3.2. Telco RAN DU 참조 설계 사양
3.2.1. Telco RAN DU 4.17 참조 설계 개요
Telco RAN distributed unit (DU) 4.17 참조 설계는 상용 하드웨어에서 실행되는 OpenShift Container Platform 4.17 클러스터를 구성하여 Telco RAN DU 워크로드를 호스팅합니다. Telco RAN DU 프로필을 실행하는 클러스터에 대해 안정적이고 반복 가능한 성능을 얻기 위해 권장, 테스트 및 지원되는 구성을 캡처합니다.
3.2.1.1. 배포 아키텍처 개요
중앙 집중식 관리형 RHACM 허브 클러스터에서 관리되는 클러스터에 telco RAN DU 4.17 참조 구성을 배포합니다. 참조 설계 사양(RDS)에는 관리 클러스터 및 허브 클러스터 구성 요소가 포함되어 있습니다.
그림 3.1. Telco RAN DU 배포 아키텍처 개요

3.2.2. Ttelco RAN DU 사용 모델 개요
다음 정보를 사용하여 허브 클러스터 및 관리형 단일 노드 OpenShift 클러스터에 대한 통신 RAN DU 워크로드, 클러스터 리소스 및 하드웨어 사양을 계획합니다.
3.2.2.1. Telco RAN DU 애플리케이션 워크로드
DU 작업자 노드에는 최대 성능을 위해 조정된 펌웨어가 있는 3세대 Xeon(Ice Lake) 2.20 Cryostat 또는 더 나은 CPU가 있어야 합니다.
5G RAN DU 사용자 애플리케이션 및 워크로드는 다음과 같은 모범 사례 및 애플리케이션 제한을 준수해야 합니다.
- 최신 버전의 Kubernetes 모범 사례를 준수하는 클라우드 네이티브 네트워크 기능(CNF)을 개발합니다.
- 고성능 네트워킹을 위해 SR-IOV를 사용합니다.
exec 프로브를 사용하여 다른 적절한 옵션을 사용할 수 없는 경우에만 사용
-
CNF에서 CPU 고정을 사용하는 경우 exec 프로브를 사용하지 마십시오. 다른 프로브 구현(예:
httpGet또는tcpSocket)을 사용합니다. - exec 프로브를 사용해야 하는 경우 exec 프로브 빈도 및 수량을 제한합니다. 최대 exec 프로브 수는 10초 미만으로 유지해야 하며 빈도를 10초 미만으로 설정하지 않아야 합니다.
-
CNF에서 CPU 고정을 사용하는 경우 exec 프로브를 사용하지 마십시오. 다른 프로브 구현(예:
대체 방법이 전혀 없는 한 exec 프로브를 사용하지 마십시오.
참고시작 프로브에는 지속적인 상태 작업 중에 최소한의 리소스가 필요합니다. exec 프로브의 제한은 주로 liveness 및 readiness 프로브에 적용됩니다.
이 사양에 설명된 참조 DU 애플리케이션 워크로드의 차원을 준수하는 테스트 워크로드는 openshift-kni/du-test-workloads 에서 확인할 수 있습니다.
3.2.2.2. Telco RAN DU 대표 참조 애플리케이션 워크로드 특성
대표적인 참조 애플리케이션 워크로드에는 다음과 같은 특징이 있습니다.
- 관리 및 제어 기능을 포함하여 vRAN 애플리케이션에 대한 최대 15개의 Pod 및 30개의 컨테이너가 있습니다.
-
Pod당 최대 2개의
ConfigMap및 4개의SecretCR 사용 - 10초 미만의 빈도로 최대 10 exec 프로브 사용
kube-apiserver에서의 증분 애플리케이션 로드는 클러스터 플랫폼 사용의 10% 미만입니다.참고플랫폼 지표에서 CPU 로드를 추출할 수 있습니다. 예를 들면 다음과 같습니다.
query=avg_over_time(pod:container_cpu_usage:sum{namespace="openshift-kube-apiserver"}[30m])- 애플리케이션 로그는 플랫폼 로그 수집기에 의해 수집되지 않습니다.
- 기본 CNI의 집계 트래픽은 1MBps 미만입니다.
3.2.2.3. Telco RAN 작업자 노드 클러스터 리소스 사용률
애플리케이션 워크로드 및 OpenShift Container Platform Pod를 포함하여 시스템에서 실행 중인 최대 Pod 수는 120입니다.
- 리소스 사용률
OpenShift Container Platform 리소스 사용률은 다음과 같은 애플리케이션 워크로드 특성을 포함한 다양한 요인에 따라 다릅니다.
- Pod 수
- 프로브 유형 및 빈도
- 커널 네트워킹을 통한 기본 CNI 또는 보조 CNI의 메시징 속도
- API 액세스 속도
- 로깅 속도
- 스토리지 IOPS
클러스터 리소스 요구 사항은 다음 조건에 따라 적용할 수 있습니다.
- 클러스터는 설명된 대표 애플리케이션 워크로드를 실행하고 있습니다.
- 클러스터는 "Telco RAN DU 작업자 노드 클러스터 리소스 사용률"에 설명된 제약 조건으로 관리됩니다.
- RAN DU 사용 모델 구성에서 선택 사항으로 명시된 구성 요소는 적용되지 않습니다.
리소스 사용률에 미치는 영향 및 Telco RAN DU 참조 디자인 범위를 벗어난 구성에 대한 KPI 대상을 충족하기 위해 추가 분석을 수행해야 합니다. 요구 사항에 따라 클러스터에서 추가 리소스를 할당해야 할 수 있습니다.
3.2.2.4. hub 클러스터 관리 특성
RHACM(Red Hat Advanced Cluster Management)은 권장되는 클러스터 관리 솔루션입니다. hub 클러스터에서 다음 제한으로 구성합니다.
- 규정 준수 평가 간격을 10분 이상 사용하여 최대 5개의 RHACM 정책을 구성합니다.
- 정책에서 최대 10개의 관리형 클러스터 템플릿을 사용합니다. 가능한 경우 hub-side template을 사용하십시오.
policy-controller및observability-controller애드온을 제외한 모든 RHACM 애드온을 비활성화합니다.Observability를 기본 구성으로 설정합니다.중요선택적 구성 요소 또는 추가 기능을 구성하면 리소스 사용량이 추가되고 전체 시스템 성능이 저하될 수 있습니다.
자세한 내용은 참조 설계 배포 구성 요소를 참조하십시오.
| 지표 | 제한 | 참고 |
|---|---|---|
| CPU 사용량 | 4000 mc 미만 - 2 코어 (4 하이퍼스레드) | 플랫폼 CPU는 예약된 각 코어의 두 하이퍼스레드를 포함하여 예약된 코어에 고정되어 있습니다. 시스템은 주기적인 시스템 작업 및 급증을 허용하도록 안정적인 상태에서 3개의 CPU (3000mc)를 사용하도록 설계되었습니다. |
| 사용된 메모리 | 16G 미만 |
3.2.2.5. Telco RAN DU RDS 구성 요소
다음 섹션에서는 telco RAN DU 워크로드를 실행하기 위해 클러스터를 구성하고 배포하는 데 사용하는 다양한 OpenShift Container Platform 구성 요소 및 구성에 대해 설명합니다.
그림 3.2. Telco RAN DU 참조 구성 요소
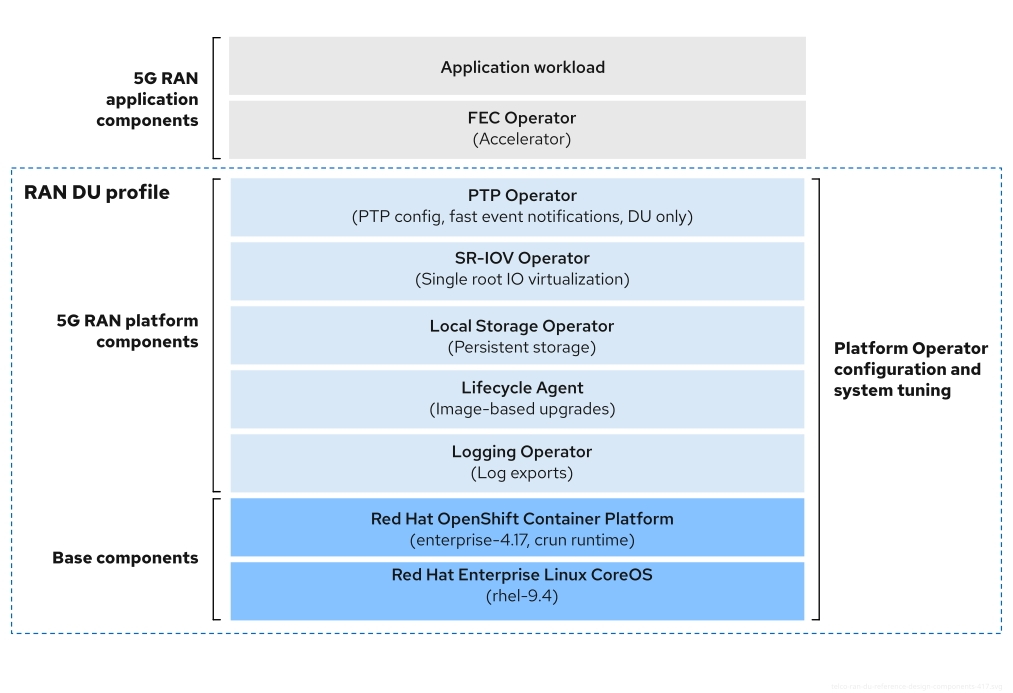
telco RAN DU 프로필에 포함되지 않은 구성 요소가 워크로드 애플리케이션에 할당된 CPU 리소스에 영향을 미치지 않도록 합니다.
트리 부족 드라이버는 지원되지 않습니다.
3.2.3. Telco RAN DU 4.17 참조 설계 구성 요소
다음 섹션에서는 RAN DU 워크로드를 실행하기 위해 클러스터를 구성하고 배포하는 데 사용하는 다양한 OpenShift Container Platform 구성 요소 및 구성에 대해 설명합니다.
3.2.3.1. 호스트 펌웨어 튜닝
- 이번 릴리스의 새로운 기능
- GitOps ZTP로 배포하는 관리 클러스터의 호스트 펌웨어 설정을 구성할 수 있습니다.
- 설명
-
초기 클러스터 배포 중에 최적의 성능을 위해 호스트 펌웨어 설정을 조정합니다. 관리 클러스터 호스트 펌웨어 설정은 hub 클러스터에서 site
ConfigCR 및 GitOps ZTP를 사용하여 관리 클러스터를 배포할 때 생성되는BareMetalHostCR(사용자 정의 리소스)으로 사용할 수 있습니다. - 제한 및 요구사항
- 하이퍼 스레딩을 활성화해야 합니다.
- 엔지니어링 고려 사항
- 최대 성능을 위해 모든 설정을 조정합니다.
- 전원 비용 절감을 위해 튜닝하지 않는 한 모든 설정은 최대 성능을 위해 예상됩니다.
- 필요에 따라 성능 저하를 위해 호스트 펌웨어를 조정할 수 있습니다.
- 보안 부팅을 활성화합니다. 보안 부팅이 활성화되면 서명된 커널 모듈만 커널에 의해 로드됩니다. 트리 외부 드라이버는 지원되지 않습니다.
3.2.3.2. Node Tuning Operator
- 이번 릴리스의 새로운 기능
- 이 릴리스에는 참조 디자인 업데이트가 없습니다
- 설명
성능 프로필을 생성하여 클러스터 성능을 조정합니다.
중요RAN DU 사용 사례를 사용하려면 대기 시간이 짧은 성능을 위해 클러스터를 조정해야 합니다.
- 제한 및 요구사항
Node Tuning Operator는
PerformanceProfileCR을 사용하여 클러스터를 구성합니다. RAN DU 프로파일PerformanceProfileCR에서 다음 설정을 구성해야 합니다.- 예약 및 분리된 코어를 선택하고 Intel 3rd Generation Xeon (Ice Lake) 2.20 Cryostat CPU에서 최소 4개의 하이퍼스레드(각주 2개 코어)를 할당하거나 최대 성능을 위해 펌웨어를 튜닝했는지 확인합니다.
-
포함된 각 코어에 대해 두 개의 하이퍼스레드 형제를 모두 포함하도록 예약된
cpuset을 설정합니다. 예약되지 않은 코어는 워크로드 예약에 할당 가능한 CPU로 사용할 수 있습니다. 하이퍼스레드 형제가 예약된 코어와 분리된 코어 간에 분할되지 않도록 합니다. - 예약 및 분리된 CPU로 설정된 내용에 따라 모든 코어에 모든 스레드를 포함하도록 예약 및 분리된 CPU를 구성합니다.
- 예약된 CPU 세트에 포함할 각 NUMA 노드의 코어 0을 설정합니다.
- 대규모 페이지 크기를 1G로 설정합니다.
관리 파티션에 워크로드를 추가해서는 안 됩니다. OpenShift 관리 플랫폼의 일부인 포드만 관리 파티션에 주석을 달아야 합니다.
- 엔지니어링 고려 사항
- RT 커널을 사용하여 성능 요구 사항을 충족해야 합니다. 그러나 필요한 경우 클러스터 성능에 해당 영향을 미치는RT 커널을 사용할 수 있습니다.
- 구성하는 대규모 페이지 수는 애플리케이션 워크로드 요구 사항에 따라 다릅니다. 이 매개변수의 변형은 예상되고 허용됩니다.
- 선택한 하드웨어 및 시스템에서 사용 중인 추가 구성 요소를 기반으로 예약 및 격리된 CPU 세트 구성에서 변동이 예상됩니다. 변형은 지정된 제한을 충족해야 합니다.
- IRQ 선호도 지원이 없는 하드웨어는 분리된 CPU에 영향을 미칩니다. 보장된 전체 CPU QoS가 있는 Pod가 할당된 CPU를 완전히 사용하도록 하려면 서버의 모든 하드웨어가 IRQ 선호도를 지원해야 합니다. 자세한 내용은 "노드의 효과적인 IRQ 선호도 설정 찾기"를 참조하십시오.
cpu CryostatingMode: AllNodes 설정을 사용하여 클러스터 배포 중에 워크로드 파티셔닝을 활성화하면 PerformanceProfile CR에 예약된 CPU가 운영 체제, 인터럽트 및 OpenShift 플랫폼 Pod에 충분한 CPU를 포함해야 합니다.
cgroup v1은 더 이상 사용되지 않는 기능입니다. 더 이상 사용되지 않는 기능은 여전히 OpenShift Container Platform에 포함되어 있으며 계속 지원됩니다. 그러나 이 기능은 향후 릴리스에서 제거될 예정이므로 새로운 배포에는 사용하지 않는 것이 좋습니다.
OpenShift Container Platform에서 더 이상 사용되지 않거나 삭제된 주요 기능의 최신 목록은 OpenShift Container Platform 릴리스 노트에서 더 이상 사용되지 않고 삭제된 기능 섹션을 참조하십시오.
3.2.3.3. PTP Operator
- 이번 릴리스의 새로운 기능
-
새로운 버전 두 가지 PTP(Precision Time Protocol) 빠른 이벤트 REST API를 사용할 수 있습니다. 소비자 애플리케이션은 PTP 이벤트 생산자 사이드카의 이벤트 REST API에 직접 등록할 수 있습니다. PTP 빠른 이벤트 REST API v2는 이벤트 소비자 3.0의 O-RAN O-Cloud 알림 API 사양을 준수합니다.
PtpOperatorConfig리소스에서ptpEventConfig.apiVersion필드를 설정하여 API 버전을 변경할 수 있습니다.
-
새로운 버전 두 가지 PTP(Precision Time Protocol) 빠른 이벤트 REST API를 사용할 수 있습니다. 소비자 애플리케이션은 PTP 이벤트 생산자 사이드카의 이벤트 REST API에 직접 등록할 수 있습니다. PTP 빠른 이벤트 REST API v2는 이벤트 소비자 3.0의 O-RAN O-Cloud 알림 API 사양을 준수합니다.
- 설명
클러스터 노드에서 PTP 지원 및 구성에 대한 자세한 내용은 "Recommended single-node OpenShift cluster configuration for vDU 애플리케이션 워크로드"에서 참조하십시오. DU 노드는 다음 모드에서 실행할 수 있습니다.
- 일반 클럭(OC)은 마스터 클록 또는 경계 클록(T-BC)에 동기화되었습니다.
- 마스터 클록 (T-GM)은 단일 또는 듀얼 카드 E810 NIC를 지원하는 GPS에서 동기화되었습니다.
- E810 NIC를 지원하는 이중 경계 클럭( NIC당 하나씩)입니다.
- 다른 NIC에 시간 소스가 여러 개인 경우 HA(고가용성) 시스템 시계가 있는 T-BC입니다.
- 선택 사항: 라디오 장치(RU)의 경계 클럭입니다.
- 제한 및 요구사항
- 듀얼 NIC 및 HA에 대한 두 개의 경계 클럭으로 제한됩니다.
- T-GM의 두 카드 E810 구성으로 제한됩니다.
- 엔지니어링 고려 사항
- 일반 클럭, 경계 클럭, 고가용성 시스템 시계가 있는 경계 클록 및 마스터 클록에 대한 구성이 제공됩니다.
-
PTP 빠른 이벤트 알림은
ConfigMapCR을 사용하여 PTP 이벤트 서브스크립션을 저장합니다. - PTP 이벤트 REST API v2에는 리소스 경로에 포함된 모든 하위 계층 리소스에 대한 글로벌 서브스크립션이 없습니다. 사용 가능한 다양한 이벤트 유형에 소비자 애플리케이션을 별도로 서브스크립션합니다.
3.2.3.4. SR-IOV Operator
- 이번 릴리스의 새로운 기능
- 이 릴리스에는 참조 디자인 업데이트가 없습니다
- 설명
-
SR-IOV Operator는 SR-IOV CNI 및 장치 플러그인을 프로비저닝하고 구성합니다.
netdevice(커널 VF) 및 DPDK(Vfio) 장치가 모두 지원되며 RAN 사용 모델에 적용됩니다. - 제한 및 요구사항
- OpenShift Container Platform 지원 장치 사용
- BIOS에서 SR-IOV 및 IOMMU 활성화: SR-IOV Network Operator는 커널 명령줄에서 IOMMU를 자동으로 활성화합니다.
