하드웨어 가속기
하드웨어 가속기
초록
1장. 하드웨어 가속기 정보
특수 하드웨어 가속기는 새롭게 등장하는 인공 지능 및 머신 러닝(AI/ML) 업계에서 중요한 역할을 합니다. 특히 하드웨어 가속기는 이 새로운 기술을 지원하는 대규모 언어 및 기타 기본 모델을 교육하고 제공하는 데 필수적입니다. 데이터 과학자, 데이터 엔지니어, ML 엔지니어 및 개발자는 데이터 집약적인 변환 및 모델 개발 및 서비스를 위한 특수 하드웨어 가속을 활용할 수 있습니다. 이러한 에코시스템의 대부분은 오픈 소스이며, 여러 파트너 및 오픈 소스 기반이 포함됩니다.
Red Hat OpenShift Container Platform은 하드웨어 가속기를 구성하는 처리 장치를 추가하는 카드 및 주변 하드웨어를 지원합니다.
- 그래픽 처리 단위(GPU)
- 통신 처리 단위(NPU)
- Application-specific integrated circuit (ASIC)
- 데이터 처리 단위(DPU)

특수 하드웨어 가속기는 AI/ML 개발을 위한 다양한 이점을 제공합니다.
- 모두를 위한 하나의 플랫폼
- 개발자, 데이터 엔지니어, 데이터 과학자 및 DevOps를 위한 협업 환경
- Operator를 통한 확장 기능
- Operator를 사용하면 OpenShift Container Platform에 AI/ML 기능을 가져올 수 있습니다.
- 하이브리드 클라우드 지원
- 모델 개발, 제공 및 배포를 위한 온프레미스 지원
- AI/ML 워크로드 지원
- 모델 테스트, 반복, 통합, 승격 및 프로덕션을 서비스로 제공
Red Hat은 Linux(커널 및 사용자 공간) 및 Kubernetes 계층에서 RHEL(Red Hat Enterprise Linux) 및 OpenShift Container Platform 플랫폼에서 이러한 특수 하드웨어 가속기를 활성화하는 최적화된 플랫폼을 제공합니다. 이를 위해 Red Hat은 Red Hat OpenShift AI와 Red Hat OpenShift Container Platform의 검증된 기능을 엔터프라이즈급 AI 애플리케이션 플랫폼에 결합합니다.
하드웨어 Operator는 Kubernetes 클러스터의 운영 프레임워크를 사용하여 필요한 가속기 리소스를 활성화합니다. 제공된 장치 플러그인을 수동으로 또는 데몬 세트로 배포할 수도 있습니다. 이 플러그인은 클러스터에 GPU를 등록합니다.
특정 특수 하드웨어 가속기는 개발 및 테스트를 위해 보안 환경을 유지해야 하는 연결이 끊긴 환경에서 작동하도록 설계되었습니다.
1.1. 하드웨어 가속기
Red Hat OpenShift Container Platform은 다음과 같은 하드웨어 가속기를 활성화합니다.
- NVIDIA GPU
- AMD Instinct® GPU
- Intel® Gaudi®
2장. NVIDIA GPU 아키텍처
NVIDIA는 OpenShift Container Platform에서 GPU(그래픽 처리 장치) 리소스 사용을 지원합니다. OpenShift Container Platform은 대규모 Kubernetes 클러스터를 배포 및 관리하기 위해 Red Hat에서 개발하고 지원하는 보안 중심 및 강화된 Kubernetes 플랫폼입니다. OpenShift Container Platform에는 Kubernetes에 대한 개선 사항이 포함되어 있으므로 사용자가 NVIDIA GPU 리소스를 쉽게 구성하고 사용하여 워크로드를 가속화할 수 있습니다.
NVIDIA GPU Operator는 OpenShift Container Platform 내에서 Operator 프레임워크를 사용하여 GPU 가속 워크로드를 실행하는 데 필요한 NVIDIA 소프트웨어 구성 요소의 전체 라이프사이클을 관리합니다.
이러한 구성 요소에는 NVIDIA 드라이버( CUDA 활성화), GPU용 Kubernetes 장치 플러그인, NVIDIA 컨테이너 툴킷, GPU 기능 검색을 사용한 자동 노드 태그 지정, DCGM 기반 모니터링 등이 포함됩니다.
NVIDIA GPU Operator는 NVIDIA에서만 지원됩니다. NVIDIA에서 지원을 얻는 방법에 대한 자세한 내용은 NVIDIA에서 지원 받기를 참조하십시오.
2.1. NVIDIA GPU 사전 요구 사항
- GPU 작업자 노드가 하나 이상 있는 작동 중인 OpenShift 클러스터입니다.
-
필요한 단계를 수행하려면
cluster-admin으로 OpenShift 클러스터에 액세스할 수 있습니다. -
OpenShift CLI(
oc)가 설치되어 있어야 합니다. -
NFD(노드 기능 검색) Operator가 설치되고
nodefeaturediscovery인스턴스가 생성됩니다.
2.2. NVIDIA GPU 사용
다음 다이어그램은 OpenShift에 GPU 아키텍처를 활성화하는 방법을 보여줍니다.
그림 2.1. NVIDIA GPU 사용
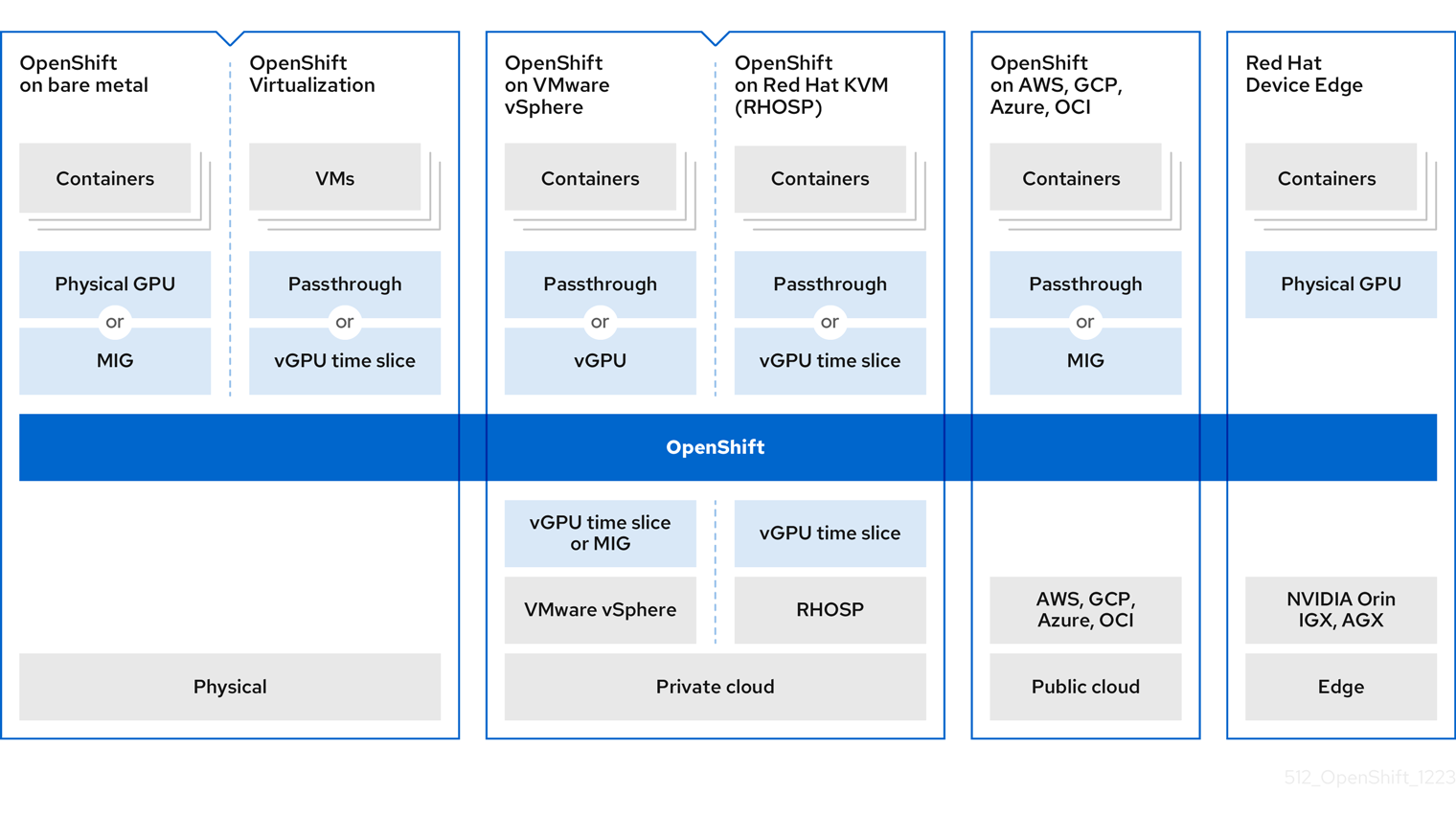
MIG는 NVIDIA Ampere 세대부터 GPU에서 지원됩니다. MIG를 지원하는 GPU 목록은 NVIDIAMIG 사용자 가이드 를 참조하십시오.
2.2.1. GPU 및 베어 메탈
NVIDIA 인증 베어 메탈 서버에 OpenShift Container Platform을 배포할 수 있지만 몇 가지 제한 사항이 있습니다.
- 컨트롤 플레인 노드는 CPU 노드일 수 있습니다.
이러한 작업자 노드에서 AI/ML 워크로드가 실행되도록 작업자 노드는 GPU 노드여야 합니다.
또한 작업자 노드는 하나 이상의 GPU를 호스팅할 수 있지만 동일한 유형이어야 합니다. 예를 들어 노드에는 두 개의 NVIDIA A100 GPU가 있을 수 있지만 A100 GPU 1개와 T4 GPU가 1개인 노드는 지원되지 않습니다. Kubernetes용 NVIDIA 장치 플러그인은 동일한 노드에서 다른 GPU 모델 혼합을 지원하지 않습니다.
- OpenShift를 사용하는 경우 하나 이상의 서버가 필요합니다. 두 개의 서버가 있는 클러스터는 지원되지 않습니다. 단일 서버 배포는 단일 노드 openShift(SNO)라고 하며 이 구성을 사용하면 고가용성 OpenShift 환경이 생성됩니다.
컨테이너화된 GPU에 액세스하기 위해 다음 방법 중 하나를 선택할 수 있습니다.
- GPU 패스스루
- MIG (Multi-Instance GPU)
2.2.2. GPU 및 가상화
많은 개발자와 기업이 컨테이너화된 애플리케이션 및 서버리스 인프라로 이동하고 있지만 VM(가상 머신)에서 실행되는 애플리케이션을 개발하고 유지 관리하는 데 많은 관심이 있습니다. Red Hat OpenShift Virtualization은 이러한 기능을 통해 기업은 클러스터 내의 컨테이너화된 워크플로우에 VM을 통합할 수 있습니다.
다음 방법 중 하나를 선택하여 작업자 노드를 GPU에 연결할 수 있습니다.
- VM(가상 머신) 내에서 GPU 하드웨어에 액세스하고 사용하기 위한 GPU 패스스루입니다.
- GPU 컴퓨팅 용량이 워크로드에 의해 포화되지 않은 경우 GPU(vGPU) 시간 분할입니다.
2.2.3. GPU 및 vSphere
다양한 GPU 유형을 호스팅할 수 있는 NVIDIA 인증 VMware vSphere 서버에 OpenShift Container Platform을 배포할 수 있습니다.
VM에서 vGPU 인스턴스를 사용하는 경우 NVIDIA GPU 드라이버를 하이퍼바이저에 설치해야 합니다. VMware vSphere의 경우 이 호스트 드라이버는 VIB 파일 형식으로 제공됩니다.
작업자 노드 VM에 할당할 수 있는 최대 vGPUS 수는 vSphere 버전에 따라 다릅니다.
- vSphere 7.0: VM당 최대 4개의 vGPU
vSphere 8.0: VM당 최대 8개의 vGPU
참고vSphere 8.0에서는 VM과 관련된 전체 또는 소수의 이기종 프로필을 여러 개 지원합니다.
작업자 노드를 GPU에 연결할 다음 방법 중 하나를 선택할 수 있습니다.
- VM(가상 머신) 내에서 GPU 하드웨어에 액세스하고 사용하기 위한 GPU 패스스루
- GPU (vGPU) 시간 분할, 일부 GPU가 필요하지 않은 경우
베어 메탈 배포와 유사하게 하나 이상의 서버가 필요합니다. 두 개의 서버가 있는 클러스터는 지원되지 않습니다.
2.2.4. GPU 및 Red Hat KVM
NVIDIA 인증 KVM(커널 기반 가상 머신) 서버에서 OpenShift Container Platform을 사용할 수 있습니다.
베어 메탈 배포와 유사하게 하나 이상의 서버가 필요합니다. 두 개의 서버가 있는 클러스터는 지원되지 않습니다.
그러나 베어 메탈 배포와 달리 서버에서 다양한 유형의 GPU를 사용할 수 있습니다. 이는 Kubernetes 노드 역할을 하는 다른 VM에 이러한 GPU를 할당할 수 있기 때문입니다. 유일한 제한 사항은 Kubernetes 노드에 자체 수준에서 동일한 GPU 유형 세트가 있어야 한다는 것입니다.
컨테이너화된 GPU에 액세스하기 위해 다음 방법 중 하나를 선택할 수 있습니다.
- VM(가상 머신) 내에서 GPU 하드웨어에 액세스하고 사용하기 위한 GPU 패스스루
- GPU(vGPU)의 일부 GPU가 필요한 것은 아닙니다.
vGPU 기능을 활성화하려면 호스트 수준에 특수 드라이버를 설치해야 합니다. 이 드라이버는 RPM 패키지로 제공됩니다. 이 호스트 드라이버는 GPU 패스스루 할당에는 전혀 필요하지 않습니다.
2.2.5. GPU 및 CSP
주요 클라우드 서비스 공급자(CSP), AWS(Amazon Web Services), Google Cloud 또는 Microsoft Azure 중 하나에 OpenShift Container Platform을 배포할 수 있습니다.
완전히 관리되는 배포와 자체 관리 배포의 두 가지 작업 모드를 사용할 수 있습니다.
- 완전 관리형 배포에서 CSP와 협력하여 모든 것이 Red Hat에 의해 자동화됩니다. CSP 웹 콘솔을 통해 OpenShift 인스턴스를 요청할 수 있으며, Red Hat에서 클러스터가 자동으로 생성되고 완전히 관리됩니다. 환경의 노드 실패 또는 오류에 대해 우려할 필요가 없습니다. Red Hat은 클러스터 가동 시간을 완전히 유지합니다. 완전 관리형 서비스는 AWS, Azure 및 Google Cloud에서 사용할 수 있습니다. AWS의 경우 OpenShift 서비스를 (AWS의 Red Hat OpenShift Service)라고 합니다. Azure의 경우 이 서비스를 Azure Red Hat OpenShift라고 합니다. Google Cloud의 경우 이 서비스를 Google Cloud에서 OpenShift Dedicated라고 합니다.
- 자체 관리 배포에서 OpenShift 클러스터를 인스턴스화하고 유지보수해야 합니다. Red Hat은 이 경우 OpenShift 클러스터 배포를 지원하는 OpenShift-install 유틸리티를 제공합니다. 자체 관리 서비스는 모든 CSP에서 전역적으로 사용할 수 있습니다.
이 컴퓨팅 인스턴스는 GPU 가속 컴퓨팅 인스턴스이고 GPU 유형이 NVIDIA AI Enterprise의 지원되는 GPU 목록과 일치해야 합니다. 예를 들어 T4, V100 및 A100은 이 목록의 일부입니다.
컨테이너화된 GPU에 액세스하기 위해 다음 방법 중 하나를 선택할 수 있습니다.
- VM(가상 머신) 내에서 GPU 하드웨어에 액세스하고 사용하기 위한 GPU 패스스루입니다.
- 전체 GPU가 필요하지 않은 경우 GPU(vGPU) 시간 분할입니다.
2.2.6. GPU 및 Red Hat Device Edge
Red Hat Device Edge는 MicroShift에 대한 액세스를 제공합니다. MicroShift는 리소스가 제한적인 (지대) 컴퓨팅에 필요한 기능 및 서비스를 통해 단일 노드 배포의 단순성을 제공합니다. Red Hat Device Edge는 리소스가 제한적인 환경에 배포된 베어 메탈, 가상, 컨테이너화된 Kubernetes 워크로드의 요구 사항을 충족합니다.
Red Hat Device Edge 환경에서 컨테이너에서 NVIDIA GPU를 활성화할 수 있습니다.
GPU 패스스루를 사용하여 컨테이너화된 GPU에 액세스합니다.
2.3. GPU 공유 방법
Red Hat과 NVIDIA는 엔터프라이즈급 OpenShift Container Platform 클러스터에서 GPU 가속 컴퓨팅을 단순화하기 위해 GPU 동시성 및 공유 메커니즘을 개발했습니다.
일반적으로 애플리케이션에는 GPU를 사용하지 않는 다른 컴퓨팅 요구 사항이 있습니다. 각 워크로드에 적합한 양의 컴퓨팅 리소스를 제공하는 것은 배포 비용을 줄이고 GPU 사용률을 극대화하는 데 중요합니다.
가상화를 포함한 프로그래밍 모델 API에서 시스템 소프트웨어 및 하드웨어 파티셔닝에 이르기까지 다양한 GPU 사용률을 개선하기 위한 동시성 메커니즘이 존재합니다. 다음 목록은 GPU 동시성 메커니즘을 보여줍니다.
- Compute Unified Device Architecture (CUDA) 스트림
- 시간 분할
- CUDA Multi-Process Service (MPS)
- 다중 인스턴스 GPU(MIG)
- vGPU를 사용한 가상화
다른 OpenShift Container Platform 시나리오에 GPU 동시성 메커니즘을 사용할 때 다음 GPU 공유 제안을 고려하십시오.
- 베어 메탈
- vGPU를 사용할 수 없습니다. CheG 지원 카드를 사용하는 것이 좋습니다.
- VMs
- vGPU가 최선의 선택입니다.
- 베어 메탈에서MIG가 없는 이전 NVIDIA 카드
- 시간 분할을 사용하는 것이 좋습니다.
- 여러 GPU가 있고 패스스루 및 vGPU를 원하는 VM
- 별도의 VM을 사용하는 것이 좋습니다.
- OpenShift Virtualization 및 여러 GPU를 사용한 베어 메탈
- 호스트된 VM에 패스스루를 사용하고 컨테이너에 시간 분할을 사용하는 것이 좋습니다.
