1장. 가시성 서비스 도입
Observability 서비스를 활성화하면 Red Hat Advanced Cluster Management for Kubernetes를 사용하여 관리 클러스터에 대한 인사이트를 확보하고 최적화할 수 있습니다. 이 정보는 비용을 절약하고 불필요한 이벤트를 예방할 수 있습니다.
1.1. 환경 관찰
Kubernetes용 Red Hat Advanced Cluster Management를 사용하면 인사이트를 확보하고 관리 클러스터를 최적화할 수 있습니다. hub 클러스터에서 Observability 서비스 Operator인 multicluster-observability-operator 를 활성화하여 관리형 클러스터의 상태를 모니터링합니다. 다음 섹션에서 멀티 클러스터 관찰 기능 서비스의 아키텍처에 대해 알아보십시오.
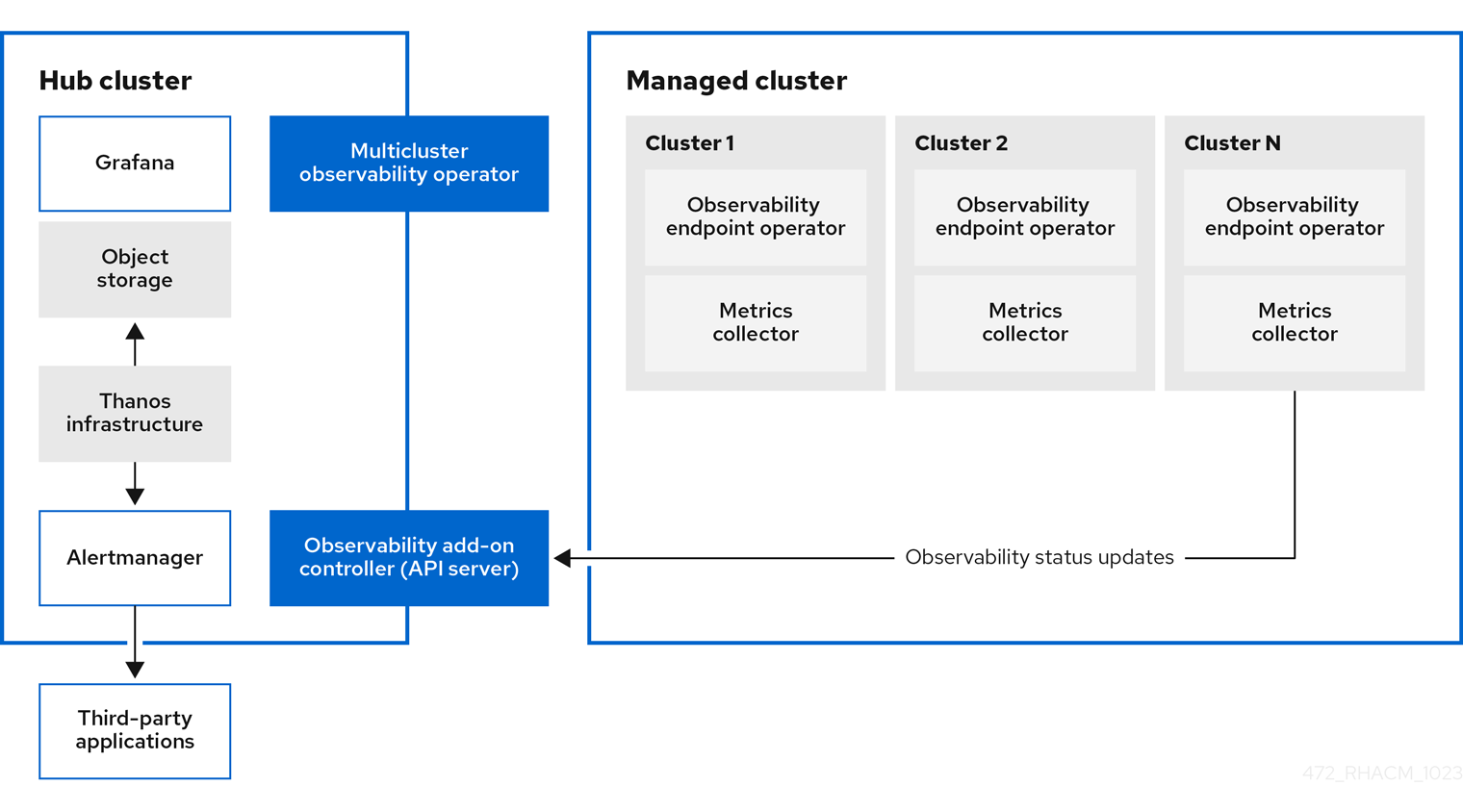
1.1.1. 가시성 서비스
기본적으로 관찰 기능은 제품 설치에 포함되어 있지만 활성화되지는 않습니다. 영구 스토리지의 요구 사항으로 인해 관찰 가능 서비스는 기본적으로 활성화되어 있지 않습니다. 관찰 기능은 지원 섹션을 참조하십시오.
