이 콘텐츠는 선택한 언어로 제공되지 않습니다.
Chapter 4. Operators
4.1. Cluster Operator
Use the Cluster Operator to deploy a Kafka cluster and other Kafka components.
The Cluster Operator is deployed using YAML installation files. For information on deploying the Cluster Operator, see the Deploying the Cluster Operator.
For information on the deployment options available for Kafka, see Kafka Cluster configuration.
On OpenShift, a Kafka Connect deployment can incorporate a Source2Image feature to provide a convenient way to add additional connectors.
4.1.1. Cluster Operator
AMQ Streams uses the Cluster Operator to deploy and manage clusters for:
- Kafka (including ZooKeeper, Entity Operator, Kafka Exporter, and Cruise Control)
- Kafka Connect
- Kafka MirrorMaker
- Kafka Bridge
Custom resources are used to deploy the clusters.
For example, to deploy a Kafka cluster:
-
A
Kafkaresource with the cluster configuration is created within the OpenShift cluster. -
The Cluster Operator deploys a corresponding Kafka cluster, based on what is declared in the
Kafkaresource.
The Cluster Operator can also deploy (through configuration of the Kafka resource):
-
A Topic Operator to provide operator-style topic management through
KafkaTopiccustom resources -
A User Operator to provide operator-style user management through
KafkaUsercustom resources
The Topic Operator and User Operator function within the Entity Operator on deployment.
Example architecture for the Cluster Operator
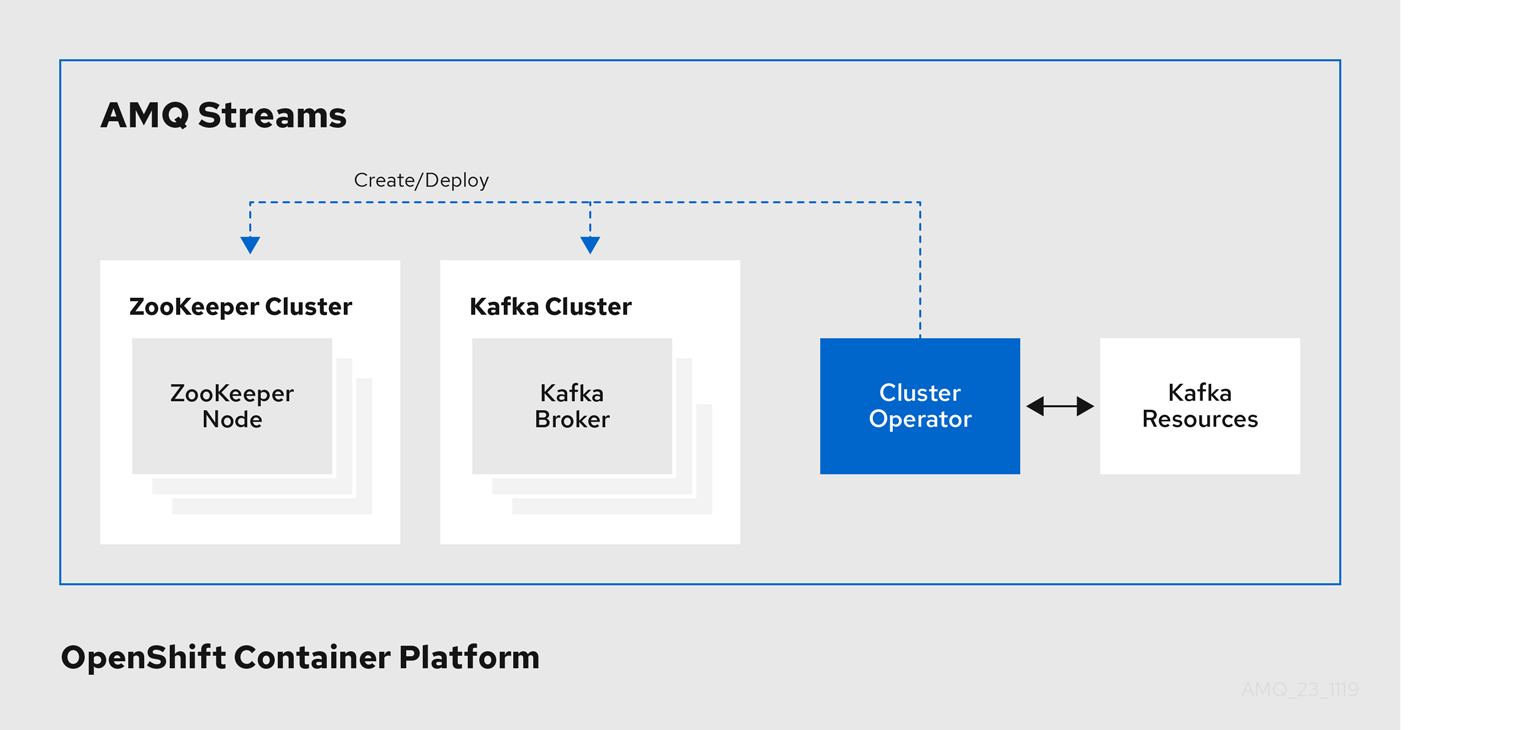
4.1.2. Reconciliation
Although the operator reacts to all notifications about the desired cluster resources received from the OpenShift cluster, if the operator is not running, or if a notification is not received for any reason, the desired resources will get out of sync with the state of the running OpenShift cluster.
