システムデザインガイド
RHEL 8 システムの設計
概要
Red Hat ドキュメントへのフィードバック (英語のみ)
Red Hat ドキュメントに関するご意見やご感想をお寄せください。また、改善点があればお知らせください。
Jira からのフィードバック送信 (アカウントが必要)
- Jira の Web サイトにログインします。
- 上部のナビゲーションバーで Create をクリックします。
- Summary フィールドにわかりやすいタイトルを入力します。
- Description フィールドに、ドキュメントの改善に関するご意見を記入してください。ドキュメントの該当部分へのリンクも追加してください。
- ダイアログの下部にある Create をクリックします。
パート I. インストールの設計
第1章 システム要件とサポート対象のアーキテクチャー
Red Hat Enterprise Linux 8 は、ワークロードの提供にかかる時間や労力の軽減に必要なツールを使用することで、ハイブリッドクラウドデプロイメント全体に安定性、安全性、一貫性のある基盤を提供します。RHEL は、対応しているハイパーバイザー環境やクラウドプロバイダー環境にゲストとしてデプロイすることも、物理インフラストラクチャーにデプロイすることもできるため、アプリケーションは、主要なハードウェアアーキテクチャープラットフォームの革新的な機能を利用できます。
インストールする前に、システム、ハードウェア、セキュリティー、メモリー、および RAID に関するガイドラインを確認してください。
システムを仮想ホストとして使用する場合は、仮想化に必要なハードウェア要件 を確認してください。
Red Hat Enterprise Linux では、次のアーキテクチャーに対応します。
- AMD アーキテクチャーおよび Intel 64 ビットアーキテクチャー
- 64 ビット ARM アーキテクチャー
- IBM Power Systems (リトルエンディアン)
- 64 ビット IBM Z アーキテクチャー
1.1. インストール先として対応しているターゲット
インストールターゲットは、Red Hat Enterprise Linux を格納し、システムを起動するストレージデバイスです。Red Hat Enterprise Linux は、IBMZ、IBM Power、AMD64、Intel 64、および 64 ビット ARM システムで、次のインストールターゲットをサポートしています。
- DASD、SCSI、SATA、SAS などの標準的な内部インターフェイスで接続されたストレージ
- Intel64、AMD64、および arm64 アーキテクチャー上の BIOS/ファームウェア RAID デバイス
-
nd_pmemドライバーがサポートする、セクターモードに設定された Intel 64 および AMD64 アーキテクチャー上の NVDIMM デバイス - DASD (IBM Z アーキテクチャーのみ) や SCSI LUN (マルチパスデバイスを含む) などのファイバーチャネルホストバスアダプターを介して接続されたストレージ。ベンダー提供のドライバーが必要になる場合があります。
- Xen 仮想マシンの Intel のプロセッサーの Xen ブロックデバイス
- KVM 仮想マシンの Intel のプロセッサーの VirtIO ブロックデバイス
Red Hat では、USB ドライブや SD メモリーカードへのインストールはサポートしていません。サードパーティーによる仮想化技術のサポートは、Red Hat Hardware Compatibility List を参照してください。
1.2. システムの仕様
Red Hat Enterprise Linux インストールプログラムはシステムのハードウェアを自動的に検出してインストールするため、特定のシステム情報を提供する必要はありません。ただし、特定の Red Hat Enterprise Linux インストールシナリオでは、将来の参照用にシステム仕様を記録しておくことを推奨します。次のようなシナリオになります。
カスタマイズしたパーティションレイアウトで RHEL をインストール
レコード:システムに接続されているディスクのモデル番号、サイズ、タイプ、およびインターフェイス。たとえば、SATA0 上には Seagate 製 ST3320613AS (320 GB)、SATA1 上には Western Digital WD7500AAKS (750 GB) です。
既存のシステムに、追加のオペレーティングシステムとして RHEL をインストール
レコード:システムで使用するパーティション。この情報には、ファイルシステムの種類、デバイスノード名、ファイルシステムのラベル、およびサイズを記載でき、パーティションを作成する際に特定のパーティションを識別できます。オペレーティングシステムの 1 つが Unix オペレーティングシステムの場合、Red Hat Enterprise Linux はデバイス名を異なる方法で報告することがあります。追加の情報は、mount コマンド、blkid コマンドを実行して表示するか、/etc/fstab ファイルを参照してください。
複数のオペレーティングシステムがインストールされている場合、Red Hat Enterprise Linux インストールプログラムはそのオペレーティングシステムを自動的に検出して、それを起動するようにブートローダーを設定しようとします。追加のオペレーティングシステムが自動的に検出されない場合は、手動で設定できます。
ローカルディスク上のイメージから RHEL をインストールする
レコード:イメージを保存するディスクとディレクトリー。
ネットワーク経由で RHEL のインストール
ネットワークを手動で設定する必要がある場合、つまり DHCP を使用しない場合です。
レコード:
- IP アドレス
- ネットマスク
- ゲートウェイの IP アドレス
- (必要に応じて) サーバーの IP アドレス
ネットワーク要件が不明な場合は、ネットワーク管理者に連絡してください。
iSCSI ターゲットへの RHEL のインストール
レコード:iSCSI ターゲットの場所ネットワークに応じて、CHAP ユーザー名とパスワードと、リバースの CHAP ユーザー名とパスワードが必要になる場合があります。
ドメインに含まれるシステムへの RHEL のインストール
ドメイン名が DHCP サーバーにより提供されることを確認してください。提供されない場合は、インストール中にドメイン名を入力する必要があります。
1.3. ディスクおよびメモリーの要件
複数のオペレーティングシステムがインストールされている場合は、割り当てられたディスク領域が Red Hat Enterprise Linux で必要なディスク領域とは異なることを確認することが重要です。場合によっては、特定のパーティションを Red Hat Enterprise Linux 専用にすることが重要になります。たとえば、AMD64、Intel 64、および 64 ビット ARM の場合は、少なくとも 2 つのパーティション (/ および swap) を RHEL 専用にする必要があります。IBM Power Systems サーバーの場合は、少なくとも 3 つのパーティション (/、swap、および PReP ブートパーティション) を RHEL 専用にする必要があります。
さらに、使用可能なディスク容量が最低 10 GiB 必要です。Red Hat Enterprise Linux をインストールするには、パーティションが分割されていないディスク領域か、削除できるパーティション内に、最低 10 GiB の容量が必要です。詳細は、パーティション設定のリファレンス を参照してください。
| インストールタイプ | 最小 RAM |
|---|---|
| ローカルメディアによるインストール (USB, DVD) |
|
| NFS ネットワークインストール |
|
| HTTP、HTTPS、または FTP ネットワークインストール |
|
最小要件よりも少ないメモリーでもインストールを完了できます。正確な要件は、環境とインストールパスにより異なります。さまざまな構成をテストして、環境に必要な最小 RAM を特定してください。キックスタートファイルを使用して Red Hat Enterprise Linux をインストールする場合も、最小 RAM 要件は標準インストールと同じです。ただし、キックスタートファイルに追加のメモリーを必要とするコマンド、または RAM ディスクにデータを書き込むコマンドが含まれている場合は、追加の RAM が必要になることがあります。詳細は、RHEL の自動インストール を参照してください。
1.4. グラフィックスディスプレイの解像度要件
Red Hat Enterprise Linux をスムーズにエラーなしにインストールするには、システムに次の最小解像度が必要です。
| 製品バージョン | 解決方法 |
|---|---|
| Red Hat Enterprise Linux 8 | 最小: 800 x 600 推奨: 1026 x 768 |
1.5. UEFI セキュアブートとベータ版リリースの要件
UEFI セキュアブートが有効になっているシステムに Red Hat Enterprise Linux のベータ版リリースをインストールする予定がある場合は、UEFI セキュアブートオプションを無効にしてから、インストールを開始します。
UEFI セキュアブートでは、オペレーティングシステムのカーネルが、対応する公開鍵を使用してシステムのファームウェアが検証する、認識済みの秘密鍵で署名されている必要があります。Red Hat Enterprise Linux ベータ版リリースの場合には、カーネルは Red Hat ベータ版固有の公開鍵で署名されていますが、この鍵はデフォルトではシステムで認識できません。その結果、インストールメディアの起動にも失敗します。
第2章 インストールメディアのカスタマイズ
詳細は、RHEL システムイメージのカスタマイズ を参照してください。
第3章 起動可能な RHEL 用インストールメディアの作成
カスタマーポータル から ISO ファイルをダウンロードして、USB や DVD などの起動可能な物理インストールメディアを準備できます。RHEL 8 以降、Red Hat は Server 用と Workstation 用の個別のバリアントを提供しなくなりました。Red Hat Enterprise Linux for x86_64 には、Server 機能と Workstation 機能の両方が含まれています。Server および Workstation の区別は、インストールまたは設定プロセス中にシステム目的ロールを通じて管理されます。
カスタマーポータルから ISO ファイルをダウンロードした後、USB や DVD などの起動可能な物理インストールメディアを作成して、インストールプロセスを続行します。
USB ドライブが禁止されているセキュアな環境では、Image Builder を使用して参照イメージを作成し、デプロイすることを検討してください。この方法により、システムの整合性を維持しながらセキュリティーポリシーへの準拠を確保できます。詳細は、Image Builder のドキュメント を参照してください。
デフォルトでは、インストールメデイアで inst.stage2= 起動オプションが使用され、特定のラベル (たとえば inst.stage2=hd:LABEL=RHEL8\x86_64) に設定されます。ランタイムイメージが含まれるファイルシステムのデフォルトのラベルを変更します。インストールシステムの起動手順をカスタマイズする場合は、このラベルが正しい値に設定されていることを確認します。
3.1. インストール起動用メディアオプション
Red Hat Enterprise Linux インストールプログラムを起動する方法はいくつかあります。
- フルインストール用 DVD または USB フラッシュドライブ
- DVD ISO イメージを使用して、フルインストールの DVD または USB フラッシュドライブを作成します。ソフトウェアパッケージをインストールする場合は、DVD または USB フラッシュドライブを、ブートデバイスおよびインストールソースとして使用できます。
- 最小インストール用の DVD、CD、または USB フラッシュドライブ
- 最小インストール用 CD、DVD、または USB フラッシュドライブは、Boot ISO イメージを使用して作成されます。これには、システムを起動し、インストールプログラムを開始するのに最低限必要なファイルのみが含まれます。コンテンツ配信ネットワーク (CDN) を使用して必要なソフトウェアパッケージをダウンロードする場合は、Boot ISO イメージに、必要なソフトウェアパッケージを含むインストールソースが必要です。
- PXE サーバー
- PXE (preboot execution environment) サーバーを使用すると、インストールプログラムをネットワーク経由で起動させることができます。システムの起動後、ローカルディスクやネットワークの場所などの別のインストールソースからインストールを完了する必要があります。
- Image Builder
- Image Builder を使用すると、システムおよびクラウドイメージをカスタマイズして、仮想環境およびクラウド環境に Red Hat Enterprise Linux をインストールできます。
3.2. 起動可能な DVD の作成
起動可能なインストール DVD は、ディスク書き込みソフトウェアや DVD バーナーを使用して作成できます。ISO イメージファイルから DVD を作成する手順は、オペレーティングシステムや、インストールされているディスク書き込みソフトウェアにより大きく異なります。DVD への ISO イメージファイルの書き込み方法は、お使いの書き込みソフトウェアのドキュメントを参照してください。
起動可能な DVD は、DVD ISO イメージ (フルインストール) または Boot ISO イメージ (最小インストール) のいずれかを使用して作成できます。ただし、DVD ISO イメージが 4.7 GB より大きくなり、1 層または 2 層 DVD に収まらない場合があります。作業を続行する前に、DVD ISO イメージファイルのサイズを確認してください。DVD ISO イメージを使用して起動可能なインストールメディアを作成する場合は、USB フラッシュドライブを使用してください。USB ドライブが禁止されている環境の場合は、Image Builder のドキュメント を参照してください。
3.3. Linux で起動可能な USB デバイスの作成
起動可能な USB デバイスを作成し、それを使用して他のマシンに Red Hat Enterprise Linux をインストールできます。この手順では、警告なしに USB ドライブ上の既存のデータが上書きされます。データをバックアップするか、空のフラッシュドライブを使用してください。起動可能な USB ドライブは、データの保存には使用できません。
前提条件
- Product Downloads ページからフルインストール DVD ISO または最小インストールブート ISO イメージをダウンロードした。
- ISO イメージに十分な容量の USB フラッシュドライブがある。必要なサイズはさまざまですが、推奨される USB サイズは 8 GB です。
手順
- USB フラッシュドライブをシステムに接続します。
ターミナルウィンドウを開き、最近のイベントのログを表示します。
$ dmesg|tailこのログの下部に、接続している USB フラッシュドライブから出力されたメッセージが表示されます。接続したデバイスの名前を記録してください。
root ユーザーとしてログインします。
$ su -プロンプトに従い root パスワードを入力します。
ドライブに割り当てられているデバイスノードを見つけます。この例で使用されているドライブの名前は
sddです。# dmesg|tail [288954.686557] usb 2-1.8: New USB device strings: Mfr=0, Product=1, SerialNumber=2 [288954.686559] usb 2-1.8: Product: USB Storage [288954.686562] usb 2-1.8: SerialNumber: 000000009225 [288954.712590] usb-storage 2-1.8:1.0: USB Mass Storage device detected [288954.712687] scsi host6: usb-storage 2-1.8:1.0 [288954.712809] usbcore: registered new interface driver usb-storage [288954.716682] usbcore: registered new interface driver uas [288955.717140] scsi 6:0:0:0: Direct-Access Generic STORAGE DEVICE 9228 PQ: 0 ANSI: 0 [288955.717745] sd 6:0:0:0: Attached scsi generic sg4 type 0 [288961.876382] sd 6:0:0:0: sdd Attached SCSI removable disk-
挿入された USB デバイスが自動的にマウントされる場合は、次の手順に進む前にマウントを解除してください。アンマウントするには、
umountコマンドを使用します。詳細は、umount を使用したファイルシステムのアンマウント を参照してください。 ISO イメージを USB デバイスに直接書き込みます。
# dd if=/image_directory/image.iso of=/dev/device- /image_directory/image.iso を、ダウンロードした ISO イメージファイルへのフルパスに置き換えます。
device を、
dmesgコマンドで取得したデバイス名に置き換えます。この例では、ISO イメージのフルパスが
/home/testuser/Downloads/rhel-8-x86_64-boot.isoで、検出されたデバイス名がsddです。# dd if=/home/testuser/Downloads/rhel-8-x86_64-boot.iso of=/dev/sddパーティション名は、通常、数字の接尾辞が付いたデバイス名です。たとえば、
sddがデバイス名の場合、デバイスsdd上のパーティションの名前は、sdd1になります。
-
ddコマンドがデバイスへのイメージの書き込みを終了するのを待ちます。syncコマンドを実行して、キャッシュされた書き込みをデバイスに同期します。データ転送が完了すると、# プロンプトが表示されます。プロンプトが表示されたら、root アカウントからログアウトし、USB ドライブを取り外します。これで、USB ドライブをブートデバイスとして使用できるようになりました。
3.4. Windows で起動可能な USB デバイスの作成
さまざまなツールを使用して、Windows システムに起動可能な USB デバイスを作成できます。https://github.com/FedoraQt/MediaWriter/releases からダウンロードできる Fedora Media Writer を使用できます。Fedora Media Writer はコミュニティー製品であるため、Red Hat のサポート対象外となります。このツールの問題は、https://github.com/FedoraQt/MediaWriter/issues から報告できます。
起動可能なドライブを作成すると、警告なしに USB ドライブ上の既存のデータが上書きされます。データをバックアップするか、空のフラッシュドライブを使用してください。起動可能な USB ドライブは、データの保存には使用できません。
前提条件
- Product Downloads ページからフルインストール DVD ISO または最小インストールブート ISO イメージをダウンロードした。
- ISO イメージに十分な容量の USB フラッシュドライブがある。必要なサイズはさまざまです。
手順
- https://github.com/FedoraQt/MediaWriter/releases から Fedora Media Writer をダウンロードしてインストールします。
- USB フラッシュドライブをシステムに接続します。
- Fedora Media Writer を開きます。
- メイン画面で をクリックして、ダウンロードしておいた Red Hat Enterprise Linux ISO イメージを選択します。
- Write Custom Image 画面で、使用するドライブを選択します。
- をクリックします。起動用メディアの作成プロセスが開始します。プロセスが完了するまでドライブを抜かないでください。ISO イメージのサイズや、USB ドライブの書き込み速度により、この操作には数分かかる場合があります。
- 操作が完了したら、USB ドライブをアンマウントします。これで USB ドライブを起動デバイスとして使用する準備が整いました。
3.5. macOS で起動可能な USB デバイスの作成
起動可能な USB デバイスを作成し、それを使用して他のマシンに Red Hat Enterprise Linux をインストールできます。起動可能な USB ドライブを作成すると、USB ドライブに以前保存されたデータがすべて警告なしに上書きされます。データをバックアップするか、空のフラッシュドライブを使用してください。起動可能な USB ドライブは、データの保存には使用できません。
前提条件
- Product Downloads ページからフルインストール DVD ISO または最小インストールブート ISO イメージをダウンロードした。
- ISO イメージに十分な容量の USB フラッシュドライブがある。必要なサイズはさまざまです。
手順
- USB フラッシュドライブをシステムに接続します。
diskutil listコマンドでデバイスパスを特定します。デバイスパスの形式は/dev/disknumberです。numberはディスクの数になります。ディスク番号は、ゼロ (0) から始まります。通常、disk0は OS X リカバリーディスク、disk1はメインの OS X インストールになります。以下の例では、disk2が USB デバイスです。$ diskutil list /dev/disk0 #: TYPE NAME SIZE IDENTIFIER 0: GUID_partition_scheme *500.3 GB disk0 1: EFI EFI 209.7 MB disk0s1 2: Apple_CoreStorage 400.0 GB disk0s2 3: Apple_Boot Recovery HD 650.0 MB disk0s3 4: Apple_CoreStorage 98.8 GB disk0s4 5: Apple_Boot Recovery HD 650.0 MB disk0s5 /dev/disk1 #: TYPE NAME SIZE IDENTIFIER 0: Apple_HFS YosemiteHD *399.6 GB disk1 Logical Volume on disk0s1 8A142795-8036-48DF-9FC5-84506DFBB7B2 Unlocked Encrypted /dev/disk2 #: TYPE NAME SIZE IDENTIFIER 0: FDisk_partition_scheme *8.1 GB disk2 1: Windows_NTFS SanDisk USB 8.1 GB disk2s1- NAME、TYPE、および SIZE の列をフラッシュドライブと比較し、USB フラッシュドライブを特定します。たとえば、NAME は、Finder ツールのフラッシュドライブアイコンのタイトルになります。この値は、フラッシュドライブの情報パネルの値と比較することもできます。
フラッシュドライブのファイルシステムボリュームをアンマウントします。
$ diskutil unmountDisk /dev/disknumber Unmount of all volumes on disknumber was successfulコマンドが完了すると、デスクトップからフラッシュドライブのアイコンが消えます。アイコンが消えない場合は、誤ったディスクを選択した可能性があります。誤ってシステムディスクのマウントを解除しようとすると、failed to unmount エラーが返されます。
フラッシュドライブに ISO イメージを書き込みます。macOS は、各ストレージデバイスに対してブロック (
/dev/disk*) とキャラクターデバイス (/dev/rdisk*) ファイルの両方を提供します。/dev/rdisknumberキャラクターデバイスにイメージを書き込む方が、/dev/disknumberブロックデバイスに書き込むよりも高速です。たとえば、/Users/user_name/Downloads/rhel-8-x86_64-boot.isoファイルを/dev/rdisk2デバイスに書き込むには、以下のコマンドを実行します。# sudo dd if=/Users/user_name/Downloads/rhel-8-x86_64-boot.iso of=/dev/rdisk2 bs=512K status=progress-
if=- インストールイメージへのパス。 -
of=- ターゲットディスクを表す raw ディスクデバイス (/dev/rdisknumber)。 -
bs=512K- データ転送を高速化するためにブロックサイズを 512 KB に設定します。 -
status=progress- 操作中に進行状況インジケーターを表示します。
-
-
ddコマンドがデバイスへのイメージの書き込みを終了するのを待ちます。データ転送が完了すると、# プロンプトが表示されます。プロンプトが表示されたら、root アカウントからログアウトして、USB ドライブを取り外します。これで USB ドライブを起動デバイスとして使用する準備が整いました。
第4章 インストールメディアの起動
USB または DVD を使用して Red Hat Enterprise Linux のインストールを起動できます。
Red Hat コンテンツ配信ネットワーク (CDN) を使用すると、RHEL を登録できます。CDN は地理的に分散された一連の Web サーバーです。これらのサーバーは、たとえば、有効なサブスクリプションを持つ RHEL ホストにパッケージや更新を提供します。
インストール中に、CDN から RHEL を登録してインストールすると、次のような利点があります。
- インストール後すぐに最新のシステムで最新のパッケージを利用できます。
- Red Hat Insights に接続し、システムの目的を有効にするための統合サポートを利用できます。
RHEL 9.6 以降、国防情報システム局 (DISA) のセキュリティー技術実装ガイド (STIG) およびその他のセキュリティープロファイルでは、初回起動時に Federal Information Processing Standards (FIPS) モードが自動的に有効になりません。FIPS 準拠を維持するには、インストールを開始する前に、fips=1 カーネルブートオプションを追加するか、FIPS を明示的に有効にするキックスタート設定を使用して、FIPS モードを手動で有効にする必要があります。インストール前に FIPS が有効になっていないと、これらのセキュリティープロファイルを使用して構築されたシステムが準拠していない可能性があり、ユーザーが知らないうちに非準拠のシステムを展開してしまう可能性があります。コンプライアンスの問題を回避するには、グラフィカルまたはテキストベースのインストーラーを起動する前に、ブートフェーズで FIPS が有効になっていることを確認してください。
前提条件
- 起動可能なインストールメディア (USB または DVD) を作成した。
手順
- Red Hat Enterprise Linux をインストールするシステムの電源を切ります。
- システムからドライブを切断します。
- システムの電源を入れます。
- 起動可能なインストールメディア (USB、DVD、または CD) を挿入します。
- システムの電源は切りますが、ブートメディアは取り出さないでください。
- システムの電源を入れます。
- メディアから起動するため特定のキーやキーの組み合わせを押さなければならない場合や、メディアから起動するようにシステムの BIOS (Basic Input/Output System) を設定しなければならない場合があります。詳細は、システムに同梱されているドキュメントをご覧ください。
- Red Hat Enterprise Linux ブート ウィンドウが開き、利用可能なさまざまなブートオプションが表示されます。
キーボードの矢印キーを使用して必要なブートオプションを選択し、Enter キー を押してブートオプションを選択します。Red Hat Enterprise Linux へようこそ 画面が開き、グラフィカルユーザーインターフェイスを使用して Red Hat Enterprise Linux をインストールできます。
起動画面で、60 秒以内に何も行わないと、インストールプログラムが自動的に開始します。
オプション:利用可能なブートオプションを編集します。
- UEFI ベースのシステム:E を押して、編集モードにします。事前定義済みのコマンドラインを変更して、ブートオプションを追加または削除します。Enter キーを押して、選択を確認します。
- BIOS ベースのシステム:キーボードの Tab キーを押して編集モードに入ります。事前定義済みのコマンドラインを変更して、ブートオプションを追加または削除します。Enter キーを押して、選択を確認します。
第5章 オプション:ブートオプションのカスタマイズ
x86_64 または ARM64 アーキテクチャーに RHEL をインストールする場合は、ブートオプションを編集して、特定の環境に応じてインストールプロセスをカスタマイズできます。
5.1. 起動オプション
ブートコマンドラインに、複数のオプションをスペースで区切って追加できます。インストールプログラム固有のブートオプションは、必ず inst で始まります。使用可能なブートオプションは次のとおりです。
- 等号 "=" 記号を使用するオプション
-
起動オプションに、
=記号を使用する値を指定する必要があります。たとえば、inst.vncpassword=オプションには値 (この場合はパスワード) を指定する必要があります。この例の正しい構文はinst.vncpassword=passwordです。 - 等号 "=" 記号を使用しないオプション
-
この起動オプションでは、値またはパラメーターを使用できません。たとえば、
rd.live.checkオプションでは、インストール開始前にインストールメディアの検証が強制されます。インストールプログラムは、このブートオプションが存在すると検証を実行します。ブートオプションが存在しないと、検証はスキップされます。
特定のメニューエントリーのブートオプションを次の方法でカスタマイズできます。
-
BIOS ベースのシステムの場合:
Tabキーを押して、コマンドラインにカスタム起動オプションを追加します。Escキーを押してboot:プロンプトにアクセスすることもできますが、必要な起動オプションは事前設定されていません。このシナリオでは、その他の起動オプションを使用する前に、Linux オプションを常に指定する必要があります。詳細は、BIOS の boot: プロンプトの編集 を参照してください。 -
UEFI ベースのシステムの場合:
eキーを押して、コマンドラインにカスタム起動オプションを追加します。準備ができたらCtrl+Xを押して、修正したオプションを起動します。
詳細は、UEFI ベースのシステムのブートオプションの編集 を参照してください。
5.2. BIOS で boot: プロンプトの編集
boot: プロンプトを使用すると、最初のオプションは、読み込むインストールプログラムのイメージファイルを常に指定する必要があります。ほとんどの場合、このイメージはキーワードを使用して指定できます。要件に応じて、追加オプションを指定できます。
前提条件
- 起動可能なインストールメディア (USB、CD、または DVD) を作成している。
- メディアからインストールを起動し、起動メニュー画面が開いている。
手順
- ブートメニューが開いたら、キーボードの Esc キーを押します。
-
boot:プロンプトにアクセスできるようになります。 - キーボードの Tab キーを押して、ヘルプコマンドを表示します。
-
キーボードの Enter キーを押して、オプションでインストールを開始します。
boot:プロンプトから起動メニュー画面に戻るには、システムを再起動して、インストールメディアから再度起動します。
5.3. > プロンプトを使用して事前定義されたブートオプションの編集
BIOS ベースの AMD64 および Intel64 システムでは、> プロンプトを使用して、事前定義されたブートオプションを編集できます。
前提条件
- 起動可能なインストールメディア (USB、CD、または DVD) を作成している。
- メディアからインストールを起動し、起動メニュー画面が開いている。
手順
-
ブートメニューでオプションを選択し、キーボードの Tab キーを押します。
>プロンプトにアクセスし、利用可能なオプションを表示します。 -
オプション:オプションの完全なセットを表示するには、
このメディアをテストして RHEL 8 をインストールを選択します。 >プロンプトに必要なオプションを追加します。たとえば、Federal Information Processing Standard (FIPS) 140 で義務付けられている暗号化モジュールのセルフチェックを有効にするには、
fips=1を追加します。>vmlinuz initrd=initrd.img inst.stage2=hd:LABEL=RHEL-9-5-0-BaseOS-x86_64 rd.live.check quiet fips=1- Enter を押してインストールを開始します。
- Esc キーを押して編集をキャンセルし、ブートメニューに戻ります。
5.5. インストール時のドライバーの更新
Red Hat Enterprise Linux のインストールプロセス中にドライバーを更新できます。ドライバーの更新は完全に任意です。必要がない限り、ドライバーの更新を実行しないでください。Red Hat Enterprise Linux のインストール中にドライバーの更新が必要であることについて、Red Hat、ハードウェアベンダー、または信頼できるサードパーティーベンダーから通知を受けたことを確認してください。
5.5.1. 概要
Red Hat Enterprise Linux は、多数のハードウェアデバイス用のドライバーに対応していますが、新たにリリースしたドライバーには対応していない可能性があります。ドライバーの更新は、そのドライバーが対応していないために、インストールが完了できない場合に限り、実行する必要があります。インストール中にドライバーを更新することは、通常、特定の設定に対応する場合に限り必要になります。たとえば、システムのストレージデバイスへのアクセスを提供するストレージアダプター用ドライバーをインストールします。
ドライバー更新ディスクは、競合するカーネルドライバーを無効にする場合があります。この方法でカーネルモジュールをアンロードすると、インストールエラーが発生することがあります。
5.5.2. ドライバー更新の種類
Red Hat、ハードウェアベンダー、信頼できるサードパーティーは、ドライバー更新を ISO イメージファイルとして提供します。ISO イメージファイルを受け取ったら、ドライバー更新の種類を選択してください。
ドライバー更新の種類
- 自動
-
このドライバー更新方法では、
OEMDRVというラベルの付いたストレージデバイス (CD、DVD、USB フラッシュドライブなど) がシステムに物理的に接続されます。インストールの開始時に、OEMDRVストレージデバイスが存在する場合は、それがドライバー更新ディスクのように扱われ、インストールプログラムはそのドライバーを自動的に読み込みます。 - アシスト付き
-
このインストールプログラムは、ドライバーの更新を指定するように促します。
OEMDRV以外の任意のローカルストレージデバイスラベルを使用できます。インストールを開始するときに、inst.ddブートオプションが指定されます。このオプションにパラメーターを付けずに使用すると、インストールプログラムはシステムに接続されているすべてのストレージデバイスを表示し、ドライバー更新を含むデバイスを選択するように促します。 - 手動
-
ドライバー更新イメージまたは RPM パッケージのパスを手動で指定します。
OEMDRV以外のラベルを持つ任意のローカルストレージ、またはインストールシステムからアクセス可能なネットワークの場所を使用できます。inst.dd=location起動オプションは、インストールの開始時に指定しますが、location は、ドライバー更新ディスクまたは ISO イメージのパスになります。このオプションを指定すると、インストールプログラムは特定の場所にあるドライバー更新を読み込みます。手動でドライバーを更新する場合は、ローカルストレージデバイス、またはネットワークの場所 (HTTP、HTTPS、または FTP サーバー) を指定できます。inst.dd=locationとinst.ddの両方を同時に使用できます。location は、ドライバー更新ディスクまたは ISO イメージのパスになります。このシナリオでは、インストールプログラムは、その場所から、利用可能なドライバーの更新を読み込み、ドライバーの更新が含まれるデバイスを選択するように求められます。
ネットワークの場所からドライバーの更新を読み込むときは、ip= option を使用してネットワークを初期化します。
制限
セキュアブート技術を使用する UEFI システムでは、すべてのドライバーが有効な証明書で署名されている必要があります。Red Hat ドライバーは、Red Hat の秘密鍵のいずれかで署名され、カーネルで対応する公開鍵により認証されます。追加で別のドライバーを読み込む場合は、それが署名されていることを確認してください。
5.5.3. ドライバー更新の準備
この手順では、CD および DVD でドライバー更新の準備を行う方法を説明します。
前提条件
- Red Hat、ハードウェアベンダー、または信頼できるサードパーティーベンダーからドライバー更新の ISO イメージを受け取っている。
- ドライバー更新の ISO イメージを CD または DVD に焼き付けている。
CD または DVD で、.iso で終了する ISO イメージファイルが 1 つしか利用できない場合、書き込み処理は成功していません。CD または DVD に ISO イメージを作成する方法は、システムの書き込みソフトウェアのドキュメントを参照してください。
手順
- ドライバー更新用 CD または DVD をシステムの CD/DVD ドライブに挿入し、システムのファイルマネージャーツールで参照します。
-
rhdd3ファイルが 1 つ利用できることを確認してください。rhdd3は、ドライバーの説明が含まれる署名ファイルと、ディレクトリーのrpmsです。このディレクトリーには、さまざまなアーキテクチャー用のドライバーが同梱される RPM パッケージが含まれます。
5.5.4. 自動ドライバー更新の実行
この手順では、インストール時にドライバーの自動更新を行う方法を説明します。
前提条件
-
OEMDRVラベルの付いた標準のディスクパーティションにドライバーの更新イメージを置くか、OEMDRVドライバー更新イメージを CD または DVD に作成します。RAID や LVM ボリュームなどの高度なストレージは、ドライバーの更新プロセス中はアクセスできない可能性があります。 -
インストールプロセスを開始する前に、ボリュームラベル
OEMDRVが付いたブロックデバイスをシステムに接続しているか、事前に準備した CD または DVD をシステムの CD/DVD ドライブに挿入している。
手順
- 前提条件の手順を完了すると、インストールプログラムの起動時にドライバーが自動的にロードされ、システムのインストールプロセス中にインストールされます。
5.5.5. アシスト付きドライバー更新の実行
この手順では、インストール時に、ドライバーのアシスト付き更新を行う方法を説明します。
前提条件
-
インストールプロセスを開始する前に、
OEMDRVボリュームラベルのないブロックデバイスをシステムに接続し、ドライバーディスクイメージをこのデバイスにコピーしたか、ドライバー更新の CD または DVD を準備して、システムの CD または DVD ドライブに挿入しました。
ISO イメージファイルを CD または DVD に書き込むが、OEMDRV ボリュームラベルがない場合は、引数なしで inst.dd オプションを使用できます。インストールプログラムは、CD または DVD からドライバーをスキャンして選択するオプションを提供します。このシナリオでは、インストールプログラムから、ドライバー更新用 ISO イメージを選択するように求められません。別のシナリオでは、起動オプション inst.dd=location で CD または DVD を使用します。これにより、インストールプログラムが、ドライバー更新に CD または DVD を自動的にスキャンできるようになります。詳細は、手動によるドライバー更新の実行 を参照してください。
手順
- ブートメニューウィンドウで Tab キーを押して、ブートコマンドラインを表示します。
-
起動オプション
inst.ddをコマンドラインに追加し、Enter を押して起動プロセスを実行します。 - メニューから、ローカルディスクパーティション、もしくは CD デバイスまたは DVD デバイスを選択します。インストールプログラムが ISO ファイル、または ドライバー更新 RPM パッケージをスキャンします。
オプション:ドライバー更新 ISO ファイルを選択します。
選択したデバイスまたはパーティション (ドライバー更新 CD または DVD を含む光学ドライブなど) に、ISO イメージファイルではなく、ドライバー更新 RPM パッケージが含まれる場合は、この手順は必要ありません。
必要なドライバーを選択します。
- キーボードの数字キーを使用して、ドライバー選択を切り替えます。
- c を押して、選択したドライバーをインストールします。選択したドライバーが読み込まれ、インストールプロセスが始まります。
5.5.6. 手動によるドライバー更新の実行
この手順では、インストール時にドライバーを手動で更新する方法を説明します。
前提条件
- ドライバー更新の ISO イメージファイルを USB フラッシュドライブまたは Web サーバーに配置し、コンピューターに接続しました。
手順
- ブートメニューウィンドウで Tab キーを押して、ブートコマンドラインを表示します。
-
inst.dd=location起動オプションをコマンドに追加します。場所は、ドライバー更新のファイルがある場所です。通常、イメージファイルは Web サーバー http://server.example.com/dd.iso など、または USB フラッシュドライブ/dev/sdb1などに置きます。ドライバー更新を含む RPM パッケージ http://server.example.com/dd.rpm などを指定することもできます。 - Enter を押して、起動プロセスを実行してください。指定した場所で利用可能なドライバーが自動的に読み込まれ、インストールプロセスが始まります。
5.5.7. ドライバーの無効
この手順では、誤動作しているドライバーを無効にする方法を説明します。
前提条件
- インストールプログラムブートメニューを起動している。
手順
- ブートメニューで Tab キーを押して、ブートコマンドラインを表示します。
起動オプション
modprobe.blacklist=driver_nameをコマンドラインに追加します。driver_name を、無効にするドライバーの名前に置き換えます。以下に例を示します。
modprobe.blacklist=ahci起動オプション
modprobe.blacklist=を使用して無効にしたドライバーは、インストール済みシステムで無効になり、/etc/modprobe.d/anaconda-blacklist.confファイルに表示されます。- Enter を押して、起動プロセスを実行してください。
第6章 インストーラーでのシステムのカスタマイズ
インストールのカスタマイズフェーズでは、Red Hat Enterprise Linux のインストールを有効にするために、特定の設定タスクを実行する必要があります。これらのタスクには、以下が含まれます。
- ストレージを設定し、マウントポイントを割り当てます。
- インストールするソフトウェアを含むベース環境を選択します。
- root ユーザーのパスワードを設定するか、ローカルユーザーを作成します。
必要に応じて、システム設定を指定したり、ホストをネットワークに接続したりするなど、システムをさらにカスタマイズすることもできます。
6.1. インストーラーの言語の設定
インストールを開始する前に、インストールプログラムで使用する言語を選択できます。
前提条件
- インストールメディアを作成している。
- Boot ISO イメージファイルを使用してインストールソースを指定している。
- インストールを起動している。
手順
- ブートメニューから Red hat Enterprise Linux オプションを選択すると、Welcome to Red Hat Enterprise Screen が表示されます。
Welcome to Red Hat Enterprise Linux 画面の左側のペインで、言語を選択します。または、テキストボックスを使用して希望の言語を検索します。
注記言語はデフォルトで事前に選択されています。ネットワークアクセスが設定されている、つまりローカルメディアではなくネットワークサーバーからシステムを起動した場合、事前選択の言語は、GeoIP モジュールの位置自動検出機能により決定します。起動コマンドラインまたは PXE サーバー設定で
inst.lang=オプションを使用すると、起動オプションで定義した言語が選択されます。- Red Hat Enterprise Linux へようこそ 画面の右側のペインから、お住まいの地域に合ったロケーションを選択してください。
- をクリックして、グラフィカルインストールウィンドウに進みます。
Red Hat Enterprise Linux のプレリリース版をインストールしようとしている場合は、インストールメディアのプレリリースステータスに関する警告メッセージが表示されます。
- インストールを続行するには、 をクリックします。あるいは、
- インストールを終了してシステムを再起動するには、 をクリックします。
6.2. ストレージデバイスの設定
さまざまなストレージデバイスに Red Hat Enterprise Linux をインストールできます。インストール先 画面で、ローカルでアクセス可能な、基本的なストレージデバイスを設定できます。ディスクやソリッドステートドライブなどのローカルシステムに直接接続する基本的なストレージデバイスは、その画面の Local Standard Disks セクションに表示されます。64 ビットの IBM Z の場合は、このセクションに、アクティベートした DASD (Direct Access Storage Devices) が含まれます。
既知の問題により、HyperPAV エイリアスとして設定した DASD を、インストールの完了後に自動的にシステムに割り当てることができません。このようなストレージデバイスはインストール時に利用できますが、インストールが完了して再起動しても、すぐにはアクセスできません。HyperPAV エイリアスデバイスを接続するには、システムの /etc/dasd.conf 設定ファイルに手動で追加します。
6.2.1. インストール先の設定
Installation Destination ウィンドウを使用して、Red Hat Enterprise Linux のインストール先として使用するディスクなどのストレージオプションを設定できます。ディスクは、1 つ以上選択する必要があります。
前提条件
- Installation Summary 画面が開いている。
- データが含まれているディスクを使用する予定の場合は、データをバックアップする。たとえば、既存の Microsoft Windows パーティションを縮小し、Red Hat Enterprise Linux を 2 つ目のシステムとしてインストールする場合、または以前のリリースの Red Hat Enterprise Linux をアップグレードする場合です。パーティションの操作は常にリスクが伴います。たとえば、何らかの理由でプロセスが中断または失敗した場合は、ディスクのデータが失われる可能性があります。
手順
Installation Summary 画面から、Installation Destination をクリックします。Installation Destination 画面で、以下の操作を行います。
Local Standard Disks セクションから、必要なストレージデバイスを選択します。選択したストレージデバイスには白いチェックマークが表示されます。白いチェックマークが付いていないディスクはインストール時には使用されません。自動パーティショニングを選択した場合は無視され、手動パーティショニングでは使用できません。
Local Standard Disks には、SATA、IDE、SCSI ディスク、USB フラッシュ、外部ディスクなど、ローカルで使用可能なすべてのストレージデバイスが表示されます。インストールプログラムの起動後に接続したストレージデバイスは検出されません。リムーバブルドライブを使用して Red Hat Enterprise Linux をインストールする場合は、デバイスを削除するとシステムが使用できなくなります。
オプション:新しいディスクを接続するために追加のローカルストレージデバイスを設定する場合は、ウィンドウの右下にある [更新] リンクをクリックします。Rescan Disks ダイアログボックスが開きます。
をクリックし、スキャン処理が完了するまで待ちます。
インストール時に行ったストレージへの変更は、Rescan Disks をクリックするとすべて失われます。
- をクリックして、Installation Destination 画面に戻ります。検出したディスク (新しいディスクを含む) はすべて、ローカルの標準ディスク セクションに表示されます。
オプション: 特殊なストレージデバイスを追加するには、 をクリックします。
Storage Device Selection ウィンドウが開き、インストールプログラムがアクセスできるすべてのストレージデバイスがリスト表示されます。
オプション: [ストレージ設定] で、自動パーティション分割の [自動] ラジオボタンを選択します。
パーティション設定はカスタマイズできます。詳細は、手動パーティションの設定 を参照してください。
- オプション: 既存のパーティションレイアウトからスペースを再利用するには 、[追加のスペースを使用できるようにします] を選択します。たとえば、使用するディスクに別のオペレーティングシステムが含まれており、このシステムのパーティションを小さくして、Red Hat Enterprise Linux 用の領域を広くする場合などです。
オプション: データの暗号化 を選択し、Linux Unified Key Setup (LUKS) を使用して、(
/bootなどの) システムを起動する必要があるパーティションを除いた、すべてのパーティションを暗号化します。ディスクを暗号化すると、セキュリティーがさらに強化されます。をクリックします。Disk Encryption Passphrase ダイアログボックスが開きます。
- Passphrase フィールドと Confirm フィールドにパスフレーズを入力します。
をクリックして、ディスクの暗号化を完了します。
警告LUKS パスフレーズが分からなくなると、暗号化されたパーティションと、その上にあるデータには完全にアクセスできなくなります。分からなくなったパスフレーズを復元する方法はありません。ただし、キックスタートインストールを実行した場合は、インストール中に暗号パスフレーズを保存し、バックアップ用に暗号化パスフレーズを作成できます。詳細は、RHEL の自動インストール ドキュメントを参照してください。
オプション: 画面左下の 完全なディスク要約とブートローダー をクリックして、ブートローダーを追加するストレージデバイスを選択します。詳細は、ブートローダーの設定 を参照してください。
大概は、ブートローダーをデフォルトの場所に置いておくだけで十分です。たとえば、他のブートローダーからのチェーンロードを必要とするシステムなど、一部の設定ではブートドライブを手動で指定する必要があります。
- をクリックします。
オプション: 自動パーティション分割 と 追加のスペースを確保したい オプションを選択した場合、または選択したディスクに Red Hat Enterprise Linux をインストールするための十分な空き領域がない場合は、ディスク領域の回収 ダイアログボックスが表示されます。そこには、設定されているすべてのディスクデバイスとそれらのデバイス上のすべてのパーティションがリスト表示されます。このダイアログボックスには、現在選択中のパッケージセットを使用したインストールを行う際にシステムに必要となる最小ディスク領域と、解放した領域の容量に関する情報が表示されます。解放プロセスを開始するには、以下を実行します。
- 表示された、利用可能なストレージデバイスのリストを確認します。再利用可能な領域 列には、各エントリーから再利用できる領域のサイズが表示されます。
- 領域を解放するディスクまたはパーティションを選択します。
- 既存のデータを保持しながらパーティション上の空き領域を使用するには、 ボタンを使用します。
- そのパーティション、または選択したディスク上の既存のデータを含むすべてのパーティションを削除するには、 ボタンを使用します。
- 既存のデータを含むすべてのディスク上のすべての既存のパーティションを削除し、この領域を Red Hat Enterprise Linux のインストールに使用できるようにするには、 ボタンを使用します。
をクリックして変更を適用し、グラフィカルインストールに戻ります。
Installation Summary ウィンドウで をクリックするまで、ディスクの変更は行われません。Reclaim Space ダイアログでは、サイズ変更または削除する対象としてパーティションがマークされるだけです。アクションは実行されません。
6.2.2. インストール先の設定時の特殊なケース
インストール先を設定するときに考慮すべき特殊なケースを以下に示します。
-
BIOS によっては、RAID カードからの起動に対応していないため注意が必要です。その場合は、別のディスクなど、RAID アレイ以外のパーティションに
/bootパーティションを作成する必要があります。そのような RAID カードへのパーティション作成には、内蔵ディスクを使用する必要があります。また、/bootパーティションは、ソフトウェア RAID の設定にも必要です。システムのパーティション設定を自動で選択した場合は、/bootパーティションを手動で修正する必要があります。 - Red Hat Enterprise Linux ブートローダーが、別のブートローダーから チェーンロード するように設定するには、インストール先 画面で 完全なディスク要約とブートローダー をクリックして、手動でブートドライブを指定する必要があります。
- マルチパスのストレージデバイスと、非マルチパスのストレージデバイスの両方が使用されているシステムに Red Hat Enterprise Linux をインストールすると、インストールプログラムによる自動パーティション設定のレイアウトに、マルチパスのデバイスと非マルチパスのデバイスが混在したボリュームグループが作成されます。これはマルチパスストレージの目的に反することになります。Installation Destination ウィンドウで、マルチパスデバイスまたは非マルチパスデバイスのどちらかを選択してください。もしくは、手動のパーティション設定を実行してください。
6.2.3. ブートローダーの設定
Red Hat Enterprise Linux は、GRand Unified Bootloader バージョン 2 (GRUB2) を、AMD64、Intel 64、IBM Power Systems、および ARM として使用します。64 ビットの IBM Z では、zipl ブートローダーが使用されます。
ブートローダーは、システムの起動時に実行し、制御をオペレーティングシステムに読み込み、転送する最初のプログラムです。GRUB2 は、互換性のあるオペレーティングシステム (Microsoft Windows を含む) であれば起動可能で、チェーンロードを使用すれば、未対応のオペレーティングシステムのブートローダーにも読み込んだ指示を渡すことができます。
GRUB2 をインストールすると、既存のブートローダーを上書きできます。
オペレーティングシステムがすでにインストールされていると、Red Hat Enterprise Linux インストールプログラムはそのブートローダーを自動的に検出して、別のオペレーティングシステムを起動するように設定します。そのブートローダーが正しく検出されない場合は、インストールの完了後に、追加のオペレーティングシステムを手動で設定できます。
複数のディスクを搭載した Red Hat Enterprise Linux システムをインストールする場合は、ブートローダーをインストールするディスクを手動で指定することを推奨します。
手順
インストール先 画面で 完全なディスク要約とブートローダー をクリックします。選択したディスク ダイアログボックスが開きます。
ブートローダーは、選択したデバイス、または UEFI システムにインストールされます。ガイド付きパーティションの作成時に、そのデバイスに EFI システムパーティション が作成されます。
- 起動デバイスを変更するには、リストからデバイスを選択して をクリックします。起動デバイスとして設定できるデバイスは 1 つだけです。
- 新しいブートローダーのインストールを無効にする場合は、現在起動用として設定されているデバイスを選択し、 をクリックします。これにより、いずれのデバイスにも GRUB2 がインストールされないようになります。
ブートローダーをインストールしないを選択した場合は、システムを直接起動できなくなるため、別の起動方法 (市販のスタンドアロンのブートローダーアプリケーションなど) を使用しなければならなくなります。ブートローダーをインストールしないは、システムを起動させる方法が別に確保されている場合に限定してください。
ブートローダーは、システムが BIOS または UEFI のファームウェアを使用しているか、ブートドライブに GUID Partition Table (GPT) または Master Boot Record (MBR) (msdos としても知られている) があるかどうかによって、特別なパーティションを作成する必要があります。自動パーティション作成を使用していると、インストールプログラムがパーティションを作成します。
6.2.4. ストレージデバイスの選択
ストレージデバイス選択画面には、インストールプログラムがアクセスできるストレージデバイスがリスト表示されます。システムや利用可能なハードウェアによっては、一部のタブが表示されない場合があります。デバイスは、次のタブに分類されます。
- マルチパスデバイス
- 同じシステムにある、複数の SCSI コントローラーやファイバーチャネルポートなどの複数のパスからアクセスできるストレージデバイスです。インストールプログラムで検出できるのは、16 文字または 32 文字の長さのシリアル番号を持つマルチパスストレージデバイスのみです。
- その他の SAN デバイス
- SAN (Storage Area Network) 上にあるデバイスです。
- ファームウェア RAID
- ファームウェア RAID コントローラーに接続されているストレージデバイスです。
- NVDIMM デバイス
- 特定の状況下では、Red Hat Enterprise Linux 8 は、Intel 64 アーキテクチャーおよび AMD64 アーキテクチャー上で、(NVDIMM) デバイスからセクターモードで起動および実行できます。
- IBM Z デバイス
- zSeries Linux FCP (ファイバーチャネルプロトコル) ドライバーで接続されたストレージデバイス、論理ユニット (LUN)、または DASD です。
6.2.5. ストレージデバイスのフィルタリング
ストレージデバイス選択画面では、WWID (World Wide Identifier)、ポート、ターゲット、または論理ユニット番号 (LUN) のいずれかを使用して、ストレージデバイスをフィルタリングできます。
前提条件
- Installation Summary 画面が開いている。
手順
- Installation Summary 画面から、Installation Destination をクリックします。Installation Destination ウィンドウが開き、使用可能なすべてのドライブがリスト表示されます。
- Specialized & Network Disks セクションで、 をクリックします。ストレージデバイスの選択画面が表示されます。
ポート、ターゲット、LUN、または WWID で検索するには、Search by タブをクリックします。
WWID または LUN で検索するには、対応する入力テキストフィールドに値を入力する必要があります。
- Search ドロップダウンメニューから必要なオプションを選択します。
- をクリックして検索を開始します。各デバイスと、対応するチェックボックスが、別の行に表示されます。
インストールプロセス時に必要なデバイスが利用できるようにするには、チェックボックスを選択します。
後続のインストールプロセスで、選択したデバイスの中から、Red Hat Enterprise Linux をインストールするデバイスを選択できます。その他のデバイスの中から、インストール済みシステムに自動的にマウントするものを選択できます。選択したデバイスがインストールプロセスにより自動的に消去されることはなく、デバイスを選択しても、デバイスに保存されているデータが危険にさらされることはありません。
注記インストール後に
/etc/fstabファイルを変更することで、システムにデバイスを追加できます。- をクリックして Installation Destination ウィンドウに戻ります。
ここで選択しないストレージデバイスはすべて、インストールプログラムでは表示されなくなります。別のブートローダーからこのブートローダーをチェーンロードする場合は、ここに表示されているすべてのデバイスを選択します。
6.2.6. 高度なストレージオプションの使用
高度なストレージデバイスを使用するには、iSCSI (SCSI over TCP/IP) ターゲットまたは FCoE (Fibre Channel over Ethernet) の SAN (Storage Area Network) を設定できます。
インストールに iSCSI ストレージデバイスを使用する場合は、インストールプログラム側で iSCSI ストレージデバイスを iSCSI ターゲットとして検出し、そのターゲットにアクセスするための iSCSI セッションを作成できるようにする必要があります。各手順で、CHAP (Challenge Handshake Authentication Protocol) 認証用のユーザー名とパスワードが必要になる場合があります。さらに、検出、またはセッション作成のいずれの場合も、iSCSI ターゲット側でターゲットの接続先となるシステムの iSCSI イニシエーターを認証する (リバース CHAP) ように設定することもできます。CHAP とリバース CHAP を併用する場合は、相互 CHAP または双方向 CHAP と呼ばれます。相互 CHAP を使用すると、特に CHAP 認証とリバース CHAP 認証でユーザー名やパスワードが異なる場合などに、iSCSI 接続に対する最大限の安全レベルを確保できます。
iSCSI 検出と iSCSI ログインの手順を繰り返して、必要な iSCSI ストレージをすべて追加します。初回の検出試行後は、iSCSI イニシエーターの名前を変更できません。iSCSI イニシエーターの名前を変更する場合は、インストールを最初からやり直す必要があります。
6.2.6.1. iSCSI セッションの検出および開始
Red Hat Enterprise Linux インストーラーは、次の 2 つの方法で iSCSI ディスクを検出し、ログインできます。
- iBFT (iSCSI Boot Firmware Table)
-
インストーラーは、起動すると、システムの BIOS またはアドオンブート ROM が iBFT をサポートしているかどうかをチェックします。BIOS は、iSCSI から起動できるシステム用の BIOS 拡張です。BIOS が iBFT に対応している場合は、インストーラーは BIOS から設定済みのブートディスクの iSCSI ターゲット情報を読み取り、このターゲットにログインして、インストールターゲットとして利用可能にします。iSCSI ターゲットに自動的に接続するには、ターゲットにアクセスするためのネットワークデバイスをアクティブ化します。これを行うには、起動オプション
ip=ibftを使用します。詳細は、ネットワーク起動オプション を参照してください。 - iSCSI ターゲットの手動検出および追加
- インストーラーのグラフィカルユーザーインターフェイスで iSCSI セッションを検出して開始し、使用可能な iSCSI ターゲット (ネットワークストレージデバイス) を特定できます。
前提条件
- Installation Summary 画面が開いている。
手順
- Installation Summary 画面から、Installation Destination をクリックします。Installation Destination ウィンドウが開き、使用可能なすべてのドライブがリスト表示されます。
- Specialized & Network Disks セクションで、 をクリックします。ストレージデバイスの選択画面が表示されます。
をクリックします。iSCSI ストレージターゲットの追加 画面が開きます。
重要この方法を使用して手動で追加した iSCSI ターゲットには
/bootパーティションを置くことができません。/bootパーティションを含む iSCSI ターゲットを iBFT で使用するように設定する必要があります。ただし、インストールされたシステムが、たとえば iPXE を使用して、ファームウェアの iBFT 以外の方法で提供された iBFT 設定で iSCSI から起動する場合は、inst.nonibftiscsibootインストーラー起動オプションを使用して/bootパーティション制限を削除できます。- ターゲットの IP アドレス フィールドに、iSCSI ターゲットの IP アドレスを入力します。
iSCSI Initiator Name フィールドに、iSCSI 修飾名 (IQN) の形式で iSCSI イニシエーターの名前を入力します。IQN エントリーには次を含めてください。
-
iqn.の文字列 (ピリオドが必要)。 -
日付コード (企業や組織のインターネットドメイン名またはサブドメイン名が登録された年と月。記述の順序は年を表す 4 桁の数字、ハイフン、月を表す 2 桁の数字、ピリオドの順で設定されます)。たとえば、2010 年 9 月の場合は
2010-09.のようになります。 -
企業や組織のインターネットのドメイン名またはサブドメイン名 (トップレベルのドメインを先頭にして逆順で表します)。たとえば、
storage.example.comのサブドメインは、com.example.storageのようになります。 コロン (:) と、ドメインまたはサブドメイン内でその iSCSI イニシエーターを固有に識別する文字列。たとえば、
:diskarrays-sn-a8675309です。完全な IQN は
iqn.2010-09.storage.example.com:diskarrays-sn-a8675309のようになります。構造を理解しやすくするために、インストールプログラムにより、iSCSI Initiator Nameフィールドにこの形式の名前が事前に入力されます。IQN の詳細は、tools.ietf.org の RFC 3720 - Internet Small Computer Systems Interface (iSCSI) に記載されている 3.2.6. iSCSI Names と、tools.ietf.org の RFC 3721 - Internet Small Computer Systems Interface (iSCSI) Naming and Discovery に記載されている 1. iSCSI Names and Addresses を参照してください。
-
認証のタイプの探索ドロップダウンメニューを使用して、iSCSI 検出に使用する認証タイプを指定します。以下のタイプが使用できます。- 証明書なし
- CHAP 秘密鍵
- CHAP 秘密鍵とリバースペア
次のいずれかを行います。
-
認証タイプに
CHAP ペアを選択した場合は、CHAP ユーザー名とCHAP パスワードの各フィールドに、iSCSI ターゲットのユーザー名とパスワードを入力します。 -
認証タイプに
CHAP 秘密鍵と逆順鍵を選択した場合は、CHAP ユーザー名とCHAP パスワードの各フィールドに、iSCSI ターゲットのユーザー名とパスワードを入力します。また、リバース CHAP ユーザー名とCHAP パスワードの各フィールドに、iSCSI イニシエーターのユーザー名とパスワードを入力します。
-
認証タイプに
-
オプション:
[ターゲットをネットワークインターフェイスにバインドする]チェックボックスをオンにします。 をクリックします。
入力した情報に基づいて、インストールプログラムが iSCSI ターゲットを調べます。検出に成功すると、
iSCSI ターゲットを追加画面には、ターゲットで検出された iSCSI ノードのリストが表示されます。インストールに使用するノードのチェックボックスを選択します。
ノードのログイン認証のタイプメニューには、認証のタイプの探索メニューと同じオプションがあります。ただし、ディスカバリー認証に証明書が必要な場合は、見つかったノードに同じ証明書を使用してログインします。-
探索に証明書を使用ドロップダウンメニューをクリックします。適切な認証情報を指定すると、 ボタンが利用可能になります。 - をクリックして、iSCSI セッションを開始します。
インストーラーは iscsiadm を使用して iSCSI ターゲットを検索し、ログインしますが、iscsiadm は自動的にこれらのターゲットに関する情報を iscsiadm iSCSI データベースに保存します。その後、インストーラーはこのデータベースをインストール済みシステムにコピーし、root パーティションに使用されていない iSCSI ターゲットをマークします。これにより、システムは起動時に自動的にそのターゲットにログインします。root パーティションが iSCSI ターゲットに配置されている場合、initrd がこのターゲットにログインするため、インストーラーは、同じターゲットへのログインが複数回試行されるのを避けるために、このターゲットを起動スクリプトに含めません。
6.2.6.2. FCoE パラメーターの設定
FCoE パラメーターを適切に設定することで、Installation Destination ウィンドウから FCoE (Fibre Channel over Ethernet) デバイスを検出できます。
前提条件
- Installation Summary 画面が開いている。
手順
- Installation Summary 画面から、Installation Destination をクリックします。Installation Destination ウィンドウが開き、使用可能なすべてのドライブがリスト表示されます。
- Specialized & Network Disks セクションで、 をクリックします。ストレージデバイスの選択画面が表示されます。
- をクリックします。FCoE ストレージデバイスを検出するようにネットワークインターフェイスを設定するダイアログボックスが開きます。
-
NICドロップダウンメニューで、FCoE スイッチに接続するネットワークインターフェイスを選択します。 - をクリックして、SAN デバイスのネットワークをスキャンします。
必要なチェックボックスを選択します。
- Use DCB: Data Center Bridging (DCB) は、ストレージネットワークやクラスターでイーサネット接続の効率性を向上させる目的で設計されたイーサネットプロトコルに対する拡張セットです。このチェックボックスを選択して、インストールプログラムによる DCB 認識を有効または無効にします。このオプションは、ネットワークインターフェイスでホストベースの DCBX クライアントを必要とする場合にのみ有効にします。ハードウェアの DCBX クライアントを使用するインターフェイスで設定する場合は、このチェックボックスを無効にします。
- Use auto vlan: 自動 VLAN はデフォルトで有効になり、VLAN 検出を行うかどうかを指定します。このチェックボックスを選択すると、リンク設定が検証された後、イーサネットインターフェイスで FIP (FCoE Initiation Protocol) VLAN 検出プロトコルが実行します。設定が行われていない場合は、検出されたすべての FCoE VLAN に対してネットワークインターフェイスが自動的に作成され、VLAN インターフェイスに FCoE のインスタンスが作成されます。
-
検出された FCoE デバイスが、インストール先 画面の
他の SAN デバイスタブに表示されます。
6.2.6.3. DASD ストレージデバイスの設定
Installation Destination ウィンドウから DASD ストレージデバイスを検出して設定できます。
前提条件
- Installation Summary 画面が開いている。
手順
- Installation Summary 画面から、Installation Destination をクリックします。Installation Destination ウィンドウが開き、使用可能なすべてのドライブがリスト表示されます。
- Specialized & Network Disks セクションで、 をクリックします。ストレージデバイスの選択画面が表示されます。
- をクリックします。Add DASD Storage Target ダイアログボックスが開きます。0.0.0204 などのデバイス番号を指定して、インストールの開始時に検出されなかった追加の DASD を接続するように求められます。
- Device number フィールドに、接続する DASD のデバイス番号を入力します。
をクリックします。
指定したデバイス番号を持つ DASD が検出され、その DASD が接続されていない場合は、ダイアログボックスが閉じ、新たに検出されたドライブが、ドライブのリストに表示されます。次に、必要なデバイスのチェックボックスを選択して、 をクリックします。インストール先 画面の ローカルの標準ディスク セクションで、新しい DASD が選択できるようになります (
DASD device 0.0.xxxxと表示されます)。
無効なデバイス番号を入力した場合、または指定したデバイス番号の DASD がすでにシステムに割り当てられている場合は、ダイアログボックスにエラーメッセージとその理由が表示され、別のデバイス番号で再試行するように求められます。
6.2.6.4. FCP デバイスの設定
FCP デバイスは、64 ビットの IBM Z が DASD デバイスの代わりに、または DASD デバイスに加えて、SCSI デバイスを使用できるようにするものです。FCP デバイスは交換ファブリックスイッチを提供し、これにより 64 ビットの IBM Z システムが SCSI LUN を従来の DASD デバイスとして用いる使い方に加えて、ディスクデバイスとして使えるようにします。
前提条件
- Installation Summary 画面が開いている。
-
FCP のみのインストールで、DASD がないことを示すために、CMS 設定ファイルから
DASD=オプションを削除するか、パラメーターファイルからrd.dasd=オプションを削除した。
手順
- Installation Summary 画面から、Installation Destination をクリックします。Installation Destination ウィンドウが開き、使用可能なすべてのドライブがリスト表示されます。
- Specialized & Network Disks セクションで、 をクリックします。ストレージデバイスの選択画面が表示されます。
をクリックします。Add zFCP Storage Target ダイアログボックスが開き、FCP (ファイバーチャネルプロトコル) ストレージデバイスを追加できます。
64 ビットの IBM Z では、インストールプログラムが FCP LUN をアクティベートするために、FCP デバイスを手動で入力する必要があります。これは、グラフィカルインストールで指定するか、パラメーターもしくは CMS 設定ファイル内で一意のパラメーターエントリーとして指定することで可能になります。設定する各サイトに固有の値を入力する必要があります。
- 4 桁の 16 進数のデバイス番号を、デバイス番号 フィールドに入力します。
RHEL-8.6 以前のリリースをインストールする場合、
zFCPデバイスが NPIV モードで設定されていない場合や、zfcp.allow_lun_scan=0カーネルモジュールパラメーターでauto LUNスキャンが無効になっている場合は、以下の値を指定します。- 16 桁の 16 進数の WWPN (World Wide Port Number) を、WWPN フィールドに入力します。
- 16 桁の 16 進数の FCP LUN 識別子を、LUN フィールドに入力します。
- をクリックして、FCP デバイスに接続します。
新しく追加されたデバイスが、Installation Destination ウィンドウの IBM Z タブに表示されます。
16 進法で小文字のみを使用してください。間違った値を入力して をクリックすると、インストールプログラムにより警告が表示されます。設定情報の編集と、探索の再試行が可能です。値の詳細は、ハードウェアに添付のドキュメントを参照し、システム管理者に確認してください。
6.2.7. NVDIMM デバイスへのインストール
不揮発性デュアルインラインメモリーモジュール (NVDIMM) デバイスは、電源が供給されていない時に、RAM のパフォーマンスと、ディスクのようなデータの持続性を兼ね備えています。特定の状況下では、NVDIMM デバイスから Red Hat Enterprise Linux 8 を起動して実行できます。
6.2.7.1. NVDIMM デバイスをインストール先として使用するための基準
Red Hat Enterprise Linux 8 は、nd_pmem ドライバーがサポートする Intel 64 アーキテクチャーおよび AMD64 アーキテクチャーにある、セクターモードの不揮発性デュアルインラインメモリーモジュール (NVDIMM) デバイスにインストールできます。
NVDIMM デバイスをストレージとして使用するための条件
NVDIMM デバイスをストレージとして使用するには、次の条件を満たす必要があります。
- システムのアーキテクチャーが Intel 64 または AMD64 である。
- NVDIMM デバイスがセクターモードに設定されている。インストールプログラムにより NVDIMM デバイスをこのモードに再設定できます。
- NVDIMM デバイスが、nd_pmem ドライバーで対応している。
NVDIMM デバイスからの起動の条件
以下の条件が満たされる場合には、NVDIMM デバイスからの起動が可能です。
- NVDIMM デバイスを使用するための条件がすべて満たされている。
- システムが UEFI を使用している。
- システムで使用可能なファームウェアまたは UEFI ドライバーが NVDIMM デバイスをサポートしている。UEFI ドライバーは、デバイス自体のオプション ROM から読み込むことができます。
- NVDIMM デバイスが名前空間で利用可能である。
システムの起動中に高性能な NVDIMM デバイスを利用するには、/boot ディレクトリーおよび /boot/efi ディレクトリーをデバイスに置きます。NVDIMM デバイスの XIP (Execute-in-place) 機能は、起動時にはサポートされません。カーネルは従来どおりメモリーに読み込まれます。
6.2.7.2. グラフィカルインストールモードを使用した NVDIMM デバイスの設定
不揮発性デュアルインラインメモリーモジュール (NVDIMM) デバイスは、Red Hat Enterprise Linux 8 で使用するために、グラフィカルインストールを使用して正しく設定する必要があります。
NVDIMM デバイスを再設定するプロセスにより、デバイスに格納されていたデータがすべて失われます。
前提条件
- NVDIMM デバイスがシステムに存在し、その他の、インストールターゲットとして使用するための条件を満たしている。
- インストールが起動し、インストール概要 画面が開いている。
手順
- Installation Summary 画面から、Installation Destination をクリックします。Installation Destination ウィンドウが開き、使用可能なすべてのドライブがリスト表示されます。
- Specialized & Network Disks セクションで、 をクリックします。ストレージデバイスの選択画面が表示されます。
- NVDIMM デバイス タブをクリックします。
デバイスを再設定する場合は、リストから選択します。
デバイスがリストにない場合は、セクターモードになっていません。
- をクリックします。再設定ダイアログが開きます。
必要なセクターサイズを入力し、 をクリックします。
サポートされるセクターサイズは 512 バイトおよび 4096 バイトです。
- 再設定が終了したら、 をクリックします。
- デバイスのチェックボックスを選択します。
をクリックして Installation Destination ウィンドウに戻ります。
再設定した NVDIMM は、特殊なディスクおよびネットワークディスク セクションに表示されます。
- をクリックして、インストール概要 画面に戻ります。
NVDIMM デバイスがインストール先として選択できるようになります。デバイスが起動の要件を満たしている場合は、そのように設定できます。
6.3. root ユーザーの設定とローカルアカウントの作成
6.3.1. root パスワードの設定
インストールプロセスを完了し、管理者 (スーパーユーザーまたは root としても知られている) アカウントでログインするには、root パスワードを設定する必要があります。これらのタスクには、ソフトウェアパッケージのインストールおよび更新と、ネットワーク、ファイアウォール設定、ストレージオプションなどのシステム全体の設定の変更と、ユーザー、グループ、およびファイルのパーミッションの追加または修正が含まれます。
インストールしたシステムの root 権限を取得するには、root アカウントを使用するか、管理者権限を持つユーザーアカウント (wheel グループのメンバー) を作成します。root アカウントは、インストール中に作成されます。管理者アクセスが必要なタスクを実行する必要がある場合に限り、管理者アカウントに切り替えてください。
root アカウントは、システムを完全に制御できます。このアカウントへのアクセスを不正に入手すると、ユーザーの個人ファイルへのアクセスや削除が可能になります。
手順
- インストール概要 画面から、ユーザー設定 > root パスワード を選択します。root パスワード 画面が開きます。
root パスワード フィールドにパスワードを入力します。
強力な root パスワードを作成するための要件は次のとおりです。
- 最低でも 8 文字の長さが 必要
- 数字、文字 (大文字と小文字)、記号を含めることができる
- 大文字と小文字が区別される
- 確認 フィールドにも同じパスワードを入力します。
をクリックして root パスワードを確認し、Installation Summary ウィンドウに戻ります。
脆弱なパスワードを使用して続行する場合は、 を 2 回クリックする必要があります。
6.3.2. ユーザーアカウントの作成
ユーザーアカウントを作成してインストールを完了します。ユーザーアカウントを作成しない場合は、root としてシステムに直接ログインする必要がありますが、これは 推奨されません。
手順
- インストール概要 画面で、ユーザー設定 > ユーザーの作成 を選択します。ユーザーの作成 画面が開きます。
- フルネーム フィールドに、ユーザーアカウント名を入力します。John Smith.
ユーザー名 フィールドに、ユーザー名 (jsmith など) を入力します。
コマンドラインからログインするには、ユーザー名 を使用します。グラフィカル環境をインストールする場合、グラフィカルログインマネージャーは、フルネーム を使用します。
ユーザーに管理者権限が必要な場合は、このユーザーを管理者にする チェックボックスを選択します (インストールプログラムにより、このユーザーが
wheelグループに追加されます)。管理者ユーザーは、
sudoコマンドを実行し、rootパスワードの代わりにユーザーパスワードを使用して、rootのみが実行できるタスクを実行できます。こちらを使用した方が便利な場合もありますが、セキュリティーリスクを引き起こす可能性があります。Require a password to use this account チェックボックスを選択します。
ユーザーに管理者権限を与える場合は、アカウントがパスワードで保護されていることを確認してください。アカウントにパスワードを割り当てない場合は、ユーザーに管理者特権を与えないでください。
- Password フィールドにパスワードを入力します。
- Confirm password フィールドに同じパスワードを入力します。
- をクリックして変更を適用し、Installation Summary 画面に戻ります。
6.3.3. ユーザーの詳細設定の編集
以下の手順では、Advanced User Configuration ダイアログボックスでユーザーアカウントのデフォルト設定を編集する方法を説明します。
手順
- Create User 画面で、 をクリックします。
-
必要に応じて、Home directory フィールドの詳細を変更します。このフィールドには、デフォルトで
/home/usernameが表示されます。 User and Groups IDs セクションでは、次のことができます。
Specify a user ID manually チェックボックスを選択し、 または を使用して、必要な値を入力します。
デフォルト値は 1000 です。ユーザー ID (UID) の 0 ~ 999 はシステムが予約しているため、ユーザーに割り当てることができません。
Specify a group ID manually チェックボックスを選択し、 または を使用して、必要な値を入力します。
デフォルトのグループ名はユーザー名と同じで、デフォルトのグループ ID (GID) は 1000 です。GID の 0 ~ 999 はシステムが予約しているため、ユーザーグループに割り当てることができません。
Group Membership フィールドに、コンマ区切りの追加グループリストを指定します。グループが存在しない場合は作成されます。追加されるグループにカスタムの GID を指定する場合は、カスタムの GID を括弧に入れて指定します。新しいグループにカスタムの GID を指定しない場合は、GID が自動的に割り当てられます。
作成されたユーザーアカウントには、デフォルトグループメンバーシップが常に 1 つあります (Specify a group ID manually フィールドに設定した ID を持つユーザーのデフォルトグループ)。
- をクリックして更新を適用し、Create User 画面に戻ります。
6.4. 手動パーティションの設定
手動パーティション設定を使用して、ディスクパーティションおよびマウントポイントを設定し、Red Hat Enterprise Linux がインストールされているファイルシステムを定義できます。インストールの前に、ディスクデバイスにパーティションを設定するかどうかを検討する必要があります。直接または LVM を使用して、LUN でパーティション設定を使用する場合の利点と欠点の詳細は、Red Hat ナレッジベースソリューション advantages and disadvantages to using partitioning on LUNs を参照してください。
Standard Partitions、LVM、LVM thin provisioning など、さまざまなパーティションおよびストレージオプションが利用できます。これらのオプションは、システムのストレージを効果的に管理するうえで、さまざまな利点と設定を提供します。
- 標準パーティション
-
標準パーティションには、ファイルシステムやスワップ領域が格納されます。標準パーティションは、
/boot、BIOS Boot、およびEFI System パーティションで最も一般的に使用されます。LVM 論理ボリュームは、他のほとんどの用途にも使用できます。 - LVM
-
デバイスタイプに
LVM(または論理ボリューム管理) を選択すると、LVM 論理ボリュームが作成されます。LVM は、物理ディスク使用時のパフォーマンスを向上させます。また、パフォーマンスや信頼性を向上させる高度な設定 (1 つのマウントポイントに複数の物理ディスクを使用する、ソフトウェア RAID を設定するなど) を可能にします。 - LVM シンプロビジョニング
- シンプロビジョニングを使用すると、シンプールと呼ばれる、空き領域のストレージプールを管理でき、アプリケーションで必要になった時に任意の数のデバイスに割り当てることができます。ストレージ領域の割り当ての費用対効果を高くする必要がある場合は、プールを動的に拡張できます。
Red Hat Enterprise Linux のインストールには、少なくとも 1 つのパーティションが必要です。少なくとも /、/home、/boot、および swap パーティションまたはボリュームを使用してください。必要に応じて、その他のパーティションやボリュームを作成することもできます。
データを失わないように、先に進める前に、データのバックアップを作成しておくことが推奨されます。デュアルブートシステムをアップグレードまたは作成する場合は、保存しておくストレージデバイスの全データのバックアップを作成してください。
6.4.1. 推奨されるパーティション設定スキーム
次のマウントポイントに個別のファイルシステムを作成してください。ただし、必要に応じて /usr、/var および /tmp のマウントポイントでファイルシステムを作成することもできます。
-
/boot -
/(ルート) -
/home -
swap -
/boot/efi -
PReP
このパーティションスキームは、ベアメタルのデプロイメントに推奨されますが、仮想およびクラウドのデプロイメントには適用されません。
/bootパーティション (最小限 1 GiB のサイズを推奨)-
/bootにマウントするパーティションには、オペレーティングシステムのカーネルが含まれます。これにより、起動プロセス中に使用されるファイルと共に Red Hat Enterprise Linux 8 が起動します。ほとんどのファームウェアには制限があるため、ファームウェアを保持するための小さなパーティションを作成してください。ほとんどの場合は、1 GiB の boot パーティションで十分です。その他のマウントポイントとは異なり、LVM ボリュームを/bootに使用することはできません。/bootは、別のディスクパーティションに置く必要があります。
RAID カードを実装している場合、BIOS タイプは、RAID カードからの起動に対応していない場合がある点に注意してください。これに該当する場合は、/boot パーティションは別のディスクなどの RAID アレイ以外のパーティションに作成する必要があります。
-
通常、
/bootパーティションは、インストールプログラムにより自動的に作成されます。ただし、/(ルート) パーティションが 2 TiB を超え、起動に (U)EFI を使用する場合は、マシンを正常に起動させるため、2 TiB 未満の/bootパーティションを別途作成する必要があります。 -
手動でパーティション設定する場合は、必ず
/bootパーティションをディスクの最初の 2 TB 以内に配置してください。/bootパーティションを 2 TB の境界を超えて配置すると、インストールが成功しても、システムが起動に失敗します。この制限を超える/bootパーティションを BIOS が読み取れないためです。
/(10 GiB のサイズを推奨)ここは "
/"、つまりルートディレクトリーが配置される場所です。ルートディレクトリーは、ディレクトリー構造のトップレベルです。デフォルトでは、書き込み先のパスに別のファイルシステムがマウントされていない限り (/boot、/homeなど)、すべてのファイルがこのファイルシステムに書き込まれます。root ファイルシステムが 5 GiB の場合は最小インストールが可能ですが、パッケージグループをいくつでもインストールできるように、少なくとも 10 GiB を割り当てておくことが推奨されます。
/ ディレクトリーと /root ディレクトリーを混同しないよう注意してください。/root ディレクトリーは root ユーザーのホームディレクトリーになります。/root ディレクトリーは、root ディレクトリーと区別するため、スラッシュルート ディレクトリーと呼ばれることがあります。
/home: 最小限 1 GiB のサイズを推奨しています-
システムデータとユーザーデータを別々に格納する場合は、
/homeディレクトリー用の専用ファイルシステムを作成します。ファイルシステムのサイズは、ローカルで保存するデータ量やユーザー数などを基に決定してください。こうすることで、ユーザーデータのファイルを消去せずに Red Hat Enterprise Linux 8 をアップグレードしたり、再インストールできるようになります。自動パーティション設定を選択する場合は、/homeファイルシステムが確実に作成されるように、インストールに少なくとも 55 GiB のディスク領域を確保しておくことを推奨します。 swapパーティション (1 GiB 以上のサイズを推奨)仮想メモリーは、swap ファイルシステムによりサポートされています。つまり、システムが処理しているデータを格納する RAM が不足すると、そのデータは swap ファイルシステムに書き込まれます。swap サイズはシステムメモリーのワークロードに依存するため、システムメモリーの合計ではありません。したがって、システムメモリーサイズの合計とは等しくなりません。システムメモリーの作業負荷を判断するためには、システムで実行するアプリケーションの種類、およびそのアプリケーションにより生じる負荷を分析することが重要になります。アプリケーションにより生じる負荷に関するガイダンスは、アプリケーション提供元または開発側より提供されます。
システムで swap 領域が不足すると、システムの RAM メモリーがすべて使用されるため、カーネルがプロセスを終了します。swap 領域が大き過ぎても、割り当てられているストレージデバイスがアイドル状態となり、リソース運用面では効率が悪くなります。また、swap 領域が大き過ぎるとメモリーリークに気付きにくくなる可能性があります。swap パーティションの最大サイズおよび詳細は、
mkswap(8)の man ページを参照してください。システムの RAM の容量別に推奨される swap サイズと、ハイバネートするのに十分なサイズを以下の表に示します。インストールプログラムでシステムのパーティション設定を自動的に設定すると、swap パーティションのサイズはこのガイドラインに沿って決められます。自動パーティション設定では、ハイバネートは使用しないことを前提としています。このため、swap パーティションの上限がディスクの合計サイズの最大 10 % に制限され、インストールプログラムでは、1 TiB を上回るサイズの swap パーティションが作成されません。ハイバネートを行うために十分な swap 領域を設定したい場合、もしくはシステムのストレージ領域の 10 % 以上を swap パーティションに設定したい場合、または 1 TiB を超えるサイズにしたい場合は、パーティション設定のレイアウトを手動で編集する必要があります。
| システム内の RAM の容量 | 推奨されるスワップ領域 | ハイバネートを許可する場合に推奨されるスワップ領域 |
|---|---|---|
| 2 GiB 未満 | RAM 容量の 2 倍 | RAM 容量の 3 倍 |
| 2 GiB - 8 GiB | RAM 容量と同じ | RAM 容量の 2 倍 |
| 8 GiB - 64 GiB | 4 GiB から RAM 容量の半分まで | RAM 容量の 1.5 倍 |
| 64 GiB を超える場合 | ワークロードによる (最小 4 GiB) | ハイバネートは推奨されない |
/boot/efiパーティション (サイズは 200 MiB を推奨)- UEFI ベースの AMD64、Intel 64、および 64 ビットの ARM は、200 MiB の EFI システムパーティションが必要です。推奨される最小サイズは 200 MiB で、デフォルトサイズは 600 MiB で、最大サイズは 600 MiB です。BIOS システムは、EFI システムパーティションを必要としません。
値が、範囲の境界線上にある場合 (システムの RAM が 2 GiB、8 GiB、または 64 GiB などの場合)、swap 領域の決定やハイバネートへのサポートは適宜判断してください。システムリソースに余裕がある場合は、スワップ領域を増やすとパフォーマンスが向上することがあります。
swap 領域を複数のストレージデバイスに分散させても、swap 領域のパフォーマンスが向上します (高速ドライブやコントローラー、インターフェイスなどを備えたシステムで特に効果的)。
多くのシステムでは、パーティションおよびボリュームの数は上述の最小数より多くなります。パーティション設定は、システム固有のニーズに応じて決定してください。パーティションを設定する方法が分からない場合は、インストールプログラムで提供されているデフォルトの自動パーティションのレイアウトをご利用ください。
すぐに必要となるパーティションにのみストレージ容量を割り当ててください。必要に応じて空き容量をいつでも割り当てることができます。
PReP起動パーティション (4 - 8 MiB のサイズを推奨)-
IBM Power System サーバーに Red Hat Enterprise Linux をインストールする場合は、ディスクの最初のパーティションに
PReP起動パーティションが含まれている必要があります。このパーティションには、他の IBM Power Systems サーバーで Red Hat Enterprise Linux を起動できるようにする GRUB ブートローダーが格納されます。
6.4.2. サポート対象のハードウェアストレージ
Red Hat Enterprise Linux のメジャーバージョン間でストレージ技術がどのように設定され、そのサポートがどのように変更したかを理解することが重要になります。
ハードウェア RAID
インストールプロセスを開始する前に、コンピューターのマザーボードが提供する RAID 機能、またはコントローラーカードが接続する RAID 機能を設定する必要があります。アクティブな RAID アレイは、それぞれ Red Hat Enterprise Linux 内で 1 つのドライブとして表示されます。
ソフトウェア RAID
システムに複数のディスクが搭載されている場合は、Red Hat Enterprise Linux インストールプログラムを使用して、複数のドライブを 1 つの Linux ソフトウェア RAID アレイとして動作させることができます。ソフトウェア RAID アレイを使用すると、RAID 機能は専用のハードウェアではなく、オペレーティングシステムにより制御されることになります。
以前から存在している RAID アレイの全メンバーデバイスが、パーティションが設定されていないディスクまたはドライブの場合、インストールプログラムは、アレイをディスクとして扱い、アレイを削除する方法はありません。
USB ディスク
インストール後に外付け USB ストレージを接続して設定できます。ほとんどのデバイスはカーネルにより認識されますが、認識されないデバイスもあります。インストール中にこれらのディスクを設定する必要がない場合は切断して、潜在的な問題を回避してください。
NVDIMM デバイス
不揮発性デュアルインラインメモリーモジュール (NVDIMM) デバイスをストレージとして使用するには、次の条件を満たす必要があります。
- Red Hat Enterprise Linux のバージョンが、7.6 以降である。
- システムのアーキテクチャーが Intel 64 または AMD64 である。
- デバイスが、セクターモードに設定されている。Anaconda で、NVDIMM デバイスをこのモードに再設定できます。
- nd_pmem ドライバーがそのデバイスに対応している。
さらに以下の条件が満たされる場合には、NVDIMM デバイスからの起動が可能です。
- システムが UEFI を使用している。
- システムで使用可能なファームウェアまたは UEFI ドライバーがデバイスをサポートしている。UEFI ドライバーは、デバイス自体のオプション ROM から読み込むことができます。
- デバイスが名前空間で利用可能である。
システムの起動中に高性能な NVDIMM デバイスを利用するには、デバイスに /boot ディレクトリーおよび /boot/efi ディレクトリーを置きます。
NVDIMM デバイスの XIP (Execute-in-place) 機能は、起動時にはサポートされません。カーネルは従来どおりメモリーに読み込まれます。
Intel の BIOS RAID に関する注意点
Red Hat Enterprise Linux は、Intel BIOS RAID セットへのインストールに、mdraid を使用します。このセットは起動プロセスで自動検出されるため、起動するたびにデバイスノードパスが変わる可能性があります。デバイスノードのパス (/dev/sda など) を、ファイルシステムのラベルまたはデバイス UUID に置き換えてください。ファイルシステムのラベルとデバイスの UUID は、blkid コマンドを使用すると確認できます。
6.4.3. 手動パーティションの設定
手動パーティション設定を使用すると、要件に基づいてディスクのパーティションを設定できます。
前提条件
- Installation Summary 画面が開いている。
- インストールプログラムで、すべてのディスクが利用可能である。
手順
インストールに使用するディスクを選択します。
- インストール先 をクリックして、インストール先 画面を開きます。
- 対応するアイコンをクリックして、インストールに必要なディスクを選択します。選択したディスクにはチェックマークが表示されています。
- ストレージの設定 で、カスタム ラジオボタンを選択します。
- オプション: LUKS によるストレージの暗号化を有効にする場合は、データを暗号化する チェックボックスを選択します。
- をクリックします。
ストレージの暗号化を選択した場合は、ディスク暗号化パスフレーズを入力するダイアログボックスが開きます。LUKS パスフレーズを入力します。
2 つのテキストフィールドにパスフレーズを入力してください。キーボードレイアウトを切り替えるには、キーボードアイコンを使用します。
警告パスフレーズを入力するダイアログボックスでは、キーボードレイアウトを変更できません。インストールプログラムでパスフレーズを入力するには、英語のキーボードレイアウトを選択します。
- をクリックします。手動パーティション設定 画面が開きます。
削除したマウントポイントが、左側のペインにリスト表示されます。マウントポイントは、検出されたオペレーティングシステムのインストールごとにまとめられています。したがって、複数のインストールでパーティションを共有していると、ファイルシステムによっては複数回表示されることがあります。
- 左側のペインでマウントポイントを選択します。カスタマイズ可能なオプションが右側のペインに表示されます。
- オプション: システムに既存のファイルシステムがある場合には、インストールに十分な領域があることを確認してください。パーティションを削除するには、リストから選択して、 ボタンをクリックします。ダイアログには、削除されたパーティションが属するシステムが使用しているその他のパーティションをすべて削除するチェックボックスがあります。
オプション: 既存のパーティションがなく、開始点としてパーティションのセットを作成する場合は、左側のペインから希望するパーティションスキーム (Red Hat Enterprise Linux のデフォルトは LVM) を選択し、[Click here to create them automatically] リンクをクリックします。
注記/bootパーティション、/(ルート) ボリューム、およびswapボリュームが、利用可能なストレージのサイズに合わせて作成され、左側のペインにリスト表示されます。これらが標準的なインストールのファイルシステムですが、ファイルシステムとマウントポイントをさらに追加することもできます。- をクリックして変更を適用し、インストール概要 画面に戻ります。
6.4.4. 対応ファイルシステム
手動パーティション設定を行うと、Red Hat Enterprise Linux で利用可能なさまざまなファイルシステムとパーティションタイプを利用して、パフォーマンスを最適化し、互換性を確保し、ディスク領域を効率的に管理できます。
- xfs
-
XFS ファイルシステムは、Red Hat Enterprise Linux のデフォルトのファイルシステムです。これは、最大 16 エクサバイト (約 1,600 万テラバイト) のファイルシステム、最大 8 エクサバイト (約 800 万テラバイト) のファイル、および数千万のエントリーを含むディレクトリー構造に対応する、拡張性に優れた高性能ファイルシステムです。
XFSは、メタデータジャーナリングもサポートしているため、クラッシュに対するより迅速な復元が容易になります。1 つの XFS ファイルシステムでサポートされる最大サイズは 1 PB です。XFS を縮小して空き領域を確保することはできません。 - ext4
-
ext4ファイルシステムは、ext3ファイルシステムをベースとし、改善が加えられています。より大きなファイルシステム、そしてより大きなファイルに対応するようになり、ディスク領域の割り当てに要する時間が短縮され効率化されています。また、ディレクトリー内のサブディレクトリーの数に制限がなく、ファイルシステムチェックが速くなり、ジャーナリングがより強力になりました。1 つのext4ファイルシステムで対応している最大サイズは 50 TB です。 - ext3
-
ext3ファイルシステムはext2ファイルシステムをベースとし、ジャーナリング機能という大きな利点を備えています。ジャーナリングファイルシステムを使用すると、クラッシュが発生するたびに fsck ユーティリティーを実行してメタデータの整合性をチェックする必要がないため、突然終了したあとに、ファイルシステムの復元に要する時間を短縮できます。 - ext2
-
ext2ファイルシステムは標準の Unix ファイルタイプに対応しています (通常のファイル、ディレクトリー、シンボリックリンクなど)。最大 255 文字までの長いファイル名を割り当てることができます。 - swap
- swap パーティションは、仮想メモリーに対応するために使用されます。つまり、システムが処理しているデータを格納する RAM が不足すると、そのデータが swap パーティションに書き込まれます。
- vfat
VFATファイルシステムは Linux ファイルシステムです。FAT ファイルシステムにある Microsoft Windows の長いファイル名と互換性があります。注記VFATファイルシステムは、Linux システムのパーティションではサポートされていません。たとえば、/、/var、/usrなどです。- BIOS ブート
- BIOS 互換モードで、BIOS システムおよび UEFI システムの GUID パーティションテーブル (GPT) を使用するデバイスから起動するのに必要な、非常に小さいパーティションです。
- EFI システムパーティション
- UEFI システムの GUID パーティションテーブル (GPT) でデバイスを起動する場合に必要な、小さいパーティションです。
- PReP
-
この小さなブートパーティションは、ディスクの最初のパーティションにあります。
PReP起動パーティションには GRUB2 ブートローダーが含まれ、その他の IBM Power Systems サーバーが Red Hat Enterprise Linux を起動できるようにします。
6.4.5. マウントポイントのファイルシステム追加
マウントポイントのファイルシステムは複数追加できます。XFS、ext4、ext3、ext2、swap、VFAT、および BIOS ブート、EFI システムパーティション、PReP などの特定のパーティションなど、利用可能なファイルシステムとパーティションタイプを使用して、システムのストレージを効果的に設定できます。
前提条件
- パーティションの計画が完了している。
-
/var/mail、/usr/tmp、/lib、/sbin、/lib64、/binなどのシンボリックリンクを含むパスにマウントポイントを指定していないことを確認する。RPM パッケージを含むペイロードは、特定のディレクトリーへのシンボリックリンクの作成に依存します。
手順
- をクリックして、マウントポイントのファイルシステムを作成します。マウントポイントを追加します ダイアログが表示されます。
-
マウントポイント ドロップダウンメニューから、事前に設定したパスの中から 1 つ選択するか、別のパスを入力します。たとえば、root パーティションの場合は
/を選択し、ブートパーティションの場合は/bootを選択します。 ファイルシステムのサイズを 要求される容量 フィールドに入力します。たとえば
2GiBです。Desired Capacity に値を指定しなかった場合、または使用可能な領域よりも大きいサイズを指定した場合、残りの空き領域がすべて使用されます。
- をクリックしてパーティションを作成し、手動パーティション設定 画面に戻ります。
6.4.6. マウントポイントのファイルシステム用ストレージの設定
手動で作成した各マウントポイントのパーティションスキームを設定できます。利用可能なオプションは、Standard Partition、LVM、および LVM Thin Provisioning です。Red Hat Enterprise Linux 8 では、Btrf のサポートが非推奨になりました。
/boot パーティションは、選択した値に関係なく、常に標準パーティションに置かれます。
手順
- 非 LVM マウントポイントを 1 つ配置するデバイスを変更するには、左側のペインから必要なマウントポイントを選択します。
- Device(s) 見出しの下にある をクリックします。マウントポイントの設定 ダイアログが開きます。
- 1 つ以上のデバイスを選択し、 をクリックして選択を確認し、手動パーティション設定 画面に戻ります。
- をクリックして、変更を適用します。
- 手動パーティション設定 画面左下で ストレージデバイスが選択されています リンクをクリックして、選択したディスク ダイアログを開いて、ディスク情報を確認します。
- オプション: ローカルディスクとパーティションをすべてリフレッシュするには、 ボタン (円形の矢印ボタン) をクリックします。この作業が必要になるのは、インストールプログラム以外で高度なパーティション設定を行った場合のみです。 ボタンをクリックすると、インストールプログラムに行った設定変更がすべてリセットされます。
6.4.7. マウントポイントのファイルシステムのカスタマイズ
特定の設定を行う場合は、パーティションまたはボリュームをカスタマイズできます。/usr または /var には重要なコンポーネントが含まれているため、このディレクトリーのパーティションをルートボリュームとは別の場所に設定すると、起動プロセスが非常に複雑になります。iSCSI ドライブや FCoE などの場所に配置してしまった場合には、システムが起動できなくなったり、電源オフや再起動の際に Device is busy のエラーでハングしたりする可能性があります。
これらの制限は /usr と /var にのみ適用され、その下のディレクトリーには適用されません。たとえば、/var/www 向けの個別パーティションは問題なく機能します。
手順
左側のペインから、マウントポイントを選択します。
図6.1 パーティションのカスタマイズ
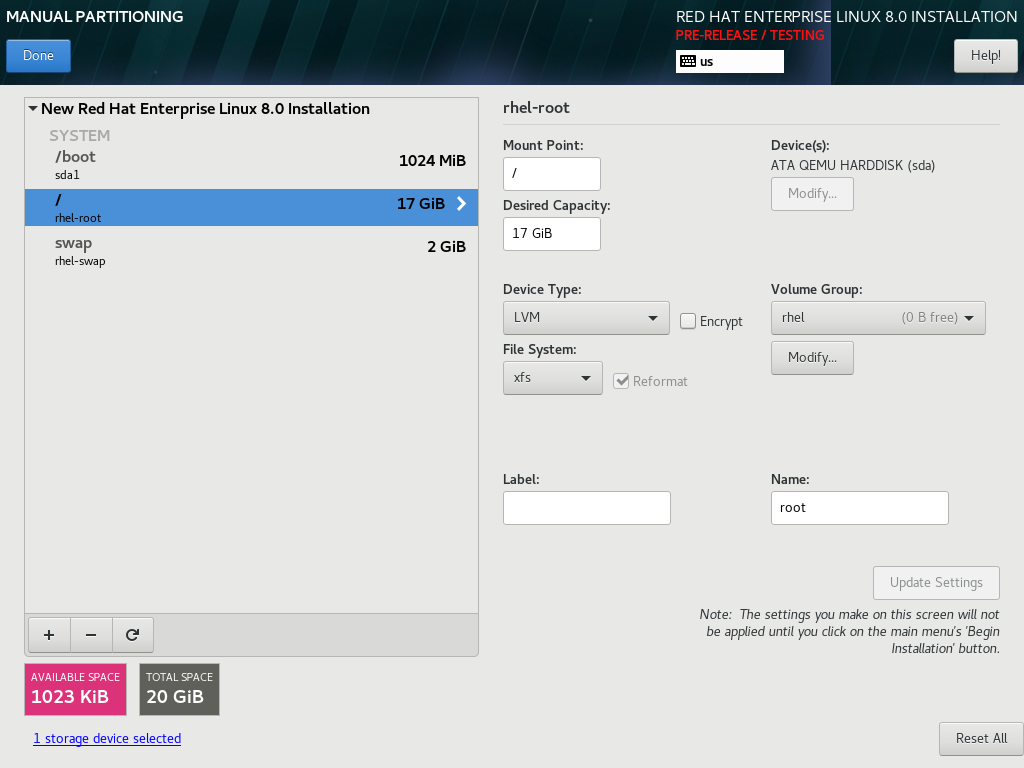
右側のペインで、次のオプションをカスタマイズできます。
-
マウントポイント フィールドに、ァイルシステムのマウントポイントを入力します。たとえば、ファイルシステムが root ファイルシステムの場合は
/を入力します。/bootファイルシステムの場合は/bootを入力します。swap ファイルシステムの場合は、ファイルシステムタイプをswapに設定すれば十分であるため、マウントポイントを設定しないでください。 - 割り当てる容量 フィールドに、ファイルシステムのサイズを入力します。単位には KiB や GiB が使用できます。単位を指定しない場合は、MiB がデフォルトになります。
ドロップダウンの デバイスタイプ から、必要なデバイスタイプ
標準パーティション、LVM、またはLVM シンプロビジョニングを選択します。注記RAIDは、パーティションの作成に 2 つ以上のディスクが選択されている場合にのみ使用できます。RAIDを選択した場合は、RAID レベルも設定できます。同様に、LVMを選択した場合は、ボリュームグループを選択できます。- パーティションまたはボリュームを暗号化する場合は、暗号化 チェックボックスを選択します。後続のインストールプログラムで、パスワードを設定する必要があります。LUKS バージョン ドロップダウンメニューが表示されます。
- ドロップダウンメニューから、LUKS バージョンを選択します。
ファイルシステム ドロップダウンメニューから、このパーティションまたはボリュームに適したファイルシステムタイプを選択します。
注記VFATファイルシステムは、Linux システムのパーティションではサポートされていません。たとえば、/、/var、/usrなどです。- 既存のパーティションをフォーマットする場合は 再フォーマット チェックボックスを選択します。データを保持するには、再フォーマット チェックボックスの選択を解除します。新たに作成したパーティションとボリュームは再フォーマットする必要があるため、チェックボックスの選択を解除することはできません。
- ラベル フィールドのパーティションにラベルを割り当てます。ラベルを使用すると、個別のパーティションの認識とアドレス指定が容易になります。
-
名前 フィールドに名前を入力します。標準パーティションは、作成時に自動的に名前が付けられます。標準パーティションの名前を編集することはできません。たとえば、
/bootの名前sda1を編集することはできません。
-
マウントポイント フィールドに、ァイルシステムのマウントポイントを入力します。たとえば、ファイルシステムが root ファイルシステムの場合は
- をクリックして変更を適用し、必要に応じてカスタマイズする別のパーティションを選択します。変更は、Installation Summary ウィンドウで をクリックするまで適用されません。
- オプション: パーティションの変更を破棄して、最初からやり直すには、 をクリックします。
ファイルシステムとマウントポイントをすべて作成してカスタマイズしたら、 をクリックします。ファイルシステムの暗号化を選択すると、パスフレーズを作成するように求められます。
Summary of Changes ダイアログボックスが開き、インストールプログラムの全ストレージアクションの概要が表示されます。
- をクリックして変更を適用し、Installation Summary ウィンドウに戻ります。
6.4.8. /home ディレクトリーの維持
Red Hat Enterprise Linux 8 グラフィカルインストールでは、RHEL 7 システムで使用されていた /home ディレクトリーを保存できます。RHEL 7 システムの別の /home パーティションに、/home ディレクトリーが存在する場合に限り、/home を予約できます。
さまざまな設定を含む /home ディレクトリーを保持すると、新しい Red Hat Enterprise Linux 8 システムで新しい RHEL 7 システムでの GNOME Shell 環境を、RHEL 8 システムと同じように設定できるようになります。これは、以前の RHEL 7 システムと同様、同じユーザー名と ID を持つ Red Hat Enterprise Linux 8 のユーザーに対してのみ適用されることに注意してください。
前提条件
- コンピューターに RHEL 7 がインストールされている。
-
/homeディレクトリーが RHEL 7 システムの別の/homeパーティションにある。 -
Red Hat Enterprise Linux 8 の
Installation Summaryウィンドウが開いている。
手順
- インストール先 をクリックして、インストール先 画面を開きます。
- ストレージの設定 で、カスタム ラジオボタンを選択します。完了をクリックします。
- をクリックすると、手動パーティション設定 画面が開きます。
/homeパーティションを選択し、Mount Point:下に/homeを入力し、Reformat チェックボックスの選択を解除します。図6.2 /home がフォーマットされていないことを確認
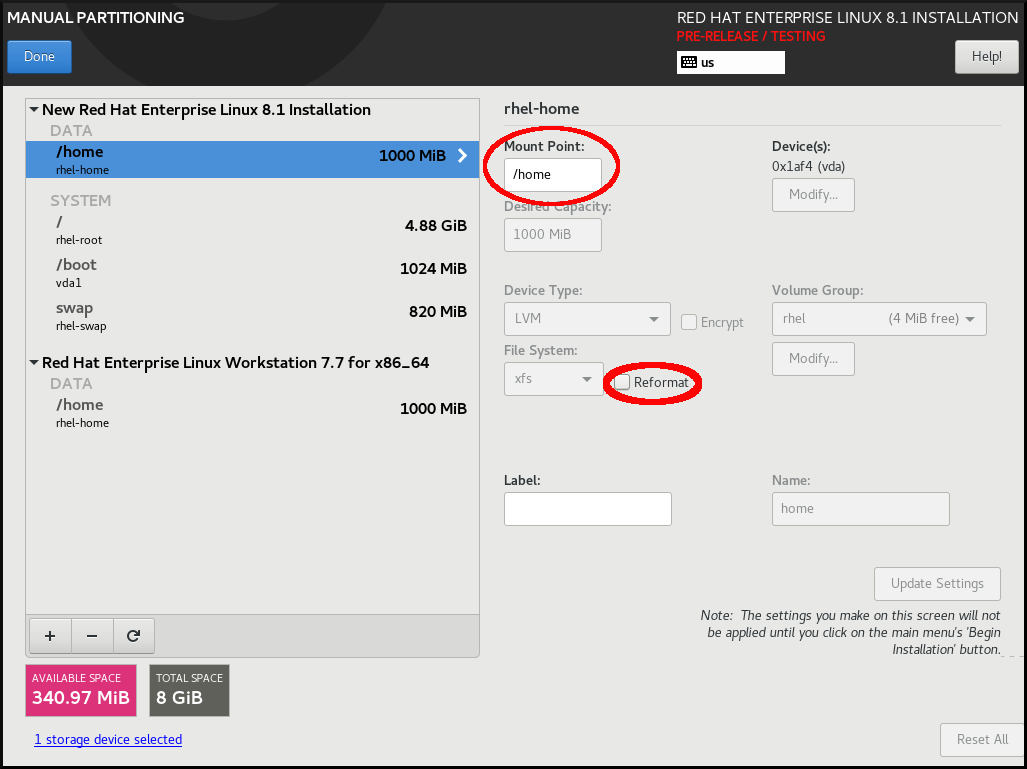
-
オプション: マウントポイントのファイルシステムのカスタマイズの説明に従って、Red Hat Enterprise Linux 8 システムに必要な
/homeパーティションのさまざまなアスペクトをカスタマイズすることができます。ただし、RHEL 7 システムから/homeを保持するには、Reformat チェックボックスの選択を解除する必要があります。 - 要件に従ってすべてのパーティションをカスタマイズしたら、をクリックします。変更の概要 ダイアログボックスが開きます。
-
変更の概要 ダイアログボックスに
/homeの変更が表示されていないことを確認します。つまり、/homeパーティションは保持されます。 - をクリックして変更を適用し、インストール概要 画面に戻ります。
6.4.9. インストール中のソフトウェア RAID の作成
Redundant Arrays of Independent Disks (RAID) デバイスは、パフォーマンスを向上させ、一部の設定ではより優れたフォールトトレランスを提供するように配置された複数のストレージデバイスから構築されます。RAID デバイスの作成は 1 つのステップで終わり、必要に応じてディスクを追加または削除できます。システムでは、1 つの物理ディスクに 1 つの RAID パーティションが作成できるため、インストールプログラムで使用できるディスク数により、利用できる RAID デバイスのレベルが決定します。たとえば、システムにディスクが 2 つある場合は、RAID 10 デバイスを作成することはできません。少なくともディスクが 3 つ必要になるためです。RHEL は、システムのストレージパフォーマンスと信頼性を最適化するために、インストールされたシステムにストレージを設定するための LVM および LVM シンプロビジョニングを使用したソフトウェア RAID 0、RAID 1、RAID 4、RAID 5、RAID 6、および RAID 10 タイプをサポートしています。
64 ビットの IBM Z では、ストレージサブシステムが RAID を透過的に使用します。ソフトウェア RAID を手動で設定する必要はありません。
前提条件
- RAID 設定オプションは、インストール用に複数のディスクを選択している場合にのみ表示される。作成する RAID タイプに応じて、少なくとも 2 つのディスクが必要です。
- マウントポイントを作成している。マウントポイントを設定して、RAID デバイスを設定します。
- インストール先 画面で ラジオボタンを選択している。
手順
- 手動パーティション設定 画面の左側のペインで、必要なパーティションを選択します。
- デバイス セクションの下にある をクリックします。マウントポイントの設定 ダイアログボックスが開きます。
- RAID デバイスに追加するディスクを選択して、 をクリックします。
- デバイスタイプ ドロップダウンメニューをクリックして、RAID を選択します。
- ファイルシステム のドロップダウンメニューをクリックして、目的のファイルシステムタイプを選択します。
- RAID レベル ドロップダウンメニューをクリックして、目的の RAID レベルを選択します。
- をクリックして、変更を保存します。
- をクリックして設定を適用し、インストールの概要 ウィンドウに戻ります。
6.4.10. LVM 論理ボリュームの作成
論理ボリュームマネージャー (LVM) は、ディスクや LUN などの基盤となる物理ストレージ領域を、シンプルかつ論理的に表示します。物理ストレージ上のパーティションは物理ボリュームとして表示され、ボリュームグループにグループ化できます。各ボリュームグループは複数の論理ボリュームに分割できます。各論理ボリュームは標準のディスクパーティションによく似ています。したがって、LVM 論理ボリュームは、複数の物理ディスクにまたがることが可能なパーティションとして機能します。
- LVM 設定は、グラフィカルインストールプログラムでのみ利用できます。テキストモードによるインストールの場合は、LVM を設定できません。
-
LVM 設定を作成するには、Ctrl+Alt+F2 を押し、別の仮想コンソールのシェルプロンプトを使用します。このシェルで
vgcreateおよびlvmコマンドを実行できます。テキストモードのインストールに戻るには Ctrl+Alt+F1 を押します。
手順
Manual Partitioning ウィンドウから、次のいずれかの方法で新しいマウントポイントを作成します。
- Click here to create them automatically オプションを使用するか、+ ボタンをクリックします。
- ドロップダウンリストからマウントポイントを選択するか、手動で入力します。
ファイルシステムのサイズを Desired Capacity フィールドに入力します。たとえば、
/の場合は 70 GiB、/bootの場合は 1 GiB です。注記:既存のマウントポイントを使用する場合は、この手順をスキップします。
- マウントポイントを選択します。
ドロップダウンメニューで
LVMを選択します。ボリュームグループ ドロップダウンメニューが表示され、新たに作成したボリュームグループ名が表示されます。注記設定ダイアログではボリュームグループの物理エクステントのサイズは指定できません。このサイズは、常にデフォルト値の 4 MiB に設定されます。別の物理エクステントのボリュームグループを作成する場合は、対話シェルに切り替えて、
vgcreateコマンドで手動で作成するか、キックスタートファイルでvolgroup --pesize=sizeコマンドを使用して作成します。キックスタートの詳細は、RHEL の自動インストール を参照してください。- をクリックして、インストール概要 画面に戻ります。
6.4.11. LVM 論理ボリュームを設定する
新しく作成した LVM 論理ボリュームを要件に基づいて設定できます。
/boot パーティションを LVM ボリュームに配置することには対応していません。
手順
Manual Partitioning ウィンドウから、次のいずれかの方法でマウントポイントを作成します。
- Click here to create them automatically オプションを使用するか、+ ボタンをクリックします。
- ドロップダウンリストからマウントポイントを選択するか、手動で入力します。
ファイルシステムのサイズを Desired Capacity フィールドに入力します。たとえば、
/の場合は 70 GiB、/bootの場合は 1 GiB です。注記:既存のマウントポイントを使用する場合は、この手順をスキップします。
- マウントポイントを選択します。
-
デバイスタイプ ドロップダウンメニューをクリックして、
LVMを選択します。ボリュームグループ ドロップダウンメニューが表示され、新たに作成したボリュームグループ名が表示されます。 をクリックして、新たに作成したボリュームグループを設定します。ボリュームグループの設定 ダイアログボックスが開きます。
注記設定ダイアログではボリュームグループの物理エクステントのサイズは指定できません。このサイズは、常にデフォルト値の 4 MiB に設定されます。別の物理エクステントのボリュームグループを作成する場合は、対話シェルに切り替えて、
vgcreateコマンドで手動で作成するか、キックスタートファイルでvolgroup --pesize=sizeコマンドを使用して作成します。詳細は、RHEL の自動インストール ドキュメントを参照してください。オプション: RAID レベル ドロップダウンメニューから、必要な RAID レベルを選択します。
利用可能な RAID レベルは、実際の RAID デバイスと同じです。
- ボリュームグループに暗号化のマークを付けるには、暗号化 チェックボックスを選択します。
Size policy ドロップダウンメニューから、ボリュームグループに対して次のサイズポリシーのいずれかを選択します。
利用可能なポリシーオプションは以下のようになります。
- Automatic
- ボリュームグループのサイズは自動で設定されるため、設定した論理ボリュームを格納するのに適切なサイズになります。ボリュームグループに空の領域が必要ない場合に最適です。
- As large as possible
- 設定した論理ボリュームのサイズに関係なく、最大サイズのボリュームグループが作成されます。これは、ほとんどのデータを LVM に保存する場合、または後で既存の論理ボリュームのサイズを拡大する可能性がある場合、もしくはこのグループに別の論理ボリュームを作成する必要がある場合などに最適です。
- Fixed
- このオプションではボリュームグループのサイズを正確に設定できます。設定している論理ボリュームが格納できるサイズにする必要があります。ボリュームグループに設定する容量が正確に分かっている場合に便利です。
- をクリックして設定を適用し、手動パーティション設定 画面に戻ります。
- をクリックして、変更を保存します。
- をクリックして、インストール概要 画面に戻ります。
6.4.12. パーティション設定に関するアドバイス
すべてのシステムに最善となる分割方法はありません。インストール済みシステムをどのように使用するかによって異なります。ただし、次のヒントは、ニーズに最適なレイアウトを見つけるのに役立つかもしれません。
- たとえば、特定のパーティションを特定のディスクに配置する必要がある場合など、特定の要件を満たすパーティションを最初に作成します。
-
機密データを格納する可能性があるパーティションやボリュームには、暗号化を検討してください。暗号化を行うと、権限を持たない人が物理ストレージデバイスにアクセスできても、暗号化したパーティションにあるデータにアクセスできなくなります。ほとんどの場合は、少なくともユーザーデータが含まれる
/homeパーティションを暗号化してください。 -
場合によっては、
/、/boot、および/home以外のディレクトリーに個別のマウントポイントを作成すると役に立つかもしれません。たとえば、MySQLデータベースを実行するサーバーで、/var/lib/mysql用のマウントポイントを別に持つことで、後でバックアップからデータベースを復元しなくても、再インストール中にデータベースを保存できます。ただし、不要なマウントポイントがあると、ストレージ管理がより困難になります。 -
一部のディレクトリーには、配置できるパーティションレイアウトに関して特別な制限がいくつか適用されます。特に、
/bootディレクトリーは常に、(LVM ボリュームではなく) 物理パーティションに存在する必要があります。 - Linux を初めて使用する場合は、さまざまなシステムディレクトリーとそのコンテンツの詳細を、Linux ファイルシステム階層標準 を確認してください。
- 各カーネルには、おおよそ次のものが必要です。60MiB (initrd 34MiB、11MiB vmlinuz、および 5MiB System.map)
- レスキューモードの場合:100MiB (initrd 76MiB、11MiB vmlinuz、および 5MiB システムマップ)
システムで
kdumpを有効にすると、さらに約 40 MiB(33 MiB の別の initrd) が必要になります。最も一般的なユースケースでは、
/bootにはデフォルトの 1 GiB のパーティションサイズが必要です。ただし、複数のカーネルリリースまたはエラータカーネルを保持する予定の場合は、このパーティションのサイズを増やしてください。-
/varディレクトリーには、Apache Web サーバーなど、多数のアプリケーションのコンテンツが格納されていて、YUM パッケージマネージャーが、ダウンロードしたパッケージの更新を一時的に保管するのに使用します。/varを含むパーティションまたはボリュームは、最低 5 GB となることを確認してください。 -
/usrディレクトリーには、一般的な Red Hat Enterprise Linux インストールの大抵のソフトウェアが格納されています。このディレクトリーを含むパーティションまたはボリュームは、最小インストールの場合は最低 5 GiB、グラフィカル環境のインストールの場合は最低 10 GiB 必要です。 /usrまたは/varのパーティションをルートボリュームとは別の場所に設定すると、これらのディレクトリーには起動に欠かせないコンポーネントが含まれているため、起動プロセスが非常に複雑になります。iSCSI ドライブや FCoE などの場所に配置してしまった場合には、システムが起動できなくなったり、電源オフや再起動の際にDevice is busyのエラーでハングしたりする可能性があります。これらの制限は
/usrと/varにのみ適用され、その下のディレクトリーには適用されません。たとえば、/var/www向けの個別パーティションは、問題なく機能します。重要一部のセキュリティーポリシーでは、管理がより複雑になりますが、
/usrと/varの分離が必要になります。-
LVM ボリュームグループ内の一部領域を未割り当てのまま残しておくことを検討してください。このように未割り当ての領域を残すことで、領域の要件が変化した際に、その他のボリュームからデータを削除したくない場合に、柔軟性が得られます。また、パーティションに
LVM シンプロビジョニングデバイスタイプを選択し、ボリュームに未使用の領域を自動的に処理させることもできます。 - XFS ファイルシステムのサイズを縮小することはできません。このファイルシステムのパーティションまたはボリュームを小さくする必要がある場合は、データのバックアップを作成し、ファイルシステムを破棄して、代わりに小規模なファイルシステムを新たに作成する必要があります。したがって、後でパーティションレイアウトを変更する予定の場合には、代わりに ext4 ファイルシステムを使用してください。
-
インストール後にディスクを追加したり、仮想マシンのディスクを拡張したりしてストレージを拡張する予定がある場合は、論理ボリュームマネージャー (LVM) を使用します。LVM を使用すると、新しいドライブに物理ボリュームを作成し、必要に応じてそのボリュームをボリュームグループおよび論理ボリュームに割り当てることができます。たとえば、システムの
/home(または論理ボリュームに存在するその他のディレクトリー) は簡単に拡張できます。 - システムのファームウェア、起動ドライブのサイズ、および起動ドライブのディスクラベルによっては、BIOS の起動パーティションまたは EFI システムパーティションの作成が必要になる場合があります。システムで BIOS ブートまたは EFI システムパーティションが 必要ない 場合は、グラフィカルインストールで BIOS ブートまたは EFI システムパーティションを作成することはできません。この場合は、メニューに表示されなくなります。
-
インストール後にストレージ設定に変更を加える必要がある場合は、Red Hat Enterprise Linux リポジトリーで役に立つツールがいくつか提供されています。コマンドラインツールを使用する場合は、
system-storage-managerを試してみてください。
6.5. ベース環境と追加ソフトウェアの選択
必要なソフトウェアパッケージを選択するには、Software Selectio ウィンドウを使用します。パッケージは、ベース環境と追加ソフトウェア別に編成されています。
- Base Environment には、定義済みのパッケージが含まれています。たとえば、Server with GUI (デフォルト)、Server、Minimal Install、Workstation、Custom Operating System、Virtualization Host など、ベース環境を 1 つだけ選択できます。可用性は、インストールソースとして使用されているインストール ISO イメージにより異なります。
- 選択した環境の追加ソフトウェア には、ベース環境用の追加のソフトウェアパッケージが含まれています。複数のソフトウェアパッケージを選択できます。
事前に定義された環境と追加のソフトウェアを使用して、システムをカスタマイズします。ただし、標準的なインストールでは、インストールする個々のパッケージを選択することはできません。特定の環境に含まれるパッケージを表示するには、インストールソースメディア (DVD、CD、USB) にある repository/repodata/*-comps-repository.architecture.xml ファイルを参照してください。XML ファイルには、ベース環境としてインストールされたパッケージの詳細が記載されています。利用可能な環境には <environment> タグ、そして追加のソフトウェアパッケージには <group> タグが付いています。
どのパッケージをインストールする必要があるかわからない場合は、Minimal Install ベース環境を選択してください。最小インストールでは、基本バージョンの Red Hat Enterprise Linux と、最低限の追加ソフトウェアがインストールされます。システムのインストールが完了し、初めてログインした後、YUM パッケージマネージャーを使用して追加のソフトウェアをインストールできます。YUM パッケージマネージャーの詳細は、基本的なシステム設定の設定 ドキュメントを参照してください。
-
任意の RHEL 8 システムから
yum group listコマンドを使用して、ソフトウェア選択の一部としてシステムにインストールされているパッケージのリストを表示します。詳細は、基本的なシステム設定 を参照してください。 -
インストールするパッケージを制御する必要がある場合は、キックスタートファイルの
%packagesセクションにパッケージを定義します。
前提条件
- インストールソースを設定している。
- インストールプログラムが、パッケージのメタデータをダウンロードしている。
- Installation Summary 画面が開いている。
手順
- インストール概要 画面で、ソフトウェアの選択 をクリックします。ソフトウェアの選択 画面が開きます。
ベース環境 ペインで、ベース環境を選択します。たとえば、Server with GUI (デフォルト)、Server、Minimal Install、Workstation、Custom Operating System、Custom Operating System など、ベース環境を 1 つだけ選択できます。デフォルトでは、Server with GUI ベース環境が選択されています。
図6.3 Red Hat Enterprise Linux ソフトウェアの選択
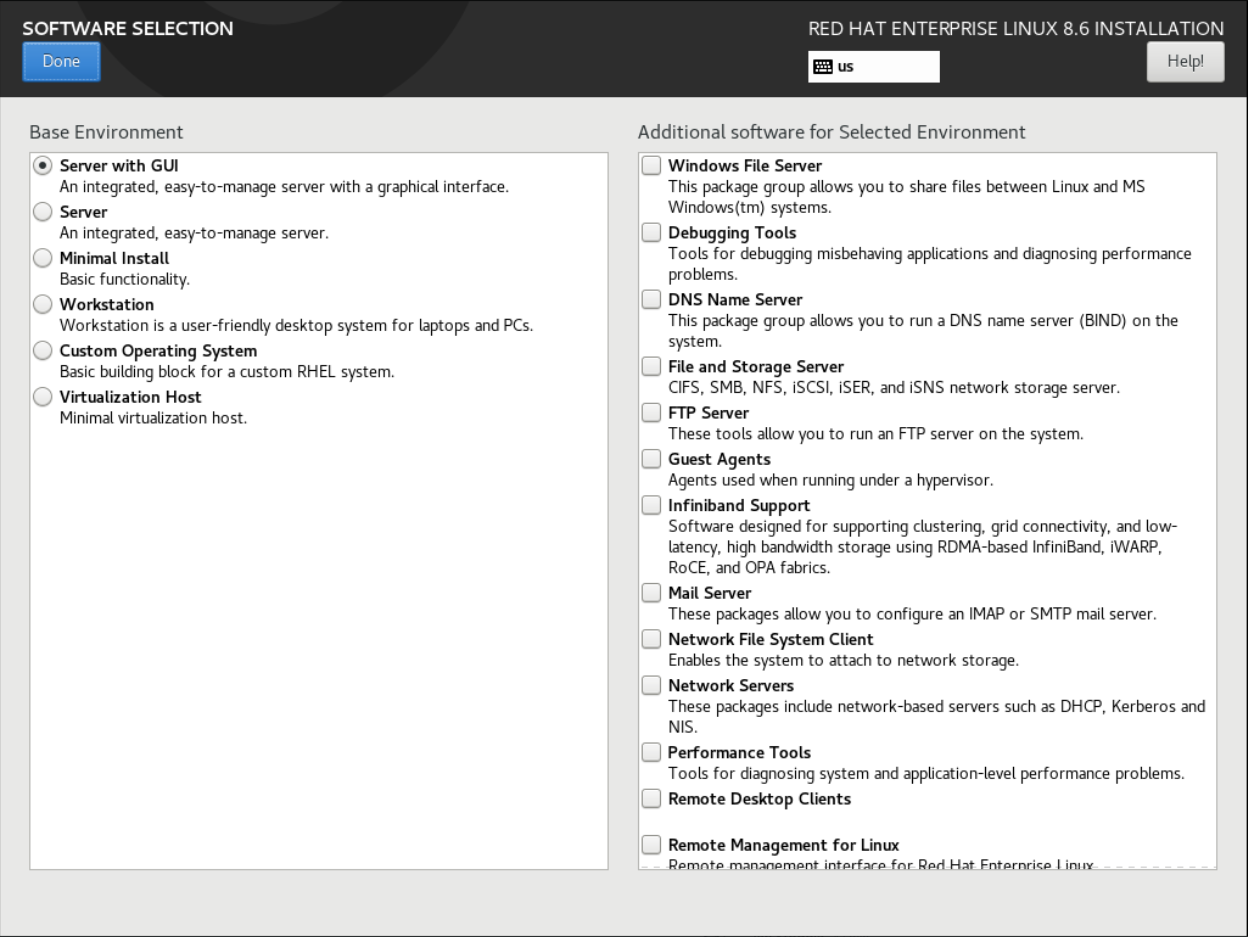
- 選択した環境の追加ソフトウェア ペインから、1 つ以上のオプションを選択します。
- をクリックして設定を適用し、グラフィカルインストールに戻ります。
6.6. オプション: ネットワークとホスト名の設定
ネットワークとホスト名 画面は、ネットワークインターフェイスを設定するために使用されます。ここで選択したオプションは、インストール済みシステムだけでなく、インストール時にリモートからパッケージをダウンロードするなどのタスクを行う際にも利用できます。
以下の手順に従って、ネットワークとホスト名を設定します。
手順
- インストール概要 画面から、 をクリックします。
- 左側のペインのリストから、インターフェイスを選択します。詳細が右側のペインに表示されます。
スイッチを切り替えて、選択したインターフェイスを有効または無効にします。
インターフェイスを手動で追加または削除することはできません。
- をクリックして、仮想ネットワークインターフェイスを追加します。仮想ネットワークインターフェイスは、チーム、ボンド、ブリッジ、または VLAN のいずれかです。
- を選択して、仮想インターフェイスを削除します。
- をクリックして、既存のインターフェイスの IP アドレス、DNS サーバー、またはルーティング設定 (仮想と物理の両方) などの設定を変更します。
ホスト名 フィールドに、システムのホスト名を入力します。
ホスト名は、
hostname.domainname形式の完全修飾ドメイン名 (FQDN)、またはドメインなしの短縮ホスト名のいずれかにします。多くのネットワークには、自動的に接続したシステムにドメイン名を提供する DHCP (Dynamic Host Configuration Protocol) サービスがあります。DHCP サービスがこのシステムにドメイン名を割り当てるようにするには、短縮ホスト名のみを指定します。ホスト名に使用できるのは、英数字と
-または.のみです。ホスト名は 64 文字以下である必要があります。ホスト名は、-および.で開始したり終了したりできません。DNS に準拠するには、FQDN の各部分は 63 文字以下で、ドットを含む FQDN の合計の長さは 255 文字を超えることができません。localhostの値は、ターゲットシステムの静的ホスト名が指定されておらず、(たとえば、DHCP または DNS を使用する NetworkManager による) ネットワーク設定時に、インストールされるシステムの実際のホスト名が設定されることを示しています。静的 IP およびホスト名の設定を使用する場合、短縮名または FQDN を使用するかどうかは、計画したシステムのユースケースによって異なります。Red Hat Identity Management はプロビジョニング時に FQDN を設定しますが、サードパーティーのソフトウェア製品によっては短縮名が必要になる場合があります。いずれの場合も、すべての状況で両方のフォームの可用性を確保するには、
IP FQDN short-aliasの形式で/etc/hostsにホストのエントリーを追加します。- をクリックして、ホスト名をインストーラー環境に適用します。
- また、ネットワークおよびホスト名 画面では、ワイヤレスオプションを選択できます。右側のペインで をクリックして Wifi 接続を選択します。必要に応じてパスワードを入力し、 をクリックします。
6.6.1. 仮想ネットワークインターフェイスの追加
仮想ネットワークインターフェイスを追加できます。
手順
- ネットワークとホスト名 画面で、 ボタンをクリックして、仮想ネットワークインターフェイスを追加します。デバイスの追加 ダイアログが開きます。
使用可能な 4 つのタイプの仮想インターフェイスから 1 つ選択してください。
- Bond: NIC (ネットワークインターフェイスコントローラー) のボンドです。複数の物理ネットワークインターフェイスを 1 つのボンドチャネルに結合する方法です。
- Bridge: NIC ブリッジングです。複数のネットワークを 1 つの集積ネットワークに接続します。
- Team: NIC のチーミングです。複数のリンクを集約する新しい実装方法です。小型のカーネルドライバーを提供することでパケットフローを高速で処理し、各種アプリケーションがその他のすべてのタスクをユーザー領域で行うように設計されています。
- Vlan (仮想 LAN): それぞれ独立している複数のブロードキャストドメインを作成する方法です。
インターフェイスの種類を選択し、 をクリックします。インターフェイスの編集ダイアログボックスが開き、選択したインターフェイスタイプに使用できる設定を編集できます。
詳細は、ネットワークインターフェイスの編集 を参照してください。
- をクリックして仮想インターフェイス設定を確認し、ネットワークおよびホスト名 画面に戻ります。
- オプション: 仮想インターフェイスの設定を変更するには、インターフェイスを選択し、 をクリックします。
6.6.2. ネットワークインターフェイス設定の編集
インストール時に使用する一般的な有線接続の設定を編集できます。その他の種類のネットワークの設定方法は、一部の設定パラメーターが異なる場合がありますが、ここで説明する内容とあまり変わりません。
64 ビットの IBM Z では、ネットワークサブチャンネルをあらかじめグループ化してオンラインに設定する必要があるため、新しい接続を追加することはできません。これは現在、起動段階でのみ行われます。
手順
手動でネットワーク接続を設定するには、ネットワークおよびホスト名 画面からインターフェイスを選択し、 をクリックします。
選択したインターフェイスに固有の編集ダイアログが開きます。表示されるオプションは接続の種類によって異なります。使用可能なオプションは、接続の種類が物理インターフェイス (有線または無線のネットワークインターフェイスコントローラー) か、仮想インターフェイスの追加 で設定した仮想インターフェイス (ボンド、ブリッジ、チーム、または Vlan) かによって若干異なります。
6.6.3. インターフェイス接続の有効化または無効化
特定のインターフェイス接続を有効または無効にできます。
手順
- 全般 タブをクリックします。
-
優先的に自動的に接続 チェックボックスを選択して、デフォルトで接続を有効にします。デフォルトの優先度設定は
0のままにします。 オプション: すべてのユーザーがこのネットワークに接続できる オプションを使用して、システム上のすべてのユーザーがこのネットワークに接続できないようにするか、無効にします。このオプションを無効にすると、
rootだけがこのネットワークに接続できます。重要有線接続で有効にすると、システムは起動時または再起動時に自動的に接続されます。無線接続では、インターフェイスにより、範囲内の既知の無線ネットワークへの接続が試されます。
nm-connection-editorツールを含む NetworkManager の詳細は、Configuring and managing networking のドキュメントを参照してください。をクリックして変更を適用し、ネットワークおよびホスト名 画面に戻ります。
インストール中のこの時点ではその他のユーザーが作成されないため、
root以外の特定のユーザーだけがこのインターフェイスを使用するように許可することはできません。別のユーザーが使用する接続が必要な場合は、インストール後に設定する必要があります。
6.6.4. 静的な IPv4 または IPv6 の設定
デフォルトでは、現在のネットワーク設定に応じて、IPv4 と IPv6 の両方が自動設定に指定されています。つまり、ローカルの IP アドレス、DNS アドレスなどのアドレスは、インターフェイスがネットワークに接続すると自動的に検出されます。多くの場合はこれで十分ですが、IPv4 Settings タブと IPv6 Settings タブで静的な設定を行うこともできます。IPv4 設定または IPv6 設定を設定するには、以下の手順を実行します。
手順
- 静的ネットワーク設定を行うには、IPv 設定タブのいずれかに移動し、方式 ドロップダウンメニューから、自動 以外の方法 (手動 など) を選択します。アドレス ペインが有効になります。
- オプション: IPv6 設定 タブでは、メソッドを 無視する に設定して、このインターフェイスの IPv6 を無効にできます。
- をクリックして、アドレス設定を入力します。
-
追加の DNS サーバー フィールドに IP アドレスを入力します。DNS サーバーの IP アドレス (
10.0.0.1,10.0.0.8など) を 1 つ以上設定できます。 Require IPvX addressing for this connection to complete チェックボックスをオンにします。
IPv4 Settings または IPv6 Settings タブでこのオプションを選択すると、IPv4 または IPv6 が成功した場合にのみこの接続が許可されます。IPv4 および IPv6 の両方でこのオプションを無効にしたままにしておくと、いずれかの IP プロトコル設定に成功した場合にインターフェイスが接続できるようになります。
- をクリックして変更を適用し、ネットワークおよびホスト名 画面に戻ります。
6.6.5. ルートの作成
ルートを設定することで、特定の接続へのアクセスを制御できます。
手順
- IPv4 設定 タブおよび IPv6 設定 タブで、 をクリックして特定の IP プロトコルのルーティング設定を行います。そのインターフェイス用のルート編集ダイアログが開きます。
- をクリックして、ルートを追加します。
- 1 つ以上の静的ルートを設定し、設定していないすべてのルートを無効にするには、自動的に得られたルートを無視する チェックボックスを選択します。
この接続はネットワーク上のリソースにのみ使用 チェックボックスを選択して、デフォルトルートにはならないようにします。
このオプションは、静的ルートを設定していなくても選択できます。このルートは、ローカルまたは VPN 接続を必要とするイントラネットページなど、特定のリソースにアクセスするためにのみ使用されます。公開されているリソースには別の (デフォルトの) ルートが使用されます。追加ルートが設定されているのとは異なり、この設定はインストール済みシステムに転送されます。このオプションは、複数のインターフェイスを設定する場合に限り役に立ちます。
- をクリックして設定を保存し、インターフェイス固有のルートの編集ダイアログボックスに戻ります。
- をクリックして設定を適用し、ネットワークおよびホスト名 画面に戻ります。
6.7. オプション: キーボードレイアウトの設定
Installation Summary 画面からキーボードレイアウトを設定できます。
ロシア語 のようにラテン文字を受け付けないレイアウトを使用する場合は、一緒に 英語 (US) レイアウトも追加して、2 つのレイアウトを切り替えられるようにキーボードを設定します。ラテン文字を含まないレイアウトを選択すると、この後のインストールプロセスで有効な root パスワードおよびユーザー認証情報を入力できない場合があります。これにより、インストールを完了できない可能性があります。
手順
- Installation Summary ウィンドウで、Keyboard をクリックします。
- をクリックして Add a Keyboard Layout ウィンドウを開き、別のレイアウトに変更します。
- リストを参照してレイアウトを選択するか、Search フィールドを使用します。
- 必要なレイアウトを選択し、 をクリックします。デフォルトレイアウトの下に新しいレイアウトが表示されます。
- 必要に応じて をクリックして、使用可能なレイアウトを切り替えるキーボードスイッチを設定します。レイアウト切り替えのオプション 画面が開きます。
- 切り替え用のキーの組み合わせを設定するには、1 つ以上のキーの組み合わせを選択し、 をクリックして選択を確定します。
- オプション: レイアウトを選択したら、[キーボード] ボタンをクリックすると、選択したレイアウトの視覚的な表現を表示する新しいダイアログボックスが開きます。
- をクリックして設定を適用し、グラフィカルインストールに戻ります。
6.8. オプション: 言語サポートの設定
Installation Summary 画面から言語設定を変更できます。
手順
- インストール概要 画面で 言語サポート をクリックします。言語サポート 画面が開きます。左側のペインには、利用可能な言語グループのリストが表示されます。グループの中から 1 つ以上の言語を設定すると、チェックマークが表示され、対応する言語が強調表示されます。
- 左側のペインからグループをクリックして追加の言語を選択し、右側のペインから地域のオプションを選択します。設定するすべての言語に対してこのプロセスを繰り返します。
- オプション: 必要に応じて、テキストボックスに入力して言語グループを検索します。
- をクリックして設定を適用し、グラフィカルインストールに戻ります。
6.10. オプション: システムをサブスクライブし、Red Hat Insights をアクティブ化する
Red Hat Insights は SaaS (Software-as-a-Service) 製品で、継続的に、登録済みの Red Hat ベースのシステムに詳細な分析を提供し、物理環境、仮想環境、クラウド環境、およびコンテナーデプロイメントでセキュリティー、パフォーマンス、および安定性に関する脅威をプロアクティブに特定します。RHEL システムを Red Hat Insights に 登録 すると、予測分析、セキュリティーアラート、パフォーマンス最適化ツールにアクセスできるようになり、セキュアで効率的かつ安定した IT 環境を維持できるようになります。
Red Hat アカウントまたはアクティベーションキーの詳細を使用して Red Hat に登録できます。Connect to Red Hat オプションを使用して、システムを Red Hat Insights に接続できます。
手順
- Installation Summary 画面の Software で、Connect to Red Hat をクリックします。
Account または Activation Key を選択します。
- Account を選択した場合は、Red Hat カスタマーポータルのユーザー名とパスワードの詳細を入力します。
Activation Key を選択した場合は、組織 ID とアクティベーションキーを入力します。
サブスクリプションにアクティベーションキーが登録されている限り、複数のアクティベーションキーをコンマで区切って入力できます。
Set System Purpose チェックボックスをオンにします。
- アカウントで Simple Content Access モードが有効になっている場合でも、サブスクリプションサービスの消費量を正確にレポートするには、システムの目的の値を設定することが重要です。
- アカウントがエンタイトルメントモードである場合、システムの目的を設定すると、エンタイトルメントサーバーが Red Hat Enterprise Linux 8 システムの使用目的を満たす最適なサブスクリプションを決定し、自動的に割り当てることが可能になります。
- 対応するドロップダウンリストから、必要な Role、SLA、および Usage を選択します。
- Red Hat Insights への接続 チェックボックスはデフォルトで有効になっています。Red Hat Insights に接続する必要がない場合には、チェックボックスの選択を解除します。
オプション: オプション をデプロイメントします。
- ネットワーク環境で、外部のインターネットアクセスまたは HTTP プロキシーを介したコンテンツサーバーへのアクセスのみが許可されている場合は、HTTP プロキシーの使用 チェックボックスを選択します。HTTP プロキシーを使用していない場合は、HTTP プロキシーの使用 チェックボックスの選択を解除します。
Satellite Server を実行しているか、内部テストを実行している場合は、カスタムサーバーの URL チェックボックスと カスタムベース URL チェックボックスを選択して、必要な情報を入力します。
重要-
カスタムサーバーの URL フィールドには HTTP プロトコル (
nameofhost.comなど) が必要ありません。ただし、Custom base URL フィールドには HTTP プロトコルが必要です。 - 登録後に カスタムベース URL を変更するには、登録を解除し、新しい詳細を指定してから再登録する必要があります。
-
カスタムサーバーの URL フィールドには HTTP プロトコル (
をクリックしてシステムを登録します。システムが正常に登録され、サブスクリプションが割り当てられると、Red Hat への接続 ウィンドウに、割り当てられているサブスクリプションの詳細が表示されます。
サブスクリプションのサイズによっては、登録および割り当てのプロセスが完了するのに最大 1 分かかることがあります。
をクリックして、インストール概要 画面に戻ります。
Red Hat への接続 の下に 登録 メッセージが表示されます。
6.11. オプション:インストールにネットワークベースのリポジトリーを使用する
自動検出されたインストールメディア、Red Hat CDN、またはネットワークのいずれかからインストールソースを設定できます。インストール概要 画面を最初に開いた時に、インストールプログラムが、システムの起動に使用されたメディアの種類に基づいて、インストールソースを設定しようとします。完全な Red Hat Enterprise Linux Server DVD は、ソースをローカルメディアとして設定します。
前提条件
- Product Downloads ページからフルインストール DVD ISO または最小インストールブート ISO イメージをダウンロードした。
- 起動可能なインストールメディアを作成している。
- Installation Summary 画面が開いている。
手順
インストール概要 画面から、インストールソース をクリックします。インストールソース 画面が開きます。
- 自動検出したインストールメディア セクションを見直して、詳細を確認します。インストールソースを含むメディア (DVD) からインストールプログラムを起動した場合は、このオプションがデフォルトで選択されます。
- をクリックして、メディアの整合性を確認します。
Additional repositories セクションを確認し、AppStream チェックボックスがデフォルトで選択されていることを確認します。
BaseOS および AppStream リポジトリーは、フルインストールイメージの一部としてインストールされます。Red Hat Enterprise Linux 8 のフルインストールを行う場合は、AppStream リポジトリーのチェックボックスを無効にしないでください。
- オプション:Red Hat CDN オプションを選択して、システムを登録し、RHEL サブスクリプションを割り当てて、Red Hat コンテンツ配信ネットワーク (CDN) から RHEL をインストールします。
オプション:ネットワーク上 オプションを選択して、ローカルメディアの代わりに、ネットワーク上からパッケージをダウンロードしてインストールします。このオプションは、ネットワーク接続がアクティブな場合にのみ利用できます。GUI でネットワーク接続を設定する方法は、ネットワークおよびホスト名のオプションの設定 を参照してください。
注記ネットワーク上の場所から追加のリポジトリーをダウンロードしてインストールしない場合は、ソフトウェア選択の設定 に進みます。
- ネットワーク上 ドロップダウンメニューを選択し、パッケージのダウンロードに使用するプロトコルを指定します。この設定は、使用するサーバーによって異なります。
-
アドレスフィールドに、(プロトコルなしで) サーバーアドレスを入力します。NFS を選択すると、入力フィールドが開き、カスタムの NFS マウントオプション を指定できます。このフィールドでは、システム上の
nfs(5)man ページにリストされているオプションを使用できます。 NFS のインストールソースを選択する場合は、ホスト名とパスをコロン (
:) で区切ってアドレスを指定します。たとえば、server.example.com:/path/to/directoryのように指定します。以下の手順は任意で、ネットワークアクセスにプロキシーが使用されているかどうかのみが必要となります。
- をクリックして、HTTP または HTTPS ソースのプロキシーを設定します。
- HTTP プロキシーの有効化 チェックボックスを選択し、プロキシーホスト フィールドに URL を入力します。
- プロキシーサーバーで認証が必要な場合は、認証を使用する チェックボックスを選択します。
- ユーザー名とパスワードを入力します。
をクリックして設定を終了し、プロキシーの設定... ダイアログボックスを終了します。
注記HTTP または HTTPS の URL が、リポジトリーミラーを参照する場合は、URL type ドロップダウンリストから必要なオプションを選択します。ソースの設定が終わると、選択に対して環境と追加のソフトウェアパッケージがすべて利用できます。
- をクリックして、リポジトリーを追加します。
- をクリックして、リポジトリーを削除します。
- アイコンをクリックして、現在のエントリーを、インストールソース 画面を開いたときに表示されていた設定に戻します。
リポジトリーを有効または無効にするには、リストの各エントリーで 有効 列のチェックボックスをクリックします。
ネットワークにプライマリーリポジトリーを設定するときと同じように、追加リポジトリーに名前を付けて設定できます。
- をクリックして設定を適用し、Installation Summary ウィンドウに戻ります。
6.12. オプション: Kdump カーネルクラッシュダンプメカニズムの設定
Kdump は、カーネルのクラッシュダンプメカニズムです。システムがクラッシュすると、Kdump が、障害発生時のシステムメモリーの内容をキャプチャーします。キャプチャーしたメモリーを解析すると、クラッシュの原因を見つけることができます。Kdump が有効になっている場合は、システムメモリー (RAM) のごく一部をそれ自身に予約する必要があります。予約したメモリーは、メインのカーネルにアクセスできません。
手順
- インストール概要 画面から、Kdump をクリックします。Kdump 画面が開きます。
- kdump を有効にする チェックボックスを選択します。
- メモリー予約設定を、自動 または 手動 のいずれかから選択します。
- 手動 を選択し、+ ボタンおよび - ボタンを使用して、予約されるメモリー フィールドに、予約するメモリー量 (メガバイト) を入力します。予約入力フィールドの下にある 使用可能なシステムメモリー には、選択したサイズの RAM を予約してから、メインシステムにアクセスできるメモリーの量が示されます。
- をクリックして設定を適用し、グラフィカルインストールに戻ります。
予約するメモリーの量は、システムのアーキテクチャー (AMD64 と Intel 64 の要件は IBM Power とは異なります) と、システムメモリーの総量により決まります。ほとんどの場合は、自動予約で十分です。
カーネルクラッシュダンプの保存場所などの追加設定は、インストール後に system-config-kdump グラフィカルインターフェイスで設定するか、/etc/kdump.conf 設定ファイルに手動で設定できます。
6.13. オプション: セキュリティープロファイルの選択
Red Hat Enterprise Linux 8 のインストール中にセキュリティーポリシーを適用し、初回起動前にシステムで使用するように設定できます。
6.13.1. セキュリティーポリシーの概要
Red Hat Enterprise Linux には、特定のセキュリティーポリシーに合わせてシステムの自動設定を有効にする OpenSCAP スイートが同梱されています。このポリシーは、SCAP (Security Content Automation Protocol) 標準を使用して実装されます。パッケージは、AppStream リポジトリーで利用できます。ただし、デフォルトでは、インストールおよびインストール後のプロセスではポリシーが強制されないため、特に設定しない限りチェックは行われません。
インストールプログラムでは、セキュリティーポリシーを適用することは必須ではありません。システムにセキュリティーポリシーを適用する場合は、選択したプロファイルに定義した制限を使用してシステムがインストールされます。openscap-scanner パッケージおよび scap-security-guide パッケージがパッケージ選択に追加され、コンプライアンスおよび脆弱性スキャンのプリインストールツールが利用できるようになります。
セキュリティーポリシーを選択すると、Anaconda GUI インストーラーでは、ポリシーの要件に準拠する設定が必要になります。パッケージの選択が競合したり、別のパーティションが定義されている場合があります。要件がすべて満たされた場合に限り、インストールを開始できます。
インストールプロセスの終了時に、選択した OpenSCAP セキュリティーポリシーにより、システムが自動的に強化され、スキャンされてコンプライアンスが確認され、インストール済みシステムの /root/openscap_data ディレクトリーにスキャン結果が保存されます。
デフォルトでは、インストーラーは、インストールイメージにバンドルされている scap-security-guide パッケージの内容を使用します。外部コンテンツは、HTTP サーバー、HTTPS サーバー、または FTP サーバーから読み込むこともできます。
6.13.2. セキュリティープロファイルの設定
Installation Summary ウィンドウからセキュリティーポリシーを設定できます。
前提条件
- Installation Summary 画面が開いている。
手順
- Installation Summary ウィンドウで、Security Profile をクリックします。Security Profile ウィンドウが開きます。
- システムでセキュリティーポリシーを有効にするには、Apply security policy スイッチを ON に切り替えます。
- 上部ペインに表示されているプロファイルから 1 つ選択します。
をクリックします。
インストール前に適用が必要なプロファイルの変更が、下部ペインに表示されます。
カスタムプロファイルを使用するには、 をクリックします。
別の画面が開いて、有効なセキュリティーコンテンツの URL を入力できます。
をクリックして URL を取得します。
HTTP サーバー、HTTPS サーバー、または FTP サーバーから、カスタムプロファイルを読み込むこともできます。コンテンツのフルアドレス (http:// などのプロトコルを含む) を使用してください。カスタムプロファイルを読み込む前に、ネットワーク接続がアクティブになっている必要があります。インストールプログラムは、コンテンツの種類を自動的に検出します。
- をクリックして、Security Profile ウィンドウに戻ります。
- をクリックして設定を適用し、Installation Summary ウィンドウに戻ります。
6.13.3. Server with GUI と互換性のないプロファイル
SCAP Security Guide の一部として提供される一部のセキュリティープロファイルは、Server with GUI ベース環境に含まれる拡張パッケージセットと互換性がありません。したがって、次のいずれかのプロファイルに準拠するシステムをインストールする場合は、Server with GUI を選択しないでください。
| プロファイル名 | プロファイル ID | 理由 | 備考 |
|---|---|---|---|
| CIS Red Hat Enterprise Linux 8 Benchmark for Level 2 - Server |
|
パッケージ | |
| CIS Red Hat Enterprise Linux 8 Benchmark for Level 1 - Server |
|
パッケージ | |
| Unclassified Information in Non-federal Information Systems and Organizations (NIST 800-171) |
|
| |
| Protection Profile for General Purpose Operating Systems |
|
| |
| DISA STIG for Red Hat Enterprise Linux 8 |
|
パッケージ | RHEL バージョン 8.4 以降で、RHEL システムを DISA STIG に準拠した Server with GUI としてインストールするには、DISA STIG with GUI プロファイルを使用できます。 |
6.13.4. キックスタートを使用したベースライン準拠の RHEL システムのデプロイメント
特定のベースラインに準拠した RHEL システムをデプロイできます。この例では、OSPP (Protection Profile for General Purpose Operating System) を使用します。
前提条件
-
RHEL 8 システムに、
scap-security-guideパッケージがインストールされている。
手順
-
キックスタートファイル
/usr/share/scap-security-guide/kickstart/ssg-rhel8-ospp-ks.cfgを、選択したエディターで開きます。 -
設定要件を満たすように、パーティション設定スキームを更新します。OSPP に準拠するには、
/boot、/home、/var、/tmp、/var/log、/var/tmp、および/var/log/auditの個別のパーティションを保持する必要があります。パーティションのサイズのみ変更することができます。 - キックスタートを使用した自動インストールの実行 の説明に従って、キックスタートインストールを開始します。
キックスタートファイルのパスワードでは、OSPP の要件が確認されていません。
検証
インストール完了後にシステムの現在のステータスを確認するには、システムを再起動して新しいスキャンを開始します。
# oscap xccdf eval --profile ospp --report eval_postinstall_report.html /usr/share/xml/scap/ssg/content/ssg-rhel8-ds.xml
第7章 サブスクリプションサービスの変更
サブスクリプションを管理するには、Red Hat Subscription Management Server または Red Hat Satellite Server に RHEL システムを登録します。必要に応じて、後でサブスクリプションサービスを変更できます。登録しているサブスクリプションサービスを変更するには、現在のサービスからシステムの登録を解除し、新しいサービスに登録します。
システムの更新を受信するには、いずれかの管理サーバーにシステムを登録します。
このセクションは、Red Hat Subscription Management Server および Red Hat Satellite Server から RHEL システムの登録を解除する方法を説明します。
前提条件
以下のいずれかでシステムを登録している。
- Red Hat Subscription Management Server
- Red Hat Satellite Server version 6.11
システムの更新を受信するには、いずれかの管理サーバーにシステムを登録します。
7.1. Subscription Management Server からの登録解除
このセクションでは、コマンドラインと Subscription Manager ユーザーインターフェイスを使用して、Red Hat Subscription Management Server から RHEL システムの登録を解除する方法を説明します。
7.1.1. コマンドラインでの登録解除
unregister コマンドを使用して、Red Hat Subscription Management Server から RHEL システムの登録を解除します。
手順
root ユーザーで unregister コマンドにパラメーターを付けずに実行します。
# subscription-manager unregister- プロンプトが表示されたら、root パスワードを入力します。
システムが Subscription Management Server から登録解除され、ステータス 'The system is currently not registered' が表示され、 ボタンが有効になります。
中断しなかったサービスを続けるには、いずれかの管理サービスでシステムの再登録を行います。管理サービスでシステムを登録しないと、システムの更新を受け取らないことがあります。システムの登録の詳細は、コマンドラインを使用したシステムの登録 を参照してください。
7.1.2. Subscription Manager ユーザーインターフェイスを使用した登録解除
Subscription Manager ユーザーインターフェイスを使用して、Red Hat Subscription Management Server から RHEL システムの登録を解除できます。
手順
- システムにログインします。
- 画面左上で、アクティビティー をクリックします。
- メニューオプションから、アプリケーションを表示する アイコンをクリックします。
- Red Hat Subscription Manager アイコンをクリックするか、検索に Red Hat Subscription Manager と入力します。
認証が必要です ダイアログボックスで管理者パスワードを入力します。サブスクリプション 画面が開き、サブスクリプションの現在のステータス、システムの目的、インストール済み製品が表示されます。未登録の製品には、赤い X 印が表示されます。
システムで特権タスクを実行するには、認証が必要です。
- ボタンをクリックします。
システムが Subscription Management Server から登録解除され、ステータス 'The system is currently not registered' が表示され、 ボタンが有効になります。
中断しなかったサービスを続けるには、いずれかの管理サービスでシステムの再登録を行います。管理サービスでシステムを登録しないと、システムの更新を受け取らないことがあります。システムの登録の詳細は、Subscription Manager ユーザーインターフェイスを使用したシステム登録 を参照してください。
7.2. Satellite Server からの登録解除
Satellite Server から Red Hat Enterprise Linux システムの登録を解除するには、Satellite Server からシステムを削除します。
詳細は、Red Hat Satellite からのホストの削除 を参照してください。
第8章 RHEL ベータ版リリースをインストールおよび起動するために UEFI セキュアブートが有効なシステムを準備する
オペレーティングシステムのセキュリティーを強化するには、UEFI セキュアブートが有効になっているシステムで Red Hat Enterprise Linux ベータ版リリースを起動したときに、署名の検証に UEFI セキュアブート機能を使用します。
8.1. UEFI セキュアブートおよび RHEL ベータ版リリース
UEFI セキュアブートでは、オペレーティングシステムカーネルが、認識された秘密キーで署名されている必要があります。UEFI セキュアブートは、対応する公開キーを使用して署名を検証します。
Red Hat Enterprise Linux 8 のベータリリースの場合には、カーネルは Red Hat ベータ固有の秘密鍵で署名されます。UEFI セキュアブートは、対応する公開鍵を使用して署名を検証しようとしますが、このハードウェアはベータ版の秘密鍵を認識しないため、Red Hat Enterprise Linux ベータ版のリリースシステムは起動に失敗します。そのため、ベータリリースで UEFI セキュアブートを使用するには、MOK (Machine Owner Key) 機能を使用して Red Hat ベータ公開キーをシステムに追加します。
8.2. UEFI セキュアブートのベータ公開鍵の追加
このセクションでは、UEFI セキュアブート用に Red Hat Enterprise Linux ベータ版の公開鍵を追加する方法を説明します。
前提条件
- システムで UEFI セキュアブートが無効になっています。
- Red Hat Enterprise Linux ベータ版リリースがインストールされており、システムの再起動もセキュアブートが無効になっている。
- システムにログインし、初期セットアップ 画面でタスクを完了します。
手順
システムの Machine Owner Key (MOK) リストに Red Hat ベータ版の公開鍵の登録を開始します。
# mokutil --import /usr/share/doc/kernel-keys/$(uname -r)/kernel-signing-ca.cer$(uname -r)はカーネルバージョン (4.18.0-80.el8.x86_64 など) に置き換えられます。- プロンプトが表示されたらパスワードを入力します。
- システムを再起動し、任意のキーを押して起動を続行します。Shim UEFI キー管理ユーティリティーは、システム起動時に起動します。
- Enroll MOK を選択します。
- Continue を選択します。
- Yes を選択し、パスワードを入力します。この鍵はシステムのファームウェアにインポートされます。
- Reboot を選択します。
- システムでセキュアブートを有効にします。
8.3. ベータ版公開鍵の削除
Red Hat Enterprise Linux ベータ版リリースを削除し、Red Hat Enterprise Linux General Availability (GA) リリースをインストールするか、別のオペレーティングシステムをインストールする予定の場合は、ベータ版の公開鍵を削除します。
この手順では、ベータ版の公開鍵を削除する方法を説明します。
手順
システムの Machine Owner Key (MOK) リストから Red Hat ベータ版の公開鍵の削除を開始します。
# mokutil --reset- プロンプトが表示されたらパスワードを入力します。
- システムを再起動し、任意のキーを押して起動を続行します。Shim UEFI キー管理ユーティリティーは、システム起動時に起動します。
- Reset MOK を選択します。
- Continue を選択します。
- Yes を選択し、手順 2 で指定したパスワードを入力します。この鍵はシステムのファームウェアから削除されます。
- Reboot を選択します。
付録A 起動オプションのリファレンス
起動オプションを使用すると、インストールプログラムのデフォルトの動作を変更できます。
A.1. インストールソースの起動オプション
このセクションでは、さまざまなインストールソースのブートオプションを説明します。
- inst.repo=
inst.repo=起動オプションはインストールソースを指定します。つまり、パッケージリポジトリーと、そのリポジトリーを記述する有効な.treeinfoファイルを提供する場所にあたります。たとえば、inst.repo=cdromになります。inst.repo=オプションの対象は、以下のいずれかのインストールメディアになります。-
インストール可能なツリー (インストールプログラムのイメージ、パッケージ群、リポジトリーデータおよび有効な
.treeinfoファイルを含むディレクトリー設定) - DVD (システムの DVD ドライブにある物理ディスク)
Red Hat Enterprise Linux のフルインストール用 DVD の ISO イメージ (ディスク、またはシステムにアクセスできるネットワーク上の場所)
inst.repo=起動オプションでは、さまざまなインストール方法を設定します。以下の表は、inst.repo=起動オプションの詳細な構文を記載します。Expand 表A.1 inst.repo= ブートオプションおよびインストールソースのタイプおよびフォーマット ソースタイプ 起動オプションの形式 ソースの形式 CD/DVD ドライブ
inst.repo=cdrom:<device>物理ディスクとしてのインストール DVD。 [a]
マウント可能なデバイス (HDD および USB スティック)
inst.repo=hd:<device>:/<path>インストール DVD のイメージファイル
NFS サーバー
inst.repo=nfs:[options:]<server>:/<path>インストール DVD のイメージファイル、またはインストールツリー (インストール DVD にあるディレクトリーおよびファイルの完全なコピー)。 [b]
HTTP サーバー
inst.repo=http://<host>/<path>インストールツリー (インストール DVD 上にあるディレクトリーおよびファイルの完全なコピー)。
HTTPS サーバー
inst.repo=https://<host>/<path>FTP サーバー
inst.repo=ftp://<username>:<password>@<host>/<path>HMC
inst.repo=hmc[a] device が省略された場合、インストールプログラムはインストール DVD を含むドライブを自動的に検索します。[b] NFS サーバーのオプションでは、デフォルトで NFS プロトコルのバージョン 3 が使用されます。別のバージョンを使用するには、nfsvers=Xを オプション に追加し、X を、使用するバージョン番号に置き換えます。
-
インストール可能なツリー (インストールプログラムのイメージ、パッケージ群、リポジトリーデータおよび有効な
ディスクデバイス名は、次の形式で設定します。
-
カーネルデバイス名 (例:
/dev/sda1またはsdb2) -
ファイルシステムのラベル (例:
LABEL=FlashまたはLABEL=RHEL8) -
ファイルシステムの UUID (例:
UUID=8176c7bf-04ff-403a-a832-9557f94e61db)
英数字以外は \xNN で表す必要があります。NN は文字の 16 進数表示になります。たとえば、\x20 なら空白 (" ") になります。
- inst.addrepo=
inst.addrepo=起動オプションを使用して、別のインストールソースとして、メインリポジトリー (inst.repo=) とともに追加のリポジトリーを追加します。起動時に、inst.addrepo=起動オプションを複数回使用できます。以下の表では、inst.addrepo=起動オプションの構文の詳細を記載します。注記REPO_NAMEはリポジトリーの名前であり、インストールプロセスでは必須です。これらのリポジトリーは、インストールプロセス時にのみ使用され、インストールしたシステムにはインストールされません。
統一された ISO に関する詳細は、Unified ISO を参照してください。
| インストールソース | 起動オプションの形式 | 関連情報 |
|---|---|---|
| URL にあるインストール可能なツリー |
| 指定の URL にあるインストール可能なツリーを探します。 |
| NFS パスにあるインストール可能なツリー |
|
指定した NFS パスのインストール可能なツリーを探します。コロンは、ホストの後に必要です。インストールプログラムは、RFC 2224 に従って URL の解析を行うのではなく、 |
| インストール環境でインストール可能なツリー |
|
インストール環境の指定した場所にあるインストール可能なツリーを探します。このオプションを使用するには、インストールプログラムが利用可能なソフトウェアグループのロードを試行する前に、リポジトリーがマウントされる必要があります。このオプションの利点は、起動可能な ISO に複数のリポジトリーを利用でき、ISO からメインリポジトリーと追加のリポジトリーの両方をインストールできることです。追加のリポジトリーへのパスは |
| ディスク |
| 指定した <device> パーティションをマウントして、<path> で指定した ISO からインストールします。<path> を指定しないと、インストールプログラムは <device> 上の有効なインストール ISO を探します。このインストール方法には、有効なインストール可能ツリーを持つ ISO が必要です。 |
- inst.stage2=
inst.stage2=起動オプションは、インストールプログラムのランタイムイメージの場所を指定します。このオプションは、有効な.treeinfoファイルが含まれるディレクトリーへのパスを想定し、.treeinfoファイルからランタイムイメージの場所を読み取ります。.treeinfoファイルが利用できないと、インストールプログラムは、images/install.imgからイメージを読み込もうとします。inst.stage2オプションを指定しない場合、インストールプログラムはinst.repoオプションで指定された場所を使用しようとします。このオプションは、後でインストールプログラム内でインストールソースを手動で指定する場合に使用します。たとえば、インストールソースとしてコンテンツ配信ネットワーク (CDN) を選択する場合などに使用します。インストール DVD および Boot ISO には、それぞれの ISO からインストールプログラムを起動するための適切な
inst.stage2オプションがすでに含まれています。インストールソースを指定する場合は、代わりに
inst.repo=オプションを使用します。注記デフォルトでは、インストールメデイアで
inst.stage2=起動オプションが使用され、これは特定のラベル (たとえばinst.stage2=hd:LABEL=RHEL-x-0-0-BaseOS-x86_64) に設定されています。ランタイムイメージが含まれるファイルシステムのデフォルトラベルを修正する場合、またはカスタマイズされた手順を使用してインストールシステムを起動する場合は、inst.stage2=起動オプションに正しい値が設定されていることを確認してください。- inst.noverifyssl
inst.noverifyssl起動オプションを使用して、追加のキックスタートリポジトリーを除き、すべての HTTPS 接続の SSL 証明書が検証されないようにします。ただし、--noverifysslはリポジトリーごとに設定できます。たとえば、リモートのインストールソースが自己署名 SSL 証明書を使用している場合には、
inst.noverifyssl起動オプションは、SSL 証明書を検証せずにインストーラーがインストールを完了できるようにします。inst.stage2=を使用してソースを指定する場合の例inst.stage2=https://hostname/path_to_install_image/ inst.noverifysslinst.repo=を使用してソースを指定する場合の例inst.repo=https://hostname/path_to_install_repository/ inst.noverifyssl- inst.stage2.all
inst.stage2.all起動オプションを使用して、複数の HTTP、HTTPS、または FTP ソースを指定します。inst.stage2=起動オプションは、inst.stage2.allオプションとともに複数回使用して、成功するまで、イメージを順番にフェッチできます。以下に例を示します。inst.stage2.all inst.stage2=http://hostname1/path_to_install_tree/ inst.stage2=http://hostname2/path_to_install_tree/ inst.stage2=http://hostname3/path_to_install_tree/- inst.dd=
-
インストール時にドライバーの更新を実行する場合は、
inst.dd=起動オプションを使用します。インストール時にドライバーを更新する方法の詳細は、インストール時のドライバーの更新 を参照してください。 - inst.repo=hmc
このオプションにより、外部ネットワーク設定の必要がなくなるため、インストールのオプションが増えます。Binary DVD から起動すると、インストーラープログラムにより、追加のカーネルパラメーターを入力するように求められます。DVD をインストールソースとして設定するには、
inst.repo=hmcオプションをカーネルパラメーターに追加します。インストールプログラムは、サポート要素 (SE) およびハードウェア管理コンソール (HMC) のファイルアクセスを有効にし、DVD から stage2 のイメージをフェッチし、ソフトウェア選択のために DVD のパッケージへのアクセスを提供します。重要inst.repoブートオプションを使用するには、ユーザーが 少なくとも Privilege Class B で設定されていることを確認してください。ユーザー設定の詳細は、IBM のドキュメント を参照してください。- プロキシー=
このブートオプションは、HTTP、HTTPS、および FTP プロトコルからインストールを実行するときに使用されます。以下に例を示します。
[PROTOCOL://][USERNAME[:PASSWORD]@]HOST[:PORT]- inst.nosave=
inst.nosave=起動オプションを指定して、インストールログや関連ファイルがインストール済みのシステムに保存されないように制御します (例:input_ks、output_ks、all_ks、logs、all)。複数の値をコンマで区切って組み合わせることができます。以下に例を示します。inst.nosave=Input_ks,logs注記inst.nosaveブートオプションは、インストール済みのシステムから、キックスタートのログや入力/出力などの Kickstart %post スクリプトで削除できないファイルの除外に使用されます。input_ks- キックスタートによる入力を保存する機能を無効にします。
output_ks- インストールプログラムで生成されたキックスタートによる出力を保存する機能を無効にします。
all_ks- キックスタートによる入出力を保存する機能を無効にします。
logs- すべてのインストールログを保存する機能を無効にします。
all- すべてのキックスタート結果とすべてのログを保存する機能を無効にします。
- inst.multilib
-
inst.multilib起動オプションを使用して、DNF のmultilib_policyを、best ではなく all に設定します。 - inst.memcheck
-
inst.memcheck起動オプションは、インストールを完了するのにシステムに十分な RAM があることを確認するためのチェックを実行します。RAM が十分でない場合は、インストールプロセスが停止します。システムのチェックはおおよそのもので、インストールの際のメモリー使用率は、パッケージ選択やユーザーインターフェイス (グラフィカル、テキスト)、その他のパラメーターにより異なります。 - inst.nomemcheck
-
inst.nomemcheck起動オプションは、インストールを完了するのに十分な RAM があるかどうかの確認を実行しません。最小メモリー量未満のインストールの実行はサポートされておらず、インストールプロセスが失敗する可能性があります。
A.2. ネットワーク起動オプション
シナリオでローカルイメージから起動するのではなく、ネットワーク経由でイメージから起動する必要がある場合は、次のオプションを使用してネットワーク起動をカスタマイズできます。
dracut ツールを使用してネットワークを初期化します。dracut オプションの完全なリストは、システムの dracut.cmdline(7) man ページを参照してください。
- ip=
ip=起動オプションは、1 つ以上のネットワークインターフェイスを設定します。複数のインターフェイスを設定するには、次のいずれかの方法を使用します。-
インターフェイスごとに 1 回ずつ、
ipオプションを複数回使用します。これを行うには、rd.neednet=1オプションを使用し、bootdevオプションを使用してプライマリーブートインターフェイスを指定します。 -
ipオプションを 1 回使用してから、Kickstart を使用してさらにインターフェイスを設定します。このオプションでは、複数の形式が使用できます。以下の表は、最も一般的なオプションの情報が含まれます。
-
インターフェイスごとに 1 回ずつ、
以下の表では、下記の点を前提としています。
-
ipパラメーターはクライアントの IP アドレスを指定し、IPv6には角括弧が必要です (例: 192.0.2.1 または [2001:db8::99])。 -
gatewayパラメーターはデフォルトゲートウェイになります。IPv6には角括弧必要です。 -
netmaskパラメーターは使用するネットマスクです。完全ネットマスク (255.255.255.0 など) または接頭辞 (64 など) を使用できます。 hostnameパラメーターはクライアントシステムのホスト名です。このパラメーターは任意です。Expand 表A.3 ネットワークインターフェイスを設定するためのブートオプション形式 起動オプションの形式 設定方法 ip=method全インターフェイスの自動設定
ip=interface:method特定インターフェイスの自動設定
ip=ip::gateway:netmask:hostname:interface:none静的設定 (例: IPv4
ip=192.0.2.1::192.0.2.254:255.255.255.0:server.example.com:enp1s0:none)IPv6:
ip=[2001:db8::1]::[2001:db8::fffe]:64:server.example.com:enp1s0:noneip=ip::gateway:netmask:hostname:interface:method:mtuオーバーライドを使用した特定インターフェイスの自動設定
自動インターフェイスの設定方法
オーバーライドを使用した特定インターフェイスの自動設定では、dhcpなど、指定した自動設定方法を使用してインターフェイスを起動しますが、自動取得した IP アドレス、ゲートウェイ、ネットマスク、ホスト名、他のパラメーターなどで指定したものは無効にします。パラメーターはすべて任意となるため、無効にするパラメーターだけを指定します。methodパラメーターには、以下のいずれかを使用します。- DHCP
-
dhcp - IPv6 DHCP
-
dhcp6 - IPv6 自動設定
-
auto6 - iBFT (iSCSI Boot Firmware Table)
-
ibft
注記-
ipオプションを指定せずに、inst.ks=http://host/pathなどのネットワークアクセスを必要とするブートオプションを使用する場合、ipオプションのデフォルト値はip=dhcpです。 -
iSCSI ターゲットに自動的に接続するには、
ip=ibftブートオプションを使用して、ターゲットにアクセスするネットワークデバイスをアクティブ化します。
- nameserver=
nameserver=オプションは、ネームサーバーのアドレスを指定します。このオプションは複数回使用できます。注記ip=パラメーターには角括弧が必要です。ただし、IPv6 アドレスには角括弧が使用できません。IPv6 アドレスに使用する正しい構文はnameserver=2001:db8::1のようになります。- bootdev=
-
bootdev=オプションは、起動インターフェイスを指定します。このオプションは、ipオプションを複数回使用する場合に必要になります。 - ifname=
ifname=オプションは、特定の MAC アドレスを持つネットワークデバイスにインターフェイス名を割り当てます。このオプションは複数回使用できます。構文は、ifname=interface:MACです。以下に例を示します。ifname=eth0:01:23:45:67:89:ab注記ifname=オプションは、インストール中にカスタムのネットワークインターフェイス名を設定する際にサポートされる唯一の方法となります。- inst.dhcpclass=
-
inst.dhcpclass=オプションは、DHCP のベンダークラス識別子を指定します。dhcpdサービスでは、この値はvendor-class-identifierとして認識されます。デフォルト値はanaconda-$(uname -srm)です。inst.dhcpclass=オプションが正しく適用されるようにするには、インストールの早い段階でipオプションも追加してネットワークのアクティブ化を要求します。 - inst.waitfornet=
-
inst.waitfornet=SECONDS起動オプションを使用すると、インストールシステムは、ネットワーク接続を待ってからインストールします。SECONDS引数で指定する値は、ネットワーク接続がない場合でもすぐにはタイムアウトにせず、ネットワーク接続を待ち続け、インストールプロセスを継続する最大秒数を表します。 - vlan=
vlan=オプションを使用して、仮想 LAN (VLAN) デバイスに特定の名前を付け、指定インターフェイスにそのデバイスを設定します。構文はvlan=name:interfaceです。以下に例を示します。vlan=vlan5:enp0s1これにより、
enp0s1インターフェイスにvlan5という名前の VLAN デバイスが設定されます。name は以下のような形式をとります。
-
VLAN_PLUS_VID:
vlan0005 -
VLAN_PLUS_VID_NO_PAD:
vlan5 -
DEV_PLUS_VID:
enp0s1.0005 DEV_PLUS_VID_NO_PAD:
enp0s1.5- bond=
bond=オプションを使用して、bond=name[:interfaces][:options]構文でボンディングデバイスを設定します。name はボンディングデバイス名に置き換え、interfaces は物理 (イーサネット) インターフェイスのコンマ区切りリストに置き換え、options はボンディングオプションのコンマ区切りリストに置き換えます。以下に例を示します。bond=bond0:enp0s1,enp0s2:mode=active-backup,tx_queues=32,downdelay=5000利用可能なオプションのリストは、ボンディングコマンド
modinfoを実行します。- team=
team=オプションを使用して、team=name:interfaces構文でチームデバイスを設定します。チームデバイスの基礎となるインターフェイスとして使用されるように、name はチームデバイスの望ましい名前に、interfaces は物理 (イーサネット) デバイスのコンマ区切りリストに置き換えます。以下に例を示します。team=team0:enp0s1,enp0s2- bridge=
bridge=オプションを使用して、bridge=name:interfaces構文でブリッジデバイスを設定します。ブリッジデバイスの基礎となるインターフェイスとして使用されるように、name はブリッジデバイスの望ましい名前に、interfaces は物理 (イーサネット) デバイスのコンマ区切りリストに置き換えます。以下に例を示します。bridge=bridge0:enp0s1,enp0s2
A.3. コンソール起動オプション
このセクションでは、コンソール、モニターディスプレイ、およびキーボードの起動オプションを設定する方法を説明します。
- console=
-
console=オプションを使用して、プライマリーコンソールとして使用するデバイスを指定します。たとえば、最初のシリアルポートでコンソールを使用するには、console=ttyS0を使用します。console=引数を使用する場合、インストールはテキスト UI から始まります。console=オプションを複数回使用する必要がある場合は、指定したすべてのコンソールにブートメッセージが表示されます。ただし、インストールプログラムは、最後に指定されたコンソールのみを使用します。たとえば、console=ttyS0 console=ttyS1と指定すると、インストールプログラムではttyS1が使用されます。 - inst.lang=
-
inst.lang=オプションを使用して、インストール時に使用する言語を設定します。ロケールのリストを表示するには、コマンドlocale -a | grep _またはlocalectl list-locales | grep _コマンドを実行します。 - inst.singlelang
-
inst.singlelangを指定して単一の言語モードでインストールを行うと、そのインストール言語と言語サポート設定に対する対話オプションを利用できません。inst.lang起動オプションまたはlangキックスタートコマンドを使用して言語を指定すると、オプションが指定されます。言語を指定しないと、インストールプログラムのロケールはデフォルトでen_US.UTF-8となります。 - inst.geoloc=
インストールプログラムで、地理位置情報の使用方法を設定するには、
inst.geoloc=オプションを使用します。地理位置情報は、言語およびタイムゾーンの事前設定に使用され、inst.geoloc=value構文を使用します。valueには、以下のいずれかのパラメーターを使用します。-
地理位置情報の無効化:
inst.geoloc=0 -
Fedora GeoIP API (
inst.geoloc=provider_fedora_geoip) の使用。 Hostip.info GeoIP API (
inst.geoloc=provider_hostip) の使用。inst.geoloc=オプションを指定しない場合、デフォルトのオプションはprovider_fedora_geoipです。
-
地理位置情報の無効化:
- inst.keymap=
-
inst.keymap=オプションを使用して、インストールに使用するキーボードレイアウトを指定します。 - inst.cmdline
-
inst.cmdlineオプションを使用して、インストールプログラムをコマンドラインモードで強制的に実行します。このモードでは対話が使用できないため、キックスタートファイルまたはコマンドラインですべてのオプションを指定する必要があります。 - inst.graphical
-
インストールプログラムをグラフィカルモードで強制的に実行するには、
inst.graphicalオプションを使用します。グラフィカルモードがデフォルトです。 - inst.text
-
inst.textオプションを使用して、グラフィカルモードではなく、テキストモードでインストールプログラムを強制的に実行します。 - inst.noninteractive
-
inst.noninteractive起動オプションを使用して、非対話モードでインストールプログラムを実行します。非対話型モード (およびinst.noninteractive) では、ユーザーとの対話は許可されていません。グラフィカルまたはテキストインストールでinst.nointeractiveオプションを使用できます。inst.noninteractiveオプションをテキストモードで使用すると、inst.cmdlineオプションと同じように動作します。 - inst.resolution=
-
inst.resolution=オプションを使用して、グラフィカルモードで、画面の解像度を指定します。形式はNxMです。N は画面の幅で、M は画面の高さ (ピクセル単位) です。推奨される解像度は 1024x768 です。 - inst.vnc
-
inst.vncオプションを使用して、Virtual Network Computing (VNC) を使用したグラフィカルインストールを実行します。インストールプログラムと対話するには VNC クライアントアプリケーションを使用する必要があります。VNC 共有を有効にすると、複数のクライアントに接続できます。VNC を使用してインストールしたシステムは、テキストモードで起動します。 - inst.vncpassword=
-
inst.vncpassword=オプションを使用して、インストールプログラムが使用する VNC サーバーにパスワードを設定します。 - inst.vncconnect=
-
inst.vncconnect=オプションを使用して、指定されたホストの場所にあるリスニング VNC クライアントに接続します (例:inst.vncconnect=<host>[:<port>])。デフォルトのポートは 5900 です。このオプションを使用するには、コマンドvncviewer -listenを入力します。 - inst.xdriver=
-
inst.xdriver=オプションを使用して、インストール時およびインストール済みシステムで使用される X ドライバーの名前を指定します。 - inst.usefbx
-
inst.usefbxオプションを使用して、ハードウェア固有のドライバーではなく、フレームバッファー X ドライバーを使用するようにインストールプログラムに要求します。このオプションは、inst.xdriver=fbdevオプションと同等です。 - modprobe.blacklist=
modprobe.blacklist=オプションを使用して、1 つ以上のドライバーを拒否リストに追加するか、完全に無効にします。このオプションを使用して無効にしたドライバー (mods) は、インストールの開始時にロードできません。インストールが完了すると、インストールされたシステムはこれらの設定を保持します。拒否リストに指定したドライバーのリストは、/etc/modprobe.d/ディレクトリーにあります。複数のドライバーを無効にするには、コンマ区切りリストを使用します。以下に例を示します。modprobe.blacklist=ahci,firewire_ohci注記modprobe.blacklistは、さまざまなコマンドラインオプションと組み合わせて使用できます。たとえば、既存のドライバーの更新バージョンがドライバー更新ディスクから確実に読み込まれるようにするには、inst.ddオプションを使用します。modprobe.blacklist=virtio_blk- inst.xtimeout=
-
inst.xtimeout=オプションを使用して、X サーバーの起動のタイムアウトを秒単位で指定します。 - inst.sshd
インストール時に、SSH を使用してシステムに接続し、インストールの進捗を監視できるように、
inst.sshdオプションを使用して、sshdサービスを開始します。SSH の詳細は、システムのssh(1)man ページを参照してください。デフォルトでは、sshdオプションは、64 ビットの IBM Z アーキテクチャーでのみ自動的に起動します。その他のアーキテクチャーでは、sshdは、inst.sshdオプションを使用しない限り起動しません。注記インストール中に、root アカウントにはデフォルトでパスワードが設定されていません。キックスタートコマンド
sshpwを使用して、インストール時に root パスワードを設定できます。- inst.kdump_addon=
-
インストールプログラムで Kdump 設定画面 (アドオン) を有効または無効にするには、
inst.kdump_addon=オプションを使用します。この画面はデフォルトで有効になっているため、無効にする場合はinst.kdump_addon=offを使用します。アドオンを無効にすると、グラフィカルおよびテキストベースのインターフェイスと、キックスタートコマンド%addon com_redhat_kdumpの両方で Kdump 画面が無効になります。
A.4. デバッグ起動オプション
このセクションでは、問題をデバッグするときに使用できるオプションを説明します。
- inst.rescue
-
inst.rescueオプションを使用して、システムの診断と修正のためのレスキュー環境を実行します。詳細は、Red Hat ナレッジベースソリューション repair a filesystem in rescue mode を参照してください。 - inst.updates=
inst.updates=オプションを使用して、インストール時に適用するupdates.imgファイルの場所を指定します。updates.imgファイルは、いくつかのソースの 1 つから取得できます。Expand 表A.4 updates.img ファイルソース ソース 説明 例 ネットワークからの更新
updates.imgのネットワーク上の場所を指定します。インストールツリーを変更する必要はありません。この方法を使用するには、カーネルコマンドラインを編集してinst.updatesを追加します。inst.updates=http://website.com/path/to/updates.img.ディスクイメージからの更新
フロッピードライブまたは USB キーに
updates.imgを保存できます。これは、ファイルシステムタイプがext2のupdates.imgでのみ可能です。イメージの内容をフロッピードライブに保存するには、フロッピーディスクを挿入し、次のコマンドを実行します。dd if=updates.img of=/dev/fd0 bs=72k count=20USB キーまたはフラッシュメディアを使用するには、/dev/fd0を、USB キーのデバイス名に置き換えます。インストールツリーからの更新
CD、ディスク、HTTP、または FTP のインストールを使用する場合は、すべてのインストールツリーが
.imgファイルを検出できるように、インストールツリーにupdates.imgを保存できます。このファイル名は、updates.imgにする必要があります。NFS インストールの場合は、ファイルを
images/ディレクトリーまたはRHupdates/ディレクトリーに保存します。- inst.loglevel=
inst.loglevel=オプションを使用して、端末に記録するログメッセージの最小レベルを指定します。このオプションは、ターミナルログにのみ適用されます。ログファイルには、常にすべてのレベルのメッセージが含まれます。このオプションで可能な値は、最低レベルから最高レベルまで次のとおりです。-
debug -
info -
warning -
error -
critical
-
デフォルト値は info となるため、デフォルトでは、info から critical までのメッセージがログの端末に表示されます。
- inst.syslog=
-
インストールの開始時に、指定されたホスト上の
syslogプロセスにログメッセージを送信します。inst.syslog=は、リモートsyslogプロセスが着信接続を受け入れるように設定されている場合にのみ使用できます。 - inst.virtiolog=
-
inst.virtiolog =オプションを使用して、ログの転送に使用する virtio ポート (/dev/virtio-ports/nameにある文字デバイス) を指定します。デフォルト値は、org.fedoraproject.anaconda.log.0です。 - inst.zram=
インストール中の zRAM スワップの使用を制御します。このオプションは、システム RAM 内に圧縮されたブロックデバイスを作成し、ディスクを使用する代わりにそれをスワップ領域として使用します。この設定により、使用可能なメモリーが少ない状態でインストールプログラムを実行し、インストール速度を向上させることができます。次の値を使用して、
inst.zram=オプションを設定できます。- inst.zram=1 は、システムメモリーサイズに関係なく、zRAM スワップを有効にします。デフォルトでは、2GiB 以下の RAM を搭載したシステムで zRAM のスワップが有効になっています。
- inst.zram=0 は、システムメモリーサイズに関係なく、zRAM スワップを無効にします。デフォルトでは、2GiB を超えるメモリーを搭載したシステムでは zRAM のスワップが無効になっています。
- rd.live.ram
-
images/install.imgのstage 2イメージを RAM にコピーします。これにより、インストールに必要なメモリーがイメージのサイズ (通常は 400 ~ 800MB) だけ増加することに注意してください。 - inst.nokill
- 致命的なエラーが発生したとき、またはインストールプロセスの最後に、インストールプログラムが再起動しないようにします。再起動時に失われるインストールログをキャプチャーするのに使用します。
- inst.noshell
- インストール中にターミナルセッション 2 (tty2) でシェルを防止します。
- inst.notmux
- インストール中に tmux を使用しないようにします。この出力は、ターミナル制御文字なしで生成され、非対話用になります。
- inst.remotelog=
-
TCP 接続を使用してすべてのログをリモート
host:portに送信します。リスナーがなく、インストールが通常通りに進まない場合は、接続が中断されます。
A.5. ストレージ起動オプション
このセクションでは、ストレージデバイスからの起動をカスタマイズするために指定できるオプションを説明します。
- inst.nodmraid
-
dmraidサポートを無効にします。
使用する場合は注意が必要です。ファームウェア RAID アレイの一部として誤って特定されたディスクがある場合は、古い RAID メタデータが存在する可能性があります。これらは、dmraid や wipefs などの適切なツールを使用して削除する必要があります。
- inst.nompath
- マルチパスデバイスのサポートを無効にします。このオプションは、システムに誤検知があり、通常のブロックデバイスをマルチパスデバイスとして誤って識別する場合にのみ使用してください。
使用する場合は注意が必要です。マルチパスハードウェアではこのオプションを使用しないでください。このオプションを使用してマルチパスデバイスのシングルパスにインストールすることはサポートされていません。
- inst.gpt
-
インストールプログラムがパーティション情報を Master Boot Record (MBR) ではなく GUID Partition Table (GPT) にインストールするように強制します。このオプションは、BIOS 互換モードである場合を除き、UEFI ベースのシステムでは有効ではありません。通常、BIOS 互換モードの BIOS ベースのシステムおよび UEFI ベースのシステムは、ディスクのサイズが 2^32 セクター以上でない限り、パーティション情報の格納に MBR スキーマを使用しようとします。ディスクセクターは通常 512 バイトで、通常これは 2 TiB に相当します。
inst.gptブートオプションを使用すると、GPT をより小さなディスクに書き込むことができます。 - inst.wait_for_disks=
-
inst.wait_for_disks=オプションを使用して、インストールの開始時にディスクデバイスが表示されるまでインストールプログラムが待機する秒数を指定します。キックスタートファイルまたはカーネルドライバーを自動的にロードするためにOEMDRV-labeledデバイスを使用しているものの、起動プロセス中にデバイスが表示されるまでに時間がかかる場合は、このオプションを使用します。デフォルトでは、インストールプログラムは5秒間待機します。遅延を最小限に抑えるには、0秒を使用します。
A.6. 廃止予定の起動オプション
このセクションは、非推奨の起動オプションを説明します。これらのオプションはインストールプログラムでも使用できますが、非推奨とされています。また、Red Hat Enterprise Linux の今後のリリースで削除される予定です。
- method
-
methodオプションは、inst.repoのエイリアスです。 - dns
-
dnsの代わりにnameserverを使用します。ネームサーバーはコンマ区切りのリストを受け付けず、代わりに複数のネームサーバーオプションを使用することに注意してください。 - netmask、gateway、hostname
-
netmask、gateway、およびhostnameオプションは、ipオプションの一部として利用できます。 - ip=bootif
-
PXE 指定の
BOOTIFオプションが自動的に使用されるため、ip=bootifを使用する必要はありません。 - ksdevice
Expand 表A.5 ksdevice 起動オプションの値 値 情報 存在しない
該当なし
ksdevice=linkこのオプションがデフォルトの動作と同じ場合に無視されます。
ksdevice=bootifBOOTIF=が存在する場合は、このオプションはデフォルトであるため無視されます。ksdevice=ibftip=ibftに変更詳細はipを参照してください。ksdevice=<MAC>BOOTIF=${MAC/:/-}に変更ksdevice=<DEV>bootdevに置き換え
A.7. 削除済みの起動オプション
このセクションでは、Red Hat Enterprise Linux から削除された起動オプションを説明します。
dracut では、高度な起動オプションを利用できます。dracut の詳細は、システム上の dracut.cmdline(7) man ページを参照してください。
- askmethod、asknetwork
-
initramfsは完全に非対話的に実行されるため、askmethodとasknetworkのオプションは削除されました。inst.repoを使用して、適切なネットワークオプションを指定します。 - blacklist、nofirewire
-
modprobeオプションは、カーネルモジュールのブロックリストを処理するようになりました。modprobe.blacklist=<mod1>,<mod2>を使用します。modprobe.blacklist=firewire_ohciを使用して、FireWire モジュールを拒否リストに入れることができます。 - inst.headless=
-
headless=オプションでは、インストールしているシステムにディスプレイハードウェアがなく、インストールプログラムがディスプレイハードウェアを検索する必要がないことを指定しています。 - inst.decorated
-
inst.decoratedオプションは、装飾画面でのグラフィカルインストールの指定に使用されていまいた。デフォルトでは、画面は装飾されないため、タイトルバーやサイズ変更などの機能はありません。このオプションは不要になりました。 - repo=nfsiso
-
inst.repo=nfs:オプションを使用します。 - serial
-
console=ttyS0オプションを指定します。 - updates
-
inst.updatesオプションを指定します。 - essid、wepkey、wpakey
- dracut はワイヤレスネットワークをサポートしません。
- ethtool
- このオプションは不要になりました。
- gdb
-
dracut ベースの
initramfsのデバッグには多くのオプションが使用できるため、このオプションは削除されました。 - inst.mediacheck
-
dracut オプションの rd.live.checkオプション指定してください。 - ks=floppy
-
inst.ks=hd:<device>オプションを指定します。 - display
-
UI のリモートディスプレイには、
inst.vncオプションを指定します。 - utf8
- このオプションは、デフォルトの TERM 設定が期待通りに動作するため、不要になりました。
- noipv6
-
IPv6 はカーネルに組み込まれたため、インストールプログラムによる削除はできません。
ipv6.disable=1を使用して ipv6 を無効にすることができます。この設定は、インストール済みシステムによって使用されます。 - upgradeany
- インストールプログラムがアップグレードを処理しなくなるため、このオプションは不要になりました。
第9章 RHEL システムイメージのカスタマイズ
9.1. RHEL Image Builder の説明
システムをデプロイするには、システムイメージを作成します。RHEL システムイメージを作成するには、RHEL Image Builder ツールを使用します。RHEL Image Builder を使用することで、RHEL のカスタマイズされたシステムイメージを作成できます。これには、クラウドプラットフォームへのデプロイメント用に準備されたシステムイメージが含まれます。RHEL Image Builder は、各出力タイプのセットアップの詳細を自動的に処理するため、手動でイメージを作成する方法よりも使いやすく、作業が高速です。RHEL Image Builder の機能には、composer-cli ツールのコマンドライン、または RHEL Web コンソールのグラフィカルユーザーインターフェイスを使用してアクセスできます。
RHEL 8.3 以降では、osbuild-composer バックエンドが lorax-composer に取って代わります。新しいサービスには、イメージビルド向けの REST API が含まれます。
9.1.1. RHEL Image Builder の用語
RHEL Image Builder は次の概念を使用します。
- ブループリント
ブループリントは、カスタマイズされたシステムイメージの説明です。システムの一部となるパッケージとカスタマイズが一覧表示されます。ブループリントをカスタマイズして編集し、特定のバージョンとして保存できます。ブループリントからシステムイメージを作成すると、イメージは RHEL Image Builder インターフェイスでブループリントに関連付けられます。
ブループリントは TOML 形式で作成します。
- Compose
- コンポーズは、特定のブループリントの特定のバージョンに基づいた、システムイメージの個別のビルドです。用語としての Compose は、システムイメージと、その作成、入力、メタデータ、およびそのプロセス自体のログを指します。
- カスタマイズ
- カスタマイズは、パッケージではないイメージの仕様です。これには、ユーザー、グループ、および SSH 鍵が含まれます。
9.1.2. RHEL Image Builder の出力形式
RHEL Image Builder は、次の表に示す複数の出力形式でイメージを作成できます。
| 説明 | CLI 名 | ファイル拡張子 |
|---|---|---|
| QEMU イメージ |
|
|
| ディスクアーカイブ |
|
|
| Amazon Web Services |
|
|
| Microsoft Azure |
|
|
| Google Cloud Platform |
|
|
| VMware vSphere |
|
|
| VMware vSphere |
|
|
| Openstack |
|
|
| RHEL for Edge Commit |
|
|
| RHEL for Edge Container |
|
|
| RHEL for Edge Installer |
|
|
| RHEL for Edge Raw イメージ |
|
|
| RHEL for Edge Simplified Installer |
|
|
| RHEL for Edge AMI |
|
|
| RHEL for Edge VMDK |
|
|
| RHEL インストーラー |
|
|
| Oracle Cloud Infrastructure |
|
|
サポートされているタイプを確認するには、次のコマンドを実行します。
# composer-cli compose types9.1.3. イメージビルドでサポートされているアーキテクチャー
RHEL Image Builder は、次のアーキテクチャーのイメージのビルドをサポートしています。
-
AMD および Intel 64 ビット (
x86_64) -
ARM64 (
aarch64) -
IBM Z (
s390x) - IBM POWER システム
ただし、RHEL Image Builder はマルチアーキテクチャービルドをサポートしていません。実行しているのと同じシステムアーキテクチャーのイメージのみをビルドします。たとえば、RHEL Image Builder が x86_64 システムで実行している場合は、x86_64 アーキテクチャーのイメージのみをビルドできます。
9.2. RHEL Image Builder のインストール
RHEL Image Builder は、カスタムのシステムイメージを作成するツールです。RHEL Image Builder を使用する前に、RHEL Image Builder をインストールする必要があります。
9.2.1. RHEL Image Builder のシステム要件
RHEL Image Builder を実行するホストは、次の要件を満たしている必要があります。
| パラメーター | 最低要求値 |
|---|---|
| System type | 専用のホストまたは仮想マシン。RHEL Image Builder は、Red Hat Universal Base Images (UBI) などのコンテナーではサポートされていないことに注意してください。 |
| プロセッサー | 2 コア |
| メモリー | 4 GiB |
| ディスク領域 | `/var/cache/` ファイルシステムに 20 GiB の空き領域 |
| アクセス権限 | root |
| ネットワーク | Red Hat コンテンツ配信ネットワーク (CDN) へのインターネット接続 |
インターネットに接続できない場合は、分離されたネットワークで RHEL Image Builder を使用してください。そのためには、Red Hat コンテンツ配信ネットワーク (CDN) に接続しないように、ローカルリポジトリーを参照するようにデフォルトのリポジトリーをオーバーライドする必要があります。コンテンツが内部でミラーリングされていることを確認するか、Red Hat Satellite を使用してください。
9.2.2. RHEL Image Builder のインストール
RHEL Image Builder をインストールして、osbuild-composer パッケージのすべての機能にアクセスできるようにします。
前提条件
- RHEL Image Builder をインストールする RHEL ホストにログインしている。
- ホストが Red Hat Subscription Manager (RHSM) または Red Hat Satellite にサブスクライブしている。
-
RHEL Image Builder パッケージをインストールできるように、
BaseOSリポジトリーおよびAppStreamリポジトリーを有効化している。
手順
RHEL Image Builder とその他の必要なパッケージをインストールします。
# yum install osbuild-composer composer-cli cockpit-composer-
osbuild-composer- カスタマイズした RHEL オペレーティングシステムイメージをビルドするサービス。 -
composer-cli- このパッケージにより、CLI インターフェイスへのアクセスが可能になります。 -
cockpit-composer- このパッケージにより、Web UI インターフェイスへのアクセスが可能になります。Web コンソールは、cockpit-composerパッケージの依存関係としてインストールされます。
-
RHEL Image Builder ソケットを有効にして起動します。
# systemctl enable --now osbuild-composer.socketWeb コンソールで RHEL Image Builder を使用する場合は、それを有効にして起動します。
# systemctl enable --now cockpit.socketosbuild-composerサービスとcockpitサービスは、最初のアクセス時に自動的に起動します。ログアウトおよびログインしなくても
composer-cliコマンドのオートコンプリート機能がすぐに動作するように、シェル設定スクリプトをロードします。$ source /etc/bash_completion.d/composer-cli
osbuild-composer パッケージは、Red Hat Enterprise Linux 8.3 以降の新機能すべてに焦点を当てた新しいバックエンドエンジンで、デフォルト設定として推奨されています。以前のバックエンドの lorax-composer は非推奨となり、Red Hat Enterprise Linux 8 ライフサイクルの残りの期間、一部の修正のみを受信し、今後のメジャーリリースから削除される予定です。osbuild-composer を優先するには、lorax-composer のアンインストールを推奨します。
検証
composer-cliを実行して、インストールが動作することを確認します。# composer-cli status show
トラブルシューティング
システムジャーナルを使用して、RHEL Image Builder のアクティビティーを追跡できます。さらに、ファイル内のログメッセージを見つけることができます。
トレースバックのジャーナル出力を見つけるには、次のコマンドを実行します。
$ journalctl | grep osbuild複数のサービスインスタンスを起動できるテンプレートサービスである
osbuild-worker@.serviceなどのローカルワーカーを表示するには、以下を実行します。$ journalctl -u osbuild-worker*実行中のサービスを表示するには:
$ journalctl -u osbuild-composer.service
9.2.3. lorax-composer RHEL Image Builder バックエンドに戻す手順
osbuild-composer バックエンドは、はるかに拡張性が高くなっていますが、現時点では以前の lorax-composer バックエンドとの機能パリティーがありません。
以前のバックエンドに戻すには、以下の手順に従います。
前提条件
-
osbuild-composerパッケージがインストールされている。
手順
osbuild-composer バックエンドを削除します。
# yum remove osbuild-composer # yum remove weldr-client/etc/yum.confファイルで、osbuild-composerパッケージの除外エントリーを追加します。# cat /etc/yum.conf [main] gpgcheck=1 installonly_limit=3 clean_requirements_on_remove=True best=True skip_if_unavailable=False exclude=osbuild-composer weldr-clientlorax-composerパッケージをインストールします。# yum install lorax-composer composer-clilorax-composerサービスを有効にして開始し、再起動するたびに開始します。# systemctl enable --now lorax-composer.socket # systemctl start lorax-composer
9.3. RHEL Image Builder CLI を使用したシステムイメージの作成
RHEL Image Builder は、カスタムのシステムイメージを作成するツールです。RHEL Image Builder を制御し、カスタムシステムイメージを作成するには、コマンドライン (CLI) または Web コンソールインターフェイスを使用できます。
9.3.1. RHEL Image Builder コマンドラインインターフェイスの紹介
RHEL Image Builder コマンドラインインターフェイス (CLI) を使用してブループリントを作成するには、適切なオプションとサブコマンドを指定して composer-cli コマンドを実行します。
コマンドラインのワークフローの概要は次のとおりです。
- ブループリントを作成するか、既存のブループリント定義をプレーンテキストファイルにエクスポート (保存) します。
- テキストエディターでこのファイルを編集します。
- ブループリントテキストファイルを Image Builder にインポートします。
- Compose を実行して、ブループリントからイメージをビルドします。
- イメージファイルをエクスポートしてダウンロードします。
composer-cli コマンドには、ブループリントを作成する基本的なサブコマンドとは別に、設定したブループリントと Compose の状態を調べるための多くのサブコマンドが用意されています。
9.3.2. RHEL Image Builder を非 root ユーザーとして使用する
非 root として composer-cli コマンドを実行するには、ユーザーが weldr グループに属している必要があります。
前提条件
- ユーザーを作成している。
手順
ユーザーを
weldrまたはrootグループに追加するには、次のコマンドを実行します:$ sudo usermod -a -G weldr user $ newgrp weldr
9.3.3. コマンドラインを使用したブループリントの作成
RHEL Image Builder のコマンドラインインターフェイス (CLI) を使用して、新しいブループリントを作成できます。ブループリントには、最終的なイメージと、パッケージやカーネルのカスタマイズなどのそのカスタマイズが記述されています。
前提条件
-
root ユーザーまたは
weldrグループのメンバーであるユーザーとしてログインしている。
手順
次の内容のプレーンテキストファイルを作成します。
name = "BLUEPRINT-NAME" description = "LONG FORM DESCRIPTION TEXT" version = "0.0.1" modules = [] groups = []BLUEPRINT-NAME および LONG FORM DESCRIPTION TEXT は、ブループリントの名前および説明に置き換えます。
0.0.1 は、セマンティックバージョニングスキームに従ってバージョン番号に置き換えます。
ブループリントに含まれるすべてのパッケージに、次の行をファイルに追加します。
[[packages]] name = "package-name" version = "package-version"package-name は、
httpd、gdb-doc、coreutilsなどのパッケージ名に置き換えます。必要に応じて、package-version を使用するバージョンに置き換えます。このフィールドは、
dnfバージョンの指定に対応します。- 特定のバージョンについては、8.7.0 などの正確なバージョン番号を使用してください。
- 利用可能な最新バージョンについては、アスタリスク * を使用してください。
- 最新のマイナーバージョンを指定する場合は、8.* などの形式を使用してください。
ニーズに合わせてブループリントをカスタマイズします。たとえば、Simultaneous Multi Threading (SMT) を無効にするには、ブループリントファイルに次の行を追加します。
[customizations.kernel] append = "nosmt=force"その他に利用できるカスタマイズについては、サポートされているイメージのカスタマイズ を参照してください。
[]と[[]]は TOML で表現される異なるデータ構造であることに注意してください。-
[customizations.kernel]ヘッダーは、キーと各値のペアの集合によって定義される単一のテーブルを表します (例:append = "nosmt=force")。 -
[[packages]]ヘッダーはテーブルの配列を表します。最初のインスタンスで、配列とその最初のテーブル要素を定義します (例:name = "package-name"、version = "package-version")。後続の各インスタンスで、指定の順序で、その配列内に新しいテーブル要素を作成して定義します。
-
- たとえば、ファイルを BLUEPRINT-NAME.toml として保存し、テキストエディターを閉じます。
オプション: Blueprint TOML ファイルのすべての設定が正しく解析されているかどうかを確認します。ブループリントを保存し、保存した出力を入力ファイルと比較します。
# composer-cli blueprints save BLUEPRINT-NAME.toml-
保存した
BLUEPRINT-NAME.tomlファイルを入力ファイルと比較します。
-
保存した
ブループリントをプッシュします。
# composer-cli blueprints push BLUEPRINT-NAME.tomlBLUEPRINT-NAME は、前の手順で使用した値に置き換えます。
注記composer-cliを非 root として使用してイメージを作成するには、ユーザーをweldrまたはrootグループに追加します。# usermod -a -G weldr user $ newgrp weldr
検証
ブループリントがプッシュされ存在していることを確認するには、既存のブループリントを一覧表示します。
# composer-cli blueprints list追加したばかりのブループリント設定を表示します。
# composer-cli blueprints show BLUEPRINT-NAMEブループリントに記載されているコンポーネントおよびバージョンと、その依存関係が有効かどうかを確認します。
# composer-cli blueprints depsolve BLUEPRINT-NAMERHEL Image Builder がカスタムリポジトリーのパッケージの依存関係を解決できない場合は、
osbuild-composerキャッシュを削除します。3$ sudo rm -rf /var/cache/osbuild-composer/* $ sudo systemctl restart osbuild-composer
9.3.4. コマンドラインを使用したブループリントの編集
コマンドライン (CLI) で既存のブループリントを編集して、たとえば、新しいパッケージを追加したり、新しいグループを定義したり、カスタマイズしたイメージを作成したりできます。
前提条件
- ブループリントを作成している。
手順
既存のブループリントをリストします。
# composer-cli blueprints listブループリントをローカルテキストファイルに保存します。
# composer-cli blueprints save BLUEPRINT-NAME- BLUEPRINT-NAME .toml ファイルをテキストエディターで編集し、変更を加えます。
編集を完了する前に、ファイルが有効なブループリントであることを確認します。
ブループリントに次の行が存在する場合は、それを削除します。
packages = []- たとえば、バージョン番号を 0.0.1 から 0.1.0 に増やします。RHEL Image Builder のブループリントバージョンでは、セマンティックバージョニングスキームを使用する必要があります。また、バージョンを変更しない場合、パッチバージョンコンポーネントが自動的に増加することにも注意してください。
- ファイルを保存し、テキストエディターを閉じます。
ブループリントを RHEL Image Builder にプッシュして戻します。
# composer-cli blueprints push BLUEPRINT-NAME.toml注記ブループリントを RHEL Image Builder にインポートして戻すには、
.toml拡張子を含むファイル名を指定しますが、他のコマンドではブループリント名のみを使用します。
検証
RHEL Image Builder にアップロードした内容が編集内容と一致することを確認するには、ブループリントの内容をリストします。
# composer-cli blueprints show BLUEPRINT-NAMEブループリントに記載されているコンポーネントおよびバージョンと、その依存関係が有効かどうかを確認します。
# composer-cli blueprints depsolve BLUEPRINT-NAME
9.3.5. RHEL Image Builder コマンドラインでのシステムイメージの作成
RHEL Image Builder のコマンドラインインターフェイスを使用して、カスタマイズした RHEL イメージをビルドできます。そのためには、ブループリントとイメージタイプを指定する必要があります。必要に応じて、ディストリビューションを指定することもできます。ディストリビューションを指定しない場合は、ホストシステムと同じディストリビューションとバージョンが使用されます。アーキテクチャーもホストのアーキテクチャーと同じになります。
前提条件
- イメージにブループリントを用意している。コマンドラインを使用して RHEL Image Builder ブループリントを作成するを 参照してください。
手順
オプション: 作成できるイメージ形式をリストします。
# composer-cli compose typesCompose を起動します。
# composer-cli compose start BLUEPRINT-NAME IMAGE-TYPEBLUEPRINT-NAME をブループリントの名前に、IMAGE-TYPE をイメージのタイプに置き換えます。使用可能な値は、
composer-cli compose typesコマンドの出力を参照してください。作成プロセスはバックグラウンドで開始され、作成者の Universally Unique Identifier (UUID) が表示されます。
イメージの作成が完了するまでに最大 10 分かかる場合があります。
Compose のステータスを確認するには、以下のコマンドを実行します。
# composer-cli compose statusCompose が完了すると、ステータスが FINISHED になります。リスト内の Compose を識別するには、その UUID を使用します。
Compose プロセスが完了したら、作成されたイメージファイルをダウンロードします。
# composer-cli compose image UUIDUUID は、前の手順で示した UUID 値に置き換えます。
検証
イメージを作成した後、次のコマンドを使用してイメージ作成の進行状況を確認できます。
イメージのメタデータをダウンロードして、Compose 用のメタデータの
.tarファイルを取得します。$ sudo composer-cli compose metadata UUIDイメージのログをダウンロードします。
$ sudo composer-cli compose logs UUIDこのコマンドは、イメージ作成のログを含む
.tarファイルを作成します。ログが空の場合は、ジャーナルを確認できます。ジャーナルを確認してください。
$ journalctl | grep osbuildイメージのマニフェストを確認します。
$ sudo cat /var/lib/osbuild-composer/jobs/job_UUID.jsonジャーナルで job_UUID .json を見つけることができます。
9.3.6. RHEL Image Builder コマンドラインの基本的なコマンド
RHEL Image Builder コマンドラインインターフェイスでは、以下のサブコマンドを利用できます。
ブループリント操作
- 利用可能なブループリント一覧の表示
# composer-cli blueprints list- TOML 形式でブループリントの内容の表示
# composer-cli blueprints show <BLUEPRINT-NAME>- TOML 形式のブループリントの内容を
BLUEPRINT-NAME.tomlファイルに保存 (エクスポート) # composer-cli blueprints save <BLUEPRINT-NAME>- ブループリントの削除
# composer-cli blueprints delete <BLUEPRINT-NAME>- TOML 形式のブループリントファイルを RHEL Image Builder へプッシュ (インポート)
# composer-cli blueprints push <BLUEPRINT-NAME>
ブループリントでイメージの設定
- 利用可能なイメージタイプをリスト表示します。
# composer-cli compose types- Compose の起動
# composer-cli compose start <BLUEPRINT> <COMPOSE-TYPE>- Compose のリスト表示
# composer-cli compose list- Compose、およびそのステータスのリスト表示
# composer-cli compose status- 実行中の Compose のキャンセル
# composer-cli compose cancel <COMPOSE-UUID>- 完了した Compose の削除
# composer-cli compose delete <COMPOSE-UUID>- Compose の詳細情報の表示
# composer-cli compose info <COMPOSE-UUID>- Compose のイメージファイルのダウンロード
# composer-cli compose image <COMPOSE-UUID>- サブコマンドとオプションをもっと見る
# composer-cli help
9.3.7. RHEL Image Builder のブループリント形式
RHEL Image Builder のブループリントは、TOML 形式のプレーンテキストとしてユーザーに表示されます。
一般的なブループリントファイルの要素には、次のものが含まれます。
- ブループリントのメタデータ
name = "<BLUEPRINT-NAME>" description = "<LONG FORM DESCRIPTION TEXT>" version = "<VERSION>"BLUEPRINT-NAME および LONG FORM DESCRIPTION TEXT フィールドは、ブループリントの名前と説明です。
VERSION は、セマンティックバージョニングスキームに従ったバージョン番号であり、ブループリントファイル全体で 1 つだけ存在するものです。
- イメージに追加するグループ
[[groups]] name = "group-name"group エントリーは、イメージにインストールするパッケージのグループを説明します。グループは、次のパッケージカテゴリーを使用します。
- 必須
- デフォルト
任意
group-name は、anaconda-tools、widget、wheel または users などのグループの名前です。ブループリントは、必須パッケージとデフォルトパッケージをインストールします。オプションパッケージを選択するメカニズムはありません。
- イメージに追加するパッケージ
[[packages]] name = "<package-name>" version = "<package-version>"package-name は、httpd、gdb-doc、または coreutils などのパッケージの名前です。
package-version は使用するバージョンです。このフィールドは、
dnfバージョンの指定に対応します。- 特定のバージョンについては、8.7.0 などの正確なバージョン番号を使用してください。
- 利用可能な最新バージョンを指定する場合は、アスタリスク (*) を使用します。
最新のマイナーバージョンの場合は、8.* などの形式を使用します。
追加するすべてのパッケージにこのブロックを繰り返します。
RHEL Image Builder ツールのパッケージとモジュールの間に違いはありません。どちらも RPM パッケージの依存関係として扱われます。
9.3.8. サポートされているイメージのカスタマイズ
ブループリントに次のようなカスタマイズを追加することで、イメージをカスタマイズできます。
- RPM パッケージの追加
- サービスの有効化
- カーネルコマンドラインパラメーターのカスタマイズ
とりわけ、ブループリント内ではいくつかのイメージのカスタマイズを使用できます。カスタマイズを使用すると、デフォルトのパッケージでは使用できないパッケージやグループをイメージに追加できます。これらのオプションを使用するには、ブループリントでカスタマイズを設定し、それを RHEL Image Builder にインポート (プッシュ) します。
9.3.8.1. ディストリビューションの選択
distro フィールドを使用して、イメージを作成するときやブループリント内の依存関係を解決するときに使用するディストリビューションを指定できます。distro フィールドが空白のままの場合、ブループリントはホストのオペレーティングシステムディストリビューションを自動的に使用します。ディストリビューションを指定しない場合、ブループリントはホストディストリビューションを使用します。ホストオペレーティングシステムをアップグレードすると、指定されたディストリビューションがないブループリントは、アップグレードされたオペレーティングシステムのバージョンを使用してイメージをビルドします。
新しいシステムで古いメジャーバージョンのイメージをビルドできます。たとえば、RHEL 10 ホストを使用して、RHEL 9 および RHEL 8 のイメージを作成できます。ただし、古いシステムで新しいメジャーバージョンのイメージをビルドすることはできません。
RHEL Image Builder ホストとは異なるオペレーティングシステムイメージをビルドすることはできません。たとえば、RHEL システムを使用して Fedora または CentOS のイメージをビルドすることはできません。
指定の RHEL イメージを常にビルドするように、RHEL ディストリビューションを使用してブループリントをカスタマイズします。
name = "blueprint_name" description = "blueprint_version" version = "0.1" distro = "different_minor_version"以下に例を示します。
name = "tmux" description = "tmux image with openssh" version = "1.2.16" distro = "rhel-9.5"
別のマイナーバージョンをビルドするには、"different_minor_version" を置き換えます。たとえば、RHEL 8.10 イメージをビルドする場合は、distro = "rhel-810" を使用します。RHEL 8.10 イメージでは、RHEL 8.9 以前のリリースなどのマイナーバージョンをビルドできます。
9.3.8.2. パッケージグループの選択
パッケージグループを使用してブループリントをカスタマイズします。イメージにインストールするパッケージのグループを、groups リストに記述します。パッケージグループはリポジトリーのメタデータで定義されます。各グループには、主にユーザーインターフェイスでの表示に使用されるわかりやすい名前と、キックスタートファイルでよく使用される ID があります。この場合、ID を使用してグループをリストする必要があります。グループでは、必須、デフォルト、任意の 3 つの方法でパッケージを分類できます。ブループリントには、必須パッケージとデフォルトパッケージのみがインストールされます。任意のパッケージを選択することはできません。
name 属性は、必須の文字列であり、リポジトリー内のパッケージグループ ID と正確に一致する必要があります。
現在、osbuild-composer のパッケージとモジュールの間に違いはありません。どちらも RPM パッケージの依存関係として扱われます。
パッケージを使用してブループリントをカスタマイズします。
[[groups]] name = "group_name"group_nameは、グループの名前に置き換えます。たとえば、anaconda-toolsです。[[groups]] name = "anaconda-tools"
9.3.8.3. コンテナーの埋め込み
ブループリントをカスタマイズして、最新の RHEL コンテナーを埋め込むことができます。ソースを含むオブジェクトと、必要に応じて tls-verify 属性をコンテナーリストに含めます。
イメージに埋め込むコンテナーイメージを、コンテナーリストのエントリーに記述します。
-
source- 必須フィールド。これは、レジストリーにあるコンテナーイメージへの参照です。この例では、registry.access.redhat.comレジストリーを使用します。タグのバージョンを指定できます。デフォルトのタグバージョンは latest です。 -
name- ローカルレジストリー内のコンテナーの名前。 -
tls-verify- ブールフィールド。tls-verify ブールフィールドは、Transport Layer Security を制御します。デフォルト値は true です。
埋め込まれたコンテナーは自動的に起動しません。これを起動するには、systemd ユニットファイルまたは quadlets を作成し、ファイルをカスタマイズします。
registry.access.redhat.com/ubi9/ubi:latestのコンテナーとホストのコンテナーを埋め込むには、ブループリントに次のカスタマイズを追加します。[[containers]] source = "registry.access.redhat.com/ubi9/ubi:latest" name = "local-name" tls-verify = true [[containers]] source = "localhost/test:latest" local-storage = true
containers-auth.json ファイルを使用して、保護されたコンテナーリソースにアクセスできます。コンテナーレジストリーの認証情報 を参照してください。
9.3.8.4. イメージのホスト名の設定
customizations.hostname は、最終イメージのホスト名を設定するために使用できるオプションの文字列です。このカスタマイズはオプションであり、設定しない場合、ブループリントはデフォルトのホスト名を使用します。
ブループリントをカスタマイズしてホスト名を設定します。
[customizations] hostname = "baseimage"
9.3.8.5. 追加ユーザーの指定
ユーザーをイメージに追加し、必要に応じて SSH キーを設定します。このセクションのフィールドは、name を除いてすべてオプションです。
手順
ブループリントをカスタマイズして、イメージにユーザーを追加します。
[[customizations.user]] name = "USER-NAME" description = "USER-DESCRIPTION" password = "PASSWORD-HASH" key = "PUBLIC-SSH-KEY" home = "/home/USER-NAME/" shell = "/usr/bin/bash" groups = ["users", "wheel"] uid = NUMBER gid = NUMBER[[customizations.user]] name = "admin" description = "Administrator account" password = "$6$CHO2$3rN8eviE2t50lmVyBYihTgVRHcaecmeCk31L..." key = "PUBLIC SSH KEY" home = "/srv/widget/" shell = "/usr/bin/bash" groups = ["widget", "users", "wheel"] uid = 1200 gid = 1200 expiredate = 12345GID はオプションであり、イメージにすでに存在している必要があります。GID は、必要に応じて、パッケージによって作成されるか、ブループリントによって
[[customizations.group]]エントリーを使用して作成されます。PASSWORD-HASH は、実際の
password hashに置き換えます。password hashを生成するには、次のようなコマンドを使用します。$ python3 -c 'import crypt,getpass;pw=getpass.getpass();print(crypt.crypt(pw) if (pw==getpass.getpass("Confirm: ")) else exit())'その他のプレースホルダーを、適切な値に置き換えます。
nameの値を入力し、不要な行は省略します。追加するすべてのユーザーにこのブロックを繰り返します。
9.3.8.6. 追加グループの指定
作成されるシステムイメージのグループを指定します。name 属性と gid 属性は両方とも必須です。
グループを使用してブループリントをカスタマイズします。
[[customizations.group]] name = "GROUP-NAME" gid = NUMBER追加するすべてのグループにこのブロックを繰り返します。以下に例を示します。
[[customizations.group]] name = "widget" gid = 1130
9.3.8.7. 既存ユーザーの SSH キーの設定
customizations.sshkey を使用して、最終イメージ内の既存ユーザーの SSH キーを設定できます。user 属性と key 属性は両方とも必須です。
既存ユーザーの SSH キーを設定してブループリントをカスタマイズします。
[[customizations.sshkey]] user = "root" key = "PUBLIC-SSH-KEY"以下に例を示します。
[[customizations.sshkey]] user = "root" key = "SSH key for root"注記既存ユーザーに対してのみ、
customizations.sshkeyカスタマイズを設定できます。ユーザーを作成して SSH キーを設定するには、追加ユーザーの指定 のカスタマイズを参照してください。
9.3.8.8. カーネル引数の追加
ブートローダーのカーネルコマンドラインに引数を追加できます。デフォルトでは、RHEL Image Builder はデフォルトのカーネルをイメージにビルドします。ただし、ブループリントでカーネルを設定することでカーネルをカスタマイズできます。
デフォルト設定にカーネルの起動パラメーターオプションを追加します。
[customizations.kernel] append = "KERNEL-OPTION"以下に例を示します。
[customizations.kernel] name = "kernel-debug" append = "nosmt=force"
9.3.8.9. リアルタイムカーネルを使用した RHEL イメージのビルド
リアルタイムカーネル (kernel-rt) を使用して RHEL イメージをビルドするには、デフォルトカーネルとして kernel-rt が正しく選択されたイメージをビルドできるように、リポジトリーをオーバーライドする必要があります。/usr/share/osbuild-composer/repositories/ ディレクトリーの .json を使用してください。その後、ビルドしたイメージをシステムにデプロイし、リアルタイムカーネル機能を使用できます。
リアルタイムカーネルは、Red Hat Enterprise Linux の動作認定を受けた AMD64 および Intel 64 サーバープラットフォームで動作します。
前提条件
- システムが登録され、RHEL が RHEL for Real Time サブスクリプションに割り当てられている。dnf を使用した RHEL for Real Time のインストール を参照してください。
手順
以下のディレクトリーを作成します。
# mkdir /etc/osbuild-composer/repositories//usr/share/osbuild-composer/repositories/rhel-8.version.jsonファイルの内容を新しいディレクトリーにコピーします。# cp /usr/share/osbuild-composer/repositories/rhel-8.version.json /etc/osbuild-composer/repositories/etc/osbuild-composer/repositories/rhel-8.version.jsonファイルを編集して、RT カーネルリポジトリーを含めます。# grep -C 6 kernel-rt /etc/osbuild-composer/repositories/rhel-8.version.json "baseurl": "https://cdn.redhat.com/content/dist/rhel8/8.version/x86_64/appstream/os", "gpgkey": "-----BEGIN PGP PUBLIC KEY BLOCK-----\n\nm………..=\n=UZd/\n-----END PGP PUBLIC KEY BLOCK-----\n", "rhsm": true, "check_gpg": true }, { "name": "kernel-rt", "baseurl": "https://cdn.redhat.com/content/dist/rhel8/8.version/x86_64/rt/os", "gpgkey": "-----BEGIN PGP PUBLIC KEY BLOCK-----\n\nmQINBEr………fg==\n=UZd/\n-----END PGP PUBLIC KEY BLOCK-----\n", "rhsm": true, "check_gpg": true },サービスを再起動します。
# systemctl restart osbuild-composerkernel-rtが.jsonファイルに含まれていることを確認します。# composer-cli sources list # composer-cli sources info kernel-rt以前に設定した URL が表示されます。
ブループリントを作成します。ブループリントに、"[customizations.kernel]" カスタマイズを追加します。以下は、ブループリントに "[customizations.kernel]" を追加した例です。
name = "rt-kernel-image" description = "" version = "2.0.0" modules = [] groups = [] distro = "rhel-8_version_" [[customizations.user]] name = "admin" password = "admin" groups = ["users", "wheel"] [customizations.kernel] name = "kernel-rt" append = ""ブループリントをサーバーにプッシュします。
# composer-cli blueprints push rt-kernel-image.toml作成したブループリントからイメージをビルドします。次の例では、(
.qcow2) イメージをビルドします。# composer-cli compose start rt-kernel-image qcow2- ビルドしたイメージを、リアルタイムカーネル機能を使用するシステムにデプロイします。
検証
イメージから仮想マシンを起動した後、デフォルトのカーネルとして
kernel-rtが正しく選択されたイメージがビルドされていることを確認します。$ cat /proc/cmdline BOOT_IMAGE=(hd0,got3)/vmlinuz-5.14.0-362.24.1..el8_version_.x86_64+rt...
9.3.8.10. タイムゾーンと NTP の設定
ブループリントをカスタマイズして、タイムゾーンと Network Time Protocol (NTP) を設定できます。timezone 属性と ntpservers 属性は両方ともオプションの文字列です。タイムゾーンをカスタマイズしない場合、システムは 協定世界時 (UTC) を使用します。NTP サーバーを設定しない場合、システムはデフォルトのディストリビューションを使用します。
必要な
timezoneとntpserversを使用してブループリントをカスタマイズします。[customizations.timezone] timezone = "TIMEZONE" ntpservers = "NTP_SERVER"以下に例を示します。
[customizations.timezone] timezone = "US/Eastern" ntpservers = ["0.north-america.pool.ntp.org", "1.north-america.pool.ntp.org"]注記Google Cloud などの一部のイメージタイプには、すでに NTP サーバーがセットアップされています。そのようなイメージでは、選択されている環境で NTP サーバーを起動する必要があるため、これをオーバーライドすることはできません。ただし、ブループリントでタイムゾーンをカスタマイズできます。
9.3.8.11. ロケール設定のカスタマイズ
作成されるシステムイメージのロケール設定をカスタマイズできます。language 属性と keyboard 属性は両方とも必須です。他の多くの言語を追加できます。最初に追加する言語はプライマリー言語で、他の言語はセカンダリー言語です。
手順
ロケール設定を行います。
[customizations.locale] languages = ["LANGUAGE"] keyboard = "KEYBOARD"以下に例を示します。
[customizations.locale] languages = ["en_US.UTF-8"] keyboard = "us"言語でサポートされている値を一覧表示するには、以下のコマンドを実行します。
$ localectl list-localesキーボードでサポートされている値を一覧表示するには、以下のコマンドを実行します。
$ localectl list-keymaps
9.3.8.12. ファイアウォールのカスタマイズ
生成されたシステムイメージのファイアウォールを設定します。デフォルトでは、ファイアウォールは、sshd など、ポートを明示的に有効にするサービスを除き、着信接続をブロックします。
[customizations.firewall] または [customizations.firewall.services] を使用したくない場合は、属性を削除するか、空のリスト [] に設定します。デフォルトのファイアウォールセットアップのみを使用する場合は、ブループリントからカスタマイズを省略できます。
Google および OpenStack テンプレートは、環境のファイアウォールを明示的に無効にします。ブループリントを設定してこの動作をオーバーライドすることはできません。
手順
他のポートとサービスを開くには、次の設定を使用してブループリントをカスタマイズします。
[customizations.firewall] ports = ["PORTS"]ここで、
portsは、ポート、または開くポートとプロトコルの範囲を含む文字列のオプションのリストです。port:protocol形式を使用してポートを設定できます。portA-portB:protocol形式を使用してポート範囲を設定できます。以下に例を示します。[customizations.firewall] ports = ["22:tcp", "80:tcp", "imap:tcp", "53:tcp", "53:udp", "30000-32767:tcp", "30000-32767:udp"]/etc/servicesの数値ポートまたはその名前を使用して、ポートリストを有効または無効にすることができます。customizations.firewall.serviceセクションで、どのファイアウォールサービスを有効または無効にするかを指定します。[customizations.firewall.services] enabled = ["SERVICES"] disabled = ["SERVICES"]利用可能なファイアウォールサービスを確認できます。
$ firewall-cmd --get-services以下に例を示します。
[customizations.firewall.services] enabled = ["ftp", "ntp", "dhcp"] disabled = ["telnet"]注記firewall.servicesにリストされているサービスは、/etc/servicesファイルで使用可能なservice-namesとは異なります。
9.3.8.13. サービスの有効化または無効化
システムの起動時に有効にするサービスを制御することができます。一部のイメージタイプでは、イメージが正しく機能するようにすでにサービスが有効または無効になっており、このセットアップをオーバーライドすることができません。ブループリントの [customizations.services] 設定はこれらのサービスを置き換えるものではありませんが、イメージテンプレートにすでに存在するサービスのリストにサービスを追加します。
起動時に有効にするサービスをカスタマイズします。
[customizations.services] enabled = ["SERVICES"] disabled = ["SERVICES"]以下に例を示します。
[customizations.services] enabled = ["sshd", "cockpit.socket", "httpd"] disabled = ["postfix", "telnetd"]
9.3.8.14. キックスタートファイルへの ISO イメージの注入
[customization.installer] ブループリントのカスタマイズを使用すると、イメージインストーラー や エッジインストーラー などの ISO インストーラーのビルドに独自のキックスタートファイルを追加して、ベアメタルデプロイメント用の ISO イメージを構築する際の柔軟性を高めることができます。
キックスタートはシステム上の最初のディスクを自動的に再フォーマットするように設定されています。そのため、既存のオペレーティングシステムまたはデータを有するマシンで ISO を起動すると、破壊的な結果を招く可能性があります。
次の中から、独自のキックスタートファイルを追加する方法を選択できます。
- インストールプロセス中にすべての値を設定する。
-
キックスタートで
unattended = trueフィールドを有効にし、デフォルト設定を使用した完全に無人のインストールを実行する。 - キックスタートフィールドを使用して独自のキックスタートを注入する。これにより、すべての必須フィールドを指定した場合に完全に無人のインストールが実行されるか、またはインストーラーが欠落している可能性のあるいくつかのフィールドの入力を要求することになります。
Anaconda インストーラーの ISO イメージタイプでは、次のブループリントのカスタマイズがサポートされています。
[customizations.installer]
unattended = true
sudo-nopasswd = ["user", "%wheel"]
無人:インストールを完全に自動化するキックスタートファイルを作成します。これには、デフォルトで次のオプションの設定が含まれます。
- テキスト表示モード
- en_US.UTF-8 言語/ロケール
- US キーボードレイアウト
- UTC タイムゾーン
- zerombr、clearpart、autopart による最初のディスクの自動的なワイプおよびパーティション設定
- DHCP と自動アクティブ化を有効にするネットワークオプション
以下に例を示します。
liveimg --url file:///run/install/<_repo_>/liveimg.tar.gz
lang en_US.UTF-8
keyboard us
timezone UTC
zerombr
clearpart --all --initlabel
text
autopart --type=plain --fstype=xfs --nohome
reboot --eject
network --device=link --bootproto=dhcp --onboot=on --activate
sudo-nopasswd:インストール後に /etc/sudoers.d にドロップインファイルを作成し、指定されたユーザーとグループがパスワードなしで sudo を実行できるようにするスニペットをキックスタートファイルに追加します。グループには % という接頭辞を付ける必要があります。たとえば、値を ["user", "%wheel"] に設定すると、次のようなキックスタートの %post セクションが作成されます。
%post
echo -e "user\tALL=(ALL)\tNOPASSWD: ALL" > "/etc/sudoers.d/user"
chmod 0440 /etc/sudoers.d/user
echo -e "%wheel\tALL=(ALL)\tNOPASSWD: ALL" > "/etc/sudoers.d/%wheel"
chmod 0440 /etc/sudoers.d/%wheel
restorecon -rvF /etc/sudoers.d
%endインストーラーキックスタート
または、次のカスタマイズを使用して、カスタムのキックスタートを含めることもできます。
[customizations.installer.kickstart]
contents = """
text --non-interactive
zerombr
clearpart --all --initlabel --disklabel=gpt
autopart --noswap --type=lvm
network --bootproto=dhcp --device=link --activate --onboot=on
"""
osbuild-composer を使用すると、image-installer または edge-installer イメージタイプに関連する場合に、システムをインストールするコマンド liveimg または ostreesetup が自動的に追加されます。[customizations.installer.kickstart] によるカスタマイズを、他のインストーラーカスタマイズと組み合わせて使用することはできません。
9.3.8.15. パーティションモードの指定
ビルドするディスクイメージをパーティション設定する方法を選択するには、partitioning_mode 変数を使用します。サポートされている次のモードでイメージをカスタマイズできます。
-
auto-lvm: 1 つ以上のファイルシステムのカスタマイズがない限り、RAW パーティションモードを使用します。ある場合は、LVM パーティションモードを使用します。 -
lvm: 追加のマウントポイントがない場合でも、常に LVM パーティションモードを使用します。 -
raw: マウントポイントが 1 つ以上ある場合でも、RAW パーティションを使用します。 次のカスタマイズを使用して、
partitioning_mode変数を使用してブループリントをカスタマイズできます。[customizations] partitioning_mode = "lvm"
9.3.8.16. カスタムファイルシステム設定の指定
ブループリントでカスタムファイルシステム設定を指定できるため、デフォルトのレイアウト設定ではなく、特定のディスクレイアウトでイメージを作成できます。ブループリントでデフォルト以外のレイアウト設定を使用すると、次の利点が得られます。
- セキュリティーベンチマークへの準拠
- ディスク外エラーに対する保護
- パフォーマンスの向上
- 既存のセットアップとの整合性
OSTree イメージには読み取り専用などの独自のマウントルールがあるため、OSTree システムではファイルシステムのカスタマイズはサポートされません。次のイメージタイプはサポートされません。
-
image-installer -
edge-installer -
edge-simplified-installer
さらに、次のイメージタイプはパーティション設定されたオペレーティングシステムイメージを作成しないため、ファイルシステムのカスタマイズをサポートしません。
-
edge-commit -
edge-container -
tar -
container
ただし、次のイメージタイプではファイルシステムのカスタマイズがサポートされています。
-
simplified-installer -
edge-raw-image -
edge-ami -
edge-vsphere
OSTree システムの一部例外を除き、ファイルシステムの /root レベルで任意のディレクトリー名を選択できます (例: `/local`、`/mypartition`、/$PARTITION)。論理ボリュームでは、これらの変更は LVM パーティションシステム上で行われます。別の論理ボリューム上の /var、`/var/log`、および /var/lib/containers ディレクトリーがサポートされています。root レベルでの例外は次のとおりです。
- "/home": {Deny: true},
- "/mnt": {Deny: true},
- "/opt": {Deny: true},
- "/ostree": {Deny: true},
- "/root": {Deny: true},
- "/srv": {Deny: true},
- "/var/home": {Deny: true},
- "/var/mnt": {Deny: true},
- "/var/opt": {Deny: true},
- "/var/roothome": {Deny: true},
- "/var/srv": {Deny: true},
- "/var/usrlocal": {Deny: true},
RHEL 8.10 および 9.5 より前のリリースディストリビューションの場合、ブループリントは次の mountpoints とそのサブディレクトリーをサポートしています。
-
/- ルートマウントポイント -
/var -
/home -
/opt -
/srv/ -
/usr -
/app -
/data -
/tmp
RHEL 9.5 および 8.10 以降のリリースディストリビューションでは、オペレーティングシステム用に予約されている特定のパスを除き、任意のカスタムマウントポイントを指定できます。
次のマウントポイントとそのサブディレクトリーに任意のカスタムマウントポイントを指定することはできません。
-
/bin -
/boot/efi -
/dev -
/etc -
/lib -
/lib64 -
/lost+found -
/proc -
/run -
/sbin -
/sys -
/sysroot -
/var/lock -
/var/run
ブループリントで /usr カスタムマウントポイントのファイルシステムはカスタマイズできますが、そのサブディレクトリーはカスタマイズできません。
マウントポイントのカスタマイズは、RHEL 8.5 ディストリビューション以降、CLI を使用した場合のみサポートされます。以前のディストリビューションでは、root パーティションをマウントポイントとして指定し、size 引数をイメージ size のエイリアスとして指定することしかできません。RHEL 8.6 以降、osbuild-composer-46.1-1.el8 RPM 以降のバージョンでは、物理パーティションは使用できなくなり、ファイルシステムのカスタマイズによって論理ボリュームが作成されます。
カスタマイズされたイメージに複数のパーティションがある場合、LVM でカスタマイズされたファイルシステムパーティションを使用してイメージを作成し、実行時にそれらのパーティションのサイズを変更できます。これを行うには、ブループリントでカスタマイズされたファイルシステム設定を指定して、必要なディスクレイアウトでイメージを作成します。デフォルトのファイルシステムレイアウトは変更されません。ファイルシステムをカスタマイズせずにプレーンイメージを使用すると、cloud-init によってルートパーティションのサイズが変更されます。
ブループリントは、ファイルシステムのカスタマイズを LVM パーティションに自動的に変換します。
カスタムファイルブループリントのカスタマイズを使用して、新しいファイルを作成したり、既存のファイルを置き換えたりできます。指定するファイルの親ディレクトリーが存在している必要があります。存在しない場合、イメージのビルドが失敗します。[[customizations.directories]] のカスタマイズで親ディレクトリーを指定して、親ディレクトリーが存在することを確認してください。
ファイルのカスタマイズを他のブループリントのカスタマイズと組み合わせると、他のカスタマイズの機能に影響が生じたり、現在のファイルのカスタマイズがオーバーライドされる可能性があります。
9.3.8.16.1. カスタマイズされたファイルをブループリントで指定する
[[customizations.files]] ブループリントのカスタマイズを使用すると、次のことが可能になります。
- 新しいテキストファイルを作成する。
- 既存のファイルを変更する。警告: これにより、既存のコンテンツが上書きされる可能性があります。
- 作成するファイルのユーザーとグループの所有権を設定する。
- モード許可を 8 進数形式で設定する。
以下のファイルは作成または置き換えることはできません。
-
/etc/fstab -
/etc/shadow -
/etc/passwd -
/etc/group
[[customizations.files]] および [[customizations.directories]] ブループリントのカスタマイズを使用して、イメージ内にカスタマイズされたファイルとディレクトリーを作成できます。これらのカスタマイズは、/etc ディレクトリーでのみ使用できます。
これらのブループリントのカスタマイズは、OSTree コミットをデプロイするイメージタイプ (edge-raw-image、edge-installer、edge-simplified-installer など) を除く、すべてのイメージタイプでサポートされます。
mode、user、または group がすでに設定されているイメージ内にすでに存在するディレクトリーパスで customizations.directories を使用すると、イメージビルドで既存のディレクトリーの所有権または権限の変更を防ぐことができません。
9.3.8.16.2. カスタマイズされたディレクトリーをブループリントで指定する
[[customizations.directories]] ブループリントのカスタマイズを使用すると、以下を行うことができます。
- 新しいディレクトリーを作成する。
- 作成するディレクトリーのユーザーとグループの所有権を設定する。
- ディレクトリーモードのパーミッションを 8 進数形式で設定する。
- 必要に応じて親ディレクトリーを作成する。
[[customizations.files]] ブループリントのカスタマイズを使用すると、次のことが可能になります。
- 新しいテキストファイルを作成する。
- 既存のファイルを変更する。警告: これにより、既存のコンテンツが上書きされる可能性があります。
- 作成するファイルのユーザーとグループの所有権を設定する。
- モード許可を 8 進数形式で設定する。
以下のファイルは作成または置き換えることはできません。
-
/etc/fstab -
/etc/shadow -
/etc/passwd -
/etc/group
以下のカスタマイズが可能です。
ブループリントのファイルシステム設定をカスタマイズします。
[[customizations.filesystem]] mountpoint = "MOUNTPOINT" minsize = MINIMUM-PARTITION-SIZEMINIMUM-PARTITION-SIZE値には、デフォルトのサイズ形式はありません。ブループリントのカスタマイズでは、kB から TB、および KiB から TiB の値と単位がサポートされています。たとえば、マウントポイントのサイズをバイト単位で定義できます。[[customizations.filesystem]] mountpoint = "/var" minsize = 1073741824単位を使用してマウントポイントのサイズを定義します。以下に例を示します。
[[customizations.filesystem]] mountpoint = "/opt" minsize = "20 GiB"[[customizations.filesystem]] mountpoint = "/boot" minsize = "1 GiB"minsizeを設定して最小パーティションを定義します。以下に例を示します。[[customizations.filesystem]] mountpoint = "/var" minsize = 2147483648[[customizations.directories]]を使用して、イメージ用にカスタマイズされたディレクトリーを/etcディレクトリーの下に作成します。[[customizations.directories]] path = "/etc/directory_name" mode = "octal_access_permission" user = "user_string_or_integer" group = "group_string_or_integer" ensure_parents = booleanブループリントの各エントリーを説明します。
-
path- 必須 - 作成するディレクトリーへのパスを入力します。/etcディレクトリー下の絶対パスである必要があります。 -
mode- オプション - ディレクトリーのアクセスパーミッションを 8 進数形式で設定します。パーミッションを指定しない場合、デフォルトで 0755 に設定されます。先頭のゼロは任意です。 -
user- オプション - ユーザーをディレクトリーの所有者として設定します。ユーザーを指定しない場合は、デフォルトでrootに設定されます。ユーザーは文字列または整数として指定できます。 -
group- オプション - グループをディレクトリーの所有者として設定します。グループを指定しない場合は、デフォルトでrootになります。グループは文字列または整数として指定できます。 -
ensure_parents- オプション - 必要に応じて親ディレクトリーを作成するかどうかを指定します。値を指定しない場合は、デフォルトでfalseに設定されます。
-
[[customizations.directories]]を使用して、イメージ用にカスタマイズされたファイルを/etcディレクトリーの下に作成します。[[customizations.files]] path = "/etc/directory_name" mode = "octal_access_permission" user = "user_string_or_integer" group = "group_string_or_integer" data = "Hello world!"ブループリントの各エントリーを説明します。
-
path- 必須 - 作成するファイルへのパスを入力します。/etcディレクトリー下の絶対パスである必要があります。 -
mode- オプション - ファイルのアクセスパーミッションを 8 進数形式で設定します。パーミッションを指定しない場合、デフォルトで 0644 に設定されます。先頭のゼロは任意です。 -
user- オプション - ユーザーをファイルの所有者として設定します。ユーザーを指定しない場合は、デフォルトでrootに設定されます。ユーザーは文字列または整数として指定できます。 -
group- オプション - グループをファイルの所有者として設定します。グループを指定しない場合は、デフォルトでrootになります。グループは文字列または整数として指定できます。 -
data- オプション - プレーンテキストファイルの内容を指定します。コンテンツを指定しない場合は、空のファイルが作成されます。
-
9.3.8.17. ブループリントでボリュームグループと論理ボリュームの命名を指定する
RHEL Image Builder は次の操作に使用できます。
-
高度なパーティションレイアウトを使用して RHEL ディスクイメージを作成します。カスタムのマウントポイント、LVM ベースのパーティション、LVM ベースの SWAP を使用してディスクイメージを作成できます。たとえば、
config.tomlファイルを使用して、/および/bootディレクトリーのサイズを変更できます。 -
使用するファイルシステムを選択します。
ext4とxfsのどちらかを選択できます。 - スワップパーティションと LV を追加します。ディスクイメージに LV ベースの SWAP を含めることができます。
- LVM エンティティーの名前を変更します。イメージ内の論理ボリューム (LV) とボリュームグループ (VG) にカスタム名を付けることができます。
次のオプションはサポートされていません。
- 1 つのイメージに複数の PV または VG を含める
- SWAP ファイル
-
/dev/shmや/tmpなどの非物理パーティションのマウントオプション
たとえば、以下のようになります。ファイルシステムが存在する VG および LG カスタマイズ名を追加します。
[[customizations.disk.partitions]]
type = "plain"
label = "data"
mountpoint = "/data"
fs_type = "ext4"
minsize = "50 GiB"
[[customizations.disk.partitions]]
type = "lvm"
name = "mainvg"
minsize = "20 GiB"
[[customizations.disk.partitions.logical_volumes]]
name = "rootlv"
mountpoint = "/"
label = "root"
fs_type = "ext4"
minsize = "2 GiB"
[[customizations.disk.partitions.logical_volumes]]
name = "homelv"
mountpoint = "/home"
label = "home"
fs_type = "ext4"
minsize = "2 GiB"
[[customizations.disk.partitions.logical_volumes]]
name = "swaplv"
fs_type = "swap"
minsize = "1 GiB"9.3.9. RHEL Image Builder によってインストールされるパッケージ
RHEL Image Builder を使用してシステムイメージを作成すると、システムは一連のベースパッケージグループをインストールします。
ブループリントにコンポーネントを追加する場合は、追加したコンポーネント内のパッケージが他のパッケージコンポーネントと競合しないようにしてください。そうしないと、システムは依存関係を解決できず、カスタマイズされたイメージの作成に失敗します。次のコマンドを実行して、パッケージ間に競合がないかどうかを確認できます。
# composer-cli blueprints depsolve BLUEPRINT-NAME
デフォルトでは、RHEL Image Builder は Core グループをパッケージの基本リストとして使用します。
| イメージタイプ | デフォルトパッケージ |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
9.3.10. カスタムイメージで有効なサービス
Image Builder を使用してカスタムイメージを設定する場合、イメージが使用するデフォルトのサービスは次のように決定されます。
-
osbuild-composerユーティリティーを使用する RHEL リリース - イメージの種類
たとえば、ami イメージタイプは、デフォルトで sshd、chronyd、および cloud-init サービスを有効にします。これらのサービスが有効になっていない場合、カスタムイメージは起動しません。
| イメージタイプ | デフォルトで有効化されているサービス |
|---|---|
|
| sshd, cloud-init, cloud-init-local, cloud-config, cloud-final |
|
| sshd, cloud-init, cloud-init-local, cloud-config, cloud-final |
|
| cloud-init |
|
| デフォルトでは、追加のサービスは有効になりません。 |
|
| デフォルトでは、追加のサービスは有効になりません。 |
|
| sshd, chronyd, waagent, cloud-init, cloud-init-local, cloud-config, cloud-final |
|
| sshd、chronyd、vmtoolsd、cloud-init |
注記:システムの起動時に有効にするサービスをカスタマイズできます。ただし、カスタマイズは、前述のイメージタイプに対してデフォルトで有効になっているサービスを上書きしません。
9.4. RHEL Image Builder Web コンソールインターフェイスを使用したシステムイメージの作成
RHEL Image Builder は、カスタムのシステムイメージを作成するツールです。RHEL Image Builder を制御してカスタムシステムイメージを作成する場合は、Web コンソールインターフェイスを使用できます。
9.4.1. RHEL Web コンソールでの RHEL Image Builder ダッシュボードへのアクセス
RHEL Web コンソール用の cockpit-composer プラグインを使用すると、グラフィカルインターフェイスを使用して Image Builder のブループリントと設定を管理できます。
前提条件
- システムへの root アクセス権限がある。
- RHEL Image Builder がインストールされている。
-
cockpit-composerパッケージがインストールされている。
手順
-
ホスト上で、Web ブラウザーで
https://<_localhost_>:9090/を開きます。 - root ユーザーとして Web コンソールにログインします。
RHEL Image Builder のコントロールを表示するには、ウィンドウの左上隅にある ボタンをクリックします。
RHEL Image Builder ダッシュボードが開き、既存のブループリントがあればそれがリストされます。
9.4.2. Web コンソールインターフェイスでのブループリントの作成
カスタマイズした RHEL システムイメージをビルドするには、ブループリントを作成する必要があります。利用可能なカスタマイズはすべて任意です。次の方法を使用して、カスタマイズしたブループリントを作成できます。
- CLI を使用する。サポートされているイメージのカスタマイズ を参照してください。
- Web コンソールを使用する。次の手順に従ってください。
これらのブループリントのカスタマイズは、Red Hat Enterprise Linux 9.2 以降のバージョンおよび Red Hat Enterprise Linux 8.8 以降のバージョンで利用できます。
前提条件
- ブラウザーの Web コンソールから RHEL Image Builder アプリケーションを開いている。RHEL Web コンソールでの RHEL Image Builder GUI へのアクセス を参照してください。
手順
右上隅にある をクリックします。
ブループリントの名前と説明のフィールドを含むダイアログウィザードが開きます。
Detailsページで以下を行います。- ブループリントの名前と、必要に応じてその説明を入力します。
- をクリックします。
オプション:
Packagesページで以下を行います。-
Available packagesの検索で、パッケージ名を入力します。 - ボタンをクリックして Chosen packages フィールドに移動します。
- 前の手順を繰り返して、必要な数のパッケージを検索して含めます。
をクリックします。
注記特に指定がない限り、これらのカスタマイズはすべてオプションです。
-
-
Kernelページで、カーネル名とコマンドライン引数を入力します。 File systemページで、お使いのイメージファイルシステムに合わせてUse automatic partitioningまたはManually configure partitionsを選択します。パーティションを手動で設定するには、次の手順を実行します。ボタンをクリックします。
Configure partitionsセクションが開き、Red Hat 標準およびセキュリティーガイドに基づく設定が表示されます。ドロップダウンメニューから、パーティションを設定するための詳細を入力します。
Mount pointフィールドに、以下のマウントポイントタイプオプションのいずれかを選択します。-
/- ルートマウントポイント -
/app -
/boot -
/data -
/home -
/opt -
/srv/ -
/usr -
/usr/local /var/tmpなどの追加のパスをMount pointに追加することもできます。例: 接頭辞/varと、追加パス/tmpで、/var/tmpになります。注記選択した Mount point のタイプに応じて、ファイルシステムのタイプが
xfsに変わります。
-
ファイルシステムの
Minimum size partitionフィールドに、必要な最小パーティションサイズを入力します。Minimum size ドロップダウンメニューでは、GiB、MiB、KiBなどの一般的なサイズ単位を使用できます。デフォルトの単位はGiBです。注記Minimum sizeとは、作業用イメージの作成には小さすぎる場合にも RHEL Image Builder がパーティションサイズを増加できるという意味です。
さらにパーティションを追加するには、 ボタンをクリックします。以下のエラーメッセージが表示された場合は、以下を行います。
Duplicate partitions:Only one partition at each mount point can be created.- ボタンをクリックして、重複したパーティションを削除します。
- 作成するパーティションの新しいマウントポイントを選択します。
- パーティションの設定が完了したら、 をクリックします。
Servicesページで、サービスを有効または無効にします。- 有効または無効にするサービス名をコンマまたはスペースで区切るか、 キーを押して入力します。 をクリックします。
-
Enabled servicesを入力します。 -
Disabled servicesを入力します。
Firewallページで、ファイアウォールを設定します。-
Portsと、有効または無効にするファイアウォールサービスを入力します。 - ボタンをクリックして、各ゾーンのファイアウォールルールを個別に管理します。 をクリックします。
-
Usersページで、以下の手順に従ってユーザーを追加します。- をクリックします。
-
Username、Password、およびSSH keyを入力します。Server administratorチェックボックスをクリックして、ユーザーを特権ユーザーとしてマークすることもできます。 をクリックします。
Groupsページで、次の手順を実行してグループを追加します。ボタンをクリックします。
-
Group nameとGroup IDを入力します。グループをさらに追加できます。 をクリックします。
-
SSH keysページで、キーを追加します。ボタンをクリックします。
- SSH キーを入力します。
-
Userを入力します。 をクリックします。
Timezoneページで、タイムゾーンを設定します。Timezoneフィールドに、システムイメージに追加するタイムゾーンを入力します。たとえば、次のタイムゾーン形式を追加します。"US/Eastern"。タイムゾーンを設定しない場合、システムはデフォルトとして協定世界時 (UTC) を使用します。
-
NTP serversを入力します。 をクリックします。
Localeページで、以下の手順を実行します。-
Keyboard検索フィールドに、システムイメージに追加するパッケージ名を入力します。たとえば、["en_US.UTF-8"] と入力します。 -
Languages検索フィールドに、システムイメージに追加するパッケージ名を入力します。たとえば、"us" と入力します。 をクリックします。
-
Othersページで、次の手順を実行します。-
Hostnameフィールドに、システムイメージに追加するホスト名を入力します。ホスト名を追加しない場合、オペレーティングシステムによってホスト名が決定されます。 -
Simplifier Installer イメージでのみ必須:
Installation Devicesフィールドに、システムイメージの有効なノードを入力します。たとえば、dev/sda1と入力します。 をクリックします。
-
FDO 用のイメージをビルドする場合にのみ必須:
FIDO device onboardingページで、次の手順を実行します。Manufacturing server URLフィールドに、次の情報を入力します。-
DIUN public key insecureフィールドに、セキュアでない公開鍵を入力します。 -
DIUN public key hashフィールドに、公開鍵ハッシュを入力します。 -
DIUN public key root certsフィールドに、公開鍵ルート証明書を入力します。 をクリックします。
-
OpenSCAPページで、次の手順を実行します。-
Datastreamフィールドに、システムイメージに追加するdatastream修復手順を入力します。 -
Profile IDフィールドに、システムイメージに追加するprofile_idセキュリティープロファイルを入力します。 をクリックします。
-
Ignition を使用するイメージをビルドする場合にのみ必須:
Ignitionページで、次の手順を実行します。-
Firstboot URLフィールドに、システムイメージに追加するパッケージ名を入力します。 -
Embedded Dataフィールドに、ファイルをドラッグまたはアップロードします。 をクリックします。
-
-
.
