14.3. 고가용성 구현
HA(고가용성)를 구현하여 안정성을 향상시킬 수 있으며, 브로커 클러스터가 하나 이상의 브로커가 오프라인 상태가 되더라도 브로커 클러스터를 계속 작동할 수 있습니다.
HA 구현에는 몇 가지 단계가 포함됩니다.
- 14.2절. “브로커 클러스터 생성” 에 설명된 대로 HA 구현을 위해 브로커 클러스터를 구성합니다.
- 실시간 백업 그룹이 무엇인지 이해하고 요구 사항을 가장 잘 충족하는 HA 정책을 선택해야 합니다. AMQ Broker에서 HA가 작동하는 방법 이해를 참조하십시오.
적절한 HA 정책을 선택한 경우 클러스터의 각 브로커에 대해 HA 정책을 구성합니다. 다음 내용을 참조하십시오.
- 페일오버를 사용하도록 클라이언트 애플리케이션을 구성합니다.
고가용성을 위해 구성된 브로커 클러스터의 문제를 해결해야 하는 이후의 경우 클러스터에서 브로커를 실행하는 각 JVM(Java Virtual Machine) 인스턴스에 대해 Garbage Collection(GC) 로깅을 활성화하는 것이 좋습니다. JVM에서 GC 로그를 활성화하는 방법을 알아보려면 JVM에서 사용하는 JDK(Java Development Kit) 버전에 대한 공식 문서를 참조하십시오. AMQ Broker에서 지원하는 JVM 버전에 대한 자세한 내용은 Red Hat AMQ 7 지원 구성을 참조하십시오.
14.3.1. 고가용성 이해
AMQ Broker에서는 클러스터의 브로커를 실시간 백업 그룹으로 그룹화하여 HA(고가용성)를 구현합니다. 라이브 백업 그룹에서 라이브 브로커는 백업 브로커에 연결되어 있으며 실패할 경우 라이브 브로커를 대신할 수 있습니다. AMQ Broker는 Live-backup 그룹 내에서 페일오버( HA 정책라고 함)에 대한 몇 가지 다른 전략도 제공합니다.
14.3.1.1. Live-backup 그룹에서 고가용성을 제공하는 방법
AMQ Broker에서는 클러스터의 브로커를 연결하여 라이브 백업 그룹을 구성하여 HA(고가용성)를 구현합니다. Live-backup 그룹은 장애 조치( failover )를 제공하므로 한 브로커가 실패하면 다른 브로커가 메시지 처리를 대신할 수 있습니다.
실시간 백업 그룹은 하나 이상의 백업 브로커(단일 슬레이브 브로커라고도 함)에 연결된 하나의 라이브 브로커( 마스터 브로커라고도 함)로 구성됩니다. 라이브 브로커는 클라이언트 요청에 서비스를 제공하고 백업 브로커는 패시브 모드로 대기합니다. 라이브 브로커가 실패하면 백업 브로커가 라이브 브로커를 대체하여 클라이언트가 다시 연결하고 작업을 계속할 수 있습니다.
14.3.1.2. 고가용성 정책
HA(고가용성) 정책은 라이브 백업 그룹에서 장애 조치가 발생하는 방법을 정의합니다. AMQ Broker는 다양한 HA 정책을 제공합니다.
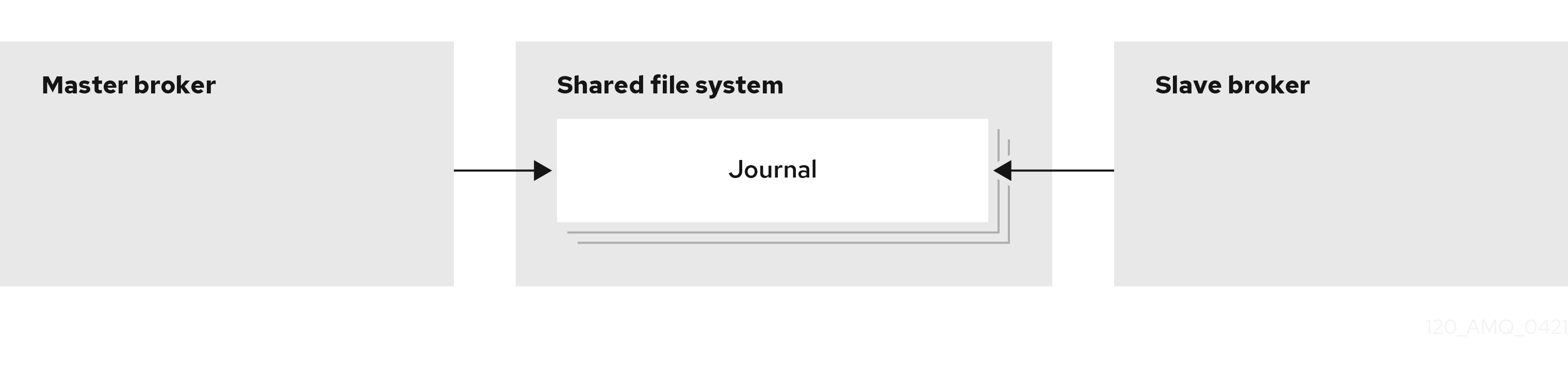
- 공유 저장소(권장)
실시간 및 백업 브로커는 메시징 데이터를 공유 파일 시스템의 공통 디렉터리(일반적으로 SAN(Storage Area Network) 또는 NFS(Network File System) 서버)에 저장합니다. JDBC 기반 지속성을 구성한 경우 지정된 데이터베이스에 브로커 데이터를 저장할 수도 있습니다. 공유 저장소를 사용하면 라이브 브로커가 실패하면 백업 브로커는 공유 저장소에서 메시지 데이터를 로드하여 실패한 라이브 브로커를 대신합니다.
대부분의 경우 복제 대신 공유 저장소를 사용해야 합니다. 공유 저장소는 네트워크를 통해 데이터를 복제하지 않기 때문에 일반적으로 복제보다 성능이 향상됩니다. 또한 공유 저장소는 라이브 브로커와 백업이 동시에 유지되는 네트워크 분리 ( "스플릿 브레인"라고도 함) 문제를 방지할 수 있습니다.
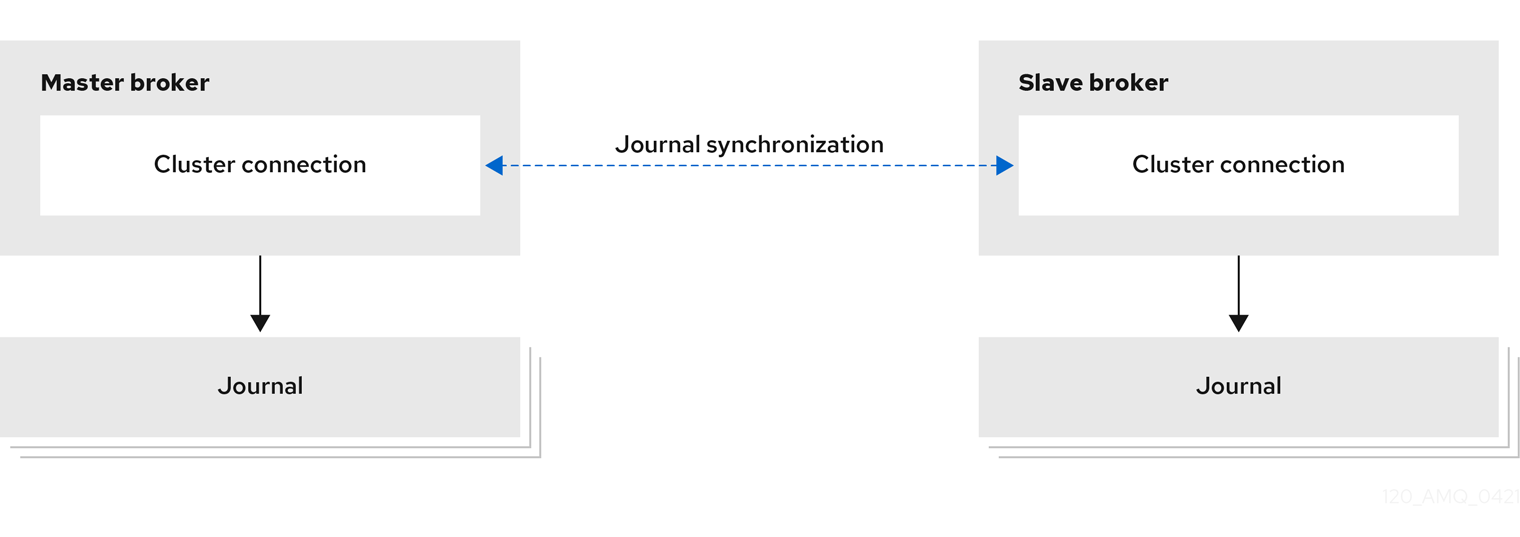
- 복제
라이브 및 백업 브로커는 네트워크를 통해 메시징 데이터를 지속적으로 동기화합니다. 라이브 브로커가 실패하면 백업 브로커는 동기화된 데이터를 로드하여 실패한 라이브 브로커에 대해 작업을 수행합니다.