추가 리소스
2.3.1. CUDA 스트림
CUDA(Compute Unified Device Architecture)는 GPU의 일반 컴퓨팅을 위해 NVIDIA에서 개발한 병렬 컴퓨팅 플랫폼 및 프로그래밍 모델입니다.
스트림은 GPU에서 문제순으로 실행되는 일련의 작업입니다. CUDA 명령은 일반적으로 기본 스트림에서 순차적으로 실행되며 이전 작업이 완료될 때까지 작업이 시작되지 않습니다.
다양한 스트림의 작업을 비동기적으로 처리하면 병렬 작업을 실행할 수 있습니다. 한 스트림에서 발행된 작업은 다른 작업이 다른 스트림으로 발행되기 전, 중 또는 후에 실행됩니다. 이를 통해 GPU는 정해진 순서로 여러 작업을 동시에 실행하여 성능이 향상됩니다.
추가 리소스
2.3.2. 시간 분할
GPU 시간 분할은 여러 CUDA 애플리케이션을 실행할 때 과부하된 GPU에서 예약된 워크로드를 상호 저장합니다.
GPU의 복제본 세트를 정의하여 Kubernetes에서 GPU를 시간 분할할 수 있으며 각각 워크로드를 실행하기 위해 개별적으로 Pod에 배포할 수 있습니다. MIG(Multi-instance GPU)와 달리 복제본 간 메모리 또는 내결함성이 없지만 일부 워크로드의 경우 공유하지 않는 것보다 좋습니다. 내부적으로 GPU 시간 분할은 동일한 기본 GPU의 복제본에서 멀티플렉션에 사용됩니다.
시간 분할에 대한 클러스터 전체 기본 구성을 적용할 수 있습니다. 노드별 구성을 적용할 수도 있습니다. 예를 들어 Cryostat T4 GPU가 있는 노드에만 시간 분할 구성을 적용하고 다른 GPU 모델의 노드를 수정할 수 없습니다.
클러스터 전체 기본 구성을 적용한 다음 노드에 레이블을 지정하여 해당 노드에 노드별 구성을 지정하여 이러한 두 가지 접근 방식을 결합할 수 있습니다.
2.3.3. CUDA 다중 프로세스 서비스
CUDA Multi-Process Service(MPS)를 사용하면 단일 GPU가 여러 CUDA 프로세스를 사용할 수 있습니다. 프로세스는 GPU에서 병렬로 실행되며 GPU 컴퓨팅 리소스의 포화 상태를 제거합니다. 또한 MPS는 다양한 프로세스에서 커널 작업 및 메모리를 복사하여 사용률을 향상시킬 수 있습니다.
추가 리소스
2.3.4. 다중 인스턴스 GPU
MG(Multi-instance GPU)를 사용하여 GPU 컴퓨팅 단위와 메모리를 여러MIG 인스턴스로 분할할 수 있습니다. 이러한 각 인스턴스는 시스템 관점에서 독립 실행형 GPU 장치를 나타내며 노드에서 실행되는 모든 애플리케이션, 컨테이너 또는 가상 머신에 연결할 수 있습니다. GPU를 사용하는 소프트웨어는 이러한 기타 각 인스턴스를 개별 GPU로 처리합니다.
MIG는 전체 GPU의 전체 성능이 필요하지 않은 애플리케이션이 있는 경우에 유용합니다. 새로운 NVIDIA Ampere 아키텍처의 MIG 기능을 사용하면 하드웨어 리소스를 여러 GPU 인스턴스로 분할할 수 있으며 각 GPU 인스턴스는 운영 체제에서 독립적인 CUDA 지원 GPU로 사용할 수 있습니다.
NVIDIA GPU Operator 버전 1.7.0 이상은 A100 및 A30 Ampere 카드에 대해MIG 지원을 제공합니다. 이러한 GPU 인스턴스는 전용 하드웨어 리소스와 완전히 격리된 최대 7개의 독립 CUDA 애플리케이션을 지원하도록 설계되었습니다.
2.3.5. vGPU를 사용한 가상화
가상 머신(VM)은 NVIDIA vGPU를 사용하여 단일 물리적 GPU에 직접 액세스할 수 있습니다. 엔터프라이즈 전체의 VM에서 공유하여 다른 장치에서 액세스할 수 있는 가상 GPU를 생성할 수 있습니다.
이 기능은 GPU 성능의 기능과 vGPU가 제공하는 관리 및 보안 이점을 결합합니다. vGPU가 제공하는 추가 이점으로 VM 환경에 대한 사전 관리 및 모니터링, 혼합 VDI 및 컴퓨팅 워크로드를 위한 워크로드 분산, 여러 VM의 리소스 공유 등이 포함됩니다.
추가 리소스
2.4. OpenShift Container Platform 용 NVIDIA GPU 기능
- NVIDIA 컨테이너 툴킷
- NVIDIA 컨테이너 툴킷을 사용하면 GPU 가속 컨테이너를 생성하고 실행할 수 있습니다. 툴킷에는 NVIDIA GPU를 사용하도록 컨테이너를 자동으로 구성하는 컨테이너 런타임 라이브러리 및 유틸리티가 포함되어 있습니다.
- NVIDIA AI Enterprise
NVIDIA AI Enterprise는 NVIDIA 인증 시스템에서 지원, 인증 및 지원되는 포괄적인 AI 및 데이터 분석 소프트웨어 제품군입니다.
NVIDIA AI Enterprise는 Red Hat OpenShift Container Platform을 지원합니다. 지원되는 설치 방법은 다음과 같습니다.
- GPU Passthrough가 있는 베어 메탈 또는 VMware vSphere의 OpenShift Container Platform.
- NVIDIA vGPU를 사용하는 VMware vSphere의 OpenShift Container Platform.
- GPU 기능 검색
Kubernetes용 NVIDIA GPU 기능 검색은 노드에서 사용 가능한 GPU에 대한 레이블을 자동으로 생성할 수 있는 소프트웨어 구성 요소입니다. GPU 기능 검색에서는 NFD(노드 기능 검색)를 사용하여 이 레이블을 수행합니다.
NFD(Node Feature Discovery Operator)는 하드웨어 관련 정보로 노드에 레이블을 지정하여 OpenShift Container Platform 클러스터에서 하드웨어 기능 및 구성 검색을 관리합니다. NFD는 PCI 카드, 커널, OS 버전과 같은 노드별 속성을 사용하여 호스트에 레이블을 지정합니다.
"Node Feature Discovery"를 검색하여 Operator Hub에서 NFD Operator를 찾을 수 있습니다.
- OpenShift Virtualization을 사용하는 NVIDIA GPU Operator
이 시점까지 GPU Operator는 GPU 가속 컨테이너를 실행하기 위해 작업자 노드만 프로비저닝했습니다. 이제 GPU Operator를 사용하여 GPU 가속 VM(가상 머신)을 실행하기 위해 작업자 노드를 프로비저닝할 수도 있습니다.
해당 노드에서 실행되도록 구성된 GPU 워크로드에 따라 작업자 노드에 다른 소프트웨어 구성 요소를 배포하도록 GPU Operator를 구성할 수 있습니다.
- GPU 모니터링 대시보드
- 모니터링 대시보드를 설치하여 OpenShift Container Platform 웹 콘솔의 클러스터 모니터링 페이지에 대한 GPU 사용 정보를 표시할 수 있습니다. GPU 사용률 정보에는 사용 가능한 GPU 수, 전력 소비(단위: 와트), 온도(단위: 섭씨), 사용률(%) 및 각 GPU에 대한 기타 메트릭이 포함됩니다.
3장. AMD GPU Operator
OpenShift Container Platform 클러스터 내의 AMD GPU Operator와 결합된 AMD Instinct GPU 액셀러레이터를 사용하면 머신 학습,ative AI 및 GPU 가속 애플리케이션에 대한 컴퓨팅 기능을 원활하게 활용할 수 있습니다.
이 문서에서는 AMD GPU Operator를 활성화, 구성 및 테스트하는 데 필요한 정보를 제공합니다. 자세한 내용은 AMD Instinct™ Accelerators 를 참조하십시오.
3.1. AMD GPU Operator 정보
AMD GPU Operator의 하드웨어 가속 기능은 인텔리전스 및 머신 러닝(AI/ML) 애플리케이션을 생성하기 위해 Red Hat OpenShift AI를 사용하는 데이터 과학자 및 개발자에게 향상된 성능 및 비용 효율성을 제공합니다. 특정 GPU 기능의 영역을 가속화하면 CPU 처리 및 메모리 사용량을 최소화하여 전체 애플리케이션 속도, 메모리 사용량 및 대역폭 제한을 개선할 수 있습니다.
3.2. AMD GPU Operator 설치
클러스터 관리자는 OpenShift CLI 및 웹 콘솔을 사용하여 AMD GPU Operator를 설치할 수 있습니다. 이는 Node Feature Discovery Operator, Kernel Module Management Operator 및 AMD GPU Operator를 설치해야 하는 다단계 절차입니다. 연속으로 다음 단계를 사용하여 Operator의 AMD 커뮤니티 릴리스를 설치합니다.
다음 단계
- Node Feature Discovery Operator 를 설치합니다.
- Kernel Module Management Operator 를 설치합니다.
- AMD GPU Operator 를 설치하고 구성합니다.
3.3. AMD GPU Operator 테스트
다음 절차에 따라 ROCmInfo 설치를 테스트하고 AMDMI210 GPU의 로그를 확인합니다.
프로세스
ROCmInfo를 테스트하는 YAML 파일을 생성합니다.
$ cat << EOF > rocminfo.yaml apiVersion: v1 kind: Pod metadata: name: rocminfo spec: containers: - image: docker.io/rocm/pytorch:latest name: rocminfo command: ["/bin/sh","-c"] args: ["rocminfo"] resources: limits: amd.com/gpu: 1 requests: amd.com/gpu: 1 restartPolicy: Never EOFrocminfoPod를 생성합니다.$ oc create -f rocminfo.yaml출력 예
apiVersion: v1 pod/rocminfo createdMI210 GPU 1개로
rocmnfo로그를 확인합니다.$ oc logs rocminfo | grep -A5 "Agent"출력 예
HSA Agents ========== ******* Agent 1 ******* Name: Intel(R) Xeon(R) Gold 6330 CPU @ 2.00GHz Uuid: CPU-XX Marketing Name: Intel(R) Xeon(R) Gold 6330 CPU @ 2.00GHz Vendor Name: CPU -- Agent 2 ******* Name: Intel(R) Xeon(R) Gold 6330 CPU @ 2.00GHz Uuid: CPU-XX Marketing Name: Intel(R) Xeon(R) Gold 6330 CPU @ 2.00GHz Vendor Name: CPU -- Agent 3 ******* Name: gfx90a Uuid: GPU-024b776f768a638b Marketing Name: AMD Instinct MI210 Vendor Name: AMDPod를 삭제합니다.
$ oc delete -f rocminfo.yaml출력 예
pod "rocminfo" deleted
4장. Intel Gaudi AI 액셀러레이터
OpenShift Container Platform 상속 AI 및 머신 러닝(AI/ML) 애플리케이션에 Intel Gaudi AI 가속기를 사용할 수 있습니다. Intel Gaudi AI 액셀러레이터는 최적화된 딥 러닝 워크로드를 위한 비용 효율적이고 유연하며 확장 가능한 솔루션을 제공합니다.
Red Hat은 Intel Gaudi 2 및 Intel Gaudi 3 장치를 지원합니다. Intel Gaudi 3 장치는 교육 속도와 에너지 효율성에 상당한 개선을 제공합니다.
4.1. Intel Gaudi AI 액셀러레이터 사전 요구 사항
- GPU 작업자 노드가 하나 이상 있는 작동 중인 OpenShift Container Platform 클러스터가 있어야 합니다.
- 필요한 단계를 수행하기 위해 cluster-admin으로 OpenShift Container Platform 클러스터에 액세스할 수 있습니다.
-
OpenShift CLI(
oc)가 설치되어 있습니다. -
NFD(Node Feature Discovery) Operator를 설치하고
NodeFeatureDiscovery인스턴스를 생성했습니다.
5장. NVIDIA GPUDirect Memory Access(RDMA)
NVIDIA GPUDirect Memory Access(RDMA)를 사용하면 한 컴퓨터의 애플리케이션이 운영 체제를 통해 액세스하지 않고도 다른 컴퓨터의 메모리에 직접 액세스할 수 있습니다. 이를 통해 프로세스의 커널 개입을 우회하여 리소스를 확보하고 네트워크 통신을 처리하는 데 일반적으로 필요한 CPU 오버헤드를 크게 줄일 수 있습니다. 이는 GPU 가속 워크로드를 클러스터 전체에 분산하는 데 유용합니다. 그리고 RDMA는 높은 대역폭과 낮은 대기 시간 애플리케이션에 매우 적합하기 때문에 큰 데이터 및 머신러닝 애플리케이션에 이상적입니다.
현재 NVIDIA GPUDirect RDMA에 대한 세 가지 구성 방법이 있습니다.
- 공유 장치
- 이 방법을 사용하면 NVIDIA GPUDirect RDMA 장치를 장치가 노출되는 OpenShift Container Platform 작업자 노드의 여러 Pod 간에 공유할 수 있습니다.
- 호스트 장치
- 이 방법은 Pod에서 추가 호스트 네트워크를 생성하여 작업자 노드에서 직접 물리적 이더넷 액세스를 제공합니다. 플러그인을 사용하면 네트워크 장치를 호스트 네트워크 네임스페이스에서 Pod의 네트워크 네임스페이스로 이동할 수 있습니다.
- SR-IOV 레거시 장치
- SR-IOV(Single Root IO Virtualization) 방법은 이더넷 어댑터와 같은 단일 네트워크 장치를 여러 Pod와 공유할 수 있습니다. SR-IOV는 호스트 노드에서 물리적 기능(PF)으로 인식되는 장치를 여러 VF(가상 기능)로 분할합니다. VF는 다른 네트워크 장치와 같이 사용됩니다.
이러한 각 방법은 NVIDIA GPUDirect RDMA over Converged Ethernet (RoCE) 또는 Infiniband 인프라에서 사용할 수 있으며 총 6개의 구성 방법을 제공합니다.
5.1. NVIDIA GPUDirect RDMA 사전 요구 사항
NVIDIA GPUDirect RDMA 구성의 모든 방법은 특정 Operator를 설치해야 합니다. Operator를 설치하려면 다음 단계를 사용하십시오.
- Node Feature Discovery Operator 를 설치합니다.
- SR-IOV Operator 를 설치합니다.
- NVIDIA Network Operator (NVIDIA 문서)를 설치합니다.
- NVIDIA GPU Operator (NVIDIA 문서)를 설치합니다.
5.2. IRDMA 커널 모듈 비활성화
DellR750xa를 포함한 일부 시스템에서는 IRDMA 커널 모듈이 DOCA 드라이버를 언로드하고 로드할 때 NVIDIA Network Operator에 문제가 발생합니다. 다음 절차에 따라 모듈을 비활성화합니다.
프로세스
다음 명령을 실행하여 다음 머신 구성 파일을 생성합니다.
$ cat <<EOF > 99-machine-config-blacklist-irdma.yaml출력 예
apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: worker name: 99-worker-blacklist-irdma spec: kernelArguments: - "module_blacklist=irdma"클러스터에 머신 구성을 생성하고 다음 명령을 실행하여 노드가 재부팅될 때까지 기다립니다.
$ oc create -f 99-machine-config-blacklist-irdma.yaml출력 예
machineconfig.machineconfiguration.openshift.io/99-worker-blacklist-irdma created다음 명령을 실행하여 모듈이 로드되지 않은 각 노드의 디버그 Pod에서 확인합니다.
$ oc debug node/nvd-srv-32.nvidia.eng.rdu2.dc.redhat.com Starting pod/nvd-srv-32nvidiaengrdu2dcredhatcom-debug-btfj2 ... To use host binaries, run `chroot /host` Pod IP: 10.6.135.11 If you don't see a command prompt, try pressing enter. sh-5.1# chroot /host sh-5.1# lsmod|grep irdma sh-5.1#
5.3. 영구 이름 지정 규칙 생성
경우에 따라 재부팅 후 장치 이름이 유지되지 않습니다. 예를 들어 R760xa 시스템에서 Mellanox 장치는 재부팅 후 이름이 변경될 수 있습니다. MachineConfig 를 사용하여 지속성을 설정하여 이 문제를 방지할 수 있습니다.
프로세스
노드의 작업자 노드에서 파일로 MAC 주소 이름을 수집하고 유지해야 하는 인터페이스의 이름을 제공합니다. 이 예에서는
70-persistent-net.rules파일을 사용하고 세부 정보를 캐시합니다.$ cat <<EOF > 70-persistent-net.rules SUBSYSTEM=="net",ACTION=="add",ATTR{address}=="b8:3f:d2:3b:51:28",ATTR{type}=="1",NAME="ibs2f0" SUBSYSTEM=="net",ACTION=="add",ATTR{address}=="b8:3f:d2:3b:51:29",ATTR{type}=="1",NAME="ens8f0np0" SUBSYSTEM=="net",ACTION=="add",ATTR{address}=="b8:3f:d2:f0:36:d0",ATTR{type}=="1",NAME="ibs2f0" SUBSYSTEM=="net",ACTION=="add",ATTR{address}=="b8:3f:d2:f0:36:d1",ATTR{type}=="1",NAME="ens8f0np0" EOF파일을 줄 바꿈 없이 base64 문자열로 변환하고 출력을 변수
PERSIST로 설정합니다.$ PERSIST=`cat 70-persistent-net.rules| base64 -w 0`$ echo $PERSISTU1VCU1lTVEVNPT0ibmV0IixBQ1RJT049PSJhZGQiLEFUVFJ7YWRkcmVzc309PSJiODozZjpkMjozYjo1MToyOCIsQVRUUnt0eXBlfT09IjEiLE5BTUU9ImliczJmMCIKU1VCU1lTVEVNPT0ibmV0IixBQ1RJT049PSJhZGQiLEFUVFJ7YWRkcmVzc309PSJiODozZjpkMjozYjo1MToyOSIsQVRUUnt0eXBlfT09IjEiLE5BTUU9ImVuczhmMG5wMCIKU1VCU1lTVEVNPT0ibmV0IixBQ1RJT049PSJhZGQiLEFUVFJ7YWRkcmVzc309PSJiODozZjpkMjpmMDozNjpkMCIsQVRUUnt0eXBlfT09IjEiLE5BTUU9ImliczJmMCIKU1VCU1lTVEVNPT0ibmV0IixBQ1RJT049PSJhZGQiLEFUVFJ7YWRkcmVzc309PSJiODozZjpkMjpmMDozNjpkMSIsQVRUUnt0eXBlfT09IjEiLE5BTUU9ImVuczhmMG5wMCIK다음 명령을 실행하여 머신 구성을 생성하고 사용자 정의 리소스 파일에서 base64 인코딩을 설정합니다.