In order to handle failovers properly, a periodic reconciliation process is executed by the Cluster Operator so that it can compare the state of the desired resources with the current cluster deployments in order to have a consistent state across all of them. You can set the time interval for the periodic reconciliations using the [STRIMZI_FULL_RECONCILIATION_INTERVAL_MS] variable.
4.1.3. Cluster Operator Configuration
The Cluster Operator can be configured through the following supported environment variables:
STRIMZI_NAMESPACEA comma-separated list of namespaces that the operator should operate in. When not set, set to empty string, or to
*the Cluster Operator will operate in all namespaces. The Cluster Operator deployment might use the OpenShift Downward API to set this automatically to the namespace the Cluster Operator is deployed in. See the example below:env: - name: STRIMZI_NAMESPACE valueFrom: fieldRef: fieldPath: metadata.namespaceenv: - name: STRIMZI_NAMESPACE valueFrom: fieldRef: fieldPath: metadata.namespaceCopy to Clipboard Copied! Toggle word wrap Toggle overflow -
STRIMZI_FULL_RECONCILIATION_INTERVAL_MS - Optional, default is 120000 ms. The interval between periodic reconciliations, in milliseconds.
STRIMZI_LOG_LEVEL-
Optional, default
INFO. The level for printing logging messages. The value can be set to:ERROR,WARNING,INFO,DEBUG, andTRACE. STRIMZI_OPERATION_TIMEOUT_MS- Optional, default 300000 ms. The timeout for internal operations, in milliseconds. This value should be increased when using AMQ Streams on clusters where regular OpenShift operations take longer than usual (because of slow downloading of Docker images, for example).