라이브 브로커와 백업 브로커 간의 데이터 동기화를 통해 라이브 브로커가 실패하면 메시징 데이터가 손실되지 않습니다. 실시간 및 백업 브로커가 처음 참여할 때 라이브 브로커는 기존 데이터를 네트워크를 통해 백업 브로커에 복제합니다. 이 초기 단계가 완료되면 라이브 브로커는 라이브 브로커가 받을 때 영구 데이터를 백업 브로커에 복제합니다. 즉, 라이브 브로커가 네트워크를 벗어나면 백업 브로커에 라이브 브로커가 수신한 모든 영구 데이터가 있습니다.
복제는 네트워크를 통해 데이터를 동기화하므로 네트워크 실패로 인해 라이브 브로커와 해당 백업이 동시에 유지되는 네트워크 분리가 발생할 수 있습니다.
- 라이브 전용(HA 제한)
라이브 브로커가 정상적으로 중지되면 메시지 및 트랜잭션 상태를 다른 라이브 브로커에 복사한 다음 종료합니다. 그러면 클라이언트가 다른 브로커에 다시 연결하여 메시지를 계속 전송 및 수신할 수 있습니다.
추가 리소스
- 라이브 백업 그룹의 브로커 간에 공유되는 영구 메시지 데이터에 대한 자세한 내용은 6.1절. “저널에 메시지 데이터 유지” 을 참조하십시오.
14.3.1.3. 복제 정책 제한
복제를 사용하여 고가용성을 제공할 때 실시간 브로커와 백업 브로커 모두 "스플릿 브레인"이라고 하는 동시에 활성화될 수 있는 위험이 존재합니다.
분할 브레인은 라이브 브로커와 백업의 연결이 끊어지면 발생할 수 있습니다. 이 경우 라이브 브로커와 해당 백업이 동시에 활성화될 수 있습니다. 이 상황에서 브로커 간에 메시지 복제가 없기 때문에 각 브로커는 클라이언트를 제공하고 다른 사람을 인식하지 않고 메시지를 처리합니다. 이 경우 각 브로커는 완전히 다른 저널을 가지고 있습니다. 이 상황에서 복구하는 것은 매우 어려울 수 있으며 경우에 따라 불가능합니다.
- 분할 브레인 의 가능성을 제거하려면 공유 저장소 HA 정책을 사용하십시오.
복제 HA 정책을 사용하는 경우 다음 단계를 수행하여 분할 브레인이 발생하는 위험을 줄입니다.
브로커가 ZooKeeper Coordination 서비스를 사용하여 브로커를 조정하려면 최소 3 개의 노드에 ZooKeeper를 배포하십시오. 브로커가 하나의 ZooKeeper 노드에 대한 연결이 끊어지면 3 개 이상의 노드를 사용하면 실시간 백업 브로커 쌍이 복제 중단이 발생할 때 브로커를 조정할 수 있습니다.
클러스터의 다른 사용 가능한 브로커를 사용하여 쿼럼을 제공하는 임베디드 브로커 조정을 사용하려면 3개 이상의 라이브 백업 쌍 을 사용하여 분할 브레인을 발생시킬 가능성을 줄일 수 있습니다. 3개 이상의 라이브 백업 쌍을 사용하면 실시간 백업 브로커 쌍이 복제 중단이 발생할 때 발생하는 쿼럼 투표에서 대부분의 결과를 얻을 수 있습니다.
복제 HA 정책을 사용할 때 몇 가지 추가 고려 사항은 다음과 같습니다.
- 라이브 브로커가 실패하고 백업이 라이브로 전환되면 새 백업 브로커가 라이브에 연결되거나 원래 라이브 브로커에 실패할 때까지 추가 복제가 수행되지 않습니다.
- Live-backup 그룹의 백업 브로커가 실패하면 라이브 브로커는 계속 메시지를 제공합니다. 그러나 다른 브로커가 백업으로 추가되거나 원래 백업 브로커가 다시 시작될 때까지 메시지가 복제되지 않습니다. 이 기간 동안 메시지는 라이브 브로커에만 유지됩니다.
- 브로커가 임베디드 브로커 조정을 사용하고 라이브 백업 쌍에서 두 브로커가 모두 종료된 경우 메시지 손실을 방지하기 위해 최근 활성 브로커를 먼저 다시 시작해야 합니다. 가장 최근의 활성 브로커가 백업 브로커인 경우 먼저 다시 시작할 수 있도록 이 브로커를 마스터 브로커로 수동으로 재구성해야 합니다.
14.3.3. 복제 고가용성 구성
복제 HA(고가용성) 정책을 사용하여 브로커 클러스터에 HA를 구현할 수 있습니다. 복제를 사용하면 라이브 및 백업 브로커 간에 영구 데이터가 동기화됩니다. 라이브 브로커에서 오류가 발생하면 메시지 데이터가 백업 브로커와 동기화되며 실패한 라이브 브로커에 대해 이 데이터가 사용됩니다.
공유 파일 시스템이 없는 경우 공유 저장소에 대한 대안으로 복제를 사용해야 합니다. 그러나 복제를 통해 라이브 브로커와 해당 백업이 동시에 활성화되는 시나리오가 발생할 수 있습니다.
라이브 및 백업 브로커는 네트워크를 통해 메시징 데이터를 동기화해야 하므로 복제는 성능 오버헤드를 추가합니다. 이 동기화 프로세스에서는 저널 작업을 차단하지만 클라이언트를 차단하지는 않습니다. 데이터 동기화를 위해 저널 작업을 차단할 수 있는 최대 시간을 구성할 수 있습니다.
실시간 백업 브로커 쌍 간 복제 연결이 중단되면 브로커는 라이브 브로커가 아직 활성화되어 있는지 또는 사용할 수 없는지와 백업 브로커에 대한 장애 조치가 필요한지 여부를 결정할 방법이 필요합니다. 이러한 조정을 제공하기 위해 다음 중 하나를 사용하도록 브로커를 구성할 수 있습니다.
- Apache ZooKeeper 조정 서비스
- 클러스터의 다른 브로커를 사용하여 쿼럼 선택을 제공하는 임베디드 브로커 조정.
14.3.3.1. 조정 방법 선택
복제 중단 시 장애 조치가 필요한지 여부를 결정하기 위해 ZooKeeper 조정 서비스 또는 임베디드 브로커 조정을 사용하도록 브로커를 구성할 수 있습니다. 이 섹션에서는 조정 방법을 선택할 때 고려할 수 있는 데이터 일관성을 관리하는 방법의 인프라 요구 사항과 차이점에 대해 설명합니다.
