1.8. LVS (Linux Virtual Server)
LVS (Linux Virtual Server)는 실제 서버를 통해 IP 로드 밸런스를 맞추기 위한 통합된 소프트웨어 구성 요소 모음입니다. LVS는 동일하게 설정된 한 쌍의 컴퓨터 상에서 실행됩니다: 즉 하나는 활성 LVS 라우터이고 다른 하나는 백업 LVS 라우터이어야 합니다. 활성 LVS 라우터는 두가지 역할을 수행합니다:
- 실제 서버를 통한 로드 밸런스
- 각각의 실제 서버에서의 서비스 무결성 확인
백업 LVS 라우터는 활성 LVS 라우터를 모니터하고 활성 LVS 라우터에 문제가 발생할 경우 백업됩니다.
그림 1.19. “Components of a Running LVS Cluster” provides an overview of the LVS components and their interrelationship.
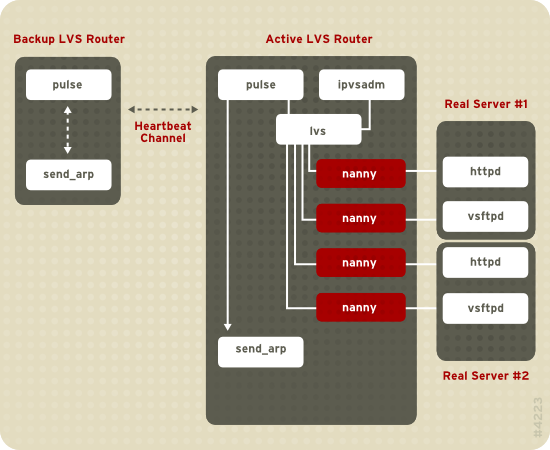
그림 1.19. Components of a Running LVS Cluster
pulse 데몬은 활성 및 비활성 LVS 라우터에서 실행됩니다. 백업 LVS 라우터에서 pulse는 활성 라우터의 공개 인터페이스로 heartbeat를 보내어 활성 LVS 라우터가 올바르게 작동하는 지를 확인합니다. 활성 LVS 라우터에서 pulse는 lvs 데몬을 시작하고 백업 LVS 라우터에서의 heartbeat 쿼리에 응답합니다.
일단
lvs 데몬이 시작되면 이는 ipvsadm 유틸리티를 호출하여 커널에 있는 IPVS (IP Virtual Server) 라우팅 테이블을 설정 및 관리하고 각각의 실제 서버에 있는 설정된 가상 서버에 필요한 nanny 프로세스를 시작합니다. 각각의 nanny 프로세스는 하나의 실제 서버에서 설정된 서비스의 상태를 확인하고 실제 서버에 있는 서비스가 잘 작동하지 않을 경우 lvs 데몬에 보고합니다. 작동 불량 사항이 발견되면, lvs 데몬은 ipvsadm에 지시하여 IPVS 라우팅 테이블에서 실제 서버를 삭제합니다.
백업 LVS 라우터가 활성 LVS 라우터에서 응답을 받지 못하면, 모든 가상 IP 주소를 백업 LVS 라우터의 NIC 하드웨어 주소 (MAC 주소)로 다시 지정하기 위해
send_arp를 호출하여 장애조치를 시작하고, 활성 LVS 라우터에 있는 lvs 데몬을 종료하기 위해 공개 및 개인 네트워크 인터페이스를 통해 활성 LVS 라우터에 명령을 보낸 후, 설정된 가상 서버의 요청을 수락하기 위해 백업 LVS 라우터에 있는 lvs 데몬을 시작합니다.
호스트 서비스 (예: 웹사이트 또는 데이터베이스 어플리케이션)에 액세스하는 외부 사용자에게 LVS는 하나의 서버로 나타납니다. 하지만, 사용자는 실제적으로 LVS 라우터 뒤에 있는 실제 서버에 액세스하게 됩니다.
실제 서버에 있는 데이터를 공유하기 위해 LVS에 내장된 구성 요소가 없기 때문에 다음과 같은 두가지 옵션이 필요합니다:
- 실제 서버를 통한 데이터 동기화
- 공유된 데이터 액세스에 필요한 토폴로지에 세번째 레이어 추가
첫 번째 옵션은 다수의 사용자가 실제 서버에서 업로드하거나 데이터를 변경하는 것을 허용하지 않는 서버에 적합합니다. 실제 서버에서 다수의 사용자가 데이터를 수정할 수 있게 할 경우 (예: 전자 상거래 웹사이트) 세번째 레이어를 추가하는 것이 좋습니다.