STRIMZI_KAFKA_IMAGES-
Required. This provides a mapping from Kafka version to the corresponding Docker image containing a Kafka broker of that version. The required syntax is whitespace or comma separated
<version>=<image>pairs. For example2.4.1=registry.redhat.io/amq7/amq-streams-kafka-24-rhel7:1.5.0, 2.5.0=registry.redhat.io/amq7/amq-streams-kafka-25-rhel7:1.5.0. This is used when aKafka.spec.kafka.versionproperty is specified but not theKafka.spec.kafka.image, as described in Section 3.1.19, “Container images”. STRIMZI_DEFAULT_KAFKA_INIT_IMAGE-
Optional, default
registry.redhat.io/amq7/amq-streams-rhel7-operator:1.5.0. The image name to use as default for the init container started before the broker for initial configuration work (that is, rack support), if no image is specified as thekafka-init-imagein the Section 3.1.19, “Container images”. STRIMZI_DEFAULT_TLS_SIDECAR_KAFKA_IMAGE-
Optional, default
registry.redhat.io/amq7/amq-streams-kafka-25-rhel7:1.5.0. The image name to use as the default when deploying the sidecar container which provides TLS support for Kafka, if no image is specified as theKafka.spec.kafka.tlsSidecar.imagein the Section 3.1.19, “Container images”. STRIMZI_KAFKA_CONNECT_IMAGES-
Required. This provides a mapping from the Kafka version to the corresponding Docker image containing a Kafka connect of that version. The required syntax is whitespace or comma separated
<version>=<image>pairs. For example2.4.1=registry.redhat.io/amq7/amq-streams-kafka-24-rhel7:1.5.0, 2.5.0=registry.redhat.io/amq7/amq-streams-kafka-25-rhel7:1.5.0. This is used when aKafkaConnect.spec.versionproperty is specified but not theKafkaConnect.spec.image, as described in Section 3.2.12, “Container images”. STRIMZI_KAFKA_CONNECT_S2I_IMAGES-
Required. This provides a mapping from the Kafka version to the corresponding Docker image containing a Kafka connect of that version. The required syntax is whitespace or comma separated
<version>=<image>pairs. For example2.4.1=registry.redhat.io/amq7/amq-streams-kafka-24-rhel7:1.5.0, 2.5.0=registry.redhat.io/amq7/amq-streams-kafka-25-rhel7:1.5.0. This is used when aKafkaConnectS2I.spec.versionproperty is specified but not theKafkaConnectS2I.spec.image, as described in Section 3.3.12, “Container images”. STRIMZI_KAFKA_MIRROR_MAKER_IMAGES-
Required. This provides a mapping from the Kafka version to the corresponding Docker image containing a Kafka mirror maker of that version. The required syntax is whitespace or comma separated
<version>=<image>pairs. For example2.4.1=registry.redhat.io/amq7/amq-streams-kafka-24-rhel7:1.5.0, 2.5.0=registry.redhat.io/amq7/amq-streams-kafka-25-rhel7:1.5.0. This is used when aKafkaMirrorMaker.spec.versionproperty is specified but not theKafkaMirrorMaker.spec.image, as described in Section 3.4.2.14, “Container images”. STRIMZI_DEFAULT_TOPIC_OPERATOR_IMAGE-
Optional, default
registry.redhat.io/amq7/amq-streams-rhel7-operator:1.5.0. The image name to use as the default when deploying the topic operator, if no image is specified as theKafka.spec.entityOperator.topicOperator.imagein the Section 3.1.19, “Container images” of theKafkaresource. STRIMZI_DEFAULT_USER_OPERATOR_IMAGE-
Optional, default
registry.redhat.io/amq7/amq-streams-rhel7-operator:1.5.0. The image name to use as the default when deploying the user operator, if no image is specified as theKafka.spec.entityOperator.userOperator.imagein the Section 3.1.19, “Container images” of theKafkaresource. STRIMZI_DEFAULT_TLS_SIDECAR_ENTITY_OPERATOR_IMAGE-
Optional, default
registry.redhat.io/amq7/amq-streams-kafka-25-rhel7:1.5.0. The image name to use as the default when deploying the sidecar container which provides TLS support for the Entity Operator, if no image is specified as theKafka.spec.entityOperator.tlsSidecar.imagein the Section 3.1.19, “Container images”. STRIMZI_IMAGE_PULL_POLICY-
Optional. The
ImagePullPolicywhich will be applied to containers in all pods managed by AMQ Streams Cluster Operator. The valid values areAlways,IfNotPresent, andNever. If not specified, the OpenShift defaults will be used. Changing the policy will result in a rolling update of all your Kafka, Kafka Connect, and Kafka MirrorMaker clusters. STRIMZI_IMAGE_PULL_SECRETS-
Optional. A comma-separated list of
Secretnames. The secrets referenced here contain the credentials to the container registries where the container images are pulled from. The secrets are used in theimagePullSecretsfield for allPodscreated by the Cluster Operator. Changing this list results in a rolling update of all your Kafka, Kafka Connect, and Kafka MirrorMaker clusters. STRIMZI_KUBERNETES_VERSIONOptional. Overrides the OpenShift version information detected from the API server. See the example below:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow KUBERNETES_SERVICE_DNS_DOMAINOptional. Overrides the default OpenShift DNS domain name suffix.