$ cat <<EOF > 99-machine-config-udev-network.yamlapiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: worker name: 99-machine-config-udev-network spec: config: ignition: version: 3.2.0 storage: files: - contents: source: data:text/plain;base64,$PERSIST filesystem: root mode: 420 path: /etc/udev/rules.d/70-persistent-net.rules다음 명령을 실행하여 클러스터에 머신 구성을 생성합니다. 명령을 실행하면 예상되는 출력에
machineconfig.machineconfiguration.openshift.io/99-machine-config-udev-network가 생성된것으로 표시됩니다.$ oc create -f 99-machine-config-udev-network.yamlget mcp명령을 사용하여 머신 구성 상태를 확인합니다.$ oc get mcp출력 예
NAME CONFIG UPDATED UPDATING DEGRADED MACHINECOUNT READYMACHINECOUNT UPDATEDMACHINECOUNT DEGRADEDMACHINECOUNT AGE master rendered-master-9adfe851c2c14d9598eea5ec3df6c187 True False False 1 1 1 0 6h21m worker rendered-worker-4568f1b174066b4b1a4de794cf538fee False True False 2 0 0 0 6h21m
노드가 재부팅되고 업데이트 필드가 false 로 반환되면 디버그 Pod의 장치를 확인하여 노드에서 검증할 수 있습니다.
5.4. NFD Operator 구성
NFD(Node Feature Discovery) Operator는 하드웨어 관련 정보로 노드에 레이블을 지정하여 OpenShift Container Platform 클러스터에서 하드웨어 기능 및 구성 검색을 관리합니다. NFD는 PCI 카드, 커널, 운영 체제 버전과 같은 노드별 속성을 사용하여 호스트에 레이블을 지정합니다.
사전 요구 사항
- NFD Operator가 설치되어 있습니다.
프로세스
다음 명령을 실행하여
openshift-nfd네임스페이스의 Pod를 보고 Operator가 설치되어 실행 중인지 확인합니다.$ oc get pods -n openshift-nfd출력 예
NAME READY STATUS RESTARTS AGE nfd-controller-manager-8698c88cdd-t8gbc 2/2 Running 0 2mNFD 컨트롤러가 실행되면
NodeFeatureDiscovery인스턴스를 생성하여 클러스터에 추가합니다.NFD Operator의
ClusterServiceVersion사양은 Operator 페이로드에 포함된 NFD 피연산자 이미지를 포함하여 기본값을 제공합니다. 다음 명령을 실행하여 값을 검색합니다.$ NFD_OPERAND_IMAGE=`echo $(oc get csv -n openshift-nfd -o json | jq -r '.items[0].metadata.annotations["alm-examples"]') | jq -r '.[] | select(.kind == "NodeFeatureDiscovery") | .spec.operand.image'`선택 사항: 기본
deviceClassWhiteList필드에 항목을 추가하여 NVIDIA BlueField DPU와 같은 더 많은 네트워크 어댑터를 지원합니다.apiVersion: nfd.openshift.io/v1 kind: NodeFeatureDiscovery metadata: name: nfd-instance namespace: openshift-nfd spec: instance: '' operand: image: '${NFD_OPERAND_IMAGE}' servicePort: 12000 prunerOnDelete: false topologyUpdater: false workerConfig: configData: | core: sleepInterval: 60s sources: pci: deviceClassWhitelist: - "02" - "03" - "0200" - "0207" - "12" deviceLabelFields: - "vendor"다음 명령을 실행하여 'NodeFeatureDiscovery' 인스턴스를 생성합니다.
$ oc create -f nfd-instance.yaml출력 예
nodefeaturediscovery.nfd.openshift.io/nfd-instance created다음 명령을 실행하여
openshift-nfd네임스페이스의 Pod를 보고 인스턴스가 실행 중인지 확인합니다.$ oc get pods -n openshift-nfd출력 예
NAME READY STATUS RESTARTS AGE nfd-controller-manager-7cb6d656-jcnqb 2/2 Running 0 4m nfd-gc-7576d64889-s28k9 1/1 Running 0 21s nfd-master-b7bcf5cfd-qnrmz 1/1 Running 0 21s nfd-worker-96pfh 1/1 Running 0 21s nfd-worker-b2gkg 1/1 Running 0 21s nfd-worker-bd9bk 1/1 Running 0 21s nfd-worker-cswf4 1/1 Running 0 21s nfd-worker-kp6gg 1/1 Running 0 21s짧은 시간을 기다린 다음 NFD가 노드에 라벨을 추가했는지 확인합니다. NFD 라벨에는
feature.node.kubernetes.io가 접두사로 지정되어 있으므로 쉽게 필터링할 수 있습니다.$ oc get node -o json | jq '.items[0].metadata.labels | with_entries(select(.key | startswith("feature.node.kubernetes.io")))' { "feature.node.kubernetes.io/cpu-cpuid.ADX": "true", "feature.node.kubernetes.io/cpu-cpuid.AESNI": "true", "feature.node.kubernetes.io/cpu-cpuid.AVX": "true", "feature.node.kubernetes.io/cpu-cpuid.AVX2": "true", "feature.node.kubernetes.io/cpu-cpuid.CETSS": "true", "feature.node.kubernetes.io/cpu-cpuid.CLZERO": "true", "feature.node.kubernetes.io/cpu-cpuid.CMPXCHG8": "true", "feature.node.kubernetes.io/cpu-cpuid.CPBOOST": "true", "feature.node.kubernetes.io/cpu-cpuid.EFER_LMSLE_UNS": "true", "feature.node.kubernetes.io/cpu-cpuid.FMA3": "true", "feature.node.kubernetes.io/cpu-cpuid.FP256": "true", "feature.node.kubernetes.io/cpu-cpuid.FSRM": "true", "feature.node.kubernetes.io/cpu-cpuid.FXSR": "true", "feature.node.kubernetes.io/cpu-cpuid.FXSROPT": "true", "feature.node.kubernetes.io/cpu-cpuid.IBPB": "true", "feature.node.kubernetes.io/cpu-cpuid.IBRS": "true", "feature.node.kubernetes.io/cpu-cpuid.IBRS_PREFERRED": "true", "feature.node.kubernetes.io/cpu-cpuid.IBRS_PROVIDES_SMP": "true", "feature.node.kubernetes.io/cpu-cpuid.IBS": "true", "feature.node.kubernetes.io/cpu-cpuid.IBSBRNTRGT": "true", "feature.node.kubernetes.io/cpu-cpuid.IBSFETCHSAM": "true", "feature.node.kubernetes.io/cpu-cpuid.IBSFFV": "true", "feature.node.kubernetes.io/cpu-cpuid.IBSOPCNT": "true", "feature.node.kubernetes.io/cpu-cpuid.IBSOPCNTEXT": "true", "feature.node.kubernetes.io/cpu-cpuid.IBSOPSAM": "true", "feature.node.kubernetes.io/cpu-cpuid.IBSRDWROPCNT": "true", "feature.node.kubernetes.io/cpu-cpuid.IBSRIPINVALIDCHK": "true", "feature.node.kubernetes.io/cpu-cpuid.IBS_FETCH_CTLX": "true", "feature.node.kubernetes.io/cpu-cpuid.IBS_OPFUSE": "true", "feature.node.kubernetes.io/cpu-cpuid.IBS_PREVENTHOST": "true", "feature.node.kubernetes.io/cpu-cpuid.INT_WBINVD": "true", "feature.node.kubernetes.io/cpu-cpuid.INVLPGB": "true", "feature.node.kubernetes.io/cpu-cpuid.LAHF": "true", "feature.node.kubernetes.io/cpu-cpuid.LBRVIRT": "true", "feature.node.kubernetes.io/cpu-cpuid.MCAOVERFLOW": "true", "feature.node.kubernetes.io/cpu-cpuid.MCOMMIT": "true", "feature.node.kubernetes.io/cpu-cpuid.MOVBE": "true", "feature.node.kubernetes.io/cpu-cpuid.MOVU": "true", "feature.node.kubernetes.io/cpu-cpuid.MSRIRC": "true", "feature.node.kubernetes.io/cpu-cpuid.MSR_PAGEFLUSH": "true", "feature.node.kubernetes.io/cpu-cpuid.NRIPS": "true", "feature.node.kubernetes.io/cpu-cpuid.OSXSAVE": "true", "feature.node.kubernetes.io/cpu-cpuid.PPIN": "true", "feature.node.kubernetes.io/cpu-cpuid.PSFD": "true", "feature.node.kubernetes.io/cpu-cpuid.RDPRU": "true", "feature.node.kubernetes.io/cpu-cpuid.SEV": "true", "feature.node.kubernetes.io/cpu-cpuid.SEV_64BIT": "true", "feature.node.kubernetes.io/cpu-cpuid.SEV_ALTERNATIVE": "true", "feature.node.kubernetes.io/cpu-cpuid.SEV_DEBUGSWAP": "true", "feature.node.kubernetes.io/cpu-cpuid.SEV_ES": "true", "feature.node.kubernetes.io/cpu-cpuid.SEV_RESTRICTED": "true", "feature.node.kubernetes.io/cpu-cpuid.SEV_SNP": "true", "feature.node.kubernetes.io/cpu-cpuid.SHA": "true", "feature.node.kubernetes.io/cpu-cpuid.SME": "true", "feature.node.kubernetes.io/cpu-cpuid.SME_COHERENT": "true", "feature.node.kubernetes.io/cpu-cpuid.SPEC_CTRL_SSBD": "true", "feature.node.kubernetes.io/cpu-cpuid.SSE4A": "true", "feature.node.kubernetes.io/cpu-cpuid.STIBP": "true", "feature.node.kubernetes.io/cpu-cpuid.STIBP_ALWAYSON": "true", "feature.node.kubernetes.io/cpu-cpuid.SUCCOR": "true", "feature.node.kubernetes.io/cpu-cpuid.SVM": "true", "feature.node.kubernetes.io/cpu-cpuid.SVMDA": "true", "feature.node.kubernetes.io/cpu-cpuid.SVMFBASID": "true", "feature.node.kubernetes.io/cpu-cpuid.SVML": "true", "feature.node.kubernetes.io/cpu-cpuid.SVMNP": "true", "feature.node.kubernetes.io/cpu-cpuid.SVMPF": "true", "feature.node.kubernetes.io/cpu-cpuid.SVMPFT": "true", "feature.node.kubernetes.io/cpu-cpuid.SYSCALL": "true", "feature.node.kubernetes.io/cpu-cpuid.SYSEE": "true", "feature.node.kubernetes.io/cpu-cpuid.TLB_FLUSH_NESTED": "true", "feature.node.kubernetes.io/cpu-cpuid.TOPEXT": "true", "feature.node.kubernetes.io/cpu-cpuid.TSCRATEMSR": "true", "feature.node.kubernetes.io/cpu-cpuid.VAES": "true", "feature.node.kubernetes.io/cpu-cpuid.VMCBCLEAN": "true", "feature.node.kubernetes.io/cpu-cpuid.VMPL": "true", "feature.node.kubernetes.io/cpu-cpuid.VMSA_REGPROT": "true", "feature.node.kubernetes.io/cpu-cpuid.VPCLMULQDQ": "true", "feature.node.kubernetes.io/cpu-cpuid.VTE": "true", "feature.node.kubernetes.io/cpu-cpuid.WBNOINVD": "true", "feature.node.kubernetes.io/cpu-cpuid.X87": "true", "feature.node.kubernetes.io/cpu-cpuid.XGETBV1": "true", "feature.node.kubernetes.io/cpu-cpuid.XSAVE": "true", "feature.node.kubernetes.io/cpu-cpuid.XSAVEC": "true", "feature.node.kubernetes.io/cpu-cpuid.XSAVEOPT": "true", "feature.node.kubernetes.io/cpu-cpuid.XSAVES": "true", "feature.node.kubernetes.io/cpu-hardware_multithreading": "false", "feature.node.kubernetes.io/cpu-model.family": "25", "feature.node.kubernetes.io/cpu-model.id": "1", "feature.node.kubernetes.io/cpu-model.vendor_id": "AMD", "feature.node.kubernetes.io/kernel-config.NO_HZ": "true", "feature.node.kubernetes.io/kernel-config.NO_HZ_FULL": "true", "feature.node.kubernetes.io/kernel-selinux.enabled": "true", "feature.node.kubernetes.io/kernel-version.full": "5.14.0-427.35.1.el9_4.x86_64", "feature.node.kubernetes.io/kernel-version.major": "5", "feature.node.kubernetes.io/kernel-version.minor": "14", "feature.node.kubernetes.io/kernel-version.revision": "0", "feature.node.kubernetes.io/memory-numa": "true", "feature.node.kubernetes.io/network-sriov.capable": "true", "feature.node.kubernetes.io/pci-102b.present": "true", "feature.node.kubernetes.io/pci-10de.present": "true", "feature.node.kubernetes.io/pci-10de.sriov.capable": "true", "feature.node.kubernetes.io/pci-15b3.present": "true", "feature.node.kubernetes.io/pci-15b3.sriov.capable": "true", "feature.node.kubernetes.io/rdma.available": "true", "feature.node.kubernetes.io/rdma.capable": "true", "feature.node.kubernetes.io/storage-nonrotationaldisk": "true", "feature.node.kubernetes.io/system-os_release.ID": "rhcos", "feature.node.kubernetes.io/system-os_release.OPENSHIFT_VERSION": "4.17", "feature.node.kubernetes.io/system-os_release.OSTREE_VERSION": "417.94.202409121747-0", "feature.node.kubernetes.io/system-os_release.RHEL_VERSION": "9.4", "feature.node.kubernetes.io/system-os_release.VERSION_ID": "4.17", "feature.node.kubernetes.io/system-os_release.VERSION_ID.major": "4", "feature.node.kubernetes.io/system-os_release.VERSION_ID.minor": "17" }검색된 네트워크 장치가 있는지 확인합니다.
$ oc describe node | grep -E 'Roles|pci' | grep pci-15b3 feature.node.kubernetes.io/pci-15b3.present=true feature.node.kubernetes.io/pci-15b3.sriov.capable=true feature.node.kubernetes.io/pci-15b3.present=true feature.node.kubernetes.io/pci-15b3.sriov.capable=true
5.5. SR-IOV Operator 구성
SR-IOV(Single Root I/O Virtualization)는 단일 장치에서 여러 Pod에 공유를 제공하여 NVIDIA GPUDirect RDMA의 성능을 향상시킵니다.
사전 요구 사항
- SR-IOV Operator가 설치되어 있습니다.
프로세스
다음 명령을 실행하여
openshift-sriov-network-operator네임스페이스에서 Pod를 확인하여 Operator가 설치 및 실행 중인지 확인합니다.$ oc get pods -n openshift-sriov-network-operator출력 예
NAME READY STATUS RESTARTS AGE sriov-network-operator-7cb6c49868-89486 1/1 Running 0 22s기본
SriovOperatorConfigCR이 MLNX_OFED 컨테이너에서 작동하도록 하려면 이 명령을 실행하여 다음 값을 업데이트합니다.apiVersion: sriovnetwork.openshift.io/v1 kind: SriovOperatorConfig metadata: name: default namespace: openshift-sriov-network-operator spec: enableInjector: true enableOperatorWebhook: true logLevel: 2다음 명령을 실행하여 클러스터에 리소스를 생성합니다.
$ oc create -f sriov-operator-config.yaml출력 예
sriovoperatorconfig.sriovnetwork.openshift.io/default created다음 명령을 실행하여 MOFED 컨테이너가 작업할 수 있도록 sriov-operator를 패치합니다.
$ oc patch sriovoperatorconfig default --type=merge -n openshift-sriov-network-operator --patch '{ "spec": { "configDaemonNodeSelector": { "network.nvidia.com/operator.mofed.wait": "false", "node-role.kubernetes.io/worker": "", "feature.node.kubernetes.io/pci-15b3.sriov.capable": "true" } } }'출력 예
sriovoperatorconfig.sriovnetwork.openshift.io/default patched
5.6. NVIDIA 네트워크 Operator 구성
NVIDIA 네트워크 Operator는 NVIDIA 네트워킹 리소스 및 드라이버 및 장치 플러그인과 같은 네트워킹 관련 구성 요소를 관리하여 NVIDIA GPUDirect RDMA 워크로드를 활성화합니다.
사전 요구 사항
- NVIDIA 네트워크 Operator를 설치했습니다.
