第10章 フェデレーションされたプランニング
コアでは、Data Virtualization はフェデレーションされたリレーショナルデータベースエンジンです。このクエリーエンジンでは、すべてのデータソースを 1 つの仮想データベースとして扱い、単一の SQL クエリーを介してそのデータソースにアクセスすることができます。その結果、手動でコーディングする代わりに、アプリケーションのビルドやデータソース間の他のリレーショナルデータベース操作を実行することにフォーカスできます。
10.1. プランニングの概要
クエリーエンジンが受信 SQL クエリーを受け取ると、以下の操作を実行します。
- pidgin-gitopsValidates 構文を 解析 し、内部フォームに変換します。
- すべての識別子を関数ライブラリーにメタデータと関数に 解決 します。
- メタデータの参照とタイプの署名に基づいた SQL セマンティクスの 検証
- 式と基準を簡素化するために SQL を 書き換え ます。
- 論理計画の最適化 で、通常の SQL を、詳細な最適化のための論理プランに反転します。Data Virtualization オプティマイザーは、主にルールベースです。クエリー構造とヒントに基づいて、特定のルールセットが適用されます。これらのルールは、より多くのルールの実行をトリガーする可能性があります。複数のルール内で、Data Virtualization はコスト情報を活用します。論理計画の最適化手順は、『 クライアント開発ガイド』 で説明されているように、'SET SHOWPLAN DEBUG' クラッシュを使用して確認できます。手順の例は、『 Query Planner 』 の「Reading a debug plan 」を参照してください。論理プランノードおよびルールベースの最適化の詳細については、「 Query Planner 」を参照してください。
- 処理計画変換 gitops-gitopsConvert は、ノードが基本的な処理操作を表す実行可能なフォームにロジック計画を反転します。最後の処理計画がクエリープランとして表示されます。詳細は、「 プランのクエリー」を参照 してください。