- SR-IOV VF는 PF에서 링크 상태 업데이트를 수신하지 않습니다. 링크 다운 탐지가 필요한 경우 프로토콜 수준에서 이를 구성해야 합니다.
Secure Boot 또는 커널 잠금을 사용하는 펌웨어 업데이트를 지원하지 않는 NIC는 애플리케이션 워크로드에 필요한 VF 수를 지원하기 위해 충분한 VF(가상 기능)로 사전 구성해야 합니다.
참고문서화되지 않은
disablePlugins옵션을 사용하여 지원되지 않는 NIC에 대해 SR-IOV Operator 플러그인을 비활성화해야 할 수 있습니다.
- 엔지니어링 고려 사항
-
vfio드라이버 유형의 SR-IOV 인터페이스는 일반적으로 높은 처리량 또는 짧은 대기 시간이 필요한 애플리케이션의 보조 네트워크를 활성화하는 데 사용됩니다. -
SriovNetwork및SriovNetworkNodePolicy고객 리소스 (CR)의 구성과 수에 대한 고객의 변화가 예상됩니다. -
IOMMU 커널 명령줄 설정은 설치 시
MachineConfigCR에 적용됩니다. 이렇게 하면SriovOperatorCR에서 노드를 추가할 때 노드가 재부팅되지 않습니다. - 노드를 병렬로 드레이닝하는 SR-IOV 지원은 단일 노드 OpenShift 클러스터에는 적용되지 않습니다.
-
배포에서
SriovOperatorConfigCR을 제외하면 CR이 자동으로 생성되지 않습니다. - 워크로드를 특정 노드로 고정하거나 제한하는 시나리오에서는 SR-IOV 병렬 노드 드레이닝 기능으로 인해 Pod 일정이 변경되지 않습니다. 이러한 시나리오에서 SR-IOV Operator는 병렬 노드 드레이닝 기능을 비활성화합니다.
-
3.2.3.5. 로깅
- 이번 릴리스의 새로운 기능
- 이번 릴리스에서는 Cluster Logging Operator 6.0이 새로 추가되었습니다. 새 API 버전에 맞게 기존 구현을 업데이트합니다.
- 설명
- 로깅을 사용하여 원격 분석을 위해 far edge 노드에서 로그를 수집합니다. 권장되는 로그 수집기는 Vector입니다.
- 엔지니어링 고려 사항
- 예를 들어, 인프라 및 감사 로그 이외의 로그를 처리하려면 추가 로깅 속도를 기반으로 하는 추가 CPU 및 네트워크 대역폭이 필요합니다.
OpenShift Container Platform 4.14부터 Vector는 참조 로그 수집기입니다.
참고RAN 사용 모델에서 fluentd 사용은 더 이상 사용되지 않습니다.
3.2.3.6. SRIOV-FEC Operator
- 이번 릴리스의 새로운 기능
- 이 릴리스에는 참조 디자인 업데이트가 없습니다
- 설명
- SRIOV-FEC Operator는 FEC 액셀러레이터 하드웨어를 지원하는 선택적 타사 Certified Operator입니다.
- 제한 및 요구사항
FEC Operator v2.7.0부터 다음을 수행합니다.
-
SecureBoot지원 -
PF의vfio드라이버를 사용하려면 Pod에 삽입되는vfio-token을 사용해야 합니다. Pod의 애플리케이션은 EAL 매개변수--vfio-vf-token을 사용하여VF토큰을 DPDK에 전달할 수 있습니다.
-
- 엔지니어링 고려 사항
-
SRIOV-FEC Operator는
분리된CPU 세트의 CPU 코어를 사용합니다. - 예를 들어 검증 정책을 확장하여 FEC 준비 상태를 사전 점검의 일부로 검증할 수 있습니다.
-
SRIOV-FEC Operator는
3.2.3.7. 라이프사이클 에이전트
- 이번 릴리스의 새로운 기능
- 이 릴리스에는 참조 디자인 업데이트가 없습니다
- 설명
- Lifecycle Agent는 단일 노드 OpenShift 클러스터에 대한 로컬 라이프사이클 관리 서비스를 제공합니다.
- 제한 및 요구사항
- Lifecycle Agent는 추가 작업자가 있는 다중 노드 클러스터 또는 단일 노드 OpenShift 클러스터에는 적용되지 않습니다.
- 클러스터를 설치할 때 생성하는 영구 볼륨이 필요합니다. 파티션 요구 사항은 GitOps ZTP를 사용할 때 "ostree stateroots 간 공유 컨테이너 디렉터리 구성"을 참조하십시오.
3.2.3.8. Local Storage Operator
- 이번 릴리스의 새로운 기능
- 이 릴리스에는 참조 디자인 업데이트가 없습니다
- 설명
-
Local Storage Operator를 사용하여 애플리케이션에서
PVC리소스로 사용할 수 있는 영구 볼륨을 생성할 수 있습니다. 생성하는PV리소스의 수 및 유형은 요구 사항에 따라 다릅니다. - 엔지니어링 고려 사항
-
PV를 생성하기 전에PVCR에 대한 백업 스토리지를 생성합니다. 파티션, 로컬 볼륨, LVM 볼륨 또는 전체 디스크일 수 있습니다. 디스크 및 파티션을 올바르게 할당하도록 각 장치에 액세스하는 데 사용되는 하드웨어 경로에서
LocalVolumeCR의 장치 목록을 참조하십시오. 논리 이름(예:/dev/sda)은 노드를 재부팅해도 일관성이 보장되지 않습니다.자세한 내용은 장치 식별자에 대한 RHEL 9 설명서 를 참조하십시오.
-
3.2.3.9. LVM 스토리지
- 이번 릴리스의 새로운 기능
- 이 릴리스에는 참조 디자인 업데이트가 없습니다
LVM(Logical Volume Manager) 스토리지는 선택적 구성 요소입니다.
LVM 스토리지를 스토리지 솔루션으로 사용하면 Local Storage Operator를 대체합니다. CPU 리소스는 플랫폼 오버헤드로 관리 파티션에 할당됩니다. 참조 구성에는 이러한 스토리지 솔루션 중 하나가 포함되어야 하지만 둘 다 포함되지는 않습니다.
- 설명
-
LVM 스토리지는 블록 및 파일 스토리지에 대한 동적 프로비저닝을 제공합니다. LVM 스토리지는 애플리케이션에서
PVC리소스로 사용할 수 있는 로컬 장치에서 논리 볼륨을 생성합니다. 볼륨 확장 및 스냅샷도 가능합니다. - 제한 및 요구사항
- 단일 노드 OpenShift 클러스터에서 영구 스토리지는 둘 다 아닌 LVM 스토리지 또는 로컬 스토리지에서 제공해야 합니다.
- 볼륨 스냅샷은 참조 구성에서 제외됩니다.
- 엔지니어링 고려 사항
- LVM 스토리지는 RAN DU 사용 사례의 로컬 스토리지 구현으로 사용할 수 있습니다. LVM 스토리지를 스토리지 솔루션으로 사용하면 Local Storage Operator가 교체되고 필요한 CPU가 플랫폼 오버헤드로 관리 파티션에 할당됩니다. 참조 구성에는 이러한 스토리지 솔루션 중 하나가 포함되어야 하지만 둘 다 포함되지는 않습니다.
- 스토리지 요구 사항에 충분한 디스크 또는 파티션을 사용할 수 있는지 확인합니다.
3.2.3.10. 워크로드 파티셔닝
- 이번 릴리스의 새로운 기능
- 이 릴리스에는 참조 디자인 업데이트가 없습니다
- 설명
- 워크로드 파티셔닝은 DU 프로파일의 일부인 OpenShift 플랫폼과 Day 2 Operator Pod를 예약된 CPU 세트에 고정하고 노드 회계에서 예약된 CPU를 제거합니다. 이렇게 하면 사용자 워크로드에서 예약되지 않은 모든 CPU 코어를 사용할 수 있습니다.
- 제한 및 요구사항
-
Pod를 관리 파티션에 적용할 수 있도록네임스페이스및 Pod CR에 주석을 달 수 있어야 합니다. - CPU 제한이 있는 Pod는 파티션에 할당할 수 없습니다. 변경으로 Pod QoS를 변경할 수 있기 때문입니다.
- 관리 파티션에 할당할 수 있는 최소 CPU 수에 대한 자세한 내용은 Node Tuning Operator 를 참조하십시오.
-
- 엔지니어링 고려 사항
- 워크로드 파티셔닝은 모든 관리 Pod를 예약된 코어에 고정합니다. 워크로드 시작, 노드 재부팅 또는 기타 시스템 이벤트가 발생할 때 발생하는 CPU 사용 급증을 고려하여 예약된 세트에 코어 수를 할당해야 합니다.
3.2.3.11. 클러스터 튜닝
- 이번 릴리스의 새로운 기능
- 이 릴리스에는 참조 디자인 업데이트가 없습니다
- 설명
- 설치 전에 활성화하거나 비활성화할 수 있는 선택적 구성 요소의 전체 목록은 "클러스터 기능"을 참조하십시오.
- 제한 및 요구사항
- 설치 관리자가 프로비저닝한 설치 방법에서는 클러스터 기능을 사용할 수 없습니다.
모든 플랫폼 튜닝 구성을 적용해야 합니다. 다음 표에는 필요한 플랫폼 튜닝 구성이 나열되어 있습니다.
Expand 표 3.2. 클러스터 기능 구성 기능 설명 선택적 클러스터 기능 제거
단일 노드 OpenShift 클러스터에서만 선택적 클러스터 Operator를 비활성화하여 OpenShift Container Platform 풋프린트를 줄입니다.
- Marketplace 및 Node Tuning Operator를 제외한 모든 선택적 Operator를 제거합니다.
클러스터 모니터링 구성
다음을 수행하여 공간 절약을 위해 모니터링 스택을 구성합니다.
-
로컬
alertmanager및telemeter구성 요소를 비활성화합니다. -
RHACM 관찰 기능을 사용하는 경우 경고를 허브 클러스터에 전달하려면 적절한
additionalAlertManagerConfigsCR로 CR을 보강해야 합니다. Prometheus보존 기간을 24시간으로 줄입니다.참고RHACM 허브 클러스터는 관리되는 클러스터 메트릭을 집계합니다.
네트워킹 진단 비활성화
필요하지 않으므로 단일 노드 OpenShift에 대한 네트워킹 진단을 비활성화합니다.
단일 OperatorHub 카탈로그 소스 구성
RAN DU 배포에 필요한 Operator만 포함하는 단일 카탈로그 소스를 사용하도록 클러스터를 구성합니다. 각 카탈로그 소스는 클러스터에서 CPU 사용을 늘립니다. 단일
CatalogSource를 사용하면 플랫폼 CPU 예산에 적합합니다.Console Operator 비활성화
콘솔이 비활성화된 콘솔과 함께 클러스터가 배포된 경우
ConsoleCR(ConsoleOperatorDisable.yaml)이 필요하지 않습니다. 콘솔이 활성화된 상태에서 클러스터가 배포된 경우ConsoleCR을 적용해야 합니다.
- 엔지니어링 고려 사항
OpenShift Container Platform 4.16 이상에서는
PerformanceProfileCR을 적용할 때 클러스터에서 cgroups v1로 자동 되돌리지 않습니다. 클러스터에서 실행되는 워크로드에 cgroup v1이 필요한 경우 cgroups v1을 사용하도록 클러스터를 구성해야 합니다.참고cgroups v1을 구성해야 하는 경우 구성을 초기 클러스터 배포의 일부로 설정합니다.
3.2.3.12. 머신 구성
- 이번 릴리스의 새로운 기능
- 이 릴리스에는 참조 디자인 업데이트가 없습니다
- 제한 및 요구사항
CRI-O wipe disable
MachineConfig는 디스크의 이미지가 정의된 유지 관리 창에서 예약된 유지 관리 중이 아닌 정적이라고 가정합니다. 이미지가 정적임을 확인하려면 PodimagePullPolicy필드를Always로 설정하지 마십시오.Expand 표 3.3. 머신 구성 옵션 기능 설명 컨테이너 런타임
모든 노드 역할에 대해 컨테이너 런타임을
crun으로 설정합니다.kubelet 구성 및 컨테이너 마운트 숨기기
kubelet 하우스키핑 및 제거 모니터링의 빈도를 줄여 CPU 사용량을 줄입니다. kubelet 및 CRI-O에 표시되는 컨테이너 마운트 네임스페이스를 생성하여 시스템 마운트 검사 리소스 사용량을 줄입니다.
SCTP
선택적 구성(기본적으로 활성화)은 SCTP를 활성화합니다. SCTP는 RAN 애플리케이션에 필요하지만 RHCOS에서 기본적으로 비활성화되어 있습니다.
kdump
선택적 설정(기본적으로 사용)을 사용하면 커널 패닉이 발생할 때 kdump에서 디버그 정보를 캡처할 수 있습니다.
참고kdump를 활성화하는 참조 CR에는 참조 구성에 포함된 드라이버 및 커널 모듈 세트에 따라 메모리 예약이 증가합니다.
CRI-O 제거 비활성화
클린 종료 후 CRI-O 이미지 캐시 자동 제거 기능을 비활성화합니다.
SR-IOV 관련 커널 인수
커널 명령줄에 추가 SR-IOV 관련 인수가 포함됩니다.
RCU 일반 systemd 서비스
시스템이 완전히 시작된 후
rcu_normal를 설정합니다.일회성 시간 동기화
컨트롤 플레인 또는 작업자 노드에 대한 일회성 NTP 시스템 시간 동기화 작업을 실행합니다.
3.2.3.13. Telco RAN DU 배포 구성 요소
다음 섹션에서는 RHACM(Red Hat Advanced Cluster Management)을 사용하여 허브 클러스터를 구성하는 데 사용하는 다양한 OpenShift Container Platform 구성 요소 및 구성에 대해 설명합니다.
3.2.3.13.1. Red Hat Advanced Cluster Management
- 이번 릴리스의 새로운 기능
- 이 릴리스에는 참조 디자인 업데이트가 없습니다
- 설명
RHACM(Red Hat Advanced Cluster Management)은 배포된 클러스터에 대한 MCE(Multi Cluster Engine) 설치 및 지속적인 라이프사이클 관리 기능을 제공합니다. 유지 관리 기간 중 클러스터에
정책CR(사용자 정의 리소스)을 적용하여 클러스터 구성과 업그레이드를 선언적으로 관리합니다.토폴로지 Aware Lifecycle Manager(TALM)에서 관리하는 대로 RHACM 정책 컨트롤러를 사용하여 정책을 적용합니다. 정책 컨트롤러는 구성, 업그레이드 및 클러스터 상태를 처리합니다.
관리형 클러스터를 설치할 때 RHACM은 사용자 지정 디스크 파티셔닝, 역할 할당 및 머신 구성 풀에 할당을 지원하기 위해 라벨을 개별 노드에 적용합니다.
SiteConfig또는ClusterInstanceCR을 사용하여 이러한 구성을 정의합니다.- 제한 및 요구사항
-
ArgoCD 애플리케이션당 300개의
SiteConfigCR. 여러 애플리케이션을 사용하여 단일 허브 클러스터에서 지원하는 최대 클러스터 수를 달성할 수 있습니다. -
단일 허브 클러스터는 5
PolicyCR이 각 클러스터에 바인딩된 최대 3500개의 배포된 단일 노드 OpenShift 클러스터를 지원합니다.
-
ArgoCD 애플리케이션당 300개의
- 엔지니어링 고려 사항
- RHACM 정책 허브 측 템플릿을 사용하여 클러스터 구성을 보다 효과적으로 확장할 수 있습니다. 단일 그룹 정책 또는 그룹과 클러스터별 값이 템플릿으로 대체되는 일반 그룹 정책 수를 사용하여 정책 수를 크게 줄일 수 있습니다.
-
클러스터별 구성: 관리 클러스터에는 일반적으로 개별 클러스터에 고유한 몇 가지 구성 값이 있습니다. 이러한 구성은 클러스터 이름을 기반으로
ConfigMapCR에서 가져온 값을 사용하여 RHACM 정책 허브 쪽 템플릿을 사용하여 관리해야 합니다. - 관리 클러스터에 CPU 리소스를 저장하려면 클러스터의 GitOps ZTP 설치 후 정적 구성을 적용하는 정책을 관리 클러스터에서 바인딩해야 합니다.
3.2.3.13.2. 토폴로지 인식 라이프사이클 관리자
- 이번 릴리스의 새로운 기능
- 이 릴리스에는 참조 디자인 업데이트가 없습니다
- 설명
- TALM( topology Aware Lifecycle Manager)은 클러스터 및 Operator 업그레이드, 구성 등을 포함한 변경 사항이 네트워크로 롤아웃되는 방식을 관리하기 위해 허브 클러스터에서만 실행되는 Operator입니다.
- 제한 및 요구사항
- TALM은 400 배치로 동시 클러스터 배포를 지원합니다.
- 사전 캐싱 및 백업 기능은 단일 노드 OpenShift 클러스터에만 사용할 수 있습니다.
- 엔지니어링 고려 사항
-
ran.openshift.io/ztp-deploy-ECDSA 주석이 있는 정책만 초기 클러스터 설치 중에 TALM에 의해 자동으로 적용됩니다. -
추가
ClusterGroupUpgradeCR을 생성하여 TALM이 수정하는 정책을 제어할 수 있습니다.
-
3.2.3.13.3. GitOps 및 GitOps ZTP 플러그인
- 이번 릴리스의 새로운 기능
- 이 릴리스에는 참조 디자인 업데이트가 없습니다
- 설명
GitOps 및 GitOps ZTP 플러그인은 클러스터 배포 및 구성을 관리하기 위한 GitOps 기반 인프라를 제공합니다. 클러스터 정의 및 구성은 Git에서 선언적 상태로 유지됩니다. site
ConfigOperator가 설치 CR로 렌더링하는 허브 클러스터에ClusterInstanceCR을 적용할 수 있습니다. 또는 GitOps ZTP 플러그인을 사용하여SiteConfigCR에서 직접 설치 CR을 생성할 수 있습니다. GitOps ZTP 플러그인은PolicyGenTemplateCR을 기반으로 하는 정책의 구성 CR 자동 래핑을 지원합니다.참고기준 참조 구성 CR을 사용하여 관리형 클러스터에서 여러 버전의 OpenShift Container Platform을 배포하고 관리할 수 있습니다. 기준 CR과 함께 사용자 정의 CR을 사용할 수 있습니다.