Reviewページで、ブループリントの詳細を確認します。 をクリックします。
RHEL Image Builder ビューが開き、既存のブループリントのリストが表示されます。
9.4.3. RHEL Image Builder Web コンソールインターフェイスでのブループリントのインポート
既存のブループリントをインポートして使用できます。システムがすべての依存関係を自動的に解決します。
前提条件
- ブラウザーの Web コンソールから RHEL Image Builder アプリケーションを開いている。
- RHEL Image Builder Web コンソールインターフェイスで使用するためにインポートするブループリントがある。
手順
-
RHEL Image Builder ダッシュボードで、 をクリックします。
Import blueprintが開きます。 -
Uploadフィールドから、既存のブループリントをドラッグまたはアップロードします。TOMLとJSONのどちらかの形式のブループリントを使用できます。 - をクリックします。ダッシュボードに、インポートしたブループリントがリストされます。
検証
インポートしたブループリントをクリックすると、インポートしたブループリントのすべてのカスタマイズを含むダッシュボードにアクセスできます。
インポートしたブループリント用に選択されているパッケージを確認するには、
Packagesタブに移動します。- すべてのパッケージの依存関係を一覧表示するには、 をクリックします。リストは検索可能で、並べ替えることもできます。
次のステップ
オプション: カスタマイズを変更するには、以下を実行します。
-
Customizationsダッシュボードから、変更するカスタマイズをクリックします。必要に応じて、 をクリックして、利用可能なすべてのカスタマイズオプションに移動できます。
-
9.4.4. RHEL Image Builder Web コンソールインターフェイスからのブループリントのエクスポート
ブループリントをエクスポートして、別のシステムでカスタマイズを使用できます。ブループリントは TOML または JSON 形式でエクスポートできます。どちらの形式も CLI だけでなく API インターフェイスでも使用できます。
前提条件
- ブラウザーの Web コンソールから RHEL Image Builder アプリケーションを開いている。
- エクスポートするブループリントがある。
手順
- Image Builder ダッシュボードで、エクスポートするブループリントを選択します。
-
Export blueprintをクリックします。Export blueprintが開きます。 ボタンをクリックしてブループリントをファイルとしてダウンロードするか、 ボタンをクリックしてブループリントをクリップボードにコピーします。
- オプション: ボタンをクリックしてブループリントをコピーします。
検証
- エクスポートしたブループリントをテキストエディターで開き、検査して確認します。
9.4.5. Web コンソールインターフェイスで RHEL Image Builder を使用してシステムイメージを作成する
次の手順を実行すると、ブループリントからカスタマイズされた RHEL システムイメージを作成できます。
前提条件
- ブラウザーの Web コンソールから RHEL Image Builder アプリケーションを開いている。
- ブループリントを作成している。
手順
- RHEL Image Builder ダッシュボードで、blueprint タブをクリックします。
- ブループリントのテーブルで、イメージをビルドするブループリントを見つけます。
- 選択したブループリントの右側で、 をクリックします。Create image ダイアログウィザードが開きます。
Image output ページで、次の手順を実行します。
- Select a blueprint リストから、必要なイメージのタイプを選択します。
Image output type リストから、必要なイメージの出力タイプを選択します。
選択したイメージの種類に応じて、さらに詳細を追加する必要があります。
- をクリックします。
Review ページで、イメージの作成に関する詳細を確認し、 をクリックします。
イメージのビルドが開始され、完了するまでに最大 20 分かかります。
検証
イメージのビルドが完了したら、次のことが可能になります。
イメージをダウンロードします。
- RHEL Image Builder ダッシュボードで、Node options (⫶) メニューをクリックし、Download image を選択します。
イメージのログをダウンロードして要素を検査し、問題がないかどうかを確認します。
- RHEL Image Builder ダッシュボードで、Node options (⫶) メニューをクリックし、Download logs を選択します。
9.5. RHEL Image Builder を使用したクラウドイメージの準備とアップロード
RHEL Image Builder は、さまざまなクラウドプラットフォームですぐに使用できるカスタムシステムイメージを作成できます。カスタマイズした RHEL システムイメージをクラウドで使用するには、指定の出力タイプを使用して RHEL Image Builder でシステムイメージを作成し、イメージをアップロードするようにシステムを設定し、クラウドアカウントへイメージをアップロードします。RHEL Web コンソールの Image Builder アプリケーションを介して、カスタマイズされたイメージクラウドをプッシュできます。これは、AWS や Microsoft Azure クラウドなど、Red Hat サポート対象のサービスプロバイダーの一部で利用できます。AWS Cloud AMI に直接イメージを作成して自動的にアップロードする および Microsoft Azure クラウドに直接 VHD イメージを作成して自動的にアップロードする を参照してください。
9.5.1. AMI イメージの準備と AWS へのアップロード
RHEL Image Builder を使用してカスタムイメージを作成し、そのイメージを手動または自動で AWS クラウドにアップロードできます。
9.5.1.1. AWS AMI イメージを手動でアップロードする準備
AWS AMI イメージをアップロードする前に、イメージをアップロードするためのシステムを設定する必要があります。
前提条件
- AWS IAM アカウントマネージャー にアクセスキー ID を設定している。
- 書き込み可能な S3 bucket を準備する必要があります。Creating S3 bucket を参照してください。
手順
Python 3 および
pipツールをインストールします。# yum install python3 python3-pippip で
AWS コマンドラインツールをインストールします。# pip3 install awscliプロファイルを設定します。ターミナルで、認証情報、リージョン、および出力形式を指定するように求められます。
$ aws configure AWS Access Key ID [None]: AWS Secret Access Key [None]: Default region name [None]: Default output format [None]:バケットの名前を定義し、バケットを作成します。
$ BUCKET=bucketname $ aws s3 mb s3://$BUCKETbucketnameは、実際のバケット名に置き換えます。この名前は、グローバルで一意となるように指定する必要があります。上記で、バケットが作成されます。S3 バケットへのアクセス許可を付与するには、AWS Identity and Access Management (IAM) で
vmimportS3 ロールを作成します (まだ作成していない場合)。信頼ポリシーの設定で、JSON 形式で
trust-policy.jsonファイルを作成します。以下に例を示します。{ "Version": "2022-10-17", "Statement": [{ "Effect": "Allow", "Principal": { "Service": "vmie.amazonaws.com" }, "Action": "sts:AssumeRole", "Condition": { "StringEquals": { "sts:Externalid": "vmimport" } } }] }ロールポリシーの設定を含む
role-policy.jsonファイルを JSON 形式で作成します。以下に例を示します。{ "Version": "2012-10-17", "Statement": [{ "Effect": "Allow", "Action": ["s3:GetBucketLocation", "s3:GetObject", "s3:ListBucket"], "Resource": ["arn:aws:s3:::%s", "arn:aws:s3:::%s/"] }, { "Effect": "Allow", "Action": ["ec2:ModifySnapshotAttribute", "ec2:CopySnapshot", "ec2:RegisterImage", "ec2:Describe"], "Resource": "*" }] } $BUCKET $BUCKETtrust-policy.jsonファイルを使用して、Amazon Web Services アカウントのロールを作成します。$ aws iam create-role --role-name vmimport --assume-role-policy-document file://trust-policy.jsonrole-policy.jsonファイルを使用して、インラインポリシードキュメントを埋め込みます。$ aws iam put-role-policy --role-name vmimport --policy-name vmimport --policy-document file://role-policy.json
9.5.1.2. CLI を使用して AMI イメージを AWS に手動でアップロードする
RHEL Image Builder を使用して ami イメージをビルドし、CLI を使用して Amazon AWS Cloud サービスプロバイダーに直接手動でアップロードすることができます。
前提条件
-
AWS IAM アカウントマネージャーに
Access Key IDを設定している。 - 書き込み可能な S3 bucket を準備する必要があります。Creating S3 bucket を参照してください。
- 定義済みの青写真がある。
手順
テキストエディターを使用して、次の内容の設定ファイルを作成します。
provider = "aws" [settings] accessKeyID = "AWS_ACCESS_KEY_ID" secretAccessKey = "AWS_SECRET_ACCESS_KEY" bucket = "AWS_BUCKET" region = "AWS_REGION" key = "IMAGE_KEY"フィールドの値を
accessKeyID、secretAccessKey、bucket、およびregionの認証情報に置き換えます。IMAGE_KEY値は、EC2 にアップロードする仮想マシンイメージの名前です。- ファイルを CONFIGURATION-FILE.toml として保存し、テキストエディターを閉じます。
Compose を開始して AWS にアップロードします。
# composer-cli compose start blueprint-name image-type image-key configuration-file.toml以下を置き換えます。
- blueprint-name は、作成したブループリントの名前に置き換えます。
-
image-type は、
amiイメージタイプに置き換えます。 - image-key は、EC2 にアップロードする仮想マシンイメージの名前に置き換えます。
configuration-file.toml は、クラウドプロバイダーの設定ファイルの名前に置き換えます。
注記カスタマイズしたイメージの送信先となるバケットの正しい AWS Identity and Access Management (IAM) 設定が必要です。イメージをアップロードする前にバケットにポリシーを設定しておく必要があります。
イメージビルドのステータスを確認します。
# composer-cli compose statusイメージのアップロードプロセスが完了すると、"FINISHED" ステータスが表示されます。
検証
イメージのアップロードが成功したことを確認するには、以下を行います。
-
メニューで EC2 にアクセスし、AWS コンソールで正しいリージョンを選択します。イメージが正常にアップロードされたことを示すには、イメージが
availableステータスになっている必要があります。 - Dashboard でイメージを選択し、 をクリックします。
9.5.1.3. イメージを作成して AWS Cloud AMI に自動的にアップロードする
RHEL Image Builder を使用して (.raw) イメージを作成し、Upload to AWS チェックボックスをオンにして、作成した出力イメージを Amazon AWS Cloud AMI サービスプロバイダーに直接自動的にプッシュすることができます。
前提条件
-
rootまたはwheelグループでシステムにアクセスできる。 - ブラウザーで、RHEL Web コンソールの RHEL Image Builder インターフェイスを開いている。
- ブループリントを作成している。Web コンソールインターフェイスでのブループリントの作成 を参照してください。
- AWS IAM アカウントマネージャーにアクセスキー ID を設定している。
- 書き込み可能な S3 バケット を準備している。
手順
- RHEL Image Builder のダッシュボードで、以前に作成した ブループリント名 をクリックします。
- タブを選択します。
をクリックして、カスタマイズしたイメージを作成します。
Create Image ウィンドウが開きます。
-
Type ドロップダウンメニューから、
Amazon Machine Image Disk (.raw)を選択します。 - イメージを AWS Cloud にアップロードするには、Upload to AWS チェックボックスをオンして、 をクリックします。
AWS へのアクセスを認証するには、対応するフィールドに
AWS access key IDおよびAWS secret access keyを入力します。 をクリックします。注記新規アクセスキー ID を作成する場合にのみ、AWS シークレットアクセスキーを表示できます。秘密鍵が分からない場合は、新しいアクセスキー ID を生成します。
-
Image nameフィールドにイメージ名を、Amazon S3 bucket nameフィールドに Amazon バケット名を入力して、カスタマイズイメージを追加するバケットのAWS regionフィールドを入力します。 をクリックします。 情報を確認し、 をクリックします。
必要に応じて、 をクリックして誤った情報を変更します。
注記カスタマイズイメージを送信するバケットの正しい IAM 設定が必要です。この手順では IAM のインポートとエクスポートを使用するため、バケットにイメージをアップロードする前にバケットに ポリシー を設定する必要があります。詳細は、IAM ユーザーの必要なパーミッション を参照してください。
-
Type ドロップダウンメニューから、
右上のポップアップで、保存の進行状況が通知されます。イメージ作成の開始、イメージ作成の進捗、およびその後の AWS Cloud にアップロードに関する情報も通知されます。
プロセスが完了すると、Image build complete のステータスが表示されます。
ブラウザーで、Service→EC2 にアクセスします。
-
AWS コンソールのダッシュボードメニューで、正しいリージョン を選択します。イメージのステータスは、アップロードされていることを示す
Availableでなければなりません。 - AWS ダッシュボードでイメージを選択し、 をクリックします。
-
AWS コンソールのダッシュボードメニューで、正しいリージョン を選択します。イメージのステータスは、アップロードされていることを示す
- 新しいウィンドウが開きます。イメージを開始するために必要なリソースに応じて、インスタンスタイプを選択します。 をクリックします。
- インスタンスの開始の詳細を確認します。変更が必要な場合は、各セクションを編集できます。 をクリックします。
インスタンスを起動する前に、インスタンスにアクセスするための公開鍵を選択します。
既存のキーペアを使用するか、キーペアーを新規作成します。
次の手順に従って、EC2 で新規キーペアを作成し、新規インスタンスにアタッチします。
- ドロップダウンメニューリストから、Create a new key pair を選択します。
- 新しいキーペアに名前を入力します。新しいキーペアが生成されます。
- Download Key Pair をクリックして、新しいキーペアをローカルシステムに保存します。
をクリックしてインスタンスを起動します。
Initializing と表示されるインスタンスのステータスを確認できます。
- インスタンスのステータスが running になると、 ボタンが有効になります。
をクリックします。ウィンドウが表示され、SSH を使用して接続する方法の説明が表示されます。
- 優先する接続方法として スタンドアロン SSH クライアント を選択し、ターミナルを開きます。
秘密鍵を保存する場所で、SSH が機能するために鍵が公開されていることを確認してください。これには、以下のコマンドを実行します。
$ chmod 400 <_your-instance-name.pem_>パブリック DNS を使用してインスタンスに接続します。
$ ssh -i <_your-instance-name.pem_> ec2-user@<_your-instance-IP-address_>yesと入力して、接続の続行を確定します。その結果、SSH 経由でインスタンスに接続されます。
検証
- SSH でインスタンスに接続している間にアクションが実行できるかどうかを確認します。
9.5.2. VHD イメージを準備して Microsoft Azure にアップロードする
RHEL Image Builder を使用すると、カスタムイメージを作成し、そのイメージを手動または自動で Microsoft Azure クラウドにアップロードできます。
9.5.2.1. Microsoft Azure VHD イメージを手動でアップロードする準備
Microsoft Azure クラウドに手動でアップロードできる VHD イメージを作成するには、RHEL Image Builder を使用できます。
前提条件
- Microsoft Azure リソースグループとストレージアカウントがある。
-
Python がインストールされている。
AZ CLIツールは Python に依存しています。
手順
Microsoft リポジトリーキーをインポートします。
# rpm --import https://packages.microsoft.com/keys/microsoft.asc次の情報を使用して、ローカルの
azure-cli.repoリポジトリーを作成します。azure-cli.repoリポジトリーを/etc/yum.repos.d/に保存します。[azure-cli] name=Azure CLI baseurl=https://packages.microsoft.com/yumrepos/vscode enabled=1 gpgcheck=1 gpgkey=https://packages.microsoft.com/keys/microsoft.ascMicrosoft Azure CLI をインストールします。
# yumdownloader azure-cli # rpm -ivh --nodeps azure-cli-2.0.64-1.el7.x86_64.rpm注記Microsoft Azure CLI パッケージのダウンロードバージョンは、現在利用可能なバージョンによって異なる場合があります。
Microsoft Azure CLI を実行します。
$ az loginターミナルに次のメッセージが表示されます。
Note, we have launched a browser for you to login.For old experience with device code, use "az login --use-device-code次に、ターミナルは、ログインできる場所から https://microsoft.com/devicelogin へのリンクのあるブラウザーを開きます。注記リモート (SSH) セッションを実行している場合、ログインページのリンクはブラウザーで開きません。この場合、リンクをブラウザーにコピーしてログインし、リモートセッションを認証できます。サインインするには、Web ブラウザーを使用してページ https://microsoft.com/devicelogin を開き、デバイスコードを入力して認証します。
Microsoft Azure のストレージアカウントのキーをリスト表示します。
$ az storage account keys list --resource-group <resource_group_name> --account-name <storage_account_name>resource-group-name を Microsoft Azure リソースグループの名前に置き換え、storage-account-name を Microsoft Azure ストレージアカウントの名前に置き換えます。
注記次のコマンドを使用して、使用可能なリソースを一覧表示できます。
$ az resource list上記のコマンドの出力にある値
key1をメモします。ストレージコンテナーを作成します。
$ az storage container create --account-name <storage_account_name>\ --account-key <key1_value> --name <storage_account_name>storage-account-name は、ストレージアカウント名に置き換えます。
9.5.2.2. VHD イメージを Microsoft Azure クラウドに手動でアップロードする
カスタマイズした VHD イメージを作成したら、それを手動で Microsoft Azure クラウドにアップロードできます。
前提条件
- Microsoft Azure VHD イメージをアップロードするようにシステムを設定している。Microsoft Azure VHD イメージのアップロードの準備 を参照してください。
RHEL Image Builder で Microsoft Azure VHD イメージを作成している。
-
GUI で、
Azure Disk Image (.vhd)イメージタイプを使用します。 -
CLI で、
vhd出力タイプを使用します。
-
GUI で、
手順
イメージを Microsoft Azure にプッシュし、そこからインスタンスを作成します。
$ az storage blob upload --account-name <_account_name_> --container-name <_container_name_> --file <_image_-disk.vhd> --name <_image_-disk.vhd> --type page ...Microsoft Azure Blob ストレージへのアップロードが完了したら、そこから Microsoft Azure イメージを作成します。
$ az image create --resource-group <_resource_group_name_> --name <_image_>-disk.vhd --os-type linux --location <_location_> --source https://$<_account_name_>.blob.core.windows.net/<_container_name_>/<_image_>-disk.vhd - Running ...注記RHEL Image Builder で作成するイメージは、V1 = BIOS と V2 = UEFI の両方のインスタンスタイプをサポートするハイブリッドイメージを生成するため、
--hyper-v-generation引数を指定できます。デフォルトのインスタンスタイプは V1 です。
検証
Microsoft Azure ポータル、または以下のようなコマンドを使用して、インスタンスを作成します。
$ az vm create --resource-group <_resource_group_name_> --location <_location_> --name <_vm_name_> --image <_image_>-disk.vhd --admin-username azure-user --generate-ssh-keys - Running ...-
秘密鍵を使用して、SSH 経由で、作成されたインスタンスにアクセスします。
azure-userとしてログインします。このユーザー名は前の手順で設定したものです。
9.5.2.3. VHD イメージを作成して Microsoft Azure クラウドに自動的にアップロードする
RHEL Image Builder を使用して .vhd イメージを作成すると、Microsoft Azure クラウドサービスプロバイダーの Blob Storage に自動的にアップロードされます。
前提条件
- システムへの root アクセス権があります。
- RHEL Web コンソールの RHEL Image Builder インターフェイスにアクセスできる。
- ブループリントを作成している。Web コンソールインターフェイスでの RHEL Image Builder ブループリントの作成 を参照してください。
- Microsoft ストレージアカウント が作成されました。
- 書き込み可能な Blob Storage が準備されました。
手順
- RHEL Image Builder ダッシュボードで、使用するブループリントを選択します。
- タブをクリックします。
をクリックして、カスタマイズした
.vhdイメージを作成します。Create image ウィザードが開きます。
-
Type ドロップダウンメニューリストから
Microsoft Azure (.vhd)を選択します。 - イメージを Microsoft Azure クラウドにアップロードするには、Upload to Azure チェックボックスをオンします。
- Image Size を入力し、 をクリックします。
-
Type ドロップダウンメニューリストから
Upload to Azure ページで、次の情報を入力します。
認証ページで、次のように入力します。
- Storage account の名前。これは、Microsoft Azure portal の Storage account ページにあります。
- Storage access key:これは、Access Key ストレージページにあります。
- をクリックします。
Authentication ページで、次のように入力します。
- イメージ名
- Storage container。これは、イメージのアップロード先の Blob コンテナーです。Microsoft Azure portal の Blob service セクションにあります。
- をクリックします。
Review ページで をクリックします。RHEL Image Builder が起動し、アップロードプロセスが開始します。
Microsoft Azure Cloud にプッシュしたイメージにアクセスします。
- Microsoft Azure ポータル にアクセスします。
- 検索バーに "storage account" と入力し、リストから Storage accounts をクリックします。
- 検索バーに "Images" と入力し、Services の下にある最初のエントリーを選択します。Image Dashboard にリダイレクトされます。
- ナビゲーションパネルで、Containers をクリックします。
-
作成したコンテナーを見つけます。コンテナー内には、RHEL Image Builder を使用して作成およびプッシュした
.vhdファイルがあります。
検証
仮想マシンイメージを作成して起動できることを確認します。
- 検索バーに images account と入力し、リストから Images をクリックします。
- をクリックします。
- ドロップダウンリストから、前に使用したリソースグループを選択します。
- イメージの名前を入力します。
- OS type で Linux を選択します。
- VM generation で Gen 2 を選択します。
- Storage Blob で をクリックし、VHD ファイルに到達するまでストレージアカウントとコンテナーをクリックします。
- ページの最後にある Select をクリックします。
- Account Type を選択します (例: Standard SSD)。
- をクリックし、 をクリックします。イメージが作成されるまでしばらく待機します。
仮想マシンを起動するには、次の手順に従います。
- をクリックします。
- ヘッダーのメニューバーから をクリックします。
- 仮想マシンの名前を入力します。
- Size セクションと Administrator account セクションに入力します。
をクリックし、 をクリックします。デプロイメントの進行状況を確認できます。
デプロイメントが完了したら、仮想マシン名をクリックしてインスタンスのパブリック IP アドレスを取得し、SSH を使用して接続します。
- ターミナルを開いて SSH 接続を作成し、仮想マシンに接続します。
9.5.2.4. VMDK イメージのアップロードと vSphere での RHEL 仮想マシンの作成
RHEL Image Builder を使用すると、カスタマイズした VMware vSphere システムイメージを Open virtualization format (.ova) または Virtual disk (.vmdk) 形式で作成できます。これらのイメージを VMware vSphere クライアントにアップロードできます。govc import.vmdk CLI ツールを使用して、.vmdk または .ova イメージを VMware vSphere にアップロードできます。作成した vmdk には、インストール済みの cloud-init パッケージが含まれています。このパッケージを使用して、たとえばユーザーデータを使用してユーザーをプロビジョニングできます。
VMware vSphere GUI を使用した vmdk イメージのアップロードはサポートされていません。
前提条件
- ユーザー名とパスワードをカスタマイズしたブループリントを作成している。
-
RHEL Image Builder を使用して VMware vSphere イメージを
.ovaまたは.vmdk形式で作成し、ホストシステムにダウンロードしている。 -
govcCLI ツールをインストールして設定し、import.vmdkコマンドが使用可能である。
手順
GOVC 環境変数を使用して、ユーザー環境で次の値を設定します。
GOVC_URL GOVC_DATACENTER GOVC_FOLDER GOVC_DATASTORE GOVC_RESOURCE_POOL GOVC_NETWORK- VMware vSphere イメージをダウンロードしたディレクトリーに移動します。
次の手順に従って、vSphere で VMware vSphere イメージを起動します。
VMware vSphere イメージを vSphere にインポートします。
$ govc import.vmdk ./composer-api.vmdk foldername.ova形式の場合:$ govc import.ova ./composer-api.ova foldername電源をオンにせずに vSphere に仮想マシンを作成します。
govc vm.create \ -net.adapter=vmxnet3 \ -m=4096 -c=2 -g=rhel8_64Guest \ -firmware=efi -disk=”foldername/composer-api.vmdk” \ -disk.controller=scsi -on=false \ vmname.ova形式の場合は、行-firmware=efi -disk=”foldername/composer-api.vmdk” \を `-firmware=efi -disk=”foldername/composer-api.ova” \ に置き換えます。仮想マシンの電源をオンにします。
govc vm.power -on vmname仮想マシンの IP アドレスを取得します。
govc vm.ip vmnameブループリントで指定したユーザー名とパスワードで、SSH を使用して、仮想マシンにログインします。
$ ssh admin@<_ip_address_of_the_vm_>注記govc datastore.uploadコマンドを使用してローカルホストから宛先に.vmdkイメージをコピーしても、コピーして作成したイメージを使用することはできません。vSphere GUI にはimport.vmdkコマンドを使用するオプションがないため、vSphere GUI は直接アップロードをサポートしません。そのため、.vmdkイメージを vSphere GUI から使用することはできません。
9.5.2.5. Image Builder GUI を使用して VMDK イメージを作成し、vSphere に自動的にアップロードする
RHEL Image Builder GUI ツールを使用して VMware イメージをビルドし、そのイメージを vSphere インスタンスに直接自動的にプッシュできます。これにより、イメージファイルをダウンロードして手動でプッシュする必要がなくなります。作成した vmdk には、インストール済みの cloud-init パッケージが含まれています。このパッケージを使用して、たとえばユーザーデータを使用してユーザーをプロビジョニングできます。RHEL Image Builder を使用して .vmdk イメージをビルドし、vSphere インスタンスサービスプロバイダーに直接プッシュするには、次の手順に従います。
前提条件
-
rootまたはweldrグループのメンバーである。 - ブラウザーで https://localhost:9090/RHEL Image Builder を開いている。
- ブループリントを作成している。Web コンソールインターフェイスでの RHEL Image Builder ブループリントの作成 を参照してください。
- vSphere アカウント がある。
手順
- 作成したブループリントの タブをクリックします。
をクリックして、カスタマイズしたイメージを作成します。
イメージタイプウィンドウが開きます。
Image type ウィンドウで、以下を実行します。
- ドロップダウンメニューから、タイプ VMware vSphere (.vmdk) を選択します。
- Upload to VMware チェックボックスをチェックして、イメージを vSphere にアップロードします。
- オプション: インスタンス化するイメージのサイズを設定します。最小のデフォルトサイズは 2 GB です。
- をクリックします。
Upload to VMware ウィンドウの Authentication の下に以下の情報を入力します。
- ユーザー名: vSphere アカウントのユーザー名。
- パスワード: vSphere アカウントのパスワード。
Upload to VMware ウィンドウの Destination の下に、イメージのアップロード先に関する以下の情報を入力します。
- Image name: イメージの名前。
- Host: VMware vSphere の URL。
- Cluster: クラスターの名前。
- Data center:データセンターの名前。
- Data store: データストアの名前。
- Next をクリックします。
確認 ウィンドウで、イメージ作成の詳細を確認し、 をクリックします。
をクリックして、誤った情報を変更できます。
RHEL Image Builder は、RHEL vSphere イメージの Compose をキューに追加し、指定した vSphere インスタンスのクラスターにイメージを作成してアップロードします。
注記イメージビルドおよびアップロードプロセスの完了には数分かかります。
プロセスが完了すると、Image build complete のステータスが表示されます。
検証
イメージステータスのアップロードが正常に完了したら、アップロードしたイメージから仮想マシン (VM) を作成し、ログインできます。改善点を報告する場合は、以下のように行います。
- VMware vSphere クライアントにアクセスします。
- 指定した vSphere インスタンスのクラスターでイメージを検索します。
- アップロードしたイメージを選択します。
- 選択したイメージを右クリックします。
New Virtual Machineをクリックします。New Virtual Machine ウィンドウが開きます。
New Virtual Machine ウィンドウで、以下の詳細を指定します。
-
New Virtual Machineを選択します。 - 仮想マシンの名前とフォルダーを選択します。
- コンピューターリソースの選択: この操作の宛先コンピューターリソースを選択します
- ストレージを選択:たとえば、NFS-Node1 を選択します。
- 互換性を選択:イメージは BIOS のみである必要があります。
- ゲストオペレーティングシステムを選択します。たとえば、Linux および Red Hat Fedora (64-bit) を選択します。
- ハードウェアのカスタマイズ:仮想マシンを作成する場合は、右上の Device Configuration ボタンでデフォルトの New Hard Disk を削除し、ドロップダウンを使用して Existing Hard Disk ディスクイメージを選択します。
- 完了する準備ができました:詳細を確認し、Finish をクリックしてイメージを作成します。
-
VMs タブに移動します。
- リストから、作成した仮想マシンを選択します。
- パネルから Start ボタンをクリックします。仮想マシンイメージを読み込み中であることを示す新しいウィンドウが表示されます。
- ブループリント用に作成した認証情報を使用してログインします。
ブループリントに追加したパッケージがインストールされていることを確認できます。以下に例を示します。
$ rpm -qa | grep firefox
9.5.3. カスタム GCE イメージの準備と GCP へのアップロードする
RHEL Image Builder を使用してカスタムイメージを作成し、そのイメージを Oracle Cloud Infrastructure (OCI) インスタンスに自動的にアップロードできます。
9.5.3.1. RHEL Image Builder を使用した GCP へのイメージのアップロード
RHEL Image Builder を使用すると、gce イメージをビルドし、ユーザーまたは GCP サービスアカウントの認証情報を指定して、gce イメージを GCP 環境に直接アップロードできます。
9.5.3.1.1. CLI を使用して gce イメージを設定して GCP にアップロードする
RHEL Image Builder CLI を使用して、gce イメージを GCP にアップロードするための認証情報を含む設定ファイルを設定します。
イメージが起動しなくなるため、gce イメージを GCP に手動でインポートすることはできません。アップロードするには、gcloud または RHEL Image Builder を使用する必要があります。
前提条件
イメージを GCP にアップロードするための有効な Google アカウントと認証情報がある。認証情報は、ユーザーアカウントまたはサービスアカウントから取得できます。認証情報に関連付けられたアカウントには、少なくとも次の IAM ロールが割り当てられている必要があります。
-
roles/storage.admin- ストレージオブジェクトの作成と削除 -
roles/compute.storageAdmin- 仮想マシンイメージの Compute Engine へのインポート
-
- 既存の GCP バケットがあります。
手順
テキストエディターを使用して、次の内容の
gcp-config.toml設定ファイルを作成します。provider = "gcp" [settings] bucket = "GCP_BUCKET" region = "GCP_STORAGE_REGION" object = "OBJECT_KEY" credentials = "GCP_CREDENTIALS"-
GCP_BUCKETは既存のバケットを指します。アップロード中のイメージの中間ストレージオブジェクトを格納するために使用されます。 -
GCP_STORAGE_REGIONは、通常の Google ストレージリージョンであり、デュアルまたはマルチリージョンです。 -
OBJECT_KEYは、中間ストレージオブジェクトの名前です。アップロード前に存在してはならず、アップロードプロセスが完了すると削除されます。オブジェクト名が.tar.gzで終わらない場合、拡張子がオブジェクト名に自動的に追加されます。 GCP_CREDENTIALSは、GCP からダウンロードした認証情報 JSON ファイルのBase64エンコードされたスキームです。認証情報によって、GCP がイメージをアップロードするプロジェクトが決まります。注記GCP での認証に別のメカニズムを使用する場合、
gcp-config.tomlファイルでのGCP_CREDENTIALSの指定は任意です。他の認証方法は、Authenticating with GCP を参照してください。
-
GCP からダウンロードした JSON ファイルから
GCP_CREDENTIALSを取得します。$ sudo base64 -w 0 cee-gcp-nasa-476a1fa485b7.json追加のイメージ名とクラウドプロバイダープロファイルを使用して Compose を作成します。
$ sudo composer-cli compose start BLUEPRINT-NAME gce IMAGE_KEY gcp-config.tomlイメージビルド、アップロード、およびクラウド登録プロセスは、完了に最大 10 分かかる場合があります。
検証
イメージのステータスが FINISHED であることを確認します。
$ sudo composer-cli compose status
9.5.3.1.2. RHEL Image Builder によるさまざまな GCP 認証情報の認証順序の並べ替え
RHEL Image Builder でいくつかの異なる種類の認証情報を使用して、GCP で認証できます。複数の認証情報セットを使用して GCP で認証するように RHEL Image Builder が設定されている場合、次の優先順位で認証情報が使用されます。
-
設定ファイルで
composer-cliコマンドで指定された認証情報。 -
osbuild-composerワーカー設定で設定された認証情報。 次の方法で認証方法を自動的に見つけようとする、
Google GCP SDKライブラリーからのApplication Default Credentials。- GOOGLE_APPLICATION_CREDENTIALS 環境変数が設定されている場合、Application Default Credentials は、変数が指すファイルから認証情報を読み込んで使用しようとします。
Application Default Credentials は、コードを実行しているリソースに関連付けられたサービスアカウントを使用して認証を試みます。たとえば、Google Compute Engine 仮想マシンです。
注記イメージをアップロードする GCP プロジェクトを決定するには、GCP 認証情報を使用する必要があります。したがって、すべてのイメージを同じ GCP プロジェクトにアップロードする場合を除き、
composer-cliコマンドを使用してgcp-config.toml設定ファイルに認証情報を指定する必要があります。
9.5.3.1.2.1. composer-cli コマンドで GCP 認証情報を指定する
アップロードターゲット設定の gcp-config.toml ファイルで、GCP 認証情報を指定できます。時間を節約するために、Google アカウント認証情報の JSON ファイルの Base64 エンコードスキームを使用します。
手順
GOOGLE_APPLICATION_CREDENTIALS環境変数に保存されているパスを使用して、Google アカウント認証情報ファイルのエンコードされたコンテンツを取得するには、次のコマンドを実行します。$ base64 -w 0 "${GOOGLE_APPLICATION_CREDENTIALS}"アップロードターゲット設定の
gcp-config.tomlファイルで、認証情報を設定します。provider = "gcp" [settings] provider = "gcp" [settings] credentials = "GCP_CREDENTIALS"
9.5.3.1.2.2. osbuild-composer ワーカー設定で認証情報を指定する
すべてのイメージビルドでグローバルに GCP に使用される GCP 認証認証情報を設定できます。このようにして、イメージを同じ GCP プロジェクトにインポートする場合、GCP へのすべてのイメージのアップロードに同じ認証情報を使用できます。
手順
/etc/osbuild-worker/osbuild-worker.tomlワーカー設定で、次の認証情報の値を設定します。[gcp] credentials = "PATH_TO_GCP_ACCOUNT_CREDENTIALS"
9.5.4. カスタムイメージの準備と OCI への直接アップロード
RHEL Image Builder を使用してカスタムイメージを作成し、そのイメージを Oracle Cloud Infrastructure (OCI) インスタンスに自動的にアップロードできます。
9.5.4.1. カスタムイメージを作成して OCI に自動的にアップロードする
RHEL Image Builder を使用すると、カスタマイズしたイメージをビルドし、そのイメージを Oracle Cloud Infrastructure (OCI) インスタンスに直接自動的にプッシュできます。その後、OCI ダッシュボードからイメージインスタンスを開始できます。
前提条件
-
システムに対して
rootまたはweldrグループのユーザーアクセスがある。 - Oracle Cloud アカウントを持っている。
- 管理者によって OCI ポリシー でセキュリティーアクセスが許可されている必要があります。
-
選択した
OCI_REGIONに OCI バケットを作成しました。
手順
- ブラウザーで Web コンソールの RHEL Image Builder インターフェイスを開きます。
- をクリックします。Create blueprint ウィザードが開きます。
- Details ページで、ブループリントの名前を入力し、必要に応じて説明を入力します。 をクリックします。
- Packages ページで、イメージに含めるコンポーネントとパッケージを選択します。 をクリックします。
- Customizations ページで、ブループリントに必要なカスタマイズを設定します。 をクリックします。
- Review ページで をクリックします。
- イメージを作成するには、 をクリックします。Create image ウィザードが開きます。
Image output ページで、次の手順を実行します。
- "Select a blueprint" ドロップダウンメニューから、必要なブループリントを選択します。
-
"Image output type" ドロップダウンメニューから、
Oracle Cloud Infrastructure (.qcow2)を選択します。 - イメージを OCI にアップロードするには、Upload OCI チェックボックスをオンにします。
- "image size" を入力します。 をクリックします。
Upload to OCI - Authentication ページで、次の必須の詳細を入力します。
- ユーザー OCID: ユーザーの詳細を表示するページのコンソールで確認できます。
- 秘密鍵
Upload to OCI - Destination ページで、次の必須の詳細を入力し、 をクリックします。
- イメージ名: アップロードするイメージの名前。
- OCI バケット
- バケット namespace
- バケットリージョン
- バケットコンパートメント
- バケットテナンシー
- ウィザードの詳細を確認し、 をクリックします。
RHEL Image Builder が、RHEL .qcow2 イメージの Compose をキューに追加します。
検証
- OCI ダッシュボード → カスタムイメージにアクセスします。
- イメージに指定した Compartment を選択し、Import image テーブルでイメージを見つけます。
- イメージ名をクリックして、イメージ情報を確認します。
9.5.5. カスタマイズした QCOW2 イメージを準備して OpenStack に直接アップロードする
RHEL Image Builder を使用してカスタムの .qcow2 イメージを作成し、OpenStack クラウドデプロイメントに手動でアップロードできます。
9.5.5.1. OpenStack への QCOW2 イメージのアップロード
RHEL Image Builder ツールを使用すると、OpenStack クラウドデプロイメントにアップロードし、そこでインスタンスを起動するのに適した、カスタマイズした .qcow2 イメージを作成できます。RHEL Image Builder は QCOW2 フォーマットでイメージを作成しますが、OpenStack に固有の変更がさらに加えられています。
RHEL Image Builder を OpenStack イメージタイプで使用して作成する一般的な QCOW2 イメージタイプの出力フォーマットを間違えないでください。これも QCOW2 フォーマットですが、OpenStack に固有の変更がさらに含まれています。
前提条件
- ブループリントを作成している。
手順
QCOW2イメージの作成を開始します。# composer-cli compose start blueprint_name openstackビルドの状態を確認します。
# composer-cli compose statusイメージのビルドが完了したら、イメージをダウンロードできます。
QCOW2イメージをダウンロードします。# composer-cli compose image UUID- OpenStack ダッシュボードにアクセスし、 をクリックします。
-
左側のメニューで、
Adminタブを選択します。 System PanelからImageをクリックします。Create An Imageウィザードが開きます。Create An Imageウィザードで、以下を行います。- イメージの名前を入力します。
-
BrowseをクリックしてQCOW2イメージをアップロードします。 -
Formatドロップダウンリストから、QCOW2 - QEMU Emulatorを選択します。 をクリックします。
左側のメニューで
Projectタブを選択します。-
ComputeメニューからInstancesを選択します。 ボタンをクリックします。
インスタンスの
Launch Instanceが開きます。-
Detailsページで、インスタンスの名前を入力します。 をクリックします。 -
Sourceページで、アップロードしたイメージの名前を選択します。 をクリックします。 Flavorページで、ニーズに最適なマシンリソースを選択します。 をクリックします。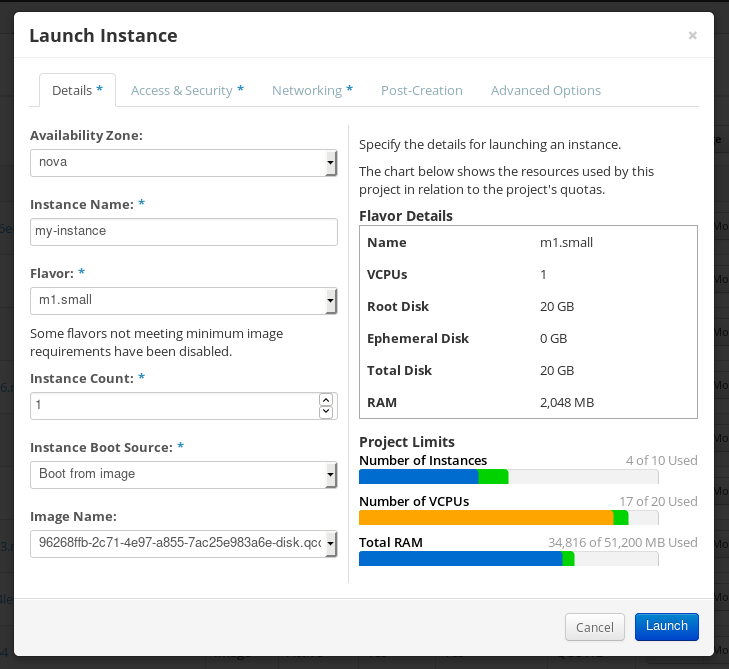
-
-
イメージから任意のメカニズム (CLI または OpenStack Web UI) を使用して、イメージインスタンスを実行できます。秘密鍵を使用して、SSH 経由で、作成されたインスタンスにアクセスします。
cloud-userとしてログインします。
9.5.6. カスタマイズした RHEL イメージを準備して Alibaba Cloud にアップロードする
RHEL Image Builder で作成した、カスタマイズしれた .ami イメージを Alibaba Cloud にアップロードできます。
9.5.6.1. カスタマイズされた RHEL イメージを Alibaba Cloud にアップロードする準備
カスタマイズされた RHEL イメージを Alibaba Cloud にデプロイするには、まずカスタマイズされたイメージを検証する必要があります。Alibaba Cloud は、イメージを使用する前に特定の要件を満たすようにカスタムイメージを要求するため、イメージが正常に起動するように特別な設定が必要になります。
RHEL Image Builder は、Alibaba の要件に準拠したイメージを生成します。ただし、Red Hat は、Alibaba image_check ツール を使用して、イメージのフォーマット準拠を確認することも推奨します。
前提条件
- RHEL Image Builder を使用して Alibaba イメージを作成している。
手順
- Alibaba の image_check ツールを使用して、チェックするイメージを含むシステムに接続します。
image_check ツールをダウンロードします。
$ curl -O https://docs-aliyun.cn-hangzhou.oss.aliyun-inc.com/assets/attach/73848/cn_zh/1557459863884/image_checkイメージのコンプライアンスツールのファイルパーミッションを変更します。
# chmod +x image_check次のコマンドを実行して、イメージコンプライアンスツールのチェックを起動します。
# ./image_checkこのツールは、システム設定を検証し、画面に表示されるレポートを生成します。image_check ツールは、イメージのコンプライアンスツールが実行されているフォルダーにこのレポートを保存します。
トラブルシューティング
いずれかの 検出項目 が失敗した場合は、ターミナルの指示に従って修正してください。
9.5.6.2. カスタマイズされた RHEL イメージを Alibaba にアップロードする
RHEL Image Builder で作成した、カスタマイズした AMI イメージを Object Storage Service (OSS) にアップロードできます。
前提条件
- Alibaba イメージのアップロードを設定している。Alibaba にイメージをアップロードするための準備 を参照してください。
-
RHEL Image Builder を使用して
amiイメージを作成している。 - バケットがある。Creating a bucket を参照してください。
- アクティブな Alibaba アカウント がある。
- OSS をアクティベートしている。
手順
- OSS コンソール にログインします。
- 左側のバケットメニューで、イメージをアップロードするバケットを選択します。
- 右上のメニューで、Files タブをクリックします。
をクリックします。右側のダイアログウィンドウが開きます。以下を設定します。
- アップロード先:これを選択すると、現在 のディレクトリーまたは 指定した ディレクトリーにファイルをアップロードします。
- ファイル ACL:アップロードしたファイルのパーミッションのタイプを選択します。
- をクリックします。
- OSS コンソールにアップロードするイメージを選択します。
- をクリックします。
9.5.6.3. Alibaba Cloud へのイメージのインポート
RHEL Image Builder で作成した、カスタマイズした Alibaba RHEL イメージを Elastic Compute Service (ECS) にインポートするには、次の手順に従います。
前提条件
- Alibaba イメージのアップロードを設定している。Alibaba にイメージをアップロードするための準備 を参照してください。
-
RHEL Image Builder を使用して
amiイメージを作成している。 - バケットがある。Creating a bucket を参照してください。
- アクティブな Alibaba アカウント がある。
- OSS をアクティベートしている。
- イメージを OSS (Object Storage Service) にアップロードしている。Alibaba へのイメージのアップロード を参照してください。
手順
ECS コンソール にログインします。
- 左側のメニューで、 をクリックします。
- 右上にある をクリックします。ダイアログウィンドウが開きます。
イメージが含まれる正しいリージョンを設定していることを確認します。以下の情報を入力します。
-
OSS Object Address:OSS Object Address の取得方法を参照してください。 -
Image Name -
オペレーティングシステム -
System Disk Size -
システムアーキテクチャー -
プラットフォーム:Red Hat
-
オプション:以下の情報を指定します。
-
Image Format- アップロードしたイメージの形式に応じてqcow2またはami。 -
Image Description Add Images of Data Disksアドレスは、OSS 管理コンソールで確認できます。左側のメニューで必要なバケットを選択した後:
-
-
Filesセクションを選択します。 適切なイメージの右側にある Details リンクをクリックします。
画面右側にウィンドウが表示され、イメージの詳細が表示されます。
OSSオブジェクトアドレスはURLボックスにあります。をクリックします。
注記インポートプロセスの時間は、イメージのサイズによって異なります。
カスタマイズされたイメージが ECS コンソールにインポートされます。
9.5.6.4. Alibaba Cloud を使用したカスタマイズされた RHEL イメージのインスタンスの作成
Alibaba ECS コンソールを使用して、カスタマイズされた RHEL イメージのインスタンスを作成できます。
前提条件
- OSS をアクティベートして、カスタムイメージをアップロードしている。
- イメージを ECS コンソールに正常にインポートしている。Alibaba へのイメージのインポート を参照してください。
手順
- ECS コンソール にログインします。
- 左側のメニューで、インスタンス を選択します。
- 右上隅にある インスタンスの作成 をクリックします。新しいウィンドウにリダイレクトされます。
- 必要な情報をすべて完了します。詳細は、Creating an instance by using the wizard を参照してください。
Create Instance をクリックして、順番を確認します。
注記サブスクリプションによっては、Create Instance ではなく Create Order が表示されます。
その結果、アクティブなインスタンスを Alibaba ECS Console からデプロイする準備が整いました。
第10章 キックスタートを使用した自動インストールの実行
10.1. 自動インストールのワークフロー
キックスタートを使用したインストールは、ローカルの DVD またはディスクを使用するか、NFS、FTP、HTTP、または HTTPS サーバーで実行できます。このセクションでは、キックスタートの使用方法の概要を説明します。
- キックスタートファイルを作成します。手動で作成したり、手動インストール後に保存したキックファイルファイルをコピーしたり、オンライン生成ツールを使用してファイルを作成したりして、後で編集したりできます。
- リムーバブルメディア、ディスク、または HTTP (S) サーバー、FTP サーバー、または NFS サーバーに置いたインストールプログラムでキックスタートファイルを使用できるようにします。
- インストール開始に使用する起動用メディアを作成します。
- インストールソースをインストールプログラムに利用できるようにします。
- ブートメディアおよびキックスタートファイルを使用して、インストールを開始します。これは、キックスタートファイルが必須のコマンドおよびセクションをすべて含む場合に、インストールが自動的に行われます。必須部分が 1 つ以上欠けている場合、またはエラーが発生した場合は、インストールを手動で行う必要があります。
10.2. キックスタートファイルの作成
次の方法を使用してキックスタートファイルを作成できます。
- オンラインのキックスタート設定ツールを使用する。
- 手動インストールのログとして作成したキックスタートファイルをコピーする。
- キックスタートファイル全体を手動で書き込む。
Red Hat Enterprise Linux 8 インストール用に Red Hat Enterprise Linux 7 キックスタートファイルを変換します。
変換ツールの詳細は、Kickstart generator lab を参照してください。
- 仮想環境およびクラウド環境では、Image Builder を使用してカスタムシステムイメージを作成します。
一部の非常に特殊なインストールオプションは、キックスタートファイルを手動で編集することによってのみ設定できます。
10.2.1. キックスタート設定ツールを使用したキックスタートファイルの作成
Red Hat カスタマーポータルのアカウントをお持ちの場合は、カスタマーポータルで提供している Labs の Kickstart Generator ツールを使用して、キックスタートファイルをオンラインで生成できます。このツールは基本的な設定を段階的に説明し、作成したキックスタートファイルのダウンロードを可能にします。
前提条件
- Red Hat カスタマーポータルアカウントとアクティブな Red Hat サブスクリプションを持っている。
手順
- Lab で提供されている Kickstart Generator の情報は https://access.redhat.com/labsinfo/kickstartconfig を参照してください。
- 見出しの左にある Go to Application ボタンをクリックし、次のページが読み込まれるのを待ちます。
- ドロップダウンメニューで Red Hat Enterprise Linux 8 を選択し、ページが更新するのを待ちます。
フォーム内のフィールドを使用して、インストールするシステムを記述します。
フォームの左側にあるリンクを使用すれば、フォームのセクション間をすばやく移動できます。
生成されたキックスタートファイルをダウンロードするには、ページの先頭に戻り、赤色の Download ボタンをクリックします。
Web ブラウザーによりファイルが保存されます。
pykickstart パッケージをインストールします。
# yum install pykickstartキックスタートファイルに
ksvalidatorを実行します。$ ksvalidator -v RHEL8 /path/to/kickstart.ks/path/to/kickstart.ks を、確認するキックスタートファイルのパスに置き換えます。
検証ツールは、インストールの成功を保証しているわけではありません。このツールは、構文が正しく、ファイルに非推奨のオプションが含まれていないことだけを保証します。キックスタートファイルの
%preセクション、%postセクション、および%packagesセクションは検証されません。
10.2.2. 手動インストールを実行したキックスタートファイルの作成
キックスタートファイルの作成方法としては、Red Hat Enterprise Linux の手動インストールにより作成されたファイルを使用することが推奨される方法となります。インストールが完了すると、インストール中に選択したものがすべて、インストール済みシステムの /root/ ディレクトリーに置かれているキックスタートファイル anaconda-ks.cfg に保存されます。このファイルを使用して、以前とまったく同じ方法でインストールを行えます。または、このファイルをコピーして必要な変更を加え、その後のインストールで使用することもできます。
手順
RHEL をインストールします。詳細は、インストールメディアからの RHEL の対話型インストール を参照してください。
インストール時に、管理者権限を持つユーザーを作成します。
- インストール済みシステムでインストールを完了し、再起動します。
- 管理者アカウントでシステムにログインします。
/root/anaconda-ks.cfgファイルを、任意の場所にコピーします。ファイルには、ユーザーとパスワードの情報が含まれます。端末内のファイルの内容を表示するには、次のコマンドを実行します。
# cat /root/anaconda-ks.cfg出力をコピーして、別のファイルに選択を保存できます。
- 別の場所にファイルをコピーするには、ファイルマネージャーを使用します。root 以外のユーザーがそのファイルを読み込めるように、コピーしたファイルのアクセス権を忘れずに変更してください。
pykickstart パッケージをインストールします。
# yum install pykickstartキックスタートファイルに
ksvalidatorを実行します。$ ksvalidator -v RHEL8 /path/to/kickstart.ks/path/to/kickstart.ks を、確認するキックスタートファイルのパスに置き換えます。
検証ツールは、インストールの成功を保証しているわけではありません。このツールは、構文が正しく、ファイルに非推奨のオプションが含まれていないことだけを保証します。キックスタートファイルの %pre セクション、%post セクション、および %packages セクションは検証されません。
10.2.3. 以前の RHEL インストールからキックスタートファイルを変換する
Kickstart Converter ツールを使用して、RHEL 7 キックスタートファイルを RHEL 8 または 9 インストールで使用するために変換したり、RHEL 8 キックスタートファイルを RHEL 9 で使用するために変換したりできます。ツールの詳細と、そのツールで RHEL キックスタートファイルを変換する方法は、https://access.redhat.com/labs/kickstartconvert/ を参照してください。
手順
キックスタートファイルを準備したら、pykickstart パッケージをインストールします。
# yum install pykickstartキックスタートファイルに
ksvalidatorを実行します。$ ksvalidator -v RHEL8 /path/to/kickstart.ks/path/to/kickstart.ks を、確認するキックスタートファイルのパスに置き換えます。
検証ツールは、インストールの成功を保証しているわけではありません。このツールは、構文が正しく、ファイルに非推奨のオプションが含まれていないことだけを保証します。キックスタートファイルの %pre セクション、%post セクション、および %packages セクションは検証されません。
10.2.4. Image Builder を使用したカスタムイメージの作成
Red Hat Image Builder を使用して、仮想デプロイメント用およびクラウドデプロイメント用にカスタマイズされたシステムイメージを作成できます。
Image Builder を使用したカスタムイメージの作成の詳細は、RHEL システムイメージのカスタマイズ を参照してください。
10.3. UEFI HTTP または PXE インストールソースへのキックスタートファイルの追加
キックスタートファイルの準備ができたら、それをインストール先システムへのインストールに使用できるようになります。
10.3.1. ネットワークインストール用のポート
次の表は、ネットワークベースの各種インストールにファイルを提供するためにサーバーで開く必要があるポートの一覧です。
| 使用プロトコル | 開くべきポート |
|---|---|
| HTTP | 80 |
| HTTPS | 443 |
| FTP | 21 |
| NFS | 2049、111、20048 |
| TFTP | 69 |
10.3.2. NFS サーバー上でのインストールファイルの共有
キックスタートスクリプトファイルを NFS サーバーに保存できます。NFS サーバーに保存すると、キックスタートファイル用の物理メディアを使用しなくても、単一のソースから複数のシステムをインストールできます。
前提条件
- ローカルネットワーク上の Red Hat Enterprise Linux 8 を使用するサーバーへの管理者レベルのアクセス権がある。
- インストールするシステムがサーバーに接続できる。
- サーバー上のファイアウォールがインストール先のシステムからの接続を許可している。
必ず inst.ks と inst.repo で異なるパスを使用してください。NFS を使用してキックスタートをホストする場合、同じ NFS 共有を使用してインストールソースをホストすることはできません。
手順
root で以下のコマンドを実行して、
nfs-utilsパッケージをインストールします。# yum install nfs-utils- キックスタートファイルを、NFS サーバーのディレクトリーにコピーします。
テキストエディターで
/etc/exportsファイルを開き、以下の構文の行を追加します。/exported_directory/ clients/exported_directory/ を、キックスタートファイルを保存しているディレクトリーのフルパスに置き換えます。clients の代わりに、この NFS サーバーからインストールするコンピューターのホスト名または IP アドレス、すべてのコンピューターが ISO イメージにアクセスするためのサブネットワーク、またはネットワークアクセスのあるコンピューターが NFS サーバーにアクセスして ISO イメージを使用できるようにする場合はアスタリスク記号 (
*) を使用します。このフィールドの形式に関する詳細は、man ページの exports(5) を参照してください。/rhel8-install/ディレクトリーを、すべてのクライアントに対する読み取り専用として使用できるようにする基本設定は次のようになります。/rhel8-install *-
/etc/exportsファイルを保存して、テキストエディターを終了します。 nfs サービスを起動します。
# systemctl start nfs-server.service/etc/exportsファイルに変更を加える前にサービスを稼働していた場合は、以下のコマンドを実行して、稼働中の NFS サーバーで設定を再ロードします。# systemctl reload nfs-server.serviceキックスタートファイルは NFS 経由でアクセス可能になり、インストールに使用できるようになりました。
キックスタートソースを指定する場合は、プロトコルに nfs: を使用して、サーバーのホスト名または IP アドレス、コロン記号 (:)、およびそのファイルを保存しているディレクトリーを指定します。たとえば、サーバーのホスト名が myserver.example.com で、そのファイルを /rhel8-install/my-ks.cfg に保存した場合、指定するインストールソースの起動オプションは inst.ks=nfs:myserver.example.com:/rhel8-install/my-ks.cfg となります。
10.3.3. HTTP または HTTPS サーバー上でのインストールファイルの共有
キックスタートスクリプトファイルを HTTP または HTTPS サーバーに保存できます。キックスタートファイルを HTTP または HTTPS サーバーに保存すると、キックスタートファイル用の物理メディアを使用しなくても、単一のソースから複数のシステムをインストールできます。
前提条件
- ローカルネットワーク上の Red Hat Enterprise Linux 8 を使用するサーバーへの管理者レベルのアクセス権がある。
- インストールするシステムがサーバーに接続できる。
- サーバー上のファイアウォールがインストール先のシステムからの接続を許可している。
手順
キックスタートファイルを HTTP に保存するには、
httpdパッケージをインストールします。# yum install httpdHTTPS にキックスタートファイルを保存するには、
httpdパッケージおよびmod_sslパッケージをインストールします。# yum install httpd mod_ssl警告Apache Web サーバー設定で SSL セキュリティーが有効になっている場合は、TLSv1 プロトコルのみが有効で、SSLv2 と SSLv3 は無効になっていることを確認してください。POODLE SSL 脆弱性 (CVE-2014-3566) の影響を受けないようにするためです。詳細は、Red Hat ナレッジベースソリューション Resolution for POODLE SSLv3.0 vulnerability を参照してください。
重要自己署名証明書付きの HTTPS サーバーを使用する場合は、
inst.noverifysslオプションを指定してインストールプログラムを起動する必要があります。-
/var/www/html/ディレクトリーのサブディレクトリーに、HTTP(S) サーバーへのキックスタートファイルをコピーします。 httpd サービスを起動します。
# systemctl start httpd.serviceキックスタートファイルはアクセス可能になり、インストールとして使用できるようになりました。
キックスタートファイルの場所を指定する場合は、プロトコルに
http://またはhttps://を使用して、サーバーのホスト名または IP アドレス、キックスタートファイルのパス (HTTP サーバーの root への相対パス) を指定します。たとえば、HTTP を使用して、サーバーのホスト名がmyserver.example.comで、キックスタートファイルを/var/www/html/rhel8-install/my-ks.cfgにコピーした場合、指定するインストールソースはhttp://myserver.example.com/rhel8-install/my-ks.cfgとなります。
10.3.4. FTP サーバー上でのインストールファイルの共有
キックスタートスクリプトファイルを FTP サーバーに保存できます。スクリプトを FTP サーバーに保存すると、キックスタートファイル用の物理メディアを使用しなくても、単一のソースから複数のシステムをインストールできます。
前提条件
- ローカルネットワーク上の Red Hat Enterprise Linux 8 を使用するサーバーへの管理者レベルのアクセス権がある。
- インストールするシステムがサーバーに接続できる。
- サーバー上のファイアウォールがインストール先のシステムからの接続を許可している。
手順
root で以下のコマンドを実行して、
vsftpdパッケージをインストールします。# yum install vsftpd必要に応じて、
/etc/vsftpd/vsftpd.conf設定ファイルをテキストエディターで開いて編集します。-
anonymous_enable=NOの行をanonymous_enable=YESに変更します。 -
write_enable=YESの行をwrite_enable=NOに変更します。 pasv_min_port=min_portとpasv_max_port=max_portの行を追加します。min_portとmax_portを、FTP サーバーがパッシブモードで使用するポート番号の範囲 (10021と10031など) に置き換えます。このステップは、各種のファイアウォール/NAT 設定を採用するネットワーク環境に必要です。
オプション: カスタムの変更を設定に追加します。利用可能なオプションは、vsftpd.conf(5) の man ページを参照してください。この手順では、デフォルトのオプションが使用されていることを前提としています。
警告vsftpd.confファイルで SSL/TLS セキュリティーを設定している場合は、TLSv1 プロトコルのみを有効にし、SSLv2 と SSLv3 は無効にしてください。POODLE SSL 脆弱性 (CVE-2014-3566) の影響を受けないようにするためです。詳細は、Red Hat ナレッジベースソリューション Resolution for POODLE SSLv3.0 vulnerability を参照してください。
-
サーバーのファイアウォールを設定します。
ファイアウォールを有効にします。
# systemctl enable firewalld # systemctl start firewalld直前の手順の FTP ポートおよびポート範囲のファイアウォールで有効にします。
# firewall-cmd --add-port min_port-max_port/tcp --permanent # firewall-cmd --add-service ftp --permanent # firewall-cmd --reloadmin_port-max_port を、
/etc/vsftpd/vsftpd.conf設定ファイルに入力したポート番号に置き換えます。
-
/var/ftp/ディレクトリーまたはそのサブディレクトリーに、FTP サーバーへのキックスタートファイルをコピーします。 正しい SELinux コンテキストとアクセスモードがファイルに設定されていることを確認してください。
# restorecon -r /var/ftp/your-kickstart-file.ks # chmod 444 /var/ftp/your-kickstart-file.ksvsftpdサービスを開始します。# systemctl start vsftpd.service/etc/vsftpd/vsftpd.confファイルを変更する前から、このサービスがすでに実行されていた場合は、サービスを再起動して必ず編集後のファイルを読み込ませてください。# systemctl restart vsftpd.servicevsftpdサービスを有効にして、システムの起動プロセス時に開始するようにします。# systemctl enable vsftpdキックスタートファイルはアクセス可能になり、同じネットワークのシステムからのインストールとして使用できるようになりました。
注記インストールソースを設定するには、プロトコルに
ftp://を使用して、サーバーのホスト名または IP アドレス、キックスタートファイルのパス (FTP サーバーの root への相対パス) を指定します。たとえば、サーバーのホスト名がmyserver.example.comで、ファイルを/var/ftp/my-ks.cfgにコピーした場合、指定するインストールソースはftp://myserver.example.com/my-ks.cfgとなります。
10.4. 半自動インストール: RHEL インストーラーでキックスタートファイルを利用できるようにする
キックスタートファイルの準備ができたら、それをインストール先システムへのインストールに使用できるようになります。
10.4.1. ローカルボリューム上でのインストールファイルの共有
この手順では、インストールするシステムのボリュームにキックスタートスクリプトファイルを保存する方法を説明します。この方法により、別のシステムは必要なくなります。
前提条件
- USB スティックなど、インストールするマシンに移動できるドライブがある。
-
ドライブには、インストールプログラムで読み取ることができるパーティションが含まれている。対応しているタイプは、
ext2、ext3、ext4、xfs、およびfatです。 - ドライブがシステムに接続されており、そのボリュームがマウントされている。
手順
ボリューム情報のリストを表示し、キックスタートファイルをコピーするボリュームの UUID をメモします。
# lsblk -l -p -o name,rm,ro,hotplug,size,type,mountpoint,uuid- ボリュームのファイルシステムに移動します。
- このファイルシステムにキックスタートファイルをコピーします。
-
inst.ks=オプションを使用して後で使用する文字列をメモしておきます。この文字列の形式はhd:UUID=volume-UUID:path/to/kickstart-file.cfgです。パスは、ファイルシステムシステム階層の/(root) ではなく、ファイルシステムの root に相対的になります。volume-UUID を、上記の UUID に置き換えます。 ドライブボリュームのマウントをすべて解除します。
# umount /dev/xyz ...スペースで区切って、コマンドにすべてのボリュームを追加します。
10.4.2. 自動ロードのためにローカルボリューム上でインストールファイルを共有する
特別な名前が付けられたキックスタートファイルを、インストールするシステムで特別な名前が付けられたボリュームの root に置くことができます。これにより、別のシステムが必要なくなり、インストールプログラムによってファイルが自動的にロードされます。
前提条件
- USB スティックなど、インストールするマシンに移動できるドライブがある。
-
ドライブには、インストールプログラムで読み取ることができるパーティションが含まれている。対応しているタイプは、
ext2、ext3、ext4、xfs、およびfatです。 - ドライブがシステムに接続されており、そのボリュームがマウントされている。
手順
キックスタートファイルをコピーするボリューム情報をリスト表示します。
# lsblk -l -p- ボリュームのファイルシステムに移動します。
- このファイルシステムの root にキックスタートファイルをコピーします。
-
キックスタートファイルの名前を
ks.cfgに変更します。 ボリュームの名前を
OEMDRVに変更します。ext2、ext3、およびext4のファイルシステムの場合:# e2label /dev/xyz OEMDRVXFS ファイルシステムの場合:
# xfs_admin -L OEMDRV /dev/xyz
/dev/xyz を、ボリュームのブロックデバイスのパスに置き換えます。
ドライブボリュームのマウントをすべて解除します。
# umount /dev/xyz ...スペースで区切って、コマンドにすべてのボリュームを追加します。
10.5. キックスタートインストールの開始
キックスタートインストールは、複数の方法で開始できます。
- 自動的に PXE ブートで起動オプションを編集することもできます。
- 特定の名前を持つボリュームに、自動的にファイルを提供することもできます。
Red Hat コンテンツ配信ネットワーク (CDN) を使用すると、RHEL を登録できます。CDN は地理的に分散された一連の Web サーバーです。これらのサーバーは、たとえば、有効なサブスクリプションを持つ RHEL ホストにパッケージや更新を提供します。
インストール中に、CDN から RHEL を登録してインストールすると、次のような利点があります。
- インストール後すぐに最新のシステムで最新のパッケージを利用できます。
- Red Hat Insights に接続し、システムの目的を有効にするための統合サポートを利用できます。
10.5.1. PXE を使用した自動キックスタートインストールの開始
AMD64、Intel 64、および 64 ビット ARM システム、ならびに IBM Power Systems サーバーでは、PXE サーバーを使用して起動する機能があります。PXE サーバーの設定時に、ブートローダー設定ファイルに起動オプションを追加できます。これにより、インストールを自動的に開始できるようになります。このアプローチにより、ブートプロセスを含めたインストールを完全に自動化できるようになります。
この手順は一般的な参考資料として提供されています。詳細な手順はシステムのアーキテクチャーによって異なります。すべてのオプションが、すべてのアーキテクチャーで使用できるわけではありません (たとえば、64 ビットの IBM Z で PXE ブートを使用することはできません)。
前提条件
- インストールするシステムからアクセスできる場所に、キックスタートファイルを用意しておきます。
- システムを起動してインストールを開始するために使用できる PXE サーバーが用意されています。
手順
PXE サーバー上でブートローダー設定ファイルを開き、
inst.ks=起動オプションを適切な行に追加します。ファイル名と構文は、システムのアーキテクチャーおよびハードウェアにより異なります。BIOS が搭載される AMD64 システムおよび Intel 64 システムのファイル名は、デフォルトまたはシステムの IP アドレスをベースにしたもののいずれかになります。このケースでは、インストールエントリーにある append 行に、
inst.ks=オプションを追加します。設定ファイルの append 行は以下のようになります。append initrd=initrd.img inst.ks=http://10.32.5.1/mnt/archive/RHEL-8/8.x/x86_64/kickstarts/ks.cfgGRUB ブートローダーを使用するシステム (UEFI ファームウェアを搭載した AMD64、Intel 64、64 ビット ARM システム、および IBM Power Systems サーバー) では、ファイル名は
grub.cfgです。このファイルのインストールエントリーに含まれる kernel 行に、inst.ks=オプションを追加します。設定ファイルの kernel 行の例を以下に示します。kernel vmlinuz inst.ks=http://10.32.5.1/mnt/archive/RHEL-8/8.x/x86_64/kickstarts/ks.cfg
ネットワークサーバーからインストールを起動します。
これでキックスタートファイルで指定されているインストールオプションを使用したインストールが開始します。キックスタートファイルに問題がなく、必要なコマンドがすべて含まれていれば、インストールは完全に自動で行われます。
UEFI セキュアブートが有効になっているシステムに、Red Hat Enterprise Linux ベータ版リリースをインストールした場合は、システムの Machine Owner Key (MOK) リストにベータ版の公開鍵を追加します。
10.5.2. ローカルボリュームを使用した自動キックスタートインストールの開始
特別にラベルが追加されたストレージボリュームで、特定の名前が付いたキックスタートファイルを置くことで、キックスタートインストールを開始できます。
前提条件
-
ラベル
OEMDRVで準備されたボリューム、およびそのルートにks.cfgとして存在するキックスタートファイルがあります。 - このボリュームを含むドライブは、インストールプログラムの起動時にシステムで使用できます。
手順
- ローカルメディア (CD、DVD、USB フラッシュドライブなど) を使用してシステムを起動します。
起動プロンプトで、必要な起動オプションを指定します。
-
必要なリポジトリーがネットワーク上にある場合は、
ip=オプションを使用したネットワークの設定が必要になる場合があります。インストーラーは、このオプションを使用せずに、デフォルトで DHCP プロトコルを使用するすべてのネットワークデバイスを設定しようとします。 必要なパッケージがインストールされるソフトウェアソースにアクセスするには
inst.repo=オプションを追加しないといけない場合があります。このオプションを指定しないと、キックスタートファイルでインストールソースを指定する必要があります。インストールソースの詳細は、インストールプログラムの設定とフロー制御のためのキックスタートコマンド を参照してください。
-
必要なリポジトリーがネットワーク上にある場合は、
追加した起動オプションを確認してインストールを開始します。
インストールが開始し、キックスタートファイルが自動的に検出され、自動化されたキックスタートインストールを開始します。
UEFI セキュアブートが有効になっているシステムに、Red Hat Enterprise Linux ベータ版リリースをインストールした場合は、システムの Machine Owner Key (MOK) リストにベータ版の公開鍵を追加します。UEFI セキュアブートおよび Red Hat Enterprise Linux ベータ版リリースの詳細は、UEFI セキュアブートとベータ版リリースの要件 を参照してください。
10.5.3. IBM Z でインストールを起動して LPAR に RHEL をインストールする
10.5.3.1. SFTP、FTPS、または FTP サーバーから RHEL インストールを起動して IBM Z LPAR にインストールする
SFTP、FTPS、または FTP サーバーを使用して、RHEL を LPAR にインストールできます。
手順
- LPAR に新しいオペレーティングシステムをインストールできる十分な権限を持つユーザーとして、IBM Z Hardware Management Console (HMC) または Support Element (SE) にログインします。
- Systems タブで、作業するメインフレームを選択し、Partitions タブで、インストールする LPAR を選択します。
- 画面下部の Daily の下にある Operating System Messages を探します。Operating System Messages をダブルクリックして、Linux の起動メッセージが表示されるテキストコンソールを表示します。
- Load from Removable Media or Server をダブルクリックします。
次のダイアログボックスで、SFTP/FTPS/FTP Server を選択し、次の情報を入力します。
- Host Computer - インストール元となる FTP サーバーのホスト名または IP アドレス (ftp.redhat.com など) です。
- User ID - FTP サーバーのユーザー名または、anonymous を指定します。
- Password - パスワード匿名でログインする場合は、メールアドレスを使用します。
- File location (optional) - Red Hat Enterprise Linux for IBM Z を保持している FTP サーバー上のディレクトリー (例 :/rhel/s390x/)。
- Continue をクリックします。
- 続いて表示されるダイアログボックスで、generic.ins のデフォルト選択はそのままにして、Continue をクリックします。
10.5.3.2. 準備した DASD から RHEL インストールを起動して IBM Z LPAR にインストールする
すでに準備されている DASD を使用して LPAR に Red Hat Enterprise Linux をインストールする場合は、この手順を使用します。
手順
- LPAR に新しいオペレーティングシステムをインストールできる十分な権限を持つユーザーとして、IBM Z Hardware Management Console (HMC) または Support Element (SE) にログインします。
- Systems タブで、作業するメインフレームを選択し、Partitions タブで、インストールする LPAR を選択します。
- 画面下部の Daily の下にある Operating System Messages を探します。Operating System Messages をダブルクリックして、Linux の起動メッセージが表示されるテキストコンソールを表示します。
- Load をダブルクリックします。
- 続いて表示されるダイアログボックスの Load type で Normal を選択します。
- Load address に、DASD のデバイス番号を入力します。
- OK ボタンをクリックします。
10.5.3.3. FCP で接続された SCSI ディスクから RHEL インストールを起動して IBM Z LPAR にインストールする
すでに準備されている FCP 接続 SCSI ディスクを使用して Red Hat Enterprise Linux を LPAR にインストールする場合は、この手順を使用します。
手順
- LPAR に新しいオペレーティングシステムをインストールできる十分な権限を持つユーザーとして、IBM Z Hardware Management Console (HMC) または Support Element (SE) にログインします。
- Systems タブで、作業するメインフレームを選択し、Partitions タブで、インストールする LPAR を選択します。
- 画面下部の Daily の下にある Operating System Messages を探します。Operating System Messages をダブルクリックして、Linux の起動メッセージが表示されるテキストコンソールを表示します。
- Load をダブルクリックします。
- 続いて表示されるダイアログボックスの Load typeで SCSI を選択します。
- Load address (ロードアドレス) には、SCSI ディスクに接続している FCP チャネルのデバイス番号を入力します。
- World wide port name には、ディスクを含むストレージシステムの WWPN の 16 進数を入力します。
- Logical unit number には、ディスクの LUN を、16 桁の 16 進数で入力します。
- Boot record logical block address は 0 のままにしておきます。また、Operating system specific load parameters は空のままにしておきます。
- OK ボタンをクリックします。
10.5.3.4. FCP 接続 SCSI DVD ドライブから RHEL インストールを起動して IBM Z LPAR にインストールする
これには、FCP-SCSI ブリッジに接続された SCSI DVD ドライブが必要であり、そのブリッジは IBM Z マシンの FCP アダプターに接続されます。FCP アダプターを設定し、LPAR で利用可能にしておく必要があります。
手順
- LPAR に新しいオペレーティングシステムをインストールできる十分な権限を持つユーザーとして、IBM Z Hardware Management Console (HMC) または Support Element (SE) にログインします。
- [システム] タブで、操作するメインフレームを選択し、[パーティション] タブでインストールする LPAR を選択します。
- 画面下部の Daily の下にある Operating System Messages を探します。Operating System Messages をダブルクリックして、Linux の起動メッセージが表示されるテキストコンソールを表示します。
- DVD ドライブに Red Hat Enterprise Linux for 64-bit IBM Z DVD を挿入します。
- Load をダブルクリックします。
- 続いて表示されるダイアログボックスの Load typeで SCSI を選択します。
- Load address (ロードアドレス)には、FCP-to-SCSI ブリッジに接続している FCP チャネルのデバイス番号を入力します。
- World wide port name には、FCP-to-SCSI ブリッジの WWPN の 16 進数を入力します。
- Logical unit number (論理ユニット番号) には、DVD ドライブの LUN の 16 進数を入力します。
- ブートプログラムセレクター として番号 1 を入力し、Red Hat Enterprise Linux for 64 ビット IBM Z DVD 上のブートエントリーを選択します。
- Boot record logical block address は 0 のままにしておきます。また、Operating system specific load parameters は空のままにしておきます。
- OK ボタンをクリックします。
10.5.4. IBM Z でインストールを起動して z/VM に RHEL をインストールする
z/VM 環境にインストールする場合は、以下から起動できます。
- z/VM 仮想リーダー
- DASD または FCP 接続の SCSI ディスク (zipl ブートローダーを設定済み)
- FCP 接続の SCSI DVD ドライブ
10.5.4.1. z/VM Reader を使用して RHEL インストールを起動する
z/VM リーダーから起動できます。
手順
必要に応じて、z/VM の TCP/IP ツールを含むデバイスを CMS ディスクのリストに追加します。以下に例を示します。
cp link tcpmaint 592 592 acc 592 fmfm を
FILEMODE文字で置き換えます。FTPS サーバーに接続するために、次のように実行します。
ftp <host> (securehostは、ブートイメージ (kernel.imgおよびinitrd.img) をホストする FTP サーバーのホスト名または IP アドレスです。ログインして以下のコマンドを実行します。既存の
kernel.imgファイル、initrd.imgファイル、generic.prmファイル、またはredhat.execファイルを上書きしている場合は、(replオプションを使用します。cd /location/of/install-tree/images/ ascii get generic.prm (repl get redhat.exec (repl locsite fix 80 binary get kernel.img (repl get initrd.img (repl quitオプション: CMS コマンド
filelist を使用して受信したファイルとその形式を表示し、ファイルが正しく転送されたかどうかを確認します。kernel.imgとinitrd.imgでは、Format 列の固定レコード長の形式が F と示され、Lrecl 列のレコード長が 80 であることが重要です。以下に例を示します。VMUSER FILELIST A0 V 169 Trunc=169 Size=6 Line=1 Col=1 Alt=0 Cmd Filename Filetype Fm Format Lrecl Records Blocks Date Time REDHAT EXEC B1 V 22 1 1 4/15/10 9:30:40 GENERIC PRM B1 V 44 1 1 4/15/10 9:30:32 INITRD IMG B1 F 80 118545 2316 4/15/10 9:30:25 KERNEL IMG B1 F 80 74541 912 4/15/10 9:30:17PF3 を押して filelist を終了し、CMS プロンプトに戻ります。
必要に応じて、
generic.prm内の起動パラメーターをカスタマイズします。詳細は、ブートパラメーターのカスタマイズ を参照してください。CMS 設定ファイルを使用して、ストレージデバイスおよびネットワークデバイスを設定する方法もあります。そのような場合は、
CMSDASD=パラメーターおよびCMSCONFFILE=パラメーターをgeneric.prmに追加します。最後に、REXX スクリプト redhat.exec を実行してインストールプログラムを起動します。
redhat
10.5.4.2. 準備した DASD を使用して RHEL インストールを起動する
設定済み DASD を使用するには、以下の手順を実行します。
手順
準備済みの DASD から起動して、Red Hat Enterprise Linux インストールプログラムを参照する zipl ブートメニューエントリーを選択します。コマンドを次の形式で使用します。
cp ipl DASD_device_number loadparm boot_entry_numberDASD_device_number を、起動デバイスのデバイス番号に置き換え、boot_entry_number を、このデバイスの zipl 設定メニューに置き換えます。以下に例を示します。
cp ipl eb1c loadparm 0
10.5.4.3. FCP で接続された準備済みの SCSI ディスクを使用して RHEL インストールを起動する
FCP で接続された準備済みの SCSI ディスクから起動するには、次の手順を実行します。
手順
FCP ストレージエリアネットワーク内に準備した SCSI ディスクにアクセスできるように z/VM の SCSI ブートローダーを設定します。Red Hat Enterprise Linux インストールプログラムを参照する設定済み zipl ブートメニューエントリーを選択します。コマンドを次の形式で使用します。
cp set loaddev portname WWPN lun LUN bootprog boot_entry_numberWWPN を、ストレージシステムのワールドワイドポート名に置き換え、LUN を、ディスクの論理ユニット番号に置き換えます。16 桁の 16 進数は、それぞれ 8 桁の 2 つのペアに分割する必要があります。以下に例を示します。
cp set loaddev portname 50050763 050b073d lun 40204011 00000000 bootprog 0オプション: 次のコマンドで設定を確認します。
query loaddev以下のコマンドを使用して、ディスクを含むストレージシステムに接続している FCP デバイスを起動します。
cp ipl FCP_device以下に例を示します。
cp ipl fc00
10.5.4.4. FCP 接続 SCSI DVD ドライブを使用して RHEL インストールを起動する
以下の手順に従って、設定済み FCP を接続した SCSI DVD ドライブを使用します。
前提条件
- SCSI DVD ドライブを FCP-to-SCSI ブリッジに接続し、このブリッジを 64 ビットの IBM Z の FCP アダプターに接続する必要があります。FCP アダプターを設定して z/VM 環境で使用できるようにしておきます。
手順
- DVD ドライブに Red Hat Enterprise Linux for 64-bit IBM Z DVD を挿入します。
FCP Storage Area Network の DVD ドライブにアクセスできるように z/VM の SCSI ブートローダーを設定し、Red Hat Enterprise Linux for 64-bit IBM Z DVD のブートエントリーに
1を指定します。コマンドを次の形式で使用します。cp set loaddev portname WWPN lun FCP_LUN bootprog 1WWPN は、FCP-to-SCSI ブリッジの WWPN に、FCP_LUN は、DVD ドライブの LUN に置き換えます。16 桁の 16 進数は、それぞれ 8 桁の 2 つのペアに分割する必要があります。以下に例を示します。
cp set loaddev portname 20010060 eb1c0103 lun 00010000 00000000 bootprog 1オプション: 次のコマンドで設定を確認します。
cp query loaddevFCP-to-SCSI ブリッジに接続している FCP デバイスで IPL を行います。
cp ipl FCP_device以下に例を示します。
cp ipl fc00
10.5.5. インストール中のコンソールとロギング
Red Hat Enterprise Linux インストーラーは、tmux 端末マルチプレクサーを使用して、メインのインターフェイスのほかに複数の画面を表示し、制御します。この画面は、それぞれ目的が異なり、インストールプロセス中に発生した問題をトラブルシューティングするのに使用できるさまざまなログを表示します。画面の 1 つでは、起動オプションまたはキックスタートコマンドを使用して明示的に無効にしない限り、root 権限で使用できる対話式シェルプロンプトを使用できます。
端末マルチプレクサーは、仮想コンソール 1 で実行しています。インストール環境を、tmux に変更する場合は、Ctrl+Alt+F1 を押します。仮想コンソール 6 で実行されているメインのインストールインターフェイスに戻るには、Ctrl+Alt+F6 を押します。テキストモードでインストールする場合は、仮想コンソール 1 (tmux) で起動し、コンソール 6 に切り替えると、グラフィカルインターフェイスではなくシェルプロンプトが開きます。
tmux を実行しているコンソールには、利用可能な画面が 5 つあります。その内容と、キーボードショートカットは、以下の表で説明します。キーボードショートカットは 2 段階となっており、最初に Ctrl+b を押し、両方のキーを離してから、使用する画面で数字キーを押す必要があります。
また、Ctrl+b n、Alt+ Tab、および Ctrl+b p を使用して、次または前の tmux 画面に切り替えることもできます。
| ショートカット | 内容 |
|---|---|
| Ctrl+b 1 | メインのインストールプログラム画面。テキストベースのプロンプト (テキストモードのインストール中もしくは VNC Direct モードを使用の場合) とデバッグ情報があります。 |
| Ctrl+b 2 |
|
| Ctrl+b 3 |
インストールログ: |
| Ctrl+b 4 |
ストレージログ - |
| Ctrl+b 5 |
プログラムログ - |
第11章 高度な設定オプション
11.1. システムの目的の設定
システムの目的を使用して、Red Hat Enterprise Linux 8 システムの使用目的を記録します。システムの目的を設定すると、エンタイトルメントサーバーは最も適切なサブスクリプションを自動接続できます。このセクションは、キックスタートを使用して、システムの目的を設定する方法を説明します。
次の利点があります。
- システム管理および事業運営に関する詳細なシステムレベルの情報
- システムを調達した理由とその目的を判断する際のオーバーヘッドを削減
- Subscription Manager の自動割り当てと、システムの使用状況の自動検出および調整のカスタマーエクスペリエンスの向上
11.1.1. 概要
以下のいずれかの方法でシステムの目的のデータを入力できます。
- イメージの作成時
- Connect to Red Hat 画面を使用してシステムを登録し、Red Hat サブスクリプションを割り当てる際の GUI インストール時
-
syspurpose Kickstartコマンドを使用したキックスタートインストール時 -
syspurposeコマンドラインツール (CLI) を使用したインストール後
システムの目的を記録するために、システムの目的の以下のコンポーネントを設定できます。選択された値は、登録時にエンタイトルメントサーバーが、システムに最適なサブスクリプションを割り当てるのに使用されます。
- ロール
- Red Hat Enterprise Linux Server
- Red Hat Enterprise Linux Workstation
- Red Hat Enterprise Linux Compute Node
- サービスレベルアグリーメント
- Premium
- Standard
- Self-Support
- 使用方法
- Production
- Development/Test
- Disaster Recovery
11.1.2. キックスタートでシステムの目的の設定
以下の手順に従って、インストール時にシステムの目的を設定します。これを行うには、キックスタート設定ファイルで、キックスタートコマンドの syspurpose を使用します。
システムの目的は Red Hat Enterprise Linux インストールプログラムでは任意の機能ですが、最適なサブスクリプションを自動的にアタッチするためにシステムの目的を設定することを強く推奨します。
インストール完了後にシステムの目的を有効にすることもできます。これを行うには、syspurpose コマンドラインツールを使用します。syspurpose ツールのコマンドは、syspurpose Kickstart コマンドとは異なります。
キックスタートコマンド syspurpose では、以下のアクションが利用可能です。
- ロール
システムで計画しているロールを設定します。このアクションは以下の形式を使用します。
syspurpose --role=割り当てられるロールは以下のとおりです。
-
Red Hat Enterprise Linux Server -
Red Hat Enterprise Linux Workstation -
Red Hat Enterprise Linux Compute Node
-
- SLA
システムで計画している SLA を設定します。このアクションは以下の形式を使用します。
syspurpose --sla=割り当てられる SLA は以下の通りです。
-
Premium -
Standard -
Self-Support
-
- 使用方法
システムで計画している使用目的を設定します。このアクションは以下の形式を使用します。
syspurpose --usage=割り当てられる使用方法は以下の通りです。
-
Production -
Development/Test -
Disaster Recovery
-
- アドオン
追加のレイヤード製品または機能。複数のアイテムを追加するには、階層化製品/機能ごとに 1 回使用する
--addonを複数回指定します。このアクションは以下の形式を使用します。syspurpose --addon=
11.2. UEFI HTTP インストールソースの準備
ローカルネットワーク上のサーバーの管理者は、ネットワーク上の他のシステムの HTTP ブートとネットワークインストールを有効にするように HTTP サーバーを設定できます。
11.2.1. ネットワークインストールの概要
ネットワークインストールでは、インストールサーバーへのアクセスがあるシステムに、Red Hat Enterprise Linux をインストールできます。ネットワークインストールには、少なくとも 2 つのシステムが必要です。
- サーバー
- DHCP サーバー、HTTP、HTTPS、FTP または NFS サーバー、および PXE ブートの場合は TFTP サーバーを実行するシステム。各サーバーを実行する物理システムが同じである必要はありませんが、このセクションの手順では、1 つのシステムですべてのサーバーを実行していることが想定されています。
- クライアント
- Red Hat Enterprise Linux をインストールしているシステム。インストールが開始すると、クライアントは DHCP サーバーに問い合わせ、HTTP サーバーまたは TFTP サーバーからブートファイルを受け取り、HTTP サーバー、HTTPS サーバー、FTP サーバー、または NFS サーバーからインストールイメージをダウンロードします。その他のインストール方法とは異なり、クライアントはインストールを開始するのに物理的な起動メディアを必要としません。
ネットワークからクライアントを起動するには、ファームウェアまたはクライアントのクイックブートメニューでネットワークブートを有効にします。ハードウェアによっては、ネットワークから起動するオプションが無効になっていたり、利用できない場合があります。
HTTP または PXE を使用してネットワークから Red Hat Enterprise Linux をインストールする準備を行う手順は次のとおりです。
手順
- インストール ISO イメージまたはインストールツリーを NFS サーバー、HTTPS サーバー、HTTP サーバー、または FTP サーバーにエクスポートします。
- HTTP または TFTP サーバーと DHCP サーバーを設定し、サーバー上で HTTP または TFTP サービスを起動します。
- クライアントを起動して、インストールを開始します。
次のネットワークブートプロトコルを選択できます。
- HTTP
- Red Hat は、クライアント UEFI がサポートしている場合は HTTP ブートを使用することを推奨します。通常、HTTP ブートは信頼性に優れています。
- PXE (TFTP)
- PXE ブートはクライアントシステムによって広くサポートされています。ただし、このプロトコルを介したブートファイルの送信は低速で、タイムアウトにより失敗する可能性があります。
11.2.2. ネットワークブート用の DHCPv4 サーバーの設定
サーバー上で DHCP バージョン 4 (DHCPv4) サービスを有効にし、ネットワークブート機能を提供できるようにします。
前提条件
IPv4 プロトコルを介したネットワークインストールを準備中である。
IPv6 の場合は、ネットワークブート用の DHCPv6 サーバーの設定 を参照してください。
サーバーのネットワークアドレスがわかっている。
以下の手順の例では、サーバーには次の設定のネットワークカードが搭載されています。
- IPv4 アドレス
- 192.168.124.2/24
- IPv4 ゲートウェイ
- 192.168.124.1
手順
DHCP サーバーをインストールします。
yum install dhcp-serverDHCPv4 サーバーをセットアップします。
/etc/dhcp/dhcpd.confファイルに次の設定を入力します。アドレスはネットワークカードと一致するように置き換えます。option architecture-type code 93 = unsigned integer 16; subnet 192.168.124.0 netmask 255.255.255.0 { option routers 192.168.124.1; option domain-name-servers 192.168.124.1; range 192.168.124.100 192.168.124.200; class "pxeclients" { match if substring (option vendor-class-identifier, 0, 9) = "PXEClient"; next-server 192.168.124.2; if option architecture-type = 00:07 { filename "redhat/EFI/BOOT/BOOTX64.EFI"; } else { filename "pxelinux/pxelinux.0"; } } class "httpclients" { match if substring (option vendor-class-identifier, 0, 10) = "HTTPClient"; option vendor-class-identifier "HTTPClient"; filename "http://192.168.124.2/redhat/EFI/BOOT/BOOTX64.EFI"; } }DHCPv4 サービスを起動します。
# systemctl enable --now dhcpd
11.2.3. ネットワークブート用の DHCPv6 サーバーの設定
サーバー上で DHCP バージョン 6 (DHCPv4) サービスを有効にし、ネットワークブート機能を提供できるようにします。
前提条件
IPv6 プロトコルを介したネットワークインストールを準備中である。
IPv4 の場合は、ネットワークブート用の DHCPv4 サーバーの設定 を参照してください。
サーバーのネットワークアドレスがわかっている。
以下の手順の例では、サーバーには次の設定のネットワークカードが搭載されています。
- IPv6 アドレス
- fd33:eb1b:9b36::2/64
- IPv6 ゲートウェイ
- fd33:eb1b:9b36::1
手順
DHCP サーバーをインストールします。
yum install dhcp-serverDHCPv6 サーバーをセットアップします。
/etc/dhcp/dhcpd6.confファイルに次の設定を入力します。アドレスはネットワークカードと一致するように置き換えます。option dhcp6.bootfile-url code 59 = string; option dhcp6.vendor-class code 16 = {integer 32, integer 16, string}; subnet6 fd33:eb1b:9b36::/64 { range6 fd33:eb1b:9b36::64 fd33:eb1b:9b36::c8; class "PXEClient" { match substring (option dhcp6.vendor-class, 6, 9); } subclass "PXEClient" "PXEClient" { option dhcp6.bootfile-url "tftp://[fd33:eb1b:9b36::2]/redhat/EFI/BOOT/BOOTX64.EFI"; } class "HTTPClient" { match substring (option dhcp6.vendor-class, 6, 10); } subclass "HTTPClient" "HTTPClient" { option dhcp6.bootfile-url "http://[fd33:eb1b:9b36::2]/redhat/EFI/BOOT/BOOTX64.EFI"; option dhcp6.vendor-class 0 10 "HTTPClient"; } }DHCPv6 サービスを起動します。
# systemctl enable --now dhcpd6DHCPv6 パケットがファイアウォールの RP フィルターによって破棄されている場合は、そのログを確認してください。ログに
rpfilter_DROPエントリーが含まれている場合は、/etc/firewalld/firewalld.confファイルで次の設定を使用してフィルターを無効にします。IPv6_rpfilter=no
11.2.4. HTTP ブート用の HTTP サーバーの設定
サーバーがネットワーク上で HTTP ブートリソースを提供できるように、サーバーに httpd サービスをインストールして有効にする必要があります。
前提条件
サーバーのネットワークアドレスがわかっている。
次の例では、サーバーには IPv4 アドレス
192.168.124.2のネットワークカードが搭載されています。
手順
HTTP サーバーをインストールします。
# yum install httpd/var/www/html/redhat/ディレクトリーを作成します。# mkdir -p /var/www/html/redhat/- RHEL DVD ISO ファイルをダウンロードします。All Red Hat Enterprise Linux Downloads を参照してください。
ISO ファイルのマウントポイントを作成します。
# mkdir -p /var/www/html/redhat/iso/ISO ファイルをマウントします。
# mount -o loop,ro -t iso9660 path-to-RHEL-DVD.iso /var/www/html/redhat/isoマウントされた ISO ファイルからブートローダー、カーネル、
initramfsを HTML ディレクトリーにコピーします。# cp -r /var/www/html/redhat/iso/images /var/www/html/redhat/ # cp -r /var/www/html/redhat/iso/EFI /var/www/html/redhat/ブートローダー設定を編集可能にします。
# chmod 644 /var/www/html/redhat/EFI/BOOT/grub.cfg/var/www/html/redhat/EFI/BOOT/grub.cfgファイルを編集し、次のように内容を置き換えます。set default="1" function load_video { insmod efi_gop insmod efi_uga insmod video_bochs insmod video_cirrus insmod all_video } load_video set gfxpayload=keep insmod gzio insmod part_gpt insmod ext2 set timeout=60 # END /etc/grub.d/00_header # search --no-floppy --set=root -l 'RHEL-9-3-0-BaseOS-x86_64' # BEGIN /etc/grub.d/10_linux # menuentry 'Install Red Hat Enterprise Linux 9.3' --class fedora --class gnu-linux --class gnu --class os { linuxefi ../../images/pxeboot/vmlinuz inst.repo=http://192.168.124.2/redhat/iso quiet initrdefi ../../images/pxeboot/initrd.img } menuentry 'Test this media & install Red Hat Enterprise Linux 9.3' --class fedora --class gnu-linux --class gnu --class os { linuxefi ../../images/pxeboot/vmlinuz inst.repo=http://192.168.124.2/redhat/iso quiet initrdefi ../../images/pxeboot/initrd.img } submenu 'Troubleshooting -->' { menuentry 'Install Red Hat Enterprise Linux 9.3 in text mode' --class fedora --class gnu-linux --class gnu --class os { linuxefi ../../images/pxeboot/vmlinuz inst.repo=http://192.168.124.2/redhat/iso inst.text quiet initrdefi ../../images/pxeboot/initrd.img } menuentry 'Rescue a Red Hat Enterprise Linux system' --class fedora --class gnu-linux --class gnu --class os { linuxefi ../../images/pxeboot/vmlinuz inst.repo=http://192.168.124.2/redhat/iso inst.rescue quiet initrdefi ../../images/pxeboot/initrd.img } }このファイル内で、次の文字列を置き換えます。
- RHEL-9-3-0-BaseOS-x86_64 および Red Hat Enterprise Linux 9.3
- ダウンロードした RHEL のバージョンと一致するようにバージョン番号を編集します。
- 192.168.124.2
- サーバーの IP アドレスに置き換えます。
EFI ブートファイルを実行可能にします。
# chmod 755 /var/www/html/redhat/EFI/BOOT/BOOTX64.EFIファイアウォールでポートを開いて、HTTP (80)、DHCP (67、68)、および DHCPv6 (546、547) トラフィックを許可します。
# firewall-cmd --zone public \ --add-port={80/tcp,67/udp,68/udp,546/udp,547/udp}このコマンドは、次にサーバーを再起動するまで、一時的にアクセスを有効にします。
-
オプション: 永続的アクセスを有効にするには、コマンドに
--permanentオプションを追加します。 ファイアウォールルールを再読み込みします。
# firewall-cmd --reloadHTTP サーバーを起動します。
# systemctl enable --now httpdhtmlディレクトリーとそのコンテンツを読み取り可能および実行可能にします。# chmod -cR u=rwX,g=rX,o=rX /var/www/htmlhtmlディレクトリーの SELinux コンテキストを復元します。# restorecon -FvvR /var/www/html
第12章 PXE インストールソースの準備
PXE ブートとネットワークインストールを有効にするには、PXE サーバーで TFTP と DHCP を設定する必要があります。
12.1. ネットワークインストールの概要
ネットワークインストールでは、インストールサーバーへのアクセスがあるシステムに、Red Hat Enterprise Linux をインストールできます。ネットワークインストールには、少なくとも 2 つのシステムが必要です。
- サーバー
- DHCP サーバー、HTTP、HTTPS、FTP または NFS サーバー、および PXE ブートの場合は TFTP サーバーを実行するシステム。各サーバーを実行する物理システムが同じである必要はありませんが、このセクションの手順では、1 つのシステムですべてのサーバーを実行していることが想定されています。
- クライアント
- Red Hat Enterprise Linux をインストールしているシステム。インストールが開始すると、クライアントは DHCP サーバーに問い合わせ、HTTP サーバーまたは TFTP サーバーからブートファイルを受け取り、HTTP サーバー、HTTPS サーバー、FTP サーバー、または NFS サーバーからインストールイメージをダウンロードします。その他のインストール方法とは異なり、クライアントはインストールを開始するのに物理的な起動メディアを必要としません。
ネットワークからクライアントを起動するには、ファームウェアまたはクライアントのクイックブートメニューでネットワークブートを有効にします。ハードウェアによっては、ネットワークから起動するオプションが無効になっていたり、利用できない場合があります。
HTTP または PXE を使用してネットワークから Red Hat Enterprise Linux をインストールする準備を行う手順は次のとおりです。
手順
- インストール ISO イメージまたはインストールツリーを NFS サーバー、HTTPS サーバー、HTTP サーバー、または FTP サーバーにエクスポートします。
- HTTP または TFTP サーバーと DHCP サーバーを設定し、サーバー上で HTTP または TFTP サービスを起動します。
- クライアントを起動して、インストールを開始します。
次のネットワークブートプロトコルを選択できます。
- HTTP
- Red Hat は、クライアント UEFI がサポートしている場合は HTTP ブートを使用することを推奨します。通常、HTTP ブートは信頼性に優れています。
- PXE (TFTP)
- PXE ブートはクライアントシステムによって広くサポートされています。ただし、このプロトコルを介したブートファイルの送信は低速で、タイムアウトにより失敗する可能性があります。
12.2. ネットワークブート用の DHCPv4 サーバーの設定
サーバー上で DHCP バージョン 4 (DHCPv4) サービスを有効にし、ネットワークブート機能を提供できるようにします。
前提条件
IPv4 プロトコルを介したネットワークインストールを準備中である。
IPv6 の場合は、ネットワークブート用の DHCPv6 サーバーの設定 を参照してください。
サーバーのネットワークアドレスがわかっている。
以下の手順の例では、サーバーには次の設定のネットワークカードが搭載されています。
- IPv4 アドレス
- 192.168.124.2/24
- IPv4 ゲートウェイ
- 192.168.124.1
手順
DHCP サーバーをインストールします。
yum install dhcp-serverDHCPv4 サーバーをセットアップします。
/etc/dhcp/dhcpd.confファイルに次の設定を入力します。アドレスはネットワークカードと一致するように置き換えます。option architecture-type code 93 = unsigned integer 16; subnet 192.168.124.0 netmask 255.255.255.0 { option routers 192.168.124.1; option domain-name-servers 192.168.124.1; range 192.168.124.100 192.168.124.200; class "pxeclients" { match if substring (option vendor-class-identifier, 0, 9) = "PXEClient"; next-server 192.168.124.2; if option architecture-type = 00:07 { filename "redhat/EFI/BOOT/BOOTX64.EFI"; } else { filename "pxelinux/pxelinux.0"; } } class "httpclients" { match if substring (option vendor-class-identifier, 0, 10) = "HTTPClient"; option vendor-class-identifier "HTTPClient"; filename "http://192.168.124.2/redhat/EFI/BOOT/BOOTX64.EFI"; } }DHCPv4 サービスを起動します。
# systemctl enable --now dhcpd
12.3. ネットワークブート用の DHCPv6 サーバーの設定
サーバー上で DHCP バージョン 6 (DHCPv4) サービスを有効にし、ネットワークブート機能を提供できるようにします。
前提条件
IPv6 プロトコルを介したネットワークインストールを準備中である。
IPv4 の場合は、ネットワークブート用の DHCPv4 サーバーの設定 を参照してください。
サーバーのネットワークアドレスがわかっている。
以下の手順の例では、サーバーには次の設定のネットワークカードが搭載されています。
- IPv6 アドレス
- fd33:eb1b:9b36::2/64
- IPv6 ゲートウェイ
- fd33:eb1b:9b36::1
手順
DHCP サーバーをインストールします。
yum install dhcp-serverDHCPv6 サーバーをセットアップします。
/etc/dhcp/dhcpd6.confファイルに次の設定を入力します。アドレスはネットワークカードと一致するように置き換えます。option dhcp6.bootfile-url code 59 = string; option dhcp6.vendor-class code 16 = {integer 32, integer 16, string}; subnet6 fd33:eb1b:9b36::/64 { range6 fd33:eb1b:9b36::64 fd33:eb1b:9b36::c8; class "PXEClient" { match substring (option dhcp6.vendor-class, 6, 9); } subclass "PXEClient" "PXEClient" { option dhcp6.bootfile-url "tftp://[fd33:eb1b:9b36::2]/redhat/EFI/BOOT/BOOTX64.EFI"; } class "HTTPClient" { match substring (option dhcp6.vendor-class, 6, 10); } subclass "HTTPClient" "HTTPClient" { option dhcp6.bootfile-url "http://[fd33:eb1b:9b36::2]/redhat/EFI/BOOT/BOOTX64.EFI"; option dhcp6.vendor-class 0 10 "HTTPClient"; } }DHCPv6 サービスを起動します。
# systemctl enable --now dhcpd6DHCPv6 パケットがファイアウォールの RP フィルターによって破棄されている場合は、そのログを確認してください。ログに
rpfilter_DROPエントリーが含まれている場合は、/etc/firewalld/firewalld.confファイルで次の設定を使用してフィルターを無効にします。IPv6_rpfilter=no
12.4. BIOS ベースのクライアント用に TFTP サーバーを設定する
BIOS ベースの AMD および Intel 64 ビットシステムでは、TFTP サーバーと DHCP サーバーを設定し、PXE サーバー上で TFTP サービスを起動する必要があります。
手順
root で、次のパッケージをインストールします。
# yum install tftp-serverファイアウォールで、
tftp serviceサービスへの着信接続を許可します。# firewall-cmd --add-service=tftpこのコマンドは、次にサーバーを再起動するまで、一時的にアクセスを有効にします。
オプション: 永続的アクセスを有効にするには、コマンドに
--permanentオプションを追加します。ISO インストールファイルの場所によっては、HTTP などのサービスの着信接続を許可しないといけない場合があります。
DVD ISO イメージファイルの
SYSLINUXパッケージからpxelinux.0ファイルにアクセスします。ここで、my_local_directory は、作成するディレクトリーの名前です。# mount -t iso9660 /path_to_image/name_of_image.iso /mount_point -o loop,ro# cp -pr /mount_point/BaseOS/Packages/syslinux-tftpboot-version-architecture.rpm /my_local_directory# umount /mount_pointパッケージをデプロイメントします。
# rpm2cpio syslinux-tftpboot-version-architecture.rpm | cpio -dimvtftpboot/にpxelinux/ディレクトリーを作成し、そのディレクトリーからpxelinux/ディレクトリーにすべてのファイルをコピーします。# mkdir /var/lib/tftpboot/pxelinux# cp /my_local_directory/tftpboot/* /var/lib/tftpboot/pxelinuxpxelinux/ディレクトリーにpxelinux.cfg/ディレクトリーを作成します。# mkdir /var/lib/tftpboot/pxelinux/pxelinux.cfgdefaultという名前の設定ファイルを作成し、以下の例のようにpxelinux.cfg/ディレクトリーに追加します。default vesamenu.c32 prompt 1 timeout 600 display boot.msg label linux menu label ^Install system menu default kernel images/RHEL-8/vmlinuz append initrd=images/RHEL-8/initrd.img ip=dhcp inst.repo=http://192.168.124.2/RHEL-8/x86_64/iso-contents-root/ label vesa menu label Install system with ^basic video driver kernel images/RHEL-8/vmlinuz append initrd=images/RHEL-8/initrd.img ip=dhcp inst.xdriver=vesa nomodeset inst.repo=http://192.168.124.2/RHEL-8/x86_64/iso-contents-root/ label rescue menu label ^Rescue installed system kernel images/RHEL-8/vmlinuz append initrd=images/RHEL-8/initrd.img inst.rescue inst.repo=http:///192.168.124.2/RHEL-8/x86_64/iso-contents-root/ label local menu label Boot from ^local drive localboot 0xffff-
このランタイムイメージなしでは、インストールプログラムは起動できません。
inst.stage2起動オプションを使用して、イメージの場所を指定します。または、inst.repo=オプションを使用して、イメージおよびインストールソースを指定することも可能です。 -
inst.repoで使用したインストールソースの場所には、有効なtreeinfoファイルが含まれている必要があります。 -
インストールソースとして RHEL8 インストール DVD を選択すると、
.treeinfoファイルが BaseOS リポジトリーおよび AppStream リポジトリーを指定します。単一のinst.repoオプションを使用することで両方のリポジトリーを読み込むことができます。
-
このランタイムイメージなしでは、インストールプログラムは起動できません。
/var/lib/tftpboot/ディレクトリーに、ブートイメージファイルを保存するサブディレクトリーを作成し、そのディレクトリーにブートイメージファイルをコピーします。この例のディレクトリーは、/var/lib/tftpboot/pxelinux/images/RHEL-8/になります。# mkdir -p /var/lib/tftpboot/pxelinux/images/RHEL-8/ # cp /path_to_x86_64_images/pxeboot/{vmlinuz,initrd.img} /var/lib/tftpboot/pxelinux/images/RHEL-8/tftp.socketサービスを開始して有効にします。# systemctl enable --now tftp.socketこれにより、PXE 起動サーバーでは、PXE クライアントにサービスを提供する準備が整いました。クライアント (Red Hat Enterprise Linux のインストール先システム) を起動し、起動ソースを指定するように求められたら、PXE ブート を選択してネットワークインストールを開始できます。
12.5. UEFI ベースのクライアント用に TFTP サーバーを設定する
UEFI ベースの AMD64、Intel 64、および 64 ビット ARM システムでは、TFTP サーバーと DHCP サーバーを設定し、PXE サーバー上で TFTP サービスを起動する必要があります。
Red Hat Enterprise Linux 8 UEFI PXE ブートは、MAC ベースの GRUB メニューファイルの小文字のファイル形式をサポートします。たとえば、GRUB の MAC アドレスファイル形式は grub.cfg-01-aa-bb-cc-dd-ee-ff です。
手順
root で、次のパッケージをインストールします。
# yum install tftp-serverファイアウォールで、
tftp serviceサービスへの着信接続を許可します。# firewall-cmd --add-service=tftpこのコマンドは、次にサーバーを再起動するまで、一時的にアクセスを有効にします。
オプション: 永続的アクセスを有効にするには、コマンドに
--permanentオプションを追加します。ISO インストールファイルの場所によっては、HTTP などのサービスの着信接続を許可しないといけない場合があります。
DVD ISO イメージから EFI ブートイメージファイルにアクセスします。
# mount -t iso9660 /path_to_image/name_of_image.iso /mount_point -o loop,roDVD ISO イメージから EFI ブートイメージをコピーします。
# mkdir /var/lib/tftpboot/redhat # cp -r /mount_point/EFI /var/lib/tftpboot/redhat/ # umount /mount_pointコピーしたファイルのパーミッションを修正します。
# chmod -R 755 /var/lib/tftpboot/redhat//var/lib/tftpboot/redhat/efi/boot/grub.cfgの内容を次の例に置き換えます。set timeout=60 menuentry 'RHEL 8' { linux images/RHEL-8/vmlinuz ip=dhcp inst.repo=http://192.168.124.2/RHEL-8/x86_64/iso-contents-root/ initrd images/RHEL-8/initrd.img }-
このランタイムイメージなしでは、インストールプログラムは起動できません。
inst.stage2起動オプションを使用して、イメージの場所を指定します。または、inst.repo=オプションを使用して、イメージおよびインストールソースを指定することも可能です。 -
inst.repoで使用したインストールソースの場所には、有効なtreeinfoファイルが含まれている必要があります。 -
インストールソースとして RHEL8 インストール DVD を選択すると、
.treeinfoファイルが BaseOS リポジトリーおよび AppStream リポジトリーを指定します。単一のinst.repoオプションを使用することで両方のリポジトリーを読み込むことができます。
-
このランタイムイメージなしでは、インストールプログラムは起動できません。
/var/lib/tftpboot/ディレクトリーに、ブートイメージファイルを保存するサブディレクトリーを作成し、そのディレクトリーにブートイメージファイルをコピーします。この例では、ディレクトリーは/var/lib/tftpboot/images/RHEL-8/です。# mkdir -p /var/lib/tftpboot/images/RHEL-8/ # cp /mount_point/images/pxeboot/{vmlinuz,initrd.img} /var/lib/tftpboot/images/RHEL-8/tftp.socketサービスを開始して有効にします。# systemctl enable --now tftp.socketこれにより、PXE 起動サーバーでは、PXE クライアントにサービスを提供する準備が整いました。クライアント (Red Hat Enterprise Linux のインストール先システム) を起動し、起動ソースを指定するように求められたら、PXE ブート を選択してネットワークインストールを開始できます。
12.6. IBM Power システム用のネットワークサーバーの設定
GRUB を使用して、IBM Power システム用のネットワークブートサーバーを設定できます。
手順
root で、次のパッケージをインストールします。
# yum install tftp-server dhcp-servertftpサービスへの着信接続をファイアウォールで許可します。# firewall-cmd --add-service=tftpこのコマンドは、次にサーバーを再起動するまで、一時的にアクセスを有効にします。
オプション: 永続的アクセスを有効にするには、コマンドに
--permanentオプションを追加します。ISO インストールファイルの場所によっては、HTTP などのサービスの着信接続を許可しないといけない場合があります。
TFTP のルート内に GRUB ネットワーク起動ディレクトリーを作成します。
# grub2-mknetdir --net-directory=/var/lib/tftpboot Netboot directory for powerpc-ieee1275 created. Configure your DHCP server to point to /boot/grub2/powerpc-ieee1275/core.elfこの手順で説明しているように、コマンドの出力は、DHCP 設定で設定する必要があるファイル名をユーザーに通知します。
PXE サーバーを x86 マシンで実行している場合は、tftp のルート内に
GRUB2ネットワークブートディレクトリーを作成する前に、grub2-ppc64le-modulesをインストールする必要があります。# yum install grub2-ppc64le-modules
以下の例のように、GRUB 設定ファイル (
/var/lib/tftpboot/boot/grub2/grub.cfg) を作成します。set default=0 set timeout=5 echo -e "\nWelcome to the Red Hat Enterprise Linux 8 installer!\n\n" menuentry 'Red Hat Enterprise Linux 8' { linux grub2-ppc64/vmlinuz ro ip=dhcp inst.repo=http://192.168.124.2/RHEL-8/x86_64/iso-contents-root/ initrd grub2-ppc64/initrd.img }-
このランタイムイメージなしでは、インストールプログラムは起動できません。
inst.stage2起動オプションを使用して、イメージの場所を指定します。または、inst.repo=オプションを使用して、イメージおよびインストールソースを指定することも可能です。 -
inst.repoで使用したインストールソースの場所には、有効なtreeinfoファイルが含まれている必要があります。 -
インストールソースとして RHEL8 インストール DVD を選択すると、
.treeinfoファイルが BaseOS リポジトリーおよび AppStream リポジトリーを指定します。単一のinst.repoオプションを使用することで両方のリポジトリーを読み込むことができます。
-
このランタイムイメージなしでは、インストールプログラムは起動できません。
このコマンドを使用して DVD ISO イメージをマウントします。
# mount -t iso9660 /path_to_image/name_of_iso/ /mount_point -o loop,roディレクトリーを作成し、DVD ISO イメージから
initrd.imgファイルおよびvmlinuzファイルをコピーします。以下に例を示します。# cp /mount_point/ppc/ppc64/{initrd.img,vmlinuz} /var/lib/tftpboot/grub2-ppc64/以下の例のように、
GRUB2に同梱されているブートイメージを使用するように DHCP サーバーを設定します。DHCP サーバーがすでに設定されている場合は、DHCP サーバーでこの手順を実行します。subnet 192.168.0.1 netmask 255.255.255.0 { allow bootp; option routers 192.168.0.5; group { #BOOTP POWER clients filename "boot/grub2/powerpc-ieee1275/core.elf"; host client1 { hardware ethernet 01:23:45:67:89:ab; fixed-address 192.168.0.112; } } }-
ネットワーク設定に合わせて、サンプルパラメーターの
subnet、netmask、routers、fixed-address、およびhardware ethernetを変更します。file nameパラメーターは、この手順で先ほどgrub2-mknetdirコマンドで出力したファイル名です。 DHCP サーバーで
dhcpdサービスを開始して有効にします。localhost で DHCP サーバーを設定している場合は、ローカルホストでdhcpdサービスを開始して有効にします。# systemctl enable --now dhcpdtftp.socketサービスを開始して有効にします。# systemctl enable --now tftp.socketこれにより、PXE 起動サーバーでは、PXE クライアントにサービスを提供する準備が整いました。クライアント (Red Hat Enterprise Linux のインストール先システム) を起動し、起動ソースを指定するように求められたら、PXE ブート を選択してネットワークインストールを開始できます。
第13章 キックスタートの参照
付録B キックスタートスクリプトのファイル形式の参照
このリファレンスでは、キックスタートファイルの形式を詳しく説明します。
B.1. キックスタートファイルの形式
キックスタートスクリプトは、インストールプログラムが認識するキーワードが含まれ、インストールの指示を提供するプレーンテキストのファイルです。ファイルを ASCII テキストとして保存できるテキストエディター (例: Linux システムの Gedit または vim、Windows システムの メモ帳) は、キックスタートファイルの作成や編集に使用できます。キックスタート設定ファイルには好きな名前を付けることができますが、後で他の設定ファイルやダイアログでこの名前を指定する必要があるため、シンプルな名前にしておくことが推奨されます。
- コマンド
- コマンドは、インストールの命令として役に立つキーワードです。各コマンドは 1 行で記載する必要があります。コマンドにはオプションを指定できます。コマンドとオプションの指定方法は、シェルで Linux コマンドを使用するのと似ています。
- セクション
-
パーセント
%文字で始まる特殊コマンドは、セクションを開始します。セクションのコマンドの解釈は、セクションの外に置かれたコマンドとは異なります。すべてのセクションは、%endコマンドで終了する必要があります。 - セクションタイプ
利用可能なセクションは以下のとおりです。
-
アドオンセクション。これらのセクションは、
%addon addon_nameコマンドを使用します。 -
パッケージの選択セクション。
%packagesから始まります。これを使用してインストールするパッケージを指定します。これには、パッケージグループやモジュールなど、間接的な指定も含まれます。 -
スクリプトセクション。これは、
%pre、%pre-install、%post、および%onerrorで開始します。これらのセクションは必須ではありません。
-
アドオンセクション。これらのセクションは、
- コマンドセクション
-
コマンドセクションは、スクリプトセクションや
%packagesセクション以外の、キックスタートファイルのコマンドに使用される用語です。 - スクリプトセクション数および順序付け
-
コマンドセクションを除くすべてのセクションはオプションであり、複数回表示できます。特定タイプのスクリプトセクションが評価される際に、キックスタートにあるそのタイプのセクションがすべて、表示順に評価されます。たとえば、
%postが 2 つある場合は、表示されている順に評価されます。ただし、さまざまなタイプのスクリプトセクションを任意の順序で指定する必要はありません。%preセクションの前に、%postセクションがあるかどうかは問題ありません。
- コメント
-
キックスタートコマンドは、ハッシュ文字
#始まる行です。このような行は、インストールプログラムには無視されます。
必須項目以外は省略しても構いません。必須項目を省略すると、インストールプログラムがインタラクティブモードに変更され、通常の対話型インストールと同じように、ユーザーが関連する項目に回答できるようになります。キックスタートスクリプトは、cmdline コマンドで非対話的に宣言することもできます。非対話モードでは、回答していない項目があるとインストールプロセスが中断します。
テキストまたはグラフィカルモードのキックスタートインストール時にユーザーの対話が必要な場合は、インストールを完了するために更新が必須であるウィンドウのみに入力してください。スポークを入力すると、キックスタートの設定がリセットされる可能性があります。設定のリセットは、インストール先ウィンドウの入力後に、ストレージに関連するキックスタートコマンドに特化して適用されます。
B.2. キックスタートでのパッケージ選択
キックスタートは、インストールするパッケージを選択するために、%packages コマンドで始まるセクションを使用します。この方法で、パッケージ、グループ、環境、モジュールストリーム、およびモジュールプロファイルをインストールできます。
B.2.1. パッケージの選択セクション
%packages コマンドを使用して、インストールするソフトウェアパッケージを説明するキックスタートセクションを開始します。%packages セクションは、%end コマンドで終了する必要があります。
パッケージは、環境、グループ、モジュールストリーム、モジュールプロファイル、またはパッケージ名で指定できます。関連パッケージを含むいくつかの環境およびグループが定義されます。環境およびグループのリストは、Red Hat Enterprise Linux 8 インストール DVD の repository/repodata/*-comps-repository.architecture.xml ファイルを参照してください。
*-comps-repository.architecture.xml ファイルには、利用可能な環境 (<environment> タグでマーク) およびグループ (<group> タグ) を記述した構造が含まれています。各エントリーには、ID、ユーザー可視性の値、名前、説明、パッケージリストがあります。グループがインストールに選択されていると、パッケージリストで mandatory とマークされたパッケージが常にインストールされ、default とマークされたパッケージは、他で個別に除外されていない場合に限りインストールされます。また、optional とマークされたパッケージは、グループが選択されている場合でも、他で明確に含める必要があります。
パッケージグループや環境は、その ID (<id> タグ) もしくは名前 (<name> タグ) を使用して指定できます。
どのパッケージをインストールするべきかわからない場合は、Minimal Install 環境を選択することが推奨されます。最小インストール では、Red Hat Enterprise Linux 8 の実行に必須のパッケージのみが提供されます。これにより、システムが脆弱性の影響を受ける可能性が大幅に減ります。必要な場合は、インストール後に追加パッケージをインストールできます。最小インストール の詳細は、セキュリティーの強化 の 必要なパッケージの最小限のインストール のセクションを参照してください。Initial Setup は、デスクトップ環境と X Window System がインストールに含まれ、グラフィカルログインが有効になっていないと、キックスタートファイルからシステムをインストールした後に実行できません。
64 ビットシステムに 32 ビットパッケージをインストールするには、次を行います。
-
%packagesセクションに--multilibオプションを指定します。 -
glibc.i686のように、そのパッケージの構築対象である 32 ビットアーキテクチャーをパッケージ名に追記します。
B.2.2. パッケージの選択コマンド
このコマンドは、キックスタートファイルの %packages セクションで使用できます。
- 環境の指定
@^記号で開始する行で、インストールする環境全体を指します。%packages @^Infrastructure Server %endこれは、
インフラストラクチャーサーバー環境の一部となるパッケージをすべてインストールします。利用可能なすべての環境は、Red Hat Enterprise Linux 8 インストール DVD のrepository/repodata/*-comps-repository.architecture.xmlファイルで説明されています。キックスタートファイルに指定する必要があるのは、1 つの環境だけです。追加の環境を指定すると、最後に指定した環境のみが使用されます。
- グループの指定
1 行に 1 エントリーずつグループを指定します。
*-comps-repository.architecture.xmlファイルに指定したとおりに、@記号に続いてグループのフルネームまたはグループ ID を指定します。以下に例を示します。%packages @X Window System @Desktop @Sound and Video %endCoreグループは常に選択されるため、%packagesセクションで指定する必要はありません。- 個別パッケージの指定
1 行に 1 エントリーで、名前で個別のパッケージを指定します。アスタリスク記号 (
*) をパッケージ名のワイルドカードとして使用できます。以下に例を示します。%packages sqlite curl aspell docbook* %enddocbook*エントリーには、ワイルドカードを使用したパターンに適合するdocbook-dtdsパッケージおよびdocbook-styleパッケージが含まれます。- モジュールストリームのプロファイルの指定
プロファイルの構文を使用して、モジュールストリープのポリシーを、1 行ごとに指定します。
%packages @module:stream/profile %endこれにより、モジュールストリームで指定したプロファイルに記載されているパッケージがすべてインストールされます。
- モジュールにデフォルトのストリームが指定されている場合は、削除できます。デフォルトのストリームが指定されていない場合は、指定する必要があります。
- モジュールストリームにデフォルトのプロファイルが指定されている場合は、削除できます。デフォルトのプロファイルが指定されていない場合は、指定する必要があります。
- 異なるストリームでモジュールを複数回インストールすることはできません。
- 同じモジュールおよびストリームの複数プロファイルをインストールできます。
モジュールおよびグループは、
@記号で始まる同じ構文を使用します。同じ名前のモジュールとパッケージグループが存在する場合は、モジュールが優先されます。Red Hat Enterprise Linux 8 では、モジュールは AppStream リポジトリーにのみ存在します。利用可能なモジュールのリストを表示するには、インストールされている Red Hat Enterprise Linux 8 システムで
yum module listコマンドを使用します。キックスタートコマンド
moduleを使用して、モジュールストリームを有効にし、直接命名して、モジュールストリームに含まれるパッケージをインストールすることもできます。- 環境、グループ、パッケージの除外
ダッシュ (
-) を先頭に付け、インストールから除外するパッケージやグループを指定します。以下に例を示します。%packages -@Graphical Administration Tools -autofs -ipa*compat %end
キックスタートファイルで * のみを使用して、利用可能なパッケージをすべてインストールする方法はサポートされていません。
%packages セクションのデフォルト動作は、オプションを使用して変更する方法がいくつかあります。オプションの中には、全パッケージの選択で機能するものと、特定のグループにのみ機能するものがあります。
B.2.3. 一般的なパッケージ選択のオプション
%packages では、以下のオプションが使用できます。オプションを使用するには、パッケージ選択セクションの最初に追加します。以下に例を示します。
%packages --multilib --ignoremissing--default- パッケージのデフォルトセットをインストールします。これは、対話式インストールの パッケージの選択 画面でその他を選択しない場合にインストールされるパッケージセットに対応するものです。
--excludedocs-
パッケージに含まれているドキュメンテーションをインストールしません。ほとんどの場合、通常
/usr/share/docディレクトリーにインストールされるファイルを除外しますが、個別に除外されるファイルは個別のパッケージによります。 --ignoremissing- インストールを停止してインストールの中断または続行を確認する代わりに、インストールソースにないパッケージ、グループ、モジュールストリーム、モジュールプロファイル、および環境を無視します。
--instLangs=- インストールする言語リストを指定します。これはパッケージグループレベルの選択とは異なります。このオプションでは、インストールするパッケージグループを記述するのではなく、RPM マクロを設定して、個別パッケージからインストールする翻訳ファイルを制御します。
--multilib64 ビットのシステムに 32 ビットのパッケージをインストールできるように、multilib パッケージ用にインストールされたシステムを設定し、このセクションで説明しているようにパッケージをインストールします。
通常、AMD64 および Intel 64 のシステムでは、x86_64 パッケージおよび noarch パッケージのみをインストールできます。ただし、--multilib オプションを使用すると、32 ビット AMD および i686 Intel のシステムパッケージが存在する場合は自動的にインストールされます。
これは
%packagesセクションで明示的に指定されているパッケージにのみ適用されます。キックスタートファイルで指定されずに依存関係としてのみインストールされるパッケージは、他のアーキテクチャーで利用可能な場合でも、必要とされるアーキテクチャーのバージョンにのみインストールされます。システムのインストール時に、Anaconda が
multilibモードでパッケージをインストールするように設定できます。以下のいずれかのオプションを使用してmultilibモードを有効にします。以下の行でキックスタートファイルを設定します。
%packages --multilib --default %end- インストールイメージの起動中に、inst.multilib 起動オプションを追加します。
--nocore@Coreパッケージグループのインストールを無効にします。これを使用しない場合は、デフォルトでインストールされます。--nocoreでの@Coreパッケージグループの無効化は、軽量コンテナーの作成にのみ使用してください。--nocoreを指定してデスクトップやサーバーのシステムをインストールすると、システムが使用できなくなります。注記-
@Coreパッケージグループ内のパッケージを、-@Coreを使用して除外することはできません。@Coreパッケージグループを除外する唯一の方法は、--nocoreオプションを使用することです。 -
@Coreパッケージグループは、作業 system のインストールに必要なパッケージの最小セットとして定義されています。これは、パッケージマニフェスト および 対象範囲の詳細 で定義されているコアパッケージには関係ありません。
-
--excludeWeakdeps- 弱い依存関係からのパッケージのインストールを無効にします。これは、Recommends フラグおよび Supplements フラグで選択したパッケージセットにリンクされたパッケージです。デフォルトでは、弱い依存関係がインストールされます。
--retries=- YUM がパッケージのダウンロードを試みる回数を設定します (再試行)。デフォルト値は 10 です。このオプションはインストール時にのみ適用され、インストールされているシステムの YUM 設定には影響を及ぼしません。
--timeout=- YUM のタイムアウトを秒単位で設定します。デフォルト値は 30 です。このオプションはインストール時にのみ適用され、インストールされているシステムの YUM 設定には影響を及ぼしません。
B.2.4. 特定パッケージグループ用のオプション
以下のオプションは、単一パッケージグループにのみ適用されます。キックスタートファイルの %packages コマンドで使用する代わりに、グループ名に追加します。以下に例を示します。
%packages
@Graphical Administration Tools --optional
%end--nodefaults- デフォルト選択ではなく、グループの必須パッケージのみをインストールします。
--optionalデフォルトの選択に加えて、
*-comps-repository.architecture.xmlファイルのグループ定義でオプションの印が付けられているパッケージをインストールします。Scientific Supportなどの一部のパッケージグループには、必須パッケージやデフォルトパッケージが指定されておらず、任意のパッケージのみが指定されています。この場合は、--optionalオプションを常に使用する必要があり、このオプションを使用しないと、このグループからパッケージをインストールすることができません。
--nodefaults および --optional オプションは併用できません。--nodefaults を使用して、インストール中に必須パッケージのみをインストールし、インストール後にインストール済みシステムにオプションのパッケージをインストールできます。
B.3. キックスタートファイル内のスクリプト
キックスタートファイルには以下のスクリプトを追加できます。
-
%pre -
%pre-install -
%post
このセクションでは、スクリプトに関する以下の情報を提供します。
- 実行時間
- スクリプトに追加できるコマンドのタイプ
- スクリプトの目的
- スクリプトオプション
B.3.1. %pre スクリプト
%pre スクリプトは、キックスタートファイルの読み込み直後 (スクリプトが完全に解析され、インストールが開始する前) にシステムで実行されます。各セクションは、%pre で開始し、%end で終了する必要があります。
%pre スクリプトは、ネットワークおよびストレージデバイスのアクティベートおよび設定に使用できます。また、インストール環境で利用可能なインタープリターを使用して、スクリプトを実行することもできます。インストールを進める前に特定の設定を必要とするネットワークやストレージがある場合や、追加のログパラメーターや環境変数などを設定するスクリプトがある場合には、%pre スクリプトが便利になります。
%pre スクリプトでの問題のデバッグは難しくなる可能性があるため、%pre スクリプトは必要な場合にのみ使用することが推奨されます。
キックスタートの %pre セクションは、インストーラーイメージ (inst.stage2) がフェッチされた後に発生するインストールの段階で実行されます。これは、root がインストーラー環境 (インストーラーイメージ) に切り替わった 後、および Anaconda インストーラー自体が起動した 後 に実行されます。次に、%pre の設定が適用され、キックスタートの URL などで設定されたインストールリポジトリーからパッケージを取得するために使用できます。ただし、ネットワークからイメージ (inst.stage2) をフェッチするようにネットワークを設定するために使用する ことはできません。
インストール環境の /sbin ディレクトリーおよび /bin ディレクトリーにあるほとんどのユーティリティーの他に、%pre スクリプトでは、ネットワーク、ストレージ、およびファイルシステムに関連するコマンドを使用できます。
%pre セクションのネットワークにはアクセスできます。この時点では name サービスが設定されていないため、URL ではなく IP アドレスだけが有効です。
pre スクリプトは、chroot 環境では実行しません。
B.3.1.1. %pre スクリプトセクションのオプション
以下のオプションを使用して、インストール前のスクリプトの動作を変更できます。オプションを使用するには、スクリプトの最初の部分で %pre 行にオプションを追加してください。以下に例を示します。
%pre --interpreter=/usr/libexec/platform-python
-- Python script omitted --
%end--interpreter=Python などの別のスクリプト言語を指定できます。システムで利用可能なスクリプト言語は、どれでも使用できます。ほとんどの場合は、
/usr/bin/sh、/usr/bin/bash、および/usr/libexec/platform-pythonになります。platform-pythonインタープリターは、Python バージョン 3.6 を使用することに注意してください。新しいパスおよびバージョン用に、Python スクリプトを以前の RHEL バージョンから変更する必要があります。また、platform-pythonはシステムツール向けです。インストール環境外でpython36を使用してください。Red Hat Enterprise Linux の Python の詳細は、基本的なシステム設定 の Python の概要 を参照してください。--erroronfail-
スクリプトが失敗するとエラーを表示し、インストールを停止します。エラーメッセージは、失敗の原因がログ記録されている場所を示します。インストールされたシステムは、不安定で起動できない状態になる可能性があります。
inst.nokillオプションを使用して、スクリプトをデバッグできます。 --log=スクリプトの出力を、指定したログファイルに記録します。以下に例を示します。
%pre --log=/tmp/ks-pre.log
B.3.2. %pre-install スクリプト
pre-install スクリプトのコマンドは、以下のタスクの完了後に実行されます。
- システムのパーティションを設定した。
- ファイルシステムは /mnt/sysroot の下に作成およびマウントされます
- ネットワークが起動オプションとキックスタートコマンドに従って設定されている。
各 %pre-install セクションは、%pre-install で開始し、%end で終了します。
%pre-install スクリプトを使用してインストールを修正して、パッケージのインストール前に保証されている ID があるユーザーとグループを追加できます。
インストールに必要な変更には、%post スクリプトを使用することが推奨されます。%pre-install スクリプトは、%post スクリプトが必要な変更に満たない場合に限り使用します。
pre-install スクリプトは chroot 環境では動作しません。
B.3.2.1. %pre-install スクリプトセクションオプション
以下のオプションを使用して、pre-install のスクリプトの動作を変更できます。オプションを使用する場合は、スクリプトの先頭にある %pre-install 行に追加してください。以下に例を示します。
%pre-install --interpreter=/usr/libexec/platform-python
-- Python script omitted --
%end
同じまたは異なるインタープリターを使用して、複数の %pre-install セクションを含めることができます。設定したものは、キックスタートファイル内の参照順に評価されます。
--interpreter=Python などの別のスクリプト言語を指定できます。システムで利用可能なスクリプト言語は、どれでも使用できます。ほとんどの場合は、
/usr/bin/sh、/usr/bin/bash、および/usr/libexec/platform-pythonになります。platform-pythonインタープリターは Python バージョン 3.6 を使用します。新しいパスおよびバージョン用に、Python スクリプトを以前の RHEL バージョンから変更する必要があります。また、platform-pythonはシステムツール向けです。インストール環境外でpython36を使用してください。Red Hat Enterprise Linux の Python の詳細は、基本的なシステム設定 の Python の概要 を参照してください。--erroronfail-
スクリプトが失敗するとエラーを表示し、インストールを停止します。エラーメッセージは、失敗の原因がログ記録されている場所を示します。インストールされたシステムは、不安定で起動できない状態になる可能性があります。
inst.nokillオプションを使用して、スクリプトをデバッグできます。 --log=スクリプトの出力を、指定したログファイルに記録します。以下に例を示します。
%pre-install --log=/mnt/sysroot/root/ks-pre.log
B.3.3. %post スクリプト
%post スクリプトは、インストールが完了した後、システムが最初に再起動する前に実行されるインストール後のスクリプトです。このセクションでは、システムのサブスクリプションなどのタスクを実行できます。
インストールが完了し、システムを最初に再起動する前に、システムで実行するコマンドを追加するオプションがあります。このセクションは、%post で始まり、%end で終了します。
%post セクションは、追加ソフトウェアのインストールや、追加のネームサーバーの設定といった機能に役に立ちます。インストール後のスクリプトは chroot 環境で実行するため、インストールメディアからスクリプトや RPM をコピーするなどの作業はデフォルトでは機能しません。この動作は、以下に記載されるように --nochroot オプションを使用することで変更できます。その後、%post スクリプトはインストール環境で実行し、インストール済みのターゲットシステムの chroot で実行することはありません。
インストール後のスクリプトは chroot 環境で実行されるため、ほとんどの systemctl コマンドはいかなるアクションも拒否します。
%post セクションの実行中は、インストールメディアを挿入したままにする必要があります。
B.3.3.1. %post スクリプトセクションオプション
以下のオプションを使用して、インストール後のスクリプトの動作を変更できます。オプションを使用するには、スクリプトの最初の部分で %post 行にオプションを追加してください。以下に例を示します。
%post --interpreter=/usr/libexec/platform-python
-- Python script omitted --
%end--interpreter=Python などの別のスクリプト言語を指定できます。以下に例を示します。
%post --interpreter=/usr/libexec/platform-pythonシステムで利用可能なスクリプト言語は、どれでも使用できます。ほとんどの場合は、
/usr/bin/sh、/usr/bin/bash、および/usr/libexec/platform-pythonになります。platform-pythonインタープリターは Python バージョン 3.6 を使用します。新しいパスおよびバージョン用に、Python スクリプトを以前の RHEL バージョンから変更する必要があります。また、platform-pythonはシステムツール向けです。インストール環境外でpython36を使用してください。Red Hat Enterprise Linux の Python の詳細は、基本的なシステム設定 の Python の概要 を参照してください。--nochrootchroot 環境外で実行するコマンドを指定できます。
以下の例では、/etc/resolv.conf ファイルを、インストールしたばかりのファイルシステムにコピーします。
%post --nochroot cp /etc/resolv.conf /mnt/sysroot/etc/resolv.conf %end--erroronfail-
スクリプトが失敗するとエラーを表示し、インストールを停止します。エラーメッセージは、失敗の原因がログ記録されている場所を示します。インストールされたシステムは、不安定で起動できない状態になる可能性があります。
inst.nokillオプションを使用して、スクリプトをデバッグできます。 --log=スクリプトの出力を、指定したログファイルに記録します。ログファイルのパスを指定する際には、
--nochrootオプションを使用するかどうかを考慮する必要があります。--nochrootがない場合の例を示します。%post --log=/root/ks-post.log--nochrootを使用した場合は、以下のようになります。%post --nochroot --log=/mnt/sysroot/root/ks-post.log
B.3.3.2. たとえば、以下のようになります。インストール後スクリプトで NFS のマウント
この %post セクション例では、NFS 共有をマウントし、共有の /usr/new-machines/ に置かれた runme スクリプトを実行します。キックスタートモードでは NFS ファイルのロックがサポートされないため、-o nolock オプションが必要です。
# Start of the %post section with logging into /root/ks-post.log
%post --log=/root/ks-post.log
# Mount an NFS share
mkdir /mnt/temp
mount -o nolock 10.10.0.2:/usr/new-machines /mnt/temp
openvt -s -w -- /mnt/temp/runme
umount /mnt/temp
# End of the %post section
%endB.3.3.3. 以下に例を示します。インストール後のスクリプトで subscription-manager の実行
キックスタートを使用したインストールで最もよく使用されるインストール後のスクリプトの 1 つは、Red Hat Subscription Manager を使用したインストール済みシステムの自動登録です。以下は、%post スクリプトの自動サブスクリプションの例です。
%post --log=/root/ks-post.log
subscription-manager register --username=admin@example.com --password=secret --auto-attach
%end
subscription-manager のコマンドラインスクリプトで、システムが Red Hat Subscription Management サーバー (カスタマーポータルによるサブスクリプション管理、Satellite 6、CloudForms System Engine) に登録されます。このスクリプトは、システムに最も適したサブスクリプションをそのシステムに自動的に割り当てる場合にも使用できます。カスタマーポータルに登録する場合は、Red Hat Network ログイン認証情報を使用します。Satellite 6 または CloudForms System Engine に登録する場合は、ローカル管理者が提供する認証情報に加え、--serverurl、--org、--environment などの subscription-manager オプションも指定する必要があります。共有キックスタートファイルで、--username --password 値を公開しないようにするには、認証情報が、--org --activationkey の組み合わせの形式で使用されます。
登録コマンドで追加オプションを使用してシステムの優先サービスレベルを設定し、更新およびエラータを、以前のストリームで修正が必要な Extended Update Support サブスクリプションをお持ちのお客様の、特定のマイナーリリースバージョンの RHEL に制限することができます。
subscription-manager コマンドの使用に関する詳細は、Red Hat ナレッジベースソリューション キックスタートファイルで subscription-manager を使用する方法を 参照してください。
B.4. Anaconda 設定セクション
追加のインストールオプションは、キックスタートファイルの %anaconda セクションで設定できます。このセクションでは、インストールシステムのユーザーインターフェイスの動作を制御します。
本セクションは、キックスタートコマンドの後、キックスタートファイルの終わりの方に配置し、%anaconda で始まり %end で終了します。
現在、%anaconda セクションで使用できる唯一のコマンドは pwpolicy です。
例B.1 %anaconda スクリプトのサンプル
以下は、%anaconda セクションの例です。
%anaconda
pwpolicy root --minlen=10 --strict
%end
上記の例では、%anaconda セクションではパスワードポリシーを設定します。root パスワードは 10 文字以上にする必要があり、この要件に一致しないものは厳密に禁止されます。
B.5. キックスタートでのエラー処理セクション
Red Hat Enterprise Linux 7 以降、キックスタートインストールでは、インストールプログラムで致命的なエラーが発生するとカスタムスクリプトが実行されます。このような状況の例としては、インストールで要求されたパッケージのエラー、VNC の起動失敗 (設定で指定されている場合)、ストレージデバイスのスキャン中に発生したエラーなどが挙げられます。このようなイベントが発生した場合、インストールが中断します。このようなイベントを分析するために、インストールプログラムは、キックスタートファイルで指定されているすべての %onerror スクリプトを時系列順に実行します。トレースバックが発生した場合は、%onerror スクリプトを実行できます。
それぞれの %onerror スクリプトが、%end で終了する必要があります。
inst.cmdline を使用してすべてのエラーを致命的なエラーにすることで、あらゆるエラーに対してエラーハンドラーを強制できます。
エラー処理のセクションでは、次のオプションを受け入れます。
--erroronfail-
スクリプトが失敗するとエラーを表示し、インストールを停止します。エラーメッセージは、失敗の原因がログ記録されている場所を示します。インストールされたシステムは、不安定で起動できない状態になる可能性があります。
inst.nokillオプションを使用して、スクリプトをデバッグできます。 --interpreter=Python などの別のスクリプト言語を指定できます。以下に例を示します。
%onerror --interpreter=/usr/libexec/platform-pythonシステムで利用可能なスクリプト言語は、どれでも使用できます。ほとんどの場合は、
/usr/bin/sh、/usr/bin/bash、および/usr/libexec/platform-pythonになります。platform-pythonインタープリターは Python バージョン 3.6 を使用します。新しいパスおよびバージョン用に、Python スクリプトを以前の RHEL バージョンから変更する必要があります。また、platform-pythonはシステムツール向けです。インストール環境外でpython36を使用してください。Red Hat Enterprise Linux の Python の詳細は、基本的なシステム設定 の Python の概要 を参照してください。--log=- スクリプトの出力を、指定したログファイルに記録します。
B.6. キックスタートのアドオンセクション
Red Hat Enterprise Linux 7 以降は、キックスタートインストールでアドオンをサポートするようになりました。これらのアドオンは、多くの方法で基本的なキックスタート (および Anaconda) の機能を拡張できます。
キックスタートファイルでアドオンを使用するには、%addon addon_name options コマンドを使用し、%end ステートメントでコマンドを終了します。これはインストール前およびインストール後スクリプトのセクションと似ています。たとえば、デフォルトで Anaconda で提供される Kdump アドオンを使用する場合は、次のコマンドを使用します。
%addon com_redhat_kdump --enable --reserve-mb=auto
%end
%addon コマンドには、独自のオプションが含まれていません。すべてのオプションは実際のアドオンに依存しています。
付録C キックスタートのコマンドおよびオプションのリファレンス
ここでは、Red Hat Enterprise Linux インストールプログラムがサポートするキックスタートコマンドの一覧を提供します。コマンドは、いくつかのカテゴリーに分かれ、アルファベット順に記載されています。コマンドが複数のカテゴリーに該当する場合は、該当するすべてのカテゴリーに記載されます。
C.1. キックスタートの変更
以下のセクションでは、Red Hat Enterprise Linux 8 におけるキックスタートコマンドおよびオプションの変更を説明します。
RHEL 8 で auth または authconfig が非推奨に
authconfig ツールおよびパッケージが削除されたため、Red Hat Enterprise Linux 8 では、キックスタートコマンドの auth または authconfig が非推奨になっています。
コマンドラインで実行した authconfig コマンドと同様、キックスタートスクリプトの authconfig コマンドが authselect-compat ツールを使用して、新しい authselect ツールを実行するようになりました。この互換性層や、その既知の問題の説明は、authselect-migration(7) man ページを参照してください。このインストールプログラムは、非推奨のコマンドの使用を自動的に検出し、互換性層を提供する authselect-compat パッケージをインストールします。
キックスタートで Btrfs がサポート対象外に
Red Hat Enterprise Linux 8 は、Btrfs ファイルシステムに対応していません。そのため、グラフィカルユーザーインターフェイス (GUI) およびキックスタートコマンドが Btrfs に対応しなくなりました。
以前の RHEL リリースのキックスタートファイルの使用
以前の RHEL リリースのキックスタートファイルを使用する場合は、Red Hat Enterprise Linux 8 BaseOS リポジトリーおよび AppStream リポジトリーの詳細について、Considerations in adopting RHEL 8 の Repositories のセクションを参照してください。
C.1.1. キックスタートで非推奨になったコマンドおよびオプション
次のキックスタートのコマンドとオプションが、Red Hat Enterprise Linux 8 で非推奨になりました。
特定のオプションだけがリスト表示されている場合は、基本コマンドおよびその他のオプションは引き続き利用でき、非推奨ではありません。
-
authまたはauthconfig(代わりにauthselectを使用) -
device -
deviceprobe -
dmraid -
install- サブコマンドまたはメソッドをそのままコマンドとして使用します。 -
multipath -
bootloader --upgrade -
ignoredisk --interactive -
partition --active -
reboot --kexec -
syspurpose- 代わりにsubscription-manager syspurposeを使用してください
auth コマンドまたは authconfig コマンドを除き、キックスタートファイルのコマンドを使用すると、ログに警告が出力されます。
inst.ksstrict ブートオプションで、auth コマンドまたは authconfig コマンドを除いた非推奨のコマンドの警告をエラーに変えることができます。
C.1.2. キックスタートから削除されたコマンドおよびオプション
次のキックスタートのコマンドとオプションが、Red Hat Enterprise Linux 8 から完全に削除されました。キックスタートファイルでこれを使用すると、エラーが発生します。
-
device -
deviceprobe -
dmraid -
install- サブコマンドまたはメソッドをそのままコマンドとして使用します。 -
multipath -
bootloader --upgrade -
ignoredisk --interactive -
partition --active -
harddrive --biospart -
upgrade(このコマンドはすでに非推奨になっています) -
btrfs -
part/partition btrfs -
part --fstype btrfsまたはpartition --fstype btrfs -
logvol --fstype btrfs -
raid --fstype btrfs -
unsupported_hardware
特定のオプションおよび値だけが表示されている場合は、基本コマンドおよびその他のオプションは引き続き利用でき、削除されません。
C.2. インストールプログラムの設定とフロー制御のためのキックスタートコマンド
このリストのキックスタートコマンドは、インストールのモードとコースを制御し、最後に何が起こるかを制御します。
C.2.1. cdrom
キックスタートコマンドの cdrom は任意です。これは、システムの最初の光学ドライブからインストールを実行します。このコマンドは 1 回だけ使用してください。
構文
cdrom備考
-
cdromコマンドは、以前はinstallコマンドとともに使用する必要がありました。installコマンドが非推奨になり、(installが暗黙的に使用されるようになったため)cdromは独立して使用できるようになりました。 - このコマンドにはオプションはありません。
-
実際にインストールを実行するには、カーネルコマンドラインで
inst.repoオプションが指定されていない限り、cdrom、harddrive、hmc、nfs、liveimg、ostreesetup、rhsm、またはurlのいずれかを指定する必要があります。
C.2.2. cmdline
キックスタートコマンドの cmdline は任意です。完全に非対話式のコマンドラインモードでインストールを実行します。対話のプロンプトがあるとインストールは停止します。このコマンドは 1 回だけ使用してください。
構文
cmdline注記
-
完全に自動となるインストールでは、キックスタートファイルで利用可能なモード (
graphical、text、またはcmdline) のいずれかを指定するか、起動オプションconsole=を使用する必要があります。モードが指定されていないと、可能な場合はグラフィカルモードが使用されるか、VNC モードおよびテキストモードからの選択が求められます。 - このコマンドにはオプションはありません。
- このモードは、x3270 端末と共に 64 ビットの IBM Z システムで使用する場合に便利です。
C.2.3. driverdisk
キックスタートコマンドの driverdisk は任意です。このコマンドを使用して、インストールプログラムに追加ドライバーを提供します。
ドライバーディスクは、キックスタートを使用したインストール中に、デフォルトでは含まれていないドライバーを追加する場合に使用します。ドライバーディスクのコンテンツを、システムのディスクにあるパーティションのルートディレクトリーにコピーする必要があります。次に、driverdisk コマンドを使用して、インストールプログラムがドライバーディスクとその場所を検索するように指定する必要があります。このコマンドは 1 回だけ使用してください。
構文
driverdisk [partition|--source=url|--biospart=biospart]オプション
この方法のいずれかで、ドライバーディスクの場所を指定する必要があります。
-
partition - ドライバーディスクを含むパーティション。パーティションは、パーティション名 (例:
sdb1) だけでなく、完全なパス (例:/dev/sdb1) として指定する必要があります。 --source=- ドライバーディスクの URL。以下のようになります。driverdisk --source=ftp://path/to/dd.img driverdisk --source=http://path/to/dd.img driverdisk --source=nfs:host:/path/to/dd.img-
--biospart=- ドライバーディスクを含む BIOS パーティション (82p2など)。
注記
ドライバーディスクは、ネットワーク経由や initrd から読み込むのではなく、ローカルディスクまたは同様のデバイスから読み込むこともできます。以下の手順に従います。
- ディスクドライブ、USB、または同様のデバイスにドライバーディスクを読み込みます。
- このデバイスにラベルを設定します (DD など)。
キックスタートファイルに以下の行を追加します。
driverdisk LABEL=DD:/e1000.rpm
DD を具体的なラベルに置き換え、e1000.rpm を具体的な名前に置き換えます。LABEL ではなく、inst.repo コマンドがサポートするものを使用して、ディスクドライブを指定してください。
C.2.4. eula
キックスタートコマンドの eula は任意です。ユーザーとの対話なしでエンドユーザーライセンス契約 (EULA) に同意するには、このオプションを使用します。このオプションを使用すると、インストールを終了して、システムを最初に再起動した後に、ライセンス契約に同意するように求められなくなります。このコマンドは 1 回だけ使用してください。
構文
eula [--agreed]オプション
-
--agreed(必須) - EULA に同意します。このオプションは必ず使用する必要があります。使用しないとeulaコマンド自体を使用する意味がなくなります。
C.2.5. firstboot
キックスタートコマンドの firstboot は任意です。初めてシステムを起動した時に、初期セットアップ アプリケーションを開始するかどうかを指定します。有効にする場合は、initial-setup パッケージをインストールする必要があります。何も指定しないとデフォルトで無効になるオプションです。このコマンドは 1 回だけ使用してください。
構文
firstboot OPTIONSオプション
-
--enableまたは--enabled- システムの初回起動時に、初期セットアップを開始します。 -
--disableまたは--disabled- システムの初回起動時に、初期セットアップを開始しません。 -
--reconfig- システムの起動時に、初期セットアップが再設定モードで開始します。このモードでは、デフォルトのオプションに加えて、root パスワード、時刻と日付、ネットワークとホスト名の設定オプションが有効になります。
C.2.6. graphical
キックスタートコマンドの graphical は任意です。これは、グラフィカルモードでインストールを実行します。これはデフォルトです。このコマンドは 1 回だけ使用してください。
構文
graphical [--non-interactive]オプション
-
--non-interactive- 完全に非対話式のモードでインストールを実行します。このモードでは、ユーザーの対話が必要になるとインストールを終了します。
注記
-
完全に自動となるインストールでは、キックスタートファイルで利用可能なモード (
graphical、text、またはcmdline) のいずれかを指定するか、起動オプションconsole=を使用する必要があります。モードが指定されていないと、可能な場合はグラフィカルモードが使用されるか、VNC モードおよびテキストモードからの選択が求められます。
C.2.7. halt
キックスタートコマンドの halt は任意です。
インストールが正常に完了するとシステムを一時停止します。手動インストールと同じく、Anaconda のメッセージが表示され、ユーザーがキーを押すのを待ってから再起動が行われます。キックスタートを使用したインストールでは、完了方法の指定がない場合、このオプションがデフォルトとして使用されます。このコマンドは 1 回だけ使用してください。
構文
halt注記
-
haltコマンドはshutdown -Hコマンドと同じです。詳細は、システム上の shutdown(8) man ページを参照してください。 -
他の完了方法は、
poweroff、reboot、shutdownなどのコマンドをご覧ください。 - このコマンドにはオプションはありません。
C.2.8. harddrive
キックスタートコマンドの harddrive は任意です。ローカルドライブにある完全インストール用の ISO イメージまたは Red Hat インストールツリーからインストールします。ドライブは、インストールプログラムがマウントできるファイルシステムでフォーマットする必要があります (ext2、ext3、ext4、vfat、または xfs)。このコマンドは 1 回だけ使用してください。
構文
harddrive OPTIONSオプション
-
--partition=- インストールするパーティションを指定する場合に使用します (sdb2など)。 -
--dir=- 完全インストール用 DVD の ISO イメージやインストールツリーのvariantディレクトリーを格納しているディレクトリーを指定する場合に使用します。
例
harddrive --partition=hdb2 --dir=/tmp/install-tree注記
-
harddriveコマンドは、installコマンドとともに使用する必要がありました。installコマンドが非推奨になり、(installが暗黙的に使用されるようになったため)harddriveは独立して使用できるようになりました。 -
実際にインストールを実行するには、カーネルコマンドラインで
inst.repoオプションが指定されていない限り、cdrom、harddrive、hmc、nfs、liveimg、ostreesetup、rhsm、またはurlのいずれかを指定する必要があります。
C.2.9. install (非推奨)
キックスタートコマンド install は、Red Hat Enterprise Linux 8 で非推奨になりました。そのメソッドは、別々のコマンドとして使用します。
キックスタートコマンドの install は任意です。デフォルトのインストールモードを指定します。
構文
install
installation_method備考
-
installコマンドに続いて、インストール方法のコマンドを指定する必要があります。インストール方法のコマンドは、別の行に指定する必要があります。 方法は次のとおりです。
-
cdrom -
harddrive -
hmc -
nfs -
liveimg -
url
メソッドの詳細は、個別のリファレンスページを参照してください。
-
C.2.10. liveimg
キックスタートコマンドの liveimg は任意です。パッケージの代わりに、ディスクイメージからインストールを実行します。このコマンドは 1 回だけ使用してください。
構文
liveimg --url=SOURCE [OPTIONS]必須オプション
-
--url=- インストール元となる場所です。HTTP、HTTPS、FTP、fileが対応プロトコルになります。
任意のオプション
-
--url=- インストール元となる場所です。HTTP、HTTPS、FTP、fileが対応プロトコルになります。 -
--proxy=- インストール実行時に使用するHTTP、HTTPS、またはFTPプロキシーを指定します。 -
--checksum=- 検証に使用するイメージファイルのチェックサムSHA256を使用するオプションの引数です。 -
--noverifyssl-HTTPSサーバーへの接続の際に、SSL 確認を無効にします。
例
liveimg --url=file:///images/install/squashfs.img --checksum=03825f567f17705100de3308a20354b4d81ac9d8bed4bb4692b2381045e56197 --noverifyssl注記
-
イメージは、ライブ ISO イメージの
squashfs.imgファイル、圧縮 tar ファイル (.tar、.tbz、.tgz、.txz、.tar.bz2、.tar.gz、または.tar.xz)、もしくはインストールメディアでマウントできるファイルシステムであればどれでも構いません。ext2、ext3、ext4、vfat、xfsなどが対応ファイルシステムになります。 -
ドライバーディスクで
liveimgインストールモードを使用している場合、ディスク上のドライバーがインストールされるシステムに自動的に含まれることはありません。これらのドライバーが必要な場合は、手動でインストールするか、キックスタートスクリプトの%postセクションでインストールします。 -
実際にインストールを実行するには、カーネルコマンドラインで
inst.repoオプションが指定されていない限り、cdrom、harddrive、hmc、nfs、liveimg、ostreesetup、rhsm、またはurlのいずれかを指定する必要があります。 -
liveimgコマンドは、以前はinstallコマンドとともに使用する必要がありました。installコマンドが非推奨になり、(installが暗黙的に使用されるようになったため)liveimgは独立して使用できるようになりました。
C.2.11. ログ
キックスタートコマンドの logging は任意です。インストール時に Anaconda に記録されるエラーログを制御します。インストール済みのシステムには影響しません。このコマンドは 1 回だけ使用してください。
ロギングは TCP でのみサポートされています。リモートロギングの場合は、--port= オプションで指定するポート番号がリモートサーバーで開いていることを確認してください。デフォルトのポートは 514 です。
構文
logging OPTIONS任意のオプション
-
--host=- 指定したリモートホストにログ情報を送信します。ログを受け取るには、リモートホストで設定した syslogd プロセスが実行している必要があります。 -
--port=- リモートの syslogd プロセスがデフォルト以外のポートを使用する場合は、このオプションを使用して設定します。 -
--level=- tty3 に表示されるメッセージの最低レベルを指定します。ただし、このレベルに関係なくログファイルには全メッセージが送信されます。設定できるレベルはdebug、info、warning、error、criticalになります。
C.2.12. mediacheck
キックスタートコマンドの mediacheck は任意です。このコマンドを使用すると、インストール開始前にメディアチェックの実行が強制されます。このコマンドではインストール時の介入が必要となるため、デフォルトでは無効になっています。このコマンドは 1 回だけ使用してください。
構文
mediacheck注記
-
このキックスタートコマンドは、
rd.live.check起動オプションに相当します。 - このコマンドにはオプションはありません。
C.2.13. nfs
キックスタートコマンドの nfs は任意です。指定した NFS サーバーからインストールを実行します。このコマンドは 1 回だけ使用してください。
構文
nfs OPTIONSオプション
-
--server=- インストール元となるサーバーを指定します (ホスト名または IP)。 -
--dir=- インストールツリーのvariantディレクトリーを格納しているディレクトリーを指定する場合に使用します。 -
--opts=- NFS エクスポートのマウントに使用するマウントポイントを指定します (オプション)。
例
nfs --server=nfsserver.example.com --dir=/tmp/install-tree備考
-
nfsコマンドは、以前はinstallコマンドとともに使用する必要がありました。installコマンドが非推奨になり、(installが暗黙的に使用されるようになったため)nfsは独立して使用できるようになりました。 -
実際にインストールを実行するには、カーネルコマンドラインで
inst.repoオプションが指定されていない限り、cdrom、harddrive、hmc、nfs、liveimg、ostreesetup、rhsm、またはurlのいずれかを指定する必要があります。
C.2.14. ostreesetup
キックスタートコマンドの ostreesetup は任意です。これは、OStree ベースのインストールを設定するのに使用されます。このコマンドは 1 回だけ使用してください。
構文
ostreesetup --osname=OSNAME [--remote=REMOTE] --url=URL --ref=REF [--nogpg]必須オプション:
-
--osname=OSNAME- OS インストール用の root の管理 -
--url=URL- インストール元となるリポジトリーの URL -
--ref=REF- インストールに使用するリポジトリーのブランチー名
任意のオプション:
-
--remote=REMOTE- リモートリポジトリーの場所。 -
--nogpg- GPG 鍵の検証の無効化
注記
- OStree ツールの詳細は、アップストリームのドキュメント https://ostreedev.github.io/ostree/ を参照してください。
C.2.15. poweroff
キックスタートコマンドの poweroff は任意です。インストールが正常に完了したら、システムをシャットダウンして電源を切ります。通常、手動のインストールでは Anaconda によりメッセージが表示され、ユーザーがキーを押すのを待ってから再起動が行われます。このコマンドは 1 回だけ使用してください。
構文
poweroff注記
-
poweroffオプションはshutdown -Pコマンドと同じです。詳細は、システム上の shutdown(8) man ページを参照してください。 -
他の完了方法は、
halt、reboot、shutdownなどのキックスタートコマンドをご覧ください。キックスタートファイルに完了方法が明示的には指定されていない場合は、haltオプションがデフォルトの完了方法になります。 -
poweroffオプションは、使用中のハードウェアに大きく依存します。特に、BIOS、APM (advanced power management)、ACPI (advanced configuration and power interface) などの特定ハードウェアコンポーネントは、システムカーネルと対話できる状態にする必要があります。使用システムの APM/ACPI 機能の詳細に関しては、ハードウェアのマニュアルを参照してください。 - このコマンドにはオプションはありません。
C.2.16. reboot
キックスタートコマンドの reboot は任意です。インストールが正常に完了したらシステムを再起動するように、インストールプログラムに指示します (引数なし)。通常、キックスタートは、メッセージを表示し、ユーザーがキーを押してから再起動します。このコマンドは 1 回だけ使用してください。
構文
reboot OPTIONSオプション
-
--eject- 再起動の前に起動可能なメディア (DVD、USB、またはその他のメディア) の取り出しを試みます。 --kexec- 完全な再起動を実行する代わりにkexecシステムコールを使用します。BIOS やファームウェアが通常実行するハードウェアの初期化を行わずに、インストールしたシステムを即座にメモリーに読み込みます。重要このオプションは非推奨になっており、テクノロジープレビューとしてのみ利用できます。テクノロジープレビュー機能に対する Red Hat のサポート範囲の詳細は、テクノロジープレビュー機能のサポート範囲 を参照してください。
kexecの使用時には、(完全なシステム再起動では通常クリアされる) デバイスレジスターにデータが残ります。デバイスドライバーによってはこれが問題になる可能性もあります。
注記
-
インストールメディアやインストール方法によっては、
rebootオプションを使用するとインストールプロセスがループして完了しなくなる場合があります。 -
rebootオプションはshutdown -rコマンドと同じです。詳細は、システム上の shutdown(8) man ページを参照してください。 -
64 ビットの IBM Z でコマンドラインによるインストールを行う際は、
rebootを指定してインストールを完全自動化します。 -
その他の完了方法は、
halt、poweroff、shutdownなどのキックスタートオプションをご覧ください。キックスタートファイルに完了方法が明示的には指定されていない場合は、haltオプションがデフォルトの完了方法になります。
C.2.17. rhsm
キックスタートコマンドの rhsm は任意です。ここでは、インストールプログラムにより、CDN から RHEL が登録されインストールされるようになっています。このコマンドは 1 回だけ使用してください。
キックスタートコマンド rhsm は、システムの登録時にカスタムの %post スクリプトを使用する要件を削除します。
オプション
-
--organization=- 組織 ID を使用して CDN から RHEL を登録してインストールします。 -
--activation-key=- アクティベーションキーを使用して、CDN から RHEL を登録してインストールします。使用するアクティベーションキーがサブスクリプションに登録されている限り、アクティベーションキーごとに 1 回使用するオプションを複数回使用できます。 -
--connect-to-insights- ターゲットシステムを Red Hat Insights に接続します。 -
--proxy=- HTTP プロキシーを設定します。
rhsmキックスタートコマンドを使用してインストールソースリポジトリーを CDN に切り替えるには、次の条件を満たす必要があります。-
カーネルコマンドラインで、
inst.stage2=<URL>を使用してインストールイメージを取得したが、inst.repo=を使用してインストールソースを指定していない。 -
キックスタートファイルで、
url、cdrom、harddrive、liveimg、nfs、およびostreeセットアップコマンドを使用してインストールソースを指定していない。
-
カーネルコマンドラインで、
-
起動オプションを使用して指定したインストールソース URL、またはキックスタートファイルに含まれるインストールソース URL は、キックスタートファイルに有効な認証情報を持つ
rhsmコマンドが含まれている場合でも CDN よりも優先されます。システムが登録されていますが、URL インストールソースからインストールされています。これにより、以前のインストールプロセスが通常通りに動作するようになります。
C.2.18. shutdown
キックスタートコマンドの shutdown は任意です。インストールが正常に完了したら、システムをシャットダウンします。このコマンドは 1 回だけ使用してください。
構文
shutdown注記
-
キックスタートオプションの
shutdownは、shutdownコマンドと同じです。詳細は、システム上の shutdown(8) man ページを参照してください。 -
その他の完了方法は、
halt、poweroff、rebootなどのキックスタートオプションをご覧ください。キックスタートファイルに完了方法が明示的には指定されていない場合は、haltオプションがデフォルトの完了方法になります。 - このコマンドにはオプションはありません。
C.2.19. sshpw
キックスタートコマンドの sshpw は任意です。
インストール中に、SSH 接続によりインストールプログラムと対話操作を行い、その進捗状況を監視できます。sshpw コマンドを使用して、ログオンするための一時的なアカウントを作成します。コマンドの各インスタンスにより、インストール環境でしか存在しない個別アカウントが作成されます。ここで作成されたアカウントは、インストールが完了したシステムには転送されません。
構文
sshpw --username=name [OPTIONS] password必須オプション
-
--username=name - ユーザー名を入力します。このオプションは必須です。 - password - このユーザーに使用するパスワードです。このオプションは必須です。
任意のオプション
--iscrypted- このオプションを追加すると、パスワード引数はすでに暗号化済みと仮定されます。--plaintextと相互排他的になります。暗号化したパスワードを作成する場合は Python を使用します。$ python3 -c 'import crypt,getpass;pw=getpass.getpass();print(crypt.crypt(pw) if (pw==getpass.getpass("Confirm: ")) else exit())'上記の例では、ランダムの salt を使用して、パスワードの sha512 暗号と互換性があるハッシュが生成されます。
-
--plaintext- このオプションを使用すると、パスワードの引数はプレーンテキストであると仮定されます。--iscryptedと相互排他的になります。 -
--lock- このオプションを指定すると、このアカウントはデフォルトでロックされます。つまり、ユーザーはコンソールからログインできなくなります。 -
--sshkey- このオプションを指定すると、<password> 文字列が ssh 鍵の値として解釈されます。
注記
-
デフォルトでは、
sshサーバーは、インストール時に起動しません。インストール時にsshを使用できるようにするには、カーネル起動オプションinst.sshdを使用してシステムを起動します。 インストール中、別のユーザーの
sshアクセスを許可する一方で、root のsshアクセスを無効にする場合は、次のコマンドを実行します。sshpw --username=example_username example_password --plaintext sshpw --username=root example_password --lock単に root の
sshアクセスを無効にするには、以下のコマンドを使用します。sshpw --username=root example_password --lock
C.2.20. text
キックスタートコマンドの text は任意です。テキストモードでキックスタートインストールを実行します。キックスタートインストールは、デフォルトでグラフィカルモードで実行します。このコマンドは 1 回だけ使用してください。
構文
text [--non-interactive]オプション
-
--non-interactive- 完全に非対話式のモードでインストールを実行します。このモードでは、ユーザーの対話が必要になるとインストールを終了します。
注記
-
完全に自動となるインストールでは、キックスタートファイルで利用可能なモード (
graphical、text、またはcmdline) のいずれかを指定するか、起動オプションconsole=を使用する必要がある点に注意してください。モードが指定されていないと、可能な場合はグラフィカルモードが使用されるか、VNC モードおよびテキストモードからの選択が求められます。
C.2.21. url
キックスタートコマンドの url は任意です。これは、FTP、HTTP、または HTTPS プロトコルを使用して、リモートサーバーのインストールツリーイメージからインストールするのに使用されます。URL は 1 つだけ指定できます。このコマンドは 1 回だけ使用してください。
--url、--metalink、または --mirrorlist オプションのいずれかを指定する必要があります。
構文
url --url=FROM [OPTIONS]オプション
-
--url=FROM- インストール元となるHTTP、HTTPS、FTP、またはファイルの場所を指定します。 -
--mirrorlist=- インストール元となるミラー URL を指定します。 -
--proxy=- インストール時に使用するHTTP、HTTPS、またはFTPプロキシーを指定します。 -
--noverifyssl-HTTPSサーバーへの接続時に SSL 検証を無効にします。 -
--metalink=URL- インストール元となるメタリンク URL を指定します。変数の置換は、URLの$releaseverおよび$basearchで行います。
例
HTTP サーバーからインストールするには、以下を行います。
url --url=http://server/pathFTP サーバーからインストールするには、以下を行います。
url --url=ftp://username:password@server/path
注記
-
urlコマンドは、以前はinstallコマンドとともに使用する必要がありました。installコマンドが非推奨になり、(installが暗黙的に使用されるようになったため)urlは独立して使用できるようになりました。 -
実際にインストールを実行するには、カーネルコマンドラインで
inst.repoオプションが指定されていない限り、cdrom、harddrive、hmc、nfs、liveimg、ostreesetup、rhsm、またはurlのいずれかを指定する必要があります。
C.2.22. vnc
キックスタートコマンドの vnc は任意です。これにより、VNC を介して、リモートにグラフィカルインストールを表示できます。
テキストインストールではサイズと言語の一部が制限されるため、通常はテキストモードよりもこの方法が好まれます。追加のオプション指定がないと、このコマンドは、パスワードを使用せずに、インストールシステムで VNC サーバーを開始し、接続に必要な詳細を表示します。このコマンドは 1 回だけ使用してください。
構文
vnc [--host=host_name] [--port=port] [--password=password]オプション
--host=- 指定したホスト名でリッスンしている VNC ビューアープロセスに接続します。
--port=- リモート VNC ビューアープロセスがリッスンしているポートを指定します。このオプションを使用しないと、Anaconda は VNC のデフォルトポートである 5900 を使用します。
--password=- VNC セッションへの接続に必要なパスワードを設定します。これはオプションですが、推奨されます。
C.2.23. hmc
hmc キックスタートコマンドは任意です。IBM Z 上の SE/HMC を使用してインストールメディアからインストールする場合に使用します。このコマンドにはオプションがありません。
構文
hmcC.2.24. %include
キックスタートコマンドの %include は任意です。
%include コマンドを使用して、キックスタートファイル内の別のファイルのコンテンツが、キックスタートファイルの %include コマンドの場所にあるかのように設定します。
この包含は、%pre スクリプトセクションの後にのみ評価されるため、%pre セクションでスクリプトにより生成されたファイルに使用できます。%pre セクションを評価する前にファイルを指定するには、%ksappend コマンドを使用します。
構文
%include path/to/fileC.2.25. %ksappend
キックスタートコマンドの %ksappend は任意です。
%ksappend コマンドを使用して、キックスタートファイル内の別のファイルのコンテンツが、キックスタートファイルの %ksappend コマンドの場所にあるかのように設定します。
この包含は、%include コマンドで使用するのとは異なり、%pre スクリプトセクションの前に評価されます。
構文
%ksappend path/to/fileC.3. システム設定用キックスタートコマンド
このリストのキックスタートコマンドは、ユーザー、リポジトリー、サーバーなど、システムの詳細を設定します。
C.3.1. auth または authconfig (非推奨)
非推奨になったキックスタートコマンドの auth または authconfig を使用する代わりに authselect コマンドを使用します。auth および authconfig は、限定された後方互換性にのみ利用できます。
キックスタートコマンドの auth または authconfig は任意です。authconfig ツールを使用してシステムの認証オプションを設定します。インストール完了後もコマンドラインで実行できます。このコマンドは 1 回だけ使用してください。
構文
authconfig [OPTIONS]注記
-
キックスタートコマンドの
authまたはauthconfigコマンドは、以前はauthconfigツールと呼ばれていました。このツールは、Red Hat Enterprise Linux 8 では非推奨になりました。このキックスタートコマンドは、authselect-compatツールを使用して、新しいauthselectツールを呼び出せるようになりました。互換性層の説明と、その既知の問題は、authselect-migration(7) の man ページを参照してください。インストールプログラムが自動的に非推奨のコマンドの使用を検出し、互換性層を提供するために、システムにauthselect-compatパッケージをインストールします。 - デフォルトでは、パスワードがシャドウ化されています。
-
安全対策上、
SSLプロトコルで OpenLDAP を使用する場合はサーバー設定内のSSLv2およびSSLv3のプロトコルを必ず無効にしてください。POODLE SSL 脆弱性 (CVE-2014-3566) の影響を受けないようにするためです。詳細は、Red Hat ナレッジベースソリューション Resolution for POODLE SSLv3.0 vulnerability を参照してください。
C.3.2. authselect
キックスタートコマンドの authselect は任意です。authselect コマンドを使用してシステムの認証オプションを設定します。インストール完了後もコマンドラインで実行できます。このコマンドは 1 回だけ使用してください。
構文
authselect [OPTIONS]注記
-
このコマンドは、すべてのオプションを
authselectコマンドに渡します。詳細は、authselect(8) の man ページ、およびauthselect --helpコマンドを参照してください。 -
このコマンドは、Red Hat Enterprise Linux 8 で非推奨になった
authまたはauthconfigコマンドを、authconfigツールに置き換えます。 - デフォルトでは、パスワードがシャドウ化されています。
-
安全対策上、
SSLプロトコルで OpenLDAP を使用する場合はサーバー設定内のSSLv2およびSSLv3のプロトコルを必ず無効にしてください。POODLE SSL 脆弱性 (CVE-2014-3566) の影響を受けないようにするためです。詳細は、Red Hat ナレッジベースソリューション Resolution for POODLE SSLv3.0 vulnerability を参照してください。
C.3.3. ファイアウォール (firewall)
キックスタートコマンドの firewall は任意です。インストール済みシステムにファイアウォール設定を指定します。
構文
firewall --enabled|--disabled [incoming] [OPTIONS]必須オプション
-
--enabledまたは--enable- DNS 応答や DHCP 要求など、発信要求に対する応答ではない着信接続を拒否します。このマシンで実行中のサービスへのアクセスが必要な場合は、特定サービスに対してファイアウォールの通過許可を選択できます。 -
--disabledまたは--disable- iptable ルールを一切設定しません。
任意のオプション
-
--trust-em1などのデバイスを指定することで、ファイアウォールを通過するこのデバイスへの着信トラフィックおよびこのデバイスからの発信トラフィックをすべて許可します。複数のデバイスをリスト表示するには、--trust em1 --trust em2などのオプションをさらに使用します。--trust em1, em2などのようなコンマ区切りは使用しないでください。 -
--remove-service- サービスがファイアウォールを通過するのを許可しません。 incoming - 指定したサービスがファイアウォールを通過できるように、以下のいずれかに置き換えます (複数のサービスを指定できます)。
-
--ssh -
--smtp -
--http -
--ftp
-
-
--port=- port:protocol の形式で指定したポートのファイアウォール通過を許可できます。たとえば、IMAP アクセスがファイアウォールを通過できるようにする場合は、imap:tcpと指定します。ポート番号を明示的に指定することもできます。ポート 1234 の UDP パケットを許可する場合は1234:udpと指定します。複数のポートを指定する場合は、コンマで区切って指定します。 --service=- このオプションは、サービスがファイアウォールを通過できるように高レベルの方法を提供します。サービスの中には複数のポートを開く必要があったり (cups、avahiなど)、サービスが正常に動作するよう特殊な設定を必要とするものがあります。このような場合は、--portオプションでポート単位での指定を行ったり、--service=を使用して必要なポートをすべて一度に開くことが可能です。firewalld パッケージ内の
firewall-offline-cmdプログラムで認識できるオプションは、すべて使用できます。firewalldサービスを実行している場合は、firewall-cmd --get-servicesを実行すると、認識できるサービス名のリストが表示されます。-
--use-system-defaults- ファイアウォールを設定しません。このオプションにより、anaconda では何も実行せず、システムが、パッケージまたは ostree で提供されるデフォルトに依存するようになります。このオプションを他のオプションと共に使用すると、他のすべてのオプションは無視されます。
C.3.4. group
キックスタートコマンドの group は任意です。システムに新しいユーザーグループを作成します。
group --name=name [--gid=gid]必須オプション
-
--name=- グループ名を指定します。
任意のオプション
-
--gid=- グループの GID です。指定しないとシステムの GID 以外で次に使用可能な GID がデフォルト設定されます。
注記
- 指定された名前や GID を持つグループが存在すると、このコマンドは失敗します。
-
userコマンドは、新たに作成したユーザーに新しいグループを作成するのに使用できます。
C.3.5. keyboard (必須)
キックスタートコマンド keyboard が必要です。これは、システムに利用可能なキーボードレイアウトを 1 つまたは複数設定します。このコマンドは 1 回だけ使用してください。
構文
keyboard --vckeymap|--xlayouts OPTIONSオプション
-
--vckeymap=- 使用するVConsoleキーマップを指定します。/usr/lib/kbd/keymaps/xkb/ディレクトリーの各ファイル名から.map.gz拡張子を外したものが、有効なキーマップ名になります。 --xlayouts=- 使用する X のレイアウトを、空白なしのコンマで区切ったリストで指定します。setxkbmap(1)と同じ形式 (layout形式 (czなど)、またはlayout (variant)形式 (cz (qwerty)など)) の値をとります。使用できるレイアウトは、
Layoutsのxkeyboard-config(7)man ページをご覧ください。--switch=- レイアウト切り替えのオプションリストを指定します (複数のキーボードレイアウト切り替え用のショートカット)。複数のオプションは、空白なしのコンマで区切ってください。setxkbmap(1)と同じ形式の値を受け取ります。使用できる切り替えオプションは、
xkeyboard-config(7)の man ページのOptionsをご覧ください。
注記
-
--vckeymap=オプションまたは--xlayouts=オプションのいずれかを使用する必要があります。
例
以下の例では、--xlayouts= オプションを使用して 2 種類のキーボードレイアウト (English (US) と Czech (qwerty)) を設定し、切り替えオプションは、Alt+Shift を使用するように指定しています。
keyboard --xlayouts=us,'cz (qwerty)' --switch=grp:alt_shift_toggleC.3.6. lang (必須)
キックスタートコマンドの lang が必要です。これは、インストール時に使用する言語と、インストール済みシステムで使用するデフォルト言語を設定します。このコマンドは 1 回だけ使用してください。
構文
lang language [--addsupport=language,...]必須オプション
-
language- この言語のサポートをインストールし、システムのデフォルトとして設定します。
任意のオプション
--addsupport=- 追加言語のサポートを指定します。空白を入れずコンマで区切った形式を受け取ります。以下に例を示します。lang en_US --addsupport=cs_CZ,de_DE,en_UK
注記
-
locale -a | grep _コマンドまたはlocalectl list-locales | grep _コマンドは、ロケールのリストを返します。 -
テキストモードのインストールでは、特定の言語には対応していません (中国語、日本語、韓国語、インド系言語など)。
langコマンドでこの言語を指定しても、インストールプロセスは英語で続行します。ただし、インストール後のシステムでは選択した言語がデフォルトの言語として使用されます。
例
言語を英語に設定するには、キックスタートファイルに次の行が含まれている必要があります。
lang en_USC.3.7. module
キックスタートコマンドの module は任意です。このコマンドを使用すると、キックスタートスクリプトでパッケージのモジュールストリームが有効になります。
構文
module --name=NAME [--stream=STREAM]必須オプション
--name=- 有効にするモジュールの名前を指定します。NAME を、実際の名前に置き換えます。
任意のオプション
--stream=有効にするモジュールストリームの名前を指定します。STREAM を、実際の名前に置き換えます。
デフォルトストリームが定義されているモジュールには、このオプションを指定する必要はありません。デフォルトストリームのないモジュールの場合、このオプションは必須であり省略するとエラーになります。異なるストリームでモジュールを複数回有効にすることはできません。
注記
-
このコマンドと
%packagesセクションを組み合わせて使用すると、モジュールとストリームを明示的に指定せずに、有効なモジュールとストリームの組み合わせで提供されるパッケージをインストールできます。モジュールは、パッケージをインストールする前に有効にする必要があります。moduleコマンドでモジュールを有効にしたら、%packagesセクションにパッケージのリストを追加することで、このモジュールで有効にしたパッケージをインストールできます。 -
1 つの
moduleコマンドで、1 つのモジュールとストリームの組み合わせのみを有効にできます。複数のモジュールを有効にするには、複数のmoduleコマンドを使用します。異なるストリームでモジュールを複数回有効にすることはできません。 -
Red Hat Enterprise Linux 8 では、モジュールは AppStream リポジトリーにのみ存在します。利用可能なモジュールのリストを表示するには、インストールされている Red Hat Enterprise Linux 8 システムで
yum module listコマンドを実行します。
C.3.8. repo
キックスタートコマンドの repo は任意です。パッケージインストール用のソースとして使用可能な追加の yum リポジトリーを設定します。複数の repo 行を追加できます。
構文
repo --name=repoid [--baseurl=url|--mirrorlist=url|--metalink=url] [OPTIONS]必須オプション
-
--name=- リポジトリー ID を入力します。このオプションは必須です。以前に追加したリポジトリーと名前が競合する場合は無視されます。インストールプログラムでは事前設定したリポジトリーのリストが使用されるため、このリストにあるリポジトリーと同じ名前のものは追加できません。
URL オプション
これらのオプションは相互排他的で、オプションです。ここでは、yum のリポジトリーの設定ファイル内で使用できる変数はサポートされません。文字列 $releasever および $basearch を使用できます。これは、URL の該当する値に置き換えられます。
-
--baseurl=- リポジトリーの URL を入力します。 -
--mirrorlist=- リポジトリーのミラーのリストを指す URL を入力します。 -
--metalink=- リポジトリーのメタリンクを持つ URL です。
任意のオプション
-
--install- 指定したリポジトリーの設定を、インストールしたシステムの/etc/yum.repos.d/ディレクトリーに保存します。このオプションを使用しない場合は、キックスタートファイルで設定したリポジトリーの使用はインストール中に限られ、インストール後のシステムでは使用できません。 -
--cost=- このリポジトリーに割り当てるコストを整数で入力します。複数のリポジトリーで同じパッケージを提供している場合に、リポジトリーの使用優先順位がこの数値で決まります。コストの低いリポジトリーは、コストの高いリポジトリーよりも優先されます。 -
--excludepkgs=- このリポジトリーからは読み出してはならないパッケージ名のリストをコンマ区切りで指定します。複数のリポジトリーで同じパッケージが提供されていて、特定のリポジトリーから読み出す場合に便利なオプションです。(publicanといった) 完全なパッケージ名と (gnome-*といった) グロブの両方が使えます。 -
--includepkgs=- このリポジトリーから取得できるパッケージ名およびグロブのリストをコンマ区切りで指定します。リポジトリーが提供するその他のパッケージは無視されます。これは、リポジトリーが提供する他のパッケージをすべて除外しながら、リポジトリーから 1 つのパッケージまたはパッケージセットをインストールする場合に便利です。 -
--proxy=[protocol://][username[:password]@]host[:port]- このリポジトリーにだけ使用する HTTP/HTTPS/FTP プロキシーを指定します。この設定は他のリポジトリーには影響しません。また、HTTP インストールではinstall.imgの読み込みにも影響はありません。 -
--noverifyssl-HTTPSサーバーへの接続の際に、SSL 確認を無効にします。
備考
- インストールに使用するリポジトリーは安定した状態を維持してください。インストールが終了する前にリポジトリーに変更が加えられると、インストールが失敗する可能があります。
C.3.9. rootpw (必須)
キックスタートコマンドの rootpw が必要です。システムの root パスワードを password 引数に設定します。このコマンドは 1 回だけ使用してください。
構文
rootpw [--iscrypted|--plaintext] [--lock] password必須オプション
-
password - パスワード指定。プレーンテキストまたは暗号化された文字列。以下の
--iscryptedおよび--plaintextを参照してください。
オプション
--iscrypted- このオプションを追加すると、パスワード引数はすでに暗号化済みと仮定されます。--plaintextと相互排他的になります。暗号化したパスワードを作成する場合は python を使用します。$ python -c 'import crypt,getpass;pw=getpass.getpass();print(crypt.crypt(pw) if (pw==getpass.getpass("Confirm: ")) else exit())'上記の例では、ランダムの salt を使用して、パスワードの sha512 暗号と互換性があるハッシュが生成されます。
-
--plaintext- このオプションを使用すると、パスワードの引数はプレーンテキストであると仮定されます。--iscryptedと相互排他的になります。 -
--lock- このオプションを指定すると、root アカウントはデフォルトでロックされます。つまり、root ユーザーはコンソールからログインできなくなります。また、グラフィカルおよびテキストベースの手動インストールで、Root Password ウィンドウが無効になります。
C.3.10. selinux
キックスタートコマンドの selinux は任意です。インストール済みシステムの SELinux の状態を設定します。デフォルトの SELinux ポリシーは enforcing です。このコマンドは 1 回だけ使用してください。
構文
selinux [--disabled|--enforcing|--permissive]オプション
--enforcing-
SELinux をデフォルトの対象ポリシーである
enforcingで有効にします。 --permissive- SELinux のポリシーに基づく警告を出力します。ただし、実際にはポリシーは実施されません。
--disabled- システムで SELinux を完全に無効にします。
C.3.11. services
キックスタートコマンドの services は任意です。デフォルトの systemd ターゲット下で実行するデフォルトのサービスセットを変更します。無効にするサービスのリストは、有効にするサービスのリストの前に処理されます。したがって、サービスが両方のリストに記載されていると、そのサービスは有効になります。
構文
services [--disabled=list] [--enabled=list]オプション
-
--disabled=- 無効にするサービスをコンマ区切りで指定します。 -
--enabled=- 有効にするサービスをコンマ区切りで指定します。
注記
-
services要素を使用してsystemdサービスを有効にする場合は、指定されたサービスファイルを含むパッケージを%packagesセクションに含めるようにしてください。 複数のサービスは、スペースを入れずにコンマで区切って含める必要があります。たとえば、4 つのサービスを無効にするには、次のように実行します。
services --disabled=auditd,cups,smartd,nfslockスペースを含めると、最初のスペースまでのサービスだけが有効化または無効化されます。以下に例を示します。
services --disabled=auditd, cups, smartd, nfslockこの場合は、
auditdサービスしか無効になりません。4 つのサービスをすべて無効にするには、エントリーから空白を取り除きます。
C.3.12. skipx
キックスタートコマンドの skipx は任意です。存在する場合は、インストール済みシステムで X が設定されていません。
パッケージ選択のオプションでディスプレイマネージャーをインストールすると、このパッケージにより X の設定が作成されるため、インストールが完了したシステムは graphical.target にデフォルト設定されることになります。これにより、skipx オプションが無効になります。このコマンドは 1 回だけ使用してください。
構文
skipx注記
- このコマンドにはオプションはありません。
C.3.13. sshkey
キックスタートコマンドの sshkey は任意です。インストール済みシステムで、指定したユーザーの authorized_keys ファイルに SSH キーを追加します。
構文
sshkey --username=user "ssh_key"必須オプション
-
--username=- 鍵をインストールするユーザー。 - ssh_key - 完全な SSH 鍵のフィンガープリント。引用符でラップする必要があります。
C.3.14. syspurpose
キックスタートコマンドの syspurpose は任意です。インストール後にシステムがどのように使用されるかを説明するシステムの目的を設定します。この情報により、適切なサブスクリプションエンタイトルメントがシステムに適用されます。このコマンドは 1 回だけ使用してください。
Red Hat Enterprise Linux 8.6 以降では、1 つの subscription-manager syspurpose モジュールで role、service-level、usage、および addons サブコマンドを利用可能にすることで、1 つのモジュールでシステムの目的の属性を管理および表示できます。以前は、システム管理者は 4 つのスタンドアロンの syspurpose コマンドのいずれかを使用して各属性を管理していました。このスタンドアロンの syspurpose コマンドは RHEL 8.6 以降非推奨となり、RHEL 9 では削除される予定です。Red Hat は、現在のリリースのライフサイクル中にバグ修正とこの機能に対するバグ修正やサポートを提供しますが、この機能は機能強化の対象外となります。RHEL 9 以降、単一の subscription-manager syspurpose コマンドとその関連のサブコマンドは、システムの目的を使用する唯一の方法です。
構文
syspurpose [OPTIONS]オプション
--role=- 希望するシステムロールを設定します。利用できる値は次のとおりです。- Red Hat Enterprise Linux Server
- Red Hat Enterprise Linux Workstation
- Red Hat Enterprise Linux Compute Node
--sla=- サービスレベルアグリーメントを設定します。利用できる値は次のとおりです。- Premium
- Standard
- Self-Support
--usage=- システムの使用方法。利用できる値は次のとおりです。- Production
- Disaster Recovery
- Development/Test
-
--addon=- のレイヤード製品または機能を指定します。このオプションは複数回使用できます。
注記
スペースで値を入力し、二重引用符で囲みます。
syspurpose --role="Red Hat Enterprise Linux Server"-
システムの目的を設定することが強く推奨されますが、Red Hat Enterprise Linux インストールプログラムでは任意の機能です。インストールが完了してからシステムの目的を有効にする場合は、コマンドラインツールの
syspurposeを使用できます。
Red Hat Enterprise Linux 8.6 以降では、1 つの subscription-manager syspurpose モジュールで role、service-level、usage、および addons サブコマンドを利用可能にすることで、1 つのモジュールでシステムの目的の属性を管理および表示できます。以前は、システム管理者は 4 つのスタンドアロンの syspurpose コマンドのいずれかを使用して各属性を管理していました。このスタンドアロンの syspurpose コマンドは RHEL 8.6 以降非推奨となり、RHEL 9 では削除される予定です。Red Hat は、現在のリリースのライフサイクル中にバグ修正とこの機能に対するバグ修正やサポートを提供しますが、この機能は機能強化の対象外となります。RHEL 9 以降、単一の subscription-manager syspurpose コマンドとその関連のサブコマンドは、システムの目的を使用する唯一の方法です。
C.3.15. timezone (必須)
キックスタートコマンド timezone が必要です。システムのタイムゾーンを設定します。このコマンドは 1 回だけ使用してください。
構文
timezone timezone [OPTIONS]必須オプション
- timezone - システムに設定するタイムゾーン
任意のオプション
-
--utc- これを指定すると、ハードウェアクロックが UTC (グリニッジ標準) 時間に設定されているとシステムは見なします。 -
--nontp- NTP サービスの自動起動を無効にします。 -
--ntpservers=- 使用する NTP サーバーを空白を入れないコンマ区切りのリストで指定します。
注記
Red Hat Enterprise Linux 8 では、タイムゾーン名は pytz パッケージにより提供される pytz.all_timezones のリストを使用して検証されます。以前のリリースでは、名前は現在使用されているリストのサブセットである pytz.common_timezones に対して検証されていました。グラフィックおよびテキストモードのインターフェイスには、引き続きより制限の多い pytz.common_timezones のリストが使用される点に注意してください。別のタイムゾーン定義を使用するには、キックスタートファイルを使用する必要があります。
C.3.16. user
キックスタートコマンドの user は任意です。システムに新しいユーザーを作成します。
構文
user --name=username [OPTIONS]必須オプション
-
--name=- ユーザー名を入力します。このオプションは必須です。
任意のオプション
-
--gecos=- ユーザーの GECOS 情報を指定します。これは、コンマ区切りのさまざまなシステム固有フィールドの文字列です。ユーザーのフルネームやオフィス番号などを指定するのに使用されます。詳細は、passwd(5)の man ページを参照してください。 -
--groups=- デフォルトグループの他にもユーザーが所属すべきグループ名のコンマ区切りのリストです。このグループは、ユーザーアカウントの作成前に存在する必要があります。詳細は、groupコマンドを参照してください。 -
--homedir=- ユーザーのホームディレクトリーです。これが設定されない場合は、/home/usernameがデフォルトになります。 -
--lock- このオプションを指定すると、このアカウントはデフォルトでロックされます。つまり、ユーザーはコンソールからログインできなくなります。また、グラフィカルおよびテキストベースの手動インストールで、ユーザーの作成 ウィンドウが無効になります。 -
--password=- 新規のユーザーパスワードです。指定しないと、そのアカウントはデフォルトでロックされます。 --iscrypted- このオプションを追加すると、パスワード引数はすでに暗号化済みと仮定されます。--plaintextと相互排他的になります。暗号化したパスワードを作成する場合は python を使用します。$ python -c 'import crypt,getpass;pw=getpass.getpass();print(crypt.crypt(pw) if (pw==getpass.getpass("Confirm: ")) else exit())'上記の例では、ランダムの salt を使用して、パスワードの sha512 暗号と互換性があるハッシュが生成されます。
-
--plaintext- このオプションを使用すると、パスワードの引数はプレーンテキストであると仮定されます。--iscryptedと相互排他的になります。 -
--shell=- ユーザーのログインシェルです。指定しないと、システムのデフォルトが使用されます。 -
--uid=- ユーザーの UID (User ID) です。指定しないと、次に利用可能なシステム以外の UID をデフォルトにします。 -
--gid=- ユーザーのグループで使用される GID (Group ID) です。指定しないと、次に利用可能なシステム以外のグループ ID をデフォルトにします。
注記
--uidと--gidのオプションを使用して、通常のユーザーとそのデフォルトグループに1000ではなく5000から始まる範囲の ID を設定することを検討してください。これは、システムユーザーおよびグループに予約してある0-999の範囲が今後広がり、通常のユーザーの ID と重複する可能性があるためです。選択した UID および GID の範囲がユーザーの作成時に自動的に適用されるように、インストール後に UID および GID の下限を変更する場合は、基本的なシステム設定 の umask を使用した、新規ファイルのデフォルト権限の設定 セクションを参照してください。
ファイルおよびディレクトリーはさまざまなパーミッションで作成され、パーミッションは、ファイルまたはディレクトリーを作成するアプリケーションによる影響を受けます。たとえば、
mkdirコマンドは、すべてのパーミッションを有効にしてディレクトリーを作成します。ただし、user file-creation mask設定で指定されたように、アプリケーションは、新規に作成したファイルに特定パーミッションを付与しません。user file-creation maskは、umaskコマンドで管理できます。新規ユーザー向けのuser file-creation maskのデフォルト設定は、インストールシステム上の/etc/login.defs設定ファイルのUMASK変数で定義されます。これを設定しない場合は、デフォルト値022を使用します。デフォルト値を使用し、アプリケーションがファイルを作成した場合は、ファイルの所有者以外のユーザーに書き込みパーミッションが付与されません。ただし、これは他の設定やスクリプトで無効にできます。詳細は、基本的なシステム設定 の umask を使用した、新規ファイルのデフォルト権限の設定 セクションを参照してください。
C.3.17. xconfig
キックスタートコマンドの xconfig は任意です。X Window System を設定します。このコマンドは 1 回だけ使用してください。
構文
xconfig [--startxonboot]オプション
-
--startxonboot- インストール済みシステムでグラフィカルログインを使用します。
注記
-
Red Hat Enterprise Linux 8 には KDE デスクトップ環境が含まれていないため、アップストリームに記載されている
--defaultdesktop=を使用しないでください。
C.4. ネットワーク設定用キックスタートコマンド
このリストのキックスタートコマンドにより、システムにネットワークを設定できます。
C.4.1. ネットワーク (任意)
オプションの network キックスタートコマンドを使用して、ターゲットシステムのネットワーク情報を設定し、インストール環境でネットワークデバイスをアクティブにします。最初の network コマンドで指定しているデバイスが自動的にアクティベートされます。--activate オプションを使用して、デバイスを明示的にアクティブ化するように要求することもできます。
実行中のインストーラーによって使用されている、すでにアクティブなネットワークデバイスを再設定すると、インストールが失敗したり、フリーズしたりすることがあります。そのような場合は、NFS 経由でインストーラーのランタイムイメージ (stage2) にアクセスするために使用されるネットワークデバイスの再設定を避けてください。
構文
network OPTIONSオプション
--activate- インストール環境でこのデバイスをアクティブにします。すでにアクティブ化しているデバイスに対して
--activateオプションを使用すると (たとえば、キックスタートファイルを取得できるよう起動オプションで設定したインターフェイスなど)、キックスタートファイルで指定している詳細を使用するようデバイスが再アクティブ化されます。デバイスにデフォルトのルートを使用しないようにするには、
--nodefrouteオプションを使用します。--no-activate- インストール環境でこのデバイスをアクティブにしません。デフォルトでは、
--activateオプションにかかわらず、Anaconda はキックスタートファイルの 1 番目のネットワークデバイスをアクティブにします。--no-activateオプションを使用して、デフォルトの設定を無効にできます。--bootproto=-dhcp、bootp、ibftまたはstaticのいずれかを指定します。dhcpがデフォルトのオプションになります。dhcpとbootpは同じように処理されます。デバイスのipv4設定を無効にするには、--noipv4オプションを使用します。注記このオプションは、デバイスの ipv4 設定を行います。ipv6 の設定には、
--ipv6オプションおよび--ipv6gatewayオプションを使用します。DHCP メソッドでは、DHCP サーバーシステムを使用してネットワーク設定を取得します。BOOTP メソッドも同様で、BOOTP サーバーがネットワーク設定を提供する必要があります。システムが DHCP を使用するようにする場合は、以下のように指定します。
network --bootproto=dhcpBOOTP を使用してネットワーク設定を取得する場合は、キックスタートファイルで次の行を使用します。
network --bootproto=bootpiBFT で指定されている設定を使用する場合は、以下のようにします。
network --bootproto=ibftstaticメソッドの場合は、キックスタートファイルに IP アドレスおよびネットマスクを指定する必要があります。これらの情報は静的となるため、インストール時およびインストール後にも使用されます。静的なネットワーク設定情報はすべて 一行で 指定する必要があります。コマンドラインのようにバックスラッシュ (
\) を使用して行を折り返すことはできません。network --bootproto=static --ip=10.0.2.15 --netmask=255.255.255.0 --gateway=10.0.2.254 --nameserver=10.0.2.1ネームサーバーは同時に複数設定することもできます。以下のように、1 つの
--nameserver=オプションに対して、ネームサーバーの IP アドレスをコンマ区切りで指定します。network --bootproto=static --ip=10.0.2.15 --netmask=255.255.255.0 --gateway=10.0.2.254 --nameserver=192.168.2.1,192.168.3.1--device=-networkコマンドで設定する (また最終的に Anaconda でアクティベートさせる) デバイスを指定します。最初 に使用される
networkコマンドに--device=オプションがない場合は、Anaconda の起動オプションinst.ks.device=の値が使用されます (使用可能な場合)。この動作は非推奨と見なされています。ほとんどの場合、すべてのnetworkコマンドに必ず--device=を指定してください。同じキックスタートファイルに記載される 2 番目以降の
networkコマンドの動作は、--device=オプションを指定しないと詳細が不明になります。1 番目以降のnetworkコマンドに、このオプションを指定していることを確認してください。起動するデバイスは、以下のいずれかの方法で指定します。
-
インターフェイスのデバイス名を使用して指定する (
em1など) -
インターフェイスの MAC アドレスを使用して指定する (
01:23:45:67:89:abなど) -
linkキーワードを使用する (リンクがup状態になっている 1 番目のインターフェイス)。 -
キーワード
bootifを使用する。これは、pxelinux がBOOTIF変数に設定した MAC アドレスを使用します。pxelinux にBOOTIF変数を設定する場合は、pxelinux.cfgファイルにIPAPPEND 2を設定します。
以下に例を示します。
network --bootproto=dhcp --device=em1-
インターフェイスのデバイス名を使用して指定する (
--ipv4-dns-search/--ipv6-dns-search- DNS 検索ドメインを手動で設定します。これらのオプションを--deviceオプションと一緒に使用し、それぞれの NetworkManager プロパティーをミラーリングする必要があります。次に例を示します。network --device ens3 --ipv4-dns-search domain1.example.com,domain2.example.com-
--ipv4-ignore-auto-dns/--ipv6-ignore-auto-dns- DHCP からの DNS 設定を無視するように設定します。これらのオプションは--deviceオプションと一緒に使用する必要があります。これらのオプションには引数は必要ありません。 -
--ip=- デバイスの IP アドレスを指定します。 -
--ipv6=- デバイスの IPv6 アドレスを address[/prefix length] の形式で指定します (例:3ffe:ffff:0:1::1/128)。prefix を省略すると、64が使用されます。autoを使用すると自動設定に、dhcpを使用すると DHCPv6 限定の設定 (ルーター広告なし) となります。 -
--gateway=- 単一 IPv4 アドレスのデフォルトゲートウェイを指定します。 -
--ipv6gateway=- 単一 IPv6 アドレスのデフォルトゲートウェイを指定します。 -
--nodefroute- インターフェイスがデフォルトのルートとして設定されないようにします。iSCSI ターゲット用に別のサブネットにある NIC など、--activate=オプションで追加デバイスをアクティブにする場合は、このオプションを使用します。 -
--nameserver=- IP アドレスに DNS ネームサーバーを指定します。複数のネームサーバーを指定するには、このオプションを 1 回使用し、各 IP アドレスをコンマで区切ります。 -
--netmask=- インストール後のシステムのネットワークマスクを指定します。 --hostname=- ターゲットシステムのホスト名を設定するために使用されます。ホスト名は、hostname.domainname形式の完全修飾ドメイン名 (FQDN)、またはドメインなしの短縮ホスト名のいずれかにします。多くのネットワークには、自動的に接続したシステムにドメイン名を提供する DHCP (Dynamic Host Configuration Protocol) サービスがあります。DHCP サービスが、このマシンにドメイン名を割り当てるようにするには、短縮ホスト名のみを指定してください。静的 IP およびホスト名の設定を使用する場合、短縮名または FQDN を使用するかどうかは、計画したシステムのユースケースによって異なります。Red Hat Identity Management はプロビジョニング時に FQDN を設定しますが、サードパーティーのソフトウェア製品によっては短縮名が必要になる場合があります。いずれの場合も、すべての状況で両方のフォームの可用性を確保するには、
IP FQDN short-aliasの形式で/etc/hostsにホストのエントリーを追加します。localhostの値は、ターゲットシステムの静的ホスト名が指定されておらず、(たとえば、DHCP または DNS を使用する NetworkManager による) ネットワーク設定時に、インストールされるシステムの実際のホスト名が設定されることを示しています。ホスト名に使用できるのは、英数字と
-または.のみです。ホスト名は 64 文字以下である必要があります。ホスト名は、-および.で開始したり終了したりできません。DNS に準拠するには、FQDN の各部分は 63 文字以下で、ドットを含む FQDN の合計の長さは 255 文字を超えることができません。ターゲットシステムのホスト名のみを設定する場合は、
networkコマンドで--hostnameオプションを使用し、他のオプションは含めないでください。ホスト名の設定時に追加オプションを指定すると、
networkコマンドは指定したオプションを使用してデバイスを設定します。--deviceオプションを使用して設定するデバイスを指定しないと、デフォルトの--device linkの値が使用されます。また、--bootprotoオプションを使用してプロトコルを指定しないと、デバイスはデフォルトで DHCP を使用するように設定されます。-
--ethtool=- ethtool プログラムに渡されるネットワークデバイスの低レベルの追加設定を指定します。 -
--onboot=- システムの起動時にデバイスを有効にするかどうかを指定します。 -
--dhcpclass=- DHCP クラスを指定します。 -
--mtu=- デバイスの MTU を指定します。 -
--noipv4- このデバイスで IPv4 を無効にします。 -
--noipv6- このデバイスで IPv6 を無効にします。 --bondslaves=- このオプションを使用すると、--bondslaves=オプションで定義されたセカンダリーデバイスを使用して、--device=オプションで指定したボンディングデバイスが作成されます。以下に例を示します。network --device=bond0 --bondslaves=em1,em2上記のコマンドは、インターフェイスの
em1およびem2をセカンダリーデバイスとして使用し、ボンドデバイスbond0を作成します。オプションの
--bondopts=---bondslaves=および--device=を使用して指定されるボンドインターフェイス用のオプションパラメーターのリストです。このリスト内のオプションは、コンマ (“,”) またはセミコロン (“;”) で区切る必要があります。オプション自体にコンマが含まれている場合はセミコロンを使用してください。以下に例を示します。network --bondopts=mode=active-backup,balance-rr;primary=eth1重要--bondopts=mode=パラメーターは、balance-rrやbroadcastなどのフルモード名にしか対応しません。0や3などの数値による表記には対応していません。利用可能なモードとサポートされているモードのリストは、ネットワークの設定および管理ガイド を参照してください。-
--vlanid=---device=で指定したデバイスを親として作成する仮想デバイスの仮想 LAN (VLAN) の ID 番号 (802.1q タグ) を指定します。たとえば、network --device=em1 --vlanid=171を使用すると仮想 LAN デバイスのem1.171が作成されます。 --interfacename=- 仮想 LAN デバイスのカスタムのインターフェイス名を指定します。--vlanid=オプションで生成されるデフォルト名が望ましくない場合に使用してください。--vlanid=と併用する必要があります。以下に例を示します。network --device=em1 --vlanid=171 --interfacename=vlan171上記のコマンドにより、
em1デバイスに ID171の仮想 LAN インターフェイスvlan171が作成されます。インターフェイスには任意の名前 (
my-vlanなど) を付けることができますが、場合によっては次の命名規則に従う必要があります。-
名前にドット (
.) を含める場合は、NAME.IDの形式にする必要があります。NAME は任意の名前で構いませんが ID は VLAN ID にする必要があります。たとえば、em1.171、my-vlan.171などにします。 -
vlanで開始する名前を付ける場合は、vlanIDの形式にする必要があります。たとえば、vlan171などにします。
-
名前にドット (
--teamslaves=- このオプションで指定したセカンダリーデバイスを使用して、--device=オプションで指定したチームデバイスが作成されます。セカンダリーデバイスはコンマで区切ります。各セカンダリーデバイスの後ろにその設定を指定できます。\記号でエスケープした二重引用符で、一重引用符の JSON 文字列を囲っている部分が実際の設定になります。以下に例を示します。network --teamslaves="p3p1'{\"prio\": -10, \"sticky\": true}',p3p2'{\"prio\": 100}'"--teamconfig=オプションも参照してください。--teamconfig=- チームデバイスの設定を二重引用符で囲って指定します。これは、二重引用符と\記号でエスケープした JSON 文字列になります。デバイス名は、--device=オプションで指定し、セカンダリーデバイスとその設定は、--teamslaves=オプションで指定します。以下に例を示します。network --device team0 --activate --bootproto static --ip=10.34.102.222 --netmask=255.255.255.0 --gateway=10.34.102.254 --nameserver=10.34.39.2 --teamslaves="p3p1'{\"prio\": -10, \"sticky\": true}',p3p2'{\"prio\": 100}'" --teamconfig="{\"runner\": {\"name\": \"activebackup\"}}"--bridgeslaves=- このオプションを使用すると、--device=オプションで指定したデバイス名でネットワークブリッジが作成され、このネットワークブリッジに、--bridgeslaves=オプションで指定したデバイスが追加されます。以下に例を示します。network --device=bridge0 --bridgeslaves=em1--bridgeopts=- オプションでブリッジしたインターフェイス用パラメーターのリストをコンマで区切って指定します。使用できる値はstp、priority、forward-delay、hello-time、max-age、ageing-timeなどです。これらのパラメーターの詳細は、nm-settings(5)man ページまたは ネットワーク設定仕様 にある ブリッジ設定 の表を参照してください。ネットワークブリッジの一般情報は、Configuring and managing networking も参照してください。
-
--bindto=mac- インストールされたシステムのデバイス設定ファイルをインターフェイス名 (DEVICE) へのデフォルトのバインドではなく、デバイスの MAC アドレス (HWADDR) にバインドします。このオプションは--device=オプションとは独立しています。同じnetworkコマンドでデバイス名、link、またはbootifが指定されていても、--bindto=macが適用されます。
注記
-
命名方法の変更により、Red Hat Enterprise Linux では
eth0などのethNデバイス名を使用できなくなりました。デバイスの命名スキームの詳細は、アップストリームドキュメント Predictable Network Interface Names を参照してください。 - キックスタートのオプションまたは起動オプションを使用して、ネットワークにあるインストールリポジトリーを指定したものの、インストール開始時にネットワークが利用できない状態になっている場合は、インストール概要 ウィンドウが表示される前に、ネットワーク接続の設定を求める ネットワークの設定 ウィンドウが表示されます。詳細は、ネットワークおよびホスト名のオプションの設定 を参照してください。
C.4.2. realm
キックスタートコマンドの realm は任意です。Active Directory や IPA ドメインを参加させます。このコマンドの詳細は、システム上の realm(8) man ページの join セクションを参照してください。
構文
realm join [OPTIONS] domain必須オプション
-
domain- 参加するドメイン。
オプション
-
--computer-ou=OU=- コンピューターアカウントを作成するために、組織単位の識別名を指定します。識別名の形式は、クライアントソフトウェアおよびメンバーシップのソフトウェアにより異なります。通常、識別名のルート DSE の部分は省略できます。 -
--no-password- パスワードの入力なしで自動的に参加します。 -
--one-time-password=- ワンタイムパスワードを使用して参加します。すべてのレルムで使用できるとは限りません。 -
--client-software=- ここで指定したクライアントソフトウェアを実行できるレルムにしか参加しません。使用できる値はsssdやwinbindなどになります。すべてのレルムがすべての値に対応しているとは限りません。デフォルトでは、クライアントソフトウェアは自動的に選択されます。 -
--server-software=- ここで指定したサーバーソフトウェアを実行できるレルムにしか参加しません。使用できる値はactive-directoryやfreeipaなどになります。 -
--membership-software=- レルムに参加する際に、このソフトウェアを使用します。使用できる値はsambaやadcliなどになります。すべてのレルムがすべての値に対応しているとは限りません。デフォルトでは、メンバーシップソフトウェアは自動的に選択されます。
C.5. ストレージを処理するキックスタートコマンド
このセクションのキックスタートコマンドは、デバイス、ディスク、パーティション、LVM、ファイルシステムなど、ストレージの設定を行います。
sdX (または /dev/sdX) 形式では、デバイス名が再起動後に維持される保証がないため、一部のキックスタートコマンドの使用が複雑になる可能性があります。コマンドにデバイスノード名が必要な場合は、/dev/disk の項目を代わりに使用できます。以下に例を示します。
part / --fstype=xfs --onpart=sda1
上記のコマンドの代わりに、以下のいずれかを使用します。
part / --fstype=xfs --onpart=/dev/disk/by-path/pci-0000:00:05.0-scsi-0:0:0:0-part1
part / --fstype=xfs --onpart=/dev/disk/by-id/ata-ST3160815AS_6RA0C882-part1
このアプローチを使用すると、コマンドは常に同じストレージデバイスをターゲットとします。これは、大規模なストレージ環境で特に役立ちます。システム上で使用可能なデバイス名を調べるには、対話型インストール中に ls -lR/dev/disk コマンドを使用できます。ストレージデバイスを一貫して参照するさまざまな方法の詳細は、永続的な命名属性の概要 を参照してください。
C.5.1. device (非推奨)
キックスタートコマンドの device は任意です。追加のカーネルモジュールを読み込むのに使用します。
ほとんどの PCI システムでは、イーサネットカードや SCSI カードが自動検出されます。ただし、旧式のシステムや一部の PCI では、適切なデバイスを検出できるようキックスタートにヒントを追加する必要があります。追加モジュールをインストールするようにインストールプログラムに指示する device コマンドは、以下の形式を使用します。
構文
device moduleName --opts=optionsオプション
- moduleName - インストールが必要なカーネルモジュール名に置き換えます。
--opts=: カーネルモジュールに渡すオプションです。以下に例を示します。device --opts="aic152x=0x340 io=11"
C.5.2. ignoredisk
キックスタートコマンドの ignoredisk は任意です。インストールプログラムが、指定したディスクを無視するようになります。
自動パーティション設定を使用して、特定のディスクを無視したい場合に便利なオプションです。たとえば、ignoredisk を使用せずに SAN クラスターに導入しようとすると、インストールプログラムが SAN へのパッシブパスを検出し、パーティションテーブルがないことを示すエラーが返されるため、キックスタートが失敗します。このコマンドは 1 回だけ使用してください。
構文
ignoredisk --drives=drive1,drive2,... | --only-use=driveオプション
-
--drives=driveN,…- driveN を、sda、sdbのいずれかに置き換えます。,hda,… などになります。 --only-use=driveN,…- インストールプログラムで使用するディスクのリストを指定します。これ以外のディスクはすべて無視されます。たとえば、インストール中にsdaディスクを使用し、他はすべて無視する場合は以下のコマンドを使用します。ignoredisk --only-use=sdaLVM を使用しないマルチパスのデバイスを指定する場合は、次のコマンドを実行します。
ignoredisk --only-use=disk/by-id/dm-uuid-mpath-2416CD96995134CA5D787F00A5AA11017LVM を使用するマルチパスのデバイスを指定する場合は、次のコマンドを実行します。
ignoredisk --only-use==/dev/disk/by-id/dm-uuid-mpath-bootloader --location=mbr
--drives または --only-use のいずれかのみを指定する必要があります。
備考
-
--interactiveオプションは、Red Hat Enterprise Linux 8 で非推奨となりました。このオプションにより、高度なストレージ画面を手動で操作できます。 論理ボリュームマネージャー (LVM) を使用しないマルチパスデバイスを無視するには、
disk/by-id/dm-uuid-mpath-WWIDという形式を使用します。WWID はデバイスの World-Wide Identifier です。たとえば、WWID2416CD96995134CA5D787F00A5AA11017のディスクを無視する場合は以下を使用します。ignoredisk --drives=disk/by-id/dm-uuid-mpath-2416CD96995134CA5D787F00A5AA11017
-
mpathaなどのデバイス名でマルチパスデバイスを指定しないでください。このようなデバイス名は、特定のディスクに固有の名前ではありません。インストール中の/dev/mpathaという名前のディスクは必ずしも期待したディスクを指すとは限りません。したがって、clearpartコマンドを使用する際は、間違ったディスクが対象となる可能性があります。 sdX(または/dev/sdX) 形式では、デバイス名が再起動後に維持される保証がないため、一部のキックスタートコマンドの使用が複雑になる可能性があります。コマンドにデバイスノード名が必要な場合は、/dev/diskの項目を代わりに使用できます。以下に例を示します。part / --fstype=xfs --onpart=sda1上記のコマンドの代わりに、以下のいずれかを使用します。
part / --fstype=xfs --onpart=/dev/disk/by-path/pci-0000:00:05.0-scsi-0:0:0:0-part1 part / --fstype=xfs --onpart=/dev/disk/by-id/ata-ST3160815AS_6RA0C882-part1このアプローチを使用すると、コマンドは常に同じストレージデバイスをターゲットとします。これは、大規模なストレージ環境で特に役立ちます。システム上で使用可能なデバイス名を調べるには、対話型インストール中に
ls -lR/dev/diskコマンドを使用できます。ストレージデバイスを一貫して参照するさまざまな方法の詳細は、永続的な命名属性の概要 を参照してください。
C.5.3. clearpart
キックスタートコマンドの clearpart は任意です。新しいパーティションを作成する前に、システムからパーティションを削除します。デフォルトでは、パーティションは削除されません。このコマンドは 1 回だけ使用してください。
構文
clearpart OPTIONSオプション
--all- システムにあるすべてのパーティションを消去します。このオプションを使用すると、接続しているネットワークストレージなど、インストールプログラムでアクセスできるディスクがすべて消去されます。使用する場合は注意が必要です。
clearpartに--drives=オプションを使用して消去するドライブのみを指定する、ネットワークストレージは後で接続する (キックスタートファイルの%postセクションを利用するなど)、ネットワークストレージのアクセスに使用されるカーネルモジュールを拒否リストに記載するなどの手段を取ると、保持したいストレージが消去されるのを防ぐことができます。--drives=- ドライブを指定してパーティションを消去します。次の例では、プライマリー IDE コントローラーの 1 番目と 2 番目のドライブにあるパーティションをすべて消去することになります。clearpart --drives=hda,hdb --allマルチパスのデバイスを消去する場合は、
disk/by-id/scsi-WWIDの形式を使用します。WWID はデバイスの World-Wide Identifier になります。WWID58095BEC5510947BE8C0360F604351918のディスクを消去する場合は以下を使用します。clearpart --drives=disk/by-id/scsi-58095BEC5510947BE8C0360F604351918マルチパスのデバイスを消去する場合はこの形式が適しています。ただし、エラーが発生する場合は、そのマルチパスデバイスが論理ボリュームマネージャー (LVM) を使用していなければ、
disk/by-id/dm-uuid-mpath-WWIDの形式を使用して消去することもできます。WWID はデバイスの World-Wide Identifier です。WWID2416CD96995134CA5D787F00A5AA11017のディスクを消去する場合は以下を使用します。clearpart --drives=disk/by-id/dm-uuid-mpath-2416CD96995134CA5D787F00A5AA11017mpathaなどのデバイス名でマルチパスデバイスを指定しないでください。このようなデバイス名は、特定のディスクに固有の名前ではありません。インストール中の/dev/mpathaという名前のディスクは必ずしも期待したディスクを指すとは限りません。したがって、clearpartコマンドを使用する際は、間違ったディスクが対象となる可能性があります。--initlabel- フォーマット用に指定されたそれぞれのアーキテクチャーで全ディスクに対してデフォルトのディスクラベルを作成して、ディスクを初期化します。たとえば、x86 の場合は msdos になります。--initlabelによりすべてのディスクが処理されてしまうため、フォーマット対象のドライブだけを接続することが重要です。--initlabelが使用されていない場合でも、clearpartによってクリアされたディスクにはラベルが作成されます。clearpart --initlabel --drives=names_of_disks以下に例を示します。
clearpart --initlabel --drives=dasda,dasdb,dasdc--list=- 消去するパーティションを指定します。このオプションを使用すると、--allおよび--linuxのオプションが上書きされます。異なるドライブ間で使用できます。以下に例を示します。clearpart --list=sda2,sda3,sdb1-
--disklabel=LABEL- 使用するデフォルトのディスクラベルを設定します。そのプラットフォームでサポートされるディスクラベルのみが設定できます。たとえば、64 ビットの Intel アーキテクチャーおよび AMD アーキテクチャーでは、msdosディスクラベルおよびgptディスクラベルが使用できますが、dasdは使用できません。 -
--linux- すべての Linux パーティションを消去します。 -
--none(デフォルト) - パーティションを消去しません。 -
--cdl- LDL DASD を CDL 形式に再フォーマットします。
注記
sdX(または/dev/sdX) 形式では、デバイス名が再起動後に維持される保証がないため、一部のキックスタートコマンドの使用が複雑になる可能性があります。コマンドにデバイスノード名が必要な場合は、/dev/diskの項目を代わりに使用できます。以下に例を示します。part / --fstype=xfs --onpart=sda1上記のコマンドの代わりに、以下のいずれかを使用します。
part / --fstype=xfs --onpart=/dev/disk/by-path/pci-0000:00:05.0-scsi-0:0:0:0-part1 part / --fstype=xfs --onpart=/dev/disk/by-id/ata-ST3160815AS_6RA0C882-part1このアプローチを使用すると、コマンドは常に同じストレージデバイスをターゲットとします。これは、大規模なストレージ環境で特に役立ちます。システム上で使用可能なデバイス名を調べるには、対話型インストール中に
ls -lR/dev/diskコマンドを使用できます。ストレージデバイスを一貫して参照するさまざまな方法の詳細は、永続的な命名属性の概要 を参照してください。-
clearpartコマンドを使用する場合は、論理パーティションにはpart --onpartコマンドは使用できません。
C.5.4. zerombr
キックスタートコマンドの zerombr は任意です。zerombr は、ディスク上で見つかった無効なパーティションテーブルを初期化し、無効なパーティションテーブルを持つディスクの中身をすべて破棄します。このコマンドは、フォーマットされていない DASD (Direct Access Storage Device) ディスクを備えた 64 ビットの IBM Z システムでインストールを実行する場合に必要です。このコマンドを使用しないと、フォーマットされていないディスクがインストール時にフォーマットされず、使用されません。このコマンドは 1 回だけ使用してください。
構文
zerombr注記
-
64 ビットの IBM Z では
zerombrが指定された場合、インストールプログラムに見えている Direct Access Storage Device (DASD) でまだ低レベルフォーマット処理がなされていないものは、自動的に dasdfmt で低レベルフォーマット処理がなされます。このコマンドでは、対話型インストール中のユーザー選択も行われません。 -
zerombrが指定されておらず、少なくとも 1 つの未フォーマットの DASD がインストールプログラムに見えている場合、非対話形式のキックスタートを使用したインストールは失敗に終わります。 -
zerombrが指定されておらず、少なくとも 1 つの未フォーマットの DASD がインストールプログラムに見えている場合、ユーザーがすべての見えている未フォーマットの DASD のフォーマットに同意しなければ、対話形式のインストールは終了します。この状況を回避するには、インストール中に使用する DASD のみをアクティベートします。DASD は、インストール完了後にいつでも追加できます。 - このコマンドにはオプションはありません。
C.5.5. bootloader
キックスタートコマンドの bootloader は必須です。ブートローダーをインストールする方法を指定します。このコマンドは 1 回だけ使用してください。
構文
bootloader [OPTIONS]オプション
--append=- 追加のカーネルパラメーターを指定します。複数のパラメーターを指定する場合は空白で区切ります。以下に例を示します。bootloader --location=mbr --append="hdd=ide-scsi ide=nodma"plymouthパッケージをインストールすると、rhgbパラメーターおよびquietパラメーターをここで指定しなくても、もしくは--append=コマンドを使用しなくても、自動的に追加されます。この動作を無効にするには、plymouthのインストールを明示的に拒否します。%packages -plymouth %endこのオプションは、Meltdown および Spectre に起因する脆弱性の問題を軽減するために実装されたメカニズムを無効にする場合に便利です。投機的実行を悪用するもので、今日のほとんどのプロセッサーで確認されています (CVE-2017-5754、CVE-2017-5753、および CVE-2017-5715)。場合によっては、これらのメカニズムは不要で、有効にしてもセキュリティーは向上せずパフォーマンスが低下する可能性があります。これらのメカニズムを無効にするには、無効にするオプションをキックスタートファイルに追加します (AMD64/Intel 64 システムの例:
bootloader --append="nopti noibrs noibpb")。警告脆弱性の問題を軽減するメカニズムを無効にする場合は、システムが攻撃の危険にさらされていないことを確認する必要があります。Meltdown および Spectre に起因する脆弱性については、Red Hat vulnerability response article の記事を参照してください。
--boot-drive=- ブートローダーの書き込み先のドライブを指定します。つまり、コンピューターが起動するドライブです。ブートドライブにマルチパスデバイスを使用する場合は、disk/by-id/dm-uuid-mpath-WWID 名を使用してデバイスを指定します。重要現在、
ziplブートローダーを使用する 64 ビットの IBM Z システムの Red Hat Enterprise Linux インストールでは、--boot-drive=オプションが無視されます。ziplをインストールすると、そこに起動ドライブがあると判断されます。-
--leavebootorder- インストールプログラムが、ブートローダーのインストール済みシステムリストの最上位に Red Hat Enterprise Linux 8 を追加し、その順番と既存の全エントリーを保持します。
このオプションは、Power システムのみに適用されます。UEFI システムにはこのオプションを使用しないでください。
--driveorder=- BIOS の起動順序で最初のドライブを指定します。以下に例を示します。bootloader --driveorder=sda,hda--location=- ブートレコードの書き込み先を指定します。使用できる値は以下のとおりです。mbr- デフォルトのオプションです。ドライブが使用しているのが Master Boot Record (MBR) スキームか GUID Partition Table (GPT) スキームかによって、動作が異なります。GPT フォーマット済みディスクの場合は、ブートローダーのステージ 1.5 が BIOS 起動パーティションにインストールされます。
MBR フォーマット済みディスクの場合は、MBR と 1 番目のパーティションの間にある空白領域にステージ 1.5 がインストールされます。
-
partition- カーネルを置くパーティションの 1 番目のセクターに、ブートローダーをインストールします。 -
none- ブートローダーをインストールしません。
ほとんどの場合、このオプションは指定する必要がありません。
-
--nombr- MBR にブートローダーをインストールしません。 --password=- GRUB を使用している場合に、このオプションで指定したパスワードが、ブートローダーパスワードに設定されます。このオプションは、任意のカーネルオプションが渡される可能性のある GRUB2 シェルへのアクセスを制限する場合に使用してください。パスワードが指定されている場合、GRUB はユーザー名も要求します。ユーザー名は常に
rootです。--iscrypted---password=オプションを使用してブートローダーのパスワードを指定すると、通常、キックスタートファイルにプレーンテキスト形式で保存されます。このパスワードを暗号化する場合に、このオプションを使用して暗号化パスワードを生成します。暗号化したパスワードを生成するには、
grub2-mkpasswd-pbkdf2コマンドを使用し、使用するパスワードを入力し、コマンドからの出力 (grub.pbkdf2で始まるハッシュ) をキックスタートファイルにコピーします。暗号化したパスワードがあるキックスタートエントリーのbootloaderの例を以下に示します。bootloader --iscrypted --password=grub.pbkdf2.sha512.10000.5520C6C9832F3AC3D149AC0B24BE69E2D4FB0DBEEDBD29CA1D30A044DE2645C4C7A291E585D4DC43F8A4D82479F8B95CA4BA4381F8550510B75E8E0BB2938990.C688B6F0EF935701FF9BD1A8EC7FE5BD2333799C98F28420C5CC8F1A2A233DE22C83705BB614EA17F3FDFDF4AC2161CEA3384E56EB38A2E39102F5334C47405E-
--timeout=- ブートローダーがデフォルトオプションで起動するまでの待ち時間を指定します (秒単位)。 -
--default=- ブートローダー設定内のデフォルトのブートイメージを設定します。 -
--extlinux- GRUB の代わりに extlinux ブートローダーを使用します。このオプションが動作するには、extlinux が対応しているシステムのみです。 -
--disabled- このオプションは、--location=noneのより強力なバージョンになります。--location=noneは単にブートローダーのインストールを無効にしますが、--disabledだとブートローダーのインストールを無効にするほか、ブートローダーを含むパッケージのインストールを無効にするため、領域が節約できます。
注記
- Red Hat は、全マシンにブートローダーのパスワードを設定することを強く推奨します。ブートローダーが保護されていないと、攻撃者によりシステムの起動オプションが修正され、システムへの不正アクセスが許可されてしまう可能性があります。
- AMD64、Intel 64、および 64 ビット ARM のシステムにブートローダーをインストールするのに、特殊なパーティションが必要になります。このパーティションの種類とサイズは、ブートローダーをインストールしているディスクが、MBR (Master Boot Record) または GPT (GUID Partition Table) スキーマを使用しているかどうかにより異なります。詳細は、ブートローダーの設定 セクションを参照してください。
sdX(または/dev/sdX) 形式では、デバイス名が再起動後に維持される保証がないため、一部のキックスタートコマンドの使用が複雑になる可能性があります。コマンドにデバイスノード名が必要な場合は、/dev/diskの項目を代わりに使用できます。以下に例を示します。part / --fstype=xfs --onpart=sda1上記のコマンドの代わりに、以下のいずれかを使用します。
part / --fstype=xfs --onpart=/dev/disk/by-path/pci-0000:00:05.0-scsi-0:0:0:0-part1 part / --fstype=xfs --onpart=/dev/disk/by-id/ata-ST3160815AS_6RA0C882-part1このアプローチを使用すると、コマンドは常に同じストレージデバイスをターゲットとします。これは、大規模なストレージ環境で特に役立ちます。システム上で使用可能なデバイス名を調べるには、対話型インストール中に
ls -lR/dev/diskコマンドを使用できます。ストレージデバイスを一貫して参照するさまざまな方法の詳細は、永続的な命名属性の概要 を参照してください。-
--upgradeオプションは、Red Hat Enterprise Linux 8 で非推奨となりました。
C.5.6. autopart
キックスタートコマンドの autopart は任意です。自動的にパーティションを作成します。
自動的に作成されるパーティションは、ルート (/) パーティション (1 GiB 以上)、swap パーティション、およびアーキテクチャーに応じた適切な /boot パーティションです。容量が十分にあるドライブの場合 (50 GiB 以上)、/home パーティションも作成されます。このコマンドは 1 回だけ使用してください。
構文
autopart OPTIONSオプション
--type=- 事前定義済み自動パーティション設定スキームの中から、使用するスキームを選択します。次の値を取ります。-
lvm: LVM パーティション設定スキーム -
plain:LVM がない普通のパーティション -
thinp:LVM シンプロビジョニングのパーティション設定スキーム
-
-
--fstype=- 利用可能なファイルシステムのタイプを選択します。利用可能な値は、ext2、ext3、ext4、xfs、およびvfatです。デフォルトのファイルシステムはxfsです。 -
--nohome-/homeパーティションの自動作成を無効にします。 -
--nolvm- 自動パーティション設定に LVM を使用しません。このオプションは--type=plainと同じです。 -
--noboot-/bootパーティションを作成しません。 -
--noswap- swap パーティションを作成しません。 --encrypted- Linux Unified Key Setup (LUKS) ですべてのパーティションを暗号化します。手動によるグラフィカルインストールを行った際の初期パーティション設定ウィンドウで表示される Encrypt partitions (パーティションの暗号化) のチェックボックスと同じです。注記1 つまたは複数のパーティションを暗号化する際には、安全な暗号化を行うため、Anaconda が 256 ビットのエントロピーを収集しようとします。エントロピーの収集には時間がかかる場合があります。十分なエントロピーが収集されたかどうかにかかわらず、このプロセスは最大 10 分後に終了します。
プロセスは、インストールシステムと対話することにより高速化できます (キーボードで入力またはマウスの移動)。仮想マシンにインストールしている場合は、
virtio-rngデバイス (仮想乱数ジェネレーター) をゲストに登録できます。-
--luks-version=LUKS_VERSION- ファイルシステムの暗号化に使用する LUKS 形式のバージョンを指定します。--encryptedと併用しないと有効ではありません。 -
--passphrase=- 暗号化した全デバイスに、デフォルトのシステムワイドパスフレーズを指定します。 -
--escrowcert=URL_of_X.509_certificate- 暗号化した全ボリュームのデータ暗号化の鍵を/root配下にファイル形式で格納します。URL_of_X.509_certificate で指定した URL の X.509 証明書を使用して暗号化します。鍵は暗号化したボリュームごとに別のファイルとして格納されます。--encryptedと併用しないと有効ではありません。 -
--backuppassphrase- 暗号化されたボリュームにそれぞれランダムに生成されたパスフレーズを追加します。パスフレーズは、/root配下に別々のファイルで格納され、--escrowcertで指定した X.509 証明書を使用して暗号化されます。--escrowcertと併用しないと有効ではありません。 -
--cipher=- Anaconda のデフォルトであるaes-xts-plain64では十分ではない場合に使用する暗号化の種類を指定します。--encryptedオプションと併用してください。単独で使用しても暗号化されません。使用できる暗号化の種類は セキュリティーの強化 に記載されていますが、Red Hat では、aes-xts-plain64またはaes-cbc-essiv:sha256のいずれかの使用を強く推奨しています。 -
--pbkdf=PBKDF- LUKS 鍵スロット用の PBKDF (Password-Based Key Derivation Function) アルゴリズムを設定します。cryptsetup(8) の man ページも併せて参照してください。--encryptedと併用しないと有効ではありません。 -
--pbkdf-memory=PBKDF_MEMORY- PBKDF のメモリーコストを設定します。cryptsetup(8) の man ページも併せて参照してください。--encryptedと併用しないと有効ではありません。 -
--pbkdf-time=PBKDF_TIME- PBKDF パスフレーズ処理にかかるミリ秒数を設定します。cryptsetup(8) の man ページの--iter-timeも併せて参照してください。このオプションは、--encryptedが指定される場合に限り有効になり、--pbkdf-iterationsと相互に排他的になります。 -
--pbkdf-iterations=PBKDF_ITERATIONS- 反復の数を直接設定し、PBKDF ベンチマークを回避します。cryptsetup(8) の man ページの--pbkdf-force-iterationsも併せて参照してください。このオプションは、--encryptedが指定されている場合に限り有効になり、--pbkdf-timeと相互に排他的になります。
注記
-
autopartオプションは、同じキックスタートファイル内では、part/partition、raid、logvol、volgroupなどのオプションとは併用できません。 -
autopartコマンドは必須ではありませんが、キックスタートスクリプトにpartコマンドまたはmountコマンドがない場合は、このコマンドを組み込む必要があります。 -
CMS タイプの 1 つの FBA DASD にインストールする場合は、
autopart --nohomeのキックスタートオプションを使用することが推奨されます。これを使用すると、インストールプログラムが別の/homeパーティションを作成しません。その後、インストールは成功します。 -
LUKS パスフレーズが分からなくなると、暗号化されたパーティションと、その上にあるデータには完全にアクセスできなくなります。分からなくなったパスフレーズを復元する方法はありません。ただし、
--escrowcertを使用して暗号パスフレーズを保存し、--backuppassphraseオプションを使用してバックアップの暗号化パスフレーズを作成できます。 -
autopart、autopart --type=lvm、またはautopart=thinpを使用する場合は、ディスクのセクターサイズに一貫性があることを確認してください。
C.5.7. reqpart
キックスタートコマンドの reqpart は任意です。使用中のハードウェアプラットホームで必要となるパーティションを自動的に作成します。UEFI ファームウェアのシステム向けに /boot/efi パーティション、BIOS ファームウェアおよび GPT のシステム向けに biosboot パーティション、IBM Power Systems 向けに PRePBoot パーティションが作成されます。このコマンドは 1 回だけ使用してください。
構文
reqpart [--add-boot]オプション
-
--add-boot- ベースコマンドが作成するプラットホーム固有のパーティションとは別に、/bootパーティションを作成します。
備考
-
このコマンドは、
autopartと一緒に使用することはできません。autopartは、reqpartコマンドが実行するすべての操作を実行し、さらに/やswapなどの他のパーティションまたは論理ボリュームも作成するためです。autopartとは異なり、このコマンドは、プラットホーム固有のパーティションの作成のみを行い、ドライブの残りは空のままにするため、カスタムレイアウトの作成が可能になります。
C.5.8. part または partition
キックスタートコマンド part または partition が必要です。このコマンドは、システムにパーティションを作成します。
構文
part|partition mntpoint [OPTIONS]オプション
mntpoint - パーティションをマウントする場所です。値は次のいずれかの形式になります。
/path/、/usr、/homeなど。swapこのパーティションは、swap 領域として使用されます。
自動的に swap パーティションのサイズを確定させる場合は、
--recommendedオプションを使用します。swap --recommended有効なサイズが割り当てられますが、システムに対して正確に調整されたサイズではありません。
自動的に swap パーティションサイズを確定しながら、ハイバネート用に余剰領域も割り当てる場合は、
--hibernationオプションを使用します。swap --hibernation--recommendedで割り当てられる swap 領域に加え、システムの RAM 容量が加算されたサイズが割り当てられるようになります。これらのコマンドによって割り当てられるスワップサイズは、AMD64、Intel 64、および 64 ビット ARM システムの 推奨されるパーティション設定スキーム を参照してください。raid.idこのパーティションはソフトウェア RAID に使用されます (
raidを参照)。pv.idこのパーティションは LVM に使用されます (
logvolを参照)。biosbootこのパーティションは、BIOS 起動パーティションに使用されます。GPT (GUID Partition Table) を使用する BIOS ベースの AMD64 および Intel 64 のシステムには、1 MiB の BIOS 起動パーティションが必要になります。ブートローダーは、このパーティションにインストールされます。UEFI システムには必要ありません。詳細は
bootloaderコマンドをご覧ください。/boot/efiEFI システムパーティションです。UEFI ベースの AMD64、Intel 64、および 64 ビットの ARM には 50 MiB の EFI パーティションが必要になります。推奨サイズは 200 MiB です。BIOS システムには必要ありません。詳細は
bootloaderコマンドをご覧ください。
-
--size=- パーティションの最小サイズを MiB 単位で指定します。500などの整数値を使用してください (単位は不要)。指定したサイズが小さすぎる場合、インストールが失敗します。--sizeの値は、必要となる領域の最小値として指定します。サイズに関する推奨事項は、推奨されるパーティション設定スキーム を参照してください。 -
--grow- 利用可能な領域 (存在する場合) が埋まるまで、または最大サイズ設定 (指定されている場合) までパーティションを拡張するよう指定します。swap パーティションに--maxsize=を設定せずに--grow=を使用すると、swap パーティションの最大サイズは、Anaconda により制限されます。物理メモリーが 2 GiB 未満のシステムの場合は、物理メモリー量の 2 倍に制限されます。物理メモリーが 2 GiB 以上のシステムの場合は、物理メモリー量に 2GiB を足した量に制限されます。 -
--maxsize=- パーティションが grow に設定されている場合の最大サイズを MiB 単位で指定します。500などの整数値を使用してください (単位は不要)。 -
--noformat- パーティションをフォーマットしない場合に指定します。--onpartコマンドと併用してください。 --onpart=または--usepart=- パーティションを配置するデバイスを指定します。既存の空のデバイスを使用し、新たに指定したタイプにフォーマットします。以下に例を示します。partition /home --onpart=hda1上記では、
/homeパーティションが/dev/hda1に配置されます。このオプションを使用して、パーティションを論理ボリュームに追加することもできます。以下に例を示します。
partition pv.1 --onpart=hda2この場合は、デバイスがシステムに存在している必要があります。
--onpartオプションでデバイスを作成するわけではありません。パーティションではなく、ドライブ全体を指定することも可能です。その場合、Anaconda はパーティションテーブルを作成せずに、ドライブをフォーマットして使用します。ただし、この方法でフォーマットされたデバイスでは、GRUB のインストールがサポートされません。GRUB のインストールは、パーティションテーブルのあるドライブに配置する必要があります。
partition pv.1 --onpart=hdb--ondisk=または--ondrive=- 既存ディスクに (partコマンドで指定した) パーティションを作成します。このコマンドは常にパーティションを作成します。特定のディスクに強制的にパーティションを作成します。たとえば、--ondisk=sdbを使用すると、パーティションは 2 番目の SCSI ディスクに作成されます。論理ボリュームマネージャー (LVM) を使用しないマルチパスデバイスを指定するには、
disk/by-id/dm-uuid-mpath-WWIDという形式を使用します。WWID はデバイスの World-Wide Identifier です。たとえば、WWID2416CD96995134CA5D787F00A5AA11017のディスクを指定する場合は以下を使用します。part / --fstype=xfs --grow --asprimary --size=8192 --ondisk=disk/by-id/dm-uuid-mpath-2416CD96995134CA5D787F00A5AA11017警告mpathaなどのデバイス名でマルチパスデバイスを指定しないでください。このようなデバイス名は、特定のディスクに固有の名前ではありません。インストール時に、/dev/mpathaという名前のディスクが必ずしも期待したディスクを指すとは限りません。したがって、partコマンドを使用する際は、間違ったディスクが対象となる可能性があります。-
--asprimary- パーティションが プライマリー パーティションとして割り当てられるように強制実行します。(通常、すでに割り当てられているプライマリーパーティションが多すぎるという理由で) パーティションをプライマリーとして割り当てられない場合は、パーティション設定のプロセスが失敗します。このオプションは、Master Boot Record (MBR) をディスクが使用する場合にのみ有効で、GUID Partition Table (GPT) ラベルが付いたディスクでは有効ではありません。 -
--fsprofile=- このパーティションでファイルシステムを作成するプログラムに渡すのに使用するタイプを指定します。ファイルシステムの作成時に使用されるさまざまなチューニングパラメーターは、この使用タイプにより定義されます。ファイルシステム側で使用タイプという概念に対応し、有効なタイプを指定する設定ファイルがないと、このオプションは正しく機能しません。ext2、ext3、ext4の場合、この設定ファイルは/etc/mke2fs.confになります。 --mkfsoptions=- このパーティションでファイルシステムを作成するプログラムに渡す追加のパラメーターを指定します。これは--fsprofileと似ていますが、プロフィールの概念に対応するものだけではなく、すべてのファイルシステムで機能するものです。引数のリストでは処理が行われないため、mkfs プログラムに直接渡すことが可能な形式で提供する必要があります。つまり、複数のオプションはコンマ区切りにするか、二重引用符で囲む必要があります (ファイルシステムによって異なります)。以下に例を示します。part /opt/foo1 --size=512 --fstype=ext4 --mkfsoptions="-O ^has_journal,^flex_bg,^metadata_csum" part /opt/foo2 --size=512 --fstype=xfs --mkfsoptions="-m bigtime=0,finobt=0"
詳細は、作成しているファイルシステムの man ページを参照してください。たとえば、mkfs.ext4 または mkfs.xfs です。
-
--fstype=- パーティションのファイルシステムタイプを設定します。使用できる値は、xfs、ext2、ext3、ext4、swap、vfat、efi、およびbiosbootになります。 --fsoptions=- ファイルシステムをマウントする場合に使用するオプションの文字列を自由形式で指定します。この文字列は、インストール後の/etc/fstabファイルにコピーされるため、引用符で囲む必要があります。注記EFI システムパーティション (
/boot/efi) では、anaconda が値をハードコードし、ユーザー指定の--fsoptions値を無視します。-
--label=- 個別パーティションにラベルを割り当てます。 -
--recommended- パーティションのサイズを自動的に確定します。推奨されるスキームの詳細は、AMD64、Intel 64、および 64 ビット ARM の 推奨されるパーティション設定スキーム を参照してください。このオプションは、/bootパーティションやswap領域といったファイルシステムになるパーティションにのみ使用できます。LVM 物理ボリュームや RAID メンバーの作成には使用できません。 -
--onbiosdisk- BIOS で検出された特定のディスクに強制的にパーティションを作成します。 --encrypted---passphraseオプションで入力したパスフレーズを使用して、LUKS (Linux Unified Key Setup) でこのパーティションを暗号化するように指定します。このパスフレーズを指定しないと、Anaconda は、autopart --passphraseコマンドで設定されるデフォルトのシステムワイドパスフレーズを使用します。このデフォルトのパスフレーズも設定されていない場合は、インストールプロセスが中断して、パスフレーズの入力が求められます。注記1 つまたは複数のパーティションを暗号化する際には、安全な暗号化を行うため、Anaconda が 256 ビットのエントロピーを収集しようとします。エントロピーの収集には時間がかかる場合があります。十分なエントロピーが収集されたかどうかにかかわらず、このプロセスは最大 10 分後に終了します。
プロセスは、インストールシステムと対話することにより高速化できます (キーボードで入力またはマウスの移動)。仮想マシンにインストールしている場合は、
virtio-rngデバイス (仮想乱数ジェネレーター) をゲストに登録できます。-
--luks-version=LUKS_VERSION- ファイルシステムの暗号化に使用する LUKS 形式のバージョンを指定します。--encryptedと併用しないと有効ではありません。 -
--passphrase=- このパーティションの暗号化を行う際に使用するパスフレーズを入力します。--encryptedオプションと併用してください。単独で使用しても暗号化されません。 -
--cipher=- Anaconda のデフォルトであるaes-xts-plain64では十分ではない場合に使用する暗号化の種類を指定します。--encryptedオプションと併用してください。単独で使用しても暗号化されません。使用できる暗号化の種類は セキュリティーの強化 に記載されていますが、Red Hat では、aes-xts-plain64またはaes-cbc-essiv:sha256のいずれかの使用を強く推奨しています。 -
--escrowcert=URL_of_X.509_certificate- 暗号化した全パーティションのデータ暗号化の鍵を/root配下にファイルとして格納します。URL_of_X.509_certificate で指定した URL の X.509 証明書を使用して暗号化します。鍵は、暗号化したパーティションごとに別のファイルとして格納されます。--encryptedと併用しないと有効ではありません。 -
--backuppassphrase- 暗号化されたパーティションにそれぞれランダムに生成されたパスフレーズを追加します。パスフレーズは、/root配下に別々のファイルで格納され、--escrowcertで指定した X.509 証明書を使用して暗号化されます。--escrowcertと併用しないと有効ではありません。 -
--pbkdf=PBKDF- LUKS 鍵スロット用の PBKDF (Password-Based Key Derivation Function) アルゴリズムを設定します。cryptsetup(8) の man ページも併せて参照してください。--encryptedと併用しないと有効ではありません。 -
--pbkdf-memory=PBKDF_MEMORY- PBKDF のメモリーコストを設定します。cryptsetup(8) の man ページも併せて参照してください。--encryptedと併用しないと有効ではありません。 -
--pbkdf-time=PBKDF_TIME- PBKDF パスフレーズ処理にかかるミリ秒数を設定します。cryptsetup(8) の man ページの--iter-timeも併せて参照してください。このオプションは、--encryptedが指定される場合に限り有効になり、--pbkdf-iterationsと相互に排他的になります。 -
--pbkdf-iterations=PBKDF_ITERATIONS- 反復の数を直接設定し、PBKDF ベンチマークを回避します。cryptsetup(8) の man ページの--pbkdf-force-iterationsも併せて参照してください。このオプションは、--encryptedが指定されている場合に限り有効になり、--pbkdf-timeと相互に排他的になります。 -
--resize=- 既存パーティションのサイズを変更します。このオプションを使用する際は、--size=オプションで目的のサイズ (MiB 単位) を指定し、--onpart=オプションで目的のパーティションを指定します。
注記
-
partコマンドは必須ではありませんが、キックスタートスクリプトにはpart、autopart、またはmountのいずれかを指定する必要があります。 -
--activeオプションは、Red Hat Enterprise Linux 8 で非推奨となりました。 - 何らかの理由でパーティションの設定ができなかった場合には、診断メッセージが仮想コンソール 3 に表示されます。
-
--noformatおよび--onpartを使用しないと、作成されたパーティションはすべてインストールプロセスの一部としてフォーマット化されます。 sdX(または/dev/sdX) 形式では、デバイス名が再起動後に維持される保証がないため、一部のキックスタートコマンドの使用が複雑になる可能性があります。コマンドにデバイスノード名が必要な場合は、/dev/diskの項目を代わりに使用できます。以下に例を示します。part / --fstype=xfs --onpart=sda1上記のコマンドの代わりに、以下のいずれかを使用します。
part / --fstype=xfs --onpart=/dev/disk/by-path/pci-0000:00:05.0-scsi-0:0:0:0-part1 part / --fstype=xfs --onpart=/dev/disk/by-id/ata-ST3160815AS_6RA0C882-part1このアプローチを使用すると、コマンドは常に同じストレージデバイスをターゲットとします。これは、大規模なストレージ環境で特に役立ちます。システム上で使用可能なデバイス名を調べるには、対話型インストール中に
ls -lR/dev/diskコマンドを使用できます。ストレージデバイスを一貫して参照するさまざまな方法の詳細は、永続的な命名属性の概要 を参照してください。-
LUKS パスフレーズが分からなくなると、暗号化されたパーティションと、その上にあるデータには完全にアクセスできなくなります。分からなくなったパスフレーズを復元する方法はありません。ただし、
--escrowcertを使用して暗号パスフレーズを保存し、--backuppassphraseオプションを使用してバックアップの暗号化パスフレーズを作成できます。
C.5.9. raid
キックスタートコマンドの raid は任意です。ソフトウェアの RAID デバイスを組み立てます。
構文
raid mntpoint --level=level --device=device-name partitions*オプション
mntpoint - RAID ファイルシステムをマウントする場所です。
/にマウントする場合、boot パーティション (/boot) がなければ RAID レベルは 1 にする必要があります。boot パーティションがある場合は、/bootパーティションをレベル 1 にしてください。ルート (/) パーティションのタイプはどれでも構いません。partitions* (複数パーティションの指定が可能) には RAID アレイに追加する RAID 識別子を指定します。重要-
IBM Power Systems で RAID デバイスの準備は行ったものの、インストール中に再フォーマットを行っていない場合で、この RAID デバイスに
/bootパーティションおよび PReP パーティションの配置を予定している場合は、RAID メタデータのバージョンが0.90または1.0になっていることを確認してください。mdadmメタデータバージョン1.1および1.2は、/bootおよび PReP パーティションではサポートされていません。 -
PowerNV システムでは、
PRePBoot パーティションは必要ありません。
-
IBM Power Systems で RAID デバイスの準備は行ったものの、インストール中に再フォーマットを行っていない場合で、この RAID デバイスに
-
--level=- 使用する RAID レベルを指定します (0、1、4、5、6、10 のいずれか)。 --device=- 使用する RAID デバイス名を指定します (例:--device=root)。重要mdraid名をmd0の形式で使用しないでください。このような名前は永続性が保証されていません。代わりに、root、swapなど意味のある名前にしてください。意味のある名前を使用すると、/dev/md/nameから、アレイに割り当てられている/dev/mdXノードへのシンボリックリンクが作成されます。名前を割り当てることができない古い (v0.90 メタデータ) アレイがある場合は、ファイルシステムラベルまたは UUID でアレイを指定できます。たとえば、
--device=LABEL=rootまたは--device=UUID=93348e56-4631-d0f0-6f5b-45c47f570b88です。RAID デバイス上のファイルシステムの UUID または RAID デバイス自体の UUID を使用できます。RAID デバイスの UUID は
8-4-4-4-12形式である必要があります。mdadm によって報告される UUID は、変更する必要がある8:8:8:8形式です。たとえば、93348e56:4631d0f0:6f5b45c4:7f570b88は93348e56-4631-d0f0-6f5b-45c47f570b88に変更する必要があります。-
--chunksize=- RAID ストレージのチャンクサイズを KiB 単位で設定します。場合によっては、デフォルトのサイズ (512 Kib) 以外のチャンクサイズを使用すると、RAID のパフォーマンスが向上することもあります。 -
--spares=- RAID アレイに割り当てられるスペアドライブの数を指定します。スペアドライブは、ドライブに障害が発生した場合にアレイの再設定に使用されます。 -
--fsprofile=- このパーティションでファイルシステムを作成するプログラムに渡すのに使用するタイプを指定します。ファイルシステムの作成時に使用されるさまざまなチューニングパラメーターは、この使用タイプにより定義されます。ファイルシステム側で使用タイプという概念に対応し、有効なタイプを指定する設定ファイルがないと、このオプションは正しく機能しません。ext2、ext3、ext4 の場合、この設定ファイルは/etc/mke2fs.confにあります。 -
--fstype=- RAID アレイのファイルシステムタイプを設定します。xfs、ext2、ext3、ext4、swap、およびvfatが使用できる値になります。 -
--fsoptions=- ファイルシステムをマウントする場合に使用するオプションの文字列を自由形式で指定します。この文字列は、インストール後の/etc/fstabファイルにコピーされるため、引用符で囲む必要があります。EFI システムパーティション (/boot/efi) では、anaconda が値をハードコードし、ユーザー指定の--fsoptions値を無視します。 --mkfsoptions=- このパーティションでファイルシステムを作成するプログラムに渡す追加のパラメーターを指定します。引数のリストでは処理が行われないため、mkfs プログラムに直接渡すことが可能な形式で提供する必要があります。つまり、複数のオプションはコンマ区切りにするか、二重引用符で囲む必要があります (ファイルシステムによって異なります)。以下に例を示します。part /opt/foo1 --size=512 --fstype=ext4 --mkfsoptions="-O ^has_journal,^flex_bg,^metadata_csum" part /opt/foo2 --size=512 --fstype=xfs --mkfsoptions="-m bigtime=0,finobt=0"
詳細は、作成しているファイルシステムの man ページを参照してください。たとえば、mkfs.ext4 または mkfs.xfs です。
-
--label=- 作成するファイルシステムのラベルを指定します。指定ラベルが別のファイルシステムですでに使用されている場合は、新しいラベルが作成されます。 -
--noformat- 既存の RAID デバイスを使用し、RAID アレイのフォーマットは行いません。 -
--useexisting- 既存の RAID デバイスを使用し、再フォーマット化を行います。 --encrypted---passphraseオプションで入力したパスフレーズを使用して、LUKS (Linux Unified Key Setup) でこの RAID デバイスを暗号化するように指定します。このパスフレーズを指定しないと、Anaconda は、autopart --passphraseコマンドで設定されるデフォルトのシステムワイドパスフレーズを使用します。このデフォルトのパスフレーズも設定されていない場合は、インストールプロセスが中断して、パスフレーズの入力が求められます。注記1 つまたは複数のパーティションを暗号化する際には、安全な暗号化を行うため、Anaconda が 256 ビットのエントロピーを収集しようとします。エントロピーの収集には時間がかかる場合があります。十分なエントロピーが収集されたかどうかにかかわらず、このプロセスは最大 10 分後に終了します。
プロセスは、インストールシステムと対話することにより高速化できます (キーボードで入力またはマウスの移動)。仮想マシンにインストールしている場合は、
virtio-rngデバイス (仮想乱数ジェネレーター) をゲストに登録できます。-
--luks-version=LUKS_VERSION- ファイルシステムの暗号化に使用する LUKS 形式のバージョンを指定します。--encryptedと併用しないと有効ではありません。 -
--cipher=- Anaconda のデフォルトであるaes-xts-plain64では十分ではない場合に使用する暗号化の種類を指定します。--encryptedオプションと併用してください。単独で使用しても暗号化されません。使用できる暗号化の種類は セキュリティーの強化 に記載されていますが、Red Hat では、aes-xts-plain64またはaes-cbc-essiv:sha256のいずれかの使用を強く推奨しています。 -
--passphrase=- この RAID デバイスの暗号化を行う際に使用するパスフレーズを入力します。--encryptedオプションと併用してください。単独で使用しても暗号化されません。 -