프로세스
다음 명령을 실행하여 컨트롤러가
nvidia-network-operator네임스페이스에서 실행되고 있는지 확인하여 네트워크 Operator가 설치 및 실행 중인지 확인합니다.$ oc get pods -n nvidia-network-operator출력 예
NAME READY STATUS RESTARTS AGE nvidia-network-operator-controller-manager-6f7d6956cd-fw5wg 1/1 Running 0 5mOperator가 실행되면
NicClusterPolicy사용자 정의 리소스 파일을 생성합니다. 선택한 장치는 시스템 구성에 따라 다릅니다. 이 예에서 Infiniband 인터페이스ibs2f0은 하드 코딩되며 공유 NVIDIA GPUDirect RDMA 장치로 사용됩니다.apiVersion: mellanox.com/v1alpha1 kind: NicClusterPolicy metadata: name: nic-cluster-policy spec: nicFeatureDiscovery: image: nic-feature-discovery repository: ghcr.io/mellanox version: v0.0.1 docaTelemetryService: image: doca_telemetry repository: nvcr.io/nvidia/doca version: 1.16.5-doca2.6.0-host rdmaSharedDevicePlugin: config: | { "configList": [ { "resourceName": "rdma_shared_device_ib", "rdmaHcaMax": 63, "selectors": { "ifNames": ["ibs2f0"] } }, { "resourceName": "rdma_shared_device_eth", "rdmaHcaMax": 63, "selectors": { "ifNames": ["ens8f0np0"] } } ] } image: k8s-rdma-shared-dev-plugin repository: ghcr.io/mellanox version: v1.5.1 secondaryNetwork: ipoib: image: ipoib-cni repository: ghcr.io/mellanox version: v1.2.0 nvIpam: enableWebhook: false image: nvidia-k8s-ipam repository: ghcr.io/mellanox version: v0.2.0 ofedDriver: readinessProbe: initialDelaySeconds: 10 periodSeconds: 30 forcePrecompiled: false terminationGracePeriodSeconds: 300 livenessProbe: initialDelaySeconds: 30 periodSeconds: 30 upgradePolicy: autoUpgrade: true drain: deleteEmptyDir: true enable: true force: true timeoutSeconds: 300 podSelector: '' maxParallelUpgrades: 1 safeLoad: false waitForCompletion: timeoutSeconds: 0 startupProbe: initialDelaySeconds: 10 periodSeconds: 20 image: doca-driver repository: nvcr.io/nvidia/mellanox version: 24.10-0.7.0.0-0 env: - name: UNLOAD_STORAGE_MODULES value: "true" - name: RESTORE_DRIVER_ON_POD_TERMINATION value: "true" - name: CREATE_IFNAMES_UDEV value: "true"다음 명령을 실행하여 클러스터에
NicClusterPolicy사용자 정의 리소스를 생성합니다.$ oc create -f network-sharedrdma-nic-cluster-policy.yaml출력 예
nicclusterpolicy.mellanox.com/nic-cluster-policy createdDOCA/MOFED 컨테이너에서 다음 명령을 실행하여
NicClusterPolicy를 검증합니다.$ oc get pods -n nvidia-network-operator출력 예
NAME READY STATUS RESTARTS AGE doca-telemetry-service-hwj65 1/1 Running 2 160m kube-ipoib-cni-ds-fsn8g 1/1 Running 2 160m mofed-rhcos4.16-9b5ddf4c6-ds-ct2h5 2/2 Running 4 160m nic-feature-discovery-ds-dtksz 1/1 Running 2 160m nv-ipam-controller-854585f594-c5jpp 1/1 Running 2 160m nv-ipam-controller-854585f594-xrnp5 1/1 Running 2 160m nv-ipam-node-xqttl 1/1 Running 2 160m nvidia-network-operator-controller-manager-5798b564cd-5cq99 1/1 Running 2 5d23h rdma-shared-dp-ds-p9vvg 1/1 Running 0 85m다음 명령을 실행하여
mofed컨테이너에rsh로 접속하여 상태를 확인하세요.$ MOFED_POD=$(oc get pods -n nvidia-network-operator -o name | grep mofed) $ oc rsh -n nvidia-network-operator -c mofed-container ${MOFED_POD} sh-5.1# ofed_info -s출력 예
OFED-internal-24.07-0.6.1:sh-5.1# ibdev2netdev -v출력 예
0000:0d:00.0 mlx5_0 (MT41692 - 900-9D3B4-00EN-EA0) BlueField-3 E-series SuperNIC 400GbE/NDR single port QSFP112, PCIe Gen5.0 x16 FHHL, Crypto Enabled, 16GB DDR5, BMC, Tall Bracket fw 32.42.1000 port 1 (ACTIVE) ==> ibs2f0 (Up) 0000:a0:00.0 mlx5_1 (MT41692 - 900-9D3B4-00EN-EA0) BlueField-3 E-series SuperNIC 400GbE/NDR single port QSFP112, PCIe Gen5.0 x16 FHHL, Crypto Enabled, 16GB DDR5, BMC, Tall Bracket fw 32.42.1000 port 1 (ACTIVE) ==> ens8f0np0 (Up)IPoIBNetwork사용자 지정 리소스 파일을 생성합니다.apiVersion: mellanox.com/v1alpha1 kind: IPoIBNetwork metadata: name: example-ipoibnetwork spec: ipam: | { "type": "whereabouts", "range": "192.168.6.225/28", "exclude": [ "192.168.6.229/30", "192.168.6.236/32" ] } master: ibs2f0 networkNamespace: default다음 명령을 실행하여 클러스터에서
IPoIBNetwork리소스를 생성합니다.$ oc create -f ipoib-network.yaml출력 예
ipoibnetwork.mellanox.com/example-ipoibnetwork created다른 인터페이스에 대한
MacvlanNetwork사용자 지정 리소스 파일을 만듭니다.apiVersion: mellanox.com/v1alpha1 kind: MacvlanNetwork metadata: name: rdmashared-net spec: networkNamespace: default master: ens8f0np0 mode: bridge mtu: 1500 ipam: '{"type": "whereabouts", "range": "192.168.2.0/24", "gateway": "192.168.2.1"}'다음 명령을 실행하여 클러스터에 리소스를 생성합니다.
$ oc create -f macvlan-network.yaml출력 예
macvlannetwork.mellanox.com/rdmashared-net created
5.7. GPU Operator 구성
GPU Operator는 NVIDIA 드라이버, GPU용 장치 플러그인, NVIDIA Container Toolkit 및 GPU 프로비저닝에 필요한 기타 구성 요소의 관리를 자동화합니다.
사전 요구 사항
- GPU Operator가 설치되어 있습니다.
프로세스
다음 명령을 실행하여 Operator Pod가 네임스페이스 아래의 Pod를 확인하도록 실행 중인지 확인합니다.
$ oc get pods -n nvidia-gpu-operator출력 예
NAME READY STATUS RESTARTS AGE gpu-operator-b4cb7d74-zxpwq 1/1 Running 0 32s다음 예와 유사한 GPU 클러스터 정책 사용자 정의 리소스 파일을 생성합니다.
apiVersion: nvidia.com/v1 kind: ClusterPolicy metadata: name: gpu-cluster-policy spec: vgpuDeviceManager: config: default: default enabled: true migManager: config: default: all-disabled name: default-mig-parted-config enabled: true operator: defaultRuntime: crio initContainer: {} runtimeClass: nvidia use_ocp_driver_toolkit: true dcgm: enabled: true gfd: enabled: true dcgmExporter: config: name: '' serviceMonitor: enabled: true enabled: true cdi: default: false enabled: false driver: licensingConfig: nlsEnabled: true configMapName: '' certConfig: name: '' rdma: enabled: false kernelModuleConfig: name: '' upgradePolicy: autoUpgrade: true drain: deleteEmptyDir: false enable: false force: false timeoutSeconds: 300 maxParallelUpgrades: 1 maxUnavailable: 25% podDeletion: deleteEmptyDir: false force: false timeoutSeconds: 300 waitForCompletion: timeoutSeconds: 0 repoConfig: configMapName: '' virtualTopology: config: '' enabled: true useNvidiaDriverCRD: false useOpenKernelModules: true devicePlugin: config: name: '' default: '' mps: root: /run/nvidia/mps enabled: true gdrcopy: enabled: true kataManager: config: artifactsDir: /opt/nvidia-gpu-operator/artifacts/runtimeclasses mig: strategy: single sandboxDevicePlugin: enabled: true validator: plugin: env: - name: WITH_WORKLOAD value: 'false' nodeStatusExporter: enabled: true daemonsets: rollingUpdate: maxUnavailable: '1' updateStrategy: RollingUpdate sandboxWorkloads: defaultWorkload: container enabled: false gds: enabled: true image: nvidia-fs version: 2.20.5 repository: nvcr.io/nvidia/cloud-native vgpuManager: enabled: false vfioManager: enabled: true toolkit: installDir: /usr/local/nvidia enabled: trueGPU
ClusterPolicy사용자 정의 리소스가 생성되면 다음 명령을 실행하여 클러스터에 리소스를 생성합니다.$ oc create -f gpu-cluster-policy.yaml출력 예
clusterpolicy.nvidia.com/gpu-cluster-policy created다음 명령을 실행하여 Operator가 설치되어 실행 중인지 확인합니다.
$ oc get pods -n nvidia-gpu-operator출력 예
NAME READY STATUS RESTARTS AGE gpu-feature-discovery-d5ngn 1/1 Running 0 3m20s gpu-feature-discovery-z42rx 1/1 Running 0 3m23s gpu-operator-6bb4d4b4c5-njh78 1/1 Running 0 4m35s nvidia-container-toolkit-daemonset-bkh8l 1/1 Running 0 3m20s nvidia-container-toolkit-daemonset-c4hzm 1/1 Running 0 3m23s nvidia-cuda-validator-4blvg 0/1 Completed 0 106s nvidia-cuda-validator-tw8sl 0/1 Completed 0 112s nvidia-dcgm-exporter-rrw4g 1/1 Running 0 3m20s nvidia-dcgm-exporter-xc78t 1/1 Running 0 3m23s nvidia-dcgm-nvxpf 1/1 Running 0 3m20s nvidia-dcgm-snj4j 1/1 Running 0 3m23s nvidia-device-plugin-daemonset-fk2xz 1/1 Running 0 3m23s nvidia-device-plugin-daemonset-wq87j 1/1 Running 0 3m20s nvidia-driver-daemonset-416.94.202410211619-0-ngrjg 4/4 Running 0 3m58s nvidia-driver-daemonset-416.94.202410211619-0-tm4x6 4/4 Running 0 3m58s nvidia-node-status-exporter-jlzxh 1/1 Running 0 3m57s nvidia-node-status-exporter-zjffs 1/1 Running 0 3m57s nvidia-operator-validator-l49hx 1/1 Running 0 3m20s nvidia-operator-validator-n44nn 1/1 Running 0 3m23s선택 사항: Pod가 실행 중인지 확인하면 NVIDIA 드라이버 daemonset Pod에 원격 쉘이 로드되었는지 확인하고 NVIDIA 모듈이 로드되었는지 확인합니다. 특히
nvidia_peermem이 로드되었는지 확인합니다.$ oc rsh -n nvidia-gpu-operator $(oc -n nvidia-gpu-operator get pod -o name -l app.kubernetes.io/component=nvidia-driver) sh-4.4# lsmod|grep nvidia출력 예
nvidia_fs 327680 0 nvidia_peermem 24576 0 nvidia_modeset 1507328 0 video 73728 1 nvidia_modeset nvidia_uvm 6889472 8 nvidia 8810496 43 nvidia_uvm,nvidia_peermem,nvidia_fs,gdrdrv,nvidia_modeset ib_uverbs 217088 3 nvidia_peermem,rdma_ucm,mlx5_ib drm 741376 5 drm_kms_helper,drm_shmem_helper,nvidia,mgag200-
선택 사항:
nvidia-smi유틸리티를 실행하여 드라이버 및 하드웨어에 대한 세부 정보를 표시합니다.
sh-4.4# nvidia-smi+ .출력 예
Wed Nov 6 22:03:53 2024
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 550.90.07 Driver Version: 550.90.07 CUDA Version: 12.4 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA A40 On | 00000000:61:00.0 Off | 0 |
| 0% 37C P0 88W / 300W | 1MiB / 46068MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
| 1 NVIDIA A40 On | 00000000:E1:00.0 Off | 0 |
| 0% 28C P8 29W / 300W | 1MiB / 46068MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| No running processes found |
+-----------------------------------------------------------------------------------------+드라이버 Pod에 있는 동안
nvidia-smi명령을 사용하여 GPU 클럭을 최대값으로 설정합니다.$ oc rsh -n nvidia-gpu-operator nvidia-driver-daemonset-416.94.202410172137-0-ndhzc sh-4.4# nvidia-smi -i 0 -lgc $(nvidia-smi -i 0 --query-supported-clocks=graphics --format=csv,noheader,nounits | sort -h | tail -n 1)출력 예
GPU clocks set to "(gpuClkMin 1740, gpuClkMax 1740)" for GPU 00000000:61:00.0 All done.sh-4.4# nvidia-smi -i 1 -lgc $(nvidia-smi -i 1 --query-supported-clocks=graphics --format=csv,noheader,nounits | sort -h | tail -n 1)출력 예
GPU clocks set to "(gpuClkMin 1740, gpuClkMax 1740)" for GPU 00000000:E1:00.0 All done.다음 명령을 실행하여 노드 설명 화면에서 리소스를 사용할 수 있는지 확인합니다.
$ oc describe node -l node-role.kubernetes.io/worker=| grep -E 'Capacity:|Allocatable:' -A9출력 예
Capacity: cpu: 128 ephemeral-storage: 1561525616Ki hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 263596712Ki nvidia.com/gpu: 2 pods: 250 rdma/rdma_shared_device_eth: 63 rdma/rdma_shared_device_ib: 63 Allocatable: cpu: 127500m ephemeral-storage: 1438028263499 hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 262445736Ki nvidia.com/gpu: 2 pods: 250 rdma/rdma_shared_device_eth: 63 rdma/rdma_shared_device_ib: 63 -- Capacity: cpu: 128 ephemeral-storage: 1561525616Ki hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 263596672Ki nvidia.com/gpu: 2 pods: 250 rdma/rdma_shared_device_eth: 63 rdma/rdma_shared_device_ib: 63 Allocatable: cpu: 127500m ephemeral-storage: 1438028263499 hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 262445696Ki nvidia.com/gpu: 2 pods: 250 rdma/rdma_shared_device_eth: 63 rdma/rdma_shared_device_ib: 63
5.8. 머신 구성 생성
리소스 Pod를 생성하기 전에 사용자 권한 없이도 GPU 및 네트워킹 리소스에 대한 액세스를 제공하는 machineconfig.yaml CR(사용자 정의 리소스)을 생성해야 합니다.
프로세스
MachineconfigCR을 생성합니다.apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: worker name: 02-worker-container-runtime spec: config: ignition: version: 3.2.0 storage: files: - contents: source: data:text/plain;charset=utf-8;base64,W2NyaW8ucnVudGltZV0KZGVmYXVsdF91bGltaXRzID0gWwoibWVtbG9jaz0tMTotMSIKXQo= mode: 420 overwrite: true path: /etc/crio/crio.conf.d/10-custom
5.9. 워크로드 Pod 생성
이 섹션의 절차를 사용하여 공유 및 호스트 장치에 대한 워크로드 Pod를 생성합니다.
5.9.2. RoCE에서 호스트 장치 RDMA 생성
NVIDIA Network Operator에 대한 호스트 장치 RDMA(Remote Direct Memory Access)에 대한 워크로드 Pod를 생성하고 Pod 구성을 테스트합니다.
사전 요구 사항
- Operator가 실행 중인지 확인합니다.
-
존재하는 경우
NicClusterPolicyCR(사용자 정의 리소스)을 삭제합니다.
프로세스
다음과 같이 새 호스트 장치
NicClusterPolicy(CR)를 생성합니다.$ cat <<EOF > network-hostdev-nic-cluster-policy.yaml apiVersion: mellanox.com/v1alpha1 kind: NicClusterPolicy metadata: name: nic-cluster-policy spec: ofedDriver: image: doca-driver repository: nvcr.io/nvidia/mellanox version: 24.10-0.7.0.0-0 startupProbe: initialDelaySeconds: 10 periodSeconds: 20 livenessProbe: initialDelaySeconds: 30 periodSeconds: 30 readinessProbe: initialDelaySeconds: 10 periodSeconds: 30 env: - name: UNLOAD_STORAGE_MODULES value: "true" - name: RESTORE_DRIVER_ON_POD_TERMINATION value: "true" - name: CREATE_IFNAMES_UDEV value: "true" sriovDevicePlugin: image: sriov-network-device-plugin repository: ghcr.io/k8snetworkplumbingwg version: v3.7.0 config: | { "resourceList": [ { "resourcePrefix": "nvidia.com", "resourceName": "hostdev", "selectors": { "vendors": ["15b3"], "isRdma": true } } ] } EOF다음 명령을 사용하여 클러스터에
NicClusterPolicyCR을 생성합니다.$ oc create -f network-hostdev-nic-cluster-policy.yaml출력 예
nicclusterpolicy.mellanox.com/nic-cluster-policy createdDOCA/MOFED 컨테이너에서 다음 명령을 사용하여 호스트 장치
NicClusterPolicyCR을 확인합니다.$ oc get pods -n nvidia-network-operator출력 예
NAME READY STATUS RESTARTS AGE mofed-rhcos4.16-696886fcb4-ds-9sgvd 2/2 Running 0 2m37s mofed-rhcos4.16-696886fcb4-ds-lkjd4 2/2 Running 0 2m37s nvidia-network-operator-controller-manager-68d547dbbd-qsdkf 1/1 Running 0 141m sriov-device-plugin-6v2nz 1/1 Running 0 2m14s sriov-device-plugin-hc4t8 1/1 Running 0 2m14s다음 명령을 사용하여 리소스가 클러스터
oc describe node섹션에 표시되는지 확인합니다.$ oc describe node -l node-role.kubernetes.io/worker=| grep -E 'Capacity:|Allocatable:' -A7출력 예
Capacity: cpu: 128 ephemeral-storage: 1561525616Ki hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 263596708Ki nvidia.com/hostdev: 2 pods: 250 Allocatable: cpu: 127500m ephemeral-storage: 1438028263499 hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 262445732Ki nvidia.com/hostdev: 2 pods: 250 -- Capacity: cpu: 128 ephemeral-storage: 1561525616Ki hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 263596704Ki nvidia.com/hostdev: 2 pods: 250 Allocatable: cpu: 127500m ephemeral-storage: 1438028263499 hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 262445728Ki nvidia.com/hostdev: 2 pods: 250HostDeviceNetworkCR 파일을 생성합니다.$ cat <<EOF > hostdev-network.yaml apiVersion: mellanox.com/v1alpha1 kind: HostDeviceNetwork metadata: name: hostdev-net spec: networkNamespace: "default" resourceName: "hostdev" ipam: | { "type": "whereabouts", "range": "192.168.3.225/28", "exclude": [ "192.168.3.229/30", "192.168.3.236/32" ] } EOF다음 명령을 사용하여 클러스터에서
HostDeviceNetwork리소스를 생성합니다.$ oc create -f hostdev-network.yaml출력 예
hostdevicenetwork.mellanox.com/hostdev-net created다음 명령을 사용하여 리소스가 클러스터
oc describe node섹션에 표시되는지 확인합니다.$ oc describe node -l node-role.kubernetes.io/worker=| grep -E 'Capacity:|Allocatable:' -A8출력 예
Capacity: cpu: 128 ephemeral-storage: 1561525616Ki hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 263596708Ki nvidia.com/gpu: 2 nvidia.com/hostdev: 2 pods: 250 Allocatable: cpu: 127500m ephemeral-storage: 1438028263499 hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 262445732Ki nvidia.com/gpu: 2 nvidia.com/hostdev: 2 pods: 250 -- Capacity: cpu: 128 ephemeral-storage: 1561525616Ki hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 263596680Ki nvidia.com/gpu: 2 nvidia.com/hostdev: 2 pods: 250 Allocatable: cpu: 127500m ephemeral-storage: 1438028263499 hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 262445704Ki nvidia.com/gpu: 2 nvidia.com/hostdev: 2 pods: 250
5.9.3. RoCE에서 SR-IOV 레거시 모드 RDMA 생성
RoCE에서 SR-IOV(Single Root I/O Virtualization) 레거시 모드 호스트 장치 RDMA를 구성합니다.
프로세스
새 호스트 장치
NicClusterPolicyCR(사용자 정의 리소스)을 생성합니다.$ cat <<EOF > network-sriovleg-nic-cluster-policy.yaml apiVersion: mellanox.com/v1alpha1 kind: NicClusterPolicy metadata: name: nic-cluster-policy spec: ofedDriver: image: doca-driver repository: nvcr.io/nvidia/mellanox version: 24.10-0.7.0.0-0 startupProbe: initialDelaySeconds: 10 periodSeconds: 20 livenessProbe: initialDelaySeconds: 30 periodSeconds: 30 readinessProbe: initialDelaySeconds: 10 periodSeconds: 30 env: - name: UNLOAD_STORAGE_MODULES value: "true" - name: RESTORE_DRIVER_ON_POD_TERMINATION value: "true" - name: CREATE_IFNAMES_UDEV value: "true" EOF다음 명령을 사용하여 클러스터에 정책을 생성합니다.
