14장. 브로커 클러스터 설정
클러스터는 함께 그룹화된 여러 브로커 인스턴스로 구성됩니다. 브로커 클러스터는 메시지 처리 부하를 여러 브로커에 분산하여 성능을 향상시킵니다. 또한 브로커 클러스터는 고가용성을 통해 다운타임을 최소화할 수 있습니다.
브로커를 다양한 클러스터 토폴로지에서 함께 연결할 수 있습니다. 클러스터 내에서 각 활성 브로커는 자체 메시지를 관리하고 자체 연결을 처리합니다.
클러스터 전체의 클라이언트 연결의 균형을 유지하고 메시지를 재배포하여 브로커 부족을 방지할 수도 있습니다.
14.1. 브로커 클러스터 이해
브로커 클러스터를 생성하기 전에 몇 가지 중요한 클러스터링 개념을 이해해야 합니다.
14.1.1. 브로커 클러스터의 메시지 로드 밸런싱 방법
브로커가 클러스터를 형성하기 위해 연결되면 AMQ Broker는 브로커 간 메시지 부하를 자동으로 분산합니다. 이렇게 하면 클러스터가 높은 메시지 처리량을 유지할 수 있습니다.
4 개의 브로커로 구성된 대칭 클러스터를 고려하십시오. 각 브로커는 OrderQueue 라는 큐로 구성됩니다. OrderProducer 클라이언트는 Broker1 에 연결하고 메시지를 OrderQueue 에 보냅니다. Broker1 은 라운드 로빈 방식으로 메시지를 다른 브로커로 전달합니다. 각 브로커에 연결된 OrderConsumer 클라이언트는 메시지를 사용합니다.
그림 14.1. 메시지 로드 밸런싱
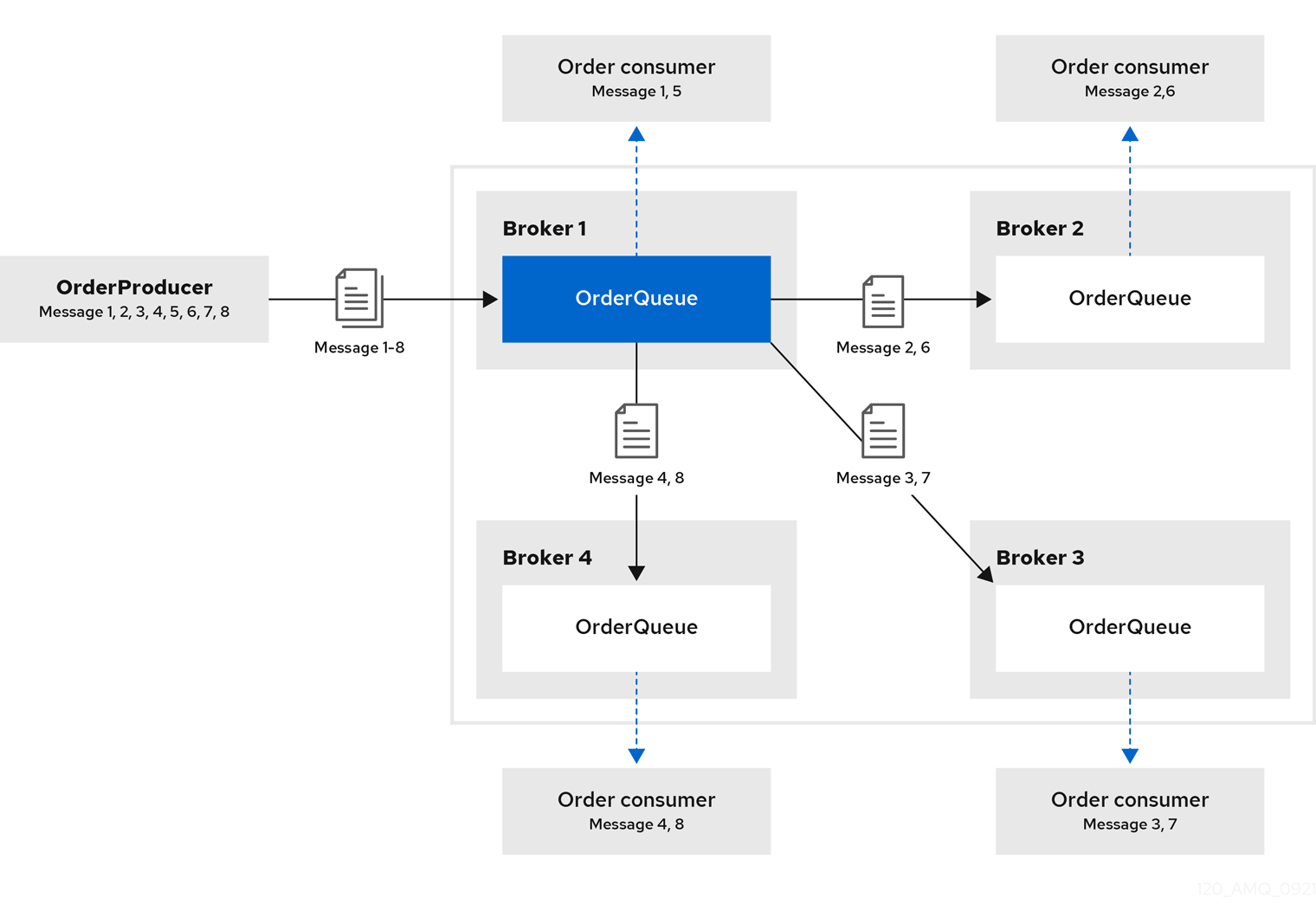
메시지 부하 분산을 사용하지 않으면 Broker1 으로 전송된 메시지가 Broker1 에 남아 있으며 OrderConsumer1 만 사용할 수 있습니다.
