6.3. 도구
I/O 서브시스템에서 성능 문제를 진단하기 위한 여러 유용한 도구가 있습니다. vmstat는 시스템 성능에 대한 개요를 제공합니다. 다음의 칼럼은 I/O에 가장 관련되어 있습니다:
si (swap in), so (swap out), bi (block in), bo (block out), wa (I/O wait time). si 및 so는 스왑 공간이 데이터 파티션 및 전체 메모리 압력 표시자와 같은 장치에 있을 때 유용합니다. si 및 bi는 읽기 작업인 반면 so 및 bo는 쓰기 작업입니다. 각 카테고리는 킬로바이트 단위로 보고됩니다. wa는 대기 시간으로 실행 큐의 어느 부분이 I/O 완료를 기다리며 차단되어 있는지를 보여줍니다.
vmstat로 시스템을 분석하면 I/O 서브시스템이 성능 문제의 원인인지에 대한 여부를 알 수 있습니다.
free, buff, cache 칼럼도 눈여겨볼 만 합니다. cache 값이 bo 값과 함께 증가하고 이후에 cache가 감소하고 free가 증가하는 경우 시스템은 페이지 캐시의 비활성화 및 다시 쓰기를 실행하고 있음을 나타냅니다.
vmstat에 의해 보고되는 I/O 수는 모든 장치의 모든 I/O 합계임에 유의합니다. I/O 서브시스템에 성능 차이가 있을 수 있다고 판단되면 장치에 따라 I/O 보고를 분류하는 iostat로 문제를 보다 자세히 검사할 수 있습니다. 평균 요청 크기, 초 당 읽기 및 쓰기 수, 진행 중인 I/O 병합 양과 같은 보다 자세한 정보를 검색할 수 있습니다.
평균 요청 크기와 평균 큐 크기 (
avgqu-sz)를 사용하여 스토리지 성능을 특성화할 때 생성한 그래프를 사용하여 스토리지 성능을 예상할 수 있습니다. 여기서 일부 일반화가 적용됩니다. 예를 들어, 평균 요청 크기가 4KB이고 평균 큐 크기가 1일 경우 처리량이 매우 고성능일 가능성은 낮습니다.
성능 수가 예상 성능에 매핑되지 않는 경우, blktrace를 사용하여 보다 정교한 분석을 실행할 수 있습니다. blktrace 유틸리티는 I/O 서브시스템에 소요되는 시간에 대한 자세한 정보를 제공합니다. I/O에서의 출력은 바이너리 추적 파일 모음으로 이는 blkparse와 같은 다른 유틸리티를 사용하여 사후 처리할 수 있습니다.
blkparse는 blktrace에 동료 유틸리티입니다. 이는 추적에서 원 출력을 읽고 간략한 텍스트 버전을 만듭니다.
다음은 blktrace 출력의 예입니다:
8,64 3 1 0.000000000 4162 Q RM 73992 + 8 [fs_mark]
8,64 3 0 0.000012707 0 m N cfq4162S / alloced
8,64 3 2 0.000013433 4162 G RM 73992 + 8 [fs_mark]
8,64 3 3 0.000015813 4162 P N [fs_mark]
8,64 3 4 0.000017347 4162 I R 73992 + 8 [fs_mark]
8,64 3 0 0.000018632 0 m N cfq4162S / insert_request
8,64 3 0 0.000019655 0 m N cfq4162S / add_to_rr
8,64 3 0 0.000021945 0 m N cfq4162S / idle=0
8,64 3 5 0.000023460 4162 U N [fs_mark] 1
8,64 3 0 0.000025761 0 m N cfq workload slice:300
8,64 3 0 0.000027137 0 m N cfq4162S / set_active wl_prio:0 wl_type:2
8,64 3 0 0.000028588 0 m N cfq4162S / fifo=(null)
8,64 3 0 0.000029468 0 m N cfq4162S / dispatch_insert
8,64 3 0 0.000031359 0 m N cfq4162S / dispatched a request
8,64 3 0 0.000032306 0 m N cfq4162S / activate rq, drv=1
8,64 3 6 0.000032735 4162 D R 73992 + 8 [fs_mark]
8,64 1 1 0.004276637 0 C R 73992 + 8 [0]
출력 예에서 볼 수 있듯이 출력은 밀집되어 있어 읽기 어렵습니다. 어떤 프로세스가 장치에 I/O 출력을 실행하고 있는지를 아는데 유용하지만 blkparse를 사용하면 추가 정보 요약이 이해하기 쉬운 형식으로 제공됩니다. blkparse 요약 정보는 출력의 맨 마지막에 인쇄됩니다:
Total (sde):
Reads Queued: 19, 76KiB Writes Queued: 142,183, 568,732KiB
Read Dispatches: 19, 76KiB Write Dispatches: 25,440, 568,732KiB
Reads Requeued: 0 Writes Requeued: 125
Reads Completed: 19, 76KiB Writes Completed: 25,315, 568,732KiB
Read Merges: 0, 0KiB Write Merges: 116,868, 467,472KiB
IO unplugs: 20,087 Timer unplugs: 0
요약에서는 평균 I/O 비율, 병합 활동을 보여주며 읽기 워크로드와 쓰기 워크로드를 비교합니다. 하지만 대부분의 경우 blkparse 출력은 출력 자체를 사용하는데 너무 볼륨이 큽니다. 다행히 데이터를 시각화하는데 몇 가지 유용한 도구가 있습니다.
btt는 I/O 스택의 다른 영역에서 I/O가 소요한 시간에 대한 분석을 제공합니다. 이러한 영역은 다음과 같습니다:
- Q — 블록 I/O가 대기열에 있음
- G — 요청 취득새로 대기열이된 블록 I/O는 기존 요청과 병합하기 위한 후보가 아니기 때문에 새로운 블록 레이어 요청이 할당됩니다.