By default, services assigned in the OpenShift cluster have a DNS domain name that uses the default suffix
cluster.local.For example, for broker kafka-0:
<cluster-name>-kafka-0.<cluster-name>-kafka-brokers.<namespace>.svc.cluster.local
<cluster-name>-kafka-0.<cluster-name>-kafka-brokers.<namespace>.svc.cluster.localCopy to Clipboard Copied! Toggle word wrap Toggle overflow The DNS domain name is added to the Kafka broker certificates used for hostname verification.
If you are using a different DNS domain name suffix in your cluster, change the
KUBERNETES_SERVICE_DNS_DOMAINenvironment variable from the default to the one you are using in order to establish a connection with the Kafka brokers.
4.1.4. Role-Based Access Control (RBAC)
4.1.4.1. Provisioning Role-Based Access Control (RBAC) for the Cluster Operator
For the Cluster Operator to function it needs permission within the OpenShift cluster to interact with resources such as Kafka, KafkaConnect, and so on, as well as the managed resources, such as ConfigMaps, Pods, Deployments, StatefulSets, Services, and so on. Such permission is described in terms of OpenShift role-based access control (RBAC) resources:
-
ServiceAccount, -
RoleandClusterRole, -
RoleBindingandClusterRoleBinding.
In addition to running under its own ServiceAccount with a ClusterRoleBinding, the Cluster Operator manages some RBAC resources for the components that need access to OpenShift resources.
OpenShift also includes privilege escalation protections that prevent components operating under one ServiceAccount from granting other ServiceAccounts privileges that the granting ServiceAccount does not have. Because the Cluster Operator must be able to create the ClusterRoleBindings, and RoleBindings needed by resources it manages, the Cluster Operator must also have those same privileges.
4.1.4.2. Delegated privileges
When the Cluster Operator deploys resources for a desired Kafka resource it also creates ServiceAccounts, RoleBindings, and ClusterRoleBindings, as follows:
The Kafka broker pods use a
ServiceAccountcalledcluster-name-kafka-
When the rack feature is used, the
strimzi-cluster-name-kafka-initClusterRoleBindingis used to grant thisServiceAccountaccess to the nodes within the cluster via aClusterRolecalledstrimzi-kafka-broker - When the rack feature is not used no binding is created
-
When the rack feature is used, the
-
The ZooKeeper pods use a
ServiceAccountcalledcluster-name-zookeeper The Entity Operator pod uses a
ServiceAccountcalledcluster-name-entity-operator-
The Topic Operator produces OpenShift events with status information, so the
ServiceAccountis bound to aClusterRolecalledstrimzi-entity-operatorwhich grants this access via thestrimzi-entity-operatorRoleBinding
-
The Topic Operator produces OpenShift events with status information, so the
-
The pods for
KafkaConnectandKafkaConnectS2Iresources use aServiceAccountcalledcluster-name-cluster-connect -
The pods for
KafkaMirrorMakeruse aServiceAccountcalledcluster-name-mirror-maker -
The pods for
KafkaBridgeuse aServiceAccountcalledcluster-name-bridge
4.1.4.3. ServiceAccount
The Cluster Operator is best run using a ServiceAccount:
Example ServiceAccount for the Cluster Operator
The Deployment of the operator then needs to specify this in its spec.template.spec.serviceAccountName:
Partial example of Deployment for the Cluster Operator
Note line 12, where the the strimzi-cluster-operator ServiceAccount is specified as the serviceAccountName.
4.1.4.4. ClusterRoles
The Cluster Operator needs to operate using ClusterRoles that gives access to the necessary resources. Depending on the OpenShift cluster setup, a cluster administrator might be needed to create the ClusterRoles.
Cluster administrator rights are only needed for the creation of the ClusterRoles. The Cluster Operator will not run under the cluster admin account.