서비스가 활성화되면 observability-endpoint-operator 가 가져온 클러스터 또는 생성된 각 클러스터에 자동으로 배포됩니다. 이 컨트롤러는 Red Hat OpenShift Container Platform Prometheus에서 데이터를 수집한 다음 Red Hat Advanced Cluster Management hub 클러스터로 전송합니다. hub 클러스터가 로컬 클러스터로 가져오는 경우 관찰 기능도 활성화되고 허브 클러스터에서 메트릭이 수집됩니다.
관찰 서비스에서는 Prometheus Alertmanager 인스턴스를 배포하여 타사 애플리케이션과 경고를 전달할 수 있습니다. 대시보드(정적) 또는 데이터 탐색을 통해 데이터 시각화를 활성화하는 Grafana 인스턴스도 포함되어 있습니다. Red Hat Advanced Cluster Management는 Grafana의 8.5.20 버전을 지원합니다. Grafana 대시보드를 설계할 수도 있습니다. 자세한 내용은 Grafana 대시보드 설계를 참조하십시오. 사용자 정의 레코딩 규칙 또는 경고 규칙을 생성하여 관찰 기능을 사용자 지정할 수 있습니다.
1.1.2. 지원
- Red Hat Advanced Cluster Management는 Red Hat OpenShift Data Foundation (이전 Red Hat OpenShift Container Storage)에서 테스트 및 완벽하게 지원됩니다.
- Red Hat Advanced Cluster Management는 S3 API 호환 사용자 제공 타사 오브젝트 스토리지에서 멀티 클러스터 관찰 기능 Operator의 기능을 지원합니다. Observability 서비스는 Thanos 지원되고 안정적인 오브젝트 저장소를 사용합니다.
- Red Hat Advanced Cluster Management는 근본적인 원인을 파악하는 데 도움이 되도록 상업적으로 합리적인 노력을 기울입니다. 지원 티켓이 발생하고 근본적인 원인이 고객 제공 S3 호환 오브젝트 스토리지의 결과인 경우 고객 지원 채널을 사용하여 문제를 해결해야 합니다.
- Red Hat Advanced Cluster Management는 고객이 발행한 지원 티켓을 해결하기 위해 최선을 다하고 있습니다. 여기서 확인된 근본 원인은 S3 호환 오브젝트 스토리지 공급자입니다.
1.1.3. 메트릭 유형
기본적으로 OpenShift Container Platform은 Telemetry 서비스를 사용하여 Red Hat에 지표를 보냅니다. acm_managed_cluster_info 는 Red Hat Advanced Cluster Management에서 사용할 수 있으며 Telemetry에 포함되어 있지만 Red Hat Advanced Cluster Management Observe 환경 개요 대시보드에는 표시되지 않습니다.
프레임워크에서 지원하는 메트릭 유형의 다음 표를 확인합니다.