- M — 블록 I/O는 기존 요청과 병합됩니다.
- I — 요청이 장치 큐에 삽입됩니다.
- D — 요청이 장치에 발급됩니다.
- C — 요청은 드라이버에 의해 완료됩니다.
- P — 블럭 장치 큐가 연결되어 요청 집계를 허용합니다.
- U — 장치 큐가 연결 해제되어 장치에 발급된 요청 집계를 허용합니다.
btt는 각 영역간 이동에 소요된 시간 뿐 만 아니라 다른 영역에서 소요된 시간도 분류합니다:
- Q2Q — 블록 층에 전송된 요청 사이의 시간
- Q2G — 블록 I/O가 대기 상태에서 요청이 할당될 때 가지의 시간
- G2I — 요청이 할당되는 시간 부터 장치의 큐에 넣을 때 까지의 시간
- Q2M — 블록 I/O가 대기열에 있는 시간 부터 기존 요청과 병합될 때 까지의 시간
- I2D — 요청이 장치 큐에 삽입된 시간 부터 실제로 장치에 발급될 때 가지의 시간
- M2D — 블록 I/O가 기존 요청과 병합된 시간 부터 요청이 장치 발급될 때 까지의 시간
- D2C — 장치에서 요청된 서비스 시간
- Q2C — 요청에 대해 블록 층에서 총 소요된 시간
위의 표에서 워크로드에 대해 많은 것을 추론할 수 있습니다. 예를 들어, Q2Q가 Q2C 보다 훨씬 클 경우 이는 애플리케이션이 빠르게 연속으로 I/O를 실행하지 않는다는 것을 의미합니다. 즉, 성능 문제는 I/O 서브시스템과 전혀 관련되지 않을 수 있습니다. D2C가 매우 높은 경우 장치가 요청을 수행하는데 오랜 시간이 소요되는 것입니다. 이는 장치가 단순히 오버로드되고 있거나 (공유 리소스이기 때문일 수 있음) 또는 장치에 전송된 워크로드가 최적의 것이 아님을 의미하는 것일 수 있습니다. Q2G가 매우 높은 경우 동시에 많은 요청이 대기열에 있음을 의미합니다. 즉 스토리지가 I/O 로드를 처리할 수 없음을 의미합니다.
마지막으로 seekwatcher는 blktrace 바이너리 데이터를 소비하고 논리 블록 주소 (LBA), 처리 속도, 초 당 탐색 횟수, 초당 I/O (IOPS)를 포함하는 플롯 세트를 생성합니다.
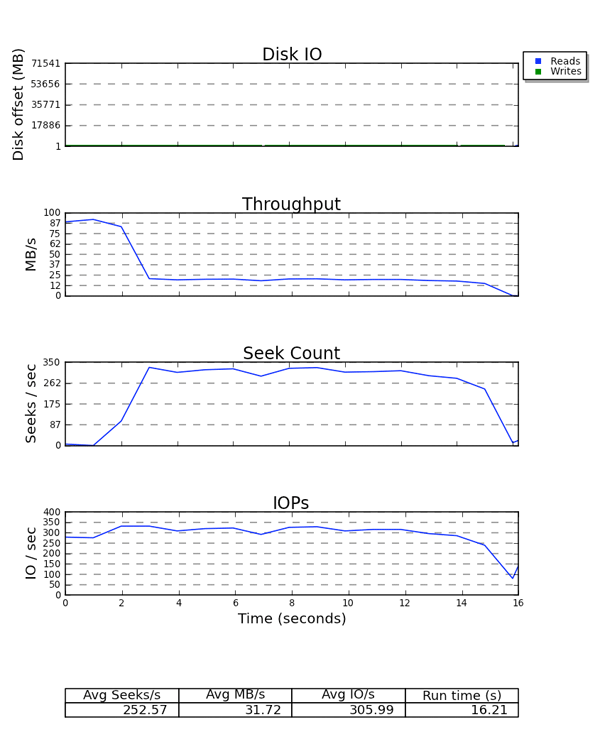
그림 6.2. seekwatcher 출력의 예
모든 플롯은 X 축으로 시간을 사용합니다. LBA 플롯은 읽기 및 쓰기가 다른 색으로 표시되어 있습니다. 처리량과 초당 탐색 횟수 그래프의 관계를 주목해 볼 만 합니다. 탐색 구분 스토리지의 경우 이 두 플롯 사이에 반비례 관계가 존재합니다. IOPS 그래프는 장치에서 예상 처리량을 얻을 수 없지만 IOPS 제한에 도달한 경우에 유용합니다.