The ClusterRoles follow the principle of least privilege and contain only those privileges needed by the Cluster Operator to operate Kafka, Kafka Connect, and ZooKeeper clusters. The first set of assigned privileges allow the Cluster Operator to manage OpenShift resources such as StatefulSets, Deployments, Pods, and ConfigMaps.
Cluster Operator uses ClusterRoles to grant permission at the namespace-scoped resources level and cluster-scoped resources level:
ClusterRole with namespaced resources for the Cluster Operator
The second includes the permissions needed for cluster-scoped resources.
ClusterRole with cluster-scoped resources for the Cluster Operator
The strimzi-kafka-broker ClusterRole represents the access needed by the init container in Kafka pods that is used for the rack feature. As described in the Delegated privileges section, this role is also needed by the Cluster Operator in order to be able to delegate this access.
ClusterRole for the Cluster Operator allowing it to delegate access to OpenShift nodes to the Kafka broker pods
The strimzi-topic-operator ClusterRole represents the access needed by the Topic Operator. As described in the Delegated privileges section, this role is also needed by the Cluster Operator in order to be able to delegate this access.
ClusterRole for the Cluster Operator allowing it to delegate access to events to the Topic Operator
4.1.4.5. ClusterRoleBindings
The operator needs ClusterRoleBindings and RoleBindings which associates its ClusterRole with its ServiceAccount: ClusterRoleBindings are needed for ClusterRoles containing cluster-scoped resources.
Example ClusterRoleBinding for the Cluster Operator
ClusterRoleBindings are also needed for the ClusterRoles needed for delegation:
Examples RoleBinding for the Cluster Operator
ClusterRoles containing only namespaced resources are bound using RoleBindings only.
4.2. Topic Operator
The Topic Operator manages Kafka topics through custom resources.
The Topic Operator is deployed:
4.2.1. Topic Operator
The Topic Operator provides a way of managing topics in a Kafka cluster through OpenShift resources.
Example architecture for the Topic Operator
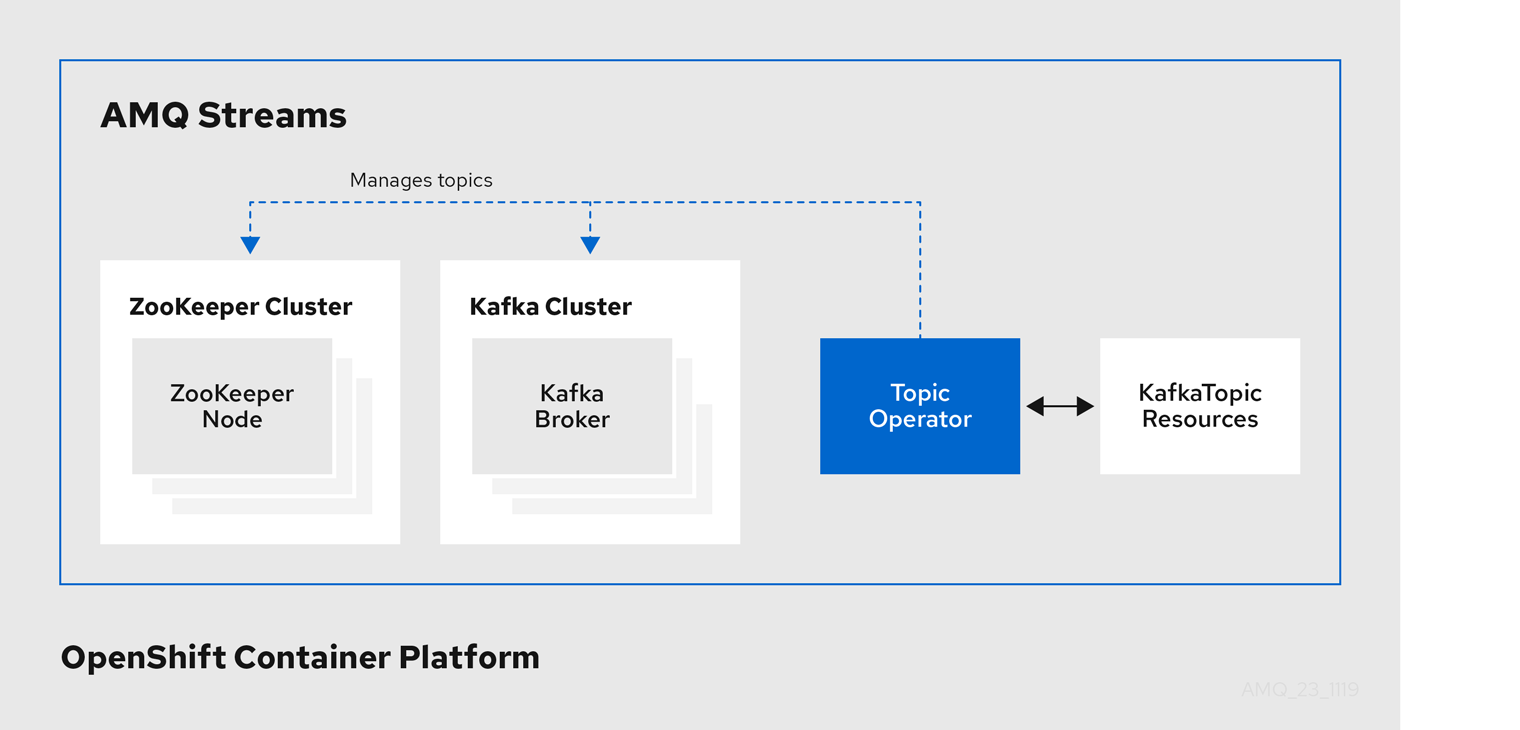
The role of the Topic Operator is to keep a set of KafkaTopic OpenShift resources describing Kafka topics in-sync with corresponding Kafka topics.
Specifically, if a KafkaTopic is:
- Created, the Topic Operator creates the topic
- Deleted, the Topic Operator deletes the topic
- Changed, the Topic Operator updates the topic
Working in the other direction, if a topic is:
-