--escrowcert=URL_of_X.509_certificate- このデバイス用のデータ暗号化の鍵を/root配下にファイルとして格納します。鍵は、URL_of_X.509_certificate で指定した URL の X.509 証明書を使用して暗号化します。--encryptedと併用しないと有効ではありません。 -
--backuppassphrase- このデバイスにランダムに生成されたパスフレーズを追加します。パスフレーズは/root配下にファイルとして保存し、--escrowcertで指定した X.509 証明書を使用して暗号化されます。--escrowcertと併用しないと有効ではありません。 -
--pbkdf=PBKDF- LUKS 鍵スロット用の PBKDF (Password-Based Key Derivation Function) アルゴリズムを設定します。cryptsetup(8) の man ページも併せて参照してください。--encryptedと併用しないと有効ではありません。 -
--pbkdf-memory=PBKDF_MEMORY- PBKDF のメモリーコストを設定します。cryptsetup(8) の man ページも併せて参照してください。--encryptedと併用しないと有効ではありません。 -
--pbkdf-time=PBKDF_TIME- PBKDF パスフレーズ処理にかかるミリ秒数を設定します。cryptsetup(8) の man ページの--iter-timeも併せて参照してください。このオプションは、--encryptedが指定される場合に限り有効になり、--pbkdf-iterationsと相互に排他的になります。 -
--pbkdf-iterations=PBKDF_ITERATIONS- 反復の数を直接設定し、PBKDF ベンチマークを回避します。cryptsetup(8) の man ページの--pbkdf-force-iterationsも併せて参照してください。このオプションは、--encryptedが指定されている場合に限り有効になり、--pbkdf-timeと相互に排他的になります。
例
以下の例では、/ には RAID レベル 1 のパーティション、/home には RAID レベル 5 のパーティションを作成します。ここでは、システムには SCSI ディスクが 3 つあることが前提です。各ドライブに 1 つずつ、3 つの swap パーティションを作成します。
part raid.01 --size=6000 --ondisk=sda
part raid.02 --size=6000 --ondisk=sdb
part raid.03 --size=6000 --ondisk=sdc
part swap --size=512 --ondisk=sda
part swap --size=512 --ondisk=sdb
part swap --size=512 --ondisk=sdc
part raid.11 --size=1 --grow --ondisk=sda
part raid.12 --size=1 --grow --ondisk=sdb
part raid.13 --size=1 --grow --ondisk=sdc
raid / --level=1 --device=rhel8-root --label=rhel8-root raid.01 raid.02 raid.03
raid /home --level=5 --device=rhel8-home --label=rhel8-home raid.11 raid.12 raid.13注記
-
LUKS パスフレーズが分からなくなると、暗号化されたパーティションと、その上にあるデータには完全にアクセスできなくなります。分からなくなったパスフレーズを復元する方法はありません。ただし、
--escrowcertを使用して暗号パスフレーズを保存し、--backuppassphraseオプションを使用してバックアップの暗号化パスフレーズを作成できます。
C.5.10. volgroup
キックスタートコマンドの volgroup は任意です。論理ボリュームマネージャー (LVM) グループを作成します。
構文
volgroup name [OPTIONS] [partition*]必須オプション
- name - 新しいボリュームグループの名前。
オプション
- partition - ボリュームグループのバッキングストレージとして使用する物理ボリュームパーティション。
-
--noformat- 既存のボリュームグループを使用し、フォーマットは行いません。 --useexisting- 既存のボリュームグループを使用し、そのボリュームグループを再フォーマットします。このオプションを使用する場合は partition は指定しないでください。以下に例を示します。volgroup rhel00 --useexisting --noformat-
--pesize=- ボリュームグループの物理エクステントのサイズをキビバイト (KiB) 単位で設定します。デフォルト値は 4096 (4 MiB) で、最小値は 1024 (1 MiB) になります。 -
--reserved-space=- ボリュームグループに未使用で残す領域を MiB 単位で指定します。新規作成のボリュームグループにのみ適用されます。 -
--reserved-percent=- 未使用で残すボリュームグループ領域全体の割合を指定します。新規作成のボリュームグループにのみ適用されます。
注記
まずパーティションを作成します。次に論理ボリュームグループを作成して、論理ボリュームを作成します。以下に例を示します。
part pv.01 --size 10000 volgroup my_volgrp pv.01 logvol / --vgname=my_volgrp --size=2000 --name=rootキックスタートを使用して Red Hat Enterprise Linux をインストールする場合は、論理ボリューム名およびボリュームグループ名にダッシュ (
-) 記号を使用しないでください。この文字を使用すると、インストール自体は正常に完了しますが、/dev/mapper/ディレクトリー内の論理ボリューム名とボリュームグループ名にダッシュが二重に付いてしまうことになります。たとえば、logvol-01という名前の論理ボリュームを格納するvolgrp-01という名前のボリュームグループなら、/dev/mapper/volgrp--01-logvol--01というような表記になってしまいます。この制約が適用されるのは、新規作成の論理ボリュームおよびボリュームグループ名のみです。既存の論理ボリュームまたはボリュームグループを
--noformatオプションを使用して再利用する場合は、名前が変更されません。
C.5.11. logvol
キックスタートコマンドの logvol は任意です。このコマンドは、論理ボリュームマネージャー (LVM) の論理ボリュームを作成します。
構文
logvol mntpoint --vgname=name --name=name [OPTIONS]必須オプション
mntpointパーティションがマウントされているマウントポイント。次のいずれかの形式になります。
/path/または/homeなどswapこのパーティションは、swap 領域として使用されます。
自動的に swap パーティションのサイズを確定させる場合は、
--recommendedオプションを使用します。swap --recommended自動的に swap パーティションサイズを確定し、ハイバネート用に追加領域も配分するには、
--hibernationオプションを使用します。swap --hibernation--recommendedで割り当てられる swap 領域に加え、システムの RAM 容量が加算されたサイズが割り当てられるようになります。これらのコマンドによって割り当てられるスワップサイズは、AMD64、Intel 64、および 64 ビット ARM システムの 推奨されるパーティション設定スキーム を参照してください。
--vgname=name- ボリュームグループの名前。
--name=name- 論理ボリュームの名前。
任意のオプション
--noformat- 既存の論理ボリュームを使用し、フォーマットは行いません。
--useexisting- 既存の論理ボリュームを使用し、再フォーマットします。
--fstype=-
論理ボリュームのファイルシステムのタイプを設定します。
xfs、ext2、ext3、ext4、swap、およびvfatが使用できる値になります。 --fsoptions=ファイルシステムをマウントする場合に使用するオプションの文字列を自由形式で指定します。この文字列は、インストール後の
/etc/fstabファイルにコピーされるため、引用符で囲む必要があります。注記EFI システムパーティション (
/boot/efi) では、anaconda が値をハードコードし、ユーザー指定の--fsoptions値を無視します。--mkfsoptions=このパーティションでファイルシステムを作成するプログラムに渡す追加のパラメーターを指定します。引数のリストでは処理が行われないため、mkfs プログラムに直接渡すことが可能な形式で提供する必要があります。つまり、複数のオプションはコンマ区切りにするか、二重引用符で囲む必要があります (ファイルシステムによって異なります)。以下に例を示します。
part /opt/foo1 --size=512 --fstype=ext4 --mkfsoptions="-O ^has_journal,^flex_bg,^metadata_csum" part /opt/foo2 --size=512 --fstype=xfs --mkfsoptions="-m bigtime=0,finobt=0"
詳細は、作成しているファイルシステムの man ページを参照してください。たとえば、mkfs.ext4 または mkfs.xfs です。
--fsprofile=-
このパーティションでファイルシステムを作成するプログラムに渡すのに使用するタイプを指定します。ファイルシステムの作成時に使用されるさまざまなチューニングパラメーターは、この使用タイプにより定義されます。ファイルシステム側で使用タイプという概念に対応し、有効なタイプを指定する設定ファイルがないと、このオプションは正しく機能しません。
ext2、ext3、およびext4の場合、この設定ファイルは/etc/mke2fs.confになります。 --label=- 論理ボリュームのラベルを設定します。
--grow- 論理ボリュームを拡張して、利用可能なサイズ (存在する場合) を埋めるか、指定されている場合は最大サイズまで埋めます。このオプションを使用する必要があるのは、ディスクイメージに最小限のストレージ領域を事前に割り当てており、ボリュームを拡大して使用可能な領域を埋める場合のみです。物理的な環境では、これは 1 回限りのアクションです。ただし、仮想環境では、仮想マシンが仮想ディスクにデータを書き込むとボリュームサイズが増加します。
--size=-
論理ボリュームのサイズを MiB 単位で指定します。このオプションを、
--percent=オプションと併用することはできません。 --percent=サイズを静的に指定した論理ボリュームを考慮に入れた後のボリュームグループにある空き領域を表すパーセンテージとして、論理ボリュームのサイズを指定します。このオプションは
--size=オプションと併用することはできません。重要論理ボリュームの新規作成時には、
--size=オプションで静的なサイズを指定するか、--percent=オプションで残りの空き領域をパーセンテージとして指定する必要があります。1 つの論理ボリュームで、両方のオプションを使用することはできません。--maxsize=-
論理ボリュームを grow に設定した場合の最大サイズを MiB 単位で指定します。
500などの整数値を使用してください (単位は不要)。 --recommended- 論理ボリュームを作成して、システムのハードウェアに基づいてそのボリュームのサイズを自動的に確定するために、このオプションを使用します。推奨されるスキームの詳細は、AMD64、Intel 64、および 64 ビット ARM システムの 推奨されるパーティション設定スキーム を参照してください。
--resize-
論理ボリュームのサイズを変更します。このオプションを使用する場合は、
--useexistingと--sizeも指定する必要があります。 --encryptedこの論理ボリュームを、
--passphrase=オプションで入力したパスフレーズを使用する LUKS (Linux Unified Key Setup) で暗号化します。このパスフレーズを指定しない場合は、インストールプログラムがautopart --passphraseコマンドで設定されるデフォルトのシステムワイドパスフレーズを使用します。このデフォルトのパスフレーズも設定されていない場合は、インストールプロセスが中断されてパスフレーズの入力が求められます。注記1 つまたは複数のパーティションを暗号化する際には、安全な暗号化を行うため、Anaconda が 256 ビットのエントロピーを収集しようとします。エントロピーの収集には時間がかかる場合があります。十分なエントロピーが収集されたかどうかにかかわらず、このプロセスは最大 10 分後に終了します。
プロセスは、インストールシステムと対話することにより高速化できます (キーボードで入力またはマウスの移動)。仮想マシンにインストールしている場合は、
virtio-rngデバイス (仮想乱数ジェネレーター) をゲストに登録できます。--passphrase=-
この論理ボリュームを暗号化する際に使用するパスフレーズを指定します。
--encryptedオプションと併用してください。単独で使用しても暗号化されません。 --cipher=-
Anaconda のデフォルトである
aes-xts-plain64では十分ではない場合に使用する暗号化の種類を指定します。--encryptedオプションと併用してください。単独で使用しても暗号化されません。使用できる暗号化の種類は セキュリティーの強化 に記載されていますが、Red Hat では、aes-xts-plain64またはaes-cbc-essiv:sha256のいずれかの使用を強く推奨しています。 --escrowcert=URL_of_X.509_certificate-
暗号化した全ボリュームのデータ暗号化の鍵を
/root配下にファイルとして格納します。URL_of_X.509_certificate で指定した URL の X.509 証明書を使用して暗号化します。鍵は暗号化したボリュームごとに別のファイルとして格納されます。--encryptedと併用しないと有効ではありません。 --luks-version=LUKS_VERSION-
ファイルシステムの暗号化に使用する LUKS 形式のバージョンを指定します。
--encryptedと併用しないと有効ではありません。 --backuppassphrase-
暗号化されたボリュームにそれぞれランダムに生成されたパスフレーズを追加します。パスフレーズは、
/root配下に別々のファイルで格納され、--escrowcertで指定した X.509 証明書を使用して暗号化されます。--escrowcertと併用しないと有効ではありません。 --pbkdf=PBKDF-
LUKS 鍵スロット用の PBKDF (Password-Based Key Derivation Function) アルゴリズムを設定します。cryptsetup(8) の man ページも併せて参照してください。
--encryptedと併用しないと有効ではありません。 --pbkdf-memory=PBKDF_MEMORY-
PBKDF のメモリーコストを設定します。cryptsetup(8) の man ページも併せて参照してください。
--encryptedと併用しないと有効ではありません。 --pbkdf-time=PBKDF_TIME-
PBKDF パスフレーズ処理にかかるミリ秒数を設定します。cryptsetup(8) の man ページの
--iter-timeも併せて参照してください。このオプションは、--encryptedが指定される場合に限り有効になり、--pbkdf-iterationsと相互に排他的になります。 --pbkdf-iterations=PBKDF_ITERATIONS-
反復の数を直接設定し、PBKDF ベンチマークを回避します。cryptsetup(8) の man ページの
--pbkdf-force-iterationsも併せて参照してください。このオプションは、--encryptedが指定されている場合に限り有効になり、--pbkdf-timeと相互に排他的になります。 --thinpool-
シンプール論理ボリュームを作成します。(
noneのマウントポイントの使用) --metadatasize=size- 新しいシンプールデバイスのメタデータ領域のサイズ (MiB 単位) を指定します。
--chunksize=size- 新しいシンプールデバイスのチャンクサイズ (KiB) を指定します。
--thin-
シン論理ボリュームを作成します。(
--poolnameが必要です。) --poolname=name-
シン論理ボリュームを作成するシンプールの名前を指定します。
--thinオプションが必要です。 --profile=name-
シン論理ボリュームで使用する設定プロファイル名を指定します。これを使用する場合は、この名前は特定の論理ボリュームのメタデータにも含まれることになります。デフォルトで使用できるプロファイルは
defaultとthin-performanceで、/etc/lvm/profile/ディレクトリーで定義します。詳細はlvm(8)の man ページを参照してください。 --cachepvs=- 該当ボリュームのキャッシュとして使用する物理ボリュームをコンマ区切りで記入します。
--cachemode=当該論理ボリュームのキャッシュに使用するモードを指定します (
writebackまたはwritethroughになります)。注記キャッシュされた論理ボリュームとそのモードの詳細は、システム上の
lvmcache(7)man ページを参照してください。--cachesize=-
論理ボリュームにアタッチするキャッシュのサイズを MiB 単位で指定します。このオプションは、
--cachepvs=オプションと併用する必要があります。
注記
キックスタートを使用して Red Hat Enterprise Linux をインストールする場合は、論理ボリューム名およびボリュームグループ名にダッシュ (
-) 記号を使用しないでください。この文字を使用すると、インストール自体は正常に完了しますが、/dev/mapper/ディレクトリー内の論理ボリューム名とボリュームグループ名にダッシュが二重に付いてしまうことになります。たとえば、ボリュームグループvolgrp-01に論理ボリュームlogvol-01が格納されている場合は、以下のような表記になります。/dev/mapper/volgrp—01-logvol—01.この制約が適用されるのは、新規作成の論理ボリュームおよびボリュームグループ名のみです。既存の論理ボリュームまたはボリュームグループを
--noformatオプションを使用して再利用する場合は、名前が変更されません。-
LUKS パスフレーズが分からなくなると、暗号化されたパーティションと、その上にあるデータには完全にアクセスできなくなります。分からなくなったパスフレーズを復元する方法はありません。ただし、
--escrowcertを使用して暗号パスフレーズを保存し、--backuppassphraseオプションを使用してバックアップの暗号化パスフレーズを作成できます。
例
まずパーティションを作成します。次に論理ボリュームグループを作成して、論理ボリュームを作成します。
part pv.01 --size 3000 volgroup myvg pv.01 logvol / --vgname=myvg --size=2000 --name=rootvol最初にパーティションを作成します。次に論理ボリュームグループを作成して、ボリュームグループに残っている領域の 90 % を占める論理ボリュームを作成します。
part pv.01 --size 1 --grow volgroup myvg pv.01 logvol / --vgname=myvg --name=rootvol --percent=90
C.5.12. snapshot
キックスタートコマンドの snapshot は任意です。インストールプロセス時に、このコマンドを使用して LVM のシンボリュームのスナップショットを作成できます。これにより、インストール前後の論理ボリュームのバックアップ作成が可能になります。
複数のスナップショットを作成するには、キックスタートコマンドの snaphost を複数回追加します。
構文
snapshot vg_name/lv_name --name=snapshot_name --when=pre-install|post-installオプション
-
vg_name/lv_name- スナップショットの作成元となるボリュームグループや論理ボリュームの名前を設定します。 -
--name=snapshot_name- スナップショットの名前を設定します。この名前は、ボリュームグループ内で一意のものにする必要があります。 -
--when=pre-install|post-install- インストール前もしくは完了後にスナップショットを作成することを指定します。
C.5.13. mount
キックスタートコマンドの mount は任意です。これは、既存のブロックデバイスにマウントポイントを割り当て、必要に応じて、指定の形式で再フォーマットします。
構文
mount [OPTIONS] device mountpoint必須オプション:
-
device- マウントするブロックデバイス。 -
mountpoint-deviceをマウントする場所。/、/usrなどの有効なマウントポイントを指定する必要があります。デバイスがマウントできない場合 (swapなど) はnoneと指定します。
任意のオプション:
-
--reformat=- デバイスを再フォーマットする際の新しいフォーマット (例:ext4) を指定します。 -
--mkfsoptions=---reformat=で指定した新しいファイルシステムを作成するコマンドに渡す追加のオプションを指定します。ここで指定するオプションのリストは処理されません。したがって、直接mkfsプログラムに渡すことのできる形式で指定する必要があります。オプションのリストは、コンマ区切りとするか、二重引用符で囲む必要があります (ファイルシステムによって異なります)。詳細は、作成するファイルシステムのmkfsの man ページで確認してください (例:mkfs.ext4(8)またはmkfs.xfs(8))。 -
--mountoptions=- ファイルシステムをマウントする場合に使用するオプションを含む文字列を、自由形式で指定します。この文字列はインストールされたシステムの/etc/fstabファイルにコピーされるため、二重引用符で囲んでください。マウントオプションの全リストはmount(8)の man ページを、概要はfstab(5)を参照してください。
注記
-
キックスタートの他の多くのストレージ設定コマンドとは異なり、
mountの場合には、キックスタートファイルにすべてのストレージ設定を記述する必要がありません。確認する必要があるのは、記述されたブロックデバイスがシステムに存在することだけです。ただし、すべてのデバイスがマウントされたストレージスタックを 作成する 場合には、part等の他のコマンドを使用する必要があります。 -
同じキックスタートファイル内で、
mountをpart、logvol、またはautopartなどの他のストレージ関連コマンドと併用することはできません。
C.5.14. zipl
キックスタートコマンドの zipl は任意です。これは 64 ビットの IBM Z の ZIPL 設定を指定します。このコマンドは 1 回だけ使用してください。
オプション
-
--secure-boot- インストールシステムで対応しているかどうかを、セキュアな起動を有効にします。
インストールシステムは、IBM z14 以降のシステムにインストールする場合、IBM z14 またはそれ以前のモデルからは起動できません。
-
--force-secure-boot- セキュアな起動を無条件で有効にします。
IBM z14 以前のモデルでは、インストールに対応していません。
-
--no-secure-boot- セキュアな起動を無効にします。
Secure Boot は、IBM z14 とそれ以前のモデルでは対応していません。IBM z14 以前のモデルでインストール済みシステムを起動する場合は、--no-secure-boot を使用します。
C.5.15. fcoe
キックスタートコマンドの fcoe は任意です。Enhanced Disk Drive Services (EDD) で検出されたデバイス以外で、自動的にアクティベートする FCoE デバイスを指定します。
構文
fcoe --nic=name [OPTIONS]オプション
-
--nic=(必須) - アクティベートするデバイス名です。 -
--dcb=- データセンターブリッジ (DCB) の設定を確立します。 -
--autovlan- VLAN を自動的に検出します。このオプションはデフォルトで有効になっています。
C.5.16. iscsi
キックスタートコマンドの iscsi は任意です。インストール時に接続する追加の iSCSI ストレージを指定します。
構文
iscsi --ipaddr=address [OPTIONS]必須オプション
-
--ipaddr=(必須) - 接続先ターゲットの IP アドレスを指定します。
任意のオプション
-
--port=(必須) - ポート番号を指定します。存在しない場合は、--port=3260がデフォルトで自動的に使用されます。 -
--target=- ターゲットの IQN (iSCSI 修飾名) を指定します。 -
--iface=- ネットワーク層で確定されるデフォルトのネットワークインターフェイスではなく、特定のネットワークインターフェイスに接続をバインドします。これを一度使用したら、キックスタート内のiscsiコマンドのインスタンスではすべて指定する必要があります。 -
--user=- ターゲットでの認証に必要なユーザー名を指定します。 -
--password=- ターゲットに指定したユーザー名のパスワードを指定します。 -
--reverse-user=- 逆 CHAP 認証を使用するターゲットのイニシエーターでの認証に必要なユーザー名を指定します。 -
--reverse-password=- イニシエーターに指定したユーザー名のパスワードを指定します。
注記
-
また、
iscsiコマンドを使用する場合は、iscsinameコマンドで iSCSI ノードに名前を割り当てる必要があります。iscsinameコマンドは、キックスタートファイルで、iscsiコマンドより先に指定してください。 -
iSCSI ストレージは、できる限り
iscsiコマンドではなくシステムの BIOS またはファームウェア (Intel システムの場合は iBFT) 内で設定してください。BIOS またはファームウェア内で設定されたディスクは Anaconda で自動的に検出されて使用されるため、キックスタートファイルで特に設定する必要がありません。 -
iscsiコマンドを使用する必要がある場合は、インストールの開始時にネットワークがアクティブであること、iscsiコマンドが、キックスタートファイルでclearpartやignorediskなどのコマンドによる iSCSI ディスクの参照よりも前に指定されていることを確認してください。
C.5.17. iscsiname
キックスタートコマンドの iscsiname は任意です。これは、iscsi コマンドが指定した iSCSI ノードに名前を割り当てます。このコマンドは 1 回だけ使用してください。
構文
iscsiname iqnameオプション
-
iqname- iSCSI ノードに割り当てる名前。
注記
-
キックスタートファイルで
iscsiコマンドを使用する場合は、キックスタートファイルでiscsinameearlier を指定する必要があります。
C.5.18. nvdimm
キックスタートコマンドの nvdimm は任意です。これは、NVDIMM (Non-Volatile Dual In-line Memory Module) デバイスでアクションを実行します。デフォルトでは、NVDIMM デバイスはインストールプログラムによって無視されます。このデバイスでのインストールを有効にするには、nvdimm コマンドを使用する必要があります。
構文
nvdimm action [OPTIONS]アクション
reconfigure- 指定した NVDIMM デバイスを特定のモードに再設定します。なお、指定したデバイスは暗示的にインストール先と識別されるため、同じデバイスに対するこれ以降のnvdimm useコマンドは冗長になります。このアクションは以下の形式を使用します。nvdimm reconfigure [--namespace=NAMESPACE] [--mode=MODE] [--sectorsize=SECTORSIZE]--namespace=- 名前空間でデバイスを指定します。以下に例を示します。nvdimm reconfigure --namespace=namespace0.0 --mode=sector --sectorsize=512-
--mode=- モードを指定します。現在、利用できる値はsectorだけです。 --sectorsize=- セクターサイズ (セクターモードの場合)。以下に例を示します。nvdimm reconfigure --namespace=namespace0.0 --mode=sector --sectorsize=512サポートされるセクターサイズは 512 バイトおよび 4096 バイトです。
use- NVDIMM デバイスを、インストールのターゲットに指定します。デバイスはnvdimm reconfigureコマンドでセクターモードに設定されている必要があります。このアクションは以下の形式を使用します。nvdimm use [--namespace=NAMESPACE|--blockdevs=DEVICES]--namespace=- 名前空間でデバイスを指定します。以下に例を示します。nvdimm use --namespace=namespace0.0--blockdevs=- 使用する NVDIMM デバイスに対応するブロックデバイスをコンマ区切りリストで指定します。ワイルドカードとしてアスタリスク*が使用できます。以下に例を示します。nvdimm use --blockdevs=pmem0s,pmem1s nvdimm use --blockdevs=pmem*
C.5.19. zfcp
キックスタートコマンドの zfcp は任意です。Fibre チャンネルデバイスを定義します。
このオプションは、64 ビットの IBM Z にのみ適用されます。下記のオプションをすべて指定する必要があります。
構文
zfcp --devnum=devnum [--wwpn=wwpn --fcplun=lun]オプション
-
--devnum=- デバイス番号 (zFCP アダプターデバイスバス ID)。 -
--wwpn=- デバイスの WWPN (ワールドワイドポートネーム)。0xで始まる 16 桁の番号になります。 -
--fcplun=- デバイスの論理ユニット番号 (LUN)。0xで始まる 16 桁の番号になります。
自動 LUN スキャンが利用できる場合や、8 以降のリリースをインストールする場合は、FCP デバイスバス ID を指定するだけで十分です。それ以外の場合は、3 つのパラメーターがすべて必要になります。自動 LUN スキャンは、zfcp.allow_lun_scan モジュールパラメーターで無効にされていない場合 (デフォルトでは有効)、NPIV モードで動作する FCP デバイスで使用できます。これは、指定されたバス ID を持つ FCP デバイスに接続されたストレージエリアネットワークで見つかったすべての SCSI デバイスへのアクセスを提供します。
例
zfcp --devnum=0.0.4000 --wwpn=0x5005076300C213e9 --fcplun=0x5022000000000000
zfcp --devnum=0.0.4000C.6. RHEL インストールプログラムで提供されるアドオン向けキックスタートコマンド
本セクションのキックスタートコマンドは、Red Hat Enterprise Linux インストールプログラム(Kdump および OpenSCAP) にデフォルトで提供されるアドオンに関連しています。
C.6.1. %addon com_redhat_kdump
キックスタートコマンドの %addon com_redhat_kdump は任意です。このコマンドは、kdump カーネルクラッシュのダンプメカニズムを設定します。
構文
%addon com_redhat_kdump [OPTIONS]
%endこのコマンドは、ビルトインのキックスタートコマンドではなくアドオンであることから、構文は通常のものとは異なります。
注記
Kdump とは、システムのメモリーの内容を保存して後で分析できるように、カーネルのクラッシュをダンプするメカニズムを指します。これは、kexec に依存し、別のカーネルのコンテキストから、システムを再起動することなく Linux カーネルを起動し、通常は失われてしまう 1 番目のカーネルメモリーの内容を維持できます。
システムクラッシュが発生すると、kexec は 2 番目のカーネルで起動します (キャプチャーカーネル)。このキャプチャーカーネルは、システムメモリーの予約部分に収納されています。このため、Kdump は、クラッシュしたカーネルメモリーの内容 (クラッシュダンプ) をキャプチャーして、指定した場所に保存します。このキックスタートコマンドを使用して設定することはできません。インストール後に /etc/kdump.conf 設定ファイルを編集して設定する必要があります。
Kdump の詳細は、kdump のインストール を参照してください。
オプション
-
--enable- インストール済みのシステムで kdump を有効にします。 -
--disable- インストール済みのシステムで kdump を無効にします。 --reserve-mb=- kdump 用に予約するメモリーの量 (MiB 単位)。以下に例を示します。%addon com_redhat_kdump --enable --reserve-mb=128 %end数値の代わりに
autoと指定することもできます。その場合は、インストールプログラムは、Managing, monitoring and updating the kernel の Memory requirements for kdump のセクションに記載の基準に基づいて、メモリーの量を自動的に決定します。kdump を有効にして、
--reserve-mb=オプションを指定しないと、autoの値が使用されます。-
--enablefadump- 対応するシステム (特に IBM Power Systems サーバー) へのファームウェア補助によるダンピングを有効にします。
C.6.2. %addon org_fedora_oscap
キックスタートコマンドの %addon org_fedora_oscap は任意です。
OpenSCAP インストールプログラムのアドオンは、インストールシステム上で SCAP (Security Content Automation Protocol) のコンテンツ (セキュリティーポリシー) を適用するために使用されます。Red Hat Enterprise Linux 7.2 以降、このアドオンがデフォルトで有効になりました。有効にすると、この機能の提供に必要なパッケージが自動的にインストールされます。ただし、デフォルトではポリシーが強制されることがなく、明確に設定されている場合を除いて、インストール時およびインストール後にチェックが行われません。
セキュリティーポリシーの適用はすべてのシステムで必要なわけではありません。この画面は、特定のポリシーが業務規定や法令で義務付けられている場合に限り使用してください。
多くのコマンドとは異なり、このアドオンは通常のオプションを受け付けず、%addon 定義の本文で鍵と値のペアを使用します。空白は無視されます。値は一重引用符 (') または二重引用符 (") で囲みます。
構文
%addon org_fedora_oscap
key = value
%end鍵
アドオンは以下の鍵を認識します。
content-typeセキュリティーコンテンツのタイプ。値は、
datastream、archive、rpm、またはscap-security-guideになります。content-typeをscap-security-guideにすると、アドオンは scap-security-guide パッケージが提供するコンテンツを使用します。このパッケージは起動用メディアにあります。つまり、profileを除く他のすべての鍵の影響がなくなります。content-url- セキュリティーコンテンツの場所。コンテンツは、HTTP、HTTPS、FTP のいずれかを使用してアクセスできるようにする必要があります。ローカルストレージは現在、サポートされていません。リモートの場所にあるコンテンツ定義に到達するネットワーク接続が必要になります。
datastream-id-
content-urlで参照されているデータストリームの ID。content-typeがdatastreamの場合にのみ使用します。 xccdf-id- 使用するベンチマークの ID。
content-path- 使用するデータストリームまたは XCCDF ファイルのパスを、アーカイブ内の相対パスで指定します。
profile-
適用するプロファイルの ID。デフォルトのプロファイルを使用する場合は
defaultを使用してください。 フィンガープリント (fingerprint)-
content-urlで参照されるコンテンツの MD5、SHA1、または SHA2 のチェックサム。 tailoring-path- 使用するテーラリングファイルのパスを、アーカイブの相対パスで指定します。
例
インストールメディアの scap-security-guide のコンテンツを使用する
%addon org_fedora_oscapセクションの例は、以下のようになります。例C.1 SCAP Security Guide を使用した OpenSCAP アドオン定義の例
%addon org_fedora_oscap content-type = scap-security-guide profile = xccdf_org.ssgproject.content_profile_pci-dss %endWeb サーバーからカスタムプロファイルを読み込むより複雑な例は、以下のようになります。
例C.2 データストリームを使用した OpenSCAP アドオン定義の例
%addon org_fedora_oscap content-type = datastream content-url = http://www.example.com/scap/testing_ds.xml datastream-id = scap_example.com_datastream_testing xccdf-id = scap_example.com_cref_xccdf.xml profile = xccdf_example.com_profile_my_profile fingerprint = 240f2f18222faa98856c3b4fc50c4195 %end
C.7. Anaconda で使用されるコマンド
pwpolicy コマンドは、キックスタートファイルの %anaconda セクションでのみ使用できる Anaconda UI 固有のコマンドです。
C.7.1. pwpolicy
キックスタートコマンドの pwpolicy は任意です。このコマンドを使用して、インストール中にカスタムパスワードポリシーを適用します。このポリシーでは、ユーザーアカウントの root、ユーザー、または luks ユーザーのパスワードを作成する必要があります。パスワードの長さや強度などの要因により、パスワードの有効性が決まります。
構文
pwpolicy name [--minlen=length] [--minquality=quality] [--strict|--notstrict] [--emptyok|--notempty] [--changesok|--nochanges]必須オプション
-
name -
root、user、またはluksに置き換え、それぞれrootパスワード、ユーザーパスワード、もしくは LUKS パスフレーズのポリシーを強制します。
任意のオプション
-
--minlen=- パスワードの最低文字数を設定します。デフォルト値は6です。 -
--minquality=-libpwqualityライブラリーで定義されるパスワードの最低限の質を設定します。デフォルト値は1です。 -
--strict- 厳密なパスワード強制を有効にします。--minquality=と--minlen=で指定された要件を満たさないパスワードは拒否されます。このオプションはデフォルトで無効になっています。 -
--notstrict---minquality=オプションおよび-minlen=オプションで指定した最小要件を 満たさない パスワードは、GUI で 完了 を 2 回クリックすると可能になります。テキストモードインターフェイスでは、同様のメカニズムが使用されます。 -
--emptyok- 空のパスワードの使用を許可します。デフォルトでユーザーパスワードに有効となっています。 -
--notempty- 空のパスワードの使用を許可しません。root パスワードと LUKS パスフレーズについて、デフォルトで有効になっています。 -
--changesok- キックスタートファイルでパスワードが設定されていても、ユーザーインターフェイスでのパスワード変更を許可します。デフォルトでは無効です。 -
--nochanges- キックスタートファイルで設定されているパスワードの変更を許可しません。デフォルトでは有効です。
注記
-
pwpolicyコマンドは、キックスタートファイルの%anacondaセクションでのみ使用できる Anaconda UI 固有のコマンドです。 -
libpwqualityライブラリーは、パスワードの最低要件 (長さおよび質) の確認に使用されます。libpwquality パッケージが提供するpwscoreコマンドおよびpwmakeコマンドを使用してパスワードの質のスコアを確認するか、特定スコアのパスワードをランダムに作成できます。これらのコマンドの詳細は、pwscore(1)およびpwmake(1)の man ページを参照してください。
C.8. システム復旧用キックスタートコマンド
このセクションのキックスタートコマンドは、インストールされたシステムを修復します。
C.8.1. rescue
キックスタートコマンドの rescue は任意です。これは、root 権限を備えたシェル環境と、インストールを修復して次のような問題のトラブルシューティングを行うための一連のシステム管理ツールを提供します。
- ファイルシステムを読み取り専用としてマウントする
- ドライバーディスクで提供されているドライバーを拒否リスト登録または追加する
- システムパッケージをインストールまたはアップグレードする
- パーティションを管理する
キックスタートレスキューモードは、systemd およびサービスマネージャーの一部として提供されるレスキューモードおよび緊急モードとは異なります。
rescue コマンドは、システム自体を変更することはありません。読み取り/書き込みモードでシステムを /mnt/sysimage の下にマウントすることにより、レスキュー環境を設定するだけです。システムをマウントしないか、読み取り専用モードでマウントするかを選択できます。このコマンドは 1 回だけ使用してください。
構文
rescue [--nomount|--romount]オプション
-
--nomountまたは--romount- インストールを完了したシステムをレスキュー環境でマウントする方法を制御します。デフォルトでは、インストールプログラムによりシステムの検出が行われてから、読み取りと書き込みのモードでシステムのマウントが行われ、マウントされた場所が通知されます。オプションでマウントを行わない (--nomountオプション)、または読み取り専用モードでマウントする (--romountオプション) のいずれかを選択できます。指定できるのはどちらか一方です。
注記
レスキューモードを実行するには、キックスタートファイルのコピーを作成し、それに rescue コマンドを含めます。
rescue コマンドを使用すると、インストーラーは次の手順を実行します。
-
%preスクリプトを実行します。 レスキューモードの環境をセットアップします。
以下のキックスタートコマンドが有効になります。
- updates
- sshpw
- logging
- lang
- network
高度なストレージ環境を設定します。
以下のキックスタートコマンドが有効になります。
- fcoe
- iscsi
- iscsiname
- nvdimm
- zfcp
システムをマウントします。
rescue [--nomount|--romount]%post スクリプトを実行します。
この手順は、インストールされたシステムが読み取り/書き込みモードでマウントされている場合にのみ実行されます。
- シェルを開始します。
- システムを再起動します。
パート II. セキュリティーの設計
第14章 インストール中およびインストール直後の RHEL の保護
セキュリティーへの対応は、Red Hat Enterprise Linux をインストールする前にすでに始まっています。最初からシステムのセキュリティーを設定することで、追加のセキュリティー設定を実装することがより簡単になります。
14.1. ディスクパーティション設定
ディスクパーティション設定の推奨プラクティスは、ベアメタルマシンへのインストールと、インストール済みオペレーティングシステムを含む仮想ディスクハードウェアおよびファイルシステムの調整をサポートする仮想化環境またはクラウド環境とでは異なります。
ベアメタルインストール でデータの分離と保護を確実に行うには、/boot、/、/home、/tmp、/var/tmp/ ディレクトリー用に個別のパーティションを作成します。
/boot-
このパーティションは、システムの起動時にシステムが最初に読み込むパーティションです。システムを RHEL 8 で起動するために使用されるブートローダーとカーネルイメージは、このパーティションに保存されます。このパーティションは暗号化しないでください。このパーティションが
/`に含まれており、そのパーティションが暗号化されているなどの理由で利用できなくなると、システムを起動できなくなります。 /home-
ユーザーデータ (
/home) が別のパーティションではなく/に保存されていると、このパーティションが満杯になり、オペレーティングシステムが不安定になる可能性があります。また、システムを RHEL 8 の次のバージョンにアップグレードする場合、インストール中にデータが上書きされないため、/homeパーティションにデータを保持しておくと、はるかに簡単になります。root パーティション (/) が破損すると、データが完全に失われます。したがって、パーティションを分けることが、データ損失に対する保護につながります。また、このパーティションを、頻繁にバックアップを作成する対象にすることも可能です。 /tmpおよび/var/tmp/-
/tmpディレクトリーおよび/var/tmp/ディレクトリーは、どちらも長期保存の必要がないデータを保存するのに使用されます。しかし、このいずれかのディレクトリーでデータがあふれると、ストレージ領域がすべて使用されてしまう可能性があります。このディレクトリーは/に置かれているため、こうした状態が発生すると、システムが不安定になり、クラッシュする可能性があります。そのため、このディレクトリーは個別のパーティションに移動することが推奨されます。
仮想マシンまたはクラウドインスタンス の場合、/boot、/home、/tmp、および /var/tmp パーティションの分離は任意です。/ パーティションがいっぱいになり始めたら、仮想ディスクのサイズとそのパーティションを拡張できるためです。/ パーティションがいっぱいにならないように、その使用状況を定期的にチェックするモニタリングを設定してから、仮想ディスクのサイズを適宜拡張してください。
インストールプロセス時に、パーティションを暗号化するオプションがあります。パスフレーズを入力する必要があります。これは、パーティションのデータを保護するのに使用されるバルク暗号鍵を解除する鍵として使用されます。
14.2. インストールプロセス時のネットワーク接続の制限
RHEL 8 をインストールする場合、インストールメディアは特定の時点のシステムのスナップショットを表します。そのため、セキュリティー修正が最新のものではなく、このインストールメディアで設定するシステムが公開されてから修正された特定の問題に対して安全性に欠ける場合があります。
脆弱性が含まれる可能性のあるオペレーティングシステムをインストールする場合には、必ず、公開レベルを、必要最小限のネットワークゾーンに限定してください。最も安全な選択肢は、インストールプロセス時にマシンをネットワークから切断した状態にするネットワークなしのゾーンです。インターネット接続からのリスクが最も高く、一方で LAN またはイントラネット接続で十分な場合もあります。セキュリティーのベストプラクティスに従うには、ネットワークから RHEL 8 をインストールするときに、リポジトリーに最も近いゾーンを選択します。
14.3. 必要なパッケージの最小限のインストール
コンピューターの各ソフトウェアには脆弱性が潜んでいる可能性があるため、実際に使用するパッケージのみをインストールすることがベストプラクティスになります。インストールを DVD から行う場合は、インストールしたいパッケージのみを選択するようにします。その他のパッケージが必要になる場合は、後でいつでもシステムに追加できます。
14.4. インストール後の手順
次の手順は、RHEL 8 のインストール直後に実行する必要があるセキュリティー関連の手順です。
システムを更新します。root で以下のコマンドを実行します。
# yum updateファイアウォールサービスの
firewalldは、Red Hat Enterprise Linux のインストールによって自動的に有効になりますが、キックスタート設定などで明示的に無効になっている場合があります。このような場合は、ファイアウォールを再度有効にしてください。firewalldを開始するには、root で次のコマンドを実行します。# systemctl start firewalld # systemctl enable firewalldセキュリティーを強化するために、不要なサービスは無効にしてください。たとえば、コンピューターにプリンターがインストールされていない場合は、次のコマンドを使用して、
cupsサービスを無効にします。# systemctl disable cupsアクティブなサービスを確認するには、次のコマンドを実行します。
$ systemctl list-units | grep service
14.5. Web コンソールを使用して CPU のセキュリティーの問題を防ぐために SMT を無効化する手順
CPU SMT (Simultaneous Multi Threading) を悪用する攻撃が発生した場合に SMT を無効にします。SMT を無効にすると、L1TF や MDS などのセキュリティー脆弱性を軽減できます。
SMT を無効にすると、システムパフォーマンスが低下する可能性があります。
前提条件
- RHEL 8 Web コンソールがインストールされている。
- cockpit サービスが有効になっている。
ユーザーアカウントが Web コンソールにログインできる。
手順は、Web コンソールのインストールおよび有効化 を参照してください。
手順
RHEL 8 Web コンソールにログインします。
詳細は、Web コンソールへのログイン を参照してください。
- Overview タブで、System information フィールドを見つけて、View hardware details をクリックします。
CPU Security 行で、Mitigations をクリックします。
このリンクがない場合は、システムが SMT に対応していないため、攻撃を受けません。
- CPU Security Toggles テーブルで、Disable simultaneous multithreading (nosmt) オプションに切り替えます。
- ボタンをクリックします。
システムの再起動後、CPU は SMT を使用しなくなりました。
第15章 システム全体の暗号化ポリシーの使用
システム全体の暗号化ポリシーは、コア暗号化サブシステムを設定するシステムコンポーネントで、TLS、IPsec、SSH、DNSSec、および Kerberos の各プロトコルに対応します。これにより、管理者が選択できる小規模セットのポリシーを提供します。
15.1. システム全体の暗号化ポリシー
システム全体のポリシーを設定すると、RHEL のアプリケーションはそのポリシーに従い、ポリシーを満たしていないアルゴリズムやプロトコルを使用するように明示的に要求されない限り、その使用を拒否します。つまり、システムが提供した設定で実行する際に、デフォルトのアプリケーションの挙動にポリシーを適用しますが、必要な場合は上書きできます。
RHEL 8 には、以下の定義済みポリシーが含まれています。
デフォルト- デフォルトのシステム全体の暗号化ポリシーレベルで、現在の脅威モデルに対して安全なものです。TLS プロトコルの 1.2 と 1.3、IKEv2 プロトコル、および SSH2 プロトコルが使用できます。RSA 鍵と Diffie-Hellman パラメーターは長さが 2048 ビット以上であれば許容されます。
LEGACY-
Red Hat Enterprise Linux 5 以前との互換性を最大限に確保します。攻撃対象領域が増えるため、セキュリティーが低下します。
DEFAULTレベルでのアルゴリズムとプロトコルに加えて、TLS プロトコル 1.0 および 1.1 を許可します。アルゴリズム DSA、3DES、および RC4 が許可され、RSA 鍵と Diffie-Hellman パラメーターの長さが 1023 ビット以上であれば許容されます。 FUTURE将来の潜在的なポリシーをテストすることを目的とした、より厳格な将来を見据えたセキュリティーレベル。このポリシーでは、署名アルゴリズムでの SHA-1 の使用は許可されません。TLS プロトコルの 1.2 と 1.3、IKEv2 プロトコル、および SSH2 プロトコルが使用できます。RSA 鍵と Diffie-Hellman パラメーターは、ビット長が 3072 以上だと許可されます。システムが公共のインターネット上で通信する場合、相互運用性の問題が発生する可能性があります。
重要カスタマーポータル API の証明書が使用する暗号化鍵は
FUTUREのシステム全体の暗号化ポリシーが定義する要件を満たさないので、現時点でredhat-support-toolユーティリティーは、このポリシーレベルでは機能しません。この問題を回避するには、カスタマーポータル API への接続中に
DEFAULT暗号化ポリシーを使用します。FIPSFIPS 140 要件に準拠します。RHEL システムを FIPS モードに切り替える
fips-mode-setupツールは、このポリシーを内部的に使用します。FIPSポリシーに切り替えても、FIPS 140 標準への準拠は保証されません。また、システムを FIPS モードに設定した後、すべての暗号キーを再生成する必要があります。多くのシナリオでは、これは不可能です。また、RHEL はシステム全体のサブポリシー
FIPS:OSPPを提供します。これには、Common Criteria (CC) 認証に必要な暗号化アルゴリズムに関する追加の制限が含まれています。このサブポリシーを設定すると、システムの相互運用性が低下します。たとえば、3072 ビットより短い RSA 鍵と DH 鍵、追加の SSH アルゴリズム、および複数の TLS グループを使用できません。また、FIPS:OSPPを設定すると、Red Hat コンテンツ配信ネットワーク (CDN) 構造への接続が防止されます。さらに、FIPS:OSPPを使用する IdM デプロイメントには Active Directory (AD) を統合できません。FIPS:OSPPを使用する RHEL ホストと AD ドメイン間の通信が機能しないか、一部の AD アカウントが認証できない可能性があります。注記FIPS:OSPP暗号化サブポリシーを設定すると、システムが CC 非準拠になります。RHEL システムを CC 標準に準拠させる唯一の正しい方法は、cc-configパッケージで提供されているガイダンスに従うことです。認定済み RHEL バージョン、検証レポート、CC ガイドへのリンクのリストについては、Red Hat カスタマーポータルの Product compliance ページの Common Criteria セクションを参照してください。
Red Hat は、LEGACY ポリシーを使用する場合を除き、すべてのライブラリーがセキュアなデフォルト値を提供するように、すべてのポリシーレベルを継続的に調整します。LEGACY プロファイルはセキュアなデフォルト値を提供しませんが、このプロファイルには、簡単に悪用できるアルゴリズムは含まれていません。このため、提供されたポリシーで有効なアルゴリズムのセットまたは許容可能な鍵サイズは、Red Hat Enterprise Linux の存続期間中に変更する可能性があります。
このような変更は、新しいセキュリティー標準や新しいセキュリティー調査を反映しています。Red Hat Enterprise Linux のライフサイクル全体にわたって特定のシステムとの相互運用性を確保する必要がある場合は、そのシステムと対話するコンポーネントのシステム全体の暗号化ポリシーからオプトアウトするか、カスタム暗号化ポリシーを使用して特定のアルゴリズムを再度有効にする必要があります。
ポリシーレベルで許可されていると記載されている特定のアルゴリズムと暗号は、アプリケーションがそれらをサポートしている場合にのみ使用できます。
LEGACY | DEFAULT | FIPS | FUTURE | |
|---|---|---|---|---|
| IKEv1 | いいえ | いいえ | いいえ | いいえ |
| 3DES | はい | いいえ | いいえ | いいえ |
| RC4 | はい | いいえ | いいえ | いいえ |
| DH | 最低 1024 ビット | 最低 2048 ビット | 最低 2048 ビット[a] | 最低 3072 ビット |
| RSA | 最低 1024 ビット | 最低 2048 ビット | 最低 2048 ビット | 最低 3072 ビット |
| DSA | はい | いいえ | いいえ | いいえ |
| TLS v1.0 | はい | いいえ | いいえ | いいえ |
| TLS v1.1 | はい | いいえ | いいえ | いいえ |
| デジタル署名における SHA-1 | はい | はい | いいえ | いいえ |
| CBC モード暗号 | はい | はい | はい | いいえ[b] |
| 256 ビットより小さい鍵を持つ対称暗号 | はい | はい | はい | いいえ |
| 証明書における SHA-1 および SHA-224 の署名 | はい | はい | はい | いいえ |
[a]
RFC 7919 および RFC 3526 で定義されている Diffie-Hellman グループのみを使用できます。
[b]
TLS の CBC 暗号が無効になっています。TLS 以外のシナリオでは、 AES-128-CBC は無効になっていますが、AES-256-CBC が有効になります。AES-256-CBC も無効にするには、カスタムのサブポリシーを適用します。
| ||||
15.2. システム全体の暗号化ポリシーの変更
update-crypto-policies ツールを使用してシステムを再起動すると、システム全体の暗号化ポリシーを変更できます。
前提条件
- システムの root 権限がある。
手順
オプション: 現在の暗号化ポリシーを表示します。
$ update-crypto-policies --show DEFAULT新しい暗号化ポリシーを設定します。
# update-crypto-policies --set <POLICY> <POLICY><POLICY>は、設定するポリシーまたはサブポリシー (FUTURE、LEGACY、FIPS:OSPPなど) に置き換えます。システムを再起動します。
# reboot
検証
現在の暗号化ポリシーを表示します。
$ update-crypto-policies --show <POLICY>
15.3. システム全体の暗号化ポリシーを、以前のリリースと互換性のあるモードに切り替え
Red Hat Enterprise Linux 8 におけるデフォルトのシステム全体の暗号化ポリシーでは、現在は古くて安全ではないプロトコルは許可されません。Red Hat Enterprise Linux 6 およびそれ以前のリリースとの互換性が必要な場合には、安全でない LEGACY ポリシーレベルを利用できます。
LEGACY ポリシーレベルに設定すると、システムおよびアプリケーションの安全性が低下します。
手順
システム全体の暗号化ポリシーを
LEGACYレベルに切り替えるには、rootで以下のコマンドを実行します。# update-crypto-policies --set LEGACY Setting system policy to LEGACY
15.4. Web コンソールでシステム全体の暗号化ポリシーを設定する
RHEL Web コンソールインターフェイスで、システム全体の暗号化ポリシーとサブポリシーのいずれかを直接設定できます。4 つの事前定義されたシステム全体の暗号化ポリシーに加え、グラフィカルインターフェイスを介して、次のポリシーとサブポリシーの組み合わせを適用することもできます。
DEFAULT:SHA1-
SHA-1アルゴリズムが有効になっているDEFAULTポリシー。 LEGACY:AD-SUPPORT-
Active Directory サービスの相互運用性を向上させる、セキュリティーの低い設定を含む
LEGACYポリシー。 FIPS:OSPP-
Common Criteria for Information Technology Security Evaluation 標準によって要求される追加の制限を含む
FIPSポリシー。
システム全体のサブポリシー FIPS:OSPP には、Common Criteria (CC) 認定に必要な暗号化アルゴリズムに関する追加の制限が含まれています。そのため、このサブポリシーを設定すると、システムの相互運用性が低下します。たとえば、3072 ビットより短い RSA 鍵と DH 鍵、追加の SSH アルゴリズム、および複数の TLS グループを使用できません。また、FIPS:OSPP を設定すると、Red Hat コンテンツ配信ネットワーク (CDN) 構造への接続が防止されます。さらに、FIPS:OSPP を使用する IdM デプロイメントには Active Directory (AD) を統合できません。FIPS:OSPP を使用する RHEL ホストと AD ドメイン間の通信が機能しないか、一部の AD アカウントが認証できない可能性があります。
FIPS:OSPP 暗号化サブポリシーを設定すると、システムが CC 非準拠になる ことに注意してください。RHEL システムを CC 標準に準拠させる唯一の正しい方法は、cc-config パッケージで提供されているガイダンスに従うことです。認定された RHEL バージョン、検証レポート、および National Information Assurance Partnership (NIAP) の Web サイトでホストされる CC ガイドへのリンクのリストは、Red Hat カスタマーポータルページの Product compliance の Common Criteria セクションを参照してください。
前提条件
- RHEL 8 Web コンソールがインストールされている。
- cockpit サービスが有効になっている。
ユーザーアカウントが Web コンソールにログインできる。
手順は、Web コンソールのインストールおよび有効化 を参照してください。
-
sudoを使用して管理コマンドを入力するための root権限または権限がある。
手順
RHEL 8 Web コンソールにログインします。
詳細は、Web コンソールへのログイン を参照してください。
Overview ページの Configuration カードで、Crypto policy の横にある現在のポリシー値をクリックします。
Change crypto policy ダイアログウィンドウで、システムで使用を開始するポリシーをクリックします。
- ボタンをクリックします。
検証
再起動後、Web コンソールに再度ログインし、暗号化ポリシー の値が選択したものと一致していることを確認します。
あるいは、
update-crypto-policies --showコマンドを入力して、現在のシステム全体の暗号化ポリシーをターミナルに表示することもできます。
15.5. システム全体の暗号化ポリシーからアプリケーションを除外する
アプリケーションで使用される暗号化関連の設定をカスタマイズする必要がある場合は、サポートされる暗号スイートとプロトコルをアプリケーションで直接設定することが推奨されます。
/etc/crypto-policies/back-ends ディレクトリーからアプリケーション関連のシンボリックリンクを削除することもできます。カスタマイズした暗号化設定に置き換えることもできます。この設定により、除外されたバックエンドを使用するアプリケーションに対するシステム全体の暗号化ポリシーが使用できなくなります。この修正は、Red Hat ではサポートされていません。
15.5.1. システム全体の暗号化ポリシーをオプトアウトする例
wget
wget ネットワークダウンローダーで使用される暗号化設定をカスタマイズするには、--secure-protocol オプションおよび --ciphers オプションを使用します。以下に例を示します。
$ wget --secure-protocol=TLSv1_1 --ciphers="SECURE128" https://example.com
詳細は、wget(1) man ページの HTTPS (SSL/TLS) Options のセクションを参照してください。
curl
curl ツールで使用する暗号を指定するには、--ciphers オプションを使用して、その値に、コロンで区切った暗号化のリストを指定します。以下に例を示します。
$ curl https://example.com --ciphers '@SECLEVEL=0:DES-CBC3-SHA:RSA-DES-CBC3-SHA'
詳細は、curl(1) の man ページを参照してください。
Firefox
Web ブラウザーの Firefox でシステム全体の暗号化ポリシーをオプトアウトできない場合でも、Firefox の設定エディターで、対応している暗号と TLS バージョンをさらに詳細に制限できます。アドレスバーに about:config と入力し、必要に応じて security.tls.version.min の値を変更します。たとえば、security.tls.version.min を 1 に設定すると、最低でも TLS 1.0 が必要になり、security.tls.version.min 2 が TLS 1.1 になります。
OpenSSH
OpenSSH サーバーに対するシステム全体の暗号化ポリシーを除外するには、/etc/sysconfig/sshd ファイルの CRYPTO_POLICY= 変数行のコメントを除外します。この変更後、/etc/ssh/sshd_config ファイルの Ciphers セクション、MACs セクション、KexAlgoritms セクション、および GSSAPIKexAlgorithms セクションで指定した値は上書きされません。
詳細は、sshd_config(5) の man ページを参照してください。
OpenSSH クライアントのシステム全体の暗号化ポリシーをオプトアウトするには、次のいずれかのタスクを実行します。
-
指定のユーザーの場合は、
~/.ssh/configファイルのユーザー固有の設定でグローバルのssh_configを上書きします。 -
システム全体の場合は、
/etc/ssh/ssh_config.d/ディレクトリーにあるドロップイン設定ファイルに暗号化ポリシーを指定します。このとき、辞書式順序で05-redhat.confファイルよりも前に来るように、5 未満の 2 桁の接頭辞と、.confという接尾辞を付けます (例:04-crypto-policy-override.conf)。
詳細は、ssh_config(5) の man ページを参照してください。
Libreswan
詳細は、Securing networks の Configuring IPsec connections that opt out of the system-wide crypto policies を参照してください。
15.6. サブポリシーを使用したシステム全体の暗号化ポリシーのカスタマイズ
この手順を使用して、有効な暗号化アルゴリズムまたはプロトコルのセットを調整します。
既存のシステム全体の暗号化ポリシーの上にカスタムサブポリシーを適用するか、そのようなポリシーを最初から定義することができます。
スコープが設定されたポリシーの概念により、バックエンドごとに異なるアルゴリズムセットを有効にできます。各設定ディレクティブは、特定のプロトコル、ライブラリー、またはサービスに限定できます。
また、ディレクティブでは、ワイルドカードを使用して複数の値を指定する場合にアスタリスクを使用できます。
/etc/crypto-policies/state/CURRENT.pol ファイルには、ワイルドカードデプロイメント後に現在適用されているシステム全体の暗号化ポリシーのすべての設定がリスト表示されます。暗号化ポリシーをより厳密にするには、/usr/share/crypto-policies/policies/FUTURE.pol ファイルにリストされている値を使用することを検討してください。
サブポリシーの例は、/usr/share/crypto-policies/policies/modules/ ディレクトリーにあります。このディレクトリーのサブポリシーファイルには、コメントアウトされた行に説明が含まれています。
システム全体の暗号化ポリシーのカスタマイズは、RHEL 8.2 から利用できます。スコープ指定ポリシーの概念と、RHEL 8.5 以降でワイルドカードを使用するオプションを使用できます。
手順
/etc/crypto-policies/policies/modules/ディレクトリーをチェックアウトします。# cd /etc/crypto-policies/policies/modules/調整用のサブポリシーを作成します。次に例を示します。
# touch MYCRYPTO-1.pmod # touch SCOPES-AND-WILDCARDS.pmod重要ポリシーモジュールのファイル名には大文字を使用します。
任意のテキストエディターでポリシーモジュールを開き、システム全体の暗号化ポリシーを変更するオプションを挿入します。次に例を示します。
# vi MYCRYPTO-1.pmodmin_rsa_size = 3072 hash = SHA2-384 SHA2-512 SHA3-384 SHA3-512# vi SCOPES-AND-WILDCARDS.pmod# Disable the AES-128 cipher, all modes cipher = -AES-128-* # Disable CHACHA20-POLY1305 for the TLS protocol (OpenSSL, GnuTLS, NSS, and OpenJDK) cipher@TLS = -CHACHA20-POLY1305 # Allow using the FFDHE-1024 group with the SSH protocol (libssh and OpenSSH) group@SSH = FFDHE-1024+ # Disable all CBC mode ciphers for the SSH protocol (libssh and OpenSSH) cipher@SSH = -*-CBC # Allow the AES-256-CBC cipher in applications using libssh cipher@libssh = AES-256-CBC+- 変更をモジュールファイルに保存します。
ポリシーの調整を、システム全体の暗号化ポリシーレベル
DEFAULTに適用します。# update-crypto-policies --set DEFAULT:MYCRYPTO-1:SCOPES-AND-WILDCARDS暗号化設定を実行中のサービスやアプリケーションで有効にするには、システムを再起動します。
# reboot
検証
/etc/crypto-policies/state/CURRENT.polファイルに変更が含まれていることを確認します。以下に例を示します。$ cat /etc/crypto-policies/state/CURRENT.pol | grep rsa_size min_rsa_size = 3072
15.7. システム全体の暗号化ポリシーをカスタマイズして SHA-1 を無効化
SHA-1 ハッシュ関数は本質的に設計面で弱く、暗号解析機能によって攻撃を受けやすいため、RHEL 8 ではデフォルトで SHA-1 を使用していません。ただし、一部のサードパーティーアプリケーション (公開署名など) は SHA-1 を使用します。システムの署名アルゴリズムで SHA-1 の使用を無効にするには、NO-SHA1 ポリシーモジュールを使用できます。
NO-SHA1 ポリシーモジュールが無効にするのは、署名の SHA-1 ハッシュ関数だけでそれ以外は無効になりません。特に、NO-SHA1 モジュールでも、ハッシュベースのメッセージ認証コード (HMAC) とともに SHA-1 を使用できます。HMAC セキュリティープロパティーは、対応するハッシュ関数の衝突耐性に依存しないので、HMAC に SHA-1 を使用している場合に最近の SHA-1 への攻撃による影響は大幅に低くなっています。
シナリオで特定の鍵交換 (KEX) アルゴリズムの組み合わせ (例: diffie-hellman-group-exchange-sha1) を無効にする必要があるが、他の組み合わせでは関連する KEX とアルゴリズムの両方を使用する場合は、Red Hat ナレッジベースソリューション SSH で diffie-hellman-group1-sha1 アルゴリズムを無効にする手順を 参照して、SSH のシステム全体の暗号化ポリシーをオプトアウトし、SSH を直接設定する手順を確認してください。
SHA-1 を無効にするモジュールは、RHEL 8.3 で利用できます。システム全体の暗号化ポリシーのカスタマイズは、RHEL 8.2 から利用できます。
手順
ポリシーの調整を、システム全体の暗号化ポリシーレベル
DEFAULTに適用します。# update-crypto-policies --set DEFAULT:NO-SHA1暗号化設定を実行中のサービスやアプリケーションで有効にするには、システムを再起動します。
# reboot
15.8. システム全体のカスタム暗号化ポリシーの作成および設定
完全なポリシーファイルを作成して使用することで、システム全体の暗号化ポリシーを特定の状況向けにカスタマイズできます。
システム全体の暗号化ポリシーのカスタマイズは、RHEL 8.2 から利用できます。
手順
カスタマイズのポリシーファイルを作成します。
# cd /etc/crypto-policies/policies/ # touch MYPOLICY.polまたは、定義されている 4 つのポリシーレベルのいずれかをコピーします。
# cp /usr/share/crypto-policies/policies/DEFAULT.pol /etc/crypto-policies/policies/MYPOLICY.pol必要に応じて、テキストエディターでファイルを編集します。以下のようにしてカスタム暗号化ポリシーを使用します。
# vi /etc/crypto-policies/policies/MYPOLICY.polシステム全体の暗号化ポリシーをカスタムレベルに切り替えます。
# update-crypto-policies --set MYPOLICY暗号化設定を実行中のサービスやアプリケーションで有効にするには、システムを再起動します。
# reboot
15.9. crypto_policies RHEL システムロールを使用した FUTURE 暗号化ポリシーによるセキュリティーの強化
crypto_policies RHEL システムロールを使用して、管理対象ノードで FUTURE ポリシーを設定できます。このポリシーは、たとえば次のことを実現するのに役立ちます。
- 将来の新たな脅威への対応: 計算能力の向上を予測します。
- セキュリティーの強化: 強力な暗号化標準により、より長い鍵長とよりセキュアなアルゴリズムを必須にします。
- 高度なセキュリティー標準への準拠: 医療、通信、金融などの分野ではデータの機密性が高く、強力な暗号化を利用できることが重要です。
通常、FUTURE は、機密性の高いデータを扱う環境、将来の規制に備える環境、長期的なセキュリティーストラテジーを採用する環境に適しています。
レガシーのシステムやソフトウェアでは、FUTURE ポリシーによって強制される、より最新しく厳格なアルゴリズムやプロトコルをサポートする必要はありません。たとえば、古いシステムでは TLS 1.3 以上の鍵サイズがサポートされていない可能性があります。これにより互換性の問題が発生する可能性があります。
また、強力なアルゴリズムを使用すると、通常、計算負荷が増加し、システムのパフォーマンスに悪影響が及ぶ可能性があります。
前提条件
- コントロールノードと管理対象ノードの準備が完了している。
- 管理対象ノードで Playbook を実行できるユーザーとしてコントロールノードにログインしている。
-
管理対象ノードへの接続に使用するアカウントに、そのノードに対する
sudo権限がある。
手順
次の内容を含む Playbook ファイル (例:
~/playbook.yml) を作成します。--- - name: Configure cryptographic policies hosts: managed-node-01.example.com tasks: - name: Configure the FUTURE cryptographic security policy on the managed node ansible.builtin.include_role: name: redhat.rhel_system_roles.crypto_policies vars: - crypto_policies_policy: FUTURE - crypto_policies_reboot_ok: trueサンプル Playbook で指定されている設定は次のとおりです。
crypto_policies_policy: FUTURE-
管理対象ノードで必要な暗号化ポリシー (
FUTURE) を設定します。これは、基本ポリシー、またはいくつかのサブポリシーを含む基本ポリシーのどちらかです。指定した基本ポリシーとサブポリシーが、管理対象ノードで使用可能である必要があります。デフォルト値はnullです。つまり、設定は変更されず、crypto_policiesRHEL システムロールは Ansible fact のみを収集します。 crypto_policies_reboot_ok: true-
すべてのサービスとアプリケーションが新しい設定ファイルを読み取るように、暗号化ポリシーの変更後にシステムを再起動します。デフォルト値は
falseです。
Playbook で使用されるすべての変数の詳細は、コントロールノードの
/usr/share/ansible/roles/rhel-system-roles.crypto_policies/README.mdファイルを参照してください。Playbook の構文を検証します。
$ ansible-playbook --syntax-check ~/playbook.ymlこのコマンドは構文を検証するだけであり、有効だが不適切な設定から保護するものではないことに注意してください。
Playbook を実行します。
$ ansible-playbook ~/playbook.yml
システム全体のサブポリシー FIPS:OSPP には、Common Criteria (CC) 認定に必要な暗号化アルゴリズムに関する追加の制限が含まれています。そのため、このサブポリシーを設定すると、システムの相互運用性が低下します。たとえば、3072 ビットより短い RSA 鍵と DH 鍵、追加の SSH アルゴリズム、および複数の TLS グループを使用できません。また、FIPS:OSPP を設定すると、Red Hat コンテンツ配信ネットワーク (CDN) 構造への接続が防止されます。さらに、FIPS:OSPP を使用する IdM デプロイメントには Active Directory (AD) を統合できません。FIPS:OSPP を使用する RHEL ホストと AD ドメイン間の通信が機能しないか、一部の AD アカウントが認証できない可能性があります。
FIPS:OSPP 暗号化サブポリシーを設定すると、システムが CC 非準拠になる ことに注意してください。RHEL システムを CC 標準に準拠させる唯一の正しい方法は、cc-config パッケージで提供されているガイダンスに従うことです。認定された RHEL バージョン、検証レポート、および National Information Assurance Partnership (NIAP) の Web サイトでホストされる CC ガイドへのリンクのリストは、Red Hat カスタマーポータルページの Product compliance の Common Criteria セクションを参照してください。
検証
コントロールノードで、たとえば
verify_playbook.ymlという名前の別の Playbook を作成します。--- - name: Verification hosts: managed-node-01.example.com tasks: - name: Verify active cryptographic policy ansible.builtin.include_role: name: redhat.rhel_system_roles.crypto_policies - name: Display the currently active cryptographic policy ansible.builtin.debug: var: crypto_policies_activeサンプル Playbook で指定されている設定は次のとおりです。
crypto_policies_active-
crypto_policies_policy変数で受け入れられる形式の現在アクティブなポリシー名が含まれているエクスポートされた Ansible fact。
Playbook の構文を検証します。
$ ansible-playbook --syntax-check ~/verify_playbook.ymlPlaybook を実行します。
$ ansible-playbook ~/verify_playbook.yml TASK [debug] ************************** ok: [host] => { "crypto_policies_active": "FUTURE" }crypto_policies_active変数は、管理対象ノード上のアクティブなポリシーを示します。
第16章 PKCS #11 で暗号化ハードウェアを使用するようにアプリケーションを設定
スマートカードや、エンドユーザー認証用の暗号化トークン、サーバーアプリケーション用のハードウェアセキュリティーモジュール (HSM) など、専用の暗号化デバイスで秘密情報の一部を分離することで、セキュリティー層が追加されます。RHEL では、PKCS #11 API を使用した暗号化ハードウェアへの対応がアプリケーション間で統一され、暗号ハードウェアでの秘密の分離が複雑なタスクではなくなりました。
16.1. PKCS #11 による暗号化ハードウェアへの対応
Public-Key Cryptography Standard (PKCS) #11 は、暗号化情報を保持し、暗号化機能を実行する暗号化デバイスへのアプリケーションプログラミングインターフェイス (API) を定義します。
PKCS #11 では、各ハードウェアまたはソフトウェアデバイスを統一された方法でアプリケーションに提示するオブジェクトである 暗号化トークン が導入されています。したがって、アプリケーションは、通常はユーザーによって使用されるスマートカードなどのデバイスや、通常はコンピューターによって使用されるハードウェアセキュリティーモジュールを PKCS #11 暗号化トークンとして認識します。
PKCS #11 トークンには、証明書、データオブジェクト、公開鍵、秘密鍵、または秘密鍵を含むさまざまなオブジェクトタイプを保存できます。これらのオブジェクトは、PKCS #11 Uniform Resource Identifier (URI) スキームを通じて一意に識別できます。
PKCS #11 の URI は、オブジェクト属性に従って、PKCS #11 モジュールで特定のオブジェクトを識別する標準的な方法です。これにより、URI の形式で、すべてのライブラリーとアプリケーションを同じ設定文字列で設定できます。
RHEL では、デフォルトでスマートカード用に OpenSC PKCS #11 ドライバーが提供されています。ただし、ハードウェアトークンと HSM には、システムにカウンターパートを持たない独自の PKCS #11 モジュールがあります。この PKCS #11 モジュールは p11-kit ツールで登録できます。これは、システムの登録済みスマートカードドライバーにおけるラッパーとして機能します。
システムで独自の PKCS #11 モジュールを有効にするには、新しいテキストファイルを /etc/pkcs11/modules/ ディレクトリーに追加します。
/etc/pkcs11/modules/ ディレクトリーに新しいテキストファイルを作成すると、独自の PKCS #11 モジュールをシステムに追加できます。たとえば、p11-kit の OpenSC 設定ファイルは、以下のようになります。
$ cat /usr/share/p11-kit/modules/opensc.module
module: opensc-pkcs11.so16.2. スマートカードに保存した SSH 鍵による認証
スマートカードに ECDSA 鍵と RSA 鍵を作成して保存し、そのスマートカードを使用して OpenSSH クライアントで認証することができます。スマートカード認証は、デフォルトのパスワード認証に代わるものです。
前提条件
-
クライアントで、
openscパッケージをインストールして、pcscdサービスを実行している。
手順
PKCS #11 の URI を含む OpenSC PKCS #11 モジュールが提供する鍵のリストを表示し、その出力を
keys.pubファイルに保存します。$ ssh-keygen -D pkcs11: > keys.pub公開鍵をリモートサーバーに転送します。
ssh-copy-idコマンドを使用し、前の手順で作成したkeys.pubファイルを指定します。$ ssh-copy-id -f -i keys.pub <username@ssh-server-example.com>ECDSA 鍵を使用して <ssh-server-example.com> に接続します。鍵を一意に参照する URI のサブセットのみを使用することもできます。次に例を示します。
$ ssh -i "pkcs11:id=%01?module-path=/usr/lib64/pkcs11/opensc-pkcs11.so" <ssh-server-example.com> Enter PIN for 'SSH key': [ssh-server-example.com] $OpenSSH は
p11-kit-proxyラッパーを使用し、OpenSC PKCS #11 モジュールがp11-kitツールに登録されているため、前のコマンドを簡略化できます。$ ssh -i "pkcs11:id=%01" <ssh-server-example.com> Enter PIN for 'SSH key': [ssh-server-example.com] $PKCS #11 の URI の
id=の部分を飛ばすと、OpenSSH が、プロキシーモジュールで利用可能な鍵をすべて読み込みます。これにより、必要な入力の量を減らすことができます。$ ssh -i pkcs11: <ssh-server-example.com> Enter PIN for 'SSH key': [ssh-server-example.com] $オプション:
~/.ssh/configファイルで同じ URI 文字列を使用して、設定を永続化できます。$ cat ~/.ssh/config IdentityFile "pkcs11:id=%01?module-path=/usr/lib64/pkcs11/opensc-pkcs11.so" $ ssh <ssh-server-example.com> Enter PIN for 'SSH key': [ssh-server-example.com] $sshクライアントユーティリティーが、この URI とスマートカードの鍵を自動的に使用するようになります。
16.3. スマートカード上の証明書を使用して認証するアプリケーションの設定
アプリケーションでスマートカードを使用して認証することにより、セキュリティーが強化され、自動化が簡素化される場合があります。次の方法を使用して、Public Key Cryptography Standard (PKCS) #11 URI をアプリケーションに統合できます。
-
FirefoxWeb ブラウザーは、p11-kit-proxyPKCS #11 モジュールを自動的にロードします。つまり、システムで対応しているすべてのスマートカードが自動的に検出されます。TLS クライアント認証を使用する場合、追加のセットアップは必要ありません。サーバーが要求したときにスマートカードの鍵と証明書が自動的に使用されます。 -
アプリケーションが
GnuTLSまたはNSSライブラリーを使用している場合、PKCS #11 URI はすでにサポートされています。また、OpenSSLライブラリーに依存するアプリケーションは、openssl-pkcs11パッケージによって提供されるpkcs11エンジンを通じて、スマートカードを含む暗号化ハードウェアモジュールにアクセスできます。 -
スマートカード上の秘密鍵を操作する必要があり、
NSS、GnuTLS、OpenSSLを使用しないアプリケーションは、特定の PKCS #11 モジュールの PKCS #11 API を使用するのではなく、p11-kitAPI を直接使用して、スマートカードを含む暗号化ハードウェアモジュールを操作できます。 wgetネットワークダウンローダーを使用すると、ローカルに保存された秘密鍵と証明書へのパスの代わりに PKCS #11 URI を指定できます。これにより、安全に保管された秘密鍵と証明書を必要とするタスクのスクリプトの作成が簡素化される可能性があります。以下に例を示します。$ wget --private-key 'pkcs11:token=softhsm;id=%01;type=private?pin-value=111111' --certificate 'pkcs11:token=softhsm;id=%01;type=cert' https://example.com/また、
curlツールを使用する場合は、PKCS #11 URI を指定することもできます。$ curl --key 'pkcs11:token=softhsm;id=%01;type=private?pin-value=111111' --cert 'pkcs11:token=softhsm;id=%01;type=cert' https://example.com/
16.4. Apache で秘密鍵を保護する HSM の使用
Apache HTTP サーバーは、ハードウェアセキュリティーモジュール (HSM) に保存されている秘密鍵と連携できます。これにより、鍵の漏えいや中間者攻撃を防ぐことができます。通常、これを行うには、ビジーなサーバーに高パフォーマンスの HSM が必要になります。
HTTPS プロトコルの形式でセキュアな通信を行うために、Apache HTTP サーバー (httpd) は OpenSSL ライブラリーを使用します。OpenSSL は、PKCS #11 にネイティブに対応しません。HSM を使用するには、エンジンインターフェイスを介して PKCS #11 モジュールへのアクセスを提供する openssl-pkcs11 パッケージをインストールする必要があります。通常のファイル名ではなく PKCS #11 の URI を使用すると、/etc/httpd/conf.d/ssl.conf 設定ファイルでサーバーの鍵と証明書を指定できます。以下に例を示します。
SSLCertificateFile "pkcs11:id=%01;token=softhsm;type=cert"
SSLCertificateKeyFile "pkcs11:id=%01;token=softhsm;type=private?pin-value=111111"
httpd-manual パッケージをインストールして、TLS 設定を含む Apache HTTP サーバーの完全ドキュメントを取得します。/etc/httpd/conf.d/ssl.conf 設定ファイルで利用可能なディレクティブの詳細は、/usr/share/httpd/manual/mod/mod_ssl.html を参照してください。
16.5. Nginx で秘密鍵を保護する HSM の使用
Nginx HTTP サーバーは、ハードウェアセキュリティーモジュール (HSM) に保存されている秘密鍵と連携できます。これにより、鍵の漏えいや中間者攻撃を防ぐことができます。通常、これを行うには、ビジーなサーバーに高パフォーマンスの HSM が必要になります。
Nginx は暗号化操作に OpenSSL を使用するため、PKCS #11 への対応は openssl-pkcs11 エンジンを介して行う必要があります。Nginx は現在、HSM からの秘密鍵の読み込みのみに対応します。また、証明書は通常のファイルとして個別に提供する必要があります。/etc/nginx/nginx.conf 設定ファイルの server セクションで ssl_certificate オプションおよび ssl_certificate_key オプションを変更します。
ssl_certificate /path/to/cert.pem
ssl_certificate_key "engine:pkcs11:pkcs11:token=softhsm;id=%01;type=private?pin-value=111111";
Nginx 設定ファイルの PKCS #11 URI に接頭辞 engine:pkcs11: が必要なことに注意してください。これは、他の pkcs11 接頭辞がエンジン名を参照するためです。
第18章 セキュリティーコンプライアンスおよび脆弱性スキャンの開始
18.1. RHEL における設定コンプライアンスツール
次の設定コンプライアンスツールを使用すると、Red Hat Enterprise Linux で完全に自動化されたコンプライアンス監査を実行できます。このツールは SCAP (Security Content Automation Protocol) 規格に基づいており、コンプライアンスポリシーの自動化に合わせるように設計されています。
- SCAP Workbench
-
scap-workbenchグラフィカルユーティリティーは、単一のローカルシステムまたはリモートシステム上で設定および脆弱性スキャンを実行するように設計されています。これらのスキャンと評価に基づくセキュリティーレポートの生成にも使用できます。 - OpenSCAP
OpenSCAPライブラリーは、付随するoscapコマンドラインユーティリティーとともに、ローカルシステムで設定スキャンと脆弱性スキャンを実行するように設計されています。これにより、設定コンプライアンスのコンテンツを検証し、スキャンおよび評価に基づいてレポートおよびガイドを生成します。重要OpenSCAP の使用中にメモリー消費の問題が発生する可能性があります。これにより、プログラムが途中で停止し、結果ファイルが生成されない可能性があります。詳細については、ナレッジベース記事 OpenSCAP のメモリー消費の問題 を参照してください。
- SCAP Security Guide (SSG)
-
scap-security-guideパッケージは、Linux システム用のセキュリティーポリシーのコレクションを提供します。このガイダンスは、セキュリティー強化に関する実践的なアドバイスのカタログで構成されています (該当する場合は、法規制要件へのリンクが含まれます)。このプロジェクトは、一般的なポリシー要件と特定の実装ガイドラインとの間にあるギャップを埋めることを目的としています。 - Script Check Engine (SCE)
-
SCAP プロトコルの拡張機能である SCE を使用すると、管理者は Bash、Python、Ruby などのスクリプト言語を使用してセキュリティーコンテンツを作成できます。SCE 拡張機能は、
openscap-engine-sceパッケージで提供されます。SCE 自体は SCAP 標準規格の一部ではありません。
複数のリモートシステムで自動コンプライアンス監査を実行する必要がある場合は、Red Hat Satellite 用の OpenSCAP ソリューションを利用できます。
18.2. Red Hat Security Advisories OVAL フィード
Red Hat Enterprise Linux のセキュリティー監査機能は、標準規格セキュリティー設定共通化手順 (Security Content Automation Protocol (SCAP)) を基にしています。SCAP は、自動化された設定、脆弱性およびパッチの確認、技術的な制御コンプライアンスアクティビティー、およびセキュリティーの測定に対応している多目的な仕様のフレームワークです。
SCAP 仕様は、スキャナーまたはポリシーエディターの実装が義務付けられていなくても、セキュリティーコンテンツの形式がよく知られて標準化されているエコシステムを作成します。これにより、組織は、採用しているセキュリティーベンダーの数に関係なく、セキュリティーポリシー (SCAP コンテンツ) を構築するのは一度で済みます。
セキュリティー検査言語 OVAL (Open Vulnerability Assessment Language) は、SCAP に不可欠で最も古いコンポーネントです。その他のツールやカスタマイズされたスクリプトとは異なり、OVAL は、宣言型でリソースが必要な状態を記述します。OVAL コードは、スキャナーと呼ばれる OVAL インタープリターツールを使用して直接実行されることは決してありません。OVAL が宣言型であるため、評価されるシステムの状態が偶然修正されることはありません。
他のすべての SCAP コンポーネントと同様に、OVAL は XML に基づいています。SCAP 標準規格は、いくつかのドキュメント形式を定義します。この形式にはそれぞれ異なる種類の情報が記載され、異なる目的に使用されます。
Red Hat 製品セキュリティー を使用すると、Red Hat 製品をお使いのお客様に影響を及ぼすセキュリティー問題をすべて追跡して調査します。Red Hat カスタマーポータルで簡潔なパッチやセキュリティーアドバイザリーを適時提供します。Red Hat は OVAL パッチ定義を作成してサポートし、マシンが判読可能なセキュリティーアドバイザリーを提供します。
プラットフォーム、バージョン、およびその他の要因が異なるため、Red Hat 製品セキュリティーによる脆弱性の重大度定性評価は、サードパーティーが提供する Common Vulnerability Scoring System (CVSS) のベースライン評価と完全に一致しているわけではありません。したがって、サードパーティーが提供する定義ではなく、RHSA OVAL 定義を使用することが推奨されます。
各 RHSA OVAL 定義 は完全なパッケージとして利用でき、新しいセキュリティーアドバイザリーが Red Hat カスタマーポータルで利用可能になってから 1 時間以内に更新されます。
各 OVAL パッチ定義は、Red Hat セキュリティーアドバイザリー (RHSA) と 1 対 1 にマッピングしています。RHSA には複数の脆弱性に対する修正が含まれるため、各脆弱性は、共通脆弱性識別子 (Common Vulnerabilities and Exposures (CVE)) 名ごとに表示され、公開バグデータベースの該当箇所へのリンクが示されます。
RHSA OVAL 定義は、システムにインストールされている RPM パッケージで脆弱なバージョンを確認するように設計されています。この定義は拡張でき、パッケージが脆弱な設定で使用されているかどうかを見つけるなど、さらに確認できるようにすることができます。この定義は、Red Hat が提供するソフトウェアおよび更新に対応するように設計されています。サードパーティーソフトウェアのパッチ状態を検出するには、追加の定義が必要です。
Red Hat Insights for Red Hat Enterprise Linux コンプライアンスサービス は、IT セキュリティーおよびコンプライアンス管理者が Red Hat Enterprise Linux システムのセキュリティーポリシーのコンプライアンスを評価、監視、およびレポートするのに役立ちます。また、コンプライアンスサービス UI 内で完全に SCAP セキュリティーポリシーを作成および管理することもできます。
18.3. 脆弱性スキャン
18.3.1. Red Hat Security Advisories OVAL フィード
Red Hat Enterprise Linux のセキュリティー監査機能は、標準規格セキュリティー設定共通化手順 (Security Content Automation Protocol (SCAP)) を基にしています。SCAP は、自動化された設定、脆弱性およびパッチの確認、技術的な制御コンプライアンスアクティビティー、およびセキュリティーの測定に対応している多目的な仕様のフレームワークです。
SCAP 仕様は、スキャナーまたはポリシーエディターの実装が義務付けられていなくても、セキュリティーコンテンツの形式がよく知られて標準化されているエコシステムを作成します。これにより、組織は、採用しているセキュリティーベンダーの数に関係なく、セキュリティーポリシー (SCAP コンテンツ) を構築するのは一度で済みます。
セキュリティー検査言語 OVAL (Open Vulnerability Assessment Language) は、SCAP に不可欠で最も古いコンポーネントです。その他のツールやカスタマイズされたスクリプトとは異なり、OVAL は、宣言型でリソースが必要な状態を記述します。OVAL コードは、スキャナーと呼ばれる OVAL インタープリターツールを使用して直接実行されることは決してありません。OVAL が宣言型であるため、評価されるシステムの状態が偶然修正されることはありません。
他のすべての SCAP コンポーネントと同様に、OVAL は XML に基づいています。SCAP 標準規格は、いくつかのドキュメント形式を定義します。この形式にはそれぞれ異なる種類の情報が記載され、異なる目的に使用されます。
Red Hat 製品セキュリティー を使用すると、Red Hat 製品をお使いのお客様に影響を及ぼすセキュリティー問題をすべて追跡して調査します。Red Hat カスタマーポータルで簡潔なパッチやセキュリティーアドバイザリーを適時提供します。Red Hat は OVAL パッチ定義を作成してサポートし、マシンが判読可能なセキュリティーアドバイザリーを提供します。
プラットフォーム、バージョン、およびその他の要因が異なるため、Red Hat 製品セキュリティーによる脆弱性の重大度定性評価は、サードパーティーが提供する Common Vulnerability Scoring System (CVSS) のベースライン評価と完全に一致しているわけではありません。したがって、サードパーティーが提供する定義ではなく、RHSA OVAL 定義を使用することが推奨されます。
各 RHSA OVAL 定義 は完全なパッケージとして利用でき、新しいセキュリティーアドバイザリーが Red Hat カスタマーポータルで利用可能になってから 1 時間以内に更新されます。
各 OVAL パッチ定義は、Red Hat セキュリティーアドバイザリー (RHSA) と 1 対 1 にマッピングしています。RHSA には複数の脆弱性に対する修正が含まれるため、各脆弱性は、共通脆弱性識別子 (Common Vulnerabilities and Exposures (CVE)) 名ごとに表示され、公開バグデータベースの該当箇所へのリンクが示されます。
RHSA OVAL 定義は、システムにインストールされている RPM パッケージで脆弱なバージョンを確認するように設計されています。この定義は拡張でき、パッケージが脆弱な設定で使用されているかどうかを見つけるなど、さらに確認できるようにすることができます。この定義は、Red Hat が提供するソフトウェアおよび更新に対応するように設計されています。サードパーティーソフトウェアのパッチ状態を検出するには、追加の定義が必要です。
Red Hat Insights for Red Hat Enterprise Linux コンプライアンスサービス は、IT セキュリティーおよびコンプライアンス管理者が Red Hat Enterprise Linux システムのセキュリティーポリシーのコンプライアンスを評価、監視、およびレポートするのに役立ちます。また、コンプライアンスサービス UI 内で完全に SCAP セキュリティーポリシーを作成および管理することもできます。
18.3.2. システムの脆弱性のスキャン
oscap コマンドラインユーティリティーを使用すると、ローカルシステムのスキャン、設定コンプライアンスコンテンツの確認、ならびにスキャンおよび評価を基にしたレポートとガイドの生成が可能です。このユーティリティーは、OpenSCAP ライブラリーのフロントエンドとしてサービスを提供し、その機能を処理する SCAP コンテンツのタイプに基づいてモジュール (サブコマンド) にグループ化します。
前提条件
-
openscap-scannerおよびbzip2パッケージがインストールされます。
手順
システムに最新 RHSA OVAL 定義をダウンロードします。
# wget -O - https://www.redhat.com/security/data/oval/v2/RHEL8/rhel-8.oval.xml.bz2 | bzip2 --decompress > rhel-8.oval.xmlシステムの脆弱性をスキャンし、vulnerability.html ファイルに結果を保存します。
# oscap oval eval --report vulnerability.html rhel-8.oval.xml
検証
結果をブラウザーで確認します。以下に例を示します。
$ firefox vulnerability.html &
18.3.3. リモートシステムの脆弱性のスキャン
SSH プロトコル経由で oscap-ssh ツールを使用して、OpenSCAP スキャナーでリモートシステムの脆弱性をチェックできます。
前提条件
-
openscap-utilsおよびbzip2パッケージは、スキャンに使用するシステムにインストールされます。 -
リモートシステムに
openscap-scannerパッケージがインストールされている。 - リモートシステムで SSH サーバーが実行している。
手順
システムに最新 RHSA OVAL 定義をダウンロードします。
# wget -O - https://www.redhat.com/security/data/oval/v2/RHEL8/rhel-8.oval.xml.bz2 | bzip2 --decompress > rhel-8.oval.xmlリモートシステムの脆弱性をスキャンし、結果をファイルに保存します。
# oscap-ssh <username>@<hostname> <port> oval eval --report <scan-report.html> rhel-8.oval.xml以下を置き換えます。
-
<username>@<hostname>は、リモートシステムのユーザー名とホスト名に置き換えます。 -
<port>は、リモートシステムにアクセスできるポート番号 (例:22) です。 -
<scan-report.html>は、oscapがスキャン結果を保存するファイル名です。
-
18.4. 設定コンプライアンススキャン
18.4.1. RHEL の設定コンプライアンス
設定コンプライアンススキャンを使用して、特定の組織で定義されているベースラインに準拠できます。たとえば、米国政府と協力している場合は、システムを Operating System Protection Profile (OSPP) に準拠させ、支払い処理業者の場合は、システムを Payment Card Industry Data Security Standard (PCI-DSS) に準拠させなければならない場合があります。設定コンプライアンススキャンを実行して、システムセキュリティーを強化することもできます。
Red Hat は、対象コンポーネント向けの Red Hat のベストプラクティスに従っているため、SCAP Security Guide パッケージで提供される Security Content Automation Protocol (SCAP) コンテンツに従うことを推奨します。
SCAP Security Guide パッケージは、SCAP 1.2 および SCAP 1.3 標準規格に準拠するコンテンツを提供します。openscap scanner ユーティリティーは、SCAP Security Guide パッケージで提供される SCAP 1.2 および SCAP 1.3 コンテンツの両方と互換性があります。
設定コンプライアンススキャンを実行しても、システムが準拠しているとは限りません。
SCAP Security Guide スイートは、データストリームドキュメントの形式で、複数のプラットフォームのプロファイルを提供します。データストリームは、定義、ベンチマーク、プロファイル、および個々のルールが含まれるファイルです。各ルールでは、コンプライアンスの適用性と要件を指定します。RHEL は、セキュリティーポリシーを扱う複数のプロファイルを提供します。Red Hat データストリームには、業界標準の他に、失敗したルールの修正に関する情報も含まれます。
コンプライアンススキャンリソースの構造
Data stream
├── xccdf
| ├── benchmark
| ├── profile
| | ├──rule reference
| | └──variable
| ├── rule
| ├── human readable data
| ├── oval reference
├── oval ├── ocil reference
├── ocil ├── cpe reference
└── cpe └── remediationプロファイルは、OSPP、PCI-DSS、Health Insurance Portability and Accountability Act (HIPAA) などのセキュリティーポリシーに基づく一連のルールです。これにより、セキュリティー標準規格に準拠するために、システムを自動で監査できます。
プロファイルを変更 (調整) して、パスワードの長さなどの特定のルールをカスタマイズできます。プロファイルの調整の詳細は、SCAP Workbench を使用したセキュリティープロファイルのカスタマイズ を参照してください。
18.4.2. OpenSCAP スキャン結果の例
OpenSCAP スキャンに適用されるデータストリームとプロファイル、およびシステムのさまざまなプロパティーに応じて、各ルールから特定の結果が生成される場合があります。以下に考えられる結果とその意味の簡単な説明を示します。
- Pass
- スキャンでは、このルールとの競合が見つかりませんでした。
- Fail
- スキャンで、このルールとの競合が検出されました。
- Not checked
- OpenSCAP はこのルールの自動評価を実行しません。システムがこのルールに手動で準拠しているかどうかを確認してください。
- Not applicable
- このルールは、現在の設定には適用されません。
- Not selected
- このルールはプロファイルには含まれません。OpenSCAP はこのルールを評価せず、結果にこのようなルールは表示されません。
- Error
-
スキャンでエラーが発生しました。詳細は、
--verbose DEVELオプションを指定してoscapコマンドで確認できます。Red Hat カスタマーポータル でサポートケースを作成するか、Red Hat Jira の RHEL プロジェクト でチケットを作成します。 - Unknown
-
スキャンで予期しない状況が発生しました。詳細は、
`--verbose DEVELオプションを指定してoscapコマンドを入力できます。Red Hat カスタマーポータル でサポートケースを作成するか、Red Hat Jira の RHEL プロジェクト でチケットを作成します。
18.4.3. 設定コンプライアンスのプロファイルの表示
スキャンまたは修復にプロファイルを使用することを決定する前に、oscap info サブコマンドを使用して、プロファイルを一覧表示し、詳細な説明を確認できます。
前提条件
-
openscap-scannerパッケージおよびscap-security-guideパッケージがインストールされている。
手順
SCAP Security Guide プロジェクトが提供するセキュリティーコンプライアンスプロファイルで利用可能なファイルをすべて表示します。
$ ls /usr/share/xml/scap/ssg/content/ ssg-firefox-cpe-dictionary.xml ssg-rhel6-ocil.xml ssg-firefox-cpe-oval.xml ssg-rhel6-oval.xml … ssg-rhel6-ds-1.2.xml ssg-rhel8-oval.xml ssg-rhel8-ds.xml ssg-rhel8-xccdf.xml …oscap infoサブコマンドを使用して、選択したデータストリームに関する詳細情報を表示します。データストリームを含む XML ファイルは、名前に-ds文字列で示されます。Profilesセクションでは、利用可能なプロファイルと、その ID のリストを確認できます。$ oscap info /usr/share/xml/scap/ssg/content/ssg-rhel8-ds.xml Profiles: … Title: Health Insurance Portability and Accountability Act (HIPAA) Id: xccdf_org.ssgproject.content_profile_hipaa Title: PCI-DSS v3.2.1 Control Baseline for Red Hat Enterprise Linux 8 Id: xccdf_org.ssgproject.content_profile_pci-dss Title: OSPP - Protection Profile for General Purpose Operating Systems Id: xccdf_org.ssgproject.content_profile_ospp …データストリームファイルからプロファイルを選択し、選択したプロファイルに関する追加情報を表示します。そのためには、
oscap infoに--profileオプションを指定した後に、直前のコマンドの出力で表示された ID の最後のセクションを指定します。たとえば、HIPPA プロファイルの ID はxccdf_org.ssgproject.content_profile_hipaaで、--profileオプションの値はhipaaです。$ oscap info --profile hipaa /usr/share/xml/scap/ssg/content/ssg-rhel8-ds.xml … Profile Title: Health Insurance Portability and Accountability Act (HIPAA) Description: The HIPAA Security Rule establishes U.S. national standards to protect individuals’ electronic personal health information that is created, received, used, or maintained by a covered entity. …
18.4.4. 特定のベースラインによる設定コンプライアンスの評価
oscap コマンドラインツールを使用して、システムまたはリモートシステムが特定のベースラインに準拠しているかどうかを判断し、結果をレポートに保存できます。
前提条件
-
openscap-scannerパッケージおよびscap-security-guideパッケージがインストールされている。 - システムが準拠する必要があるベースライン内のプロファイルの ID を知っている必要があります。ID を見つけるには、設定コンプライアンスのプロファイルの表示 セクションを参照してください。
手順
ローカルシステムをスキャンして、選択したプロファイルへの準拠を評価し、スキャン結果をファイルに保存します。
$ oscap xccdf eval --report <scan-report.html> --profile <profileID> /usr/share/xml/scap/ssg/content/ssg-rhel8-ds.xml以下を置き換えます。
-
<scan-report.html>は、oscapがスキャン結果を保存するファイル名です。 -
<profileID>は、システムが準拠する必要があるプロファイル ID (例:hipaa) です。
-
オプション:リモートシステムをスキャンして、選択したプロファイルへの準拠を評価し、スキャン結果をファイルに保存します。
$ oscap-ssh <username>@<hostname> <port> xccdf eval --report <scan-report.html> --profile <profileID> /usr/share/xml/scap/ssg/content/ssg-rhel8-ds.xml以下を置き換えます。
-
<username>@<hostname>は、リモートシステムのユーザー名とホスト名に置き換えます。 -
<port>は、リモートシステムにアクセスできるポート番号です。 -
<scan-report.html>は、oscapがスキャン結果を保存するファイル名です。 -
<profileID>は、システムが準拠する必要があるプロファイル ID (例:hipaa) です。
-
18.5. 特定のベースラインに合わせたシステムの修復
特定のベースラインに合わせて RHEL システムを修正できます。SCAP Security Guide で提供されるプロファイルに合わせてシステムを修正できます。使用可能なプロファイルのリストの詳細は、設定コンプライアンスのプロファイルの表示 を参照してください。
修正 オプションが有効な状態でのシステム評価は、慎重に行わないとシステムが機能不全に陥る場合があります。Red Hat は、セキュリティーを強化した修正で加えられた変更を元に戻す自動手段は提供していません。修復は、デフォルト設定の RHEL システムで対応しています。インストール後にシステムが変更した場合は、修正を実行しても、必要なセキュリティープロファイルに準拠しない場合があります。
前提条件
-
scap-security-guideパッケージがインストールされている。
手順
--remediateオプションを指定したoscapコマンドを使用してシステムを修復します。# oscap xccdf eval --profile <profileID> --remediate /usr/share/xml/scap/ssg/content/ssg-rhel8-ds.xml<profileID>は、システムが準拠する必要があるプロファイル ID (例:hipaa) に置き換えます。- システムを再起動します。
検証
システムがプロファイルに準拠しているかどうかを評価し、スキャン結果をファイルに保存します。
$ oscap xccdf eval --report <scan-report.html> --profile <profileID> /usr/share/xml/scap/ssg/content/ssg-rhel8-ds.xml以下を置き換えます。
-
<scan-report.html>は、oscapがスキャン結果を保存するファイル名です。 -
<profileID>は、システムが準拠する必要があるプロファイル ID (例:hipaa) です。
-
18.6. SSG Ansible Playbook を使用した特定のベースラインに合わせたシステムの修正
SCAP Security Guide プロジェクトの Ansible Playbook ファイルを使用して、特定のベースラインに合わせてシステムを修正できます。SCAP Security Guide によって提供されるすべてのプロファイルに合わせて修正できます。
修正 オプションが有効な状態でのシステム評価は、慎重に行わないとシステムが機能不全に陥る場合があります。Red Hat は、セキュリティーを強化した修正で加えられた変更を元に戻す自動手段は提供していません。修復は、デフォルト設定の RHEL システムで対応しています。インストール後にシステムが変更した場合は、修正を実行しても、必要なセキュリティープロファイルに準拠しない場合があります。
前提条件
-
scap-security-guideパッケージがインストールされている。 -
ansible-coreパッケージがインストールされている。詳細は、Ansible インストールガイドを参照してください。 -
rhc-worker-playbookパッケージがインストールされている。 - システムの修正に使用するプロファイルの ID がわかっている。詳細は、設定コンプライアンスのプロファイルの表示 を参照してください。
RHEL 8.6 以降がインストールされている。RHEL のインストールの詳細は、インストールメディアから RHEL を対話的にインストールする を参照してください。
注記RHEL 8.5 以前のバージョンでは、Ansible パッケージは Ansible Core ではなく Ansible Engine を通じて提供され、さまざまなサポートレベルが提供されていました。パッケージは RHEL 8.6 以降の Ansible Automation コンテンツと互換性がない可能性があるため、Ansible Engine は使用しないでください。詳細は、Scope of support for the Ansible Core package included in the RHEL 9 and RHEL 8.6 and later AppStream repositories を参照してください。
手順
Ansible を使用して、選択したプロファイルに準拠するようにシステムを修正します。
# ANSIBLE_COLLECTIONS_PATH=/usr/share/rhc-worker-playbook/ansible/collections/ansible_collections/ ansible-playbook -i "localhost," -c local /usr/share/scap-security-guide/ansible/rhel8-playbook-<profileID>.ymlこのコマンドで Playbook を実行するには、
ANSIBLE_COLLECTIONS_PATH環境変数が必要です。<profileID>は、選択したプロファイルのプロファイル ID に置き換えます。- システムを再起動します。
検証
システムが選択したプロファイルに準拠しているかどうかを評価し、スキャン結果をファイルに保存します。
# oscap xccdf eval --profile <profileID> --report <scan-report.html> /usr/share/xml/scap/ssg/content/ssg-rhel8-ds.xml<scan-report.html>は、oscapがスキャン結果を保存するファイル名に置き換えます。
18.7. システムを特定のベースラインに合わせるための修復用 Ansible Playbook の作成
システムを特定のベースラインに合わせるために必要な修復のみを含む Ansible Playbook を作成できます。この Playbook は、すでに満たされている要件を含んでいないため、小型です。Playbook を作成しても、システムは一切変更されません。ここでは、後で適用するためのファイルを準備するだけです。
RHEL 8.6 では、Ansible Engine は、組み込みモジュールのみを含む ansible-core パッケージに置き換えられました。Ansible 修復の多くは、community コレクションおよび Portable Operating System Interface (POSIX) コレクションのモジュールを使用することに注意してください。これは組み込みモジュールには含まれていません。この場合は、Bash 修復を Ansible 修復の代わりに使用できます。RHEL 8.6 の Red Hat Connector には、修復 Playbook が Ansible Core で機能するために必要な Ansible モジュールが含まれています。
前提条件
-
scap-security-guideパッケージがインストールされている。 -
ansible-coreパッケージがインストールされている。詳細は、Ansible インストールガイドを参照してください。 -
rhc-worker-playbookパッケージがインストールされている。 - システムの修正に使用するプロファイルの ID がわかっている。詳細は、設定コンプライアンスのプロファイルの表示 を参照してください。
手順
システムをスキャンして結果を保存します。
# oscap xccdf eval --profile <profileID> --results <profile-results.xml> /usr/share/xml/scap/ssg/content/ssg-rhel8-ds.xml結果が含まれるファイルで、結果 ID の値を見つけます。
# oscap info <profile-results.xml>ステップ 1 で生成されたファイルに基づいて Ansible Playbook を生成します。
# oscap xccdf generate fix --fix-type ansible --result-id xccdf_org.open-scap_testresult_xccdf_org.ssgproject.content_profile_<profileID> --output <profile-remediations.yml> <profile-results.xml>-
生成された
<profile-remediations.yml>ファイルに、ステップ 1 で実行したスキャンで失敗したルールに対する Ansible 修復が含まれていることを確認します。 Ansible を使用して、選択したプロファイルに準拠するようにシステムを修正します。
# ANSIBLE_COLLECTIONS_PATH=/usr/share/rhc-worker-playbook/ansible/collections/ansible_collections/ ansible-playbook -i "localhost," -c local <profile-remediations.yml>`このコマンドで Playbook を実行するには、
ANSIBLE_COLLECTIONS_PATH環境変数が必要です。警告修正オプションが有効な状態でのシステム評価は、慎重に行わないとシステムが機能不全に陥る場合があります。Red Hat は、セキュリティーを強化した修正で加えられた変更を元に戻す自動手段は提供していません。修復は、デフォルト設定の RHEL システムで対応しています。インストール後にシステムが変更した場合は、修正を実行しても、必要なセキュリティープロファイルに準拠しない場合があります。
検証
システムが選択したプロファイルに準拠しているかどうかを評価し、スキャン結果をファイルに保存します。
# oscap xccdf eval --profile <profileID> --report <scan-report.html> /usr/share/xml/scap/ssg/content/ssg-rhel8-ds.xml<scan-report.html>は、oscapがスキャン結果を保存するファイル名に置き換えます。
18.8. 後でアプリケーションを修復するための Bash スクリプトの作成
この手順を使用して、システムを HIPAA などのセキュリティープロファイルと調整する修正を含む Bash スクリプトを作成します。次の手順では、システムに変更を加えることなく、後のアプリケーション用にファイルを準備する方法を説明します。
前提条件
-
RHEL システムに、
scap-security-guideパッケージがインストールされている。
手順
oscapコマンドを使用してシステムをスキャンし、結果を XML ファイルに保存します。以下の例では、oscapはhipaaプロファイルに対してシステムを評価します。# oscap xccdf eval --profile hipaa --results <hipaa-results.xml> /usr/share/xml/scap/ssg/content/ssg-rhel8-ds.xml結果が含まれるファイルで、結果 ID の値を見つけます。
# oscap info <hipaa-results.xml>手順 1 で生成された結果ファイルに基づいて Bash スクリプトを生成します。
# oscap xccdf generate fix --fix-type bash --result-id <xccdf_org.open-scap_testresult_xccdf_org.ssgproject.content_profile_hipaa> --output <hipaa-remediations.sh> <hipaa-results.xml>-
<hipaa-remediations.sh>ファイルには、手順 1 で実行されたスキャン中に失敗したルールの修復が含まれます。この生成されたファイルを確認したら、このファイルと同じディレクトリー内で、./<hipaa-remediations.sh>コマンドを使用してファイルを適用できます。
検証
-
お使いのテキストエディターで、手順 1 で実行したスキャンで失敗したルールが
<hipaa-remediations.sh>ファイルに含まれていることを確認します。
18.9. SCAP Workbench を使用したカスタムプロファイルでシステムのスキャン
SCAP Workbench (scap-workbench) パッケージはグラフィカルユーティリティーで、1 台のローカルシステムまたはリモートシステムで設定スキャンと脆弱性スキャンを実行し、システムの修復を実行して、スキャン評価に基づくレポートを生成します。oscap コマンドラインユーティリティーとの比較は、SCAP Workbench には限定的な機能しかないことに注意してください。SCAP Workbench は、データストリームファイルの形式でセキュリティーコンテンツを処理します。
18.9.1. SCAP Workbench を使用したシステムのスキャンおよび修復
選択したセキュリティーポリシーに対してシステムを評価するには、以下の手順に従います。
前提条件
-
scap-workbenchパッケージがシステムにインストールされている。
手順
GNOME Classicデスクトップ環境からSCAP Workbenchを実行するには、Super キーを押してアクティビティーの概要を開き、scap-workbenchと入力して Enterを押します。または、次のコマンドを実行します。$ scap-workbench &以下のオプションのいずれかを使用してセキュリティーポリシーを選択します。
-
開始ウィンドウの
Load Contentボタン -
Open content from SCAP Security Guide FileメニューのOpen Other Contentで、XCCDF、SCAP RPM、またはデータストリームファイルの各ファイルを検索します。
-
開始ウィンドウの
チェックボックスを選択して、システム設定の自動修正を行うことができます。このオプションを有効にすると、
SCAP Workbenchは、ポリシーにより適用されるセキュリティールールに従ってシステム設定の変更を試みます。このプロセスは、システムスキャン時に失敗した関連チェックを修正する必要があります。警告修正オプションが有効な状態でのシステム評価は、慎重に行わないとシステムが機能不全に陥る場合があります。Red Hat は、セキュリティーを強化した修正で加えられた変更を元に戻す自動手段は提供していません。修復は、デフォルト設定の RHEL システムで対応しています。インストール後にシステムが変更した場合は、修正を実行しても、必要なセキュリティープロファイルに準拠しない場合があります。ボタンをクリックし、選択したプロファイルでシステムをスキャンします。
-
スキャン結果を XCCDF ファイル、ARF ファイル、または HTML ファイルの形式で保存するには、 コンボボックスをクリックします。
HTML Reportオプションを選択して、スキャンレポートを、人間が判読できる形式で生成します。XCCDF 形式および ARF (データストリーム) 形式は、追加の自動処理に適しています。3 つのオプションはすべて繰り返し選択できます。 - 結果ベースの修復をファイルにエクスポートするには、ポップアップメニューの を使用します。
18.9.2. SCAP Workbench を使用したセキュリティープロファイルのカスタマイズ
セキュリティープロファイルをカスタマイズするには、特定のルール (パスワードの最小長など) のパラメーターを変更し、別の方法で対象とするルールを削除し、追加のルールを選択して内部ポリシーを実装できます。プロファイルをカスタマイズして新しいルールの定義はできません。
以下の手順は、プロファイルをカスタマイズ (調整) するための SCAP Workbench の使用を示しています。oscap コマンドラインユーティリティーで使用するようにカスタマイズしたプロファイルを保存することもできます。
前提条件
-
scap-workbenchパッケージがシステムにインストールされている。
手順
-
SCAP Workbenchを実行し、Open content from SCAP Security GuideまたはFileメニューのOpen Other Contentを使用してカスタマイズするプロファイルを選択します。 選択したセキュリティープロファイルを必要に応じて調整するには、 ボタンをクリックします。
これにより、元のデータストリームファイルを変更せずに現在選択されているプロファイルを変更できる新しいカスタマイズウィンドウが開きます。新しいプロファイル ID を選択します。
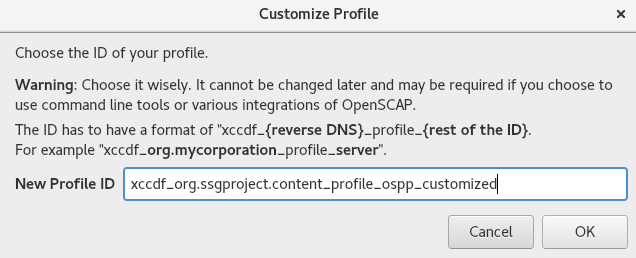
- 論理グループに分けられたルールを持つツリー構造を使用するか、 フィールドを使用して変更するルールを検索します。
ツリー構造のチェックボックスを使用した include ルールまたは exclude ルール、または必要に応じてルールの値を変更します。
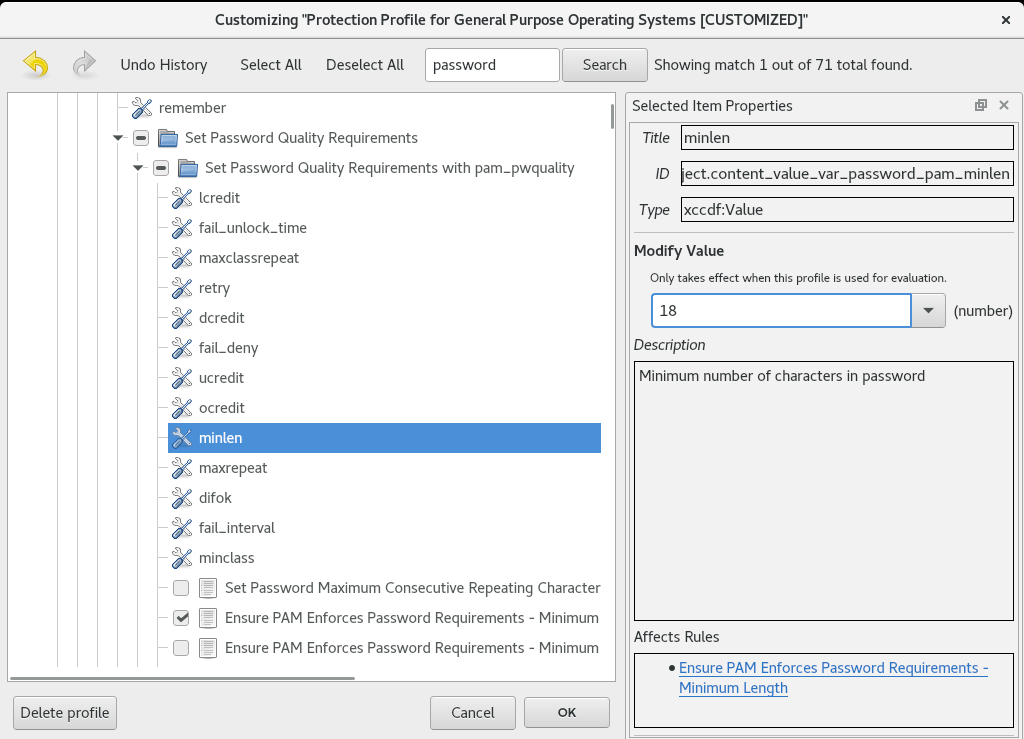
- ボタンをクリックして変更を確認します。
変更内容を永続的に保存するには、以下のいずれかのオプションを使用します。
-
FileメニューのSave Customization Onlyを使用して、カスタマイズファイルを別途保存します。 FileメニューSave Allを選択して、すべてのセキュリティーコンテンツを一度に保存します。Into a directoryオプションを選択すると、SCAP Workbenchは、データストリームファイルおよびカスタマイズファイルの両方を、指定した場所に保存します。これはバックアップソリューションとして使用できます。As RPMオプションを選択すると、SCAP Workbenchに、データストリームファイル、ならびにカスタマイズファイルを含む RPM パッケージの作成を指示できます。これは、リモートでスキャンできないシステムにセキュリティーコンテンツを配布したり、詳細な処理のためにコンテンツを配信するのに便利です。
-
SCAP Workbench は、カスタマイズしたプロファイル向けの結果ベースの修正に対応していないため、oscap コマンドラインユーティリティーでエクスポートした修正を使用します。
18.10. コンテナーおよびコンテナーイメージの脆弱性スキャン
以下の手順を使用して、コンテナーまたはコンテナーイメージのセキュリティー脆弱性を検索します。
oscap-podman コマンドは、RHEL 8.2 で利用できます。RHEL 8.1 および 8.0 の場合は、ナレッジベースの記事 Using OpenSCAP for scanning containers in RHEL 8 で説明されている回避策を利用します。
前提条件
-
openscap-utilsおよびbzip2パッケージがインストールされます。
手順
システムに最新 RHSA OVAL 定義をダウンロードします。
# wget -O - https://www.redhat.com/security/data/oval/v2/RHEL8/rhel-8.oval.xml.bz2 | bzip2 --decompress > rhel-8.oval.xmlコンテナーまたはコンテナーイメージの ID を取得します。以下に例を示します。
# podman images REPOSITORY TAG IMAGE ID CREATED SIZE registry.access.redhat.com/ubi8/ubi latest 096cae65a207 7 weeks ago 239 MBコンテナーまたはコンテナーイメージで脆弱性をスキャンし、結果を vulnerability.html ファイルに保存します。
# oscap-podman 096cae65a207 oval eval --report vulnerability.html rhel-8.oval.xmloscap-podmanコマンドには root 権限が必要で、コンテナーの ID は最初の引数であることに注意してください。
検証
結果をブラウザーで確認します。以下に例を示します。
$ firefox vulnerability.html &
18.11. 特定のベースラインを使用したコンテナーまたはコンテナーイメージのセキュリティーコンプライアンスの評価
コンテナーまたはコンテナーイメージが、Operating System Protection Profile (OSPP)、Payment Card Industry Data Security Standard (PCI-DSS)、Health Insurance Portability and Accountability Act (HIPAA) などの特定のセキュリティーベースラインに準拠しているかどうかを評価できます。
oscap-podman コマンドは、RHEL 8.2 で利用できます。RHEL 8.1 および 8.0 の場合は、ナレッジベースの記事 Using OpenSCAP for scanning containers in RHEL 8 で説明されている回避策を利用します。
前提条件
-
openscap-utilsパッケージおよびscap-security-guideパッケージがインストールされている。 - システムへの root アクセス権があります。
手順
コンテナーまたはコンテナーイメージの ID を見つけます。
-
コンテナーの ID を見つけるには、
podman ps -aコマンドを入力します。 -
コンテナーイメージの ID を見つけるには、
podman imagesコマンドを入力します。
-
コンテナーの ID を見つけるには、
コンテナーまたはコンテナーイメージがプロファイルに準拠しているかどうかを評価し、スキャン結果をファイルに保存します。
# oscap-podman <ID> xccdf eval --report <scan-report.html> --profile <profileID> /usr/share/xml/scap/ssg/content/ssg-rhel8-ds.xml以下を置き換えます。
-
<ID>は、コンテナーまたはコンテナーイメージの ID です。 -
<scan-report.html>は、oscapがスキャン結果を保存するファイル名です。 -
<profileID>は、システムが準拠する必要があるプロファイル ID (例:hipaa、ospp、pci-dss) です。
-
検証
結果をブラウザーで確認します。以下に例を示します。
$ firefox <scan-report.html> &
notapplicable とマークされたルールは、ベアメタルおよび仮想化システムにのみ適用され、コンテナーまたはコンテナーイメージには適用されません。
18.12. AIDE で整合性の確認
Advanced Intrusion Detection Environment (AIDE) は、システムにファイルのデータベースを作成し、そのデータベースを使用してファイルの整合性を確保し、システムの侵入を検出するユーティリティーです。
18.12.1. AIDE のインストール
AIDE を使用してファイル整合性チェックを開始するには、対応するパッケージをインストールし、AIDE データベースを初期化する必要があります。
前提条件
-
AppStreamリポジトリーが有効になっている。
手順
aideパッケージをインストールします。# yum install aide初期データベースを生成します。
# aide --init Start timestamp: 2024-07-08 10:39:23 -0400 (AIDE 0.16) AIDE initialized database at /var/lib/aide/aide.db.new.gz Number of entries: 55856 --------------------------------------------------- The attributes of the (uncompressed) database(s): --------------------------------------------------- /var/lib/aide/aide.db.new.gz … SHA512 : mZaWoGzL2m6ZcyyZ/AXTIowliEXWSZqx IFYImY4f7id4u+Bq8WeuSE2jasZur/A4 FPBFaBkoCFHdoE/FW/V94Q==-
オプション:デフォルト設定では、
aide --initコマンドは、/etc/aide.confファイルで定義するディレクトリーとファイルのセットのみを確認します。ディレクトリーまたはファイルを AIDE データベースに追加し、監視パラメーターを変更するには、/etc/aide.confを変更します。 データベースの使用を開始するには、初期データベースのファイル名から末尾の
.newを削除します。# mv /var/lib/aide/aide.db.new.gz /var/lib/aide/aide.db.gz-
オプション:AIDE データベースの場所を変更するには、
/etc/aide.confファイルを編集し、DBDIR値を変更します。追加のセキュリティーのデータベース、設定、/usr/sbin/aideバイナリーファイルを、読み取り専用メディアなどの安全な場所に保存します。
18.12.2. AIDE を使用した整合性チェックの実行
crond サービスを使用すると、AIDE で定期的なファイル整合性チェックをスケジュールできます。
前提条件
- AIDE が適切にインストールされ、データベースが初期化されている。AIDE のインストール を参照してください。
手順
手動でチェックを開始するには、以下を行います。
# aide --check Start timestamp: 2024-07-08 10:43:46 -0400 (AIDE 0.16) AIDE found differences between database and filesystem!! Summary: Total number of entries: 55856 Added entries: 0 Removed entries: 0 Changed entries: 1 --------------------------------------------------- Changed entries: --------------------------------------------------- f ... ..S : /root/.viminfo --------------------------------------------------- Detailed information about changes: --------------------------------------------------- File: /root/.viminfo SELinux : system_u:object_r:admin_home_t:s | unconfined_u:object_r:admin_home 0 | _t:s0 …少なくとも、AIDE を毎週実行するようにシステムを設定します。最適な設定としては、AIDE を毎日実行します。たとえば、
cronコマンドを使用して毎日午前 04:05 に AIDE を実行するようにスケジュールするには、/etc/crontabファイルに次の行を追加します。05 4 * * * root /usr/sbin/aide --check
18.12.3. AIDE データベースの更新
パッケージの更新や設定ファイルの調整など、システムの変更が確認できたら、基本となる AIDE データベースも更新します。
前提条件
- AIDE が適切にインストールされ、データベースが初期化されている。AIDE のインストール を参照してください。
手順
基本となる AIDE データベースを更新します。
# aide --updateaide --updateコマンドは、/var/lib/aide/aide.db.new.gzデータベースファイルを作成します。-
整合性チェックで更新したデータベースを使用するには、ファイル名から末尾の
.newを削除します。
18.12.4. ファイル整合性ツール:AIDE および IMA
Red Hat Enterprise Linux は、システム上のファイルとディレクトリーの整合性をチェックおよび保持するためのさまざまなツールを提供します。次の表は、シナリオに適したツールを決定するのに役立ちます。
| 比較項目 | Advanced Intrusion Detection Environment (AIDE) | Integrity Measurement Architecture (IMA) |
|---|---|---|
| 確認対象 | AIDE は、システム上のファイルとディレクトリーのデータベースを作成するユーティリティーです。このデータベースは、ファイルの整合性をチェックし、侵入を検出するのに役立ちます。 | IMA は、以前に保存された拡張属性と比較してファイル測定値 (ハッシュ値) をチェックすることにより、ファイルが変更されているかどうかを検出します。 |
| 確認方法 | AIDE はルールを使用して、ファイルとディレクトリーの整合性状態を比較します。 | IMA は、ファイルハッシュ値を使用して侵入を検出します。 |
| 理由 | 検出 - AIDE は、ルールを検証することにより、ファイルが変更されているかどうかを検出します。 | 検出と防止 - IMA は、ファイルの拡張属性を置き換えることにより、攻撃を検出および防止します。 |
| 使用方法 | AIDE は、ファイルまたはディレクトリーが変更されたときに脅威を検出します。 | 誰かがファイル全体の変更を試みた時に、IMA は脅威を検出します。 |
| 範囲 | AIDE は、ローカルシステム上のファイルとディレクトリーの整合性をチェックします。 | IMA は、ローカルシステムとリモートシステムのセキュリティーを確保します。 |
18.13. LUKS を使用したブロックデバイスの暗号化
ディスク暗号化を使用すると、ブロックデバイス上のデータを暗号化して保護できます。デバイスの復号化されたコンテンツにアクセスするには、認証としてパスフレーズまたは鍵を入力します。これは、デバイスがシステムから物理的に取り外された場合でも、デバイスのコンテンツを保護するのに役立つため、モバイルコンピューターやリムーバブルメディアにとって重要です。LUKS 形式は、Red Hat Enterprise Linux におけるブロックデバイスの暗号化のデフォルト実装です。
18.13.1. LUKS ディスクの暗号化
Linux Unified Key Setup-on-disk-format (LUKS) は、暗号化されたデバイスの管理を簡素化するツールセットを提供します。LUKS を使用すると、ブロックデバイスを暗号化し、複数のユーザーキーでマスターキーを復号化できるようになります。パーティションの一括暗号化には、このマスターキーを使用します。
Red Hat Enterprise Linux は、LUKS を使用してブロックデバイスの暗号化を実行します。デフォルトではインストール時に、ブロックデバイスを暗号化するオプションが指定されていません。ディスクを暗号化するオプションを選択すると、コンピューターを起動するたびにパスフレーズの入力が求められます。このパスフレーズは、パーティションを復号化するバルク暗号鍵のロックを解除します。デフォルトのパーティションテーブルを変更する場合は、暗号化するパーティションを選択できます。この設定は、パーティションテーブル設定で行われます。
Ciphers
LUKS に使用されるデフォルトの暗号は aes-xts-plain64 です。LUKS のデフォルトの鍵サイズは 512 ビットです。Anaconda XTS モードを使用した LUKS のデフォルトの鍵サイズは 512 ビットです。使用可能な暗号は次のとおりです。
- 高度暗号化標準 (Advanced Encryption Standard, AES)
- Twofish
- Serpent
LUKS によって実行される操作
- LUKS は、ブロックデバイス全体を暗号化するため、脱着可能なストレージメディアやノート PC のディスクドライブといった、モバイルデバイスのコンテンツを保護するのに適しています。
- 暗号化されたブロックデバイスの基本的な内容は任意であり、スワップデバイスの暗号化に役立ちます。また、とりわけデータストレージ用にフォーマットしたブロックデバイスを使用する特定のデータベースに関しても有用です。
- LUKS は、既存のデバイスマッパーのカーネルサブシステムを使用します。
- LUKS はパスフレーズのセキュリティーを強化し、辞書攻撃から保護します。
- LUKS デバイスには複数のキースロットが含まれているため、バックアップキーやパスフレーズを追加できます。
LUKS は次のシナリオには推奨されません。
- LUKS などのディスク暗号化ソリューションは、システムの停止時にしかデータを保護しません。システムの電源がオンになり、LUKS がディスクを復号化すると、そのディスクのファイルは、そのファイルにアクセスできるすべてのユーザーが使用できます。
- 同じデバイスに対する個別のアクセスキーを複数のユーザーが持つ必要があるシナリオ。LUKS1 形式はキースロットを 8 個提供し、LUKS2 形式はキースロットを最大 32 個提供します。
- ファイルレベルの暗号化を必要とするアプリケーション。
18.13.2. RHEL の LUKS バージョン
Red Hat Enterprise Linux では、LUKS 暗号化のデフォルト形式は LUKS2 です。古い LUKS1 形式は引き続き完全にサポートされており、以前の Red Hat Enterprise Linux リリースと互換性のある形式で提供されます。LUKS2 再暗号化は、LUKS1 再暗号化と比較して、より堅牢で安全に使用できる形式と考えられています。
LUKS2 形式を使用すると、バイナリー構造を変更することなく、さまざまな部分を後に更新できます。LUKS2 は、内部的にメタデータに JSON テキスト形式を使用し、メタデータの冗長性を提供し、メタデータの破損を検出し、メタデータのコピーから自動的に修復します。
LUKS2 と LUKS1 はディスクの暗号化に異なるコマンドを使用するため、LUKS1 のみをサポートするシステムでは LUKS2 を使用しないでください。LUKS バージョンに誤ったコマンドを使用すると、データが失われる可能性があります。
| LUKS バージョン | 暗号化コマンド |
|---|---|
| LUKS2 |
|
| LUKS1 |
|
オンラインの再暗号化
LUKS2 形式は、デバイスが使用中の間に、暗号化したデバイスの再暗号化に対応します。たとえば、以下のタスクを実行するにあたり、デバイスでファイルシステムをアンマウントする必要はありません。
- ボリュームキーの変更
暗号化アルゴリズムの変更
暗号化されていないデバイスを暗号化する場合は、ファイルシステムのマウントを解除する必要があります。暗号化の短い初期化後にファイルシステムを再マウントできます。
LUKS1 形式は、オンライン再暗号化に対応していません。
変換
特定の状況では、LUKS1 を LUKS2 に変換できます。具体的には、以下のシナリオでは変換ができません。
-
LUKS1 デバイスが、Policy-Based Decryption (PBD) Clevis ソリューションにより使用されているとマークされている。
cryptsetupツールは、luksmetaメタデータが検出されると、そのデバイスを変換することを拒否します。 - デバイスがアクティブになっている。デバイスが非アクティブ状態でなければ、変換することはできません。
18.13.3. LUKS2 再暗号化中のデータ保護のオプション
LUKS2 では、再暗号化プロセスで、パフォーマンスやデータ保護の優先度を設定する複数のオプションを選択できます。resilience オプションには次のモードが用意されています。cryptsetup reencrypt --resilience resilience-mode /dev/<device_ID> コマンドを使用すると、これらのモードのいずれかを選択できます。<device_ID> は、デバイスの ID に置き換えてください。
checksumデフォルトのモード。データ保護とパフォーマンスのバランスを取ります。
このモードでは、再暗号化領域内のセクターのチェックサムが個別に保存されます。チェックサムは、LUKS2 によって再暗号化されたセクターについて、復旧プロセスで検出できます。このモードでは、ブロックデバイスセクターの書き込みがアトミックである必要があります。
journal- 最も安全なモードですが、最も遅いモードでもあります。このモードでは、再暗号化領域をバイナリー領域にジャーナル化するため、LUKS2 はデータを 2 回書き込みます。
none-
noneモードではパフォーマンスが優先され、データ保護は提供されません。SIGTERMシグナルやユーザーによる Ctrl+C キーの押下など、安全なプロセス終了からのみデータを保護します。予期しないシステム障害やアプリケーション障害が発生すると、データが破損する可能性があります。
LUKS2 の再暗号化プロセスが強制的に突然終了した場合、LUKS2 は以下のいずれかの方法で復旧を実行できます。
- 自動
次のいずれかのアクションを実行すると、次回の LUKS2 デバイスを開くアクション中に自動復旧アクションがトリガーされます。
-
cryptsetup openコマンドを実行する。 -
systemd-cryptsetupコマンドを使用してデバイスを接続する。
-
- 手動
-
LUKS2 デバイスで
cryptsetup repair /dev/<device_ID>コマンドを使用します。
18.13.4. LUKS2 を使用したブロックデバイスの既存データの暗号化
LUKS2 形式を使用して、まだ暗号化されていないデバイスの既存のデータを暗号化できます。新しい LUKS ヘッダーは、デバイスのヘッドに保存されます。
前提条件
- ブロックデバイスにファイルシステムがある。
データのバックアップを作成している。
警告ハードウェア、カーネル、または人的ミスにより、暗号化プロセス時にデータが失われる場合があります。データの暗号化を開始する前に、信頼性の高いバックアップを作成してください。
手順
暗号化するデバイスにあるファイルシステムのマウントをすべて解除します。次に例を示します。
# umount /dev/mapper/vg00-lv00LUKS ヘッダーを保存するための空き容量を確認します。シナリオに合わせて、次のいずれかのオプションを使用します。
論理ボリュームを暗号化する場合は、以下のように、ファイルシステムのサイズを変更せずに、論理ボリュームを拡張できます。以下に例を示します。
# lvextend -L+32M /dev/mapper/vg00-lv00-
partedなどのパーティション管理ツールを使用してパーティションを拡張します。 -
このデバイスのファイルシステムを縮小します。ext2、ext3、または ext4 のファイルシステムには
resize2fsユーティリティーを使用できます。XFS ファイルシステムは縮小できないことに注意してください。
暗号化を初期化します。
# cryptsetup reencrypt --encrypt --init-only --reduce-device-size 32M /dev/mapper/vg00-lv00 lv00_encrypted /dev/mapper/lv00_encrypted is now active and ready for online encryption.デバイスをマウントします。
# mount /dev/mapper/lv00_encrypted /mnt/lv00_encrypted永続的なマッピングのエントリーを
/etc/crypttabファイルに追加します。luksUUIDを見つけます。# cryptsetup luksUUID /dev/mapper/vg00-lv00 a52e2cc9-a5be-47b8-a95d-6bdf4f2d9325任意のテキストエディターで
/etc/crypttabを開き、このファイルにデバイスを追加します。$ vi /etc/crypttab lv00_encrypted UUID=a52e2cc9-a5be-47b8-a95d-6bdf4f2d9325 nonea52e2cc9-a5be-47b8-a95d-6bdf4f2d9325 は、デバイスの
luksUUIDに置き換えます。dracutで initramfs を更新します。$ dracut -f --regenerate-all
/etc/fstabファイルに永続的なマウントのエントリーを追加します。アクティブな LUKS ブロックデバイスのファイルシステムの UUID を見つけます。
$ blkid -p /dev/mapper/lv00_encrypted /dev/mapper/lv00-encrypted: UUID="37bc2492-d8fa-4969-9d9b-bb64d3685aa9" BLOCK_SIZE="4096" TYPE="xfs" USAGE="filesystem"任意のテキストエディターで
/etc/fstabを開き、このファイルにデバイスを追加します。次に例を示します。$ vi /etc/fstab UUID=37bc2492-d8fa-4969-9d9b-bb64d3685aa9 /home auto rw,user,auto 037bc2492-d8fa-4969-9d9b-bb64d3685aa9 は、ファイルシステムの UUID に置き換えます。
オンライン暗号化を再開します。
# cryptsetup reencrypt --resume-only /dev/mapper/vg00-lv00 Enter passphrase for /dev/mapper/vg00-lv00: Auto-detected active dm device 'lv00_encrypted' for data device /dev/mapper/vg00-lv00. Finished, time 00:31.130, 10272 MiB written, speed 330.0 MiB/s
検証
既存のデータが暗号化されているかどうかを確認します。
# cryptsetup luksDump /dev/mapper/vg00-lv00 LUKS header information Version: 2 Epoch: 4 Metadata area: 16384 [bytes] Keyslots area: 16744448 [bytes] UUID: a52e2cc9-a5be-47b8-a95d-6bdf4f2d9325 Label: (no label) Subsystem: (no subsystem) Flags: (no flags) Data segments: 0: crypt offset: 33554432 [bytes] length: (whole device) cipher: aes-xts-plain64 [...]暗号化された空のブロックデバイスのステータスを表示します。
# cryptsetup status lv00_encrypted /dev/mapper/lv00_encrypted is active and is in use. type: LUKS2 cipher: aes-xts-plain64 keysize: 512 bits key location: keyring device: /dev/mapper/vg00-lv00
18.13.5. 独立したヘッダーがある LUKS2 を使用してブロックデバイスの既存データの暗号化
LUKS ヘッダーを保存するための空き領域を作成せずに、ブロックデバイスの既存のデータを暗号化できます。ヘッダーは、追加のセキュリティー層としても使用できる、独立した場所に保存されます。この手順では、LUKS2 暗号化形式を使用します。
前提条件
- ブロックデバイスにファイルシステムがある。
データがバックアップ済みである。
警告ハードウェア、カーネル、または人的ミスにより、暗号化プロセス時にデータが失われる場合があります。データの暗号化を開始する前に、信頼性の高いバックアップを作成してください。
手順
以下のように、そのデバイスのファイルシステムをすべてアンマウントします。
# umount /dev/<nvme0n1p1><nvme0n1p1>は、アンマウントするパーティションに対応するデバイス識別子に置き換えます。暗号化を初期化します。
# cryptsetup reencrypt --encrypt --init-only --header </home/header> /dev/<nvme0n1p1> <nvme_encrypted> WARNING! ======== Header file does not exist, do you want to create it? Are you sure? (Type 'yes' in capital letters): YES Enter passphrase for </home/header>: Verify passphrase: /dev/mapper/<nvme_encrypted> is now active and ready for online encryption.以下を置き換えます。
-
</home/header>には、独立した LUKS ヘッダーを含むファイルへのパスを指定します。後で暗号化したデバイスのロックを解除するために、独立した LUKS ヘッダーにアクセスできる必要があります。 -
<nvme_encrypted>は、暗号化後に作成されるデバイスマッパーの名前に置き換えます。
-
デバイスをマウントします。
# mount /dev/mapper/<nvme_encrypted> /mnt/<nvme_encrypted>永続的なマッピングのエントリーを
/etc/crypttabファイルに追加します。# <nvme_encrypted> /dev/disk/by-id/<nvme-partition-id> none header=</home/header><nvme-partition-id>は、NVMe パーティションの識別子に置き換えます。dracutを使用して initramfs を再生成します。# dracut -f --regenerate-all -v/etc/fstabファイルに永続的なマウントのエントリーを追加します。アクティブな LUKS ブロックデバイスのファイルシステムの UUID を見つけます。
$ blkid -p /dev/mapper/<nvme_encrypted> /dev/mapper/<nvme_encrypted>: UUID="37bc2492-d8fa-4969-9d9b-bb64d3685aa9" BLOCK_SIZE="4096" TYPE="xfs" USAGE="filesystem"テキストエディターで
/etc/fstabを開き、このファイルにデバイスを追加します。次に例を示します。UUID=<file_system_UUID> /home auto rw,user,auto 0<file_system_UUID> を、前の手順で見つかったファイルシステムの UUID に置き換えます。
オンライン暗号化を再開します。
# cryptsetup reencrypt --resume-only --header </home/header> /dev/<nvme0n1p1> Enter passphrase for /dev/<nvme0n1p1>: Auto-detected active dm device '<nvme_encrypted>' for data device /dev/<nvme0n1p1>. Finished, time 00m51s, 10 GiB written, speed 198.2 MiB/s
検証
独立したヘッダーがある LUKS2 を使用するブロックデバイスの既存のデータが暗号化されているかどうかを確認します。
# cryptsetup luksDump </home/header> LUKS header information Version: 2 Epoch: 88 Metadata area: 16384 [bytes] Keyslots area: 16744448 [bytes] UUID: c4f5d274-f4c0-41e3-ac36-22a917ab0386 Label: (no label) Subsystem: (no subsystem) Flags: (no flags) Data segments: 0: crypt offset: 0 [bytes] length: (whole device) cipher: aes-xts-plain64 sector: 512 [bytes] [...]暗号化された空のブロックデバイスのステータスを表示します。
# cryptsetup status <nvme_encrypted> /dev/mapper/<nvme_encrypted> is active and is in use. type: LUKS2 cipher: aes-xts-plain64 keysize: 512 bits key location: keyring device: /dev/<nvme0n1p1>
18.13.6. LUKS2 を使用した空のブロックデバイスの暗号化
LUKS2 形式を使用して、空のブロックデバイスを暗号化して、暗号化ストレージとして使用できます。
前提条件
-
空のブロックデバイス。
lsblkなどのコマンドを使用して、そのデバイス上に実際のデータ (ファイルシステムなど) がないかどうかを確認できます。
手順
暗号化した LUKS パーティションとしてパーティションを設定します。
# cryptsetup luksFormat /dev/nvme0n1p1 WARNING! ======== This will overwrite data on /dev/nvme0n1p1 irrevocably. Are you sure? (Type 'yes' in capital letters): YES Enter passphrase for /dev/nvme0n1p1: Verify passphrase:暗号化した LUKS パーティションを開きます。
# cryptsetup open /dev/nvme0n1p1 nvme0n1p1_encrypted Enter passphrase for /dev/nvme0n1p1:これにより、パーティションのロックが解除され、デバイスマッパーを使用してパーティションが新しいデバイスにマッピングされます。暗号化されたデータを上書きしないように、このコマンドは、デバイスが暗号化されたデバイスであり、
/dev/mapper/device_mapped_nameパスを使用して LUKS を通じてアドレス指定されることをカーネルに警告します。暗号化されたデータをパーティションに書き込むためのファイルシステムを作成します。このパーティションには、デバイスマップ名を介してアクセスする必要があります。
# mkfs -t ext4 /dev/mapper/nvme0n1p1_encryptedデバイスをマウントします。
# mount /dev/mapper/nvme0n1p1_encrypted mount-point
検証
空のブロックデバイスが暗号化されているかどうかを確認します。
# cryptsetup luksDump /dev/nvme0n1p1 LUKS header information Version: 2 Epoch: 3 Metadata area: 16384 [bytes] Keyslots area: 16744448 [bytes] UUID: 34ce4870-ffdf-467c-9a9e-345a53ed8a25 Label: (no label) Subsystem: (no subsystem) Flags: (no flags) Data segments: 0: crypt offset: 16777216 [bytes] length: (whole device) cipher: aes-xts-plain64 sector: 512 [bytes] [...]暗号化された空のブロックデバイスのステータスを表示します。
# cryptsetup status nvme0n1p1_encrypted /dev/mapper/nvme0n1p1_encrypted is active and is in use. type: LUKS2 cipher: aes-xts-plain64 keysize: 512 bits key location: keyring device: /dev/nvme0n1p1 sector size: 512 offset: 32768 sectors size: 20938752 sectors mode: read/write
18.13.7. Web コンソールで LUKS パスフレーズの設定
システムの既存の論理ボリュームに暗号化を追加する場合は、ボリュームをフォーマットすることでしか実行できません。
前提条件
- RHEL 8 Web コンソールがインストールされている。
- cockpit サービスが有効になっている。
ユーザーアカウントが Web コンソールにログインできる。
手順は、Web コンソールのインストールおよび有効化 を参照してください。
-
cockpit-storagedパッケージがシステムにインストールされている。 - 暗号化なしで、既存の論理ボリュームを利用できます。
手順
RHEL 8 Web コンソールにログインします。
詳細は、Web コンソールへのログイン を参照してください。
- パネルで、Storage をクリックします。
- ストレージ テーブルで、暗号化するストレージデバイスのメニューボタン をクリックし、 をクリックします。
- Encryption field で、暗号化仕様 LUKS1 または LUKS2 を選択します。
- 新しいパスフレーズを設定し、確認します。
- オプション: その他の暗号化オプションを変更します。
- フォーマット設定の最終処理
- Format をクリックします。
18.13.8. Web コンソールで LUKS パスフレーズの変更
Web コンソールで、暗号化されたディスクまたはパーティションで LUKS パスフレーズを変更します。
前提条件
- RHEL 8 Web コンソールがインストールされている。
- cockpit サービスが有効になっている。
ユーザーアカウントが Web コンソールにログインできる。
手順は、Web コンソールのインストールおよび有効化 を参照してください。
-
cockpit-storagedパッケージがシステムにインストールされている。
手順
RHEL 8 Web コンソールにログインします。
詳細は、Web コンソールへのログイン を参照してください。
- パネルで、Storage をクリックします。
- Storage テーブルで、暗号化されたデータを含むディスクを選択します。
- ディスクページで、Keys セクションまでスクロールし、編集ボタンをクリックします。
パスフレーズの変更 ダイアログウィンドウで、以下を行います。
- 現在のパスフレーズを入力します。
- 新しいパスフレーズを入力します。
- 新しいパスフレーズを確認します。
- Save をクリックします。
18.13.9. コマンドラインを使用した LUKS パスフレーズの変更
コマンドラインを使用して、暗号化されたディスクまたはパーティションの LUKS パスフレーズを変更します。cryptsetup ユーティリティーを使用すると、さまざまな設定オプションと機能を使用して暗号化プロセスを制御し、既存の自動化ワークフローにプロセスを統合できます。
前提条件
-
sudoを使用して管理コマンドを入力するための root権限または権限がある。
手順
LUKS 暗号化デバイスの既存のパスフレーズを変更します。
# cryptsetup luksChangeKey /dev/<device_ID><device_ID>は、デバイス指定子 (例:sda) に置き換えます。複数のキースロットが設定されている場合は、使用するスロットを指定できます。
# cryptsetup luksChangeKey /dev/<device_ID> --key-slot <slot_number><slot_number>は、変更するキースロットの番号に置き換えます。現在のパスフレーズと新しいパスフレーズを入力します。
Enter passphrase to be changed: Enter new passphrase: Verify passphrase:新しいパスフレーズを検証します。
# cryptsetup --verbose open --test-passphrase /dev/<device_ID>
検証
新しいパスフレーズでデバイスのロックを解除できることを確認します。
Enter passphrase for /dev/<device_ID>: Key slot <slot_number> unlocked. Command successful.
18.13.10. storage RHEL システムロールを使用して LUKS2 暗号化ボリュームを作成する
storage ロールを使用し、Ansible Playbook を実行して、LUKS で暗号化されたボリュームを作成および設定できます。
前提条件
- コントロールノードと管理対象ノードの準備が完了している。
- 管理対象ノードで Playbook を実行できるユーザーとしてコントロールノードにログインしている。
-
管理対象ノードへの接続に使用するアカウントに、そのノードに対する
sudo権限がある。
手順
機密性の高い変数を暗号化されたファイルに保存します。
vault を作成します。
$ ansible-vault create ~/vault.yml New Vault password: <vault_password> Confirm New Vault password: <vault_password>ansible-vault createコマンドでエディターが開いたら、機密データを<key>: <value>形式で入力します。luks_password: <password>- 変更を保存して、エディターを閉じます。Ansible は vault 内のデータを暗号化します。
次の内容を含む Playbook ファイル (例:
~/playbook.yml) を作成します。--- - name: Manage local storage hosts: managed-node-01.example.com vars_files: - ~/vault.yml tasks: - name: Create and configure a volume encrypted with LUKS ansible.builtin.include_role: name: redhat.rhel_system_roles.storage vars: storage_volumes: - name: barefs type: disk disks: - sdb fs_type: xfs fs_label: <label> mount_point: /mnt/data encryption: true encryption_password: "{{ luks_password }}"Playbook で使用されるすべての変数の詳細は、コントロールノードの
/usr/share/ansible/roles/rhel-system-roles.storage/README.mdファイルを参照してください。Playbook の構文を検証します。
$ ansible-playbook --ask-vault-pass --syntax-check ~/playbook.ymlこのコマンドは構文を検証するだけであり、有効だが不適切な設定から保護するものではないことに注意してください。
Playbook を実行します。
$ ansible-playbook --ask-vault-pass ~/playbook.yml
検証
LUKS 暗号化ボリュームの
luksUUID値を見つけます。# ansible managed-node-01.example.com -m command -a 'cryptsetup luksUUID /dev/sdb' 4e4e7970-1822-470e-b55a-e91efe5d0f5cボリュームの暗号化ステータスを表示します。
# ansible managed-node-01.example.com -m command -a 'cryptsetup status luks-4e4e7970-1822-470e-b55a-e91efe5d0f5c' /dev/mapper/luks-4e4e7970-1822-470e-b55a-e91efe5d0f5c is active and is in use. type: LUKS2 cipher: aes-xts-plain64 keysize: 512 bits key location: keyring device: /dev/sdb ...作成された LUKS 暗号化ボリュームを確認します。
# ansible managed-node-01.example.com -m command -a 'cryptsetup luksDump /dev/sdb' LUKS header information Version: 2 Epoch: 3 Metadata area: 16384 [bytes] Keyslots area: 16744448 [bytes] UUID: 4e4e7970-1822-470e-b55a-e91efe5d0f5c Label: (no label) Subsystem: (no subsystem) Flags: (no flags) Data segments: 0: crypt offset: 16777216 [bytes] length: (whole device) cipher: aes-xts-plain64 sector: 512 [bytes] ...
18.14. ポリシーベースの複号を使用した暗号化ボリュームの自動アンロックの設定
ポリシーベースの複号 (PBD) は、物理マシンおよび仮想マシンにおいて、ハードドライブで暗号化した root ボリュームおよびセカンダリーボリュームのロックを解除できるようにする一連の技術です。PBD は、ユーザーパスワード、TPM (Trusted Platform Module) デバイス、システムに接続する PKCS #11 デバイス (たとえばスマートカード) などのさまざまなロックの解除方法、もくしは特殊なネットワークサーバーを使用します。
PBD を使用すると、ポリシーにさまざまなロックの解除方法を組み合わせて、さまざまな方法で同じボリュームのロックを解除できるようにすることができます。RHEL における PBD の現在の実装は、Clevis フレームワークと、ピン と呼ばれるプラグインで構成されます。各ピンは、個別のアンロック機能を提供します。現在利用できるピンは以下のとおりです。
tang- ネットワークサーバーを使用してボリュームのロックを解除できます。
tpm2- TPM2 ポリシーを使用してボリュームのロックを解除できます。
sss- Shamir の秘密共有 (SSS) 暗号化方式を使用して、高可用性システムを導入できます。
18.14.1. NBDE (Network-Bound Disk Encryption)
Network Bound Disc Encryption (NBDE) は、ポリシーベースの復号 (PBD) のサブカテゴリーであり、暗号化されたボリュームを特別なネットワークサーバーにバインドできるようにします。NBDE の現在の実装には、Tang サーバー自体と、Tang サーバー用の Clevis ピンが含まれます。
RHEL では、NBDE は次のコンポーネントとテクノロジーによって実装されます。
図18.1 LUKS1 で暗号化したボリュームを使用する場合の NBDE スキーム(luksmeta パッケージは、LUKS2 ボリュームには使用されません)
Tang は、ネットワークのプレゼンスにデータをバインドするためのサーバーです。セキュリティーが保護された特定のネットワークにシステムをバインドする際に利用可能なデータを含めるようにします。Tang はステートレスで、TLS または認証は必要ありません。エスクローベースのソリューション (サーバーが暗号鍵をすべて保存し、使用されたことがあるすべての鍵に関する知識を有する) とは異なり、Tang はクライアントの鍵と相互作用することはないため、クライアントから識別情報を得ることがありません。
Clevis は、自動化された復号用のプラグイン可能なフレームワークです。NBDE では、Clevis は、LUKS ボリュームの自動アンロックを提供します。clevis パッケージは、クライアントで使用される機能を提供します。
Clevis ピン は、Clevis フレームワークへのプラグインです。このようなピンの 1 つに、Tang があります。これは NBDE サーバーとのやり取りを実装するプラグインです。
Clevis および Tang は、一般的なクライアントおよびサーバーのコンポーネントで、ネットワークがバインドされた暗号化を提供します。RHEL では、LUKS と組み合わせて使用され、ルートおよび非ルートストレージボリュームを暗号化および復号して、ネットワークにバインドされたディスク暗号化を実現します。
クライアントおよびサーバーのコンポーネントはともに José ライブラリーを使用して、暗号化および複号の操作を実行します。
NBDE のプロビジョニングを開始すると、Tang サーバーの Clevis ピンは、Tang サーバーの、アドバタイズされている非対称鍵のリストを取得します。もしくは、鍵が非対称であるため、Tang の公開鍵のリストを帯域外に配布して、クライアントが Tang サーバーにアクセスしなくても動作できるようにします。このモードは オフラインプロビジョニング と呼ばれます。
Tang 用の Clevis ピンは、公開鍵のいずれかを使用して、固有で、暗号論的に強力な暗号鍵を生成します。この鍵を使用してデータを暗号化すると、この鍵は破棄されます。Clevis クライアントは、使いやすい場所に、このプロビジョニング操作で生成した状態を保存する必要があります。データを暗号化するこのプロセスは プロビジョニング手順 と呼ばれています。
LUKS バージョン 2 (LUKS2) は、RHEL のデフォルトのディスク暗号化形式であるため、NBDE のプロビジョニング状態は、LUKS2 ヘッダーにトークンとして保存されます。luksmeta パッケージによる NBDE のプロビジョニング状態は、LUKS1 で暗号化したボリュームにのみ使用されます。
Tang 用の Clevis ピンは、規格を必要とせずに LUKS1 と LUKS2 の両方をサポートします。Clevis はプレーンテキストファイルを暗号化できますが、ブロックデバイスの暗号化には cryptsetup ツールを使用する必要があります。詳細については、 Encrypting block devices using LUKS を参照してください。
クライアントがそのデータにアクセスする準備ができると、プロビジョニング手順で生成したメタデータを読み込み、応答して暗号鍵を戻します。このプロセスは 復旧手順 と呼ばれます。
Clevis は、NBDE ではピンを使用して LUKS ボリュームをバインドしているため、自動的にロックが解除されます。バインドプロセスが正常に終了すると、提供されている Dracut アンロックを使用してディスクをアンロックできます。
kdump カーネルクラッシュのダンプメカニズムが、システムメモリーのコンテンツを LUKS で暗号化したデバイスに保存するように設定されている場合には、2 番目のカーネル起動時にパスワードを入力するように求められます。
18.14.2. enforcing モードの SELinux を使用して Tang サーバーをデプロイする
Tang サーバーを使用して、Clevis 対応クライアント上の LUKS 暗号化ボリュームのロックを自動的に解除できます。最小限のシナリオでは、tang パッケージをインストールし、systemctl enable tangd.socket --now コマンドを入力することにより、ポート 80 に Tang サーバーをデプロイします。次の手順の例では、SELinux 強制モードの限定サービスとしてカスタムポートで実行されている Tang サーバーのデプロイメントを示しています。
前提条件
-
policycoreutils-python-utilsパッケージおよび依存関係がインストールされている。 -
firewalldサービスが実行している。
手順
tangパッケージとその依存関係をインストールするには、rootで以下のコマンドを実行します。# yum install tang7500/tcp などの不要なポートを選択し、
tangdサービスがそのポートにバインドできるようにします。# semanage port -a -t tangd_port_t -p tcp 7500ポートは 1 つのサービスのみで一度に使用できるため、すでに使用しているポートを使用しようとすると、
ValueError:Port already definedエラーが発生します。ファイアウォールのポートを開きます。
# firewall-cmd --add-port=7500/tcp # firewall-cmd --runtime-to-permanenttangdサービスを有効にします。# systemctl enable tangd.socketオーバーライドファイルを作成します。
# systemctl edit tangd.socket以下のエディター画面で、
/etc/systemd/system/tangd.socket.d/ディレクトリーにある空のoverride.confファイルを開き、次の行を追加して、Tang サーバーのデフォルトのポートを、80 から、以前取得した番号に変更します。[Socket] ListenStream= ListenStream=7500重要# Anything between hereと# Lines below thisで始まる行の間に以前のコードスニペットを挿入します。挿入しない場合、システムは変更を破棄します。-
変更を保存し、エディターを終了します。デフォルトの
viエディターでこれを実行するには、Esc キーを押してコマンドモードに切り替え、:wqと入力して Enter キーを押します。 変更した設定を再読み込みします。
# systemctl daemon-reload設定が機能していることを確認します。
# systemctl show tangd.socket -p Listen Listen=[::]:7500 (Stream)tangdサービスを開始します。# systemctl restart tangd.sockettangdが、systemdのソケットアクティベーションメカニズムを使用しているため、最初に接続するとすぐにサーバーが起動します。最初の起動時に、一組の暗号鍵が自動的に生成されます。鍵の手動生成などの暗号化操作を実行するには、joseユーティリティーを使用します。
検証
NBDE クライアントで、次のコマンドを使用して、Tang サーバーが正しく動作していることを確認します。このコマンドにより、暗号化と復号化に渡すものと同じメッセージが返される必要があります。
# echo test | clevis encrypt tang '{"url":"<tang.server.example.com:7500>"}' -y | clevis decrypt test
18.14.3. Tang サーバーの鍵のローテーションおよびクライアントでのバインディングの更新
セキュリティー上の理由から、Tang サーバーの鍵をローテーションし、クライアント上の既存のバインディングを定期的に更新してください。鍵をローテートするのに適した間隔は、アプリケーション、鍵のサイズ、および組織のポリシーにより異なります。
したがって、nbde_server RHEL システムロールを使用して、Tang 鍵をローテーションできます。詳細は 複数の Tang サーバー設定での nbde_server システムロールの使用 を参照してください。
前提条件
- Tang サーバーが実行している。
-
clevisパッケージおよびclevis-luksパッケージがクライアントにインストールされている。 -
RHEL 8.2 に、
clevis luks list、clevis luks report、およびclevis luks regenが追加されていることに注意してください。
手順
/var/db/tang鍵データベースディレクトリーのすべての鍵の名前の前に.を指定して、アドバタイズメントに対して非表示にします。以下の例のファイル名は、Tang サーバーの鍵データベースディレクトリーにある一意のファイル名とは異なります。# cd /var/db/tang # ls -l -rw-r--r--. 1 root root 349 Feb 7 14:55 UV6dqXSwe1bRKG3KbJmdiR020hY.jwk -rw-r--r--. 1 root root 354 Feb 7 14:55 y9hxLTQSiSB5jSEGWnjhY8fDTJU.jwk # mv UV6dqXSwe1bRKG3KbJmdiR020hY.jwk .UV6dqXSwe1bRKG3KbJmdiR020hY.jwk # mv y9hxLTQSiSB5jSEGWnjhY8fDTJU.jwk .y9hxLTQSiSB5jSEGWnjhY8fDTJU.jwk名前が変更され、Tang サーバーのアドバタイズに対してすべての鍵が非表示になっていることを確認します。
# ls -l total 0Tang サーバーの
/var/db/tangで/usr/libexec/tangd-keygenコマンドを使用して新しい鍵を生成します。# /usr/libexec/tangd-keygen /var/db/tang # ls /var/db/tang 3ZWS6-cDrCG61UPJS2BMmPU4I54.jwk zyLuX6hijUy_PSeUEFDi7hi38.jwkTang サーバーが、以下のように新規キーペアから署名キーを公開していることを確認します。
# tang-show-keys 7500 3ZWS6-cDrCG61UPJS2BMmPU4I54NBDE クライアントで
clevis luks reportコマンドを使用して、Tang サーバーでアドバタイズされた鍵が同じままかどうかを確認します。clevis luks listコマンドを使用すると、関連するバインディングのあるスロットを特定できます。以下に例を示します。# clevis luks list -d /dev/sda2 1: tang '{"url":"http://tang.srv"}' # clevis luks report -d /dev/sda2 -s 1 ... Report detected that some keys were rotated. Do you want to regenerate luks metadata with "clevis luks regen -d /dev/sda2 -s 1"? [ynYN]新しい鍵の LUKS メタデータを再生成するには、直前のコマンドプロンプトで
yを押すか、clevis luks regenコマンドを使用します。# clevis luks regen -d /dev/sda2 -s 1すべての古いクライアントが新しい鍵を使用することを確認したら、Tang サーバーから古い鍵を削除できます。次に例を示します。
# cd /var/db/tang # rm .*.jwk
クライアントが使用している最中に古い鍵を削除すると、データが失われる場合があります。このような鍵を誤って削除した場合は、クライアントで clevis luks regen コマンドを実行し、LUKS パスワードを手動で提供します。
18.14.4. Web コンソールで Tang キーを使用して自動ロック解除を設定する
Tang サーバーが提供する鍵を使用して、LUKS で暗号化したストレージデバイスの自動ロック解除を設定できます。
前提条件
- RHEL 8 Web コンソールがインストールされている。
- cockpit サービスが有効になっている。
ユーザーアカウントが Web コンソールにログインできる。
手順は、Web コンソールのインストールおよび有効化 を参照してください。
-
cockpit-storagedとclevis-luksパッケージがシステムにインストールされている。 -
cockpit.socketサービスがポート 9090 で実行されている。 - Tang サーバーを利用できる。詳細は、Deploying a Tang server with SELinux in enforcing mode 参照してください。
-
sudoを使用して管理コマンドを入力するための root権限または権限がある。
手順
RHEL 8 Web コンソールにログインします。
詳細は、Web コンソールへのログイン を参照してください。
- 管理者アクセスに切り替え、認証情報を入力して、 をクリックします。Storage テーブルで、自動的にロックを解除するために追加する予定の暗号化ボリュームが含まれるディスクをクリックします。
次のページに選択したディスクの詳細が表示されたら、Keys セクションの をクリックして Tang 鍵を追加します。
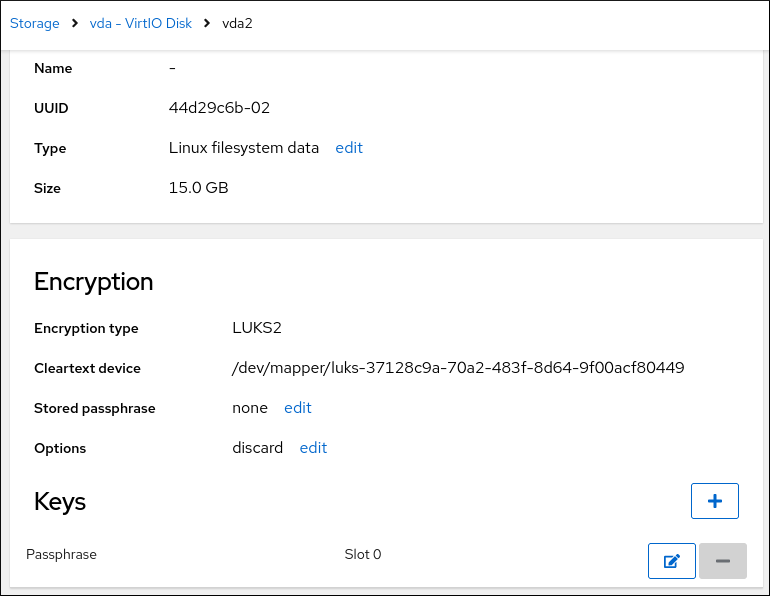
Key sourceとしてTang keyserverを選択し、Tang サーバーのアドレスと、LUKS で暗号化されたデバイスのロックを解除するパスワードを入力します。 をクリックして確定します。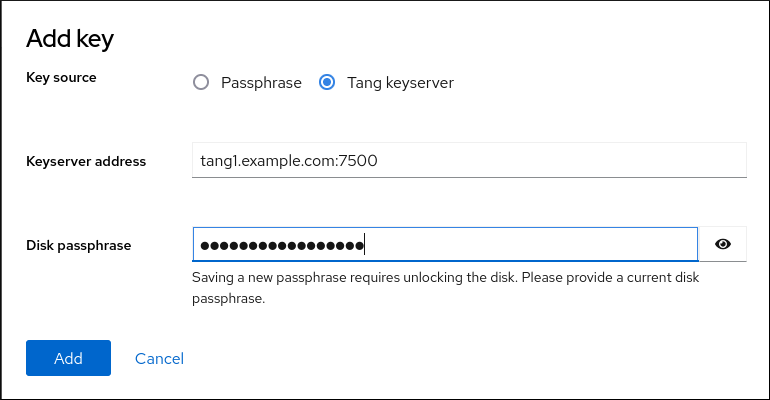
以下のダイアログウインドウは、鍵ハッシュが一致することを確認するコマンドを提供します。
Tang サーバーのターミナルで、
tang-show-keysコマンドを使用して、比較のためにキーハッシュを表示します。この例では、Tang サーバーはポート 7500 で実行されています。# tang-show-keys 7500 x100_1k6GPiDOaMlL3WbpCjHOy9ul1bSfdhI3M08wO0Web コンソールと前述のコマンドの出力のキーハッシュが同じ場合は、 をクリックします。
-
RHEL 8.8 以降では、暗号化されたルートファイルシステムと Tang サーバーを選択した後、カーネルコマンドラインへの
rd.neednet=1パラメーターの追加、clevis-dracutパッケージのインストール、および初期 RAM ディスク (initrd) の再生成をスキップできます。非ルートファイルシステムの場合、Web コンソールは、remote-cryptsetup.targetおよびclevis-luks-akspass.pathsystemdユニットを有効にし、clevis-systemdパッケージをインストールし、_netdevパラメーターをfstabおよびcrypttab設定ファイルに追加するようになりました。
検証
新規に追加された Tang キーが
Keyserverタイプの Keys セクションにリスト表示されていることを確認します。
バインディングが初期ブートで使用できることを確認します。次に例を示します。
# lsinitrd | grep clevis-luks lrwxrwxrwx 1 root root 48 Jan 4 02:56 etc/systemd/system/cryptsetup.target.wants/clevis-luks-askpass.path -> /usr/lib/systemd/system/clevis-luks-askpass.path …
18.14.5. 基本的な NBDE および TPM2 暗号化クライアント操作
Clevis フレームワークは、プレーンテキストファイルを暗号化し、JSON Web Encryption (JWE) 形式の暗号化テキストと LUKS 暗号化ブロックデバイスの両方を復号できます。Clevis クライアントは、暗号化操作に Tang ネットワークサーバーまたは Trusted Platform Module 2.0(TPM 2.0) チップのいずれかを使用できます。
次のコマンドは、プレーンテキストファイルが含まれる例で Clevis が提供する基本的な機能を示しています。また、NBDE または Clevis + TPM のデプロイメントのトラブルシューティングにも使用できます。
Tang サーバーにバインドされた暗号化クライアント
Clevis 暗号化クライアントが Tang サーバーにバインドサれることを確認するには、
clevis encrypt tangサブコマンドを使用します。$ clevis encrypt tang '{"url":"http://tang.srv:port"}' < input-plain.txt > secret.jwe The advertisement contains the following signing keys: _OsIk0T-E2l6qjfdDiwVmidoZjA Do you wish to trust these keys? [ynYN] y上記の例の
http://tang.srv:portURL は、tangがインストールされているサーバーの URL と一致するように変更します。secret.jwe出力ファイルには、JWE 形式で暗号化した暗号文が含まれます。この暗号文はinput-plain.txt入力ファイルから読み込まれます。また、設定に SSH アクセスなしで Tang サーバーとの非対話型の通信が必要な場合は、アドバタイズメントをダウンロードしてファイルに保存できます。
$ curl -sfg http://tang.srv:port/adv -o adv.jwsadv.jwsファイル内のアドバタイズメントは、ファイルやメッセージの暗号化など、後続のタスクに使用します。$ echo 'hello' | clevis encrypt tang '{"url":"http://tang.srv:port","adv":"adv.jws"}'データを複号するには、
clevis decryptコマンドを実行して、暗号文 (JWE) を提供します。$ clevis decrypt < secret.jwe > output-plain.txt
TPM2.0 を使用する暗号化クライアント
TPM 2.0 チップを使用して暗号化するには、JSON 設定オブジェクト形式の引数のみが使用されている
clevis encrypt tpm2サブコマンドを使用します。$ clevis encrypt tpm2 '{}' < input-plain.txt > secret.jwe別の階層、ハッシュ、および鍵アルゴリズムを選択するには、以下のように、設定プロパティーを指定します。
$ clevis encrypt tpm2 '{"hash":"sha256","key":"rsa"}' < input-plain.txt > secret.jweデータを復号するには、JSON Web Encryption (JWE) 形式の暗号文を提供します。
$ clevis decrypt < secret.jwe > output-plain.txt
ピンは、PCR (Platform Configuration Registers) 状態へのデータのシーリングにも対応します。このように、PCP ハッシュ値が、シーリング時に使用したポリシーと一致する場合にのみ、データのシーリングを解除できます。
たとえば、SHA-256 バンクに対して、インデックス 0 および 7 の PCR にデータをシールするには、以下を行います。
$ clevis encrypt tpm2 '{"pcr_bank":"sha256","pcr_ids":"0,7"}' < input-plain.txt > secret.jwePCR のハッシュは書き換えることができ、暗号化されたボリュームのロックを解除することはできなくなりました。このため、PCR の値が変更された場合でも、暗号化されたボリュームのロックを手動で解除できる強力なパスフレーズを追加します。
shim-x64 パッケージのアップグレード後にシステムが暗号化されたボリュームを自動的にロック解除できない場合は、Red Hat ナレッジベースソリューション Clevis TPM2 no longer decrypts LUKS devices after a restart を参照してください。
18.14.6. LUKS 暗号化ボリュームのロックを自動解除するように NBDE クライアントを設定する
Clevis フレームワークを使用すると、選択した Tang サーバーが使用可能な場合に、LUKS 暗号化ボリュームのロックを自動解除するようにクライアントを設定できます。これにより、Network-Bound Disk Encryption (NBDE) デプロイメントが作成されます。
前提条件
- Tang サーバーが実行されていて、使用できるようにしてある。
手順
既存の LUKS 暗号化ボリュームのロックを自動的に解除するには、
clevis-luksサブパッケージをインストールします。# yum install clevis-luksPBD 用 LUKS 暗号化ボリュームを特定します。次の例では、ブロックデバイスは /dev/sda2 と呼ばれています。
# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sda 8:0 0 12G 0 disk ├─sda1 8:1 0 1G 0 part /boot └─sda2 8:2 0 11G 0 part └─luks-40e20552-2ade-4954-9d56-565aa7994fb6 253:0 0 11G 0 crypt ├─rhel-root 253:0 0 9.8G 0 lvm / └─rhel-swap 253:1 0 1.2G 0 lvm [SWAP]clevis luks bindコマンドを使用して、ボリュームを Tang サーバーにバインドします。# clevis luks bind -d /dev/sda2 tang '{"url":"http://tang.srv"}' The advertisement contains the following signing keys: _OsIk0T-E2l6qjfdDiwVmidoZjA Do you wish to trust these keys? [ynYN] y You are about to initialize a LUKS device for metadata storage. Attempting to initialize it may result in data loss if data was already written into the LUKS header gap in a different format. A backup is advised before initialization is performed. Do you wish to initialize /dev/sda2? [yn] y Enter existing LUKS password:このコマンドは、以下の 4 つの手順を実行します。
- LUKS マスター鍵と同じエントロピーを使用して、新しい鍵を作成します。
- Clevis で新しい鍵を暗号化します。
- LUKS2 ヘッダートークンに Clevis JWE オブジェクトを保存するか、デフォルト以外の LUKS1 ヘッダーが使用されている場合は LUKSMeta を使用します。
- LUKS を使用する新しい鍵を有効にします。
注記バインド手順では、空き LUKS パスワードスロットが少なくとも 1 つあることが前提となっています。そのスロットの 1 つを
clevis luks bindコマンドが使用します。ボリュームは、現在、既存のパスワードと Clevis ポリシーを使用してロックを解除できます。
システムの起動プロセスの初期段階でディスクバインディングを処理するには、インストール済みのシステムで
dracutツールを使用します。RHEL では、Clevis はホスト固有の設定オプションを指定せずに汎用initrd(初期 RAM ディスク) を生成し、カーネルコマンドラインにrd.neednet=1などのパラメーターを自動的に追加しません。初期の起動時にネットワークを必要とする Tang ピンを使用する場合は、--hostonly-cmdline引数を使用し、dracutが Tang バインディングを検出するとrd.neednet=1を追加します。clevis-dracutパッケージをインストールします。# yum install clevis-dracut初期 RAM ディスクを再生成します。
# dracut -fv --regenerate-all --hostonly-cmdlineまたは、
/etc/dracut.conf.d/ディレクトリーに .conf ファイルを作成し、そのファイルにhostonly_cmdline=yesオプションを追加します。すると、--hostonly-cmdlineなしでdracutを使用できます。次に例を示します。# echo "hostonly_cmdline=yes" > /etc/dracut.conf.d/clevis.conf # dracut -fv --regenerate-allClevis がインストールされているシステムで
grubbyツールを使用して、システム起動時の早い段階で Tang ピンのネットワークを利用できるようにすることができます。# grubby --update-kernel=ALL --args="rd.neednet=1"
検証
Clevis JWE オブジェクトが LUKS ヘッダーに正常に配置されていることを確認します。
clevis luks listコマンドを使用します。# clevis luks list -d /dev/sda2 1: tang '{"url":"http://tang.srv:port"}'バインディングが初期ブートで使用できることを確認します。次に例を示します。
# lsinitrd | grep clevis-luks lrwxrwxrwx 1 root root 48 Jan 4 02:56 etc/systemd/system/cryptsetup.target.wants/clevis-luks-askpass.path -> /usr/lib/systemd/system/clevis-luks-askpass.path …
18.14.7. 静的な IP 設定を持つ NBDE クライアントの設定
(DHCP を使用しない) 静的な IP 設定を持つクライアントに NBDE を使用するには、ネットワーク設定を dracut ツールに手動で渡す必要があります。
前提条件
- Tang サーバーが実行されていて、使用できるようにしてある。
Tang サーバーによって暗号化されたボリュームのロックを自動解除するように NBDE クライアントが設定されている。
詳細は、LUKS 暗号化ボリュームのロックを自動解除するように NBDE クライアントを設定する を参照してください。
手順
静的ネットワーク設定を、
dracutコマンドのkernel-cmdlineオプションの値として指定できます。次に例を示します。# dracut -fv --regenerate-all --kernel-cmdline "ip=192.0.2.10::192.0.2.1:255.255.255.0::ens3:none nameserver=192.0.2.100"または、静的ネットワーク情報を含む .conf ファイルを
/etc/dracut.conf.d/ディレクトリーに作成し、初期 RAM ディスクイメージを再生成します。# cat /etc/dracut.conf.d/static_ip.conf kernel_cmdline="ip=192.0.2.10::192.0.2.1:255.255.255.0::ens3:none nameserver=192.0.2.100" # dracut -fv --regenerate-all
18.14.8. TPM 2.0 ポリシーを使用して LUKS 暗号化ボリュームの手動登録を設定する
Trusted Platform Module 2.0 (TPM 2.0) ポリシーを使用して、LUKS 暗号化ボリュームのロック解除を設定できます。
前提条件
- アクセス可能な TPM2.0 互換デバイス。
- システムが 64 ビット Intel アーキテクチャー、または 64 ビット AMD アーキテクチャーである。
手順
既存の LUKS 暗号化ボリュームのロックを自動的に解除するには、
clevis-luksサブパッケージをインストールします。# yum install clevis-luksPBD 用 LUKS 暗号化ボリュームを特定します。次の例では、ブロックデバイスは /dev/sda2 と呼ばれています。
# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sda 8:0 0 12G 0 disk ├─sda1 8:1 0 1G 0 part /boot └─sda2 8:2 0 11G 0 part └─luks-40e20552-2ade-4954-9d56-565aa7994fb6 253:0 0 11G 0 crypt ├─rhel-root 253:0 0 9.8G 0 lvm / └─rhel-swap 253:1 0 1.2G 0 lvm [SWAP]clevis luks bindコマンドを使用して、ボリュームを TPM 2.0 デバイスにバインドします。以下に例を示します。# clevis luks bind -d /dev/sda2 tpm2 '{"hash":"sha256","key":"rsa"}' ... Do you wish to initialize /dev/sda2? [yn] y Enter existing LUKS password:このコマンドは、以下の 4 つの手順を実行します。
- LUKS マスター鍵と同じエントロピーを使用して、新しい鍵を作成します。
- Clevis で新しい鍵を暗号化します。
- LUKS2 ヘッダートークンに Clevis JWE オブジェクトを保存するか、デフォルト以外の LUKS1 ヘッダーが使用されている場合は LUKSMeta を使用します。
LUKS を使用する新しい鍵を有効にします。
注記バインド手順では、空き LUKS パスワードスロットが少なくとも 1 つあることが前提となっています。そのスロットの 1 つを
clevis luks bindコマンドが使用します。あるいは、特定の Platform Configuration Registers (PCR) の状態にデータをシールする場合は、
clevis luks bindコマンドにpcr_bankとpcr_ids値を追加します。以下に例を示します。# clevis luks bind -d /dev/sda2 tpm2 '{"hash":"sha256","key":"rsa","pcr_bank":"sha256","pcr_ids":"0,1"}'重要PCR ハッシュ値がシール時に使用されるポリシーと一致し、ハッシュを書き換えることができる場合にのみ、データをアンシールできるため、PCR の値が変更された場合、暗号化されたボリュームのロックを手動で解除できる強力なパスフレーズを追加します。
shim-x64パッケージをアップグレードした後、システムが暗号化されたボリュームを自動的にロック解除できない場合は、Red Hat ナレッジベースソリューション Clevis TPM2 no longer decrypts LUKS devices after a restart を参照してください。
- ボリュームは、現在、既存のパスワードと Clevis ポリシーを使用してロックを解除できます。
システムの起動プロセスの初期段階でディスクバインディングを処理するようにするには、インストール済みのシステムで
dracutツールを使用します。# yum install clevis-dracut # dracut -fv --regenerate-all
検証
Clevis JWE オブジェクトが LUKS ヘッダーに適切に置かれていることを確認するには、
clevis luks listコマンドを使用します。# clevis luks list -d /dev/sda2 1: tpm2 '{"hash":"sha256","key":"rsa"}'
18.14.9. LUKS で暗号化したボリュームからの Clevis ピンの手動削除
clevis luks bind コマンドで作成されたメタデータを手動で削除する場合や、Clevis が追加したパスフレーズを含む鍵スロットを一掃するには、以下の手順を行います。
LUKS で暗号化したボリュームから Clevis ピンを削除する場合は、clevis luks unbind コマンドを使用することが推奨されます。clevis luks unbind を使用した削除手順は、1 回のステップで構成され、LUKS1 ボリュームおよび LUKS2 ボリュームの両方で機能します。次のコマンド例は、バインド手順で作成されたメタデータを削除し、/dev/sda2 デバイスの鍵スロット 1 を削除します。
# clevis luks unbind -d /dev/sda2 -s 1前提条件
- Clevis バインディングを使用した LUKS 暗号化ボリューム。
手順
/dev/sda2などのボリュームがどの LUKS バージョンであるかを確認し、Clevis にバインドされているスロットおよびトークンを特定します。# cryptsetup luksDump /dev/sda2 LUKS header information Version: 2 ... Keyslots: 0: luks2 ... 1: luks2 Key: 512 bits Priority: normal Cipher: aes-xts-plain64 ... Tokens: 0: clevis Keyslot: 1 ...上記の例では、Clevis トークンは
0で識別され、関連付けられたキースロットは1です。LUKS2 暗号化の場合は、トークンを削除します。
# cryptsetup token remove --token-id 0 /dev/sda2デバイスが LUKS1 で暗号化されていて、
Version:1という文字列がcryptsetup luksDumpコマンドの出力に含まれている場合は、luksmeta wipeコマンドでこの追加手順を実行します。# luksmeta wipe -d /dev/sda2 -s 1Clevis パスフレーズを含む鍵スロットを削除します。
# cryptsetup luksKillSlot /dev/sda2 1
18.14.10. キックスタートを使用して LUKS 暗号化ボリュームの自動登録を設定する
この手順に従って、LUKS で暗号化されたボリュームの登録に Clevis を使用する自動インストールプロセスを設定します。
手順
一時パスワードを使用して、LUKS 暗号化が有効になっているディスクを、
/boot以外のすべてのマウントポイントで分割するように、キックスタートに指示します。パスワードは、登録プロセスの手順に使用するための一時的なものです。part /boot --fstype="xfs" --ondisk=vda --size=256 part / --fstype="xfs" --ondisk=vda --grow --encrypted --passphrase=temppassOSPP 準拠のシステムには、より複雑な設定が必要であることに注意してください。次に例を示します。
part /boot --fstype="xfs" --ondisk=vda --size=256 part / --fstype="xfs" --ondisk=vda --size=2048 --encrypted --passphrase=temppass part /var --fstype="xfs" --ondisk=vda --size=1024 --encrypted --passphrase=temppass part /tmp --fstype="xfs" --ondisk=vda --size=1024 --encrypted --passphrase=temppass part /home --fstype="xfs" --ondisk=vda --size=2048 --grow --encrypted --passphrase=temppass part /var/log --fstype="xfs" --ondisk=vda --size=1024 --encrypted --passphrase=temppass part /var/log/audit --fstype="xfs" --ondisk=vda --size=1024 --encrypted --passphrase=temppass関連する Clevis パッケージを
%packagesセクションに追加して、インストールします。%packages clevis-dracut clevis-luks clevis-systemd %end- オプション: 必要に応じて暗号化されたボリュームのロックを手動で解除できるようにするには、一時パスフレーズを削除する前に強力なパスフレーズを追加します。詳細は、Red Hat ナレッジベースソリューション 既存の LUKS デバイスにパスフレーズ、キー、またはキーファイルを追加する方法 を参照してください。
clevis luks bindを呼び出して、%postセクションのバインディングを実行します。その後、一時パスワードを削除します。%post clevis luks bind -y -k - -d /dev/vda2 \ tang '{"url":"http://tang.srv"}' <<< "temppass" cryptsetup luksRemoveKey /dev/vda2 <<< "temppass" dracut -fv --regenerate-all %end設定が起動初期にネットワークを必要とする Tang ピンに依存している場合、または静的 IP 設定の NBDE クライアントを使用している場合は、Configuring manual enrollment of LUKS-encrypted volumesに従って
dracutコマンドを変更する必要があります。clevis luks bindコマンドの-yオプションは、RHEL 8.3 から使用できることに注意してください。RHEL 8.2 以前では、clevis luks bindコマンドで-yを-fに置き換え、Tang サーバーからアドバタイズメントをダウンロードします。%post curl -sfg http://tang.srv/adv -o adv.jws clevis luks bind -f -k - -d /dev/vda2 \ tang '{"url":"http://tang.srv","adv":"adv.jws"}' <<< "temppass" cryptsetup luksRemoveKey /dev/vda2 <<< "temppass" dracut -fv --regenerate-all %end警告cryptsetup luksRemoveKeyコマンドは、それを適用する LUKS2 デバイスがそれ以上に管理されるのを防ぎます。LUKS1 デバイスに対してのみdmsetupコマンドを使用して、削除されたマスターキーを回復できます。
Tang サーバーの代わりに TPM 2.0 ポリシーを使用する場合は、同様の手順を使用できます。
18.14.11. LUKS で暗号化されたリムーバブルストレージデバイスの自動ロック解除を設定する
LUKS 暗号化 USB ストレージデバイスの自動ロック解除プロセスを設定できます。
手順
USB ドライブなど、LUKS で暗号化したリムーバブルストレージデバイスを自動的にアンロックするには、
clevis-udisks2パッケージをインストールします。# yum install clevis-udisks2システムを再起動し、LUKS で暗号化したボリュームの手動登録の設定 に従って、
clevis luks bindコマンドを使用したバインディング手順を実行します。以下に例を示します。# clevis luks bind -d /dev/sdb1 tang '{"url":"http://tang.srv"}'LUKS で暗号化したリムーバブルデバイスは、GNOME デスクトップセッションで自動的にアンロックできるようになりました。Clevis ポリシーにバインドするデバイスは、
clevis luks unlockコマンドでアンロックできます。# clevis luks unlock -d /dev/sdb1
Tang サーバーの代わりに TPM 2.0 ポリシーを使用する場合は、同様の手順を使用できます。
18.14.12. 高可用性 NBDE システムをデプロイする
Tang は、高可用性デプロイメントを構築する方法を 2 つ提供します。
- クライアントの冗長性 (推奨)
-
クライアントは、複数の Tang サーバーにバインドする機能を使用して設定する必要があります。この設定では、各 Tang サーバーに独自の鍵があり、クライアントは、このサーバーのサブセットに接続することで復号できます。Clevis はすでに、
sssプラグインを使用してこのワークフローに対応しています。Red Hat は、高可用性のデプロイメントにこの方法を推奨します。 - 鍵の共有
-
冗長性を確保するために、Tang のインスタンスは複数デプロイできます。2 つ目以降のインスタンスを設定するには、
tangパッケージをインストールし、SSH経由でrsyncを使用してその鍵ディレクトリーを新規ホストにコピーします。鍵を共有すると鍵への不正アクセスのリスクが高まり、追加の自動化インフラストラクチャーが必要になるため、Red Hat はこの方法を推奨していません。
シャミアの秘密分散を使用した高可用性 NBDE
シャミアの秘密分散 (SSS) は、秘密を複数の固有のパーツに分割する暗号スキームです。秘密を再構築するには、いくつかのパーツが必要になります。数値はしきい値と呼ばれ、SSS はしきい値スキームとも呼ばれます。
Clevis は、SSS の実装を提供します。鍵を作成し、これをいくつかのパーツに分割します。各パーツは、SSS も再帰的に含む別のピンを使用して暗号化されます。また、しきい値 t も定義します。NBDE デプロイメントで少なくとも t の部分を復号すると、暗号化鍵が復元され、復号プロセスが成功します。Clevis がしきい値で指定されている数よりも小さい部分を検出すると、エラーメッセージが出力されます。
例 1:2 台の Tang サーバーを使用した冗長性
次のコマンドは、2 台の Tang サーバーのうち少なくとも 1 台が使用可能な場合に、LUKS で暗号化されたデバイスを復号します。
# clevis luks bind -d /dev/sda1 sss '{"t":1,"pins":{"tang":[{"url":"http://tang1.srv"},{"url":"http://tang2.srv"}]}}'上記のコマンドでは、以下の設定スキームを使用していました。
{
"t":1,
"pins":{
"tang":[
{
"url":"http://tang1.srv"
},
{
"url":"http://tang2.srv"
}
]
}
}
この設定では、リストに記載されている 2 台の tang サーバーのうち少なくとも 1 つが利用可能であれば、SSS しきい値 t が 1 に設定され、clevis luks bind コマンドが秘密を正常に再構築します。
例 2:Tang サーバーと TPM デバイスで共有している秘密
次のコマンドは、tang サーバーと tpm2 デバイスの両方が利用可能な場合に、LUKS で暗号化したデバイスを正常に復号します。
# clevis luks bind -d /dev/sda1 sss '{"t":2,"pins":{"tang":[{"url":"http://tang1.srv"}], "tpm2": {"pcr_ids":"0,7"}}}'SSS しきい値 't' が '2' に設定されている設定スキームは以下のようになります。
{
"t":2,
"pins":{
"tang":[
{
"url":"http://tang1.srv"
}
],
"tpm2":{
"pcr_ids":"0,7"
}
}
}18.14.13. NBDE ネットワークで仮想マシンをデプロイする
clevis luks bind コマンドは、LUKS マスター鍵を変更しません。これは、仮想マシンまたはクラウド環境で使用する、LUKS で暗号化したイメージを作成する場合に、このイメージを実行するすべてのインスタンスがマスター鍵を共有することを意味します。これにはセキュリティーの観点で大きな問題があるため、常に回避する必要があります。
これは、Clevis の制限ではなく、LUKS の設計原理です。シナリオでクラウド内のルートボリュームを暗号化する必要がある場合は、クラウド内の Red Hat Enterprise Linux の各インスタンスに対しても (通常はキックスタートを使用して) インストールプロセスを実行します。このイメージは、LUKS マスター鍵を共有しなければ共有できません。
仮想化環境で自動ロック解除をデプロイメントするには、lorax や virt-install などのシステムとキックスタートファイル (キックスタートを使用した LUKS 暗号化ボリュームの自動登録の設定参照) またはその他の自動プロビジョニングツールを使用して、各暗号化 VM に固有のマスターキーを確実に付与します。
18.14.14. NBDE を使用してクラウド環境用の自動登録可能な仮想マシンイメージをビルドする
自動登録可能な暗号化イメージをクラウド環境にデプロイすると、特有の課題が発生する可能性があります。他の仮想化環境と同様に、LUKS マスター鍵を共有しないように、1 つのイメージから起動するインスタンス数を減らすことが推奨されます。
したがって、ベストプラクティスは、どのパブリックリポジトリーでも共有されず、限られたインスタンスのデプロイメントのベースを提供するように、イメージをカスタマイズすることです。作成するインスタンスの数は、デプロイメントのセキュリティーポリシーで定義する必要があります。また、LUKS マスター鍵の攻撃ベクトルに関連するリスク許容度に基づいて決定する必要があります。
LUKS に対応する自動デプロイメントを構築するには、Lorax、virt-install などのシステムとキックスタートファイルを一緒に使用し、イメージ構築プロセス中にマスター鍵の一意性を確保する必要があります。
クラウド環境では、ここで検討する 2 つの Tang サーバーデプロイメントオプションが利用できます。まず、クラウド環境そのものに Tang サーバーをデプロイできます。もしくは、2 つのインフラストラクチャー間で VPN リンクを使用した独立したインフラストラクチャーで、クラウドの外に Tang サーバーをデプロイできます。
クラウドに Tang をネイティブにデプロイすると、簡単にデプロイできます。ただし、別のシステムの暗号文のデータ永続化層でインフラストラクチャーを共有します。Tang サーバーの秘密鍵および Clevis メタデータは、同じ物理ディスクに保存できる場合があります。この物理ディスクでは、暗号文データへのいかなる不正アクセスが可能になります。
データを保存する場所と Tang を実行するシステムを、常に物理的に分離してください。クラウドと Tang サーバーを分離することで、Tang サーバーの秘密鍵が、Clevis メタデータと誤って結合することがないようにします。さらに、これにより、クラウドインフラストラクチャーが危険にさらされている場合に、Tang サーバーのローカル制御を提供します。
18.14.15. コンテナーとしての Tang のデプロイ
tang コンテナーイメージは、OpenShift Container Platform (OCP) クラスターまたは別の仮想マシンで実行する Clevis クライアントの Tang-server 復号化機能を提供します。
前提条件
-
podmanパッケージとその依存関係がシステムにインストールされている。 -
podman login registry.redhat.ioコマンドを使用してregistry.redhat.ioコンテナーカタログにログインしている。詳細は、Red Hat コンテナーレジストリーの認証 を参照してください。 - Clevis クライアントは、Tang サーバーを使用して、自動的にアンロックする LUKS で暗号化したボリュームを含むシステムにインストールされている。
手順
registry.redhat.ioレジストリーからtangコンテナーイメージをプルします。# podman pull registry.redhat.io/rhel8/tangコンテナーを実行し、そのポートを指定して Tang 鍵へのパスを指定します。上記の例では、
tangコンテナーを実行し、ポート 7500 を指定し、/var/db/tangディレクトリーの Tang 鍵へのパスを示します。# podman run -d -p 7500:7500 -v tang-keys:/var/db/tang --name tang registry.redhat.io/rhel8/tangTang はデフォルトでポート 80 を使用しますが、Apache HTTP サーバーなどの他のサービスと共存する可能性があることに注意してください。
オプション: セキュリティーを強化するために、Tang キーを定期的にローテーションします。
tangd-rotate-keysスクリプトを使用できます。以下に例を示します。# podman run --rm -v tang-keys:/var/db/tang registry.redhat.io/rhel8/tang tangd-rotate-keys -v -d /var/db/tang Rotated key 'rZAMKAseaXBe0rcKXL1hCCIq-DY.jwk' -> .'rZAMKAseaXBe0rcKXL1hCCIq-DY.jwk' Rotated key 'x1AIpc6WmnCU-CabD8_4q18vDuw.jwk' -> .'x1AIpc6WmnCU-CabD8_4q18vDuw.jwk' Created new key GrMMX_WfdqomIU_4RyjpcdlXb0E.jwk Created new key _dTTfn17sZZqVAp80u3ygFDHtjk.jwk Keys rotated successfully.
検証
Tang サーバーが存在しているために自動アンロック用に LUKS で暗号化したボリュームが含まれているシステムで、Clevis クライアントが Tang を使用してプレーンテキストのメッセージを暗号化および復号化できることを確認します。
# echo test | clevis encrypt tang '{"url":"http://localhost:7500"}' | clevis decrypt The advertisement contains the following signing keys: x1AIpc6WmnCU-CabD8_4q18vDuw Do you wish to trust these keys? [ynYN] y test上記のコマンド例は、localhost URL で Tang サーバーが利用できる場合にその出力の最後に
テスト文字列を示し、ポート 7500 経由で通信します。
18.14.16. RHEL システムロールを使用した NBDE の設定
nbde_client および nbde_server RHEL システムロールを使用すると、Clevis および Tang を使用した Policy-Based Decryption (PBD) ソリューションを自動でデプロイできます。rhel-system-roles パッケージには、これらのシステムロール、関連する例、リファレンスドキュメントが含まれます。
18.14.16.1. 複数の Tang サーバーのセットアップに nbde_server RHEL システムロールを使用する
nbde_server システムロールを使用すると、自動ディスク暗号化ソリューションの一部として、Tang サーバーをデプロイして管理できます。このロールは以下の機能をサポートします。
- Tang 鍵のローテーション
- Tang 鍵のデプロイおよびバックアップ
前提条件
- コントロールノードと管理対象ノードの準備が完了している。
- 管理対象ノードで Playbook を実行できるユーザーとしてコントロールノードにログインしている。
-
管理対象ノードへの接続に使用するアカウントに、そのノードに対する
sudo権限がある。
手順
次の内容を含む Playbook ファイル (例:
~/playbook.yml) を作成します。--- - name: Deploy a Tang server hosts: tang.server.example.com tasks: - name: Install and configure periodic key rotation ansible.builtin.include_role: name: redhat.rhel_system_roles.nbde_server vars: nbde_server_rotate_keys: yes nbde_server_manage_firewall: true nbde_server_manage_selinux: trueこのサンプル Playbook により、Tang サーバーのデプロイと鍵のローテーションが実行されます。
サンプル Playbook で指定されている設定は次のとおりです。
nbde_server_manage_firewall: true-
firewallシステムロールを使用して、nbde_serverロールで使用されるポートを管理します。 nbde_server_manage_selinux: trueselinuxシステムロールを使用して、nbde_serverロールで使用されるポートを管理します。Playbook で使用されるすべての変数の詳細は、コントロールノードの
/usr/share/ansible/roles/rhel-system-roles.nbde_server/README.mdファイルを参照してください。
Playbook の構文を検証します。
$ ansible-playbook --syntax-check ~/playbook.ymlこのコマンドは構文を検証するだけであり、有効だが不適切な設定から保護するものではないことに注意してください。
Playbook を実行します。
$ ansible-playbook ~/playbook.yml
検証
NBDE クライアントで、次のコマンドを使用して、Tang サーバーが正しく動作していることを確認します。このコマンドにより、暗号化と復号化に渡すものと同じメッセージが返される必要があります。
# ansible managed-node-01.example.com -m command -a 'echo test | clevis encrypt tang '{"url":"<tang.server.example.com>"}' -y | clevis decrypt' test
18.14.16.2. nbde_client RHEL システムロールを使用して DHCP を使用する Clevis クライアントを設定する
nbde_client システムロールにより、複数の Clevis クライアントを自動的にデプロイできます。
このロールを使用すると、LUKS で暗号化されたボリュームを 1 つ以上の Network-Bound (NBDE) サーバー (Tang サーバー) にバインドすることが可能です。パスフレーズを使用して既存のボリュームの暗号化を保持するか、削除できます。パスフレーズを削除したら、NBDE だけを使用してボリュームのロックを解除できます。これは、システムのプロビジョニング後に削除する必要がある一時鍵またはパスワードを使用して、ボリュームが最初に暗号化されている場合に役立ちます。
パスフレーズと鍵ファイルの両方を指定する場合には、ロールは最初に指定した内容を使用します。有効なバインディングが見つからない場合は、既存のバインディングからパスフレーズの取得を試みます。
Policy-Based Decryption (PBD) では、デバイスとスロットのマッピングの形でバインディングを定義します。そのため、同じデバイスに対して複数のバインドを設定できます。デフォルトのスロットは 1 です。
nbde_client システムロールは、Tang バインディングのみをサポートします。したがって、TPM2 バインディングには使用できません。
前提条件
- コントロールノードと管理対象ノードの準備が完了している。
- 管理対象ノードで Playbook を実行できるユーザーとしてコントロールノードにログインしている。
-
管理対象ノードへの接続に使用するアカウントに、そのノードに対する
sudo権限がある。 - LUKS を使用してすでに暗号化されているボリューム。
手順
次の内容を含む Playbook ファイル (例:
~/playbook.yml) を作成します。--- - name: Configure clients for unlocking of encrypted volumes by Tang servers hosts: managed-node-01.example.com tasks: - name: Create NBDE client bindings ansible.builtin.include_role: name: redhat.rhel_system_roles.nbde_client vars: nbde_client_bindings: - device: /dev/rhel/root encryption_key_src: /etc/luks/keyfile nbde_client_early_boot: true state: present servers: - http://server1.example.com - http://server2.example.com - device: /dev/rhel/swap encryption_key_src: /etc/luks/keyfile servers: - http://server1.example.com - http://server2.example.comこのサンプル Playbook は、2 台の Tang サーバーのうち少なくとも 1 台が利用可能な場合に、LUKS で暗号化した 2 つのボリュームを自動的にアンロックするように Clevis クライアントを設定します。
サンプル Playbook で指定されている設定は次のとおりです。
state: present-
stateの値は、Playbook を実行した後の設定を示します。新しいバインディングを作成するか、既存のバインディングを更新する場合は、presentを使用します。clevis luks bindとは異なり、state: presentを使用してデバイススロットにある既存のバインディングを上書きすることもできます。absentに設定すると、指定したバインディングが削除されます。 nbde_client_early_boot: truenbde_clientロールは、デフォルトで、起動初期段階で Tang ピン用のネットワークを利用可能にします。この機能を無効にする必要がある場合は、Playbook にnbde_client_early_boot: false変数を追加します。Playbook で使用されるすべての変数の詳細は、コントロールノードの
/usr/share/ansible/roles/rhel-system-roles.nbde_client/README.mdファイルを参照してください。
Playbook の構文を検証します。
$ ansible-playbook --syntax-check ~/playbook.ymlこのコマンドは構文を検証するだけであり、有効だが不適切な設定から保護するものではないことに注意してください。
Playbook を実行します。
$ ansible-playbook ~/playbook.yml
検証
NBDE クライアントで、Tang サーバーによって自動的にロック解除される暗号化ボリュームの LUKS ピンに、対応する情報が含まれていることを確認します。
# ansible managed-node-01.example.com -m command -a 'clevis luks list -d /dev/rhel/root' 1: tang '{"url":"<http://server1.example.com/>"}' 2: tang '{"url":"<http://server2.example.com/>"}'nbde_client_early_boot: false変数を使用しない場合は、起動初期にバインディングが使用できることを確認します。次に例を示します。# ansible managed-node-01.example.com -m command -a 'lsinitrd | grep clevis-luks' lrwxrwxrwx 1 root root 48 Jan 4 02:56 etc/systemd/system/cryptsetup.target.wants/clevis-luks-askpass.path -> /usr/lib/systemd/system/clevis-luks-askpass.path …
18.14.16.3. nbde_client RHEL システムロールを使用して静的 IP Clevis クライアントを設定する
nbde_client RHEL システムロールは、Dynamic Host Configuration Protocol (DHCP) を使用する環境にのみ対応しています。静的 IP 設定の NBDE クライアントでは、ネットワーク設定をカーネルブートパラメーターとして渡す必要があります。
通常、管理者は Playbook を再利用します。Ansible が起動初期段階で静的 IP アドレスを割り当てるホストごとに、個別の Playbook を管理することはありません。そうすることにより、Playbook 内の変数を使用し、外部ファイルで設定を提供できます。そのため、必要なのは Playbook 1 つと設定を含むファイル 1 つだけです。
前提条件
- コントロールノードと管理対象ノードの準備が完了している。
- 管理対象ノードで Playbook を実行できるユーザーとしてコントロールノードにログインしている。
-
管理対象ノードへの接続に使用するアカウントに、そのノードに対する
sudo権限がある。 - LUKS を使用してすでに暗号化されているボリューム。
手順
ホストのネットワーク設定を含むファイル (例:
static-ip-settings-clients.yml) を作成し、ホストに動的に割り当てる値を追加します。clients: managed-node-01.example.com: ip_v4: 192.0.2.1 gateway_v4: 192.0.2.254 netmask_v4: 255.255.255.0 interface: enp1s0 managed-node-02.example.com: ip_v4: 192.0.2.2 gateway_v4: 192.0.2.254 netmask_v4: 255.255.255.0 interface: enp1s0次の内容を含む Playbook ファイル (例:
~/playbook.yml) を作成します。- name: Configure clients for unlocking of encrypted volumes by Tang servers hosts: managed-node-01.example.com,managed-node-02.example.com vars_files: - ~/static-ip-settings-clients.yml tasks: - name: Create NBDE client bindings ansible.builtin.include_role: name: redhat.rhel_system_roles.network vars: nbde_client_bindings: - device: /dev/rhel/root encryption_key_src: /etc/luks/keyfile servers: - http://server1.example.com - http://server2.example.com - device: /dev/rhel/swap encryption_key_src: /etc/luks/keyfile servers: - http://server1.example.com - http://server2.example.com - name: Configure a Clevis client with static IP address during early boot ansible.builtin.include_role: name: redhat.rhel_system_roles.bootloader vars: bootloader_settings: - kernel: ALL options: - name: ip value: "{{ clients[inventory_hostname]['ip_v4'] }}::{{ clients[inventory_hostname]['gateway_v4'] }}:{{ clients[inventory_hostname]['netmask_v4'] }}::{{ clients[inventory_hostname]['interface'] }}:none"この Playbook は、
~/static-ip-settings-clients.ymlファイルにリストされている各ホストの特定の値を動的に読み取ります。Playbook で使用されるすべての変数の詳細は、コントロールノードの
/usr/share/ansible/roles/rhel-system-roles.network/README.mdファイルを参照してください。Playbook の構文を検証します。
$ ansible-playbook --syntax-check ~/playbook.ymlこのコマンドは構文を検証するだけであり、有効だが不適切な設定から保護するものではないことに注意してください。
Playbook を実行します。
$ ansible-playbook ~/playbook.yml
第19章 SELinux の使用
19.1. SELinux の使用
Security Enhanced Linux (SELinux) は、新たにシステムセキュリティーの層を提供します。SELinux は、基本的に次の質問に答えます。May <subject> do <action> to <object>? 以下に例を示します。Web サーバーが、ユーザーのホームディレクトリーにあるファイルにアクセスできる可能性がありますか?
19.1.1. SELinux の概要
ユーザー、グループ、およびその他のアクセス権に基づいた標準のアクセスポリシーは Discretionary Access Control (DAC) として知られており、システム管理者が、包括的で詳細なセキュリティーポリシー (たとえば、特定のアプリケーションではログファイルの表示だけを許可し、その他のアプリケーションではログファイルに新しいデータを追加するのを許可するなど) を作成することはできません。
Security Enhanced Linux (SELinux) は Mandatory Access Control (MAC) を実装します。それぞれのプロセスおよびシステムリソースには、SELinux コンテキスト と呼ばれる特別なセキュリティーラベルがあります。SELinux コンテキストは SELinux ラベル として参照されることがありますが、システムレベルの詳細を抽象化し、エンティティーのセキュリティープロパティーに焦点を当てた識別子です。これにより、SELinux ポリシーでオブジェクトを参照する方法に一貫性を持たせ、他の識別方法に含まれる曖昧さがなくなりました。たとえば、バインドマウントを使用するシステムで、ファイルに、有効なパス名を複数設定できます。
SELinux ポリシーは、プロセスが、互いに、またはさまざまなシステムリソースと相互作用する方法を定義する一連のルールにこのコンテキストを使用します。デフォルトでは、最初にルールが明示的にアクセスを許可し、その後ポリシーが任意の対話を許可します。
SELinux ポリシールールが DAC ルールの後に確認されている点に注意してください。DAC ルールがアクセスを拒否すると、SELinux ポリシールールは使用されません。これは、従来の DAC ルールがそのアクセスを拒否すると、SELinux 拒否がログに記録されないということを示しています。
SELinux コンテキストには、複数のフィールド (ユーザー、ロール、タイプ、セキュリティーレベル) があります。プロセスとシステムリソースとの間で許可される相互作用を定義する最も一般的なポリシールールは、完全な SELinux コンテキストではなく、SELinux タイプを使用するため、SELinux ポリシーでは、SELinux のタイプ情報がおそらく最も重要です。SELinux のタイプの名前は、最後に _t が付きます。たとえば、Web サーバーのタイプ名は httpd_t です。/var/www/html/ にあるファイルおよびディレクトリーのタイプコンテキストは、通常 httpd_sys_content_t です。/tmp および /var/tmp/ にあるファイルおよびディレクトリーのタイプコンテキストは、通常 tmp_t です。Web サーバーポートのタイプコンテキストは http_port_t です。
Apache (httpd_t として実行する Web サーバープロセス) を許可するポリシールールがあります。このルールでは、通常 /var/www/html/ にあるコンテキストを持つファイルおよびディレクトリーと、その他の Web サーバーディレクトリー (httpd_sys_content_t) へのアクセスを許可します。通常、/tmp および /var/tmp/ に含まれるファイルのポリシーには、許可ルールがないため、アクセスは許可されません。SELinux を使用すれば、Apache が危険にさらされ、悪意のあるスクリプトがアクセスを得た場合でも、/tmp ディレクトリーにアクセスすることはできなくなります。
図19.1 Apache と MariaDB を安全に実行する SELinux の例
このスキーマが示すように、SELinux は、httpd_t として実行している Apache プロセスが /var/www/html/ ディレクトリーにアクセスするのは許可しますが、同じ Apache プロセスが /data/mysql/ ディレクトリーにアクセスするのは拒否します。これは、httpd_t タイプコンテキストと mysqld_db_t タイプコンテキストに許可ルールがないのが原因です。一方、mysqld_t として実行する MariaDB プロセスは /data/mysql/ ディレクトリーにアクセスできますが、SELinux により、mysqld_t タイプを持つプロセスが、httpd_sys_content_t とラベルが付いた /var/www/html/ ディレクトリーにアクセスするのは拒否されます。
19.1.2. SELinux を実行する利点
SELinux は、次のような利点を提供します。
- プロセスとファイルにはすべてラベルが付いています。SELinux ポリシーにより、プロセスがファイルと相互作用する方法と、プロセスが互いに相互作用する方法が定義されます。アクセスは、それを特別に許可する SELinux ポリシールールが存在する場合に限り許可されます。
- SELinux はきめ細かなアクセス制御を提供します。SELinux のアクセスは、ユーザーの裁量と、Linux のユーザー ID およびグループ ID に基づいて制御される従来の UNIX アクセス権だけでなく、SELinux のユーザー、ロール、タイプなど (必要に応じてセキュリティーレベルも) の、入手可能なすべての情報に基づいて決定されます。
- SELinux ポリシーは管理者が定義し、システム全体に適用されます。
- SELinux は権限昇格攻撃を軽減できます。プロセスはドメインで実行するため、互いに分離しています。SELinux ポリシールールは、プロセスがどのようにファイルやその他のプロセスにアクセスするかを定義します。プロセスへのアクセスが不正に行われても、攻撃者は、そのプロセスの通常の機能と、そのプロセスがアクセスするように設定されているファイルにしかアクセスできません。たとえば、Apache HTTP Server へのアクセスが不正に行われても、そのアクセスを許可する特別な SELinux ポリシールールが追加されたり、設定された場合を除き、ユーザーのホームディレクトリーにあるファイルを読み込むプロセスを攻撃者が利用することはできません。
- SELinux はデータの機密性と整合性を強化し、信頼できない入力からプロセスを保護できます。
SELinux は、ウイルス対策ソフトウェア、セキュアなパスワード、ファイアウォール、その他のセキュリティーシステムに代わるものではなく、既存のセキュリティーソリューションを強化することを目的としたものです。SELinux を実行している場合でも、ソフトウェアを最新の状態にする、推測が困難なパスワードを使用する、ファイアウォールを使用するなど、優れたセキュリティー対策を続けることが重要です。
19.1.3. SELinux の例
以下の例は、SELinux がどのようにセキュリティーを向上するかを説明します。
- デフォルトのアクションは拒否です。アクセスを許可する SELinux のポリシールール (ファイルを開くプロセスなど) が存在しない場合は、アクセスが拒否されます。
-
SELinux は、Linux ユーザーに制限をかけられます。SELinux ポリシーには、制限がかけられた SELinux ユーザーが多数含まれます。Linux ユーザーを、制限がかけられた SELinux ユーザーにマッピングして、SELinux ユーザーに適用されているセキュリティールールおよびメカニズムを利用できます。たとえば、Linux ユーザーを SELinux
user_uユーザーにマッピングすると、その Linux ユーザーは、sudoやsuなどの setuid (set user ID) アプリケーションを実行できなくなります。 - プロセスとデータの分離が向上します。SELinux ドメイン の概念により、特定のファイルやディレクトリーにアクセスできるプロセスの定義が可能になります。たとえば、SELinux を実行している場合に、(許可が設定されていない限り) 攻撃者は Samba サーバーを危険にさらすことはできず、その Samba サーバーを攻撃ベクトルとして使用して、その他のプロセス (MariaDB など) が使用するファイルの読み書きを行うことはできません。
-
SELinux は、設定ミスによるダメージを軽減します。ドメインネームシステム (DNS) サーバーは、多くの場合、ゾーン転送で相互に情報をレプリケートします。攻撃者は、ゾーン転送を使用して、虚偽の情報で DNS サーバーを更新できます。RHEL で Berkeley Internet Name Domain (BIND) を DNS サーバーとして実行している場合、管理者がゾーン転送を実行できるサーバーを制限するのを忘れた場合でも、デフォルトの SELinux ポリシーによってゾーンファイルの更新が妨げられます。 [1] BIND
namedのデーモン自体、およびその他のプロセスによって、ゾーン転送を使用します。 -
SELinux を使用しない場合、攻撃者は脆弱性を悪用して Apache Web サーバーのパストラバーサルを行い、
../などの特別な要素を使用してファイルシステムに保存されているファイルやディレクトリーにアクセスできます。SELinux を enforcing モードで実行しているサーバーに対して攻撃者が攻撃を試みた場合、SELinux は、httpdプロセスがアクセスしてはならないファイルへのアクセスを拒否します。SELinux はこのタイプの攻撃を完全にブロックすることはできませんが、効果的に緩和します。 -
Enforcing モードの SELinux は、非 SMAP プラットフォームでのカーネル NULL ポインター逆参照 Operator の悪用を正常に防止します (CVE-2019-9213)。攻撃者は、null ページのマッピングをチェックしない
mmap関数の脆弱性を利用して、このページに任意のコードを配置します。 -
deny_ptraceSELinux ブール値と Enforcing モードの SELinux は、システムを PTRACE_TRACEME 脆弱性 (CVE-2019-13272) から保護します。このような設定により、攻撃者がroot権限を取得できるシナリオが防止されます。 -
nfs_export_all_rwおよびnfs_export_all_roSELinux ブール値は、/homeディレクトリーの偶発的な共有など、ネットワークファイルシステム (NFS) の設定ミスを防ぐための使いやすいツールを提供します。
19.1.4. SELinux のアーキテクチャーおよびパッケージ
SELinux は、Linux カーネルに組み込まれる Linux セキュリティーモジュール (LSM) です。カーネルの SELinux サブシステムは、管理者が制御し、システムの起動時に読み込まれるセキュリティーポリシーにより動作します。システムにおけるセキュリティー関連の、カーネルレベルのアクセス操作はすべて SELinux により傍受され、読み込んだセキュリティーポリシーのコンテキストに従って検討されます。読み込んだポリシーが操作を許可すると、その操作は継続します。許可しないと、その操作はブロックされ、プロセスがエラーを受け取ります。
アクセスの許可、拒否などの SELinux の結果はキャッシュされます。このキャッシュは、アクセスベクトルキャッシュ (AVC) として知られています。このように結果がキャッシュされると、確認が必要な量が減るため、SELinux ポリシーのパフォーマンスが向上します。DAC ルールがアクセスを拒否した場合は、SELinux ポリシールールが適用されないことに注意してください。未加工の監査メッセージのログは、行頭に type=AVC 文字列が追加されて、/var/log/audit/audit.log に記録されます。
RHEL 8 では、システムサービスは systemd デーモンによって制御されています。systemd はすべてのサービスを起動および停止し、ユーザーとプロセスは systemctl ユーティリティーを使用して systemd と通信します。systemd デーモンは、SELinux ポリシーを調べ、呼び出しているプロセスのラベルと、呼び出し元が管理するユニットファイルのラベルを確認してから、呼び出し元のアクセスを許可するかどうかを SELinux に確認します。このアプローチにより、システムサービスの開始や停止などの、重要なシステム機能へのアクセス制御が強化されます。
また、systemd デーモンは SELinux Access Manager としても起動します。systemctl を実行しているプロセス、または systemd に D-Bus メッセージを送信したプロセスのラベルを取得します。次に、デーモンは、プロセスが設定するユニットファイルのラベルを探します。最後に、SELinux ポリシーでプロセスラベルとユニットファイルラベルとの間で特定のアクセスが許可されている場合、systemd はカーネルから情報を取得できます。これは、特定のサービスに対して、systemd と相互作用を必要とする、危険にさらされたアプリケーションを SELinux が制限できることを意味します。ポリシー作成者は、このような粒度の細かい制御を使用して、管理者を制限することもできます。
プロセスが別のプロセスに D-Bus メッセージを送信しているときに、この 2 つのプロセスの D-Bus 通信が SELinux ポリシーで許可されていない場合は、システムが USER_AVC 拒否メッセージを出力し、D-Bus 通信がタイムアウトになります。2 つのプロセス間の D-Bus 通信は双方向に機能することに注意してください。
SELinux ラベリングが誤っているために問題が発生するのを回避するには、systemctl start コマンドを使用してサービスを開始するようにしてください。
RHEL 8 では、SELinux を使用するために以下のパッケージが提供されています。
-
ポリシー -
selinux-policy-targeted、selinux-policy-mls -
ツール -
policycoreutils、policycoreutils-gui、libselinux-utils、policycoreutils-python-utils、setools-console、checkpolicy
19.1.5. SELinux のステータスおよびモード
SELinux は、3 つのモード (Enforcing、Permissive、または Disabled) のいずれかで実行できます。
- Enforcing モードは、デフォルトのモードで、推奨される動作モードです。SELinux は、Enforcing モードでは正常に動作し、読み込んだセキュリティーポリシーをシステム全体に強制します。
- Permissive モードでは、システムは、読み込んだセキュリティーポリシーを SELinux が強制しているように振る舞い、オブジェクトのラベリングや、アクセスを拒否したエントリーをログに出力しますが、実際に操作を拒否しているわけではありません。Permissive モードは、実稼働システムで使用することは推奨されませんが、SELinux ポリシーの開発やデバッグには役に立ちます。
- Disabled モードを使用することは推奨されません。システムは、SELinux ポリシーの強制を回避するだけでなく、ファイルなどの任意の永続オブジェクトにラベルを付けなくなり、将来的に SELinux を有効にすることが難しくなります。
Enforcing モードと Permissive モードとの間を切り替えるには setenforce ユーティリティーを使用してください。setenforce で行った変更は、システムを再起動すると元に戻ります。Enforcing モードに変更するには、Linux の root ユーザーで、setenforce 1 コマンドを実行します。Permissive モードに変更するには、setenforce 0 コマンドを実行します。getenforce ユーティリティーを使用して、現在の SELinux モードを表示します。
# getenforce
Enforcing# setenforce 0
# getenforce
Permissive# setenforce 1
# getenforce
EnforcingRed Hat Enterprise Linux では、システムを Enforcing モードで実行している場合に、個々のドメインを Permissive モードに設定できます。たとえば、httpd_t ドメインを Permissive に設定するには、以下のコマンドを実行します。
# semanage permissive -a httpd_tPermissive ドメインは、システムのセキュリティーを侵害できる強力なツールです。Red Hat は、特定のシナリオのデバッグ時など、Permissive ドメインを使用する場合は注意することを推奨します。
19.2. SELinux のステータスおよびモードの変更
SELinux が有効になっている場合は、Enforcing モードまたは Permissive モードのいずれかで実行できます。以下のセクションでは、これらのモードに永続的に変更する方法を説明します。
19.2.1. SELinux のステータスおよびモードの永続的変更
SELinux のステータスおよびモード で説明されているように、SELinux は有効または無効にできます。有効にした場合の SELinux のモードには、Enforcing および Permissive の 2 つがあります。
getenforce コマンド、または sestatus コマンドを使用して、SELinux が実行しているモードを確認できます。getenforce コマンドは、Enforcing、Permissive、または Disabled を返します。
sestatus コマンドは SELinux のステータスと、使用されている SELinux ポリシーを返します。
$ sestatus
SELinux status: enabled
SELinuxfs mount: /sys/fs/selinux
SELinux root directory: /etc/selinux
Loaded policy name: targeted
Current mode: enforcing
Mode from config file: enforcing
Policy MLS status: enabled
Policy deny_unknown status: allowed
Memory protection checking: actual (secure)
Max kernel policy version: 31Permissive モードで SELinux を実行すると、ユーザーやプロセスにより、さまざまなファイルシステムオブジェクトのラベルが間違って設定される可能性があります。SELinux が無効になっている間に作成されたファイルシステムのオブジェクトには、ラベルが追加されません。ただし、SELinux では、ファイルシステムオブジェクトのラベルが正しいことが必要になるため、これにより Enforcing モードに変更したときに問題が発生します。
SELinux では、誤ったラベル付けやラベル付けされていないファイルが問題を引き起こすことを防ぐため、Disabled 状態から Permissive モードまたは Enforcing モードに変更すると、ファイルシステムのラベルが自動的に再設定されます。root で fixfiles -F onboot コマンドを使用して、-F オプションを含む /.autorelabel ファイルを作成し、次回のシステムの再起動時にファイルに再ラベル付けされるようにします。
再ラベル付けのためにシステムを再起動する前に、enforcing=0 カーネルオプションを使用するなどして、システムが Permissive モードで起動することを確認します。これにより、selinux-autorelabel サービスを起動する前に、systemd が必要とするラベルのないファイルがシステムにある場合に、システムが起動に失敗することを防ぎます。詳細は、RHBZ#2021835 を参照してください。
19.2.2. SELinux の Permissive モードへの変更
SELinux を Permissive モードで実行していると、SELinux ポリシーは強制されません。システムは動作し続け、SELinux がオペレーションを拒否せず AVC メッセージをログに記録できるため、このログを使用して、トラブルシューティングやデバッグ、ならびに SELinux ポリシーの改善に使用できます。この場合、各 AVC は一度だけログに記録されます。
前提条件
-
selinux-policy-targetedパッケージ、libselinux-utilsパッケージ、およびpolicycoreutilsパッケージがインストールされている。 -
selinux=0またはenforcing=0カーネルパラメーターは使用されません。
手順
任意のテキストエディターで
/etc/selinux/configファイルを開きます。以下に例を示します。# vi /etc/selinux/configSELINUX=permissiveオプションを設定します。# This file controls the state of SELinux on the system. # SELINUX= can take one of these three values: # enforcing - SELinux security policy is enforced. # permissive - SELinux prints warnings instead of enforcing. # disabled - No SELinux policy is loaded. SELINUX=permissive # SELINUXTYPE= can take one of these two values: # targeted - Targeted processes are protected, # mls - Multi Level Security protection. SELINUXTYPE=targetedシステムを再起動します。
# reboot
検証
システムの再起動後に、
getenforceコマンドがPermissiveを返すことを確認します。$ getenforce Permissive
19.2.3. SELinux の Enforcing モードへの変更
SELinux を Enforcing モードで実行している場合は、SELinux ポリシーが強制され、SELinux ポリシールールに基づいてアクセスが拒否されます。RHEL では、システムに SELinux を最初にインストールした時に、Enforcing モードがデフォルトで有効になります。
前提条件
-
selinux-policy-targetedパッケージ、libselinux-utilsパッケージ、およびpolicycoreutilsパッケージがインストールされている。 -
selinux=0またはenforcing=0カーネルパラメーターは使用されません。
手順
任意のテキストエディターで
/etc/selinux/configファイルを開きます。以下に例を示します。# vi /etc/selinux/configSELINUX=enforcingオプションを設定します。# This file controls the state of SELinux on the system. # SELINUX= can take one of these three values: # enforcing - SELinux security policy is enforced. # permissive - SELinux prints warnings instead of enforcing. # disabled - No SELinux policy is loaded. SELINUX=enforcing # SELINUXTYPE= can take one of these two values: # targeted - Targeted processes are protected, # mls - Multi Level Security protection. SELINUXTYPE=targeted変更を保存して、システムを再起動します。
# reboot次にシステムを起動する際に、SELinux はシステム内のファイルおよびディレクトリーのラベルを再設定し、SELinux が無効になっている間に作成したファイルおよびディレクトリーに SELinux コンテキストを追加します。
検証
システムの再起動後に、
getenforceコマンドがEnforcingを返すことを確認します。$ getenforce Enforcing
トラブルシューティング
Enforcing モードに変更したあと、SELinux ポリシールールが間違っていたか、設定されていなかったため、SELinux が一部のアクションを拒否する場合があります。
SELinux に拒否されるアクションを表示するには、root で以下のコマンドを実行します。
# ausearch -m AVC,USER_AVC,SELINUX_ERR,USER_SELINUX_ERR -ts todaysetroubleshoot-serverパッケージがインストールされている場合は、次のコマンドも使用できます。# grep "SELinux is preventing" /var/log/messagesSELinux が有効で、Audit デーモン (
auditd) がシステムで実行していない場合は、dmesgコマンドの出力で SELinux メッセージを検索します。# dmesg | grep -i -e type=1300 -e type=1400
詳細は Troubleshooting problems related to SELinux を参照してください。
19.2.4. 以前無効にしたシステムで SELinux を有効にする
以前に SELinux を無効にしていたシステムで SELinux を有効にする場合は、システムの起動失敗やプロセスの失敗などの問題を回避するために、まずアクセスベクターキャッシュ (AVC) メッセージを permissive モードで解決します。
Permissive モードで SELinux を実行すると、ユーザーやプロセスにより、さまざまなファイルシステムオブジェクトのラベルが間違って設定される可能性があります。SELinux が無効になっている間に作成されたファイルシステムのオブジェクトには、ラベルが追加されません。ただし、SELinux では、ファイルシステムオブジェクトのラベルが正しいことが必要になるため、これにより Enforcing モードに変更したときに問題が発生します。
SELinux では、誤ったラベル付けやラベル付けされていないファイルが問題を引き起こすことを防ぐため、Disabled 状態から Permissive モードまたは Enforcing モードに変更すると、ファイルシステムのラベルが自動的に再設定されます。
再ラベル付けのためにシステムを再起動する前に、enforcing=0 カーネルオプションを使用するなどして、システムが Permissive モードで起動することを確認します。これにより、selinux-autorelabel サービスを起動する前に、systemd が必要とするラベルのないファイルがシステムにある場合に、システムが起動に失敗することを防ぎます。詳細は、RHBZ#2021835 を参照してください。
手順
- SELinux を Permissive モードで有効にします。詳細は Permissive モードへの変更 を参照してください。
システムを再起動します。
# reboot- SELinux 拒否メッセージを確認します。詳細は、SELinux 拒否の特定 を参照してください。
次の再起動時に、ファイルが再ラベル付けされていることを確認します。
# fixfiles -F onbootこれにより、
-Fオプションを含む/.autorelabelファイルが作成されます。警告fixfiles -F onbootコマンドを入力する前に、必ず Permissive モードに切り替えてください。デフォルトでは、
autorelabelはシステムで使用可能な CPU コアと同じ数のスレッドを並列に使用します。ラベルの自動再設定中に単一のスレッドのみを使用するには、fixfiles -T 1 onbootコマンドを使用します。- 拒否がない場合は、Enforcing モードに切り替えます。詳細は システムの起動時に SELinux モードの変更 を参照してください。
検証
システムの再起動後に、
getenforceコマンドがEnforcingを返すことを確認します。$ getenforce Enforcing
次のステップ
Enforcing モードで SELinux を使用してカスタムアプリケーションを実行するには、次のいずれかのシナリオを選択してください。
-
unconfined_service_tドメインでアプリケーションを実行します。 - アプリケーションに新しいポリシーを記述します。詳細は、カスタム SELinux ポリシーの作成 のセクションを参照してください。
19.2.5. SELinux の無効化
SELinux を無効にすると、システムが SELinux ポリシーをロードしなくなります。その結果、システムは SELinux ポリシーを適用せず、Access Vector Cache (AVC) メッセージをログに記録しません。したがって、SELinux を実行する利点 はすべて失われます。
パフォーマンスが重視されるシステムなど、セキュリティーを弱めても重大なリスクが生じない特殊な状況を除き、SELinux を無効にしないでください。
実稼働環境でデバッグを実行する必要がある場合は、SELinux を永続的に無効にするのではなく、一時的に permissive モードを使用してください。Permissive モードの詳細は Permissive モードへの変更 を参照してください。
前提条件
grubbyパッケージがインストールされている。$ rpm -q grubby grubby-<version>
手順
ブートローダーを設定して、カーネルコマンドラインに
selinux=0を追加します。$ sudo grubby --update-kernel ALL --args selinux=0システムを再起動します。
$ reboot
検証
再起動したら、
getenforceコマンドがDisabledを返すことを確認します。$ getenforce Disabled
代替方法
RHEL 8 では、/etc/selinux/config ファイルの SELINUX=disabled オプションを使用して SELinux を無効にする 非推奨 の方法を引き続き使用できます。その結果、カーネルは SELinux が有効な状態で起動し、起動プロセスの後半で無効モードに切り替わります。その結果、メモリーリークや競合状態が発生し、カーネルパニックが発生する可能性があります。この方法を使用するには以下を実行します。
任意のテキストエディターで
/etc/selinux/configファイルを開きます。以下に例を示します。# vi /etc/selinux/configSELINUX=disabledオプションを設定します。# This file controls the state of SELinux on the system. # SELINUX= can take one of these three values: # enforcing - SELinux security policy is enforced. # permissive - SELinux prints warnings instead of enforcing. # disabled - No SELinux policy is loaded. SELINUX=disabled # SELINUXTYPE= can take one of these two values: # targeted - Targeted processes are protected, # mls - Multi Level Security protection. SELINUXTYPE=targeted変更を保存して、システムを再起動します。
# reboot
19.2.6. システムの起動時に SELinux モードの変更
ブート時に、次のカーネルパラメーターを設定して、SELinux の実行方法を変更できます。
enforcing=0このパラメーターを設定すると、システムを起動する際に、Permissive モードで起動します。これは、問題のトラブルシューティングを行うときに便利です。ファイルシステムの破損がひどい場合は、Permissive モードを使用することが、問題を検出するための唯一の選択肢となるかもしれません。また、Permissive モードでは、ラベルの作成が適切に行われます。このモードで作成した AVC メッセージは、Enforcing モードと同じになるとは限りません。
Permissive モードでは、一連の同じ拒否の最初の拒否のみが報告されます。一方、Enforcing モードでは、ディレクトリーの読み込みに関する拒否が発生し、アプリケーションが停止する場合がします。Permissive モードでは、表示される AVC メッセージは同じですが、アプリケーションは、ディレクトリー内のファイルを読み続け、拒否が発生するたびに AVC を取得します。
selinux=0このパラメーターにより、カーネルは、SELinux インフラストラクチャーのどの部分も読み込まないようになります。init スクリプトは、システムが
selinux=0パラメーターで起動したことを認識し、/.autorelabelファイルのタイムスタンプを変更します。これにより、次回 SELinux を有効にしてシステムを起動する際にシステムのラベルが自動的に再設定されます。重要実稼働環境では
selinux=0パラメーターを使用しないでください。システムをデバッグするには、SELinux を無効にする代わりに、一時的に permissive モードを使用してください。autorelabel=1このパラメーターにより、システムで、以下のコマンドと同様の再ラベルが強制的に行われます。
# touch /.autorelabel # rebootファイルシステムに間違ったラベルが付いたオブジェクトが大量に含まれる場合は、システムを Permissive モードで起動して自動再ラベルプロセスを正常に実行します。
パート III. ネットワークの設計
第20章 ifcfg ファイルで IP ネットワークの設定
インターフェイス設定(ifcfg)ファイルは、個々のネットワークデバイスのソフトウェアインターフェイスを制御します。これは、システムの起動時に、このファイルを使用して、どのインターフェイスを起動するかと、どのように設定するかを決定します。これらのファイルの名前は ifcfg-name_pass です。接尾辞 name は、設定ファイルが制御するデバイスの名前を指します。通常、ifcfg ファイルの接尾辞は、設定ファイル自体の DEVICE ディレクティブが指定する文字列と同じです。
NetworkManager は、鍵ファイル形式で保存されたプロファイルに対応します。ただし、NetworkManager の API を使用してプロファイルを作成または更新する場合、NetworkManager はデフォルトで ifcfg 形式を使用します。
将来のメジャーリリースの RHEL では、鍵ファイル形式がデフォルトになります。設定ファイルを手動で作成して管理する場合は、鍵ファイル形式の使用を検討してください。詳細は、キーファイル形式の NetworkManager 接続プロファイル を参照してください。
20.1. ifcfg ファイルの静的ネットワーク設定でインタフェースの設定
NetworkManager ユーティリティーおよびアプリケーションを使用しない場合は、ifcfg ファイルを作成してネットワークインターフェイスを手動で設定できます。
手順
ifcfgファイルを使用して、静的ネットワークで、インターフェイスenp1s0を設定するには、/etc/sysconfig/network-scripts/ディレクトリー内に、以下のような内容でifcfg-enp1s0という名前のファイルを作成します。IPv4設定の場合は、以下のようになります。DEVICE=enp1s0 BOOTPROTO=none ONBOOT=yes PREFIX=24 IPADDR=192.0.2.1 GATEWAY=192.0.2.254IPv6設定の場合は、以下のようになります。DEVICE=enp1s0 BOOTPROTO=none ONBOOT=yes IPV6INIT=yes IPV6ADDR=2001:db8:1::2/64
20.2. ifcfg ファイルの動的ネットワーク設定でインタフェースの設定
NetworkManager ユーティリティーおよびアプリケーションを使用しない場合は、ifcfg ファイルを作成してネットワークインターフェイスを手動で設定できます。
手順
ifcfgファイルの動的ネットワークを使用して、インターフェイス em1 を設定するには、/etc/sysconfig/network-scripts/ディレクトリーに、以下のような内容で、ifcfg-em1という名前のファイルを作成します。DEVICE=em1 BOOTPROTO=dhcp ONBOOT=yes送信するインターフェイスを設定するには、以下を行います。
DHCPサーバーに別のホスト名を追加し、ifcfgファイルに以下の行を追加します。DHCP_HOSTNAME=hostnameDHCPサーバーに、別の完全修飾ドメイン名 (FQDN) を追加し、ifcfgファイルに以下の行を追加します。DHCP_FQDN=fully.qualified.domain.name
注記この設定は、いずれか一方のみを使用できます。
DHCP_HOSTNAMEとDHCP_FQDNの両方を指定すると、DHCP_FQDNのみが使用されます。インターフェイスが特定の
DNSサーバーを使用するよう設定するには、ifcfgファイルに以下の行を追加します。PEERDNS=no DNS1=ip-address DNS2=ip-addressここで、ip-address は
DNSサーバーのアドレスです。これにより、ネットワークサービスは指定したDNSサーバーで/etc/resolv.confを更新します。DNSサーバーアドレスは、1 つだけ必要です。もう 1 つは任意です。
20.3. ifcfg ファイルでシステム全体およびプライベート接続プロファイルの管理
デフォルトでは、ホスト上のすべてのユーザーが ifcfg ファイルで定義された接続を使用できます。ifcfg ファイルに USERS パラメーターを追加すると、この動作を特定ユーザーに制限できます。
前提条件
-
ifcfgファイルがすでに存在します。
手順
特定のユーザーに制限する
/etc/sysconfig/network-scripts/ディレクトリーのifcfgファイルを編集し、以下を追加します。USERS="username1 username2 ..."接続をリアクティブにします。
# nmcli connection up connection_name
第21章 IPVLAN の使用
IPVLAN は、仮想ネットワークデバイス用のドライバーで、コンテナー環境でホストネットワークにアクセスするのに使用できます。IPVLAN は外部ネットワークに対し、ホストネットワーク内で作成された IPVLAN デバイスの数に関わらず、MAC アドレスを 1 つ公開します。つまり、ユーザーは複数コンテナーに複数の IPVLAN デバイスを持つことができますが、対応するスイッチは MAC アドレスを 1 つ読み込むということです。IPVLAN ドライバーは、ローカルスイッチで管理できる MAC アドレスの数に制限がある場合に役立ちます。
21.1. IPVLAN モード
IPVLAN では、次のモードが使用できます。
L2 モード
IPVLAN の L2 モード では、仮想デバイスはアドレス解決プロトコル (ARP) リクエストを受信して応答します。
netfilterフレームワークは、仮想デバイスを所有するコンテナー内でのみ動作します。netfilterチェーンは、コンテナー化したトラッフィクにあるデフォルトの名前空間では実行されません。L2 モードを使用すると、パフォーマンスは高くなりますが、ネットワークトラフィックの制御性は低下します。L3 モード
L3 モードでは、仮想デバイスは L3 以上のトラフィックのみを処理します。仮想デバイスは ARP リクエストに応答せず、関連するピアの IPVLAN IP アドレスは、隣接エントリーをユーザーが手動で設定する必要があります。関連するコンテナーの送信トラフィックはデフォルトの名前空間の
netfilterの POSTROUTING および OUTPUT チェーンに到達する一方、ingress トラフィックは L2 モード と同様にスレッド化されます。L3 モード を使用すると、制御性は高くなりますが、ネットワークトラフィックのパフォーマンスは低下します。L3S モード
L3S モード では、仮想デバイスは L3 モード と同様の処理をしますが、関連するコンテナーの egress トラフィックと ingress トラフィックの両方がデフォルトの名前空間の
netfilterチェーンに到達する点が異なります。L3S モード は、L3 モード と同様の動作をしますが、ネットワークの制御が強化されます。
IPVLAN 仮想デバイスは、L3 モードおよび L3S モードでは、ブロードキャストトラフィックおよびマルチキャストトラフィックを受信しません。
21.2. IPVLAN および MACVLAN の比較
以下の表は、MACVLAN と IPVLAN の主な相違点を示しています。
| MACVLAN | IPVLAN |
|---|---|
| 各 MACVLAN デバイスに対して、MAC アドレスを使用します。 スイッチが MAC テーブルに保存できる MAC アドレスの最大数に達すると、接続が失われる可能性があることに注意してください。 | IPVLAN デバイスの数を制限しない MAC アドレスを 1 つ使用します。 |
| グローバル名前空間の netfilter ルールは、子名前空間の MACVLAN デバイスとの間のトラフィックに影響を与えることはできません。 | L3 モード および L3S モード の IPVLAN デバイスとの間のトラフィックを制御できます。 |
IPVLAN と MACVLAN はどちらも、いかなるレベルのカプセル化も必要としません。
21.3. iproute2 を使用した IPVLAN デバイスの作成および設定
この手順では、iproute2 を使用して IPVLAN デバイスを設定する方法を説明します。
手順
IPVLAN デバイスを作成するには、次のコマンドを実行します。
# ip link add link real_NIC_device name IPVLAN_device type ipvlan mode l2ネットワークインターフェイスコントローラー (NIC) は、コンピューターをネットワークに接続するハードウェアコンポーネントです。
例21.1 IPVLAN デバイスの作成
# ip link add link enp0s31f6 name my_ipvlan type ipvlan mode l2 # ip link 47: my_ipvlan@enp0s31f6: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/ether e8:6a:6e:8a:a2:44 brd ff:ff:ff:ff:ff:ffIPv4アドレスまたはIPv6アドレスをインターフェイスに割り当てるには、次のコマンドを実行します。# ip addr add dev IPVLAN_device IP_address/subnet_mask_prefixL3 モード または L3S モード の IPVLAN デバイスを設定する場合は、以下の設定を行います。
リモートホストのリモートピアのネイバー設定を行います。
# ip neigh add dev peer_device IPVLAN_device_IP_address lladdr MAC_addressMAC_address は、IPVLAN デバイスのベースである実際の NIC の MAC アドレスになります。
L3 モード の IPVLAN デバイスを設定する場合は、次のコマンドを実行します。
# ip route add dev <real_NIC_device> <peer_IP_address/32>L3S モード の場合は、次のコマンドを実行します。
# ip route add dev real_NIC_device peer_IP_address/32IP アドレスは、リモートピアのアドレスを使用します。
IPVLAN デバイスをアクティブに設定するには、次のコマンドを実行します。
# ip link set dev IPVLAN_device upIPVLAN デバイスがアクティブであることを確認するには、リモートホストで次のコマンドを実行します。
# ping IP_addressIP_address には、IPVLAN デバイスの IP アドレスを使用します。
第22章 異なるインターフェイスでの同じ IP アドレスの再利用
VRF (Virtual Routing and Forwarding) を使用すると、管理者は、同じホストで複数のルーティングテーブルを同時に使用できます。このため、VRF はレイヤー 3 でネットワークをパーティションで区切ります。これにより、管理者は、VRF ドメインごとに個別の独立したルートテーブルを使用してトラフィックを分離できるようになります。この技術は、レイヤー 2 でネットワークのパーティションを作成する仮想 LAN (VLAN) に類似しており、ここではオペレーティングシステムが異なる VLAN タグを使用して、同じ物理メディアを共有するトラフィックを分離させます。
レイヤー 2 のパーティションにある VRF の利点は、関与するピアの数に対して、ルーティングが適切にスケーリングすることです。
Red Hat Enterprise Linux は、各 VRF ドメインに仮想 vrt デバイスを使用し、既存のネットワークデバイスを VRF デバイスに追加して、VRF ドメインにルートを含めます。元のデバイスに接続していたアドレスとルートは、VRF ドメイン内に移動します。
各 VRF ドメインが互いに分離しているることに注意してください。
22.1. 別のインターフェイスで同じ IP アドレスを永続的に再利用する
VRF (Virtual Routing and Forwarding) 機能を使用して、1 台のサーバーの異なるインターフェイスで同じ IP アドレスを永続的に使用できます。
同じ IP アドレスを再利用しながら、リモートのピアが VRF インターフェイスの両方に接続するようにするには、ネットワークインターフェイスが異なるブロードキャストドメインに属する必要があります。ネットワークのブロードキャストドメインは、ノードのいずれかによって送信されたブロードキャストトラフィックを受信するノードセットです。ほとんどの設定では、同じスイッチに接続されているすべてのノードが、同じブロードキャストドメインに属するようになります。
前提条件
-
rootユーザーとしてログインしている。 - ネットワークインターフェイスが設定されていない。
手順
最初の VRF デバイスを作成して設定します。
VRF デバイスの接続を作成し、ルーティングテーブルに割り当てます。たとえば、ルーティングテーブル
1001に割り当てられたvrf0という名前の VRF デバイスを作成するには、次のコマンドを実行します。# nmcli connection add type vrf ifname vrf0 con-name vrf0 table 1001 ipv4.method disabled ipv6.method disabledvrf0デバイスを有効にします。# nmcli connection up vrf0上記で作成した VRF にネットワークデバイスを割り当てます。たとえば、イーサネットデバイス
enp1s0をvrf0VRF デバイスに追加し、IP アドレスとサブネットマスクをenp1s0に割り当てるには、次のコマンドを実行します。# nmcli connection add type ethernet con-name vrf.enp1s0 ifname enp1s0 master vrf0 ipv4.method manual ipv4.address 192.0.2.1/24vrf.enp1s0接続をアクティベートします。# nmcli connection up vrf.enp1s0
次の VRF デバイスを作成して設定します。
VRF デバイスを作成し、ルーティングテーブルに割り当てます。たとえば、ルーティングテーブル
1002に割り当てられたvrf1という名前の VRF デバイスを作成するには、次のコマンドを実行します。# nmcli connection add type vrf ifname vrf1 con-name vrf1 table 1002 ipv4.method disabled ipv6.method disabledvrf1デバイスをアクティベートします。# nmcli connection up vrf1上記で作成した VRF にネットワークデバイスを割り当てます。たとえば、イーサネットデバイス
enp7s0をvrf1VRF デバイスに追加し、IP アドレスとサブネットマスクをenp7s0に割り当てるには、次のコマンドを実行します。# nmcli connection add type ethernet con-name vrf.enp7s0 ifname enp7s0 master vrf1 ipv4.method manual ipv4.address 192.0.2.1/24vrf.enp7s0デバイスをアクティベートします。# nmcli connection up vrf.enp7s0
22.2. 複数のインターフェイスで同じ IP アドレスを一時的に再利用
VRF (Virtual Routing and Forwarding) 機能を使用して、1 台のサーバーの異なるインターフェイスで同じ IP アドレスを一時的に使用できます。この手順は、システムの再起動後に設定が一時的で失われてしまうため、テスト目的にのみ使用します。
同じ IP アドレスを再利用しながら、リモートのピアが VRF インターフェイスの両方に接続するようにするには、ネットワークインターフェイスが異なるブロードキャストドメインに属する必要があります。ネットワークのブロードキャストドメインは、ノードのいずれかによって送信されたブロードキャストトラフィックを受信するノードセットです。ほとんどの設定では、同じスイッチに接続されているすべてのノードが、同じブロードキャストドメインに属するようになります。
前提条件
-
rootユーザーとしてログインしている。 - ネットワークインターフェイスが設定されていない。
手順
最初の VRF デバイスを作成して設定します。
VRF デバイスを作成し、ルーティングテーブルに割り当てます。たとえば、
1001ルーティングテーブルに割り当てられたblueという名前の VRF デバイスを作成するには、次のコマンドを実行します。# ip link add dev blue type vrf table 1001blueデバイスを有効にします。# ip link set dev blue upVRF デバイスにネットワークデバイスを割り当てます。たとえば、イーサネットデバイス
enp1s0を、VRF デバイスblueに追加するには、次のコマンドを実行します。# ip link set dev enp1s0 master blueenp1s0デバイスを有効にします。# ip link set dev enp1s0 upIP アドレスとサブネットマスクを
enp1s0デバイスに割り当てます。たとえば、192.0.2.1/24に設定するには、以下を実行します。# ip addr add dev enp1s0 192.0.2.1/24
次の VRF デバイスを作成して設定します。
VRF デバイスを作成し、ルーティングテーブルに割り当てます。たとえば、ルーティングテーブル
1002に割り当てられたredという名前の VRF デバイスを作成するには、次のコマンドを実行します。# ip link add dev red type vrf table 1002redデバイスを有効にします。# ip link set dev red upVRF デバイスにネットワークデバイスを割り当てます。たとえば、イーサネットデバイス
enp7s0を、VRF デバイスredに追加するには、次のコマンドを実行します。# ip link set dev enp7s0 master redenp7s0デバイスを有効にします。# ip link set dev enp7s0 upVRF ドメイン
blueのenp1s0に使用したものと同じ IP アドレスとサブネットマスクをenp7s0デバイスに割り当てます。# ip addr add dev enp7s0 192.0.2.1/24
- オプション:上記の説明に従って、さらに VRF デバイスを作成します。
第23章 ネットワークのセキュリティー保護
23.1. 2 台のシステム間で OpenSSH を使用した安全な通信の使用
SSH (Secure Shell) は、クライアント/サーバーアーキテクチャーを使用する 2 つのシステム間で安全な通信を提供し、ユーザーがリモートでサーバーホストシステムにログインできるようにするプロトコルです。FTP や Telnet などの他のリモート通信プロトコルとは異なり、SSH はログインセッションを暗号化します。これにより、侵入者が接続から暗号化されていないパスワードを収集するのを防ぎます。
23.1.1. SSH 鍵ペアの生成
ローカルシステムで SSH 鍵ペアを生成し、生成された公開鍵を OpenSSH サーバーにコピーすることで、パスワードを入力せずに OpenSSH サーバーにログインできます。鍵を作成する各ユーザーは、この手順を実行する必要があります。
システムを再インストールした後も以前に生成した鍵ペアを保持するには、新しい鍵を作成する前に ~/.ssh/ ディレクトリーをバックアップします。再インストール後に、このディレクトリーをホームディレクトリーにコピーします。これは、(root を含む) システムの全ユーザーで実行できます。
前提条件
- OpenSSH サーバーに鍵を使用して接続するユーザーとしてログインしている。
- OpenSSH サーバーが鍵ベースの認証を許可するように設定されている。
手順
ECDSA 鍵ペアを生成します。
$ ssh-keygen -t ecdsa Generating public/private ecdsa key pair. Enter file in which to save the key (/home/<username>/.ssh/id_ecdsa): Enter passphrase (empty for no passphrase): <password> Enter same passphrase again: <password> Your identification has been saved in /home/<username>/.ssh/id_ecdsa. Your public key has been saved in /home/<username>/.ssh/id_ecdsa.pub. The key fingerprint is: SHA256:Q/x+qms4j7PCQ0qFd09iZEFHA+SqwBKRNaU72oZfaCI <username>@<localhost.example.com> The key's randomart image is: +---[ECDSA 256]---+ |.oo..o=++ | |.. o .oo . | |. .. o. o | |....o.+... | |o.oo.o +S . | |.=.+. .o | |E.*+. . . . | |.=..+ +.. o | | . oo*+o. | +----[SHA256]-----+パラメーターなしで
ssh-keygenコマンドを使用して RSA 鍵ペアを生成することも、ssh-keygen -t ed25519コマンドを入力して Ed25519 鍵ペアを生成することもできます。Ed25519 アルゴリズムは FIPS-140 に準拠しておらず、FIPS モードでは OpenSSH は Ed25519 鍵で機能しないことに注意してください。公開鍵をリモートマシンにコピーします。
$ ssh-copy-id <username>@<ssh-server-example.com> /usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed <username>@<ssh-server-example.com>'s password: … Number of key(s) added: 1 Now try logging into the machine, with: "ssh '<username>@<ssh-server-example.com>'" and check to make sure that only the key(s) you wanted were added.<username>@<ssh-server-example.com>は、認証情報に置き換えます。セッションで
ssh-agentプログラムを使用しない場合は、上記のコマンドで、最後に変更した~/.ssh/id*.pub公開鍵をコピーします (インストールされていない場合)。別の公開キーファイルを指定したり、ssh-agentにより、メモリーにキャッシュされた鍵よりもファイル内の鍵の方が優先順位を高くするには、-iオプションを指定してssh-copy-idコマンドを使用します。
検証
鍵ファイルを使用して OpenSSH サーバーにログインします。
$ ssh -o PreferredAuthentications=publickey <username>@<ssh-server-example.com>
23.1.2. OpenSSH サーバーで鍵ベースの認証を唯一の方法として設定する
システムのセキュリティーを強化するには、OpenSSH サーバーでパスワード認証を無効にして鍵ベースの認証を有効にします。
前提条件
-
openssh-serverパッケージがインストールされている。 -
サーバーで
sshdデーモンが実行している。 鍵を使用して OpenSSH サーバーに接続できる。
詳細は、SSH 鍵ペアの生成 セクションを参照してください。
手順
テキストエディターで
/etc/ssh/sshd_config設定を開きます。以下に例を示します。# vi /etc/ssh/sshd_configPasswordAuthenticationオプションをnoに変更します。PasswordAuthentication no-
新しいデフォルトインストール以外のシステムでは、
PubkeyAuthenticationパラメーターが設定されていないか、yesに設定されていることを確認します。 ChallengeResponseAuthenticationディレクティブをnoに設定します。設定ファイル内では対応するエントリーがコメントアウトされていること、およびデフォルト値が
yesであることに注意してください。NFS がマウントされたホームディレクトリーで鍵ベースの認証を使用するには、SELinux ブール値
use_nfs_home_dirsを有効にします。# setsebool -P use_nfs_home_dirs 1- リモートで接続している場合は、コンソールもしくは帯域外アクセスを使用せず、パスワード認証を無効にする前に、鍵ベースのログインプロセスをテストします。
sshdデーモンを再読み込みし、変更を適用します。# systemctl reload sshd
23.1.3. ssh-agent を使用した SSH 認証情報のキャッシュ
SSH 接続を開始するたびにパスフレーズを入力しなくても済むように、ssh-agent ユーティリティーを使用して、ログインセッションの SSH 秘密鍵をキャッシュできます。エージェントが実行中で、鍵のロックが解除されている場合、鍵のパスワードを再入力することなく、この鍵を使用して SSH サーバーにログインできます。秘密鍵とパスフレーズのセキュリティーが確保されます。
前提条件
- SSH デーモンが実行されており、ネットワーク経由でアクセスできるリモートホストがある。
- リモートホストにログインするための IP アドレスまたはホスト名および認証情報を把握している。
パスフレーズで SSH キーペアを生成し、公開鍵をリモートマシンに転送している。
詳細は、SSH 鍵ペアの生成 セクションを参照してください。
手順
セッションで
ssh-agentを自動的に起動するためのコマンドを~/.bashrcファイルに追加します。任意のテキストエディターで
~/.bashrcを開きます。次に例を示します。$ vi ~/.bashrc以下の行をファイルに追加します。
eval $(ssh-agent)- 変更を保存し、エディターを終了します。
~/.ssh/configファイルに次の行を追加します。AddKeysToAgent yesセッションでこのオプションを使用して
ssh-agentが起動されると、エージェントはホストに初めて接続するときにのみパスワードを要求します。
検証
エージェントにキャッシュされた秘密鍵に対応する公開鍵を使用するホストにログインします。次に例を示します。
$ ssh <example.user>@<ssh-server@example.com>パスフレーズを入力する必要がないことに注意してください。
23.1.4. スマートカードに保存した SSH 鍵による認証
スマートカードに ECDSA 鍵と RSA 鍵を作成して保存し、そのスマートカードを使用して OpenSSH クライアントで認証することができます。スマートカード認証は、デフォルトのパスワード認証に代わるものです。
前提条件
-
クライアントで、
openscパッケージをインストールして、pcscdサービスを実行している。
手順
PKCS #11 の URI を含む OpenSC PKCS #11 モジュールが提供する鍵のリストを表示し、その出力を
keys.pubファイルに保存します。$ ssh-keygen -D pkcs11: > keys.pub公開鍵をリモートサーバーに転送します。
ssh-copy-idコマンドを使用し、前の手順で作成したkeys.pubファイルを指定します。$ ssh-copy-id -f -i keys.pub <username@ssh-server-example.com>ECDSA 鍵を使用して <ssh-server-example.com> に接続します。鍵を一意に参照する URI のサブセットのみを使用することもできます。次に例を示します。
$ ssh -i "pkcs11:id=%01?module-path=/usr/lib64/pkcs11/opensc-pkcs11.so" <ssh-server-example.com> Enter PIN for 'SSH key': [ssh-server-example.com] $OpenSSH は
p11-kit-proxyラッパーを使用し、OpenSC PKCS #11 モジュールがp11-kitツールに登録されているため、前のコマンドを簡略化できます。$ ssh -i "pkcs11:id=%01" <ssh-server-example.com> Enter PIN for 'SSH key': [ssh-server-example.com] $PKCS #11 の URI の
id=の部分を飛ばすと、OpenSSH が、プロキシーモジュールで利用可能な鍵をすべて読み込みます。これにより、必要な入力の量を減らすことができます。$ ssh -i pkcs11: <ssh-server-example.com> Enter PIN for 'SSH key': [ssh-server-example.com] $オプション:
~/.ssh/configファイルで同じ URI 文字列を使用して、設定を永続化できます。$ cat ~/.ssh/config IdentityFile "pkcs11:id=%01?module-path=/usr/lib64/pkcs11/opensc-pkcs11.so" $ ssh <ssh-server-example.com> Enter PIN for 'SSH key': [ssh-server-example.com] $sshクライアントユーティリティーが、この URI とスマートカードの鍵を自動的に使用するようになります。
23.2. TLS の計画および実施
TLS (トランスポート層セキュリティー) は、ネットワーク通信のセキュリティー保護に使用する暗号化プロトコルです。優先する鍵交換プロトコル、認証方法、および暗号化アルゴリズムを設定してシステムのセキュリティー設定を強化する際には、対応するクライアントの範囲が広ければ広いほど、セキュリティーのレベルが低くなることを認識しておく必要があります。反対に、セキュリティー設定を厳密にすると、クライアントとの互換性が制限され、システムからロックアウトされるユーザーが出てくる可能性もあります。可能な限り厳密な設定を目指し、互換性に必要な場合に限り、設定を緩めるようにしてください。
23.2.1. SSL プロトコルおよび TLS プロトコル
Secure Sockets Layer (SSL) プロトコルは、元々はインターネットを介した安全な通信メカニズムを提供するために、Netscape Corporation により開発されました。その後、このプロトコルは、Internet Engineering Task Force (IETF) により採用され、Transport Layer Security (TLS) に名前が変更になりました。
TLS プロトコルは、アプリケーションプロトコル層と、TCP/IP などの信頼性の高いトランスポート層の間にあります。これは、アプリケーションプロトコルから独立しているため、さまざまなプロトコルの下に階層化できます。(HTTP、FTP、SMTP など)
| プロトコルのバージョン | 推奨される使用方法 |
|---|---|
| SSL v2 | 使用しないでください。深刻なセキュリティー上の脆弱性があります。RHEL 7 以降、コア暗号ライブラリーから削除されました。 |
| SSL v3 | 使用しないでください。深刻なセキュリティー上の脆弱性があります。RHEL 8 以降、コア暗号ライブラリーから削除されました。 |
| TLS 1.0 |
使用は推奨されません。相互運用性を保証した方法では軽減できない既知の問題があり、最新の暗号スイートには対応しません。RHEL 8 では、 |
| TLS 1.1 |
必要に応じて相互運用性の目的で使用します。最新の暗号スイートには対応しません。RHEL 8 では、 |
| TLS 1.2 | 最新の AEAD 暗号スイートに対応します。このバージョンは、システム全体のすべての暗号化ポリシーで有効になっていますが、このプロトコルの必須ではない部分に脆弱性があります。また、TLS 1.2 では古いアルゴリズムも使用できます。 |
| TLS 1.3 | 推奨されるバージョン。TLS 1.3 は、既知の問題があるオプションを取り除き、より多くのネゴシエーションハンドシェイクを暗号化することでプライバシーを強化し、最新の暗号アルゴリズムをより効果的に使用することで速度を速めることができます。TLS 1.3 は、システム全体のすべての暗号化ポリシーでも有効になっています。 |
23.2.2. RHEL 8 における TLS のセキュリティー上の検討事項
RHEL 8 では、システム全体の暗号化ポリシーにより、暗号化に関する検討事項が大幅に簡素化されています。DEFAULT 暗号化ポリシーは TLS 1.2 および 1.3 のみを許可します。システムが以前のバージョンの TLS を使用して接続をネゴシエートできるようにするには、アプリケーション内で次の暗号化ポリシーから除外するか、update-crypto-policies コマンドで LEGACY ポリシーに切り替える必要があります。詳細は、システム全体の暗号化ポリシーの使用 を参照してください。
大概のデプロイメントは、RHEL 8 に含まれるライブラリーが提供するデフォルト設定で十分に保護されます。TLS 実装は、可能な場合は、安全なアルゴリズムを使用する一方で、レガシーなクライアントまたはサーバーとの間の接続は妨げません。セキュリティーが保護されたアルゴリズムまたはプロトコルに対応しないレガシーなクライアントまたはサーバーの接続が期待できないまたは許可されない場合に、厳密なセキュリティー要件の環境で、強化設定を適用します。
TLS 設定を強化する最も簡単な方法は、update-crypto-policies --set FUTURE コマンドを実行して、システム全体の暗号化ポリシーレベルを FUTURE に切り替えます。
LEGACY 暗号化ポリシーで無効にされているアルゴリズムは、Red Hat の RHEL 8 セキュリティーのビジョンに準拠しておらず、それらのセキュリティープロパティーは信頼できません。これらのアルゴリズムを再度有効化するのではなく、使用しないようにすることを検討してください。たとえば、古いハードウェアとの相互運用性のためにそれらを再度有効化することを決めた場合は、それらを安全でないものとして扱い、ネットワークの相互作用を個別のネットワークセグメントに分離するなどの追加の保護手段を適用します。パブリックネットワーク全体では使用しないでください。
RHEL システム全体の暗号化ポリシーに従わない場合、またはセットアップに適したカスタム暗号化ポリシーを作成する場合は、カスタム設定で必要なプロトコル、暗号スイート、および鍵の長さについて、以下の推奨事項を使用します。
23.2.2.1. プロトコル
最新バージョンの TLS は、最高のセキュリティーメカニズムを提供します。古いバージョンの TLS に対応しないといけないような特別な事態がない限り、システムは、TLS バージョン 1.2 以上を使用して接続をネゴシエートできるようにしてください。
RHEL 8 は TLS バージョン 1.3 をサポートしていますが、このプロトコルのすべての機能が RHEL 8 コンポーネントで完全にサポートされているわけではない点に注意してください。たとえば、接続レイテンシーを短縮する 0-RTT (Zero Round Trip Time) 機能は、Apache Web サーバーではまだ完全にはサポートされていません。
23.2.2.2. 暗号スイート
旧式で、安全ではない暗号化スイートではなく、最近の、より安全なものを使用してください。暗号化スイートの eNULL および aNULL は、暗号化や認証を提供しないため、常に無効にしてください。RC4 や HMAC-MD5 をベースとした暗号化スイートには深刻な欠陥があるため、可能な場合はこれも無効にしてください。いわゆるエクスポート暗号化スイートも同様です。エクスポート暗号化スイートは意図的に弱くなっているため、侵入が容易になっています。
128 ビット未満のセキュリティーしか提供しない暗号化スイートでは直ちにセキュリティーが保護されなくなるというわけではありませんが、使用できる期間が短いため考慮すべきではありません。アルゴリズムが 128 ビット以上のセキュリティーを使用している場合は、少なくとも数年間は解読不可能であることが期待されているため、強く推奨されます。3DES 暗号は 168 ビットを使用していると言われていますが、実際に提供されているのは 112 ビットのセキュリティーであることに注意してください。
サーバーの鍵が危険にさらされた場合でも、暗号化したデータの機密性を保証する (完全な) 前方秘匿性 (PFS) に対応する暗号スイートを常に優先します。ここでは、速い RSA 鍵交換は除外されますが、ECDHE および DHE は使用できます。この 2 つを比べると、ECDHE の方が速いため推奨されます。
また、AES-GCM などの AEAD 暗号は、パディングオラクル攻撃の影響は受けないため、CBC モード暗号よりも推奨されます。さらに、多くの場合、特にハードウェアに AES 用の暗号化アクセラレーターがある場合、AES-GCM は CBC モードの AES よりも高速です。
ECDSA 証明書で ECDHE 鍵交換を使用すると、トランザクションは純粋な RSA 鍵交換よりもさらに高速になります。レガシークライアントに対応するため、サーバーには証明書と鍵のペアを 2 つ (新しいクライアント用の ECDSA 鍵と、レガシー用の RSA 鍵) インストールできます。
23.2.2.3. 公開鍵の長さ
RSA 鍵を使用する際は、SHA-256 以上で署名され、鍵の長さが 3072 ビット以上のものが常に推奨されます (これは、実際に 128 ビットであるセキュリティーに対して十分な大きさです)。
システムのセキュリティー強度は、チェーンの中の最も弱いリンクが示すものと同じになります。たとえば、強力な暗号化だけではすぐれたセキュリティーは保証されません。鍵と証明書も同様に重要で、認証機関 (CA) が鍵の署名に使用するハッシュ機能と鍵もまた重要になります。
23.2.3. アプリケーションで TLS 設定の強化
RHEL では、システム全体の暗号化ポリシー は、暗号化ライブラリーを使用するアプリケーションが、既知の安全でないプロトコル、暗号化、またはアルゴリズムを許可しないようにするための便利な方法を提供します。
暗号化設定をカスタマイズして、TLS 関連の設定を強化する場合は、このセクションで説明する暗号化設定オプションを使用して、必要最小量でシステム全体の暗号化ポリシーを上書きできます。
いずれの設定を選択しても、サーバーアプリケーションが サーバー側が指定した順序 で暗号を利用することを確認し、使用される暗号化スイートの選択がサーバーでの設定順に行われるように設定してください。
23.2.3.1. TLS を使用するように Apache HTTP サーバーを設定
Apache HTTP Server は、TLS のニーズに OpenSSL ライブラリーおよび NSS ライブラリーの両方を使用できます。RHEL 8 では、mod_ss パッケージで mod_ssl 機能が提供されます。
# yum install mod_ssl
mod_ssl パッケージは、/etc/httpd/conf.d/ssl.conf 設定ファイルをインストールします。これは、Apache HTTP Server の TLS 関連の設定を変更するのに使用できます。
httpd-manual パッケージをインストールして、TLS 設定を含む Apache HTTP Server の完全ドキュメントを取得します。/etc/httpd/conf.d/ssl.conf 設定ファイルで利用可能なディレクティブの詳細は、/usr/share/httpd/manual/mod/mod_ssl.html を参照してください。さまざまな設定の例は、/usr/share/httpd/manual/ssl/ssl_howto.html ファイルに記載されています。
/etc/httpd/conf.d/ssl.conf 設定ファイルの設定を修正する場合は、少なくとも下記の 3 つのディレクティブを確認してください。
SSLProtocol- このディレクティブを使用して、許可する TLS または SSL のバージョンを指定します。
SSLCipherSuite- 優先する暗号化スイートを指定する、もしくは許可しないスイートを無効にするディレクティブです。
SSLHonorCipherOrder-
コメントを解除して、このディレクティブを
onに設定すると、接続先のクライアントは指定した暗号化の順序に従います。
たとえば、TLS 1.2 プロトコルおよび 1.3 プロトコルだけを使用する場合は、以下を実行します。
SSLProtocol all -SSLv3 -TLSv1 -TLSv1.1詳細は、Deploying different types of servers の Configuring TLS encryption on an Apache HTTP Server の章を参照してください。
23.2.3.2. TLS を使用するように Nginx HTTP およびプロキシーサーバーを設定
Nginx で TLS 1.3 サポートを有効にするには、/etc/nginx/nginx.conf 設定ファイルの server セクションで、ssl_protocols オプションに TLSv1.3 値を追加します。
server {
listen 443 ssl http2;
listen [::]:443 ssl http2;
....
ssl_protocols TLSv1.2 TLSv1.3;
ssl_ciphers
....