AMQ Broker는 첫 번째 브로커에 첫 번째 메시지 그룹을 배포하고 두 번째 브로커에 두 번째 메시지 그룹에 메시지를 자동으로 로드 밸런싱합니다. 브로커가 시작된 순서는 브로커가 첫 번째, 두 번째 등의 브로커를 결정합니다.
다음을 구성할 수 있습니다.
- 일치하는 큐가 있는 브로커에 메시지를 로드 밸런싱하는 클러스터입니다.
- 활성 소비자와 일치하는 큐가 있는 브로커에 메시지를 로드 밸런싱하는 클러스터입니다.
- 클러스터는 부하 분산이 아니라 소비자가 있는 큐에 대한 소비자가 없는 대기열에서 메시지 재배포를 수행합니다.
- 소비자가 없는 큐의 메시지를 소비자가 있는 큐에 자동으로 재배포하는 주소입니다.
추가 리소스
-
메시지 로드 밸런싱 정책은 각 브로커의 클러스터 연결에서
message-load-balancing속성을 사용하여 구성됩니다. 자세한 내용은 부록 C. 클러스터 연결 구성 CloudEvent의 내용을 참조하십시오. - 메시지 재배포에 대한 자세한 내용은 14.4.2절. “메시지 재배포 구성” 을 참조하십시오.
14.1.2. 브로커 클러스터가 안정성을 개선하는 방법
브로커 클러스터는 고가용성과 페일오버를 가능하게 하여 독립 실행형 브로커보다 더 안정적입니다. 고가용성을 구성하면 브로커가 실패 이벤트가 발생하더라도 클라이언트 애플리케이션이 메시지를 계속 보내고 받을 수 있는지 확인할 수 있습니다.
고가용성을 통해 클러스터의 브로커는 실시간 백업 그룹으로 그룹화됩니다. 실시간 백업 그룹은 클라이언트 요청에 서비스를 제공하는 라이브 브로커와 실패할 경우 라이브 브로커를 교체하기 위해 수동적으로 기다리는 하나 이상의 백업 브로커로 구성됩니다. 오류가 발생하면 백업 브로커는 라이브 백업 그룹의 라이브 브로커를 대체하고 클라이언트가 다시 연결 및 작업을 계속합니다.
14.1.3. 클러스터 제한 사항
다음 제한은 클러스터된 환경에서 AMQ 브로커를 사용하는 경우 적용됩니다.
- 임시 대기열
- 장애 조치 중에 클라이언트에 임시 큐를 사용하는 소비자가 있는 경우 이러한 대기열은 자동으로 다시 생성됩니다. 다시 생성된 큐 이름이 원래 큐 이름과 일치하지 않아 메시지 재배포가 실패하고 기존 임시 큐에 설정된 메시지를 유지할 수 있습니다. 클러스터에서 임시 대기열을 사용하지 않는 것이 좋습니다. 예를 들어 요청/응답 패턴을 사용하는 애플리케이션은 JMSReplyTo 주소에 고정 대기열을 사용해야 합니다.
14.1.4. 노드 ID 이해
브로커 노드 ID 는 브로커 인스턴스의 저널을 처음 생성하고 초기화할 때 프로그래밍 방식으로 생성된 GUID(Globally Unique Identifier)입니다. 노드 ID는 server.lock 파일에 저장됩니다. 노드 ID는 브로커가 독립 실행형 인스턴스인지 클러스터의 일부인지에 관계없이 브로커 인스턴스를 고유하게 식별하는 데 사용됩니다. Live-backup 브로커 쌍은 동일한 저널을 공유하므로 동일한 노드 ID를 공유합니다.