Created within the Kafka cluster, the Operator creates a
KafkaTopic -
Deleted from the Kafka cluster, the Operator deletes the
KafkaTopic -
Changed in the Kafka cluster, the Operator updates the
KafkaTopic
This allows you to declare a KafkaTopic as part of your application’s deployment and the Topic Operator will take care of creating the topic for you. Your application just needs to deal with producing or consuming from the necessary topics.
If the topic is reconfigured or reassigned to different Kafka nodes, the KafkaTopic will always be up to date.
4.2.2. Identifying a Kafka cluster for topic handling
A KafkaTopic resource includes a label that defines the appropriate name of the Kafka cluster (derived from the name of the Kafka resource) to which it belongs.
The label is used by the Topic Operator to identify the KafkaTopic resource and create a new topic, and also in subsequent handling of the topic.
If the label does not match the Kafka cluster, the Topic Operator cannot identify the KafkaTopic and the topic is not created.
4.2.3. Understanding the Topic Operator
A fundamental problem that the operator has to solve is that there is no single source of truth: Both the KafkaTopic resource and the topic within Kafka can be modified independently of the operator. Complicating this, the Topic Operator might not always be able to observe changes at each end in real time (for example, the operator might be down).
To resolve this, the operator maintains its own private copy of the information about each topic. When a change happens either in the Kafka cluster, or in OpenShift, it looks at both the state of the other system and at its private copy in order to determine what needs to change to keep everything in sync. The same thing happens whenever the operator starts, and periodically while it is running.
For example, suppose the Topic Operator is not running, and a KafkaTopic my-topic gets created. When the operator starts it will lack a private copy of "my-topic", so it can infer that the KafkaTopic has been created since it was last running. The operator will create the topic corresponding to "my-topic" and also store a private copy of the metadata for "my-topic".
The private copy allows the operator to cope with scenarios where the topic configuration gets changed both in Kafka and in OpenShift, so long as the changes are not incompatible (for example, both changing the same topic config key, but to different values). In the case of incompatible changes, the Kafka configuration wins, and the KafkaTopic will be updated to reflect that.