}詳細は、Deploying different types of servers の Adding TLS encryption to an Nginx web server の章を参照してください。
23.2.3.3. TLS を使用するように Dovecot メールサーバーを設定
Dovecot メールサーバーのインストールが TLS を使用するように設定するには、/etc/dovecot/conf.d/10-ssl.conf 設定ファイルを修正します。このファイルで利用可能な基本的な設定ディレクティブの一部は、/usr/share/doc/dovecot/wiki/SSL.DovecotConfiguration.txt ファイルで説明されています。このファイルは Dovecot の標準インストールに含まれています。
/etc/dovecot/conf.d/10-ssl.conf 設定ファイルの設定を修正する場合は、少なくとも下記の 3 つのディレクティブを確認してください。
ssl_protocols- このディレクティブを使用して、許可または無効にする TLS または SSL のバージョンを指定します。
ssl_cipher_list- 優先する暗号化スイートを指定する、もしくは許可しないスイートを無効にするディレクティブです。
ssl_prefer_server_ciphers-
コメントを解除して、このディレクティブを
yesに設定すると、接続先のクライアントは指定した暗号化の順序に従います。
たとえば、/etc/dovecot/conf.d/10-ssl.conf 内の次の行が、TLS 1.1 以降だけを許可します。
ssl_protocols = !SSLv2 !SSLv3 !TLSv123.3. IPsec VPN のセットアップ
仮想プライベートネットワーク (VPN) は、インターネット経由でローカルネットワークに接続する方法です。Libreswan により提供される IPsec は、VPN を作成するための望ましい方法です。Libreswan は、VPN のユーザー空間 IPsec 実装です。VPN は、インターネットなどの中間ネットワークにトンネルを設定して、使用中の LAN と別のリモート LAN との間の通信を可能にします。セキュリティー上の理由から、VPN トンネルは常に認証と暗号化を使用します。暗号化操作では、Libreswan は NSS ライブラリーを使用します。
23.3.1. IPsec VPN 実装としての Libreswan
RHEL では、IPsec プロトコルを使用して仮想プライベートネットワーク (VPN) を設定できます。これは、Libreswan アプリケーションによりサポートされます。Libreswan は、Openswan アプリケーションの延長であり、Openswan ドキュメントの多くの例は Libreswan でも利用できます。
VPN の IPsec プロトコルは、IKE (Internet Key Exchange) プロトコルを使用して設定されます。IPsec と IKE は同義語です。IPsec VPN は、IKE VPN、IKEv2 VPN、XAUTH VPN、Cisco VPN、または IKE/IPsec VPN とも呼ばれます。Layer 2 Tunneling Protocol (L2TP) も使用する IPsec VPN のバリアントは、通常、L2TP/IPsec VPN と呼ばれ、optional のリポジトリーによって提供される xl2tpd パッケージが必要です。
Libreswan は、オープンソースのユーザー空間の IKE 実装です。IKE v1 および v2 は、ユーザーレベルのデーモンとして実装されます。IKE プロトコルも暗号化されています。IPsec プロトコルは Linux カーネルで実装され、Libreswan は、VPN トンネル設定を追加および削除するようにカーネルを設定します。
IKE プロトコルは、UDP ポート 500 および 4500 を使用します。IPsec プロトコルは、以下の 2 つのプロトコルで構成されます。
- 暗号セキュリティーペイロード (ESP) (プロトコル番号が 50)
- 認証ヘッダー (AH) (プロトコル番号 51)
AH プロトコルの使用は推奨されていません。AH のユーザーは、null 暗号化で ESP に移行することが推奨されます。
IPsec プロトコルは、以下の 2 つの操作モードを提供します。
- トンネルモード (デフォルト)
- トランスポートモード
IKE を使用せずに IPsec を使用してカーネルを設定できます。これは、手動キーリング と呼ばれます。また、ip xfrm コマンドを使用して手動キーを設定できますが、これはセキュリティー上の理由からは強く推奨されません。Libreswan は、Netlink インターフェイスを使用して Linux カーネルと通信します。カーネルはパケットの暗号化と復号化を実行します。
Libreswan は、ネットワークセキュリティーサービス (NSS) 暗号化ライブラリーを使用します。NSS は、連邦情報処理標準 (FIPS) の公開文書 140-2 での使用が認定されています。
Libreswan および Linux カーネルが実装する IKE/IPsec の VPN は、RHEL で使用することが推奨される唯一の VPN 技術です。その他の VPN 技術は、そのリスクを理解せずに使用しないでください。
RHEL では、Libreswan はデフォルトで システム全体の暗号化ポリシー に従います。これにより、Libreswan は、デフォルトのプロトコルとして IKEv2 を含む現在の脅威モデルに対して安全な設定を使用するようになります。詳細は、システム全体の暗号化ポリシーの使用 を参照してください。
IKE/IPsec はピアツーピアプロトコルであるため、Libreswan では、"ソース" および "宛先"、または "サーバー" および "クライアント" という用語を使用しません。終了点 (ホスト) を参照する場合は、代わりに "左" と "右" という用語を使用します。これにより、ほとんどの場合、両方の終了点で同じ設定も使用できます。ただし、管理者は通常、ローカルホストに "左" を使用し、リモートホストに "右" を使用します。
leftid と rightid オプションは、認証プロセス内の各ホストの識別として機能します。詳細は、man ページの ipsec.conf(5) を参照してください。
23.3.2. Libreswan の認証方法
Libreswan は複数の認証方法をサポートしますが、それぞれは異なるシナリオとなっています。
事前共有キー (PSK)
事前共有キー (PSK) は、最も簡単な認証メソッドです。セキュリティー上の理由から、PSK は 64 文字未満は使用しないでください。FIPS モードでは、PSK は、使用される整合性アルゴリズムに応じて、、最低強度の要件に準拠する必要があります。authby=secret 接続を使用して PSK を設定できます。
Raw RSA 鍵
Raw RSA 鍵 は、静的なホスト間またはサブネット間の IPsec 設定で一般的に使用されます。各ホストは、他のすべてのホストのパブリック RSA 鍵を使用して手動で設定され、Libreswan はホストの各ペア間で IPsec トンネルを設定します。この方法は、多数のホストでは適切にスケーリングされません。
ipsec newhostkey コマンドを使用して、ホストで Raw RSA 鍵を生成できます。ipsec showhostkey コマンドを使用して、生成された鍵をリスト表示できます。leftrsasigkey= の行は、CKA ID キーを使用する接続設定に必要です。Raw RSA 鍵に authby=rsasig 接続オプションを使用します。
X.509 証明書
X.509 証明書 は、共通の IPsec ゲートウェイに接続するホストが含まれる大規模なデプロイメントに一般的に使用されます。中央の 認証局 (CA) は、ホストまたはユーザーの RSA 証明書に署名します。この中央 CA は、個別のホストまたはユーザーの取り消しを含む、信頼のリレーを行います。
たとえば、openssl コマンドおよび NSS certutil コマンドを使用して X.509 証明書を生成できます。Libreswan は、leftcert= 設定オプションの証明書のニックネームを使用して NSS データベースからユーザー証明書を読み取るため、証明書の作成時にニックネームを指定します。
カスタム CA 証明書を使用する場合は、これを Network Security Services(NSS) データベースにインポートする必要があります。ipsec import コマンドを使用して、PKCS #12 形式の証明書を Libreswan NSS データベースにインポートできます。
Libreswan は、section 3.1 of RFC 4945 で説明されているように、すべてのピア証明書のサブジェクト代替名 (SAN) としてインターネット鍵 Exchange(IKE) ピア ID を必要とします。require-id-on-certificate=no 接続オプションを設定してこのチェックを無効にすると、システムが中間者攻撃に対して脆弱になる可能性があります。
SHA-1 および SHA-2 で RSA を使用した X.509 証明書に基づく認証に authby=rsasig 接続オプションを使用します。authby= を ecdsa に設定し、authby=rsa-sha2 を介した SHA-2 による RSA Probabilistic Signature Scheme (RSASSA-PSS) デジタル署名ベースの認証を設定することにより、SHA-2 を使用する ECDSA デジタル署名に対してさらに制限することができます。デフォルト値は authby=rsasig,ecdsa です。
証明書と authby= 署名メソッドが一致する必要があります。これにより、相互運用性が向上し、1 つのデジタル署名システムでの認証が維持されます。
NULL 認証
null 認証 は、認証なしでメッシュの暗号化を取得するために使用されます。これは、パッシブ攻撃は防ぎますが、アクティブ攻撃は防ぎません。ただし、IKEv2 は非対称認証メソッドを許可するため、NULL 認証はインターネットスケールのオポチュニスティック IPsec にも使用できます。このモデルでは、クライアントはサーバーを認証しますが、サーバーはクライアントを認証しません。このモデルは、TLS を使用して Web サイトのセキュリティーを保護するのと似ています。NULL 認証に authby=null を使用します。
量子コンピューターに対する保護
上記の認証方法に加えて、Post-quantum Pre-shared Key (PPK) メソッドを使用して、量子コンピューターによる潜在的な攻撃から保護することができます。個々のクライアントまたはクライアントグループは、帯域外で設定された事前共有鍵に対応する PPK ID を指定することにより、独自の PPK を使用できます。
事前共有キーで IKEv1 を使用すると、量子攻撃者から保護されます。IKEv2 の再設計は、この保護をネイティブに提供しません。Libreswan は、Post-quantum Pre-shared Key (PPK) を使用して、量子攻撃から IKEv2 接続を保護します。
任意の PPK 対応を有効にする場合は、接続定義に ppk=yes を追加します。PPK が必要な場合は ppk=insist を追加します。次に、各クライアントには、帯域外で通信する (および可能であれば量子攻撃に対して安全な) シークレット値を持つ PPK ID を付与できます。PPK はランダム性において非常に強力で、辞書の単語に基づいていません。PPK ID と PPK データは、次のように ipsec.secrets ファイルに保存されます。
@west @east : PPKS "user1" "thestringismeanttobearandomstr"
PPKS オプションは、静的な PPK を参照します。実験的な関数は、ワンタイムパッドに基づいた動的 PPK を使用します。各接続では、ワンタイムパッドの新しい部分が PPK として使用されます。これを使用すると、ファイル内の動的な PPK の部分がゼロで上書きされ、再利用を防ぐことができます。複数のタイムパッドマテリアルが残っていないと、接続は失敗します。詳細は、man ページの ipsec.secrets(5) を参照してください。
動的 PPK の実装はサポート対象外のテクノロジープレビューとして提供されます。注意して使用してください。
23.3.3. Libreswan のインストール
Libreswan IPsec/IKE 実装を通じて VPN を設定する前に、対応するパッケージをインストールし、ipsec サービスを開始して、ファイアウォールでサービスを許可する必要があります。
前提条件
-
AppStreamリポジトリーが有効になっている。
手順
libreswanパッケージをインストールします。# yum install libreswanLibreswan を再インストールする場合は、古いデータベースファイルを削除し、新しいデータベースを作成します。
# systemctl stop ipsec # rm /etc/ipsec.d/*db # ipsec initnssipsecサービスを開始して有効にし、システムの起動時にサービスを自動的に開始できるようにします。# systemctl enable ipsec --nowファイアウォールで、
ipsecサービスを追加して、IKE プロトコル、ESP プロトコル、および AH プロトコルの 500/UDP ポートおよび 4500/UDP ポートを許可するように設定します。# firewall-cmd --add-service="ipsec" # firewall-cmd --runtime-to-permanent
23.3.4. ホスト間の VPN の作成
raw RSA キーによる認証を使用して、左 および 右 と呼ばれる 2 つのホスト間に、ホストツーホスト IPsec VPN を作成するように Libreswan を設定できます。
前提条件
-
Libreswan がインストールされ、
ipsecサービスが各ノードで開始している。
手順
各ホストで Raw RSA 鍵ペアを生成します。
# ipsec newhostkey前の手順で生成した鍵の
ckaidを返します。左 で次のコマンドを実行して、そのckaidを使用します。以下に例を示します。# ipsec showhostkey --left --ckaid 2d3ea57b61c9419dfd6cf43a1eb6cb306c0e857d上のコマンドの出力により、設定に必要な
leftrsasigkey=行が生成されます。次のホスト (右) でも同じ操作を行います。# ipsec showhostkey --right --ckaid a9e1f6ce9ecd3608c24e8f701318383f41798f03/etc/ipsec.d/ディレクトリーで、新しいmy_host-to-host.confファイルを作成します。上の手順のipsec showhostkeyコマンドの出力から、RSA ホストの鍵を新規ファイルに書き込みます。以下に例を示します。conn mytunnel leftid=@west left=192.1.2.23 leftrsasigkey=0sAQOrlo+hOafUZDlCQmXFrje/oZm [...] W2n417C/4urYHQkCvuIQ== rightid=@east right=192.1.2.45 rightrsasigkey=0sAQO3fwC6nSSGgt64DWiYZzuHbc4 [...] D/v8t5YTQ== authby=rsasig鍵をインポートしたら、
ipsecサービスを再起動します。# systemctl restart ipsec接続を読み込みます。
# ipsec auto --add mytunnelトンネルを確立します。
# ipsec auto --up mytunnelipsecサービスの開始時に自動的にトンネルを開始するには、以下の行を接続定義に追加します。auto=start- DHCP またはステートレスアドレス自動設定 (SLAAC) が設定されたネットワークでこのホストを使用すると、接続がリダイレクトされる危険性があります。詳細と軽減策については、接続がトンネルを回避しないように VPN 接続を専用ルーティングテーブルに割り当てる を参照してください。
23.3.5. サイト間 VPN の設定
2 つのネットワークを結合してサイト間の IPsec VPN を作成する場合は、その 2 つのホスト間の IPsec トンネルが作成されます。これにより、ホストは終了点として動作し、1 つまたは複数のサブネットからのトラフィックが通過できるように設定されます。したがって、ホストを、ネットワークのリモート部分にゲートウェイとして見なすことができます。
サイト間の VPN の設定は、設定ファイル内で複数のネットワークまたはサブネットを指定する必要がある点のみが、ホスト間の VPN とは異なります。
前提条件
- ホスト間の VPN が設定されている。
手順
ホスト間の VPN の設定が含まれるファイルを、新規ファイルにコピーします。以下に例を示します。
# cp /etc/ipsec.d/my_host-to-host.conf /etc/ipsec.d/my_site-to-site.conf上の手順で作成したファイルに、サブネット設定を追加します。以下に例を示します。
conn mysubnet also=mytunnel leftsubnet=192.0.1.0/24 rightsubnet=192.0.2.0/24 auto=start conn mysubnet6 also=mytunnel leftsubnet=2001:db8:0:1::/64 rightsubnet=2001:db8:0:2::/64 auto=start # the following part of the configuration file is the same for both host-to-host and site-to-site connections: conn mytunnel leftid=@west left=192.1.2.23 leftrsasigkey=0sAQOrlo+hOafUZDlCQmXFrje/oZm [...] W2n417C/4urYHQkCvuIQ== rightid=@east right=192.1.2.45 rightrsasigkey=0sAQO3fwC6nSSGgt64DWiYZzuHbc4 [...] D/v8t5YTQ== authby=rsasig- DHCP またはステートレスアドレス自動設定 (SLAAC) が設定されたネットワークでこのホストを使用すると、接続がリダイレクトされる危険性があります。詳細と軽減策については、接続がトンネルを回避しないように VPN 接続を専用ルーティングテーブルに割り当てる を参照してください。
23.3.6. リモートアクセスの VPN の設定
ロードウォーリアーとは、モバイルクライアントと動的に割り当てられた IP アドレスを使用する移動するユーザーのことです。モバイルクライアントは、X.509 証明書を使用して認証します。
以下の例では、IKEv2 の設定を示しています。IKEv1 XAUTH プロトコルは使用していません。
サーバー上では以下の設定になります。
conn roadwarriors
ikev2=insist
# support (roaming) MOBIKE clients (RFC 4555)
mobike=yes
fragmentation=yes
left=1.2.3.4
# if access to the LAN is given, enable this, otherwise use 0.0.0.0/0
# leftsubnet=10.10.0.0/16
leftsubnet=0.0.0.0/0
leftcert=gw.example.com
leftid=%fromcert
leftxauthserver=yes
leftmodecfgserver=yes
right=%any
# trust our own Certificate Agency
rightca=%same
# pick an IP address pool to assign to remote users
# 100.64.0.0/16 prevents RFC1918 clashes when remote users are behind NAT
rightaddresspool=100.64.13.100-100.64.13.254
# if you want remote clients to use some local DNS zones and servers
modecfgdns="1.2.3.4, 5.6.7.8"
modecfgdomains="internal.company.com, corp"
rightxauthclient=yes
rightmodecfgclient=yes
authby=rsasig
# optionally, run the client X.509 ID through pam to allow or deny client
# pam-authorize=yes
# load connection, do not initiate
auto=add
# kill vanished roadwarriors
dpddelay=1m
dpdtimeout=5m
dpdaction=clearロードウォーリアーのデバイスであるモバイルクライアントでは、上記の設定に多少変更を加えて使用します。
conn to-vpn-server
ikev2=insist
# pick up our dynamic IP
left=%defaultroute
leftsubnet=0.0.0.0/0
leftcert=myname.example.com
leftid=%fromcert
leftmodecfgclient=yes
# right can also be a DNS hostname
right=1.2.3.4
# if access to the remote LAN is required, enable this, otherwise use 0.0.0.0/0
# rightsubnet=10.10.0.0/16
rightsubnet=0.0.0.0/0
fragmentation=yes
# trust our own Certificate Agency
rightca=%same
authby=rsasig
# allow narrowing to the server’s suggested assigned IP and remote subnet
narrowing=yes
# support (roaming) MOBIKE clients (RFC 4555)
mobike=yes
# initiate connection
auto=startDHCP またはステートレスアドレス自動設定 (SLAAC) が設定されたネットワークでこのホストを使用すると、接続がリダイレクトされる危険性があります。詳細と軽減策については、接続がトンネルを回避しないように VPN 接続を専用ルーティングテーブルに割り当てる を参照してください。
23.3.7. メッシュ VPN の設定
any-to-any VPN とも呼ばれるメッシュ VPN ネットワークは、全ノードが IPsec を使用して通信するネットワークです。この設定では、IPsec を使用できないノードの例外が許可されます。メッシュの VPN ネットワークは、以下のいずれかの方法で設定できます。
- IPSec を必要とする。
- IPsec を優先するが、平文通信へのフォールバックを可能にする。
ノード間の認証は、X.509 証明書または DNSSEC (DNS Security Extensions) を基にできます。
これらの接続は通常の Libreswan 設定であるため、オポチュニスティック IPsec に通常の IKEv2 認証方法を使用できます。ただし、right=%opportunisticgroup エントリーで定義されるオポチュニスティック IPsec を除きます。一般的な認証方法は、一般に共有される認証局 (CA) を使用して、X.509 証明書に基づいてホストを相互に認証させる方法です。クラウドデプロイメントでは通常、標準の手順の一部として、クラウド内の各ノードに証明書を発行します。
1 つのホストが侵害されると、グループの PSK シークレットも侵害されるため、PreSharedKey (PSK) 認証は使用しないでください。
NULL 認証を使用すると、認証なしでノード間に暗号化をデプロイできます。これを使用した場合、受動的な攻撃者からのみ保護されます。
以下の手順では、X.509 証明書を使用します。この証明書は、Dogtag Certificate System などの任意の種類の CA 管理システムを使用して生成できます。Dogtag は、各ノードの証明書が PKCS #12 形式 (.p12 ファイル) で利用可能であることを前提としています。これには、秘密鍵、ノード証明書、およびその他のノードの X.509 証明書を検証するのに使用されるルート CA 証明書が含まれます。
各ノードでは、その X.509 証明書を除いて、同じ設定を使用します。これにより、ネットワーク内で既存ノードを再設定せずに、新規ノードを追加できます。PKCS #12 ファイルには "分かりやすい名前" が必要であるため、名前には "node" を使用します。これにより、すべてのノードに対して、この名前を参照する設定ファイルが同一になります。
前提条件
-
Libreswan がインストールされ、
ipsecサービスが各ノードで開始している。 新しい NSS データベースが初期化されている。
すでに古い NSS データベースがある場合は、古いデータベースファイルを削除します。
# systemctl stop ipsec # rm /etc/ipsec.d/*db次のコマンドを使用して、新しいデータベースを初期化できます。
# ipsec initnss
手順
各ノードで PKCS #12 ファイルをインポートします。この手順では、PKCS #12 ファイルの生成に使用するパスワードが必要になります。
# ipsec import nodeXXX.p12IPsec required(private)、IPsec optional(private-or-clear)、およびNo IPsec(clear) プロファイルに、以下のような 3 つの接続定義を作成します。# cat /etc/ipsec.d/mesh.conf conn clear auto=ondemand1 type=passthrough authby=never left=%defaultroute right=%group conn private auto=ondemand type=transport authby=rsasig failureshunt=drop negotiationshunt=drop ikev2=insist left=%defaultroute leftcert=nodeXXXX leftid=%fromcert2 rightid=%fromcert right=%opportunisticgroup conn private-or-clear auto=ondemand type=transport authby=rsasig failureshunt=passthrough negotiationshunt=passthrough # left left=%defaultroute leftcert=nodeXXXX3 leftid=%fromcert leftrsasigkey=%cert # right rightrsasigkey=%cert rightid=%fromcert right=%opportunisticgroup- 1
auto変数にはいくつかのオプションがあります。ondemand接続オプションは、IPsec 接続を開始するオポチュニスティック IPsec や、常にアクティブにする必要のない明示的に設定した接続に使用できます。このオプションは、カーネル内にトラップ XFRM ポリシーを設定し、そのポリシーに一致する最初のパケットを受信したときに IPsec 接続を開始できるようにします。オポチュニスティック IPsec を使用する場合も、明示的に設定した接続を使用する場合も、次のオプションを使用すると、IPsec 接続を効果的に設定および管理できます。
addオプション-
接続設定をロードし、リモート開始に応答できるように準備します。ただし、接続はローカル側から自動的に開始されません。コマンド
ipsec auto --upを使用して、IPsec 接続を手動で開始できます。 startオプション- 接続設定をロードし、リモート開始に応答できるように準備します。さらに、リモートピアへの接続を即座に開始します。このオプションは、永続的かつ常にアクティブな接続に使用できます。
- 2
leftid変数とrightid変数は、IPsec トンネル接続の右チャネルと左チャネルを指定します。これらの変数を使用して、ローカル IP アドレスの値、またはローカル証明書のサブジェクト DN を取得できます (設定している場合)。- 3
leftcert変数は、使用する NSS データベースのニックネームを定義します。
ネットワークの IP アドレスを対応するカテゴリーに追加します。たとえば、すべてのノードが
10.15.0.0/16ネットワーク内に存在し、すべてのノードで IPsec 暗号化を使用する必要がある場合は、次のコマンドを実行します。# echo "10.15.0.0/16" >> /etc/ipsec.d/policies/private特定のノード (
10.15.34.0/24など) を IPsec の有無にかかわらず機能させるには、そのノードを private-or-clear グループに追加します。# echo "10.15.34.0/24" >> /etc/ipsec.d/policies/private-or-clearホストを、
10.15.1.2など、IPsec の機能がない clear グループに定義する場合は、次のコマンドを実行します。# echo "10.15.1.2/32" >> /etc/ipsec.d/policies/clear/etc/ipsec.d/policiesディレクトリーのファイルは、各新規ノードのテンプレートから作成することも、Puppet または Ansible を使用してプロビジョニングすることもできます。すべてのノードでは、例外のリストが同じか、異なるトラフィックフローが期待される点に注意してください。したがって、あるノードで IPsec が必要になり、別のノードで IPsec を使用できないために、ノード間の通信ができない場合もあります。
ノードを再起動して、設定したメッシュに追加します。
# systemctl restart ipsec- DHCP またはステートレスアドレス自動設定 (SLAAC) が設定されたネットワークでこのホストを使用すると、接続がリダイレクトされる危険性があります。詳細と軽減策については、接続がトンネルを回避しないように VPN 接続を専用ルーティングテーブルに割り当てる を参照してください。
検証
pingコマンドを使用して IPsec トンネルを開きます。# ping <nodeYYY>インポートされた証明書を含む NSS データベースを表示します。
# certutil -L -d sql:/etc/ipsec.d Certificate Nickname Trust Attributes SSL,S/MIME,JAR/XPI west u,u,u ca CT,,ノード上の開いているトンネルを確認します。
# ipsec trafficstatus 006 #2: "private#10.15.0.0/16"[1] ...<nodeYYY>, type=ESP, add_time=1691399301, inBytes=512, outBytes=512, maxBytes=2^63B, id='C=US, ST=NC, O=Example Organization, CN=east'
23.3.8. FIPS 準拠の IPsec VPN のデプロイ
Libreswan を使用して、FIPS 準拠の IPsec VPN ソリューションをデプロイできます。これを行うには、FIPS モードの Libreswan で使用できる暗号化アルゴリズムと無効になっている暗号化アルゴリズムを特定します。
前提条件
-
AppStreamリポジトリーが有効になっている。
手順
libreswanパッケージをインストールします。# yum install libreswanLibreswan を再インストールする場合は、古い NSS データベースを削除します。
# systemctl stop ipsec # rm /etc/ipsec.d/*dbipsecサービスを開始して有効にし、システムの起動時にサービスを自動的に開始できるようにします。# systemctl enable ipsec --nowファイアウォールで、
ipsecサービスを追加して、IKE プロトコル、ESP プロトコル、および AH プロトコルの500および4500UDP ポートを許可するように設定します。# firewall-cmd --add-service="ipsec" # firewall-cmd --runtime-to-permanentシステムを FIPS モードに切り替えます。
# fips-mode-setup --enableシステムを再起動して、カーネルを FIPS モードに切り替えます。
# reboot
検証
Libreswan が FIPS モードで実行されていることを確認します。
# ipsec whack --fipsstatus 000 FIPS mode enabledまたは、
systemdジャーナルでipsecユニットのエントリーを確認します。$ journalctl -u ipsec ... Jan 22 11:26:50 localhost.localdomain pluto[3076]: FIPS Product: YES Jan 22 11:26:50 localhost.localdomain pluto[3076]: FIPS Kernel: YES Jan 22 11:26:50 localhost.localdomain pluto[3076]: FIPS Mode: YESFIPS モードで使用可能なアルゴリズムを表示するには、次のコマンドを実行します。
# ipsec pluto --selftest 2>&1 | head -11 FIPS Product: YES FIPS Kernel: YES FIPS Mode: YES NSS DB directory: sql:/etc/ipsec.d Initializing NSS Opening NSS database "sql:/etc/ipsec.d" read-only NSS initialized NSS crypto library initialized FIPS HMAC integrity support [enabled] FIPS mode enabled for pluto daemon NSS library is running in FIPS mode FIPS HMAC integrity verification self-test passedFIPS モードで無効化されたアルゴリズムをクエリーするには、次のコマンドを実行します。
# ipsec pluto --selftest 2>&1 | grep disabled Encryption algorithm CAMELLIA_CTR disabled; not FIPS compliant Encryption algorithm CAMELLIA_CBC disabled; not FIPS compliant Encryption algorithm SERPENT_CBC disabled; not FIPS compliant Encryption algorithm TWOFISH_CBC disabled; not FIPS compliant Encryption algorithm TWOFISH_SSH disabled; not FIPS compliant Encryption algorithm NULL disabled; not FIPS compliant Encryption algorithm CHACHA20_POLY1305 disabled; not FIPS compliant Hash algorithm MD5 disabled; not FIPS compliant PRF algorithm HMAC_MD5 disabled; not FIPS compliant PRF algorithm AES_XCBC disabled; not FIPS compliant Integrity algorithm HMAC_MD5_96 disabled; not FIPS compliant Integrity algorithm HMAC_SHA2_256_TRUNCBUG disabled; not FIPS compliant Integrity algorithm AES_XCBC_96 disabled; not FIPS compliant DH algorithm MODP1024 disabled; not FIPS compliant DH algorithm MODP1536 disabled; not FIPS compliant DH algorithm DH31 disabled; not FIPS compliantFIPS モードで許可されているすべてのアルゴリズムと暗号のリストを表示するには、次のコマンドを実行します。
# ipsec pluto --selftest 2>&1 | grep ESP | grep FIPS | sed "s/^.*FIPS//" {256,192,*128} aes_ccm, aes_ccm_c {256,192,*128} aes_ccm_b {256,192,*128} aes_ccm_a [*192] 3des {256,192,*128} aes_gcm, aes_gcm_c {256,192,*128} aes_gcm_b {256,192,*128} aes_gcm_a {256,192,*128} aesctr {256,192,*128} aes {256,192,*128} aes_gmac sha, sha1, sha1_96, hmac_sha1 sha512, sha2_512, sha2_512_256, hmac_sha2_512 sha384, sha2_384, sha2_384_192, hmac_sha2_384 sha2, sha256, sha2_256, sha2_256_128, hmac_sha2_256 aes_cmac null null, dh0 dh14 dh15 dh16 dh17 dh18 ecp_256, ecp256 ecp_384, ecp384 ecp_521, ecp521
23.3.9. パスワードによる IPsec NSS データベースの保護
デフォルトでは、IPsec サービスは、初回起動時に空のパスワードを使用して Network Security Services (NSS) データベースを作成します。セキュリティーを強化するために、パスワード保護を追加できます。
以前の RHEL 6.6 リリースでは、NSS 暗号化ライブラリーが FIPS 140-2 Level 2 標準で認定されているため、FIPS 140-2 要件を満たすパスワードで IPsec NSS データベースを保護する必要がありました。RHEL 8 では、この規格の NIST 認定 NSS がこの規格のレベル 1 に認定されており、このステータスではデータベースのパスワード保護は必要ありません。
前提条件
-
/etc/ipsec.d/ディレクトリーに NSS データベースファイルが含まれます。
手順
Libreswan の
NSSデータベースのパスワード保護を有効にします。# certutil -N -d sql:/etc/ipsec.d Enter Password or Pin for "NSS Certificate DB": Enter a password which will be used to encrypt your keys. The password should be at least 8 characters long, and should contain at least one non-alphabetic character. Enter new password:前の手順で設定したパスワードを含む
/etc/ipsec.d/nsspasswordファイルを作成します。以下はその例です。# cat /etc/ipsec.d/nsspassword NSS Certificate DB:_<password>_nsspasswordファイルは次の構文を使用します。<token_1>:<password1> <token_2>:<password2>デフォルトの NSS ソフトウェアトークンは
NSS Certificate DBです。システムが FIPS モードで実行し場合は、トークンの名前がNSS FIPS 140-2 Certificate DBになります。選択したシナリオに応じて、
nsspasswordファイルの完了後にipsecサービスを起動または再起動します。# systemctl restart ipsec
検証
NSS データベースに空でないパスワードを追加した後に、
ipsecサービスが実行中であることを確認します。# systemctl status ipsec ● ipsec.service - Internet Key Exchange (IKE) Protocol Daemon for IPsec Loaded: loaded (/usr/lib/systemd/system/ipsec.service; enabled; vendor preset: disable> Active: active (running)...Journalログに初期化が成功したことを確認するエントリーが含まれていることを確認します。# journalctl -u ipsec ... pluto[6214]: Initializing NSS using read-write database "sql:/etc/ipsec.d" pluto[6214]: NSS Password from file "/etc/ipsec.d/nsspassword" for token "NSS Certificate DB" with length 20 passed to NSS pluto[6214]: NSS crypto library initialized ...
23.3.10. TCP を使用するように IPsec VPN を設定
Libreswan は、RFC 8229 で説明されているように、IKE パケットおよび IPsec パケットの TCP カプセル化に対応します。この機能により、UDP 経由でトラフィックが転送されないように、IPsec VPN をネットワークに確立し、セキュリティーのペイロード (ESP) を強化できます。フォールバックまたはメインの VPN トランスポートプロトコルとして TCP を使用するように VPN サーバーおよびクライアントを設定できます。TCP カプセル化にはパフォーマンスコストが大きくなるため、UDP がシナリオで永続的にブロックされている場合に限り、TCP を主な VPN プロトコルとして使用してください。
前提条件
- リモートアクセス VPN が設定されている。
手順
config setupセクションの/etc/ipsec.confファイルに以下のオプションを追加します。listen-tcp=yesUDP で最初の試行に失敗した場合に TCP カプセル化をフォールバックオプションとして使用するには、クライアントの接続定義に以下の 2 つのオプションを追加します。
enable-tcp=fallback tcp-remoteport=4500または、UDP を永続的にブロックしている場合は、クライアントの接続設定で以下のオプションを使用します。
enable-tcp=yes tcp-remoteport=4500
23.3.11. IPsec 接続を高速化するために、ESP ハードウェアオフロードの自動検出と使用を設定
Encapsulating Security Payload (ESP) をハードウェアにオフロードすると、Ethernet で IPsec 接続が加速します。デフォルトでは、Libreswan は、ハードウェアがこの機能に対応しているかどうかを検出するため、ESP ハードウェアのオフロードを有効にします。機能が無効になっているか、明示的に有効になっている場合は、自動検出に戻すことができます。
前提条件
- ネットワークカードは、ESP ハードウェアオフロードに対応します。
- ネットワークドライバーは、ESP ハードウェアのオフロードに対応します。
- IPsec 接続が設定され、動作する。
手順
-
ESP ハードウェアオフロードサポートの自動検出を使用する接続の
/etc/ipsec.d/ディレクトリーにある Libreswan 設定ファイルを編集します。 -
接続の設定で
nic-offloadパラメーターが設定されていないことを確認します。 nic-offloadを削除した場合は、ipsecを再起動します。# systemctl restart ipsec
検証
IPsec 接続が使用するイーサネットデバイスの
tx_ipsecおよびrx_ipsecカウンターを表示します。# ethtool -S enp1s0 | grep -E "_ipsec" tx_ipsec: 10 rx_ipsec: 10IPsec トンネルを介してトラフィックを送信します。たとえば、リモート IP アドレスに ping します。
# ping -c 5 remote_ip_addressイーサネットデバイスの
tx_ipsecおよびrx_ipsecカウンターを再度表示します。# ethtool -S enp1s0 | grep -E "_ipsec" tx_ipsec: 15 rx_ipsec: 15カウンターの値が増えると、ESP ハードウェアオフロードが動作します。
23.3.12. IPsec 接続を加速化するためにボンディングでの ESP ハードウェアオフロードの設定
Encapsulating Security Payload (ESP) をハードウェアにオフロードすると、IPsec 接続が加速します。フェイルオーバーの理由でネットワークボンディングを使用する場合、ESP ハードウェアオフロードを設定する要件と手順は、通常のイーサーネットデバイスを使用する要件と手順とは異なります。たとえば、このシナリオでは、ボンディングでオフロードサポートを有効にし、カーネルはボンディングのポートに設定を適用します。
前提条件
-
ボンディングのすべてのネットワークカードが、ESP ハードウェアオフロードをサポートしている。各ボンディングポートがこの機能をサポートしているかどうかを確認するには、
ethtool -k <interface_name> | grep "esp-hw-offload"コマンドを使用します。 - ボンディングが設定されており動作する。
-
ボンディングで
active-backupモードを使用している。ボンディングドライバーは、この機能の他のモードはサポートしていません。 - IPsec 接続が設定され、動作する。
手順
ネットワークボンディングで ESP ハードウェアオフロードのサポートを有効にします。
# nmcli connection modify bond0 ethtool.feature-esp-hw-offload onこのコマンドにより、
bond0接続での ESP ハードウェアオフロードのサポートが有効になります。bond0接続を再度アクティブにします。# nmcli connection up bond0ESP ハードウェアオフロードに使用すべき接続の
/etc/ipsec.d/ディレクトリーにある Libreswan 設定ファイルを編集し、nic-offload=yesステートメントを接続エントリーに追加します。conn example ... nic-offload=yesipsecサービスを再起動します。# systemctl restart ipsec
検証
検証方法は、カーネルのバージョンやドライバーなど、さまざまな要素によって異なります。たとえば、一部のドライバーはカウンターを備えていますが、その名前はさまざまです。詳細は、お使いのネットワークドライバーのドキュメントを参照してください。
次の検証手順は、Red Hat Enterprise Linux 8 上の ixgbe ドライバーに対して使用できます。
ボンディングのアクティブなポートを表示します。
# grep "Currently Active Slave" /proc/net/bonding/bond0 Currently Active Slave: enp1s0アクティブなポートの
tx_ipsecカウンターおよびrx_ipsecカウンターを表示します。# ethtool -S enp1s0 | grep -E "_ipsec" tx_ipsec: 10 rx_ipsec: 10IPsec トンネルを介してトラフィックを送信します。たとえば、リモート IP アドレスに ping します。
# ping -c 5 remote_ip_addressアクティブなポートの
tx_ipsecカウンターおよびrx_ipsecカウンターを再度表示します。# ethtool -S enp1s0 | grep -E "_ipsec" tx_ipsec: 15 rx_ipsec: 15カウンターの値が増えると、ESP ハードウェアオフロードが動作します。
23.3.13. RHEL システムロールを使用した VPN 接続の設定
VPN は、信頼できないネットワーク経由でトラフィックをセキュアに送信するための暗号化接続です。vpn RHEL システムロールを使用すると、VPN 設定の作成プロセスを自動化できます。
vpn RHEL システムロールは、VPN プロバイダーとして、IPsec 実装である Libreswan のみをサポートしています。
23.3.13.1. vpn RHEL システムロールを使用して PSK 認証によるホスト間 IPsec VPN を作成する
IPsec を使用すると、VPN を介してホストを相互に直接接続できます。ホストは事前共有鍵 (PSK) を使用して相互に認証できます。vpn RHEL システムロールを使用すると、PSK 認証による IPsec ホスト間接続を作成するプロセスを自動化できます。
デフォルトでは、このロールはトンネルベースの VPN を作成します。
前提条件
- コントロールノードと管理対象ノードの準備が完了している。
- 管理対象ノードで Playbook を実行できるユーザーとしてコントロールノードにログインしている。
-
管理対象ノードへの接続に使用するアカウントに、そのノードに対する
sudo権限がある。
手順
次の内容を含む Playbook ファイル (例:
~/playbook.yml) を作成します。--- - name: Configuring VPN hosts: managed-node-01.example.com, managed-node-02.example.com tasks: - name: IPsec VPN with PSK authentication ansible.builtin.include_role: name: redhat.rhel_system_roles.vpn vars: vpn_connections: - hosts: managed-node-01.example.com: managed-node-02.example.com: auth_method: psk auto: start vpn_manage_firewall: true vpn_manage_selinux: trueサンプル Playbook で指定されている設定は次のとおりです。
hosts: <list>VPN を設定するホストを含む YAML ディクショナリーを定義します。エントリーが Ansible 管理対象ノードでない場合は、
hostnameパラメーターに完全修飾ドメイン名 (FQDN) または IP アドレスを指定する必要があります。次に例を示します。... - hosts: ... external-host.example.com: hostname: 192.0.2.1このロールは、各管理対象ノード上の VPN 接続を設定します。接続の名前は
<host_A>-to-<host_B>です (例:managed-node-01.example.com-to-managed-node-02.example.com)。このロールは外部 (管理対象外) ノード上で Libreswan を設定することはできないことに注意してください。そのようなホストでは手動で設定を作成する必要があります。auth_method: psk-
ホスト間の PSK 認証を有効にします。ロールはコントロールノードで
opensslを使用して PSK を作成します。 auto: <start-up_method>-
接続の起動方法を指定します。有効な値は
add、ondemand、start、およびignoreです。詳細は、Libreswan がインストールされているシステム上のipsec.conf(5)man ページを参照してください。この変数のデフォルト値は null です。この値は自動起動操作を実行しないことを示します。 vpn_manage_firewall: true-
ロールにより、管理対象ノード上の
firewalldサービスで必要なポートを開くことを指定します。 vpn_manage_selinux: true- ロールにより、IPsec ポートに必要な SELinux ポートタイプを設定することを指定します。
Playbook で使用されるすべての変数の詳細は、コントロールノードの
/usr/share/ansible/roles/rhel-system-roles.vpn/README.mdファイルを参照してください。Playbook の構文を検証します。
$ ansible-playbook --syntax-check ~/playbook.ymlこのコマンドは構文を検証するだけであり、有効だが不適切な設定から保護するものではないことに注意してください。
Playbook を実行します。
$ ansible-playbook ~/playbook.yml
検証
接続が正常に開始されたことを確認します。次に例を示します。
# ansible managed-node-01.example.com -m shell -a 'ipsec trafficstatus | grep "managed-node-01.example.com-to-managed-node-02.example.com"' ... 006 #3: "managed-node-01.example.com-to-managed-node-02.example.com", type=ESP, add_time=1741857153, inBytes=38622, outBytes=324626, maxBytes=2^63B, id='@managed-node-02.example.com'このコマンドは、VPN 接続がアクティブでないと成功しないことに注意してください。Playbook 内の
auto変数をstart以外の値に設定する場合は、まず管理対象ノードで接続を手動でアクティブ化する必要がある場合があります。
23.3.13.2. vpn RHEL システムロールを使用して、個別のデータプレーンとコントロールプレーンおよび PSK 認証によるホスト間 IPsec VPN を作成する
IPsec を使用すると、VPN を介してホストを相互に直接接続できます。たとえば、制御メッセージの傍受や妨害のリスクを最小限に抑えてセキュリティーを強化するために、データトラフィックと制御トラフィックの両方に個別の接続を設定できます。vpn RHEL システムロールを使用すると、個別のデータプレーンとコントロールプレーンおよび PSK 認証を使用して IPsec ホスト間接続を作成するプロセスを自動化できます。
前提条件
- コントロールノードと管理対象ノードの準備が完了している。
- 管理対象ノードで Playbook を実行できるユーザーとしてコントロールノードにログインしている。
-
管理対象ノードへの接続に使用するアカウントに、そのノードに対する
sudo権限がある。
手順
次の内容を含む Playbook ファイル (例:
~/playbook.yml) を作成します。--- - name: Configuring VPN hosts: managed-node-01.example.com, managed-node-02.example.com tasks: - name: IPsec VPN with PSK authentication ansible.builtin.include_role: name: redhat.rhel_system_roles.vpn vars: vpn_connections: - name: control_plane_vpn hosts: managed-node-01.example.com: hostname: 203.0.113.1 # IP address for the control plane managed-node-02.example.com: hostname: 198.51.100.2 # IP address for the control plane auth_method: psk auto: start - name: data_plane_vpn hosts: managed-node-01.example.com: hostname: 10.0.0.1 # IP address for the data plane managed-node-02.example.com: hostname: 172.16.0.2 # IP address for the data plane auth_method: psk auto: start vpn_manage_firewall: true vpn_manage_selinux: trueサンプル Playbook で指定されている設定は次のとおりです。
hosts: <list>VPN を設定するホストを含む YAML ディクショナリーを定義します。接続の名前は
<name>-<IP_address_A>-to-<IP_address_B>です (例:control_plane_vpn-203.0.113.1-to-198.51.100.2)。このロールは、各管理対象ノード上の VPN 接続を設定します。このロールは外部 (管理対象外) ノード上で Libreswan を設定することはできないことに注意してください。そのようなホストでは手動で設定を作成する必要があります。
auth_method: psk-
ホスト間の PSK 認証を有効にします。ロールはコントロールノードで
opensslを使用して事前共有鍵を作成します。 auto: <start-up_method>-
接続の起動方法を指定します。有効な値は
add、ondemand、start、およびignoreです。詳細は、Libreswan がインストールされているシステム上のipsec.conf(5)man ページを参照してください。この変数のデフォルト値は null です。この値は自動起動操作を実行しないことを示します。 vpn_manage_firewall: true-
ロールにより、管理対象ノード上の
firewalldサービスで必要なポートを開くことを指定します。 vpn_manage_selinux: true- ロールにより、IPsec ポートに必要な SELinux ポートタイプを設定することを指定します。
Playbook で使用されるすべての変数の詳細は、コントロールノードの
/usr/share/ansible/roles/rhel-system-roles.vpn/README.mdファイルを参照してください。Playbook の構文を検証します。
$ ansible-playbook --syntax-check ~/playbook.ymlこのコマンドは構文を検証するだけであり、有効だが不適切な設定から保護するものではないことに注意してください。
Playbook を実行します。
$ ansible-playbook ~/playbook.yml
検証
接続が正常に開始されたことを確認します。次に例を示します。
# ansible managed-node-01.example.com -m shell -a 'ipsec trafficstatus | grep "control_plane_vpn-203.0.113.1-to-198.51.100.2"' ... 006 #3: "control_plane_vpn-203.0.113.1-to-198.51.100.2", type=ESP, add_time=1741860073, inBytes=0, outBytes=0, maxBytes=2^63B, id='198.51.100.2'このコマンドは、VPN 接続がアクティブでないと成功しないことに注意してください。Playbook 内の
auto変数をstart以外の値に設定する場合は、まず管理対象ノードで接続を手動でアクティブ化する必要がある場合があります。
23.3.13.3. vpn RHEL システムロールを使用して、証明書ベースの認証による複数ホスト間の IPsec メッシュ VPN を作成する
Libreswan はオポチュニスティックメッシュの作成をサポートしています。これは、各ホストで 1 つの設定を使用して、多数のホスト間で IPsec 接続を確立するためのものです。メッシュにホストを追加する場合、既存のホストの設定を更新する必要はありません。セキュリティーを強化するには、Libreswan で証明書ベースの認証を使用します。
vpn RHEL システムロールを使用すると、証明書ベースの認証による管理対象ノード間の VPN メッシュの設定を自動化できます。
前提条件
- コントロールノードと管理対象ノードの準備が完了している。
- 管理対象ノードで Playbook を実行できるユーザーとしてコントロールノードにログインしている。
-
管理対象ノードへの接続に使用するアカウントに、そのノードに対する
sudo権限がある。 各管理対象ノード用に PKCS #12 ファイルを用意した。
各ファイルには次のものを含めます。
- 認証局 (CA) 証明書
- ノードの秘密鍵
- ノードのクライアント証明書
-
ファイル名は
<managed_node_name_as_in_the_inventory>.p12とします。 - ファイルは Playbook と同じディレクトリーに保存します。
手順
~/inventoryファイルを編集し、cert_name変数を追加します。managed-node-01.example.com cert_name=managed-node-01.example.com managed-node-02.example.com cert_name=managed-node-02.example.com managed-node-03.example.com cert_name=managed-node-03.example.comcert_name変数は、各ホストの証明書で使用されるコモンネーム (CN) フィールドの値に設定します。通常、CN フィールドは完全修飾ドメイン名 (FQDN) に設定します。機密性の高い変数を暗号化されたファイルに保存します。
vault を作成します。
$ ansible-vault create ~/vault.yml New Vault password: <vault_password> Confirm New Vault password: <vault_password>ansible-vault createコマンドでエディターが開いたら、機密データを<key>: <value>形式で入力します。pkcs12_pwd: <password>- 変更を保存して、エディターを閉じます。Ansible は vault 内のデータを暗号化します。
次の内容を含む Playbook ファイル (例:
~/playbook.yml) を作成します。- name: Configuring VPN hosts: managed-node-01.example.com, managed-node-02.example.com, managed-node-03.example.com vars_files: - ~/vault.yml tasks: - name: Install LibreSwan ansible.builtin.package: name: libreswan state: present - name: Identify the path to IPsec NSS database ansible.builtin.set_fact: nss_db_dir: "{{ '/etc/ipsec.d/' if ansible_distribution in ['CentOS', 'RedHat'] and ansible_distribution_major_version is version('8', '=') else '/var/lib/ipsec/nss/' }}" - name: Locate IPsec NSS database files ansible.builtin.find: paths: "{{ nss_db_dir }}" patterns: "*.db" register: db_files - name: Remove IPsec NSS database files ansible.builtin.file: path: "{{ item.path }}" state: absent loop: "{{ db_files.files }}" when: db_files.matched > 0 - name: Initialize IPsec NSS database ansible.builtin.command: cmd: ipsec initnss - name: Copy PKCS #12 file to the managed node ansible.builtin.copy: src: "~/{{ inventory_hostname }}.p12" dest: "/etc/ipsec.d/{{ inventory_hostname }}.p12" mode: 0600 - name: Import PKCS #12 file in IPsec NSS database ansible.builtin.shell: cmd: 'pk12util -d {{ nss_db_dir }} -i /etc/ipsec.d/{{ inventory_hostname }}.p12 -W "{{ pkcs12_pwd }}"' - name: Remove PKCS #12 file ansible.builtin.file: path: "/etc/ipsec.d/{{ inventory_hostname }}.p12" state: absent - name: Opportunistic mesh IPsec VPN with certificate-based authentication ansible.builtin.include_role: name: redhat.rhel_system_roles.vpn vars: vpn_connections: - opportunistic: true auth_method: cert policies: - policy: private cidr: default - policy: private cidr: 192.0.2.0/24 - policy: clear cidr: 192.0.2.1/32 vpn_manage_firewall: true vpn_manage_selinux: trueサンプル Playbook で指定されている設定は次のとおりです。
opportunistic: true-
複数ホスト間のオポチュニスティックメッシュを有効にします。
policies変数は、どのサブネットとホストのトラフィックを暗号化する必要があるか、または暗号化できるか、またどのサブネットとホストでクリアテキストでの接続の使用を継続するかを定義します。 auth_method: cert- 証明書ベースの認証を有効にします。これを行うには、インベントリーで各管理対象ノードの証明書のニックネームを指定する必要があります。
policies: <list_of_policies>Libreswan ポリシーを YAML リスト形式で定義します。
デフォルトのポリシーは
private-or-clearです。これをprivateに変更するには、上記の Playbook に、デフォルトのcidrエントリーに応じた適切なポリシーを含めます。Ansible コントロールノードが管理対象ノードと同じ IP サブネットにある場合は、Playbook の実行中に SSH 接続が失われるのを防ぐために、コントロールノードの IP アドレスに
clearポリシーを追加します。たとえば、メッシュを192.0.2.0/24サブネット用に設定する必要があり、コントロールノードが IP アドレス192.0.2.1を使用する場合、Playbook に示されているように、192.0.2.1/32のclearポリシーが必要です。ポリシーの詳細は、Libreswan がインストールされているシステム上の
ipsec.conf(5)man ページを参照してください。vpn_manage_firewall: true-
ロールにより、管理対象ノード上の
firewalldサービスで必要なポートを開くことを指定します。 vpn_manage_selinux: true- ロールにより、IPsec ポートに必要な SELinux ポートタイプを設定することを指定します。
Playbook で使用されるすべての変数の詳細は、コントロールノードの
/usr/share/ansible/roles/rhel-system-roles.vpn/README.mdファイルを参照してください。Playbook の構文を検証します。
$ ansible-playbook --ask-vault-pass --syntax-check ~/playbook.ymlこのコマンドは構文を検証するだけであり、有効だが不適切な設定から保護するものではないことに注意してください。
Playbook を実行します。
$ ansible-playbook --ask-vault-pass ~/playbook.yml
検証
メッシュ内のノードで、別のノードに ping を送信して接続をアクティブ化します。
[root@managed-node-01]# ping managed-node-02.example.com接続がアクティブであることを確認します。
[root@managed-node-01]# ipsec trafficstatus 006 #2: "private#192.0.2.0/24"[1] ...192.0.2.2, type=ESP, add_time=1741938929, inBytes=372408, outBytes=545728, maxBytes=2^63B, id='CN=managed-node-02.example.com'
23.3.14. システム全体の暗号化ポリシーをオプトアウトする IPsec 接続の設定
接続向けのシステム全体の暗号化ポリシーのオーバーライド
RHEL のシステム全体の暗号化ポリシーでは、%default と呼ばれる特別な接続が作成されます。この接続には、ikev2 オプション、esp オプション、および ike オプションのデフォルト値が含まれます。ただし、接続設定ファイルに上記のオプションを指定すると、デフォルト値を上書きできます。
たとえば、次の設定では、AES および SHA-1 または SHA-2 で IKEv1 を使用し、AES-GCM または AES-CBC で IPsec (ESP) を使用する接続が可能です。
conn MyExample
...
ikev2=never
ike=aes-sha2,aes-sha1;modp2048
esp=aes_gcm,aes-sha2,aes-sha1
...AES-GCM は IPsec (ESP) および IKEv2 で利用できますが、IKEv1 では利用できません。
全接続向けのシステム全体の暗号化ポリシーの無効化
すべての IPsec 接続のシステム全体の暗号化ポリシーを無効にするには、/etc/ipsec.conf ファイルで次の行をコメントアウトします。
include /etc/crypto-policies/back-ends/libreswan.config
次に、接続設定ファイルに ikev2=never オプションを追加してください。
23.3.15. IPsec VPN 設定のトラブルシューティング
IPsec VPN 設定に関連する問題は主に、一般的な理由が原因で発生する可能性が高くなっています。このような問題が発生した場合は、問題の原因が以下のシナリオのいずれかに該当するかを確認して、対応するソリューションを適用します。
基本的な接続のトラブルシューティング
VPN 接続関連の問題の多くは、管理者が不適当な設定オプションを指定してエンドポイントを設定した新しいデプロイメントで発生します。また、互換性のない値が新たに実装された場合に、機能していた設定が突然動作が停止する可能性があります。管理者が設定を変更した場合など、このような結果になることがあります。また、管理者が暗号化アルゴリズムなど、特定のオプションに異なるデフォルト値を使用して、ファームウェアまたはパッケージの更新をインストールした場合などです。
IPsec VPN 接続が確立されていることを確認するには、次のコマンドを実行します。
# ipsec trafficstatus
006 #8: "vpn.example.com"[1] 192.0.2.1, type=ESP, add_time=1595296930, inBytes=5999, outBytes=3231, id='@vpn.example.com', lease=100.64.13.5/32出力が空の場合や、エントリーで接続名が表示されない場合など、トンネルが破損します。
接続に問題があることを確認するには、以下を実行します。
vpn.example.com 接続をもう一度読み込みます。
# ipsec auto --add vpn.example.com 002 added connection description "vpn.example.com"次に、VPN 接続を開始します。
# ipsec auto --up vpn.example.com
ファイアウォール関連の問題
最も一般的な問題は、IPSec エンドポイントの 1 つ、またはエンドポイント間にあるルーターにあるファイアウォールで Internet Key Exchange (IKE) パケットがドロップされるという点が挙げられます。
IKEv2 の場合には、以下の例のような出力は、ファイアウォールに問題があることを示しています。
# ipsec auto --up vpn.example.com 181 "vpn.example.com"[1] 192.0.2.2 #15: initiating IKEv2 IKE SA 181 "vpn.example.com"[1] 192.0.2.2 #15: STATE_PARENT_I1: sent v2I1, expected v2R1 010 "vpn.example.com"[1] 192.0.2.2 #15: STATE_PARENT_I1: retransmission; will wait 0.5 seconds for response 010 "vpn.example.com"[1] 192.0.2.2 #15: STATE_PARENT_I1: retransmission; will wait 1 seconds for response 010 "vpn.example.com"[1] 192.0.2.2 #15: STATE_PARENT_I1: retransmission; will wait 2 seconds for ...IKEv1 の場合は、最初のコマンドの出力は以下のようになります。
# ipsec auto --up vpn.example.com 002 "vpn.example.com" #9: initiating Main Mode 102 "vpn.example.com" #9: STATE_MAIN_I1: sent MI1, expecting MR1 010 "vpn.example.com" #9: STATE_MAIN_I1: retransmission; will wait 0.5 seconds for response 010 "vpn.example.com" #9: STATE_MAIN_I1: retransmission; will wait 1 seconds for response 010 "vpn.example.com" #9: STATE_MAIN_I1: retransmission; will wait 2 seconds for response ...
IPsec の設定に使用される IKE プロトコルは暗号化されているため、tcpdump ツールを使用して、トラブルシューティングできるサブセットは一部のみです。ファイアウォールが IKE パケットまたは IPsec パケットをドロップしている場合は、tcpdump ユーティリティーを使用して原因を見つけることができます。ただし、tcpdump は IPsec VPN 接続に関する他の問題を診断できません。
eth0インターフェイスで VPN および暗号化データすべてのネゴシエーションを取得するには、次のコマンドを実行します。# tcpdump -i eth0 -n -n esp or udp port 500 or udp port 4500 or tcp port 4500
アルゴリズム、プロトコル、およびポリシーが一致しない場合
VPN 接続では、エンドポイントが IKE アルゴリズム、IPsec アルゴリズム、および IP アドレス範囲に一致する必要があります。不一致が発生した場合には接続は失敗します。以下の方法のいずれかを使用して不一致を特定した場合は、アルゴリズム、プロトコル、またはポリシーを調整して修正します。
リモートエンドポイントが IKE/IPsec を実行していない場合は、そのパケットを示す ICMP パケットが表示されます。以下に例を示します。
# ipsec auto --up vpn.example.com ... 000 "vpn.example.com"[1] 192.0.2.2 #16: ERROR: asynchronous network error report on wlp2s0 (192.0.2.2:500), complainant 198.51.100.1: Connection refused [errno 111, origin ICMP type 3 code 3 (not authenticated)] ...IKE アルゴリズムが一致しない例:
# ipsec auto --up vpn.example.com ... 003 "vpn.example.com"[1] 193.110.157.148 #3: dropping unexpected IKE_SA_INIT message containing NO_PROPOSAL_CHOSEN notification; message payloads: N; missing payloads: SA,KE,NiIPsec アルゴリズムが一致しない例:
# ipsec auto --up vpn.example.com ... 182 "vpn.example.com"[1] 193.110.157.148 #5: STATE_PARENT_I2: sent v2I2, expected v2R2 {auth=IKEv2 cipher=AES_GCM_16_256 integ=n/a prf=HMAC_SHA2_256 group=MODP2048} 002 "vpn.example.com"[1] 193.110.157.148 #6: IKE_AUTH response contained the error notification NO_PROPOSAL_CHOSENまた、IKE バージョンが一致しないと、リモートエンドポイントが応答なしの状態でリクエストをドロップする可能性がありました。これは、すべての IKE パケットをドロップするファイアウォールと同じです。
IKEv2 (Traffic Selectors - TS) の IP アドレス範囲が一致しない例:
# ipsec auto --up vpn.example.com ... 1v2 "vpn.example.com" #1: STATE_PARENT_I2: sent v2I2, expected v2R2 {auth=IKEv2 cipher=AES_GCM_16_256 integ=n/a prf=HMAC_SHA2_512 group=MODP2048} 002 "vpn.example.com" #2: IKE_AUTH response contained the error notification TS_UNACCEPTABLEIKEv1 の IP アドレス範囲で一致しない例:
# ipsec auto --up vpn.example.com ... 031 "vpn.example.com" #2: STATE_QUICK_I1: 60 second timeout exceeded after 0 retransmits. No acceptable response to our first Quick Mode message: perhaps peer likes no proposalIKEv1 で PreSharedKeys (PSK) を使用する場合には、どちらでも同じ PSK に配置されなければ、IKE メッセージ全体の読み込みができなくなります。
# ipsec auto --up vpn.example.com ... 003 "vpn.example.com" #1: received Hash Payload does not match computed value 223 "vpn.example.com" #1: sending notification INVALID_HASH_INFORMATION to 192.0.2.23:500IKEv2 では、mismatched-PSK エラーが原因で AUTHENTICATION_FAILED メッセージが表示されます。
# ipsec auto --up vpn.example.com ... 002 "vpn.example.com" #1: IKE SA authentication request rejected by peer: AUTHENTICATION_FAILED
最大伝送単位 (MTU)
ファイアウォールが IKE または IPSec パケットをブロックする以外で、ネットワークの問題の原因として、暗号化パケットのパケットサイズの増加が最も一般的です。ネットワークハードウェアは、最大伝送単位 (MTU) を超えるパケットを 1500 バイトなどのサイズに断片化します。多くの場合、断片化されたパケットは失われ、パケットの再アセンブルに失敗します。これにより、小さいサイズのパケットを使用する ping テスト時には機能し、他のトラフィックでは失敗するなど、断続的な問題が発生します。このような場合に、SSH セッションを確立できますが、リモートホストに 'ls -al /usr' コマンドに入力した場合など、すぐにターミナルがフリーズします。
この問題を回避するには、トンネル設定ファイルに mtu=1400 のオプションを追加して、MTU サイズを縮小します。
または、TCP 接続の場合は、MSS 値を変更する iptables ルールを有効にします。
# iptables -I FORWARD -p tcp --tcp-flags SYN,RST SYN -j TCPMSS --clamp-mss-to-pmtu
各シナリオで上記のコマンドを使用して問題が解決されない場合は、set-mss パラメーターで直接サイズを指定します。
# iptables -I FORWARD -p tcp --tcp-flags SYN,RST SYN -j TCPMSS --set-mss 1380ネットワークアドレス変換 (NAT)
IPsec ホストが NAT ルーターとしても機能すると、誤ってパケットが再マッピングされる可能性があります。以下の設定例はこの問題を示しています。
conn myvpn
left=172.16.0.1
leftsubnet=10.0.2.0/24
right=172.16.0.2
rightsubnet=192.168.0.0/16
…アドレスが 172.16.0.1 のシステムには NAT ルールが 1 つあります。
iptables -t nat -I POSTROUTING -o eth0 -j MASQUERADEアドレスが 10.0.2.33 のシステムがパケットを 192.168.0.1 に送信する場合に、ルーターは IPsec 暗号化を適用する前にソースを 10.0.2.33 から 172.16.0.1 に変換します。
次に、ソースアドレスが 10.0.2.33 のパケットは conn myvpn 設定と一致しなくなるので、IPsec ではこのパケットが暗号化されません。
この問題を解決するには、ルーターのターゲット IPsec サブネット範囲の NAT を除外するルールを挿入します。以下に例を示します。
iptables -t nat -I POSTROUTING -s 10.0.2.0/24 -d 192.168.0.0/16 -j RETURNカーネル IPsec サブシステムのバグ
たとえば、バグが原因で IKE ユーザー空間と IPsec カーネルの同期が解除される場合など、カーネル IPsec サブシステムに問題が発生する可能性があります。このような問題がないかを確認するには、以下を実行します。
$ cat /proc/net/xfrm_stat
XfrmInError 0
XfrmInBufferError 0
...上記のコマンドの出力でゼロ以外の値が表示されると、問題があることを示しています。この問題が発生した場合は、新しい サポートケース を作成し、1 つ前のコマンドの出力と対応する IKE ログを添付してください。
Libreswan のログ
デフォルトでは、Libreswan は syslog プロトコルを使用してログに記録します。journalctl コマンドを使用して、IPsec に関連するログエントリーを検索できます。ログへの対応するエントリーは pluto IKE デーモンにより送信されるため、以下のように、キーワード "pluto" を検索します。
$ journalctl -b | grep pluto
ipsec サービスのライブログを表示するには、次のコマンドを実行します。
$ journalctl -f -u ipsec
ロギングのデフォルトレベルで設定問題が解決しない場合は、/etc/ipsec.conf ファイルの config setup セクションに plutodebug=all オプションを追加してデバッグログを有効にします。
デバッグロギングは多くのエントリーを生成し、journald サービスまたは syslogd サービスレートのいずれかが syslog メッセージを制限する可能性があることに注意してください。完全なログを取得するには、ロギングをファイルにリダイレクトします。/etc/ipsec.conf を編集し、config setup セクションに logfile=/var/log/pluto.log を追加します。
23.3.16. control-center による VPN 接続の確立
グラフィカルインターフェイスで Red Hat Enterprise Linux を使用する場合は、この VPN 接続を GNOME control-center で設定できます。
前提条件
-
NetworkManager-libreswan-gnomeパッケージがインストールされている。
手順
-
Super キーを押して
Settingsと入力し、Enter を押してcontrol-centerアプリケーションを開きます。 -
左側の
Networkエントリーを選択します。 - + アイコンをクリックします。
-
VPNを選択します。 Identityメニューエントリーを選択して、基本的な設定オプションを表示します。一般
Gateway- リモート VPN ゲートウェイの名前またはIPアドレスです。認証
Type-
IKEv2 (証明書)- クライアントは、証明書により認証されます。これはより安全です (デフォルト)。 IKEv1(XAUTH): クライアントは、ユーザー名とパスワード、または事前共有キー (PSK) で認証されます。Advancedセクションでは、以下の設定が可能です。図23.1 VPN 接続の詳細なオプション
 警告
警告gnome-control-centerアプリケーションを使用して IPsec ベースの VPN 接続を設定すると、Advancedダイアログには設定が表示されますが、変更することはできません。したがって、詳細な IPsec オプションを変更できません。nm-connection-editorツールまたはnmcliツールを使用して、詳細なプロパティーの設定を実行します。識別
Domain- 必要な場合は、ドメイン名を入力します。セキュリティー
-
Phase1 Algorithms- Libreswan パラメーターikeに対応します。暗号化チャネルの認証およびセットアップに使用するアルゴリズムを入力します。 Phase2 Algorithms- Libreswan パラメーターespに対応します。IPsecネゴシエーションに使用するアルゴリズムを入力します。Disable PFSフィールドで PFS (Perfect Forward Secrecy) を無効にし、PFS に対応していない古いサーバーとの互換性があることを確認します。-
Phase1 Lifetime- Libreswan パラメーターikelifetimeに対応します。このパラメーターは、トラフィックの暗号化に使用される鍵がどのぐらい有効であるかどうかを示します。 Phase2 Lifetime- Libreswan パラメーターsalifetimeに対応します。このパラメーターは、接続の特定インスタンスが期限切れになるまでの持続時間を指定します。セキュリティー上の理由から、暗号化キーは定期的に変更する必要があります。
Remote network- Libreswan パラメーターrightsubnetに対応します。このパラメーターは、VPN から到達できる宛先のプライベートリモートネットワークです。絞り込むことのできる
narrowingフィールドを確認します。これは IKEv2 ネゴシエーションの場合にのみ有効であることに注意してください。-
Enable fragmentation- Libreswan パラメーターのfragmentationに対応します。IKE 断片化を許可するかどうかを指定します。有効な値は、yes(デフォルト) またはnoです。 -
Enable Mobike- Libreswan パラメーターmobikeに対応します。最初から接続を再起動しなくても、接続がエンドポイントを移行することを Mobility and Multihoming Protocol (MOBIKE, RFC 4555) が許可するかどうかを設定します。これは、有線、無線、またはモバイルデータの接続の切り替えを行うモバイルデバイスで使用されます。値は、no(デフォルト) またはyesです。
-
メニューエントリーを選択します。
IPv4 Method
-
Automatic (DHCP)- 接続しているネットワークが動的IPアドレスの割り当てにDHCPサーバーを使用する場合は、このオプションを選択します。 -
Link-Local Only- 接続しているネットワークにDHCPサーバーがなく、IPアドレスを手動で割り当てない場合は、このオプションを選択します。接頭辞169.254/16付きのランダムなアドレスが、RFC 3927 に従って割り当てられます。 -
Manual-IPアドレスを手動で割り当てたい場合は、このオプションを選択します。 Disable- この接続ではIPv4は無効化されています。DNS
DNSセクションでは、AutomaticがONになっているときに、これをOFFに切り替えて、使用する DNS サーバーの IP アドレスを入力します。IP アドレスはコンマで区切ります。Routes
Routesセクションでは、AutomaticがONになっている場合は、DHCP からのルートが使用されますが、他の静的ルートを追加することもできることに注意してください。OFFの場合は、静的ルートだけが使用されます。-
Address- リモートネットワークまたはホストのIPアドレスを入力します。 -
Netmask- 上記で入力したIPアドレスのネットマスクまた接頭辞長。 -
Gateway- 上記で入力したリモートネットワーク、またはホストにつながるゲートウェイのIPアドレス。 Metric- このルートに与える優先値であるネットワークコスト。数値が低い方が優先されます。Use this connection only for resources on its network (この接続はネットワーク上のリソースのためだけに使用)
このチェックボックスを選択すると、この接続はデフォルトルートになりません。このオプションを選択すると、この接続で自動的に学習したルートを使用することが明確なトラフィックか、手動で入力したトラフィックのみがこの接続を経由します。
-
VPN接続のIPv6設定を設定するには、 メニューエントリーを選択します。IPv6 Method
-
Automatic-IPv6ステートレスアドレス自動設定 (SLAAC) を使用して、ハードウェアのアドレスとルーター通知 (RA) に基づくステートレスの自動設定を作成するには、このオプションを選択します。 -
Automatic, DHCP only- RA を使用しないで、DHCPv6からの情報を直接要求してステートフルな設定を作成する場合は、このオプションを選択します。 -
Link-Local Only- 接続しているネットワークにDHCPサーバーがなく、IPアドレスを手動で割り当てない場合は、このオプションを選択します。接頭辞FE80::0付きのランダムなアドレスが、RFC 4862 に従って割り当てられます。 -
Manual-IPアドレスを手動で割り当てたい場合は、このオプションを選択します。 Disable- この接続ではIPv6は無効化されています。DNS、Routes、Use this connection only for resources on its networkが、一般的なIPv4設定となることに注意してください。
-
-
VPN接続の編集が終了したら、 ボタンをクリックして設定をカスタマイズするか、 ボタンをクリックして、既存の接続に保存します。 -
プロファイルを
ONに切り替え、VPN接続をアクティブにします。 - DHCP またはステートレスアドレス自動設定 (SLAAC) が設定されたネットワークでこのホストを使用すると、接続がリダイレクトされる危険性があります。詳細と軽減策については、接続がトンネルを回避しないように VPN 接続を専用ルーティングテーブルに割り当てる を参照してください。
23.3.17. nm-connection-editor による VPN 接続の設定
Red Hat Enterprise Linux をグラフィカルインターフェイスで使用する場合は、nm-connection-editor アプリケーションを使用して VPN 接続を設定できます。
前提条件
-
NetworkManager-libreswan-gnomeパッケージがインストールされている。 インターネット鍵交換バージョン 2 (IKEv2) 接続を設定する場合は、以下のようになります。
- 証明書が、IPsec ネットワークセキュリティーサービス (NSS) データベースにインポートされている。
- NSS データベースの証明書のニックネームが知られている。
手順
ターミナルを開き、次のコマンドを入力します。
$ nm-connection-editor- ボタンをクリックして、新しい接続を追加します。
-
IPsec ベースの VPN接続タイプを選択し、 をクリックします。 VPNタブで、以下を行います。Gatewayフィールドに VPN ゲートウェイのホスト名または IP アドレスを入力し、認証タイプを選択します。認証タイプに応じて、異なる追加情報を入力する必要があります。-
IKEv2 (Certifiate)は、証明書を使用してクライアントを認証します。これは、より安全です。この設定には、IPsec NSS データベースの証明書のニックネームが必要です。 IKEv1 (XAUTH)は、ユーザー名とパスワード (事前共有鍵) を使用してユーザーを認証します。この設定は、以下の値を入力する必要があります。- ユーザー名
- Password
- グループ名
- シークレット
-
リモートサーバーが IKE 交換のローカル識別子を指定する場合は、
Remote IDフィールドに正確な文字列を入力します。リモートサーバーで Libreswan を実行すると、この値はサーバーのleftidパラメーターに設定されます。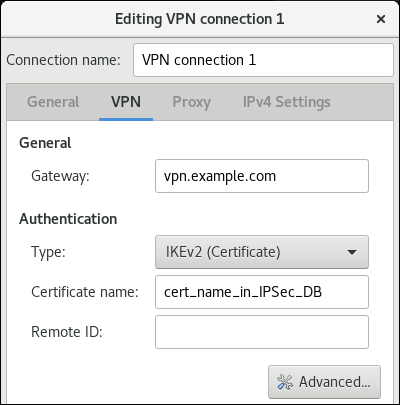
オプション: ボタンをクリックして追加の設定を指定します。以下の設定を指定できます。
識別
-
ドメイン- 必要に応じてドメイン名を入力します。
-
セキュリティー
-
Phase1 アルゴリズムは、Libreswan パラメーターikeに対応します。暗号化チャンネルの認証および設定に使用するアルゴリズムを入力します。 Phase2 アルゴリズムは、Libreswan パラメーターespに対応します。IPsecネゴシエーションに使用するアルゴリズムを入力します。Disable PFSフィールドで PFS (Perfect Forward Secrecy) を無効にし、PFS に対応していない古いサーバーとの互換性があることを確認します。-
Phase1 ライフタイムは、Libreswan パラメーターikelifetimeに対応します。このパラメーターは、トラフィックの暗号化に使用される鍵が有効である期間を定義します。 -
Phase2 ライフタイムは、Libreswan パラメーターsalifetimeに対応します。このパラメーターは、セキュリティー関連が有効である期間を定義します。
-
接続性
リモートネットワークは、Libreswan パラメーターrightsubnetに対応し、VPN から到達できる宛先のプライベートリモートネットワークです。絞り込むことのできる
narrowingフィールドを確認します。これは IKEv2 ネゴシエーションの場合にのみ有効であることに注意してください。-
フラグメンテーションの有効化は、Libreswan パラメーターの断片化に対応します。IKE 断片化を許可するかどうかを指定します。有効な値は、yes(デフォルト) またはnoです。 -
Mobike の有効化は、Libreswan パラメーターmobikeに対応します。パラメーターは、最初から接続を再起動しなくても、接続がエンドポイントを移行することを Mobility and Multihoming Protocol (MOBIKE) (RFC 4555) が許可するかどうかを定義します。これは、有線、無線、またはモバイルデータの接続の切り替えを行うモバイルデバイスで使用されます。値は、no(デフォルト) またはyesです。
IPv4 設定タブで、IP 割り当て方法を選択し、必要に応じて、追加の静的アドレス、DNS サーバー、検索ドメイン、ルートを設定します。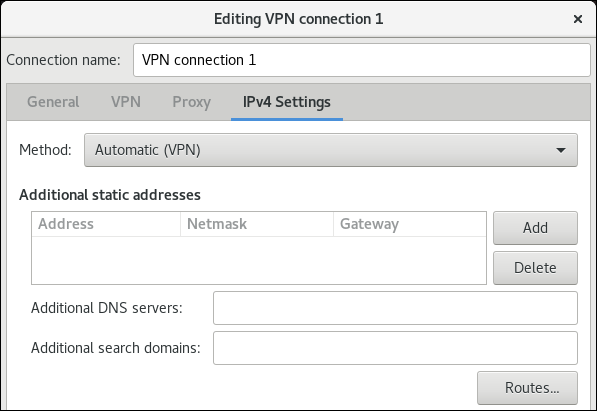
- 接続を読み込みます。
-
nm-connection-editorを閉じます。 - DHCP またはステートレスアドレス自動設定 (SLAAC) が設定されたネットワークでこのホストを使用すると、接続がリダイレクトされる危険性があります。詳細と軽減策については、接続がトンネルを回避しないように VPN 接続を専用ルーティングテーブルに割り当てる を参照してください。
ボタンをクリックして新しい接続を追加する場合は、NetworkManager により、その接続用の新しい設定が作成され、既存の接続の編集に使用するのと同じダイアログが表示されます。このダイアログの違いは、既存の接続プロファイルに Details メニューエントリーがあることです。
23.3.18. 接続がトンネルを回避しないように VPN 接続を専用ルーティングテーブルに割り当てる
DHCP サーバーとステートレスアドレス自動設定 (SLAAC) はどちらも、クライアントのルーティングテーブルにルートを追加できます。悪意のある DHCP サーバーがこの機能を使用すると、たとえば、VPN 接続を使用するホストに対して、VPN トンネルではなく物理インターフェイス経由でトラフィックをリダイレクトするように強制できます。この脆弱性は TunnelVision とも呼ばれ、CVE-2024-3661 の脆弱性に関する記事で説明されています。
この脆弱性を軽減するために、VPN 接続を専用のルーティングテーブルに割り当てることができます。これを行うと、DHCP 設定または SLAAC が、VPN トンネル宛のネットワークパケットに関するルーティング決定を操作できなくなります。
次の条件が 1 つ以上環境に当てはまる場合は、この手順を実行してください。
- 少なくとも 1 つのネットワークインターフェイスが DHCP または SLAAC を使用している。
- ネットワークで、不正な DHCP サーバーを防ぐ DHCP スヌーピングなどのメカニズムが使用されていない。
トラフィック全体を VPN 経由でルーティングすると、ホストがローカルネットワークリソースにアクセスできなくなります。
前提条件
- NetworkManager 1.40.16-18 以降を使用します。
手順
- 使用するルーティングテーブルを決定します。次の手順ではテーブル 75 を使用します。デフォルトでは、RHEL はテーブル 1 - 254 を使用しないため、それらのテーブルのうちどれでも使用できます。
VPN ルートを専用のルーティングテーブルに割り当てるように VPN 接続プロファイルを設定します。
# nmcli connection modify <vpn_connection_profile> ipv4.route-table 75 ipv6.route-table 75上記のコマンドで使用したテーブルに低い優先度値を設定します。
# nmcli connection modify <vpn_connection_profile> ipv4.routing-rules "priority 32345 from all table 75" ipv6.routing-rules "priority 32345 from all table 75"優先度の値は 1 - 32766 の範囲で指定できます。値が低いほど、優先度が高くなります。
VPN 接続を再接続します。
# nmcli connection down <vpn_connection_profile> # nmcli connection up <vpn_connection_profile>
検証
テーブル 75 の IPv4 ルートを表示します。
# ip route show table 75 ... 192.0.2.0/24 via 192.0.2.254 dev vpn_device proto static metric 50 default dev vpn_device proto static scope link metric 50この出力から、リモートネットワークへのルートとデフォルトゲートウェイの両方がルーティングテーブル 75 に割り当てられており、すべてのトラフィックがトンネルを介してルーティングされることを確認できます。VPN 接続プロファイルで
ipv4.never-default trueを設定すると、デフォルトルートが作成されず、この出力には表示されません。テーブル 75 の IPv6 ルートを表示します。
# ip -6 route show table 75 ... 2001:db8:1::/64 dev vpn_device proto kernel metric 50 pref medium default dev vpn_device proto static metric 50 pref mediumこの出力から、リモートネットワークへのルートとデフォルトゲートウェイの両方がルーティングテーブル 75 に割り当てられており、すべてのトラフィックがトンネルを介してルーティングされることを確認できます。VPN 接続プロファイルで
ipv4.never-default trueを設定すると、デフォルトルートが作成されず、この出力には表示されません。
23.4. MACsec を使用した同じ物理ネットワーク内のレイヤー 2 トラフィックの暗号化
MACsec を使用して、2 つのデバイス間の通信を (ポイントツーポイントで) セキュリティー保護できます。たとえば、ブランチオフィスがメトロイーサネット接続を介してセントラルオフィスに接続されている場合、オフィスを接続する 2 つのホストで MACsec を設定して、セキュリティーを強化できます。
23.4.1. MACsec がセキュリティーを強化する方法
Media Access Control Security (MACsec) は、イーサーネットリンクで異なるトラフィックタイプを保護するレイヤー 2 プロトコルです。これには以下が含まれます。
- Dynamic Host Configuration Protocol (DHCP)
- アドレス解決プロトコル (ARP)
- IPv4 および IPv6 トラフィック
- TCP や UDP などの IP 経由のトラフィック
MACsec はデフォルトで、LAN 内のすべてのトラフィックを GCM-AES-128 アルゴリズムで暗号化および認証し、事前共有キーを使用して参加者ホスト間の接続を確立します。事前共有キーを変更するには、MACsec を使用するすべてのネットワークホストで NM 設定を更新する必要があります。
MACsec 接続では、イーサネットネットワークカード、VLAN、トンネルデバイスなどのイーサネットデバイスを親として使用します。暗号化された接続のみを使用して他のホストと通信するように MACsec デバイスにのみ IP 設定を指定することも、親デバイスに IP 設定を設定することもできます。後者の場合、親デバイスを使用して、暗号化されていない接続と暗号化された接続用の MACsec デバイスで他のホストと通信できます。
MACsec には特別なハードウェアは必要ありません。たとえば、ホストとスイッチの間のトラフィックのみを暗号化する場合を除き、任意のスイッチを使用できます。このシナリオでは、スイッチが MACsec もサポートする必要があります。
つまり、次の 2 つの一般的なシナリオに合わせて MACsec を設定できます。
- ホストからホストへ
- ホストからスイッチへ、およびスイッチから他のホストへ
MACsec は、同じ物理 LAN または仮想 LAN 内にあるホスト間でのみ使用できます。
リンク層 (Open Systems Interconnection (OSI) モデルのレイヤー 2 とも呼ばれます) での通信を保護するために MACsec セキュリティー標準を使用すると、主に次のような利点が得られます。
- レイヤー 2 で暗号化することで、レイヤー 7 で個々のサービスを暗号化する必要がなくなります。これにより、各ホストの各エンドポイントで多数の証明書を管理することに関連するオーバーヘッドが削減されます。
- ルーターやスイッチなどの直接接続されたネットワークデバイス間のポイントツーポイントセキュリティー。
- アプリケーションや上位レイヤープロトコルに変更を加える必要がなくなります。
23.4.2. nmcli を使用した MACsec 接続の設定
nmcli ユーティリティーを使用して、MACsec を使用するようにイーサネットインターフェイスを設定できます。たとえば、イーサネット経由で接続された 2 つのホスト間に MACsec 接続を作成できます。
手順
MACsec を設定する最初のホストで:
事前共有鍵の接続アソシエーション鍵 (CAK) と接続アソシエーション鍵名 (CKN) を作成します。
16 バイトの 16 進 CAK を作成します。
# dd if=/dev/urandom count=16 bs=1 2> /dev/null | hexdump -e '1/2 "%04x"' 50b71a8ef0bd5751ea76de6d6c98c03a32 バイトの 16 進 CKN を作成します。
# dd if=/dev/urandom count=32 bs=1 2> /dev/null | hexdump -e '1/2 "%04x"' f2b4297d39da7330910a74abc0449feb45b5c0b9fc23df1430e1898fcf1c4550
- 両方のホストで、MACsec 接続を介して接続します。
MACsec 接続を作成します。
# nmcli connection add type macsec con-name macsec0 ifname macsec0 connection.autoconnect yes macsec.parent enp1s0 macsec.mode psk macsec.mka-cak 50b71a8ef0bd5751ea76de6d6c98c03a macsec.mka-ckn f2b4297d39da7330910a74abc0449feb45b5c0b9fc23df1430e1898fcf1c4550前の手順で生成された CAK および CKN を
macsec.mka-cakおよびmacsec.mka-cknパラメーターで使用します。この値は、MACsec で保護されるネットワーク内のすべてのホストで同じである必要があります。MACsec 接続で IP を設定します。
IPv4設定を指定します。たとえば、静的IPv4アドレス、ネットワークマスク、デフォルトゲートウェイ、および DNS サーバーをmacsec0接続に設定するには、以下のコマンドを実行します。# nmcli connection modify macsec0 ipv4.method manual ipv4.addresses '192.0.2.1/24' ipv4.gateway '192.0.2.254' ipv4.dns '192.0.2.253'IPv6設定を指定しますたとえば、静的IPv6アドレス、ネットワークマスク、デフォルトゲートウェイ、および DNS サーバーをmacsec0接続に設定するには、以下のコマンドを実行します。# nmcli connection modify macsec0 ipv6.method manual ipv6.addresses '2001:db8:1::1/32' ipv6.gateway '2001:db8:1::fffe' ipv6.dns '2001:db8:1::fffd'
接続をアクティベートします。
# nmcli connection up macsec0
検証
トラフィックが暗号化されていることを確認します。
# tcpdump -nn -i enp1s0オプション: 暗号化されていないトラフィックを表示します。
# tcpdump -nn -i macsec0MACsec の統計を表示します。
# ip macsec showintegrity-only (encrypt off) および encryption (encrypt on) の各タイプの保護に対して個々のカウンターを表示します。
# ip -s macsec show
23.5. firewalld の使用および設定
ファイアウォールは、外部からの不要なトラフィックからマシンを保護する方法です。ファイアウォールルール セットを定義することで、ホストマシンへの着信ネットワークトラフィックを制御できます。このようなルールは、着信トラフィックを分類して、拒否または許可するために使用されます。
firewalld は、D-Bus インターフェイスを使用して、動的にカスタマイズできるファイアウォールを提供するファイアウォールサービスデーモンです。動的であるため、ルールが変更されるたびにファイアウォールデーモンを再起動する必要なく、ルールの作成、変更、削除が可能になります。
firewalld を使用して、一般的なケースの大部分で必要なパケットフィルタリングを設定できます。firewalld がシナリオをカバーしていない場合、またはルールを完全に制御したい場合は、nftables フレームワークを使用します。
firewalld は、ゾーン、ポリシー、サービスの概念を使用してトラフィック管理を単純化します。ゾーンはネットワークを論理的に分離します。ネットワークインターフェイスおよびソースをゾーンに割り当てることができます。ポリシーは、ゾーン間のトラフィックの流れを拒否または許可するために使用されます。ファイアウォールサービスは、特定のサービスに着信トラフィックを許可するのに必要なすべての設定を扱う事前定義のルールで、ゾーンに適用されます。
サービスは、ネットワーク接続に 1 つ以上のポートまたはアドレスを使用します。ファイアウォールは、ポートに基づいて接続のフィルターを設定します。サービスに対してネットワークトラフィックを許可するには、そのポートを開く必要があります。firewalld は、明示的に開いていないポートのトラフィックをすべてブロックします。trusted などのゾーンでは、デフォルトですべてのトラフィックを許可します。
firewalld は、ランタイム設定と永続設定を別々に維持します。そのため、ランタイムのみの変更が可能です。ランタイム設定は、firewalld の再読み込みまたは再起動後は保持されません。起動時に、永続的な設定から入力されます。
nftables バックエンドを備えた firewalld は、--direct オプションを使用してカスタム nftables ルールを firewalld に渡すことをサポートしていないことに注意してください。
23.5.1. firewalld、nftables、または iptables を使用する場合
RHEL 8 では、シナリオに応じて次のパケットフィルタリングユーティリティーを使用できます。
-
firewalld:firewalldユーティリティーは、一般的な使用例のファイアウォール設定を簡素化します。 -
nftables:nftablesユーティリティーを使用して、ネットワーク全体など、複雑なパフォーマンスに関する重要なファイアウォールを設定します。 -
iptables:Red Hat Enterprise Linux のiptablesユーティリティーは、legacyバックエンドの代わりにnf_tablesカーネル API を使用します。nf_tablesAPI は、iptablesコマンドを使用するスクリプトが、Red Hat Enterprise Linux で引き続き動作するように、後方互換性を提供します。新しいファイアウォールスクリプトの場合は、nftablesを使用します。
さまざまなファイアウォール関連サービス (firewalld、nftables、または iptables) が相互に影響を与えないようにするには、RHEL ホストでそのうち 1 つだけを実行し、他のサービスを無効にします。
23.5.2. ファイアウォールゾーン
firewalld ユーティリティーを使用すると、ネットワーク内のインターフェイスおよびトラフィックに対する信頼レベルに応じて、ネットワークをさまざまなゾーンに分離できます。接続は 1 つのゾーンにしか指定できませんが、そのゾーンは多くのネットワーク接続に使用できます。
firewalld はゾーンに関して厳格な原則に従います。
- トラフィックは 1 つのゾーンのみに流入します。
- トラフィックは 1 つのゾーンのみから流出します。
- ゾーンは信頼のレベルを定義します。
- ゾーン内トラフィック (同じゾーン内) はデフォルトで許可されます。
- ゾーン間トラフィック (ゾーンからゾーン) はデフォルトで拒否されます。
原則 4 と 5 は原則 3 の結果です。
原則 4 は、ゾーンオプション --remove-forward を使用して設定できます。原則 5 は、新しいポリシーを追加することで設定できます。
NetworkManager は、firewalld にインターフェイスのゾーンを通知します。次のユーティリティーを使用して、ゾーンをインターフェイスに割り当てることができます。
-
NetworkManager -
firewall-configユーティリティー -
firewall-cmdユーティリティー - RHEL Web コンソール
RHEL Web コンソール、firewall-config、および firewall-cmd は、 適切な NetworkManager 設定ファイルのみを編集できます。Web コンソール、firewall-cmd または firewall-config を使用してインターフェイスのゾーンを変更する場合、リクエストは NetworkManager に転送され、firewalld では処理されません。
/usr/lib/firewalld/zones/ ディレクトリーには事前定義されたゾーンが保存されており、利用可能なネットワークインターフェイスに即座に適用できます。このファイルは、修正しないと /etc/firewalld/zones/ ディレクトリーにコピーされません。事前定義したゾーンのデフォルト設定は以下のようになります。
block-
適した例:
IPv4の場合は icmp-host-prohibited メッセージ、IPv6の場合は icmp6-adm-prohibited メッセージで、すべての着信ネットワーク接続が拒否されます。 - 受け入れる接続: システム内から開始したネットワーク接続のみ。
-
適した例:
dmz- 適した例: パブリックにアクセス可能で、内部ネットワークへのアクセスが制限されている DMZ 内のコンピューター。
- 受け入れる接続: 選択した着信接続のみ。
drop適した例: 着信ネットワークパケットは、通知なしで遮断されます。
- 受け入れる接続: 発信ネットワーク接続のみ。
external- 適した例: マスカレードを特にルーター用に有効にした外部ネットワーク。ネットワーク上の他のコンピューターを信頼できない状況。
- 受け入れる接続: 選択した着信接続のみ。
home- 適した例: ネットワーク上の他のコンピューターをほぼ信頼できる自宅の環境。
- 受け入れる接続: 選択した着信接続のみ。
internal- 適した例: ネットワーク上の他のコンピューターをほぼ信頼できる内部ネットワーク。
- 受け入れる接続: 選択した着信接続のみ。
public- 適した例: ネットワーク上の他のコンピューターを信頼できないパブリックエリア。
- 受け入れる接続: 選択した着信接続のみ。
trusted- 受け入れる接続: すべてのネットワーク接続。
work適した例: ネットワーク上の他のコンピューターをほぼ信頼できる職場の環境。
- 受け入れる接続: 選択した着信接続のみ。
このゾーンのいずれかを デフォルト ゾーンに設定できます。インターフェイス接続を NetworkManager に追加すると、デフォルトゾーンに割り当てられます。インストール時は、firewalld のデフォルトゾーンは public ゾーンです。デフォルトゾーンは変更できます。
ユーザーがすぐに理解できるように、ネットワークゾーン名は分かりやすい名前にしてください。
セキュリティー問題を回避するために、ニーズおよびリスク評価に合わせて、デフォルトゾーンの設定の見直しを行ったり、不要なサービスを無効にしてください。
23.5.3. ファイアウォールポリシー
ファイアウォールポリシーは、ネットワークの望ましいセキュリティー状態を指定します。これらのポリシーは、さまざまなタイプのトラフィックに対して実行するルールとアクションの概要を示します。通常、ポリシーには次のタイプのトラフィックに対するルールが含まれます。
- 着信トラフィック
- 送信トラフィック
- 転送トラフィック
- 特定のサービスとアプリケーション
- ネットワークアドレス変換 (NAT)
ファイアウォールポリシーは、ファイアウォールゾーンの概念を使用します。各ゾーンは、許可するトラフィックを決定する特定のファイアウォールルールのセットに関連付けられます。ポリシーは、ステートフルかつ一方向にファイアウォールルールを適用します。つまり、トラフィックの一方向のみを考慮します。firewalld のステートフルフィルタリングにより、トラフィックのリターンパスは暗黙的に許可されます。
ポリシーは、イングレスゾーンとエグレスゾーンに関連付けられます。イングレスゾーンは、トラフィックが発生する (受信される) 場所です。エグレスゾーンは、トラフィックが出る (送信される) 場所です。
ポリシーで定義されたファイアウォールのルールは、ファイアウォールゾーンを参照して、複数のネットワークインターフェイス全体に一貫した設定を適用できます。
23.5.4. ファイアウォールのルール
ファイアウォールのルールを使用して、ネットワークトラフィックを許可またはブロックする特定の設定を実装できます。その結果、ネットワークトラフィックのフローを制御して、システムをセキュリティーの脅威から保護できます。
ファイアウォールのルールは通常、さまざまな属性に基づいて特定の基準を定義します。属性は次のとおりです。
- ソース IP アドレス
- 宛先 IP アドレス
- 転送プロトコル (TCP、UDP など)
- ポート
- ネットワークインターフェイス
firewalld ユーティリティーは、ファイアウォールのルールをゾーン (public、internal など) とポリシーに整理します。各ゾーンには、特定のゾーンに関連付けられたネットワークインターフェイスのトラフィック自由度のレベルを決定する独自のルールセットがあります。
23.5.5. ファイアウォールの直接ルール
firewalld サービスは、次のような複数の方法でルールを設定できます。
- 通常のルール
- 直接的なルール
これらの違いの 1 つは、各メソッドが基盤となるバックエンド (iptables または nftables) とどのように対話するかです。
ダイレクトルールは、iptables との直接のやり取りを可能にする高度な低レベルのルールです。これらは、firewalld の構造化されたゾーンベースの管理をバイパスして、より詳細な制御を可能にします。生の iptables 構文を使用して、firewall-cmd コマンドで直接ルールを手動で定義します。たとえば、firewall-cmd --direct --add-rule ipv4 filter INPUT 0 -s 198.51.100.1 -j DROP です。このコマンドは、198.51.100.1 の送信元 IP アドレスからのトラフィックをドロップする iptables ルールを追加します。
ただし、直接ルールを使用すると欠点もあります。特に、nftables が 主要なファイアウォールバックエンドである場合に当てはまります。以下に例を示します。
-
直接ルールは維持が難しく、
nftablesベースのfirewalld設定と競合する可能性があります。 -
直接ルールは、生の式やステートフルオブジェクトなど、
nftablesにある高度な機能をサポートしません。 -
直接的なルールは将来に耐えられません。
iptablesコンポーネントは非推奨であり、最終的には RHEL から削除されます。
前述の理由により、firewalld の 直接ルールを nftables に置き換えることを検討してください。詳細は、ナレッジベースソリューション firewalld の直接ルールを nftables に置き換える方法 を参照してください。
23.5.6. 事前定義された firewalld サービス
事前定義された firewalld サービスは、低レベルのファイアウォールルール上に組み込みの抽象化レイヤーを提供します。これは、SSH や HTTP などの一般的に使用されるネットワークサービスを、対応するポートとプロトコルにマッピングすることによって実現されます。これらを毎回手動で指定する代わりに、名前付きの定義済みサービスを参照することができます。これにより、ファイアウォールの管理がよりシンプルになり、エラーが減り、より直感的になります。
利用可能な定義済みサービスを表示するには:
# firewall-cmd --get-services RH-Satellite-6 RH-Satellite-6-capsule afp amanda-client amanda-k5-client amqp amqps apcupsd audit ausweisapp2 bacula bacula-client bareos-director bareos-filedaemon bareos-storage bb bgp bitcoin bitcoin-rpc bitcoin-testnet bitcoin-testnet-rpc bittorrent-lsd ceph ceph-exporter ceph-mon cfengine checkmk-agent cockpit collectd condor-collector cratedb ctdb dds...特定の定義済みサービスをさらに検査するには:
# sudo firewall-cmd --info-service=RH-Satellite-6 RH-Satellite-6 ports: 5000/tcp 5646-5647/tcp 5671/tcp 8000/tcp 8080/tcp 9090/tcp protocols: source-ports: modules: destination: includes: foreman helpers:出力例では、
RH-Satellite-6定義済みサービスがポート 5000/tcp、5646-5647/tcp、5671/tcp、8000/tcp、8080/tcp、9090/tcp をリッスンしていることを示しています。さらに、RH-Satellite-6 は別の定義済みサービスからルールを継承します。この場合は職長です。
定義済みの各サービスは 、/usr/lib/firewalld/services/ ディレクトリーに同じ名前の XML ファイルとして保存されます。
23.5.7. ファイアウォールゾーンでの作業
ゾーンは、着信トラフィックをより透過的に管理する概念を表しています。ゾーンはネットワークインターフェイスに接続されているか、ソースアドレスの範囲に割り当てられます。各ゾーンは個別にファイアウォールルールを管理しますが、これにより、複雑なファイアウォール設定を定義してトラフィックに割り当てることができます。
23.5.7.1. 特定のゾーンのファイアウォール設定をカスタマイズすることによるセキュリティーの強化
ファイアウォール設定を変更し、特定のネットワークインターフェイスまたは接続を特定のファイアウォールゾーンに関連付けることで、ネットワークセキュリティーを強化できます。ゾーンの詳細なルールと制限を定義することで、意図したセキュリティーレベルに基づいて受信トラフィックと送信トラフィックを制御できます。
たとえば、次のような利点が得られます。
- 機密データの保護
- 不正アクセスの防止
- 潜在的なネットワーク脅威の軽減
前提条件
-
firewalldサービスが実行している。
手順
利用可能なファイアウォールゾーンをリスト表示します。
# firewall-cmd --get-zonesfirewall-cmd --get-zonesコマンドは、システムで利用可能なすべてのゾーンを表示し、特定のゾーンの詳細は表示しません。すべてのゾーンの詳細情報を表示するには、firewall-cmd --list-all-zonesコマンドを使用します。- この設定に使用するゾーンを選択します。
選択したゾーンのファイアウォール設定を変更します。たとえば、
SSHサービスを許可し、ftpサービスを削除するには、次のようにします。# firewall-cmd --add-service=ssh --zone=<your_chosen_zone> # firewall-cmd --remove-service=ftp --zone=<same_chosen_zone>ネットワークインターフェイスをファイアウォールゾーンに割り当てます。
使用可能なネットワークインターフェイスをリスト表示します。
# firewall-cmd --get-active-zonesゾーンがアクティブかどうかは、その設定と一致するネットワークインターフェイスまたはソースアドレス範囲の存在によって決定します。デフォルトゾーンは、未分類のトラフィックに対してアクティブですが、ルールに一致するトラフィックがない場合は常にアクティブになるわけではありません。
選択したゾーンにネットワークインターフェイスを割り当てます。
# firewall-cmd --zone=<your_chosen_zone> --change-interface=<interface_name> --permanentネットワークインターフェイスをゾーンに割り当てることは、特定のインターフェイス (物理または仮想) 上のすべてのトラフィックに一貫したファイアウォール設定を適用する場合に適しています。
firewall-cmdコマンドを--permanentオプションとともに使用すると、多くの場合、NetworkManager 接続プロファイルが更新され、ファイアウォール設定に対する変更が永続化します。このfirewalldと NetworkManager の統合により、ネットワークとファイアウォールの設定に一貫性が確保されます。
検証
選択したゾーンの更新後の設定を表示します。
# firewall-cmd --zone=<your_chosen_zone> --list-allコマンド出力には、割り当てられたサービス、ネットワークインターフェイス、ネットワーク接続 (ソース) を含むすべてのゾーン設定が表示されます。
23.5.7.2. デフォルトゾーンの変更
システム管理者は、設定ファイルのネットワークインターフェイスにゾーンを割り当てます。特定のゾーンに割り当てられないインターフェイスは、デフォルトゾーンに割り当てられます。firewalld サービスを再起動するたびに、firewalld は、デフォルトゾーンの設定を読み込み、それをアクティブにします。他のすべてのゾーンの設定は保存され、すぐに使用できます。
通常、ゾーンは NetworkManager により、NetworkManager 接続プロファイルの connection.zone 設定に従って、インターフェイスに割り当てられます。また、再起動後、NetworkManager はこれらのゾーンを "アクティブ化" するための割り当てを管理します。
前提条件
-
firewalldサービスが実行している。
手順
デフォルトゾーンを設定するには、以下を行います。
現在のデフォルトゾーンを表示します。
# firewall-cmd --get-default-zone新しいデフォルトゾーンを設定します。
# firewall-cmd --set-default-zone <zone_name>注記この手順では、
--permanentオプションを使用しなくても、設定は永続化します。
23.5.7.3. ゾーンへのネットワークインターフェイスの割り当て
複数のゾーンに複数のルールセットを定義して、使用されているインターフェイスのゾーンを変更することで、迅速に設定を変更できます。各インターフェイスに特定のゾーンを設定して、そのゾーンを通過するトラフィックを設定できます。
手順
特定インターフェイスにゾーンを割り当てるには、以下を行います。
アクティブゾーン、およびそのゾーンに割り当てられているインターフェイスをリスト表示します。
# firewall-cmd --get-active-zones別のゾーンにインターフェイスを割り当てます。
# firewall-cmd --zone=zone_name --change-interface=interface_name --permanent
23.5.7.4. ソースの追加
着信トラフィックを特定のゾーンに転送する場合は、そのゾーンにソースを追加します。ソースは、CIDR (Classless Inter-domain Routing) 表記法の IP アドレスまたは IP マスクになります。
ネットワーク範囲が重複している複数のゾーンを追加する場合は、ゾーン名で順序付けされ、最初のゾーンのみが考慮されます。
現在のゾーンにソースを設定するには、次のコマンドを実行します。
# firewall-cmd --add-source=<source>特定ゾーンのソース IP アドレスを設定するには、次のコマンドを実行します。
# firewall-cmd --zone=zone-name --add-source=<source>
以下の手順は、信頼される ゾーンで 192.168.2.15 からのすべての着信トラフィックを許可します。
手順
利用可能なすべてのゾーンをリストします。
# firewall-cmd --get-zones永続化モードで、信頼ゾーンにソース IP を追加します。
# firewall-cmd --zone=trusted --add-source=192.168.2.15新しい設定を永続化します。
# firewall-cmd --runtime-to-permanent
23.5.7.5. ソースの削除
ゾーンからソースを削除すると、当該ソースに指定したルールは、そのソースから発信されたトラフィックに適用されなくなります。代わりに、トラフィックは、その発信元のインターフェイスに関連付けられたゾーンのルールと設定にフォールバックするか、デフォルトゾーンに移動します。
手順
必要なゾーンに対して許可されているソースのリストを表示します。
# firewall-cmd --zone=zone-name --list-sourcesゾーンからソースを永続的に削除します。
# firewall-cmd --zone=zone-name --remove-source=<source>新しい設定を永続化します。
# firewall-cmd --runtime-to-permanent
23.5.7.6. nmcli を使用して接続にゾーンを割り当て
nmcli ユーティリティーを使用して、firewalld ゾーンを NetworkManager 接続に追加できます。
手順
ゾーンを
NetworkManager接続プロファイルに割り当てます。# nmcli connection modify profile connection.zone zone_name接続をアクティベートします。
# nmcli connection up profile
23.5.7.7. ifcfg ファイルでゾーンをネットワーク接続に手動で割り当て
NetworkManager で接続を管理する場合は、NetworkManager が使用するゾーンを認識する必要があります。すべてのネットワーク接続プロファイルに対してゾーンを指定できるため、ポータブルデバイスを備えたコンピューターの場所に応じて、さまざまなファイアウォール設定を柔軟に行うことができます。したがって、ゾーンおよび設定には、会社または自宅など、様々な場所を指定できます。
手順
接続のゾーンを設定するには、
/etc/sysconfig/network-scripts/ifcfg-connection_nameファイルを変更して、この接続にゾーンを割り当てる行を追加します。ZONE=zone_name
23.5.7.8. 新しいゾーンの作成
カスタムゾーンを使用するには、新しいゾーンを作成したり、事前定義したゾーンなどを使用したりします。新しいゾーンには --permanent オプションが必要となり、このオプションがなければコマンドは動作しません。
前提条件
-
firewalldサービスが実行している。
手順
新しいゾーンを作成します。
# firewall-cmd --permanent --new-zone=zone-name新しいゾーンを使用可能にします。
# firewall-cmd --reloadこのコマンドは、すでに実行中のネットワークサービスを中断することなく、最近の変更をファイアウォール設定に適用します。
検証
作成したゾーンが永続設定に追加されたかどうかを確認します。
# firewall-cmd --get-zones --permanent
23.5.7.9. Web コンソールを使用したゾーンの有効化
RHEL Web コンソールを使用して、事前定義された既存のファイアウォールゾーンを特定のインターフェイスまたは IP アドレスの範囲に適用できます。
前提条件
- RHEL 8 Web コンソールがインストールされている。
- cockpit サービスが有効になっている。
ユーザーアカウントが Web コンソールにログインできる。
手順は、Web コンソールのインストールおよび有効化 を参照してください。
手順
RHEL 8 Web コンソールにログインします。
詳細は、Web コンソールへのログイン を参照してください。
- Networking をクリックします。
ボタンをクリックします。
ボタンが表示されない場合は、管理者権限で Web コンソールにログインしてください。
- Firewall セクションの Add new zone をクリックします。
ゾーンの追加 ダイアログボックスで、信頼レベル オプションからゾーンを選択します。
Web コンソールには、
firewalldサービスで事前定義されたすべてのゾーンが表示されます。- インターフェイス で、選択したゾーンが適用されるインターフェイスを選択します。
許可されたサービス で、ゾーンを適用するかどうかを選択できます。
- サブネット全体
または、以下の形式の IP アドレスの範囲
- 192.168.1.0
- 192.168.1.0/24
- 192.168.1.0/24, 192.168.1.0
ボタンをクリックします。
検証
Firewall セクションの設定を確認します。
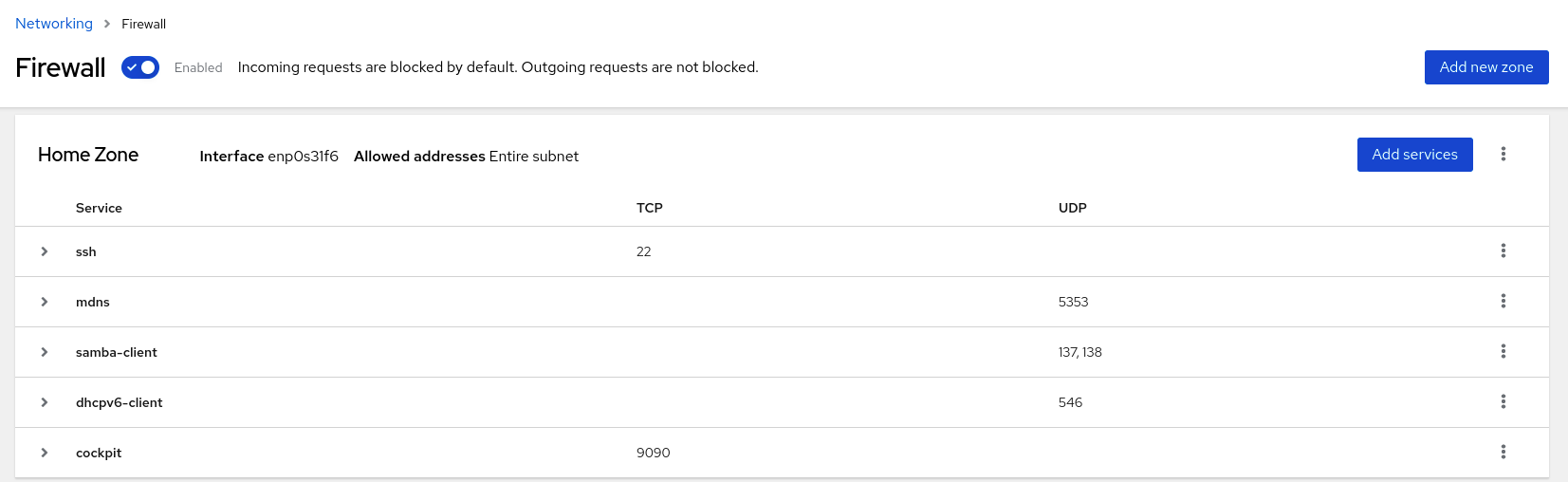
23.5.7.10. Web コンソールを使用したゾーンの無効化
Web コンソールを使用して、ファイアウォール設定のファイアウォールゾーンを無効にできます。
前提条件
- RHEL 8 Web コンソールがインストールされている。
- cockpit サービスが有効になっている。
ユーザーアカウントが Web コンソールにログインできる。
手順は、Web コンソールのインストールおよび有効化 を参照してください。
手順
RHEL 8 Web コンソールにログインします。
詳細は、Web コンソールへのログイン を参照してください。
- Networking をクリックします。
ボタンをクリックします。
ボタンが表示されない場合は、管理者権限で Web コンソールにログインしてください。
削除するゾーンの オプションアイコン をクリックします。

- Delete をクリックします。
これでゾーンが無効になり、そのゾーンに設定されたオープンなサービスおよびポートがインターフェイスに含まれなくなります。
23.5.7.11. 着信トラフィックにデフォルトの動作を設定するゾーンターゲットの使用
すべてのゾーンに対して、特に指定されていない着信トラフィックを処理するデフォルト動作を設定できます。そのような動作は、ゾーンのターゲットを設定することで定義されます。4 つのオプションがあります。
-
ACCEPT:指定したルールで許可されていないパケットを除いた、すべての着信パケットを許可します。 -
REJECT:指定したルールで許可されているパケット以外の着信パケットをすべて拒否します。firewalldがパケットを拒否すると、送信元マシンに拒否について通知されます。 -
DROP:指定したルールで許可されているパケット以外の着信パケットをすべて破棄します。firewalldがパケットを破棄すると、ソースマシンにパケット破棄の通知がされません。 -
default:REJECTと似ていますが、特定のシナリオで特別な意味を持ちます。
前提条件
-
firewalldサービスが実行している。
手順
ゾーンにターゲットを設定するには、以下を行います。
特定ゾーンに対する情報をリスト表示して、デフォルトゾーンを確認します。
# firewall-cmd --zone=zone-name --list-allゾーンに新しいターゲットを設定します。
# firewall-cmd --permanent --zone=zone-name --set-target=<default|ACCEPT|REJECT|DROP>
23.5.7.12. IP セットを使用した許可リストの動的更新の設定
ほぼリアルタイムで更新を行うことで、予測不可能な状況でも IP セット内の特定の IP アドレスまたは IP アドレス範囲を柔軟に許可できます。これらの更新は、セキュリティー脅威の検出やネットワーク動作の変化など、さまざまなイベントによってトリガーされます。通常、このようなソリューションでは自動化を活用して手動処理を減らし、素早く状況に対応することでセキュリティーを向上させます。
前提条件
-
firewalldサービスが実行している。
手順
分かりやすい名前で IP セットを作成します。
# firewall-cmd --permanent --new-ipset=allowlist --type=hash:ipこの
allowlistという新しい IP セットには、ファイアウォールで許可する IP アドレスが含まれています。IP セットに動的更新を追加します。
# firewall-cmd --permanent --ipset=allowlist --add-entry=198.51.100.10この設定により、新しく追加した、ネットワークトラフィックを渡すことがファイアウォールにより許可される IP アドレスで、
allowlistの IP セットが更新されます。先に作成した IP セットを参照するファイアウォールのルールを作成します。
# firewall-cmd --permanent --zone=public --add-source=ipset:allowlistこのルールがない場合、IP セットはネットワークトラフィックに影響を与えません。デフォルトのファイアウォールポリシーが優先されます。
ファイアウォール設定をリロードして、変更を適用します。
# firewall-cmd --reload
検証
すべての IP セットをリスト表示します。
# firewall-cmd --get-ipsets allowlistアクティブなルールをリスト表示します。
# firewall-cmd --list-all public (active) target: default icmp-block-inversion: no interfaces: enp0s1 sources: ipset:allowlist services: cockpit dhcpv6-client ssh ports: protocols: ...コマンドライン出力の
sourcesセクションでは、どのトラフィックの発信元 (ホスト名、インターフェイス、IP セット、サブネットなど) が、特定のファイアウォールゾーンへのアクセスを許可または拒否されているかについて洞察が得られます。上記の場合、allowlistIP セットに含まれる IP アドレスが、publicゾーンのファイアウォールを通してトラフィックを渡すことが許可されています。IP セットの内容を調べます。
# cat /etc/firewalld/ipsets/allowlist.xml <?xml version="1.0" encoding="utf-8"?> <ipset type="hash:ip"> <entry>198.51.100.10</entry> </ipset>
次のステップ
-
スクリプトまたはセキュリティーユーティリティーを使用して脅威インテリジェンスのフィードを取得し、それに応じて
allowlistを自動的に更新します。
23.5.8. firewalld でネットワークトラフィックの制御
firewalld パッケージは、事前定義された多数のサービスファイルをインストールし、それらをさらに追加したり、カスタマイズしたりできます。さらに、これらのサービス定義を使用して、サービスが使用するプロトコルとポート番号を知らなくても、サービスのポートを開いたり閉じたりできます。
23.5.8.1. CLI を使用した事前定義サービスによるトラフィックの制御
トラフィックを制御する最も簡単な方法は、事前定義したサービスを firewalld に追加する方法です。これにより、必要なすべてのポートが開き、service definition file に従ってその他の設定が変更されます。
前提条件
-
firewalldサービスが実行している。
手順
firewalldのサービスがまだ許可されていないことを確認します。# firewall-cmd --list-services ssh dhcpv6-clientこのコマンドは、デフォルトゾーンで有効になっているサービスをリスト表示します。
firewalldのすべての事前定義サービスをリスト表示します。# firewall-cmd --get-services RH-Satellite-6 amanda-client amanda-k5-client bacula bacula-client bitcoin bitcoin-rpc bitcoin-testnet bitcoin-testnet-rpc ceph ceph-mon cfengine condor-collector ctdb dhcp dhcpv6 dhcpv6-client dns docker-registry ...このコマンドは、デフォルトゾーンで利用可能なサービスのリストを表示します。
firewalldが許可するサービスのリストにサービスを追加します。# firewall-cmd --add-service=<service_name>このコマンドは、指定したサービスをデフォルトゾーンに追加します。
新しい設定を永続化します。
# firewall-cmd --runtime-to-permanentこのコマンドは、これらのランタイムの変更をファイアウォールの永続的な設定に適用します。デフォルトでは、これらの変更はデフォルトゾーンの設定に適用されます。
検証
すべての永続的なファイアウォールのルールをリスト表示します。
# firewall-cmd --list-all --permanent public target: default icmp-block-inversion: no interfaces: sources: services: cockpit dhcpv6-client ssh ports: protocols: forward: no masquerade: no forward-ports: source-ports: icmp-blocks: rich rules:このコマンドは、デフォルトのファイアウォールゾーン (
public) の永続的なファイアウォールのルールを含む完全な設定を表示します。firewalldサービスの永続的な設定の有効性を確認します。# firewall-cmd --check-config success永続的な設定が無効な場合、コマンドは詳細を含むエラーを返します。
# firewall-cmd --check-config Error: INVALID_PROTOCOL: 'public.xml': 'tcpx' not from {'tcp'|'udp'|'sctp'|'dccp'}永続的な設定ファイルを手動で検査して設定を確認することもできます。メインの設定ファイルは
/etc/firewalld/firewalld.confです。ゾーン固有の設定ファイルは/etc/firewalld/zones/ディレクトリーにあり、ポリシーは/etc/firewalld/policies/ディレクトリーにあります。
23.5.8.2. Web コンソールを使用したファイアウォールのサービスの有効化
デフォルトでは、サービスはデフォルトのファイアウォールゾーンに追加されます。他のネットワークインターフェイスで別のファイアウォールゾーンも使用する場合は、最初にゾーンを選択してから、そのサービスをポートとともに追加する必要があります。
RHEL 8 Web コンソールには、事前定義の firewalld サービスが表示され、それらをアクティブなファイアウォールゾーンに追加することができます。
RHEL 8 Web コンソールは、firewalld サービスを設定します。
また、Web コンソールは、Web コンソールに追加されていない一般的な firewalld ルールを許可しません。
前提条件
- RHEL 8 Web コンソールがインストールされている。
- cockpit サービスが有効になっている。
ユーザーアカウントが Web コンソールにログインできる。
手順は、Web コンソールのインストールおよび有効化 を参照してください。
手順
RHEL 8 Web コンソールにログインします。
詳細は、Web コンソールへのログイン を参照してください。
- Networking をクリックします。
ボタンをクリックします。
ボタンが表示されない場合は、管理者権限で Web コンソールにログインしてください。
Firewall セクションで、サービスを追加するゾーンを選択し、Add Services をクリックします。
- サービスの追加 ダイアログボックスで、ファイアウォールで有効にするサービスを見つけます。
シナリオに応じてサービスを有効にします。
- Add Services をクリックします。
この時点で、RHEL 8 Web コンソールは、ゾーンの Services リストにサービスを表示します。
23.5.8.3. Web コンソールを使用したカスタムポートの設定
RHEL Web コンソールを使用して、サービスのカスタムポートを追加および設定できます。
前提条件
- RHEL 8 Web コンソールがインストールされている。
- cockpit サービスが有効になっている。
ユーザーアカウントが Web コンソールにログインできる。
手順は、Web コンソールのインストールおよび有効化 を参照してください。
-
firewalldサービスが実行している。
手順
RHEL 8 Web コンソールにログインします。
詳細は、Web コンソールへのログイン を参照してください。
- Networking をクリックします。
ボタンをクリックします。
ボタンが表示されない場合は、Web コンソールに管理者権限でログインしてください。
ファイアウォール セクションで、カスタムポートを設定するゾーンを選択し、サービスの追加 をクリックします。
- サービスの追加 ダイアログボックスで、 ラジオボタンをクリックします。
TCP フィールドおよび UDP フィールドに、例に従ってポートを追加します。以下の形式でポートを追加できます。
- ポート番号 (22 など)
- ポート番号の範囲 (5900-5910 など)
- エイリアス (nfs、rsync など)
注記各フィールドには、複数の値を追加できます。値はコンマで区切り、スペースは使用しないでください。8080,8081,http
TCP filed、UDP filed、またはその両方にポート番号を追加した後、Name フィールドでサービス名を確認します。
名前 フィールドには、このポートを予約しているサービスの名前が表示されます。このポートが無料で、サーバーがこのポートで通信する必要がない場合は、名前を書き換えることができます。
- 名前 フィールドに、定義されたポートを含むサービスの名前を追加します。
ボタンをクリックします。
設定を確認するには、ファイアウォール ページに移動し、ゾーンの サービス リストでサービスを見つけます。
23.5.9. ゾーン間で転送されるトラフィックのフィルタリング
firewalld を使用すると、異なる firewalld ゾーン間のネットワークデータのフローを制御できます。ルールとポリシーを定義することで、これらのゾーン間を移動するトラフィックをどのように許可またはブロックするかを管理できます。
ポリシーオブジェクト機能は、firewalld で正引きフィルターと出力フィルターを提供します。firewalld を使用して、異なるゾーン間のトラフィックをフィルタリングし、ローカルでホストされている仮想マシンへのアクセスを許可して、ホストを接続できます。
23.5.9.1. ポリシーオブジェクトとゾーンの関係
ポリシーオブジェクトを使用すると、サービス、ポート、リッチルールなどの firewalld のプリミティブをポリシーに割り当てることができます。ポリシーオブジェクトは、ステートフルおよび一方向の方法でゾーン間を通過するトラフィックに適用することができます。
# firewall-cmd --permanent --new-policy myOutputPolicy
# firewall-cmd --permanent --policy myOutputPolicy --add-ingress-zone HOST
# firewall-cmd --permanent --policy myOutputPolicy --add-egress-zone ANY
HOST および ANY は、イングレスゾーンおよびエグレスゾーンのリストで使用されるシンボリックゾーンです。
-
HOSTシンボリックゾーンは、firewalld を実行しているホストから発信されるトラフィック、またはホストへの宛先を持つトラフィックのポリシーを許可します。 -
ANYシンボリックゾーンは、現行および将来のすべてのゾーンにポリシーを適用します。ANYシンボリックゾーンは、すべてのゾーンのワイルドカードとして機能します。
23.5.9.2. 優先度を使用したポリシーのソート
同じトラフィックセットに複数のポリシーを適用できるため、優先度を使用して、適用される可能性のあるポリシーの優先順位を作成する必要があります。
ポリシーをソートする優先度を設定するには、次のコマンドを実行します。
# firewall-cmd --permanent --policy mypolicy --set-priority -500この例では、-500 の優先度は低くなりますが、優先度は高くなります。したがって、-500 は、-100 より前に実行されます。
優先度の数値が小さいほど優先度が高く、最初に適用されます。
23.5.9.3. ポリシーオブジェクトを使用した、ローカルでホストされているコンテナーと、ホストに物理的に接続されているネットワークとの間でのトラフィックのフィルタリング
ポリシーオブジェクト機能を使用すると、ユーザーは Podman ゾーンと firewalld ゾーン間のトラフィックをフィルタリングできます。
Red Hat は、デフォルトではすべてのトラフィックをブロックし、Podman ユーティリティーに必要なサービスを選択して開くことを推奨します。
手順
新しいファイアウォールポリシーを作成します。
# firewall-cmd --permanent --new-policy podmanToAnyPodman から他のゾーンへのすべてのトラフィックをブロックし、Podman で必要なサービスのみを許可します。
# firewall-cmd --permanent --policy podmanToAny --set-target REJECT # firewall-cmd --permanent --policy podmanToAny --add-service dhcp # firewall-cmd --permanent --policy podmanToAny --add-service dns # firewall-cmd --permanent --policy podmanToAny --add-service https新しい Podman ゾーンを作成します。
# firewall-cmd --permanent --new-zone=podmanポリシーのイングレスゾーンを定義します。
# firewall-cmd --permanent --policy podmanToHost --add-ingress-zone podman他のすべてのゾーンのエグレスゾーンを定義します。
# firewall-cmd --permanent --policy podmanToHost --add-egress-zone ANYエグレスゾーンを ANY に設定すると、Podman と他のゾーンの間でフィルタリングすることになります。ホストに対してフィルタリングする場合は、エグレスゾーンを HOST に設定します。
firewalld サービスを再起動します。
# systemctl restart firewalld
検証
他のゾーンに対する Podman ファイアウォールポリシーを検証します。
# firewall-cmd --info-policy podmanToAny podmanToAny (active) ... target: REJECT ingress-zones: podman egress-zones: ANY services: dhcp dns https ...
23.5.9.4. ポリシーオブジェクトのデフォルトターゲットの設定
ポリシーには --set-target オプションを指定できます。以下のターゲットを使用できます。
-
ACCEPT- パケットを受け入れます -
DROP- 不要なパケットを破棄します -
REJECT- ICMP 応答で不要なパケットを拒否します CONTINUE(デフォルト) - パケットは、次のポリシーとゾーンのルールに従います。# firewall-cmd --permanent --policy mypolicy --set-target CONTINUE
検証
ポリシーに関する情報の確認
# firewall-cmd --info-policy mypolicy
23.5.10. firewalld を使用した NAT の設定
firewalld では、以下のネットワークアドレス変換 (NAT) タイプを設定できます。
- マスカレーディング
- 宛先 NAT (DNAT)
- リダイレクト
23.5.10.1. ネットワークアドレス変換のタイプ
以下は、ネットワークアドレス変換 (NAT) タイプになります。
- マスカレーディング
この NAT タイプのいずれかを使用して、パケットのソース IP アドレスを変更します。たとえば、インターネットサービスプロバイダー (ISP) は、プライベート IP 範囲 (
10.0.0.0/8など) をルーティングしません。ネットワークでプライベート IP 範囲を使用し、ユーザーがインターネット上のサーバーにアクセスできるようにする必要がある場合は、この範囲のパケットのソース IP アドレスをパブリック IP アドレスにマップします。マスカレードは、出力インターフェイスの IP アドレスを自動的に使用します。したがって、出力インターフェイスが動的 IP アドレスを使用する場合は、マスカレードを使用します。
- 宛先 NAT (DNAT)
- この NAT タイプを使用して、着信パケットの宛先アドレスとポートを書き換えます。たとえば、Web サーバーがプライベート IP 範囲の IP アドレスを使用しているため、インターネットから直接アクセスできない場合は、ルーターに DNAT ルールを設定し、着信トラフィックをこのサーバーにリダイレクトできます。
- リダイレクト
- このタイプは、パケットをローカルマシンの別のポートにリダイレクトする DNAT の特殊なケースです。たとえば、サービスが標準ポートとは異なるポートで実行する場合は、標準ポートからこの特定のポートに着信トラフィックをリダイレクトすることができます。
23.5.10.2. IP アドレスのマスカレードの設定
システムで IP マスカレードを有効にできます。IP マスカレードは、インターネットにアクセスする際にゲートウェイの向こう側にある個々のマシンを隠します。
手順
externalゾーンなどで IP マスカレーディングが有効かどうかを確認するには、rootで次のコマンドを実行します。# firewall-cmd --zone=external --query-masqueradeこのコマンドでは、有効な場合は
yesと出力され、終了ステータスは0になります。無効の場合はnoと出力され、終了ステータスは1になります。zoneを省略すると、デフォルトのゾーンが使用されます。IP マスカレードを有効にするには、
rootで次のコマンドを実行します。# firewall-cmd --zone=external --add-masquerade-
この設定を永続化するには、
--permanentオプションをコマンドに渡します。 IP マスカレードを無効にするには、
rootで次のコマンドを実行します。# firewall-cmd --zone=external --remove-masqueradeこの設定を永続化するには、
--permanentをコマンドラインに渡します。
23.5.10.3. DNAT を使用した着信 HTTP トラフィックの転送
宛先ネットワークアドレス変換 (DNAT) を使用して、着信トラフィックを 1 つの宛先アドレスおよびポートから別の宛先アドレスおよびポートに転送できます。通常、外部ネットワークインターフェイスからの着信リクエストを特定の内部サーバーまたはサービスにリダイレクトする場合に役立ちます。
前提条件
-
firewalldサービスが実行している。
手順
着信 HTTP トラフィックを転送します。
# firewall-cmd --zone=public --add-forward-port=port=80:proto=tcp:toaddr=198.51.100.10:toport=8080 --permanent上記のコマンドは、次の設定で DNAT ルールを定義します。
-
--zone=public- DNAT ルールを設定するファイアウォールゾーン。必要なゾーンに合わせて調整できます。 -
--add-forward-port- ポート転送ルールを追加することを示すオプション。 -
port=80- 外部宛先ポート。 -
proto=tcp- TCP トラフィックを転送することを示すプロトコル。 -
toaddr=198.51.100.10- 宛先 IP アドレス。 -
toport=8080- 内部サーバーの宛先ポート。 -
--permanent- 再起動後も DNAT ルールを永続化するオプション。
-
ファイアウォール設定をリロードして、変更を適用します。
# firewall-cmd --reload
検証
使用したファイアウォールゾーンの DNAT ルールを確認します。
# firewall-cmd --list-forward-ports --zone=public port=80:proto=tcp:toport=8080:toaddr=198.51.100.10あるいは、対応する XML 設定ファイルを表示します。
# cat /etc/firewalld/zones/public.xml <?xml version="1.0" encoding="utf-8"?> <zone> <short>Public</short> <description>For use in public areas. You do not trust the other computers on networks to not harm your computer. Only selected incoming connections are accepted.</description> <service name="ssh"/> <service name="dhcpv6-client"/> <service name="cockpit"/> <forward-port port="80" protocol="tcp" to-port="8080" to-addr="198.51.100.10"/> <forward/> </zone>
23.5.10.4. 非標準ポートからのトラフィックをリダイレクトして、標準ポートで Web サービスにアクセスできるようにする
リダイレクトメカニズムを使用すると、ユーザーが URL でポートを指定しなくても、非標準ポートで内部的に実行される Web サービスにアクセスできるようになります。その結果、URL はよりシンプルになり、ブラウジングエクスペリエンスが向上します。一方で、非標準ポートは依然として内部で、または特定の要件のために使用されます。
前提条件
-
firewalldサービスが実行している。
手順
NAT リダイレクトルールを作成します。
# firewall-cmd --zone=public --add-forward-port=port=<standard_port>:proto=tcp:toport=<non_standard_port> --permanent上記のコマンドは、次の設定で NAT リダイレクトルールを定義します。
-
--zone=public- ルールを設定するファイアウォールゾーン。必要なゾーンに合わせて調整できます。 -
--add-forward-port=port=<non_standard_port>- 着信トラフィックを最初に受信するソースポートを使用したポート転送 (リダイレクト) ルールを追加することを示すオプション。 -
proto=tcp- TCP トラフィックをリダイレクトすることを示すプロトコル。 -
toport=<standard_port>- 着信トラフィックがソースポートで受信された後にリダイレクトされる宛先ポート。 -
--permanent- 再起動後もルールを永続化するオプション。
-
ファイアウォール設定をリロードして、変更を適用します。
# firewall-cmd --reload
検証
使用したファイアウォールゾーンのリダイレクトルールを確認します。
# firewall-cmd --list-forward-ports port=8080:proto=tcp:toport=80:toaddr=あるいは、対応する XML 設定ファイルを表示します。
# cat /etc/firewalld/zones/public.xml <?xml version="1.0" encoding="utf-8"?> <zone> <short>Public</short> <description>For use in public areas. You do not trust the other computers on networks to not harm your computer. Only selected incoming connections are accepted.</description> <service name="ssh"/> <service name="dhcpv6-client"/> <service name="cockpit"/> <forward-port port="8080" protocol="tcp" to-port="80"/> <forward/> </zone>
23.5.11. リッチルールの優先度設定
リッチルールにより、ファイアウォールルールをより高度かつ柔軟に定義できるようになります。リッチルールは、サービスやポートなどが複雑なファイアウォールルールを表現するのに十分でない場合に特に役立ちます。
リッチルールの背後にある概念:
- 粒度と柔軟性
- より具体的な基準に基づいて、ネットワークトラフィックの詳細な条件を定義できます。
- ルール構造
リッチルールは、ファミリー (IPv4 または IPv6) と、それに続く条件およびアクションで設定されます。
rule family="ipv4|ipv6" [conditions] [actions]- conditions
- 特定の基準が満たされた場合にのみ、豊富なルールを適用できます。
- actions
- 条件に一致するネットワークトラフィックに対して何が起こるかを定義できます。
- 複数の条件を組み合わせる
- より具体的かつ複雑なフィルタリングを作成できます。
- 階層的な制御と再利用性
- 豊富なルールを、ゾーンやサービスなどの他のファイアウォールメカニズムと組み合わせることができます。
デフォルトでは、リッチルールはルールアクションに基づいて設定されます。たとえば、許可 ルールよりも 拒否 ルールが優先されます。リッチルールで priority パラメーターを使用すると、管理者はリッチルールとその実行順序をきめ細かく制御できます。priority パラメーターを使用すると、ルールはまず優先度の値によって昇順にソートされます。多くのルールが同じ priority を持つ場合、ルールの順序はルールアクションによって決まります。アクションも同じである場合、順序は定義されない可能性があります。
23.5.11.1. priority パラメーターを異なるチェーンにルールを整理する方法
リッチルールの priority パラメーターは、-32768 から 32767 までの任意の数値に設定でき、数値が小さいほど優先度が高くなります。
firewalld サービスは、優先度の値に基づいて、ルールを異なるチェーンに整理します。
-
優先度が 0 未満 - ルールは
_pre接尾辞が付いたチェーンにリダイレクトされます。 -
優先度が 0 を超える - ルールは
_post接尾辞が付いたチェーンにリダイレクトされます。 -
優先度が 0 - アクションに基づいて、ルールは、
_log、_deny、または_allowのアクションを使用してチェーンにリダイレクトされます。
このサブチェーンでは、firewalld は優先度の値に基づいてルールを分類します。
23.5.11.2. リッチルールの優先度の設定
以下は、priority パラメーターを使用して、他のルールで許可または拒否されていないすべてのトラフィックをログに記録するリッチルールを作成する方法を示しています。このルールを使用して、予期しないトラフィックにフラグを付けることができます。
手順
優先度が非常に低いルールを追加して、他のルールと一致していないすべてのトラフィックをログに記録します。
# firewall-cmd --add-rich-rule='rule priority=32767 log prefix="UNEXPECTED: " limit value="5/m"'このコマンドでは、ログエントリーの数を、毎分
5に制限します。
検証
前の手順のコマンドで作成した
nftablesルールを表示します。# nft list chain inet firewalld filter_IN_public_post table inet firewalld { chain filter_IN_public_post { log prefix "UNEXPECTED: " limit rate 5/minute } }
23.5.12. firewalld ゾーン内の異なるインターフェイスまたはソース間でのトラフィック転送の有効化
ゾーン内転送は、firewalld ゾーン内のインターフェイスまたはソース間のトラフィック転送を可能にする firewalld 機能です。
23.5.12.1. ゾーン内転送と、デフォルトのターゲットが ACCEPT に設定されているゾーンの違い
ゾーン内転送を有効にすると、1 つの firewalld ゾーン内のトラフィックは、あるインターフェイスまたはソースから別のインターフェイスまたはソースに流れることができます。ゾーンは、インターフェイスおよびソースの信頼レベルを指定します。信頼レベルが同じ場合、トラフィックは同じゾーン内に留まります。
firewalld のデフォルトゾーンでゾーン内転送を有効にすると、現在のデフォルトゾーンに追加されたインターフェイスおよびソースにのみ適用されます。
firewalld は、異なるゾーンを使用して着信トラフィックと送信トラフィックを管理します。各ゾーンには独自のルールと動作のセットがあります。たとえば、trusted ゾーンでは、転送されたトラフィックがデフォルトですべて許可されます。
他のゾーンでは、異なるデフォルト動作を設定できます。標準ゾーンでは、ゾーンのターゲットが default に設定されている場合、転送されたトラフィックは通常デフォルトで破棄されます。
ゾーン内の異なるインターフェイスまたはソース間でトラフィックを転送する方法を制御するには、ゾーンのターゲットを理解し、それに応じてゾーンのターゲットを設定する必要があります。
23.5.12.2. ゾーン内転送を使用したイーサネットと Wi-Fi ネットワーク間でのトラフィックの転送
ゾーン内転送を使用して、同じ firewalld ゾーン内のインターフェイスとソース間のトラフィックを転送することができます。この機能には次の利点があります。
-
有線デバイスと無線デバイスの間のシームレスな接続性 (
enp1s0に接続されたイーサネットネットワークとwlp0s20に接続された Wi-Fi ネットワークの間でトラフィックを転送可能) - 柔軟な作業環境のサポート
- ネットワーク内の複数のデバイスまたはユーザーがアクセスして使用できる共有リソース (プリンター、データベース、ネットワーク接続ストレージなど)
- 効率的な内部ネットワーク (スムーズな通信、レイテンシーの短縮、リソースへのアクセス性など)
この機能は、個々の firewalld ゾーンに対して有効にすることができます。
手順
カーネルでパケット転送を有効にします。
# echo "net.ipv4.ip_forward=1" > /etc/sysctl.d/95-IPv4-forwarding.conf # sysctl -p /etc/sysctl.d/95-IPv4-forwarding.confゾーン内転送を有効にするインターフェイスが
internalゾーンにのみ割り当てられていることを確認します。# firewall-cmd --get-active-zones現在、インターフェイスが
internal以外のゾーンに割り当てられている場合は、以下のように再割り当てします。# firewall-cmd --zone=internal --change-interface=interface_name --permanentenp1s0およびwlp0s20インターフェイスをinternalゾーンに追加します。# firewall-cmd --zone=internal --add-interface=enp1s0 --add-interface=wlp0s20ゾーン内転送を有効にします。
# firewall-cmd --zone=internal --add-forward
検証
次の検証では、両方のホストに nmap-ncat パッケージがインストールされている必要があります。
-
ゾーン転送を有効にしたホストの
enp1s0インターフェイスと同じネットワーク上にあるホストにログインします。 ncatで echo サービスを起動し、接続をテストします。# ncat -e /usr/bin/cat -l 12345-
wlp0s20インターフェイスと同じネットワークにあるホストにログインします。 enp1s0と同じネットワークにあるホスト上で実行している echo サーバーに接続します。# ncat <other_host> 12345- 何かを入力して を押します。テキストが返送されることを確認します。
23.5.13. RHEL システムロールを使用した firewalld の設定
RHEL システムロールは、Ansible 自動化ユーティリティーのコンテンツセットです。このコンテンツを、Ansible Automation ユーティリティーと組み合わせることで、複数のシステムを同時にリモートで管理するための一貫した設定インターフェイスが実現します。
rhel-system-roles パッケージには、rhel-system-roles.firewall RHEL システムロールが含まれています。このロールは、firewalld サービスの自動設定のために導入されました。
firewall RHEL システムロールを使用すると、次のようなさまざまな firewalld パラメーターを設定できます。
- ゾーン
- パケットを許可すべきサービス
- ポートへのトラフィックアクセスの許可、拒否、またはドロップ
- ゾーンのポートまたはポート範囲の転送
23.5.13.1. firewall RHEL システムロールを使用した firewalld 設定のリセット
時間が経つにつれて、ファイアウォール設定の更新が累積し、予想外のセキュリティーリスクが発生する可能性があります。firewall RHEL システムロールを使用すると、firewalld 設定を自動的にデフォルト状態にリセットできます。これにより、意図しない、またはセキュアでないファイアウォールルールを効率的に削除し、管理を簡素化できます。
前提条件
- コントロールノードと管理対象ノードの準備が完了している。
- 管理対象ノードで Playbook を実行できるユーザーとしてコントロールノードにログインしている。
-
管理対象ノードへの接続に使用するアカウントに、そのノードに対する
sudo権限がある。
手順
次の内容を含む Playbook ファイル (例:
~/playbook.yml) を作成します。--- - name: Reset firewalld example hosts: managed-node-01.example.com tasks: - name: Reset firewalld ansible.builtin.include_role: name: redhat.rhel_system_roles.firewall vars: firewall: - previous: replacedサンプル Playbook で指定されている設定は次のとおりです。
previous: replaced既存のユーザー定義設定をすべて削除し、
firewalld設定をデフォルトにリセットします。previous:replacedパラメーターを他の設定と組み合わせると、firewallロールは新しい設定を適用する前に既存の設定をすべて削除します。Playbook で使用されるすべての変数の詳細は、コントロールノードの
/usr/share/ansible/roles/rhel-system-roles.firewall/README.mdファイルを参照してください。
Playbook の構文を検証します。
$ ansible-playbook --syntax-check ~/playbook.ymlこのコマンドは構文を検証するだけであり、有効だが不適切な設定から保護するものではないことに注意してください。
Playbook を実行します。
$ ansible-playbook ~/playbook.yml
検証
コントロールノードでこのコマンドを実行して、管理対象ノードのすべてのファイアウォール設定がデフォルト値にリセットされたことをリモートで確認します。
# ansible managed-node-01.example.com -m ansible.builtin.command -a 'firewall-cmd --list-all-zones'
23.5.13.2. firewall RHEL システムロールを使用して、firewalld の着信トラフィックをあるローカルポートから別のローカルポートに転送する
firewall RHEL システムロールを使用して、あるローカルポートから別のローカルポートへの着信トラフィックの転送をリモートで設定できます。
たとえば、同じマシン上に複数のサービスが共存し、同じデフォルトポートが必要な環境の場合、ポートの競合が発生する可能性があります。この競合によりサービスが中断され、ダウンタイムが発生する可能性があります。firewall RHEL システムロールを使用すると、トラフィックを効率的に別のポートに転送して、サービスの設定を変更せずにサービスを同時に実行できます。
前提条件
- コントロールノードと管理対象ノードの準備が完了している。
- 管理対象ノードで Playbook を実行できるユーザーとしてコントロールノードにログインしている。
-
管理対象ノードへの接続に使用するアカウントに、そのノードに対する
sudo権限がある。
手順
次の内容を含む Playbook ファイル (例:
~/playbook.yml) を作成します。--- - name: Configure firewalld hosts: managed-node-01.example.com tasks: - name: Forward incoming traffic on port 8080 to 443 ansible.builtin.include_role: name: redhat.rhel_system_roles.firewall vars: firewall: - forward_port: 8080/tcp;443; state: enabled runtime: true permanent: trueサンプル Playbook で指定されている設定は次のとおりです。
forward_port:8080/tcp;443- TCP プロトコルを使用してローカルポート 8080 に送信されるトラフィックが、ポート 443 に転送されます。
runtime: trueランタイム設定の変更を有効にします。デフォルトは
trueに設定されています。Playbook で使用されるすべての変数の詳細は、コントロールノードの
/usr/share/ansible/roles/rhel-system-roles.firewall/README.mdファイルを参照してください。
Playbook の構文を検証します。
$ ansible-playbook --syntax-check ~/playbook.ymlこのコマンドは構文を検証するだけであり、有効だが不適切な設定から保護するものではないことに注意してください。
Playbook を実行します。
$ ansible-playbook ~/playbook.yml
検証
コントロールノードで次のコマンドを実行して、管理対象ノードの転送ポートをリモートで確認します。
# ansible managed-node-01.example.com -m ansible.builtin.command -a 'firewall-cmd --list-forward-ports' managed-node-01.example.com | CHANGED | rc=0 >> port=8080:proto=tcp:toport=443:toaddr=
23.5.13.3. firewall RHEL システムロールを使用した firewalld DMZ ゾーンの設定
システム管理者は、firewall RHEL システムロールを使用して、enp1s0 インターフェイス上に dmz ゾーンを設定し、ゾーンへの HTTPS トラフィックを許可できます。これにより、外部ユーザーが Web サーバーにアクセスできるようにします。
前提条件
- コントロールノードと管理対象ノードの準備が完了している。
- 管理対象ノードで Playbook を実行できるユーザーとしてコントロールノードにログインしている。
-
管理対象ノードへの接続に使用するアカウントに、そのノードに対する
sudo権限がある。
手順
次の内容を含む Playbook ファイル (例:
~/playbook.yml) を作成します。--- - name: Configure firewalld hosts: managed-node-01.example.com tasks: - name: Creating a DMZ with access to HTTPS port and masquerading for hosts in DMZ ansible.builtin.include_role: name: redhat.rhel_system_roles.firewall vars: firewall: - zone: dmz interface: enp1s0 service: https state: enabled runtime: true permanent: truePlaybook で使用されるすべての変数の詳細は、コントロールノードの
/usr/share/ansible/roles/rhel-system-roles.firewall/README.mdファイルを参照してください。Playbook の構文を検証します。
$ ansible-playbook --syntax-check ~/playbook.ymlこのコマンドは構文を検証するだけであり、有効だが不適切な設定から保護するものではないことに注意してください。
Playbook を実行します。
$ ansible-playbook ~/playbook.yml
検証
コントロールノードで次のコマンドを実行して、管理対象ノードの
dmzゾーンに関する情報をリモートで確認します。# ansible managed-node-01.example.com -m ansible.builtin.command -a 'firewall-cmd --zone=dmz --list-all' managed-node-01.example.com | CHANGED | rc=0 >> dmz (active) target: default icmp-block-inversion: no interfaces: enp1s0 sources: services: https ssh ports: protocols: forward: no masquerade: no forward-ports: source-ports: icmp-blocks:
23.6. nftables の使用
シナリオが、firewalld でカバーされる一般的なパケットフィルタリングのケースに該当しない場合、またはルールを完全に制御したい場合は、nftables フレームワークを使用できます。
nftables フレームワークは、パケットを分類機能を提供し、iptables、ip6tables、arptables、ebtables、および ipset ユーティリティーの後継となります。利便性、機能、パフォーマンスにおいて、以前のパケットフィルタリングツールに多くの改良が追加されました。以下に例を示します。
- 線形処理の代わりに組み込みルックアップテーブルを使用
-
IPv4プロトコルおよびIPv6プロトコルに対する 1 つのフレームワーク - ルールセット全体を取得、更新、保存するのではなく、トランザクションを通じてカーネルルールセットをその場で更新する
-
ルールセットにおけるデバッグおよびトレースへの対応 (
nftrace) およびトレースイベントの監視 (nftツール) - より統一されたコンパクトな構文、プロトコル固有の拡張なし
- サードパーティーのアプリケーション用 Netlink API
nftables フレームワークは、テーブルを使用してチェーンを保存します。このチェーンには、アクションを実行する個々のルールが含まれます。nft ユーティリティーは、以前のパケットフィルタリングフレームワークのツールをすべて置き換えます。libnftnl ライブラリーを介して、nftables Netlink API との低レベルの対話に libnftables ライブラリーを使用できます。
ルールセット変更が適用されていることを表示するには、nft list ruleset コマンドを使用します。カーネルルールセットをクリアするには、nft flush ruleset コマンドを使用します。同じカーネルインフラストラクチャーを使用するため、iptables-nft コマンドでインストールされたルールセットにも影響する可能性があることに注意してください。
23.6.1. nftables テーブル、チェーン、およびルールの作成および管理
nftables ルールセットを表示して管理できます。
23.6.1.1. nftables テーブルの基本
nftables のテーブルは、チェーン、ルール、セットなどのオブジェクトを含む名前空間です。
各テーブルにはアドレスファミリーが割り当てられている必要があります。アドレスファミリーは、このテーブルが処理するパケットタイプを定義します。テーブルを作成する際に、以下のいずれかのアドレスファミリーを設定できます。
-
ip:IPv4 パケットだけに一致します。アドレスファミリーを指定しないと、これがデフォルトになります。 -
ip6:IPv6 パケットだけに一致します。 -
inet:IPv4 パケットと IPv6 パケットの両方に一致します。 -
arp:IPv4 アドレス解決プロトコル (ARP) パケットに一致します。 -
bridge:ブリッジデバイスを通過するパケットに一致します。 -
netdev:ingress からのパケットに一致します。
テーブルを追加する場合、使用する形式はファイアウォールスクリプトにより異なります。
ネイティブ構文のスクリプトでは、以下を使用します。
table <table_address_family> <table_name> { }シェルスクリプトで、以下を使用します。
nft add table <table_address_family> <table_name>
23.6.1.2. nftables チェーンの基本
テーブルは、ルールのコンテナーであるチェーンで構成されます。次の 2 つのルールタイプが存在します。
- ベースチェーン:ネットワークスタックからのパケットのエントリーポイントとしてベースチェーンを使用できます。
-
通常のチェーン:
jumpターゲットとして通常のチェーンを使用し、ルールをより適切に整理できます。
ベースチェーンをテーブルに追加する場合に使用する形式は、ファイアウォールスクリプトにより異なります。
ネイティブ構文のスクリプトでは、以下を使用します。
table <table_address_family> <table_name> { chain <chain_name> { type <type> hook <hook> priority <priority> policy <policy> ; } }シェルスクリプトで、以下を使用します。
nft add chain <table_address_family> <table_name> <chain_name> { type <type> hook <hook> priority <priority> \; policy <policy> \; }シェルがセミコロンをコマンドの最後として解釈しないようにするには、セミコロンの前にエスケープ文字
\を配置します。
どちらの例でも、ベースチェーン を作成します。通常のチェーン を作成する場合、中括弧内にパラメーターを設定しないでください。
チェーンタイプ
チェーンタイプとそれらを使用できるアドレスファミリーとフックの概要を以下に示します。
| 型 | アドレスファミリー | フック | 説明 |
|---|---|---|---|
|
| all | all | 標準のチェーンタイプ |
|
|
|
| このタイプのチェーンは、接続追跡エントリーに基づいてネイティブアドレス変換を実行します。最初のパケットのみがこのチェーンタイプをトラバースします。 |
|
|
|
| このチェーンタイプを通過する許可済みパケットは、IP ヘッダーの関連部分が変更された場合に、新しいルートルックアップを引き起こします。 |
チェーンの優先度
priority パラメーターは、パケットが同じフック値を持つチェーンを通過する順序を指定します。このパラメーターは、整数値に設定することも、標準の priority 名を使用することもできます。
以下のマトリックスは、標準的な priority 名とその数値の概要、それらを使用できるファミリーおよびフックの概要です。
| テキストの値 | 数値 | アドレスファミリー | フック |
|---|---|---|---|
|
|
|
| all |
|
|
|
| all |
|
|
|
|
|
|
|
|
| |
|
|
|
| all |
|
|
| all | |
|
|
|
| all |
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
チェーンポリシー
チェーンポリシーは、このチェーンのルールでアクションが指定されていない場合に、nftables がパケットを受け入れるかドロップするかを定義します。チェーンには、以下のいずれかのポリシーを設定できます。
-
accept(デフォルト) -
drop
23.6.1.3. nftables ルールの基本
ルールは、このルールを含むチェーンを渡すパケットに対して実行するアクションを定義します。ルールに一致する式も含まれる場合、nftables は、以前の式がすべて適用されている場合にのみアクションを実行します。
チェーンにルールを追加する場合、使用する形式はファイアウォールスクリプトにより異なります。
ネイティブ構文のスクリプトでは、以下を使用します。
table <table_address_family> <table_name> { chain <chain_name> { type <type> hook <hook> priority <priority> ; policy <policy> ; <rule> } }シェルスクリプトで、以下を使用します。
nft add rule <table_address_family> <table_name> <chain_name> <rule>このシェルコマンドは、チェーンの最後に新しいルールを追加します。チェーンの先頭にルールを追加する場合は、
nft addの代わりにnft insertコマンドを使用します。
23.6.1.4. nft コマンドを使用したテーブル、チェーン、ルールの管理
コマンドラインまたはシェルスクリプトで nftables ファイアウォールを管理するには、nft ユーティリティーを使用します。
この手順のコマンドは通常のワークフローを表しておらず、最適化されていません。この手順では、nft コマンドを使用して、一般的なテーブル、チェーン、およびルールを管理する方法を説明します。
手順
テーブルが IPv4 パケットと IPv6 パケットの両方を処理できるように、
inetアドレスファミリーを使用してnftables_svcという名前のテーブルを作成します。# nft add table inet nftables_svc受信ネットワークトラフィックを処理する
INPUTという名前のベースチェーンをinet nftables_svcテーブルに追加します。# nft add chain inet nftables_svc INPUT { type filter hook input priority filter \; policy accept \; }シェルがセミコロンをコマンドの最後として解釈しないようにするには、
\文字を使用してセミコロンをエスケープします。INPUTチェーンにルールを追加します。たとえば、INPUTチェーンの最後のルールとして、ポート 22 および 443 で着信 TCP トラフィックを許可し、他の着信トラフィックを、Internet Control Message Protocol (ICMP) ポートに到達できないというメッセージで拒否します。# nft add rule inet nftables_svc INPUT tcp dport 22 accept # nft add rule inet nftables_svc INPUT tcp dport 443 accept # nft add rule inet nftables_svc INPUT reject with icmpx type port-unreachableここで示されたように
nft add ruleコマンドを実行すると、nftはコマンド実行と同じ順序でルールをチェーンに追加します。ハンドルを含む現在のルールセットを表示します。
# nft -a list table inet nftables_svc table inet nftables_svc { # handle 13 chain INPUT { # handle 1 type filter hook input priority filter; policy accept; tcp dport 22 accept # handle 2 tcp dport 443 accept # handle 3 reject # handle 4 } }ハンドル 3 で既存ルールの前にルールを挿入します。たとえば、ポート 636 で TCP トラフィックを許可するルールを挿入するには、以下を入力します。
# nft insert rule inet nftables_svc INPUT position 3 tcp dport 636 acceptハンドル 3 で、既存ルールの後ろにルールを追加します。たとえば、ポート 80 で TCP トラフィックを許可するルールを追加するには、以下を入力します。
# nft add rule inet nftables_svc INPUT position 3 tcp dport 80 acceptハンドルでルールセットを再表示します。後で追加したルールが指定の位置に追加されていることを確認します。
# nft -a list table inet nftables_svc table inet nftables_svc { # handle 13 chain INPUT { # handle 1 type filter hook input priority filter; policy accept; tcp dport 22 accept # handle 2 tcp dport 636 accept # handle 5 tcp dport 443 accept # handle 3 tcp dport 80 accept # handle 6 reject # handle 4 } }ハンドル 6 でルールを削除します。
# nft delete rule inet nftables_svc INPUT handle 6ルールを削除するには、ハンドルを指定する必要があります。
ルールセットを表示し、削除されたルールがもう存在しないことを確認します。
# nft -a list table inet nftables_svc table inet nftables_svc { # handle 13 chain INPUT { # handle 1 type filter hook input priority filter; policy accept; tcp dport 22 accept # handle 2 tcp dport 636 accept # handle 5 tcp dport 443 accept # handle 3 reject # handle 4 } }INPUTチェーンから残りのルールをすべて削除します。# nft flush chain inet nftables_svc INPUTルールセットを表示し、
INPUTチェーンが空であることを確認します。# nft list table inet nftables_svc table inet nftables_svc { chain INPUT { type filter hook input priority filter; policy accept } }INPUTチェーンを削除します。# nft delete chain inet nftables_svc INPUTこのコマンドを使用して、まだルールが含まれているチェーンを削除することもできます。
ルールセットを表示し、
INPUTチェーンが削除されたことを確認します。# nft list table inet nftables_svc table inet nftables_svc { }nftables_svcテーブルを削除します。# nft delete table inet nftables_svcこのコマンドを使用して、まだルールが含まれているテーブルを削除することもできます。
注記ルールセット全体を削除するには、個別のコマンドですべてのルール、チェーン、およびテーブルを手動で削除するのではなく、
nft flush rulesetコマンドを使用します。
23.6.2. iptables から nftables への移行
ファイアウォール設定が依然として iptables ルールを使用している場合は、iptables ルールを nftables に移行できます。
23.6.2.1. firewalld、nftables、または iptables を使用する場合
RHEL 8 では、シナリオに応じて次のパケットフィルタリングユーティリティーを使用できます。
-
firewalld:firewalldユーティリティーは、一般的な使用例のファイアウォール設定を簡素化します。 -
nftables:nftablesユーティリティーを使用して、ネットワーク全体など、複雑なパフォーマンスに関する重要なファイアウォールを設定します。 -
iptables:Red Hat Enterprise Linux のiptablesユーティリティーは、legacyバックエンドの代わりにnf_tablesカーネル API を使用します。nf_tablesAPI は、iptablesコマンドを使用するスクリプトが、Red Hat Enterprise Linux で引き続き動作するように、後方互換性を提供します。新しいファイアウォールスクリプトの場合は、nftablesを使用します。
さまざまなファイアウォール関連サービス (firewalld、nftables、または iptables) が相互に影響を与えないようにするには、RHEL ホストでそのうち 1 つだけを実行し、他のサービスを無効にします。
23.6.2.2. nftables フレームワークの概念
iptables フレームワークと比較すると、nftables はより最新で効率的かつ柔軟な代替手段を提供します。nftables フレームワークは、iptables よりも高度な機能と改善を提供し、ルール管理を簡素化し、パフォーマンスを向上させます。これにより、nftables は 複雑で高性能なネットワーク環境に対する最新の代替手段となります。
- テーブルと名前空間
-
nftablesでは、テーブルは、関連するファイアウォールチェーン、セット、フローテーブル、およびその他のオブジェクトをグループ化する組織単位または名前空間を表します。nftablesでは、テーブルによってファイアウォールルールと関連コンポーネントをより柔軟に構造化できます。一方、iptablesでは、テーブルは特定の目的に合わせてより厳密に定義されていました。 - テーブルファミリー
-
nftables内の各テーブルは、特定のファミリー (ip、ip6、inet、arp、bridge、またはnetdev) に関連付けられています。この関連付けによって、テーブルが処理できるパケットが決まります。たとえば、ipファミリーのテーブルは IPv4 パケットのみを処理します。一方、inetはテーブルファミリーの特殊なケースです。IPv4 パケットと IPv6 パケットの両方を処理できるため、プロトコル全体で統一されたアプローチを提供します。特殊なテーブルファミリーのもう 1 つの例はnetdevです。これは、ネットワークデバイスに直接適用されるルールに使用され、デバイスレベルでのフィルタリングを可能にするためです。 - ベースチェーン
nftablesのベースチェーンは、パケット処理パイプライン内の高度に設定可能なエントリーポイントであり、ユーザーは次の内容を指定できます。- チェーンの種類 (例: フィルター)
- パケット処理パスのフックポイント (例: 入力、出力、転送)
- チェーンの優先順位
この柔軟性により、パケットがネットワークスタックを通過するときにルールが適用されるタイミングと方法を正確に制御できます。チェーンの特殊なケースは
ルートチェーンであり、パケットヘッダーに基づいてカーネルによって行われるルーティングの決定に影響を与えるために使用されます。- ルール処理用の仮想マシン
nftablesフレームワークは、ルールを処理するために内部仮想マシンを使用します。この仮想マシンは、アセンブリ言語の操作 (レジスターへのデータのロード、比較の実行など) に似た命令を実行します。このようなメカニズムにより、非常に柔軟かつ効率的なルール処理が可能になります。nftablesの機能強化は、その仮想マシンの新しい命令として導入できます。これには通常、新しいカーネルモジュールと、libnftnlライブラリーおよびnftコマンドラインユーティリティーの更新が必要です。または、カーネルを変更することなく、既存の命令を革新的な方法で組み合わせることで、新しい機能を導入することもできます。
nftablesルールの構文は、基盤となる仮想マシンの柔軟性を反映しています。たとえば、ルールメタマークセット tcp dport マップ{22: 1, 80:2 }TCP 宛先ポートが 22 の場合はパケットのファイアウォールマークを 1 に設定し、ポートが 80 の場合は 2 に設定します。これは、複雑なロジックを簡潔に表現できることを示しています。- 複雑なフィルタリングと判定マップ
nftablesフレームワークは、iptablesで IP アドレス、ポート、その他のデータタイプ、そして最も重要なそれらの組み合わせの一括マッチングに使用されるipsetユーティリティーの機能を統合および拡張します。この統合により、大規模で動的なデータセットをnftables内で直接管理することが容易になります。次に、nftables は、任意のデータタイプに対して複数の値または範囲に基づいてパケットを照合することをネイティブにサポートしているため、複雑なフィルタリング要件を処理する機能が強化されます。nftables を使用すると、パケット内の任意のフィールドを操作できます。nftablesでは、セットは名前付きまたは匿名のいずれかになります。名前付きセットは複数のルールによって参照され、動的に変更することができます。匿名セットはルール内でインラインで定義され、不変です。セットには、IP アドレスとポート番号のペアなど、異なるタイプの組み合わせである要素を含めることができます。この機能により、複雑な条件の一致における柔軟性が向上します。セットを管理するために、カーネルは特定の要件 (パフォーマンス、メモリー効率など) に基づいて最も適切なバックエンドを選択できます。セットは、キーと値のペアを持つマップとしても機能できます。値の部分は、データポイント (パケットヘッダーに書き込む値) として、または判定やジャンプ先のチェーンとして使用できます。これにより、判定マップと呼ばれる複雑で動的なルール動作が可能になります。- 柔軟なルール形式
nftablesルールの構造は簡単です。条件とアクションは左から右に順に適用されます。この直感的な形式により、ルールの作成とトラブルシューティングが簡素化されます。ルール内の条件は論理的に (ANDOperator を使用して) 結合されており、ルールが一致するにはすべての条件が true と評価される必要があります。いずれかの条件が失敗した場合、評価は次のルールに進みます。
nftables内のアクションは、dropやacceptなど、パケットに対するそれ以上のルール処理を停止する最終的なものになることがあります。counter log meta mark set 0x3などの非ターミナルアクションは、特定のタスク (パケットのカウント、ログ記録、マークの設定など) を実行しますが、後続のルールを評価できます。
23.6.2.3. 廃止された iptables フレームワークの概念
積極的にメンテナンスされている nftables フレームワークと同様に、非推奨の iptables フレームワークを使用すると、さまざまなパケットフィルタリングタスク、ログ記録と監査、NAT 関連の設定タスクなどを実行できます。
iptables フレームワークは複数のテーブルに構造化されており、各テーブルは特定の目的のために設計されています。
filter- デフォルトのテーブルは、一般的なパケットフィルタリングを保証します
nat- ネットワークアドレス変換 (NAT) の場合、パケットの送信元アドレスと宛先アドレスの変更が含まれます。
mangle- 特定のパケット変更では、高度なルーティング決定のためにパケットヘッダーの変更を行うことができます。
raw- 接続追跡の前に必要な設定
これらのテーブルは個別のカーネルモジュールとして実装されており、各テーブルは INPUT、OUTPUT、FORWARD などの組み込みチェーンの固定セットを提供します。チェーンは、パケットが評価される一連のルールです。これらのチェーンは、カーネル内のパケット処理フローの特定のポイントにフックします。チェーンは異なるテーブル間で同じ名前を持ちますが、実行順序はそれぞれのフックの優先順位によって決まります。ルールが正しい順序で適用されるように、優先順位はカーネルによって内部的に管理されます。
もともと、iptables は IPv4 トラフィックを処理するために設計されました。しかし、IPv6 プロトコルの開始に伴い、iptables と同等の機能を提供し、ユーザーが IPv6 パケットのファイアウォールルールを作成および管理できるようにするために、ip6tables ユーティリティーを導入する必要がありました。同じロジックで、Address Resolution Protocol (ARP) を処理するために arptables ユーティリティーが作成され、イーサネットブリッジフレームを処理するために ebtables ユーティリティーが開発されました。これらのツールを使用すると、さまざまなネットワークプロトコルにわたって iptables のパケットフィルタリング機能を適用し、包括的なネットワークカバレッジを提供できるようになります。
iptables の機能を強化するために、拡張機能の開発が開始されました。機能拡張は通常、ユーザー空間の動的共有オブジェクト (DSO) とペアになったカーネルモジュールとして実装されます。拡張機能により、ファイアウォールルールで使用してより高度な操作を実行できる一致とターゲットが導入されます。拡張機能により、複雑な一致とターゲットが可能になります。たとえば、特定のレイヤー 4 プロトコルヘッダー値を一致させたり操作したり、レート制限を実行したり、クォータを適用したりすることができます。一部の拡張機能は、デフォルトの iptables 構文の制限に対処するように設計されています (例: マルチポート一致拡張機能)。この拡張機能により、単一のルールを複数の非連続ポートに一致させることができるため、ルール定義が簡素化され、必要な個別のルールの数を減らすことができます。
ipset は、iptables に対する特別な種類の機能拡張です。これはカーネルレベルのデータ構造であり、iptables と一緒に使用して、パケットと照合できる IP アドレス、ポート番号、その他のネットワーク関連要素のコレクションを作成します。これらのセットにより、ファイアウォールルールの作成と管理のプロセスが大幅に合理化、最適化、高速化されます。
23.6.2.4. iptables および ip6tables ルールセットの nftables への変換
iptables-restore-translate ユーティリティーおよび ip6tables-restore-translate ユーティリティーを使用して、iptables および ip6tables ルールセットを nftables に変換します。
前提条件
-
nftablesパッケージおよびiptablesパッケージがインストールされている。 -
システムに
iptablesルールおよびip6tablesルールが設定されている。
手順
iptablesルールおよびip6tablesルールをファイルに書き込みます。# iptables-save >/root/iptables.dump # ip6tables-save >/root/ip6tables.dumpダンプファイルを
nftables命令に変換します。# iptables-restore-translate -f /root/iptables.dump > /etc/nftables/ruleset-migrated-from-iptables.nft # ip6tables-restore-translate -f /root/ip6tables.dump > /etc/nftables/ruleset-migrated-from-ip6tables.nft-
必要に応じて、生成された
nftablesルールを手動で更新して、確認します。 nftablesサービスが生成されたファイルをロードできるようにするには、以下を/etc/sysconfig/nftables.confファイルに追加します。include "/etc/nftables/ruleset-migrated-from-iptables.nft" include "/etc/nftables/ruleset-migrated-from-ip6tables.nft"iptablesサービスを停止し、無効にします。# systemctl disable --now iptablesカスタムスクリプトを使用して
iptablesルールを読み込んだ場合は、スクリプトが自動的に開始されなくなったことを確認し、再起動してすべてのテーブルをフラッシュします。nftablesサービスを有効にして起動します。# systemctl enable --now nftables
検証
nftablesルールセットを表示します。# nft list ruleset
23.6.2.5. 単一の iptables および ip6tables ルールセットの nftables への変換
Red Hat Enterprise Linux は、iptables ルールまたは ip6tables ルールを、nftables で同等のルールに変換する iptables-translate ユーティリティーおよび ip6tables-translate ユーティリティーを提供します。
前提条件
-
nftablesパッケージがインストールされている。
手順
以下のように、
iptablesまたはip6tablesの代わりにiptables-translateユーティリティーまたはip6tables-translateユーティリティーを使用して、対応するnftablesルールを表示します。# iptables-translate -A INPUT -s 192.0.2.0/24 -j ACCEPT nft add rule ip filter INPUT ip saddr 192.0.2.0/24 counter accept拡張機能によっては変換機能がない場合もあります。このような場合には、ユーティリティーは、以下のように、前に
#記号が付いた未変換ルールを出力します。# iptables-translate -A INPUT -j CHECKSUM --checksum-fill nft # -A INPUT -j CHECKSUM --checksum-fill
23.6.2.6. 一般的な iptables コマンドと nftables コマンドの比較
以下は、一般的な iptables コマンドと nftables コマンドの比較です。
すべてのルールをリスト表示します。
Expand iptables nftables iptables-savenft list ruleset特定のテーブルおよびチェーンをリスト表示します。
Expand iptables nftables iptables -Lnft list table ip filteriptables -L INPUTnft list chain ip filter INPUTiptables -t nat -L PREROUTINGnft list chain ip nat PREROUTINGnftコマンドは、テーブルおよびチェーンを事前に作成しません。これらは、ユーザーが手動で作成した場合にのみ存在します。firewalld によって生成されたルールの一覧表示:
# nft list table inet firewalld # nft list table ip firewalld # nft list table ip6 firewalld
23.6.3. nftables を使用した NAT の設定
nftables を使用すると、以下のネットワークアドレス変換 (NAT) タイプを設定できます。
- マスカレーディング
- ソース NAT (SNAT)
- 宛先 NAT (DNAT)
- リダイレクト
iifname パラメーターおよび oifname パラメーターでは実インターフェイス名のみを使用でき、代替名 (altname) には対応していません。
23.6.3.1. NAT タイプ
以下は、ネットワークアドレス変換 (NAT) タイプになります。
- マスカレードおよびソースの NAT (SNAT)
この NAT タイプのいずれかを使用して、パケットのソース IP アドレスを変更します。たとえば、インターネットサービスプロバイダー (ISP) は、プライベート IP 範囲 (
10.0.0.0/8など) をルーティングしません。ネットワークでプライベート IP 範囲を使用し、ユーザーがインターネット上のサーバーにアクセスできるようにする必要がある場合は、この範囲のパケットのソース IP アドレスをパブリック IP アドレスにマップします。マスカレードと SNAT は互いに非常に似ています。相違点は次のとおりです。
- マスカレードは、出力インターフェイスの IP アドレスを自動的に使用します。したがって、出力インターフェイスが動的 IP アドレスを使用する場合は、マスカレードを使用します。
- SNAT は、パケットのソース IP アドレスを指定された IP に設定し、出力インターフェイスの IP アドレスを動的に検索しません。そのため、SNAT の方がマスカレードよりも高速です。出力インターフェイスが固定 IP アドレスを使用する場合は、SNAT を使用します。
- 宛先 NAT (DNAT)
- この NAT タイプを使用して、着信パケットの宛先アドレスとポートを書き換えます。たとえば、Web サーバーがプライベート IP 範囲の IP アドレスを使用しているため、インターネットから直接アクセスできない場合は、ルーターに DNAT ルールを設定し、着信トラフィックをこのサーバーにリダイレクトできます。
- リダイレクト
- このタイプは、チェーンフックに応じてパケットをローカルマシンにリダイレクトする DNAT の特殊なケースです。たとえば、サービスが標準ポートとは異なるポートで実行する場合は、標準ポートからこの特定のポートに着信トラフィックをリダイレクトすることができます。
23.6.3.2. nftables を使用したマスカレードの設定
マスカレードを使用すると、ルーターは、インターフェイスを介して送信されるパケットのソース IP を、インターフェイスの IP アドレスに動的に変更できます。これは、インターフェイスに新しい IP が割り当てられている場合に、nftables はソース IP の置き換え時に新しい IP を自動的に使用することを意味します。
ens3 インターフェイスを介してホストから出るパケットの送信元 IP を、ens3 で設定された IP に置き換えます。
手順
テーブルを作成します。
# nft add table natテーブルに、
preroutingチェーンおよびpostroutingチェーンを追加します。# nft add chain nat postrouting { type nat hook postrouting priority 100 \; }重要preroutingチェーンにルールを追加しなくても、nftablesフレームワークでは、着信パケット返信に一致するようにこのチェーンが必要になります。--オプションをnftコマンドに渡して、シェルが負の priority 値をnftコマンドのオプションとして解釈しないようにする必要があることに注意してください。postroutingチェーンに、ens3インターフェイスの出力パケットに一致するルールを追加します。# nft add rule nat postrouting oifname "ens3" masquerade
23.6.3.3. nftables を使用したソース NAT の設定
ルーターでは、ソース NAT (SNAT) を使用して、インターフェイスを介して特定の IP アドレスに送信するパケットの IP を変更できます。次に、ルーターは送信パケットのソース IP を置き換えます。
手順
テーブルを作成します。
# nft add table natテーブルに、
preroutingチェーンおよびpostroutingチェーンを追加します。# nft add chain nat postrouting { type nat hook postrouting priority 100 \; }重要postroutingチェーンにルールを追加しなくても、nftablesフレームワークでは、このチェーンが発信パケット返信に一致するようにする必要があります。--オプションをnftコマンドに渡して、シェルが負の priority 値をnftコマンドのオプションとして解釈しないようにする必要があることに注意してください。ens3を介した発信パケットのソース IP を192.0.2.1に置き換えるルールをpostroutingチェーンに追加します。# nft add rule nat postrouting oifname "ens3" snat to 192.0.2.1
23.6.3.4. nftables を使用した宛先 NAT の設定
宛先 NAT (DNAT) を使用すると、ルーター上のトラフィックを、インターネットから直接アクセスできないホストにリダイレクトできます。
たとえば、DNAT を使用すると、ルーターはポート 80 および 443 に送信された受信トラフィックを、IP アドレス 192.0.2.1 の Web サーバーにリダイレクトします。
手順
テーブルを作成します。
# nft add table natテーブルに、
preroutingチェーンおよびpostroutingチェーンを追加します。# nft -- add chain nat prerouting { type nat hook prerouting priority -100 \; } # nft add chain nat postrouting { type nat hook postrouting priority 100 \; }重要postroutingチェーンにルールを追加しなくても、nftablesフレームワークでは、このチェーンが発信パケット返信に一致するようにする必要があります。--オプションをnftコマンドに渡して、シェルが負の priority 値をnftコマンドのオプションとして解釈しないようにする必要があることに注意してください。preroutingチェーンに、ルーターのens3インターフェイスのポート80および443への受信トラフィックを、IP アドレス192.0.2.1の Web サーバーにリダイレクトするルールを追加します。# nft add rule nat prerouting iifname ens3 tcp dport { 80, 443 } dnat to 192.0.2.1環境に応じて、SNAT ルールまたはマスカレードルールを追加して、Web サーバーから返されるパケットのソースアドレスを送信者に変更します。
ens3インターフェイスが動的 IP アドレスを使用している場合は、マスカレードルールを追加します。# nft add rule nat postrouting oifname "ens3" masqueradeens3インターフェイスが静的 IP アドレスを使用する場合は、SNAT ルールを追加します。たとえば、ens3が IP アドレス198.51.100.1を使用している場合は、以下のようになります。# nft add rule nat postrouting oifname "ens3" snat to 198.51.100.1
パケット転送を有効にします。
# echo "net.ipv4.ip_forward=1" > /etc/sysctl.d/95-IPv4-forwarding.conf # sysctl -p /etc/sysctl.d/95-IPv4-forwarding.conf
23.6.3.5. nftables を使用したリダイレクトの設定
redirect 機能は、チェーンフックに応じてパケットをローカルマシンにリダイレクトする宛先ネットワークアドレス変換 (DNAT) の特殊なケースです。
たとえば、ローカルホストのポート 22 に送信された着信および転送されたトラフィックを 2222 ポートにリダイレクトすることができます。
手順
テーブルを作成します。
# nft add table natテーブルに
preroutingチェーンを追加します。# nft -- add chain nat prerouting { type nat hook prerouting priority -100 \; }--オプションをnftコマンドに渡して、シェルが負の priority 値をnftコマンドのオプションとして解釈しないようにする必要があることに注意してください。22ポートの着信トラフィックを2222ポートにリダイレクトするルールをpreroutingチェーンに追加します。# nft add rule nat prerouting tcp dport 22 redirect to 2222
23.6.4. nftables スクリプトの作成および実行
nftables フレームワークを使用する主な利点は、スクリプトの実行がアトミックであることです。つまり、システムがスクリプト全体を適用するか、エラーが発生した場合には実行を阻止することを意味します。これにより、ファイアウォールは常に一貫した状態になります。
さらに、nftables スクリプト環境を使用すると、次のことができます。
- コメントの追加
- 変数の定義
- 他のルールセットファイルの組み込み
nftables パッケージをインストールすると、Red Hat Enterprise Linux が自動的に *.nft スクリプトを /etc/nftables/ ディレクトリーに作成します。このスクリプトには、さまざまな目的でテーブルと空のチェーンを作成するコマンドが含まれます。
23.6.4.1. 対応している nftables スクリプトの形式
nftables スクリプト環境では、次の形式でスクリプトを記述できます。
nft list rulesetコマンドと同じ形式でルールセットが表示されます。#!/usr/sbin/nft -f # Flush the rule set flush ruleset table inet example_table { chain example_chain { # Chain for incoming packets that drops all packets that # are not explicitly allowed by any rule in this chain type filter hook input priority 0; policy drop; # Accept connections to port 22 (ssh) tcp dport ssh accept } }nftコマンドと同じ構文:#!/usr/sbin/nft -f # Flush the rule set flush ruleset # Create a table add table inet example_table # Create a chain for incoming packets that drops all packets # that are not explicitly allowed by any rule in this chain add chain inet example_table example_chain { type filter hook input priority 0 ; policy drop ; } # Add a rule that accepts connections to port 22 (ssh) add rule inet example_table example_chain tcp dport ssh accept
23.6.4.2. nftables スクリプトの実行
nftables スクリプトは、nft ユーティリティーに渡すか、スクリプトを直接実行することで実行できます。
手順
nftablesスクリプトをnftユーティリティーに渡して実行するには、次のコマンドを実行します。# nft -f /etc/nftables/<example_firewall_script>.nftnftablesスクリプトを直接実行するには、次のコマンドを実行します。1 回だけ実行する場合:
スクリプトが以下のシバンシーケンスで始まることを確認します。
#!/usr/sbin/nft -f重要-fパラメーターを省略すると、nftユーティリティーはスクリプトを読み込まず、Error: syntax error, unexpected newline, expecting stringのように表示されます。オプション: スクリプトの所有者を
rootに設定します。# chown root /etc/nftables/<example_firewall_script>.nft所有者のスクリプトを実行ファイルに変更します。
# chmod u+x /etc/nftables/<example_firewall_script>.nft
スクリプトを実行します。
# /etc/nftables/<example_firewall_script>.nft出力が表示されない場合は、システムがスクリプトを正常に実行します。
nft はスクリプトを正常に実行しますが、ルールの配置やパラメーター不足、またはスクリプト内のその他の問題により、ファイアウォールが期待通りの動作を起こさない可能性があります。
23.6.4.3. nftables スクリプトでコメントの使用
nftables スクリプト環境は、# 文字の右側から行末までのすべてをコメントとして解釈します。
コメントは、行の先頭またはコマンドの横から開始できます。
...
# Flush the rule set
flush ruleset
add table inet example_table # Create a table
...23.6.4.4. nftables スクリプトでの変数の使用
nftables スクリプトで変数を定義するには、define キーワードを使用します。シングル値および匿名セットを変数に保存できます。より複雑なシナリオの場合は、セットまたは決定マップを使用します。
- 値を 1 つ持つ変数
以下の例は、値が
enp1s0のINET_DEVという名前の変数を定義します。define INET_DEV = enp1s0スクリプトで変数を使用するには、
$記号と、それに続く変数名を指定します。... add rule inet example_table example_chain iifname $INET_DEV tcp dport ssh accept ...- 匿名セットを含む変数
以下の例では、匿名セットを含む変数を定義します。
define DNS_SERVERS = { 192.0.2.1, 192.0.2.2 }スクリプトで変数を使用するには、
$記号と、それに続く変数名を指定します。add rule inet example_table example_chain ip daddr $DNS_SERVERS accept注記中括弧は、変数がセットを表していることを示すため、ルールで使用する場合は、特別なセマンティクスを持ちます。
23.6.4.5. nftables スクリプトへのファイルの追加
nftables スクリプト環境では、include ステートメントを使用して他のスクリプトを含めることができます。
絶対パスまたは相対パスのないファイル名のみを指定すると、nftables には、デフォルトの検索パスのファイルが含まれます。これは、Red Hat Enterprise Linux では /etc に設定されています。
例23.1 デフォルト検索ディレクトリーからのファイルを含む
デフォルトの検索ディレクトリーからファイルを指定するには、次のコマンドを実行します。
include "example.nft"例23.2 ディレクトリーの *.nft ファイルをすべて含む
*.nft で終わるすべてのファイルを /etc/nftables/rulesets/ ディレクトリーに保存するには、次のコマンドを実行します。
include "/etc/nftables/rulesets/*.nft"
include ステートメントは、ドットで始まるファイルに一致しないことに注意してください。
23.6.4.6. システムの起動時に nftables ルールの自動読み込み
systemd サービス nftables は、/etc/sysconfig/nftables.conf ファイルに含まれるファイアウォールスクリプトを読み込みます。
前提条件
-
nftablesスクリプトは、/etc/nftables/ディレクトリーに保存されます。
手順
/etc/sysconfig/nftables.confファイルを編集します。-
nftablesパッケージのインストールで/etc/nftables/に作成された*.nftスクリプトを変更した場合は、これらのスクリプトのincludeステートメントのコメントを解除します。 新しいスクリプトを作成した場合は、
includeステートメントを追加してこれらのスクリプトを含めます。たとえば、nftablesサービスの起動時に/etc/nftables/example.nftスクリプトを読み込むには、以下を追加します。include "/etc/nftables/_example_.nft"
-
オプション:
nftablesサービスを開始して、システムを再起動せずにファイアウォールルールを読み込みます。# systemctl start nftablesnftablesサービスを有効にします。# systemctl enable nftables
23.6.5. nftables コマンドでのセットの使用
nftables フレームワークは、セットをネイティブに対応します。たとえば、ルールが複数の IP アドレス、ポート番号、インターフェイス、またはその他の一致基準に一致する必要がある場合など、セットを使用できます。
23.6.5.1. nftables での匿名セットの使用
匿名セットには、ルールで直接使用する { 22, 80, 443 } などの中括弧で囲まれたコンマ区切りの値が含まれます。IP アドレスやその他の一致基準にも匿名セットを使用できます。
匿名セットの欠点は、セットを変更する場合はルールを置き換える必要があることです。動的なソリューションの場合は、nftables で名前付きセットの使用 で説明されているように名前付きセットを使用します。
前提条件
-
inetファミリーにexample_chainチェーンおよびexample_tableテーブルがある。
手順
たとえば、ポート
22、80、および443に着信トラフィックを許可するルールを、example_tableのexample_chainに追加するには、次のコマンドを実行します。# nft add rule inet example_table example_chain tcp dport { 22, 80, 443 } acceptオプション:
example_table内のすべてのチェーンとそのルールを表示します。# nft list table inet example_table table inet example_table { chain example_chain { type filter hook input priority filter; policy accept; tcp dport { ssh, http, https } accept } }
23.6.5.2. nftables で名前付きセットの使用
nftables フレームワークは、変更可能な名前付きセットに対応します。名前付きセットは、テーブル内の複数のルールで使用できる要素のリストまたは範囲です。匿名セットに対する別の利点として、セットを使用するルールを置き換えることなく、名前付きセットを更新できます。
名前付きセットを作成する場合は、セットに含まれる要素のタイプを指定する必要があります。以下のタイプを設定できます。
-
192.0.2.1や192.0.2.0/24など、IPv4 アドレスまたは範囲を含むセットの場合はipv4_addr。 -
2001:db8:1::1や2001:db8:1::1/64など、IPv6 アドレスまたは範囲を含むセットの場合はipv6_addr。 -
52:54:00:6b:66:42など、メディアアクセス制御 (MAC) アドレスのリストを含むセットの場合はether_addr。 -
tcpなど、インターネットプロトコルタイプの一覧が含まれるセットの場合はinet_proto。 -
sshなど、インターネットサービスの一覧を含むセットの場合はinet_service。 -
パケットマークの一覧を含むセットの場合は
mark。パケットマークは、任意の 32 ビットの正の整数値 (0から2147483647) にすることができます。
前提条件
-
example_chainチェーンとexample_tableテーブルが存在する。
手順
空のファイルを作成します。以下の例では、IPv4 アドレスのセットを作成します。
複数の IPv4 アドレスを格納することができるセットを作成するには、次のコマンドを実行します。
# nft add set inet example_table example_set { type ipv4_addr \; }IPv4 アドレス範囲を保存できるセットを作成するには、次のコマンドを実行します。
# nft add set inet example_table example_set { type ipv4_addr \; flags interval \; }
重要シェルがセミコロンをコマンドの終わりとして解釈しないようにするには、バックスラッシュでセミコロンをエスケープする必要があります。
オプション: セットを使用するルールを作成します。たとえば、次のコマンドは、
example_setの IPv4 アドレスからのパケットをすべて破棄するルールを、example_tableのexample_chainに追加します。# nft add rule inet example_table example_chain ip saddr @example_set dropexample_setが空のままなので、ルールには現在影響がありません。IPv4 アドレスを
example_setに追加します。個々の IPv4 アドレスを保存するセットを作成する場合は、次のコマンドを実行します。
# nft add element inet example_table example_set { 192.0.2.1, 192.0.2.2 }IPv4 範囲を保存するセットを作成する場合は、次のコマンドを実行します。
# nft add element inet example_table example_set { 192.0.2.0-192.0.2.255 }IP アドレス範囲を指定する場合は、上記の例の
192.0.2.0/24のように、CIDR (Classless Inter-Domain Routing) 表記を使用することもできます。
23.6.5.3. 動的セットを使用してパケットパスからエントリーを追加する
nftables フレームワークの動的セットにより、パケットデータから要素を自動的に追加できます。たとえば、IP アドレス、宛先ポート、MAC アドレスなどです。この機能により、これらの要素をリアルタイムで収集し、それらを使用して拒否リスト、禁止リストなどを作成し、セキュリティーの脅威に即座に対応できるようになります。
前提条件
-
inetファミリーのexample_chainチェーンとexample_tableテーブルが存在します。
手順
空のファイルを作成します。以下の例では、IPv4 アドレスのセットを作成します。
複数の IPv4 アドレスを格納することができるセットを作成するには、次のコマンドを実行します。
# nft add set inet example_table example_set { type ipv4_addr \; }IPv4 アドレス範囲を保存できるセットを作成するには、次のコマンドを実行します。
# nft add set inet example_table example_set { type ipv4_addr \; flags interval \; }重要シェルがセミコロンをコマンドの終わりとして解釈しないようにするには、バックスラッシュでセミコロンをエスケープする必要があります。
着信パケットの送信元 IPv4 アドレスを
example_setセットに動的に追加するためのルールを作成します。# nft add rule inet example_table example_chain set add ip saddr @example_setこのコマンドは、
example_chainルールチェーンとexample_table内に新しいルールを作成し、パケットの送信元 IPv4 アドレスをexample_setに動的に追加します。
検証
ルールが追加されたことを確認します。
# nft list ruleset ... table ip example_table { set example_set { type ipv4_addr elements = { 192.0.2.250, 192.0.2.251 } } chain example_chain { type filter hook input priority 0 add @example_set { ip saddr } } }このコマンドは、現在
nftablesにロードされているルールセット全体を表示します。これは、IP がルールをアクティブにトリガーしており、example_set が関連するアドレスで更新されていることを示しています。
次のステップ
動的な IP セットを取得すると、さまざまなセキュリティー、フィルタリング、トラフィック制御の目的に使用できます。以下に例を示します。
- ネットワークトラフィックをブロック、制限、またはログに記録する
- 許可リストと組み合わせて、信頼できるユーザーのアクセスを禁止しないようにする
- 過剰なブロックを防ぐために自動タイムアウトを使用する
23.6.6. nftables コマンドにおける決定マップの使用
ディクショナリーとしても知られている決定マップにより、nft は一致基準をアクションにマッピングすることで、パケット情報に基づいてアクションを実行できます。
23.6.6.1. nftables での匿名マップの使用
匿名マップは、ルールで直接使用する { match_criteria : action } ステートメントです。ステートメントには、複数のコンマ区切りマッピングを含めることができます。
匿名マップの欠点は、マップを変更する場合には、ルールを置き換える必要があることです。動的なソリューションの場合は、nftables での名前付きマップの使用 で説明されているように名前付きマップを使用します。
たとえば、匿名マップを使用して、IPv4 プロトコルおよび IPv6 プロトコルの TCP パケットと UDP パケットの両方を異なるチェーンにルーティングし、着信 TCP パケットと UDP パケットを個別にカウントできます。
手順
新しいテーブルを作成します。
# nft add table inet example_tableexample_tableにtcp_packetsチェーンを作成します。# nft add chain inet example_table tcp_packetsこのチェーンのトラフィックをカウントする
tcp_packetsにルールを追加します。# nft add rule inet example_table tcp_packets counterexample_tableでudp_packetsチェーンを作成します。# nft add chain inet example_table udp_packetsこのチェーンのトラフィックをカウントする
udp_packetsにルールを追加します。# nft add rule inet example_table udp_packets counter着信トラフィックのチェーンを作成します。たとえば、
example_tableに、着信トラフィックをフィルタリングするincoming_trafficという名前のチェーンを作成するには、次のコマンドを実行します。# nft add chain inet example_table incoming_traffic { type filter hook input priority 0 \; }匿名マップを持つルールを
incoming_trafficに追加します。# nft add rule inet example_table incoming_traffic ip protocol vmap { tcp : jump tcp_packets, udp : jump udp_packets }匿名マップはパケットを区別し、プロトコルに基づいて別のカウンターチェーンに送信します。
トラフィックカウンターの一覧を表示する場合は、
example_tableを表示します。# nft list table inet example_table table inet example_table { chain tcp_packets { counter packets 36379 bytes 2103816 } chain udp_packets { counter packets 10 bytes 1559 } chain incoming_traffic { type filter hook input priority filter; policy accept; ip protocol vmap { tcp : jump tcp_packets, udp : jump udp_packets } } }tcp_packetsチェーンおよびudp_packetsチェーンのカウンターは、受信パケットとバイトの両方を表示します。
23.6.6.2. nftables での名前付きマップの使用
nftables フレームワークは、名前付きマップに対応します。テーブルの複数のルールでこのマップを使用できます。匿名マップに対する別の利点は、名前付きマップを使用するルールを置き換えることなく、名前付きマップを更新できることです。
名前付きマップを作成する場合は、要素のタイプを指定する必要があります。
-
一致する部分に
192.0.2.1などの IPv4 アドレスが含まれるマップの場合はipv4_addr。 -
一致する部分に
2001:db8:1::1などの IPv6 アドレスが含まれるマップの場合はipv6_addr。 -
52:54:00:6b:66:42などのメディアアクセス制御 (MAC) アドレスを含むマップの場合はether_addr。 -
一致する部分に
tcpなどのインターネットプロトコルタイプが含まれるマップの場合はinet_proto。 -
一致する部分に
sshや22などのインターネットサービス名のポート番号が含まれるマップの場合はinet_service。 -
一致する部分にパケットマークが含まれるマップの場合は
mark。パケットマークは、任意の正の 32 ビットの整数値 (0~2147483647) にできます。 -
一致する部分にカウンターの値が含まれるマップの場合は
counter。カウンター値は、正の値の 64 ビットであれば任意の値にすることができます。 -
一致する部分にクォータ値が含まれるマップの場合は
quota。クォータの値は、64 ビットの整数値にできます。
たとえば、送信元 IP アドレスに基づいて着信パケットを許可または拒否できます。名前付きマップを使用すると、このシナリオを設定するのに必要なルールは 1 つだけで、IP アドレスとアクションがマップに動的に保存されます。
手順
テーブルを作成します。たとえば、IPv4 パケットを処理する
example_tableという名前のテーブルを作成するには、次のコマンドを実行します。# nft add table ip example_tableチェーンを作成します。たとえば、
example_tableに、example_chainという名前のチェーンを作成するには、次のコマンドを実行します。# nft add chain ip example_table example_chain { type filter hook input priority 0 \; }重要シェルがセミコロンをコマンドの終わりとして解釈しないようにするには、バックスラッシュでセミコロンをエスケープする必要があります。
空のマップを作成します。たとえば、IPv4 アドレスのマッピングを作成するには、次のコマンドを実行します。
# nft add map ip example_table example_map { type ipv4_addr : verdict \; }マップを使用するルールを作成します。たとえば、次のコマンドは、両方とも
example_mapで定義されている IPv4 アドレスにアクションを適用するルールを、example_tableのexample_chainに追加します。# nft add rule example_table example_chain ip saddr vmap @example_mapIPv4 アドレスと対応するアクションを
example_mapに追加します。# nft add element ip example_table example_map { 192.0.2.1 : accept, 192.0.2.2 : drop }以下の例では、IPv4 アドレスのアクションへのマッピングを定義します。上記で作成したルールと組み合わせて、ファイアウォールは
192.0.2.1からのパケットを許可し、192.0.2.2からのパケットを破棄します。オプション:別の IP アドレスおよび action ステートメントを追加してマップを拡張します。
# nft add element ip example_table example_map { 192.0.2.3 : accept }オプション:マップからエントリーを削除します。
# nft delete element ip example_table example_map { 192.0.2.1 }オプション:ルールセットを表示します。
# nft list ruleset table ip example_table { map example_map { type ipv4_addr : verdict elements = { 192.0.2.2 : drop, 192.0.2.3 : accept } } chain example_chain { type filter hook input priority filter; policy accept; ip saddr vmap @example_map } }
23.6.7. 以下に例を示します。nftables スクリプトを使用した LAN および DMZ の保護
RHEL ルーターで nftables フレームワークを使用して、内部 LAN 内のネットワーククライアントと DMZ の Web サーバーを、インターネットやその他のネットワークからの不正アクセスから保護するファイアウォールスクリプトを作成およびインストールします。
この例はデモ目的専用で、特定の要件があるシナリオを説明しています。
ファイアウォールスクリプトは、ネットワークインフラストラクチャーとセキュリティー要件に大きく依存します。この例を使用して、独自の環境用のスクリプトを作成する際に nftables ファイアウォールの概念を理解してください。
23.6.7.1. ネットワークの状態
この例のネットワークは、以下の条件下にあります。
ルーターは以下のネットワークに接続されています。
-
インターフェイス
enp1s0を介したインターネット -
インターフェイス
enp7s0を介した内部 LAN -
enp8s0までの DMZ
-
インターフェイス
-
ルーターのインターネットインターフェイスには、静的 IPv4 アドレス (
203.0.113.1) と IPv6 アドレス (2001:db8:a::1) の両方が割り当てられています。 -
内部 LAN のクライアントは
10.0.0.0/24の範囲のプライベート IPv4 アドレスのみを使用します。その結果、LAN からインターネットへのトラフィックには、送信元ネットワークアドレス変換 (SNAT) が必要です。 -
内部 LAN の管理者用 PC は、IP アドレス
10.0.0.100および10.0.0.200を使用します。 -
DMZ は、
198.51.100.0/24および2001:db8:b::/56の範囲のパブリック IP アドレスを使用します。 -
DMZ の Web サーバーは、IP アドレス
198.51.100.5および2001:db8:b::5を使用します。 - ルーターは、LAN および DMZ 内のホストのキャッシング DNS サーバーとして機能します。
23.6.7.2. ファイアウォールスクリプトのセキュリティー要件
以下は、サンプルネットワークにおける nftables ファイアウォールの要件です。
ルーターは以下を実行できる必要があります。
- DNS クエリーを再帰的に解決します。
- ループバックインターフェイスですべての接続を実行します。
内部 LAN のクライアントは以下を実行できる必要があります。
- ルーターで実行しているキャッシング DNS サーバーをクエリーします。
- DMZ の HTTPS サーバーにアクセスします。
- インターネット上の任意の HTTPS サーバーにアクセスします。
- 管理者用の PC は、SSH を使用してルーターと DMZ 内のすべてのサーバーにアクセスできる必要があります。
DMZ の Web サーバーは以下を実行できる必要があります。
- ルーターで実行しているキャッシング DNS サーバーをクエリーします。
- インターネット上の HTTPS サーバーにアクセスして更新をダウンロードします。
インターネット上のホストは以下を実行できる必要があります。
- DMZ の HTTPS サーバーにアクセスします。
さらに、以下のセキュリティー要件が存在します。
- 明示的に許可されていない接続の試行はドロップする必要があります。
- ドロップされたパケットはログに記録する必要があります。
23.6.7.3. ドロップされたパケットをファイルにロギングするための設定
デフォルトでは、systemd は、ドロップされたパケットなどのカーネルメッセージをジャーナルに記録します。さらに、このようなエントリーを別のファイルに記録するように rsyslog サービスを設定することもできます。ログファイルが無限に大きくならないようにするために、ローテーションポリシーを設定します。
前提条件
-
rsyslogパッケージがインストールされている。 -
rsyslogサービスが実行されている。
手順
以下の内容で
/etc/rsyslog.d/nftables.confファイルを作成します。:msg, startswith, "nft drop" -/var/log/nftables.log & stopこの設定を使用すると、
rsyslogサービスはドロップされたパケットを/var/log/messagesではなく/var/log/nftables.logファイルに記録します。rsyslogサービスを再起動します。# systemctl restart rsyslogサイズが 10 MB を超える場合は、以下の内容で
/etc/logrotate.d/nftablesファイルを作成し、/var/log/nftables.logをローテーションします。/var/log/nftables.log { size +10M maxage 30 sharedscripts postrotate /usr/bin/systemctl kill -s HUP rsyslog.service >/dev/null 2>&1 || true endscript }maxage 30設定は、次のローテーション操作中にlogrotateが 30 日経過したローテーション済みログを削除することを定義します。
23.6.7.4. nftables スクリプトの作成とアクティブ化
この例は、RHEL ルーターで実行され、DMZ の内部 LAN および Web サーバーのクライアントを保護する nftables ファイアウォールスクリプトです。この例で使用されているネットワークとファイアウォールの要件の詳細は、ファイアウォールスクリプトの ネットワークの状態 および ファイアウォールスクリプトのセキュリティー要件 を参照してください。
この nftables ファイアウォールスクリプトは、デモ専用です。お使いの環境やセキュリティー要件に適応させて使用してください。
前提条件
- ネットワークは、ネットワークの状態 で説明されているとおりに設定されます。
手順
以下の内容で
/etc/nftables/firewall.nftスクリプトを作成します。# Remove all rules flush ruleset # Table for both IPv4 and IPv6 rules table inet nftables_svc { # Define variables for the interface name define INET_DEV = enp1s0 define LAN_DEV = enp7s0 define DMZ_DEV = enp8s0 # Set with the IPv4 addresses of admin PCs set admin_pc_ipv4 { type ipv4_addr elements = { 10.0.0.100, 10.0.0.200 } } # Chain for incoming trafic. Default policy: drop chain INPUT { type filter hook input priority filter policy drop # Accept packets in established and related state, drop invalid packets ct state vmap { established:accept, related:accept, invalid:drop } # Accept incoming traffic on loopback interface iifname lo accept # Allow request from LAN and DMZ to local DNS server iifname { $LAN_DEV, $DMZ_DEV } meta l4proto { tcp, udp } th dport 53 accept # Allow admins PCs to access the router using SSH iifname $LAN_DEV ip saddr @admin_pc_ipv4 tcp dport 22 accept # Last action: Log blocked packets # (packets that were not accepted in previous rules in this chain) log prefix "nft drop IN : " } # Chain for outgoing traffic. Default policy: drop chain OUTPUT { type filter hook output priority filter policy drop # Accept packets in established and related state, drop invalid packets ct state vmap { established:accept, related:accept, invalid:drop } # Accept outgoing traffic on loopback interface oifname lo accept # Allow local DNS server to recursively resolve queries oifname $INET_DEV meta l4proto { tcp, udp } th dport 53 accept # Last action: Log blocked packets log prefix "nft drop OUT: " } # Chain for forwarding traffic. Default policy: drop chain FORWARD { type filter hook forward priority filter policy drop # Accept packets in established and related state, drop invalid packets ct state vmap { established:accept, related:accept, invalid:drop } # IPv4 access from LAN and internet to the HTTPS server in the DMZ iifname { $LAN_DEV, $INET_DEV } oifname $DMZ_DEV ip daddr 198.51.100.5 tcp dport 443 accept # IPv6 access from internet to the HTTPS server in the DMZ iifname $INET_DEV oifname $DMZ_DEV ip6 daddr 2001:db8:b::5 tcp dport 443 accept # Access from LAN and DMZ to HTTPS servers on the internet iifname { $LAN_DEV, $DMZ_DEV } oifname $INET_DEV tcp dport 443 accept # Last action: Log blocked packets log prefix "nft drop FWD: " } # Postrouting chain to handle SNAT chain postrouting { type nat hook postrouting priority srcnat; policy accept; # SNAT for IPv4 traffic from LAN to internet iifname $LAN_DEV oifname $INET_DEV snat ip to 203.0.113.1 } }/etc/nftables/firewall.nftスクリプトを/etc/sysconfig/nftables.confファイルに追加します。include "/etc/nftables/firewall.nft"IPv4 転送を有効にします。
# echo "net.ipv4.ip_forward=1" > /etc/sysctl.d/95-IPv4-forwarding.conf # sysctl -p /etc/sysctl.d/95-IPv4-forwarding.confnftablesサービスを有効にして起動します。# systemctl enable --now nftables
検証
オプション:
nftablesルールセットを確認します。# nft list ruleset ...ファイアウォールが阻止するアクセスの実行を試みます。たとえば、DMZ から SSH を使用してルーターにアクセスします。
# ssh router.example.com ssh: connect to host router.example.com port 22: Network is unreachableロギング設定に応じて、以下を検索します。
ブロックされたパケットの
systemdジャーナル:# journalctl -k -g "nft drop" Oct 14 17:27:18 router kernel: nft drop IN : IN=enp8s0 OUT= MAC=... SRC=198.51.100.5 DST=198.51.100.1 ... PROTO=TCP SPT=40464 DPT=22 ... SYN ...ブロックされたパケットの
/var/log/nftables.logファイル:Oct 14 17:27:18 router kernel: nft drop IN : IN=enp8s0 OUT= MAC=... SRC=198.51.100.5 DST=198.51.100.1 ... PROTO=TCP SPT=40464 DPT=22 ... SYN ...