브로커 클러스터의 브로커 인스턴스(노드)는 서로 연결되고 브리지 및 내부 "store-and-forward" 대기열을 생성합니다. 이러한 내부 대기열의 이름은 다른 브로커 인스턴스의 노드 ID를 기반으로 합니다. 브로커 인스턴스는 자체와 일치하는 노드 ID에 대한 클러스터 브로드캐스트도 모니터링합니다. 브로커는 중복 ID를 식별하는 경우 로그에 경고 메시지를 생성합니다.
HA(복제 고가용성) 정책을 사용하는 경우 시작하고 check-for-live-server 가 true 로 설정된 마스터 브로커는 노드 ID를 사용하는 브로커를 true로 설정합니다. 마스터 브로커가 동일한 노드 ID를 사용하여 다른 브로커를 찾으면 시작되지 않거나 HA 구성에 따라 역백을 시작합니다.
노드 ID는 pacemaker 입니다. 즉, 브로커의 재시작이 유지됩니다. 그러나 브로커 인스턴스(일 저널 포함)를 삭제하면 노드 ID도 영구적으로 삭제됩니다.
추가 리소스
- 복제 HA 정책 구성에 대한 자세한 내용은 복제 고가용성 구성을 참조하십시오.
14.1.5. 공통 브로커 클러스터 토폴로지
브로커를 연결하여 대칭 또는 체인 클러스터 토폴로지를 구성할 수 있습니다. 구현하는 토폴로지는 환경 및 메시징 요구 사항에 따라 다릅니다.
대칭 클러스터
대칭 클러스터에서는 모든 브로커가 다른 모든 브로커에 연결됩니다. 즉, 모든 브로커는 다른 브로커에서 하나 이상의 홉 떨어져 있지 않습니다.
그림 14.2. 대칭 클러스터
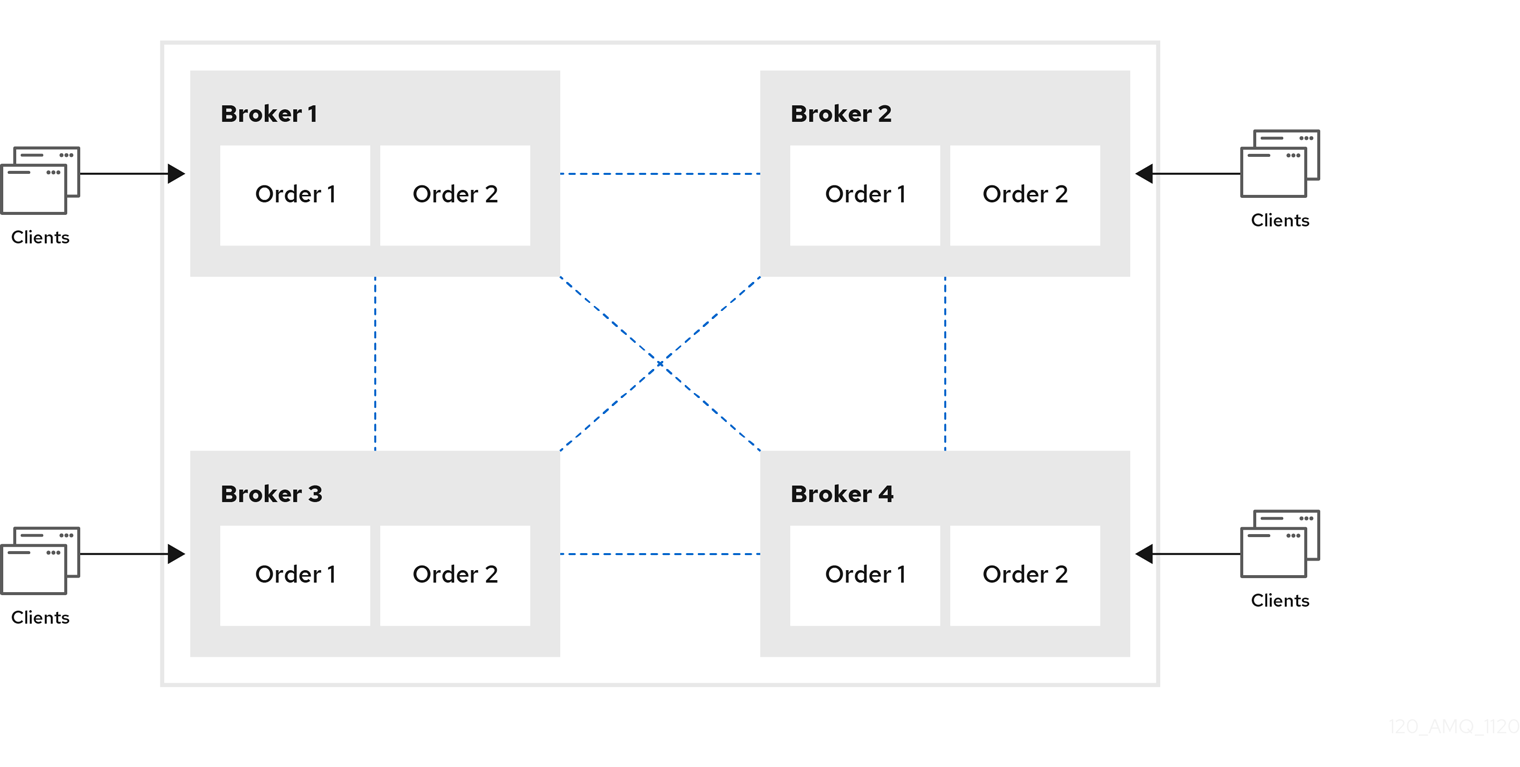