The private copy is held in the same ZooKeeper ensemble used by Kafka itself. This mitigates availability concerns, because if ZooKeeper is not running then Kafka itself cannot run, so the operator will be no less available than it would even if it was stateless.
4.2.4. Configuring the Topic Operator with resource requests and limits
You can allocate resources, such as CPU and memory, to the Topic Operator and set a limit on the amount of resources it can consume.
Prerequisites
- The Cluster Operator is running.
Procedure
Update the Kafka cluster configuration in an editor, as required:
Use
oc edit:oc edit kafka my-cluster
oc edit kafka my-clusterCopy to Clipboard Copied! Toggle word wrap Toggle overflow In the
spec.entityOperator.topicOperator.resourcesproperty in theKafkaresource, set the resource requests and limits for the Topic Operator.Copy to Clipboard Copied! Toggle word wrap Toggle overflow Apply the new configuration to create or update the resource.
Use
oc apply:oc apply -f kafka.yaml
oc apply -f kafka.yamlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
Additional resources
-
For more information about the schema of the
resourcesobject, see {K8sResourceRequirementsAPI}.
4.3. User Operator
The User Operator manages Kafka users through custom resources.
The User Operator is deployed:
4.3.1. User Operator
The User Operator manages Kafka users for a Kafka cluster by watching for KafkaUser resources that describe Kafka users, and ensuring that they are configured properly in the Kafka cluster.
For example, if a KafkaUser is:
- Created, the User Operator creates the user it describes
- Deleted, the User Operator deletes the user it describes
- Changed, the User Operator updates the user it describes
Unlike the Topic Operator, the User Operator does not sync any changes from the Kafka cluster with the OpenShift resources. Kafka topics can be created by applications directly in Kafka, but it is not expected that the users will be managed directly in the Kafka cluster in parallel with the User Operator.
The User Operator allows you to declare a KafkaUser resource as part of your application’s deployment. You can specify the authentication and authorization mechanism for the user. You can also configure user quotas that control usage of Kafka resources to ensure, for example, that a user does not monopolize access to a broker.
When the user is created, the user credentials are created in a Secret. Your application needs to use the user and its credentials for authentication and to produce or consume messages.
In addition to managing credentials for authentication, the User Operator also manages authorization rules by including a description of the user’s access rights in the KafkaUser declaration.
4.3.2. Identifying a Kafka cluster for user handling
A KafkaUser resource includes a label that defines the appropriate name of the Kafka cluster (derived from the name of the Kafka resource) to which it belongs.
The label is used by the User Operator to identify the KafkaUser resource and create a new user, and also in subsequent handling of the user.
If the label does not match the Kafka cluster, the User Operator cannot identify the kafkaUser and the user is not created.
4.3.3. Configuring the User Operator with resource requests and limits
You can allocate resources, such as CPU and memory, to the User Operator and set a limit on the amount of resources it can consume.
Prerequisites
- The Cluster Operator is running.
Procedure
Update the Kafka cluster configuration in an editor, as required:
oc edit kafka my-cluster
oc edit kafka my-clusterCopy to Clipboard Copied! Toggle word wrap Toggle overflow In the
spec.entityOperator.userOperator.resourcesproperty in theKafkaresource, set the resource requests and limits for the User Operator.Copy to Clipboard Copied! Toggle word wrap Toggle overflow Save the file and exit the editor. The Cluster Operator will apply the changes automatically.
Additional resources
-
For more information about the schema of the
resourcesobject, see {K8sResourceRequirementsAPI}.
4.4. Monitoring Operators
4.4.1. Prometheus metrics
AMQ Streams operators expose Prometheus metrics. The metrics are automatically enabled and contain information about:
- Number of reconciliations
- Number of Custom Resources the operator is processing
- Duration of reconciliations
- JVM metrics from the operators
Additionally, we provide an example Grafana dashboard.
For more information about Prometheus, see the Introducing Metrics to Kafka.