인프라 요구 사항
- 브로커가 ZooKeeper 조정 서비스를 사용하려면 브로커를 최소 3개의 Apache ZooKeeper 노드에 연결해야 합니다. 최소 3 개의 ZooKeeper 노드를 보유하면 브로커가 하나의 노드에 대한 연결이 끊어지면 계속 작동 할 수 있습니다. 브로커에 조정 서비스를 제공하기 위해 다른 애플리케이션에서 사용하는 기존 ZooKeeper 노드를 공유할 수 있습니다. Apache ZooKeeper 설정에 대한 자세한 내용은 Apache ZooKeeper 설명서를 참조하십시오.
- 클러스터의 다른 사용 가능한 브로커를 사용하여 쿼럼 선택을 제공하는 임베디드 브로커 조정을 사용하려면 3개 이상의 실시간 백업 브로커 쌍이 있어야 합니다. 3개 이상의 라이브 백업 쌍을 사용하면 실시간 백업 브로커 쌍이 복제 중단이 발생할 때 발생하는 쿼럼 투표에서 대부분의 결과를 얻을 수 있습니다.
데이터 일관성
- Apache ZooKeeper 조정 서비스를 사용하는 경우 ZooKeeper는 각 브로커의 데이터 버전을 추적하므로 복제 목적으로 브로커가 기본 또는 백업 브로커로 구성되어 있는지 여부와 관계없이 최신 저널 데이터가 있는 브로커만 활성화할 수 있습니다. 버전 추적을 사용하면 브로커가 최신 저널을 사용하여 활성화할 수 있고 클라이언트 서비스를 시작할 수 있습니다.
- 임베디드 브로커 조정을 사용하는 경우 각 브로커의 데이터 버전을 추적하는 메커니즘이 없으므로 가장 최신 저널이 있는 브로커만 라이브 브로커가 될 수 있습니다. 따라서 오래된 저널을 가진 브로커가 라이브가되고 클라이언트 서비스를 시작할 수 있으므로 저널에 차이가 발생할 수 있습니다.
14.3.3.2. 복제 중단 후 브로커의 조정 방법
이 섹션에서는 복제 연결이 중단된 후 두 조정 방법이 모두 작동하는 방법을 설명합니다.
ZooKeeper 조정 서비스 사용
복제 중단을 관리하기 위해 ZooKeeper 조정 서비스를 사용하는 경우 두 브로커 모두 여러 Apache ZooKeeper 노드에 연결되어 있어야 합니다.
- 언제든지 라이브 브로커가 ZooKeeper 노드의 대부분에 대한 연결이 끊어지면 "스플릿 브레인"이 발생하는 위험을 피하기 위해 종료됩니다.
- 언제든지 백업 브로커가 대부분의 ZooKeeper 노드에 대한 연결이 끊어지면 복제 데이터 수신을 중지하고 백업 브로커 역할을 수행하기 전에 대부분의 ZooKeeper 노드에 연결할 수 있을 때까지 기다립니다. 연결이 ZooKeeper 노드의 대부분으로 복원되면 백업 브로커는 ZooKeeper를 사용하여 데이터를 버리고 복제할 라이브 브로커를 검색해야 하는지 또는 현재 데이터가 있는 라이브 브로커가 될 수 있는지 결정합니다.
zookeeper는 다음 제어 메커니즘을 사용하여 장애 조치 프로세스를 관리합니다.
- 언제든지 단일 라이브 브로커만 소유할 수 있는 공유 임대 잠금입니다.
- 최신 버전의 브로커 데이터를 추적하는 활성화 시퀀스 카운터입니다. 각 브로커는 해당 NodeID와 함께 서버 잠금 파일에 저장된 로컬 카운터에서 저널 데이터 버전을 추적합니다. 라이브 브로커는 ZooKeeper의 조정 활성화 시퀀스 카운터에서 버전을 공유합니다.
라이브 브로커와 백업 브로커 간의 복제 연결이 손실되면 라이브 브로커는 로컬 활성화 시퀀스 카운터 값과 ZooKeeper의 전환 활성화 시퀀스 카운터 값을 1 로 증가시켜 최신 데이터가 있음을 알립니다. 이제 백업 브로커의 데이터는 오래된 것으로 간주되며 복제 연결이 복원되고 최신 데이터가 동기화될 때까지 브로커는 라이브 브로커가 될 수 없습니다.
복제 연결이 손실되면 백업 브로커는 ZooKeeper 잠금이 라이브 브로커가 소유하고 ZooKeeper의 조정 활성화 시퀀스 카운터가 로컬 카운터 값과 일치하는지 확인합니다.
- 라이브 브로커에 의해 잠금을 소유하는 경우 백업 브로커는 복제 연결이 손실되었을 때 ZooKeeper의 활성화 시퀀스 카운터가 라이브 브로커에 의해 업데이트되었음을 감지합니다. 이는 백업 브로커가 장애 조치를 시도하지 않도록 라이브 브로커가 실행 중임을 나타냅니다. 백업 브로커는 최신 데이터가 있도록 실시간 브로커를 검색하여 데이터를 복제합니다.
- 잠금이 라이브 브로커에 의해 소유되지 않은 경우 라이브 브로커는 존재하지 않습니다. 백업 브로커의 활성화 시퀀스 카운터 값이 ZooKeeper의 조정된 활성화 시퀀스 카운터 값과 동일하면 백업 브로커에 최신 데이터가 있음을 나타내는 경우 백업 브로커는 장애 조치됩니다.If the value of the activation sequence counter on the backup broker is the same as the commitment activation sequence counter on ZooKeeper, which indicates that the backup broker has up-to-date data, the backup broker fails over.
- 잠금이 라이브 브로커에 의해 소유되지 않지만 백업 브로커의 활성화 순서 카운터 값이 ZooKeeper의 카운터 값보다 작으면 백업 브로커의 데이터가 최신 데이터가 아니며 백업 브로커는 실패할 수 없습니다.
임베디드 브로커 조정 사용
실시간 백업 브로커 쌍에서 포함된 브로커 조정을 사용하여 복제 중단을 조정하는 경우 다음 두 가지 유형의 쿼럼 투표가 시작될 수 있습니다.
| 투표 유형 | 설명 | 이니시에이터 | 필수 구성 | 참가자 | 투표 결과를 기반으로 한 동작 |
|---|---|---|---|---|---|
| 백업 투표 | 백업 브로커가 라이브 브로커에 대한 복제 연결을 손실하면 백업 브로커는 이 투표 결과에 따라 시작할지 여부를 결정합니다. | 백업 브로커 | 없음. 백업 투표는 백업 브로커가 복제 파트너에 대한 연결이 끊어지면 자동으로 수행됩니다. 그러나 이러한 매개변수에 대한 사용자 지정 값을 지정하여 백업 투표의 속성을 제어할 수 있습니다.
| 클러스터의 다른 라이브 브로커 | 백업 브로커는 클러스터의 다른 라이브 브로커에서 대다수(즉, 쿼럼)가 투표하여 복제 파트너를 더 이상 사용할 수 없음을 나타내는 경우 시작됩니다. |
| 라이브 투표 | 라이브 브로커가 복제 파트너에 대한 연결이 끊어지면 라이브 브로커는 이 투표에 따라 계속 실행할지 여부를 결정합니다. | 라이브 브로커 |
라이브 투표는 라이브 브로커가 복제 파트너에 대한 연결을 잃고 | 클러스터의 다른 라이브 브로커 | 클러스터 연결이 여전히 활성 상태임을 나타내는 클러스터 브로커에서 대다수의 투표가 수신 되지 않으면 라이브 브로커가 종료됩니다. |
다음은 브로커 클러스터 구성이 쿼럼 투표 동작에 미치는 영향에 대해 기록해야 하는 몇 가지 중요한 사항입니다.