23.6.8. nftables を使用した接続の量の制限
nftables を使用して、接続の数を制限したり、一定の数の接続の確立を試みる IP アドレスをブロックして、システムリソースを過剰に使用されないようにします。
23.6.8.1. nftables を使用した接続数の制限
nft ユーティリティーの ct count パラメーターを使用すると、IP アドレスごとの同時接続数を制限できます。たとえば、この機能を使用すると、各送信元 IP アドレスがホストへの並列 SSH 接続を 2 つだけ確立できるように設定できます。
手順
inetアドレスファミリーを使用してfilterテーブルを作成します。# nft add table inet filterinputチェーンをinet filterテーブルに追加します。# nft add chain inet filter input { type filter hook input priority 0 \; }IPv4 アドレスの動的セットを作成します。
# nft add set inet filter limit-ssh { type ipv4_addr\; flags dynamic \;}IPv4 アドレスからの SSH ポート (22) への同時着信接続を 2 つだけ許可し、同じ IP からのそれ以降の接続をすべて拒否するルールを、
inputチェーンに追加します。# nft add rule inet filter input tcp dport ssh ct state new add @limit-ssh { ip saddr ct count over 2 } counter reject
検証
- 同じ IP アドレスからホストへの新しい同時 SSH 接続を 2 つ以上確立します。すでに 2 つの接続が確立されている場合、Nftables が SSH ポートへの接続を拒否します。
limit-sshダイナミックセットを表示します。# nft list set inet filter limit-ssh table inet filter { set limit-ssh { type ipv4_addr size 65535 flags dynamic elements = { 192.0.2.1 ct count over 2 , 192.0.2.2 ct count over 2 } } }elementsエントリーは、現時点でルールに一致するアドレスを表示します。この例では、elementsは、SSH ポートへのアクティブな接続がある IP アドレスを一覧表示します。出力には、アクティブな接続の数を表示しないため、接続が拒否された場合は表示されないことに注意してください。
23.6.8.2. 1 分以内に新しい着信 TCP 接続を 11 個以上試行する IP アドレスのブロック
1 分以内に 11 個以上の IPv4 TCP 接続を確立しているホストを一時的にブロックできます。
手順
ipアドレスファミリーを使用してfilterテーブルを作成します。# nft add table ip filterinputチェーンをfilterテーブルに追加します。# nft add chain ip filter input { type filter hook input priority 0 \; }1 分以内に 10 を超える TCP 接続を確立しようとするソースアドレスからのすべてのパケットを破棄するルールを追加します。
# nft add rule ip filter input ip protocol tcp ct state new, untracked meter ratemeter { ip saddr timeout 5m limit rate over 10/minute } droptimeout 5mパラメーターは、nftablesが、メーターが古いエントリーで一杯にならないように、5 分後にエントリーを自動的に削除することを定義します。
検証
メーターのコンテンツを表示するには、以下のコマンドを実行します。
# nft list meter ip filter ratemeter table ip filter { meter ratemeter { type ipv4_addr size 65535 flags dynamic,timeout elements = { 192.0.2.1 limit rate over 10/minute timeout 5m expires 4m58s224ms } } }
23.6.9. nftables ルールのデバッグ
nftables フレームワークは、管理者がルールをデバッグし、パケットがそれに一致するかどうかを確認するためのさまざまなオプションを提供します。
23.6.9.1. カウンターによるルールの作成
ルールが一致しているかどうかを確認するには、カウンターを使用できます。
-
既存のルールにカウンターを追加する手順の詳細は、
Configuring and managing networkingの Adding a counter to an existing rule を参照してください。
前提条件
- ルールを追加するチェーンが存在する。
手順
counterパラメーターで新しいルールをチェーンに追加します。以下の例では、ポート 22 で TCP トラフィックを許可し、このルールに一致するパケットとトラフィックをカウントするカウンターを使用するルールを追加します。# nft add rule inet example_table example_chain tcp dport 22 counter acceptカウンター値を表示するには、次のコマンドを実行します。
# nft list ruleset table inet example_table { chain example_chain { type filter hook input priority filter; policy accept; tcp dport ssh counter packets 6872 bytes 105448565 accept } }
23.6.9.2. 既存のルールへのカウンターの追加
ルールが一致しているかどうかを確認するには、カウンターを使用できます。
-
カウンターで新しいルールを追加する手順の詳細は、
Configuring and managing networkingの Creating a rule with the counter を参照してください。
前提条件
- カウンターを追加するルールがある。
手順
チェーンのルール (ハンドルを含む) を表示します。
# nft --handle list chain inet example_table example_chain table inet example_table { chain example_chain { # handle 1 type filter hook input priority filter; policy accept; tcp dport ssh accept # handle 4 } }ルールの代わりに、
counterパラメーターを使用してカウンターを追加します。以下の例は、前の手順で表示したルールの代わりに、カウンターを追加します。# nft replace rule inet example_table example_chain handle 4 tcp dport 22 counter acceptカウンター値を表示するには、次のコマンドを実行します。
# nft list ruleset table inet example_table { chain example_chain { type filter hook input priority filter; policy accept; tcp dport ssh counter packets 6872 bytes 105448565 accept } }
23.6.9.3. 既存のルールに一致するパケットの監視
nftables のトレース機能と、nft monitor コマンドを組み合わせることにより、管理者はルールに一致するパケットを表示できます。このルールに一致するパケットを監視するために、ルールのトレースを有効にできます。
前提条件
- カウンターを追加するルールがある。
手順
チェーンのルール (ハンドルを含む) を表示します。
# nft --handle list chain inet example_table example_chain table inet example_table { chain example_chain { # handle 1 type filter hook input priority filter; policy accept; tcp dport ssh accept # handle 4 } }ルールを置き換えてトレース機能を追加しますが、
meta nftrace set 1パラメーターを使用します。以下の例は、前の手順で表示したルールの代わりに、トレースを有効にします。# nft replace rule inet example_table example_chain handle 4 tcp dport 22 meta nftrace set 1 acceptnft monitorコマンドを使用して、トレースを表示します。以下の例は、コマンドの出力をフィルタリングして、inet example_table example_chainが含まれるエントリーのみを表示します。# nft monitor | grep "inet example_table example_chain" trace id 3c5eb15e inet example_table example_chain packet: iif "enp1s0" ether saddr 52:54:00:17:ff:e4 ether daddr 52:54:00:72:2f:6e ip saddr 192.0.2.1 ip daddr 192.0.2.2 ip dscp cs0 ip ecn not-ect ip ttl 64 ip id 49710 ip protocol tcp ip length 60 tcp sport 56728 tcp dport ssh tcp flags == syn tcp window 64240 trace id 3c5eb15e inet example_table example_chain rule tcp dport ssh nftrace set 1 accept (verdict accept) ...警告nft monitorコマンドは、トレースが有効になっているルールの数と、一致するトラフィックの量に応じて、大量の出力を表示できます。grepなどのユーティリティーを使用して出力をフィルタリングします。
23.6.10. nftables ルールセットのバックアップおよび復元
nftables ルールをファイルにバックアップし、後で復元できます。また、管理者はルールが含まれるファイルを使用して、たとえばルールを別のサーバーに転送できます。
23.6.10.1. ファイルへの nftables ルールセットのバックアップ
nft ユーティリティーを使用して、nftables ルールセットをファイルにバックアップできます。
手順
nftablesルールのバックアップを作成するには、次のコマンドを実行します。nft list ruleset形式で生成された形式の場合:# nft list ruleset > file.nftJSON 形式の場合は、以下のようになります。
# nft -j list ruleset > file.json
23.6.10.2. ファイルからの nftables ルールセットの復元
ファイルから nftables ルールセットを復元できます。
手順
nftablesルールを復元するには、以下を行います。復元するファイルが、
nft list rulesetが生成した形式であるか、nftコマンドを直接含んでいる場合は、以下のコマンドを実行します。# nft -f file.nft復元するファイルが JSON 形式の場合は、次のコマンドを実行します。
# nft -j -f file.json
パート IV. ハードディスクの設計
第24章 利用可能なファイルシステムの概要
利用可能な選択肢と、関連するトレードオフが多数あるため、アプリケーションに適したファイルシステムを選択することが重要になります。
次のセクションでは、Red Hat Enterprise Linux 8 にデフォルトで含まれるファイルシステムと、アプリケーションに最適なファイルシステムに関する推奨事項について説明します。
24.1. ファイルシステムの種類
Red Hat Enterprise Linux 8 は、さまざまなファイルシステム (FS) に対応します。さまざまな種類のファイルシステムがさまざまな問題を解決し、その使用はアプリケーションによって異なります。最も一般的なレベルでは、利用可能なファイルシステムを以下の主要なタイプにまとめることができます。
| タイプ | ファイルシステム | 属性とユースケース |
|---|---|---|
| ディスクまたはローカルのファイルシステム | XFS | XFS は、RHEL におけるデフォルトファイルシステムです。Red Hat は、互換性や、パフォーマンスおいて稀に発生する難しい問題などの特別な理由がない限り、XFS をローカルファイルシステムとしてデプロイすることを推奨します。 |
| ext4 | 従来の ext2 および ext3 ファイルシステムから進化した ext4 には、Linux で馴染みやすいという利点があります。多くの場合、パフォーマンスでは XFS に匹敵します。ext4 ファイルシステムとファイルサイズのサポート制限は、XFS よりも小さくなっています。 | |
| ネットワーク、またはクライアント/サーバーのファイルシステム | NFS | NFS は、同じネットワークにある複数のシステムでのファイル共有に使用します。 |
| SMB | SMB は、Microsoft Windows システムとのファイル共有に使用します。 | |
| 共有ストレージまたは共有ディスクのファイルシステム | GFS2 | GFS2 は、コンピュートクラスターのメンバーに共有書き込みアクセスを提供します。可能な限り、ローカルファイルシステムの機能的経験を備えた安定性と信頼性に重点が置かれています。SAS Grid、Tibco MQ、IBM Websphere MQ、および Red Hat Active MQ は、GFS2 に問題なくデプロイされています。 |
| ボリューム管理ファイルシステム | Stratis (テクノロジープレビュー) | Stratis は、XFS と LVM を組み合わせて構築されたボリュームマネージャーです。Stratis の目的は、Btrfs や ZFS などのボリューム管理ファイルシステムにより提供される機能をエミュレートすることです。このスタックを手動で構築することは可能ですが、Stratis は設定の複雑さを軽減し、ベストプラクティスを実装し、エラー情報を統合します。 |
24.2. ローカルファイルシステム
ローカルファイルシステムは、1 台のローカルサーバーで実行し、ストレージに直接接続されているファイルシステムです。
たとえば、ローカルファイルシステムは、内部 SATA ディスクまたは SAS ディスクにおける唯一の選択肢であり、ローカルドライブを備えた内蔵ハードウェア RAID コントローラーがサーバーにある場合に使用されます。ローカルファイルシステムは、SAN にエクスポートされたデバイスが共有されていない場合に、SAN が接続したストレージに最もよく使用されているファイルシステムです。
ローカルファイルシステムはすべて POSIX に準拠しており、サポートされているすべての Red Hat Enterprise Linux リリースと完全に互換性があります。POSIX 準拠のファイルシステムは、read()、write()、seek() など、明確に定義されたシステムコールのセットに対応します。
ファイルシステムの選択肢を検討するときは、必要なファイルシステムのサイズ、必要な固有の機能、実際の作業負荷下でのパフォーマンスに基づいてファイルシステムを選択してください。
- 利用可能なローカルファイルシステム
- XFS
- ext4
24.3. XFS ファイルシステム
XFS は、拡張性が高く、高性能で堅牢な、成熟した 64 ビットのジャーナリングファイルシステムで、1 台のホストで非常に大きなファイルおよびファイルシステムに対応します。Red Hat Enterprise Linux 8 ではデフォルトのファイルシステムになります。XFS は、元々 1990 年代の前半に SGI により開発され、極めて大規模なサーバーおよびストレージアレイで実行されてきた長い歴史があります。
XFS の機能は次のとおりです。
- 信頼性
- メタデータジャーナリング - システムの再起動時、およびファイルシステムの再マウント時に再生できるファイルシステム操作の記録を保持することで、システムクラッシュ後のファイルシステムの整合性を確保します。
- 広範囲に及ぶランタイムメタデータの整合性チェック
- 拡張性が高く、高速な修復ユーティリティー
- クォータジャーナリングクラッシュ後に行なわれる、時間がかかるクォータの整合性チェックが不要になります。
- スケーラビリティーおよびパフォーマンス
- 対応するファイルシステムのサイズが最大 1024 TiB
- 多数の同時操作に対応する機能
- 空き領域管理のスケーラビリティーに関する B-Tree インデックス
- 高度なメタデータ先読みアルゴリズム
- ストリーミングビデオのワークロードの最適化
- 割り当てスキーム
- エクステント (領域) ベースの割り当て
- ストライプを認識できる割り当てポリシー
- 遅延割り当て
- 領域の事前割り当て
- 動的に割り当てられる inode
- その他の機能
- Reflink ベースのファイルのコピー
- 密接に統合されたバックアップおよび復元のユーティリティー
- オンラインのデフラグ
- オンラインのファイルシステム拡張
- 包括的な診断機能
-
拡張属性 (
xattr)。これにより、システムが、ファイルごとに、名前と値の組み合わせを追加で関連付けられるようになります。 - プロジェクトまたはディレクトリーのクォータ。ディレクトリーツリー全体にクォータ制限を適用できます。
- サブセカンド (一秒未満) のタイムスタンプ
パフォーマンスの特徴
XFS は、エンタープライズレベルのワークロードがある大規模なシステムで優れたパフォーマンスを発揮します。大規模なシステムとは、相対的に CPU 数が多く、さらには複数の HBA、および外部ディスクアレイへの接続を備えたシステムです。XFS は、マルチスレッドの並列 I/O ワークロードを備えた小規模のシステムでも適切に実行します。
XFS は、シングルスレッドで、メタデータ集約型のワークロードのパフォーマンスが比較的低くなります。たとえば、シングルスレッドで小さなファイルを多数作成し、削除するワークロードがこれに当てはまります。
24.4. ext4 ファイルシステム
ext4 ファイルシステムは、ext ファイルシステムファミリーの第 4 世代です。これは、Red Hat Enterprise Linux 6 でデフォルトのファイルシステムです。
ext4 ドライバーは、ext2 および ext3 のファイルシステムの読み取りと書き込みが可能ですが、ext4 ファイルシステムのフォーマットは、ext2 ドライバーおよび ext3 ドライバーと互換性がありません。
ext4 には、以下のような新機能、および改善された機能が追加されました。
- 対応するファイルシステムのサイズが最大 50 TiB
- エクステントベースのメタデータ
- 遅延割り当て
- ジャーナルのチェックサム
- 大規模なストレージサポート
エクステントベースのメタデータと遅延割り当て機能は、ファイルシステムで使用されている領域を追跡する、よりコンパクトで効率的な方法を提供します。このような機能により、ファイルシステムのパフォーマンスが向上し、メタデータが使用する領域が低減します。遅延割り当てにより、ファイルシステムは、データがディスクにフラッシュされるまで、新しく書き込まれたユーザーデータの永続的な場所の選択を保留できます。これにより、より大きく、より連続した割り当てが可能になり、より優れた情報に基づいてファイルシステムが決定を下すことができるため、パフォーマンスが向上します。
ext4 で fsck ユーティリティーを使用するファイルシステムの修復時間は、ext2 と ext3 よりも高速です。一部のファイルシステムの修復では、最大 6 倍のパフォーマンスの向上が実証されています。
24.5. XFS と ext4 の比較
XFS は、RHEL におけるデフォルトファイルシステムです。このセクションでは、XFS および ext4 の使用方法と機能を比較します。
- メタデータエラーの動作
-
ext4 では、ファイルシステムがメタデータのエラーに遭遇した場合の動作を設定できます。デフォルトの動作では、操作を継続します。XFS が復旧できないメタデータエラーに遭遇すると、ファイルシステムをシャットダウンし、
EFSCORRUPTEDエラーを返します。 - クォータ
ext4 では、既存のファイルシステムにファイルシステムを作成する場合にクォータを有効にできます。次に、マウントオプションを使用してクォータの適用を設定できます。
XFS クォータは再マウントできるオプションではありません。初期マウントでクォータをアクティブにする必要があります。
XFS ファイルシステムで
quotacheckコマンドを実行すると影響しません。クォータアカウンティングを初めてオンにすると、XFS はクォータを自動的にチェックします。- ファイルシステムのサイズ変更
- XFS には、ファイルシステムのサイズを縮小するユーティリティーがありません。XFS ファイルシステムのサイズのみを増やすことができます。ext4 は、ファイルシステムの拡張と縮小の両方をサポートします。
- Inode 番号
ext4 ファイルシステムは、232 個を超える inode をサポートしません。
XFS は動的な inode 割り当てをサポートしています。XFS ファイルシステム上で inode が消費できる領域の量は、ファイルシステムの合計領域のパーセンテージとして計算されます。管理者は、システムの inode が不足するのを防ぐために、ファイルシステムの作成後にこのパーセンテージを調整できます (ファイルシステムに空き領域が残っている場合)。
特定のアプリケーションは、XFS ファイルシステムで 232 個を超える inode を適切に処理できません。このようなアプリケーションでは、戻り値
EOVERFLOWで 32 ビットの統計呼び出しに失敗する可能性があります。Inode 番号は、以下の条件下で 232 個を超えます。- ファイルシステムが 256 バイトの inode を持つ 1 TiB を超える。
- ファイルシステムが 512 バイトの inode を持つ 2 TiB を超える。
inode 番号が大きくてアプリケーションが失敗した場合は、
-o inode32オプションを使用して XFS ファイルシステムをマウントし、232 未満の inode 番号を実施します。inode32を使用しても、すでに 64 ビットの数値が割り当てられている inode には影響しません。重要特定の環境に必要な場合を除き、
inode32オプションは 使用しない でください。inode32オプションは割り当ての動作を変更します。これにより、下層のディスクブロックに inode を割り当てるための領域がない場合に、ENOSPCエラーが発生する可能性があります。
24.6. ローカルファイルシステムの選択
アプリケーション要件を満たすファイルシステムを選択するには、ファイルシステムをデプロイするターゲットシステムを理解する必要があります。一般的には、ext4 を特定の用途で使用する場合を除き、XFS を使用してください。
- XFS
- 大規模なデプロイメントの場合、特に大きなファイル (数百メガバイト) や大量の I/O 並行処理を扱う場合は、XFS を使用します。XFS は、高帯域幅 (200 MB/秒以上) および 1000 IOPS を超える環境で最適に動作します。ただし、ext4 と比較してメタデータ操作に多くの CPU リソースを消費します。また、ファイルシステムの縮小をサポートしていません。
- ext4
- 小規模なシステムや I/O 帯域幅が制限されている環境では、ext4 のほうが適している可能性があります。シングルスレッド、少量の I/O ワークロード、およびスループット要件が低い環境の場合は、パフォーマンスが向上します。また、ext4 はオフラインの縮小をサポートしています。これはファイルシステムのサイズ変更が必要な場合に役立ちます。
ターゲットサーバーとストレージシステムでアプリケーションのパフォーマンスをベンチマークし、選択したファイルシステムがパフォーマンスとスケーラビリティーの要件を満たしていることを確認してください。
| シナリオ | 推奨されるファイルシステム |
|---|---|
| 特別なユースケースなし | XFS |
| 大規模サーバー | XFS |
| 大規模なストレージデバイス | XFS |
| 大規模なファイル | XFS |
| マルチスレッド I/O | XFS |
| シングルスレッド I/O | ext4 |
| 制限された I/O 機能 (1000 IOPS 未満) | ext4 |
| 制限された帯域幅 (200MB/s 未満) | ext4 |
| CPU にバインドされているワークロード | ext4 |
| オフラインの縮小への対応 | ext4 |
24.7. ネットワークファイルシステム
クライアント/サーバーファイルシステムとも呼ばれるネットワークファイルシステムにより、クライアントシステムは、共有サーバーに保存されているファイルにアクセスできます。これにより、複数のシステムの、複数のユーザーが、ファイルやストレージリソースを共有できます。
このようなファイルシステムは、ファイルシステムのセットを 1 つ以上のクライアントにエクスポートする、1 つ以上のサーバーから構築されます。クライアントノードは、基盤となるブロックストレージにアクセスできませんが、より良いアクセス制御を可能にするプロトコルを使用してストレージと対話します。
- 利用可能なネットワークファイルシステム
- RHEL で最も一般的なクライアント/サーバーファイルシステムは、NFS ファイルシステムです。RHEL は、ネットワーク経由でローカルファイルシステムをエクスポートする NFS サーバーコンポーネントと、このようなファイルシステムをインポートする NFS クライアントの両方を提供します。
- RHEL には、Windows の相互運用性で一般的に使用されている Microsoft SMB ファイルサーバーに対応する CIFS クライアントも含まれています。ユーザー空間 Samba サーバーは、RHEL サーバーから Microsoft SMB サービスを使用する Windows クライアントを提供します。
24.10. ボリューム管理ファイルシステム
ボリューム管理ファイルシステムは、簡素化とスタック内の最適化の目的で、ストレージスタック全体を統合します。
- 利用可能なボリューム管理ファイルシステム
- Red Hat Enterprise Linux 8 は、Stratis ボリュームマネージャーがテクノロジープレビューとして提供します。Stratis は、ファイルシステム層に XFS を使用し、LVM、Device Mapper、およびその他のコンポーネントと統合します。
Stratis は、Red Hat Enterprise Linux 8.0 で初めてリリースされました。Red Hat が Btrfs を非推奨にした時に生じたギップを埋めると考えられています。Stratis 1.0 は、ユーザーによる複雑さを隠しつつ、重要なストレージ管理操作を実行できる直感的なコマンドラインベースのボリュームマネージャーです。
- ボリュームの管理
- プールの作成
- シンストレージプール
- スナップショット
- 自動化読み取りキャッシュ
Stratis は強力な機能を提供しますが、現時点では Btrfs や ZFS といったその他の製品と比較される可能性がある機能をいつくか欠いています。たとえば、セルフ修復を含む CRC には対応していません。
第26章 永続的な命名属性の概要
システム管理者は、永続的な命名属性を使用してストレージボリュームを参照し、再起動を何度も行っても信頼できるストレージ設定を構築する必要があります。
26.1. 非永続的な命名属性のデメリット
Red Hat Enterprise Linux では、ストレージデバイスを識別する方法が複数あります。特にドライブへのインストール時やドライブの再フォーマット時に誤ったデバイスにアクセスしないようにするため、適切なオプションを使用して各デバイスを識別することが重要になります。
従来、/dev/sd(メジャー番号)(マイナー番号) の形式の非永続的な名前は、ストレージデバイスを参照するために Linux 上で使用されます。メジャー番号とマイナー番号の範囲、および関連する sd 名は、検出されると各デバイスに割り当てられます。つまり、デバイスの検出順序が変わると、メジャー番号とマイナー番号の範囲、および関連する sd 名の関連付けが変わる可能性があります。
このような順序の変更は、以下の状況で発生する可能性があります。
- システム起動プロセスの並列化により、システム起動ごとに異なる順序でストレージデバイスが検出された場合。
-
ディスクが起動しなかったり、SCSI コントローラーに応答しなかった場合。この場合は、通常のデバイスプローブにより検出されません。ディスクはシステムにアクセスできなくなり、後続のデバイスは関連する次の
sd名が含まれる、メジャー番号およびマイナー番号の範囲があります。たとえば、通常sdbと呼ばれるディスクが検出されないと、sdcと呼ばれるディスクがsdbとして代わりに表示されます。 -
SCSI コントローラー (ホストバスアダプターまたは HBA) が初期化に失敗し、その HBA に接続されているすべてのディスクが検出されなかった場合。後続のプローブされた HBA に接続しているディスクは、別のメジャー番号およびマイナー番号の範囲、および関連する別の
sd名が割り当てられます。 - システムに異なるタイプの HBA が存在する場合は、ドライバー初期化の順序が変更する可能性があります。これにより、HBA に接続されているディスクが異なる順序で検出される可能性があります。また、HBA がシステムの他の PCI スロットに移動した場合でも発生する可能性があります。
-
ストレージアレイや干渉するスイッチの電源が切れた場合など、ストレージデバイスがプローブされたときに、ファイバーチャネル、iSCSI、または FCoE アダプターを持つシステムに接続されたディスクがアクセスできなくなる可能性があります。システムが起動するまでの時間よりもストレージアレイがオンラインになるまでの時間の方が長い場合に、電源の障害後にシステムが再起動すると、この問題が発生する可能性があります。一部のファイバーチャネルドライバーは WWPN マッピングへの永続 SCSI ターゲット ID を指定するメカニズムをサポートしますが、メジャー番号およびマイナー番号の範囲や関連する
sd名は予約されず、一貫性のある SCSI ターゲット ID 番号のみが提供されます。
そのため、/etc/fstab ファイルなどにあるデバイスを参照するときにメジャー番号およびマイナー番号の範囲や関連する sd 名を使用することは望ましくありません。誤ったデバイスがマウントされ、データが破損する可能性があります。
しかし、場合によっては他のメカニズムが使用される場合でも sd 名の参照が必要になる場合もあります (デバイスによりエラーが報告される場合など)。これは、Linux カーネルはデバイスに関するカーネルメッセージで sd 名 (および SCSI ホスト、チャネル、ターゲット、LUN タプル) を使用するためです。
26.2. ファイルシステムおよびデバイスの識別子
ファイルシステムの識別子は、ファイルシステム自体に関連付けられます。一方、デバイスの識別子は、物理ブロックデバイスに紐付けられます。適切なストレージ管理を行うには、その違いを理解することが重要です。
ファイルシステムの識別子
ファイルシステムの識別子は、ブロックデバイス上に作成された特定のファイルシステムに関連付けられます。識別子はファイルシステムの一部としても格納されます。ファイルシステムを別のデバイスにコピーしても、ファイルシステム識別子は同じです。ただし、mkfs ユーティリティーでフォーマットするなどしてデバイスを書き換えると、デバイスはその属性を失います。
ファイルシステムの識別子に含まれるものは、次のとおりです。
- 一意の ID (UUID)
- ラベル
デバイスの識別子
デバイス識別子は、ブロックデバイス (ディスクやパーティションなど) に関連付けられます。mkfs ユーティリティーでフォーマットするなどしてデバイスを書き換えた場合、デバイスはファイルシステムに格納されていないため、属性を保持します。
デバイスの識別子に含まれるものは、次のとおりです。
- World Wide Identifier (WWID)
- パーティション UUID
- シリアル番号
推奨事項
- 論理ボリュームなどの一部のファイルシステムは、複数のデバイスにまたがっています。Red Hat は、デバイスの識別子ではなくファイルシステムの識別子を使用してこのファイルシステムにアクセスすることを推奨します。
26.3. /dev/disk/ にある udev メカニズムにより管理されるデバイス名
udev メカニズムは、Linux のすべてのタイプのデバイスに使用され、ストレージデバイスだけに限定されません。/dev/disk/ ディレクトリーにさまざまな種類の永続的な命名属性を提供します。ストレージデバイスの場合、Red Hat Enterprise Linux には /dev/disk/ ディレクトリーにシンボリックリンクを作成する udev ルールが含まれています。これにより、次の方法でストレージデバイスを参照できます。
- ストレージデバイスのコンテンツ
- 一意の ID
- シリアル番号
udev の命名属性は永続的なものですが、システムを再起動しても自動的には変更されないため、設定可能なものもあります。
26.3.1. ファイルシステムの識別子
/dev/disk/by-uuid/ の UUID 属性
このディレクトリーのエントリーは、デバイスに格納されているコンテンツ (つまりデータ) 内の 一意の ID (UUID) によりストレージデバイスを参照するシンボリック名を提供します。以下に例を示します。
/dev/disk/by-uuid/3e6be9de-8139-11d1-9106-a43f08d823a6
次の構文を使用することで、UUID を使用して /etc/fstab ファイルのデバイスを参照できます。
UUID=3e6be9de-8139-11d1-9106-a43f08d823a6ファイルシステムを作成する際に UUID 属性を設定できます。後で変更することもできます。
/dev/disk/by-label/ のラベル属性
このディレクトリーのエントリーは、デバイスに格納されているコンテンツ (つまりデータ) 内の ラベル により、ストレージデバイスを参照するシンボリック名を提供します。
以下に例を示します。
/dev/disk/by-label/Boot
次の構文を使用することで、ラベルを使用して /etc/fstab ファイルのデバイスを参照できます。
LABEL=Bootファイルシステムを作成するときにラベル属性を設定できます。また、後で変更することもできます。
26.3.2. デバイスの識別子
/dev/disk/by-id/ の WWID 属性
World Wide Identifier (WWID) は永続的で、SCSI 規格によりすべての SCSI デバイスが必要とする システムに依存しない識別子 です。各ストレージデバイスの WWID 識別子は一意となることが保証され、デバイスのアクセスに使用されるパスに依存しません。この識別子はデバイスのプロパティーですが、デバイスのコンテンツ (つまりデータ) には格納されません。
この識別子は、SCSI Inquiry を発行して Device Identification Vital Product Data (0x83 ページ) または Unit Serial Number (0x80 ページ) を取得することにより獲得できます。
Red Hat Enterprise Linux では、WWID ベースのデバイス名から、そのシステムの現在の /dev/sd 名への正しいマッピングを自動的に維持します。デバイスへのパスが変更したり、別のシステムからそのデバイスへのアクセスがあった場合にも、アプリケーションはディスク上のデータ参照に /dev/disk/by-id/ 名を使用できます。
例26.1 WWID マッピング
| WWID シンボリックリンク | 非永続的なデバイス | 備考 |
|---|---|---|
|
|
|
ページ |
|
|
|
ページ |
|
|
| ディスクパーティション |
システムにより提供される永続的な名前のほかに、udev ルールを使用して独自の永続的な名前を実装し、ストレージの WWID にマップすることもできます。
/dev/disk/by-partuuid のパーティション UUID 属性
パーティション UUID (PARTUUID) 属性は、GPT パーティションテーブルにより定義されているパーティションを識別します。
例26.2 パーティション UUID のマッピング
| PARTUUID シンボリックリンク | 非永続的なデバイス |
|---|---|
|
|
|
|
|
|
|
|
|
/dev/disk/by-path/ のパス属性
この属性は、デバイスへのアクセスに使用される ハードウェアパス がストレージデバイスを参照するシンボル名を提供します。
ハードウェアパス (PCI ID、ターゲットポート、LUN 番号など) の一部が変更されると、パス属性に失敗します。このため、パス属性は信頼性に欠けます。ただし、パス属性は以下のいずれかのシナリオで役に立ちます。
- 後で置き換える予定のディスクを特定する必要があります。
- 特定の場所にあるディスクにストレージサービスをインストールする予定です。
26.4. DM Multipath を使用した World Wide Identifier
Device Mapper (DM) Multipath を設定して、World Wide Identifier (WWID) と非永続的なデバイス名をマッピングできます。
システムからデバイスへのパスが複数ある場合、DM Multipath はこれを検出するために WWID を使用します。その後、DM Multipath は /dev/mapper/wwid ディレクトリー (例: /dev/mapper/3600508b400105df70000e00000ac0000) に単一の "疑似デバイス" を表示します。
コマンド multipath -l は、非永続的な識別子へのマッピングを示します。
-
Host:Channel:Target:LUN -
/dev/sd名 -
major:minor数値
例26.3 マルチパス設定での WWID マッピング
multipath -l コマンドの出力例:
3600508b400105df70000e00000ac0000 dm-2 vendor,product
[size=20G][features=1 queue_if_no_path][hwhandler=0][rw]
\_ round-robin 0 [prio=0][active]
\_ 5:0:1:1 sdc 8:32 [active][undef]
\_ 6:0:1:1 sdg 8:96 [active][undef]
\_ round-robin 0 [prio=0][enabled]
\_ 5:0:0:1 sdb 8:16 [active][undef]
\_ 6:0:0:1 sdf 8:80 [active][undef]
DM Multipath は、各 WWID ベースのデバイス名から、システムで対応する /dev/sd 名への適切なマッピングを自動的に維持します。これらの名前は、パスが変更しても持続し、他のシステムからデバイスにアクセスする際に一貫性を保持します。
DM Multipath の user_friendly_names 機能を使用すると、WWID は /dev/mapper/mpathN 形式の名前にマップされます。デフォルトでは、このマッピングは /etc/multipath/bindings ファイルに保持されています。これらの mpathN 名は、そのファイルが維持されている限り永続的です。
user_friendly_names を使用する場合は、クラスター内で一貫した名前を取得するために追加の手順が必要です。
26.5. udev デバイス命名規則の制約
udev 命名規則の制約の一部は次のとおりです。
-
udevイベントに対してudevルールが処理されるときに、udevメカニズムはストレージデバイスをクエリーする機能に依存する可能性があるため、クエリーの実行時にデバイスにアクセスできない可能性があります。これは、ファイバーチャネル、iSCSI、または FCoE ストレージデバイスといった、デバイスがサーバーシャーシにない場合に発生する可能性が高くなります。 -
カーネルは
udevイベントをいつでも送信する可能性があるため、デバイスにアクセスできない場合に/dev/disk/by-*/リンクが削除される可能性があります。 -
udevイベントが生成されそのイベントが処理されるまでに遅延が生じる場合があります (大量のデバイスが検出され、ユーザー空間のudevサービスによる各デバイスのルールを処理するのにある程度の時間がかかる場合など)。これにより、カーネルがデバイスを検出してから、/dev/disk/by-*/の名前が利用できるようになるまでに遅延が生じる可能性があります。 -
ルールに呼び出される
blkidなどの外部プログラムによってデバイスが短期間開き、他の目的でデバイスにアクセスできなくなる可能性があります。 -
/dev/disk/ の
udevメカニズムで管理されるデバイス名は、メジャーリリース間で変更される可能性があるため、リンクの更新が必要になる場合があります。
26.6. 永続的な命名属性のリスト表示
非永続ストレージデバイスの永続的な命名属性を確認できます。
手順
UUID 属性とラベル属性をリスト表示するには、
lsblkユーティリティーを使用します。$ lsblk --fs storage-device以下に例を示します。
例26.4 ファイルシステムの UUID とラベルの表示
$ lsblk --fs /dev/sda1 NAME FSTYPE LABEL UUID MOUNTPOINT sda1 xfs Boot afa5d5e3-9050-48c3-acc1-bb30095f3dc4 /bootPARTUUID 属性をリスト表示するには、
--output +PARTUUIDオプションを指定してlsblkユーティリティーを使用します。$ lsblk --output +PARTUUID以下に例を示します。
例26.5 パーティションの PARTUUID 属性の表示
$ lsblk --output +PARTUUID /dev/sda1 NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT PARTUUID sda1 8:1 0 512M 0 part /boot 4cd1448a-01WWID 属性をリスト表示するには、
/dev/disk/by-id/ディレクトリーのシンボリックリンクのターゲットを調べます。以下に例を示します。例26.6 システムにある全ストレージデバイスの WWID の表示
$ file /dev/disk/by-id/* /dev/disk/by-id/ata-QEMU_HARDDISK_QM00001 symbolic link to ../../sda /dev/disk/by-id/ata-QEMU_HARDDISK_QM00001-part1 symbolic link to ../../sda1 /dev/disk/by-id/ata-QEMU_HARDDISK_QM00001-part2 symbolic link to ../../sda2 /dev/disk/by-id/dm-name-rhel_rhel8-root symbolic link to ../../dm-0 /dev/disk/by-id/dm-name-rhel_rhel8-swap symbolic link to ../../dm-1 /dev/disk/by-id/dm-uuid-LVM-QIWtEHtXGobe5bewlIUDivKOz5ofkgFhP0RMFsNyySVihqEl2cWWbR7MjXJolD6g symbolic link to ../../dm-1 /dev/disk/by-id/dm-uuid-LVM-QIWtEHtXGobe5bewlIUDivKOz5ofkgFhXqH2M45hD2H9nAf2qfWSrlRLhzfMyOKd symbolic link to ../../dm-0 /dev/disk/by-id/lvm-pv-uuid-atlr2Y-vuMo-ueoH-CpMG-4JuH-AhEF-wu4QQm symbolic link to ../../sda2
26.7. 永続的な命名属性の変更
ファイルシステムの UUID またはラベルの永続的な命名属性を変更できます。
udev 属性の変更はバックグラウンドで行われ、時間がかかる場合があります。udevadm settle コマンドは、変更が完全に登録されるまで待機します。そのため、その後のコマンドで確実に新しい属性を正しく使用できます。
以下のコマンドでは、次を行います。
-
new-uuid を、設定する UUID (例:
1cdfbc07-1c90-4984-b5ec-f61943f5ea50) に置き換えます。uuidgenコマンドを使用して UUID を生成できます。 -
new-label を、ラベル (例:
backup_data) に置き換えます。
前提条件
- XFS ファイルシステムをアンマウントしている (XFS ファイルシステムの属性を変更する場合)。
手順
XFS ファイルシステムの UUID またはラベル属性を変更するには、
xfs_adminユーティリティーを使用します。# xfs_admin -U new-uuid -L new-label storage-device # udevadm settleext4 ファイルシステム、ext3 ファイルシステム、ext2 ファイルシステムの UUID またはラベル属性を変更するには、
tune2fsユーティリティーを使用します。# tune2fs -U new-uuid -L new-label storage-device # udevadm settleスワップボリュームの UUID またはラベル属性を変更するには、
swaplabelユーティリティーを使用します。# swaplabel --uuid new-uuid --label new-label swap-device # udevadm settle
第27章 パーティションの使用
ディスクパーティション設定を使用して、ディスクを 1 つ以上の論理領域に分割し、各パーティションで個別に作業できるようにします。ハードディスクは、パーティションテーブルの各ディスクパーティションの場所とサイズに関する情報を保存します。このテーブルを使用すると、各パーティションはオペレーティングシステムへの論理ディスクとして表示されます。その後、それらの個々のディスクで読み取りと書き込みを行うことができます。
ブロックデバイスでパーティションを使用する利点と欠点の概要については、Red Hat ナレッジベースソリューション What are the advantages and disadvantages to using partitioning on LUNs, either directly or with LVM in between? を参照してください。
27.1. parted でディスクにパーティションテーブルを作成
parted ユーティリティーを使用して、より簡単にパーティションテーブルでブロックデバイスをフォーマットできます。
パーティションテーブルを使用してブロックデバイスをフォーマットすると、そのデバイスに保存されているすべてのデータが削除されます。
手順
インタラクティブな
partedシェルを起動します。# parted block-deviceデバイスにパーティションテーブルがあるかどうかを確認します。
(parted) printデバイスにパーティションが含まれている場合は、次の手順でパーティションを削除します。
新しいパーティションテーブルを作成します。
(parted) mklabel table-typetable-type を、使用するパーティションテーブルのタイプに置き換えます。
-
msdos(MBR の場合) -
gpt(GPT の場合)
-
例27.1 GUID パーティションテーブル (GPT) テーブルの作成
ディスクに GPT テーブルを作成するには、次のコマンドを使用します。
(parted) mklabel gptこのコマンドを入力すると、変更の適用が開始されます。
パーティションテーブルを表示して、作成されたことを確認します。
(parted) printpartedシェルを終了します。(parted) quit
27.2. parted でパーティションテーブルの表示
ブロックデバイスのパーティションテーブルを表示して、パーティションレイアウトと個々のパーティションの詳細を確認します。parted ユーティリティーを使用して、ブロックデバイスのパーティションテーブルを表示できます。
手順
partedユーティリティーを起動します。たとえば、次の出力は、デバイス/dev/sdaをリストします。# parted /dev/sdaパーティションテーブルを表示します。
(parted) print Model: ATA SAMSUNG MZNLN256 (scsi) Disk /dev/sda: 256GB Sector size (logical/physical): 512B/512B Partition Table: msdos Disk Flags: Number Start End Size Type File system Flags 1 1049kB 269MB 268MB primary xfs boot 2 269MB 34.6GB 34.4GB primary 3 34.6GB 45.4GB 10.7GB primary 4 45.4GB 256GB 211GB extended 5 45.4GB 256GB 211GB logicalオプション:次に調べるデバイスに切り替えます。
(parted) select block-device
print コマンドの出力の詳細については、以下を参照してください。
モデル:ATA SAMSUNG MZNLN256 (scsi)- ディスクタイプ、製造元、モデル番号、およびインターフェイス。
Disk /dev/sda:256GB- ブロックデバイスへのファイルパスとストレージ容量。
Partition Table: msdos- ディスクラベルの種類。
Number-
パーティション番号。たとえば、マイナー番号 1 のパーティションは、
/dev/sda1に対応します。 StartおよびEnd- デバイスにおけるパーティションの開始場所と終了場所。
Type- 有効なタイプは、メタデータ、フリー、プライマリー、拡張、または論理です。
File system-
ファイルシステムの種類。ファイルシステムの種類が不明な場合は、デバイスの
File systemフィールドに値が表示されません。partedユーティリティーは、暗号化されたデバイスのファイルシステムを認識できません。 Flags-
パーティションのフラグ設定リスト。利用可能なフラグは、
boot、root、swap、hidden、raid、lvm、またはlbaです。
27.3. parted でパーティションの作成
システム管理者は、parted ユーティリティーを使用してディスクに新しいパーティションを作成できます。
必要なパーティションは、swap、/boot/、および /(root) です。
前提条件
- ディスクのパーティションテーブル。
- 2TiB を超えるパーティションを作成する場合は、GUID Partition Table (GPT) でディスクをフォーマットしておく。
手順
partedユーティリティーを起動します。# parted block-device現在のパーティションテーブルを表示し、十分な空き領域があるかどうかを確認します。
(parted) print- 十分な空き容量がない場合は、パーティションのサイズを変更してください。
パーティションテーブルから、以下を確認します。
- 新しいパーティションの開始点と終了点
- MBR で、どのパーティションタイプにすべきか
新しいパーティションを作成します。
(parted) mkpart part-type name fs-type start end-
part-type を
primary、logical、またはextendedに置き換えます。これは MBR パーティションテーブルにのみ適用されます。 - name を任意のパーティション名に置き換えます。これは GPT パーティションテーブルに必要です。
-
fs-type を、
xfs、ext2、ext3、ext4、fat16、fat32、hfs、hfs+、linux-swap、ntfs、またはreiserfsに置き換えます。fs-type パラメーターは任意です。partedユーティリティーは、パーティションにファイルシステムを作成しないことに注意してください。 -
start と end を、パーティションの開始点と終了点を決定するサイズに置き換えます (ディスクの開始からカウントします)。
512MiB、20GiB、1.5TiBなどのサイズ接尾辞を使用できます。デフォルトサイズの単位はメガバイトです。
例27.2 小さなプライマリーパーティションの作成
MBR テーブルに 1024MiB から 2048MiB までのプライマリーパーティションを作成するには、次のコマンドを使用します。
(parted) mkpart primary 1024MiB 2048MiBコマンドを入力すると、変更の適用が開始されます。
-
part-type を
パーティションテーブルを表示して、作成されたパーティションのパーティションタイプ、ファイルシステムタイプ、サイズが、パーティションテーブルに正しく表示されていることを確認します。
(parted) printpartedシェルを終了します。(parted) quit新規デバイスノードを登録します。
# udevadm settleカーネルが新しいパーティションを認識していることを確認します。
# cat /proc/partitions
27.4. fdisk でパーティションタイプの設定
fdisk ユーティリティーを使用して、パーティションタイプまたはフラグを設定できます。
前提条件
- ディスク上のパーティション。
手順
インタラクティブな
fdiskシェルを起動します。# fdisk block-device現在のパーティションテーブルを表示して、パーティションのマイナー番号を確認します。
Command (m for help): print現在のパーティションタイプは
Type列で、それに対応するタイプ ID はId列で確認できます。パーティションタイプコマンドを入力し、マイナー番号を使用してパーティションを選択します。
Command (m for help): type Partition number (1,2,3 default 3): 2オプション:16 進数コードでリストを表示します。
Hex code (type L to list all codes): Lパーティションタイプを設定します。
Hex code (type L to list all codes): 8e変更を書き込み、
fdiskシェルを終了します。Command (m for help): write The partition table has been altered. Syncing disks.変更を確認します。
# fdisk --list block-device
27.5. parted でパーティションのサイズ変更
parted ユーティリティーを使用して、パーティションを拡張して未使用のディスク領域を利用したり、パーティションを縮小してその容量をさまざまな目的に使用したりできます。
前提条件
- パーティションを縮小する前にデータをバックアップする。
- 2TiB を超えるパーティションを作成する場合は、GUID Partition Table (GPT) でディスクをフォーマットしておく。
- パーティションを縮小する場合は、サイズを変更したパーティションより大きくならないように、最初にファイルシステムを縮小しておく。
XFS は縮小に対応していません。
手順
partedユーティリティーを起動します。# parted block-device現在のパーティションテーブルを表示します。
(parted) printパーティションテーブルから、以下を確認します。
- パーティションのマイナー番号。
- 既存のパーティションの位置とサイズ変更後の新しい終了点。
パーティションのサイズを変更します。
(parted) resizepart 1 2GiB- 1 を、サイズを変更するパーティションのマイナー番号に置き換えます。
-
2 を、サイズを変更するパーティションの新しい終了点を決定するサイズに置き換えます (ディスクの開始からカウントします)。
512MiB、20GiB、1.5TiBなどのサイズ接尾辞を使用できます。デフォルトサイズの単位はメガバイトです。
パーティションテーブルを表示して、サイズ変更したパーティションのサイズが、パーティションテーブルで正しく表示されていることを確認します。
(parted) printpartedシェルを終了します。(parted) quitカーネルが新しいパーティションを登録していることを確認します。
# cat /proc/partitions- オプション:パーティションを拡張した場合は、そこにあるファイルシステムも拡張します。
27.6. parted でパーティションの削除
parted ユーティリティーを使用すると、ディスクパーティションを削除して、ディスク領域を解放できます。
手順
インタラクティブな
partedシェルを起動します。# parted block-device-
block-device を、パーティションを削除するデバイスへのパス (例:
/dev/sda) に置き換えます。
-
block-device を、パーティションを削除するデバイスへのパス (例:
現在のパーティションテーブルを表示して、削除するパーティションのマイナー番号を確認します。
(parted) printパーティションを削除します。
(parted) rm minor-number- minor-number を、削除するパーティションのマイナー番号に置き換えます。
このコマンドを実行すると、すぐに変更の適用が開始されます。
パーティションテーブルからパーティションが削除されたことを確認します。
(parted) printpartedシェルを終了します。(parted) quitパーティションが削除されたことをカーネルが登録していることを確認します。
# cat /proc/partitions-
パーティションが存在する場合は、
/etc/fstabファイルからパーティションを削除します。削除したパーティションを宣言している行を見つけ、ファイルから削除します。 システムが新しい
/etc/fstab設定を登録するように、マウントユニットを再生成します。# systemctl daemon-reloadスワップパーティション、または LVM の一部を削除した場合は、カーネルコマンドラインからパーティションへの参照をすべて削除します。
アクティブなカーネルオプションを一覧表示し、削除されたパーティションを参照するオプションがないか確認します。
# grubby --info=ALL削除されたパーティションを参照するカーネルオプションを削除します。
# grubby --update-kernel=ALL --remove-args="option"
アーリーブートシステムに変更を登録するには、
initramfsファイルシステムを再構築します。# dracut --force --verbose
第28章 XFS の使用
これは、XFS ファイルシステムを作成および維持する方法の概要です。
28.1. XFS ファイルシステム
XFS は、拡張性が高く、高性能で堅牢な、成熟した 64 ビットのジャーナリングファイルシステムで、1 台のホストで非常に大きなファイルおよびファイルシステムに対応します。Red Hat Enterprise Linux 8 ではデフォルトのファイルシステムになります。XFS は、元々 1990 年代の前半に SGI により開発され、極めて大規模なサーバーおよびストレージアレイで実行されてきた長い歴史があります。
XFS の機能は次のとおりです。
- 信頼性
- メタデータジャーナリング - システムの再起動時、およびファイルシステムの再マウント時に再生できるファイルシステム操作の記録を保持することで、システムクラッシュ後のファイルシステムの整合性を確保します。
- 広範囲に及ぶランタイムメタデータの整合性チェック
- 拡張性が高く、高速な修復ユーティリティー
- クォータジャーナリングクラッシュ後に行なわれる、時間がかかるクォータの整合性チェックが不要になります。
- スケーラビリティーおよびパフォーマンス
- 対応するファイルシステムのサイズが最大 1024 TiB
- 多数の同時操作に対応する機能
- 空き領域管理のスケーラビリティーに関する B-Tree インデックス
- 高度なメタデータ先読みアルゴリズム
- ストリーミングビデオのワークロードの最適化
- 割り当てスキーム
- エクステント (領域) ベースの割り当て
- ストライプを認識できる割り当てポリシー
- 遅延割り当て
- 領域の事前割り当て
- 動的に割り当てられる inode
- その他の機能
- Reflink ベースのファイルのコピー
- 密接に統合されたバックアップおよび復元のユーティリティー
- オンラインのデフラグ
- オンラインのファイルシステム拡張
- 包括的な診断機能
-
拡張属性 (
xattr)。これにより、システムが、ファイルごとに、名前と値の組み合わせを追加で関連付けられるようになります。 - プロジェクトまたはディレクトリーのクォータ。ディレクトリーツリー全体にクォータ制限を適用できます。
- サブセカンド (一秒未満) のタイムスタンプ
パフォーマンスの特徴
XFS は、エンタープライズレベルのワークロードがある大規模なシステムで優れたパフォーマンスを発揮します。大規模なシステムとは、相対的に CPU 数が多く、さらには複数の HBA、および外部ディスクアレイへの接続を備えたシステムです。XFS は、マルチスレッドの並列 I/O ワークロードを備えた小規模のシステムでも適切に実行します。
XFS は、シングルスレッドで、メタデータ集約型のワークロードのパフォーマンスが比較的低くなります。たとえば、シングルスレッドで小さなファイルを多数作成し、削除するワークロードがこれに当てはまります。
28.2. ext4 および XFS で使用されるツールの比較
このセクションでは、ext4 ファイルシステムおよび XFS ファイルシステムで一般的なタスクを行うのに使用するツールを比較します。
| タスク | ext4 | XFS |
|---|---|---|
| ファイルシステムを作成する |
|
|
| ファイルシステム検査 |
|
|
| ファイルシステムのサイズを変更する |
|
|
| ファイルシステムのイメージを保存する |
|
|
| ファイルシステムのラベル付けまたはチューニングを行う |
|
|
| ファイルシステムのバックアップを作成する |
|
|
| クォータ管理 |
|
|
| ファイルマッピング |
|
|
第29章 ファイルシステムのマウント
システム管理者は、システムにファイルシステムをマウントすると、ファイルシステムのデータにアクセスできます。
29.1. Linux のマウントメカニズム
以下は、Linux でのファイルシステムのマウントに関する基本的な概念です。
Linux、UNIX、および類似のオペレーティングシステムでは、さまざまなパーティションおよびリムーバブルデバイス (CD、DVD、USB フラッシュドライブなど) にあるファイルシステムをディレクトリーツリーの特定のポイント (マウントポイント) に接続して、再度切り離すことができます。ファイルシステムがディレクトリーにマウントされている間は、そのディレクトリーの元の内容にアクセスすることはできません。
Linux では、ファイルシステムがすでに接続されているディレクトリーにファイルシステムをマウントできます。
マウント時には、次の方法でデバイスを識別できます。
-
UUID (universally unique identifier):
UUID=34795a28-ca6d-4fd8-a347-73671d0c19cbなど -
ボリュームラベル -
LABEL=homeなど -
非永続的なブロックデバイスへのフルパス -
/dev/sda3など
デバイス名、目的のディレクトリー、ファイルシステムタイプなど、必要な情報をすべて指定せずに mount コマンドを使用してファイルシステムをマウントすると、mount ユーティリティーは /etc/fstab ファイルの内容を読み取り、指定のファイルシステムが記載されているかどうかを確認します。/etc/fstab ファイルには、選択したファイルシステムがマウントされるデバイス名およびディレクトリーのリスト、ファイルシステムタイプ、およびマウントオプションが含まれます。そのため、/etc/fstab で指定されたファイルシステムをマウントする場合は、以下のコマンド構文で十分です。
マウントポイントによるマウント:
# mount directoryブロックデバイスによるマウント:
# mount device
29.2. 現在マウントされているファイルシステムのリスト表示
findmnt ユーティリティーを使用して、現在マウントされているすべてのファイルシステムを、コマンドラインでリスト表示します。
手順
マウントされているファイルシステムのリストを表示するには、
findmntユーティリティーを使用します。$ findmntリスト表示されているファイルシステムを、特定のファイルシステムタイプに制限するには、
--typesオプションを追加します。$ findmnt --types fs-type以下に例を示します。
例29.1 XFS ファイルシステムのみを表示
$ findmnt --types xfs TARGET SOURCE FSTYPE OPTIONS / /dev/mapper/luks-5564ed00-6aac-4406-bfb4-c59bf5de48b5 xfs rw,relatime ├─/boot /dev/sda1 xfs rw,relatime └─/home /dev/mapper/luks-9d185660-7537-414d-b727-d92ea036051e xfs rw,relatime
29.3. mount でファイルシステムのマウント
mount ユーティリティーを使用してファイルシステムをマウントします。
前提条件
選択したマウントポイントにファイルシステムがまだマウントされていないことを確認する。
$ findmnt mount-point
手順
特定のファイルシステムを添付する場合は、
mountユーティリティーを使用します。# mount device mount-point例29.2 XFS ファイルシステムのマウント
たとえば、UUID により識別されるローカル XFS ファイルシステムをマウントするには、次のコマンドを実行します。
# mount UUID=ea74bbec-536d-490c-b8d9-5b40bbd7545b /mnt/datamountがファイルシステムタイプを自動的に認識できない場合は、--typesオプションで指定します。# mount --types type device mount-point例29.3 NFS ファイルシステムのマウント
たとえば、リモートの NFS ファイルシステムをマウントするには、次のコマンドを実行します。
# mount --types nfs4 host:/remote-export /mnt/nfs
29.4. マウントポイントの移動
mount ユーティリティーを使用して、マウントされたファイルシステムのマウントポイントを別のディレクトリーに変更します。
手順
ファイルシステムがマウントされているディレクトリーを変更するには、以下のコマンドを実行します。
# mount --move old-directory new-directory例29.4 ホームファイルシステムの移動
たとえば、
/mnt/userdirs/ディレクトリーにマウントされたファイルシステムを/home/マウントポイントに移動するには、以下のコマンドを実行します。# mount --move /mnt/userdirs /homeファイルシステムが想定どおりに移動したことを確認します。
$ findmnt $ ls old-directory $ ls new-directory
29.5. umount でファイルシステムのアンマウント
umount ユーティリティーを使用してファイルシステムをアンマウントします。
手順
次のいずれかのコマンドを使用してファイルシステムをアンマウントします。
マウントポイントで行う場合は、以下のコマンドを実行します。
# umount mount-pointデバイスで行う場合は、以下のコマンドを実行します。
# umount device
コマンドが次のようなエラーで失敗した場合は、プロセスがリソースを使用しているため、ファイルシステムが使用中であることを意味します。
umount: /run/media/user/FlashDrive: target is busy.ファイルシステムが使用中の場合は、
fuserユーティリティーを使用して、ファイルシステムにアクセスしているプロセスを特定します。以下に例を示します。$ fuser --mount /run/media/user/FlashDrive /run/media/user/FlashDrive: 18351その後、ファイルシステムを使用しているプロセスを停止し、再度アンマウントを試みます。
29.6. Web コンソールでのファイルシステムのマウントとマウント解除
RHEL システムでパーティションを使用できるようにするには、パーティションにファイルシステムをデバイスとしてマウントする必要があります。
ファイルシステムのマウントを解除することもできます。アンマウントすると RHEL システムはその使用を停止します。ファイルシステムのマウントを解除すると、デバイスを削除 (delete または remove) または再読み込みできるようになります。
前提条件
-
cockpit-storagedパッケージがシステムにインストールされている。
- RHEL 8 Web コンソールがインストールされている。
- cockpit サービスが有効になっている。
ユーザーアカウントが Web コンソールにログインできる。
手順は、Web コンソールのインストールおよび有効化 を参照してください。
- ファイルシステムのマウントを解除する場合は、システムがパーティションに保存されているファイル、サービス、またはアプリケーションを使用しないようにする。
手順
RHEL 8 Web コンソールにログインします。
詳細は、Web コンソールへのログイン を参照してください。
- Storage タブをクリックします。
- Storage テーブルで、パーティションを削除するボリュームを選択します。
- GPT partitions セクションで、ファイルシステムをマウントまたはマウント解除するパーティションの横にあるメニューボタン をクリックします。
- または をクリックします。
29.7. 一般的なマウントオプション
次の表に、mount ユーティリティーの最も一般的なオプションを示します。次の構文を使用して、これらのマウントオプションを適用できます。
# mount --options option1,option2,option3 device mount-point| オプション | 説明 |
|---|---|
|
| ファイルシステムで非同期の入出力を可能にします。 |
|
|
|
|
|
オプション |
|
| 特定のファイルシステムでのバイナリーファイルの実行を許可します。 |
|
| イメージをループデバイスとしてマウントします。 |
|
|
デフォルトでは、 |
|
| 特定のファイルシステムでのバイナリーファイルの実行は許可しません。 |
|
| 普通のユーザー (つまり root 以外のユーザー) によるファイルシステムのマウントおよびアンマウントは許可しません。 |
|
| ファイルシステムがすでにマウントされている場合は再度マウントを行います。 |
|
| 読み取り専用でファイルシステムをマウントします。 |
|
| ファイルシステムを読み取りと書き込み両方でマウントします。 |
|
| 普通のユーザー (つまり root 以外のユーザー) によるファイルシステムのマウントおよびアンマウントを許可します。 |
第30章 複数のマウントポイントでのマウント共有
システム管理者は、マウントポイントを複製して、複数のディレクトリーからファイルシステムにアクセスするようにできます。
30.2. プライベートマウントポイントの複製の作成
マウントポイントをプライベートマウントとして複製します。複製後に、複製または元のマウントポイントにマウントするファイルシステムは、他方のマウントポイントには反映されません。
手順
元のマウントポイントから仮想ファイルシステム (VFS) ノードを作成します。
# mount --bind original-dir original-dir元のマウントポイントをプライベートとしてマークします。
# mount --make-private original-dirあるいは、選択したマウントポイントと、その下のすべてのマウントポイントのマウントタイプを変更するには、
--make-privateではなく、--make-rprivateオプションを使用します。複製を作成します。
# mount --bind original-dir duplicate-dir
例30.1 プライベートマウントポイントとして /mnt に /media を複製
/mediaディレクトリーから VFS ノードを作成します。# mount --bind /media /media/mediaディレクトリーをプライベートとしてマークします。# mount --make-private /mediaそのコピーを
/mntに作成します。# mount --bind /media /mntこれで、
/mediaと/mntはコンテンツを共有してますが、/media内のマウントはいずれも/mntに現れていないことが確認できます。たとえば、CD-ROM ドライブに空でないメディアがあり、/media/cdrom/ディレクトリーが存在する場合は、以下のコマンドを実行します。# mount /dev/cdrom /media/cdrom # ls /media/cdrom EFI GPL isolinux LiveOS # ls /mnt/cdrom #また、
/mntディレクトリーにマウントされているファイルシステムが/mediaに反映されていないことを確認することもできます。たとえば、/dev/sdc1デバイスを使用する、空でない USB フラッシュドライブをプラグインしており、/mnt/flashdisk/ディレクトリーが存在する場合は、次のコマンドを実行します。# mount /dev/sdc1 /mnt/flashdisk # ls /media/flashdisk # ls /mnt/flashdisk en-US publican.cfg
30.4. スレーブマウントポイントの複製の作成
マウントポイントを slave マウントタイプとして複製します。複製後に、元のマウントポイントにマウントしたファイルシステムは複製に反映されますが、その逆は反映されません。
手順
元のマウントポイントから仮想ファイルシステム (VFS) ノードを作成します。
# mount --bind original-dir original-dir元のマウントポイントを共有としてマークします。
# mount --make-shared original-dirあるいは、選択したマウントポイントとその下のすべてのマウントポイントのマウントタイプを変更する場合は、
--make-sharedではなく、--make-rsharedオプションを使用します。複製を作成し、これを
slaveタイプとしてマークします。# mount --bind original-dir duplicate-dir # mount --make-slave duplicate-dir
例30.3 スレーブマウントポイントとして /mnt に /media を複製
この例は、/media ディレクトリーのコンテンツが /mnt にも表示され、/mnt ディレクトリーのマウントが /media に反映されないようにする方法を示しています。
/mediaディレクトリーから VFS ノードを作成します。# mount --bind /media /media/mediaディレクトリーを共有としてマークします。# mount --make-shared /mediaその複製を
/mntに作成し、slaveとしてマークします。# mount --bind /media /mnt # mount --make-slave /mnt/media内のマウントが/mntにも表示されていることを確認します。たとえば、CD-ROM ドライブに空でないメディアがあり、/media/cdrom/ディレクトリーが存在する場合は、以下のコマンドを実行します。# mount /dev/cdrom /media/cdrom # ls /media/cdrom EFI GPL isolinux LiveOS # ls /mnt/cdrom EFI GPL isolinux LiveOSまた、
/mntディレクトリー内にマウントされているファイルシステムが/mediaに反映されていないことを確認します。たとえば、/dev/sdc1デバイスを使用する、空でない USB フラッシュドライブをプラグインしており、/mnt/flashdisk/ディレクトリーが存在する場合は、次のコマンドを実行します。# mount /dev/sdc1 /mnt/flashdisk # ls /media/flashdisk # ls /mnt/flashdisk en-US publican.cfg
30.5. マウントポイントが複製されないようにする
マウントポイントをバインド不可としてマークし、別のマウントポイントに複製できないようにします。
手順
マウントポイントのタイプをバインド不可なマウントに変更するには、以下のコマンドを使用します。
# mount --bind mount-point mount-point # mount --make-unbindable mount-pointあるいは、選択したマウントポイントとその下のすべてのマウントポイントのマウントタイプを変更する場合は、
--make-unbindableの代わりに、--make-runbindableオプションを使用します。これ以降、このマウントの複製を作成しようとすると、以下のエラーが出て失敗します。
# mount --bind mount-point duplicate-dir mount: wrong fs type, bad option, bad superblock on mount-point, missing codepage or helper program, or other error In some cases useful info is found in syslog - try dmesg | tail or so
例30.4 /media が複製されないようにする
/mediaディレクトリーが共有されないようにするには、以下のコマンドを実行します。# mount --bind /media /media # mount --make-unbindable /media
第31章 ファイルシステムの永続的なマウント
システム管理者は、ファイルシステムを永続的にマウントして、非リムーバブルストレージを設定できます。
31.1. /etc/fstab ファイル
/etc/fstab 設定ファイルを使用して、ファイルシステムの永続的なマウントポイントを制御します。/etc/fstab ファイルの各行は、ファイルシステムのマウントポイントを定義します。
空白で区切られた 6 つのフィールドが含まれています。
-
/devディレクトリーの永続的な属性またはパスで識別されるブロックデバイス。 - デバイスがマウントされるディレクトリー。
- デバイス上のファイルシステム。
-
ファイルシステムのマウントオプション。これには、ブート時にデフォルトオプションでパーティションをマウントする
defaultsオプションが含まれます。マウントオプションフィールドは、x-systemd.option形式のsystemdマウントユニットオプションも認識します。 -
dumpユーティリティーのオプションのバックアップを作成します。 -
fsckユーティリティーの順序を確認します。
systemd-fstab-generator は、エントリーを /etc/fstab ファイルから systemd-mount ユニットに動的に変換します。systemd-mount ユニットがマスクされていない限り、systemd は手動アクティベーション中に /etc/fstab から LVM ボリュームを自動マウントします。
例31.1 /etc/fstab の /boot ファイルシステム
| ブロックデバイス | マウントポイント | ファイルシステム | オプション | バックアップ | チェック |
|---|---|---|---|---|---|
|
|
|
|
|
|
|
systemd サービスは、/etc/fstab のエントリーからマウントユニットを自動的に生成します。
31.2. /etc/fstab へのファイルシステムの追加
/etc/fstab 設定ファイルでファイルシステムの永続的なマウントポイントを設定します。
手順
ファイルシステムの UUID 属性を調べます。
$ lsblk --fs storage-device以下に例を示します。
例31.2 パーティションの UUID の表示
$ lsblk --fs /dev/sda1 NAME FSTYPE LABEL UUID MOUNTPOINT sda1 xfs Boot ea74bbec-536d-490c-b8d9-5b40bbd7545b /bootこのマウントポイントのディレクトリーがない場合は、作成します。
# mkdir --parents mount-pointroot で
/etc/fstabファイルを編集し、ファイルシステムに行を追加します (UUID で識別されます)。以下に例を示します。
例31.3 /etc/fstab の /boot マウントポイント
UUID=ea74bbec-536d-490c-b8d9-5b40bbd7545b /boot xfs defaults 0 0システムが新しい設定を登録するように、マウントユニットを再生成します。
# systemctl daemon-reloadファイルシステムをマウントして、設定が機能することを確認します。
# mount mount-point
第32章 オンデマンドでのファイルシステムのマウント
システム管理者は、NFS などのファイルシステムをオンデマンドで自動的にマウントするように設定できます。
32.1. autofs サービス
autofs サービスは、ファイルシステムの自動マウントおよび自動アンマウントが可能なため (オンデマンド)、システムのリソースを節約できます。このサービスは、NFS、AFS、SMBFS、CIFS、およびローカルなどのファイルシステムをマウントする場合にも使用できます。
/etc/fstab 設定を使用した永続的なマウントの欠点の 1 つは、マウントされたファイルシステムにユーザーがアクセスする頻度に関わらず、マウントされたファイルシステムを所定の場所で維持するために、システムがリソースを割り当てる必要があることです。これは、システムが一度に多数のシステムへの NFS マウントを維持している場合などに、システムのパフォーマンスに影響を与える可能性があります。
/etc/fstab に代わるのは、カーネルベースの autofs サービスの使用です。これは次のコンポーネントで構成されています。
- ファイルシステムを実装するカーネルモジュール
- 他のすべての機能を実行するユーザー空間サービス
32.2. autofs 設定ファイル
このセクションでは、autofs サービスで使用される設定ファイルの使用方法と構文を説明します。
マスターマップファイル
autofs サービスは、デフォルトの主要設定ファイルとして、/etc/auto.master (マスターマップ) を使用します。これは、/etc/autofs.conf 設定ファイルの autofs 設定を Name Service Switch (NSS) メカニズムとともに使用することで、対応している別のネットワークソースと名前を使用するように変更できます。
すべてのオンデマンドマウントポイントはマスターマップで設定する必要があります。マウントポイント、ホスト名、エクスポートされたディレクトリー、オプションはすべて、ホストごとに手動で設定するのではなく、一連のファイル (またはサポートされているその他のネットワークソース) で指定できます。
マスターマップファイルには、autofs により制御されるマウントポイントと、それに対応する設定ファイルまたは自動マウントマップと呼ばれるネットワークソースがリスト表示されます。マスターマップの形式は次のとおりです。
mount-point map-name optionsこの形式で使用されている変数を以下に示します。
- mount-point
-
autofsマウントポイント (例:/mnt/data/) です。 - map-file
- マウントポイントのリストと、マウントポイントがマウントされるファイルシステムの場所が記載されているマップソースファイルです。
- options
- 指定した場合に、エントリーにオプションが指定されていなければ、指定されたマップ内のすべてのエントリーに適用されます。
例32.1 /etc/auto.master ファイル
以下は /etc/auto.master ファイルのサンプル行です。
/mnt/data /etc/auto.dataマップファイル
マップファイルは、個々のオンデマンドマウントポイントのプロパティーを設定します。
ディレクトリーが存在しない場合、自動マウント機能はディレクトリーを作成します。ディレクトリーが存在している状況で自動マウント機能が起動した場合は、自動マウント機能の終了時にディレクトリーが削除されることはありません。タイムアウトを指定した場合は、タイムアウト期間中ディレクトリーにアクセスしないと、ディレクトリーが自動的にアンマウントされます。
マップの一般的な形式は、マスターマップに似ています。ただし、マスターマップでは、オプションフィールドはエントリーの末尾ではなく、マウントポイントと場所の間に表示されます。
mount-point options locationこの形式で使用されている変数を以下に示します。
- mount-point
-
これは、
autofsのマウントポイントを参照しています。これは 1 つのインダイレクトマウント用の 1 つのディレクトリー名にすることも、複数のダイレクトマウント用のマウントポイントの完全パスにすることもできます。ダイレクトマップとインダイレクトマップの各エントリーキー (mount-point) の後に空白で区切られたオフセットディレクトリー (/で始まるサブディレクトリー名) が記載されます。これがマルチマウントエントリーと呼ばれるものです。 - options
-
このオプションを指定すると、マスターマップエントリーのオプション (存在する場合) に追加されます。設定エントリーの
append_optionsがnoに設定されている場合は、マスターマップのオプションの代わりにこのオプションが使用されます。 - location
-
ローカルファイルシステムのパス (Sun マップ形式のエスケープ文字
:が先頭に付き、マップ名が/で始まります)、NFS ファイルシステム、他の有効なファイルシステムの場所などのファイルシステムの場所を参照します。
例32.2 マップファイル
以下は、マップファイルのサンプルです (例: /etc/auto.misc)。
payroll -fstype=nfs4 personnel:/exports/payroll
sales -fstype=xfs :/dev/hda4
マップファイルの最初の列は、autofs マウントポイント (personnel サーバーからの sales と payroll) を示しています。2 列目は、autofs マウントのオプションを示しています。3 列目はマウントのソースを示しています。
任意の設定に基づき、autofs マウントポイントは、/home/payroll と /home/sales になります。-fstype= オプションは多くの場合省略されており、ファイルシステムが NFS の場合は必要ありません。これには、システムのデフォルトが NFS マウント用の NFSv4 である場合の NFSv4 のマウントも含まれます。
与えられた設定を使用して、プロセスが /home/payroll/2006/July.sxc などのアンマウントされたディレクトリー autofs へのアクセスを要求すると、autofs サービスは自動的にディレクトリーをマウントします。
amd マップ形式
autofs サービスは、amd 形式のマップ設定も認識します。これは Red Hat Enterprise Linux から削除された、am-utils サービス用に書き込まれた既存の自動マウント機能の設定を再利用する場合に便利です。
ただし、Red Hat は、前述のセクションで説明した簡単な autofs 形式の使用を推奨しています。
32.3. autofs マウントポイントの設定
autofs サービスを使用してオンデマンドマウントポイントを設定します。
前提条件
autofsパッケージをインストールしている。# yum install autofsautofsサービスを起動して有効にしている。# systemctl enable --now autofs
手順
-
/etc/auto.identifierにあるオンデマンドマウントポイント用のマップファイルを作成します。identifier を、マウントポイントを識別する名前に置き換えます。 - マップファイルで、autofs 設定ファイル セクションの説明に従って、マウントポイント、オプション、および場所の各フィールドを入力します。
- autofs 設定ファイル セクションの説明に従って、マップファイルをマスターマップファイルに登録します。
設定の再読み込みを許可し、新しく設定した
autofsマウントを管理できるようにします。# systemctl reload autofs.serviceオンデマンドディレクトリーのコンテンツへのアクセスを試みます。
# ls automounted-directory
32.4. autofs サービスを使用した NFS サーバーユーザーのホームディレクトリーの自動マウント
ユーザーのホームディレクトリーを自動的にマウントするように autofs サービスを設定します。
前提条件
- autofs パッケージがインストールされている。
- autofs サービスが有効で、実行している。
手順
ユーザーのホームディレクトリーをマウントする必要があるサーバーの
/etc/auto.masterファイルを編集して、マップファイルのマウントポイントと場所を指定します。これを行うには、以下の行を/etc/auto.masterファイルに追加します。/home /etc/auto.homeユーザーのホームディレクトリーをマウントする必要があるサーバー上で、
/etc/auto.homeという名前のマップファイルを作成し、以下のパラメーターでファイルを編集します。* -fstype=nfs,rw,sync host.example.com:/home/&fstypeパラメーターはデフォルトでnfsであるため、このパラメーターは飛ばして次に進むことができます。詳細は、システム上のautofs(5)man ページを参照してください。autofsサービスを再読み込みします。# systemctl reload autofs
32.5. autofs サイトの設定ファイルの上書き/拡張
クライアントシステムの特定のマウントポイントで、サイトのデフォルトを上書きすることが役に立つ場合があります。
例32.3 初期条件
たとえば、次の条件を検討します。
自動マウント機能マップは NIS に保存され、
/etc/nsswitch.confファイルには以下のディレクティブがあります。automount: files nisauto.masterファイルには以下が含まれます。+auto.masterNIS の
auto.masterマップファイルに以下が含まれます。/home auto.homeNIS の
auto.homeマップには以下が含まれます。beth fileserver.example.com:/export/home/beth joe fileserver.example.com:/export/home/joe * fileserver.example.com:/export/home/&autofs設定オプションのBROWSE_MODEはyesに設定されています。BROWSE_MODE="yes"-
ファイルマップ
/etc/auto.homeは存在しません。
手順
このセクションでは、別のサーバーからホームディレクトリーをマウントし、選択したエントリーのみで auto.home を強化する例を説明します。
例32.4 別のサーバーからのホームディレクトリーのマウント
上記の条件で、クライアントシステムが NIS マップの auto.home を上書きして、別のサーバーからホームディレクトリーをマウントする必要があるとします。
この場合、クライアントは次の
/etc/auto.masterマップを使用する必要があります。/home /etc/auto.home +auto.master/etc/auto.homeマップにエントリーが含まれています。* host.example.com:/export/home/&
自動マウント機能は最初に出現したマウントポイントのみを処理するため、/home ディレクトリーには NIS auto.home マップではなく、/etc/auto.home の内容が含まれます。
例32.5 選択されたエントリーのみを使用した auto.home の拡張
別の方法として、サイト全体の auto.home マップを少しのエントリーを使用して拡張するには、次の手順を行います。
/etc/auto.homeファイルマップを作成し、そこに新しいエントリーを追加します。最後に、NIS のauto.homeマップを含めます。これにより、/etc/auto.homeファイルマップは次のようになります。mydir someserver:/export/mydir +auto.homeこの NIS の
auto.homeマップ条件で、/homeディレクトリーの出力内容をリスト表示すると次のようになります。$ ls /home beth joe mydir
autofs は、読み取り中のファイルマップと同じ名前のファイルマップの内容を組み込まないため、上記の例は期待どおりに動作します。このように、autofs は、nsswitch 設定内の次のマップソースに移動します。
32.6. LDAP で自動マウント機能マップの格納
自動マウントマップを、autofs マップファイルではなく LDAP 設定に保存するように autofs を設定します。
前提条件
-
LDAP から自動マウント機能マップを取得するように設定されているすべてのシステムに、LDAP クライアントライブラリーをインストールする必要があります。Red Hat Enterprise Linux では、
openldapパッケージは、autofsパッケージの依存関係として自動的にインストールされます。
手順
-
LDAP アクセスを設定するには、
/etc/openldap/ldap.confファイルを変更します。BASE、URI、schemaの各オプションがサイトに適切に設定されていることを確認します。 自動マウント機能マップを LDAP に格納するためにデフォルトされた最新のスキーマが、
rfc2307bisドラフトに記載されています。このスキーマを使用する場合は、スキーマの定義のコメント文字を取り除き、/etc/autofs.conf設定ファイル内に設定する必要があります。以下に例を示します。例32.6 autofs の設定
DEFAULT_MAP_OBJECT_CLASS="automountMap" DEFAULT_ENTRY_OBJECT_CLASS="automount" DEFAULT_MAP_ATTRIBUTE="automountMapName" DEFAULT_ENTRY_ATTRIBUTE="automountKey" DEFAULT_VALUE_ATTRIBUTE="automountInformation"他のすべてのスキーマエントリーが設定内でコメントされていることを確認してください。
rfc2307bisスキーマのautomountKey属性は、rfc2307スキーマのcn属性に置き換わります。以下は、LDAP データ交換形式 (LDIF) 設定の例です。例32.7 LDIF 設定
# auto.master, example.com dn: automountMapName=auto.master,dc=example,dc=com objectClass: top objectClass: automountMap automountMapName: auto.master # /home, auto.master, example.com dn: automountMapName=auto.master,dc=example,dc=com objectClass: automount automountKey: /home automountInformation: auto.home # auto.home, example.com dn: automountMapName=auto.home,dc=example,dc=com objectClass: automountMap automountMapName: auto.home # foo, auto.home, example.com dn: automountKey=foo,automountMapName=auto.home,dc=example,dc=com objectClass: automount automountKey: foo automountInformation: filer.example.com:/export/foo # /, auto.home, example.com dn: automountKey=/,automountMapName=auto.home,dc=example,dc=com objectClass: automount automountKey: / automountInformation: filer.example.com:/export/&
32.7. systemd.automount と /etc/fstab を使用してファイルシステムを必要に応じてマウントする
/etc/fstab でマウントポイントが定義されている場合、automount systemd ユニットを使用して、必要に応じてファイルシステムをマウントします。マウントごとに自動マウントユニットを追加して有効にする必要があります。
手順
ファイルシステムの永続的なマウント の説明に従って、目的の fstab エントリーを追加します。以下に例を示します。
/dev/disk/by-id/da875760-edb9-4b82-99dc-5f4b1ff2e5f4 /mount/point xfs defaults 0 0-
前の手順で作成したエントリーの options フィールドに
x-systemd.automountを追加します。 システムが新しい設定を登録するように、新しく作成されたユニットをロードします。
# systemctl daemon-reload自動マウントユニットを起動します。
# systemctl start mount-point.automount
検証
mount-point.automountが実行されていることを確認します。# systemctl status mount-point.automount自動マウントされたディレクトリーに目的のコンテンツが含まれていることを確認します。
# ls /mount/point
32.8. systemd.automount とマウントユニットを使用してファイルシステムを必要に応じてマウントする
マウントポイントがマウントユニットによって定義されている場合、automount systemd ユニットを使用して、ファイルシステムを必要に応じてマウントします。マウントごとに自動マウントユニットを追加して有効にする必要があります。
手順
マウントユニットを作成します。以下に例を示します。
mount-point.mount [Mount] What=/dev/disk/by-uuid/f5755511-a714-44c1-a123-cfde0e4ac688 Where=/mount/point Type=xfs-
マウントユニットと同じ名前で、拡張子が
.automountのユニットファイルを作成します。 ファイルを開き、
[Automount]セクションを作成します。Where=オプションをマウントパスに設定します。[Automount] Where=/mount/point [Install] WantedBy=multi-user.targetシステムが新しい設定を登録するように、新しく作成されたユニットをロードします。
# systemctl daemon-reload代わりに、自動マウントユニットを有効にして起動します。
# systemctl enable --now mount-point.automount
検証
mount-point.automountが実行されていることを確認します。# systemctl status mount-point.automount自動マウントされたディレクトリーに目的のコンテンツが含まれていることを確認します。
# ls /mount/point
第33章 IdM からの SSSD コンポーネントを使用した autofs マップのキャッシュ
システムセキュリティーサービスデーモン (System Security Services Daemon: SSSD) は、リモートサービスディレクトリーと認証メカニズムにアクセスするシステムサービスです。データキャッシュは、ネットワーク接続が遅い場合に役立ちます。SSSD サービスが autofs マップをキャッシュするように設定するには、このセクションの以下の手順に従います。
33.1. IdM サーバーを LDAP サーバーとして使用するように autofs を手動で設定する
IdM サーバーを LDAP サーバーとして使用するように autofs を設定します。
手順
/etc/autofs.confファイルを編集し、autofsが検索するスキーマ属性を指定します。# # Other common LDAP naming # map_object_class = "automountMap" entry_object_class = "automount" map_attribute = "automountMapName" entry_attribute = "automountKey" value_attribute = "automountInformation"注記ユーザーは、
/etc/autofs.confファイルに小文字と大文字の両方で属性を書き込むことができます。オプション:LDAP 設定を指定します。これには 2 通りの方法があります。最も簡単な方法は、自動マウントサービスが LDAP サーバーと場所を自分で発見するようにすることです。
ldap_uri = "ldap:///dc=example,dc=com"このオプションでは、DNS に検出可能なサーバーの SRV レコードが含まれている必要があります。
別の方法では、使用する LDAP サーバーと LDAP 検索のベース DN を明示的に設定します。
ldap_uri = "ldap://ipa.example.com" search_base = "cn=location,cn=automount,dc=example,dc=com"autofs が IdM LDAP サーバーによるクライアント認証を許可するように
/etc/autofs_ldap_auth.confファイルを編集します。-
authrequiredを yes に変更します。 プリンシパルを IdM LDAP サーバー (host/FQDN@REALM) の Kerberos ホストプリンシパルに設定します。プリンシパル名は、GSS クライアント認証の一部として IdM ディレクトリーへの接続に使用されます。
<autofs_ldap_sasl_conf usetls="no" tlsrequired="no" authrequired="yes" authtype="GSSAPI" clientprinc="host/server.example.com@EXAMPLE.COM" />ホストプリンシパルの詳細は、IdM での正規化された DNS ホスト名の使用 を参照してください。
必要に応じて
klist -kを実行して、正確なホストプリンシパル情報を取得します。
-
33.2. autofs マップをキャッシュする SSSD の設定
SSSD サービスを使用すると、IdM サーバーに保存されている autofs マップを、IdM サーバーを使用するように autofs を設定することなくキャッシュできます。
前提条件
-
sssdパッケージがインストールされている。
手順
SSSD 設定ファイルを開きます。
# vim /etc/sssd/sssd.confSSSD が処理するサービスリストに
autofsサービスを追加します。[sssd] domains = ldap services = nss,pam,autofs[autofs]セクションを新規作成します。autofsサービスのデフォルト設定はほとんどのインフラストラクチャーに対応するため、これを空白のままにすることができます。[nss] [pam] [sudo] [autofs] [ssh] [pac]詳細は、システム上の
sssd.confman ページを参照してください。オプション:
autofsエントリーの検索ベースを設定します。デフォルトでは、これは LDAP 検索ベースですが、ldap_autofs_search_baseパラメーターでサブツリーを指定できます。[domain/EXAMPLE] ldap_search_base = "dc=example,dc=com" ldap_autofs_search_base = "ou=automount,dc=example,dc=com"SSSD サービスを再起動します。
# systemctl restart sssd.serviceSSSD が自動マウント設定のソースとしてリスト表示されるように、
/etc/nsswitch.confファイルを確認します。automount: sss filesautofsサービスを再起動します。# systemctl restart autofs.service/homeのマスターマップエントリーがあると想定し、ユーザーの/homeディレクトリーをリスト表示して設定をテストします。# ls /home/userNameリモートファイルシステムをマウントしない場合は、
/var/log/messagesファイルでエラーを確認します。必要に応じて、loggingパラメーターをdebugに設定して、/etc/sysconfig/autofsファイルのデバッグレベルを増やします。
第34章 root ファイルシステムに対する読み取り専用パーミッションの設定
場合によっては、root ファイルシステム (/) を読み取り専用パーミッションでマウントする必要があります。ユースケースの例には、システムの予期せぬ電源切断後に行うセキュリティーの向上またはデータ整合性の保持が含まれます。
34.1. 書き込みパーミッションを保持するファイルおよびディレクトリー
システムが正しく機能するためには、一部のファイルやディレクトリーで書き込みパーミッションが必要とされます。root ファイルシステムが読み取り専用モードでマウントされると、このようなファイルは、tmpfs 一時ファイルシステムを使用して RAM にマウントされます。
このようなファイルおよびディレクトリーのデフォルトセットは、/etc/rwtab ファイルから読み込まれます。このファイルをシステムに存在させるには、readonly-root パッケージが必要であることに注意してください。
dirs /var/cache/man
dirs /var/gdm
<content truncated>
empty /tmp
empty /var/cache/foomatic
<content truncated>
files /etc/adjtime
files /etc/ntp.conf
<content truncated>
/etc/rwtab ファイルーのエントリーは次の形式になります。
copy-method pathこの構文で、以下のことを行います。
- copy-method を、ファイルまたはディレクトリーを tmpfs にコピーする方法を指定するキーワードの 1 つに置き換えます。
- path を、ファイルまたはディレクトリーへのパスに置き換えます。
/etc/rwtab ファイルは、ファイルまたはディレクトリーを tmpfs にコピーする方法として以下を認識します。
empty空のパスが
tmpfsにコピーされます。以下に例を示します。empty /tmpdirsディレクトリーツリーが空の状態で
tmpfsにコピーされます。以下に例を示します。dirs /var/runfilesファイルやディレクトリーツリーはそのまま
tmpfsにコピーされます。以下に例を示します。files /etc/resolv.conf
カスタムパスを /etc/rwtab.d/ に追加する場合も同じ形式が適用されます。
34.2. ブート時に読み取り専用パーミッションでマウントするように root ファイルシステムの設定
この手順を行うと、今後システムが起動するたびに、root ファイルシステムが読み取り専用としてマウントされます。
手順
/etc/sysconfig/readonly-rootファイルで、READONLYオプションをyesに設定して、ファイルシステムを読み取り専用としてマウントします。READONLY=yes/etc/fstabファイルの root エントリー (/) にroオプションを追加します。/dev/mapper/luks-c376919e... / xfs x-systemd.device-timeout=0,ro 1 1rokernel オプションを有効にします。# grubby --update-kernel=ALL --args="ro"rwカーネルオプションが無効になっていることを確認します。# grubby --update-kernel=ALL --remove-args="rw"tmpfsファイルシステムに書き込みパーミッションでマウントするファイルとディレクトリーを追加する必要がある場合は、/etc/rwtab.d/ディレクトリーにテキストファイルを作成し、そこに設定を置きます。たとえば、
/etc/example/fileファイルを書き込みパーミッションでマウントするには、この行を/etc/rwtab.d/exampleファイルに追加します。files /etc/example/file重要tmpfsのファイルおよびディレクトリーの変更内容は、再起動後は持続しません。- システムを再起動して変更を適用します。
トラブルシューティング
誤って読み取り専用パーミッションで root ファイルシステムをマウントした場合は、次のコマンドを使用して、読み書きパーミッションで再度マウントできます。
# mount -o remount,rw /
第35章 ストレージデバイスの管理
35.1. Stratis ファイルシステムの設定
Stratis は、Red Hat Enterprise Linux 用のローカルストレージ管理ソリューションです。これは、シンプルさと使いやすさを重視し、高度なストレージ機能にアクセスできます。
Stratis は、物理ストレージデバイスのプールを管理するためにサービスとして実行され、複雑なストレージ設定のセットアップと管理を支援しながら、ローカルストレージ管理を使いやすく簡素化します。
Stratis はテクノロジープレビュー機能としてのみご利用いただけます。テクノロジープレビュー機能は、Red Hat 製品のサービスレベルアグリーメント (SLA) の対象外であり、機能的に完全ではないことがあります。Red Hat では、実稼働環境での使用を推奨していません。テクノロジープレビュー機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストを行い、フィードバックを提供していただくことを目的としています。Red Hat のテクノロジープレビュー機能のサポート範囲の詳細は、https://access.redhat.com/ja/support/offerings/techpreview/ を参照してください。
Stratis は、以下のために使用できます。
- ストレージの初期設定
- その後の変更
- 高度なストレージ機能の使用
Stratis の中心的な概念はストレージプールです。このプールは 1 つ以上のローカルディスクまたはパーティションから作成され、ファイルシステムはプールから作成されます。プールでは次のような機能が有効になります。
- ファイルシステムのスナップショット
- シンプロビジョニング
- キャッシュ
- 暗号化
35.1.1. Stratis ファイルシステムのコンポーネント
外部的には、Stratis はコマンドラインと API を通じて次のファイルシステムコンポーネントを提供します。
blockdev- ディスクやディスクパーティションなどのブロックデバイス。
pool1 つ以上のブロックデバイスで構成されます。
プールの合計サイズは固定で、ブロックデバイスのサイズと同じです。
プールには、
dm-cacheターゲットを使用した不揮発性データキャッシュなど、ほとんどの Stratis レイヤーが含まれています。Stratis は、各プールの
/dev/stratis/my-pool/ディレクトリーを作成します。このディレクトリーには、プール内の Stratis ファイルシステムを表すデバイスへのリンクが含まれています。
filesystem各プールには 0 個以上のファイルシステムを含めることができます。ファイルシステムを含むプールには、任意の数のファイルを保存できます。
ファイルシステムはシンプロビジョニングされており、合計サイズは固定されていません。ファイルシステムの実際のサイズは、そこに格納されているデータとともに大きくなります。データのサイズがファイルシステムの仮想サイズに近づくと、Stratis はシンボリュームとファイルシステムを自動的に拡張します。
ファイルシステムは XFS ファイルシステムでフォーマットされます。
重要Stratis は、XFS が認識しない、作成されたファイルシステムに関する情報を追跡します。また、XFS を使用して行われた変更によって、Stratis が自動的に更新されることはありません。ユーザーは、Stratis が管理する XFS ファイルシステムを再フォーマットまたは再設定しないでください。
Stratis は、
/dev/stratis/my-pool/my-fsパスにファイルシステムへのリンクを作成します。
Stratis は、dmsetup リストと /proc/partitions ファイルに表示される多くの Device Mapper デバイスを使用します。同様に、lsblk コマンドの出力は、Stratis の内部の仕組みとレイヤーを反映します。
35.1.2. Stratis と互換性のあるブロックデバイス
Stratis で使用可能なストレージデバイス。
対応デバイス
Stratis プールは、次の種類のブロックデバイスで動作するかどうかをテスト済みです。
- LUKS
- LVM 論理ボリューム
- MD RAID
- DM Multipath
- iSCSI
- HDD および SSD
- NVMe デバイス
対応していないデバイス
Stratis にはシンプロビジョニングレイヤーが含まれているため、Red Hat はすでにシンプロビジョニングされているブロックデバイスに Stratis プールを配置することを推奨しません。
35.1.3. Stratis のインストール
Stratis に必要なパッケージをインストールします。
手順
Stratis サービスとコマンドラインユーティリティーを提供するパッケージをインストールします。
# dnf install stratisd stratis-clistratisdサービスを開始し、ブート時に起動できるようにするには、以下を実行します。# systemctl enable --now stratisd
検証
stratisdサービスが有効になっていて実行されていることを確認します。# systemctl status stratisd stratisd.service - Stratis daemon Loaded: loaded (/usr/lib/systemd/system/stratisd.service; enabled; preset:> Active: active (running) since Tue 2025-03-25 14:04:42 CET; 30min ago Docs: man:stratisd(8) Main PID: 24141 (stratisd) Tasks: 22 (limit: 99365) Memory: 10.4M CPU: 1.436s CGroup: /system.slice/stratisd.service └─24141 /usr/libexec/stratisd --log-level debug
35.1.4. 暗号化されていない Stratis プールの作成
1 つ以上のブロックデバイスから暗号化されていない Stratis プールを作成できます。
前提条件
-
Stratis がインストールされ、
stratisdサービスが実行されている。詳細は、Stratis のインストール を参照してください。 - Stratis プールを作成するブロックデバイスは、使用もマウントもされておらず、1 GB 以上の領域がある。
IBM Z アーキテクチャーでは、
/dev/dasd*ブロックデバイスをパーティションに分割している。Stratis プールの作成には、パーティションデバイスを使用します。DASD デバイスのパーティション分割の詳細は、IBM Z での Linux インスタンスの設定 を参照してください。
Stratis プールは作成時にのみ暗号化でき、後から暗号化することはできません。
手順
Stratis プールで使用する各ブロックデバイスに存在するファイルシステム、パーティションテーブル、または RAID 署名をすべて削除します。
# wipefs --all block-deviceblock-deviceの値は、ブロックデバイスへのパスです (例:/dev/sdb)。選択したブロックデバイスに新しい暗号化されていない Stratis プールを作成します。
# stratis pool create my-pool block-deviceblock-deviceの値は、空または消去されたブロックデバイスへのパスです。次のコマンドを使用して、1 行に複数のブロックデバイスを指定することもできます。
# stratis pool create my-pool block-device-1 block-device-2
検証
新しい Stratis プールが作成されていることを確認します。
# stratis pool list
35.1.5. Web コンソールを使用した暗号化されていない Stratis プールの作成
Web コンソールを使用して、1 つ以上のブロックデバイスから暗号化されていない Stratis プールを作成できます。
前提条件
- RHEL 8 Web コンソールがインストールされている。
- cockpit サービスが有効になっている。
ユーザーアカウントが Web コンソールにログインできる。
手順は、Web コンソールのインストールおよび有効化 を参照してください。
-
Stratis がインストールされ、
stratisdサービスが実行されている。詳細は、Stratis のインストール を参照してください。 - Stratis プールを作成するブロックデバイスは、使用もマウントもされておらず、1 GB 以上の領域がある。
暗号化されていない Stratis プールの作成後に、当該 Stratis プールを暗号化することはできません。
手順
RHEL 8 Web コンソールにログインします。
詳細は、Web コンソールへのログイン を参照してください。
- をクリックします。
- ストレージ テーブルで、メニューボタンをクリックし、Stratis プールの作成を 選択します。
- 名前 フィールドに、Stratis プールの名前を入力します。
- Stratis プールの作成元となる Block devices を選択します。
- オプション:プール内に作成される各ファイルシステムの最大サイズを指定する場合は、ファイルシステムのサイズの管理 を選択します。
- をクリックします。
検証
- Storage セクションに移動し、Devices テーブルに新しい Stratis プールが表示されていることを確認します。
35.1.6. カーネルキーリング内のキーを使用して暗号化された Stratis プールを作成する
データを保護するために、カーネルキーリングを使用して、1 つ以上のブロックデバイスから暗号化された Stratis プールを作成できます。
この方法で暗号化された Stratis プールを作成すると、カーネルキーリングはプライマリー暗号化メカニズムとして使用されます。その後のシステムを再起動すると、このカーネルキーリングは、暗号化された Stratis プールのロックを解除します。
1 つ以上のブロックデバイスから暗号化された Stratis プールを作成する場合は、次の点に注意してください。
-
各ブロックデバイスは
cryptsetupライブラリーを使用して暗号化され、LUKS2形式を実装します。 - 各 Stratis プールは、一意の鍵を持つか、他のプールと同じ鍵を共有できます。これらのキーはカーネルキーリングに保存されます。
- Stratis プールを構成するブロックデバイスは、すべて暗号化または暗号化されていないデバイスである必要があります。同じ Stratis プールに、暗号化したブロックデバイスと暗号化されていないブロックデバイスの両方を含めることはできません。
- 暗号化 Stratis プールのデータキャッシュに追加されるブロックデバイスは、自動的に暗号化されます。
前提条件
-
Stratis v2.1.0 以降がインストールされ、
stratisdサービスが実行されている。詳細は、Stratis のインストール を参照してください。 - Stratis プールを作成するブロックデバイスは、使用もマウントもされておらず、1 GB 以上の領域がある。
IBM Z アーキテクチャーでは、
/dev/dasd*ブロックデバイスをパーティションに分割している。Stratis プールでパーティションを使用します。DASD デバイスのパーティション分割の詳細は、IBM Z での Linux インスタンスの設定 を参照してください。
手順
Stratis プールで使用する各ブロックデバイスに存在するファイルシステム、パーティションテーブル、または RAID 署名をすべて削除します。
# wipefs --all block-deviceblock-deviceの値は、ブロックデバイスへのパスです (例:/dev/sdb)。キーをまだ設定していない場合には、以下のコマンドを実行してプロンプトに従って、暗号化に使用するキーセットを作成します。
# stratis key set --capture-key key-descriptionkey-descriptionは、カーネルキーリングで作成されるキーへの参照になります。コマンドラインで、キー値の入力を求められます。キー値をファイルに配置し、--capture-keyオプションの代わりに--keyfile-pathオプションを使用することもできます。暗号化した Stratis プールを作成し、暗号化に使用すキーの説明を指定します。
# stratis pool create --key-desc key-description my-pool block-devicekey-description- 直前の手順で作成したカーネルキーリングに存在するキーを参照します。
my-pool- 新しい Stratis プールの名前を指定します。
block-device空のブロックデバイスまたは消去したブロックデバイスへのパスを指定します。
次のコマンドを使用して、1 行に複数のブロックデバイスを指定することもできます。
# stratis pool create --key-desc key-description my-pool block-device-1 block-device-2
検証
新しい Stratis プールが作成されていることを確認します。
# stratis pool list
35.1.7. Web コンソールを使用した暗号化された Stratis プールの作成
データを保護するために、Web コンソールを使用して、1 つ以上のブロックデバイスから暗号化された Stratis プールを作成できます。
1 つ以上のブロックデバイスから暗号化された Stratis プールを作成する場合は、次の点に注意してください。
- 各ブロックデバイスは cryptsetup ライブラリーを使用して暗号化され、LUKS2 形式を実装します。
- 各 Stratis プールは、一意の鍵を持つか、他のプールと同じ鍵を共有できます。これらのキーはカーネルキーリングに保存されます。
- Stratis プールを構成するブロックデバイスは、すべて暗号化または暗号化されていないデバイスである必要があります。同じ Stratis プールに、暗号化したブロックデバイスと暗号化されていないブロックデバイスの両方を含めることはできません。
- 暗号化 Stratis プールのデータ層に追加されるブロックデバイスは、自動的に暗号化されます。
前提条件
- RHEL 8 Web コンソールがインストールされている。
- cockpit サービスが有効になっている。
ユーザーアカウントが Web コンソールにログインできる。
手順は、Web コンソールのインストールおよび有効化 を参照してください。
-
Stratis v2.1.0 以降がインストールされ、
stratisdサービスが実行されている。 - Stratis プールを作成するブロックデバイスは、使用もマウントもされておらず、1 GB 以上の領域がある。
手順
RHEL 8 Web コンソールにログインします。
詳細は、Web コンソールへのログイン を参照してください。
- をクリックします。
- ストレージ テーブルで、メニューボタンをクリックし、Stratis プールの作成を 選択します。
- 名前 フィールドに、Stratis プールの名前を入力します。
- Stratis プールの作成元となる Block devices を選択します。
暗号化のタイプを選択します。パスフレーズ、Tang キーサーバー、またはその両方を使用できます。
パスフレーズ:
- パスフレーズを入力します。
- パスフレーズを確認してください。
Tang キーサーバー:
- キーサーバーのアドレスを入力します。詳細は、SELinux を Enforcing モードで有効にした Tang サーバーのデプロイメント を参照してください。
- オプション:プール内に作成する各ファイルシステムの最大サイズを指定する場合は、Manage filesystem sizes を選択します。
- をクリックします。
検証
- Storage セクションに移動し、Devices テーブルに新しい Stratis プールが表示されていることを確認します。
35.1.8. Web コンソールを使用した Stratis プールの名前変更
Web コンソールを使用して、既存の Stratis プールの名前を変更できます。
前提条件
- RHEL 8 Web コンソールがインストールされている。
- cockpit サービスが有効になっている。
ユーザーアカウントが Web コンソールにログインできる。
手順は、Web コンソールのインストールおよび有効化 を参照してください。
Stratis がインストールされ、
stratisdサービスが実行されている。Web コンソールがデフォルトで Stratis を検出してインストールしている。ただし、Stratis を手動でインストールする場合は、Stratis のインストール を参照してください。
- Stratis プールが作成されている。
手順
RHEL 8 Web コンソールにログインします。
詳細は、Web コンソールへのログイン を参照してください。
- をクリックします。
- Storage テーブルで、名前を変更する Stratis プールをクリックします。
- Stratis pool ページで、Name フィールドの横にある をクリックします。
- Rename Stratis pool ダイアログボックスで、新しい名前を入力します。
- をクリックします。
35.1.9. Stratis ファイルシステムでオーバープロビジョニングモードを設定する
デフォルトでは、すべての Stratis プールはオーバープロビジョニングされており、論理ファイルシステムのサイズが物理的に割り当てられた領域を超える可能性があります。Stratis はファイルシステムの使用状況を監視し、必要に応じて使用可能な領域を使用して割り当てを自動的に増やします。ただし、すでに使用可能な領域がすべて割り当てられており、プールがいっぱいの場合は、ファイルシステムに追加領域を割り当てることはできません。
ファイルシステムの容量が不足すると、ユーザーはデータを失う可能性があります。データ損失のリスクがオーバープロビジョニングの利点を上回るアプリケーションの場合、この機能を無効にできます。
Stratis はプールの使用状況を継続的に監視し、D-Bus API を使用して値を報告します。ストレージ管理者はこれらの値を監視し、容量に達しないように必要に応じてデバイスをプールに追加する必要があります。
前提条件
- Stratis がインストールされている。詳細は、Stratis のインストール を参照してください。
手順
プールを正しく設定するには、次の 2 つの方法があります。
1 つ以上のブロックデバイスからプールを作成します。
# stratis pool create pool-name /dev/sdb既存のプールにオーバープロビジョニングモードを設定します。
# stratis pool overprovision pool-name <yes|no>- "yes" に設定すると、プールへのオーバープロビジョニングが有効になります。つまり、プールでサポートされる Stratis ファイルシステムの論理サイズの合計が、使用可能なデータ領域の量を超える可能性があります。プールがオーバープロビジョニングされ、すべてのファイルシステムの論理サイズの合計がプールで使用可能な領域を超える場合、システムはオーバープロビジョニングをオフにできず、エラーを返します。
検証
Stratis プールの完全なリストを表示します。
# stratis pool list Name Total Physical Properties UUID Alerts pool-name 1.42 TiB / 23.96 MiB / 1.42 TiB ~Ca,~Cr,~Op cb7cb4d8-9322-4ac4-a6fd-eb7ae9e1e540-
ubuntu pool
listの出力に、プールのオーバープロビジョニングモードフラグが表示されているかどうかを確認します。~ は NOT を表す数学記号であるため、~Opはオーバープロビジョニングなしという意味です。 オプション:特定のプールのオーバープロビジョニングを確認します。
# stratis pool overprovision pool-name yes # stratis pool list Name Total Physical Properties UUID Alerts pool-name 1.42 TiB / 23.96 MiB / 1.42 TiB ~Ca,~Cr,~Op cb7cb4d8-9322-4ac4-a6fd-eb7ae9e1e540
35.1.10. Stratis プールの NBDE へのバインド
暗号化された Stratis プールを Network Bound Disk Encryption (NBDE) にバインドするには、Tang サーバーが必要です。Stratis プールを含むシステムが再起動すると、Tang サーバーに接続して、カーネルキーリングの説明を指定しなくても、暗号化したプールのロックを自動的に解除します。
Stratis プールを補助 Clevis 暗号化メカニズムにバインドすると、プライマリーカーネルキーリング暗号化は削除されません。
前提条件
-
Stratis v2.3.0 以降がインストールされ、
stratisdサービスが実行されている。詳細は、Stratis のインストール を参照してください。 - 暗号化した Stratis プールを作成し、暗号化に使用したキーの説明がある。詳細は、カーネルキーリング内のキーを使用して暗号化された Stratis プールを作成する を参照してください。
- Tang サーバーに接続できる。詳細は、SELinux を Enforcing モードで有効にした Tang サーバーのデプロイメント を参照してください。
手順
暗号化された Stratis プールを NBDE にバインドする。
# stratis pool bind nbde --trust-url my-pool tang-servermy-pool- 暗号化された Stratis プールの名前を指定します。
tang-server- Tang サーバーの IP アドレスまたは URL を指定します。
35.1.11. Stratis プールの TPM へのバインド
暗号化された Stratis プールを Trusted Platform Module (TPM) 2.0 にバインドすると、プールを含むシステムが再起動され、カーネルキーリングの説明を指定しなくても、プールは自動的にロック解除されます。
前提条件
-
Stratis v2.3.0 以降がインストールされ、
stratisdサービスが実行されている。詳細は、Stratis のインストール を参照してください。 - 暗号化した Stratis プールを作成し、暗号化に使用したキーの説明がある。詳細は、カーネルキーリング内のキーを使用して暗号化された Stratis プールを作成する を参照してください。
- 使用しているシステムは TPM 2.0 をサポートしている。
手順
暗号化された Stratis プールを TPM にバインドします。
# stratis pool bind tpm my-poolmy-pool- 暗号化された Stratis プールの名前を指定します。
key-description- 暗号化された Stratis プールの作成時に生成されたカーネルキーリングに存在するキーを参照します。
35.1.12. カーネルキーリングを使用した暗号化 Stratis プールのロック解除
システムの再起動後、暗号化した Stratis プール、またはこれを構成するブロックデバイスが表示されない場合があります。プールの暗号化に使用したカーネルキーリングを使用して、プールのロックを解除できます。
前提条件
-
Stratis v2.1.0 がインストールされ、
stratisdサービスが実行されている。詳細は、Stratis のインストール を参照してください。 - 暗号化された Stratis プールが作成されている。詳細は、カーネルキーリング内のキーを使用して暗号化された Stratis プールを作成する を参照してください。
手順
以前使用したものと同じキー記述を使用して、キーセットを再作成します。
# stratis key set --capture-key key-descriptionkey-descriptionは、暗号化された Stratis プールの作成時に生成されたカーネルキーリングに存在するキーを参照します。Stratis プールが表示されることを確認します。
# stratis pool list
35.1.13. 補助暗号化からの Stratis プールのバインド解除
暗号化した Stratis プールを、サポート対象の補助暗号化メカニズムからバインドを解除すると、プライマリーカーネルキーリングの暗号化はそのまま残ります。これは、最初から Clevis 暗号化を使用して作成されたプールには当てはまりません。
前提条件
- Stratis v2.3.0 以降がシステムにインストールされている。詳細は、Stratis のインストール を参照してください。
- 暗号化された Stratis プールが作成されている。詳細は、カーネルキーリング内のキーを使用して暗号化された Stratis プールを作成する を参照してください。
- 暗号化した Stratis プールは、サポート対象の補助暗号化メカニズムにバインドされます。
手順
補助暗号化メカニズムから暗号化された Stratis プールのバインドを解除します。
# stratis pool unbind clevis my-poolmy-poolは、バインドを解除する Stratis プールの名前を指定します。
35.1.14. Stratis プールの開始および停止
Stratis プールを開始および停止できます。この操作により、ファイルシステム、キャッシュデバイス、シンプール、暗号化されたデバイスなど、プールの構築に使用されたすべてのオブジェクトを解体または停止できます。プールがデバイスまたはファイルシステムをアクティブに使用している場合、警告が発行され、停止できなくなる可能性があることに注意してください。
停止状態は、プールのメタデータに記録されます。これらのプールは、プールが開始コマンドを受信するまで、次のブートでは開始されません。
前提条件
-
Stratis がインストールされ、
stratisdサービスが実行されている。詳細は、Stratis のインストール を参照してください。 - 暗号化されていない、または暗号化された Stratis プールを作成した。詳細は、暗号化されていない Stratis プールの作成 または カーネルキーリング内のキーを使用して暗号化された Stratis プールを作成する を参照してください。
手順
次のコマンドを使用して、Stratis プールを停止します。これにより、ストレージスタックが切断されますが、メタデータはすべて保持されます。
# stratis pool stop --name pool-name以下のコマンドを使用して Stratis プールを起動します。
--unlock-methodオプションは、プールが暗号化されている場合にプールのロックを解除する方法を指定します。# stratis pool start --unlock-method <keyring|clevis> --name pool-name注記プール名またはプール UUID のいずれかを使用してプールを開始できます。
検証
次のコマンドを使用して、システム上のすべてのアクティブなプールをリスト表示します。
# stratis pool list次のコマンドを使用して、停止されたプールをすべてリスト表示します。
# stratis pool list --stopped次のコマンドを使用して、停止したプールの詳細情報を表示します。UUID を指定すると、このコマンドは UUID に対応するプールに関する詳細情報を出力します。
# stratis pool list --stopped --uuid UUID
35.1.15. Stratis ファイルシステムの作成
既存の Stratis プールに Stratis ファイルシステムを作成します。
前提条件
-
Stratis がインストールされ、
stratisdサービスが実行されている。詳細は、Stratis のインストール を参照してください。 - Stratis プールが作成されている。詳細は、暗号化されていない Stratis プールの作成 または カーネルキーリング内のキーの使用 を参照してください。
手順
プール上に Stratis ファイルシステムを作成します。
# stratis filesystem create --size number-and-unit my-pool my-fsnumber-and-unit- ファイルシステムのサイズを指定します。仕様形式は、入力の標準サイズ指定形式 (B、KiB、MiB、GiB、TiB、または PiB) に準拠する必要があります。
my-pool- Stratis プールの名前を指定します。
my-fsファイルシステムの任意名を指定します。
以下に例を示します。
例35.1 Stratis ファイルシステムの作成
# stratis filesystem create --size 10GiB pool1 filesystem1
検証
プール内のファイルシステムをリスト表示して、Stratis ファイルシステムが作成されているかどうかを確認します。
# stratis fs list my-pool
35.1.16. Web コンソールを使用した Stratis プール上のファイルシステムの作成
Web コンソールを使用して、既存の Stratis プール上にファイルシステムを作成できます。
前提条件
- RHEL 8 Web コンソールがインストールされている。
- cockpit サービスが有効になっている。
ユーザーアカウントが Web コンソールにログインできる。
手順は、Web コンソールのインストールおよび有効化 を参照してください。
-
stratisdサービスを実行している。 - Stratis プールが作成されている。
手順
RHEL 8 Web コンソールにログインします。
詳細は、Web コンソールへのログイン を参照してください。
- をクリックします。
- ファイルシステムを作成する Stratis プールをクリックします。
- Stratis pool ページで、Stratis filesystems セクションまでスクロールし、 をクリックします。
- ファイルシステムの名前を入力します。
- ファイルシステムのマウントポイントを入力します。
- マウントオプションを選択します。
- At boot ドロップダウンメニューで、ファイルシステムをマウントするタイミングを選択します。
ファイルシステムを作成します。
- ファイルシステムを作成してマウントする場合は、 をクリックします。
- ファイルシステムの作成のみを行う場合は、 をクリックします。
検証
- 新しいファイルシステムは、Stratis pool ページの Stratis filesystems タブに表示されます。
35.1.17. Stratis ファイルシステムのマウント
既存の Stratis ファイルシステムをマウントして、コンテンツにアクセスします。
前提条件
-
Stratis がインストールされ、
stratisdサービスが実行されている。詳細は、Stratis のインストール を参照してください。 - Stratis ファイルシステムが作成されます。詳細は、Stratis ファイルシステムの作成 を参照してください。
手順
ファイルシステムをマウントするには、
/dev/stratis/ディレクトリーに Stratis が維持するエントリーを使用します。# mount /dev/stratis/my-pool/my-fs mount-point
これでファイルシステムは mount-point ディレクトリーにマウントされ、使用できるようになりました。
プールを停止する前に、プールに属するすべてのファイルシステムをアンマウントします。ファイルシステムがまだマウントされている場合、プールは停止しません。
35.1.18. systemd サービスを使用して/etc/fstab に非ルート Stratis ファイルシステムを設定する
systemd サービスを使用して、/etc/fstab 内の非ルートファイルシステムの設定を管理できます。
前提条件
-
Stratis がインストールされ、
stratisdサービスが実行されている。詳細は、Stratis のインストール を参照してください。 - Stratis ファイルシステムが作成されます。詳細は、Stratis ファイルシステムの作成 を参照してください。
手順
root として、
/etc/fstabファイルを編集し、非 root ファイルシステムを設定するための行を追加します。/dev/stratis/my-pool/my-fs mount-point xfs defaults,x-systemd.requires=stratis-fstab-setup@pool-uuid.service,x-systemd.after=stratis-fstab-setup@pool-uuid.service dump-value fsck_value
暗号化された Stratis プールから Stratis ファイルシステムを永続的にマウントすると、パスワードが入力されるまでブートプロセスが停止する可能性があります。プールが NBDE や TPM2 などの無人メカニズムを使用して暗号化されている場合、Stratis プールは自動的にロック解除されます。そうでない場合、ユーザーはコンソールにパスワードを入力する必要があります。
35.2. 追加のブロックデバイスで Stratis プールを拡張する
Stratis ファイルシステムのストレージ容量を増やすために、追加のブロックデバイスを Stratis プールに追加できます。手動で行うことも、Web コンソールを使用して行うこともできます。
Stratis はテクノロジープレビュー機能としてのみご利用いただけます。テクノロジープレビュー機能は、Red Hat 製品のサービスレベルアグリーメント (SLA) の対象外であり、機能的に完全ではないことがあります。Red Hat では、実稼働環境での使用を推奨していません。テクノロジープレビュー機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストを行い、フィードバックを提供していただくことを目的としています。Red Hat のテクノロジープレビュー機能のサポート範囲の詳細は、https://access.redhat.com/ja/support/offerings/techpreview/ を参照してください。
35.2.1. Stratis プールへのブロックデバイスの追加
Stratis プールに 1 つ以上のブロックデバイスを追加できます。
前提条件
-
Stratis がインストールされ、
stratisdサービスが実行されている。詳細は、Stratis のインストール を参照してください。 - Stratis プールを作成するブロックデバイスは、使用もマウントもされておらず、1 GB 以上の領域がある。
手順
1 つ以上のブロックデバイスをプールに追加するには、以下を使用します。
# stratis pool add-data my-pool device-1 device-2 device-n
35.2.2. Web コンソールを使用した Stratis プールへのブロックデバイスの追加
Web コンソールを使用して、既存の Stratis プールにブロックデバイスを追加できます。キャッシュをブロックデバイスとして追加することもできます。
前提条件
- RHEL 8 Web コンソールがインストールされている。
- cockpit サービスが有効になっている。
ユーザーアカウントが Web コンソールにログインできる。
手順は、Web コンソールのインストールおよび有効化 を参照してください。
-
stratisdサービスを実行している。 - Stratis プールが作成されている。
- Stratis プールを作成するブロックデバイスは、使用もマウントもされておらず、1 GB 以上の領域がある。
手順
RHEL 8 Web コンソールにログインします。
詳細は、Web コンソールへのログイン を参照してください。
- をクリックします。
- Storage テーブルで、ブロックデバイスを追加する Stratis プールをクリックします。
- Stratis プール ページで、 をクリックし、データまたはキャッシュとしてブロックデバイスを追加する Tier を選択します。
- パスフレーズで暗号化された Stratis プールにブロックデバイスを追加する場合は、パスフレーズを入力します。
- Block devices で、プールに追加するデバイスを選択します。
- をクリックします。
35.3. Stratis ファイルシステムの監視
Stratis ユーザーは、システムにある Stratis ファイルシステムに関する情報を表示して、その状態と空き容量を監視できます。
Stratis はテクノロジープレビュー機能としてのみご利用いただけます。テクノロジープレビュー機能は、Red Hat 製品のサービスレベルアグリーメント (SLA) の対象外であり、機能的に完全ではないことがあります。Red Hat では、実稼働環境での使用を推奨していません。テクノロジープレビュー機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストを行い、フィードバックを提供していただくことを目的としています。Red Hat のテクノロジープレビュー機能のサポート範囲の詳細は、https://access.redhat.com/ja/support/offerings/techpreview/ を参照してください。
35.3.1. Stratis ファイルシステムに関する情報の表示
stratis ユーティリティーを使用すると、Stratis ファイルシステムの合計サイズ、使用サイズ、空きサイズ、プールに属するファイルシステムとブロックデバイスなどに関する統計情報をリスト表示できます。
XFS ファイルシステムのサイズは、管理できるユーザーデータの合計量です。シンプロビジョニングされた Stratis プールでは、Stratis ファイルシステムのサイズが、割り当てられた領域よりも大きいように見える場合があります。XFS ファイルシステムのサイズは、この見かけのサイズに合わせて設定されます。つまり、通常は割り当てられた領域よりも大きくなります。df などの標準 Linux ユーティリティーは、XFS ファイルシステムのサイズを報告します。この値は通常、XFS ファイルシステムに必要な領域、つまり Stratis によって割り当てられた領域を過大評価します。
オーバープロビジョニングされた Stratis プールの使用状況を定期的に監視してください。ファイルシステムの使用量が割り当てられた領域に近づくと、Stratis はプール内の使用可能な領域を使用して割り当てを自動的に増加します。ただし、すでに使用可能な領域がすべて割り当てられていて、プールがいっぱいの場合は、追加の領域を割り当てることができず、ファイルシステムの領域が不足することになります。これにより、Stratis ファイルシステムを使用するアプリケーションでデータが失われるリスクが生じる可能性があります。
前提条件
-
Stratis がインストールされ、
stratisdサービスが実行されている。詳細は、Stratis のインストール を参照してください。
手順
システムで Stratis に使用されているすべての ブロックデバイス に関する情報を表示する場合は、次のコマンドを実行します。
# stratis blockdev Pool Name Device Node Physical Size State Tier my-pool /dev/sdb 9.10 TiB In-use Dataシステムにあるすべての Stratis プール に関する情報を表示するには、次のコマンドを実行します。
# stratis pool Name Total Physical Size Total Physical Used my-pool 9.10 TiB 598 MiBシステムにあるすべての Stratis ファイルシステム に関する情報を表示するには、次のコマンドを実行します。
# stratis filesystem Pool Name Name Used Created Device my-pool my-fs 546 MiB Nov 08 2018 08:03 /dev/stratis/my-pool/my-fs
35.3.2. Web コンソールを使用した Stratis プールの表示
Web コンソールを使用して、既存の Stratis プールとそれに含まれるファイルシステムを表示できます。
前提条件
- RHEL 8 Web コンソールがインストールされている。
- cockpit サービスが有効になっている。
ユーザーアカウントが Web コンソールにログインできる。
手順は、Web コンソールのインストールおよび有効化 を参照してください。
-
stratisdサービスを実行している。 - 既存の Stratis プールがある。
手順
- RHEL 8 Web コンソールにログインします。
- をクリックします。
Storage テーブルで、表示する Stratis プールをクリックします。
Stratis プールページには、プールおよびプール内に作成したファイルシステムに関するすべての情報が表示されます。
35.4. Stratis ファイルシステムでのスナップショットの使用
Stratis ファイルシステムのスナップショットを使用して、ファイルシステムの状態を任意の時点でキャプチャーし、後でそれを復元できます。
Stratis はテクノロジープレビュー機能としてのみご利用いただけます。テクノロジープレビュー機能は、Red Hat 製品のサービスレベルアグリーメント (SLA) の対象外であり、機能的に完全ではないことがあります。Red Hat では、実稼働環境での使用を推奨していません。テクノロジープレビュー機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストを行い、フィードバックを提供していただくことを目的としています。Red Hat のテクノロジープレビュー機能のサポート範囲の詳細は、https://access.redhat.com/ja/support/offerings/techpreview/ を参照してください。
35.4.1. Stratis スナップショットの特徴
Stratis では、スナップショットは、別の Stratis ファイルシステムのコピーとして作成した通常の Stratis ファイルシステムです。
Stratis の現在のスナップショット実装は、次のような特徴があります。
- ファイルシステムのスナップショットは別のファイルシステムです。
- スナップショットと元のファイルシステムのリンクは、有効期間中は行われません。スナップショットされたファイルシステムは、元のファイルシステムよりも長く存続します。
- スナップショットを作成するためにファイルシステムをマウントする必要はありません。
- 各スナップショットは、XFS ログに必要となる実際のバッキングストレージの約半分のギガバイトを使用します。
35.4.2. Stratis スナップショットの作成
既存の Stratis ファイルシステムのスナップショットとして Stratis ファイルシステムを作成できます。
前提条件
-
Stratis がインストールされ、
stratisdサービスが実行されている。詳細は、Stratis のインストール を参照してください。 - Stratis ファイルシステムを作成している。詳細は、Stratis ファイルシステムの作成 を参照してください。
手順
Stratis スナップショットを作成します。
# stratis fs snapshot my-pool my-fs my-fs-snapshot
スナップショットは、中心的な Stratis ファイルシステムです。Stratis スナップショットは複数作成できます。単一のオリジンファイルシステム、または別のスナップショットファイルシステムのスナップショットがあります。ファイルシステムがスナップショットの場合、origin フィールドには、詳細なファイルシステムリストの元のファイルシステムの UUID が表示されます。
35.4.3. Stratis スナップショットのコンテンツへのアクセス
Stratis ファイルシステムのスナップショットをマウントして、読み取りおよび書き込み操作でアクセスできるようにすることができます。
前提条件
-
Stratis がインストールされ、
stratisdサービスが実行されている。詳細は、Stratis のインストール を参照してください。 - Stratis スナップショットを作成している。詳細は、Stratis スナップショットの作成 を参照してください。
手順
スナップショットにアクセスするには、
/dev/stratis/my-pool/ディレクトリーから通常のファイルシステムとしてマウントします。# mount /dev/stratis/my-pool/my-fs-snapshot mount-point
35.4.4. Stratis ファイルシステムを以前のスナップショットに戻す
Stratis ファイルシステムの内容を、Stratis スナップショットでキャプチャーされた状態に戻すことができます。
前提条件
-
Stratis がインストールされ、
stratisdサービスが実行されている。詳細は、Stratis のインストール を参照してください。 - Stratis スナップショットを作成している。詳細は、Stratis スナップショットの作成 を参照してください。
手順
オプション: オプション: 後でアクセスできるように、ファイルシステムの現在の状態をバックアップします。
# stratis filesystem snapshot my-pool my-fs my-fs-backup元のファイルシステムをアンマウントして削除します。
# umount /dev/stratis/my-pool/my-fs # stratis filesystem destroy my-pool my-fs元のファイルシステムの名前でスナップショットのコピーを作成します。
# stratis filesystem snapshot my-pool my-fs-snapshot my-fs元のファイルシステムと同じ名前でアクセスできるようになったスナップショットをマウントします。
# mount /dev/stratis/my-pool/my-fs mount-point
my-fs という名前のファイルシステムの内容は、スナップショット my-fs-snapshot と同じになりました。
35.4.5. Stratis スナップショットの削除
プールから Stratis スナップショットを削除できます。スナップショットのデータは失われます。
前提条件
-
Stratis がインストールされ、
stratisdサービスが実行されている。詳細は、Stratis のインストール を参照してください。 - Stratis スナップショットを作成している。詳細は、Stratis スナップショットの作成 を参照してください。
手順
スナップショットをアンマウントします。
# umount /dev/stratis/my-pool/my-fs-snapshotスナップショットを破棄します。
# stratis filesystem destroy my-pool my-fs-snapshot
35.5. Stratis ファイルシステムの削除
既存の Stratis ファイルシステムまたはプールを削除できます。削除した Stratis ファイルシステムやプールは復元できません。
Stratis はテクノロジープレビュー機能としてのみご利用いただけます。テクノロジープレビュー機能は、Red Hat 製品のサービスレベルアグリーメント (SLA) の対象外であり、機能的に完全ではないことがあります。Red Hat では、実稼働環境での使用を推奨していません。テクノロジープレビュー機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストを行い、フィードバックを提供していただくことを目的としています。Red Hat のテクノロジープレビュー機能のサポート範囲の詳細は、https://access.redhat.com/ja/support/offerings/techpreview/ を参照してください。
35.5.1. Stratis ファイルシステムの削除
既存の Stratis ファイルシステムを削除できます。そこに保存されているデータは失われます。
前提条件
-
Stratis がインストールされ、
stratisdサービスが実行されている。詳細は、Stratis のインストール を参照してください。 - Stratis ファイルシステムを作成している。詳細は、Stratis ファイルシステムの作成 を参照してください。
手順
ファイルシステムをアンマウントします。
# umount /dev/stratis/my-pool/my-fsファイルシステムを破棄します。
# stratis filesystem destroy my-pool my-fs
検証
ファイルシステムがもう存在しないことを確認します。
# stratis filesystem list my-pool
35.5.2. Web コンソールを使用した Stratis プールからのファイルシステムの削除
Web コンソールを使用して、既存の Stratis プールからファイルシステムを削除できます。
Stratis プールのファイルシステムを削除すると、そこに含まれるすべてのデータが消去されます。
前提条件
- RHEL 8 Web コンソールがインストールされている。
- cockpit サービスが有効になっている。
ユーザーアカウントが Web コンソールにログインできる。
手順は、Web コンソールのインストールおよび有効化 を参照してください。
Stratis がインストールされ、
stratisdサービスが実行されている。Web コンソールがデフォルトで Stratis を検出してインストールしている。ただし、Stratis を手動でインストールする場合は、Stratis のインストール を参照してください。
- 既存の Stratis プールがあり、その Stratis プール上にファイルシステムが作成されている。
手順
RHEL 8 Web コンソールにログインします。
詳細は、Web コンソールへのログイン を参照してください。
- をクリックします。
- Storage テーブルで、ファイルシステムを削除する Stratis プールをクリックします。
- Stratis プール ページで、Stratis ファイルシステム セクションまでスクロールし、削除するファイルシステムのメニューボタン をクリックします。
- ドロップダウンメニューから を選択します。
- Confirm deletion ダイアログボックスで、 をクリックします。
35.5.3. Stratis プールの削除
既存の Stratis プールを削除できます。そこに保存されているデータは失われます。
前提条件
-
Stratis がインストールされ、
stratisdサービスが実行されている。詳細は、Stratis のインストール を参照してください。 Stratis プールを作成している。
- 暗号化されていないプールを作成するには、暗号化されていない Stratis プールの作成 を参照してください。
- 暗号化されたプールを作成するには、カーネルキーリング内のキーを使用して暗号化された Stratis プールを作成する を参照してください。
手順
プールにあるファイルシステムのリストを表示します。
# stratis filesystem list my-poolプール上のすべてのファイルシステムをアンマウントします。
# umount /dev/stratis/my-pool/my-fs-1 \ /dev/stratis/my-pool/my-fs-2 \ /dev/stratis/my-pool/my-fs-nファイルシステムを破棄します。
# stratis filesystem destroy my-pool my-fs-1 my-fs-2プールを破棄します。
# stratis pool destroy my-pool
検証
プールがなくなったことを確認します。
# stratis pool list
35.5.4. Web コンソールを使用した Stratis プールの削除
Web コンソールを使用して、既存の Stratis プールを削除できます。
Stratis プールを削除すると、そこに含まれるすべてのデータが消去されます。
前提条件
- RHEL 8 Web コンソールがインストールされている。
- cockpit サービスが有効になっている。
ユーザーアカウントが Web コンソールにログインできる。
手順は、Web コンソールのインストールおよび有効化 を参照してください。
-
stratisdサービスを実行している。 - 既存の Stratis プールがある。
手順
RHEL 8 Web コンソールにログインします。
詳細は、Web コンソールへのログイン を参照してください。
- をクリックします。
- ストレージ テーブルで、削除する Stratis プールのメニューボタン をクリックします。
- ドロップダウンメニューから を選択します。
- Permanently delete pool ダイアログボックスで、 をクリックします。
35.6. スワップの使用
スワップ領域を使用して、非アクティブなプロセスとデータに一時的なストレージを提供し、物理メモリーがいっぱいになった場合に発生するメモリー不足エラーを防ぎます。スワップ領域は物理メモリーの拡張として機能し、物理メモリーが使い果たされた場合でもシステムがスムーズに動作し続けることを可能にします。スワップ領域を使用するとシステムのパフォーマンスが低下する可能性があるため、スワップ領域を利用する前に物理メモリーの使用を最適化するほうが望ましい場合があることに注意してください。
35.6.1. スワップ領域の概要
Linux の スワップ領域 は、物理メモリー (RAM) が不足すると使用されます。システムに多くのメモリーリソースが必要で、RAM が不足すると、メモリーの非アクティブなページがスワップ領域に移動します。スワップ領域は、RAM が少ないマシンで役に立ちますが、RAM の代わりに使用しないようにしてください。
スワップ領域はハードドライブにあり、そのアクセス速度は物理メモリーに比べると遅くなります。スワップ領域の設定は、専用のスワップパーティション (推奨)、スワップファイル、またはスワップパーティションとスワップファイルの組み合せが考えられます。
過去数年、推奨されるスワップ領域のサイズは、システムの RAM サイズに比例して増加していました。しかし、最近のシステムには通常、数百ギガバイトの RAM が含まれます。結果として、推奨されるスワップ領域は、システムのメモリーではなく、システムメモリーのワークロードの機能とみなされます。
35.6.2. システムの推奨スワップ領域
推奨されるスワップパーティションのサイズは、システムの RAM の容量と、システムをハイバネートするのに十分なメモリーが必要かどうかによって異なります。推奨されるスワップパーティションのサイズは、インストール時に自動的に設定されます。ハイバネートを可能にするには、カスタムのパーティション分割段階でスワップ領域を編集する必要があります。
以下の推奨は、1 GB 以下など、メモリーが少ないシステムで特に重要です。このようなシステムで十分なスワップ領域を割り当てられないと、システムが不安定になったり、インストールしたシステムが起動できなくなったりする可能性があります。
| システム内の RAM の容量 | 推奨されるスワップ領域 | ハイバネートを許可する場合に推奨されるスワップ領域 |
|---|---|---|
| ⩽ 2 GB | RAM 容量の 2 倍 | RAM 容量の 3 倍 |
| > 2 GB - 8 GB | RAM 容量と同じ | RAM 容量の 2 倍 |
| > 8 GB - 64 GB | 最低 4GB | RAM 容量の 1.5 倍 |
| > 64 GB | 最低 4GB | ハイバネートは推奨されない |
システム RAM が 2 GB、8 GB、または 64 GB などの境界値の場合は、必要に応じてスワップサイズを選択してください。システムリソースに余裕がある場合は、スワップ領域を増やすとパフォーマンスが向上することがあります。
高速のドライブ、コントローラー、およびインターフェイスを搭載したシステムでは、複数のストレージデバイスにスワップ領域を分散すると、スワップ領域のパフォーマンスも向上します。
スワップ領域として割り当てたファイルシステムおよび LVM2 ボリュームは、変更時に 使用しない でください。システムプロセスまたはカーネルがスワップ領域を使用していると、スワップの修正に失敗します。free コマンドおよび cat /proc/swaps コマンドを使用して、スワップの使用量と、使用中の場所を確認します。
スワップ領域のサイズを変更するには、システムから一時的にスワップ領域を削除する必要があります。これは、実行中のアプリケーションが追加のスワップ領域に依存し、メモリーが不足する可能性がある場合に問題になる可能性があります。できれば、レスキューモードからスワップのサイズ変更を実行してください。デバッグ起動オプション を参照してください。ファイルシステムをマウントするように指示されたら、 を選択します。
35.6.3. スワップ用の LVM2 論理ボリュームの作成
スワップ用の LVM2 論理ボリュームを作成できます。ここでは、追加するスワップボリュームを /dev/VolGroup00/LogVol02 とします。
前提条件
- 十分なディスク領域がある。
手順
サイズが 2 GB の LVM2 論理ボリュームを作成します。
# lvcreate VolGroup00 -n LogVol02 -L 2G新しいスワップ領域をフォーマットします。
# mkswap /dev/VolGroup00/LogVol02次のエントリーを
/etc/fstabファイルに追加します。/dev/VolGroup00/LogVol02 none swap defaults 0 0システムが新しい設定を登録するように、マウントユニットを再生成します。
# systemctl daemon-reload論理ボリュームでスワップをアクティブにします。
# swapon -v /dev/VolGroup00/LogVol02
検証
スワップ論理ボリュームが正常に作成され、アクティブになったかをテストするには、次のコマンドを使用して、アクティブなスワップ領域を調べます。
# cat /proc/swaps total used free shared buff/cache available Mem: 30Gi 1.2Gi 28Gi 12Mi 994Mi 28Gi Swap: 22Gi 0B 22Gi# free -h total used free shared buff/cache available Mem: 30Gi 1.2Gi 28Gi 12Mi 995Mi 28Gi Swap: 17Gi 0B 17Gi
35.6.4. スワップファイルの作成
システムのメモリーが不足しているときに、スワップファイルを作成して、ソリッドステートドライブまたはハードディスク上に一時的なストレージ領域を作成できます。
前提条件
- 十分なディスク領域がある。
手順
- 新しいスワップファイルのサイズをメガバイト単位で指定してから、そのサイズに 1024 をかけてブロック数を指定します。たとえばスワップファイルのサイズが 64 MB の場合は、ブロック数が 65536 になります。
空のファイルの作成:
# dd if=/dev/zero of=/swapfile bs=1024 count=6553665536 を、必要なブロックサイズと同じ値に置き換えます。
次のコマンドでスワップファイルをセットアップします。
# mkswap /swapfileスワップファイルのセキュリティーを変更して、全ユーザーで読み込みができないようにします。
# chmod 0600 /swapfileシステムの起動時にスワップファイルを有効にするには、次のエントリーを使用して
/etc/fstabファイルを編集します。/swapfile none swap defaults 0 0次にシステムが起動すると新しいスワップファイルが有効になります。
システムが新しい
/etc/fstab設定を登録するように、マウントユニットを再生成します。# systemctl daemon-reloadすぐにスワップファイルをアクティブにします。
# swapon /swapfile
検証
新しいスワップファイルが正常に作成され、有効になったかをテストするには、次のコマンドを使用して、アクティブなスワップ領域を調べます。
$ cat /proc/swaps$ free -h
35.6.5. storage RHEL システムロールを使用してスワップボリュームを作成する
このセクションでは、Ansible Playbook の例を示します。この Playbook は、storage ロールを適用し、デフォルトのパラメーターを使用して、ブロックデバイスにスワップボリュームが存在しない場合は作成し、スワップボリュームがすでに存在する場合はそれを変更します。
前提条件
- コントロールノードと管理対象ノードの準備が完了している。
- 管理対象ノードで Playbook を実行できるユーザーとしてコントロールノードにログインしている。
-
管理対象ノードへの接続に使用するアカウントに、そのノードに対する
sudo権限がある。
手順
次の内容を含む Playbook ファイル (例:
~/playbook.yml) を作成します。--- - name: Create a disk device with swap hosts: managed-node-01.example.com roles: - rhel-system-roles.storage vars: storage_volumes: - name: swap_fs type: disk disks: - /dev/sdb size: 15 GiB fs_type: swap現在、ボリューム名 (この例では
swap_fs) は任意です。storageロールは、disks:属性にリスト表示されているディスクデバイスでボリュームを特定します。Playbook の構文を検証します。
$ ansible-playbook --syntax-check ~/playbook.ymlこのコマンドは構文を検証するだけであり、有効だが不適切な設定から保護するものではないことに注意してください。
Playbook を実行します。
$ ansible-playbook ~/playbook.yml
35.6.6. LVM2 論理ボリュームでのスワップ領域の拡張
既存の LVM2 論理ボリューム上のスワップ領域を拡張できます。ここでは、2 GB 拡張するボリュームを /dev/VolGroup00/LogVol01 とします。
前提条件
- 十分なディスク領域がある。
手順
関連付けられている論理ボリュームのスワップ機能を無効にします。
# swapoff -v /dev/VolGroup00/LogVol01LVM2 論理ボリュームのサイズを 2 GB 増やします。
# lvresize /dev/VolGroup00/LogVol01 -L +2G新しいスワップ領域をフォーマットします。
# mkswap /dev/VolGroup00/LogVol01拡張論理ボリュームを有効にします。
# swapon -v /dev/VolGroup00/LogVol01
検証
スワップの論理ボリュームの拡張に成功したかどうかをテストするには、アクティブなスワップ容量を調べます。
# cat /proc/swaps Filename Type Size Used Priority /dev/dm-1 partition 16322556 0 -2 /dev/dm-4 partition 7340028 0 -3# free -h total used free shared buff/cache available Mem: 30Gi 1.2Gi 28Gi 12Mi 994Mi 28Gi Swap: 22Gi 0B 22Gi
35.6.7. LVM2 論理ボリュームでのスワップ領域の縮小
LVM2 論理ボリュームのスワップ領域を縮小できます。ここでは、縮小するボリュームを /dev/VolGroup00/LogVol01 とします。
手順
関連付けられている論理ボリュームのスワップ機能を無効にします。
# swapoff -v /dev/VolGroup00/LogVol01スワップ署名を削除します。
# wipefs -a /dev/VolGroup00/LogVol01LVM2 論理ボリュームのサイズを変更して 512 MB 削減します。
# lvreduce /dev/VolGroup00/LogVol01 -L -512M新しいスワップ領域をフォーマットします。
# mkswap /dev/VolGroup00/LogVol01論理ボリュームでスワップをアクティブにします。
# swapon -v /dev/VolGroup00/LogVol01
検証
スワップ論理ボリュームが正常に削減されたかをテストするには、次のコマンドを使用して、アクティブなスワップ領域を調べます。
$ cat /proc/swaps$ free -h
35.6.8. スワップ用の LVM2 論理ボリュームの削除
スワップ用の LVM2 論理ボリュームを削除できます。削除するスワップボリュームを /dev/VolGroup00/LogVol02 とします。
手順
関連付けられている論理ボリュームのスワップ機能を無効にします。
# swapoff -v /dev/VolGroup00/LogVol02LVM2 論理ボリュームを削除します。
# lvremove /dev/VolGroup00/LogVol02次の関連エントリーを
/etc/fstabファイルから削除します。/dev/VolGroup00/LogVol02 none swap defaults 0 0マウントユニットを再生成して新しい設定を登録します。
# systemctl daemon-reload
検証
論理ボリュームが正常に削除されたかどうかをテストし、次のコマンドを使用してアクティブなスワップ領域を調べます。
$ cat /proc/swaps$ free -h
35.6.9. スワップファイルの削除
スワップファイルを削除できます。
手順
/swapfileスワップファイルを無効にします。# swapoff -v /swapfile-
/etc/fstabファイルからエントリーを削除します。 システムが新しい設定を登録するように、マウントユニットを再生成します。
# systemctl daemon-reload実際のファイルを削除します。
# rm /swapfile
35.7. RHEL システムロールを使用したローカルストレージの管理
Ansible を使用して LVM とローカルファイルシステム (FS) を管理するには、RHEL 8 で使用可能な RHEL システムロールの 1 つである storage ロールを使用できます。
storage ロールを使用すると、ディスク上のファイルシステム、複数のマシンにある論理ボリューム、および RHEL 7.7 以降の全バージョンでのファイルシステムの管理を自動化できます。
RHEL システムロールと、その適用方法の詳細は、RHEL システムロールの概要 を参照してください。
35.7.1. storage RHEL システムロールを使用してブロックデバイスに XFS ファイルシステムを作成する
このサンプルの Ansible Playbook では、ストレージロールを使用して、デフォルトのパラメーターでブロックデバイス上に XFS ファイルシステムを作成します。/dev/sdb デバイス上のファイルシステム、またはマウントポイントのディレクトリーが存在しない場合は、Playbook により作成されます。
storage ロールは、パーティションが分割されていないディスク全体または論理ボリューム (LV) でのみファイルシステムを作成できます。パーティションにファイルシステムを作成することはできません。
前提条件
- コントロールノードと管理対象ノードの準備が完了している。
- 管理対象ノードで Playbook を実行できるユーザーとしてコントロールノードにログインしている。
-
管理対象ノードへの接続に使用するアカウントに、そのノードに対する
sudo権限がある。
手順
次の内容を含む Playbook ファイル (例:
~/playbook.yml) を作成します。--- - name: Manage local storage hosts: managed-node-01.example.com tasks: - name: Create an XFS file system on a block device ansible.builtin.include_role: name: redhat.rhel_system_roles.storage vars: storage_volumes: - name: barefs type: disk disks: - sdb fs_type: xfsサンプル Playbook で指定されている設定は次のとおりです。
name: barefs-
現在、ボリューム名 (この例では
barefs) は任意です。storageロールは、disks属性にリストされているディスクデバイスによってボリュームを識別します。 fs_type: <file_system>-
デフォルトのファイルシステム XFS を使用する場合は、
fs_typeパラメーターを省略できます。 disks: <list_of_disks_and_volumes>ディスク名と LV 名の YAML リスト。LV 上にファイルシステムを作成するには、その LV を含んでいるボリュームグループも含めて、
disks属性に LVM 設定を指定します。詳細は、storage RHEL システムロールを使用して論理ボリュームを作成またはサイズ変更する を参照してください。LV デバイスへのパスを指定しないでください。
Playbook で使用されるすべての変数の詳細は、コントロールノードの
/usr/share/ansible/roles/rhel-system-roles.storage/README.mdファイルを参照してください。Playbook の構文を検証します。
$ ansible-playbook --syntax-check ~/playbook.ymlこのコマンドは構文を検証するだけであり、有効だが不適切な設定から保護するものではないことに注意してください。
Playbook を実行します。
$ ansible-playbook ~/playbook.yml
35.7.2. storage RHEL システムロールを使用してファイルシステムを永続的にマウントする
このサンプルの Ansible Playbook では、ストレージロールを使用して、既存のファイルシステムを永続的にマウントします。/etc/fstab ファイルに適切なエントリーを追加することで、ファイルシステムを即座に使用可能にして永続的にマウントします。これにより、ファイルシステムを再起動後もマウントしたままにできます。/dev/sdb デバイス上のファイルシステム、またはマウントポイントのディレクトリーが存在しない場合は、Playbook により作成されます。
前提条件
- コントロールノードと管理対象ノードの準備が完了している。
- 管理対象ノードで Playbook を実行できるユーザーとしてコントロールノードにログインしている。
-
管理対象ノードへの接続に使用するアカウントに、そのノードに対する
sudo権限がある。
手順
次の内容を含む Playbook ファイル (例:
~/playbook.yml) を作成します。--- - name: Manage local storage hosts: managed-node-01.example.com tasks: - name: Persistently mount a file system ansible.builtin.include_role: name: redhat.rhel_system_roles.storage vars: storage_volumes: - name: barefs type: disk disks: - sdb fs_type: xfs mount_point: /mnt/data mount_user: somebody mount_group: somegroup mount_mode: 0755Playbook で使用されるすべての変数の詳細は、コントロールノードの
/usr/share/ansible/roles/rhel-system-roles.storage/README.mdファイルを参照してください。Playbook の構文を検証します。
$ ansible-playbook --syntax-check ~/playbook.ymlこのコマンドは構文を検証するだけであり、有効だが不適切な設定から保護するものではないことに注意してください。
Playbook を実行します。
$ ansible-playbook ~/playbook.yml
35.7.3. storage RHEL システムロールを使用して論理ボリュームを作成またはサイズ変更する
storage ロールを使用して、次のタスクを実行します。
- 多数のディスクで構成されるボリュームグループに LVM 論理ボリュームを作成する
- LVM 上の既存のファイルシステムのサイズを変更する
- LVM ボリュームのサイズをプールの合計サイズのパーセンテージで表す
ボリュームグループが存在しない場合、このロールによって作成されます。ボリュームグループ内に論理ボリュームが存在する場合に、そのサイズが Playbook で指定されたサイズと一致しないと、サイズが変更されます。
論理ボリュームを縮小する場合、データの損失を防ぐために、その論理ボリューム上のファイルシステムによって、縮小する論理ボリューム内の領域が使用されていないことを確認する必要があります。
前提条件
- コントロールノードと管理対象ノードの準備が完了している。
- 管理対象ノードで Playbook を実行できるユーザーとしてコントロールノードにログインしている。
-
管理対象ノードへの接続に使用するアカウントに、そのノードに対する
sudo権限がある。
手順
次の内容を含む Playbook ファイル (例:
~/playbook.yml) を作成します。--- - name: Manage local storage hosts: managed-node-01.example.com tasks: - name: Create logical volume ansible.builtin.include_role: name: redhat.rhel_system_roles.storage vars: storage_pools: - name: myvg disks: - sda - sdb - sdc volumes: - name: mylv size: 2G fs_type: ext4 mount_point: /mnt/dataサンプル Playbook で指定されている設定は次のとおりです。
size: <size>- 単位 (GiB など) またはパーセンテージ (60% など) を使用してサイズを指定する必要があります。
Playbook で使用されるすべての変数の詳細は、コントロールノードの
/usr/share/ansible/roles/rhel-system-roles.storage/README.mdファイルを参照してください。Playbook の構文を検証します。
$ ansible-playbook --syntax-check ~/playbook.ymlこのコマンドは構文を検証するだけであり、有効だが不適切な設定から保護するものではないことに注意してください。
Playbook を実行します。
$ ansible-playbook ~/playbook.yml
検証
指定したボリュームが作成されたこと、または要求したサイズに変更されたことを確認します。
# ansible managed-node-01.example.com -m command -a 'lvs myvg'
35.7.4. storage RHEL システムロールを使用してオンラインのブロック破棄を有効にする
オンラインブロック破棄オプションを使用すると、XFS ファイルシステムをマウントし、未使用のブロックを自動的に破棄できます。
前提条件
- コントロールノードと管理対象ノードの準備が完了している。
- 管理対象ノードで Playbook を実行できるユーザーとしてコントロールノードにログインしている。
-
管理対象ノードへの接続に使用するアカウントに、そのノードに対する
sudo権限がある。
手順
次の内容を含む Playbook ファイル (例:
~/playbook.yml) を作成します。--- - name: Manage local storage hosts: managed-node-01.example.com tasks: - name: Enable online block discard ansible.builtin.include_role: name: redhat.rhel_system_roles.storage vars: storage_volumes: - name: barefs type: disk disks: - sdb fs_type: xfs mount_point: /mnt/data mount_options: discardPlaybook で使用されるすべての変数の詳細は、コントロールノードの
/usr/share/ansible/roles/rhel-system-roles.storage/README.mdファイルを参照してください。Playbook の構文を検証します。
$ ansible-playbook --syntax-check ~/playbook.ymlこのコマンドは構文を検証するだけであり、有効だが不適切な設定から保護するものではないことに注意してください。
Playbook を実行します。
$ ansible-playbook ~/playbook.yml
検証
オンラインブロック破棄オプションが有効になっていることを確認します。
# ansible managed-node-01.example.com -m command -a 'findmnt /mnt/data'
35.7.5. storage RHEL システムロールを使用してファイルシステムを作成およびマウントする
このサンプルの Ansible Playbook では、storage ロールを使用してファイルシステムを作成およびマウントします。/etc/fstab ファイルに適切なエントリーを追加することで、ファイルシステムを即座に使用可能にして永続的にマウントします。これにより、ファイルシステムを再起動後もマウントしたままにできます。/dev/sdb デバイス上のファイルシステム、またはマウントポイントのディレクトリーが存在しない場合は、Playbook により作成されます。
前提条件
- コントロールノードと管理対象ノードの準備が完了している。
- 管理対象ノードで Playbook を実行できるユーザーとしてコントロールノードにログインしている。
-
管理対象ノードへの接続に使用するアカウントに、そのノードに対する
sudo権限がある。
手順
次の内容を含む Playbook ファイル (例:
~/playbook.yml) を作成します。--- - name: Manage local storage hosts: managed-node-01.example.com tasks: -name: Create and mount a file system ansible.builtin.include_role: name: redhat.rhel_system_roles.storage vars: storage_volumes: - name: barefs type: disk disks: - sdb fs_type: ext4 fs_label: label-name mount_point: /mnt/dataサンプル Playbook で指定されている設定は次のとおりです。
disks: <list_of_devices>- ロールがボリュームを作成するときに使用するデバイス名の YAML リスト。
fs_type: <file_system>-
ロールがボリュームに設定するファイルシステムを指定します。
xfs、ext3、ext4、swap、またはunformattedを選択できます。 label-name: <file_system_label>- オプション: ファイルシステムのラベルを設定します。
mount_point: <directory>-
オプション: ボリュームを自動的にマウントする場合は、
mount_point変数をボリュームのマウント先のディレクトリーに設定します。
Playbook で使用されるすべての変数の詳細は、コントロールノードの
/usr/share/ansible/roles/rhel-system-roles.storage/README.mdファイルを参照してください。Playbook の構文を検証します。
$ ansible-playbook --syntax-check ~/playbook.ymlこのコマンドは構文を検証するだけであり、有効だが不適切な設定から保護するものではないことに注意してください。
Playbook を実行します。
$ ansible-playbook ~/playbook.yml
35.7.6. storage RHEL システムロールを使用した RAID ボリュームの設定
storage システムロールを使用すると、Red Hat Ansible Automation Platform と Ansible-Core を使用して RHEL に RAID ボリュームを設定できます。要件に合わせて RAID ボリュームを設定するためのパラメーターを使用して、Ansible Playbook を作成します。
特定の状況でデバイス名が変更する場合があります。たとえば、新しいディスクをシステムに追加するときなどです。したがって、データの損失を防ぐために、Playbook では永続的な命名属性を使用してください。永続的な命名属性の詳細は、永続的な命名属性の概要を 参照してください。
前提条件
- コントロールノードと管理対象ノードの準備が完了している。
- 管理対象ノードで Playbook を実行できるユーザーとしてコントロールノードにログインしている。
-
管理対象ノードへの接続に使用するアカウントに、そのノードに対する
sudo権限がある。
手順
次の内容を含む Playbook ファイル (例:
~/playbook.yml) を作成します。--- - name: Manage local storage hosts: managed-node-01.example.com tasks: - name: Create a RAID on sdd, sde, sdf, and sdg ansible.builtin.include_role: name: redhat.rhel_system_roles.storage vars: storage_safe_mode: false storage_volumes: - name: data type: raid disks: [sdd, sde, sdf, sdg] raid_level: raid0 raid_chunk_size: 32 KiB mount_point: /mnt/data state: presentPlaybook で使用されるすべての変数の詳細は、コントロールノードの
/usr/share/ansible/roles/rhel-system-roles.storage/README.mdファイルを参照してください。Playbook の構文を検証します。
$ ansible-playbook --syntax-check ~/playbook.ymlこのコマンドは構文を検証するだけであり、有効だが不適切な設定から保護するものではないことに注意してください。
Playbook を実行します。
$ ansible-playbook ~/playbook.yml
検証
アレイが正しく作成されたことを確認します。
# ansible managed-node-01.example.com -m command -a 'mdadm --detail /dev/md/data'
35.7.7. storage RHEL システムロールを使用して RAID を備えた LVM プールを設定する
storage システムロールを使用すると、Red Hat Ansible Automation Platform を使用して、RAID を備えた LVM プールを RHEL に設定できます。利用可能なパラメーターを使用して Ansible Playbook を設定し、RAID を備えた LVM プールを設定できます。
前提条件
- コントロールノードと管理対象ノードの準備が完了している。
- 管理対象ノードで Playbook を実行できるユーザーとしてコントロールノードにログインしている。
-
管理対象ノードへの接続に使用するアカウントに、そのノードに対する
sudo権限がある。
手順
次の内容を含む Playbook ファイル (例:
~/playbook.yml) を作成します。--- - name: Manage local storage hosts: managed-node-01.example.com tasks: - name: Configure LVM pool with RAID ansible.builtin.include_role: name: redhat.rhel_system_roles.storage vars: storage_safe_mode: false storage_pools: - name: my_pool type: lvm disks: [sdh, sdi] raid_level: raid1 volumes: - name: my_volume size: "1 GiB" mount_point: "/mnt/app/shared" fs_type: xfs state: presentPlaybook で使用されるすべての変数の詳細は、コントロールノードの
/usr/share/ansible/roles/rhel-system-roles.storage/README.mdファイルを参照してください。Playbook の構文を検証します。
$ ansible-playbook --syntax-check ~/playbook.ymlこのコマンドは構文を検証するだけであり、有効だが不適切な設定から保護するものではないことに注意してください。
Playbook を実行します。
$ ansible-playbook ~/playbook.yml
検証
プールが RAID 上にあることを確認します。
# ansible managed-node-01.example.com -m command -a 'lsblk'
35.7.8. storage RHEL システムロールを使用して RAID LVM ボリュームのストライプサイズを設定する
storage システムロールを使用すると、Red Hat Ansible Automation Platform を使用して、RHEL の RAID LVM ボリュームのストライプサイズを設定できます。利用可能なパラメーターを使用して Ansible Playbook を設定し、RAID を備えた LVM プールを設定できます。
前提条件
- コントロールノードと管理対象ノードの準備が完了している。
- 管理対象ノードで Playbook を実行できるユーザーとしてコントロールノードにログインしている。
-
管理対象ノードへの接続に使用するアカウントに、そのノードに対する
sudo権限がある。
手順
次の内容を含む Playbook ファイル (例:
~/playbook.yml) を作成します。--- - name: Manage local storage hosts: managed-node-01.example.com tasks: - name: Configure stripe size for RAID LVM volumes ansible.builtin.include_role: name: redhat.rhel_system_roles.storage vars: storage_safe_mode: false storage_pools: - name: my_pool type: lvm disks: [sdh, sdi] volumes: - name: my_volume size: "1 GiB" mount_point: "/mnt/app/shared" fs_type: xfs raid_level: raid0 raid_stripe_size: "256 KiB" state: presentPlaybook で使用されるすべての変数の詳細は、コントロールノードの
/usr/share/ansible/roles/rhel-system-roles.storage/README.mdファイルを参照してください。Playbook の構文を検証します。
$ ansible-playbook --syntax-check ~/playbook.ymlこのコマンドは構文を検証するだけであり、有効だが不適切な設定から保護するものではないことに注意してください。
Playbook を実行します。
$ ansible-playbook ~/playbook.yml
検証
ストライプサイズが必要なサイズに設定されていることを確認します。
# ansible managed-node-01.example.com -m command -a 'lvs -o+stripesize /dev/my_pool/my_volume'
35.7.9. storage RHEL システムロールを使用して LVM-VDO ボリュームを設定する
storage RHEL システムロールを使用して、圧縮と重複排除を有効にした LVM 上の VDO ボリューム (LVM-VDO) を作成できます。
storage システムロールが LVM VDO を使用するため、プールごとに作成できるボリュームは 1 つだけです。
前提条件
- コントロールノードと管理対象ノードの準備が完了している。
- 管理対象ノードで Playbook を実行できるユーザーとしてコントロールノードにログインしている。
-
管理対象ノードへの接続に使用するアカウントに、そのノードに対する
sudo権限がある。
手順
次の内容を含む Playbook ファイル (例:
~/playbook.yml) を作成します。--- - name: Manage local storage hosts: managed-node-01.example.com tasks: - name: Create LVM-VDO volume under volume group 'myvg' ansible.builtin.include_role: name: redhat.rhel_system_roles.storage vars: storage_pools: - name: myvg disks: - /dev/sdb volumes: - name: mylv1 compression: true deduplication: true vdo_pool_size: 10 GiB size: 30 GiB mount_point: /mnt/app/sharedサンプル Playbook で指定されている設定は次のとおりです。
vdo_pool_size: <size>- デバイス上でボリュームが占める実際のサイズ。サイズは、10 GiB など、人間が判読できる形式で指定できます。単位を指定しない場合、デフォルトでバイト単位に設定されます。
size: <size>- VDO ボリュームの仮想サイズ。
Playbook で使用されるすべての変数の詳細は、コントロールノードの
/usr/share/ansible/roles/rhel-system-roles.storage/README.mdファイルを参照してください。Playbook の構文を検証します。
$ ansible-playbook --syntax-check ~/playbook.ymlこのコマンドは構文を検証するだけであり、有効だが不適切な設定から保護するものではないことに注意してください。
Playbook を実行します。
$ ansible-playbook ~/playbook.yml
検証
圧縮と重複排除の現在のステータスを表示します。
$ ansible managed-node-01.example.com -m command -a 'lvs -o+vdo_compression,vdo_compression_state,vdo_deduplication,vdo_index_state' LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert VDOCompression VDOCompressionState VDODeduplication VDOIndexState mylv1 myvg vwi-a-v--- 3.00t vpool0 enabled online enabled online
35.7.10. storage RHEL システムロールを使用して LUKS2 暗号化ボリュームを作成する
storage ロールを使用し、Ansible Playbook を実行して、LUKS で暗号化されたボリュームを作成および設定できます。
前提条件
- コントロールノードと管理対象ノードの準備が完了している。
- 管理対象ノードで Playbook を実行できるユーザーとしてコントロールノードにログインしている。
-
管理対象ノードへの接続に使用するアカウントに、そのノードに対する
sudo権限がある。
手順
機密性の高い変数を暗号化されたファイルに保存します。
vault を作成します。
$ ansible-vault create ~/vault.yml New Vault password: <vault_password> Confirm New Vault password: <vault_password>ansible-vault createコマンドでエディターが開いたら、機密データを<key>: <value>形式で入力します。luks_password: <password>- 変更を保存して、エディターを閉じます。Ansible は vault 内のデータを暗号化します。
次の内容を含む Playbook ファイル (例:
~/playbook.yml) を作成します。--- - name: Manage local storage hosts: managed-node-01.example.com vars_files: - ~/vault.yml tasks: - name: Create and configure a volume encrypted with LUKS ansible.builtin.include_role: name: redhat.rhel_system_roles.storage vars: storage_volumes: - name: barefs type: disk disks: - sdb fs_type: xfs fs_label: <label> mount_point: /mnt/data encryption: true encryption_password: "{{ luks_password }}"Playbook で使用されるすべての変数の詳細は、コントロールノードの
/usr/share/ansible/roles/rhel-system-roles.storage/README.mdファイルを参照してください。Playbook の構文を検証します。
$ ansible-playbook --ask-vault-pass --syntax-check ~/playbook.ymlこのコマンドは構文を検証するだけであり、有効だが不適切な設定から保護するものではないことに注意してください。
Playbook を実行します。
$ ansible-playbook --ask-vault-pass ~/playbook.yml
検証
LUKS 暗号化ボリュームの
luksUUID値を見つけます。# ansible managed-node-01.example.com -m command -a 'cryptsetup luksUUID /dev/sdb' 4e4e7970-1822-470e-b55a-e91efe5d0f5cボリュームの暗号化ステータスを表示します。
# ansible managed-node-01.example.com -m command -a 'cryptsetup status luks-4e4e7970-1822-470e-b55a-e91efe5d0f5c' /dev/mapper/luks-4e4e7970-1822-470e-b55a-e91efe5d0f5c is active and is in use. type: LUKS2 cipher: aes-xts-plain64 keysize: 512 bits key location: keyring device: /dev/sdb ...作成された LUKS 暗号化ボリュームを確認します。
# ansible managed-node-01.example.com -m command -a 'cryptsetup luksDump /dev/sdb' LUKS header information Version: 2 Epoch: 3 Metadata area: 16384 [bytes] Keyslots area: 16744448 [bytes] UUID: 4e4e7970-1822-470e-b55a-e91efe5d0f5c Label: (no label) Subsystem: (no subsystem) Flags: (no flags) Data segments: 0: crypt offset: 16777216 [bytes] length: (whole device) cipher: aes-xts-plain64 sector: 512 [bytes] ...
第36章 ストレージの重複排除および圧縮
36.1. VDO のデプロイメント
システム管理者は、VDO を使用してストレージプールの重複を排除して、圧縮できます。
36.1.1. VDO の概要
VDO (Virtual Data Optimizer) は、重複排除、圧縮、およびシンプロビジョニングの形で、Linux でインラインのデータ削減を行います。VDO ボリュームを設定する場合は、VDO ボリュームを構築するブロックデバイスと、作成する論理ストレージのサイズを指定します。
- アクティブな仮想マシンまたはコンテナーをホストする場合、Red Hat は、物理と論理の割合を 1 対 10 にすることを推奨します。つまり、物理ストレージを 1 TB にした場合は、論理ストレージを 10 TB にします。
- Ceph が提供するタイプなどのオブジェクトストレージの場合、Red Hat は、物理と論理の割合を 1 対 3 にすることを推奨します。つまり、物理ストレージを 1 TB にした場合は、論理ストレージを 3 TB にします。
いずれの場合も、VDO が作成する論理デバイスにファイルシステムを置くだけで、直接使用することも、分散クラウドストレージアーキテクチャーの一部として使用することもできます。
VDO はシンプロビジョニングされているため、ファイルシステムとアプリケーションは、使用中の論理領域だけを認識し、実際に利用可能な物理領域は認識しません。スクリプトを使用して、実際に利用可能な領域を監視し、使用量がしきい値を超えた場合 (たとえば、VDO ボリュームの使用量が 80% になった場合) にアラートを生成します。
36.1.2. VDO デプロイメントシナリオ
VDO は、様々な方法でデプロイして、以下に対して、重複排除したストレージを提供できます。
- ブロックおよびファイルアクセスの両方
- ローカルストレージおよびリモートストレージの両方
VDO は、標準の Linux ブロックデバイスとして重複排除したストレージを公開するため、そのストレージを標準ファイルシステム、iSCSI および FC のターゲットドライバー、または統合ストレージとして使用できます。
現在、Ceph RADOS ブロックデバイス (RBD) 上での VDO ボリュームのデプロイがサポートされています。ただし、VDO ボリューム上での Red Hat Ceph Storage クラスターコンポーネントのデプロイは現在サポートされていません。
KVM
DAS (Direct Attached Storage) を使用して設定した KVM サーバーに VDO をデプロイできます。

ファイルシステム
VDO にファイルシステムを作成して、NFS サーバーまたは Samba で、NFS ユーザーまたは CIFS ユーザーに公開します。

iSCSI への VDO の配置
VDO ストレージターゲット全体を、iSCSI ターゲットとしてリモート iSCSI イニシエーターにエクスポートできます。

iSCSI で VDO ボリュームを作成する場合は、VDO ボリュームを iSCSI レイヤーの上または下に配置できます。考慮すべき点はたくさんありますが、ここでは、環境に最適な方法を選択するのに役立つガイドラインをいくつか示します。
VDO ボリュームを iSCSI レイヤーの下の iSCSI サーバー (ターゲット) に配置する場合:
- VDO ボリュームは、他の iSCSI LUN と同様に、イニシエーターに対して透過的です。シンプロビジョニングとスペースの節約をクライアントから隠すことで、LUN の外観の監視と保守が容易になります。
- VDO メタデータの読み取りまたは書き込みがないため、ネットワークトラフィックが減少し、重複排除アドバイスの読み取り検証がネットワーク全体で発生しません。
- iSCSI ターゲットで使用されているメモリーと CPU リソースにより、パフォーマンスが向上する可能性があります。たとえば、iSCSI ターゲットでボリュームの削減が行われているため、ハイパーバイザーの数を増やすことができます。
- クライアントがイニシエーターに暗号化を実装し、ターゲットの下に VDO ボリュームがある場合、スペースの節約は実現しません。
VDO ボリュームを iSCSI レイヤーの上の iSCSI クライアント (イニシエーター) に配置する場合:
- 高いスペース節約率を達成する場合、ASYNC モードでネットワーク全体のネットワークトラフィックが低下する可能性があります。
- スペースの節約を直接表示および制御し、使用状況を監視できます。
-
たとえば、
dm-cryptを使用してデータを暗号化する場合は、暗号の上に VDO を実装して、スペース効率を利用できます。
LVM
より機能豊富なシステムでは、LVM を使用して、重複排除した同じストレージプールですべて対応している複数の論理ユニット番号 (LUN) を提供できます。
以下の図は、VDO ターゲットが物理ボリュームとして登録されるため、LVM で管理できます。複数の論理ボリューム (LV1 から LV4) が、重複排除したストレージプールから作成されます。これにより、VDO は、基となる重複排除したストレージプールへのマルチプロトコル統合ブロックまたはファイルアクセスに対応できます。
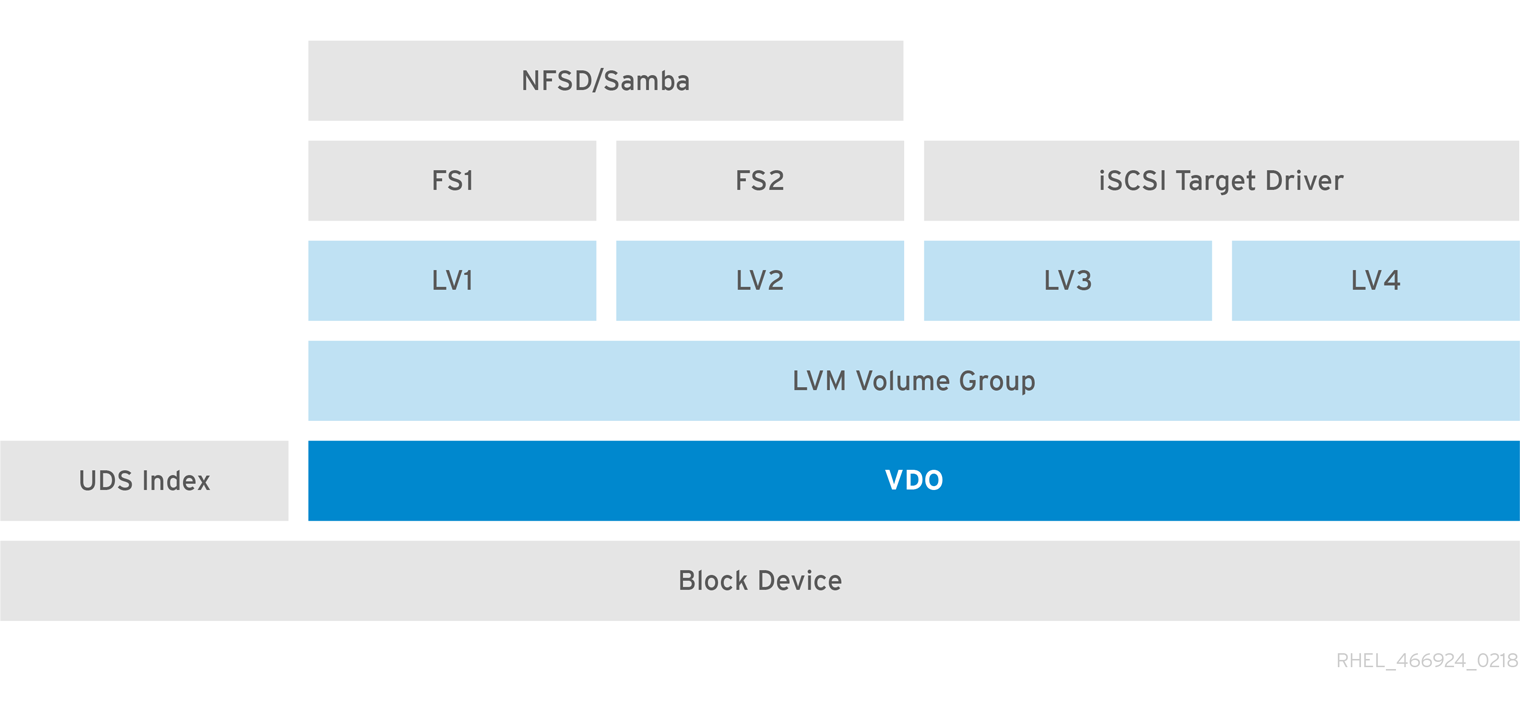
重複排除した統合ストレージ設計により、複数のファイルシステムが、LVM ツールを介して同じ重複排除ドメインを共同で使用できます。また、ファイルシステムは、LVM スナップショット、コピーオンライト、縮小機能、拡大機能、および VDO にある全機能を利用できます。
暗号化
DM Crypt などのデバイスマッパー (DM) メカニズムは VDO と互換性があります。VDO ボリュームの暗号化により、データセキュリティーと、VDO にある全ファイルシステムが重複排除されるようになります。
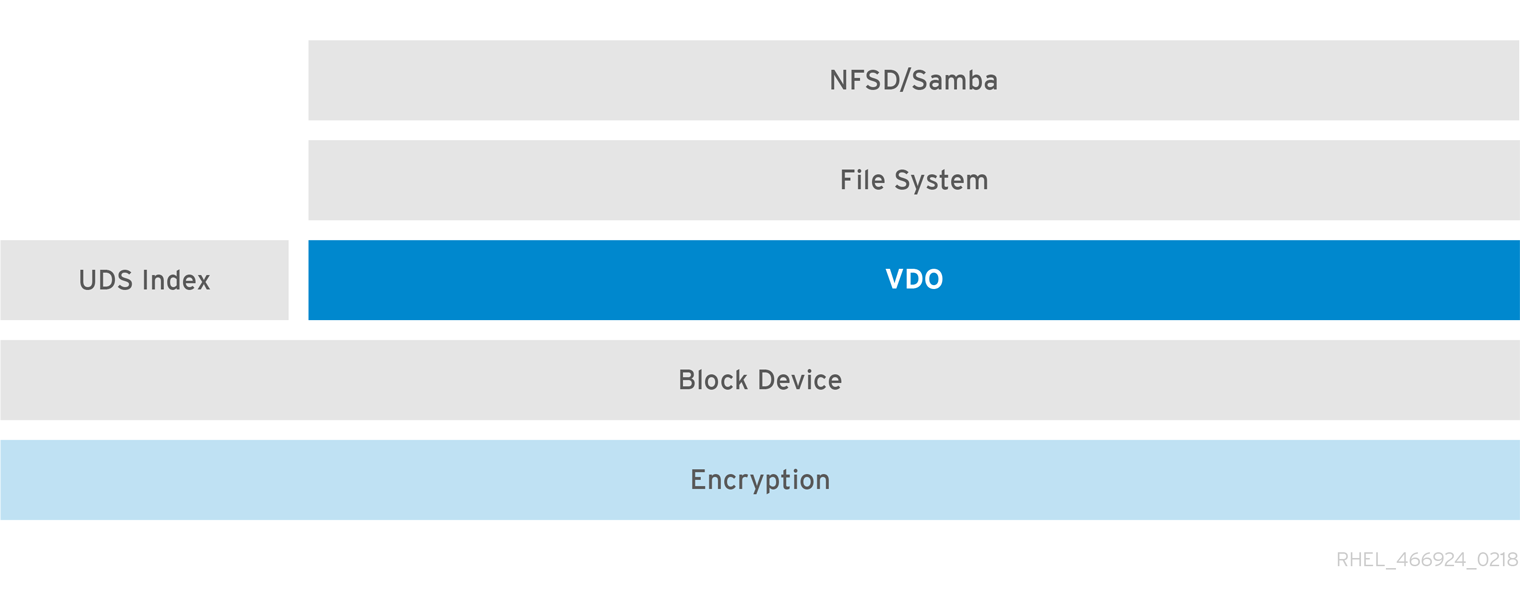
VDO で暗号化層を適用すると、データの重複排除が行われてもほとんど行われません。暗号化により、VDO が重複を排除する前に、重複ブロックを変更します。
常に VDO の下に暗号化層を配置します。
36.1.3. VDO ボリュームのコンポーネント
VDO は、バッキングストアとしてブロックデバイスを使用します。これは、複数のディスク、パーティション、またはフラットファイルで設定される物理ストレージの集約を含めることができます。ストレージ管理ツールが VDO ボリュームを作成すると、VDO は、UDS インデックスおよび VDO ボリュームのボリューム領域を予約します。UDS インデックスと VDO ボリュームは対話して、重複排除したブロックストレージを提供します。
図36.1 VDO ディスク組織

VDO ソリューションは、以下のコンポーネントで設定されます。
kvdoLinux Device Mapper 層に読み込まれるカーネルモジュールは、重複排除され、圧縮され、シンプロビジョニングされたブロックストレージボリュームを提供します。
kvdoモジュールはブロックデバイスを公開します。ブロックストレージ用にこのブロックデバイスに直接アクセスするか、XFS や ext4 などの Linux ファイルシステムを介して提示することができます。kvdoが VDO ボリュームからデータ論理ブロックを読み取る要求を受信すると、要求された論理ブロックを基礎となる物理ブロックにマッピングし、要求したデータを読み取り、返します。kvdoが VDO ボリュームにデータブロックを書き込む要求を受信すると、まず要求が DISCARD または TRIM のものであるか、またはデータが一貫してゼロかどうかを確認します。これらの条件のいずれかが true の場合、kvdoはブロックマップを更新し、リクエストを承認します。そうでない場合は、VDO はデータを処理して最適化します。udsボリューム上の Universal Deduplication Service (UDS) インデックスと通信し、データの重複を分析するカーネルモジュール。新しい各データについて、その部分が保存してあるデータ内容と同一であるかどうかを UDS が素早く判断します。インデックスが一致すると、ストレージシステムは、同じ情報を複数格納しないように、既存の項目を内部的に参照できます。
UDS インデックスは、
udsカーネルモジュールとしてカーネル内で実行します。- コマンドラインツール
- 最適化されたストレージの設定および管理
36.1.4. VDO ボリュームの物理サイズおよび論理サイズ
VDO は、物理サイズ、利用可能な物理サイズ、および論理サイズを次の方法で利用します。
- 物理サイズ
これは、基礎となるブロックデバイスと同じサイズです。VDO は、以下の目的でこのストレージを使用します。
- 重複排除および圧縮される可能性があるユーザーデータ
- UDS インデックスなどの VDO メタデータ
- 利用可能な物理サイズ
これは、VDO がユーザーデータに使用できる物理サイズの一部です。
これは、メタデータのサイズを引いた物理サイズと同等で、指定のスラブサイズでボリュームをスラブに分割した後の残りを引いたものと同じです。
- 論理サイズ
これは、VDO ボリュームがアプリケーションに提示するプロビジョニングされたサイズです。通常、これは利用可能な物理サイズよりも大きくなります。
--vdoLogicalSizeオプションを指定しないと、論理ボリュームのプロビジョニングが1:1の比率にプロビジョニングされます。たとえば、VDO ボリュームが 20 GB ブロックデバイスの上に置かれている場合は、2.5 GB が UDS インデックス用に予約されます (デフォルトのインデックスサイズが使用される場合)。残りの 17.5 GB は、VDO メタデータおよびユーザーデータに提供されます。そのため、消費する利用可能なストレージは 17.5 GB を超えません。実際の VDO ボリュームを設定するメタデータにより、これよりも少なくなる可能性があります。VDO は現在、絶対最大論理サイズ 4PB の物理ボリュームの最大 254 倍の論理サイズに対応します。
図36.2 VDO ディスク組織
この図では、VDO で重複排除したストレージターゲットがブロックデバイス上に完全に配置されています。つまり、VDO ボリュームの物理サイズは、基礎となるブロックデバイスと同じサイズになります。
36.1.5. VDO のスラブサイズ
VDO ボリュームの物理ストレージは、複数のスラブに分割されます。各スラブは、物理領域における連続した領域です。特定のボリュームのスラブはすべて同じサイズで、128 MB の 2 のべき乗倍のサイズ (最大 32 GB) になります。
小規模なテストシステムで VDO を評価しやすくするため、デフォルトのスラブサイズは 2 GB です。1 つの VDO ボリュームには、最大 8192 個のスラブを含めることができます。したがって、デフォルト設定の 2 GB のスラブを使用する場合、許可される物理ストレージは最大 16 TB です。32 GB のスラブを使用する場合、許可される物理ストレージは最大 256 TB です。VDO は常に少なくとも 1 つのスラブ全体をメタデータ用に予約します。そのため、この予約されたスラブをユーザーデータの保存に使用することはできません。
スラブサイズは、VDO ボリュームのパフォーマンスには影響しません。
| 物理ボリュームのサイズ | 推奨されるスラブサイズ |
|---|---|
| 10-99 GB | 1 GB |
| 100 GB - 1 TB | 2 GB |
| 2-256 TB | 32 GB |
VDO ボリュームの最小ディスク使用量は、デフォルト設定のスラブサイズ 2 GB、dense インデックス 0.25 を使用した場合、約 4.7 GB が必要です。これにより、0% の重複排除または圧縮で書き込むための 2 GB 弱の物理データが提供されます。
ここでの最小のディスク使用量は、デフォルトのスラブサイズと dense インデックスの合計です。
lvcreate コマンドに --vdosettings 'vdo_slab_size_mb=size-in-megabytes' オプションを指定することで、スラブサイズを制御できます。
36.1.6. VDO 要件
VDO は、配置とシステムリソースに特定の要件があります。
36.1.6.1. VDO メモリー要件
各 VDO ボリュームには、2 つの異なるメモリー要件があります。
- VDO モジュール
VDO には、固定メモリー 38 MB と変動用に容量を確保する必要があります。
- 設定済みのブロックマップキャッシュサイズ 1 MB ごとに 1.15 MB のメモリー。ブロックマップキャッシュには、最低 150 MB の RAM が必要です。
- 1 TB の論理領域ごとに 1.6 MB のメモリー。
- ボリュームが管理する物理ストレージの 1 TB ごとに 268 MB のメモリー。
- UDS インデックス
Universal Deduplication Service (UDS) には、最低 250 MB のメモリーが必要です。このメモリー量は、重複排除が使用するデフォルトの容量です。この値は、インデックスに必要なストレージ容量にも影響するため、VDO ボリュームをフォーマットするときに設定できます。
UDS インデックスに必要なメモリーは、インデックスタイプと、重複排除ウィンドウに必要なサイズで決定されます。重複排除ウィンドウとは、VDO が一致するブロックをチェックできる、以前に書き込まれたデータの量です。
Expand インデックスタイプ 重複排除ウィンドウ Dense
RAM 1 GB あたり 1 TB
Sparse
RAM 1 GB あたり 10 TB
注記VDO ボリュームの最小ディスク使用量は、デフォルト設定のスラブサイズ 2 GB、dense インデックス 0.25 を使用した場合、約 4.7 GB が必要です。これにより、0% の重複排除または圧縮で書き込むための 2 GB 弱の物理データが提供されます。
ここでの最小のディスク使用量は、デフォルトのスラブサイズと dense インデックスの合計です。
36.1.6.2. VDO ストレージの領域要件
VDO ボリュームを設定して、最大 256 TB の物理ストレージを使用するように設定できます。データを格納するのに使用できるのは、物理ストレージの一部のみです。
VDO では、2 種類の VDO メタデータと UDS インデックスにストレージが必要です。次の計算を使用して、VDO 管理ボリュームの使用可能なサイズを決定します。
- 最初のタイプの VDO メタデータは、4 GB の 物理ストレージ ごとに約 1 MB を使用し、スラブごとにさらに 1 MB を使用します。
- 2 番目のタイプの VDO メタデータは、論理ストレージ 1 GB ごとに約 1.25 MB を消費し、最も近いスラブに切り上げられます。
- UDS インデックスに必要なストレージの容量は、インデックスの種類と、インデックスに割り当てられている RAM の容量によって異なります。RAM 1 GB ごとに、dense の UDS インデックスはストレージを 17 GB 使用し、sparse の UDS インデックスはストレージを 170 GB 使用します。
36.1.6.3. ストレージスタックの VDO の 配置
配置要件に合わせて、Virtual Data Optimizer (VDO) の上または下にストレージ層を配置します。
VDO ボリュームは、シンプロビジョニングしたブロックデバイスです。後で拡張できるストレージ層の上にボリュームを配置することで、物理スペースの不足を防ぐことができます。このような拡張可能なストレージの例として、論理ボリュームマネージャー (LVM) ボリューム、または Multiple Device Redundant Array of Inexpensive/Independent Disks (MD RAID) アレイがあります。
VDO の上にシックプロビジョニングレイヤーを配置できます。シックプロビジョニングレイヤーについては、次の 2 つの側面を考慮する必要があります。
- シックデバイスの未使用の論理領域への新しいデータの書き込み。VDO またはその他のシンプロビジョニングストレージを使用している場合、この種の書き込み中にデバイスの領域が不足していると報告されることがあります。
- 新しいデータによるシックデバイスの使用済み論理領域の上書き。VDO を使用している場合、データを上書きすると、デバイスの領域が不足しているという報告が表示されることがあります。
これらの制限は、VDO 層より上のすべてのレイヤーに影響します。VDO デバイスが監視されていない場合には、VDO 層の上にあるシックプロビジョニングのボリュームで、物理領域が予期せず不足する可能性があります。
次のサポート対象およびサポート対象外の VDO ボリューム設定の例を参照してください。
図36.3 サポートされている VDO ボリューム設定
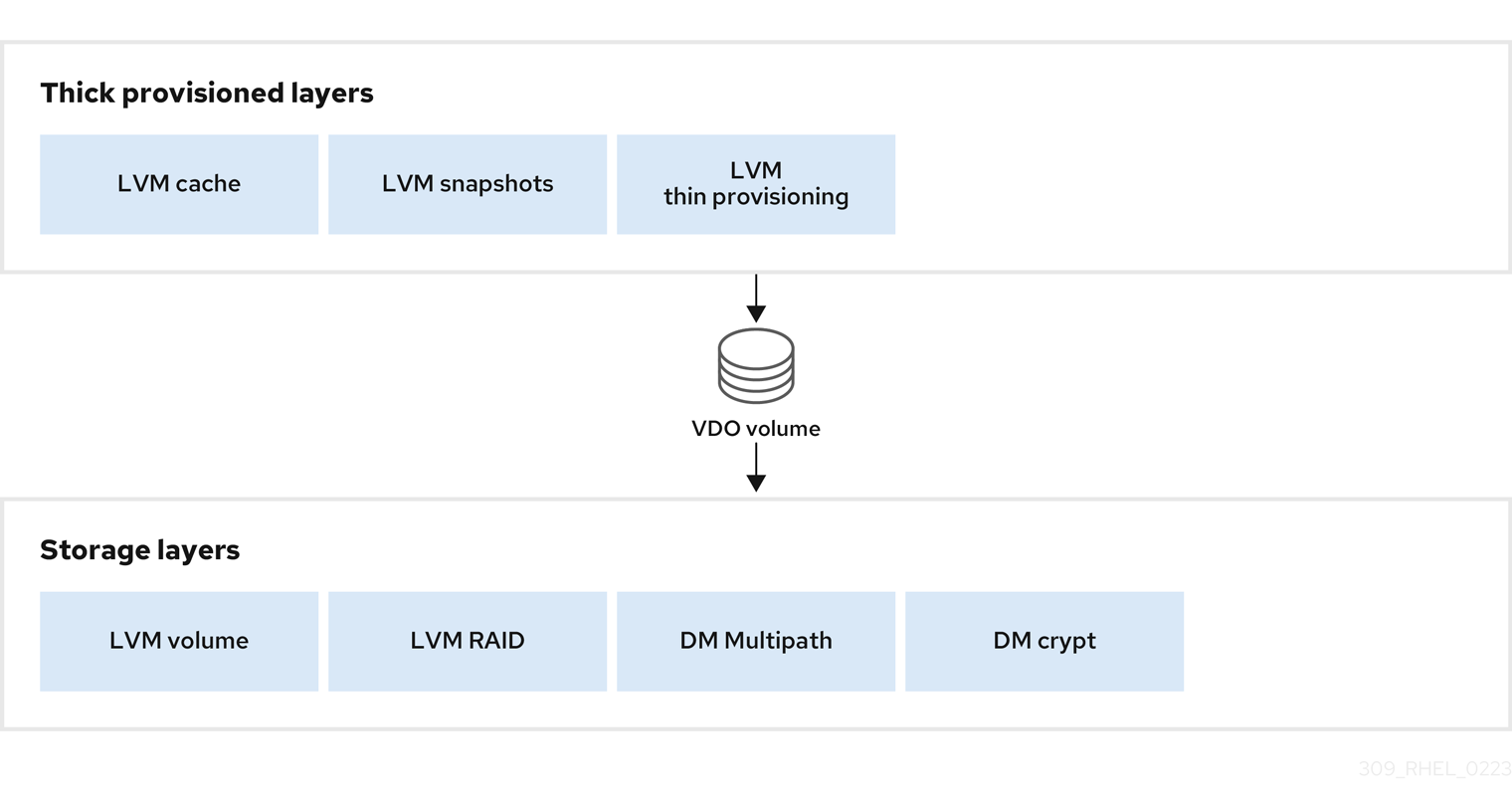
図36.4 サポートされていない VDO ボリューム設定
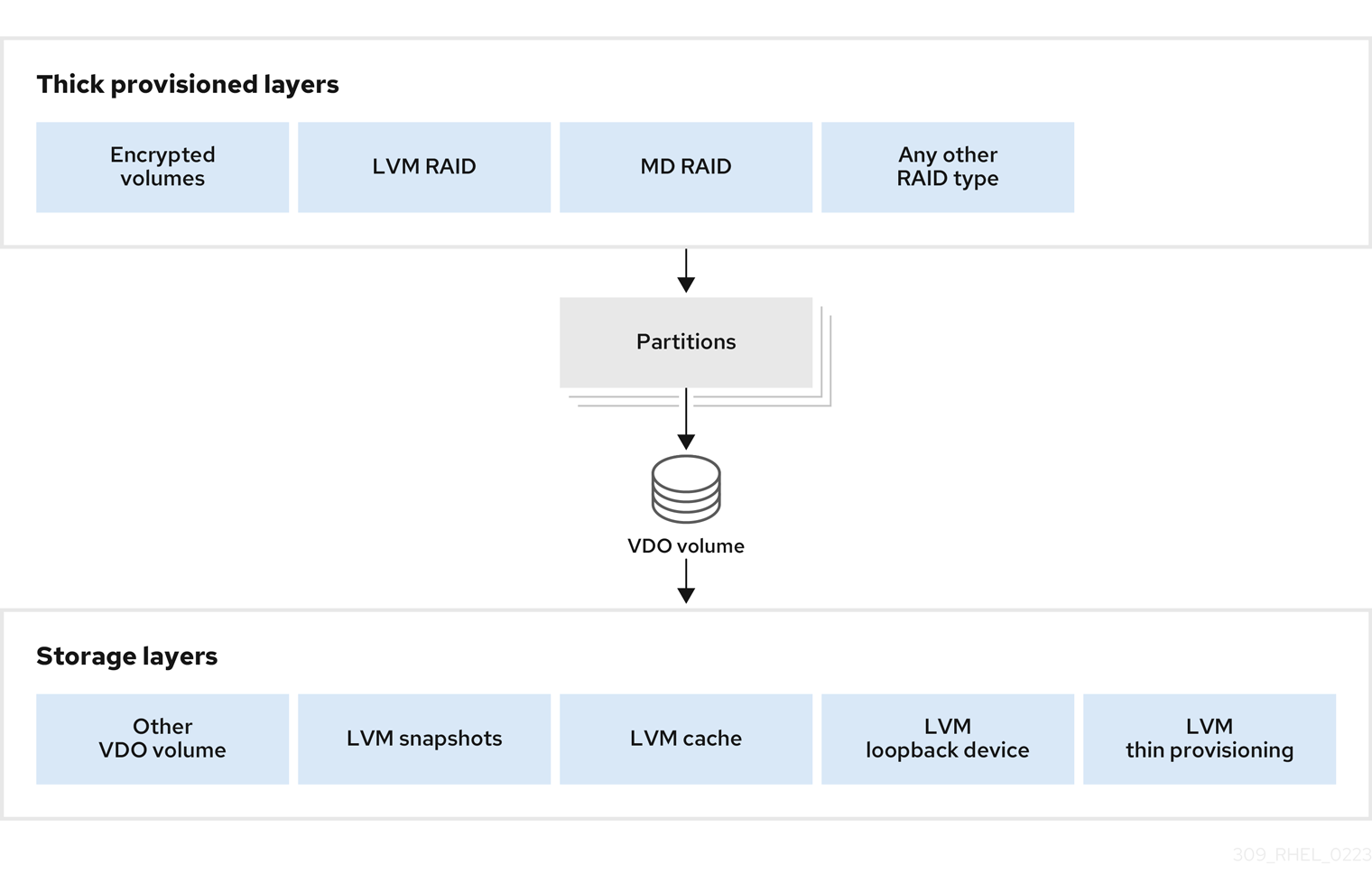
36.1.6.4. 物理サイズ別の VDO 要件の例
以下の表は、基盤となるボリュームの物理サイズに基づいた、VDO のシステム要件の概算を示しています。それぞれの表には、プライマリーストレージ、バックアップストレージなどの、目的のデプロイメントに適した要件が記載されています。
正確な数値は、VDO ボリュームの設定により異なります。
- プライマリーストレージのデプロイメント
プライマリーストレージの場合、UDS インデックスのサイズは、物理サイズの 0.01% から 25% になります。
Expand 表36.2 プライマリーストレージのストレージとメモリーの設定例 物理サイズ RAM の使用量:UDS RAM の使用量:VDO ディスク使用量 インデックスタイプ 1 TB
250 MB
472 MB
2.5 GB
Dense
10 TB
1 GB
3 GB
10 GB
Dense
250 MB
22 GB
Sparse
50 TB
1 GB
14 GB
85 GB
Sparse
100 TB
3 GB
27 GB
255 GB
Sparse
256 TB
5 GB
69 GB
425 GB
Sparse
- バックアップストレージのデプロイメント
バックアップストレージの場合、重複排除ウィンドウをバックアップセットよりも大きくする必要があります。バックアップセットや物理サイズが今後大きくなる可能性がある場合は、これをインデックスサイズに組み込んでください。
Expand 表36.3 バックアップストレージのストレージとメモリーの設定例 重複排除ウィンドウ RAM の使用量:UDS ディスク使用量 インデックスタイプ 1 TB
250 MB
2.5 GB
Dense
10 TB
2 GB
21 GB
Dense
50 TB
2 GB
170 GB
Sparse
100 TB
4 GB
340 GB
Sparse
256 TB
8 GB
700 GB
Sparse
36.1.7. VDO のインストール
VDO ボリュームの作成、マウント、管理に必要な VDO ソフトウェアをインストールできます。
手順
VDO ソフトウェアをインストールします。
# yum install lvm2 kmod-kvdo vdo
36.1.8. VDO ボリュームの作成
この手順では、ブロックデバイスに VDO ボリュームを作成します。
前提条件
- VDO ソフトウェアをインストールしている。「VDO のインストール」 を参照してください。
- 拡張可能なストレージをバッキングブロックデバイスとして使用している。詳細は、「ストレージスタックの VDO の 配置」 を参照してください。
手順
以下のすべての手順で、vdo-name を、VDO ボリュームに使用する識別子 (vdo1 など) に置き換えます。システムの VDO の各インスタンスに、それぞれ別の名前とデバイスを使用する必要があります。
VDO ボリュームを作成するブロックデバイスの永続的な名前を確認してください。永続名の詳細は、以下を参照してください。26章永続的な命名属性の概要。
永続的なデバイス名を使用しないと、今後デバイスの名前が変わった場合に、VDO が正しく起動しなくなることがあります。
VDO ボリュームを作成します。
# vdo create \ --name=vdo-name \ --device=block-device \ --vdoLogicalSize=logical-size-
block-device を、VDO ボリュームを作成するブロックデバイスの永続名に置き換えます。たとえば、
/dev/disk/by-id/scsi-3600508b1001c264ad2af21e903ad031fです。 logical-size を、VDO ボリュームが含まれる論理ストレージのサイズに置き換えます。
-
アクティブな仮想マシンまたはコンテナーストレージの場合は、使用する論理サイズが、ブロックデバイスの物理サイズの 10 倍になるようにします。たとえば、ブロックデバイスのサイズが 1 TB の場合は、
10Tを使用します。 -
オブジェクトストレージの場合は、使用する論理サイズを、ブロックデバイスの物理サイズの 3 倍になるようにします。たとえば、ブロックデバイスのサイズが 1 TB の場合は、
3Tを使用します。
-
アクティブな仮想マシンまたはコンテナーストレージの場合は、使用する論理サイズが、ブロックデバイスの物理サイズの 10 倍になるようにします。たとえば、ブロックデバイスのサイズが 1 TB の場合は、
物理ブロックデバイスが 16TiB を超える場合は、
--vdoSlabSize=32Gオプションを指定して、ボリューム上のスラブサイズを 32GiB に増やします。16TiB を超えるブロックデバイスでデフォルトのスラブサイズ 2GiB を使用すると、
vdo createコマンドが失敗し、以下のエラーが出力されます。vdo: ERROR - vdoformat: formatVDO failed on '/dev/device': VDO Status: Exceeds maximum number of slabs supported
例36.1 コンテナーストレージ用に VDO の作成
たとえば、1 TB ブロックデバイスでコンテナーストレージ用に VDO ボリュームを作成するには、次のコマンドを実行します。
# vdo create \ --name=vdo1 \ --device=/dev/disk/by-id/scsi-3600508b1001c264ad2af21e903ad031f \ --vdoLogicalSize=10T重要VDO ボリュームの作成中に問題が発生した場合は、ボリュームを削除してください。詳細は、作成に失敗した VDO ボリュームの削除 を参照してください。
-
block-device を、VDO ボリュームを作成するブロックデバイスの永続名に置き換えます。たとえば、
VDO ボリュームにファイルシステムを作成します。
XFS ファイルシステムの場合:
# mkfs.xfs -K /dev/mapper/vdo-nameext4 ファイルシステムの場合:
# mkfs.ext4 -E nodiscard /dev/mapper/vdo-name注記新しく作成された VDO ボリュームでの
-Kおよび-E nodiscardオプションの目的は、割り当てられていないブロックには影響しないため、リクエストの送信に時間を費やさないようにすることです。新しい VDO ボリュームは、100% 割り当てられていない状態で開始されます。
次のコマンドを使用して、システムが新しいデバイスノードを登録するまで待機します。
# udevadm settle
次のステップ
- ファイルシステムをマウントします。詳しくは 「VDO ボリュームのマウント」 を参照してください。
-
VDO デバイスのファイルシステムで
discard機能を有効にします。詳しくは 「定期的なブロック破棄の有効化」 を参照してください。
36.1.9. VDO ボリュームのマウント
この手順では、手動で、または永続的に、VDO ボリュームにファイルシステムをマウントします。
前提条件
- システムで VDO ボリュームが作成されている。手順は、「VDO ボリュームの作成」 を参照してください。
手順
VDO ボリュームに手動でファイルシステムをマウントするには、以下のコマンドを使用します。
# mount /dev/mapper/vdo-name mount-pointシステムの起動時にファイルシステムを自動的にマウントするように設定するには、
/etc/fstabファイルに以下の行を追加します。XFS ファイルシステムの場合:
/dev/mapper/vdo-name mount-point xfs defaults 0 0ext4 ファイルシステムの場合:
/dev/mapper/vdo-name mount-point ext4 defaults 0 0
VDO ボリュームが、iSCSI などのネットワークを必要とするブロックデバイスに配置されている場合は、
_netdevマウントオプションを追加します。
36.1.10. 定期的なブロック破棄の有効化
systemd タイマーを有効にして、サポートしているすべてのファイルシステムで未使用ブロックを定期的に破棄できます。
手順
systemdタイマーを有効にして起動します。# systemctl enable --now fstrim.timer Created symlink /etc/systemd/system/timers.target.wants/fstrim.timer → /usr/lib/systemd/system/fstrim.timer.
検証
タイマーのステータスを確認します。
# systemctl status fstrim.timer fstrim.timer - Discard unused blocks once a week Loaded: loaded (/usr/lib/systemd/system/fstrim.timer; enabled; vendor preset: disabled) Active: active (waiting) since Wed 2023-05-17 13:24:41 CEST; 3min 15s ago Trigger: Mon 2023-05-22 01:20:46 CEST; 4 days left Docs: man:fstrim May 17 13:24:41 localhost.localdomain systemd[1]: Started Discard unused blocks once a week.
36.1.11. VDO の監視
この手順では、VDO ボリュームから、使用方法と効率に関する情報を取得する方法を説明します。
前提条件
- VDO ソフトウェアをインストールしている。VDO のインストール を参照してください。
手順
vdostatsユーティリティーは、VDO ボリュームに関する情報を取得します。# vdostats --human-readable Device 1K-blocks Used Available Use% Space saving% /dev/mapper/node1osd1 926.5G 21.0G 905.5G 2% 73% /dev/mapper/node1osd2 926.5G 28.2G 898.3G 3% 64%
36.2. VDO のメンテナンス
VDO ボリュームのデプロイ後、特定のタスクを実行して、ボリュームを維持または最適化することができます。VDO ボリュームの適切な機能には、以下の一部のタスクが必要です。
前提条件
- VDO がインストールされ、デプロイされます。「VDO のデプロイメント」 を参照してください。
36.2.1. VDO ボリューム上の空き領域の管理
VDO は、シンプロビジョニングされたブロックストレージターゲットです。そのため、VDO ボリュームで領域の使用状況をアクティブに監視し、管理する必要があります。
36.2.1.1. VDO ボリュームの物理サイズおよび論理サイズ
VDO は、物理サイズ、利用可能な物理サイズ、および論理サイズを次の方法で利用します。
- 物理サイズ
これは、基礎となるブロックデバイスと同じサイズです。VDO は、以下の目的でこのストレージを使用します。
- 重複排除および圧縮される可能性があるユーザーデータ
- UDS インデックスなどの VDO メタデータ
- 利用可能な物理サイズ
これは、VDO がユーザーデータに使用できる物理サイズの一部です。
これは、メタデータのサイズを引いた物理サイズと同等で、指定のスラブサイズでボリュームをスラブに分割した後の残りを引いたものと同じです。
- 論理サイズ
これは、VDO ボリュームがアプリケーションに提示するプロビジョニングされたサイズです。通常、これは利用可能な物理サイズよりも大きくなります。
--vdoLogicalSizeオプションを指定しないと、論理ボリュームのプロビジョニングが1:1の比率にプロビジョニングされます。たとえば、VDO ボリュームが 20 GB ブロックデバイスの上に置かれている場合は、2.5 GB が UDS インデックス用に予約されます (デフォルトのインデックスサイズが使用される場合)。残りの 17.5 GB は、VDO メタデータおよびユーザーデータに提供されます。そのため、消費する利用可能なストレージは 17.5 GB を超えません。実際の VDO ボリュームを設定するメタデータにより、これよりも少なくなる可能性があります。VDO は現在、絶対最大論理サイズ 4PB の物理ボリュームの最大 254 倍の論理サイズに対応します。
図36.5 VDO ディスク組織
この図では、VDO で重複排除したストレージターゲットがブロックデバイス上に完全に配置されています。つまり、VDO ボリュームの物理サイズは、基礎となるブロックデバイスと同じサイズになります。
36.2.1.2. VDO でのシンプロビジョニング
VDO は、シンプロビジョニングされたブロックストレージターゲットです。VDO ボリュームが使用する物理領域のサイズは、ストレージのユーザーに示されるボリュームのサイズとは異なる可能性があります。この相違を活用して、ストレージのコストを削減できます。
容量不足の条件
書き込んだデータが、予想される最適化率に到達できない場合は、ストレージ領域が予想外に不足しないように注意してください。
論理ブロック (仮想ストレージ) の数が物理ブロック (実際のストレージ) の数を超えると、ファイルシステムおよびアプリケーションで領域が予想外に不足する可能性があります。このため、VDO を使用するストレージシステムは、VDO ボリュームの空きプールのサイズを監視する方法で提供する必要があります。
vdostats ユーティリティーを使用すると、この空きプールのサイズを確認できます。このユーティリティーのデフォルト出力には、Linux の df ユーティリティーと同様の形式で稼働しているすべての VDO ボリュームの情報が記載されます。以下に例を示します。
Device 1K-blocks Used Available Use%
/dev/mapper/vdo-name 211812352 105906176 105906176 50%VDO ボリュームの物理ストレージ領域が不足しそうになると、VDO は、システムログに、以下のような警告を出力します。
Oct 2 17:13:39 system lvm[13863]: Monitoring VDO pool vdo-name.
Oct 2 17:27:39 system lvm[13863]: WARNING: VDO pool vdo-name is now 80.69% full.
Oct 2 17:28:19 system lvm[13863]: WARNING: VDO pool vdo-name is now 85.25% full.
Oct 2 17:29:39 system lvm[13863]: WARNING: VDO pool vdo-name is now 90.64% full.
Oct 2 17:30:29 system lvm[13863]: WARNING: VDO pool vdo-name is now 96.07% full.
この警告メッセージは、lvm2-monitor サービスが実行している場合に限り表示されます。これは、デフォルトで有効になっています。
容量不足の状況を防ぐ方法
空きプールのサイズが特定のレベルを下回る場合は、以下を行うことができます。
- データの削除。これにより、削除したデータが重複していないと、領域が回収されます。データを削除しても、破棄が行われないと領域を解放しません。
- 物理ストレージの追加
VDO ボリュームで物理領域を監視し、領域不足を回避します。物理ブロックが不足すると、VDO ボリュームに最近書き込まれたデータや、未承認のデータが失われることがあります。
シンプロビジョニング、TRIM コマンド、および DISCARD コマンド
シンプロビジョニングによるストレージの削減から利益を得るには、データを削除するタイミングを物理ストレージ層が把握する必要があります。シンプロビジョニングされたストレージで動作するファイルシステムは、TRIM コマンドまたは DISCARD コマンドを送信して、論理ブロックが不要になったときにストレージシステムに通知します。
TRIM コマンドまたは DISCARD コマンドを送信する方法はいくつかあります。
-
discardマウントオプションを使用すると、ブロックが削除されるたびに、ファイルシステムがそのコマンドを送信できます。 -
fstrimなどのユーティリティーを使用すると、制御された方法でコマンドを送信できます。このようなユーティリティーは、どの論理ブロックが使用されていないかを検出し、TRIMコマンドまたはDISCARDコマンドの形式でストレージシステムに情報を送信するようにファイルシステムに指示します。
未使用のブロックで TRIM または DISCARD を使用する必要は、VDO に特有のものではありません。シンプロビジョニングしたストレージシステムでも、同じ課題があります。
36.2.1.3. VDO の監視
この手順では、VDO ボリュームから、使用方法と効率に関する情報を取得する方法を説明します。
前提条件
- VDO ソフトウェアをインストールしている。VDO のインストール を参照してください。
手順
vdostatsユーティリティーは、VDO ボリュームに関する情報を取得します。# vdostats --human-readable Device 1K-blocks Used Available Use% Space saving% /dev/mapper/node1osd1 926.5G 21.0G 905.5G 2% 73% /dev/mapper/node1osd2 926.5G 28.2G 898.3G 3% 64%
36.2.1.4. ファイルシステムで VDO の領域の回収
この手順では、ファイルシステムをホストする VDO ボリュームのストレージの領域を回収する方法を説明します。
ファイルシステムが、DISCARD コマンド、TRIM コマンド、または UNMAP コマンドを使用して、ブロックが空いていることを伝えない限り、VDO は領域を回収できません。
手順
- VDO ボリュームのファイルシステムが破棄操作に対応している場合は、その操作を有効化してください。未使用ブロックの破棄 を参照してください。
-
ファイルシステムが、
DISCARD、TRIM、またはUNMAPを使用していない場合は、空き領域を手動で回収できます。バイナリーゼロで設定されるファイルを保存し、空き領域を埋め、そのファイルを削除します。
36.2.1.5. ファイルシステムを使用しない VDO の領域の回収
この手順では、ファイルシステムを使用せずにブロックストレージターゲットとして使用される VDO ボリュームでストレージ領域を回収します。
手順
blkdiscardユーティリティーを使用します。たとえば、VDO ボリュームは、LVM をその上にデプロイすることで、1 つの VDO を複数のサブボリュームに分類できます。論理ボリュームのプロビジョニングを解除する前に、
blkdiscardユーティリティーを使用して、その論理ボリュームにより使用されていた領域を解放します。LVM は、
REQ_DISCARDコマンドに対応し、領域を解放するために適切な論理ブロックアドレスで VDO にリクエストを転送します。その他のボリュームマネージャーを使用する場合は、REQ_DISCARDに対応する必要があります。同じように、SCSI デバイスの場合はUNMAP、または ATA デバイスの場合はTRIMに対応している必要があります。
36.2.1.6. ファイバーチャンネルまたはイーサネットネットワーク上で VDO の領域の回収
この手順では、LIO、SCST などの SCSI ターゲットフレームワークを使用して、ファイバーチャネルストレージファブリック、またはイーサネットネットワークでホストにプロビジョニングされる VDO ボリューム (またはボリュームの一部) でストレージ領域を回収します。
手順
SCSI イニシエーターは、
UNMAPコマンドを使用して、シンプロビジョニングしたストレージターゲットで領域を解放できますが、SCSI ターゲットフレームワークに、このコマンドのサポートを通知するように設定する必要があります。これは、通常、このボリュームでシンプロビジョニングを有効にすることで行います。次のコマンドを実行して、Linux ベースの SCSI イニシエーターで
UNMAPのサポートを検証します。# sg_vpd --page=0xb0 /dev/device出力では、Maximum unmap LBA count(未マッピングの LBA の最大数) の値がゼロより大きいことを確認します。
36.2.2. VDO ボリュームの開始または停止
指定した VDO ボリューム、またはすべての VDO ボリューム、および関連の UDS インデックスを起動または停止できます。
36.2.2.1. 起動して有効にした VDO ボリューム
システムの起動時に、vdo systemd ユニットは、有効 に設定されている VDO デバイスをすべて自動的に 起動 します。
vdo パッケージをインストールすると、vdo systemd ユニットがインストールされ、デフォルトで有効になっています。このユニットは、システム起動時に vdo start --all コマンドを自動的に実行して、有効になっている VDO ボリュームをすべて起動します。
--activate=disabled オプションを vdo create コマンドに指定することで、自動的に起動しない VDO ボリュームを作成できます。
開始順序
システムによっては、LVM ボリュームを、VDO ボリュームの上または下の両方に配置できるものがあります。このようなシステムでは、適切な順序でサービスを開始する必要があります。
- 下層の LVM を最初に起動する必要があります。大概のシステムでは、LVM パッケージがインストールされていれば、この層が起動するように自動的に設定されます。
-
次に、
vdosystemdユニットを起動する必要があります。 - 最後に、稼働している VDO の上にある LVM ボリュームやその他のサービスを実行するために、その他のスクリプトを実行する必要があります。
ボリュームの停止にかかる時間
VDO ボリュームの停止にかかる時間は、ストレージデバイスの速度と、ボリュームへの書き込みが必要なデータ量により異なります。
- ボリュームは、UDS インデックスの 1GiB ごとに、約 1 GiB のデータを常に書き込みます。
- ボリュームはブロックマップキャッシュのサイズと、スラブごとに最大 8MiB のデータ量を書き込みます。
- ボリュームは、未処理のすべての IO 要求の処理を終了する必要があります。
36.2.2.2. VDO ボリュームの作成
この手順では、システムにある一部の VDO ボリューム、またはすべての VDO ボリュームを起動します。
手順
特定の VDO ボリュームを起動するには、以下のコマンドを使用します。
# vdo start --name=my-vdoすべての VDO ボリュームを起動するには、次のコマンドを実行します。
# vdo start --all
36.2.2.3. VDO ボリュームの停止
この手順では、システムで一部の VDO ボリュームまたはすべての VDO ボリュームを停止します。
手順
ボリュームを停止します。
特定の VDO ボリュームを停止するには、以下のコマンドを使用します。
# vdo stop --name=my-vdoすべての VDO ボリュームを停止するには、以下のコマンドを使用します。
# vdo stop --all
- ボリュームが、ディスクへのデータの書き込みを終了するまで待ちます。
36.2.3. システムブートで VDO ボリュームを自動的に起動
VDO ボリュームを設定し、システムの起動時に自動的に起動するようにします。自動起動を無効にすることもできます。
36.2.3.1. 起動して有効にした VDO ボリューム
システムの起動時に、vdo systemd ユニットは、有効 に設定されている VDO デバイスをすべて自動的に 起動 します。
vdo パッケージをインストールすると、vdo systemd ユニットがインストールされ、デフォルトで有効になっています。このユニットは、システム起動時に vdo start --all コマンドを自動的に実行して、有効になっている VDO ボリュームをすべて起動します。
--activate=disabled オプションを vdo create コマンドに指定することで、自動的に起動しない VDO ボリュームを作成できます。
開始順序
システムによっては、LVM ボリュームを、VDO ボリュームの上または下の両方に配置できるものがあります。このようなシステムでは、適切な順序でサービスを開始する必要があります。
- 下層の LVM を最初に起動する必要があります。大概のシステムでは、LVM パッケージがインストールされていれば、この層が起動するように自動的に設定されます。
-
次に、
vdosystemdユニットを起動する必要があります。 - 最後に、稼働している VDO の上にある LVM ボリュームやその他のサービスを実行するために、その他のスクリプトを実行する必要があります。
ボリュームの停止にかかる時間
VDO ボリュームの停止にかかる時間は、ストレージデバイスの速度と、ボリュームへの書き込みが必要なデータ量により異なります。
- ボリュームは、UDS インデックスの 1GiB ごとに、約 1 GiB のデータを常に書き込みます。
- ボリュームはブロックマップキャッシュのサイズと、スラブごとに最大 8MiB のデータ量を書き込みます。
- ボリュームは、未処理のすべての IO 要求の処理を終了する必要があります。
36.2.3.2. VDO ボリュームの有効化
この手順では、VDO ボリュームを有効にして、自動的に開始できるようにします。
手順
特定のボリュームを有効にするには、以下のコマンドを実行します。
# vdo activate --name=my-vdoすべてのボリュームを有効にするには、以下のコマンドを実行します。
# vdo activate --all
36.2.3.3. VDO ボリュームの無効化
この手順では、VDO ボリュームを無効にして、自動的に起動しないようにします。
手順
特定のボリュームを無効にするには、以下のコマンドを実行します。
# vdo deactivate --name=my-vdoすべてのボリュームを無効にするには、以下のコマンドを実行します。
# vdo deactivate --all
36.2.4. VDO 書き込みモードの選択
基となるブロックデバイスでの要件に応じて、VDO ボリュームに書き込みモードを設定できます。デフォルトでは、VDO は書き込みモードを自動的に選択します。
36.2.4.1. VDO 書き込みモード
VDO は、以下の書き込みモードに対応します。
syncVDO が
syncモードの場合、その上の層は、書き込みコマンドがデータを永続ストレージに書き込むことを想定します。したがって、このモードは、ファイルシステムやアプリケーションには必要ありません。FLUSH リクエストまたは FUA (強制ユニットアクセス) リクエストを発行すると、データは、重要な点で持続します。VDO は、書き込みコマンドが完了したときに、基となるストレージが、データが永続ストレージに書き込まれることを保証する場合に限り、
syncモードに設定する必要があります。つまり、ストレージには揮発性の書き込みキャッシュがないか、ライトスルーキャッシュが存在する必要があります。asyncVDO が
asyncモードの場合は、書き込みコマンドが承認されたときに、データが永続ストレージに書き込まれることを VDO が保証しません。ファイルシステムまたはアプリケーションは、各トランザクションの重要な点でデータの永続性を保証するために、FLUSH リクエストまたは FUA リクエストを発行する必要があります。書き込みコマンドが完了したときに、基となるストレージが永続ストレージに対するデータの書き込みを保証しない場合は、VDO を
asyncモードに設定する必要があります。これは、ストレージに揮発性のあるライトバックキャッシュがある場合です。async-unsafeこのモードには、
asyncと同じプロパティーがありますが、ACID (Atomicity, Consistency, Isolation, Durability) に準拠していません。asyncと比較して、async-unsafeのパフォーマンスは向上します。警告VDO ボリュームに関する ACID コンプライアンスを想定するアプリケーションまたはファイルシステムが稼働する場合は、
async-unsafeモードにより予想外のデータ損失が生じる可能性があります。auto-
autoモードは、各デバイスの性質に基づいて、syncまたはasyncを自動的に選択します。以下はデフォルトのオプションになります。
36.2.4.2. VDO 書き込みモードの内部処理
VDO の書き込みモードは sync と async です。以下では、これらのモードの操作について説明します。
kvdo モジュールが同期 (synch) モードで動作している場合は、以下を行います。
- リクエストのデータを一時的に、割り当てられたブロックに書き込み、リクエストを承認します。
- 承認が完了すると、ブロックデータの MurmurHash-3 署名を計算してブロックの重複排除が試行されます。これは、VDO インデックスに送信されます。
-
VDO インデックスに同じ署名とともにブロックのエントリーが含まれる場合、
kvdoは示されたブロックを読み込み、同一であるかを検証するために 2 つのブロックのバイト対バイトの比較を行います。 -
同一であることが確認されると、
kvdoはブロックマップを更新して、論理ブロックが、一致する物理ブロックを指定し、割り当てられた物理ブロックをリリースします。 -
VDO インデックスに、書き込まれているブロックの署名のエントリーを含まない場合や、示されたブロックが同じデータを含まない場合は、
kvdoはブロックマップを更新して、一時的な物理ブロックを永続的にします。
kvdo が非同期 (async) モードで動作している場合は、以下のコマンドを実行します。
- データを書き込む代わりに、リクエストをすぐに承認します。
- 上記の説明と同じように、ブロックの重複排除試行が行われます。
-
ブロックが重複していることになると、
kvdoはブロックマップを更新し、割り当てられたブロックを解放します。解放しない場合は、リクエストのデータが、割り当てられたブロックに書き込み、ブロックマップを更新して物理ブロックを永続的にします。
36.2.4.3. VDO ボリュームにおける書き込みモードの確認
この手順では、選択した VDO ボリュームに対するアクティブな書き込みモードをリスト表示します。
手順
以下のコマンドを使用して、VDO ボリュームが使用する書き込みモードを表示します。
# vdo status --name=my-vdo出力されるファイルには、以下が記載されます。
-
設定した書き込みポリシー -
sync、async、またはautoから選択されるオプションです。 -
書き込みポリシー - VDO が適用される特定の書き込みモードで、
syncまたはasyncになります。
-
設定した書き込みポリシー -
36.2.4.4. 揮発性キャッシュの確認
この手順では、ブロックデバイスに揮発性キャッシュがあるかどうかを確認します。情報を使用して、VDO 書き込みモードである sync と async のいずれかを選択できます。
手順
デバイスにライトバックキャッシュがあるかどうかを判断する場合は、以下のいずれか方法を使用します。
sysfsファイルの/sys/block/block-device/device/scsi_disk/identifier/cache_typeを読み込みます。以下に例を示します。$ cat '/sys/block/sda/device/scsi_disk/7:0:0:0/cache_type' write back$ cat '/sys/block/sdb/device/scsi_disk/1:2:0:0/cache_type' Noneまた、カーネルブートログでは、上記のデバイスに書き込みキャッシュがあるかどうかを調べることができます。
sd 7:0:0:0: [sda] Write cache: enabled, read cache: enabled, does not support DPO or FUA sd 1:2:0:0: [sdb] Write cache: disabled, read cache: disabled, supports DPO and FUA
上の例では、以下のようになります。
-
デバイス
sdaには、ライトバックキャッシュがある ことが示されています。asyncモードを使用します。 -
デバイス
sdbには、ライトバックキャッシュが ない ことが示されています。syncモードを使用します。
cache_typeの値がNoneまたはwrite throughである場合は、sync書き込みモードを使用するように VDO を設定する必要があります。-
デバイス
36.2.4.5. VDO 書き込みモードの設定
この手順では、既存のボリュームの場合、またはボリュームの新規作成時に、VDO ボリュームに書き込みモードを設定します。
誤った書き込みモードを使用すると、停電、システムクラッシュ、またはディスクとの接続が予期せず失われた時に、データが失われることがあります。
前提条件
- デバイスに対してどの書き込みモードが正しいかを確認している。「揮発性キャッシュの確認」 を参照してください。
手順
既存の VDO ボリュームまたは新規ボリュームの作成時に、書き込みモードを設定できます。
既存の VDO ボリュームを変更するには、以下のコマンドを使用します。
# vdo changeWritePolicy --writePolicy=sync|async|async-unsafe|auto \ --name=vdo-name-
VDO ボリュームの作成時に書き込みモードを指定するには、
--writePolicy=sync|async|async-unsafe|autoオプションをvdo createコマンドに追加します。
36.2.5. シャットダウンが適切に行われない場合の VDO ボリュームの復旧
シャットダウンが適切に行われない場合に VDO ボリュームを復旧して、動作を継続できます。多くのタスクは自動化されています。また、プロセスの障害により VDO ボリュームの作成に失敗した場合は、クリーンアップできます。
36.2.5.1. VDO 書き込みモード
VDO は、以下の書き込みモードに対応します。
syncVDO が
syncモードの場合、その上の層は、書き込みコマンドがデータを永続ストレージに書き込むことを想定します。したがって、このモードは、ファイルシステムやアプリケーションには必要ありません。FLUSH リクエストまたは FUA (強制ユニットアクセス) リクエストを発行すると、データは、重要な点で持続します。VDO は、書き込みコマンドが完了したときに、基となるストレージが、データが永続ストレージに書き込まれることを保証する場合に限り、
syncモードに設定する必要があります。つまり、ストレージには揮発性の書き込みキャッシュがないか、ライトスルーキャッシュが存在する必要があります。asyncVDO が
asyncモードの場合は、書き込みコマンドが承認されたときに、データが永続ストレージに書き込まれることを VDO が保証しません。ファイルシステムまたはアプリケーションは、各トランザクションの重要な点でデータの永続性を保証するために、FLUSH リクエストまたは FUA リクエストを発行する必要があります。書き込みコマンドが完了したときに、基となるストレージが永続ストレージに対するデータの書き込みを保証しない場合は、VDO を
asyncモードに設定する必要があります。これは、ストレージに揮発性のあるライトバックキャッシュがある場合です。async-unsafeこのモードには、
asyncと同じプロパティーがありますが、ACID (Atomicity, Consistency, Isolation, Durability) に準拠していません。asyncと比較して、async-unsafeのパフォーマンスは向上します。警告VDO ボリュームに関する ACID コンプライアンスを想定するアプリケーションまたはファイルシステムが稼働する場合は、
async-unsafeモードにより予想外のデータ損失が生じる可能性があります。auto-
autoモードは、各デバイスの性質に基づいて、syncまたはasyncを自動的に選択します。以下はデフォルトのオプションになります。
36.2.5.2. VDO ボリュームの復旧
シャットダウンが適切に行われなかった場合に VDO ボリュームを再起動すると、VDO は以下の操作を実行します。
- ボリューム上のメタデータの一貫性を検証する
- メタデータの一部を再構築して、必要に応じて修復する
再構築は自動で行われ、ユーザーの介入は必要ありません。
VDO は、アクティブな書き込みモードに依存する各種書き込みを再構築します。
sync-
VDO が同期ストレージで稼働していて、書き込みポリシーが
syncに設定されていた場合は、ボリュームに書き込まれたすべてのデータが完全に復元されます。 async-
書き込みポリシーが
asyncであった場合、一部の書き込みは永続性が保たれないと復元されないことがあります。これは、VDO にFLUSHコマンド、または FUA (強制ユニットアクセス) フラグでタグ付けされた書き込み I/O を送信することで行われます。これは、fsync、fdatasync、sync、umountなどのデータ整合性の操作を呼び出すことで、ユーザーモードから実行できます。
どちらのモードであっても、フラッシュによって承認されていない、あるいは確認されていない一部の書き込みも再構築されることがあります。
自動復元および手動復元
VDO ボリュームが 復旧 操作モードになると、VDO は、オンラインに戻ってから、適切ではない VDO ボリュームを自動的に再構築します。これは オンラインリカバリー と呼ばれます。
VDO が正常に VDO ボリュームを復元できない場合は、ボリュームの再起動後も持続する 読み取り専用 モードにボリュームを置きます。再構築が強制されるため、問題を手動で修正する必要があります。
36.2.5.3. VDO 操作モード
ここでは、VDO ボリュームが正常に動作しているか、エラーからの復旧であることを示すモードを説明します。
vdostats --verbose device コマンドを使用すると、VDO ボリュームの現在の操作モードを表示できます。出力内の Operating mode 属性を参照してください。
normal-
これがデフォルトの操作モードです。以下のいずれかのステータスにより別のモードが強制されない限りに、VDO ボリュームは常に
normalモードになります。新規作成された VDO ボリュームはnormalモードで起動します。 recoveringシャットダウンの前に、VDO ボリュームがすべてのメタデータを保存しない場合は、次に起動した時に自動的に
recoveringモードになります。このモードになる一般的な理由は、突然の停電や、基となるストレージデバイスの問題です。recoveringモードでは、VDO は、デバイスのデータの物理ブロックごとに参照カウントを修正します。通常、リカバリーにはかなり時間がかかります。その時間は、VDO ボリュームの大きさ、基となるストレージデバイスの速度、VDO が同時に処理するリクエスト数により異なります。VDO ボリュームは、通常は以下の例外で動作します。- 最初に、ボリュームに対する書き込み要求に利用できる領域の量が制限される場合があります。復旧するメタデータの数が多いと、より多くの空き領域が利用可能になります。
- VDO ボリュームの復旧中に書き込まれたデータは、そのデータが、復旧していないボリュームに含まれる場合に、クラッシュする前に書き込まれたデータに対する重複排除に失敗することがあります。VDO は、ボリュームの復旧中にデータを圧縮できます。圧縮したブロックの読み取りや上書きは可能です。
- オンラインリカバリーを行う際、一部の統計 (blocks in use や blocks free など) は利用できません。この統計は、再構築が完了すると利用できます。
- 継続中の復旧作業により、読み取りと書き込みの応答時間が通常よりも遅いことがあります。
recoveringモードでは、VDO ボリュームを問題なくシャットダウンできます。シャットダウンする前に復元が完了しないと、デバイスは、次回起動時に再度recoveringモードになります。VDO ボリュームは自動的に
recoveringモードを終了し、すべての参照カウントが修正されると、normalモードに移行します。管理者アクションは必要ありません。詳細は、「VDO ボリュームのオンラインリカバリー」 を参照してください。read-onlyVDO ボリュームが致命的な内部エラーに遭遇すると、
read-onlyモードになります。read-onlyモードになるイベントには、メタデータの破損や、バッキングストレージデバイスが読み取り専用になるなどが挙げられます。このモードはエラー状態です。read-onlyモードでは、データ読み取りは正常に機能しますが、データの書き込みは常に失敗します。管理者が問題を修正するまで、VDO ボリュームはread-onlyモードのままになります。VDO ボリュームを
read-onlyモードで問題なくシャットダウンできます。通常、モードは、VDO ボリュームが再起動した後も持続します。まれに、VDO ボリュームはバッキングストレージデバイスにread-only状態を記録することができません。このような場合、VDO は代わりに復旧を試みます。ボリュームが読み取り専用モードの場合、ボリュームのデータが損失または破損していないという保証はありません。このような場合、Red Hat は、読み取り専用のボリュームからデータをコピーして、バックアップからボリュームを復旧することを推奨します。
データ破損のリスクを許容できる場合は、VDO ボリュームのメタデータのオフライン再構築を強制することで、ボリュームをオンラインに戻して利用できるようにできます。再構築されたデータの整合性は保証できません。詳細は、「VDO ボリュームメタデータのオフライン再構築の強制」 を参照してください。
36.2.5.4. VDO ボリュームのオンラインリカバリー
この手順では、シャットダウンが正常に行われなかったときに、VDO ボリュームでオンラインリカバリーを実行して、メタデータを復旧します。
手順
VDO ボリュームを起動していない場合は、起動します。
# vdo start --name=my-vdoその他に何か行う必要はありません。復元は、バックグラウンドで実行します。
- blocks in use、blocks free などのボリューム統計を使用する場合は、利用可能になるまで待ちます。
36.2.5.5. VDO ボリュームメタデータのオフライン再構築の強制
この手順では、シャットダウンが正常に行われなかった場合に、VDO ボリュームメタデータの強制的なオフライン再構築を実行して、復旧します。
この手順では、ボリュームでデータが失われることがあります。
前提条件
- VDO ボリュームが起動している。
手順
ボリュームが読み取り専用モードかどうかを確認します。コマンド出力で operating mode 属性を確認します。
# vdo status --name=my-vdoボリュームが読み取り専用モードではない場合は、オフラインの再構築を強制する必要はありません。「VDO ボリュームのオンラインリカバリー」 に従って、オンラインリカバリーを実行します。
ボリュームが稼働している場合は停止します。
# vdo stop --name=my-vdo--forceRebuildオプションを指定して、ボリュームを再起動します。# vdo start --name=my-vdo --forceRebuild
36.2.5.6. 作成に失敗した VDO ボリュームの削除
この手順では、中間状態で VDO ボリュームをクリーンアップします。ボリュームの作成時に障害が発生した場合、ボリュームは中間状態になります。たとえば、以下のような場合に発生する可能性があります。
- システムのクラッシュ
- 停電
-
管理者が、実行中の
vdo createコマンドに割り込み
手順
クリーンアップを行う場合は、
--forceオプションを使用して、作成に失敗したボリュームを削除します。# vdo remove --force --name=my-vdoボリュームの作成に失敗して、管理者がシステム設定を変更して競合を発生させたため、
--forceオプションが必要となります。--forceオプションを指定しないと、vdo removeコマンドが失敗して、以下のメッセージが表示されます。[...] A previous operation failed. Recovery from the failure either failed or was interrupted. Add '--force' to 'remove' to perform the following cleanup. Steps to clean up VDO my-vdo: umount -f /dev/mapper/my-vdo udevadm settle dmsetup remove my-vdo vdo: ERROR - VDO volume my-vdo previous operation (create) is incomplete
36.2.6. UDS インデックスの最適化
UDS インデックスを特定の設定を行い、システムで最適化できます。
VDO ボリュームを 作成したら、UDS インデックスのプロパティーを変更することはできません。
36.2.6.1. VDO ボリュームのコンポーネント
VDO は、バッキングストアとしてブロックデバイスを使用します。これは、複数のディスク、パーティション、またはフラットファイルで設定される物理ストレージの集約を含めることができます。ストレージ管理ツールが VDO ボリュームを作成すると、VDO は、UDS インデックスおよび VDO ボリュームのボリューム領域を予約します。UDS インデックスと VDO ボリュームは対話して、重複排除したブロックストレージを提供します。
図36.6 VDO ディスク組織
VDO ソリューションは、以下のコンポーネントで設定されます。
kvdoLinux Device Mapper 層に読み込まれるカーネルモジュールは、重複排除され、圧縮され、シンプロビジョニングされたブロックストレージボリュームを提供します。
kvdoモジュールはブロックデバイスを公開します。ブロックストレージ用にこのブロックデバイスに直接アクセスするか、XFS や ext4 などの Linux ファイルシステムを介して提示することができます。kvdoが VDO ボリュームからデータ論理ブロックを読み取る要求を受信すると、要求された論理ブロックを基礎となる物理ブロックにマッピングし、要求したデータを読み取り、返します。kvdoが VDO ボリュームにデータブロックを書き込む要求を受信すると、まず要求が DISCARD または TRIM のものであるか、またはデータが一貫してゼロかどうかを確認します。これらの条件のいずれかが true の場合、kvdoはブロックマップを更新し、リクエストを承認します。そうでない場合は、VDO はデータを処理して最適化します。udsボリューム上の Universal Deduplication Service (UDS) インデックスと通信し、データの重複を分析するカーネルモジュール。新しい各データについて、その部分が保存してあるデータ内容と同一であるかどうかを UDS が素早く判断します。インデックスが一致すると、ストレージシステムは、同じ情報を複数格納しないように、既存の項目を内部的に参照できます。
UDS インデックスは、
udsカーネルモジュールとしてカーネル内で実行します。- コマンドラインツール
- 最適化されたストレージの設定および管理
36.2.6.2. UDS インデックス
VDO は、UDS と呼ばれる高パフォーマンスの重複排除インデックスを使用して、格納されているときにデータの重複ブロックを検出します。
UDS インデックスは、VDO 製品の基盤を提供します。新しい各データについて、その部分が保存してあるデータ内容と同一であるかどうかを素早く判断します。インデックスが一致すると、ストレージシステムは、同じ情報を複数格納しないように、既存の項目を内部的に参照できます。
UDS インデックスは、uds カーネルモジュールとしてカーネル内で実行します。
重複排除ウィンドウ は、以前書き込んだことをインデックスが記憶しているブロックの数です。重複排除ウィンドウのサイズは設定可能です。特定のウィンドウサイズでは、インデックスに特定の RAM のサイズと、特定のディスク領域が必要です。ウィンドウのサイズは、通常、--indexMem=size オプションを使用してインデックスメモリーのサイズを指定して決定されます。VDO は、自動的に使用するディスク領域を決定します。
UDS インデックスは 2 つの部分から成ります。
- 一意のブロックごとに最大 1 つのエントリーを含むメモリーでは、コンパクトな表が用いられています。
- 発生する際に、インデックスに対して示される関連のブロック名を順に記録するオンディスクコンポーネント。
UDS は、メモリーの各エントリーに対して平均 4 バイトを使用します (キャッシュを含む)。
オンディスクコンポーネントは、UDS に渡されるデータの境界履歴を維持します。UDS は、直近で確認されたブロックの名前を含む、この重複排除ウィンドウ内のデータの重複排除アドバイスを提供します。重複排除ウィンドウでは、大規模なデータリポジトリーに対して必要なメモリーの量を制限する際に、UDS はできるだけ効率的にデータのインデックスを作成します。重複排除ウィンドウの制限された性質にもかかわらず、重複排除レベルが高いデータセットのほとんどは、高度な時間的局所性も示します。つまり、ほとんどの重複排除は、ほぼ同時に書き込まれたブロックセット間で発生します。さらに、通常、書き込まれたデータは、以前に書き込まれたデータよりも、最近書き込まれたデータを複製する可能性が高くなります。したがって、特定の時間間隔での特定のワークロードでは、UDS が最新のデータのみをインデックス付けしても、すべてのデータをインデックス付けしても、重複排除率は同じになることがよくあります。
重複データの場合では、一時的な局所性が示される傾向もあるため、ストレージシステム内のすべてのブロックにインデックスを作成する必要はほとんどありません。そうでない場合、インデックスメモリーのコストは、重複排除によるストレージコストの削減を上回ります。インデックスサイズの要件は、データの摂取率に密接に関連します。たとえば、合計容量が 100 TB のストレージシステムには、毎週 1 TB の摂取率を指定します。UDS は、4 TB の重複排除ウィンドウにより、前の月に書き込まれたデータで、最も冗長性が大きいものを検出できます。
36.2.6.3. 推奨される UDS インデックス設定
本セクションでは、目的のユースケースに基づいて、UDS インデックスとともに使用することが推奨されるオプションを説明します。
一般的には、Red Hat は、すべての実稼働環境に sparse の UDS インデックスを使用することを推奨します。これは、非常に効率的なインデックスデータ構造であり、重複排除ウィンドウでブロックごとに RAM の約 10 分の 1 バイトが必要です。ディスクの場合は、ブロックごとに約 72 バイトのディスク領域が必要です。このインデックスの最小設定は、ディスクで 256 MB の RAM と約 25 GB の領域を使用します。
この設定を使用するには、--sparseIndex=enabled --indexMem=0.25 オプションを vdo create コマンドに指定します。この設定により、2.5 TB の重複排除ウィンドウが作成されます (つまり、2.5 TB の履歴が記録されます)。ほとんどのユースケースでは、2.5 TB の重複排除ウィンドウは、サイズが 10 TB までのストレージプールを重複排除するのに適しています。
ただし、インデックスのデフォルト設定は、dense のインデックスを使用します。このインデックスは RAM では非常に効率が悪い (10 倍) ですが、必要なディスク領域もはるかに少ない (10 倍) ため、制約された環境での評価に便利です。
一般に、推奨される設定は、VDO ボリュームの物理サイズの 4 分の 1 の重複排除ウィンドウです。ただし、これは実際の要件ではありません。小さな重複排除ウィンドウ (物理ストレージの量と比較) であっても、多くのユースケースで大量の重複データを確認できます。大概のウィンドウも使用できますが、ほとんどの場合、それを行う利点はほとんどありません。
36.2.7. VDO での重複排除の有効化または無効化
一部の例では、ボリュームへの読み書きを行う機能を維持しながら、VDO ボリュームに書き込まれているデータの重複排除を一時的に無効にする場合があります。重複排除を無効にすると、後続の書き込みが重複排除できなくなりますが、すでに重複排除されたデータが残ります。
36.2.7.1. VDO での重複排除
重複排除とは、重複ブロックの複数のコピーを削除することで、ストレージリソースの消費を低減させるための技術です。
同じデータを複数回書き込むのではなく、VDO は各重複ブロックを検出し、元のブロックへの参照として記録します。VDO は、VDO の上にあるストレージ層により使用されている論理ブロックアドレスから、VDO の下にあるストレージ層で使用される物理ブロックアドレスへのマッピングを維持します。
重複排除を行った後、複数の論理ブロックアドレスが同じ物理ブロックアドレスにマッピングできます。共有ブロックと呼ばれます。ブロックストレージの共有は、VDO が存在しない場合に、読み込みブロックと書き込みブロックが行われるストレージのユーザーには表示されません。
共有ブロックが上書きされると、VDO は新しいブロックデータを保存する新しい物理ブロックを割り当て、共有物理ブロックにマッピングされたその他の論理ブロックアドレスが変更されないようにします。
36.2.7.2. VDO ボリュームでの重複排除の有効化
これにより、関連の UDS インデックスを再起動し、重複排除が再びアクティブになったことを VDO ボリュームに認識させます。
重複排除はデフォルトで有効になっています。
手順
VDO ボリュームでの重複排除を再起動するには、以下のコマンドを使用します。
# vdo enableDeduplication --name=my-vdo
36.2.7.3. VDO ボリュームでの重複排除の無効化
これにより、関連の UDS インデックスを停止し、重複排除がアクティブでなくなったことを VDO ボリュームに認識させます。
手順
VDO ボリュームでの重複排除を停止するには、以下のコマンドを使用します。
# vdo disableDeduplication --name=my-vdo-
--deduplication=disabledオプションをvdo createコマンドに指定することで、新しい VDO ボリュームを作成するときに重複排除を無効にできます。
36.2.8. VDO で圧縮の有効化または無効化
VDO は、データ圧縮を提供します。これを無効にすると、パフォーマンスが最大化され、圧縮される可能性が低いデータの処理が高速化されます。再度有効にすると、スペースを節約できます。
36.2.8.1. VDO の圧縮
VDO は、ブロックレベルの重複排除の他に、HIOPS compression™ 技術を使用してインラインブロックレベルの圧縮も提供します。
VDO ボリューム圧縮はデフォルトでオンになっています。
重複排除は、仮想マシン環境とバックアップアプリケーションに最適なソリューションですが、圧縮は、通常、ログファイルやデータベースなどのブロックレベルの冗長性を見せない構造化および非構造化のファイル形式に非常に適しています。
圧縮は、重複として認識されていないブロックで動作します。VDO が初めて一意のデータを見つけた場合は、データを圧縮します。その後の、保存しているデータのコピーは、追加の圧縮手順なしに重複排除されます。
圧縮機能は、同時に多くの圧縮操作に対応できるようにする並列化されたパッケージアルゴリズムに基づいています。最初にブロックを保存し、リクエストに応答したら、圧縮時に複数のブロックを検出する最適なパックアルゴリズムが、1 つの物理ブロックに適合します。特定の物理ブロックが追加の圧縮ブロックを保持していないと判断すると、そのブロックはストレージに書き込まれます。圧縮されていないブロックは解放され、再利用されます。
要求したものに応答し、圧縮およびパッケージ化の操作を実行することにより、圧縮を使用することで課せられるレイテンシーが最小限に抑えられます。
36.2.8.2. VDO ボリュームでの圧縮の有効化
この手順では、VDO ボリュームで圧縮を有効化して、削減する領域を大きくします。
デフォルトでは圧縮が有効になっています。
手順
再び起動するには、以下のコマンドを使用します。
# vdo enableCompression --name=my-vdo
36.2.8.3. VDO ボリュームでの圧縮の無効化
この手順では、VDO ボリュームで圧縮を停止して、パフォーマンスを最大化します。もしくは、圧縮できないと思われるデータの処理を高速化します。
手順
既存の VDO ボリュームで圧縮を停止するには、次のコマンドを使用します。
# vdo disableCompression --name=my-vdo-
もしくは、新規ボリュームの作成時に、
--compression=disabledオプションをvdo createコマンドに指定して実行すると、圧縮を無効にできます。
36.2.9. VDO ボリュームのサイズの拡大
VDO ボリュームの物理サイズを増やして、基となるストレージの容量をさらに利用したり、ボリュームの論理サイズを大きくして、ボリュームが多くの領域を使用できるようにできます。
36.2.9.1. VDO ボリュームの物理サイズおよび論理サイズ
VDO は、物理サイズ、利用可能な物理サイズ、および論理サイズを次の方法で利用します。
- 物理サイズ
これは、基礎となるブロックデバイスと同じサイズです。VDO は、以下の目的でこのストレージを使用します。
- 重複排除および圧縮される可能性があるユーザーデータ
- UDS インデックスなどの VDO メタデータ
- 利用可能な物理サイズ
これは、VDO がユーザーデータに使用できる物理サイズの一部です。
これは、メタデータのサイズを引いた物理サイズと同等で、指定のスラブサイズでボリュームをスラブに分割した後の残りを引いたものと同じです。
- 論理サイズ
これは、VDO ボリュームがアプリケーションに提示するプロビジョニングされたサイズです。通常、これは利用可能な物理サイズよりも大きくなります。
--vdoLogicalSizeオプションを指定しないと、論理ボリュームのプロビジョニングが1:1の比率にプロビジョニングされます。たとえば、VDO ボリュームが 20 GB ブロックデバイスの上に置かれている場合は、2.5 GB が UDS インデックス用に予約されます (デフォルトのインデックスサイズが使用される場合)。残りの 17.5 GB は、VDO メタデータおよびユーザーデータに提供されます。そのため、消費する利用可能なストレージは 17.5 GB を超えません。実際の VDO ボリュームを設定するメタデータにより、これよりも少なくなる可能性があります。VDO は現在、絶対最大論理サイズ 4PB の物理ボリュームの最大 254 倍の論理サイズに対応します。
図36.7 VDO ディスク組織
この図では、VDO で重複排除したストレージターゲットがブロックデバイス上に完全に配置されています。つまり、VDO ボリュームの物理サイズは、基礎となるブロックデバイスと同じサイズになります。
36.2.9.2. VDO でのシンプロビジョニング
VDO は、シンプロビジョニングされたブロックストレージターゲットです。VDO ボリュームが使用する物理領域のサイズは、ストレージのユーザーに示されるボリュームのサイズとは異なる可能性があります。この相違を活用して、ストレージのコストを削減できます。
容量不足の条件
書き込んだデータが、予想される最適化率に到達できない場合は、ストレージ領域が予想外に不足しないように注意してください。
論理ブロック (仮想ストレージ) の数が物理ブロック (実際のストレージ) の数を超えると、ファイルシステムおよびアプリケーションで領域が予想外に不足する可能性があります。このため、VDO を使用するストレージシステムは、VDO ボリュームの空きプールのサイズを監視する方法で提供する必要があります。
vdostats ユーティリティーを使用すると、この空きプールのサイズを確認できます。このユーティリティーのデフォルト出力には、Linux の df ユーティリティーと同様の形式で稼働しているすべての VDO ボリュームの情報が記載されます。以下に例を示します。
Device 1K-blocks Used Available Use%
/dev/mapper/vdo-name 211812352 105906176 105906176 50%VDO ボリュームの物理ストレージ領域が不足しそうになると、VDO は、システムログに、以下のような警告を出力します。
Oct 2 17:13:39 system lvm[13863]: Monitoring VDO pool vdo-name.
Oct 2 17:27:39 system lvm[13863]: WARNING: VDO pool vdo-name is now 80.69% full.
Oct 2 17:28:19 system lvm[13863]: WARNING: VDO pool vdo-name is now 85.25% full.
Oct 2 17:29:39 system lvm[13863]: WARNING: VDO pool vdo-name is now 90.64% full.
Oct 2 17:30:29 system lvm[13863]: WARNING: VDO pool vdo-name is now 96.07% full.
この警告メッセージは、lvm2-monitor サービスが実行している場合に限り表示されます。これは、デフォルトで有効になっています。
容量不足の状況を防ぐ方法
空きプールのサイズが特定のレベルを下回る場合は、以下を行うことができます。
- データの削除。これにより、削除したデータが重複していないと、領域が回収されます。データを削除しても、破棄が行われないと領域を解放しません。
- 物理ストレージの追加
VDO ボリュームで物理領域を監視し、領域不足を回避します。物理ブロックが不足すると、VDO ボリュームに最近書き込まれたデータや、未承認のデータが失われることがあります。
シンプロビジョニング、TRIM コマンド、および DISCARD コマンド
シンプロビジョニングによるストレージの削減から利益を得るには、データを削除するタイミングを物理ストレージ層が把握する必要があります。シンプロビジョニングされたストレージで動作するファイルシステムは、TRIM コマンドまたは DISCARD コマンドを送信して、論理ブロックが不要になったときにストレージシステムに通知します。
TRIM コマンドまたは DISCARD コマンドを送信する方法はいくつかあります。
-
discardマウントオプションを使用すると、ブロックが削除されるたびに、ファイルシステムがそのコマンドを送信できます。 -
fstrimなどのユーティリティーを使用すると、制御された方法でコマンドを送信できます。このようなユーティリティーは、どの論理ブロックが使用されていないかを検出し、TRIMコマンドまたはDISCARDコマンドの形式でストレージシステムに情報を送信するようにファイルシステムに指示します。
未使用のブロックで TRIM または DISCARD を使用する必要は、VDO に特有のものではありません。シンプロビジョニングしたストレージシステムでも、同じ課題があります。
36.2.9.3. VDO ボリュームの論理サイズの拡大
この手順では、指定した VDO ボリュームの論理サイズを増やします。最初に、領域が不足しないサイズの論理が含まれる VDO ボリュームを作成できます。しばらくすると、データ消費の実際のレートを評価することができ、十分な場合には、VDO ボリュームの論理サイズを拡張して、削減して得られた領域を活用することができます。
VDO ボリュームの論理サイズを縮小することはできません。
手順
論理サイズを拡張するには、次のコマンドを実行します。
# vdo growLogical --name=my-vdo \ --vdoLogicalSize=new-logical-size論理サイズが増大すると、VDO は新しいサイズのボリュームの上にデバイスまたはファイルシステムに通知します。
36.2.9.4. VDO ボリュームの物理サイズの拡大
この手順では、VDO ボリュームに利用できる物理ストレージの量を増やします。
このように VDO ボリュームを縮小することはできません。
前提条件
基となるブロックデバイスのサイズが、VDO ボリュームの現在の物理サイズよりも大きい。
そうでない場合は、デバイスのサイズを大きくできます。正確な手順は、デバイスの種類によって異なります。たとえば、MBR パーティションまたは GPT パーティションのサイズ変更は、ストレージデバイスの管理の パーティションの使用 を参照してください。
手順
新しい物理ストレージ領域を VDO ボリュームに追加します。
# vdo growPhysical --name=my-vdo
36.2.10. VDO ボリュームの削除
システムで既存の VDO ボリュームを削除できます。
36.2.10.1. 作業中の VDO ボリュームの削除
この手順では、VDO ボリュームと、関連する UDS インデックスを削除します。
手順
- ファイルシステムのマウントを解除し、VDO ボリュームでストレージを使用しているアプリケーションを停止します。
システムから VDO ボリュームを削除するには、次のコマンドを使用します。
# vdo remove --name=my-vdo
36.2.10.2. 作成に失敗した VDO ボリュームの削除
この手順では、中間状態で VDO ボリュームをクリーンアップします。ボリュームの作成時に障害が発生した場合、ボリュームは中間状態になります。たとえば、以下のような場合に発生する可能性があります。
- システムのクラッシュ
- 停電
-
管理者が、実行中の
vdo createコマンドに割り込み
手順
クリーンアップを行う場合は、
--forceオプションを使用して、作成に失敗したボリュームを削除します。# vdo remove --force --name=my-vdoボリュームの作成に失敗して、管理者がシステム設定を変更して競合を発生させたため、
--forceオプションが必要となります。--forceオプションを指定しないと、vdo removeコマンドが失敗して、以下のメッセージが表示されます。[...] A previous operation failed. Recovery from the failure either failed or was interrupted. Add '--force' to 'remove' to perform the following cleanup. Steps to clean up VDO my-vdo: umount -f /dev/mapper/my-vdo udevadm settle dmsetup remove my-vdo vdo: ERROR - VDO volume my-vdo previous operation (create) is incomplete
36.3. 未使用ブロックの破棄
破棄操作に対応するブロックデバイスで破棄操作を実行するか、そのスケジュールを設定できます。ブロック破棄操作は、マウントされたファイルシステムで使用されなくなったファイルシステムブロックを基盤となるストレージに伝達します。ブロック破棄操作により、SSD はガベージコレクションルーチンを最適化でき、シンプロビジョニングされたストレージに未使用の物理ブロックを再利用するように通知できます。
要件
ファイルシステムの基礎となるブロックデバイスは、物理的な破棄操作に対応している必要があります。
/sys/block/<device>/queue/discard_max_bytesファイルの値がゼロではない場合は、物理的な破棄操作はサポートされます。
36.3.1. ブロック破棄操作のタイプ
以下のような、さまざまな方法で破棄操作を実行できます。
- バッチ破棄
- これは、ユーザーによって明示的にトリガーされ、選択したファイルシステム内の未使用のブロックをすべて破棄します。
- オンライン破棄
-
これは、マウント時に指定され、ユーザーの介入なしにリアルタイムでトリガーされます。オンライン破棄操作は、
usedからfree状態に移行中のブロックのみを破棄します。 - 定期的な破棄
-
systemdサービスが定期的に実行するバッチ操作です。
すべてのタイプは、XFS ファイルシステムおよび ext4 ファイルシステムでサポートされます。
推奨事項
Red Hat は、バッチ破棄または周期破棄を使用することを推奨します。
以下の場合にのみ、オンライン破棄を使用してください。
- システムのワークロードでバッチ破棄が実行できない場合
- パフォーマンス維持にオンライン破棄操作が必要な場合
36.3.2. バッチブロック破棄の実行
バッチブロック破棄操作を実行して、マウントされたファイルシステムの未使用ブロックを破棄することができます。
前提条件
- ファイルシステムがマウントされている。
- ファイルシステムの基礎となるブロックデバイスが物理的な破棄操作に対応している。
手順
fstrimユーティリティーを使用します。選択したファイルシステムでのみ破棄を実行するには、次のコマンドを使用します。
# fstrim mount-pointマウントされているすべてのファイルシステムで破棄を実行するには、次のコマンドを使用します。
# fstrim --all
fstrim コマンドを以下のいずれかで実行している場合は、
- 破棄操作に対応していないデバイス
- 複数のデバイスから構成され、そのデバイスの 1 つが破棄操作に対応していない論理デバイス (LVM または MD)
次のメッセージが表示されます。
# fstrim /mnt/non_discard
fstrim: /mnt/non_discard: the discard operation is not supported36.3.3. オンラインブロック破棄の有効化
オンラインブロック破棄操作を実行して、サポートしているすべてのファイルシステムで未使用のブロックを自動的に破棄できます。
手順
マウント時のオンライン破棄を有効にします。
ファイルシステムを手動でマウントするには、
-o discardマウントオプションを追加します。# mount -o discard device mount-point-
ファイルシステムを永続的にマウントするには、
/etc/fstabファイルのマウントエントリーにdiscardオプションを追加します。
36.3.4. storage RHEL システムロールを使用してオンラインのブロック破棄を有効にする
オンラインブロック破棄オプションを使用すると、XFS ファイルシステムをマウントし、未使用のブロックを自動的に破棄できます。
前提条件
- コントロールノードと管理対象ノードの準備が完了している。
- 管理対象ノードで Playbook を実行できるユーザーとしてコントロールノードにログインしている。
-
管理対象ノードへの接続に使用するアカウントに、そのノードに対する
sudo権限がある。
手順
次の内容を含む Playbook ファイル (例:
~/playbook.yml) を作成します。--- - name: Manage local storage hosts: managed-node-01.example.com tasks: - name: Enable online block discard ansible.builtin.include_role: name: redhat.rhel_system_roles.storage vars: storage_volumes: - name: barefs type: disk disks: - sdb fs_type: xfs mount_point: /mnt/data mount_options: discardPlaybook で使用されるすべての変数の詳細は、コントロールノードの
/usr/share/ansible/roles/rhel-system-roles.storage/README.mdファイルを参照してください。Playbook の構文を検証します。
$ ansible-playbook --syntax-check ~/playbook.ymlこのコマンドは構文を検証するだけであり、有効だが不適切な設定から保護するものではないことに注意してください。
Playbook を実行します。
$ ansible-playbook ~/playbook.yml
検証
オンラインブロック破棄オプションが有効になっていることを確認します。
# ansible managed-node-01.example.com -m command -a 'findmnt /mnt/data'
36.3.5. 定期的なブロック破棄の有効化
systemd タイマーを有効にして、サポートしているすべてのファイルシステムで未使用ブロックを定期的に破棄できます。
手順
systemdタイマーを有効にして起動します。# systemctl enable --now fstrim.timer Created symlink /etc/systemd/system/timers.target.wants/fstrim.timer → /usr/lib/systemd/system/fstrim.timer.
検証
タイマーのステータスを確認します。
# systemctl status fstrim.timer fstrim.timer - Discard unused blocks once a week Loaded: loaded (/usr/lib/systemd/system/fstrim.timer; enabled; vendor preset: disabled) Active: active (waiting) since Wed 2023-05-17 13:24:41 CEST; 3min 15s ago Trigger: Mon 2023-05-22 01:20:46 CEST; 4 days left Docs: man:fstrim May 17 13:24:41 localhost.localdomain systemd[1]: Started Discard unused blocks once a week.