| 메트릭 이름 | 메트릭 유형 | labels/tags | 상태 |
|---|---|---|---|
|
| 게이지 |
| stable |
|
| 히스토그램 | 없음 | stable. 자세한 내용은 Governance 메트릭 을 참조하십시오. |
|
| 히스토그램 | 없음 | stable. 자세한 내용은 관리 메트릭 을 참조하십시오. |
|
| 히스토그램 | 없음 | stable. 자세한 내용은 Governance 메트릭 을 참조하십시오. |
|
| 게이지 |
| stable. 자세한 내용은 Governance 메트릭 을 검토하십시오. |
|
| 게이지 |
| stable. 자세한 내용은 분석 관리 _PolicyReports_ 를 참조하십시오. |
|
| 카운터 | 없음 | stable. 콘솔 소개 설명서의 Search components 섹션을 참조하십시오. |
|
| 히스토그램 | 없음 | stable. 콘솔 소개 설명서의 Search components 섹션을 참조하십시오. |
|
| 히스토그램 | 없음 | stable. 콘솔 소개 설명서의 Search components 섹션을 참조하십시오. |
|
| 카운터 | 없음 | stable. 콘솔 소개 설명서의 Search components 섹션을 참조하십시오. |
|
| 히스토그램 | 없음 | stable. 콘솔 소개 설명서의 Search components 섹션을 참조하십시오. |
|
| 게이지 | 없음 | stable. 콘솔 소개 설명서의 Search components 섹션을 참조하십시오. |
|
| 히스토그램 | 없음 | stable. 콘솔 소개 설명서의 Search components 섹션을 참조하십시오. |
1.1.4. 관찰 가능 Pod 용량 요청
관찰 구성 요소에는 관찰 서비스를 설치하기 위해 10.0.0.11mCPU 및 11972Mi 메모리가 필요합니다. 다음 표는 observability-addons 가 활성화된 관리 클러스터 5개에 대한 Pod 용량 요청 목록입니다.
| 배포 또는 StatefulSet | 컨테이너 이름 | CPU(mCPU) | 메모리(Mi) | replicas | Pod 총 CPU | Pod 총 메모리 |
|---|---|---|---|---|---|---|
| observability-alertmanager | alertmanager | 4 | 200 | 3 | 12 | 600 |
| config-reloader | 4 | 25 | 3 | 12 | 75 | |
| alertmanager-proxy | 1 | 20 | 3 | 3 | 60 | |
| observability-grafana | grafana | 4 | 100 | 2 | 8 | 200 |
| grafana-dashboard-loader | 4 | 50 | 2 | 8 | 100 | |
| observability-observatorium-api | observatorium-api | 20 | 128 | 2 | 40 | 256 |
| observability-observatorium-operator | observatorium-operator | 100 | 100 | 1 | 10 | 50 |
| observability-rbac-query-proxy | rbac-query-proxy | 20 | 100 | 2 | 40 | 200 |
| oauth-proxy | 1 | 20 | 2 | 2 | 40 | |
| observability-thanos-compact | thanos-compact | 100 | 512 | 1 | 100 | 512 |
| observability-thanos-query | Thanos-query | 300 | 1024 | 2 | 600 | 2048 |
| observability-thanos-query-frontend | Thanos-query-frontend | 100 | 256 | 2 | 200 | 512 |
| observability-thanos-query-frontend-memcached | Memcached | 45 | 128 | 3 | 135 | 384 |
| Exporter | 5 | 50 | 3 | 15 | 150 | |
| observability-thanos-receive-controller | thanos-receive-controller | 4 | 32 | 1 | 4 | 32 |
| observability-thanos-receive-default | Thanos-receive | 300 | 512 | 3 | 900 | 1536 |
| observability-thanos-rule | Thanos-rule | 50 | 512 | 3 | 150 | 1536 |
| configmap-reloader | 4 | 25 | 3 | 12 | 75 | |
| observability-thanos-store-memcached | Memcached | 45 | 128 | 3 | 135 | 384 |
| Exporter | 5 | 50 | 3 | 15 | 150 | |
| observability-thanos-store-shard | Thanos-store | 100 | 1024 | 3 | 300 | 3072 |
1.1.5. 관찰 서비스에 사용되는 영구 저장소
중요: 영구 스토리지에 로컬 볼륨을 사용하는 로컬 스토리지 Operator 또는 스토리지 클래스를 사용하지 마십시오. 재시작 후 Pod가 다른 노드에서 다시 시작되면 데이터가 손실될 수 있습니다. 이 경우 Pod는 더 이상 노드의 로컬 스토리지에 액세스할 수 없습니다. 데이터 손실을 방지하기 위해 수신 및 규칙 포드의 영구 볼륨에 액세스할 수 있는지 확인합니다.