여러 버전별 정책을 동시에 유지하려면 Git을 사용하여 소스 CR 및 정책 CR 버전(
PolicyGenTemplate또는PolicyGenerator)을 관리합니다.참조 CR 및 사용자 정의 CR을 다른 디렉터리에 보관합니다. 이렇게 하면 사용자 정의 CR을 건드리지 않고 모든 디렉터리 콘텐츠를 간단하게 교체하여 참조 CR을 패치하고 업데이트할 수 있습니다.
- 제한
-
ArgoCD 애플리케이션당 300개의
SiteConfigCR. 여러 애플리케이션을 사용하여 단일 허브 클러스터에서 지원하는 최대 클러스터 수를 달성할 수 있습니다. -
Git의
/source-crs폴더의 콘텐츠는 GitOps ZTP 플러그인 컨테이너에 제공된 콘텐츠를 덮어씁니다. Git이 검색 경로에서 우선합니다. PolicyGenTemplate을 생성기로 포함하는kustomization.yaml파일과 동일한 디렉터리에/source-crs폴더를 추가합니다.참고이 컨텍스트에서
/source-crs디렉터리의 대체 위치는 지원되지 않습니다.-
SiteConfigCR의extraManifestPath필드는 OpenShift Container Platform 4.15 이상에서 더 이상 사용되지 않습니다. 대신 새로운extraManifests.searchPaths필드를 사용합니다.
-
ArgoCD 애플리케이션당 300개의
- 엔지니어링 고려 사항
-
멀티 노드 클러스터 업그레이드의 경우
paused필드를true로 설정하여 유지 관리 기간 동안MachineConfigPool(MCP) CR을 일시 중지할 수 있습니다.MCPCR에서maxUnavailable설정을 구성하여MCP당 노드 수를 동시에 늘릴 수 있습니다.MaxUnavailable필드는MachineConfig업데이트 중에 동시에 사용할 수 없는 풀의 노드 백분율을 정의합니다.maxUnavailable을 최대 허용 가능한 값으로 설정합니다. 이렇게 하면 업그레이드 중에 클러스터의 재부팅 횟수가 줄어들어 업그레이드 시간이 단축됩니다.MCPCR 일시 중지를 마지막으로 해제하면 변경된 모든 구성이 단일 재부팅으로 적용됩니다. -
클러스터 설치 중에
paused필드를true로 설정하고maxUnavailable을 100%로 설정하여 설치 시간을 단축하여 사용자 정의MCPCR을 일시 중지할 수 있습니다. -
콘텐츠를 업데이트할 때 파일의 혼동 또는 의도하지 않은 덮어쓰기를 방지하려면
/source-crs폴더 및 Git의 추가 매니페스트에서 사용자 제공 CR에 대해 고유하고 구분 가능한 이름을 사용합니다. -
SiteConfigCR을 사용하면 여러 추가 경로가 허용됩니다. 동일한 이름의 파일이 여러 디렉토리 경로에 있는 경우 마지막으로 발견된 파일이 우선합니다. 이를 통해 Git에 버전별 Day 0 매니페스트(extra-manifests)의 전체 세트를 배치하고 siteConfig CR에서 참조할수 있습니다. 이 기능을 사용하면 여러 OpenShift Container Platform 버전을 관리 클러스터에 동시에 배포할 수 있습니다.
-
멀티 노드 클러스터 업그레이드의 경우
3.2.3.13.4. 에이전트 기반 설치 프로그램
- 이번 릴리스의 새로운 기능
- 이 릴리스에는 참조 디자인 업데이트가 없습니다
- 설명
에이전트 기반 설치 관리자(ABI)는 중앙 집중식 인프라 없이 설치 기능을 제공합니다. 설치 프로그램은 서버에 마운트하는 ISO 이미지를 생성합니다. 서버를 부팅하면 OpenShift Container Platform을 설치하고 추가 매니페스트를 제공했습니다.
참고ABI를 사용하여 허브 클러스터 없이 OpenShift Container Platform 클러스터를 설치할 수도 있습니다. 이러한 방식으로 ABI를 사용할 때 이미지 레지스트리가 계속 필요합니다.
에이전트 기반 설치 관리자(ABI)는 선택적 구성 요소입니다.
- 제한 및 요구사항
- 설치 시 제한된 추가 매니페스트 세트를 제공할 수 있습니다.
-
RAN DU 사용 사례에 필요한
MachineConfigurationCR을 포함해야 합니다.
- 엔지니어링 고려 사항
- ABI는 기본 OpenShift Container Platform 설치를 제공합니다.
- 설치 후 Day 2 Operator 및 RAN DU 사용 사례 구성을 설치합니다.
3.2.4. Ttelco RAN distributed unit (DU) 참조 구성 CR
다음 CR(사용자 정의 리소스)을 사용하여 telco RAN DU 프로필을 사용하여 OpenShift Container Platform 클러스터를 구성하고 배포합니다. 일부 CR은 요구 사항에 따라 선택 사항입니다. 변경할 수 있는 CR 필드에는 YAML 주석을 사용하여 CR에 주석이 추가됩니다.
ztp-site-generate 컨테이너 이미지에서 RAN DU CR의 전체 세트를 추출할 수 있습니다. 자세한 내용은 GitOps ZTP 사이트 구성 리포지토리 준비를 참조하십시오.
3.2.4.1. 2일차 Operator 참조 CR
| Component | 참조 CR | 선택 사항 | 이번 릴리스의 새로운 기능 |
|---|---|---|---|
| 클러스터 로깅 | 없음 | 없음 | |
| 클러스터 로깅 | 없음 | 없음 | |
| 클러스터 로깅 | 없음 | 없음 | |
| 클러스터 로깅 | 없음 | 제공됨 | |
| 클러스터 로깅 | 없음 | 제공됨 | |
| 클러스터 로깅 | 없음 | 제공됨 | |
| 클러스터 로깅 | 없음 | 없음 | |
| Lifecycle Agent Operator | 제공됨 | 없음 | |
| Lifecycle Agent Operator | 제공됨 | 없음 | |
| Lifecycle Agent Operator | 제공됨 | 없음 | |
| Lifecycle Agent Operator | 제공됨 | 없음 | |
| Local Storage Operator | 제공됨 | 없음 | |
| Local Storage Operator | 제공됨 | 없음 | |
| Local Storage Operator | 제공됨 | 없음 | |
| Local Storage Operator | 제공됨 | 없음 | |
| Local Storage Operator | 제공됨 | 없음 | |
| LVM Operator | 제공됨 | 없음 | |
| LVM Operator | 제공됨 | 없음 | |
| LVM Operator | 제공됨 | 없음 | |
| LVM Operator | 제공됨 | 없음 | |
| LVM Operator | 제공됨 | 없음 | |
| Node Tuning Operator | 없음 | 없음 | |
| Node Tuning Operator | 없음 | 없음 | |
| PTP 빠른 이벤트 알림 | 제공됨 | 없음 | |
| PTP 빠른 이벤트 알림 | 제공됨 | 없음 | |
| PTP 빠른 이벤트 알림 | 제공됨 | 없음 | |
| PTP 빠른 이벤트 알림 | 제공됨 | 없음 | |
| PTP Operator - 고가용성 | 없음 | 없음 | |
| PTP Operator - 고가용성 | 없음 | 없음 | |
| PTP Operator | 없음 | 없음 | |
| PTP Operator | 없음 | 없음 | |
| PTP Operator | 없음 | 없음 | |
| PTP Operator | 없음 | 없음 | |
| PTP Operator | 없음 | 없음 | |
| PTP Operator | 없음 | 없음 | |
| PTP Operator | 없음 | 없음 | |
| PTP Operator | 없음 | 없음 | |
| SR-IOV FEC Operator | 제공됨 | 없음 | |
| SR-IOV FEC Operator | 제공됨 | 없음 | |
| SR-IOV FEC Operator | 제공됨 | 없음 | |
| SR-IOV FEC Operator | 제공됨 | 없음 | |
| SR-IOV Operator | 없음 | 없음 | |
| SR-IOV Operator | 없음 | 없음 | |
| SR-IOV Operator | 없음 | 없음 | |
| SR-IOV Operator | 없음 | 없음 | |
| SR-IOV Operator | 없음 | 없음 | |
| SR-IOV Operator | 없음 | 없음 | |
| SR-IOV Operator | 없음 | 없음 |
3.2.4.2. 클러스터 튜닝 참조 CR
| Component | 참조 CR | 선택 사항 | 이번 릴리스의 새로운 기능 |
|---|---|---|---|
| 구성 가능 OpenShift | 없음 | 없음 | |
| 콘솔 비활성화 | 제공됨 | 없음 | |
| 연결이 끊긴 레지스트리 | 없음 | 없음 | |
| 연결이 끊긴 레지스트리 | 없음 | 없음 | |
| 연결이 끊긴 레지스트리 | 없음 | 없음 | |
| 연결이 끊긴 레지스트리 | 없음 | 없음 | |
| 연결이 끊긴 레지스트리 | 단일 노드 OpenShift 및 다중 노드 클러스터에는 OperatorHub가 필요합니다. | 없음 | |
| 모니터링 구성 | 없음 | 없음 | |
| 네트워크 진단 비활성화 | 없음 | 없음 |
3.2.4.3. 머신 구성 참조 CR
| Component | 참조 CR | 선택 사항 | 이번 릴리스의 새로운 기능 |
|---|---|---|---|
| 컨테이너 런타임(crun) | 없음 | 없음 | |
| 컨테이너 런타임(crun) | 없음 | 없음 | |
| CRI-O wipe 비활성화 | 없음 | 없음 | |
| CRI-O wipe 비활성화 | 없음 | 없음 | |
| kdump 활성화 | 없음 | 없음 | |
| kdump 활성화 | 없음 | 없음 | |
| kubelet 구성 / 컨테이너 마운트 숨기기 | 없음 | 없음 | |
| kubelet 구성 / 컨테이너 마운트 숨기기 | 없음 | 없음 | |
| 일회성 시간 동기화 | 없음 | 없음 | |
| 일회성 시간 동기화 | 없음 | 없음 | |
| SCTP | 제공됨 | 없음 | |
| SCTP | 제공됨 | 없음 | |
| RCU 일반 설정 | 없음 | 없음 | |
| RCU 일반 설정 | 없음 | 없음 | |
| SR-IOV 관련 커널 인수 | 없음 | 없음 | |
| SR-IOV 관련 커널 인수 | 없음 | 없음 |
3.2.4.4. YAML 참조
다음은 telco RAN DU 4.17 참조 구성을 구성하는 모든 CR(사용자 정의 리소스)에 대한 전체 참조입니다.
3.2.4.4.1. 2일차 Operator 참조 YAML
ClusterLogForwarder.yaml
apiVersion: "observability.openshift.io/v1"
kind: ClusterLogForwarder
metadata:
name: instance
namespace: openshift-logging
annotations: {}
spec:
# outputs: $outputs
# pipelines: $pipelines
serviceAccount:
name: logcollector
#apiVersion: "observability.openshift.io/v1"
#kind: ClusterLogForwarder
#metadata:
# name: instance
# namespace: openshift-logging
# spec:
# outputs:
# - type: "kafka"
# name: kafka-open
# # below url is an example
# kafka:
# url: tcp://10.46.55.190:9092/test
# filters:
# - name: test-labels
# type: openshiftLabels
# openshiftLabels:
# label1: test1
# label2: test2
# label3: test3
# label4: test4
# pipelines:
# - name: all-to-default
# inputRefs:
# - audit
# - infrastructure
# filterRefs:
# - test-labels
# outputRefs:
# - kafka-open
# serviceAccount:
# name: logcollectorClusterLogNS.yaml
---
apiVersion: v1
kind: Namespace
metadata:
name: openshift-logging
annotations:
workload.openshift.io/allowed: managementClusterLogOperGroup.yaml
---
apiVersion: operators.coreos.com/v1
kind: OperatorGroup
metadata:
name: cluster-logging
namespace: openshift-logging
annotations: {}
spec:
targetNamespaces:
- openshift-loggingClusterLogServiceAccount.yaml
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: logcollector
namespace: openshift-logging
annotations: {}ClusterLogServiceAccountAuditBinding.yaml
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: logcollector-audit-logs-binding
annotations: {}
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: collect-audit-logs
subjects:
- kind: ServiceAccount
name: logcollector
namespace: openshift-loggingClusterLogServiceAccountInfrastructureBinding.yaml
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: logcollector-infrastructure-logs-binding
annotations: {}
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: collect-infrastructure-logs
subjects:
- kind: ServiceAccount
name: logcollector
namespace: openshift-loggingClusterLogSubscription.yaml
apiVersion: operators.coreos.com/v1alpha1
kind: Subscription
metadata:
name: cluster-logging
namespace: openshift-logging
annotations: {}
spec:
channel: "stable-6.0"
name: cluster-logging
source: redhat-operators-disconnected
sourceNamespace: openshift-marketplace
installPlanApproval: Manual
status:
state: AtLatestKnownImageBasedUpgrade.yaml
apiVersion: lca.openshift.io/v1
kind: ImageBasedUpgrade
metadata:
name: upgrade
spec:
stage: Idle
# When setting `stage: Prep`, remember to add the seed image reference object below.
# seedImageRef:
# image: $image
# version: $versionLcaSubscription.yaml
apiVersion: operators.coreos.com/v1alpha1
kind: Subscription
metadata:
name: lifecycle-agent
namespace: openshift-lifecycle-agent
annotations: {}
spec:
channel: "stable"
name: lifecycle-agent
source: redhat-operators-disconnected
sourceNamespace: openshift-marketplace
installPlanApproval: Manual
status:
state: AtLatestKnownLcaSubscriptionNS.yaml
apiVersion: v1
kind: Namespace
metadata:
name: openshift-lifecycle-agent
annotations:
workload.openshift.io/allowed: management
labels:
kubernetes.io/metadata.name: openshift-lifecycle-agentLcaSubscriptionOperGroup.yaml
apiVersion: operators.coreos.com/v1
kind: OperatorGroup
metadata:
name: lifecycle-agent
namespace: openshift-lifecycle-agent
annotations: {}
spec:
targetNamespaces:
- openshift-lifecycle-agentStorageClass.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
annotations: {}
name: example-storage-class
provisioner: kubernetes.io/no-provisioner
reclaimPolicy: DeleteStorageLV.yaml
apiVersion: "local.storage.openshift.io/v1"
kind: "LocalVolume"
metadata:
name: "local-disks"
namespace: "openshift-local-storage"
annotations: {}
spec:
logLevel: Normal
managementState: Managed
storageClassDevices:
# The list of storage classes and associated devicePaths need to be specified like this example:
- storageClassName: "example-storage-class"
volumeMode: Filesystem
fsType: xfs
# The below must be adjusted to the hardware.
# For stability and reliability, it's recommended to use persistent
# naming conventions for devicePaths, such as /dev/disk/by-path.
devicePaths:
- /dev/disk/by-path/pci-0000:05:00.0-nvme-1
#---
## How to verify
## 1. Create a PVC
# apiVersion: v1
# kind: PersistentVolumeClaim
# metadata:
# name: local-pvc-name
# spec:
# accessModes:
# - ReadWriteOnce
# volumeMode: Filesystem
# resources:
# requests:
# storage: 100Gi
# storageClassName: example-storage-class
#---
## 2. Create a pod that mounts it
# apiVersion: v1
# kind: Pod
# metadata:
# labels:
# run: busybox
# name: busybox
# spec:
# containers:
# - image: quay.io/quay/busybox:latest
# name: busybox
# resources: {}
# command: ["/bin/sh", "-c", "sleep infinity"]
# volumeMounts:
# - name: local-pvc
# mountPath: /data
# volumes:
# - name: local-pvc
# persistentVolumeClaim:
# claimName: local-pvc-name
# dnsPolicy: ClusterFirst
# restartPolicy: Always
## 3. Run the pod on the cluster and verify the size and access of the `/data` mountStorageNS.yaml
apiVersion: v1
kind: Namespace
metadata:
name: openshift-local-storage
annotations:
workload.openshift.io/allowed: managementStorageOperGroup.yaml
apiVersion: operators.coreos.com/v1
kind: OperatorGroup
metadata:
name: openshift-local-storage
namespace: openshift-local-storage
annotations: {}
spec:
targetNamespaces:
- openshift-local-storageStorageSubscription.yaml
apiVersion: operators.coreos.com/v1alpha1
kind: Subscription
metadata:
name: local-storage-operator
namespace: openshift-local-storage
annotations: {}
spec:
channel: "stable"
name: local-storage-operator
source: redhat-operators-disconnected
sourceNamespace: openshift-marketplace
installPlanApproval: Manual
status:
state: AtLatestKnownLVMOperatorStatus.yaml
# This CR verifies the installation/upgrade of the Sriov Network Operator
apiVersion: operators.coreos.com/v1
kind: Operator
metadata:
name: lvms-operator.openshift-storage
annotations: {}
status:
components:
refs:
- kind: Subscription
namespace: openshift-storage
conditions:
- type: CatalogSourcesUnhealthy
status: "False"
- kind: InstallPlan
namespace: openshift-storage
conditions:
- type: Installed
status: "True"
- kind: ClusterServiceVersion
namespace: openshift-storage
conditions:
- type: Succeeded
status: "True"
reason: InstallSucceededStorageLVMCluster.yaml
apiVersion: lvm.topolvm.io/v1alpha1
kind: LVMCluster
metadata:
name: lvmcluster
namespace: openshift-storage
annotations: {}
spec: {}
#example: creating a vg1 volume group leveraging all available disks on the node
# except the installation disk.
# storage:
# deviceClasses:
# - name: vg1
# thinPoolConfig:
# name: thin-pool-1
# sizePercent: 90
# overprovisionRatio: 10StorageLVMSubscription.yaml
apiVersion: operators.coreos.com/v1alpha1
kind: Subscription
metadata:
name: lvms-operator
namespace: openshift-storage
annotations: {}
spec:
channel: "stable"
name: lvms-operator
source: redhat-operators-disconnected
sourceNamespace: openshift-marketplace
installPlanApproval: Manual
status:
state: AtLatestKnownStorageLVMSubscriptionNS.yaml
apiVersion: v1
kind: Namespace
metadata:
name: openshift-storage
labels:
workload.openshift.io/allowed: "management"
openshift.io/cluster-monitoring: "true"
annotations: {}StorageLVMSubscriptionOperGroup.yaml
apiVersion: operators.coreos.com/v1
kind: OperatorGroup
metadata:
name: lvms-operator-operatorgroup
namespace: openshift-storage
annotations: {}
spec:
targetNamespaces:
- openshift-storagePerformanceProfile.yaml
apiVersion: performance.openshift.io/v2
kind: PerformanceProfile
metadata:
# if you change this name make sure the 'include' line in TunedPerformancePatch.yaml
# matches this name: include=openshift-node-performance-${PerformanceProfile.metadata.name}
# Also in file 'validatorCRs/informDuValidator.yaml':
# name: 50-performance-${PerformanceProfile.metadata.name}
name: openshift-node-performance-profile
annotations:
ran.openshift.io/reference-configuration: "ran-du.redhat.com"
spec:
additionalKernelArgs:
- "rcupdate.rcu_normal_after_boot=0"
- "efi=runtime"
- "vfio_pci.enable_sriov=1"
- "vfio_pci.disable_idle_d3=1"
- "module_blacklist=irdma"
cpu:
isolated: $isolated
reserved: $reserved
hugepages:
defaultHugepagesSize: $defaultHugepagesSize
pages:
- size: $size
count: $count
node: $node
machineConfigPoolSelector:
pools.operator.machineconfiguration.openshift.io/$mcp: ""
nodeSelector:
node-role.kubernetes.io/$mcp: ''
numa:
topologyPolicy: "restricted"
# To use the standard (non-realtime) kernel, set enabled to false
realTimeKernel:
enabled: true
workloadHints:
# WorkloadHints defines the set of upper level flags for different type of workloads.
# See https://github.com/openshift/cluster-node-tuning-operator/blob/master/docs/performanceprofile/performance_profile.md#workloadhints
# for detailed descriptions of each item.
# The configuration below is set for a low latency, performance mode.
realTime: true
highPowerConsumption: false
perPodPowerManagement: falseTunedPerformancePatch.yaml
apiVersion: tuned.openshift.io/v1
kind: Tuned
metadata:
name: performance-patch
namespace: openshift-cluster-node-tuning-operator
annotations: {}
spec:
profile:
- name: performance-patch
# Please note:
# - The 'include' line must match the associated PerformanceProfile name, following below pattern
# include=openshift-node-performance-${PerformanceProfile.metadata.name}
# - When using the standard (non-realtime) kernel, remove the kernel.timer_migration override from
# the [sysctl] section and remove the entire section if it is empty.
data: |
[main]
summary=Configuration changes profile inherited from performance created tuned
include=openshift-node-performance-openshift-node-performance-profile
[scheduler]
group.ice-ptp=0:f:10:*:ice-ptp.*
group.ice-gnss=0:f:10:*:ice-gnss.*
group.ice-dplls=0:f:10:*:ice-dplls.*
[service]
service.stalld=start,enable
service.chronyd=stop,disable
recommend:
- machineConfigLabels:
machineconfiguration.openshift.io/role: "$mcp"
priority: 19
profile: performance-patchPtpConfigBoundaryForEvent.yaml
apiVersion: ptp.openshift.io/v1
kind: PtpConfig
metadata:
name: boundary
namespace: openshift-ptp
annotations: {}
spec:
profile:
- name: "boundary"
ptp4lOpts: "-2 --summary_interval -4"
phc2sysOpts: "-a -r -m -n 24 -N 8 -R 16"
ptpSchedulingPolicy: SCHED_FIFO
ptpSchedulingPriority: 10
ptpSettings:
logReduce: "true"
ptp4lConf: |
# The interface name is hardware-specific
[$iface_slave]
masterOnly 0
[$iface_master_1]
masterOnly 1
[$iface_master_2]
masterOnly 1
[$iface_master_3]
masterOnly 1
[global]
#
# Default Data Set
#
twoStepFlag 1
slaveOnly 0
priority1 128
priority2 128
domainNumber 24
#utc_offset 37
clockClass 248
clockAccuracy 0xFE
offsetScaledLogVariance 0xFFFF
free_running 0
freq_est_interval 1
dscp_event 0
dscp_general 0
dataset_comparison G.8275.x
G.8275.defaultDS.localPriority 128
#
# Port Data Set
#
logAnnounceInterval -3
logSyncInterval -4
logMinDelayReqInterval -4
logMinPdelayReqInterval -4
announceReceiptTimeout 3
syncReceiptTimeout 0
delayAsymmetry 0
fault_reset_interval -4
neighborPropDelayThresh 20000000
masterOnly 0
G.8275.portDS.localPriority 128
#
# Run time options
#
assume_two_step 0
logging_level 6
path_trace_enabled 0
follow_up_info 0
hybrid_e2e 0
inhibit_multicast_service 0
net_sync_monitor 0
tc_spanning_tree 0
tx_timestamp_timeout 50
unicast_listen 0
unicast_master_table 0
unicast_req_duration 3600
use_syslog 1
verbose 0
summary_interval 0
kernel_leap 1
check_fup_sync 0
clock_class_threshold 135
#
# Servo Options
#
pi_proportional_const 0.0
pi_integral_const 0.0
pi_proportional_scale 0.0
pi_proportional_exponent -0.3
pi_proportional_norm_max 0.7
pi_integral_scale 0.0
pi_integral_exponent 0.4
pi_integral_norm_max 0.3
step_threshold 2.0
first_step_threshold 0.00002
max_frequency 900000000
clock_servo pi
sanity_freq_limit 200000000
ntpshm_segment 0
#
# Transport options
#
transportSpecific 0x0
ptp_dst_mac 01:1B:19:00:00:00
p2p_dst_mac 01:80:C2:00:00:0E
udp_ttl 1
udp6_scope 0x0E
uds_address /var/run/ptp4l
#
# Default interface options
#
clock_type BC
network_transport L2
delay_mechanism E2E
time_stamping hardware
tsproc_mode filter
delay_filter moving_median
delay_filter_length 10
egressLatency 0
ingressLatency 0
boundary_clock_jbod 0
#
# Clock description
#
productDescription ;;
revisionData ;;
manufacturerIdentity 00:00:00
userDescription ;
timeSource 0xA0
recommend:
- profile: "boundary"
priority: 4
match:
- nodeLabel: "node-role.kubernetes.io/$mcp"PtpConfigForHAForEvent.yaml
apiVersion: ptp.openshift.io/v1
kind: PtpConfig
metadata:
name: boundary-ha
namespace: openshift-ptp
annotations: {}
spec:
profile:
- name: "boundary-ha"
ptp4lOpts: ""
phc2sysOpts: "-a -r -m -n 24 -N 8 -R 16"
ptpSchedulingPolicy: SCHED_FIFO
ptpSchedulingPriority: 10
ptpSettings:
logReduce: "true"
haProfiles: "$profile1,$profile2"
recommend:
- profile: "boundary-ha"
priority: 4
match:
- nodeLabel: "node-role.kubernetes.io/$mcp"PtpConfigMasterForEvent.yaml
# The grandmaster profile is provided for testing only
# It is not installed on production clusters
apiVersion: ptp.openshift.io/v1
kind: PtpConfig
metadata:
name: grandmaster
namespace: openshift-ptp
annotations: {}
spec:
profile:
- name: "grandmaster"
# The interface name is hardware-specific
interface: $interface
ptp4lOpts: "-2 --summary_interval -4"
phc2sysOpts: "-a -r -m -n 24 -N 8 -R 16"
ptpSchedulingPolicy: SCHED_FIFO
ptpSchedulingPriority: 10
ptpSettings:
logReduce: "true"
ptp4lConf: |
[global]
#
# Default Data Set
#
twoStepFlag 1
slaveOnly 0
priority1 128
priority2 128
domainNumber 24
#utc_offset 37
clockClass 255
clockAccuracy 0xFE
offsetScaledLogVariance 0xFFFF
free_running 0
freq_est_interval 1
dscp_event 0
dscp_general 0
dataset_comparison G.8275.x
G.8275.defaultDS.localPriority 128
#
# Port Data Set
#
logAnnounceInterval -3
logSyncInterval -4
logMinDelayReqInterval -4
logMinPdelayReqInterval -4
announceReceiptTimeout 3
syncReceiptTimeout 0
delayAsymmetry 0
fault_reset_interval -4
neighborPropDelayThresh 20000000
masterOnly 0
G.8275.portDS.localPriority 128
#
# Run time options
#
assume_two_step 0
logging_level 6
path_trace_enabled 0
follow_up_info 0
hybrid_e2e 0
inhibit_multicast_service 0
net_sync_monitor 0
tc_spanning_tree 0
tx_timestamp_timeout 50
unicast_listen 0
unicast_master_table 0
unicast_req_duration 3600
use_syslog 1
verbose 0
summary_interval 0
kernel_leap 1
check_fup_sync 0
clock_class_threshold 7
#
# Servo Options
#
pi_proportional_const 0.0
pi_integral_const 0.0
pi_proportional_scale 0.0
pi_proportional_exponent -0.3
pi_proportional_norm_max 0.7
pi_integral_scale 0.0
pi_integral_exponent 0.4
pi_integral_norm_max 0.3
step_threshold 2.0
first_step_threshold 0.00002
max_frequency 900000000
clock_servo pi
sanity_freq_limit 200000000
ntpshm_segment 0
#
# Transport options
#
transportSpecific 0x0
ptp_dst_mac 01:1B:19:00:00:00
p2p_dst_mac 01:80:C2:00:00:0E
udp_ttl 1
udp6_scope 0x0E
uds_address /var/run/ptp4l
#
# Default interface options
#
clock_type OC
network_transport L2
delay_mechanism E2E
time_stamping hardware
tsproc_mode filter
delay_filter moving_median
delay_filter_length 10
egressLatency 0
ingressLatency 0
boundary_clock_jbod 0
#
# Clock description
#
productDescription ;;
revisionData ;;
manufacturerIdentity 00:00:00
userDescription ;
timeSource 0xA0
recommend:
- profile: "grandmaster"
priority: 4
match:
- nodeLabel: "node-role.kubernetes.io/$mcp"PtpConfigSlaveForEvent.yaml
apiVersion: ptp.openshift.io/v1
kind: PtpConfig
metadata:
name: du-ptp-slave
namespace: openshift-ptp
annotations: {}
spec:
profile:
- name: "slave"
# The interface name is hardware-specific
interface: $interface
ptp4lOpts: "-2 -s --summary_interval -4"
phc2sysOpts: "-a -r -m -n 24 -N 8 -R 16"
ptpSchedulingPolicy: SCHED_FIFO
ptpSchedulingPriority: 10
ptpSettings:
logReduce: "true"
ptp4lConf: |
[global]
#
# Default Data Set
#
twoStepFlag 1
slaveOnly 1
priority1 128
priority2 128
domainNumber 24
#utc_offset 37
clockClass 255
clockAccuracy 0xFE
offsetScaledLogVariance 0xFFFF
free_running 0
freq_est_interval 1
dscp_event 0
dscp_general 0
dataset_comparison G.8275.x
G.8275.defaultDS.localPriority 128
#
# Port Data Set
#
logAnnounceInterval -3
logSyncInterval -4
logMinDelayReqInterval -4
logMinPdelayReqInterval -4
announceReceiptTimeout 3
syncReceiptTimeout 0
delayAsymmetry 0
fault_reset_interval -4
neighborPropDelayThresh 20000000
masterOnly 0
G.8275.portDS.localPriority 128
#
# Run time options
#
assume_two_step 0
logging_level 6
path_trace_enabled 0
follow_up_info 0
hybrid_e2e 0
inhibit_multicast_service 0
net_sync_monitor 0
tc_spanning_tree 0
tx_timestamp_timeout 50
unicast_listen 0
unicast_master_table 0
unicast_req_duration 3600
use_syslog 1
verbose 0
summary_interval 0
kernel_leap 1
check_fup_sync 0
clock_class_threshold 7
#
# Servo Options
#
pi_proportional_const 0.0
pi_integral_const 0.0
pi_proportional_scale 0.0
pi_proportional_exponent -0.3
pi_proportional_norm_max 0.7
pi_integral_scale 0.0
pi_integral_exponent 0.4
pi_integral_norm_max 0.3
step_threshold 2.0
first_step_threshold 0.00002
max_frequency 900000000
clock_servo pi
sanity_freq_limit 200000000
ntpshm_segment 0
#
# Transport options
#
transportSpecific 0x0
ptp_dst_mac 01:1B:19:00:00:00
p2p_dst_mac 01:80:C2:00:00:0E
udp_ttl 1
udp6_scope 0x0E
uds_address /var/run/ptp4l
#
# Default interface options
#
clock_type OC
network_transport L2
delay_mechanism E2E
time_stamping hardware
tsproc_mode filter
delay_filter moving_median
delay_filter_length 10
egressLatency 0
ingressLatency 0
boundary_clock_jbod 0
#
# Clock description
#
productDescription ;;
revisionData ;;
manufacturerIdentity 00:00:00
userDescription ;
timeSource 0xA0
recommend:
- profile: "slave"
priority: 4
match:
- nodeLabel: "node-role.kubernetes.io/$mcp"PtpConfigBoundary.yaml
apiVersion: ptp.openshift.io/v1
kind: PtpConfig
metadata:
name: boundary
namespace: openshift-ptp
annotations: {}
spec:
profile:
- name: "boundary"
ptp4lOpts: "-2"
phc2sysOpts: "-a -r -n 24"
ptpSchedulingPolicy: SCHED_FIFO
ptpSchedulingPriority: 10
ptpSettings:
logReduce: "true"
ptp4lConf: |
# The interface name is hardware-specific
[$iface_slave]
masterOnly 0
[$iface_master_1]
masterOnly 1
[$iface_master_2]
masterOnly 1
[$iface_master_3]
masterOnly 1
[global]
#
# Default Data Set
#
twoStepFlag 1
slaveOnly 0
priority1 128
priority2 128
domainNumber 24
#utc_offset 37
clockClass 248
clockAccuracy 0xFE
offsetScaledLogVariance 0xFFFF
free_running 0
freq_est_interval 1
dscp_event 0
dscp_general 0
dataset_comparison G.8275.x
G.8275.defaultDS.localPriority 128
#
# Port Data Set
#
logAnnounceInterval -3
logSyncInterval -4
logMinDelayReqInterval -4
logMinPdelayReqInterval -4
announceReceiptTimeout 3
syncReceiptTimeout 0
delayAsymmetry 0
fault_reset_interval -4
neighborPropDelayThresh 20000000
masterOnly 0
G.8275.portDS.localPriority 128
#
# Run time options
#
assume_two_step 0
logging_level 6
path_trace_enabled 0
follow_up_info 0
hybrid_e2e 0
inhibit_multicast_service 0
net_sync_monitor 0
tc_spanning_tree 0
tx_timestamp_timeout 50
unicast_listen 0
unicast_master_table 0
unicast_req_duration 3600
use_syslog 1
verbose 0
summary_interval 0
kernel_leap 1
check_fup_sync 0
clock_class_threshold 135
#
# Servo Options
#
pi_proportional_const 0.0
pi_integral_const 0.0
pi_proportional_scale 0.0
pi_proportional_exponent -0.3
pi_proportional_norm_max 0.7
pi_integral_scale 0.0
pi_integral_exponent 0.4
pi_integral_norm_max 0.3
step_threshold 2.0
first_step_threshold 0.00002
max_frequency 900000000
clock_servo pi
sanity_freq_limit 200000000
ntpshm_segment 0
#
# Transport options
#
transportSpecific 0x0
ptp_dst_mac 01:1B:19:00:00:00
p2p_dst_mac 01:80:C2:00:00:0E
udp_ttl 1
udp6_scope 0x0E
uds_address /var/run/ptp4l
#
# Default interface options
#
clock_type BC
network_transport L2
delay_mechanism E2E
time_stamping hardware
tsproc_mode filter
delay_filter moving_median
delay_filter_length 10
egressLatency 0
ingressLatency 0
boundary_clock_jbod 0
#
# Clock description
#
productDescription ;;
revisionData ;;
manufacturerIdentity 00:00:00
userDescription ;
timeSource 0xA0
recommend:
- profile: "boundary"
priority: 4
match:
- nodeLabel: "node-role.kubernetes.io/$mcp"PtpConfigForHA.yaml
apiVersion: ptp.openshift.io/v1
kind: PtpConfig
metadata:
name: boundary-ha
namespace: openshift-ptp
annotations: {}
spec:
profile:
- name: "boundary-ha"
ptp4lOpts: ""
phc2sysOpts: "-a -r -n 24"
ptpSchedulingPolicy: SCHED_FIFO
ptpSchedulingPriority: 10
ptpSettings:
logReduce: "true"
haProfiles: "$profile1,$profile2"
recommend:
- profile: "boundary-ha"
priority: 4
match:
- nodeLabel: "node-role.kubernetes.io/$mcp"PtpConfigDualCardGmWpc.yaml