실제 서버에서 데이터를 동기화하는 방법에는 여러 가지가 있습니다. 예를 들어, 쉘 스크립트를 사용하여 동시에 실제 서버에 업데이트된 웹 페이지를 게시할 수 있습니다. 또한,
rsync와 같은 프로그램을 사용하여 일정 간격으로 모든 노드에 걸쳐 변경된 데이터를 복사할 수 있습니다. 하지만, 사용자가 수시로 파일을 업로드하거나 데이터베이스를 처리해야 하는 상황에서 데이터 동기화를 위해 스크립트를 사용하거나 또는 rsync을 사용하는 것은 동기화 기능을 최적화하지 못합니다. 따라서, 과중한 업로드, 데이터 베이스 처리량, 소통량이 있는 실제 서버에서는 데이터 동기화를 위해 3-tier 토폴로지를 사용하는 것이 좋습니다.
1.8.1. Two-Tier LVS Topology
링크 복사링크가 클립보드에 복사되었습니다!
그림 1.20. “Two-Tier LVS Topology” shows a simple LVS configuration consisting of two tiers: LVS routers and real servers. The LVS-router tier consists of one active LVS router and one backup LVS router. The real-server tier consists of real servers connected to the private network. Each LVS router has two network interfaces: one connected to a public network (Internet) and one connected to a private network. A network interface connected to each network allows the LVS routers to regulate traffic between clients on the public network and the real servers on the private network. In 그림 1.20. “Two-Tier LVS Topology”, the active LVS router uses Network Address Translation (NAT) to direct traffic from the public network to real servers on the private network, which in turn provide services as requested. The real servers pass all public traffic through the active LVS router. From the perspective of clients on the public network, the LVS router appears as one entity.
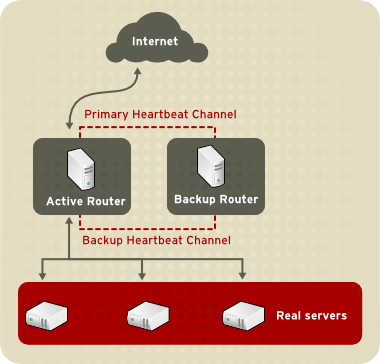
그림 1.20. Two-Tier LVS Topology
LVS 라우터로 들어온 서비스 요청은 가상 IP 주소 또는 VIP에서 인식됩니다. 이는 공개적으로 라우팅할 수 있는 주소로 사이트의 관리자가 www.example.com와 같은 FQDN (fully-qualified domain name)으로 연관지어 하나 이상의 가상 서버로 지정합니다. [1] VIP 주소는 장애 조치를 하는 동안 하나의 LVS 라우터에서 다른 라우터로 이전시키게 되므로 해당 IP 주소로 현재 위치를 유지하게 됩니다. 이를 유동 IP 주소라고 합니다.
VIP 주소는 LVS 라우터를 공개 네트워크로 연결시키는 장치와 같은 것으로 알리아스될 수 있습니다. 예를 들어, eth0가 인터넷에 연결되어 있을 경우, 여러 가상 서버는
eth0:1로 알리아스될 수 있습니다. 다른 방법으로 각각의 가상 서버는 서비스마다 분리된 장치와 연관시킬 수 있습니다. 예를 들어, HTTP 소통량은 eth0:1에서 처리될 수 있으며, FTP 소통량은 eth0:2에서 처리될 수 있습니다.
한번에 하나의 LVS 라우터만이 활성화됩니다. 활성화된 LVS 라우터의 역할은 가상 IP 주소에서 실제 서버로 서비스 요청을 보내는 것입니다. 이는 여덟개의 로드 밸런싱 알고리즘 중 하나에 기반합니다:
- 라운드 로빈 (Round-Robin) 스케줄링 — 각각의 요청을 실제 서버의 풀로 순차적으로 배분하는 방식입니다. 이러한 알고리즘을 사용하여 용량이나 부하량을 고려하지 않고 모든 실제 서버를 동일하게 다룹니다.
- 가중치 기반 라운드 로빈 (Round-Robin) 스케줄링 — 각각의 요청을 실제 서버의 풀로 순차적으로 배분하는 방식이지만 거대한 처리 용량으로 서버에 더 많은 작업을 배분합니다. 처리 용량은 사용자 지정 가중치 요인에 의해 나타나며 동적 부하 정보에 의해 상하로 조정됩니다. 이는 서버 풀에 있는 실제 서버의 용량이 다를 경우 선택할 수 있는 사항입니다. 하지만, 요청 부하량이 아주 다양할 경우, 더 가중치가 있는 서버가 서버의 공유 또는 요청량보다 더 많이 응답할 수 있습니다.