- 쿼럼 투표가 성공하려면 클러스터 크기가 대부분의 결과를 얻을 수 있어야 합니다. 따라서 클러스터에 라이브 백업 브로커 쌍이 3개 이상 있어야 합니다.
- 클러스터에 추가하는 라이브 백업 브로커 쌍이 많을수록 클러스터의 전체 내결함성이 높아집니다. 예를 들어, 세 개의 Live-backup 쌍이 있다고 가정합니다. 전체 라이브 백업 쌍이 손실되면 나머지 두 개의 live-backup 쌍은 후속 쿼럼 투표에서 대부분의 결과를 얻을 수 없습니다. 이 경우 클러스터에서 추가 복제 중단으로 인해 라이브 브로커가 종료되고 백업 브로커가 시작되지 않을 수 있습니다. 예를 들어 5개의 브로커 쌍을 사용하여 클러스터를 구성하면 클러스터에 오류가 두 개 이상 발생할 수 있지만 쿼럼 투표에서 대다수의 결과를 보장할 수 있습니다.
- 클러스터에서 실시간 백업 브로커 쌍의 수를 의도적으로 줄이면 이전에 설정된 대부분의 투표 임계값이 자동으로 줄어들지 않습니다. 이 기간 동안 손실된 복제 연결에 의해 트리거되는 쿼럼 투표는 성공할 수 없으므로 클러스터의 스플릿 브레인에 더 취약해집니다. 클러스터가 쿼럼 투표에 대한 대부분의 임계값을 다시 계산하도록 하려면 먼저 클러스터에서 제거 중인 실시간 백업 쌍을 종료합니다. 그런 다음 클러스터에서 나머지 live-backup 쌍을 다시 시작합니다. 나머지 브로커를 모두 다시 시작하면 클러스터에서 쿼럼 투표 임계값을 다시 계산합니다.
14.3.3.3. ZooKeeper 조정 서비스를 사용하여 복제 고가용성을 위한 브로커 클러스터 구성
다음 절차에서는 Apache ZooKeeper 조정 서비스를 사용하는 브로커 클러스터에 대해 복제 HA(고가용성)를 구성하는 방법을 설명합니다.
사전 요구 사항
- 한 노드에 대한 연결이 끊어지면 브로커가 계속 작동할 수 있도록 최소 3개의 Apache ZooKeeper 노드를 사용할 수 있습니다.
- zookeeper는 일시 중지 시간이 ZooKeeper 서버 눈금 시간보다 훨씬 적은 수 있도록 충분한 리소스가 있어야 합니다. 브로커의 예상 로드에 따라 브로커와 ZooKeeper 노드가 동일한 노드를 공유해야하는지 신중하게 고려하십시오. 자세한 내용은 https://zookeeper.apache.org/ 에서 참조하십시오.
절차
ZooKeeper 조정 서비스를 사용하여 복제 고가용성을 사용하도록 라이브 브로커를 구성합니다.
-
라이브 브로커의 <
broker_instance_dir> /etc/broker.xml구성 파일을 엽니다. HA 정책에 복제를 사용하도록 라이브 브로커를 구성합니다.
<configuration> <core> ... <ha-policy> <replication> <primary> <manager> ... </manager> <group-name>my-group-1</group-name> </primary> </replication> </ha-policy> ... </core> </configuration>primary- 이 브로커가 초기 구성 후 라이브 브로커로 시작됨을 나타냅니다.
group-name- 이 Live-backup 그룹의 이름입니다(선택 사항). 라이브 백업 그룹을 만들려면 동일한 그룹 이름으로 실시간 및 백업 브로커를 구성해야 합니다. 그룹 이름을 지정하지 않으면 백업 브로커는 라이브 브로커와 복제할 수 있습니다.
관리자섹션에서 라이브 브로커를 ZooKeeper 노드에 연결하도록 속성을 구성합니다.<configuration> <core> ... <ha-policy> <replication> <primary> <manager> <class-name>org.apache.activemq.artemis.quorum.zookeeper.CuratorDistributedPrimitiveManager</class-name> <properties> <property key="connect-string" value="192.168.1.10:6666,192.168.2.10:6667,192.168.3.10:6668"/> </properties> </manager> ... </primary> </replication> </ha-policy> ... </core> </configuration>class-name-
ZooKeeper 조정 서비스의 클래스 이름은
org.apache.activemq.artemis.quorum.zookeeper.CuratorDistributedPrimitiveManager입니다. 이 요소는 Apache Curator가 기본 관리자인 경우 선택 사항입니다. 속성ZooKeeper 노드의 연결 세부 정보를 제공하기 위해 키-값 쌍 집합을 지정할 수 있는
속성요소를 지정합니다.Expand 키 현재의 connect-string
라이브 브로커에 대한 ZooKeeper 노드의 IP 주소 및 포트 번호를 쉼표로 구분한 목록을 지정합니다. 예를 들어
값="192.168.1.10:6666,192.168.2.10:6667,192.168.3.10:6668"입니다.session-ms
대부분의 ZooKeeper 노드에 대한 연결이 끊어진 후 라이브 브로커가 종료되기 전에 대기하는 시간입니다. 기본값은
18000ms입니다. 유효한 값은 ZooKeeper 서버 눈금 시간 2 회에서 20 배 사이입니다.참고ZooKeeper 하트비트가 안정적으로 작동할 수 있도록 가비지 컬렉션의 ZooKeeper 일시 중지 시간은
session-ms속성 값의 0.33 미만이어야 합니다. 일시 중지 시간이 이 제한보다 적다는 것을 보장할 수 없는 경우 각 브로커의session-ms속성 값을 늘리고 느린 장애 조치를 허용합니다.중요브로커 복제 파트너는 2초마다 "ping" 패킷을 자동으로 교환하여 파트너 브로커를 사용할 수 있는지 확인합니다. 백업 브로커가 라이브 브로커로부터 응답을 받지 못하면 브로커의 연결 시간-라이브(ttl)가 만료될 때까지 백업에서 응답을 기다립니다. 기본 connection-ttl은
60000ms이므로 백업 브로커가 60초 후에 장애 조치를 시도합니다. 더 빠른 장애 조치를 허용하려면 connection-ttl 값을session-ms속성 값과 유사한 값으로 설정하는 것이 좋습니다. 새 connection-ttl을 설정하려면connection-ttl-override속성을 구성합니다.네임스페이스 (선택 사항)
브로커가 ZooKeeper 노드를 다른 애플리케이션과 공유하는 경우, 브로커에 조정 서비스를 제공하는 파일을 저장하기 위해 ZooKeeper 네임스페이스를 만들 수 있습니다. 백업 브로커에 네임스페이스를 지정하는 경우 라이브 브로커에 동일한 네임스페이스를 지정해야 합니다.
라이브 브로커의 추가 HA 속성을 구성합니다.
이러한 추가 HA 속성에는 대부분의 일반적인 사용 사례에 적합한 기본값이 있습니다. 따라서 기본 동작을 원하지 않는 경우에만 이러한 속성을 구성해야 합니다. 자세한 내용은 부록 F. 추가 복제 고가용성 구성 ScanSetting의 내용을 참조하십시오.
-
라이브 브로커의 <
ZooKeeper 조정 서비스를 사용하여 복제 고가용성을 사용하도록 백업 브로커를 구성합니다.
-
백업 브로커의 <
broker_instance_dir> /etc/broker.xml구성 파일을 엽니다. HA 정책에 복제를 사용하도록 백업 브로커를 구성합니다.