# The grandmaster profile is provided for testing only
# It is not installed on production clusters
# In this example two cards $iface_nic1 and $iface_nic2 are connected via
# SMA1 ports by a cable and $iface_nic2 receives 1PPS signals from $iface_nic1
apiVersion: ptp.openshift.io/v1
kind: PtpConfig
metadata:
name: grandmaster
namespace: openshift-ptp
annotations: {}
spec:
profile:
- name: "grandmaster"
ptp4lOpts: "-2 --summary_interval -4"
phc2sysOpts: -r -u 0 -m -w -N 8 -R 16 -s $iface_nic1 -n 24
ptpSchedulingPolicy: SCHED_FIFO
ptpSchedulingPriority: 10
ptpSettings:
logReduce: "true"
plugins:
e810:
enableDefaultConfig: false
settings:
LocalMaxHoldoverOffSet: 1500
LocalHoldoverTimeout: 14400
MaxInSpecOffset: 100
pins: $e810_pins
# "$iface_nic1":
# "U.FL2": "0 2"
# "U.FL1": "0 1"
# "SMA2": "0 2"
# "SMA1": "2 1"
# "$iface_nic2":
# "U.FL2": "0 2"
# "U.FL1": "0 1"
# "SMA2": "0 2"
# "SMA1": "1 1"
ublxCmds:
- args: #ubxtool -P 29.20 -z CFG-HW-ANT_CFG_VOLTCTRL,1
- "-P"
- "29.20"
- "-z"
- "CFG-HW-ANT_CFG_VOLTCTRL,1"
reportOutput: false
- args: #ubxtool -P 29.20 -e GPS
- "-P"
- "29.20"
- "-e"
- "GPS"
reportOutput: false
- args: #ubxtool -P 29.20 -d Galileo
- "-P"
- "29.20"
- "-d"
- "Galileo"
reportOutput: false
- args: #ubxtool -P 29.20 -d GLONASS
- "-P"
- "29.20"
- "-d"
- "GLONASS"
reportOutput: false
- args: #ubxtool -P 29.20 -d BeiDou
- "-P"
- "29.20"
- "-d"
- "BeiDou"
reportOutput: false
- args: #ubxtool -P 29.20 -d SBAS
- "-P"
- "29.20"
- "-d"
- "SBAS"
reportOutput: false
- args: #ubxtool -P 29.20 -t -w 5 -v 1 -e SURVEYIN,600,50000
- "-P"
- "29.20"
- "-t"
- "-w"
- "5"
- "-v"
- "1"
- "-e"
- "SURVEYIN,600,50000"
reportOutput: true
- args: #ubxtool -P 29.20 -p MON-HW
- "-P"
- "29.20"
- "-p"
- "MON-HW"
reportOutput: true
- args: #ubxtool -P 29.20 -p CFG-MSG,1,38,248
- "-P"
- "29.20"
- "-p"
- "CFG-MSG,1,38,248"
reportOutput: true
ts2phcOpts: " "
ts2phcConf: |
[nmea]
ts2phc.master 1
[global]
use_syslog 0
verbose 1
logging_level 7
ts2phc.pulsewidth 100000000
#cat /dev/GNSS to find available serial port
#example value of gnss_serialport is /dev/ttyGNSS_1700_0
ts2phc.nmea_serialport $gnss_serialport
leapfile /usr/share/zoneinfo/leap-seconds.list
[$iface_nic1]
ts2phc.extts_polarity rising
ts2phc.extts_correction 0
[$iface_nic2]
ts2phc.master 0
ts2phc.extts_polarity rising
#this is a measured value in nanoseconds to compensate for SMA cable delay
ts2phc.extts_correction -10
ptp4lConf: |
[$iface_nic1]
masterOnly 1
[$iface_nic1_1]
masterOnly 1
[$iface_nic1_2]
masterOnly 1
[$iface_nic1_3]
masterOnly 1
[$iface_nic2]
masterOnly 1
[$iface_nic2_1]
masterOnly 1
[$iface_nic2_2]
masterOnly 1
[$iface_nic2_3]
masterOnly 1
[global]
#
# Default Data Set
#
twoStepFlag 1
priority1 128
priority2 128
domainNumber 24
#utc_offset 37
clockClass 6
clockAccuracy 0x27
offsetScaledLogVariance 0xFFFF
free_running 0
freq_est_interval 1
dscp_event 0
dscp_general 0
dataset_comparison G.8275.x
G.8275.defaultDS.localPriority 128
#
# Port Data Set
#
logAnnounceInterval -3
logSyncInterval -4
logMinDelayReqInterval -4
logMinPdelayReqInterval 0
announceReceiptTimeout 3
syncReceiptTimeout 0
delayAsymmetry 0
fault_reset_interval -4
neighborPropDelayThresh 20000000
masterOnly 0
G.8275.portDS.localPriority 128
#
# Run time options
#
assume_two_step 0
logging_level 6
path_trace_enabled 0
follow_up_info 0
hybrid_e2e 0
inhibit_multicast_service 0
net_sync_monitor 0
tc_spanning_tree 0
tx_timestamp_timeout 50
unicast_listen 0
unicast_master_table 0
unicast_req_duration 3600
use_syslog 1
verbose 0
summary_interval -4
kernel_leap 1
check_fup_sync 0
clock_class_threshold 7
#
# Servo Options
#
pi_proportional_const 0.0
pi_integral_const 0.0
pi_proportional_scale 0.0
pi_proportional_exponent -0.3
pi_proportional_norm_max 0.7
pi_integral_scale 0.0
pi_integral_exponent 0.4
pi_integral_norm_max 0.3
step_threshold 2.0
first_step_threshold 0.00002
clock_servo pi
sanity_freq_limit 200000000
ntpshm_segment 0
#
# Transport options
#
transportSpecific 0x0
ptp_dst_mac 01:1B:19:00:00:00
p2p_dst_mac 01:80:C2:00:00:0E
udp_ttl 1
udp6_scope 0x0E
uds_address /var/run/ptp4l
#
# Default interface options
#
clock_type BC
network_transport L2
delay_mechanism E2E
time_stamping hardware
tsproc_mode filter
delay_filter moving_median
delay_filter_length 10
egressLatency 0
ingressLatency 0
boundary_clock_jbod 1
#
# Clock description
#
productDescription ;;
revisionData ;;
manufacturerIdentity 00:00:00
userDescription ;
timeSource 0x20
recommend:
- profile: "grandmaster"
priority: 4
match:
- nodeLabel: "node-role.kubernetes.io/$mcp"PtpConfigGmWpc.yaml
# The grandmaster profile is provided for testing only
# It is not installed on production clusters
apiVersion: ptp.openshift.io/v1
kind: PtpConfig
metadata:
name: grandmaster
namespace: openshift-ptp
annotations: {}
spec:
profile:
- name: "grandmaster"
ptp4lOpts: "-2 --summary_interval -4"
phc2sysOpts: -r -u 0 -m -w -N 8 -R 16 -s $iface_master -n 24
ptpSchedulingPolicy: SCHED_FIFO
ptpSchedulingPriority: 10
ptpSettings:
logReduce: "true"
plugins:
e810:
enableDefaultConfig: false
settings:
LocalMaxHoldoverOffSet: 1500
LocalHoldoverTimeout: 14400
MaxInSpecOffset: 100
pins: $e810_pins
# "$iface_master":
# "U.FL2": "0 2"
# "U.FL1": "0 1"
# "SMA2": "0 2"
# "SMA1": "0 1"
ublxCmds:
- args: #ubxtool -P 29.20 -z CFG-HW-ANT_CFG_VOLTCTRL,1
- "-P"
- "29.20"
- "-z"
- "CFG-HW-ANT_CFG_VOLTCTRL,1"
reportOutput: false
- args: #ubxtool -P 29.20 -e GPS
- "-P"
- "29.20"
- "-e"
- "GPS"
reportOutput: false
- args: #ubxtool -P 29.20 -d Galileo
- "-P"
- "29.20"
- "-d"
- "Galileo"
reportOutput: false
- args: #ubxtool -P 29.20 -d GLONASS
- "-P"
- "29.20"
- "-d"
- "GLONASS"
reportOutput: false
- args: #ubxtool -P 29.20 -d BeiDou
- "-P"
- "29.20"
- "-d"
- "BeiDou"
reportOutput: false
- args: #ubxtool -P 29.20 -d SBAS
- "-P"
- "29.20"
- "-d"
- "SBAS"
reportOutput: false
- args: #ubxtool -P 29.20 -t -w 5 -v 1 -e SURVEYIN,600,50000
- "-P"
- "29.20"
- "-t"
- "-w"
- "5"
- "-v"
- "1"
- "-e"
- "SURVEYIN,600,50000"
reportOutput: true
- args: #ubxtool -P 29.20 -p MON-HW
- "-P"
- "29.20"
- "-p"
- "MON-HW"
reportOutput: true
- args: #ubxtool -P 29.20 -p CFG-MSG,1,38,248
- "-P"
- "29.20"
- "-p"
- "CFG-MSG,1,38,248"
reportOutput: true
ts2phcOpts: " "
ts2phcConf: |
[nmea]
ts2phc.master 1
[global]
use_syslog 0
verbose 1
logging_level 7
ts2phc.pulsewidth 100000000
#cat /dev/GNSS to find available serial port
#example value of gnss_serialport is /dev/ttyGNSS_1700_0
ts2phc.nmea_serialport $gnss_serialport
leapfile /usr/share/zoneinfo/leap-seconds.list
[$iface_master]
ts2phc.extts_polarity rising
ts2phc.extts_correction 0
ptp4lConf: |
[$iface_master]
masterOnly 1
[$iface_master_1]
masterOnly 1
[$iface_master_2]
masterOnly 1
[$iface_master_3]
masterOnly 1
[global]
#
# Default Data Set
#
twoStepFlag 1
priority1 128
priority2 128
domainNumber 24
#utc_offset 37
clockClass 6
clockAccuracy 0x27
offsetScaledLogVariance 0xFFFF
free_running 0
freq_est_interval 1
dscp_event 0
dscp_general 0
dataset_comparison G.8275.x
G.8275.defaultDS.localPriority 128
#
# Port Data Set
#
logAnnounceInterval -3
logSyncInterval -4
logMinDelayReqInterval -4
logMinPdelayReqInterval 0
announceReceiptTimeout 3
syncReceiptTimeout 0
delayAsymmetry 0
fault_reset_interval -4
neighborPropDelayThresh 20000000
masterOnly 0
G.8275.portDS.localPriority 128
#
# Run time options
#
assume_two_step 0
logging_level 6
path_trace_enabled 0
follow_up_info 0
hybrid_e2e 0
inhibit_multicast_service 0
net_sync_monitor 0
tc_spanning_tree 0
tx_timestamp_timeout 50
unicast_listen 0
unicast_master_table 0
unicast_req_duration 3600
use_syslog 1
verbose 0
summary_interval -4
kernel_leap 1
check_fup_sync 0
clock_class_threshold 7
#
# Servo Options
#
pi_proportional_const 0.0
pi_integral_const 0.0
pi_proportional_scale 0.0
pi_proportional_exponent -0.3
pi_proportional_norm_max 0.7
pi_integral_scale 0.0
pi_integral_exponent 0.4
pi_integral_norm_max 0.3
step_threshold 2.0
first_step_threshold 0.00002
clock_servo pi
sanity_freq_limit 200000000
ntpshm_segment 0
#
# Transport options
#
transportSpecific 0x0
ptp_dst_mac 01:1B:19:00:00:00
p2p_dst_mac 01:80:C2:00:00:0E
udp_ttl 1
udp6_scope 0x0E
uds_address /var/run/ptp4l
#
# Default interface options
#
clock_type BC
network_transport L2
delay_mechanism E2E
time_stamping hardware
tsproc_mode filter
delay_filter moving_median
delay_filter_length 10
egressLatency 0
ingressLatency 0
boundary_clock_jbod 0
#
# Clock description
#
productDescription ;;
revisionData ;;
manufacturerIdentity 00:00:00
userDescription ;
timeSource 0x20
recommend:
- profile: "grandmaster"
priority: 4
match:
- nodeLabel: "node-role.kubernetes.io/$mcp"PtpConfigSlave.yaml
apiVersion: ptp.openshift.io/v1
kind: PtpConfig
metadata:
name: du-ptp-slave
namespace: openshift-ptp
annotations: {}
spec:
profile:
- name: "slave"
# The interface name is hardware-specific
interface: $interface
ptp4lOpts: "-2 -s"
phc2sysOpts: "-a -r -n 24"
ptpSchedulingPolicy: SCHED_FIFO
ptpSchedulingPriority: 10
ptpSettings:
logReduce: "true"
ptp4lConf: |
[global]
#
# Default Data Set
#
twoStepFlag 1
slaveOnly 1
priority1 128
priority2 128
domainNumber 24
#utc_offset 37
clockClass 255
clockAccuracy 0xFE
offsetScaledLogVariance 0xFFFF
free_running 0
freq_est_interval 1
dscp_event 0
dscp_general 0
dataset_comparison G.8275.x
G.8275.defaultDS.localPriority 128
#
# Port Data Set
#
logAnnounceInterval -3
logSyncInterval -4
logMinDelayReqInterval -4
logMinPdelayReqInterval -4
announceReceiptTimeout 3
syncReceiptTimeout 0
delayAsymmetry 0
fault_reset_interval -4
neighborPropDelayThresh 20000000
masterOnly 0
G.8275.portDS.localPriority 128
#
# Run time options
#
assume_two_step 0
logging_level 6
path_trace_enabled 0
follow_up_info 0
hybrid_e2e 0
inhibit_multicast_service 0
net_sync_monitor 0
tc_spanning_tree 0
tx_timestamp_timeout 50
unicast_listen 0
unicast_master_table 0
unicast_req_duration 3600
use_syslog 1
verbose 0
summary_interval 0
kernel_leap 1
check_fup_sync 0
clock_class_threshold 7
#
# Servo Options
#
pi_proportional_const 0.0
pi_integral_const 0.0
pi_proportional_scale 0.0
pi_proportional_exponent -0.3
pi_proportional_norm_max 0.7
pi_integral_scale 0.0
pi_integral_exponent 0.4
pi_integral_norm_max 0.3
step_threshold 2.0
first_step_threshold 0.00002
max_frequency 900000000
clock_servo pi
sanity_freq_limit 200000000
ntpshm_segment 0
#
# Transport options
#
transportSpecific 0x0
ptp_dst_mac 01:1B:19:00:00:00
p2p_dst_mac 01:80:C2:00:00:0E
udp_ttl 1
udp6_scope 0x0E
uds_address /var/run/ptp4l
#
# Default interface options
#
clock_type OC
network_transport L2
delay_mechanism E2E
time_stamping hardware
tsproc_mode filter
delay_filter moving_median
delay_filter_length 10
egressLatency 0
ingressLatency 0
boundary_clock_jbod 0
#
# Clock description
#
productDescription ;;
revisionData ;;
manufacturerIdentity 00:00:00
userDescription ;
timeSource 0xA0
recommend:
- profile: "slave"
priority: 4
match:
- nodeLabel: "node-role.kubernetes.io/$mcp"PtpOperatorConfig.yaml
apiVersion: ptp.openshift.io/v1
kind: PtpOperatorConfig
metadata:
name: default
namespace: openshift-ptp
annotations: {}
spec:
daemonNodeSelector:
node-role.kubernetes.io/$mcp: ""PtpOperatorConfigForEvent.yaml
apiVersion: ptp.openshift.io/v1
kind: PtpOperatorConfig
metadata:
name: default
namespace: openshift-ptp
annotations: {}
spec:
daemonNodeSelector:
node-role.kubernetes.io/$mcp: ""
ptpEventConfig:
apiVersion: $event_api_version
enableEventPublisher: true
transportHost: "http://ptp-event-publisher-service-NODE_NAME.openshift-ptp.svc.cluster.local:9043"PtpSubscription.yaml
---
apiVersion: operators.coreos.com/v1alpha1
kind: Subscription
metadata:
name: ptp-operator-subscription
namespace: openshift-ptp
annotations: {}
spec:
channel: "stable"
name: ptp-operator
source: redhat-operators-disconnected
sourceNamespace: openshift-marketplace
installPlanApproval: Manual
status:
state: AtLatestKnownPtpSubscriptionNS.yaml
---
apiVersion: v1
kind: Namespace
metadata:
name: openshift-ptp
annotations:
workload.openshift.io/allowed: management
labels:
openshift.io/cluster-monitoring: "true"PtpSubscriptionOperGroup.yaml
apiVersion: operators.coreos.com/v1
kind: OperatorGroup
metadata:
name: ptp-operators
namespace: openshift-ptp
annotations: {}
spec:
targetNamespaces:
- openshift-ptpAcceleratorsNS.yaml
apiVersion: v1
kind: Namespace
metadata:
name: vran-acceleration-operators
annotations: {}AcceleratorsOperGroup.yaml
apiVersion: operators.coreos.com/v1
kind: OperatorGroup
metadata:
name: vran-operators
namespace: vran-acceleration-operators
annotations: {}
spec:
targetNamespaces:
- vran-acceleration-operatorsAcceleratorsSubscription.yaml
apiVersion: operators.coreos.com/v1alpha1
kind: Subscription
metadata:
name: sriov-fec-subscription
namespace: vran-acceleration-operators
annotations: {}
spec:
channel: stable
name: sriov-fec
source: certified-operators
sourceNamespace: openshift-marketplace
installPlanApproval: Manual
status:
state: AtLatestKnownSriovFecClusterConfig.yaml
apiVersion: sriovfec.intel.com/v2
kind: SriovFecClusterConfig
metadata:
name: config
namespace: vran-acceleration-operators
annotations: {}
spec:
drainSkip: $drainSkip # true if SNO, false by default
priority: 1
nodeSelector:
node-role.kubernetes.io/master: ""
acceleratorSelector:
pciAddress: $pciAddress
physicalFunction:
pfDriver: "vfio-pci"
vfDriver: "vfio-pci"
vfAmount: 16
bbDevConfig: $bbDevConfig
#Recommended configuration for Intel ACC100 (Mount Bryce) FPGA here: https://github.com/smart-edge-open/openshift-operator/blob/main/spec/openshift-sriov-fec-operator.md#sample-cr-for-wireless-fec-acc100
#Recommended configuration for Intel N3000 FPGA here: https://github.com/smart-edge-open/openshift-operator/blob/main/spec/openshift-sriov-fec-operator.md#sample-cr-for-wireless-fec-n3000SriovNetwork.yaml
apiVersion: sriovnetwork.openshift.io/v1
kind: SriovNetwork
metadata:
name: ""
namespace: openshift-sriov-network-operator
annotations: {}
spec:
# resourceName: ""
networkNamespace: openshift-sriov-network-operator
# vlan: ""
# spoofChk: ""
# ipam: ""
# linkState: ""
# maxTxRate: ""
# minTxRate: ""
# vlanQoS: ""
# trust: ""
# capabilities: ""SriovNetworkNodePolicy.yaml
apiVersion: sriovnetwork.openshift.io/v1
kind: SriovNetworkNodePolicy
metadata:
name: $name
namespace: openshift-sriov-network-operator
annotations: {}
spec:
# The attributes for Mellanox/Intel based NICs as below.
# deviceType: netdevice/vfio-pci
# isRdma: true/false
deviceType: $deviceType
isRdma: $isRdma
nicSelector:
# The exact physical function name must match the hardware used
pfNames: [$pfNames]
nodeSelector:
node-role.kubernetes.io/$mcp: ""
numVfs: $numVfs
priority: $priority
resourceName: $resourceNameSriovOperatorConfig.yaml
apiVersion: sriovnetwork.openshift.io/v1
kind: SriovOperatorConfig
metadata:
name: default
namespace: openshift-sriov-network-operator
annotations: {}
spec:
configDaemonNodeSelector:
"node-role.kubernetes.io/$mcp": ""
# Injector and OperatorWebhook pods can be disabled (set to "false") below
# to reduce the number of management pods. It is recommended to start with the
# webhook and injector pods enabled, and only disable them after verifying the
# correctness of user manifests.
# If the injector is disabled, containers using sr-iov resources must explicitly assign
# them in the "requests"/"limits" section of the container spec, for example:
# containers:
# - name: my-sriov-workload-container
# resources:
# limits:
# openshift.io/<resource_name>: "1"
# requests:
# openshift.io/<resource_name>: "1"
enableInjector: false
enableOperatorWebhook: false
logLevel: 0SriovOperatorConfigForSNO.yaml
apiVersion: sriovnetwork.openshift.io/v1
kind: SriovOperatorConfig
metadata:
name: default
namespace: openshift-sriov-network-operator
annotations: {}
spec:
configDaemonNodeSelector:
"node-role.kubernetes.io/$mcp": ""
# Injector and OperatorWebhook pods can be disabled (set to "false") below
# to reduce the number of management pods. It is recommended to start with the
# webhook and injector pods enabled, and only disable them after verifying the
# correctness of user manifests.
# If the injector is disabled, containers using sr-iov resources must explicitly assign
# them in the "requests"/"limits" section of the container spec, for example:
# containers:
# - name: my-sriov-workload-container
# resources:
# limits:
# openshift.io/<resource_name>: "1"
# requests:
# openshift.io/<resource_name>: "1"
enableInjector: false
enableOperatorWebhook: false
# Disable drain is needed for Single Node Openshift
disableDrain: true
logLevel: 0SriovSubscription.yaml
apiVersion: operators.coreos.com/v1alpha1
kind: Subscription
metadata:
name: sriov-network-operator-subscription
namespace: openshift-sriov-network-operator
annotations: {}
spec:
channel: "stable"
name: sriov-network-operator
source: redhat-operators-disconnected
sourceNamespace: openshift-marketplace
installPlanApproval: Manual
status:
state: AtLatestKnownSriovSubscriptionNS.yaml
apiVersion: v1
kind: Namespace
metadata:
name: openshift-sriov-network-operator
annotations:
workload.openshift.io/allowed: managementSriovSubscriptionOperGroup.yaml
apiVersion: operators.coreos.com/v1
kind: OperatorGroup
metadata:
name: sriov-network-operators
namespace: openshift-sriov-network-operator
annotations: {}
spec:
targetNamespaces:
- openshift-sriov-network-operator3.2.4.4.2. 클러스터 튜닝 참조 YAML
example-sno.yaml
# example-node1-bmh-secret & assisted-deployment-pull-secret need to be created under same namespace example-sno
---
apiVersion: ran.openshift.io/v1
kind: SiteConfig
metadata:
name: "example-sno"
namespace: "example-sno"
spec:
baseDomain: "example.com"
pullSecretRef:
name: "assisted-deployment-pull-secret"
clusterImageSetNameRef: "openshift-4.16"
sshPublicKey: "ssh-rsa AAAA..."
clusters:
- clusterName: "example-sno"
networkType: "OVNKubernetes"
# installConfigOverrides is a generic way of passing install-config
# parameters through the siteConfig. The 'capabilities' field configures
# the composable openshift feature. In this 'capabilities' setting, we
# remove all the optional set of components.
# Notes:
# - OperatorLifecycleManager is needed for 4.15 and later
# - NodeTuning is needed for 4.13 and later, not for 4.12 and earlier
# - Ingress is needed for 4.16 and later
installConfigOverrides: |
{
"capabilities": {
"baselineCapabilitySet": "None",
"additionalEnabledCapabilities": [
"NodeTuning",
"OperatorLifecycleManager",
"Ingress"
]
}
}
# It is strongly recommended to include crun manifests as part of the additional install-time manifests for 4.13+.
# The crun manifests can be obtained from source-crs/optional-extra-manifest/ and added to the git repo ie.sno-extra-manifest.
# extraManifestPath: sno-extra-manifest
clusterLabels:
# These example cluster labels correspond to the bindingRules in the PolicyGenTemplate examples
du-profile: "latest"
# These example cluster labels correspond to the bindingRules in the PolicyGenTemplate examples in ../policygentemplates:
# ../policygentemplates/common-ranGen.yaml will apply to all clusters with 'common: true'
common: true
# ../policygentemplates/group-du-sno-ranGen.yaml will apply to all clusters with 'group-du-sno: ""'
group-du-sno: ""
# ../policygentemplates/example-sno-site.yaml will apply to all clusters with 'sites: "example-sno"'
# Normally this should match or contain the cluster name so it only applies to a single cluster
sites: "example-sno"
clusterNetwork:
- cidr: 1001:1::/48
hostPrefix: 64
machineNetwork:
- cidr: 1111:2222:3333:4444::/64
serviceNetwork:
- 1001:2::/112
additionalNTPSources:
- 1111:2222:3333:4444::2
# Initiates the cluster for workload partitioning. Setting specific reserved/isolated CPUSets is done via PolicyTemplate
# please see Workload Partitioning Feature for a complete guide.
cpuPartitioningMode: AllNodes
# Optionally; This can be used to override the KlusterletAddonConfig that is created for this cluster:
#crTemplates:
# KlusterletAddonConfig: "KlusterletAddonConfigOverride.yaml"
nodes:
- hostName: "example-node1.example.com"
role: "master"
# Optionally; This can be used to configure desired BIOS setting on a host:
#biosConfigRef:
# filePath: "example-hw.profile"
bmcAddress: "idrac-virtualmedia+https://[1111:2222:3333:4444::bbbb:1]/redfish/v1/Systems/System.Embedded.1"
bmcCredentialsName:
name: "example-node1-bmh-secret"
bootMACAddress: "AA:BB:CC:DD:EE:11"
# Use UEFISecureBoot to enable secure boot.
bootMode: "UEFISecureBoot"
rootDeviceHints:
deviceName: "/dev/disk/by-path/pci-0000:01:00.0-scsi-0:2:0:0"
# disk partition at `/var/lib/containers` with ignitionConfigOverride. Some values must be updated. See DiskPartitionContainer.md for more details
ignitionConfigOverride: |
{
"ignition": {
"version": "3.2.0"
},
"storage": {
"disks": [
{
"device": "/dev/disk/by-id/wwn-0x6b07b250ebb9d0002a33509f24af1f62",
"partitions": [
{
"label": "var-lib-containers",
"sizeMiB": 0,
"startMiB": 250000
}
],
"wipeTable": false
}
],
"filesystems": [
{
"device": "/dev/disk/by-partlabel/var-lib-containers",
"format": "xfs",
"mountOptions": [
"defaults",
"prjquota"
],
"path": "/var/lib/containers",
"wipeFilesystem": true
}
]
},
"systemd": {
"units": [
{
"contents": "# Generated by Butane\n[Unit]\nRequires=systemd-fsck@dev-disk-by\\x2dpartlabel-var\\x2dlib\\x2dcontainers.service\nAfter=systemd-fsck@dev-disk-by\\x2dpartlabel-var\\x2dlib\\x2dcontainers.service\n\n[Mount]\nWhere=/var/lib/containers\nWhat=/dev/disk/by-partlabel/var-lib-containers\nType=xfs\nOptions=defaults,prjquota\n\n[Install]\nRequiredBy=local-fs.target",
"enabled": true,
"name": "var-lib-containers.mount"
}
]
}
}
nodeNetwork:
interfaces:
- name: eno1
macAddress: "AA:BB:CC:DD:EE:11"
config:
interfaces:
- name: eno1
type: ethernet
state: up
ipv4:
enabled: false
ipv6:
enabled: true
address:
# For SNO sites with static IP addresses, the node-specific,
# API and Ingress IPs should all be the same and configured on
# the interface
- ip: 1111:2222:3333:4444::aaaa:1
prefix-length: 64
dns-resolver:
config:
search:
- example.com
server:
- 1111:2222:3333:4444::2
routes:
config:
- destination: ::/0
next-hop-interface: eno1
next-hop-address: 1111:2222:3333:4444::1
table-id: 254ConsoleOperatorDisable.yaml
apiVersion: operator.openshift.io/v1
kind: Console
metadata:
annotations:
include.release.openshift.io/ibm-cloud-managed: "false"
include.release.openshift.io/self-managed-high-availability: "false"
include.release.openshift.io/single-node-developer: "false"
release.openshift.io/create-only: "true"
name: cluster
spec:
logLevel: Normal
managementState: Removed
operatorLogLevel: Normal09-openshift-marketplace-ns.yaml
# Taken from https://github.com/operator-framework/operator-marketplace/blob/53c124a3f0edfd151652e1f23c87dd39ed7646bb/manifests/01_namespace.yaml
# Update it as the source evolves.
apiVersion: v1
kind: Namespace
metadata:
annotations:
openshift.io/node-selector: ""
workload.openshift.io/allowed: "management"
labels:
openshift.io/cluster-monitoring: "true"
pod-security.kubernetes.io/enforce: baseline
pod-security.kubernetes.io/enforce-version: v1.25
pod-security.kubernetes.io/audit: baseline
pod-security.kubernetes.io/audit-version: v1.25
pod-security.kubernetes.io/warn: baseline
pod-security.kubernetes.io/warn-version: v1.25
name: "openshift-marketplace"DefaultCatsrc.yaml
apiVersion: operators.coreos.com/v1alpha1
kind: CatalogSource
metadata:
name: default-cat-source
namespace: openshift-marketplace
annotations:
target.workload.openshift.io/management: '{"effect": "PreferredDuringScheduling"}'
spec:
displayName: default-cat-source
image: $imageUrl
publisher: Red Hat
sourceType: grpc
updateStrategy:
registryPoll:
interval: 1h
status:
connectionState:
lastObservedState: READYDisableOLMPprof.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: collect-profiles-config
namespace: openshift-operator-lifecycle-manager
annotations: {}
data:
pprof-config.yaml: |
disabled: TrueDisconnectedICSP.yaml
apiVersion: operator.openshift.io/v1alpha1
kind: ImageContentSourcePolicy
metadata:
name: disconnected-internal-icsp
annotations: {}
spec:
# repositoryDigestMirrors:
# - $mirrorsOperatorHub.yaml
apiVersion: config.openshift.io/v1
kind: OperatorHub
metadata:
name: cluster
annotations: {}
spec:
disableAllDefaultSources: trueReduceMonitoringFootprint.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: cluster-monitoring-config
namespace: openshift-monitoring
annotations: {}
data:
config.yaml: |
alertmanagerMain:
enabled: false
telemeterClient:
enabled: false
prometheusK8s:
retention: 24hDisableSnoNetworkDiag.yaml
apiVersion: operator.openshift.io/v1
kind: Network
metadata:
name: cluster
annotations: {}
spec:
disableNetworkDiagnostics: true3.2.4.4.3. 머신 구성 참조 YAML
enable-crun-master.yaml
apiVersion: machineconfiguration.openshift.io/v1
kind: ContainerRuntimeConfig
metadata:
name: enable-crun-master
spec:
machineConfigPoolSelector:
matchLabels:
pools.operator.machineconfiguration.openshift.io/master: ""
containerRuntimeConfig:
defaultRuntime: crunenable-crun-worker.yaml
apiVersion: machineconfiguration.openshift.io/v1
kind: ContainerRuntimeConfig
metadata:
name: enable-crun-worker
spec:
machineConfigPoolSelector:
matchLabels:
pools.operator.machineconfiguration.openshift.io/worker: ""
containerRuntimeConfig:
defaultRuntime: crun99-crio-disable-wipe-master.yaml
# Automatically generated by extra-manifests-builder
# Do not make changes directly.
apiVersion: machineconfiguration.openshift.io/v1
kind: MachineConfig
metadata:
labels:
machineconfiguration.openshift.io/role: master
name: 99-crio-disable-wipe-master
spec:
config:
ignition:
version: 3.2.0
storage:
files:
- contents:
source: data:text/plain;charset=utf-8;base64,W2NyaW9dCmNsZWFuX3NodXRkb3duX2ZpbGUgPSAiIgo=
mode: 420
path: /etc/crio/crio.conf.d/99-crio-disable-wipe.toml99-crio-disable-wipe-worker.yaml
# Automatically generated by extra-manifests-builder
# Do not make changes directly.
apiVersion: machineconfiguration.openshift.io/v1
kind: MachineConfig
metadata:
labels:
machineconfiguration.openshift.io/role: worker
name: 99-crio-disable-wipe-worker
spec:
config:
ignition:
version: 3.2.0
storage:
files:
- contents:
source: data:text/plain;charset=utf-8;base64,W2NyaW9dCmNsZWFuX3NodXRkb3duX2ZpbGUgPSAiIgo=
mode: 420
path: /etc/crio/crio.conf.d/99-crio-disable-wipe.toml06-kdump-master.yaml
# Automatically generated by extra-manifests-builder
# Do not make changes directly.
apiVersion: machineconfiguration.openshift.io/v1
kind: MachineConfig
metadata:
labels:
machineconfiguration.openshift.io/role: master
name: 06-kdump-enable-master
spec:
config:
ignition:
version: 3.2.0
systemd:
units:
- enabled: true
name: kdump.service
kernelArguments:
- crashkernel=512M06-kdump-worker.yaml
# Automatically generated by extra-manifests-builder
# Do not make changes directly.
apiVersion: machineconfiguration.openshift.io/v1
kind: MachineConfig
metadata:
labels:
machineconfiguration.openshift.io/role: worker
name: 06-kdump-enable-worker
spec:
config:
ignition:
version: 3.2.0
systemd:
units:
- enabled: true
name: kdump.service
kernelArguments:
- crashkernel=512M01-container-mount-ns-and-kubelet-conf-master.yaml
# Automatically generated by extra-manifests-builder
# Do not make changes directly.
apiVersion: machineconfiguration.openshift.io/v1
kind: MachineConfig
metadata:
labels:
machineconfiguration.openshift.io/role: master
name: container-mount-namespace-and-kubelet-conf-master
spec:
config:
ignition:
version: 3.2.0
storage:
files:
- contents:
source: data:text/plain;charset=utf-8;base64,IyEvYmluL2Jhc2gKCmRlYnVnKCkgewogIGVjaG8gJEAgPiYyCn0KCnVzYWdlKCkgewogIGVjaG8gVXNhZ2U6ICQoYmFzZW5hbWUgJDApIFVOSVQgW2VudmZpbGUgW3Zhcm5hbWVdXQogIGVjaG8KICBlY2hvIEV4dHJhY3QgdGhlIGNvbnRlbnRzIG9mIHRoZSBmaXJzdCBFeGVjU3RhcnQgc3RhbnphIGZyb20gdGhlIGdpdmVuIHN5c3RlbWQgdW5pdCBhbmQgcmV0dXJuIGl0IHRvIHN0ZG91dAogIGVjaG8KICBlY2hvICJJZiAnZW52ZmlsZScgaXMgcHJvdmlkZWQsIHB1dCBpdCBpbiB0aGVyZSBpbnN0ZWFkLCBhcyBhbiBlbnZpcm9ubWVudCB2YXJpYWJsZSBuYW1lZCAndmFybmFtZSciCiAgZWNobyAiRGVmYXVsdCAndmFybmFtZScgaXMgRVhFQ1NUQVJUIGlmIG5vdCBzcGVjaWZpZWQiCiAgZXhpdCAxCn0KClVOSVQ9JDEKRU5WRklMRT0kMgpWQVJOQU1FPSQzCmlmIFtbIC16ICRVTklUIHx8ICRVTklUID09ICItLWhlbHAiIHx8ICRVTklUID09ICItaCIgXV07IHRoZW4KICB1c2FnZQpmaQpkZWJ1ZyAiRXh0cmFjdGluZyBFeGVjU3RhcnQgZnJvbSAkVU5JVCIKRklMRT0kKHN5c3RlbWN0bCBjYXQgJFVOSVQgfCBoZWFkIC1uIDEpCkZJTEU9JHtGSUxFI1wjIH0KaWYgW1sgISAtZiAkRklMRSBdXTsgdGhlbgogIGRlYnVnICJGYWlsZWQgdG8gZmluZCByb290IGZpbGUgZm9yIHVuaXQgJFVOSVQgKCRGSUxFKSIKICBleGl0CmZpCmRlYnVnICJTZXJ2aWNlIGRlZmluaXRpb24gaXMgaW4gJEZJTEUiCkVYRUNTVEFSVD0kKHNlZCAtbiAtZSAnL15FeGVjU3RhcnQ9LipcXCQvLC9bXlxcXSQvIHsgcy9eRXhlY1N0YXJ0PS8vOyBwIH0nIC1lICcvXkV4ZWNTdGFydD0uKlteXFxdJC8geyBzL15FeGVjU3RhcnQ9Ly87IHAgfScgJEZJTEUpCgppZiBbWyAkRU5WRklMRSBdXTsgdGhlbgogIFZBUk5BTUU9JHtWQVJOQU1FOi1FWEVDU1RBUlR9CiAgZWNobyAiJHtWQVJOQU1FfT0ke0VYRUNTVEFSVH0iID4gJEVOVkZJTEUKZWxzZQogIGVjaG8gJEVYRUNTVEFSVApmaQo=
mode: 493
path: /usr/local/bin/extractExecStart
- contents:
source: data:text/plain;charset=utf-8;base64,IyEvYmluL2Jhc2gKbnNlbnRlciAtLW1vdW50PS9ydW4vY29udGFpbmVyLW1vdW50LW5hbWVzcGFjZS9tbnQgIiRAIgo=
mode: 493
path: /usr/local/bin/nsenterCmns
systemd:
units:
- contents: |
[Unit]
Description=Manages a mount namespace that both kubelet and crio can use to share their container-specific mounts
[Service]
Type=oneshot
RemainAfterExit=yes
RuntimeDirectory=container-mount-namespace
Environment=RUNTIME_DIRECTORY=%t/container-mount-namespace
Environment=BIND_POINT=%t/container-mount-namespace/mnt
ExecStartPre=bash -c "findmnt ${RUNTIME_DIRECTORY} || mount --make-unbindable --bind ${RUNTIME_DIRECTORY} ${RUNTIME_DIRECTORY}"
ExecStartPre=touch ${BIND_POINT}
ExecStart=unshare --mount=${BIND_POINT} --propagation slave mount --make-rshared /
ExecStop=umount -R ${RUNTIME_DIRECTORY}
name: container-mount-namespace.service
- dropins:
- contents: |
[Unit]
Wants=container-mount-namespace.service
After=container-mount-namespace.service
[Service]
ExecStartPre=/usr/local/bin/extractExecStart %n /%t/%N-execstart.env ORIG_EXECSTART
EnvironmentFile=-/%t/%N-execstart.env
ExecStart=
ExecStart=bash -c "nsenter --mount=%t/container-mount-namespace/mnt \
${ORIG_EXECSTART}"
name: 90-container-mount-namespace.conf
name: crio.service
- dropins:
- contents: |
[Unit]
Wants=container-mount-namespace.service
After=container-mount-namespace.service
[Service]
ExecStartPre=/usr/local/bin/extractExecStart %n /%t/%N-execstart.env ORIG_EXECSTART
EnvironmentFile=-/%t/%N-execstart.env
ExecStart=
ExecStart=bash -c "nsenter --mount=%t/container-mount-namespace/mnt \
${ORIG_EXECSTART} --housekeeping-interval=30s"
name: 90-container-mount-namespace.conf
- contents: |
[Service]
Environment="OPENSHIFT_MAX_HOUSEKEEPING_INTERVAL_DURATION=60s"
Environment="OPENSHIFT_EVICTION_MONITORING_PERIOD_DURATION=30s"
