネルで提供される RHEL システムロールは、デフォルトの AppStream リポジトリー内の RPM パッケージとして RHEL のお客様に提供されることに注意してください。また、RHEL システムロールは、Ansible Automation Hub を介して Ansible サブスクリプションをご利用のお客様に、コレクションとして提供されます。
30.1. kernel_settings RHEL システムロールを使用して選択したカーネルパラメーターの適用
kernel_settings RHEL システムロールを使用すると、複数の管理対象オペレーティングシステムにわたってさまざまなカーネルパラメーターをリモートで設定し、永続的に有効にできます。たとえば、以下を設定できます。
- 小さなページを管理するオーバーヘッドを削減し、パフォーマンスを向上するための Transparent huge page
- ループバックインターフェイスを使用してネットワーク経由で送信する最大パケットサイズ
- 同時に開くことができるファイル数の制限
前提条件
- コントロールノードと管理対象ノードの準備が完了している。
- 管理対象ノードで Playbook を実行できるユーザーとしてコントロールノードにログインしている。
-
管理対象ノードへの接続に使用するアカウントに、そのノードに対する
sudo権限がある。
手順
次の内容を含む Playbook ファイル (例:
~/playbook.yml) を作成します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow サンプル Playbook で指定されている設定は次のとおりです。
kernel_settings_sysfs: <list_of_sysctl_settings>-
sysctl設定とこの設定に割り当てる値の YAML リスト。 kernel_settings_transparent_hugepages: <value>-
メモリーサブシステムの Transparent Huge Pages (THP) 設定を制御します。THP のサポートを無効にするか (
never)、サポートをシステム全体で有効にするか (always)、またはMAD_HUGEPAGEリージョン内で有効にする (madvise) ことができます。 kernel_settings_reboot_ok: <true|false>-
デフォルトは
falseです。trueに設定すると、要求された変更を有効にするために管理対象ホストの再起動が必要かどうかをシステムロールが判断し、ホストを再起動します。falseに設定すると、再起動が必要であることを示すtrue値を持つ変数kernel_settings_reboot_requiredがロールによって返されます。この場合、ユーザーが管理対象ノードを手動で再起動する必要があります。
Playbook で使用されるすべての変数の詳細は、コントロールノードの /usr/share/ansible/roles/rhel-system-roles.kdump/README.md ファイルを参照してください。
Playbook の構文を検証します。
ansible-playbook --syntax-check ~/playbook.yml
$ ansible-playbook --syntax-check ~/playbook.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow このコマンドは構文を検証するだけであり、有効だが不適切な設定から保護するものではないことに注意してください。
Playbook を実行します。
ansible-playbook ~/playbook.yml
$ ansible-playbook ~/playbook.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
検証
影響を受けるカーネルパラメーターを確認します。
ansible managed-node-01.example.com -m command -a 'sysctl fs.file-max kernel.threads-max net.ipv6.conf.lo.mtu' ansible managed-node-01.example.com -m command -a 'cat /sys/kernel/mm/transparent_hugepage/enabled'
# ansible managed-node-01.example.com -m command -a 'sysctl fs.file-max kernel.threads-max net.ipv6.conf.lo.mtu' # ansible managed-node-01.example.com -m command -a 'cat /sys/kernel/mm/transparent_hugepage/enabled'Copy to Clipboard Copied! Toggle word wrap Toggle overflow
第31章 RHEL システムロールを使用した GRUB ブートローダーの設定
bootloader RHEL システムロールを使用すると、GRUB ブートローダーに関連する設定および管理タスクを自動化できます。
このロールは、現在、次の CPU アーキテクチャーで実行される GRUB ブートローダーの設定をサポートしています。
- AMD および Intel 64 ビットアーキテクチャー (x86-64)
- 64 ビット ARM アーキテクチャー (ARMv8.0)
- IBM Power Systems、リトルエンディアン (POWER9)
31.1. bootloader RHEL システムロールを使用した既存のブートローダーエントリーの更新
bootloader RHEL システムロールを使用して、GRUB ブートメニュー内の既存のエントリーを自動的に更新できます。この方法により、システムのパフォーマンスや動作を最適化できる特定のカーネルコマンドラインパラメーターを効率的に渡すことができます。
たとえば、カーネルや init システムからの詳細なブートメッセージが必要ないシステムを活用する場合は、bootloader を使用して管理対象ノード上の既存のブートローダーエントリーに quiet パラメーターを適用すると、よりクリーンで簡潔かつユーザーフレンドリーなブートエクスペリエンスを実現できます。
前提条件
- コントロールノードと管理対象ノードの準備が完了している。
- 管理対象ノードで Playbook を実行できるユーザーとしてコントロールノードにログインしている。
-
管理対象ノードへの接続に使用するアカウントに、そのノードに対する
sudo権限がある。 - 更新するブートローダーエントリーに対応するカーネルを特定した。
手順
次の内容を含む Playbook ファイル (例:
~/playbook.yml) を作成します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow サンプル Playbook で指定されている設定は次のとおりです。
kernel- 更新するブートローダーエントリーに関連するカーネルを指定します。
options- 選択したブートローダーエントリー (カーネル) の更新するカーネルコマンドラインパラメーターを指定します。