<configuration> <core> ... <ha-policy> <replication> <backup> <manager> ... </manager> <group-name>my-group-1</group-name> <allow-failback>true</allow-failback> </backup> </replication> </ha-policy> ... </core> </configuration>Backup- 이 브로커가 초기 구성 후 백업 브로커로 시작됨을 나타냅니다.
group-name- 이 백업이 연결되는 라이브 브로커의 그룹 이름입니다. 백업 브로커는 동일한 그룹 이름을 공유하는 라이브 브로커에만 연결됩니다. 그룹 이름을 지정하지 않으면 백업 브로커는 라이브 브로커와 복제할 수 있습니다.
allow-failbacktrue로 설정하면 현재 라이브 브로커인 백업 브로커를 허용하고 라이브 역할을 다시 복제 파트너에게 제공할 수 있습니다.라이브 (primary) 브로커로 구성된 브로커가 시작되면 최신 데이터가 있는지 확인하고 라이브 브로커로 실행할 수 있습니다. 데이터가 최신 상태가 아닌 경우 브로커는 빈 저널로 다시 시작하여 현재 라이브 브로커에 연결하여 최신 데이터를 복제할 때까지 기다립니다. 기본 브로커로 구성된 브로커는 데이터를 복제한 후 현재 활성 상태인 백업 브로커를 요청하여 장애 조치(failover)하고 다시 라이브 브로커가 될 수 있도록 다시 시작합니다.
allow-failback이true로 설정된 경우 백업 브로커는 복제 파트너가 다시 활성화될 수 있도록 다시 시작합니다.allow-failback이false로 설정된 경우 백업 브로커는 재시작되지 않으므로 두 브로커 모두 현재 역할을 유지합니다.
관리자섹션에서 백업 브로커를 ZooKeeper 노드에 연결하도록 속성을 구성합니다.<configuration> <core> ... <ha-policy> <replication> <backup> <manager> <class-name>org.apache.activemq.artemis.quorum.zookeeper.CuratorDistributedPrimitiveManager</class-name> <properties> <property key="connect-string" value="192.168.1.10:6666,192.168.2.10:6667,192.168.3.10:6668"/> </properties> </manager> ... </backup> </replication> </ha-policy> ... </core> </configuration>class-name-
ZooKeeper 조정 서비스의 클래스 이름은
org.apache.activemq.artemis.quorum.zookeeper.CuratorDistributedPrimitiveManager입니다. 이 요소는 Apache Curator가 기본 관리자인 경우 선택 사항입니다. 속성다음과 같이 ZooKeeper 노드의 연결 세부 정보를 제공하기 위해 키-값 쌍 집합을 지정할 수 있는
속성섹션을 지정합니다.Expand 키 현재의 connect-string
백업 브로커에 대해 IP 주소 및 ZooKeeper 노드의 IP 주소 및 포트 번호를 쉼표로 구분한 목록을 지정합니다. 예를 들어
값="192.168.1.10:6666,192.168.2.10:6667,192.168.3.10:6668"입니다.session-ms
대부분의 ZooKeeper 노드에 대한 연결이 끊어진 후 라이브 브로커가 종료되기 전에 대기하는 시간입니다. 기본값은
18000ms입니다. 유효한 값은 ZooKeeper 서버 눈금 시간 2 회에서 20 배 사이입니다.참고ZooKeeper 하트비트가 안정적으로 작동할 수 있도록 가비지 컬렉션의 ZooKeeper 일시 중지 시간은
session-ms속성 값의 0.33 미만이어야 합니다. 일시 중지 시간이 이 제한보다 적다는 것을 보장할 수 없는 경우 각 브로커의session-ms속성 값을 늘리고 느린 장애 조치를 허용합니다.중요브로커 복제 파트너는 2초마다 "ping" 패킷을 자동으로 교환하여 파트너 브로커를 사용할 수 있는지 확인합니다. 백업 브로커가 라이브 브로커로부터 응답을 받지 못하면 브로커의 연결 시간-라이브(ttl)가 만료될 때까지 백업에서 응답을 기다립니다. 기본 connection-ttl은
60000ms이므로 백업 브로커가 60초 후에 장애 조치를 시도합니다. 더 빠른 장애 조치를 허용하려면 connection-ttl 값을session-ms속성 값과 유사한 값으로 설정하는 것이 좋습니다. 새 connection-ttl을 설정하려면connection-ttl-override속성을 구성합니다.네임스페이스 (선택 사항)
브로커가 ZooKeeper 노드를 다른 애플리케이션과 공유하는 경우, 브로커에 조정 서비스를 제공하는 파일을 저장하기 위해 ZooKeeper 네임스페이스를 만들 수 있습니다. 백업 브로커에 네임스페이스를 지정하는 경우 라이브 브로커에 동일한 네임스페이스를 지정해야 합니다.
백업 브로커의 추가 HA 속성을 구성합니다.
이러한 추가 HA 속성에는 대부분의 일반적인 사용 사례에 적합한 기본값이 있습니다. 따라서 기본 동작을 원하지 않는 경우에만 이러한 속성을 구성해야 합니다. 자세한 내용은 부록 F. 추가 복제 고가용성 구성 ScanSetting의 내용을 참조하십시오.
-
백업 브로커의 <
- 1단계와 2단계를 반복하여 클러스터에 추가 라이브 백업 브로커 쌍을 구성합니다.
추가 리소스
- HA에 복제를 사용하는 브로커 클러스터의 예는 HA 예제 프로그램을 참조하십시오.
- 노드 ID에 대한 자세한 내용은 노드 ID 이해를 참조하십시오.
14.3.3.4. 임베디드 브로커 조정을 사용하여 복제 고가용성을 위한 브로커 클러스터 구성
임베디드 브로커 조정을 사용하여 복제하려면 "스플릿 브레인"의 위험을 줄이기 위해 적어도 3 개의 라이브 백업 쌍이 필요합니다.
다음 절차에서는 6-broker 클러스터에 대한 복제 HA(고가용성)를 구성하는 방법을 설명합니다. 이 토폴로지에서 6개의 브로커는 세 개의 라이브 백업 쌍으로 그룹화됩니다. 세 개의 라이브 브로커는 각각 전용 백업 브로커와 연결됩니다.
사전 요구 사항
최소 6개의 브로커가 있는 브로커 클러스터가 있어야 합니다.
6개의 브로커는 세 개의 라이브 백업 쌍으로 구성됩니다. 클러스터에 브로커를 추가하는 방법에 대한 자세한 내용은 14장. 브로커 클러스터 설정 을 참조하십시오.
절차
클러스터의 브로커를 라이브 백업 그룹으로 그룹화합니다.
대부분의 경우 실시간 백업 그룹은 라이브 브로커와 백업 브로커의 두 가지 브로커로 구성되어야 합니다. 클러스터에 6개의 브로커가 있는 경우 3개의 라이브 백업 그룹이 필요합니다.
하나의 라이브 브로커와 하나의 백업 브로커로 구성된 첫 번째 라이브 백업 그룹을 생성합니다.
-
라이브 브로커의 <
broker_instance_dir> /etc/broker.xml구성 파일을 엽니다. HA 정책에 복제를 사용하도록 라이브 브로커를 구성합니다.
<configuration> <core> ... <ha-policy> <replication> <master> <check-for-live-server>true</check-for-live-server> <group-name>my-group-1</group-name> <vote-on-replication-failure>true</vote-on-replication-failure> ... </master> </replication> </ha-policy> ... </core> </configuration>check-for-live-server라이브 브로커가 실패하면 이 속성은 클라이언트가 다시 시작할 때 클라이언트가 다시 실패해야 하는지 여부를 제어합니다.