$ oc create -f network-sriovleg-nic-cluster-policy.yaml출력 예
nicclusterpolicy.mellanox.com/nic-cluster-policy createdDOCA/MOFED 컨테이너에서 다음 명령을 사용하여 Pod를 확인합니다.
$ oc get pods -n nvidia-network-operator출력 예
NAME READY STATUS RESTARTS AGE mofed-rhcos4.16-696886fcb4-ds-4mb42 2/2 Running 0 40s mofed-rhcos4.16-696886fcb4-ds-8knwq 2/2 Running 0 40s nvidia-network-operator-controller-manager-68d547dbbd-qsdkf 1/1 Running 13 (4d ago) 4d21hSR-IOV 레거시 모드에서 작동하려는 장치에 대한 VF(가상 기능)를 생성하는
SriovNetworkNodePolicyCR을 생성합니다. 다음 예제를 참조하십시오.$ cat <<EOF > sriov-network-node-policy.yaml apiVersion: sriovnetwork.openshift.io/v1 kind: SriovNetworkNodePolicy metadata: name: sriov-legacy-policy namespace: openshift-sriov-network-operator spec: deviceType: netdevice mtu: 1500 nicSelector: vendor: "15b3" pfNames: ["ens8f0np0#0-7"] nodeSelector: feature.node.kubernetes.io/pci-15b3.present: "true" numVfs: 8 priority: 90 isRdma: true resourceName: sriovlegacy EOF다음 명령을 사용하여 클러스터에 CR을 생성합니다.
참고SR-IOV 글로벌 활성화가 활성화되었는지 확인합니다. 자세한 내용은 SR-IOV 를 활성화하고 Red Hat Enterprise Linux에서 " SR-IOV에 대한 MMIO 리소스가 충분하지 않음"이라는 메시지를 수신할 수 없습니다.
$ oc create -f sriov-network-node-policy.yaml출력 예
sriovnetworknodepolicy.sriovnetwork.openshift.io/sriov-legacy-policy created각 노드에는 스케줄링이 비활성화되어 있습니다. 노드가 재부팅되어 구성을 적용합니다. 다음 명령을 사용하여 노드를 볼 수 있습니다.
$ oc get nodes출력 예
NAME STATUS ROLES AGE VERSION edge-19.edge.lab.eng.rdu2.redhat.com Ready control-plane,master,worker 5d v1.29.8+632b078 nvd-srv-32.nvidia.eng.rdu2.dc.redhat.com Ready worker 4d22h v1.29.8+632b078 nvd-srv-33.nvidia.eng.rdu2.dc.redhat.com NotReady,SchedulingDisabled worker 4d22h v1.29.8+632b078노드가 재부팅된 후 각 노드에서 디버그 Pod를 열어 VF 인터페이스가 있는지 확인합니다. 다음 명령을 실행합니다.
a$ oc debug node/nvd-srv-33.nvidia.eng.rdu2.dc.redhat.com출력 예
Starting pod/nvd-srv-33nvidiaengrdu2dcredhatcom-debug-cqfjz ... To use host binaries, run `chroot /host` Pod IP: 10.6.135.12 If you don't see a command prompt, try pressing enter. sh-5.1# chroot /host sh-5.1# ip link show | grep ens8 26: ens8f0np0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP mode DEFAULT group default qlen 1000 42: ens8f0v0: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 43: ens8f0v1: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 44: ens8f0v2: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 45: ens8f0v3: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 46: ens8f0v4: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 47: ens8f0v5: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 48: ens8f0v6: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 49: ens8f0v7: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000- 필요한 경우 두 번째 노드에서 이전 단계를 반복합니다.
선택 사항: 다음 명령을 사용하여 리소스가 클러스터
oc describe node섹션에 표시되는지 확인합니다.$ oc describe node -l node-role.kubernetes.io/worker=| grep -E 'Capacity:|Allocatable:' -A8출력 예
Capacity: cpu: 128 ephemeral-storage: 1561525616Ki hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 263596692Ki nvidia.com/gpu: 2 nvidia.com/hostdev: 0 openshift.io/sriovlegacy: 8 -- Allocatable: cpu: 127500m ephemeral-storage: 1438028263499 hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 262445716Ki nvidia.com/gpu: 2 nvidia.com/hostdev: 0 openshift.io/sriovlegacy: 8 -- Capacity: cpu: 128 ephemeral-storage: 1561525616Ki hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 263596688Ki nvidia.com/gpu: 2 nvidia.com/hostdev: 0 openshift.io/sriovlegacy: 8 -- Allocatable: cpu: 127500m ephemeral-storage: 1438028263499 hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 262445712Ki nvidia.com/gpu: 2 nvidia.com/hostdev: 0 openshift.io/sriovlegacy: 8SR-IOV 레거시 모드의 VF가 있는 경우
SriovNetworkCR 파일을 생성합니다. 다음 예제를 참조하십시오.$ cat <<EOF > sriov-network.yaml apiVersion: sriovnetwork.openshift.io/v1 kind: SriovNetwork metadata: name: sriov-network namespace: openshift-sriov-network-operator spec: vlan: 0 networkNamespace: "default" resourceName: "sriovlegacy" ipam: | { "type": "whereabouts", "range": "192.168.3.225/28", "exclude": [ "192.168.3.229/30", "192.168.3.236/32" ] } EOF다음 명령을 사용하여 클러스터에 사용자 정의 리소스를 생성합니다.
$ oc create -f sriov-network.yaml출력 예
sriovnetwork.sriovnetwork.openshift.io/sriov-network created
5.10. RDMA 연결 확인
레거시 SR-IOV(Single Root I/O Virtualization) 이더넷의 경우 RDMA(Remote Direct Memory Access) 연결이 시스템 간에 작동하는지 확인합니다.
프로세스
다음 명령을 사용하여 각
rdma-workload-clientPod에 연결합니다.$ oc rsh -n default rdma-sriov-32-workload출력 예
sh-5.1#다음 명령을 사용하여 첫 번째 워크로드 Pod에 할당된 IP 주소를 확인합니다. 이 예에서 첫 번째 워크로드 Pod는 RDMA 테스트 서버입니다.
sh-5.1# ip a출력 예
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever 2: eth0@if3970: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1400 qdisc noqueue state UP group default link/ether 0a:58:0a:80:02:a7 brd ff:ff:ff:ff:ff:ff link-netnsid 0 inet 10.128.2.167/23 brd 10.128.3.255 scope global eth0 valid_lft forever preferred_lft forever inet6 fe80::858:aff:fe80:2a7/64 scope link valid_lft forever preferred_lft forever 3843: net1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000 link/ether 26:34:fd:53:a6:ec brd ff:ff:ff:ff:ff:ff altname enp55s0f0v5 inet 192.168.4.225/28 brd 192.168.4.239 scope global net1 valid_lft forever preferred_lft forever inet6 fe80::2434:fdff:fe53:a6ec/64 scope link valid_lft forever preferred_lft forever sh-5.1#이 Pod에 할당된 RDMA 서버의 IP 주소는
net1인터페이스입니다. 이 예에서 IP 주소는192.168.4.225입니다.ibstatus명령을 실행하여 각 RDMA 장치mlx5_x와 연결된link_layer유형, 이더넷 또는 Infiniband를 가져옵니다. 출력에는ACTIVE또는DOWN이 표시되는state필드를 확인하여 모든 RDMA 장치의 상태도 표시됩니다.sh-5.1# ibstatus출력 예
Infiniband device 'mlx5_0' port 1 status: default gid: 0000:0000:0000:0000:0000:0000:0000:0000 base lid: 0x0 sm lid: 0x0 state: 4: ACTIVE phys state: 5: LinkUp rate: 200 Gb/sec (4X HDR) link_layer: Ethernet Infiniband device 'mlx5_1' port 1 status: default gid: fe80:0000:0000:0000:e8eb:d303:0072:1415 base lid: 0xc sm lid: 0x1 state: 4: ACTIVE phys state: 5: LinkUp rate: 200 Gb/sec (4X HDR) link_layer: InfiniBand Infiniband device 'mlx5_2' port 1 status: default gid: 0000:0000:0000:0000:0000:0000:0000:0000 base lid: 0x0 sm lid: 0x0 state: 1: DOWN phys state: 3: Disabled rate: 200 Gb/sec (4X HDR) link_layer: Ethernet Infiniband device 'mlx5_3' port 1 status: default gid: 0000:0000:0000:0000:0000:0000:0000:0000 base lid: 0x0 sm lid: 0x0 state: 1: DOWN phys state: 3: Disabled rate: 200 Gb/sec (4X HDR) link_layer: Ethernet Infiniband device 'mlx5_4' port 1 status: default gid: 0000:0000:0000:0000:0000:0000:0000:0000 base lid: 0x0 sm lid: 0x0 state: 1: DOWN phys state: 3: Disabled rate: 200 Gb/sec (4X HDR) link_layer: Ethernet Infiniband device 'mlx5_5' port 1 status: default gid: 0000:0000:0000:0000:0000:0000:0000:0000 base lid: 0x0 sm lid: 0x0 state: 1: DOWN phys state: 3: Disabled rate: 200 Gb/sec (4X HDR) link_layer: Ethernet Infiniband device 'mlx5_6' port 1 status: default gid: 0000:0000:0000:0000:0000:0000:0000:0000 base lid: 0x0 sm lid: 0x0 state: 1: DOWN phys state: 3: Disabled rate: 200 Gb/sec (4X HDR) link_layer: Ethernet Infiniband device 'mlx5_7' port 1 status: default gid: fe80:0000:0000:0000:2434:fdff:fe53:a6ec base lid: 0x0 sm lid: 0x0 state: 4: ACTIVE phys state: 5: LinkUp rate: 200 Gb/sec (4X HDR) link_layer: Ethernet Infiniband device 'mlx5_8' port 1 status: default gid: 0000:0000:0000:0000:0000:0000:0000:0000 base lid: 0x0 sm lid: 0x0 state: 1: DOWN phys state: 3: Disabled rate: 200 Gb/sec (4X HDR) link_layer: Ethernet Infiniband device 'mlx5_9' port 1 status: default gid: 0000:0000:0000:0000:0000:0000:0000:0000 base lid: 0x0 sm lid: 0x0 state: 1: DOWN phys state: 3: Disabled rate: 200 Gb/sec (4X HDR) link_layer: Ethernet sh-5.1#작업자 노드에서 각 RDMA
mlx5장치에 대한link_layer를 가져오려면ibstat명령을 실행합니다.sh-5.1# ibstat | egrep "Port|Base|Link"출력 예
Port 1: Physical state: LinkUp Base lid: 0 Port GUID: 0x0000000000000000 Link layer: Ethernet Port 1: Physical state: LinkUp Base lid: 12 Port GUID: 0xe8ebd30300721415 Link layer: InfiniBand Port 1: Base lid: 0 Port GUID: 0x0000000000000000 Link layer: Ethernet Port 1: Base lid: 0 Port GUID: 0x0000000000000000 Link layer: Ethernet Port 1: Base lid: 0 Port GUID: 0x0000000000000000 Link layer: Ethernet Port 1: Base lid: 0 Port GUID: 0x0000000000000000 Link layer: Ethernet Port 1: Base lid: 0 Port GUID: 0x0000000000000000 Link layer: Ethernet Port 1: Physical state: LinkUp Base lid: 0 Port GUID: 0x2434fdfffe53a6ec Link layer: Ethernet Port 1: Base lid: 0 Port GUID: 0x0000000000000000 Link layer: Ethernet Port 1: Base lid: 0 Port GUID: 0x0000000000000000 Link layer: Ethernet sh-5.1#RDMA 공유 장치 또는 호스트 장치 워크로드 Pod의 경우
mlx5_x라는 RDMA 장치가 이미 알려져 있으며 일반적으로mlx5_0또는mlx5_1입니다. RDMA Legacy SR-IOV 워크로드 Pod의 경우 어떤 RDMA 장치가 어떤 VF(Virtual Function) 하위 인터페이스와 연결되어 있는지 확인해야 합니다. 다음 명령을 사용하여 이 정보를 제공합니다.sh-5.1# rdma link show출력 예
link mlx5_0/1 state ACTIVE physical_state LINK_UP link mlx5_1/1 subnet_prefix fe80:0000:0000:0000 lid 12 sm_lid 1 lmc 0 state ACTIVE physical_state LINK_UP link mlx5_2/1 state DOWN physical_state DISABLED link mlx5_3/1 state DOWN physical_state DISABLED link mlx5_4/1 state DOWN physical_state DISABLED link mlx5_5/1 state DOWN physical_state DISABLED link mlx5_6/1 state DOWN physical_state DISABLED link mlx5_7/1 state ACTIVE physical_state LINK_UP netdev net1 link mlx5_8/1 state DOWN physical_state DISABLED link mlx5_9/1 state DOWN physical_state DISABLED이 예에서 RDMA 장치 이름
mlx5_7은net1인터페이스와 연결되어 있습니다. 이 출력은 다음 명령에서 RDMA 대역폭 테스트를 수행하는 데 사용되며 작업자 노드 간의 RDMA 연결도 확인합니다.다음
ib_write_bwRDMA bandwidth test 명령을 실행합니다.sh-5.1# /root/perftest/ib_write_bw -R -T 41 -s 65536 -F -x 3 -m 4096 --report_gbits -q 16 -D 60 -d mlx5_7 -p 10000 --source_ip 192.168.4.225 --use_cuda=0 --use_cuda_dmabuf다음과 같습니다.
-
mlx5_7RDMA 장치는-d스위치로 전달됩니다. -
RDMA 서버를 시작하는 소스 IP 주소는
192.168.4.225입니다. -
--use_cuda=0,--use_cuda_dmabuf스위치는 GPUDirect RDMA를 사용함을 나타냅니다.