bootloader_reboot_ok: true- 変更を有効にするために再起動が必要であることをロールが検出し、管理対象ノードの再起動を実行します。
Playbook で使用されるすべての変数の詳細は、コントロールノードの
/usr/share/ansible/roles/rhel-system-roles.bootloader/README.mdファイルを参照してください。Playbook の構文を検証します。
ansible-playbook --syntax-check ~/playbook.yml
$ ansible-playbook --syntax-check ~/playbook.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow このコマンドは構文を検証するだけであり、有効だが不適切な設定から保護するものではないことに注意してください。
Playbook を実行します。
ansible-playbook ~/playbook.yml
$ ansible-playbook ~/playbook.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
検証
指定したブートローダーエントリーのカーネルコマンドラインパラメーターが更新されていることを確認します。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
31.2. bootloader RHEL システムロールを使用したブートメニューのパスワード保護
bootloader RHEL システムロールを使用して、GRUB ブートメニューにパスワードを自動的に設定できます。この方法により、権限のないユーザーによるブートパラメーターの変更を効率的に防止し、システムのブートをより適切に制御できます。
前提条件
- コントロールノードと管理対象ノードの準備が完了している。
- 管理対象ノードで Playbook を実行できるユーザーとしてコントロールノードにログインしている。
-
管理対象ノードへの接続に使用するアカウントに、そのノードに対する
sudo権限がある。
手順
機密性の高い変数を暗号化されたファイルに保存します。
vault を作成します。
ansible-vault create ~/vault.yml
$ ansible-vault create ~/vault.yml New Vault password: <vault_password> Confirm New Vault password: <vault_password>Copy to Clipboard Copied! Toggle word wrap Toggle overflow ansible-vault createコマンドでエディターが開いたら、機密データを<key>: <value>形式で入力します。pwd: <password>
pwd: <password>Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 変更を保存して、エディターを閉じます。Ansible は vault 内のデータを暗号化します。
次の内容を含む Playbook ファイル (例:
~/playbook.yml) を作成します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow サンプル Playbook で指定されている設定は次のとおりです。
bootloader_password: "{{ pwd }}"- この変数は、ブートパラメーターをパスワードで保護します。
bootloader_reboot_ok: true- 変更を有効にするために再起動が必要であることをロールが検出し、管理対象ノードの再起動を実行します。
重要ブートローダーのパスワードの変更は、冪等のトランザクションではありません。つまり、同じ Ansible Playbook を再度適用すると、結果が同じではなく、管理対象ノードの状態が変わります。
Playbook で使用されるすべての変数の詳細は、コントロールノードの
/usr/share/ansible/roles/rhel-system-roles.bootloader/README.mdファイルを参照してください。Playbook の構文を検証します。
ansible-playbook --syntax-check --ask-vault-pass ~/playbook.yml
$ ansible-playbook --syntax-check --ask-vault-pass ~/playbook.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow このコマンドは構文を検証するだけであり、有効だが不適切な設定から保護するものではないことに注意してください。
Playbook を実行します。
ansible-playbook --ask-vault-pass ~/playbook.yml
$ ansible-playbook --ask-vault-pass ~/playbook.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
検証
管理対象ノードで、GRUB ブートメニュー画面中に、編集のために e キーを押します。
ユーザー名とパスワードの入力を求められます。
Enter username: root-
ブートローダーのユーザー名は常に
rootであり、Ansible Playbook で指定する必要はありません。 Enter password: <password>-
ブートローダーのパスワードは、
vault.ymlファイルで定義したpwd変数に対応します。
特定のブートローダーエントリーの設定を表示または編集できます。



31.3. bootloader RHEL システムロールを使用したブートローダーメニューのタイムアウトの設定
bootloader RHEL システムロールを使用して、GRUB ブートローダーメニューのタイムアウトを自動的に設定できます。さまざまな目的で、介入する期間を更新し、デフォルト以外のブートエントリーを選択できます。
前提条件
- コントロールノードと管理対象ノードの準備が完了している。
- 管理対象ノードで Playbook を実行できるユーザーとしてコントロールノードにログインしている。
-
管理対象ノードへの接続に使用するアカウントに、そのノードに対する
sudo権限がある。
手順
次の内容を含む Playbook ファイル (例:
~/playbook.yml) を作成します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow サンプル Playbook で指定されている設定は次のとおりです。
bootloader_timeout: 10- デフォルトのエントリーを起動する前に GRUB ブートローダーメニューを表示する時間を制御する整数を入力します。
Playbook で使用されるすべての変数の詳細は、コントロールノードの
/usr/share/ansible/roles/rhel-system-roles.bootloader/README.mdファイルを参照してください。Playbook の構文を検証します。
ansible-playbook --syntax-check ~/playbook.yml