이 속성을
true로 설정하면 이전 장애 조치 후 라이브 브로커가 다시 시작되면 동일한 노드 ID가 있는 클러스터에서 다른 브로커를 검색합니다. 라이브 브로커가 동일한 노드 ID가 있는 다른 브로커를 발견하면 라이브 브로커가 실패했을 때 백업 브로커가 성공적으로 시작되었음을 나타냅니다. 이 경우 라이브 브로커는 데이터를 백업 브로커와 동기화합니다. 그런 다음 라이브 브로커는 백업 브로커를 종료하도록 요청합니다. 백업 브로커가 장애백에 대해 구성된 경우 아래와 같이 종료됩니다. 그런 다음 라이브 브로커는 활성 역할을 다시 시작하고 클라이언트가 다시 연결합니다.주의라이브 브로커에서
check-for-live-server를true로 설정하지 않으면 이전 페일오버 후 라이브 브로커를 다시 시작할 때 중복 메시징 처리가 발생할 수 있습니다. 특히 이 속성이false로 설정된 라이브 브로커를 다시 시작하면 라이브 브로커는 데이터를 백업 브로커와 동기화하지 않습니다. 이 경우 라이브 브로커는 백업 브로커가 이미 처리한 것과 동일한 메시지를 처리하여 중복을 유발할 수 있습니다.group-name- 이 Live-backup 그룹의 이름입니다(선택 사항). 라이브 백업 그룹을 만들려면 동일한 그룹 이름으로 실시간 및 백업 브로커를 구성해야 합니다. 그룹 이름을 지정하지 않으면 백업 브로커는 라이브 브로커와 복제할 수 있습니다.
vote-on-replication-failure이 속성은 활성 브로커가 중단된 복제 연결 시 실시간 투표 라는 쿼럼을 시작할지 여부를 제어합니다.
실시간 투표는 라이브 브로커가 복제 연결 중단의 원인인지 여부를 결정하는 방법입니다. 투표 결과에 따라 라이브 브로커는 계속 실행 중이거나 종료됩니다.
중요쿼럼 투표가 성공하려면 클러스터 크기가 대부분의 결과를 얻을 수 있어야 합니다. 따라서 복제 HA 정책을 사용하면 클러스터에 3개 이상의 실시간 백업 브로커 쌍이 있어야 합니다.
클러스터에서 구성한 브로커 쌍이 많을수록 클러스터의 전체 내결함성이 증가할 수 있습니다. 예를 들어, 세 개의 라이브 백업 브로커 쌍이 있다고 가정합니다. 전체 라이브 백업 쌍에 대한 연결이 끊어지면 나머지 두 개의 live-backup 쌍은 더 이상 쿼럼 투표에서 대부분의 결과를 얻을 수 없습니다. 이는 이후의 복제 중단으로 인해 라이브 브로커가 종료되고 백업 브로커가 시작되지 않을 수 있음을 의미합니다. 예를 들어 5개의 브로커 쌍을 사용하여 클러스터를 구성하면 클러스터에 오류가 두 개 이상 발생할 수 있지만 쿼럼 투표에서 대다수의 결과를 보장할 수 있습니다.
라이브 브로커의 추가 HA 속성을 구성합니다.
이러한 추가 HA 속성에는 대부분의 일반적인 사용 사례에 적합한 기본값이 있습니다. 따라서 기본 동작을 원하지 않는 경우에만 이러한 속성을 구성해야 합니다. 자세한 내용은 부록 F. 추가 복제 고가용성 구성 ScanSetting의 내용을 참조하십시오.
-
백업 브로커의 <
broker_instance_dir> /etc/broker.xml구성 파일을 엽니다. HA 정책에 복제를 사용하도록 백업 브로커를 구성합니다.
<configuration> <core> ... <ha-policy> <replication> <slave> <allow-failback>true</allow-failback> <group-name>my-group-1</group-name> <vote-on-replication-failure>true</vote-on-replication-failure> ... </slave> </replication> </ha-policy> ... </core> </configuration>allow-failback장애 조치가 발생하고 라이브 브로커에 대해 백업 브로커가 가져왔으면 이 속성은 다시 시작하고 클러스터에 다시 연결할 때 백업 브로커가 원래 라이브 브로커로 돌아가야 하는지 여부를 제어합니다.
참고failback은 실시간 백업 쌍(단일 백업 브로커와 페어링된 라이브 브로커)을 위한 것입니다. 라이브 브로커가 여러 백업으로 구성된 경우 failback이 발생하지 않습니다. 대신 장애 조치 이벤트가 발생하면 백업 브로커가 활성화되고 다음 백업이 백업이 됩니다. 원래 라이브 브로커가 다시 온라인 상태가 되면 현재 살고 있는 브로커에 이미 백업이 있기 때문에 역백을 시작할 수 없습니다.
group-name- 이 Live-backup 그룹의 이름입니다(선택 사항). 라이브 백업 그룹을 만들려면 동일한 그룹 이름으로 실시간 및 백업 브로커를 구성해야 합니다. 그룹 이름을 지정하지 않으면 백업 브로커는 라이브 브로커와 복제할 수 있습니다.
vote-on-replication-failure이 속성은 활성 브로커가 중단된 복제 연결 시 실시간 투표 라는 쿼럼을 시작할지 여부를 제어합니다. 활성 상태가 된 백업 브로커는 라이브 브로커로 간주되며 라이브 투표가 시작될 수 있습니다.
실시간 투표는 라이브 브로커가 복제 연결 중단의 원인인지 여부를 결정하는 방법입니다. 투표 결과에 따라 라이브 브로커는 계속 실행 중이거나 종료됩니다.
(선택 사항) 백업 브로커가 시작하는 쿼럼 투표의 속성을 구성합니다.
<configuration> <core> ... <ha-policy> <replication> <slave> ... <vote-retries>12</vote-retries> <vote-retry-wait>5000</vote-retry-wait> ... </slave> </replication> </ha-policy> ... </core> </configuration>vote-retries- 이 속성은 백업 브로커를 시작할 수 있는 대부분의 결과를 받기 위해 백업 브로커가 쿼럼을 다시 시도하는 횟수를 제어합니다.
vote-retry-wait- 이 속성은 쿼럼 투표의 각 재시도 사이에 백업 브로커가 대기하는 시간(밀리초)을 제어합니다.
백업 브로커의 추가 HA 속성을 구성합니다.
이러한 추가 HA 속성에는 대부분의 일반적인 사용 사례에 적합한 기본값이 있습니다. 따라서 기본 동작을 원하지 않는 경우에만 이러한 속성을 구성해야 합니다. 자세한 내용은 부록 F. 추가 복제 고가용성 구성 ScanSetting의 내용을 참조하십시오.
-
라이브 브로커의 <
클러스터의 추가 라이브 백업 그룹에 대해 2단계를 반복합니다.
클러스터에 6개의 브로커가 있는 경우 나머지 각 Live-backup 그룹에 대해 이 절차를 두 번 더 반복합니다.
추가 리소스
- HA에 복제를 사용하는 브로커 클러스터의 예는 HA 예제 프로그램을 참조하십시오.
- 노드 ID에 대한 자세한 내용은 노드 ID 이해를 참조하십시오.