パート V. ログファイルの設計
第37章 システムの監査
監査はシステムに追加のセキュリティーを提供するわけではありませんが、システム上のセキュリティーポリシー違反を検出するために使用できます。その後、SELinux などの追加のセキュリティー対策を設定することで、将来このような違反を防ぐことができます。
37.1. Linux の Audit
Linux の Audit システムは、システムのセキュリティー関連情報を追跡する方法を提供します。事前設定されたルールに基づき、Audit は、ログエントリーを生成し、システムで発生しているイベントに関する情報をできるだけ多く記録します。この情報は、ミッションクリティカルな環境でセキュリティーポリシーの違反者と、違反者によるアクションを判断する上で必須のものです。
以下は、Audit がログファイルに記録できる情報の概要です。
- イベントの日時、タイプ、結果
- サブジェクトとオブジェクトの機密性のラベル
- イベントを開始したユーザーの ID とイベントの関連性
- Audit 設定の全修正および Audit ログファイルへのアクセス試行
- SSH、Kerberos などの認証メカニズムのすべての使用
-
信頼できるデータベース (
/etc/passwdなど) への変更 - システムからの情報のインポート、およびシステムへの情報のエクスポートの試行
- ユーザー ID、サブジェクトとオブジェクトのラベルなどの属性に基づくイベントの追加と除外
Audit システムの使用は、多くのセキュリティー関連の認定における要件でもあります。Audit は、以下の認定またはコンプライアンスガイドの要件に合致するか、それを超えるように設計されています。
- Controlled Access Protection Profile (CAPP)
- Labeled Security Protection Profile (LSPP)
- Rule Set Base Access Control (RSBAC)
- NISPOM (National Industrial Security Program Operating Manual)
- Federal Information Security Management Act (FISMA)
- Payment Card Industry - Data Security Standard (PCI-DSS)
- セキュリティー技術実装ガイド (Security Technical Implementation Guide (STIG))
監査は、National Information Assurance Partnership (NIAP) および Best Security Industries (BSI) によっても評価されています。
ユースケース
- ファイルアクセスの監視
- Audit は、ファイルやディレクトリーがアクセス、修正、または実行されたか、もしくはファイル属性が変更されたかを追跡できます。これはたとえば、重要なファイルへのアクセスを検出し、これらのファイルが破損した場合に監査証跡を入手可能とする際に役に立ちます。
- システムコールの監視
-
Audit は、一部のシステムコールが使用されるたびにログエントリーを生成するように設定できます。これを使用すると、
settimeofdayやclock_adjtime、その他の時間関連のシステムコールを監視することで、システム時間への変更を追跡できます。 - ユーザーが実行したコマンドの記録
-
Audit はファイルが実行されたかどうかを追跡できるため、特定のコマンドの実行を毎回記録するようにルールを定義できます。たとえば、
/binディレクトリー内のすべての実行可能ファイルにルールを定義できます。これにより作成されるログエントリーをユーザー ID で検索すると、ユーザーごとに実行されたコマンドの監査証跡を生成できます。 - システムのパス名の実行の記録
- ルールの呼び出し時にパスを inode に変換するファイルアクセスをウォッチする以外に、ルールの呼び出し時に存在しない場合や、ルールの呼び出し後にファイルが置き換えられた場合でも、Audit がパスの実行をウォッチできるようになりました。これにより、ルールは、プログラム実行ファイルをアップグレードした後、またはインストールされる前にも機能を継続できます。
- セキュリティーイベントの記録
-
pam_faillock認証モジュールは、失敗したログイン試行を記録できます。Audit で失敗したログイン試行も記録するように設定すると、ログインを試みたユーザーに関する追加情報が提供されます。 - イベントの検索
-
Audit は
ausearchユーティリティーを提供します。これを使用すると、ログエントリーをフィルターにかけ、いくつかの条件に基づく完全な監査証跡を提供できます。 - サマリーレポートの実行
-
aureportユーティリティーを使用すると、記録されたイベントのデイリーレポートを生成できます。システム管理者は、このレポートを分析し、疑わしいアクティビティーをさらに調べることができます。 - ネットワークアクセスの監視
-
nftables、iptables、およびebtablesユーティリティーは、Audit イベントを発生するように設定できるため、システム管理者がネットワークアクセスを監視できるようになります。
システムのパフォーマンスは、Audit が収集する情報量によって影響される可能性があります。
37.2. Audit システムのアーキテクチャー
Audit システムは、ユーザー空間アプリケーションおよびユーティリティーと、カーネル側のシステムコール処理という 2 つの主要部分で構成されます。カーネルコンポーネントは、ユーザー空間アプリケーションからシステムコールを受け、これを user、task、fstype、または exit のいずれかのフィルターで振り分けます。
システムコールが exclude フィルターを通過すると、前述のフィルターのいずれかに送られます。このフィルターにより、Audit ルール設定に基づいてシステムコールが Audit デーモンに送信され、さらに処理されます。
ユーザー空間の Audit デーモンは、カーネルから情報を収集し、ログファイルのエントリーを作成します。他のユーザー空間ユーティリティーは、Audit デーモン、カーネルの Audit コンポーネント、または Audit ログファイルと相互作用します。
-
auditctlAudit 制御ユーティリティーはカーネル Audit コンポーネントと相互作用し、ルールを管理するだけでなくイベント生成プロセスの多くの設定やパラメーターも制御します。 -
残りの Audit ユーティリティーは、Audit ログファイルのコンテンツを入力として受け取り、ユーザーの要件に基づいて出力を生成します。たとえば、
aureportユーティリティーは、記録された全イベントのレポートを生成します。
RHEL 8 では、Audit dispatcher デーモン (audisp) 機能は、Audit デーモン (auditd) に統合されています。監査イベントと、リアルタイムの分析プログラムの相互作用に使用されるプラグイン設定ファイルは、デフォルトで /etc/audit/plugins.d/ ディレクトリーに保存されます。
37.3. 環境を保護するための auditd の設定
デフォルトの auditd 設定は、ほとんどの環境に適しています。ただし、環境が厳格なセキュリティーポリシーを満たす必要がある場合は、/etc/audit/auditd.conf ファイル内の Audit デーモン設定の次の設定を変更できます。
log_file-
Audit ログファイル (通常は
/var/log/audit/) を保持するディレクトリーは、別のマウントポイントにマウントされている必要があります。これにより、その他のプロセスがこのディレクトリー内の領域を使用しないようにし、Audit デーモンの残りの領域を正確に検出します。 max_log_file-
1 つの Audit ログファイルの最大サイズを指定します。Audit ログファイルを保持するパーティションで利用可能な領域をすべて使用するように設定する必要があります。
max_log_file`パラメーターは、最大ファイルサイズをメガバイト単位で指定します。指定する値は、数値にする必要があります。 max_log_file_action-
max_log_fileに設定した制限に達したときに実行するアクションを決定します。Audit ログファイルが上書きされないようにkeep_logsに設定する必要があります。 space_left-
space_left_actionパラメーターで設定されたアクションがトリガーされるディスクに残っている空き領域の量を指定します。管理者は、ディスクの領域を反映して解放するのに十分な時間を設定する必要があります。space_leftの値は、Audit ログファイルが生成されるレートによって異なります。space_left の値が整数として指定されている場合は、メガバイト (MiB) 単位の絶対サイズとして解釈されます。値が 1 〜 99 の数値の後にパーセント記号を付けて指定されている場合 (5% など)、Audit デーモンは、log_fileを含むファイルシステムのサイズに基づいて、メガバイト単位で絶対サイズを計算します。 space_left_action-
適切な通知方法を使用して、
space_left_actionパラメーターをemailまたはexecに設定することを推奨します。 admin_space_left-
admin_space_left_actionパラメーターで設定されたアクションがトリガーされる空きスペースの絶対最小量を指定します。これは、管理者によって実行されたアクションをログに記録するのに十分なスペースを残す値に設定する必要があります。このパラメーターの数値は、space_left の数値より小さくする必要があります。また、数値にパーセント記号を追加 (1% など) して、Audit デーモンが、ディスクパーティションサイズに基づいて、数値を計算するようにすることもできます。 admin_space_left_action-
singleを、システムをシングルユーザーモードにし、管理者がディスク領域を解放できるようにします。 disk_full_action-
Audit ログファイルが含まれるパーティションに空き領域がない場合に発生するアクションを指定します (
haltまたはsingleに設定する必要があります)。これにより、Audit がイベントをログに記録できなくなると、システムは、シングルユーザーモードでシャットダウンまたは動作します。 disk_error_action-
Audit ログファイルが含まれるパーティションでエラーが検出された場合に発生するアクションを指定します。このパラメーターは、ハードウェアの機能不全処理に関するローカルのセキュリティーポリシーに基づいて、
syslog、single、haltのいずれかに設定する必要があります。 flush-
incremental_asyncに設定する必要があります。これはfreqパラメーターと組み合わせて機能します。これは、ハードドライブとのハード同期を強制する前にディスクに送信できるレコードの数を指定します。freqパラメーターは100に設定する必要があります。このパラメーターにより、アクティビティーが集中した際に高いパフォーマンスを保ちつつ、Audit イベントデータがディスクのログファイルと確実に同期されるようになります。
残りの設定オプションは、ローカルのセキュリティーポリシーに合わせて設定します。
37.4. auditd の開始および制御
auditd が設定されたら、サービスを起動して Audit 情報を収集し、ログファイルに保存します。root ユーザーで次のコマンドを実行し、auditd を起動します。
# service auditd start
システムの起動時に auditd が起動するように設定するには、次のコマンドを実行します。
# systemctl enable auditd
# auditctl -e 0 で auditd を一時的に無効にし、# auditctl -e 1 で再度有効にできます。
service auditd <action> コマンドを使用すると、auditd で他のアクションを実行できます。<action> は次のいずれかです。
stop-
auditdを停止します。 restart-
auditdを再起動します。 reloadまたはforce-reload-
/etc/audit/auditd.confファイルからauditdの設定を再ロードします。 rotate-
/var/log/audit/ディレクトリーのログファイルをローテーションします。 resume- Audit イベントのログが一旦停止した後、再開します。たとえば、Audit ログファイルが含まれるディスクパーティションの未使用領域が不足している場合などです。
condrestartまたはtry-restart-
auditdがすでに起動している場合にのみ、これを再起動します。 status-
auditdの稼働状況を表示します。
service コマンドは、auditd デーモンと正しく相互作用する唯一の方法です。auid 値が適切に記録されるように、service コマンドを使用する必要があります。systemctl コマンドは、2 つのアクション (enable および status) にのみ使用できます。
37.5. Audit ログファイルについて
デフォルトでは、Audit システムはログエントリーを /var/log/audit/audit.log ファイルに保存します。ログローテーションが有効になっていれば、ローテーションされた audit.log ファイルは同じディレクトリーに保存されます。
下記の Audit ルールを追加して、/etc/ssh/sshd_config ファイルの読み取りまたは修正の試行をすべてログに記録します。
# auditctl -w /etc/ssh/sshd_config -p warx -k sshd_config
auditd デーモンが実行している場合は、たとえば次のコマンドを使用して、Audit ログファイルに新しいイベントを作成します。
$ cat /etc/ssh/sshd_config
このイベントは、audit.log ファイルでは以下のようになります。
type=SYSCALL msg=audit(1364481363.243:24287): arch=c000003e syscall=2 success=no exit=-13 a0=7fffd19c5592 a1=0 a2=7fffd19c4b50 a3=a items=1 ppid=2686 pid=3538 auid=1000 uid=1000 gid=1000 euid=1000 suid=1000 fsuid=1000 egid=1000 sgid=1000 fsgid=1000 tty=pts0 ses=1 comm="cat" exe="/bin/cat" subj=unconfined_u:unconfined_r:unconfined_t:s0-s0:c0.c1023 key="sshd_config"
type=CWD msg=audit(1364481363.243:24287): cwd="/home/shadowman"
type=PATH msg=audit(1364481363.243:24287): item=0 name="/etc/ssh/sshd_config" inode=409248 dev=fd:00 mode=0100600 ouid=0 ogid=0 rdev=00:00 obj=system_u:object_r:etc_t:s0 nametype=NORMAL cap_fp=none cap_fi=none cap_fe=0 cap_fver=0
type=PROCTITLE msg=audit(1364481363.243:24287) : proctitle=636174002F6574632F7373682F737368645F636F6E666967
上記のイベントは 4 つのレコードで構成されており、タイムスタンプとシリアル番号を共有します。レコードは、常に type= で始まります。各レコードは、スペースまたはコンマで区切られた複数の名前と値のペア (name=value ) で構成されます。上記のイベントの詳細な分析は以下のようになります。
1 つ目のレコード
type=SYSCALL-
typeフィールドには、レコードのタイプが記載されます。この例のSYSCALL値は、カーネルへのシステムコールによりこれが記録されたことを示しています。
msg=audit(1364481363.243:24287):msgフィールドには以下が記録されます。-
audit(time_stamp:ID)形式のレコードのタイムスタンプおよび一意の ID。複数のレコードが同じ Audit イベントの一部として生成されている場合は、同じタイムスタンプおよび ID を共有できます。タイムスタンプは Unix の時間形式です (1970 年 1 月 1 日 00:00:00 UTC からの秒数)。 -
カーネル空間およびユーザー空間のアプリケーションが提供するさまざまなイベント固有の
name=valueペア。
-
arch=c000003e-
archフィールドには、システムの CPU アーキテクチャーに関する情報が含まれます。c000003eの値は 16 進数表記で記録されます。ausearchコマンドで Audit レコードを検索する場合は、-iオプションまたは--interpretオプションを使用して、16 進数の値を人間が判読できる値に自動的に変換します。c000003e値はx86_64として解釈されます。 syscall=2-
syscallフィールドは、カーネルに送信されたシステムコールのタイプを記録します。値が2の場合は、/usr/include/asm/unistd_64.hファイルに、人間が判読できる値を指定できます。この場合の2は、オープンなシステムコールです。ausyscallユーティリティーでは、システムコール番号を、人間が判読できる値に変換できます。ausyscall --dumpコマンドを使用して、システムコールのリストとその数字を表示します。詳細は、ausyscall(8) の man ページを参照してください。 success=no-
successフィールドは、その特定のイベントで記録されたシステムコールが成功したかどうかを記録します。この例では、呼び出しが成功しませんでした。 exit=-13exitフィールドには、システムコールが返した終了コードを指定する値が含まれます。この値は、システムコールにより異なります。次のコマンドを実行すると、この値を人間が判読可能なものに変換できます。# ausearch --interpret --exit -13この例では、監査ログに、終了コード
-13で失敗したイベントが含まれていることが前提となります。a0=7fffd19c5592,a1=0,a2=7fffd19c5592,a3=a-
a0からa3までのフィールドは、このイベントにおけるシステムコールの最初の 4 つの引数を、16 進法で記録します。この引数は、使用されるシステムコールにより異なります。ausearchユーティリティーで解釈できます。 items=1-
itemsフィールドには、システムコールのレコードに続く PATH 補助レコードの数が含まれます。 ppid=2686-
ppidフィールドは、親プロセス ID (PPID) を記録します。この例では、2686は、bashなどの親プロセスの PPID です。 pid=3538-
pidフィールドは、プロセス ID (PID) を記録します。この例の3538はcatプロセスの PID です。 auid=1000-
auidフィールドには、loginuid である Audit ユーザー ID が記録されます。この ID は、ログイン時にユーザーに割り当てられ、ユーザーの ID が変更した後でもすべてのプロセスに引き継がれます (たとえば、su - johnコマンドでユーザーアカウントを切り替えた場合)。 uid=1000-
uidフィールドは、解析しているプロセスを開始したユーザーのユーザー ID を記録します。ユーザー ID は、ausearch -i --uid UIDのコマンドを使用するとユーザー名に変換されます。 gid=1000-
gidフィールドは、解析しているプロセスを開始したユーザーのグループ ID を記録します。 euid=1000-
euidフィールドは、解析しているプロセスを開始したユーザーの実効ユーザー ID を記録します。 suid=1000-
suidフィールドは、解析しているプロセスを開始したユーザーのセットユーザー ID を記録します。 fsuid=1000-
fsuidフィールドは、解析しているプロセスを開始したユーザーのファイルシステムユーザー ID を記録します。 egid=1000-
egidフィールドは、解析しているプロセスを開始したユーザーの実効グループ ID を記録します。 sgid=1000-
sgidフィールドは、解析しているプロセスを開始したユーザーのセットグループ ID を記録します。 fsgid=1000-
fsgidフィールドは、解析しているプロセスを開始したユーザーのファイルシステムグループ ID を記録します。 tty=pts0-
ttyフィールドは、解析しているプロセスが開始したターミナルを記録します。 ses=1-
sesフィールドは、解析しているプロセスが開始したセッションのセッション ID を記録します。 comm="cat"-
commフィールドは、解析しているプロセスを開始するために使用したコマンドのコマンドライン名を記録します。この例では、この Audit イベントを発生するのに、catコマンドが使用されました。 exe="/bin/cat"-
exeフィールドは、解析しているプロセスを開始するために使用した実行可能ファイルへのパスを記録します。 subj=unconfined_u:unconfined_r:unconfined_t:s0-s0:c0.c1023-
subjフィールドは、解析しているプロセスの実行時にラベル付けされた SELinux コンテンツを記録します。 key="sshd_config"-
keyフィールドは、Audit ログでこのイベントを生成したルールに関連付けられている管理者による定義の文字列を記録します。
2 つ目のレコード
type=CWD2 つ目のレコードの
typeフィールドの値は、CWD(現在の作業ディレクトリー) です。このタイプは、最初のレコードで指定されたシステムコールを開始したプロセスの作業ディレクトリーを記録するために使用されます。この記録の目的は、相対パスが関連する PATH 記録に保存された場合に、現行プロセスの位置を記録することにあります。これにより、絶対パスを再構築できます。
msg=audit(1364481363.243:24287)-
msgフィールドは、最初のレコードと同じタイムスタンプと ID の値を保持します。タイムスタンプは Unix の時間形式です (1970 年 1 月 1 日 00:00:00 UTC からの秒数)。 cwd="/home/user_name"-
cwdフィールドは、システムコールが開始したディレクトリーのパスになります。
3 つ目のレコード
type=PATH-
3 つ目のレコードでは、
typeフィールドの値はPATHです。Audit イベントには、システムコールに引数として渡されたすべてのパスにPATHタイプのレコードが含まれます。この Audit イベントでは、1 つのパス (/etc/ssh/sshd_config) のみが引数として使用されます。 msg=audit(1364481363.243:24287):-
msgフィールドは、1 つ目と 2 つ目のレコードと同じタイムスタンプと ID になります。 item=0-
itemフィールドは、SYSCALLタイプレコードで参照されているアイテムの合計数のうち、現在のレコードがどのアイテムであるかを示します。この数はゼロベースで、0は最初の項目であることを示します。 name="/etc/ssh/sshd_config"-
nameフィールドは、システムコールに引数として渡されたファイルまたはディレクトリーのパスを記録します。この場合、これは/etc/ssh/sshd_configファイルです。 inode=409248inodeフィールドには、このイベントで記録されたファイルまたはディレクトリーに関連する inode 番号が含まれます。以下のコマンドは、inode 番号409248に関連するファイルまたはディレクトリーを表示します。# find / -inum 409248 -print /etc/ssh/sshd_configdev=fd:00-
devフィールドは、このイベントで記録されたファイルまたはディレクトリーを含むデバイスのマイナーおよびメジャーの ID を指定します。ここでは、値が/dev/fd/0デバイスを示しています。 mode=0100600-
modeフィールドは、ファイルまたはディレクトリーのパーミッションを、st_modeフィールドのstatコマンドが返す数字表記で記録します。詳細は、stat(2)の man ページを参照してください。この場合、0100600は-rw-------として解釈されます。つまり、root ユーザーにのみ、/etc/ssh/sshd_configファイルに読み取りおよび書き込みのパーミッションが付与されます。 ouid=0-
ouidフィールドは、オブジェクトの所有者のユーザー ID を記録します。 ogid=0-
ogidフィールドは、オブジェクトの所有者のグループ ID を記録します。 rdev=00:00-
rdevフィールドには、特定ファイルにのみ記録されたデバイス識別子が含まれます。ここでは、記録されたファイルは通常のファイルであるため、このフィールドは使用されません。 obj=system_u:object_r:etc_t:s0-
objフィールドは、実行時に、記録されているファイルまたはディレクトリーにラベル付けする SELinux コンテキストを記録します。 nametype=NORMAL-
nametypeフィールドは、指定したシステムコールのコンテキストで各パスのレコード操作の目的を記録します。 cap_fp=none-
cap_fpフィールドは、ファイルまたはディレクトリーオブジェクトで許可されたファイルシステムベースの機能の設定に関連するデータを記録します。 cap_fi=none-
cap_fiフィールドは、ファイルまたはディレクトリーオブジェクトの継承されたファイルシステムベースの機能の設定に関するデータを記録します。 cap_fe=0-
cap_feフィールドは、ファイルまたはディレクトリーオブジェクトのファイルシステムベースの機能の有効ビットの設定を記録します。 cap_fver=0-
cap_fverフィールドは、ファイルまたはディレクトリーオブジェクトのファイルシステムベースの機能のバージョンを記録します。
4 つ目のレコード
type=PROCTITLE-
typeフィールドには、レコードのタイプが記載されます。この例のPROCTITLE値は、このレコードにより、カーネルへのシステムコールにより発生するこの監査イベントを発生させた完全なコマンドラインを提供することが指定されることを示しています。 proctitle=636174002F6574632F7373682F737368645F636F6E666967-
proctitleフィールドは、解析しているプロセスを開始するために使用したコマンドのコマンドラインを記録します。このフィールドは 16 進数の表記で記録され、Audit ログパーサーに影響が及ばないようにします。このテキストは、この Audit イベントを開始したコマンドに復号します。ausearchコマンドで Audit レコードを検索する場合は、-iオプションまたは--interpretオプションを使用して、16 進数の値を人間が判読できる値に自動的に変換します。636174002F6574632F7373682F737368645F636F6E666967値は、cat /etc/ssh/sshd_configとして解釈されます。
37.6. auditctl で Audit ルールを定義および実行
Audit システムは、ログファイルで取得するものを定義する一連のルールで動作します。Audit ルールは、auditctl ユーティリティーを使用してコマンドラインで設定するか、/etc/audit/rules.d/ ディレクトリーで設定できます。
auditctl コマンドを使用すると、Audit システムの基本的な機能を制御し、どの Audit イベントをログに記録するかを指定するルールを定義できます。
ファイルシステムのルールの例
すべての書き込みアクセスと
/etc/passwdファイルのすべての属性変更をログに記録するルールを定義するには、次のコマンドを実行します。# auditctl -w /etc/passwd -p wa -k passwd_changesすべての書き込みアクセスと、
/etc/selinux/ディレクトリー内の全ファイルへのアクセスと、その属性変更をすべてログに記録するルールを定義するには、次のコマンドを実行します。# auditctl -w /etc/selinux/ -p wa -k selinux_changes
システムロールのルールの例
システムで 64 ビットアーキテクチャーが使用され、システムコールの
adjtimexまたはsettimeofdayがプログラムにより使用されるたびにログエントリーを作成するルールを定義するには、次のコマンドを実行します。# auditctl -a always,exit -F arch=b64 -S adjtimex -S settimeofday -k time_changeユーザー ID が 1000 以上のシステムユーザーがファイルを削除したりファイル名を変更するたびに、ログエントリーを作成するルールを定義するには、次のコマンドを実行します。
# auditctl -a always,exit -S unlink -S unlinkat -S rename -S renameat -F auid>=1000 -F auid!=4294967295 -k delete-F auid!=4294967295オプションが、ログイン UID が設定されていないユーザーを除外するために使用されています。
実行可能なファイルルール
/bin/id プログラムのすべての実行をログに取得するルールを定義するには、次のコマンドを実行します。
# auditctl -a always,exit -F exe=/bin/id -F arch=b64 -S execve -k execution_bin_id37.7. 永続的な Audit ルールの定義
再起動後も持続するように Audit ルールを定義するには、/etc/audit/rules.d/audit.rules ファイルに直接追加するか、/etc/audit/rules.d/ ディレクトリーにあるルールを読み込む augenrules プログラムを使用する必要があります。
auditd サービスを開始すると、/etc/audit/audit.rules ファイルが生成されることに注意してください。/etc/audit/rules.d/ のファイルは、同じ auditctl コマンドライン構文を使用してルールを指定します。ハッシュ記号 (#) に続く空の行とテキストは無視されます。
また、auditctl コマンドは、以下のように -R オプションを使用して指定したファイルからルールを読み込むのに使用することもできます。
# auditctl -R /usr/share/audit/sample-rules/30-stig.rules37.8. 標準に準拠するための事前設定された監査ルールファイル
特定の認定標準 (OSPP、PCI DSS、STIG など) に準拠するように Audit を設定するには、audit パッケージとともにインストールされる事前設定済みルールファイルのセットを出発点として使用できます。サンプルルールは、/usr/share/audit/sample-rules ディレクトリーにあります。
セキュリティー標準は動的であり、変更される可能性があるため、sample-rules ディレクトリー内の Audit サンプルルールは網羅的なものではなく、最新のものでもありません。これらのルールは、Audit ルールがどのように構造化および記述されるかを示すためにのみ提供されています。これらは、最新のセキュリティー標準に即時に準拠することを保証するものではありません。特定のセキュリティーガイドラインに従ってシステムを最新のセキュリティー標準に準拠させるには、SCAP ベースのセキュリティーコンプライアンスツール を使用してください。
30-nispom.rules- NISPOM (National Industrial Security Program Operating Manual) の Information System Security の章で指定している要件を満たす Audit ルール設定
30-ospp-v42*.rules- OSPP (Protection Profile for General Purpose Operating Systems) プロファイルバージョン 4.2 に定義されている要件を満たす監査ルール設定
30-pci-dss-v31.rules- PCI DSS (Payment Card Industry Data Security Standard) v3.1 に設定されている要件を満たす監査ルール設定
30-stig.rules- セキュリティー技術実装ガイド (STIG: Security Technical Implementation Guide) で設定されている要件を満たす Audit ルール設定
上記の設定ファイルを使用するには、/etc/audit/rules.d/ ディレクトリーにコピーして、以下のように augenrules --load コマンドを使用します。
# cd /usr/share/audit/sample-rules/
# cp 10-base-config.rules 30-stig.rules 31-privileged.rules 99-finalize.rules /etc/audit/rules.d/
# augenrules --load
番号指定スキームを使用して監査ルールを順序付けできます。詳細は、/usr/share/audit/sample-rules/README-rules ファイルを参照してください。
37.9. 永続ルールを定義する augenrules の使用
augenrules スクリプトは、/etc/audit/rules.d/ ディレクトリーにあるルールを読み込み、audit.rules ファイルにコンパイルします。このスクリプトは、自然なソート順序の特定の順番で、.rules で終わるすべてのファイルを処理します。このディレクトリーのファイルは、以下の意味を持つグループに分類されます。
- 10
- カーネルと auditctl の設定
- 20
- 一般的なルールと一致する可能性があるが、別の一致が必要なルール
- 30
- 主なルール
- 40
- オプションのルール
- 50
- サーバー固有のルール
- 70
- システムのローカルルール
- 90
- ファイナライズ (イミュータブル)
ルールは、すべてを一度に使用することは意図されていません。ルールは考慮すべきポリシーの一部であり、個々のファイルは /etc/audit/rules.d/ にコピーされます。たとえば、STIG 設定でシステムを設定し、10-base-config、30-stig、31-privileged、99-finalize の各ルールをコピーします。
/etc/audit/rules.d/ ディレクトリーにルールを置いたら、--load ディレクティブで augenrules スクリプトを実行することでそれを読み込みます。
# augenrules --load
/sbin/augenrules: No change
No rules
enabled 1
failure 1
pid 742
rate_limit 0
...37.10. augenrules の無効化
augenrules ユーティリティーを無効にするには、以下の手順に従います。これにより、Audit が /etc/audit/audit.rules ファイルで定義されたルールを使用するように切り替えます。
手順
/usr/lib/systemd/system/auditd.serviceファイルを/etc/systemd/system/ディレクトリーにコピーします。# cp -f /usr/lib/systemd/system/auditd.service /etc/systemd/system/任意のテキストエディターで
/etc/systemd/system/auditd.serviceファイルを編集します。以下に例を示します。# vi /etc/systemd/system/auditd.serviceaugenrulesを含む行をコメントアウトし、auditctl -Rコマンドを含む行のコメント設定を解除します。#ExecStartPost=-/sbin/augenrules --load ExecStartPost=-/sbin/auditctl -R /etc/audit/audit.rulessystemdデーモンを再読み込みして、auditd.serviceファイルの変更を取得します。# systemctl daemon-reloadauditdサービスを再起動します。# service auditd restart
37.11. ソフトウェアの更新を監視するための Audit の設定
RHEL 8.6 以降のバージョンでは、事前設定されたルール 44-installers.rules を使用して、ソフトウェアをインストールする次のユーティリティーを監視するように Audit を設定できます。
-
dnf[2] -
yum -
pip -
npm -
cpan -
gem -
luarocks
デフォルトでは、rpm はパッケージのインストールまたは更新時に監査 SOFTWARE_UPDATE イベントをすでに提供しています。これらをリスト表示するには、コマンドラインで ausearch -m SOFTWARE_UPDATE と入力します。
RHEL 8.5 以前のバージョンでは、手動でルールを追加して、/etc/audit/rules.d/ ディレクトリーの .rules ファイルにソフトウェアをインストールするユーティリティーを監視できます。
事前設定されたルールファイルは、ppc64le および aarch64 アーキテクチャーを備えたシステムでは使用できません。
前提条件
-
auditdが、環境を保護するための auditd の設定で提供される設定に従って定義されている。
手順
RHEL 8.6 以降では、事前設定されたルールファイル
44-installers.rulesを/usr/share/audit/sample-rules/ディレクトリーから/etc/audit/rules.d/ディレクトリーにコピーします。# cp /usr/share/audit/sample-rules/44-installers.rules /etc/audit/rules.d/RHEL 8.5 以前では、
/etc/audit/rules.d/ディレクトリーに、44-installers.rulesという名前の新規ファイルを作成し、以下のルールを挿入します。-a always,exit -F perm=x -F path=/usr/bin/dnf-3 -F key=software-installer -a always,exit -F perm=x -F path=/usr/bin/yum -F同じ構文を使用して、
pipやnpmなどのソフトウェアをインストールする他のユーティリティー用に、さらにルールを追加できます。監査ルールを読み込みます。
# augenrules --load
検証
読み込まれたルールをリスト表示します。
# auditctl -l -p x-w /usr/bin/dnf-3 -k software-installer -p x-w /usr/bin/yum -k software-installer -p x-w /usr/bin/pip -k software-installer -p x-w /usr/bin/npm -k software-installer -p x-w /usr/bin/cpan -k software-installer -p x-w /usr/bin/gem -k software-installer -p x-w /usr/bin/luarocks -k software-installerインストールを実行します。以下に例を示します
# yum reinstall -y vim-enhancedAudit ログで最近のインストールイベントを検索します。次に例を示します。
# ausearch -ts recent -k software-installer –––– time->Thu Dec 16 10:33:46 2021 type=PROCTITLE msg=audit(1639668826.074:298): proctitle=2F7573722F6C6962657865632F706C6174666F726D2D707974686F6E002F7573722F62696E2F646E66007265696E7374616C6C002D790076696D2D656E68616E636564 type=PATH msg=audit(1639668826.074:298): item=2 name="/lib64/ld-linux-x86-64.so.2" inode=10092 dev=fd:01 mode=0100755 ouid=0 ogid=0 rdev=00:00 obj=system_u:object_r:ld_so_t:s0 nametype=NORMAL cap_fp=0 cap_fi=0 cap_fe=0 cap_fver=0 cap_frootid=0 type=PATH msg=audit(1639668826.074:298): item=1 name="/usr/libexec/platform-python" inode=4618433 dev=fd:01 mode=0100755 ouid=0 ogid=0 rdev=00:00 obj=system_u:object_r:bin_t:s0 nametype=NORMAL cap_fp=0 cap_fi=0 cap_fe=0 cap_fver=0 cap_frootid=0 type=PATH msg=audit(1639668826.074:298): item=0 name="/usr/bin/dnf" inode=6886099 dev=fd:01 mode=0100755 ouid=0 ogid=0 rdev=00:00 obj=system_u:object_r:rpm_exec_t:s0 nametype=NORMAL cap_fp=0 cap_fi=0 cap_fe=0 cap_fver=0 cap_frootid=0 type=CWD msg=audit(1639668826.074:298): cwd="/root" type=EXECVE msg=audit(1639668826.074:298): argc=5 a0="/usr/libexec/platform-python" a1="/usr/bin/dnf" a2="reinstall" a3="-y" a4="vim-enhanced" type=SYSCALL msg=audit(1639668826.074:298): arch=c000003e syscall=59 success=yes exit=0 a0=55c437f22b20 a1=55c437f2c9d0 a2=55c437f2aeb0 a3=8 items=3 ppid=5256 pid=5375 auid=0 uid=0 gid=0 euid=0 suid=0 fsuid=0 egid=0 sgid=0 fsgid=0 tty=pts0 ses=3 comm="dnf" exe="/usr/libexec/platform-python3.6" subj=unconfined_u:unconfined_r:unconfined_t:s0-s0:c0.c1023 key="software-installer"
dnf は RHEL ではシンボリックリンクであるため、dnf Audit ルールのパスにはシンボリックリンクのターゲットが含まれている必要があります。正しい Audit イベントを受信するには、path=/usr/bin/dnf パスを /usr/bin/dnf-3 に変更して、44-installers.rules ファイルを変更します。
37.12. Audit によるユーザーログイン時刻の監視
特定の時刻にログインしたユーザーを監視するために、特別な方法で Audit を設定する必要はありません。同じ情報を表示する異なる方法を提供する ausearch または aureport ツールを使用できます。
前提条件
-
auditdが、環境を保護するための auditd の設定で提供される設定に従って定義されている。
手順
ユーザーのログイン時刻を表示するには、次のいずれかのコマンドを使用します。
監査ログで
USER_LOGINメッセージタイプを検索します。# ausearch -m USER_LOGIN -ts '12/02/2020' '18:00:00' -sv no time->Mon Nov 22 07:33:22 2021 type=USER_LOGIN msg=audit(1637584402.416:92): pid=1939 uid=0 auid=4294967295 ses=4294967295 subj=system_u:system_r:sshd_t:s0-s0:c0.c1023 msg='op=login acct="(unknown)" exe="/usr/sbin/sshd" hostname=? addr=10.37.128.108 terminal=ssh res=failed'-
-tsオプションを使用して日付と時刻を指定できます。このオプションを使用しない場合、ausearchは今日の結果を提供し、時刻を省略すると、ausearchは午前 0 時からの結果を提供します。 -
成功したログイン試行を除外するには
-sv yesオプションを、失敗したログイン試行を除外するには-sv noを、それぞれ使用することができます。
-
ausearchコマンドの生の出力をaulastユーティリティーにパイプで渡します。このユーティリティーは、lastコマンドの出力と同様の形式で出力を表示します。以下に例を示します。# ausearch --raw | aulast --stdin root ssh 10.37.128.108 Mon Nov 22 07:33 - 07:33 (00:00) root ssh 10.37.128.108 Mon Nov 22 07:33 - 07:33 (00:00) root ssh 10.22.16.106 Mon Nov 22 07:40 - 07:40 (00:00) reboot system boot 4.18.0-348.6.el8 Mon Nov 22 07:33--login -iオプションを指定してaureportコマンドを使用し、ログインイベントのリストを表示します。# aureport --login -i Login Report ============================================ # date time auid host term exe success event ============================================ 1. 11/16/2021 13:11:30 root 10.40.192.190 ssh /usr/sbin/sshd yes 6920 2. 11/16/2021 13:11:31 root 10.40.192.190 ssh /usr/sbin/sshd yes 6925 3. 11/16/2021 13:11:31 root 10.40.192.190 ssh /usr/sbin/sshd yes 6930 4. 11/16/2021 13:11:31 root 10.40.192.190 ssh /usr/sbin/sshd yes 6935 5. 11/16/2021 13:11:33 root 10.40.192.190 ssh /usr/sbin/sshd yes 6940 6. 11/16/2021 13:11:33 root 10.40.192.190 /dev/pts/0 /usr/sbin/sshd yes 6945
パート VI. カーネルの設計
第38章 Linux カーネル
Linux カーネルと、Red Hat が提供および管理する Linux カーネル RPM パッケージ (Red Hat カーネル) を学びます。Red Hat カーネルを最新の状態に保ちます。これにより、オペレーティングシステムに最新のバグ修正、パフォーマンス強化、およびパッチがすべて適用され、新しいハードウェアとの互換性が保たれます。
38.1. カーネルとは
カーネルは Linux オペレーティングシステムのコア部分で、システムリソースを管理し、ハードウェアアプリケーションおよびソフトウェアアプリケーション間のインターフェイスを確立します。
Red Hat カーネルは、アップストリームの Linux メインラインカーネルをベースにしたカスタムカーネルです。Red Hat のエンジニアは、安定性と、最新のテクノロジーおよびハードウェアとの互換性に重点を置き、さらなる開発と強化を行っています。
Red Hat が新しいカーネルバージョンをリリースする前に、カーネルは厳格な品質保証テストをクリアしなければなりません。
Red Hat カーネルは RPM 形式でパッケージ化されているため、YUM パッケージマネージャーにより簡単にアップグレードおよび検証できます。
Red Hat によってコンパイルされていないカーネルは、Red Hat では サポートされていません。
38.2. RPM パッケージ
RPM パッケージは、ファイルのアーカイブと、これらのファイルのインストールと消去に使用されるメタデータで構成されます。具体的には、RPM パッケージには次の要素が含まれています。
- GPG 署名
- GPG 署名は、パッケージの整合性を検証するために使用されます。
- ヘッダー (パッケージのメタデータ)
- RPM パッケージマネージャーは、このメタデータを使用して、パッケージの依存関係、ファイルのインストール先、その他の情報を確認します。
- ペイロード
-
ペイロードは、システムにインストールするファイルを含む
cpioアーカイブです。
RPM パッケージには 2 つの種類があります。いずれも、同じファイル形式とツールを使用しますが、コンテンツが異なるため、目的が異なります。
ソース RPM (SRPM)
SRPM には、ソースコードと、ソースコードをバイナリー RPM にビルドする方法を記述した
specファイルが含まれています。必要に応じて、SRPM にはソースコードへのパッチを含めることができます。バイナリー RPM
バイナリー RPM には、ソースおよびパッチから構築されたバイナリーが含まれます。
38.3. Linux カーネル RPM パッケージの概要
カーネル RPM は、ファイルを含まないメタパッケージで、以下の必須サブパッケージが正しくインストールされるようにします。
kernel-core-
カーネルのバイナリーイメージ、システムをブートストラップするためのすべての
initramfs関連オブジェクト、およびコア機能を確保するための最小限の数のカーネルモジュールを提供します。このサブパッケージ単体は、仮想環境およびクラウド環境で使用して、Red Hat Enterprise Linux 8 カーネルのブート時間を短縮し、ディスクサイズを抑えます。 kernel-modules-
kernel-coreに存在しない残りのカーネルモジュールを提供します。
上記の kernel サブパッケージをいくつか用意することで、特に仮想環境やクラウド環境でのシステム管理者へのメンテナンス面を低減させることを目指します。
任意のカーネルパッケージは、以下の例のようになります。
kernel-modules-extra- 希少なハードウェア用のカーネルモジュールを提供します。このモジュールのロードはデフォルトで無効になっています。
kernel-debug- カーネル診断用に多くのデバッグオプションが有効になっているカーネルを提供しますが、これによりパフォーマンスが低下します。
kernel-tools- Linux カーネルを操作するためのツールとサポートドキュメントを提供します。
kernel-devel-
kernelパッケージに対してモジュールをビルドするのに十分なカーネルヘッダーと makefile を提供します。 kernel-abi-stablelists-
RHEL カーネル ABI に関連する情報を提供します。これには、外部 Linux カーネルモジュールが必要とするカーネルシンボルのリストや、強化を支援するための
yumプラグインが含まれます。 kernel-headers- Linux カーネルと、ユーザー空間ライブラリーおよびプログラムとの間のインターフェイスを指定する C ヘッダーファイルが含まれます。ヘッダーファイルは、ほとんどの標準プログラムをビルドするのに必要な構造と定数を定義します。
38.4. カーネルパッケージの内容の表示
リポジトリーをクエリーすると、カーネルパッケージがモジュールなどの特定のファイルを提供しているかどうかを確認できます。ファイルリストを表示するためにパッケージをダウンロードまたはインストールする必要はありません。
dnf ユーティリティーを使用して、たとえば kernel-core、kernel-modules-core、または kernel-modules パッケージのファイルリストをクエリーします。kernel パッケージはファイルを含まないメタパッケージであることに注意してください。
手順
パッケージの利用可能なバージョンをリスト表示します。
$ yum repoquery <package_name>パッケージ内のファイルをリスト表示します。
$ yum repoquery -l <package_name>
38.5. 特定のカーネルバージョンのインストール
yum パッケージマネージャーを使用して新しいカーネルをインストールします。
手順
特定のカーネルバージョンをインストールするには、次のコマンドを実行します。
# yum install kernel-5.14.0
38.6. カーネルの更新
yum パッケージマネージャーを使用してカーネルを更新します。
手順
カーネルを更新するには、次のコマンドを入力します。
# yum update kernelこのコマンドは、カーネルと、利用可能な最新バージョンへのすべての依存関係を更新します。
- システムを再起動して、変更を有効にします。
RHEL 7 から RHEL 8 にアップグレードする場合は、RHEL 7 から RHEL 8 へのアップグレード ドキュメントの関連のセクションを参照してください。
38.7. カーネルのデフォルトとしての設定
grubby コマンドラインツールと GRUB を使用して、特定のカーネルをデフォルトとして設定します。
手順
grubbyツールを使用し、デフォルトとしてカーネルを設定する以下のコマンドを実行し、
grubbyツールを使用してカーネルをデフォルトとして設定します。# grubby --set-default $kernel_pathコマンドは、
.confの接尾辞のないマシン ID を引数として使用します。注記マシン ID は
/boot/loader/entries/ディレクトリーにあります。
id引数を使用し、デフォルトとしてカーネルを設定するid引数を使用してブートエントリーのリストを表示し、任意のカーネルをデフォルトとして設定します。# grubby --info ALL | grep id # grubby --set-default /boot/vmlinuz-<version>.<architecture>注記title引数を使用してブートエントリーのリストを表示するには、# grubby --info=ALL | grep titleコマンドを実行します。
次回の起動時のみ用にデフォルトのカーネルを設定する
次のコマンドを実行し、
grub2-rebootコマンドを使用して、次回の再起動限定でデフォルトのカーネルを設定します。# grub2-reboot <index|title|id>警告取り扱いに注意して、次回の起動時限定のデフォルトのカーネルを設定します。新しいカーネル RPM、自己ビルドカーネルをインストールし、エントリーを
/boot/loader/entries/ディレクトリーに手動で追加すると、インデックス値が変更される可能性があります。
第39章 カーネルコマンドラインパラメーターの設定
カーネルコマンドラインパラメーターを使用すると、起動時に Red Hat Enterprise Linux カーネルの特定の側面の動作を変更できます。システム管理者は、起動時に設定されるオプションを制御します。特定のカーネル動作は起動時にのみ設定できることに注意してください。
カーネルコマンドラインパラメーターを変更してシステムの動作を変更すると、システムに悪影響を及ぼす可能性があります。変更を実稼働環境にデプロイする前に必ずテストしてください。詳細なガイダンスについては、Red Hat Support チームまでご連絡ください。
39.1. カーネルコマンドラインパラメーターとは
カーネルコマンドラインパラメーターを使用すると、デフォルト値を上書きしたり、特定のハードウェア設定を指定したりできます。ブート時に、次の機能を設定できます。
- Red Hat Enterprise Linux カーネル
- 初期 RAM ディスク
- ユーザー領域機能
デフォルトでは、GRUB ブートローダーを使用するシステムのカーネルコマンドラインパラメーターは、カーネルブートエントリーごとに /boot/grub2/grubenv ファイルの kernelopts 変数で定義されます。
IBM Z では、zipl ブートローダーは環境変数に対応していないため、カーネルコマンドラインパラメーターはブートエントリー設定ファイルに保存されます。したがって、kernelopts 環境変数は使用できません。
grubby ユーティリティーを使用すると、ブートローダー設定ファイルを操作できます。grubby を使用すると、次のアクションを実行できます。
- デフォルトのブートエントリーの変更
- GRUB メニューエントリーに対する引数の追加または削除
39.2. ブートエントリーについて
ブートエントリーは、設定ファイルに保存され、特定のカーネルバージョンに関連付けられたオプションのコレクションです。実際には、ブートエントリーは、システムにカーネルがインストールされているのと同じ数だけあります。ブートエントリー設定ファイルは、/boot/loader/entries/ ディレクトリーにあります。
6f9cc9cb7d7845d49698c9537337cedc-4.18.0-5.el8.x86_64.conf
上記のファイル名は、/etc/machine-id ファイルに保存されているマシン ID と、カーネルバージョンから構成されます。
ブートエントリー設定ファイルには、カーネルバージョン、初期 ramdisk イメージ、およびカーネルのコマンドラインパラメーターを含む kernelopts 環境変数に関する情報が含まれています。設定ファイルには次の内容を含めることができます。
title Red Hat Enterprise Linux (4.18.0-74.el8.x86_64) 8.0 (Ootpa)
version 4.18.0-74.el8.x86_64
linux /vmlinuz-4.18.0-74.el8.x86_64
initrd /initramfs-4.18.0-74.el8.x86_64.img $tuned_initrd
options $kernelopts $tuned_params
id rhel-20190227183418-4.18.0-74.el8.x86_64
grub_users $grub_users
grub_arg --unrestricted
grub_class kernel
kernelopts 環境変数は /boot/grub2/grubenv ファイルで定義されます。
39.3. すべてのブートエントリーでカーネルコマンドラインパラメーターの変更
システム上のすべてのブートエントリーのカーネルコマンドラインパラメーターを変更します。
前提条件
-
grubbyユーティリティーがシステムにインストールされている。 -
ziplユーティリティーが IBM Z システムにインストールされている。
手順
パラメーターを追加するには、以下を行います。
# grubby --update-kernel=ALL --args="<NEW_PARAMETER>"GRUB ブートローダーを使用するシステムの場合は、
/boot/grub2/grubenvのkernelopts変数に新しいカーネルパラメーターを追加して、ファイルを更新します。IBM Z で、ブートメニューを更新します。
# zipl
パラメーターを削除するには、次のコマンドを実行します。
# grubby --update-kernel=ALL --remove-args="<PARAMETER_TO_REMOVE>"IBM Z で、ブートメニューを更新します。
# zipl
新しくインストールされたカーネルは、以前に設定されたカーネルからカーネルコマンドラインパラメーターを継承します。
39.4. 1 つのブートエントリーでカーネルコマンドラインパラメーターの変更
システム上の単一のブートエントリーのカーネルコマンドラインパラメーターを変更します。
前提条件
-
grubbyおよびziplユーティリティーがシステムにインストールされている。
手順
パラメーターを追加するには、以下を行います。
# grubby --update-kernel=/boot/vmlinuz-$(uname -r) --args="<NEW_PARAMETER>"IBM Z で、ブートメニューを更新します。
# zipl
パラメーターを削除するには、次のコマンドを実行します。
# grubby --update-kernel=/boot/vmlinuz-$(uname -r) --remove-args="<PARAMETER_TO_REMOVE>"IBM Z で、ブートメニューを更新します。
# zipl
grub.cfg ファイルを使用するシステムでは、デフォルトで、カーネルブートエントリーごとに options パラメーターがあり、これは kernelopts 変数に設定されます。この変数は、/boot/grub2/grubenv 設定ファイルで定義されます。
GRUB システムの場合:
-
すべてのブートエントリーに対してカーネルコマンドラインパラメーターを変更する場合には、
grubbyユーティリティーは/boot/grub2/grubenvファイルのkernelopts変数を更新します。 -
1 つのブートエントリーのカーネルコマンドラインパラメーターが変更されると、
kernelopts変数の拡張やカーネルパラメーターの変更が行われ、得られた値は各ブートエントリーの/boot/loader/entries/<RELEVANT_KERNEL_BOOT_ENTRY.conf>ファイルに保存されます。
zIPL システムの場合:
-
grubbyは、個別のカーネルブートエントリーのカーネルコマンドラインパラメーターを変更して、/boot/loader/entries/<ENTRY>.confファイルに保存します。
39.5. 起動時の一時的なカーネルコマンドラインパラメーターの変更
1 回の起動プロセス中にのみカーネルパラメーターを変更することで、カーネルメニューエントリーを一時的に変更します。
この手順は単一ブートにのみ適用され、変更は永続的に行われません。
手順
- GRUB ブートメニューを起動します。
- 起動するカーネルを選択します。
- e キーを押してカーネルパラメーターを編集します。
-
カーソルを下に移動してカーネルコマンドラインを見つけます。カーネルコマンドラインは、64 ビット IBM Power シリーズおよび x86-64 BIOS ベースのシステムの場合は
linuxで始まり、UEFI システムの場合はlinuxefiで始まります。 カーソルを行の最後に移動します。
注記行の最初に移動するには Ctrl+a を押します。行の最後に移動するには Ctrl+e を押します。システムによっては、Home キーおよび End キーも機能する場合があります。
必要に応じてカーネルパラメーターを編集します。たとえば、緊急モードでシステムを実行するには、
linux行の最後にemergencyパラメーターを追加します。linux ($root)/vmlinuz-4.18.0-348.12.2.el8_5.x86_64 root=/dev/mapper/rhel-root ro crashkernel=auto resume=/dev/mapper/rhel-swap rd.lvm.lv=rhel/root rd.lvm.lv=rhel/swap rhgb quiet emergencyシステムメッセージを有効にするには、
rhgbおよびquietパラメーターを削除します。- Ctrl+x を押して、選択したカーネルと変更したコマンドラインパラメーターで起動します。
Esc キーを押してコマンドラインの編集を終了すると、ユーザーの加えた変更はすべて破棄されます。
39.6. シリアルコンソール接続を有効にする GRUB 設定
シリアルコンソールは、ネットワークがダウンしている場合にヘッドレスサーバーまたは埋め込みシステムに接続する際に便利です。あるいは、セキュリティールールを回避し、別のシステムへのログインアクセスを取得する必要がある場合などです。
シリアルコンソール接続を使用するように、デフォルトの GRUB 設定の一部を設定する必要があります。
前提条件
- root 権限がある。
手順
/etc/default/grubファイルに以下の 2 つの行を追加します。GRUB_TERMINAL="serial" GRUB_SERIAL_COMMAND="serial --speed=9600 --unit=0 --word=8 --parity=no --stop=1"最初の行は、グラフィカルターミナルを無効にします。
GRUB_TERMINALキーは、GRUB_TERMINAL_INPUTおよびGRUB_TERMINAL_OUTPUTの値を上書きします。2 行目は、ボーレート (
--speed)、パリティー、および他の値を使用中の環境とハードウェアに適合するように調整します。以下のログファイルのようなタスクには、115200 のように非常に高いボーレートが推奨されます。GRUB 設定ファイルを更新します。
BIOS ベースのマシンの場合:
# grub2-mkconfig -o /boot/grub2/grub.cfgUEFI ベースのマシンの場合:
# grub2-mkconfig -o /boot/efi/EFI/redhat/grub.cfg
- システムを再起動して、変更を有効にします。
第40章 ランタイム時のカーネルパラメーターの設定
システム管理者は、ランタイム時に Red Hat Enterprise Linux カーネルの動作を多数変更できます。sysctl コマンドを使用し、/etc/sysctl.d/ および /proc/sys/ ディレクトリー内の設定ファイルを変更して、実行時にカーネルパラメーターを設定します。
プロダクションシステムでカーネルパラメーターを設定するには、慎重なプランニングが必要です。計画外の変更を行うと、カーネルが不安定になり、システムの再起動が必要になる場合があります。カーネル値を変更する前に、有効なオプションを使用していることを確認してください。
IBM DB2 でのカーネルのチューニングに関する詳細は、Tuning Red Hat Enterprise Linux for IBM DB2 を参照してください。
40.1. カーネルパラメーターとは
カーネルパラメーターは、システムの実行中に調整できる調整可能な値です。変更を有効にするために、システムを再起動したりカーネルを再コンパイルしたりする必要がないことに注意してください。
以下を使用してカーネルパラメーターに対応できます。
-
sysctlコマンド -
/proc/sys/ディレクトリーにマウントされている仮想ファイルシステム -
/etc/sysctl.d/ディレクトリー内の設定ファイル
調整可能パラメーターは、カーネルサブシステムでクラスに分割されます。Red Hat Enterprise Linux には、以下の調整可能のクラスがあります。
| 調整パラメーターのクラス | サブシステム |
|---|---|
|
| 実行ドメインおよびパーソナリティー |
|
| 暗号化インターフェイス |
|
| カーネルのデバッグインターフェイス |
|
| デバイス固有の情報 |
|
| グローバルおよび固有の調整可能なファイルシステム |
|
| グローバルなカーネルの設定項目 |
|
| ネットワークの設定項目 |
|
| Sun Remote Procedure Call (NFS) |
|
| ユーザー名前空間の制限 |
|
| メモリー、バッファー、およびキャッシュのチューニングと管理 |
40.2. sysctl でカーネルパラメーターの一時的な設定
sysctl コマンドを使用して、実行時に一時的にカーネルパラメーターを設定します。このコマンドは、調整可能パラメーターのリスト表示およびフィルタリングにも便利です。
前提条件
- root 権限がある。
手順
すべてのパラメーターとその値をリストします。
# sysctl -a注記# sysctl -aコマンドは、ランタイム時およびシステムの起動時に調整できるカーネルパラメーターを表示します。パラメーターを一時的に設定するには、次のように入力します。
# sysctl <TUNABLE_CLASS>.<PARAMETER>=<TARGET_VALUE>上記のサンプルコマンドは、システムの実行中にパラメーター値を変更します。この変更は、再起動なしですぐに適用されます。
注記変更は、システムの再起動後にデフォルトに戻ります。
40.3. sysctl を使用したカーネルパラメーターの永続的な設定
sysctl コマンドを使用して、カーネルパラメーターを永続的に設定します。
前提条件
- root 権限がある。
手順
すべてのパラメーターをリストします。
# sysctl -aこのコマンドは、ランタイム時に設定できるカーネルパラメーターをすべて表示します。
パラメーターを永続的に設定すします。
# sysctl -w <TUNABLE_CLASS>.<PARAMETER>=<TARGET_VALUE> >> /etc/sysctl.confサンプルコマンドは、調整可能な値を変更して、
/etc/sysctl.confファイルに書き込みます。これにより、カーネルパラメーターのデフォルト値が上書きされます。変更は、再起動なしで即座に永続的に反映されます。
カーネルパラメーターを永続的に変更するには、/etc/sysctl.d/ ディレクトリーの設定ファイルを手動で変更することもできます。
40.4. /etc/sysctl.d/ の設定ファイルでカーネルパラメーターの調整
カーネルパラメーターを永続的に設定するには、/etc/sysctl.d/ ディレクトリー内の設定ファイルを手動で変更する必要があります。
前提条件
- root 権限がある。
手順
/etc/sysctl.d/に新しい設定ファイルを作成します。# vim /etc/sysctl.d/<some_file.conf>カーネルパラメーターを 1 行に 1 つずつ含めます。
<TUNABLE_CLASS>.<PARAMETER>=<TARGET_VALUE> <TUNABLE_CLASS>.<PARAMETER>=<TARGET_VALUE>- 設定ファイルを作成します。
マシンを再起動して、変更を有効にします。
または、再起動せずに変更を適用します。
# sysctl -p /etc/sysctl.d/<some_file.conf>このコマンドにより、以前に作成した設定ファイルから値を読み取ることができます。
40.5. /proc/sys/ でカーネルパラメーターの一時的な設定
/proc/sys/ 仮想ファイルシステムディレクトリー内のファイルを使用して、一時的にカーネルパラメーターを設定します。
前提条件
- root 権限がある。
手順
設定するカーネルパラメーターを特定します。
# ls -l /proc/sys/<TUNABLE_CLASS>/コマンドが返した書き込み可能なファイルは、カーネルの設定に使用できます。読み取り専用権限を持つユーザーは、現在の設定についてフィードバックを提供します。
カーネルパラメーターにターゲットの値を割り当てます。
# echo <TARGET_VALUE> > /proc/sys/<TUNABLE_CLASS>/<PARAMETER>コマンドを使用して適用された設定の変更は永続的なものではなく、システムを再起動すると消えてしまいます。
検証
新しく設定したカーネルパラメーターの値を確認します。
# cat /proc/sys/<TUNABLE_CLASS>/<PARAMETER>
第41章 kdump のインストールと設定
41.1. kdump のインストール
新しいバージョンの RHEL 8 インストールでは、kdump サービスはデフォルトでインストールされ、アクティブ化されます。
41.1.1. kdump とは
kdump は、 クラッシュダンプメカニズムを提供し、クラッシュダンプまたは vmcore ダンプファイルを生成するサービスです。vmcore に は、分析とトラブルシューティングのためのシステムメモリーの内容が含まれています。kdump は、 kexec システムコールを使用して、再起動せずに 2 番目のカーネルである キャプチャーカーネル を起動します。このカーネルはクラッシュしたカーネルのメモリーの内容をキャプチャーし、ファイルに保存します。この別のカーネルは、システムメモリーの予約部分で使用できます。
カーネルクラッシュダンプは、システム障害時に利用できる唯一の情報になります。したがって、ミッションクリティカルな環境では、kdump を稼働させることが重要です。Red Hat は、通常のカーネル更新サイクルで kexec-tools を定期的に更新してテストすることを推奨します。これは、新しいカーネル機能をインストールするときに重要です。
マシンに複数のカーネルがある場合は、インストールされているすべてのカーネルに対して、または指定したカーネルに対してのみ kdump を有効にできます。kdump をインストールすると、システムによってデフォルトの /etc/kdump.conf ファイルが作成されます。/etc/kdump.conf に はデフォルトの最小 kdump 設定が含まれており、これを編集して kdump 設定をカスタマイズできます。
41.1.2. Anaconda を使用した kdump のインストール
Anaconda インストーラーでは、対話式インストール時に kdump 設定用のグラフィカルインターフェイス画面が表示されます。kdump を有効にして、必要な量のメモリーを予約できます。
手順
Anaconda インストーラーで、KDUMP をクリックして
kdumpを有効にします。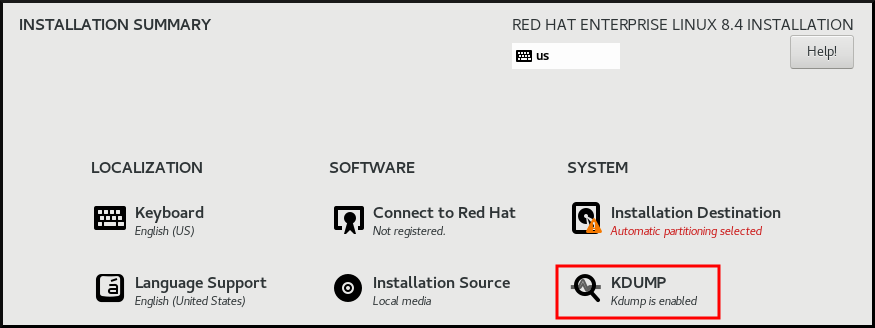
- メモリー予約をカスタマイズする必要がある場合は、Kdump Memory Reservation で Manual を選択します。
KDUMP > Memory To Be Reserved (MB) で、
kdumpに必要なメモリー予約を設定します。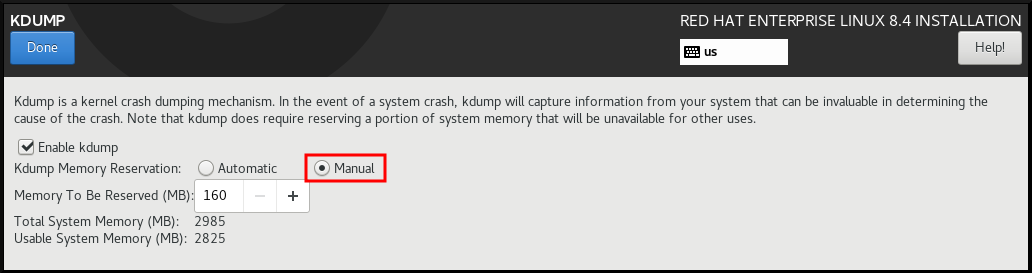
41.1.3. コマンドラインで kdump のインストール
カスタムの キックスタート インストールなどのインストール方法では、kdump がデフルトでインストールまたは有効化 されない 場合があります。その場合、次の手順で kdump を有効にできます。
前提条件
- アクティブな RHEL サブスクリプションがある。
-
システムの CPU アーキテクチャー用の
kexec-toolsパッケージを含むリポジトリーがある。 -
kdump設定とターゲットの要件をすべて満たしている。詳細は サポートされている kdump 設定とターゲット を参照してください。
手順
システムに
kdumpがインストールされているかどうかを確認します。# rpm -q kexec-toolsこのパッケージがインストールされている場合は以下を出力します。
kexec-tools-2.0.17-11.el8.x86_64このパッケージがインストールされていない場合は以下を出力します
package kexec-tools is not installedkdumpおよび必要なパッケージをインストールします。# dnf install kexec-tools
kernel-3.10.0-693.el7 以降では、Intel IOMMU ドライバーが kdump でサポートされます。kernel-3.10.0-514[.XYZ].el7 以前のバージョンでは、応答しないキャプチャーカーネルを防ぐために、Intel IOMMU が無効化されていることを確認する必要があります。
41.2. コマンドラインで kdump の設定
kdump 用メモリーは、システムの起動時に予約されます。システムの Grand Unified Bootloader (GRUB) 設定ファイルでメモリーサイズを設定できます。メモリーサイズは、設定ファイルで指定された crashkernel= 値と、システムの物理メモリーのサイズによって異なります。
41.2.1. kdump サイズの見積もり
kdump 環境を計画および構築するときは、クラッシュダンプファイルに必要な容量を把握することが重要です。
makedumpfile --mem-usage コマンドは、クラッシュダンプファイルに必要な容量を推定します。また、メモリー使用量に関するレポートを生成します。このレポートは、ダンプレベルと、除外しても問題ないページを決定するのに役立ちます。
手順
次のコマンドを入力して、メモリー使用量に関するレポートを生成します。
# makedumpfile --mem-usage /proc/kcore TYPE PAGES EXCLUDABLE DESCRIPTION ------------------------------------------------------------- ZERO 501635 yes Pages filled with zero CACHE 51657 yes Cache pages CACHE_PRIVATE 5442 yes Cache pages + private USER 16301 yes User process pages FREE 77738211 yes Free pages KERN_DATA 1333192 no Dumpable kernel data
makedumpfile --mem-usage は、必要なメモリーをページ単位で報告します。つまり、カーネルページサイズを元に、使用するメモリーのサイズを計算する必要があります。
41.2.2. メモリー使用量の設定
kdump のメモリー予約は、システムの起動中に行われます。メモリーサイズは、システムの GRUB (Grand Unified Bootloader) 設定で設定されます。メモリーサイズは、設定ファイルで指定された crashkernel= オプションの値と、システムの物理メモリーのサイズにより異なります。
crashkernel= オプションはさまざまな方法で定義できます。crashkernel= 値を指定するか、auto オプションを設定できます。crashkernel=auto パラメーターは、システムの物理メモリーの合計量に基づいて、メモリーを自動的に予約します。これを設定すると、カーネルは、キャプチャーカーネルに必要な適切な量のメモリーを自動的に予約します。これにより、OOM (Out-of-Memory) エラーの回避に役立ちます。
kdump の自動メモリー割り当ては、システムのハードウェアアーキテクチャーと利用可能なメモリーサイズによって異なります。
システムに、自動割り当ての最小メモリーしきい値より少ないメモリーしかない場合は、手動で予約メモリーの量を設定できます。
前提条件
- システムの root 権限がある。
-
kdump設定とターゲットの要件をすべて満たしている。詳細は サポートされている kdump 設定とターゲット を参照してください。
手順
crashkernel=オプションを準備してください。たとえば、128 MB のメモリーを予約するには、以下を使用します。
crashkernel=128Mまたは、インストールされているメモリーの合計量に応じて、予約メモリーサイズを変数に設定できます。変数へのメモリー予約の構文は
crashkernel=<range1>:<size1>,<range2>:<size2>です。以下に例を示します。crashkernel=512M-2G:64M,2G-:128Mシステムメモリーの合計量が 512 MB - 2 GB の範囲にある場合、64 MB のメモリーを予約します。メモリーの合計量が 2 GB を超える場合、メモリー予約は 128 MB になります。
予約メモリーのオフセット。
一部のシステムでは、
crashkernelの予約が早い段階で行われるため、特定の固定オフセットでメモリーを予約する必要があります。また、特別な用途のために、さらに多くのメモリーの予約が必要になることもあります。オフセットを定義すると、予約メモリーはそこから開始されます。予約メモリーをオフセットするには、以下の構文を使用します。crashkernel=128M@16Mこの例では、
kdumpは 16 MB (物理アドレス0x01000000) から始まる 128 MB のメモリーを予約します。offset パラメーターを 0 に設定するか、完全に省略すると、kdumpは予約メモリーを自動的にオフセットします。変数のメモリー予約を設定する場合は、この構文を使用することもできます。その場合、オフセットは常に最後に指定されます。以下に例を示します。crashkernel=512M-2G:64M,2G-:128M@16M
crashkernel=オプションをブートローダー設定に適用します。# grubby --update-kernel=ALL --args="crashkernel=<value>"<value>は、前のステップで準備したcrashkernel=オプションの値に置き換えます。
41.2.3. kdump ターゲットの設定
クラッシュダンプは通常、ローカルファイルシステムにファイルとして保存され、デバイスに直接書き込まれます。必要に応じて、NFS または SSH プロトコルを使用して、ネットワーク経由でクラッシュダンプを送信できます。クラッシュダンプファイルを保存するオプションは、一度に 1 つだけ設定できます。デフォルトの動作では、ローカルファイルシステムの /var/crash/ ディレクトリーに保存されます。
前提条件
- システムの root 権限がある。
-
kdump設定とターゲットの要件をすべて満たしている。詳細は サポートされている kdump 設定とターゲット を参照してください。
手順
ローカルファイルシステムの
/var/crash/ディレクトリーにクラッシュダンプファイルを保存するには、/etc/kdump.confファイルを変更して、パスを指定します。path /var/crashpath /var/crashオプションは、kdumpがクラッシュダンプファイルを保存するファイルシステムへのパスを表します。注記-
/etc/kdump.confファイルでダンプターゲットを指定すると、path は指定されたダンプ出力先に対する相対パスになります。 -
/etc/kdump.confファイルでダンプターゲットを指定しない場合、パスはルートディレクトリーからの 絶対 パスを表します。
現在のシステムにマウントされているファイルシステムに応じて、ダンプターゲットと調整されたダンプパスが自動的に設定されます。
-
kdumpによって生成されるクラッシュダンプファイルと付随するファイルを保護するには、ユーザー権限や SELinux コンテキストなど、ターゲットの宛先ディレクトリーの属性を適切に設定する必要があります。さらに、次のようにkdump.confファイルでkdump_post.shなどのスクリプトを定義することもできます。kdump_post <path_to_kdump_post.sh>kdump_postディレクティブは、kdumpがクラッシュダンプの取得と指定の保存先への保存を完了した 後に 実行されるシェルスクリプトまたはコマンドを指定するものです。このメカニズムを使用すると、kdumpの機能を拡張して、ファイル権限の調整などの操作を実行できます。-
kdumpターゲット設定
# *grep -v ^# /etc/kdump.conf | grep -v ^$*
ext4 /dev/mapper/vg00-varcrashvol
path /var/crash
core_collector makedumpfile -c --message-level 1 -d 31
ダンプターゲットが指定されています (ext4 /dev/mapper/vg00-varcrashvol)。そのため、ダンプターゲットは /var/crash にマウントされます。path オプションも /var/crash に設定されています。したがって、kdump は、vmcore ファイルを /var/crash/var/crash ディレクトリーに保存します。
クラッシュダンプを保存するローカルディレクトリーを変更するには、
rootユーザーとして/etc/kdump.conf設定ファイルを編集します。-
#path /var/crashの行頭にあるハッシュ記号 (#) を削除します。 値を対象のディレクトリーパスに置き換えます。以下に例を示します。
path /usr/local/cores重要RHEL 8 では、障害を回避するために、
kdumpsystemdサービスの起動時に、pathディレクティブを使用してkdumpターゲットとして定義されたディレクトリーが存在している必要があります。以前のバージョンの RHEL とは異なり、サービス起動時にディレクトリーが存在しない場合、ディレクトリーは自動的に作成されなくなりました。
-
ファイルを別のパーティションに書き込むには、
/etc/kdump.conf設定ファイルを編集します。必要に応じて
#ext4の行頭にあるハッシュ記号 (#) を削除します。-
デバイス名 (
#ext4 /dev/vg/lv_kdump行) -
ファイルシステムラベル (
#0ext4 LABEL=/boot行) -
UUID (
#ext4 UUID=03138356-5e61-4ab3-b58e-27507ac41937の行)
-
デバイス名 (
ファイルシステムタイプとデバイス名、ラベル、または UUID を必要な値に変更します。UUID 値を指定するための正しい構文は、
UUID="correct-uuid"とUUID=correct-uuidの両方です。以下に例を示します。ext4 UUID=03138356-5e61-4ab3-b58e-27507ac41937重要LABEL=またはUUID=を使用してストレージデバイスを指定することを推奨します。/dev/sda3などのディスクデバイス名は、再起動した場合に一貫性が保証されません。IBM Z ハードウェアで Direct Access Storage Device (DASD) を使用する場合は、
kdumpに進む前に、ダンプデバイスが/etc/dasd.confで正しく指定されていることを確認してください。
クラッシュダンプを直接書き込むには、
/etc/kdump.conf設定ファイルを修正します。-
#raw /dev/vg/lv_kdumpの行頭にあるハッシュ記号 (#) を削除します。 値を対象のデバイス名に置き換えます。以下に例を示します。
raw /dev/sdb1
-
NFSプロトコルを使用してクラッシュダンプをリモートマシンに保存するには、次の手順を実行します。-
#nfs my.server.com:/export/tmpの行頭にあるハッシュ記号 (#) を削除します。 値を、正しいホスト名およびディレクトリーパスに置き換えます。以下に例を示します。
nfs penguin.example.com:/export/cores変更を有効にするには、
kdumpサービスを再起動します。sudo systemctl restart kdump.service注記NFS ディレクティブを使用して NFS ターゲットを指定すると、
kdump.serviceが自動的に NFS ターゲットをマウントしてディスク容量をチェックしようとします。NFS ターゲットを事前にマウントする必要はありません。kdump.serviceがターゲットをマウントしないようにするには、kdump.confでdracut_args --mountディレクティブを使用します。これにより、kdump.serviceが--mount引数を使用してdracutユーティリティーを呼び出して NFS ターゲットを指定できるようになります。
-
SSH プロトコルを使用してクラッシュダンプをリモートマシンに保存するには、次の手順を実行します。
-
#ssh user@my.server.comの行頭にあるハッシュ記号 (#) を削除します。 - 値を正しいユーザー名およびホスト名に置き換えます。
SSH キーを設定に含めます。
-
#sshkey /root/.ssh/kdump_id_rsaの行頭にあるハッシュ記号 ("#") を削除します。 値を、ダンプ先のサーバー上の正しいキーの場所に変更します。以下に例を示します。
ssh john@penguin.example.com sshkey /root/.ssh/mykey
-
-
41.2.4. kdump コアコレクターの設定
kdump では、core_collector を使用してクラッシュダンプイメージをキャプチャーします。RHEL では、makedumpfile ユーティリティーがデフォルトのコアコレクターです。これは、以下に示すプロセスによりダンプファイルを縮小するのに役立ちます。
- クラッシュダンプファイルのサイズを圧縮し、さまざまなダンプレベルを使用して必要なページのみをコピーする
- 不要なクラッシュダンプページを除外する
- クラッシュダンプに含めるページタイプをフィルタリングする
クラッシュダンプファイルの圧縮は、RHEL 7 以降ではデフォルトで有効になっています。
クラッシュダンプファイルの圧縮をカスタマイズする必要がある場合は、以下の手順に従います。
構文
core_collector makedumpfile -l --message-level 1 -d 31オプション
-
-c、-l、または-p:zlib(-cオプションの場合)、lzo(-lオプションの場合)、またはsnappy(-pオプションの場合) のいずれかを使用して、ページごとに圧縮ダンプファイルの形式を指定します。 -
-d(dump_level): ページを除外して、ダンプファイルにコピーされないようにします。 -
--message-level: メッセージタイプを指定します。このオプションでmessage_levelを指定すると、出力の表示量を制限できます。たとえば、message_levelで 7 を指定すると、一般的なメッセージとエラーメッセージを出力します。message_levelの最大値は 31 です。
前提条件
- システムの root 権限がある。
-
kdump設定とターゲットの要件をすべて満たしている。詳細は サポートされている kdump 設定とターゲット を参照してください。
手順
-
rootとして、/etc/kdump.conf設定ファイルを編集し、#core_collector makedumpfile -l --message-level 1 -d 31の先頭からハッシュ記号 ("#") を削除します。 - 次のコマンドを入力して、クラッシュダンプファイルの圧縮を有効にします。
core_collector makedumpfile -l --message-level 1 -d 31
-l オプションにより、dump の圧縮ファイル形式を指定します。-d オプションで、ダンプレベルを 31 に指定します。--message-level オプションで、メッセージレベルを 1 に指定します。
また、-c オプションおよび -p オプションを使用した以下の例を検討してください。
-cを使用してクラッシュダンプファイルを圧縮するには、次のコマンドを実行します。core_collector makedumpfile -c -d 31 --message-level 1-pを使用してクラッシュダンプファイルを圧縮するには、次のコマンドを実行します。core_collector makedumpfile -p -d 31 --message-level 1
41.2.5. kdump のデフォルト障害応答の設定
デフォルトでは、設定したターゲットの場所で kdump がクラッシュダンプファイルの作成に失敗すると、システムが再起動し、ダンプがプロセス内で失われます。デフォルトの失敗応答を変更し、コアダンプをプライマリーターゲットに保存できない場合に別の操作を実行するように kdump を設定できます。追加のアクションは次のとおりです。
dump_to_rootfs-
コアダンプを
rootファイルシステムに保存します。 reboot- システムを再起動します。コアダンプは失われます。
halt- システムを停止します。コアダンプは失われます。
poweroff- システムの電源を切ります。コアダンプは失われます。
shell-
initramfs内からシェルセッションを実行します。コアダンプを手動で記録できます。 final_action-
kdumpの成功後、またはシェルまたはdump_to_rootfsの失敗アクションの完了時に、reboot、haltおよびpoweroffなどの追加操作を有効にします。デフォルトはrebootです。 failure_action-
カーネルクラッシュでダンプが失敗する可能性がある場合に実行するアクションを指定します。デフォルトは
rebootです。
前提条件
- root 権限
-
kdump設定とターゲットの要件をすべて満たしている。詳細は サポートされている kdump 設定とターゲット を参照してください。
手順
-
rootユーザーとして、/etc/kdump.conf設定ファイルの#failure_action行の先頭からハッシュ記号 (#) を削除します。 値を必要なアクションに置き換えます。
failure_action poweroff
41.2.6. kdump の設定ファイル
kdump カーネルの設定ファイルは /etc/sysconfig/kdump です。このファイルは、kdump カーネルコマンドラインパラメーターを制御します。ほとんどの設定では、デフォルトオプションを使用します。ただし、シナリオによっては、kdump カーネルの動作を制御するために特定のパラメーターを変更する必要があります。たとえば、KDUMP_COMMANDLINE_APPEND オプションを変更して kdump カーネルコマンドラインを追加して詳細なデバッグ出力を取得したり、KDUMP_COMMANDLINE_REMOVE オプションを変更して kdump コマンドラインから引数を削除したりします。
KDUMP_COMMANDLINE_REMOVE現在の
kdumpコマンドラインから引数を削除します。これにより、kdumpエラーやkdumpカーネルの起動失敗の原因となるパラメーターが削除されます。これらのパラメーターは、以前のKDUMP_COMMANDLINEプロセスから解析されるか、/proc/cmdlineファイルから継承されたものである場合があります。この変数が設定されていない場合は、
/proc/cmdlineファイルからすべての値が継承されます。このオプションを設定すると、問題のデバッグに役立つ情報も提供されます。特定の引数を削除するには、以下のようにして
KDUMP_COMMANDLINE_REMOVEに追加します。
# KDUMP_COMMANDLINE_REMOVE="hugepages hugepagesz slub_debug quiet log_buf_len swiotlb"KDUMP_COMMANDLINE_APPENDこのオプションは、現在のコマンドラインに引数を追加します。この引数は、以前の
KDUMP_COMMANDLINE_REMOVE変数によって解析されたものである場合があります。kdumpカーネルの場合は、mce、cgroup、numa、hest_disableなどの特定のモジュールを無効にすると、カーネルエラーを防ぐのに役立ちます。これらのモジュールは、kdump用に予約されているカーネルメモリーの大部分を消費したり、kdumpカーネルの起動失敗を引き起こしたりする可能性があります。kdumpカーネルコマンドラインでメモリーcgroupを無効にするには、以下のコマンドを実行します。
KDUMP_COMMANDLINE_APPEND="cgroup_disable=memory"41.2.7. kdump 設定のテスト
kdump を設定したら、システムクラッシュを手動でテストして、定義した kdump ターゲットに vmcore ファイルが生成されていることを確認する必要があります。vmcore ファイルは、新しく起動したカーネルのコンテキストからキャプチャーされます。したがって、vmcore にはカーネルクラッシュをデバッグするための重要な情報が含まれています。
アクティブな実稼働システムでは kdump をテストしないでください。kdump をテストするコマンドにより、カーネルがクラッシュし、データが失われます。システムアーキテクチャーに応じて、十分なメンテナンス時間を必ず確保してください。kdump のテストでは時間のかかる再起動が数回必要になる場合があります。
kdump のテスト中に vmcore ファイルが生成されない場合は、kdump のテストを成功させるために、再度テストを実行する前に問題を特定して修正してください。
手動でシステムを変更した場合は、システム変更の最後に kdump 設定をテストする必要があります。たとえば、次のいずれかの変更を行った場合は、kdump のパフォーマンスが最適になるように、kdump の設定をテストしてください。
- パッケージのアップグレード。
- ハードウェアレベルの変更 (ストレージやネットワークの変更など)。
- ファームウェアのアップグレード。
- サードパーティーのモジュールを含む新規のインストールおよびアプリケーションのアップグレード。
- ホットプラグメカニズムを使用した、このメカニズムをサポートするハードウェアへのメモリーの追加。
-
/etc/kdump.confファイルまたは/etc/sysconfig/kdumpファイルに対する変更。
前提条件
- システムの root 権限がある。
-
重要なデータがすべて保存されている。
kdumpをテストするコマンドにより、カーネルがクラッシュし、データが失われます。 - システムアーキテクチャーに応じて、十分なマシンメンテナンス時間が確保されている。
手順
kdumpサービスを有効にします。# kdumpctl restartkdumpctlを使用してkdumpサービスのステータスを確認します。# kdumpctl status kdump:Kdump is operational必要に応じて
systemctlコマンドを使用すると、出力がsystemdジャーナルに印刷されます。カーネルクラッシュを開始して、
kdumpの設定をテストします。sysrq-triggerキーの組み合わせによりカーネルがクラッシュし、必要に応じてシステムが再起動します。# echo c > /proc/sysrq-triggerカーネルの再起動時に、
/etc/kdump.confファイルで指定した場所にaddress-YYYY-MM-DD-HH:MM:SS/vmcoreファイルが作成されます。デフォルトは/var/crash/です。
41.2.8. システムクラッシュ後に kdump によって生成されるファイル
システムがクラッシュすると、kdump サービスは、カーネルメモリーをダンプファイル (vmcore) にキャプチャーします。また、トラブルシューティングと事後分析に役立つ追加の診断ファイルを生成します。
kdump によって生成されるファイル:
-
vmcore- クラッシュ時のシステムメモリーを含む主なカーネルメモリーダンプファイル。これには、kdump設定で指定されているcore_collectorプログラムの設定に従ってデータが追加されます。デフォルトでは、カーネルデータ構造、プロセス情報、スタックトレース、およびその他の診断情報が含まれます。 -
vmcore-dmesg.txt- パニックになったプライマリーカーネルからのカーネルリングバッファーログ (dmesg) の内容。 -
kexec-dmesg.log-vmcoreデータを収集するセカンダリーのkexecカーネルの実行に基づくカーネルおよびシステムログメッセージが含まれます。
41.2.9. kdump サービスの有効化および無効化
kdump 機能は、特定のカーネルまたはインストールされているすべてのカーネルで有効または無効にするように設定できます。kdump 機能を定期的にテストし、正しく動作することを検証する必要があります。
前提条件
- システムの root 権限がある。
-
kdumpの設定とターゲットの要件をすべて満たしている。サポートされている kdump 設定とターゲット を参照してください。 -
kdumpをインストールするためのすべての設定が、要件に応じてセットアップされている。
手順
multi-user.targetのkdumpサービスを有効にします。# systemctl enable kdump.service現在のセッションでサービスを起動します。
# systemctl start kdump.servicekdumpサービスを停止します。# systemctl stop kdump.servicekdumpサービスを無効にします。# systemctl disable kdump.service
kptr_restrict=1 をデフォルトとして設定することが推奨されます。kptr_restrict がデフォルトで (1) に設定されている場合、Kernel Address Space Layout (KASLR) が有効かどうかに関係なく、kdumpctl サービスがクラッシュカーネルをロードします。
kptr_restrict が 1 に設定されておらず、KASLR が有効になっている場合は、/proc/kore ファイルの内容がすべてゼロとして生成されます。kdumpctl サービスは、/proc/kcore ファイルにアクセスしてクラッシュカーネルを読み込むことができません。kexec-kdump-howto.txt ファイルには、kptr_restrict=1 に設定することを推奨する警告メッセージが表示されます。kdumpctl サービスが必ずクラッシュカーネルを読み込むように、sysctl.conf ファイルで次の内容を確認します。
-
sysctl.confファイルでのカーネルのkptr_restrict=1設定
41.2.10. カーネルドライバーが kdump を読み込まないようにする設定
/etc/sysconfig/kdump 設定ファイルに KDUMP_COMMANDLINE_APPEND= 変数を追加することで、キャプチャーカーネルが特定のカーネルドライバーをロードしないように制御できます。この方法を使用すると、kdump 初期 RAM ディスクイメージ initramfs が、指定されたカーネルモジュールをロードするのを防ぐことができます。これにより、メモリー不足 (OOM) killer エラーやその他のクラッシュカーネル障害を防ぐことができます。
次のいずれかの設定オプションを使用して、KDUMP_COMMANDLINE_APPEND= 変数を追加できます。
-
rd.driver.blacklist=<modules> -
modprobe.blacklist=<modules>
前提条件
- システムの root 権限がある。
手順
現在実行中のカーネルに読み込まれるモジュールのリストを表示します。ロードをブロックするカーネルモジュールを選択します。
$ lsmod Module Size Used by fuse 126976 3 xt_CHECKSUM 16384 1 ipt_MASQUERADE 16384 1 uinput 20480 1 xt_conntrack 16384 1/etc/sysconfig/kdumpファイルのKDUMP_COMMANDLINE_APPEND=変数を更新します。以下に例を示します。KDUMP_COMMANDLINE_APPEND="rd.driver.blacklist=hv_vmbus,hv_storvsc,hv_utils,hv_netvsc,hid-hyperv"modprobe.blacklist=<modules>設定オプションを使用した以下の例も検討してください。KDUMP_COMMANDLINE_APPEND="modprobe.blacklist=emcp modprobe.blacklist=bnx2fc modprobe.blacklist=libfcoe modprobe.blacklist=fcoe"kdumpサービスを再起動します。# systemctl restart kdump
41.2.11. 暗号化されたディスクがあるシステムでの kdump の実行
LUKS 暗号化パーティションを実行すると、システムで利用可能なメモリーが一定量必要になります。システムが必要なメモリー量を下回ると、cryptsetup ユーティリティーがパーティションのマウントに失敗します。その結果、2 番目のカーネル (キャプチャーカーネル) で、暗号化したターゲットの場所に vmcore ファイルをキャプチャーできませんでした。
kdumpctl estimate コマンドは、kdump に必要なメモリーの量を見積もるのに役立ちます。kdumpctl estimate 値は、推奨される crashkernel 値を出力します。これは、kdump に必要な最適なメモリーサイズです。
推奨の crashkernel 値は、現在のカーネルサイズ、カーネルモジュール、initramfs、および暗号化したターゲットメモリー要件に基づいて計算されます。
カスタムの crashkernel= オプションを使用している場合、kdumpctl estimate は LUKS required size 値を出力します。この値は、LUKS 暗号化ターゲットに必要なメモリーサイズです。
手順
crashkernel=の推定値を出力します。# *kdumpctl estimate* Encrypted kdump target requires extra memory, assuming using the keyslot with minimum memory requirement Reserved crashkernel: 256M Recommended crashkernel: 652M Kernel image size: 47M Kernel modules size: 8M Initramfs size: 20M Runtime reservation: 64M LUKS required size: 512M Large modules: <none> WARNING: Current crashkernel size is lower than recommended size 652M.-
crashkernel=の値を増やして、必要なメモリー量を設定します。 - システムを再起動します。
それでも kdump がダンプファイルを暗号化したターゲットに保存できない場合は、必要に応じて crashkernel= を増やしてください。
41.3. kdump の有効化
RHEL 8 システムの場合、特定のカーネルまたはインストールされているすべてのカーネルで、kdump 機能を有効または無効にするように設定できます。ただし、kdump 機能を定期的にテストし、その動作状態を検証する必要があります。
41.3.1. インストールされているすべてのカーネルでの kdump の有効化
kdump サービスは、kexec ツールのインストール後に kdump.service を有効にすることで起動します。マシンにインストールされているすべてのカーネルに対して、kdump を有効にして起動できます。
前提条件
- 管理者権限がある。
手順
インストールされているすべてのカーネルに
crashkernel=コマンドラインパラメーターを追加します。# grubby --update-kernel=ALL --args="crashkernel=xxM"xxMは必要なメモリー (メガバイト単位) です。システムを再起動します。
# rebootkdumpサービスを有効にします。# systemctl enable --now kdump.service
検証
kdumpが実行されていることを確認します。# systemctl status kdump.service ○ kdump.service - Crash recovery kernel arming Loaded: loaded (/usr/lib/systemd/system/kdump.service; enabled; vendor preset: disabled) Active: active (live)
41.3.2. 特定のインストール済みカーネルでの kdump の有効化
マシン上の特定カーネルに対して、kdump を有効にできます。
前提条件
- 管理者権限がある。
手順
マシンにインストールされているカーネルをリスト表示します。
# ls -a /boot/vmlinuz-* /boot/vmlinuz-0-rescue-2930657cd0dc43c2b75db480e5e5b4a9 /boot/vmlinuz-4.18.0-330.el8.x86_64 /boot/vmlinuz-4.18.0-330.rt7.111.el8.x86_64特定の
kdumpカーネルを、システムの Grand Unified Bootloader (GRUB) 設定に追加します。以下に例を示します。
# grubby --update-kernel=vmlinuz-4.18.0-330.el8.x86_64 --args="crashkernel=xxM"xxMは必要なメモリー予約 (メガバイト単位) です。kdumpを有効にします。# systemctl enable --now kdump.service
検証
kdumpが実行されていることを確認します。# systemctl status kdump.service ○ kdump.service - Crash recovery kernel arming Loaded: loaded (/usr/lib/systemd/system/kdump.service; enabled; vendor preset: disabled) Active: active (live)
41.3.3. kdump サービスの無効化
kdump.service を停止し、RHEL 8 システムでのサービスの起動を無効にすることができます。
前提条件
-
kdump設定とターゲットの要件をすべて満たしている。詳細は サポートされている kdump 設定とターゲット を参照してください。 -
kdumpのインストール用のオプションがすべて、要件に応じて設定されている。詳細は、kdump のインストール を参照してください。
手順
現在のセッションで
kdumpを停止するには、以下のコマンドを実行します。# systemctl stop kdump.servicekdumpを無効にするには、以下を行います。# systemctl disable kdump.service
kptr_restrict=1 をデフォルトとして設定することが推奨されます。kptr_restrict がデフォルトで (1) に設定されている場合、Kernel Address Space Layout (KASLR) が有効かどうかに関係なく、kdumpctl サービスがクラッシュカーネルをロードします。
kptr_restrict が 1 に設定されておらず、KASLR が有効になっている場合は、/proc/kore ファイルの内容がすべてゼロとして生成されます。kdumpctl サービスは、/proc/kcore ファイルにアクセスしてクラッシュカーネルを読み込むことができません。kexec-kdump-howto.txt ファイルには、kptr_restrict=1 に設定することを推奨する警告メッセージが表示されます。kdumpctl サービスが必ずクラッシュカーネルを読み込むように、sysctl.conf ファイルで次の内容を確認します。
-
sysctl.confファイルでのカーネルのkptr_restrict=1設定
41.4. Web コンソールで kdump の設定
RHEL 8 Web コンソールを使用して、kdump 設定をセットアップおよびテストできます。Web コンソールでは、起動時に kdump サービスを有効にすることができます。Web コンソールを使用すると、kdump 用に予約されたメモリーを設定し、vmcore の保存場所を非圧縮形式または圧縮形式で選択できます。
41.4.1. Web コンソールで kdump メモリーの使用量およびターゲットの場所を設定
RHEL Web コンソールインターフェイスを使用して、kdump カーネルのメモリー予約を設定し、vmcore ダンプファイルをキャプチャーするターゲットの場所を指定することもできます。
前提条件
- Web コンソールがインストールされており、アクセス可能である。詳細は、Web コンソールのインストール を参照してください。
手順
-
Web コンソールで、 タブを開き、Kernel crash dump スイッチをオンに設定して
kdumpサービスを起動します。 ターミナルで
kdumpのメモリー使用量を設定します。以下に例を示します。$ sudo grubby --update-kernel ALL --args crashkernel=512M変更を適用するにはシステムを再起動します。
- Kernel dump タブで、Crash dump location フィールドの末尾にある Edit をクリックします。
vmcoreダンプファイルを保存するターゲットディレクトリーを指定します。- ローカルファイルシステムの場合は、ドロップダウンメニューから Local Filesystem を選択します。
SSH プロトコルを使用したリモートシステムの場合は、ドロップダウンメニューから Remote over SSH を選択し、次のフィールドを指定します。
- Server フィールドに、リモートサーバーのアドレスを入力します。
- SSH key フィールドに、SSH キーの場所を入力します。
- Directory フィールドに、ターゲットディレクトリーを入力します。
NFS プロトコルを使用したリモートシステムの場合は、ドロップダウンメニューから Remote over NFS を選択し、次のフィールドを指定します。
- Server フィールドに、リモートサーバーのアドレスを入力します。
- Export フィールドに、NFS サーバーの共有フォルダーの場所を入力します。
Directory フィールドに、ターゲットディレクトリーを入力します。
注記Compression チェックボックスをオンにすると、
vmcoreファイルのサイズを削減できます。
オプション: View automation script をクリックして自動化スクリプトを表示します。
生成されたスクリプトを含むウィンドウが開きます。シェルスクリプトと Ansible Playbook 生成オプションのタブを参照できます。
オプション: Copy to clipboard をクリックしてスクリプトをコピーします。
このスクリプトを使用すると、複数のマシンに同じ設定を適用できます。
検証
- をクリックします。
Test kdump settings の下にある Crash system をクリックします。
警告システムクラッシュを開始すると、カーネルの動作が停止し、システムがクラッシュしてデータが失われます。
41.5. サポートされている kdump 設定とターゲット
kdump メカニズムは、カーネルクラッシュが発生したときにクラッシュダンプファイルを生成する Linux カーネルの機能です。カーネルダンプファイルには、カーネルクラッシュの根本原因を分析して特定するのに役立つ重要な情報が含まれています。クラッシュの原因は、ハードウェアの問題やサードパーティーのカーネルモジュールの問題など、さまざまな要因が考えられます。
提供された情報と手順を使用することで、次のアクションを実行できます。
- RHEL 8 システムでサポートされている設定とターゲットを特定します。
- kdump を設定します。
- kdump 操作を確認します。
41.5.1. kdump メモリー要件
kdump がカーネルクラッシュダンプをキャプチャーし、さらなる分析のために保存するには、システムメモリーの一部をキャプチャーカーネル用に永続的に予約しておく必要があります。予約されている場合、システムメモリーのこの部分はメインカーネルでは使用できません。
メモリー要件は、特定のシステムパラメーターによって異なります。主な要因は、システムのハードウェアアーキテクチャーです。Intel 64 や AMD64 (別称: x86_64 ) などの正確なマシンアーキテクチャーを識別し、それを標準出力に出力するには、次のコマンドを使用します。
$ uname -m
下記の最小メモリー要件のリストを使用して、利用可能な最新バージョンで kdump 用のメモリーを自動的に予約するための適切なメモリーサイズを設定できます。メモリーサイズは、システムのアーキテクチャーと利用可能な物理メモリーの合計によって異なります。
| アーキテクチャー | 使用可能なメモリー | 最小予約メモリー |
|---|---|---|
|
AMD64 と Intel 64 ( | 1 GB から 4 GB | 192 MB のメモリー |
| 4 GB から 64 GB | 256 MB のメモリー | |
| 64 GB 以上 | 512 MB のメモリー | |
|
64 ビット ARM アーキテクチャー ( | 2 GB 以上 | 480 MB のメモリー |
|
IBM Power Systems ( | 2 GB から 4 GB | 384 MB のメモリー |
| 4 GB から 16 GB | 512 MB のメモリー | |
| 16 GB から 64 GB | 1 GB のメモリー | |
| 64 GB から 128 GB | 2 GB のメモリー | |
| 128 GB 以上 | 4 GB のメモリー | |
|
IBM Z ( | 1 GB から 4 GB | 192 MB のメモリー |
| 4 GB から 64 GB | 256 MB のメモリー | |
| 64 GB 以上 | 512 MB のメモリー |
多くのシステムでは、kdump は必要なメモリー量を予測して、自動的に予約できます。この動作はデフォルトで有効になっていますが、利用可能な合計メモリーサイズが一定以上搭載されているシステムに限られます。この自動割り当て動作に必要なメモリーサイズはシステムのアーキテクチャーによって異なります。
システムのメモリー合計量に基づく予約メモリーの自動設定は、ベストエフォート予測です。実際に必要なメモリーは、I/O デバイスなどの他の要因によって異なる場合があります。十分なメモリーを使用しないと、カーネルパニックが発生したときに、デバッグカーネルがキャプチャーカーネルとして起動できなくなる可能性があります。この問題を回避するには、クラッシュカーネルメモリーを十分に増やしてください。
41.5.2. メモリー自動予約の最小しきい値
kexec-tools ユーティリティーは、デフォルトで、crashkernel コマンドラインパラメーターを設定し、kdump 用に一定量のメモリーを予約します。ただし、一部のシステムでは、ブートローダー設定ファイルで crashkernel=auto パラメーターを使用するか、グラフィカル設定ユーティリティーでこのオプションを有効にすることで、kdump 用のメモリーを割り当てることが可能です。この自動予約を機能させるには、システムで一定量の合計メモリーが使用可能である必要があります。メモリー要件はシステムのアーキテクチャーによって異なります。システムのメモリーが指定のしきい値よりも小さい場合は、メモリーを手動で設定する必要があります。
| アーキテクチャー | 必要なメモリー |
|---|---|
|
AMD64 と Intel 64 ( | 2 GB |
|
IBM Power Systems ( | 2 GB |
|
IBM Z ( | 4 GB |
起動コマンドラインの crashkernel=auto オプションは、RHEL 9 以降のリリースでは対応しなくなりました。
41.5.3. サポートしている kdump のダンプ出力先
カーネルクラッシュが発生すると、オペレーティングシステムは、設定したダンプ出力先またはデフォルトのダンプ出力先にダンプファイルを保存します。ダンプファイルは、デバイスに直接保存することも、ローカルファイルシステムにファイルとして保存することも、ネットワーク経由で送信することもできます。以下に示すダンプ出力先のリストを使用すると、kdump で現在サポートされているダンプ出力先とサポートされていないダンプ出力先を把握できます。
| ダンプ出力先の種類 | 対応しているダンプ出力先 | 対応していないダンプ出力先 |
|---|---|---|
| 物理ストレージ |
|
|
| ネットワーク |
|
|
| ハイパーバイザー |
| |
| ファイルシステム | ext[234]、XFS、および NFS ファイルシステム。 |
|
| ファームウェア |
|
41.5.4. 対応している kdump のフィルターレベル
ダンプファイルのサイズを削減するために、kdump は makedumpfile コアコレクターを使用してデータを圧縮し、さらに不要な情報を除外します。たとえば、-8 レベルを使用すると、hugepages および hugetlbfs ページを削除できます。makedumpfile が現在サポートしているレベルは `kdump` のフィルタリングレベル の表で確認できます。
| オプション | 説明 |
|---|---|
|
| ゼロページ |
|
| キャッシュページ |
|
| キャッシュプライベート |
|
| ユーザーページ |
|
| フリーページ |
41.5.5. 対応しているデフォルトの障害応答
デフォルトでは、kdump がコアダンプを作成できない場合、オペレーティングシステムが再起動します。ただし、コアダンプをプライマリーターゲットに保存できない場合に別の操作を実行するように kdump を設定できます。
| オプション | 説明 |
|---|---|
|
| root ファイルシステムにコアダンプの保存を試行します。ネットワーク上のダンプ出力先と併用する場合に特に便利なオプションです。ネットワーク上のダンプ出力先にアクセスできない場合、ローカルにコアダンプを保存するよう kdump の設定を行います。システムは、後で再起動します。 |
|
| システムを再起動します。コアダンプは失われます。 |
|
| システムを停止します。コアダンプは失われます。 |
|
| システムの電源を切ります。コアダンプは失われます。 |
|
| initramfs 内から shell セッションを実行して、ユーザーが手動でコアダンプを記録できるようにします。 |
|
|
|
41.5.6. final_action パラメーターの使用
kdump が成功した場合、または kdump が設定されたターゲットでの vmcore ファイルの保存に失敗した場合は、final_action パラメーターを使用して、reboot、halt、poweroff などの追加操作を実行できます。final_action パラメーターが指定されていない場合、デフォルトの応答は reboot です。
手順
final_actionを設定するには、/etc/kdump.confファイルを編集して、次のいずれかのオプションを追加します。-
final_action reboot -
final_action halt -
final_action poweroff
-
変更を有効にするには、
kdumpサービスを再起動します。# kdumpctl restart
41.5.7. failure_action パラメーターの使用
failure_action パラメーターは、カーネルがクラッシュした場合にダンプが失敗したときに実行するアクションを指定します。failure_action のデフォルトのアクションは、システムを再起動する reboot です。
このパラメーターは、実行する以下のアクションを認識します。
reboot- ダンプが失敗した後、システムを再起動します。
dump_to_rootfs- 非ルートダンプターゲットが設定されている場合、ダンプファイルをルートファイルシステムに保存します。
halt- システムを停止します。
poweroff- システムで実行中の操作を停止します。
shell-
initramfs内でシェルセッションを開始します。このセッションから、追加のリカバリーアクションを手動で実行できます。
手順
ダンプが失敗した場合に実行するアクションを設定するには、
/etc/kdump.confファイルを編集して、failure_actionオプションの 1 つを指定します。-
failure_action reboot -
failure_action halt -
failure_action poweroff -
failure_action shell -
failure_action dump_to_rootfs
-
変更を有効にするには、
kdumpサービスを再起動します。# kdumpctl restart
41.6. kdump 設定のテスト
kdump を設定したら、システムクラッシュを手動でテストして、定義した kdump ターゲットに vmcore ファイルが生成されていることを確認する必要があります。vmcore ファイルは、新しく起動したカーネルのコンテキストからキャプチャーされます。したがって、vmcore にはカーネルクラッシュをデバッグするための重要な情報が含まれています。
アクティブな実稼働システムでは kdump をテストしないでください。kdump をテストするコマンドにより、カーネルがクラッシュし、データが失われます。システムアーキテクチャーに応じて、十分なメンテナンス時間を必ず確保してください。kdump のテストでは時間のかかる再起動が数回必要になる場合があります。
kdump のテスト中に vmcore ファイルが生成されない場合は、kdump のテストを成功させるために、再度テストを実行する前に問題を特定して修正してください。
手動でシステムを変更した場合は、システム変更の最後に kdump 設定をテストする必要があります。たとえば、次のいずれかの変更を行った場合は、kdump のパフォーマンスが最適になるように、kdump の設定をテストしてください。
- パッケージのアップグレード。
- ハードウェアレベルの変更 (ストレージやネットワークの変更など)。
- ファームウェアのアップグレード。
- サードパーティーのモジュールを含む新規のインストールおよびアプリケーションのアップグレード。
- ホットプラグメカニズムを使用した、このメカニズムをサポートするハードウェアへのメモリーの追加。
-
/etc/kdump.confファイルまたは/etc/sysconfig/kdumpファイルに対する変更。
前提条件
- システムの root 権限がある。
-
重要なデータがすべて保存されている。
kdumpをテストするコマンドにより、カーネルがクラッシュし、データが失われます。 - システムアーキテクチャーに応じて、十分なマシンメンテナンス時間が確保されている。
手順
kdumpサービスを有効にします。# kdumpctl restartkdumpctlを使用してkdumpサービスのステータスを確認します。# kdumpctl status kdump:Kdump is operational必要に応じて
systemctlコマンドを使用すると、出力がsystemdジャーナルに印刷されます。カーネルクラッシュを開始して、
kdumpの設定をテストします。sysrq-triggerキーの組み合わせによりカーネルがクラッシュし、必要に応じてシステムが再起動します。# echo c > /proc/sysrq-triggerカーネルの再起動時に、
/etc/kdump.confファイルで指定した場所にaddress-YYYY-MM-DD-HH:MM:SS/vmcoreファイルが作成されます。デフォルトは/var/crash/です。
41.7. kexec を使用した別のカーネルの起動
kexec システムコールを使用すると、現在実行中のカーネルから別のカーネルをロードして起動することができます。kexec は カーネル内からブートローダーの機能を実行します。
kexec ユーティリティーは、kexec システムコールのカーネルおよび initramfs イメージを読み込み、別のカーネルで起動します。
以下の手順では、kexec ユーティリティーを使用して別のカーネルに再起動する時に、kexec システムコールを手動で呼び出す方法を説明します。
手順
kexecユーティリティーを実行します。# kexec -l /boot/vmlinuz-3.10.0-1040.el7.x86_64 --initrd=/boot/initramfs-3.10.0-1040.el7.x86_64.img --reuse-cmdlineこのコマンドは、
kexecシステムコール用のカーネルとinitramfsイメージを手動でロードします。システムを再起動します。
# rebootこのコマンドはカーネルを検出し、すべてのサービスをシャットダウンしてから、
kexecシステムコールを呼び出して直前の手順で指定したカーネルに再起動します。
kexec -3 コマンドを使用して、マシンを別のカーネルで再起動すると、システムは、次のカーネルを起動する前に標準のシャットダウンシーケンスを通過しません。これにより、データが失われたり、システムが応答しなくなったりする可能性があります。
41.8. カーネルドライバーが kdump を読み込まないようにする設定
/etc/sysconfig/kdump 設定ファイルに KDUMP_COMMANDLINE_APPEND= 変数を追加することで、キャプチャーカーネルが特定のカーネルドライバーをロードしないように制御できます。この方法を使用すると、kdump 初期 RAM ディスクイメージ initramfs が、指定されたカーネルモジュールをロードするのを防ぐことができます。これにより、メモリー不足 (OOM) killer エラーやその他のクラッシュカーネル障害を防ぐことができます。
次のいずれかの設定オプションを使用して、KDUMP_COMMANDLINE_APPEND= 変数を追加できます。
-
rd.driver.blacklist=<modules> -
modprobe.blacklist=<modules>
前提条件
- システムの root 権限がある。
手順
現在実行中のカーネルに読み込まれるモジュールのリストを表示します。ロードをブロックするカーネルモジュールを選択します。
$ lsmod Module Size Used by fuse 126976 3 xt_CHECKSUM 16384 1 ipt_MASQUERADE 16384 1 uinput 20480 1 xt_conntrack 16384 1/etc/sysconfig/kdumpファイルのKDUMP_COMMANDLINE_APPEND=変数を更新します。以下に例を示します。KDUMP_COMMANDLINE_APPEND="rd.driver.blacklist=hv_vmbus,hv_storvsc,hv_utils,hv_netvsc,hid-hyperv"modprobe.blacklist=<modules>設定オプションを使用した以下の例も検討してください。KDUMP_COMMANDLINE_APPEND="modprobe.blacklist=emcp modprobe.blacklist=bnx2fc modprobe.blacklist=libfcoe modprobe.blacklist=fcoe"kdumpサービスを再起動します。# systemctl restart kdump
41.9. 暗号化されたディスクがあるシステムでの kdump の実行
LUKS 暗号化パーティションを実行すると、システムで利用可能なメモリーが一定量必要になります。システムが必要なメモリー量を下回ると、cryptsetup ユーティリティーがパーティションのマウントに失敗します。その結果、2 番目のカーネル (キャプチャーカーネル) で、暗号化したターゲットの場所に vmcore ファイルをキャプチャーできませんでした。
kdumpctl estimate コマンドは、kdump に必要なメモリーの量を見積もるのに役立ちます。kdumpctl estimate 値は、推奨される crashkernel 値を出力します。これは、kdump に必要な最適なメモリーサイズです。
推奨の crashkernel 値は、現在のカーネルサイズ、カーネルモジュール、initramfs、および暗号化したターゲットメモリー要件に基づいて計算されます。
カスタムの crashkernel= オプションを使用している場合、kdumpctl estimate は LUKS required size 値を出力します。この値は、LUKS 暗号化ターゲットに必要なメモリーサイズです。
手順
crashkernel=の推定値を出力します。# *kdumpctl estimate* Encrypted kdump target requires extra memory, assuming using the keyslot with minimum memory requirement Reserved crashkernel: 256M Recommended crashkernel: 652M Kernel image size: 47M Kernel modules size: 8M Initramfs size: 20M Runtime reservation: 64M LUKS required size: 512M Large modules: <none> WARNING: Current crashkernel size is lower than recommended size 652M.-
crashkernel=の値を増やして、必要なメモリー量を設定します。 - システムを再起動します。
それでも kdump がダンプファイルを暗号化したターゲットに保存できない場合は、必要に応じて crashkernel= を増やしてください。
41.10. ファームウェア支援ダンプの仕組み
ファームウェア支援ダンプ (fadump) は、IBM POWER システムの kdump メカニズムの代わりに提供されるダンプ取得メカニズムです。kexec および kdump のメカニズムは、AMD64 および Intel 64 システムでコアダンプを取得する際に役立ちます。ただし、ミニシステムやメインフレームコンピューターなどの一部のハードウェアでは、オンボードファームウェアを使用してメモリー領域を分離し、クラッシュ分析で重要なデータが誤って上書きされることを防ぎます。fadump ユーティリティーは、fadump メカニズムと IBM POWER システム上の RHEL とのインテグレーション向けに最適化されています。
41.10.1. IBM PowerPC ハードウェアにおけるファームウェア支援ダンプ
fadump ユーティリティーは、PCI デバイスおよび I/O デバイスが搭載され、完全にリセットされたシステムから vmcore ファイルをキャプチャーします。この仕組みでは、クラッシュするとファームウェアを使用してメモリー領域を保存し、kdump ユーザー空間スクリプトをもう一度使用して vmcore ファイルを保存します。このメモリー領域には、ブートメモリー、システムレジスター、およびハードウェアのページテーブルエントリー (PTE) を除く、すべてのシステムメモリーコンテンツが含まれます。
fadump メカニズムは、パーティションを再起動し、新規カーネルを使用して以前のカーネルクラッシュからのデータをダンプすることで従来のダンプタイプに比べて信頼性が向上されています。fadump には、IBM POWER6 プロセッサーベースまたはそれ以降バージョンのハードウェアプラットフォームが必要です。
PowerPC 固有のハードウェアのリセット方法など、fadump メカニズムの詳細は、/usr/share/doc/kexec-tools/fadump-howto.txt ファイルを参照してください。
保持されないメモリー領域はブートメモリーと呼ばれており、この領域はクラッシュ後にカーネルを正常に起動するのに必要なメモリー容量です。デフォルトのブートメモリーサイズは、256 MB または全システム RAM の 5% のいずれか大きい方です。
kexec で開始されたイベントとは異なり、fadump メカニズムでは実稼働用のカーネルを使用してクラッシュダンプを復元します。PowerPC ハードウェアは、クラッシュ後の起動時に、デバイスノード /proc/device-tree/rtas/ibm.kernel-dump が proc ファイルシステム (procfs) で利用できるようにします。fadump-aware kdump スクリプトでは、保存された vmcore があるかを確認してから、システムの再起動を正常に完了させます。
41.10.2. ファームウェア支援ダンプメカニズムの有効化
IBM POWER システムのクラッシュダンプ機能は、ファームウェア支援ダンプ (fadump) メカニズムを有効にすることで強化できます。
セキュアブート環境では、GRUB ブートローダーは、Real Mode Area (RMA) と呼ばれるブートメモリー領域を割り当てます。RMA のサイズは 512 MB で、ブートコンポーネント間で分割されます。コンポーネントがサイズ割り当てを超えると、GRUB はメモリー不足 (OOM) エラーで失敗します。
RHEL 8.7 および 8.6 バージョンのセキュアブート環境では、ファームウェア支援ダンプ (fadump) メカニズムを有効にしないでください。GRUB2 ブートローダーが次のエラーで失敗します。
error: ../../grub-core/kern/mm.c:376:out of memory.
Press any key to continue…
システムは、fadump 設定のためにデフォルトの initramfs サイズを増やした場合にのみ回復可能です。
システムを回復するための回避策については、記事 System boot ends in GRUB Out of Memory (OOM) を参照してください。
手順
-
kdumpのインストールと設定 fadump=onカーネルオプションを有効にします。# grubby --update-kernel=ALL --args="fadump=on"オプション: デフォルトを使用する代わりに予約済みのブートメモリーを指定する場合は、
crashkernel= xx Mオプションを有効にします。ここで、xxは必要なメモリーの量 (メガバイト単位) です。# grubby --update-kernel=ALL --args="crashkernel=xxM fadump=on"重要ブート設定オプションを指定するときは、実行する前にすべてのブート設定オプションをテストしてください。
kdumpカーネルの起動に失敗した場合は、crashkernel=引数に指定した値を徐々に増やして、適切な値を設定します。
41.10.3. IBM Z ハードウェアにおけるファームウェア支援ダンプの仕組み
IBM Z システムは、以下のファームウェア支援ダンプメカニズムをサポートします。
-
スタンドアロンダンプ (sadump) -
VMDUMP
IBM Z システムでは、kdump インフラストラクチャーはサポート対象で、使用されています。ただし、IBM Z のファームウェア支援ダンプ (fadump) 方式のいずれかを使用すると、次のような利点があります。
-
システムコンソールは
sadumpメカニズムを開始および制御し、それをIPLブート可能なデバイスに保存します。 -
VMDUMPメカニズムはsadumpに似ています。このツールもシステムコンソールから開始しますが、ハードウェアから生成されたダンプを取得して解析用にシステムにコピーします。 -
(他のハードウェアベースのダンプメカニズムと同様に) これらの手法では、(
kdumpサービスが開始される前の) 起動初期段階におけるマシンの状態をキャプチャーできます。 -
VMDUMPには、ダンプファイルを Red Hat Enterprise Linux システムに受信するメカニズムが含まれていますが、VMDUMPの設定と制御は IBM Z ハードウェアコンソールから管理されます。
41.10.4. Fujitsu PRIMEQUEST システムにおける sadump の使用
Fujitsu sadump メカニズムは、kdump が正常に完了できない場合に fallback ダンプキャプチャーを提供します。システム管理ボード (MMB) インターフェイスから sadump を手動で呼び出すことができます。MMB を使用して、Intel 64 または AMD 64 サーバーの場合と同様に kdump を設定し、sadump を有効にします。
手順
sadumpに対してkdumpが予想どおりに起動するように/etc/sysctl.confファイルで以下の行を追加または編集します。kernel.panic=0 kernel.unknown_nmi_panic=1警告特に、
kdumpの後にシステムが再起動しないようにする必要があります。kdumpがvmcoreファイルの保存に失敗した後にシステムが再起動すると、sadumpを呼び出すことができなくなります。/etc/kdump.confのfailure_actionパラメーターをhaltまたはshellとして適切に設定します。failure_action shell
41.11. コアダンプの分析
システムクラッシュの原因を確認するには、crash ユーティリティーを使用します。これにより、GNU Debugger (GDB) に似たインタラクティブなプロンプトが提供されます。crash を使用すると、kdump、netdump、diskdump、または xendump によって作成されたコアダンプと実行中の Linux システムを分析できます。あるいは、Kernel Oops Analyzer または Kdump Helper ツールを使用することもできます。
41.11.1. crash ユーティリティーのインストール
crash ユーティリティーをインストールするために必要なパッケージと手順を説明します。crash ユーティリティーは、RHEL 8 システムにデフォルトでインストールされていない可能性があります。crash は、システムの実行中またはカーネルクラッシュが発生してコアダンプファイルが作成された後に、システムの状態を対話的に分析するためのツールです。コアダンプファイルは、vmcore ファイルとも呼ばれます。
手順
関連するリポジトリーを有効にします。
# subscription-manager repos --enable baseos repository# subscription-manager repos --enable appstream repository# subscription-manager repos --enable rhel-8-for-x86_64-baseos-debug-rpmscrashパッケージをインストールします。# yum install crashkernel-debuginfoパッケージをインストールします。# yum install kernel-debuginfoパッケージ
kernel-debuginfoは実行中のカーネルに対応し、ダンプ分析に必要なデータを提供します。
41.11.2. crash ユーティリティーの実行および終了
crash ユーティリティーは、kdump を分析するための強力なツールです。クラッシュダンプファイルに対して crash を実行すると、クラッシュ時のシステムの状態を把握し、問題の根本原因を特定し、カーネル関連の問題をトラブルシューティングできます。
前提条件
-
現在実行しているカーネルを特定します (
4.18.0-5.el8.x86_64など)。
手順
crashユーティリティーを起動するには、次の 2 つの必要なパラメーターを渡します。-
debug-info (圧縮解除された vmlinuz イメージ) (特定の
kernel-debuginfoパッケージに含まれる/usr/lib/debug/lib/modules/4.18.0-5.el8.x86_64/vmlinuxなど) 実際の vmcore ファイル (例:
/var/crash/127.0.0.1-2018-10-06-14:05:33/vmcore)結果として生じる
crashコマンドは次のようになります。# crash /usr/lib/debug/lib/modules/4.18.0-5.el8.x86_64/vmlinux /var/crash/127.0.0.1-2018-10-06-14:05:33/vmcorekdumpで取得したのと同じ <kernel> のバージョンを使用します。例41.1 crash ユーティリティーの実行
以下の例は、4.18.0-5.el8.x86_64 カーネルを使用して、2018 年 10 月 6 日 (14:05 PM) に作成されたコアダンプの分析を示しています。
... WARNING: kernel relocated [202MB]: patching 90160 gdb minimal_symbol values KERNEL: /usr/lib/debug/lib/modules/4.18.0-5.el8.x86_64/vmlinux DUMPFILE: /var/crash/127.0.0.1-2018-10-06-14:05:33/vmcore [PARTIAL DUMP] CPUS: 2 DATE: Sat Oct 6 14:05:16 2018 UPTIME: 01:03:57 LOAD AVERAGE: 0.00, 0.00, 0.00 TASKS: 586 NODENAME: localhost.localdomain RELEASE: 4.18.0-5.el8.x86_64 VERSION: #1 SMP Wed Aug 29 11:51:55 UTC 2018 MACHINE: x86_64 (2904 Mhz) MEMORY: 2.9 GB PANIC: "sysrq: SysRq : Trigger a crash" PID: 10635 COMMAND: "bash" TASK: ffff8d6c84271800 [THREAD_INFO: ffff8d6c84271800] CPU: 1 STATE: TASK_RUNNING (SYSRQ) crash>
-
debug-info (圧縮解除された vmlinuz イメージ) (特定の
対話型プロンプトを終了して
crashを停止するには、exitまたはqと入力します。crash> exit ~]#
crash コマンドは、ライブシステムをデバッグするための強力なツールとして利用することもできます。ただし、システムレベルの問題を回避するために注意して使用する必要があります。
41.11.3. crash ユーティリティーのさまざまなインジケーターの表示
crash ユーティリティーを使用して、カーネルメッセージバッファー、バックトレース、プロセスステータス、仮想メモリー情報、開いているファイルなど、さまざまなインジケータを表示します。
メッセージバッファーの表示
カーネルメッセージバッファーを表示するには、対話式プロンプトで
logコマンドを入力します。crash> log ... several lines omitted ... EIP: 0060:[<c068124f>] EFLAGS: 00010096 CPU: 2 EIP is at sysrq_handle_crash+0xf/0x20 EAX: 00000063 EBX: 00000063 ECX: c09e1c8c EDX: 00000000 ESI: c0a09ca0 EDI: 00000286 EBP: 00000000 ESP: ef4dbf24 DS: 007b ES: 007b FS: 00d8 GS: 00e0 SS: 0068 Process bash (pid: 5591, ti=ef4da000 task=f196d560 task.ti=ef4da000) Stack: c068146b c0960891 c0968653 00000003 00000000 00000002 efade5c0 c06814d0 <0> fffffffb c068150f b7776000 f2600c40 c0569ec4 ef4dbf9c 00000002 b7776000 <0> efade5c0 00000002 b7776000 c0569e60 c051de50 ef4dbf9c f196d560 ef4dbfb4 Call Trace: [<c068146b>] ? __handle_sysrq+0xfb/0x160 [<c06814d0>] ? write_sysrq_trigger+0x0/0x50 [<c068150f>] ? write_sysrq_trigger+0x3f/0x50 [<c0569ec4>] ? proc_reg_write+0x64/0xa0 [<c0569e60>] ? proc_reg_write+0x0/0xa0 [<c051de50>] ? vfs_write+0xa0/0x190 [<c051e8d1>] ? sys_write+0x41/0x70 [<c0409adc>] ? syscall_call+0x7/0xb Code: a0 c0 01 0f b6 41 03 19 d2 f7 d2 83 e2 03 83 e0 cf c1 e2 04 09 d0 88 41 03 f3 c3 90 c7 05 c8 1b 9e c0 01 00 00 00 0f ae f8 89 f6 <c6> 05 00 00 00 00 01 c3 89 f6 8d bc 27 00 00 00 00 8d 50 d0 83 EIP: [<c068124f>] sysrq_handle_crash+0xf/0x20 SS:ESP 0068:ef4dbf24 CR2: 0000000000000000このコマンドの使用方法の詳細を参照するには、
help logと入力してください。注記カーネルメッセージバッファーには、システムクラッシュに関する最も重要な情報が含まれています。カーネルメッセージバッファーは、常に最初に
vmcore-dmesg.txtファイルにダンプされます。たとえば、ターゲットロケーションに十分なスペースがないために完全なvmcoreファイルを取得できなかった場合は、カーネルメッセージバッファーから必要な情報を取得できます。デフォルトでは、vmcore-dmesg.txtは/var/crash/ディレクトリーに格納されます。
バックトレースの表示
カーネルスタックトレースを表示するには、
btコマンドを使用します。crash> bt PID: 5591 TASK: f196d560 CPU: 2 COMMAND: "bash" #0 [ef4dbdcc] crash_kexec at c0494922 #1 [ef4dbe20] oops_end at c080e402 #2 [ef4dbe34] no_context at c043089d #3 [ef4dbe58] bad_area at c0430b26 #4 [ef4dbe6c] do_page_fault at c080fb9b #5 [ef4dbee4] error_code (via page_fault) at c080d809 EAX: 00000063 EBX: 00000063 ECX: c09e1c8c EDX: 00000000 EBP: 00000000 DS: 007b ESI: c0a09ca0 ES: 007b EDI: 00000286 GS: 00e0 CS: 0060 EIP: c068124f ERR: ffffffff EFLAGS: 00010096 #6 [ef4dbf18] sysrq_handle_crash at c068124f #7 [ef4dbf24] __handle_sysrq at c0681469 #8 [ef4dbf48] write_sysrq_trigger at c068150a #9 [ef4dbf54] proc_reg_write at c0569ec2 #10 [ef4dbf74] vfs_write at c051de4e #11 [ef4dbf94] sys_write at c051e8cc #12 [ef4dbfb0] system_call at c0409ad5 EAX: ffffffda EBX: 00000001 ECX: b7776000 EDX: 00000002 DS: 007b ESI: 00000002 ES: 007b EDI: b7776000 SS: 007b ESP: bfcb2088 EBP: bfcb20b4 GS: 0033 CS: 0073 EIP: 00edc416 ERR: 00000004 EFLAGS: 00000246bt <pid>を入力して特定のプロセスのバックトレースを表示するか、help btを実行して、btの使用の詳細を表示します。
プロセスの状態表示
システム内のプロセスの状態を表示するには、
psコマンドを使用します。crash> ps PID PPID CPU TASK ST %MEM VSZ RSS COMM > 0 0 0 c09dc560 RU 0.0 0 0 [swapper] > 0 0 1 f7072030 RU 0.0 0 0 [swapper] 0 0 2 f70a3a90 RU 0.0 0 0 [swapper] > 0 0 3 f70ac560 RU 0.0 0 0 [swapper] 1 0 1 f705ba90 IN 0.0 2828 1424 init ... several lines omitted ... 5566 1 1 f2592560 IN 0.0 12876 784 auditd 5567 1 2 ef427560 IN 0.0 12876 784 auditd 5587 5132 0 f196d030 IN 0.0 11064 3184 sshd > 5591 5587 2 f196d560 RU 0.0 5084 1648 bashps <pid>を使用して、単一プロセスのステータスを表示します。psの詳細な使用方法は、help ps を使用します。
仮想メモリー情報の表示
基本的な仮想メモリー情報を表示するには、対話式プロンプトで
vmコマンドを入力します。crash> vm PID: 5591 TASK: f196d560 CPU: 2 COMMAND: "bash" MM PGD RSS TOTAL_VM f19b5900 ef9c6000 1648k 5084k VMA START END FLAGS FILE f1bb0310 242000 260000 8000875 /lib/ld-2.12.so f26af0b8 260000 261000 8100871 /lib/ld-2.12.so efbc275c 261000 262000 8100873 /lib/ld-2.12.so efbc2a18 268000 3ed000 8000075 /lib/libc-2.12.so efbc23d8 3ed000 3ee000 8000070 /lib/libc-2.12.so efbc2888 3ee000 3f0000 8100071 /lib/libc-2.12.so efbc2cd4 3f0000 3f1000 8100073 /lib/libc-2.12.so efbc243c 3f1000 3f4000 100073 efbc28ec 3f6000 3f9000 8000075 /lib/libdl-2.12.so efbc2568 3f9000 3fa000 8100071 /lib/libdl-2.12.so efbc2f2c 3fa000 3fb000 8100073 /lib/libdl-2.12.so f26af888 7e6000 7fc000 8000075 /lib/libtinfo.so.5.7 f26aff2c 7fc000 7ff000 8100073 /lib/libtinfo.so.5.7 efbc211c d83000 d8f000 8000075 /lib/libnss_files-2.12.so efbc2504 d8f000 d90000 8100071 /lib/libnss_files-2.12.so efbc2950 d90000 d91000 8100073 /lib/libnss_files-2.12.so f26afe00 edc000 edd000 4040075 f1bb0a18 8047000 8118000 8001875 /bin/bash f1bb01e4 8118000 811d000 8101873 /bin/bash f1bb0c70 811d000 8122000 100073 f26afae0 9fd9000 9ffa000 100073 ... several lines omitted ...vm <pid>を実行して、1 つのプロセスの情報を表示するか、help vmを実行して、vmの使用方法を表示します。
オープンファイルの表示
オープンファイルの情報を表示するには、
filesコマンドを実行します。crash> files PID: 5591 TASK: f196d560 CPU: 2 COMMAND: "bash" ROOT: / CWD: /root FD FILE DENTRY INODE TYPE PATH 0 f734f640 eedc2c6c eecd6048 CHR /pts/0 1 efade5c0 eee14090 f00431d4 REG /proc/sysrq-trigger 2 f734f640 eedc2c6c eecd6048 CHR /pts/0 10 f734f640 eedc2c6c eecd6048 CHR /pts/0 255 f734f640 eedc2c6c eecd6048 CHR /pts/0files <pid>を実行して、選択した 1 つのプロセスによって開かれたファイルを表示するか、help filesを実行して、filesの使用方法を表示します。
41.11.4. Kernel Oops Analyzer の使用
Kernel Oops Analyzer ツールは、ナレッジベースの既知の問題と oops メッセージを比較することで、クラッシュダンプを分析します。
前提条件
-
oopsメッセージは、Kernel Oops Analyzer にフィードするために保護されています。
手順
- Kernel Oops Analyzer ツールにアクセスします。
カーネルクラッシュの問題を診断するには、
vmcoreに生成されたカーネルの oops ログをアップロードします。-
あるいは、テキストメッセージまたは
vmcore-dmesg.txtを入力として提供することで、カーネルクラッシュの問題を診断することもできます。
-
あるいは、テキストメッセージまたは
-
DETECTをクリックして、makedumpfileからの情報に基づくoopsメッセージを既知のソリューションと比較します。
41.11.5. Kdump Helper ツール
Kdump ヘルパーツールは、提供された情報を使用して kdump を設定するのに役立ちます。Kdump Helper は、ユーザーの設定に基づいて設定スクリプトを生成します。サーバーでスクリプトを開始して実行すると、kdump サービスが設定されます。
41.12. early kdump を使用した起動時間クラッシュの取得
early kdump は、kdump メカニズムの機能です。システムサービスが起動する前の起動プロセス初期段階でシステムまたはカーネルのクラッシュが発生した場合に、vmcore ファイルをキャプチャーします。early kdump はクラッシュカーネルとクラッシュカーネルの initramfs を早い段階でメモリーにロードします。
カーネルクラッシュは、kdump サービスが起動する前のブート初期段階で発生することがあります。その場合、kdump はクラッシュしたカーネルメモリーの内容をキャプチャーして保存できません。そのため、トラブルシューティングにとって重要なクラッシュ関連の重大な情報が失われます。この問題に対処するには、kdump サービスの一部である early kdump 機能を使用できます。
41.12.1. early kdump の有効化
early kdump 機能は、初期クラッシュの vmcore 情報をキャプチャーするため、十分に早めにロードされるように、クラッシュカーネルと初期 RAM ディスクイメージ (initramfs) をセットアップします。これにより、初期のブートカーネルクラッシュに関する情報が失われるリスクを排除できます。
前提条件
- アクティブな RHEL サブスクリプションがある。
-
システムの CPU アーキテクチャー用の
kexec-toolsパッケージを含むリポジトリーがある。 -
kdumpの設定とターゲットの要件を満たしている詳細は、サポートされている kdump 設定とターゲット を参照してください。
手順
kdumpサービスが有効でアクティブであることを確認します。# systemctl is-enabled kdump.service && systemctl is-active kdump.service enabled activekdumpが有効ではなく、実行されていない場合は、必要な設定をすべて設定し、kdumpサービスが有効化されていることを確認します。起動カーネルの
initramfsイメージを、early kdump機能で再構築します。# dracut -f --add earlykdumprd.earlykdumpカーネルコマンドラインパラメーターを追加します。# grubby --update-kernel=/boot/vmlinuz-$(uname -r) --args="rd.earlykdump"システムを再起動して変更を反映します。
# reboot
検証
rd.earlykdumpが正常に追加され、early kdump機能が有効になっていることを確認します。# cat /proc/cmdline BOOT_IMAGE=(hd0,msdos1)/vmlinuz-4.18.0-187.el8.x86_64 root=/dev/mapper/rhel-root ro crashkernel=auto resume=/dev/mapper/rhel-swap rd.lvm.lv=rhel/root rd.lvm.lv=rhel/swap rhgb quiet rd.earlykdump # journalctl -x | grep early-kdump Mar 20 15:44:41 redhat dracut-cmdline[304]: early-kdump is enabled. Mar 20 15:44:42 redhat dracut-cmdline[304]: kexec: loaded early-kdump kernel
第42章 カーネルライブパッチでパッチの適用
Red Hat Enterprise Linux カーネルのライブパッチソリューションを使用すると、再起動やプロセスの再起動を行わずに実行中のカーネルにパッチを適用できます。
このソリューションでは、システム管理者は以下を行うことができます。
- 重大なセキュリティーパッチをカーネルに即座に適用することが可能。
- 長時間実行しているタスクの完了、ユーザーのログオフ、スケジュールダウンタイムを待つ必要がない。
- システムのアップタイムをより制御し、セキュリティーや安定性を犠牲にしない。
カーネルライブパッチを使用すると、セキュリティーパッチに必要な再起動の回数を減らすことができます。ただし、すべての重大または重要な CVE に対処できるわけではないことに注意してください。ライブパッチの範囲の詳細は、Red Hat ナレッジベースソリューション Is live kernel patch (kpatch) supported in Red Hat Enterprise Linux? を参照してください。
カーネルのライブマイグレーションパッチと、その他のカーネルサブコンポーネントとの間に、いくらか非互換性が存在します。カーネルのライブパッチを使用する前に、kpatch の制限 を慎重に確認してください。
カーネルのライブパッチ更新のサポート頻度の詳細は、以下を参照してください。
42.1. kpatch の制限
-
kpatch機能を使用すると、システムをすぐに再起動する必要のない、簡単なセキュリティーおよびバグ修正の更新を適用できます。 -
パッチのロード中またはロード後に
SystemTapまたはkprobeツールを使用しないでください。プローブが削除されるまでパッチは有効にならない可能性があります。
42.2. サードパーティーのライブパッチサポート
kpatch ユーティリティーは、Red Hat リポジトリー提供の RPM モジュールを含む、Red Hat がサポートする唯一のカーネルライブパッチユーティリティーです。Red Hat はサードパーティーが提供するライブパッチをサポートしていません。
サードパーティーソフトウェアのサポートポリシーの詳細は、As a customer how does Red Hat support me when I use third party components? を参照してください。
42.3. カーネルライブパッチへのアクセス
カーネルモジュール (kmod) はカーネルのライブパッチ機能を実装し、RPM パッケージとして提供されます。
すべてのお客様は、通常のチャンネルから提供されるカーネルライブパッチにアクセスできます。ただし、延長サポートサービスにサブスクライブしていないお客様は、次のマイナーリリースが利用可能になると、現行のマイナーリリースに対する新しいパッチへのアクセスを失うことになります。たとえば、標準のサブスクリプションを購入しているお客様は、RHEL 8.3 カーネルがリリースされるまで RHEL 8.2 カーネルのライブパッチのみを行うことができます。
カーネルのライブパッチのコンポーネントは、以下のようになります。
- カーネルパッチモジュール
- カーネルライブパッチの配信メカニズム
- パッチが適用されるカーネル専用に構築されたカーネルモジュール。
- パッチモジュールには、カーネルに必要な修正のコードが含まれます。
-
パッチモジュールは、
livepatchカーネルサブシステムに登録され、置換する元の関数と置換関数へのポインターを指定します。カーネルパッチモジュールは RPM として提供されます。 -
命名規則は、
kpatch_<kernel version>_<kpatch version>_<kpatch release>です。名前の "kernel version" 部分の ドット は、アンダースコア に置き換えます。
kpatchユーティリティー- パッチモジュールを管理するためのコマンドラインユーティリティー。
kpatchサービス-
multiuser.targetで必要なsystemdサービス。このターゲットは、システムの起動時にカーネルパッチをロードします。 kpatch-dnfパッケージ- RPM パッケージ形式で配信される DNF プラグイン。このプラグインは、カーネルライブパッチへの自動サブスクリプションを管理します。
42.4. カーネルのライブパッチ適用のプロセス
kpatch カーネルパッチソリューションは、livepatch カーネルサブシステムを使用して、古い関数を更新された関数にリダイレクトします。システムにライブカーネルパッチを適用すると、次のプロセスがトリガーされます。
-
カーネルパッチモジュールは、
/var/lib/kpatch/ディレクトリーにコピーされ、次回の起動時にsystemdを介して、カーネルへの再適用として登録されます。 -
kpatchモジュールは実行中のカーネルにロードされ、新しい関数は新しいコードのメモリー内のロケーションへのポインターとともにftraceメカニズムに登録されます。
カーネルがパッチを適用した関数にアクセスすると、ftrace メカニズムによって関数がリダイレクトされ、元の関数がバイパスされてカーネルが関数のパッチを適用したバージョンに誘導されます。
図42.1 カーネルライブパッチの仕組み
42.5. 現在インストールされているカーネルをライブパッチストリームにサブスクライブする手順
カーネルパッチモジュールは RPM パッケージに含まれ、パッチが適用されたカーネルバージョンに固有のものとなります。各 RPM パッケージは、徐々に蓄積されていきます。
以下の手順では、指定のカーネルに対して、今後の累積パッチ更新をすべてサブスクライブする方法を説明します。ライブパッチは累積的であるため、特定のカーネルにデプロイされている個々のパッチを選択できません。
Red Hat は、Red Hat がサポートするシステムに適用されたサードパーティーのライブパッチをサポートしません。
前提条件
- root 権限がある。
手順
オプション: カーネルのバージョンを確認します。
# uname -r 4.18.0-94.el8.x86_64カーネルのバージョンに一致するライブパッチパッケージを検索します。
# yum search $(uname -r)ライブパッチパッケージをインストールします。
# yum install "kpatch-patch = $(uname -r)"上記のコマンドでは、特定カーネルにのみに最新の累積パッチをインストールし、適用します。
ライブパッチパッケージのバージョンが 1-1 以上である場合には、パッケージにパッチモジュールが含まれます。この場合、ライブパッチパッケージのインストール時に、カーネルにパッチが自動的に適用されます。
カーネルパッチモジュールは、今後の再起動時に
systemdシステムおよびサービスマネージャーにより読み込まれる/var/lib/kpatch/ディレクトリーにもインストールされます。注記指定のカーネルに利用可能なライブパッチがない場合は、空のライブパッチパッケージがインストールされます。空のライブパッチパッケージには、kpatch_version-kpatch_release 0-0 (例:
kpatch-patch-4_18_0-94-0-0.el8.x86_64.rpm) が含まれます。空の RPM のインストールを行うと、指定のカーネルの将来のすべてのライブパッチにシステムがサブスクライブされます。
検証
インストールされているすべてのカーネルにパッチが当てられていることを確認します。
# kpatch list Loaded patch modules: kpatch_4_18_0_94_1_1 [enabled] Installed patch modules: kpatch_4_18_0_94_1_1 (4.18.0-94.el8.x86_64) …この出力は、カーネルパッチモジュールがカーネルに読み込まれていることを示しています。このカーネルには、
kpatch-patch-4_18_0-94-1-1.el8.x86_64.rpmパッケージで修正された最新のパッチが当てられています。注記kpatch listコマンドを入力しても、空のライブパッチパッケージが返されません。代わりにrpm -qa | grep kpatchコマンドを使用します。# rpm -qa | grep kpatch kpatch-patch-4_18_0-477_21_1-0-0.el8_8.x86_64 kpatch-dnf-0.9.7_0.4-2.el8.noarch kpatch-0.9.7-2.el8.noarch
42.6. ライブパッチストリームに新しいカーネルを自動的にサブスクライブする手順
kpatch-dnf YUM プラグインを使用して、カーネルパッチモジュール (別称: カーネルライブパッチ) が提供する修正にシステムをサブスクライブできます。このプラグインは、現在システムが使用するカーネルと、今後インストールされる カーネルの 自動 サブスクリプションを有効にします。
前提条件
- root 権限がある。
手順
オプション: インストールされているすべてのカーネルと現在実行中のカーネルを確認します。
# yum list installed | grep kernel Updating Subscription Management repositories. Installed Packages ... kernel-core.x86_64 4.18.0-240.10.1.el8_3 @rhel-8-for-x86_64-baseos-rpms kernel-core.x86_64 4.18.0-240.15.1.el8_3 @rhel-8-for-x86_64-baseos-rpms ... # uname -r 4.18.0-240.10.1.el8_3.x86_64kpatch-dnfプラグインをインストールします。# yum install kpatch-dnfカーネルライブパッチの自動サブスクリプションを有効にします。
# yum kpatch auto Updating Subscription Management repositories. Last metadata expiration check: 19:10:26 ago on Wed 10 Mar 2021 04:08:06 PM CET. Dependencies resolved. ================================================== Package Architecture ================================================== Installing: kpatch-patch-4_18_0-240_10_1 x86_64 kpatch-patch-4_18_0-240_15_1 x86_64 Transaction Summary =================================================== Install 2 Packages …このコマンドは、現在インストールされているすべてのカーネルをサブスクライブして、カーネルライブパッチを受け取ります。このコマンドは、インストールされている全カーネルに、最新の累積パッチ (存在する場合) をインストールして適用します。
カーネルを更新すると、新しいカーネルのインストールプロセス中にライブパッチが自動的にインストールされます。
カーネルパッチモジュールは、今後の再起動時に
systemdシステムおよびサービスマネージャーにより読み込まれる/var/lib/kpatch/ディレクトリーにもインストールされます。注記指定のカーネルに利用可能なライブパッチがない場合は、空のライブパッチパッケージがインストールされます。空のライブパッチパッケージには、kpatch_version-kpatch_release 0-0 (例:
kpatch-patch-4_18_0-240-0-0.el8.x86_64.rpm) が含まれます。空の RPM のインストールを行うと、指定のカーネルの将来のすべてのライブパッチにシステムがサブスクライブされます。
検証
インストールされているすべてのカーネルにパッチが適用されていることを確認します。
# kpatch list Loaded patch modules: kpatch_4_18_0_240_10_1_0_1 [enabled] Installed patch modules: kpatch_4_18_0_240_10_1_0_1 (4.18.0-240.10.1.el8_3.x86_64) kpatch_4_18_0_240_15_1_0_2 (4.18.0-240.15.1.el8_3.x86_64)この出力から、実行中のカーネルとインストールされている他のカーネル両方に
kpatch-patch-4_18_0-240_10_1-0-1.rpmとkpatch-patch-4_18_0-240_15_1-0-1.rpmパッケージそれぞれからの修正が適用されたことが分かります。注記kpatch listコマンドを入力しても、空のライブパッチパッケージが返されません。代わりにrpm -qa | grep kpatchコマンドを使用します。# rpm -qa | grep kpatch kpatch-patch-4_18_0-477_21_1-0-0.el8_8.x86_64 kpatch-dnf-0.9.7_0.4-2.el8.noarch kpatch-0.9.7-2.el8.noarch
42.7. ライブパッチストリームへの自動サブスクリプションの無効化
カーネルパッチモジュールが提供する修正にシステムをサブスクライブする場合、サブスクリプションは 自動的 です。この機能を無効にして、kpatch-patch パッケージの自動インストールを無効化できます。
前提条件
- root 権限がある。
手順
オプション:インストールされているすべてのカーネルと現在実行中のカーネルを確認します。
# yum list installed | grep kernel Updating Subscription Management repositories. Installed Packages ... kernel-core.x86_64 4.18.0-240.10.1.el8_3 @rhel-8-for-x86_64-baseos-rpms kernel-core.x86_64 4.18.0-240.15.1.el8_3 @rhel-8-for-x86_64-baseos-rpms ... # uname -r 4.18.0-240.10.1.el8_3.x86_64カーネルライブパッチへの自動サブスクリプションを無効にします。
# yum kpatch manual Updating Subscription Management repositories.
検証
成功した出力を確認できます。
# yum kpatch status ... Updating Subscription Management repositories. Last metadata expiration check: 0:30:41 ago on Tue Jun 14 15:59:26 2022. Kpatch update setting: manual
42.8. カーネルパッチモジュールの更新
カーネルパッチモジュールは、RPM パッケージを通じて配信および適用されます。累積的なカーネルパッチモジュールを更新するプロセスは、他の RPM パッケージの更新と同様です。
前提条件
- 現在インストールされているカーネルをライブパッチストリームにサブスクライブする手順 に従って、システムがライブパッチストリームにサブスクライブされている。
手順
現在のカーネルの新しい累積バージョンを更新します。
# yum update "kpatch-patch = $(uname -r)"上記のコマンドは、現在実行中のカーネルに利用可能な更新を自動的にインストールし、適用します。これには、新たにリリースされた累計なライブパッチが含まれます。
もしくは、インストールしたすべてのカーネルパッチモジュールを更新します。
# yum update "kpatch-patch"
システムが同じカーネルで再起動すると、kpatch.service systemd サービスにより、カーネルが自動的に再適用されます。
42.9. ライブパッチパッケージの削除
ライブパッチパッケージを削除して、Red Hat Enterprise Linux カーネルライブパッチソリューションを無効にします。
前提条件
- root 権限がある。
- ライブパッチパッケージがインストールされている。
手順
ライブパッチパッケージを選択します。
# yum list installed | grep kpatch-patch kpatch-patch-4_18_0-94.x86_64 1-1.el8 @@commandline …出力例には、インストールしたライブパッチパッケージがリストされます。
ライブパッチパッケージを削除します。
# yum remove kpatch-patch-4_18_0-94.x86_64ライブパッチパッケージが削除されると、カーネルは次回の再起動までパッチが当てられたままになりますが、カーネルパッチモジュールはディスクから削除されます。今後の再起動では、対応するカーネルにはパッチが適用されなくなります。
- システムを再起動します。
ライブパッチパッケージが削除されたことを確認します。
# yum list installed | grep kpatch-patchパッケージが正常に削除された場合、このコマンドでは何も出力されません。
検証
カーネルライブパッチソリューションが無効になっていることを確認します。
# kpatch list Loaded patch modules:この出力例では、現在読み込まれているパッチモジュールがないため、カーネルにパッチが適用されておらず、ライブパッチソリューションがアクティブでないことが示されています。
現在、Red Hat はシステムの再起動なしで、ライブパッチを元に戻すことはサポートしていません。ご不明な点がございましたら、サポートチームまでお問い合わせください。
42.10. カーネルパッチモジュールのアンインストール
Red Hat Enterprise Linux カーネルライブパッチソリューションが、以降の起動時にカーネルパッチモジュールを適用しないようにします。
前提条件
- root 権限がある。
- ライブパッチパッケージがインストールされている。
- カーネルパッチモジュールがインストールされ、ロードされている。
手順
カーネルパッチモジュールを選択します。
# kpatch list Loaded patch modules: kpatch_4_18_0_94_1_1 [enabled] Installed patch modules: kpatch_4_18_0_94_1_1 (4.18.0-94.el8.x86_64) …選択したカーネルパッチモジュールをアンインストールします。
# kpatch uninstall kpatch_4_18_0_94_1_1 uninstalling kpatch_4_18_0_94_1_1 (4.18.0-94.el8.x86_64)アンインストールしたカーネルモジュールが読み込まれていることに注意してください。
# kpatch list Loaded patch modules: kpatch_4_18_0_94_1_1 [enabled] Installed patch modules: <NO_RESULT>選択したモジュールをアンインストールすると、カーネルは次回の再起動までパッチが当てられますが、カーネルパッチモジュールはディスクから削除されます。
- システムを再起動します。
検証
カーネルパッチモジュールがアンインストールされていることを確認します。
# kpatch list Loaded patch modules: …この出力例では、カーネルパッチモジュールがロードまたはインストールされていないことが示されています。そのため、カーネルにパッチが適用されておらず、カーネルライブパッチソリューションがアクティブではありません。
42.11. kpatch.service の無効化
Red Hat Enterprise Linux カーネルライブパッチソリューションが、以降の起動時にすべてのカーネルパッチモジュールをシステム全体に適用しないようにします。
前提条件
- root 権限がある。
- ライブパッチパッケージがインストールされている。
- カーネルパッチモジュールがインストールされ、ロードされている。
手順
kpatch.serviceが有効化されていることを確認します。# systemctl is-enabled kpatch.service enabledkpatch.serviceを無効にします。# systemctl disable kpatch.service Removed /etc/systemd/system/multi-user.target.wants/kpatch.service.適用されたカーネルモジュールが依然としてロードされていることに注意してください。
# kpatch list Loaded patch modules: kpatch_4_18_0_94_1_1 [enabled] Installed patch modules: kpatch_4_18_0_94_1_1 (4.18.0-94.el8.x86_64)
- システムを再起動します。
オプション:
kpatch.serviceのステータスを確認します。# systemctl status kpatch.service ● kpatch.service - "Apply kpatch kernel patches" Loaded: loaded (/usr/lib/systemd/system/kpatch.service; disabled; vendor preset: disabled) Active: inactive (dead)出力例は、
kpatch.serviceが無効になっていることを証明しています。したがって、カーネルのライブパッチソリューションはアクティブではありません。カーネルパッチモジュールがアンロードされたことを確認します。
# kpatch list Loaded patch modules: <NO_RESULT> Installed patch modules: kpatch_4_18_0_94_1_1 (4.18.0-94.el8.x86_64)上記の出力例では、カーネルパッチモジュールがインストールされていても、カーネルにパッチが適用されていないことを示しています。
現在、Red Hat はシステムの再起動なしで、ライブパッチを元に戻すことはサポートしていません。ご不明な点がございましたら、サポートチームまでお問い合わせください。
第43章 コントロールグループを使用したアプリケーションのシステムリソース制限の設定
コントロールグループ (cgroups) カーネル機能を使用すると、アプリケーションのリソース使用状況を制御して、より効率的に使用できます。
cgroups は、以下のタスクで使用できます。
- システムリソース割り当ての制限を設定します。
- 特定のプロセスへのハードウェアリソースの割り当てにおける優先順位を設定する。
- 特定のプロセスをハードウェアリソースの取得から分離する。
43.1. コントロールグループの概要
コントロールグループ の Linux カーネル機能を使用して、プロセスを階層的に順序付けされたグループ (cgroups) に編成できます。階層 (コントロールグループツリー) は、デフォルトで /sys/fs/cgroup/ ディレクトリーにマウントされている cgroups 仮想ファイルシステムに構造を提供して定義します。
systemd サービスマネージャーは、cgroups を使用して、管理するすべてのユニットとサービスを整理します。/sys/fs/cgroup/ ディレクトリーのサブディレクトリーを作成および削除することで、cgroups の階層を手動で管理できます。
続いて、カーネルのリソースコントローラーは、cgroups 内のプロセスのシステムリソースを制限、優先順位付け、または割り当てることで、これらのプロセスの動作を変更します。これらのリソースには以下が含まれます。
- CPU 時間
- メモリー
- ネットワーク帯域幅
- これらのリソースの組み合わせ
cgroups の主なユースケースは、システムプロセスを集約し、アプリケーションとユーザー間でハードウェアリソースを分割することです。これにより、環境の効率、安定性、およびセキュリティーを強化できます。
- コントロールグループ 1
コントロールグループバージョン 1 (
cgroups-v1) はリソースごとのコントローラー階層を提供します。CPU、メモリー、I/O などのリソースごとに、独自のコントロールグループ階層があります。異なるコントロールグループ階層を組み合わせることで、1 つのコントローラーが別のコントローラーと連携してそれぞれのリソースを管理できるようになります。ただし、2 つのコントローラーが異なるプロセス階層に属している場合、連携が制限されます。cgroups-v1コントローラーは長期間にわたって開発されたため、コントロールファイルの動作と命名に一貫性がありません。- コントロールグループ 2
Control groups version 2 (
cgroups-v2) は、すべてのリソースコントローラーがマウントされる単一のコントロールグループ階層を提供します。コントロールファイルの動作と命名は、さまざまなコントローラーにおいて一貫性があります。
注記cgroups-v2は、RHEL 8.2 以降のバージョンで完全にサポートされています。詳細は Control Group v2 is now fully supported in RHEL 8 を参照してください。
43.2. カーネルリソースコントローラーの概要
カーネルリソースコントローラーは、コントロールグループの機能を有効化します。RHEL 8 は、コントロールグループバージョン 1 (cgroups-v1) および コントロールグループバージョン 2 (cgroups-v2) のさまざまなコントローラーをサポートします。
コントロールグループサブシステムとも呼ばれるリソースコントローラーは、1 つのリソース (CPU 時間、メモリー、ネットワーク帯域幅、ディスク I/O など) を表すカーネルサブシステムです。Linux カーネルは、systemd サービスマネージャーによって自動的にマウントされるリソースコントローラーの範囲を提供します。現在マウントされているリソースコントローラーの一覧は、/proc/cgroups ファイルで確認できます。
cgroups-v1 で利用可能なコントローラー
blkio- ブロックデバイスへの入出力アクセスを制限します。
cpu-
コントロールグループのタスク用の Completely Fair Scheduler (CFS) パラメーターを調整します。
cpuコントローラーは、同じマウント上のcpuacctコントローラーとともにマウントされます。 cpuacct-
コントロールグループ内のタスクが使用する CPU リソースに関する自動レポートを作成します。
cpuacctコントローラーは、同じマウント上のcpuコントローラーとともにマウントされます。 cpuset- コントロールグループタスクが、指定された CPU のサブセットでのみ実行されるように制限し、指定されたメモリーノードでのみメモリーを使用するようにタスクに指示します。
devices- コントロールグループ内のタスクのデバイスへのアクセスを制御します。
freezer- コントロールグループ内のタスクを一時停止または再開します。
memory- コントロールグループ内のタスクによるメモリー使用の制限を設定し、それらのタスクが使用したメモリーリソースに関する自動レポートを生成します。
net_cls-
特定のコントロールグループタスクから発信されたパケットを識別するために Linux トラフィックコントローラー (
tcコマンド) を有効化するクラス識別子 (classid) でネットワークパケットをタグ付けします。net_clsのサブシステムnet_ filter(iptables) でも、このタグを使用して、そのようなパケットに対するアクションを実行することができます。net_filterは、ファイアウォール識別子 (fwid) でネットワークソケットをタグ付けします。これにより、Linux ファイアウォールは、(iptablesコマンドを使用して) 特定のコントロールグループタスクから発信されたパケットを識別できるようになります。 net_prio- ネットワークトラフィックの優先度を設定します。
pids- コントロールグループ内の複数のプロセスとその子プロセスに制限を設定します。
perf_event-
perfパフォーマンス監視およびレポートユーティリティーにより、監視するタスクをグループ化します。 rdma- コントロールグループ内の Remote Direct Memory Access/InfiniB 固有リソースに制限を設定します。
hugetlb- コントロールグループ内のタスクによる大容量の仮想メモリーページの使用を制限します。
cgroups-v2 で利用可能なコントローラー
io- ブロックデバイスへの入出力アクセスを制限します。
memory- コントロールグループ内のタスクによるメモリー使用の制限を設定し、それらのタスクが使用したメモリーリソースに関する自動レポートを生成します。
pids- コントロールグループ内の複数のプロセスとその子プロセスに制限を設定します。
rdma- コントロールグループ内の Remote Direct Memory Access/InfiniB 固有リソースに制限を設定します。
cpu- コントロールグループのタスクの Completely Fair Scheduler (CFS) パラメーターを調整し、コントロールグループのタスクで使用される CPU リソースに関する自動レポートを作成します。
cpuset-
コントロールグループタスクが、指定された CPU のサブセットでのみ実行されるように制限し、指定されたメモリーノードでのみメモリーを使用するようにタスクに指示します。新しいパーティション機能により、コア機能 (
cpus{,.effective},mems{,.effective}) のみがサポートされます。 perf_event-
perfパフォーマンス監視およびレポートユーティリティーで監視するタスクをグループ化します。perf_eventは、v2 階層で自動的に有効化されています。
リソースコントローラーは、cgroups-v1 階層または cgroups-v 2 階層のいずれかで使用できますが、両方を同時に使用することはできません。
43.3. 名前空間の概要
名前空間は、ソフトウェアオブジェクトを整理および識別するための個別の空間を作成するものです。これにより、オブジェクトが相互に影響を及ぼすことがなくなります。その結果、各ソフトウェアオブジェクトが同じシステムを共有しているにもかかわらず、独自のリソースセット (マウントポイント、ネットワークデバイス、ホスト名など) が各オブジェクトに格納されます。
名前空間を使用する最も一般的なテクノロジーの 1 つとしてコンテナーが挙げられます。
特定のグローバルリソースへの変更は、その名前空間のプロセスにのみ表示され、残りのシステムまたは他の名前空間には影響しません。
プロセスがどの名前空間に所属するかを確認するには、/proc/<PID>/ns/ ディレクトリーのシンボリックリンクを確認します。
| 名前空間 | 分離 |
|---|---|
| Mount | マウントポイント |
| UTS | ホスト名および NIS ドメイン名 |
| IPC | System V IPC、POSIX メッセージキュー |
| PID | プロセス ID |
| Network | ネットワークデバイス、スタック、ポートなど。 |
| User | ユーザーおよびグループ ID |
| Control groups | コントロールグループの root ディレクトリー |
43.4. cgroups-v1 を使用したアプリケーションへの CPU 制限の設定
コントロールグループバージョン 1 (cgroups-v1) を使用してアプリケーションに対する CPU 制限を設定するには、/sys/fs/ 仮想ファイルシステムを使用します。
前提条件
- root 権限がある。
- CPU 消費制限の対象とするアプリケーションがシステムにインストールされている。
cgroups-v1コントローラーがマウントされていることを確認している。# mount -l | grep cgroup tmpfs on /sys/fs/cgroup type tmpfs (ro,nosuid,nodev,noexec,seclabel,mode=755) cgroup on /sys/fs/cgroup/systemd type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,xattr,release_agent=/usr/lib/systemd/systemd-cgroups-agent,name=systemd) cgroup on /sys/fs/cgroup/cpu,cpuacct type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,cpu,cpuacct) cgroup on /sys/fs/cgroup/perf_event type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,perf_event) cgroup on /sys/fs/cgroup/pids type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,pids) ...
手順
CPU 消費を制限するアプリケーションのプロセス ID (PID) を特定します。
# top top - 11:34:09 up 11 min, 1 user, load average: 0.51, 0.27, 0.22 Tasks: 267 total, 3 running, 264 sleeping, 0 stopped, 0 zombie %Cpu(s): 49.0 us, 3.3 sy, 0.0 ni, 47.5 id, 0.0 wa, 0.2 hi, 0.0 si, 0.0 st MiB Mem : 1826.8 total, 303.4 free, 1046.8 used, 476.5 buff/cache MiB Swap: 1536.0 total, 1396.0 free, 140.0 used. 616.4 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 6955 root 20 0 228440 1752 1472 R 99.3 0.1 0:32.71 sha1sum 5760 jdoe 20 0 3603868 205188 64196 S 3.7 11.0 0:17.19 gnome-shell 6448 jdoe 20 0 743648 30640 19488 S 0.7 1.6 0:02.73 gnome-terminal- 1 root 20 0 245300 6568 4116 S 0.3 0.4 0:01.87 systemd 505 root 20 0 0 0 0 I 0.3 0.0 0:00.75 kworker/u4:4-events_unbound ...PID 6955を持つsha1sumサンプルアプリケーションが、大量の CPU リソースを消費しています。cpuリソースコントローラーディレクトリーにサブディレクトリーを作成します。# mkdir /sys/fs/cgroup/cpu/Example/このディレクトリーはコントロールグループを表します。ここに特定のプロセスを配置して、そのプロセスに特定の CPU 制限を適用できます。同時に、いくつかの
cgroups-v1インターフェイスファイルとcpuコントローラー固有のファイルがディレクトリーに作成されます。オプション:新しく作成されたコントロールグループを確認します。
# ll /sys/fs/cgroup/cpu/Example/ -rw-r—r--. 1 root root 0 Mar 11 11:42 cgroup.clone_children -rw-r—r--. 1 root root 0 Mar 11 11:42 cgroup.procs -r—r—r--. 1 root root 0 Mar 11 11:42 cpuacct.stat -rw-r—r--. 1 root root 0 Mar 11 11:42 cpuacct.usage -r—r—r--. 1 root root 0 Mar 11 11:42 cpuacct.usage_all -r—r—r--. 1 root root 0 Mar 11 11:42 cpuacct.usage_percpu -r—r—r--. 1 root root 0 Mar 11 11:42 cpuacct.usage_percpu_sys -r—r—r--. 1 root root 0 Mar 11 11:42 cpuacct.usage_percpu_user -r—r—r--. 1 root root 0 Mar 11 11:42 cpuacct.usage_sys -r—r—r--. 1 root root 0 Mar 11 11:42 cpuacct.usage_user -rw-r—r--. 1 root root 0 Mar 11 11:42 cpu.cfs_period_us -rw-r—r--. 1 root root 0 Mar 11 11:42 cpu.cfs_quota_us -rw-r—r--. 1 root root 0 Mar 11 11:42 cpu.rt_period_us -rw-r—r--. 1 root root 0 Mar 11 11:42 cpu.rt_runtime_us -rw-r—r--. 1 root root 0 Mar 11 11:42 cpu.shares -r—r—r--. 1 root root 0 Mar 11 11:42 cpu.stat -rw-r—r--. 1 root root 0 Mar 11 11:42 notify_on_release -rw-r—r--. 1 root root 0 Mar 11 11:42 taskscpuacct.usage、cpu.cfs._period_usなどのファイルは、Exampleコントロールグループ内のプロセスに設定できる特定の設定や制限を表しています。ファイル名の先頭に、それが属するコントロールグループコントローラーの名前が付いていることに注意してください。デフォルトでは、新しく作成されたコントロールグループは、システムの CPU リソース全体へのアクセスを制限なしで継承します。
コントロールグループの CPU 制限を設定します。
# echo "1000000" > /sys/fs/cgroup/cpu/Example/cpu.cfs_period_us # echo "200000" > /sys/fs/cgroup/cpu/Example/cpu.cfs_quota_us-
cpu.cfs_period_usファイルは、コントロールグループの CPU リソースへのアクセスを再割り当てする必要がある頻度を表します。期間はマイクロ秒 (µs、"us") 単位です。上限は 1,000,000 マイクロ秒、下限は 1,000 マイクロ秒です。 cpu.cfs_quota_usファイルは、コントロールグループ内のすべてのプロセスが 1 つの期間 (cpu.cfs_period_usで定義) 中にまとめて実行できる合計時間をマイクロ秒単位で表します。コントロールグループ内のプロセスが 1 つの期間中にクォータで指定された時間をすべて使い果たすと、そのプロセスは残り期間にわたってスロットリングされ、次の期間まで実行できなくなります。下限は 1000 マイクロ秒です。上記のコマンド例は、CPU 時間制限を設定して、
Exampleコントロールグループでまとめられているすべてのプロセスは、1 秒ごと (cpu.cfs_period_usに定義されている) に、0.2 秒間だけ (cpu.cfs_quota_usに定義されている) 実行できるようにしています。
-
オプション:この制限を確認します。
# cat /sys/fs/cgroup/cpu/Example/cpu.cfs_period_us /sys/fs/cgroup/cpu/Example/cpu.cfs_quota_us 1000000 200000アプリケーションの PID を
Exampleコントロールグループに追加します。# echo "6955" > /sys/fs/cgroup/cpu/Example/cgroup.procsこのコマンドによって、特定のアプリケーションが
Exampleコントロールグループのメンバーとなり、Exampleコントロールグループに設定された CPU 制限を超えないようになります。PID はシステム内の既存のプロセスを表す必要があります。このPID 6955は、プロセスsha1sum /dev/zero &に割り当てられておりcpuコントローラーの使用例を示すために使用されています。
検証
アプリケーションが指定のコントロールグループで実行されていることを確認します。
# cat /proc/6955/cgroup 12:cpuset:/ 11:hugetlb:/ 10:net_cls,net_prio:/ 9:memory:/user.slice/user-1000.slice/user@1000.service 8:devices:/user.slice 7:blkio:/ 6:freezer:/ 5:rdma:/ 4:pids:/user.slice/user-1000.slice/user@1000.service 3:perf_event:/ 2:cpu,cpuacct:/Example 1:name=systemd:/user.slice/user-1000.slice/user@1000.service/gnome-terminal-server.serviceアプリケーションのプロセスは、アプリケーションのプロセスに CPU 制限を適用する
Exampleコントロールグループで実行されます。スロットルしたアプリケーションの現在の CPU 使用率を特定します。
# top top - 12:28:42 up 1:06, 1 user, load average: 1.02, 1.02, 1.00 Tasks: 266 total, 6 running, 260 sleeping, 0 stopped, 0 zombie %Cpu(s): 11.0 us, 1.2 sy, 0.0 ni, 87.5 id, 0.0 wa, 0.2 hi, 0.0 si, 0.2 st MiB Mem : 1826.8 total, 287.1 free, 1054.4 used, 485.3 buff/cache MiB Swap: 1536.0 total, 1396.7 free, 139.2 used. 608.3 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 6955 root 20 0 228440 1752 1472 R 20.6 0.1 47:11.43 sha1sum 5760 jdoe 20 0 3604956 208832 65316 R 2.3 11.2 0:43.50 gnome-shell 6448 jdoe 20 0 743836 31736 19488 S 0.7 1.7 0:08.25 gnome-terminal- 505 root 20 0 0 0 0 I 0.3 0.0 0:03.39 kworker/u4:4-events_unbound 4217 root 20 0 74192 1612 1320 S 0.3 0.1 0:01.19 spice-vdagentd ...PID 6955の CPU 消費が 99% から 20% に減少していることに注意してください。
cpu.cfs_period_us および cpu.cfs_quota_us に対応する cgroups-v2 は、cpu.max ファイルです。cpu.max ファイルは、cpu コントローラーから入手できます。
第44章 BPF コンパイラーコレクションでシステムパフォーマンスの分析
BPF Compiler Collection (BCC) は、Berkeley Packet Filter (BPF) の機能を組み合わせてシステムパフォーマンスを分析します。BPF を使用すると、カーネル内でカスタムプログラムを安全に実行して、パフォーマンス監視、トレース、およびデバッグ用のシステムイベントとデータにアクセスできます。BCC は、ユーザーがシステムから重要な詳細情報を抽出するための BPF プログラムの開発とデプロイを、ツールとライブラリーを使用して簡素化します。
44.1. bcc-tools パッケージのインストール
bcc-tools パッケージをインストールします。これにより、依存関係として BPF Compiler Collection (BCC) ライブラリーもインストールされます。
手順
bcc-toolsをインストールします。# yum install bcc-toolsBCC ツールは、
/usr/share/bcc/tools/ディレクトリーにインストールされます。
検証
インストールされたツールを検査します。
# ls -l /usr/share/bcc/tools/ ... -rwxr-xr-x. 1 root root 4198 Dec 14 17:53 dcsnoop -rwxr-xr-x. 1 root root 3931 Dec 14 17:53 dcstat -rwxr-xr-x. 1 root root 20040 Dec 14 17:53 deadlock_detector -rw-r--r--. 1 root root 7105 Dec 14 17:53 deadlock_detector.c drwxr-xr-x. 3 root root 8192 Mar 11 10:28 doc -rwxr-xr-x. 1 root root 7588 Dec 14 17:53 execsnoop -rwxr-xr-x. 1 root root 6373 Dec 14 17:53 ext4dist -rwxr-xr-x. 1 root root 10401 Dec 14 17:53 ext4slower ...リスト内の
docディレクトリーには、各ツールのドキュメントがあります。
44.2. bcc-tools でパフォーマンスの分析
BPF Compiler Collection (BCC) ライブラリーから事前に作成された特定のプログラムを使用して、システムパフォーマンスをイベントごとに効率的かつセキュアに分析します。BCC ライブラリーで事前作成されたプログラムセットは、追加プログラム作成の例として使用できます。
前提条件
- bcc-tools パッケージがインストールされている
- root 権限がある。
手順
execsnoopを使用してシステムプロセスを調べる-
1 つのターミナルで
execsnoopプログラムを実行します。
# /usr/share/bcc/tools/execsnooplsコマンドの短期的なプロセスを作成するために、別のターミナルで次のように入力します。$ ls /usr/share/bcc/tools/doc/execsnoopを実行している端末に、次のような出力が表示されます。PCOMM PID PPID RET ARGS ls 8382 8287 0 /usr/bin/ls --color=auto /usr/share/bcc/tools/doc/ ...execsnoopプログラムは、システムリソースを消費する新しいプロセスごとに 1 つの行を出力します。また、lsなどの非常に短期間に実行されるプログラムのプロセスを検出します。なお、ほとんどの監視ツールはそれらを登録しません。execsnoop出力には以下のフィールドが表示されます。
-
1 つのターミナルで
- PCOMM
-
親プロセス名。(
ls) - PID
-
プロセス ID。(
8382) - PPID
-
親プロセス ID。(
8287) - RET
-
exec()システムコールの戻り値 (0)。プログラムコードを新規プロセスに読み込みます。 - ARGS
- 引数を使用して起動したプログラムの場所。
execsnoop の詳細、例、オプションについては、/usr/share/bcc/tools/doc/execsnoop_example.txt ファイルを参照してください。
exec() の詳細は、exec(3) man ページを参照してください。
opensnoopを使用して、コマンドにより開かれるファイルを追跡する-
1 つのターミナルで
opensnoopプログラムを実行し、unameコマンドのプロセスによってのみ開かれたファイルを出力します。
# /usr/share/bcc/tools/opensnoop -n uname別のターミナルで、特定のファイルを開くコマンドを入力します。
$ unameopensnoopを実行している端末は、以下のような出力を表示します。PID COMM FD ERR PATH 8596 uname 3 0 /etc/ld.so.cache 8596 uname 3 0 /lib64/libc.so.6 8596 uname 3 0 /usr/lib/locale/locale-archive ...opensnoopプログラムは、システム全体でopen()システム呼び出しを監視し、unameが開こうとしたファイルごとに出力行を出力します。opensnoop出力には、以下のフィールドが表示されます。- PID
-
プロセス ID。(
8596) - COMM
-
プロセス名。(
uname) - FD
-
ファイルの記述子。開いたファイルを参照するために
open()が返す値です。(3) - ERR
- すべてのエラー。
- PATH
-
open()で開こうとしたファイルの場所。
コマンドが、存在しないファイルを読み込もうとすると、
FDコラムは-1を返し、ERRコラムは関連するエラーに対応する値を出力します。その結果、opensnoopは、適切に動作しないアプリケーションの特定に役立ちます。
-
1 つのターミナルで
opensnoop の詳細、例、オプションについては、/usr/share/bcc/tools/doc/opensnoop_example.txt ファイルを参照してください。
open() の詳細は、open(2) man ページを参照してください。
biotopを使用して、ディスク上で I/O 操作を実行している上位のプロセスを監視する-
1 つのターミナルで
biotopプログラムを引数30を指定して実行し、30 秒間のサマリーを生成します。
# /usr/share/bcc/tools/biotop 30注記引数を指定しないと、デフォルトでは 1 秒ごとに出力画面が更新されます。
別のターミナルで、次のコマンドを入力して、ローカルハードディスクデバイスからコンテンツを読み取り、出力を
/dev/zeroファイルに書き込みます。# dd if=/dev/vda of=/dev/zeroこの手順では、
biotopを示す特定の I/O トラフィックを生成します。biotopを実行している端末は、以下のような出力を表示します。PID COMM D MAJ MIN DISK I/O Kbytes AVGms 9568 dd R 252 0 vda 16294 14440636.0 3.69 48 kswapd0 W 252 0 vda 1763 120696.0 1.65 7571 gnome-shell R 252 0 vda 834 83612.0 0.33 1891 gnome-shell R 252 0 vda 1379 19792.0 0.15 7515 Xorg R 252 0 vda 280 9940.0 0.28 7579 llvmpipe-1 R 252 0 vda 228 6928.0 0.19 9515 gnome-control-c R 252 0 vda 62 6444.0 0.43 8112 gnome-terminal- R 252 0 vda 67 2572.0 1.54 7807 gnome-software R 252 0 vda 31 2336.0 0.73 9578 awk R 252 0 vda 17 2228.0 0.66 7578 llvmpipe-0 R 252 0 vda 156 2204.0 0.07 9581 pgrep R 252 0 vda 58 1748.0 0.42 7531 InputThread R 252 0 vda 30 1200.0 0.48 7504 gdbus R 252 0 vda 3 1164.0 0.30 1983 llvmpipe-1 R 252 0 vda 39 724.0 0.08 1982 llvmpipe-0 R 252 0 vda 36 652.0 0.06 ...biotop出力には、以下のフィールドが表示されます。
-
1 つのターミナルで
- PID
-
プロセス ID。(
9568) - COMM
-
プロセス名。(
dd) - DISK
-
読み取り操作を実行するディスク。(
vda) - I/O
- 実行された読み取り操作の数。(16294)
- Kbytes
- 読み取り操作によって使用したバイト数 (KB)。(14,440,636)
- AVGms
- 読み取り操作の平均 I/O 時間。(3.69)
biotop の詳細、例、およびオプションについては、/usr/share/bcc/tools/doc/biotop_example.txt ファイルを参照してください。
dd の詳細は、dd(1) man ページを参照してください。
xfsslower を使用して、予想以上に遅いファイルシステム操作を明らかにする
xfsslower は、XFS ファイルシステムによる読み取り操作、書き込み操作、開く操作、または同期操作 (fsync) の実行に費やされた時間を測定します。1 引数を指定すると、1 ms よりも遅い操作のみが表示されます。
1 つのターミナルで
xfsslowerプログラムを実行します。# /usr/share/bcc/tools/xfsslower 1注記引数を指定しないと、
xfsslowerはデフォルトで 10 ms よりも低速な操作を表示します。別のターミナルで、
vimエディターでテキストファイルを作成するコマンドを入力して、XFS ファイルシステムとのやり取りを開始します。$ vim text前の手順でファイルを保存すると、
xfsslowerを実行しているターミナルに次のような内容が表示されます。TIME COMM PID T BYTES OFF_KB LAT(ms) FILENAME 13:07:14 b'bash' 4754 R 256 0 7.11 b'vim' 13:07:14 b'vim' 4754 R 832 0 4.03 b'libgpm.so.2.1.0' 13:07:14 b'vim' 4754 R 32 20 1.04 b'libgpm.so.2.1.0' 13:07:14 b'vim' 4754 R 1982 0 2.30 b'vimrc' 13:07:14 b'vim' 4754 R 1393 0 2.52 b'getscriptPlugin.vim' 13:07:45 b'vim' 4754 S 0 0 6.71 b'text' 13:07:45 b'pool' 2588 R 16 0 5.58 b'text' ...各行は、特定のしきい値よりも時間がかかったファイルシステムの操作を表します。xfsslower
は、予期せず遅い操作の形をとる可能性のあるファイルシステムの問題を検出します。xfsslower出力には、以下のフィールドが表示されます。- COMM
-
プロセス名。(
b’bash') - T
操作の種類。(
R)- Read
- Write
- Sync
- OFF_KB
- ファイルオフセット (KB)。(0)
- FILENAME
- 読み取り、書き込み、または同期されるファイル。
xfsslower の詳細、例、およびオプションについては、/usr/share/bcc/tools/doc/xfsslower_example.txt ファイルを参照してください。
fsync の詳細は、fsync(2) の man ページを参照してください。
パート VII. 高可用性システムの設計
第45章 High Availability Add-On の概要
High Availability Add-On は、基幹実稼働サービスに、信頼性、スケーラビリティー、および可用性を提供するクラスターシステムです。
クラスターは、連携してタスクを実行する 2 つ以上のコンピューター (ノード または メンバー と呼ばれています) を指します。クラスターを使用すると、可用性の高いサービスまたはリソースを提供できます。複数のマシンによ r 冗長性は、様々な障害から保護するために使用されます。
高可用性クラスターは、単一障害点を排除し、ノードが稼働しなくなった場合に、あるクラスターノードから別のクラスターノードにサービスをフェイルオーバーして、可用性が高いサービスを提供します。通常、高可用性クラスターのサービスは、(read-write でマウントされたファイルシステム経由で) データの読み取りや書き込みを行います。したがって、あるクラスターノードが別のクラスターノードからサービスの制御を引き継ぐ際に、高可能性クラスターでデータ整合性を維持する必要があります。高可用性クラスター内のノードの障害は、クラスター外にあるクライアントからは確認できません。また、高可用性クラスターはフェイルオーバークラスターと呼ばれることがあります。High Availability Add-On は、高可用性サービス管理コンポーネントの Pacemaker を介して、高可用性クラスタリングを提供します。
Red Hat は、Red Hat 高可用性クラスターの計画、設定、保守に関する多様なドキュメントを提供しています。Red Hat クラスターのさまざまな分野に関するドキュメントのガイド付きインデックスを提供する記事リストは、Red Hat High Availability Add-On Documentation Guide を参照してください。
45.1. High Availability Add-On コンポーネント
Red Hat High Availability Add-On は、高可用性サービスを提供する複数のコンポーネントで構成されます。
High Availability Add-On の主なコンポーネントは以下のとおりです。
- クラスターインフラストラクチャー - ノードがクラスターとして連携するための基本機能 (設定ファイル管理、メンバーシップ管理、ロック管理、フェンシング) を提供します。
- 高可用性サービス管理 - ノードが動作不能になった場合に、あるクラスターノードから別のクラスターノードへのサービスのフェイルオーバーを提供します。
- クラスター管理ツール - High Availability Add-On をセットアップ、設定、管理するための設定および管理ツール。このツールは、クラスターインフラストラクチャーのコンポーネント、高可用性およびサービス管理のコンポーネント、ならびにストレージで使用されます。
以下のコンポーネントで、High Availability Add-On を補完できます。
- Red Hat GFS2 (Global File System 2) - Resilient Storage Add-On の一部であり、High Availability Add-On で使用するためのクラスターファイルシステムを提供します。GFS2 により、ストレージがローカルで各クラスターノードに接続されているかのように、ブロックレベルにおいて、複数ノードでストレージを共有できるようになります。GFS2 クラスターファイルシステムを使用する場合は、クラスターインフラストラクチャーが必要になります。
-
LVM ロックデーモン (
lvmlockd) - Resilient Storage Add-On の一部であり、クラスターストレージのボリューム管理を提供します。lvmlockdのサポートにはクラスターインフラストラクチャーも必要です。 - HAProxy - レイヤー 4 (TCP) およびレイヤー 7 (HTTP、HTTPS) サービスで高可用性の負荷分散とフェイルオーバーを提供するルーティングソフトウェア。
45.2. High Availability Add-On の概念
Red Hat High Availability Add-On クラスターの主要な概念を以下に示します。
45.2.1. フェンシング
クラスター内のノードの 1 つと通信が失敗した場合に、障害が発生したクラスターノードがアクセスする可能性があるリソースへのアクセスを、その他のノードが制限したり、解放したりできるようにする必要があります。当該クラスターノードが応答しない可能性があるため、当該クラスターノードと通信して行うことはできません。代わりに、フェンスエージェントを使用した、フェンシングと呼ばれる外部メソッドを指定する必要があります。フェンスデバイスは、クラスターが使用する外部デバイスのことで、このデバイスを使用して、不安定なノードによる共有リソースへのアクセスを制限したり、クラスターノードでハードリブートを実行します。
フェンスデバイスが設定されていないと、以前使用していたリソースが解放されていることを切断されているクラスターノードが把握できず、他のクラスターノードでサービスを実行できなくなる可能性があります。また、クラスターノードがそのリソースを解放したとシステムが誤って想定し、データが破損または損失する可能性もあります。フェンスデバイスが設定されていないと、データの整合性は保証できず、クラスター設定はサポートされません。
フェンシングの進行中は、他のクラスター操作を実行できません。クラスターノードの再起動後にフェンシングが完了するか、クラスターノードがクラスターに再度参加するまで、クラスターの通常の動作を再開することができません。
フェンシングの詳細は、Red Hat ナレッジベースソリューション Fencing in a Red Hat High Availability Cluster を参照してください。
45.2.2. クォーラム
クラスターの整合性と可用性を維持するために、クラスターシステムは、クォーラム と呼ばれる概念を使用してデータの破損や損失を防ぎます。クラスターノードの過半数がオンラインになると、クラスターでクォーラムが確立されます。クラスターでクォーラムが確立されない場合は、障害によるデータ破損の可能性を小さくするために、Pacemaker はデフォルトですべてのリソースを停止します。
クォーラムは、投票システムを使用して確立されます。クラスターノードが通常どおり機能しない場合や、クラスターの他の部分との通信が失われた場合に、動作している過半数のノードが、問題のあるノードを分離するように投票し、必要に応じて、接続を切断して別のノードに切り替えてサービスを継続 (フェンス) します。
たとえば、6 ノードクラスターで、4 つ以上のクラスターノードが動作している場合にクォーラムが確立されます。過半数のノードがオフラインまたは利用できない状態になると、クラスターでクォーラムが確立されず、Pacemaker がクラスター化サービスを停止します。
Pacemaker のクォーラム機能により、スプリットブレイン (クラスターで通信が遮断され、各部分が別のクラスターとして動作し続ける現象。同じデータへの書き込みが行われ、破損または損失が発生することがあります) と呼ばれる現象が回避されます。スプリットブレイン状態の意味と、一般的なクォーラムの概念の詳細は、Red Hat ナレッジベースの記事 Exploring Concepts of RHEL High Availability Clusters - Quorum を参照してください。
Red Hat High Availability Add-On クラスターは、スプリットブレインの状況を回避するために、votequorum サービスをフェンシングと併用します。クラスターの各システムには多くの投票数が割り当てられ、過半数の票を取得しているものだけがクラスターの操作を継続できます。
45.2.3. クラスターリソース
クラスターリソース は、クラスターサービスにより管理されるプログラム、データ、またはアプリケーションのインスタンスです。これらのリソースは、クラスター環境でリソースを管理する標準的なインターフェイスを提供するエージェントによって抽象化されます。
リソースを健全な状態に保つために、リソースの定義に監視操作を追加できます。リソースの監視操作を指定しない場合は、デフォルトで監視操作が追加されます。
クラスター内のリソースの動作は、制約 を指定することで設定できます。以下の制約のカテゴリーを設定できます。
- 場所の制約 - 場所の制約により、リソースが実行できるノードが決まります。
- 順序制約 - 順序制約は、リソースが実行される順序を決定します。
- コロケーション制約 - コロケーション制約は、リソースが他のリソースに対してどこに配置されるかを決定します。
クラスターの最も一般的な設定要素の 1 つがリソースセットです。リソースセットはまとめて配置し、順番に起動し、その逆順で停止する必要があります。この設定を簡略化するために、Pacemaker では グループ という概念がサポートされます。
45.3. Pacemaker の概要
Pacemaker は、クラスターリソースマネージャーです。クラスターインフラストラクチャーのメッセージング機能およびメンバーシップ機能を使用して、ノードおよびリソースレベルの障害を防ぎ、障害から復旧することで、クラスターサービスおよびリソースの可用性を最大化します。
45.3.1. Pacemaker アーキテクチャーコンポーネント
Pacemaker で設定されたクラスターは、クラスターメンバーシップを監視する個別のコンポーネントデーモン、サービスを管理するスクリプト、および異なるリソースを監視するリソース管理サブシステムで構成されます。
Pacemaker アーキテクチャーを形成するコンポーネントは、以下のとおりです。
- Cluster Information Base (CIB)
- Pacemaker 情報デーモンは、内部的に XML を使用して、指定コーディネータ (DC) からの現在の設定とステータス情報を他のすべてのクラスターノードに配布および同期します。DC は、CIB を使用してクラスターの状態とアクションを保存および配布するために Pacemaker によって割り当てられたノードです。
- Cluster Resource Management Daemon (CRMd)
Pacemaker クラスターリソースの動作は、このデーモンを介してルーティングされます。CRMd により管理されるリソースは、必要に応じてクライアントシステムが問い合わせることができます。また、リソースを移動したり、インスタンス化したり、変更したりできます。
各クラスターノードには、CRMd とリソースの間のインターフェイスとして動作する LRMd (Local Resource Manager daemon) も含まれます。LRMd は、起動、停止、ステータス情報のリレーなどのコマンドを、CRMd からエージェントに渡します。
- Shoot the Other Node in the Head (STONITH)
- STONITH は Pacemaker フェンシングの実装です。STONITH は、フェンス要求を処理する Pacemaker のクラスターリソースとして動作し、強制的にノードをシャットダウンし、クラスターからノードを削除してデータの整合性を確保します。STONITH は、CIB で設定し、通常のクラスターリソースとして監視できます。
- corosync
corosyncは、コアメンバーシップと、高可用性クラスターのメンバー間の通信ニーズに対応するコンポーネントで、デーモンも同じ名前になります。これは、High Availability Add-On が機能するのに必要です。corosyncは、このようなメンバーシップとメッセージング機能のほかに、以下も提供します。- クォーラムのルールおよび決定を管理します。
- クラスターの複数のメンバーに渡って調整または動作するアプリケーションへのメッセージング機能を提供します。そのため、インスタンス間で、ステートフルな情報またはその他の情報を通信できる必要があります。
-
kronosnetライブラリーをネットワークトランスポートとして使用し、複数の冗長なリンクおよび自動フェイルオーバーを提供します。
45.3.2. Pacemaker の設定および管理ツール
High Availability Add-On には、クラスターのデプロイメント、監視、および管理に使用する 2 つの設定ツールが含まれます。
pcspcsコマンドラインインターフェイスは、Pacemaker およびcorosyncハートビートデーモンを制御し、設定します。コマンドラインベースのプログラムであるpcsは、以下のクラスター管理タスクを実行できます。- Pacemaker/Corosync クラスターの作成および設定
- 実行中のクラスターの設定変更
- Pacemaker と Corosync の両方のリモートでの設定、ならびにクラスターの起動、停止、およびステータス情報の表示
pcsdWeb UI- Pacemaker/Corosync クラスターを作成および設定するグラフィカルユーザーインターフェイスです。
45.3.3. クラスターと Pacemaker の設定ファイル
Red Hat High Availability Add-On の設定ファイルは、corosync.conf および cib.xml です。
corosync.conf ファイルは、Pacemaker を構築するクラスターマネージャー (corosync) が使用するクラスターパラメーターを提供します。通常は、直接 corosync.conf を編集するのではなく、pcs インターフェイスまたは pcsd インターフェイスを使用します。
cib.xml ファイルは、クラスターの設定、およびクラスターの全リソースにおいて現在の状態を表す XML ファイルです。このファイルは、Pacemaker のクラスター情報ベース (CIB) により使用されます。CIB の内容は、自動的にクラスター全体に同期されます。cib.xml ファイルは直接編集せず、代わりに pcs インターフェイスまたは pcsd インターフェイスを使用してください。
第46章 Pacemaker の使用の開始
Pacemaker クラスターの作成に使用するツールとプロセスに慣れるために、次の手順を実行できます。ここで説明する内容は、クラスターソフトウェアの概要と、作業用のクラスターを設定せずに管理する方法に関心のあるユーザーを対象としています。
ここで説明する手順では、2 つ以上のノードとフェンシングデバイスの設定が必要となるサポート対象の Red Hat クラスターは作成されません。Red Hat のサポートポリシー、要件、および制限の詳細は、RHEL 高可用性クラスターのサポートポリシー を参照してください。
46.1. Pacemaker の使用方法
ここでは、Pacemaker を使用してクラスターを設定する方法、クラスターのステータスを表示する方法、およびクラスターサービスを設定する方法を学習します。この例では、Apache HTTP サーバーをクラスターリソースとして作成し、リソースに障害が発生した場合のクラスターの応答方法を表示します。
この例では、以下のように設定されています。
-
ノード:
z1.example.com - Floating IP アドレス: 192.168.122.120
前提条件
- RHEL 8 を実行しているノード 1 つ
- このノードで静的に割り当てられている IP アドレスの 1 つと同じネットワーク上にあるフローティング IP アドレス
-
/etc/hostsファイルに、実行中のノード名が含まれている
手順
High Availability チャンネルから Red Hat High Availability Add-On ソフトウェアパッケージをインストールし、
pcsdサービスを起動して有効にします。# yum install pcs pacemaker fence-agents-all ... # systemctl start pcsd.service # systemctl enable pcsd.servicefirewalldデーモンを実行している場合は、Red Hat High Availability Add-On で必要なポートを有効にします。# firewall-cmd --permanent --add-service=high-availability # firewall-cmd --reloadクラスターの各ノードにユーザー
haclusterのパスワードを設定し、pcsコマンドを実行するノードにあるクラスターの各ノードに対して、haclusterユーザーの認証を行います。この例では、ノードを 1 つだけ使用し、そのノードからコマンドを実行していますが、このステップはサポート対象の Red Hat High Availability マルチノードクラスターを設定する際に必要となるため、この手順に含まれています。# passwd hacluster ... # pcs host auth z1.example.comメンバーを 1 つ含む
my_clusterという名前のクラスターを作成し、クラスターのステータスを確認します。この 1 つのコマンドで、クラスターが作成され、起動します。# pcs cluster setup my_cluster --start z1.example.com ... # pcs cluster status Cluster Status: Stack: corosync Current DC: z1.example.com (version 2.0.0-10.el8-b67d8d0de9) - partition with quorum Last updated: Thu Oct 11 16:11:18 2018 Last change: Thu Oct 11 16:11:00 2018 by hacluster via crmd on z1.example.com 1 node configured 0 resources configured PCSD Status: z1.example.com: OnlineRed Hat High Availability クラスターでは、クラスターのフェンシングを設定することが必要になります。この要件の理由については、Red Hat ナレッジベースソリューション Fencing in a Red Hat High Availability Cluster で説明されています。ただし、ここでは基本的な Pacemaker コマンドの使用方法を説明することを目的としているため、
stonith-enabledクラスターのオプションをfalseに設定し、フェンシングを無効にします。警告stonith-enabled=falseの使用は、実稼働クラスターには完全に適していません。これにより、障害が発生したノードが適切にフェンスされていることを装うようにクラスターに指示されます。# pcs property set stonith-enabled=falseシステムに Web ブラウザーを設定し、Web ページを作成して簡単なテキストメッセージを表示します。
firewalldデーモンを実行している場合は、httpdで必要なポートを有効にします。注記システムの起動時に使用する場合は、
systemctl enableで、クラスターが管理するサービスを有効にしないでください。# yum install -y httpd wget ... # firewall-cmd --permanent --add-service=http # firewall-cmd --reload # cat <<-END >/var/www/html/index.html <html> <body>My Test Site - $(hostname)</body> </html> ENDApache リソースエージェントが Apache のステータスを取得できるようにするため、既存の設定に以下の内容を追加して、ステータスサーバーの URL を有効にします。
# cat <<-END > /etc/httpd/conf.d/status.conf <Location /server-status> SetHandler server-status Order deny,allow Deny from all Allow from 127.0.0.1 Allow from ::1 </Location> ENDクラスターが管理するリソース
IPaddr2およびapacheを作成します。IPaddr2リソースは、物理ノードにすでに関連付けられていない Floating IP アドレスです。IPaddr2リソースの NIC デバイスが指定されていない場合、Floating IP は、ノードで使用される静的に割り当てられた IP アドレスと同じネットワーク上に存在している必要があります。利用可能なリソースタイプのリストを表示する場合は、
pcs resource listコマンドを使用します。指定したリソースタイプに設定できるパラメーターを表示する場合は、pcs resource describe resourcetypeコマンドを使用します。たとえば、以下のコマンドは、apacheタイプのリソースに設定できるパラメーターを表示します。# pcs resource describe apache ...この例では、IP アドレスリソースと apache リソースの両方が
apachegroupグループに含まれるように設定します。これにより、両リソースが一緒に保存され、作業用のマルチノードクラスターを設定する際に、同じノードで実行できます。# pcs resource create ClusterIP ocf:heartbeat:IPaddr2 ip=192.168.122.120 --group apachegroup # pcs resource create WebSite ocf:heartbeat:apache configfile=/etc/httpd/conf/httpd.conf statusurl="http://localhost/server-status" --group apachegroup # pcs status Cluster name: my_cluster Stack: corosync Current DC: z1.example.com (version 2.0.0-10.el8-b67d8d0de9) - partition with quorum Last updated: Fri Oct 12 09:54:33 2018 Last change: Fri Oct 12 09:54:30 2018 by root via cibadmin on z1.example.com 1 node configured 2 resources configured Online: [ z1.example.com ] Full list of resources: Resource Group: apachegroup ClusterIP (ocf::heartbeat:IPaddr2): Started z1.example.com WebSite (ocf::heartbeat:apache): Started z1.example.com PCSD Status: z1.example.com: Online ...クラスターリソースを設定したら、
pcs resource configコマンドを使用して、そのリソースに設定したオプションを表示します。# pcs resource config WebSite Resource: WebSite (class=ocf provider=heartbeat type=apache) Attributes: configfile=/etc/httpd/conf/httpd.conf statusurl=http://localhost/server-status Operations: start interval=0s timeout=40s (WebSite-start-interval-0s) stop interval=0s timeout=60s (WebSite-stop-interval-0s) monitor interval=1min (WebSite-monitor-interval-1min)- ブラウザーで、設定済みの Floating IP アドレスを使用して作成した Web サイトを開くように指定します。定義したテキストメッセージが表示されるはずです。
Apache Web サービスを停止し、クラスターのステータスを確認します。
killall -9を使用して、アプリケーションレベルのクラッシュをシミュレートします。# killall -9 httpdクラスターのステータスを確認します。Web サービスは停止したためアクションは失敗しますが、クラスターソフトウェアがサービスを再起動したため、Web サイトに引き続きアクセスできることが確認できるはずです。
# pcs status Cluster name: my_cluster ... Current DC: z1.example.com (version 1.1.13-10.el7-44eb2dd) - partition with quorum 1 node and 2 resources configured Online: [ z1.example.com ] Full list of resources: Resource Group: apachegroup ClusterIP (ocf::heartbeat:IPaddr2): Started z1.example.com WebSite (ocf::heartbeat:apache): Started z1.example.com Failed Resource Actions: * WebSite_monitor_60000 on z1.example.com 'not running' (7): call=13, status=complete, exitreason='none', last-rc-change='Thu Oct 11 23:45:50 2016', queued=0ms, exec=0ms PCSD Status: z1.example.com: Onlineサービスが再開すると、障害が発生したリソースの障害 (failure) ステータスが削除されるため、クラスターステータスを確認する際に、障害が発生したアクションの通知が表示されなくなります。
# pcs resource cleanup WebSiteクラスターと、クラスターのステータスを確認したら、ノードでクラスターサービスを停止します。(この手順を試すために、実際にサービスを起動したノードが 1 つだけであっても)
--allパラメーターを追加してください。これにより実際のマルチノードクラスターの全ノードでクラスターサービスが停止します。# pcs cluster stop --all
46.2. フェイルオーバーの設定方法
以下の手順では、サービスを実行する Pacemaker クラスターの作成方法を紹介します。このサービスは、サービスを実行しているノードが利用できなくなると、現在のノードから別のノードにフェイルオーバーします。この手順を行って、2 ノードクラスターでサービスを作成する方法と、サービスを実行しているノードでサービスが失敗するとどうなるかを確認します。
この手順では、Apache HTTP サーバーを実行する 2 ノード Pacemaker クラスターを設定します。その後、1 つのノードで Apache サービスを停止し、どのようにしてサービスを利用可能のままにしているかを確認できます。
この例では、以下のように設定されています。
-
ノード:
z1.example.comおよびz2.example.com - Floating IP アドレス: 192.168.122.120
前提条件
- 相互に通信が可能な RHEL 8 を実行するノード 2 つ
- このノードで静的に割り当てられている IP アドレスの 1 つと同じネットワーク上にあるフローティング IP アドレス
-
/etc/hostsファイルに、実行中のノード名が含まれている
手順
両方のノードで、High Availability チャンネルから Red Hat High Availability Add-On ソフトウェアパッケージをインストールし、
pcsdサービスを起動して有効にします。# yum install pcs pacemaker fence-agents-all ... # systemctl start pcsd.service # systemctl enable pcsd.servicefirewalldデーモンを実行している場合は、両方のノードで、Red Hat High Availability Add-On で必要なポートを有効にします。# firewall-cmd --permanent --add-service=high-availability # firewall-cmd --reloadクラスター内の両方のノードに、
haclusterユーザーのパスワードを設定します。# passwd haclusterpcsコマンドを実行するノードで、クラスター内の各ノードに対してhaclusterユーザーの認証を行います。# pcs host auth z1.example.com z2.example.com両方のノードで、クラスターメンバーとなるクラスター
my_clusterを作成します。この 1 つのコマンドで、クラスターが作成され、起動します。pcs設定コマンドはクラスター全体に適用されるため、このコマンドは、クラスター内のいずれかのノードで実行してください。クラスター内のいずれかのノードで、以下のコマンドを実行します。
# pcs cluster setup my_cluster --start z1.example.com z2.example.comRed Hat High Availability クラスターでは、クラスターのフェンシングを設定することが必要になります。この要件の理由については、Red Hat ナレッジベースソリューション Fencing in a Red Hat High Availability Cluster で説明されています。ただし、この手順では、この設定でフェイルオーバーがどのように機能するかだけを示すために、
stonith-enabledクラスターオプションをfalseに設定してフェンシングを無効にします。警告stonith-enabled=falseの使用は、実稼働クラスターには完全に適していません。これにより、障害が発生したノードが適切にフェンスされていることを装うようにクラスターに指示されます。# pcs property set stonith-enabled=falseクラスターを作成し、フェンシングを無効にしたら、クラスターのステータスを確認します。
注記pcs cluster statusコマンドを実行したときの出力は、一時的に、システムコンポーネントの起動時の例とは若干異なる場合があります。# pcs cluster status Cluster Status: Stack: corosync Current DC: z1.example.com (version 2.0.0-10.el8-b67d8d0de9) - partition with quorum Last updated: Thu Oct 11 16:11:18 2018 Last change: Thu Oct 11 16:11:00 2018 by hacluster via crmd on z1.example.com 2 nodes configured 0 resources configured PCSD Status: z1.example.com: Online z2.example.com: Online両方のノードに Web ブラウザーを設定し、Web ページを作成して簡単なテキストメッセージを表示します。
firewalldデーモンを実行している場合は、httpdで必要なポートを有効にします。注記システムの起動時に使用する場合は、
systemctl enableで、クラスターが管理するサービスを有効にしないでください。# yum install -y httpd wget ... # firewall-cmd --permanent --add-service=http # firewall-cmd --reload # cat <<-END >/var/www/html/index.html <html> <body>My Test Site - $(hostname)</body> </html> ENDApache リソースエージェントが、クラスターの各ノードで Apache のステータスを取得できるようにするため、既存の設定に以下の内容を追加して、ステータスサーバーの URL を有効にします。
# cat <<-END > /etc/httpd/conf.d/status.conf <Location /server-status> SetHandler server-status Order deny,allow Deny from all Allow from 127.0.0.1 Allow from ::1 </Location> ENDクラスターが管理するリソース
IPaddr2およびapacheを作成します。IPaddr2リソースは、物理ノードにすでに関連付けられていない Floating IP アドレスです。IPaddr2リソースの NIC デバイスが指定されていない場合、Floating IP は、ノードで使用される静的に割り当てられた IP アドレスと同じネットワーク上に存在している必要があります。利用可能なリソースタイプのリストを表示する場合は、
pcs resource listコマンドを使用します。指定したリソースタイプに設定できるパラメーターを表示する場合は、pcs resource describe resourcetypeコマンドを使用します。たとえば、以下のコマンドは、apacheタイプのリソースに設定できるパラメーターを表示します。# pcs resource describe apache ...この例では、IP アドレスリソースおよび apache リソースの両方が、
apachegroupという名前のグループに含まれるように設定します。これにより、両リソースが一緒に保存され、同じノードで実行できます。クラスター内のいずれかのノードで、次のコマンドを実行します。
# pcs resource create ClusterIP ocf:heartbeat:IPaddr2 ip=192.168.122.120 --group apachegroup # pcs resource create WebSite ocf:heartbeat:apache configfile=/etc/httpd/conf/httpd.conf statusurl="http://localhost/server-status" --group apachegroup # pcs status Cluster name: my_cluster Stack: corosync Current DC: z1.example.com (version 2.0.0-10.el8-b67d8d0de9) - partition with quorum Last updated: Fri Oct 12 09:54:33 2018 Last change: Fri Oct 12 09:54:30 2018 by root via cibadmin on z1.example.com 2 nodes configured 2 resources configured Online: [ z1.example.com z2.example.com ] Full list of resources: Resource Group: apachegroup ClusterIP (ocf::heartbeat:IPaddr2): Started z1.example.com WebSite (ocf::heartbeat:apache): Started z1.example.com PCSD Status: z1.example.com: Online z2.example.com: Online ...このインスタンスでは、
apachegroupサービスが z1.example.com ノードで実行していることに注意してください。作成した Web サイトにアクセスし、サービスを実行しているノードでそのサービスを停止し、2 番目のノードにサービスがフェイルオーバーする方法を確認してください。
- ブラウザーで、設定済みの Floating IP アドレスを使用して作成した Web サイトを開くように指定します。定義したテキストメッセージが表示され、Web サイトを実行しているノードの名前が表示されるはずです。
Apache Web サービスを停止します。
killall -9を使用して、アプリケーションレベルのクラッシュをシミュレートします。# killall -9 httpdクラスターのステータスを確認します。Web サービスを停止したためにアクションが失敗したものの、サービスが実行していたノードでクラスターソフトウェアがサービスを再起動するため、Web サイトに引き続きアクセスできるはずです。
# pcs status Cluster name: my_cluster Stack: corosync Current DC: z1.example.com (version 2.0.0-10.el8-b67d8d0de9) - partition with quorum Last updated: Fri Oct 12 09:54:33 2018 Last change: Fri Oct 12 09:54:30 2018 by root via cibadmin on z1.example.com 2 nodes configured 2 resources configured Online: [ z1.example.com z2.example.com ] Full list of resources: Resource Group: apachegroup ClusterIP (ocf::heartbeat:IPaddr2): Started z1.example.com WebSite (ocf::heartbeat:apache): Started z1.example.com Failed Resource Actions: * WebSite_monitor_60000 on z1.example.com 'not running' (7): call=31, status=complete, exitreason='none', last-rc-change='Fri Feb 5 21:01:41 2016', queued=0ms, exec=0msサービスが再開したら、障害 (failure) ステータスを削除します。
# pcs resource cleanup WebSiteサービスを実行しているノードをスタンバイモードにします。フェンシングを無効にしているため、ノードレベルの障害 (電源ケーブルを引き抜くなど) を効果的にシミュレートできません。クラスターがこのような状態から復旧するにはフェンシングが必要になるためです。
# pcs node standby z1.example.comクラスターのステータスを確認し、サービスを実行している場所をメモします。
# pcs status Cluster name: my_cluster Stack: corosync Current DC: z1.example.com (version 2.0.0-10.el8-b67d8d0de9) - partition with quorum Last updated: Fri Oct 12 09:54:33 2018 Last change: Fri Oct 12 09:54:30 2018 by root via cibadmin on z1.example.com 2 nodes configured 2 resources configured Node z1.example.com: standby Online: [ z2.example.com ] Full list of resources: Resource Group: apachegroup ClusterIP (ocf::heartbeat:IPaddr2): Started z2.example.com WebSite (ocf::heartbeat:apache): Started z2.example.com- Web サイトにアクセスします。サービスの切断はありません。表示メッセージには、サービスを実行しているノードが含まれるはずです。
クラスターサービスを最初のノードに復元するには、そのノードをスタンドバイモードから回復します。ただし、必ずしもそのサービスが最初のノードに戻るわけではありません。
# pcs node unstandby z1.example.com最終的なクリーンナップを行うために、両方のノードでクラスターサービスを停止します。
# pcs cluster stop --all
第47章 pcs コマンドラインインターフェイス
pcs コマンドラインインターフェイスを使用すると、corosync、pacemaker、booth、sbd などのクラスターサービスを制御し、設定を簡単に行うことができます。
cib.xml 設定ファイルは直接編集しないでください。ほとんどの場合、Pacemaker は、直接編集した cib.xml ファイルを受け付けません。
47.1. pcs help display
pcs コマンドで -h オプションを使用すると、pcs コマンドのパラメーターと、その説明が表示されます。
次のコマンドは、pcs resource コマンドのパラメーターを表示します。
# pcs resource -h47.2. 未編集のクラスター設定の表示
クラスター設定ファイルは直接編集しないようにしてください。未編集のクラスター設定は、pcs cluster cib コマンドで表示できます。
pcs cluster cib filename コマンドを使用すると、未編集のクラスター設定を、指定したファイルに保存できます。クラスターを事前に設定していて、アクティブな CIB が存在する場合は、以下のコマンドを実行して、未編集の xml ファイルを保存します。
pcs cluster cib filename
たとえば、次のコマンドを使用すると、testfile という名前のファイルに、未編集の CIB の xml ファイルが保存されます。
# pcs cluster cib testfile47.3. 作業ファイルへの設定変更の保存
クラスターを設定する際に、アクティブな CIB に影響を及ぼさずに、指定したファイルに設定変更を保存できます。これにより、個々の更新を使用して実行中のクラスター設定を直ちに更新することなく、設定の更新を指定できます。
CIB をファイルに保存する方法は、未編集のクラスター設定の表示 を参照してください。そのファイルを作成したら、pcs コマンドの -f オプションを使用したアクティブな CIB ではなく、ファイルに設定変更を保存できます。変更を完了し、アクティブな CIB ファイルへの更新が用意できたら、pcs cluster cib-push コマンドでファイルの更新をプッシュできます。
手順
以下は、CIB のファイルに変更をプッシュする際に推奨される手順です。この手順は、保存した CIB ファイルのコピーを作成し、そのコピーを変更します。アクティブな CIB にその変更をプッシュする場合は、ここで、pcs cluster cib-push コマンドの diff-against オプションを指定して、元のファイルと、変更したファイルの差異だけが CIB にプッシュされるようにします。これにより、ユーザーが互いを上書きしないように、並列に変更を加えることができます。ここでは、設定ファイル全体を解析する必要はないため、Pacemaker への負荷が減ります。
ファイルへのアクティブな CIB を保存します。この例では、
original.xmlという名前のファイルに CIB が保存されます。# pcs cluster cib original.xml設定の更新に使用する作業ファイルに、保存したファイルをコピーします。
# cp original.xml updated.xml必要に応じて設定を更新します。以下のコマンドは、
updated.xmlファイルにリソースを作成しますが、現在実行しているクラスター設定にはそのリソースを追加しません。# pcs -f updated.xml resource create VirtualIP ocf:heartbeat:IPaddr2 ip=192.168.0.120 op monitor interval=30s更新したファイルを、アクティブな CIB にプッシュします。元のファイルに加えた変更のみをプッシュするように指定します。
# pcs cluster cib-push updated.xml diff-against=original.xml
もしくは、次のコマンドを使用して、CIB ファイルの現在のコンテンツ全体をプッシュできます。
pcs cluster cib-push filename
CIB ファイル全体をプッシュすると、Pacemaker はバージョンを確認して、クラスターにあるものよりも古い場合は CIB ファイルをプッシュしません。クラスターにあるものよりも古いバージョンで CIB ファイル全体を更新する必要がある場合は、pcs cluster cib-push コマンドの --config オプションを使用します。
pcs cluster cib-push --config filename47.4. クラスターのステータス表示
さまざまなコマンドを使用して、クラスターおよびそのコンポーネントのステータスを表示できます。
次のコマンドで、クラスターおよびクラスターリソースのステータスを表示します。
# pcs status
pcs status コマンドの commands パラメーター (resources、cluster、nodes、または pcsd) を指定すると、特定のクラスターコンポーネントのステータスを表示できます。
pcs status commandsたとえば、次のコマンドは、クラスターリソースのステータスを表示します。
# pcs status resourcesこのコマンドはクラスターの状態を表示しますが、クラスターリソースの状態は表示しません。
# pcs cluster status47.5. クラスターの全設定の表示
現在のクラスター設定をすべて表示する場合は、次のコマンドを実行します。
# pcs config47.6. pcs コマンドによる corosync.conf ファイルの変更
Red Hat Enterprise Linux 8.4 以降では、pcs コマンドを使用して corosync.conf ファイル内のパラメーターを変更できます。
次のコマンドは、corosync.conf ファイルのパラメーターを変更します。
pcs cluster config update [transport pass:quotes[transport options]] [compression pass:quotes[compression options]] [crypto pass:quotes[crypto options]] [totem pass:quotes[totem options]] [--corosync_conf pass:quotes[path]]
以下のコマンド例は、knet_pmtud_interval トランスポート値と、token と join の totem の値を更新します。
# pcs cluster config update transport knet_pmtud_interval=35 totem token=10000 join=10047.7. pcs コマンドでの corosync.conf ファイルの表示
次のコマンドは、corosync.conf クラスター設定ファイルの内容を表示します。
# pcs cluster corosync
Red Hat Enterprise Linux 8.4 以降では、次の例のように、pcs cluster config コマンドを使用して、corosync.conf ファイルの内容を人間が読める形式で出力できます。
クラスターが RHEL 8.7 以降で作成された場合、または UUID によるクラスターの識別 で説明されているように UUID が手動で追加された場合、このコマンドの出力にはクラスターの UUID が含まれます。
[root@r8-node-01 ~]# pcs cluster config
Cluster Name: HACluster
Cluster UUID: ad4ae07dcafe4066b01f1cc9391f54f5
Transport: knet
Nodes:
r8-node-01:
Link 0 address: r8-node-01
Link 1 address: 192.168.122.121
nodeid: 1
r8-node-02:
Link 0 address: r8-node-02
Link 1 address: 192.168.122.122
nodeid: 2
Links:
Link 1:
linknumber: 1
ping_interval: 1000
ping_timeout: 2000
pong_count: 5
Compression Options:
level: 9
model: zlib
threshold: 150
Crypto Options:
cipher: aes256
hash: sha256
Totem Options:
downcheck: 2000
join: 50
token: 10000
Quorum Device: net
Options:
sync_timeout: 2000
timeout: 3000
Model Options:
algorithm: lms
host: r8-node-03
Heuristics:
exec_ping: ping -c 1 127.0.0.1
RHEL 8.4 以降では、次の例のように、--output-format=cmd オプションを指定して pcs cluster config show コマンドを実行すると、既存の corosync.conf ファイルを再作成するために使用できる pcs 設定コマンドを表示できます。
[root@r8-node-01 ~]# pcs cluster config show --output-format=cmd
pcs cluster setup HACluster \
r8-node-01 addr=r8-node-01 addr=192.168.122.121 \
r8-node-02 addr=r8-node-02 addr=192.168.122.122 \
transport \
knet \
link \
linknumber=1 \
ping_interval=1000 \
ping_timeout=2000 \
pong_count=5 \
compression \
level=9 \
model=zlib \
threshold=150 \
crypto \
cipher=aes256 \
hash=sha256 \
totem \
downcheck=2000 \
join=50 \
token=10000第48章 Pacemaker を使用した Red Hat High Availability クラスターの作成
以下の手順では、pcs コマンドラインインターフェイスを使用して、2 ノードの Red Hat High Availability クラスターを作成します。
この例では、クラスターを設定するために、システムに以下のコンポーネントを追加する必要があります。
-
クラスターを作成するのに使用する 2 つのノード。この例では、使用されるノードは
z1.example.comおよびz2.example.comです。 - プライベートネットワーク用のネットワークスイッチ。クラスターノード同士の通信、およびその他のクラスターハードウェア (ネットワーク電源スイッチやファイバーチャネルスイッチなど) との通信にプライベートネットワークを使用することが推奨されますが、必須ではありません。
-
クラスターの各ノード用のフェンシングデバイス。この例では、APC 電源スイッチの 2 ポートを使用します。ホスト名は
zapc.example.comです。
設定が Red Hat のサポートポリシーに準拠していることを確認する必要があります。Red Hat のサポートポリシー、要件、および制限の詳細は、RHEL 高可用性クラスターのサポートポリシー を参照してください。
48.1. クラスターソフトウェアのインストール
以下の手順では、クラスターソフトウェアをインストールし、システムでクラスターの作成を設定するように設定します。
手順
クラスター内の各ノードで、システムアーキテクチャーに対応する高可用性のリポジトリーを有効にします。たとえば、x86_64 システムの高可用性リポジトリーを有効にするには、以下の
subscription-managerコマンドを入力します。# subscription-manager repos --enable=rhel-8-for-x86_64-highavailability-rpmsクラスターの各ノードに、Red Hat High Availability Add-On ソフトウェアパッケージと、使用可能なすべてのフェンスエージェントを、High Availability チャンネルからインストールします。
# yum install pcs pacemaker fence-agents-allまたは、次のコマンドを実行して、Red Hat High Availability Add-On ソフトウェアパッケージと、必要なフェンスエージェントのみをインストールすることもできます。
# yum install pcs pacemaker fence-agents-model次のコマンドは、利用できるフェンスエージェントのリストを表示します。
# rpm -q -a | grep fence fence-agents-rhevm-4.0.2-3.el7.x86_64 fence-agents-ilo-mp-4.0.2-3.el7.x86_64 fence-agents-ipmilan-4.0.2-3.el7.x86_64 ...警告Red Hat High Availability Add-On パッケージをインストールしたら、自動的に何もインストールされないように、ソフトウェア更新設定を行う必要があります。実行中のクラスターにインストールすると、予期しない動作が発生する可能性があります。詳細は RHEL 高可用性またはレジリエントストレージクラスターにソフトウェア更新を適用するのに推奨されるプラクティス を参照してください。
firewalldデーモンを実行している場合は、次のコマンドを実行して、Red Hat High Availability Add-On で必要なポートを有効にします。注記firewalldデーモンがシステムにインストールされているかどうかを確認する場合は、rpm -q firewalldコマンドを実行します。firewalld デーモンがインストールされている場合は、firewall-cmd --stateコマンドで、実行しているかどうかを確認できます。# firewall-cmd --permanent --add-service=high-availability # firewall-cmd --add-service=high-availability注記クラスターコンポーネントの理想的なファイアウォール設定は、ローカル環境によって異なります。ここでは、ノードに複数のネットワークインターフェイスがあるかどうか、オフホストのファイアウォールがあるかどうかを検討しないといけない場合があります。この例では、Pacemaker クラスターで通常必要となるポートを開きますが、ローカル条件に合わせて変更する必要があります。High Availability Add-On のポートの有効化 では、Red Hat High Availability Add-On で有効にするポートと、各ポートの使用目的が説明されています。
pcsを使用してクラスターの設定やノード間の通信を行うため、pcsの管理アカウントとなるユーザー IDhaclusterのパスワードを各ノードに設定する必要があります。haclusterユーザーのパスワードは、各ノードで同じにすることが推奨されます。# passwd hacluster Changing password for user hacluster. New password: Retype new password: passwd: all authentication tokens updated successfully.クラスターを設定する前に、各ノードで、システムの起動時に
pcsdデーモンを起動できるように、デーモンを起動して有効にしておく必要があります。このデーモンは、pcsコマンドで動作し、クラスターのノード全体で設定を管理します。クラスターの各ノードで次のコマンドを実行して、システムの起動時に
pcsdサービスが起動し、pcsdが有効になるように設定します。# systemctl start pcsd.service # systemctl enable pcsd.service
48.2. pcp-zeroconf パッケージのインストール (推奨)
クラスターを設定する際に、PCP (Performance Co-Pilot) ツールの pcp-zeroconf パッケージをインストールすることが推奨されます。PCP は、RHEL システムに推奨される Red Hat の resource-monitoring ツールです。pcp-zeroconf パッケージをインストールすると、PCP を実行してパフォーマンス監視データを収集して、フェンシング、リソース障害、およびクラスターを中断するその他のイベントの調査に役立てることができます。
PCP が有効になっているクラスターデプロイメントには、/var/log/pcp/ を含むファイルシステムで PCP が取得したデータ用に十分な領域が必要です。PCP による一般的な領域使用はデプロイメントごとに異なりますが、通常 pcp-zeroconf のデフォルト設定を使用する場合は 10Gb で十分であり、環境によっては必要な量が少なくなることがあります。一般的なアクティビティーの 14 日間におけるこのディレクトリーの使用状況を監視すると、より正確な使用状況の概算値が得られます。
手順
pcp-zeroconf パッケージをインストールするには、次のコマンドを実行します。
# yum install pcp-zeroconf
このパッケージは pmcd を有効にし、10 秒間隔でデータキャプチャーを設定します。
PCP データの確認については、Red Hat ナレッジベースソリューション Why did a RHEL High Availability cluster node reboot - and how can I prevent it from happening again? を参照してください。
48.3. 高可用性クラスターの作成
以下の手順では、Red Hat High Availability Add-On クラスターを作成します。この手順の例では、ノード z1.example.com および z2.example.com で構成されるクラスターを作成します。
手順
pcsを実行するノードで、クラスター内の各ノードに対して、pcsユーザーhaclusterを認証します。次のコマンドは、
z1.example.comとz2.example.comで構成される 2 ノードクラスターの両ノードに対して、z1.example.comのhaclusterユーザーを認証します。[root@z1 ~]# pcs host auth z1.example.com z2.example.com Username: hacluster Password: z1.example.com: Authorized z2.example.com: Authorizedz1.example.comで以下のコマンドを実行し、2 つのノードz1.example.comとz2.example.comで構成される 2 ノードクラスターmy_clusterを作成します。これにより、クラスター設定ファイルが、クラスターの両ノードに伝搬されます。このコマンドには--startオプションが含まれます。このオプションを使用すると、クラスターの両ノードでクラスターサービスが起動します。[root@z1 ~]# pcs cluster setup my_cluster --start z1.example.com z2.example.comクラスターサービスを有効にし、ノードの起動時にクラスターの各ノードでクラスターサービスが実行するようにします。
注記使用している環境でクラスターサービスを無効のままにしておきたい場合などは、この手順を省略できます。この手順を行うことで、ノードがダウンした場合にクラスターやリソース関連の問題をすべて解決してから、そのノードをクラスターに戻すことができます。クラスターサービスを無効にしている場合には、ノードを再起動する時に
pcs cluster startコマンドを使用して手作業でサービスを起動しなければならないので注意してください。[root@z1 ~]# pcs cluster enable --all
pcs cluster status コマンドを使用するとクラスターの現在の状態を表示できます。pcs cluster setup コマンドで --start オプションを使用してクラスターサービスを起動した場合は、クラスターが稼働するのに時間が少しかかる可能性があるため、クラスターとその設定で後続の動作を実行する前に、クラスターが稼働していることを確認する必要があります。
[root@z1 ~]# pcs cluster status
Cluster Status:
Stack: corosync
Current DC: z2.example.com (version 2.0.0-10.el8-b67d8d0de9) - partition with quorum
Last updated: Thu Oct 11 16:11:18 2018
Last change: Thu Oct 11 16:11:00 2018 by hacluster via crmd on z2.example.com
2 Nodes configured
0 Resources configured
...48.4. 複数のリンクを使用した高可用性クラスターの作成
pcs cluster setup コマンドを使用して、各ノードにリンクをすべて指定することで、複数のリンクを持つ Red Hat High Availability クラスターを作成できます。
2 つのリンクを持つ 2 ノードクラスターを作成する基本的なコマンドの形式は、以下のとおりです。
pcs cluster setup pass:quotes[cluster_name] pass:quotes[node1_name] addr=pass:quotes[node1_link0_address] addr=pass:quotes[node1_link1_address] pass:quotes[node2_name] addr=pass:quotes[node2_link0_address] addr=pass:quotes[node2_link1_address]
このコマンドの完全な構文は、pcs(8) の man ページを参照してください。
複数のリンクを持つクラスターを作成する場合は、次に示す内容を検討してください。
-
addr=addressパラメーターの順番は重要です。ノード名の後に指定する最初のアドレスはlink0に使用され、2 番目以降のアドレスはlink1以降に順に使用されます。 -
デフォルトでは、リンクに
link_priorityが指定されていない場合、リンクの優先度はリンク番号と同じになります。リンクの優先度は、指定された順序に従って 0、1、2、3 などになり、0 はリンクの優先順位が最も高くなります。 -
デフォルトのリンクモードは
passiveで、リンク優先度の数字が最も小さいアクティブなリンクが使用されます。 -
link_modeおよびlink_priorityのデフォルト値では、指定された最初のリンクが最も優先度の高いリンクとして使用され、そのリンクが失敗した場合は、指定された次のリンクが使用されます。 -
デフォルトのトランスポートプロトコルである
knetトランスポートプロトコルを使用して、リンクを 8 つまで指定できます。 -
addr=パラメーターの数は、すべてのノードで同じでなければなりません。 -
RHEL 8.1 以降では、
pcs cluster link add、pcs cluster link remove、pcs cluster link delete、およびpcscluster link updateコマンドを使用して、既存のクラスター内のリンクを追加、削除、および変更できます。 - シングルリンククラスターと同様、1 つのリンクで IPv4 アドレスと IPv6 アドレスを混在させないでください。ただし、1 つのリンクで IPv4 を実行し、別のリンクで IPv6 を実行することはできます。
- シングルリンククラスターと同様、1 つのリンクで IPv4 アドレスと IPv6 アドレスが混在しない IPv4 アドレスまたは IPv6 アドレスで名前が解決される限り、アドレスを IP アドレスまたは名前として指定できます。
この例では、2 つのノード rh80-node1 と rh80-node2 で設定される 2 ノードクラスター my_twolink_cluster を作成します。rh80-node1 のインターフェイスとして、IP アドレス 192.168.122.201 を link0、192.168.123.201 を link1 に設定します。rh80-node2 のインターフェイスとして、IP アドレス 192.168.122.202 を link0、192.168.123.202 を link1 に設定します。
# pcs cluster setup my_twolink_cluster rh80-node1 addr=192.168.122.201 addr=192.168.123.201 rh80-node2 addr=192.168.122.202 addr=192.168.123.202
リンク優先度を、リンク番号であるデフォルト値とは異なる値に設定するには、pcs cluster setup コマンドの link_priority オプションを使用してリンクの優先度を設定します。以下の 2 つのコマンド例のそれぞれは、2 つのインターフェイスを持つ 2 ノードクラスターを作成し、最初のリンクであるリンク 0 のリンク優先度は 1 で、2 番目のリンクであるリンク 1 のリンク優先度は 0 です。リンク 1 が最初に使用され、リンク 0 はフェイルオーバーリンクとして機能します。リンクモードが指定されていないため、デフォルトの passive に設定されます。
これら 2 つのコマンドは同等です。link キーワードの後にリンク番号を指定しないと、pcs インターフェイスは使用されていない最も小さいリンク番号からリンク番号を自動的に追加します。
# pcs cluster setup my_twolink_cluster rh80-node1 addr=192.168.122.201 addr=192.168.123.201 rh80-node2 addr=192.168.122.202 addr=192.168.123.202 transport knet link link_priority=1 link link_priority=0
# pcs cluster setup my_twolink_cluster rh80-node1 addr=192.168.122.201 addr=192.168.123.201 rh80-node2 addr=192.168.122.202 addr=192.168.123.202 transport knet link linknumber=1 link_priority=0 link link_priority=1リンクが複数ある既存のクラスターにノードを追加する方法は、リンクが複数あるクラスターへのノードの追加 を参照してください。
リンクが複数ある既存のクラスターにおいてリンクを変更する方法は、既存のクラスターへのリンクの追加および修正 を参照してください。
48.5. フェンシングの設定
クラスターの各ノードにフェンシングデバイスを設定する必要があります。フェンシングの設定コマンドおよびオプションに関する情報は Red Hat High Availability クラスターでのフェンシングの設定 を参照してください。
フェンシングに関する一般的な情報と、Red Hat High Availability クラスターにおけるその重要性については、Red Hat ナレッジベースソリューション Fencing in a Red Hat High Availability Cluster を参照してください。
フェンシングデバイスを設定する場合は、そのデバイスが、クラスター内のノードまたはデバイスと電源を共有しているかどうかに注意する必要があります。ノードとそのフェンスデバイスが電源を共有していると、その電源をフェンスできず、フェンスデバイスが失われた場合は、クラスターがそのノードをフェンスできない可能性があります。このようなクラスターには、フェンスデバイスおよびノードに冗長電源を提供するか、電源を共有しない冗長フェンスデバイスが存在する必要があります。SBD やストレージフェンシングなど、その他のフェンシング方法でも、分離した電源供給の停止時に冗長性を得られます。
手順
ここでは、ホスト名が zapc.example.com の APC 電源スイッチを使用してノードをフェンスし、fence_apc_snmp フェンスエージェントを使用します。どちらのノードも同じフェンスエージェントでフェンシングされるため、pcmk_host_map オプションを使用して、両方のフェンシングデバイスを 1 つのリソースとして設定できます。
pcs stonith create コマンドを使用して、stonith リソースとしてデバイスを設定し、フェンシングデバイスを作成します。以下のコマンドは、z1.example.com ノードおよび z2.example.com ノードの fence_apc_snmp フェンスエージェントを使用する、stonith リソース myapc を設定します。pcmk_host_map オプションにより、z1.example.com がポート 1 にマップされ、z2.example.com がポート 2 にマップされます。APC デバイスのログイン値とパスワードはいずれも apc です。デフォルトでは、このデバイスは各ノードに対して、60 秒間隔で監視を行います。
また、ノードのホスト名を指定する際に、IP アドレスを使用できます。
[root@z1 ~]# pcs stonith create myapc fence_apc_snmp ipaddr="zapc.example.com" pcmk_host_map="z1.example.com:1;z2.example.com:2" login="apc" passwd="apc"以下のコマンドは、既存のフェンシングデバイスのパラメーターを表示します。
[root@rh7-1 ~]# pcs stonith config myapc
Resource: myapc (class=stonith type=fence_apc_snmp)
Attributes: ipaddr=zapc.example.com pcmk_host_map=z1.example.com:1;z2.example.com:2 login=apc passwd=apc
Operations: monitor interval=60s (myapc-monitor-interval-60s)フェンスデバイスの設定後に、デバイスをテストする必要があります。フェンスデバイスをテストする方法は フェンスデバイスのテスト を参照してください。
ネットワークインターフェイスを無効にしてフェンスデバイスのテストを実行しないでください。フェンシングが適切にテストされなくなります。
フェンシングを設定してクラスターが起動すると、タイムアウトに到達していなくても、ネットワークの再起動時に、ネットワークを再起動するノードのフェンシングが発生します。このため、ノードで意図しないフェンシングが発生しないように、クラスターサービスの実行中はネットワークサービスを再起動しないでください。
48.6. クラスター設定のバックアップおよび復元
以下のコマンドは、tar アーカイブのクラスター設定のバックアップを作成し、バックアップからすべてのノードのクラスター設定ファイルを復元します。
手順
以下のコマンドを使用して、tar アーカイブでクラスター設定をバックアップします。ファイル名を指定しないと、標準出力が使用されます。
pcs config backup filename
pcs config backup コマンドは、CIB に設定したようにクラスターの設定だけをバックアップします。リソースデーモンの設定は、このコマンドに含まれません。たとえば、クラスターで Apache リソースを設定すると、(CIB にある) リソース設定のバックアップが作成されますが、(/etc/httpd に設定したとおり) Apache デーモン設定と、そこで使用されるファイルのバックアップは作成されません。同様に、クラスターに設定されているデータベースリソースがある場合は、データベースそのもののバックアップが作成されません。ただし、データベースのリソース設定のバックアップ (CIB) は作成されます。
以下のコマンドを使用して、バックアップからすべてのクラスターノードのクラスター設定ファイルを復元します。--local オプションを指定すると、このコマンドを実行したノードでのみクラスター設定ファイルが復元されます。ファイル名を指定しないと、標準入力が使用されます。
pcs config restore [--local] [filename]48.7. High Availability Add-On のポートの有効化
クラスターコンポーネントの理想的なファイアウォール設定は、ローカル環境によって異なります。ここでは、ノードに複数のネットワークインターフェイスがあるかどうか、オフホストのファイアウォールがあるかどうかを検討しないといけない場合があります。
firewalld デーモンを実行している場合は、次のコマンドを実行して、Red Hat High Availability Add-On で必要なポートを有効にします。
# firewall-cmd --permanent --add-service=high-availability
# firewall-cmd --add-service=high-availabilityローカルの状況に合わせて開くポートを変更することが必要になる場合があります。
firewalld デーモンがシステムにインストールされているかどうかを確認する場合は、rpm -q firewalld コマンドを実行します。firewalld デーモンをインストールしている場合は、firewall-cmd --state コマンドを使用して、そのデーモンが実行しているかどうかを確認できます。
以下の表は、Red Hat High Availability Add-On で有効にするポートとポートの使用目的を説明します。
| ポート | 必要になる場合 |
|---|---|
| TCP 2224 |
すべてのノードに必要なデフォルトの
任意のノードの |
| TCP 3121 | クラスターに Pacemaker リモートノードがある場合に、すべてのノードで必須です。
完全なクラスターノードにある Pacemaker の |
| TCP 5403 |
|
| UDP 5404-5412 |
ノード間の通信を容易にするために corosync ノードで必須です。ポート 5404-5412 を開いて、任意のノードの |
| TCP 21064 |
DLM が必要なリソースがクラスターに含まれる場合に、すべてのノードで必須です (例: |
| TCP 9929、UDP 9929 | Booth チケットマネージャーを使用してマルチサイトクラスターを確立するときに、すべてのクラスターノード、および同じノードのいずれかからの接続に対して Booth アービトレーターノードで開いている必要があります。 |
第49章 Red Hat High Availability クラスターでのアクティブ/パッシブ Apache HTTP サーバーの設定
以下の手順では、2 ノードの Red Hat Enterprise Linux High Availability Add-On クラスターでアクティブ/パッシブ Apache HTTP サーバーを設定します。このユースケースでは、クライアントは Floating IP アドレスを使用して Apache HTTP サーバーにアクセスします。Web サーバーは、クラスターにある 2 つのノードのいずれかで実行します。Web サーバーが実行しているノードが正常に動作しなくなると、Web サーバーはクラスターの 2 番目のノードで再起動し、サービスの中断は最小限に抑えられます。
以下の図は、クラスターがネットワーク電源スイッチと共有ストレージで設定された 2 ノードの Red Hat High Availability クラスターであるクラスターの高レベルの概要を示しています。クライアントは仮想 IP を使用して Apache HTTP サーバーにアクセスするため、クラスターノードはパブリックネットワークに接続されます。Apache サーバーは、ノード 1 またはノード 2 のいずれかで実行します。いずれのノードも、Apache のデータが保持されるストレージにアクセスできます。この図では、Web サーバーがノード 1 で実行しており、ノード 1 が正常に動作しなくなると、ノード 2 がサーバーを実行できます。
図49.1 2 ノードの Red Hat High Availability クラスターの Apache
このユースケースでは、システムに以下のコンポーネントが必要です。
- 各ノードに電源フェンスが設定されている 2 ノードの Red Hat High Availability クラスター。プライベートネットワークが推奨されますが、必須ではありません。この手順では、Pacemaker を使用した Red Hat High Availability クラスターの作成 で説明されているサンプルのクラスターを使用します。
- Apache に必要なパブリック仮想 IP アドレス。
- iSCSI、ファイバーチャネル、またはその他の共有ネットワークデバイスを使用する、クラスター内のノードの共有ストレージ。
クラスターは、Web サーバーで必要な LVM リソース、ファイルシステムリソース、IP アドレスリソース、Web サーバーリソースなどのクラスターコンポーネントを含む Apache リソースグループで設定されます。このリソースグループは、クラスター内のあるノードから別のノードへのフェイルオーバーが可能なため、いずれのノードでも Web サーバーを実行できます。このクラスターのリソースグループを作成する前に、以下の手順を実行します。
-
論理ボリューム
my_lv上に XFS ファイルシステムを設定します。 - Web サーバーを設定します。
上記の手順をすべて完了したら、リソースグループと、そのグループに追加するリソースを作成します。
49.1. Pacemaker クラスターで XFS ファイルシステムを使用して LVM ボリュームを設定する
この手順では、クラスターのノード間で共有されているストレージに LVM 論理ボリュームを作成します。
LVM ボリュームと、クラスターノードで使用するパーティションおよびデバイスは、クラスターノード以外には接続しないでください。
次の手順では、LVM 論理ボリュームを作成し、そのボリューム上に Pacemaker クラスターで使用する XFS ファイルシステムを作成します。この例では、LVM 論理ボリュームを作成する LVM 物理ボリュームを保管するのに、共有パーティション /dev/sdb1 が使用されます。
手順
クラスターの両ノードで以下の手順を実行し、LVM システム ID の値を、システムの
uname識別子の値に設定します。LVM システム ID を使用すると、クラスターのみがボリュームグループをアクティブにできるようになります。/etc/lvm/lvm.conf設定ファイルのsystem_id_source設定オプションをunameに設定します。# Configuration option global/system_id_source. system_id_source = "uname"ノードの LVM システム ID が、ノードの
unameに一致することを確認します。# lvm systemid system ID: z1.example.com # uname -n z1.example.com
LVM ボリュームを作成し、そのボリューム上に XFS ファイルシステムを作成します。
/dev/sdb1パーティションは共有されるストレージであるため、この手順のこの部分は、1 つのノードでのみ実行してください。[root@z1 ~]# pvcreate /dev/sdb1 Physical volume "/dev/sdb1" successfully created注記LVM ボリュームグループに、iSCSI ターゲットなど、リモートブロックストレージに存在する 1 つ以上の物理ボリュームが含まれている場合は、Red Hat は、Pacemaker が起動する前にサービスが開始されるように設定することを推奨します。Pacemaker クラスターによって使用されるリモート物理ボリュームの起動順序の設定は、Pacemaker で管理されないリソース依存関係の起動順序の設定 を参照してください。
物理ボリューム
/dev/sdb1で構成されるボリュームグループmy_vgを作成します。RHEL 8.5 以降では、
--setautoactivation nフラグを指定して、クラスターで Pacemaker が管理するボリュームグループが起動時に自動的にアクティブにならないようにします。作成する LVM ボリュームに既存のボリュームグループを使用している場合は、ボリュームグループでvgchange --setautoactivation nコマンドを使用して、このフラグをリセットできます。[root@z1 ~]# vgcreate --setautoactivation n my_vg /dev/sdb1 Volume group "my_vg" successfully createdRHEL 8.4 以前の場合は、以下のコマンドでボリュームグループを作成します。
[root@z1 ~]# vgcreate my_vg /dev/sdb1 Volume group "my_vg" successfully createdRHEL 8.4 以前においてクラスターの Pacemaker が管理するボリュームグループが起動時に自動でアクティベートされないようにする方法は、複数のクラスターノードでボリュームグループがアクティブにならないようにする方法 を参照してください。
新規ボリュームグループには、実行中のノードで、かつボリュームグループの作成元であるノードのシステム ID があることを確認します。
[root@z1 ~]# vgs -o+systemid VG #PV #LV #SN Attr VSize VFree System ID my_vg 1 0 0 wz--n- <1.82t <1.82t z1.example.comボリュームグループ
my_vgを使用して、論理ボリュームを作成します。[root@z1 ~]# lvcreate -L450 -n my_lv my_vg Rounding up size to full physical extent 452.00 MiB Logical volume "my_lv" createdlvsコマンドを使用して論理ボリュームを表示してみます。[root@z1 ~]# lvs LV VG Attr LSize Pool Origin Data% Move Log Copy% Convert my_lv my_vg -wi-a---- 452.00m ...論理ボリューム
my_lv上に XFS ファイルシステムを作成します。[root@z1 ~]# mkfs.xfs /dev/my_vg/my_lv meta-data=/dev/my_vg/my_lv isize=512 agcount=4, agsize=28928 blks = sectsz=512 attr=2, projid32bit=1 ...
(RHEL 8.5 以降)
lvm.confファイルでuse_devicesfile = 1を設定してデバイスファイルの使用を有効にした場合は、クラスター内の 2 番目のノードのデバイスファイルに共有デバイスを追加します。デフォルトでは、デバイスファイルの使用は有効になっていません。[root@z2 ~]# lvmdevices --adddev /dev/sdb1
49.2. 複数のクラスターノードでボリュームグループがアクティブにならないようにする方法 (RHEL 8.4 以前)
以下の手順で、クラスター内の Pacemaker が管理するボリュームグループが起動時に自動でアクティベートされないようにすることができます。Pacemaker ではなく、システムの起動時にボリュームグループが自動的にアクティブになる場合は、ボリュームグループが同時に複数のノードでアクティブになるリスクがあり、ボリュームグループのメタデータが破損する可能性があります。
RHEL 8.5 以降では、vgcreate コマンドに --setautoactivation n フラグを指定して、ボリュームグループを作成する場合、ボリュームグループの自動アクティベーションを無効にすることができます (Pacemaker クラスターで XFS ファイルシステムを使用して、LVM ボリュームを設定する を参照)。
この手順では、/etc/lvm/lvm.conf 設定ファイルの auto_activation_volume_list エントリーを変更します。auto_activation_volume_list エントリーは、自動アクティブ化を特定の論理ボリュームに制限するために使用されます。auto_activation_volume_list を空のリストに設定すると、自動アクティベーションは完全に無効になります。
ノードのローカルにある root およびホームディレクトリーに関係のあるボリュームグループなど、Pacemaker で管理されていないまたは共有されていないローカルのボリュームは、auto_activation_volume_list に含める必要があります。クラスターマネージャーが管理するボリュームグループはすべて、auto_activation_volume_list エントリーから除外する必要があります。
手順
クラスター内の各ノードで以下の手順を実行します。
以下のコマンドを使用して、ローカルストレージに現在設定されているボリュームグループを確認します。これにより、現在設定されているボリュームグループのリストが出力されます。このノードの root とホームディレクトリーに、別のボリュームグループの領域を割り当てると、この例のように以下のボリュームが出力に表示されます。
# vgs --noheadings -o vg_name my_vg rhel_home rhel_root/etc/lvm/lvm.conf設定ファイルのauto_activation_volume_listへのエントリーとして、my_vg以外のボリュームグループ (クラスターに定義したボリュームグループ) を追加します。たとえば、root とホームディレクトリーに別のボリュームグループの領域が割り当てられている場合は、以下のように
lvm.confファイルのauto_activation_volume_list行をアンコメントし、これらのボリュームグループをエントリーとしてauto_activation_volume_listに追加します。クラスターに対してだけ定義したボリュームグループ (この例ではmy_vg) は、このリストは含まれない点に注意してください。auto_activation_volume_list = [ "rhel_root", "rhel_home" ]注記クラスターマネージャーの外部でアクティベートするノードにローカルボリュームグループが存在しない場合は、
auto_activation_volume_listエントリーをauto_activation_volume_list = []として初期化する必要があります。initramfsブートイメージを再構築して、クラスターが制御するボリュームグループがブートイメージによりアクティベートされないようにします。以下のコマンドを使用して、initramfsデバイスを更新します。このコマンドが完了するまで最大 1 分かかる場合があります。# dracut -H -f /boot/initramfs-$(uname -r).img $(uname -r)ノードを再起動します。
注記ブートイメージを作成したノードを起動してから、新しい Linux カーネルをインストールした場合は、新しい
initrdイメージは、作成時に実行していたカーネル用で、ノードの再起動時に実行している新しいカーネル用ではありません。再起動の前後でuname -rコマンドを使用して実行しているカーネルリリースを確認し必ず正しいinitrdデバイスを使用するよう注意してください。リリースが同じでない場合には、新規カーネルで再起動した後にinitrdファイルを更新して、ノードを再起動します。ノードが再起動したら
pcs cluster statusコマンドを実行し、クラスターサービスがそのノードで再度開始されたかどうかを確認します。Error: cluster is not running on this nodeというメッセージが表示される場合は、以下のコマンドを入力します。# pcs cluster startまたは、クラスターの各ノードを再起動して、クラスターの全ノードでクラスターサービスを開始するまで待機するには、次のコマンドを使用します。
# pcs cluster start --all
49.3. Apache HTTP サーバーの設定
次の手順に従って Apache HTTP サーバーを設定します。
手順
クラスターの各ノードに、Apache HTTP サーバーがインストールされていることを確認します。Apache HTTP サーバーのステータスを確認するには、クラスターに
wgetツールがインストールされている必要があります。各ノードで、以下のコマンドを実行します。
# yum install -y httpd wgetfirewalldデーモンを実行している場合は、クラスターの各ノードで、Red Hat High Availability Add-On に必要なポートを有効にし、httpdの実行に必要なポートを有効にします。以下の例では、一般からのアクセス用にhttpdのポートを有効にしていますが、httpd用に有効にする具体的なポートは、本番環境のユースケースでは異なる場合があります。# firewall-cmd --permanent --add-service=http # firewall-cmd --permanent --zone=public --add-service=http # firewall-cmd --reloadApache リソースエージェントが、クラスターの各ノードで Apache のステータスを取得できるようにするため、既存の設定に以下の内容を追加して、ステータスサーバーの URL を有効にします。
# cat <<-END > /etc/httpd/conf.d/status.conf <Location /server-status> SetHandler server-status Require local </Location> ENDApache で提供する Web ページを作成します。
クラスター内の 1 つのノードで、XFS ファイルシステムを使用した LVM ボリュームの設定 で作成した論理ボリュームがアクティブになっていることを確認し、作成したファイルシステムをその論理ボリュームにマウントし、そのファイルシステムにファイル
index.htmlを作成します。次に、ファイルシステムをアンマウントします。# lvchange -ay my_vg/my_lv # mount /dev/my_vg/my_lv /var/www/ # mkdir /var/www/html # mkdir /var/www/cgi-bin # mkdir /var/www/error # restorecon -R /var/www # cat <<-END >/var/www/html/index.html <html> <body>Hello</body> </html> END # umount /var/www
49.4. リソースおよびリソースグループの作成
次の手順でクラスターのリソースを作成します。すべてのリソースが必ず同じノードで実行するように、このリソースを、リソースグループ apachegroup に追加します。作成するリソースは以下のとおりで、開始する順に記載されています。
-
XFS ファイルシステムを使用した LVM ボリュームの設定 で作成した LVM ボリュームグループを使用する
my_lvmという名前のLVM-activateリソース。 -
XFS ファイルシステムを使用した LVM ボリュームの設定 で作成したファイルシステムデバイス
/dev/my_vg/my_lvを使用する、my_fsという名前のFilesystemリソース。 -
apachegroupリソースグループの Floating IP アドレスであるIPaddr2リソース。物理ノードに関連付けられている IP アドレスは使用できません。IPaddr2リソースの NIC デバイスを指定していない場合は、そのノードに静的に割り当てられている IP アドレスの 1 つと同じネットワークに Floating IP が存在していないと、Floating IP アドレスを割り当てる NIC デバイスが適切に検出されません。 -
Apache HTTP サーバーの設定で定義した
index.htmlファイルと Apache 設定を使用するWebsiteという名前のapacheリソース
以下の手順で、apachegroup リソースグループと、このグループに追加するリソースを作成します。リソースは、グループに追加された順序で起動し、その逆の順序で停止します。この手順は、クラスター内のいずれかのノードで実行してください。
手順
次のコマンドは、
LVM が有効なリソースmy_lvmを作成します。リソースグループapachegroupは存在しないため、このコマンドによりリソースグループが作成されます。注記アクティブ/パッシブの HA 設定で、同じ LVM ボリュームグループを使用する
LVM が有効なリソースを複数設定するとデータが破損する場合があるため、そのようなリソースは 1 つ以上設定しないでください。また、LVM が有効なリソースは、アクティブ/パッシブの HA 設定のクローンリソースとして設定しないでください。[root@z1 ~]# pcs resource create my_lvm ocf:heartbeat:LVM-activate vgname=my_vg vg_access_mode=system_id --group apachegroupリソースを作成すると、そのリソースは自動的に起動します。以下のコマンドを使用すると、リソースが作成され、起動していることを確認できます。
# pcs resource status Resource Group: apachegroup my_lvm (ocf::heartbeat:LVM-activate): Startedpcs resource disableとpcs resource enableのコマンドを使用すると手作業によるリソースの停止と起動をリソースごと個別に行うことができます。以下のコマンドでは、設定に必要な残りのリソースを作成し、作成したリソースを既存の
apachegroupリソースグループに追加します。[root@z1 ~]# pcs resource create my_fs Filesystem device="/dev/my_vg/my_lv" directory="/var/www" fstype="xfs" --group apachegroup [root@z1 ~]# pcs resource create VirtualIP IPaddr2 ip=198.51.100.3 cidr_netmask=24 --group apachegroup [root@z1 ~]# pcs resource create Website apache configfile="/etc/httpd/conf/httpd.conf" statusurl="http://127.0.0.1/server-status" --group apachegroupリソースと、そのリソースを含むリソースグループの作成が完了したら、クラスターのステータスを確認します。4 つのリソースがすべて同じノードで実行していることに注意してください。
[root@z1 ~]# pcs status Cluster name: my_cluster Last updated: Wed Jul 31 16:38:51 2013 Last change: Wed Jul 31 16:42:14 2013 via crm_attribute on z1.example.com Stack: corosync Current DC: z2.example.com (2) - partition with quorum Version: 1.1.10-5.el7-9abe687 2 Nodes configured 6 Resources configured Online: [ z1.example.com z2.example.com ] Full list of resources: myapc (stonith:fence_apc_snmp): Started z1.example.com Resource Group: apachegroup my_lvm (ocf::heartbeat:LVM-activate): Started z1.example.com my_fs (ocf::heartbeat:Filesystem): Started z1.example.com VirtualIP (ocf::heartbeat:IPaddr2): Started z1.example.com Website (ocf::heartbeat:apache): Started z1.example.comクラスターのフェンシングデバイスを設定していないと、リソースがデフォルトで起動しません。
クラスターが稼働したら、ブラウザーで、
IPaddr2リソースとして定義した IP アドレスを指定して、"Hello" と単語が表示されるサンプル表示を確認します。Hello設定したリソースが実行されていない場合は、
pcs resource debug-start resourceコマンドを実行してリソースの設定をテストできます。apacheリソースエージェントを使用して Apache を管理する場合はsystemdが使用されません。そのため、Apache のリロードにsystemctlが使用されないようにするため、Apache によって提供されるlogrotateスクリプトを編集する必要があります。クラスター内の各ノード上で、
/etc/logrotate.d/httpdファイルから以下の行を削除します。/bin/systemctl reload httpd.service > /dev/null 2>/dev/null || trueRHEL 8.6 以降の場合は、削除した行を次の 3 行に置き換え、PID ファイルパスとして
/var/run/httpd-website.pidを指定します。ここの website は、Apache リソースの名前になります。この例では、Apache リソース名はWebsiteです。/usr/bin/test -f /var/run/httpd-Website.pid >/dev/null 2>/dev/null && /usr/bin/ps -q $(/usr/bin/cat /var/run/httpd-Website.pid) >/dev/null 2>/dev/null && /usr/sbin/httpd -f /etc/httpd/conf/httpd.conf -c "PidFile /var/run/httpd-Website.pid" -k graceful > /dev/null 2>/dev/null || trueRHEL 8.5 以前の場合は、削除した行を次の 3 行に置き換えます。
/usr/bin/test -f /run/httpd.pid >/dev/null 2>/dev/null && /usr/bin/ps -q $(/usr/bin/cat /run/httpd.pid) >/dev/null 2>/dev/null && /usr/sbin/httpd -f /etc/httpd/conf/httpd.conf -c "PidFile /run/httpd.pid" -k graceful > /dev/null 2>/dev/null || true
49.5. リソース設定のテスト
次の手順でクラスター内のリソース設定をテストします。
リソースおよびリソースグループの作成 で説明するクラスターのステータス表示では、すべてのリソースが z1.example.com ノードで実行されます。以下の手順に従い、1 番目のノードを スタンバイ モードにし、リソースグループが z2.example.com ノードにフェイルオーバーするかどうかをテストします。1 番目のノードをスタンバイモードにすると、このノードはリソースをホストできなくなります。
手順
以下のコマンドは、
z1.example.comノードをスタンバイモードにします。[root@z1 ~]# pcs node standby z1.example.comz1をスタンバイモードにしたら、クラスターのステータスを確認します。リソースはすべてz2で実行しているはずです。[root@z1 ~]# pcs status Cluster name: my_cluster Last updated: Wed Jul 31 17:16:17 2013 Last change: Wed Jul 31 17:18:34 2013 via crm_attribute on z1.example.com Stack: corosync Current DC: z2.example.com (2) - partition with quorum Version: 1.1.10-5.el7-9abe687 2 Nodes configured 6 Resources configured Node z1.example.com (1): standby Online: [ z2.example.com ] Full list of resources: myapc (stonith:fence_apc_snmp): Started z1.example.com Resource Group: apachegroup my_lvm (ocf::heartbeat:LVM-activate): Started z2.example.com my_fs (ocf::heartbeat:Filesystem): Started z2.example.com VirtualIP (ocf::heartbeat:IPaddr2): Started z2.example.com Website (ocf::heartbeat:apache): Started z2.example.com定義している IP アドレスの Web サイトは、中断せず表示されているはずです。
スタンバイモードからz1を削除するには、以下のコマンドを実行します。[root@z1 ~]# pcs node unstandby z1.example.com注記ノードを
スタンバイモードから削除しても、リソースはそのノードにフェイルオーバーしません。これは、リソースのresource-stickiness値により異なります。resource-stickinessメタ属性については、現在のノードを優先するようにリソースを設定する を参照してください。
第50章 Red Hat High Availability クラスターのアクティブ/パッシブな NFS サーバーの設定
Red Hat High Availability Add-On は、共有ストレージを使用して Red Hat Enterprise Linux High Availability アドオンクラスターで高可用性アクティブ/パッシブ NFS サーバーを実行するためのサポートを提供します。次の例では、クライアントが Floating IP アドレスを介して NFS ファイルシステムにアクセスする 2 ノードクラスターを設定します。NFS サービスは、クラスターにある 2 つのノードのいずれかで実行します。NFS サーバーが実行しているノードが正常に動作しなくなると、NFS サーバーはクラスターの 2 番目のノードで再起動し、サービスの中断が最小限に抑えられます。
このユースケースでは、システムに以下のコンポーネントが必要です。
- 各ノードに電源フェンスが設定されている 2 ノードの Red Hat High Availability クラスター。プライベートネットワークが推奨されますが、必須ではありません。この手順では、Pacemaker を使用した Red Hat High Availability クラスターの作成 で説明されているサンプルのクラスターを使用します。
- NFS サーバーに必要なパブリック仮想 IP アドレス。
- iSCSI、ファイバーチャネル、またはその他の共有ネットワークデバイスを使用する、クラスター内のノードの共有ストレージ。
既存の 2 ノードの Red Hat Enterprise Linux High Availability クラスターで高可用性アクティブ/パッシブ NFS サーバーを設定するには、以下の手順を実行する必要があります。
- クラスターのノード用に、共有ストレージの LVM 論理ボリュームにファイルシステムを設定します。
- 共有ストレージの LVM 論理ボリュームで NFS 共有を設定する。
- クラスターリソースを作成する。
- 設定した NFS サーバーをテストする。
50.1. Pacemaker クラスターで XFS ファイルシステムを使用して LVM ボリュームを設定する
この手順では、クラスターのノード間で共有されているストレージに LVM 論理ボリュームを作成します。
LVM ボリュームと、クラスターノードで使用するパーティションおよびデバイスは、クラスターノード以外には接続しないでください。
次の手順では、LVM 論理ボリュームを作成し、そのボリューム上に Pacemaker クラスターで使用する XFS ファイルシステムを作成します。この例では、LVM 論理ボリュームを作成する LVM 物理ボリュームを保管するのに、共有パーティション /dev/sdb1 が使用されます。
手順
クラスターの両ノードで以下の手順を実行し、LVM システム ID の値を、システムの
uname識別子の値に設定します。LVM システム ID を使用すると、クラスターのみがボリュームグループをアクティブにできるようになります。/etc/lvm/lvm.conf設定ファイルのsystem_id_source設定オプションをunameに設定します。# Configuration option global/system_id_source. system_id_source = "uname"ノードの LVM システム ID が、ノードの
unameに一致することを確認します。# lvm systemid system ID: z1.example.com # uname -n z1.example.com
LVM ボリュームを作成し、そのボリューム上に XFS ファイルシステムを作成します。
/dev/sdb1パーティションは共有されるストレージであるため、この手順のこの部分は、1 つのノードでのみ実行してください。[root@z1 ~]# pvcreate /dev/sdb1 Physical volume "/dev/sdb1" successfully created注記LVM ボリュームグループに、iSCSI ターゲットなど、リモートブロックストレージに存在する 1 つ以上の物理ボリュームが含まれている場合は、Red Hat は、Pacemaker が起動する前にサービスが開始されるように設定することを推奨します。Pacemaker クラスターによって使用されるリモート物理ボリュームの起動順序の設定は、Pacemaker で管理されないリソース依存関係の起動順序の設定 を参照してください。
物理ボリューム
/dev/sdb1で構成されるボリュームグループmy_vgを作成します。RHEL 8.5 以降では、
--setautoactivation nフラグを指定して、クラスターで Pacemaker が管理するボリュームグループが起動時に自動的にアクティブにならないようにします。作成する LVM ボリュームに既存のボリュームグループを使用している場合は、ボリュームグループでvgchange --setautoactivation nコマンドを使用して、このフラグをリセットできます。[root@z1 ~]# vgcreate --setautoactivation n my_vg /dev/sdb1 Volume group "my_vg" successfully createdRHEL 8.4 以前の場合は、以下のコマンドでボリュームグループを作成します。
[root@z1 ~]# vgcreate my_vg /dev/sdb1 Volume group "my_vg" successfully createdRHEL 8.4 以前においてクラスターの Pacemaker が管理するボリュームグループが起動時に自動でアクティベートされないようにする方法は、複数のクラスターノードでボリュームグループがアクティブにならないようにする方法 を参照してください。
新規ボリュームグループには、実行中のノードで、かつボリュームグループの作成元であるノードのシステム ID があることを確認します。
[root@z1 ~]# vgs -o+systemid VG #PV #LV #SN Attr VSize VFree System ID my_vg 1 0 0 wz--n- <1.82t <1.82t z1.example.comボリュームグループ
my_vgを使用して、論理ボリュームを作成します。[root@z1 ~]# lvcreate -L450 -n my_lv my_vg Rounding up size to full physical extent 452.00 MiB Logical volume "my_lv" createdlvsコマンドを使用して論理ボリュームを表示してみます。[root@z1 ~]# lvs LV VG Attr LSize Pool Origin Data% Move Log Copy% Convert my_lv my_vg -wi-a---- 452.00m ...論理ボリューム
my_lv上に XFS ファイルシステムを作成します。[root@z1 ~]# mkfs.xfs /dev/my_vg/my_lv meta-data=/dev/my_vg/my_lv isize=512 agcount=4, agsize=28928 blks = sectsz=512 attr=2, projid32bit=1 ...