출력 예
WARNING: BW peak won't be measured in this run. Perftest doesn't supports CUDA tests with inline messages: inline size set to 0 ************************************ * Waiting for client to connect... * ************************************-
다른 터미널 창을 열고 RDMA 테스트 클라이언트 포드 역할을 하는 두 번째 워크로드 Pod에서
oc rsh명령을 실행합니다.$ oc rsh -n default rdma-sriov-33-workload출력 예
sh-5.1#다음 명령을 사용하여
net1인터페이스에서 RDMA 테스트 클라이언트 포드 IP 주소를 가져옵니다.sh-5.1# ip a출력 예
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever 2: eth0@if4139: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1400 qdisc noqueue state UP group default link/ether 0a:58:0a:83:01:d5 brd ff:ff:ff:ff:ff:ff link-netnsid 0 inet 10.131.1.213/23 brd 10.131.1.255 scope global eth0 valid_lft forever preferred_lft forever inet6 fe80::858:aff:fe83:1d5/64 scope link valid_lft forever preferred_lft forever 4076: net1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000 link/ether 56:6c:59:41:ae:4a brd ff:ff:ff:ff:ff:ff altname enp55s0f0v0 inet 192.168.4.226/28 brd 192.168.4.239 scope global net1 valid_lft forever preferred_lft forever inet6 fe80::546c:59ff:fe41:ae4a/64 scope link valid_lft forever preferred_lft forever sh-5.1#다음 명령을 사용하여 각 RDMA 장치
mlx5_x와 연결된link_layer유형을 가져옵니다.sh-5.1# ibstatus출력 예
Infiniband device 'mlx5_0' port 1 status: default gid: 0000:0000:0000:0000:0000:0000:0000:0000 base lid: 0x0 sm lid: 0x0 state: 4: ACTIVE phys state: 5: LinkUp rate: 200 Gb/sec (4X HDR) link_layer: Ethernet Infiniband device 'mlx5_1' port 1 status: default gid: fe80:0000:0000:0000:e8eb:d303:0072:09f5 base lid: 0xd sm lid: 0x1 state: 4: ACTIVE phys state: 5: LinkUp rate: 200 Gb/sec (4X HDR) link_layer: InfiniBand Infiniband device 'mlx5_2' port 1 status: default gid: fe80:0000:0000:0000:546c:59ff:fe41:ae4a base lid: 0x0 sm lid: 0x0 state: 4: ACTIVE phys state: 5: LinkUp rate: 200 Gb/sec (4X HDR) link_layer: Ethernet Infiniband device 'mlx5_3' port 1 status: default gid: 0000:0000:0000:0000:0000:0000:0000:0000 base lid: 0x0 sm lid: 0x0 state: 1: DOWN phys state: 3: Disabled rate: 200 Gb/sec (4X HDR) link_layer: Ethernet Infiniband device 'mlx5_4' port 1 status: default gid: 0000:0000:0000:0000:0000:0000:0000:0000 base lid: 0x0 sm lid: 0x0 state: 1: DOWN phys state: 3: Disabled rate: 200 Gb/sec (4X HDR) link_layer: Ethernet Infiniband device 'mlx5_5' port 1 status: default gid: 0000:0000:0000:0000:0000:0000:0000:0000 base lid: 0x0 sm lid: 0x0 state: 1: DOWN phys state: 3: Disabled rate: 200 Gb/sec (4X HDR) link_layer: Ethernet Infiniband device 'mlx5_6' port 1 status: default gid: 0000:0000:0000:0000:0000:0000:0000:0000 base lid: 0x0 sm lid: 0x0 state: 1: DOWN phys state: 3: Disabled rate: 200 Gb/sec (4X HDR) link_layer: Ethernet Infiniband device 'mlx5_7' port 1 status: default gid: 0000:0000:0000:0000:0000:0000:0000:0000 base lid: 0x0 sm lid: 0x0 state: 1: DOWN phys state: 3: Disabled rate: 200 Gb/sec (4X HDR) link_layer: Ethernet Infiniband device 'mlx5_8' port 1 status: default gid: 0000:0000:0000:0000:0000:0000:0000:0000 base lid: 0x0 sm lid: 0x0 state: 1: DOWN phys state: 3: Disabled rate: 200 Gb/sec (4X HDR) link_layer: Ethernet Infiniband device 'mlx5_9' port 1 status: default gid: 0000:0000:0000:0000:0000:0000:0000:0000 base lid: 0x0 sm lid: 0x0 state: 1: DOWN phys state: 3: Disabled rate: 200 Gb/sec (4X HDR) link_layer: Ethernet선택 사항:
ibstat명령을 사용하여 Mellanox 카드의 펌웨어 버전을 가져옵니다.sh-5.1# ibstat출력 예
CA 'mlx5_0' CA type: MT4123 Number of ports: 1 Firmware version: 20.43.1014 Hardware version: 0 Node GUID: 0xe8ebd303007209f4 System image GUID: 0xe8ebd303007209f4 Port 1: State: Active Physical state: LinkUp Rate: 200 Base lid: 0 LMC: 0 SM lid: 0 Capability mask: 0x00010000 Port GUID: 0x0000000000000000 Link layer: Ethernet CA 'mlx5_1' CA type: MT4123 Number of ports: 1 Firmware version: 20.43.1014 Hardware version: 0 Node GUID: 0xe8ebd303007209f5 System image GUID: 0xe8ebd303007209f4 Port 1: State: Active Physical state: LinkUp Rate: 200 Base lid: 13 LMC: 0 SM lid: 1 Capability mask: 0xa651e848 Port GUID: 0xe8ebd303007209f5 Link layer: InfiniBand CA 'mlx5_2' CA type: MT4124 Number of ports: 1 Firmware version: 20.43.1014 Hardware version: 0 Node GUID: 0x566c59fffe41ae4a System image GUID: 0xe8ebd303007209f4 Port 1: State: Active Physical state: LinkUp Rate: 200 Base lid: 0 LMC: 0 SM lid: 0 Capability mask: 0x00010000 Port GUID: 0x546c59fffe41ae4a Link layer: Ethernet CA 'mlx5_3' CA type: MT4124 Number of ports: 1 Firmware version: 20.43.1014 Hardware version: 0 Node GUID: 0xb2ae4bfffe8f3d02 System image GUID: 0xe8ebd303007209f4 Port 1: State: Down Physical state: Disabled Rate: 200 Base lid: 0 LMC: 0 SM lid: 0 Capability mask: 0x00010000 Port GUID: 0x0000000000000000 Link layer: Ethernet CA 'mlx5_4' CA type: MT4124 Number of ports: 1 Firmware version: 20.43.1014 Hardware version: 0 Node GUID: 0x2a9967fffe8bf272 System image GUID: 0xe8ebd303007209f4 Port 1: State: Down Physical state: Disabled Rate: 200 Base lid: 0 LMC: 0 SM lid: 0 Capability mask: 0x00010000 Port GUID: 0x0000000000000000 Link layer: Ethernet CA 'mlx5_5' CA type: MT4124 Number of ports: 1 Firmware version: 20.43.1014 Hardware version: 0 Node GUID: 0x5aff2ffffe2e17e8 System image GUID: 0xe8ebd303007209f4 Port 1: State: Down Physical state: Disabled Rate: 200 Base lid: 0 LMC: 0 SM lid: 0 Capability mask: 0x00010000 Port GUID: 0x0000000000000000 Link layer: Ethernet CA 'mlx5_6' CA type: MT4124 Number of ports: 1 Firmware version: 20.43.1014 Hardware version: 0 Node GUID: 0x121bf1fffe074419 System image GUID: 0xe8ebd303007209f4 Port 1: State: Down Physical state: Disabled Rate: 200 Base lid: 0 LMC: 0 SM lid: 0 Capability mask: 0x00010000 Port GUID: 0x0000000000000000 Link layer: Ethernet CA 'mlx5_7' CA type: MT4124 Number of ports: 1 Firmware version: 20.43.1014 Hardware version: 0 Node GUID: 0xb22b16fffed03dd7 System image GUID: 0xe8ebd303007209f4 Port 1: State: Down Physical state: Disabled Rate: 200 Base lid: 0 LMC: 0 SM lid: 0 Capability mask: 0x00010000 Port GUID: 0x0000000000000000 Link layer: Ethernet CA 'mlx5_8' CA type: MT4124 Number of ports: 1 Firmware version: 20.43.1014 Hardware version: 0 Node GUID: 0x523800fffe16d105 System image GUID: 0xe8ebd303007209f4 Port 1: State: Down Physical state: Disabled Rate: 200 Base lid: 0 LMC: 0 SM lid: 0 Capability mask: 0x00010000 Port GUID: 0x0000000000000000 Link layer: Ethernet CA 'mlx5_9' CA type: MT4124 Number of ports: 1 Firmware version: 20.43.1014 Hardware version: 0 Node GUID: 0xd2b4a1fffebdc4a9 System image GUID: 0xe8ebd303007209f4 Port 1: State: Down Physical state: Disabled Rate: 200 Base lid: 0 LMC: 0 SM lid: 0 Capability mask: 0x00010000 Port GUID: 0x0000000000000000 Link layer: Ethernet sh-5.1#클라이언트 워크로드 Pod에서 사용하는 가상 기능 하위 인터페이스와 연결된 RDMA 장치를 확인하려면 다음 명령을 실행합니다. 이 예에서
net1인터페이스는 RDMA 장치mlx5_2를 사용하고 있습니다.sh-5.1# rdma link show출력 예
link mlx5_0/1 state ACTIVE physical_state LINK_UP link mlx5_1/1 subnet_prefix fe80:0000:0000:0000 lid 13 sm_lid 1 lmc 0 state ACTIVE physical_state LINK_UP link mlx5_2/1 state ACTIVE physical_state LINK_UP netdev net1 link mlx5_3/1 state DOWN physical_state DISABLED link mlx5_4/1 state DOWN physical_state DISABLED link mlx5_5/1 state DOWN physical_state DISABLED link mlx5_6/1 state DOWN physical_state DISABLED link mlx5_7/1 state DOWN physical_state DISABLED link mlx5_8/1 state DOWN physical_state DISABLED link mlx5_9/1 state DOWN physical_state DISABLED sh-5.1#다음
ib_write_bwRDMA bandwidth test 명령을 실행합니다.sh-5.1# /root/perftest/ib_write_bw -R -T 41 -s 65536 -F -x 3 -m 4096 --report_gbits -q 16 -D 60 -d mlx5_2 -p 10000 --source_ip 192.168.4.226 --use_cuda=0 --use_cuda_dmabuf 192.168.4.225다음과 같습니다.
-
mlx5_2RDMA 장치는-d스위치로 전달됩니다. -
RDMA 서버
192.168.4.225의 소스 IP 주소192.168.4.226및 대상 IP 주소입니다. --use_cuda=0,--use_cuda_dmabuf스위치는 GPUDirect RDMA를 사용함을 나타냅니다.출력 예
WARNING: BW peak won't be measured in this run. Perftest doesn't supports CUDA tests with inline messages: inline size set to 0 Requested mtu is higher than active mtu Changing to active mtu - 3 initializing CUDA Listing all CUDA devices in system: CUDA device 0: PCIe address is 61:00 Picking device No. 0 [pid = 8909, dev = 0] device name = [NVIDIA A40] creating CUDA Ctx making it the current CUDA Ctx CUDA device integrated: 0 using DMA-BUF for GPU buffer address at 0x7f8738600000 aligned at 0x7f8738600000 with aligned size 2097152 allocated GPU buffer of a 2097152 address at 0x23a7420 for type CUDA_MEM_DEVICE Calling ibv_reg_dmabuf_mr(offset=0, size=2097152, addr=0x7f8738600000, fd=40) for QP #0 --------------------------------------------------------------------------------------- RDMA_Write BW Test Dual-port : OFF Device : mlx5_2 Number of qps : 16 Transport type : IB Connection type : RC Using SRQ : OFF PCIe relax order: ON Lock-free : OFF ibv_wr* API : ON Using DDP : OFF TX depth : 128 CQ Moderation : 1 CQE Poll Batch : 16 Mtu : 1024[B] Link type : Ethernet GID index : 3 Max inline data : 0[B] rdma_cm QPs : ON Data ex. method : rdma_cm TOS : 41 --------------------------------------------------------------------------------------- local address: LID 0000 QPN 0x012d PSN 0x3cb6d7 GID: 00:00:00:00:00:00:00:00:00:00:255:255:192:168:04:226 local address: LID 0000 QPN 0x012e PSN 0x90e0ac GID: 00:00:00:00:00:00:00:00:00:00:255:255:192:168:04:226 local address: LID 0000 QPN 0x012f PSN 0x153f50 GID: 00:00:00:00:00:00:00:00:00:00:255:255:192:168:04:226 local address: LID 0000 QPN 0x0130 PSN 0x5e0128 GID: 00:00:00:00:00:00:00:00:00:00:255:255:192:168:04:226 local address: LID 0000 QPN 0x0131 PSN 0xd89752 GID: 00:00:00:00:00:00:00:00:00:00:255:255:192:168:04:226 local address: LID 0000 QPN 0x0132 PSN 0xe5fc16 GID: 00:00:00:00:00:00:00:00:00:00:255:255:192:168:04:226 local address: LID 0000 QPN 0x0133 PSN 0x236787 GID: 00:00:00:00:00:00:00:00:00:00:255:255:192:168:04:226 local address: LID 0000 QPN 0x0134 PSN 0xd9273e GID: 00:00:00:00:00:00:00:00:00:00:255:255:192:168:04:226 local address: LID 0000 QPN 0x0135 PSN 0x37cfd4 GID: 00:00:00:00:00:00:00:00:00:00:255:255:192:168:04:226 local address: LID 0000 QPN 0x0136 PSN 0x3bff8f GID: 00:00:00:00:00:00:00:00:00:00:255:255:192:168:04:226 local address: LID 0000 QPN 0x0137 PSN 0x81f2bd GID: 00:00:00:00:00:00:00:00:00:00:255:255:192:168:04:226 local address: LID 0000 QPN 0x0138 PSN 0x575c43 GID: 00:00:00:00:00:00:00:00:00:00:255:255:192:168:04:226 local address: LID 0000 QPN 0x0139 PSN 0x6cf53d GID: 00:00:00:00:00:00:00:00:00:00:255:255:192:168:04:226 local address: LID 0000 QPN 0x013a PSN 0xcaaf6f GID: 00:00:00:00:00:00:00:00:00:00:255:255:192:168:04:226 local address: LID 0000 QPN 0x013b PSN 0x346437 GID: 00:00:00:00:00:00:00:00:00:00:255:255:192:168:04:226 local address: LID 0000 QPN 0x013c PSN 0xcc5865 GID: 00:00:00:00:00:00:00:00:00:00:255:255:192:168:04:226 remote address: LID 0000 QPN 0x026d PSN 0x359409 GID: 00:00:00:00:00:00:00:00:00:00:255:255:192:168:04:225 remote address: LID 0000 QPN 0x026e PSN 0xe387bf GID: 00:00:00:00:00:00:00:00:00:00:255:255:192:168:04:225 remote address: LID 0000 QPN 0x026f PSN 0x5be79d GID: 00:00:00:00:00:00:00:00:00:00:255:255:192:168:04:225 remote address: LID 0000 QPN 0x0270 PSN 0x1b4b28 GID: 00:00:00:00:00:00:00:00:00:00:255:255:192:168:04:225 remote address: LID 0000 QPN 0x0271 PSN 0x76a61b GID: 00:00:00:00:00:00:00:00:00:00:255:255:192:168:04:225 remote address: LID 0000 QPN 0x0272 PSN 0x3d50e1 GID: 00:00:00:00:00:00:00:00:00:00:255:255:192:168:04:225 remote address: LID 0000 QPN 0x0273 PSN 0x1b572c GID: 00:00:00:00:00:00:00:00:00:00:255:255:192:168:04:225 remote address: LID 0000 QPN 0x0274 PSN 0x4ae1b5 GID: 00:00:00:00:00:00:00:00:00:00:255:255:192:168:04:225 remote address: LID 0000 QPN 0x0275 PSN 0x5591b5 GID: 00:00:00:00:00:00:00:00:00:00:255:255:192:168:04:225 remote address: LID 0000 QPN 0x0276 PSN 0xfa2593 GID: 00:00:00:00:00:00:00:00:00:00:255:255:192:168:04:225 remote address: LID 0000 QPN 0x0277 PSN 0xd9473b GID: 00:00:00:00:00:00:00:00:00:00:255:255:192:168:04:225 remote address: LID 0000 QPN 0x0278 PSN 0x2116b2 GID: 00:00:00:00:00:00:00:00:00:00:255:255:192:168:04:225 remote address: LID 0000 QPN 0x0279 PSN 0x9b83b6 GID: 00:00:00:00:00:00:00:00:00:00:255:255:192:168:04:225 remote address: LID 0000 QPN 0x027a PSN 0xa0822b GID: 00:00:00:00:00:00:00:00:00:00:255:255:192:168:04:225 remote address: LID 0000 QPN 0x027b PSN 0x6d930d GID: 00:00:00:00:00:00:00:00:00:00:255:255:192:168:04:225 remote address: LID 0000 QPN 0x027c PSN 0xb1a4d GID: 00:00:00:00:00:00:00:00:00:00:255:255:192:168:04:225 --------------------------------------------------------------------------------------- #bytes #iterations BW peak[Gb/sec] BW average[Gb/sec] MsgRate[Mpps] 65536 10329004 0.00 180.47 0.344228 --------------------------------------------------------------------------------------- deallocating GPU buffer 00007f8738600000 destroying current CUDA Ctx sh-5.1#긍정적인 테스트는 Mpps에서 예상되는 BW 평균과 MsgRate를 보고 있습니다.
ib_write_bw명령이 완료되면 서버 측 출력도 서버 Pod에 표시됩니다. 다음 예제를 참조하십시오.출력 예
WARNING: BW peak won't be measured in this run. Perftest doesn't supports CUDA tests with inline messages: inline size set to 0 ************************************ * Waiting for client to connect... * ************************************ Requested mtu is higher than active mtu Changing to active mtu - 3 initializing CUDA Listing all CUDA devices in system: CUDA device 0: PCIe address is 61:00 Picking device No. 0 [pid = 9226, dev = 0] device name = [NVIDIA A40] creating CUDA Ctx making it the current CUDA Ctx CUDA device integrated: 0 using DMA-BUF for GPU buffer address at 0x7f447a600000 aligned at 0x7f447a600000 with aligned size 2097152 allocated GPU buffer of a 2097152 address at 0x2406400 for type CUDA_MEM_DEVICE Calling ibv_reg_dmabuf_mr(offset=0, size=2097152, addr=0x7f447a600000, fd=40) for QP #0 --------------------------------------------------------------------------------------- RDMA_Write BW Test Dual-port : OFF Device : mlx5_7 Number of qps : 16 Transport type : IB Connection type : RC Using SRQ : OFF PCIe relax order: ON Lock-free : OFF ibv_wr* API : ON Using DDP : OFF CQ Moderation : 1 CQE Poll Batch : 16 Mtu : 1024[B] Link type : Ethernet GID index : 3 Max inline data : 0[B] rdma_cm QPs : ON Data ex. method : rdma_cm TOS : 41 --------------------------------------------------------------------------------------- Waiting for client rdma_cm QP to connect Please run the same command with the IB/RoCE interface IP --------------------------------------------------------------------------------------- local address: LID 0000 QPN 0x026d PSN 0x359409 GID: 00:00:00:00:00:00:00:00:00:00:255:255:192:168:04:225 local address: LID 0000 QPN 0x026e PSN 0xe387bf GID: 00:00:00:00:00:00:00:00:00:00:255:255:192:168:04:225 local address: LID 0000 QPN 0x026f PSN 0x5be79d GID: 00:00:00:00:00:00:00:00:00:00:255:255:192:168:04:225 local address: LID 0000 QPN 0x0270 PSN 0x1b4b28 GID: 00:00:00:00:00:00:00:00:00:00:255:255:192:168:04:225 local address: LID 0000 QPN 0x0271 PSN 0x76a61b GID: 00:00:00:00:00:00:00:00:00:00:255:255:192:168:04:225 local address: LID 0000 QPN 0x0272 PSN 0x3d50e1 GID: 00:00:00:00:00:00:00:00:00:00:255:255:192:168:04:225 local address: LID 0000 QPN 0x0273 PSN 0x1b572c GID: 00:00:00:00:00:00:00:00:00:00:255:255:192:168:04:225 local address: LID 0000 QPN 0x0274 PSN 0x4ae1b5 GID: 00:00:00:00:00:00:00:00:00:00:255:255:192:168:04:225 local address: LID 0000 QPN 0x0275 PSN 0x5591b5 GID: 00:00:00:00:00:00:00:00:00:00:255:255:192:168:04:225 local address: LID 0000 QPN 0x0276 PSN 0xfa2593 GID: 00:00:00:00:00:00:00:00:00:00:255:255:192:168:04:225 local address: LID 0000 QPN 0x0277 PSN 0xd9473b GID: 00:00:00:00:00:00:00:00:00:00:255:255:192:168:04:225 local address: LID 0000 QPN 0x0278 PSN 0x2116b2 GID: 00:00:00:00:00:00:00:00:00:00:255:255:192:168:04:225 local address: LID 0000 QPN 0x0279 PSN 0x9b83b6 GID: 00:00:00:00:00:00:00:00:00:00:255:255:192:168:04:225 local address: LID 0000 QPN 0x027a PSN 0xa0822b GID: 00:00:00:00:00:00:00:00:00:00:255:255:192:168:04:225 local address: LID 0000 QPN 0x027b PSN 0x6d930d GID: 00:00:00:00:00:00:00:00:00:00:255:255:192:168:04:225 local address: LID 0000 QPN 0x027c PSN 0xb1a4d GID: 00:00:00:00:00:00:00:00:00:00:255:255:192:168:04:225 remote address: LID 0000 QPN 0x012d PSN 0x3cb6d7 GID: 00:00:00:00:00:00:00:00:00:00:255:255:192:168:04:226 remote address: LID 0000 QPN 0x012e PSN 0x90e0ac GID: 00:00:00:00:00:00:00:00:00:00:255:255:192:168:04:226 remote address: LID 0000 QPN 0x012f PSN 0x153f50 GID: 00:00:00:00:00:00:00:00:00:00:255:255:192:168:04:226 remote address: LID 0000 QPN 0x0130 PSN 0x5e0128 GID: 00:00:00:00:00:00:00:00:00:00:255:255:192:168:04:226 remote address: LID 0000 QPN 0x0131 PSN 0xd89752 GID: 00:00:00:00:00:00:00:00:00:00:255:255:192:168:04:226 remote address: LID 0000 QPN 0x0132 PSN 0xe5fc16 GID: 00:00:00:00:00:00:00:00:00:00:255:255:192:168:04:226 remote address: LID 0000 QPN 0x0133 PSN 0x236787 GID: 00:00:00:00:00:00:00:00:00:00:255:255:192:168:04:226 remote address: LID 0000 QPN 0x0134 PSN 0xd9273e GID: 00:00:00:00:00:00:00:00:00:00:255:255:192:168:04:226 remote address: LID 0000 QPN 0x0135 PSN 0x37cfd4 GID: 00:00:00:00:00:00:00:00:00:00:255:255:192:168:04:226 remote address: LID 0000 QPN 0x0136 PSN 0x3bff8f GID: 00:00:00:00:00:00:00:00:00:00:255:255:192:168:04:226 remote address: LID 0000 QPN 0x0137 PSN 0x81f2bd GID: 00:00:00:00:00:00:00:00:00:00:255:255:192:168:04:226 remote address: LID 0000 QPN 0x0138 PSN 0x575c43 GID: 00:00:00:00:00:00:00:00:00:00:255:255:192:168:04:226 remote address: LID 0000 QPN 0x0139 PSN 0x6cf53d GID: 00:00:00:00:00:00:00:00:00:00:255:255:192:168:04:226 remote address: LID 0000 QPN 0x013a PSN 0xcaaf6f GID: 00:00:00:00:00:00:00:00:00:00:255:255:192:168:04:226 remote address: LID 0000 QPN 0x013b PSN 0x346437 GID: 00:00:00:00:00:00:00:00:00:00:255:255:192:168:04:226 remote address: LID 0000 QPN 0x013c PSN 0xcc5865 GID: 00:00:00:00:00:00:00:00:00:00:255:255:192:168:04:226 --------------------------------------------------------------------------------------- #bytes #iterations BW peak[Gb/sec] BW average[Gb/sec] MsgRate[Mpps] 65536 10329004 0.00 180.47 0.344228 --------------------------------------------------------------------------------------- deallocating GPU buffer 00007f447a600000 destroying current CUDA Ctx
-
6장. DAS(Dynamic Accelerator Slicer) Operator
Dynamic Accelerator Slicer Operator는 기술 프리뷰 기능 전용입니다. 기술 프리뷰 기능은 Red Hat 프로덕션 서비스 수준 계약(SLA)에서 지원되지 않으며 기능적으로 완전하지 않을 수 있습니다. 따라서 프로덕션 환경에서 사용하는 것은 권장하지 않습니다. 이러한 기능을 사용하면 향후 제품 기능을 조기에 이용할 수 있어 개발 과정에서 고객이 기능을 테스트하고 피드백을 제공할 수 있습니다.