name: 30-kubelet-interval-tuning.conf
name: kubelet.service01-container-mount-ns-and-kubelet-conf-worker.yaml
# Automatically generated by extra-manifests-builder
# Do not make changes directly.
apiVersion: machineconfiguration.openshift.io/v1
kind: MachineConfig
metadata:
labels:
machineconfiguration.openshift.io/role: worker
name: container-mount-namespace-and-kubelet-conf-worker
spec:
config:
ignition:
version: 3.2.0
storage:
files:
- contents:
source: data:text/plain;charset=utf-8;base64,IyEvYmluL2Jhc2gKCmRlYnVnKCkgewogIGVjaG8gJEAgPiYyCn0KCnVzYWdlKCkgewogIGVjaG8gVXNhZ2U6ICQoYmFzZW5hbWUgJDApIFVOSVQgW2VudmZpbGUgW3Zhcm5hbWVdXQogIGVjaG8KICBlY2hvIEV4dHJhY3QgdGhlIGNvbnRlbnRzIG9mIHRoZSBmaXJzdCBFeGVjU3RhcnQgc3RhbnphIGZyb20gdGhlIGdpdmVuIHN5c3RlbWQgdW5pdCBhbmQgcmV0dXJuIGl0IHRvIHN0ZG91dAogIGVjaG8KICBlY2hvICJJZiAnZW52ZmlsZScgaXMgcHJvdmlkZWQsIHB1dCBpdCBpbiB0aGVyZSBpbnN0ZWFkLCBhcyBhbiBlbnZpcm9ubWVudCB2YXJpYWJsZSBuYW1lZCAndmFybmFtZSciCiAgZWNobyAiRGVmYXVsdCAndmFybmFtZScgaXMgRVhFQ1NUQVJUIGlmIG5vdCBzcGVjaWZpZWQiCiAgZXhpdCAxCn0KClVOSVQ9JDEKRU5WRklMRT0kMgpWQVJOQU1FPSQzCmlmIFtbIC16ICRVTklUIHx8ICRVTklUID09ICItLWhlbHAiIHx8ICRVTklUID09ICItaCIgXV07IHRoZW4KICB1c2FnZQpmaQpkZWJ1ZyAiRXh0cmFjdGluZyBFeGVjU3RhcnQgZnJvbSAkVU5JVCIKRklMRT0kKHN5c3RlbWN0bCBjYXQgJFVOSVQgfCBoZWFkIC1uIDEpCkZJTEU9JHtGSUxFI1wjIH0KaWYgW1sgISAtZiAkRklMRSBdXTsgdGhlbgogIGRlYnVnICJGYWlsZWQgdG8gZmluZCByb290IGZpbGUgZm9yIHVuaXQgJFVOSVQgKCRGSUxFKSIKICBleGl0CmZpCmRlYnVnICJTZXJ2aWNlIGRlZmluaXRpb24gaXMgaW4gJEZJTEUiCkVYRUNTVEFSVD0kKHNlZCAtbiAtZSAnL15FeGVjU3RhcnQ9LipcXCQvLC9bXlxcXSQvIHsgcy9eRXhlY1N0YXJ0PS8vOyBwIH0nIC1lICcvXkV4ZWNTdGFydD0uKlteXFxdJC8geyBzL15FeGVjU3RhcnQ9Ly87IHAgfScgJEZJTEUpCgppZiBbWyAkRU5WRklMRSBdXTsgdGhlbgogIFZBUk5BTUU9JHtWQVJOQU1FOi1FWEVDU1RBUlR9CiAgZWNobyAiJHtWQVJOQU1FfT0ke0VYRUNTVEFSVH0iID4gJEVOVkZJTEUKZWxzZQogIGVjaG8gJEVYRUNTVEFSVApmaQo=
mode: 493
path: /usr/local/bin/extractExecStart
- contents:
source: data:text/plain;charset=utf-8;base64,IyEvYmluL2Jhc2gKbnNlbnRlciAtLW1vdW50PS9ydW4vY29udGFpbmVyLW1vdW50LW5hbWVzcGFjZS9tbnQgIiRAIgo=
mode: 493
path: /usr/local/bin/nsenterCmns
systemd:
units:
- contents: |
[Unit]
Description=Manages a mount namespace that both kubelet and crio can use to share their container-specific mounts
[Service]
Type=oneshot
RemainAfterExit=yes
RuntimeDirectory=container-mount-namespace
Environment=RUNTIME_DIRECTORY=%t/container-mount-namespace
Environment=BIND_POINT=%t/container-mount-namespace/mnt
ExecStartPre=bash -c "findmnt ${RUNTIME_DIRECTORY} || mount --make-unbindable --bind ${RUNTIME_DIRECTORY} ${RUNTIME_DIRECTORY}"
ExecStartPre=touch ${BIND_POINT}
ExecStart=unshare --mount=${BIND_POINT} --propagation slave mount --make-rshared /
ExecStop=umount -R ${RUNTIME_DIRECTORY}
name: container-mount-namespace.service
- dropins:
- contents: |
[Unit]
Wants=container-mount-namespace.service
After=container-mount-namespace.service
[Service]
ExecStartPre=/usr/local/bin/extractExecStart %n /%t/%N-execstart.env ORIG_EXECSTART
EnvironmentFile=-/%t/%N-execstart.env
ExecStart=
ExecStart=bash -c "nsenter --mount=%t/container-mount-namespace/mnt \
${ORIG_EXECSTART}"
name: 90-container-mount-namespace.conf
name: crio.service
- dropins:
- contents: |
[Unit]
Wants=container-mount-namespace.service
After=container-mount-namespace.service
[Service]
ExecStartPre=/usr/local/bin/extractExecStart %n /%t/%N-execstart.env ORIG_EXECSTART
EnvironmentFile=-/%t/%N-execstart.env
ExecStart=
ExecStart=bash -c "nsenter --mount=%t/container-mount-namespace/mnt \
${ORIG_EXECSTART} --housekeeping-interval=30s"
name: 90-container-mount-namespace.conf
- contents: |
[Service]
Environment="OPENSHIFT_MAX_HOUSEKEEPING_INTERVAL_DURATION=60s"
Environment="OPENSHIFT_EVICTION_MONITORING_PERIOD_DURATION=30s"
name: 30-kubelet-interval-tuning.conf
name: kubelet.service99-sync-time-once-master.yaml
# Automatically generated by extra-manifests-builder
# Do not make changes directly.
apiVersion: machineconfiguration.openshift.io/v1
kind: MachineConfig
metadata:
labels:
machineconfiguration.openshift.io/role: master
name: 99-sync-time-once-master
spec:
config:
ignition:
version: 3.2.0
systemd:
units:
- contents: |
[Unit]
Description=Sync time once
After=network-online.target
Wants=network-online.target
[Service]
Type=oneshot
TimeoutStartSec=300
ExecCondition=/bin/bash -c 'systemctl is-enabled chronyd.service --quiet && exit 1 || exit 0'
ExecStart=/usr/sbin/chronyd -n -f /etc/chrony.conf -q
RemainAfterExit=yes
[Install]
WantedBy=multi-user.target
enabled: true
name: sync-time-once.service99-sync-time-once-worker.yaml
# Automatically generated by extra-manifests-builder
# Do not make changes directly.
apiVersion: machineconfiguration.openshift.io/v1
kind: MachineConfig
metadata:
labels:
machineconfiguration.openshift.io/role: worker
name: 99-sync-time-once-worker
spec:
config:
ignition:
version: 3.2.0
systemd:
units:
- contents: |
[Unit]
Description=Sync time once
After=network-online.target
Wants=network-online.target
[Service]
Type=oneshot
TimeoutStartSec=300
ExecCondition=/bin/bash -c 'systemctl is-enabled chronyd.service --quiet && exit 1 || exit 0'
ExecStart=/usr/sbin/chronyd -n -f /etc/chrony.conf -q
RemainAfterExit=yes
[Install]
WantedBy=multi-user.target
enabled: true
name: sync-time-once.service03-sctp-machine-config-master.yaml
# Automatically generated by extra-manifests-builder
# Do not make changes directly.
apiVersion: machineconfiguration.openshift.io/v1
kind: MachineConfig
metadata:
labels:
machineconfiguration.openshift.io/role: master
name: load-sctp-module-master
spec:
config:
ignition:
version: 2.2.0
storage:
files:
- contents:
source: data:,
verification: {}
filesystem: root
mode: 420
path: /etc/modprobe.d/sctp-blacklist.conf
- contents:
source: data:text/plain;charset=utf-8,sctp
filesystem: root
mode: 420
path: /etc/modules-load.d/sctp-load.conf03-sctp-machine-config-worker.yaml
# Automatically generated by extra-manifests-builder
# Do not make changes directly.
apiVersion: machineconfiguration.openshift.io/v1
kind: MachineConfig
metadata:
labels:
machineconfiguration.openshift.io/role: worker
name: load-sctp-module-worker
spec:
config:
ignition:
version: 2.2.0
storage:
files:
- contents:
source: data:,
verification: {}
filesystem: root
mode: 420
path: /etc/modprobe.d/sctp-blacklist.conf
- contents:
source: data:text/plain;charset=utf-8,sctp
filesystem: root
mode: 420
path: /etc/modules-load.d/sctp-load.conf08-set-rcu-normal-master.yaml
# Automatically generated by extra-manifests-builder
# Do not make changes directly.
apiVersion: machineconfiguration.openshift.io/v1
kind: MachineConfig
metadata:
labels:
machineconfiguration.openshift.io/role: master
name: 08-set-rcu-normal-master
spec:
config:
ignition:
version: 3.2.0
storage:
files:
- contents:
source: data:text/plain;charset=utf-8;base64,IyEvYmluL2Jhc2gKIwojIERpc2FibGUgcmN1X2V4cGVkaXRlZCBhZnRlciBub2RlIGhhcyBmaW5pc2hlZCBib290aW5nCiMKIyBUaGUgZGVmYXVsdHMgYmVsb3cgY2FuIGJlIG92ZXJyaWRkZW4gdmlhIGVudmlyb25tZW50IHZhcmlhYmxlcwojCgojIERlZmF1bHQgd2FpdCB0aW1lIGlzIDYwMHMgPSAxMG06Ck1BWElNVU1fV0FJVF9USU1FPSR7TUFYSU1VTV9XQUlUX1RJTUU6LTYwMH0KCiMgRGVmYXVsdCBzdGVhZHktc3RhdGUgdGhyZXNob2xkID0gMiUKIyBBbGxvd2VkIHZhbHVlczoKIyAgNCAgLSBhYnNvbHV0ZSBwb2QgY291bnQgKCsvLSkKIyAgNCUgLSBwZXJjZW50IGNoYW5nZSAoKy8tKQojICAtMSAtIGRpc2FibGUgdGhlIHN0ZWFkeS1zdGF0ZSBjaGVjawpTVEVBRFlfU1RBVEVfVEhSRVNIT0xEPSR7U1RFQURZX1NUQVRFX1RIUkVTSE9MRDotMiV9CgojIERlZmF1bHQgc3RlYWR5LXN0YXRlIHdpbmRvdyA9IDYwcwojIElmIHRoZSBydW5uaW5nIHBvZCBjb3VudCBzdGF5cyB3aXRoaW4gdGhlIGdpdmVuIHRocmVzaG9sZCBmb3IgdGhpcyB0aW1lCiMgcGVyaW9kLCByZXR1cm4gQ1BVIHV0aWxpemF0aW9uIHRvIG5vcm1hbCBiZWZvcmUgdGhlIG1heGltdW0gd2FpdCB0aW1lIGhhcwojIGV4cGlyZXMKU1RFQURZX1NUQVRFX1dJTkRPVz0ke1NURUFEWV9TVEFURV9XSU5ET1c6LTYwfQoKIyBEZWZhdWx0IHN0ZWFkeS1zdGF0ZSBhbGxvd3MgYW55IHBvZCBjb3VudCB0byBiZSAic3RlYWR5IHN0YXRlIgojIEluY3JlYXNpbmcgdGhpcyB3aWxsIHNraXAgYW55IHN0ZWFkeS1zdGF0ZSBjaGVja3MgdW50aWwgdGhlIGNvdW50IHJpc2VzIGFib3ZlCiMgdGhpcyBudW1iZXIgdG8gYXZvaWQgZmFsc2UgcG9zaXRpdmVzIGlmIHRoZXJlIGFyZSBzb21lIHBlcmlvZHMgd2hlcmUgdGhlCiMgY291bnQgZG9lc24ndCBpbmNyZWFzZSBidXQgd2Uga25vdyB3ZSBjYW4ndCBiZSBhdCBzdGVhZHktc3RhdGUgeWV0LgpTVEVBRFlfU1RBVEVfTUlOSU1VTT0ke1NURUFEWV9TVEFURV9NSU5JTVVNOi0wfQoKIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIwoKd2l0aGluKCkgewogIGxvY2FsIGxhc3Q9JDEgY3VycmVudD0kMiB0aHJlc2hvbGQ9JDMKICBsb2NhbCBkZWx0YT0wIHBjaGFuZ2UKICBkZWx0YT0kKCggY3VycmVudCAtIGxhc3QgKSkKICBpZiBbWyAkY3VycmVudCAtZXEgJGxhc3QgXV07IHRoZW4KICAgIHBjaGFuZ2U9MAogIGVsaWYgW1sgJGxhc3QgLWVxIDAgXV07IHRoZW4KICAgIHBjaGFuZ2U9MTAwMDAwMAogIGVsc2UKICAgIHBjaGFuZ2U9JCgoICggIiRkZWx0YSIgKiAxMDApIC8gbGFzdCApKQogIGZpCiAgZWNobyAtbiAibGFzdDokbGFzdCBjdXJyZW50OiRjdXJyZW50IGRlbHRhOiRkZWx0YSBwY2hhbmdlOiR7cGNoYW5nZX0lOiAiCiAgbG9jYWwgYWJzb2x1dGUgbGltaXQKICBjYXNlICR0aHJlc2hvbGQgaW4KICAgIColKQogICAgICBhYnNvbHV0ZT0ke3BjaGFuZ2UjIy19ICMgYWJzb2x1dGUgdmFsdWUKICAgICAgbGltaXQ9JHt0aHJlc2hvbGQlJSV9CiAgICAgIDs7CiAgICAqKQogICAgICBhYnNvbHV0ZT0ke2RlbHRhIyMtfSAjIGFic29sdXRlIHZhbHVlCiAgICAgIGxpbWl0PSR0aHJlc2hvbGQKICAgICAgOzsKICBlc2FjCiAgaWYgW1sgJGFic29sdXRlIC1sZSAkbGltaXQgXV07IHRoZW4KICAgIGVjaG8gIndpdGhpbiAoKy8tKSR0aHJlc2hvbGQiCiAgICByZXR1cm4gMAogIGVsc2UKICAgIGVjaG8gIm91dHNpZGUgKCsvLSkkdGhyZXNob2xkIgogICAgcmV0dXJuIDEKICBmaQp9CgpzdGVhZHlzdGF0ZSgpIHsKICBsb2NhbCBsYXN0PSQxIGN1cnJlbnQ9JDIKICBpZiBbWyAkbGFzdCAtbHQgJFNURUFEWV9TVEFURV9NSU5JTVVNIF1dOyB0aGVuCiAgICBlY2hvICJsYXN0OiRsYXN0IGN1cnJlbnQ6JGN1cnJlbnQgV2FpdGluZyB0byByZWFjaCAkU1RFQURZX1NUQVRFX01JTklNVU0gYmVmb3JlIGNoZWNraW5nIGZvciBzdGVhZHktc3RhdGUiCiAgICByZXR1cm4gMQogIGZpCiAgd2l0aGluICIkbGFzdCIgIiRjdXJyZW50IiAiJFNURUFEWV9TVEFURV9USFJFU0hPTEQiCn0KCndhaXRGb3JSZWFkeSgpIHsKICBsb2dnZXIgIlJlY292ZXJ5OiBXYWl0aW5nICR7TUFYSU1VTV9XQUlUX1RJTUV9cyBmb3IgdGhlIGluaXRpYWxpemF0aW9uIHRvIGNvbXBsZXRlIgogIGxvY2FsIHQ9MCBzPTEwCiAgbG9jYWwgbGFzdENjb3VudD0wIGNjb3VudD0wIHN0ZWFkeVN0YXRlVGltZT0wCiAgd2hpbGUgW1sgJHQgLWx0ICRNQVhJTVVNX1dBSVRfVElNRSBdXTsgZG8KICAgIHNsZWVwICRzCiAgICAoKHQgKz0gcykpCiAgICAjIERldGVjdCBzdGVhZHktc3RhdGUgcG9kIGNvdW50CiAgICBjY291bnQ9JChjcmljdGwgcHMgMj4vZGV2L251bGwgfCB3YyAtbCkKICAgIGlmIFtbICRjY291bnQgLWd0IDAgXV0gJiYgc3RlYWR5c3RhdGUgIiRsYXN0Q2NvdW50IiAiJGNjb3VudCI7IHRoZW4KICAgICAgKChzdGVhZHlTdGF0ZVRpbWUgKz0gcykpCiAgICAgIGVjaG8gIlN0ZWFkeS1zdGF0ZSBmb3IgJHtzdGVhZHlTdGF0ZVRpbWV9cy8ke1NURUFEWV9TVEFURV9XSU5ET1d9cyIKICAgICAgaWYgW1sgJHN0ZWFkeVN0YXRlVGltZSAtZ2UgJFNURUFEWV9TVEFURV9XSU5ET1cgXV07IHRoZW4KICAgICAgICBsb2dnZXIgIlJlY292ZXJ5OiBTdGVhZHktc3RhdGUgKCsvLSAkU1RFQURZX1NUQVRFX1RIUkVTSE9MRCkgZm9yICR7U1RFQURZX1NUQVRFX1dJTkRPV31zOiBEb25lIgogICAgICAgIHJldHVybiAwCiAgICAgIGZpCiAgICBlbHNlCiAgICAgIGlmIFtbICRzdGVhZHlTdGF0ZVRpbWUgLWd0IDAgXV07IHRoZW4KICAgICAgICBlY2hvICJSZXNldHRpbmcgc3RlYWR5LXN0YXRlIHRpbWVyIgogICAgICAgIHN0ZWFkeVN0YXRlVGltZT0wCiAgICAgIGZpCiAgICBmaQogICAgbGFzdENjb3VudD0kY2NvdW50CiAgZG9uZQogIGxvZ2dlciAiUmVjb3Zlcnk6IFJlY292ZXJ5IENvbXBsZXRlIFRpbWVvdXQiCn0KCnNldFJjdU5vcm1hbCgpIHsKICBlY2hvICJTZXR0aW5nIHJjdV9ub3JtYWwgdG8gMSIKICBlY2hvIDEgPiAvc3lzL2tlcm5lbC9yY3Vfbm9ybWFsCn0KCm1haW4oKSB7CiAgd2FpdEZvclJlYWR5CiAgZWNobyAiV2FpdGluZyBmb3Igc3RlYWR5IHN0YXRlIHRvb2s6ICQoYXdrICd7cHJpbnQgaW50KCQxLzM2MDApImgiLCBpbnQoKCQxJTM2MDApLzYwKSJtIiwgaW50KCQxJTYwKSJzIn0nIC9wcm9jL3VwdGltZSkiCiAgc2V0UmN1Tm9ybWFsCn0KCmlmIFtbICIke0JBU0hfU09VUkNFWzBdfSIgPSAiJHswfSIgXV07IHRoZW4KICBtYWluICIke0B9IgogIGV4aXQgJD8KZmkK
mode: 493
path: /usr/local/bin/set-rcu-normal.sh
systemd:
units:
- contents: |
[Unit]
Description=Disable rcu_expedited after node has finished booting by setting rcu_normal to 1
[Service]