Red Hat Advanced Cluster Management를 설치할 때 PVC(영구 볼륨 클레임)를 자동으로 연결할 수 있도록 다음과 같은 PV(영구 볼륨)를 생성해야 합니다. 기본 스토리지 클래스가 지정되지 않았거나 기본이 아닌 스토리지 클래스를 사용하여 PV를 호스팅하려는 경우 MultiClusterObservability 사용자 정의 리소스에 스토리지 클래스를 정의해야 합니다. Prometheus에서 사용하는 것과 유사하게 Block Storage를 사용하는 것이 좋습니다. 또한 alertmanager,thanos-compactor,thanos-ruler,thanos-receive-default 및 thanos-store-shard 의 각 복제본에는 자체 PV가 있어야 합니다. 다음 표를 확인하십시오.
| 영구 볼륨 이름 | 목적 |
| alertmanager |
Alertmanager는 |
| thanos-compact | compactor에는 처리를 위해 중간 데이터와 버킷 상태 캐시를 위해 로컬 디스크 공간이 필요합니다. 필요한 공간은 기본 블록의 크기에 따라 다릅니다. 콤팩터는 모든 소스 블록을 다운로드할 수 있는 충분한 공간이 있어야 하며 압축 해제된 블록을 디스크에 빌드해야 합니다. 디스크상의 데이터는 재시작 시 안전하게 삭제되며 크래시 루프 압축기를 사용하지 않는 첫 번째 시도여야 합니다. 그러나 재시작 사이에 버킷 상태 캐시를 효과적으로 사용하려면 compactor 영구 디스크를 제공하는 것이 좋습니다. |
| Thanos-rule |
thanos ruler는 고정된 간격으로 쿼리를 실행하여 선택한 쿼리 API에 대해 Prometheus 기록 및 경고 규칙을 평가합니다. 규칙 결과는 Prometheus 2.0 스토리지 형식의 디스크에 다시 작성됩니다. 이 상태 저장 세트에 남아 있는 데이터의 시간 또는 일 또는 일 양은 API 버전 |
| thanos-receive-default |
Thanos 수신자는 수신 데이터(프로세스 원격 쓰기 요청)를 수락하고 Prometheus TSDB의 로컬 인스턴스에 씁니다. 주기적으로 (모든 2 시간), TSDB 블록은 장기 저장 및 압축을 위해 오브젝트 스토리지에 업로드됩니다. 이 상태 저장 세트에 유지되는 데이터의 양 또는 일(로컬 캐시 역할)은 API Version |
| thanos-store-shard | 이 게이트웨이는 주로 API 게이트웨이 역할을 하므로 상당한 양의 로컬 디스크 공간이 필요하지 않습니다. 시작 시 Thanos 클러스터에 참여하여 액세스할 수 있는 데이터를 알립니다. 로컬 디스크의 모든 원격 블록에 대한 소량의 정보를 유지하고 버킷과 동기화됩니다. 이 데이터는 일반적으로 시작 시간이 증가함에 따라 재시작 시 삭제되는 것이 안전합니다. |
참고: 시계열 기록 데이터는 오브젝트 저장소에 저장됩니다. Thanos는 오브젝트 스토리지를 지표 및 관련 메타데이터의 기본 스토리지로 사용합니다. 오브젝트 스토리지 및 다운샘플링에 대한 자세한 내용은 관찰 서비스 활성화를 참조하십시오.
1.1.6. 추가 리소스
- 관찰 기능 활성화에 대한 자세한 내용은 Enabling observability service 를 참조하십시오.
- 관찰 서비스, 가시성 서비스, 메트릭 및 기타 데이터를 구성하는 방법을 알아보려면 관찰 기능을 사용자 정의할 수 있습니다.
- Grafana 대시보드를 사용하여 읽기 .
- OpenShift Container Platform 설명서에서 Telemetry를 사용하여 수집 및 전송되는 메트릭 유형을 확인합니다. 자세한 내용은 Telemetry에서 수집한 정보를 참조하십시오.
- 자세한 내용은 관리 메트릭 을 참조하십시오.
- Insights PolicyReports를 참조하십시오.
- Prometheus 레코딩 규칙 을 참조하십시오.
- Prometheus 경고 규칙도 참조하십시오.
- 콘솔 소개에서 검색으로 돌아갑니다.