論理クエリー計画は、ソーステーブルのデータを予想される結果セットに変換するために使用される操作のツリーです。ツリーの下部(テーブル)から上部(出力)にデータフロー。主要な 論理操作は、条件に基づいて行を 選択 (選択またはフィルタリング)、プロジェクト (プロジェクトまたはコンピュート列値)、結合 (テーブルからのデータの取得)、ソート (ORDER BY)、重複削除 (SELECT DISTINCT)、グループ (GROUP BY)、および ユニオン (UNION)です。
たとえば、1970 からすべてのエンジニアリング従業員を取得する以下のクエリーについて考えてみましょう。
サンプルクエリー
SELECT e.title, e.lastname FROM Employees AS e JOIN Departments AS d ON e.dept_id = d.dept_id WHERE year(e.birthday) >= 1970 AND d.dept_name = 'Engineering'論理的には、Employees テーブルと Departments テーブルからのデータが取得され、指定したとおりに結合されてフィルターされ、最後に出力列が展開されます。そのため、正規のクエリー計画は以下のようになります。
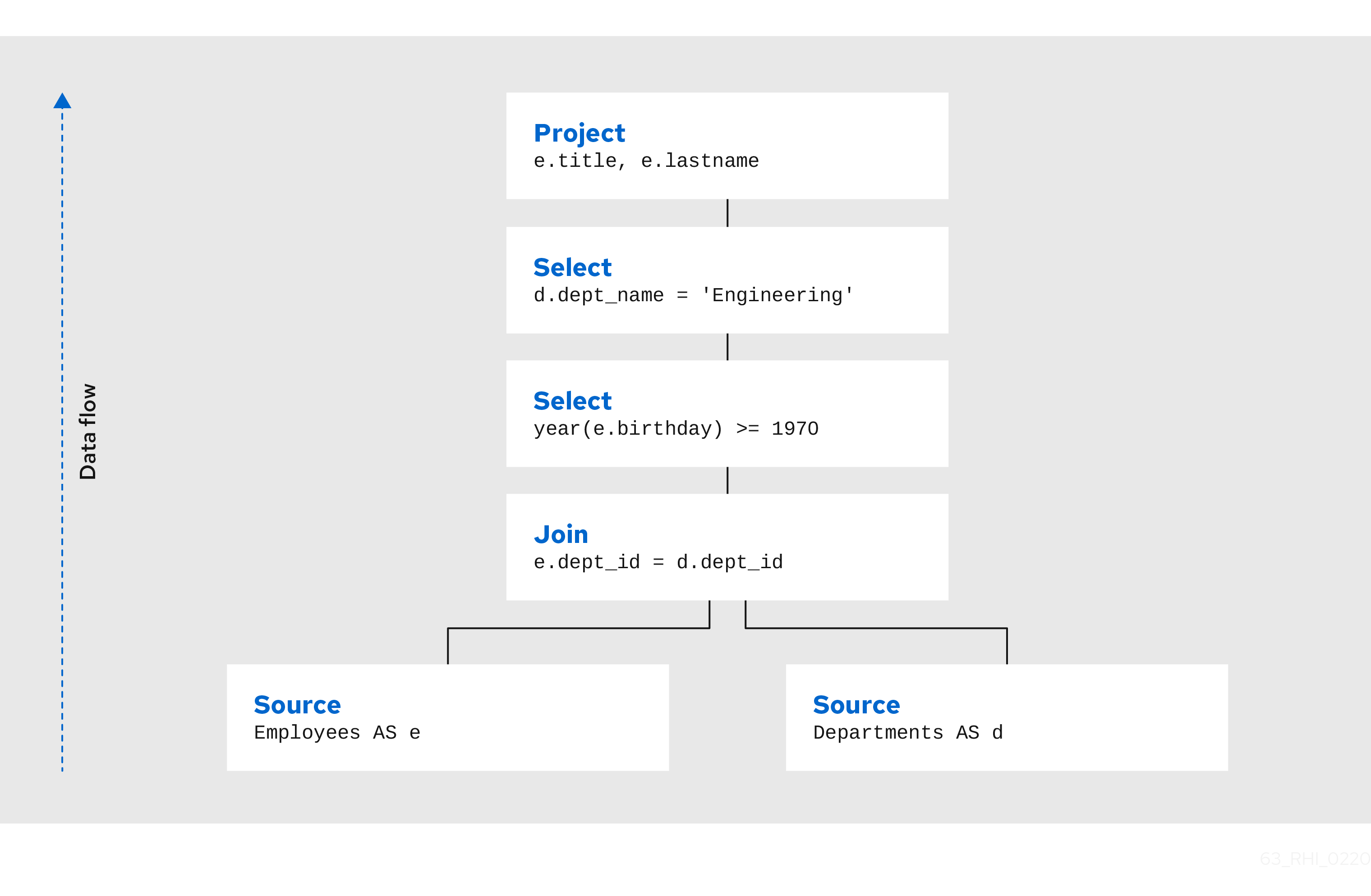
結合から下層のテーブルからデータフローが選択され、最終的にプロジェクトが最終結果を生成します。各ノード間で渡されるデータは、列と行を持つ結果セットの論理的です。
当然ながら、これは、プランが実際に実行される方法ではありません。この初期計画から、クエリープランナーはクエリー計画ツリーで変換を実行し、同じ結果を取得する同等のプランを迅速に生成します。フェデレーションされたクエリープランナーとリレーショナルデータベースプランナーの両方が、同じ概念と多くの同じプラン変換を処理します。この例では、Departments と Employees テーブルの基準がツリーにプッシュされ、結果をできるだけ早くフィルターします。
いずれの場合も、目的はクエリーの結果をできるだけ早く取得することです。ただし、リレーショナルデータベースプランナーは、主にストレージからデータをプルする際にアクセスパスを最適化することで、これを実現します。
これとは対照的に、フェデレーションされたクエリープランナーはデータソースに負担を課すため、ストレージアクセスに関する懸念はありません。フェデレーションされたクエリープランナーの最も重要な考慮事項は、データ転送を最小限に抑えることです。