Type=simple
ExecStart=/usr/local/bin/set-rcu-normal.sh
# Maximum wait time is 600s = 10m:
Environment=MAXIMUM_WAIT_TIME=600
# Steady-state threshold = 2%
# Allowed values:
# 4 - absolute pod count (+/-)
# 4% - percent change (+/-)
# -1 - disable the steady-state check
# Note: '%' must be escaped as '%%' in systemd unit files
Environment=STEADY_STATE_THRESHOLD=2%%
# Steady-state window = 120s
# If the running pod count stays within the given threshold for this time
# period, return CPU utilization to normal before the maximum wait time has
# expires
Environment=STEADY_STATE_WINDOW=120
# Steady-state minimum = 40
# Increasing this will skip any steady-state checks until the count rises above
# this number to avoid false positives if there are some periods where the
# count doesn't increase but we know we can't be at steady-state yet.
Environment=STEADY_STATE_MINIMUM=40
[Install]
WantedBy=multi-user.target
enabled: true
name: set-rcu-normal.service08-set-rcu-normal-worker.yaml
# Automatically generated by extra-manifests-builder
# Do not make changes directly.
apiVersion: machineconfiguration.openshift.io/v1
kind: MachineConfig
metadata:
labels:
machineconfiguration.openshift.io/role: worker
name: 08-set-rcu-normal-worker
spec:
config:
ignition:
version: 3.2.0
storage:
files:
- contents:
source: data:text/plain;charset=utf-8;base64,IyEvYmluL2Jhc2gKIwojIERpc2FibGUgcmN1X2V4cGVkaXRlZCBhZnRlciBub2RlIGhhcyBmaW5pc2hlZCBib290aW5nCiMKIyBUaGUgZGVmYXVsdHMgYmVsb3cgY2FuIGJlIG92ZXJyaWRkZW4gdmlhIGVudmlyb25tZW50IHZhcmlhYmxlcwojCgojIERlZmF1bHQgd2FpdCB0aW1lIGlzIDYwMHMgPSAxMG06Ck1BWElNVU1fV0FJVF9USU1FPSR7TUFYSU1VTV9XQUlUX1RJTUU6LTYwMH0KCiMgRGVmYXVsdCBzdGVhZHktc3RhdGUgdGhyZXNob2xkID0gMiUKIyBBbGxvd2VkIHZhbHVlczoKIyAgNCAgLSBhYnNvbHV0ZSBwb2QgY291bnQgKCsvLSkKIyAgNCUgLSBwZXJjZW50IGNoYW5nZSAoKy8tKQojICAtMSAtIGRpc2FibGUgdGhlIHN0ZWFkeS1zdGF0ZSBjaGVjawpTVEVBRFlfU1RBVEVfVEhSRVNIT0xEPSR7U1RFQURZX1NUQVRFX1RIUkVTSE9MRDotMiV9CgojIERlZmF1bHQgc3RlYWR5LXN0YXRlIHdpbmRvdyA9IDYwcwojIElmIHRoZSBydW5uaW5nIHBvZCBjb3VudCBzdGF5cyB3aXRoaW4gdGhlIGdpdmVuIHRocmVzaG9sZCBmb3IgdGhpcyB0aW1lCiMgcGVyaW9kLCByZXR1cm4gQ1BVIHV0aWxpemF0aW9uIHRvIG5vcm1hbCBiZWZvcmUgdGhlIG1heGltdW0gd2FpdCB0aW1lIGhhcwojIGV4cGlyZXMKU1RFQURZX1NUQVRFX1dJTkRPVz0ke1NURUFEWV9TVEFURV9XSU5ET1c6LTYwfQoKIyBEZWZhdWx0IHN0ZWFkeS1zdGF0ZSBhbGxvd3MgYW55IHBvZCBjb3VudCB0byBiZSAic3RlYWR5IHN0YXRlIgojIEluY3JlYXNpbmcgdGhpcyB3aWxsIHNraXAgYW55IHN0ZWFkeS1zdGF0ZSBjaGVja3MgdW50aWwgdGhlIGNvdW50IHJpc2VzIGFib3ZlCiMgdGhpcyBudW1iZXIgdG8gYXZvaWQgZmFsc2UgcG9zaXRpdmVzIGlmIHRoZXJlIGFyZSBzb21lIHBlcmlvZHMgd2hlcmUgdGhlCiMgY291bnQgZG9lc24ndCBpbmNyZWFzZSBidXQgd2Uga25vdyB3ZSBjYW4ndCBiZSBhdCBzdGVhZHktc3RhdGUgeWV0LgpTVEVBRFlfU1RBVEVfTUlOSU1VTT0ke1NURUFEWV9TVEFURV9NSU5JTVVNOi0wfQoKIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIwoKd2l0aGluKCkgewogIGxvY2FsIGxhc3Q9JDEgY3VycmVudD0kMiB0aHJlc2hvbGQ9JDMKICBsb2NhbCBkZWx0YT0wIHBjaGFuZ2UKICBkZWx0YT0kKCggY3VycmVudCAtIGxhc3QgKSkKICBpZiBbWyAkY3VycmVudCAtZXEgJGxhc3QgXV07IHRoZW4KICAgIHBjaGFuZ2U9MAogIGVsaWYgW1sgJGxhc3QgLWVxIDAgXV07IHRoZW4KICAgIHBjaGFuZ2U9MTAwMDAwMAogIGVsc2UKICAgIHBjaGFuZ2U9JCgoICggIiRkZWx0YSIgKiAxMDApIC8gbGFzdCApKQogIGZpCiAgZWNobyAtbiAibGFzdDokbGFzdCBjdXJyZW50OiRjdXJyZW50IGRlbHRhOiRkZWx0YSBwY2hhbmdlOiR7cGNoYW5nZX0lOiAiCiAgbG9jYWwgYWJzb2x1dGUgbGltaXQKICBjYXNlICR0aHJlc2hvbGQgaW4KICAgIColKQogICAgICBhYnNvbHV0ZT0ke3BjaGFuZ2UjIy19ICMgYWJzb2x1dGUgdmFsdWUKICAgICAgbGltaXQ9JHt0aHJlc2hvbGQlJSV9CiAgICAgIDs7CiAgICAqKQogICAgICBhYnNvbHV0ZT0ke2RlbHRhIyMtfSAjIGFic29sdXRlIHZhbHVlCiAgICAgIGxpbWl0PSR0aHJlc2hvbGQKICAgICAgOzsKICBlc2FjCiAgaWYgW1sgJGFic29sdXRlIC1sZSAkbGltaXQgXV07IHRoZW4KICAgIGVjaG8gIndpdGhpbiAoKy8tKSR0aHJlc2hvbGQiCiAgICByZXR1cm4gMAogIGVsc2UKICAgIGVjaG8gIm91dHNpZGUgKCsvLSkkdGhyZXNob2xkIgogICAgcmV0dXJuIDEKICBmaQp9CgpzdGVhZHlzdGF0ZSgpIHsKICBsb2NhbCBsYXN0PSQxIGN1cnJlbnQ9JDIKICBpZiBbWyAkbGFzdCAtbHQgJFNURUFEWV9TVEFURV9NSU5JTVVNIF1dOyB0aGVuCiAgICBlY2hvICJsYXN0OiRsYXN0IGN1cnJlbnQ6JGN1cnJlbnQgV2FpdGluZyB0byByZWFjaCAkU1RFQURZX1NUQVRFX01JTklNVU0gYmVmb3JlIGNoZWNraW5nIGZvciBzdGVhZHktc3RhdGUiCiAgICByZXR1cm4gMQogIGZpCiAgd2l0aGluICIkbGFzdCIgIiRjdXJyZW50IiAiJFNURUFEWV9TVEFURV9USFJFU0hPTEQiCn0KCndhaXRGb3JSZWFkeSgpIHsKICBsb2dnZXIgIlJlY292ZXJ5OiBXYWl0aW5nICR7TUFYSU1VTV9XQUlUX1RJTUV9cyBmb3IgdGhlIGluaXRpYWxpemF0aW9uIHRvIGNvbXBsZXRlIgogIGxvY2FsIHQ9MCBzPTEwCiAgbG9jYWwgbGFzdENjb3VudD0wIGNjb3VudD0wIHN0ZWFkeVN0YXRlVGltZT0wCiAgd2hpbGUgW1sgJHQgLWx0ICRNQVhJTVVNX1dBSVRfVElNRSBdXTsgZG8KICAgIHNsZWVwICRzCiAgICAoKHQgKz0gcykpCiAgICAjIERldGVjdCBzdGVhZHktc3RhdGUgcG9kIGNvdW50CiAgICBjY291bnQ9JChjcmljdGwgcHMgMj4vZGV2L251bGwgfCB3YyAtbCkKICAgIGlmIFtbICRjY291bnQgLWd0IDAgXV0gJiYgc3RlYWR5c3RhdGUgIiRsYXN0Q2NvdW50IiAiJGNjb3VudCI7IHRoZW4KICAgICAgKChzdGVhZHlTdGF0ZVRpbWUgKz0gcykpCiAgICAgIGVjaG8gIlN0ZWFkeS1zdGF0ZSBmb3IgJHtzdGVhZHlTdGF0ZVRpbWV9cy8ke1NURUFEWV9TVEFURV9XSU5ET1d9cyIKICAgICAgaWYgW1sgJHN0ZWFkeVN0YXRlVGltZSAtZ2UgJFNURUFEWV9TVEFURV9XSU5ET1cgXV07IHRoZW4KICAgICAgICBsb2dnZXIgIlJlY292ZXJ5OiBTdGVhZHktc3RhdGUgKCsvLSAkU1RFQURZX1NUQVRFX1RIUkVTSE9MRCkgZm9yICR7U1RFQURZX1NUQVRFX1dJTkRPV31zOiBEb25lIgogICAgICAgIHJldHVybiAwCiAgICAgIGZpCiAgICBlbHNlCiAgICAgIGlmIFtbICRzdGVhZHlTdGF0ZVRpbWUgLWd0IDAgXV07IHRoZW4KICAgICAgICBlY2hvICJSZXNldHRpbmcgc3RlYWR5LXN0YXRlIHRpbWVyIgogICAgICAgIHN0ZWFkeVN0YXRlVGltZT0wCiAgICAgIGZpCiAgICBmaQogICAgbGFzdENjb3VudD0kY2NvdW50CiAgZG9uZQogIGxvZ2dlciAiUmVjb3Zlcnk6IFJlY292ZXJ5IENvbXBsZXRlIFRpbWVvdXQiCn0KCnNldFJjdU5vcm1hbCgpIHsKICBlY2hvICJTZXR0aW5nIHJjdV9ub3JtYWwgdG8gMSIKICBlY2hvIDEgPiAvc3lzL2tlcm5lbC9yY3Vfbm9ybWFsCn0KCm1haW4oKSB7CiAgd2FpdEZvclJlYWR5CiAgZWNobyAiV2FpdGluZyBmb3Igc3RlYWR5IHN0YXRlIHRvb2s6ICQoYXdrICd7cHJpbnQgaW50KCQxLzM2MDApImgiLCBpbnQoKCQxJTM2MDApLzYwKSJtIiwgaW50KCQxJTYwKSJzIn0nIC9wcm9jL3VwdGltZSkiCiAgc2V0UmN1Tm9ybWFsCn0KCmlmIFtbICIke0JBU0hfU09VUkNFWzBdfSIgPSAiJHswfSIgXV07IHRoZW4KICBtYWluICIke0B9IgogIGV4aXQgJD8KZmkK
mode: 493
path: /usr/local/bin/set-rcu-normal.sh
systemd:
units:
- contents: |
[Unit]
Description=Disable rcu_expedited after node has finished booting by setting rcu_normal to 1
[Service]
Type=simple
ExecStart=/usr/local/bin/set-rcu-normal.sh
# Maximum wait time is 600s = 10m:
Environment=MAXIMUM_WAIT_TIME=600
# Steady-state threshold = 2%
# Allowed values:
# 4 - absolute pod count (+/-)
# 4% - percent change (+/-)
# -1 - disable the steady-state check
# Note: '%' must be escaped as '%%' in systemd unit files
Environment=STEADY_STATE_THRESHOLD=2%%
# Steady-state window = 120s
# If the running pod count stays within the given threshold for this time
# period, return CPU utilization to normal before the maximum wait time has
# expires
Environment=STEADY_STATE_WINDOW=120
# Steady-state minimum = 40
# Increasing this will skip any steady-state checks until the count rises above
# this number to avoid false positives if there are some periods where the
# count doesn't increase but we know we can't be at steady-state yet.
Environment=STEADY_STATE_MINIMUM=40
[Install]
WantedBy=multi-user.target
enabled: true
name: set-rcu-normal.service3.2.5. Telco RAN DU 참조 구성 소프트웨어 사양
다음 정보는 Intelco RAN DU 참조 설계 사양(RDS) 검증된 소프트웨어 버전을 설명합니다.
3.2.5.1. Telco RAN DU 4.17 검증 소프트웨어 구성 요소
Red Hat telco RAN DU 4.17 솔루션은 OpenShift Container Platform 관리 클러스터 및 허브 클러스터에 대해 다음과 같은 Red Hat 소프트웨어 제품을 사용하여 검증되었습니다.
| Component | 소프트웨어 버전 |
|---|---|
| 관리형 클러스터 버전 | 4.17 |
| Cluster Logging Operator | 6.0 |
| Local Storage Operator | 4.17 |
| OADP(OpenShift API for Data Protection) | 1.4.1 |
| PTP Operator | 4.17 |
| SRIOV Operator | 4.17 |
| SRIOV-FEC Operator | 2.9 |
| 라이프사이클 에이전트 | 4.17 |
| Component | 소프트웨어 버전 |
|---|---|
| hub 클러스터 버전 | 4.17 |
| Red Hat Advanced Cluster Management(RHACM) | 2.11 |
| GitOps ZTP 플러그인 | 4.17 |
| Red Hat OpenShift GitOps | 1.13 |
| 토폴로지 인식 라이프사이클 관리자(TALM) | 4.17 |