14.3.4. 라이브 전용으로 제한된 고가용성 구성
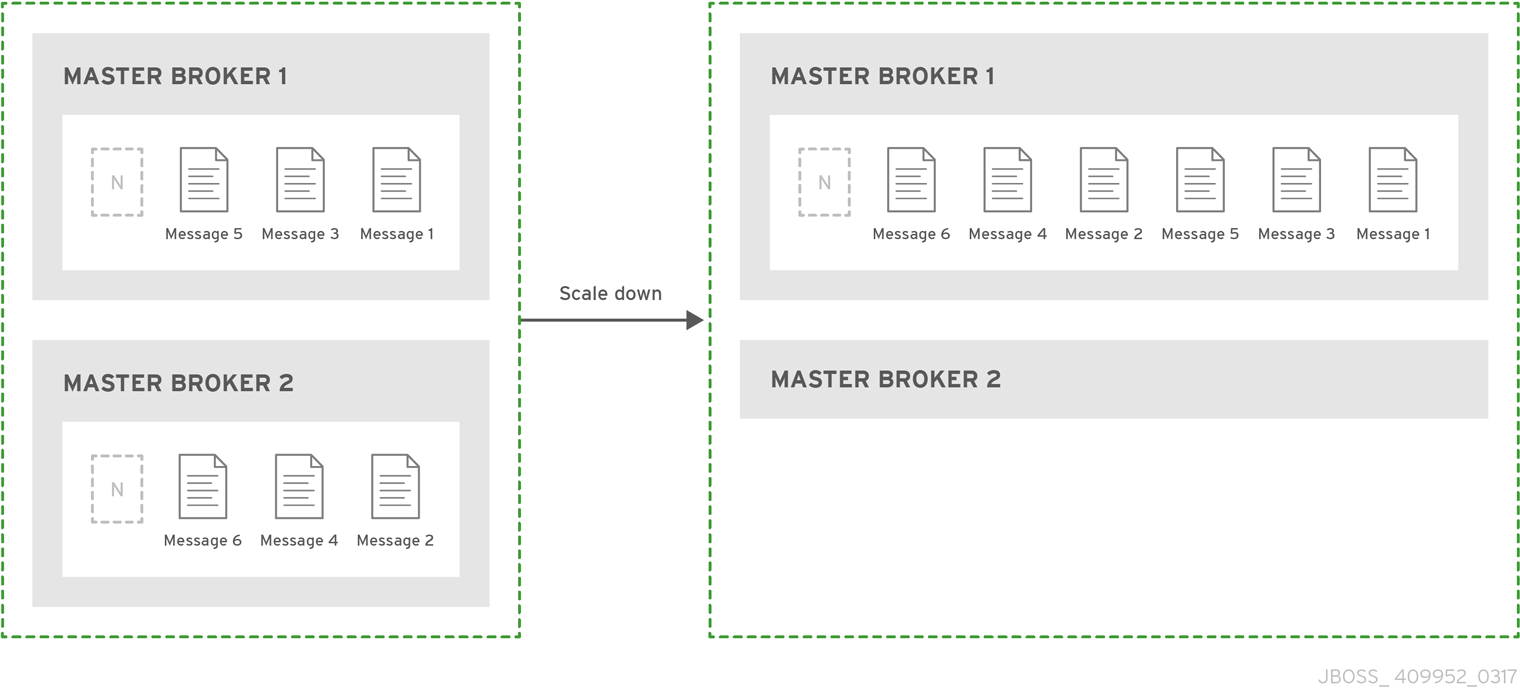
실시간 전용 HA 정책을 사용하면 메시지를 손실하지 않고 클러스터의 브로커를 종료할 수 있습니다. 라이브 전용을 사용하면 라이브 브로커가 정상적으로 중지되면 해당 메시지 및 트랜잭션 상태를 다른 라이브 브로커에 복사한 다음 종료합니다. 그러면 클라이언트가 다른 브로커에 다시 연결하여 메시지를 계속 전송 및 수신할 수 있습니다.
라이브 전용 HA 정책은 브로커가 정상적으로 중지된 경우에만 사례를 처리합니다. 예기치 않은 브로커 오류를 처리하지 않습니다.
라이브 전용 HA는 메시지 손실을 방지하지만 메시지 순서를 보존하지 않을 수 있습니다. 실시간 전용 HA로 구성된 브로커가 중지되면 다른 브로커의 대기열 끝에 메시지가 추가됩니다.
브로커가 축소를 준비하면 클라이언트가 메시지를 처리할 준비가 되었는지 알려주기 전에 메시지를 전달합니다. 그러나 클라이언트는 초기 브로커의 축소를 완료한 후에만 새 브로커에 다시 연결해야 합니다. 이렇게 하면 클라이언트가 다시 연결할 때 대기열 또는 트랜잭션과 같은 모든 상태를 다른 브로커에서 사용할 수 있습니다. 일반 재연결 설정은 클라이언트가 다시 연결할 때 적용되므로 규모를 축소하는 데 필요한 시간을 처리할 수 있도록 충분히 높은 설정을 설정해야 합니다.
다음 절차에서는 축소하도록 클러스터의 각 브로커를 구성하는 방법을 설명합니다. 이 절차를 완료한 후 브로커가 정상적으로 중지될 때마다 해당 메시지와 트랜잭션 상태를 클러스터의 다른 브로커로 복사합니다.
절차
-
첫 번째 브로커의 <
broker_instance_dir> /etc/broker.xml구성 파일을 엽니다. 라이브 전용 HA 정책을 사용하도록 브로커를 구성합니다.
<configuration> <core> ... <ha-policy> <live-only> </live-only> </ha-policy> ... </core> </configuration>브로커 클러스터를 축소하는 방법을 구성합니다.
이 브로커를 축소해야 하는 브로커 또는 브로커 그룹을 지정합니다.
Expand 를…으로 축소하려면 다음을 수행합니다. 이 작업을 수행합니다. 클러스터의 특정 브로커
축소할 브로커의 커넥터를 지정합니다.
<live-only> <scale-down> <connectors> <connector-ref>broker1-connector</connector-ref> </connectors> </scale-down> </live-only>클러스터의 모든 브로커
브로커 클러스터의 검색 그룹을 지정합니다.
<live-only> <scale-down> <discovery-group-ref discovery-group-name="my-discovery-group"/> </scale-down> </live-only>특정 브로커 그룹의 브로커
브로커 그룹을 지정합니다.
<live-only> <scale-down> <group-name>my-group-name</group-name> </scale-down> </live-only>- 클러스터의 나머지 각 브로커에 대해 이 절차를 반복합니다.
추가 리소스
- 라이브 전용을 사용하여 클러스터를 축소하는 브로커 클러스터의 예는 스케일 다운 예제 프로그램을 참조하십시오.
14.3.5. 일관된 백업으로 고가용성 구성
실시간 백업 그룹을 구성하는 대신 다른 라이브 브로커와 동일한 JVM에 백업 브로커를 공동 배치할 수 있습니다. 이 구성에서 각 라이브 브로커는 JVM에서 백업 브로커를 생성하고 시작하도록 다른 라이브 브로커를 요청하도록 구성됩니다.