- 최소 접속 (Least-Connection) 스케줄링 — 가장 접속이 적은 실제 서버로 더 많은 요청을 배분하는 방식입니다. 이는 동적인 스케줄링 알고리즘 유형 중 하나로, 요청 부하에 극도로 다양한 처리량이 있을 경우 유용합니다. 각각의 서버 노드에 대략 비슷한 처리 용량이 있는 실제 서버 풀의 경우에도 적합합니다. 실제 서버가 다양한 처리 용량이 있고, 가중치 기반 최소 접속 스케줄링일 경우 아주 적합합니다.
- 가중치 기반 최소 접속 (Weighted Least-Connections) 스케줄링 (기본값) — 처리 용량과 관련하여 가장 접속이 적은 서버로 더 많은 요청을 배분하는 방식입니다. 처리 용량은 사용자 지정 가중치 요인에 의해 나타나며, 동적 부하 정보에 의해 상하로 조정됩니다. 실제 서버 풀에 다양한 처리 용량의 하드웨어가 있을 경우 이러한 알로리즘이 적합합니다.
- LBLC (Locality-Based Least-Connection) 스케줄링 — 목적지 IP와 관련하여 가장 접속이 적은 서버로 더 많은 요청을 배분하는 방식입니다. 이러한 알고리즘은 프록시-캐쉬 서버 클러스터에서 사용됩니다. 이는 서버가 서버 처리 용량을 초과하지 않고 반부하에 서버가 있지 않을 경우 IP 주소를 최소로 부하되는 실제 서버로 할당하게 되어 IP 주소에 대한 패킷을 해당 주소에 대한 서버로 라우팅합니다.
- LBLCR (Locality-Based Least-Connection with Replication) 스케줄링 — 목적지 IP와 관련하여 가장 접속이 적은 서버로 더 많은 요청을 배분하는 방식입니다. 이러한 알고리즘은 프록시-캐쉬 서버 클러스터에 사용됩니다. 대상 IP 주소를 실제 서버 노드의 서브셋으로 묶는 다는 점에서 LBLC 스케줄링과 다릅니다. 이는 서브셋에 있는 가장 접속이 적은 서버로 요청을 라우트합니다. 목적지 IP 주소에 대해 모든 노드가 처리 용량을 초과할 경우, 가장 접속이 적은 실제 서버를 실제 서버의 전체 풀에서 목적지 IP의 실제 서버에 대한 서브셋으로 추가하여 해당 목적지 IP 주소에 대한 새로운 서버를 복사합니다. 최고로 과부화된 노드는 실제 서버 서브셋에서 빠지게 됩니다.
- 소스 해쉬 (Source Hash) 스케줄링 — 정적 해쉬 테이블에 있는 소스 IP를 찾아 실제 서버의 풀로 요청을 배분하는 방식입니다. 이러한 알고리즘은 여러 방화벽이 있는 LVS 라우터에 사용됩니다.
또한, 활성화된 LVS 라우터는 send/expect 스크립트를 통해 실제 서버에 있는 특정 서비스의 전반적인 상태를 정적으로 모니터합니다. HTTPS나 SSL과 같은 정적인 데이터에 필요한 서비스의 상태를 점검하기 위해 외부에서 실행 가능하게 할 수 있습니다. 실제 서버에서의 서비스가 잘 작동하지 않을 경우, 활성화된 LVS 라우터는 서버가 정상적인 작동 상태로 돌아올 때 까지 실제 서버로의 작업 전송을 중단합니다.
백업 LVS 라우터는 대기 시스템의 역할을 실행합니다. 주기적으로 LVS 라우터는 주요 외부 공개 인터페이스, 장애 조치 상태, 개인 인터페이스를 통해 하트비트 메시지 (heartbeat message)를 교환합니다. 백업 LVS 라우터는 정해진 간격 내로 하트비트 메시지를 받지 못하면, 장애 조치를 초기화하고 활성화된 LVS 라우터의 역할을 실행합니다. 장애 조치가 진행되는 동안 백업 LVS 라우터는 ARP spoofing이라는 기술을 사용하여 장애가 발생한 라우터에 의해 VIP 주소를 전달 받게 됩니다. — 여기서 백업 LVS 라우터는 IP 패킷의 목적지를 장애가 발생한 노드로 지정했음을 알립니다. 장애가 발생한 노드가 정상으로 돌아오면, 백업 LVS 라우터는 다시 백업 역할을 실행하게 됩니다.
The simple, two-tier configuration in 그림 1.20. “Two-Tier LVS Topology” is suited best for clusters serving data that does not change very frequently — such as static web pages — because the individual real servers do not automatically synchronize data among themselves.