대칭 클러스터의 각 브로커는 클러스터의 다른 모든 브로커와 해당 큐에서 청취하는 소비자에 존재하는 모든 큐를 알고 있습니다. 따라서 대칭 클러스터에서는 체인 클러스터보다 메시지를 더 최적으로 로드 밸런싱하고 재배포할 수 있습니다.
대칭 클러스터는 체인 클러스터보다 설정하기 쉽지만 네트워크 제한으로 인해 브로커가 직접 연결되지 않는 환경에서 사용하기 어려울 수 있습니다.
체인 클러스터
체인 클러스터에서 클러스터의 각 브로커는 클러스터의 모든 브로커에 직접 연결되지 않습니다. 대신 브로커는 체인의 각 끝에 브로커와 체인을 형성하고 다른 모든 브로커는 체인의 이전 브로커 및 다음 브로커에 연결하기 만합니다.
그림 14.3. 체인 클러스터
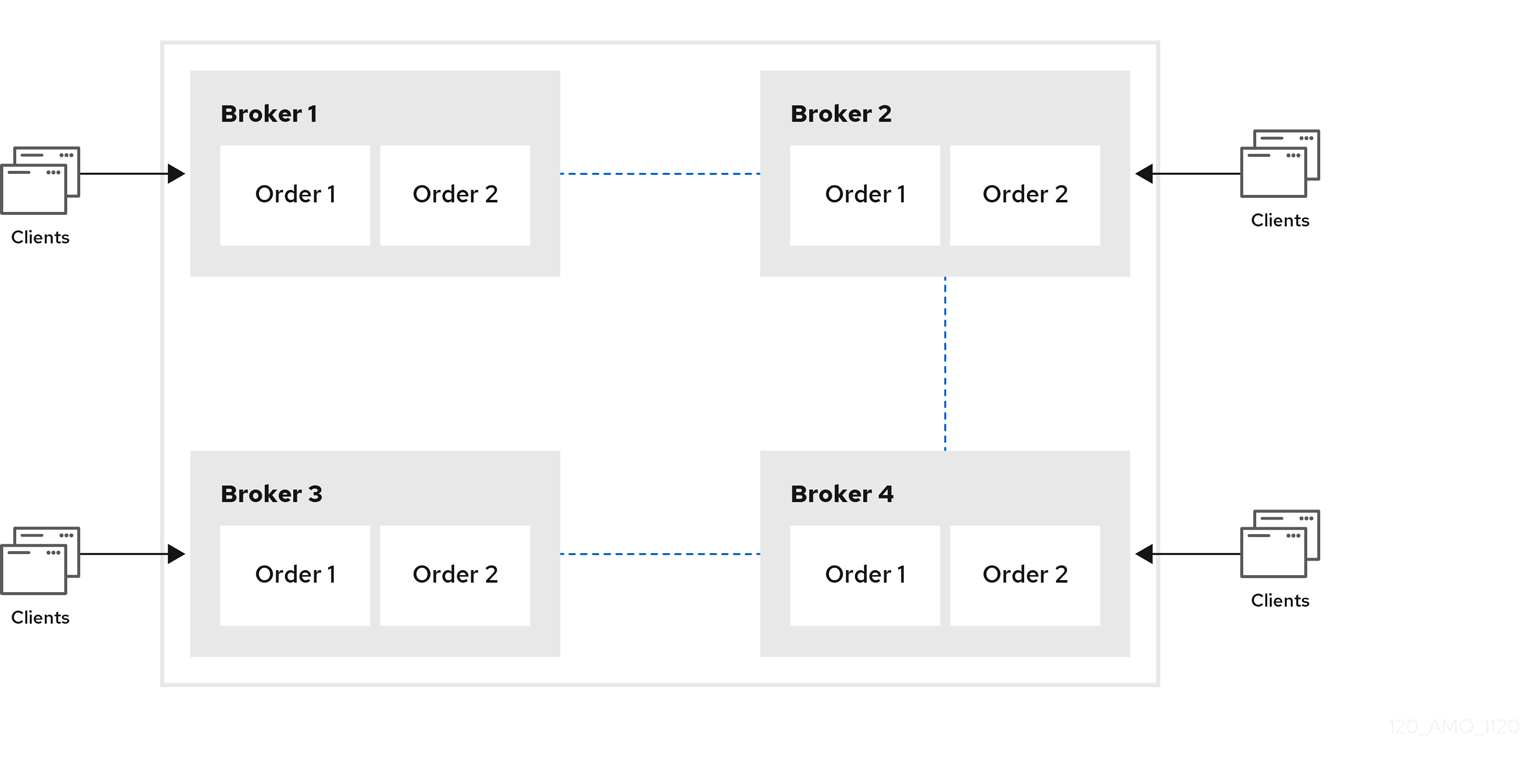
체인 클러스터는 대칭 클러스터보다 설정하기가 더 어렵지만 브로커가 별도의 네트워크에 있고 직접 연결할 수 없는 경우 유용할 수 있습니다. 체인 클러스터를 사용하면 중개 브로커는 두 브로커를 간접적으로 연결하여 두 브로커가 직접 연결되지 않은 경우에도 메시지 간에 전달될 수 있습니다.
14.1.6. 브로커 검색 방법
Discovery는 클러스터의 브로커가 연결 세부 정보를 서로 전파하는 메커니즘입니다. AMQ Broker는 동적 검색 및 정적 검색을 모두 지원합니다.
동적 검색
클러스터의 각 브로커는 UDP 멀티 캐스트 또는ECDHE를 통해 다른 멤버에 대한 연결 설정을 브로드캐스트합니다. 이 방법에서는 각 브로커가 다음을 사용합니다.
- 클러스터 연결에 대한 정보를 클러스터의 다른 잠재적 멤버에 푸시하는 브로드캐스트 그룹입니다.