(RHEL 8.5 以降)
lvm.confファイルでuse_devicesfile = 1を設定してデバイスファイルの使用を有効にした場合は、クラスター内の 2 番目のノードのデバイスファイルに共有デバイスを追加します。デフォルトでは、デバイスファイルの使用は有効になっていません。[root@z2 ~]# lvmdevices --adddev /dev/sdb1
50.2. 複数のクラスターノードでボリュームグループがアクティブにならないようにする方法 (RHEL 8.4 以前)
以下の手順で、クラスター内の Pacemaker が管理するボリュームグループが起動時に自動でアクティベートされないようにすることができます。Pacemaker ではなく、システムの起動時にボリュームグループが自動的にアクティブになる場合は、ボリュームグループが同時に複数のノードでアクティブになるリスクがあり、ボリュームグループのメタデータが破損する可能性があります。
RHEL 8.5 以降では、vgcreate コマンドに --setautoactivation n フラグを指定して、ボリュームグループを作成する場合、ボリュームグループの自動アクティベーションを無効にすることができます (Pacemaker クラスターで XFS ファイルシステムを使用して、LVM ボリュームを設定する を参照)。
この手順では、/etc/lvm/lvm.conf 設定ファイルの auto_activation_volume_list エントリーを変更します。auto_activation_volume_list エントリーは、自動アクティブ化を特定の論理ボリュームに制限するために使用されます。auto_activation_volume_list を空のリストに設定すると、自動アクティベーションは完全に無効になります。
ノードのローカルにある root およびホームディレクトリーに関係のあるボリュームグループなど、Pacemaker で管理されていないまたは共有されていないローカルのボリュームは、auto_activation_volume_list に含める必要があります。クラスターマネージャーが管理するボリュームグループはすべて、auto_activation_volume_list エントリーから除外する必要があります。
手順
クラスター内の各ノードで以下の手順を実行します。
以下のコマンドを使用して、ローカルストレージに現在設定されているボリュームグループを確認します。これにより、現在設定されているボリュームグループのリストが出力されます。このノードの root とホームディレクトリーに、別のボリュームグループの領域を割り当てると、この例のように以下のボリュームが出力に表示されます。
# vgs --noheadings -o vg_name my_vg rhel_home rhel_root/etc/lvm/lvm.conf設定ファイルのauto_activation_volume_listへのエントリーとして、my_vg以外のボリュームグループ (クラスターに定義したボリュームグループ) を追加します。たとえば、root とホームディレクトリーに別のボリュームグループの領域が割り当てられている場合は、以下のように
lvm.confファイルのauto_activation_volume_list行をアンコメントし、これらのボリュームグループをエントリーとしてauto_activation_volume_listに追加します。クラスターに対してだけ定義したボリュームグループ (この例ではmy_vg) は、このリストは含まれない点に注意してください。auto_activation_volume_list = [ "rhel_root", "rhel_home" ]注記クラスターマネージャーの外部でアクティベートするノードにローカルボリュームグループが存在しない場合は、
auto_activation_volume_listエントリーをauto_activation_volume_list = []として初期化する必要があります。initramfsブートイメージを再構築して、クラスターが制御するボリュームグループがブートイメージによりアクティベートされないようにします。以下のコマンドを使用して、initramfsデバイスを更新します。このコマンドが完了するまで最大 1 分かかる場合があります。# dracut -H -f /boot/initramfs-$(uname -r).img $(uname -r)ノードを再起動します。
注記ブートイメージを作成したノードを起動してから、新しい Linux カーネルをインストールした場合は、新しい
initrdイメージは、作成時に実行していたカーネル用で、ノードの再起動時に実行している新しいカーネル用ではありません。再起動の前後でuname -rコマンドを使用して実行しているカーネルリリースを確認し必ず正しいinitrdデバイスを使用するよう注意してください。リリースが同じでない場合には、新規カーネルで再起動した後にinitrdファイルを更新して、ノードを再起動します。ノードが再起動したら
pcs cluster statusコマンドを実行し、クラスターサービスがそのノードで再度開始されたかどうかを確認します。Error: cluster is not running on this nodeというメッセージが表示される場合は、以下のコマンドを入力します。# pcs cluster startまたは、クラスターの各ノードを再起動して、クラスターの全ノードでクラスターサービスを開始するまで待機するには、次のコマンドを使用します。
# pcs cluster start --all
50.4. クラスターの NFS サーバーへリソースおよびリソースグループを設定
以下の手順で、クラスター内の NFS サーバーのクラスターリソースを設定します。
クラスターにフェンシングデバイスを設定していないと、リソースはデフォルトでは起動しないことに注意してください。
設定したリソースが実行していない場合は、pcs resource debug-start resource コマンドを実行して、リソースの設定をテストします。このコマンドは、クラスターの制御や認識の範囲外でサービスを起動します。設定したリソースが再稼働したら、pcs resource cleanup resource を実行して、クラスターが更新を認識するようにします。
手順
以下の手順では、システムリソースを設定します。これらのリソースがすべて同じノードで実行するように、これらのリソースはリソースグループ nfsgroup に含まれます。リソースは、グループに追加された順序で起動し、その逆の順序で停止します。この手順は、クラスター内のいずれかのノードで実行してください。
LVM が有効なリソース
my_lvmを作成します。リソースグループmy_lvmは存在しないため、このコマンドによりリソースグループが作成されます。警告データ破損のリスクとなるため、アクティブ/パッシブの HA 設定で、同じ LVM ボリュームグループを使用する
LVM が有効なリソースを複数設定しないでください。また、LVM が有効なリソースは、アクティブ/パッシブの HA 設定のクローンリソースとして設定しないでください。[root@z1 ~]# pcs resource create my_lvm ocf:heartbeat:LVM-activate vgname=my_vg vg_access_mode=system_id --group nfsgroupクラスターのステータスを確認し、リソースが実行していることを確認します。
root@z1 ~]# pcs status Cluster name: my_cluster Last updated: Thu Jan 8 11:13:17 2015 Last change: Thu Jan 8 11:13:08 2015 Stack: corosync Current DC: z2.example.com (2) - partition with quorum Version: 1.1.12-a14efad 2 Nodes configured 3 Resources configured Online: [ z1.example.com z2.example.com ] Full list of resources: myapc (stonith:fence_apc_snmp): Started z1.example.com Resource Group: nfsgroup my_lvm (ocf::heartbeat:LVM-activate): Started z1.example.com PCSD Status: z1.example.com: Online z2.example.com: Online Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabledクラスターに
Filesystemリソースを設定します。次のコマンドは、
nfsshareという名前の XFSFilesystemリソースをnfsgroupリソースグループの一部として設定します。このファイルシステムは、XFS ファイルシステムを使用した LVM ボリュームの設定 で作成した LVM ボリュームグループと XFS ファイルシステムを使用し、NFS 共有の設定 で作成した/nfsshareディレクトリーにマウントされます。[root@z1 ~]# pcs resource create nfsshare Filesystem device=/dev/my_vg/my_lv directory=/nfsshare fstype=xfs --group nfsgroupoptions=optionsパラメーターを使用すると、Filesystemリソースのリソース設定にマウントオプションを指定できます。すべての設定オプションを確認する場合は、pcs resource describe Filesystemコマンドを実行します。my_lvmリソースおよびnfsshareリソースが実行していることを確認します。[root@z1 ~]# pcs status ... Full list of resources: myapc (stonith:fence_apc_snmp): Started z1.example.com Resource Group: nfsgroup my_lvm (ocf::heartbeat:LVM-activate): Started z1.example.com nfsshare (ocf::heartbeat:Filesystem): Started z1.example.com ...nfsgroupリソースグループに、nfs-daemonという名前のnfsserverリソースを作成します。注記nfsserverリソースを使用して、nfs_shared_infodirパラメーターを指定できます。これは、NFS サーバーが、NFS 関連のステートフル情報を保管するのに使用するディレクトリーです。この属性は、このエクスポートのコレクションで作成した
Filesystemリソースのいずれかのサブディレクトリーに設定することが推奨されます。これにより、NFS サーバーは、このリソースグループを再配置する必要がある場合に別のノードで使用できるデバイスに、ステートフル情報を保存します。この例では、以下のように設定されています。-
/nfsshareは、Filesystemリソースにより管理される shared-storage ディレクトリーです。 -
/nfsshare/exports/export1および/nfsshare/exports/export2は、エクスポートディレクトリーです。 -
/nfsshare/nfsinfoは、nfsserverリソースの共有情報ディレクトリーです。
[root@z1 ~]# pcs resource create nfs-daemon nfsserver nfs_shared_infodir=/nfsshare/nfsinfo nfs_no_notify=true --group nfsgroup [root@z1 ~]# pcs status ...-
exportfsリソースを追加して、/nfsshare/exportsディレクトリーをエクスポートします。このリソースは、nfsgroupリソースグループに含まれます。これにより、NFSv4 クライアントの仮想ディレクトリーが構築されます。このエクスポートには、NFSv3 クライアントもアクセスできます。注記fsid=0オプションは、NFSv4 クライアントに仮想ディレクトリーを作成する場合にのみ必要です。詳細は、Red Hat ナレッジベースソリューション How do I configure the fsid option in an NFS server’s /etc/exports file? を参照してください。[root@z1 ~]# pcs resource create nfs-root exportfs clientspec=192.168.122.0/255.255.255.0 options=rw,sync,no_root_squash directory=/nfsshare/exports fsid=0 --group nfsgroup [root@z1 ~]# pcs resource create nfs-export1 exportfs clientspec=192.168.122.0/255.255.255.0 options=rw,sync,no_root_squash directory=/nfsshare/exports/export1 fsid=1 --group nfsgroup [root@z1 ~]# pcs resource create nfs-export2 exportfs clientspec=192.168.122.0/255.255.255.0 options=rw,sync,no_root_squash directory=/nfsshare/exports/export2 fsid=2 --group nfsgroupNFS 共有にアクセスするために、NFS クライアントが使用する Floating IP アドレスリソースを追加します。このリソースは、リソースグループ
nfsgroupに含まれます。このデプロイメント例では、192.168.122.200 を Floating IP アドレスとして使用します。[root@z1 ~]# pcs resource create nfs_ip IPaddr2 ip=192.168.122.200 cidr_netmask=24 --group nfsgroupNFS デプロイメント全体が初期化されたら、NFSv3 の再起動通知を送信する
nfsnotifyリソースを追加します。このリソースは、リソースグループnfsgroupに含まれます。注記NFS の通知が適切に処理されるようにするには、Floating IP アドレスにホスト名が関連付けられており、それが NFS サーバーと NFS クライアントで同じである必要があります。
[root@z1 ~]# pcs resource create nfs-notify nfsnotify source_host=192.168.122.200 --group nfsgroupリソースとリソースの制約を作成したら、クラスターのステータスを確認できます。すべてのリソースが同じノードで実行していることに注意してください。
[root@z1 ~]# pcs status ... Full list of resources: myapc (stonith:fence_apc_snmp): Started z1.example.com Resource Group: nfsgroup my_lvm (ocf::heartbeat:LVM-activate): Started z1.example.com nfsshare (ocf::heartbeat:Filesystem): Started z1.example.com nfs-daemon (ocf::heartbeat:nfsserver): Started z1.example.com nfs-root (ocf::heartbeat:exportfs): Started z1.example.com nfs-export1 (ocf::heartbeat:exportfs): Started z1.example.com nfs-export2 (ocf::heartbeat:exportfs): Started z1.example.com nfs_ip (ocf::heartbeat:IPaddr2): Started z1.example.com nfs-notify (ocf::heartbeat:nfsnotify): Started z1.example.com ...
50.5. NFS リソース設定のテスト
以下の手順を使用して、高可用性クラスターで NFS リソース設定を検証できます。NFSv3 または NFSv4 のいずれかで、エクスポートされたファイルシステムをマウントできるはずです。
50.5.1. NFS エクスポートのテスト
-
クラスターノードで
firewalldデーモンを実行している場合は、システムが NFS アクセスに必要とするポートがすべてのノードで有効になっていることを確認してください。 デプロイメントと同じネットワークにあるクラスター外部のノードで NFS 共有をマウントして、NFS 共有が表示されることを確認します。この例では、192.168.122.0/24 ネットワークを使用します。
# showmount -e 192.168.122.200 Export list for 192.168.122.200: /nfsshare/exports/export1 192.168.122.0/255.255.255.0 /nfsshare/exports 192.168.122.0/255.255.255.0 /nfsshare/exports/export2 192.168.122.0/255.255.255.0NFSv4 で NFS 共有をマウントできることを確認する場合は、クライアントノードのディレクトリーに NFS 共有をマウントします。マウントしたら、エクスポートディレクトリーの内容が表示されることを確認します。テスト後に共有をアンマウントします。
# mkdir nfsshare # mount -o "vers=4" 192.168.122.200:export1 nfsshare # ls nfsshare clientdatafile1 # umount nfsshareNFSv3 で NFS 共有をマウントできることを確認します。マウントしたら、テストファイル
clientdatafile1が表示されていることを確認します。NFSv4 とは異なり、NFSv3 は仮想ファイルシステムを使用しないため、特定のエクスポートをマウントする必要があります。テスト後に共有をアンマウントします。# mkdir nfsshare # mount -o "vers=3" 192.168.122.200:/nfsshare/exports/export2 nfsshare # ls nfsshare clientdatafile2 # umount nfsshare
50.5.2. フェイルオーバーのテスト
クラスター外のノードで、NFS 共有をマウントし、NFS 共有の設定 で作成した
clientdatafile1ファイルへのアクセスを確認します。# mkdir nfsshare # mount -o "vers=4" 192.168.122.200:export1 nfsshare # ls nfsshare clientdatafile1クラスター内で、
nfsgroupを実行しているノードを確認します。この例では、nfsgroupがz1.example.comで実行しています。[root@z1 ~]# pcs status ... Full list of resources: myapc (stonith:fence_apc_snmp): Started z1.example.com Resource Group: nfsgroup my_lvm (ocf::heartbeat:LVM-activate): Started z1.example.com nfsshare (ocf::heartbeat:Filesystem): Started z1.example.com nfs-daemon (ocf::heartbeat:nfsserver): Started z1.example.com nfs-root (ocf::heartbeat:exportfs): Started z1.example.com nfs-export1 (ocf::heartbeat:exportfs): Started z1.example.com nfs-export2 (ocf::heartbeat:exportfs): Started z1.example.com nfs_ip (ocf::heartbeat:IPaddr2): Started z1.example.com nfs-notify (ocf::heartbeat:nfsnotify): Started z1.example.com ...クラスター内のノードから、
nfsgroupを実行しているノードをスタンバイモードにします。[root@z1 ~]# pcs node standby z1.example.comnfsgroupが、別のクラスターノードで正常に起動することを確認します。[root@z1 ~]# pcs status ... Full list of resources: Resource Group: nfsgroup my_lvm (ocf::heartbeat:LVM-activate): Started z2.example.com nfsshare (ocf::heartbeat:Filesystem): Started z2.example.com nfs-daemon (ocf::heartbeat:nfsserver): Started z2.example.com nfs-root (ocf::heartbeat:exportfs): Started z2.example.com nfs-export1 (ocf::heartbeat:exportfs): Started z2.example.com nfs-export2 (ocf::heartbeat:exportfs): Started z2.example.com nfs_ip (ocf::heartbeat:IPaddr2): Started z2.example.com nfs-notify (ocf::heartbeat:nfsnotify): Started z2.example.com ...NFS 共有をマウントしたクラスターの外部のノードから、この外部ノードが NFS マウント内のテストファイルに引き続きアクセスできることを確認します。
# ls nfsshare clientdatafile1フェイルオーバー時に、クライアントに対するサービスが一時的に失われますが、クライアントはユーザーが介入しなくても回復します。デフォルトでは、NFSv4 を使用するクライアントの場合は、マウントの復旧に最大 90 秒かかることがあります。この 90 秒は、システムの起動時にサーバーが監視する NFSv4 ファイルのリースの猶予期間です。NFSv3 クライアントでは、数秒でマウントへのアクセスが回復します。
クラスター内のノードから、最初に
nfsgroupを実行していたノードをスタンバイモードから削除します。注記ノードを
スタンバイモードから削除しても、リソースはそのノードにフェイルオーバーしません。これは、リソースのresource-stickiness値により異なります。resource-stickinessメタ属性については、現在のノードを優先するようにリソースを設定する を参照してください。[root@z1 ~]# pcs node unstandby z1.example.com
第51章 クラスター内の GFS2 ファイルシステム
Red Hat 高可用性クラスターで GFS2 ファイルシステムを設定するには、次の管理手順を使用します。
51.1. クラスターに GFS2 ファイルシステムを設定
次の手順で、GFS2 ファイルシステムを含む Pacemaker クラスターをセットアップできます。この例では、2 ノードクラスター内の 3 つの論理ボリューム上に 3 つの GFS2 ファイルシステムを作成します。
前提条件
- 両方のクラスターノードにクラスターソフトウェアをインストールして起動し、基本的な 2 ノードクラスターを作成している。
- クラスターのフェンシングを設定している。
Pacemaker クラスターの作成とクラスターのフェンシングの設定は、Pacemaker を使用した Red Hat High Availability クラスターの作成 を参照してください。
手順
クラスター内の両方のノードで、システムアーキテクチャーに対応する Resilient Storage のリポジトリーを有効にします。たとえば、x86_64 システムの Resilient Storage リポジトリーを有効にするには、以下の
subscription-managerコマンドを入力します。# subscription-manager repos --enable=rhel-8-for-x86_64-resilientstorage-rpmsResilient Storage リポジトリーは、High Availability リポジトリーのスーパーセットであることに注意してください。Resilient Storage リポジトリーを有効にする場合は、High Availability リポジトリーを有効にする必要はありません。
クラスターの両方のノードで、
lvm2-lockdパッケージ、gfs2-utilsパッケージ、およびdlmパッケージをインストールします。AppStream チャンネルおよび Resilient Storage チャンネルにサブスクライブして、これらのパッケージをサポートする必要があります。# yum install lvm2-lockd gfs2-utils dlmクラスターの両方のノードで、
/etc/lvm/lvm.confファイルのuse_lvmlockd設定オプションをuse_lvmlockd=1に設定します。... use_lvmlockd = 1 ...グローバル Pacemaker パラメーター
no-quorum-policyをfreezeに設定します。注記デフォルトでは、
no-quorum-policyの値はstopに設定され、定足数が失われると、残りのパーティションのリソースがすべて即座に停止されます。通常、このデフォルト設定は最も安全なオプションで最適なおプションですが、ほとんどのリソースとは異なり、GFS2 が機能するにはクォーラムが必要です。クォーラムが失われると、GFS2 マウントを使用したアプリケーション、GFS2 マウント自体の両方が正しく停止できません。クォーラムなしでこれらのリソースを停止しようとすると失敗し、最終的にクォーラムが失われるたびにクラスター全体がフェンスされます。この状況に対処するには、GFS2 の使用時の
no-quorum-policyをfreezeに設定します。この設定では、クォーラムが失われると、クォーラムが回復するまで残りのパーティションは何もしません。[root@z1 ~]# pcs property set no-quorum-policy=freezedlmリソースをセットアップします。これは、クラスター内で GFS2 ファイルシステムを設定するために必要な依存関係です。この例では、dlmリソースを作成し、リソースグループlockingに追加します。[root@z1 ~]# pcs resource create dlm --group locking ocf:pacemaker:controld op monitor interval=30s on-fail=fenceリソースグループがクラスターの両方のノードでアクティブになるように、
lockingリソースグループのクローンを作成します。[root@z1 ~]# pcs resource clone locking interleave=truelockingリソースグループの一部としてlvmlockdリソースを設定します。[root@z1 ~]# pcs resource create lvmlockd --group locking ocf:heartbeat:lvmlockd op monitor interval=30s on-fail=fenceクラスターのステータスを確認し、クラスターの両方のノードで
lockingリソースグループが起動していることを確認します。[root@z1 ~]# pcs status --full Cluster name: my_cluster [...] Online: [ z1.example.com (1) z2.example.com (2) ] Full list of resources: smoke-apc (stonith:fence_apc): Started z1.example.com Clone Set: locking-clone [locking] Resource Group: locking:0 dlm (ocf::pacemaker:controld): Started z1.example.com lvmlockd (ocf::heartbeat:lvmlockd): Started z1.example.com Resource Group: locking:1 dlm (ocf::pacemaker:controld): Started z2.example.com lvmlockd (ocf::heartbeat:lvmlockd): Started z2.example.com Started: [ z1.example.com z2.example.com ]クラスターの 1 つのノードで、2 つの共有ボリュームグループを作成します。一方のボリュームグループには GFS2 ファイルシステムが 2 つ含まれ、もう一方のボリュームグループには GFS2 ファイルシステムが 1 つ含まれます。
注記LVM ボリュームグループに、iSCSI ターゲットなど、リモートブロックストレージに存在する 1 つ以上の物理ボリュームが含まれている場合は、Red Hat は、Pacemaker が起動する前にサービスが開始されるように設定することを推奨します。Pacemaker クラスターによって使用されるリモート物理ボリュームの起動順序の設定は、Pacemaker で管理されないリソース依存関係の起動順序の設定 を参照してください。
以下のコマンドは、共有ボリュームグループ
shared_vg1を/dev/vdbに作成します。[root@z1 ~]# vgcreate --shared shared_vg1 /dev/vdb Physical volume "/dev/vdb" successfully created. Volume group "shared_vg1" successfully created VG shared_vg1 starting dlm lockspace Starting locking. Waiting until locks are ready...以下のコマンドは、共有ボリュームグループ
shared_vg2を/dev/vdcに作成します。[root@z1 ~]# vgcreate --shared shared_vg2 /dev/vdc Physical volume "/dev/vdc" successfully created. Volume group "shared_vg2" successfully created VG shared_vg2 starting dlm lockspace Starting locking. Waiting until locks are ready...クラスター内の 2 番目のノードで以下を実行します。
(RHEL 8.5 以降)
lvm.confファイルでuse_devicesfile = 1を設定してデバイスファイルの使用を有効にした場合は、共有デバイスをデバイスファイルに追加します。デフォルトでは、デバイスファイルの使用は有効になっていません。[root@z2 ~]# lvmdevices --adddev /dev/vdb [root@z2 ~]# lvmdevices --adddev /dev/vdc共有ボリュームグループごとにロックマネージャーを起動します。
[root@z2 ~]# vgchange --lockstart shared_vg1 VG shared_vg1 starting dlm lockspace Starting locking. Waiting until locks are ready... [root@z2 ~]# vgchange --lockstart shared_vg2 VG shared_vg2 starting dlm lockspace Starting locking. Waiting until locks are ready...
クラスター内の 1 つのノードで、共有論理ボリュームを作成し、ボリュームを GFS2 ファイルシステムでフォーマットします。ファイルシステムをマウントするノードごとに、ジャーナルが 1 つ必要になります。クラスター内の各ノードに十分なジャーナルを作成してください。ロックテーブル名の形式は、ClusterName:FSName です。ClusterName は、GFS2 ファイルシステムが作成されているクラスターの名前です。FSName はファイルシステム名です。これは、クラスター経由のすべての
lock_dlmファイルシステムで一意である必要があります。[root@z1 ~]# lvcreate --activate sy -L5G -n shared_lv1 shared_vg1 Logical volume "shared_lv1" created. [root@z1 ~]# lvcreate --activate sy -L5G -n shared_lv2 shared_vg1 Logical volume "shared_lv2" created. [root@z1 ~]# lvcreate --activate sy -L5G -n shared_lv1 shared_vg2 Logical volume "shared_lv1" created. [root@z1 ~]# mkfs.gfs2 -j2 -p lock_dlm -t my_cluster:gfs2-demo1 /dev/shared_vg1/shared_lv1 [root@z1 ~]# mkfs.gfs2 -j2 -p lock_dlm -t my_cluster:gfs2-demo2 /dev/shared_vg1/shared_lv2 [root@z1 ~]# mkfs.gfs2 -j2 -p lock_dlm -t my_cluster:gfs2-demo3 /dev/shared_vg2/shared_lv1すべてのノードで論理ボリュームを自動的にアクティブにするために、各論理ボリュームに
LVM が有効なリソースを作成します。ボリュームグループ
shared_vg1の論理ボリュームshared_lv1に、LVM が有効なリソースsharedlv1を作成します。このコマンドは、リソースを含むリソースグループshared_vg1も作成します。この例のリソースグループの名前は、論理ボリュームを含む共有ボリュームグループと同じになります。[root@z1 ~]# pcs resource create sharedlv1 --group shared_vg1 ocf:heartbeat:LVM-activate lvname=shared_lv1 vgname=shared_vg1 activation_mode=shared vg_access_mode=lvmlockdボリュームグループ
shared_vg1の論理ボリュームshared_lv2に、LVM が有効なリソースsharedlv2を作成します。このリソースは、リソースグループshared_vg1に含まれます。[root@z1 ~]# pcs resource create sharedlv2 --group shared_vg1 ocf:heartbeat:LVM-activate lvname=shared_lv2 vgname=shared_vg1 activation_mode=shared vg_access_mode=lvmlockdボリュームグループ
shared_vg2の論理ボリュームshared_lv1に、LVM が有効なリソースsharedlv3を作成します。このコマンドは、リソースを含むリソースグループshared_vg2も作成します。[root@z1 ~]# pcs resource create sharedlv3 --group shared_vg2 ocf:heartbeat:LVM-activate lvname=shared_lv1 vgname=shared_vg2 activation_mode=shared vg_access_mode=lvmlockd
リソースグループのクローンを新たに 2 つ作成します。
[root@z1 ~]# pcs resource clone shared_vg1 interleave=true [root@z1 ~]# pcs resource clone shared_vg2 interleave=truedlmリソースおよびlvmlockdリソースを含むlockingリソースグループが最初に起動するように、順序の制約を設定します。[root@z1 ~]# pcs constraint order start locking-clone then shared_vg1-clone Adding locking-clone shared_vg1-clone (kind: Mandatory) (Options: first-action=start then-action=start) [root@z1 ~]# pcs constraint order start locking-clone then shared_vg2-clone Adding locking-clone shared_vg2-clone (kind: Mandatory) (Options: first-action=start then-action=start)コロケーション制約を設定して、
vg1およびvg2のリソースグループがlockingリソースグループと同じノードで起動するようにします。[root@z1 ~]# pcs constraint colocation add shared_vg1-clone with locking-clone [root@z1 ~]# pcs constraint colocation add shared_vg2-clone with locking-cloneクラスターの両ノードで、論理ボリュームがアクティブであることを確認します。数秒の遅延が生じる可能性があります。
[root@z1 ~]# lvs LV VG Attr LSize shared_lv1 shared_vg1 -wi-a----- 5.00g shared_lv2 shared_vg1 -wi-a----- 5.00g shared_lv1 shared_vg2 -wi-a----- 5.00g [root@z2 ~]# lvs LV VG Attr LSize shared_lv1 shared_vg1 -wi-a----- 5.00g shared_lv2 shared_vg1 -wi-a----- 5.00g shared_lv1 shared_vg2 -wi-a----- 5.00gファイルシステムリソースを作成し、各 GFS2 ファイルシステムをすべてのノードに自動的にマウントします。
このファイルシステムは Pacemaker のクラスターリソースとして管理されるため、
/etc/fstabファイルには追加しないでください。マウントオプションは、options=optionsを使用してリソース設定の一部として指定できます。すべての設定オプションを確認する場合は、pcs resource describe Filesystemコマンドを実行します。以下のコマンドは、ファイルシステムのリソースを作成します。これらのコマンドは各リソースを、そのファイルシステムの論理ボリュームを含むリソースグループに追加します。
[root@z1 ~]# pcs resource create sharedfs1 --group shared_vg1 ocf:heartbeat:Filesystem device="/dev/shared_vg1/shared_lv1" directory="/mnt/gfs1" fstype="gfs2" options=noatime op monitor interval=10s on-fail=fence [root@z1 ~]# pcs resource create sharedfs2 --group shared_vg1 ocf:heartbeat:Filesystem device="/dev/shared_vg1/shared_lv2" directory="/mnt/gfs2" fstype="gfs2" options=noatime op monitor interval=10s on-fail=fence [root@z1 ~]# pcs resource create sharedfs3 --group shared_vg2 ocf:heartbeat:Filesystem device="/dev/shared_vg2/shared_lv1" directory="/mnt/gfs3" fstype="gfs2" options=noatime op monitor interval=10s on-fail=fence
検証
GFS2 ファイルシステムが、クラスターの両方のノードにマウントされていることを確認します。
[root@z1 ~]# mount | grep gfs2 /dev/mapper/shared_vg1-shared_lv1 on /mnt/gfs1 type gfs2 (rw,noatime,seclabel) /dev/mapper/shared_vg1-shared_lv2 on /mnt/gfs2 type gfs2 (rw,noatime,seclabel) /dev/mapper/shared_vg2-shared_lv1 on /mnt/gfs3 type gfs2 (rw,noatime,seclabel) [root@z2 ~]# mount | grep gfs2 /dev/mapper/shared_vg1-shared_lv1 on /mnt/gfs1 type gfs2 (rw,noatime,seclabel) /dev/mapper/shared_vg1-shared_lv2 on /mnt/gfs2 type gfs2 (rw,noatime,seclabel) /dev/mapper/shared_vg2-shared_lv1 on /mnt/gfs3 type gfs2 (rw,noatime,seclabel)クラスターのステータスを確認します。
[root@z1 ~]# pcs status --full Cluster name: my_cluster [...] Full list of resources: smoke-apc (stonith:fence_apc): Started z1.example.com Clone Set: locking-clone [locking] Resource Group: locking:0 dlm (ocf::pacemaker:controld): Started z2.example.com lvmlockd (ocf::heartbeat:lvmlockd): Started z2.example.com Resource Group: locking:1 dlm (ocf::pacemaker:controld): Started z1.example.com lvmlockd (ocf::heartbeat:lvmlockd): Started z1.example.com Started: [ z1.example.com z2.example.com ] Clone Set: shared_vg1-clone [shared_vg1] Resource Group: shared_vg1:0 sharedlv1 (ocf::heartbeat:LVM-activate): Started z2.example.com sharedlv2 (ocf::heartbeat:LVM-activate): Started z2.example.com sharedfs1 (ocf::heartbeat:Filesystem): Started z2.example.com sharedfs2 (ocf::heartbeat:Filesystem): Started z2.example.com Resource Group: shared_vg1:1 sharedlv1 (ocf::heartbeat:LVM-activate): Started z1.example.com sharedlv2 (ocf::heartbeat:LVM-activate): Started z1.example.com sharedfs1 (ocf::heartbeat:Filesystem): Started z1.example.com sharedfs2 (ocf::heartbeat:Filesystem): Started z1.example.com Started: [ z1.example.com z2.example.com ] Clone Set: shared_vg2-clone [shared_vg2] Resource Group: shared_vg2:0 sharedlv3 (ocf::heartbeat:LVM-activate): Started z2.example.com sharedfs3 (ocf::heartbeat:Filesystem): Started z2.example.com Resource Group: shared_vg2:1 sharedlv3 (ocf::heartbeat:LVM-activate): Started z1.example.com sharedfs3 (ocf::heartbeat:Filesystem): Started z1.example.com Started: [ z1.example.com z2.example.com ] ...
51.2. クラスターでの暗号化 GFS2 ファイルシステムの設定
(RHEL 8.4 以降) 次の手順で、LUKS で暗号化した GFS2 ファイルシステムを含む Pacemaker クラスターを作成できます。この例では、論理ボリュームに 1 つの GFS2 ファイルシステムを作成し、そのファイルシステムを暗号化します。暗号化された GFS2 ファイルシステムは、LUKS 暗号化に対応する crypt リソースエージェントを使用してサポートされます。
この手順は、以下の 3 つの部分で設定されます。
- Pacemaker クラスター内で共有論理ボリュームを設定する
-
論理ボリュームを暗号化して
cryptリソースを作成する - GFS2 ファイルシステムで暗号化された論理ボリュームをフォーマットしてクラスター用のファイルシステムリソースを作成する
51.2.2. 論理ボリュームの暗号化および暗号化リソースの作成
前提条件
- Pacemaker クラスターに共有論理ボリュームを設定している。
手順
クラスター内の 1 つのノードで、crypt キーを含めて新しいファイルを作成し、ファイルにパーミッションを設定して root でのみ読み取りできるようにします。
[root@z1 ~]# touch /etc/crypt_keyfile [root@z1 ~]# chmod 600 /etc/crypt_keyfilecrypt キーを作成します。
[root@z1 ~]# dd if=/dev/urandom bs=4K count=1 of=/etc/crypt_keyfile 1+0 records in 1+0 records out 4096 bytes (4.1 kB, 4.0 KiB) copied, 0.000306202 s, 13.4 MB/s [root@z1 ~]# scp /etc/crypt_keyfile root@z2.example.com:/etc/-pパラメーターを使用して設定したパーミッションを保持した状態で、crypt キーファイルをクラスター内の他のノードに配布します。[root@z1 ~]# scp -p /etc/crypt_keyfile root@z2.example.com:/etc/LVM ボリュームに暗号化デバイスを作成して、暗号化された GFS2 ファイルシステムを設定します。
[root@z1 ~]# cryptsetup luksFormat /dev/shared_vg1/shared_lv1 --type luks2 --key-file=/etc/crypt_keyfile WARNING! ======== This will overwrite data on /dev/shared_vg1/shared_lv1 irrevocably. Are you sure? (Type 'yes' in capital letters): YESshared_vg1ボリュームグループの一部として crypt リソースを作成します。[root@z1 ~]# pcs resource create crypt --group shared_vg1 ocf:heartbeat:crypt crypt_dev="luks_lv1" crypt_type=luks2 key_file=/etc/crypt_keyfile encrypted_dev="/dev/shared_vg1/shared_lv1"
検証
crypt リソースが crypt デバイスを作成していることを確認します。この例では crypt デバイスは /dev/mapper/luks_lv1 です。
[root@z1 ~]# ls -l /dev/mapper/
...
lrwxrwxrwx 1 root root 7 Mar 4 09:52 luks_lv1 -> ../dm-3
...51.2.3. GFS2 ファイルシステムで暗号化された論理ボリュームをフォーマットしてクラスター用のファイルシステムリソースを作成します。
前提条件
- 論理ボリュームを暗号化し、crypt リソースを作成している。
手順
クラスター内の 1 つのノードで、GFS2 ファイルシステムを使用してボリュームをフォーマットします。ファイルシステムをマウントするノードごとに、ジャーナルが 1 つ必要になります。クラスター内の各ノードに十分なジャーナルを作成してください。ロックテーブル名の形式は、ClusterName:FSName です。ClusterName は、GFS2 ファイルシステムが作成されているクラスターの名前です。FSName はファイルシステム名です。これは、クラスター経由のすべての
lock_dlmファイルシステムで一意である必要があります。[root@z1 ~]# mkfs.gfs2 -j3 -p lock_dlm -t my_cluster:gfs2-demo1 /dev/mapper/luks_lv1 /dev/mapper/luks_lv1 is a symbolic link to /dev/dm-3 This will destroy any data on /dev/dm-3 Are you sure you want to proceed? [y/n] y Discarding device contents (may take a while on large devices): Done Adding journals: Done Building resource groups: Done Creating quota file: Done Writing superblock and syncing: Done Device: /dev/mapper/luks_lv1 Block size: 4096 Device size: 4.98 GB (1306624 blocks) Filesystem size: 4.98 GB (1306622 blocks) Journals: 3 Journal size: 16MB Resource groups: 23 Locking protocol: "lock_dlm" Lock table: "my_cluster:gfs2-demo1" UUID: de263f7b-0f12-4d02-bbb2-56642fade293ファイルシステムリソースを作成し、GFS2 ファイルシステムをすべてのノードに自動的にマウントします。
ファイルシステムは Pacemaker のクラスターリソースとして管理されるため、
/etc/fstabファイルには追加しないでください。マウントオプションは、options=optionsを使用してリソース設定の一部として指定できます。すべての設定オプションを確認する場合は、pcs resource describe Filesystemコマンドを実行します。以下のコマンドは、ファイルシステムのリソースを作成します。このコマンドは、対象のファイルシステムの論理ボリュームリソースを含むリソースグループに、リソースを追加します。
[root@z1 ~]# pcs resource create sharedfs1 --group shared_vg1 ocf:heartbeat:Filesystem device="/dev/mapper/luks_lv1" directory="/mnt/gfs1" fstype="gfs2" options=noatime op monitor interval=10s on-fail=fence
検証
GFS2 ファイルシステムが、クラスターの両方のノードにマウントされていることを確認します。
[root@z1 ~]# mount | grep gfs2 /dev/mapper/luks_lv1 on /mnt/gfs1 type gfs2 (rw,noatime,seclabel) [root@z2 ~]# mount | grep gfs2 /dev/mapper/luks_lv1 on /mnt/gfs1 type gfs2 (rw,noatime,seclabel)クラスターのステータスを確認します。
[root@z1 ~]# pcs status --full Cluster name: my_cluster [...] Full list of resources: smoke-apc (stonith:fence_apc): Started z1.example.com Clone Set: locking-clone [locking] Resource Group: locking:0 dlm (ocf::pacemaker:controld): Started z2.example.com lvmlockd (ocf::heartbeat:lvmlockd): Started z2.example.com Resource Group: locking:1 dlm (ocf::pacemaker:controld): Started z1.example.com lvmlockd (ocf::heartbeat:lvmlockd): Started z1.example.com Started: [ z1.example.com z2.example.com ] Clone Set: shared_vg1-clone [shared_vg1] Resource Group: shared_vg1:0 sharedlv1 (ocf::heartbeat:LVM-activate): Started z2.example.com crypt (ocf::heartbeat:crypt) Started z2.example.com sharedfs1 (ocf::heartbeat:Filesystem): Started z2.example.com Resource Group: shared_vg1:1 sharedlv1 (ocf::heartbeat:LVM-activate): Started z1.example.com crypt (ocf::heartbeat:crypt) Started z1.example.com sharedfs1 (ocf::heartbeat:Filesystem): Started z1.example.com Started: [z1.example.com z2.example.com ] ...
51.3. RHEL7 から RHEL8 へ GFS2 ファイルシステムの移行
GFS2 ファイルシステムを含む RHEL 8 クラスターを設定する場合は、既存の Red Hat Enterprise 7 論理ボリュームを使用できます。
Red Hat Enterprise Linux 8 では、LVM は、clvmd の代わりに LVM ロックデーモン lvmlockd を使用して、アクティブ/アクティブのクラスターで共有ストレージデバイスを管理します。これにより、アクティブ/アクティブのクラスターに共有論理ボリュームとして使用する必要がある論理ボリュームを設定する必要があります。また、これにより、LVM が有効 なリソースを使用して LVM ボリュームを管理し、lvmlockd リソースエージェントを使用して lvmlockd デーモンを管理する必要があります。共有論理ボリュームを使用して、GFS2 ファイルシステムを含む Pacemaker クラスターを設定する手順は、クラスターに GFS2 ファイルシステムを設定 を参照してください。
GFS2 ファイルシステムを含む RHEL8 クラスターを設定する際に、既存の Red Hat Enterprise Linux 7 論理ボリュームを使用する場合は、RHEL8 クラスターから以下の手順を実行します。この例では、クラスター化された RHEL 7 論理ボリュームが、ボリュームグループ upgrade_gfs_vg に含まれます。
既存のファイルシステムを有効にするために、RHEL8 クラスターの名前は、GFS2 ファイルシステムに含まれる RHEL7 クラスターと同じになります。
手順
- GFS2 ファイルシステムを含む論理ボリュームが現在非アクティブであることを確認してください。すべてのノードがボリュームグループを使用して停止した場合にのみ、この手順は安全です。
クラスター内の 1 つのノードから、強制的にボリュームグループをローカルに変更します。
[root@rhel8-01 ~]# vgchange --lock-type none --lock-opt force upgrade_gfs_vg Forcibly change VG lock type to none? [y/n]: y Volume group "upgrade_gfs_vg" successfully changedクラスター内の 1 つのノードから、ローカルボリュームグループを共有ボリュームグループに変更します。
[root@rhel8-01 ~]# vgchange --lock-type dlm upgrade_gfs_vg Volume group "upgrade_gfs_vg" successfully changedクラスター内の各ノードで、ボリュームグループのロックを開始します。
[root@rhel8-01 ~]# vgchange --lockstart upgrade_gfs_vg VG upgrade_gfs_vg starting dlm lockspace Starting locking. Waiting until locks are ready... [root@rhel8-02 ~]# vgchange --lockstart upgrade_gfs_vg VG upgrade_gfs_vg starting dlm lockspace Starting locking. Waiting until locks are ready...
この手順を実行すると、各論理ボリュームに、LVM が有効 なリソースを作成できます。
第52章 Red Hat High Availability クラスターでのフェンシングの設定
応答しないノードがデータへのアクセスを続けている可能性があります。データが安全であることを確認する場合は、STONITH を使用してノードをフェンシングすることが唯一の方法になります。STONITH は "Shoot The Other Node In The Head" の頭字語で、不安定なノードや同時アクセスによるデータの破損を防ぐことができます。STONITH を使用すると、別のノードからデータをアクセスする前に、そのノードが完全にオフラインであることを確認できます。
STONITH はクラスター化したサービスを停止できない場合にも役に立ちます。この場合は、クラスターが STONITH を使用してノード全体を強制的にオフラインにし、その後サービスを別の場所で開始すると安全です。
フェンシングと Red Hat High Availability クラスターにおけるその重要性に関する一般的な情報については、Red Hat ナレッジベースソリューション Red Hat High Availability クラスターにおけるフェンシングを 参照してください。
クラスターのノードにフェンスデバイスを設定して、Pacemaker クラスターに STONITH を実装します。
52.1. 利用可能なフェンスエージェントと、そのオプションの表示
以下のコマンドは、利用可能なフェンスエージェントと、特定のフェンスエージェントで利用可能なオプションを表示できます。
システムのハードウェアによって、クラスターに使用するフェンシングデバイスのタイプが決まります。サポートされているプラットフォームとアーキテクチャー、およびさまざまなフェンシングデバイスについては、記事 Cluster Platforms and Architectures の Support Policies for RHEL High Availability Clusters セクションを参照してください。
使用可能なすべてのフェンスエージェントのリストを表示するには、次のコマンドを実行します。フィルターを指定すると、フィルターに一致するフェンスエージェントのみが表示されます。
pcs stonith list [filter]指定したフェンスエージェントのオプションを表示するには、次のコマンドを実行します。
pcs stonith describe [stonith_agent]たとえば、次のコマンドでは Telnet または SSH 経由の APC 用フェンスエージェントのオプションを表示します。
# pcs stonith describe fence_apc
Stonith options for: fence_apc
ipaddr (required): IP Address or Hostname
login (required): Login Name
passwd: Login password or passphrase
passwd_script: Script to retrieve password
cmd_prompt: Force command prompt
secure: SSH connection
port (required): Physical plug number or name of virtual machine
identity_file: Identity file for ssh
switch: Physical switch number on device
inet4_only: Forces agent to use IPv4 addresses only
inet6_only: Forces agent to use IPv6 addresses only
ipport: TCP port to use for connection with device
action (required): Fencing Action
verbose: Verbose mode
debug: Write debug information to given file
version: Display version information and exit
help: Display help and exit
separator: Separator for CSV created by operation list
power_timeout: Test X seconds for status change after ON/OFF
shell_timeout: Wait X seconds for cmd prompt after issuing command
login_timeout: Wait X seconds for cmd prompt after login
power_wait: Wait X seconds after issuing ON/OFF
delay: Wait X seconds before fencing is started
retry_on: Count of attempts to retry power on
fence_sbd エージェントを除き、method オプションを提供するフェンスエージェントで cycle の値はサポートされていません。データが破損する可能性があるため、この値は指定しないでください。ただし、fence_sbd の場合でもメソッドは指定せず、デフォルト値を使用する必要があります。
52.2. フェンスデバイスの作成
フェンスデバイスを作成するコマンドの形式は、以下のとおりです。利用可能なフェンスデバイス作成オプションのリストは、pcs stonith -h の出力を参照してください。
pcs stonith create stonith_id stonith_device_type [stonith_device_options] [op operation_action operation_options]以下のコマンドは、1 つのノードに対して、1 つのフェンシングデバイスを作成します。
# pcs stonith create MyStonith fence_virt pcmk_host_list=f1 op monitor interval=30s1 つのノードのみをフェンスできるフェンスデバイスや、複数のノードをフェンスできるデバイスもあります。フェンシングデバイスの作成時に指定するパラメーターは、フェンシングデバイスが対応しているか、必要としているかにより異なります。
- フェンスデバイスの中には、フェンスできるノードを自動的に判断できるものがあります。
-
フェンシングデバイスの作成時に
pcmk_host_listパラメーターを使用すると、フェンシングデバイスで制御されるすべてのマシンを指定できます。 -
フェンスデバイスによっては、フェンスデバイスが理解する仕様へのホスト名のマッピングが必要となるものがあります。フェンシングデバイスの作成時に、
pcmk_host_mapパラメーターを使用して、ホスト名をマッピングできます。
pcmk_host_list パラメーターおよび pcmk_host_map パラメーターの詳細は、フェンシングデバイスの一般的なプロパティー を参照してください。
フェンスデバイスを設定したら、デバイスをテストして正しく機能していることを確認してください。フェンスデバイスをテストする方法は フェンスデバイスのテスト を参照してください。
52.3. フェンシングデバイスの一般的なプロパティー
フェンシングデバイスにも設定可能な一般的なプロパティーや、フェンスの動作を決定するさまざまなクラスタープロパティーがあります。
クラスターノードは、フェンスリソースが開始しているかどうかに関わらず、フェンスデバイスでその他のクラスターノードをフェンスできます。以下の例外を除き、リソースが開始しているかどうかは、デバイスの定期的なモニターのみを制御するものとなり、使用可能かどうかは制御しません。
-
フェンシングデバイスは、
pcs stonith disable stonith_idコマンドを実行して無効にできます。これにより、ノードがそのデバイスを使用できないように設定できます。 -
特定のノードがフェンスデバイスを使用できないようにするには、
pcs constraint location … avoidsコマンドで、フェンスリソースの場所制約を設定できます。 -
stonith-enabled=falseを設定すると、フェンシングがすべて無効になります。ただし、実稼働環境でフェンシングを無効にすることは適していないため、フェンシングが無効になっている場合は、Red Hat ではクラスターがサポートされないことに注意してください。
以下の表は、フェンシングデバイスに設定できる一般的なプロパティーを説明します。
| フィールド | タイプ | デフォルト | 説明 |
|---|---|---|---|
|
| 文字列 |
ホスト名を、ホスト名に対応していないデバイスのポート番号へマッピングします。たとえば、 | |
|
| 文字列 |
このデバイスで制御するマシンのリストです ( | |
|
| 文字列 |
*
* それが設定されておらず、フェンスデバイスが
* それ以外で、フェンスデバイスが
* それ以外は、 |
デバイスで制御するマシンを指定します。使用できる値は、 |
以下の表では、フェンシングデバイスに設定できるその他のプロパティーをまとめています。これらのオプションは高度な設定を行う場合にのみ使用されます。
| フィールド | タイプ | デフォルト | 説明 |
|---|---|---|---|
|
| 文字列 | port |
port の代替パラメーターです。デバイスによっては、標準の port パラメーターに対応していない場合や、そのデバイス固有のパラメーターも提供している場合があります。このパラメーターを使用して、デバイス固有の代替パラメーターを指定します。これは、フェンシングするマシンを示します。クラスターが追加パラメーターを提供しないようにする場合は、 |
|
| 文字列 | reboot |
|
|
| 時間 | 60s |
|
|
| 整数 | 2 |
タイムアウト期間内に、 |
|
| 文字列 | off |
|
|
| 時間 | 60s |
|
|
| 整数 | 2 | タイムアウト期間内に、off コマンドを再試行する回数の上限です。複数の接続に対応していないデバイスもあります。デバイスが別のタスクでビジー状態になると操作が失敗する場合があるため、タイムアウトに達していなければ、Pacemaker が操作を自動的に再試行します。Pacemaker によるオフ動作の再試行回数を変更する場合に使用します。 |
|
| 文字列 | list |
|
|
| 時間 | 60s | list 操作にタイムアウトを指定します。デバイスによって、この操作が完了するのにかかる時間が、通常と大きく異なる場合があります。このパラメーターを使用して、list 操作にデバイス固有のタイムアウトを指定します。 |
|
| 整数 | 2 |
タイムアウト期間内に、 |
|
| 文字列 | monitor |
|
|
| 時間 | 60s |
|
|
| 整数 | 2 |
タイムアウト期間内に、 |
|
| 文字列 | status |
|
|
| 時間 | 60s |
|
|
| 整数 | 2 | タイムアウト期間内に、status コマンドを再試行する回数の上限です。複数の接続に対応していないデバイスもあります。デバイスが別のタスクでビジー状態になると操作が失敗する場合があるため、タイムアウトに達していなければ、Pacemaker が操作を自動的に再試行します。Pacemaker による status 動作の再試行回数を変更する場合に使用します。 |
|
| 文字列 | 0s |
フェンシング操作のベース遅延を有効にし、ベース遅延の値を指定します。Red Hat Enterprise Linux 8.6 以降では、 |
|
| 時間 | 0s |
フェンシング操作のランダム遅延を有効にし、ベース遅延とランダム遅延を組み合わせた最大値である最大遅延を指定します。たとえば、ベース遅延が 3 で、 |
|
| 整数 | 1 |
このデバイスで並行して実行できる操作の上限です。最初に、クラスタープロパティーの |
|
| 文字列 | on |
高度な使用のみ |
|
| 時間 | 60s |
高度な使用のみ |
|
| 整数 | 2 |
高度な使用のみタイムアウト期間内に、 |
個々のフェンスデバイスに設定できるプロパティーのほかにも、以下の表で説明しているように、フェンス動作を判断するクラスタープロパティーも設定できます。
| オプション | デフォルト | 説明 |
|---|---|---|
|
| true |
障害が発生したノードと、停止できないリソースが含まれるノードをフェンスする必要があることを示します。データを保護するには、
Red Hat は、この値が |
|
| reboot |
フェンシングデバイスに送信するアクション。使用できる値は |
|
| 60s | STONITH アクションが完了するのを待つ時間。 |
|
| 10 | クラスターがすぐに再起動できなくなるまで、ターゲットでフェンシングが失敗する回数。 |
|
| ノードがハードウェアウォッチドッグによって強制終了すまで待機する最大時間。この値は、ハードウェアウォッチドッグのタイムアウト値の倍に設定することが推奨されます。このオプションは、ウォッチドッグのみの SBD 設定がフェンシングに使用される場合にのみ必要です。 | |
|
| true (RHEL 8.1 以降) | フェンシング操作を並行して実行できるようにします。 |
|
| stop |
(Red Hat Enterprise Linux 8.2 以降) 独自のフェンシングの通知を受信した場合は、クラスターノードがどのように反応するかを決定します。クラスターノードは、フェンシングの設定が間違っている場合に独自のフェンシングの通知を受信するか、ファブリックフェンシングがクラスター通信を遮断しない状態である可能性があります。許可される値は、Pacemaker をすぐに停止し、停止したままにする
このプロパティーのデフォルト値は |
|
| 0 (無効) | (RHEL 8.3 以降) フェンシング遅延を設定します。これにより、スプリットブレイン状況で、実行中のリソースが最も少ないノードまたは最も重要でないノードがフェンシングされるノードになるように、2 ノードクラスターを設定できます。フェンシング遅延パラメーターとその相互作用に関する一般的な情報は、フェンシング遅延 を参照してください。 |
クラスターのプロパティーの設定は、クラスターのプロパティーの設定と削除 を参照してください。
52.4. フェンシング遅延
2 ノードクラスターでクラスター通信が失われると、一方のノードがこれを先に検出し、他方のノードをフェンスすることがあります。ただし、両方のノードが同時に検出した場合、各ノードが他方のノードのフェンシングを開始した結果、両方のノードの電源がオフになるかリセットされる可能性があります。フェンシング遅延を設定すると、両方のクラスターノードが相互にフェンスし合う可能性を減らすことができます。3 つ以上のノードを持つクラスターでも遅延を設定できますが、クォーラムのあるパーティションしかフェンシングを開始しないため、通常は利点がありません。
システム要件に応じて、さまざまなタイプのフェンシング遅延を設定できます。
静的フェンシング遅延
静的フェンシング遅延は、事前に定義された固定の遅延です。1 つのノードに静的遅延を設定すると、そのノードがフェンシングされる可能性が高くなります。これは、通信の切断を検出した後、他のノードが先にフェンシングを開始する可能性が高まるためです。active/passive クラスターでは、passive ノードに遅延を設定すると、通信が切断されたときに passive ノードがフェンスされる可能性が高くなります。静的遅延を設定するには、
pcs_delay_baseクラスタープロパティーを使用します。各ノードに個別のフェンスデバイスが使用されている場合、または RHEL 8.6 以降ではすべてのノードに単一のフェンスデバイスが使用されている場合に、このプロパティーを設定できます。動的フェンシング遅延
動的フェンシング遅延はランダムです。この遅延は変化する可能性があり、フェンシングが必要なタイミングで決定されます。ランダム遅延を設定し、ベース遅延とランダム遅延を組み合わせた最大値を
pcs_delay_maxクラスタープロパティーで指定します。各ノードのフェンシング遅延がランダムの場合、どのノードがフェンスされるかもランダムです。この機能は、active/active 設計のすべてのノードに対して単一のフェンスデバイスを使用してクラスターが設定されている場合に便利です。優先フェンシング遅延
優先フェンシング遅延は、アクティブなリソースの優先度に基づきます。すべてのリソースの優先度が同じ場合、実行中のリソースが最も少ないノードがフェンスされます。ほとんどの場合、遅延関連のパラメーターは 1 つしか使用しませんが、複数のパラメーターを組み合わせることも可能です。遅延関連のパラメーターを組み合わせると、リソースの優先度の値が加算されて、総遅延となります。優先フェンシング遅延は、
priority-fencing-delayクラスタープロパティーを使用して設定します。この機能を使用すると、ノード間の通信が失われたときに、実行中のリソースが最も少ないノードがフェンスされる可能性が高くなるため、active/active クラスター設計で役立つ場合があります。
pcmk_delay_base クラスタープロパティー
pcmk_delay_base クラスタープロパティーを設定すると、フェンシングのベース遅延が有効になり、ベース遅延の値が指定されます。
pcmk_delay_base プロパティーに加えて pcmk_delay_max クラスタープロパティーを設定すると、この静的遅延にランダム遅延を追加した合計値が最大遅延を下回るように、全体の遅延が導出されます。pcmk_delay_base を設定し、pcmk_delay_max を設定しない場合は、遅延にランダムなコンポーネントは含まれず、遅延は pcmk_delay_base の値となります。
Red Hat Enterprise Linux 8.6 以降では、pcmk_delay_base パラメーターを使用して、ノードごとに異なる値を指定できます。これにより、ノードごとに異なる遅延を使用して、単一のフェンスデバイスを 2 ノードクラスターで使用できます。別個の遅延を使用するために 2 つの別個のデバイスを設定する必要はありません。ノードごとに異なる値を指定するには、pcmk_host_map と同様の構文を使用して、ホスト名をそのノードの遅延値にマップします。たとえば、node1:0;node2:10s は、node1 をフェンシングするときに遅延を使用せず、node2 をフェンシングするときに 10 秒の遅延を使用します。
pcmk_delay_max クラスタープロパティー
pcmk_delay_max クラスタープロパティーを設定すると、フェンシング操作のランダム遅延が有効になり、ベース遅延とランダム遅延を組み合わせた最大値である最大遅延が指定されます。たとえば、ベース遅延が 3 で、pcmk_delay_max が 10 の場合、ランダム遅延は 3 - 10 になります。
pcmk_delay_max プロパティーに加えて pcmk_delay_base クラスタープロパティーを設定すると、この静的遅延にランダム遅延を追加した合計値が最大遅延を下回るように、全体の遅延が導出されます。pcmk_delay_max を設定し、pcmk_delay_base を設定しない場合は、遅延に静的なコンポーネントは含まれません。
priority-fencing-delay クラスタープロパティー
(RHEL 8.3 以降) priority-fencing-delay クラスタープロパティーを設定すると、スプリットブレイン状況で実行されているリソースが最も少ないノードまたは最も重要でないノードがフェンスされるノードになるように 2 ノードクラスターを設定できます。
priority-fencing-delay プロパティーは期間に設定できます。このプロパティーのデフォルト値は 0 (無効) です。このプロパティーがゼロ以外の値に設定されている場合や、priority メタ属性が 1 つ以上のリソースに対して設定されている場合は、スプリットブレインが発生すると、実行中の全リソースの合計優先度が最も高いノードが稼働状態を維持する可能性が高くなります。たとえば、pcs resource defaults update priority=1 と pcs property set priority-fencing-delay=15s を設定し、他の優先度が設定されていない場合には、最も多くのリソースを実行するノード以外はフェンシングを開始するまで 15 秒間待機するため、最も多くのリソースを実行するノードが稼働状態を維持する可能性が高くなります。特定のリソースが他のリソースよりも重要である場合は、優先度を高く設定できます。
プロモート可能なクローンに優先順位が設定されている場合には、そのクローンのマスターロールを実行しているノードの優先度が 1 ポイント追加されます。
フェンシング遅延の相互作用
複数のタイプのフェンシング遅延を設定すると、以下のようになります。
-
priority-fencing-delayプロパティーで遅延を設定すると、その遅延はpcmk_delay_baseとpcmk_delay_maxのフェンスデバイスプロパティーの遅延に追加されます。この動作により、両方のノードの優先度が同等の場合、またはノードの損失以外の理由で両方のノードをフェンシングする必要がある場合 (たとえば、on-fail=fencingがリソースモニター操作用に設定されている場合)、ある程度の遅延を許容します。これらの遅延を組み合わせて設定する場合は、優先ノードが優先されるよう、priority-fencing-delayプロパティーを、pcmk_delay_baseおよびpcmk_delay_maxの最大遅延よりもはるかに大きい値に設定します。このプロパティーを 2 倍の値に設定すると、常に安全です。 -
Pacemaker 自体がスケジュールしたフェンシングしか、フェンシング遅延を監視しません。
dlm_controldなどの外部コードでスケジュールされるフェンシングや、pcs stonith fenceコマンドで実装されるフェンシングは、フェンスデバイスに必要な情報を提供しません。 -
個々のフェンスエージェントの中には遅延パラメーターが実装されたものがあります。このパラメーターは、エージェントによって決定された名前を持ち、
pcmk_delay_* プロパティーで設定された遅延の影響は受けません。両方の遅延が設定されている場合は、その両方が一緒に追加され、通常は併用されません。
52.5. フェンスデバイスのテスト
フェンシングは、Red Hat Cluster インフラストラクチャーの基本的な部分を設定しているため、フェンシングが適切に機能していることを確認またはテストすることは重要です。
Pacemaker クラスターノードまたは Pacemaker リモートノードがフェンスされると、オペレーティングシステムのグレースフルシャットダウンではなく、ハードキルが実行されるはずです。システムがノードをフェンスするときにグレースフルシャットダウンが発生する場合は、/etc/systemd/logind.conf ファイルで ACPI soft-off を無効にして、電源ボタンが押されたことを示す信号をシステムが無視するようにします。logind.conf ファイルで ACPI ソフトオフを無効にする手順については、logind.conf ファイルで ACPI ソフトオフを無効にするを 参照してください。
手順
以下の手順で、フェンスデバイスをテストします。
デバイスへの接続に使用する ssh、telnet、HTTP などのリモートプロトコルを使用して、手動でログインしてフェンスデバイスをテストしたり、出力される内容を確認します。たとえば、IPMI 対応デバイスのフェンシングを設定する場合は、
ipmitoolを使用してリモートでのログインを試行します。手動でログインする際に使用するオプションに注意してください。これらのオプションは、フェンスエージェントを使用する際に必要になる場合があります。フェンシングデバイスにログインできない場合は、そのデバイスが ping 可能であること、ファイアウォール設定がフェンシングデバイスへのアクセスを妨げていないこと、フェンシングデバイスでリモートアクセスが有効になっていること、認証情報が正しいことなどを確認します。
フェンスエージェントスクリプトを使用して、フェンスエージェントを手動で実行します。フェンスエージェントを実行するのに、クラスターサービスが実行している必要はないため、デバイスをクラスターに設定する前にこのステップを完了できます。これにより、先に進む前に、フェンスデバイスが適切に応答することを確認できます。
注記これらの例では、iLO デバイスの
fence_ipmilanフェンスエージェントスクリプトを使用します。実際に使用するフェンスエージェントと、そのエージェントを呼び出すコマンドは、お使いのサーバーハードウェアによって異なります。指定するオプションを確認するには、フェンスエージェントの man ページを参照してください。通常は、フェンスデバイスのログイン、パスワードなどの情報と、その他のフェンスデバイスに関する情報を把握しておく必要があります。以下の例は、
-o statusパラメーターを指定してfence_ipmilanフェンスエージェントスクリプトを実行する場合に使用する形式になります。このコマンドを実行すると、フェンシングは実行せずに、別のノードのフェンスデバイスインターフェイスのステータスを確認します。ノードの再起動を試行する前にデバイスをテストして、動作させることができます。このコマンドを実行する際に、iLO デバイスの電源をオン/オフにするパーミッションを持つ iLO ユーザーの名前およびパスワードを指定します。# fence_ipmilan -a ipaddress -l username -p password -o status以下の例は、
-o rebootパラメーターを指定してfence_ipmilanフェンスエージェントスクリプトを実行するのに使用する形式になります。このコマンドを 1 つのノードで実行すると、この iLO デバイスで管理するノードが再起動します。# fence_ipmilan -a ipaddress -l username -p password -o rebootフェンスエージェントがステータス、オフ、オン、または再起動の動作を適切に実行しない場合は、ハードウェア、フェンスデバイスの設定、およびコマンドの構文を確認する必要があります。さらに、デバッグ出力を有効にした状態で、フェンスエージェントスクリプトを実行できます。デバッグ出力は、一部のフェンスエージェントで、フェンスデバイスにログインする際に、フェンスエージェントスクリプトに問題が発生しているイベントシーケンスの場所を確認するのに役に立ちます。
# fence_ipmilan -a ipaddress -l username -p password -o status -D /tmp/$(hostname)-fence_agent.debug発生した障害を診断する際に、フェンスデバイスに手動でログインする際に指定したオプションが、フェンスエージェントスクリプトでフェンスエージェントに渡した内容と同一であることを確認する必要があります。
フェンスエージェントが、暗号化した接続に対応する場合は、証明書の検証で障害が生じているためにエラーが出力される場合があり、ホストを信頼することや、フェンスエージェントの
ssl-insecureパラメーターを使用することが求められます。同様に、ターゲットデバイスで SSL/TLS を無効にした場合は、フェンスエージェントに SSL パラメーターを設定する際に、これを考慮しないといけない場合があります。注記テストしているフェンスエージェントが
fence_dracまたはfence_iloの場合、もしくはその他の、継続して失敗しているシステム管理デバイスのフェンスエージェントの場合は、フォールバックしてfence_ipmilanを試行します。大半のシステム管理カードは IPMI リモートログインに対応しており、フェンスエージェントとしてはfence_ipmilanだけに対応しています。フェンスデバイスを、手動で機能したオプションと同じオプションでクラスターに設定し、クラスターを起動したら、以下の例にあるように、任意のノードから
pcs stonith fenceコマンドを実行してフェンシングをテストします (または複数のノードから複数回実行します)。pcs stonith fenceコマンドは m クラスター設定を CIB から読み取り、フェンス動作を実行するように設定したフェンスエージェントを呼び出します。これにより、クラスター設定が正確であることが確認できます。# pcs stonith fence node_namepcs stonith fenceコマンドに成功した場合は、フェンスイベントの発生時に、クラスターのフェンシング設定が機能します。このコマンドが失敗すると、クラスター管理が取得した設定でフェンスデバイスを起動することができません。以下の問題を確認し、必要に応じてクラスター設定を更新します。- フェンス設定を確認します。たとえば、ホストマップを使用したことがある場合は、指定したホスト名を使用して、システムがノードを見つけられるようにする必要があります。
- デバイスのパスワードおよびユーザー名に、bash シェルが誤って解釈する可能性がある特殊文字が含まれるかどうかを確認します。パスワードとユーザー名を引用符で囲んで入力すると、この問題に対処できます。
-
pcs stonithコマンドで IP アドレスまたはホスト名を使用してデバイスに接続できるかどうかを確認してください。たとえば、stonith コマンドでホスト名を指定し、IP アドレスを使用して行ったテストは有効ではありません。 フェンスデバイスが使用するプロトコルにアクセスできる場合は、そのプロトコルを使用してデバイスへの接続を試行します。たとえば、多くのエージェントが ssh または telnet を使用します。デバイスへの接続は、デバイスの設定時に指定した認証情報を使用して試行する必要があります。これにより、有効なプロンプトを取得し、そのデバイスにログインできるかどうかを確認できます。
すべてのパラメーターが適切であることが確認できたものの、フェンスデバイスには接続できない時に、フェンスデバイスでログ機能が使用できる場合は、ログを確認できます。これにより、ユーザーが接続したかどうかと、ユーザーが実行したコマンドが表示されます。
/var/log/messagesファイルで stonith やエラーを確認すれば、発生している問題のヒントが得られる可能性もあります。また、エージェントによっては、より詳細な情報が得られる場合があります。
フェンスデバイステストに成功し、クラスターが稼働したら、実際の障害をテストします。このテストでは、クラスターで、トークンの損失を生じさせる動作を実行します。
ネットワークを停止します。ネットワークの利用方法は、設定により異なります。ただし、多くの場合は、ネットワークケーブルまたは電源ケーブルをホストから物理的に抜くことができます。ネットワーク障害のシミュレーションの詳細は、Red Hat ナレッジベースソリューション What is the proper way to simulate a network failure on a RHEL Cluster? を参照してください。
注記ネットワークや電源ケーブルを物理的に切断せずに、ローカルホストのネットワークインターフェイスを無効にすることは、フェンシングのテストとしては推奨されません。実際に発生する障害を正確にシミュレートしていないためです。
ローカルのファイアウォールを使用して、corosync の受信トラフィックおよび送信トラフィックをブロックします。
以下の例では corosync をブロックします。ここでは、デフォルトの corosync ポートと、ローカルのファイアウォールとして
firewalldが使用されていることと、corosync が使用するネットワークインターフェイスがデフォルトのファイアウォールゾーンにあることが前提となっています。# firewall-cmd --direct --add-rule ipv4 filter OUTPUT 2 -p udp --dport=5405 -j DROP # firewall-cmd --add-rich-rule='rule family="ipv4" port port="5405" protocol="udp" dropsysrq-triggerでクラッシュをシミュレートし、マシンをクラッシュします。ただし、カーネルパニックを発生させると、データが損失する可能性があることに注意してください。クラッシュする前に、クラスターリソースを無効にすることが推奨されます。# echo c > /proc/sysrq-trigger
52.6. フェンスレベルの設定
Pacemaker は、フェンストポロジーと呼ばれる機能を用いて、複数デバイスでのノードのフェンシングに対応します。トポロジーを実装するには、通常の方法で各デバイスを作成し、設定のフェンストポロジーセクションでフェンスレベルを 1 つ以上定義します。
Pacemaker は、以下のようにフェンシングレベルを処理します。
- レベルは、1 から昇順で試行されていきます。
- デバイスに障害が発生すると、現在のレベルの処理が終了します。同レベルのデバイスには試行されず、次のレベルが試行されます。
- すべてのデバイスのフェンシングが正常に完了すると、そのレベルが継承され、他のレベルは試行されなくなります。
- いずれかのレベルで成功するか、すべてのレベルが試行され失敗すると、操作は終了します。
ノードにフェンスレベルを追加する場合は、次のコマンドを使用します。デバイスは、stonith ID をコンマ区切りのリストとして指定します。stonith ID が、指定したレベルで試行されます。
pcs stonith level add level node devices次のコマンドを使用すると現在設定されている全フェンスレベルが表示されます。
pcs stonith level
以下の例では、ノード rh7-2 に、2 つのフェンスデバイス (il0 フェンスデバイス my_ilo と、apc フェンスデバイス my_apc) が設定されています。このコマンドはフェンスレベルを設定し、デバイス my_ilo に障害が発生し、ノードがフェンスできない場合に、Pacemaker がデバイス my_apc の使用を試行できるようにします。この例では、レベル設定後の pcs stonith level コマンドの出力も表示されています。
# pcs stonith level add 1 rh7-2 my_ilo
# pcs stonith level add 2 rh7-2 my_apc
# pcs stonith level
Node: rh7-2
Level 1 - my_ilo
Level 2 - my_apc次のコマンドは、指定したノードおよびデバイスのフェンスレベルを削除します。ノードやデバイスを指定しないと、指定したフェンスレベルがすべてのノードから削除されます。
pcs stonith level remove level [node_id] [stonith_id] ... [stonith_id]以下のコマンドを使用すると、指定したノードや stonith id のフェンスレベルが削除されます。ノードや stonith id を指定しないと、すべてのフェンスレベルが削除されます。
pcs stonith level clear [node]|stonith_id(s)]複数の stonith ID を指定する場合はコンマで区切って指定します。空白は入力しないでください。以下に例を示します。
# pcs stonith level clear dev_a,dev_b次のコマンドは、フェンスレベルで指定されたフェンスデバイスとノードがすべて存在することを確認します。
pcs stonith level verify
フェンストポロジーのノードは、ノード名に適用する正規表現と、ノードの属性 (およびその値) で指定できます。たとえば、次のコマンドでは、ノード node1、node2、および node3 がフェンスデバイス apc1 および apc2 を使用するように設定し、ノード node4、node5、および node6 がフェンスデバイス apc3 および apc4 を使用するように設定します。
# pcs stonith level add 1 "regexp%node[1-3]" apc1,apc2
# pcs stonith level add 1 "regexp%node[4-6]" apc3,apc4次のコマンドでは、ノード属性のマッチングを使用して、同じように設定します。
# pcs node attribute node1 rack=1
# pcs node attribute node2 rack=1
# pcs node attribute node3 rack=1
# pcs node attribute node4 rack=2
# pcs node attribute node5 rack=2
# pcs node attribute node6 rack=2
# pcs stonith level add 1 attrib%rack=1 apc1,apc2
# pcs stonith level add 1 attrib%rack=2 apc3,apc452.7. 冗長電源のフェンシング設定
冗長電源にフェンシングを設定する場合は、ホストを再起動するときに、クラスターが、最初に両方の電源をオフにしてから、いずれかの電源をオンにするようにする必要があります。
ノードの電源が完全にオフにならないと、ノードがリソースを解放しない場合があります。このとき、解放できなかったリソースに複数のノードが同時にアクセスして、リソースが破損する可能性があります。
以下の例にあるように、各デバイスを一度だけ定義し、両方のデバイスがノードのフェンスに必要であると指定する必要があります。
# pcs stonith create apc1 fence_apc_snmp ipaddr=apc1.example.com login=user passwd='7a4D#1j!pz864' pcmk_host_map="node1.example.com:1;node2.example.com:2"
# pcs stonith create apc2 fence_apc_snmp ipaddr=apc2.example.com login=user passwd='7a4D#1j!pz864' pcmk_host_map="node1.example.com:1;node2.example.com:2"
# pcs stonith level add 1 node1.example.com apc1,apc2
# pcs stonith level add 1 node2.example.com apc1,apc252.8. 設定済みのフェンスデバイスの表示
以下のコマンドは、現在設定されているフェンスデバイスをすべて表示します。stonith_id が指定されている場合、コマンドはその設定されたフェンシングデバイスのみのオプションを表示します。--full オプションが指定されている場合、すべての設定されたフェンシングオプションが表示されます。
pcs stonith config [stonith_id] [--full]52.9. pcs コマンドとしてのフェンスデバイスのエクスポート
Red Hat Enterprise Linux 8.7 以降では、pcs stonith config コマンドの --output-format=cmd オプションを使用して、別のシステムで設定されたフェンスデバイスを再作成するために使用できる pcs コマンドを表示できます。
次のコマンドは、fence_apc_snmp フェンスデバイスを作成し、デバイスを再作成するために使用できる pcs コマンドを表示します。
# pcs stonith create myapc fence_apc_snmp ip="zapc.example.com" pcmk_host_map="z1.example.com:1;z2.example.com:2" username="apc" password="apc"
# pcs stonith config --output-format=cmd
Warning: Only 'text' output format is supported for stonith levels
pcs stonith create --no-default-ops --force -- myapc fence_apc_snmp \
ip=zapc.example.com password=apc 'pcmk_host_map=z1.example.com:1;z2.example.com:2' username=apc \
op \
monitor interval=60s id=myapc-monitor-interval-60s52.10. フェンスデバイスの修正と削除
次のコマンドを使用して、現在設定されているフェンシングデバイスのオプションを変更または追加します。
pcs stonith update stonith_id [stonith_device_options]
pcs stonith update コマンドを使用して SCSI フェンシングデバイスを更新すると、フェンシングリソースが実行されていたものと同じノードで実行中のすべてのリソースが再起動されます。RHEL 8.5 以降では、次のコマンドのいずれかのバージョンを使用して、他のクラスターリソースを再起動せずに SCSI デバイスを更新できます。RHEL 8.7 以降では、SCSI フェンシングデバイスをマルチパスデバイスとして設定できます。
pcs stonith update-scsi-devices stonith_id set device-path1 device-path2
pcs stonith update-scsi-devices stonith_id add device-path1 remove device-path2
現在の設定からフェンシングデバイスを削除するには、pcs stonith delete stonith_id コマンドを使用します。次のコマンドは、フェンシングデバイス stonith1 を削除します。
# pcs stonith delete stonith152.11. 手動によるクラスターノードのフェンシング
次のコマンドで、ノードを手動でフェンスできます。--off を指定すると、stonith に API コールの off を使用し、ノードをオフにします (再起動はしません)。
pcs stonith fence node [--off]ノードがアクティブでない場合でも、フェンスデバイスがそのノードをフェンスできない状況では、ノードのリソースをクラスターが復旧できない可能性があります。この場合は、ノードの電源が切れたことを手動で確認した後、次のコマンドを入力して、ノードの電源が切れたことをクラスターに確認し、そのリソースを回復のために解放できます。
指定したノードが実際にオフになっていない状態で、クラスターソフトウェア、または通常クラスターが制御するサービスを実行すると、データ破損またはクラスター障害が発生します。
pcs stonith confirm node52.12. フェンスデバイスの無効化
フェンシングデバイス/リソースを無効にする場合は、pcs stonith disable コマンドを実行します。
以下のコマンドは、フェンスデバイス myapc を無効にします。
# pcs stonith disable myapc52.13. ノードがフェンシングデバイスを使用しないように設定する手順
特定のノードがフェンシングデバイスを使用できないようにするには、フェンスリソースの場所の制約を設定します。
以下の例では、フェンスデバイスの node1-ipmi が、node1 で実行されないようにします。
# pcs constraint location node1-ipmi avoids node152.14. 統合フェンスデバイスで使用する ACPI の設定
クラスターが統合フェンスデバイスを使用する場合は、即時かつ完全なフェンシングを実行できるように、ACPI (Advanced Configuration and Power Interface) を設定する必要があります。
クラスターノードが統合フェンスデバイスでフェンシングされるように設定されている場合は、そのノードの ACPI Soft-Off を無効にします。ACPI Soft-Off を無効にすることにより、統合フェンスデバイスは、クリーンシャットダウンを試行する代わりに、ノードを即時に、かつ完全にオフにできます (例: shutdown -h now)。それ以外の場合は、ACPI Soft-Off が有効になっていると、統合フェンスデバイスがノードをオフにするのに 4 秒以上かかることがあります (以下の注記部分を参照してください)。さらに、ACPI Soft-Off が有効になっていて、ノードがシャットダウン時にパニック状態になるか、フリーズすると、統合フェンスデバイスがノードをオフにできない場合があります。このような状況では、フェンシングが遅延するか、失敗します。したがって、ノードが統合フェンスデバイスでフェンシングされ、ACPI Soft-Off が有効になっている場合は、クラスターが徐々に復元します。または管理者の介入による復旧が必要になります。
ノードのフェンシングにかかる時間は、使用している統合フェンスデバイスによって異なります。統合フェンスデバイスの中には、電源ボタンを押し続けるのと同じ動作を実行するものもあります。この場合は、ノードがオフになるのに 4 秒から 5 秒かかります。また、電源ボタンを押してすぐ離すのと同等の動作を行い、ノードの電源をオフにする行為をオペレーティングシステムに依存する統合フェンスデバイスもあります。この場合は、ノードがオフになるのにかかる時間は 4~ 5 秒よりも長くなります。
- ACPI Soft-Off を無効にする場合は、BIOS 設定を "instant-off"、またはこれに類似する設定に変更することが推奨されます。これにより、"BIOS で ACPI Soft-Off を無効化" で説明しているように、ノードは遅延なくオフになります。
システムによっては、BIOS で ACPI Soft-Off を無効にできません。お使いのクラスターでは、BIOS で ACPI Soft-Off を無効にできない場合に、以下のいずれかの方法で ACPI Soft-Off を無効にできます。
-
/etc/systemd/logind.confファイルにHandlePowerKey=ignoreを設定し、以下のように "logind.conf ファイルで ACPI Soft-Off の無効化" に記載されているように、ノードがフェンシングされるとすぐにオフになることを確認します。これが、ACPI Soft-Off を無効にする 1 つ目の代替方法です。 以下の GRUB ファイルで ACPI を完全に無効にする で説明されているように、カーネルブートコマンドラインに
acpi=offを追加します。これは、ACPI Soft-Off を無効にする 2 つ目の代替方法です。この方法の使用が推奨される場合、または 1 つ目の代替方法が利用できない場合に使用してください。重要この方法は、ACPI を完全に無効にします。コンピューターの中には、ACPI が完全が無効になってるとシステムが正しく起動しないものもあります。お使いのクラスターに適した方法が他にない場合に 限り、この方法を使用してください。
52.14.1. BIOS で ACPI Soft-Off を無効化
以下の手順で、各クラスターノードの BIOS を設定して、ACPI Soft-Off を無効にできます。
BIOS で ACPI Soft-Off を無効にする手順は、サーバーシステムにより異なる場合があります。この手順は、お使いのハードウェアのドキュメントで確認する必要があります。
手順
-
ノードを再起動して
BIOS CMOS Setup Utilityプログラムを起動します。 - 電源メニュー (または同等の電源管理メニュー) に移動します。
電源メニューで、
Soft-Off by PWR-BTTN機能 (または同等) をInstant-Off(または、遅延なく電源ボタンでノードをオフにする同等の設定) に設定します。BIOS CMOS 設定ユーティリティーは、ACPI FunctionがEnabledに設定され、Soft-Off by PWR-BTTNがInstant-Offに設定されていることを示しています。注記ACPI Function、Soft-Off by PWR-BTTN、およびInstant-Offに相当するものは、コンピューターによって異なります。ただし、この手順の目的は、電源ボタンを使用して遅延なしにコンピューターをオフにするように BIOS を設定することです。-
BIOS CMOS Setup Utilityプラグラムを終了します。BIOS 設定が保存されます。 - ノードがフェンシングされるとすぐにオフになることを確認します。フェンスデバイスをテストする方法は フェンスデバイスのテスト を参照してください。
BIOS CMOS Setup Utility
`Soft-Off by PWR-BTTN` set to
`Instant-Off`+---------------------------------------------|-------------------+
| ACPI Function [Enabled] | Item Help |
| ACPI Suspend Type [S1(POS)] |-------------------|
| x Run VGABIOS if S3 Resume Auto | Menu Level * |
| Suspend Mode [Disabled] | |
| HDD Power Down [Disabled] | |
| Soft-Off by PWR-BTTN [Instant-Off | |
| CPU THRM-Throttling [50.0%] | |
| Wake-Up by PCI card [Enabled] | |
| Power On by Ring [Enabled] | |
| Wake Up On LAN [Enabled] | |
| x USB KB Wake-Up From S3 Disabled | |
| Resume by Alarm [Disabled] | |
| x Date(of Month) Alarm 0 | |
| x Time(hh:mm:ss) Alarm 0 : 0 : | |
| POWER ON Function [BUTTON ONLY | |
| x KB Power ON Password Enter | |
| x Hot Key Power ON Ctrl-F1 | |
| | |
| | |
+---------------------------------------------|-------------------+
この例では、ACPI Function が Enabled に設定され、Soft-Off by PWR-BTTN が Instant-Off に設定されていることを示しています。
52.14.2. logind.conf ファイルで ACPI Soft-Off の無効化
/etc/systemd/logind.conf ファイルで電源キーの処理を無効にする場合は、以下の手順を行います。
手順
/etc/systemd/logind.confファイルに、以下の設定を定義します。HandlePowerKey=ignoresystemd-logindサービスを再起動します。# systemctl restart systemd-logind.service- ノードがフェンシングされるとすぐにオフになることを確認します。フェンスデバイスをテストする方法は フェンスデバイスのテスト を参照してください。
52.14.3. GRUB ファイルで ACPI を完全に無効にする
ACPI Soft-Off は、カーネルの GRUB メニューエントリーに acpi=off を追加して無効にできます。
この方法は、ACPI を完全に無効にします。コンピューターの中には、ACPI が完全が無効になってるとシステムが正しく起動しないものもあります。お使いのクラスターに適した方法が他にない場合に 限り、この方法を使用してください。
手順
GRUB ファイルで ACPI を無効にするには、次の手順に従います。
以下のように、
grubbyツールで、--argsオプションと--update-kernelオプションを使用して、各クラスターノードのgrub.cfgファイルを変更します。# grubby --args=acpi=off --update-kernel=ALL- ノードを再起動します。
- ノードがフェンシングされるとすぐにオフになることを確認します。フェンスデバイスをテストする方法は フェンスデバイスのテスト を参照してください。
第53章 クラスターリソースの設定
次のコマンドを使用して、クラスターリソースを作成および削除します。
クラスターリソースを作成するコマンドの形式は、以下のとおりです。
pcs resource create resource_id [standard:[provider:]]type [resource_options] [op operation_action operation_options [operation_action operation options]...] [meta meta_options...] [clone [clone_options] | master [master_options] [--wait[=n]]主なクラスターリソースの作成オプションには、以下が含まれます。
-
--beforeおよび--afterオプションは、リソースグループに含まれるリソースを基準にして、追加するリソースの位置を指定します。 -
--disabledオプションは、リソースが自動的に起動しないことを示しています。
クラスター内に作成できるリソースの数に制限はありません。
リソースの制約を設定して、クラスター内のそのリソースの動作を指定できます。
リソース作成の例
以下のコマンドは、仕様 ocf、プロバイダー heartbeat、およびタイプ IPaddr2 で、リソース VirtualIP を作成します。このリソースのフローティングアドレスは 192.168.0.120 であり、システムは、30 秒間隔で、リソースが実行しているかどうかを確認します。
# pcs resource create VirtualIP ocf:heartbeat:IPaddr2 ip=192.168.0.120 cidr_netmask=24 op monitor interval=30s
または、以下のように、standard フィールドおよび provider フィールドを省略できます。規格とプロバイダーはそれぞれ ocf と heartbeat にデフォルト設定されます。
# pcs resource create VirtualIP IPaddr2 ip=192.168.0.120 cidr_netmask=24 op monitor interval=30s設定済みリソースの削除
次のコマンドを使用して、設定済みのリソースを削除します。
pcs resource delete resource_id
たとえば、次のコマンドは、リソース ID が VirtualIP の既存リソースを削除します。
# pcs resource delete VirtualIP53.1. リソースエージェント識別子
リソースに定義する識別子は、リソースに使用するエージェント、そのエージェントを検索する場所、およびそれが準拠する仕様をクラスターに指示します。
以下の表は、リソースエージェントのこれらのプロパティーを説明しています。
| フィールド | 説明 |
|---|---|
| standard | エージェントが準拠する規格。使用できる値とその意味は以下のとおりです。
*
*
*
*
* |
| type |
使用するリソースエージェントの名前 (例: |
| provider |
OCF 仕様により、複数のベンダーで同じリソースエージェントを指定できます。Red Hat が提供するエージェントのほとんどは、プロバイダーに |
以下の表には、利用可能なリソースプロパティーを表示するコマンドをまとめています。
| pcs 表示コマンド | 出力 |
|---|---|
|
| 利用できる全リソースのリストを表示 |
|
| 利用できるリソースエージェントのリストを表示 |
|
| 利用できるリソースエージェントプロバイダーのリストを表示 |
|
| 利用できるリソースを指定文字列でフィルターしたリストを表示。仕様名、プロバイダー名、タイプ名などでフィルターを指定して、リソースを表示できます。 |
53.2. リソース固有のパラメーターの表示
各リソースで以下のコマンドを使用すると、リソースの説明、そのリソースに設定できるパラメーター、およびそのリソースに設定されるデフォルト値が表示されます。
pcs resource describe [standard:[provider:]]type
たとえば、以下のコマンドは、apache タイプのリソース情報を表示します。
# pcs resource describe ocf:heartbeat:apache
This is the resource agent for the Apache Web server.
This resource agent operates both version 1.x and version 2.x Apache
servers.
...53.3. リソースのメタオプションの設定
リソースには、リソース固有のパラメーターの他に、リソースオプションを設定できます。このような追加オプションは、クラスターがリソースの動作を決定する際に使用されます。
以下の表は、リソースのメタオプションを示しています。
| フィールド | デフォルト | 説明 |
|---|---|---|
|
|
| すべてのリソースをアクティブにできない場合に、クラスターは優先度の低いリソースを停止して、優先度が高いリソースを実行し続けます。 |
|
|
| クラスターがこのリソースを維持しようとする状態を示します。設定できる値は以下のとおりです。
*
*
*
*
RHEL 8.5 以降では、 |
|
|
|
クラスターによるリソースの起動および停止を許可するかどうかを示します。使用できる値は |
|
| 0 | リソースを同じ場所に残すための優先度の値です。この属性の詳細は、現在のノードを優先するリソースの設定 を参照してください。 |
|
| Calculated | リソースを起動できる条件を示します。
以下の条件を除き、
*
*
*
* |
|
|
|
指定したリソースが任意のノードで失敗した回数です。この回数を超えると、そのノードには、このリソースのホストとして不適格とするマークが付けられます。値を 0 にするとこの機能は無効になり、ノードに不適格マークが付けられることはありません。 |
|
|
| 失敗が新たに発生することなくこの時間が経過した場合に、以前に失敗したリソースアクションを無視します。これにより、障害が発生したノードでリソースが以前に移行しきい値に達した場合、そのノードにリソースを戻すことができる可能性があります。0 の値を指定すると、失敗が期限切れになりません。 警告:この値が低く、保留中のクラスターアクティビティーによってクラスターがその時間内に障害に応答できない場合は、繰り返しアクションによって障害が報告され続けても、障害は完全に無視され、リソースの回復は行われません。このオプションの値は、少なくとも、クラスター内の全リソースの最長アクションタイムアウトよりも大きくする必要があります。時間または日数単位の値が適切です。 |
|
|
| リソースが複数のノードでアクティブであることが検出された場合に、クラスターが実行すべき動作を示します。設定できる値は以下のとおりです。
*
*
*
* |
|
|
|
(RHEL 8.4 以降) リソースがリソースグループに含まれる場合に作成された暗黙的なコロケーションの成約など、従属リソース (target_resource) としてリソース関連のコロケーション成約すべてに、 |
|
|
|
(RHEL 8.7 以降) |
53.3.1. リソースオプションのデフォルト値の変更
Red Hat Enterprise Linux 8.3 以降では、pcs resource defaults update コマンドを使用して、すべてのリソースのリソースオプションのデフォルト値を変更できます。たとえば、次のコマンドは、resource-stickiness のデフォルト値を 100 にリセットします。
# pcs resource defaults update resource-stickiness=100
以前のリリースのすべてのリソースのデフォルトを設定する元の pcs resource defaults name=value コマンドは、複数のデフォルトが設定されない限りサポートされます。ただし、pcs resource defaults update が、コマンドの推奨されるバージョンになりました。
53.3.2. リソースセットのリソースオプションのデフォルト値の変更
Red Hat Enterprise Linux 8.3 以降では、pcs resource defaults set create コマンドを使用して複数のリソースデフォルトのセットを作成し、リソース 式を含むルールを指定できます。RHEL 8.3 では、このコマンドで指定したルールは、and、or および括弧を含め、resource 式のみを使用できます。RHEL 8.4 では、このコマンドで指定したルールは、and、or および括弧など、resource と date 式のみを使用できます。
pcs resource defaults set create コマンドを使用して、特定タイプの全リソースにデフォルトのリソース値を設定できます。たとえば、停止に時間がかかるデータベースを実行している場合は、データベースタイプの全リソースで resource-stickiness のデフォルト値を増やすことで、想定している頻度よりも多く、このようなリソースが他のノードに移動されるのを回避できます。
以下のコマンドは、pqsql タイプの全リソースに、resource-stickiness のデフォルト値を 100 に設定します。
-
リソースのデフォルトセット名を指定する
idオプションは必須ではありません。このオプションを設定すると、pcsが自動的に ID を生成します。この値を設定すると、より分かりやすい名前に設定できます。 この例では、
::pgsqlは、クラスやプロバイダーは任意でタイプがpgsqlを指定します。-
ocf:heartbeat:pgsqlを指定すると、クラスがocf、プロバイダーがheartbeat、タイプがpgsqlに指定されます。 -
ocf:pacemaker:を指定すると、タイプは任意でクラスがocf、プロバイダーがpacemakerに指定されます。
-
# pcs resource defaults set create id=pgsql-stickiness meta resource-stickiness=100 rule resource ::pgsql
既存セットのデフォルト値を変更する場合は、pcs resource defaults set update コマンドを使用します。
53.3.3. 現在設定されているリソースのデフォルトの表示
pcs resource defaults コマンドは、指定したルールなど、現在設定されているリソースオプションのデフォルト値のリストを表示します。
次の例では resource-stickiness のデフォルト値を 100 にリセットした後のコマンド出力を示しています。
# pcs resource defaults
Meta Attrs: rsc_defaults-meta_attributes
resource-stickiness=100
以下の例では、タイプが pqsql の全リソースの resource-stickiness のデフォルト値を 100 にリセットし、id オプションを id=pgsql-stickiness に設定します。
# pcs resource defaults
Meta Attrs: pgsql-stickiness
resource-stickiness=100
Rule: boolean-op=and score=INFINITY
Expression: resource ::pgsql53.3.4. リソース作成でメタオプションの設定
リソースのメタオプションにおけるデフォルト値のリセットの有無に関わらず、リソースを作成する際に、特定リソースのリソースオプションをデフォルト以外の値に設定できます。以下は、リソースのメタオプションの値を指定する際に使用する pcs resource create コマンドの形式です。
pcs resource create resource_id [standard:[provider:]]type [resource options] [meta meta_options...]
たとえば、以下のコマンドでは resource-stickiness の値を 50 に設定したリソースを作成します。
# pcs resource create VirtualIP ocf:heartbeat:IPaddr2 ip=192.168.0.120 meta resource-stickiness=50また、次のコマンドを使用すると既存のリソース、グループ、クローン作成したリソースなどのリソースメタオプションの値を作成することもできます。
pcs resource meta resource_id | group_id | clone_id meta_options
以下の例では、dummy_resource という名前の既存リソースがあります。このコマンドは、failure-timeout メタオプションの値を 20 秒に設定します。これにより 20 秒でリソースが同じノード上で再起動を試行できるようになります。
# pcs resource meta dummy_resource failure-timeout=20s
上記のコマンドを実行した後、リソースの値を表示して、failure-timeout=20s が設定されているかどうかを確認できます。
# pcs resource config dummy_resource
Resource: dummy_resource (class=ocf provider=heartbeat type=Dummy)
Meta Attrs: failure-timeout=20s
...53.4. リソースグループの設定
クラスターの最も一般的な設定要素の 1 つがリソースセットです。リソースセットはまとめて配置し、順番に起動し、その逆順で停止する必要があります。この設定を簡単にするため、Pacemaker はリソースグループの概念をサポートします。
53.4.1. リソースグループの作成
以下のコマンドを使用してリソースグループを作成し、グループに追加するリソースを指定します。グループが存在しない場合は、このコマンドによりグループが作成されます。グループが存在する場合は、このコマンドにより別のリソースがグループに追加されます。リソースは、このコマンドで指定された順序で起動し、その逆順で停止します。
pcs resource group add group_name resource_id [resource_id] ... [resource_id] [--before resource_id | --after resource_id]
このコマンドの --before オプションおよび --after オプションを使用して、追加するリソースの位置を、そのグループにすでに含まれるリソースを基準にして指定できます。
以下のコマンドを使用して、リソースを作成するときに、既存のグループに新しいリソースを追加することもできます。以下のコマンドでは、作成するリソースが group_name グループに追加されます。group_name グループが存在しない場合は作成されます。
pcs resource create resource_id [standard:[provider:]]type [resource_options] [op operation_action operation_options] --group group_nameグループに含まれるリソースの数に制限はありません。グループの基本的なプロパティーは以下のとおりです。
- グループ内に、複数のリソースが置かれています。
- リソースは、指定した順序で起動します。グループ内に実行できないリソースがあると、そのリソースの後に指定されたリソースは実行できません。
- リソースは、指定した順序と逆の順序で停止します。
以下の例では、既存リソースの IPaddr と Email が含まれるリソースグループ shortcut が作成されます。
# pcs resource group add shortcut IPaddr Emailこの例では、以下のように設定されています。
-
IPaddrが起動してから、Emailが起動します。 -
Emailリソースが停止してから、IPAddrが停止します。 -
IPaddrを実行できない場合は、Emailも実行できません。 -
Emailを実行できなくても、IPaddrには影響ありません。
53.4.2. リソースグループの削除
以下のコマンドを使用して、グループからリソースを削除します。グループにリソースが残っていないと、このコマンドによりグループ自体が削除されます。
pcs resource group remove group_name resource_id...53.4.3. リソースグループの表示
以下のコマンドは、現在設定されているリソースグループをリスト表示します。
pcs resource group list53.4.4. グループオプション
リソースグループには、priority オプション、target-role オプション、または is-managed オプションを設定できます。このオプションは、1 つのリソースに設定されている場合と同じ意味を維持します。リソースのメタオプションの詳細は、リソースのメタオプションの設定 を参照してください。
53.4.5. グループの粘着性
粘着性は、リソースを現在の場所に留ませる優先度の度合いを示し、グループで加算されます。グループのアクティブなリソースが持つ stickiness 値の合計が、グループの合計になります。そのため、resource-stickiness のデフォルト値が 100 で、グループに 7 つのメンバーがあり、そのメンバーの 5 つがアクティブな場合は、グループ全体でスコアが 500 の現在の場所が優先されます。
53.5. リソース動作の決定
リソースの制約を設定して、クラスター内のそのリソースの動作を指定できます。以下の制約のカテゴリーを設定できます。
-
場所の制約 - 場所の制約は、リソースが実行できるノードを決定します。場所の制約を設定する方法は、リソースを実行するノードの決定 を参照してください。 -
順序制約 - 順序制約は、リソースが実行される順序を決定します。順序の制約を設定する方法は、クラスターリソースの実行順序の決定 を参照してください。 -
コロケーション制約 - コロケーション制約は、リソースが他のリソースに対してどこに配置されるかを決定します。コロケーションの制約の詳細は、クラスターリソースのコロケーション を参照してください。
複数リソースをまとめて配置して、順番に起動するまたは逆順で停止する一連の制約を簡単に設定する方法として、Pacemaker ではリソースグループという概念に対応しています。リソースグループの作成後に、個別のリソースの制約を設定するようにグループ自体に制約を設定できます。
第54章 リソースを実行するノードの決定
場所の制約は、リソースを実行するノードを指定します。場所の制約を設定することで、たとえば特定のノードで優先してリソースを実行する、または特定のノードではリソースを実行しないことを決定できます。
場所の制約に加え、リソースが実行されるノードは、そのリソースの resource-stickiness 値に影響されます。これは、リソースが現在実行しているノードに留まることをどの程度優先するかを決定します。resource-stickiness 値の設定に関する詳細は、現在のノードを優先するリソースの設定 を参照してください。
54.1. 場所の制約の設定
基本的な場所の制約を設定し、オプションの score 値で制約の相対的な優先度を指定することで、リソースの実行を特定のノードで優先するか、回避するかを指定できます。
以下のコマンドは、リソースの実行を、指定した 1 つまたは複数のノードで優先するように、場所の制約を作成します。1 回のコマンドで、特定のリソースの制約を複数のノードに対して作成できます。
pcs constraint location rsc prefers node[=score] [node[=score]] ...次のコマンドは、リソースが指定ノードを回避する場所の制約を作成します。
pcs constraint location rsc avoids node[=score] [node[=score]] ...次の表は、場所の制約を設定する基本的なオプションを説明します。
| フィールド | 説明 |
|---|---|
|
| リソース名 |
|
| ノード名 |
|
|
指定のリソースが指定のノードを優先するべきか回避するべきかを示す優先度を示す正の整数値。
数値スコア ( |
以下のコマンドは、Webserver リソースが、node1 ノードで優先的に実行するように指定する場所の制約を作成します。
# pcs constraint location Webserver prefers node1
pcs では、コマンドラインの場所の制約に関する正規表現に対応しています。この制約は、リソース名に一致する正規表現に基づいて、複数のリソースに適用されます。これにより、1 つのコマンドラインで複数の場所の制約を設定できます。
次のコマンドは、dummy0 から dummy9 までのリソースの実行が node1 に優先されるように指定する場所の制約を作成します。
# pcs constraint location 'regexp%dummy[0-9]' prefers node1Pacemaker は、http://pubs.opengroup.org/onlinepubs/9699919799/basedefs/V1_chap09.html#tag_09_04 で説明しているように、POSIX 拡張正規表現を使用するため、以下のコマンドを実行しても同じ制約を指定できます。
# pcs constraint location 'regexp%dummy[[:digit:]]' prefers node154.2. ノードのサブセットへのリソース検出を制限
Pacemaker がどこでリソースを開始しても、開始する前にそのリソースがすでに実行しているかどうかを確認するために、すべてのノードでワンタイム監視操作 ("プローブ" とも呼ばれています) を実行します。このリソース検出のプロセスは、監視を実行できないノードではエラーになる場合があります。
ノードに場所の制約を設定する際に、pcs constraint location コマンドの resource-discovery オプションを指定して、指定したリソースに対して、Pacemaker がこのノードでリソース検出を実行するかどうかの優先度を指定できます。物理的にリソースが稼働可能なノードのサブセットでリソース検出を制限すると、ノードが大量に存在する場合にパフォーマンスを大幅に改善できます。pacemaker_remote を使用して、ノード数を 100 単位で拡大する場合は、このオプションの使用を検討してください。
以下のコマンドは、pcs constraint location コマンドで resource-discovery オプションを指定する場合の形式を示しています。このコマンドでは、基本的な場所の制約に対応します。score を正の値にすると、リソースが特定のノードで優先的に実行するように設定されます。score を負の値にすると、リソースがノードを回避するように設定されます。基本的な場所の制約と同様に、制約にリソースの正規表現を使用することもできます。
pcs constraint location add id rsc node score [resource-discovery=option]以下の表は、リソース検出の制約を設定する基本パラメーターを説明します。
| フィールド | 説明 |
|
| 制約自体にユーザーが選択した名前。 |
|
| リソース名 |
|
| ノード名 |
|
| 指定のリソースが指定のノードを優先するべきか回避するべきかを示す優先度を示す整数値。スコアが正の値の場合は、ノードを優先するようにリソースを設定する基本的な場所の制約となり、負の場合は、ノードを回避するようにリソースを設定する基本的な場所の制約となります。
数値スコア ( |
|
|
*
*
* |
resource-discovery を never または exclusive に設定すると、Pacemaker が、想定されていない場所で実行している不要なサービスのインスタンスを検出して停止する機能がなくなります。関連するソフトウェアをアンインストールしたままにするなどして、リソース検出なしでサービスがノードでアクティブにならないようにすることは、システム管理者の責任です。
54.3. 場所の制約方法の設定
場所の制約を使用する場合は、リソースをどのノードで実行できるかを指定する一般的な方法を設定できます。
- オプトインクラスター - デフォルトではリソースをどこでも実行できないクラスターを設定し、特定のリソースに対して許可されたノードを選択的に有効にします。
- オプトアウトクラスター - デフォルトですべてのリソースをどこでも実行できるクラスターを設定し、特定のノードで実行できないリソースに対して場所の制約を作成します。
クラスターでオプトインまたはオプトアウトのどちらを選択するかは、優先する設定やクラスターの設定により異なります。ほとんどのリソースをほとんどのノードで実行できるようにする場合は、オプトアウトを使用した方が設定しやすくなる可能性があります。ほとんどのリソースを、一部のノードでのみ実行する場合は、オプトインを使用した方が設定しやすくなる可能性があります。
54.3.1. "オプトイン" クラスターの設定
オプトインクラスターを作成する場合は、クラスタープロパティー symmetric-cluster を false に設定し、デフォルトでは、いずれのノードでもリソースの実行を許可しないようにします。
# pcs property set symmetric-cluster=false
個々のリソースでノードを有効にします。以下のコマンドは、場所の制約を設定し、Webserver リソースでは example-1 ノードが優先され、Database リソースでは example-2 ノードが優先されるようにし、いずれのリソースも優先ノードに障害が発生した場合は example-3 ノードにフェイルオーバーできるようにします。オプトインクラスターに場所の制約を設定する場合は、スコアをゼロに設定すると、リソースに対してノードの優先や回避を指定せずに、リソースをノードで実行できます。
# pcs constraint location Webserver prefers example-1=200
# pcs constraint location Webserver prefers example-3=0
# pcs constraint location Database prefers example-2=200
# pcs constraint location Database prefers example-3=054.3.2. "オプトアウト" クラスターの設定
オプトアウトクラスターを作成するには、クラスタープロパティー symmetric-cluster を true に設定し、デフォルトで、すべてのノードでリソースの実行を許可します。これは、symmetric-cluster が明示的に設定されていない場合のデフォルト設定です。
# pcs property set symmetric-cluster=true
以下のコマンドを実行すると、""オプトイン" クラスター" の設定の例と同じ設定になります。全ノードのスコアは暗黙で 0 になるため、優先ノードに障害が発生した場合はいずれのリソースも example-3 ノードにフェイルオーバーできます。
# pcs constraint location Webserver prefers example-1=200
# pcs constraint location Webserver avoids example-2=INFINITY
# pcs constraint location Database avoids example-1=INFINITY
# pcs constraint location Database prefers example-2=200INFINITY は、スコアのデフォルト値であるため、上記コマンドでは、スコアに INFINITY を指定する必要はないことに注意してください。
54.4. 現在のノードを優先するリソースの設定
リソースには、リソースのメタオプションの設定 で説明されているように、リソースの作成時にメタ属性として設定できる resource-stickiness 値があります。resource-stickiness 値は、現在実行しているノード上にリソースが残す量を決定します。Pacemaker は、他の設定 (場所の制約の score 値など) とともに resource-stickiness 値を考慮して、リソースを別のノードに移動するか、そのまま残すかを決定します。
resource-stickiness の値を 0 にすると、クラスターは、必要に応じてリソースを移動して、ノード間でリソースのバランスを調整できます。これにより、関連のないリソースが起動または停止したときにリソースが移動する可能性があります。stickiness が高くなると、リソースは現在の場所に留まり、その他の状況が stickiness を上回る場合に限り移動するようになります。これにより、新しく追加したノードに割り当てられたリソースは、管理者の介入なしには利用できなくなる可能性があります。
デフォルトでは、resource-stickiness の値が 0 の状態でリソースが作成されます。resource-stickiness が 0 に設定され、場所の制約がない Pacemaker のデフォルト動作では、クラスターノード間で均等に分散されるようにリソースを移動します。この設定では、正常なリソースの移動頻度が想定よりも増える可能性があります。この動作を防ぐには、デフォルトの resource-stickiness の値を 1 に設定します。このデフォルトはクラスター内のすべてのリソースに適用されます。この値を小さく指定すると、作成する他の制約で簡単に上書きできますが、Pacemaker がクラスター全体で正常なリソースを不必要に移動するのを防ぐには十分です。
以下のコマンドは、デフォルトの resource-stickiness 値を 1 に設定します。
# pcs resource defaults update resource-stickiness=1
resource-stickiness に正の値が設定されている場合、リソースは新たに追加されたノードに移動しません。この時点でリソースバランスが必要な場合は、resource-stickiness の値を一時的に 0 に設定できます。
場所の制約スコアが resource-stickiness の値よりも大きい場合には、クラスターは場所の制約が指定するノードに、正常なリソースを依然として移動する可能性があります。
Pacemaker がリソースを配置する場所を決定する方法の詳細は、ノード配置ストラテジーの設定 を参照してください。
第55章 クラスターリソースの実行順序の決定
リソースが実行する順序を指定する、順序の制約を設定できます。
次は、順序の制約を設定するコマンドの形式です。
pcs constraint order [action] resource_id then [action] resource_id [options]以下の表では、順序の制約を設定する場合のプロパティーとオプションをまとめています。
| フィールド | 説明 |
|---|---|
| resource_id | 動作を行うリソースの名前。 |
| action | リソースに対して指示されるアクション。action プロパティーでは、以下の値が使用できます。
*
*
*
*
動作を指定しない場合のデフォルトの動作は |
|
|
制約の実施方法。
*
*
* |
|
|
true の場合、逆の制約は逆のアクションに適用されます (たとえば、A の開始後に B が開始する場合は、B が A が停止前に停止する場合など) 。 |
次のコマンドを使用すると、すべての順序の制約からリソースが削除されます。
pcs constraint order remove resource1 [resourceN]...55.1. 強制的な順序付けの設定
必須順序制約は、最初のリソースに対する最初のアクションが正常に完了しない限り、2 番目のリソースの 2 番目のアクションが開始しないことを示しています。命令できるアクションが stop または start で、昇格可能なクローンが demote および promote とします。たとえば、"A then B" ("start A then start B" と同等) は、A が適切に開始しない限り、B が開始しないことを示しています。順序の制約は、この制約の kind オプションが Mandatory に設定されているか、デフォルトのままに設定されている場合は必須になります。
symmetrical オプションが true に設定されているか、デフォルトのままにすると、逆のアクションの命令は逆順になります。start と stop のアクションは対称になり、demote と promote は対称になります。たとえば、対称的に、"promote A then start B" 順序は "stop B then demote A" (B が正常に停止するまで A が降格しないこと) を示しています。対称順序は、A の状態を変更すると、B に予定されているアクションが発生すること示しています。たとえば、"A then B" と設定した場合は、失敗により A が再起動すると、B が最初に停止してから、A が停止し、それにより A が開始し、それにより B が開始することを示します。
クラスターは、それぞれの状態変化に対応することに注意してください。2 番目のリソースで停止操作を開始する前に 1 番目のリソースが再起動し、起動状態にあると、2 番目のリソースを再起動する必要がありません。
55.2. 勧告的な順序付けの設定
順序の制約に kind=Optional オプションを指定すると、制約はオプションと見なされ、両方のリソースが指定の動作を実行する場合にのみ適用されます。1 番目に指定しているリソースの状態を変更しても、2 番目に指定しているリソースには影響しません。
次のコマンドは、VirtualIP と dummy_resource という名前のリソースに、勧告的な順序の制約を設定します。
# pcs constraint order VirtualIP then dummy_resource kind=Optional55.3. リソースセットへの順序の設定
一般的に、管理者は、複数のリソースの連鎖を作成する場合に順序を設定します (例: リソース A が開始してからリソース B を開始し、その後にリソース C を開始)。複数のリソースを作成して同じ場所に配置し (コロケーションを指定)、起動の順序を設定する必要がある場合は、このようなリソースが含まれるリソースグループを設定できます。
ただし、特定の順序で起動する必要があるリソースをリソースグループとして設定することが適切ではない場合があります。
- リソースを順番に起動するように設定する必要があるものの、リソースは必ずしも同じ場所に配置しない場合
- リソース C の前にリソース A または B のいずれかが起動する必要があるものの、A と B の間には関係が設定されていない場合
- リソース C およびリソース D の前にリソース A およびリソース B の両方が起動している必要があるものの、A と B、または C と D の間には関係が設定されていない場合
このような状況では、pcs constraint order set コマンドを使用して、1 つまたは複数のリソースセットに対して順序の制約を作成できます。
pcs constraint order set コマンドを使用して、リソースセットに以下のオプションを設定できます。
sequential- リソースセットに順序を付ける必要があるかどうかを指定します。trueまたはfalseに設定できます。デフォルト値はtrueです。sequentialをfalseに設定すると、セットのメンバーに順序を設定せず、順序の制約にあるセット間で順序付けできます。そのため、このオプションは、制約に複数のセットが登録されている場合に限り有効です。それ以外の場合は、制約を設定しても効果がありません。-
require-all- 続行する前にセットの全リソースがアクティブである必要があるかどうかを指定します。trueまたはfalseに設定できます。require-allをfalseに設定すると、次のセットに進む前に、セットの 1 つのリソースのみを開始する必要があります。require-allをfalseに設定しても、sequentialがfalseに設定されている順序なしセットと併用しない限り、効果はありません。デフォルト値はtrueです。 -
action- クラスターリソースの実行順序の決定 の表順序の制約のプロパティーで説明されているように、start、promote、demote、またはstopに設定できます。 -
role-Stopped、Started、Master、またはSlaveに設定できます。RHEL 8.5 以降では、pcsコマンドラインインターフェイスは、roleの値としてPromotedとUnpromoted を受け入れます。PromotedおよびUnpromotedロールは、MasterおよびSlaveロールと機能的に等価です。
pcs constraint order set コマンドの setoptions パラメーターの後に、リソースのセットに対する以下の制約オプションを設定できます。
-
id- 定義する制約の名前を指定します。 -
kind-クラスターリソースの実行順序の決定 の「順序の制約のプロパティー」の表で説明されているように、制約を有効にする方法を指定します。 -
symmetrical-クラスターリソースの実行順序の決定 の「順序の制約のプロパティー」の表で説明しているように、逆の作用に逆の制約を適用するかどうかを設定します。
pcs constraint order set resource1 resource2 [resourceN]... [options] [set resourceX resourceY ... [options]] [setoptions [constraint_options]]
D1、D2、D3 という 3 つのリソースがある場合は、次のコマンドを実行すると、この 3 つのリソースを、順序を指定したリソースセットとして設定します。
# pcs constraint order set D1 D2 D3
この例では、A、B、C、D、E、および F という名前の 6 つのリソースがある場合に、以下のように、起動するリソースセットに順序制約を設定します。
-
AとBは、互いに独立して起動します。 -
AまたはBのいずれかが開始すると、Cが開始します。 -
Cが開始すると、Dが開始します。 -
Dが開始したら、EとFが互いに独立して起動します。
symmetrical=false が設定されているため、リソースの停止は、この制約の影響を受けません。
# pcs constraint order set A B sequential=false require-all=false set C D set E F sequential=false setoptions symmetrical=false55.4. Pacemaker で管理されないリソース依存関係の起動順序の設定
クラスターは、クラスターが管理していない依存関係を持つリソースを含めることができます。この場合は、Pacemaker を起動する前にその依存関係を起動し、Pacemaker が停止した後に停止する必要があります。
systemd resource-agents-deps ターゲットを使用してこの条件を設定するために、スタートアップ順序を設定できます。このターゲットに対して systemd ドロップインユニットを作成すると、Pacemaker はこのターゲットに対して相対的な順序を適切に設定できます。
たとえば、クラスターが管理していない外部サービス foo に依存するリソースがクラスターに含まれている場合は、以下の手順を実行します。
以下を含むドロップインユニット
/etc/systemd/system/resource-agents-deps.target.d/foo.confを作成します。[Unit] Requires=foo.service After=foo.service-
systemctl daemon-reloadコマンドを実行します。
この方法で指定するクラスターの依存関係はサービス以外のものとなります。たとえば、/srv にファイルシステムをマウントする依存関係がある場合は、以下の手順を実行してください。
-
/etc/fstabファイルに/srvが記載されていることを確認します。これは、システムマネージャーの設定が再読み込みされる際に、システムの起動時にsystemdファイルのsrv.mountに自動的に変換されます。詳細は、man ページのsystemd.mount(5) およびsystemd-fstab-generator(8) を参照してください。 ディスクのマウント後に Pacemaker が起動するようにするには、以下を含むドロップインユニット
/etc/systemd/system/resource-agents-deps.target.d/srv.confを作成します。[Unit] Requires=srv.mount After=srv.mount-
systemctl daemon-reloadコマンドを実行します。
Pacemaker クラスターが使用する LVM ボリュームグループに、iSCSI ターゲットなど、リモートブロックストレージに存在する 1 つ以上の物理ボリュームが含まれている場合は、Pacemaker が起動する前にサービスが開始されるように、ターゲット用に systemd resource-agents-deps ターゲットと systemd ドロップインユニットを設定することができます。
以下の手順では、blk-availability.service を依存関係として設定します。blk-availability.service サービスは、iscsi.service などのサービスが含まれるラッパーです。お使いのデプロイメントでこれが必要な場合は、blk-availability の代わりに iscsi.service(iSCSI のみ) または remote-fs.target を依存関係として設定できます。
以下を含むドロップインユニット
/etc/systemd/system/resource-agents-deps.target.d/blk-availability.confを作成します。[Unit] Requires=blk-availability.service After=blk-availability.service-
systemctl daemon-reloadコマンドを実行します。
第56章 クラスターリソースのコロケーション
あるリソースの場所を、別のリソースの場所に依存させるように指定する場合は、コロケーションの制約を設定します。
2 つのリソース間にコロケーション制約を作成すると、リソースがノードに割り当てられる割り当てる順序に重要な影響を及ぼす点に注意してください。リソース B の場所を把握していない場合は、リソース B に相対的となるようにリソース A を配置することができません。このため、コロケーションの制約を作成する場合は、リソース A をリソース B に対してコロケーションを設定するのか、もしくはリソース B をリソース A に対してコロケーションを設定するのかを考慮する必要があります。
また、コロケーションの制約を作成する際に注意しておきたいもう 1 つの点として、リソース A をリソース B に対してコロケーションを設定すると仮定した場合は、クラスターがリソース B に選択するノードを決定する際に、リソース A の優先度も考慮に入れます。
次のコマンドはコロケーションの制約を作成します。
pcs constraint colocation add [master|slave] source_resource with [master|slave] target_resource [score] [options]以下の表は、コロケーション制約を設定するのに使用するプロパティーおよびオプションをまとめています。
| パラメーター | 説明 |
|---|---|
| source_resource | コロケーションソース。制約の条件を満たさない場合、クラスターではこのリソースの実行を許可しないことを決定する可能性があります。 |
| target_resource | コロケーションターゲット。クラスターは、このリソースの配置先を決定してから、ソースリソースの配置先を決定します。 |
| score |
正の値を指定するとリソースが同じノードで実行します。負の値を指定すると同じノードで実行しなくなります。デフォルト値である + |
|
| (RHEL 8.4 以降) 従属リソースが移行のしきい値に達して失敗した場合に、クラスターで別のノードにプライマリーリソース (source_resource) と従属リソース (target_resource) を移行するか、クラスターでサーバーの切り替えなしに従属リソースをオフラインのままにするかを決定します。
このオプションの値が
このオプションの値が |
56.1. リソースの強制的な配置の指定
制約スコアが +INFINITY または -INFINITY の場合は常に強制的な配置が発生します。制約条件が満たされないと source_resource の実行が許可されません。score=INFINITY の場合、target_resource がアクティブではないケースが含まれます。
myresource1 を、常に myresource2 と同じマシンで実行する必要がある場合は、次のような制約を追加します。
# pcs constraint colocation add myresource1 with myresource2 score=INFINITY
INFINITY を使用しているため、(何らかの理由で) myresource2 がクラスターのいずれのノードでも実行できない場合は、myresource1 の実行が許可されません。
または、逆の設定、つまり myresource1 が myresource2 と同じマシンでは実行されないようにクラスターを設定することもできます。この場合は score=-INFINITY を使用します。
# pcs constraint colocation add myresource1 with myresource2 score=-INFINITY
ここでも、-INFINITY を指定することで、制約は結合しています。このため、実行できる場所として残っているノードで myresource2 がすでに実行されている場合は、いずれのノードでも myresource1 を実行できなくなります。
56.2. リソースの勧告的な配置の指定
リソースの勧告的な配置は、リソースの配置は推奨ではあるものの、必須ではありません。制約のスコアが -INFINITY より大きく、INFINITY より小さい場合、クラスターは希望の設定に対応しようとしますが、クラスターリソースの一部を停止するという選択肢がある場合には、その設定が無視される場合があります。
56.3. 複数リソースのコロケーション
お使いの設定で、コロケーションと起動の順番を指定してリソースを作成する必要がある場合には、このようなリソースを含むリソースグループを設定できます。ただし、コロケーションを設定する必要があるリソースをリソースグループとして設定することが適切ではない場合もあります。
- リソースのセットにコロケーションを設定する必要があるものの、リソースが必ずしも順番に起動する必要がない場合
- リソース C を、リソース A またはリソース B のいずれかに対してコロケーションを設定する必要があるものの、リソース A とリソース B との間に関係が設定されていない場合
- リソース C およびリソース D を、リソース A およびリソース B の両方に対してコロケーションを設定する必要があるものの、A と B の間、または C と D の間に関係が設定されていない場合
このような状況では、pcs constraint colocation set コマンドを使用して、リソースの 1 つまたは複数のセットでコロケーションの制約を作成できます。
pcs constraint colocation set コマンドを使用すると、以下のオプションをリソースのセットに設定できます。
sequential- セットのメンバーで相互のコロケーションが必要であるかどうかを指定します。trueまたはfalseに設定できます。sequentialをfalseに設定すると、このセットのメンバーがアクティブであるかどうかに関係なく、このセットのメンバーを、制約の中で、このセットの後にリストされている他のセットに対してコロケーションを設定できます。そのため、このオプションは制約でこのセットの後に他のセットが指定されている場合に限り有効です。他のセットが指定されていない場合は、制約の効果がありません。-
role-Stopped、Started、Master、またはSlaveに設定できます。
pcs constraint colocation set コマンドの setoptions パラメーターの後に、リソースのセットに対する以下の制約オプションを設定できます。
-
id- 定義する制約の名前を指定します。 -
score- 制約の優先度を示します。このオプションの詳細は、場所の制約の設定 の「場所の制約オプション」の表を参照してください。
セットのメンバーをリストすると、各メンバーは、自身の前のメンバーに対してコロケーションが設定されます。たとえば、"set A B" は "B が A の場所に配置される" ことを意味します。しかし、複数のセットをリストする場合、各セットはその後のメンバーと同じ場所に配置されます。たとえば、"set C D sequential=false set A B" は、"C と D のセットが、A と B のセットと同じ場所に配置されること" を意味します (ただし、C と D には関係がなく、B は A にはコロケーションが設定されています)。
以下のコマンドは、リソースのセットにコロケーションの制約を作成します。
pcs constraint colocation set resource1 resource2] [resourceN]... [options] [set resourceX resourceY] ... [options]] [setoptions [constraint_options]]コロケーション制約を削除する場合はコマンドに source_resource を付けて使用します。
pcs constraint colocation remove source_resource target_resource第57章 リソース制約とリソース依存関係の表示
設定した制約を表示させるコマンドがいくつかあります。設定されたリソース制約をすべて表示するか、特定のタイプのリソース制約だけに表示を制限することもできます。また、設定したリソース依存関係を表示できます。
設定済みの全制約の表示
以下のコマンドは、現在の場所、順序、ロケーションの制約をすべて表示します。--full オプションを指定すると、制約の内部 ID が表示されます。
pcs constraint [list|show] [--full]RHEL 8.2 以降では、リソース制約をリスト表示しても、期限切れの制約はデフォルトで表示されなくなりました。
リストに期限切れの制約を含めるには、pcs constraint コマンドに --all オプションを使用します。これにより、期限切れの制約のリストが表示され、制約とそれに関連するルールが (expired) として表示されます。
場所の制約の表示
以下のコマンドは、現在の場所の制約をリスト表示します。
-
resourcesを指定すると、リソース別に場所の制約が表示されます。これはデフォルトの動作です。 -
nodesを指定すると、ノード別に場所の制約が表示されます。 - 特定のリソースまたはノードを指定すると、そのリソースまたはノードの情報のみが表示されます。
pcs constraint location [show [resources [resource...]] | [nodes [node...]]] [--full]順序の制約の表示
以下のコマンドは、現在の順序の制約をすべて表示します。
pcs constraint order [show]コロケーション制約の表示
次のコマンドは、現在のコロケーション制約をリスト表示します。
pcs constraint colocation [show]リソース固有の制約の表示
以下のコマンドは、特定リソースを参照する制約をリスト表示します。
pcs constraint ref resource ...リソース依存関係の表示 (Red Hat Enterprise Linux 8.2 以降)
次のコマンドは、クラスターリソース間の関係をツリー構造で表示します。
pcs resource relations resource [--full]
--full オプションを指定すると、制約 ID およびリソースタイプを含む追加情報が表示されます。
以下の例では、3 つのリソースが設定されています。C, D、および E。
# pcs constraint order start C then start D
Adding C D (kind: Mandatory) (Options: first-action=start then-action=start)
# pcs constraint order start D then start E
Adding D E (kind: Mandatory) (Options: first-action=start then-action=start)
# pcs resource relations C
C
`- order
| start C then start D
`- D
`- order
| start D then start E
`- E
# pcs resource relations D
D
|- order
| | start C then start D
| `- C
`- order
| start D then start E
`- E
# pcs resource relations E
E
`- order
| start D then start E
`- D
`- order
| start C then start D
`- C以下の例では、2 つのリソースが設定されています。A および B。リソース A および B はリソースグループ G の一部です。
# pcs resource relations A
A
`- outer resource
`- G
`- inner resource(s)
| members: A B
`- B
# pcs resource relations B
B
`- outer resource
`- G
`- inner resource(s)
| members: A B
`- A
# pcs resource relations G
G
`- inner resource(s)
| members: A B
|- A
`- B第58章 ルールによるリソースの場所の決定
さらに複雑な場所の制約には、Pacemaker のルールを使用してリソースの場所を決定できます。
58.1. Pacemaker ルール
Pacemaker ルールを使用すると、設定をより動的に作成できます。ルールには、(ノード属性を使用して) 時間ベースで異なる処理グループにマシンを割り当て、場所の制約の作成時にその属性を使用する方法があります。
各ルールには、日付などの様々な式だけでなく、その他のルールも含めることができます。ルールの boolean-op フィールドに応じて各種の式の結果が組み合わされ、最終的にそのルールが true または false のどちらに評価されるかどうかが決まります。次の動作は、ルールが使用される状況に応じて異なります。
| フィールド | 説明 |
|---|---|
|
|
リソースが指定のロールにある場合にのみ適用するルールを制限します。使用できる値は以下のようになります。 |
|
|
ルールが |
|
|
ルールが |
|
|
複数の式オブジェクトからの結果を組み合わせる方法。使用できる値は |
58.1.1. ノード属性の式
ノードで定義される属性に応じてリソースを制御する場合に使用されるノード属性の式です。
| フィールド | 説明 |
|---|---|
|
| テストするノード属性。 |
|
|
値をテストする方法を指定します。使用できる値は、 |
|
| 実行する比較動作。設定できる値は以下のとおりです。
*
*
*
*
*
*
*
* |
|
|
比較のためにユーザーが提供した値 ( |
管理者が追加する属性のほかに、以下の表で説明されているように、クラスターは、使用可能な各ノードに特殊な組み込みノード属性を定義します。
| 名前 | 説明 |
|---|---|
|
| ノード名 |
|
| ノード ID |
|
|
ノードタイプ。使用できる値は、 |
|
|
このノードが指定コントローラー (DC) の場合は |
|
|
|
|
|
|
|
| 関連する昇格可能なクローンがこのノードで果たすロール。昇格可能なクローンに対する場所の制約のルール内でのみ有効です。 |
58.1.2. 時刻と日付ベースの式
日付の式は、現在の日付と時刻に応じてリソースまたはクラスターオプションを制御する場合に使用します。オプションで日付の詳細を含めることができます。
| フィールド | 説明 |
|---|---|
|
| ISO 8601 仕様に準じた日付と時刻。 |
|
| ISO 8601 仕様に準じた日付と時刻。 |
|
| 状況に応じて、現在の日付と時刻を start と end のいずれかの日付、または両方の日付と比較します。設定できる値は以下のとおりです。
*
*
*
* |
58.1.3. 日付の詳細
日付の詳細は、時間に関係する cron のような式を作成するのに使用されます。各フィールドには 1 つの数字または範囲が含まれます。指定のないフィールドは、デフォルトを 0 に設定するのではなく、無視されます。
たとえば、monthdays="1" は各月の最初の日と一致し、hours="09-17" は午前 9 時から午後 5 時まで (両時間を含む) の時間と一致します。ただし、weekdays="1,2" または weekdays="1-2,5-6" には複数の範囲が含まれるため、指定することはできません。
| フィールド | 説明 |
|---|---|
|
| 日付の一意の名前 |
|
| 設定できる値は、0-23 |
|
| 設定できる値は、0-31 (月および年により異なる) |
|
| 設定できる値は、1-7 (1=月曜、7=日曜) |
|
| 設定できる値は、1-366 (年により異なる) |
|
| 設定できる値は、1-12 |
|
|
設定できる値は、1-53 ( |
|
| グレゴリオ暦 (新暦) に準じる年 |
|
|
グレゴリオ暦の年とは異なる場合がある (例: |
|
| 設定できる値は、0-7 (0 は新月。4 満月) |
58.2. ルールを使用して Pacemaker の場所の制約を設定する
以下のコマンドを使用して、ルールを使用する Pacemaker 制約を使用します。score を省略すると、デフォルトの INFINITY に設定されます。resource-discovery を省略すると、デフォルトの always に設定されます。
resource-discovery オプションの詳細は、ノードのサブセットへのリソース検出を制限 を参照してください。
基本的な場所の制約と同様に、制約にリソースの正規表現を使用することもできます。
ルールを使用して場所の制約を設定する場合は、score を正または負の値にすることができます。正の値は "prefers" を示し、負の値は "avoids" を示します。
pcs constraint location rsc rule [resource-discovery=option] [role=master|slave] [score=score | score-attribute=attribute] expressionexpression オプションは、以下のいずれかに設定できます。ここで、duration_options および date_spec_options は、日付の詳細 の「日付詳細のプロパティー」の表で説明されているように、hours、monthdays、weekdays、yeardays、months、weeks、years、weekyears、moon になります。
-
defined|not_defined attribute -
attribute lt|gt|lte|gte|eq|ne [string|integer|number(RHEL 8.4 以降)|version] value -
date gt|lt date -
date in_range date to date -
date in_range date to duration duration_options … -
date-spec date_spec_options -
expression and|or expression -
(expression)
持続時間は、計算により in_range 操作の終了を指定する代替方法です。たとえば、19 カ月間を期間として指定できます。
以下の場所の制約は、現在が 2018 年の任意の時点である場合に true の式を設定します。
# pcs constraint location Webserver rule score=INFINITY date-spec years=2018以下のコマンドは、月曜日から金曜日までの 9 am から 5 pm までが true となる式を設定します。hours の値 16 には、時間 (hour) の値が一致する 16:59:59 までが含まれます。
# pcs constraint location Webserver rule score=INFINITY date-spec hours="9-16" weekdays="1-5"以下のコマンドは、13 日の金曜日が満月になると true になる式を設定します。
# pcs constraint location Webserver rule date-spec weekdays=5 monthdays=13 moon=4ルールを削除するには、以下のコマンドを使用します。削除しているルールがその制約内で最後のルールになる場合は、その制約も削除されます。
pcs constraint rule remove rule_id第59章 クラスターリソースの管理
クラスターリソースの表示、変更、および管理に使用できるコマンドは複数あります。
59.1. 設定されているリソースの表示
設定されているリソースのリストを表示する場合は、次のコマンドを使用します。
pcs resource status
例えば、VirtualIP と言う名前のリソースと WebSite という名前のリソースでシステムを設定していた場合、pcs resource status コマンドを実行すると次のような出力が得られます。
# pcs resource status
VirtualIP (ocf::heartbeat:IPaddr2): Started
WebSite (ocf::heartbeat:apache): Startedリソースに設定されているパラメーターを表示する場合は、次のコマンドを使用します。
pcs resource config resource_id
たとえば、次のコマンドは、現在設定されているリソース VirtualIP のパラメーターを表示します。
# pcs resource config VirtualIP
Resource: VirtualIP (type=IPaddr2 class=ocf provider=heartbeat)
Attributes: ip=192.168.0.120 cidr_netmask=24
Operations: monitor interval=30sRHEL 8.5 以降では、個々のリソースのステータスを表示するには、次のコマンドを使用します。
pcs resource status resource_id
たとえば、システムが VirtualIP という名前のリソースで設定されていると、pcs resource status VirtualIP コマンドは以下の出力を表示します。
# pcs resource status VirtualIP
VirtualIP (ocf::heartbeat:IPaddr2): StartedRHEL 8.5 以降では、特定のノードで実行されているリソースのステータスを表示するには、次のコマンドを使用します。このコマンドを使用すると、クラスターとリモートノードの両方でリソースのステータスを表示できます。
pcs resource status node=node_id
たとえば、node-01 が VirtualIP および WebSite という名前のリソースを実行している場合、pcs resource status node=node-01 コマンドは以下の出力を表示します。
# pcs resource status node=node-01
VirtualIP (ocf::heartbeat:IPaddr2): Started
WebSite (ocf::heartbeat:apache): Started59.2. pcs コマンドとしてのクラスターリソースのエクスポート
Red Hat Enterprise Linux 8.7 以降では、pcs resource config コマンドの --output-format=cmd オプションを使用して、別のシステムで設定されたクラスターリソースを再作成するために使用できる pcs コマンドを表示できます。
以下のコマンドは、Red Hat 高可用性クラスター内のアクティブ/パッシブ Apache HTTP サーバー用に作成された 4 つのリソース (LVM-activate リソース、Filesystem リソース、IPaddr2 リソース、および Apache リソース) を作成します。
# pcs resource create my_lvm ocf:heartbeat:LVM-activate vgname=my_vg vg_access_mode=system_id --group apachegroup
# pcs resource create my_fs Filesystem device="/dev/my_vg/my_lv" directory="/var/www" fstype="xfs" --group apachegroup
# pcs resource create VirtualIP IPaddr2 ip=198.51.100.3 cidr_netmask=24 --group apachegroup
# pcs resource create Website apache configfile="/etc/httpd/conf/httpd.conf" statusurl="http://127.0.0.1/server-status" --group apachegroup
リソースを作成した後、次のコマンドを実行すると、別のシステムでそれらのリソースを再作成するために使用できる pcs コマンドが表示されます。
# pcs resource config --output-format=cmd
pcs resource create --no-default-ops --force -- my_lvm ocf:heartbeat:LVM-activate \
vg_access_mode=system_id vgname=my_vg \
op \
monitor interval=30s id=my_lvm-monitor-interval-30s timeout=90s \
start interval=0s id=my_lvm-start-interval-0s timeout=90s \
stop interval=0s id=my_lvm-stop-interval-0s timeout=90s;
pcs resource create --no-default-ops --force -- my_fs ocf:heartbeat:Filesystem \
device=/dev/my_vg/my_lv directory=/var/www fstype=xfs \
op \
monitor interval=20s id=my_fs-monitor-interval-20s timeout=40s \
start interval=0s id=my_fs-start-interval-0s timeout=60s \
stop interval=0s id=my_fs-stop-interval-0s timeout=60s;
pcs resource create --no-default-ops --force -- VirtualIP ocf:heartbeat:IPaddr2 \
cidr_netmask=24 ip=198.51.100.3 \
op \
monitor interval=10s id=VirtualIP-monitor-interval-10s timeout=20s \
start interval=0s id=VirtualIP-start-interval-0s timeout=20s \
stop interval=0s id=VirtualIP-stop-interval-0s timeout=20s;
pcs resource create --no-default-ops --force -- Website ocf:heartbeat:apache \
configfile=/etc/httpd/conf/httpd.conf statusurl=http://127.0.0.1/server-status \
op \
monitor interval=10s id=Website-monitor-interval-10s timeout=20s \
start interval=0s id=Website-start-interval-0s timeout=40s \
stop interval=0s id=Website-stop-interval-0s timeout=60s;
pcs resource group add apachegroup \
my_lvm my_fs VirtualIP Website
pcs コマンドまたは 1 つの設定済みリソースのみ再作成するために使用できるコマンドを表示するには、そのリソースのリソース ID を指定します。
# pcs resource config VirtualIP --output-format=cmd
pcs resource create --no-default-ops --force -- VirtualIP ocf:heartbeat:IPaddr2 \
cidr_netmask=24 ip=198.51.100.3 \
op \
monitor interval=10s id=VirtualIP-monitor-interval-10s timeout=20s \
start interval=0s id=VirtualIP-start-interval-0s timeout=20s \
stop interval=0s id=VirtualIP-stop-interval-0s timeout=20s59.3. リソースパラメーターの修正
設定されているリソースのパラメーターを変更する場合は、次のコマンドを使用します。
pcs resource update resource_id [resource_options]
以下のコマンドシーケンスでは、VirtualIP リソースに設定したパラメーターの初期値、ip パラメーターの値を変更するコマンド、変更されたパラメーター値を示しています。
# pcs resource config VirtualIP
Resource: VirtualIP (type=IPaddr2 class=ocf provider=heartbeat)
Attributes: ip=192.168.0.120 cidr_netmask=24
Operations: monitor interval=30s
# pcs resource update VirtualIP ip=192.169.0.120
# pcs resource config VirtualIP
Resource: VirtualIP (type=IPaddr2 class=ocf provider=heartbeat)
Attributes: ip=192.169.0.120 cidr_netmask=24
Operations: monitor interval=30s
pcs resource update コマンドを使用してリソースの動作を更新すると、特に呼び出しのないオプションはデフォルト値にリセットされます。
59.4. クラスターリソースの障害ステータスの解除
リソースに障害が発生した場合は、pcs status コマンドでクラスターの状態を表示すると失敗メッセージが表示されます。障害の原因を解決しようとしたら、pcs status コマンドを再度実行してリソースの更新されたステータスを確認できます。また、pcs resource failcount show --full コマンドを使用してクラスターリソースの障害数を確認できます。
pcs resource cleanup コマンドを使用して、リソースの障害ステータスをクリアできます。pcs resource cleanup コマンドは、リソースのステータスと、リソースの failcount 値をリセットします。このコマンドは、リソースの操作履歴も削除し、現在の状態を再検出します。
次のコマンドは、resource_id で指定されたリソースのリソースステータスと failcount 値をリセットします。
pcs resource cleanup resource_id
resource_id を指定しないと、pcs resource cleanup コマンドは失敗数ですべてのリソースのリソースステータスと failcount 値をリセットします。
pcs resource cleanup resource_id コマンドの他に、pcs resource refresh resource_id コマンドを使用して、リソースのステータスをリセットし、リソースの操作履歴を消去することもできます。pcs resource cleanup コマンドと同様に、オプションを指定せずに pcs resource refresh コマンドを実行し、すべてのリソースのリソースステータスと failcount 値をリセットできます。
pcs resource cleanup コマンドおよび pcs resource refresh コマンドの両方が、リソースの操作履歴を消去し、リソースの現在の状態を再検出します。pcs resource cleanup コマンドは、クラスターの状態に示されているように、アクションが失敗したリソースでのみ動作しますが、pcs resource refresh コマンドは、現在の状態に関係なくリソース上で動作します。
59.5. クラスター内のリソースの移動
Pacemaker は、リソースを別のノードに移動するように設定し、必要に応じて手動でリソースを移動するように設定する様々なメカニズムを提供します。
クラスターリソースの手動による移行 に従って、pcs resource move コマンドと pcs resource relocate コマンドで、クラスターのリソースを手動で移動します。このコマンドの他にも、クラスターリソースの無効化、有効化、および禁止 に従ってリソースを有効、無効、および禁止にしてクラスターリソースの挙動を制御することもできます。
失敗した回数が、定義した値を超えると、新しいノードに移動し、外部接続が失われた時にリソースを移動するようにクラスターを設定できます。
59.5.1. 障害発生によるリソースの移動
リソースの作成時に、リソースに migration-threshold オプションを設定し、定義した回数だけ障害が発生した場合にリソースが新しいノードに移動されるように設定できます。このしきい値に一度到達すると、このノードでは、以下が行われるまで、障害が発生したリソースを実行できなくなります。
-
リソースの
failure-timeout値に到達します。 -
管理者は
pcs resource cleanupコマンドを使用して、リソースの失敗数を手動でリセットします。
デフォルトで、migration-threshold の値が INFINITY に設定されています。INFINITY は、内部的に非常に大きな有限数として定義されます。0 にすると、migration-threshold 機能が無効になります。
リソースの migration-threshold を設定するのと、リソースの状態を維持しながら別の場所に移動させるようにリソースの移動を設定するのは同じではありません。
次の例では、dummy_resource リソースに、移行しきい値 10 を追加します。この場合は、障害が 10 回発生すると、そのリソースが新しいノードに移動します。
# pcs resource meta dummy_resource migration-threshold=10次のコマンドを使用すると、クラスター全体にデフォルトの移行しきい値を追加できます。
# pcs resource defaults update migration-threshold=10
リソースの現在の障害ステータスと制限を確認するには、pcs resource failcount show コマンドを使用します。
移行しきい値の概念には、リソース起動の失敗とリソース停止の失敗の 2 つの例外があります。クラスタープロパティー start-failure-is-fatal が true に設定された場合 (デフォルト) は、起動の失敗により failcount が INFINITY に設定され、リソースが常に即座に移動するようになります。
停止時の失敗は、起動時とは若干異なり、極めて重大となります。リソースの停止に失敗し STONITH が有効になっていると、リソースを別のノードで起動できるように、クラスターによるノードのフェンスが行われます。STONITH を有効にしていない場合はクラスターに続行する手段がないため、別のノードでのリソース起動は試行されません。ただし、障害のタイムアウト後に再度停止が試行されます。
59.5.2. 接続状態の変更によるリソースの移動
以下の 2 つのステップに従って、外部の接続が失われた場合にリソースが移動するようにクラスターを設定します。
-
pingリソースをクラスターに追加します。pingリソースは、同じ名前のシステムユーティリティーを使用して、マシン (DNS ホスト名または IPv4/IPv6 アドレスによって指定されるリスト) にアクセス可能であるかをテストし、その結果を使用してpingdと呼ばれるノード属性を維持します。 - 接続が失われたときに別のノードにリソースを移動させる、リソース場所制約を設定します。
以下の表には、ping リソースに設定できるプロパティーを紹介しています。
| フィールド | 説明 |
|---|---|
|
| 今後の変更が発生するまでに待機する (弱める) 時間。これにより、クラスターノードが、わずかに異なる時間に接続が失われたことに気が付いたときに、クラスターでリソースがバウンスするのを防ぎます。 |
|
| 接続された ping ノードの数は、ノードの数にこの値を掛けて、スコアを取得します。複数の ping ノードが設定された場合に便利です。 |
|
| 現在の接続状態を判断するために接続するマシン。使用できる値には、解決可能な DNS ホスト名、IPv4 アドレス、および IPv6 アドレスが含まれます。ホストリストのエントリーはスペースで区切られます。 |
次のコマンド例は、gateway.example.com への接続を検証する ping リソースを作成します。実際には、ネットワークゲートウェイやルーターへの接続を検証します。リソースがすべてのクラスターノードで実行されるように、ping リソースをクローンとして設定します。
# pcs resource create ping ocf:pacemaker:ping dampen=5s multiplier=1000 host_list=gateway.example.com clone
以下の例は、既存のリソース Webserver に場所制約ルールを設定します。これにより、Webserver リソースが現在実行しているホストが gateway.example.com へ ping できない場合に、Webserver リソースを gateway.example.com へ ping できるホストに移動します。
# pcs constraint location Webserver rule score=-INFINITY pingd lt 1 or not_defined pingd59.6. 監視操作の無効化
定期的な監視を停止する最も簡単な方法は、監視を削除することです。ただし、一時的に無効にしたい場合もあります。このような場合は、操作の定義に enabled="false" を追加します。監視操作を再度有効にするには、操作の定義に enabled="true" を設定します。
pcs resource update コマンドを使用してリソースの動作を更新すると、特に呼び出しのないオプションはデフォルト値にリセットされます。たとえば、カスタムのタイムアウト値 600 を使用して監視操作を設定している場合に以下のコマンドを実行すると、タイムアウト値がデフォルト値の 20 にリセットされます (pcs resource op default コマンドを使用しても、デフォルト値を設定できます)。
# pcs resource update resourceXZY op monitor enabled=false
# pcs resource update resourceXZY op monitor enabled=trueこのオプションの元の値 600 を維持するために、監視操作に戻す場合は、以下の例のように、その値を指定する必要があります。
# pcs resource update resourceXZY op monitor timeout=600 enabled=true59.7. クラスターリソースタグの設定および管理
Red Hat Enterprise Linux 8.3 以降では、pcs コマンドを使用してクラスターリソースにタグを付けることができます。これにより、1 つのコマンドで、指定したリソースセットを有効化、無効化、マネージド化、または管理非対象化することができます。
59.7.1. カテゴリー別に管理するためのクラスターリソースのタグ付け
以下の手順では、リソースタグを使用して 2 つのリソースをタグ付けし、タグ付けされたリソースを無効にします。この例では、タグ付けする既存のリソースの名前は d-01 および d-02 です。
手順
special-resourcesという名前のタグ (d-01およびd-02) を作成します。[root@node-01]# pcs tag create special-resources d-01 d-02リソースタグ設定を表示します。
[root@node-01]# pcs tag config special-resources d-01 d-02special-resourcesタグが付けられた全リソースを無効にします。[root@node-01]# pcs resource disable special-resourcesリソースのステータスを表示して、
d-01およびd-02リソースが無効になっていることを確認します。[root@node-01]# pcs resource * d-01 (ocf::pacemaker:Dummy): Stopped (disabled) * d-02 (ocf::pacemaker:Dummy): Stopped (disabled)
pcs resource disable コマンドに加え、pcs resource enable、pcs resource manage および pcs resource unmanage コマンドはタグ付けされたリソースの管理をサポートします。
リソースタグを作成したら、以下を実行します。
-
pcs tag deleteコマンドを使用して、リソースタグを削除できます。 -
pcs tag updateコマンドを使用して、既存のリソースタグのリソースタグ設定を変更できます。
59.7.2. タグ付けされたクラスターリソースの削除
pcs コマンドでは、タグ付けされたクラスターリソースを削除できません。タグ付けられたリソースを削除するには、以下の手順に従います。
手順
リソースタグを削除します。
以下のコマンドは、
special-resourcesタグの付いたすべてのリソースからこのリソースタグを削除します。[root@node-01]# pcs tag remove special-resources [root@node-01]# pcs tag No tags defined以下のコマンドは、リソース
d-01からのみリソースタグspecial-resourcesを削除します。[root@node-01]# pcs tag update special-resources remove d-01
リソースを削除します。
[root@node-01]# pcs resource delete d-01 Attempting to stop: d-01... Stopped
第60章 複数のノードでアクティブなクラスターリソース (クローンリソース) の作成
クラスターリソースが複数のノードでアクティブになるように、リソースのクローンを作成できます。たとえば、ノードの分散のために、クローンとなるリソースを使用して、クラスター全体に分散させる IP リソースのインスタンスを複数設定できます。リソースエージェントが対応していれば、任意のリソースのクローンを作成できます。クローンは、1 つのリソースまたは 1 つのリソースグループで構成されます。
同時に複数のノードでアクティブにできるリソースのみがクローンに適しています。たとえば、共有メモリーデバイスから ext4 などの非クラスター化ファイルシステムをマウントする Filesystem リソースのクローンは作成しないでください。ext4 パーティションはクラスターを認識しないため、同時に複数のノードから繰り返し行われる読み取りや書き込みの操作には適していません。
60.1. クローンリソースの作成および削除
リソースと、そのリソースのクローンを同時に作成できます。
次の単一のコマンドでリソースを作成し、リソースのクローンを作成します。
RHEL 8.4 以降:
pcs resource create resource_id [standard:[provider:]]type [resource options] [meta resource meta options] clone [clone_id] [clone options]RHEL 8.3 以前:
pcs resource create resource_id [standard:[provider:]]type [resource options] [meta resource meta options] clone [clone options]
デフォルトでは、クローンの名前は resource_id-clone となります。
RHEL 8.4 以降では、clone_id オプションの値を指定して、クローンのカスタム名を設定できます。
1 つのコマンドで、リソースグループの作成と、リソースグループのクローン作成の両方を行うことはできません。
作成済みリソースまたはリソースグループのクローンを作成する場合は、次のコマンドを実行します。
RHEL 8.4 以降:
pcs resource clone resource_id | group_id [clone_id][clone options]...RHEL 8.3 以前:
pcs resource clone resource_id | group_id [clone options]...
デフォルトでは、クローンの名前は resource_id-clone または group_name-clone です。RHEL 8.4 以降では、clone_id オプションの値を指定して、クローンのカスタム名を設定できます。
リソース設定の変更が必要なのは、1 つのノードのみです。
制約を設定する場合は、グループ名またはクローン名を必ず使用します。
リソースのクローンを作成すると、クローンのデフォルト名は、リソース名に -clone を付けた名前になります。次のコマンドは、タイプが apache のリソース webfarm と、そのクローンとなるリソース webfarm-clone を作成します。
# pcs resource create webfarm apache clone
あるリソースまたはリソースグループのクローンを、別のクローンの後にくるように作成する場合は、多くの場合 interleave=true オプションを設定する必要があります。これにより、依存されているクローンが同じノードで停止または開始した時に、依存しているクローンのコピーを停止または開始できるようになります。このオプションを設定しない場合は、次のようになります。クローンリソース B がクローンリソース A に依存していると、ノードがクラスターから離れてから戻ってきてから、そのノードでリソース A が起動すると、リソース B の全コピーが、全ノードで再起動します。これは、依存しているクローンリソースに interleave オプションが設定されていない場合は、そのリソースの全インスタンスが、そのリソースが依存しているリソースの実行インスタンスに依存するためです。
リソースまたはリソースグループのクローンを削除する場合は、次のコマンドを使用します。リソースやリソースグループ自体は削除されません。
pcs resource unclone resource_id | clone_id | group_name以下の表には、クローンのリソースに指定できるオプションを示しています。
| フィールド | 説明 |
|---|---|
|
| リソースのメタオプションの設定 の「リソースのメタオプション」の表で説明されているように、クローンされたリソースから継承されるオプション。 |
|
| 起動するリソースのコピーの数。デフォルトは、クラスター内のノード数です。 |
|
|
1 つのノードで起動できるリソースのコピー数。デフォルト値は |
|
|
クローンのコピーを停止したり起動する時に、前もって、およびアクションが成功した時に、他のコピーに通知します。使用できる値は |
|
|
クローンの各コピーで異なる機能を実行させるかどうか。使用できる値は
このオプションの値を
このオプションの値を |
|
|
コピーを、(並列ではなく) 連続して開始する必要があります。使用できる値は |
|
|
(クローン間の) 順序制約の動作を変更して、(2 番目のクローンの全インスタンスが終了するまで待機する代わりに) 2 番目のクローンと同じノードにあるコピーが起動または停止するとすぐに、最初のクローンのコピーが起動または停止できるようにします。使用できる値は |
|
|
このフィールドに値を指定した場合は、 |
安定した割り当てパターンを実現するために、クローンは、デフォルトでわずかに固定 (sticky) されています。これは、クローンが実行しているノードにとどまることをわずかに優先することを示します。resource-stickiness の値を指定しないと、クローンが使用する値は 1 となります。値を小さくすることで他のリソースのスコア計算への阻害を最小限に抑えながら、Pacemaker によるクラスター内の不要なコピーの移動を阻止することができます。resource-stickiness リソースのメタオプションを設定する方法は、リソースのメタオプションの設定 を参照してください。
60.2. クローンリソース制約の表示
ほとんどの場合、アクティブなクラスターノードに対するクローンのコピーは 1 つです。ただし、リソースクローンの clone-max には、そのクラスター内のノード合計より小さい数を設定できます。この場合は、リソースの場所の制約を使用して、クラスターが優先的にコピーを割り当てるノードを指定できます。これらの制約は、クローンの ID を使用する必要があることを除いて、通常のリソースの制約と同じように記述されます。
次のコマンドは、クラスターがリソースのクローン webfarm-clone を node1 に優先的に割り当てる場所の制約を作成します。
# pcs constraint location webfarm-clone prefers node1
順序制約の動作はクローンでは若干異なります。以下の例では、interleave クローンオプションをデフォルトの false のままにしているため、起動する必要がある webfarm-clone のすべてのインスタンスが起動するまで、webfarm-stats のインスタンスは起動しません。webfarm-clone のコピーを 1 つも起動できない場合にのみ、webfarm-stats がアクティブになりません。さらに、webfarm-stats が停止するまで待機してから、webfarm-clone が停止します。
# pcs constraint order start webfarm-clone then webfarm-stats通常のリソース (またはリソースグループ) とクローンのコロケーションは、リソースを、クローンのアクティブコピーを持つ任意のマシンで実行できることを意味します。クラスターは、クローンが実行している場所と、リソース自体の場所の優先度に基づいてコピーを選択します。
クローン間のコロケーションも可能です。この場合、クローンに対して許可できる場所は、そのクローンが実行中のノード (または実行するノード) に限定されます。割り当ては通常通り行われます。
以下のコマンドは、コロケーション制約を作成し、webfarm-stats リソースが webfarm-clone のアクティブなコピーと同じノードで実行するようにします。
# pcs constraint colocation add webfarm-stats with webfarm-clone60.3. 昇格可能なクローンリソース
昇格可能なクローンリソースは、promotable メタ属性が true に設定されているクローンリソースです。昇格可能なクローンリソースにより、インスタンスの操作モードは、master および slave のいずれかにできます。モードの名前には特別な意味はありませんが、インスタンスの起動時に、Slave 状態で起動する必要があるという制限があります。
60.3.1. 昇格可能なクローンリソースの作成
次のコマンドを実行すると、リソースを昇格可能なクローンとして作成できます。
RHEL 8.4 以降:
pcs resource create resource_id [standard:[provider:]]type [resource options] promotable [clone_id] [clone options]RHEL 8.3 以前:
pcs resource create resource_id [standard:[provider:]]type [resource options] promotable [clone options]
デフォルトでは、昇格可能なクローンの名前は resource_id-clone となります。
RHEL 8.4 以降では、clone_id オプションの値を指定して、クローンのカスタム名を設定できます。
また、次のコマンドを使用して、作成済みのリソースまたはリソースグループから、昇格可能なリソースを作成することもできます。
RHEL 8.4 以降:
pcs resource promotable resource_id [clone_id] [clone options]RHEL 8.3 以前:
pcs resource promotable resource_id [clone options]
デフォルトでは、昇格可能なクローンの名前は resource_id-clone または group_name-clone になります。
RHEL 8.4 以降では、clone_id オプションの値を指定して、クローンのカスタム名を設定できます。
以下の表には、昇格可能なリソースに指定できる追加クローンオプションを示しています。
| フィールド | 説明 |
|---|---|
|
| 昇格できるリソースのコピー数。デフォルト値は 1 です。 |
|
| 1 つのノードで昇格できるリソースのコピー数。デフォルト値は 1 です。 |
60.3.2. 昇格可能なリソース制約の表示
ほとんどの場合、昇格可能なリソースには、アクティブなクラスターノードごとに 1 つのコピーがあります。そうではない場合は、リソースの場所制約を使用して、クラスターが優先的にコピーを割り当てるノードを指定できます。これらの制約は、通常のリソースと同様に記述されます。
リソースのロールをマスターにするかスレーブにするかを指定するコロケーション制約を作成できます。次のコマンドは、リソースのコロケーション制約を作成します。
pcs constraint colocation add [master|slave] source_resource with [master|slave] target_resource [score] [options]コロケーションの制約の詳細は、クラスターリソースのコロケーション を参照してください。
昇格可能なリソースが含まれる順序制約を設定する場合に、リソースに指定できるアクションに、リソースのスレーブロールからマスターへのロールの昇格を指定する promote があります。また、demote を指定すると、マスターからスレーブにリソースを降格できます。
順序制約を設定するコマンドは次のようになります。
pcs constraint order [action] resource_id then [action] resource_id [options]リソースの順序制約の詳細は、クラスターリソースの実行順序の決定 を参照してください。
60.4. 障害時の昇格リソースの降格
RHEL 8.3 以降では、昇格可能なリソースを設定して、そのリソースの 昇格 または 監視 アクションが失敗した場合、またはリソースが実行されているパーティションがクォーラムを失った場合に、リソースは降格されますが完全には停止されません。これにより、リソースを完全に停止したときに、手動で介入する必要がなくなります。
昇格可能なリソースを
promoteアクションが失敗したときに降格するように設定するには、以下の例のようにon-fail操作メタオプションをdemoteに設定します。# pcs resource op add my-rsc promote on-fail="demote"monitorアクションが失敗したときに昇格可能なリソースを降格するように設定するには、intervalをゼロ以外の値に設定し、on-fail操作メタオプションをdemoteに設定して、ロールをMasterに設定します。# pcs resource op add my-rsc monitor interval="10s" on-fail="demote" role="Master"-
クラスターパーティションでクォーラムが失われると、昇格されたリソースが降格されますが、実行され続け、他のすべてのリソースが停止されるようにクラスターを設定するには、
no-quorum-policyクラスタープロパティーをdemoteに設定します。
操作の on-fail メタ属性を demote に設定しても、リソースの昇格を決定する方法には影響しません。影響を受けるノードのプロモーションスコアが引き続き最高となっている場合は、再度昇格するように選択されます。
第61章 クラスターノードの管理
クラスターサービスの起動や停止、クラスターノードの追加や削除など、クラスターノードの管理に使用できる、さまざまな pcs コマンドがあります。
61.1. クラスターサービスの停止
次のコマンドで、指定ノード (複数指定可) のクラスターサービスを停止します。pcs cluster start と同様に --all オプションを使うと全ノードのクラスターサービスが停止されます。ノードを指定しない場合はローカルノードのクラスターサービスのみが停止されます。
pcs cluster stop [--all | node] [...]
次のコマンドで、ローカルノードのクラスターサービスを強制的に停止できます。このコマンドは、kill -9 コマンドを実行します。
pcs cluster kill61.2. クラスターサービスの有効化および無効化
次のコマンドを使用して、クラスターサービスを有効にします。これにより、指定した 1 つ以上のノードで起動時にクラスターサービスが実行されるように設定されます。
ノードがフェンスされた後にクラスターに自動的に再参加するようになり、クラスターが最大強度を下回る時間が最小限に抑えられます。クラスターサービスを有効にしていないと、クラスターサービスを手動で開始する前に、管理者が問題を調査できます。これにより、たとえばハードウェアに問題があるノードで再度問題が発生する可能性がある場合は、クラスターに戻さないようにできます。
-
--allオプションを使用すると、全ノードでクラスターサービスが有効になります。 - ノードを指定しないと、ローカルノードでのみクラスターサービスが有効になります。
pcs cluster enable [--all | node] [...]指定した 1 つまたは複数のノードの起動時に、クラスターサービスが実行されないよう設定する場合は、次のコマンドを使用します。
-
--allオプションを指定すると、全ノードでクラスターサービスが無効になります。 - ノードを指定しないと、ローカルノードでのみクラスターサービスが無効になります。
pcs cluster disable [--all | node] [...]61.3. クラスターノードの追加
次の手順で既存のクラスターに新しいノードを追加します。
この手順は、corosync を実行している標準クラスターを追加します。corosync 以外のノードをクラスターに統合する方法は corosync 以外のノードのクラスターへの統合: pacemaker_remote サービス を参照してください。
運用保守期間中に、既存のクラスターにノードを追加することが推奨されます。これにより、新しいノードとそのフェンシング設定に対して、適切なリソースとデプロイメントのテストを実行できます。
この例では、clusternode-01.example.com、clusternode-02.example.com、および clusternode-03.example.com が既存のクラスターノードになります。新たに追加するノードは newnode.example.com になります。
手順
クラスターに追加する新しいノードで、以下の作業を行います。
クラスターパッケージをインストールします。クラスターで SBD、Booth チケットマネージャー、またはクォーラムデバイスを使用する場合は、対応するパッケージ (
sbd、booth-site、corosync-qdevice) を、新しいノードにも手動でインストールする必要があります。[root@newnode ~]# yum install -y pcs fence-agents-allクラスターパッケージに加えて、既存のクラスターノードにインストールしたクラスターで実行しているすべてのサービスをインストールおよび設定する必要があります。たとえば、Red Hat の高可用性クラスターで Apache HTTP サーバーを実行している場合は、追加するノードにサーバーをインストールする必要があります。また、サーバーのステータスを確認する
wgetツールも必要です。firewalldデーモンを実行している場合は、次のコマンドを実行して、Red Hat High Availability Add-On で必要なポートを有効にします。# firewall-cmd --permanent --add-service=high-availability # firewall-cmd --add-service=high-availabilityユーザー ID
haclusterのパスワードを設定します。クラスターの各ノードで、同じパスワードを使用することが推奨されます。[root@newnode ~]# passwd hacluster Changing password for user hacluster. New password: Retype new password: passwd: all authentication tokens updated successfully.次のコマンドを実行して
pcsdサービスを開始し、システムの起動時にpcsdが有効になるようにします。# systemctl start pcsd.service # systemctl enable pcsd.service
既存クラスターのノードの 1 つで、以下の作業を行います。
新しいクラスターノードで
haclusterユーザーを認証します。[root@clusternode-01 ~]# pcs host auth newnode.example.com Username: hacluster Password: newnode.example.com: Authorized新しいノードを既存のクラスターに追加します。さらに、このコマンドは
corosync.confクラスター設定ファイルをクラスターのすべてのノード (追加する新しいノードを含む) に対して同期します。[root@clusternode-01 ~]# pcs cluster node add newnode.example.com
クラスターに追加する新しいノードで、以下の作業を行います。
新しいノードで、クラスターサービスを開始して有効にします。
[root@newnode ~]# pcs cluster start Starting Cluster... [root@newnode ~]# pcs cluster enable- 新しいクラスターノードに対して、フェンシングデバイスを設定してテストします。
61.4. クラスターノードの削除
次のコマンドは、指定したノードをシャットダウンして、クラスター内のその他のすべてのノードで、クラスターの設定ファイル corosync.conf からそのノードを削除します。
pcs cluster node remove node61.5. リンクが複数あるクラスターへのノードの追加
複数のリンクを持つクラスターにノードを追加する場合は、すべてのリンクにアドレスを指定する必要があります。
以下の例では、ノード rh80-node3 をクラスターに追加し、1 番目のリンクに IP アドレス 192.168.122.203 を、2 番目のリンクに 192.168.123.203 を指定します。
# pcs cluster node add rh80-node3 addr=192.168.122.203 addr=192.168.123.20361.6. 既存のクラスターへのリンクの追加および修正
RHEL 8.1 以降では、ほとんどの場合、クラスターを再起動せずに既存のクラスター内のリンクを追加または変更できます。
61.6.1. 既存クラスターへのリンクの追加および削除
実行中のクラスターに新しいリンクを追加するには、pcs cluster link add コマンドを使用します。
- リンクの追加時に、各ノードのアドレスを指定する必要があります。
-
リンクの追加および削除は、
knetトランスポートプロトコルを使用している場合に限り可能です。 - クラスター内で常に 1 つはリンクを定義する必要があります。
- クラスター内のリンクの最大数は 8 で、指定番号は 0-7 です。3、6、7 のみを指定するなど、リンクはどれでも定義できます。
-
リンク番号を指定せずにリンクを追加すると、
pcsは利用可能なリンクで番号が一番小さいものを使用します。 -
現在設定されているリンクのリンク番号は、
corosync.confファイルに含まれます。corosync.confファイルを表示するには、pcs cluster corosyncコマンドまたはpcs cluster config showコマンド (RHEL 8.4 以降の場合) を実行します。
以下のコマンドは、リンク番号 5 を 3 つのノードクラスターに追加します。
[root@node1 ~] # pcs cluster link add node1=10.0.5.11 node2=10.0.5.12 node3=10.0.5.31 options linknumber=5
既存のリンクを削除するには、pcs cluster link delete コマンドまたは pcs cluster link remove コマンドを使用します。以下のコマンドのいずれかを実行すると、クラスターからリンク番号 5 が削除されます。
[root@node1 ~] # pcs cluster link delete 5
[root@node1 ~] # pcs cluster link remove 561.6.2. リンクが複数あるクラスター内のリンクの変更
クラスターに複数のリンクがあり、そのいずれかを変更する場合は、以下の手順を実行します。
手順
変更するリンクを削除します。
[root@node1 ~] # pcs cluster link remove 2アドレスとオプションを更新して、クラスターにリンクを追加し直します。
[root@node1 ~] # pcs cluster link add node1=10.0.5.11 node2=10.0.5.12 node3=10.0.5.31 options linknumber=2
61.6.3. 単一リンクを使用したクラスターのリンクアドレスの変更
クラスターで 1 つのみリンクを使用し、別のアドレスを使用するようにリンクを変更する必要がある場合は、以下の手順を実行します。この例では、元のリンクはリンク 1 です。
新しいアドレスおよびオプションを指定して新規リンクを追加します。
[root@node1 ~] # pcs cluster link add node1=10.0.5.11 node2=10.0.5.12 node3=10.0.5.31 options linknumber=2元のリンクを削除します。
[root@node1 ~] # pcs cluster link remove 1
クラスターへのリンクの追加時に、現在使用中のアドレスは指定できないことに注意してください。たとえば、リンクが 1 つある 2 ノードクラスターがあり、ノード 1 つだけでアドレスを変更する場合に上記の手順を使用して、新規アドレスと既存のアドレスを指定するリンクを新たに追加できません。代わりに、以下の例のように、既存のリンクを削除し、アドレスを更新したリンクを追加しなおすことができます。
この例では、以下のように設定されています。
- 既存クラスターのリンクはリンク 1 で、ノード 1 に 10.0.5.11 のアドレスを使用し、ノード 2 に 10.0.5.12 アドレスを使用します。
- ノード 2 のアドレスを 10.0.5.31 に変更します。
手順
リンクが 1 つである 2 ノードクラスターのアドレスのいずれかのみを更新するには、以下の手順に従います。
現在使用されていないアドレスを使用して、既存のクラスターに新しい一時的なリンクを追加します。
[root@node1 ~] # pcs cluster link add node1=10.0.5.13 node2=10.0.5.14 options linknumber=2元のリンクを削除します。
[root@node1 ~] # pcs cluster link remove 1変更後の新しいリンクを追加します。
[root@node1 ~] # pcs cluster link add node1=10.0.5.11 node2=10.0.5.31 options linknumber=1作成した一時的なリンクを削除します。
[root@node1 ~] # pcs cluster link remove 2
61.6.4. リンクが 1 つのクラスター内のリンクオプションの変更
クラスターで使用されているリンクが 1 つのみで、そのリンクのオプションを変更しつつも、使用するアドレスを変更しない場合には、一時的なリンクを追加してからリンクを削除し、リンクを別のものに更新できます。
この例では、以下のように設定されています。
- 既存クラスターのリンクはリンク 1 で、ノード 1 に 10.0.5.11 のアドレスを使用し、ノード 2 に 10.0.5.12 アドレスを使用します。
-
リンクオプション
link_priorityを 11 に変更します。
手順
次の手順で、1 つのリンクを持つクラスターでリンクオプションを変更します。
現在使用されていないアドレスを使用して、既存のクラスターに新しい一時的なリンクを追加します。
[root@node1 ~] # pcs cluster link add node1=10.0.5.13 node2=10.0.5.14 options linknumber=2元のリンクを削除します。
[root@node1 ~] # pcs cluster link remove 1元のリンクのオプションを更新して追加し直します。
[root@node1 ~] # pcs cluster link add node1=10.0.5.11 node2=10.0.5.12 options linknumber=1 link_priority=11一時的なリンクを削除します。
[root@node1 ~] # pcs cluster link remove 2
61.6.5. 新しいリンクの追加時にリンクの変更はできません。
設定で新しいリンクを追加することができない場合や、既存のリンクを 1 つ変更することが唯一のオプションである場合は、以下の手順を使用します。これにより、クラスターをシャットダウンする必要があります。
手順
以下の例では、クラスター内のリンク番号 1 を更新し、リンクの link_priority オプションを 11 に設定します。
クラスターのクラスターサービスを停止します。
[root@node1 ~] # pcs cluster stop --allリンクアドレスとオプションを更新します。
pcs cluster link updateコマンドでは、すべてのノードアドレスとオプションを指定する必要はありません。代わりに、変更するアドレスのみを指定できます。この例では、node1およびnode3のアドレスを変更し、link_priorityオプションのみを変更します。[root@node1 ~] # pcs cluster link update 1 node1=10.0.5.11 node3=10.0.5.31 options link_priority=11オプションを削除するには、
option=形式で Null 値にオプションを設定します。クラスターを再起動します。
[root@node1 ~] # pcs cluster start --all
61.7. ノードのヘルスストラテジーの設定
ノードは、そのクラスターメンバーシップを維持するためには十分に機能していても、別の側面では正常に機能しておらず、リソースにとって適切ではないロケーションになることがあります。たとえば、ディスクドライブが SMART エラーを報告していたり、CPU の負荷が高くなっている場合などがそうです。RHEL 8.7 以降では、Pacemaker のノードヘルスストラテジーを使用して、正常でないノードからリソースを自動的に移動できます。
次のヘルスノードリソースエージェントを使用して、ノードのヘルスを監視できます。このエージェントは、CPU とディスクのステータスに基づいてノードの属性を設定します。
-
ocf:pacemaker:HealthCPU: CPU のアイドリングを監視 -
ocf:pacemaker:HealthIOWait: CPU I/O 待機を監視 -
ocf:pacemaker:HealthSMART: ディスクドライブの SMART ステータスを監視 -
ocf:pacemaker:SysInfo: ローカルシステム情報を使用してさまざまなノード属性を設定し、ディスク領域の使用状況を監視するヘルスエージェントとしても機能
さらに、すべてのリソースエージェントがヘルスノードストラテジーの定義に使用できるノード属性を提供する可能性があります。
手順
次の手順では、CPU I/O 待機が 15% を超えるノードからリソースを移動するクラスターのヘルスノードストラテジーを設定します。
health-node-strategyクラスタープロパティーを設定して、Pacemaker がノードヘルスの変化に応答する方法を定義します。# pcs property set node-health-strategy=migrate-on-redヘルスノードリソースエージェントを使用するクラスターリソースのクローンを作成し、
allow-unhealthy-nodesリソースメタオプションを設定して、ノードのヘルスが回復したかどうかをクラスターが検出してリソースをノードに戻すかどうかを定義します。すべてのノードのヘルスを継続的にチェックするには、定期的な監視アクションを使用してこのリソースを設定します。この例では、
HealthIOWaitリソースエージェントを作成して CPU I/O 待機を監視し、ノードからリソースを移動するための制限を 15% に設定します。このコマンドは、allow-unhealthy-nodesリソースメタオプションをtrueに設定し、繰り返しの監視間隔を 10 秒に設定します。# pcs resource create io-monitor ocf:pacemaker:HealthIOWait red_limit=15 op monitor interval=10s meta allow-unhealthy-nodes=true clone
61.8. 多数のリソースを使用した大規模なクラスターの設定
デプロイするクラスターにノードとリソースが多数含まれる場合に、クラスターの以下のパラメーターのデフォルト値を変更する必要がある場合があります。
cluster-ipc-limitクラスタープロパティーcluster-ipc-limitクラスタープロパティーは、あるクラスターデーモンが別のクラスターデーモンを切断するまでに対応できる IPC メッセージバッグログの最大数になります。多数のリソースを消去するか、大規模なクラスターで同時にリソースを変更すると、多数の CIB 更新が一度に行われます。これが原因で、CIB イベントキューのしきい値に到達するまでに Pacemaker サービスで全設定の更新を処理する時間がない場合には、低速なクライアントがエビクトされる可能性がありました。大規模なクラスターで使用するための
cluster-ipc-limitの推奨値は、クラスターのリソース数にノード数を乗算した値です。この値は、クラスターデーモン PID の "Evicting client" メッセージがログに表示されると増える可能性があります。pcs property setコマンドを使用して、cluster-ipc-limitの値をデフォルト値 500 から増やすことができます。たとえば、リソースが 200 個ある 10 ノードクラスターの場合には、以下のコマンドを使用してcluster-ipc-limitの値を 2000 に設定できます。# pcs property set cluster-ipc-limit=2000PCMK_ipc_bufferPacemaker パラメーター非常に大規模なデプロイメントでは、内部 Pacemaker メッセージがメッセージバッファーのサイズを超える可能性があります。バッファーサイズを超えると、以下の形式のシステムログにメッセージが表示されます。
Compressed message exceeds X% of configured IPC limit (X bytes); consider setting PCMK_ipc_buffer to X or higherこのメッセージが表示されると、各ノードの
/etc/sysconfig/pacemaker設定ファイルでPCMK_ipc_bufferの値を増やしてください。たとえば、PCMK_ipc_bufferの値をデフォルト値から 13396332 バイトに増やすには、以下のようにクラスター内の各ノードの/etc/sysconfig/pacemakerファイルのアンコメントされているPCMK_ipc_bufferフィールドを変更します。PCMK_ipc_buffer=13396332この変更を適用するには、次のコマンドを実行します。
# systemctl restart pacemaker
第62章 Pacemaker クラスターのプロパティー
クラスターのプロパティーは、クラスター操作中に生じる可能性のある各状況でのクラスターの動作を制御します。
62.1. クラスタープロパティーおよびオプションの要約
以下の表には、Pacemaker クラスターのプロパティーのデフォルト値や、設定可能な値などをまとめています。
フェンス動作を決定するクラスタープロパティーがあります。これらのプロパティーの詳細は、フェンシングデバイスの一般的なプロパティー の表フェンスの動作を決定するクラスタープロパティーを参照してください。
この表に記載しているプロパティー以外にも、クラスターソフトウェアで公開されるクラスタープロパティーがあります。このようなプロパティーでは、デフォルト値を別の値には変更しないことが推奨されます。
| オプション | デフォルト | 説明 |
|---|---|---|
|
| 0 | クラスターを並列に実行できるリソースアクションの数。"正しい値" は、ネットワークおよびクラスターノードの速度と負荷によって異なります。デフォルト値の 0 は、任意のノードで CPU の負荷が高い場合に動的に制限を課すことを意味します。 |
|
| -1 (無制限) | クラスターが、ノードで並行に実行することが許可されている移行ジョブの数。 |
|
| stop | クラスターにクォーラムがない場合のアクション。設定できる値は以下のとおりです。 * ignore - 全リソースの管理を続行する * freeze - リソース管理は継続するが、影響を受けるパーティションに含まれないノードのリソースは復帰させない * stop - 影響を受けるクラスターパーティション内の全リソースを停止する * suicide - 影響を受けるクラスターパーティション内の全ノードをフェンスする * demote - クラスターパーティションがクォーラムを失うと、プロモートされたリソースを降格し、その他のリソースを停止する |
|
| true | リソースを、デフォルトで任意のノードで実行できるかどうかを示します。 |
|
| 60s | (アクションの実行を除く) ネットワーク上のラウンドトリップ遅延です。"正しい値" は、ネットワークおよびクラスターノードの速度と負荷によって異なります。 |
|
| 20s | 起動時に他のノードからの応答を待つ時間。"正しい" 値は、ネットワークの速度と負荷、および使用するスイッチの種類によって異なります。 |
|
| true | 削除されたリソースを停止すべきかどうかを示します。 |
|
| true | 削除されたアクションをキャンセルするかどうかを示します。 |
|
| true |
特定のノードでリソースの起動に失敗した場合に、そのノードで開始試行を行わないようにするかを示します。
|
|
| -1 (すべて) | ERROR となるスケジューラー入力を保存する数。問題を報告する場合に使用されます。 |
|
| -1 (すべて) | WARNING となるスケジューラー入力を保存する数。問題を報告する場合に使用されます。 |
|
| -1 (すべて) | "normal" となるスケジューラー入力を保存する数。問題を報告する場合に使用されます。 |
|
| Pacemaker が現在実行しているメッセージングスタック。情報提供および診断目的に使用されます。ユーザーは設定できません。 | |
|
| クラスターの DC (Designated Controller) で Pacemaker のバージョン。診断目的に使用され、ユーザーは設定できません。 | |
|
| 15 分 |
Pacemaker は基本的にイベント駆動型で、失敗によるタイムアウトやほとんどの時間ベースのルールについてクラスターを再確認するタイミングを予め把握します。Pacemaker は、このプロパティーで指定された非アクティブ期間の後にもクラスターを再確認します。このクラスターの再確認には 2 つの目的があります。 |
|
| false | メンテナンスモードでは、クラスターが "干渉されない" モードになり、指示されない限り、サービスを起動したり、停止したりしません。メンテナンスモードが完了すると、クラスターは、サービスの現在の状態のサニティーチェックを実行してから、これを必要とするサービスを停止するか、開始します。 |
|
| 20min | 正常にシャットダウンして終了を試みるのをやめる時間。高度な使用のみ。 |
|
| false | クラスターがすべてのリソースを停止します。 |
|
| false |
クラスターが、 |
|
| default | クラスターノードでリソースの配置を決定する際に、クラスターが使用率属性を考慮にいれるかどうかと、どのように考慮するかを示します。 |
|
| none | ヘルスリソースエージェントと組み合わせて使用し、Pacemaker がノードヘルスの変化にどのように応答するかを制御します。設定できる値は以下のとおりです。
*
*
*
* |
62.2. クラスターのプロパティーの設定と削除
クラスタープロパティーの値を設定するには、次の pcs コマンドを使用します。
pcs property set property=value
たとえば、symmetric-cluster の値を false に設定する場合は、次のコマンドを使用します。
# pcs property set symmetric-cluster=false設定からクラスタープロパティーを削除する場合は、次のコマンドを使用します。
pcs property unset property
または、pcs property set コマンドの値フィールドを空白にしても、クラスタープロパティーを設定から削除できます。これにより、そのプロパティーの値がデフォルト値に戻されます。たとえば、symmetric-cluster プロパティーを false に設定したことがある場合は、設定した値が次のコマンドにより削除され、symmetric-cluster の値がデフォルト値の true に戻されます。
# pcs property set symmetic-cluster=62.3. クラスタープロパティー設定のクエリー
ほとんどの場合、各種のクラスターコンポーネントの値を表示するために pcs コマンドを使用する際、pcs list または pcs show を交互に使用できます。次の例では、pcs list は、複数のプロパティーの設定を完全に表示するのに使用される形式で、pcs show は、特定のプロパティーの値を表示する場合に使用される形式です。
クラスターに設定されたプロパティー設定の値を表示する場合は、次の pcs コマンドを使用します。
pcs property list明示的に設定されていないプロパティー設定のデフォルト値など、クラスターのプロパティー設定の値をすべて表示する場合は、次のコマンドを使用します。
pcs property list --all特定のクラスタープロパティーの現在の値を表示する場合は、次のコマンドを使用します。
pcs property show property
たとえば、cluster-infrastructure プロパティーの現在の値を表示する場合は、次のコマンドを実行します。
# pcs property show cluster-infrastructure
Cluster Properties:
cluster-infrastructure: cman情報提供の目的で、次のコマンドを使用して、プロパティーがデフォルト以外の値に設定されているかどうかに関わらず、プロパティーのデフォルト値のリストを表示できます。
pcs property [list|show] --defaults62.4. pcs コマンドとしてのクラスタープロパティーのエクスポート
Red Hat Enterprise Linux 8.9 以降では、pcs property config コマンドの --output-format=cmd オプションを使用して、別のシステムで設定されたクラスタープロパティーを再作成するために使用できる pcs コマンドを表示できます。
次のコマンドは、migration-limit クラスタープロパティーを 10 に設定します。
# pcs property set migration-limit=10
クラスタープロパティーを設定した後に次のコマンドを実行すると、別のシステムでクラスタープロパティーを設定するために使用できる pcs コマンドが表示されます。
# pcs property config --output-format=cmd
pcs property set --force -- \
migration-limit=10 \
placement-strategy=minimal第63章 仮想ドメインをリソースとして設定
pcs resource create コマンドを使用して、VirtualDomain をリソースタイプとして指定すると、libvirt 仮想化フレームワークが管理する仮想ドメインを、クラスターリソースとして設定できます。
仮想ドメインをリソースとして設定する場合は、以下の点を考慮してください。
- 仮想ドメインは、クラスターリソースとして設定する前に停止する必要があります。
- 仮想ドメインをクラスターリソースにすると、クラスターツールを使用しない限り、起動、停止、または移行を行うことができません。
- クラスターリソースとして設定した仮想ドメインを、ホストの起動時に起動するように設定することはできません。
- 仮想ドメインの実行を許可するすべてのノードは、その仮想ドメインに必要な設定ファイルおよびストレージデバイスにアクセスできるようにする必要があります。
クラスターが仮想ドメイン内のサービスを管理できるようにする場合は、仮想ドメインをゲストノードとして設定できます。
63.1. 仮想ドメインリソースのオプション
以下の表は、VirtualDomain リソースに設定できるリソースオプションを説明します。
| フィールド | デフォルト | 説明 |
|---|---|---|
|
|
(必須) この仮想ドメインの | |
|
| システムに依存 |
接続先のハイパーバイザーの URI。 |
|
|
|
停止時にドメインを常に強制的にシャットダウン ("破棄") します。デフォルト動作では、正常なシャットダウンの試行に失敗した後でのみ、強制シャットダウンを実行します。仮想ドメイン (または仮想化バックエンド) が正常なシャットダウンに対応していない場合に限り、これを |
|
| システムに依存 |
移行中にリモートハイパーバイザーに接続するのに使用されるトランスポート。このパラメーターを省略すると、リソースは |
|
| 専用の移行ネットワークを使用します。移行 URI は、このパラメーターの値をノード名の末尾に追加することで構成されます。ノード名が完全修飾ドメイン名 (FQDN) の場合は、FQDN の最初のピリオド (.) の直前に接尾辞を挿入します。この構成されたホスト名がローカルで解決可能であり、関連する IP アドレスが優先ネットワークを介して到達可能であることを確認してください。 | |
|
|
仮想ドメイン内でサービスの監視を追加で実行する場合は、監視するスクリプトのリストとともに、このパラメーターを追加します。備考:監視スクリプトを使用する場合、 | |
|
|
|
|
|
|
|
true に設定すると、監視の実行時に、エージェントが |
|
| ランダムハイポート |
このポートは、 |
|
|
仮想マシンイメージが保存されるスナップショットディレクトリーへのパス。このパラメーターが設定されていると、仮想マシンの RAM 状態は、停止時にスナップショットディレクトリーのファイルに保存されます。起動時にドメインのステータスファイルが存在すると、ドメインは、最後に停止する直前の状態に復元されます。このオプションは、 |
VirtualDomain リソースオプションに加えて、allow-migrate メタデータオプションを設定して、リソースの別のノードへのライブ移行を許可できます。このオプションを true に設定すると、状態を失うことなくリソースを移行できます。このオプションがデフォルトの状態である false に設定されていると、仮想ドメインは、ノード間で移行される際に、最初のノードでシャットダウンしてから、2 番目のノードで再起動します。
63.2. 仮想ドメインリソースの作成
以下の手順では、以前に作成した仮想マシンのクラスターに VirtualDomain リソースを作成します。
手順
仮想マシンを管理するために
VirtualDomainリソースエージェントを作成する場合、Pacemaker では、ディスクのファイルに、仮想マシンのxml設定ファイルをダンプする必要があります。たとえば、guest1という名前の仮想マシンを作成した場合は、ゲストを実行できるクラスターノードのいずれかにファイルにxmlファイルをダンプします。任意のファイル名を使用できますが、この例では/etc/pacemaker/guest1.xmlを使用します。# virsh dumpxml guest1 > /etc/pacemaker/guest1.xml-
仮想マシンの
xml設定ファイルを、各ノードの同じ場所にあるゲストを実行できるその他のすべてのクラスターノードにコピーします。 - 仮想ドメインの実行が許可されているすべてのノードが、その仮想ドメインに必要なストレージデバイスにアクセスできるようにします。
- 仮想ドメインが、仮想ドメインを実行する各ノードで起動および停止できることを別途テストします。
- ゲストノードが実行している場合はシャットダウンします。Pacemaker は、クラスターで設定されているノードを起動します。仮想マシンは、ホストの起動時に自動的に起動するように設定することはできません。
pcs resource createコマンドを使用して、VirtualDomainリソースを設定します。たとえば、次のコマンドは、VMという名前のVirtualDomainリソースを設定します。allow-migrateオプションはtrueに設定されるため、pcs resource move VM nodeXコマンドはライブ移行として実行されます。この例では、
migration_transportがsshに設定されます。SSH 移行が適切に機能するには、鍵を使用しないロギングがノード間で機能する必要があります。# pcs resource create VM VirtualDomain config=/etc/pacemaker/guest1.xml migration_transport=ssh meta allow-migrate=true
第64章 クラスタークォーラムの設定
Red Hat High Availability Add-On クラスターは、スプリットブレインの状況を回避するために、votequorum サービスをフェンシングと併用します。クラスターの各システムには多くの投票数が割り当てられ、過半数の票を取得しているものだけがクラスターの操作を継続できます。サービスは、すべてのノードに読み込むか、いずれのノードにも読み込まないようにする必要があります。サービスをクラスターノードのサブセットに読み込むと、結果が予想できなくなります。サービスがクラスターノードのサブセットにロードされると、結果が予想不可能になります。votequorum サービスの設定および操作の詳細は、votequorum (5) の man ページを参照してください。
64.1. クォーラムオプションの設定
pcs cluster setup コマンドを使用してクラスターを作成する場合は、クォーラム設定の特殊な機能を使用できます。以下の表には、これらのオプションをまとめています。
| オプション | 説明 |
|---|---|
|
|
これを有効にすると、クラスターは、決定論的に最大 50% のノードが同時に失敗しても存続されます。クラスターパーティションや、
|
|
| 有効にすると、最低 1 回、同時にすべてのノードが現れた後に、初回だけ、クラスターがクォーラムに達します。
|
|
|
有効にすると、クラスターは特定の状況で |
|
|
クラスターのノードが失われた後の、 |
このオプションの設定および使用の詳細は、man ページの votequorum(5) を参照してください。
64.2. クォーラムオプションの変更
pcs quorum update コマンドを使用して、クラスターの一般的なクォーラムオプションを変更できます。このコマンドを実行する場合は、クラスターを停止する必要があります。クォーラムオプションの詳細は votequorum(5) の man ページを参照してください。
pcs quorum update コマンドの形式は次のとおりです。
pcs quorum update [auto_tie_breaker=[0|1]] [last_man_standing=[0|1]] [last_man_standing_window=[time-in-ms] [wait_for_all=[0|1]]
以下の一連のコマンドは、wait_for_all クォーラムオプションを変更し、このオプションの更新された状態を表示します。クラスターの稼働中はこのコマンドを実行できないことに注意してください。
[root@node1:~]# pcs quorum update wait_for_all=1
Checking corosync is not running on nodes...
Error: node1: corosync is running
Error: node2: corosync is running
[root@node1:~]# pcs cluster stop --all
node2: Stopping Cluster (pacemaker)...
node1: Stopping Cluster (pacemaker)...
node1: Stopping Cluster (corosync)...
node2: Stopping Cluster (corosync)...
[root@node1:~]# pcs quorum update wait_for_all=1
Checking corosync is not running on nodes...
node2: corosync is not running
node1: corosync is not running
Sending updated corosync.conf to nodes...
node1: Succeeded
node2: Succeeded
[root@node1:~]# pcs quorum config
Options:
wait_for_all: 164.3. クォーラム設定およびステータスの表示
クラスターを実行したら、以下のクラスタークォーラムコマンドを実行して、クォーラムの設定やステータスを表示できます。
次のコマンドは、クォーラムの設定を表示します。
pcs quorum [config]次のコマンドは、クォーラムのランタイム状態を表示します。
pcs quorum status64.4. クォーラムに達しないクラスターの実行
長時間クラスターでノードを使用しなかったためにクォーラムが失われた場合に、pcs quorum expected-votes コマンドを使用して、ライブクラスターの expected_votes パラメーターの値を変更できます。これにより、クォーラムがない場合でも、クラスターは操作を継続できます。
ライブクラスターで期待される票数 (vote) を変更する場合は、細心の注意を払って行ってください。期待される票数を手動で変更したために、実行しているクラスターが 50% 未満となる場合は、クラスターの他のノードを個別に起動してクラスターサービスを開始できるため、データの破損や予期せぬ結果が発生することがあります。この値を変更する場合は、wait_for_all パラメーターが有効になっていることを確認してください。
次のコマンドは、ライブクラスターで期待される票数を、指定の値に設定します。これはライブクラスターにのみ影響し、設定ファイルは変更されません。リロードが行われると、expected_votes の値は、設定ファイルの値にリセットされます。
pcs quorum expected-votes votes
クォーラムに達していない状態でクラスターにリソース管理を続行させたい場合は、pcs quorum unblock コマンドを使用して、クォーラムの確立時にクラスターがすべてのノードを待機することのないようにします。
このコマンドは細心の注意を払って使用する必要があります。このコマンドを実行する前に、現在クラスターにないノードの電源を切り、共有リソースにアクセスできない状態であることを確認する必要があります。
# pcs quorum unblock第65章 corosync 以外のノードのクラスターへの統合: pacemaker_remote サービス
pacemaker_remote サービスを使用すると、corosync を実行していないノードをクラスターに統合し、そのリソースが実際のクラスターノードであるかのように、クラスターがリソースを管理できます。
pacemaker_remote サービスが提供する機能には以下が含まれます。
-
pacemaker_remoteサービスを使用すると、RHEL 8.1 の 32 ノードのサポート制限を超えた拡張が可能になります。 -
pacemaker_remoteサービスを使用すると、仮想環境をクラスターリソースとして管理でき、さらに仮想環境内の個別のサービスをクラスターリソースとして管理できます。
pacemaker_remote サービスは、以下の用語を使用して記述されます。
-
クラスターノード - 高可用性サービス (
pacemakerおよびcorosync) を実行するノード。 -
リモートノード -
Corosyncクラスターメンバーシップを必要とせずにクラスターにリモートで統合するためにpacemaker_remoteを実行するノード。リモートノードは、ocf:pacemaker:remoteリソースエージェントを使用するクラスターリソースとして設定されます。 -
ゲストノード -
pacemaker_remoteサービスを実行している仮想ゲストノード。仮想ゲストリソースはクラスターにより管理されます。クラスターにより起動し、リモートノードとしてクラスターに統合されます。 -
pacemaker_remote - Pacemaker クラスター環境内のリモートノードおよび KVM ゲストノード内でリモートアプリケーション管理を実行できるサービスデーモン。このサービスは、corosync を実行していないノードでリソースをリモートで管理できる Pacemaker のローカル実行プログラムデーモン (
pacemaker-execd) の拡張バージョンです。
pacemaker_remote サービスを実行している Pacemaker クラスターには次のような特徴があります。
-
リモートノードおよびゲストノードは、
pacemaker_remoteサービスを実行します (仮想マシン側で必要な設定はほとんどありません)。 -
クラスターノードで実行しているクラスタースタック (
pacemakerおよびcorosync) はリモートノードでpacemaker_remoteサービスに接続するため、クラスターに統合できます。 -
クラスターノードで実行しているクラスタースタック (
pacemakerおよびcorosync) はゲストノードを開始し、ゲストノードでpacemaker_remoteサービスに即座に接続するため、クラスターに統合できます。
クラスターノードと、クラスターノードが管理するリモートおよびゲストノードの主な違いは、リモートおよびゲストノードはクラスタースタックを実行しないことです。そのため、リモートおよびゲストノードには以下の制限があります。
- クォーラムでは実行されない
- フェンシングデバイスの動作を実行しない
- クラスターの指定コントローラー (DC) として機能できない
-
pcsコマンドは一部しか実行できない
その一方で、リモートノードおよびゲストノードは、クラスタースタックに関連するスケーラビリティーの制限に拘束されません。
このような制限事項以外に、リモートノードとゲストノードは、リソース管理に関してクラスターノードと同様に動作し、リモートノードとゲストノード自体をフェンスすることができます。クラスターは、各リモートノードおよびゲストノードでリソースを管理および監視する機能を完全に備えています。制約を構築したり、スタンバイ状態にしたり、pcs コマンドを使用してクラスターノードで実行するその他の操作を実行したりできます。リモートノードおよびゲストノードは、クラスターノードと同様にクラスターステータスの出力に表示されます。
65.1. pacemaker_remote ノードのホストおよびゲストの認証
クラスターノードと pacemaker_remote の間の接続には、TLS (Transport Layer Security) が使用され、PSK (Pre-Shared Key) の暗号化と TCP 上の認証 (デフォルトで 3121 ポートを使用) でセキュア化されます。そのため、クラスターノードと、pacemaker_remote を実行しているノードは、同じ秘密鍵を共有する必要があります。デフォルトでは、クラスターノードとリモートノードの両方でこのキーを /etc/pacemaker/authkey に配置する必要があります。
pcs cluster node add-guest コマンドまたは pcs cluster node add-remote コマンドを 初めて実行すると、認証キー が作成され、クラスター内の既存のすべてのノードにインストールされます。後で任意のタイプの新しいノードを作成すると、既存の authkey が 新しいノードにコピーされます。
65.2. KVM ゲストノードの設定
Pacemaker ゲストノードは、pacemaker_remote サービスを実行する仮想ゲストノードです。仮想ゲストノードはクラスターにより管理されます。
65.2.1. ゲストノードリソースのオプション
ゲストノードとして動作するように仮想マシンを設定する場合は、仮想マシンを管理する VirtualDomain リソースを作成します。VirtualDomain リソースに設定できるオプションの説明は、仮想ドメインリソースのオプション の「仮想ドメインリソースのリソースオプション」の表を参照してください。
VirtualDomain リソースオプションのほかにも、メタデータオプションはリソースをゲストノードとして定義し、接続パラメーターを定義します。pcs cluster node add-guest コマンドを使用して、これらのリソースオプションを設定します。以下の表は、これらのメタデータオプションを説明しています。
| フィールド | デフォルト | 説明 |
|---|---|---|
|
| <none> | このリソースが定義するゲストノードの名前。リソースをゲストノードとして有効にし、ゲストノードの識別に使用される一意名を定義します。警告:この値を、リソースやノードの ID と重複させることはできません。 |
|
| 3121 |
|
|
|
| 接続先の IP アドレスまたはホスト名 |
|
| 60s | 保留中のゲスト接続がタイムアウトするまでの時間 |
65.2.2. 仮想マシンのゲストノードとしての統合
以下の手順では、libvirt と KVM 仮想ゲストを使用して、Pacemaker で仮想マシンを起動し、そのマシンをゲストノードとして統合する手順の概要を説明します。
手順
-
VirtualDomainリソースを設定します。 すべての仮想マシンで次のコマンドを実行し、
pacemaker_remoteパッケージをインストールし、pcsdサービスを起動し、これを起動時に実行できるようにし、ファイアウォールを介して、TCP の 3121 ポートを許可します。# yum install pacemaker-remote resource-agents pcs # systemctl start pcsd.service # systemctl enable pcsd.service # firewall-cmd --add-port 3121/tcp --permanent # firewall-cmd --add-port 2224/tcp --permanent # firewall-cmd --reload- 各仮想マシンに、すべてのノードが認識できる静的ネットワークアドレスと一意なホスト名を割り当てます。
ゲストノードとして統合しようとしているノードに
pcsを認証していない場合は認証します。# pcs host auth nodename次のコマンドを使用して、既存の
VirtualDomainリソースをゲストノードに変換します。このコマンドは、追加するゲストノードではなく、クラスターノードで実行する必要があります。リソースを変換する以外にも、このコマンドは/etc/pacemaker/authkeyをゲストノードにコピーし、ゲストノードでpacemaker_remoteデーモンを起動して有効にします。任意に定義できるゲストノードのノード名は、ノードのホスト名とは異なる場合があります。# pcs cluster node add-guest nodename resource_id [options]VirtualDomainリソースの作成後は、クラスターの他のノードと同じように、ゲストノードを扱うことができます。たとえば、クラスターノードから実行される次のコマンドのように、リソースを作成し、リソースにリソース制約を設定してゲストノードで実行できます。ゲストノードはグループに追加できます。これにより、ストレージデバイス、ファイルシステム、および仮想マシンをグループ化できます。# pcs resource create webserver apache configfile=/etc/httpd/conf/httpd.conf op monitor interval=30s # pcs constraint location webserver prefers nodename
65.3. Pacemaker リモートノードの設定
リモートノードは、ocf:pacemaker:remote がリソースエージェントとして指定された状態で、クラスターリソースとして定義されます。pcs cluster node add-remote コマンドを使用してこのリソースを作成します。
65.3.1. リモートノードリソースのオプション
以下の表は、remote リソースに設定できるリソースオプションを示しています。
| フィールド | デフォルト | 説明 |
|---|---|---|
|
| 0 | リモートノードへのアクティブな接続が切断された後、リモートノードへの再接続を試みる前に待機する時間 (秒単位)。この待機期間は繰り返し発生します。待機期間の後に再接続に失敗した場合、待機期間の後に、新しい再接続が試行されます。このオプションが使用されると、Pacemaker は待機期間の後に無限にリモートノードへ接続を試みます。 |
|
|
| 接続するサーバーの場所。IP アドレスまたはホスト名を指定できます。 |
|
| 接続する TCP ポート。 |
65.3.2. リモートノードの設定の概要
以下のセクションでは、Pacemaker リモートノードを設定し、そのノードを既存の Pacemaker クラスター環境に統合する手順の概要を説明します。
手順
リモートノードを設定するノードで、ローカルファイアウォールを介してクラスター関連のサービスを許可します。
# firewall-cmd --permanent --add-service=high-availability success # firewall-cmd --reload success注記iptablesを直接使用する場合や、firewalld以外のファイアウォールソリューションを使用する場合は、以下のポートを開きます。TCP ポート 2224 および 3121リモートノードに、
pacemaker_remoteデーモンをインストールします。# yum install -y pacemaker-remote resource-agents pcsリモートノードで、
pcsdを開始し、有効にします。# systemctl start pcsd.service # systemctl enable pcsd.serviceリモートノードとして追加するノードに
pcsを認証していない場合は、認証します。# pcs host auth remote1以下のコマンドを使用して、リモートノードリソースをクラスターに追加します。このコマンドは、関連するすべての設定ファイルを新規ノードに追加し、ノードを起動し、これをシステムの起動時に
pacemaker_remoteを開始するように設定することもできます。このコマンドは、追加するリモートノードではなく、クラスターノードで実行する必要があります。# pcs cluster node add-remote remote1remoteリソースをクラスターに追加した後、リモートノードを、クラスター内の他のノードを処理するのと同じように処理できます。たとえば、以下のコマンドをクラスターノードから実行すると、リソースを作成し、そのリソースにリソース制約を配置して、リモートノードで実行できます。# pcs resource create webserver apache configfile=/etc/httpd/conf/httpd.conf op monitor interval=30s # pcs constraint location webserver prefers remote1警告リソースグループ、コロケーション制約、または順序制約でノード接続リソースを利用しないでください。
- リモートノードのフェンスリソースを設定します。リモートノードは、クラスターノードと同じ方法でフェンスされます。クラスターノードと同様に、リモートノードで使用するフェンスリソースを設定します。リモートノードはフェンシングアクションを開始できないことに注意してください。クラスターノードのみが、実際に別のノードに対してフェンシング操作を実行できます。
65.4. ポートのデフォルトの場所の変更
Pacemaker または pacemaker_remote のいずれかのポートのデフォルトの場所を変更する必要がある場合は、これらのデーモンのどちらにも影響を与える PCMK_remote_port 環境変数を設定できます。この環境変数は、以下のように /etc/sysconfig/pacemaker に配置して有効にできます。
\#==#==# Pacemaker Remote
...
#
# Specify a custom port for Pacemaker Remote connections
PCMK_remote_port=3121
特定のゲストノードまたはリモートノードで使用されるデフォルトのポートを変更する場合は、PCMK_remote_port 変数を、そのノードの /etc/sysconfig/pacemaker ファイルに設定する必要があります。また、ゲストノードまたはリモートノードの接続を作成するクラスターリソースを、同じポート番号で設定する必要もあります (ゲストノードの場合は remote-port メタデータオプション、リモートノードの場合は port オプションを使用します)。
65.5. pacemaker_remote ノードを含むシステムのアップグレード
アクティブな Pacemaker リモートノードで pacemaker_remote サービスが停止すると、クラスターは、ノードの停止前に、リソースをノードから正常に移行します。これにより、クラスターからノードを削除せずに、ソフトウェアのアップグレードやその他の定期的なメンテナンスを実行できるようになりました。ただし、pacemaker_remote がシャットダウンすると、クラスターは即座に再接続を試みます。リソースの監視タイムアウトが発生する前に pacemaker_remote が再起動しないと、クラスターは監視操作が失敗したと判断します。
アクティブな Pacemaker リモートノードで、pacemaker_remote サービスが停止したときに監視が失敗しないようにするには、以下の手順に従って、pacemaker_remote を停止する可能性があるシステム管理を実行する前に、ノードをクラスターから削除します。
手順
ノードからすべてのサービスを除去する
pcs resource disable resourcenameコマンドを使用して、ノードの接続リソースを停止します。接続リソースは、リモートノードの場合はocf:pacemaker:remoteリソース、通常はゲストノードの場合はocf:heartbeat:VirtualDomainリソースになります。ゲストノードの場合、このコマンドは VM も停止するため、メンテナンスを実行するには、クラスターの外部で (たとえば、virshを使用して) VM を起動する必要があります。pcs resource disable resourcename- 必要なメンテナンスを実行します。
ノードをクラスターに戻す準備ができたら、
pcs resource enableコマンドでリソースを再度有効にします。pcs resource enable resourcename
第66章 クラスターメンテナンスの実行
クラスターのノードでメンテナンスを実行するには、そのクラスターで実行しているリソースおよびサービスを停止するか、移行する必要がある場合があります。または、サービスを変更しない状態で、クラスターソフトウェアの停止が必要になる場合があります。Pacemaker は、システムメンテナンスを実行するための様々な方法を提供します。
- クラスターの別のノードでサービスが継続的に実行している状態で、クラスター内のノードを停止する必要がある場合は、そのクラスターノードをスタンバイモードにすることができます。スタンバイノードのノードは、リソースをホストすることができなくなります。ノードで現在アクティブなリソースは、別のノードに移行するか、(他のノードがそのリソースを実行できない場合は) 停止します。スタンバイモードの詳細は、ノードをスタンバイモードに を参照してください。
個々のリソースを停止せずに、そのリソースを現在実行中のノードから移動する必要がある場合は、
pcs resource moveコマンドを使用してリソースを別のノードに移動できます。pcs resource moveコマンドを実行すると、現在実行しているノードでそれが実行されないように、制約がリソースに追加されます。リソースを戻す準備ができたら、pcs resource clearまたはpcs constraint deleteコマンドを実行すると、制約を削除できます。ただし、このコマンドを実行しても、リソースが必ずしも元のノードに戻る訳ではありません。その時点でリソースが実行できる場所は、リソースを最初に設定した方法によって異なるためです。pcs resource relocate runコマンドを使用すると、リソースを優先ノードに移動できます。-
実行中のリソースを完全に停止し、クラスターがそれを再起動しないようにする必要がある場合は、
pcs resource disableコマンドを使用できます。pcs resource disableコマンドの詳細は、クラスターリソースの無効化、有効化、および禁止 を参照してください。 -
Pacemaker が、リソースに対して何らかのアクションを実行しないようにする場合 (たとえば、リソースのメンテナンス中に復元アクションを無効にする場合や、
/etc/sysconfig/pacemaker設定をリロードする必要がある場合) は、リソースの非管理モードへの設定 で説明されているようにpcs resource unmanageコマンドを使用します。Pacemaker Remote 接続リソースは、非管理モードにしないでください。 -
クラスターを、サービスの開始や停止が行われない状態にする必要がある場合は、
maintenance-modeクラスタープロパティーを設定できます。クラスターをメンテナンスモードにすると、すべてのリソースが自動的に非管理モードになります。クラスターをメンテナンスモードにする方法は、クラスターをメンテナンスモードに を参照してください。 - RHEL High Availability Add-On および Resilient Storage Add-On に含まれるパッケージを更新する必要がある場合は、RHEL 高可用性クラスターの更新 で説明されているように、一度に 1 つのパッケージを更新するか、全体のクラスターに対して更新を行うことができます。
- Pacemaker リモートノードでメンテナンスを実行する必要がある場合は、リモートノードおよびゲストノードのアップグレード で説明されているように、リモートノードリソースを無効にすることで、ノードをクラスターから削除できます。
- RHEL クラスターで仮想マシンを移行する必要がある場合は、RHEL クラスターでの仮想マシンの移行 で説明するように、まず仮想マシンでクラスターサービスを停止してクラスターからノードを削除し、移行後にクラスターのバックアップを開始する必要があります。
66.1. ノードをスタンバイモードに
クラスターノードがスタンバイモードになると、ノードがリソースをホストできなくなります。ノードで現在アクティブなリソースは、すべて別のノードに移行されます。
以下のコマンドは、指定ノードをスタンバイモードにします。--all を指定すると、このコマンドはすべてのノードをスタンバイモードにします。
このコマンドは、リソースのパッケージを更新する場合に使用できます。また、設定をテストして、ノードを実際にシャットダウンせずに復元のシュミレーションを行う場合にも、このコマンドを使用できます。
pcs node standby node | --all
次のコマンドは、指定したノードをスタンバイモードから外します。このコマンドを実行すると、指定ノードはリソースをホストできるようになります。--all を指定すると、このコマンドはすべてのノードをスタンバイモードから外します。
pcs node unstandby node | --all
pcs node standby コマンドを実行すると、指定されたノードでリソースが実行されないことに注意してください。pcs node unstandby コマンドを実行すると、指定されたノードでリソースを実行できます。このコマンドを実行しても、リソースが必ずしも指定のノードに戻る訳ではありません。その時点でリソースが実行できる場所は、リソースを最初に設定した方法によって異なります。
66.2. クラスターリソースの手動による移行
クラスターの設定を無視して、強制的にリソースを現在の場所から移行させることができます。次のような 2 つの状況が考えられます。
- ノードがメンテナンスで、そのノードで実行中の全リソースを別のノードに移行する必要がある
- 個別に指定したリソースを移行する必要がある
ノードで実行中の全リソースを別のノードに移行する場合は、そのノードをスタンバイモードにします。
個別に指定したリソースは、以下のいずれかの方法で移行できます。
-
pcs resource moveコマンドを使用して、現在実行中のノードからリソースを移動できます。 -
pcs resource relocate runコマンドを使用して、現在のクラスターステータス、制約、リソースの場所、およびその他の設定によって決定される優先ノードへリソースを移動できます。
66.2.1. 現在のノードからのリソースの移動
現在実行しているノードからリソースを移動するには、以下のコマンドを使用して、リソースの resource_id を定義どおりに指定します。移動するリソースを実行する移行先のノードを指定する場合は、destination_node を指定します。
pcs resource move resource_id [destination_node] [--master] [lifetime=lifetime]
pcs resource move コマンドを実行すると、現在実行しているノードでリソースが実行されないように、制約がリソースに追加されます。RHEL 8.6 以降では、このコマンドに --autodelete オプションを指定できます。これにより、リソースが移動されると、このコマンドによって作成された場所の制約が自動的に削除されます。以前のリリースでは、pcs resource clear または pcs constraint delete コマンドを実行して、制約を手動で削除できます。制約を削除しても、リソースが必ずしも元のノードに戻る訳ではありません。この時点でリソースが実行できる場所は、リソースの最初の設定方法によって異なります。
pcs resource move コマンドで --master パラメーターを指定すると、制約はリソースの昇格されたインスタンスにのみ適用されます。
任意で pcs resource move コマンドの lifetime パラメーターを設定すると、制限が維持される期間を指定できます。lifetime パラメーターの単位は、ISO 8601 に定義されている形式に従って指定します。ISO 8601 では、Y (年)、M (月)、W (週)、D (日)、H (時)、M (分)、S (秒) のように、単位を大文字で指定する必要があります。
分単位の M と、月単位の M を区別するには、分単位の値の前に PT を指定する必要があります。たとえば、lifetime パラメーターが 5M の場合は 5 カ月の間隔を示し、lifetime パラメーターが PT5M の場合は 5 分の間隔を示します。
以下のコマンドは、resource1 リソースを example-node2 ノードへ移動し、1 時間 30 分は元のノードへ戻らないようにします。
pcs resource move resource1 example-node2 lifetime=PT1H30M
以下のコマンドは、resource1 リソースを example-node2 ノードへ移行し、30 分は元のノードへ戻らないようにします。
pcs resource move resource1 example-node2 lifetime=PT30M66.2.2. リソースを優先ノードへ移行
フェイルオーバーや管理者の手作業によるノードの移行により、リソースが移行した後、フェイルオーバーの原因となった状況が改善されたとしても、そのリソースが必ずしも元のノードに戻るとは限りません。リソースを優先ノードへ移行するには、以下のコマンドを実行します。優先ノードは、現在のクラスター状態、制約、リソースの場所、およびその他の設定により決定され、時間とともに変更する可能性があります。
pcs resource relocate run [resource1] [resource2] ...リソースを指定しないと、すべてのリソースが優先ノードに移行します。
このコマンドは、リソースのスティッキネスを無視し、各リソースの優先ノードを算出します。優先ノードの算出後、リソースを優先ノードに移行する場所の制約を作成します。リソースが移行すると、制約が自動的に削除されます。pcs resource relocate run コマンドによって作成された制約をすべて削除するには、pcs resource relocate clear コマンドを入力します。リソースの現在のステータスと、resource stickiness を無視した最適なノードを表示するには、pcs resource relocate show コマンドを入力します。
66.3. クラスターリソースの無効化、有効化、および禁止
pcs resource move コマンドや pcs resource relocate コマンドのほかにも、クラスターリソースの動作を制御するのに使用できる様々なコマンドがあります。
クラスターリソースの無効化
実行中のリソースを手動で停止し、クラスターが再起動しないようにする場合は、以下のコマンドを使用します。その他の設定 (制約、オプション、失敗など) によっては、リソースが起動した状態のままになる可能性があります。--wait オプションを指定すると、pcs はリソースが停止するまで 'n' 秒間待機します。その後、リソースが停止した場合は 0 を返し、リソースが停止しなかった場合は 1 を返します。'n' を指定しないと、デフォルトの 60 分に設定されます。
pcs resource disable resource_id [--wait[=n]]RHEL 8.2 以降では、リソースを無効にしても他のリソースに影響がない場合にのみ、リソースを無効にするように指定できます。これを確認することは、複雑なリソース関係が設定されている場合は手作業では不可能です。
-
pcs resource disable --simulateコマンドは、クラスター設定を変更せずに、リソースを無効にする効果を表示します。 -
pcs resource disable --safeコマンドは、あるノードから別のノードに移行されるなど、その他のリソースが何らかの影響を受けない場合にのみリソースを無効にします。pcs resource safe-disableコマンドは、pcs resource disable --safeコマンドのエイリアスです。 -
pcs resource disable --safe --no-strictコマンドは、他のリソースが停止または降格されない場合にのみ、リソースを無効にします。
RHEL 8.5 以降では、pcs resource disable --safe コマンドに --brief オプションを指定して、エラーのみを出力できます。RHEL 8.5 では、安全な無効化操作に失敗した場合に pcs resource disable --safe コマンドが生成するエラーレポートには、影響を受けるリソース ID も含まれます。リソースの無効化によって影響を受けるリソースのリソース ID のみを把握する必要がある場合は、--brief オプションを使用します。これにより、詳細なシミュレーション結果は提供されません。
クラスターリソースの有効化
クラスターがリソースを起動できるようにするには、次のコマンドを使用します。他の設定によっては、リソースが停止したままになることがありす。--wait オプションを指定すると、pcs はリソースが開始するまで最長で 'n' 秒間待機します。その後、リソースが開始した場合には 0、リソースが開始しなかった場合には 1 を返します。'n' を指定しないと、デフォルトの 60 分に設定されます。
pcs resource enable resource_id [--wait[=n]]特定のノードでリソースが実行されないようにする
指定したノードでリソースが実行されないようにする場合は、次のコマンドを使用します。ノードを指定しないと、現在実行中のノードでリソースが実行されないようになります。
pcs resource ban resource_id [node] [--master] [lifetime=lifetime] [--wait[=n]]
pcs resource ban コマンドを実行すると、場所制約である -INFINITY がリソースに追加され、リソースが指定のノードで実行されないようにします。pcs resource clearまたは pcs constraint delete コマンドを実行すると制約を削除できます。このコマンドを実行しても、リソースが必ずしも指定のノードに戻る訳ではありません。その時点でリソースが実行できる場所は、リソースを最初に設定した方法によって異なります。
pcs resource ban コマンドの --master パラメーターを指定すると、制約の範囲がマスターロールに限定され、resource_id の代わりに master_id を指定する必要があります。
任意で pcs resource ban コマンドに lifetime パラメーターを設定し、制約が持続する期間を指定できます。
任意で、pcs resource ban コマンドに --wait[=n] パラメーターを設定し、移行先のノードでリソースが起動するまでの待機時間 (秒単位) できます。待機時間がこの値を超えると、リソースが起動した場合に 0 が返され、リソースが起動しなかった場合は 1 が返されます。n の値を指定しないと、デフォルトのリソースのタイムアウト値が使用されます。
現在のノードでリソースを強制的に起動
pcs resource コマンドの debug-start パラメーターを使用して、指定されたリソースを現在のノードで強制的に起動し、クラスターの推奨事項を無視して、リソースの起動からの出力を表示します。これは、主にデバッグリソースに使用されます。クラスターでのリソースの起動は (ほぼ) 毎回 Pacemaker で行われ、pcs コマンドで直接行われるわけではありません。リソースが起動しない原因は、大抵、リソースが誤って設定されているか (システムログでデバッグします)、リソースが起動しないように制約が設定されているか、リソースが無効になっているかのいずれかになります。この場合は、次のコマンドを使用してリソースの設定をテストできます。ただし、通常は、クラスター内でリソースを起動するのに使用しないでください。
debug-start コマンドの形式を以下に示します。
pcs resource debug-start resource_id66.4. リソースの非管理モードへの設定
リソースが 非管理 モードの場合、リソースは引き続き設定に含まれますが、Pacemaker はこのリソースを管理しません。
以下のコマンドは、指定のリソースを 非管理 モードに設定します。
pcs resource unmanage resource1 [resource2] ...