Red Hat 기술 프리뷰 기능의 지원 범위에 대한 자세한 내용은 기술 프리뷰 기능 지원 범위를 참조하십시오.
Dynamic Accelerator Slicer(DAS) Operator를 사용하면 노드가 부팅될 때 정의된 정적으로 분할된 GPU를 사용하는 대신 OpenShift Container Platform에서 GPU 액셀러레이터를 동적으로 분할할 수 있습니다. 이를 통해 특정 워크로드 요구 사항에 따라 GPU를 동적으로 분할하여 리소스 활용도를 높일 수 있습니다.
동적 분할은 클러스터의 모든 노드에서 미리 필요한 모든 액셀러레이터 파티션을 모르는 경우 유용합니다.
DAS Operator에는 현재 NVIDIA MG(Multi-Instance GPU)에 대한 참조 구현이 포함되어 있으며 향후 다른 공급업체의 NVIDIA MPS 또는 GPU와 같은 추가 기술을 지원하도록 설계되었습니다.
제한
Dynamic Accelerator Slicer Operator를 사용하는 경우 다음과 같은 제한 사항이 적용됩니다.
- 잠재적인 비호환성을 파악하고 다양한 GPU 드라이버 및 운영 체제에서 시스템이 원활하게 작동하는지 확인해야 합니다.
- Operator는 H100 및 A100과 같은 특정 NSXG 호환 NVIDIA GPU 및 드라이버에서만 작동합니다.
- Operator는 노드의 GPU 서브 세트만 사용할 수 없습니다.
- NVIDIA 장치 플러그인은 Dynamic Accelerator Slicer Operator와 함께 사용하여 클러스터의 GPU 리소스를 관리할 수 없습니다.
DAS Operator는MIG 지원 GPU에서 작동하도록 설계되었습니다. 이는 전체 GPU 대신MIG 슬라이스를 할당합니다. DAS Operator를 설치하면 전체 GPU를 할당하는 nvidia.com/gpu: "1" 과 같은 NVIDIA 장치 플러그인을 통해 표준 리소스 요청을 사용할 수 없습니다.
6.1. Dynamic Accelerator Slicer Operator 설치
클러스터 관리자는 OpenShift Container Platform 웹 콘솔 또는 OpenShift CLI를 사용하여 DAS(Dynamic Accelerator Slicer) Operator를 설치할 수 있습니다.
6.1.1. 웹 콘솔을 사용하여 Dynamic Accelerator Slicer Operator 설치
클러스터 관리자는 OpenShift Container Platform 웹 콘솔을 사용하여 DAS(Dynamic Accelerator Slicer) Operator를 설치할 수 있습니다.
사전 요구 사항
-
cluster-admin권한이 있는 계정을 사용하여 OpenShift Container Platform 클러스터에 액세스할 수 있습니다. 필요한 사전 요구 사항을 설치했습니다.
- cert-manager Operator for Red Hat OpenShift
- NFD(Node Feature Discovery) Operator
- NVIDIA GPU Operator
- NodeFeatureDiscovery CR
프로세스
HMAC 지원을 위해 NVIDIA GPU Operator를 구성합니다.
- OpenShift Container Platform 웹 콘솔에서 Ecosystem → Installed Operators 로 이동합니다.
- 설치된 Operator 목록에서 NVIDIA GPU Operator 를 선택합니다.
- ClusterPolicy 탭을 클릭한 다음 Create ClusterPolicy 를 클릭합니다.
YAML 편집기에서 기본 콘텐츠를 다음 클러스터 정책 구성으로 교체하여 기본 NVIDIA 장치 플러그인을 비활성화하고>-<G 지원을 활성화합니다.
apiVersion: nvidia.com/v1 kind: ClusterPolicy metadata: name: gpu-cluster-policy spec: daemonsets: rollingUpdate: maxUnavailable: "1" updateStrategy: RollingUpdate dcgm: enabled: true dcgmExporter: config: name: "" enabled: true serviceMonitor: enabled: true devicePlugin: config: default: "" name: "" enabled: false mps: root: /run/nvidia/mps driver: certConfig: name: "" enabled: true kernelModuleConfig: name: "" licensingConfig: configMapName: "" nlsEnabled: true repoConfig: configMapName: "" upgradePolicy: autoUpgrade: true drain: deleteEmptyDir: false enable: false force: false timeoutSeconds: 300 maxParallelUpgrades: 1 maxUnavailable: 25% podDeletion: deleteEmptyDir: false force: false timeoutSeconds: 300 waitForCompletion: timeoutSeconds: 0 useNvidiaDriverCRD: false useOpenKernelModules: false virtualTopology: config: "" gdrcopy: enabled: false gds: enabled: false gfd: enabled: true mig: strategy: mixed migManager: config: default: "" name: default-mig-parted-config enabled: true env: - name: WITH_REBOOT value: 'true' - name: MIG_PARTED_MODE_CHANGE_ONLY value: 'true' nodeStatusExporter: enabled: true operator: defaultRuntime: crio initContainer: {} runtimeClass: nvidia use_ocp_driver_toolkit: true sandboxDevicePlugin: enabled: true sandboxWorkloads: defaultWorkload: container enabled: false toolkit: enabled: true installDir: /usr/local/nvidia validator: plugin: env: - name: WITH_WORKLOAD value: "false" cuda: env: - name: WITH_WORKLOAD value: "false" vfioManager: enabled: true vgpuDeviceManager: enabled: true vgpuManager: enabled: false- 생성 을 클릭하여 클러스터 정책을 적용합니다.
-
워크로드 → Pod 로 이동하여
nvidia-gpu-operator네임스페이스를 선택하여 클러스터 정책 배포를 모니터링합니다. NVIDIA GPU Operator 클러스터 정책이
Ready상태가 될 때까지 기다립니다. 다음을 통해 이를 모니터링할 수 있습니다.- 에코시스템 → 설치된 Operator → NVIDIA GPU Operator 로 이동합니다.
-
ClusterPolicy 탭을 클릭하고 상태가
ready인지 확인합니다.
-
nvidia-gpu-operator네임스페이스를 선택하고 워크로드 → Pod로 이동하여 NVIDIA GPU Operator 네임스페이스의 모든 Pod 가 실행 중인지 확인합니다. MIG 지원 GPU가 있는 노드에 레이블을 지정하여MIG 모드를 활성화합니다.
- 컴퓨팅 → 노드로 이동합니다.
- MIG 가능 GPU가 있는 노드를 선택합니다.
- 작업 → 라벨 편집을 클릭합니다.
-
nvidia.com/mig.config=all-enabled레이블을 추가합니다. - 저장을 클릭합니다.
CheG 가능 GPU를 사용하여 각 노드에 대해 반복합니다.
중요MIG 레이블을 적용하면 레이블이 지정된 노드가 재부팅되어 HMACG 모드를 활성화합니다. 계속하기 전에 노드가 다시 온라인 상태가 될 때까지 기다립니다.
-
nvidia.com/mig.config=all-enabled레이블이 Labels 섹션에 표시되는지 확인하여 GPU 노드에서 NSXG 모드가 성공적으로 활성화되었는지 확인합니다. 레이블을 찾으려면 컴퓨팅 → 노드로 이동하여 GPU 노드를 선택하고 세부 정보 탭을 클릭합니다.
- OpenShift Container Platform 웹 콘솔에서 에코시스템 → 소프트웨어 카탈로그 를 클릭합니다.
- 필터 상자에서 Dynamic Accelerator Slicer 또는 DAS 를 검색하여 DAS Operator를 찾습니다.
- Dynamic Accelerator Slicer 를 선택하고 설치를 클릭합니다.
Operator 설치 페이지에서 다음을 수행합니다.
- 설치 모드에서 모든 네임스페이스(기본값) 를 선택합니다.
- 설치된 네임스페이스 → Operator 권장 네임스페이스: 프로젝트 das-operator를 선택합니다.
-
새 네임스페이스를 생성하는 경우 네임스페이스 이름으로
das-operator를 입력합니다. - 업데이트 채널을 선택합니다.
- 승인 전략으로 자동 또는 수동 을 선택합니다.
- 설치를 클릭합니다.
- OpenShift Container Platform 웹 콘솔에서 에코시스템 → 설치된 Operator 를 클릭합니다.
- 목록에서 DAS Operator 를 선택합니다.
- 제공된 API 테이블 열에서 DASOperator 를 클릭합니다. 그러면 Operator 세부 정보 페이지의 DASOperator 탭으로 이동합니다.
- DASOperator 생성을 클릭합니다. 그러면 DASOperator YAML 보기가 표시됩니다.
YAML 편집기에서 다음 예제를 붙여넣습니다.
DASOperatorCR의 예apiVersion: inference.redhat.com/v1alpha1 kind: DASOperator metadata: name: cluster1 namespace: das-operator spec: logLevel: Normal operatorLogLevel: Normal managementState: Managed- 1
DASOperatorCR의 이름은cluster여야 합니다.
- 생성을 클릭합니다.
검증
DAS Operator가 성공적으로 설치되었는지 확인하려면 다음을 수행하십시오.
- 에코시스템 → 설치된 Operator 페이지로 이동합니다.
-
Dynamic Accelerator Slicer 가
das-operator네임스페이스에 성공 상태로 나열되어 있는지 확인합니다.
DASOperator CR이 성공적으로 설치되었는지 확인하려면 다음을 수행하십시오.
-
DASOperatorCR을 생성한 후 웹 콘솔에서 DASOperator 목록 보기로 이동합니다. CR의 Status 필드는 모든 구성 요소가 실행 중일 때 Available 로 변경됩니다. 선택 사항입니다. OpenShift CLI에서 다음 명령을 실행하여
DASOperatorCR이 성공적으로 설치되었는지 확인할 수 있습니다.$ oc get dasoperator -n das-operator출력 예
NAME STATUS AGE cluster Available 3m
설치 중에 Operator는 실패 상태를 표시할 수 있습니다. 나중에 Succeeded 메시지와 함께 설치에 성공하면 실패 메시지를 무시할 수 있습니다.
Pod를 확인하여 설치를 확인할 수도 있습니다.
-
워크로드 → Pod 페이지로 이동하여
das-operator네임스페이스를 선택합니다. 모든 DAS Operator 구성 요소 Pod가 실행 중인지 확인합니다.
-
DAS-operatorPod (main Operator Controller) -
DAS-operator-webhookPod (webhook 서버) -
DAS-schedulerPod(scheduler 플러그인) -
DAS-daemonsetPod(MIG 호환 GPU가 있는 노드에서만)
-
das-daemonset Pod는 rpcG 호환 GPU 하드웨어가 있는 노드에만 표시됩니다. daemonset Pod가 표시되지 않는 경우 클러스터에 지원되는 GPU 하드웨어가 있고 NVIDIA GPU Operator가 올바르게 구성되었는지 확인합니다.
문제 해결
Operator가 설치되지 않은 경우 다음 절차를 사용하십시오.
- 에코시스템 → 설치된 Operator 페이지로 이동하여 Operator 서브스크립션 및 설치 계획 탭의 상태에 장애 또는 오류가 있는지 검사합니다.
-
워크로드 → Pod 페이지로 이동하여
das-operator네임스페이스에서 Pod 로그를 확인합니다.
6.1.2. CLI를 사용하여 Dynamic Accelerator Slicer Operator 설치
클러스터 관리자는 OpenShift CLI를 사용하여 DAS(Dynamic Accelerator Slicer) Operator를 설치할 수 있습니다.
사전 요구 사항
-
cluster-admin권한이 있는 계정을 사용하여 OpenShift Container Platform 클러스터에 액세스할 수 있습니다. -
OpenShift CLI(
oc)가 설치되어 있습니다. 필요한 사전 요구 사항을 설치했습니다.
- cert-manager Operator for Red Hat OpenShift
- NFD(Node Feature Discovery) Operator
- NVIDIA GPU Operator
- NodeFeatureDiscovery CR
프로세스
HMAC 지원을 위해 NVIDIA GPU Operator를 구성합니다.
다음 클러스터 정책을 적용하여 기본 NVIDIA 장치 플러그인을 비활성화하고MIG 지원을 활성화합니다. 다음 콘텐츠를 사용하여
gpu-cluster-policy.yaml이라는 파일을 생성합니다.apiVersion: nvidia.com/v1 kind: ClusterPolicy metadata: name: gpu-cluster-policy spec: daemonsets: rollingUpdate: maxUnavailable: "1" updateStrategy: RollingUpdate dcgm: enabled: true dcgmExporter: config: name: "" enabled: true serviceMonitor: enabled: true devicePlugin: config: default: "" name: "" enabled: false mps: root: /run/nvidia/mps driver: certConfig: name: "" enabled: true kernelModuleConfig: name: "" licensingConfig: configMapName: "" nlsEnabled: true repoConfig: configMapName: "" upgradePolicy: autoUpgrade: true drain: deleteEmptyDir: false enable: false force: false timeoutSeconds: 300 maxParallelUpgrades: 1 maxUnavailable: 25% podDeletion: deleteEmptyDir: false force: false timeoutSeconds: 300 waitForCompletion: timeoutSeconds: 0 useNvidiaDriverCRD: false useOpenKernelModules: false virtualTopology: config: "" gdrcopy: enabled: false gds: enabled: false gfd: enabled: true mig: strategy: mixed migManager: config: default: "" name: default-mig-parted-config enabled: true env: - name: WITH_REBOOT value: 'true' - name: MIG_PARTED_MODE_CHANGE_ONLY value: 'true' nodeStatusExporter: enabled: true operator: defaultRuntime: crio initContainer: {} runtimeClass: nvidia use_ocp_driver_toolkit: true sandboxDevicePlugin: enabled: true sandboxWorkloads: defaultWorkload: container enabled: false toolkit: enabled: true installDir: /usr/local/nvidia validator: plugin: env: - name: WITH_WORKLOAD value: "false" cuda: env: - name: WITH_WORKLOAD value: "false" vfioManager: enabled: true vgpuDeviceManager: enabled: true vgpuManager: enabled: false다음 명령을 실행하여 클러스터 정책을 적용합니다.
$ oc apply -f gpu-cluster-policy.yaml다음 명령을 실행하여 NVIDIA GPU Operator 클러스터 정책이
Ready상태에 도달하는지 확인합니다.$ oc get clusterpolicies.nvidia.com gpu-cluster-policy -wSTATUS열에준비상태가 표시될 때까지 기다립니다.출력 예
NAME STATUS AGE gpu-cluster-policy ready 2025-08-14T08:56:45Z다음 명령을 실행하여 NVIDIA GPU Operator 네임스페이스의 모든 Pod가 실행 중인지 확인합니다.
$ oc get pods -n nvidia-gpu-operator모든 Pod에
Running또는Completed상태가 표시되어야 합니다.다음 명령을 실행하여MIG 지원 GPU가 있는 노드에 레이블을 지정하여MIG 모드를 활성화합니다.
$ oc label node $NODE_NAME nvidia.com/mig.config=all-enabled --overwrite$NODE_NAME을>-<G 가능 GPU가 있는 각 노드의 이름으로 바꿉니다.중요MIG 레이블을 적용한 후 레이블이 지정된 노드가 재부팅되어>-<G 모드를 활성화합니다. 계속하기 전에 노드가 다시 온라인 상태가 될 때까지 기다립니다.
다음 명령을 실행하여 노드가MIG 모드를 성공적으로 활성화했는지 확인합니다.
$ oc get nodes -l nvidia.com/mig.config=all-enabled
DAS Operator의 네임스페이스를 생성합니다.
das-operator네임스페이스를 정의하는 다음NamespaceCR(사용자 정의 리소스)을 생성하고 YAML을das-namespace.yaml파일에 저장합니다.apiVersion: v1 kind: Namespace metadata: name: das-operator labels: name: das-operator openshift.io/cluster-monitoring: "true"다음 명령을 실행하여 네임스페이스를 생성합니다.
$ oc create -f das-namespace.yaml
다음 오브젝트를 생성하여 이전 단계에서 생성한 네임스페이스에 DAS Operator를 설치합니다.
다음
OperatorGroupCR을 생성하고 YAML을das-operatorgroup.yaml파일에 저장합니다.apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: generateName: das-operator- name: das-operator namespace: das-operator다음 명령을 실행하여
OperatorGroupCR을 생성합니다.$ oc create -f das-operatorgroup.yaml다음
SubscriptionCR을 생성하고 YAML을das-sub.yaml파일에 저장합니다.서브스크립션의 예
apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: das-operator namespace: das-operator spec: channel: "stable" installPlanApproval: Automatic name: das-operator source: redhat-operators sourceNamespace: openshift-marketplace다음 명령을 실행하여 서브스크립션 오브젝트를 생성합니다.
$ oc create -f das-sub.yamldas-operator프로젝트로 변경합니다.$ oc project das-operator다음
DASOperatorCR을 생성하고 YAML을das-dasoperator.yaml파일에 저장합니다.DASOperatorCR의 예apiVersion: inference.redhat.com/v1alpha1 kind: DASOperator metadata: name: cluster1 namespace: das-operator spec: managementState: Managed logLevel: Normal operatorLogLevel: Normal- 1
DASOperatorCR의 이름은cluster여야 합니다.