- 클러스터의 다른 브로커에 대한 클러스터 연결 정보를 수신하고 저장하는 검색 그룹입니다.
정적 검색
네트워크에서 UDP 또는ECDHE를 사용할 수 없거나 클러스터의 각 멤버를 수동으로 지정하려면 정적 검색을 사용할 수 있습니다. 이 방법에서는 두 번째 브로커에 연결하고 연결 세부 정보를 전송하여 브로커가 클러스터에 "가져오기"합니다. 그런 다음 두 번째 브로커는 이러한 세부 사항을 클러스터의 다른 브로커에 전파합니다.
14.1.7. 클러스터 크기 조정 고려 사항
브로커 클러스터를 생성하기 전에 메시징 처리량, 토폴로지 및 고가용성 요구 사항을 고려하십시오. 이러한 요소는 클러스터에 포함할 브로커 수에 영향을 미칩니다.
클러스터를 생성한 후 브로커를 추가하고 제거하여 크기를 조정할 수 있습니다. 메시지를 손실하지 않고 브로커를 추가하고 제거할 수 있습니다.
메시징 처리량
클러스터에는 필요한 메시징 처리량을 제공하기에 충분한 브로커가 포함되어야 합니다. 클러스터에서 브로커가 많을수록 처리량이 증가합니다. 그러나 대규모 클러스터는 관리하기가 복잡할 수 있습니다.
토폴로지
대칭 클러스터 또는 체인 클러스터를 생성할 수 있습니다. 선택한 토폴로지 유형은 필요한 브로커 수에 영향을 미칩니다.
자세한 내용은 14.1.5절. “공통 브로커 클러스터 토폴로지”의 내용을 참조하십시오.
고가용성
HA(고가용성)가 필요한 경우 클러스터를 생성하기 전에 HA 정책을 선택하는 것이 좋습니다. 각 마스터 브로커에는 하나 이상의 슬레이브 브로커가 있어야 하므로 HA 정책은 클러스터 크기에 영향을 미칩니다.
자세한 내용은 14.3절. “고가용성 구현”의 내용을 참조하십시오.