$ ansible-playbook --syntax-check ~/playbook.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow このコマンドは構文を検証するだけであり、有効だが不適切な設定から保護するものではないことに注意してください。
Playbook を実行します。
ansible-playbook ~/playbook.yml
$ ansible-playbook ~/playbook.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
検証
管理対象ノードをリモートで再起動します。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 管理対象ノードで、GRUB ブートメニュー画面を確認します。
The highlighted entry will be executed automatically in 10sGRUB が自動的にデフォルトエントリーを使用するまで、このブートメニューを表示する時間。
別の方法: 管理対象ノードの
/boot/grub2/grub.cfgファイル内の "timeout" 設定をリモートでクエリーすることもできます。Copy to Clipboard Copied! Toggle word wrap Toggle overflow

31.4. bootloader RHEL システムロールを使用したブートローダー設定情報の収集
bootloader RHEL システムロールを使用して、GRUB ブートローダーエントリーに関する情報を自動的に収集できます。この情報を使用して、カーネルや初期 RAM ディスクイメージパスなど、システムブートパラメーターの正しい設定を確認できます。
その結果、たとえば次のことが可能になります。
- ブートの失敗を防止する。
- トラブルシューティング時に既知の正常な状態に戻す。
- セキュリティー関連のカーネルコマンドラインパラメーターを確実に正しく設定する。
前提条件
- コントロールノードと管理対象ノードの準備が完了している。
- 管理対象ノードで Playbook を実行できるユーザーとしてコントロールノードにログインしている。
-
管理対象ノードへの接続に使用するアカウントに、そのノードに対する
sudo権限がある。
手順
次の内容を含む Playbook ファイル (例:
~/playbook.yml) を作成します。Copy to Clipboard Copied! Toggle word wrap Toggle overflow Playbook で使用されるすべての変数の詳細は、コントロールノードの
/usr/share/ansible/roles/rhel-system-roles.bootloader/README.mdファイルを参照してください。Playbook の構文を検証します。
ansible-playbook --syntax-check ~/playbook.yml
$ ansible-playbook --syntax-check ~/playbook.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow このコマンドは構文を検証するだけであり、有効だが不適切な設定から保護するものではないことに注意してください。
Playbook を実行します。
ansible-playbook ~/playbook.yml
$ ansible-playbook ~/playbook.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
検証
コントロールノードで前述の Playbook を実行すると、次の例のようなコマンドライン出力が表示されます。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow コマンドライン出力には、ブートエントリーに関する次の重要な設定情報が表示されます。
args- 起動プロセス中に GRUB2 ブートローダーによってカーネルに渡されるコマンドラインパラメーター。このパラメーターは、カーネル、initramfs、その他のブート時コンポーネントのさまざまな設定と動作を設定します。
id- ブートローダーメニュー内の各ブートエントリーに割り当てられる一意の識別子。マシン ID とカーネルバージョンで構成されています。
root- カーネルがマウントし、ブート中にプライマリーファイルシステムとして使用するルートファイルシステム。
第32章 高度なエラー報告の使用
Advanced Error Reporting (AER) を使用すると、Peripheral Component Interconnect Express (PCIe) デバイスのエラーイベントの通知を受け取ります。RHEL はデフォルトでこのカーネル機能を有効にし、報告されたエラーをカーネルログに収集します。rasdaemon プログラムを使用すると、これらのエラーは解析され、データベースに保存されます。
32.1. AER の概要
Advanced Error Reporting (AER) は、Peripheral Component Interconnect Express (PCIe) デバイスの拡張エラーレポートを提供するカーネル機能です。AER カーネルドライバーは、次の目的で PCIe AER 機能をサポートするルートポートを接続します。
- 包括的なエラー情報を収集する
- エラーをユーザーに報告する
- エラー回復アクションを実行する
AER がエラーをキャプチャすると、error メッセージがコンソールに送信されます。修復可能なエラーの場合、コンソール出力は 警告 です。
例32.1 AER 出力の例
32.2. AER メッセージの収集および表示
AER メッセージを収集して表示するには、rasdaemon プログラムを使用します。
手順
rasdaemonパッケージをインストールします。yum install rasdaemon
# yum install rasdaemonCopy to Clipboard Copied! Toggle word wrap Toggle overflow rasdaemonサービスを有効にして開始します。systemctl enable --now rasdaemon
# systemctl enable --now rasdaemon Created symlink /etc/systemd/system/multi-user.target.wants/rasdaemon.service → /usr/lib/systemd/system/rasdaemon.service.Copy to Clipboard Copied! Toggle word wrap Toggle overflow ras-mc-ctlコマンドを発行します。ras-mc-ctl --summary ras-mc-ctl --errors
# ras-mc-ctl --summary # ras-mc-ctl --errorsCopy to Clipboard Copied! Toggle word wrap Toggle overflow このコマンドは、ログに記録されたエラーの概要を表示するか (
--summaryオプション)、エラーデータベースに保存されているエラーを表示します (--errorsオプション)。