그림 14.4. 공동 배치 라이브 및 백업 브로커
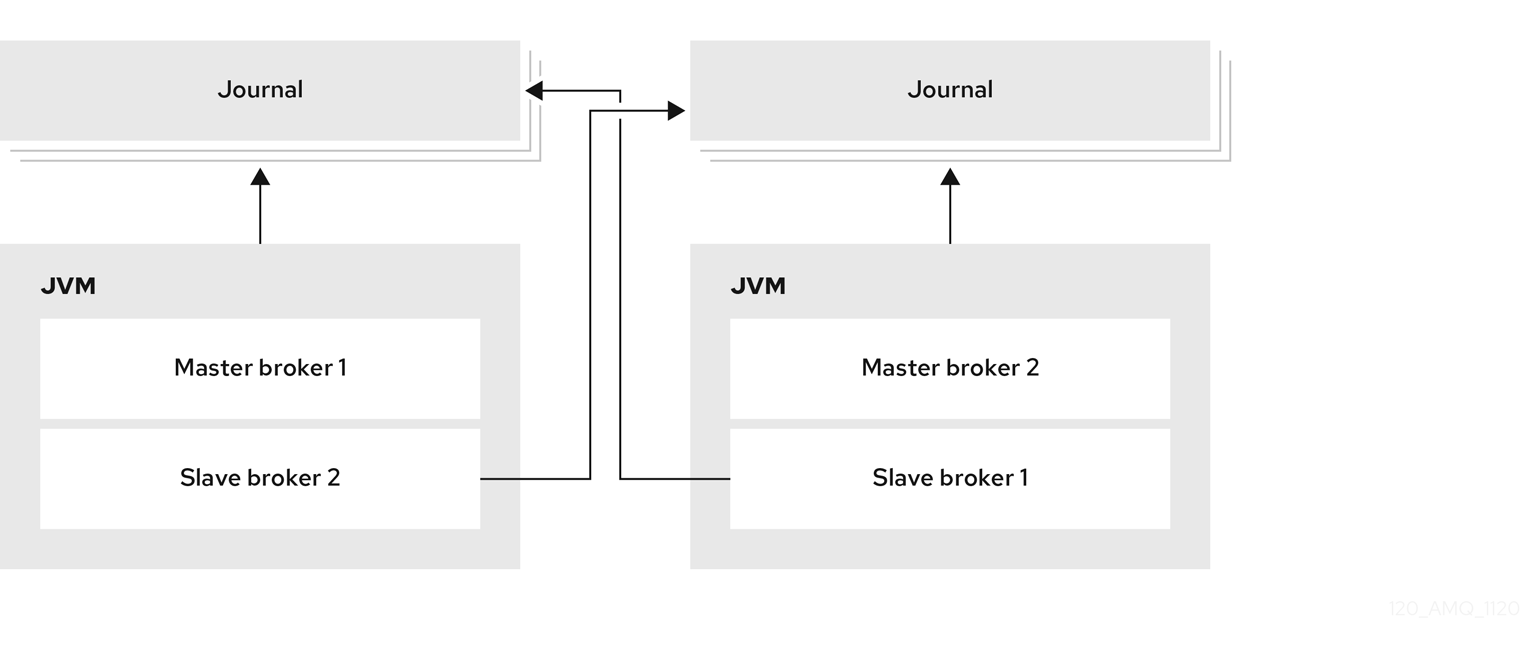
공유 저장소 또는 복제와 함께 HA(고가용성) 정책으로 colocation을 사용할 수 있습니다. 새 백업 브로커는 이를 생성하는 라이브 브로커의 구성을 상속합니다. 백업 이름은 co places_backup_n 으로 설정됩니다. 여기서 n 은 라이브 브로커가 생성한 백업 수입니다.
또한 백업 브로커는 해당 커넥터 및 어셉터를 생성하는 라이브 브로커의 구성을 상속합니다. 기본적으로 100의 포트 오프셋은 각각에 적용됩니다. 예를 들어 라이브 브로커에 포트 61616에 대한 어셉터가 있으면 생성된 첫 번째 백업 브로커가 포트 61716을 사용하는 경우 두 번째 백업은 61816을 사용하는 등의 작업을 수행합니다.
저널, 대용량 메시지 및 페이징의 디렉터리는 선택한 HA 정책에 따라 설정됩니다. 공유 저장소를 선택하는 경우 요청 브로커는 대상 브로커에 사용할 디렉터리를 알립니다. 복제를 선택하면 디렉터리가 생성 브로커에서 상속되고 새 백업의 이름이 추가됩니다.
이 절차에서는 클러스터의 각 브로커가 공유 저장소 HA를 사용하고 클러스터의 다른 브로커와 함께 생성 및 배치되도록 백업을 요청합니다.
절차
-
첫 번째 브로커의 <
broker_instance_dir> /etc/broker.xml구성 파일을 엽니다. HA 정책 및 공동 할당을 사용하도록 브로커를 구성합니다.
이 예제에서 브로커는 공유 저장소 HA 및 공동 배치로 구성됩니다.
<configuration> <core> ... <ha-policy> <shared-store> <colocated> <request-backup>true</request-backup> <max-backups>1</max-backups> <backup-request-retries>-1</backup-request-retries> <backup-request-retry-interval>5000</backup-request-retry-interval/> <backup-port-offset>150</backup-port-offset> <excludes> <connector-ref>remote-connector</connector-ref> </excludes> <master> <failover-on-shutdown>true</failover-on-shutdown> </master> <slave> <failover-on-shutdown>true</failover-on-shutdown> <allow-failback>true</allow-failback> <restart-backup>true</restart-backup> </slave> </colocated> </shared-store> </ha-policy> ... </core> </configuration>request-backup-
이 속성을
true로 설정하면 이 브로커는 클러스터의 다른 라이브 브로커에 의해 백업 브로커를 생성할 것을 요청합니다. max-backups-
이 브로커가 생성할 수 있는 백업 브로커 수입니다. 이 속성을
0으로 설정하면 이 브로커는 클러스터의 다른 브로커의 백업 요청을 수락하지 않습니다. backup-request-retries-
이 브로커가 백업 브로커를 생성하도록 요청해야 하는 횟수입니다. 기본값은
-1이며 이는 무제한 시도를 의미합니다. backup-request-retry-interval-
브로커가 백업 브로커를 생성하는 요청을 재시도하기 전에 대기해야 하는 시간(밀리초)입니다. 기본값은
5000초 또는 5초입니다. backup-port-offset-
새 백업 브로커에 대한 어셉터 및 커넥터에 사용할 포트 오프셋입니다. 이 브로커가 클러스터의 다른 브로커에 대한 백업을 생성하는 요청을 수신하면 이 양에 따라 포트 오프셋으로 백업 브로커를 생성합니다. 기본값은
100입니다. 제외(선택 사항)-
백업 포트 오프셋에서 커넥터를 제외합니다. 백업 포트 오프셋에서 제외해야 하는 외부 브로커를 위한 커넥터를 구성한 경우 각 커넥터에 대해 <
connector-ref>를 추가합니다. master- 이 브로커의 공유 저장소 또는 복제 장애 조치 구성입니다.
slave- 이 브로커의 백업에 대한 공유 저장소 또는 복제 장애 조치 구성입니다.
- 클러스터의 나머지 각 브로커에 대해 이 절차를 반복합니다.
추가 리소스
- 공동 배치 백업을 사용하는 브로커 클러스터의 예는 HA 예제 프로그램을 참조하십시오.
14.3.6. 장애 조치(failover)를 수행하도록 클라이언트 구성
브로커 클러스터에서 고가용성을 구성한 후 페일오버하도록 클라이언트를 구성합니다. 클라이언트 장애 조치를 사용하면 브로커가 실패하면 연결된 클라이언트가 최소 다운 타임으로 클러스터의 다른 브로커에 다시 연결할 수 있습니다.
일시적인 네트워크 문제가 발생하는 경우 AMQ Broker는 동일한 브로커에 연결을 자동으로 다시 연결합니다. 이는 클라이언트가 동일한 브로커에 다시 연결하는 경우를 제외하고 장애 조치와 유사합니다.
두 가지 유형의 클라이언트 장애 조치를 구성할 수 있습니다.
- 자동 클라이언트 페일오버
- 클라이언트에서 처음 연결할 때 브로커 클러스터에 대한 정보를 받습니다. 연결된 브로커가 실패하면 클라이언트는 브로커의 백업에 자동으로 다시 연결하고 백업 브로커는 장애 조치 전에 각 연결에 존재하는 모든 세션과 소비자를 다시 만듭니다.
- 애플리케이션 수준 클라이언트 장애 조치
- 자동 클라이언트 장애 조치(Failover) 대신 실패 처리기에서 자체 사용자 지정 다시 연결 논리를 사용하여 클라이언트 애플리케이션을 코딩할 수 있습니다.As an alternative to automatic client failover, you can instead code your client applications with your own custom reconnection logic in a failure handler.
절차
AMQ Core Protocol JMS를 사용하여 자동 또는 애플리케이션 수준 페일오버로 클라이언트 애플리케이션을 구성합니다.
자세한 내용은 AMQ Core Protocol JMS 클라이언트 사용을 참조하십시오.