다음 명령을 실행하여
dasoperatorCR을 생성합니다.oc create -f das-dasoperator.yaml
검증
다음 명령을 실행하여 Operator 배포가 성공했는지 확인합니다.
$ oc get pods출력 예
NAME READY STATUS RESTARTS AGE das-daemonset-6rsfd 1/1 Running 0 5m16s das-daemonset-8qzgf 1/1 Running 0 5m16s das-operator-5946478b47-cjfcp 1/1 Running 0 5m18s das-operator-5946478b47-npwmn 1/1 Running 0 5m18s das-operator-webhook-59949d4f85-5n9qt 1/1 Running 0 68s das-operator-webhook-59949d4f85-nbtdl 1/1 Running 0 68s das-scheduler-6cc59dbf96-4r85f 1/1 Running 0 68s das-scheduler-6cc59dbf96-bf6ml 1/1 Running 0 68s배포에 성공하면
Running상태의 모든 포드가 표시됩니다. 배포에는 다음이 포함됩니다.- das-operator
- 기본 Operator 컨트롤러 Pod
- das-operator-webhook
- Pod 요청 변경을 위한 Webhook 서버 Pod
- das-scheduler
- MIG 슬라이스 할당을 위한 스케줄러 플러그인 Pod
- das-daemonset
MIG 호환 GPU가 있는 노드에서만 실행되는 DaemonSet Pod
참고das-daemonsetPod는>-<G 호환 GPU 하드웨어가 있는 노드에만 표시됩니다. daemonset Pod가 표시되지 않는 경우 클러스터에 지원되는 GPU 하드웨어가 있고 NVIDIA GPU Operator가 올바르게 구성되었는지 확인합니다.
6.2. Dynamic Accelerator Slicer Operator 설치 제거
Operator 설치 방법에 따라 다음 절차 중 하나를 사용하여 DAS(Dynamic Accelerator Slicer) Operator를 제거합니다.
6.2.1. 웹 콘솔을 사용하여 Dynamic Accelerator Slicer Operator 설치 제거
OpenShift Container Platform 웹 콘솔을 사용하여 DAS(Dynamic Accelerator Slicer) Operator를 설치 제거할 수 있습니다.
사전 요구 사항
-
cluster-admin권한이 있는 계정을 사용하여 OpenShift Container Platform 클러스터에 액세스할 수 있습니다. - DAS Operator가 클러스터에 설치되어 있습니다.
프로세스
- OpenShift Container Platform 웹 콘솔에서 Ecosystem → Installed Operators 로 이동합니다.
- 설치된 Operator 목록에서 Dynamic Accelerator Slicer 를 찾습니다.
-
DAS Operator의 옵션 메뉴
 를 클릭하고 Operator 설치 제거를 선택합니다.
를 클릭하고 Operator 설치 제거를 선택합니다.
- 확인 대화 상자에서 설치 제거를 클릭하여 제거를 확인합니다.
- 홈 → 프로젝트로 이동합니다.
- 검색 상자에서 das-operator 를 검색하여 DAS Operator 프로젝트를 찾습니다.
-
das-operator 프로젝트 옆에 있는 옵션 메뉴
를 클릭하고 프로젝트 삭제 를 선택합니다.
-
확인 대화 상자에서 대화 상자에
das-operator를 입력하고 삭제를 클릭하여 삭제 를 확인합니다.
검증
- 에코시스템 → 설치된 Operator 페이지로 이동합니다.
- DAS(Dynamic Accelerator Slicer) Operator가 더 이상 나열되지 않는지 확인합니다.
선택 사항입니다. 다음 명령을 실행하여
das-operator네임스페이스 및 해당 리소스가 제거되었는지 확인합니다.$ oc get namespace das-operator명령에서 네임스페이스를 찾을 수 없음을 나타내는 오류를 반환해야 합니다.
DAS Operator를 설치 제거해도 모든 GPU 슬라이스 할당이 제거되고 GPU 슬라이스에 의존하는 실행 중인 워크로드가 실패할 수 있습니다. 제거를 진행하기 전에 중요한 워크로드가 GPU 슬라이스를 사용하지 않는지 확인합니다.
6.2.2. CLI를 사용하여 Dynamic Accelerator Slicer Operator 설치 제거
OpenShift CLI를 사용하여 DAS(Dynamic Accelerator Slicer) Operator를 설치 제거할 수 있습니다.
사전 요구 사항
-
cluster-admin권한이 있는 계정을 사용하여 OpenShift Container Platform 클러스터에 액세스할 수 있습니다. -
OpenShift CLI(
oc)가 설치되어 있습니다. - DAS Operator가 클러스터에 설치되어 있습니다.
프로세스
다음 명령을 실행하여 설치된 Operator를 나열하여 DAS Operator 서브스크립션을 찾습니다.
$ oc get subscriptions -n das-operator출력 예
NAME PACKAGE SOURCE CHANNEL das-operator das-operator redhat-operators stable다음 명령을 실행하여 서브스크립션을 삭제합니다.
$ oc delete subscription das-operator -n das-operator다음 명령을 실행하여 CSV(클러스터 서비스 버전)를 나열하고 삭제합니다.
$ oc get csv -n das-operator$ oc delete csv <csv-name> -n das-operator다음 명령을 실행하여 operator 그룹을 제거합니다.
$ oc delete operatorgroup das-operator -n das-operator다음 명령을 실행하여 나머지
할당 클레임리소스를 삭제합니다.$ oc delete allocationclaims --all -n das-operator다음 명령을 실행하여 DAS Operator 네임스페이스를 제거합니다.
$ oc delete namespace das-operator
검증
다음 명령을 실행하여 DAS Operator 리소스가 제거되었는지 확인합니다.
$ oc get namespace das-operator명령에서 네임스페이스를 찾을 수 없음을 나타내는 오류를 반환해야 합니다.
다음 명령을 실행하여
할당 클레임사용자 정의 리소스 정의가 남아 있지 않은지 확인합니다.$ oc get crd | grep allocationclaim명령은 사용자 정의 리소스 정의를 찾을 수 없음을 나타내는 오류를 반환해야 합니다.
DAS Operator를 설치 제거해도 모든 GPU 슬라이스 할당이 제거되고 GPU 슬라이스에 의존하는 실행 중인 워크로드가 실패할 수 있습니다. 제거를 진행하기 전에 중요한 워크로드가 GPU 슬라이스를 사용하지 않는지 확인합니다.
6.3. Dynamic Accelerator Slicer Operator를 사용하여 GPU 워크로드 배포
DAS(Dynamic Accelerator Slicer) Operator에서 관리하는 GPU 슬라이스를 요청하는 워크로드를 배포할 수 있습니다. Operator는 GPU 액셀러레이터를 동적으로 분할하고 사용 가능한 GPU 슬라이스로 워크로드를 예약합니다.
사전 요구 사항
- 클러스터에서 사용할 수 있는MIG 지원 GPU 하드웨어가 있습니다.
-
NVIDIA GPU Operator가 설치되고
ClusterPolicy에 Ready 상태가 표시됩니다. - DAS Operator가 설치되어 있습니다.
프로세스
다음 명령을 실행하여 네임스페이스를 생성합니다.
oc new-project cuda-workloadsNVIDIA>-<G 리소스를 사용하여 GPU 리소스를 요청하는 배포를 생성합니다.
apiVersion: apps/v1 kind: Deployment metadata: name: cuda-vectoradd spec: replicas: 2 selector: matchLabels: app: cuda-vectoradd template: metadata: labels: app: cuda-vectoradd spec: restartPolicy: Always containers: - name: cuda-vectoradd image: nvcr.io/nvidia/k8s/cuda-sample:vectoradd-cuda12.5.0-ubi8 resources: limits: nvidia.com/mig-1g.5gb: "1" command: - sh - -c - | env && /cuda-samples/vectorAdd && sleep 3600다음 명령을 실행하여 배포 구성을 적용합니다.
$ oc apply -f cuda-vectoradd-deployment.yaml다음 명령을 실행하여 배포가 생성되고 Pod가 예약되었는지 확인합니다.
$ oc get deployment cuda-vectoradd출력 예
NAME READY UP-TO-DATE AVAILABLE AGE cuda-vectoradd 2/2 2 2 2m다음 명령을 실행하여 Pod의 상태를 확인합니다.
$ oc get pods -l app=cuda-vectoradd출력 예
NAME READY STATUS RESTARTS AGE cuda-vectoradd-6b8c7d4f9b-abc12 1/1 Running 0 2m cuda-vectoradd-6b8c7d4f9b-def34 1/1 Running 0 2m
검증
다음 명령을 실행하여
할당 클레임리소스가 배포 Pod에 대해 생성되었는지 확인합니다.$ oc get allocationclaims -n das-operator출력 예
NAME AGE 13950288-57df-4ab5-82bc-6138f646633e-harpatil000034jma-qh5fm-worker-f-57md9-cuda-vectoradd-0 2m ce997b60-a0b8-4ea4-9107-cf59b425d049-harpatil000034jma-qh5fm-worker-f-fl4wg-cuda-vectoradd-0 2m다음 명령을 실행하여 Pod의 리소스 할당 중 하나를 확인하여 GPU 슬라이스가 올바르게 할당되었는지 확인합니다.
$ oc describe pod -l app=cuda-vectoradd다음 명령을 실행하여 로그를 확인하여 CUDA 샘플 애플리케이션이 성공적으로 실행되는지 확인합니다.
$ oc logs -l app=cuda-vectoradd출력 예
[Vector addition of 50000 elements] Copy input data from the host memory to the CUDA device CUDA kernel launch with 196 blocks of 256 threads Copy output data from the CUDA device to the host memory Test PASSED환경 변수를 확인하여 다음 명령을 실행하여 GPU 장치가 컨테이너에 올바르게 노출되었는지 확인합니다.
$ oc exec deployment/cuda-vectoradd -- env | grep -E "(NVIDIA_VISIBLE_DEVICES|CUDA_VISIBLE_DEVICES)"출력 예
NVIDIA_VISIBLE_DEVICES=MIG-d8ac9850-d92d-5474-b238-0afeabac1652 CUDA_VISIBLE_DEVICES=MIG-d8ac9850-d92d-5474-b238-0afeabac1652이러한 환경 변수는 GPUMIG 슬라이스가 올바르게 할당되었으며 컨테이너 내의 CUDA 런타임에 표시되는 것을 나타냅니다.
6.4. Dynamic Accelerator Slicer Operator 문제 해결
DAS(Dynamic Accelerator Slicer) Operator에 문제가 있는 경우 다음 문제 해결 단계를 사용하여 문제를 진단하고 해결합니다.
사전 요구 사항
- DAS Operator가 설치되어 있습니다.
- cluster-admin 역할의 사용자로 OpenShift Container Platform 클러스터에 액세스할 수 있습니다.
6.4.1. DAS Operator 구성 요소 디버깅
프로세스
다음 명령을 실행하여 모든 DAS Operator 구성 요소의 상태를 확인합니다.
$ oc get pods -n das-operator출력 예
NAME READY STATUS RESTARTS AGE das-daemonset-6rsfd 1/1 Running 0 5m16s das-daemonset-8qzgf 1/1 Running 0 5m16s das-operator-5946478b47-cjfcp 1/1 Running 0 5m18s das-operator-5946478b47-npwmn 1/1 Running 0 5m18s das-operator-webhook-59949d4f85-5n9qt 1/1 Running 0 68s das-operator-webhook-59949d4f85-nbtdl 1/1 Running 0 68s das-scheduler-6cc59dbf96-4r85f 1/1 Running 0 68s das-scheduler-6cc59dbf96-bf6ml 1/1 Running 0 68s다음 명령을 실행하여 DAS Operator 컨트롤러의 로그를 검사합니다.
$ oc logs -n das-operator deployment/das-operator다음 명령을 실행하여 웹 후크 서버의 로그를 확인합니다.
$ oc logs -n das-operator deployment/das-operator-webhook다음 명령을 실행하여 스케줄러 플러그인의 로그를 확인합니다.
$ oc logs -n das-operator deployment/das-scheduler다음 명령을 실행하여 장치 플러그인 데몬 세트의 로그를 확인합니다.
$ oc logs -n das-operator daemonset/das-daemonset
6.4.2. 모니터링 할당 클레임
프로세스
다음 명령을 실행하여 활성
할당 클레임리소스를 검사합니다.$ oc get allocationclaims -n das-operator출력 예
NAME AGE 13950288-57df-4ab5-82bc-6138f646633e-harpatil000034jma-qh5fm-worker-f-57md9-cuda-vectoradd-0 5m ce997b60-a0b8-4ea4-9107-cf59b425d049-harpatil000034jma-qh5fm-worker-f-fl4wg-cuda-vectoradd-0 5m다음 명령을 실행하여 특정
할당 클레임에대한 자세한 정보를 확인합니다.$ oc get allocationclaims -n das-operator -o yaml출력 예(truncated)
apiVersion: inference.redhat.com/v1alpha1 kind: AllocationClaim metadata: name: 13950288-57df-4ab5-82bc-6138f646633e-harpatil000034jma-qh5fm-worker-f-57md9-cuda-vectoradd-0 namespace: das-operator spec: gpuUUID: GPU-9003fd9c-1ad1-c935-d8cd-d1ae69ef17c0 migPlacement: size: 1 start: 0 nodename: harpatil000034jma-qh5fm-worker-f-57md9 podRef: kind: Pod name: cuda-vectoradd-f4b84b678-l2m69 namespace: default uid: 13950288-57df-4ab5-82bc-6138f646633e profile: 1g.5gb status: conditions: - lastTransitionTime: "2025-08-06T19:28:48Z" message: Allocation is inUse reason: inUse status: "True" type: State state: inUse다음 명령을 실행하여 다른 상태의 클레임을 확인합니다.
$ oc get allocationclaims -n das-operator -o jsonpath='{range .items[*]}{.metadata.name}{"\t"}{.status.state}{"\n"}{end}'출력 예
13950288-57df-4ab5-82bc-6138f646633e-harpatil000034jma-qh5fm-worker-f-57md9-cuda-vectoradd-0 inUse ce997b60-a0b8-4ea4-9107-cf59b425d049-harpatil000034jma-qh5fm-worker-f-fl4wg-cuda-vectoradd-0 inUse다음 명령을 실행하여
할당 클레임리소스와 관련된 이벤트를 확인합니다.$ oc get events -n das-operator --field-selector involvedObject.kind=AllocationClaim다음 명령을 실행하여
NodeAccelerator리소스를 확인하여 GPU 하드웨어 탐지를 확인합니다.$ oc get nodeaccelerator -n das-operator출력 예
NAME AGE harpatil000034jma-qh5fm-worker-f-57md9 96m harpatil000034jma-qh5fm-worker-f-fl4wg 96mNodeAccelerator리소스는 DAS Operator에서 탐지한 GPU 가능 노드를 나타냅니다.
추가 정보
할당 클레임 사용자 정의 리소스는 다음 정보를 추적합니다.
- GPU UUID
- GPU 장치의 고유 식별자입니다.
- 슬라이스 위치
- GPU에 있는MIG 슬라이스의 위치입니다.
- Pod 참조
- GPU 슬라이스를 요청한 Pod입니다.
- 상태
-
클레임의 현재 상태(
staged,created또는released)입니다.
클레임은 스테이징된 상태에서 시작하고 모든 요청이 충족되면 생성되는 전환입니다. Pod가 삭제되면 연결된 클레임이 자동으로 정리됩니다.
6.4.3. GPU 장치 가용성 확인
프로세스
GPU 하드웨어가 있는 노드에서 다음 명령을 실행하여 CDI 장치가 생성되었는지 확인합니다.
$ oc debug node/<node-name>sh-4.4# chroot /host sh-4.4# ls -l /var/run/cdi/다음 명령을 실행하여 NVIDIA GPU Operator 상태를 확인합니다.
$ oc get clusterpolicies.nvidia.com -o jsonpath='{.items[0].status.state}'출력에
ready이 표시되어야 합니다.
6.4.4. 로그 상세 정보 표시 증가
프로세스
더 자세한 디버깅 정보를 얻으려면 다음을 수행합니다.
다음 명령을 실행하여 로그 세부 정보 표시를 늘리도록
DASOperator리소스를 편집합니다.$ oc edit dasoperator -n das-operatoroperatorLogLevel필드를Debug또는Trace로 설정합니다.spec: operatorLogLevel: Debug- 변경 사항을 저장하고 Operator Pod가 증가한 상세 정보 표시로 다시 시작되는지 확인합니다.
6.4.5. 일반적인 문제 및 솔루션
kubernetes/kubernetes#128043 으로 인해 승인에 실패하는 경우 Pod가 UnexpectedAdmissionError 상태가 될 수 있습니다. 배포와 같은 상위 수준의 컨트롤러에서 관리하는 Pod는 자동으로 다시 생성됩니다. 그러나 가져온 Pod는 oc delete pod 를 사용하여 수동으로 정리해야 합니다. 업스트림 문제가 해결될 때까지 컨트롤러를 사용하는 것이 좋습니다.
사전 요구 사항이 충족되지 않음
DAS Operator가 제대로 시작하거나 제대로 작동하지 않는 경우 모든 사전 요구 사항이 설치되었는지 확인합니다.
- cert-manager
- NFD(Node Feature Discovery) Operator
- NVIDIA GPU Operator
Legal Notice
Copyright © Red Hat
OpenShift documentation is licensed under the Apache License 2.0 (https://www.apache.org/licenses/LICENSE-2.0).
Modified versions must remove all Red Hat trademarks.
Portions adapted from https://github.com/kubernetes-incubator/service-catalog/ with modifications by Red Hat.
Red Hat, Red Hat Enterprise Linux, the Red Hat logo, the Shadowman logo, JBoss, OpenShift, Fedora, the Infinity logo, and RHCE are trademarks of Red Hat, Inc., registered in the United States and other countries.
Linux® is the registered trademark of Linus Torvalds in the United States and other countries.
Java® is a registered trademark of Oracle and/or its affiliates.
XFS® is a trademark of Silicon Graphics International Corp. or its subsidiaries in the United States and/or other countries.
MySQL® is a registered trademark of MySQL AB in the United States, the European Union and other countries.
Node.js® is an official trademark of the OpenJS Foundation.
The OpenStack® Word Mark and OpenStack logo are either registered trademarks/service marks or trademarks/service marks of the OpenStack Foundation, in the United States and other countries and are used with the OpenStack Foundation’s permission. We are not affiliated with, endorsed or sponsored by the OpenStack Foundation, or the OpenStack community.
All other trademarks are the property of their respective owners.