以下のコマンドは、リソースをデフォルトの 管理 モードに設定します。
pcs resource manage resource1 [resource2] ...
pcs resource manage または pcs resource unmanage コマンドを使用して、リソースグループの名前を指定できます。このコマンドは、グループのすべてのリソースに対して実行されるため、1 つのコマンドでグループ内の全リソースすべて 管理 または 非管理 モードに設定し、グループに含まれるリソースを個別に管理できます。
66.5. クラスターをメンテナンスモードに
クラスターがメンテナンスモードの場合、クラスターは指示されない限り、サービスを開始したり、停止したりしません。メンテナンスモードが完了すると、クラスターは、サービスの現在の状態のサニティーチェックを実行してから、これを必要とするサービスを停止するか、開始します。
クラスターをメンテナンスモードにするには、以下のコマンドを使用して、maintenance-mode クラスタープロパティーを true に設定します。
# pcs property set maintenance-mode=true
クラスターをメンテナンスモードから外すには、次のコマンドを使用して、maintenance-mode クラスタープロパティーを false に設定します。
# pcs property set maintenance-mode=false設定からクラスタープロパティーを削除する場合は、次のコマンドを使用します。
pcs property unset property
または、pcs property set コマンドの値フィールドを空白にしても、クラスタープロパティーを設定から削除できます。これにより、そのプロパティーの値がデフォルト値に戻されます。たとえば、symmetric-cluster プロパティーを false に設定したことがある場合は、設定した値が次のコマンドにより削除され、symmetric-cluster の値がデフォルト値の true に戻されます。
# pcs property set symmetric-cluster=66.6. RHEL 高可用性クラスターの更新
RHEL High Availability Add-On および Resilient Storage Add-On を設定するパッケージを、個別または一括で更新するには、以下に示す一般的な方法のいずれかを使用できます。
- ローリング更新:サービスからノードを、一度に 1 つずつ削除し、そのソフトウェアを更新してから、そのノードをクラスターに戻します。これにより、各ノードの更新中も、クラスターがサービスの提供とリソースの管理を継続できます。
- クラスター全体の更新:クラスター全体を停止し、更新をすべてのノードに適用してから、クラスターのバックアップを開始します。
Red Hat Enterprise Linux の High Availability クラスターおよび Resilient Storage クラスターのソフトウェア更新手順を実行する場合は、更新を開始する前に、更新を行うノードがクラスターのアクティブなメンバーではないことを確認する必要があります。
これらの各方法の詳細な説明および更新手順は RHEL 高可用性またはレジリエントストレージクラスターにソフトウェア更新を適用するのに推奨されるプラクティス を参照してください。
66.7. リモートノードおよびゲストノードのアップグレード
アクティブなリモートノードまたはゲストノードで pacemaker_remote サービスが停止すると、クラスターは、ノードを停止する前に、ノードからリソースを適切に移行します。これにより、クラスターからノードを削除せずに、ソフトウェアのアップグレードやその他の定期的なメンテナンスを実行できるようになりました。ただし、pacemaker_remote がシャットダウンすると、クラスターは即座に再接続を試みます。リソースの監視タイムアウトが発生する前に pacemaker_remote が再起動しないと、クラスターは監視操作が失敗したと判断します。
アクティブな Pacemaker リモートノードで、pacemaker_remote サービスが停止したときに監視が失敗しないようにするには、以下の手順に従って、pacemaker_remote を停止する可能性があるシステム管理を実行する前に、ノードをクラスターから削除します。
手順
ノードからすべてのサービスを除去する
pcs resource disable resourcenameコマンドを使用して、ノードの接続リソースを停止します。接続リソースは、リモートノードの場合はocf:pacemaker:remoteリソース、通常はゲストノードの場合はocf:heartbeat:VirtualDomainリソースになります。ゲストノードの場合、このコマンドは VM も停止するため、メンテナンスを実行するには、クラスターの外部で (たとえば、virshを使用して) VM を起動する必要があります。pcs resource disable resourcename- 必要なメンテナンスを実行します。
ノードをクラスターに戻す準備ができたら、
pcs resource enableコマンドでリソースを再度有効にします。pcs resource enable resourcename
66.8. RHEL クラスターでの仮想マシンの移行
Support Policies for RHEL High Availability Clusters - General Conditions with Virtualized Cluster Members の説明にあるように、Red Hat ではハイパーバイザーまたはホスト全体でのアクティブなクラスターノードのライブマイグレーションはサポートしていません。ライブマイグレーションを実行する必要がある場合は、まず仮想マシンでクラスターサービスを停止してクラスターからノードを削除し、移行後にクラスターのバックアップを開始する必要があります。以下の手順では、クラスターから仮想マシンを削除し、仮想マシンを移行し、クラスターに仮想マシンを復元する手順の概要を説明します。
以下の手順では、クラスターから仮想マシンを削除し、仮想マシンを移行し、クラスターに仮想マシンを復元する手順の概要を説明します。
以下の手順では、全クラスターノードとして使用する仮想マシンが対象で、特別な配慮なしでライブマイグレーションが可能なクラスターリソースとして管理される仮想マシン (例: ゲストノードとして使用する仮想マシン) は対象外です。RHEL High Availability および Resilient Storage Add-On を設定するパッケージを更新するのに必要な一般的な手順は、RHEL 高可用性またはレジリエントストレージクラスターにソフトウェア更新を適用するのに推奨されるプラクティス を参照してください。
この手順を実行する前に、クラスターノードの削除がクラスタークォーラム (定足数) に与える影響を考慮してください。たとえば、3 ノードクラスターがあり、1 つのノードを削除すると、クラスターはノードの障害に耐えられなくなります。これは、3 ノードクラスターのノードがすでに 1 つダウンしている場合、2 つ目のノードを削除するとクォーラムが失われるためです。
手順
- 移行する仮想マシンで実行しているリソースやソフトウェアの停止または移動を行う前に準備を行う必要がある場合は、以下の手順を実行します。
仮想マシンで以下のコマンドを実行し、仮想マシン上のクラスターソフトウェアを停止します。
# pcs cluster stop- 仮想マシンのライブマイグレーションを実行します。
仮想マシンでクラスターサービスを起動します。
# pcs cluster start
66.9. UUID によるクラスターの識別
Red Hat Enterprise Linux 8.7 以降では、クラスターを作成すると、UUID が関連付けられます。クラスター名は一意のクラスター識別子ではないため、同じ名前の複数のクラスターを管理する設定管理データベースなどのサードパーティーツールは、その UUID によってクラスターを一意に識別できます。現在のクラスター UUID は、pcs cluster config [show] コマンドで表示できます。このコマンドの出力には、クラスター UUID が含まれています。
UUID を既存のクラスターに追加するには、次のコマンドを実行します。
# pcs cluster config uuid generate既存の UUID でクラスターの UUID を再生成するには、次のコマンドを実行します。
# pcs cluster config uuid generate --force第67章 論理ボリュームの設定および管理
67.1. 論理ボリューム管理の概要
論理ボリュームマネージャー (LVM) は、抽象化レイヤーを物理ストレージ上に作成します。これは論理ストレージボリュームを作成するのに役立ちます。これにより、物理ストレージを直接使用する場合に比べて柔軟性が高まります。
さらに、ハードウェアストレージ設定がソフトウェアから隠されているため、アプリケーションを停止したりファイルシステムをアンマウントしたりすることなく、ボリュームのサイズを変更したり移動したりできます。したがって、運用コストが削減できます。
67.1.1. LVM のアーキテクチャー
以下は、LVM のコンポーネントです。
- 物理ボリューム
- 物理ボリューム (PV) は、LVM 使用用に指定されたパーティションまたはディスク全体です。詳細は、LVM 物理ボリュームの管理 を参照してください。
- ボリュームグループ
- ボリュームグループ (VG) は物理ボリューム (PV) の集合です。これにより、論理ボリュームに割り当て可能なディスク領域のプールが作成されます。詳細は、LVM ボリュームグループの管理 を参照してください。
- 論理ボリューム
- 論理ボリュームは使用可能なストレージデバイスを表します。詳細は、基本的な論理ボリューム管理 および 高度な論理ボリューム管理 を参照してください。
以下の図は、LVM のコンポーネントを示しています。
図67.1 LVM 論理ボリュームのコンポーネント
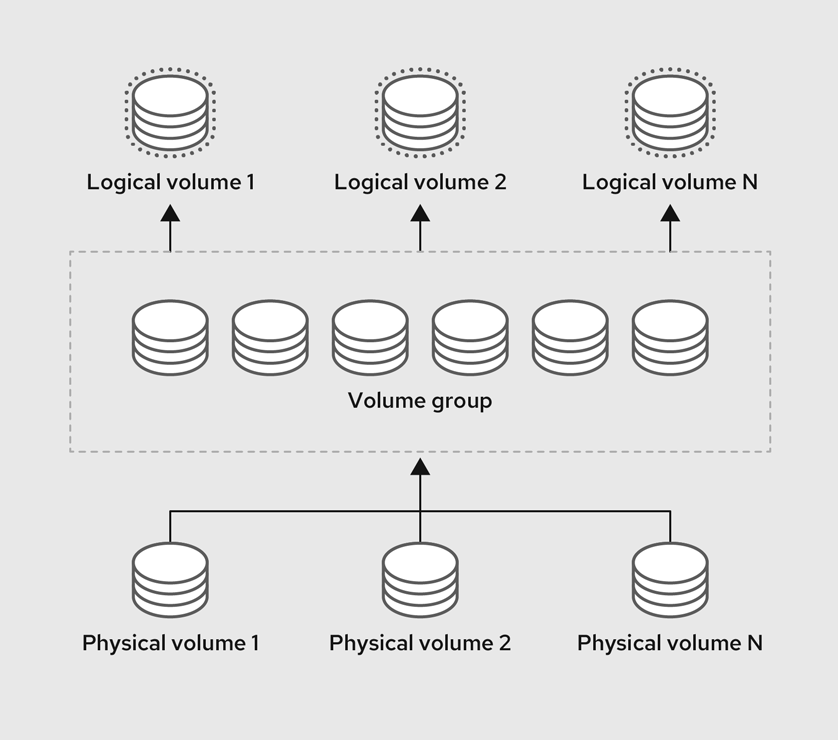
67.1.2. LVM の利点
物理ストレージを直接使用する場合と比較して、論理ボリュームには、以下のような利点があります。
- 容量の柔軟性
- 論理ボリュームを使用すると、ディスクとパーティションを 1 つの論理ボリュームに集約できます。この機能を使用すると、ファイルシステムを複数のデバイスにまたがって拡張でき、1 つの大きなファイルシステムとして扱うことができます。
- 便利なデバイスの命名
- 論理ストレージボリュームは、ユーザー定義のカスタマイズした名前で管理できます。
- サイズ変更可能なストレージボリューム
- 基になるデバイスを再フォーマットしたり、パーティションを再作成したりせずに、簡単なソフトウェアコマンドを使用して論理ボリュームのサイズを拡大または縮小できます。詳細は、論理ボリュームのサイズ変更 を参照してください。
- オンラインデータ移動
より新しく、高速で、耐障害性の高いストレージサブシステムをデプロイするには、
pvmoveコマンドを使用して、システムがアクティブな間にデータを移動できます。データは、ディスクが使用中の場合でもディスクに再配置できます。たとえば、ホットスワップ可能なディスクを削除する前に空にできます。データの移行方法の詳細は、
pvmoveman ページおよび ボリュームグループからの物理ボリュームの削除 を参照してください。- ストライプ化ボリューム
- 2 つ以上のデバイスにまたがってデータをストライプ化する論理ボリュームを作成できます。これにより、スループットが大幅に向上します。詳細は、ストライプ化論理ボリュームの作成 を参照してください。
- RAID ボリューム
- 論理ボリュームは、データの RAID を設定する際に便利な方法を提供します。これにより、デバイス障害に対する保護が可能になり、パフォーマンスが向上します。詳細は、RAID 論理ボリュームの設定 を参照してください。
- ボリュームスナップショット
- 論理ボリュームの特定の時点のコピーであるスナップショットを作成して、一貫性のあるバックアップを作成したり、実際のデータに影響を与えずに変更の影響をテストしたりすることができます。詳細は、論理ボリュームのスナップショットの管理 を参照してください。
- シンボリューム
- 論理ボリュームはシンプロビジョニングできます。これにより、利用可能な物理容量よりも大きな論理ボリュームを作成できます。詳細は、シン論理ボリュームの作成 を参照してください。
- キャッシュ
- キャッシュは、SSD などの高速デバイスを使用して論理ボリュームからデータをキャッシュし、パフォーマンスを向上させます。詳細は、論理ボリュームのキャッシュ を参照してください。
67.2. LVM 物理ボリュームの管理
物理ボリューム (PV) は、LVM が使用する物理ストレージデバイスまたはストレージデバイス上のパーティションです。
初期化プロセス中に、LVM ディスクラベルとメタデータがデバイスに書き込まれます。これにより、LVM が論理ボリューム管理スキームの一部としてデバイスを追跡および管理できるようになります。
初期化後にメタデータのサイズを増やすことはできません。より大きなメタデータが必要な場合は、初期化プロセス中に適切なサイズを設定する必要があります。
初期化プロセスが完了したら、PV をボリュームグループ (VG) に割り当てることができます。この VG を論理ボリューム (LV) に分割できます。論理ボリュームは、オペレーティングシステムとアプリケーションがストレージに使用できる仮想ブロックデバイスです。
最適なパフォーマンスを確保するには、LVM 用にディスク全体を単一の PV としてパーティション設定してください。
67.2.1. LVM 物理ボリュームの作成
pvcreate コマンドを使用して、LVM で使用する物理ボリュームを初期化できます。
前提条件
- 管理アクセスがある。
-
lvm2パッケージがインストールされている。
手順
物理ボリュームとして使用するストレージデバイスを特定します。使用可能なすべてのストレージデバイスをリスト表示するには、次のコマンドを使用します。
$ lsblkLVM 物理ボリュームを作成します。
# pvcreate /dev/sdb/dev/sdb は、物理ボリュームとして初期化するデバイスの名前に置き換えます。
検証手順
作成された物理ボリュームを表示します。
# pvs PV VG Fmt Attr PSize PFree /dev/sdb lvm2 a-- 28.87g 13.87g
67.2.2. LVM 物理ボリュームの削除
pvremove コマンドを使用して、LVM で使用する物理ボリュームを削除できます。
前提条件
- 管理アクセスがある。
手順
物理ボリュームをリスト表示して、削除するデバイスを特定します。
# pvs PV VG Fmt Attr PSize PFree /dev/sdb1 lvm2 --- 28.87g 28.87g物理ボリュームを削除します。
# pvremove /dev/sdb1/dev/sdb1 は、物理ボリュームに関連付けられたデバイスの名前に置き換えます。
物理ボリュームがボリュームグループに含まれている場合は、まずボリュームグループから削除する必要があります。
ボリュームグループに複数の物理ボリュームが含まれている場合は、
vgreduceコマンドを使用します。# vgreduce VolumeGroupName /dev/sdb1VolumeGroupName は、ボリュームグループの名前に置き換えます。/dev/sdb1 は、デバイス名に置き換えます。
ボリュームグループに物理ボリュームが 1 つだけ含まれている場合は、
vgremoveコマンドを使用します。# vgremove VolumeGroupNameVolumeGroupName は、ボリュームグループの名前に置き換えます。
検証
物理ボリュームが削除されたことを確認します。
# pvs
67.2.3. Web コンソールで論理ボリュームの作成
論理ボリュームは物理ドライブとして動作します。RHEL 8 Web コンソールを使用して、ボリュームグループに LVM 論理ボリュームを作成できます。
前提条件
- RHEL 8 Web コンソールがインストールされている。
- cockpit サービスが有効になっている。
ユーザーアカウントが Web コンソールにログインできる。
手順は、Web コンソールのインストールおよび有効化 を参照してください。
-
cockpit-storagedパッケージがシステムにインストールされている。 - ボリュームグループが作成されている。
手順
RHEL 8 Web コンソールにログインします。
詳細は、Web コンソールへのログイン を参照してください。
- Storage をクリックします。
- Storage テーブルで、論理ボリュームを作成するボリュームグループをクリックします。
- Logical volume group ページで、LVM2 logical volumes セクションまでスクロールし、 をクリックします。
- Name フィールドに、新しい論理ボリュームの名前を入力します。名前にスペースを含めないでください。
ドロップダウンメニューで、Block device for filesystems を選択します。
この設定では、ボリュームグループに含まれるすべてのドライブの容量の合計に等しい最大ボリュームサイズを持つ論理ボリュームを作成できます。
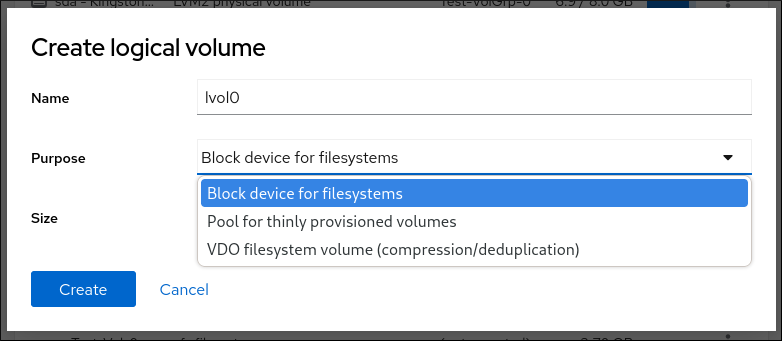
論理ボリュームのサイズを定義します。以下を検討してください。
- この論理ボリュームを使用するシステムにどのぐらいの容量が必要か
- 作成する論理ボリュームの数
領域をすべて使用する必要はありません。必要な場合は、後で論理ボリュームを大きくすることができます。
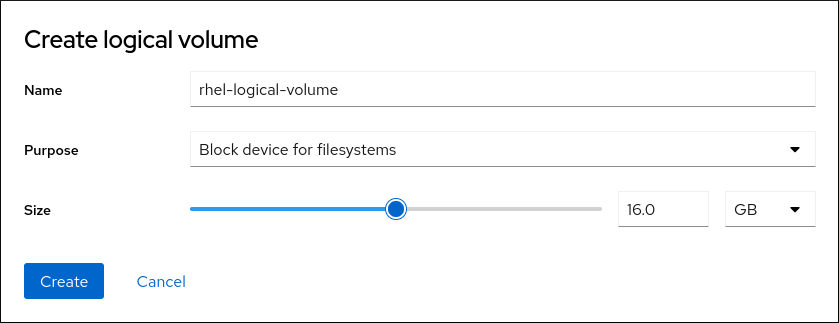
をクリックします。
論理ボリュームが作成されます。論理ボリュームを使用するには、ボリュームをフォーマットしてマウントする必要があります。
検証
Logical volume ページで、LVM2 logical volumes セクションまでスクロールし、新しい論理ボリュームがリストされているかどうかを確認します。
67.2.4. Web コンソールで論理ボリュームのフォーマット
論理ボリュームは物理ドライブとして動作します。これらを使用するには、ファイルシステムでフォーマットする必要があります。
論理ボリュームをフォーマットすると、ボリューム上のすべてのデータが消去されます。
選択するファイルシステムにより、論理ボリュームに使用できる設定パラメーターが決まります。たとえば、XFS ファイルシステムはボリュームの縮小をサポートしていません。
前提条件
- RHEL 8 Web コンソールがインストールされている。
- cockpit サービスが有効になっている。
ユーザーアカウントが Web コンソールにログインできる。
手順は、Web コンソールのインストールおよび有効化 を参照してください。
-
cockpit-storagedパッケージがシステムにインストールされている。 - 論理ボリュームが作成されている。
- システムに対する root アクセス権限を持っている。
手順
RHEL 8 Web コンソールにログインします。
詳細は、Web コンソールへのログイン を参照してください。
- をクリックします。
- Storage テーブルで、論理ボリュームが作成されたボリュームグループをクリックします。
- Logical volume group ページで、LVM2 logical volumes セクションまでスクロールします。
- フォーマットするボリュームグループの横にあるメニューボタン をクリックします。
ドロップダウンメニューから を選択します。
- Name フィールドに、ファイルシステムの名前を入力します。
マウントポイント フィールドに、マウントパスを追加します。
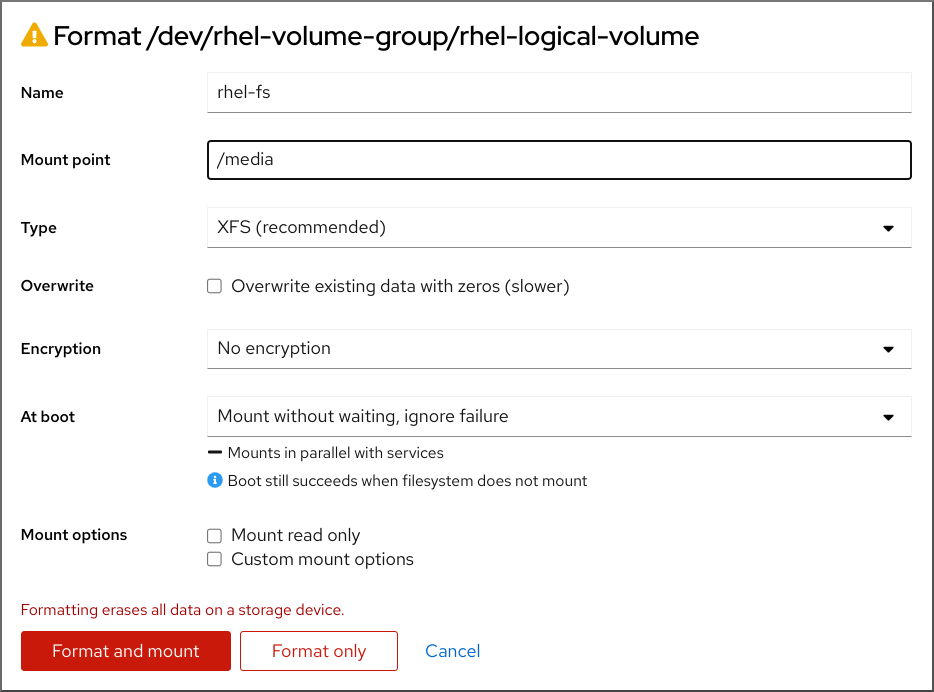
ドロップダウンメニューで、ファイルシステムを選択します。
XFS ファイルシステムは大規模な論理ボリュームをサポートし、オンラインの物理ドライブを停止せずに、既存のファイルシステムの拡大および縮小を行うことができます。別のストレージの使用を希望しない場合は、このファイルシステムを選択したままにしてください。
XFS は、XFS ファイルシステムでフォーマットしたボリュームサイズを縮小することには対応していません。
ext4 ファイルシステムは以下に対応します。
- 論理ボリューム
- オンラインの物理ドライブを停止せずに切り替え
- ファイルシステムの拡張
- ファイルシステムの縮小
RHEL Web コンソールでディスク全体をゼロで書き換える場合は、Overwrite existing data with zeros チェックボックスをオンにします。このプログラムはディスク全体を調べるため、このオプションを使用すると遅くなりますが、安全性は高まります。ディスクにデータが含まれていて、上書きする必要がある場合は、このオプションを使用します。
Overwrite existing data with zeros チェックボックスを選択しない場合、RHEL Web コンソールはディスクヘッダーのみを書き換えます。これにより、フォーマットの速度が向上します。
論理ボリュームで暗号化を有効にする場合は、 ドロップダウンメニューで暗号化のタイプを選択します。
LUKS1 (Linux Unified Key Setup) または LUKS2 暗号化を使用したバージョンを選択できます。これを使用すると、パスフレーズを使用してボリュームを暗号化できます。
- ドロップダウンメニューで、システムの起動後に論理ボリュームをいつマウントするかを選択します。
- 必要な Mount options を選択します。
論理ボリュームをフォーマットします。
- ボリュームをフォーマットしてすぐにマウントする場合は、 をクリックします。
ボリュームをマウントせずにフォーマットする場合は、 をクリックします。
ボリュームのサイズや、選択するオプションによって、フォーマットに数分かかることがあります。
検証
Logical volume group ページで、LVM2 logical volumes セクションまでスクロールし、論理ボリュームをクリックして詳細と追加オプションを確認します。
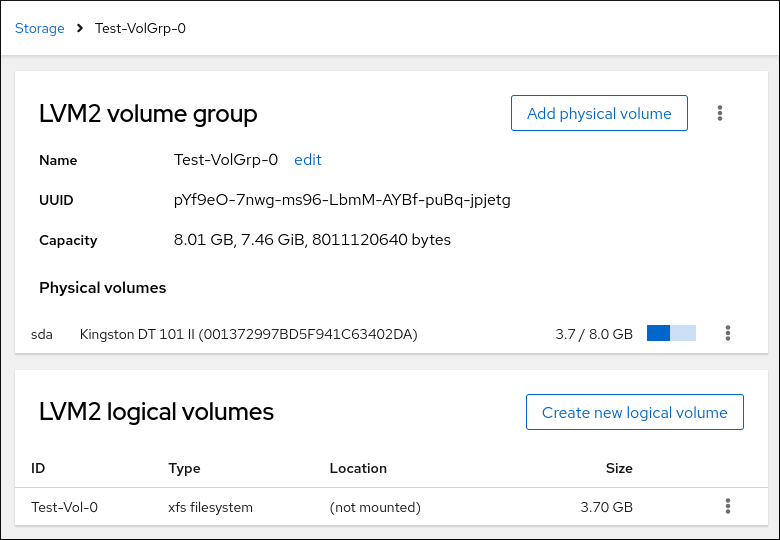
- オプションを選択した場合は、論理ボリュームの行末にあるメニューボタンをクリックし、 を選択して論理ボリュームを使用します。
67.2.5. Web コンソールで論理ボリュームのサイズを変更する
RHEL 8 Web コンソールで論理ボリュームを拡張または縮小できます。この手順の例では、ボリュームをオフラインにせずに論理ボリュームのサイズを拡大および縮小する方法を説明します。
GFS2 または XFS のファイルシステムを含むボリュームを減らすことはできません。
前提条件
- RHEL 8 Web コンソールがインストールされている。
- cockpit サービスが有効になっている。
ユーザーアカウントが Web コンソールにログインできる。
手順は、Web コンソールのインストールおよび有効化 を参照してください。
-
cockpit-storagedパッケージがシステムにインストールされている。 - 論理ボリュームのサイズ変更に対応するファイルシステムを含む既存の論理ボリューム。
手順
- RHEL Web コンソールにログインします。
- をクリックします。
- Storage テーブルで、論理ボリュームが作成されたボリュームグループをクリックします。
Logical volume group ページで、LVM2 logical volumes セクションまでスクロールし、サイズを変更するボリュームグループの横にあるメニューボタン をクリックします。
メニューから Grow または Shrink を選択してボリュームのサイズを変更します。
ボリュームの増加:
- ボリュームのサイズを増やすには、 を選択します。
Grow logical volume ダイアログボックスで、論理ボリュームのサイズを調整します。

をクリックします。
LVM はシステム停止を引き起こすことなく論理ボリュームを拡張します。
ボリュームの縮小:
- ボリュームのサイズを縮小するには、 を選択します。
Shrink logical volume ダイアログボックスで、論理ボリュームのサイズを調整します。

をクリックします。
LVM はシステム停止を引き起こすことなく論理ボリュームを縮小します。
67.3. LVM ボリュームグループの管理
ボリュームグループ (VG) を作成および使用すると、複数の物理ボリューム (PV) を 1 つのストレージエンティティーにまとめて管理およびサイズ変更できます。
LVM で割り当てることができる最小単位の領域のことを、エクステントといいます。物理エクステント (PE) と論理エクステント (LE) のデフォルトサイズは 4 MiB です。このサイズは設定可能です。すべてのエクステントは同じサイズです。
VG 内に論理ボリューム (LV) を作成すると、LVM が PV に物理エクステントを割り当てます。LV 内の論理エクステントは、VG 内の物理エクステントと 1 対 1 で対応します。LV を作成するために PE を指定する必要はありません。LVM は利用可能な PE を検出してそれらを組み合わせて、要求されたサイズの LV を作成します。
VG 内では、複数の LV を作成できます。各 LV は、従来のパーティションのように機能しますが、複数の物理ボリュームにまたがって動的にサイズを変更する機能を備えています。VG はディスク領域の割り当てを自動的に管理できます。
67.3.1. LVM ボリュームグループの作成
vgcreate コマンドを使用してボリュームグループ (VG) を作成できます。非常に大きいボリュームまたは非常に小さいボリュームのエクステントサイズを調整すると、パフォーマンスとストレージ効率を最適化できます。エクステントサイズは、VG を作成するときに指定できます。エクステントサイズを変更するには、ボリュームグループを再作成する必要があります。
前提条件
- 管理アクセスがある。
-
lvm2パッケージがインストールされている。 - 1 つ以上の物理ボリュームが作成されている。物理ボリュームの作成方法は、LVM 物理ボリュームの作成 を参照してください。
手順
VG に含める PV をリスト表示して特定します。
# pvsVG を作成します。
# vgcreate VolumeGroupName PhysicalVolumeName1 PhysicalVolumeName2VolumeGroupName は、作成するボリュームグループの名前に置き換えます。PhysicalVolumeName は、PV の名前に置き換えます。
VG を作成するときにエクステントサイズを指定するには、
-s ExtentSizeオプションを使用します。ExtentSize は、エクステントサイズに置き換えます。サイズの接尾辞を指定しなかった場合、このコマンドではデフォルトで MB が使用されます。
検証
VG が作成されたことを確認します。
# vgs VG #PV #LV #SN Attr VSize VFree VolumeGroupName 1 0 0 wz--n- 28.87g 28.87g
67.3.2. Web コンソールでボリュームグループの作成
1 つ以上の物理ドライブまたは他のストレージデバイスからボリュームグループを作成します。
論理ボリュームは、ボリュームグループから作成されます。各ボリュームグループに、複数の論理ボリュームを追加できます。
前提条件
- RHEL 8 Web コンソールがインストールされている。
- cockpit サービスが有効になっている。
ユーザーアカウントが Web コンソールにログインできる。
手順は、Web コンソールのインストールおよび有効化 を参照してください。
-
cockpit-storagedパッケージがシステムにインストールされている。 - ボリュームグループを作成する物理ドライブ、またはその他の種類のストレージデバイス。
手順
RHEL 8 Web コンソールにログインします。
詳細は、Web コンソールへのログイン を参照してください。
- をクリックします。
- Storage テーブルで、メニューボタンをクリックします。
ドロップダウンメニューから、Create LVM2 volume group を選択します。
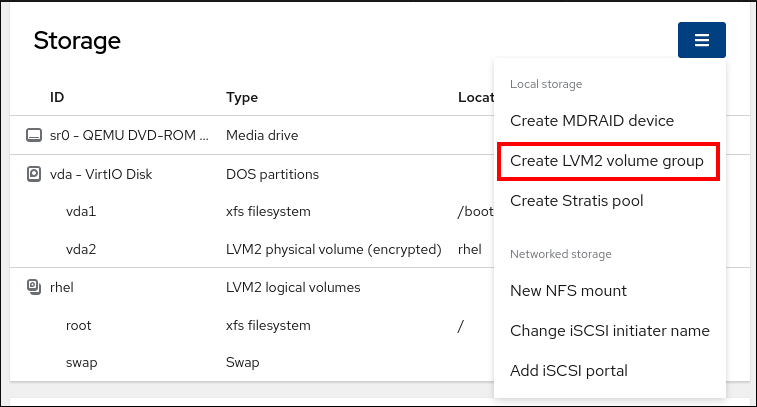
- Name フィールドにボリュームグループの名前を入力します。名前にスペースを含めることはできません。
ボリュームグループを作成するために組み合わせるドライブを選択します。
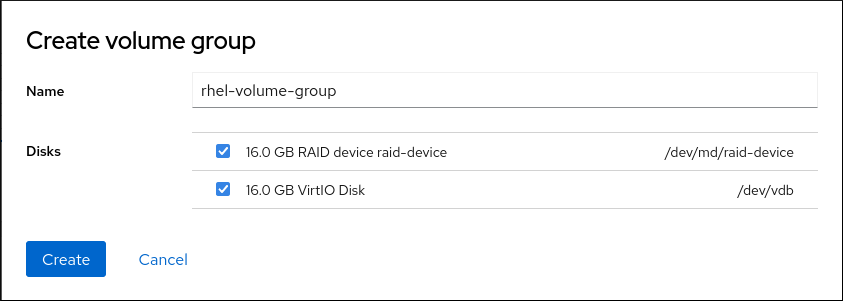
RHEL Web コンソールは、未使用のブロックデバイスのみを表示します。リストにデバイスが表示されない場合は、そのデバイスがシステムで使用されていないことを確認するか、デバイスを空で未使用の状態にフォーマットしてください。使用されるデバイスには、たとえば次のようなものがあります。
- ファイルシステムでフォーマットしたデバイス
- 別のボリュームグループの物理ボリューム
- 別のソフトウェアの RAID デバイスのメンバーになる物理ボリューム
をクリックします。
ボリュームグループが作成されている。
検証
- Storage ページで、新しいボリュームグループが Storage テーブルにリストされているかどうかを確認します。
67.3.3. LVM ボリュームグループの名前変更
vgrename コマンドを使用してボリュームグループ (VG) の名前を変更できます。
前提条件
- 管理アクセスがある。
-
lvm2パッケージがインストールされている。 - 1 つ以上の物理ボリュームが作成されている。物理ボリュームの作成方法は、LVM 物理ボリュームの作成 を参照してください。
- ボリュームグループが作成されている。ボリュームグループの作成の詳細は、「LVM ボリュームグループの作成」 を参照してください。
手順
名前を変更する VG をリスト表示して特定します。
# vgsVG の名前を変更します。
# vgrename OldVolumeGroupName NewVolumeGroupNameOldVolumeGroupName は、VG の名前に置き換えます。NewVolumeGroupName は、VG の新しい名前に置き換えます。
検証
VG に新しい名前が付けられたことを確認します。
# vgs VG #PV #LV #SN Attr VSize VFree NewVolumeGroupName 1 0 0 wz--n- 28.87g 28.87g
67.3.4. LVM ボリュームグループの拡張
vgextend コマンドを使用して、物理ボリューム (PV) をボリュームグループ (VG) に追加できます。
前提条件
- 管理アクセスがある。
-
lvm2パッケージがインストールされている。 - 1 つ以上の物理ボリュームが作成されている。物理ボリュームの作成方法は、LVM 物理ボリュームの作成 を参照してください。
- ボリュームグループが作成されている。ボリュームグループの作成の詳細は、「LVM ボリュームグループの作成」 を参照してください。
手順
拡張する VG をリスト表示して特定します。
# vgsVG に追加する PV をリスト表示して特定します。
# pvsVG を拡張します。
# vgextend VolumeGroupName PhysicalVolumeNameVolumeGroupName は、VG の名前に置き換えます。PhysicalVolumeName は、PV の名前に置き換えます。
検証
VG に新しい PV が含まれていることを確認します。
# pvs PV VG Fmt Attr PSize PFree /dev/sda VolumeGroupName lvm2 a-- 28.87g 28.87g /dev/sdd VolumeGroupName lvm2 a-- 1.88g 1.88g
67.3.5. LVM ボリュームグループの結合
vgmerge コマンドを使用して、既存の 2 つのボリュームグループ (VG) を結合できます。結合元ボリュームが結合先ボリュームにマージされます。
前提条件
- 管理アクセスがある。
-
lvm2パッケージがインストールされている。 - 1 つ以上の物理ボリュームが作成されている。物理ボリュームの作成方法は、LVM 物理ボリュームの作成 を参照してください。
- 2 つ以上のボリュームグループが作成されている。ボリュームグループの作成の詳細は、「LVM ボリュームグループの作成」 を参照してください。
手順
マージする VG をリスト表示して特定します。
# vgs VG #PV #LV #SN Attr VSize VFree VolumeGroupName1 1 0 0 wz--n- 28.87g 28.87g VolumeGroupName2 1 0 0 wz--n- 1.88g 1.88g結合元 VG を結合先 VG にマージします。
# vgmerge VolumeGroupName2 VolumeGroupName1VolumeGroupName2 は、結合元 VG の名前に置き換えます。VolumeGroupName1 は、結合先 VG の名前に置き換えます。
検証
VG に新しい PV が含まれていることを確認します。
# vgs VG #PV #LV #SN Attr VSize VFree VolumeGroupName1 2 0 0 wz--n- 30.75g 30.75g
67.3.6. ボリュームグループからの物理ボリュームの削除
ボリュームグループ (VG) から未使用の物理ボリューム (PV) を削除するには、vgreduce コマンドを使用します。vgreduce コマンドは、空の物理ボリュームを 1 つまたは複数削除して、ボリュームグループの容量を縮小します。これにより、物理ボリュームが解放され、異なるボリュームグループで使用したり、システムから削除できるようになります。
手順
物理ボリュームがまだ使用中の場合は、同じボリュームグループから別の物理ボリュームにデータを移行します。
# pvmove /dev/vdb3 /dev/vdb3: Moved: 2.0% ... /dev/vdb3: Moved: 79.2% ... /dev/vdb3: Moved: 100.0%既存のボリュームグループ内の他の物理ボリュームに空きエクステントが十分にない場合は、以下を行います。
/dev/vdb4 から、物理ボリュームを新規作成します。
# pvcreate /dev/vdb4 Physical volume "/dev/vdb4" successfully created新しく作成した物理ボリュームをボリュームグループに追加します。
# vgextend VolumeGroupName /dev/vdb4 Volume group "VolumeGroupName" successfully extendedデータを /dev/vdb3 から /dev/vdb4 に移動します。
# pvmove /dev/vdb3 /dev/vdb4 /dev/vdb3: Moved: 33.33% /dev/vdb3: Moved: 100.00%
ボリュームグループから物理ボリューム /dev/vdb3 を削除します。
# vgreduce VolumeGroupName /dev/vdb3 Removed "/dev/vdb3" from volume group "VolumeGroupName"
検証
/dev/vdb3 物理ボリュームが VolumeGroupName ボリュームグループから削除されていることを確認します。
# pvs PV VG Fmt Attr PSize PFree Used /dev/vdb1 VolumeGroupName lvm2 a-- 1020.00m 0 1020.00m /dev/vdb2 VolumeGroupName lvm2 a-- 1020.00m 0 1020.00m /dev/vdb3 lvm2 a-- 1020.00m 1008.00m 12.00m
67.3.7. LVM ボリュームグループの分割
この物理ボリュームに未使用領域が十分にあれば、新たにディスクを追加しなくてもボリュームグループを作成できます。
初期設定では、ボリュームグループ VolumeGroupName1 は、/dev/vdb1、/dev/vdb2、および /dev/vdb3 で構成されます。この手順を完了すると、ボリュームグループ VolumeGroupName1 は /dev/vdb1 と /dev/vdb2 で構成され、2 番目のボリュームグループ VolumeGroupName2 は /dev/vdb3 で構成されます。
前提条件
-
ボリュームグループに十分な空き領域がある。
vgscanコマンドを使用すると、現在ボリュームグループで利用可能な空き領域の容量を確認できます。 -
既存の物理ボリュームの空き容量に応じて、
pvmoveコマンドを使用して、使用されている物理エクステントをすべて他の物理ボリュームに移動します。詳細は、ボリュームグループからの物理ボリュームの削除 を参照してください。
手順
既存のボリュームグループ VolumeGroupName1 を、新しいボリュームグループ VolumeGroupName2 に分割します。
# vgsplit VolumeGroupName1 VolumeGroupName2 /dev/vdb3 Volume group "VolumeGroupName2" successfully split from "VolumeGroupName1"注記既存のボリュームグループを使用して論理ボリュームを作成した場合は、次のコマンドを実行して論理ボリュームを非アクティブにします。
# lvchange -a n /dev/VolumeGroupName1/LogicalVolumeName2 つのボリュームグループの属性を表示します。
# vgs VG #PV #LV #SN Attr VSize VFree VolumeGroupName1 2 1 0 wz--n- 34.30G 10.80G VolumeGroupName2 1 0 0 wz--n- 17.15G 17.15G
検証
新しく作成したボリュームグループ VolumeGroupName2 が、/dev/vdb3 物理ボリュームで構成されていることを確認します。
# pvs PV VG Fmt Attr PSize PFree Used /dev/vdb1 VolumeGroupName1 lvm2 a-- 1020.00m 0 1020.00m /dev/vdb2 VolumeGroupName1 lvm2 a-- 1020.00m 0 1020.00m /dev/vdb3 VolumeGroupName2 lvm2 a-- 1020.00m 1008.00m 12.00m
67.3.8. ボリュームグループを別のシステムへ移動
次のコマンドを使用して、LVM ボリュームグループ (VG) 全体を別のシステムに移動できます。
vgexport- 既存のシステムでこのコマンドを使用して、システムから非アクティブな VG にアクセスできないようにします。VG にアクセスできなくなったら、その物理ボリューム (PV) の接続を解除できます。
vgimport- 他のシステムでこのコマンドを使用して、新しいシステムで、古いシステムで非アクティブだった VG にアクセスできるようにします。
前提条件
- 移動するボリュームグループ内のアクティブなボリュームのファイルにアクセスしているユーザーがいない。
手順
LogicalVolumeName 論理ボリュームをアンマウントします。
# umount /dev/mnt/LogicalVolumeNameボリュームグループ内のすべての論理ボリュームを非アクティブ化します。これにより、ボリュームグループでこれ以上の動作が発生しないようにします。
# vgchange -an VolumeGroupName vgchange -- volume group "VolumeGroupName" successfully deactivatedボリュームグループをエクスポートして、削除元のシステムがボリュームグループにアクセスできないようにします。
# vgexport VolumeGroupName vgexport -- volume group "VolumeGroupName" successfully exportedエクスポートされたボリュームグループを表示します。
# pvscan PV /dev/sda1 is in exported VG VolumeGroupName [17.15 GB / 7.15 GB free] PV /dev/sdc1 is in exported VG VolumeGroupName [17.15 GB / 15.15 GB free] PV /dev/sdd1 is in exported VG VolumeGroupName [17.15 GB / 15.15 GB free] ...- システムをシャットダウンし、ボリュームグループを構成するディスクを取り外し、新しいシステムに接続します。
ディスクを新しいシステムに接続し、ボリュームグループをインポートして、新しいシステムからアクセスできるようにします。
# vgimport VolumeGroupName注記vgimportコマンドの--force引数を使用すると、物理ボリュームがないボリュームグループをインポートし、その後vgreduce --removemissingコマンドを実行できます。ボリュームグループをアクティブ化します。
# vgchange -ay VolumeGroupNameファイルシステムをマウントして使用できるようにします。
# mkdir -p /mnt/VolumeGroupName/users # mount /dev/VolumeGroupName/users /mnt/VolumeGroupName/users
関連情報
-
システム上の
vgimport(8)、vgexport(8)、およびvgchange(8)man ページ
67.3.9. LVM ボリュームグループの削除
vgremove コマンドを使用して、既存のボリュームグループを削除できます。削除できるボリュームグループは、論理ボリュームが含まれていないものだけです。
前提条件
- 管理アクセスがある。
手順
ボリュームグループに論理ボリュームが含まれていないことを確認します。
# vgs -o vg_name,lv_count VolumeGroupName VG #LV VolumeGroupName 0VolumeGroupName は、ボリュームグループの名前に置き換えます。
ボリュームグループを削除します。
# vgremove VolumeGroupNameVolumeGroupName は、ボリュームグループの名前に置き換えます。
67.3.10. クラスター環境での LVM ボリュームグループの削除
クラスター環境では、LVM は lockspace <qualifier> を使用して、複数のマシン間で共有されるボリュームグループへのアクセスを調整します。ボリュームグループを削除する前に lockspace を停止し、削除プロセス中に他のノードがボリュームグループにアクセスしたり変更したりしないようにする必要があります。
前提条件
- 管理アクセスがある。
- ボリュームグループには論理ボリュームがありません。
手順
ボリュームグループに論理ボリュームが含まれていないことを確認します。
# vgs -o vg_name,lv_count VolumeGroupName VG #LV VolumeGroupName 0VolumeGroupName は、ボリュームグループの名前に置き換えます。
ボリュームグループを削除するノードを除くすべてのノードで
lockspaceを停止します。# vgchange --lockstop VolumeGroupNameVolumeGroupName は、ボリュームグループの名前に置き換えます。ロックが停止するまで待ちます。
ボリュームグループを削除します。
# vgremove VolumeGroupNameVolumeGroupName は、ボリュームグループの名前に置き換えます。
67.4. LVM 論理ボリュームの管理
論理ボリュームは、ファイルシステム、データベース、またはアプリケーションが使用できる仮想のブロックストレージデバイスです。LVM 論理ボリュームを作成する場合は、物理ボリューム (PV) をボリュームグループ (Volume Group: VG) に統合します。これによりディスク領域のプールが作成され、そこから LVM 論理ボリューム (Logical Volume: LV) を割り当てます。
67.4.1. 論理ボリューム機能の概要
論理ボリュームマネージャー (LVM) を使用すると、従来のパーティションスキームでは実現できない柔軟かつ効率的な方法でディスクストレージを管理できます。以下は、ストレージの管理と最適化に使用される主要な LVM 機能の概要です。
- 連結
- 連結では、1 つ以上の物理ボリュームの領域を 1 つの論理ボリュームに結合し、物理ストレージを効果的にマージします。
- ストライピング
- ストライピングは、データを複数の物理ボリュームに分散することで、データの I/O 効率を最適化します。並列 I/O 操作を可能にすることで、シーケンシャルな読み取りおよび書き込みのパフォーマンスを向上させます。
- RAID
- LVM は、RAID レベル 0、1、4、5、6、10 に対応します。RAID 論理ボリュームを作成するとき、LVM は、データまたはアレイ内のパリティーサブボリュームごとに、サイズが 1 エクステントのメタデータサブボリュームを作成します。
- シンプロビジョニング
- シンプロビジョニングを使用すると、使用可能な物理ストレージよりも大きい論理ボリュームを作成できます。シンプロビジョニングでは、事前に決められた量ではなく、実際の使用量に基づいてシステムがストレージを動的に割り当てます。
- スナップショット
- LVM スナップショットを使用すると、論理ボリュームの特定時点のコピーを作成できます。スナップショットは、最初は空の状態です。元の論理ボリュームに変更が発生すると、スナップショットがコピーオンライト (CoW) により変更前の状態をキャプチャーします。変更があった場合にのみ、元の論理ボリュームの状態を保持するためにサイズが増加します。
- キャッシュ
- LVM は、高速ブロックデバイス (SSD ドライブなど) を、大規模で低速なブロックデバイスのライトバックまたはライトスルーのキャッシュとして使用することに対応します。既存の論理ボリュームのパフォーマンスを改善するためにキャッシュ論理ボリュームを作成したり、大規模で低速なデバイスと共に小規模で高速なデバイスで構成される新規のキャッシュ論理ボリュームを作成したりできます。
67.4.2. 論理ボリュームのスナップショットの管理
スナップショットは、特定時点における別の LV の内容をミラーリングする論理ボリューム (LV) です。
67.4.2.1. 論理ボリュームスナップショットにてういて
スナップショットを作成すると、特定時点における別の LV のコピーとして機能する新しい LV が作成されます。スナップショット LV は、最初は実際のデータを含んでいません。代わりに、スナップショット作成時における元の LV のデータブロックを参照します。
スナップショットのストレージ使用率を定期的に監視することが重要です。スナップショットに割り当てられている領域の 100% に達すると、スナップショットが無効になります。
スナップショットが完全にいっぱいになる前に拡張することが重要です。これは、lvextend コマンドを使用して手動で行うことも、/etc/lvm/lvm.conf ファイルを使用して自動的に行うこともできます。
- シック LV スナップショット
- 元の LV のデータが変更されると、コピーオンライト (CoW) システムによって、変更前の元のデータがスナップショットにコピーされます。この方法では、変更が発生した場合にのみスナップショットのサイズが増加し、スナップショット作成時における元のボリュームの状態が保存されます。シックスナップショットは、事前に一定量のストレージ領域を割り当てる必要がある LV の一種です。この量は後で増減できますが、元の LV にどのような変更を加える予定かを検討してください。そうすることで、割り当てる領域が多すぎるためにリソースが無駄になったり、割り当てる領域が少なすぎるためにスナップショットのサイズを頻繁に増やす必要が生じたりすることがなくなります。
- シン LV スナップショット
シンスナップショットは、既存のシンプロビジョニングされた LV から作成される LV の一種です。シンスナップショットでは、事前に追加の領域を割り当てる必要はありません。最初は、元の LV とそのスナップショットの両方が同じデータブロックを共有します。元の LV に変更が加えられると、新しいデータが別のブロックに書き込まれますが、スナップショットは元のブロックを参照し続け、スナップショット作成時における LV データの特定時点のビューが保持されます。
シンプロビジョニングは、必要に応じてディスク領域を割り当てることで、ストレージを効率的に最適化および管理する方法です。そのため、各 LV に事前に大量のストレージを割り当てる必要がなく、複数の LV を作成できます。ストレージがシンプール内のすべての LV で共有されるため、リソースをより効率的に使用できます。シンプールは、必要に応じて LV に領域を割り当てます。
- シック LV スナップショットとシン LV スナップショットの選択
- シック LV スナップショットとシン LV スナップショットの選択は、スナップショットの作成元とする LV のタイプによって直接決まります。元の LV がシック LV である場合、スナップショットもシックになります。元の LV がシン LV の場合は、スナップショットもシンになります。
67.4.2.2. シック論理ボリュームスナップショットの管理
シック LV スナップショットを作成するときは、ストレージ要件とスナップショットの想定される有効期間を考慮することが重要です。元のボリュームに予想される変更に基づいて、十分なストレージを割り当てる必要があります。スナップショットは、想定される有効期間中の変更を取り込むのに十分なサイズである必要がありますが、元の LV のサイズを超えることはできません。変更頻度が低いと予想される場合は、10% - 15% の小さいスナップショットサイズで十分な場合があります。変更頻度が高い LV の場合は、30% 以上を割り当てる必要がある場合があります。
スナップショットが完全にいっぱいになる前に拡張することが重要です。スナップショットに割り当てられている領域の 100% に達すると、スナップショットが無効になります。lvs -o lv_name,data_percent,origin コマンドを使用すると、スナップショットの容量を監視できます。
67.4.2.2.1. シック論理ボリュームスナップショットの作成
lvcreate コマンドを使用して、シック LV スナップショットを作成できます。
前提条件
- 管理アクセスがある。
- 物理ボリュームが作成されている。詳細は、LVM 物理ボリュームの作成 を参照してください。
- ボリュームグループが作成されている。詳細は、LVM ボリュームグループの作成 を参照してください。
- 論理ボリュームが作成されている。詳細は、論理ボリュームの作成 を参照してください。
手順
スナップショットを作成する LV を特定します。
# lvs -o vg_name,lv_name,lv_size VG LV LSize VolumeGroupName LogicalVolumeName 10.00gスナップショットのサイズは LV のサイズを超えることはできません。
シック LV スナップショットを作成します。
# lvcreate --snapshot --size SnapshotSize --name SnapshotName VolumeGroupName/LogicalVolumeNameSnapshotSize は、スナップショットに割り当てるサイズ (例: 10 G) に置き換えます。SnapshotName は、スナップショット論理ボリュームに付ける名前に置き換えます。VolumeGroupName は、元の論理ボリュームを含むボリュームグループの名前に置き換えます。LogicalVolumeName は、スナップショットの作成元とする論理ボリュームの名前に置き換えます。
検証
スナップショットが作成されたことを確認します。
# lvs -o lv_name,origin LV Origin LogicalVolumeName SnapshotName LogicalVolumeName
67.4.2.2.2. 論理ボリュームスナップショットの手動拡張
スナップショットに割り当てられている領域の 100% に達すると、スナップショットが無効になります。スナップショットが完全にいっぱいになる前に拡張することが重要です。これは、lvextend コマンドを使用して手動で実行できます。
前提条件
- 管理アクセスがある。
手順
ボリュームグループ、論理ボリューム、スナップショットのソースボリュームの名前、使用率、およびサイズをリスト表示します。
# lvs -o vg_name,lv_name,origin,data_percent,lv_size VG LV Origin Data% LSize VolumeGroupName LogicalVolumeName 10.00g VolumeGroupName SnapshotName LogicalVolumeName 82.00 5.00gシックプロビジョニングされたスナップショットを拡張します。
# lvextend --size +AdditionalSize VolumeGroupName/SnapshotNameAdditionalSize は、スナップショットに追加する容量 (例: +1G) に置き換えます。VolumeGroupName は、ボリュームグループの名前に置き換えます。SnapshotName は、スナップショットの名前に置き換えます。
検証
LV が拡張されたことを確認します。
# lvs -o vg_name,lv_name,origin,data_percent,lv_size VG LV Origin Data% LSize VolumeGroupName LogicalVolumeName 10.00g VolumeGroupName SnapshotName LogicalVolumeName 68.33 6.00g
67.4.2.2.3. シック論理ボリュームスナップショットの自動拡張
スナップショットに割り当てられている領域の 100% に達すると、スナップショットが無効になります。スナップショットが完全にいっぱいになる前に拡張することが重要です。これは自動的に実行できます。
前提条件
- 管理アクセスがある。
手順
-
rootユーザーとして、任意のエディターで/etc/lvm/lvm.confファイルを開きます。 snapshot_autoextend_threshold行とsnapshot_autoextend_percent行のコメントを解除し、各パラメーターを必要な値に設定します。snapshot_autoextend_threshold = 70 snapshot_autoextend_percent = 20snapshot_autoextend_thresholdは、LVM がスナップショットの自動拡張を開始するパーセンテージを指定します。たとえば、このパラメーターを 70 に設定すると、容量の 70% に達したときに LVM がスナップショットの拡張を試みます。snapshot_autoextend_percentは、しきい値に達したときにスナップショットを何パーセント拡張するかを指定します。たとえば、パラメーターを 20 に設定すると、スナップショットが現在のサイズの 20% 増加します。- 変更を保存し、エディターを終了します。
lvm2-monitorを再起動します。# systemctl restart lvm2-monitor
67.4.2.2.4. シック論理ボリュームのスナップショットのマージ
シック LV スナップショットを、スナップショットの作成元となった元の論理ボリュームにマージできます。マージプロセスでは、元の LV がスナップショット作成時点の状態に戻されます。マージが完了すると、スナップショットは削除されます。
元の LV とスナップショット LV 間のマージは、どちらかがアクティブな場合、延期されます。両方の LV が再アクティブ化され、使用されていない場合にのみ続行されます。
前提条件
- 管理アクセスがある。
手順
LV、そのボリュームグループ、およびそのパスをリスト表示します。
# lvs -o lv_name,vg_name,lv_path LV VG Path LogicalVolumeName VolumeGroupName /dev/VolumeGroupName/LogicalVolumeName SnapshotName VolumeGroupName /dev/VolumeGroupName/SnapshotNameLV がマウントされている場所を確認します。
# findmnt -o SOURCE,TARGET /dev/VolumeGroupName/LogicalVolumeName # findmnt -o SOURCE,TARGET /dev/VolumeGroupName/SnapshotName/dev/VolumeGroupName/LogicalVolumeName は、論理ボリュームへのパスに置き換えます。/dev/VolumeGroupName/SnapshotName は、スナップショットへのパスに置き換えます。
LV をアンマウントします。
# umount /LogicalVolume/MountPoint # umount /Snapshot/MountPoint/LogicalVolume/MountPoint は、論理ボリュームのマウントポイントに置き換えます。/Snapshot/MountPoint は、スナップショットのマウントポイントに置き換えます。
LV を非アクティブ化します。
# lvchange --activate n VolumeGroupName/LogicalVolumeName # lvchange --activate n VolumeGroupName/SnapshotNameVolumeGroupName は、ボリュームグループの名前に置き換えます。LogicalVolumeName は、論理ボリュームの名前に置き換えます。SnapshotName は、スナップショットの名前に置き換えます。
シック LV スナップショットを元の LV にマージします。
# lvconvert --merge SnapshotNameSnapshotName は、スナップショットの名前に置き換えます。
LV をアクティブ化します。
# lvchange --activate y VolumeGroupName/LogicalVolumeNameVolumeGroupName は、ボリュームグループの名前に置き換えます。LogicalVolumeName は、論理ボリュームの名前に置き換えます。
LV をマウントします。
# umount /LogicalVolume/MountPoint/LogicalVolume/MountPoint は、論理ボリュームのマウントポイントに置き換えます。
検証
スナップショットが削除されたことを確認します。
# lvs -o lv_name
67.4.2.3. シン論理ボリュームスナップショットの管理
ストレージ効率を優先する場合は、シンプロビジョニングが適しています。ストレージ領域の動的割り当てにより、初期のストレージコストが削減され、利用可能なストレージリソースが最大限に使用されます。動的なワークロードがある環境や、時間の経過とともにストレージが増加する環境では、シンプロビジョニングによって柔軟性が向上します。これにより、ストレージ領域を事前に大量に割り当てることなく、ストレージシステムをニーズの変化に適応させることができます。動的な割り当てにより、オーバープロビジョニングが可能になります。つまり、すべての LV の合計サイズが、シンプールの物理サイズを超えることがあります。これは、すべての領域が同時に使用されるわけではないということを前提にしているためです。
67.4.2.3.1. シン論理ボリュームスナップショットの作成
lvcreate コマンドを使用して、シン LV スナップショットを作成できます。シン LV スナップショットを作成するときは、スナップショットサイズを指定しないでください。サイズのパラメーターを含めると、代わりにシックスナップショットが作成されます。
前提条件
- 管理アクセスがある。
- 物理ボリュームが作成されている。詳細は、LVM 物理ボリュームの作成 を参照してください。
- ボリュームグループが作成されている。詳細は、LVM ボリュームグループの作成 を参照してください。
- 論理ボリュームが作成されている。詳細は、論理ボリュームの作成 を参照してください。
手順
スナップショットを作成する LV を特定します。
# lvs -o lv_name,vg_name,pool_lv,lv_size LV VG Pool LSize PoolName VolumeGroupName 152.00m ThinVolumeName VolumeGroupName PoolName 100.00mシン LV スナップショットを作成します。
# lvcreate --snapshot --name SnapshotName VolumeGroupName/ThinVolumeNameSnapshotName は、スナップショット論理ボリュームに付ける名前に置き換えます。VolumeGroupName は、元の論理ボリュームを含むボリュームグループの名前に置き換えます。ThinVolumeName は、スナップショットの作成元とするシン論理ボリュームの名前に置き換えます。
検証
スナップショットが作成されたことを確認します。
# lvs -o lv_name,origin LV Origin PoolName SnapshotName ThinVolumeName ThinVolumeName
67.4.2.3.2. シン論理ボリュームスナップショットのマージ
シン LV スナップショットを、スナップショットの作成元となった元の論理ボリュームにマージできます。マージプロセスでは、元の LV がスナップショット作成時点の状態に戻されます。マージが完了すると、スナップショットは削除されます。
前提条件
- 管理アクセスがある。
手順
LV、そのボリュームグループ、およびそのパスをリスト表示します。
# lvs -o lv_name,vg_name,lv_path LV VG Path ThinPoolName VolumeGroupName ThinSnapshotName VolumeGroupName /dev/VolumeGroupName/ThinSnapshotName ThinVolumeName VolumeGroupName /dev/VolumeGroupName/ThinVolumeName元の LV がマウントされている場所を確認します。
# findmnt -o SOURCE,TARGET /dev/VolumeGroupName/ThinVolumeNameVolumeGroupName/ThinVolumeName は、論理ボリュームへのパスに置き換えます。
LV をアンマウントします。
# umount /ThinLogicalVolume/MountPoint/ThinLogicalVolume/MountPoint は、論理ボリュームのマウントポイントに置き換えます。/ThinSnapshot/MountPoint は、スナップショットのマウントポイントに置き換えます。
LV を非アクティブ化します。
# lvchange --activate n VolumeGroupName/ThinLogicalVolumeNameVolumeGroupName は、ボリュームグループの名前に置き換えます。ThinLogicalVolumeName は、論理ボリュームの名前に置き換えます。
シン LV スナップショットを元の LV にマージします。
# lvconvert --mergethin VolumeGroupName/ThinSnapshotNameVolumeGroupName は、ボリュームグループの名前に置き換えます。ThinSnapshotName は、スナップショットの名前に置き換えます。
LV をマウントします。
# umount /ThinLogicalVolume/MountPoint/ThinLogicalVolume/MountPoint は、論理ボリュームのマウントポイントに置き換えます。
検証
元の LV がマージされたことを確認します。
# lvs -o lv_name
67.4.3. RAID0 ストライプ化論理ボリュームの作成
RAID0 論理ボリュームは、論理ボリュームデータをストライプサイズ単位で複数のデータサブボリューム全体に分散します。以下の手順では、ディスク間でデータをストライピングする mylv という LVM RAID0 論理ボリュームを作成します。
前提条件
- 3 つ以上の物理ボリュームを作成している。物理ボリュームの作成方法は、LVM 物理ボリュームの作成 を参照してください。
- ボリュームグループを作成している。詳細は、LVM ボリュームグループの作成 を参照してください。
手順
既存のボリュームグループから RAID0 論理ボリュームを作成します。次のコマンドは、ボリュームグループ myvg から RAID0 ボリューム mylv を作成します。このボリュームは、サイズが 2G で、ストライプが 3 つあります。ストライプのサイズは 4kB です。
# lvcreate --type raid0 -L 2G --stripes 3 --stripesize 4 -n mylv my_vg Rounding size 2.00 GiB (512 extents) up to stripe boundary size 2.00 GiB(513 extents). Logical volume "mylv" created.RAID0 論理ボリュームにファイルシステムを作成します。以下のコマンドを使用すると、論理ボリュームに ext4 ファイルシステムが作成されます。
# mkfs.ext4 /dev/my_vg/mylv論理ボリュームをマウントして、ファイルシステムのディスクの領域使用率を報告します。
# mount /dev/my_vg/mylv /mnt # df Filesystem 1K-blocks Used Available Use% Mounted on /dev/mapper/my_vg-mylv 2002684 6168 1875072 1% /mnt
検証
作成された RAID0 ストライピング論理ボリュームを表示します。
# lvs -a -o +devices,segtype my_vg LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert Devices Type mylv my_vg rwi-a-r--- 2.00g mylv_rimage_0(0),mylv_rimage_1(0),mylv_rimage_2(0) raid0 [mylv_rimage_0] my_vg iwi-aor--- 684.00m /dev/sdf1(0) linear [mylv_rimage_1] my_vg iwi-aor--- 684.00m /dev/sdg1(0) linear [mylv_rimage_2] my_vg iwi-aor--- 684.00m /dev/sdh1(0) linear
67.4.4. 論理ボリュームからのディスクの削除
この手順では、ディスクを交換するか、別のボリュームで使用するために、既存の論理ボリュームからディスクを削除する方法を説明します。
ディスクを削除する前に、LVM 物理ボリュームのエクステントを、別のディスクまたはディスクセットに移動する必要があります。
手順
LV を使用する際に、物理ボリュームの使用済み容量と空き容量を表示します。
# pvs -o+pv_used PV VG Fmt Attr PSize PFree Used /dev/vdb1 myvg lvm2 a-- 1020.00m 0 1020.00m /dev/vdb2 myvg lvm2 a-- 1020.00m 0 1020.00m /dev/vdb3 myvg lvm2 a-- 1020.00m 1008.00m 12.00mデータを他の物理ボリュームに移動します。
既存のボリュームグループ内の他の物理ボリュームに空きエクステントが十分にある場合は、以下のコマンドを使用してデータを移動します。
# pvmove /dev/vdb3 /dev/vdb3: Moved: 2.0% ... /dev/vdb3: Moved: 79.2% ... /dev/vdb3: Moved: 100.0%既存のボリュームグループ内の他の物理ボリュームに空きエクステントが十分にない場合は、以下のコマンドを使用して新しい物理ボリュームを追加し、新たに作成した物理ボリュームを使用してボリュームグループを拡張し、この物理ボリュームにデータを移動します。
# pvcreate /dev/vdb4 Physical volume "/dev/vdb4" successfully created # vgextend myvg /dev/vdb4 Volume group "myvg" successfully extended # pvmove /dev/vdb3 /dev/vdb4 /dev/vdb3: Moved: 33.33% /dev/vdb3: Moved: 100.00%
物理ボリュームを削除します。
# vgreduce myvg /dev/vdb3 Removed "/dev/vdb3" from volume group "myvg"論理ボリュームに、障害のある物理ボリュームが含まれる場合は、その論理ボリュームを使用することはできません。見つからない物理ボリュームをボリュームグループから削除します。その物理ボリュームに論理ボリュームが割り当てられていない場合は、
vgreduceコマンドの--removemissingパラメーターを使用できます。# vgreduce --removemissing myvg
67.4.5. Web コンソールを使用してボリュームグループ内の物理ドライブを変更する
RHEL 8 Web コンソールを使用して、ボリュームグループ内のドライブを変更できます。
前提条件
- 古いまたは不具合がある物理ドライブを交換するための新しい物理ドライブ。
- この設定には、物理ドライブがボリュームグループに編成されていることが必要になります。
67.4.5.1. Web コンソールでボリュームグループに物理デバイスを追加
RHEL 8 Web コンソールを使用して、既存の論理ボリュームに新しい物理ドライブまたはその他のタイプのボリュームを追加できます。
前提条件
- RHEL 8 Web コンソールがインストールされている。
- cockpit サービスが有効になっている。
ユーザーアカウントが Web コンソールにログインできる。
手順は、Web コンソールのインストールおよび有効化 を参照してください。
-
cockpit-storagedパッケージがシステムにインストールされている。 - ボリュームグループが作成されている。
- マシンに新しいドライブが接続されている。
手順
RHEL 8 Web コンソールにログインします。
詳細は、Web コンソールへのログイン を参照してください。
- Storage をクリックします。
- Storage テーブルで、物理ドライブを追加するボリュームグループをクリックします。
- LVM2 volume group ページで、 をクリックします。
- Add Disks ダイアログボックスでドライブを選択し、 をクリックします。
検証
- LVM2 volume group ページで、Physical volumes セクションをチェックして、新しい物理ドライブがボリュームグループで使用可能かどうかを確認します。
67.4.5.2. Web コンソールでボリュームグループから物理ドライブを削除
論理ボリュームに複数の物理ドライブが含まれている場合は、オンラインの物理ドライブのいずれかを削除できます。
システムは、削除時に、削除するドライブから全てのデータを自動的に別のデバイスに移動します。これには少し時間がかかる場合があります。
Web コンソールは、物理ドライブを削除するための十分な容量があるかどうかを検証します。
前提条件
- RHEL 8 Web コンソールがインストールされている。
- cockpit サービスが有効になっている。
ユーザーアカウントが Web コンソールにログインできる。
手順は、Web コンソールのインストールおよび有効化 を参照してください。
-
cockpit-storagedパッケージがシステムにインストールされている。 - 複数の物理ドライブが接続するボリュームグループ
手順
- RHEL 8 Web コンソールにログインします。
- Storage をクリックします。
- Storage テーブルで、物理ドライブを追加するボリュームグループをクリックします。
- LVM2 volume group ページで、Physical volumes セクションまでスクロールします。
- 削除する物理ボリュームの横にあるメニューボタン をクリックします。
ドロップダウンメニューから を選択します。
ディスクを削除するための十分な容量が論理ボリュームにあるかどうかを RHEL 8 Web コンソールが検証します。データを転送するための空き領域がない場合は、ディスクを削除することはできず、最初に別のディスクを追加してボリュームグループの容量を増やす必要があります。詳細については、Web コンソールで物理ドライブを論理ボリュームに追加する を参照してください。
67.4.6. 論理ボリュームの削除
lvremove コマンドを使用して、スナップショットを含む既存の論理ボリュームを削除できます。
前提条件
- 管理アクセスがある。
手順
論理ボリュームとそのパスをリスト表示します。
# lvs -o lv_name,lv_path LV Path LogicalVolumeName /dev/VolumeGroupName/LogicalVolumeName論理ボリュームがマウントされている場所を確認します。
# findmnt -o SOURCE,TARGET /dev/VolumeGroupName/LogicalVolumeName SOURCE TARGET /dev/mapper/VolumeGroupName-LogicalVolumeName /MountPoint/dev/VolumeGroupName/LogicalVolumeName は、論理ボリュームへのパスに置き換えます。
論理ボリュームをアンマウントします。
# umount /MountPoint/MountPoint は、論理ボリュームのマウントポイントに置き換えます。
論理ボリュームを削除します。
# lvremove VolumeGroupName/LogicalVolumeNameVolumeGroupName/LogicalVolumeName は、論理ボリュームへのパスに置き換えます。
67.4.7. RHEL システムロールを使用した LVM 論理ボリュームの管理
storage ロールを使用して、次のタスクを実行します。
- 複数のディスクで設定されるボリュームグループに LVM 論理ボリュームを作成します。
- 論理ボリューム上に特定のラベルを付けて ext4 ファイルシステムを作成します。
- ext4 ファイルシステムを永続的にマウントします。
前提条件
-
storageロールを含む Ansible Playbook がある。
67.4.7.1. storage RHEL システムロールを使用して論理ボリュームを作成またはサイズ変更する
storage ロールを使用して、次のタスクを実行します。
- 多数のディスクで構成されるボリュームグループに LVM 論理ボリュームを作成する
- LVM 上の既存のファイルシステムのサイズを変更する
- LVM ボリュームのサイズをプールの合計サイズのパーセンテージで表す
ボリュームグループが存在しない場合、このロールによって作成されます。ボリュームグループ内に論理ボリュームが存在する場合に、そのサイズが Playbook で指定されたサイズと一致しないと、サイズが変更されます。
論理ボリュームを縮小する場合、データの損失を防ぐために、その論理ボリューム上のファイルシステムによって、縮小する論理ボリューム内の領域が使用されていないことを確認する必要があります。
前提条件
- コントロールノードと管理対象ノードの準備が完了している。
- 管理対象ノードで Playbook を実行できるユーザーとしてコントロールノードにログインしている。
-
管理対象ノードへの接続に使用するアカウントに、そのノードに対する
sudo権限がある。
手順
次の内容を含む Playbook ファイル (例:
~/playbook.yml) を作成します。--- - name: Manage local storage hosts: managed-node-01.example.com tasks: - name: Create logical volume ansible.builtin.include_role: name: redhat.rhel_system_roles.storage vars: storage_pools: - name: myvg disks: - sda - sdb - sdc volumes: - name: mylv size: 2G fs_type: ext4 mount_point: /mnt/dataサンプル Playbook で指定されている設定は次のとおりです。
size: <size>- 単位 (GiB など) またはパーセンテージ (60% など) を使用してサイズを指定する必要があります。
Playbook で使用されるすべての変数の詳細は、コントロールノードの
/usr/share/ansible/roles/rhel-system-roles.storage/README.mdファイルを参照してください。Playbook の構文を検証します。
$ ansible-playbook --syntax-check ~/playbook.ymlこのコマンドは構文を検証するだけであり、有効だが不適切な設定から保護するものではないことに注意してください。
Playbook を実行します。
$ ansible-playbook ~/playbook.yml
検証
指定したボリュームが作成されたこと、または要求したサイズに変更されたことを確認します。
# ansible managed-node-01.example.com -m command -a 'lvs myvg'
67.4.8. storage RHEL システムロールを使用して LVM 上の既存のファイルシステムのサイズを変更する
ストレージ RHEL システムロールを使用して、ファイルシステムを持つ LVM 論理ボリュームのサイズを変更できます。
削減する論理ボリュームにファイルシステムがある場合は、データの損失を防ぐために、削減する論理ボリューム内の領域がファイルシステムによって使用されていないことを確認する必要があります。
前提条件
- コントロールノードと管理対象ノードの準備が完了している。
- 管理対象ノードで Playbook を実行できるユーザーとしてコントロールノードにログインしている。
-
管理対象ノードへの接続に使用するアカウントに、そのノードに対する
sudo権限がある。
手順
次の内容を含む Playbook ファイル (例:
~/playbook.yml) を作成します。--- - name: Manage local storage hosts: managed-node-01.example.com tasks: - name: Resize LVM logical volume with file system ansible.builtin.include_role: name: redhat.rhel_system_roles.storage vars: storage_pools: - name: myvg disks: - /dev/sda - /dev/sdb - /dev/sdc volumes: - name: mylv1 size: 10 GiB fs_type: ext4 mount_point: /opt/mount1 - name: mylv2 size: 50 GiB fs_type: ext4 mount_point: /opt/mount2この Playbook は、以下の既存のファイルシステムのサイズを変更します。
-
/opt/mount1にマウントされるmylv1ボリュームの Ext4 ファイルシステムは、そのサイズを 10 GiB に変更します。 -
/opt/mount2にマウントされるmylv2ボリュームの Ext4 ファイルシステムは、そのサイズを 50 GiB に変更します。
Playbook で使用されるすべての変数の詳細は、コントロールノードの
/usr/share/ansible/roles/rhel-system-roles.storage/README.mdファイルを参照してください。-
Playbook の構文を検証します。
$ ansible-playbook --syntax-check ~/playbook.ymlこのコマンドは構文を検証するだけであり、有効だが不適切な設定から保護するものではないことに注意してください。
Playbook を実行します。
$ ansible-playbook ~/playbook.yml
検証
論理ボリュームのサイズが要求されたサイズに変更されたことを確認します。
# ansible managed-node-01.example.com -m command -a 'lvs myvg'ファイルシステムツールを使用してファイルシステムのサイズを確認します。たとえば、ext4 の場合、dumpe2fs ツールによって報告されたブロック数とブロックサイズを掛け合わせてファイルシステムのサイズを計算します。
# ansible managed-node-01.example.com -m command -a 'dumpe2fs -h /dev/myvg/mylv | grep -E "Block count|Block size"'
67.5. 論理ボリュームのサイズ変更
論理ボリュームを作成したら、ボリュームのサイズを変更できます。
67.5.1. ストライプ化論理ボリュームの拡張
lvextend コマンドを使用して必要なサイズを指定すると、ストライプ化論理ボリューム (LV) を拡張できます。
前提条件
- ボリュームグループ (VG) を構成する基礎となる物理ボリューム (PV) に、ストライプをサポートするのに十分な空き領域がある。
手順
オプション:ボリュームグループを表示します。
# vgs VG #PV #LV #SN Attr VSize VFree myvg 2 1 0 wz--n- 271.31G 271.31Gオプション:ボリュームグループの全領域を使用して、ストライプを作成します。
# lvcreate -n stripe1 -L 271.31G -i 2 myvg Using default stripesize 64.00 KB Rounding up size to full physical extent 271.31 GiBオプション:新しい物理ボリュームを追加して、myvg ボリュームグループを拡張します。
# vgextend myvg /dev/sdc1 Volume group "myvg" successfully extendedこの手順を繰り返して、ストライプのタイプと使用する領域の量に応じて、十分な物理ボリュームを追加します。たとえば、ボリュームグループ全体を使用する双方向ストライプの場合、少なくとも 2 つの物理ボリュームを追加する必要があります。
myvg VG の一部であるストライプ論理ボリューム stripe1 を拡張します。
# lvextend myvg/stripe1 -L 542G Using stripesize of last segment 64.00 KB Extending logical volume stripe1 to 542.00 GB Logical volume stripe1 successfully resizedまた、stripe1 論理ボリュームを拡張して、myvg ボリュームグループの未割り当て領域をすべて埋めることもできます。
# lvextend -l+100%FREE myvg/stripe1 Size of logical volume myvg/stripe1 changed from 1020.00 MiB (255 extents) to <2.00 GiB (511 extents). Logical volume myvg/stripe1 successfully resized.
検証
拡張したストライプ LV の新しいサイズを確認します。
# lvs LV VG Attr LSize Pool Origin Data% Move Log Copy% Convert stripe1 myvg wi-ao---- 542.00 GB
67.6. LVM レポートのカスタマイズ
LVM は、カスタマイズしたレポートを生成するための幅広い設定オプションとコマンドラインオプションを備えています。出力のソート、単位の指定、選択基準の使用、および lvm.conf ファイルの更新を行って LVM レポートをカスタマイズできます。
67.6.1. LVM 表示の形式の制御
追加オプションなしで pvs、lvs、または vgs コマンドを使用すると、デフォルトの並べ替え順序でデフォルトのフィールドセットが表示されます。pvs コマンドのデフォルトフィールドには、物理ボリュームの名前で並べ替えられた次の情報が含まれています。
# pvs
PV VG Fmt Attr PSize PFree
/dev/vdb1 VolumeGroupName lvm2 a-- 17.14G 17.14G
/dev/vdb2 VolumeGroupName lvm2 a-- 17.14G 17.09G
/dev/vdb3 VolumeGroupName lvm2 a-- 17.14G 17.14GPV- 物理ボリューム名。
VG- ボリュームグループ名。
Fmt-
物理ボリュームのメタデータ形式:
lvm2またはlvm1。 Attr- 物理ボリュームのステータス: (a) - 割り当て可能、または (x) - エクスポート済み。
PSize- 物理ボリュームのサイズ。
PFree- 物理ボリュームにある残りの空き領域。
カスタムフィールドの表示
デフォルトとは異なるフィールドセットを表示するには、-o オプションを使用します。次の例では、物理ボリュームの名前、サイズ、空き容量のみを表示します。
# pvs -o pv_name,pv_size,pv_free
PV PSize PFree
/dev/vdb1 17.14G 17.14G
/dev/vdb2 17.14G 17.09G
/dev/vdb3 17.14G 17.14GLVM 表示の並べ替え
特定の基準で結果を並べ替えるには、-O オプションを使用します。次の例では、エントリーを物理ボリュームの空き領域で昇順に並べ替えます。
# pvs -o pv_name,pv_size,pv_free -O pv_free
PV PSize PFree
/dev/vdb2 17.14G 17.09G
/dev/vdb1 17.14G 17.14G
/dev/vdb3 17.14G 17.14G
結果を降順で並べ替えるには、- 文字とともに -O オプションを使用します。
# pvs -o pv_name,pv_size,pv_free -O -pv_free
PV PSize PFree
/dev/vdb1 17.14G 17.14G
/dev/vdb3 17.14G 17.14G
/dev/vdb2 17.14G 17.09G67.6.2. LVM 表示の単位の指定
LVM 表示コマンドの --units 引数を指定すると、LVM デバイスのサイズを 2 進数単位または 10 進数単位で表示できます。すべての引数については次の表を参照してください。
| 単位の種類 | 説明 | 利用可能なオプション | Default |
|---|---|---|---|
| 2 進数単位 | 単位は 2 の累乗 (1024 の倍数) で表示されます。 |
|
|
| 10 進数単位 | 単位は 1000 の倍数で表示されます。 |
| 該当なし |
| カスタム単位 |
数量と 2 進数または 10 進数の単位の組み合わせ。たとえば、結果を 4 メビバイトで表示するには、 | 該当なし | 該当なし |
単位の値を指定しない場合は、人間が判読できる形式 (
r) がデフォルトで使用されます。次のvgsコマンドは、VG のサイズを人間が判読できる形式で表示します。最適な単位が使用されます。また、丸め記号<によって、実際のサイズが近似値であり、931 ギビバイト未満であることが示されます。# vgs myvg VG #PV #LV #SN Attr VSize VFree myvg 1 1 0 wz-n <931.00g <930.00g次の
pvsコマンドは、/dev/vdb物理ボリュームの出力を 2 進数のギビバイト単位で表示します。# pvs --units g /dev/vdb PV VG Fmt Attr PSize PFree /dev/vdb myvg lvm2 a-- 931.00g 930.00g次の
pvsコマンドは、/dev/vdb物理ボリュームの出力を 10 進数のギガバイト単位で表示します。# pvs --units G /dev/vdb PV VG Fmt Attr PSize PFree /dev/vdb myvg lvm2 a-- 999.65G 998.58G次の
pvsコマンドは、出力を 512 バイトのセクター単位で表示します。# pvs --units s PV VG Fmt Attr PSize PFree /dev/vdb myvg lvm2 a-- 1952440320S 1950343168SLVM 表示コマンドには、カスタム単位を指定できます。次の例では、
pvsコマンドの出力を 4 メビバイト単位で表示します。# pvs --units 4m PV VG Fmt Attr PSize PFree /dev/vdb myvg lvm2 a-- 238335.00U 238079.00U
67.6.3. LVM 設定ファイルのカスタマイズ
lvm.conf ファイルを編集することで、お客様固有のストレージおよびシステム要件に応じて LVM 設定をカスタマイズできます。たとえば、lvm.conf ファイルを編集して、フィルター設定の変更、ボリュームグループの自動アクティブ化の設定、シンプールの管理、またはスナップショットの自動拡張を行うことができます。
手順
-
任意のエディターで
lvm.confファイルを開きます。 デフォルトの表示値を変更する設定のコメントを解除して変更し、
lvm.confファイルをカスタマイズします。lvsの出力に表示されるフィールドをカスタマイズするには、lvs_colsパラメーターのコメントを解除して変更します。lvs_cols="lv_name,vg_name,lv_attr"pvs、vgs、lvsコマンドの空のフィールドを非表示にするには、compact_output=1設定のコメントを解除します。compact_output = 1pvs、vgs、およびlvsコマンドのデフォルトの単位としてギガバイトを設定するには、units = "r"設定をunits = "G"に置き換えます。units = "G"
lvm.confファイルの対応するセクションのコメントが解除されていることを確認します。たとえば、lvs_colsパラメーターを変更するには、reportセクションのコメントを解除する必要があります。report { ... }
検証
lvm.confファイルを変更した後、変更した値を表示します。# lvmconfig --typeconfig diff
67.6.4. LVM 選択基準の定義
選択基準は、<field> <operator> <value> 形式の一連のステートメントであり、比較演算子を使用して特定のフィールドの値を定義します。選択基準に一致するオブジェクトが処理または表示されます。オブジェクトは、物理ボリューム (PV)、ボリュームグループ (VG)、または論理ボリューム (LV) です。ステートメントは、論理演算子とグループ化演算子によって結合します。
選択基準を定義するには、-S または --select オプションの後に 1 つまたは複数のステートメントを使用します。
-S オプションは、各オブジェクトに名前を付けるのではなく、処理するオブジェクトを記述することによって機能します。これは、多くのオブジェクトを処理する場合や、各オブジェクトを個別に検索して名前を付けることが難しい場合や、複雑な特性セットを持つオブジェクトを検索する場合に役立ちます。-S オプションは、多くの名前を入力しなくても済むようにショートカットとして使用することもできます。
フィールドと使用可能な演算子の完全なセットを表示するには、lvs -S help コマンドを使用します。lvs をレポートまたは処理コマンドに置き換えると、そのコマンドの詳細が表示されます。
-
レポートコマンドには、
pvs、vgs、lvs、pvdisplay、vgdisplay、lvdisplay、およびdmsetup info -cが含まれます。 -
処理コマンドには、
pvchange、vgchange、lvchange、vgimport、vgexport、vgremove、およびlvremoveが含まれます。
pvs コマンドを使用した選択基準の例
次の
pvsコマンドの例では、名前に文字列nvmeが含まれる物理ボリュームのみが表示されます。# pvs -S name=~nvme PV Fmt Attr PSize PFree /dev/nvme2n1 lvm2 --- 1.00g 1.00g次の
pvsコマンドの例では、myvgボリュームグループ内の物理デバイスのみが表示されます。# pvs -S vg_name=myvg PV VG Fmt Attr PSize PFree /dev/vdb1 myvg lvm2 a-- 1020.00m 396.00m /dev/vdb2 myvg lvm2 a-- 1020.00m 896.00m
lvs コマンドを使用した選択基準の例
次の
lvsコマンドの例では、サイズが 100 m より大きく 200 m 未満の論理ボリュームのみが表示されます。# lvs -S 'size > 100m && size < 200m' LV VG Attr LSize Cpy%Sync rr myvg rwi-a-r--- 120.00m 100.00次の
lvsコマンドの例では、名前にlvolと 0 から 2 までの任意の数字が含まれる論理ボリュームのみが表示されます。# lvs -S name=~lvol[02] LV VG Attr LSize lvol0 myvg -wi-a----- 100.00m lvol2 myvg -wi------- 100.00m次の
lvsコマンドの例では、raid1セグメントタイプを持つ論理ボリュームのみが表示されます。# lvs -S segtype=raid1 LV VG Attr LSize Cpy%Sync rr myvg rwi-a-r--- 120.00m 100.00
高度な例
選択基準を他のオプションと組み合わせることができます。
次の
lvchangeコマンドの例では、アクティブな論理ボリュームにのみ特定のタグmytagを追加します。# lvchange --addtag mytag -S active=1 Logical volume myvg/mylv changed. Logical volume myvg/lvol0 changed. Logical volume myvg/lvol1 changed. Logical volume myvg/rr changed.次の
lvsコマンドの例では、名前が_pmspareと一致しないすべての論理ボリュームを表示し、デフォルトのヘッダーをカスタムのものに変更します。# lvs -a -o lv_name,vg_name,attr,size,pool_lv,origin,role -S 'name!~_pmspare' LV VG Attr LSize Pool Origin Role thin1 example Vwi-a-tz-- 2.00g tp public,origin,thinorigin thin1s example Vwi---tz-- 2.00g tp thin1 public,snapshot,thinsnapshot thin2 example Vwi-a-tz-- 3.00g tp public tp example twi-aotz-- 1.00g private [tp_tdata] example Twi-ao---- 1.00g private,thin,pool,data [tp_tmeta] example ewi-ao---- 4.00m private,thin,pool,metadata次の
lvchangeコマンドの例では、role=thinsnapshotおよびorigin=thin1の論理ボリュームを、通常のアクティブ化コマンドの実行中にスキップするようにフラグ付けします。# lvchange --setactivationskip n -S 'role=thinsnapshot && origin=thin1' Logical volume myvg/thin1s changed.次の
lvsコマンドの例では、次の 3 つの条件すべてに一致する論理ボリュームのみが表示されます。-
名前に
_tmetaが含まれている。 -
ロールが
metadataである。 - サイズが 4m 以下である。
# lvs -a -S 'name=~_tmeta && role=metadata && size <= 4m' LV VG Attr LSize [tp_tmeta] myvg ewi-ao---- 4.00m-
名前に
関連情報
-
システム上の
lvmreport(7)man ページ
67.7. RAID 論理ボリュームの設定
論理ボリュームマネージャー (LVM) を使用して、Redundant Array of Independent Disks (RAID) ボリュームを作成および管理できます。LVM は、RAID レベル 0、1、4、5、6、10 に対応します。LVM RAID ボリュームには以下の特徴があります。
- LVM は、Multiple Devices (MD) カーネルドライバーを活用した RAID 論理ボリュームを作成して管理する
- アレイから RAID1 イメージを一時的に分割し、後でアレイにマージし直すことが可能
- LVM RAID ボリュームはスナップショットに対応
- RAID 論理ボリュームはクラスターには対応していません。RAID 論理ボリュームは 1 台のマシンに排他的に作成およびアクティブ化できますが、複数のマシンで同時にアクティブにすることはできません。
-
RAID 論理ボリューム (LV) を作成するとき、LVM は、データまたはアレイ内のパリティーサブボリュームごとに、サイズが 1 エクステントのメタデータサブボリュームを作成します。たとえば、2 方向の RAID1 アレイを作成すると、メタデータサブボリュームが 2 つ (
lv_rmeta_0およびlv_rmeta_1) と、データサブボリュームが 2 つ (lv_rimage_0およびlv_rimage_1) 作成されます。 - RAID LV に整合性を追加すると、ソフト破損が軽減または防止されます。
67.7.1. RAID レベルとリニアサポート
レベル 0、1、4、5、6、10、リニアなど、RAID 別の対応設定は以下のとおりです。
- レベル 0
ストライピングとも呼ばれる RAID レベル 0 は、パフォーマンス指向のストライピングデータマッピング技術です。これは、アレイに書き込まれるデータがストライプに分割され、アレイのメンバーディスク全体に書き込まれることを意味します。これにより低い固有コストで高い I/O パフォーマンスを実現できますが、冗長性は提供されません。
RAID レベル 0 実装は、アレイ内の最小デバイスのサイズまで、メンバーデバイス全体にだけデータをストライピングします。つまり、複数のデバイスのサイズが少し異なる場合、それぞれのデバイスは最小ドライブと同じサイズであるかのように処理されます。したがって、レベル 0 アレイの共通ストレージ容量は、すべてのディスクの合計容量です。メンバーディスクのサイズが異なる場合、RAID0 は使用可能なゾーンを使用して、それらのディスクのすべての領域を使用します。
- レベル 1
RAID レベル 1 (ミラーリング) は、アレイの各メンバーディスクに同一のデータを書き込み、ミラー化されたコピーを各ディスクに残すことによって冗長性を提供します。ミラーリングは、データの可用性の単純化と高レベルにより、いまでも人気があります。レベル 1 は 2 つ以上のディスクと連携して、非常に優れたデータ信頼性を提供し、読み取り集中型のアプリケーションに対してパフォーマンスが向上しますが、比較的コストが高くなります。
RAID レベル 1 は、アレイ内のすべてのディスクに同じ情報を書き込むためコストがかかります。これにより、データの信頼性が提供されますが、レベル 5 などのパリティーベースの RAID レベルよりもスペース効率が大幅に低下します。ただし、この領域の非効率性にはパフォーマンス上の利点があります。パリティーベースの RAID レベルは、パリティーを生成するためにかなり多くの CPU 電力を消費しますが、RAID レベル 1 は単に同じデータを、CPU オーバーヘッドが非常に少ない複数の RAID メンバーに複数回書き込むだけです。そのため、RAID レベル 1 は、ソフトウェア RAID が使用されているマシンや、マシンの CPU リソースが一貫して RAID アクティビティー以外の操作でアレイ化されます。
レベル 1 アレイのストレージ容量は、ハードウェア RAID 内でミラーリングされている最小サイズのハードディスクの容量と同じか、ソフトウェア RAID 内でミラーリングされている最小のパーティションと同じ容量になります。レベル 1 の冗長性は、すべての RAID タイプの中で最も高いレベルであり、アレイは 1 つのディスクのみで動作できます。
- レベル 4
レベル 4 は、1 つのディスクドライブでパリティー連結を使用して、データを保護します。パリティー情報は、アレイ内の残りのメンバーディスクのコンテンツに基づいて計算されます。この情報は、アレイ内のいずれかのディスクに障害が発生した場合にデータの再構築に使用できます。その後、再構築されたデータを使用して、交換前に失敗したディスクに I/O 要求に対応でき、交換後に失敗したディスクを接続します。
パリティー専用ディスクは、RAID アレイへのすべての書き込みトランザクションにおいて固有のボトルネックとなるため、ライトバックキャッシングなどの付随する技術なしにレベル 4 が使用されることはほとんどありません。または、システム管理者が意図的にこのボトルネックを考慮してソフトウェア RAID デバイスを設計している特定の状況下で使用されます。たとえば、アレイにデータが格納されると書き込みトランザクションがほとんどないようなアレイです。RAID レベル 4 にはほとんど使用されないため、Anaconda ではこのオプションとしては使用できません。ただし、実際には必要な場合は、ユーザーが手動で作成できます。
ハードウェア RAID レベル 4 のストレージ容量は、最小メンバーパーティションの容量にパーティションの数を掛けて 1 を引いた値に等しくなります。RAID レベル 4 アレイのパフォーマンスは常に非対称です。つまり、読み込みは書き込みを上回ります。これは、パリティーを生成するときに書き込み操作が余分な CPU リソースとメインメモリー帯域幅を消費し、実際のデータをディスクに書き込むときに余分なバス帯域幅も消費するためです。これは、データだけでなくパリティーも書き込むためです。読み取り操作は、アレイが劣化状態にない限り、データを読み取るだけでパリティーを読み取る必要はありません。その結果、読み取り操作では、通常の操作条件下で同じ量のデータ転送を行う場合でも、ドライブおよびコンピューターのバス全体に生成されるトラフィックが少なくなります。
- レベル 5
これは RAID の最も一般的なタイプです。RAID レベル 5 は、アレイのすべてのメンバーディスクドライブにパリティーを分散することにより、レベル 4 に固有の書き込みボトルネックを排除します。パリティー計算プロセス自体のみがパフォーマンスのボトルネックです。最近の CPU はパリティーを非常に高速に計算できます。しかし、RAID 5 アレイに多数のディスクを使用していて、すべてのデバイスの合計データ転送速度が十分に高い場合、パリティー計算がボトルネックになる可能性があります。
レベル 5 のパフォーマンスは非対称であり、読み取りは書き込みよりも大幅に優れています。RAID レベル 5 のストレージ容量は、レベル 4 と同じです。
- レベル 6
パフォーマンスではなくデータの冗長性と保存が最重要事項であるが、レベル 1 の領域の非効率性が許容できない場合は、これが RAID の一般的なレベルです。レベル 6 では、複雑なパリティースキームを使用して、アレイ内の 2 つのドライブから失われたドライブから復旧できます。複雑なパリティースキームにより、ソフトウェア RAID デバイスで CPU 幅が大幅に高くなり、書き込みトランザクションの際に増大度が高まります。したがって、レベル 6 はレベル 4 や 5 よりもパフォーマンスにおいて、非常に非対称です。
RAID レベル 6 アレイの合計容量は、RAID レベル 5 および 4 と同様に計算されますが、デバイス数から追加パリティーストレージ領域用に 2 つのデバイス (1 ではなく) を引きます。
- レベル 10
この RAID レベルでは、レベル 0 のパフォーマンスとレベル 1 の冗長性を組み合わせます。また、2 台以上のデバイスを使用するレベル 1 アレイの無駄なスペースをある程度削減することができます。レベル 10 では、たとえば、データごとに 2 つのコピーのみを格納するように設定された 3 ドライブアレイを作成することができます。これにより、全体用のアレイサイズを最小デバイスのみと同じサイズ (3 つのデバイス、レベル 1 アレイなど) ではなく、最小デバイスのサイズの 1.5 倍にすることができます。これにより、CPU プロセスの使用量が RAID レベル 6 のようにパリティーを計算するのを防ぎますが、これは領域効率が悪くなります。
RAID レベル 10 の作成は、インストール時には対応していません。インストール後に手動で作成できます。
- リニア RAID
リニア RAID は、より大きな仮想ドライブを作成するドライブのグループ化です。
リニア RAID では、あるメンバードライブからチャンクが順次割り当てられます。最初のドライブが完全に満杯になったときにのみ次のドライブに移動します。これにより、メンバードライブ間の I/O 操作が分割される可能性はないため、パフォーマンスの向上は見られません。リニア RAID は冗長性がなく、信頼性は低下します。メンバードライブが 1 台でも故障すると、アレイ全体が使用できなくなり、データが失われる可能性があります。容量はすべてのメンバーディスクの合計になります。
67.7.2. LVM RAID のセグメントタイプ
RAID 論理ボリュームを作成するには、RAID タイプを lvcreate コマンドの --type 引数として指定します。ほとんどのユーザーの場合、raid1、raid4、raid5、raid6、raid10 の 5 つの使用可能なプライマリータイプのいずれかを指定するだけで十分です。
以下の表は、考えられる RAID セグメントタイプを示しています。
| セグメントタイプ | 説明 |
|---|---|
|
|
RAID1 ミラーリング。 |
|
| RAID4 専用パリティーディスク |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| ストライピング。RAID0 では、ストライプサイズの単位で、複数のデータサブボリュームに論理ボリュームデータが分散されます。これは、パフォーマンスを向上させるために使用します。論理ボリュームのデータは、いずれかのデータサブボリュームで障害が発生すると失われます。 |
67.7.3. RAID0 を作成するためのパラメーター
RAID0 ストライピング論理ボリュームは、lvcreate --type raid0[meta] --stripes _Stripes --stripesize StripeSize VolumeGroup [PhysicalVolumePath] コマンドを使用して作成することができます。
次の表は、RAID0 ストライピング論理ボリュームを作成するときに使用できるさまざまなパラメーターを説明しています。
| パラメーター | 説明 |
|---|---|
|
|
|
|
| 論理ボリュームを分散するデバイスの数を指定します。 |
|
| 各ストライプのサイズをキロバイト単位で指定します。これは、次のデバイスに移動する前にデバイスに書き込まれるデータの量です。 |
|
| 使用するボリュームグループを指定します。 |
|
| 使用するデバイスを指定します。指定しない場合は、LVM によって、Stripes オプションに指定されているデバイスの数が、各ストライプに 1 つずつ選択されます。 |
67.7.4. RAID 論理ボリュームの作成
-m 引数に指定する値に応じて、複数のコピーを持つ RAID1 アレイを作成できます。同様に、-i 引数を使用して、RAID 0、4、5、6、10 論理ボリュームのストライピング数を指定できます。-I 引数で、ストライプのサイズを指定することもできます。以下の手順では、異なるタイプの RAID 論理ボリュームを作成するさまざまな方法を説明します。
手順
2 方向 RAID を作成します。以下のコマンドは、ボリュームグループ my_vg 内にサイズが 1G の 2 方向 RAID1 アレイ my_lv を作成します。
# lvcreate --type raid1 -m 1 -L 1G -n my_lv my_vg Logical volume "my_lv" created.ストライピングで RAID5 アレイを作成します。次のコマンドは、ボリュームグループ my_vg に、3 つのストライプと 1 つの暗黙のパリティードライブ (my_lv) を持つ、サイズが 1G の RAID5 アレイを作成します。LVM ストライピングボリュームと同様にストライピングの数を指定できることに注意してください。正しい数のパリティードライブが自動的に追加されます。
# lvcreate --type raid5 -i 3 -L 1G -n my_lv my_vgストライピングで RAID6 アレイを作成します。次のコマンドは、ボリュームグループ my_vg に 3 つの 3 ストライプと 2 つの暗黙的なパリティードライブ (my_lv という名前) を持つ RAID6 アレイを作成します。これは、1G 1 ギガバイトのサイズです。
# lvcreate --type raid6 -i 3 -L 1G -n my_lv my_vg
検証
2 ウェイ RAID1 アレイである LVM デバイス my_vg/my_lv を表示します。
# lvs -a -o name,copy_percent,devices my_vg LV Copy% Devices my_lv 6.25 my_lv_rimage_0(0),my_lv_rimage_1(0) [my_lv_rimage_0] /dev/sde1(0) [my_lv_rimage_1] /dev/sdf1(1) [my_lv_rmeta_0] /dev/sde1(256) [my_lv_rmeta_1] /dev/sdf1(0)
67.7.5. storage RHEL システムロールを使用して RAID を備えた LVM プールを設定する
storage システムロールを使用すると、Red Hat Ansible Automation Platform を使用して、RAID を備えた LVM プールを RHEL に設定できます。利用可能なパラメーターを使用して Ansible Playbook を設定し、RAID を備えた LVM プールを設定できます。
前提条件
- コントロールノードと管理対象ノードの準備が完了している。
- 管理対象ノードで Playbook を実行できるユーザーとしてコントロールノードにログインしている。
-
管理対象ノードへの接続に使用するアカウントに、そのノードに対する
sudo権限がある。
手順
次の内容を含む Playbook ファイル (例:
~/playbook.yml) を作成します。--- - name: Manage local storage hosts: managed-node-01.example.com tasks: - name: Configure LVM pool with RAID ansible.builtin.include_role: name: redhat.rhel_system_roles.storage vars: storage_safe_mode: false storage_pools: - name: my_pool type: lvm disks: [sdh, sdi] raid_level: raid1 volumes: - name: my_volume size: "1 GiB" mount_point: "/mnt/app/shared" fs_type: xfs state: presentPlaybook で使用されるすべての変数の詳細は、コントロールノードの
/usr/share/ansible/roles/rhel-system-roles.storage/README.mdファイルを参照してください。Playbook の構文を検証します。
$ ansible-playbook --syntax-check ~/playbook.ymlこのコマンドは構文を検証するだけであり、有効だが不適切な設定から保護するものではないことに注意してください。
Playbook を実行します。
$ ansible-playbook ~/playbook.yml
検証
プールが RAID 上にあることを確認します。
# ansible managed-node-01.example.com -m command -a 'lsblk'
67.7.6. RAID0 ストライプ化論理ボリュームの作成
RAID0 論理ボリュームは、論理ボリュームデータをストライプサイズ単位で複数のデータサブボリューム全体に分散します。以下の手順では、ディスク間でデータをストライピングする mylv という LVM RAID0 論理ボリュームを作成します。
前提条件
- 3 つ以上の物理ボリュームを作成している。物理ボリュームの作成方法は、LVM 物理ボリュームの作成 を参照してください。
- ボリュームグループを作成している。詳細は、LVM ボリュームグループの作成 を参照してください。
手順
既存のボリュームグループから RAID0 論理ボリュームを作成します。次のコマンドは、ボリュームグループ myvg から RAID0 ボリューム mylv を作成します。このボリュームは、サイズが 2G で、ストライプが 3 つあります。ストライプのサイズは 4kB です。
# lvcreate --type raid0 -L 2G --stripes 3 --stripesize 4 -n mylv my_vg Rounding size 2.00 GiB (512 extents) up to stripe boundary size 2.00 GiB(513 extents). Logical volume "mylv" created.RAID0 論理ボリュームにファイルシステムを作成します。以下のコマンドを使用すると、論理ボリュームに ext4 ファイルシステムが作成されます。
# mkfs.ext4 /dev/my_vg/mylv論理ボリュームをマウントして、ファイルシステムのディスクの領域使用率を報告します。
# mount /dev/my_vg/mylv /mnt # df Filesystem 1K-blocks Used Available Use% Mounted on /dev/mapper/my_vg-mylv 2002684 6168 1875072 1% /mnt
検証
作成された RAID0 ストライピング論理ボリュームを表示します。
# lvs -a -o +devices,segtype my_vg LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert Devices Type mylv my_vg rwi-a-r--- 2.00g mylv_rimage_0(0),mylv_rimage_1(0),mylv_rimage_2(0) raid0 [mylv_rimage_0] my_vg iwi-aor--- 684.00m /dev/sdf1(0) linear [mylv_rimage_1] my_vg iwi-aor--- 684.00m /dev/sdg1(0) linear [mylv_rimage_2] my_vg iwi-aor--- 684.00m /dev/sdh1(0) linear
67.7.7. storage RHEL システムロールを使用して RAID LVM ボリュームのストライプサイズを設定する
storage システムロールを使用すると、Red Hat Ansible Automation Platform を使用して、RHEL の RAID LVM ボリュームのストライプサイズを設定できます。利用可能なパラメーターを使用して Ansible Playbook を設定し、RAID を備えた LVM プールを設定できます。
前提条件
- コントロールノードと管理対象ノードの準備が完了している。
- 管理対象ノードで Playbook を実行できるユーザーとしてコントロールノードにログインしている。
-
管理対象ノードへの接続に使用するアカウントに、そのノードに対する
sudo権限がある。
手順
次の内容を含む Playbook ファイル (例:
~/playbook.yml) を作成します。--- - name: Manage local storage hosts: managed-node-01.example.com tasks: - name: Configure stripe size for RAID LVM volumes ansible.builtin.include_role: name: redhat.rhel_system_roles.storage vars: storage_safe_mode: false storage_pools: - name: my_pool type: lvm disks: [sdh, sdi] volumes: - name: my_volume size: "1 GiB" mount_point: "/mnt/app/shared" fs_type: xfs raid_level: raid0 raid_stripe_size: "256 KiB" state: presentPlaybook で使用されるすべての変数の詳細は、コントロールノードの
/usr/share/ansible/roles/rhel-system-roles.storage/README.mdファイルを参照してください。Playbook の構文を検証します。
$ ansible-playbook --syntax-check ~/playbook.ymlこのコマンドは構文を検証するだけであり、有効だが不適切な設定から保護するものではないことに注意してください。
Playbook を実行します。
$ ansible-playbook ~/playbook.yml
検証
ストライプサイズが必要なサイズに設定されていることを確認します。
# ansible managed-node-01.example.com -m command -a 'lvs -o+stripesize /dev/my_pool/my_volume'
67.7.8. ソフトデータの破損
データストレージにおけるソフト破損は、ストレージデバイスから取得したデータが、そのデバイスに書き込まれるデータとは異なることを意味します。破損したデータは、ストレージデバイスで無期限に存在する可能性があります。破損したデータは、このデータを取得および使用するまで、検出されない可能性があります。
設定のタイプに応じて、Redundant Array of Independent Disks (RAID) 論理ボリューム (LV) は、デバイスに障害が発生した場合のデータ損失を防ぎます。RAID アレイで構成されているデバイスに障害が発生した場合、その RAID LV の一部である他のデバイスからデータを回復できます。ただし、RAID 設定により、データの一貫性は確保されません。ソフト破損、無兆候破損、ソフトエラー、およびサイレントエラーでは、システム設計やソフトウェアが想定どおりに機能し続けている場合でも、破損するデータを示す用語です。
DM 整合性で新しい RAID LV を作成したり、既存の RAID LV に整合性を追加する場合は、以下の点を考慮してください。
- 整合性メタデータには、追加のストレージ領域が必要です。各 RAID イメージには、データに追加されるチェックサムがあるため、500MB の全データに 4 MB のストレージ領域が必要になります。
- 一部の RAID 設定には、より多くの影響がありますが、データにアクセスする際のレイテンシーにより、DM 整合性を追加するとパフォーマンスに影響が及びます。RAID1 設定は通常、RAID5 またはそのバリアントよりも優れたパフォーマンスを提供します。
- RAID 整合性ブロックサイズは、パフォーマンスにも影響を及ぼします。RAID 整合性ブロックサイズが大きいと、パフォーマンスが向上します。ただし、RAID 整合性ブロックのサイズが小さくなると、後方互換性がより高くなります。
-
利用可能な整合性モードには、
bitmapまたはjournalの 2 つがあります。通常、bitmap整合性モードは、journalモードよりも優れたパフォーマンスを提供します。
パフォーマンスの問題が発生した場合は、整合性で RAID1 を使用するか、特定の RAID 設定のパフォーマンスをテストして、要件を満たすことを確認してください。
67.7.9. DM 整合性を備えた RAID 論理ボリュームの作成
デバイスマッパー (DM) 整合性を備えた RAID LV を作成するか、既存の RAID 論理ボリューム (LV) に整合性を追加すると、ソフト破損によるデータ損失のリスクが軽減されます。LV を使用する前に、整合性の同期と RAID メタデータが完了するのを待ちます。そうしないと、バックグラウンドの初期化が LV のパフォーマンスに影響する可能性があります。
デバイスマッパー (DM) 整合性は、RAID レベル 1、4、5、6、10 で使用され、ソフト破損によるデータ損失を軽減または防止します。RAID レイヤーでは、データの結合のないコピーが、ソフト破損エラーを修正できるようになります。
手順
DM 整合性のある RAID LV を作成します。次の例では、my_vg ボリュームグループに test-lv という名前の整合性を持つ新しい RAID LV を作成します。使用可能なサイズは 256M で、RAID レベルは 1 です。
# lvcreate --type raid1 --raidintegrity y -L 256M -n test-lv my_vg Creating integrity metadata LV test-lv_rimage_0_imeta with size 8.00 MiB. Logical volume "test-lv_rimage_0_imeta" created. Creating integrity metadata LV test-lv_rimage_1_imeta with size 8.00 MiB. Logical volume "test-lv_rimage_1_imeta" created. Logical volume "test-lv" created.注記既存の RAID LV に DM 整合性を追加するには、次のコマンドを実行します。
# lvconvert --raidintegrity y my_vg/test-lvRAID LV に整合性を追加すると、その RAID LV で実行可能な操作の数が制限されます。
オプション: 特定の操作を実行する前に整合性を削除します。
# lvconvert --raidintegrity n my_vg/test-lv Logical volume my_vg/test-lv has removed integrity.
検証
追加された DM 整合性に関する情報を表示します。
my_vg ボリュームグループ内に作成された test-lv RAID LV の情報を表示します。
# lvs -a my_vg LV VG Attr LSize Origin Cpy%Sync test-lv my_vg rwi-a-r--- 256.00m 2.10 [test-lv_rimage_0] my_vg gwi-aor--- 256.00m [test-lv_rimage_0_iorig] 93.75 [test-lv_rimage_0_imeta] my_vg ewi-ao---- 8.00m [test-lv_rimage_0_iorig] my_vg -wi-ao---- 256.00m [test-lv_rimage_1] my_vg gwi-aor--- 256.00m [test-lv_rimage_1_iorig] 85.94 [...]以下は、この出力から得られるさまざまなオプションを説明したものです。
g属性-
これは、Attr 列の下にある属性のリストで、RAID イメージが整合性を使用していることを示します。整合性は、チェックサムを
_imetaRAID LV に保存します。 Cpy%Sync列- 最上位の RAID LV と各 RAID イメージの両方の同期の進行状況を示します。
- RAID イメージ
-
LV 列に
raid_image_Nで表示されます。 LV列- これにより、最上位の RAID LV と各 RAID イメージの同期の進行状況が 100% と表示されるようになります。
各 RAID LV のタイプを表示します。
# lvs -a my-vg -o+segtype LV VG Attr LSize Origin Cpy%Sync Type test-lv my_vg rwi-a-r--- 256.00m 87.96 raid1 [test-lv_rimage_0] my_vg gwi-aor--- 256.00m [test-lv_rimage_0_iorig] 100.00 integrity [test-lv_rimage_0_imeta] my_vg ewi-ao---- 8.00m linear [test-lv_rimage_0_iorig] my_vg -wi-ao---- 256.00m linear [test-lv_rimage_1] my_vg gwi-aor--- 256.00m [test-lv_rimage_1_iorig] 100.00 integrity [...]各 RAID イメージで検出された不一致の数をカウントする増分カウンターがあります。my_vg/test-lv の下の
rimage_0から整合性で検出されたデータの不一致を表示します。# lvs -o+integritymismatches my_vg/test-lv_rimage_0 LV VG Attr LSize Origin Cpy%Sync IntegMismatches [test-lv_rimage_0] my_vg gwi-aor--- 256.00m [test-lv_rimage_0_iorig] 100.00 0この例では、整合性はデータの不一致を検出していないため、
IntegMismatchesカウンターはゼロ (0) を示しています。以下の例に示すように、
/var/log/messagesログファイル内のデータ整合性情報を表示します。例67.1 カーネルメッセージログから dm-integrity の不一致の例
device-mapper: integrity: dm-12:セクター 0x24e7 でチェックサムが失敗しました。
例67.2 カーネルメッセージログからの dm-integrity データ修正の例
md/raid1:mdX: 読み込みエラーが修正されました (dm-16 の 9448 の 8 セクター)
67.7.10. RAID 論理ボリュームの別の RAID レベルへの変換
LVM は RAID テイクオーバーをサポートしています。これは、RAID 論理ボリュームの RAID レベルを別の RAID レベルに変換 (たとえば RAID 5 から RAID 6) することを意味します。RAID レベルを変更して、デバイスの障害に対する耐障害性を増減できます。
手順
RAID 論理ボリュームを作成します。
# lvcreate --type raid5 -i 3 -L 500M -n my_lv my_vg Using default stripesize 64.00 KiB. Rounding size 500.00 MiB (125 extents) up to stripe boundary size 504.00 MiB (126 extents). Logical volume "my_lv" created.RAID 論理ボリュームを表示します。
# lvs -a -o +devices,segtype LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert Devices Type my_lv my_vg rwi-a-r--- 504.00m 100.00 my_lv_rimage_0(0),my_lv_rimage_1(0),my_lv_rimage_2(0),my_lv_rimage_3(0) raid5 [my_lv_rimage_0] my_vg iwi-aor--- 168.00m /dev/sda(1) linearRAID 論理ボリュームを別の RAID レベルに変換します。
# lvconvert --type raid6 my_vg/my_lv Using default stripesize 64.00 KiB. Replaced LV type raid6 (same as raid6_zr) with possible type raid6_ls_6. Repeat this command to convert to raid6 after an interim conversion has finished. Are you sure you want to convert raid5 LV my_vg/my_lv to raid6_ls_6 type? [y/n]: y Logical volume my_vg/my_lv successfully converted.オプション: このコマンドで変換を繰り返すように求められた場合は、次のコマンドを実行します。
# lvconvert --type raid6 my_vg/my_lv
検証
RAID レベルを変換した RAID 論理ボリュームを表示します。
# lvs -a -o +devices,segtype LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert Devices Type my_lv my_vg rwi-a-r--- 504.00m 100.00 my_lv_rimage_0(0),my_lv_rimage_1(0),my_lv_rimage_2(0),my_lv_rimage_3(0),my_lv_rimage_4(0) raid6 [my_lv_rimage_0] my_vg iwi-aor--- 172.00m /dev/sda(1) linear
67.7.11. リニアデバイスの RAID 論理ボリュームへの変換
既存のリニア論理ボリュームを RAID 論理ボリュームに変換することができます。この操作を行うには、lvconvert コマンドの --type 引数を使用します。
RAID 論理ボリュームは、メタデータとデータのサブボリュームのペアで構成されています。リニアデバイスを RAID1 アレイに変換すると、新しいメタデータサブボリュームが作成され、リニアボリュームと同じ物理ボリューム上の元の論理ボリュームと関連付けられます。追加のイメージは、メタデータ/データサブボリュームのペアに追加されます。複製元の論理ボリュームとペアのメタデータイメージを同じ物理ボリュームに配置できないと、lvconvert は失敗します。
手順
変換が必要な論理ボリュームデバイスを表示します。
# lvs -a -o name,copy_percent,devices my_vg LV Copy% Devices my_lv /dev/sde1(0)リニア論理ボリュームを RAID デバイスに変換します。以下のコマンドは、ボリュームグループ __my_vg のリニア論理ボリューム my_lv を、2 方向の RAID1 アレイに変換します。
# lvconvert --type raid1 -m 1 my_vg/my_lv Are you sure you want to convert linear LV my_vg/my_lv to raid1 with 2 images enhancing resilience? [y/n]: y Logical volume my_vg/my_lv successfully converted.
検証
論理ボリュームが RAID デバイスに変換されているかどうかを確認します。
# lvs -a -o name,copy_percent,devices my_vg LV Copy% Devices my_lv 6.25 my_lv_rimage_0(0),my_lv_rimage_1(0) [my_lv_rimage_0] /dev/sde1(0) [my_lv_rimage_1] /dev/sdf1(1) [my_lv_rmeta_0] /dev/sde1(256) [my_lv_rmeta_1] /dev/sdf1(0)
67.7.12. LVM RAID1 論理ボリュームを LVM リニア論理ボリュームに変換
既存の RAID1 LVM 論理ボリュームを LVM リニア論理ボリュームに変換することができます。この操作を行うには、lvconvert コマンドを使用し、-m0 引数を指定します。これにより、RAID アレイを構成する全 RAID データサブボリュームおよび全 RAID メタデータサブボリュームが削除され、最高レベルの RAID1 イメージがリニア論理ボリュームとして残されます。
手順
既存の LVM RAID1 論理ボリュームを表示します。
# lvs -a -o name,copy_percent,devices my_vg LV Copy% Devices my_lv 100.00 my_lv_rimage_0(0),my_lv_rimage_1(0) [my_lv_rimage_0] /dev/sde1(1) [my_lv_rimage_1] /dev/sdf1(1) [my_lv_rmeta_0] /dev/sde1(0) [my_lv_rmeta_1] /dev/sdf1(0)既存の RAID1 LVM 論理ボリュームを LVM リニア論理ボリュームに変換します。以下のコマンドは、LVM RAID1 論理ボリューム my_vg/my_lv を、LVM リニアデバイスに変換します。
# lvconvert -m0 my_vg/my_lv Are you sure you want to convert raid1 LV my_vg/my_lv to type linear losing all resilience? [y/n]: y Logical volume my_vg/my_lv successfully converted.LVM RAID1 論理ボリュームを LVM リニアボリュームに変換する場合は、削除する物理ボリュームを指定することもできます。以下の例では、
lvconvertコマンドは /dev/sde1 を削除して、/dev/sdf1 をリニアデバイスを構成する物理ボリュームとして残すように指定します。# lvconvert -m0 my_vg/my_lv /dev/sde1
検証
RAID1 論理ボリュームが LVM リニアデバイスに変換されたかどうかを確認します。
# lvs -a -o name,copy_percent,devices my_vg LV Copy% Devices my_lv /dev/sdf1(1)
67.7.13. ミラーリングされた LVM デバイスの RAID1 論理ボリュームへの変換
セグメントタイプのミラーを持つ既存のミラーリングされた LVM デバイスを RAID1 LVM デバイスに変換できます。この操作を行うには、--type raid1 引数を指定して、lvconvert コマンドを使用します。これにより、mimage という名前のミラーサブボリュームの名前が、rimage という名前の RAID サブボリュームに変更されます。
さらに、ミラーログも削除し、対応するデータサブボリュームと同じ物理ボリューム上に、データサブボリューム用の rmeta という名前のメタデータサブボリュームを作成します。
手順
ミラーリングされた論理ボリューム my_vg/my_lv のレイアウトを表示します。
# lvs -a -o name,copy_percent,devices my_vg LV Copy% Devices my_lv 15.20 my_lv_mimage_0(0),my_lv_mimage_1(0) [my_lv_mimage_0] /dev/sde1(0) [my_lv_mimage_1] /dev/sdf1(0) [my_lv_mlog] /dev/sdd1(0)ミラーリングされた論理ボリューム my_vg/my_lv を RAID1 論理ボリュームに変換します。
# lvconvert --type raid1 my_vg/my_lv Are you sure you want to convert mirror LV my_vg/my_lv to raid1 type? [y/n]: y Logical volume my_vg/my_lv successfully converted.
検証
ミラーリングされた論理ボリュームが RAID1 論理ボリュームに変換されているかどうかを確認します。
# lvs -a -o name,copy_percent,devices my_vg LV Copy% Devices my_lv 100.00 my_lv_rimage_0(0),my_lv_rimage_1(0) [my_lv_rimage_0] /dev/sde1(0) [my_lv_rimage_1] /dev/sdf1(0) [my_lv_rmeta_0] /dev/sde1(125) [my_lv_rmeta_1] /dev/sdf1(125)
67.7.14. 既存の RAID1 デバイスのイメージ数を変更
LVM ミラーリングの実装でイメージの数を変更できる方法と同様に、既存の RAID1 アレイのイメージの数を変更できます。
lvconvert コマンドを使用して RAID1 論理ボリュームにイメージを追加すると、次の操作を実行できます。
- 結果として作成されるデバイス用イメージの総数を指定する
- デバイスに追加するイメージの数
- オプションで、新しいメタデータ/データイメージのペアが存在する物理ボリュームを指定する
手順
2 ウェイ RAID1 アレイである LVM デバイス my_vg/my_lv を表示します。
# lvs -a -o name,copy_percent,devices my_vg LV Copy% Devices my_lv 6.25 my_lv_rimage_0(0),my_lv_rimage_1(0) [my_lv_rimage_0] /dev/sde1(0) [my_lv_rimage_1] /dev/sdf1(1) [my_lv_rmeta_0] /dev/sde1(256) [my_lv_rmeta_1] /dev/sdf1(0)メタデータサブボリューム (
rmetaと呼ばれる) は、対応するデータサブボリューム (rimage) と同じ物理デバイスに常に存在します。メタデータ/データのサブボリュームのペアは、--allocをどこかに指定しない限り、RAID アレイにある別のメタデータ/データサブボリュームのペアと同じ物理ボリュームには作成されません。2 ウェイ RAID1 論理ボリューム my_vg/my_lv を 3 ウェイ RAID1 論理ボリュームに変換します。
# lvconvert -m 2 my_vg/my_lv Are you sure you want to convert raid1 LV my_vg/my_lv to 3 images enhancing resilience? [y/n]: y Logical volume my_vg/my_lv successfully converted.既存の RAID1 デバイスのイメージ数を変更する場合の例を以下に示します。
また、RAID にイメージを追加する際に、使用する物理ボリュームを指定することもできます。次のコマンドは、アレイに使用する物理ボリューム /dev/sdd1 を指定することにより、2 方向 RAID1 論理ボリューム my_vg/my_lv を 3 方向 RAID1 論理ボリュームに変換します。
# lvconvert -m 2 my_vg/my_lv /dev/sdd13 方向 RAID1 論理ボリュームを 2 方向 RAID1 論理ボリュームに変換します。
# lvconvert -m1 my_vg/my_lv Are you sure you want to convert raid1 LV my_vg/my_lv to 2 images reducing resilience? [y/n]: y Logical volume my_vg/my_lv successfully converted.削除するイメージを含む物理ボリューム /dev/sde1 を指定して、3 方向 RAID1 論理ボリュームを 2 方向 RAID1 論理ボリュームに変換します。
# lvconvert -m1 my_vg/my_lv /dev/sde1また、イメージとその関連付けられたメタデータのサブボリュームを削除すると、それよりも大きな番号のイメージが下に移動してそのスロットを引き継ぎます。
lv_rimage_0、lv_rimage_1、およびlv_rimage_2で構成される 3 方向 RAID1 アレイからlv_rimage_1を削除すると、lv_rimage_0とlv_rimage_1で構成される RAID1 アレイになります。サブボリュームlv_rimage_2の名前が、空のスロットを引き継いでlv_rimage_1になります。
検証
既存の RAID1 デバイスのイメージ数を変更した後に、RAID1 デバイスを表示します。
# lvs -a -o name,copy_percent,devices my_vg LV Cpy%Sync Devices my_lv 100.00 my_lv_rimage_0(0),my_lv_rimage_1(0),my_lv_rimage_2(0) [my_lv_rimage_0] /dev/sdd1(1) [my_lv_rimage_1] /dev/sde1(1) [my_lv_rimage_2] /dev/sdf1(1) [my_lv_rmeta_0] /dev/sdd1(0) [my_lv_rmeta_1] /dev/sde1(0) [my_lv_rmeta_2] /dev/sdf1(0)
67.7.15. RAID イメージを複数の論理ボリュームに分割
RAID 論理ボリュームのイメージを分割して新しい論理ボリュームを形成できます。既存の RAID1 論理ボリュームから RAID イメージを削除する場合と同様に、RAID データのサブボリューム (およびその関連付けられたメタデータのサブボリューム) をデバイスから削除する場合、それより大きい番号のイメージは、そのスロットを埋めるために番号が変更になります。そのため、RAID アレイを構成する論理ボリューム上のインデックス番号は連続する整数となります。
RAID1 アレイがまだ同期していない場合は、RAID イメージを分割できません。
手順
2 ウェイ RAID1 アレイである LVM デバイス my_vg/my_lv を表示します。
# lvs -a -o name,copy_percent,devices my_vg LV Copy% Devices my_lv 12.00 my_lv_rimage_0(0),my_lv_rimage_1(0) [my_lv_rimage_0] /dev/sde1(1) [my_lv_rimage_1] /dev/sdf1(1) [my_lv_rmeta_0] /dev/sde1(0) [my_lv_rmeta_1] /dev/sdf1(0)RAID イメージを別の論理ボリュームに分割します。
以下の例は、2 方向の RAID1 論理ボリューム my_lv を、my_lv と new の 2 つのリニア論理ボリュームに分割します。
# lvconvert --splitmirror 1 -n new my_vg/my_lv Are you sure you want to split raid1 LV my_vg/my_lv losing all resilience? [y/n]: y以下の例は、3 方向の RAID1 論理ボリューム my_lv を、2 方向の RAID1 論理ボリューム my_lv と、リニア論理ボリューム new に分割します。
# lvconvert --splitmirror 1 -n new my_vg/my_lv
検証
RAID 論理ボリュームのイメージを分割した後に、論理ボリュームを表示します。
# lvs -a -o name,copy_percent,devices my_vg LV Copy% Devices my_lv /dev/sde1(1) new /dev/sdf1(1)
67.7.16. RAID イメージの分割とマージ
lvconvert コマンドで、--splitmirrors 引数とともに --trackchanges 引数を使用すると、すべての変更を追跡しながら、RAID1 アレイのイメージを一時的に読み取り専用に分割できます。この機能を使えば、イメージを分割した後に変更した部分のみを再同期しながら、後でイメージをアレイに統合することができます。
--trackchanges 引数を使用して RAID イメージを分割する場合、分割するイメージを指定することはできますが、分割されるボリューム名を変更することはできません。また、作成されたボリュームには以下の制約があります。
- 作成された新規ボリュームは読み取り専用です。
- 新規ボリュームのサイズは変更できません。
- 残りのアレイの名前は変更できません。
- 残りのアレイのサイズは変更できません。
- 新規のボリュームと、残りのアレイを個別にアクティブにすることはできません。
分割されたイメージを結合することができます。イメージをマージすると、イメージが分割されてから変更したアレイの部分のみが再同期されます。
手順
RAID 論理ボリュームを作成します。
# lvcreate --type raid1 -m 2 -L 1G -n my_lv my_vg Logical volume "my_lv" createdオプション: 作成した RAID 論理ボリュームを表示します。
# lvs -a -o name,copy_percent,devices my_vg LV Copy% Devices my_lv 100.00 my_lv_rimage_0(0),my_lv_rimage_1(0),my_lv_rimage_2(0) [my_lv_rimage_0] /dev/sdb1(1) [my_lv_rimage_1] /dev/sdc1(1) [my_lv_rimage_2] /dev/sdd1(1) [my_lv_rmeta_0] /dev/sdb1(0) [my_lv_rmeta_1] /dev/sdc1(0) [my_lv_rmeta_2] /dev/sdd1(0)作成した RAID 論理ボリュームからイメージを分割し、残りのアレイへの変更を追跡します。
# lvconvert --splitmirrors 1 --trackchanges my_vg/my_lv my_lv_rimage_2 split from my_lv for read-only purposes. Use 'lvconvert --merge my_vg/my_lv_rimage_2' to merge back into my_lvオプション: イメージを分割した後の論理ボリュームを表示します。
# lvs -a -o name,copy_percent,devices my_vg LV Copy% Devices my_lv 100.00 my_lv_rimage_0(0),my_lv_rimage_1(0) [my_lv_rimage_0] /dev/sdc1(1) [my_lv_rimage_1] /dev/sdd1(1) [my_lv_rmeta_0] /dev/sdc1(0) [my_lv_rmeta_1] /dev/sdd1(0)ボリュームをアレイにマージして戻します。
# lvconvert --merge my_vg/my_lv_rimage_1 my_vg/my_lv_rimage_1 successfully merged back into my_vg/my_lv
検証
マージされた論理ボリュームを表示します。
# lvs -a -o name,copy_percent,devices my_vg LV Copy% Devices my_lv 100.00 my_lv_rimage_0(0),my_lv_rimage_1(0) [my_lv_rimage_0] /dev/sdc1(1) [my_lv_rimage_1] /dev/sdd1(1) [my_lv_rmeta_0] /dev/sdc1(0) [my_lv_rmeta_1] /dev/sdd1(0)
67.7.17. RAID 障害ポリシーを allocate に設定する
/etc/lvm/lvm.conf ファイルで、raid_fault_policy フィールドを allocate パラメーターに設定できます。この設定を使用すると、システムは障害が発生したデバイスをボリュームグループのスペアデバイスと交換しようとします。スペアデバイスがない場合は、システムログにこの情報が追加されます。
手順
RAID 論理ボリュームを表示します。
# lvs -a -o name,copy_percent,devices my_vg LV Copy% Devices my_lv 100.00 my_lv_rimage_0(0),my_lv_rimage_1(0),my_lv_rimage_2(0) [my_lv_rimage_0] /dev/sdb1(1) [my_lv_rimage_1] /dev/sdc1(1) [my_lv_rimage_2] /dev/sdd1(1) [my_lv_rmeta_0] /dev/sdb1(0) [my_lv_rmeta_1] /dev/sdc1(0) [my_lv_rmeta_2] /dev/sdd1(0)/dev/sdb デバイスに障害が発生したら、RAID 論理ボリュームを表示します。
# lvs --all --options name,copy_percent,devices my_vg /dev/sdb: open failed: No such device or address Couldn't find device with uuid A4kRl2-vIzA-uyCb-cci7-bOod-H5tX-IzH4Ee. WARNING: Couldn't find all devices for LV my_vg/my_lv_rimage_1 while checking used and assumed devices. WARNING: Couldn't find all devices for LV my_vg/my_lv_rmeta_1 while checking used and assumed devices. LV Copy% Devices my_lv 100.00 my_lv_rimage_0(0),my_lv_rimage_1(0),my_lv_rimage_2(0) [my_lv_rimage_0] [unknown](1) [my_lv_rimage_1] /dev/sdc1(1) [...]/dev/sdb デバイスに障害が発生した場合は、システムログを表示してエラーメッセージを確認することもできます。
lvm.confファイルで、raid_fault_policyフィールドをallocateに設定します。# vi /etc/lvm/lvm.conf raid_fault_policy = "allocate"注記raid_fault_policyをallocateに設定しても、スペアデバイスがない場合、割り当ては失敗し、論理ボリュームがそのままの状態になります。割り当てが失敗した場合は、lvconvert --repairコマンドを使用して、失敗したデバイスを修復および交換できます。詳細は、論理ボリュームに障害が発生した RAID デバイスの交換 を参照してください。
検証
障害が発生したデバイスがボリュームグループの新しいデバイスに置き換えられたかどうかを確認します。
# lvs -a -o name,copy_percent,devices my_vg Couldn't find device with uuid 3lugiV-3eSP-AFAR-sdrP-H20O-wM2M-qdMANy. LV Copy% Devices lv 100.00 lv_rimage_0(0),lv_rimage_1(0),lv_rimage_2(0) [lv_rimage_0] /dev/sdh1(1) [lv_rimage_1] /dev/sdc1(1) [lv_rimage_2] /dev/sdd1(1) [lv_rmeta_0] /dev/sdh1(0) [lv_rmeta_1] /dev/sdc1(0) [lv_rmeta_2] /dev/sdd1(0)注記障害が発生したデバイスは交換されたが、デバイスがまだボリュームグループから削除されていないため、LVM によって障害が発生したデバイスが検出されなかったことが表示されます。
vgreduce --removemissing my_vgコマンドを実行すると、障害が発生したデバイスをボリュームグループから削除できます。
67.7.18. RAID 障害ポリシーを warn に設定する
lvm.conf ファイルで、raid_fault_policy フィールドを warn パラメーターに設定できます。この設定を使用すると、システムは、障害が発生したデバイスを示す警告をシステムログに追加します。警告に基づいて、その後の手順を決定できます。
デフォルトでは、lvm.conf の raid_fault_policy フィールドの値は warn です。
手順
RAID 論理ボリュームを表示します。
# lvs -a -o name,copy_percent,devices my_vg LV Copy% Devices my_lv 100.00 my_lv_rimage_0(0),my_lv_rimage_1(0),my_lv_rimage_2(0) [my_lv_rimage_0] /dev/sdb1(1) [my_lv_rimage_1] /dev/sdc1(1) [my_lv_rimage_2] /dev/sdd1(1) [my_lv_rmeta_0] /dev/sdb1(0) [my_lv_rmeta_1] /dev/sdc1(0) [my_lv_rmeta_2] /dev/sdd1(0)lvm.conf ファイルで、raid_fault_policy フィールドを warn に設定します。
# vi /etc/lvm/lvm.conf # This configuration option has an automatic default value. raid_fault_policy = "warn"/dev/sdb デバイスに障害が発生したら、システムログを表示してエラーメッセージを表示します。
# grep lvm /var/log/messages Apr 14 18:48:59 virt-506 kernel: sd 25:0:0:0: rejecting I/O to offline device Apr 14 18:48:59 virt-506 kernel: I/O error, dev sdb, sector 8200 op 0x1:(WRITE) flags 0x20800 phys_seg 0 prio class 2 [...] Apr 14 18:48:59 virt-506 dmeventd[91060]: WARNING: VG my_vg is missing PV 9R2TVV-bwfn-Bdyj-Gucu-1p4F-qJ2Q-82kCAF (last written to /dev/sdb). Apr 14 18:48:59 virt-506 dmeventd[91060]: WARNING: Couldn't find device with uuid 9R2TVV-bwfn-Bdyj-Gucu-1p4F-qJ2Q-82kCAF. Apr 14 18:48:59 virt-506 dmeventd[91060]: Use 'lvconvert --repair my_vg/ly_lv' to replace failed device./dev/sdb デバイスに障害が発生すると、システムログにエラーメッセージが表示されます。ただし、この場合、LVM はイメージの 1 つを置き換えて、RAID デバイスを自動的に修復しようとはしません。したがって、デバイスに障害が発生したら、
lvconvertコマンドの--repair引数を使用してデバイスを置き換えることができます。詳細は、論理ボリュームに障害が発生した RAID デバイスの交換 を参照してください。
67.7.19. 動作中の RAID デバイスの交換
lvconvert コマンドの --replace 引数を使用して、論理ボリューム内の動作中の RAID デバイスを交換できます。
RAID デバイスに障害が発生した場合、次のコマンドは機能しません。
前提条件
- RAID デバイスに障害が発生していません。
手順
RAID1 アレイを作成します。
# lvcreate --type raid1 -m 2 -L 1G -n my_lv my_vg Logical volume "my_lv" created作成した RAID1 アレイを調べます。
# lvs -a -o name,copy_percent,devices my_vg LV Copy% Devices my_lv 100.00 my_lv_rimage_0(0),my_lv_rimage_1(0),my_lv_rimage_2(0) [my_lv_rimage_0] /dev/sdb1(1) [my_lv_rimage_1] /dev/sdb2(1) [my_lv_rimage_2] /dev/sdc1(1) [my_lv_rmeta_0] /dev/sdb1(0) [my_lv_rmeta_1] /dev/sdb2(0) [my_lv_rmeta_2] /dev/sdc1(0)要件に応じて、次のいずれかの方法で RAID デバイスを交換します。
交換する物理ボリュームを指定して、RAID1 デバイスを交換します。
# lvconvert --replace /dev/sdb2 my_vg/my_lv交換に使用する物理ボリュームを指定して、RAID1 デバイスを交換します。
# lvconvert --replace /dev/sdb1 my_vg/my_lv /dev/sdd1複数の replace 引数を指定して、一度に複数の RAID デバイスを交換します。
# lvconvert --replace /dev/sdb1 --replace /dev/sdc1 my_vg/my_lv
検証
交換する物理ボリュームを指定した後、RAID1 アレイを調べます。
# lvs -a -o name,copy_percent,devices my_vg LV Copy% Devices my_lv 37.50 my_lv_rimage_0(0),my_lv_rimage_1(0),my_lv_rimage_2(0) [my_lv_rimage_0] /dev/sdb1(1) [my_lv_rimage_1] /dev/sdc2(1) [my_lv_rimage_2] /dev/sdc1(1) [my_lv_rmeta_0] /dev/sdb1(0) [my_lv_rmeta_1] /dev/sdc2(0) [my_lv_rmeta_2] /dev/sdc1(0)交換に使用する物理ボリュームを指定した後、RAID1 アレイを調べます。
# lvs -a -o name,copy_percent,devices my_vg LV Copy% Devices my_lv 28.00 my_lv_rimage_0(0),my_lv_rimage_1(0) [my_lv_rimage_0] /dev/sda1(1) [my_lv_rimage_1] /dev/sdd1(1) [my_lv_rmeta_0] /dev/sda1(0) [my_lv_rmeta_1] /dev/sdd1(0)一度に複数の RAID デバイスを交換した後、RAID1 アレイを調べます。
# lvs -a -o name,copy_percent,devices my_vg LV Copy% Devices my_lv 60.00 my_lv_rimage_0(0),my_lv_rimage_1(0),my_lv_rimage_2(0) [my_lv_rimage_0] /dev/sda1(1) [my_lv_rimage_1] /dev/sdd1(1) [my_lv_rimage_2] /dev/sde1(1) [my_lv_rmeta_0] /dev/sda1(0) [my_lv_rmeta_1] /dev/sdd1(0) [my_lv_rmeta_2] /dev/sde1(0)
67.7.20. 論理ボリュームに障害が発生した RAID デバイスの交換
RAID は従来の LVM ミラーリングとは異なります。LVM ミラーリングの場合は、障害が発生したデバイスを削除します。そうしないと、障害が発生したデバイスで RAID アレイが動作し続ける間、ミラーリングされた論理ボリュームがハングします。RAID1 以外の RAID レベルの場合、デバイスを削除すると、デバイスはより低いレベルの RAID に変換されます (たとえば、RAID6 から RAID5 へ、または RAID4 または RAID5 から RAID0 への変換)。
LVM では、障害が発生したデバイスを取り外して代替デバイスを割り当てる代わりに、lvconvert コマンドの --repair 引数を使用して、RAID 論理ボリューム内で物理ボリュームとして機能する障害が発生したデバイスを交換できます。
前提条件
ボリュームグループには、障害が発生したデバイスを置き換えるのに十分な空き容量を提供する物理ボリュームが含まれています。
ボリュームグループに十分な空きエクステントがある物理ボリュームがない場合は、
vgextendユーティリティーを使用して、十分なサイズの物理ボリュームを新たに追加します。
手順
RAID 論理ボリュームを表示します。
# lvs --all --options name,copy_percent,devices my_vg LV Cpy%Sync Devices my_lv 100.00 my_lv_rimage_0(0),my_lv_rimage_1(0),my_lv_rimage_2(0) [my_lv_rimage_0] /dev/sde1(1) [my_lv_rimage_1] /dev/sdc1(1) [my_lv_rimage_2] /dev/sdd1(1) [my_lv_rmeta_0] /dev/sde1(0) [my_lv_rmeta_1] /dev/sdc1(0) [my_lv_rmeta_2] /dev/sdd1(0)/dev/sdc デバイスに障害が発生したら、RAID 論理ボリュームを表示します。
# lvs --all --options name,copy_percent,devices my_vg /dev/sdc: open failed: No such device or address Couldn't find device with uuid A4kRl2-vIzA-uyCb-cci7-bOod-H5tX-IzH4Ee. WARNING: Couldn't find all devices for LV my_vg/my_lv_rimage_1 while checking used and assumed devices. WARNING: Couldn't find all devices for LV my_vg/my_lv_rmeta_1 while checking used and assumed devices. LV Cpy%Sync Devices my_lv 100.00 my_lv_rimage_0(0),my_lv_rimage_1(0),my_lv_rimage_2(0) [my_lv_rimage_0] /dev/sde1(1) [my_lv_rimage_1] [unknown](1) [my_lv_rimage_2] /dev/sdd1(1) [my_lv_rmeta_0] /dev/sde1(0) [my_lv_rmeta_1] [unknown](0) [my_lv_rmeta_2] /dev/sdd1(0)障害が発生したデバイスを交換します。
# lvconvert --repair my_vg/my_lv /dev/sdc: open failed: No such device or address Couldn't find device with uuid A4kRl2-vIzA-uyCb-cci7-bOod-H5tX-IzH4Ee. WARNING: Couldn't find all devices for LV my_vg/my_lv_rimage_1 while checking used and assumed devices. WARNING: Couldn't find all devices for LV my_vg/my_lv_rmeta_1 while checking used and assumed devices. Attempt to replace failed RAID images (requires full device resync)? [y/n]: y Faulty devices in my_vg/my_lv successfully replaced.オプション: 障害が発生したデバイスを置き換える物理ボリュームを手動で指定します。
# lvconvert --repair my_vg/my_lv replacement_pv代替の論理ボリュームを調べます。
# lvs --all --options name,copy_percent,devices my_vg /dev/sdc: open failed: No such device or address /dev/sdc1: open failed: No such device or address Couldn't find device with uuid A4kRl2-vIzA-uyCb-cci7-bOod-H5tX-IzH4Ee. LV Cpy%Sync Devices my_lv 43.79 my_lv_rimage_0(0),my_lv_rimage_1(0),my_lv_rimage_2(0) [my_lv_rimage_0] /dev/sde1(1) [my_lv_rimage_1] /dev/sdb1(1) [my_lv_rimage_2] /dev/sdd1(1) [my_lv_rmeta_0] /dev/sde1(0) [my_lv_rmeta_1] /dev/sdb1(0) [my_lv_rmeta_2] /dev/sdd1(0)障害が発生したデバイスをボリュームグループから削除するまで、LVM ユーティリティーは、障害が発生したデバイスが見つけられないことを示しています。
障害が発生したデバイスをボリュームグループから削除します。
# vgreduce --removemissing my_vg
検証
障害が発生したデバイスを取り外した後、利用可能な物理ボリュームを表示します。
# pvscan PV /dev/sde1 VG rhel_virt-506 lvm2 [<7.00 GiB / 0 free] PV /dev/sdb1 VG my_vg lvm2 [<60.00 GiB / 59.50 GiB free] PV /dev/sdd1 VG my_vg lvm2 [<60.00 GiB / 59.50 GiB free] PV /dev/sdd1 VG my_vg lvm2 [<60.00 GiB / 59.50 GiB free]障害が発生したデバイスを交換した後、論理ボリュームを調べます。
# lvs --all --options name,copy_percent,devices my_vg my_lv_rimage_0(0),my_lv_rimage_1(0),my_lv_rimage_2(0) [my_lv_rimage_0] /dev/sde1(1) [my_lv_rimage_1] /dev/sdb1(1) [my_lv_rimage_2] /dev/sdd1(1) [my_lv_rmeta_0] /dev/sde1(0) [my_lv_rmeta_1] /dev/sdb1(0) [my_lv_rmeta_2] /dev/sdd1(0)
67.7.21. RAID 論理ボリュームでのデータ整合性の確認
LVM は、RAID 論理ボリュームのスクラビングに対応します。RAID スクラビングは、アレイ内のデータおよびパリティーブロックをすべて読み込み、それが一貫しているかどうかを確認するプロセスです。lvchange --syncaction repair コマンドは、アレイでバックグラウンドの同期アクションを開始します。
手順
オプション:次のいずれかのオプションを設定して、RAID 論理ボリュームが初期化される速度を制御します。
-
--maxrecoveryrate Rate[bBsSkKmMgG]は、RAID 論理ボリュームの最大復旧速度を設定し、通常の I/O 操作が排除されないようにします。 --minrecoveryrate Rate[bBsSkKmMgG]は、RAID 論理ボリュームの最小復旧速度を設定し、負荷の高い通常の I/O がある場合でも、同期操作の I/O が最小スループットを達成できるようにします。# lvchange --maxrecoveryrate 4K my_vg/my_lv Logical volume _my_vg/my_lv_changed.4K は、アレイに含まれる各デバイスの 1 秒あたりの値である復旧速度の値に置き換えます。接尾辞を指定しないと、デバイスごとの 1 秒あたりの kiB が想定されます。
# lvchange --syncaction repair my_vg/my_lvRAID スクラビング操作を実行すると、
syncアクションに必要なバックグラウンド I/O が、LVM デバイスへの他の I/O (ボリュームグループメタデータの更新など) よりも優先される可能性があります。これにより、他の LVM 操作が遅くなる可能性があります。注記これらの最大および最小 I/O 速度は、RAID デバイスを作成するときに使用することもできます。たとえば、
lvcreate --type raid10 -i 2 -m 1 -L 10G --maxrecoveryrate 128 -n my_lv my_vgを使用すると、ボリュームグループ my_vg 内に、3 ストライプでサイズが 10 G、最大復旧速度が 128 kiB/秒/デバイスの 2 方向の RAID10 アレイ my_lv が作成されます。
-
アレイ内の不一致数を修復せずに、アレイ内の不一致の数を表示します。
# lvchange --syncaction check my_vg/my_lvこのコマンドは、アレイでバックグラウンドの同期アクションを開始します。
-
オプション:
var/log/syslogファイルでカーネルメッセージを確認します。 アレイ内の不一致を修正します。
# lvchange --syncaction repair my_vg/my_lvこのコマンドは、RAID 論理ボリューム内の障害が発生したデバイスを修復または交換します。このコマンドを実行したら、
var/log/syslogファイルでカーネルメッセージを確認できます。
検証
スクラビング操作に関する情報を表示します。
# lvs -o +raid_sync_action,raid_mismatch_count my_vg/my_lv LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert SyncAction Mismatches my_lv my_vg rwi-a-r--- 500.00m 100.00 idle 0
67.7.22. RAID1 論理ボリュームでの I/O 操作
lvchange コマンドの --writemostly パラメーターおよび --writebehind パラメーターを使用して、RAID1 論理ボリュームのデバイスに対する I/O 操作を制御できます。これらのパラメーターを使用する形式は次のとおりです。
--[raid]writemostly PhysicalVolume[:{t|y|n}]RAID1 論理ボリューム内のデバイスは、
write-mostlyとしてマークして、必要な場合を除き、これらのドライブに対するすべての読み取りアクションを回避します。このパラメーターを設定することにより、ドライブに対する I/O 操作の回数を最小限に抑えることができます。このパラメーターを設定するには、
lvchange --writemostly /dev/sdb my_vg/my_lvコマンドを使用します。次の方法で
writemostly属性を設定できます。:y-
デフォルトでは、論理ボリューム内の指定された物理ボリュームの
writemostly属性の値は yes です。 :n-
writemostlyフラグを削除するには、物理ボリュームに:nを追加します。 :twritemostly属性の値を切り替えるには、--writemostly引数を指定します。この引数は、1 つのコマンドで複数回使用できます (例:
lvchange --writemostly /dev/sdd1:n --writemostly /dev/sdb1:t --writemostly /dev/sdc1:y my_vg/my_lv)。これにより、論理ボリュームに含まれるすべての物理ボリュームのwritemostly属性を一度に切り替えることができます。
--[raid]writebehind IOCountwritemostlyとしてマークされた保留中の書き込みの最大数を指定します。これらは、RAID1 論理ボリューム内のデバイスに適用される書き込み操作の数です。このパラメーターの値を超えると、RAID アレイがすべての書き込みアクションの完了を通知する前に、構成デバイスへのすべての書き込みアクションが同期的に完了します。このパラメーターは、
lvchange --writebehind 100 my_vg/my_lvコマンドを使用して設定できます。writemostly属性の値をゼロに設定すると、設定がクリアされます。この設定では、システムが値を任意に選択します。
67.7.23. RAID ボリュームの再形成
RAID の再形成とは、RAID レベルを変更せずに、RAID 論理ボリュームの属性を変更することを意味します。変更できる属性には、RAID レイアウト、ストライプのサイズ、ストライプの数などがあります。
手順
RAID 論理ボリュームを作成します。
# lvcreate --type raid5 -i 2 -L 500M -n my_lv my_vg Using default stripesize 64.00 KiB. Rounding size 500.00 MiB (125 extents) up to stripe boundary size 504.00 MiB (126 extents). Logical volume "my_lv" created.RAID 論理ボリュームを表示します。
# lvs -a -o +devices LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert Devices my_lv my_vg rwi-a-r--- 504.00m 100.00 my_lv_rimage_0(0),my_lv_rimage_1(0),my_lv_rimage_2(0) [my_lv_rimage_0] my_vg iwi-aor--- 252.00m /dev/sda(1) [my_lv_rimage_1] my_vg iwi-aor--- 252.00m /dev/sdb(1) [my_lv_rimage_2] my_vg iwi-aor--- 252.00m /dev/sdc(1) [my_lv_rmeta_0] my_vg ewi-aor--- 4.00m /dev/sda(0) [my_lv_rmeta_1] my_vg ewi-aor--- 4.00m /dev/sdb(0) [my_lv_rmeta_2] my_vg ewi-aor--- 4.00m /dev/sdc(0)オプション: RAID 論理ボリュームの
stripesイメージとstripesizeを表示します。# lvs -o stripes my_vg/my_lv #Str 3# lvs -o stripesize my_vg/my_lv Stripe 64.00k要件に応じて次の方法を使用して、RAID 論理ボリュームの属性を変更します。
RAID 論理ボリュームの
stripesイメージを変更します。# lvconvert --stripes 3 my_vg/my_lv Using default stripesize 64.00 KiB. WARNING: Adding stripes to active logical volume my_vg/my_lv will grow it from 126 to 189 extents! Run "lvresize -l126 my_vg/my_lv" to shrink it or use the additional capacity. Are you sure you want to add 1 images to raid5 LV my_vg/my_lv? [y/n]: y Logical volume my_vg/my_lv successfully converted.RAID 論理ボリュームの
stripesizeを変更します。# lvconvert --stripesize 128k my_vg/my_lv Converting stripesize 64.00 KiB of raid5 LV my_vg/my_lv to 128.00 KiB. Are you sure you want to convert raid5 LV my_vg/my_lv? [y/n]: y Logical volume my_vg/my_lv successfully converted.maxrecoveryrate属性とminrecoveryrate属性を変更します。# lvchange --maxrecoveryrate 4M my_vg/my_lv Logical volume my_vg/my_lv changed.# lvchange --minrecoveryrate 1M my_vg/my_lv Logical volume my_vg/my_lv changed.syncaction属性を変更します。# lvchange --syncaction check my_vg/my_lvwritemostly属性とwritebehind属性を変更します。# lvchange --writemostly /dev/sdb my_vg/my_lv Logical volume my_vg/my_lv changed.# lvchange --writebehind 100 my_vg/my_lv Logical volume my_vg/my_lv changed.
検証
RAID 論理ボリュームの
stripesイメージとstripesizeを表示します。# lvs -o stripes my_vg/my_lv #Str 4# lvs -o stripesize my_vg/my_lv Stripe 128.00kmaxrecoveryrate属性を変更した後、RAID 論理ボリュームを表示します。# lvs -a -o +raid_max_recovery_rate LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert MaxSync my_lv my_vg rwi-a-r--- 10.00g 100.00 4096 [my_lv_rimage_0] my_vg iwi-aor--- 10.00g [...]minrecoveryrate属性を変更した後、RAID 論理ボリュームを表示します。# lvs -a -o +raid_min_recovery_rate LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert MinSync my_lv my_vg rwi-a-r--- 10.00g 100.00 1024 [my_lv_rimage_0] my_vg iwi-aor--- 10.00g [...]syncaction属性を変更した後、RAID 論理ボリュームを表示します。# lvs -a LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert my_lv my_vg rwi-a-r--- 10.00g 2.66 [my_lv_rimage_0] my_vg iwi-aor--- 10.00g [...]
67.7.24. RAID 論理ボリュームのリージョンサイズの変更
RAID 論理ボリュームを作成する場合、/etc/lvm/lvm.conf ファイルの raid_region_size パラメーターは、RAID 論理ボリュームのリージョンサイズを表します。RAID 論理ボリュームを作成した後、ボリュームのリージョンサイズを変更できます。このパラメーターは、ダーティーまたはクリーンな状態を追跡する粒度を定義します。ビットマップ内のダーティービットは、システム障害などの RAID ボリュームのダーティーシャットダウン後に同期するワークセットを定義します。
raid_region_size をより高い値に設定すると、ビットマップのサイズと輻輳が軽減されます。ただし、リージョンの同期が完了するまで RAID への書き込みが延期されるため、リージョンの再同期中の write 操作に影響が生じます。
手順
RAID 論理ボリュームを作成します。
# lvcreate --type raid1 -m 1 -L 10G test Logical volume "lvol0" created.RAID 論理ボリュームを表示します。
# lvs -a -o +devices,region_size LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert Devices Region lvol0 test rwi-a-r--- 10.00g 100.00 lvol0_rimage_0(0),lvol0_rimage_1(0) 2.00m [lvol0_rimage_0] test iwi-aor--- 10.00g /dev/sde1(1) 0 [lvol0_rimage_1] test iwi-aor--- 10.00g /dev/sdf1(1) 0 [lvol0_rmeta_0] test ewi-aor--- 4.00m /dev/sde1(0) 0 [lvol0_rmeta_1] test ewi-aor--- 4.00mRegion 列は、raid_region_size パラメーターの値を示します。
オプション:
raid_region_sizeパラメーターの値を表示します。# cat /etc/lvm/lvm.conf | grep raid_region_size # Configuration option activation/raid_region_size. # raid_region_size = 2048RAID 論理ボリュームのリージョンサイズを変更します。
# lvconvert -R 4096K my_vg/my_lv Do you really want to change the region_size 512.00 KiB of LV my_vg/my_lv to 4.00 MiB? [y/n]: y Changed region size on RAID LV my_vg/my_lv to 4.00 MiB.RAID 論理ボリュームを再同期します。
# lvchange --resync my_vg/my_lv Do you really want to deactivate logical volume my_vg/my_lv to resync it? [y/n]: y
検証
RAID 論理ボリュームを表示します。
# lvs -a -o +devices,region_size LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert Devices Region lvol0 test rwi-a-r--- 10.00g 6.25 lvol0_rimage_0(0),lvol0_rimage_1(0) 4.00m [lvol0_rimage_0] test iwi-aor--- 10.00g /dev/sde1(1) 0 [lvol0_rimage_1] test iwi-aor--- 10.00g /dev/sdf1(1) 0 [lvol0_rmeta_0] test ewi-aor--- 4.00m /dev/sde1(0) 0Region 列には、
raid_region_sizeパラメーターの変更後の値が表示されます。lvm.confファイル内のraid_region_sizeパラメーターの値を確認します。# cat /etc/lvm/lvm.conf | grep raid_region_size # Configuration option activation/raid_region_size. # raid_region_size = 4096
67.8. 論理ボリュームのスナップショット
LVM スナップショット機能を使用すると、サービスを中断することなく、ある時点でのボリュームの仮想イメージ (/dev/sda など) を作成できます。
67.8.1. スナップショットボリュームの概要
スナップショットを作成した後で元のボリューム (スナップショットの元になるボリューム) を変更すると、スナップショット機能は、ボリュームの状態を再構築できるように、変更前の変更されたデータ領域のコピーを作成します。スナップショットを作成しても、作成元への完全な読み取り/書き込みのアクセスは引き続き可能です。
スナップショットは、スナップショットの作成後に変更したデータ部分のみをコピーするため、スナップショット機能に必要なストレージは最小限になります。たとえば、コピー元がほとんど更新されない場合は、作成元の 3 ~ 5 % の容量があれば十分にスナップショットを維持できます。バックアップ手順に代わるものではありません。スナップショットコピーは仮想コピーであり、実際のメディアバックアップではありません。
作成元のボリュームへの変更を保管するために確保する領域は、スナップショットのサイズによって異なります。たとえば、スナップショットを作成してから作成元を完全に上書きする場合に、その変更の保管に必要なスナップショットのサイズは、作成元のボリュームと同等か、それ以上になります。スナップショットのサイズは定期的に監視する必要があります。たとえば、/usr など、その大部分が読み取り用に使用されるボリュームの短期的なスナップショットに必要な領域は、/home のように大量の書き込みが行われるボリュームの長期的なスナップショットに必要な領域よりも小さくなります。
スナップショットが満杯になると、作成元のボリュームの変更を追跡できなくなるため、そのスナップショットは無効になります。ただし、スナップショットが無効になるのを防ぐために、使用量が snapshot_autoextend_threshold 値を超えるたびにスナップショットを自動的に拡張するように LVM を設定できます。スナップショットは完全にサイズ変更可能で、次の操作を実行できます。
- ストレージ容量に余裕がある場合は、スナップショットボリュームのサイズを大きくして、削除されないようにすることができます。
- スナップショットのボリュームサイズが必要以上に大きければ、そのボリュームのサイズを縮小して、他の論理ボリュームで必要となる領域を確保できます。
スナップショットボリュームには、次の利点があります。
- 最も一般的な用途は、継続的にデータを更新している稼動中のシステムを停止せずに、論理ボリューム上でバックアップを実行する必要がある場合にスナップショットを撮ることです。
-
スナップショットファイルシステムで
fsckコマンドを実行し、ファイルシステムの整合性をチェックすれば、複製元のファイルシステムを修復する必要があるかどうかを判断できます。 - スナップショットは読み取りおよび書き込み用であるため、スナップショットを撮ってそのスナップショットにテストを実行することにより、実際のデータに触れることなく、実稼働データにアプリケーションのテストを実行できます。
- LVM ボリュームを作成して、Red Hat の仮想化と併用することが可能です。LVM スナップショットを使用して、仮想ゲストイメージのスナップショットを作成できます。このスナップショットは、最小限のストレージを使用して、既存のゲストの変更や新規ゲストの作成を行う上で利便性の高い方法を提供します。
67.8.2. コピーオンライトスナップショットの作成
作成時には、Copy-on-Write (COW) スナップショットにはデータが含まれません。代わりに、スナップショットの作成時点の元のボリュームのデータブロックを参照します。元のボリューム上のデータが変更されると、COW システムは変更が行われる前に、元の変更されていないデータをスナップショットにコピーします。この方法では、変更が発生した場合にのみスナップショットのサイズが増加し、スナップショット作成時における元のボリュームの状態が保存されます。COW スナップショットは、短期的なバックアップやデータの変更が最小限である状況に効果的で、特定の時点をキャプチャーして復元するためのスペースを節約する方法を提供します。COW スナップショットを作成するときは、元のボリュームへの予想される変更に基づいて、十分なストレージを割り当てます。
スナップショットを作成する前に、ストレージ要件とスナップショットの想定される有効期間を考慮することが重要です。スナップショットのサイズは、意図された有効期間中の変更をキャプチャーするのに十分な大きさである必要がありますが、元の LV のサイズを超えることはできません。変更頻度が低いと予想される場合は、10% - 15% の小さいスナップショットサイズで十分な場合があります。変更頻度が高い LV の場合は、30% 以上を割り当てる必要がある場合があります。
スナップショットのストレージ使用率を定期的に監視することが重要です。スナップショットに割り当てられている領域の 100% に達すると、スナップショットが無効になります。lvs コマンドを使用してスナップショットに関する情報を表示できます。
スナップショットが完全にいっぱいになる前に拡張することが重要です。これは、lvextend コマンドを使用して手動で実行できます。または、/etc/ lvm/lvm.conf ファイルで snapshot_autoextend_threshold および snapshot_autoextend_percent パラメーターを設定して自動拡張を設定することもできます。この設定により、dmeventd は 使用量が定義されたしきい値に達したときにスナップショットを自動的に拡張できるようになります。
COW スナップショットを使用すると、スナップショットが作成された時点のファイルシステムの読み取り専用バージョンにアクセスできます。これにより、元のファイルシステムで進行中の操作を中断することなく、バックアップやデータ分析が可能になります。スナップショットがマウントされ使用されている間も、元の論理ボリュームとそのファイルシステムは引き続き更新され、正常に使用できます。
次の手順では、ボリュームグループ vg001 から origin という名前の論理ボリュームを作成し、その snap という名前のスナップショットを作成する方法を説明します。
前提条件
- 管理アクセスがある。
- ボリュームグループが作成されている。詳細は、LVM ボリュームグループの作成 を参照してください。
手順
ボリュームグループ vg001 から、論理ボリューム origin を作成します。
# lvcreate -L 1G -n origin vg001/dev/vg001/origin LV の snap という名前のサイズが 100 MB の スナップショットを作成します。
# lvcreate --size 100M --name snap --snapshot /dev/vg001/origin元のボリュームと、使用されているスナップショットボリュームの現在の割合を表示します。
# lvs -a -o +devices LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert Devices origin vg001 owi-a-s--- 1.00g /dev/sde1(0) snap vg001 swi-a-s--- 100.00m origin 0.00 /dev/sde1(256)
67.8.3. スナップショットと元のボリュームのマージ
--merge オプションを指定して lvconvert コマンドを使用し、スナップショットを元のボリューム (作成元) にマージします。データやファイルを失った場合や、システムを以前の状態に復元する必要がある場合に、システムのロールバックを実行できます。スナップショットボリュームをマージすると、作成された論理ボリュームには、元のボリュームの名前、マイナー番号、および UUID が含まれます。マージの進行中、作成元に対する読み取りまたは書き込みは、マージ中のスナップショットに対して実行されているかのように見えます。マージが完了すると、マージされたスナップショットは削除されます。
作成元のボリュームとスナップショットボリュームの両方が起動されておらず、アクティブでない場合、マージはすぐに開始されます。それ以外の場合は、作成元またはスナップショットのいずれかがアクティブ化され、両方が閉じられた後にマージが開始されます。スナップショットを閉じることができない作成元 (root ファイルシステムなど) にマージできるのは、作成元のボリュームがアクティブ化された後です。
手順
スナップショットボリュームをマージします。以下のコマンドは、スナップショットボリューム vg001/snap をその 作成元 にマージします。
# lvconvert --merge vg001/snap Merging of volume vg001/snap started. vg001/origin: Merged: 100.00%元のボリュームを表示します。
# lvs -a -o +devices LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert Devices origin vg001 owi-a-s--- 1.00g /dev/sde1(0)
67.8.4. snapshot RHEL システムロールを使用して LVM スナップショットを作成する
新しい snapshot RHEL システムロールを使用すると、LVM スナップショットを作成できます。また、snapshot_lvm_action パラメーターを check に設定すると、このシステムロールにより、作成したスナップショットに十分な領域があるかどうか、名前が競合していないかどうかがチェックされます。作成したスナップショットをマウントするには、snapshot_lvm_action を mount に設定します。
次の例では、nouuid オプションが設定されています。これは XFS ファイルシステムを扱う場合にのみ必要です。XFS では、同じ UUID を持つ複数のファイルシステムを同時にマウントすることはサポートされていません。
前提条件
- コントロールノードと管理対象ノードの準備が完了している。
- 管理対象ノードで Playbook を実行できるユーザーとしてコントロールノードにログインしている。
-
管理対象ノードへの接続に使用するアカウントに、そのノードに対する
sudo権限がある。
手順
次の内容を含む Playbook ファイル (例:
~/playbook.yml) を作成します。--- - name: Run the snapshot system role hosts: managed-node-01.example.com vars: snapshot_lvm_set: name: snapset1 volumes: - name: data1 snapshot vg: data_vg lv: data1 percent_space_required: 25 mountpoint: /data1_snapshot options: nouuid mountpoint_create: true - name: data2 snapshot vg: data_vg lv: data2 percent_space_required: 25 mountpoint: /data2_snapshot options: nouuid mountpoint_create: true tasks: - name: Create a snapshot set ansible.builtin.include_role: name: redhat.rhel_system_roles.snapshot vars: snapshot_lvm_action: snapshot - name: Verify the set of snapshots for the LVs ansible.builtin.include_role: name: redhat.rhel_system_roles.snapshot vars: snapshot_lvm_action: check snapshot_lvm_verify_only: true - name: Mount the snapshot set ansible.builtin.include_role: name: redhat.rhel_system_roles.snapshot vars: snapshot_lvm_action: mountこの場合、
snapshot_lvm_setパラメーターは、同じボリュームグループ (VG) からの特定の論理ボリューム (LV) を示しています。このパラメーターを設定する際に、異なる VG からの LV を指定することもできます。Playbook の構文を検証します。
$ ansible-playbook --syntax-check ~/playbook.ymlこのコマンドは構文を検証するだけであり、有効だが不適切な設定から保護するものではないことに注意してください。
Playbook を実行します。
$ ansible-playbook ~/playbook.yml
検証
管理対象ノードで、作成されたスナップショットを表示します。
# lvs LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert data1 data_vg owi-a-s--- 1.00g data1_snapset1 data_vg swi-a-s--- 208.00m data1 0.00 data2 data_vg owi-a-s--- 1.00g data2_snapset1 data_vg swi-a-s--- 208.00m data2 0.00管理対象ノードで、/data1_snapshot と /data2_snapshot の存在を確認して、マウント操作が成功したかどうかを確認します。
# ls -al /data1_snapshot # ls -al /data2_snapshot
67.8.5. snapshot RHEL システムロールを使用して LVM スナップショットをアンマウントする
snapshot_lvm_action パラメーターを umount に設定することで、特定のスナップショットまたはすべてのスナップショットをアンマウントできます。
前提条件
- コントロールノードと管理対象ノードの準備が完了している。
- 管理対象ノードで Playbook を実行できるユーザーとしてコントロールノードにログインしている。
-
管理対象ノードへの接続に使用するアカウントに、そのノードに対する
sudo権限がある。 - スナップショットセットに <_snapset1_> という名前を使用してスナップショットを作成した。
-
snapshot_lvm_actionをmountに設定してスナップショットをマウントしたか、手動でスナップショットをマウントした。
手順
次の内容を含む Playbook ファイル (例:
~/playbook.yml) を作成します。特定の LVM スナップショットをアンマウントします。
--- - name: Unmount the snapshot specified by the snapset hosts: managed-node-01.example.com vars: snapshot_lvm_snapset_name: snapset1 snapshot_lvm_action: umount snapshot_lvm_vg: data_vg snapshot_lvm_lv: data2 snapshot_lvm_mountpoint: /data2_snapshot roles: - rhel-system-roles.snapshotこの場合、
snapshot_lvm_lvパラメーターは特定の論理ボリューム (LV) を表し、snapshot_lvm_vgパラメーターは特定のボリュームグループ (VG) を示しています。LVM スナップショットのセットをアンマウントします。
--- - name: Unmount a set of snapshots hosts: managed-node-01.example.com vars: snapshot_lvm_action: umount snapshot_lvm_set: name: snapset1 volumes: - name: data1 snapshot vg: data_vg lv: data1 mountpoint: /data1_snapshot - name: data2 snapshot vg: data_vg lv: data2 mountpoint: /data2_snapshot roles: - rhel-system-roles.snapshotこの場合、
snapshot_lvm_setパラメーターは、同じ VG からの特定の LV を示しています。このパラメーターを設定する際に、異なる VG からの LV を指定することもできます。
Playbook の構文を検証します。
$ ansible-playbook --syntax-check ~/playbook.ymlこのコマンドは構文を検証するだけであり、有効だが不適切な設定から保護するものではないことに注意してください。
Playbook を実行します。
$ ansible-playbook ~/playbook.yml
67.8.6. snapshot RHEL システムロールを使用して LVM スナップショットを拡張する
新しい snapshot RHEL システムロールを使用して、snapshot_lvm_action パラメーターを extend に設定することで、LVM スナップショットを拡張できるようになりました。snapshot_lvm_percent_space_required パラメーターを、スナップショットを拡張した後に割り当てる必要な領域に設定できます。
前提条件
- コントロールノードと管理対象ノードの準備が完了している。
- 管理対象ノードで Playbook を実行できるユーザーとしてコントロールノードにログインしている。
-
管理対象ノードへの接続に使用するアカウントに、そのノードに対する
sudo権限がある。 - 特定のボリュームグループおよび論理ボリュームのスナップショットを作成した。
手順
次の内容を含む Playbook ファイル (例:
~/playbook.yml) を作成します。percent_space_requiredパラメーターの値を指定して、すべての LVM スナップショットを拡張します。--- - name: Extend all snapshots hosts: managed-node-01.example.com vars: snapshot_lvm_action: extend snapshot_lvm_set: name: snapset1 volumes: - name: data1 snapshot vg: data_vg lv: data1 percent_space_required: 40 - name: data2 snapshot vg: data_vg lv: data2 percent_space_required: 40 roles: - rhel-system-roles.snapshotこの場合、
snapshot_lvm_setパラメーターは、同じ VG からの特定の LV を示しています。このパラメーターを設定する際に、異なる VG からの LV を指定することもできます。セット内の VG と LV のペアごとに
percent_space_requiredを異なる値に設定して、LVM スナップショットセットを拡張します。--- - name: Extend the snapshot hosts: managed-node-01.example.com vars: snapshot_extend_set: name: snapset1 volumes: - name: data1 snapshot vg: data_vg lv: data1 percent_space_required: 30 - name: data2 snapshot vg: data_vg lv: data2 percent_space_required: 40 tasks: - name: Extend data1 to 30% and data2 to 40% vars: snapshot_lvm_set: "{{ snapshot_extend_set }}" snapshot_lvm_action: extend ansible.builtin.include_role: name: redhat.rhel_system_roles.snapshot
Playbook の構文を検証します。
$ ansible-playbook --syntax-check ~/playbook.ymlこのコマンドは構文を検証するだけであり、有効だが不適切な設定から保護するものではないことに注意してください。
Playbook を実行します。
$ ansible-playbook ~/playbook.yml
検証
管理対象ノードで、30% 拡張されたスナップショットを表示します。
# lvs LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert data1 data_vg owi-a-s--- 1.00g data1_snapset1 data_vg swi-a-s--- 308.00m data1 0.00 data2 data_vg owi-a-s--- 1.00g data2_snapset1 data_vg1 swi-a-s--- 408.00m data2 0.00
67.8.7. snapshot RHEL システムロールを使用して LVM スナップショットを元に戻す
新しい snapshot RHEL システムロールを使用して、snapshot_lvm_action パラメーターを revert に設定することで、LVM スナップショットを元のボリュームに戻すことができます。
論理ボリュームとスナップショットボリュームの両方が開いておらずアクティブでない場合は、元に戻す操作がすぐに開始されます。そうでない場合は、元のボリュームまたはスナップショットがアクティブ化され、両方が閉じられた後に元に戻す操作が開始されます。
前提条件
- コントロールノードと管理対象ノードの準備が完了している。
- 管理対象ノードで Playbook を実行できるユーザーとしてコントロールノードにログインしている。
-
管理対象ノードへの接続に使用するアカウントに、そのノードに対する
sudo権限がある。 - スナップセット名として <_snapset1_> を使用して、特定のボリュームグループおよび論理ボリュームのスナップショットを作成した。
手順
次の内容を含む Playbook ファイル (例:
~/playbook.yml) を作成します。特定の LVM スナップショットを元のボリュームに戻します。
--- - name: Revert a snapshot to its original volume hosts: managed-node-01.example.com vars: snapshot_lvm_snapset_name: snapset1 snapshot_lvm_action: revert snapshot_lvm_vg: data_vg snapshot_lvm_lv: data2 roles: - rhel-system-roles.snapshotこの場合、
snapshot_lvm_lvパラメーターは特定の論理ボリューム (LV) を表し、snapshot_lvm_vgパラメーターは特定のボリュームグループ (VG) を示しています。LVM スナップショットのセットを元のボリュームに戻します。
--- - name: Revert a set of snapshot hosts: managed-node-01.example.com vars: snapshot_lvm_action: revert snapshot_lvm_set: name: snapset1 volumes: - name: data1 snapshot vg: data_vg lv: data1 - name: data2 snapshot vg: data_vg lv: data2 roles: - rhel-system-roles.snapshotこの場合、
snapshot_lvm_setパラメーターは、同じ VG からの特定の LV を示しています。このパラメーターを設定する際に、異なる VG からの LV を指定することもできます。注記revert操作は、完了するまでに時間がかかる場合があります。
Playbook の構文を検証します。
$ ansible-playbook --syntax-check ~/playbook.ymlこのコマンドは構文を検証するだけであり、有効だが不適切な設定から保護するものではないことに注意してください。
Playbook を実行します。
$ ansible-playbook ~/playbook.ymlホストを再起動するか、次の手順に従って論理ボリュームを非アクティブ化してから再アクティブ化します。
$ umount /data1; umount /data2 $ lvchange -an data_vg/data1 data_vg/data2 $ lvchange -ay data_vg/data1 data_vg/data2 $ mount /data1; mount /data2
検証
管理対象ノードで、元に戻したスナップショットを表示します。
# lvs LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert data1 data_vg -wi-a----- 1.00g data2 data_vg -wi-a----- 1.00g
67.8.8. snapshot RHEL システムロールを使用して LVM スナップショットを削除する
新しい snapshot RHEL システムロールを使用して、スナップショットの接頭辞またはパターンを指定し、snapshot_lvm_action パラメーターを remove に設定することで、すべての LVM スナップショットを削除できます。
前提条件
- コントロールノードと管理対象ノードの準備が完了している。
- 管理対象ノードで Playbook を実行できるユーザーとしてコントロールノードにログインしている。
-
管理対象ノードへの接続に使用するアカウントに、そのノードに対する
sudo権限がある。 - スナップセット名として <_snapset1_> を使用して、特定のスナップショットを作成した。
手順
次の内容を含む Playbook ファイル (例:
~/playbook.yml) を作成します。特定の LVM スナップショットを削除します。
--- - name: Remove a snapshot hosts: managed-node-01.example.com vars: snapshot_lvm_snapset_name: snapset1 snapshot_lvm_action: remove snapshot_lvm_vg: data_vg roles: - rhel-system-roles.snapshotこの場合、
snapshot_lvm_vgパラメーターは、ボリュームグループ (VG) からの特定の論理ボリューム (LV) を示しています。LVM スナップショットのセットを削除します。
--- - name: Remove a set of snapshots hosts: managed-node-01.example.com vars: snapshot_lvm_action: remove snapshot_lvm_set: name: snapset1 volumes: - name: data1 snapshot vg: data_vg lv: data1 - name: data2 snapshot vg: data_vg lv: data2 roles: - rhel-system-roles.snapshotこの場合、
snapshot_lvm_setパラメーターは、同じ VG からの特定の LV を示しています。このパラメーターを設定する際に、異なる VG からの LV を指定することもできます。
Playbook の構文を検証します。
$ ansible-playbook --syntax-check ~/playbook.ymlこのコマンドは構文を検証するだけであり、有効だが不適切な設定から保護するものではないことに注意してください。
Playbook を実行します。
$ ansible-playbook ~/playbook.yml
67.9. シンプロビジョニングされたボリューム (シンボリューム) の作成および管理
Red Hat Enterprise Linux は、シンプロビジョニングされたスナップショットボリュームと論理ボリュームをサポートします。
- シンプロビジョニングされた論理ボリュームを使用すると、利用可能な物理ストレージよりも大きな論理ボリュームを作成できます。
- シンプロビジョニングされたスナップショットボリュームを使用すると、同じデータボリュームにより多くの仮想デバイスを格納できます。
67.9.1. シンプロビジョニングの概要
最新のストレージスタックの多くは、シックプロビジョニングとシンプロビジョニングのどちらかを選択できるようになりました。
- シックプロビジョニングは、ブロックストレージの従来の動作を実行でき、実際の使用状況に関係なくブロックが割り当てられます。
- シンプロビジョニングは、ブロックストレージのプールよりも大きいサイズ (データを保存する物理デバイスよりもサイズが大きくなる可能性のあるブロックストレージ) をプロビジョニングできるので、過剰にプロビジョニングされる可能性があります。個々のブロックは実際に使用されるまで割り当てられないため、オーバープロビジョニングが発生する可能性があります。同じプールを共有する複数のシンプロビジョニングされたデバイスがある場合に、これらのデバイスは過剰にプロビジョニングされる可能性があります。
シンプロビジョニングを使用すると、物理ストレージをオーバーコミットでき、代わりにシンプールと呼ばれる空き領域のプールを管理できます。アプリケーションで必要な場合は、このシンプールを任意の数のデバイスに割り当てることができます。シンプールは、ストレージ領域をコスト効率よく割り当てる必要がある場合に、動的に拡張できます。
たとえば、10 人のユーザーから、各自のアプリケーションに使用するファイルシステムをそれぞれ 100GB 要求された場合には、各ユーザーに 100GB のファイルシステムを作成します (ただし、実際には 100GB 未満のストレージが、必要に応じて使用されます)。
シンプロビジョニングを使用する場合は、ストレージプールを監視して、使用可能な物理スペースが不足したときに容量を追加することが重要です。
以下は、シンプロビジョニングされたデバイスを使用する利点です。
- 使用可能な物理ストレージよりも大きい論理ボリュームを作成できます。
- 同じデータボリュームに保存する仮想デバイスを増やすことができます。
- データ要件をサポートするために論理的かつ自動的に拡張できるファイルシステムを作成できます。未使用のブロックはプールに戻され、プール内の任意のファイルシステムで使用できます。
シンプロビジョニングされたデバイスを使用する場合に発生する可能性のある欠点は次のとおりです。
- シンプロビジョニングされたボリュームには、使用可能な物理ストレージが不足するという固有のリスクがあります。基盤となるストレージを過剰にプロビジョニングした場合に、使用可能な物理ストレージが不足しているために停止する可能性があります。たとえば、バッキング用に 1T の物理ストレージのみを使用して、10T のシンプロビジョニングストレージを作成する場合に、この 1T が使い果たされると、ボリュームは使用不可または書き込み不能になります。
-
ボリュームが、シンプロビジョニングデバイスの後の階層に破棄するように送信していない場合には、使用量の計算が正確でなくなります。たとえば、
-o discard mountオプションを指定せずにファイルシステムを配置し、シンプロビジョニングされたデバイス上でfstrimを定期的に実行しないと、以前に使用されたストレージの割り当てが解除されることはありません。このような場合に、実際に使用していなくても、時間の経過とともにプロビジョニングされた量をすべて使用することになります。 - 使用可能な物理スペースが不足しないように、論理的および物理的な使用状況を監視する必要があります。
- スナップショットのあるファイルシステムでは、コピーオンライト (CoW) 操作が遅くなる可能性があります。
- データブロックは複数のファイルシステム間で混在する可能性があり、エンドユーザーにそのように表示されない場合でも、基盤となるストレージのランダムアクセス制限につながります。
67.9.2. シンプロビジョニングされた論理ボリュームの作成
シンプロビジョニングされた論理ボリュームを使用すると、利用可能な物理ストレージよりも大きな論理ボリュームを作成できます。シンプロビジョニングされたボリュームセットを作成すると、システムは要求されるストレージの全量を割り当てる代わりに、実際に使用する容量を割り当てることができます。
lvcreate コマンドに -T (または --thin) オプションを付けて、シンプールまたはシンボリュームを作成できます。また、lvcreate の -T オプションを使用して、1 つのコマンドで同時にシンプールとシンプロビジョニングされたボリュームの両方を作成することもできます。この手順では、シンプロビジョニングされた論理ボリュームを作成および拡張する方法について説明します。
前提条件
- ボリュームグループを作成している。詳細は、LVM ボリュームグループの作成 を参照してください。
手順
シンプールを作成します。
# lvcreate -L 100M -T vg001/mythinpool Thin pool volume with chunk size 64.00 KiB can address at most 15.81 TiB of data. Logical volume "mythinpool" created.物理領域のプールを作成しているため、プールのサイズを指定する必要があります。
lvcreateコマンドの-Tオプションでは引数を使用できません。コマンドで指定する他のオプションをもとに、作成するデバイスのタイプを決定します。次の例に示すように、追加のパラメーターを使用してシンプールを作成することもできます。また、
lvcreateコマンドの ----thinpoolパラメーターを指定して、シンプールを作成することもできます。-Tオプションとは異なり、-thinpoolパラメーターでは、作成するシンプール論理ボリュームの名前を指定する必要があります。次の例では、-thinpoolパラメーターを使用して、サイズが 100M のボリュームグループ vg001 に mythinpool という名前のシンプールを作成します。# lvcreate -L 100M --thinpool mythinpool vg001 Thin pool volume with chunk size 64.00 KiB can address at most 15.81 TiB of data. Logical volume "mythinpool" created.プールの作成ではストライピングがサポートされているため、
-iおよび-Iオプションを使用してストライプを作成できます。次のコマンドは、ボリュームグループ vg001 に、thinpool という名前の 2 つの 64 KB ストライプと 256 KB のチャンクサイズを持つ 100 M シンプールを作成します。また、vg001/thinvolume という名前でサイズが 1T のシンボリュームを作成します。注記ボリュームグループに十分な空き領域がある 2 つの物理ボリュームがあることを確認してください。そうでない場合にはシンプールを作成できません。
# lvcreate -i 2 -I 64 -c 256 -L 100M -T vg001/thinpool -V 1T --name thinvolume
シンボリュームを作成します。
# lvcreate -V 1G -T vg001/mythinpool -n thinvolume WARNING: Sum of all thin volume sizes (1.00 GiB) exceeds the size of thin pool vg001/mythinpool (100.00 MiB). WARNING: You have not turned on protection against thin pools running out of space. WARNING: Set activation/thin_pool_autoextend_threshold below 100 to trigger automatic extension of thin pools before they get full. Logical volume "thinvolume" created.このような場合には、ボリュームを含むプールのサイズよりも大きい、ボリュームの仮想サイズを指定しています。次の例に示すように、追加のパラメーターを使用してシンボリュームを作成することもできます。
シンボリュームとシンプールの両方を作成するには、
lvcreateコマンドの-Tオプションを使用して、サイズと仮想サイズの両方の引数を指定します。# lvcreate -L 100M -T vg001/mythinpool -V 1G -n thinvolume Thin pool volume with chunk size 64.00 KiB can address at most 15.81 TiB of data. WARNING: Sum of all thin volume sizes (1.00 GiB) exceeds the size of thin pool vg001/mythinpool (100.00 MiB). WARNING: You have not turned on protection against thin pools running out of space. WARNING: Set activation/thin_pool_autoextend_threshold below 100 to trigger automatic extension of thin pools before they get full. Logical volume "thinvolume" created.残りの空き領域を使用してシンボリュームとシンプールを作成するには、
100%FREEオプションを使用します。# lvcreate -V 1G -l 100%FREE -T vg001/mythinpool -n thinvolume Thin pool volume with chunk size 64.00 KiB can address at most <15.88 TiB of data. Logical volume "thinvolume" created.既存の論理ボリュームをシンプールボリュームに変換するには、
lvconvertコマンドの--thinpoolパラメーターを使用します。また、-poolmetadataパラメーターを--thinpoolパラメーターと組み合わせて使用して、既存の論理ボリュームをシンプールボリュームのメタデータボリュームに変換する必要があります。以下の例は、ボリュームグループ vg001 の既存の論理ボリューム lv1 を、シンプールボリュームに変換します。また、ボリュームグループ vg001 の既存の論理ボリューム lv2 を、そのシンプールボリュームのメタデータボリュームに変換します。
# lvconvert --thinpool vg001/lv1 --poolmetadata vg001/lv2 Converted vg001/lv1 to thin pool.注記論理ボリュームをシンプールボリュームまたはシンプールメタデータボリュームに変換すると、論理ボリュームのコンテンツが破棄されます。
lvconvertはデバイスのコンテンツを保存するのではなく、コンテンツを上書きするためです。デフォルトでは、
lvcreateコマンドは、次の式を使用してシンプールメタデータ論理ボリュームのおおよそのサイズを設定します。Pool_LV_size / Pool_LV_chunk_size * 64スナップショットが大量にある場合や、シンプールのサイズが小さく、後で急激に大きくなることが予測される場合は、
lvcreateコマンドの--poolmetadatasizeパラメーターで、シンプールのメタデータボリュームのデフォルト値を大きくしないといけない場合があります。シンプールのメタデータ論理ボリュームで対応している値は 2 MiB - 16 GiB です。次の例は、シンプールのメタデータボリュームのデフォルト値を増やす方法を示しています。
# lvcreate -V 1G -l 100%FREE -T vg001/mythinpool --poolmetadatasize 16M -n thinvolume Thin pool volume with chunk size 64.00 KiB can address at most 15.81 TiB of data. Logical volume "thinvolume" created.
作成されたシンプールとシンボリュームを表示します。
# lvs -a -o +devices LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert Devices [lvol0_pmspare] vg001 ewi------- 4.00m /dev/sda(0) mythinpool vg001 twi-aotz-- 100.00m 0.00 10.94 mythinpool_tdata(0) [mythinpool_tdata] vg001 Twi-ao---- 100.00m /dev/sda(1) [mythinpool_tmeta] vg001 ewi-ao---- 4.00m /dev/sda(26) thinvolume vg001 Vwi-a-tz-- 1.00g mythinpool 0.00オプション:
lvextendコマンドを使用して、シンプールのサイズを拡張します。ただし、シンプールのサイズを縮小することはできません。注記シンプールとシンボリュームの作成中に
-l100%FREE引数を使用すると、このコマンドは失敗します。以下のコマンドは、既存のシンプールのサイズ (100M) を変更し、さらに 100M 分を拡張します。
# lvextend -L+100M vg001/mythinpool Size of logical volume vg001/mythinpool_tdata changed from 100.00 MiB (25 extents) to 200.00 MiB (50 extents). WARNING: Sum of all thin volume sizes (1.00 GiB) exceeds the size of thin pool vg001/mythinpool (200.00 MiB). WARNING: You have not turned on protection against thin pools running out of space. WARNING: Set activation/thin_pool_autoextend_threshold below 100 to trigger automatic extension of thin pools before they get full. Logical volume vg001/mythinpool successfully resized# lvs -a -o +devices LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert Devices [lvol0_pmspare] vg001 ewi------- 4.00m /dev/sda(0) mythinpool vg001 twi-aotz-- 200.00m 0.00 10.94 mythinpool_tdata(0) [mythinpool_tdata] vg001 Twi-ao---- 200.00m /dev/sda(1) [mythinpool_tdata] vg001 Twi-ao---- 200.00m /dev/sda(27) [mythinpool_tmeta] vg001 ewi-ao---- 4.00m /dev/sda(26) thinvolume vg001 Vwi-a-tz-- 1.00g mythinpool 0.00オプション: シンプールとシンボリュームの名前を変更するには、次のコマンドを使用します。
# lvrename vg001/mythinpool vg001/mythinpool1 Renamed "mythinpool" to "mythinpool1" in volume group "vg001" # lvrename vg001/thinvolume vg001/thinvolume1 Renamed "thinvolume" to "thinvolume1" in volume group "vg001"名前を変更した後に、シンプールとシンボリュームを表示します。
# lvs LV VG Attr LSize Pool Origin Data% Move Log Copy% Convert mythinpool1 vg001 twi-a-tz 100.00m 0.00 thinvolume1 vg001 Vwi-a-tz 1.00g mythinpool1 0.00オプション: シンプールを削除するには、次のコマンドを使用します。
# lvremove -f vg001/mythinpool1 Logical volume "thinvolume1" successfully removed. Logical volume "mythinpool1" successfully removed.
67.9.3. Web コンソールでシンプロビジョニングボリュームのプールの作成
シンプロビジョニングされたボリューム用のプールを作成します。
前提条件
- RHEL 8 Web コンソールがインストールされている。
- cockpit サービスが有効になっている。
ユーザーアカウントが Web コンソールにログインできる。
手順は、Web コンソールのインストールおよび有効化 を参照してください。
-
cockpit-storagedパッケージがシステムにインストールされている。 - ボリュームグループが作成されている。
手順
RHEL 8 Web コンソールにログインします。
詳細は、Web コンソールへのログイン を参照してください。
- Storage をクリックします。
- Storage テーブルで、シンボリュームを作成するボリュームグループをクリックします。
- Logical volume group ページで、LVM2 logical volumes セクションまでスクロールし、 をクリックします。
- Name フィールドに、新しい論理ボリュームの名前を入力します。名前にスペースを含めないでください。
ドロップダウンメニューで、Pool for thinly provisioned volumes を選択します。
この設定では、ボリュームグループに含まれるすべてのドライブの容量の合計に等しい最大ボリュームサイズを持つ論理ボリュームを作成できます。
論理ボリュームのサイズを定義します。以下を検討してください。
- この論理ボリュームを使用するシステムに必要なスペースの量。
- 作成する論理ボリュームの数
領域をすべて使用する必要はありません。必要な場合は、後で論理ボリュームを大きくすることができます。
をクリックします。
シンボリュームのプールが作成され、プールにシンボリュームを追加できるようになりました。
67.9.4. Web コンソールでシンプロビジョニングされた論理ボリュームの作成
Web コンソールを使用して、プール内にシンプロビジョニングされた論理ボリュームを作成できます。複数のシンボリュームを追加でき、各シンボリュームは、シンボリュームのプールと同じ大きさにできます。
シンボリュームを使用する場合は、論理ボリュームの物理的な空き容量を定期的に確認する必要があります。
前提条件
- RHEL 8 Web コンソールがインストールされている。
- cockpit サービスが有効になっている。
ユーザーアカウントが Web コンソールにログインできる。
手順は、Web コンソールのインストールおよび有効化 を参照してください。
-
cockpit-storagedパッケージがシステムにインストールされている。 - シンボリュームのプールを作成している。
手順
RHEL 8 Web コンソールにログインします。
詳細は、Web コンソールへのログイン を参照してください。
- Storage をクリックします。
- Storage テーブルで、シンボリュームを作成するボリュームグループのメニューボタンをクリックします。
- Logical volume group ページで、LVM2 logical volumes セクションまでスクロールし、シン論理ボリュームを作成するプールをクリックします。
- Pool for thinly provisioned LVM2 logical volumes ページで、Thinly provisioned LVM2 logical volumes セクションまでスクロールし、Create new thinly provisioned logical volume をクリックします。
- Create thin volume ダイアログボックスで、シンボリュームの名前を入力します。名前にスペースは使用しないでください。
- シンボリュームのサイズを定義します。
Create をクリックします。
シン論理ボリュームが作成されます。ボリュームを使用する前にフォーマットする必要があります。
67.9.5. チャンクサイズの概要
チャンクは、スナップショットストレージ専用の物理ディスクの最大単位です。
チャンクサイズを使用するには、以下の基準を使用します。
- チャンクサイズが小さいほどメタデータが増え、パフォーマンスも低下しますが、スナップショットで領域の使用率が向上します。
- チャンクサイズが大きいほどメタデータ操作は少なくなりますが、スナップショットの領域効率が低下します。
デフォルトでは、lvm2 は 64 KiB のチャンクサイズから開始し、そのチャンクサイズに対して適切なメタデータサイズを推定します。lvm2 が作成および使用できるメタデータの最小サイズは 2 MiB です。メタデータのサイズを 128 MiB より大きくする必要がある場合、lvm2 はチャンクサイズを増やすため、メタデータのサイズはコンパクトなまま保たれます。しかし、これによりチャンクサイズの値が大きくなり、スナップショットの使用におけるスペース効率が低下する可能性があります。このような場合、チャンクサイズを小さくし、メタデータサイズを大きくすることを推奨します。
要件に従ってチャンクサイズを指定するには、-c または --chunksize パラメーターを使用して、lvm2 の推定チャンクサイズを無効にします。シンプールの作成後はチャンクサイズを変更できないことに注意してください。
ボリュームデータサイズが TiB の範囲にある場合は、サポートされる最大サイズである約 15.8 GiB をメタデータサイズとして使用し、要件に従ってチャンクサイズを設定します。ただし、ボリュームのデータサイズを拡張し、チャンクサイズを小さくする必要がある場合には、メタデータサイズを拡大できないことに注意してください。
不適切なチャンクサイズとメタデータサイズの組み合わせを使用すると、ユーザーが metadata スペースを使い果たしたり、アドレス指定可能な最大シンプールデータサイズが制限されているためにシンプールサイズをそれ以上拡張できなくなったりして、問題が発生する可能性があります。
67.9.6. シンプロビジョニングのスナップショットボリューム
Red Hat Enterprise Linux は、シンプロビジョニングされたスナップショットボリュームをサポートします。シン論理ボリュームのスナップショットにより、シン論理ボリューム (LV) を作成することもできます。シンプロビジョニングのスナップショットボリュームには、他のシンボリュームと同じ特性があります。ボリュームのアクティブ化、拡張、名前変更、削除、さらにはスナップショット作成も個別に行うことができます。
すべてのシンボリュームや、LVM スナップショットボリュームと同様に、シンプロビジョニングのスナップショットボリュームは、クラスターのノード間では対応していません。スナップショットボリュームは、1 つのクラスターノードで排他的にアクティブにする必要があります。
従来のスナップショットでは、作成されたスナップショットごとに新しい領域を割り当てる必要があります。この領域では、作成元に変更が加えられてもデータが保持されます。ただし、シンプロビジョニングスナップショットは、作成元と同じ領域を共有します。シン LV のスナップショットは、シン LV とそのスナップショットのいずれかに共通のデータブロックが共有されるので効率的です。シン LV のスナップショットを作成することも、他のシンスナップショットから作成することもできます。再帰スナップショットに共通のブロックもシンプールで共有されます。
シンプロビジョニングのスナップショットボリュームの利点は以下のとおりです。
- オリジンのスナップショットの数を増やしても、パフォーマンスへの影響はほとんどありません。
- シンスナップショットボリュームは、新しいデータのみが書き込まれ、各スナップショットにコピーされないため、ディスク使用量を減らすことができます。
- 従来のスナップショットの要件でしたが、シンスナップショットボリュームを作成元と同時にアクティブにする必要はありません。
- スナップショットからオリジンを復元する場合、シンスナップショットをマージする必要はありません。オリジンを削除して、代わりにスナップショットを使用できます。従来のスナップショットには、コピーバックする必要がある変更を保存する別のボリュームがあります。つまり、元のスナップショットにマージしてリセットする必要があります。
- 従来のスナップショットと比較して、許可されるスナップショットの上限数がはるかに増えています。
シンプロビジョニングのスナップショットボリュームを使用する利点は数多くありますが、従来の LVM スナップショットボリューム機能の方がニーズに適している場合もあります。すべてのタイプのボリュームで従来のスナップショットを使用できます。ただし、シンスナップショットを使用するには、シンプロビジョニングを使用する必要があります。
シンプロビジョニングのスナップショットボリュームのサイズを制限することはできません。スナップショットは、必要な場合はシンプール内の全領域を使用します。一般的には、使用するスナップショットの形式を決定する際に、使用しているサイトの特定要件を考慮するようにしてください。
デフォルトで、シンスナップショットボリュームは、通常のアクティブ化コマンドの実行時に省略されます。
67.9.7. シンプロビジョニングのスナップショットボリュームの作成
シンプロビジョニングされたスナップショットボリュームを使用すると、同じデータボリュームにより多くの仮想デバイスを格納できます。
シンプロビジョニングのスナップショットボリュームを作成する場合、ボリュームのサイズは指定しません。サイズパラメーターを指定すると、作成されるスナップショットはシンプロビジョニングのスナップショットボリュームにはならず、データを保管するためにシンプールを使用することもありません。たとえば、lvcreate -s vg/thinvolume -L10M コマンドは、作成元ボリュームがシンボリュームであっても、シンプロビジョニングのスナップショットを作成しません。
シンプロビジョニングのスナップショットは、シンプロビジョニングされた作成元ボリューム用に作成するか、シンプロビジョニングされていない作成元ボリューム用にも作成できます。次の手順では、シンプロビジョニングされたスナップショットボリュームを作成するさまざまな方法について説明します。
前提条件
- シンプロビジョニングされた論理ボリュームを作成ている。詳細は、シンプロビジョニングの概要 を参照してください。
手順
シンプロビジョニングされたスナップショットボリュームを作成します。以下のコマンドは、シンプロビジョニングされた論理ボリューム vg001/thinvolume で、シンプロビジョニングのスナップショットボリューム (名前: mysnapshot1) を作成します。
# lvcreate -s --name mysnapshot1 vg001/thinvolume Logical volume "mysnapshot1" created# lvs LV VG Attr LSize Pool Origin Data% Move Log Copy% Convert mysnapshot1 vg001 Vwi-a-tz 1.00g mythinpool thinvolume 0.00 mythinpool vg001 twi-a-tz 100.00m 0.00 thinvolume vg001 Vwi-a-tz 1.00g mythinpool 0.00注記シンプロビジョニングを使用する場合は、ストレージ管理者がストレージプールを監視し、容量が満杯になり始めたら容量を追加することが重要です。シンボリュームのサイズを拡張する方法は、シンプロビジョニングされた論理ボリュームの作成 を参照してください。
シンプロビジョニングされていない論理ボリュームの、シンプロビジョニングされたスナップショットを作成することもできます。シンプロビジョニングされていない論理ボリュームはシンプール内に含まれていないため、外部の複製元と呼ばれます。外部の作成元ボリュームは、複数の異なるシンプールからであっても、多くのシンプロビジョニングのスナップショットボリュームで使用でき、共有できます。外部の作成元は、シンプロビジョニングのスナップショットが作成される際に非アクティブであり、かつ読み取り専用である必要があります。
次の例では、origin_volume という名前の読み取り専用の非アクティブな論理ボリュームのシンスナップショットボリュームを作成します。このシンプロビジョニングのスナップショットボリュームの名前は mythinsnap です。論理ボリューム origin_volume は、既存のシンプール vg001/pool を使用する、ボリュームグループ vg001 内のシンプロビジョニングのスナップショットボリューム mythinsnap に対する外部の作成元になります。作成元のボリュームは、スナップショットボリュームと同じボリュームグループに属している必要があります。作成元の論理ボリュームを指定するときは、ボリュームグループを指定しないでください。
# lvcreate -s --thinpool vg001/pool origin_volume --name mythinsnap以下のコマンドを実行して、最初のスナップショットボリュームの 2 番目のシンプロビジョニングのスナップショットボリュームを作成できます。
# lvcreate -s vg001/mysnapshot1 --name mysnapshot2 Logical volume "mysnapshot2" created.3 番目のシンプロビジョニングされたスナップショットボリュームを作成するには、次のコマンドを使用します。
# lvcreate -s vg001/mysnapshot2 --name mysnapshot3 Logical volume "mysnapshot3" created.
検証
シンスナップショット論理ボリュームのすべての祖先と子孫のリストを表示します。
$ lvs -o name,lv_ancestors,lv_descendants vg001 LV Ancestors Descendants mysnapshot2 mysnapshot1,thinvolume mysnapshot3 mysnapshot1 thinvolume mysnapshot2,mysnapshot3 mysnapshot3 mysnapshot2,mysnapshot1,thinvolume mythinpool thinvolume mysnapshot1,mysnapshot2,mysnapshot3ここでは、以下のようになります。
- thinvolume は、ボリュームグループ vg001 で元となるボリュームです。
- mysnapshot1 は thinvolume のスナップショットです。
- mysnapshot2 は mysnapshot1 のスナップショットです。
mysnapshot3 は mysnapshot2 のスナップショットです、
注記lv_ancestorsフィールドとlv_descendantsフィールドには、既存の依存関係が表示されます。ただし、削除されたエントリーは追跡しません。このチェーンの最中にエントリーが削除されると、依存関係チェーンが壊れるためです。
67.9.8. Web コンソールを使用してシンプロビジョニングされたスナップショットボリュームの作成
RHEL Web コンソールでシン論理ボリュームのスナップショットを作成し、前回のスナップショット以降ディスクに記録された変更をバックアップできます。
前提条件
- RHEL 8 Web コンソールがインストールされている。
- cockpit サービスが有効になっている。
ユーザーアカウントが Web コンソールにログインできる。
手順は、Web コンソールのインストールおよび有効化 を参照してください。
-
cockpit-storagedパッケージがシステムにインストールされている。 - シンプロビジョニングボリュームが作成されている。
手順
- RHEL 8 Web コンソールにログインします。
- Storage をクリックします。
- Storage テーブルで、シンボリュームを作成するボリュームグループをクリックします。
- Logical volume group ページで、LVM2 logical volumes セクションまでスクロールし、シン論理ボリュームを作成するプールをクリックします。
- Pool for thinly provisioned LVM2 logical volumes ページで、Thinly provisioned LVM2 logical volumes セクションまでスクロールし、論理ボリュームの横にあるメニューボタン をクリックします。
ドロップダウンメニューから、Create snapshot を選択します。
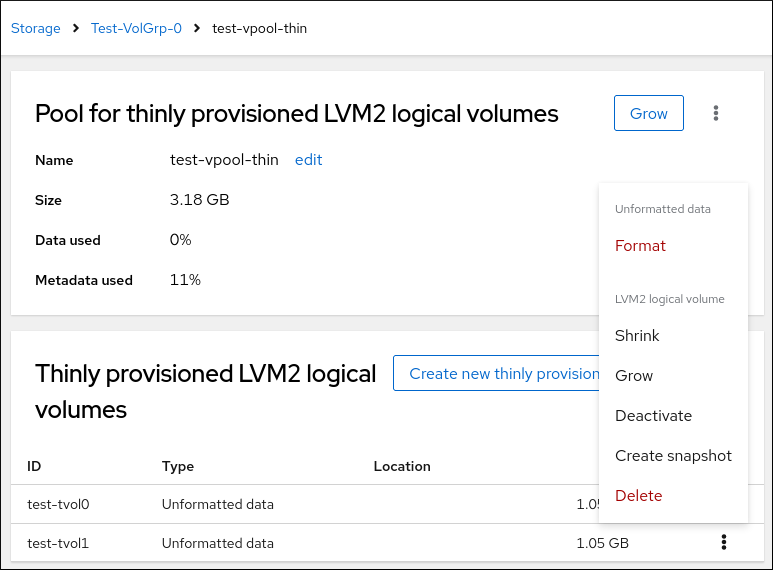
Name フィールドにスナップショット名を入力します。

- をクリックします。
- Pool for thinly provisioned LVM2 logical volumes ページで、Thinly provisioned LVM2 logical volumes セクションまでスクロールし、新しく作成されたスナップショットの横にあるメニューボタン をクリックします。
ドロップダウンメニューから Activate を選択してボリュームをアクティブ化します。
67.10. キャッシュを有効にして論理ボリュームのパフォーマンスを改善
LVM 論理ボリュームにキャッシュを追加して、パフォーマンスを向上できます。LVM は、SSD などの高速なデバイスを使用して、論理ボリュームに I/O 操作をキャッシュします。
以下の手順では、高速デバイスから特別な論理ボリュームを作成し、この特別な論理ボリュームを元の論理ボリュームに接続して、パフォーマンスを向上させます。
67.10.1. LVM でのキャッシュの取得方法
LVM は、以下のようなキャッシュの取得方法を提供します。論理ボリューム上のさまざまなタイプの I/O パターンに適しています。
dm-cacheこのメソッドは、高速なボリユームで頻繁に使用されるデータをキャッシュして、このようなデータへのアクセス時間を短縮します。このメソッドは、読み取りおよび書き込みの両方の操作をキャッシュします。
dm-cacheメソッドは、cacheタイプの論理ボリュームを作成します。dm-writecacheこのメソッドは、書き込み操作のみをキャッシュします。高速なボリュームは書き込み操作を保存し、それらをバックグラウンドで低速なディスクに移行します。高速ボリュームは通常 SSD または永続メモリー (PMEM) ディスクです。
dm-writecacheメソッドは、writecacheタイプの論理ボリュームを作成します。
67.10.2. LVM キャッシュコンポーネント
LVM は、キャッシュを LVM 論理ボリュームに追加するためのサポートを提供します。LVM キャッシュは、LVM 論理ボリュームタイプを使用します。
- Main LV
- より大きく、より遅い、元のボリューム。
- キャッシュプール LV
-
メイン LV からデータをキャッシュするために使用できる複合 LV。キャッシュデータを保持するためのデータと、キャッシュデータを管理するためのメタデータの 2 つのサブ LV があります。データおよびメタデータ用に特定のディスクを設定できます。キャッシュプールは
dm-cacheでのみ使用できます。 - Cachevol LV
-
メイン LV からデータをキャッシュするために使用できる線形 LV。データとメタデータ用に個別のディスクを設定することはできません。
cachevolは、dm-cacheまたはdm-writecacheでのみ使用できます。
これらの関連付けられた LV はすべて、同じボリュームグループにある必要があります。
メインの論理ボリューム (LV) を、キャッシュされたデータを保持する高速で通常は小さい LV と組み合わせることができます。高速 LV は、SSD ドライブなどの高速ブロックデバイスから作成されます。論理ボリュームのキャッシュを有効にすると、LVM は元のボリュームの名前を変更および非表示にし、元の論理ボリュームで設定される新しい論理ボリュームを表示します。新しい論理ボリュームの設定は、キャッシュ方法と、cachevol オプションまたは cachepool オプションを使用しているかどうかによって異なります。
cachevol オプションおよび cachepool オプションは、キャッシングコンポーネントの配置に対するさまざまなレベルの制御を公開します。
-
cachevolオプションを使用すると、高速なデバイスは、データブロックのキャッシュされたコピーとキャッシュ管理用のメタデータの両方を保存します。 cachepoolオプションを使用すると、別のデバイスはデータブロックのキャッシュコピーとキャッシュ管理用のメタデータを保存できます。dm-writecacheメソッドは、cachepoolと互換性がありません。
すべての設定において、LVM は、結果として作成される 1 つのデバイスを公開し、すべてのキャッシングコンポーネントをグループ化します。作成されるデバイスは、元の低速な論理ボリュームと同じ名前になります。
67.10.3. 論理ボリュームの dm-cache キャッシュの有効化
この手順では、dm-cache メソッドを使用して、論理ボリュームで一般的に使用されるデータのキャッシュを有効にします。
前提条件
-
システムに、
dm-cacheを使用した高速化したい低速な論理ボリュームがある。 - 低速な論理ボリュームを含むボリュームグループには、高速ブロックデバイスに未使用の物理ボリュームも含まれます。
手順
高速デバイスに
cachevolボリュームを作成します。# lvcreate --size cachevol-size --name <fastvol> <vg> </dev/fast-pv>以下の値を置き換えます。
cachevol-size-
5Gなどのcachevolボリュームのサイズ fastvol-
cachevolボリュームの名前 vg- ボリュームグループ名
/dev/fast-pv高速ブロックデバイスへのパス (例:
/dev/sdf)例67.3
cachevolボリュームの作成# lvcreate --size 5G --name fastvol vg /dev/sdf Logical volume "fastvol" created.
cachevolボリュームをメインの論理ボリュームに接続して、キャッシュを開始します。# lvconvert --type cache --cachevol <fastvol> <vg/main-lv>以下の値を置き換えます。
fastvol-
cachevolボリュームの名前 vg- ボリュームグループ名
main-lv低速な論理ボリュームの名前
例67.4 メイン LV への
cachevolボリュームの接続# lvconvert --type cache --cachevol fastvol vg/main-lv Erase all existing data on vg/fastvol? [y/n]: y Logical volume vg/main-lv is now cached.
検証
新しく作成した論理ボリュームで
dm-cacheが有効になっているかどうかを確認します。# lvs --all --options +devices <vg> LV Pool Type Devices main-lv [fastvol_cvol] cache main-lv_corig(0) [fastvol_cvol] linear /dev/fast-pv [main-lv_corig] linear /dev/slow-pv
67.10.4. 論理ボリュームに cachepool を使用した dm-cache キャッシュの有効化
この手順では、キャッシュデータとキャッシュメタデータ論理ボリュームを個別に作成し、ボリュームをキャッシュプールに統合することができます。
前提条件
-
システムに、
dm-cacheを使用した高速化したい低速な論理ボリュームがある。 - 低速な論理ボリュームを含むボリュームグループには、高速ブロックデバイスに未使用の物理ボリュームも含まれます。
手順
高速デバイスに
cachepoolボリュームを作成します。# lvcreate --type cache-pool --size <cachepool-size> --name <fastpool> <vg /dev/fast>以下の値を置き換えます。
cachepool-size-
cachepoolのサイズ (例:5G) fastpool-
cachepoolボリュームの名前 vg- ボリュームグループ名
/dev/fast高速ブロックデバイスへのパス (例:
/dev/sdf1)注記--poolmetadataオプションを使用して、cache-pool の作成時にプールメタデータの場所を指定できます。例67.5
cachevolボリュームの作成# lvcreate --type cache-pool --size 5G --name fastpool vg /dev/sde Logical volume "fastpool" created.
キャッシュを開始するために、メイン論理ボリュームに
cachepoolをアタッチします。# lvconvert --type cache --cachepool <fastpool> <vg/main>以下の値を置き換えます。
fastpool-
cachepoolボリュームの名前 vg- ボリュームグループ名
main低速な論理ボリュームの名前
例67.6 メイン LV への
cachepoolの接続# lvconvert --type cache --cachepool fastpool vg/main Do you want wipe existing metadata of cache pool vg/fastpool? [y/n]: y Logical volume vg/main is now cached.
検証
cache-poolタイプで新しく作成したデバイスボリュームを調べます。# lvs --all --options +devices <vg> LV Pool Type Devices [fastpool_cpool] cache-pool fastpool_pool_cdata(0) [fastpool_cpool_cdata] linear /dev/sdf1(4) [fastpool_cpool_cmeta] linear /dev/sdf1(2) [lvol0_pmspare] linear /dev/sdf1(0) main [fastpoool_cpool] cache main_corig(0) [main_corig] linear /dev/sdf1(O)
67.10.5. 論理ボリュームの dm-writecache キャッシュの有効化
この手順では、dm-writecache メソッドを使用して、論理ボリュームへの書き込み I/O 操作のキャッシュを有効にします。
前提条件
-
システムに、
dm-writecacheを使用した高速化したい低速な論理ボリュームがある。 - 低速な論理ボリュームを含むボリュームグループには、高速ブロックデバイスに未使用の物理ボリュームも含まれます。
- 低速な論理ボリュームがアクティブな場合は、非アクティブ化する。
手順
低速な論理ボリュームがアクティブな場合は、非アクティブにします。
# lvchange --activate n <vg>/<main-lv>以下の値を置き換えます。
vg- ボリュームグループ名
main-lv- 低速な論理ボリュームの名前
高速なデバイス上に非アクティブな
cachevolボリュームを作成します。# lvcreate --activate n --size <cachevol-size> --name <fastvol> <vg> </dev/fast-pv>以下の値を置き換えます。
cachevol-size-
5Gなどのcachevolボリュームのサイズ fastvol-
cachevolボリュームの名前 vg- ボリュームグループ名
/dev/fast-pv高速ブロックデバイスへのパス (例:
/dev/sdf)例67.7 非アクティブ化された
cachevolボリュームの作成# lvcreate --activate n --size 5G --name fastvol vg /dev/sdf WARNING: Logical volume vg/fastvol not zeroed. Logical volume "fastvol" created.
cachevolボリュームをメインの論理ボリュームに接続して、キャッシュを開始します。# lvconvert --type writecache --cachevol <fastvol> <vg/main-lv>以下の値を置き換えます。
fastvol-
cachevolボリュームの名前 vg- ボリュームグループ名
main-lv低速な論理ボリュームの名前
例67.8 メイン LV への
cachevolボリュームの接続# lvconvert --type writecache --cachevol fastvol vg/main-lv Erase all existing data on vg/fastvol? [y/n]?: y Using writecache block size 4096 for unknown file system block size, logical block size 512, physical block size 512. WARNING: unable to detect a file system block size on vg/main-lv WARNING: using a writecache block size larger than the file system block size may corrupt the file system. Use writecache block size 4096? [y/n]: y Logical volume vg/main-lv now has writecache.
作成された論理ボリュームをアクティベートします。
# lvchange --activate y <vg/main-lv>以下の値を置き換えます。
vg- ボリュームグループ名
main-lv- 低速な論理ボリュームの名前
検証
新たに作成されたデバイスを確認します。
# lvs --all --options +devices vg LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert Devices main-lv vg Cwi-a-C--- 500.00m [fastvol_cvol] [main-lv_wcorig] 0.00 main-lv_wcorig(0) [fastvol_cvol] vg Cwi-aoC--- 252.00m /dev/sdc1(0) [main-lv_wcorig] vg owi-aoC--- 500.00m /dev/sdb1(0)
67.10.6. 論理ボリュームのキャッシュの無効化
この手順では、論理ボリュームで現在有効な dm-cache キャッシュまたは dm-writecache キャッシュを無効にします。
前提条件
- キャッシュは、論理ボリュームで有効になります。
手順
論理ボリュームを非アクティブにします。
# lvchange --activate n <vg>/<main-lv>vg はボリュームグループ名に置き換え、main-lv はキャッシュが有効になっている論理ボリュームの名前に置き換えます。
cachevolボリュームまたはcachepoolボリュームの割り当てを解除します。# lvconvert --splitcache <vg>/<main-lv>以下の値を置き換えます。
vg はボリュームグループ名に置き換え、main-lv はキャッシュが有効になっている論理ボリュームの名前に置き換えます。
例67.9
cachevolまたはcachepoolボリュームの接続解除# lvconvert --splitcache vg/main-lv Detaching writecache already clean. Logical volume vg/main-lv writecache has been detached.
検証
論理ボリュームが接続されていないことを確認します。
# lvs --all --options +devices <vg> LV Attr Type Devices fastvol -wi------- linear /dev/fast-pv main-lv -wi------- linear /dev/slow-pv
67.11. 論理ボリュームのアクティブ化
デフォルトでは、論理ボリュームを作成すると、アクティブ状態になります。アクティブ状態の論理ボリュームは、ブロックデバイスを介して使用できます。アクティブ化された論理ボリュームにはアクセスでき、変更される可能性があります。
個々の論理ボリュームを非アクティブにして、カーネルに認識しないようにする必要がある状況はさまざまです。個々の論理ボリュームは、lvchange コマンドの -a オプションを使用してアクティブまたは非アクティブにできます。
個々の論理ボリュームを非アクティブにする形式を以下に示します。
# lvchange -an vg/lv個々の論理ボリュームをアクティブにする形式を以下に示します。
# lvchange -ay vg/lv
vgchange コマンドの -a オプションを使用して、ボリュームグループの論理ボリュームをすべてアクティブまたは非アクティブにできます。これは、ボリュームグループの個々の論理ボリュームに lvchange -a コマンドを実行するのと同じです。
以下は、ボリュームグループの論理ボリュームをすべて非アクティブにする形式です。
# vgchange -an vg以下は、ボリュームグループ内のすべての論理ボリュームをアクティブにする形式です。
# vgchange -ay vg
systemd-mount ユニットがマスクされていない限り、手動アクティベーション中に、systemd は /etc/fstab ファイルからの対応するマウントポイントで LVM ボリュームを自動的にマウントします。
67.11.1. 論理ボリュームおよびボリュームグループの自動アクティブ化の制御
論理ボリュームの自動アクティブ化は、システム起動時に論理ボリュームをイベントベースで自動的にアクティブにすることを指します。システムでデバイスが利用可能になると (デバイスのオンラインイベント)、systemd/udev は、各デバイスに lvm2-pvscan サービスを実行します。このサービスは、named デバイスを読み込む pvscan --cache -aay device コマンドを実行します。デバイスがボリュームグループに属している場合、pvscan コマンドは、そのボリュームグループに対する物理ボリュームがすべて、そのシステムに存在するかどうかを確認します。存在する場合は、このコマンドが、そのボリュームグループにある論理ボリュームをアクティブにします。
VG または LV に自動アクティブ化プロパティーを設定できます。自動アクティブ化のプロパティーが無効になっている場合、VG または LV は、-aay オプションを使用した vgchange、lvchange、または pvscan などの自動アクティブ化を実行するコマンドによってアクティブ化されません。VG で自動アクティブ化が無効になっていると、その VG で LV が自動アクティブ化されず、自動アクティブ化のプロパティーの効果はありません。VG で自動アクティブ化が有効化されている場合、個々の LV に対して自動アクティブ化を無効にできます。
手順
次のいずれかの方法で自動アクティブ化設定を更新できます。
コマンドラインを使用して VG の自動アクティブ化を制御します。
# vgchange --setautoactivation <y|n>コマンドラインを使用して LV の自動アクティブ化を制御します。
# lvchange --setautoactivation <y|n>次の設定オプションのいずれかを使用して、
/etc/lvm/lvm.conf設定ファイルで LV の自動アクティブ化を制御します。global/event_activationevent_activationが無効になっている場合、systemd/udevは、システムの起動時に存在する物理ボリュームでのみ、論理ボリュームを自動アクティブにします。すべての物理ボリュームが表示されていないと、一部の論理ボリュームが自動的にアクティブにならない場合もあります。activation/auto_activation_volume_listauto_activation_volume_listを空のリストに設定すると、自動アクティベーションは完全に無効になります。特定の論理ボリュームとボリュームグループにauto_activation_volume_listを設定すると、自動アクティベーションは、設定した論理ボリュームに制限されます。
67.11.2. 論理ボリュームのアクティブ化の制御
以下の方法で、論理ボリュームのアクティブ化を制御できます。
-
/etc/lvm/confファイルのactivation/volume_list設定で行います。これにより、どの論理ボリュームをアクティブにするかを指定できます。このオプションの使用方法の詳細は/etc/lvm/lvm.conf設定ファイルを参照してください。 - 論理ボリュームのアクティブ化スキップフラグで行います。このフラグが論理ボリュームに設定されていると、通常のアクティベーションコマンド時にそのボリュームがスキップされます。
または、lvcreate または lvchange コマンドで --setactivationskip y|n オプションを使用して、アクティブ化スキップフラグを有効化または無効化できます。
手順
以下の方法で、論理ボリュームのアクティブ化スキップフラグを設定できます。
このアクティブ化スキップフラグが論理ボリュームに設定されているかを確認するには、
lvsコマンドを実行します。実行すると、以下のようなk属性が表示されます。# lvs vg/thin1s1 LV VG Attr LSize Pool Origin thin1s1 vg Vwi---tz-k 1.00t pool0 thin1標準オプション
-ayまたは--activate yの他に、-Kオプションまたは--ignoreactivationskipオプションを使用して、k属性セットで論理ボリュームをアクティブにできます。デフォルトでは、シンプロビジョニングのスナップショットボリュームに、作成時にアクティブ化スキップのフラグが付いています。
/etc/lvm/lvm.confファイルのauto_set_activation_skip設定で、新たに作成した、シンプロビジョニングのスナップショットボリュームの、デフォルトのアクティブ化スキップ設定を制御できます。以下のコマンドは、アクティブ化スキップフラグが設定されているシンスナップショット論理ボリュームをアクティブ化します。
# lvchange -ay -K VG/SnapLV以下のコマンドは、アクティブ化スキップフラグがないシンスナップショットを作成します。
# lvcreate -n SnapLV -kn -s vg/ThinLV --thinpool vg/ThinPoolLV以下のコマンドは、スナップショット論理ボリュームから、アクティブ化スキップフラグを削除します。
# lvchange -kn VG/SnapLV
検証
アクティブ化スキップフラグのないシンスナップショットが作成されているか確認します。
# lvs -a -o +devices,segtype LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert Devices Type SnapLV vg Vwi-a-tz-- 100.00m ThinPoolLV ThinLV 0.00 thin ThinLV vg Vwi-a-tz-- 100.00m ThinPoolLV 0.00 thin ThinPoolLV vg twi-aotz-- 100.00m 0.00 10.94 ThinPoolLV_tdata(0) thin-pool [ThinPoolLV_tdata] vg Twi-ao---- 100.00m /dev/sdc1(1) linear [ThinPoolLV_tmeta] vg ewi-ao---- 4.00m /dev/sdd1(0) linear [lvol0_pmspare] vg ewi------- 4.00m /dev/sdc1(0) linear
67.11.3. 共有論理ボリュームのアクティベーション
以下のように、lvchange コマンドおよび vgchange コマンドの -a オプションを使用して、共有論理ボリュームの論理ボリュームのアクティブ化を制御できます。
| コマンド | アクティベーション |
|---|---|
|
| 共有論理ボリュームを排他モードでアクティベートし、1 台のホストのみが論理ボリュームをアクティベートできるようにします。アクティベーションが失敗 (論理ボリュームが別のホストでアクティブの場合に発生する可能性あり) すると、エラーが報告されます。 |
|
| 共有モードで共有論理ボリュームをアクティブにし、複数のホストが論理ボリュームを同時にアクティブにできるようにします。アクティブできない場合は (その論理ボリュームは別のホストで排他的にアクティブになっている場合に発生する可能性あり)、エラーが報告されます。スナップショットなど、論理タイプが共有アクセスを禁止している場合は、コマンドがエラーを報告して失敗します。複数のホストから同時に使用できない論理ボリュームタイプには、シン、キャッシュ、RAID、およびスナップショットがあります。 |
|
| 論理ボリュームを非アクティブにします。 |
67.11.4. 欠落しているデバイスを含む論理ボリュームのアクティブ化
--activationmode partial|degraded|complete オプションを指定した lvchange コマンドを使用して、デバイスがない LV をアクティベートするかどうかを制御できます。値の説明は次のとおりです。
| アクティベーションモード | 意味 |
|---|---|
| complete | 物理ボリュームが見つからない論理ボリュームのみをアクティベートすることを許可します。これが最も制限的なモードです。 |
| degraded | 物理ボリュームが見つからない RAID 論理ボリュームをアクティベートすることを許可します。 |
| partial | 物理ボリュームが見つからない論理ボリュームをすべてアクティベートすることを許可します。このオプションは、回復または修復にのみ使用してください。 |
activationmode のデフォルト値は、/etc/lvm/lvm.conf ファイルの activationmode 設定により決まります。コマンドラインオプションが指定されていない場合に使用されます。
67.12. LVM デバイスの可視性および使用を制限する
論理ボリュームマネージャー (LVM) がスキャンできるデバイスを制御することにより、LVM で表示および使用できるデバイスを制限できます。
LVM デバイススキャンの設定を調整するには、/etc/lvm/lvm.conf ファイルで LVM デバイスフィルター設定を編集します。lvm.conf ファイル内のフィルターは、一連の単純な正規表現で構成されています。システムは、これらの式を /dev ディレクトリー内の各デバイス名に適用して、検出された各ブロックデバイスを受け入れるか拒否するかを決定します。
67.12.1. LVM フィルタリング用の永続的な識別子
/dev/sda などの従来の Linux デバイス名は、システム変更や再起動中に変更される可能性があります。World Wide Identifier (WWID)、汎用一意識別子 (UUID)、パス名などの永続的な命名属性 (PNA) は、ストレージデバイスの固有の特性に基づいており、ハードウェア設定の変更に対して耐久性があります。そのため、システムの再起動後もストレージデバイスがより安定し、予測可能になります。
LVM フィルタリングに永続的なデバイス識別子を実装すると、LVM 設定の安定性と信頼性が向上します。また、デバイス名が動的な性質を持つことによるシステム起動失敗のリスクも軽減されます。
67.12.2. LVM デバイスフィルター
論理ボリュームマネージャー (LVM) デバイスフィルターは、デバイス名パターンのリストです。これを使用すると、システムがデバイスを評価して LVM での使用が有効であると認めるのに使用する一連の必須基準を指定できます。LVM デバイスフィルターを使用すると、LVM が使用するデバイスを制御できます。これは、偶発的なデータ損失やストレージデバイスへの不正アクセスを防ぐのに役立ちます。
67.12.2.1. LVM デバイスフィルターのパターンの特性
LVM デバイスフィルターのパターンは正規表現の形式です。正規表現は文字で区切られ、許可の場合は a、拒否の場合は r が前に付きます。デバイスに一致する最初の正規表現は、LVM が特定のデバイスを許可するか、拒否 (無視) するかを判断します。次に、LVM はデバイスのパスに一致する最初の正規表現をリスト内で検索します。LVM はこの正規表現を使用して、デバイスを a の結果により承認するか、r の結果により拒否するかを決定します。
単一のデバイスに複数のパス名がある場合、LVM はリストの順序に従ってこれらのパス名にアクセスします。r パターンの前に、少なくとも 1 つのパス名が a パターンと一致する場合、LVM はデバイスを許可します。しかし、a パターンが見つかる前にすべてのパス名が r パターンと一致した場合、デバイスは拒否されます。
パターンに一致しないパス名は、デバイスの許可ステータスに影響を与えません。デバイスのパターンに一致するパス名がまったくない場合も、LVM はデバイスを許可します。
システム上のデバイスごとに、udev ルールは複数のシンボリックリンクを生成します。ディレクトリーには、システム上の各デバイスが複数のパス名を通じてアクセスできるように、/dev/disk/by-id/、/dev/disk/by-uuid/、/dev/disk/by-path/ などのシンボリックリンクが含まれています。
フィルター内のデバイスを拒否するには、その特定のデバイスに関連付けられたすべてのパス名が、対応する r 拒否表現と一致する必要があります。ただし、考えられる拒否対象のパス名をすべて特定するのは困難な場合があります。そのため、一連の特定の a 表現の後に 1 つの r|.*| 表現を使用して、特定のパスを明確に限定して許可し、その他のすべてを拒否するフィルターを作成することを推奨します。
フィルターで特定のデバイスを定義するときは、カーネル名の代わりにそのデバイスのシンボリックリンク名を使用します。/dev/sda など、デバイスのカーネル名は変更される可能性がありますが、/dev/disk/by-id/wwn-* などの特定のシンボリックリンク名は変更されません。
デフォルトのデバイスフィルターは、システムに接続されているすべてのデバイスを許可します。理想的なユーザー設定のデバイスフィルターは、1 つ以上のパターンを許可し、それ以外はすべて拒否します。たとえば、r|.*| で終わるパターンリストなどが挙げられます。
LVM デバイスのフィルター設定は、lvm.conf ファイルの devices/filter および devices/global_filter 設定フィールドにあります。devices/filter 設定フィールドと devices/global_filter 設定フィールドは同等のものです。
67.12.2.2. LVM デバイスフィルター設定の例
次の例は、LVM がスキャンして後で使用するデバイスを制御するためのフィルター設定を示しています。lvm.conf ファイルでデバイスフィルターを設定するには、次を参照してください。
コピーまたはクローン作成された物理ボリューム (PV) を処理するときに、PV の重複に関する警告が表示される場合があります。これはフィルターをセットアップすることで解決できます。PV の重複警告を防ぐ LVM デバイスフィルターの例 のフィルター設定の例を参照してください。
すべてのデバイスをスキャンするには、次のように入力します。
filter = [ "a|.*|" ]ドライブにメディアが含まれていない場合の遅延を避けるために
cdromデバイスを削除するには、次のように入力します。filter = [ "r|^/dev/cdrom$|" ]すべてのループデバイスを追加し、他のすべてのデバイスを削除するには、次のように入力します。
filter = [ "a|loop|", "r|.*|" ]すべてのループデバイスと SCSI デバイスを追加し、他のすべてのブロックデバイスを削除するには、次のように入力します。
filter = [ "a|loop|", "a|/dev/sd.*|", "r|.*|" ]最初の SCSI ドライブにパーティション 8 のみを追加し、他のすべてのブロックデバイスを削除するには、次のように入力します。
filter = [ "a|^/dev/sda8$|", "r|.*|" ]WWID によって識別される特定のデバイスおよびすべてのマルチパスデバイスからすべてのパーティションを追加するには、次のように入力します。
filter = [ "a|/dev/disk/by-id/<disk-id>.|", "a|/dev/mapper/mpath.|", "r|.*|" ]また、このコマンドは、他のブロックデバイスを削除します。
67.12.2.3. LVM デバイスフィルター設定の適用
lvm.conf 設定ファイル内にフィルターを設定することにより、LVM がどのデバイスをスキャンするかを制御できます。
前提条件
- 使用するデバイスフィルターパターンが準備されている。
手順
実際に
/etc/lvm/lvm.confファイルを変更せずに、次のコマンドを使用してデバイスフィルターパターンをテストします。以下にフィルター設定の例を示します。# lvs --config 'devices{ filter = [ "a|/dev/emcpower.|", "r|.|" ] }'/etc/lvm/lvm.confファイルの設定セクションdevicesにデバイスフィルターパターンを追加します。filter = [ "a|/dev/emcpower.*|", "r|*.|" ]再起動時に必要なデバイスのみをスキャンします。
# dracut --force --verboseこのコマンドによって、LVM が必要なデバイスのみを再起動時にスキャンするように
initramfsファイルシステムを再構築します。
67.13. LVM の割り当ての制御
デフォルトでは、ボリュームグループは normal 割り当てポリシーを使用します。これにより、同じ物理ボリューム上に並行ストライプを配置しないなどの常識的な規則に従って物理エクステントが割り当てられます。vgcreate コマンドで --alloc 引数を使用すると、別の割り当てポリシー (contiguous、anywhere、または cling) を指定できます。一般的に、normal 以外の割り当てポリシーが必要となるのは、通常とは異なる、標準外のエクステント割り当てを必要とする特別なケースのみです。
67.13.1. 指定したデバイスからのエクステントの割り当て
lvcreate コマンドと lvconvert コマンドを使用する際に、コマンドラインの末尾でデバイス引数を使用すると、特定のデバイスからの割り当てに制限できます。より詳細に制御するために、各デバイスの実際のエクステント範囲を指定できます。このコマンドは単に、指定した物理ボリューム (PV) を引数として使用して、新しい論理ボリューム (LV) にエクステントを割り当てます。各 PV から利用可能なエクステントがなくなるまでエクステントを取得し、その後、次にリストされている PV からエクステントを取得します。リストされているすべての PV の領域が、要求された LV サイズに対して不足する場合、コマンドは失敗します。このコマンドは、指定した PV からのみ割り当てを行うことに注意してください。Raid LV は、個別の RAID イメージまたは個別のストライプにシーケンシャル PV を使用します。PV のサイズが RAID イメージ全体に対して十分でない場合、デバイスの使用量を完全に予測することはできません。
手順
ボリュームグループ (VG) を作成します。
# vgcreate <vg_name> <PV> ...ここでは、以下のようになります。
-
<vg_name>は VG の名前です。 -
<PV>は PV です。
-
PV を割り当てて、リニアや RAID などのさまざまなボリュームタイプを作成できます。
エクステントを割り当ててリニアボリュームを作成します。
# lvcreate -n <lv_name> -L <lv_size> <vg_name> [ <PV> ... ]ここでは、以下のようになります。
-
<lv_name>は LV の名前です。 -
<lv_size>は LV のサイズです。デフォルトの単位はメガバイトです。 -
<vg_name>は VG の名前です。 [ <PV ...> ]は PV です。コマンドラインでは、PV の 1 つを指定することも、すべての PV を指定することもできます。何も指定しないことも可能です。
1 つの PV を指定すると、当該 PV から LV のエクステントが割り当てられます。
注記PV に LV 全体に対する十分な空きエクステントがない場合、
lvcreateは失敗します。- 2 つの PV を指定した場合、LV のエクステントは、当該 PV のうちの 1 つ、または両方の PV の組み合わせから割り当てられます。
PV を指定しない場合、エクステントは VG 内の PV の 1 つ、または VG 内のすべての PV の任意の組み合わせから割り当てられます。
注記このような場合、LVM は、指定した PV または使用可能な PV のすべてを使用しない可能性があります。最初の PV に LV 全体に対して十分な空きエクステントがある場合、他の PV はおそらく使用されません。ただし、最初の PV に空きエクステントの割り当てサイズが設定されていない場合、LV の一部は最初の PV から割り当てられ、一部は 2 番目の PV から割り当てられる可能性があります。
例67.10 1 つの PV からのエクステントの割り当て
この例では、
lv1エクステントがsdaから割り当てられます。# lvcreate -n lv1 -L1G vg /dev/sda例67.11 2 つの PV からのエクステントの割り当て
この例では、
lv2エクステントがsda、sdb、または両方の組み合わせから割り当てられます。# lvcreate -n lv2 L1G vg /dev/sda /dev/sdb例67.12 PV を指定しないエクステントの割り当て
この例では、
lv3エクステントが、VG 内の PV の 1 つ、または VG 内のすべての PV の任意の組み合わせから割り当てられます。# lvcreate -n lv3 -L1G vgまたは、以下を実行します。
-
エクステントを割り当てて RAID ボリュームを作成します。
# lvcreate --type <segment_type> -m <mirror_images> -n <lv_name> -L <lv_size> <vg_name> [ <PV> ... ]ここでは、以下のようになります。
-
<segment_type>は、指定したセグメントタイプ (例:raid5、mirror、snapshot) です。 -
<mirror_images>は、指定した数のイメージを含む、raid1またはミラーリングされた LV を作成します。たとえば、-m 1を指定すると、2 つのイメージを含むraid1LV が作成されます。 -
<lv_name>は LV の名前です。 -
<lv_size>は LV のサイズです。デフォルトの単位はメガバイトです。 -
<vg_name>は VG の名前です。 <[PV ...]>は PV です。最初の RAID イメージは最初の PV から割り当てられ、2 番目の RAID イメージは 2 番目の PV から割り当てられます。以後も同様です。
例67.13 2 つの PV からの RAID イメージの割り当て
この例では、
lv4の最初の RAID イメージはsdaから割り当てられ、2 番目のイメージはsdbから割り当てられます。# lvcreate --type raid1 -m 1 -n lv4 -L1G vg /dev/sda /dev/sdb例67.14 3 つの PV からの RAID イメージの割り当て
この例では、
lv5の最初の RAID イメージはsdaから割り当てられ、2 番目のイメージはsdbから割り当てられ、3 番目のイメージはsdcから割り当てられます。# lvcreate --type raid1 -m 2 -n lv5 -L1G vg /dev/sda /dev/sdb /dev/sdc
-
67.13.2. LVM の割り当てポリシー
LVM の操作で物理エクステントを 1 つまたは複数の論理ボリューム (LV) に割り当てる必要がある場合、割り当ては以下のように行われます。
- ボリュームグループで割り当てられていない物理エクステントのセットが、割り当てのために生成されます。コマンドラインの末尾に物理エクステントの範囲を指定すると、指定した物理ボリューム (PV) の中で、その範囲内で割り当てられていない物理エクステントだけが、割り当て用エクステントとして考慮されます。
-
割り当てポリシーは順番に試行されます。最も厳格なポリシー (
contiguous) から始まり、最後は--allocオプションで指定した割り当てポリシーか、特定の LV やボリュームグループ (VG) にデフォルトとして設定されている割り当てポリシーが試行されます。各割り当てポリシーでは、埋める必要がある空の LV 領域の最小番号の論理エクステントから始まり、割り当てポリシーによる制限に従って、できるだけ多くの領域の割り当てを行います。領域が足りなくなると、LVM は次のポリシーに移動します。
割り当てポリシーの制限は以下のとおりです。
contiguousポリシーでは、LV の最初の論理エクステントを除き、論理エクステントの物理的位置が、直前の論理エクステントの物理的位置に隣接している必要があります。LV がストライプ化またはミラーリングされている場合、
contiguousの割り当て制限は、領域を必要とする各ストライプまたは RAID イメージに個別に適用されます。-
clingの割り当てポリシーでは、既存の LV に追加する論理エクステントに使用される PV が、その LV にある少なくとも 1 つの論理エクステントですでに使用されている必要があります。 -
normalの割り当てポリシーでは、並行 LV 内の同じオフセットで、並行 LV (つまり、異なるストライプまたは RAID イメージ) にすでに割り当てられている論理エクステントと同じ PV を共有する物理エクステントは選択されません。 -
割り当て要求を満たすのに十分な空きエクステントがあっても、
normalの割り当てポリシーによって使用されない場合は、たとえ同じ PV に 2 つのストライプを配置することによってパフォーマンスが低下しても、anywhereの割り当てポリシーがその空きエクステントを使用します。
vgchange コマンドを使用して、割り当てポリシーを変更できます。
今後の更新で、定義された割り当てポリシーに基づくレイアウト操作のコードが変更される可能性があることに注意してください。たとえば、割り当て可能な空き物理エクステントの数が同じ 2 つの空の物理ボリュームをコマンドラインで指定する場合、現行バージョンの LVM では、それが表示されている順番に使用が検討されます。ただし、今後のリリースで、そのプロパティーが変更されない保証はありません。特定の LV 用に特定のレイアウトが必要な場合は、各手順に適用される割り当てポリシーに基づいて LVM がレイアウトを決定することがないように、lvcreate と lvconvert を順に使用してレイアウトを構築してください。
67.13.3. 物理ボリュームでの割り当て防止
pvchange コマンドを使用すると、単一または複数の物理ボリュームの空き領域で物理エクステントが割り当てられないようにすることができます。これは、ディスクエラーが発生した場合や、物理ボリュームを削除する場合に必要となる可能性があります。
手順
device_nameでの物理エクステントの割り当てを無効にするには、次のコマンドを使用します。# pvchange -x n /dev/sdk1pvchangeコマンドで-xy引数を使用すると、無効にされていた割り当てを許可できます。
67.14. LVM のトラブルシューティング
論理ボリュームマネージャー (LVM) ツールを使用して、LVM ボリュームおよびグループのさまざまな問題のトラブルシューティングを行うことができます。
67.14.1. LVM での診断データの収集
LVM コマンドが想定どおりに機能しない場合は、以下の方法で診断情報を収集できます。
手順
以下の方法を使用して、さまざまな診断データを収集します。
-
-v引数を LVM コマンドに追加して、コマンドの出力の詳細レベルを増やします。vを追加すると、詳細度をさらに増やすことができます。vは最大 4 つ許可されます (例:-vvvv)。 -
/etc/lvm/lvm.conf設定ファイルのlogセクションで、levelオプションの値を増やします。これにより、LVM がシステムログにより多くの情報を提供します。 問題が論理ボリュームのアクティブ化に関連する場合は、アクティブ化中に LVM がログメッセージをログに記録できるようにします。
-
/etc/lvm/lvm.conf設定ファイルのlogセクションでactivation = 1オプションを設定します。 -
LVM コマンドに
-vvvvオプションを付けて実行します。 - コマンドの出力を確認します。
activationオプションを0にリセットします。オプションを
0にリセットしないと、メモリー不足の状況でシステムが応答しなくなる可能性があります。
-
診断目的で情報ダンプを表示します。
# lvmdump追加のシステム情報を表示します。
# lvs -v# pvs --all# dmsetup info --columns-
/etc/lvm/backup/ディレクトリーの最後の LVM メタデータのバックアップと、/etc/lvm/archive/ディレクトリー内のアーカイブバージョンを確認します。 現在の設定情報を確認します。
# lvmconfig-
/run/lvm/hintsキャッシュファイルで、物理ボリュームを持つデバイスを記録します。
-
67.14.2. 障害が発生した LVM デバイスに関する情報の表示
障害が発生した論理ボリュームマネージャー (LVM) ボリュームに関するトラブルシューティング情報は、障害の原因を特定するのに役立ちます。最も一般的な LVM ボリューム障害の例を以下に示します。
例67.15 障害が発生したボリュームグループ
この例では、ボリュームグループ myvg を設定するデバイスの 1 つで障害が発生しました。ボリュームグループの使用可能性は、障害の種類によって異なります。たとえば、RAID ボリュームも関係している場合、ボリュームグループは引き続き使用できます。障害が発生したデバイスに関する情報も確認できます。
# vgs --options +devices
/dev/vdb1: open failed: No such device or address
/dev/vdb1: open failed: No such device or address
WARNING: Couldn't find device with uuid 42B7bu-YCMp-CEVD-CmKH-2rk6-fiO9-z1lf4s.
WARNING: VG myvg is missing PV 42B7bu-YCMp-CEVD-CmKH-2rk6-fiO9-z1lf4s (last written to /dev/sdb1).
WARNING: Couldn't find all devices for LV myvg/mylv while checking used and assumed devices.
VG #PV #LV #SN Attr VSize VFree Devices
myvg 2 2 0 wz-pn- <3.64t <3.60t [unknown](0)
myvg 2 2 0 wz-pn- <3.64t <3.60t [unknown](5120),/dev/vdb1(0)例67.16 障害が発生した論理ボリューム
この例では、デバイスの 1 つで障害が発生しました。このような障害が、ボリュームグループ内の論理ボリュームに障害が発生する原因となることがあります。コマンドの出力には、障害が発生した論理ボリュームが表示されます。
# lvs --all --options +devices
/dev/vdb1: open failed: No such device or address
/dev/vdb1: open failed: No such device or address
WARNING: Couldn't find device with uuid 42B7bu-YCMp-CEVD-CmKH-2rk6-fiO9-z1lf4s.
WARNING: VG myvg is missing PV 42B7bu-YCMp-CEVD-CmKH-2rk6-fiO9-z1lf4s (last written to /dev/sdb1).
WARNING: Couldn't find all devices for LV myvg/mylv while checking used and assumed devices.
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert Devices
mylv myvg -wi-a---p- 20.00g [unknown](0) [unknown](5120),/dev/sdc1(0)例67.17 RAID 論理ボリュームのイメージの障害
次の例は、RAID 論理ボリュームのイメージに障害が発生した場合の pvs および lvs ユーティリティーからのコマンド出力を示しています。論理ボリュームは引き続き使用できます。
# pvs
Error reading device /dev/sdc1 at 0 length 4.
Error reading device /dev/sdc1 at 4096 length 4.
Couldn't find device with uuid b2J8oD-vdjw-tGCA-ema3-iXob-Jc6M-TC07Rn.
WARNING: Couldn't find all devices for LV myvg/my_raid1_rimage_1 while checking used and assumed devices.
WARNING: Couldn't find all devices for LV myvg/my_raid1_rmeta_1 while checking used and assumed devices.
PV VG Fmt Attr PSize PFree
/dev/sda2 rhel_bp-01 lvm2 a-- <464.76g 4.00m
/dev/sdb1 myvg lvm2 a-- <836.69g 736.68g
/dev/sdd1 myvg lvm2 a-- <836.69g <836.69g
/dev/sde1 myvg lvm2 a-- <836.69g <836.69g
[unknown] myvg lvm2 a-m <836.69g 736.68g# lvs -a --options name,vgname,attr,size,devices myvg
Couldn't find device with uuid b2J8oD-vdjw-tGCA-ema3-iXob-Jc6M-TC07Rn.
WARNING: Couldn't find all devices for LV myvg/my_raid1_rimage_1 while checking used and assumed devices.
WARNING: Couldn't find all devices for LV myvg/my_raid1_rmeta_1 while checking used and assumed devices.
LV VG Attr LSize Devices
my_raid1 myvg rwi-a-r-p- 100.00g my_raid1_rimage_0(0),my_raid1_rimage_1(0)
[my_raid1_rimage_0] myvg iwi-aor--- 100.00g /dev/sdb1(1)
[my_raid1_rimage_1] myvg Iwi-aor-p- 100.00g [unknown](1)
[my_raid1_rmeta_0] myvg ewi-aor--- 4.00m /dev/sdb1(0)
[my_raid1_rmeta_1] myvg ewi-aor-p- 4.00m [unknown](0)67.14.3. ボリュームグループから見つからない LVM 物理ボリュームの削除
物理ボリュームに障害が発生した場合は、ボリュームグループ内の残りの物理ボリュームをアクティブにし、その物理ボリュームを使用していたすべての論理ボリュームをボリュームグループから削除できます。
手順
ボリュームグループ内の残りの物理ボリュームをアクティベートします。
# vgchange --activate y --partial myvg削除する論理ボリュームを確認します。
# vgreduce --removemissing --test myvgボリュームグループから、失われた物理ボリュームを使用していた論理ボリュームをすべて削除します。
# vgreduce --removemissing --force myvgオプション: 保持する論理ボリュームを誤って削除した場合には、
vgreduce操作を元に戻すことができます。# vgcfgrestore myvg警告シンプールを削除すると、LVM は操作を元に戻すことができません。
67.14.4. 見つからない LVM 物理ボリュームのメタデータの検索
物理ボリュームのボリュームグループメタデータ領域が誤って上書きされたり、破棄されたりする場合は、メタデータ領域が正しくないことを示すエラーメッセージか、システムが特定の UUID を持つ物理ボリュームを見つけることができないことを示すエラーメッセージが表示されます。
この手順では、物理ボリュームが見つからないか、破損している、アーカイブされた最新のメタデータを見つけます。
手順
物理ボリュームを含むボリュームグループのアーカイブされたメタデータファイルを検索します。アーカイブされたメタデータファイルは、
/etc/lvm/archive/volume-group-name_backup-number.vgパスにあります。# cat /etc/lvm/archive/myvg_00000-1248998876.vg00000-1248998876 を backup-number に置き換えます。ボリュームグループの番号が最も高い、既知の有効なメタデータファイルの最後のものを選択します。
物理ボリュームの UUID を検索します。以下の方法のいずれかを使用します。
論理ボリュームをリスト表示します。
# lvs --all --options +devices Couldn't find device with uuid 'FmGRh3-zhok-iVI8-7qTD-S5BI-MAEN-NYM5Sk'.-
アーカイブされたメタデータファイルを確認します。ボリュームグループ設定の
physical_volumesセクションで、id =のラベルが付いた値として UUID を検索します。 --partialオプションを使用してボリュームグループを非アクティブにします。# vgchange --activate n --partial myvg PARTIAL MODE. Incomplete logical volumes will be processed. WARNING: Couldn't find device with uuid 42B7bu-YCMp-CEVD-CmKH-2rk6-fiO9-z1lf4s. WARNING: VG myvg is missing PV 42B7bu-YCMp-CEVD-CmKH-2rk6-fiO9-z1lf4s (last written to /dev/vdb1). 0 logical volume(s) in volume group "myvg" now active
67.14.5. LVM 物理ボリュームでのメタデータの復元
この手順では、破損したり、新しいデバイスに置き換えたりする物理ボリュームのメタデータを復元します。物理ボリュームのメタデータ領域を書き換えて、物理ボリュームからデータを復旧できる場合があります。
作業用の LVM 論理ボリュームでこの手順を実行しないでください。誤った UUID を指定すると、データが失われることになります。
前提条件
- 見つからない物理ボリュームのメタデータを特定している。詳細は、見つからない LVM 物理ボリュームのメタデータの検索 を参照してください。
手順
物理ボリュームでメタデータを復元します。
# pvcreate --uuid physical-volume-uuid \ --restorefile /etc/lvm/archive/volume-group-name_backup-number.vg \ block-device注記コマンドは、LVM メタデータ領域のみを上書きし、既存のデータ領域には影響を与えません。
例67.18 /dev/vdb1 での物理ボリュームの復元
以下の例では、以下のプロパティーで
/dev/vdb1デバイスを物理ボリュームとしてラベル付けします。-
FmGRh3-zhok-iVI8-7qTD-S5BI-MAEN-NYM5Skの UUID VG_00050.vgに含まれるメタデータ情報 (ボリュームグループの最新のアーカイブメタデータ)# pvcreate --uuid "FmGRh3-zhok-iVI8-7qTD-S5BI-MAEN-NYM5Sk" \ --restorefile /etc/lvm/archive/VG_00050.vg \ /dev/vdb1 ... Physical volume "/dev/vdb1" successfully created
-
ボリュームグループのメタデータを復元します。
# vgcfgrestore myvg Restored volume group myvgボリュームグループの論理ボリュームを表示します。
# lvs --all --options +devices myvg現在、論理ボリュームは非アクティブです。以下に例を示します。
LV VG Attr LSize Origin Snap% Move Log Copy% Devices mylv myvg -wi--- 300.00G /dev/vdb1 (0),/dev/vdb1(0) mylv myvg -wi--- 300.00G /dev/vdb1 (34728),/dev/vdb1(0)論理ボリュームのセグメントタイプが RAID の場合は、論理ボリュームを再同期します。
# lvchange --resync myvg/mylv論理ボリュームを非アクティブにします。
# lvchange --activate y myvg/mylv-
ディスク上の LVM メタデータが、それを上書きしたものと同じかそれ以上のスペースを使用する場合は、この手順で物理ボリュームを回復できます。メタデータを上書きしたものがメタデータ領域を超えると、ボリューム上のデータが影響を受ける可能性があります。そのデータを復元するには、
fsckコマンドを使用することができます。
検証
アクティブな論理ボリュームを表示します。
# lvs --all --options +devices LV VG Attr LSize Origin Snap% Move Log Copy% Devices mylv myvg -wi--- 300.00G /dev/vdb1 (0),/dev/vdb1(0) mylv myvg -wi--- 300.00G /dev/vdb1 (34728),/dev/vdb1(0)
67.14.6. LVM 出力の丸めエラー
ボリュームグループの領域使用量を報告する LVM コマンドは、報告された数を 2 進法に切り上げ、人間が判読できる出力を提供します。これには、vgdisplay ユーティリティーおよび vgs ユーティリティーが含まれます。
丸めの結果、報告された空き領域の値は、ボリュームグループが提供する物理エクステントよりも大きくなる可能性があります。報告された空き領域のサイズの論理ボリュームを作成しようとすると、以下のエラーが発生する可能性があります。
Insufficient free extentsエラーを回避するには、ボリュームグループの空き物理エクステントの数を調べる必要があります。これは、空き領域の正確な値です。次に、エクステントの数を使用して、論理ボリュームを正常に作成できます。
67.14.7. LVM ボリューム作成時の丸めエラーの防止
LVM 論理ボリュームを作成する場合は、丸めエラーを防ぐために論理ボリュームの論理エクステントの数を指定できます。
手順
ボリュームグループの空き物理エクステントの数を検索します。
# vgdisplay myvg例67.19 ボリュームグループの空きエクステント
たとえば、以下のボリュームグループには 8780 個のの空き物理エクステントがあります。
--- Volume group --- VG Name myvg System ID Format lvm2 Metadata Areas 4 Metadata Sequence No 6 VG Access read/write [...] Free PE / Size 8780 / 34.30 GB論理ボリュームを作成します。ボリュームサイズをバイトではなくエクステントに入力します。
例67.20 エクステントの数を指定して論理ボリュームを作成
# lvcreate --extents 8780 --name mylv myvg例67.21 残りの領域をすべて使用する論理ボリュームの作成
または、論理ボリュームを拡張して、ボリュームグループ内の残りの空き領域の割合を使用できます。以下に例を示します。
# lvcreate --extents 100%FREE --name mylv myvg
検証
ボリュームグループが使用するエクステントの数を確認します。
# vgs --options +vg_free_count,vg_extent_count VG #PV #LV #SN Attr VSize VFree Free #Ext myvg 2 1 0 wz--n- 34.30G 0 0 8780
67.14.8. LVM メタデータとそのディスク上の場所
LVM ヘッダーとメタデータ領域は、さまざまなオフセットとサイズで使用できます。
デフォルトの LVM ディスクヘッダー:
-
label_header構造とpv_header構造にあります。 - ディスクの 2 番目の 512 バイトセクターにあります。なお、物理ボリューム (PV) の作成時にデフォルト以外の場所が指定された場合、ヘッダーは最初のセクターまたは 3 番目のセクターにある可能性があります。
標準の LVM メタデータ領域:
- ディスクの先頭から 4096 バイトの位置から開始します。
- ディスクの先頭から 1 MiB の位置で終了します。
-
mda_header構造を含む 512 バイトのセクターで開始します。
メタデータテキスト領域は、mda_header セクターの後に始まり、メタデータ領域の終わりまで続きます。LVM VG メタデータテキストは、メタデータテキスト領域に循環的に書き込まれます。mda_header は、テキスト領域内の最新の VG メタデータの場所を指します。
# pvck --dump headers /dev/sda コマンドを使用して、ディスクから LVM ヘッダーを出力できます。このコマンドは、label_header、pv_header、mda_header、およびメタデータテキストが見つかった場合はその場所を出力します。正常でないフィールドは CHECK 接頭辞を付けて出力されます。
LVM メタデータ領域のオフセットは PV を作成したマシンのページサイズと一致するため、メタデータ領域はディスクの先頭から 8K、16K、または 64K の位置から開始する場合もあります。
PV の作成時に、より大きなメタデータ領域またはより小さなメタデータ領域を指定できます。その場合、メタデータ領域は 1 MiB 以外の位置で終了する可能性があります。pv_header は、メタデータ領域のサイズを指定します。
PV を作成するときに、必要に応じて 2 番目のメタデータ領域をディスクの末尾で有効にすることができます。pv_header にはメタデータ領域の場所が含まれます。
67.14.9. ディスクからの VG メタデータの抽出
状況に応じて、次のいずれかの手順を選択して、ディスクから VG メタデータを抽出します。抽出したメタデータを保存する方法は、抽出したメタデータのファイルへの保存 を参照してください。
修復には、ディスクからメタデータを抽出せずに /etc/lvm/backup/ にあるバックアップファイルを使用できます。
手順
有効な
mda_headerから参照される現在のメタデータテキストを出力します。# pvck --dump metadata <disk>例67.22 有効な
mda_headerからのメタデータテキスト# pvck --dump metadata /dev/sdb metadata text at 172032 crc Oxc627522f # vgname test segno 59 --- <raw metadata from disk> ---有効な
mda_headerの検出に基づいて、メタデータ領域で見つかったすべてのメタデータコピーの場所を出力します。# pvck --dump metadata_all <disk>例67.23 メタデータ領域内のメタデータコピーの場所
# pvck --dump metadata_all /dev/sdb metadata at 4608 length 815 crc 29fcd7ab vg test seqno 1 id FaCsSz-1ZZn-mTO4-Xl4i-zb6G-BYat-u53Fxv metadata at 5632 length 1144 crc 50ea61c3 vg test seqno 2 id FaCsSz-1ZZn-mTO4-Xl4i-zb6G-BYat-u53Fxv metadata at 7168 length 1450 crc 5652ea55 vg test seqno 3 id FaCsSz-1ZZn-mTO4-Xl4i-zb6G-BYat-u53Fxvたとえば、ヘッダーが欠落しているか破損している場合は、
mda_headerを使用せずにメタデータ領域内のメタデータのすべてのコピーを検索します。# pvck --dump metadata_search <disk>例67.24
mda_headerを使用しないメタデータ領域内のメタデータコピー# pvck --dump metadata_search /dev/sdb Searching for metadata at offset 4096 size 1044480 metadata at 4608 length 815 crc 29fcd7ab vg test seqno 1 id FaCsSz-1ZZn-mTO4-Xl4i-zb6G-BYat-u53Fxv metadata at 5632 length 1144 crc 50ea61c3 vg test seqno 2 id FaCsSz-1ZZn-mTO4-Xl4i-zb6G-BYat-u53Fxv metadata at 7168 length 1450 crc 5652ea55 vg test seqno 3 id FaCsSz-1ZZn-mTO4-Xl4i-zb6G-BYat-u53Fxvメタデータの各コピーの説明を表示するには、
dumpコマンドに-vオプションを追加します。# pvck --dump metadata -v <disk>例67.25 各メタデータコピーの説明の表示
# pvck --dump metadata -v /dev/sdb metadata text at 199680 crc 0x628cf243 # vgname my_vg seqno 40 --- my_vg { id = "dmEbPi-gsgx-VbvS-Uaia-HczM-iu32-Rb7iOf" seqno = 40 format = "lvm2" status = ["RESIZEABLE", "READ", "WRITE"] flags = [] extent_size = 8192 max_lv = 0 max_pv = 0 metadata_copies = 0 physical_volumes { pv0 { id = "8gn0is-Hj8p-njgs-NM19-wuL9-mcB3-kUDiOQ" device = "/dev/sda" device_id_type = "sys_wwid" device_id = "naa.6001405e635dbaab125476d88030a196" status = ["ALLOCATABLE"] flags = [] dev_size = 125829120 pe_start = 8192 pe_count = 15359 } pv1 { id = "E9qChJ-5ElL-HVEp-rc7d-U5Fg-fHxL-2QLyID" device = "/dev/sdb" device_id_type = "sys_wwid" device_id = "naa.6001405f3f9396fddcd4012a50029a90" status = ["ALLOCATABLE"] flags = [] dev_size = 125829120 pe_start = 8192 pe_count = 15359 }
このファイルは修復に使用できます。最初のメタデータ領域は、デフォルトでダンプメタデータに使用されます。ディスクの末尾に 2 番目のメタデータ領域がある場合は、--settings "mda_num=2" オプションを使用して、代わりに 2 番目のメタデータ領域をダンプメタデータに使用できます。
67.14.10. 抽出したメタデータのファイルへの保存
修復のためにダンプされたメタデータを使用する必要がある場合は、-f オプションと --settings オプションを使用して、抽出したメタデータをファイルに保存する必要があります。
手順
-
-f <filename>を--dump metadataに追加すると、指定されたファイルに raw メタデータが書き込まれます。このファイルは修復に使用できます。 -
-f <filename>を--dump metadata_allまたは--dump metadata_searchに追加すると、すべての場所の raw メタデータが指定されたファイルに書き込まれます。 --dump metadata_all|metadata_searchからメタデータテキストのインスタンスを 1 つ保存するには、--settings "metadata_offset=<offset>"を追加します。<offset>には、リスト表示された出力の "metadata at <offset>" の値を使用します。例67.26 コマンドの出力:
# pvck --dump metadata_search --settings metadata_offset=5632 -f meta.txt /dev/sdb Searching for metadata at offset 4096 size 1044480 metadata at 5632 length 1144 crc 50ea61c3 vg test seqno 2 id FaCsSz-1ZZn-mTO4-Xl4i-zb6G-BYat-u53Fxv # head -2 meta.txt test { id = "FaCsSz-1ZZn-mTO4-Xl4i-zb6G-BYat-u53Fxv"
67.14.11. pvcreate コマンドと vgcfgrestore コマンドを使用した、LVM ヘッダーとメタデータが破損したディスクの修復
破損した物理ボリューム、または新しいデバイスに置き換えられた物理ボリューム上のメタデータとヘッダーを復元できます。物理ボリュームのメタデータ領域を書き換えて、物理ボリュームからデータを復旧できる場合があります。
これらの手順は、各コマンドの意味、現在のボリュームのレイアウト、実現する必要があるレイアウト、およびバックアップメタデータファイルの内容をよく理解している場合にのみ、細心の注意を払って使用する必要があります。これらのコマンドはデータを破損する可能性があるため、トラブルシューティングについては Red Hat グローバルサポートサービスに問い合わせることを推奨します。
前提条件
- 見つからない物理ボリュームのメタデータを特定している。詳細は、見つからない LVM 物理ボリュームのメタデータの検索 を参照してください。
手順
pvcreateおよびvgcfgrestoreコマンドに必要な次の情報を収集します。# pvs -o+uuidコマンドを実行すると、ディスクと UUID に関する情報を収集できます。-
metadata-file は、VG の最新のメタデータバックアップファイルへのパスです (例:
/etc/lvm/backup/<vg-name>)。 - vg-name は、破損または欠落している PV がある VG の名前です。
-
このデバイスの破損した PV の UUID は、
# pvs -i+uuidコマンドの出力から取得した値です。 -
disk は、PV が配置されるディスクの名前です (例:
/dev/sdb)。これが正しいディスクであることを確認するか、Red Hat サポートにお問い合わせください。正しいディスクでない場合、次の手順に従うとデータが失われる可能性があります。
-
metadata-file は、VG の最新のメタデータバックアップファイルへのパスです (例:
ディスク上に LVM ヘッダーを再作成します。
# pvcreate --restorefile <metadata-file> --uuid <UUID> <disk>必要に応じて、ヘッダーが有効であることを確認します。
# pvck --dump headers <disk>ディスク上に VG メタデータを復元します。
# vgcfgrestore --file <metadata-file> <vg-name>必要に応じて、メタデータが復元されていることを確認します。
# pvck --dump metadata <disk>
VG のメタデータバックアップファイルがない場合は、抽出したメタデータのファイルへの保存 の手順を使用して取得できます。
検証
新しい物理ボリュームが損傷しておらず、ボリュームグループが正しく機能していることを確認するには、次のコマンドの出力を確認します。
# vgs
67.14.12. pvck コマンドを使用した、LVM ヘッダーとメタデータが破損したディスクの修復
これは pvcreate コマンドと vgcfgrestore コマンドを使用した、LVM ヘッダーとメタデータが破損したディスクの修復 の代替手段です。pvcreate および vgcfgrestore コマンドが機能しない場合があります。この方法は、損傷したディスクにターゲットを絞っています。
この方法では、pvck --dump で抽出されたメタデータ入力ファイル、または /etc/lvm/backup のバックアップファイルを使用します。可能であれば、同じ VG 内の別の PV から、または PV 上の 2 番目のメタデータ領域から pvck --dump によって保存されたメタデータを使用します。詳細は、抽出したメタデータのファイルへの保存 を参照してください。
手順
ディスク上のヘッダーとメタデータを修復します。
# pvck --repair -f <metadata-file> <disk>ここでは、以下のようになります。
-
<metadata-file> は、VG の最新のメタデータを含むファイルです。これは
/etc/lvm/backup/vg-nameにすることも、pvck --dump metadata_searchコマンド出力から取得した、raw メタデータテキストを含むファイルにすることもできます。 -
<disk> は、PV が配置されるディスクの名前です (例:
/dev/sdb)。データの損失を防ぐために、それが正しいディスクであることを確認してください。ディスクが正しいかどうかわからない場合は、Red Hat サポートにお問い合わせください。
-
<metadata-file> は、VG の最新のメタデータを含むファイルです。これは
メタデータファイルがバックアップファイルの場合、VG にメタデータを保持する各 PV で pvck --repair を実行する必要があります。メタデータファイルが別の PV から抽出された raw メタデータである場合、pvck --repair は破損した PV でのみ実行する必要があります。
検証
新しい物理ボリュームが損傷しておらず、ボリュームグループが正しく機能していることを確認するには、次のコマンドの出力を確認します。
# vgs <vgname># pvs <pvname># lvs <lvname>
67.14.13. LVM RAID のトラブルシューティング
LVM RAID デバイスのさまざまな問題のトラブルシューティングを実行して、データエラーの修正、デバイスの復旧、障害が発生したデバイスの置き換えを行うことができます。
67.14.13.1. RAID 論理ボリュームでのデータ整合性の確認
LVM は、RAID 論理ボリュームのスクラビングに対応します。RAID スクラビングは、アレイ内のデータおよびパリティーブロックをすべて読み込み、それが一貫しているかどうかを確認するプロセスです。lvchange --syncaction repair コマンドは、アレイでバックグラウンドの同期アクションを開始します。
手順
オプション: 次のいずれかのオプションを設定して、RAID 論理ボリュームが初期化される速度を制御します。
-
--maxrecoveryrate Rate[bBsSkKmMgG]は、RAID 論理ボリュームの最大復旧速度を設定し、通常の I/O 操作が排除されないようにします。 --minrecoveryrate Rate[bBsSkKmMgG]は、RAID 論理ボリュームの最小復旧速度を設定し、負荷の高い通常の I/O がある場合でも、同期操作の I/O が最小スループットを達成できるようにします。# lvchange --maxrecoveryrate 4K my_vg/my_lv Logical volume _my_vg/my_lv_changed.4K は、アレイに含まれる各デバイスの 1 秒あたりの値である復旧速度の値に置き換えます。接尾辞を指定しないと、デバイスごとの 1 秒あたりの kiB が想定されます。
# lvchange --syncaction repair my_vg/my_lvRAID スクラビング操作を実行すると、
syncアクションに必要なバックグラウンド I/O が、LVM デバイスへの他の I/O (ボリュームグループメタデータの更新など) よりも優先される可能性があります。これにより、他の LVM 操作が遅くなる可能性があります。注記これらの最大および最小 I/O 速度は、RAID デバイスを作成するときに使用することもできます。たとえば、
lvcreate --type raid10 -i 2 -m 1 -L 10G --maxrecoveryrate 128 -n my_lv my_vgを使用すると、ボリュームグループ my_vg 内に、3 ストライプでサイズが 10 G、最大復旧速度が 128 kiB/秒/デバイスの 2 方向の RAID10 アレイ my_lv が作成されます。
-
アレイ内の不一致数を修復せずに、アレイ内の不一致の数を表示します。
# lvchange --syncaction check my_vg/my_lvこのコマンドは、アレイでバックグラウンドの同期アクションを開始します。
-
オプション:
var/log/syslogファイルでカーネルメッセージを確認します。 アレイ内の不一致を修正します。
# lvchange --syncaction repair my_vg/my_lvこのコマンドは、RAID 論理ボリューム内の障害が発生したデバイスを修復または交換します。このコマンドを実行したら、
var/log/syslogファイルでカーネルメッセージを確認できます。
検証
スクラビング操作に関する情報を表示します。
# lvs -o +raid_sync_action,raid_mismatch_count my_vg/my_lv LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert SyncAction Mismatches my_lv my_vg rwi-a-r--- 500.00m 100.00 idle 0
67.14.13.2. 論理ボリュームに障害が発生した RAID デバイスの交換
RAID は従来の LVM ミラーリングとは異なります。LVM ミラーリングの場合は、障害が発生したデバイスを削除します。そうしないと、障害が発生したデバイスで RAID アレイが動作し続ける間、ミラーリングされた論理ボリュームがハングします。RAID1 以外の RAID レベルの場合、デバイスを削除すると、デバイスはより低いレベルの RAID に変換されます (たとえば、RAID6 から RAID5 へ、または RAID4 または RAID5 から RAID0 への変換)。
LVM では、障害が発生したデバイスを取り外して代替デバイスを割り当てる代わりに、lvconvert コマンドの --repair 引数を使用して、RAID 論理ボリューム内で物理ボリュームとして機能する障害が発生したデバイスを交換できます。
前提条件
ボリュームグループには、障害が発生したデバイスを置き換えるのに十分な空き容量を提供する物理ボリュームが含まれています。
ボリュームグループに十分な空きエクステントがある物理ボリュームがない場合は、
vgextendユーティリティーを使用して、十分なサイズの物理ボリュームを新たに追加します。
手順
RAID 論理ボリュームを表示します。
# lvs --all --options name,copy_percent,devices my_vg LV Cpy%Sync Devices my_lv 100.00 my_lv_rimage_0(0),my_lv_rimage_1(0),my_lv_rimage_2(0) [my_lv_rimage_0] /dev/sde1(1) [my_lv_rimage_1] /dev/sdc1(1) [my_lv_rimage_2] /dev/sdd1(1) [my_lv_rmeta_0] /dev/sde1(0) [my_lv_rmeta_1] /dev/sdc1(0) [my_lv_rmeta_2] /dev/sdd1(0)/dev/sdc デバイスに障害が発生したら、RAID 論理ボリュームを表示します。
# lvs --all --options name,copy_percent,devices my_vg /dev/sdc: open failed: No such device or address Couldn't find device with uuid A4kRl2-vIzA-uyCb-cci7-bOod-H5tX-IzH4Ee. WARNING: Couldn't find all devices for LV my_vg/my_lv_rimage_1 while checking used and assumed devices. WARNING: Couldn't find all devices for LV my_vg/my_lv_rmeta_1 while checking used and assumed devices. LV Cpy%Sync Devices my_lv 100.00 my_lv_rimage_0(0),my_lv_rimage_1(0),my_lv_rimage_2(0) [my_lv_rimage_0] /dev/sde1(1) [my_lv_rimage_1] [unknown](1) [my_lv_rimage_2] /dev/sdd1(1) [my_lv_rmeta_0] /dev/sde1(0) [my_lv_rmeta_1] [unknown](0) [my_lv_rmeta_2] /dev/sdd1(0)障害が発生したデバイスを交換します。
# lvconvert --repair my_vg/my_lv /dev/sdc: open failed: No such device or address Couldn't find device with uuid A4kRl2-vIzA-uyCb-cci7-bOod-H5tX-IzH4Ee. WARNING: Couldn't find all devices for LV my_vg/my_lv_rimage_1 while checking used and assumed devices. WARNING: Couldn't find all devices for LV my_vg/my_lv_rmeta_1 while checking used and assumed devices. Attempt to replace failed RAID images (requires full device resync)? [y/n]: y Faulty devices in my_vg/my_lv successfully replaced.オプション: 障害が発生したデバイスを置き換える物理ボリュームを手動で指定します。
# lvconvert --repair my_vg/my_lv replacement_pv代替の論理ボリュームを調べます。
# lvs --all --options name,copy_percent,devices my_vg /dev/sdc: open failed: No such device or address /dev/sdc1: open failed: No such device or address Couldn't find device with uuid A4kRl2-vIzA-uyCb-cci7-bOod-H5tX-IzH4Ee. LV Cpy%Sync Devices my_lv 43.79 my_lv_rimage_0(0),my_lv_rimage_1(0),my_lv_rimage_2(0) [my_lv_rimage_0] /dev/sde1(1) [my_lv_rimage_1] /dev/sdb1(1) [my_lv_rimage_2] /dev/sdd1(1) [my_lv_rmeta_0] /dev/sde1(0) [my_lv_rmeta_1] /dev/sdb1(0) [my_lv_rmeta_2] /dev/sdd1(0)障害が発生したデバイスをボリュームグループから削除するまで、LVM ユーティリティーは、障害が発生したデバイスが見つけられないことを示しています。
障害が発生したデバイスをボリュームグループから削除します。
# vgreduce --removemissing my_vg
検証
障害が発生したデバイスを取り外した後、利用可能な物理ボリュームを表示します。
# pvscan PV /dev/sde1 VG rhel_virt-506 lvm2 [<7.00 GiB / 0 free] PV /dev/sdb1 VG my_vg lvm2 [<60.00 GiB / 59.50 GiB free] PV /dev/sdd1 VG my_vg lvm2 [<60.00 GiB / 59.50 GiB free] PV /dev/sdd1 VG my_vg lvm2 [<60.00 GiB / 59.50 GiB free]障害が発生したデバイスを交換した後、論理ボリュームを調べます。
# lvs --all --options name,copy_percent,devices my_vg my_lv_rimage_0(0),my_lv_rimage_1(0),my_lv_rimage_2(0) [my_lv_rimage_0] /dev/sde1(1) [my_lv_rimage_1] /dev/sdb1(1) [my_lv_rimage_2] /dev/sdd1(1) [my_lv_rmeta_0] /dev/sde1(0) [my_lv_rmeta_1] /dev/sdb1(0) [my_lv_rmeta_2] /dev/sdd1(0)
67.14.14. マルチパス化された LVM デバイスに対する重複した物理ボリューム警告のトラブルシューティング
マルチパスストレージで LVM を使用する場合は、ボリュームグループまたは論理ボリュームのリストを表示する LVM コマンドを実行すると、以下のようなメッセージが表示される場合があります。
Found duplicate PV GDjTZf7Y03GJHjteqOwrye2dcSCjdaUi: using /dev/dm-5 not /dev/sdd
Found duplicate PV GDjTZf7Y03GJHjteqOwrye2dcSCjdaUi: using /dev/emcpowerb not /dev/sde
Found duplicate PV GDjTZf7Y03GJHjteqOwrye2dcSCjdaUi: using /dev/sddlmab not /dev/sdfこれらの警告のトラブルシューティングにより、LVM が警告を表示する理由を理解し、または警告を非表示にできます。
67.14.14.1. 重複した PV 警告の原因
Device Mapper Multipath (DM Multipath)、EMC PowerPath、または Hitachi Dynamic Link Manager (HDLM) などのマルチパスソフトウェアがシステム上のストレージデバイスを管理すると、特定の論理ユニット (LUN) への各パスが異なる SCSI デバイスとして登録されます。
マルチパスソフトウェアは、各パスにマップする新しいデバイスを作成します。各 LUN には、同じ基礎となるデータを参照する /dev ディレクトリーに複数のデバイスノードがあるため、すべてのデバイスノードには同じ LVM メタデータが含まれます。
| マルチパスソフトウェア | LUN への SCSI パス | マルチパスデバイスパスへのマッピング |
|---|---|---|
| DM Multipath |
|
|
| EMC PowerPath |
| |
| HDLM |
|
複数のデバイスノードが原因で、LVM ツールは同じメタデータを複数回検出し、複製として報告します。
67.14.14.2. PV の重複警告が発生した場合
LVM は、以下のいずれかのケースで重複した PV 警告を表示します。
- 同じデバイスへの単一パス
出力に表示される 2 つデバイスは、両方とも同じデバイスへの単一パスです。
以下の例は、重複デバイスが、同じデバイスへの両方の単一パスである、重複した PV の警告を示しています。
Found duplicate PV GDjTZf7Y03GJHjteqOwrye2dcSCjdaUi: using /dev/sdd not /dev/sdfmultipath -llコマンドを使用して現在の DM Multipath トポロジーをリスト表示すると、同じマルチパスマップの下に/dev/sddと/dev/sdfの両方を確認できます。これらの重複メッセージは警告のみで、LVM 操作が失敗しているわけではありません。代わりに、LVM が物理ボリュームとしてデバイスのいずれかのみを使用して他を無視していることを警告します。
メッセージは、LVM が誤ったデバイスを選択するか、ユーザーが警告を中断していることを示す場合は、フィルターを適用できます。フィルターは、物理ボリュームに必要なデバイスのみを検索し、マルチパスデバイスへの基礎となるパスを省略するように LVM を設定します。その結果、警告が表示されなくなりました。
- マルチパスマップ
出力に表示される 2 つのデバイスは、両方ともマルチパスマップです。
以下の例は、両方のマルチパスマップである 2 つのデバイスに対する重複した物理ボリューム警告を示しています。重複した物理ボリュームは、同じデバイスへの異なるパスではなく、2 つのデバイスに置かれます。
Found duplicate PV GDjTZf7Y03GJHjteqOwrye2dcSCjdaUi: using /dev/mapper/mpatha not /dev/mapper/mpathc Found duplicate PV GDjTZf7Y03GJHjteqOwrye2dcSCjdaUi: using /dev/emcpowera not /dev/emcpowerhこの状況は、同じデバイスへの両方の単一パスであるデバイスに対する重複する警告よりも複雑です。これらの警告は、多くの場合、マシンがアクセスできないデバイス (LUN クローンやミラーなど) にアクセスしていることを意味します。
マシンから削除するデバイスが分からないと、この状況は復旧できない可能性があります。Red Hat は、この問題に対処するために Red Hat テクニカルサポートにお問い合わせください。
67.14.14.3. PV の重複警告を防ぐ LVM デバイスフィルターの例
以下の例は、1 つの論理ユニット (LUN) への複数のストレージパスによって引き起こされる、重複した物理ボリュームの警告を回避する LVM デバイスフィルターを示しています。
論理ボリュームマネージャー (LVM) のフィルターを設定して、すべてのデバイスのメタデータをチェックできます。メタデータには、ルートボリュームグループを含むローカルハードディスクドライブとマルチパスデバイスが含まれます。マルチパスデバイスへの基礎となるパス (/dev/sdb、/dev/sdd など) を拒否すると、マルチパスデバイス自体で一意の各メタデータ領域が一度検出されるため、重複した物理ボリュームの警告を回避できます。
最初のハードディスクドライブ上の 2 番目のパーティションとデバイスマッパー (DM) マルチパスデバイスを許可し、それ以外をすべて拒否するには、次のように入力します。
filter = [ "a|/dev/sda2$|", "a|/dev/mapper/mpath.*|", "r|.*|" ]すべての HP SmartArray コントローラーと EMC PowerPath デバイスを許可するには、次のように入力します。
filter = [ "a|/dev/cciss/.*|", "a|/dev/emcpower.*|", "r|.*|" ]最初の IDE ドライブおよびマルチパスデバイス上のパーティションを許可するには、次のように入力します。
filter = [ "a|/dev/hda.*|", "a|/dev/mapper/mpath.*|", "r|.*|" ]